Embed Size (px)
Citation preview

Copyright
By
David Andrew Falcon Ayala
2006

Software Process Improvement for an ATE Test Program Group
through the Implementation of a Process Management System
By
David Andrew Falcon Ayala, B.S.E.E.
Master’s Report
Presented to the Faculty of the Graduate School of
The University of Texas at Austin
In Partial Fulfillment
Of the Requirements
For the Degree of
Master’s of Science in Engineering
The University of Texas at Austin
May 2006

Software Process Improvement for an ATE Test Program Group
through the Implementation of a Process Management System
Approved bySupervising Committee:Dewayne Perry
Herb Krasner

Dedication
Este papel se dedica a todos mis amigos y familia que han tolerado mi problemas por los
cuatro años pasados.

Acknowledgements
Thank you to Advanced Micro Device’s Management Team for their support and
encouragement in the creation of this project.
May 2006
v

Abstract
Software Process Improvement for an ATE Test Program Group
through the Implementation of a Process Management System
David Andrew Falcon Ayala, M.S.E.
The University of Texas at Austin, 2006
Supervisor: Dewayne Perry & Herb Krasner
For any small organization that is, experiencing substantial growth within its
industry, the coordination and communication of this ever-increasing workload can be an
almost insurmountable task. However in order to cope with this situation, a software
based work process management system can be designed around the existing business
processes. Institutionalizing such a system will allow an ad hoc organization to achieve a
measurable, repeatable, and ultimately predictable work process. This case study will
present these issues in specific context of a software development group, whose main
responsibility is the creation of Automatic Test Equipment (ATE) test programs for
semiconductor devices. It will be shown that given the opportunity to gather
requirements using software engineering principles, the rate of user adoption will be high,
the system will successfully monitor the proper process, and the proposed benefits of a
process management system will finally be realized by the organization.
vi

Table of Contents
List of Tables..........................................................................................................ix
List of Figures..........................................................................................................x
Introduction..............................................................................................................1
The AMD Organization: Functional vs. Product..........................................2
ATE Test Program Team................................................................................3
Engineering Software Services.......................................................................4
Problem Statement..........................................................................................5
Current State of Affairs...................................................................................6
Cost of No Monitoring....................................................................................7
Organizational Metrics for Success................................................................7
Knowledge Acquisition - what is the real problem?................................................9
Collaboration with ATE Team Contact........................................................10
Questions for ATE Team..............................................................................10
Work Process and Scenarios................................................................12
Data Requirements...............................................................................14
Reports and Notifications....................................................................15
Feedback.......................................................................................................16
Revise, Discuss, and Iterate...................................................................................17
Implementation Technology: Serena Software’s Team Track....................18
Early System Prototype.................................................................................19
ALPHA Version: New, Improved and More Complex...............................22
BETA Version: Putting it All Together.......................................................26
System Rollout.......................................................................................................36
TESTING: Final Version.............................................................................36
TRAINING: Phase One...............................................................................38
TRAINING: Phase Two..............................................................................39
vii

DEPLOYMENT: Phase Three.....................................................................39
Conclusion.............................................................................................................41
Summary.......................................................................................................41
Success..........................................................................................................42
Future Work..................................................................................................43
Appendix A: Figure of AMD Matrix Organization..............................................44
Appendix B: Initial Questionnaire for ATE Team...............................................45
Appendix C: Questionnaire Feedback from ATE Team........................................46
Appendix D: Quick Guide for Manually Linking Releases..................................50
Appendix E: Figure of One to One Program Change to Release Link.................51
Appendix F: Figure of Multi-Effect Program Change to Release Link................52
Bibliography..........................................................................................................53
Vita 54
viii

List of Tables
Table 1: Table of Required Program Request Data Requirements...................................31Table 2: Table of Required Program Change Data Requirements...................................33Table 3: Table of Required Program Release Data Requirements...................................35
ix

List of Figures
Figure 1: Final Process Used for System Development.....................................................2Figure 2: Organizational Breakdown of ATE....................................................................4Figure 3: Proposed Metrics for Defining Organizational Success.....................................8Figure 4: First Phase of Development Process (Knowledge Acquisition).........................9Figure 5: Waterfall Development Cycle...........................................................................13Figure 6: Second Phase of Development Process (Revise, Discuss, & Iterate)...............17Figure 7: Team Track Product Description......................................................................18Figure 8: Program Request Prototype Workflow.............................................................20Figure 9: Program Release Prototype Workflow..............................................................20Figure 10: Program Request ALPHA Workflow.............................................................22Figure 11: Program Change ALPHA Workflow..............................................................23Figure 12: Program Release ALPHA Workflow..............................................................24Figure 13: Program Request BETA Workflow................................................................27Figure 14: Program Change BETA Workflow.................................................................28Figure 15: Program Release BETA Workflow.................................................................29Figure 16: Third Phase of Development Process (Rollout)...............................................36Figure 17: AMD Rollout Schedule for the ATE Program Tracking System...................37Figure 18: Internal ATE Team Track Documentation.....................................................40Figure 19: Final Development Process Used for System Development...........................42
x

Introduction
The business benefits of using a process management system to drive software
process improvement include improved productivity, early defect detection, and shorter
time to market. These benefits are actually well understood and desired by the AMD
organization. In the past, there have been two attempts to deliver such a system to the
Automated Test Equipment (ATE) group, but both systems failed to attract enough users.
It is the assertion of this case study that if given the opportunity to gather accurate
requirements using software engineering principles, that the resulting system will be
successfully adopted by ATE engineers. The most appropriate software engineering
principles include: (1) determine the real problem before writing requirements; (2) use an
appropriate process model; (3) give products to customers early; (4) people are the key to
success; and (5) take responsibility. The actual process used to gather accurate
requirements, design the appropriate work process, and deploy the system is shown
below.
FEEDBACK Questions for
ATE Team Collaboration
With ATE Team
PROTOTYPE
ALPHA
Training for ATE Team
BETA
Deployment into ATE
Organization
Figure 1: Final Process Used for System Development.
1

Once deployed the process management system should expose the real-world
work process used by the ATE group, thus the system should leave the ATE group with a
measurable, repeatable, and predictable work process. The known non-functional
requirements of the system include usability and accountability, given past failures, and
the single metric for successful deployment includes traceability of tracked items.
THE AMD ORGANIZATION: FUNCTIONAL VS. PRODUCT
Advanced Micro Devices (AMD) has traditionally been recognized as one of the
smaller semiconductor companies within the microprocessor industry. This recognition
is not unfounded when the size of a typical functional team is less than a dozen people.
Within the product-manufacturing department, this nimble size is taken advantage of
through the use of a matrix organization. Functional silos are collated by groups who
perform similar skills but were previously separated by product oriented groups. A single
product management group was created and staffed by only product managers, whom
then request resources from resource managers in charge of the functional silos. This
resource manager is known internally as a Center of Excellence (COE). A pictorial view
of this organizational breakdown can be seen in Appendix A. With this matrix setup in
place the central authority for delivering a processor product to the marketplace was de-
centralized. This left resources traditionally responsible for following a product from
design (TAPEOUT) to end of life (EOL), were now free to float from one product
manager to another without retaining responsibility for each product. The clear
advantage for AMD was an immediate increase in productivity from employees and
better knowledge transfer between virtual product groups. The long-term advantage was
that product groups were no longer re-creating software tools and work processes for
each new major product design. Tools and processes could now be re-used or with 2

minimal effort upgraded to fulfill the new product requirements for development and
manufacturing. However, this change is structure was not without its problems.
Communication and coordination between COE and product managers became extremely
critical in planning and managing product derivations. This is the single most pervasive
problem that faces the organization as a whole.
ATE TEST PROGRAM TEAM
The functional group of interest in this paper is the ATE test program team, which
is responsible for the development of test platform environments, creation of test
programs, and operational program deployments at various manufacturing facilities. This
means that the ATE team is responsible for designing, developing, and deploying
microprocessor test insertion steps within the various manufacturing sites for multiple
products. The scope of technical expertise includes, but is not limited to, hardware, and
software related issues. The ATE team is organized with a single top-level manager who
coordinates with the product managers the development priority of test program releases
in production. Under this top-level manager are the “Test Lead” engineers whom are
organized by ATE tester platform. Under each of these test platforms team leads are the
“Program Owners” who are directly responsible for getting test program development
and deployment done on time.
Figure 2: Organizational Breakdown of ATE.3

The number of test programs that must be created is typically calculated by the
number of product derivations in production and the number of test insertions that must
be performed on a specific product derivation to ensure quality and reliability for the
customer. A single product could potentially go through several insertions before it is
ready to be shipped to a customer. The amount of workload seen in this group is
considerable even in a small environment, let alone the number of product derivations
that could be generated from a single major product family. In addition, the number of
different ATE platforms that are needed to implement a single test flow can require
different development environments that may be specific to a single ATE vendor. Hence,
re-work of testing methodology has to be written in potentially different implementation
languages. Along with these conditions the number of manufacturing test facilities could
be distributed between several worldwide locations. Thus, the organizational need for a
centralized repository of active projects, so that they can coordinate activity more
effectively.
ENGINEERING SOFTWARE SERVICES
The team responsible for developing software based data analysis tools for
internal engineering effort is Engineering Software Services (ESS). This group was
initially created by collecting autonomous software developers from within the product-
manufacturing departments. These autonomous engineers had previously been
developing software solutions for a specific functional group. The solutions developed
by the ESS group contain a mixture of short-term and long-term projects. Most of these
projects are developed using several short iterative development cycles that follow an
evolutionary process. The development team is responsible for all areas of the software
development process including: requirements gathering, architecture, design, 4

implementation, testing, deployment, maintenance, and documentation. While the ESS
group in not considered it’s own independent functional silo, the ESS group is embedded
within a functional organization that contains similar software skill sets. However the
reporting hierarchy is setup so the ESS group is responsible for the whole product-
manufacturing department, not just it’s own functional silo. With previously successful
management of engineering tool development, the ESS group has now moved into
traditionally held Information Technology (IT) governance functions, especially with the
ATE group’s request for a program request system that will be adopted by the whole
product-manufacturing department.
PROBLEM STATEMENT
The substantial market growth seen in AMD due to the x86-64 bit
microprocessors has induced internal growing pains, which is usually felt in the
functional teams that were staffed with less than a dozen people before the growth. The
specific task that the ATE group would like monitored is the software test program
development and deployment process. The complexity inherent to this exists from the
fact that the ATE group must maintain several different vendor brands of test equipment
that require the implementation of different software languages, hence software re-use is
extremely limited. In addition, the number of test insertion steps that must be maintained
adds further complexity with regards to test coverage (where and when should a program
change be implemented). With all this the ATE group is continually restrained by the
following principles: that the test insertion time must be as short as possible and the
earlier a problem is found the more cost effective the production flow. This is counter-
balanced by the occurrence of any failures discovered in the sampled quality/reliability
test insertion steps. The organizational breakdown of the ATE test team is such that a 5

developer is responsible for potentially multiple test programs, products, and releases.
While there is high-level oversight of major feature implementation, low-level test
coverage can be duplicated due to a lack of accountability and traceability. In addition,
rollout of small features to all test insertion steps can be hindered by a lack of
communication and coordination. For these reasons the ATE test team is requesting that
a “Team Track” implementation be deployed to try and resolve some of these issues.
CURRENT STATE OF AFFAIRS
Now there is no centralized monitoring system used by the ATE team to capture
the release schedule of test programs to the various manufacturing facilities. The ATE
group must also contend with the lack of any organized mechanism for recording
program requests that come from the various organizations within AMD and other
manufacturing foundry partners. While the ATE group has made attempts in the past to
create request-tracking systems, these systems have never been adopted by enough users
to be considered successful. These past failures are seen as a lack of upper management
support in the context of user adoption. However, the larger problem with the previous
two test program request systems resides in the rigid workflow that was enforced. The
failed systems both implemented the same process workflow: (1) Submit Request; (2)
Notify Manager of Request; (3) Wait for Manager Validation; (4) Assign Request to
Engineer; (5) Notify Submitter of Request Assignment; (6) Close Request; (7) Notify
Submitter Request is Closed. This workflow is in direct contradiction with the
established work environment of the ATE group. This lack of alignment between the
implemented workflow and the real-world process is the primary reason hypothesized for
the failure of both systems.
6

COST OF NO MONITORING
So with the ATE group swelling in head count and a lack of any formalized
monitoring/tracking system in place, the cost of doing nothing is starting to hinder
productivity. The most obvious problem facing the ATE group is duplication of effort
due to a lack of coordination between “Team Leads”. If the coordination between “Team
Leads” is broken then important program features go missing in certain families of test
program releases, thus directly costing the company a lose of potential profit. The loss of
customer confidence may not be a dramatic problem, but vitally important to the
profitability of the company. The customer of ATE being any of the functional groups
with the PDE organization responsible for delivering microprocessors to customers,
groups responsible for devising yield enhancement strategies, and other outside
manufacturing foundry partners. The loss of confidence from these groups of people can
indirectly affect the overall productivity between organizations, which would increase the
cost of doing business, thus making it harder for the company to turn a profit. At the end
of the day though, the most visible metric for defining success come from the time it
takes to deliver the first revision of any new product. The longer the ATE group goes
without a usable monitoring system the longer it will take for this group to deliver new
products to the market, let alone manage existing products in production.
ORGANIZATIONAL METRICS FOR SUCCESS
Defining specific criteria for measuring success is at best tricky considering
previous attempts at a program request system were deemed failures due to the lack of
user adoption. This fact will probably still be the main metric for perceived success,
however the following metrics should also prove helpful.
7

Figure 3: Proposed Metrics for Defining Organizational Success.
The system should be backwards compatible with the current implementation of
the “Team Track” system, to not break existing reports that monitor usage. Currently
there are 16 distinct reports that are used within the PDE organization that monitor silicon
characterization and debug activities. These reports will need to be verified periodically
to ensure that the new program request system does not break them. The system should
be flexible enough so that additional “Team Track” components can be added without
compromising the integrity of the design. This is measured by verifying that any new
addition still allows previously entered issues to continue to function. It is not explicitly
stated that removal of components is a metric for success, but it will be assumed for the
purpose of this project that it is not a requirement for successful rollout. The system
should also try to minimize the cost of maintenance that is placed on the implementing
organization (ESS). Were applicable the maintenance costs should be offloaded to the
organization requesting the system. The scope of the project should also not allow,
“Feature creep” to take over the initial high priority requirements. Of the 22 defined
scenarios, the system should at least cover 50% of these requirements. This metric was
actually specified by direct management, as an acceptable measure of completion.
8

Knowledge Acquisition - what is the real problem?
Knowledge acquisition is the first part of the development process used for
delivering the process managements system.
FEEDBACK
Questions for ATE Team
Collaboration With
ATE Team
Knowledge Acquisition
Figure 4: First Phase of Development Process (Knowledge Acquisition).
The software engineering principles used to start this phase included: (4) people
are the key to success; and (5) take responsibility. The right people included a “Process
Champion”, who became the key factor for a successful rollout. Taking responsibility for
the project means to be concerned with more than just the explicit requirements that were
initially gathered. In fact, the responsibility principle means to focus on more than just
the functional requirements. Focus will be needed on the non-functional properties like
usability and accountability.
Collaborating with the ATE team contact is critical for following the third
software engineering principle (determine the real problem). This phase will align the
process champion and developer with regards to goals, methodology, implementation
technology, and project purpose. Once that phase is completed, the next two phases
serve to discover the basic work process followed by the group and where in that work
process does the real problem exist. Together this will generate enough requirements to
eventually move forward with an initial design prototype.
9

COLLABORATION WITH ATE TEAM CONTACT
The single most important person responsible for accurate requirements was an
engineer from within the ATE organization. This engineer is was a relatively new
employee within the ATE team, but had several years of work experience from a large
ATE company that had strict test program release procedures. This unique view of the
two companies provided enough motivation for the ATE contact engineer to pay serious
attention to the knowledge acquisition activities. It was through this engineer that the
core team of beta users was coordinated to meet at regular intervals depending on
availability. Most delays in the knowledge acquisition phases were due to the inability of
the core team to communicate. Most ATE engineers regularly travel between the
Singapore manufacturing facilities and the Austin engineering site. The ATE contact
engineer also ended up communicating directly to the ATE management team the
primary reasons why they should allow both of us to spend the time to collect accurate
requirements before putting together a beta system. This proved to be helpful in gaining
management support for the project since the argument for requirements came directly
from within the ATE organization by a person trusted and respected by other ATE
engineers. One of the reasons that the previous ATE request system failed was due to a
lack of trust between the ATE group and the ESS group. The resultant system failed
primarily because it did not help solve the real problems within the ATE group.
QUESTIONS FOR ATE TEAM
The initial request for a tracking system came from the ATE manager as a
proposal for a simple bug tracking system, however this proposal was not submitted to
the ESS organization. With the previous failure of ESS to deliver a system that was used
by the ATE team, the new proposal was routed back to ESS by the system administration
10

team as out of their scope. With responsibility for implementation back inside the ESS
group, the ATE manager then assigned the previously discussed engineer as the primary
contact between the two teams. The ATE contact engineer then proceeded to re-design
the request proposal to include not only bug reports but also any request that an outside
resource may make to the ATE team for a test program change. This re-design then
sparked requests from within the ATE group to be able to monitor the test program
release that each request gets implemented into. This is the proposal that was initially
given as requirements to the ESS group. The first meeting with the ATE contact engineer
involved not actually talking about the requirements given, but to discuss the work
process that should be followed. The primary purpose of this meeting was to build a
level of trust with the ATE contact and to align our roles in the requirements process, to
not be counter-productive. Surprisingly this meeting was quite successful in terms of
building trust. The main points made about the importance of gathering accurate
requirements was well understood and received, which allowed a certain level of
flexibility. This proved useful in presenting the opinion that we should isolate
requirement concepts to help reduce the complexity inherent to the overall process. It
was agreed that we would gather work process & scenario information first, we would
then gather data requirements, and lastly we would gather implementation specific
requirements like reports, graph, and email notifications. The initial requirements
document presented by the ATE team prior to this agreement was used as a template for
generating a questionnaire that was presented to the ATE contact engineer. Along with
the benefits of documenting the questions needed for requirements elicitation, the
primary purpose of generating the questionnaire was to allow for disconnected
communication between the ATE group and ESS group. For the initial weeks of
11

requirements gathering, most of the ATE team was not geographically located in the
same location as the ESS team. Therefore, the questionnaire turned into a valuable tool
for communication across the different geographical locations. This allowed the ATE
contact engineer to categorize answers and organize the feedback for ESS into a
structured format.
It should be noted that the implementation technology was already determined to
be “Team Track”, which is used successfully by other organization within AMD. The
ATE contact engineer was shown prior to the questionnaire generation, the “Team Track”
technology constraints. This was accomplished through a meeting with the platform
infrastructure team, who also uses “Team Track”. This proved be a successful meeting
since many of the “Team Track” design concepts were demonstrated. We agreed to
restrain from offering early implementation suggestions to the ATE team, since we did
not want to elicit implementation specific requirements at this early stage. With both of
us now on the same page, we began to gather work process and scenario requirements
from the ATE team.
Work Process and Scenarios
The initial requirements giver were clearly not sufficient for completing a
successful implementation given the past failures. The ATE contact engineer helped to
discover the process of determining the current work process used by the ATE team for
delivering test programs. As with any software organization they did follow a simplified
version of the waterfall development model.
12

Figure 5: Waterfall Development Cycle.
Requirements are usually generated by various internal/external organizations that
represent the various stages within the microprocessor life cycle. Design is handled by a
group of ATE engineers; know as “Test Leads”, whom are responsible for delivering all
test programs to the various AMD manufacturing sites. There are AMD manufacturing
and engineering sites in North America, Europe, Asia, and India. The actual coding and
unit testing is completed by any number of generic “Engineering Resources” that can
come from different teams external to the ATE team. These work assignments are made
by the test program manager known as a “Program Owner”. Actual integration and
system testing is left to the responsibility of the geographically local ATE teams at each
production and engineering manufacturing site. This discovery process logistically took
several weeks to accomplish because many of the “Program Owners”, whom we needed
to answer the questionnaire, were at remote manufacturing sites in Singapore or
Germany. As part of the discovery process, it was found that the process of validating
test programs for release to production could go through several rounds of back and forth
13

between the integration teams and the “Program Owners”. This results in patching the
test program several revisions before it actually makes it to the test floor. It is also worth
noting that the “Program Owners” would routinely revise test programs while in
production to address quality issues with the test program code itself. Depending on
where in the manufacturing flow this lapse in test coverage occurred it is left to the
preceding test insertion step to capture any fallout generated by this work process. This
usage scenario is clearly a process problem that should be monitored for improvement.
As part of the feedback from the questionnaire, it was also found that the most
requested usage case specified involved simple “Program Request” to “Program Release”
traceability. The “Program Owners” did not agree on the view though, some wanted to
see all “Request” implemented in a specific “Release” or they wanted to see all the
affected “Releases” connected to a specific “Request”. This will prove to be a useful
observation later on during the actual implementation. The next most requested usage
feature had to do with email notifications triggered by the dates that certain key events
occurred like initial program release to production, submission date of requests, due dates
for requests, release dates of program releases and patch dates. The fact that program
requests could only be submitted through the process management system was the final
most requested usage scenario. Although this usage scenario was requested, the fact
remains that unless upper management was willing to ignore requests that were received
through email notifications. No conceivable system in the world would ever be capable
of fulfilling this last requirement.
Data Requirements
While the ATE contact engineer and I both initially only asked for data
requirements for “Program Requests” in the questionnaire, we both agreed that the scope 14

of the new system should include tracking “Program Releases” due to the results of the
first questionnaire. The typical AMD domain specific data was listed in the feedback of
the first questionnaire. These include product attributes, test insertion, organization,
contacts, fabrication technology, design identifier, ATE platform, ATE test program, due
date, release date, request duration, description, priority, scope, and type of request. A
second set of questions was then sent back to the “Program Owners”, which asked for
data requirements for a “Program Release” tracking system. The data requirements not
surprisingly looked similar to the data requirements for a “Program Request” system. Of
note is the inclusion of patch level (L or R), patch revision number, release date, and
release type (full or patch), along with the exclusion of request type. It will be shown
later that the process of gathering data requirements comes mostly during the presentation
and testing of the BETA version of the system.
Reports and Notifications
The last part of gathering requirements concentrated on the type of reports,
graphs, and email notifications that the “Program Owners” wanted to see. This was done
informally through the usage of an early prototype with specific “Program Owners”
whom were designated as ATE beta users. This process was conducted as a one on one
meeting with individual beta users to demonstrate possible functionality within the
system. This allowed the beta users to understand the confines of the implementation
technology before formulating specific requirements. Although we did tell, all beta users
that we did want to take all required requirements irrelevant of implementation
technology constraints. It was communicated that several reports should exist for the
various roles within ATE. This includes reports to show a list of all active program
requests, a list of all active program releases, a list of all program requests implemented 15

for a specific program release, a list of all program releases affected for a specific
program request, a list of all upcoming program releases, and a list of all active program
request & releases. This was the highest priority for the ATE team with respect to other
functionality, which should be an indication of how disjointed the ATE team is currently.
In fact, this was seen as the sole metric of successful completion for this project by ATE
management. Delivering a system that was able of producing the above reports, and then
the new system would be seen as a success. The beta users also re-iterated the various
email notifications that could be possible given the implementation technology. This
included: sending emails to “Test Leads” when new program requests are submitted;
sending emails to “Program Owners” when requests are connected to releases; sending
emails to local ATE teams when releases are sent to production; sending emails to
“Engineering Resources” when they are assigned a request to fulfill; and sending emails
to a request submitter when requests are completed. All these notifications were seen as
necessary but not required for rollout.
FEEDBACK
While the requirements gathering activities are presented in the knowledge
acquisition as one section, the process of gathering requirements was iterative and
concurrent with other early implementation specific prototyping activities. During the
gathering of feedback from the first questionnaire the ATE contact engineer was in
contact with all “Program Owners” discussing their answers, so that the “Program
Owners” had an opportunity to revise their answers easily. This process iterated several
times over many weeks, until a final consolidated answer sheet was presented to the ESS
group. The first prototype did not occur until feedback from the first questionnaire was
received and analyzed. 16

Revise, Discuss, and Iterate
The software engineering principles used in this phase of development include:
(2) use an appropriate process model; (3) give product to customers early; and (4) people
are the key to success. The appropriate process model for this phase of development will
be an iterative evolutionary development process, which does facilitate accurate
requirements gathering. Delivering multiple versions of the system for discussion with
the customer will be shown to also be productive. The right beta testers for each iterative
discussion are also shown to be critical for accurate requirements gathering.
So for several weeks as a PROTOTYPE, ALPHA and BETA version of the
process management system was being built, the process of gathering requirements
continued to iterate as each new piece of functionality was being implemented and
presented. This process of revise, discuss, and iterate drives the rest of the development
cycle.
PROTOTYPE
ALPHA
BETA
Revise, Discuss, & Iterate
Figure 6: Second Phase of Development Process (Revise, Discuss, & Iterate).
While this may seem like a lot of wasted time, the process allows a chaotic
organization to implement a methodical and repeatable development process for
gathering accurate requirements.
17

IMPLEMENTATION TECHNOLOGY: SERENA SOFTWARE’S TEAM TRACK
Team Track is a web-based process management system developed by Serena
Software for IT organizations. It is a three tiered web application with a Microsoft SQL
Server2000 database backend system, a Microsoft Windows 2000 application server, and
a web-based user client.
Figure 7: Team Track Product Description.
18

The Platform Infrastructure group within AMD has successfully deployed Team
Track for several years. The decision to use this implementation technology was pre-
determined by the ATE group because of these past successes by the Platform
Infrastructure group. Team Track allows the user to configure almost every aspect of its
web interface and functionality. This flexibility is all built around the concept a
“Workflow” which describes the work process that will be enforced. In defining this
“Workflow” in Team Track, the administration application generates a GUI that is
comprised of boxes (states) and arrows (transitions). Once this “Workflow” is defined in
the administration application, the Team Track client allows for “Trigger” and
“Notification” rules to be applied on top of the defined work process. A “Trigger” is an
internal messaging system between the defined Team Track states (boxes) in the
“Workflow”. The actual behavior that a “Trigger” defines is specified by the available
transitions (arrows) in a “Workflow”. Each incoming state can then define different
conditional rules for behavior enabled by the incoming “Trigger”. A “Notification” is an
external messaging system that is capable of sending emails based on conditional rules
defined by the Team Track administrator. In addition, escalation rules can be applied to
“Notifications” that are time bound if a conditional rule has not been satisfied for a
specific length of time.
EARLY SYSTEM PROTOTYPE
With the first questionnaire analyzed and agreement with the ATE group that the
system needed to also include “Program Release” tracking, an early prototype was
developed to help demonstrate possible functionality. This included the design of two
separate “Workflows”, one for the “Program Request” and a second for the “Program
19

Release” system. The “Program Request” system included only three states (validate,
release pending, closed) and three transitions (submit, assign, close).
Figure 8: Program Request Prototype Workflow.
The “Program Release” system was even simpler, since we did not have a lot of
background information about the specific process. This “Workflow” included only two
states (in progress, program released) and two transitions (submit, release to production).
Figure 9: Program Release Prototype Workflow.
With these simple prototypes, the process of demonstrating the capabilities of the
Team Track system to the small group of beta users to elicit more feedback began. One
feature that is not clearly shown is Team Track’s functionality for manually linking items
together. For this implementation, this functionality is the most critical feature for a
successful implementation. Without this feature, there is no other way for Team Track to
associate a release to a request. Team Track does have the concept of parent-child
association between tracked items, but that functionality does not make logical sense for
20

this situation. A release does not spawn requests and a request does not always spawn a
new release. This leaves the manual linking functionality as the only design option for
implementation. Because of the inherit problems with manual features, this functionality
must be clearly defined in the training documentation. A final version of this
documentation can be seen in Appendix D. This is an obvious weakness of the system
and must be addressed with proper training from the ESS team.
At this point, we make the recommendation to the beta users that external
organizations should submit all test program requests through the first “Workflow”. This
group of “ATE Requestors” should not be allowed to initiate new test program releases,
whether they are full releases or just patch releases. This leaves the “ATE Test Leads”
and “Program Owners” as the only groups that should have the capability of initiating test
program releases. While demonstrating the manual linking process, it was clear that the
scope of possible program requests could cover a broad range of responsibilities. This
means that a request may have to be possibly implemented for a whole family of test
program releases, each of which may be managed by different “Program Owners” and
actually implemented by different “Engineering Resources”. This proves a fatal
limitation to the early prototype system, because a single program request can only be
owned by a single user. With this feedback, a logical use of the parent-child subtask
functionality was discovered. We formulate the concept of a program change, which is
logically spawned from a program request. It will be the program change, which the
“Program Owners” will have to manually link to program releases. With this change in
project scope, we also come up with the requirement that a program request must be able
to spawn an unlimited number of program changes. This can be accomplished using the
sub-task transition definition in Team Track. A sub-task transition will allow the process
21

management system to submit a new “Workflow” and automatically link the items
together in a parent-child association. With this insight, an ALPHA version of the system
is developed.
ALPHA VERSION: NEW, IMPROVED AND MORE COMPLEX
While several rounds of development and experimentation went into this phase of
the development, what is presented is the final version used for the demonstration of the
ALPHA version. This version of the program request still implements three states
(validate request, request open, request closed), but now has four transitions (submit,
assign1, assign2, close) including two sub-task transitions. These transitions were setup
to submit new program changes into the database and automatically link those new items
to its parent program request.
22

Figure 10: Program Request ALPHA Workflow.
A part of the sub-task transition’s functionality is the capability of copying over
field values from the parent item into the child item’s fields. Of primary concern is the
capability of copying over any title and descriptions that were entered in by the program
request submitter. This should help reduce the amount of time it takes for a “Program
Owner” to assign program changes, thus improving the usability of the system.
The new program change is a simplified version of the earlier program request
prototype with just two states (program change, closed program change) and two
transitions (submit, close). Again, this simplified workflow is only necessary for
scheduling and assigning distributed tasks generated by a single program request.
Figure 11: Program Change ALPHA Workflow.
Feedback received about the program change was only concerned about the steps
needed to manually link a program change to a program release. Team Track has six
different types of links available for a user to assign between items, and for our purposes,
we will by default use the most flexible link definition, which is a bi-directional link that
passes triggers in both directions. It was also confirmed that only “Program Owners” and
“Test Leads” should be able to generate new program changes. Moreover, that
“Engineering Resources” must be identified within the program change somehow. These
23

“Engineering Resources” are then responsible for closing the program change item after
the actual code changes have been completed and committed to the SVM code repository.
The program release also included new changes to its “Workflow” with the
addition of a program patch state/transition. Feedback received from the prototype
demonstrations discovered that a program could be patched after it has been released to
production. To model this behavior, an additional state was added to expose that the
released program is now available to be patched. A patch transition was also added to
denote when a “Program Owner” releases patches to the program release into production.
Figure 12: Program Release ALPHA Workflow.
Feedback from for this part of the system took quite a while to achieve, since the
actual patching process is complex. Most “Program Owners” offered up different
24

scenarios when and how a program can be patched. This discovery process also
uncovered the patch level and revision notation used internally to measure the quality of a
program release.
The following represents the known patching process:
A release is sent to the local AMD manufacturing site (SGP, DRESDEN) where
the release is validated for production.
If the local ATE team finds any problem with the release, then feedback is sent to
the “Program Owner” and the program is considered to have a patch level (L/R)
and its patch revision (n) incremented by one.
The program release is then sent again to the local AMD manufacturing site
where the release is validated for production. This is repeated until the program is
validated for use in production.
The local ATE team is not the only group that can initiate a L-patch revision. A
“Program Owner” may add in more code changes for various reasons to the
program release. The scope of these changes can encompass almost any reason.
Once the program has been validated for release into production the program
patch level (R) is changed and its patch revision (n) is set back to zero.
Once released into production a program release can be patched again.
Nevertheless, the scope of these changes is limited to quality and reliability
changes only. However, this rule is routinely violated due to pressure from the
various requesting organizations. The level of violation is not known and the
desire to measure this was constantly communicated.
At this stage all beta users were discouraged from submitting domain specific data
requirements, but general data requirements were gathered like title, description, new
25

note, owner, manager, duration, submit date, priority, item link, and list of program
owners. All of these are of interest no matter which ATE system is being implemented
(request, change, release). This is valuable since a “Workflow” design can be setup as a
hierarchy of “Workflows”, which allow descendant “Workflows” to inherit field values
along with state and transition definitions. It is note worthy to step back and view the
ALPHA version of the system as a design that will continue to grow in complexity. This
increase in complexity comes with a direct tradeoff, which is the amount of training
needed for the “Program Owners” must increase to compensate for the complexity of the
process management system. It is with this in mind that the BETA version is designed to
include features that were not requested by stakeholders, however this address the
usability and accountability of the overall system.
BETA VERSION: PUTTING IT ALL TOGETHER
The BETA version presented represents the final version demonstrated to the
large set of “Test Leads”, “Program Managers”, and “Program Owners”. This version
most closely resembles the final system that was rolled out to the ATE group. During the
development of this BETA system, the basic data requirements were added to the system
for demonstration purposes only, but AMD domain specific requirements were still left
undefined until agreement could be reached that the work process was properly modeled
in each “Workflow”. Previous experience from working on the creation of a Team Track
“Workflow” showed that the effort of defining domain specific fields was wasted until
the “Workflow” was properly modeled. The debate about the usefulness of a particular
field was not broached until a final BETA system was presented.
With that stated, the program request added a new state (hold) that allows the
“Program Owner” to reject a request. A transition was also added to re-submit the 26

request once it has been updated by the request submitter. Update transitions were added
to the states (validate request & request open), these transitions allow users to update the
field definitions without changing the state definition. Sub-task functionality from the
ALPHA version was maintained and a transition rule was defined for the “Request Open”
state that allows the program request to automatically run the “Close Request” transition
if all the spawned sub-tasks are in-active. This was not so much a request from the
“Program Owners” as much as it was something they wished it could do. This
functionality was exposed through discussions with Serena Software.
Figure 13: Program Request BETA Workflow.
27

It was already noted that the system’s complexity had grown to a point, that
special attention to employee training was critical for user adoption. Another non-
required feature that was added to the system was a trigger notification that was enabled
during the “Close Request” transition. The trigger rule defines that when the “Close
Request” transition is run, trigger messages are sent to all linked child items. The
specific behavior is defined in the program change, since this is the only “Workflow” that
is capable of being set as a child item to a program request. The purpose of this trigger is
to allow the system to be as flexible as possible. The program change that receives this
trigger will be setup to automatically close itself, which allows a “Program Owner” the
capability of closes multiple changes, with just one click. Email notification rules were
also setup given the feedback from the ALPHA demonstrations. The three notification
rules defined for Program Request: notify all program owners when a request is
submitted, notify all program owners & request submitter when the request has not been
assigned after two weeks, and notify request submitter when the program request has
closed.
The program change structurally remains the same as the ALPHA version, but
with some minor additions. A required field was added to the “Submit” transition, which
requires that at least one link to a program release is added. This should help enforce the
connection between request and release.
Figure 14: Program Change BETA Workflow.28

The program release is perhaps the most revised of the three “Workflows”, since
intense investigation was put towards defining the patching process. Except for the
“Submit” transition and “Program in Progress” state, the entire “Workflow” for the
program release was re-designed to model the known patching process. Four new states
were added, along with seven new transitions. Seven notification rules were also added
to the “Workflow” for emailing specific distribution lists depending on which transition
was run. The first three new states are used to classify the distinct phases a test program
may inhabit between the time it is initially released for verification and when the test
program finally makes it to the production test floor.
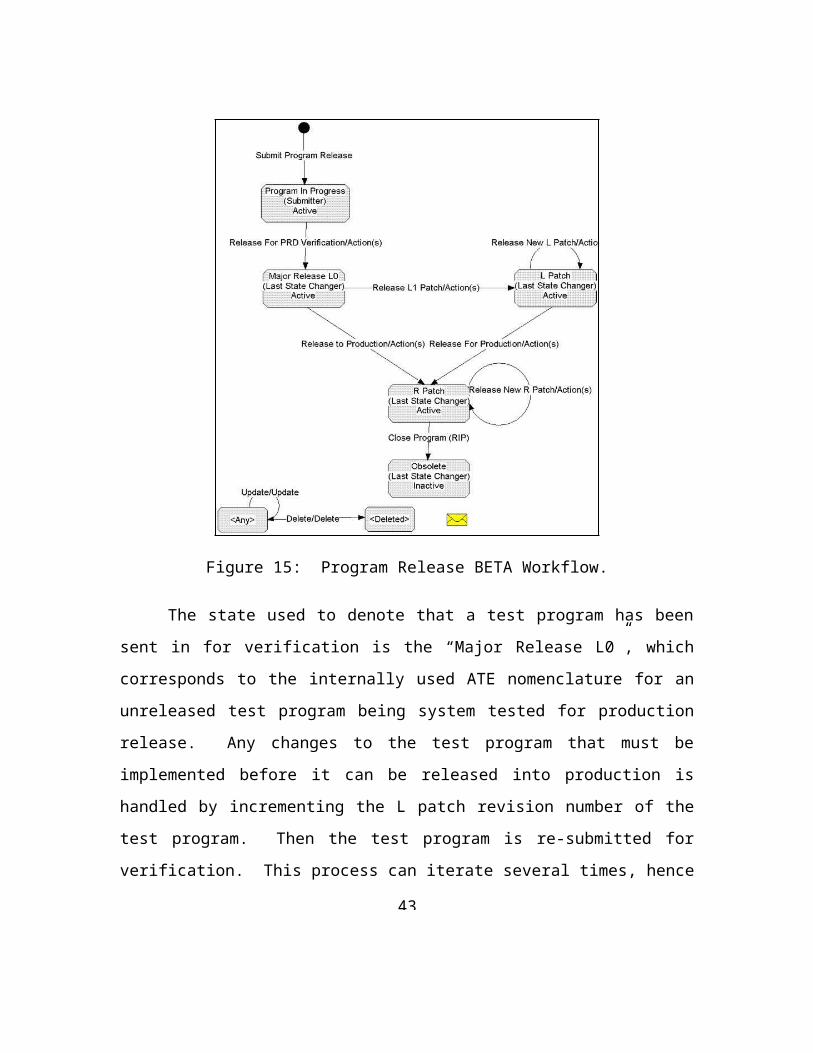
Figure 15: Program Release BETA Workflow.
29

The state used to denote that a test program has been sent in for verification is the
“Major Release L0”, which corresponds to the internally used ATE nomenclature for an
unreleased test program being system tested for production release. Any changes to the
test program that must be implemented before it can be released into production is
handled by incrementing the L patch revision number of the test program. Then the test
program is re-submitted for verification. This process can iterate several times, hence the
addition of an update transition called “Release New L Patch” which just loops back to
the “L Patch” state. Once the test program is ready to put into production, the release is
moved to the “R Patch” state, which represents a fully released production test program.
During production a test program is still viable for new changes to be implemented into,
this is usually referred to as an “R Patch”, again it only involves incrementing the R patch
revision number. However, this also means that the test program has to be re-validated
again and it is possible to cycle through another round of program changes. This is the
reason that another update transition called “Release New R Patch” was added. The R
patch process only allows certain types of changes to be implemented into the code, like
bug fixes and other quality-oriented changes. The L patch process will allow any type of
change to be implemented. While the Team Track system cannot enforce these domain
rules, the training documentation must clearly define these domain rules. It must also be
documented that linking program changes to program releases should only occur during
the “Active” states of a program release. At a certain point in time though, a test program
in production can no longer be used to patch in more changes. The program release must
be retired (inactive), so this is exposed by the addition of the “Obsolete” state. For all six
transitions that are used to represent some form of a “Release”, a trigger message was
added to send out messages to all the linked program changes. The program change
30

already has a trigger rule defined that will try and close them if any trigger messages are
received. This non-requested functionality was added to help user adoption of the
system. Although potential abuse of the system could occur, this functionality will be
clearly defined in the training documentation. The addition of an update transition that
can be applied on any of the defined states was requested by the ATE contact engineer as
a way to help fix mistakes that might occur during the initial training phase.
Through several rounds of discussions about the early data requirements gathered
from the questionnaire, the ATE contact engineer and myself worked with “Program
Owners” to define the type of AMD domain specific fields that were necessary in the
system. To check the validity of incoming program requests, the users suggested
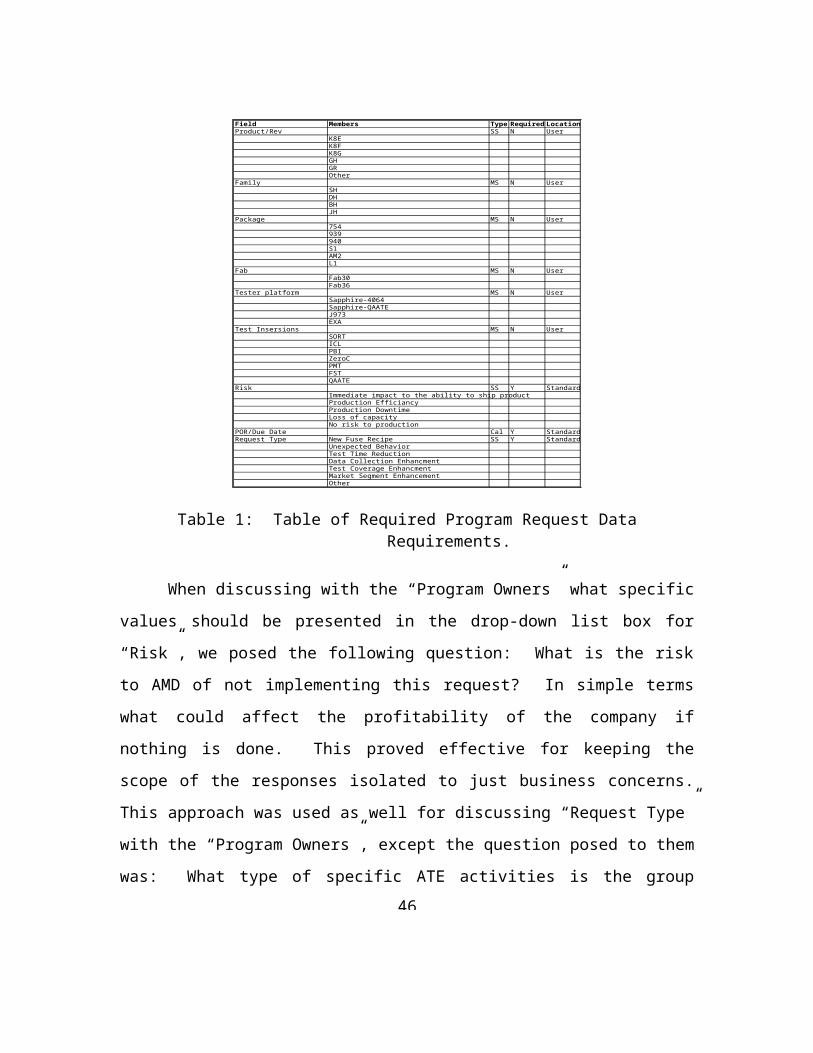
evaluation using the following program request fields: “Risk” and “Request Type”.
Field Members Type Required LocationProduct/Rev SS N User
K8EK8FK8GGHGROther
Family MS N UserSHDHBHJH
Package MS N User754939940S1AM2L1
Fab MS N UserFab30Fab36
Tester platform MS N UserSapphire-4064Sapphire-QAATEJ973EXA
Test Insersions MS N UserSORTICLPBIZeroCPMTFSTQAATE
Risk SS Y StandardImmediate impact to the ability to ship productProduction EfficiancyProduction DowntimeLoss of capacityNo risk to production
POR/Due Date Cal Y StandardRequest Type New Fuse Recipe SS Y Standard
Unexpected BehaviorTest Time ReductionData Collection EnhancmentTest Coverage EnhancmentMarket Segment EnhancementOther
31

Table 1: Table of Required Program Request Data Requirements.
When discussing with the “Program Owners” what specific values should be
presented in the drop-down list box for “Risk”, we posed the following question: What is
the risk to AMD of not implementing this request? In simple terms what could affect the
profitability of the company if nothing is done. This proved effective for keeping the
scope of the responses isolated to just business concerns. This approach was used as well
for discussing “Request Type” with the “Program Owners”, except the question posed to
them was: What type of specific ATE activities is the group responsible for? This also
proved useful in isolating the responses to just address requests that fall within the scope
of the ATE organization. Otherwise why would a user submit a “Request Type” that was
not the responsibility of the ATE group. While this may seem like a trivial matter, this is
where feature creep was most battled, since most “Program Owners” wanted to deliver an
endless list of possibilities. The two questions presented above were successful in
focusing most “Program Owners”.
From the “Workflow” for the “Program Change” it may appear that this system
had very little design work put into it, but the most difficult part for the “Program
Owners” was actually defining what type of data the users wanted to collect. It was
suggested by Dr. Perry that attention be paid to metrics for classifying software defects.
With this in mind the two most important data fields defined in the ‘Program Change” are
“Change Type” and “Change Reason”. Within Team Track, it is possible to define
functional dependencies between two fields, such that a selection in one field can select a
sub-set in the second field. This kind of functional dependency was setup for the fields
described above. For the “Change Type” field I had enough previous ATE domain
knowledge that I was able to present several classifications that were driving factors for
32

development activities including: business market changes, test enhancements, new
development, program maintenance, and bug fixes. With these classifications, a meeting
with the ATE contact engineer and an ATE “Team Lead” to discuss what kind of data
choices should be presented for both the “Change Type” and “Change Reason” was
setup.
Field Dependancies Members Type Required LocationProgram Name Text Y StandardJob Name Text N StandardDifficulty SS N Standard
Very EasyEasyMediumHardVery Hard
Expected Completion date Cal Y StandardRequest Type New Fuse Recipe SS Y Standard
Unexpected BehaviorTest Time ReductionData Collection EnhancmentTest Coverage EnhancmentMarket Segment EnhancementOther
Change Type SS Y StandardProgram DefectProgram EnhancementProgram MaintnanceMarket Segment Change/Addition
Change Reason Change Type SS Y StandardProgram Defect
Poor RequirementsDesign FlawImplementation FlawPoor VerificiationOther
Program EnhancementPlannedUnplanned
Program MaintnanceBinning changesData CollectionFuse RecipeOther
Market Segment Change/AdditionChangeAddition
Table 2: Table of Required Program Change Data Requirements.
Each classification was discussed separately, so that we might discern if there was
any overlap between each of the classifications. During this discussion, it was
33

highlighted that overlap only existed between the “Business Market” and “New
Development” classifications, since most new development is only triggered by a planned
change in the market segment. So we agreed to remove the “New Development”
classification to eliminate this overlap and decrease the amount of confusion these fields
might generate. In addition, we wanted the user to be very clear about the type of change
they needed to implement.
The “Program Release” system turned out to be the simplest in terms of defining
required data fields. The data fields of most interest by the ATE group were the
“Expected Release & Production Date” which is set before the program is actually
released for initial verification. In addition, a geographical site (SGP, Dresden, AMKOR,
SHZ) field was added for reporting purposes. In fact no data requirements were gathered
for the “Program Release” that might prove useful for later process improvements. With
that in mind, we added two numeric field types: L_Patch and R_Patch. The “L_Patch”
field is only exposed once a program release has been released for verification, while the
“R_Patch” field is only exposed once a program has been put into production. Team
Track has the ability to setup simple math calculations for numeric fields. These
calculations can only be set during a transition and each transition must be setup
separately. Therefore, for the transitions that affect the “L_Patch” like “Release New L
Patch”, a calculation to increment the revision number by one was setup. The same
calculation is also setup for the “R_Patch” field and its corresponding transitions.
34

Field Members Type Required LocationProduct/Rev SS Y Standard
K8D StandardK8E StandardK8F StandardK8G StandardGH StandardGR Standard
Family SS Y StandardSHDHSDHBHJH
Package MS Y Standard754939940S1AM2L1
Tester platform SS Y StandardSapphire - 4064Sapphire - QAATEJ973
Insertions MS Y StandardSORTICLPBIZeroCPMTFSTQAATE
Release Priority SS N UserHigh Med Low
Expected Release date Cal Y UserExpeced Production date (1st Site) Cal Y UserReleased at Site Check Y User
Table 3: Table of Required Program Release Data Requirements.
The desired effect is to be able to track the number of times a “Program Release”
is repeatedly patched before it gets into production, the duration each patch consumes,
and the associated changes that drive each patch. The same should be tracked for the R
patch field. These fields should allow for some simple process improvements targeted
for the “Program Release” system.
35

System Rollout
The final phase of the project is concluded once the process management system
has been made available to the entire organization. At which time the rate of user
adoption will be monitored during the Test Alignment Meetings. For this last phase, the
following software engineering principles were used: (4) people are the key to success;
and (5) take responsibility. Below is the breakdown of activity that will be described.
Training for ATE Team
Deployment into ATE Team
System Rollout
Figure 16: Third Phase of Development Process (Rollout).
Training the right people to use the process management system has already been
shown to be an effective tool for securing the confidence of the ATE group. Proper
documentation should allow the disjointed organizations to effectively utilize the system.
Once these parts of the development process are completed then the actual deployment of
the process management system should be simple.
TESTING: FINAL VERSION
With the BETA demonstrations completed and all feedback incorporated into the
final version, the system is ready for rollout. So a testing phase is needed to resolve the
remaining issues related to data collection, email notifications, training documentation
and reporting concerns. Below is the schedule used for rolling out the final system into
production.
36

Figure 17: AMD Rollout Schedule for the ATE Program Tracking System.
The testing phase was scheduled to last two weeks, which turned out to be plenty
of time for the “Team Leads” to investigate all the implemented features. There were
several bugs found with the notification rules, but these rules were quickly fixed. The
only email notification that required special attention was the pre-existing distribution list
used to notify all relevant manufacturing sites of when a program is released for
validation. The generic user account that was created to handle this notification needed
special user permissions in order for the notification rule to work correctly. The Serena
Software support team was needed to help resolve this specific problem. However, for
the most part the feedback was minor with respect to the scope of the previous changes.
37

TRAINING: PHASE ONE
The first phase of training was focused directly on the group of “Program
Owners” who use the “Program Release” part of the system. A pre-requisite for using the
“Program Request” and “Program Change” workflow is that there must be active
“Program Releases” available be linked with each item. To satisfy this pre-requisite, the
“Program Owners” entered their active program releases into the system as part of
training. While some program releases were already entered into the system for testing
purposes, that test data was cleared out of the database before training occurred. We
thoroughly expected mistakes to occur during training, so the “Delete” transition was
enabled for “Program Owners” to fix any mistakes. This training only took one hour to
complete, since a subset of these people had actually been beta users. Moreover, after a
week most program releases for ATE test platforms were successfully entered into the
system. The remaining program releases must be backfilled by “Program Owners” who
are not local to the AMD Austin site, which is the purpose of phase two of training.
Along with training on how to submit “Program Releases”, the “Program Owners” were
shown how the “Program Release” and “Program Change” system enforces the link
between a release and a request. A view of these instructions, along with the possible
linking configurations can be seen in Appendix D, E, and F. During this training session
we recommended that, an important part of user adoption involved the use of specific
Team Track listing reports in the pre-existing Test Alignment Meeting, which occurs
every week. It was our recommendation, based on past experience with groups
successfully adopting Team Track, that these listing reports be used to generate the Test
Alignment agenda. And that all new “Program Changes“ spawned from “Program
Requests” be created during this meeting. This should encourage usage between the
38

Team Track system and ATE personnel. It has been shown in the past that when
established meetings are driven by Team Track listing reports, that user adoption is
usually high.
TRAINING: PHASE TWO
The second phase of training involves training non-Austin ATE “Program
Owners” about how to access and use the “Program Release” system. Fortunately for us,
several ATE test engineers from Singapore and Dresden were visiting the Austin site
during this phase of rollout. Again the same training session was offered however this
session took over two hours to complete. The same recommendations were offered and
feedback from this group of ATE engineers focused more on the mechanics of the overall
Team Track system. They did request that more training documents be generated,
especially with respect to how to accomplish the linking between changes and releases.
Again this can be seen in Appendix D.
DEPLOYMENT: PHASE THREE
The third phase was the least defined part of the rollout plan, since many of the
external organizations could not be directly trained. Significant management support is
needed for this part of the rollout plan to succeed. Re-aligning the channels of
communication, that are currently used to deliver program requests, will have to be
disconnected. These external organizations will need to be notified by the ATE
management team that the only features implemented from this point forward will need
to be Team Track requests. Otherwise, the technical rollout occurred when all Team
Track users were added to the “Requestor” permission group. Documentation was also
generated along with listing reports to support the traceability of releases to requests.
39

Figure 18: Internal ATE Team Track Documentation.
40

Conclusion
SUMMARY
The explosive growth that Advanced Micro Devices is currently experiencing, has
generated problems with coordination and communication of work items. This problem
is compounded due the matrix (functional vs. product) style organization of the Product
Development Engineering division. Given the well documented benefits of work process
tracking systems, the actual implementation and utilization of such systems has yet to be
fully realized. The reason for this lack of realization is primarily due to the lack of
accurate requirements used in designing such a system. The ATE group requested such a
system to be developed many times before, knowing that they wanted to achieve a
measurable, repeatable, and predictable work process. But each time before, the lack of
accurate requirements either due to a lack of trust or lack of experience, resulted in
systems that were not adopted by the engineering community.
It is theorized in this case study that if given the opportunity to apply software
engineering principles for gathering accurate requirements. That the resulting process
management system designed would finally fulfill the known non-functional benefits of
usability, traceability and accountability. Thus successful rollout of the system would
occur throughout the organization. The software engineering principles followed
include: (1) determine the real problem before writing requirements; (2) use an
appropriate process model; (3) give products to customers early; (4) people are the key to
success; and (5) take responsibility.
41

SUCCESS
The results of the case study are actually surprising in how effective the resulting
system functioned. The final development model that was used, was found to be highly
effective in gathering accurate requirements from a chaotic organization.
FEEDBACK Questions for ATE Team
Collaboration With
ATE Team
PROTOTYPE
ALPHA
Training for ATE Team
BETA
Deployment into ATE
Organization
Figure 19: Final Development Process Used for System Development.
The time committed to such tasks proved to be highly effective, however the
downside to this was the large amount of time that had to be consumed. The single most
discussed problem with the development cycle that was used, was the amount of time it
took to develop the whole system. However even with this long development cycle, the
resultant system was immediately seen as a major success within the department. The
final consensus from most “Program Owners” was that the final model of the “Program
Release”, should be used by other software test program development teams. The ATE
group now views this a viable solution for aligning deployment methodology between the
outside development groups. The discovery of how critical is it to have a resource that
can be seen as the “Process Champion” within the organization. Also once listing reports
were generated that allowed the ATE group to view Requests traced all the way to
Releases, and Releases traced all the way back to Requests; the project as a whole was
deemed successful. Now the ATE group is using these listing reports to drive the agenda
42

of their Test Alignment Meetings. The actual user adoption rate has been very high, with
the exception of one platform team in Singapore, all “Program Owners” have adopted the
Team Track implementation. This lone team in Singapore is targeted for Team Track
training in the next quarter of the year. Collection of historical data will be an ongoing
process, as the ATE team discovers the multitude of possible analysis that can be mined
once enough history has been collected. It will be up to the ATE group to decide which
process improvements should get first priority, but the recommendation of the ESS
organization was to monitor the frequency of program release patches. The reduction
and/or stabilization of repeated patching activity is directly proportional to the quality of
the delivered test programs. On the whole, the Team Track implementation for the ATE
group is seen as a major win for the ESS group.
FUTURE WORK
Almost immediately after phase two was completed, the Manufacturing
Technology (MTECH) organization requested to know the feasibility of adapting the
current Team Track system, to expose all other teams within MTECH. This is the next
major evolution in the system. The flexible part of the design, will allow ESS to re-use
the “Program Request” and “Program Change” workflows. But for each new team
adapted to the system, a new “Program Release” workflow will need to be designed for
each specific new team. This should allow for a balance between re-use and
customization. The second major revision will include the adaptation of the system to
include “Engineering Development” of test programs. In general the adoption rate has
been the most surprising in how quickly the engineering community has adopted the
system. The end result is that the ATE group now has a measurable work process, that
can be repeated over many teams.43
Appendix A: Figure of AMD Matrix Organization
44

Appendix B: Initial Questionnaire for ATE Team
45

Appendix C: Questionnaire Feedback from ATE Team
46
47

48

49

Appendix D: Quick Guide for Manually Linking Releases
50

Appendix E: Figure of One to One Program Change to Release Link
51

Appendix F: Figure of Multi-Effect Program Change to Release Link
52

Bibliography
[1] A.M. Davis, “Fifteen principles of software engineering.”, Software, IEEE, Volume 11, Issue 6, Nov. 1994 Page(s):94 - 96, 101.
[2] Ali, S.; Soh, B.; Torabi, T.; “Using Software Engineering Principles to Develop Reusable Business Rules.”, Information and Communication Technologies, 2005. ICICT 2005. First International Conference on 27-28 Aug. 2005 Page(s):276 – 283.
[3] Robert B. Grady, “Practical Software Metrics For Project Management and Process Improvement.”, Prentice Hall PTR, Upper Saddle River, N.J., 1992.
[4] Wolfhart B. Goethert, Elizabeth K. Bailey, Mary B. Busby, “Software Effort & Schedule Measurement: A Framework for Counting Staff-hours and Reporting Schedule Information.”, Technical Report, Software Engineering Institute, Carnegie Mellon University, Pittsburgh, Pennsylvania, September 1992.
[5] J. Herbsleb, A. Carleton, J. Rozum, J. Siegel, and D.Zubrow, "Benefits of CMM-based Software Process Improvement: Initial Results," Software Engineering Institute, CMU/SEI-94-TR-13, 1994.
[6] A.B. Jakobsen, “Bottom up process improvement tricks”, Software, IEEE, Volume; 15, Issue 1, Jan.-Feb. 1998 pages: 64-68.
[7] Len Bass, Paul Clements, Rick Kazman. “Software Architecture in Practice”, Second Edition. Addison-Wesley. Boston, MA. 2003. p123.
[8] Shtub A., Bard J. and Globerson S. 1994. “Project Management – Engineering, Technology and Implementation”. Englewood Cliffs. Prentice-Hall.
[9] Dean Leffingwell and Don Widrig. “Managing Software Requirements: A Unified Approach”. Addison-Wesley, 2000.
53

Vita
David Andrew Falcon Ayala was born August 3rd, 1974 in Corpus Christi, Texas.
His parents are Amado Ayala Jr. of Corpus Christi, Texas and Patricia Falcon Ayala of
Corpus Christi, Texas. David attended The University of Texas at San Antonio (UTSA)
where he graduated with a B.S in Electrical Engineering in May of 1998.
David’s industry experience includes 8 years as a product development engineer
at Advanced Micro Devices, located in Austin, Texas. His primary responsibilities
include the development and maintenance of microprocessor yield analysis software as
well as general software support for the Product Development Engineering team.
Permanent address: 4512 Clarno Dr. Austin, TX 78749
This report was typed by David Andrew Falcon Ayala.
54






















![Report_Final [PDF Library]](https://img.pdfslide.net/doc/110x75/5477ef00b4af9f87108b4ab9/reportfinal-pdf-library.jpg)






