Embed Size (px)
Citation preview

Tom Peterka
Mathematics and Computer Science Division
Data Movement Support for Analysis
Tom Peterka, Rob Ross Argonne National Laboratory
Abon Choudhuri, Teng-Yok Lee, Han-Wei Shen The Ohio State University Wes Kendall University of Tennessee, Knoxville
Attila Gyulassy, Valerio Pascucci University of Utah
Early stages of Rayleigh-Taylor Instability flow
CScADS Summer Workshop 7/26/11

Premises and Challenges
2
Premises
All analyses are different. The user is the expert.
The user already has a serial computational module for the analysis.
Parallelizing from scratch is daunting, steep learning curve, scalability not trivial.
Scalable data movement is the key.
A common set of operations can be identified and encoded in a library.
DIY helps the user parallelize their analysis algorithm with data movement tools.
Challenges
Data model: MPI datatypes (currently)
Execution model: in situ or postprocessing
Parallelism model: MPI message passing (currently)
Load balancing: Zoltan-based repartitioning (in the works)
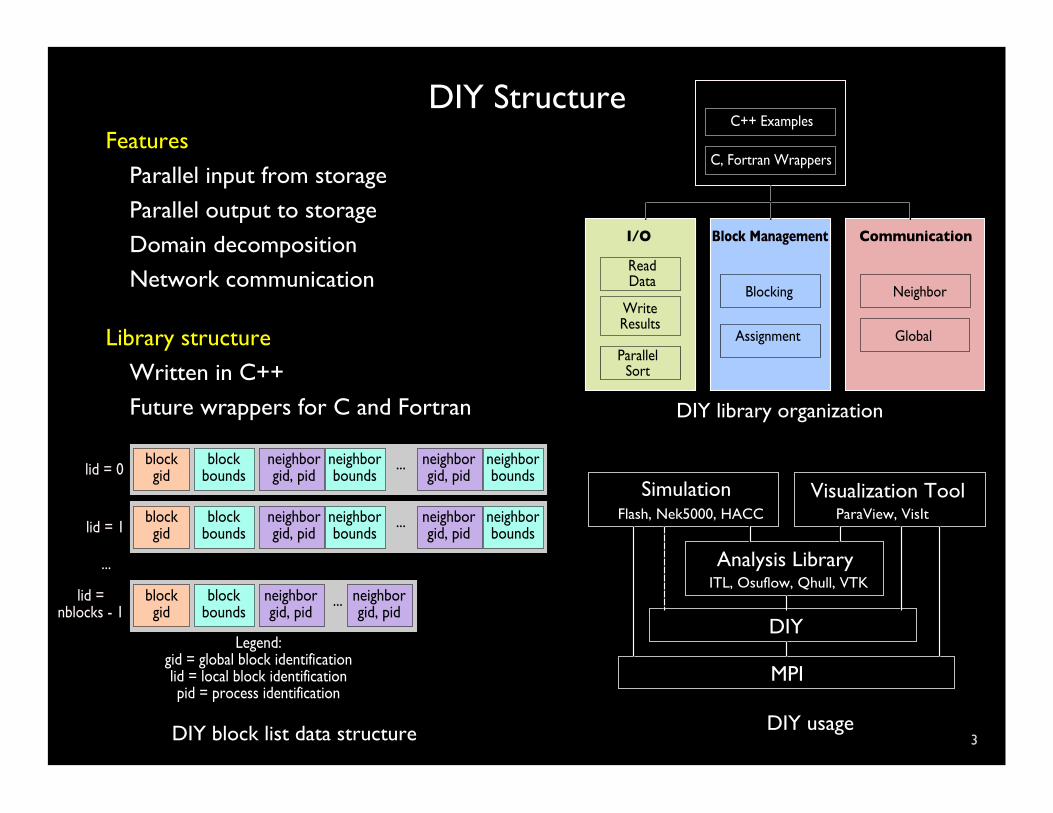
DIY Structure
3
Library structure
Written in C++ Future wrappers for C and Fortran DIY library organization
!"#$%&'(
)*'&+*
,*'-.#/$
0123'(4(+/25(+66"(7
877#$/9"/4
0::2;<+96*"7
!""#$%&'$()*
+#(%,-.&)&/010)' 2(113)$%&'$()
="+>?+4+
456
@+(+**"*A'(4
5(#4"2="7B*47
DIY block list data structure
Features
Parallel input from storage Parallel output to storage Domain decomposition Network communication
!"#$%&'(
!"#$%!#)*(+
*,'&-!#.&'(/01'(
222 *,'&-!#.&'(/01'(
!"#$%&'(
!"#$%!#)*(+
*,'&-!#.&'(/01'(
222
"'(0304
"'(0305
"'(030*!"#$%+0605
7,&,*(8&'(030&"#!9"0!"#$%0'(,*:';'$9:'#*"'(030"#$9"0!"#$%0'(,*:';'$9:'#*1'(0301.#$,++0'(,*:';'$9:'#*
*,'&-!#.&'(/01'(
*,'&-!#.!#)*(+
*,'&-!#.!#)*(+
!"#$%&'(
!"#$%!#)*(+
*,'&-!#.&'(/01'(
222 *,'&-!#.&'(/01'(
*,'&-!#.!#)*(+
*,'&-!#.!#)*(+
222
!"#$%&'"() *"+$&%",&'"()-.((%
/)&%0+"+-1"23&30
4%&+56-789:;;;6-</== >&3&*"8?6-*"+@'
@.16-A+$B%(?6-C5$%%6-*.D
E@F
G>@
DIY usage
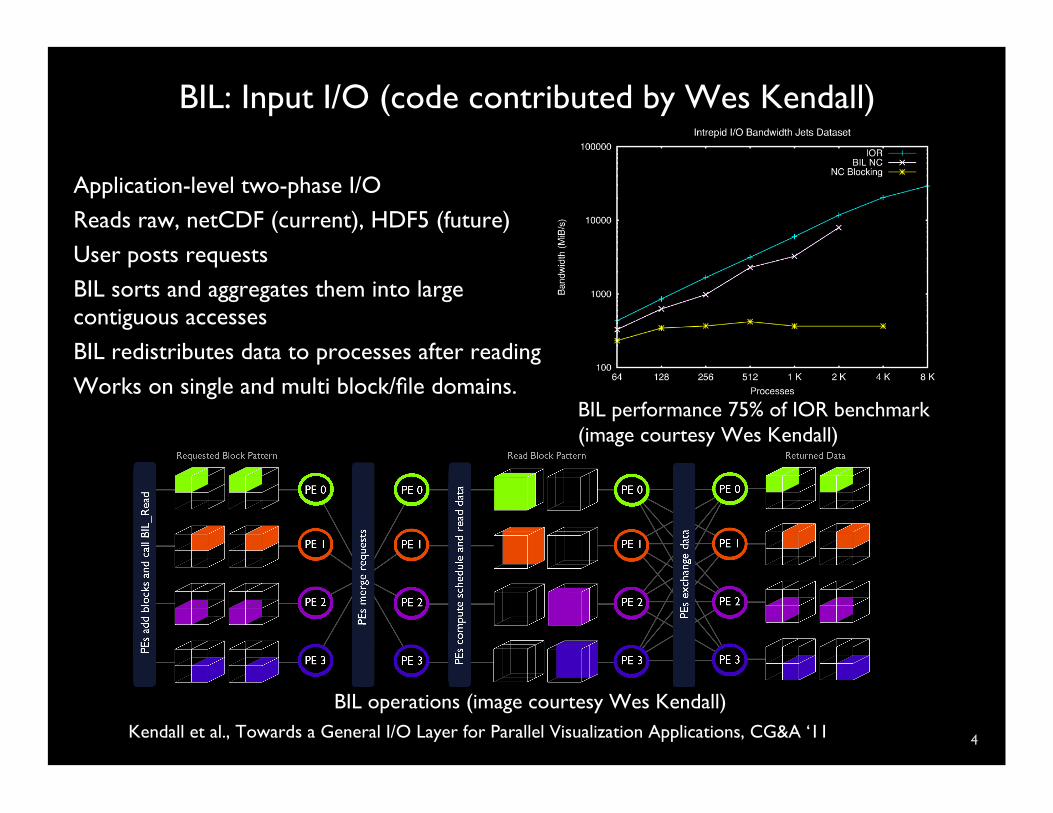
BIL: Input I/O (code contributed by Wes Kendall)
4
Application-level two-phase I/O Reads raw, netCDF (current), HDF5 (future) User posts requests BIL sorts and aggregates them into large contiguous accesses
BIL redistributes data to processes after reading Works on single and multi block/file domains.
BIL operations (image courtesy Wes Kendall)
BIL performance 75% of IOR benchmark (image courtesy Wes Kendall)
Kendall et al., Towards a General I/O Layer for Parallel Visualization Applications, CG&A ‘11
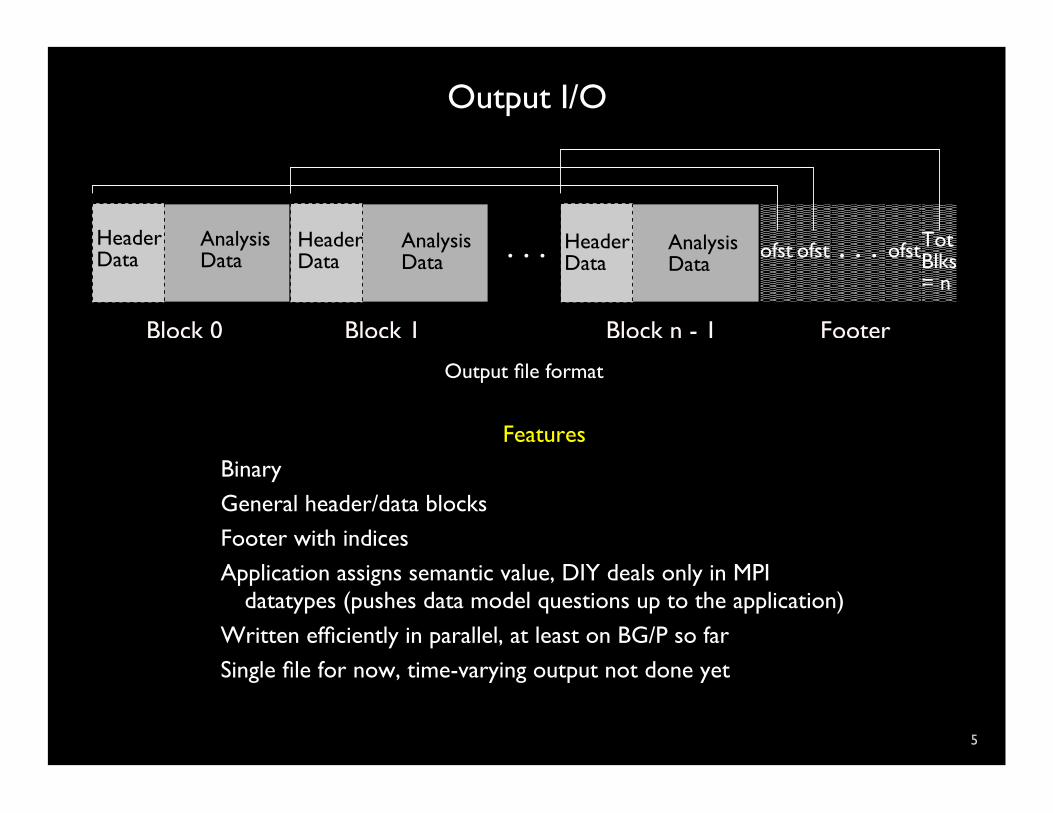
Output I/O
5
Features
Binary General header/data blocks Footer with indices Application assigns semantic value, DIY deals only in MPI
datatypes (pushes data model questions up to the application)
Written efficiently in parallel, at least on BG/P so far Single file for now, time-varying output not done yet
Output file format
!"#$"%&#'#
()#*+,-,&#'# ././. ././.01,' 01,' 01,'20'3*4,
5/)
3*064/7 3*064/8 3*064/)/9/8 :00'"%
!"#$"%&#'#
()#*+,-,&#'#
!"#$"%&#'#
()#*+,-,&#'#
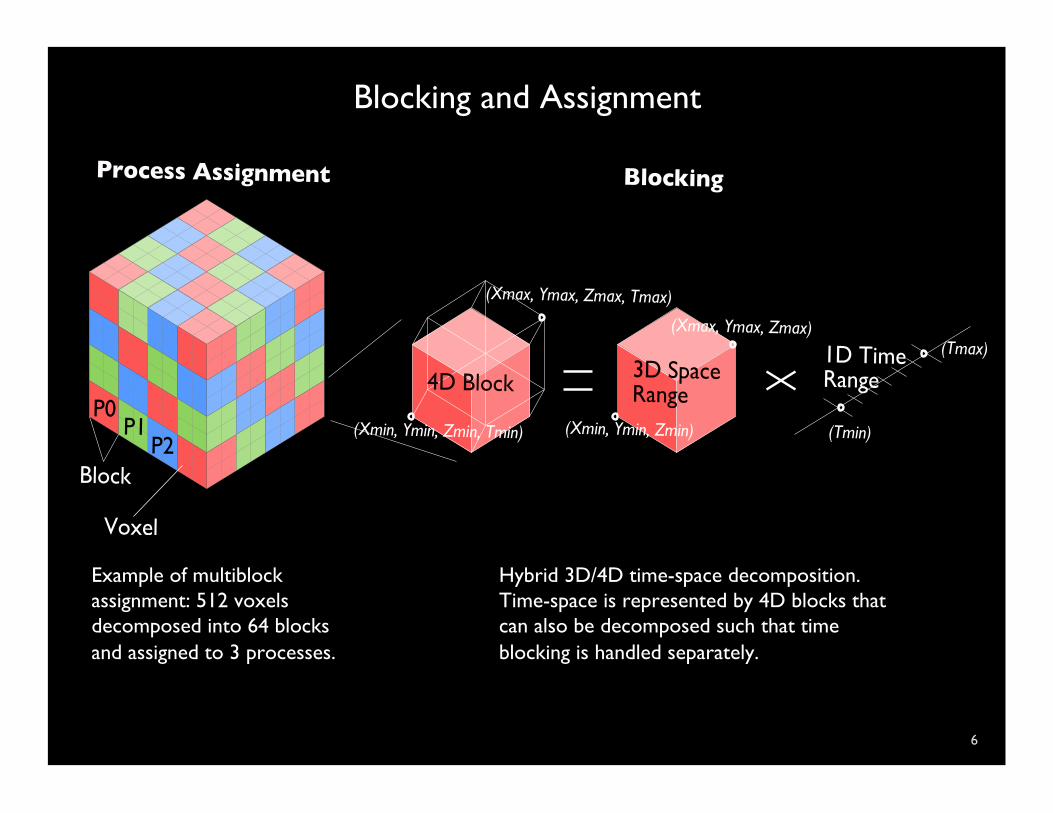
Blocking and Assignment
6
Hybrid 3D/4D time-space decomposition. Time-space is represented by 4D blocks that can also be decomposed such that time blocking is handled separately.
Example of multiblock assignment: 512 voxels decomposed into 64 blocks and assigned to 3 processes.
!"#$%
&#'("
)*)+),
-./!"#$% 0./123$(4356(
+./789(4356(
!"#$%&'(#$%&')#$%&'*#$%+
!"#,-&'(#,-&')#,-&'*#,-+
!"#$%&'(#$%&')#$%+
!"#,-&'(#,-&')#,-+
!*#$%+
!*#,-+
!"#$%&&'(&&)*+,%+- ./#$0)+*

Communication Patterns: Nearest Neighbor
7
!"#$%&'' ( ) * + , - .
/ 0 (' (( () (* (+ (,
!"#$%&(
!12#342
5"$46$#1&4"&7#84918&:$:3;262&"8<:8:3313&=8641&812#342&4"&24"8:>1
' ( ) * + , - .
/ 0 (' (( () (* (+ (,
' ( ) * + , - .
/ 0 (' (( () (* (+ (,
Peterka et al., A Study of Parallel Particle Tracing for Steady-State and Time-Varying Flow Fields, IPDPS ‘11
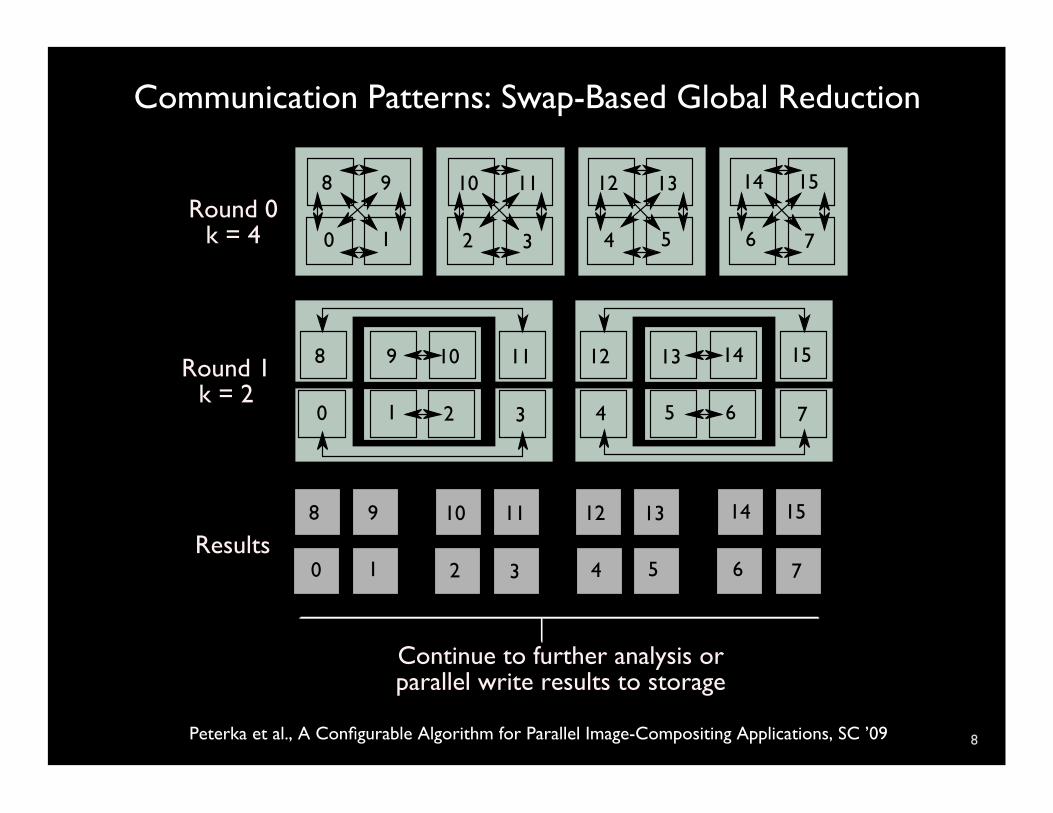
Communication Patterns: Swap-Based Global Reduction
8
!"#$%&'(&)&* ' + , - * . / 0
1 2 +' ++ +, +- +* +.
!"#$%&+(&)&,
!34#564
7"$68$#3&6"&9#:6;3:&<$<5=484&":><:<5535&?:863&:34#564&6"&46":<@3
' + , - * . / 0
1 2 +' ++ +, +- +* +.
' + , - * . / 0
1 2 +' ++ +, +- +* +.
Peterka et al., A Configurable Algorithm for Parallel Image-Compositing Applications, SC ’09
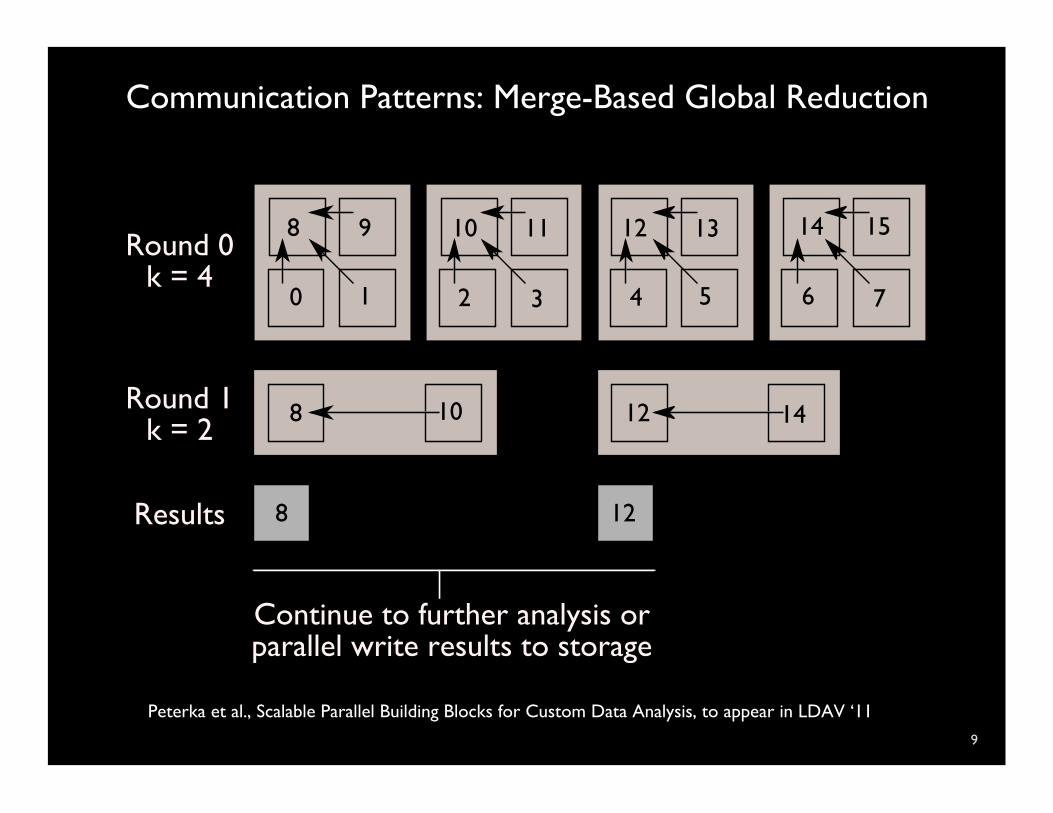
Communication Patterns: Merge-Based Global Reduction
9
!"#$%&'(&)&*
' + , - * . / 0
1 2 +' ++ +, +- +* +.
1 +' +, +*
1 +,
!"#$%&+(&)&,
!34#564
7"$68$#3&6"&9#:6;3:&<$<5=484&":><:<5535&?:863&:34#564&6"&46":<@3
Peterka et al., Scalable Parallel Building Blocks for Custom Data Analysis, to appear in LDAV ‘11

Example API Use
10
// setup and domain decomposition int dim = 3; // number of dimensions in the problem
int tot_blocks = 8; // total number of blocks int64_t data_size[3] = {10, 10, 10}; // data size
int64_t given[3] = {0, 0, 0}; // constraints on blocking (none) Assignment *assignment = new Assignment(tot_blocks, nblocks, maxblocks,
MPI_COMM_WORLD); Blocking *blocking = new Blocking(dim, tot_blocks, data_size, 0, 0, 0, given, assignment,
MPI_COMM_WORLD);
// read data for (int i = 0; i < nblocks; i++) {
blocking->BlockStartsSizes(i, min, size); int bil_data_size[3] = { data_size[2], data_size[1], data_size[0] };
int bil_min[3] = { min[2], min[1], min[0] }; int bil_size[3] = { size[2], size[1], size[0] };
BIL_Add_block_raw(dim, bil_data_size, bil_min, bil_size, infile, MPI_INT, (void**)&(data[i])); }
BIL_Read();

Example API Continued
11
// local analysis …
// merge results
int rounds = 2; // two rounds of merging int kvalues[2] = {4, 2}; // k-way merging, eg 4-way followed by 2-way merge
int nb_merged; // number of output merged blocks Merge *merge = new Merge(MPI_COMM_WORLD);
nb_merged = merge->MergeBlocks((char**)merged_results, (int **)NULL, nblocks, (char**&)results, rounds, &kvalues[0], io, assignment, &ComputeMerge, &CreateItem,&DeleteItem, &CreateType);
// write results IO *io = new IO(dim, tot_blocks, maxblocks, MPI_COMM_WORLD); io->WriteAnaInit(outfile); io->WriteAllAna((void **)merged_results, nb_merged, maxblocks, dtype);
io->WriteAnaFinalize();
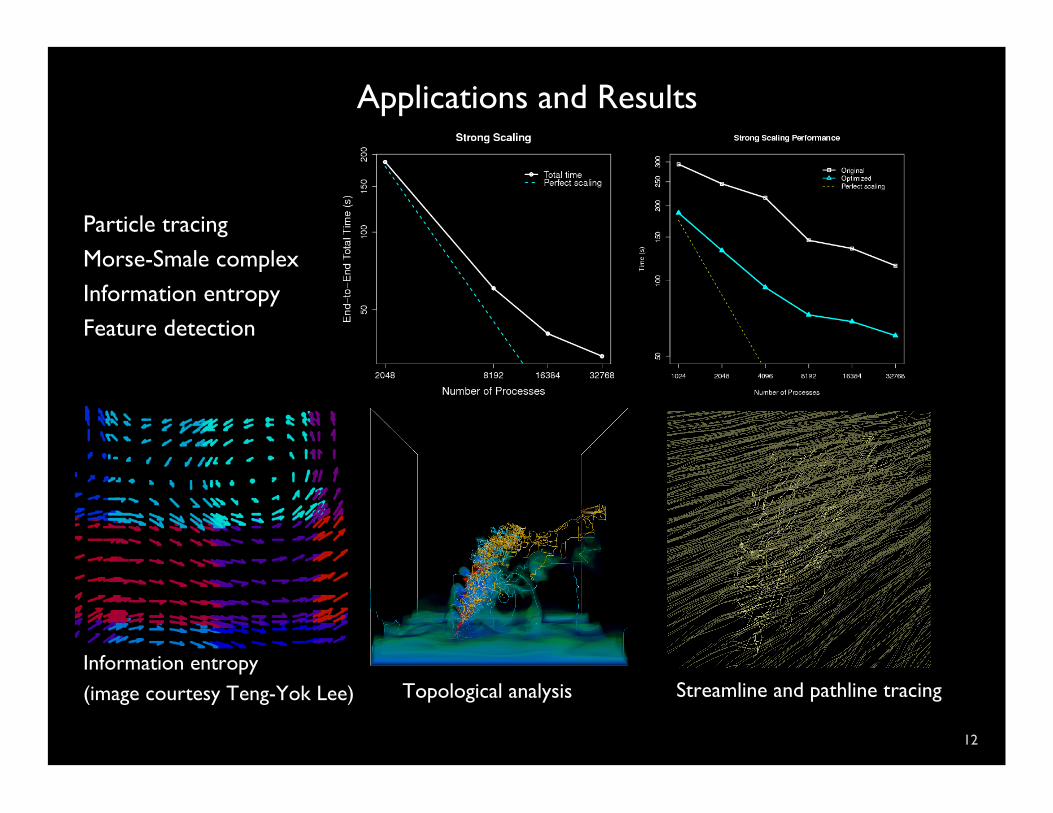
Applications and Results
12
Particle tracing
Morse-Smale complex Information entropy Feature detection
Information entropy (image courtesy Teng-Yok Lee) Topological analysis Streamline and pathline tracing

Summary
13
Successes
Supports numerous, diverse analysis techniques. Flexible combination of data movements.
Both postprocessing and in situ. Scales well.
Limitations
Low level data type Intrusive in situ
Takes space, can crash, requires recompilation Requires effort on the part of the user
Needs a program and programmer.
To Do
Finish installing existing code AMR and unstructured decomposition Particle decomposition Hybrid parallelism?

Tom Peterka
Mathematics and Computer Science Division
Data Movement Support for Analysis
https://svn.mcs.anl.gov/repos/diy/trunk
CScADS Summer Workshop 7/26/11
Peterka et al., Scalable Parallel Building Blocks for Custom Data Analysis, to appear in LDAV ‘11





























