Embed Size (px)
Citation preview

DataStax TechDay - Munich
Christian Johannsen, Solutions Engineer
1
DataStax TechDay - Munich
• Christian Johannsen
• Solutions Engineer
• +49(0)151 15055115
• @cjohannsen81
2

DataStax TechDay - Munich
• 09:30am - 10:00am | Coffee and Registration
• 10:00am - 10:30am | Welcome and Introduction
• 10:30am - 11:00am | Guest Speaker
• 11:00am - 12:00pm | Cassandra Overview, Replication, Capacity Management
• 12:00pm - 01:00pm | Lunch
• 01:00pm - 02:00pm | Read/Write Data, Tuneable Consistency, Managing Cassandra
• 02:00pm - 03:15pm | Cassandra Schema/Types, Data Modelling Example
• 03:15pm - 03:30pm | DataStax Enterprise, Hadoop, Solr and Spark(Shark)
• 03:30pm - 04:00pm | Wrap up and Q&A
3

©2013 DataStax Confidential. Do not distribute without consent.
Today’s Objectives
• Cassandra Terminology and Architecture Review
• Understanding the Cassandra schema
• DataStax Enterprise Analytics
4

A Look at Apache Cassandra…

• Apache Cassandra is a distributed (“NoSQL”) database
• massively scalable and available
• providing extreme performance
• designed to handle big data workloads
• across multiple data center
• no single point of failure
What is Apache Cassandra?
Why use Cassandra?
100,000
txns/sec
200,000
txns/sec
400,000
txns/sec
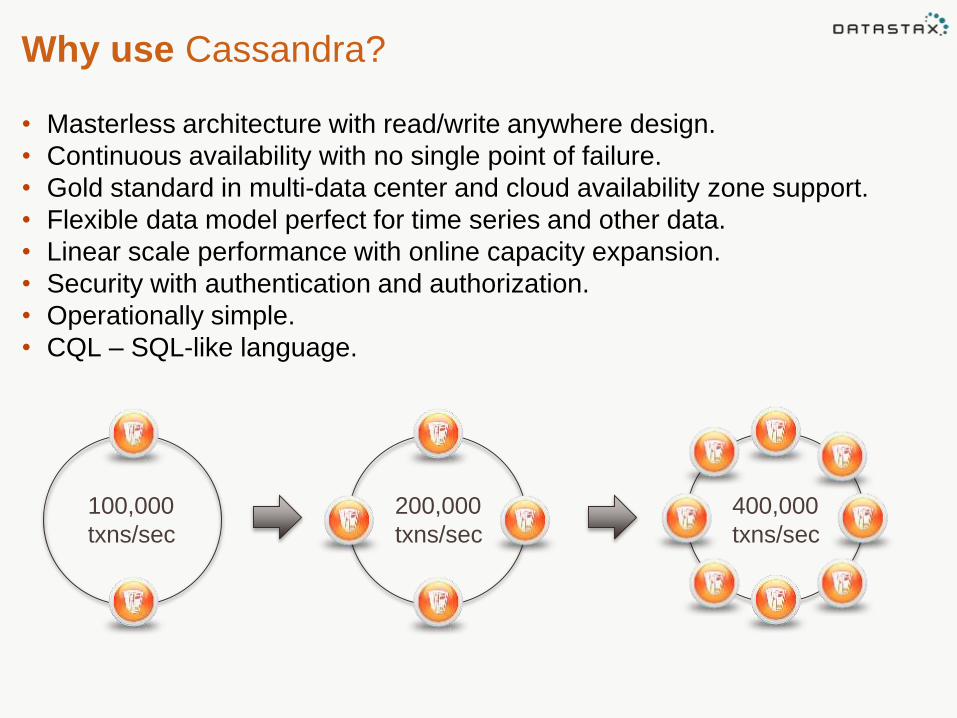
• Masterless architecture with read/write anywhere design.
• Continuous availability with no single point of failure.
• Gold standard in multi-data center and cloud availability zone support.
• Flexible data model perfect for time series and other data.
• Linear scale performance with online capacity expansion.
• Security with authentication and authorization.
• Operationally simple.
• CQL – SQL-like language.

©2013 DataStax Confidential. Do not distribute without consent.
History of Cassandra
8
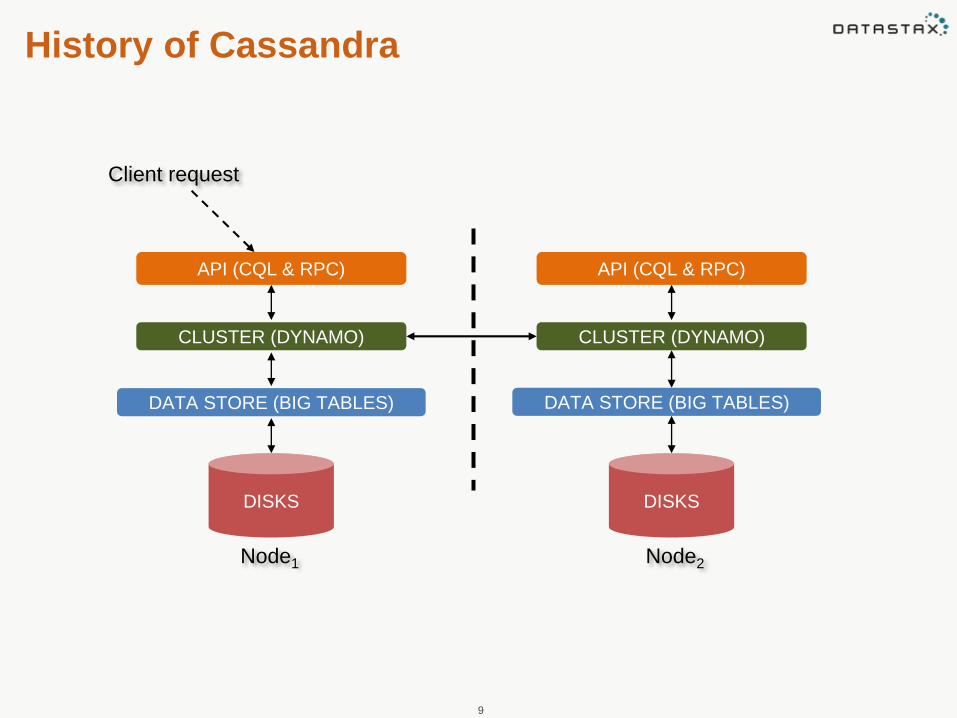
• Amazon Dynamo partitioning and replication
• Log-structured ColumnFamily data model similar to Bigtable's
9
DATA STORE (BIG TABLES)
CLUSTER (DYNAMO)
API (CQL & RPC)
DISKS
Node1
Client request
Node2
CLUSTER (DYNAMO)
API (CQL & RPC)
DISKS
DATA STORE (BIG TABLES)
History of Cassandra

• Cassandra was designed with the understanding
that system/hardware failures can and do occur
• Peer-to-peer, distributed system
• All nodes the same
• Data partitioned among all nodes in the cluster
• Custom data replication to ensure fault tolerance
• Read/Write-anywhere design
Cassandra Architecture Overview

• Each node communicates with each other through the Gossip
protocol, which exchanges information across the cluster every
second
• A commit log is used on each node to capture write activity.
Data durability is assured
• Data also written to an in-memory structure (memtable) and
then to disk once the memory structure is full (an SStable)
Cassandra Architecture Highlights

©2013 DataStax Confidential. Do not distribute without consent.
Cassandra Terminology
12
• Cluster - A ring of Cassandra nodes
• Node - A Cassandra instance
• Replication-Factor (RF) - How many copies of your data?
• Replication-Strategy - SimpleStrategy vs.
NetworkTopologyStrategy
• Consistency-Level (CL) - What Consistency should be
ensured for read/writes?
• Partitioner - Decides which node store which rows
(Murmur3Partinioner as default)
• Tokens - Hash values assigned to nodes

©2013 DataStax Confidential. Do not distribute without consent.
Cassandra Node
13
A computer server running Cassandra
©2013 DataStax Confidential. Do not distribute without consent.
Cassandra Node
14
©2013 DataStax Confidential. Do not distribute without consent.
Cassandra Cluster
15
A group of Cassandra nodes working together

©2013 DataStax Confidential. Do not distribute without consent.
Cassandra Datacenter
16
DC1 DC2

©2013 DataStax Confidential. Do not distribute without consent.
Logical Datacenter
17
©2013 DataStax Confidential. Do not distribute without consent.
Physical Datacenter
18
©2013 DataStax Confidential. Do not distribute without consent.
Cloud-based Datacenters
19
©2013 DataStax Confidential. Do not distribute without consent.
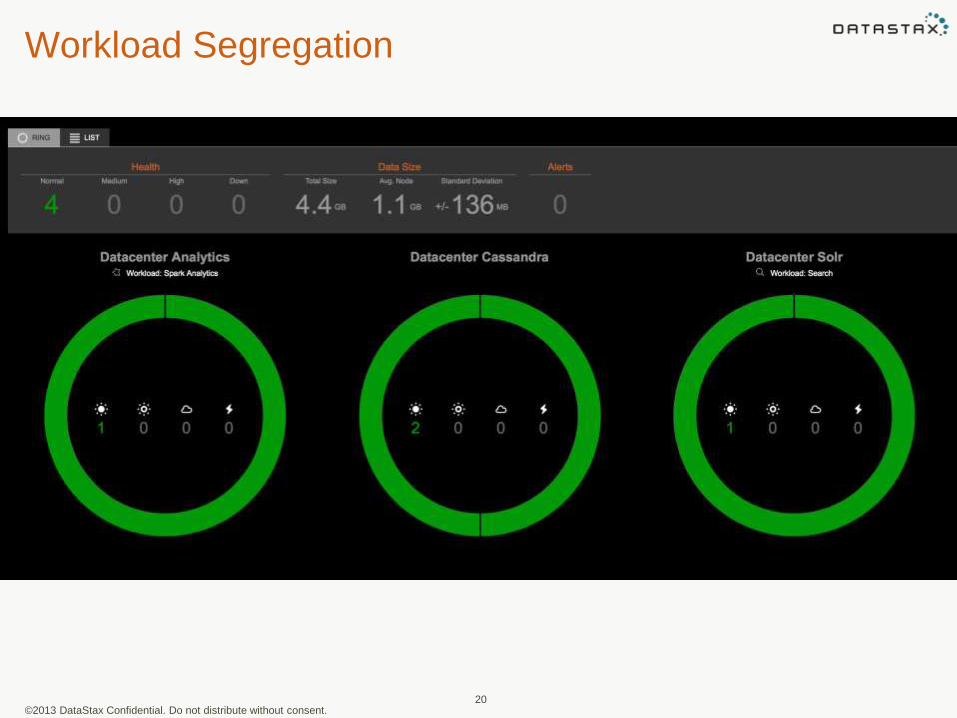
Workload Segregation
20
©2013 DataStax Confidential. Do not distribute without consent.
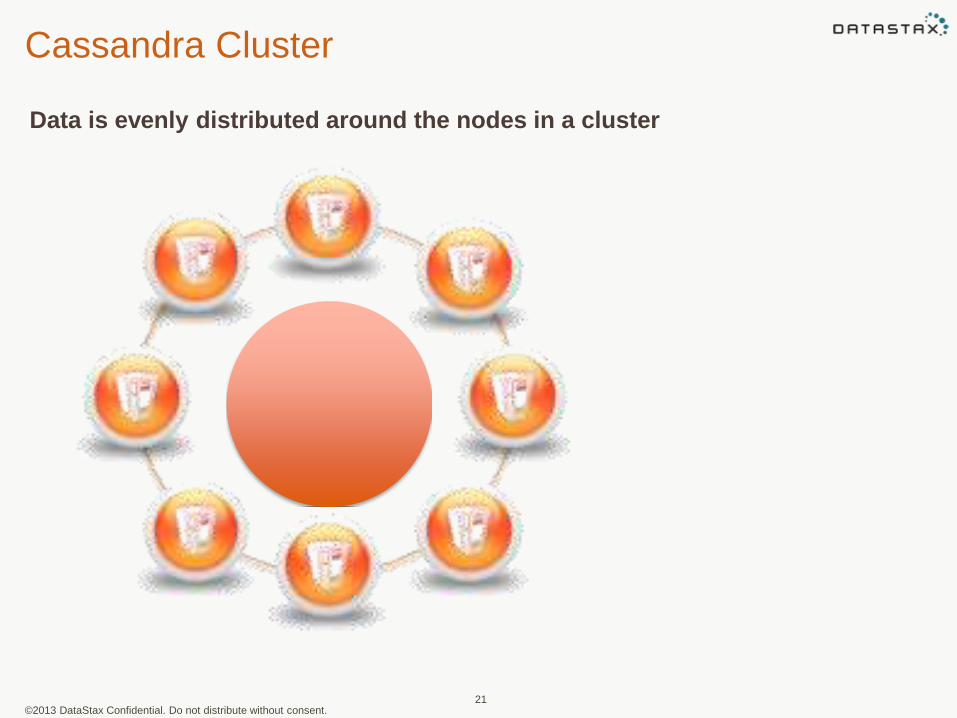
Cassandra Cluster
21
Data is evenly distributed around the nodes in a cluster
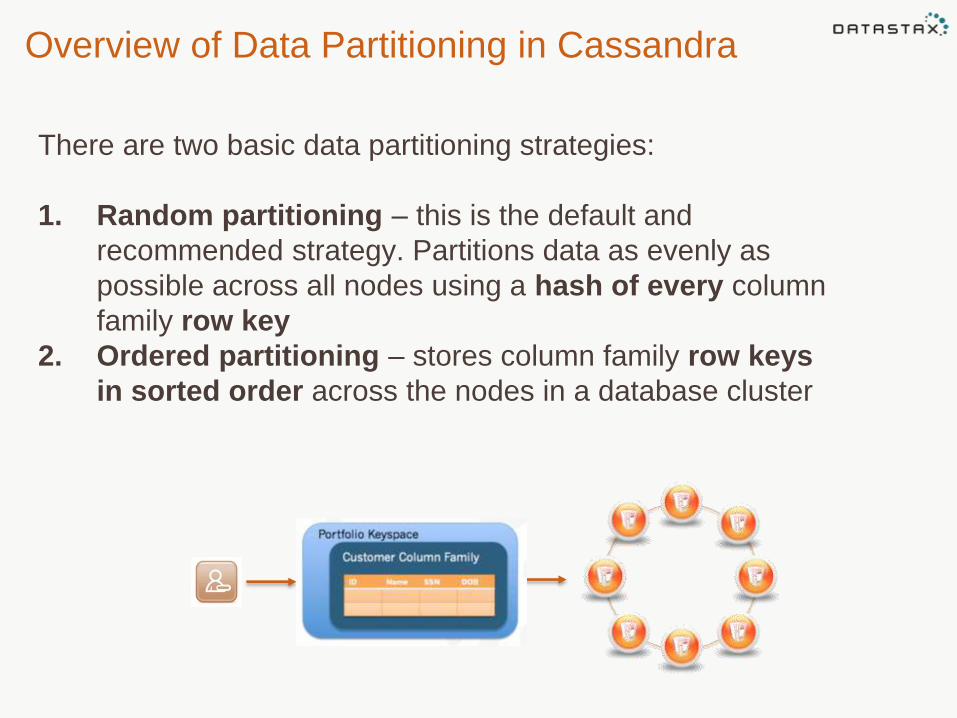
There are two basic data partitioning strategies:
1. Random partitioning – this is the default and
recommended strategy. Partitions data as evenly as
possible across all nodes using a hash of every column
family row key
2. Ordered partitioning – stores column family row keys
in sorted order across the nodes in a database cluster
Overview of Data Partitioning in Cassandra

©2013 DataStax Confidential. Do not distribute without consent.
Data Distribution and Partitioning
• Each node “owns” a set of tokens
• A node’s token range is manually configured or randomly assigned when the node joins the cluster (vNodes)
• A partition key is defined for each table
• The partitioner applies a hash function to convert a partition key to a token. This determines which node(s) store that piece of data.
• By default, Cassandra users the Murmur3Partitioner
23

©2013 DataStax Confidential. Do not distribute without consent.
What is a Hash Algorithm?
• A function used to map data of arbitrary size to data of fixed size
• Slight differences in input produce large differences in output
24
Input MurmurHash
1 8213365047359667313
2 5293579765126103566
3 -155496620801056360
4 -663977588974966463
5 958005880272148645
The Murmur3Partitioner uses the MurmurHash function. This hashing function
creates a 64-bit hash value of the row key. The possible range of hash values
is from -263 to +263.
©2013 DataStax Confidential. Do not distribute without consent.
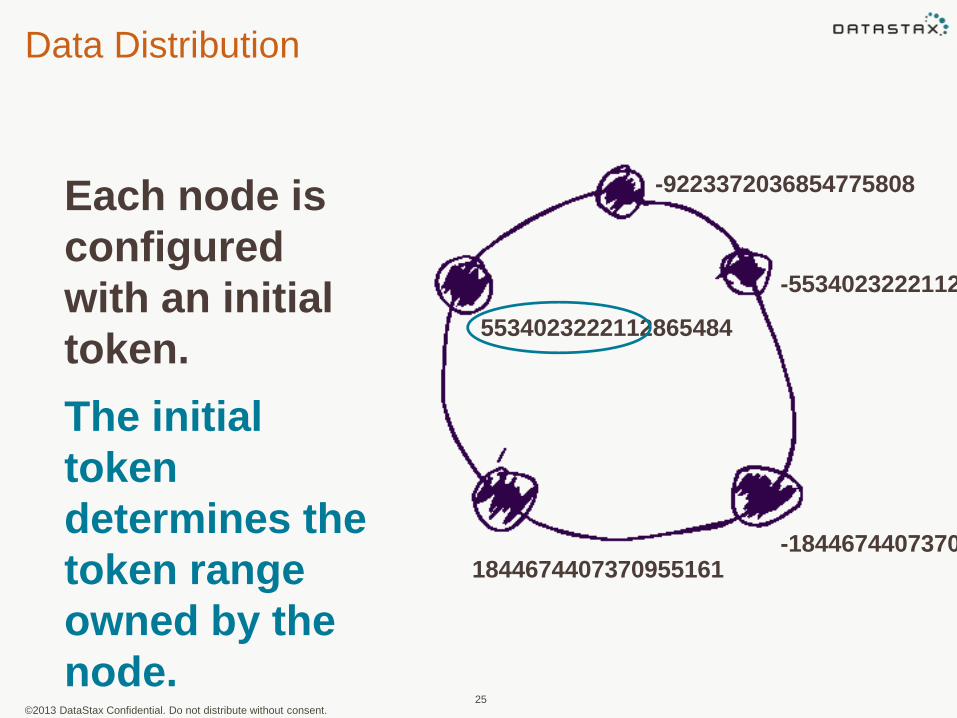
Data Distribution
25
-9223372036854775808
-5534023222112865485
-18446744073709551621844674407370955161
5534023222112865484
Each node is
configured
with an initial
token.
The initial
token
determines the
token range
owned by the
node.
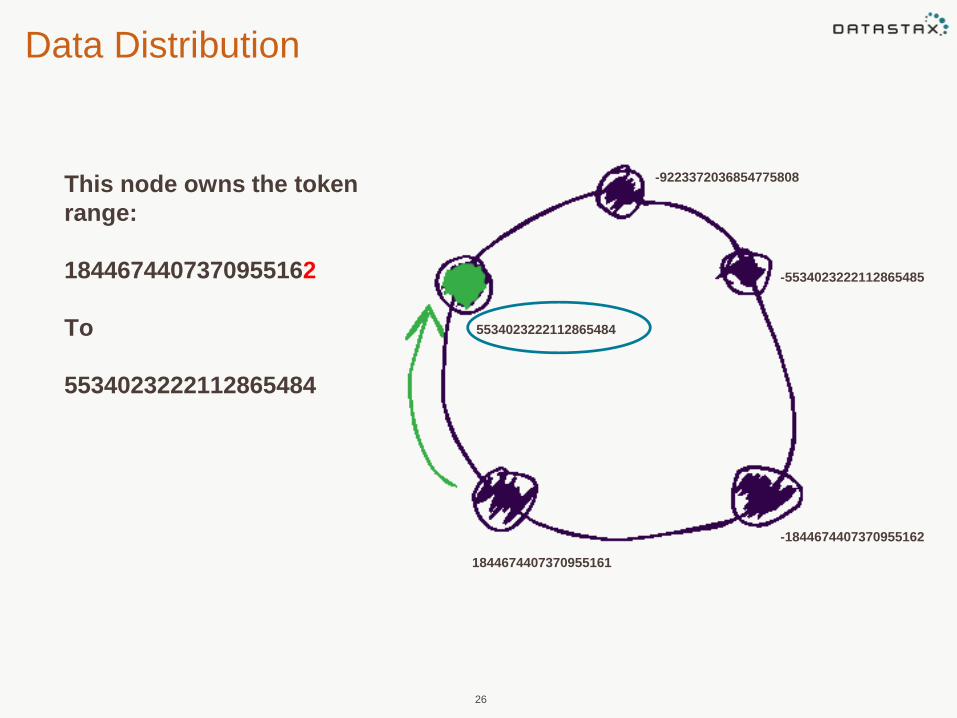
26
-9223372036854775808
-5534023222112865485
-1844674407370955162
1844674407370955161
5534023222112865484
This node owns the token
range:
1844674407370955162
To
5534023222112865484
Data Distribution
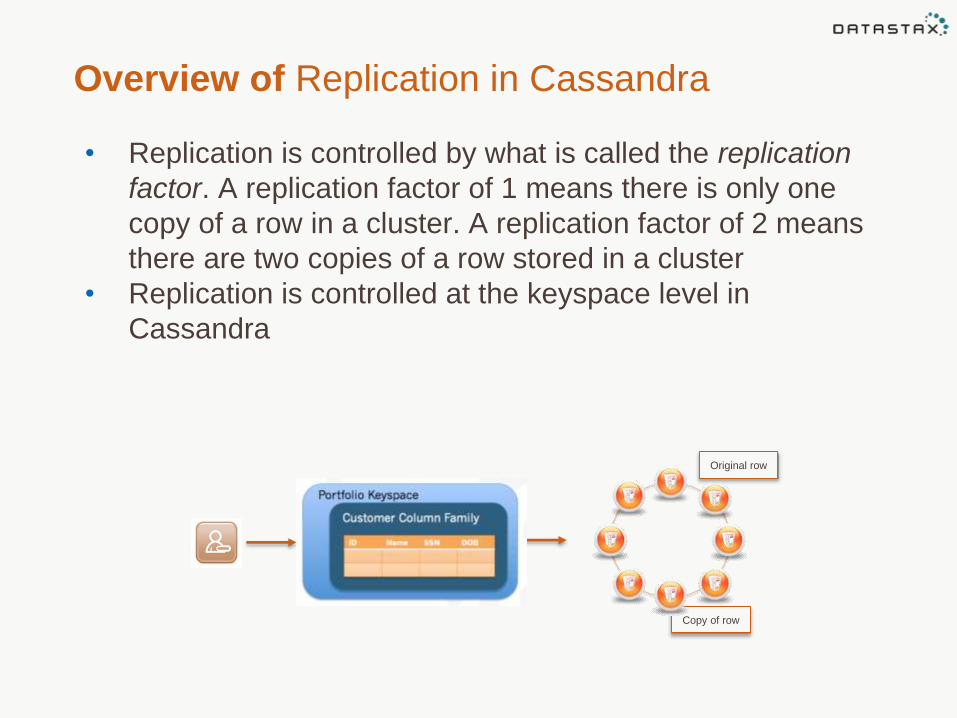
Overview of Replication in Cassandra
• Replication is controlled by what is called the replication
factor. A replication factor of 1 means there is only one
copy of a row in a cluster. A replication factor of 2 means
there are two copies of a row stored in a cluster
• Replication is controlled at the keyspace level in
Cassandra
Original row
Copy of row
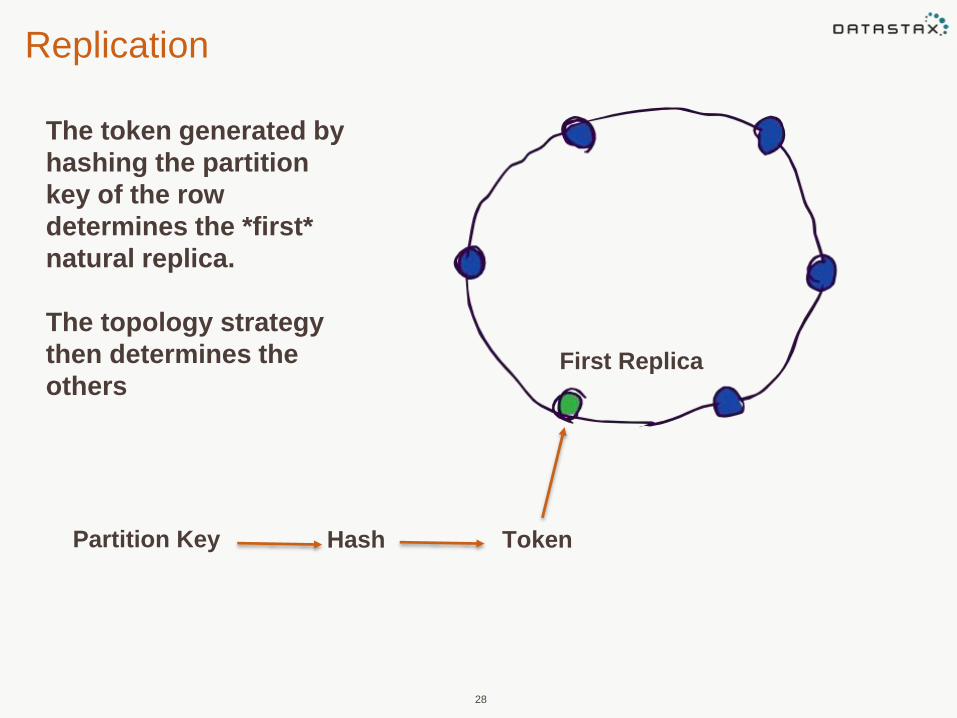
Replication
28
The token generated by
hashing the partition
key of the row
determines the *first*
natural replica.
The topology strategy
then determines the
others
Partition Key Hash Token
First Replica
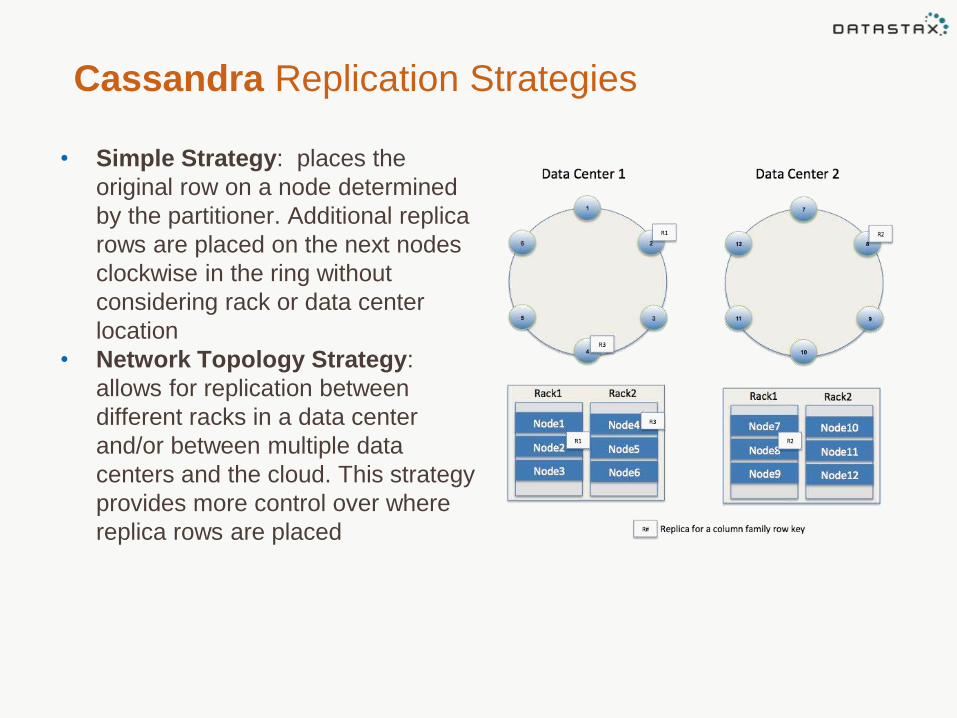
Cassandra Replication Strategies
• Simple Strategy: places the
original row on a node determined
by the partitioner. Additional replica
rows are placed on the next nodes
clockwise in the ring without
considering rack or data center
location
• Network Topology Strategy:
allows for replication between
different racks in a data center
and/or between multiple data
centers and the cloud. This strategy
provides more control over where
replica rows are placed
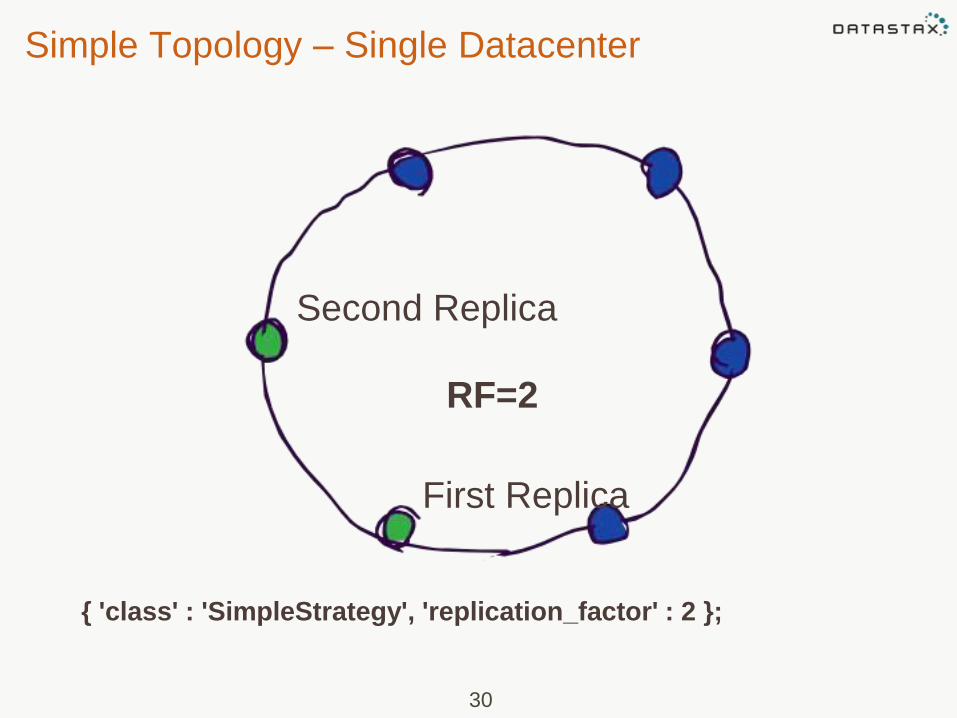
30
RF=2
First Replica
Second Replica
{ 'class' : 'SimpleStrategy', 'replication_factor' : 2 };
Simple Topology – Single Datacenter
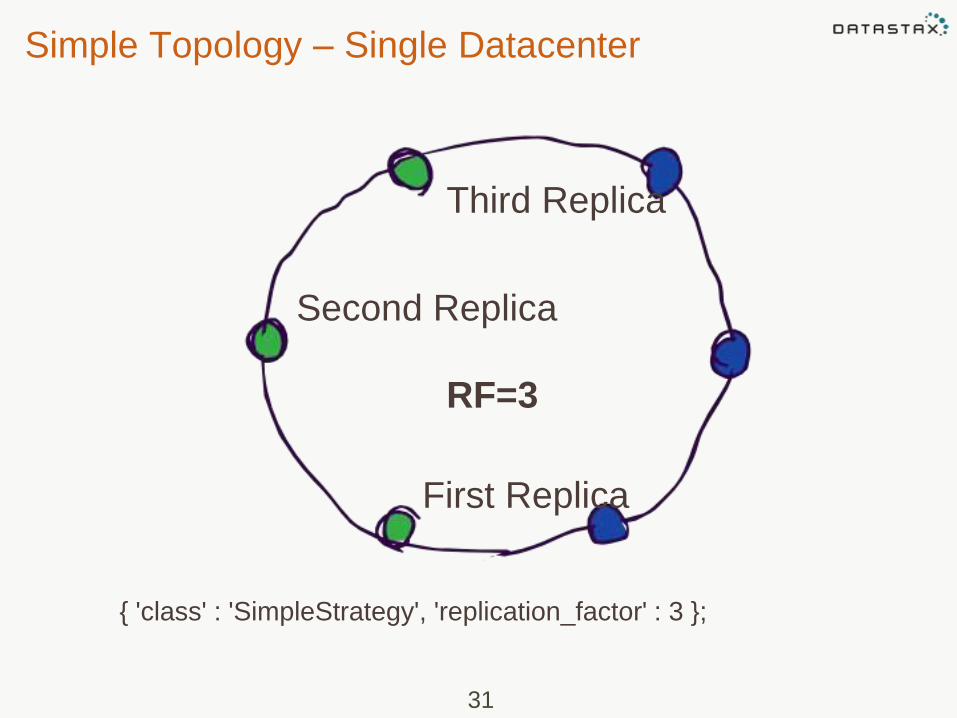
31
RF=3
First Replica
Second Replica
Third Replica
{ 'class' : 'SimpleStrategy', 'replication_factor' : 3 };
Simple Topology – Single Datacenter
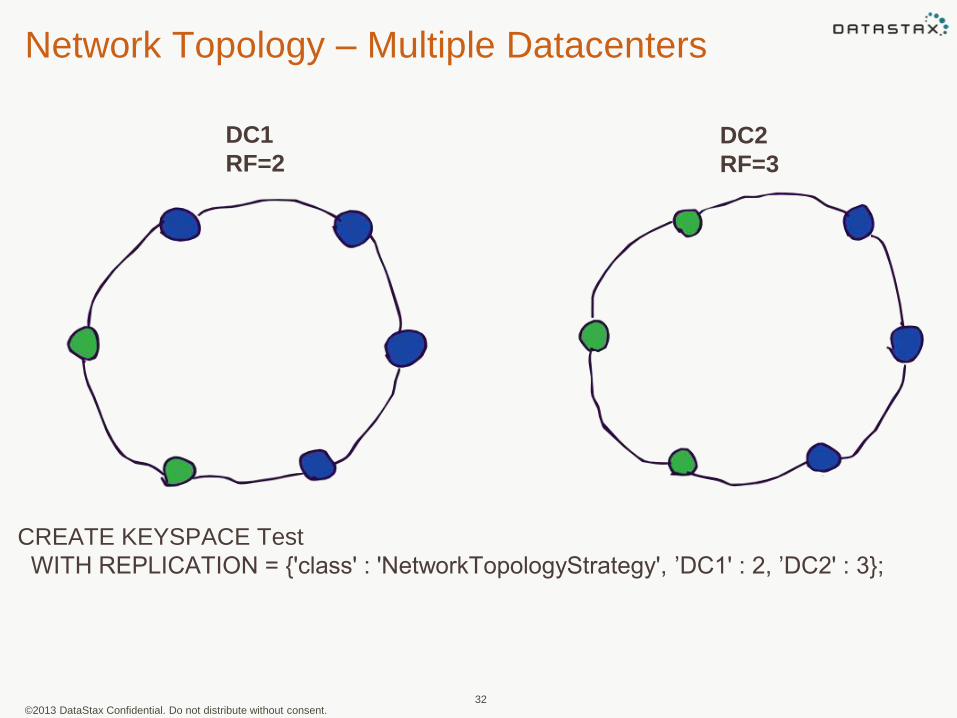
©2013 DataStax Confidential. Do not distribute without consent.
Network Topology – Multiple Datacenters
32
DC1
RF=2DC2
RF=3
CREATE KEYSPACE Test
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', ’DC1' : 2, ’DC2' : 3};
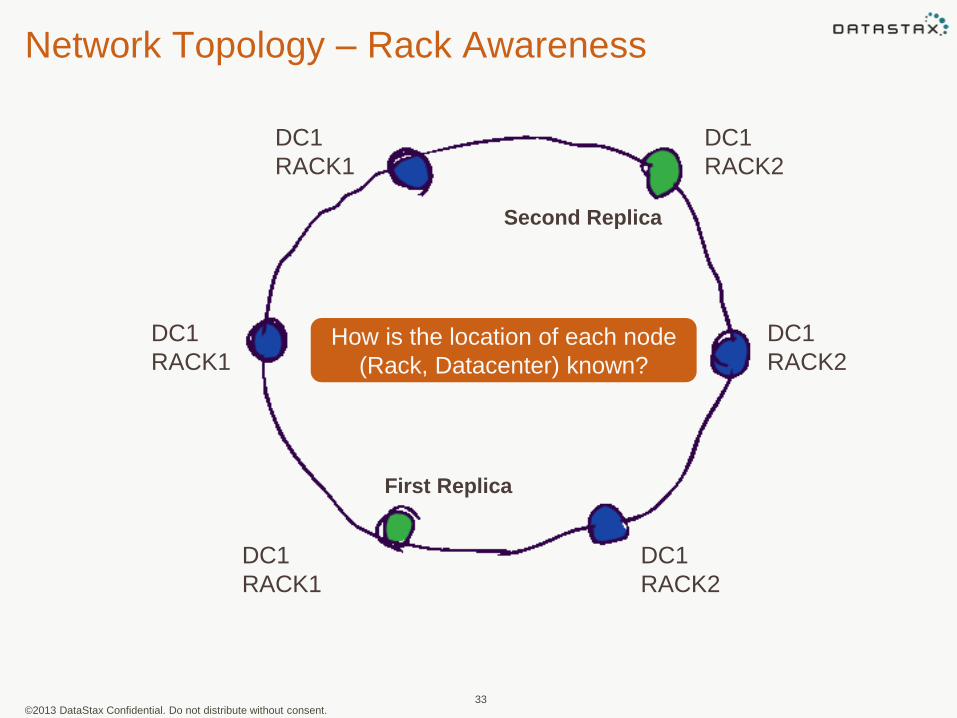
©2013 DataStax Confidential. Do not distribute without consent.
Network Topology – Rack Awareness
33
DC1
RACK1
DC1
RACK1
DC1
RACK1
DC1
RACK2
DC1
RACK2
DC1
RACK2
RF=2
First Replica
Second Replica
How is the location of each node
(Rack, Datacenter) known?

©2013 DataStax Confidential. Do not distribute without consent.
Snitches
• A snitch determines which data centers and racks are written to and read from.
• Snitches inform Cassandra about the network topology so that requests are routed efficiently and allows Cassandra to distribute replicas by grouping machines into data centers and racks. All nodes must have exactly the same snitch configuration. Cassandra does its best not to have more than one replica on the same rack (which is not necessarily a physical location).
35

©2013 DataStax Confidential. Do not distribute without consent.
Snitch Types
SimpleSnitch
• single-data center deployments (or single-zone in public clouds)
RackInferringSnitch
• determines the location of nodes by rack and data center, which are assumed to correspond to the 3rd and 2nd octet of the node's IP address
PropertyFileSnitch
• user-defined description of the network details
• cassandra-topology.properties file
GossipingPropertyFileSnitch
• defines a local node's data center and rack
• uses gossip for propagating this information to other nodes
• conf/cassandra-rackdc.properties
Amazon Snitches
• EC2Snitch
• EC2MultiRegionSnitch
36

©2013 DataStax Confidential. Do not distribute without consent.
Gossip = Internode Communications
• Gossip is a peer-to-peer communication protocol in which nodes periodically exchange information about themselves and about other nodes they know about.
• Cassandra uses gossip to discover location and state information about the other nodes participating in a Cassandra cluster
37
©2013 DataStax Confidential. Do not distribute without consent.
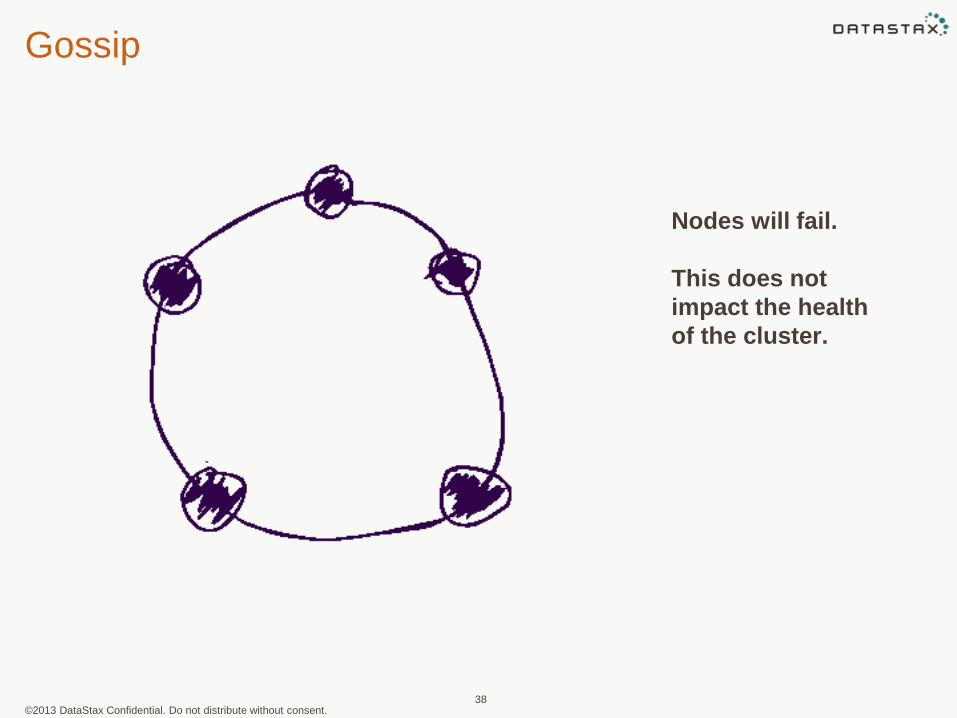
Gossip
38
Nodes will fail.
This does not
impact the health
of the cluster.
©2013 DataStax Confidential. Do not distribute without consent.
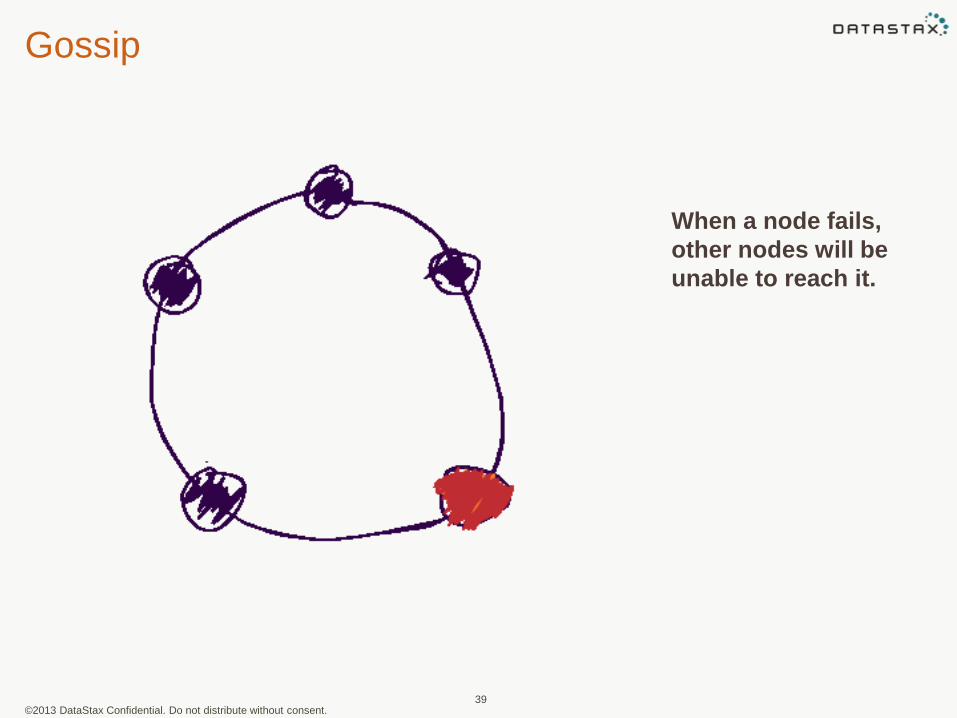
Gossip
39
When a node fails,
other nodes will be
unable to reach it.
©2013 DataStax Confidential. Do not distribute without consent.
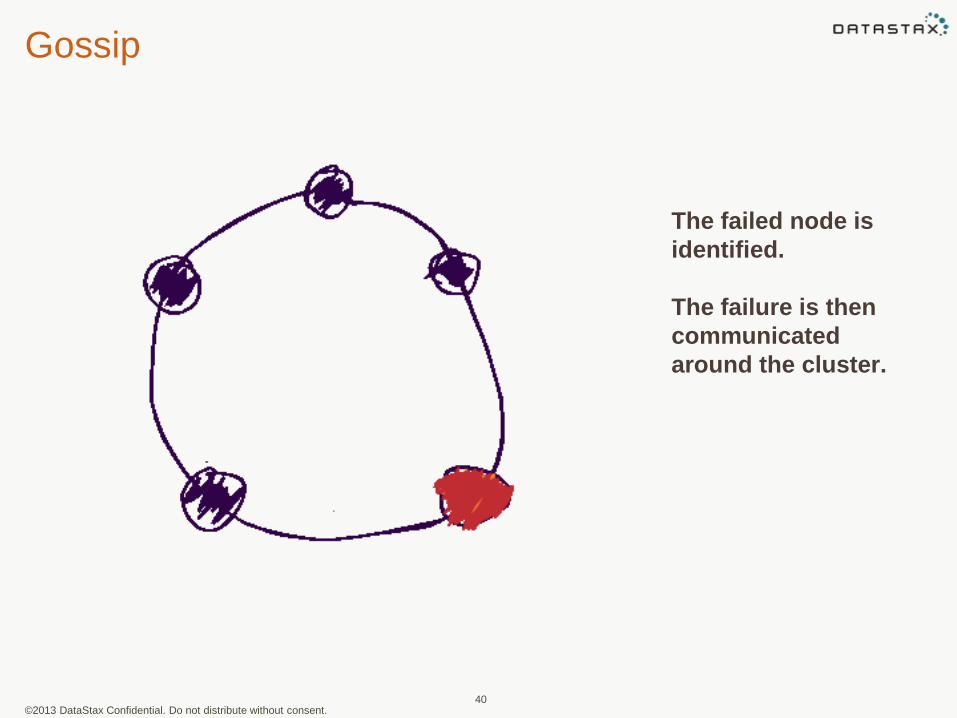
Gossip
40
The failed node is
identified.
The failure is then
communicated
around the cluster.

©2013 DataStax Confidential. Do not distribute without consent.
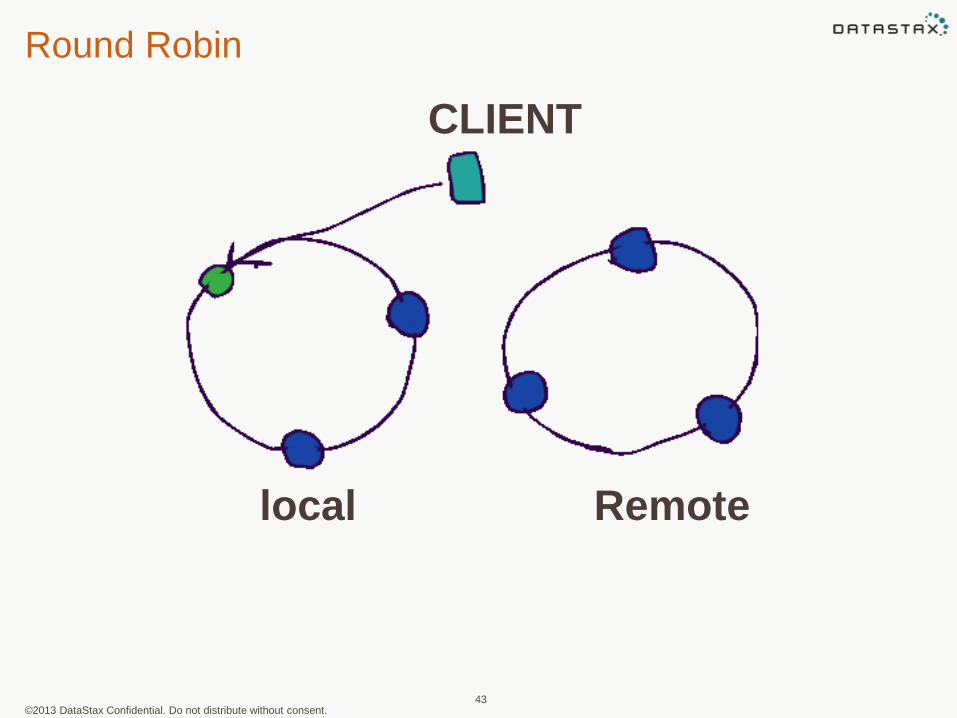
Load Balancing - Driver
• Each node handles client requests, but the balancing policy is configurable
• Round Robin – evenly distributes queries across all nodes in the cluster, regardless of datacenter
• DC-Aware Round Robin – prefers hosts in the local datacenter and only uses nodes in remote datacenters when local hosts cannot be reached
• Token-Aware – queries are first sent to local replicas
41

Load Balancing - Java Driver
• You can define the Load-Balancing Policy in the client application
42
cluster = Cluster.builder()
.addContactPoints("192.168.50.100", "192.168.50.101")
.withLoadBalancingPolicy(new DCAwareRoundRobinPolicy("DC1"))
.withRetryPolicy(DowngradingConsistencyRetryPolicy.INSTANCE)
.build();
session = cluster.connect(keyspace);
©2013 DataStax Confidential. Do not distribute without consent.
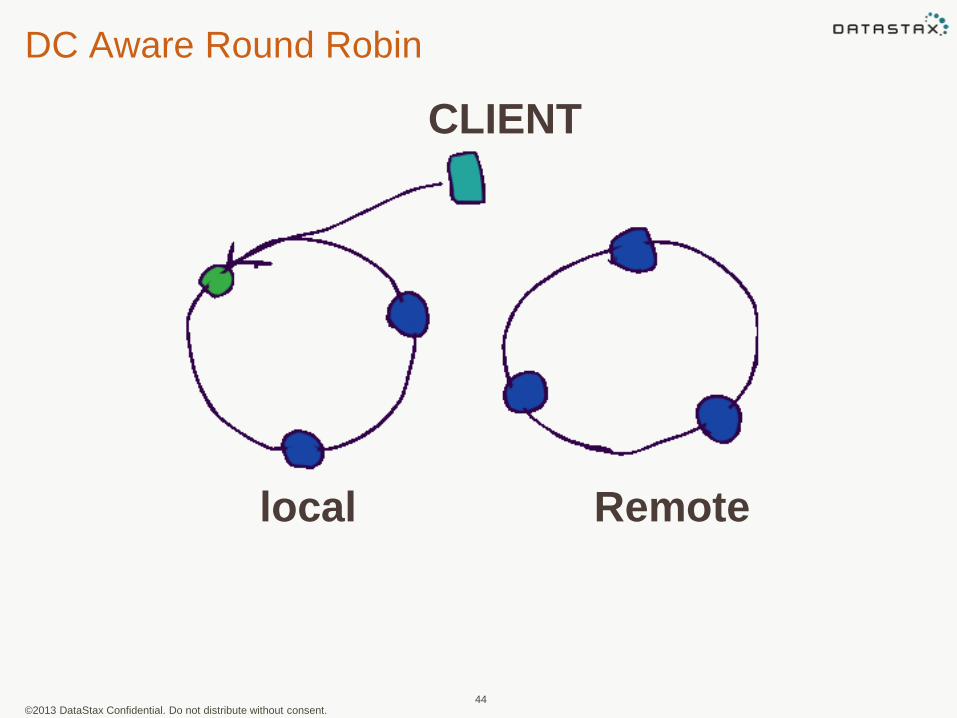
Round Robin
43
local Remote
CLIENT
©2013 DataStax Confidential. Do not distribute without consent.
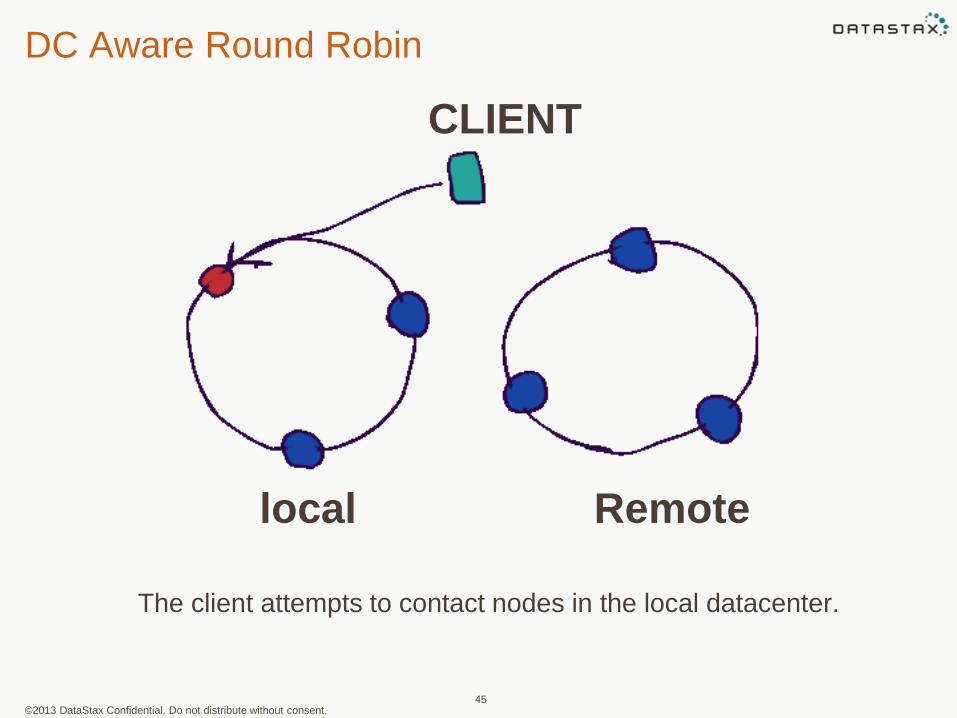
DC Aware Round Robin
44
local Remote
CLIENT
©2013 DataStax Confidential. Do not distribute without consent.
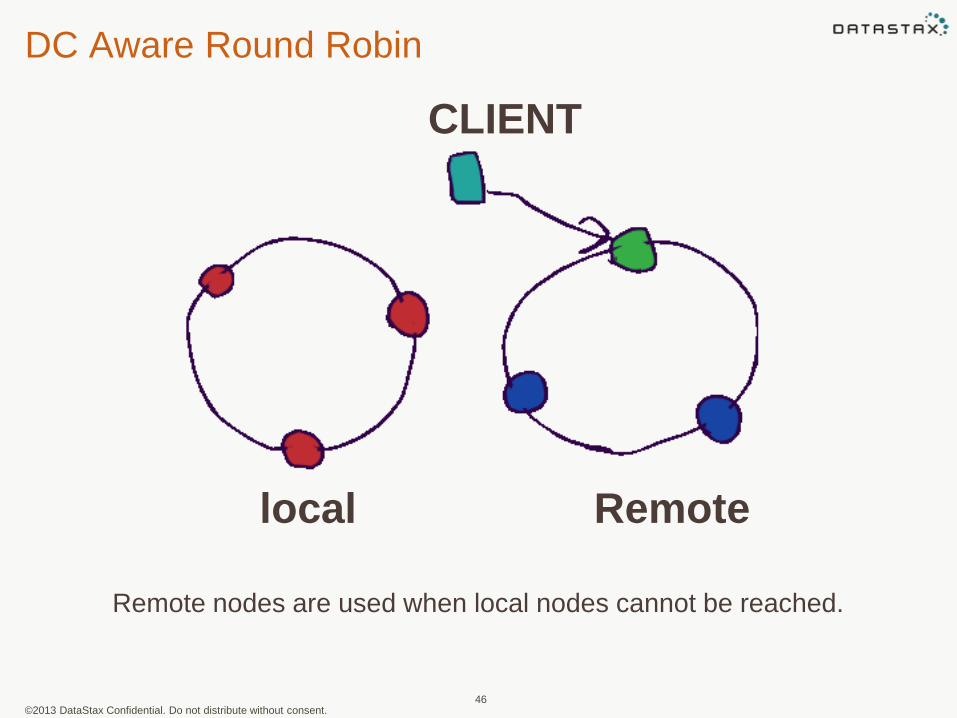
DC Aware Round Robin
45
The client attempts to contact nodes in the local datacenter.
local Remote
CLIENT
©2013 DataStax Confidential. Do not distribute without consent.
DC Aware Round Robin
46
Remote nodes are used when local nodes cannot be reached.
local Remote
CLIENT

©2013 DataStax Confidential. Do not distribute without consent.
Adding Capacity without vNodes
Cassandra allows you to add capacity as needed• New nodes to existing datacenter• Add a new datacenter
To add a new node:• Specify an initial_token• Configure seed nodes it should contact to learn about the
cluster and establish the gossip process• The name of the cluster it is joining and how the node
should be addressed within the cluster.• Any other non-default settings made to cassandra.yaml on
your existing cluster should also be made on the new node before it is started.
47
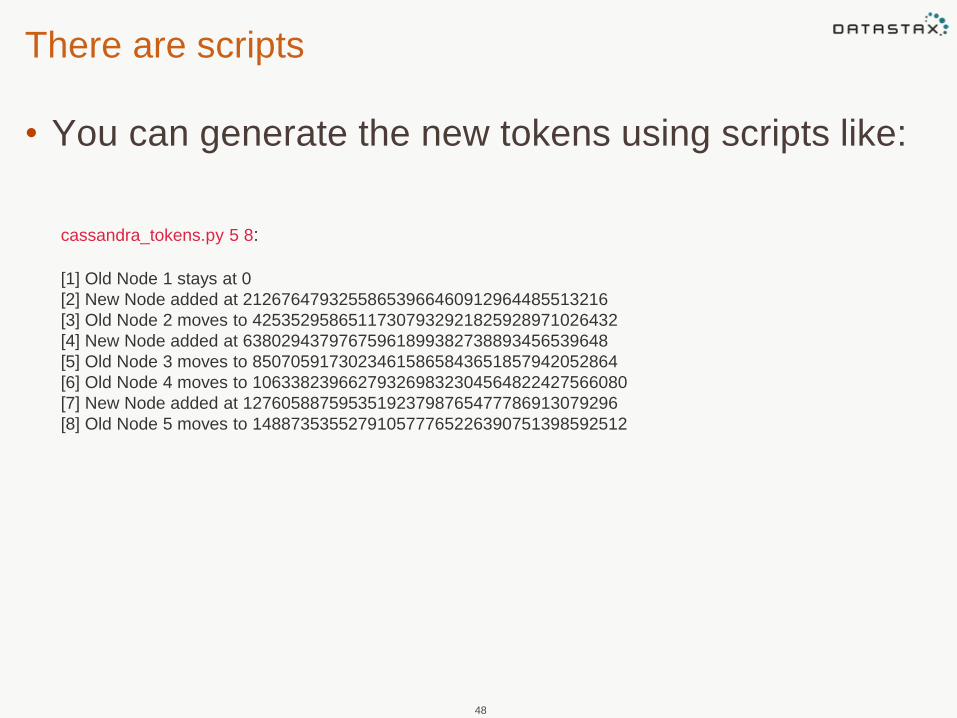
There are scripts
• You can generate the new tokens using scripts like:
48
cassandra_tokens.py 5 8:
[1] Old Node 1 stays at 0
[2] New Node added at 21267647932558653966460912964485513216
[3] Old Node 2 moves to 42535295865117307932921825928971026432
[4] New Node added at 63802943797675961899382738893456539648
[5] Old Node 3 moves to 85070591730234615865843651857942052864
[6] Old Node 4 moves to 106338239662793269832304564822427566080
[7] New Node added at 127605887595351923798765477786913079296
[8] Old Node 5 moves to 148873535527910577765226390751398592512
©2013 DataStax Confidential. Do not distribute without consent.
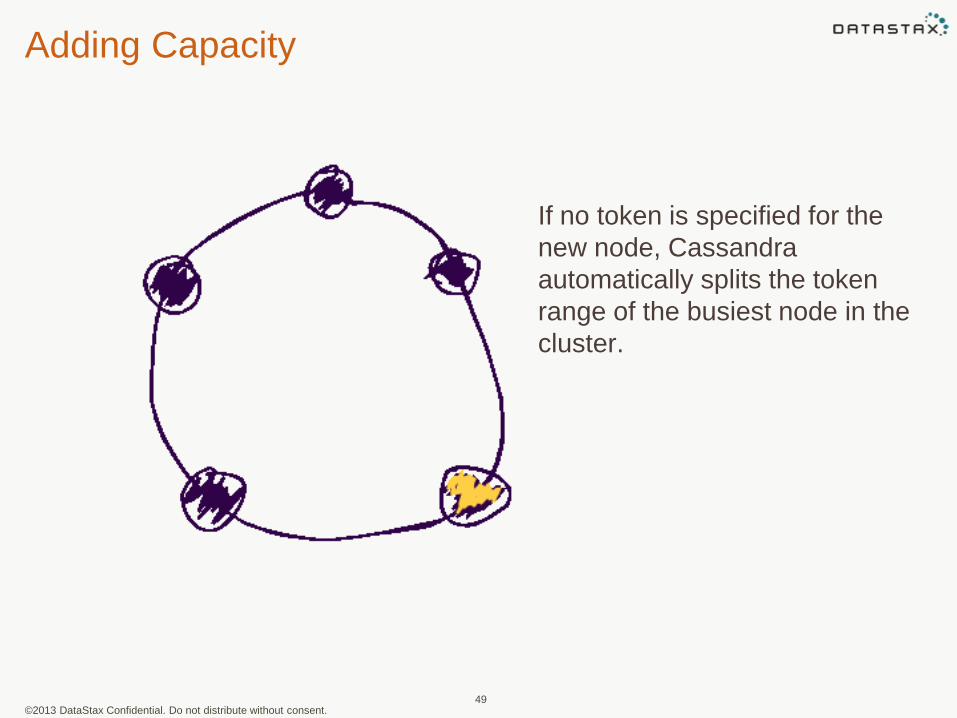
Adding Capacity
49
If no token is specified for the
new node, Cassandra
automatically splits the token
range of the busiest node in the
cluster.
©2013 DataStax Confidential. Do not distribute without consent.
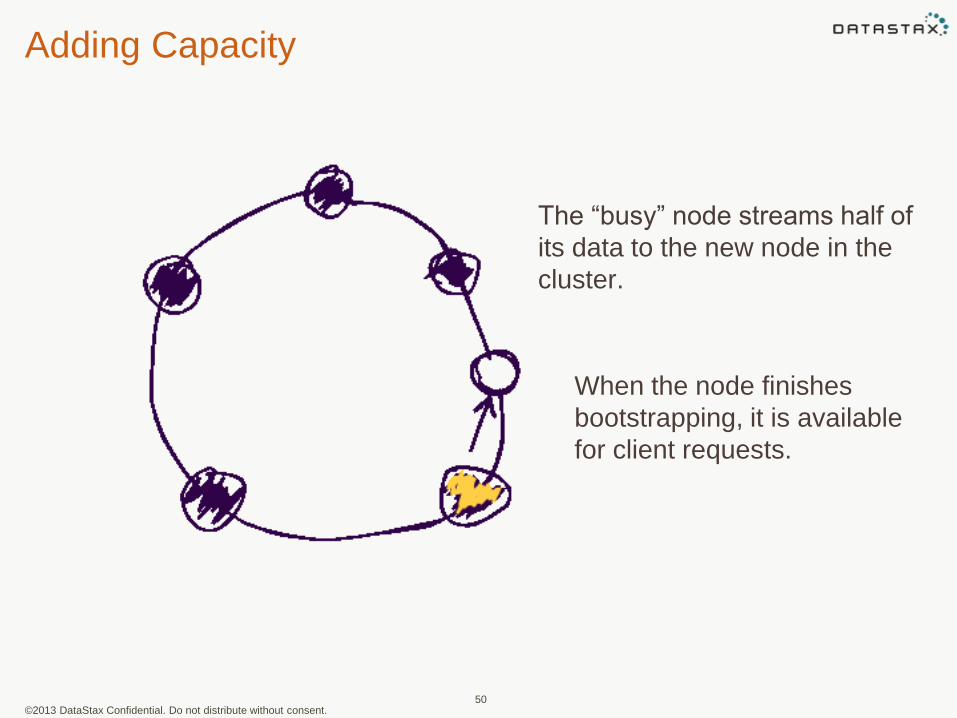
Adding Capacity
50
The “busy” node streams half of
its data to the new node in the
cluster.
When the node finishes
bootstrapping, it is available
for client requests.

©2013 DataStax Confidential. Do not distribute without consent.
Rebalancing a Live Cluster
• Determine new tokens
• Optimize for smallest number of moves
• Optimize for least amount of data transfer
• Move the nodes
For each node that needs to move:
nodetool move new_token
51

©2013 DataStax Confidential. Do not distribute without consent.
Vnodes (Virtual Nodes)
Instead of each node owning a single token range, Vnodes divide each node into many ranges (256).
Vnodes simplify many tasks in Cassandra:
• You no longer have to calculate and assign tokens to each node.
• Rebalancing a cluster is no longer necessary when adding or removing nodes. When a node joins the cluster, it assumes responsibility for an even portion of data from the other nodes in the cluster. If a node fails, the load is spread evenly across other nodes in the cluster.
• Rebuilding a dead node is faster because it involves every other node in the cluster and because data is sent to the replacement node incrementally instead of waiting until the end of the validation phase.
• Improves the use of heterogeneous machines in a cluster. You can assign a proportional number of vnodes to smaller and larger machines.
53
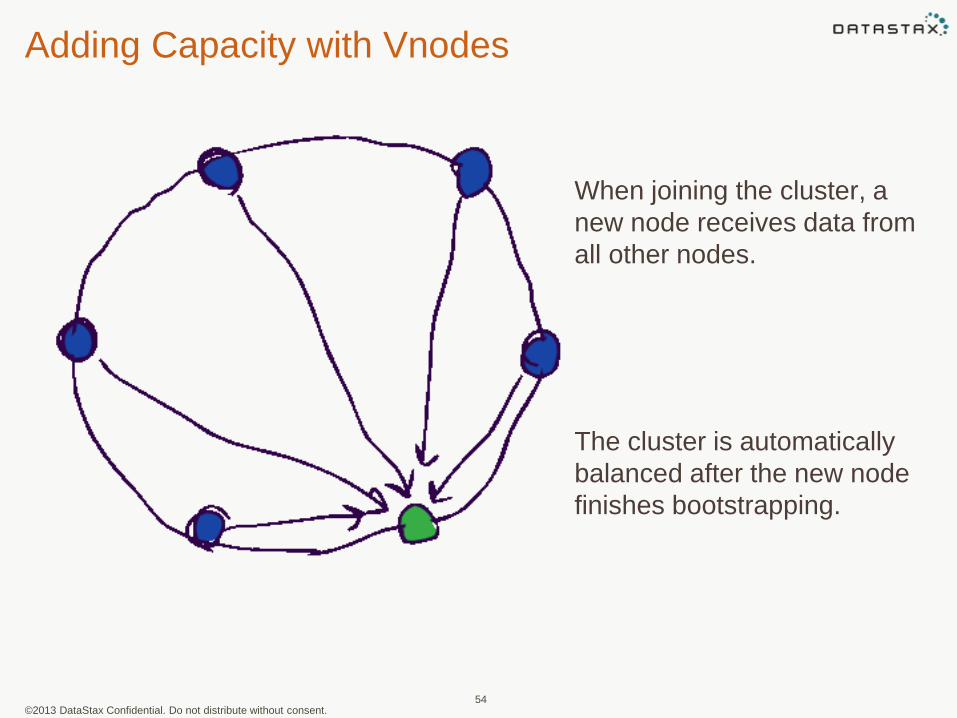
©2013 DataStax Confidential. Do not distribute without consent.
Adding Capacity with Vnodes
54
When joining the cluster, a
new node receives data from
all other nodes.
The cluster is automatically
balanced after the new node
finishes bootstrapping.
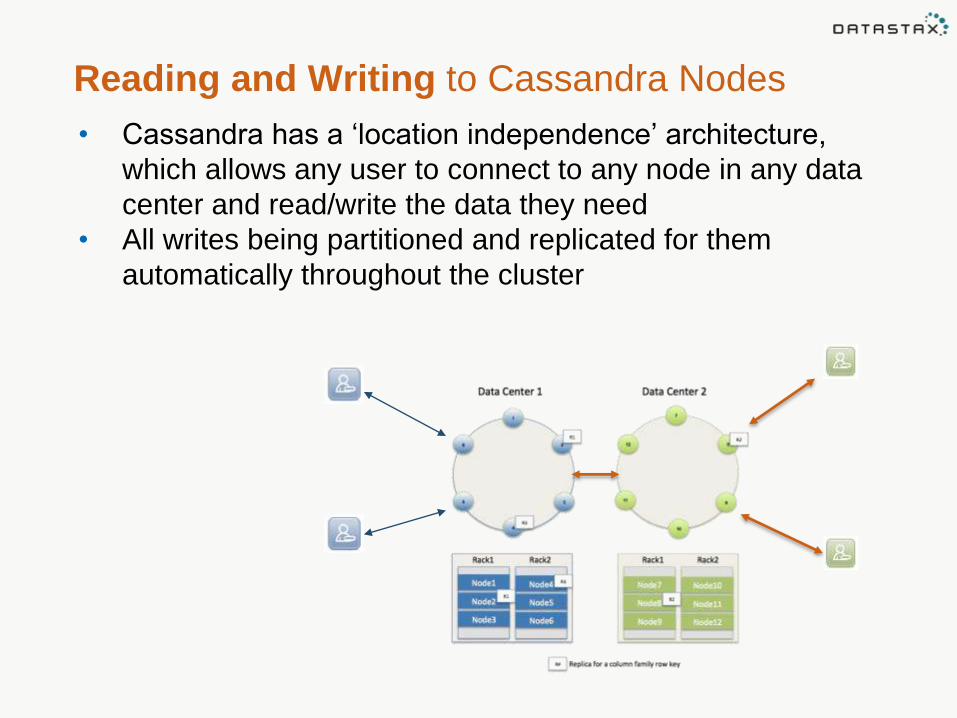
Reading and Writing to Cassandra Nodes
• Cassandra has a ‘location independence’ architecture,
which allows any user to connect to any node in any data
center and read/write the data they need
• All writes being partitioned and replicated for them
automatically throughout the cluster
©2013 DataStax Confidential. Do not distribute without consent.
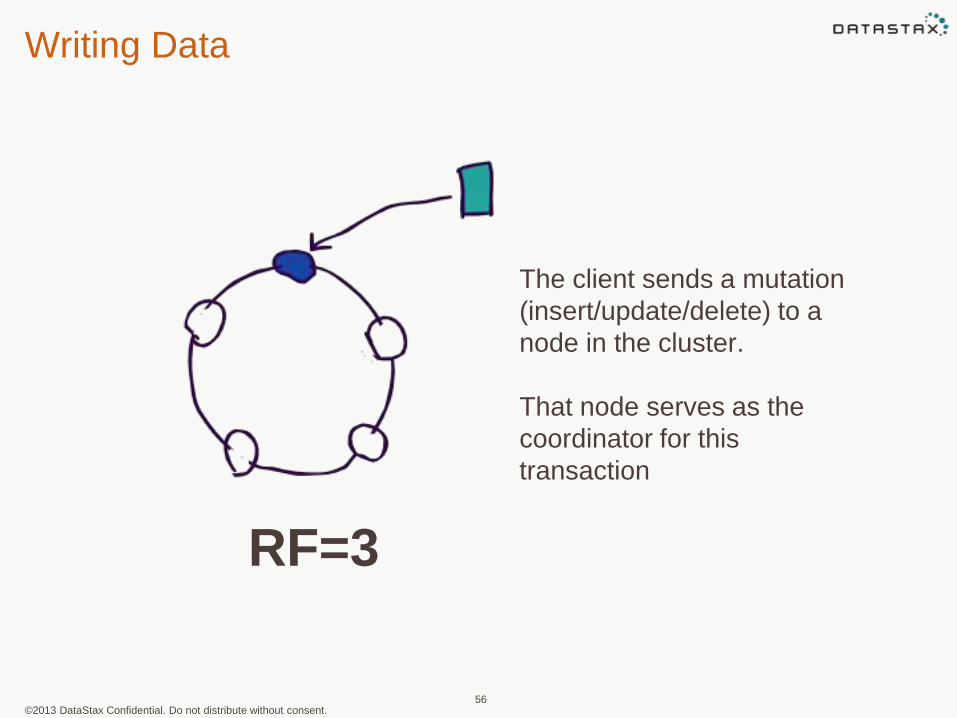
Writing Data
56
The client sends a mutation
(insert/update/delete) to a
node in the cluster.
That node serves as the
coordinator for this
transaction
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
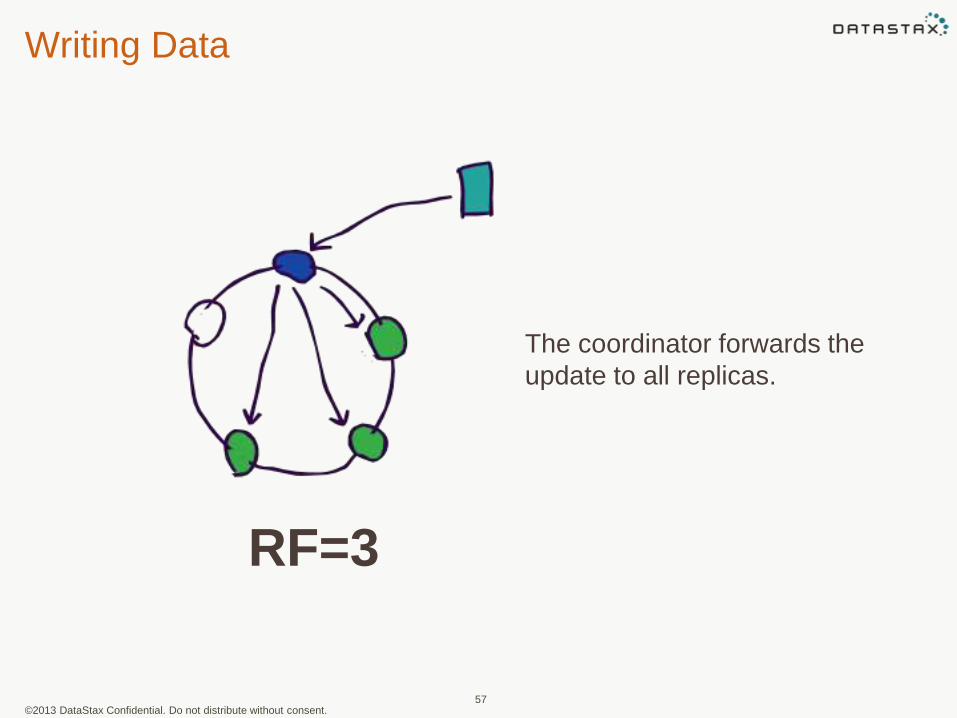
Writing Data
57
The coordinator forwards the
update to all replicas.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
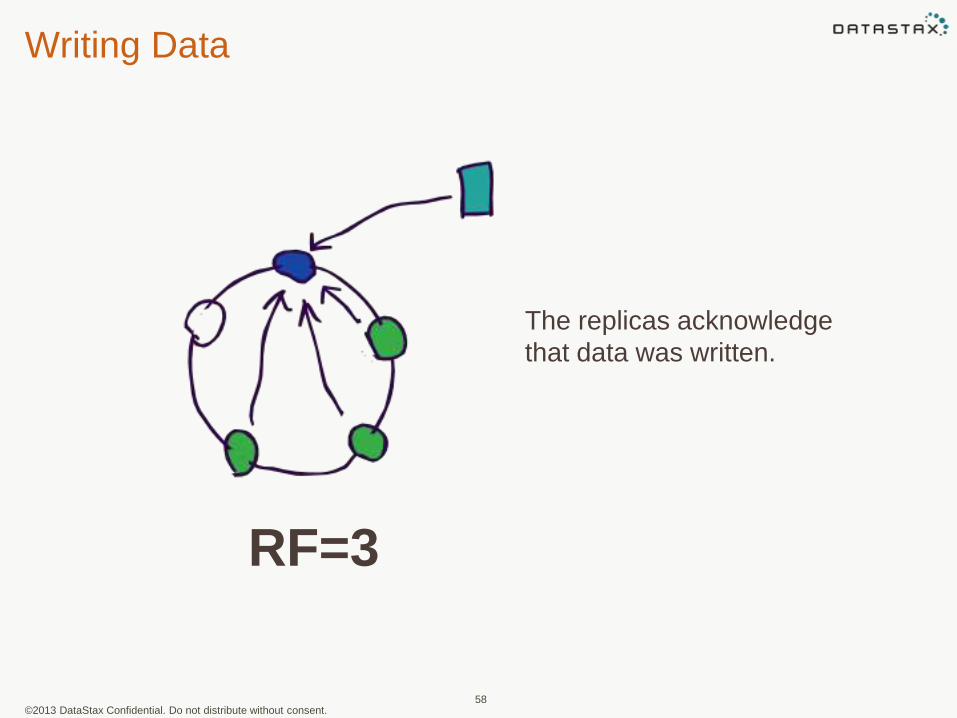
Writing Data
58
The replicas acknowledge
that data was written.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
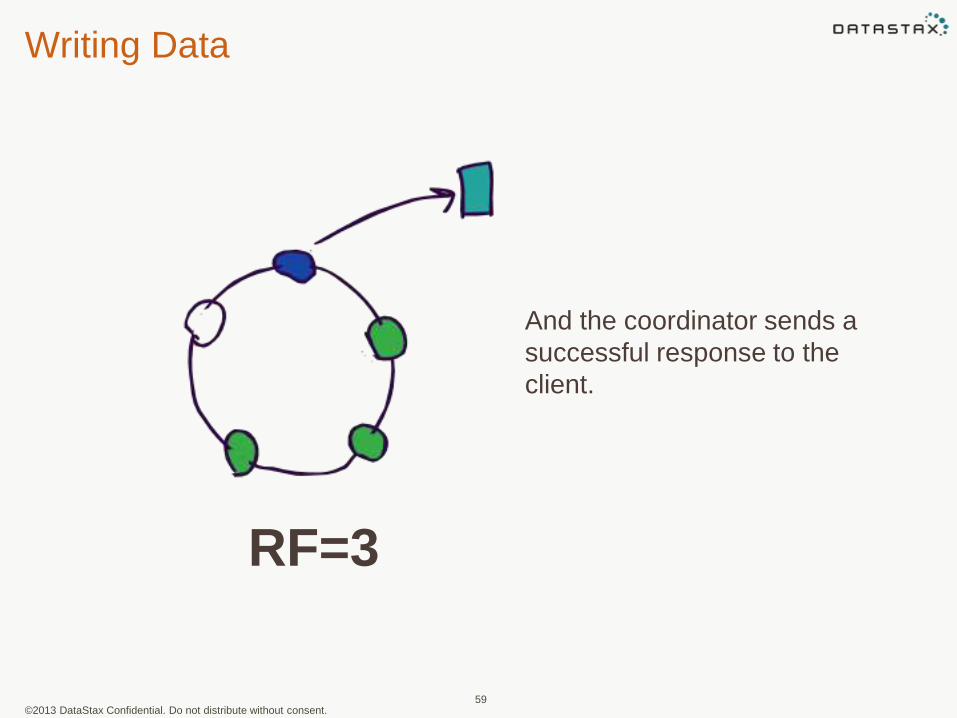
Writing Data
59
And the coordinator sends a
successful response to the
client.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
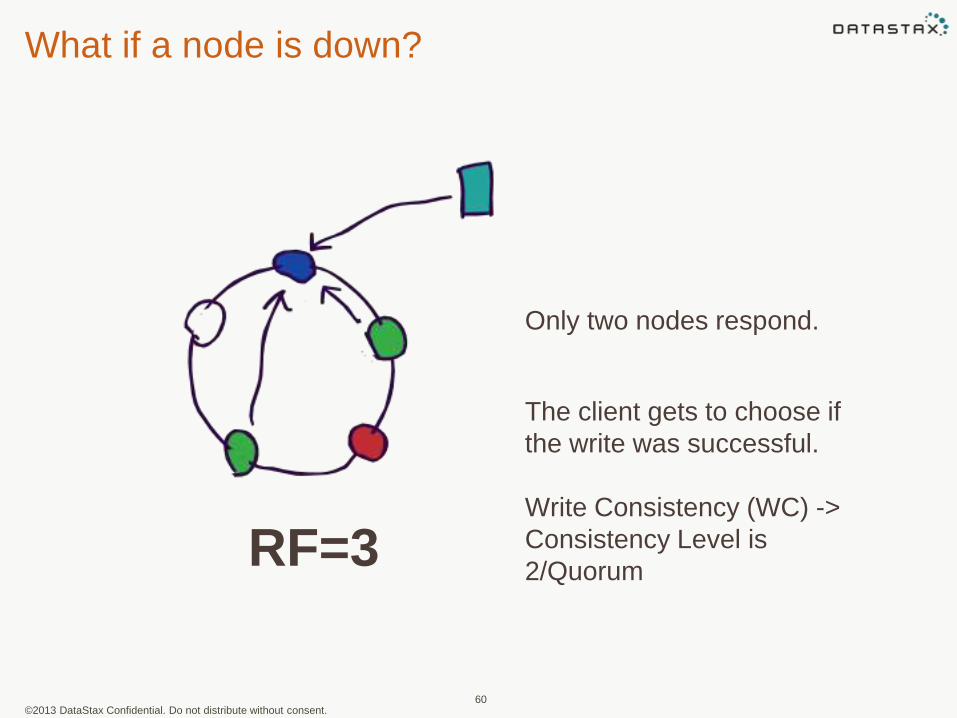
What if a node is down?
60
Only two nodes respond.
The client gets to choose if
the write was successful.
Write Consistency (WC) ->
Consistency Level is
2/QuorumRF=3

Tunable Data Consistency
• Choose between strong and eventual consistency
(one to all responding) depending on the need
• Can be done on a per-operation basis, and for both
reads and writes
• Handles multi-data center operations
• Any
• One
• Quorum
• Local_Quorum
• Each_Quorum
• All
Writes
• One
• Quorum
• Local_Quorum
• Each_Quorum
• All
Reads

©2013 DataStax Confidential. Do not distribute without consent.
Consistency
• ONE
Returns data from the nearest replica.
• QUORUM
Returns the most recent data from the majority of replicas.
• ALL
Returns the most recent data from all replicas.
62

©2013 DataStax Confidential. Do not distribute without consent.
Quorum means > 50%
63
CL = QUORUM
Will this write succeed?
YES!!
A majority of replicas
received the mutation.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
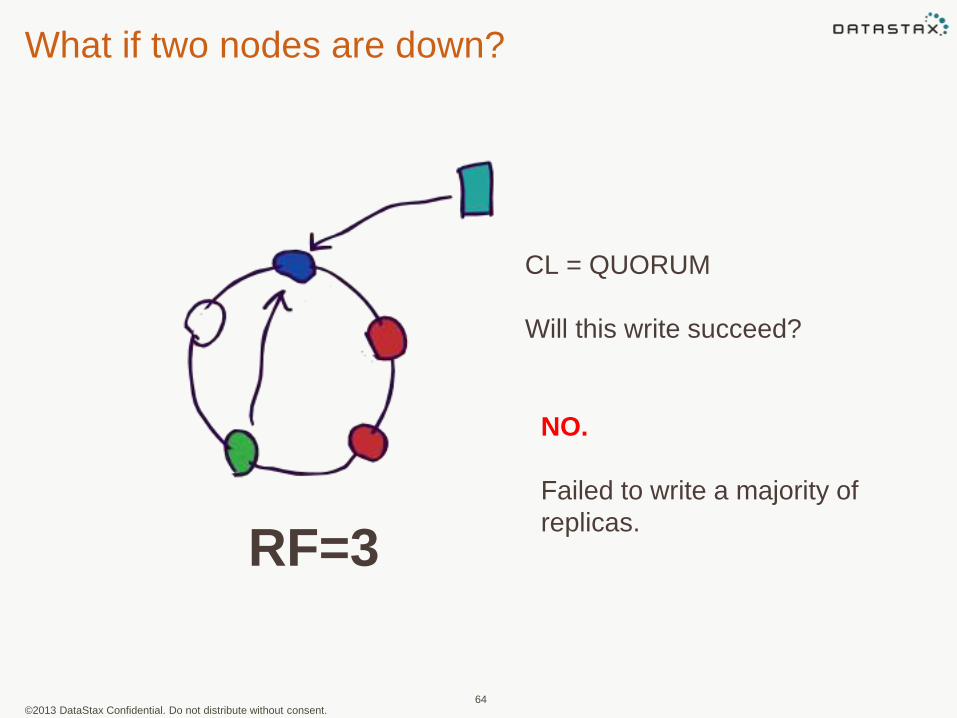
What if two nodes are down?
64
CL = QUORUM
Will this write succeed?
NO.
Failed to write a majority of
replicas.
RF=3

©2013 DataStax Confidential. Do not distribute without consent.
Retry Policy - Client Driver
A policy that defines a default behavior to adopt when a request returns an exception.
Such policy allows to centralize the handling of query retries, allowing to minimize the need for exception catching/handling in business code.
DowngradingConsistencyRetryPolicy - A retry policy that retries a query with a lower consistency level than the one initially requested.
65

Load Balancing - Java Driver
• You can define the Load-Balancing Policy in the client application
66
cluster = Cluster.builder()
.addContactPoints("192.168.50.100", "192.168.50.101")
.withLoadBalancingPolicy(new DCAwareRoundRobinPolicy("DC1"))
.withRetryPolicy(DowngradingConsistencyRetryPolicy.INSTANCE)
.build();
session = cluster.connect(keyspace);

©2013 DataStax Confidential. Do not distribute without consent.
The client can still decide how to proceed
67
CL = QUORUM
DataStax Driver = DowngradingConsistencyRetryPolicy
Will this write succeed?
YES!
With consistency
downgraded to ONE, the
write will succeed.RF=3
©2013 DataStax Confidential. Do not distribute without consent.
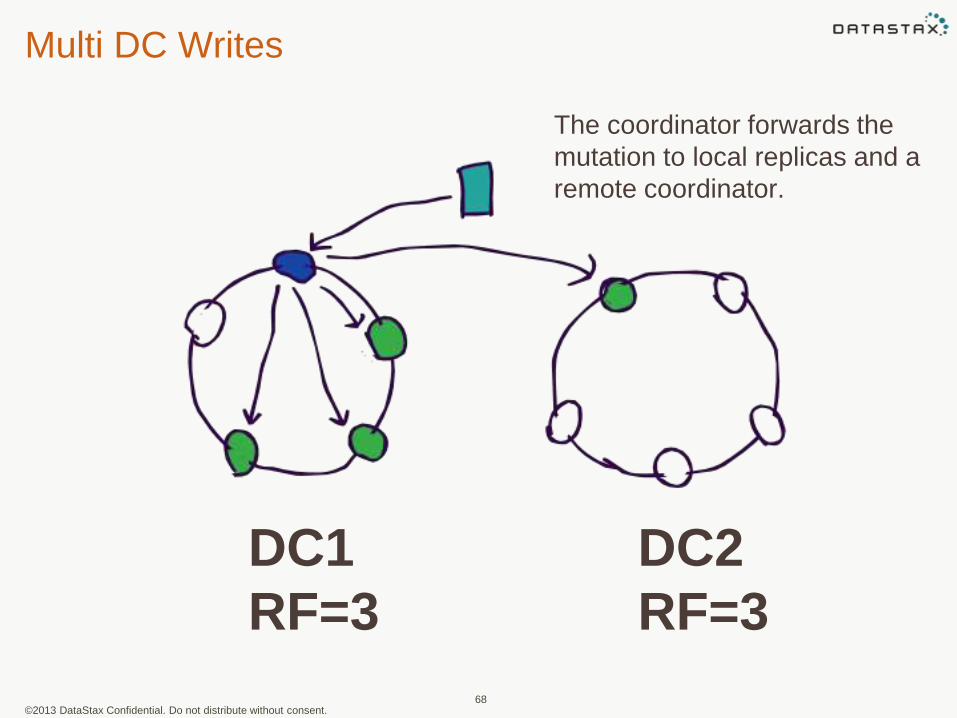
Multi DC Writes
68
DC1
RF=3
DC2
RF=3
The coordinator forwards the
mutation to local replicas and a
remote coordinator.
©2013 DataStax Confidential. Do not distribute without consent.
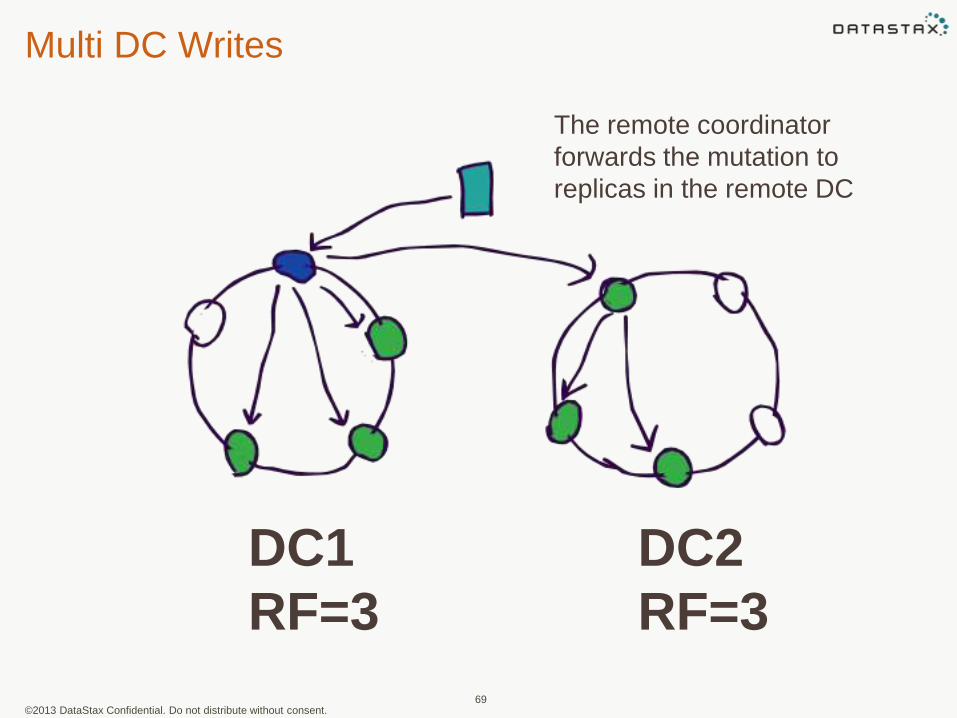
Multi DC Writes
69
DC1
RF=3
DC2
RF=3
The remote coordinator
forwards the mutation to
replicas in the remote DC
©2013 DataStax Confidential. Do not distribute without consent.
Multi DC Writes
70
DC1
RF=3
DC2
RF=3
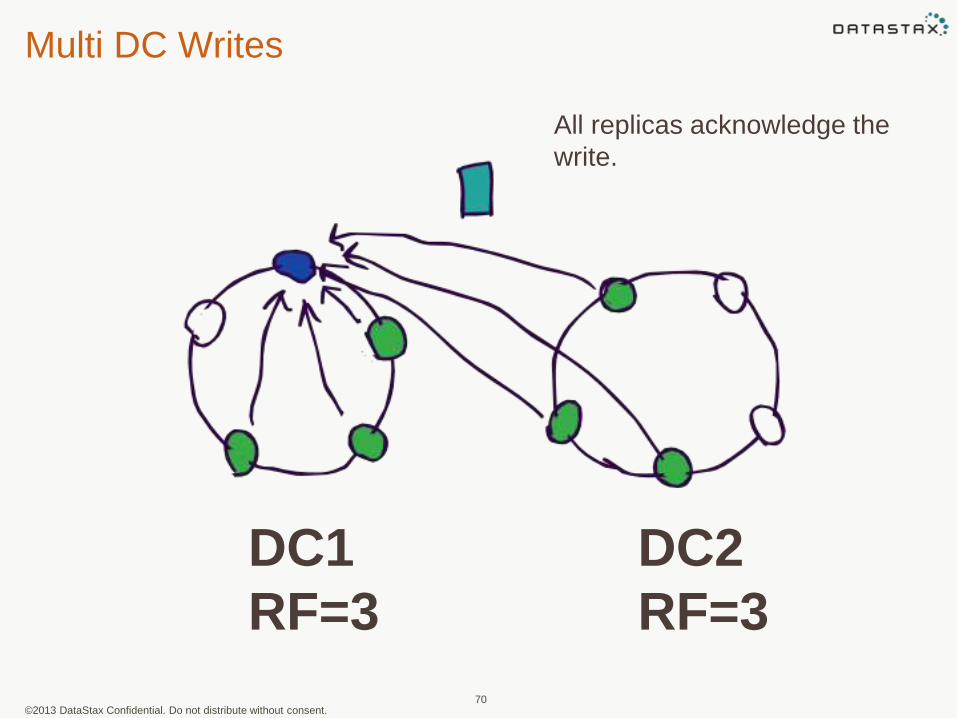
All replicas acknowledge the
write.
©2013 DataStax Confidential. Do not distribute without consent.
Reading Data
71
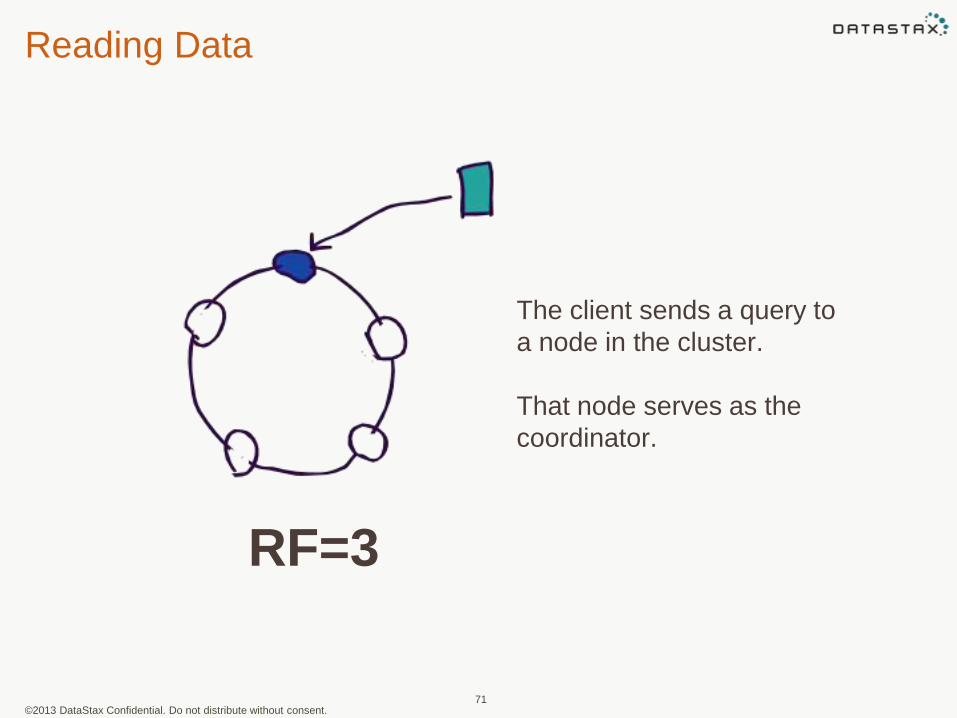
The client sends a query to
a node in the cluster.
That node serves as the
coordinator.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
Reading Data
72
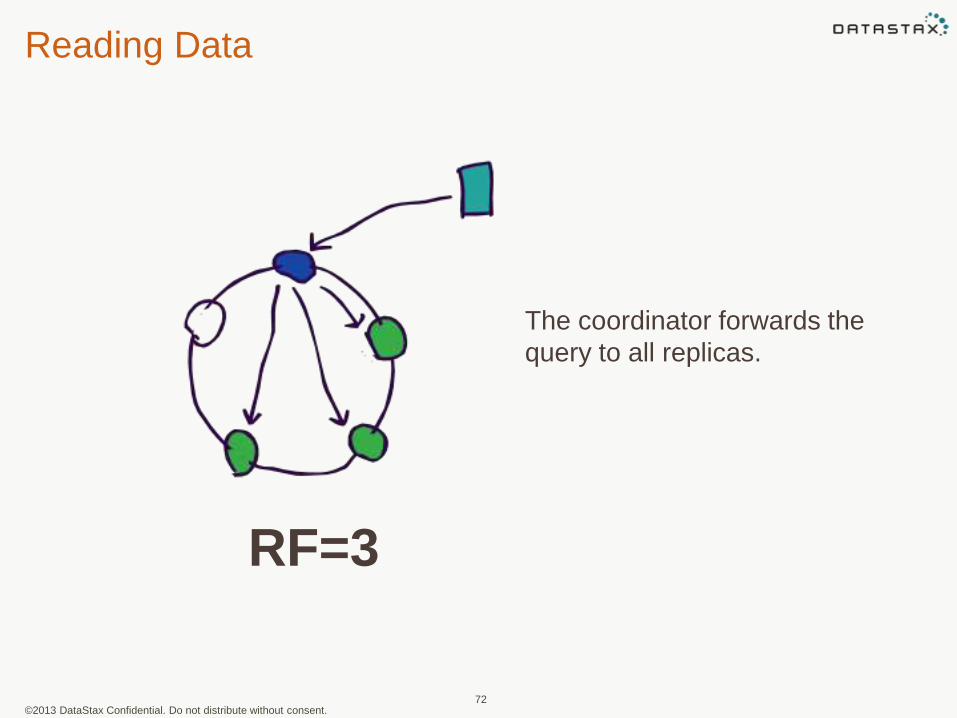
The coordinator forwards the
query to all replicas.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
Reading Data
73
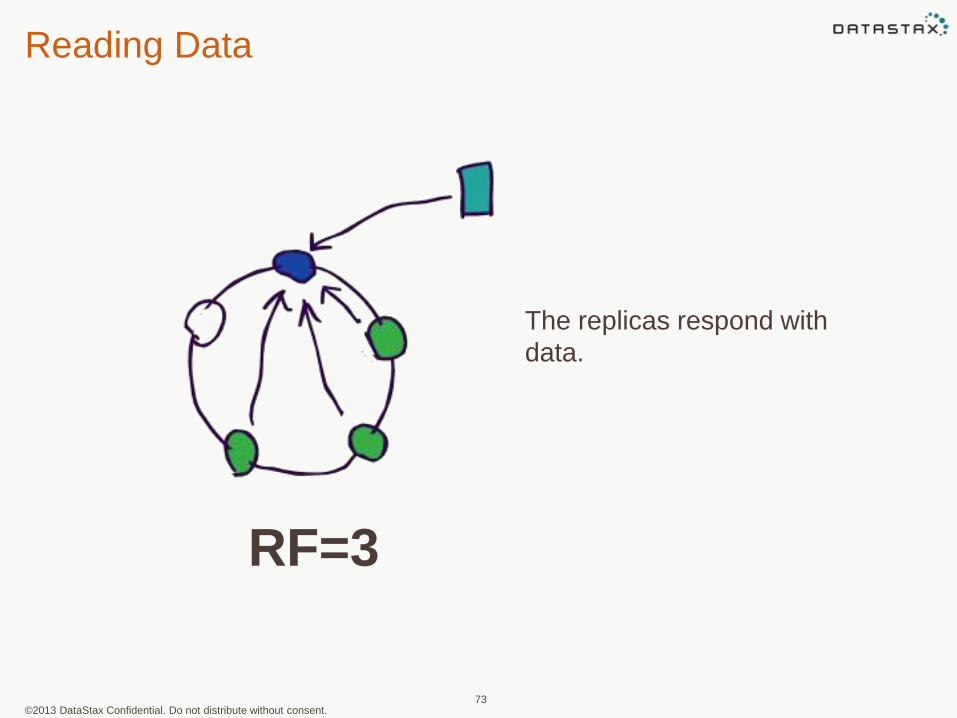
The replicas respond with
data.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
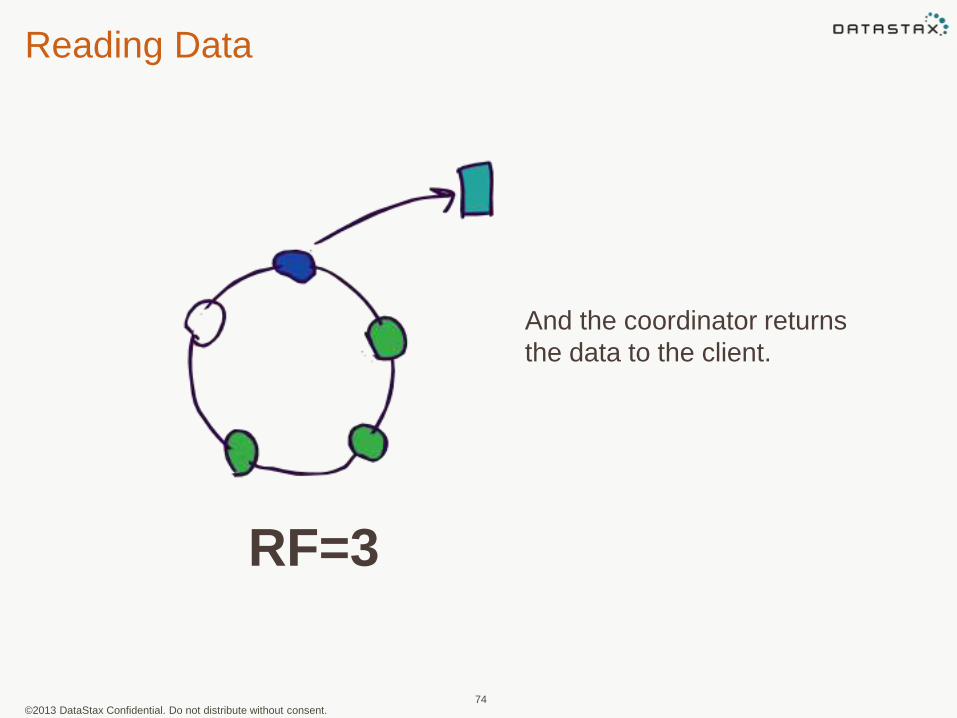
Reading Data
74
And the coordinator returns
the data to the client.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
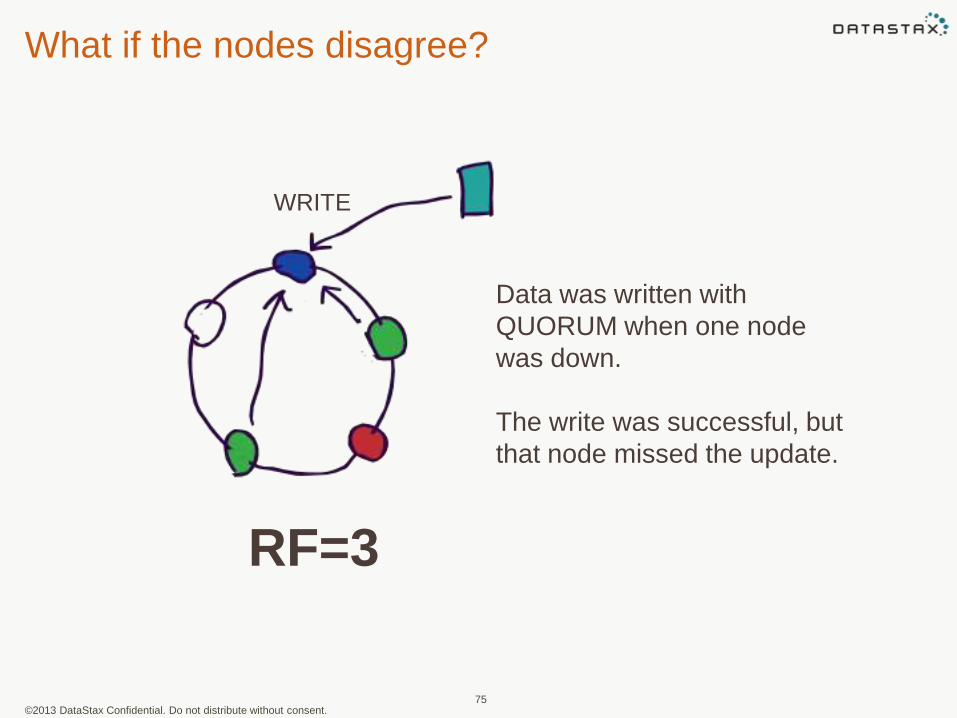
What if the nodes disagree?
75
Data was written with
QUORUM when one node
was down.
The write was successful, but
that node missed the update.
RF=3
WRITE
©2013 DataStax Confidential. Do not distribute without consent.
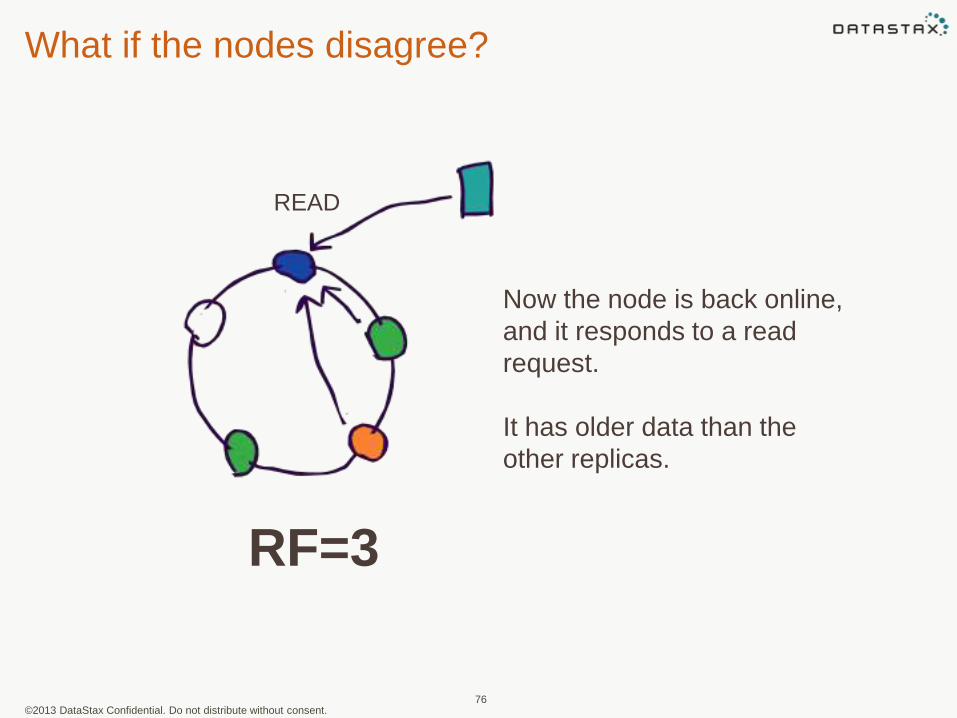
What if the nodes disagree?
76
Now the node is back online,
and it responds to a read
request.
It has older data than the
other replicas.
RF=3
READ
©2013 DataStax Confidential. Do not distribute without consent.
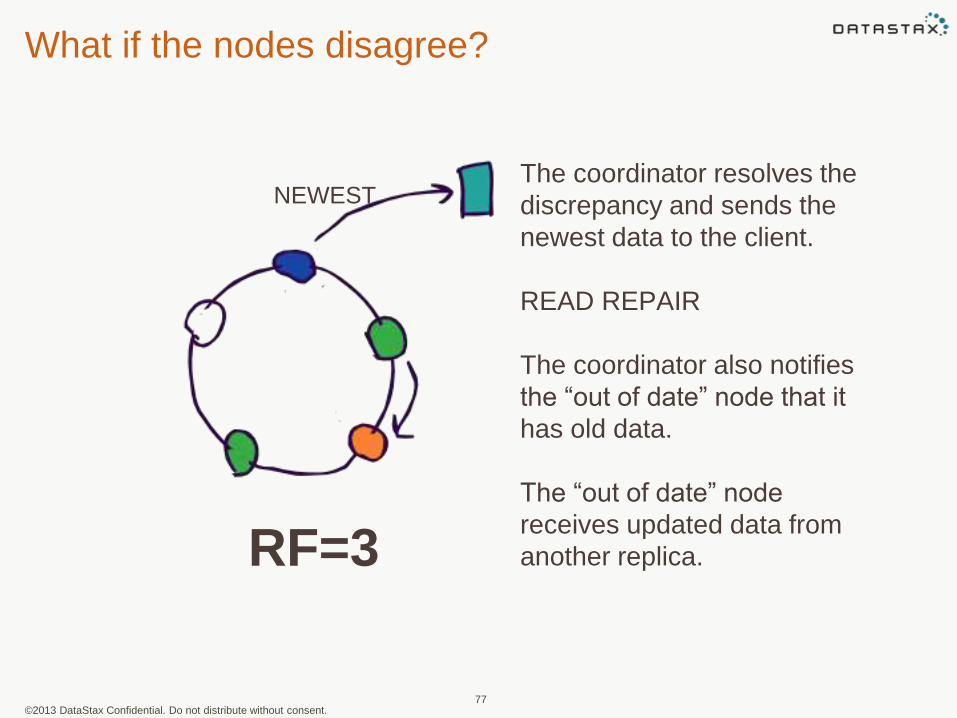
What if the nodes disagree?
77
The coordinator resolves the
discrepancy and sends the
newest data to the client.
READ REPAIR
The coordinator also notifies
the “out of date” node that it
has old data.
The “out of date” node
receives updated data from
another replica.RF=3
NEWEST
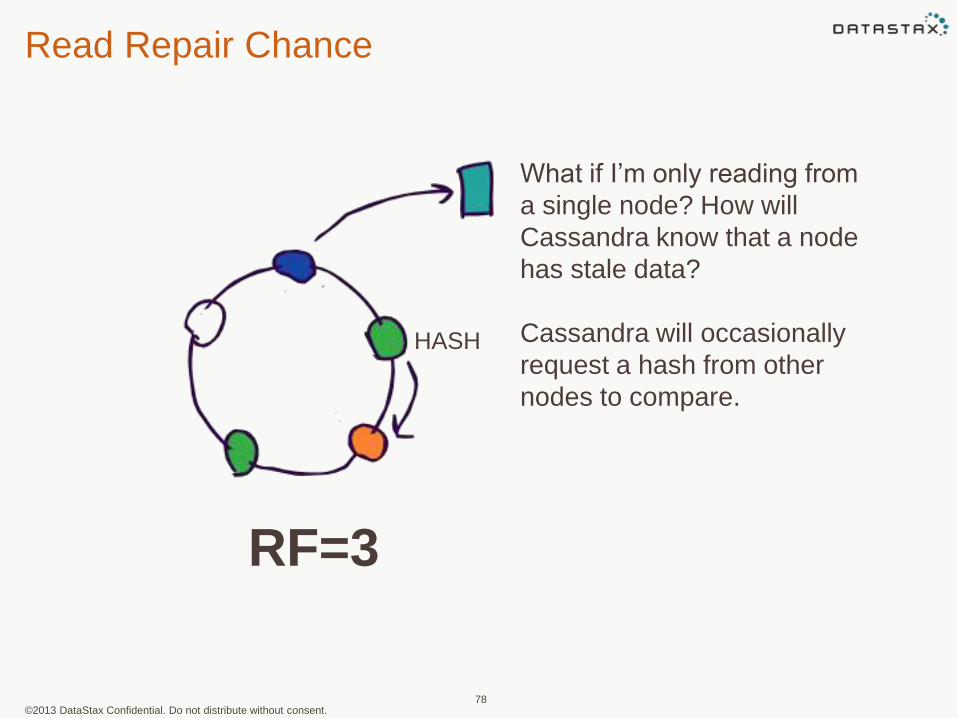
©2013 DataStax Confidential. Do not distribute without consent.
Read Repair Chance
78
What if I’m only reading from
a single node? How will
Cassandra know that a node
has stale data?
Cassandra will occasionally
request a hash from other
nodes to compare.
RF=3
HASH
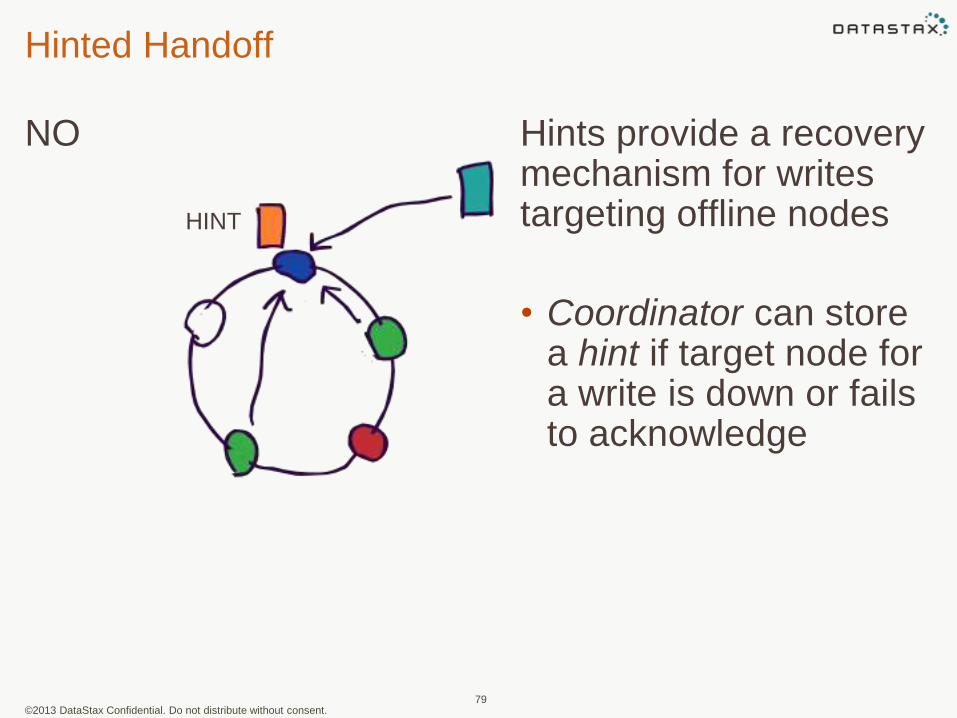
©2013 DataStax Confidential. Do not distribute without consent.
Hinted Handoff
NO
79
HINT
Hints provide a recovery mechanism for writes targeting offline nodes
• Coordinator can store a hint if target node for a write is down or fails to acknowledge
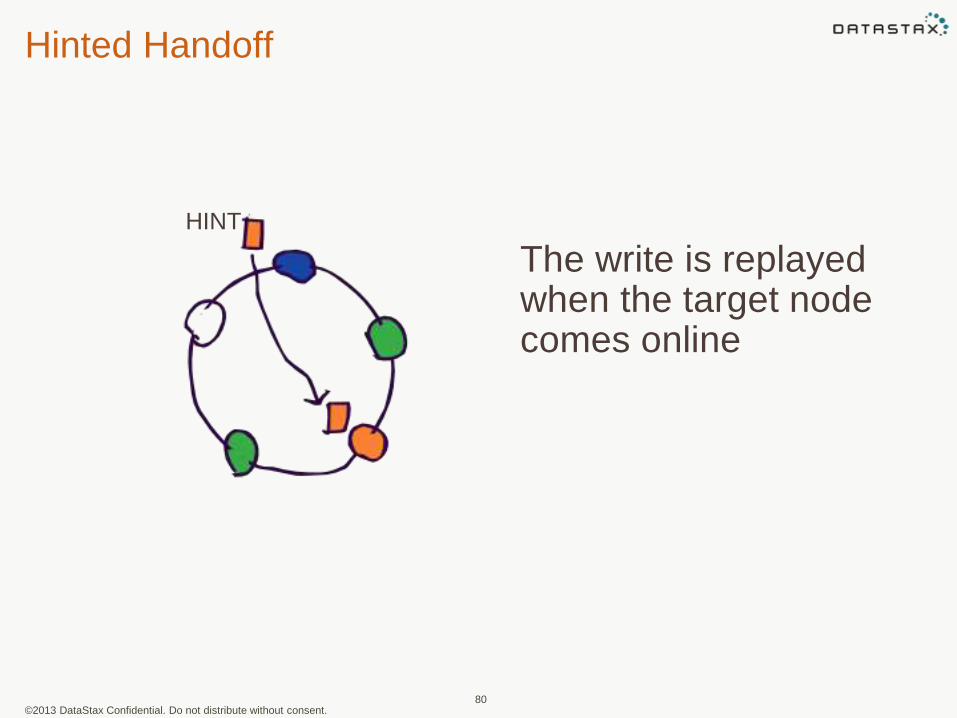
©2013 DataStax Confidential. Do not distribute without consent.
Hinted Handoff
80
HINT
The write is replayed when the target node comes online
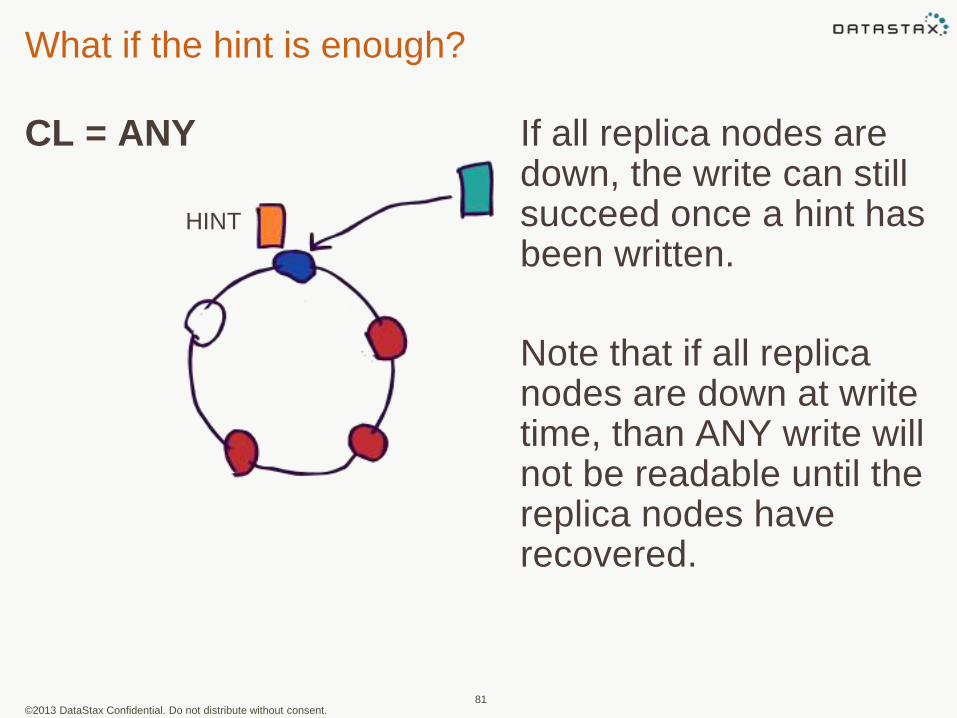
©2013 DataStax Confidential. Do not distribute without consent.
What if the hint is enough?
CL = ANY
81
HINT
If all replica nodes are down, the write can still succeed once a hint has been written.
Note that if all replica nodes are down at write time, than ANY write will not be readable until the replica nodes have recovered.
©2013 DataStax Confidential. Do not distribute without consent.
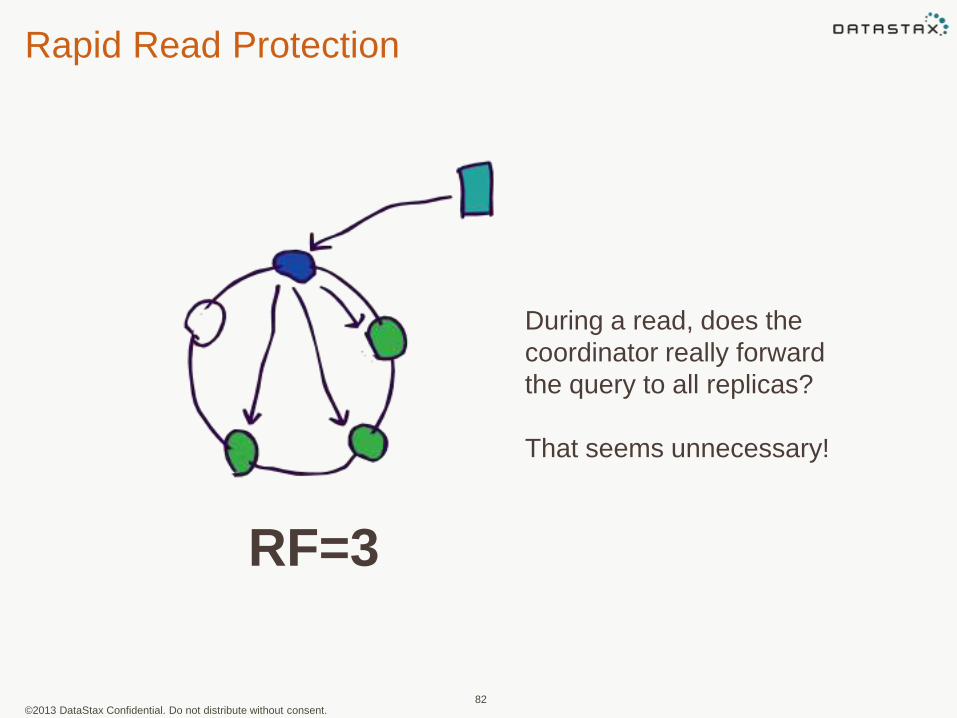
Rapid Read Protection
82
During a read, does the
coordinator really forward
the query to all replicas?
That seems unnecessary!
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
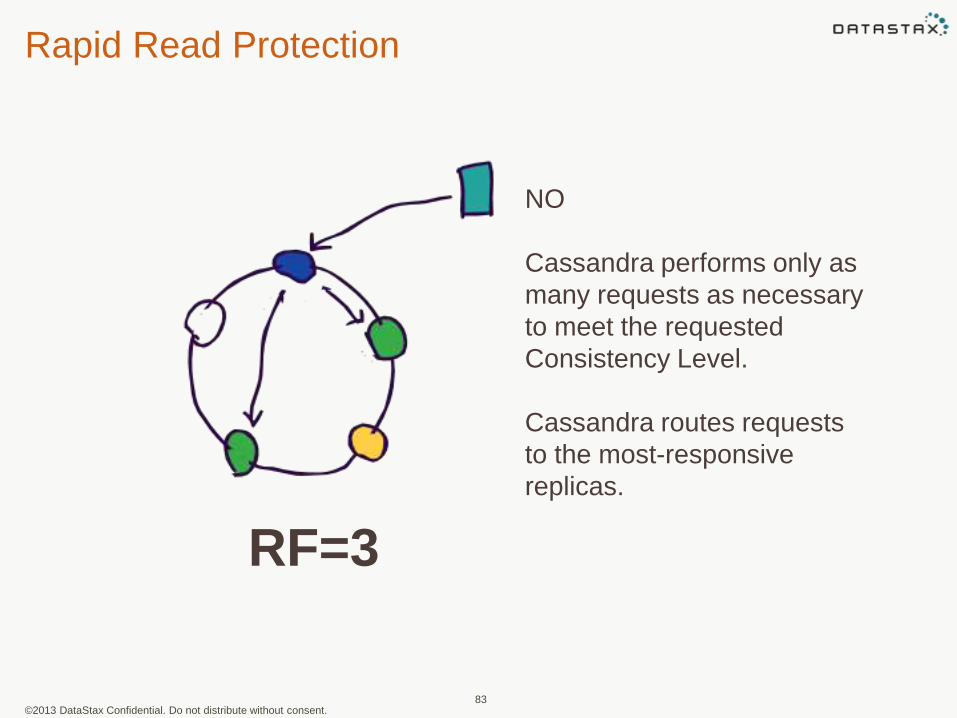
Rapid Read Protection
83
NO
Cassandra performs only as
many requests as necessary
to meet the requested
Consistency Level.
Cassandra routes requests
to the most-responsive
replicas.
RF=3
©2013 DataStax Confidential. Do not distribute without consent.
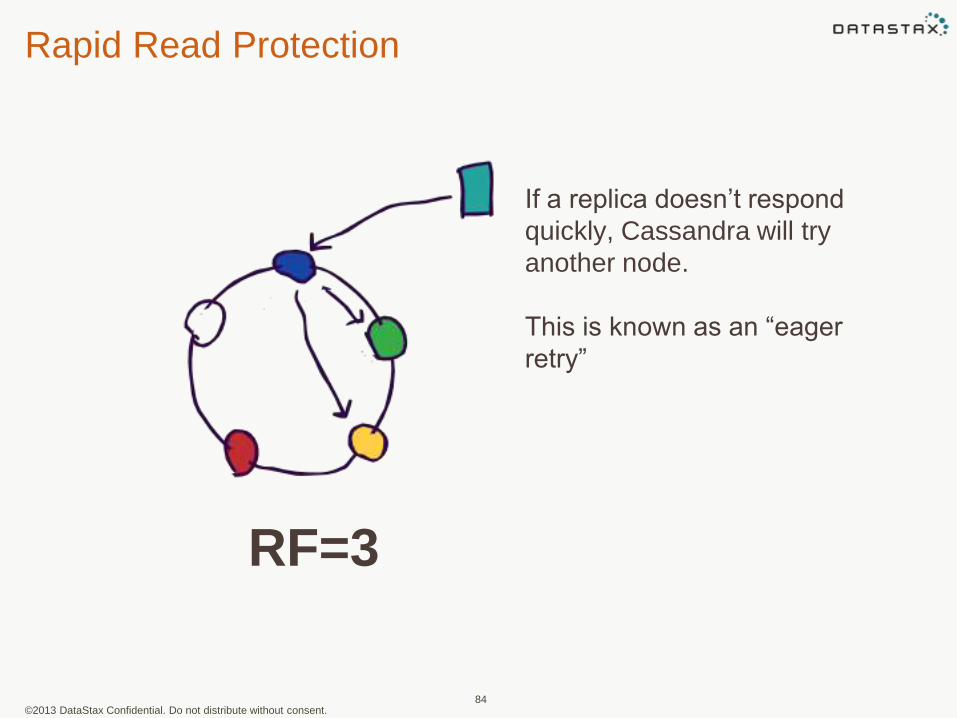
Rapid Read Protection
84
If a replica doesn’t respond
quickly, Cassandra will try
another node.
This is known as an “eager
retry”
RF=3
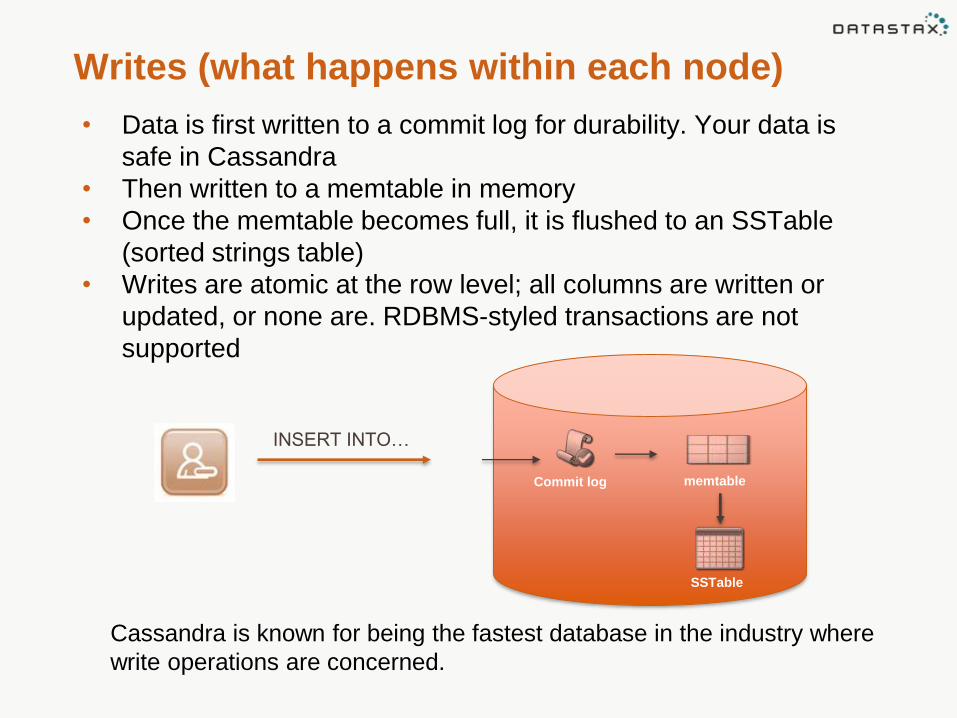
Writes (what happens within each node)
• Data is first written to a commit log for durability. Your data is
safe in Cassandra
• Then written to a memtable in memory
• Once the memtable becomes full, it is flushed to an SSTable
(sorted strings table)
• Writes are atomic at the row level; all columns are written or
updated, or none are. RDBMS-styled transactions are not
supported
INSERT INTO…
Commit log memtable
SSTable
Cassandra is known for being the fastest database in the industry where
write operations are concerned.
©2013 DataStax Confidential. Do not distribute without consent.
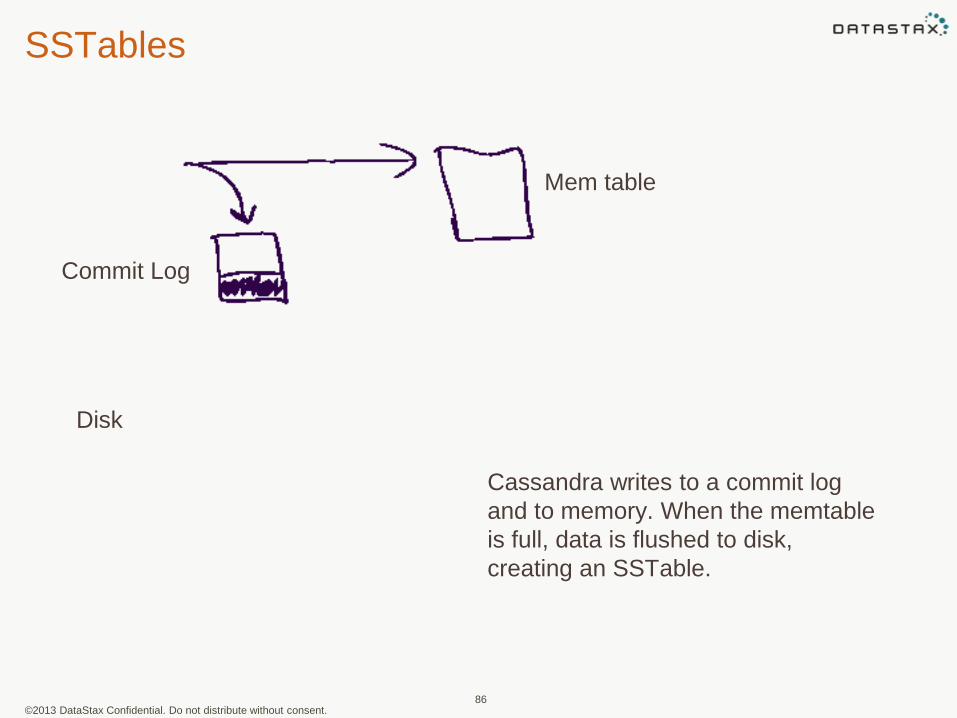
SSTables
86
Commit Log
Mem table
Cassandra writes to a commit log
and to memory. When the memtable
is full, data is flushed to disk,
creating an SSTable.
Disk
©2013 DataStax Confidential. Do not distribute without consent.
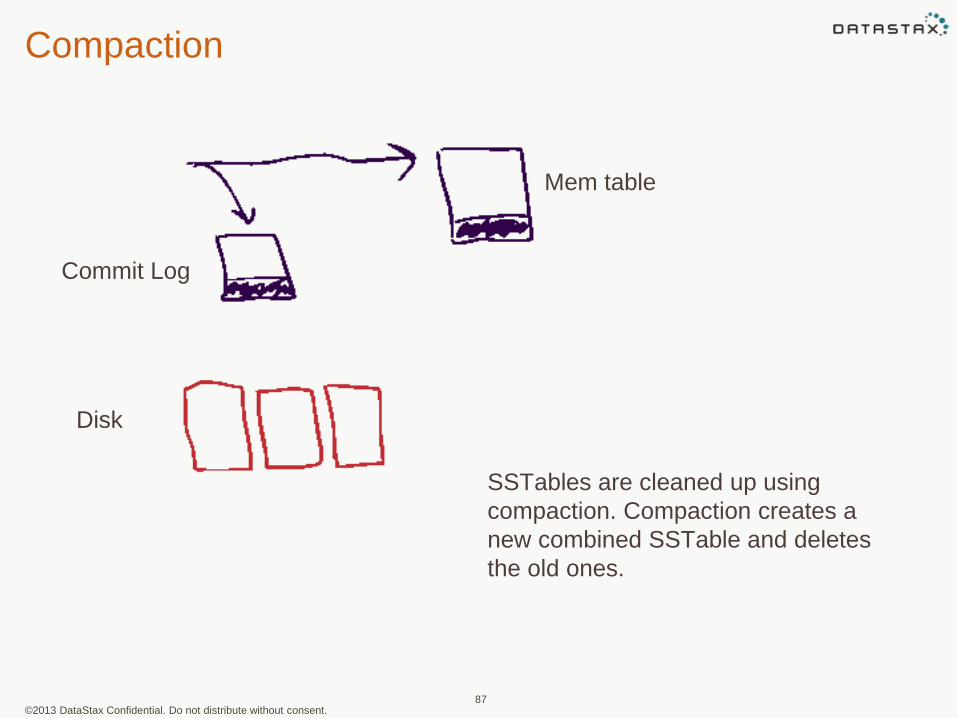
Compaction
87
Commit Log
Mem table
SSTables are cleaned up using
compaction. Compaction creates a
new combined SSTable and deletes
the old ones.
Disk
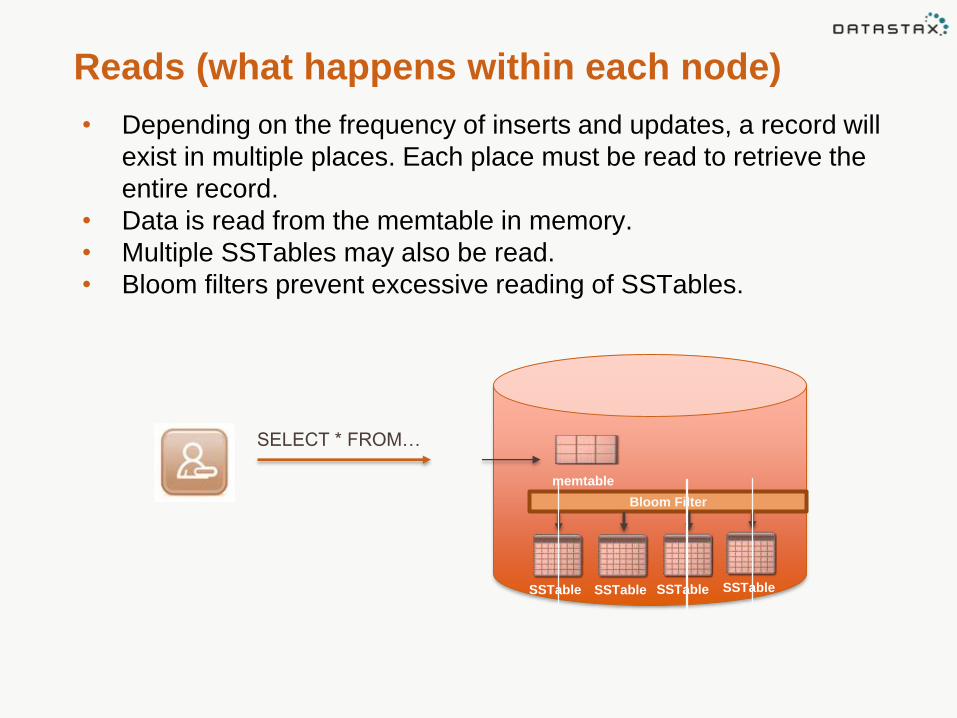
Reads (what happens within each node)
• Depending on the frequency of inserts and updates, a record will
exist in multiple places. Each place must be read to retrieve the
entire record.
• Data is read from the memtable in memory.
• Multiple SSTables may also be read.
• Bloom filters prevent excessive reading of SSTables.
SELECT * FROM…
memtable
SSTable
Bloom Filter
SSTableSSTableSSTable

Bloom Filters
• Bloom Filters = all partition keys in data file
• are a space-efficient probabilistic data structure that is used to test whether an element is a member of a set
• Cassandra uses bloom filters to save IO when performing a key lookup
89

Deletes
• Hard to delete things in a distributed systems
• Keep track of Replicas
• SSTables are immutable
• Cassandra does not immediately remove data
marked for deletion from disk.
• Data is marked with tombstones
• The deletion occurs during compaction
• If you use the sized-tiered or date-tiered compaction
strategy, you can drop data immediately using a
manual compaction process

©2013 DataStax Confidential. Do not distribute without consent.
Terminology Review
• Node
• Cluster
• Datacenter
• Gossip
• Snitch
• Replication Factor
• Consistency Level
91

Managing a Cluster

• Visual, browser-based user
interface negates need to install
client software
• Administration tasks carried out
in point-and-click fashion
• Allows for visual rebalance of
data across a cluster when new
nodes are added
• Contains proactive alerts that
warn of impending issues.
• Built-in external notification
abilities
• Visually perform and schedule
backup operations
DataStax OpsCenter
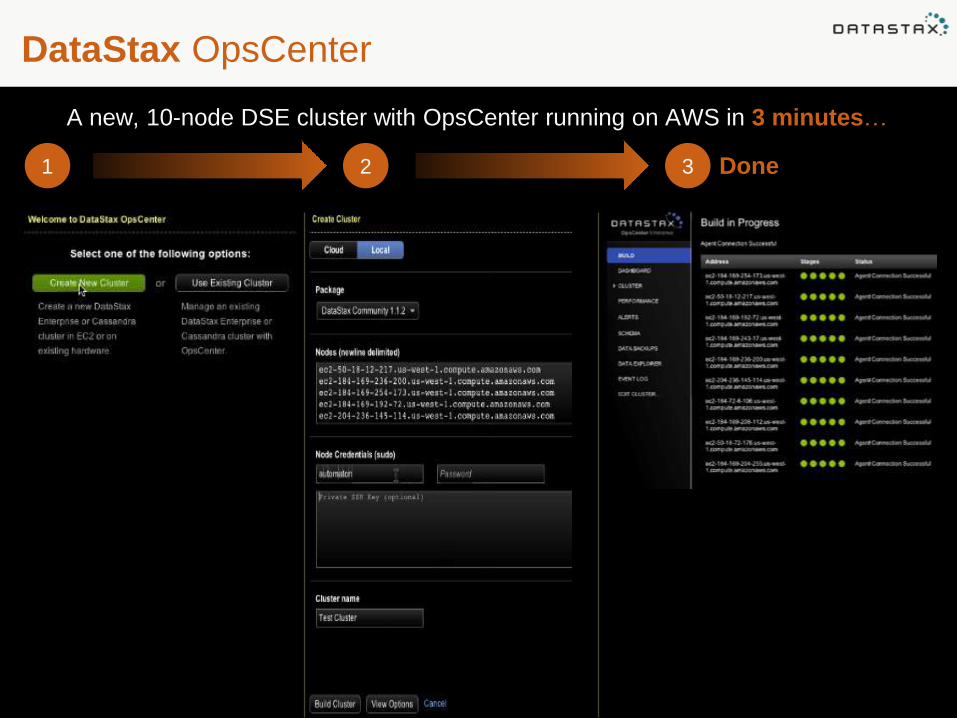
DataStax OpsCenter
A new, 10-node Cassandra (or Hadoop) cluster with OpsCenter running in 3 minutes… A new, 10-node DSE cluster with OpsCenter running on AWS in 3 minutes…
Done1 2 3
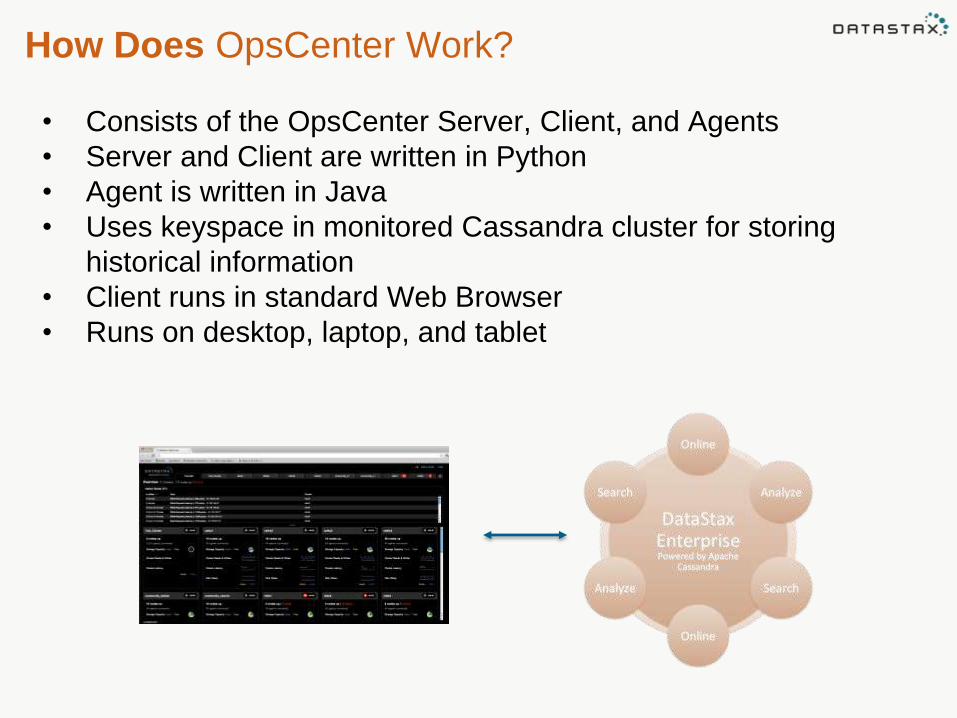
• Consists of the OpsCenter Server, Client, and Agents
• Server and Client are written in Python
• Agent is written in Java
• Uses keyspace in monitored Cassandra cluster for storing
historical information
• Client runs in standard Web Browser
• Runs on desktop, laptop, and tablet
How Does OpsCenter Work?

Cassandra Schema

©2013 DataStax Confidential. Do not distribute without consent.
Cassandra Schema
• Columns and column components
• Tables
• Keyspaces
97
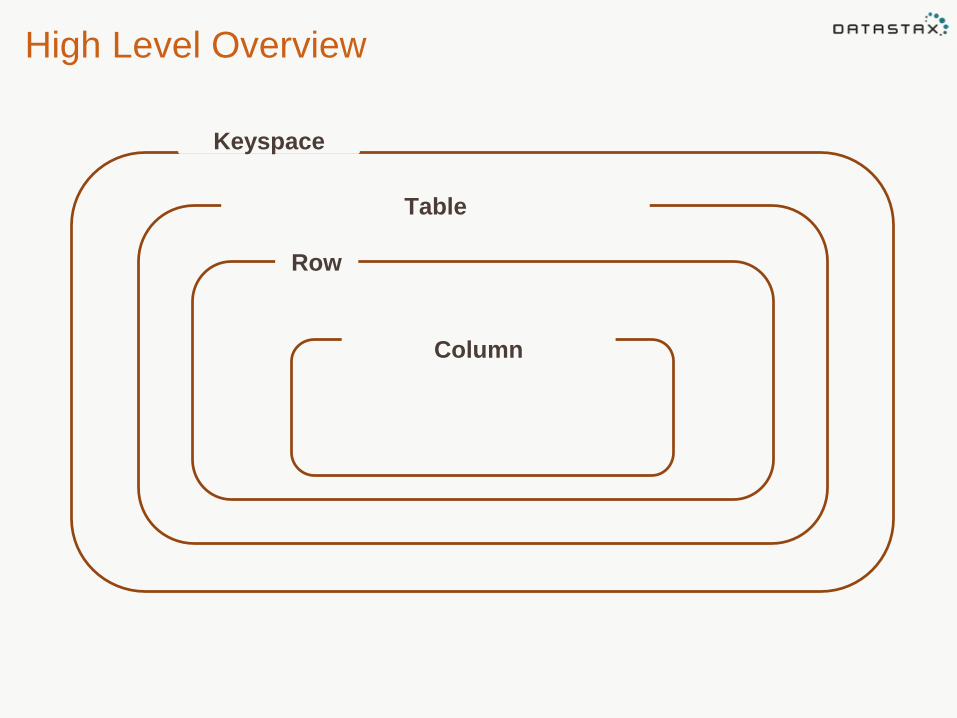
High Level Overview
Keyspace
Table
Row
Column

Components of the Column
The column is the fundamental data type in
Cassandra and includes:
• Column name
• Column value
• Timestamp
• TTL (Optional)

Column Name
• Can be any value
• Can be any type
• Not optional
• Must be unique
• Stored with every value
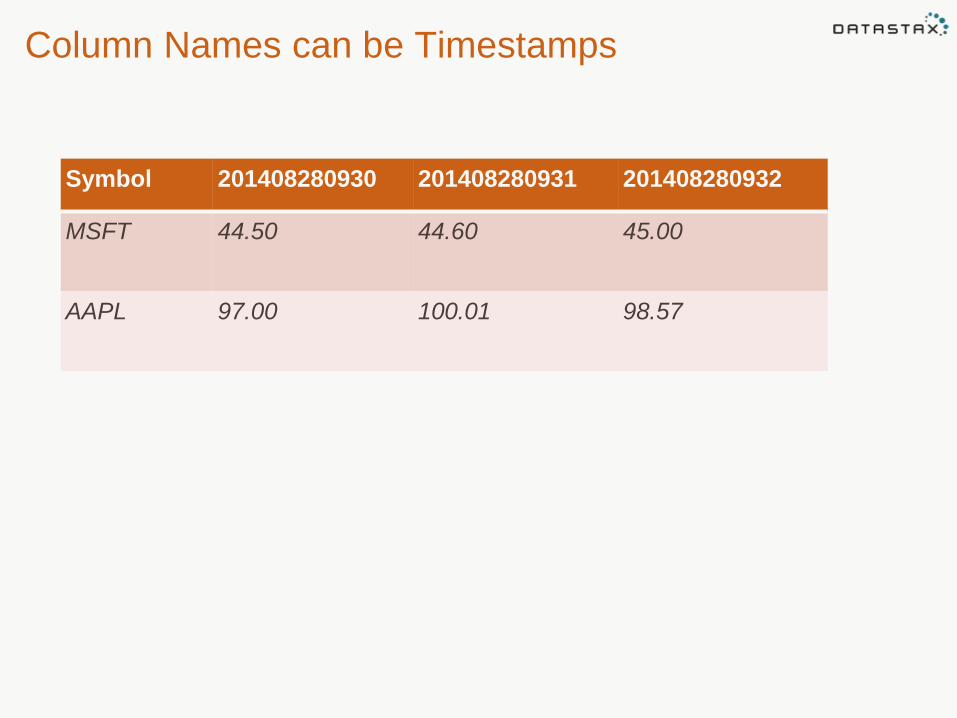
Column Names can be Timestamps
Symbol 201408280930 201408280931 201408280932
MSFT 44.50 44.60 45.00
AAPL 97.00 100.01 98.57

Column Value
• Any value
• Any type
• Can be empty – but is required

Column Names and Values
• The data type for a column value is called a validator.
• The data type for a column name is called a comparator.
• Cassandra validates that data type of the keys of rows.
• Columns are sorted, and stored in sorted order on disk, so you have to specify a comparator for columns. This can be reversed… more on this later
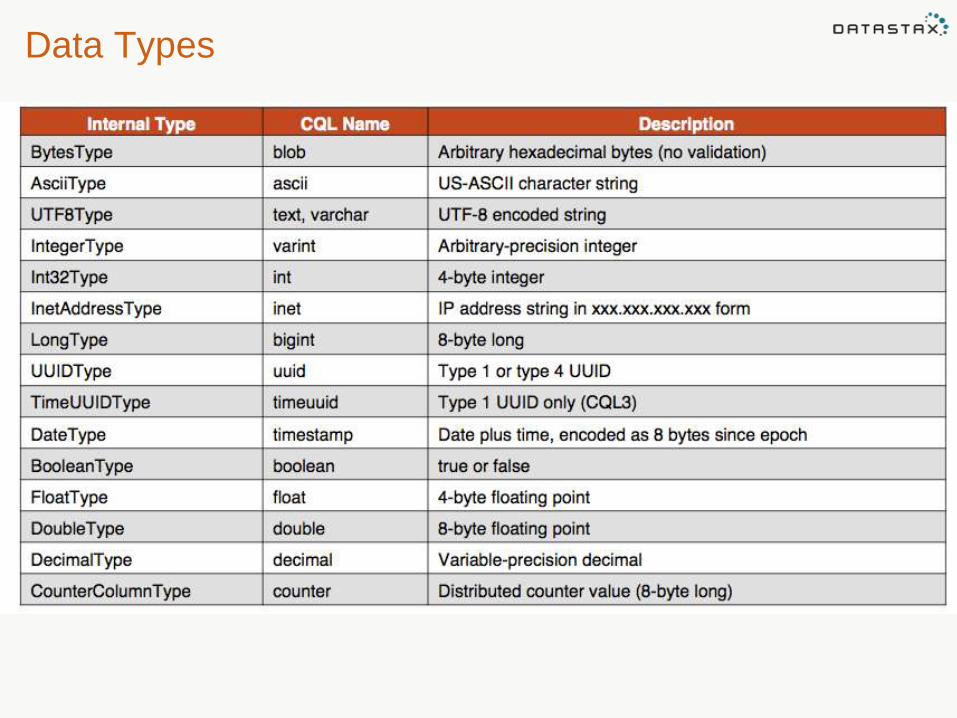
Data Types

Column TimeStamp
• 64-bit integer
• Best Practice
– Should be created in a consistent manner by all
your clients
SELECT WRITETIME (title)
FROM songs WHERE id = 8a172618-b121-4136-bb10-f665cfc469eb;
writetime(title)
------------------
1353890782373000

Column TTL
• Defined on INSERT
• Positive delay (in seconds)
• After time expires it is marked for deletion
INSERT INTO clicks
(userid, date, url)
VALUES (123456, ‘2014-08-28 10:00’, ‘http://www.datastax.com’)
USING TTL 86400;
Select TTL(url) FROM clicks
WHERE userid = 123456;
ttl(url)
-----------------
85908

Special Types of Columns
• Counter
• Collections

Counters
• Allows for addition / subtraction
• 64-bit value
• No timestamp
update recommendation_summary
set num_products = num_products + 1
where recommendation = 'highly recommend';

Collections
• Collections give you three types:
- Set (A distinct group of unordered elements)
- List (An ordered sequence of elements)
- Map (Composed of a collection of key, value pairs)
• Each allow for dynamic updates
CREATE TABLE collections_example (
id int PRIMARY KEY,
set_example set<text>,
list_example list<text>,
map_example map<int,text>
);

Cassandra Collections - Set
• Set is sorted by CQL type comparator
INSERT INTO collections_example (id, set_example)
VALUES(1, {'1-one', '2-two'});
set_example set<text>
Collection
nameCollection
type
CQL
Type

Set Operations
UPDATE collections_example
SET set_example = set_example + {'3-three'} WHERE id = 1;
UPDATE collections_example
SET set_example = set_example + {'0-zero'} WHERE id = 1;
UPDATE collections_example
SET set_example = set_example - {'3-three'} WHERE id = 1;
• Adding an element to the set
• After adding this element, it will sort to the beginning.
• Removing an element from the set

Cassandra Collections - List
Ordered by insertion
list_example list<text>
Collection
nameCollection
type
CQL
Type
INSERT INTO collections_example (id, list_example)
VALUES(1, ['1-one', '2-two']);

List Operations
• Adding an element to the end of a list
UPDATE collections_example
SET list_example = list_example + ['3-three'] WHERE id = 1;
UPDATE collections_example
SET list_example = ['0-zero'] + list_example WHERE id = 1;
• Adding an element to the beginning of a list
UPDATE collections_example
SET list_example = list_example - ['3-three'] WHERE id = 1;
• Deleting an element from a list
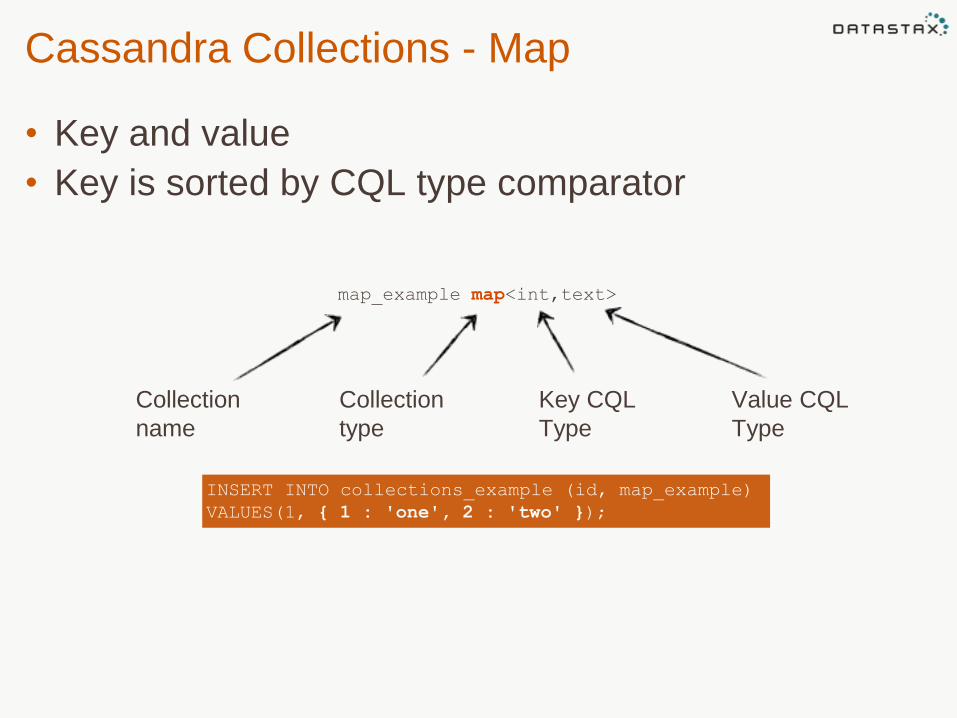
Cassandra Collections - Map
• Key and value
• Key is sorted by CQL type comparator
INSERT INTO collections_example (id, map_example)
VALUES(1, { 1 : 'one', 2 : 'two' });
map_example map<int,text>
Collection
name
Collection
type
Value CQL
Type
Key CQL
Type

Map Operations
• Add an element to the map
10
9
UPDATE collections_example
SET map_example[3] = 'three' WHERE id = 1;
UPDATE collections_example
SET map_example[3] = 'tres' WHERE id = 1;
DELETE map_example[3]
FROM collections_example WHERE id = 1;
• Update an existing element in the map
• Delete an element in the map
The Cassandra Schema
Consists of:
• Column
• Cloumn Family / Table
• Keyspace

Tables (Column Families)
• Similar to relational tables
• Groupings of Rows
• Tunable Consistency
• De-Normalization
• To avoid I/O
• Simplify the Read Path
• Static or Dynamic
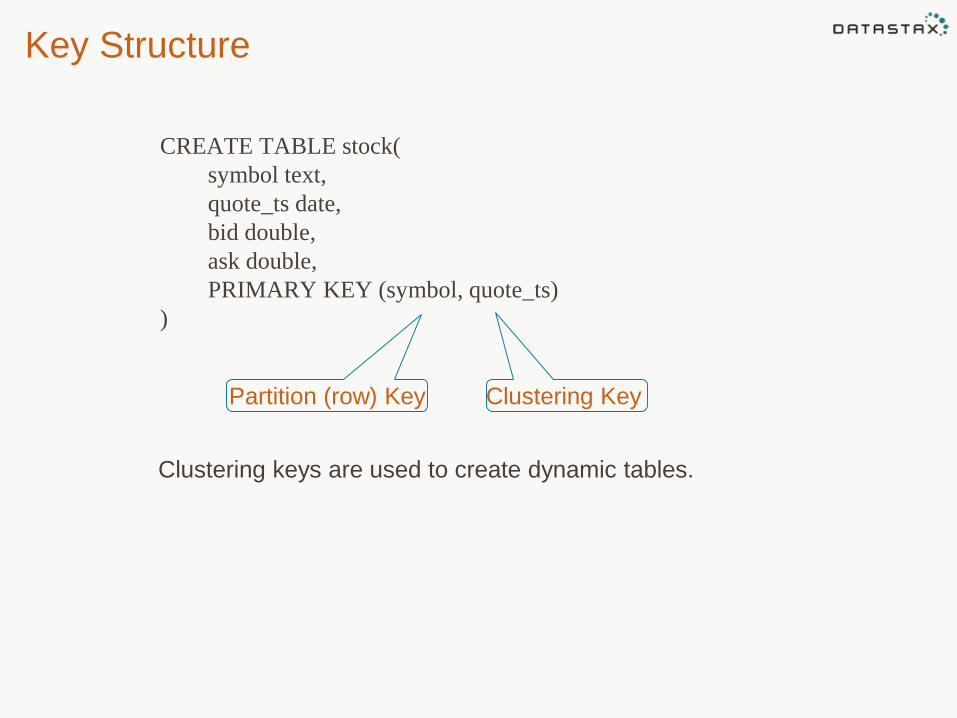
Key Structure
CREATE TABLE stock(
symbol text,
quote_ts date,
bid double,
ask double,
PRIMARY KEY (symbol, quote_ts)
)
Partition (row) Key Clustering Key
Clustering keys are used to create dynamic tables.
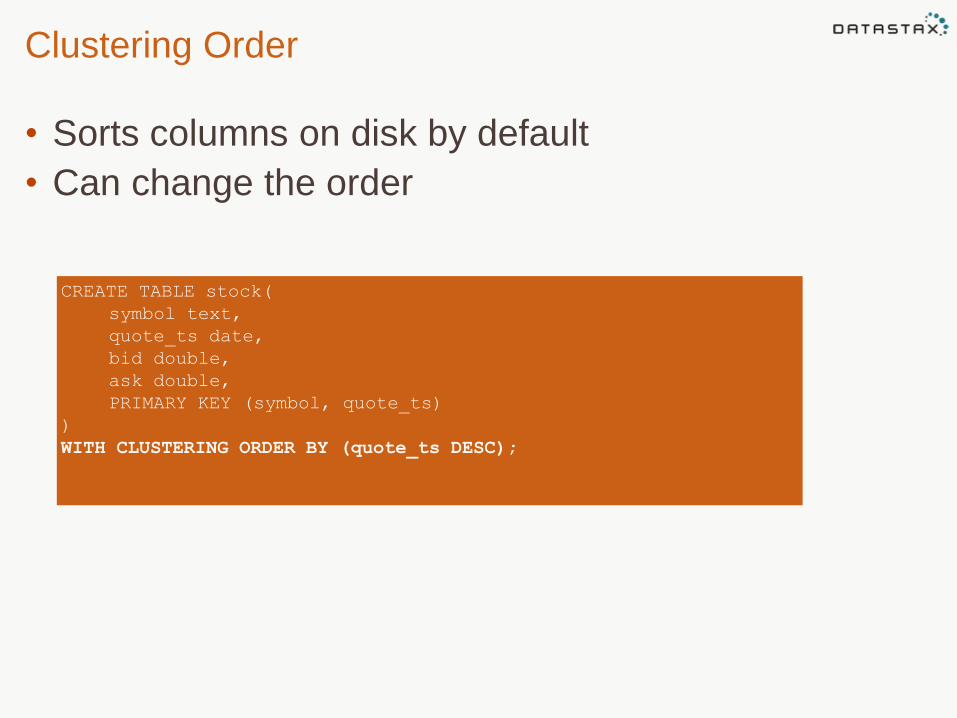
Clustering Order
• Sorts columns on disk by default
• Can change the order
CREATE TABLE stock(
symbol text,
quote_ts date,
bid double,
ask double,
PRIMARY KEY (symbol, quote_ts)
)
WITH CLUSTERING ORDER BY (quote_ts DESC);

Sorting
• Clustering columns can be used with ORDER BY
Select * from stock where symbol = ‘IBM’
ORDER BY quote_ts DESC
LIMIT 1;
Symbol Quote_ts Bid Ask
IBM 2014-08-02 189.00 189.50
Returns the most recent quote for IBM:

©2013 DataStax Confidential. Do not distribute without consent.
Composite Partition Keys
user_id and order_id are used to create the token
125
create table user_order(
user_id int,
order_id timeuuid,
product_id int,
product_name varchar,
cost double,
sale_price double,
quantity int,
total_price double,
total_cost double,
PRIMARY KEY ((user_id, order_id), product_id)
);
user_id:order_id product_id product_name cost
1234 product01 189.50
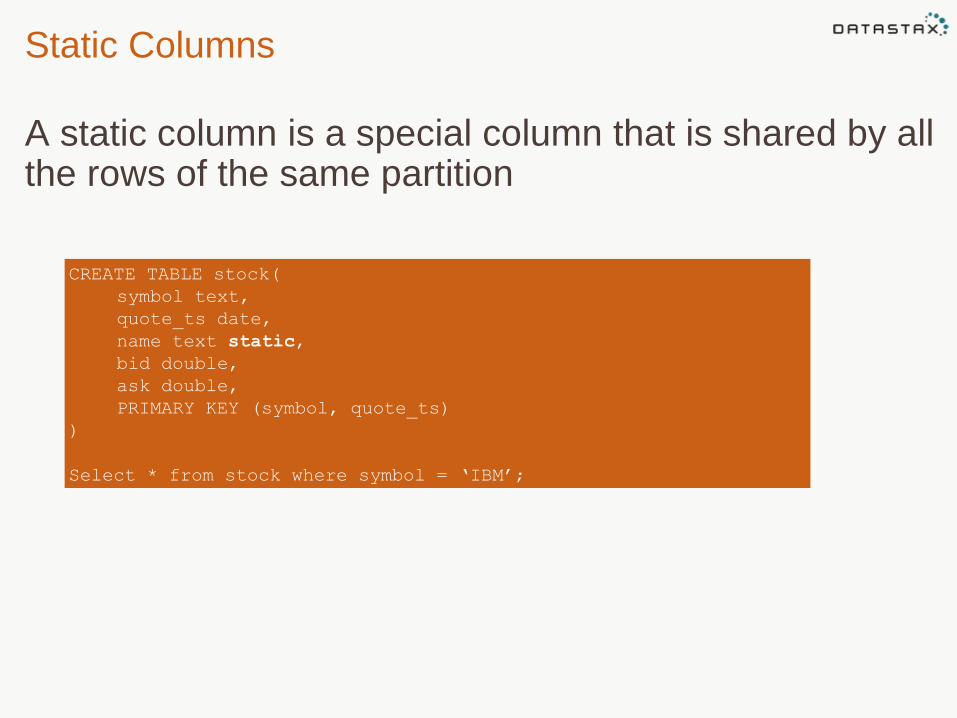
Static Columns
A static column is a special column that is shared by all the rows of the same partition
CREATE TABLE stock(
symbol text,
quote_ts date,
name text static,
bid double,
ask double,
PRIMARY KEY (symbol, quote_ts)
)
Select * from stock where symbol = ‘IBM’;

Static Columns
Symbol Name Quote_ts Bid Ask
IBM Inter Bus Mach 2014-08-01 190.00 191.00
IBM Inter Bus Mach 2014-08-02 189.00 189.50
CQL Rows:
IBMName 2014-08-01:Bid 2014-08-01:Ask 2014-08-02:Bid 2014-08-02:Ask
Inter Bus Mach 190.00 191.00 189.00 189.50
Storage Row:

Size Limits
• Column family component size considerations
• Data from a one row must fit on one node
• Data from any given row never spans multiple nodes
• For best performance, 100MB per partition
• Maximum columns per row is 2 billion
• In practice – 10 to 20 thousand
• Maximum data size per cell (column value) is 2 GB
• In practice – 10 MB

The Cassandra Schema
Consists of:
• Column
• Column Family
• Keyspace

Keyspaces
• Are groupings of Column Families
• Replication strategies
• Replication factor
CREATE KEYSPACE demodb
WITH REPLICATION = {‘class’ : ‘SimpleStrategy’, ‘replication_factor’ : 3};
ALTER KEYSPACE demodb
WITH REPLICATION = {‘class’ : ‘NetworkTopologyStrategy’, ‘DC1’ : 3};

Cassandra Query Language - CQL
• Very similar to RDBMS SQL syntax
• Create objects via DDL (e.g. CREATE…)
• Core DML commands supported: INSERT, UPDATE,
DELETE
• Query data with SELECT
SELECT *
FROM USERS
WHERE STATE = ‘TX’;

Cassandra Query Language - CQL
DataStax DevCenter – a free, visual query tool for creating and running CQL
statements against Cassandra and DataStax Enterprise.
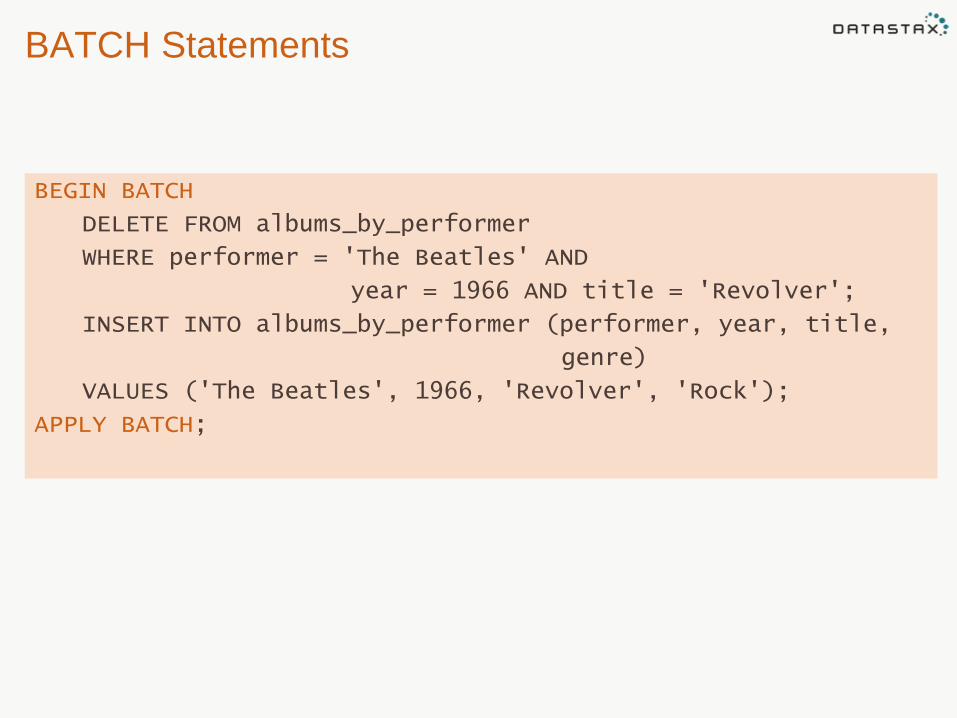
BATCH Statements
BEGIN BATCH
DELETE FROM albums_by_performer
WHERE performer = 'The Beatles' AND
year = 1966 AND title = 'Revolver';
INSERT INTO albums_by_performer (performer, year, title,
genre)
VALUES ('The Beatles', 1966, 'Revolver', 'Rock');
APPLY BATCH;
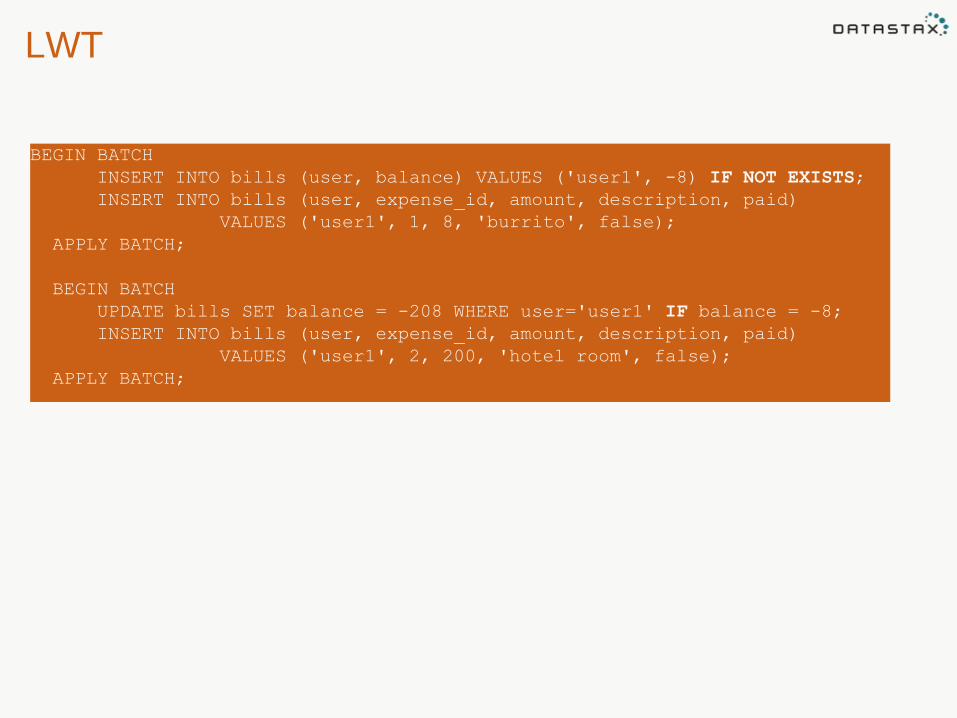
LWT
BEGIN BATCH
INSERT INTO bills (user, balance) VALUES ('user1', -8) IF NOT EXISTS;
INSERT INTO bills (user, expense_id, amount, description, paid)
VALUES ('user1', 1, 8, 'burrito', false);
APPLY BATCH;
BEGIN BATCH
UPDATE bills SET balance = -208 WHERE user='user1' IF balance = -8;
INSERT INTO bills (user, expense_id, amount, description, paid)
VALUES ('user1', 2, 200, 'hotel room', false);
APPLY BATCH;

• The schema used in Cassandra is modeled after after Google
Bigtable. It is a row-oriented, column structure
• A keyspace is akin to a database in the RDBMS world
• A column family is similar to an RDBMS table but is more
flexible/dynamic
ID Name SSN DOB
Portfolio Keyspace
Customer Column Family
Cassandra Schema Review

Cassandra 2.1
136

User Defined Types
137
CREATE TYPE address (
street text,
city text,
zip_code int,
phones set<text>
)
CREATE TABLE users (
id uuid PRIMARY KEY,
name text,
addresses map<text, address>
)
SELECT id, name, addresses.city, addresses.phones FROM users;
id | name | addresses.city | addresses.phones
--------------------+----------------+--------------------------
63bf691f | chris | Berlin | {’0201234567', ’0796622222'}

Secondary Index on Collections
138
CREATE TABLE songs (
id uuid PRIMARY KEY,
artist text,
album text,
title text,
data blob,
tags set<text>
);
CREATE INDEX song_tags_idx ON songs(tags);
SELECT * FROM songs WHERE tags CONTAINS 'blues';
id | album | artist | tags | title
----------+---------------+-------------------+-----------------------+------------------
5027b27e | Country Blues | Lightnin' Hopkins | {'acoustic', 'blues'} | Worrying My Mind

Data Modeling
It´s all about data
• Sensors
• CPU, Network Card, Electronic Power Meter, Resource Utilization, Weather
• Clickstream data, WebAnalytics
• Historical trends
• Stock Ticker
• Anything that varies on a temporal basis
• Top Ten Most Popular Videos
140
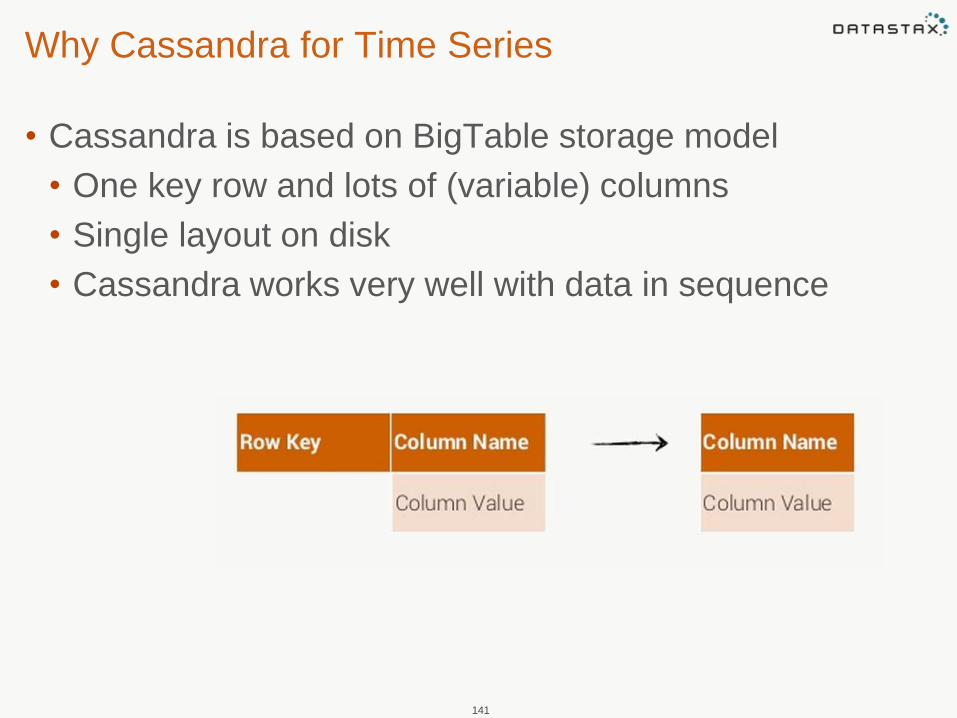
Why Cassandra for Time Series
• Cassandra is based on BigTable storage model
• One key row and lots of (variable) columns
• Single layout on disk
• Cassandra works very well with data in sequence
141

Time Series - Table Definition
• Data partitioned by weather station ID and time
• WeatherStationID is PRIMARY KEY (CQL) = PARTITION KEY (Cassandra),
event_time is Clustering Column (Together = Compound Primary Key)
• Clustering determines clustering (storage process that creates index and keeps
data in order based on the index)
• When rows for a partition key are stored in order based on clustering columns
retrieval is very efficient
CREATE TABLE temperature (
weatherstation_id text,
event_time timestamp,
temperature text,
PRIMARY KEY (weatherstation_id,event_time)
);
142

Time Series - Example
• Storing weather data, One weather station
• Temperature measurement every minute
• Retrieving data by row key (WeatherStationID) and
column key (event_time) is efficient
143

Time Series - INSERT and QUERY
• Inserts are simple and easy
INSERT INTO
temperature(weatherstation_id,event_time,temperature)
VALUES (’1234ABCD’,’2013-04-03 07:01:00′,’72F’);
• Row can be retrieved by Row Key
• Column Value can be retrieved by Row Key and Column Key
• WHERE Statement possible on Primary Key and Indexed Columns (event_time)
SELECT event_time,temperature
FROM temperature
WHERE weatherstation_id=’1234ABCD’;
144
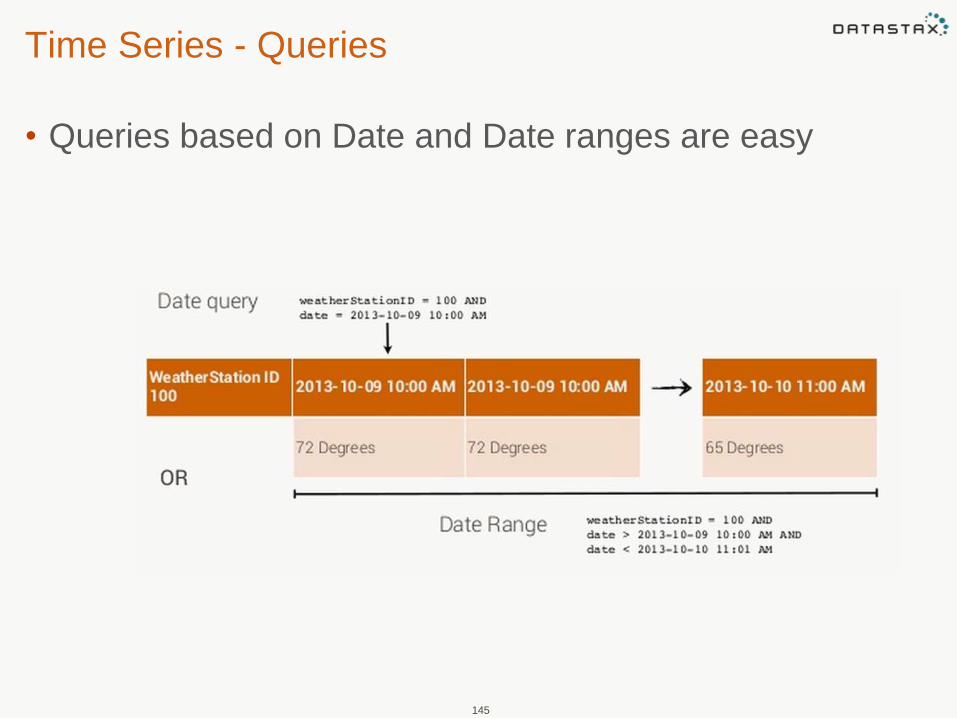
Time Series - Queries
• Queries based on Date and Date ranges are easy
145

Time Series - Partitioning
• With the previous table, you can end up with a very large row on 1 partition i.e. (per millisecond for example)
• This would have to fit on 1 node, Cassandra can store 2 billion columns per storage row (on one node reads = hotspots)
• The solution is to have a composite Partition Key (date) to split things up:
CREATE TABLE temperature_by_day (
weatherstation_id text,
date text,
event_time timestamp,
temperature text,
PRIMARY KEY ((weatherstation_id,date),event_time)
);
146

Time Series - Partitioning
• Using date (portion of timestamp) as available value
• Query all data from a single day
SELECT *
FROM temperature_by_day
WHERE weatherstation_id=’1234ABCD’
AND date=’2013-04-03′;
147
WeatherStationI
D:date
timestamp timestamp timestamp
temperature temperature temperature
Data Modeling
• Any questions?
• Feel free to learn more about data modeling online:
Part 1: The Data Model is Dead, Long Live the Data Model
http://www.youtube.com/watch?v=px6U2n74q3g
Part 2: Become a Super Modeler
http://www.youtube.com/watch?v=qphhxujn5Es
Part 3: The World's Next Top Data Model
http://www.youtube.com/watch?v=HdJlsOZVGwM
148

DataStax Enterprise
149
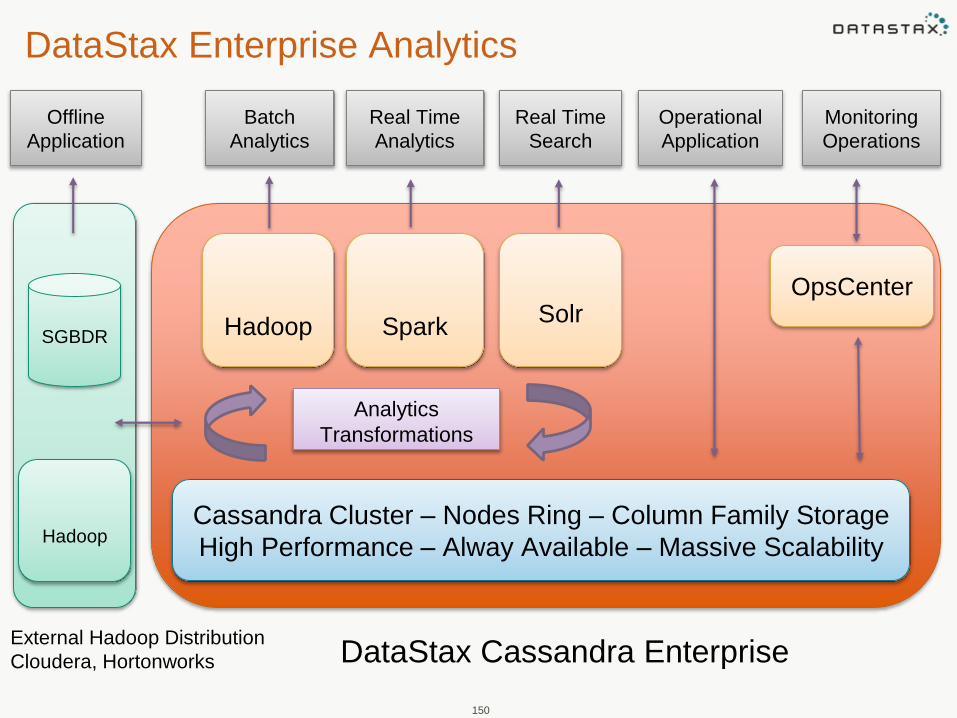
DataStax Enterprise Analytics
150
Cassandra Cluster – Nodes Ring – Column Family Storage
High Performance – Alway Available – Massive Scalability
Hadoop
Offline
Application
DataStax Cassandra EnterpriseExternal Hadoop Distribution
Cloudera, Hortonworks
SparkSolr
OpsCenter
Hadoop
Monitoring
Operations
Operational
Application
Real Time
Search
Real Time
Analytics
Batch
Analytics
SGBDR
Analytics
Transformations

DataStax Enterprise Analytics
• Designed for running analytics on Cassandra data
• There are 4 ways to do Analytics on Cassandra data:
1. Integrated Search (Solr)
2. Integrated Batch Analytics (MapReduce, Hive, Pig,
Mahout) on Cassandra
3. External Batch Analytics (Hadoop; certified with
Cloudera, HortonWorks)
4. Integrated Near Real-Time Analytics (Spark)
151
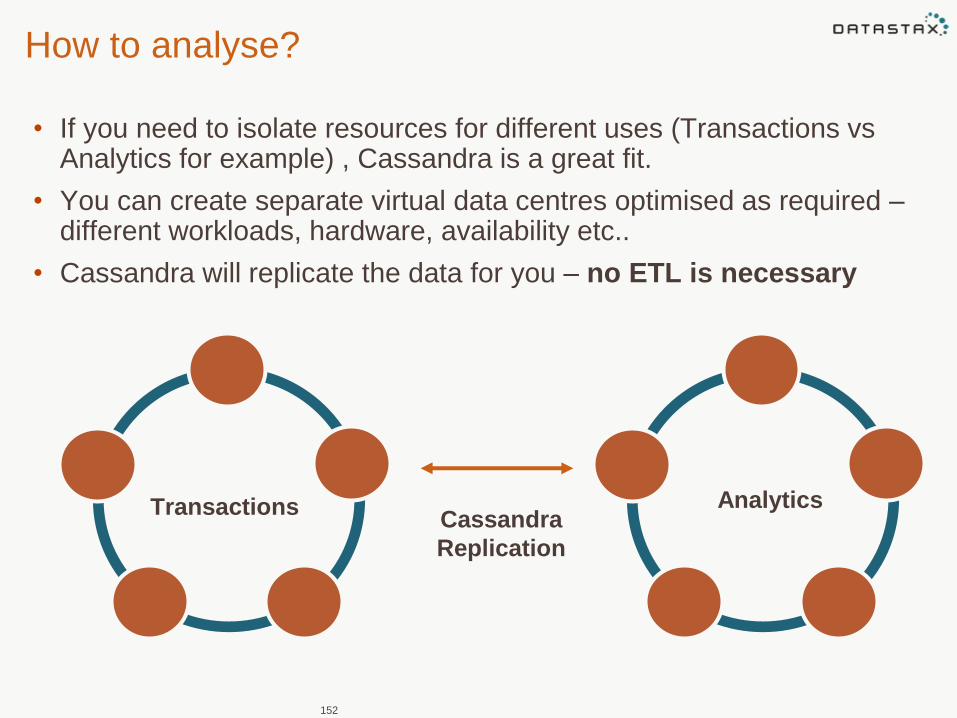
How to analyse?
152
• If you need to isolate resources for different uses (Transactions vs Analytics for example) , Cassandra is a great fit.
• You can create separate virtual data centres optimised as required –different workloads, hardware, availability etc..
• Cassandra will replicate the data for you – no ETL is necessary
Cassandra
Replication
Transactions Analytics

Search

What is Solr?
• Created by CNet as “enterprise search” wrapper to Lucene
• Enterprise = Admin Interface, Extensions, API to manage and structure support (than just free form text)
• Lucene alone is a powerful information retrieval engine
• Set of jar´s, lower building blocks
• Elasticsearch is another Lucene wrapper
• Indexes JSON documents
• focus on distributed search server vs. “enterprise search”
154

Solr Search
• Search != Query
• Query: implies an exact set of results
• “give me all cafe visits of this year for user xyz”
• Search: fuzzier, with typical inexact sets of results
• “give me the top web pages containing “apache” and “cassandra”
155

©2013 DataStax Confidential. Do not distribute without consent.
Solr Integration in DSE Analytics
• 100% Solr/Lucene compatible • Very fast performance • Real-time search operations; indexes can be rebuilt on the fly • Provides data durability (overcomes Solr’s lack of write-
ahead log - if community Solr node goes down, data can be lost)
• Overcomes Solr write bottleneck – can read/write to any Solr node
• Automatic sharding via Cassandra replication• Search indexes can span multiple data centers (regular Solr
cannot)• Online scalability via adding new nodes• Built-in failover; continuously available
156

Batch Analytics
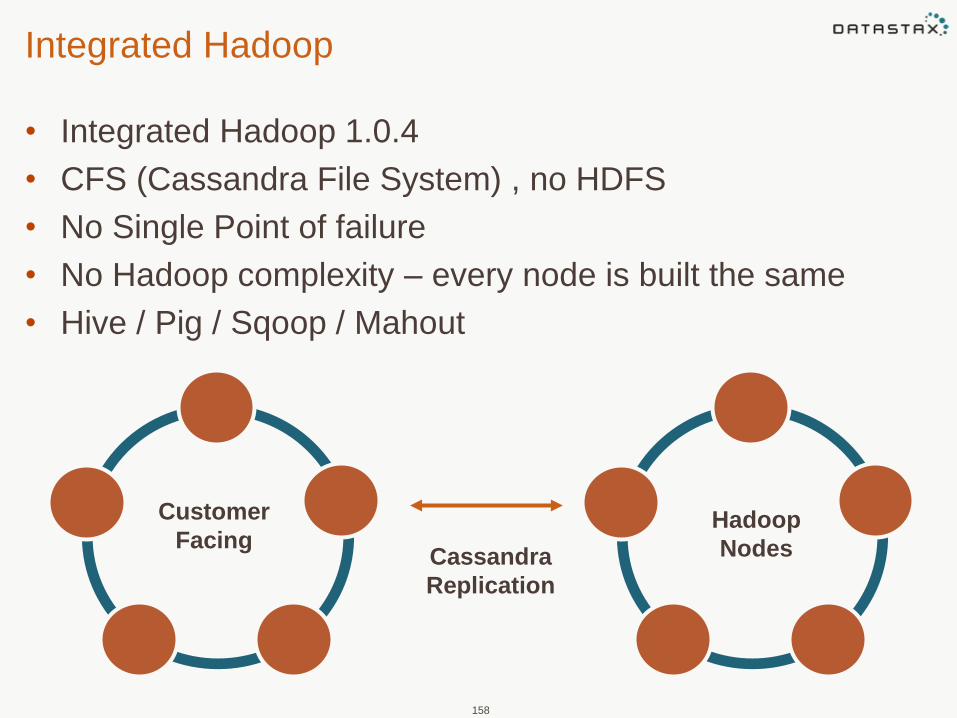
Integrated Hadoop
• Integrated Hadoop 1.0.4
• CFS (Cassandra File System) , no HDFS
• No Single Point of failure
• No Hadoop complexity – every node is built the same
• Hive / Pig / Sqoop / Mahout
158
Cassandra
Replication
Customer
FacingHadoop
Nodes
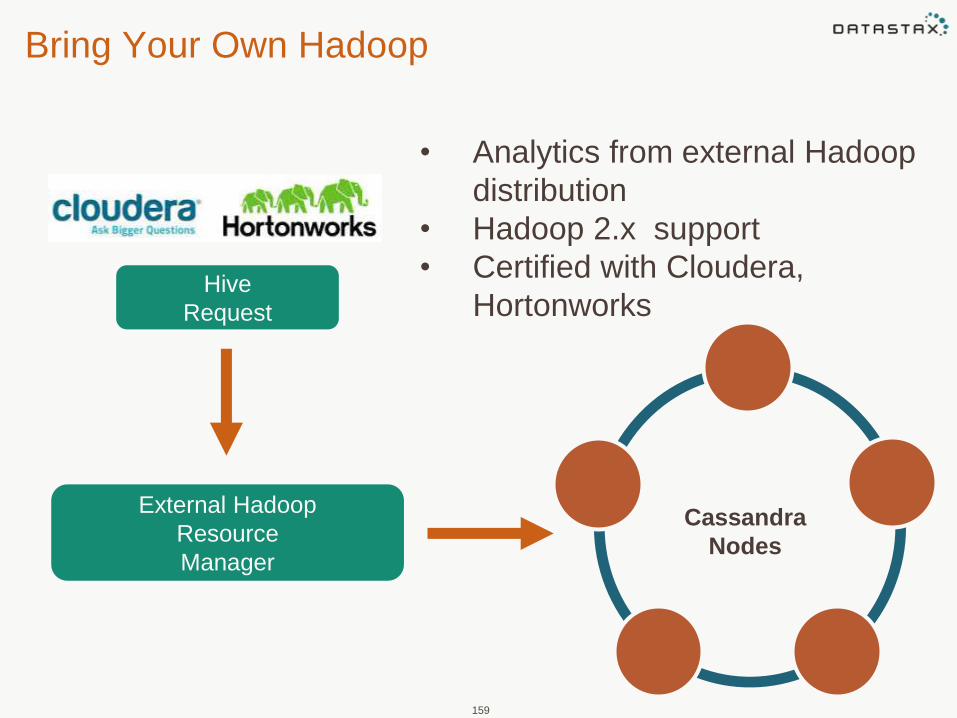
Bring Your Own Hadoop
159
External Hadoop
Resource
Manager
Hive
Request
• Analytics from external Hadoop
distribution
• Hadoop 2.x support
• Certified with Cloudera,
Hortonworks
Cassandra
Nodes

Near-Realtime Analytics
160
©2013 DataStax Confidential. Do not distribute without consent.
Apache Spark
• Apache Project since 2010 - Analytics Framework
• 10-100x faster than Hadoop MapReduce
• In-Memory Storage for Read&Write data
• Single JVM Processor per node
• Rich Scala, Java and Python API´s
• 2x-5x less code
• Interactive Shell
161

Apache Spark
• Data model independent queries
• cross-table operations (JOIN, UNION, etc.)!
• complex analytics (e.g. machine learning)
• data transformation, aggregation etc.
• -> Migration, Mutation and Aggregation scenarios!
• stream processing (coming soon)
• all nodes are Spark workers
• by default resilient to worker failures
• first node promoted as Spark Master
• Standby Master promoted on failure
• Master HA available in Datastax Enterprise!
162
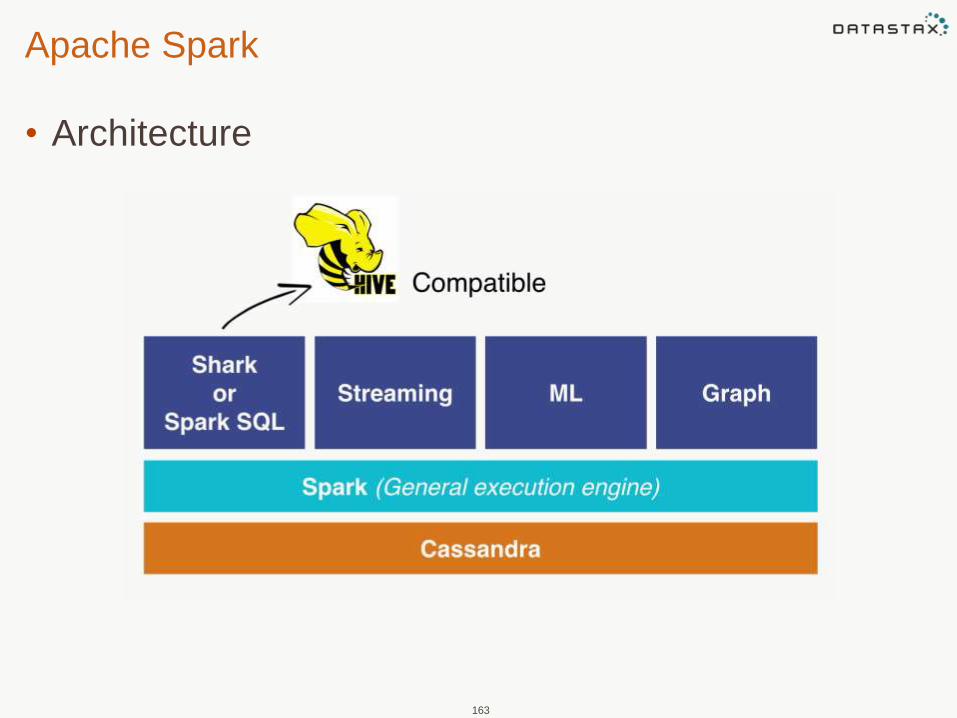
Apache Spark
• Architecture
163

Howto Spark?
• DataStax Cassandra Spark driver
• OpenSource: https://github.com/datastax/cassandra-
driver-spark
• Compatible with
• Spark 0.9+
• Cassandra 2.0+
• DataStax Enterprise 4.5+
164
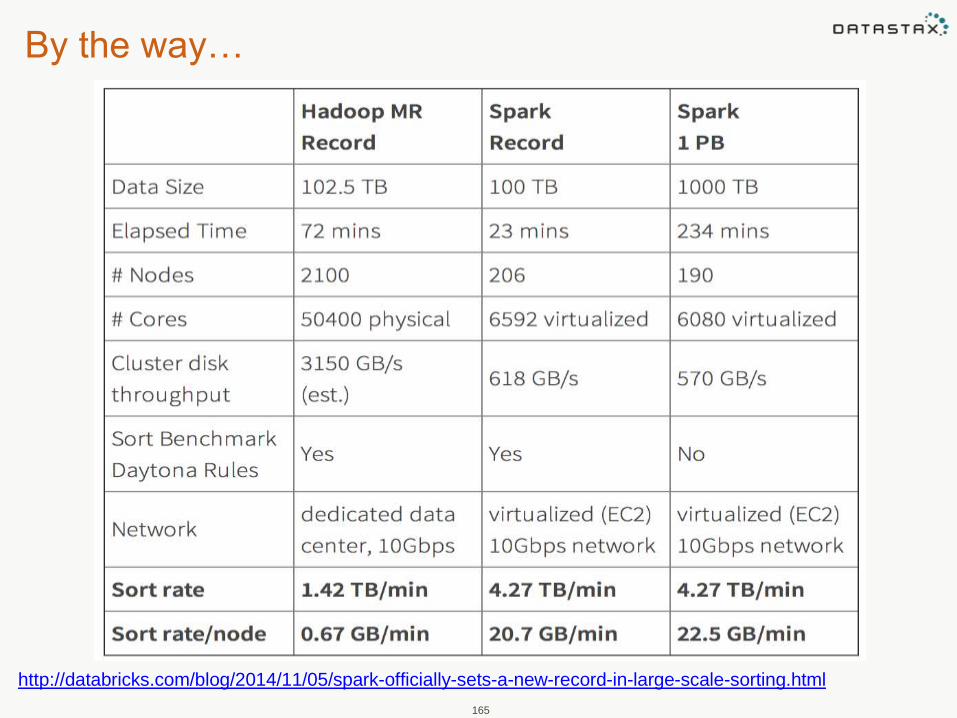
By the way…
165
http://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html

Drivers

Native Drivers
• Different Native Drivers available: Java, Python etc.
• Load Balancing Policies (Client Driver receives Updates)
• Data Centre Aware
• Latency Aware
• Token Aware
• Reconnection policies
• Retry policies
• Downgrading Consistency
• Plus others..
• http://www.datastax.com/download/clientdrivers
167

Java Driver for Cassandra
Session 7: The Java Driver
• Driver uses CQL Version 3
• layered architecture, driver core at the bottom
• handles connection pools, node discovery etc.
• Rich Features:
• Node Discovery
• Configurable Load-Balancing
• Transparent Failover
• Cassandra Trace-Handling
• Configurable Retry-Policy
• relies on Netty to provide non-blocking I/O with Cassandra for providing a fully asynchronous architecture

Java Driver for Cassandra - Example
169
package com.example.cassandra;
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Host;
import com.datastax.driver.core.Metadata;
public class SimpleClient {
private Cluster cluster;
public void connect(String node) {
cluster = Cluster.builder()
.addContactPoint(node)
.build();
Metadata metadata = cluster.getMetadata();
System.out.printf("Connected to cluster: %s\n",
metadata.getClusterName());
for ( Host host : metadata.getAllHosts() ) {
System.out.printf("Datatacenter: %s; Host: %s; Rack: %s\n",
host.getDatacenter(), host.getAddress(), host.getRack());
}
}
public void close() {
cluster.close();
}
public static void main(String[] args) {
SimpleClient client = new SimpleClient();
client.connect("127.0.0.1");
client.close();
}
}

Python Driver for Cassandra
• Driver uses CQL Version 3
• layered architecture, driver core at the bottom
• handles connection pools, node discovery etc.
• Rich Features:
• Node Discovery
• Configurable Load-Balancing
• Transparent Failover
• Cassandra Trace-Handling
• Configurable Retry-Policy
170

Python Driver for Cassandra - Example
171
from cassandra.cluster import Cluster
import logging
log = logging.getLogger()
log.setLevel('INFO')
class SimpleClient(object):
session = None
def connect(self, nodes):
cluster = Cluster(nodes)
metadata = cluster.metadata
self.session = cluster.connect()
log.info('Connected to cluster: ' + metadata.cluster_name)
for host in metadata.all_hosts():
log.info('Datacenter: %s; Host: %s; Rack: %s',
host.datacenter, host.address, host.rack)
def close(self):
self.session.cluster.shutdown()
log.info('Connection closed.')
def main():
logging.basicConfig()
client = SimpleClient()
client.connect(['127.0.0.1'])
client.close()
if __name__ == "__main__":
main()

Python Driver for Cassandra - CQLEngine
• CQL Model Wrapper
• versus
172
from cqlengine import columns
from cqlengine.models import Model
class Person(Model):
id = columns.UUID(primary_key=True)
first_name = columns.Text()
last_name = columns.Text()
CREATE TABLE cqlengine.person (
id uuid,
first_name text,
last_name text,
PRIMARY KEY (id)
)

DataStax Enterprise
173

Why DataStax Enterprise?
174
Open Source/Community Enterprise Software
• Apache Cassandra (employ
Cassandra chair and 90+% of the
committers)
• DataStax Community Edition
• DataStax OpsCenter
• DataStax DevCenter
• DataStax Drivers/Connectors
• Online Documentation
• Online Training
• Mailing lists and forums
• DataStax Enterprise Edition
• Certified Cassandra
• Built-in Analytics
• Built-in Enterprise Search
• Enterprise Security
• DataStax OpsCenter
• Expert Support
• Consultative Help
• Professional Training
DataStax supports both the open source community and modern
business enterprises.
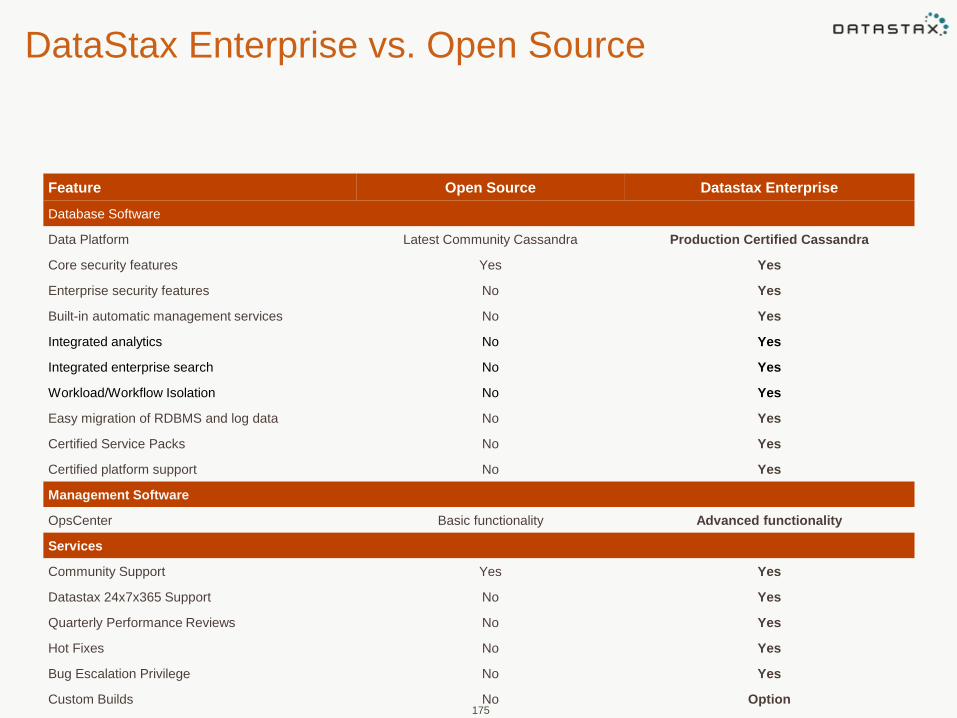
DataStax Enterprise vs. Open Source
175
Feature Open Source Datastax Enterprise
Database Software
Data Platform Latest Community Cassandra Production Certified Cassandra
Core security features Yes Yes
Enterprise security features No Yes
Built-in automatic management services No Yes
Integrated analytics No Yes
Integrated enterprise search No Yes
Workload/Workflow Isolation No Yes
Easy migration of RDBMS and log data No Yes
Certified Service Packs No Yes
Certified platform support No Yes
Management Software
OpsCenter Basic functionality Advanced functionality
Services
Community Support Yes Yes
Datastax 24x7x365 Support No Yes
Quarterly Performance Reviews No Yes
Hot Fixes No Yes
Bug Escalation Privilege No Yes
Custom Builds No Option
EOL Support No Yes
176
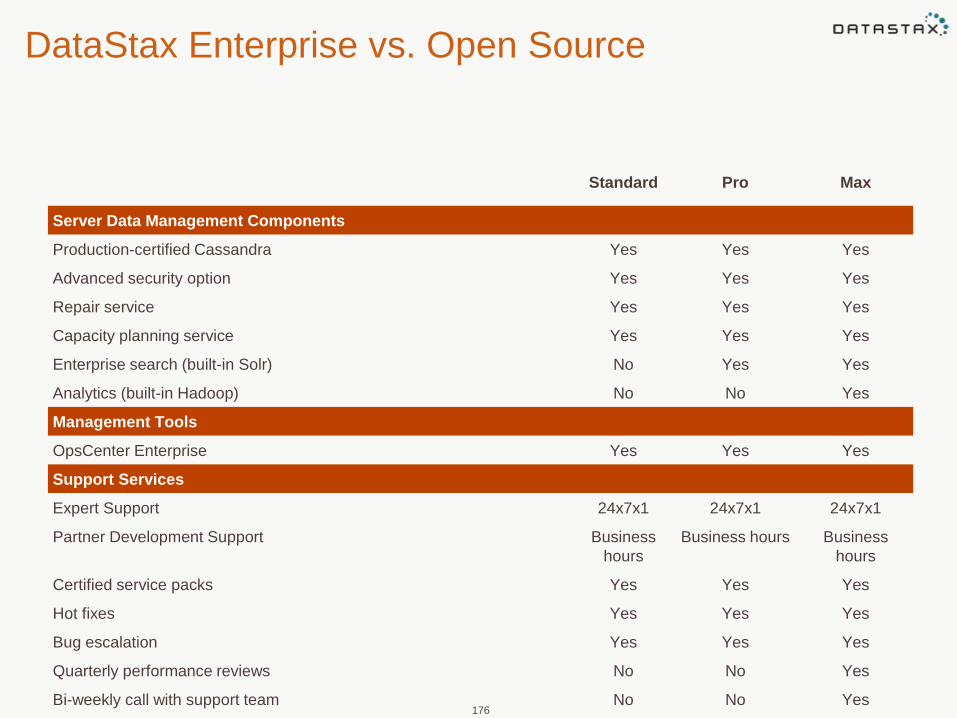
DataStax Enterprise vs. Open Source
Standard Pro Max
Server Data Management Components
Production-certified Cassandra Yes Yes Yes
Advanced security option Yes Yes Yes
Repair service Yes Yes Yes
Capacity planning service Yes Yes Yes
Enterprise search (built-in Solr) No Yes Yes
Analytics (built-in Hadoop) No No Yes
Management Tools
OpsCenter Enterprise Yes Yes Yes
Support Services
Expert Support 24x7x1 24x7x1 24x7x1
Partner Development Support Business
hours
Business hours Business
hours
Certified service packs Yes Yes Yes
Hot fixes Yes Yes Yes
Bug escalation Yes Yes Yes
Quarterly performance reviews No No Yes
Bi-weekly call with support team No No Yes
Custom builds No No Option

©2013 DataStax Confidential. Do not distribute without consent.
DSE Analytics
DEMO

178
Thanks!

![DataStaxODBCdriverforApache ......[DataStax ODBC driver for Apache Cassandra and DataStax Enterprise with CQL connector 32-bit] Description=DataStax ODBC driver for Apache Cassandra](https://img.pdfslide.net/doc/110x75/5ec5d38556938a726220ac95/datastaxodbcdriverforapache-datastax-odbc-driver-for-apache-cassandra-and.jpg)

















![[MinhaVida TechDay] NoSQL](https://img.pdfslide.net/doc/110x75/5561e8dcd8b42aa5068b5142/minhavida-techday-nosql.jpg)