Embed Size (px)
Citation preview

SS 07 Anwendungs-Seminar
„Database Tuning & Administration“,
University of Konstanz
Lehrstuhl: Database & Information Systems Group
Prof. Dr. Marc. H. Scholl
Betreuung: Christian Grün
Matthias Röger, Thomas Zink; Information Engineering
Datenbank-Tuning & Administration MS SQL SERVER 2005 EXPRESS
SS 07 Anwendungs-Seminar
„Database Tuning & Administration“,
University of Konstanz
Lehrstuhl: Database & Information Systems Group
Prof. Dr. Marc. H. Scholl
Betreuung: Christian Grün
Matthias Röger, Thomas Zink; Information Engineering

Gliederung
• Einführung
• Statistik
• Indizes
Allgemeine Darstellung
Vergleichs-Studie
• Join-Verfahren
Allgemeine Darstellung
Anwendung Join-Operationen
• Auswirkung Variation Größe des Server-Arbeits-Speichers
• Abfrage-Optimierung TPC-H
Auswirkung Indizes auf Query-Plan und Ausführungszeit
Analyse ausgewählter Queries
• Fazit
• Einführung
• Statistik
• Indizes
Allgemeine Darstellung
Vergleichs-Studie
• Join-Verfahren
Allgemeine Darstellung
Anwendung Join-Operationen
• Auswirkung Variation Größe des Server-Arbeits-Speichers
• Abfrage-Optimierung TPC-H
Auswirkung Indizes auf Query-Plan und Ausführungszeit
Analyse ausgewählter Queries
• Fazit
2

Einführung
MS SQL SERVER 2005
• Integrierte Plattform für die Verwaltung von unternehmensweiten Daten.
• Werkzeuge zur Erstellung, Verwalten und Anwendung von Applikationen sind integriert.
• Wichtige Dienste:
- Relationaler Datenbank-Server
- Dienst für Datenanalyse, Berichtswesen und Datenintegration.
• Datenbank-Server kann relationale sowie XML-Daten verwalten.
• Express Edition kostenlos verfügbar.
MS SQL SERVER 2005
• Integrierte Plattform für die Verwaltung von unternehmensweiten Daten.
• Werkzeuge zur Erstellung, Verwalten und Anwendung von Applikationen sind integriert.
• Wichtige Dienste:
- Relationaler Datenbank-Server
- Dienst für Datenanalyse, Berichtswesen und Datenintegration.
• Datenbank-Server kann relationale sowie XML-Daten verwalten.
• Express Edition kostenlos verfügbar.
3

Einführung
Wichtige Tools zur Verwaltung der Serversoftware und zur Kommunikation mit der
Datenbank:
• sqlcmd
- Arbeitet auf Befehlszeilen-Ebene.
• SQL Server Management Studio Express
- Graphische Benutzerschnittstelle
- Wichtig für die Performance-Analyse.
- Ermöglicht das Testen von Abfragen in unterschiedlicher Form / mit unterschiedlichen
Indizes.
- Textuelle und graphische Ausgabe der Query-Pläne von Abfragen.
Wichtige Tools zur Verwaltung der Serversoftware und zur Kommunikation mit der
Datenbank:
• sqlcmd
- Arbeitet auf Befehlszeilen-Ebene.
• SQL Server Management Studio Express
- Graphische Benutzerschnittstelle
- Wichtig für die Performance-Analyse.
- Ermöglicht das Testen von Abfragen in unterschiedlicher Form / mit unterschiedlichen
Indizes.
- Textuelle und graphische Ausgabe der Query-Pläne von Abfragen.
4

Ansatzpunkte zur Query-Optimierung
Möglichkeiten zur Optimierung von Abfragen
• Allg. Nutzung Statistiken
• Nutzung der Informationen des Optimierers / Analyse-Tools
• Indizes
• Join-Verfahren
• Eingreifen durch „Hints‘ in Ausführungsplan
• Query Rewrite
• Hauptspeichergröße
• Indizierte Views• f
Möglichkeiten zur Optimierung von Abfragen
• Allg. Nutzung Statistiken
• Nutzung der Informationen des Optimierers / Analyse-Tools
• Indizes
• Join-Verfahren
• Eingreifen durch „Hints‘ in Ausführungsplan
• Query Rewrite
• Hauptspeichergröße
• Indizierte Views• f
5

Statistik
Die Entscheidung, ob ein Index verwendet wird oder nicht, hängt vom Index-Typ und von
der Index-Selektivität ab.
Ermittlung der Selektivität eines Index:
Optimierer verwendet spezielle Statistiken, um die Selektivität von Indizes zu ermitteln.
Diese Statistiken beschreiben die Selektivität und die Verteilung der Werte einer indizierten
Spalte.
Wesentliche Statistiken über:
• Anzahl Tabellenreihen
• Anzahl physikalischer Seiten
• Anzahl der Reihen, die für Statistik verwendet wurden
• Selektivität des ersten Indexspaltenpräfixes
• Durchschnittliche Länge aller Indexspalten
• Datum des letzten Updates
Die Entscheidung, ob ein Index verwendet wird oder nicht, hängt vom Index-Typ und von
der Index-Selektivität ab.
Ermittlung der Selektivität eines Index:
Optimierer verwendet spezielle Statistiken, um die Selektivität von Indizes zu ermitteln.
Diese Statistiken beschreiben die Selektivität und die Verteilung der Werte einer indizierten
Spalte.
Wesentliche Statistiken über:
• Anzahl Tabellenreihen
• Anzahl physikalischer Seiten
• Anzahl der Reihen, die für Statistik verwendet wurden
• Selektivität des ersten Indexspaltenpräfixes
• Durchschnittliche Länge aller Indexspalten
• Datum des letzten Updates
6

Statistik / Histogramm
Ein Histogramm gibt wertvolle Informationen über die entsprechenden Daten.
Beispiel Histogramm:
7

Eingesetzte Indizes
Einfacher Index
• Index auf ein Feld in der Tabelle.
• Pro Query kann mehr als ein Index zum Einsatz kommen.
• Je kleiner ein Index Feld, umso mehr Records pro Page.
Composite (zusammengesetzter) Index
• Index mit mehreren Feldern.
• Selektivität des ersten Feldes für Optimierer .
ausschlaggebend bei Entscheidung für/gegen Index.
Covering (abdeckender) Index
• Enthält alle Felder welche in einer Query auftreten.
• Kein extra Zugriff auf Datenseiten mehr notwendig.
Index mit „Included Columns“
• Spalten der WHERE-Klausel als Index-Spalten; zusätzlich Spalten der SELECT-Klausel als „eingeschlossene Spalten“ (Nichtschlüsselspalten), welche der Blattebene hinzugefügt werden.
Clustered Index
• Die Tabelle selbst ist der Index.
Einfacher Index
• Index auf ein Feld in der Tabelle.
• Pro Query kann mehr als ein Index zum Einsatz kommen.
• Je kleiner ein Index Feld, umso mehr Records pro Page.
Composite (zusammengesetzter) Index
• Index mit mehreren Feldern.
• Selektivität des ersten Feldes für Optimierer .
ausschlaggebend bei Entscheidung für/gegen Index.
Covering (abdeckender) Index
• Enthält alle Felder welche in einer Query auftreten.
• Kein extra Zugriff auf Datenseiten mehr notwendig.
Index mit „Included Columns“
• Spalten der WHERE-Klausel als Index-Spalten; zusätzlich Spalten der SELECT-Klausel als „eingeschlossene Spalten“ (Nichtschlüsselspalten), welche der Blattebene hinzugefügt werden.
Clustered Index
• Die Tabelle selbst ist der Index.
8

Analyse: Anwendung verschiedener Indizes
Anwendung verschiedener Indizes auf Query 6:
1) Ohne Indizes
2) Nichtgruppierter Index, einzeln auf alle Spalten der Where-Klausel à dex
à Index nicht ausgewählt
3) Nichtgruppierter Index, einzeln auf alle Spalten der Where-Klausel,
à Index-Nutzung (IX_shipdate) erzwungen
4) Gruppierter Index auf l_Shipdate
5) Gruppierter Index auf l_Discount
6) Zusammengesetzter, ungruppierter Index auf alle Spalten der Where-Klausel
à Index nicht ausgewählt
7) Zusammengesetzter, ungruppierter Index auf alle Spalten der Where-Klausel,
à Index-Nutzung erzwungen
8) Zusammengesetzter, gruppierter Index auf alle Spalten der Where-Klausel
9) Covered Index
Geschätzte Selektivität
anhand Histogramm:
l_quantity 0,50l_discount 0,30l_shipdate 0,15
Anzahl gesamt: 3.891.692
Anwendung verschiedener Indizes auf Query 6:
1) Ohne Indizes
2) Nichtgruppierter Index, einzeln auf alle Spalten der Where-Klausel à dex
à Index nicht ausgewählt
3) Nichtgruppierter Index, einzeln auf alle Spalten der Where-Klausel,
à Index-Nutzung (IX_shipdate) erzwungen
4) Gruppierter Index auf l_Shipdate
5) Gruppierter Index auf l_Discount
6) Zusammengesetzter, ungruppierter Index auf alle Spalten der Where-Klausel
à Index nicht ausgewählt
7) Zusammengesetzter, ungruppierter Index auf alle Spalten der Where-Klausel,
à Index-Nutzung erzwungen
8) Zusammengesetzter, gruppierter Index auf alle Spalten der Where-Klausel
9) Covered Index9

Join-Operationen
Folgende JOIN-Implementierungen stellt der SQL SERVER zur Verfügung:
• Geschachteltes Loop-Join• Sort-/Merge-Join• Hash-Join
Geschachteltes Loop-Join
Sehr langsam, falls kein Index für eine der Join-Spalten. Falls eine der beiden Join-Spalten einen Index aufweist, ist diesesVerfahren wesentlich performanter.
Sort-/Merge-Join
Schritt1: Sortieren der beiden Spalten nach den aufsteigenden Werten der Join-SpaltenSchritt2: Mischen jener Reihen der beiden Tabellen, in denen die Werte der Join-Spalten übereinstimmen zu einer Reihe
der Ergebnistabelle.
Hash-Join-Verfahren
verwendet die Hash-Funktion auf die Join-Spalte einer der beiden zu verknüpfenden Tabellen. Danach werden die Reihender zweiten Tabelle in der Hash Tabelle gesucht. Das Hash-Join-Verfahren ist performanter als das Sort-/Merge-JoinVerfahren, wenn die beiden Tabellen sehr groß sind und die Sortierung der Tabellen noch nicht durchgeführt wurde.
Folgende JOIN-Implementierungen stellt der SQL SERVER zur Verfügung:
• Geschachteltes Loop-Join• Sort-/Merge-Join• Hash-Join
Geschachteltes Loop-Join
Sehr langsam, falls kein Index für eine der Join-Spalten. Falls eine der beiden Join-Spalten einen Index aufweist, ist diesesVerfahren wesentlich performanter.
Sort-/Merge-Join
Schritt1: Sortieren der beiden Spalten nach den aufsteigenden Werten der Join-SpaltenSchritt2: Mischen jener Reihen der beiden Tabellen, in denen die Werte der Join-Spalten übereinstimmen zu einer Reihe
der Ergebnistabelle.
Hash-Join-Verfahren
verwendet die Hash-Funktion auf die Join-Spalte einer der beiden zu verknüpfenden Tabellen. Danach werden die Reihender zweiten Tabelle in der Hash Tabelle gesucht. Das Hash-Join-Verfahren ist performanter als das Sort-/Merge-JoinVerfahren, wenn die beiden Tabellen sehr groß sind und die Sortierung der Tabellen noch nicht durchgeführt wurde.
10
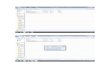
Analyse Join-Verfahren
Query 14
Sort-/Merge-Join (ohne index): 7333 ms
Sort-/Merge-Join (clustered index): 2776 ms
Hash-Join-Verfahren (ohne index): 5312 ms
Geschätzte Selektivität
l_shipdate 0,013Anzahl gesamt: 3.891.692Query 14
Sort-/Merge-Join (ohne index): 7333 ms
Sort-/Merge-Join (clustered index): 2776 ms
Hash-Join-Verfahren (ohne index): 5312 ms
11
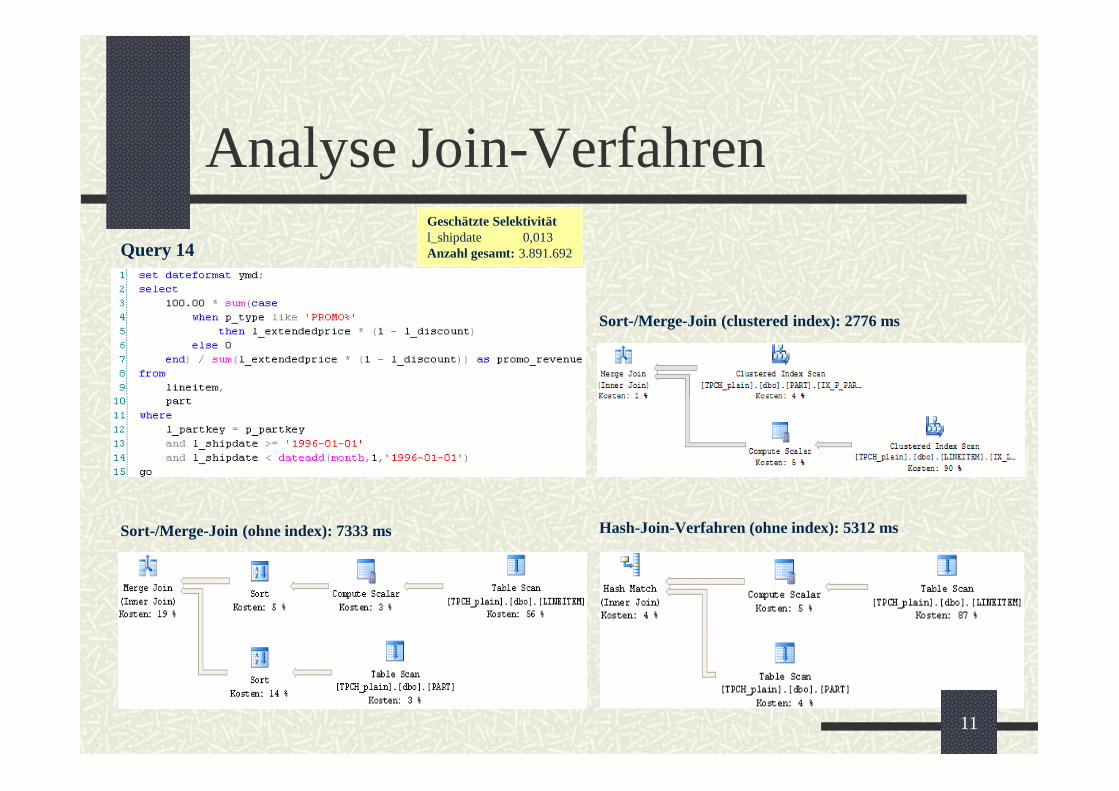
Analyse Join-Verfahren
Geschachteltes Loop-Join (clustered index): 6760 ms
Hash-Join-Verfahren (mit index): 219 ms
Geschachteltes Loop-Join (clustered index): 6760 ms
Hash-Join-Verfahren (mit index): 219 ms
12
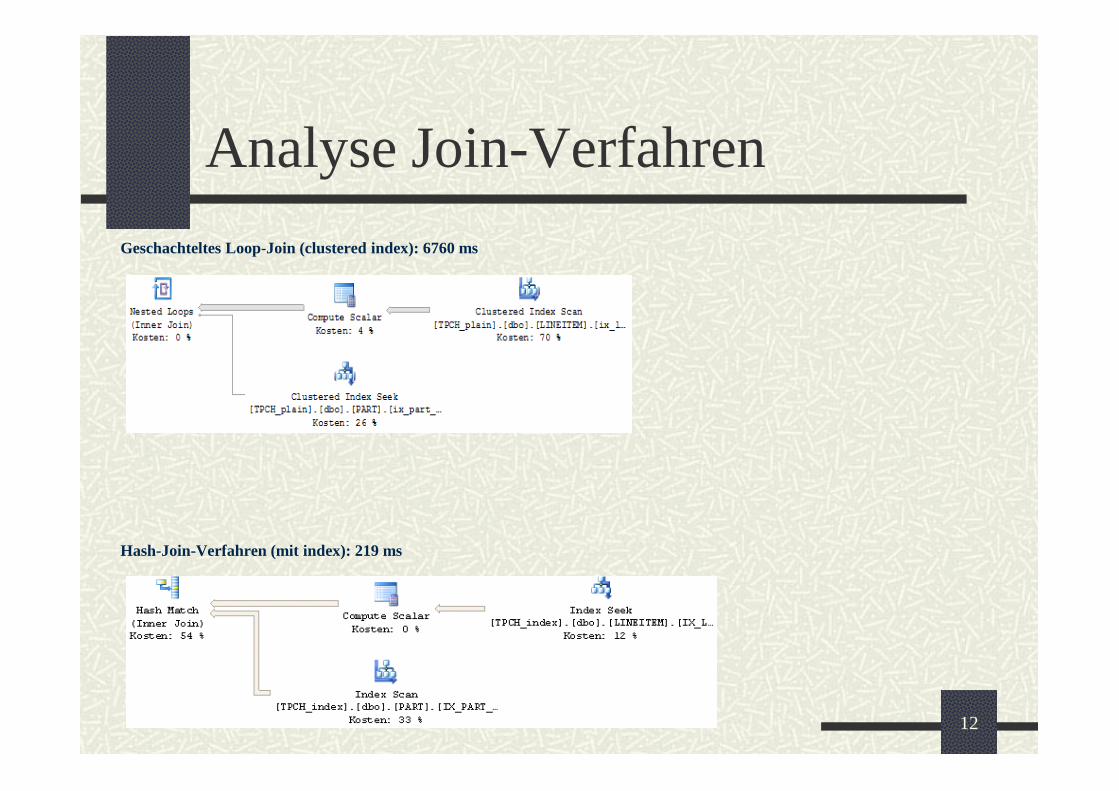
Variation der Größe des Server-Arbeitsspeichers
Vergleich der Ausführungszeit:
Ausgewählte Queries mit min / max
verfügbarem Server-Arbeitsspeicher.
Verfügbarer Speicher:
• Min S-Arbeitsspeicher 16 MB
• Max S-Arbeitsspeicher 1 GB
Vergleich der Ausführungszeit:
Ausgewählte Queries mit min / max
verfügbarem Server-Arbeitsspeicher.
Verfügbarer Speicher:
• Min S-Arbeitsspeicher 16 MB
• Max S-Arbeitsspeicher 1 GB
13
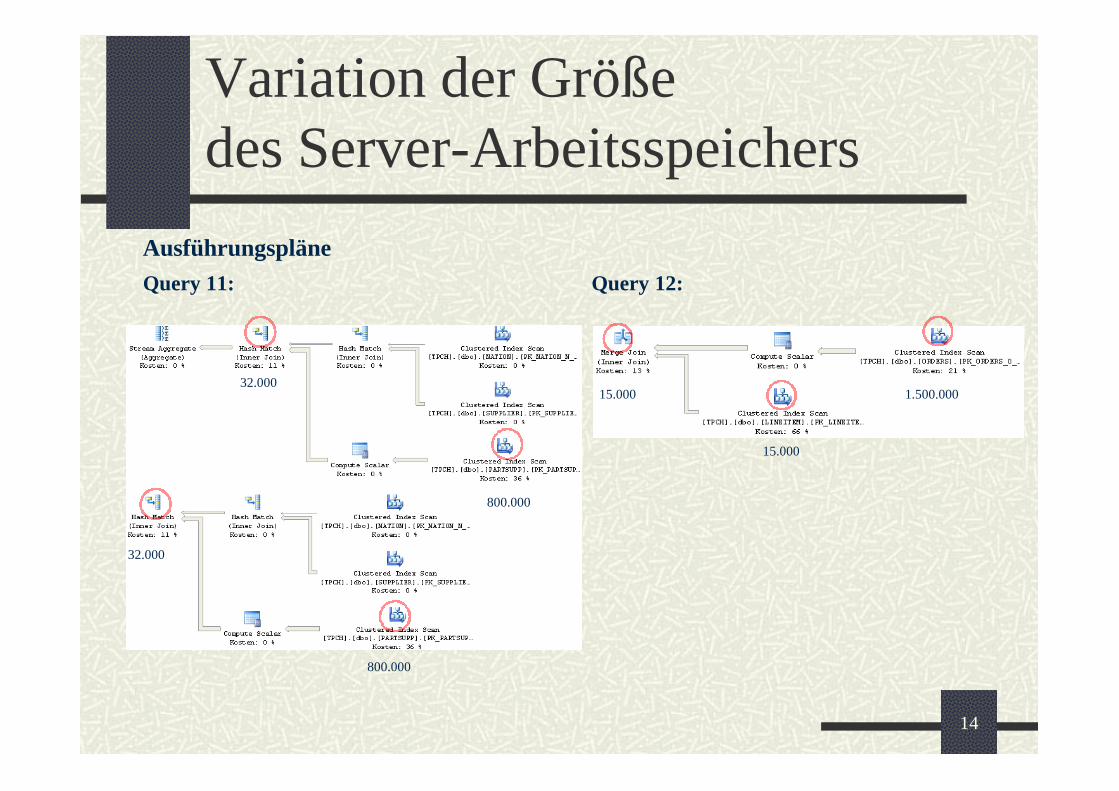
Variation der Größe des Server-Arbeitsspeichers
Ausführungspläne
Query 11: Query 12:
32.0001.500.00015.000
Ausführungspläne
Query 11: Query 12:
800.000
800.000
32.000
1.500.000
15.000
15.000
14

Query-Analyzer: „Missing Index“
Abfrageoptimierer verfügt über tolles Feature:
• Information über gewünschte Indizes
• Angaben über erwartete Beschleunigung der Abfrageleistung bei Verwendung der entsprechenden Indizes.
Beispielhafter Ausschnitt des xml-Files mit Information zum vom Abfrageoptimierer
geforderten Index:
Abfrageoptimierer verfügt über tolles Feature:
• Information über gewünschte Indizes
• Angaben über erwartete Beschleunigung der Abfrageleistung bei Verwendung der entsprechenden Indizes.
Beispielhafter Ausschnitt des xml-Files mit Information zum vom Abfrageoptimierer
geforderten Index:
15
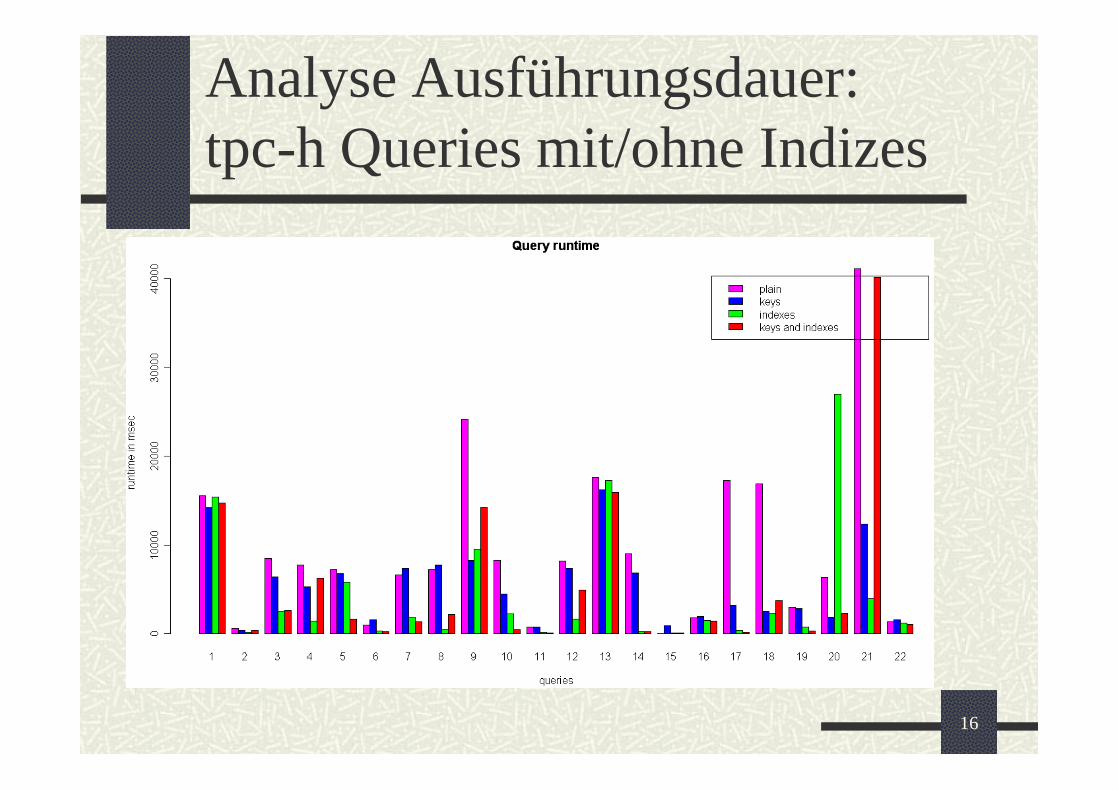
Analyse Ausführungsdauer:tpc-h Queries mit/ohne Indizes
16
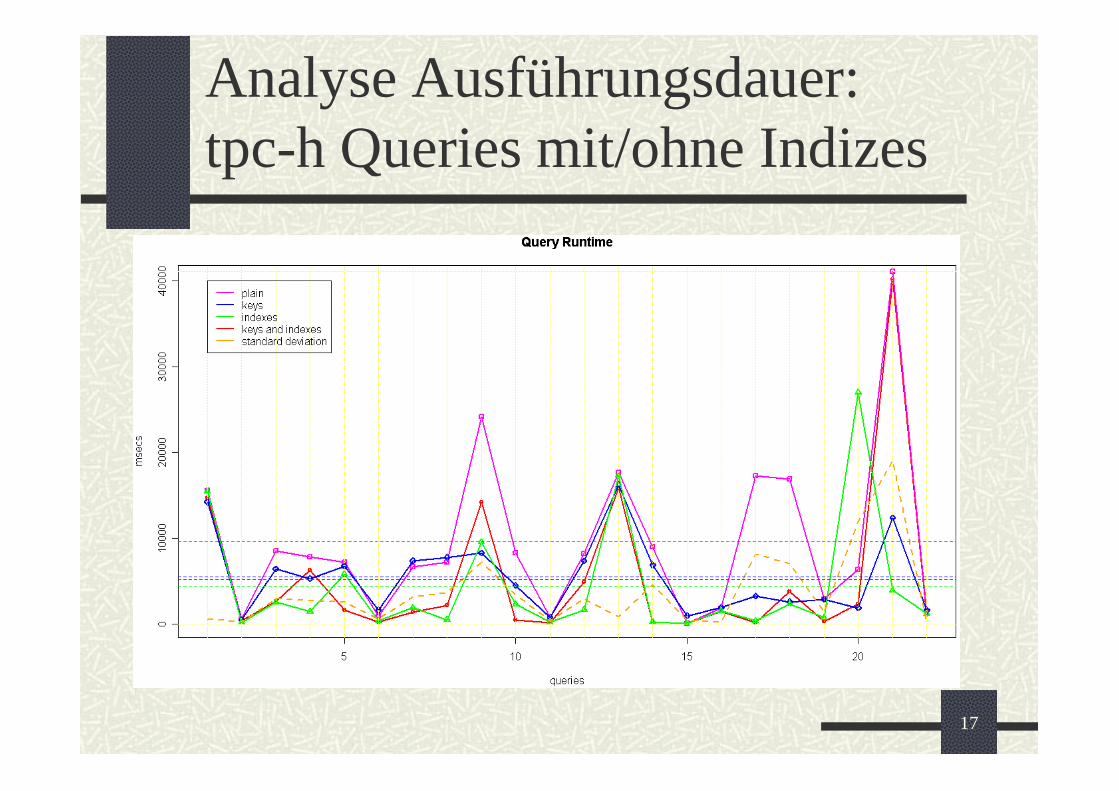
Analyse Ausführungsdauer:tpc-h Queries mit/ohne Indizes
17

Index-Tuning
Query 10: Hinweise des Optimierers:
CREATE NONCLUSTERED INDEX
IX_LINEITEM_L_RETURNFLAG
ON dbo.LINEITEM (L_RETURNFLAG)
INCLUDE (L_ORDERKEY, L_EXTENDEDPRICE,
L_DISCOUNT);
Go
CREATE NONCLUSTERED INDEX
IX_ORDERS_O_ORDERDATE
ON dbo.ORDERS (O_ORDERDATE)
INCLUDE (O_ORDERKEY, O_CUSTKEY);
Go 18
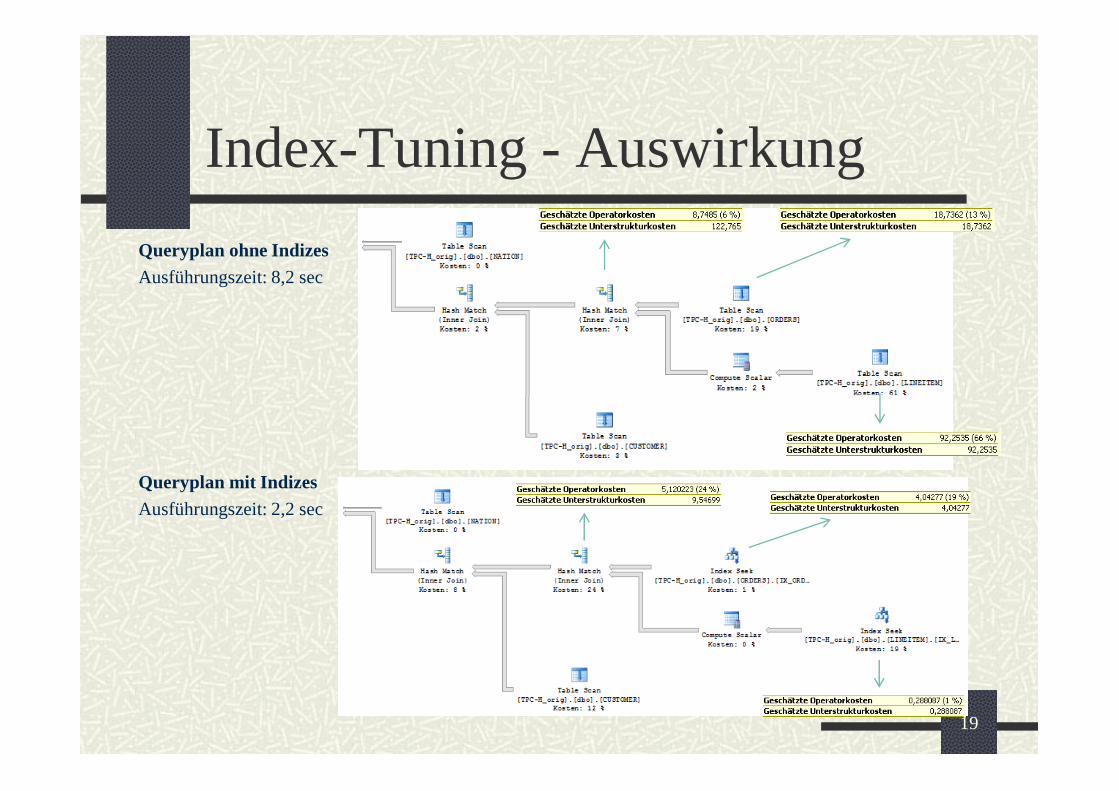
Index-Tuning - Auswirkung
Queryplan ohne Indizes
Ausführungszeit: 8,2 sec
Queryplan mit Indizes
Ausführungszeit: 2,2 sec
19

Analyse Query 1
• Query 1 fast gleiche Ausführungszeiten für alle Kombinationen.
• Welche Keys / Indizes werden verwendet?
• Wie viele Daten werden gebraucht?
20
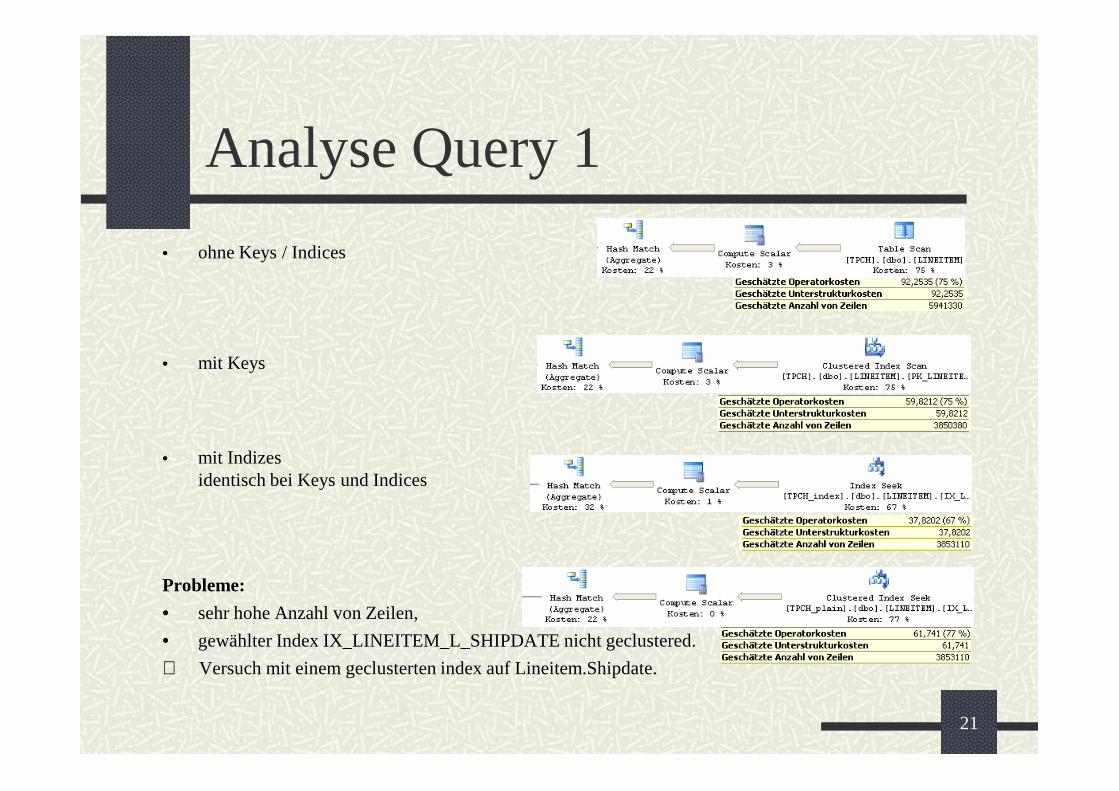
Analyse Query 1
• ohne Keys / Indices
• mit Keys
• mit Indizesidentisch bei Keys und Indices
Probleme:
• sehr hohe Anzahl von Zeilen,
• gewählter Index IX_LINEITEM_L_SHIPDATE nicht geclustered.
à Versuch mit einem geclusterten index auf Lineitem.Shipdate.
• ohne Keys / Indices
• mit Keys
• mit Indizesidentisch bei Keys und Indices
Probleme:
• sehr hohe Anzahl von Zeilen,
• gewählter Index IX_LINEITEM_L_SHIPDATE nicht geclustered.
à Versuch mit einem geclusterten index auf Lineitem.Shipdate.
21
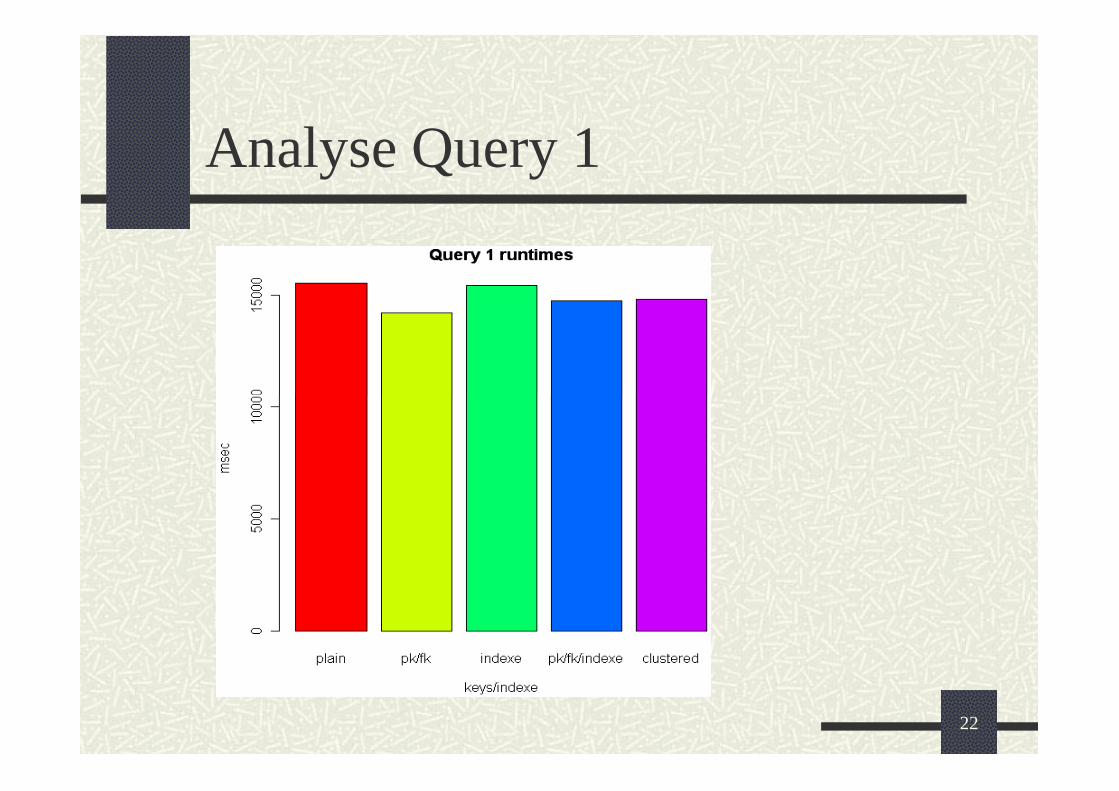
Analyse Query 1
22

Analyse Query 20
Feststellung: 10 fache Ausführungszeit bei Nutzung
von Indexen (im Vergleich zu Keys).
Problem: Tablescan auf PART
Anlegen eines Index auf Tabelle PART
Neuer Testlauf mit Indexen
Neuer Testlauf mit Indexen und Keys
23
Feststellung: 10 fache Ausführungszeit bei Nutzung
von Indexen (im Vergleich zu Keys).
Problem: Tablescan auf PART
Anlegen eines Index auf Tabelle PART
Neuer Testlauf mit Indexen
Neuer Testlauf mit Indexen und Keys
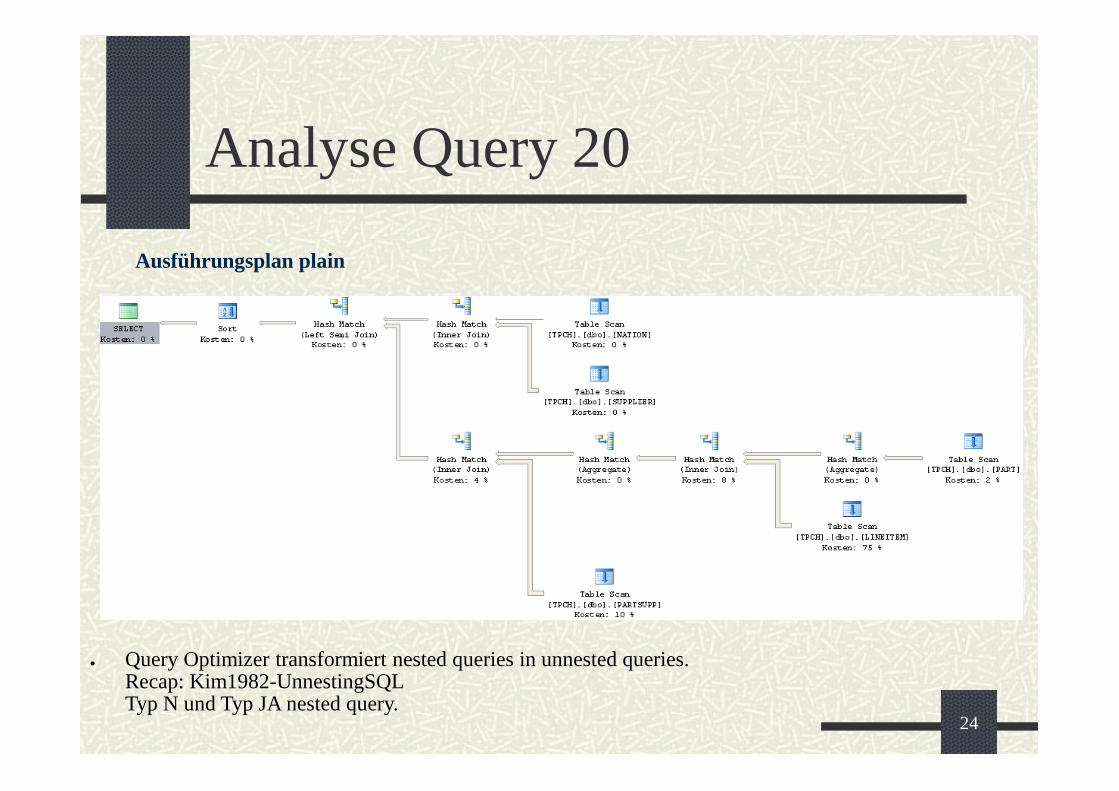
Analyse Query 20
Ausführungsplan plain
24
Query Optimizer transformiert nested queries in unnested queries.Recap: Kim1982-UnnestingSQLTyp N und Typ JA nested query.
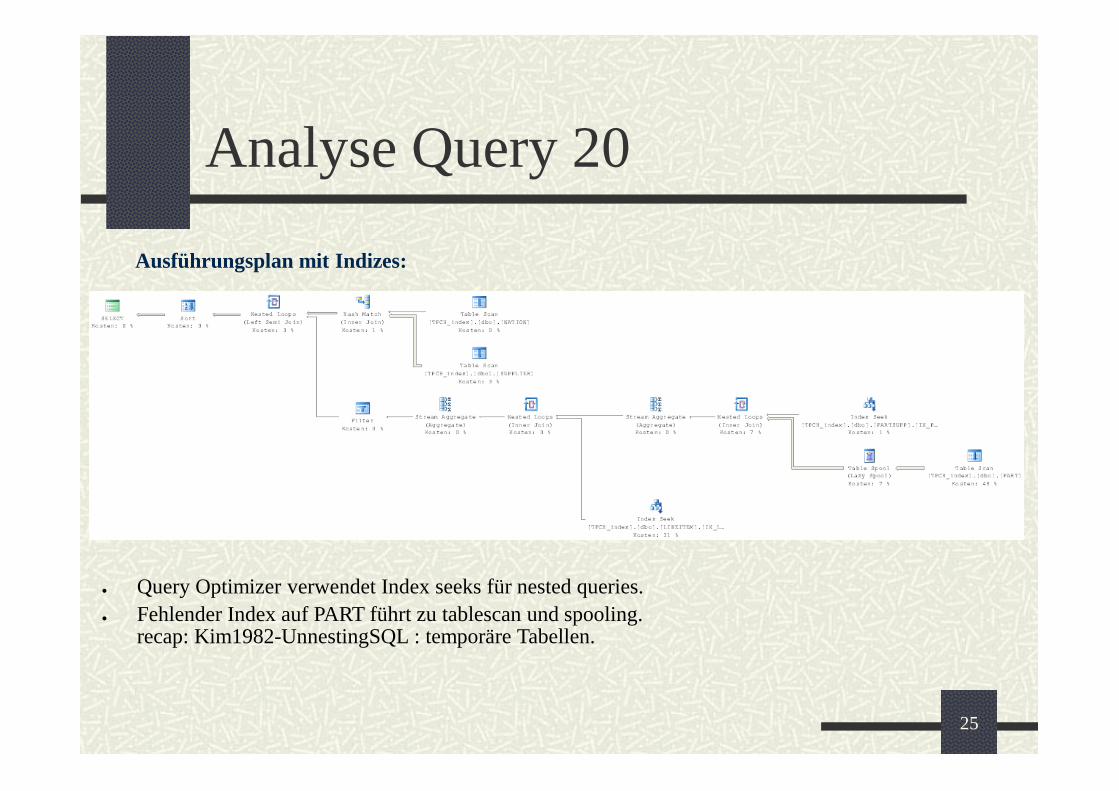
Analyse Query 20
Ausführungsplan mit Indizes:
25
Query Optimizer verwendet Index seeks für nested queries.Fehlender Index auf PART führt zu tablescan und spooling.recap: Kim1982-UnnestingSQL : temporäre Tabellen.

Analyse Query 20
Ausführungsplan mit Schlüssel und Indizes:
Sowohl PKs als auch vorhandene Indizes werden gescannt und für nested loops verwendet.Nur noch 1 nested loops operation (anstatt 3).
26
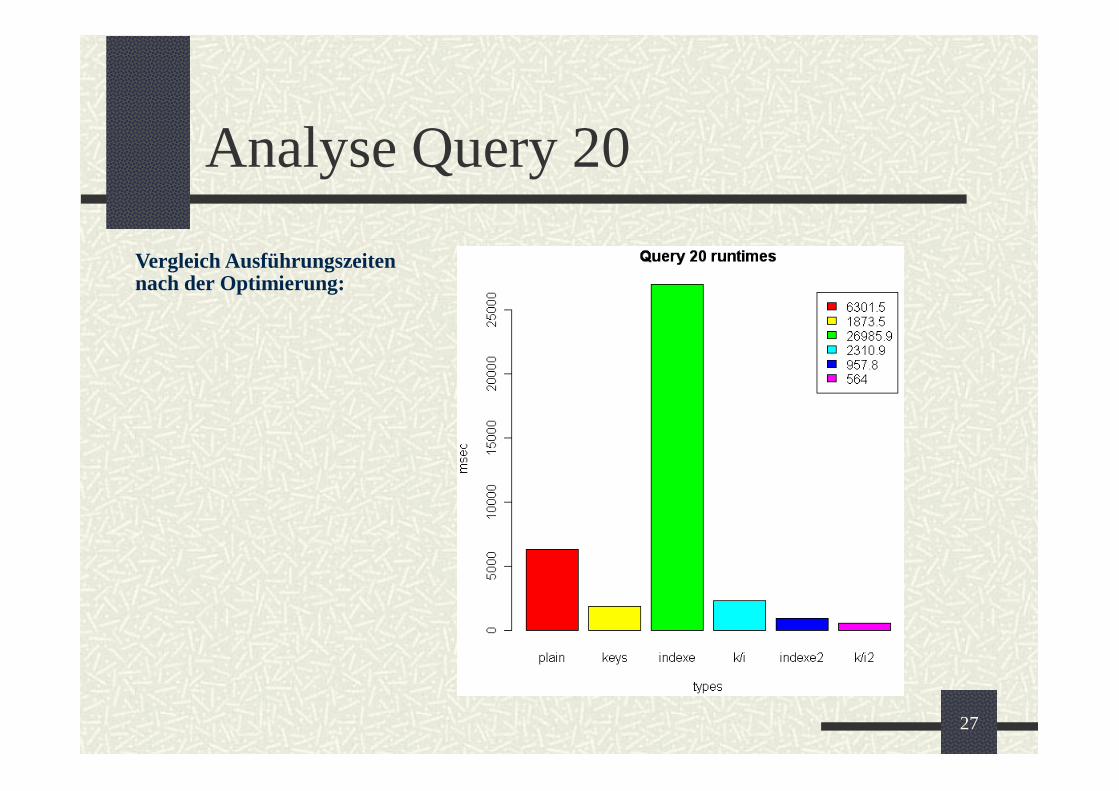
Analyse Query 20
Vergleich Ausführungszeiten
nach der Optimierung:
27

Analyse Query 21
3 nested loops, Typ J und DLaufzeit mit Keys und Indizes benötigt die 10-facheAusführungszeit im Vergleich zur ausschließlichen Verwendung von Indizes bzw. Keys.
28

Analyse Query 21Ausschnitt Ausführungsplan Plain:
Transformation der nested loops.3 table scans auf LINEITEM (kann im Buffer behalten werden).
29
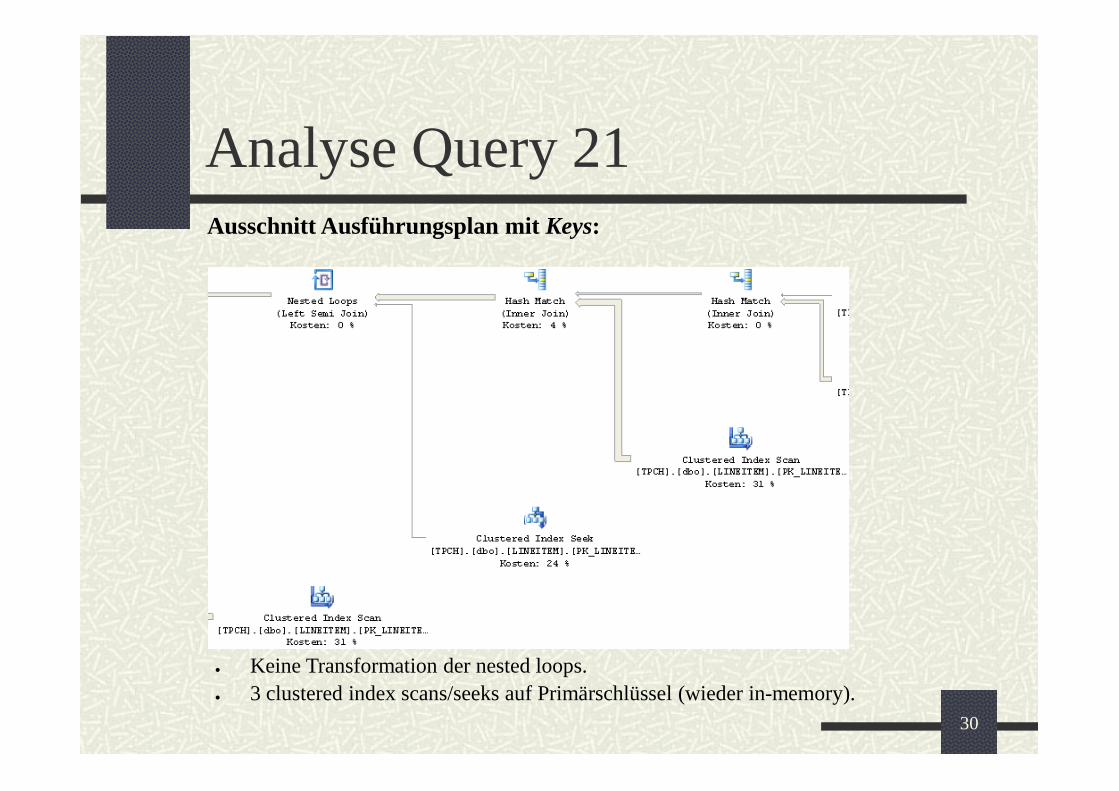
Analyse Query 21Ausschnitt Ausführungsplan mit Keys:
Keine Transformation der nested loops.3 clustered index scans/seeks auf Primärschlüssel (wieder in-memory).
30
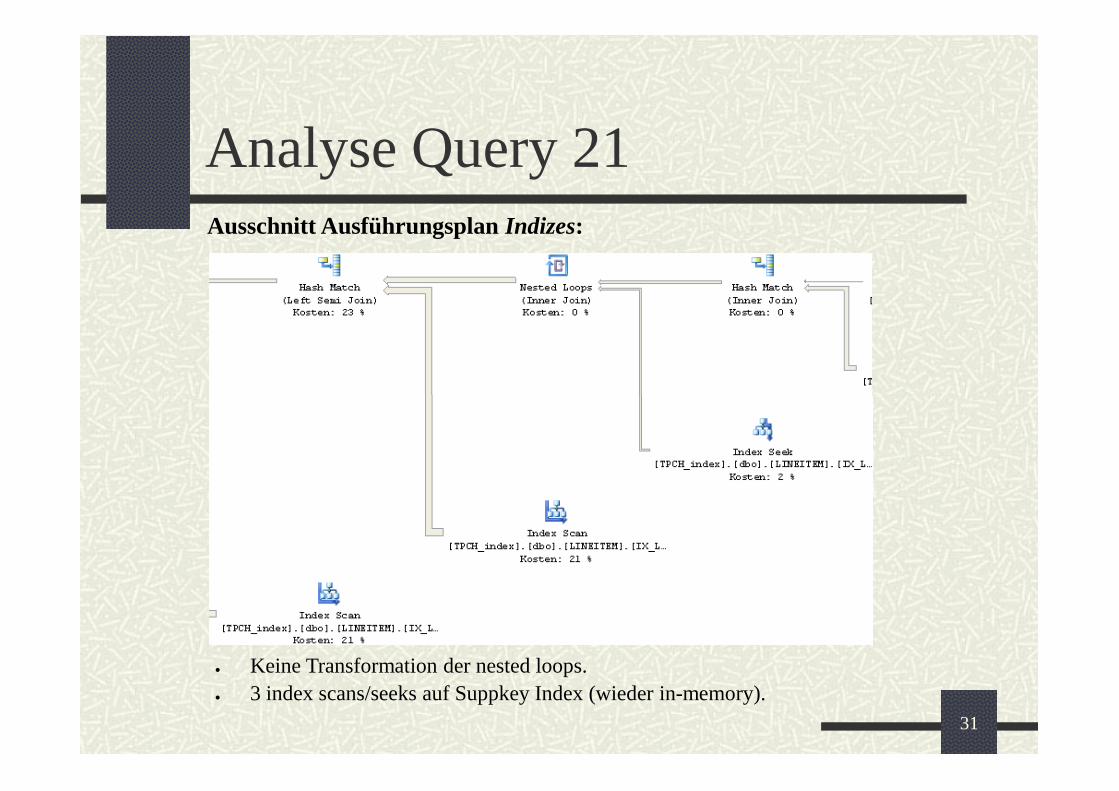
Analyse Query 21Ausschnitt Ausführungsplan Indizes:
Keine Transformation der nested loops.3 index scans/seeks auf Suppkey Index (wieder in-memory).
31

Analyse Query 21Ausschnitt Ausführungsplan Keys und Indizes:
Keine Transformation der nested loops.Scant abwechselnd PK und Index, daher mehrmaliges lesen von HD notwendig.Keine Nutzung des Buffers möglich. 32
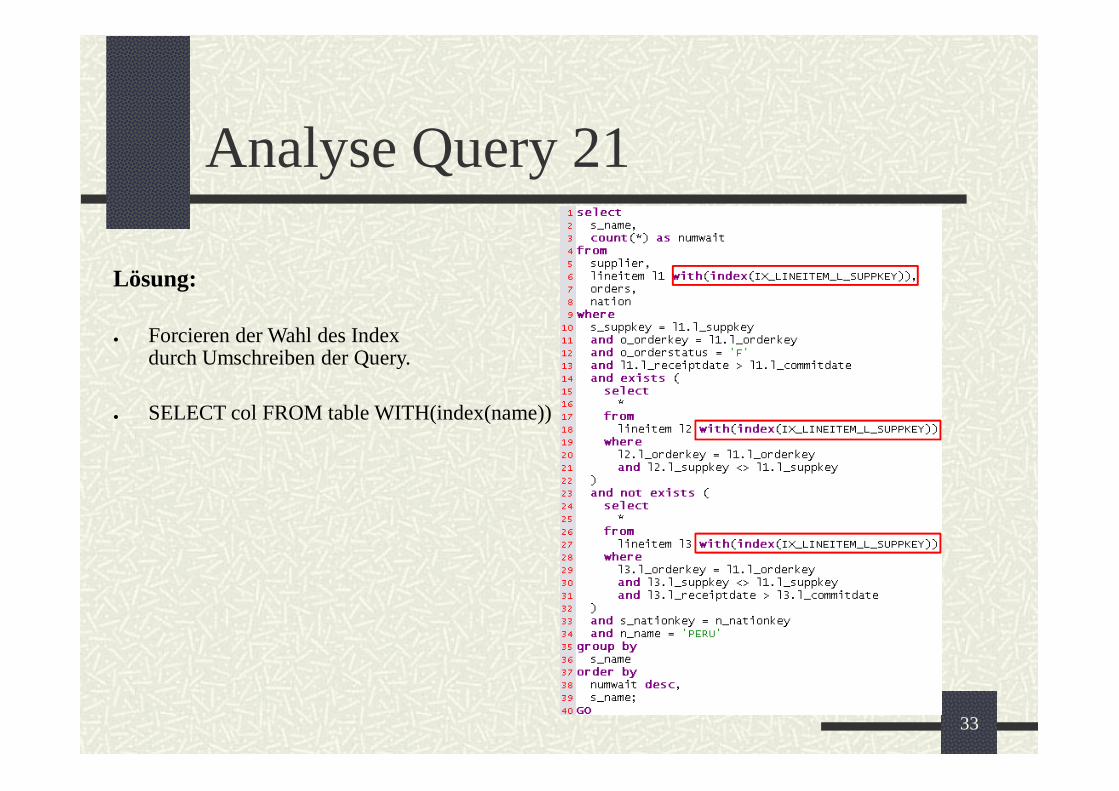
Analyse Query 21
Lösung:
Forcieren der Wahl des Indexdurch Umschreiben der Query.
SELECT col FROM table WITH(index(name))
33
Lösung:
Forcieren der Wahl des Indexdurch Umschreiben der Query.
SELECT col FROM table WITH(index(name))
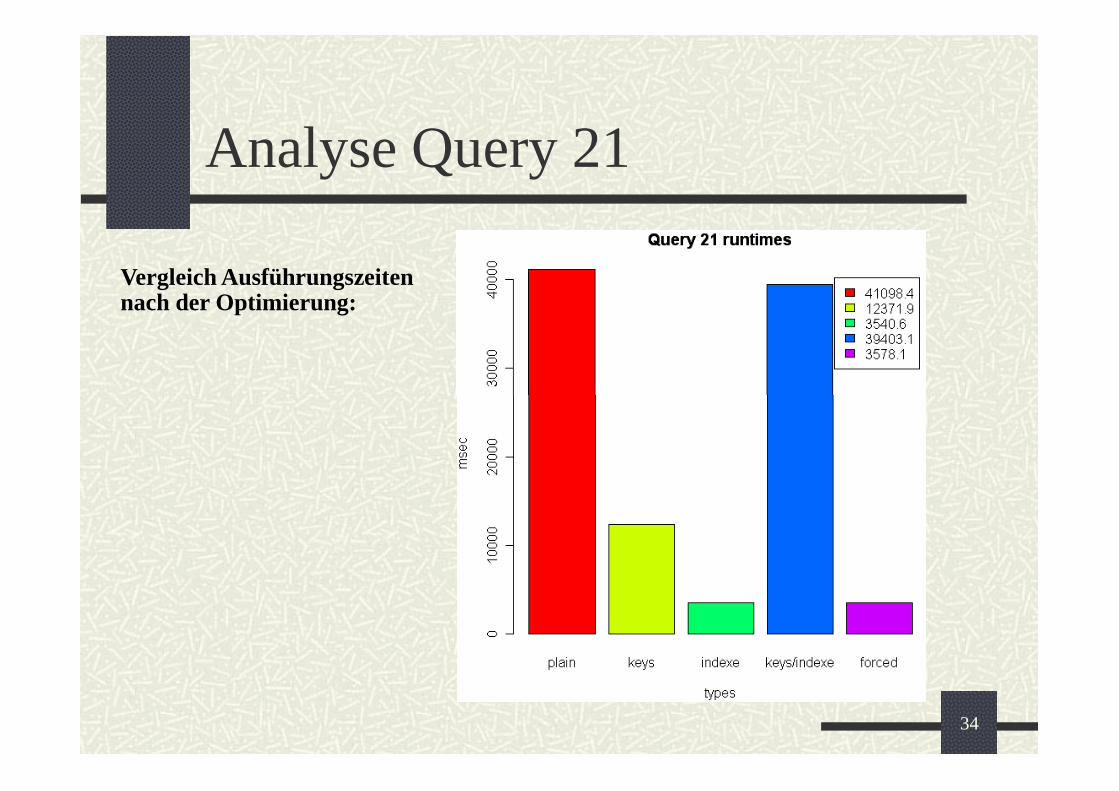
Analyse Query 21
Vergleich Ausführungszeiten
nach der Optimierung:
34
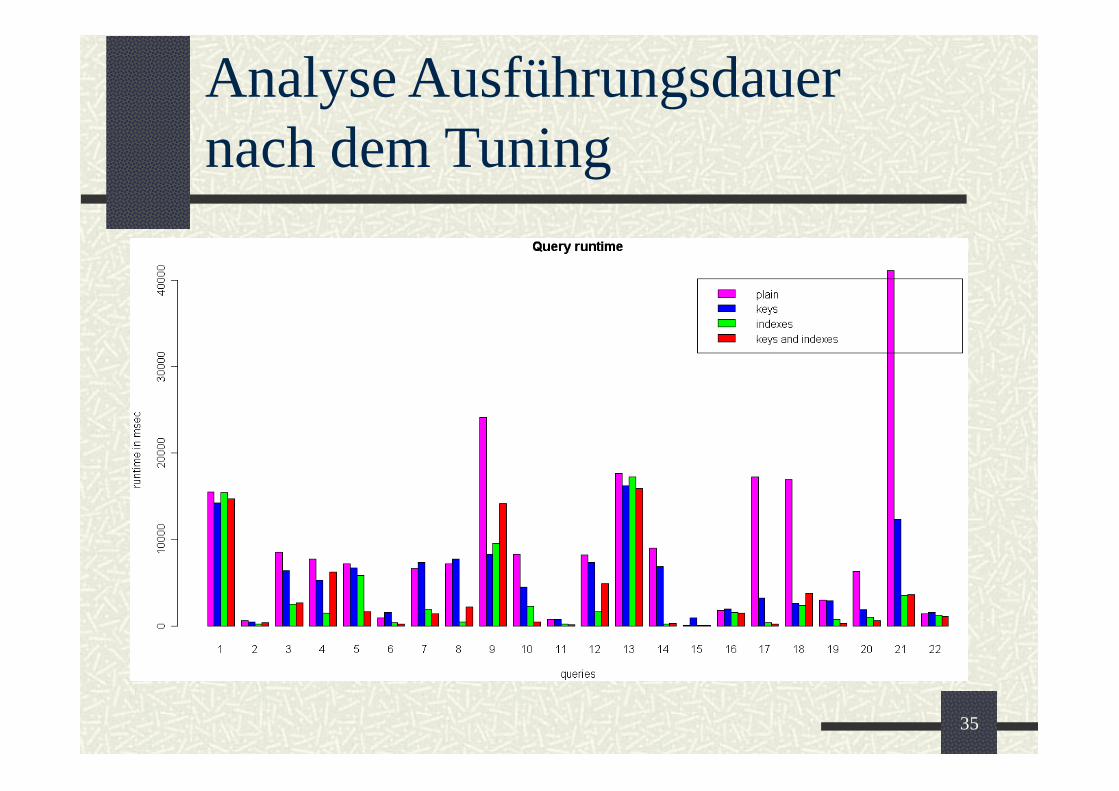
Analyse Ausführungsdauernach dem Tuning
35
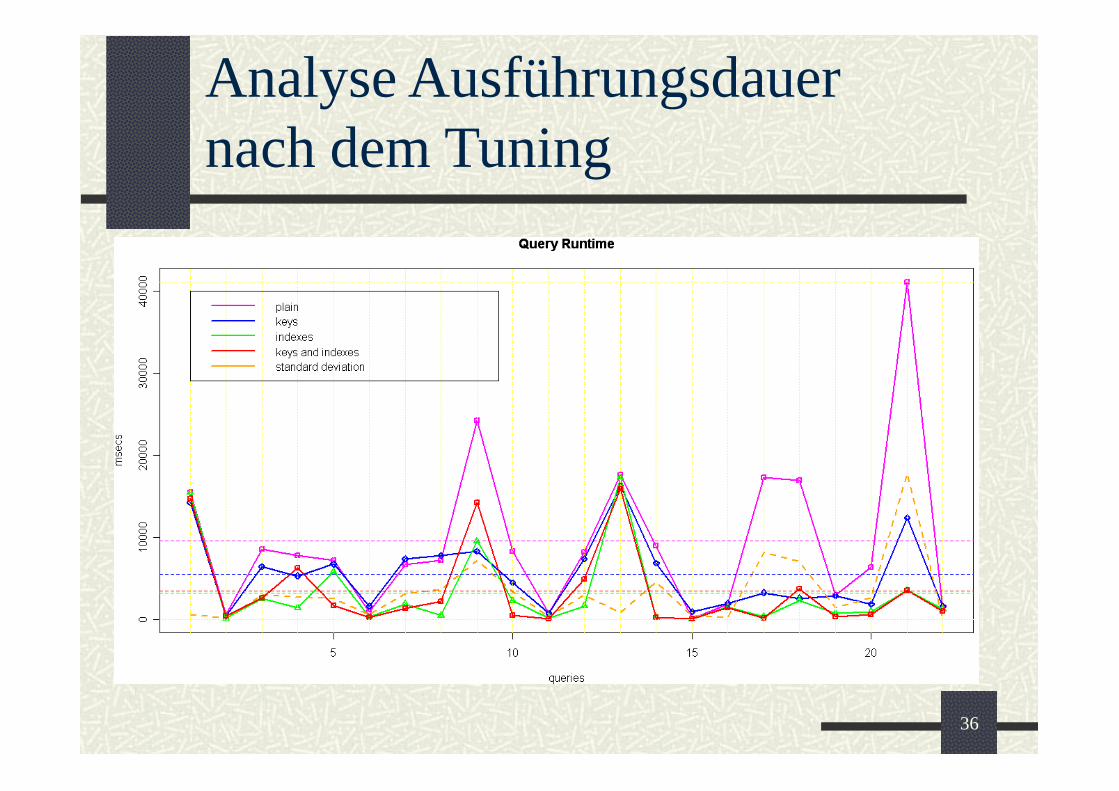
Analyse Ausführungsdauernach dem Tuning
36

Fazit
• SQL SERVER 2005 Express verfügt über einen leistungsfähigen Query-Optimierer.
• Wählt in den meisten Fällen einen günstigen Query-Plan aus.
• Anwender ist dafür verantwortlich, die vom Query-Optimierer benötigten Daten bereit zu stellen und aktuell zu halten.
• „Blindes Vertrauen“ in die Leistungsfähigkeit des Query-Optimierers nicht angebracht.
• Anwender muss „seine Daten“ kennen, um entsprechende Indizes, Statistiken, Aktualisierungen u. ä. vornehmen und auf deren Basis..
• .. in die Ausführungspläne eingreifen zu können und somit das an die jeweilige Situation angepasste Optimum zu erreichen.
• SQL SERVER 2005 Express verfügt über einen leistungsfähigen Query-Optimierer.
• Wählt in den meisten Fällen einen günstigen Query-Plan aus.
• Anwender ist dafür verantwortlich, die vom Query-Optimierer benötigten Daten bereit zu stellen und aktuell zu halten.
• „Blindes Vertrauen“ in die Leistungsfähigkeit des Query-Optimierers nicht angebracht.
• Anwender muss „seine Daten“ kennen, um entsprechende Indizes, Statistiken, Aktualisierungen u. ä. vornehmen und auf deren Basis..
• .. in die Ausführungspläne eingreifen zu können und somit das an die jeweilige Situation angepasste Optimum zu erreichen.
37
Fragen ?
38

Literatur-Verzeichnis
Interessante Literatur, welche während des Seminars Verwendung fand:
- Integrierte Hilfe des SQL Server 2005 Express.
- Skript „Architecture and Implementation of Database Management Systems, Universität Konstanz, Prof. Dr. Marc H. Scholl, WS 2006/07.
- Relational database index design and the optimizers: DB2, Oracle, SQL server, Wiley & Sons Verlag, Tapio Lahdenmäki, 2005.
- SQL Server 2005 Documentation, URL: http://msdn2.microsoft.com/en-us/library/ms203721.aspx[letzter Aufruf 17.07.07].
- SQL Server 2005 – Eine umfassende Einführung, dpunkt.verlag, Dusan Petkovic, 2006.
- SQL Server 2005 – Das Handbuch für Administratoren, Addison-Wesley Verlag, Buck Woody, 2007.
- SQL Server 2005 – Programmierhandbuch, Software & Support Verlag, Andreas Kosch, 2006.
Interessante Literatur, welche während des Seminars Verwendung fand:
- Integrierte Hilfe des SQL Server 2005 Express.
- Skript „Architecture and Implementation of Database Management Systems, Universität Konstanz, Prof. Dr. Marc H. Scholl, WS 2006/07.
- Relational database index design and the optimizers: DB2, Oracle, SQL server, Wiley & Sons Verlag, Tapio Lahdenmäki, 2005.
- SQL Server 2005 Documentation, URL: http://msdn2.microsoft.com/en-us/library/ms203721.aspx[letzter Aufruf 17.07.07].
- SQL Server 2005 – Eine umfassende Einführung, dpunkt.verlag, Dusan Petkovic, 2006.
- SQL Server 2005 – Das Handbuch für Administratoren, Addison-Wesley Verlag, Buck Woody, 2007.
- SQL Server 2005 – Programmierhandbuch, Software & Support Verlag, Andreas Kosch, 2006.
39














![SQL Server TSQL [Read-Only] - csuohio.educis.csuohio.edu/~sschung/IST331/SQL_Server_TSQL.pdf · Microsoft SQL Server. SQL Server 2005 Microsoft-SQL Server 2005 is a relational database](https://img.pdfslide.net/doc/110x75/5e202cff7110143c3f45a3d1/sql-server-tsql-read-only-sschungist331sqlservertsqlpdf-microsoft-sql.jpg)