Embed Size (px)
Citation preview

Introduction to Machine Learning Summer SchoolJune 18, 2018 - June 29, 2018, Chicago
Instructor:SuriyaGunasekar,TTIChicago
22June2018
Day5:Generativemodels,structured
classification

Topicssofar
• Linearregression• Classification
o nearestneighbors,decisiontrees,logisticregression
• Yesterdayo Maximummarginclassifiers,Kerneltrick
• Todayo Quickreviewofprobabilityo Generativemodels– naiveBayesclassifiero StructuredPrediction– conditionalrandomfields
1

SeveralslidesadaptedfromDavidSontagwhointurncreditsLukeZettlemoyer,CarlosGuestrin,DanKlein,and
Vibhav Gogate
2

Bayesian/probabilisticlearning
• Usesprobabilitytomodeldataand/orquantifyuncertaintiesinpredictiono Systematicframeworktoincorporatepriorknowledgeo Frameworkforcomposingandreasoningaboutuncertainityo Whatistheconfidenceinthepredictiongivenobservationssofar?
• Modelassumptionsneednothold(andoftendonothold)inrealityo evenso,manyprobabilisticmodelsworkreallywellinpractice
3

Quickoverviewofrandomvariables• Randomvariables:Avariableaboutwhichwe(may)haveuncertainty
o e.g.,𝑊 = 𝑤𝑒𝑎𝑡ℎ𝑒𝑟𝑡𝑜𝑚𝑜𝑟𝑟𝑜𝑤,or𝑇 = 𝑡𝑒𝑚𝑝𝑒𝑟𝑎𝑡𝑢𝑟𝑒• Forallrandomvariables𝑋 domain𝒳 of𝑋 isthesetofvalues𝑋 cantake• Discreterandomvariables:probabilitydistributionisatable
o FordiscreteRV𝑋, ∀𝑥 ∈ 𝒳, Pr 𝑋 = 𝑥 ≥ 0 and ∑ Pr 𝑋 = 𝑥 = 1�?∈𝒳
• Continuousrandom𝑋 withdomain𝒳 ⊆ ℝo Cumulativedistributionfunction 𝐹C 𝑡 = Pr(𝑋 ≤ 𝑡)
§ again𝐹C 𝑡 ∈ 0,1 andalso𝐹C −∞ = 0, 𝐹C +∞ = 1o Probabilitydensityfunction (ifexists)𝑃C 𝑡 = KLM N
KO§ Isalwayspositive,butcanbegreaterthan1
4
Pr 𝑊 = 𝑠𝑢𝑛 = 0.6

Quickoverviewofrandomvariables
• ExpectationDiscreteRV 𝐄 𝑓(𝑋) = ∑ 𝑓(𝑥)Pr(𝑋 = 𝑥)�
?∈𝒳
• Mean 𝐄 𝑋• Variance 𝐄 𝑋 − 𝐄 𝑋 V
5

Jointdistributions
• Jointdistributionofrandomvariables𝑋W, 𝑋V, … , 𝑋Y isdefinedforall𝑥W ∈ 𝒳W, 𝑥V ∈ 𝒳V,… , 𝑥Y ∈ 𝒳Y
𝑝 𝑥W, 𝑥V, … , 𝑥Y = Pr(𝑋W = 𝑥W, 𝑋V = 𝑥V,… , 𝑋Y = 𝑥Y)
• Howmaynumbersneededfor𝑑 variableseachhavingdomainofKvalues?
o 𝐾Y!!Toomanynumbers,usuallysomeassumptionismadetoreducenumberofprobabilities
6

Marginaldistribution
• Sub-tablesobtainedbyeliminationofvariables• Probabilitydistributionofasubsetofvariables
7

Marginaldistribution
• Sub-tablesobtainedbyeliminationofvariables• Probabilitydistributionofasubsetofvariables• Given:jointdistribution𝑝 𝑥W, 𝑥V, … , 𝑥Y = Pr(𝑋W = 𝑥W, 𝑋V = 𝑥V, … , 𝑋Y = 𝑥Y)for𝑥W ∈ 𝒳W, 𝑥V ∈ 𝒳V,… , 𝑥Y ∈ 𝒳Y
• Saywewantgetamarginalofjust𝑥W, 𝑥V, 𝑥\,thatiswewanttoget𝑝 𝑥W, 𝑥V, 𝑥] = Pr(XW = xW, XV = xV, 𝑋] = 𝑥])
• Thiscanbeobtainedbymariginalizing𝑝 𝑥W, 𝑥V, 𝑥] = ` ` … ` 𝑝(𝑥W, 𝑥V, 𝑧b, 𝑥], 𝑧\, … , 𝑧Y)
�
cd∈𝒳d
�
ce∈𝒳e
�
cf∈𝒳f
8

Conditioning
• Randomvariables𝑋 and𝑌 withdomains𝒳 and𝒴
Pr 𝑋 = 𝑥 𝑌 = 𝑦 =Pr 𝑋 = 𝑥, 𝑌 = 𝑦
Pr 𝑌 = 𝑦
9
• Probabilitydistributionsofasubsetofvariableswithfixedvaluesofothers

Conditioning
• Randomvariables𝑋 and𝑌 withdomains𝒳 and𝒴
Pr 𝑋 = 𝑥 𝑌 = 𝑦 =Pr 𝑋 = 𝑥, 𝑌 = 𝑦
Pr 𝑌 = 𝑦• Conditionalexpectation
𝐄[𝑓(𝑋)|𝑌 = 𝑦] = ` 𝑓 𝑥 Pr 𝑋 = 𝑥 𝑌 = 𝑦�
?∈𝒳
• ℎ 𝑦 = 𝐄[𝑓(𝑋)|𝑌 = 𝑦] isafunctionof𝑦
• ℎ 𝑌 isarandomvariablewithdistributiongivenbyPr(ℎ 𝑌 = ℎ(𝑦)) = Pr(𝑌 = 𝑦)
10

Productrule
11
• Goingfromconditionaldistributiontojointdistribution
Pr 𝑋 = 𝑥 𝑌 = 𝑦 =Pr 𝑋 = 𝑥, 𝑌 = 𝑦
Pr 𝑌 = 𝑦
Pr 𝑋 = 𝑥, 𝑌 = 𝑦 = Pr(𝑌 = 𝑦) Pr 𝑋 = 𝑥 𝑌 = 𝑦• Whatabouttheevariables?
Pr 𝑋W = 𝑥W, 𝑋V = 𝑥V, 𝑋b = 𝑥b =
Pr(𝑋W = 𝑥W) Pr 𝑋V = 𝑥V 𝑋W = 𝑥W Pr 𝑋b = 𝑥b 𝑋W = 𝑥W, 𝑋V = 𝑥V• Moregenerally,
Pr 𝑋W = 𝑥W, 𝑋V = 𝑥V, … , 𝑋Y = 𝑥Y
= Pr(𝑋W = 𝑥W)mPr(𝑋n = 𝑥n|𝑋noW = 𝑥noW, 𝑋noV = 𝑥noV, … , 𝑋W = 𝑥W)Y
npV

Optimalunrestrictedclassifier
• 𝐶 classclassificationproblem𝒴 = {1,2, … , 𝐶}• PopulationdistributionLet 𝒙, 𝑦 ∼ 𝒟• Considerthepopulation0-1lossofclassifier𝑦x(𝑥)
𝐿 𝑦x ≜ 𝐄𝒙,{ 𝟏 𝑦 ≠ 𝑦x 𝒙 = Pr~,�
𝑦 ≠ 𝑦x 𝒙
= Pr 𝒙 Pr(𝑦 ≠ 𝑦x(𝒙)|𝒙)
• Pr(𝑦 ≠ 𝑦x 𝒙 |𝒙) = 1 − Pr(𝑦 = 𝑦x 𝒙 |𝒙)• OptimalunrestrictedclassifierorBayesoptimalclassifier
𝑦x∗∗ 𝒙 = argmax�
Pr(𝑦 = 𝑐|𝒙)
Riskofclassifier𝑦x(𝒙)
Conditionalrisk𝐿(𝑦x|𝒙)
12
Checkthatthisisminimizedfor𝑦x 𝑥 = argmax
�Pr(𝑦 = 𝑐|𝑥)

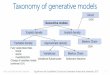
Generativevsdiscriminativemodels
• Recalloptimalunrestrictedpredictorforfollowingcaseso Regression+squaredlossà 𝑓∗∗(𝒙) = 𝐄 𝑦 𝒙o Classification+0-1lossà 𝑦x∗∗ 𝒙 = argmax
�Pr(𝑦 = 𝑐|𝒙)
• Non-probabilisticapproach:don'tdealwithprobabilities,justestimate𝑓(𝒙) directlytothedata.
• Discriminativemodels:Estimate/infertheconditionaldensityPr(𝑦|𝒙)o Typicallyusesaparametricmodel𝑓�(𝒙) ofPr(𝑦|𝒙)
• Generativemodels: EstimatethefulljointprobabilitydensityPr 𝑦, 𝒙o NormalizetofindtheconditionaldensityPr(𝑦|𝒙)o SpecifymodelsforPr 𝒙, 𝑦 or[Pr 𝒙|𝑦 andPr(𝑦)]o Why?Intwoslides!
13

Bayesrule
• Optimalclassifier𝑦x∗∗ 𝑥 = argmax
�Pr 𝑦 = 𝑐 𝑥
• Bayesrule:Pr(𝑥, 𝑦) = Pr 𝑦 𝑥 Pr(𝑥) = Pr(𝑥|𝑦) Pr(𝑦)
𝑦x∗∗ 𝑥 = argmax�
Pr 𝑦 = 𝑐 𝑥
= argmax�
Pr 𝑥 𝑦 = 𝑐 Pr 𝑦 = 𝑐Pr 𝑥
= argmax�
Pr 𝑥 𝑦 = 𝑐 Pr 𝑦 = 𝑐
14

Bayesrule
• Optimalclassifier𝑦x∗∗ 𝑥 = argmax
�Pr 𝑦 = 𝑐 𝑥
= argmax�
Pr 𝑥 𝑦 = 𝑐 Pr 𝑦 = 𝑐
• Whyisthishelpful?o Oneconditionalmightbetrickytomodelwithpriorknowledgebuttheothersimple
o e.g.,saywewanttospecifyamodelfordigitrecognition
§ comparespecifyingPr(image|digit = 1) vsPr(digit = 1|image)
15
à digit1Binaryimages

Generativemodelforclassification
argmax�
Pr 𝑦 = 𝑐 𝑥
= argmax�
Pr 𝑥 𝑦 = 𝑐 Pr 𝑦 = 𝑐
• Cclassclassificationwithbinaryfeatures𝑥 ∈ ℝY and𝑦 ∈ 1,2, … , 𝐶
• WanttospecifyPr(𝑥|𝑦) = Pr(𝑥W, 𝑥V, … , 𝑥Y|𝑦)
• Ifeachof𝑥W, 𝑥V, … , 𝑥Y cantakeoneofKvalues.HowmanyparameterstospecifyPr(𝑥|𝑦)?o 𝐶𝐾Y!!Toomany
16

NaiveBayesassumption
SpecifyingPr(𝒙|𝑦) = Pr(𝑥W, 𝑥V, … , 𝑥Y|𝑦) requires𝐶𝐾Y
NaiveBayesassumption:featuresareindependentgivenclass𝑦• e.g.,fortwofeatures
Pr(𝑥W, 𝑥V|𝑦) = Pr(𝑥W|𝑦) Pr(𝑥V|𝑦)• moregenerally,
Pr(𝑥W, 𝑥V, … , 𝑥Y|𝑦) = Pr(𝑥W|𝑦) Pr(𝑥V|𝑦)…Pr(𝑥Y|𝑦)= ∏ Pr(𝑥n|𝑦)Y
npW
• numberofparametersifeachof𝑥W, 𝑥V, … , 𝑥Y cantakeoneofKvalues?o 𝐶𝐾𝑑
17

NaiveBayesclassifier• NaiveBayesassumption:featuresareindependentgivenclass:
Pr(𝑥W, 𝑥V, … , 𝑥Y|𝑦) = ∏ Pr(𝑥n|𝑦)YnpW
• Cclasses𝒴 = {1,2, … , 𝐶} dbinaryfeature𝒳 = 0,1 Y
• Modelparameters:specifyfrompriorknowledgeand/orlearnfromdatao PriorsPr 𝑦 = 𝑐 à #parameters 𝐶 − 1o ConditionalprobabilitiesPr(𝑥n = 1|𝑦 = 𝑐)à #parameters 𝐶𝑑
§ if𝑥W, 𝑥V, … , 𝑥� takesoneof𝐾 discretevaluesratherthanbinaryà#parameters 𝐾 − 1 𝐶𝑑
§ if𝑥W, 𝑥V, … , 𝑥� arecontinuous,additionallymodelPr(𝑥n|𝑦 = 𝑐) assomeparametricdistribution,likeGaussianPr(𝑥n|𝑦 = 𝑐) ∼𝒩(𝜇n,�, 𝜎),andestimatetheparameters(𝜇n,�, 𝜎) fromdata
• Classifierrule:𝑦x�� 𝑥 = argmax
�Pr 𝑥W, 𝑥V, … , 𝑥Y 𝑦 = 𝑐 Pr(𝑦 = 𝑐)
= argmax�
Pr(𝑦 = 𝑐)mPr(𝑥n|𝑦 = 𝑐)Y
npW18

Digitrecognizer
19Slidecredit:DavidSontag

Whathastobelearned?
20Slidecredit:DavidSontag

MLEforparametersofNB
• Trainingdataset𝑆 = 𝑥 � , 𝑦 � : 𝑖 = 1,2, … , 𝑁• MaximumlikelihoodestimationfornaiveBayeswithdiscretefeaturesandlabels• Assume𝑆 hasiid examples
o Prior:whatistheprobabilityofobservinglabel𝑦
Pr 𝑦 = 𝑐 =∑ 𝟏 𝑦 � = 𝑐��pW
𝑁o Conditionaldistribution:
Pr 𝑥n = 𝑧n|𝑌 = 𝑐 =∑ 1[𝑥n
� = 𝑧n, 𝑦 � = 𝑐]��pW
∑ 1[𝑦 � = 𝑐]��pW
21
``𝟏 𝑦 � = 𝑐� �
�
�
��
``𝟏 𝑥n� = 𝑧n�, 𝑦 � = 𝑐
�
�
�
c��

MLEforparametersofNB
22Slidecredit:DavidSontag

SmoothingforparametersofNB
• Trainingdataset𝑆 = 𝑥 � , 𝑦 � : 𝑖 = 1,2, … , 𝑁• MaximumlikelihoodestimationfornaiveBayeswithdiscretefeaturesandlabels• Assume𝑆 hasiid examples
o Prior:whatistheprobabilityofobservinglabel𝑦
Pr 𝑦 = 𝑐 =∑ 𝟏 𝑦 � = 𝑐��
𝑁o Conditionaldistribution:
Pr 𝑥n = 𝑧n|𝑌 = 𝑐 =∑ 1 𝑥n
� = 𝑧n, 𝑦 � = 𝑐�� + 𝜖∑ 1 𝑦 � = 𝑐�� + ∑ 𝜖�
c��
23

SmoothingforparametersofNB
• Trainingdataset𝑆 = 𝑥 � , 𝑦 � : 𝑖 = 1,2, … , 𝑁• MaximumlikelihoodestimationfornaiveBayeswithdiscretefeaturesandlabels• Assume𝑆 hasiid examples
o Prior:whatistheprobabilityofobservinglabel𝑦
Pr 𝑦 = 𝑐 =∑ 𝟏 𝑦 � = 𝑐��
𝑁o Conditionaldistribution:
Pr 𝑥n = 𝑧n|𝑌 = 𝑐 =∑ 1 𝑥n
� = 𝑧n, 𝑦 � = 𝑐�� + 𝜖∑ 1 𝑦 � = 𝑐�� + ∑ 𝜖�
c��
24

SmoothingforparametersofNB
• Trainingdataset𝑆 = 𝑥 � , 𝑦 � : 𝑖 = 1,2, … , 𝑁• MaximumlikelihoodestimationfornaiveBayeswithdiscretefeaturesandlabels• Assume𝑆 hasiid examples
o Prior:whatistheprobabilityofobservinglabel𝑦
Pr 𝑦 = 𝑐 =∑ 𝟏 𝑦 � = 𝑐��
𝑁o Conditionaldistribution:
Pr 𝑥n = 𝑧n|𝑌 = 𝑐 =∑ 1 𝑥n
� = 𝑧n, 𝑦 � = 𝑐�� + 𝜖∑ 1 𝑦 � = 𝑐�� + ∑ 𝜖�
c��
25
``𝟏 𝑥n� = 𝑧n�, 𝑦 � = 𝑐 + 𝜖
�
�
�
c��

Missingfeatures
OneofthekeystrengthsofBayesianapproachesisthattheycannaturallyhandlemissingdata• Whathappensifwedon’thavevalueofsomefeature𝑥n
(�)
o e.g.,applicantscredithistoryunknowno e.g.,somemedicaltestsnotperformed
• HowtocomputePr 𝑥W, 𝑥V, … 𝑥�oW, ? , 𝑥��W … , 𝑥Y 𝑦 ?o e.g.,threecointossesE = 𝐻, ? , 𝑇o ⇒ Pr 𝐸 = Pr 𝐻,𝐻, 𝑇 +Pr({𝐻, 𝑇, 𝑇})
• Moregenerally
Pr 𝑥W, 𝑥V, … 𝑥�oW, ? , 𝑥��W … , 𝑥Y 𝑦 =`Pr 𝑥W, 𝑥V, … 𝑥�oW, 𝑧�, 𝑥��W … , 𝑥Y 𝑦�
c
26Slidecredit:DavidSontag

MissingfeaturesinnaiveBayes
Pr 𝑥W, 𝑥V, … 𝑥�oW, ? , 𝑥��W … , 𝑥Y 𝑦
=`Pr 𝑥W, 𝑥V, … 𝑥�oW, 𝑧�, 𝑥��W … , 𝑥Y 𝑦�
c
=` Pr 𝑧� 𝑦 mPr 𝑥n 𝑦�
n¡�
�
c
=mPr 𝑥n 𝑦�
n¡�
`Pr 𝑧� 𝑦�
c
=mPr 𝑥n 𝑦�
n¡�
27
• Simplyignorethemissingvaluesandcomputelikelihoodbasedonlyobservedfeatures
• noneedtofill-inorexplicitlymodelmissingvalues

28
NaiveBayes• Generativemodel
o ModelPr(𝒙|𝑦) andPr(𝑦)
• Prediction: modelsthefulljointdistributionandusesBayesruletogetPr(𝑦|𝒙)
• Cangeneratedatagivenlabel• Naturallyhandlesmissingdata
LogisticRegression• Discriminativemodel
o ModelPr(𝑦|𝒙)
• Prediction:directlymodelswhatwewantPr(𝑦|𝒙)
• Cannotgeneratedata• Cannothandlemissingdataeasily