Embed Size (px)
Citation preview

Data Analysis for High-Throughput Sequencing
Mark Reimers
Tobias Guennel
Department of Biostatistics

Unto the Frontiers of Ignorance
“I love the way this workshop starts off with things we understand fairly well and works up to the cutting edge of things we don’t understand at all”
- Mike Neale, Oct 14, 2010

The New Boyfriend/Girlfriend

Where Does HTS Really Make the Difference?
• Sequencing for novel variants
• ChIP-Seq for DNA-binding proteins or less common histone marks
• Allele-specific expression
• COMING SOON
• DNA methylation

Outline
• Biases in reads
• RNA-Seq– normalization– basic tests– differential splicing
• Finding peaks in ChIP-Seq

Technical Biases – Sequence StartThe initial bases of reads are highly biased, and the bias depends on RNA/DNA preparation
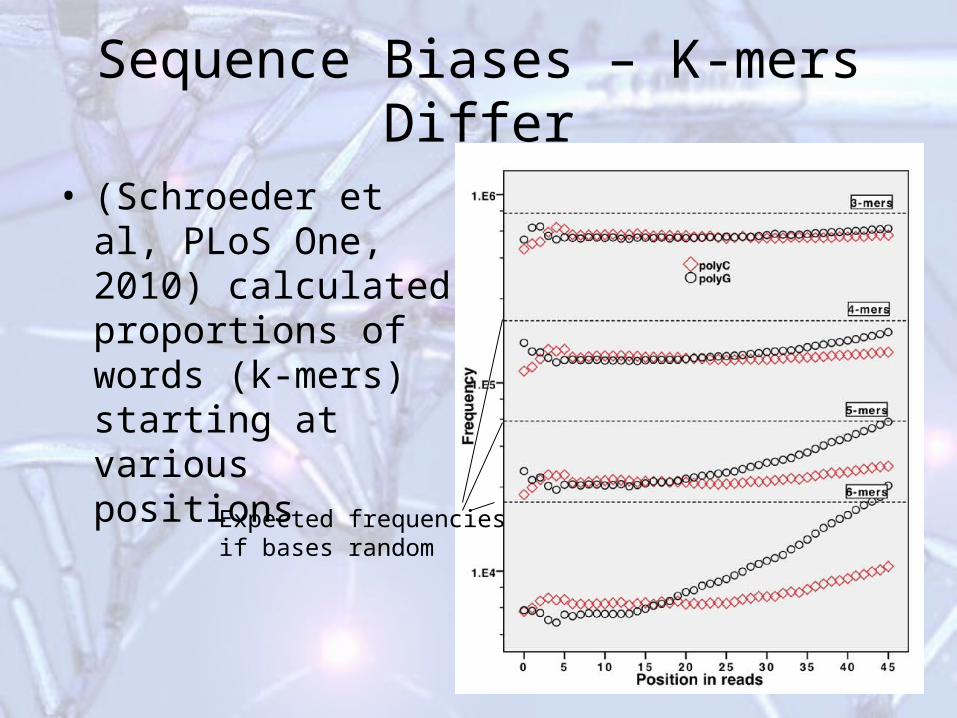
Sequence Biases – K-mers Differ
• (Schroeder et al, PLoS One, 2010) calculated proportions of words (k-mers) starting at various positions
Expected frequenciesif bases random
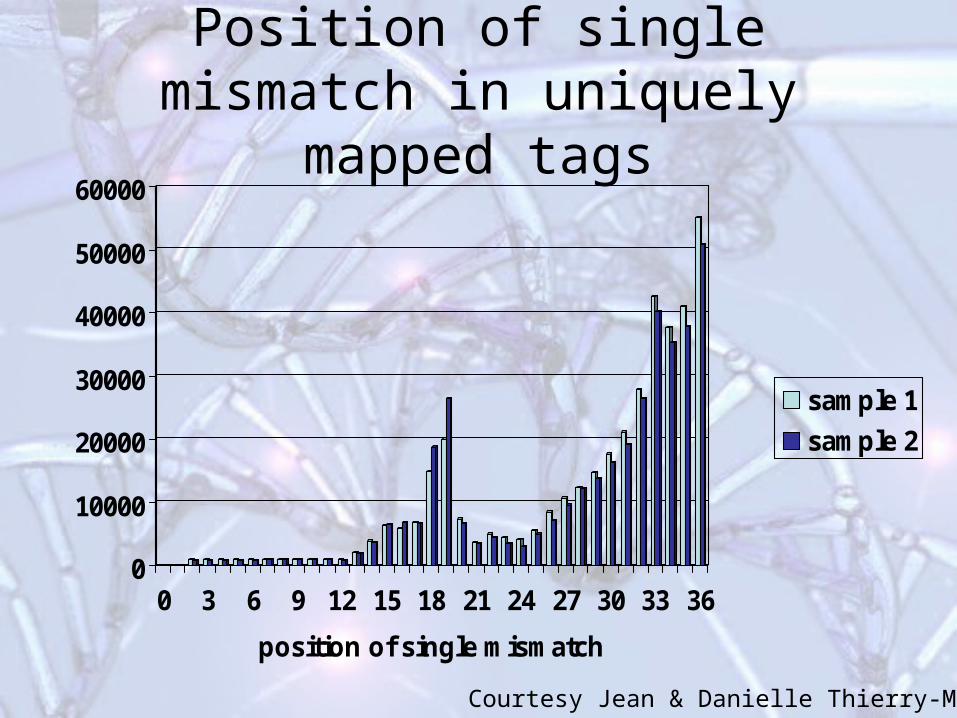
Position of single mismatch in uniquely mapped tags
0
10000
20000
30000
40000
50000
60000
0 3 6 9 12 15 18 21 24 27 30 33 36
position of single mismatch
sample 1
sample 2
Courtesy Jean & Danielle Thierry-Mieg

Types of mismatches in uniquely mapped tags with a single mismatch are profoundly
asymmetric and biased
0
100000
200000
300000
400000
500000
600000
700000
800000In
se
rt G
De
lete
C
Ins
ert
C
De
lete
G
Ins
ert
T
Ins
ert
A
De
lete
A
De
lete
T
C >
G
T >
G
A >
T
A >
G
C >
T
T >
C
T >
A
C >
A
G >
C
A >
C
G >
A
G >
T
An
y s
ing
le
Courtesy Jean & Danielle Thierry-Mieg
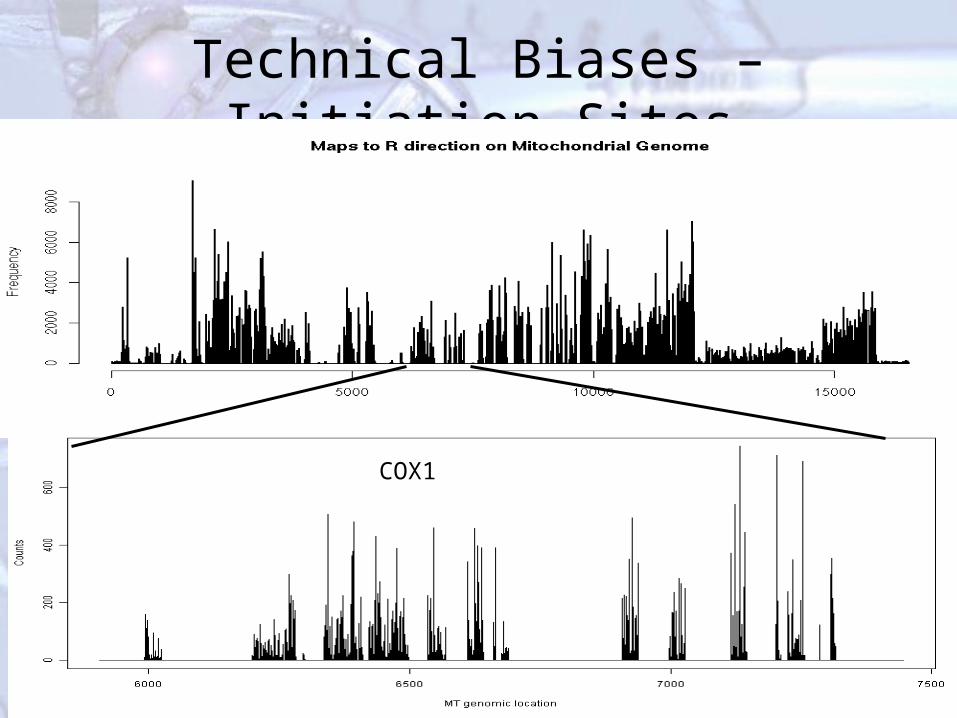
Technical Biases – Initiation Sites
COX1
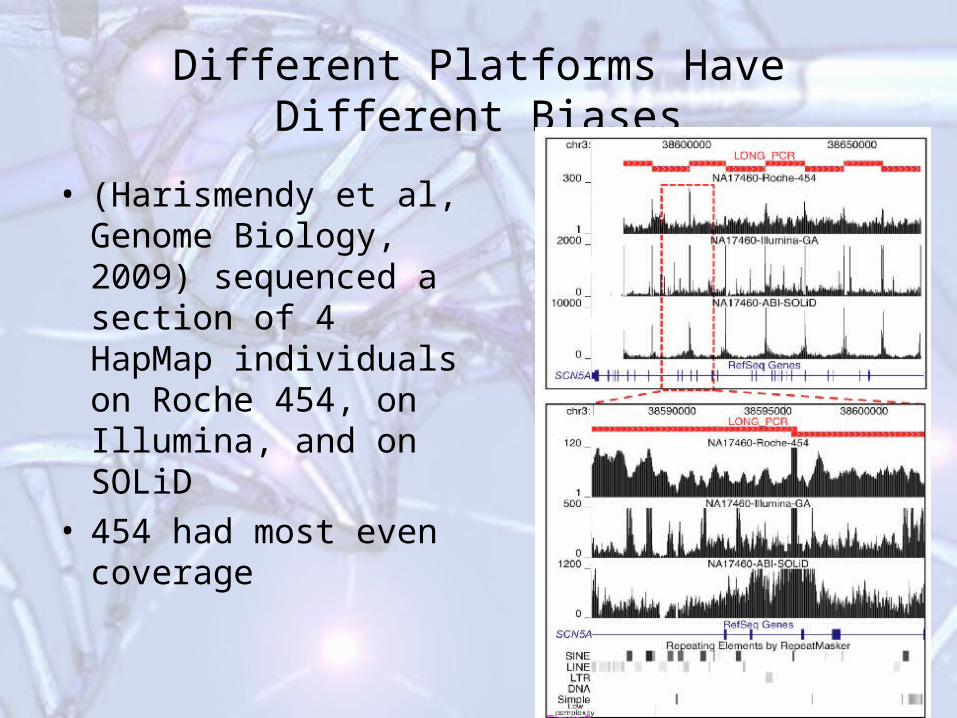
Different Platforms Have Different Biases
• (Harismendy et al, Genome Biology, 2009) sequenced a section of 4 HapMap individuals on Roche 454, on Illumina, and on SOLiD
• 454 had most even coverage
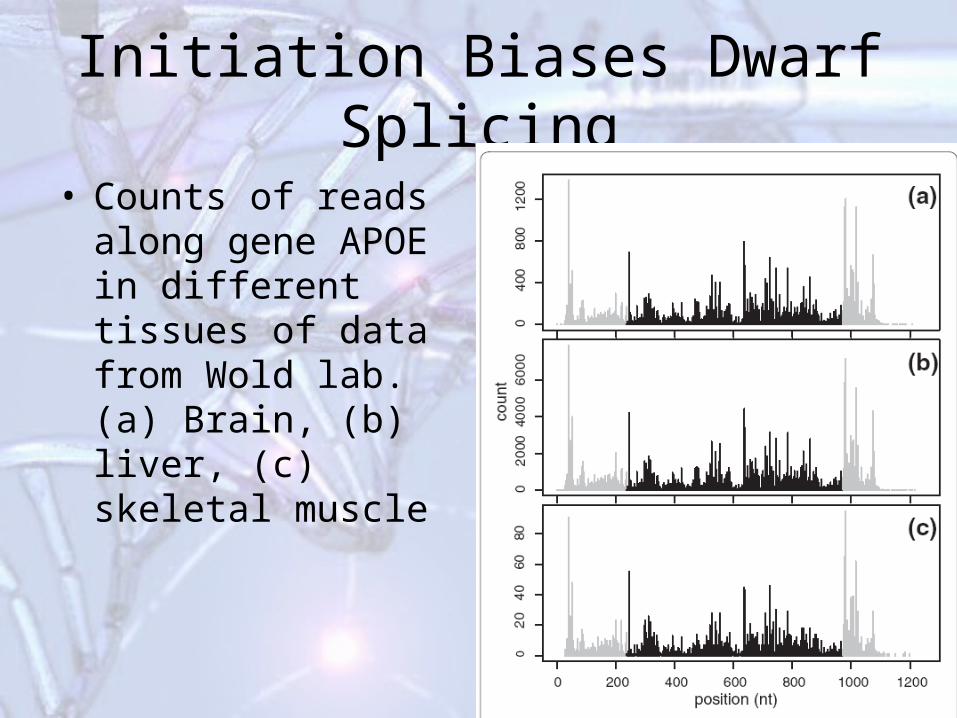
Initiation Biases Dwarf Splicing
• Counts of reads along gene APOE in different tissues of data from Wold lab. (a) Brain, (b) liver, (c) skeletal muscle

Variation in Technical Biases
• Sometimes the initial base biases change substantially – most base proportions change together – one PC explains 95%
• In most preparations the initiation site biases change by a few percent
• In a few preparations the initiation site biases change by ~20%-30%
• This may have consequences for representation in ChIP-Seq assays

RNA-Seq Data Analysis

Biases in Proportions
• Fragments compete for real-estate on the lane
• If a few dozen genes are highly expressed in one tissue, they will competitively inhibit the sequencing of other genes, resulting in what appears to be lower expression

Effects of Competition
• (Robinson & Oshlak, Genome Biology, 2010)

A Simple Normalization
• Align the medians of the housekeeping genes, or the genes that are not expressed at very high levels in any sample, across the samples

A Simple Model for Counts
• Poisson distribution of counts within a gene with mean proportional to Np
• SD of variation equal to square root of Np
• Problem: Actual variation of counts between replicate samples is significantly higher than root Np
• Probably reflecting systematic biases

Hacks for Over-Dispersion
• Like fudge-factor in GWAS
• Use negative binomial model– There is no relation to meaning of distribution
– numbers of nulls until something happens– Convenient way to parametrise over-
dispersion
• Bioconductor package edgeR estimates parameters by Maximum Likelihood

Alternate Transcripts: Splicing Index
• For each exon, the proportion of transcripts in which the exon appears
• Hard to estimate because different exons have different representation probabilities
• Use ratios of exons
• Use constitutive exons (if known) as baseline: for them SI=1
from Wang et al, Nature, 2008
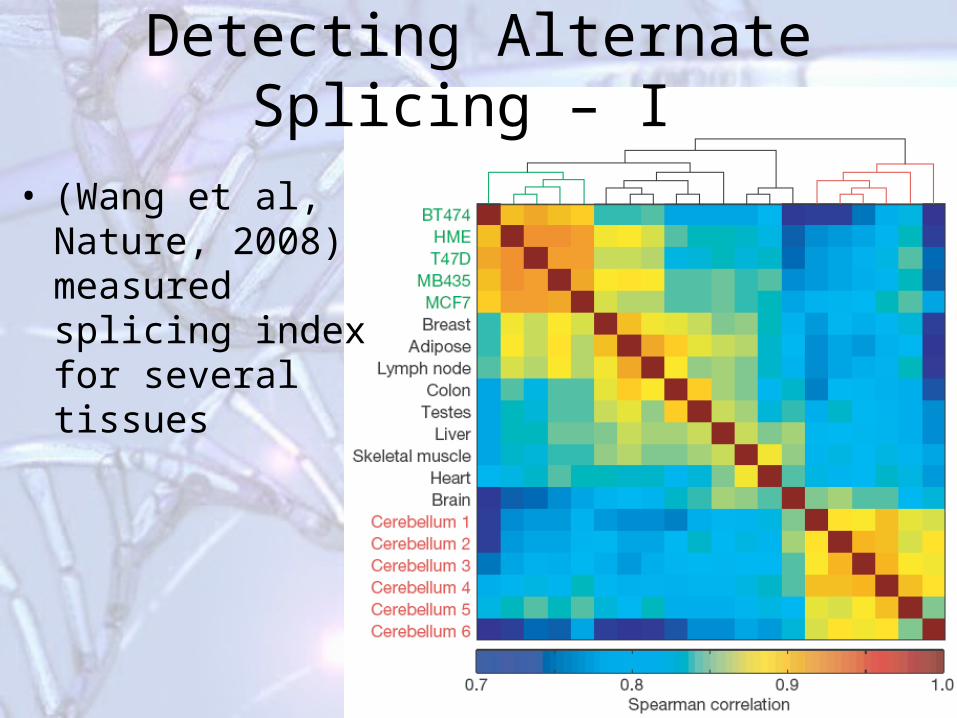
Detecting Alternate Splicing – I
• (Wang et al, Nature, 2008) measured splicing index for several tissues

Splicing: Junction Reads
• Some reads will span two different exons
• Need long enough reads to be able to reliably map both sides
• Can use information from one exon to identify gene and restrict possibilities for 5’ end other exon
from Wang et al NAR 2010
ChIP-Seq

Courtesy Raphael Gottardo

A View of ChIP-Seq Data
• Typically reads are quite sparsely distributed over the genome
• Controls (i.e. no pull-down by antibody) often show smaller peaks at the same locations
• Probably due to open chromatin at promoter
Rozowsky et al Nature Methods, 2009
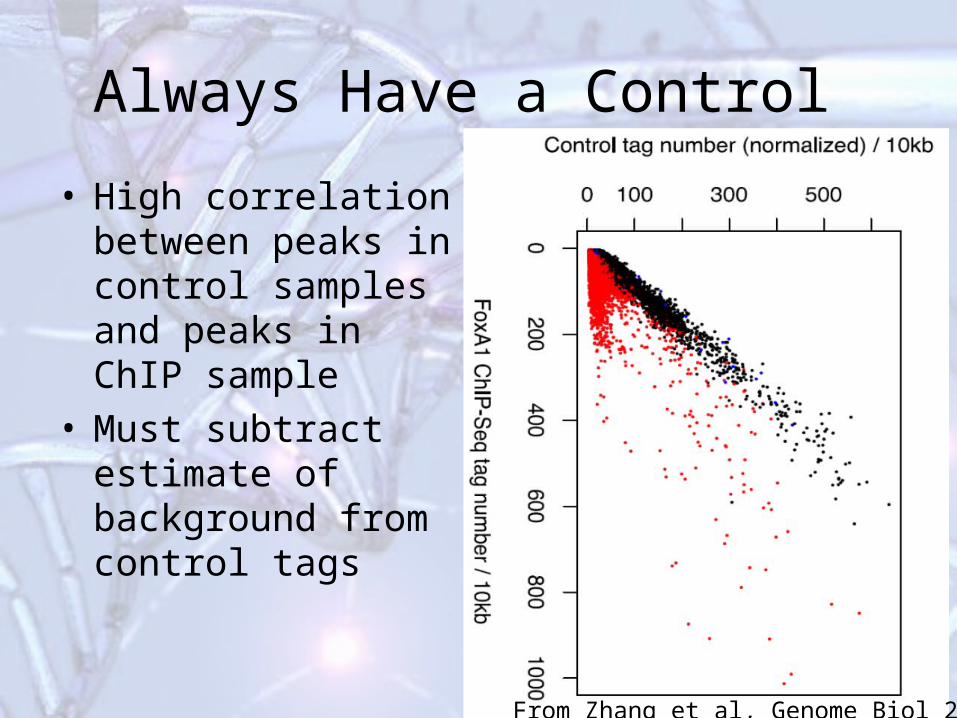
Always Have a Control
• High correlation between peaks in control samples and peaks in ChIP sample
• Must subtract estimate of background from control tags
From Zhang et al, Genome Biol 2008

Locating Binding Sites
• Use the fact that reads on opposite sides of the site represent are sequenced in opposite senses
From Zhao et al NAR 2009


![Stundenbild Project-based Learning Dr. Christian Reimers reimers@astro.univie.ac.at ASTROID [1] Künstlerische Darstellung](https://img.pdfslide.net/doc/110x75/55204d7549795902118ca7a7/stundenbild-project-based-learning-dr-christian-reimers-reimersastrounivieacat-httpwwwvirtuelleschuleatcosmos-astroid-1-kuenstlerische-darstellung.jpg)


























