Embed Size (px)
Citation preview

Prof. Dr. Peter Chamoni - Datenbanksysteme - Wintersemester 2014/2015 1
Prof. Dr. Peter Chamoni
DatenbanksystemeKapitel 3: Datenorganisation
Mercator School of ManagementLehrstuhl für Wirtschaftsinformatik, insb. Business Intelligence
Prof. Dr. Peter Chamoni

Prof. Dr. Peter Chamoni – Datenbanksysteme 2
Gliederung
1 Grundlagen - Datenbanksysteme
2 SQL – Data Definition Language
4 Datenintegrität und Transaktionsverwaltung
5 SQL – Data Manipulation Language
6 Neue Konzepte der Datenbanktechnologie
3 Datenorganisation

Prof. Dr. Peter Chamoni – Datenbanksysteme 3
Gliederung
3 Datenorganisation
3.1 Grundlagen der Datenorganisation
3.2 Physische Datenorganisation - Speichersystem
3.3 Logische Datenorganisation - Zugriffssystem
3.4 Logische Datenorganisation - Zugriffsmethoden
3.5 Exkurs: Bäume
Prof. Dr. Peter Chamoni – Datenbanksysteme 4
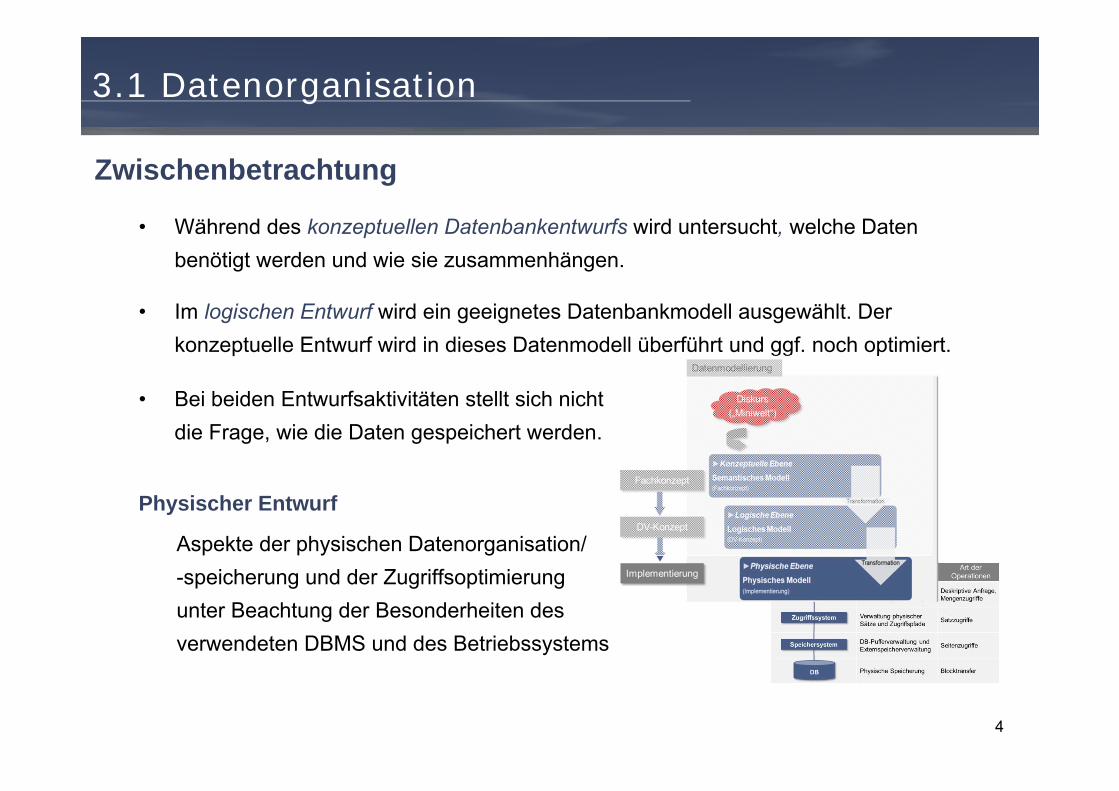
• Während des konzeptuellen Datenbankentwurfs wird untersucht, welche Daten benötigt werden und wie sie zusammenhängen.
• Im logischen Entwurf wird ein geeignetes Datenbankmodell ausgewählt. Der konzeptuelle Entwurf wird in dieses Datenmodell überführt und ggf. noch optimiert.
• Bei beiden Entwurfsaktivitäten stellt sich nicht die Frage, wie die Daten gespeichert werden.
Physischer Entwurf
Aspekte der physischen Datenorganisation/ -speicherung und der Zugriffsoptimierungunter Beachtung der Besonderheiten des verwendeten DBMS und des Betriebssystems
3.1 Datenorganisation
Zwischenbetrachtung

Prof. Dr. Peter Chamoni – Datenbanksysteme 5
3.1 Grundlagen der Datenorganisation
Zentrale Fragen im Rahmen des physischen Entwurfsprozesses
• Wie erfolgt die Abbildung der logischen Ebene auf die physische Ebene?
• Wie wird in einer Datenbank die Speicherung der Daten organisiert?
• Wie kann effizient auf diese gespeicherten Daten zugegriffen werden?
• Die Leistungsfähigkeit eines DBMS wird maßgeblich bestimmt durch
- die Daten- und Zugriffsstrukturen auf der physischen Ebene und
- die physische Speicherorganisation Hauptspeicher ↔ sekundäre Speichermedien
Einführung in die Datenorganisation (I)

Prof. Dr. Peter Chamoni – Datenbanksysteme
3.1 Grundlagen der Datenorganisation
Ziel der Datenorganisation
… ist es, Daten logisch so zu strukturieren und physisch so zu speichern, dass sie - einen schnellen Zugriff gestatten,
- leicht zu aktualisieren sind,
- sich beliebig auswerten und verknüpfen lassen sowie
- vor Verlust, Zerstörung und unbefugtem Zugriff geschützt sind.
• Außerdem soll ein effizientes Speichermanagement betrieben werden, das heißt
- eine dem tatsächlichen Bedarf angepasste Speicherkapazität und
- die Vermeidung von Redundanzen, d.h. der Mehrfachspeicherung derselben Daten.
6
Einführung in die Datenorganisation (II)
Effizienter Zugriff auf DatenEffizienter, sicherer
Zugriff auf Daten
Effizientes Speichermanagement

Prof. Dr. Peter Chamoni – Datenbanksysteme 7
3.1 Grundlagen der Datenorganisation
Arten der Datenorganisation
• Logische Datenorganisation
Gegenstand: (programmgesteuerte) Zugriffsformen auf Daten- Analyse und Strukturierung der Daten hinsichtlich
ihrer Zusammenhänge
- Festlegung von Zugriffspfaden auf diese Daten
• Physische Datenorganisation
Gegenstand: (hardwaremäßige) Speicherung von Daten
- Gesamtheit aller Verfahren und Vorschriften zur Aufbewahrung von Daten auf oder in Speichermedien
- Optimierung der physischen Speicherstruktur
- Zusammenhang zwischen Speichermedium und Zugriffsform
Einführung in die Datenorganisation (III)

Prof. Dr. Peter Chamoni – Datenbanksysteme 8
3.1 Grundlagen der Datenorganisation
Grundbegriffe der Datenorganisation (I)
Datenstrukturen
• Datenelement (Datenfeld)- Kleinste logische Dateneinheit, die aus einem oder mehreren Zeichen
besteht und nicht weiter zerlegbar ist.- Physisch wird ein Datenelement in einem
Datenfeld gespeichert.
• DatensatzGruppierung von inhaltlich zusammenhängen-den Datenelementen, die verschiedene Eigen-schaften desselben Objekts beschreiben.
• DateiLogische Zusammenfassung von Datensätzen mit gleicher Struktur
• Datenbank (i.w.S.)Zusammenfassung logisch zusammengehöriger Dateien

Prof. Dr. Peter Chamoni – Datenbanksysteme 9
3.1 Grundlagen der Datenorganisation
Datei
… ist eine Sammlung gleichartiger Datensätze, die primär zur dauerhaften Speicherung von Daten auf einem Speichermedium dient.
• Speicherung- Logischer Datensatz
• Datensatz aus inhaltlich zusammengehörigen Datenelementen
• „Elementareinheit“ einer Datei
- Physischer Datensatz (Seite, Block)• enthält einen oder mehrere logische Datensätze
• „Elementareinheit des Plattenspeichers“
Allgemein besteht eine Datei somit aus mehreren physischenDatensätzen (Seiten); jede Seite enthält einen oder mehrere logische Datensätze.
Grundbegriffe der Datenorganisation (II)

Prof. Dr. Peter Chamoni – Datenbanksysteme 10
3.1 Grundlagen der Datenorganisation
Datei
Grundbegriffe der Datenorganisation (III)
Physische Datensätze

Prof. Dr. Peter Chamoni – Datenbanksysteme 11
3.1 Grundlagen der Datenorganisation
Zentrale Fragen im Rahmen des physischen Entwurfsprozesses
• Wie erfolgt die Abbildung der logischen Ebene auf die physische Ebene?
Grundbegriffe der Datenorganisation (IV)
Saake, Heuer (1999, S. 19)

Prof. Dr. Peter Chamoni – Datenbanksysteme 12
Gliederung
3 Datenorganisation
3.1 Grundlagen der Datenorganisation
3.2 Physische Datenorganisation - Speichersystem
3.3 Logische Datenorganisation - Zugriffssystem
3.4 Logische Datenorganisation - Zugriffsmethoden
3.5 Exkurs: Bäume

Prof. Dr. Peter Chamoni – Datenbanksysteme 13
3.2 Physische Datenorganisation - Speichersystem
Zentrale Fragen im Rahmen des physischen Entwurfsprozesses
• Wie wird in einer Datenbank die Speicherung der Daten organisiert?
Einführung
Saake, Heuer (1999, S. 19)
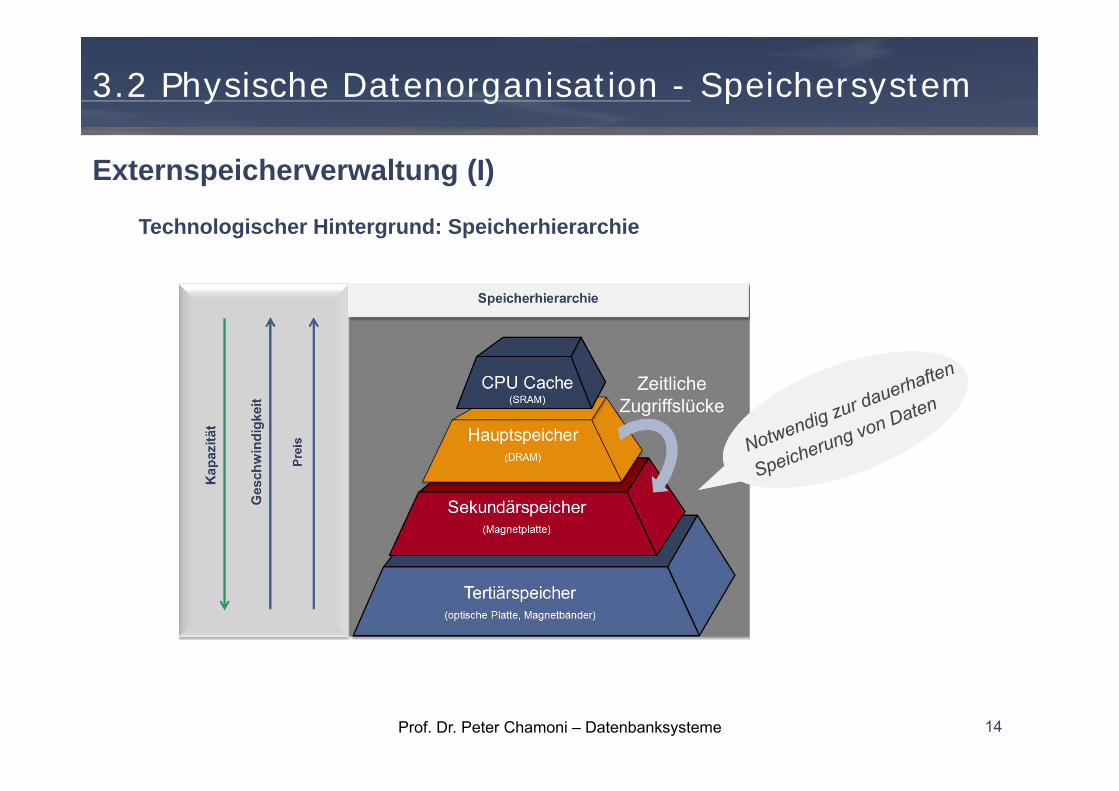
Prof. Dr. Peter Chamoni – Datenbanksysteme
Technologischer Hintergrund: Speicherhierarchie
14
3.2 Physische Datenorganisation - Speichersystem
Externspeicherverwaltung (I)
ZeitlicheZugriffslücke

Prof. Dr. Peter Chamoni – Datenbanksysteme
Sekundärspeicher – Aufbau von Plattenspeichern (1)
Logischer Aufbau
• Direkter Zugriff über logische Seitennummern
• Diese werden vom Betriebssystem oder Platten-Controller auf die physische Adresse (Zylinder-Nr | Spur-Nr | Sektor-Nr) transformiert.
Physischer Aufbau
• Eine Reihe übereinanderliegender, rotierender Magnetplatten
• Strukturierung:Sektor → Spur → Zylinder (übereinanderliegende Spuren)
• Seite: eine Reihe zusammenhängender Sektoren auf einer bestimmten Spur
15
3.2 Physische Datenorganisation - Speichersystem
Externspeicherverwaltung (II)
Seite
Physischer AdressraumPhysischer Adressraum

Prof. Dr. Peter Chamoni – Datenbanksysteme
Sekundärspeicher – Aufbau von Plattenspeichern (2)
• Auf physischer Ebene: blockorientierte (seitenorientierte) Aufzeichnung und Zugriff
• Seite ist die kleinste Transfereinheit, die zwischen Haupt- und Sekundärspeicher übertragen wird.
• Wahlfreier Zugriff
• Typische Blockgrößen (block size, page size): 512 Byte,1k, 2k, 4k, …
• Eine Datei verteilt sich je nach Größe auf mehrere Seiten; jede Datei nutzt eine Seite exklusiv, d.h. auf einer Seite befinden sich nur logische Datensätze dieser Datei.
16
3.2 Physische Datenorganisation - Speichersystem
Externspeicherverwaltung (III)
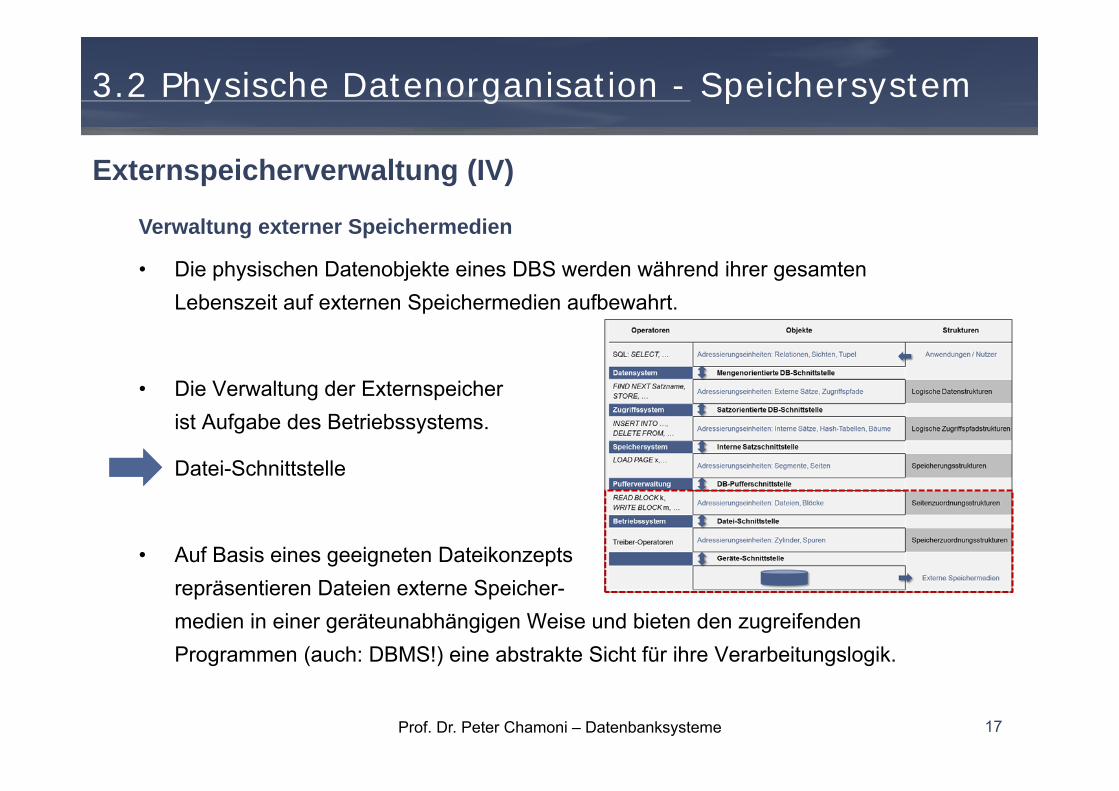
Prof. Dr. Peter Chamoni – Datenbanksysteme
Verwaltung externer Speichermedien
• Die physischen Datenobjekte eines DBS werden während ihrer gesamten Lebenszeit auf externen Speichermedien aufbewahrt.
• Die Verwaltung der Externspeicherist Aufgabe des Betriebssystems.
• Datei-Schnittstelle
• Auf Basis eines geeigneten Dateikonzepts repräsentieren Dateien externe Speicher-medien in einer geräteunabhängigen Weise und bieten den zugreifenden Programmen (auch: DBMS!) eine abstrakte Sicht für ihre Verarbeitungslogik.
17
3.2 Physische Datenorganisation - Speichersystem
Externspeicherverwaltung (IV)

Prof. Dr. Peter Chamoni – Datenbanksysteme
Datenbankmanagementsystem
Wichtigstes Ziel
• Transfer von Daten zwischen Hauptspeicher und Plattenspeicher möglichst effizient gestalten:
- optimieren/minimieren der Anzahl der Zugriffe
- Anzahl der Blöcke minimieren
- so viel Blöcke wie möglich im Hauptspeicher halten (→ Puffer Manager)
• Hauptspeicherbereiche des DBMS so angepasst, dass sich die Anzahl physischer Zugriffe auf die sekundären Speichermedien minimiert.
18
3.2 Physische Datenorganisation - Speichersystem
DB-Pufferverwaltung
Externspeicher
Hauptspeicher

Prof. Dr. Peter Chamoni – Datenbanksysteme 19
Gliederung
3 Datenorganisation
3.1 Grundlagen der Datenorganisation
3.2 Physische Datenorganisation - Speichersystem
3.3 Logische Datenorganisation - Zugriffssystem
3.4 Logische Datenorganisation - Zugriffsmethoden
3.5 Exkurs: Bäume

Prof. Dr. Peter Chamoni – Datenbanksysteme 20
3.3 Logische Datenorganisation - Zugriffssystem
Zentrale Fragen im Rahmen des physischen Entwurfsprozesses
• Wie kann effizient auf die gespeicherten Daten zugegriffen werden?
Einführung (I)
Interne (logische) Datenstrukturen

Prof. Dr. Peter Chamoni – Datenbanksysteme 21
3.3 Logische Datenorganisation - Zugriffssystem
Einordnung
• Das Speichersystem fordert von der DB-Pufferschnittstelle „Seiten“ an und interpretiert diese Seiten als „interne Datensätze“.
• „Interne Datensätze“ stellen die interne Realisierung von logischen Datensätzen mit Hilfe
- von Zeigern,
- speziellen Indexeinträgen
- und weiteren Hilfsstrukturen dar.
• Diese „internen Datensätze“ werden an das Zugriffssystem weitergereicht.
• Das Zugriffssystem wiederum abstrahiert von der konkreten Realisierung einer Speicherstruktur und geht von „logischen“ Datensätzen in Dateien aus.
Einführung (II)
Prof. Dr. Peter Chamoni – Datenbanksysteme 22
3.3 Logische Datenorganisation - Zugriffssystem
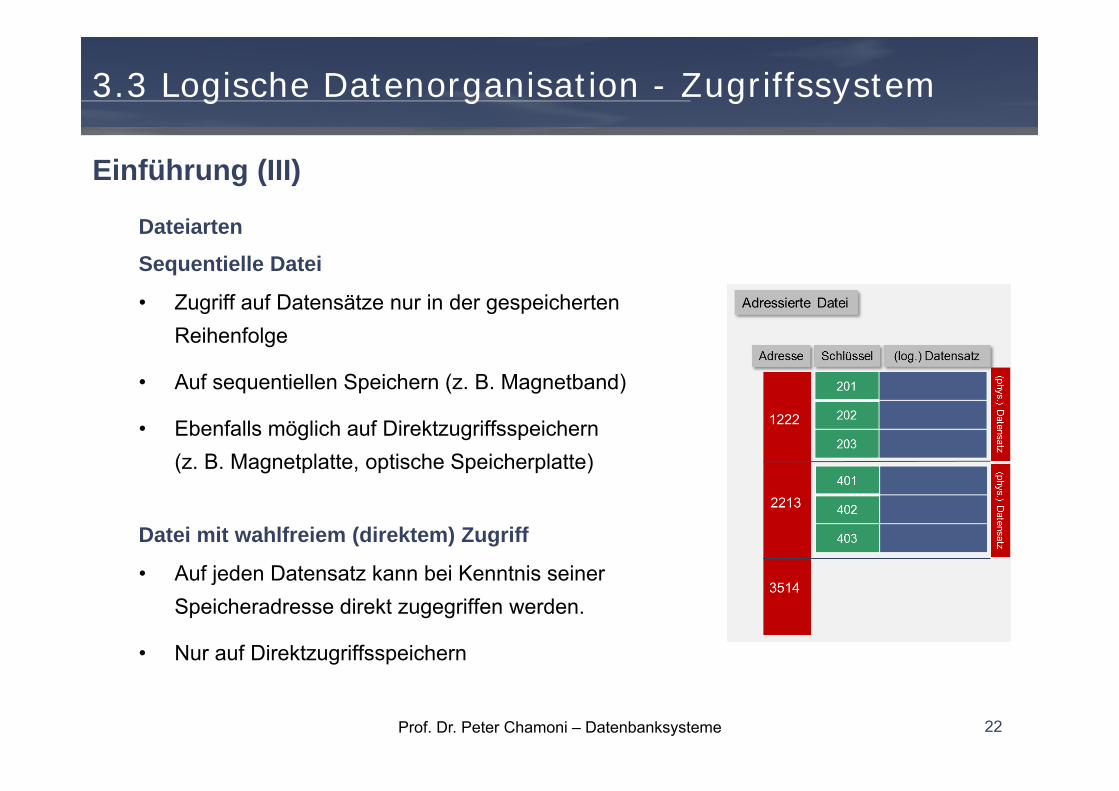
Dateiarten
Sequentielle Datei
• Zugriff auf Datensätze nur in der gespeicherten Reihenfolge
• Auf sequentiellen Speichern (z. B. Magnetband)
• Ebenfalls möglich auf Direktzugriffsspeichern (z. B. Magnetplatte, optische Speicherplatte)
Datei mit wahlfreiem (direktem) Zugriff
• Auf jeden Datensatz kann bei Kenntnis seiner Speicheradresse direkt zugegriffen werden.
• Nur auf Direktzugriffsspeichern
Einführung (III)

Prof. Dr. Peter Chamoni – Datenbanksysteme 23
3.3 Logische Datenorganisation - Zugriffssystem
• Dateioperationen- Einfügen eines Datensatzes
- Löschen eines Datensatzes
- Modifizieren eines Datensatzes
- Suchen und Finden eines Datensatzes
• Zugriff auf Datensätze
Datensätze können in einer Datei - geordnet oder
- gehashed (gestreut)
gespeichert sein. Diese Anordnung bestimmt mögliche Zugriffsformen.
Einführung (IV)

Prof. Dr. Peter Chamoni – Datenbanksysteme 24
3.3 Logische Datenorganisation - Zugriffssystem
Zugriffsformen
• Ermöglichung des direkten Zugriffs auf die logischen Datensätze anhand bestimmter Eigenschaften
- i.d.R Attributwerte- z.B. Primärschlüssel
• Verfügbarkeit einer speziellen internen Datei, der Indexdatei. Diese enthält
- Zugriffskriterium („Suchschlüssel“) und
- Adressverweise auf die Datensätze
• Im Falle einer Indexdatei ist somit der Zugriffspfad auf die Datensätze einer Datei selber eine Datei.
Einführung (V)
[vgl.: Zehnder (2005), S. 222]
„Zugriffspfad“
Prof. Dr. Peter Chamoni – Datenbanksysteme 25
3.3 Logische Datenorganisation - Zugriffssystem
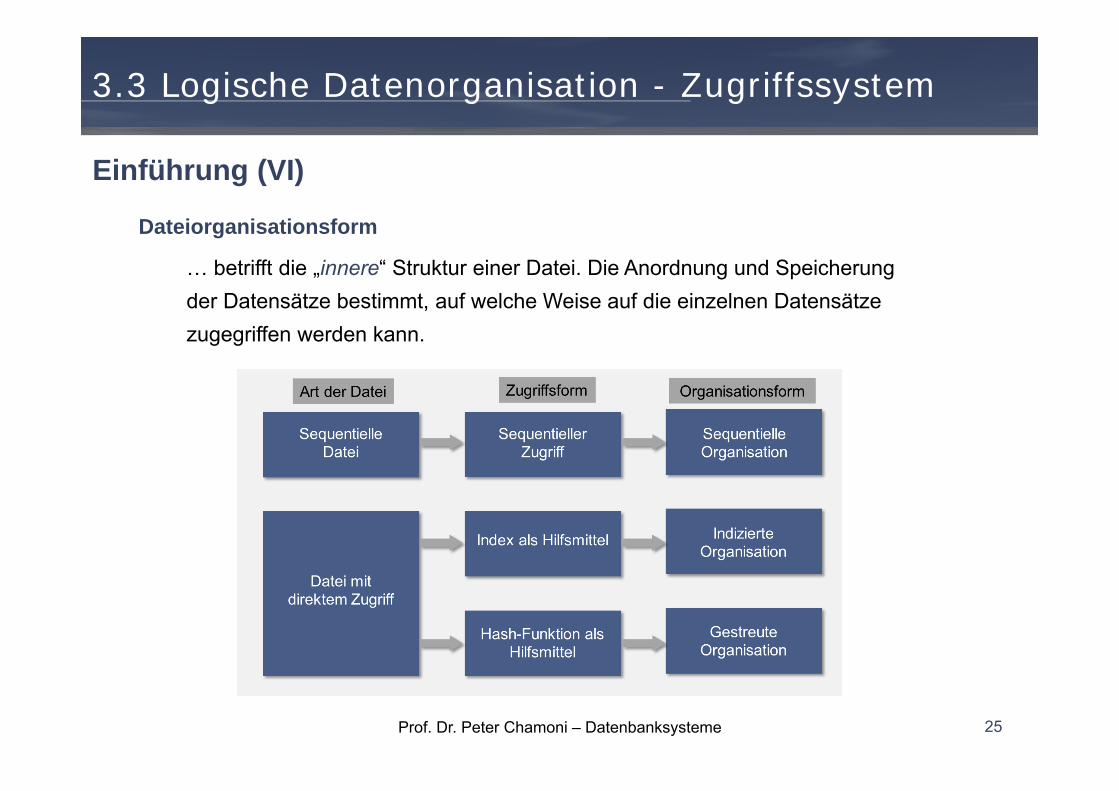
Einführung (VI)
Dateiorganisationsform
… betrifft die „innere“ Struktur einer Datei. Die Anordnung und Speicherung der Datensätze bestimmt, auf welche Weise auf die einzelnen Datensätze zugegriffen werden kann.

Prof. Dr. Peter Chamoni – Datenbanksysteme 26
3.3 Logische Datenorganisation - Zugriffssystem
Sequentielle Dateiorganisation
• Speicherungsform
Die Datensätze sind hintereinander fortlaufend abgelegt. Dieses kann in zwei Formen geschehen:
• unsortiert Sätze werden in der Reihenfolge ihrer Eingabe gespeichert.
• sortiertDateien sind nach einem Sortierkriterium entweder auf-oder absteigend sortiert. Neue Sätze müssen dann an der entsprechenden Stelle eingefügt werden. (nur möglich auf Speichermedien mit direktem Zugriff)
• Zugriffsform
Sequentieller Zugriff, d.h. Datensätze können nur in einer bestimmten Reihenfolge angesprochen werden.
Dateiorganisationsformen (I)
Sortierschlüssel
Zeiger

Prof. Dr. Peter Chamoni – Datenbanksysteme 27
3.3 Logische Datenorganisation - Zugriffssystem
Indizierte Dateiorganisation
• Speicherungsform
Die Datensätze sind sequentiell unter fortlaufender Adresse in der Datei gespeichert. Dieser sequentiellen Hauptdatei werden eine oder mehrere Indexdateienvorangestellt.
• Zugriffsform
In der Indexdatei (Index) sind - der Suchschlüssel (Indexschlüssel) als Zugriffskriterium und
- der Verweis auf die Speicheradresse des jeweiligen Datensatzes
abgelegt. Der Zugriff auf die Datensätze in der Hauptdatei erfolgt indirekt über die Indexdatei.
Dateiorganisationsformen (II)

Prof. Dr. Peter Chamoni – Datenbanksysteme 28
3.3 Logische Datenorganisation - Zugriffssystem
Gestreute Dateiorganisation (Hash)
• Speicherungsform
Die Datensätze liegen „verstreut“ und voneinander unabhängig im Speicherbereich.Die Zuordnung von Schlüssel zur Speicheradresse der Datensätzeerfolgt über eine Rechenvorschrift,der sog. Hash-Funktion.
• Zugriffsform
Beim „Hashing“ wird mit Hilfe einer Hashfunktion der Schlüssel eines Datensatzes auf die Seitenadresse abgebildet (Hashwert). Auf jeden Datensatz kann bei Kenntnis dieses Hashwerts direkt zugegriffen werden.
Dateiorganisationsformen (III)

Prof. Dr. Peter Chamoni – Datenbanksysteme 29
Gliederung
3 Datenorganisation
3.1 Grundlagen der Datenorganisation
3.2 Physische Datenorganisation - Speichersystem
3.3 Logische Datenorganisation - Zugriffssystem
3.4 Logische Datenorganisation - Zugriffsmethoden
3.5 Exkurs: Bäume

Prof. Dr. Peter Chamoni – Datenbanksysteme 30
3.4 Logische Datenorganisation - Zugriffsmethoden
• Kombination von sequentieller Hauptdatei und Indexdatei (zweistufige Struktur)
• Definition eines Index über ein (Zugriffs-) Attribut, den sog. Suchschlüssel
Indexarten
• Primärindexenthält den eindeutigen Primärschlüssel als „Suchschlüssel“ und den Verweis auf Datensatz.
• Sekundärindexenthält ein Nicht-Schlüsselattribut als „Suchschlüssel“ sowie einen Verweis auf den Datensatz.
SQL-Syntax
Indexsequentielle Dateiorganisation (I)
CREATE INDEX <Indexbezeichnung>
ON <Tabellenname> (<„Suchschlüssel“> [ASC|DESC]);
CREATE INDEX <Indexbezeichnung>
ON <Tabellenname> (<„Suchschlüssel“> [ASC|DESC]);

Prof. Dr. Peter Chamoni – Datenbanksysteme
3.4 Logische Datenorganisation - Zugriffsmethoden
Indexdatei
Realisierung des Index als
• Unsortierte Datei
• Sortierte Datei - Physisch sortierter Index
- Logisch sortierter Index
31
Indexsequentielle Dateiorganisation (II)
unsortiert
sortiert

Prof. Dr. Peter Chamoni – Datenbanksysteme 32
3.4 Logische Datenorganisation - Zugriffsmethoden
Indexsequentielle Dateiorganisation (III)
Physisch-sortierter Index
• Die Sortierreihenfolge der Indexeinträge in der Indexdatei entspricht der physischen Reihenfolge dieser Datensätze im Speicher.
• „sequentielle Liste“
• Suchverfahren bei physisch-sortiertem Index z.B.
- Binäres Suchen
- m-Wege-Suchen (2-stufiger Index)

Prof. Dr. Peter Chamoni – Datenbanksysteme 33
3.4 Logische Datenorganisation - Zugriffsmethoden
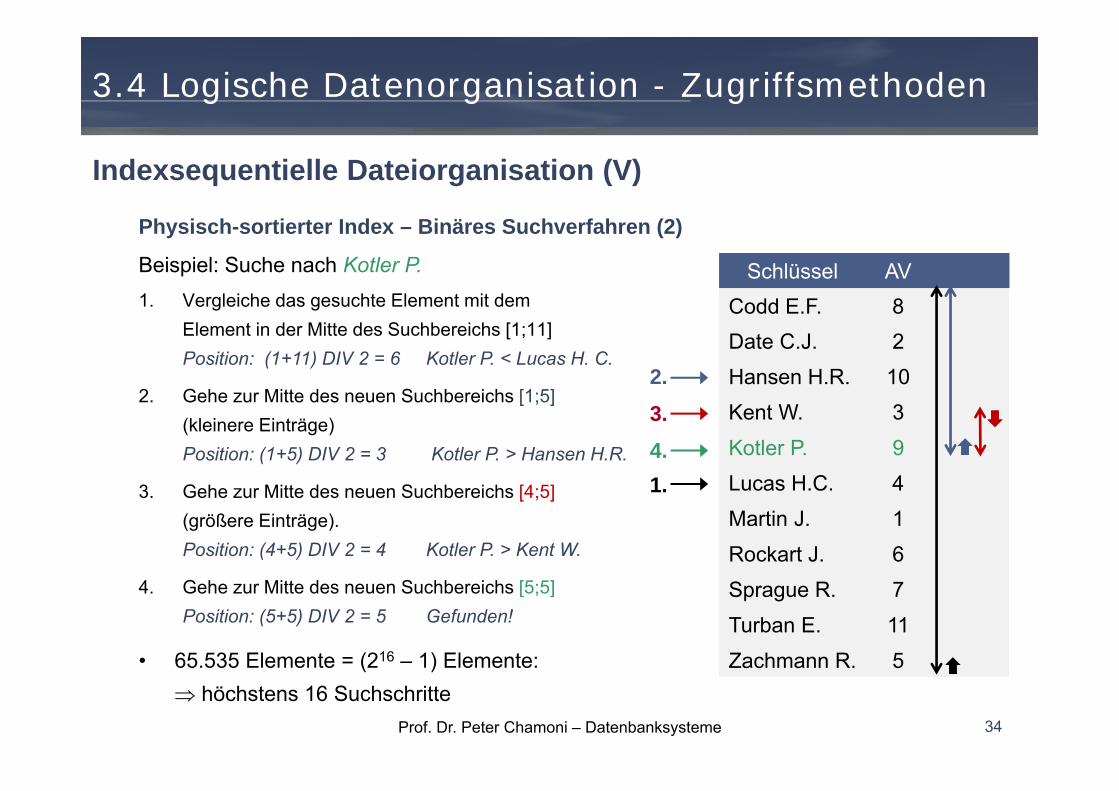
Physisch-sortierter Index – Binäres Suchverfahren (1)Verfahren
Ein wiederholtes Halbieren des Suchbereichs, des Intervalls [l;r]
• Annahme Das gesuchte Element liegt in der Mitte des Indexbereiches: m = (l+r) DIV 2
→ Vergleich des gesuchten Elements mit dem Element in der Mitte.
• Ist dieses Element größer als das gesuchte Element, wird die Suche in der oberen Hälfte des Index fortgesetzt: Suchbereich [l; m-1]
• Ist dieses Element kleiner als das gesuchte Element, wird die Suche in der unteren Hälfte des Index fortgesetzt: Suchbereich [m+1; r]
• Die Suche wird so lange fortgesetzt, bis das gesuchte Element gefunden wurde oder die Länge des Suchbereichs = 1 ist.
Indexsequentielle Dateiorganisation (IV)
Prof. Dr. Peter Chamoni – Datenbanksysteme 34
3.4 Logische Datenorganisation - Zugriffsmethoden
Physisch-sortierter Index – Binäres Suchverfahren (2)
Beispiel: Suche nach Kotler P.1. Vergleiche das gesuchte Element mit dem
Element in der Mitte des Suchbereichs [1;11]Position: (1+11) DIV 2 = 6 Kotler P. < Lucas H. C.
2. Gehe zur Mitte des neuen Suchbereichs [1;5](kleinere Einträge)Position: (1+5) DIV 2 = 3 Kotler P. > Hansen H.R.
3. Gehe zur Mitte des neuen Suchbereichs [4;5](größere Einträge).Position: (4+5) DIV 2 = 4 Kotler P. > Kent W.
4. Gehe zur Mitte des neuen Suchbereichs [5;5]Position: (5+5) DIV 2 = 5 Gefunden!
• 65.535 Elemente = (216 – 1) Elemente: höchstens 16 Suchschritte
Indexsequentielle Dateiorganisation (V)
Schlüssel AVCodd E.F. 8Date C.J. 2Hansen H.R. 10Kent W. 3
Kotler P. 9Lucas H.C. 4Martin J. 1
Rockart J. 6Sprague R. 7Turban E. 11
Zachmann R. 5
2.3.4.1.

Prof. Dr. Peter Chamoni – Datenbanksysteme 35
3.4 Logische Datenorganisation - Zugriffsmethoden
Physisch-sortierter Index – m-Wege Suchverfahren (1)Verfahren
Die Indexdatei wird in Blöcke konstanter Länge eingeteilt. (hier: Indexstufe 2)
1. Ermittlung des Datenblocks, in dem sich der Suchschlüssel befindet.- Gehe zum letzten Element des ersten Blocks.
- Falls der Suchschlüssel größer ist als dieses Element: Gehe zum nächsten Block.
- Andernfalls befindet sich das gesuchte Element in diesem Block.
2. Zur Suche des Schlüssels im gefundenen Block wird i.d.R. ein anderes Suchverfahren verwendet, z.B.
- Sequentielle Suche
- Binäre Suche u.w.
Indexsequentielle Dateiorganisation (VI)
Index:Stufe 1
Index:Stufe 2

Prof. Dr. Peter Chamoni – DatenbanksystemeAV = Adressverweis, RA = Relative Adresse 36
3.4 Logische Datenorganisation - Zugriffsmethoden
Indexsequentielle Dateiorganisation (VII)
RA Schlüssel AVHauptdatei
1 Codd E.F. 8
2 Date C.J. 2
3 Hansen H.R. 10
4 Kent W. 3
5 Kotler P. 9
6 Lucas H.C. 4
7 Martin J. 1
8 Rockart J. 6
9 Sprague R. 7
10 Turban E. 11
11 Zachmann R. 5
Hauptdatei
Schlüssel AVIndex 2
Kent W. 4
Rockart J. 8
Zachmann R. 11
Physisch-sortierter Index – m-Wege Suchverfahren (2)
Beispiel: mit einem 2-stufigen, hierarchischen Index
Index: Stufe 1 Index: Stufe 2Verweis auf das
letzte Element im jeweiligen Block
z.B. BinäreSuche
z.B. BinäreSuche

Prof. Dr. Peter Chamoni – Datenbanksysteme 37
3.4 Logische Datenorganisation - Zugriffsmethoden
Logisch-sortierter Index (1)
• Die Reihenfolge der Indexeinträge wird über Zeiger festgelegt, nichtdurch die physische Reihenfolge der Datensätze im Speicher.
• „gekettete Liste“
• Suchverfahren
- Verfahren: Sequentielle SucheZugriffspfad: Ketten (Chaining)Die Reihenfolge der Indexeinträge wird über einen Zeiger auf die physische Adresse des nächsten Indexeintrags festgelegt.
- Verfahren: BaumverfahrenZugriffspfad: BaumstrukturDie Reihenfolge der Indexeinträge wird über Zeiger auf die nach-folgenden Datensätze festgelegt.
Indexsequentielle Dateiorganisation (VIII)

Prof. Dr. Peter Chamoni – Datenbanksysteme 38
3.4 Logische Datenorganisation - Zugriffsmethoden
Logisch-sortierter Index (2) - Ketten
• (Adress-) Verkettung
Innerhalb eines Datensatzes verweist ein Zeiger (pointer) auf die physische Adresse des nachfolgenden Satzes (Nachfolger).
• Der Zeiger des letzten Datensatzes wird besonders gekennzeichnet:
entweder durch einen „Ende-Vermerk“
oder durch einen Verweis auf die Adresse des ersten Satzes der Kette.
• Der Zeiger auf den 1. Satz heißt Anker.
Indexsequentielle Dateiorganisation (IX)
Prof. Dr. Peter Chamoni – Datenbanksysteme 39
3.4 Logische Datenorganisation - Zugriffsmethoden
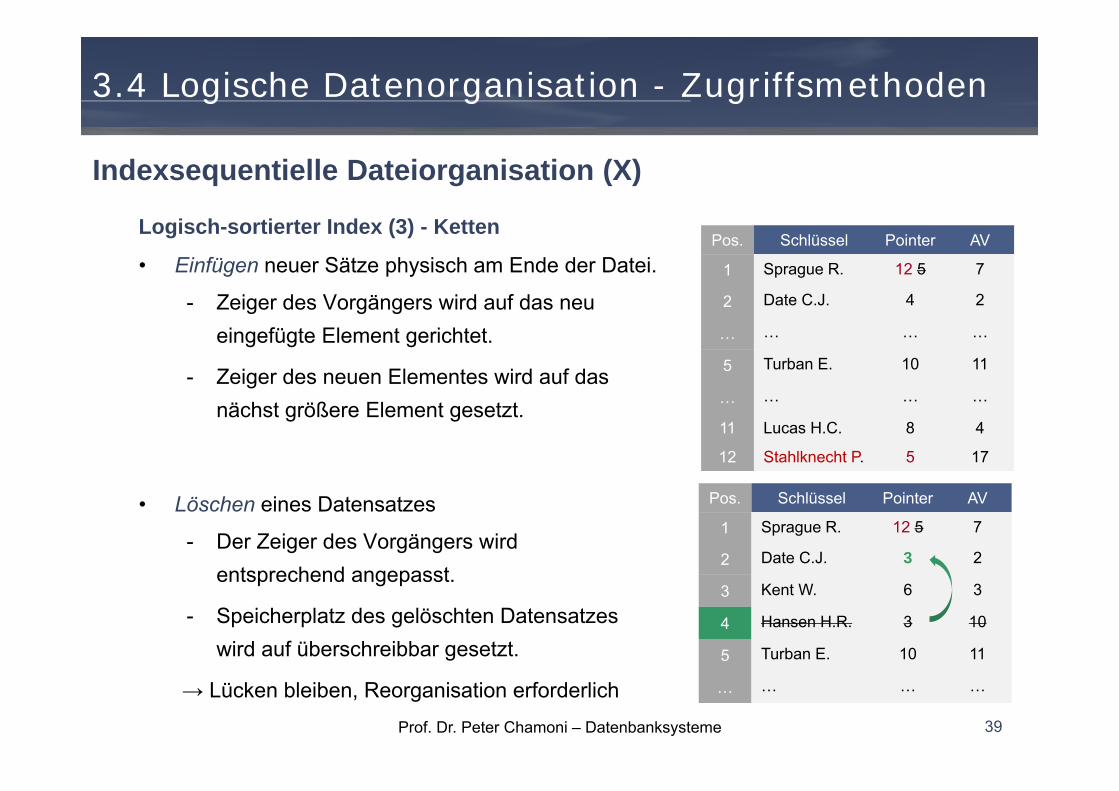
Logisch-sortierter Index (3) - Ketten
• Einfügen neuer Sätze physisch am Ende der Datei.
- Zeiger des Vorgängers wird auf das neu eingefügte Element gerichtet.
- Zeiger des neuen Elementes wird auf das nächst größere Element gesetzt.
• Löschen eines Datensatzes
- Der Zeiger des Vorgängers wird entsprechend angepasst.
- Speicherplatz des gelöschten Datensatzes wird auf überschreibbar gesetzt.
→ Lücken bleiben, Reorganisation erforderlich
Indexsequentielle Dateiorganisation (X)
Pos. Schlüssel Pointer AV
1 Sprague R. 12 5 7
2 Date C.J. 4 2
… … … …
5 Turban E. 10 11
… … … …
11 Lucas H.C. 8 4
12 Stahlknecht P. 5 17
Pos. Schlüssel Pointer AV
1 Sprague R. 12 5 7
2 Date C.J. 3 2
3 Kent W. 6 3
4 Hansen H.R. 3 10
5 Turban E. 10 11
… … … …
Prof. Dr. Peter Chamoni – Datenbanksysteme 40
3.4 Logische Datenorganisation - Zugriffsmethoden
Indexsequentielle Dateiorganisation (XI)
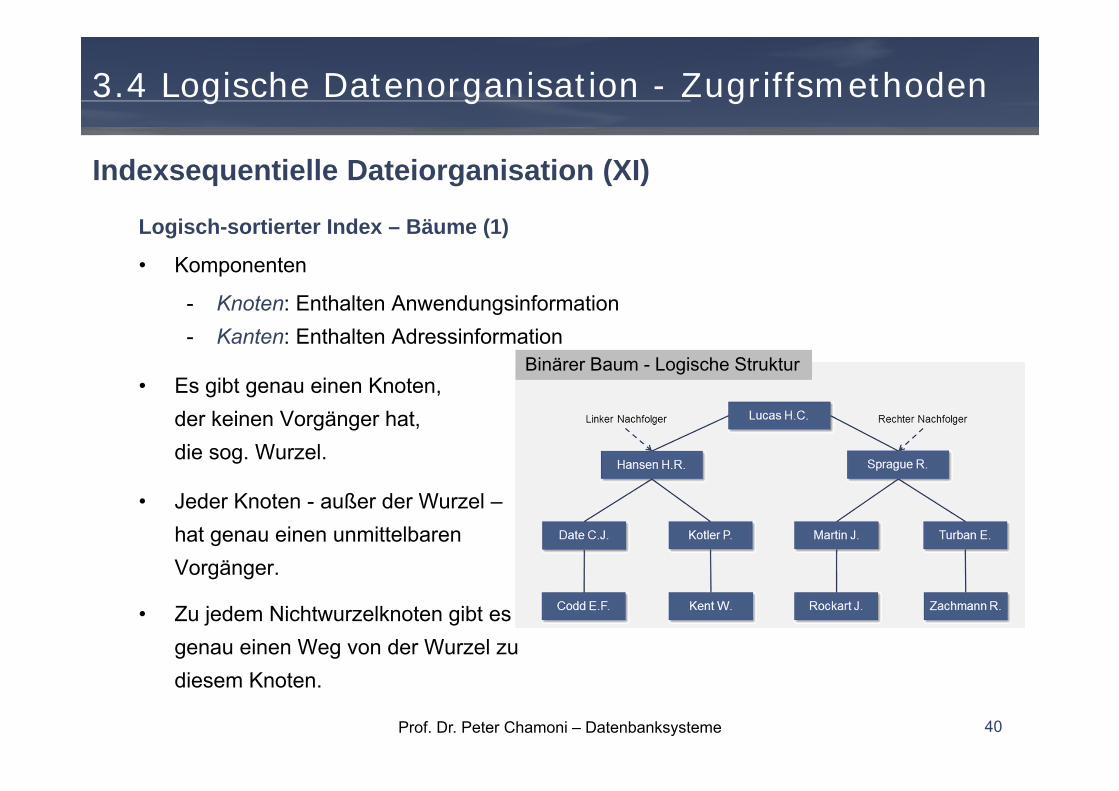
Logisch-sortierter Index – Bäume (1)
• Komponenten
- Knoten: Enthalten Anwendungsinformation- Kanten: Enthalten Adressinformation
• Es gibt genau einen Knoten, der keinen Vorgänger hat, die sog. Wurzel.
• Jeder Knoten - außer der Wurzel –hat genau einen unmittelbaren Vorgänger.
• Zu jedem Nichtwurzelknoten gibt esgenau einen Weg von der Wurzel zu diesem Knoten.
Binärer Baum - Logische Struktur

Prof. Dr. Peter Chamoni – Datenbanksysteme 41
3.4 Logische Datenorganisation - Zugriffsmethoden
Indexsequentielle Dateiorganisation (XII)
KF li = linkes Kettenfeld, KF re = rechtes Kettenfeld, AV = Adressverweis
Binärer Baum - Logische Struktur Binärer Baum – Physische Repräsentation
Logisch-sortierter Index – Bäume (2)
Prof. Dr. Peter Chamoni – Datenbanksysteme
3.4 Logische Datenorganisation - Zugriffsmethoden
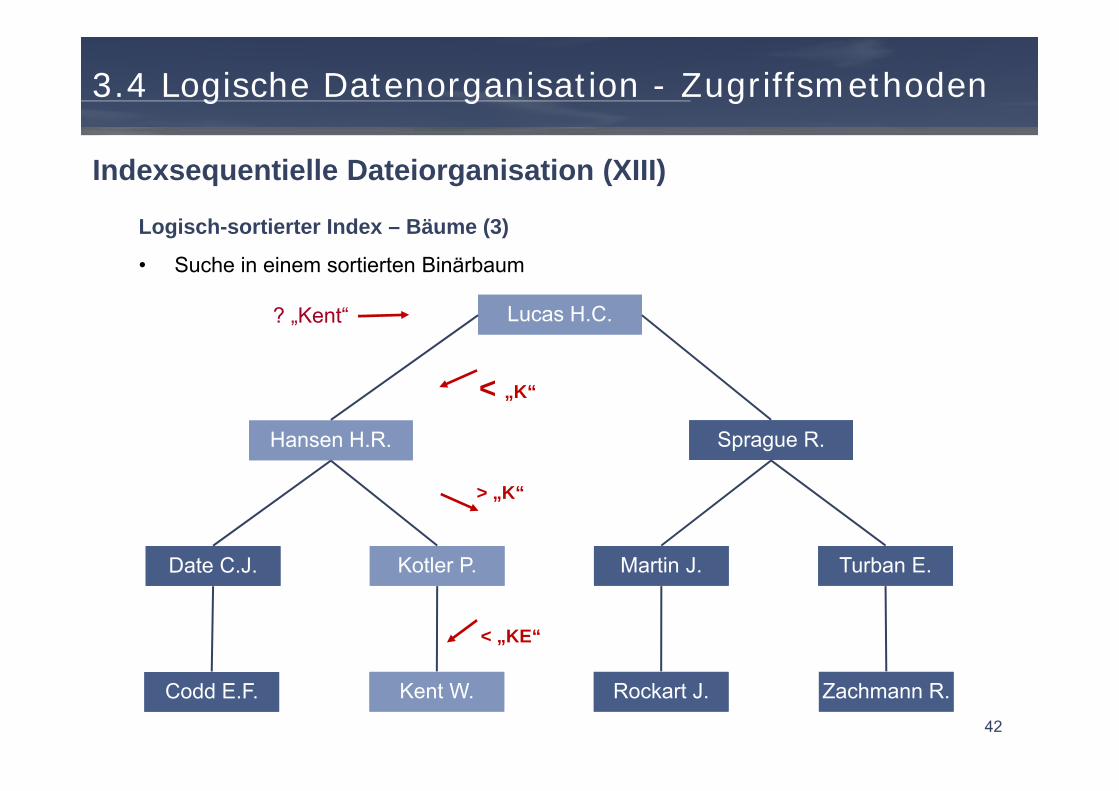
Indexsequentielle Dateiorganisation (XIII)
Lucas H.C.Lucas H.C.
Date C.J.Date C.J. Kotler P.Kotler P. Martin J.Martin J. Turban E.Turban E.
Hansen H.R.Hansen H.R. Sprague R.Sprague R.
Kent W.Kent W. Rockart J.Rockart J.
? „Kent“
< „K“
> „K“
< „KE“
Logisch-sortierter Index – Bäume (3)
• Suche in einem sortierten Binärbaum
Codd E.F.Codd E.F. Zachmann R.Zachmann R.42

Prof. Dr. Peter Chamoni – Datenbanksysteme 43
3.4 Logische Datenorganisation - Zugriffsmethoden
Hash-Verfahren (1)Prinzip
• Vorgegeben: ein Array fester Größe, das die Datensätze speichern soll (Hashtabelle)
• Eine Hash-Funktion berechnet für jeden Datensatz auf Basis des Zugriffsschlüssels die Speicheradresse im Array.
• Die Hash-Funktion basiert nur auf dem Wert des Zugriffsschlüssels.
• Als Ergebnis kann die Speicherstelle eines Datensatzes mit einem einzigen Zugriff gelesen werden.
Gestreute Dateiorganisation (I)
Divisions-Rest-Methode:h(k) = k mod m

Prof. Dr. Peter Chamoni – Datenbanksysteme 44
3.4 Logische Datenorganisation - Zugriffsmethoden
Hash-Verfahren (2)
• Schlüsseltransformation: Speicheradresse wird aus dem Schlüssel berechnet
Problem: Welche Funktion soll zur Berechnung verwendet werden?
• Eine Hash-Funktion sollte folgendes leisten:
- Die Wahrscheinlichkeit von Kollisionen für typische Mengen von Zugriffsschlüsseln minimieren.I.d.R. weniger Speicheradressen als mögliche Zugriffsschlüssel;Da die Hash-Funktion keine Daten über bereits gespeicherte Sätze nutzen kann,
können Mehrfachbelegungen (Kollisionen) prinzipiell nicht vermieden werden.
- Das Hash-Verfahren muss eine Kollisionsstrategie realisieren, die bei einer Mehrfachbelegung die Speicherung der Datensätze ermöglicht, denen eine bereits besetzte Speicherstelle zugeordnet wurde.
Gestreute Dateiorganisation (II)

Prof. Dr. Peter Chamoni – Datenbanksysteme 45
3.4 Logische Datenorganisation - Zugriffsmethoden
Hash-Verfahren (3)Beispiel für die Anwendung eines Hash-Algorithmus
I. Bestimmung des Schlüsselwerts
• Schlüssel Autor (alphabetisch, 10 Zeichen)
- Z.B. Suche nach "HANSEN…"
- Zeichen: |H| |A| |N| |S| |E| |N| | | | | | | | |
- EBCDIC: 200 193 213 226 197 213 64 64 64 64
• Wert = 200 * 2.569 + 193 * 2.568 + 213 * 2.567 + 226 * 2.566 + 197 * 2.565 + 213 * 2.564 + 64 * 2.563 + 64 * 2.562 + 64 * 2.561 + 64 * 2.560
= 94.804.893.278.549.498.118.208
Gestreute Dateiorganisation (III)

Prof. Dr. Peter Chamoni – Datenbanksysteme 46
3.4 Logische Datenorganisation - Zugriffsmethoden
Hash-Verfahren (4)Fortsetzung des Beispiels für die Anwendung eines Hash-Algorithmus
II. Hash-Verfahren• Vorgabe: Größe des Arrays (Hashtabelle): 1117 relative Adressen
• Hash-Funktion (Divisions-Rest-Methode)Zuordnung des Schlüsselwerts zu einer von 1117 relativen Adressen:
Adresse = 94.804.893.278.549.498.118.208 mod 1117 = 403
• Speichern des Schlüssels an der Adresse 403.
III. Möglicherweise Kollision!• An dieser Adresse könnte bereits ein anderer Schlüssel stehen (Kollision!)
• Kollisionsbehandlung:
z. B.: Suche nach dem Schlüssel im Überlaufbereich, der die kollidierendenSätze in untereinander verketteter Form enthält.
Gestreute Dateiorganisation (IV)
Prof. Dr. Peter Chamoni – Datenbanksysteme 47
3.4 Logische Datenorganisation - Zugriffsmethoden
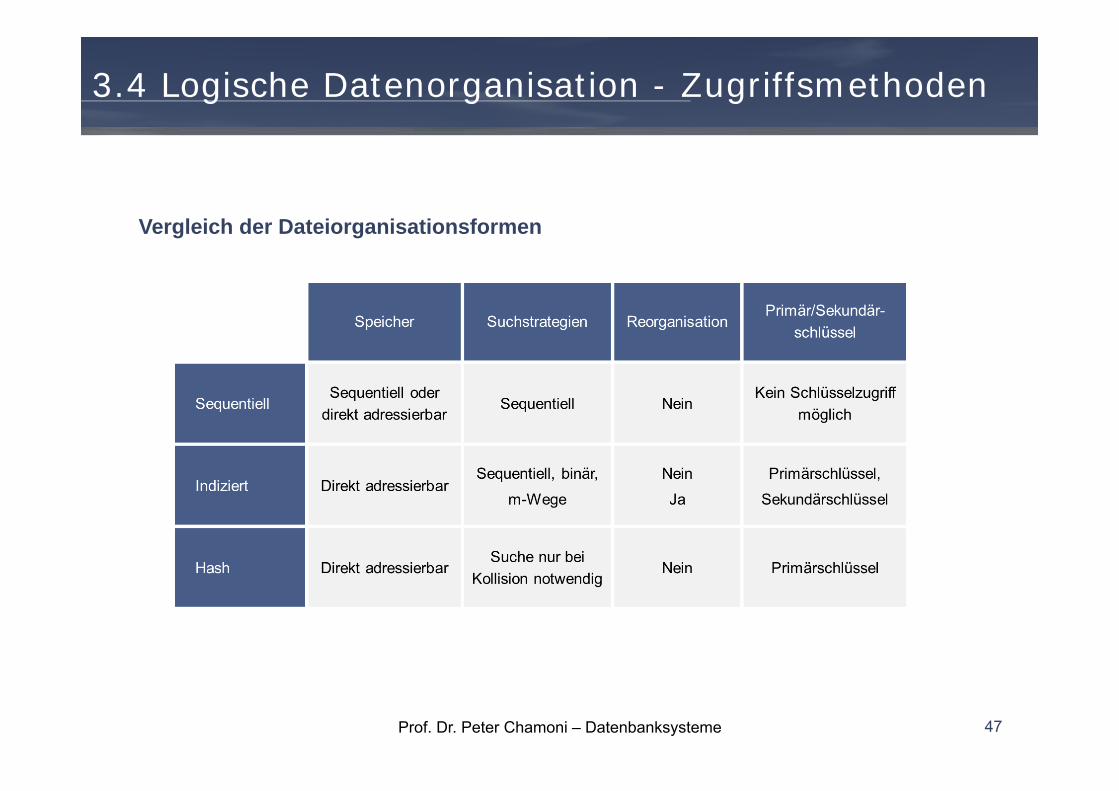
Vergleich der Dateiorganisationsformen

Prof. Dr. Peter Chamoni – Datenbanksysteme 48
3.4 Schlussbetrachtung
• Wie erfolgt die Abbildung der logischen Ebene auf die physische Ebene?
• Wie wird in einer Datenbank die Speicherung der Daten organisiert?
• Wie kann effizient auf diese gespeicherten Daten zugegriffen werden?
Zentrale Fragen im Rahmen des physischen Entwurfsprozesses
Saake, Heuer (1999, S. 90)
1
2
3
1
3
2
ZugriffssystemZugriffssystem
Speichersystem
Speichersystem

Prof. Dr. Peter Chamoni – Datenbanksysteme 49
Gliederung
3 Datenorganisation
3.1 Grundlagen der Datenorganisation
3.2 Physische Datenorganisation - Speichersystem
3.3 Logische Datenorganisation - Zugriffssystem
3.4 Logische Datenorganisation - Zugriffsmethoden
3.5 Exkurs: Bäume

Prof. Dr. Peter Chamoni – Datenbanksysteme 50
3.5 Exkurs: Bäume
Graph
• Ein gerichteter Graph besteht aus
- einer Menge von Knoten K und
- einer Mengen von Kanten E.
Eine gerichtete Kante ist durch ein geordnetes Paar von Knoten bestimmt ist. Hierbei gibt die erste Komponente den Anfangsknoten, die zweite den Endknoten an.
• Ein Kreis ist eine Folge von verschiedenen Knoten , wobeiund weiterhin .
Grundbegriffe (I)
11,...,niE ),k(k 1ii E),k(k 1n 1,...,n)(iki

Prof. Dr. Peter Chamoni – Datenbanksysteme 51
3.5 Exkurs: Bäume
Baum (1)
• Ein gerichteter Baum ist ein zusammenhängender gerichteter Graph ohne Kreise.
• Ist in einem gerichteten Baum der Knoten k2 von dem Knoten k1 aus durch eine Kante erreichbar, so ist der Knoten k1 der Vorgänger des Knotens k2
und der Knoten k2 der Nachfolger des Knotens k1.
• Eine Wurzel ist ein Knoten eines Baumes, der keinen Vorgänger besitzt.
• Ein Blatt ist ein Knoten eines Baumes, der keinen Nachfolger besitzt.
• Ein gerichteter Wurzelbaum ist ein gerichteter Baum mit genau einer Wurzel.
• Ein innerer Knoten eines Baumes ist ein Knoten, der weder Wurzel noch Blatt
eines Baumes ist.
• In einem Baum besitzt jeder Knoten mit Ausnahme der Wurzel genau einen Vorgänger.
Grundbegriffe (II)

Prof. Dr. Peter Chamoni – Datenbanksysteme 52
3.5 Exkurs: Bäume
Baum (2)
• Zu jedem Nichtwurzelknoten gibt es genau einen Weg von der Wurzel zu diesem Knoten.
• Die Tiefe eines Baumes gibt den längsten Weg eines Blattes zur Wurzel an.
• Das Gewicht eines Baumes gibt die Anzahl der Knoten an.
Grundbegriffe (III)
Prof. Dr. Peter Chamoni – Datenbanksysteme 53
3.5 Exkurs: Bäume
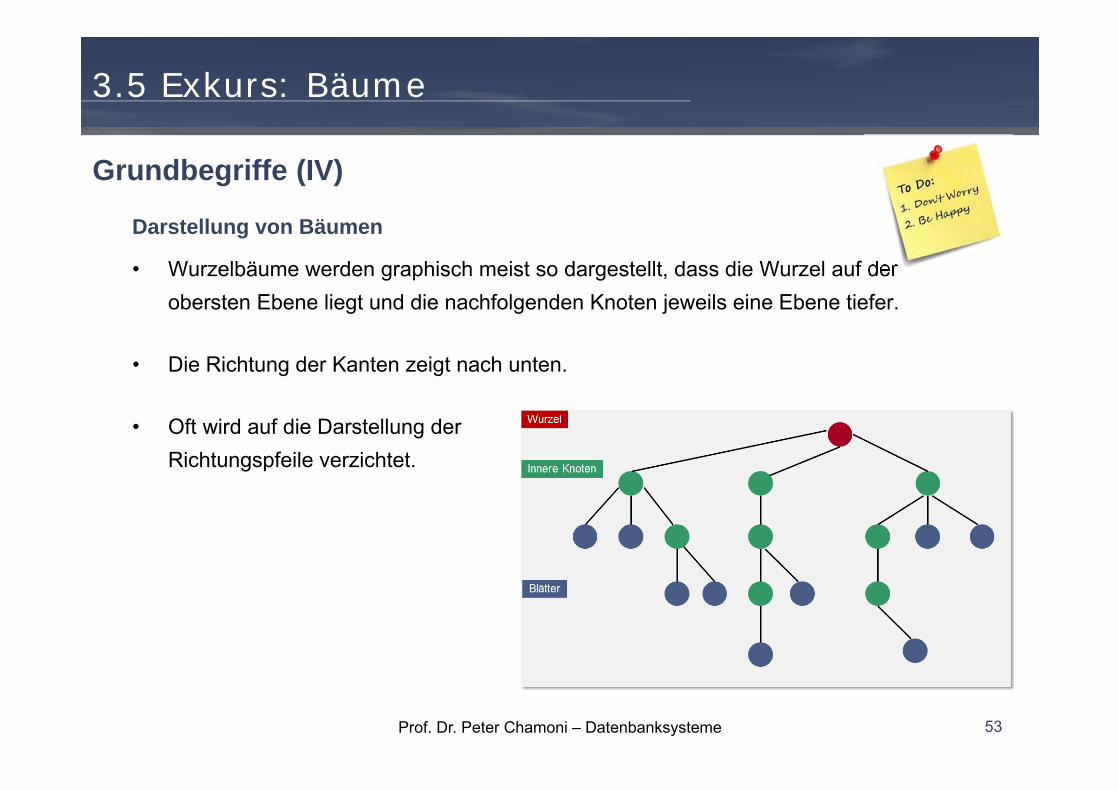
Darstellung von Bäumen
• Wurzelbäume werden graphisch meist so dargestellt, dass die Wurzel auf der obersten Ebene liegt und die nachfolgenden Knoten jeweils eine Ebene tiefer.
• Die Richtung der Kanten zeigt nach unten.
• Oft wird auf die Darstellung der Richtungspfeile verzichtet.
Grundbegriffe (IV)
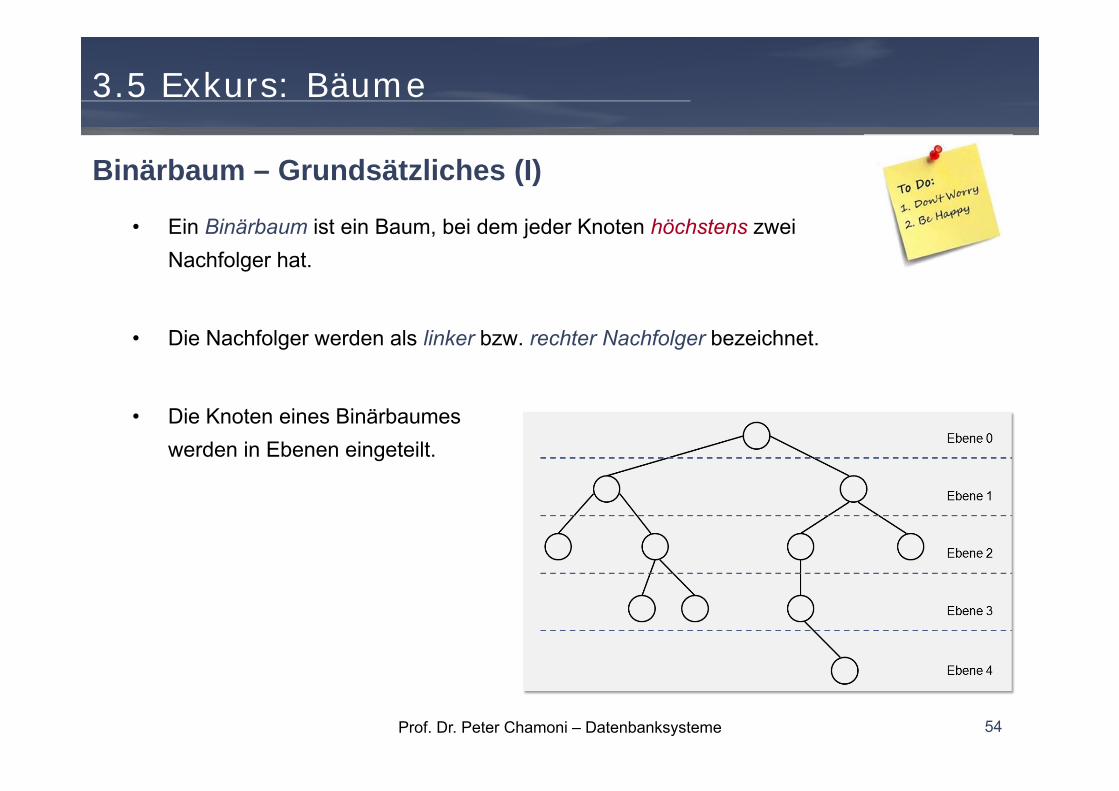
Prof. Dr. Peter Chamoni – Datenbanksysteme 54
3.5 Exkurs: Bäume
• Ein Binärbaum ist ein Baum, bei dem jeder Knoten höchstens zwei Nachfolger hat.
• Die Nachfolger werden als linker bzw. rechter Nachfolger bezeichnet.
• Die Knoten eines Binärbaumes werden in Ebenen eingeteilt.
Binärbaum – Grundsätzliches (I)
Prof. Dr. Peter Chamoni – Datenbanksysteme 55
3.5 Exkurs: Bäume
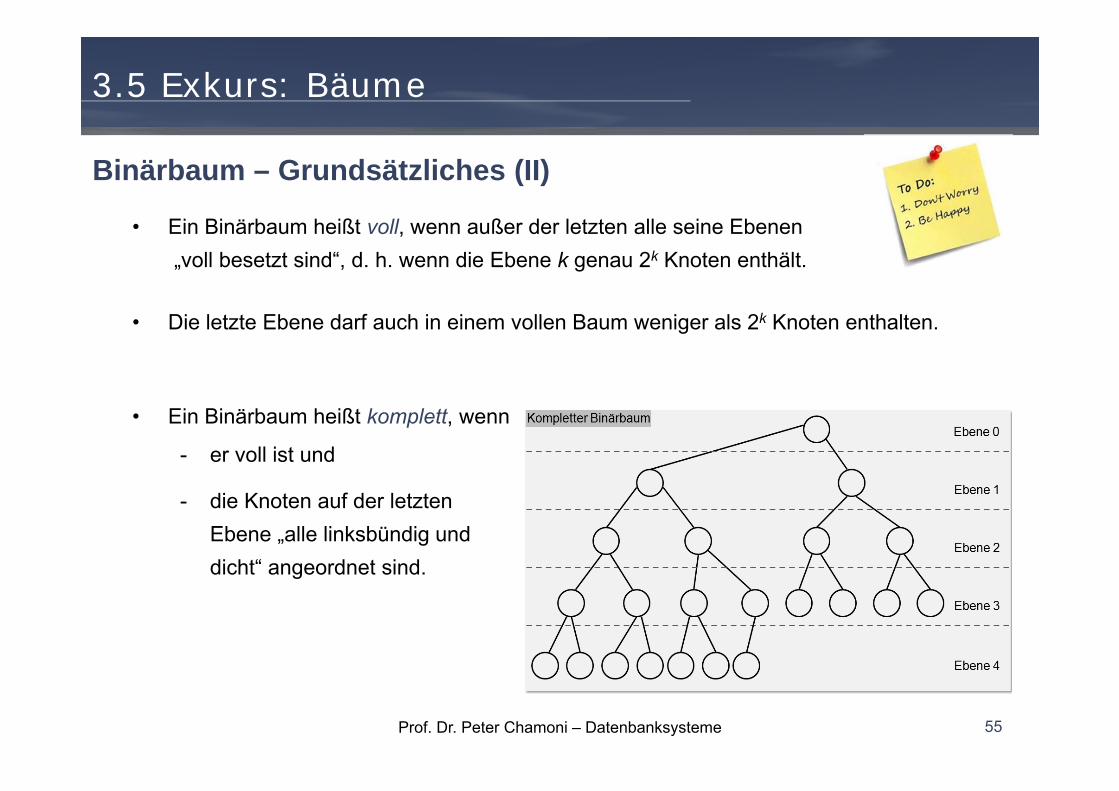
• Ein Binärbaum heißt voll, wenn außer der letzten alle seine Ebenen„voll besetzt sind“, d. h. wenn die Ebene k genau 2k Knoten enthält.
• Die letzte Ebene darf auch in einem vollen Baum weniger als 2k Knoten enthalten.
• Ein Binärbaum heißt komplett, wenn
- er voll ist und
- die Knoten auf der letzten Ebene „alle linksbündig und dicht“ angeordnet sind.
Binärbaum – Grundsätzliches (II)
Prof. Dr. Peter Chamoni – Datenbanksysteme 56
3.5 Exkurs: Bäume
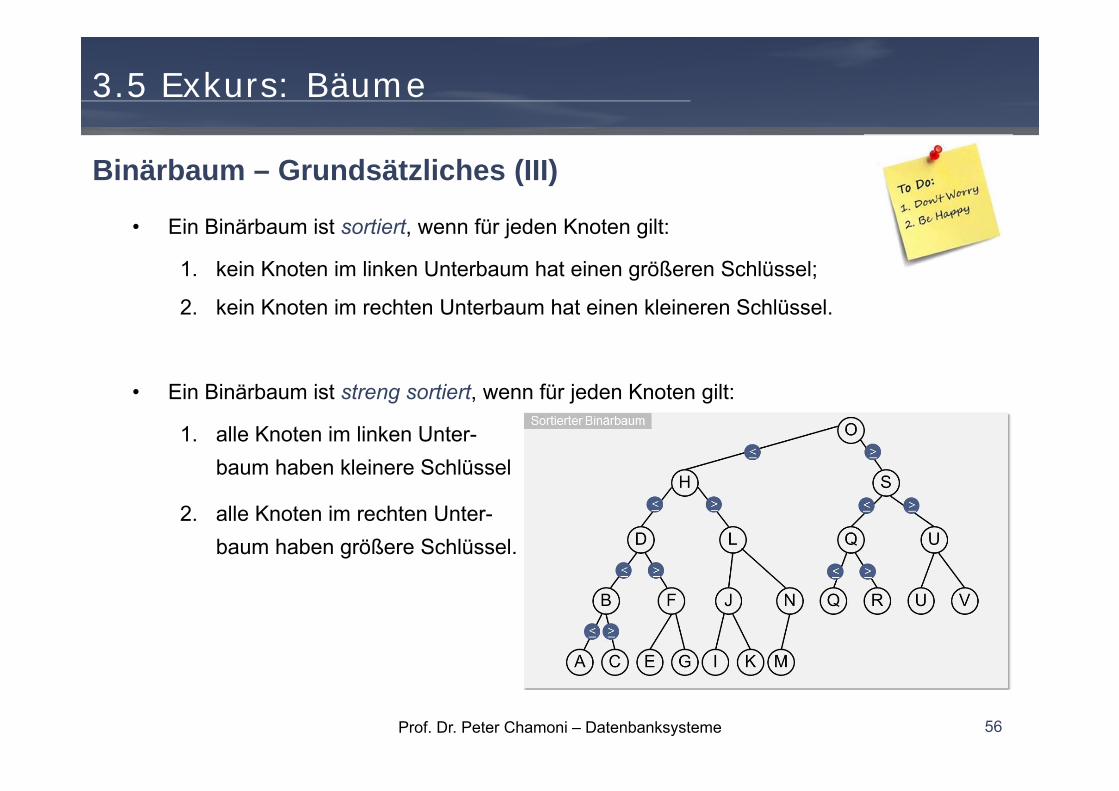
• Ein Binärbaum ist sortiert, wenn für jeden Knoten gilt:
1. kein Knoten im linken Unterbaum hat einen größeren Schlüssel;
2. kein Knoten im rechten Unterbaum hat einen kleineren Schlüssel.
• Ein Binärbaum ist streng sortiert, wenn für jeden Knoten gilt:
1. alle Knoten im linken Unter-baum haben kleinere Schlüssel
2. alle Knoten im rechten Unter-baum haben größere Schlüssel.
Binärbaum – Grundsätzliches (III)
Prof. Dr. Peter Chamoni – Datenbanksysteme 57
3.5 Exkurs: Bäume
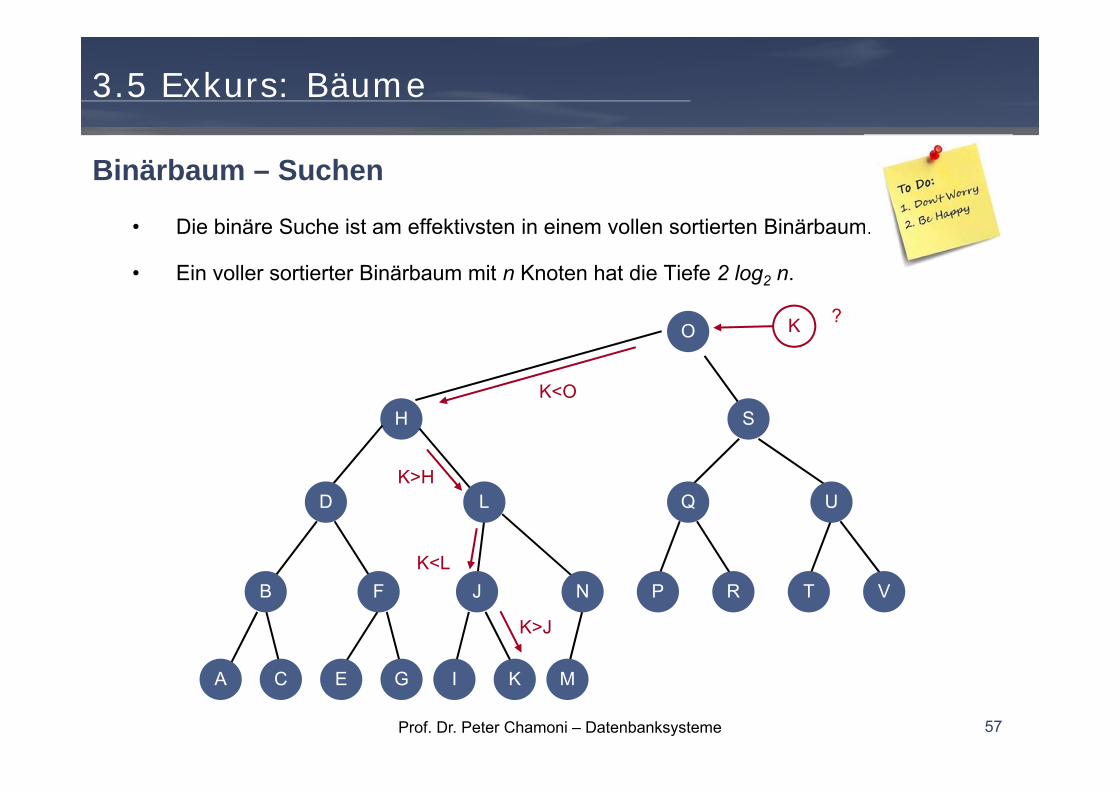
• Die binäre Suche ist am effektivsten in einem vollen sortierten Binärbaum.
• Ein voller sortierter Binärbaum mit n Knoten hat die Tiefe 2 log2 n.
Binärbaum – Suchen
O
H
K ?
K<O
K<L
K>J
MGECA KI
J N PFB TR V
K>HD L Q U
S

Prof. Dr. Peter Chamoni – Datenbanksysteme 58
3.5 Exkurs: Bäume
• Ein B-Baum der Ordnung m ist ein Baum mit folgenden Eigenschaften:
1. Alle Blätter haben die gleiche Tiefe.
2. Jeder Knoten mit Ausnahme der Wurzel und der Blätter hat wenigstens (m/2) Söhne.
3. Die Wurzel hat wenigstens 2 Söhne.
4. Jeder Knoten hat höchstens m Söhne.
5. Jeder Knoten mit i Söhnen hat (i-1) Schlüssel.
B-Baum (I)

Prof. Dr. Peter Chamoni – Datenbanksysteme 59
3.5 Exkurs: Bäume
Ausgangspunkt
Ausgeglichener, balancierter Suchbaum,d.h. alle Pfade von der Wurzel zu den Blättern des Baumes sind gleich lang.
Einsatzbereiche
• SpeicherstrukturenHauptspeicher-Implementierungsstruktur: binäre Bäume
• DatenbankbereichKnoten der Suchbäume zugeschnitten auf Seitenstruktur des DBSDaten liegen sortiert auf dem Datenträger: - Aufteilung des Speichers in Indexblöcke und Datenblöcke.- Knoten
Indexblöcke enthalten neben dem Schlüssel auch die Adresse des Datenblockes.→ Suchen findet in Indexblöcken statt. Ein letzter Zugriff liest den gefundenen Datenblock.
B-Baum (II)


![Übung Datenbanksysteme I Relationale Algebra - hpi.de · Thorsten Papenbrock | Übung Datenbanksysteme I – Relationale Algebra 5 Modellnummer Prozessorgeschwindigkeit [MHz] Festplattengröße](https://img.pdfslide.net/doc/110x75/5d670d8088c9931d358b8071/uebung-datenbanksysteme-i-relationale-algebra-hpide-thorsten-papenbrock-.jpg)