Embed Size (px)
Citation preview

Data Fabric IGIntroduction
2
about 50 interviews & about 75 community interactions Data Management and Processing is too time consuming
and costly due to organization heterogeneity. Federating data including logical layer information (tracing
provenance, understanding creation context, checking identity and integrity, etc.) is too costly.
DM and DP is not ready for Big Data due to the lack of usage of automated procedures incorporating proper data organization mechanisms.
Observations I from Recent Overview

3
Due to lack of software that is supporting proper data organizations we continue to create legacy data.
Example: a key biologists is spending 75% of his time for data management - a waste of money and human capital.
To a large extent results are not reproducible.
Senior Domain People agree: need a change data organization and procedures but risky path and lack data professionals people hesitate since they miss clear perspectives
Observations II from Recent Overview

4Data Fabric Sketch
a very rough sketch of the Data production and processing machinery of data-driven science
One Big Question for RDA:
How can we maximally support this machinery
• unload researchers,
• make science reproducible,
• etc.
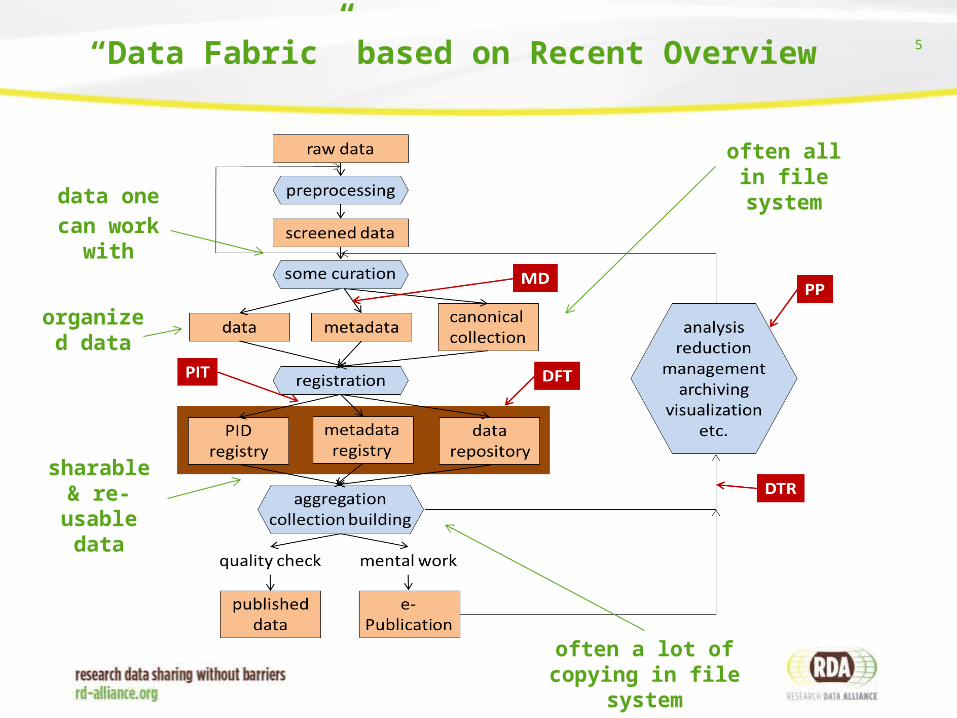
5“Data Fabric” based on Recent Overview
data one
can work with
organized data
sharable & re-usable
data
often all in file system
often a lot of copying in file system
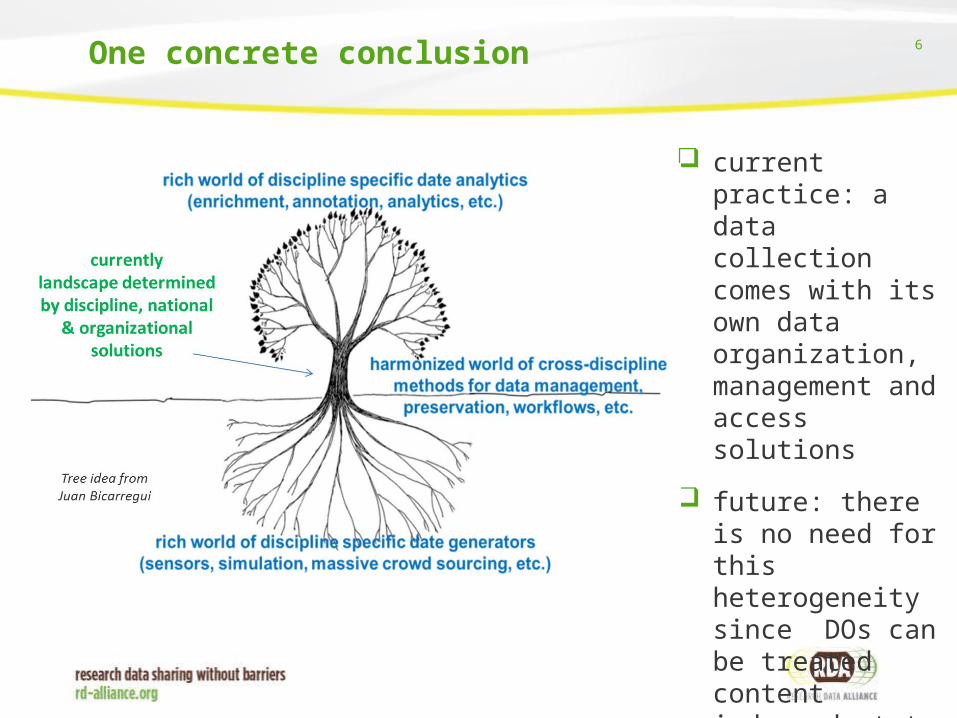
6One concrete conclusion
current practice: a data collection comes with its own data organization, management and access solutions
future: there is no need for this heterogeneity since DOs can be treated content independent to a certain extent
7
started with a number of WG activities in P1 DTR, PP, PIT, MD, DFT – the old ones some people found this urgent and interesting topics almost at the end and some questions: what now, how does it
all fit into landscape, etc.? they started this DF brainstorming
even more groups started are there general themes in the data landscape
the whole issue of data publishing/citation/etc. the whole issue of scientific culture/legal & ethical aspects our daily data work in the departments – the Data Fabric may be more
Until now in RDA

8
what is the scope of RDA’s Data Fabric? what are the characteristics of RDA’s Data Fabric?
(term is used in industry already: efficient computational machine)
what are the components of RDA’s Data Fabric? what should the DF IG do within RDA and what not?
A few Questions arise

9
DF is about making departments’ data science reproducible creating the conditions for trust in the anonymous data domain identifying mechanisms, components and interfaces making data
science efficient and cost effective discussing cross-disciplinary approaches defining a framework that allows to include new components or
component variants in a flexible way
Example: DF will state necessity of a worldwide available machinery to register &
resolve DOs, we will say something about registered attribute types and specify an API
but we will not say how to implement and use such a system
Scope and Characteristics of RDA’s DF

10
DF is NOT about prescribing an overarching architecture we need to follow specifying an implementation of such an architecture discussing specific technologies and tools more than discussing the processing machinery (not
publication, citation, l & e, etc.)
DF is about highly automated procedures or at least guidance to follow such procedures.
Scope and Characteristics of RDA’s DF

11
domain of registered data objects (DO) incl. basic organization principles (data, code, knowledge)
domain of registered actors (ORCID, etc.) domain of trusted repositories for DOs accepted policy principles (proper organizing
mechanisms, self-documenting, certified, etc.) set of trusted registries (types&concepts, metadata and
provenance schemas, metadata instances, repositories, PIDs, policies, etc.)
what about semantics – so important!
much already out there, need to see how this can all fit together and how we can foster software development
Components of RDA’s DF (just first ideas)

12
DF IG must be an inclusive open platform for interaction DF IG needs to place the various WGs/IGs on the
landscape DF IG needs to identify barriers across groups DF IG can work as umbrella to maintain WG results open position papers will summarize the state of
discussions and provoke convergence debates it will NOT take council’s of TAB’s role
DF IG way of acting

13
1. What are DF’s Scope and Characteristics?
2. What are DF’s components, interfaces, mechanisms?
3. How should DF act?
4. Who will chair DF IG?
Task of today DF IG BoF





























