Embed Size (px)
Citation preview

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 1/43
Types of Data & Data Preprocessing
Prof. Navneet Goyal
Department of Computer Science & Information Systems
BITS, Pilani

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 2/43
Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchygeneration
Summary

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 3/43
Why Preprocess Data?
Data in the real world is dirty
Incomplete: lacking attribute values, lackingcertain attributes of interest, or containing
only aggregate data Noisy: containing errors or outliers
Inconsistent: containing discrepancies incodes or names
Welcome to the real world!
No quality data, no quality mining results!
Quality decisions must be based on qualitydata

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 4/43
Understanding Your Data
Descriptive Data summarization
Foundation for data processing
Central tendency: Mean, Mode, Median
Data Dispersion: Quartiles, Interquartilerange (IQR), Variance
Distributive Measure:sum,count,max,min
Algebraic Measure: algebraic fn. Onone or more distributive measure
Example: average weighted average

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 5/43
Understanding Your Data
Mean is sensitive to extreme values
Solution: Trimming
For skewed data: median is a bettermeasure (middle values of orderedset)
Holistic measure: cannot be
computed by data partitioning
Example:
Computationally more expensive
median

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 6/43
Understanding Your Data
Mode: most frequently occurring data value Unimodal, bimodal, trimodal, multimodal No mode!! Dispersion of data: range, quartile, outliers
Range=max-min k th percentile of a set of data in numerical order is the
value x i having the property that k% of data values lieat or below x i
Median is Quartiles: Q1(25th percentile), Q3 (75th percentile)
Give idea about center, spread, & shape of distribution IQR = Q3 – Q1 (all holistic measures)
50th percentile

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 7/43
Understanding Your Data
Outliers: single out values falling at least1.5 x IQR above Q3 or below Q1
Which of the measures discussed so far are
one or more of the data values? 5-member summary:
minimum, Q1, Median, Q3, maximum
(since Q1, Median, Q3 contain no information about the tails)
Boxplots
Variance & Std. Dev.
Interpret σ=0 & σ>0

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 8/43
Major Tasks in DataPreprocessing
Data cleaning Fill in missing values, smooth noisy data,
identify or remove outliers, and resolve
inconsistencies Data integration Integration of multiple databases, data
cubes, or files
Data transformation Normalization and aggregation

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 9/43
Major Tasks in DataPreprocessing
Data reduction (sampling) Obtains reduced representation in volume
but produces the same or similar analytical
results Data discretization Part of data reduction but with particular
importance, especially for numerical data

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 10/43
Forms of data preprocessing
Figure taken from Han & kamber Book: Data Mining Concepts & Techniques, 2e

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 11/43
Data Cleaning
Data cleaning tasks
Fill in missing values
Identify outliers and smooth out noisy
data
Correct inconsistent data

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 12/43
Missing Data
Data is not always available
E.g., many tuples have no recorded value for several
attributes, such as customer income in sales data
Missing data may be due to equipment malfunction
inconsistent with other recorded data and thus
deleted
data not entered due to misunderstanding certain data may not be considered important at the
time of entry
not register history or changes of the data
Missing data may need to be inferred.

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 13/43
How to HandleMissing Data?
Ignore the tuple: usually done when class label is missing
(assuming the tasks is classification—not effective when the
percentage of missing values per attribute varies
considerably)
Fill in the missing value manually: tedious + infeasible?
Use a global constant to fill in the missing value: e.g.,
―unknown‖, a new class?!
Use the attribute mean to fill in the missing value
Use the attribute mean for all samples belonging to the same
class to fill in the missing value: smarter
Use the most probable value to fill in the missing value:
inference-based such as Bayesian formula or decision tree

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 14/43
Noisy Data Noise: random error or variance in a measured
variable
Incorrect attribute values may be due to
faulty data collection instruments
data entry problems data transmission problems
technology limitation
inconsistency in naming convention
Other data problems which requires data cleaning
duplicate records
incomplete data
inconsistent data
Smooth out the data to remove noise

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 15/43
Smoothing Techniques
Binning method:
first sort data and partition into (equi-depth) bins
then one can smooth by bin means, smooth by bin
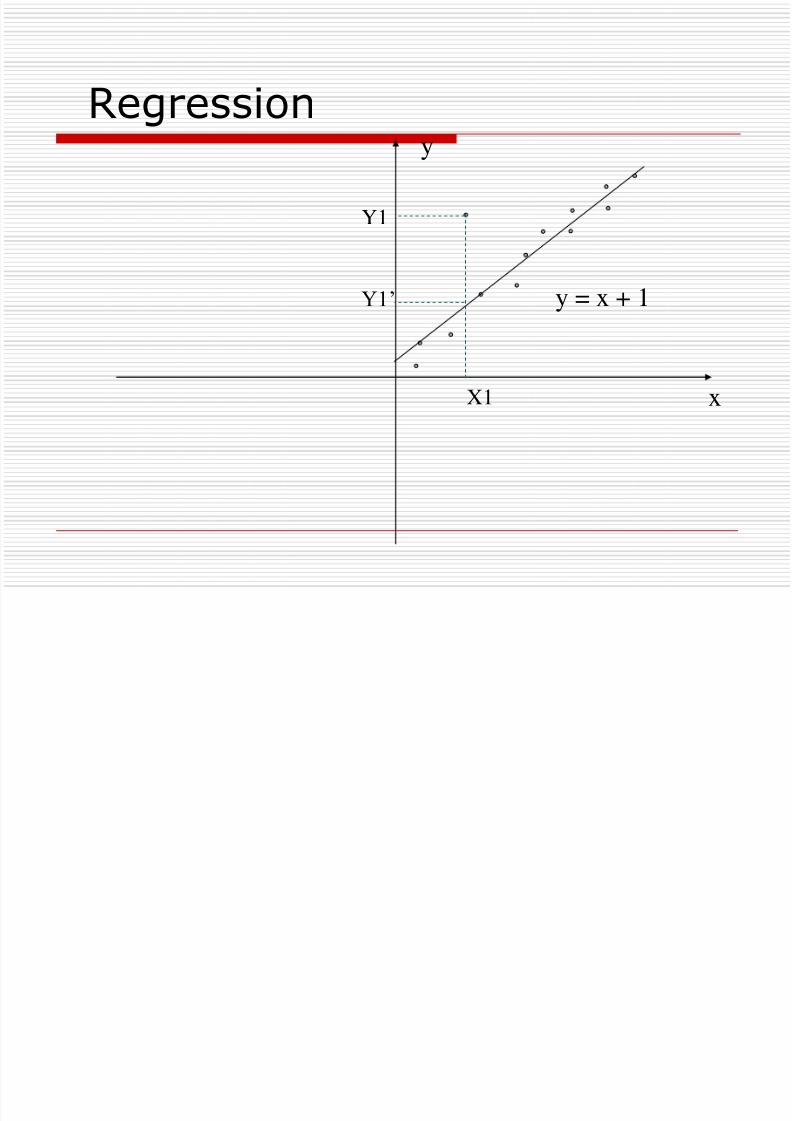
median, smooth by bin boundaries, etc. Clustering
detect and remove outliers
Combined computer and human inspection
detect suspicious values and check by human
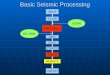
Regression
smooth by fitting the data into regression functions

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 16/43
Binning
Binning methods smooth a sorted datavalue by consulting its neighborhood,that is, values around it
Sorted values are distributed into anumber of ‗buckets‘ or ‗bins‘
Binning does local smoothing
Different binning methods illustrated byan example
Also used as data discretization tech.

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 17/43
Simple Discretization Methods:Binning
Equal-width (distance) partitioning: It divides the range into N intervals of equal size:
uniform grid if A and B are the lowest and highest values of the
attribute, the width of intervals will be: W = (B- A)/N. Most straightforward But outliers may dominate presentation Skewed data is not handled well.
Equal-depth (frequency) partitioning:
It divides the range into N intervals, each containingapproximately same number of samples Good data scaling Managing categorical attributes can be tricky.

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 18/43
Binning Methods for DataSmoothing
Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21,24, 25, 26, 28, 29, 34
Partition into (equi-depth) bins:- Bin 1: 4, 8, 9, 15
- Bin 2: 21, 21, 24, 25- Bin 3: 26, 28, 29, 34 Smoothing by bin means:
- Bin 1: 9, 9, 9, 9- Bin 2: 23, 23, 23, 23
- Bin 3: 29, 29, 29, 29 Smoothing by bin boundaries:- Bin 1: 4, 4, 4, 15- Bin 2: 21, 21, 25, 25- Bin 3: 26, 26, 26, 34
8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 19/43
Regression
x
y
y = x + 1
X1
Y1
Y1’
8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 20/43
Cluster Analysis

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 21/43
Data Smoothing & Reduction
Many methods discussed above for datasmoothing are also methods for datareduction involving discretization
For eg. Binning reduces the number of distinct values per attribute ( a form of data reduction for logic-based data
mining methods such a decision treeinduction

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 22/43
Data Integration Data integration:
combines data from multiple sources into a coherentstore
Schema integration
integrate metadata from different sources Entity identification problem: identify real world
entities from multiple data sources, e.g., A.cust-id B.cust-#
Detecting and resolving data value conflicts for the same real world entity, attribute values from
different sources are different
possible reasons: different representations, differentscales, e.g., metric vs. British units

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 23/43
Handling Redundant Datain Data Integration
Redundant data occur often when integration of
multiple databases
The same attribute may have different names in
different databases
One attribute may be a ―derived‖ attribute in another
table, e.g., annual revenue
Redundant data may be detected by correlation
analysis (Pearson‘s Correlation Coefficient)
Correlation does not imply Causality
Careful integration of the data from multiple sources
may help reduce/avoid redundancies and
inconsistencies and improve mining speed and quality

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 24/43
Data Transformation
Smoothing: remove noise from data
Aggregation: summarization, data cube construction
Generalization: concept hierarchy climbing
Normalization: scaled to fall within a small, specifiedrange
min-max normalization
z-score normalization
normalization by decimal scaling
Attribute/feature construction
New attributes constructed from the given ones

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 25/43
Data Transformation:Normalization
min-max normalization
z-score normalization (zero-mean)
normalization by decimal scaling
A A A
A A
A
minnewminnewmaxnewminmax
minvv _)__('
A
A
devstand
meanvv
_'
j
vv
10' Where j is the smallest integer such that Max(| |)<1'v

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 26/43
Data Transformation:Attribute Construction
New attributes are constructed from givenattributes and added
Improves accuracy
Helps in understanding of structure in hig-dimensional data
For eg. Add area based on attributes height
& width Knowing about relationships among
attributes help in knowledge discovery

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 27/43
Data Reduction Strategies
Warehouse may store terabytes of data:Complex data analysis/mining may take a verylong time to run on the complete data set
Data reduction Obtains a reduced representation of the data set
that is much smaller in volume but yet produces thesame (or almost the same) analytical results
Data reduction strategies
Data cube aggregation Attribute subset selection (feature subset selection)
Dimensionality reduction
Numerosity reduction
Discretization and concept hierarchy generation

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 28/43
Data Cube Aggregation
Cube at the lowest level of abstraction – base cuboid
Cube at highest level of abstraction – apex cuboid
Cubes are created at various levels of abstraction,
depending upon the analysis task – cubiods
Cube is a lattice of cuboids
Data volume reduces as we move up from base to apex
cubiod
While doing data mining, the smallest available cuboid
relevant to the given task should be used
Cube aggregation gives smaller data without loss of
information necessary for the analysis task

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 29/43
Attribute subset selection
Also called Feature subset selection
Leave out irrelevant attributes and pick only relevantattributes
Difficult and time consuming process
Reduces the data size by removing irrelevant orredundant attributes (dimensions)
Goal is to select a minimum set of features such that theresulting probability distribution of data classes is as close as
possible to the original distribution given the values of allfeatures
Additional benefit: less attributes appear in discoveredpatterns, making interpretation easier

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 30/43
Attribute subset selection
How to select a good representative subset? For N attributes, 2N possible subsets Heuristic methods (due to exponential # of
choices)
Heuristic methods that explore a reducedsearch space are generally used
Greedy algorithms Heuristic methods:
step-wise forward selection step-wise backward elimination combining forward selection and backward
elimination decision-tree induction
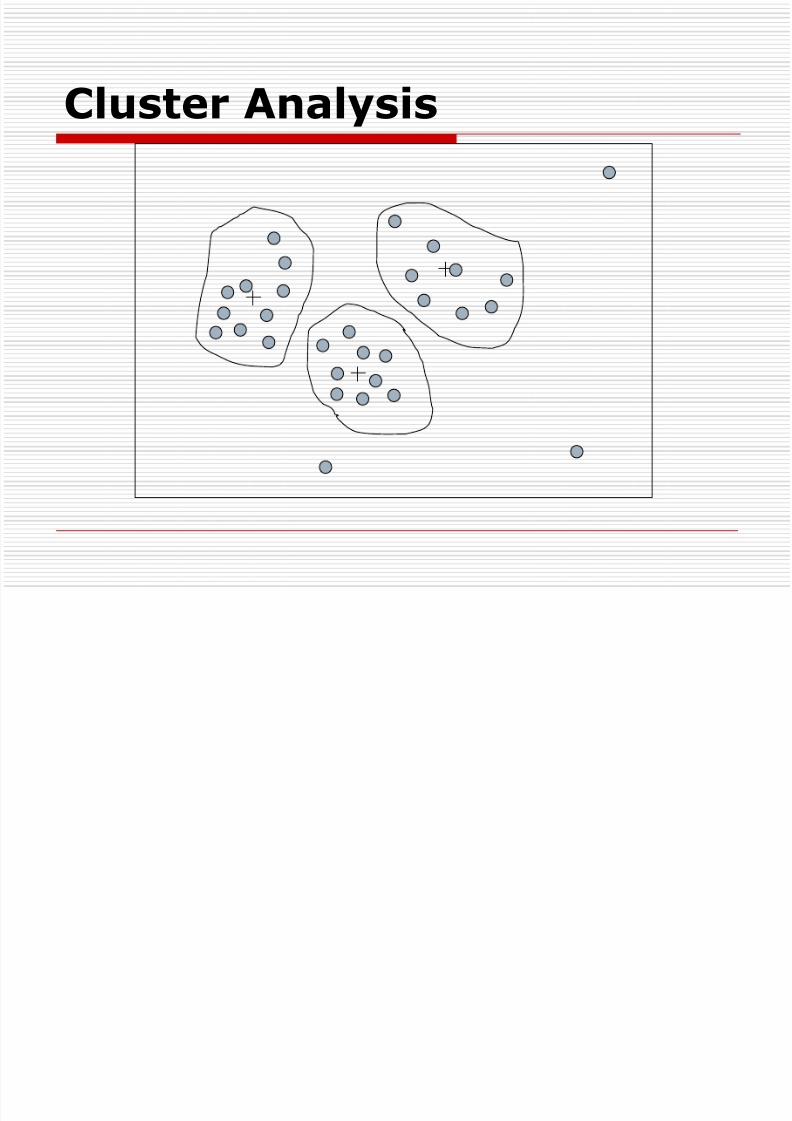
8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 31/43
Example of Decision TreeInduction
Initial attribute set:
{A1, A2, A3, A4, A5, A6}
A4 ?
A1? A6?
Class 1 Class 2 Class 1 Class 2
> Reduced attribute set: {A1, A4, A6}

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 32/43
Wavelet Transforms
Discrete wavelet transform (DWT): linear signal
processing
Compressed approximation: store only a small fraction of
the strongest of the wavelet coefficients
Similar to discrete Fourier transform (DFT), but better
lossy compression, localized in space
Method:
Length, L, must be an integer power of 2 (padding with 0s, when
necessary)
Each transform has 2 functions: smoothing, difference
Applies to pairs of data, resulting in two set of data of length L/2
Applies two functions recursively, until reaches the desired length
Haar2 Daubechie4
Figure taken from Han & kamber Book: Data Mining Concepts & Techniques, 2e

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 33/43
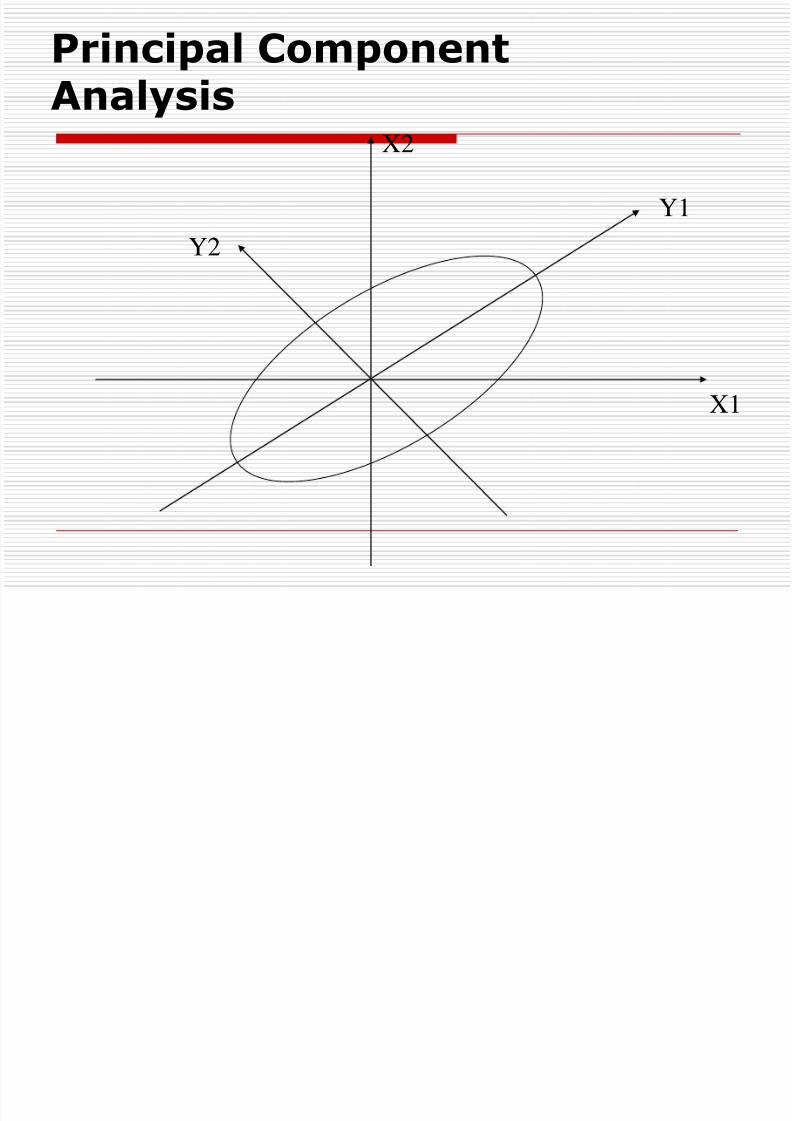
Given N data vectors from k -dimensions,
find c <= k orthogonal vectors that can be
best used to represent data
The original data set is reduced to oneconsisting of N data vectors on c principal
components (reduced dimensions)
Each data vector is a linear combination of
the c principal component vectors
Works for numeric data only
Used when the number of dimensions is
large
Principal ComponentAnalysis
8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 34/43
X2
X1
Y1
Y2
Principal ComponentAnalysis

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 35/43
Numerosity Reduction
Can we reduce the data volume by
choosing alternative ‗smaller forms of
data representation?
Techniques:
Parametric
Non-parametric methods

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 36/43
Numerosity Reduction
Parametric methods
Assume the data fits some model, estimate
model parameters, store only the parameters,
and discard the data (except possible outliers) Log-linear models
Non-parametric methods
Do not assume models. Stores reduced
representations of the data
Major families: histograms, clustering, sampling

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 37/43
Regression and Log-Linear Models
Linear regression: Data are modeled to fit a straight
line
Often uses the least-square method to fit the line
Multiple regression: allows a response variable Y to
be modeled as a linear function of multidimensional
feature vector
Log-linear model: approximates discrete
multidimensional probability distributions

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 38/43
Linear regression: Y = + X
Two parameters , and specify the line and areto be estimated by using the data at hand.
using the least squares criterion to the known
values of Y 1 , Y 2 , …, X 1 , X 2 , …. Multiple regression: Y = b0 + b1 X1 + b2 X2.
Many nonlinear functions can be transformed intothe above.
Log-linear models: The multi-way table of joint probabilities is
approximated by a product of lower-order tables.
Probability: p(a, b, c, d) = ab ac ad bcd
Regress Analysis andLog-Linear Models
8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 39/43
Histograms
A popular datareduction technique
Divide data intobuckets and store
average (sum) foreach bucket
Can be constructedoptimally in one
dimension usingdynamic programming
Related to quantizationproblems.
0
5
10
15
20
25
30
35
40
10000 30000 50000 70000 90000

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 40/43
Clustering
Partition data set into clusters, and one can store
cluster representation only
Can be very effective if data is clustered but not if
data is ―smeared‖
Can have hierarchical clustering and be stored in
multi-dimensional index tree structures
There are many choices of clustering definitions and
clustering algorithms, further detailed in Chapter 8

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 41/43
Sampling
Allow a mining algorithm to run in complexity that ispotentially sub-linear to the size of the data
Choose a representative subset of the data
Simple random sampling may have very poorperformance in the presence of skew
Develop adaptive sampling methods
Stratified sampling:
Approximate the percentage of each class (or
subpopulation of interest) in the overall database Used in conjunction with skewed data
Sampling may not reduce database I/Os (page at atime).

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 42/43
Sampling
Raw Data

8/3/2019 Data Pre Processing - NG
http://slidepdf.com/reader/full/data-pre-processing-ng 43/43
Sampling
Raw Data Cluster/Stratified Sample