Embed Size (px)
Citation preview

DATA PARTITIONING FOR DISTRIBUTED ENTITY MATCHINGToralf Kirsten, Lars Kolb, Michael Hartung, Anika Groß,Hanna Köpcke, Erhard Rahm
Database Group Leipzighttp://dbs.uni-leipzig.de
Singapore, 13thSeptember 2010

2 / 20
• Detection of entities in one ore more sources that refer to the same real-world object
• Entity comparisons•Comparisons based on string similarity•Two sources: m2
•Combination of several matchers•Aggregation of individual results
• Runtime•Execution times up to several hours for a single attribute
matcher•Worse for machine learning approaches
• Memory requirements•Source and intermediate results do not fit in memory•Chunk-wise processing
ENTITY MATCHING
Data Partitioning for Distributed Entity Matching
…

3 / 20
• Blocking•Group similar entities within blocks•Restrict entity matching to entities from the same block•Supported by entity matching frameworks
• Parallelization•Split match computation in sub-tasks •Execute them in parallel on multiple multi-core nodes•Currently utilized by only few frameworks
HOW TO SPEED UP ENTITY MATCHING?
Data Partitioning for Distributed Entity Matching
??

4 / 20
CONTRIBUTIONS• Generic data partitioning strategies for parallel matching• Size-based partitioning for evaluating the Cartesian
product of input entities•Blocking-based matching•Applicable to arbitrary matchers
• Load balancing regarding available resources and match strategy
• Service-based infrastructure for parallel entity matching
• Evaluation of the strategies for different types of matchers and datasets
Data Partitioning for Distributed Entity Matching

5 / 20
OUTLINE
• Motivation• Overview• Partitioning Strategies
•Size-based Partitioning•Blocking-based Partitioning
• Match Infrastructure• Evaluation• Conclusion & Future Work
Data Partitioning for Distributed Entity Matching

6 / 20
OVERVIEW
Data Partitioning for Distributed Entity Matching
• Set of entities, described via attributes• Partitioning strategy
•Partition input data•Match task generation
• Parallel execution of a match strategy•One or several matchers•Combination of individual match results (manually,
training-based)•Treated as black box
InputSource
InputSource
IntegratedSource
...
instance data
integration
......
Partitioning Strategies
Size-basedPartitioning
max. partition size
Match TaskGeneration
MT2
MT1
Task list
Match TaskGeneration
BlockingPartitionTuning
source-specific
blocking key
min./max. partition
size
M1
M2
Mt
...
MatchResult
⋃
Result Aggregatio
n
Parallel Matching

7 / 20
• Applicable to Cartesian product of input entities• Split n input entities into p partitions of fairly equal size m
•p = n/m•Range partitioning, Round Robin
• Match task compares two of these partitions•Match partitions Pi and Pj if i ≤ j
•p+p(p-1)/2 match tasks
• Promises good load balancing and scalability to many nodes
SIZE-BASED PARTITIONING
Data Partitioning for Distributed Entity Matching
Input Set
P1 P2 … Pp-1 Pp
InputSet
P1 x
P2 x x
… … … …
Pp-1 x x … x
Pp x x … x x

8 / 20
SIZE-BASED PARTITIONING – SUITABLE PARTITION SIZE M?• m determines number of partitions and match tasks
• m many small match tasks, high communication overhead• m memory bottlenecks
• m restricted by computing environment•Memory requirements of a match task in O(m2)•Average memory requirement per match task: cms∙m2
• Multiple cores share available memory•m ≤ •2 GB RAM, 4 cores, cms=20B
max. partition size m = = 5,000
Data Partitioning for Distributed Entity Matching

9 / 20
BLOCKING-BASED PARTITIONING• Blocking – logical clustering of possibly matching entities
•Blocks of largely varying size•Entities with missing attribute values
•Assigned to dedicated misc block•Have to be compared with entities of all blocks
• Simple approach – one match task per block•Poor load balancing and/or high communication overhead
•Large blocks dominate execution time and consume much memory•Small blocks slow down parallel matching due high
communication overhead compared to time for matching
•Partition tuning to split or aggregate blocks
Data Partitioning for Distributed Entity Matching

10 / 20
BLOCKING-BASED PARTITIONING – PARTITION TUNING • Large blocks for which matching would consume to
much memory are split into equally-sized partitions• Max. partition size m chosen according to memory
requirement estimation• All sub-partitions of a split block have to be matched
with each other
Data Partitioning for Distributed Entity Matching
Drives & Storage (3,250)
3½ (1,300)
2½ (600)
Blu-ray (60)
HD-DVD (40)
Misc (600)
3½ 1 (700)
3½ 2 (600)
CD-RW (50)
DVD-RW (600)
Max. partition size = 700
Blo
ckin
g b
y t
yp
e

11 / 20
BLOCKING-BASED PARTITIONING – PARTITION TUNING • Small blocks with sizes below min. partition size are
aggregated into larger ones• Less partitions less match tasks reduced
communication and scheduling overhead• Aggregation introduces unnecessary comparisons and
may lead to false-positives
Data Partitioning for Distributed Entity Matching
Drives & Storage (3,250)
3½ (1,300)
2½ (600)
Blu-ray (60)
HD-DVD (40)
misc (600)
3½ 1 (700)
3½ 2 (600)
CD-RW (50)
DVD-RW (600)
Min. partition size = 70
Blu-ray
Max. partition size = 700
Blo
ckin
g b
y t
yp
e
CD-RW (150)HD-DVD (100)HD-DVD

12 / 20
BLOCKING-BASED PARTITIONING – MATCH TASK GENERATION• One match task per normal (non-misc) block that has not
been split• Blocks that have been split in k sub-partitions result in
k+k(k-1)/2 match tasks• The misc block (or its sub-partitions) have to be matched
with all blocks (sub-partitions)
Data Partitioning for Distributed Entity Matching
Drives & Storage (3,250)
3½ (1,300)
2½ (600)
Blu-ray (60)
HD-DVD (40)
Misc (600)
3½ 1 (700)
3½ 2 (600)
CD-RW (50)
DVD-RW (600)
Blu-ray HD-DVDCD-RW (150)
↷Drives & Storage
3½
2½
Blu-
ray
HD-DVD
CD-
RW DVD-RW misc
3½1
3½ 2
Drives&
Storage
3½
3½ 1
3½ 2
2½
Blu-ray
HD-DVD
CD-RW
DVD-RW
misc
Drives & Storage
3½
2½
Blu-
ray
HD-DVD
CD-
RW DVD-RW misc
3½1
3½ 2
Drives&
Storage
3½
3½ 1
3½ 2
2½ X
Blu-ray
XHD-DVD
CD-RW
DVD-RW X
misc
Drives & Storage
3½
2½
Blu-
ray
HD-DVD
CD-
RW DVD-RW misc
3½1
3½ 2
Drives&
Storage
3½
3½ 1 X
3½ 2 X X
2½ X
Blu-ray
XHD-DVD
CD-RW
DVD-RW X
misc
Drives & Storage
3½
2½
Blu-
ray
HD-DVD
CD-
RW DVD-RW misc
3½1
3½ 2
Drives&
Storage
3½
3½ 1 X
3½ 2 X X
2½ X
Blu-ray
XHD-DVD
CD-RW
DVD-RW X
misc X X X X X X
13 / 20
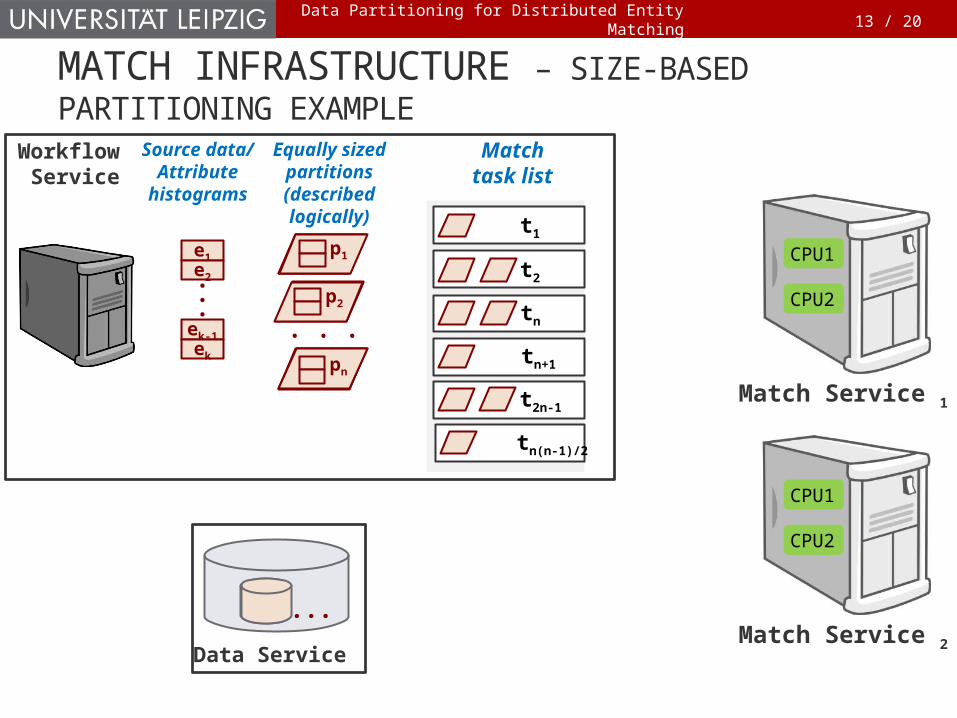
MATCH INFRASTRUCTURE – SIZE-BASED PARTITIONING EXAMPLE
Data Partitioning for Distributed Entity Matching
CPU1CPU2
CPU1CPU2
Data Service
Workflow Service
...
e1e2
ek-1ek
Source data/
Attribute histograms
Match Service 1
Match Service 2
Match task listt1
Equally sized
partitions(described logically)
.. .pn
p1
p2
t2p1p1
p2tn
pntn+1
p2
t2n-1
pn
tn(n-1)/2
...

14 / 20
INFRASTRUCTURE – SIZE-BASED PARTITIONING EXAMPLE
Data Partitioning for Distributed Entity Matching
CPU1CPU2
CPU1CPU2
Data Service
Workflow Service
Match Service 1
Match Service 2
Match task listt1
t2
tn
tn+1
t2n-1
tn(n-1)/2
...
t1
t2
tn
tn+1
t2n-1
tn(n-1)/2
CPU1
...
...
CPU2..
.
CPU2..
.
CPU1
...
CPU1
...
CPU2
.. ...
.
Unify partial match results

15 / 20
EVALUATION• Datasets
• 114,000 electronic product offers• Small subset of 20,000 offers
• Two matchers• WAM – Levenshtein, Trigram (weighted average)• LRM – Jaccard, Trigram, Cosine (machine learning)
• Computing environment• Up to 16 cores (4 nodes with 4x2.66GHz and 4GB RAM)• 3GB RAM heap size
Data Partitioning for Distributed Entity Matching

16 / 20
EVALUATION – INFLUENCE OF THE MAX. PARTITION SIZE• 20,000 electronic product offers• Cartesian product• Single node, 4 match threads
Data Partitioning for Distributed Entity Matching
WAM: mmax =1,000
LRM: mmax = 500
17 / 20
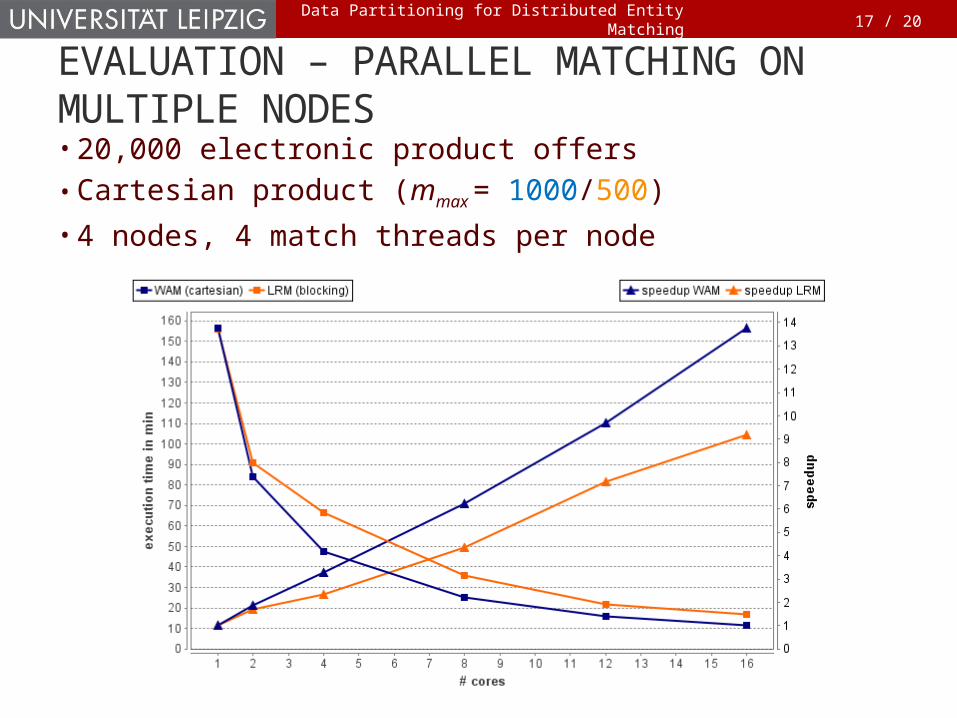
• 20,000 electronic product offers• Cartesian product (mmax = 1000/500)
• 4 nodes, 4 match threads per node
EVALUATION – PARALLEL MATCHING ON MULTIPLE NODES
Data Partitioning for Distributed Entity Matching

18 / 20
• 114,000 electronic product offers• Blocking (mmax = 1000/500, mmin = 200/100)
• 4 nodes, 4 match threads per node
EVALUATION – PARALLEL MATCHING ON MULTIPLE NODES
Data Partitioning for Distributed Entity Matching

19 / 20
CONCLUSIONS & FUTURE WORK• Two generic data partitioning strategies for parallel
matching with any matchers•Size-based partitioning•Blocking-based partitioning
• Partition tuning to achieve evenly loaded nodes• Evaluation on newly developed service-based
infrastructure
• Adapt approaches to cloud architectures• Parallelize Blocking• Investigate optimizations within match strategies
Data Partitioning for Distributed Entity Matching

20 / 20Data Partitioning for Distributed Entity Matching
Please also note our contribution to the VLDB experiments and analysis track:
Evaluation of entity resolution approaches on real-world match problemsHanna Köpcke, Andreas Thor, Erhard Rahm
Date: 14 September 2010, TuesdayTime: 17:30 hoursRoom: Swallow
THANK YOU FOR YOUR ATTENTION





























