Embed Size (px)
Citation preview

Data Mining AlgorithmsData Mining Algorithms
ClusteringClustering

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 22
Clustering OutlineClustering Outline
Goal:Goal: Provide an overview of the clustering Provide an overview of the clustering problem and introduce some of the basic problem and introduce some of the basic algorithmsalgorithms
Clustering Problem OverviewClustering Problem OverviewClustering TechniquesClustering Techniques–Hierarchical AlgorithmsHierarchical Algorithms–Partitional AlgorithmsPartitional Algorithms–Genetic AlgorithmGenetic Algorithm–Clustering Large DatabasesClustering Large Databases

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 44
General Applications of General Applications of Clustering Clustering
Pattern RecognitionPattern RecognitionSpatial Data Analysis Spatial Data Analysis – create thematic maps in GIS by clustering feature create thematic maps in GIS by clustering feature
spacesspaces– detect spatial clusters and explain them in spatial data detect spatial clusters and explain them in spatial data
miningmining
Image ProcessingImage ProcessingEconomic Science (especially market research)Economic Science (especially market research)WWWWWW– Document classificationDocument classification– Cluster Weblog data to discover groups of similar Cluster Weblog data to discover groups of similar
access patternsaccess patterns

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 55
Examples of Clustering Examples of Clustering ApplicationsApplications
Marketing:Marketing: Help marketers discover distinct groups in Help marketers discover distinct groups in their customer bases, and then use this knowledge to their customer bases, and then use this knowledge to develop targeted marketing programsdevelop targeted marketing programs
Land use:Land use: Identification of areas of similar land use in an Identification of areas of similar land use in an earth observation databaseearth observation database
Insurance:Insurance: Identifying groups of motor insurance policy Identifying groups of motor insurance policy holders with a high average claim costholders with a high average claim cost
City-planning:City-planning: Identifying groups of houses according to Identifying groups of houses according to their house type, value, and geographical locationtheir house type, value, and geographical location
Earth-quake studies:Earth-quake studies: Observed earth quake epicenters Observed earth quake epicenters should be clustered along continent faultsshould be clustered along continent faults

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 66
Clustering vs. ClassificationClustering vs. Classification
No prior knowledgeNo prior knowledge– Number of clustersNumber of clusters– Meaning of clustersMeaning of clusters– Cluster results are dynamicCluster results are dynamic
Unsupervised learningUnsupervised learning

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 77
Classification vs. ClusteringClassification vs. ClusteringClassification: Supervised learning:
Learns a method for predicting the instance class from pre-labeled (classified) instances

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 88
ClusteringClusteringUnsupervised learning:
Finds “natural” grouping of instances given un-labeled data

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 99
Clustering HousesClustering Houses
Size Based
Geographic Distance Based

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1010
Clustering MethodsClustering MethodsMany different method and algorithms:Many different method and algorithms:
–For numeric and/or symbolic dataFor numeric and/or symbolic data
–Deterministic vs. probabilisticDeterministic vs. probabilistic
–Exclusive vs. overlappingExclusive vs. overlapping
–Hierarchical vs. flatHierarchical vs. flat
–Top-down vs. bottom-upTop-down vs. bottom-up

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1111
Clustering IssuesClustering Issues
Outlier handlingOutlier handling
Dynamic dataDynamic data
Interpreting resultsInterpreting results
Evaluating resultsEvaluating results
Number of clustersNumber of clusters
Data to be usedData to be used
ScalabilityScalability

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1212
Impact of Outliers on Impact of Outliers on ClusteringClustering

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1313
Clustering EvaluationClustering Evaluation
Manual inspectionManual inspection
Benchmarking on existing labelsBenchmarking on existing labels
Cluster quality measuresCluster quality measures–distance measuresdistance measures–high similarity within a cluster, low across high similarity within a cluster, low across
clustersclusters

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1414
Data StructuresData Structures
Data matrixData matrix
Dissimilarity matrixDissimilarity matrix
npx...nfx...n1x
...............ipx...ifx...i1x
...............1px...1fx...11x
0...)2,()1,(
:::
)2,3()
...ndnd
0dd(3,1
0d(2,1)
0

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1515
Measure the Quality of ClusteringMeasure the Quality of Clustering
Dissimilarity/Similarity metricDissimilarity/Similarity metric: Similarity is expressed in : Similarity is expressed in terms of a distance function, which is typically metric:terms of a distance function, which is typically metric:
dd((i, ji, j))
There is a separate There is a separate “quality“quality” function that measures the ” function that measures the “goodness“goodness” of a cluster.” of a cluster.
The definitions of distance functions are usually very The definitions of distance functions are usually very different for different for interval-scaled, boolean, categorical, ordinal interval-scaled, boolean, categorical, ordinal and ratio variables.and ratio variables.
Weights should be associated with different variables Weights should be associated with different variables based on applications and data semantics.based on applications and data semantics.
It is hard to define It is hard to define “similar enough” or “good enough”“similar enough” or “good enough” – the answer is typically highly subjective.the answer is typically highly subjective.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1616
Type of data in clustering Type of data in clustering analysisanalysis
Interval-scaled variables:Interval-scaled variables:
Binary variables:Binary variables:
Nominal, ordinal, and ratio variables:Nominal, ordinal, and ratio variables:
Variables of mixed types:Variables of mixed types:

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1717
Similarity and Dissimilarity Similarity and Dissimilarity Between ObjectsBetween Objects
DistancesDistances are normally used to measure the are normally used to measure the
similaritysimilarity or or dissimilaritydissimilarity between two data between two data
objectsobjects
Some popular ones include: Some popular ones include: Minkowski distanceMinkowski distance::
where where ii = ( = (xxi1i1, , xxi2i2, …, , …, xxipip) and) and j j = ( = (xxj1j1, , xxj2j2, …, , …, xxjpjp) are two ) are two
pp-dimensional data objects, and -dimensional data objects, and qq is a positive integer is a positive integer
If If qq = = 11, , dd is is Manhattan distanceManhattan distance
pp
jx
ix
jx
ix
jx
ixjid )||...|||(|),(
2211
||...||||),(2211 pp jxixjxixjxixjid

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1818
Similarity and Dissimilarity Similarity and Dissimilarity Between Objects (Cont.)Between Objects (Cont.)
If qIf q = = 22,, d d is Euclidean distance:is Euclidean distance:
– PropertiesProperties
d(i,j)d(i,j) 0 0
d(i,i)d(i,i) = 0 = 0
d(i,j)d(i,j) = = d(j,i)d(j,i)
d(i,j)d(i,j) d(i,k)d(i,k) + + d(k,j)d(k,j)
)||...|||(|),( 22
22
2
11 pp jx
ix
jx
ix
jx
ixjid

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 1919
Binary VariablesBinary VariablesA contingency table for binary dataA contingency table for binary data
Simple matching coefficient (invariant, if the binary Simple matching coefficient (invariant, if the binary
variable is variable is symmetricsymmetric):):
Jaccard coefficient (noninvariant if the binary variable is Jaccard coefficient (noninvariant if the binary variable is
asymmetricasymmetric): ):
dcbacb jid
),(
pdbcasum
dcdc
baba
sum
0
1
01
cbacb jid
),(
Object i
Object j

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2020
Dissimilarity between Dissimilarity between Binary VariablesBinary Variables
ExampleExample
– gender is a symmetric attributegender is a symmetric attribute– the remaining attributes are asymmetric binarythe remaining attributes are asymmetric binary– let the values Y and P be set to 1, and the value N be set to 0let the values Y and P be set to 1, and the value N be set to 0
Name Gender Fever Cough Test-1 Test-2 Test-3 Test-4
Jack M Y N P N N NMary F Y N P N P NJim M Y P N N N N
75.0211
21),(
67.0111
11),(
33.0102
10),(
maryjimd
jimjackd
maryjackd

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2121
Nominal VariablesNominal Variables
A generalization of the binary variable in that it can take A generalization of the binary variable in that it can take
more than 2 states, e.g., red, yellow, blue, greenmore than 2 states, e.g., red, yellow, blue, green
Method 1: Simple matchingMethod 1: Simple matching– mm: # of matches,: # of matches, p p: total # of variables: total # of variables
Method 2: use a large number of binary variablesMethod 2: use a large number of binary variables– creating a new binary variable for each of the creating a new binary variable for each of the MM nominal states nominal states
pmpjid ),(

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2222
Clustering ProblemClustering Problem
Given a database D={tGiven a database D={t11,t,t22,…,t,…,tnn} of tuples } of tuples and an integer value k, the and an integer value k, the Clustering Clustering ProblemProblem is to define a mapping is to define a mapping f:Df:D{1,..,k}{1,..,k} where each where each ttii is assigned to one cluster is assigned to one cluster KKjj, , 1<=j<=k.1<=j<=k.
A A ClusterCluster, K, Kjj,, contains precisely those contains precisely those tuples mapped to it.tuples mapped to it.Unlike classification problem, clusters are Unlike classification problem, clusters are not known a priori.not known a priori.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2323
Types of Clustering Types of Clustering
HierarchicalHierarchical – Nested set of clusters – Nested set of clusters created.created.Partitional Partitional – One set of clusters created.– One set of clusters created.Incremental Incremental – Each element handled one – Each element handled one at a time.at a time.SimultaneousSimultaneous – All elements handled – All elements handled together.together.Overlapping/Non-overlappingOverlapping/Non-overlapping

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2424
Major Clustering ApproachesMajor Clustering Approaches
Partitioning algorithmsPartitioning algorithms: Construct various partitions and : Construct various partitions and
then evaluate them by some criterionthen evaluate them by some criterion
Hierarchy algorithmsHierarchy algorithms: Create a hierarchical decomposition : Create a hierarchical decomposition
of the set of data (or objects) using some criterionof the set of data (or objects) using some criterion
Density-basedDensity-based:: based on connectivity and density functions based on connectivity and density functions
Grid-basedGrid-based:: based on a multiple-level granularity structure based on a multiple-level granularity structure
Model-basedModel-based:: A model is hypothesized for each of the A model is hypothesized for each of the
clusters and the idea is to find the best fit of that model to clusters and the idea is to find the best fit of that model to
each othereach other

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2525
Clustering ApproachesClustering Approaches
Clustering
Hierarchical Partitional Categorical Large DB
Agglomerative Divisive Sampling Compression

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2626
Cluster ParametersCluster Parameters

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2727
Distance Between ClustersDistance Between Clusters
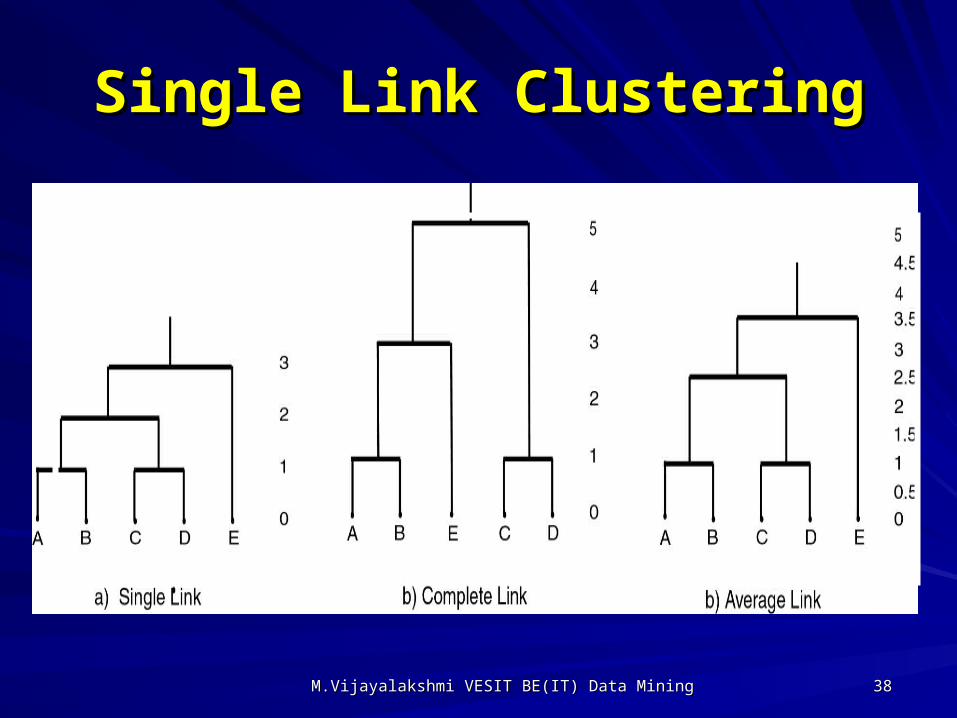
Single LinkSingle Link: smallest distance between : smallest distance between pointspointsComplete LinkComplete Link:: largest distance between largest distance between pointspointsAverage Link:Average Link: average distance between average distance between pointspointsCentroid:Centroid: distance between centroidsdistance between centroids

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2828
Hierarchical ClusteringHierarchical Clustering
Clusters are created in levels actually creating Clusters are created in levels actually creating sets of clusters at each level.sets of clusters at each level.AgglomerativeAgglomerative– Initially each item in its own clusterInitially each item in its own cluster– Iteratively clusters are merged togetherIteratively clusters are merged together– Bottom UpBottom Up
DivisiveDivisive– Initially all items in one clusterInitially all items in one cluster– Large clusters are successively dividedLarge clusters are successively divided– Top DownTop Down

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 2929
Hierarchical ClusteringHierarchical ClusteringUse distance matrix as clustering criteria. This Use distance matrix as clustering criteria. This method does not require the number of clusters method does not require the number of clusters kk as an input, but needs a termination condition as an input, but needs a termination condition
Step 0 Step 1 Step 2 Step 3 Step 4
b
d
c
e
a a b
d e
c d e
a b c d e
Step 4 Step 3 Step 2 Step 1 Step 0
agglomerative(AGNES)
divisive(DIANA)

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3030
Hierarchical AlgorithmsHierarchical Algorithms
Single LinkSingle Link
MST Single LinkMST Single Link
Complete LinkComplete Link
Average LinkAverage Link

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3131
DendrogramDendrogramA tree data structure A tree data structure which illustrates which illustrates hierarchical clustering hierarchical clustering techniques.techniques.
Each level shows clusters Each level shows clusters for that level.for that level.– Leaf – individual clustersLeaf – individual clusters– Root – one clusterRoot – one cluster
A cluster at level A cluster at level ii is the is the union of its children union of its children clusters at level clusters at level i+1.i+1.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3232
Levels of ClusteringLevels of Clustering

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3333
Agglomerative ExampleAgglomerative ExampleAA BB CC DD EE
AA 00 11 22 22 33
BB 11 00 22 44 33
CC 22 22 00 11 55
DD 22 44 11 00 33
EE 33 33 55 33 00
BA
E C
D
4
Threshold of
2 3 51
A B C D E

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3434
MST ExampleMST Example
AA BB CC DD EE
AA 00 11 22 22 33
BB 11 00 22 44 33
CC 22 22 00 11 55
DD 22 44 11 00 33
EE 33 33 55 33 00
BA
E C
D

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3535
Agglomerative AlgorithmAgglomerative Algorithm

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3636
Single LinkSingle Link
View all items with links (distances) View all items with links (distances) between them.between them.
Finds maximal connected components Finds maximal connected components in this graph.in this graph.
Two clusters are merged if there is at Two clusters are merged if there is at least one edge which connects them.least one edge which connects them.
Uses threshold distances at each level.Uses threshold distances at each level.
Could be agglomerative or divisive.Could be agglomerative or divisive.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3737
MST Single Link AlgorithmMST Single Link Algorithm
M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3838
Single Link ClusteringSingle Link Clustering

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 3939
AGNES (Agglomerative Nesting)AGNES (Agglomerative Nesting)
Implemented in statistical analysis packages, e.g., Implemented in statistical analysis packages, e.g., SplusSplus
Use the Single-Link method and the dissimilarity Use the Single-Link method and the dissimilarity matrix. matrix.
Merge nodes that have the least dissimilarityMerge nodes that have the least dissimilarity
Go on in a non-descending fashionGo on in a non-descending fashion
Eventually all nodes belong to the same clusterEventually all nodes belong to the same cluster

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4040
A Dendrogram Shows How the Clusters are Merged Hierarchically
Decompose data objects into a several levels of nested partitioning (tree of clusters), called a dendrogram.
A clustering of the data objects is obtained by cutting the dendrogram at the desired level, then each connected component forms a cluster.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4141
DIANA (Divisive Analysis)DIANA (Divisive Analysis)
Implemented in statistical analysis packages, e.g., Implemented in statistical analysis packages, e.g., SplusSplus
Inverse order of AGNESInverse order of AGNES
Eventually each node forms a cluster on its ownEventually each node forms a cluster on its own

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4242
Partitional ClusteringPartitional Clustering
NonhierarchicalNonhierarchical
Creates clusters in one step as opposed to Creates clusters in one step as opposed to several steps.several steps.
Since only one set of clusters is output, Since only one set of clusters is output, the user normally has to input the desired the user normally has to input the desired number of clusters, k.number of clusters, k.
Usually deals with static sets.Usually deals with static sets.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4343
Partitioning AlgorithmsPartitioning Algorithms
Partitioning method:Partitioning method: Construct a partition of a database Construct a partition of a database DD of of nn objects into a set of objects into a set of kk clusters clustersGiven a Given a kk, find a partition of , find a partition of k clusters k clusters that optimizes the that optimizes the chosen partitioning criterionchosen partitioning criterion– GlobalGlobal optimal: exhaustively enumerate all partitions optimal: exhaustively enumerate all partitions– Heuristic methods: Heuristic methods: k-meansk-means and and k-medoidsk-medoids
algorithmsalgorithms– k-meansk-means: Each cluster is represented by the center : Each cluster is represented by the center
of the clusterof the cluster– k-medoidsk-medoids or PAM (Partition around medoids): or PAM (Partition around medoids):
Each cluster is represented by one of the objects in Each cluster is represented by one of the objects in the cluster the cluster

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4444
Partitional AlgorithmsPartitional Algorithms
MSTMST
Squared ErrorSquared Error
K-MeansK-Means
Nearest NeighborNearest Neighbor
PAMPAM
BEABEA
GAGA

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4545
MST AlgorithmMST Algorithm

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4646
K-MeansK-MeansInitial set of clusters randomly chosen.Initial set of clusters randomly chosen.
Iteratively, items are moved among sets Iteratively, items are moved among sets of clusters until the desired set is of clusters until the desired set is reached.reached.High degree of similarity among High degree of similarity among elements in a cluster is obtained.elements in a cluster is obtained.
Given a cluster KGiven a cluster Kii={t={ti1i1,t,ti2i2,…,t,…,timim}, the }, the
cluster meancluster mean is m is mii = (1/m)(t = (1/m)(ti1i1 + … + t + … + timim))

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4747
K-Means ExampleK-Means ExampleGiven: {2,4,10,12,3,20,30,11,25}, k=2Given: {2,4,10,12,3,20,30,11,25}, k=2
Randomly assign means: mRandomly assign means: m11=3,m=3,m22=4=4
KK11={2,3}, K={2,3}, K22={4,10,12,20,30,11,25}, ={4,10,12,20,30,11,25}, mm11=2.5,m=2.5,m22=16=16
KK11={2,3,4},K={2,3,4},K22={10,12,20,30,11,25}, m={10,12,20,30,11,25}, m11=3,m=3,m22=18=18
KK11={2,3,4,10},K={2,3,4,10},K22={12,20,30,11,25}, ={12,20,30,11,25}, mm11=4.75,m=4.75,m22=19.6=19.6
KK11={2,3,4,10,11,12},K={2,3,4,10,11,12},K22={20,30,25}, m={20,30,25}, m11=7,m=7,m22=25=25
Stop as the clusters with these means are the Stop as the clusters with these means are the same.same.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4848
The The K-MeansK-Means Clustering Clustering MethodMethod
Given k, the k-means algorithm is implemented in 4 steps:– Partition objects into k nonempty subsets– Compute seed points as the centroids of the
clusters of the current partition. The centroid is the center (mean point) of the cluster.
– Assign each object to the cluster with the nearest seed point.
– Go back to Step 2, stop when no more new assignment.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 4949
Comments on the Comments on the K-MeansK-Means Method MethodStrengthStrength – Relatively efficientRelatively efficient: : OO((tkntkn), where ), where nn is # objects, is # objects, kk is # is #
clusters, and clusters, and t t is # iterations. Normally, is # iterations. Normally, kk, , tt << << nn..– Often terminates at a Often terminates at a local optimumlocal optimum. The . The global optimumglobal optimum
may be found using techniques such as: may be found using techniques such as: deterministic deterministic annealingannealing and and genetic algorithmsgenetic algorithms
WeaknessWeakness– Applicable only when Applicable only when meanmean is defined, then what about is defined, then what about
categorical data?categorical data?– Need to specify Need to specify k, k, the the numbernumber of clusters, in advance of clusters, in advance– Unable to handle noisy data and Unable to handle noisy data and outliersoutliers– Not suitable to discover clusters with Not suitable to discover clusters with non-convex shapesnon-convex shapes

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5050
Nearest NeighborNearest Neighbor
Items are iteratively merged into the Items are iteratively merged into the existing clusters that are closest.existing clusters that are closest.
IncrementalIncremental
Threshold, t, used to determine if items Threshold, t, used to determine if items are added to existing clusters or a new are added to existing clusters or a new cluster is created.cluster is created.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5151
Variations of the Variations of the K-MeansK-Means Method MethodA few variants of the A few variants of the k-meansk-means which differ in which differ in– Selection of the initial Selection of the initial kk means means– Dissimilarity calculationsDissimilarity calculations– Strategies to calculate cluster meansStrategies to calculate cluster means
Handling categorical data: Handling categorical data: k-modesk-modes – Replacing means of clusters with Replacing means of clusters with modesmodes– Using new dissimilarity measures to deal with Using new dissimilarity measures to deal with
categorical objectscategorical objects– Using a Using a frequencyfrequency-based method to update modes of -based method to update modes of
clustersclusters– A mixture of categorical and numerical data: A mixture of categorical and numerical data: k-prototypek-prototype
methodmethod

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5252
TheThe K K--MedoidsMedoids Clustering MethodClustering Method
Find Find representativerepresentative objects, called objects, called medoidsmedoids, in clusters, in clusters
PAMPAM (Partitioning Around Medoids,) (Partitioning Around Medoids,)
– starts from an initial set of medoids and iteratively starts from an initial set of medoids and iteratively replaces one of the medoids by one of the non-replaces one of the medoids by one of the non-medoids if it improves the total distance of the resulting medoids if it improves the total distance of the resulting clusteringclustering
– PAMPAM works effectively for small data sets, but does not works effectively for small data sets, but does not scale well for large data setsscale well for large data sets
CLARACLARA
CLARANSCLARANS): Randomized sampling Focusing + spatial ): Randomized sampling Focusing + spatial data structuredata structure

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5353
PAM (Partitioning Around Medoids)PAM (Partitioning Around Medoids)
PAM - Use real object to represent the clusterPAM - Use real object to represent the cluster
– Select Select kk representative objects arbitrarily representative objects arbitrarily
– For each pair of non-selected object For each pair of non-selected object hh and selected and selected
object object ii, calculate the total swapping cost , calculate the total swapping cost TCTCihih
– For each pair of For each pair of ii and and hh, ,
If If TCTCihih < 0, < 0, ii is replaced by is replaced by hh
Then assign each non-selected object to the most Then assign each non-selected object to the most
similar representative objectsimilar representative object
– repeat steps 2-3 until there is no changerepeat steps 2-3 until there is no change

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5454
PAMPAM
Partitioning Around Medoids (PAM) Partitioning Around Medoids (PAM) (K-Medoids)(K-Medoids)Handles outliers well.Handles outliers well.Ordering of input does not impact results.Ordering of input does not impact results.Does not scale well.Does not scale well.Each cluster represented by one item, Each cluster represented by one item, called the called the medoid.medoid.Initial set of k medoids randomly chosen.Initial set of k medoids randomly chosen.

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5555
PAMPAM

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5656
PAM AlgorithmPAM Algorithm

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5757
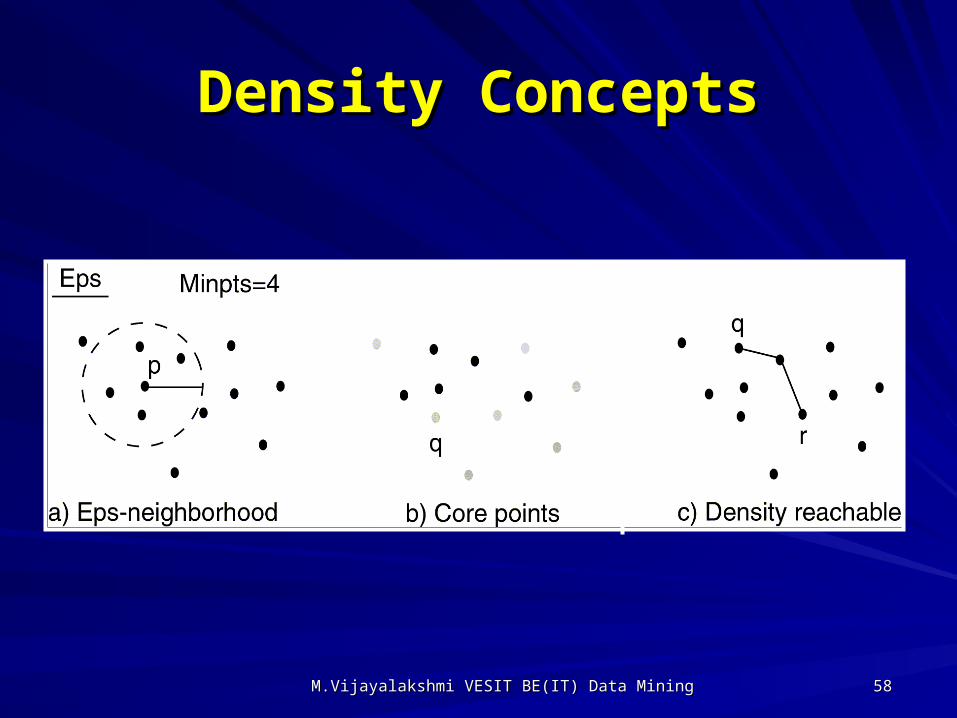
DBSCANDBSCAN
Density Based Spatial Clustering of Density Based Spatial Clustering of Applications with NoiseApplications with NoiseOutliers will not effect creation of cluster.Outliers will not effect creation of cluster.InputInput– MinPts MinPts – minimum number of points in – minimum number of points in
clustercluster– EpsEps – for each point in cluster there must – for each point in cluster there must
be another point in it less than this distance be another point in it less than this distance away.away.
M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5858
Density ConceptsDensity Concepts

M.Vijayalakshmi VESIT BE(IT) Data MiningM.Vijayalakshmi VESIT BE(IT) Data Mining 5959
Comparison of Clustering Comparison of Clustering TechniquesTechniques





























