Embed Size (px)
Citation preview

L 8th Seminar on Neural Network Applications in Electrical Engineering, NEUREL-2006 ET_TX ~~~Faculty of Electrical Engineering, University of Belgrade, Serbia, September 25-27, 2006 / [f200i,* h~~~ittp://neu rel.etf`.Ibg.ac.u, http://www.ewh .ieee.org/reg/8/conferences .htm I a"IE E<o
Data Mining a Prostate Cancer Dataset Using
Neural Networks
Kenneth Revett
Abstract Prostate cancer remains one of the leadingcauses of cancer death worldwide, with a reported incidencerate of 650,000 cases per annum worldwide. The causalfactors of prostate cancer still remain to be determined. Inthis paper, we investigate a medical dataset containingclinical information on 502 prostate cancer patients usingthe machine learning technique of rough sets and radialbasis function neural network.. Our preliminary resultsyield a classification accuracy of 90%, with high sensitivityand specificity (both at approximately 91%). Our resultsyield a predictive positive value (PPN) of 81% and apredictive negative value (PNV) of 95%.
Keywords cancer classifier ,machine learning, prostatecancer dataset, reducts, Rough sets
I. INTRODUCTION
Prostate cancer is the second leading cause of mortalityin men, exceeded only by lung cancer. The cause(s)of this forn of cancer remain to be elucidated, but
factors such as diet, heredity, and environmental factorsthat effect male hornones (androgens) have beenimplicated in epidemiological studies [1-3]. Currently,two standard tests are used for early detection of prostatecancer:
* Digital rectal examination (DRE). With the DRE, aphysician palpates the prostate in order to feel lumpsor masses.
* PSA test. The PSA blood test measures the level of aprotein called prostate-specific antigen. It is able todetect early prostate cancer, although it haslimitations.
There are many unresolved questions surrounding PSAtesting. The test is not accurate enough to eithercompletely rule out or confirn the presenceof cancer. Current treatments entail chemotherapy,surgery or a combination of the two depending on thestage of disease progression. Further, the incidence ofprostate cancer increases with age. This will present anincreased incidence as the world population tends towardsincreased longevity. This trend is alarming and warrants
Kenneth Revett is with the University of Westminster, HarrowSchool of Computer Science, London, England HAI 3TP, (phone+44(0)207-911-5000, fax +44(0)207-911-5906, email:revettk westminster. ac.uk).
investigating the causative factors in prostate cancerthrough all available means. In this paper, we present theresults of a machine learning technique based on roughsets and neural networks (RBF) to the study of aclinically relevant prostate cancer dataset.
In this study, we investigate a dataset containing dataon 502 (29%/71% live/dead) patients that were diagnosedwith prostate cancer. The dataset contains 18 attributesincluding the decision attribute (see section 2.1 for alisting of the attributes) with 27 missing values (0.3%).We investigated this dataset with respect to thefollowing: i) attribute pruning, ii) classificationaccuracy and iii) rule induction. Pruning(dimensionality reduction) removes variablesthat are not directly related to the classificationprocess. This feature of rough sets makes thedataset much easier to work with and may helpto highlight the relevant classification featuresof the data. Once the redundant features havebeen pruned from the dataset, a RBF neuralnetwork was developed and applied to the datato perform the actual classification. In the nextsection, we present a very brief overview ofrough sets, followed by the application of aRadial basis Function (RBF) neural network,followed by a results section and lastly asummary of this work.
II. METHODS
In this study, we employed the rough setsparadigm as a pre-processing step. The purposeof this step was to reduce the dataset in terms ofattributes as much as possible in order tominimise the computational work required totrain a neural network based classifier. We nextbriefly describe the rough sets algorithm andalso the neural network classifier - the radialbasis function neural network (RBF). We usethe classification accuracy of rough sets as abenchmark for the classification accuracyobtained from the RBF algorithm.
1-4244-0433-9/06/$20.00 (©2006 IEEE. 157

A. Rough SetsIn order to apply rough sets, which is a
supervised machine learning paradigm, the dataset must be transformed into a decision table(DT) from which rules are generated to providean automated classification capacity. Ingenerating the decision table, each row consistsof an observation (also called an object) andeach column is an attribute, with the last one asthe decision for this object {d}. Formally, a DTis a pair A = (U, Au{d}) where d a A is thedecision attribute, where U is a finite non-empty set of objects called the universe and A isa finite non-empty set of attributes such thata:U->Va is called the value set of a. Rough setsseeks data reduction through the concept ofequivalence classes (through the indiscernibiliyrelation). By generating such classes, one canreduce the number of attributes in the decisiontable by selecting any member of theequivalence class as a representation of theentire class. This process generates a series ofreducts - which are subsequently used in theclassification process. Finding the reducts is anNP-hard problem, but fortunately there are goodheuristics that can compute a sufficient amountof approximate reducts in reasonable time to beusable. An order based genetic algorithm (o-GA) (cf [4,5]) is used to search through thedecision table for approximate reducts whichresult in a series of 'if..then..' decision rules.We then apply these decision rules to the testdata and measure specificity and sensitivity ofthe resulting classifications. Lastly, weexamined in a systematic fashion, whichattributes were required for the decision process- this can be determined by examining thecorrelation, coverage, and support of theattributes in the final set of decision rules[6],[7]. This provides both a classificationaccuracy that can be used as a benchmark forother techniques, and also a reduced decisiontable. This reduced DT is used as the input fortraining a RBF neural network and theclassification results are compared with thoseproduced by rough sets alone.
B. Radial Basis Function Neural network
Radial Basis Functions are powerful techniquesfor interpolation in multidimensional space. A
RBF is a function which has built into adistance criterion with respect to a centre.Radial basis functions have been applied in thearea of neural networks where they may be usedas a replacement for the sigmoidal hidden layertransfer function in multilayer perceptrons. RBFnetworks have 2 layers of processing: In thefirst, input is mapped onto each RBF in the'hidden' layer. The RBF chosen is usually aGaussian. In regression problems the outputlayer is then a linear combination of hiddenlayer values representing mean predicted output.The interpretation of this output layer value isthe same as a regression model in statistics. Inclassification problems the output layer istypically a sigmoid function of a linearcombination of hidden layer values,representing a posterior probability.Performance in both cases is often improved byshrinkage techniques, known as ridge regressionin classical statistics and known to correspondto a prior belief in small parameter values (andtherefore smooth output functions) in aBayesian framework.RBF networks have the advantage of notsuffering from local minima in the same way asmultilayer perceptrons. This is because the onlyparameters that are adjusted in the learningprocess are the linear mapping from hiddenlayer to output layer. Linearity ensures that theerror surface is quadratic and therefore has asingle easily found minimum. In regressionproblems this can be found in one matrixoperation. In classification problems the fixednon-linearity introduced by the sigmoid outputfunction is most efficiently dealt with usingiterated reweighted least squares.RBF networks have the disadvantage of
requiring good coverage of the input space byradial basis functions. RBF centres aredetermined with reference to the distribution ofthe input data, but without reference to theprediction task. As a result, representationalresources may be wasted on areas of the inputspace that are irrelevant to the learning task. Acommon solution is to associate each data pointwith its own centre, although this can make thelinear system to be solved in the final layerrather large, and requires shrinkage techniquesto avoid overfitting. For a more completedescription, please see [8].
158
III. RESULTS
In this study, we explored the dataset from 2different perspectives. Initially, we wished tosee how rough sets could be used to reduce thedimensionality of the data - in addition toproviding a classification accuracy benchmark.We then employed a powerful RBF neuralnetwork technique. In addition to pure
classification accuracy, we wished to determineif data reduction using rough sets enhanced theclassification accuracy of the RBF.
Table 1. The dataset used in this study. Thenumbers in parentheses refer to the number ofcategories for that particular attribute. Fordetails on category values, see reference [9].
Attribute Name Attribute TypePatient number DoubleStage DoubleTreatment Integer (4)Dtime(follow up time in Doublemonths)Date on Study DoubleAge IntegerWeight index (wt(kg) - Integerht(cm) + 200)Pf Integer (4)Hx (history of cardio- Doublevascular disease)Sbp Systolic bp DoubleDbp Diastolic bp DoubleEKG Integer (7)Hg (serum haemoglobin Double(g/l OOml)Sz (size of primary Doubletumour (cmA2)Index of Stage and DoubleHistologySerum Prostatic Acid DoublePhosphataseBone Metatastases DoubleStatus Double (10)
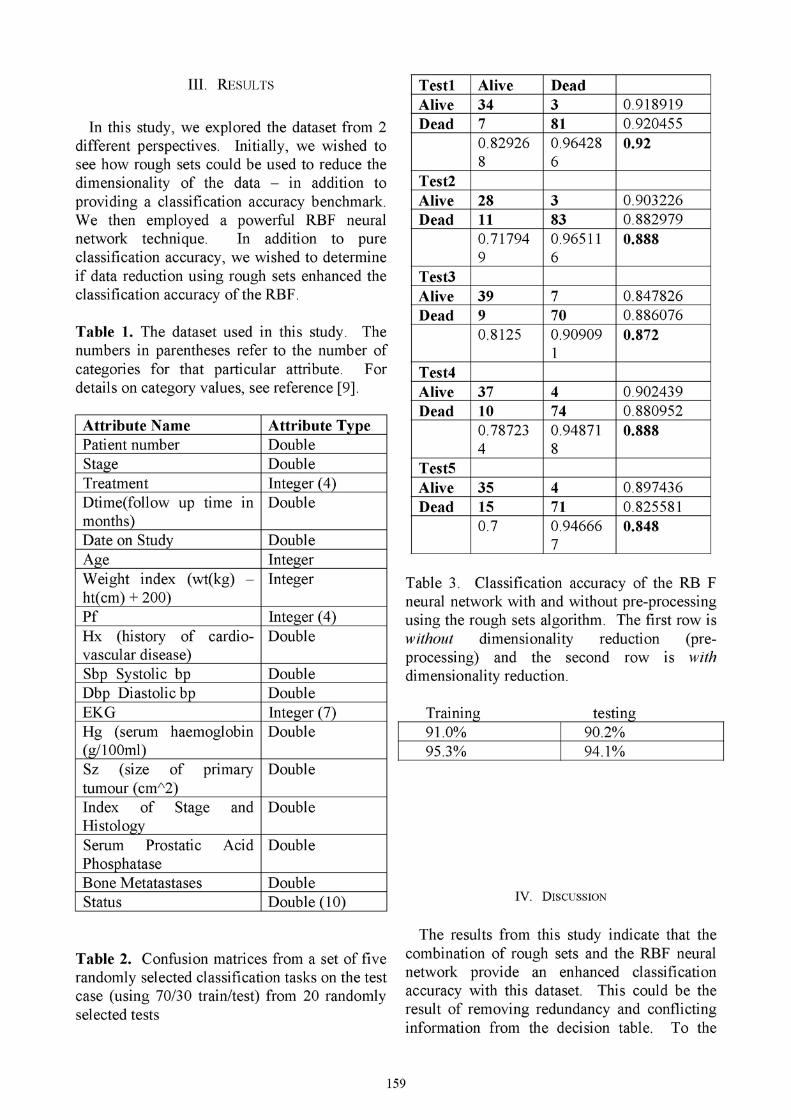
Table 2. Confusion matrices from a set of fiverandomly selected classification tasks on the testcase (using 70/30 train/test) from 20 randomlyselected tests
Table 3. Classification accuracy of the RB Fneural network with and without pre-processingusing the rough sets algorithm. The first row iswithout dimensionality reduction (pre-processing) and the second row is withdimensionality reduction.
Training testing91.0%O 90.2%l95.3%0 94.1%l
IV. DIscussIoN
The results from this study indicate that thecombination of rough sets and the RBF neuralnetwork provide an enhanced classificationaccuracy with this dataset. This could be theresult of removing redundancy and conflictinginformation from the decision table. To the
159
Testl Alive DeadAlive 34 3 0.918919Dead 7 81 0.920455
0.82926 0.96428 0.928 6
Test2Alive 28 3 0.903226Dead 11 83 0.882979
0.71794 0.96511 0.8889 6
Test3Alive 39 7 0.847826Dead 9 70 0.886076
0.8125 0.90909 0.8721
Test4Alive 37 4 0.902439Dead 10 74 0.880952
0.78723 0.94871 0.8884 8
Test5Alive 35 4 0.897436Dead 15 71 0.825581
0.7 0.94666 0.8487

authors knowledge, there has not been anyprevious study which investigated thecombination of rough sets and RBF neuralnetworks on this type of dataset.The combination provides a robust method for
reducing non-informative attributes. Theresulting classifier was enhanced when theattribute reduction was applied, indicating thatthere was indeed contradictory data within thedecision table that prevented the RBF neuralnetwork from escaping some local minimum(a)within the search space. With sparse andimportant datasets that are derived from thebiomedical literature, one must take every stepnecessary to ensure that the maximal amount ofinformation has been extracted in theexamination of such datasets. Rough setsprovides a unique method for performing thisoperation in a standardised method. Inherent toits operation is the concept of redundancyexcavation - through the concepts ofequivalence classes, attributes that are notinformative can be removed without resulting ina drop in the classification accuracy. Thisability is an extremely valuable tool fordatamining. In cases where the classificationaccuracy of rough is sub-maximal, this usuallyindicates that the data contains inconsistencies.For instance, the same set of antecedents mayyield two different decision class values. Thisissue was not addressed in this paper - althoughthrough the concept of approximate reducts andvariable precision reducts, inconsistencies canbe handled quite reasonably. In the currentdataset, the classification accuracy was higherwith the RBF - which in the end justifies thecombination approach employed in thispreliminary study. It is quite possible that thenon-linearity of the hidden layer in the RBF wasable to handlepossible inconsistencies within the dataset. Thiscombination of machine learning algorithmsprovides data miners with the tools required toextract useful and important information from
small biomedical datasets. In the future, we willexpand the set of classifiers and also exploreapproximate reducts in order to determine theextent of the inconsistencies within the data andalso as a means of removing them.
V. REFERENCES
[1] D.F. Andrews and A.M. Herzberg, Data, aCollection of Problems from Many Fieldsfor the Student and Research Worker.Springer-Verlag, New York, 1985.
[2] A.Jemal, T. Murray, E. Ward E, A. Samuels,Cancer Statistics, 2005. CA Cancer J Clin55:10-30, 2005.
[3] P. Kalra, J. Togami, G. Bansal, A.W.Partin,M.K. Brawer, R.J. Babaian, L.S. Ross, &C.S. Niederberger: A NeurocomputationalModel for Prostate Carcinoma Detection:Cancer, Volume 98, Issue 9 ,November2003.
[4] H.S. Nguyen & A. Skowron, Quantizationof real-valued attributes, Proc SecondInternational Conference on InformationScience, pp 34-37, 1995.
[5] Ohrn,. "Discernibility and Rough Sets inMedicine" Tools and Applications.Department of Computer and InformationScience. Trondheim, Norway, NorwegianUniversity of Science and Technology: 239,1999.
[6] [Z. Pawlak, Rough Sets, InternationalJournal of Computer and InformationSciences, II, pp. 341-356, 1982
[7] J. Wroblewski.: Theoretical Foundations ofOrder-Based Genetic Algorithms.Fundamenta Informaticae 28(3-4) pp. 423-430, 1996.
[8] Haykin, S. Adaptive Filter Theory, 3rd ed.,Upper Saddle River, NJ: Prentice-Hall, 1996
[9] DP, Green SB: Bulletin Cancer, Paris67:477-488, 1980.
160













![Chapter 2 Introduction to Neural networktomczak/PDF/[Grbic]Neural...Chapter 2 Introduction to Neural network 2.1 Introduction to Artiflcial Neural Net-work Artiflcial Neural Networks](https://img.pdfslide.net/doc/110x75/5f22a87bbf292e3b5d18b33c/chapter-2-introduction-to-neural-network-tomczakpdfgrbicneural-chapter-2.jpg)















