Embed Size (px)
Citation preview

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
ICS 278: Data Mining
Lecture 14: Document Clustering and Topic Extraction
Padhraic SmythDepartment of Information and Computer Science
University of California, Irvine

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Text Mining
• Information Retrieval
• Text Classification
• Text Clustering
• Information Extraction

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Document Clustering
• Set of documents D in term-vector form– no class labels this time– want to group the documents into K groups or into a taxonomy– Each cluster hypothetically corresponds to a “topic”
• Methods:– Any of the well-known clustering methods– K-means
• E.g., “spherical k-means”, normalize document distances
– Hierarchical clustering– Probabilistic model-based clustering methods
• e.g., mixtures of multinomials
• Single-topic versus multiple-topic models– Extensions to author-topic models

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
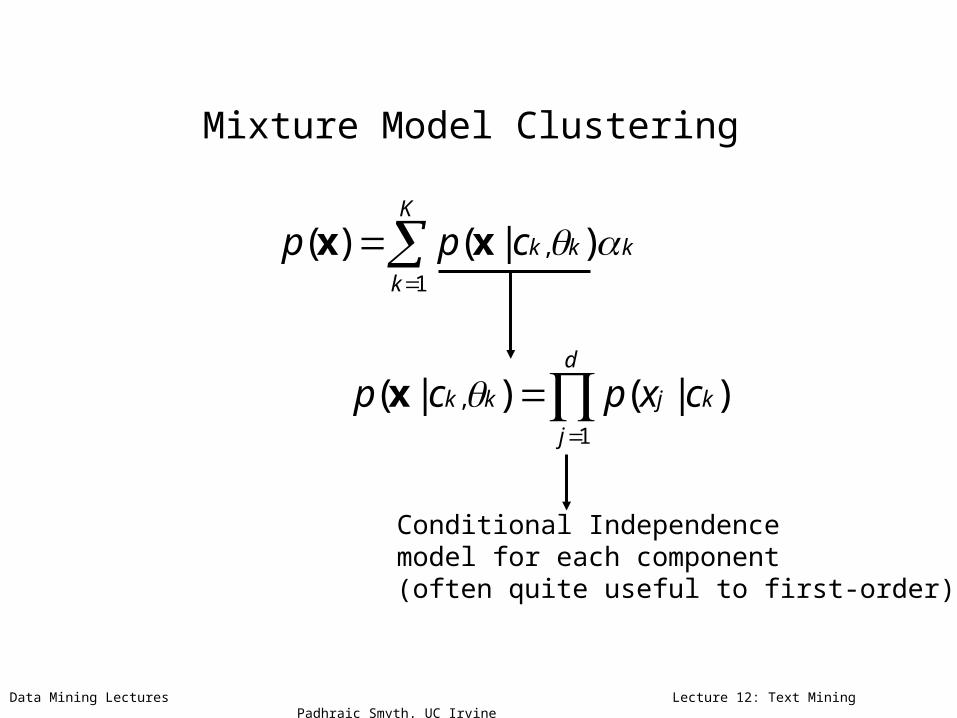
Mixture Model Clustering
k
K
k
kkcpp
1
, )|()( xx

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Mixture Model Clustering
k
K
k
kkcpp
1
, )|()( xx
d
j
kjkk cxpcp1
, )|()|( x
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Mixture Model Clustering
k
K
k
kkcpp
1
, )|()( xx
d
j
kjkk cxpcp1
, )|()|( x
Conditional Independencemodel for each component(often quite useful to first-order)
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
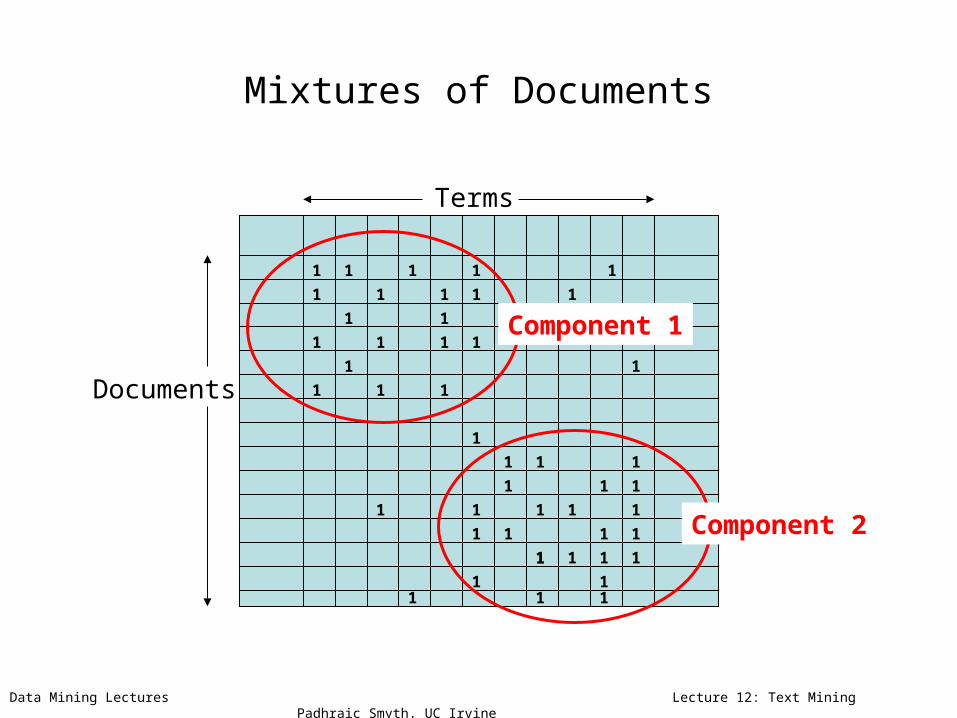
Mixtures of Documents
1 1 1 1
1 1 1 11
1
1 1 1
1
11
1 1 1
1
1
1
1 1
1
1
11 1 1
1
1
1
1
1
1
1
1 1 1
1
1
1
Terms
Documents
1
1
1
1
Component 1
Component 2
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1 1 1 1
1 1 1 11
1
1 1 1
1
11
1 1 1
1
1
1
1 1
1
1
11 1 1
1
1
1
1
1
1
1
1 1 1
1
1
1
Terms
Documents
1
1
1
1
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1 1 1 1
1 1 1 11
1
1 1 1
1
11
1 1 1
1
1
1
1 1
1
1
11 1 1
1
1
1
1
1
1
1
1 1 1
1
1
1
Terms
Documents
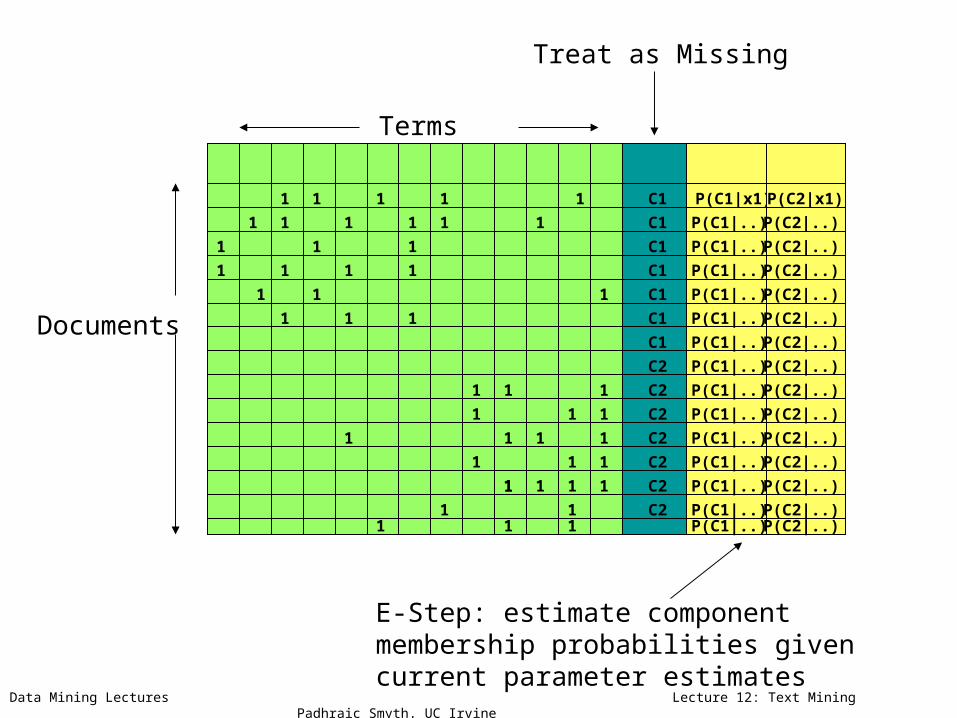
C1
C1
C1
C1
C1
C1
C1
C2
C2
C2
C2
C2
C2
C2
1
1
1
1
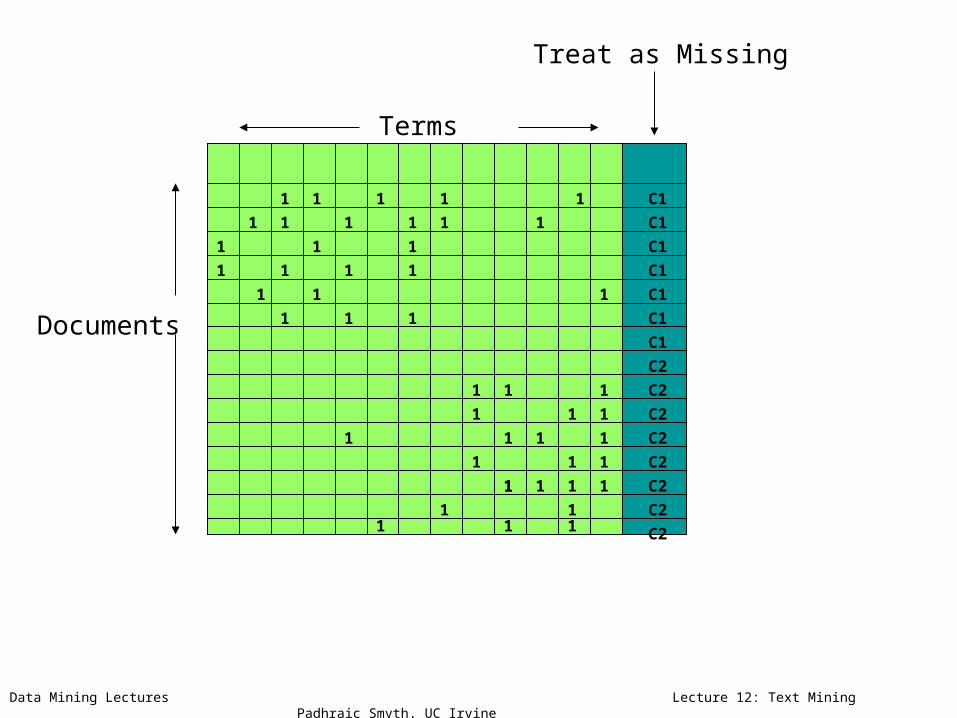
Treat as Missing
C2
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1 1 1 1
1 1 1 11
1
1 1 1
1
11
1 1 1
1
1
1
1 1
1
1
11 1 1
1
1
1
1
1
1
1
1 1 1
1
1
1
Terms
Documents
C1
C1
C1
C1
C1
C1
C1
C2
C2
C2
C2
C2
C2
C2
1
1
1
1
Treat as Missing
P(C1|x1)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)P(C1|..)
P(C2|x1)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)P(C2|..)
E-Step: estimate componentmembership probabilities given current parameter estimates
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1 1 1 1
1 1 1 11
1
1 1 1
1
11
1 1 1
1
1
1
1 1
1
1
11 1 1
1
1
1
1
1
1
1
1 1 1
1
1
1
Terms
Documents
C1
C1
C1
C1
C1
C1
C1
C2
C2
C2
C2
C2
C2
C2
1
1
1
1
Treat as Missing
P(C1|x1)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)
P(C1|..)P(C1|..)
P(C2|x1)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)
P(C2|..)P(C2|..)
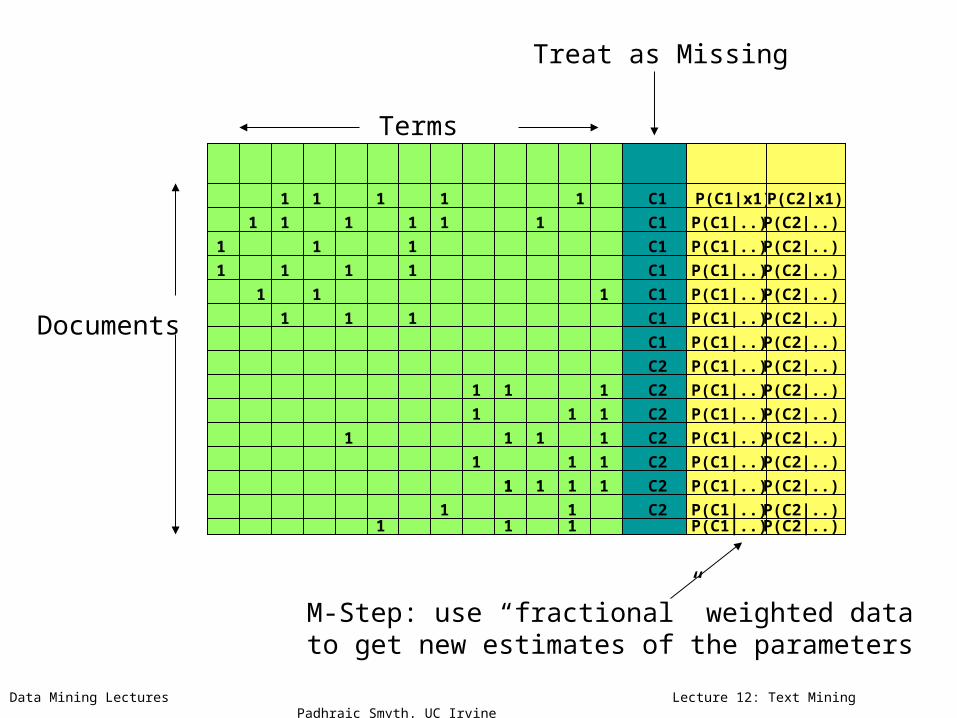
M-Step: use “fractional” weighted datato get new estimates of the parameters
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
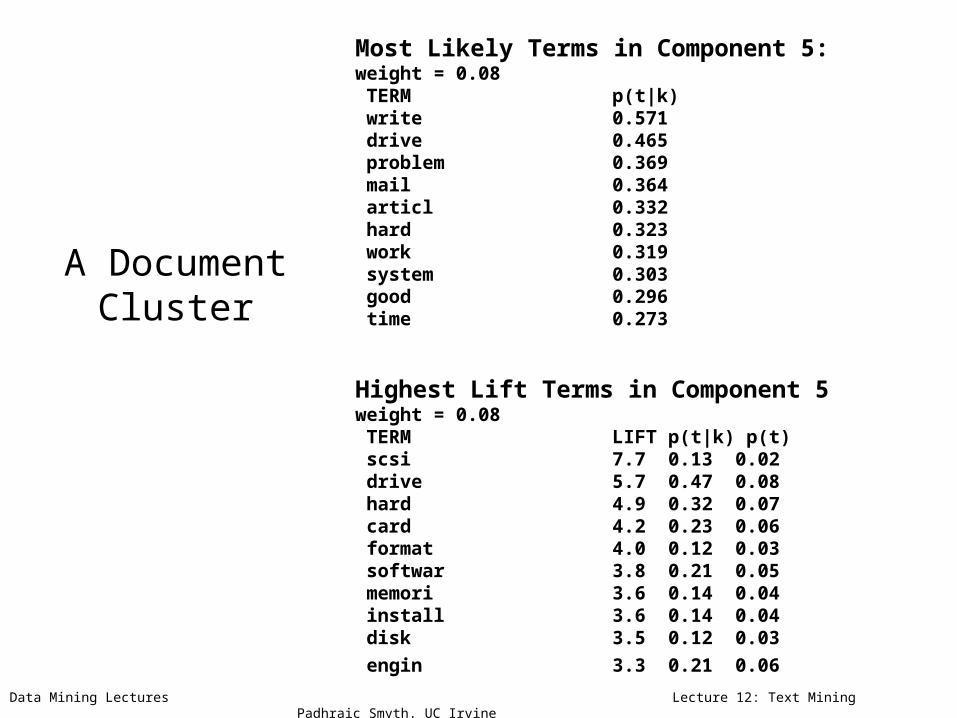
A Document Cluster
Most Likely Terms in Component 5: weight = 0.08 TERM p(t|k) write 0.571 drive 0.465 problem 0.369 mail 0.364 articl 0.332 hard 0.323 work 0.319 system 0.303 good 0.296 time 0.273
Highest Lift Terms in Component 5 weight = 0.08 TERM LIFT p(t|k) p(t) scsi 7.7 0.13 0.02 drive 5.7 0.47 0.08 hard 4.9 0.32 0.07 card 4.2 0.23 0.06 format 4.0 0.12 0.03 softwar 3.8 0.21 0.05 memori 3.6 0.14 0.04 install 3.6 0.14 0.04 disk 3.5 0.12 0.03
engin 3.3 0.21 0.06
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
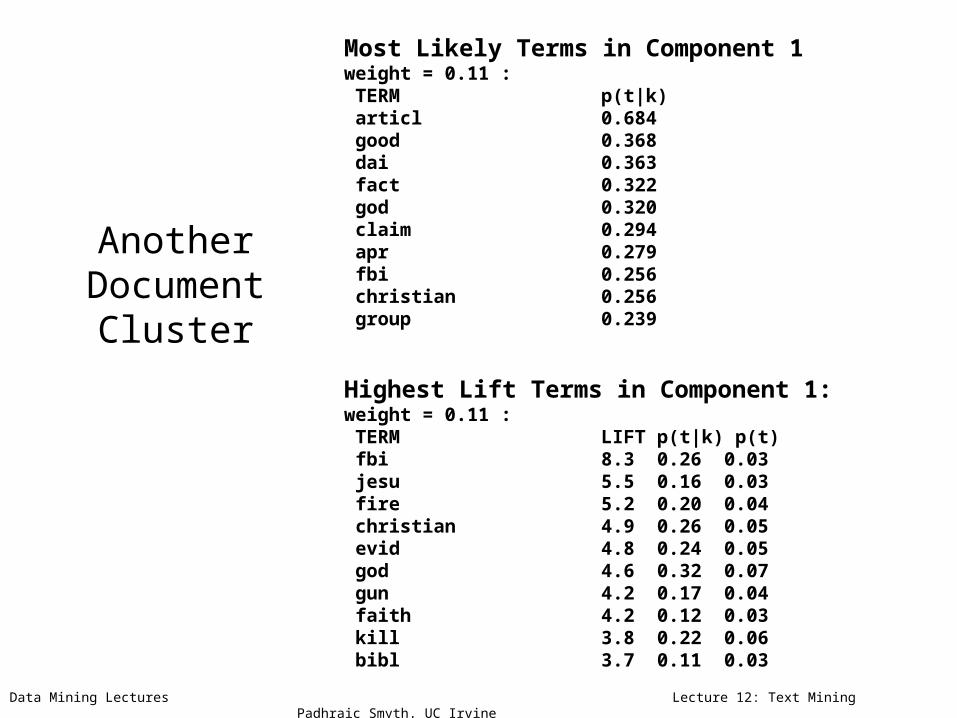
Another Document
Cluster
Most Likely Terms in Component 1weight = 0.11 : TERM p(t|k) articl 0.684 good 0.368 dai 0.363 fact 0.322 god 0.320 claim 0.294 apr 0.279 fbi 0.256 christian 0.256 group 0.239
Highest Lift Terms in Component 1: weight = 0.11 : TERM LIFT p(t|k) p(t) fbi 8.3 0.26 0.03 jesu 5.5 0.16 0.03 fire 5.2 0.20 0.04 christian 4.9 0.26 0.05 evid 4.8 0.24 0.05 god 4.6 0.32 0.07 gun 4.2 0.17 0.04 faith 4.2 0.12 0.03 kill 3.8 0.22 0.06 bibl 3.7 0.11 0.03

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
A topic is represented as a (multinomial) distribution over words
SPEECH .0691 WORDS .0671 RECOGNITION .0412 WORD .0557
SPEAKER .0288 USER .0230 PHONEME .0224 DOCUMENTS .0205
CLASSIFICATION .0154 TEXT .0195 SPEAKERS .0140 RETRIEVAL .0152
FRAME .0135 INFORMATION .0144 PHONETIC .0119 DOCUMENT .0144
PERFORMANCE .0111 LARGE .0102 ACOUSTIC .0099 COLLECTION .0098
BASED .0098 KNOWLEDGE .0087 PHONEMES .0091 MACHINE .0080
UTTERANCES .0091 RELEVANT .0077 SET .0089 SEMANTIC .0076
LETTER .0088 SIMILARITY .0071
… …
Example topic #1 Example topic #2
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
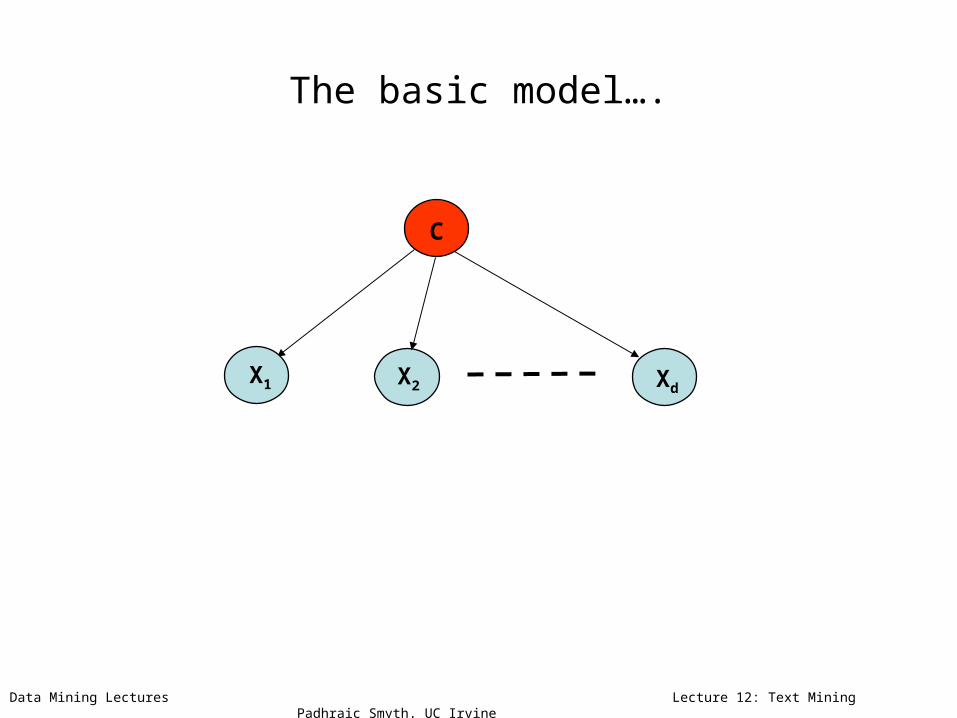
The basic model….
C
X1 X2 Xd
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
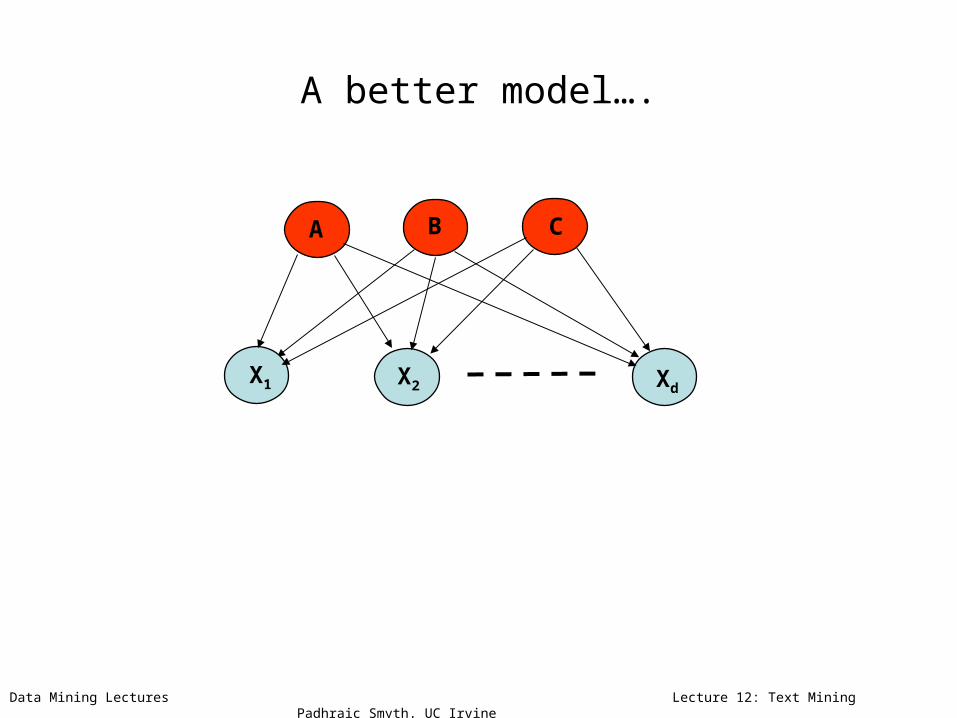
A better model….
A
X1 X2 Xd
B C
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
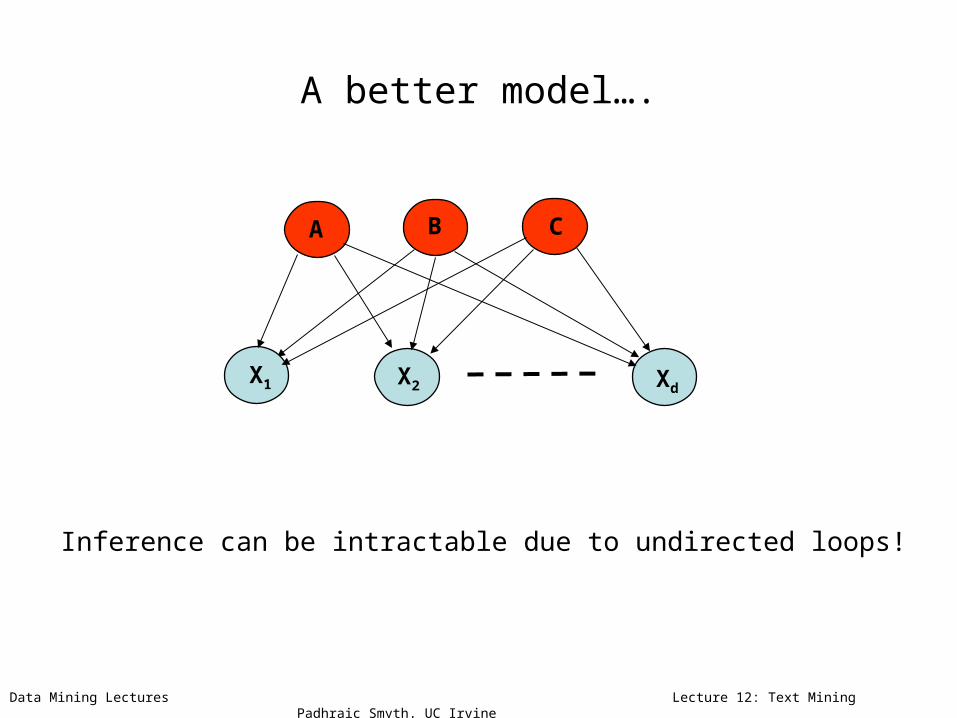
A better model….
A
X1 X2 Xd
B C
Inference can be intractable due to undirected loops!

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
A better model for documents….
• Multi-topic model– A document is generated from multiple components
– Multiple components can be active at once
– Each component = multinomial distribution
– Parameter estimation is tricky
– Very useful: • “parses” into high-level semantic components
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
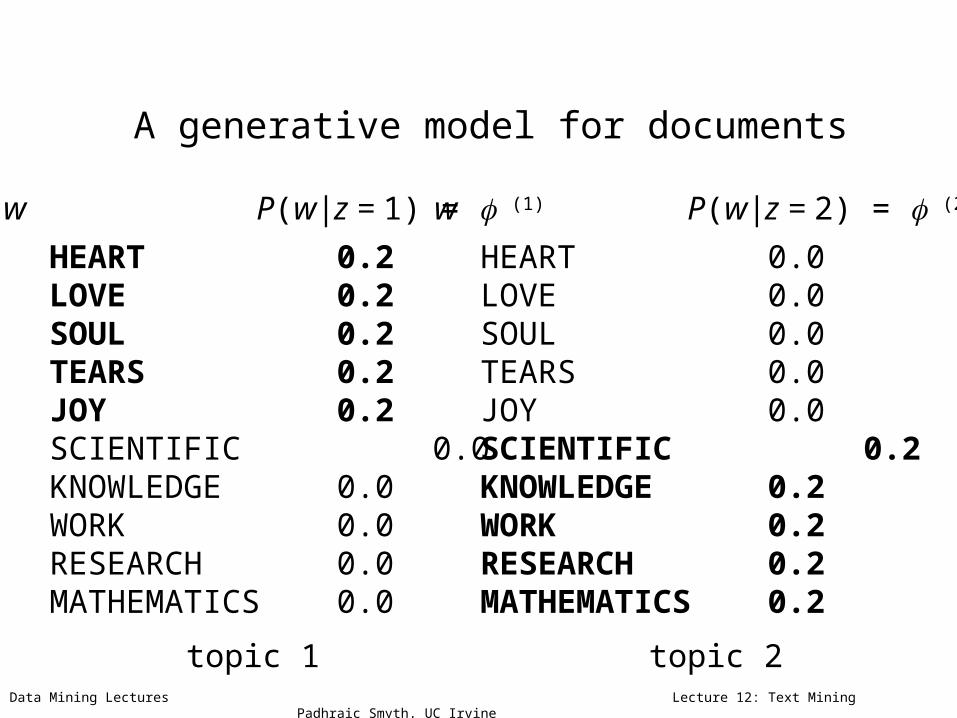
A generative model for documents
HEART 0.2 LOVE 0.2SOUL 0.2TEARS 0.2JOY 0.2SCIENTIFIC 0.0KNOWLEDGE 0.0WORK 0.0RESEARCH 0.0MATHEMATICS 0.0
HEART 0.0 LOVE 0.0SOUL 0.0TEARS 0.0JOY 0.0 SCIENTIFIC 0.2KNOWLEDGE 0.2WORK 0.2RESEARCH 0.2MATHEMATICS 0.2
topic 1 topic 2
w P(w|z = 1) = (1) w P(w|z = 2) = (2)

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Choose mixture weights for each document, generate “bag of words”
= {P(z = 1), P(z = 2)}
{0, 1}
{0.25, 0.75}
{0.5, 0.5}
{0.75, 0.25}
{1, 0}
MATHEMATICS KNOWLEDGE RESEARCH WORK MATHEMATICS RESEARCH WORK SCIENTIFIC MATHEMATICS WORK
SCIENTIFIC KNOWLEDGE MATHEMATICS SCIENTIFIC HEART LOVE TEARS KNOWLEDGE HEART
MATHEMATICS HEART RESEARCH LOVE MATHEMATICS WORK TEARS SOUL KNOWLEDGE HEART
WORK JOY SOUL TEARS MATHEMATICS TEARS LOVE LOVE LOVE SOUL
TEARS LOVE JOY SOUL LOVE TEARS SOUL SOUL TEARS JOY
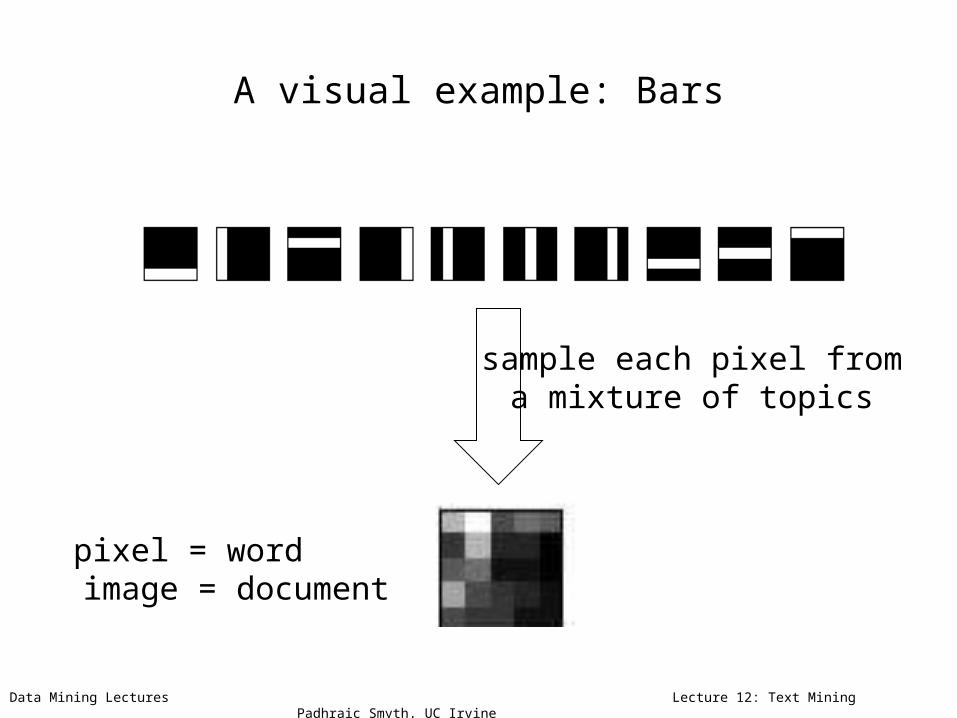
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
pixel = word image = document
sample each pixel froma mixture of topics
A visual example: Bars

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
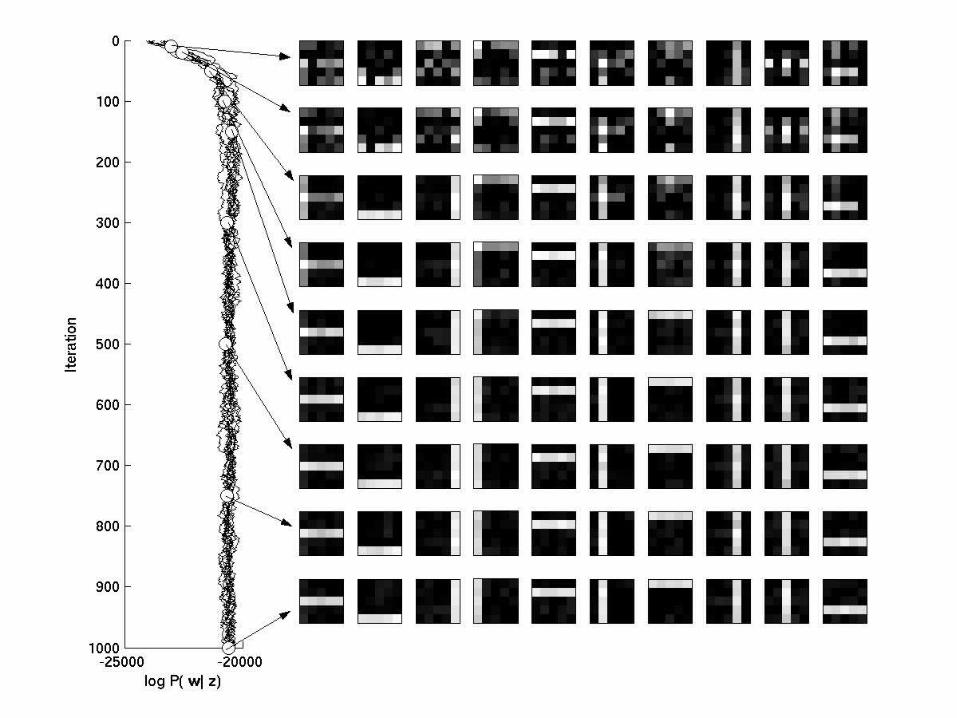
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Interpretable decomposition
• SVD gives a basis for the data, but not an interpretable one
• The true basis is not orthogonal, so rotation does no good
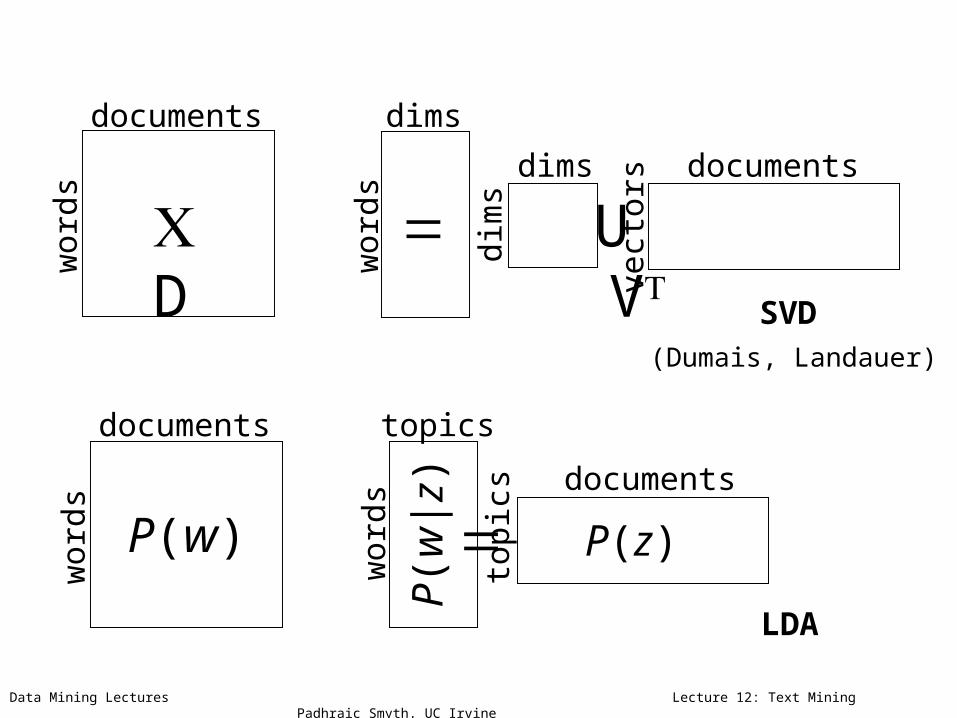
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
wor
ds
documents
U D V
wor
ds
dims
dims
dim
s
vect
ors documents
SVD
wor
ds
documents
wor
ds
topics
topi
csdocuments
LDA
P(w
|z)
P(z)P(w)
(Dumais, Landauer)

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
History of multi-topic models
• Latent class models in statistics• Hoffman 1999
– Original application to documents
• Blei, Ng, and Jordan (2001, 2003)– Variational methods
• Griffiths and Steyvers (2003)– Gibbs sampling approach (very efficient)
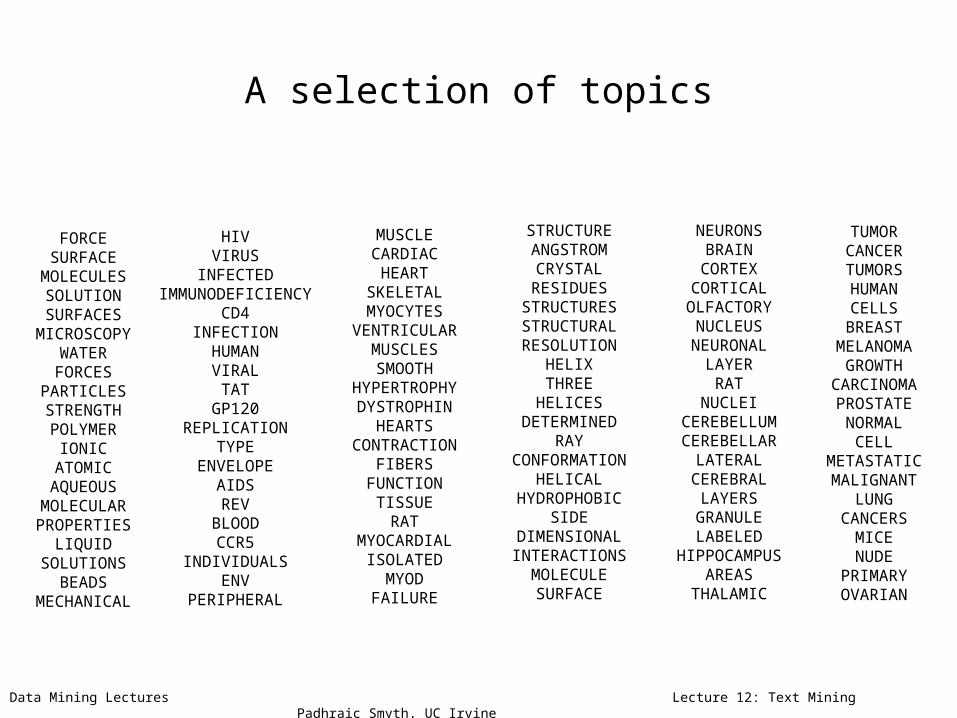
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
FORCESURFACE
MOLECULESSOLUTIONSURFACES
MICROSCOPYWATERFORCES
PARTICLESSTRENGTHPOLYMER
IONICATOMIC
AQUEOUSMOLECULARPROPERTIES
LIQUIDSOLUTIONS
BEADSMECHANICAL
HIVVIRUS
INFECTEDIMMUNODEFICIENCY
CD4INFECTION
HUMANVIRAL
TATGP120
REPLICATIONTYPE
ENVELOPEAIDSREV
BLOODCCR5
INDIVIDUALSENV
PERIPHERAL
MUSCLECARDIAC
HEARTSKELETALMYOCYTES
VENTRICULARMUSCLESSMOOTH
HYPERTROPHYDYSTROPHIN
HEARTSCONTRACTION
FIBERSFUNCTION
TISSUERAT
MYOCARDIALISOLATED
MYODFAILURE
STRUCTUREANGSTROM
CRYSTALRESIDUES
STRUCTURESSTRUCTURALRESOLUTION
HELIXTHREE
HELICESDETERMINED
RAYCONFORMATION
HELICALHYDROPHOBIC
SIDEDIMENSIONALINTERACTIONS
MOLECULESURFACE
NEURONSBRAIN
CORTEXCORTICAL
OLFACTORYNUCLEUS
NEURONALLAYER
RATNUCLEI
CEREBELLUMCEREBELLAR
LATERALCEREBRAL
LAYERSGRANULELABELED
HIPPOCAMPUSAREAS
THALAMIC
A selection of topics
TUMORCANCERTUMORSHUMANCELLS
BREASTMELANOMA
GROWTHCARCINOMA
PROSTATENORMAL
CELLMETASTATICMALIGNANT
LUNGCANCERS
MICENUDE
PRIMARYOVARIAN
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
PARASITEPARASITES
FALCIPARUMMALARIA
HOSTPLASMODIUM
ERYTHROCYTESERYTHROCYTE
MAJORLEISHMANIA
INFECTEDBLOOD
INFECTIONMOSQUITOINVASION
TRYPANOSOMACRUZI
BRUCEIHUMANHOSTS
ADULTDEVELOPMENT
FETALDAY
DEVELOPMENTALPOSTNATAL
EARLYDAYS
NEONATALLIFE
DEVELOPINGEMBRYONIC
BIRTHNEWBORN
MATERNALPRESENTPERIOD
ANIMALSNEUROGENESIS
ADULTS
CHROMOSOMEREGION
CHROMOSOMESKB
MAPMAPPING
CHROMOSOMALHYBRIDIZATION
ARTIFICIALMAPPED
PHYSICALMAPS
GENOMICDNA
LOCUSGENOME
GENEHUMAN
SITUCLONES
MALEFEMALEMALES
FEMALESSEX
SEXUALBEHAVIOROFFSPRING
REPRODUCTIVEMATINGSOCIALSPECIES
REPRODUCTIONFERTILITY
TESTISMATE
GENETICGERM
CHOICESRY
STUDIESPREVIOUS
SHOWNRESULTSRECENTPRESENT
STUDYDEMONSTRATED
INDICATEWORK
SUGGESTSUGGESTED
USINGFINDINGS
DEMONSTRATEREPORT
INDICATEDCONSISTENT
REPORTSCONTRAST
A selection of topics
MECHANISMMECHANISMSUNDERSTOOD
POORLYACTION
UNKNOWNREMAIN
UNDERLYINGMOLECULAR
PSREMAINS
SHOWRESPONSIBLE
PROCESSSUGGESTUNCLEARREPORT
LEADINGLARGELYKNOWN
MODELMODELS
EXPERIMENTALBASED
PROPOSEDDATA
SIMPLEDYNAMICSPREDICTED
EXPLAINBEHAVIOR
THEORETICALACCOUNTTHEORY
PREDICTSCOMPUTER
QUANTITATIVEPREDICTIONSCONSISTENT
PARAMETERS
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
PARASITEPARASITES
FALCIPARUMMALARIA
HOSTPLASMODIUM
ERYTHROCYTESERYTHROCYTE
MAJORLEISHMANIA
INFECTEDBLOOD
INFECTIONMOSQUITOINVASION
TRYPANOSOMACRUZI
BRUCEIHUMANHOSTS
ADULTDEVELOPMENT
FETALDAY
DEVELOPMENTALPOSTNATAL
EARLYDAYS
NEONATALLIFE
DEVELOPINGEMBRYONIC
BIRTHNEWBORN
MATERNALPRESENTPERIOD
ANIMALSNEUROGENESIS
ADULTS
CHROMOSOMEREGION
CHROMOSOMESKB
MAPMAPPING
CHROMOSOMALHYBRIDIZATION
ARTIFICIALMAPPED
PHYSICALMAPS
GENOMICDNA
LOCUSGENOME
GENEHUMAN
SITUCLONES
MALEFEMALEMALES
FEMALESSEX
SEXUALBEHAVIOROFFSPRING
REPRODUCTIVEMATINGSOCIALSPECIES
REPRODUCTIONFERTILITY
TESTISMATE
GENETICGERM
CHOICESRY
STUDIESPREVIOUS
SHOWNRESULTSRECENTPRESENT
STUDYDEMONSTRATED
INDICATEWORK
SUGGESTSUGGESTED
USINGFINDINGS
DEMONSTRATEREPORT
INDICATEDCONSISTENT
REPORTSCONTRAST
A selection of topics
MECHANISMMECHANISMSUNDERSTOOD
POORLYACTION
UNKNOWNREMAIN
UNDERLYINGMOLECULAR
PSREMAINS
SHOWRESPONSIBLE
PROCESSSUGGESTUNCLEARREPORT
LEADINGLARGELYKNOWN
MODELMODELS
EXPERIMENTALBASED
PROPOSEDDATA
SIMPLEDYNAMICSPREDICTED
EXPLAINBEHAVIOR
THEORETICALACCOUNTTHEORY
PREDICTSCOMPUTER
QUANTITATIVEPREDICTIONSCONSISTENT
PARAMETERS
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
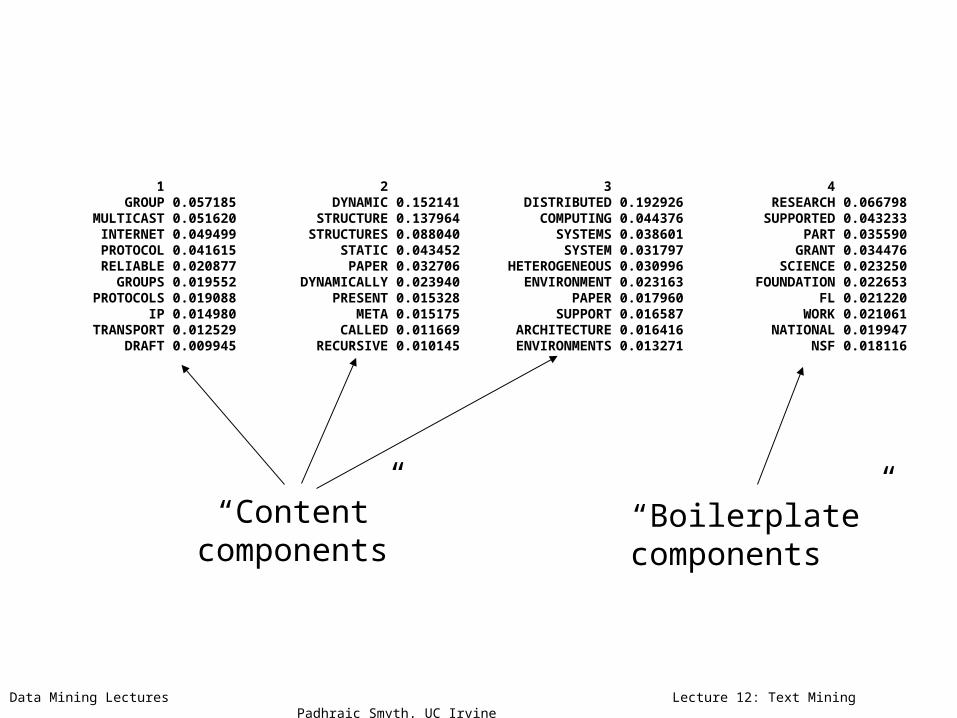
1 2 3 4 GROUP 0.057185 DYNAMIC 0.152141 DISTRIBUTED 0.192926 RESEARCH 0.066798 MULTICAST 0.051620 STRUCTURE 0.137964 COMPUTING 0.044376 SUPPORTED 0.043233 INTERNET 0.049499 STRUCTURES 0.088040 SYSTEMS 0.038601 PART 0.035590 PROTOCOL 0.041615 STATIC 0.043452 SYSTEM 0.031797 GRANT 0.034476 RELIABLE 0.020877 PAPER 0.032706 HETEROGENEOUS 0.030996 SCIENCE 0.023250 GROUPS 0.019552 DYNAMICALLY 0.023940 ENVIRONMENT 0.023163 FOUNDATION 0.022653 PROTOCOLS 0.019088 PRESENT 0.015328 PAPER 0.017960 FL 0.021220 IP 0.014980 META 0.015175 SUPPORT 0.016587 WORK 0.021061 TRANSPORT 0.012529 CALLED 0.011669 ARCHITECTURE 0.016416 NATIONAL 0.019947 DRAFT 0.009945 RECURSIVE 0.010145 ENVIRONMENTS 0.013271 NSF 0.018116
“Content” components
“Boilerplate” components

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
5 6 7 8 DIMENSIONAL 0.038901 RULES 0.090569 ORDER 0.192759 GRAPH 0.095687 POINTS 0.037263 CLASSIFICATION 0.062699 TERMS 0.048688 PATH 0.061784 SURFACE 0.031438 RULE 0.062174 PARTIAL 0.044907 GRAPHS 0.061217 GEOMETRIC 0.025006 ACCURACY 0.028926 HIGHER 0.041284 PATHS 0.030151 SURFACES 0.020152 ATTRIBUTES 0.023090 REDUCTION 0.035061 EDGE 0.028590 MESH 0.016875 INDUCTION 0.021909 PAPER 0.028602 NUMBER 0.022775 PLANE 0.013902 CLASSIFIER 0.019418 TERM 0.018204 CONNECTED 0.016817 POINT 0.013780 SET 0.018303 ORDERING 0.017652 DIRECTED 0.014405 GEOMETRY 0.013780 ATTRIBUTE 0.016204 SHOW 0.017022 NODES 0.013625 PLANAR 0.012385 CLASSIFIERS 0.015417 MAGNITUDE 0.015526 VERTICES 0.013554
9 10 11 12 INFORMATION 0.281237 SYSTEM 0.143873 PAPER 0.077870 LANGUAGE 0.158786 TEXT 0.048675 FILE 0.054076 CONDITIONS 0.041187 PROGRAMMING 0.097186 RETRIEVAL 0.044046 OPERATING 0.053963 CONCEPT 0.036268 LANGUAGES 0.082410 SOURCES 0.029548 STORAGE 0.039072 CONCEPTS 0.033457 FUNCTIONAL 0.032815 DOCUMENT 0.029000 DISK 0.029957 DISCUSSED 0.027414 SEMANTICS 0.027003 DOCUMENTS 0.026503 SYSTEMS 0.029221 DEFINITION 0.024673 SEMANTIC 0.024341 RELEVANT 0.018523 KERNEL 0.028655 ISSUES 0.024603 NATURAL 0.016410 CONTENT 0.016574 ACCESS 0.018293 PROPERTIES 0.021511 CONSTRUCTS 0.014129 AUTOMATICALLY 0.009326 MANAGEMENT 0.017218 IMPORTANT 0.021370 GRAMMAR 0.013640 DIGITAL 0.008777 UNIX 0.016878 EXAMPLES 0.019754 LISP 0.010326

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
13 14 15 16 MODEL 0.429185 PAPER 0.050411 TYPE 0.088650 KNOWLEDGE 0.212603 MODELS 0.201810 APPROACHES 0.045245 SPECIFICATION 0.051469 SYSTEM 0.090852 MODELING 0.066311 PROPOSED 0.043132 TYPES 0.046571 SYSTEMS 0.051978 QUALITATIVE 0.018417 CHANGE 0.040393 FORMAL 0.036892 BASE 0.042277 COMPLEX 0.009272 BELIEF 0.025835 VERIFICATION 0.029987 EXPERT 0.020172 QUANTITATIVE 0.005662 ALTERNATIVE 0.022470 SPECIFICATIONS 0.024439 ACQUISITION 0.017816 CAPTURE 0.005301 APPROACH 0.020905 CHECKING 0.024439 DOMAIN 0.016638 MODELED 0.005301 ORIGINAL 0.019026 SYSTEM 0.023259 INTELLIGENT 0.015737 ACCURATELY 0.004639 SHOW 0.017852 PROPERTIES 0.018242 BASES 0.015390 REALISTIC 0.004278 PROPOSE 0.016991 ABSTRACT 0.016826 BASED 0.014004
“Style” components

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Recent Results on Author-Topic Models

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
A k
w 3 w N
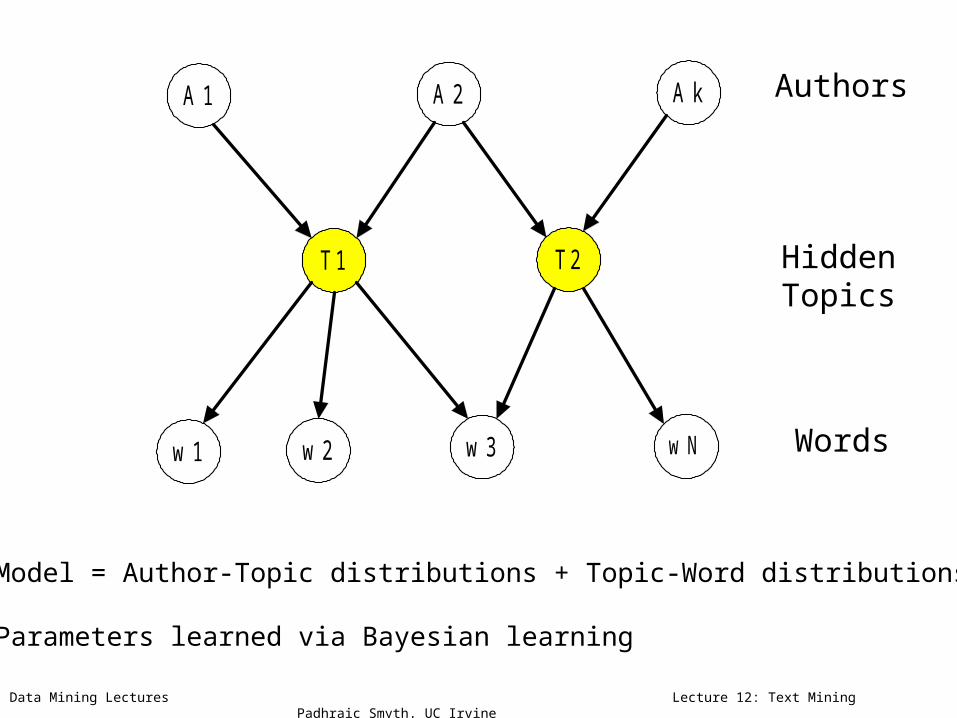
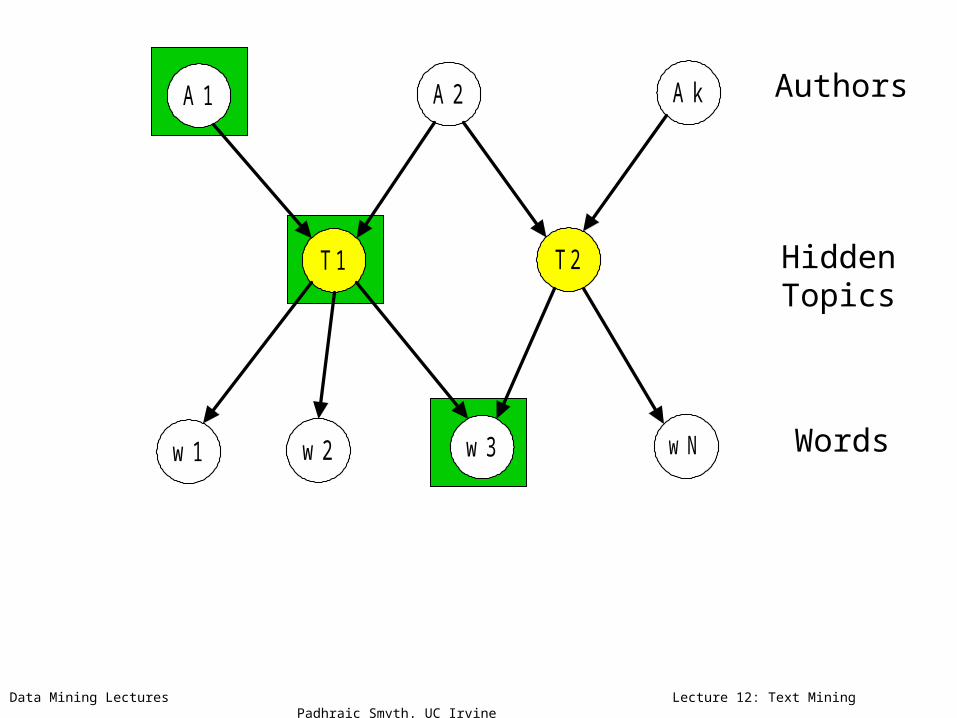
Authors
Words
Can we model authors, given documents?
(more generally, build statistical profiles of entitiesgiven sparse observed data)
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics
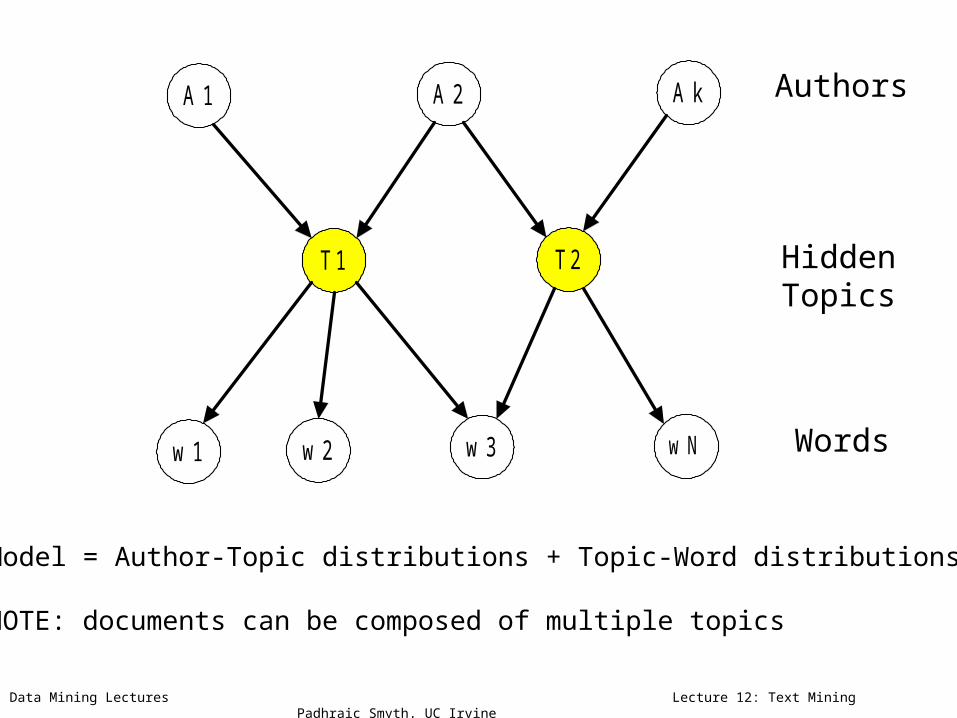
Model = Author-Topic distributions + Topic-Word distributions
Parameters learned via Bayesian learning
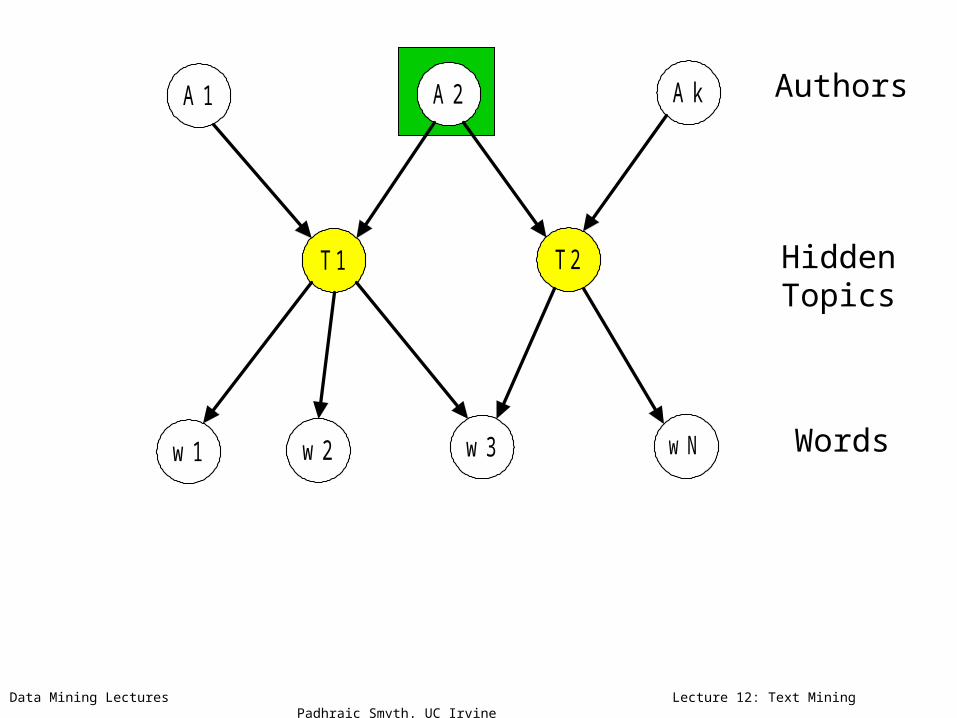
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics
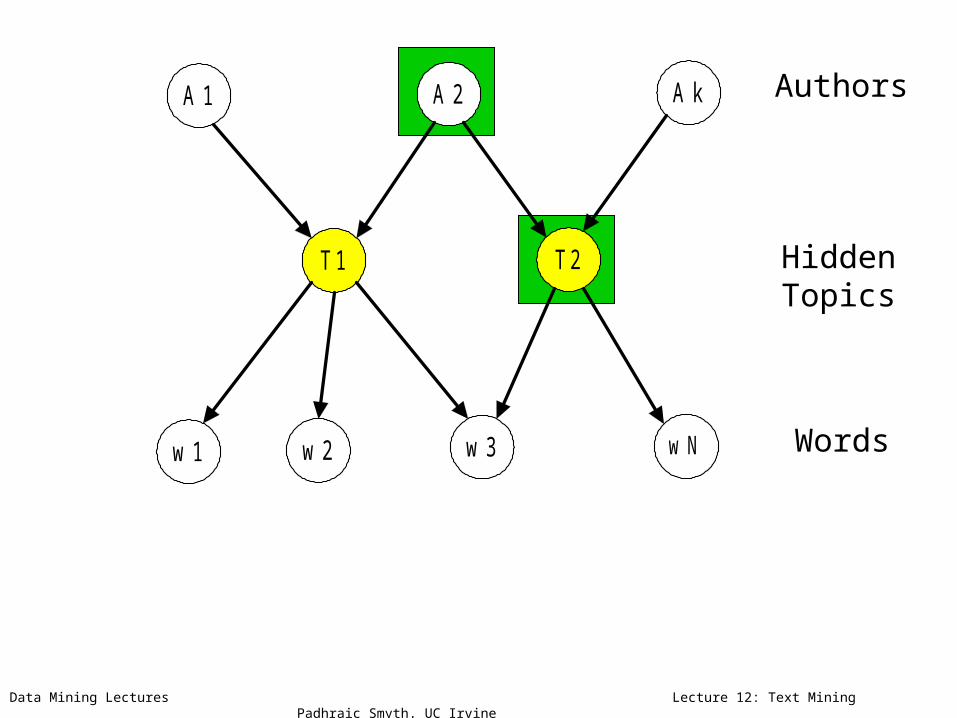
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics
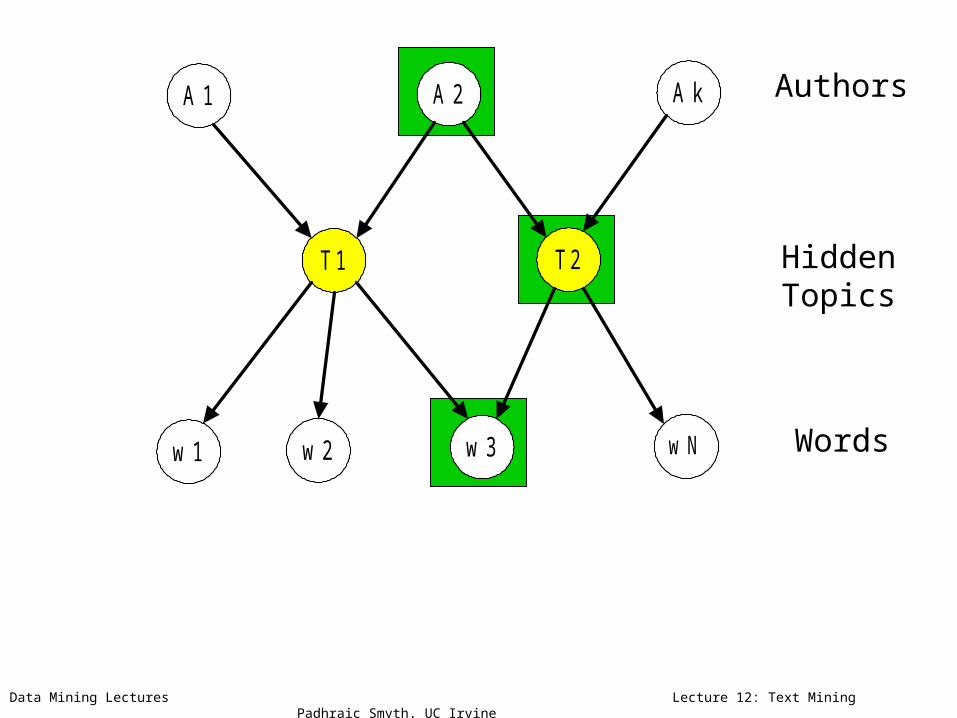
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics
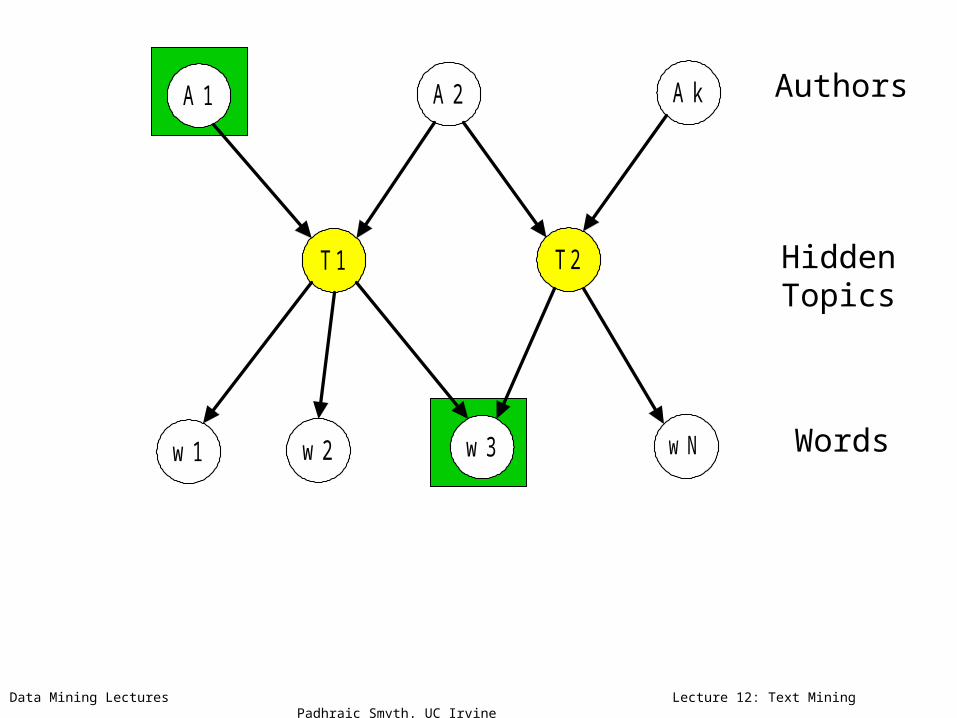
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1 w 2
T1
w 3 w N
T2
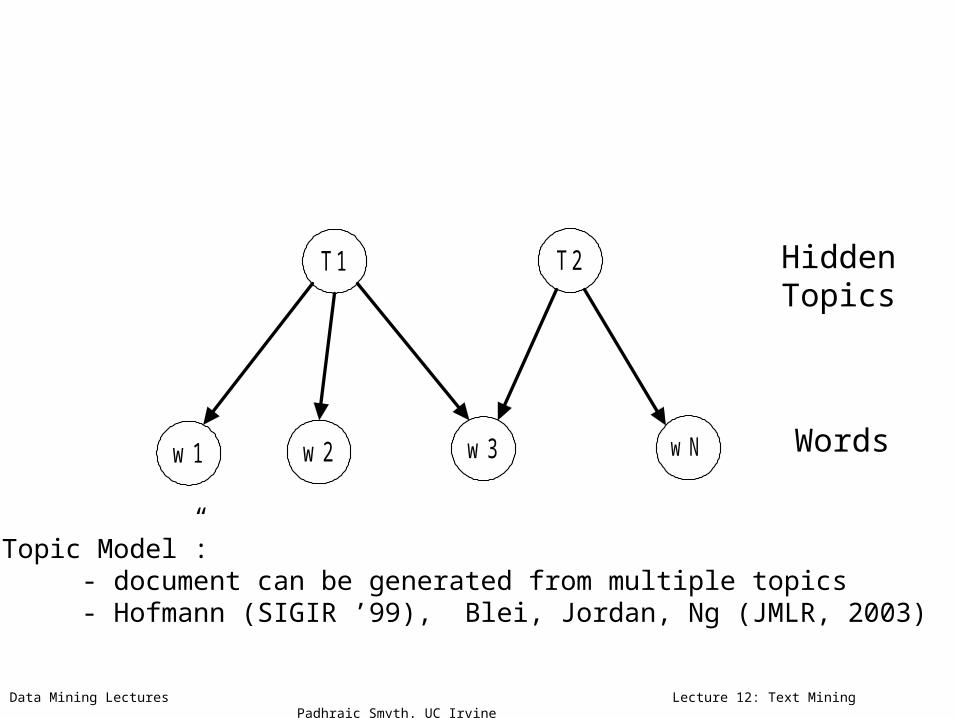
“Topic Model”:- document can be generated from multiple topics- Hofmann (SIGIR ’99), Blei, Jordan, Ng (JMLR, 2003)
Words
HiddenTopics
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
w 1
A 1 A 2
w 2
T1
A k
w 3 w N
T2
Authors
Words
HiddenTopics
Model = Author-Topic distributions + Topic-Word distributions
NOTE: documents can be composed of multiple topics

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
The Author-Topic Model: Assumptions of Generative Model
• Each author is associated with a topics mixture
• Each document is a mixture of topics
• With multiple authors, the document will be a mixture of the topics mixtures of the coauthors
• Each word in a text is generated from one topic and one author (potentially different for each word)

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Generative Process
• Let’s assume authors A1 and A2 collaborate and produce a paper– A1 has multinomial topic distribution
– A2 has multinomial topic distribution
• For each word in the paper:
1. Sample an author x (uniformly) from A1, A2
2. Sample a topic z from a X
3. Sample a word w from a multinomial topic distribution z
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
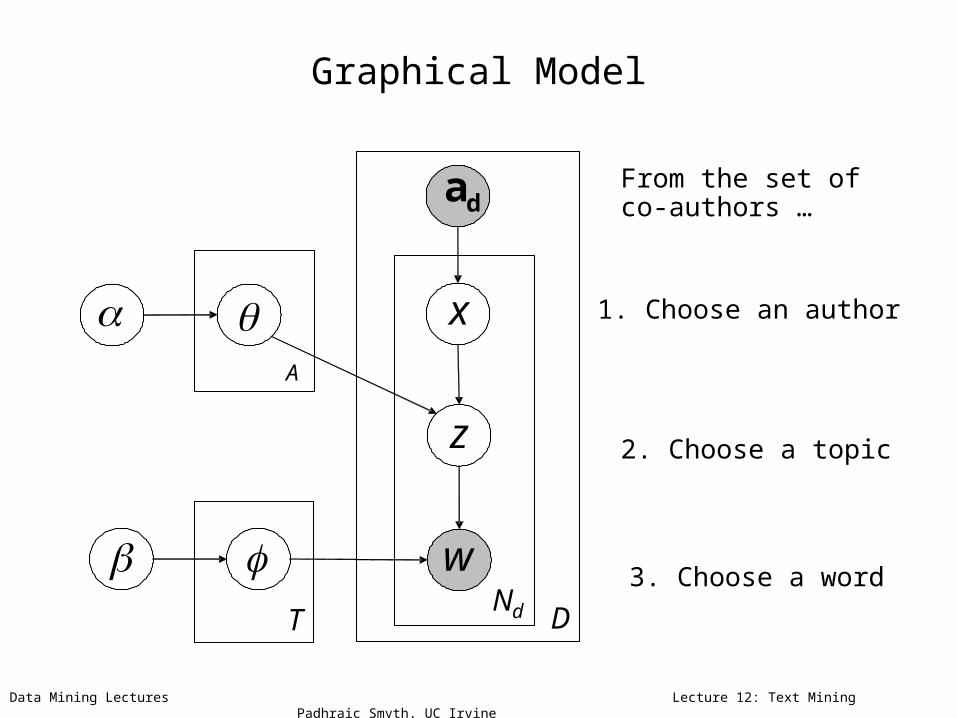
Graphical Model
1. Choose an author
2. Choose a topic
3. Choose a word
From the set of co-authors …
x
z
w
D
A
T
da
Nd

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Data
• 1700 proceedings papers from NIPS (2000+ authors)(NIPS = Neural Information Processing Systems)
• 160,000 CiteSeer abstracts (85,000+ authors)
• Removed stop words
• Word order is irrelevant, just use word counts
• Processing time:Nips: 2000 Gibbs iterations 12 hours on PC workstationCiteSeer: 700 Gibbs iterations 111 hours
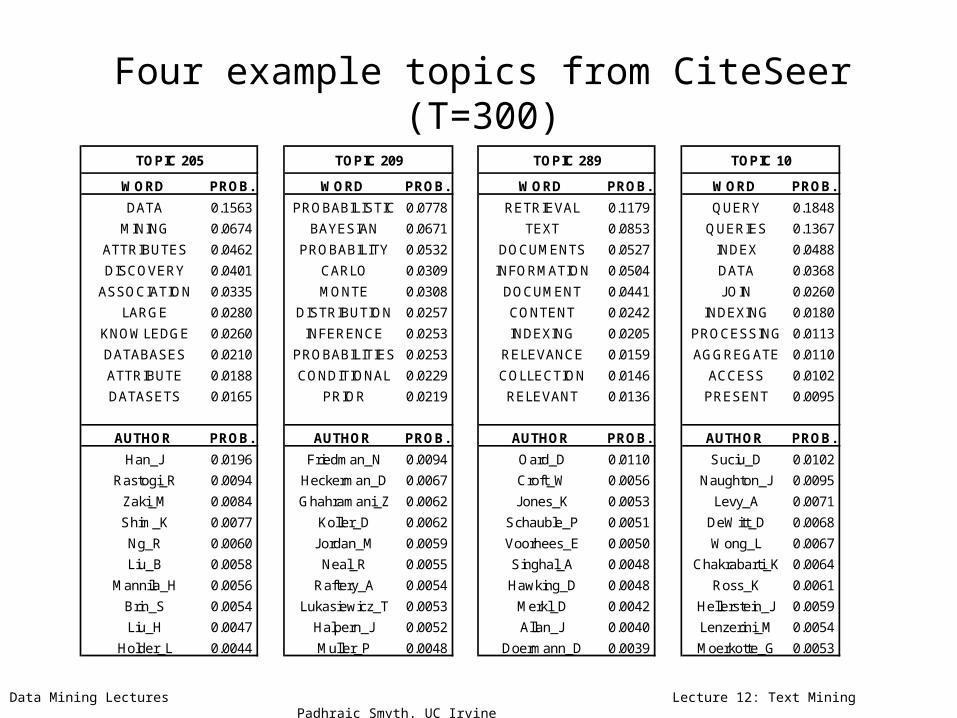
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Four example topics from CiteSeer (T=300)
WORD PROB. WORD PROB. WORD PROB. WORD PROB.
DATA 0.1563 PROBABILISTIC 0.0778 RETRIEVAL 0.1179 QUERY 0.1848
MINING 0.0674 BAYESIAN 0.0671 TEXT 0.0853 QUERIES 0.1367
ATTRIBUTES 0.0462 PROBABILITY 0.0532 DOCUMENTS 0.0527 INDEX 0.0488
DISCOVERY 0.0401 CARLO 0.0309 INFORMATION 0.0504 DATA 0.0368
ASSOCIATION 0.0335 MONTE 0.0308 DOCUMENT 0.0441 JOIN 0.0260
LARGE 0.0280 DISTRIBUTION 0.0257 CONTENT 0.0242 INDEXING 0.0180
KNOWLEDGE 0.0260 INFERENCE 0.0253 INDEXING 0.0205 PROCESSING 0.0113
DATABASES 0.0210 PROBABILITIES 0.0253 RELEVANCE 0.0159 AGGREGATE 0.0110
ATTRIBUTE 0.0188 CONDITIONAL 0.0229 COLLECTION 0.0146 ACCESS 0.0102
DATASETS 0.0165 PRIOR 0.0219 RELEVANT 0.0136 PRESENT 0.0095
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.
Han_J 0.0196 Friedman_N 0.0094 Oard_D 0.0110 Suciu_D 0.0102
Rastogi_R 0.0094 Heckerman_D 0.0067 Croft_W 0.0056 Naughton_J 0.0095
Zaki_M 0.0084 Ghahramani_Z 0.0062 Jones_K 0.0053 Levy_A 0.0071
Shim_K 0.0077 Koller_D 0.0062 Schauble_P 0.0051 DeWitt_D 0.0068
Ng_R 0.0060 Jordan_M 0.0059 Voorhees_E 0.0050 Wong_L 0.0067
Liu_B 0.0058 Neal_R 0.0055 Singhal_A 0.0048 Chakrabarti_K 0.0064
Mannila_H 0.0056 Raftery_A 0.0054 Hawking_D 0.0048 Ross_K 0.0061
Brin_S 0.0054 Lukasiewicz_T 0.0053 Merkl_D 0.0042 Hellerstein_J 0.0059
Liu_H 0.0047 Halpern_J 0.0052 Allan_J 0.0040 Lenzerini_M 0.0054
Holder_L 0.0044 Muller_P 0.0048 Doermann_D 0.0039 Moerkotte_G 0.0053
TOPIC 205 TOPIC 209 TOPIC 289 TOPIC 10
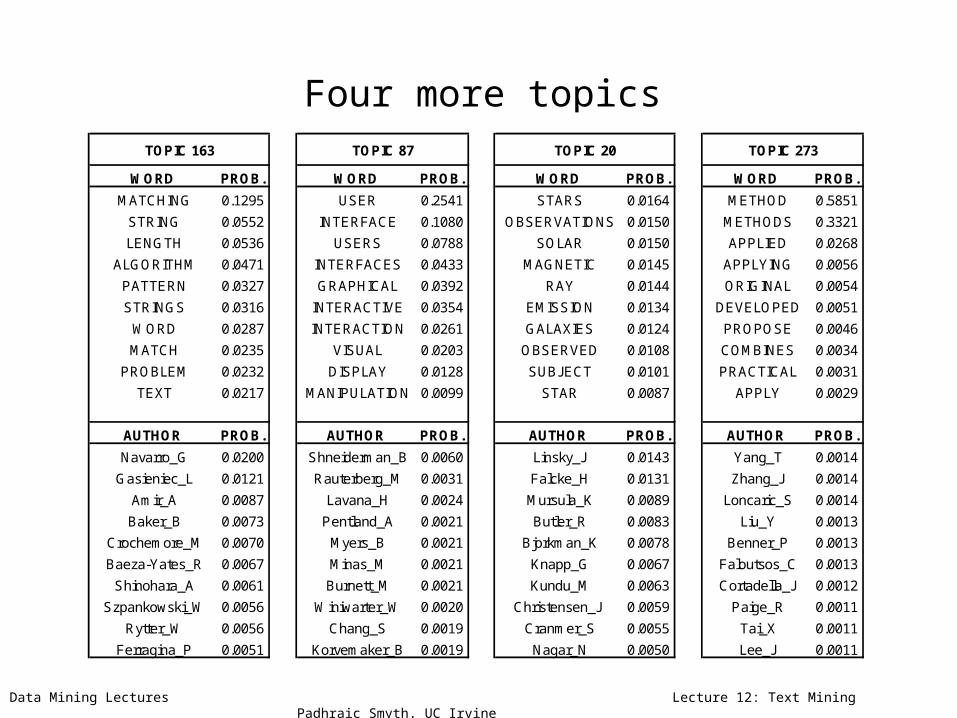
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Four more topics
WORD PROB. WORD PROB. WORD PROB. WORD PROB.
MATCHING 0.1295 USER 0.2541 STARS 0.0164 METHOD 0.5851
STRING 0.0552 INTERFACE 0.1080 OBSERVATIONS 0.0150 METHODS 0.3321
LENGTH 0.0536 USERS 0.0788 SOLAR 0.0150 APPLIED 0.0268
ALGORITHM 0.0471 INTERFACES 0.0433 MAGNETIC 0.0145 APPLYING 0.0056
PATTERN 0.0327 GRAPHICAL 0.0392 RAY 0.0144 ORIGINAL 0.0054
STRINGS 0.0316 INTERACTIVE 0.0354 EMISSION 0.0134 DEVELOPED 0.0051
WORD 0.0287 INTERACTION 0.0261 GALAXIES 0.0124 PROPOSE 0.0046
MATCH 0.0235 VISUAL 0.0203 OBSERVED 0.0108 COMBINES 0.0034
PROBLEM 0.0232 DISPLAY 0.0128 SUBJECT 0.0101 PRACTICAL 0.0031
TEXT 0.0217 MANIPULATION 0.0099 STAR 0.0087 APPLY 0.0029
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.
Navarro_G 0.0200 Shneiderman_B 0.0060 Linsky_J 0.0143 Yang_T 0.0014
Gasieniec_L 0.0121 Rauterberg_M 0.0031 Falcke_H 0.0131 Zhang_J 0.0014
Amir_A 0.0087 Lavana_H 0.0024 Mursula_K 0.0089 Loncaric_S 0.0014
Baker_B 0.0073 Pentland_A 0.0021 Butler_R 0.0083 Liu_Y 0.0013
Crochemore_M 0.0070 Myers_B 0.0021 Bjorkman_K 0.0078 Benner_P 0.0013
Baeza-Yates_R 0.0067 Minas_M 0.0021 Knapp_G 0.0067 Faloutsos_C 0.0013
Shinohara_A 0.0061 Burnett_M 0.0021 Kundu_M 0.0063 Cortadella_J 0.0012
Szpankowski_W 0.0056 Winiwarter_W 0.0020 Christensen_J 0.0059 Paige_R 0.0011
Rytter_W 0.0056 Chang_S 0.0019 Cranmer_S 0.0055 Tai_X 0.0011
Ferragina_P 0.0051 Korvemaker_B 0.0019 Nagar_N 0.0050 Lee_J 0.0011
TOPIC 163 TOPIC 87 TOPIC 20 TOPIC 273

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Some likely topics per author (CiteSeer)
• Author = Andrew McCallum, U Mass:– Topic 1: classification, training, generalization, decision, data,…– Topic 2: learning, machine, examples, reinforcement, inductive,…..– Topic 3: retrieval, text, document, information, content,…
• Author = Hector Garcia-Molina, Stanford:- Topic 1: query, index, data, join, processing, aggregate….
- Topic 2: transaction, concurrency, copy, permission, distributed….- Topic 3: source, separation, paper, heterogeneous, merging…..
• Author = Paul Cohen, USC/ISI:- Topic 1: agent, multi, coordination, autonomous, intelligent….- Topic 2: planning, action, goal, world, execution, situation…- Topic 3: human, interaction, people, cognitive, social, natural….
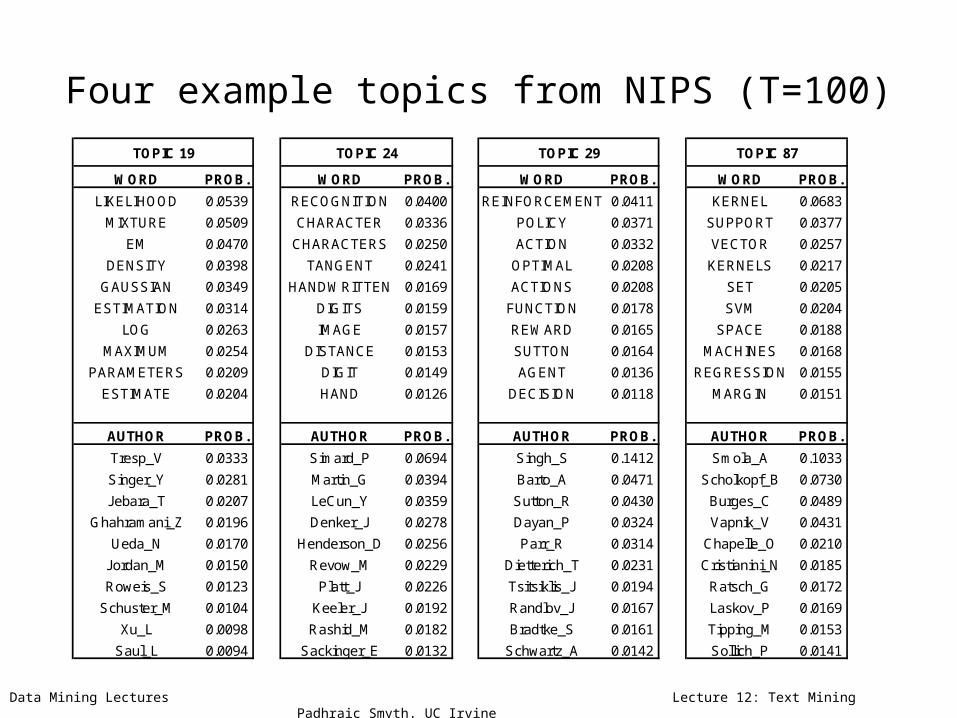
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Four example topics from NIPS (T=100)
WORD PROB. WORD PROB. WORD PROB. WORD PROB.
LIKELIHOOD 0.0539 RECOGNITION 0.0400 REINFORCEMENT 0.0411 KERNEL 0.0683
MIXTURE 0.0509 CHARACTER 0.0336 POLICY 0.0371 SUPPORT 0.0377
EM 0.0470 CHARACTERS 0.0250 ACTION 0.0332 VECTOR 0.0257
DENSITY 0.0398 TANGENT 0.0241 OPTIMAL 0.0208 KERNELS 0.0217
GAUSSIAN 0.0349 HANDWRITTEN 0.0169 ACTIONS 0.0208 SET 0.0205
ESTIMATION 0.0314 DIGITS 0.0159 FUNCTION 0.0178 SVM 0.0204
LOG 0.0263 IMAGE 0.0157 REWARD 0.0165 SPACE 0.0188
MAXIMUM 0.0254 DISTANCE 0.0153 SUTTON 0.0164 MACHINES 0.0168
PARAMETERS 0.0209 DIGIT 0.0149 AGENT 0.0136 REGRESSION 0.0155
ESTIMATE 0.0204 HAND 0.0126 DECISION 0.0118 MARGIN 0.0151
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.
Tresp_V 0.0333 Simard_P 0.0694 Singh_S 0.1412 Smola_A 0.1033
Singer_Y 0.0281 Martin_G 0.0394 Barto_A 0.0471 Scholkopf_B 0.0730
Jebara_T 0.0207 LeCun_Y 0.0359 Sutton_R 0.0430 Burges_C 0.0489
Ghahramani_Z 0.0196 Denker_J 0.0278 Dayan_P 0.0324 Vapnik_V 0.0431
Ueda_N 0.0170 Henderson_D 0.0256 Parr_R 0.0314 Chapelle_O 0.0210
Jordan_M 0.0150 Revow_M 0.0229 Dietterich_T 0.0231 Cristianini_N 0.0185
Roweis_S 0.0123 Platt_J 0.0226 Tsitsiklis_J 0.0194 Ratsch_G 0.0172
Schuster_M 0.0104 Keeler_J 0.0192 Randlov_J 0.0167 Laskov_P 0.0169
Xu_L 0.0098 Rashid_M 0.0182 Bradtke_S 0.0161 Tipping_M 0.0153
Saul_L 0.0094 Sackinger_E 0.0132 Schwartz_A 0.0142 Sollich_P 0.0141
TOPIC 19 TOPIC 24 TOPIC 29 TOPIC 87
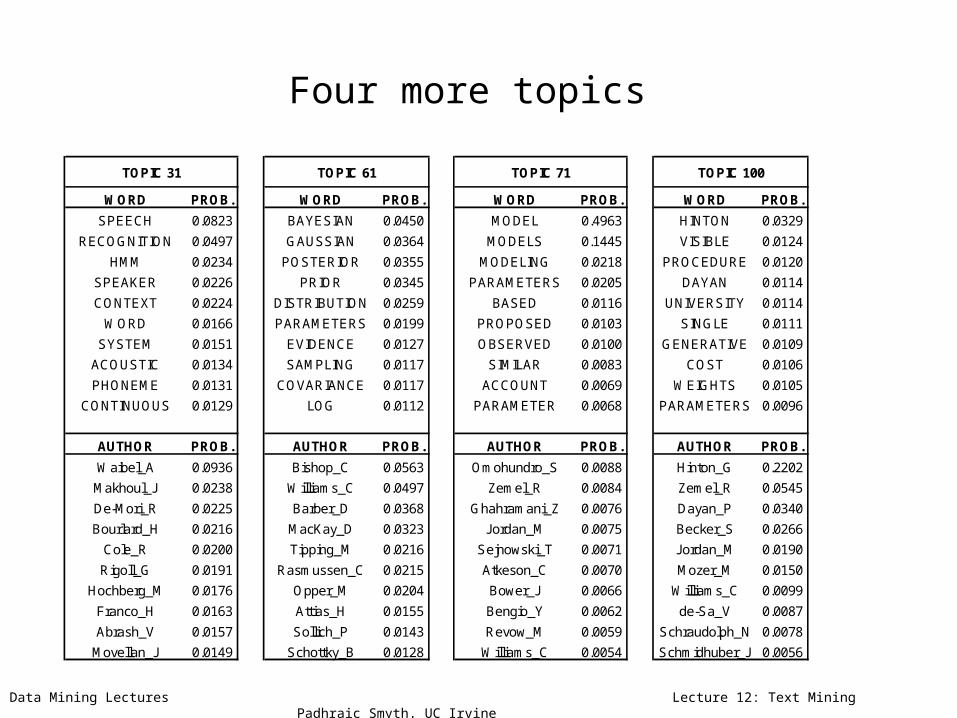
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Four more topics
WORD PROB. WORD PROB. WORD PROB. WORD PROB.
SPEECH 0.0823 BAYESIAN 0.0450 MODEL 0.4963 HINTON 0.0329
RECOGNITION 0.0497 GAUSSIAN 0.0364 MODELS 0.1445 VISIBLE 0.0124
HMM 0.0234 POSTERIOR 0.0355 MODELING 0.0218 PROCEDURE 0.0120
SPEAKER 0.0226 PRIOR 0.0345 PARAMETERS 0.0205 DAYAN 0.0114
CONTEXT 0.0224 DISTRIBUTION 0.0259 BASED 0.0116 UNIVERSITY 0.0114
WORD 0.0166 PARAMETERS 0.0199 PROPOSED 0.0103 SINGLE 0.0111
SYSTEM 0.0151 EVIDENCE 0.0127 OBSERVED 0.0100 GENERATIVE 0.0109
ACOUSTIC 0.0134 SAMPLING 0.0117 SIMILAR 0.0083 COST 0.0106
PHONEME 0.0131 COVARIANCE 0.0117 ACCOUNT 0.0069 WEIGHTS 0.0105
CONTINUOUS 0.0129 LOG 0.0112 PARAMETER 0.0068 PARAMETERS 0.0096
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.
Waibel_A 0.0936 Bishop_C 0.0563 Omohundro_S 0.0088 Hinton_G 0.2202
Makhoul_J 0.0238 Williams_C 0.0497 Zemel_R 0.0084 Zemel_R 0.0545
De-Mori_R 0.0225 Barber_D 0.0368 Ghahramani_Z 0.0076 Dayan_P 0.0340
Bourlard_H 0.0216 MacKay_D 0.0323 Jordan_M 0.0075 Becker_S 0.0266
Cole_R 0.0200 Tipping_M 0.0216 Sejnowski_T 0.0071 Jordan_M 0.0190
Rigoll_G 0.0191 Rasmussen_C 0.0215 Atkeson_C 0.0070 Mozer_M 0.0150
Hochberg_M 0.0176 Opper_M 0.0204 Bower_J 0.0066 Williams_C 0.0099
Franco_H 0.0163 Attias_H 0.0155 Bengio_Y 0.0062 de-Sa_V 0.0087
Abrash_V 0.0157 Sollich_P 0.0143 Revow_M 0.0059 Schraudolph_N 0.0078
Movellan_J 0.0149 Schottky_B 0.0128 Williams_C 0.0054 Schmidhuber_J 0.0056
TOPIC 31 TOPIC 61 TOPIC 71 TOPIC 100

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Stability of Topics
• Content of topics is arbitrary across runs of model(e.g., topic #1 is not the same across runs)
• However, – Majority of topics are stable over processing time– Majority of topics can be aligned across runs
• Topics appear to represent genuine structure in data
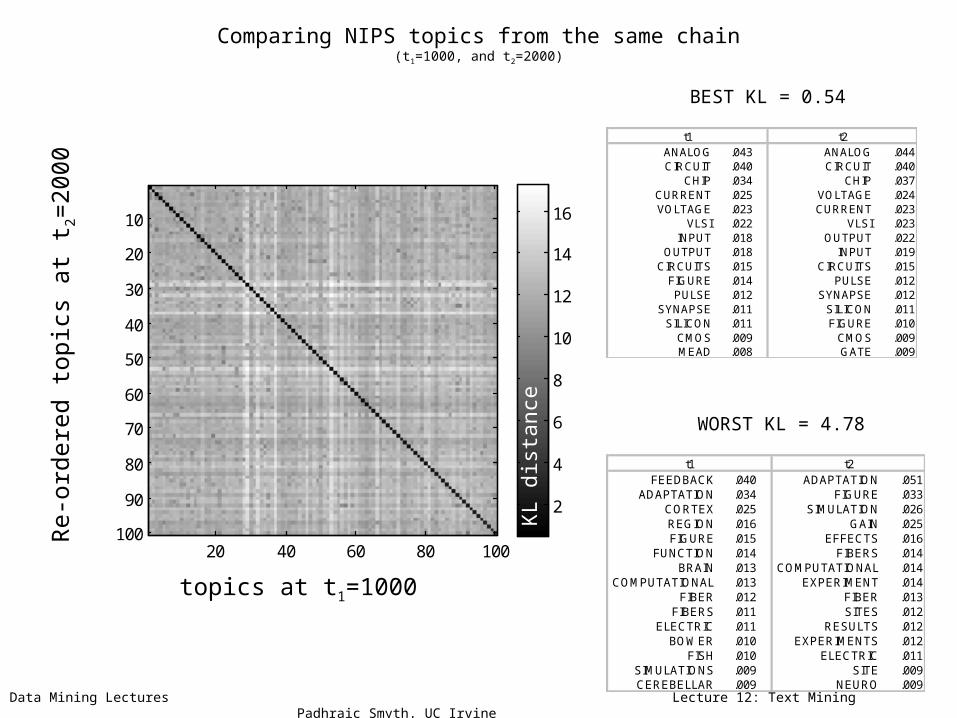
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
20 40 60 80 100
10
20
30
40
50
60
70
80
90
100
2
4
6
8
10
12
14
16
Comparing NIPS topics from the same chain(t1=1000, and t2=2000)
KL
dist
ance
topics at t1=1000
Re-
orde
red
topi
cs a
t t 2
=20
00
BEST KL = 0.54
WORST KL = 4.78
ANALOG .043 ANALOG .044CIRCUIT .040 CIRCUIT .040
CHIP .034 CHIP .037CURRENT .025 VOLTAGE .024VOLTAGE .023 CURRENT .023
VLSI .022 VLSI .023INPUT .018 OUTPUT .022
OUTPUT .018 INPUT .019CIRCUITS .015 CIRCUITS .015
FIGURE .014 PULSE .012PULSE .012 SYNAPSE .012
SYNAPSE .011 SILICON .011SILICON .011 FIGURE .010
CMOS .009 CMOS .009MEAD .008 GATE .009
t1 t2
FEEDBACK .040 ADAPTATION .051ADAPTATION .034 FIGURE .033
CORTEX .025 SIMULATION .026REGION .016 GAIN .025FIGURE .015 EFFECTS .016
FUNCTION .014 FIBERS .014BRAIN .013 COMPUTATIONAL .014
COMPUTATIONAL .013 EXPERIMENT .014FIBER .012 FIBER .013
FIBERS .011 SITES .012ELECTRIC .011 RESULTS .012
BOWER .010 EXPERIMENTS .012FISH .010 ELECTRIC .011
SIMULATIONS .009 SITE .009CEREBELLAR .009 NEURO .009
t1 t2

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
20 40 60 80 100
10
20
30
40
50
60
70
80
90
1004
6
8
10
12
14
16
18
Comparing NIPS topics and CiteSeer topics
KL
dist
ance
NIPS topics
Re-
orde
red
Cite
See
r to
pics
KL = 2.88
KL = 4.48
MODEL .493 MODEL .498MODELS .143 MODELS .227
MODELING .022 MODELING .055PARAMETERS .020 DYNAMIC .009
BASED .012 MODELED .008PROPOSED .010 FRAMEWORK .007
NIPS CiteSeer
SPEECH .082 SPEECH .058RECOGNITION .049 RECOGNITION .047
HMM .023 WORD .018SPEAKER .022 SYSTEM .014CONTEXT .022 SPEAKER .012
WORD .016 ACOUSTIC .010
NIPS CiteSeer
SYSTEM .234 SYSTEM .497SYSTEMS .090 SYSTEMS .350
REAL .020 BASED .012BASED .018 PAPER .012
COMPUTER .014 COMPLEX .010APPROACH .011 DEVELOPED .008
NIPS CiteSeer
KL = 4.92
FUNCTION .159 FUNCTIONS .124FUNCTIONS .115 FUNCTION .118
APPROXIMATION .069 ORDER .023LINEAR .026 APPROXIMATION .022
BASIS .018 LINEAR .016APPROXIMATE .016 INTERVAL .014
NIPS CiteSeer
KL = 5.0

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Detecting Unusual Papers by Authors
• For any paper by an author, we can calculate how surprising words in a document are: some papers are on unusual topics by author
Papers ranked by unusualness (perplexity) for C. Faloutsos
Papers ranked by unusualness (perplexity) for M. Jordan

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Author Separation
A method1 is described which like the kernel1 trick1 in support1 vector1 machines1 SVMs1 lets us generalize distance1 based2 algorithms to operate in feature1 spaces usually nonlinearly related to the input1 space This is done by identifying a class of kernels1 which can be represented as norm1 based2 distances1 in Hilbert spaces It turns1 out that common kernel1 algorithms such as SVMs1 and kernel1 PCA1 are actually really distance1 based2 algorithms and can be run2 with that class of kernels1 too As well as providing1 a useful new insight1 into how these algorithms work the present2 work can form the basis1 for conceiving new algorithms
This paper presents2 a comprehensive approach for model2 based2 diagnosis2 which includes proposals for characterizing and computing2 preferred2 diagnoses2 assuming that the system2 description2 is augmented with a system2 structure2 a directed2 graph2 explicating the interconnections between system2 components2 Specifically we first introduce the notion of a consequence2 which is a syntactically2 unconstrained propositional2 sentence2 that characterizes all consistency2 based2 diagnoses2 and show2 that standard2 characterizations of diagnoses2 such as minimal conflicts1 correspond to syntactic2 variations1 on a consequence2 Second we propose a new syntactic2 variation on the consequence2 known as negation2 normal form NNF and discuss its merits compared to standard variations Third we introduce a basic algorithm2 for computing consequences in NNF given a structured system2 description We show that if the system2 structure2 does not contain cycles2 then there is always a linear size2 consequence2 in NNF which can be computed in linear time2 For arbitrary1 system2 structures2 we show a precise connection between the complexity2 of computing2 consequences and the topology of the underlying system2 structure2 Finally we present2 an algorithm2 that enumerates2 the preferred2 diagnoses2 characterized by a consequence2 The algorithm2 is shown1 to take linear time2 in the size2 of the consequence2 if the preference criterion1 satisfies some general conditions
Written by(1) Scholkopf_B
Written by(2) Darwiche_A
• Can model attribute words to authors correctly within a document?
• Test of model: 1) artificially combine abstracts from different authors 2) check whether assignment is to correct original author

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Applications of Author-Topic Models
• “Expert Finder”– “Find researchers who are knowledgeable in cryptography
and machine learning within 100 miles of Washington DC”– “Find reviewers for this set of NSF proposals who are active
in relevant topics and have no conflicts of interest”
• Prediction– Given a document and some subset of known authors for
the paper (k=0,1,2…), predict the other authors– Predict how many papers in different topics will appear
next year
• Change Detection/Monitoring– Which authors are on the leading edge of new topics?– Characterize the “topic trajectory” of this author over time
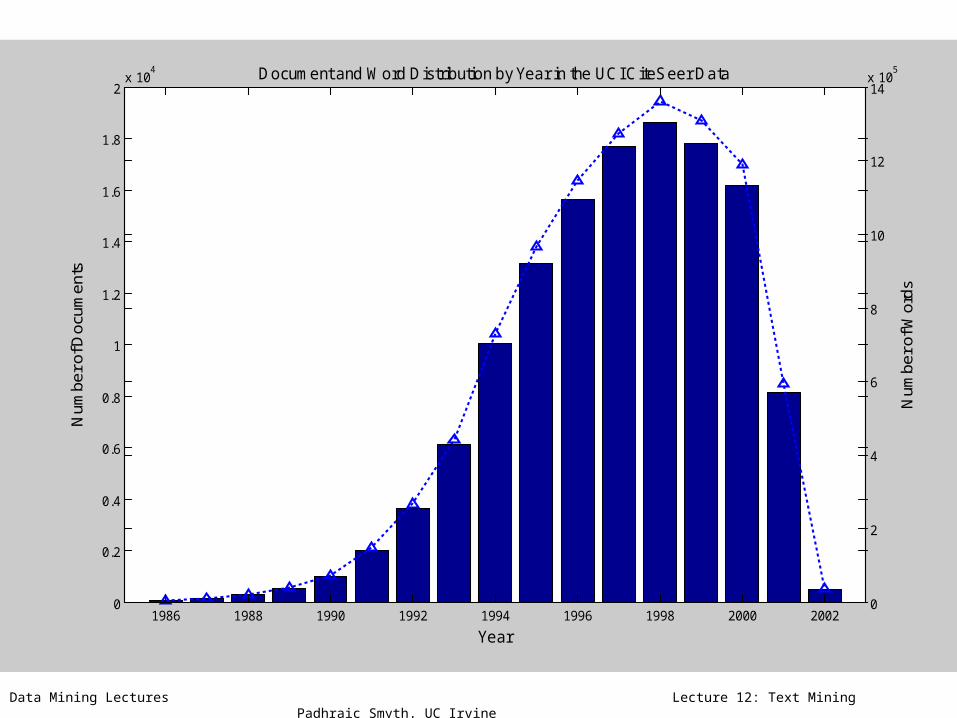
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1986 1988 1990 1992 1994 1996 1998 2000 20020
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2x 10
4
Year
Nu
mb
er o
f Do
cum
ents
Document and Word Distribution by Year in the UCI CiteSeer Data
Nu
mb
er o
f Wo
rds
0
2
4
6
8
10
12
14x 10
5
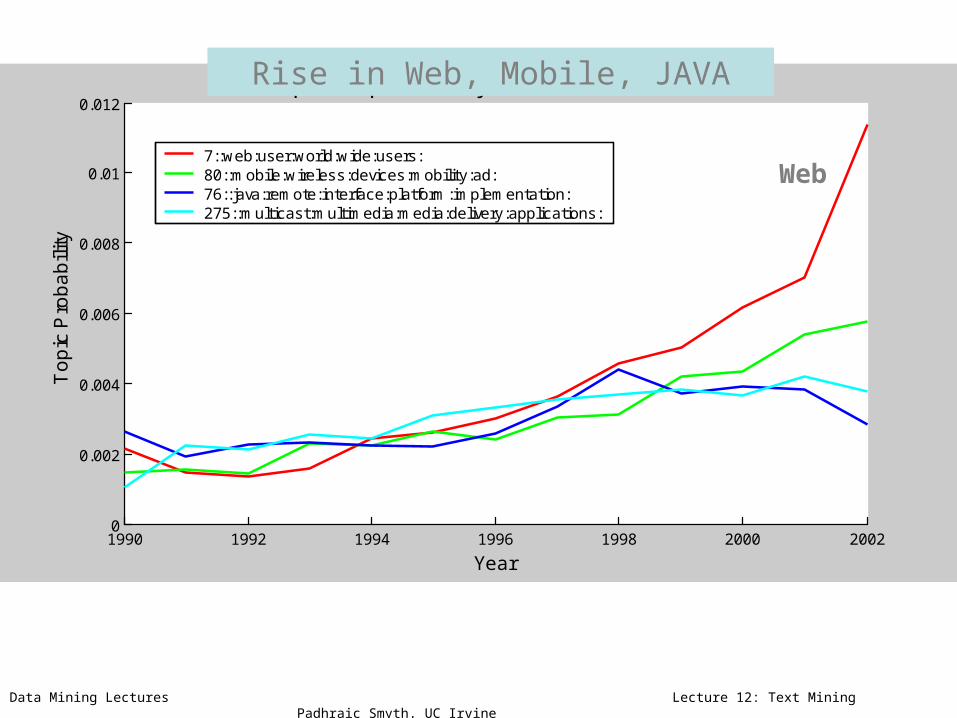
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20020
0.002
0.004
0.006
0.008
0.01
0.012Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
7::web:user:world:wide:users:80::mobile:wireless:devices:mobility:ad:76::java:remote:interface:platform:implementation:275::multicast:multimedia:media:delivery:applications:
Rise in Web, Mobile, JAVA
Web
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021
2
3
4
5
6
7
8x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
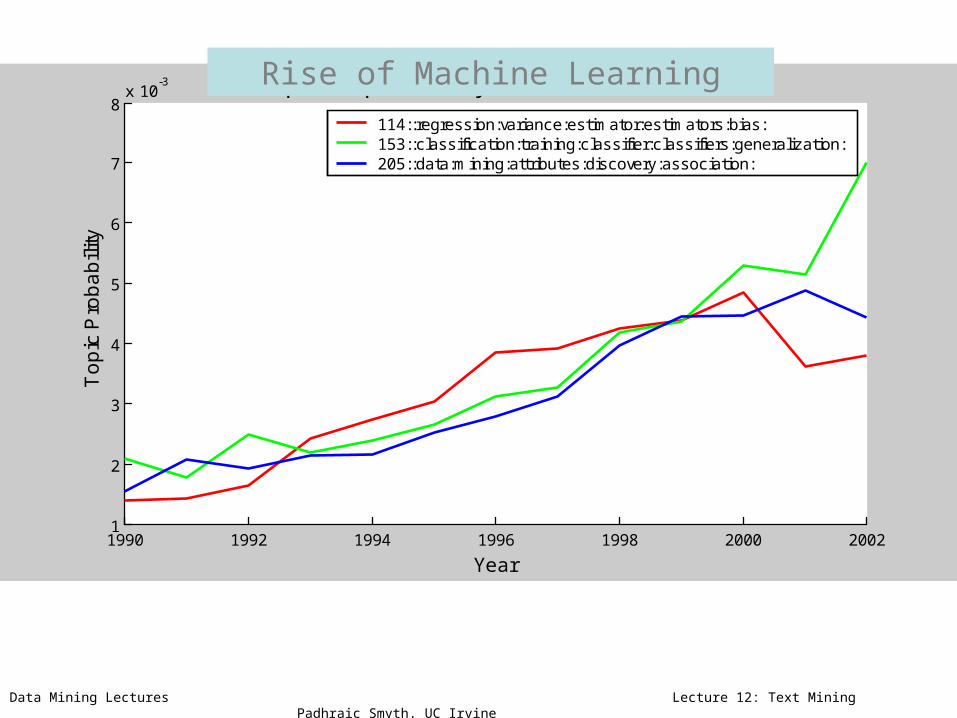
114::regression:variance:estimator:estimators:bias:153::classification:training:classifier:classifiers:generalization:205::data:mining:attributes:discovery:association:
Rise of Machine Learning
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021.5
2
2.5
3
3.5
4
4.5
5
5.5x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
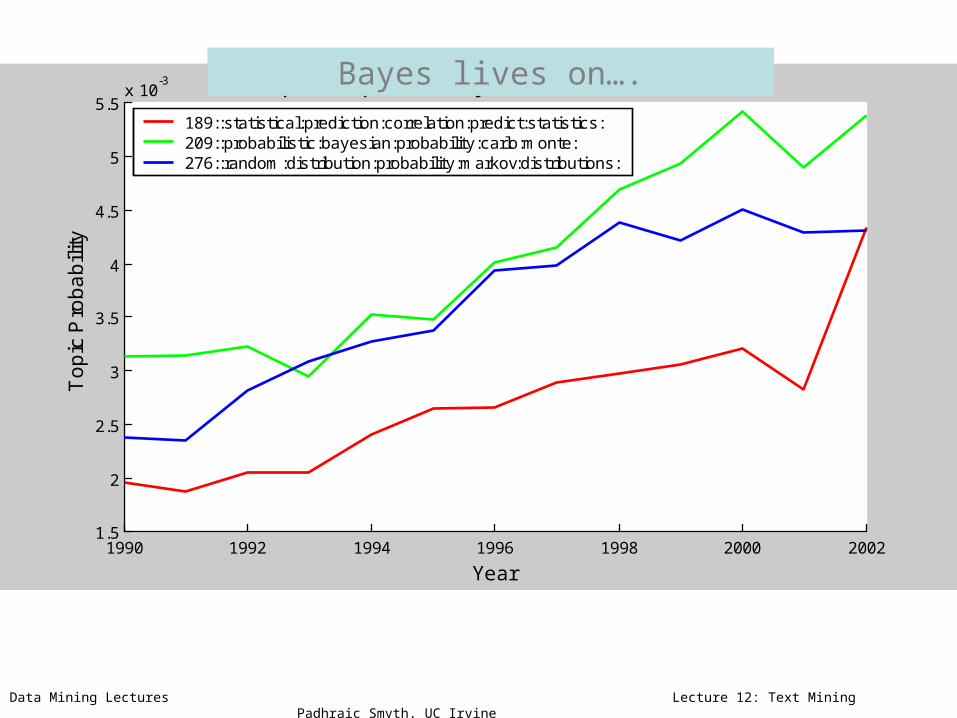
189::statistical:prediction:correlation:predict:statistics:209::probabilistic:bayesian:probability:carlo:monte:276::random:distribution:probability:markov:distributions:
Bayes lives on….
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20022
3
4
5
6
7
8
9
10
11x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
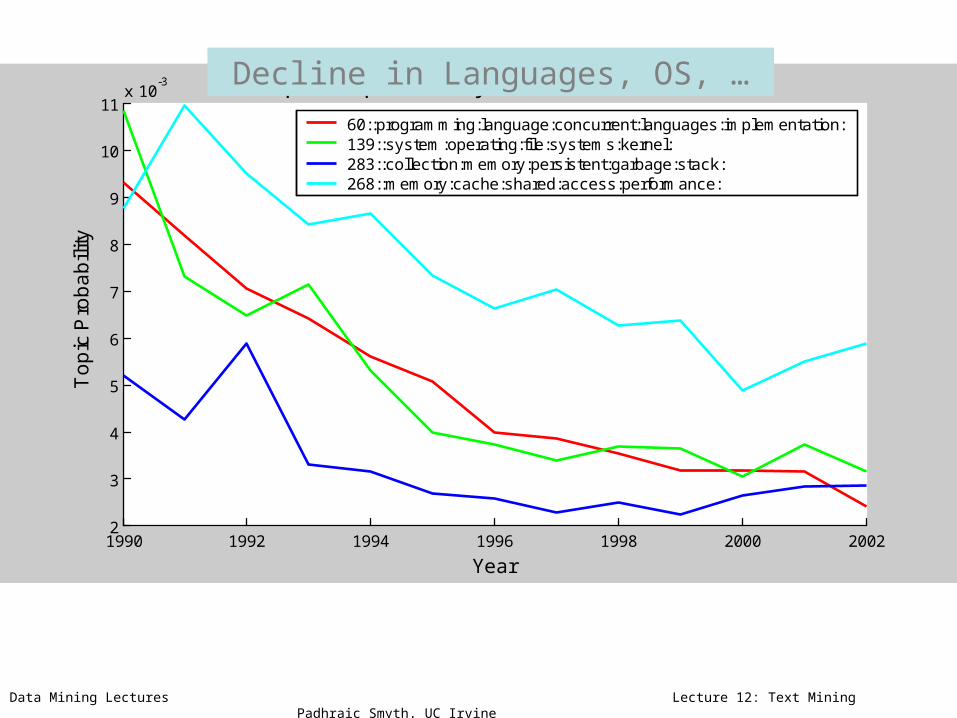
60::programming:language:concurrent:languages:implementation:139::system:operating:file:systems:kernel:283::collection:memory:persistent:garbage:stack:268::memory:cache:shared:access:performance:
Decline in Languages, OS, …
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20022
4
6
8
10
12
14x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
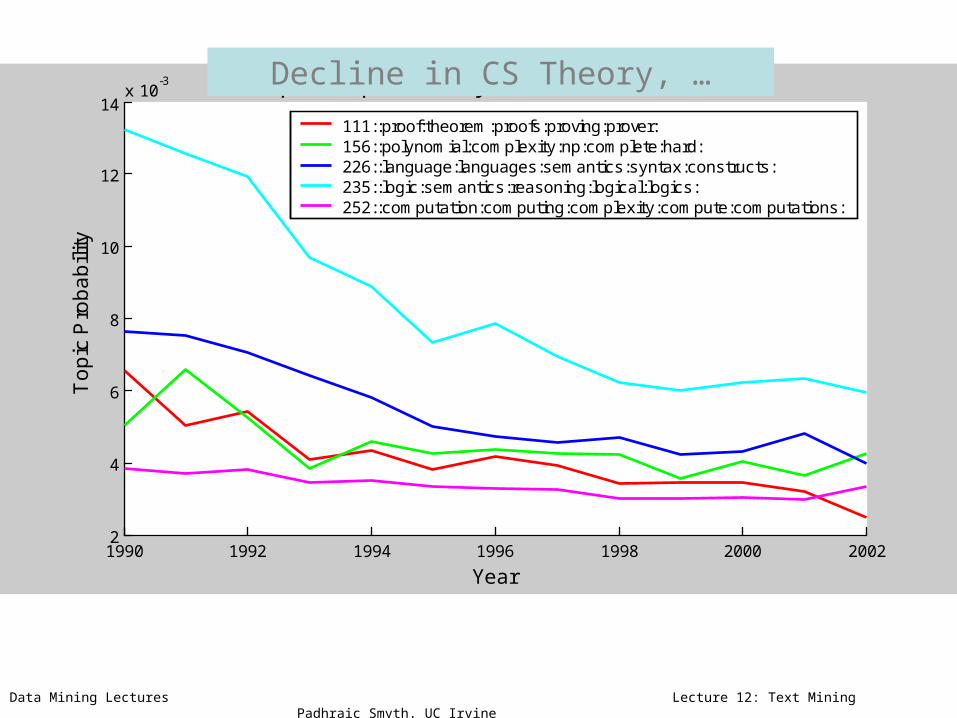
111::proof:theorem:proofs:proving:prover:156::polynomial:complexity:np:complete:hard:226::language:languages:semantics:syntax:constructs:235::logic:semantics:reasoning:logical:logics:252::computation:computing:complexity:compute:computations:
Decline in CS Theory, …
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021
2
3
4
5
6
7
8
9x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
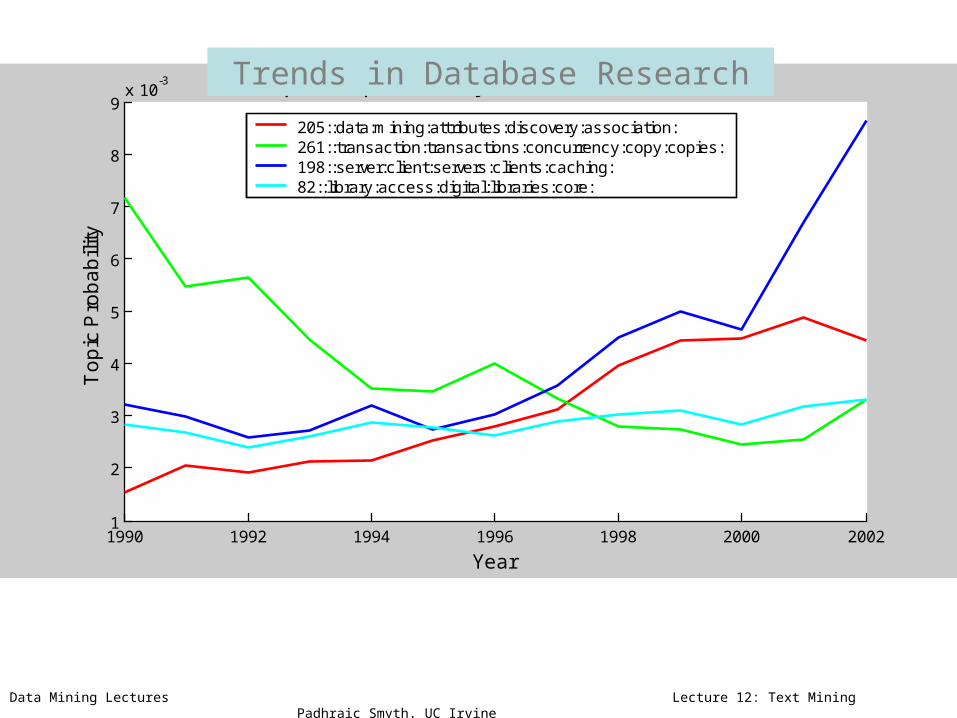
205::data:mining:attributes:discovery:association:261::transaction:transactions:concurrency:copy:copies:198::server:client:servers:clients:caching:82::library:access:digital:libraries:core:
Trends in Database Research
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20022
3
4
5
6
7
8x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
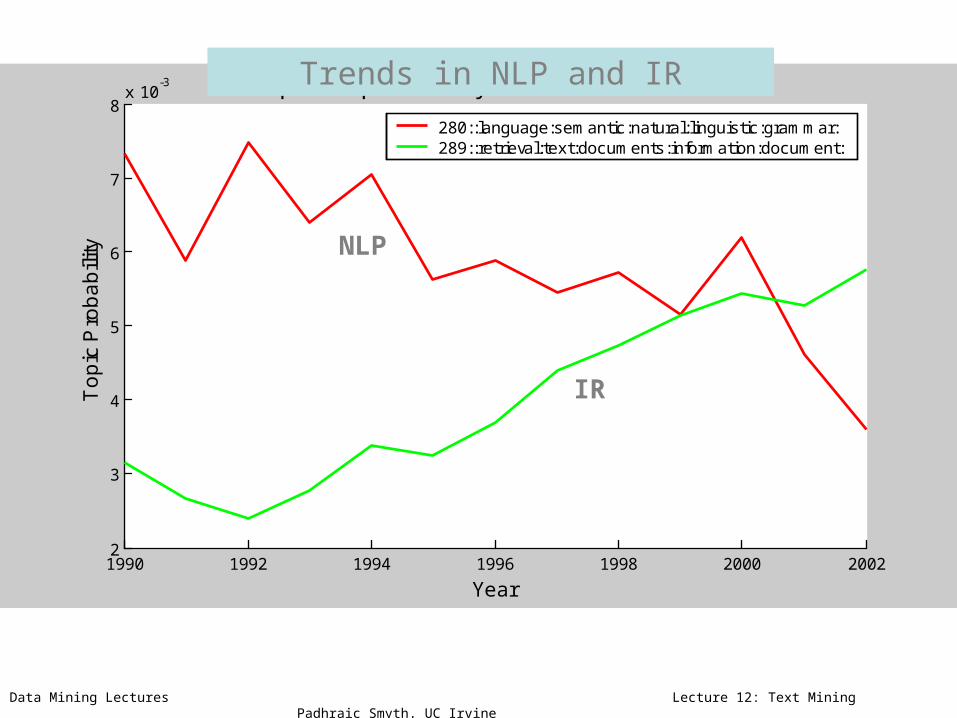
280::language:semantic:natural:linguistic:grammar:289::retrieval:text:documents:information:document:
Trends in NLP and IR
IR
NLP
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021
2
3
4
5
6
7
8
9x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
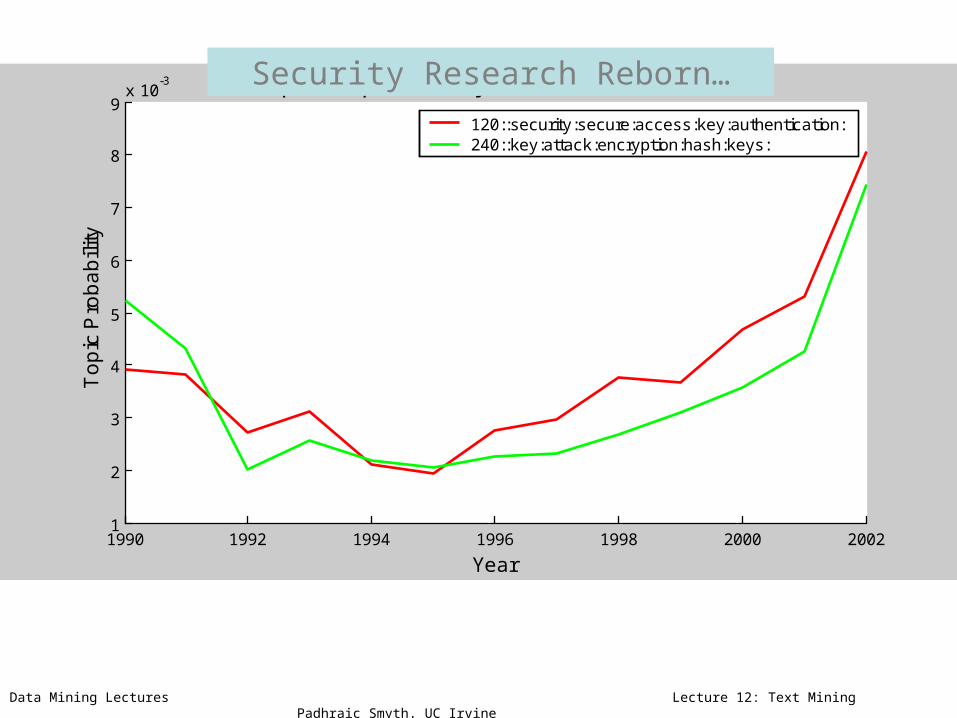
120::security:secure:access:key:authentication:240::key:attack:encryption:hash:keys:
Security Research Reborn…
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021
2
3
4
5
6
7x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
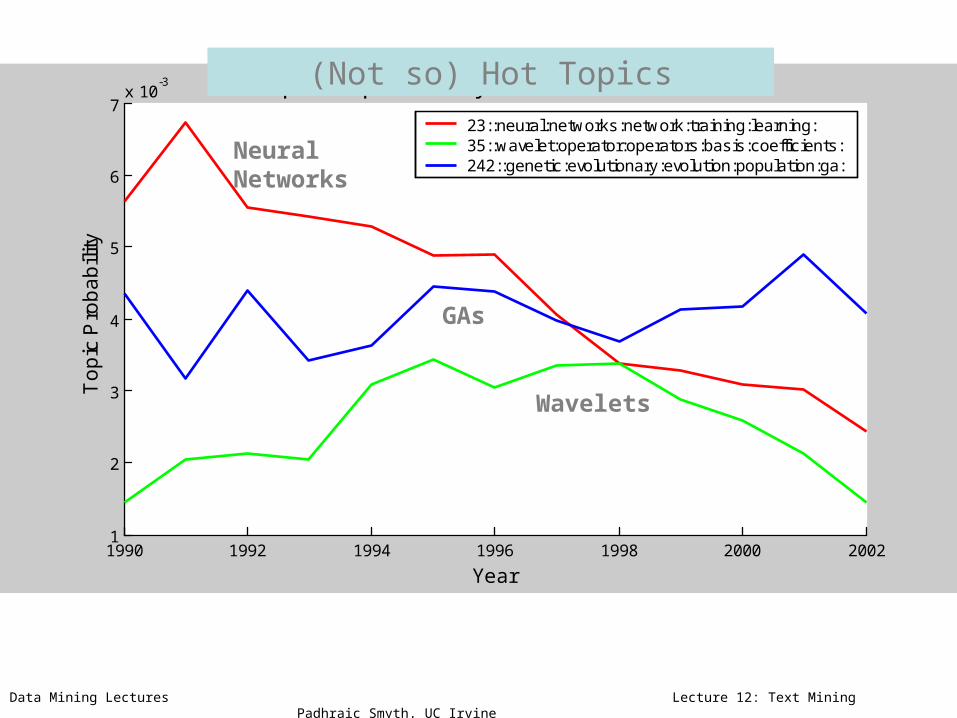
23::neural:networks:network:training:learning:35::wavelet:operator:operators:basis:coefficients:242::genetic:evolutionary:evolution:population:ga:
(Not so) Hot Topics
NeuralNetworks
GAs
Wavelets
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021.5
2
2.5
3
3.5
4
4.5
5x 10
-3 Topic Proportions by Year in CiteSeer Data
Year
To
pic
Pro
ba
bili
ty
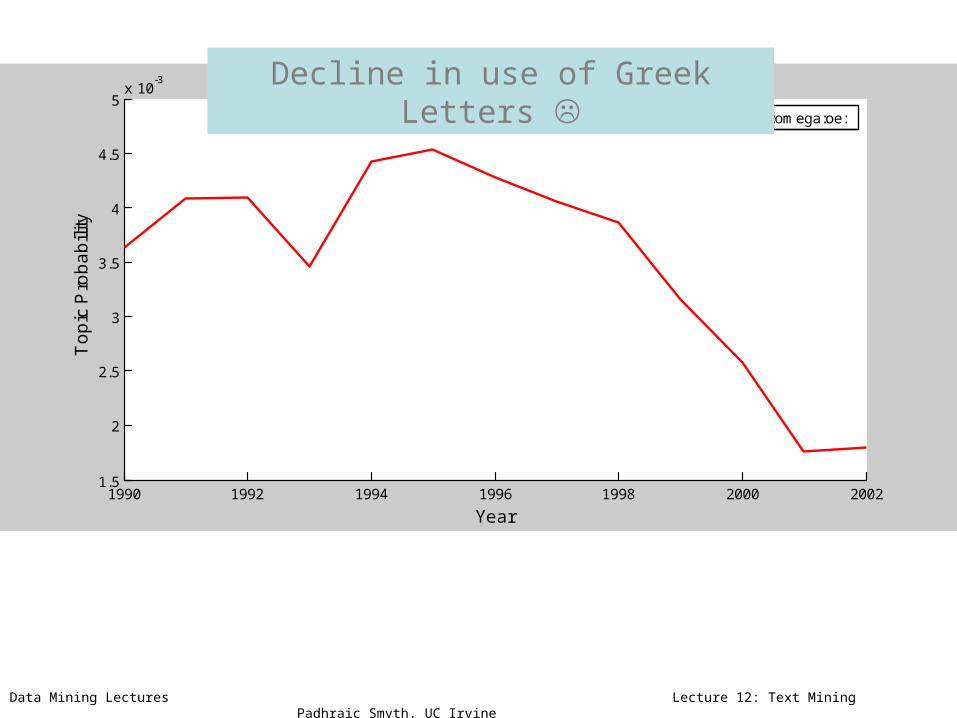
157::gamma:delta:ff:omega:oe:
Decline in use of Greek Letters

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Future Work
• Theory development– Incorporate citation information, collaboration networks– Other document types, e.g., email
• handling subject lines, email threads, and “to” and “cc” fields
• New datasets:– Enron email corpus– Web pages– PubMed abstracts (possibly)

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
New applications of author-topic models
• Black box for text document collection summarization– Automatically extract a summary of relevant topics and author
patterns for a large data set such as Enron email
• “Expert Finder”– “Find researchers who are knowledgeable in cryptography and
machine learning within 100 miles of Washington DC”– “Find reviewers for this set of NSF proposals who are active in
relevant topics and have no conflicts of interest”
• Change Detection/Monitoring– Which authors are on the leading edge of new topics?– Characterize the “topic trajectory” of this author over time
• Prediction (work in progress)– Given a document and some subset of known authors for the paper
(k=0,1,2…), predict the other authors– Predict how many papers in different topics will appear next year
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
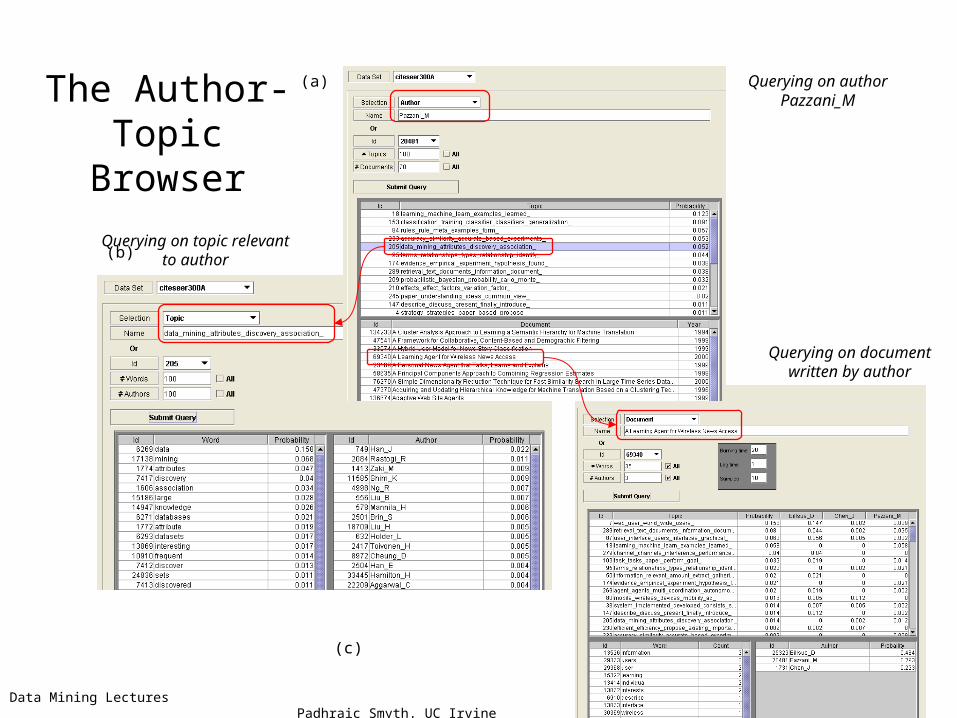
The Author-Topic Browser
(b)
(a)
(c)
Querying on author Pazzani_M
Querying on topic relevant to author
Querying on document written by author
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
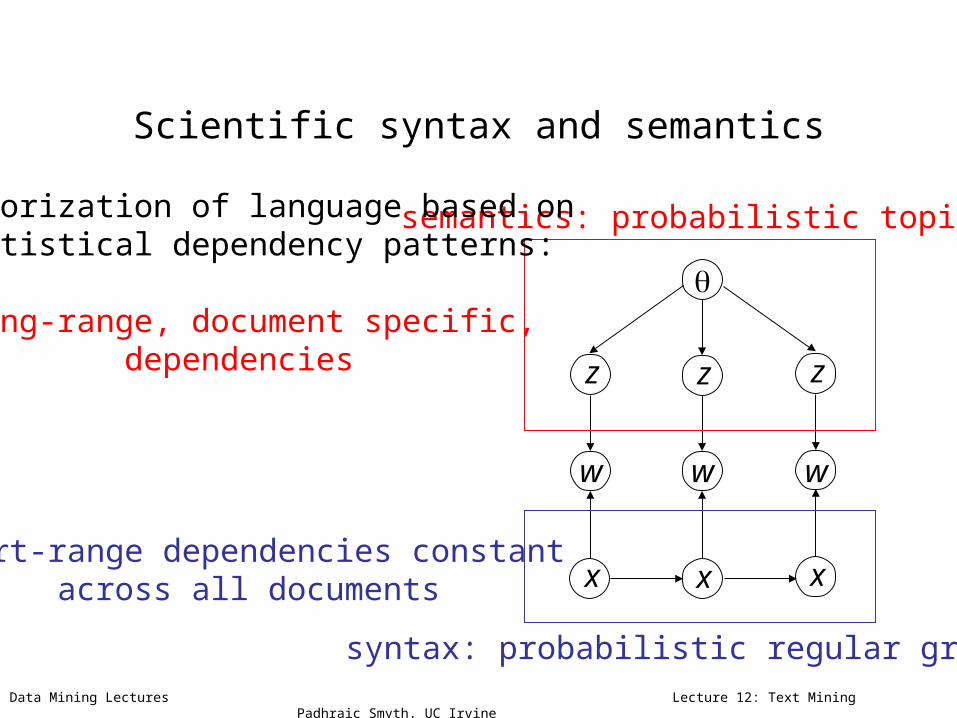
Scientific syntax and semantics
z
w
zz
w w
xxx
semantics: probabilistic topics
syntax: probabilistic regular grammar
Factorization of language based onstatistical dependency patterns:
long-range, document specific,dependencies
short-range dependencies constantacross all documents
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
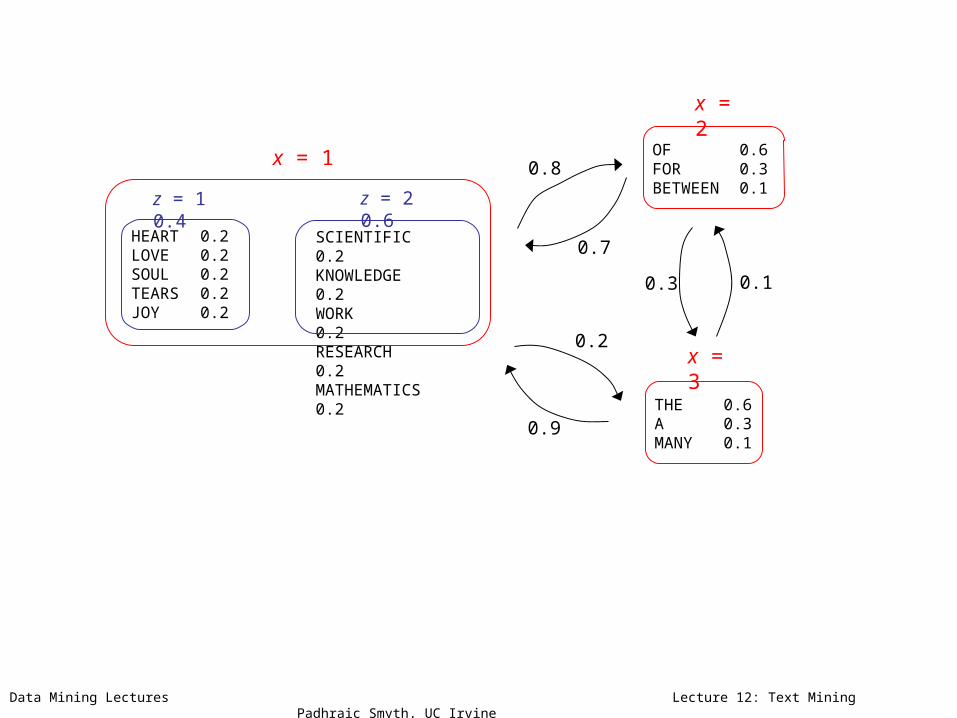
HEART 0.2 LOVE 0.2SOUL 0.2TEARS 0.2JOY 0.2
z = 1 0.4
SCIENTIFIC 0.2 KNOWLEDGE 0.2WORK 0.2RESEARCH 0.2MATHEMATICS 0.2
z = 2 0.6
x = 1
THE 0.6 A 0.3MANY 0.1
x = 3
OF 0.6 FOR 0.3BETWEEN 0.1
x = 2
0.9
0.1
0.2
0.8
0.7
0.3
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
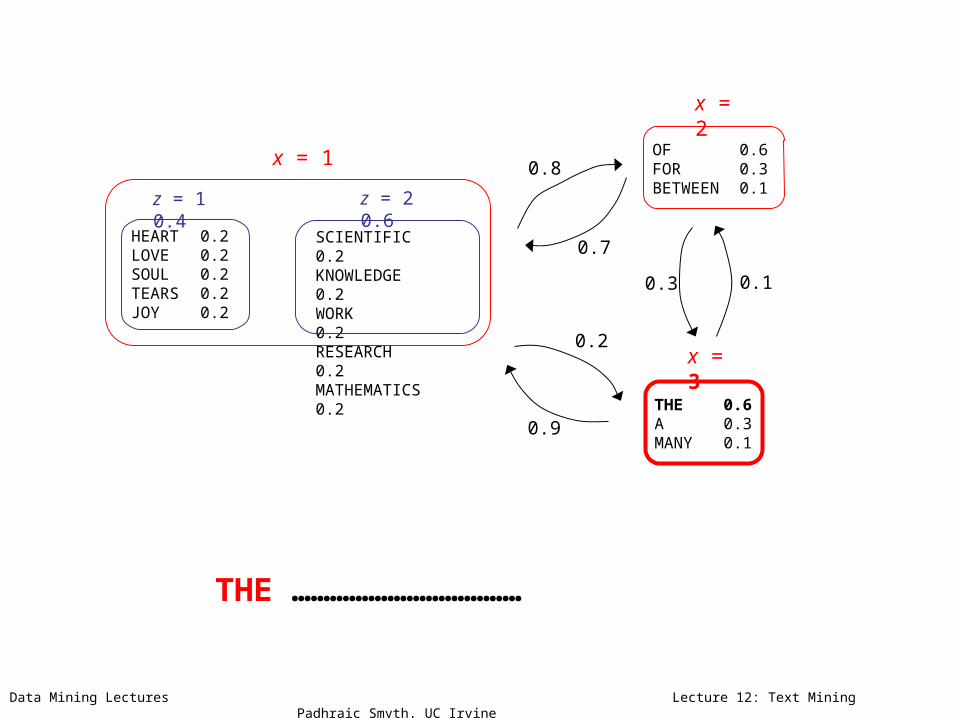
HEART 0.2 LOVE 0.2SOUL 0.2TEARS 0.2JOY 0.2
SCIENTIFIC 0.2 KNOWLEDGE 0.2WORK 0.2RESEARCH 0.2MATHEMATICS 0.2
THE 0.6 A 0.3MANY 0.1
OF 0.6 FOR 0.3BETWEEN 0.1
0.9
0.1
0.2
0.8
0.7
0.3
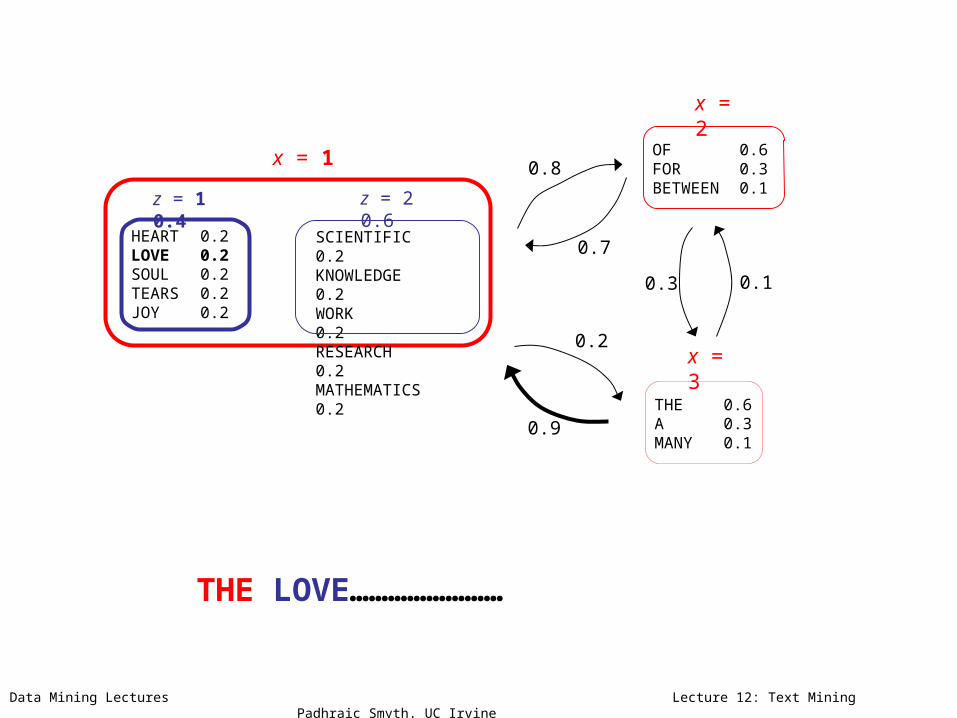
THE ………………………………
z = 1 0.4 z = 2 0.6
x = 1
x = 3
x = 2
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
HEART 0.2 LOVE 0.2SOUL 0.2TEARS 0.2JOY 0.2
SCIENTIFIC 0.2 KNOWLEDGE 0.2WORK 0.2RESEARCH 0.2MATHEMATICS 0.2
THE 0.6 A 0.3MANY 0.1
OF 0.6 FOR 0.3BETWEEN 0.1
0.9
0.1
0.2
0.8
0.7
0.3
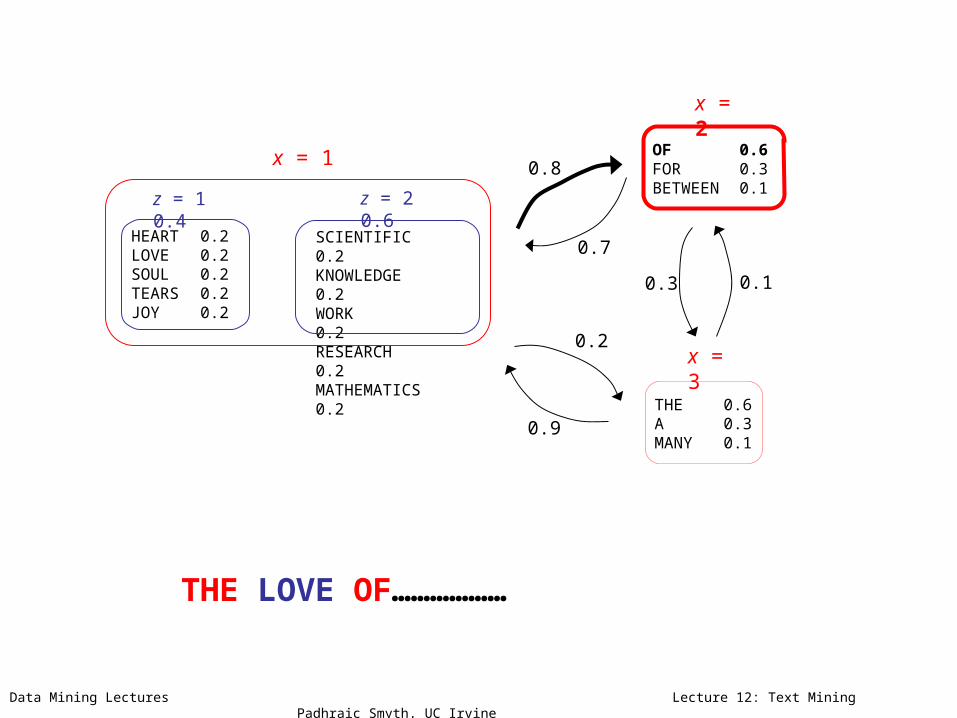
THE LOVE……………………
z = 1 0.4 z = 2 0.6
x = 1
x = 3
x = 2
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
HEART 0.2 LOVE 0.2SOUL 0.2TEARS 0.2JOY 0.2
SCIENTIFIC 0.2 KNOWLEDGE 0.2WORK 0.2RESEARCH 0.2MATHEMATICS 0.2
THE 0.6 A 0.3MANY 0.1
OF 0.6 FOR 0.3BETWEEN 0.1
0.9
0.1
0.2
0.8
0.7
0.3
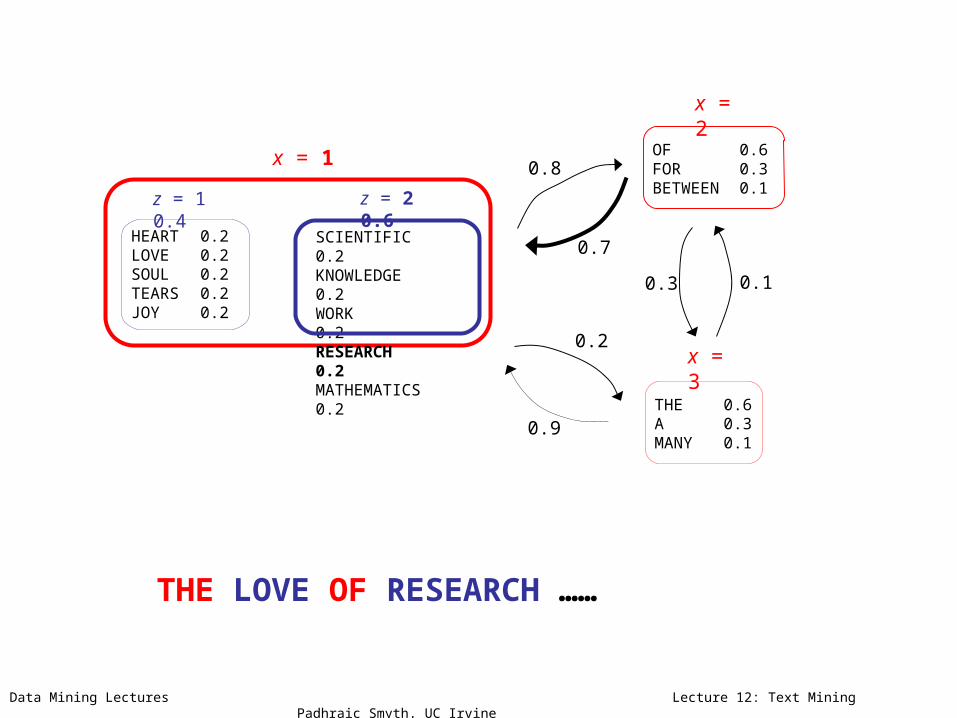
THE LOVE OF………………
z = 1 0.4 z = 2 0.6
x = 1
x = 3
x = 2
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
HEART 0.2 LOVE 0.2SOUL 0.2TEARS 0.2JOY 0.2
SCIENTIFIC 0.2 KNOWLEDGE 0.2WORK 0.2RESEARCH 0.2MATHEMATICS 0.2
THE 0.6 A 0.3MANY 0.1
OF 0.6 FOR 0.3BETWEEN 0.1
0.9
0.1
0.2
0.8
0.7
0.3
THE LOVE OF RESEARCH ……
z = 1 0.4 z = 2 0.6
x = 1
x = 3
x = 2
Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
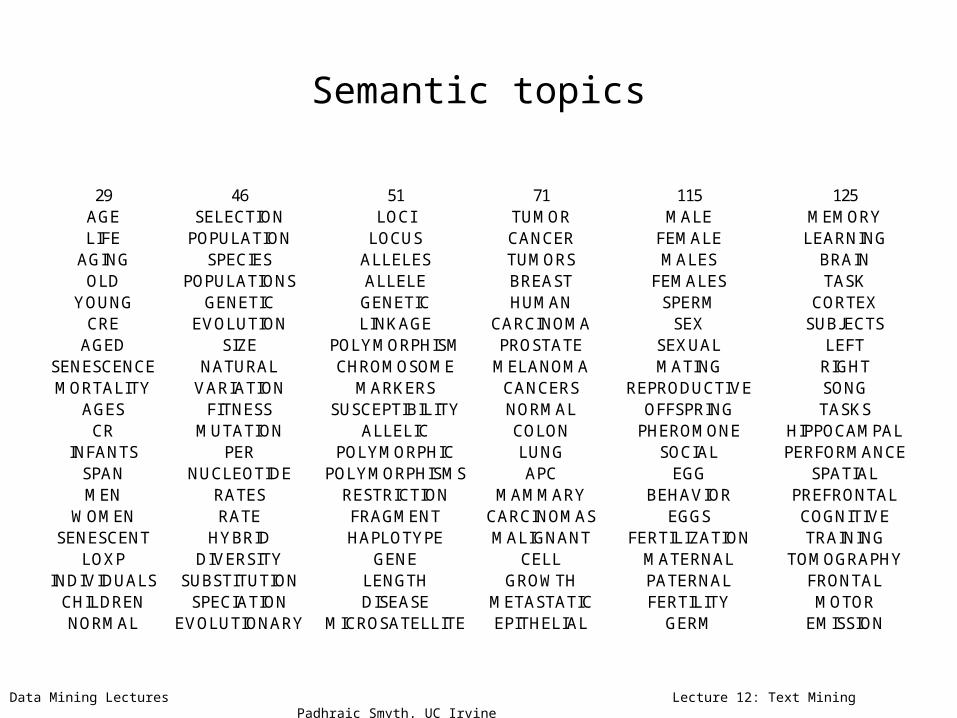
Semantic topics
29 46 51 71 115 125AGE SELECTION LOCI TUMOR MALE MEMORYLIFE POPULATION LOCUS CANCER FEMALE LEARNING
AGING SPECIES ALLELES TUMORS MALES BRAINOLD POPULATIONS ALLELE BREAST FEMALES TASK
YOUNG GENETIC GENETIC HUMAN SPERM CORTEXCRE EVOLUTION LINKAGE CARCINOMA SEX SUBJECTS
AGED SIZE POLYMORPHISM PROSTATE SEXUAL LEFTSENESCENCE NATURAL CHROMOSOME MELANOMA MATING RIGHTMORTALITY VARIATION MARKERS CANCERS REPRODUCTIVE SONG
AGES FITNESS SUSCEPTIBILITY NORMAL OFFSPRING TASKSCR MUTATION ALLELIC COLON PHEROMONE HIPPOCAMPAL
INFANTS PER POLYMORPHIC LUNG SOCIAL PERFORMANCESPAN NUCLEOTIDE POLYMORPHISMS APC EGG SPATIALMEN RATES RESTRICTION MAMMARY BEHAVIOR PREFRONTAL
WOMEN RATE FRAGMENT CARCINOMAS EGGS COGNITIVESENESCENT HYBRID HAPLOTYPE MALIGNANT FERTILIZATION TRAINING
LOXP DIVERSITY GENE CELL MATERNAL TOMOGRAPHYINDIVIDUALS SUBSTITUTION LENGTH GROWTH PATERNAL FRONTAL
CHILDREN SPECIATION DISEASE METASTATIC FERTILITY MOTORNORMAL EVOLUTIONARY MICROSATELLITE EPITHELIAL GERM EMISSION

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Syntactic classes
REMAINED
5 8 14 25 26 30 33IN ARE THE SUGGEST LEVELS RESULTS BEEN
FOR WERE THIS INDICATE NUMBER ANALYSIS MAYON WAS ITS SUGGESTING LEVEL DATA CAN
BETWEEN IS THEIR SUGGESTS RATE STUDIES COULDDURING WHEN AN SHOWED TIME STUDY WELLAMONG REMAIN EACH REVEALED CONCENTRATIONS FINDINGS DIDFROM REMAINS ONE SHOW VARIETY EXPERIMENTS DOES
UNDER REMAINED ANY DEMONSTRATE RANGE OBSERVATIONS DOWITHIN PREVIOUSLY INCREASED INDICATING CONCENTRATION HYPOTHESIS MIGHT
THROUGHOUT BECOME EXOGENOUS PROVIDE DOSE ANALYSES SHOULDTHROUGH BECAME OUR SUPPORT FAMILY ASSAYS WILLTOWARD BEING RECOMBINANT INDICATES SET POSSIBILITY WOULD
INTO BUT ENDOGENOUS PROVIDES FREQUENCY MICROSCOPY MUSTAT GIVE TOTAL INDICATED SERIES PAPER CANNOT
INVOLVING MERE PURIFIED DEMONSTRATED AMOUNTS WORK
THEYAFTER APPEARED TILE SHOWS RATES EVIDENCE ALSO
ACROSS APPEAR FULL SO CLASS FINDINGAGAINST ALLOWED CHRONIC REVEAL VALUES MUTAGENESIS BECOME
WHEN NORMALLY ANOTHER DEMONSTRATES AMOUNT OBSERVATION MAGALONG EACH EXCESS SUGGESTED SITES MEASUREMENTS LIKELY

Data Mining Lectures Lecture 12: Text Mining Padhraic Smyth, UC Irvine
Syntactic classes
REMAINED
5 8 14 25 26 30 33IN ARE THE SUGGEST LEVELS RESULTS BEEN
FOR WERE THIS INDICATE NUMBER ANALYSIS MAYON WAS ITS SUGGESTING LEVEL DATA CAN
BETWEEN IS THEIR SUGGESTS RATE STUDIES COULDDURING WHEN AN SHOWED TIME STUDY WELLAMONG REMAIN EACH REVEALED CONCENTRATIONS FINDINGS DIDFROM REMAINS ONE SHOW VARIETY EXPERIMENTS DOES
UNDER REMAINED ANY DEMONSTRATE RANGE OBSERVATIONS DOWITHIN PREVIOUSLY INCREASED INDICATING CONCENTRATION HYPOTHESIS MIGHT
THROUGHOUT BECOME EXOGENOUS PROVIDE DOSE ANALYSES SHOULDTHROUGH BECAME OUR SUPPORT FAMILY ASSAYS WILLTOWARD BEING RECOMBINANT INDICATES SET POSSIBILITY WOULD
INTO BUT ENDOGENOUS PROVIDES FREQUENCY MICROSCOPY MUSTAT GIVE TOTAL INDICATED SERIES PAPER CANNOT
INVOLVING MERE PURIFIED DEMONSTRATED AMOUNTS WORK
THEYAFTER APPEARED TILE SHOWS RATES EVIDENCE ALSO
ACROSS APPEAR FULL SO CLASS FINDINGAGAINST ALLOWED CHRONIC REVEAL VALUES MUTAGENESIS BECOME
WHEN NORMALLY ANOTHER DEMONSTRATES AMOUNT OBSERVATION MAGALONG EACH EXCESS SUGGESTED SITES MEASUREMENTS LIKELY





























