Embed Size (px)
Citation preview

De-duplication Technology and Practices for Integrated Child-Health Information Systems
Susan M. Salkowitz, MA, MGA Salkowitz Associates, LLC
Stephen Clyde, PhD
Utah State University, Computer Science Department
Preparation of this publication was supported by a contract from All Kids Count, a program of The Robert Wood Johnson Foundation.

ii
De-duplication Technology and Practices for Integrated Child-Health Information Systems
Susan M. Salkowitz, MA, MGA Salkowitz Associates, LLC
Stephen Clyde, PhD
Utah State University, Computer Science Department

iii
October 2003
This publication was supported by a contract from All Kids Count, a program of The Robert Wood Johnson Foundation, to Salkowitz Associates, LLC and the Computer Science Department of Utah State University. The views, content and citations reflect those of Salkowitz Associates, LLC and the Computer Science Department of Utah State University Ordering Information This publication is available online at the Public Health Informatics Institute web site, www.phii.org. Copyright © 2003 by All Kids Count, Public Health Informatics Institute. All rights reserved.

iv
Acknowledgements This is to acknowledge the participation and support of the following Connections projects, their staffs and consultants: Centers for Disease Control Janet Kelly, National Immunization Program Connections Project Ellen Wild, Director of Programs Patricia Richmond, Program Associate Kansas Integrated Public Health System (KIPHS) Pete Kitch, MBA, Director, KIPHS Project Office Larry Garrett, Staff Epidemiologist , KIPHS Project Office Maine Bureau of Health Lisa Tuttle, MPH, Director, Maine Immunization Program John Pease, Immunization Systems Manager Michael Wenzel, Health Program Manager Missouri Department of Health and Senior Services Garland Land, Center Director, Center for Health Information, Management and Evaluation Nancy L. Hoffman, RN , Deputy Center Director, Center for Health Information, Management and Evaluation Mare Dicneite Bill Gathright George Lauer New York City Department of Health and Mental Hygiene Amy Metroka, Director, Citywide Immunization Registry Paul Schaeffer, MPA, Research Scientist Alex Ternier, Citywide Immunization Registry Vikki Pappadouka Citywide Immunization Registry Oregon Department of Human Services Sherry Spence, MCH Data Systems Coordinator, Office of Family Health, Health Services Marion Sturtevant Buck Woodward Barbara Canavan- Director, Oregon Immunization ALERT, Health Services Don Dumond

v
Rhode Island Department of Health Amy Zimmerman, MPH, Chief Children�s Preventive Services Mike Simoli, Data Manager Mike Berry HLN Consulting, LLC Utah Department of Health Rhoda Nicholas, MBA, PMP, Director of Product Strategy and eGovernment John Eichwald, MA, CHARM Program Manager Barry Nangle, PhD, Director, Center for Health Data Chris Pratt Nancy Pare Other acknowledgements Douglas R. Murray, Director Arkansas Center for Health Statistics Tsai Mei Lin SAS analyst, Arkansas Center for Health Statistics

vi
Table of Contents Acknowledgements ........................................................................................................iv Table of Contents ...........................................................................................................vi Executive Summary .....................................................................................................viii 1. Introduction .............................................................................................................1 2 Overview of De-duplication Technology .................................................................3
2.1 Data-item Transformation ................................................................................3 2.1.1 Dates and times ........................................................................................3 2.1.2 Addresses.................................................................................................4 2.1.3 Measurements and Demographics ............................................................5 2.1.4 Names ......................................................................................................5
2.2 Match Technologies.........................................................................................6 2.2.1 �When� issues..........................................................................................7 2.2.2 �How� issues............................................................................................8 2.2.3 �What� issues.........................................................................................11
2.3 Record Coalescing (Linking or Merging) .......................................................11 2.4 Integration Classifications..............................................................................12
2.4.1 Stand-alone systems ...............................................................................12 2.4.2 Software Development Kits....................................................................13 2.4.3 Server-based systems .............................................................................13
3 Software Products..................................................................................................14 3.1 Products and Their Classification...................................................................14 3.2 Off-line Evaluation ........................................................................................19
3.2.1 Cost........................................................................................................20 3.2.2 Supported Platforms ...............................................................................22 3.2.3 Existing Applications .............................................................................24 3.2.4 Matching Technology.............................................................................26 3.2.5 Merging Technology ..............................................................................28 3.2.6 Product Support......................................................................................29
3.3 Benchmark Evaluation...................................................................................30 3.3.1 Step 1 - Benchmark Evaluation Criteria and Testing Techniques ............30 3.3.2 Step 2 - Setup and Learn the Product ......................................................36 3.3.3 Step 3 - Measure the Product Against the Evaluation Criteria .................36 3.3.4 Step 4 � Compile, Interpret, and Document the Results ..........................38
3.4 Discussion .....................................................................................................38 3.4.1 Finding common basis for comparison..........................................................38 3.4.2 Obtaining evaluation software.......................................................................39 3.4.3 Obtaining or creating meaningful test data ....................................................39 3.4.4 Interpretation of results .................................................................................39
4. Review of De-duplication in Integrated Child-Health Information Systems in Eight Connections Projects .....................................................................................................40
4.1 Rhode Island ..................................................................................................52 4.2 Oregon...........................................................................................................54 4.3 Oregon Immunization ALERT.......................................................................56

vii
4.4 New York City...............................................................................................57 4.5 Missouri.........................................................................................................60 4.6 Kansas ...........................................................................................................63 4.7 Maine ............................................................................................................65 4.8 Utah...............................................................................................................68
5. Observations from Study .......................................................................................71 5.1 Technical Observations ..................................................................................71
5.1.1 Overall de-duplication processes and algorithms ....................................71 5.1.2 Level of automation ...............................................................................71 5.1.3 Record Matching....................................................................................72 5.1.4 Source of information and effective data element for matching...............72 5.1.5 Record Merging .....................................................................................73 5.1.6 Deployment Timetables..........................................................................74
5.2 Non-technical Issues ......................................................................................74 5.2.1 Scope and Organization of the Integration Effort....................................74 5.2.2 Intended Use of the Integrated Data........................................................74 5.2.3 Role of the Immunization Registry Beginnings.......................................75 5.2.4 Role of Vital Records .............................................................................75 5.2.5. Role of Communities of Practice ............................................................76 5.2.6 Program Mandates and Organizational Structure ....................................76 5.2.7 Academic Research ................................................................................77 5.2.8 Strategic Planning ..................................................................................77
5.3 Future Study ..................................................................................................78 5.3.1 Testing and Assessment .........................................................................78 5.3.2 Useful Data Elements and Types of Comparisons...................................79 5.3.3 Impact of Privacy Issues.........................................................................79 5.3.4 Birth-Death Matching.............................................................................79
References.....................................................................................................................80 APPENDIX A � Additional Reference Material ............................................................81
Survey Questionnaire ................................................................................................81 Information from Rhode Island..................................................................................81 Information from Oregon...........................................................................................81 Information from Maine ............................................................................................81 Information from Missouri ........................................................................................81 Information from Arkansas Project ............................................................................81

viii
Executive Summary Child health integration projects create enterprise-wide, person-centric systems from disparate files with different business rules for identification. Data cleaning activities termed de-duplication are performed to match and merge records appropriately. Projects are challenged to select the most effective de-duplication tools and strategies for their environments. Interested Connections projects requested this study to research de-duplication software and approaches, perform limited testing and technical analysis, and document the findings in matrices, showing effectiveness, underlying approach, cost and other factors. This report provides a description, analysis and evaluation of de-duplication software based on vendor information and limited testing, documents de-duplication practices of the participating projects, and discusses different approaches and their efficacy. The study yielded no single best product, but provides a framework to examine alternatives and determine the trade-offs to choose products and strategies that match project requirements. It demonstrates the value of the community of practice and identifies areas for further work.

1
1. Introduction Duplicate records in any database can cause serious data-quality problems and prohibit an information system from reaching its full potential. This is particularly true for people-centric health systems where the real value of the data comes from a user�s ability to view as much information about a person as possible, within the confines of confidentiality guidelines. If the information for a person is spread across multiple, unrelated records, then a user might miss important data about that person. The more complete and accurate the information, the better the services health-care professionals can provide. Fragmented and duplicate data can be particularly acute for integrated child-health information systems, because
• The data for a child comes from multiple sources; • There is no universal key that allows the integrated system to correlate records
from these different sources; • Alternate identifiers, such as names, are often incomplete or subject to change; • The original data may contain errors (e.g. keyboarding errors, missing
information, etc.); and • Similar fields in the various record structures may have inconsistent meanings.
De-duplication is the process of removing redundant data from the database, preventing fragmented and duplicate information from getting into the system, and assuring that queries and updates apply to the correct record [7]. These are difficult issues because redundant information may be hard to spot, correct data may exist in lots of different records, and data may be represented in alternate but equivalent ways. At the Connections1 meeting in Rhode Island in September 2002, several members expressed interest in a study to evaluate de-duplication algorithms on the basis of effectiveness and cost and to determine which combination of available data elements produce the best match rates. They suggested that a project to perform research, technical analysis and limited testing, and to document the findings in a matrix showing trade-offs, effectiveness and cost would be useful to all projects and advance integration efforts. This report presents the results of the ensuing research project. It first examines technology and off-the-shelf products that support de-duplication in some way. To make the de-duplication process more tractable, researchers and software developers divide it into three sub-problems:
• data-item transformation • matching • merging
1 The Connections group is a community of practice sponsored by All Kids Count, a program of The Robert Wood Johnson Foundation.

2
Section 2 describes these sub-problems in more detail and gives some background information on the solutions currently available for each. Section 3 provides a framework for reviewing products that support de-duplication activities and presents a sample evaluation. This report also describes de-duplication processes currently found in eight integrated child-health information systems built by members of the Connections group. Each of these integration projects involves the creation of an enterprise-wide, person-centric system that contains records of individual children and supports programmatic services, operations, reporting, and tracking. They import, link or access files from disparate sources that have different standards and business rules for identifying children, lack universal keys, and contain data inconsistencies and errors. Section 4 compares and summarizes these projects in terms of their scope and approach to de-duplication. The credibility and usefulness of an integrated information system depends heavily on its ability to perform quality assurance tasks, starting with de-duplication. However, de-duplication is complex, resource-intensive and costly process. Integration projects need to consider a number of technical and non-technical issues. Section 5 summarizes these issues and presents some ideas for handling them based on the technology, products, and projects reviewed in Sections 2-4. Section 5 also presents several ideas for future research that would further benefit the integration projects.

3
2 Overview of De-duplication Technology Removing duplicate information in people-centric integrated child-health information systems consists of three main sub-problems: data-item transformation, record matching, and record coalescing. Sections 2.1 � 2.3 discuss basic concepts for these three sub-problems. Solutions to these problems vary not only in underlying technology but also in how they can hook into information systems, particularly integrated health-care systems. Section 2.4 summarizes three general approaches, which we refer to in this paper as Integration Classifications and will use later to help categorize de-duplication products. Independent of the technology or its integration, the ultimate goal is to remove duplicate information. Evaluating the success of a goal, however, is not a trivial matter. Section 3 discusses ways to test and measure the accuracy and efficiency of a complete de-duplication product.
2.1 Data-item Transformation The effectiveness of record matching depends on the quality of the data in the individual records. Data-item transformation involves standardizing and simplifying values in individual records so subsequent record matching can be more efficient and accurate. Such transformations typically map existing values for one type of data (field) to a new (hopefully cleaner) set of values. For example, birth dates are transformed to cleaner birth dates. However, in general, any set of fields can be mapped to any other set of fields. Gelhardas, et al. defined an SQL-like language for defining such data transformations as part of their data-cleaning framework [7]. High-end databases, such as Microsoft SQL Server and Oracle, support similar capabilities. Ideally, every field involved in the matching process should go through a cleaning process. However, for some data fields, this isn�t practical for nor will it lead to significant improvements in matching. Some good candidates for data-item standardization are dates and times, addresses, measurements and demographics, and names.
2.1.1 Dates and times Dates and times, such as birth dates, birth times, vaccination dates, and screening timestamps, can play key roles in determining potential matches. To make efficient comparisons, the dates and times should be in a common, well-defined format. In principle, this is simply a matter of implementing the appropriate date and time transformations. However, in practice, such conversions have to deal with several sticky problems, including garbage data, missing or partial data, inconsistent semantics, and �magic numbers.� See sidebar discussion below for descriptions of these problems.

4
2.1.2 Addresses The reformatting and verification of address information has perhaps one of the biggest potential payoffs in terms of improving the effectiveness of record matching. Addresses, if accurate and standardized, can be excellent discriminators for otherwise similar records. Also, since relatively few people will typically have the same address (except in communities with large apartments or multi-family dwellings), they can help narrow down the search space and thereby improve the speed of the matching process. Putting addresses into a standard format and verifying them against known addresses is a difficult problem. However, there are hundreds of off-the-shelf products and services that do just that. The United States Postal Service (USPS) has developed certification system for these products and services, called the Coding Accuracy Support System (CASS) [15]. CASS enables the USPS to evaluate a product in three areas: ZIP+4 delivery point coding, carrier route coding, and five-digit coding [15]. If a product achieves an accuracy of 98% or better on a test database of 100,000 addresses, the USPS will certify that product for six months [3]. The USPS updates its list of certified vendors on a regular basis. See http://www.usps.com. As of Sept. 5, 2003, there are 500 companies that sell CASS-
Garbage dataGarbage data are any values that do not represent meaningful information with respect to the fields they are in. Garbage data can occur for any number of reasons, the most common being inadequate input-validation during data entry. Other reasons include erroneous conversion of legacy data and shifting in the field�s meaning over time. Regardless of the reason, a solution to garbage data should involve both corrective and preventive actions. Because of the nearly random nature of garbage, corrective actions often require manual inspection and editing of individual records. If there are reoccurring patterns in the garbage, then a database programmer may be able to build a script that automatically cleans up that particular kind of garbage. Preventive actions for garbage data attempt to fix design or implementation failures that allow garbage data to get into the system. Missing or partial data Missing or partial data for data/time fields may not be too serious, as long as the matching process compares missing or partial values in a consistent way. Consider a date field that has year, month, and day subfields and allows the day subfield to be unknown (null). In this case, care needs to be taken during comparison. May 2003 (with no day specified) should match any date between May 1, 2003 and May 31, 2003. Inconsistent semantics Inconsistent semantics exist when the values of a field can have different meanings. Consider an integrated child-health information system that captures summary information (date and event type) for various events, such as newborn screenings, vaccinations, and hearing screenings. Because the information is coming from different sources, the values for event date may actually have different semantics. For one system, date values might represent day on which the event started; in others, it might represent the day on which the event ended or the day on which the event was entered into the system. Such inconsistencies arise when the individual systems that comprise an integrated system evolve independently (which is typically the case) or as field semantics change over time. The solution to inconsistent semantics is basically the same as for garbage data, except the corrective action is often more amenable to automation. Magic numbers Magic numbers are valid values that have been given special meaning. For example, a birth date field might contain a �99/99/99� to mean that the baby was stillborn. Magic numbers can be particularly problematic for integrated health-care system because their meaning is not likely to be shared across all the participating health-care programs. Matching records based using such values can have unexpected and undesirable results. The solution is to convert magic number to common, standardized values that represent their intended meaning. This may necessitate defining new data fields that hold extra information about special conditions. For example, the system could translate the above �99/99/99� to a null birth date and flag in a separate field that explicitly means stillborn.

5
certified products or services for [16]. These products range from stand-alone, self-contained software systems to customizable package with network interfaces to pay-as-you-go Internet services. Some of the products work in a batch mode that is intended for behind-the-scenes clean up of existing data. Others provide an interface for interactive address correction. Still others support both modes of operation. The products range in price from several hundred to tens of thousands of dollars. The low-end products are mostly stand-alone systems that provide limited features and don�t support any kind of integration with existing information systems. Most of the high-end products work in multiple modes, support a variety of interactive or batch interfaces, and are customizable. A more detailed evaluation of address-cleaning software is beyond the scope of this report. However, integration projects that are considering buying or building address-cleaning software should look at packages that support both interactive and batch processing. They will provide the most flexibility in terms of how they integrate into the health system. Stand-alone address-cleaning systems are not likely to represent cost-effective solutions.
2.1.3 Measurements and Demographics If the matching process takes into account measurements or demographics, then to be effective, it is important to standardize the data in these fields as well. For example, consider an integrated system that involves vital statistics and newborn screening data. One system may record a child�s birth weight in ounces and the other in grams. This often occurs depending on whether the birth weight comes from a birth record, medical record, or anecdotal record. To compare these numbers for matching purposes, they need to be in a common unit of measure. Similarly, if the matching process uses race or ethnicity, the system needs to make sure that the possible values for these fields are well defined and consistent. For example, a program�s ethnic definitions may vary from census definitions or patients may self-identify their race differently from how it is officially classified. In both cases, if race and ethnicity are to play a role in the matching process, data-transformation software must map them to common classification schemes. On the surface, it would seem that simple data transformation operations would be able to standardize measurements and demographics. However, like date and time values, measurements and demographics can suffer from garbage data, missing or partial results, inconsistent semantics, and magic numbers. The same solutions discussed above for dates and times apply here. Even relatively static fields like race and ethnicity are subject to these problems because their categorizations can change over time.
2.1.4 Names Since names are widely used in record matching, they are obvious candidates for standardization and simplification. However, as with addresses, this is a difficult and potential costly endeavor because name data can contain a wide variety of

6
inconsistencies. Smith explains that these problems have many causes, including data entry errors, the use of aliases and nicknames, difference in spellings, cultural factors, and historical factors [13]. Green and Lutz, also explain:
One type of data that has been persistently problematic for automatic processing is that of named entities, especially personal names. Unlike other data elements, such as Social Security numbers or other kinds of ID�s named entities, names can show significant, sanctioned variation. Furthermore, names tend to be much more variable in spelling than other lexical items. Predicting the way a particular name of a particular individual will be spelled is often problematic [8].
Researchers and developers have tried many different approaches for standardizing and simplifying names for matching purposes. One approach attempts to break the name down into individual pieces, organizing by type of name and transforms those pieces into values that can more readily compared. For example, a name like �Maria Jessica dela Lopez Garcia� would result in the following pieces: a baptismal name of �Maria,� a given name of �Jessica,� a particle of �dela,� a patronimic name of �Lopez,� and a matronimic name of �Garcia.� Using Soundex [11] or some other encoding scheme, each of these pieces could then be simplified for comparison. The problem with this approach is determining the pieces and their name types. This can be difficult even in databases that store names in two or three fields, such as last name, first name, and middle initial. Many names, like �Maria Jessica dela Lopez Garcia� don�t fit the pattern, and leave data-entry staff to their own devices for interrupting and entering the name into the system. Consequently, two different data-entry people could easily add the same child to a system with two very different names. Other approaches simply remove extraneous characters from names and then let the matching process do string comparison and edit-distance comparisons. String comparisons are fast, but don�t allow for data-entry errors or spelling variations. Edit-distance comparisons can be slow, but are relatively forgiving for common data-entry errors and some types of spelling variations. Off-the-shelf name transformation and classification products are available. One example is the NameClassifier� by Language System Analysis. A detailed evaluation of name or other data-item transformation products is beyond the scope of this study.
2.2 Match Technologies Given a subject record (either an existing record in a database or information about a person that might be added to a database), matching is the process of finding existing records that might be for the same person. Some researchers further divide matching into two sub-problems: finding candidate records and clustering then into groups of matching or potentially matching records [7]. There are three questions about any given matching product that are of particular interest for integrated health systems:

7
1. When does the matching occur? 2. How does the matching algorithm work? 3. What data does or can the matching algorithm use?
2.2.1 �When� issues There are two basic answers to the first question: interactive front-end and automated back-end. Systems that support front-end matching allow users to look for potential matches prior to adding a new record into the system or during the processing of adding a new record. If a match is found, it is used instead of adding the new record. The aim of front-end matching is to minimize the number of duplicate records that actually get into the database. It can also take advantage of a user�s first-hand knowledge about the person. For example, consider the following scenario:
1. A mother brings a child named �Sue Smith� into a clinic and a clerk begins a data-entry process for the child.
2. Using front-end matching software, the clerk first searches for existing �Sue Smith� records.
3. The matching software returns three candidates, so the clerk asks the mother for more details like current address and child�s birth date.
4. Based on this first-hand information, the clerk then determines that one of the three existing records is actually for this �Sue Smith�.
5. Instead of creating a new record (and a potential duplicate), the clerk simply uses this existing record.
Obviously, if the matching software had returned zero candidates or if the clerk determined that none of them were for this child, then the clerk would add a new record. Back-end matching occurs among records that are already in a database. Systems that support this mode of operation periodically step through the records in a database and check to see if each one matches any others. Typically, a back-end approach involves organizing records into groups or clusters, each representing a set of possible matches. Some back-end matching systems compute a confidence rating for each cluster that indicates how likely the match is real. Furthermore, some systems will even try to automatically resolve the duplicates in a group, if the confidence rating is high enough. (See the Section 2.3 for more information on different ways that duplicates can be resolved.) Such systems may also set aside for manual review any clusters that represent potential matches, but for which the confidence is not high enough to process automatically. Instead, a user will review these clusters more closely at a later time and then determine if they actually match. Here is a typical scenario for a back-end solution.
1. The matching software first selects a subject record from the database, for example, �Joe Jones�.
2. It then finds four potential matches for �Joe Jones�, and creates a cluster containing the original record and the four matches.

8
3. At the same time, it computes a confidence rating indicating that the likelihood of these records all being for the same child is good, but not high enough to resolve automatically.
4. The matching software sets the cluster aside for manual review. 5. Some time later, a user inspects the records more closely, determines that they are
all for the same child, and proceeds with an interactive merging of the data. The advantage of a back-end approach is the system can automatically find and resolve large numbers of exact duplicates without any human intervention. This can be very valuable for integrated systems where large numbers of records are coming from multiple sources. The disadvantage of a back-end approach is that, even though some deferred user interaction is possible, the approach cannot easily take advantage of first-hand user knowledge in determining actual matches. When a cluster is formed and set aside for manual review, the user who reviews that cluster will probably not have immediate access to the real person(s) represented by the records in the cluster. Researching the records to make a matching determination can time consuming and costly. Some matching software products support both front-end and back-end processes. Since both approaches have complementary advantages, an integrated health system could benefit from both.
2.2.2 �How� issues Matching algorithms come in four basic flavors: single-field comparison, multi-field matching, rule-based matching, and machine learning. 2.2.2.1 Single-field comparison algorithms Algorithms based on single-field comparisons attempt to find potential matches by quickly comparing individual fields, typically under a user�s direction. WinPure (described further in Section 3) is an example of a product that takes this approach. The user simply chooses a field in the record structure, such as phone number, and the system clusters together all the records with similar values for that field. This approach can be fast, but is limited in terms of how it finds meaningful matches. 2.2.2.2 Multi-field matching algorithms Multi-field matching algorithms can take a wide range of forms. However, they all attempt to find matches by comparing multiple fields from two records and then computing some kind of aggregate matching score by combining the results of the individual field comparisons. Often the algorithm is customizable in terms of which fields it uses, the comparison functions for each field, and how it combines individual field results to form record matching scores. A couple of differences between products with customizable multi-field matching are the number of individual comparisons that they support and the kinds of fields that they allow to be compared. For example, PostalSoft only allows matching on up to eight different fields. All but three of these have to come from a pre-defined list typically

9
consisting of address-book fields. Many fields common in health information systems, such as birth date, are not in the list. Three of the eight fields can be user-defined. Another way in which products differ is the types of comparisons that they support. Below is a list of some common categories of comparison functions:
Relational This category includes basic equals, less than, greater than, and not equals kinds of comparison functions.
Partial string The category includes string comparison functions that limit the comparison to a specific number of characters, e.g. just the first five letters of the last name.
Containment This category includes functions that can determine whether a field value is either fully or partially contained within another.
Ranges This category includes functions that determine whether a numerical or data field value is within some specified range of another, e.g. the birth date differs by no more than seven days.
Edit-distance This category includes functions that determine the minimum of number of editing operations (insert a character, delete a character, or replace a character) necessary for making two values the same. Edit-distance is a good approximation of keystroke errors that may have occurred if the two values were supposed to be the same.
Soundex Matching Soundex comparisons match strings (typically names) with different spellings but similar sequences of character sounds. They do this by first removing non-essential characters (all non-initial vowels, H�s, Y�s, and W�s) from the words in the string and then, based on a set of rules, encode the remaining characters as sequence of digits. These numerical sequences represent standardized sounds for key letters; they do not represent the pronunciation of the words in the strings. Two strings are then compared by these corresponding Soundex encodings. Robert Russell first proposed the original Soundex idea in 1918, long before the electronic information system. Since then, researchers have proposed many variations of the idea [11]. Today, many database systems provide direct support for information retrieval based on Soundex comparisons.

10
Orthographic comparisons Unlike Soundex comparisons, the functions attempt to compare words (typically names) based on their pronunciation [4, 9, 10].
Some products also suppose probabilistic field comparisons that take into account the frequency of the possible field values. The more frequent the value, the weaker the comparison. For example, in comparing first names, the strength of two matching �Michael� values would be considerably less than the strength of two matching �Sylvester� values because �Michael� is more probable and therefore less discriminating. Probabilistic field comparisons can improve the accuracy of a matching algorithm but require more computation, and therefore may be slower. The ways in which multi-field matching algorithms combine the results of individual field comparison range from simple logical combinations (AND�s and OR�s) to weighted sums where is each field comparison counts for a certain percentage of the total match score. 2.2.2.3 Rule-based matching algorithms Rule-based matching algorithms are similar to multi-field matching algorithms in that they can involve multi-field comparisons and a variety of comparison functions. However, they don�t determine a match by combining the individual field comparisons into a single score. Instead, they apply a set of decision rules, i.e. �IF<condition>THEN <action>� statements. The conditions consist of field comparisons, and the actions consist of �match� or �no-match� conclusions. If a rule�s condition is true, then its action is taken. Below is a very simple example rule set. In the conditions, the �<r>.<field>� notation represents a field value, where r is either r1 (a subject record) or r2 (a candidate matching record) and field is a name of a field in the record structure. 1. IF r1.social_security_number = r2.social_security_number THEN match 2. IF SoundexCompare(r1.last_name, r2.last_name) AND SoundexCompare(r1.first_name, r2.first_name) AND EditDistance(r1.birth_place, r2.place)<2 AND r1.birth_date = r2.birth_date AND r1.multiplicity = r2.multiplicity AND r1.birth_order = r2.birth_order THEN match The advantage of rule-based matching over multi-field matching is that it can short-circuit the comparison computations by testing high-confidence or most discriminating rules first. For example, with the above rule set, a rule-based algorithm would test rule #1 first. If doing so, it would compare just the SSN�s of the two records. If they are exactly the same, it would declare the records a match and it would not continue with the other field comparisons. In many cases, this would result in dramatically speeding up the overall matching time.

11
2.2.2.4 Machine-learning algorithms The problem with multi-field comparison and rule-based approaches is that someone has to figure out which fields are most useful in determining matches, how to best compare those fields, and how the result of these comparisons determine (or don�t determine) matches. A machine-learning algorithm attempts to solve this problem by allowing the software to customize itself. It does this through a training process in which pairs of records are fed into the system along with their true match/no-match status. For each training pair, the system attempts to compute its own match/no-match result based on its current settings. If it gets the right answer, it reinforces the current settings. If it gets the wrong answer, it tries to figure out what would have helped produce the right answer and alters its settings a little in that direction. By running lots of training data through the system, it can eventually tune its own configuration to correctly compute all answers. At this point, the system should be able to accurately match other pairs of records not in the training data. The challenge with machine-learning algorithms is in creating a training set that represents all the problematic variations in the real data and will enable the algorithm to converge on a stable configuration.
2.2.3 �What� issues Theoretically, matching algorithms can match records based on any piece of available data. However, in practice, off-the-shelf products often make assumptions about what information is available and what will be the most discriminating. For integrated child-health information systems, the key is whether the product can be configured or adapted to use fields that are not common in other person-centric files. Some good discriminators for child-health information systems include birth date, birth multiplicity, birth order, and mother�s maiden name.
2.3 Record Coalescing (Linking or Merging) Once a system has found some matching records and organized them into groups or clusters, the next step is to remove the duplicate data. We call this process record coalescing. For front-end matching systems, record coalescing can occur as an integral part of the matching process and will typically deal with just one cluster at a time. For back-end systems, the system may attempt to do some records coalescing (for high-confidence matches) immediately or it may defer this process for later. In general, record coalescing can be accomplished by doing one of the following:
1. Deleting all but one of the records in a cluster 2. Merging the data from all the records in a cluster into one record 3. Linking together all the clusters in a cluster so that if one of them is retrieved, the
other can also be easily retrieved if necessary. The first option is not realistic for health information systems since it could result in the loss of valuable information. Unfortunately, it is sometimes the only option supported by low-end products. The choice between the second and third options depends largely on

12
the design of the information system and on external constraints. In some cases, there are restrictions against modifying patient records. For example, in Maine, changes cannot be made to Medicaid address data, except through the Medicaid system by authorized Medicaid personnel. In this case, the only choice is to logically link the matching records together. If merging is possible, then it is often a cleaner choice because it eliminates redundant data and thereby avoids confusion. Merging, however, is not a trivial matter. Some of the problems include:
1. Standardizing the data-item values, which involve many of the same issues raised in Section 2.1 but on a broader scale.
2. Resolving data-item conflicts, which answers questions like �which source of the data is more authoritative�, �can missing information (a null value) overwrite an existing value�, �should all known values for a field be kept�, etc.
3. Determining when in the overall process merges take place. 4. Determining who will be responsible for merging and resolving records.
These issues can be very complex and need to be addressed in the context of a specific integrated system.
2.4 Integration Classifications The number of different ways in which de-duplication technology is packaged and integrated into information systems is almost as large as the number of individual products. However, in an attempt to characterize the technology and classify the products, we can break them into three general categories: stand-alone systems, software development kits, and server-based systems.
2.4.1 Stand-alone systems With stand-alone systems, there is no program coupling between the information system and the de-duplication software, except for the transfer of records between the two. A user typically has to manually:
1. Export all of the records from the information system 2. Import them into the de-duplication system 3. Perform the de-duplication activities 4. Export all the records from the de-duplication system 5. Import them back into the information system
Obviously for large systems, like integrated child-health information systems, this is not practical. In some cases, the de-duplication software might be able to automate steps 1, 2, 4, and 5 but only if it can directly read the information system�s database. Still, these steps would take considerable time for large databases and the information system may have to be off-line during the whole process in order to avoid synchronization problems.

13
2.4.2 Software Development Kits Software Development Kits (SDK�s) are libraries of re-usable de-duplication software components. Information-system programmers can use these software components to integrate de-duplication functionality directly into the systems that they build. SDK�s offer programmers a high-degree of flexibility, since the programmers are in control of how and where the de-duplication occurs in the information system. However, using a SDK creates a significant dependency between the information-system and an outside product. If the SDK�s change (sometimes in very modest ways), then the information-system will likely also have to change. Among software developers, this is referred to as high coupling and is typically considered undesirable.
2.4.3 Server-based systems Like SDK�s, server-based products allow information systems to access de-duplication features directly in the code. However, the de-duplication software is logically separate from the information system and typically runs as an independent process called a �server�. A server provides access to �services� like address cleaning, record matching, or merging via well-defined programming interfaces. As long as these interfaces don�t change, updates to the de-duplication software will not cause changes to the information system. So, server-based approaches offer a high-degree of flexibility like the SDK�s, but without the high coupling. Server-based approaches can also lead to other benefits, including improved scalability and better performance through the use of concurrency. Since the de-duplication software runs in a separate process, it can live on a different computer and can thus allow the computational resources to grow more incrementally. Theoretically, programmers could also replicate the de-duplication server on multiple machines. This would allow the information system to execute concurrent de-duplication operations and thereby improve overall performance.

14
3 Software Products Many products that address the de-duplication process are already commercially available. Some of these simply deal with a single part of the process, while others deal with most or all of it. This section summarizes an evaluation of a sampling of these products. Although it is not exhaustive, it provides some insights into the state-of-the-art for commercial de-duplication products and the challenges associated with evaluating such products.
• Section 3.1 lists the evaluation candidates and categorizes them according to which part(s) of the de-duplicate process they address.
• Section 3.2 describes a first-pass evaluation that looked at eight different products using criteria that can be tested without actually running the software. We�ll refer to this evaluation as the off-line evaluation.
• Section 3.3 discusses a more in-depth evaluation that tests a product against a known data set. We�ll refer to this kind of evaluation as benchmark evaluation. Because of the limited availability of actual software, the team was able to conduct a benchmark evaluation for only one product.
• Section 3.4 discusses this and other challenges associated with reviewing and selecting de-duplication products.
3.1 Products and Their Classification Table 3.1 identifies a wide range of de-duplication products that could be candidates for the off-line and benchmark evaluations. However, it is not an exhaustive list. For example, the US Postal Service alone has certified over 1170 address-cleaning products [16], and this is just the tip of the de-duplication software domain. Furthermore, an exhaustive list would not be of much long-term value since products are always coming and going. The real value of Table 3.1 is in illustrating how to begin an evaluation by identifying and classifying candidate products. The first column of Table 3.1 contains the product names and vendor information. The second column provides brief descriptions of the products. The 3rd, 4th, and 5th columns indicate whether each project deals with data-item transformation (e.g., address cleaning), matching, and/or merging, respectively. The column labeled Integration Type indicates whether each product is packaged as a stand-alone software system, a software development kit (SDK), or a server-based system (see Section 2.4.). The last two columns indicate whether the project team could obtain sufficient technical documentation for off-line evaluation and a copy of the actual software for a benchmark evaluation. For this project, the team explored the Internet, studied existing health-care information systems, and looked at people-centric database systems, such as genealogical systems, to uncover what products were currently in use and to get ideas for classifying them. Note

15
that some products that have come up in conversations with various Connections members are not in the table because the project team could not find any information about them.

16
Tab
le 3
.1 �
Can
dida
te P
rodu
cts
Prod
uct N
ame
Vend
or
Des
crip
tion
Supp
ort
s D
ata-
item
Tr
ans.
Su
ppor
ts
Mat
chin
g Su
ppor
ts
Mer
ging
In
tegr
atio
n Ty
pe
Tech
. In
fo.
Avai
labl
e
Eval
. So
ftwar
e Av
aila
ble
Ab In
itio
Ab In
itio
Hig
h-pe
rform
ance
sof
twar
e lib
rary
and
gra
phic
al
envi
ronm
ent f
or d
ata
trans
form
atio
n.
Y N
N
St
and-
alon
e Y
N
AMAD
EA
ISO
FT
Dat
a ex
tract
ion,
tran
sfor
mat
ion,
an
d re
al-ti
me
repo
rting
sof
twar
e.
Y N
N
St
and-
alon
e N
N
iMan
ageD
ata(
tm)
BioC
omp
Syst
ems
Inc.
Acce
sses
, cle
ans,
filte
rs,
conv
erts
and
tran
sfor
ms
data
fro
m te
xt fi
les,
Exc
el, O
racl
e D
atab
ases
, SQ
L Se
rver
da
taba
ses,
and
mor
e.
Y Y
Y St
and-
alon
e or
SD
K Y
Y
Cen
trus
Mer
ge/P
urge
Li
brar
y Q
ualit
ativ
e M
arke
ting
Softw
are
Cle
ans
cust
omer
info
rmat
ion
and
iden
tifie
s du
plic
ate
reco
rds.
Y
Y Y
Stan
d-al
one
N
N
Cho
iceM
aker
2.2
C
hoic
eMak
er
Dat
a qu
ality
and
dat
abas
e re
cord
mat
chin
g, m
ergi
ng, &
de
dupl
icat
ion
softw
are
base
d on
pa
tent
ed A
I and
mac
hine
le
arni
ng te
chni
ques
.
N
Y Y
Serv
er-b
ased
or
Sta
nd-a
lone
Y N
Dat
a M
anag
er
GG
Mat
e Vi
sual
Bas
ic G
UI a
pplic
atio
n fo
r da
ta tr
ansf
orm
atio
n fo
r W
in95
/Win
98.
Y Y
Y St
and-
alon
e Y
Y
Dat
aSet
V
Inte
rcon
IIA
Mat
chin
g, d
edup
�ing,
retri
evin
g &
Min
ing
Suite
. Y
Y Y
Stan
d-al
one
or
SDK
N
Y
Dat
asko
pe
Life
Cyc
le S
oftw
are
Dep
artm
ent-l
evel
tool
s to
map
, tra
nsfo
rm, a
larm
, out
put a
nd
view
hig
h vo
lum
es o
f bin
ary
or
ASC
II in
put d
ata.
Y N
N
St
and-
alon
e Y/
N
Y
17
Dat
a To
ols
Twin
s D
ata
Tool
s C
lean
s ad
dres
ses
in d
atab
ase
that
sup
port
OD
BC c
onne
ctio
ns,
prov
ides
pre
-def
ined
mat
chin
g al
gorit
hms.
Y N
N
Se
rver
-bas
ed
No
No
DfP
ower
D
ataF
lux
Cor
pora
tion
Poin
t and
clic
k dr
iven
. Ana
lyze
s da
ta a
nd s
tand
ardi
zes
data
fie
lds,
de-
dupl
icat
es a
nd h
as
built
-in d
atab
ase
conn
ectiv
ity.
Y Y
Y St
and-
alon
e Ye
s/N
o Ye
s
Dou
bleT
ake,
Sty
leLi
st,
Pers
onat
or
Peop
lesm
ith
Split
s na
mes
, add
ress
es a
nd
city
, sta
te a
nd z
ip c
odes
. Sev
eral
m
atch
code
s su
ppor
ted,
sev
eral
m
atch
ing
crite
ria u
sed
sim
ulta
neou
sly,
OD
BC a
cces
s.
N
Y Y
Stan
d-al
one
Yes/
No
Yes
DQ
Now
D
Q N
ow
Prof
iling,
cle
ansi
ng, a
nd d
edup
to
ols,
pro
vidi
ng a
cle
ar v
iew
of
the
data
.
Y Y
Y St
and-
alon
e Ye
s/N
o Ye
s
Grit
Bot
Rule
Que
st R
esea
rch
Iden
tifie
s an
omal
ies
in d
ata
(com
patib
le w
ith S
ee5
and
Cub
ist).
Y N
N
SD
K N
o Ye
s
Hum
min
gbird
ETL
H
umm
ingb
ird
Dat
a in
tegr
atio
n so
lutio
n.
Y Y
Y St
and-
alon
e Ye
s Ye
s
Post
alSo
ft,
first
Logi
c
Cle
ans
cust
omer
rela
ted
info
rmat
ion.
Cle
anin
g pr
oces
s is
co
mpo
sed
by 6
ste
ps: P
arsi
ng,
Cor
rect
ion,
Sta
ndar
diza
tion,
D
ata
Enha
ncem
ent,
Mat
chin
g,
Con
solid
atin
g
Y Y
Y St
and-
alon
e Ye
s/N
o Ye
s
Inte
grity
, Va
lity
So
lve
data
pro
blem
s co
mm
on
whe
n re
-eng
inee
ring
Lega
cy
Syst
ems,
Dat
a m
inin
g, d
ata
typi
ng, e
ntity
iden
tific
atio
n in
vest
igat
ion,
sta
ndar
diza
tion,
m
atch
ing
and
surv
ivor
ship
Y Y
Y St
and-
alon
e Ye
s/N
o N
o
Link
Solv
Li
nkSo
lv
De-
dupl
icat
ion
Softw
are
N
Y Y
Stan
d-al
one
No
No

18
mat
chIT
, H
elpI
T Sy
stem
s Li
mite
d
Poin
t and
clic
k in
terfa
ce;
Use
rs s
peci
fy m
atch
key
s
Allo
ws
user
to d
efin
e fie
lds
to
com
pare
and
thei
r im
porta
nce
Y Y
Y St
and-
alon
e Ye
s/N
o Ye
s/N
o
Mer
ge/P
urge
Plu
s,
Gro
up1
Softw
are
Cle
ans
nam
es a
nd a
ddre
sses
. Fi
xed
set o
f sup
porte
d m
atch
ing
optio
ns. A
pplie
s to
mul
tiple
file
s.
Y Y
Y St
and-
alon
e,
Tool
Kit
N
N
NoD
upes
, Q
uess
, Inc
.
Cle
ans
spec
ific-
dom
ain
data
re
late
d to
indi
vidu
als,
com
pani
es
and
prod
ucts
, use
r lev
el o
f m
atch
ing,
cus
tom
izab
le.
N
Y Y
Stan
d-al
one
Yes/
No
Yes
SSA-
Nam
e/D
ata
Clu
ster
ing
Engi
ne,
Sear
ch S
oftw
are
Amer
ica
Cla
ims
to s
olve
man
y da
ta
prob
lem
s, c
lean
s cu
stom
er n
on-
form
atte
d re
late
d in
form
atio
n,
gene
rate
s m
ultip
le k
eys
and
stor
es th
em in
a d
atab
ase
inde
x,
perm
its it
erat
ive
tuni
ng
N
Y Y
SDK
Yes/
No
Yes
Sync
sort
Sync
sort
Fast
hig
h-vo
lum
e so
rting
, fil
terin
g, re
form
attin
g,
aggr
egat
ing,
and
mor
e
Y N
N
St
and-
alon
e Ye
s/N
o Ye
s
Sure
Cle
anse
D
Q G
loba
l Im
prov
es d
ata
accu
racy
by
ensu
ring
unde
rlyin
g da
taba
ses
are
dupl
icat
e-fre
e.
Y Y
Y SD
K, S
tand
-al
one
Yes/
No
Yes
Twin
Find
er
Om
ikro
n
Cle
ans
nam
es a
nd a
ddre
sses
fro
m d
oubl
ette
s. U
ses
the
lingu
al/m
athe
mat
ical
FAC
T al
gorit
hm fo
r fuz
zy p
atte
rn-
mat
chin
g.
Y Y
Y St
and-
alon
e Ye
s Ye
s
Win
Pure
Pro
W
inPu
re
Pow
erfu
l dat
a cl
eani
ng s
oftw
are,
in
clud
ing
dupl
icat
ion
rem
oval
, em
ail s
ugge
stio
ns, s
tatis
tics
and
mor
e.
N
Y Y
Stan
d-al
one
Yes/
No
Yes

19
3.2 Off-line Evaluation Since resources for this project were limited, the off-line evaluation could only cover a relatively small number of products. Based on comments from the Connections group, the team established the following guidelines for prioritizing the products and selecting eight of them for the off-line evaluation. Table 3.2 lists those that were selected.
• Products that support matching and merging took precedence over products that supported just data-item transformation.
Rationale: The focus of this study is on de-duplication in integrated health systems and in these kinds of systems, matching and merging are the tougher problems.
• Server-based or SDK products
took precedence over stand-alone products.
Rationale: Stand-alone products are difficult (if not impossible) to incorporate into integrated systems because by definition they do not provide an electronic interface for submitting de-duplication requests. See Section 2.4. Server-based systems or SDKs do, and therefore, have at least some potential for being incorporated into an integrated system.
• Products with insufficient technical documents would not be considered for the
off-line evaluation.
Rationale: There is no sense in evaluating a product if technical documentation is not available.
The availability of technical documentation information ended up dominating the selection process. Because the server-based or SDK products are typically more flexible and require more custom configuration, the technical documentation that was available up-front for these products was less specific. As a result, the list of selected products contained more stand-alone systems than originally desired. The off-line evaluation involved studying product information and technical documentation for each of the selected products and comparing them in the following areas: cost, platform, existing applications, matching technology, merging technology, and product support. Sections 3.2.1 � 3.2.6 summarize the findings in each of these areas. Appendix A contains the complete set of data for the off-line evaluation.
Table 3.2 � Products selected for the off-line evaluation
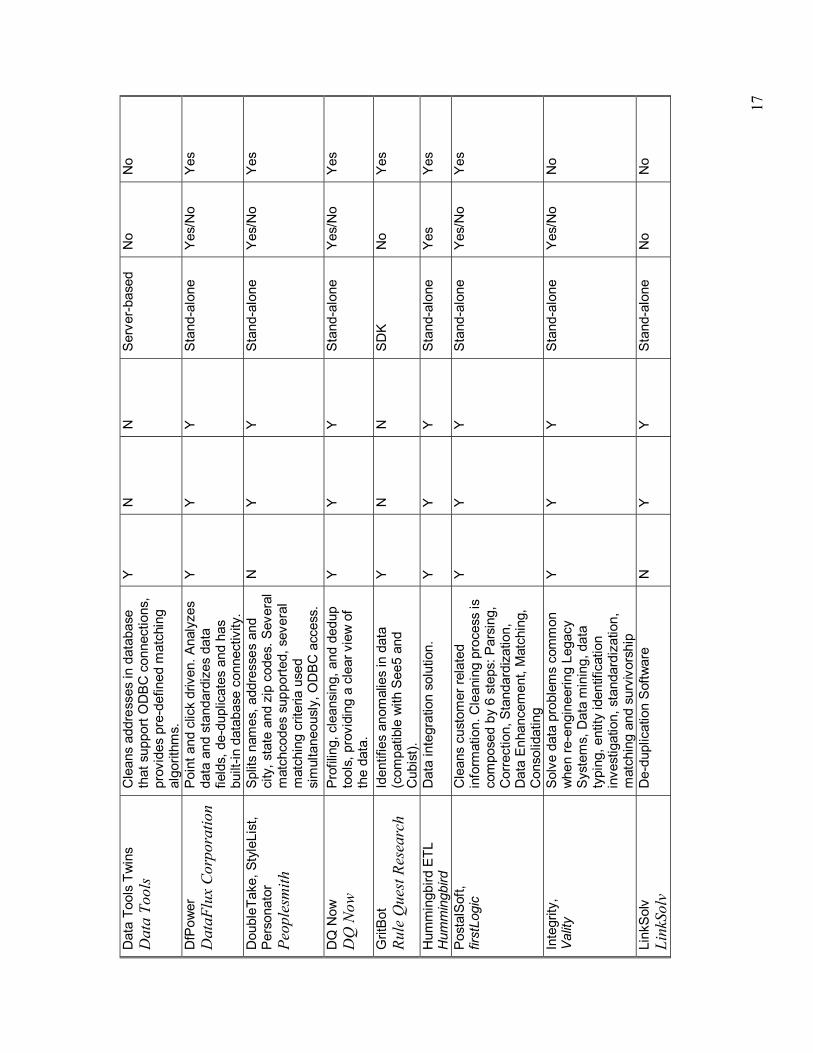
ChoiceMaker 2.2, ChoiceMaker DataSet V, Intercon Systems, Inc. DfPower, DataFlux Corporation PostalSoft, firstLogic Merge/Purge Plus, Group1 Software DoubleTake, Stylelist, and Personator, Peoplesmith SSA-Name/Data Clustering Engine, Search Software America WinPure, Winpure, Ltd.

20
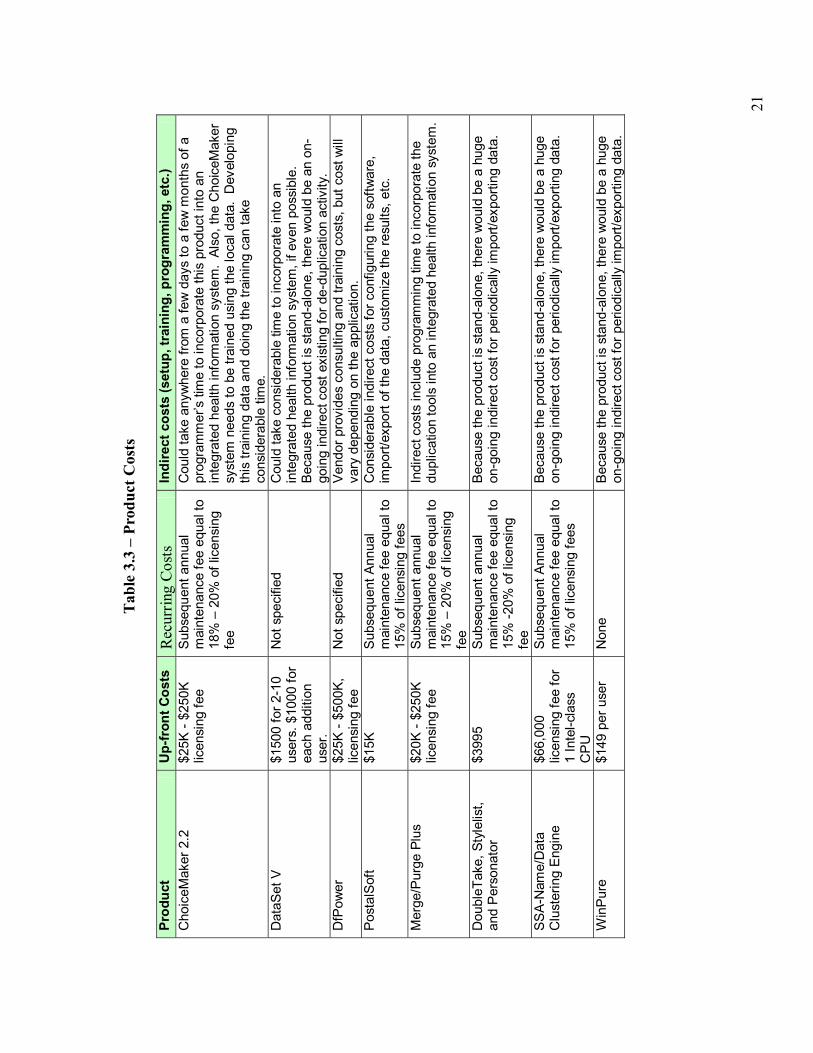
3.2.1 Cost Since the products in Table 3.1, and even those in Table 3.2, vary considerably in their categorization and sophistication, it�s difficult to compare prices directly. However, one way to form a basis for comparison is to separate the costs into three areas: up-front, recurring, and indirect costs. The up-front costs include one-time purchasing or licensing costs. Recurring costs include any periodic maintenance or update fees, per-use charges, or subscription fees. The indirect costs include programming, setup, training, and other miscellaneous costs. Indirect costs can be one-time, periodic, or ongoing. Because of all the variables that can affect them, they cannot be expressed here simply in terms of dollars. Table 3.3 summarizes cost information with respect to these three areas for each of the eight products. Note that even with this break down the costs cannot be compared directly. For example, some have licensing fees based on the size or type of the organization (ChoiceMaker, DfPower, and Merge/PurgePlus); others are based on the number of users (DataSet V, WinPure); and still others take into account the size or type of computer that will host the software (SSA-Name/Data Clustering Engine). The best way to compare costs is to do it in the context of a specific application. This will allow the evaluator to fix certain variables like size of organization, number of records, and type and size of the host machine.
21
Tab
le 3
.3 �
Pro
duct
Cos
ts
Pr
oduc
t U
p-fr
ont C
osts
R
ecur
ring
Cos
ts
Indi
rect
cos
ts (s
etup
, tra
inin
g, p
rogr
amm
ing,
etc
.) C
hoic
eMak
er 2
.2
$25K
- $2
50K
licen
sing
fee
Subs
eque
nt a
nnua
l m
aint
enan
ce fe
e eq
ual t
o 18
% �
20%
of l
icen
sing
fe
e
Cou
ld ta
ke a
nyw
here
from
a fe
w d
ays
to a
few
mon
ths
of a
pr
ogra
mm
er�s
tim
e to
inco
rpor
ate
this
pro
duct
into
an
inte
grat
ed h
ealth
info
rmat
ion
syst
em.
Also
, the
Cho
iceM
aker
sy
stem
nee
ds to
be
train
ed u
sing
the
loca
l dat
a. D
evel
opin
g th
is tr
aini
ng d
ata
and
doin
g th
e tra
inin
g ca
n ta
ke
cons
ider
able
tim
e.
Dat
aSet
V
$150
0 fo
r 2-1
0 us
ers.
$10
00 fo
r ea
ch a
dditi
on
user
.
Not
spe
cifie
d C
ould
take
con
side
rabl
e tim
e to
inco
rpor
ate
into
an
inte
grat
ed h
ealth
info
rmat
ion
syst
em, i
f eve
n po
ssib
le.
Beca
use
the
prod
uct i
s st
and-
alon
e, th
ere
wou
ld b
e an
on-
goin
g in
dire
ct c
ost e
xist
ing
for d
e-du
plic
atio
n ac
tivity
. D
fPow
er
$25K
- $5
00K,
lic
ensi
ng fe
e N
ot s
peci
fied
Vend
or p
rovi
des
cons
ultin
g an
d tra
inin
g co
sts,
but
cos
t will
va
ry d
epen
ding
on
the
appl
icat
ion.
Po
stal
Soft
$15K
Su
bseq
uent
Ann
ual
mai
nten
ance
fee
equa
l to
15%
of l
icen
sing
fees
Con
side
rabl
e in
dire
ct c
osts
for c
onfig
urin
g th
e so
ftwar
e,
impo
rt/ex
port
of th
e da
ta, c
usto
miz
e th
e re
sults
, etc
.
Mer
ge/P
urge
Plu
s $2
0K -
$250
K lic
ensi
ng fe
e Su
bseq
uent
ann
ual
mai
nten
ance
fee
equa
l to
15%
� 2
0% o
f lic
ensi
ng
fee
Indi
rect
cos
ts in
clud
e pr
ogra
mm
ing
time
to in
corp
orat
e th
e du
plic
atio
n to
ols
into
an
inte
grat
ed h
ealth
info
rmat
ion
syst
em.
Dou
bleT
ake,
Sty
lelis
t, an
d Pe
rson
ator
$3
995
Subs
eque
nt a
nnua
l m
aint
enan
ce fe
e eq
ual t
o 15
% -2
0% o
f lic
ensi
ng
fee
Beca
use
the
prod
uct i
s st
and-
alon
e, th
ere
wou
ld b
e a
huge
on
-goi
ng in
dire
ct c
ost f
or p
erio
dica
lly im
port/
expo
rting
dat
a.
SSA-
Nam
e/D
ata
Clu
ster
ing
Engi
ne
$66,
000
licen
sing
fee
for
1 In
tel-c
lass
C
PU
Subs
eque
nt A
nnua
l m
aint
enan
ce fe
e eq
ual t
o 15
% o
f lic
ensi
ng fe
es
Beca
use
the
prod
uct i
s st
and-
alon
e, th
ere
wou
ld b
e a
huge
on
-goi
ng in
dire
ct c
ost f
or p
erio
dica
lly im
port/
expo
rting
dat
a.
Win
Pure
$1
49 p
er u
ser
Non
e Be
caus
e th
e pr
oduc
t is
stan
d-al
one,
ther
e w
ould
be
a hu
ge
on-g
oing
indi
rect
cos
t for
per
iodi
cally
impo
rt/ex
porti
ng d
ata.

22
3.2.2 Supported Platforms Table 3.1 classifies the products in terms of their Integration Type, which could be stand-alone, server-based, or SDK. (See Section 2.4 for descriptions of the three general categories.) Although this classification gives a broad view of a product�s potential for being incorporated into an integrated system, it by no means tells the whole story. Another critical question related to integration potential is, what platforms do the products support? Informally, a platform is any computing environment defined by hardware specifications, an operating system, communication software, and any other prerequisite software (virtual machines, databases, etc.) Many of the products support a variety of platforms, while others are tied to a specific one. They also vary with respect to the degree of their dependency on a platform. Those that are heavily tied to a specific platform may be slower to take advantage of advances in hardware, new operating systems and databases, etc. Table 3.4 summarizes platform support findings for the eight selected products.

23
Tab
le 3
.4 �
Pla
tform
Req
uire
men
ts o
r R
estr
ictio
ns
Pr
oduc
t H
ardw
are
Ope
ratin
g Sy
stem
s C
omm
unic
atio
n So
ftwar
e O
ther
Sof
twar
e
Cho
iceM
aker
2.2
N
o sp
ecia
l re
quire
men
ts
Non
e �
can
run
on a
nyth
ing
that
su
ppor
ts a
JVM
.
Unk
now
n St
rong
dep
ende
ncy
on th
e Ja
va V
irtua
l Mac
hine
(J
VM).
How
ever
, a re
ason
able
impl
emen
tatio
n of
the
JVM
exi
sts
for a
lmos
t eve
ry ty
pe o
f ope
ratin
g sy
stem
. D
ataS
et V
N
o sp
ecia
l re
quire
men
ts
Win
dow
s N
one
Non
e
DfP
ower
N
o sp
ecia
l re
quire
men
ts
Linu
x, U
nix,
W
indo
ws
Non
e N
one
Post
alSo
ft N
o sp
ecia
l re
quire
men
ts
Linu
x, U
nix,
W
indo
ws
95 o
r hi
gher
Non
e N
o ad
ditio
nal s
oftw
are
requ
ired,
exc
ept t
hat a
ll th
e C
Ds
give
n w
ith p
rodu
ct s
houl
d be
cop
ied
onto
the
syst
em.
Mer
ge/P
urge
Plu
s N
o sp
ecia
l re
quire
men
ts
Win
dow
s 95
or
high
er
Unk
now
n U
nkno
wn
Dou
bleT
ake,
Sty
lelis
t, an
d Pe
rson
ator
N
o sp
ecia
l re
quire
men
ts
Win
dow
s 95
or
high
er
Unk
now
n U
nkno
wn
SSA-
Nam
e/D
ata
Clu
ster
ing
Engi
ne
No
spec
ial
requ
irem
ents
Li
nux,
Uni
x,
Win
dow
s XP
, NT
Non
e U
nkno
wn
Win
Pure
N
o sp
ecia
l re
quire
men
ts
Stro
ng
depe
nden
cy o
n W
indo
ws,
but
su
ppor
ts a
ny
vers
ion
of
Win
dow
s
Not
app
licab
le s
ince
th
e pr
oduc
t is
com
plet
ely
stan
d-al
one
Non
e

24
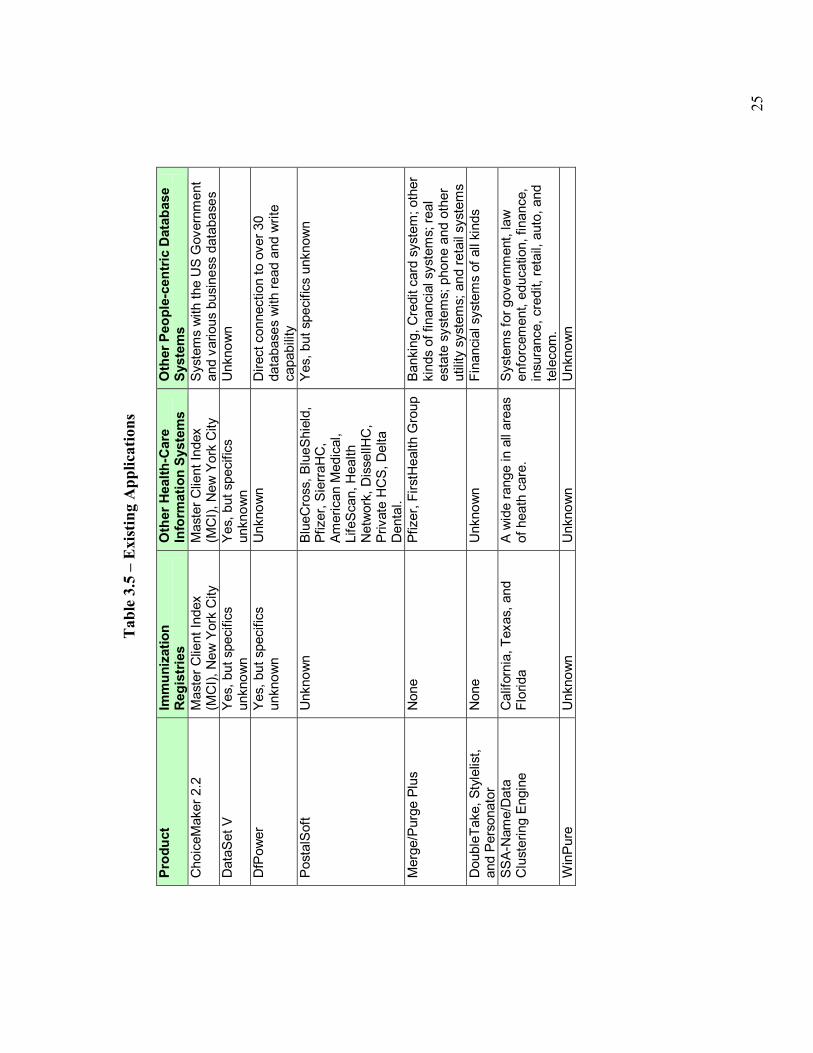
3.2.3 Existing Applications Table 3.5 summarizes known uses for each of the products in three domains: immunization registries, other health information systems, and other people-centric database systems in general. The broader a product�s existing use, the more likely it can be adapted into new situations.
25
Tab
le 3
.5 �
Exi
stin
g A
pplic
atio
ns
Pr
oduc
t Im
mun
izat
ion
Reg
istr
ies
Oth
er H
ealth
-Car
e In
form
atio
n Sy
stem
s O
ther
Peo
ple-
cent
ric D
atab
ase
Syst
ems
Cho
iceM
aker
2.2
M
aste
r Clie
nt In
dex
(MC
I), N
ew Y
ork
City
M
aste
r Clie
nt In
dex
(MC
I), N
ew Y
ork
City
Sy
stem
s w
ith th
e U
S G
over
nmen
t an
d va
rious
bus
ines
s da
taba
ses
Dat
aSet
V
Yes,
but
spe
cific
s un
know
n Ye
s, b
ut s
peci
fics
unkn
own
Unk
now
n
DfP
ower
Ye
s, b
ut s
peci
fics
unkn
own
Unk
now
n D
irect
con
nect
ion
to o
ver 3
0 da
taba
ses
with
read
and
writ
e ca
pabi
lity
Post
alSo
ft U
nkno
wn
Blue
Cro
ss, B
lueS
hiel
d,
Pfiz
er, S
ierra
HC
, Am
eric
an M
edic
al,
Life
Scan
, Hea
lth
Net
wor
k, D
isse
llHC
, Pr
ivat
e H
CS,
Del
ta
Den
tal.
Yes,
but
spe
cific
s un
know
n
Mer
ge/P
urge
Plu
s N
one
Pfiz
er, F
irstH
ealth
Gro
up
Bank
ing,
Cre
dit c
ard
syst
em; o
ther
ki
nds
of fi
nanc
ial s
yste
ms;
real
es
tate
sys
tem
s; p
hone
and
oth
er
utilit
y sy
stem
s; a
nd re
tail
syst
ems
Dou
bleT
ake,
Sty
lelis
t, an
d Pe
rson
ator
N
one
Unk
now
n Fi
nanc
ial s
yste
ms
of a
ll ki
nds
SSA-
Nam
e/D
ata
Clu
ster
ing
Engi
ne
Cal
iforn
ia, T
exas
, and
Fl
orid
a A
wid
e ra
nge
in a
ll ar
eas
of h
eath
car
e.
Syst
ems
for g
over
nmen
t, la
w
enfo
rcem
ent,
educ
atio
n, fi
nanc
e,
insu
ranc
e, c
redi
t, re
tail,
aut
o, a
nd
tele
com
. W
inPu
re
Unk
now
n U
nkno
wn
Unk
now
n

26
3.2.4 Matching Technology The off-line evaluation looked at matching technology, at searching and user-interaction approaches, and at the degree of customization supported in both these areas. The effectiveness of a de-duplication process in a health information system depends heavily on the ability to find potential matches for a given child. If the de-duplication software�s search method were too broad, it would return too many possible matches for a given child. This would place extra burden on the user to further narrow down the matches and would raise the on-going costs of de-duplication. If the search method were too tight, it would not return valid matches and cause the de-duplication process to be ineffective. In both cases, the user might overlook existing duplicates and add new ones to the system. Part of any searching process involves comparing individual data items. Some of the products, such as WinPure, take a very simplistic approach that is based on single-field comparisons and a couple of basic comparison functions. Other products, like ChoiceMaker, use sophisticated machine-learning approaches that can automatically adjust individual data-item comparisons (or more precisely, their relative importance) to a specific locale or information system. Table 3.6 summarizes the searching and comparing techniques used by each of the selected products. In addition to describing each product�s approach to searching and comparing, it ranks their robustness and customizability as high, medium, or low. A high robustness means that the product can support sophisticated search and comparison rules, e.g. multiple data-items and fuzzy comparisons. A high customizability means that a system integrator or programmer can tune the product to better fit the unique characteristics of a given information system. Note that some products, like WinPure, offer some flexibility in how searching is done, but place the burden of using different searching techniques on the end-user. For this evaluation, such flexibility is not considered customizable since the tool is not being configured for more efficient use in the future.

27
Tab
le 3
.6 �
Sea
rchi
ng a
nd C
ompa
riso
n
Prod
uct
Sear
chin
g an
d Co
mpa
rison
R
obus
tnes
s C
usto
miz
abili
tyC
hoic
eMak
er 2
.2
Mac
hine
Lea
rnin
g an
d Pr
obab
ilist
ic a
ppro
ach.
The
y us
e St
ring
Mat
chin
g al
gorit
hms
and
man
y pr
oprie
tary
al
gorit
hms
to m
aint
ain
conf
iden
tialit
y.
Hig
h H
igh
Dat
aSet
V
Cla
ims
prop
rieta
ry m
etho
ds, b
asic
ally
com
parin
g ev
ery
reco
rd w
ith e
very
oth
er re
cord
in th
e da
taba
se.
Low
Lo
w
DfP
ower
Th
e m
atch
ing
is p
roba
bilis
tic a
nd m
achi
ne le
arni
ng. I
t al
so in
clud
es d
eter
min
istic
app
roac
hes.
H
igh
Hig
h
Post
alSo
ft Fi
nds
mat
ches
bas
ed o
n th
e st
anda
rd a
nd u
ser-
spec
ified
fiel
ds. T
he u
ser c
an s
et h
is th
resh
olds
for
com
paris
on. I
t is
a ru
le-b
ased
app
roac
h.
Med
ium
M
ediu
m
Mer
ge/P
urge
Plu
s Fi
nds
mat
ches
bas
ed o
n na
mes
and
add
ress
es o
nly.
Lo
w
Low
D
oubl
eTak
e, S
tyle
list,
and
Pers
onat
or
Find
s m
atch
es u
sing
a ru
le-b
ased
app
roac
h th
at re
ads
data
dire
ctly
from
a la
rge
varie
ty o
f dat
abas
es.
Hig
h H
igh
SSA-
Nam
e/D
ata
Clu
ster
ing
Engi
ne
Use
s a
rule
-bas
ed a
ppro
ach.
Inc
lude
s pr
e-pa
ckag
ed
sear
ch a
nd m
atch
ing
rule
s th
at w
ork
wel
l for
mos
t po
pula
tions
, but
allo
ws
cust
om ru
les
to o
verri
de th
e pr
e-pa
ckag
ed ru
les.
Hig
h H
igh
Win
Pure
Fi
ndin
g m
atch
es b
ased
on
any
sing
le c
olum
n an
d a
user
-sel
ect c
ompa
rison
met
hod.
It a
ppea
rs to
sup
port
a lim
ited
num
ber o
f bas
ic c
ompa
re fu
nctio
ns, s
uch
as 1
-ch
arac
ter e
dit d
ista
nce,
alth
ough
they
see
m to
be
very
lim
ited
and
infle
xibl
e in
sea
rchi
ng.
Low
M
ediu
m

28
In general, the more robust and adaptable a searching method is, the better its chances are of finding the best set of possible matches for a given child. After a searching operation returns a list of possible matches, something has to be done with that information. Two choices exist: a) the de-duplication software can allow a user to interactively identify the actual matches or b) the system can try to do that automatically. Table 3.7 summarizes the approach used by each of the selected products and indicates its level of customizability. Which approach is best depends on how an information system intends to integrate the de-duplication software. If integration is on the front-end, then there are distinct advantages to allowing the user to assist with match refinement activity. If the de-duplication is on the back-end, then allowing user interaction is not feasible or at least not immediately so.
3.2.5 Merging Technology The off-line evaluation looked at merging technology in four general areas: duplicate removal, data conflict resolution, and user-interaction. It also looked at the degree of customization supported in each of these areas. Duplicate removal deals with how the software coalesces redundant data. In general, there are three basic approaches: deleting duplicate records without merging values, linking matching records so that the information system can find all related records, and merging data from all matching records into one complete record. The 2nd column of Table 3.8 indicates which of these approaches each product supports. If the software supports merge matching records, then it must also deal with potential data conflicts. For example, consider a situation where a child has two records in the system, one with a birth date of 8/1/2003 and another with a birth date of 8/4/2003. Which one is correct? There are three basic approaches to resolving such data conflicts: the system gives precedence to one source of information over another (source-based precedence), lets the user choose which value to keep (user-directed), or simply keeps
Table 3.7 � User-interaction For Match Refinement (Clustering)
Product Supports User Interaction
Customizability
ChoiceMaker 2.2 Yes High DataSet V No Medium DfPower Yes High PostalSoft Yes Low Merge/Purge Plus Yes Medium DoubleTake, Stylelist, and Personator
Yes Medium
SSA-Name/Data Clustering Engine
No Medium
WinPure Yes Low
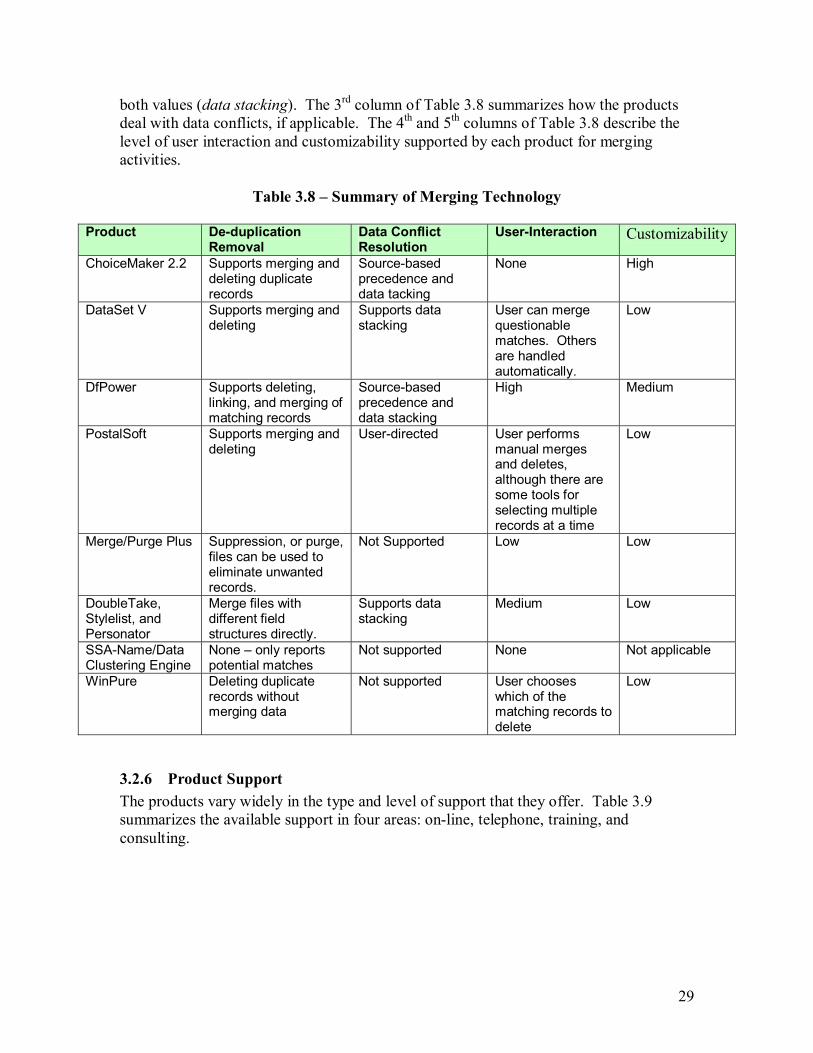
29
both values (data stacking). The 3rd column of Table 3.8 summarizes how the products deal with data conflicts, if applicable. The 4th and 5th columns of Table 3.8 describe the level of user interaction and customizability supported by each product for merging activities.
Table 3.8 � Summary of Merging Technology
Product De-duplication Removal
Data Conflict Resolution
User-Interaction Customizability
ChoiceMaker 2.2 Supports merging and deleting duplicate records
Source-based precedence and data tacking
None High
DataSet V Supports merging and deleting
Supports data stacking
User can merge questionable matches. Others are handled automatically.
Low
DfPower Supports deleting, linking, and merging of matching records
Source-based precedence and data stacking
High Medium
PostalSoft Supports merging and deleting
User-directed User performs manual merges and deletes, although there are some tools for selecting multiple records at a time
Low
Merge/Purge Plus Suppression, or purge, files can be used to eliminate unwanted records.
Not Supported Low Low
DoubleTake, Stylelist, and Personator
Merge files with different field structures directly.
Supports data stacking
Medium Low
SSA-Name/Data Clustering Engine
None � only reports potential matches
Not supported None Not applicable
WinPure Deleting duplicate records without merging data
Not supported User chooses which of the matching records to delete
Low
3.2.6 Product Support The products vary widely in the type and level of support that they offer. Table 3.9 summarizes the available support in four areas: on-line, telephone, training, and consulting.
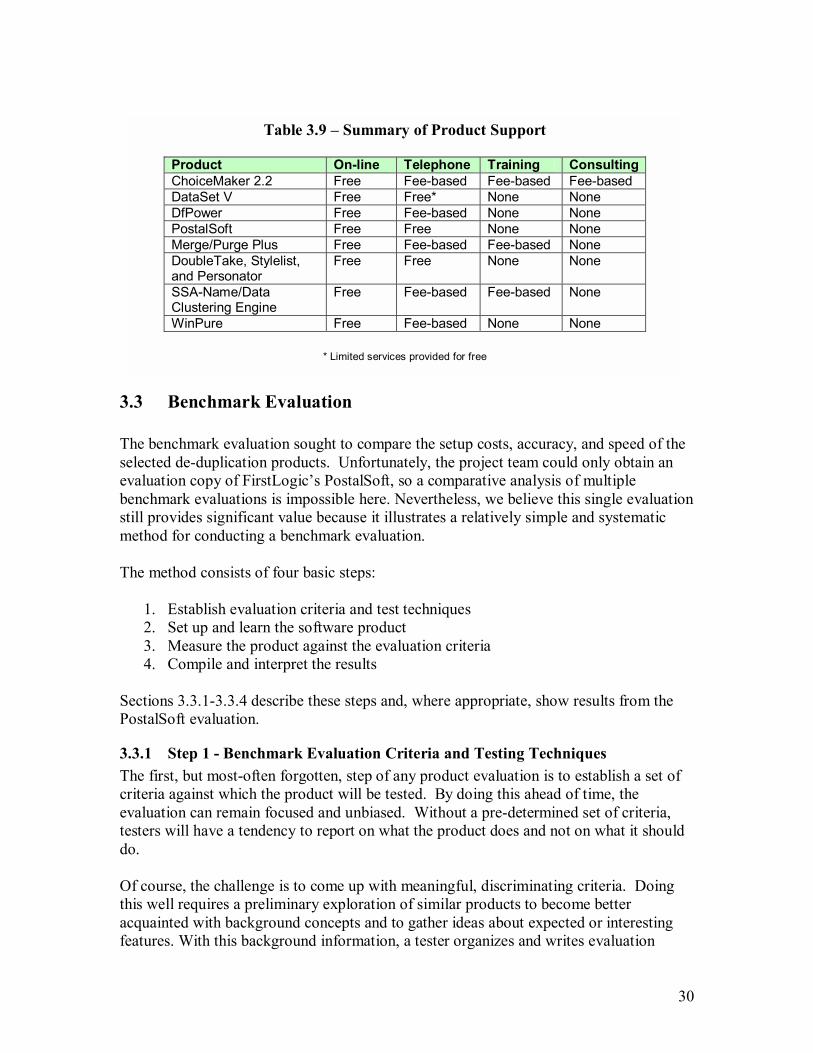
30
3.3 Benchmark Evaluation The benchmark evaluation sought to compare the setup costs, accuracy, and speed of the selected de-duplication products. Unfortunately, the project team could only obtain an evaluation copy of FirstLogic�s PostalSoft, so a comparative analysis of multiple benchmark evaluations is impossible here. Nevertheless, we believe this single evaluation still provides significant value because it illustrates a relatively simple and systematic method for conducting a benchmark evaluation. The method consists of four basic steps:
1. Establish evaluation criteria and test techniques 2. Set up and learn the software product 3. Measure the product against the evaluation criteria 4. Compile and interpret the results
Sections 3.3.1-3.3.4 describe these steps and, where appropriate, show results from the PostalSoft evaluation.
3.3.1 Step 1 - Benchmark Evaluation Criteria and Testing Techniques The first, but most-often forgotten, step of any product evaluation is to establish a set of criteria against which the product will be tested. By doing this ahead of time, the evaluation can remain focused and unbiased. Without a pre-determined set of criteria, testers will have a tendency to report on what the product does and not on what it should do. Of course, the challenge is to come up with meaningful, discriminating criteria. Doing this well requires a preliminary exploration of similar products to become better acquainted with background concepts and to gather ideas about expected or interesting features. With this background information, a tester organizes and writes evaluation
Table 3.9 � Summary of Product Support
Product On-line Telephone Training Consulting ChoiceMaker 2.2 Free Fee-based Fee-based Fee-based DataSet V Free Free* None None DfPower Free Fee-based None None PostalSoft Free Free None None Merge/Purge Plus Free Fee-based Fee-based None DoubleTake, Stylelist, and Personator
Free Free None None
SSA-Name/Data Clustering Engine
Free Fee-based Fee-based None
WinPure Free Fee-based None None
* Limited services provided for free

31
criteria, which are measurable conditions that discriminate whether a product meets expectations. For each criterion, a tester should also describe one or more techniques or test cases for evaluating the product against that criterion. Table 3.10 lists the criteria and testing techniques for this benchmark evaluation, organized by setup, accuracy, and performance. Since the nature and complexity of the setup process can vary considerable depending on the product�s integration type, the criteria in this area tries to ascertain whether there is sufficient documentation for installation, configuration (or training), and integration with an integrated information system. The testing techniques for these criteria require subjective judgments based on observations made during the installation, configuration, and integration processes. The criteria for the accuracy area consider whether the product can correctly identify duplicates in the presence of common data errors without mistakenly matching any records that are not actually duplicates. The testing techniques for these criteria prescribe using the CDC de-duplicate testing toolkit [5]. This toolkit includes a test data set of 550 records, 251 of which are duplicates, and tools for analyzing the results. The duplicate records differ from their matches in ways commonly found in immunization registries (see Table 3.11.) More about this toolkit is available on the CDC website [http://www.cdc.gov]. The test data also contains pairs of records that are similar but should not considered duplicates. They are used to check whether the product incorrectly matches records that shouldn�t be matched. Table 3.12 describes the different categories of similarity and shows the number of records in each one. The criteria and testing techniques for the execution speed area try to determine if the product will perform well for an average-sized integrated child health information system. Among the projects summarized in Section 4, the annual birth cohorts range from 6,000 to 125,000 with the average of 46,000. If an integrated child health information system kept records on-line for 10 years, then it would be reasonable to expect the database to contain 500,000 records at any point in time.

32
T
able
3.1
0 �
Ben
chm
ark
Eva
luat
ion
Cri
teri
a Ar
ea
Crit
eria
Te
stin
g Te
chni
que
Mea
sure
men
t Se
tup
The
prod
uct s
houl
d co
me
with
det
aile
d in
stru
ctio
ns fo
r ins
talla
tion
and
conf
igur
atio
n (o
r tra
inin
g).
Stud
y th
e in
stru
ctio
ns a
nd d
o th
e in
stal
latio
n an
d co
nfig
urat
ion
(or t
rain
ing)
. Kee
p no
tes
durin
g th
e pr
oces
s ab
out t
he k
inds
of
prob
lem
s th
at a
rise.
Mak
e a
subj
ectiv
e as
sess
men
t of p
rodu
ct
with
resp
ect t
o th
is c
riter
ion.
Rat
e on
a s
cale
of 0
to 4
, with
4
bein
g th
e hi
ghes
t and
mea
ning
th
at a
ll ex
pect
atio
ns w
ith re
spec
t to
this
crit
erio
n w
ere
met
. If
the
prod
uct i
s st
and-
alon
e it
shou
ld p
rovi
de
suffi
cien
t doc
umen
t for
set
ting
up th
e im
porti
ng
and
expo
rting
of t
he d
ata;
oth
erw
ise,
it s
houl
d pr
ovid
e su
ffici
ent d
ocum
enta
tion
for i
nter
faci
ng
it w
ith a
n in
form
atio
n sy
stem
.
Stud
y th
e ap
prop
riate
doc
umen
tatio
n an
d se
t it u
p fo
r eith
er
impo
rting
dat
a or
acc
eptin
g da
ta fr
om a
test
info
rmat
ion
syst
em.
Rat
e on
a s
cale
of 0
to 4
, with
4
bein
g th
e hi
ghes
t and
mea
ning
th
at a
ll ex
pect
atio
ns w
ith re
spec
t to
this
crit
erio
n w
ere
met
.
The
conf
igur
atio
n or
trai
ning
sho
uld
be s
aved
so
it d
oesn
�t ha
ve to
redo
ne e
very
tim
e th
e pr
oduc
t is
used
or u
pdat
ed.
Test
to s
ee if
the
conf
igur
atio
n is
per
sist
ent.
Run
mul
tiple
tim
es
and
note
if a
ny p
art o
f the
set
up p
roce
ss h
as to
be
redo
ne.
Also
, re
inst
all t
he p
rodu
ct a
nd n
ote
how
muc
h of
the
conf
igur
atio
n is
re
mem
bere
d.
Rat
e on
a s
cale
of 0
to 4
, with
4
bein
g th
e hi
ghes
t and
mea
ning
th
at a
ll ex
pect
atio
ns w
ith re
spec
t to
this
crit
erio
n w
ere
met
. Ac
cura
cy Th
e pr
oduc
t sho
uld
corr
ectly
iden
tify
90%
or
mor
e of
the
dupl
icat
e re
cord
s in
a te
st d
ata
set
with
kno
wn
dupl
icat
es th
at re
pres
ent c
omm
on
data
pro
blem
s.
Usi
ng th
e C
DC
test
dat
a se
t [5]
, run
the
mat
chin
g so
ftwar
e an
d ge
nera
te a
list
wha
t it d
eter
min
es to
be
certa
in d
uplic
ates
(can
be
aut
omat
ical
ly m
erge
d or
reje
cted
) and
pot
entia
l dup
licat
es
(thos
e th
at n
eed
hum
an re
solu
tion)
. An
alyz
e th
ese
resu
lts fo
r ty
pe o
f dat
a pr
oble
ms
iden
tifie
d by
CD
C.
See
Tabl
e 3.
11
Perc
ent o
f kno
wn
dupl
icat
es
corr
ectly
mar
ked
as e
ither
cer
tain
du
plic
ates
or p
oten
tial d
uplic
ates
, br
oken
dow
n by
type
of d
ata
prob
lem
.
The
prod
uct s
houl
d do
not
mar
k an
y du
plic
ates
th
at a
ren�
t act
ually
dup
licat
e �
no fa
lse
posi
tives
.
Usi
ng a
test
dat
a se
t, ru
n th
e m
atch
ing
softw
are
and
reco
rd w
hat
it de
term
ines
are
not
dup
licat
es.
Brea
k th
e re
sults
dow
n by
type
of
dat
a pr
oble
m.
See
Tabl
e 3.
11
Perc
ent o
f kno
wn
non-
dupl
icat
es
corr
ectly
iden
tifie
d by
the
softw
are
as n
on-d
uplic
ates
. Ex
ecut
ion
Spee
d
The
prod
uct s
houl
d de
term
ine
whe
ther
any
gi
ven
reco
rd is
a d
uplic
ate,
pot
entia
l dup
licat
e,
or n
on-d
uplic
ate
in a
reas
onab
le a
mou
nt o
f tim
e (le
ss th
an s
ever
al s
econ
ds.)
Usi
ng a
test
dat
a se
t with
kno
wn
dupl
icat
es, r
un th
e m
atch
ing
softw
are
for a
t lea
st 1
,000
reco
rds
agai
nst a
dat
abas
e of
at l
east
50
0,00
0 re
cord
s. R
ecor
d th
e tim
e it
take
s to
pro
cess
the
1,00
0 re
cord
s.
Aver
age
cloc
k-tim
e / r
ecor
d C
PU ti
me
/ rec
ord
IO w
ait t
ime
/ rec
ord

33
Table 3.11 � Common Types of Data Problems that Among Duplicate Records
Duplicate Problem Types
Description Count
First Name Spelling Nicknames, typos, or variations of first name. These can sometimes match by Soundex or partial matching.
51
Last Name Spelling Typos or misspellings of last name. These can sometimes match by Soundex or partial matching.
24
First Name Hyphenation
Hyphenated first name has missing hyphen or missing one part of name.
15
Last Name Hyphenation
Hyphenated last name has missing hyphen or missing one part of name.
23
First Name Reversed w/Last Name
First name has been reversed with last name; for some names not easy to distinguish
4
First Name Reversed w/Middle Name
First name has been reversed with middle name 4
Middle Name Reversed w/Last Name
Middle name has been reversed with last name. 4
Different Last Name Last name is totally different due to re-marriage, foster care, or other reasons.
14
First Name as �Baby� Child has been entered into the system possibly with hospital data prior to naming.
9
Suffix included in First Name
Suffix erroneously included in first name field. 7
Suffix included in Last Name
Suffix erroneously included in last name field. 5
Date of Birth Difference
Date of birth for same person does not match due to error in day, month, year or some combination of these.
61
Gender Difference Gender for same child does not match other record due to error.
4
Duplicate Core Data (first,last,DOB,sex)
The first name, last name, date of birth and gender fields are identical in both records although other fields may not completely match. These cases are common and normally not considered a problem by registries.
16
Exact Duplicate (all demographic fields)
Every demographic field is an identical duplicate. (This includes the child names, mother names, DOB, & gender. Some may even have identical vaccines as would occur when an electronic submission is re-sent.) These cases are common and normally not considered a problem by registries.
10
Total Duplicates 251 Note that these duplicate problem types and their meanings come from the reporting categories of CDC�s de-duplication analysis tool. See User Manual for the De-duplication Toolkit, p. 7 [14].

34
Table 3.12 �Types of Similar, but Non-duplicate Records in CDC Test Set
Type of Similarity
Description
Notes Count
First Name Spelling
For each case, two records have same last names and same DOB but they have first names spelled different and mothers are different.
Records could be confused as same person with spelling first name problem.
6
First Name Spelling + Diff DOB
For each case, two records have same last name but first name and DOB have some differences. (May still be similar but not exact match). Mothers are different.
Records could be confused as same person with first name and DOB errors.
8
Last Name Spelling
For each case, two records have same first names and same DOB but they have last names spelled different and mothers are different.
Records could be confused as same person with spelling last name problem
8
First Name Hyphenation
For each case, two records have the same DOB and last name and have a first name hyphenation difference. Mothers are different.
Records could be confused as same person with a first name hyphenation problem.
2
Last Name Hyphenation
For each case, two records have the same DOB and first name and have a last name hyphenation difference. Mothers are different.
Records could be confused as same person with a last name hyphenation problem.
2
First Name Reversed w/Last Name
For each case, two records have the same DOB and have reversed first and last names from each other. Mothers are different.
Records could be confused as same person first and last name switched.
2
First Name Reversed w/Middle Name
For each case, two records have the same DOB and last name and have reversed first and middle names from each other. Mothers are different.
Records could be confused as same person first and middle name switched.
2
First Name Reversed w/Middle Name and Diff DOB
For each case, two records have different DOBs and reversed first and middle names. (May still be similar but not exact match). Mothers are different.
Records could be confused as duplicate with reverse first/middle and DOB errors.
2
Middle Name Reversed w/Last Name
For each case, two records have the same DOB and first name and have reversed middle and last names from each other. Mothers are different.
Records could be confused as same person middle and last name switched.
2
Different last name
For each case, two records have same first names and same DOB, but they have different last names and mother data.
Records could be confused as same person with different last name
14
First Name as �Baby�
For each case, two records have �baby� as part of first name, same last name, and same date of birth. Other fields differ.
Compares to duplicate cases where �baby� was part of first name.
2
35
Date of Birth Difference
For each case, two records are two people with same or similar names and different date of birth and mother data.
Records could be confused as same person with date of birth error.
12
Gender Difference
For each case, two records have similar first names, same last name, and same DOB but they have different gender and mother data.
Records could be confused as same person with an error in gender code
2
Duplicate Core Dat(first, last, dob, sex
For each case, two records have same first and last names, date of birth, and gender - but different middle names and mother data.
Records could be confused as same person.
2
Multi-births For each case, two or more records represent twins and triplets. All fields match except for first name, maybe middle. (Mothers are the same).
Records could be confused as same person with first name error.
10
Siblings For each case, two records represent two brothers and/or sisters. All fields match except DOB, first and middle names. (Mothers are the same).
Records could be confused as same person with first name and DOB errors.
4
Cousins For each case two records have similarities in some fields � could be last names or mom�s names
Records could be confused as the same person with first name, last name, and DOB errors.
4
Soundex match For each case, two records have same DOB. First and/or last names will match based on soundex but don�t really look that much alike. (E.g. Morgan and Morrison). Mothers are different.
Records could be confused as same person with first name and/or last name errors, if too much reliance on soundex.
6
Total non-duplicates that look like duplicates 90 Note that these similarity types and their meanings come directly from the reporting categories of CDC�s de-duplication analysis tool. See User Manual for the De-duplication Toolkit, p. 9 [14].

36
3.3.2 Step 2 - Setup and Learn the Product After establishing the evaluation criteria and testing techniques, the next step is to install the product, configure or train it, integrate it into a simulated information system, and then become proficient in its use. Since the setup is one of the evaluation areas with testing techniques, testers need to keep notes about the process and then make some subjective assessments about the product.
3.3.3 Step 3 - Measure the Product Against the Evaluation Criteria The next step is to test against the evaluation criteria using the techniques specified with the criteria in each of three areas. 3.3.3.1 Setup Table 3.13 summarizes the results for the PostalSoft evaluation in the setup area. Note the ratings are subjective and, because there were no other products to compare against, they offer little insight except to say that PostalSoft fell short of the expectations, particularly with respect to the third criterion.
Table 3.13 � Evaluation Results for PostalSoft in the Setup Area
Criteria Notes Rating The product should come with detailed instructions for installation and configuration.
The set up process had some problems. Technical support was called (several times?) to resolve those problems.
2
If the product is stand-alone it should provide sufficient documentation for setting up the importing and exporting of the data. If the product is a server-based system or SDK, it should provide sufficient documentation for integrating it into an existing information system.
Although the product came with reasonable documentation for doing the import, the process was not as smooth as expected. One call to a support line was necessary.
3
The configuration or training should be saved so it doesn�t have to be redone every time the product is used or updated.
Although it allows the user to save custom matching rules, it does not allow the user to save all of the necessary configuration parameters for importing and exporting.
1
3.3.3.2 Accuracy Since the PostalSoft product is a stand-alone system, the testing techniques for the criteria in the accuracy area requires the tester to do the following:
1. Load the test data into PostalSoft. 2. Use the product to remove the duplicates. This involves selecting or creating a set of
matching rules, running the match/merge tools, and reviewing the match groups (clustering).
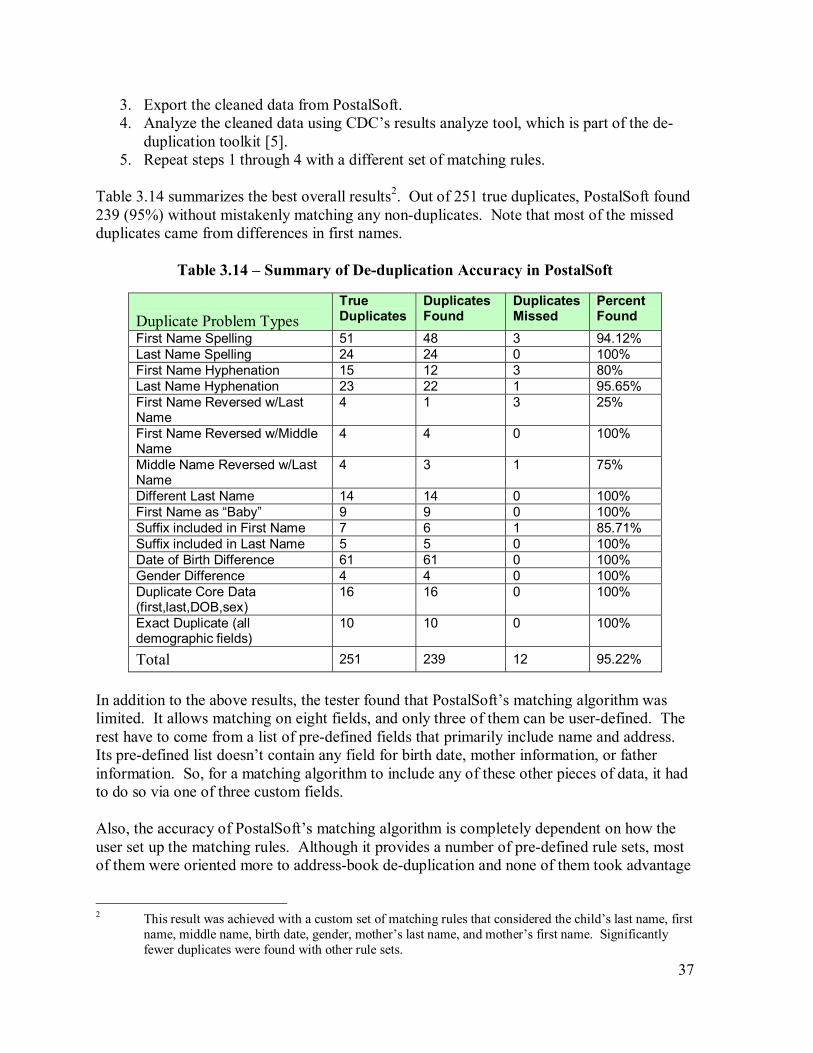
37
3. Export the cleaned data from PostalSoft. 4. Analyze the cleaned data using CDC�s results analyze tool, which is part of the de-
duplication toolkit [5]. 5. Repeat steps 1 through 4 with a different set of matching rules.
Table 3.14 summarizes the best overall results2. Out of 251 true duplicates, PostalSoft found 239 (95%) without mistakenly matching any non-duplicates. Note that most of the missed duplicates came from differences in first names.
Table 3.14 � Summary of De-duplication Accuracy in PostalSoft
Duplicate Problem Types
True Duplicates
Duplicates Found
Duplicates Missed
Percent Found
First Name Spelling 51 48 3 94.12% Last Name Spelling 24 24 0 100% First Name Hyphenation 15 12 3 80% Last Name Hyphenation 23 22 1 95.65% First Name Reversed w/Last Name
4 1 3 25%
First Name Reversed w/Middle Name
4 4 0 100%
Middle Name Reversed w/Last Name
4 3 1 75%
Different Last Name 14 14 0 100% First Name as �Baby� 9 9 0 100% Suffix included in First Name 7 6 1 85.71% Suffix included in Last Name 5 5 0 100% Date of Birth Difference 61 61 0 100% Gender Difference 4 4 0 100% Duplicate Core Data (first,last,DOB,sex)
16 16 0 100%
Exact Duplicate (all demographic fields)
10 10 0 100%
Total 251 239 12 95.22%
In addition to the above results, the tester found that PostalSoft�s matching algorithm was limited. It allows matching on eight fields, and only three of them can be user-defined. The rest have to come from a list of pre-defined fields that primarily include name and address. Its pre-defined list doesn�t contain any field for birth date, mother information, or father information. So, for a matching algorithm to include any of these other pieces of data, it had to do so via one of three custom fields. Also, the accuracy of PostalSoft�s matching algorithm is completely dependent on how the user set up the matching rules. Although it provides a number of pre-defined rule sets, most of them were oriented more to address-book de-duplication and none of them took advantage
2 This result was achieved with a custom set of matching rules that considered the child�s last name, first
name, middle name, birth date, gender, mother�s last name, and mother�s first name. Significantly fewer duplicates were found with other rule sets.

38
of birth date and parent information. Non-technical users may have a difficult time selecting an approach to choosing a set of matching rules or setting up new ones. 3.3.3.3 Execution Speed Although execution speed seemed like an important characteristic to test, the criteria reasonable, and the testing technique justified, this part of the evaluation turned out to be impractical. Given the budget and schedule constraints of this project, the project team was unable to construct a meaningful test data set of the required size (500,000 records). Creating such a test data set would be of great value and an important objective of a possible future project.
3.3.4 Step 4 � Compile, Interpret, and Document the Results The last step is to compile, interpret, and document the results in a form that can be easily communicated and understood. Typically, a full de-duplication tool study for an integration project would test multiple products. The results for each of these evaluations would then provide a basis for making comparisons and drawing conclusions. Since this project included only one sample benchmark evaluation, examples of such comparisons and interpretations cannot be given here. However, in general, the key to this step is to make comparisons that are well formed (based on common measures, characteristics, etc.) and interpretations that are supported by the data, and then to write them up in a form that clearly and concisely communicates the results.
3.4 Discussion Completing a meaningful tool evaluation for any kind of product is a non-trivial activity. However, there are some special challenges in evaluating de-duplication products for integrated health information systems. This section identifies and discusses four of these challenges.
3.4.1 Finding common basis for comparison The most notable one is finding a common basis for comparison. As discussed earlier, the technologies behind de-duplication solutions vary with respect to the parts of the problem they address, the types of data cleaning that they provide, the sophistication of the matching algorithms, and their support for record merging or linking. Also, the products offer different opportunities for integrating de-duplication into existing information systems (or not). Some are geared toward one-time or periodic use, as is the case for most stand-alone products. Others, like server-based products, provide a variety of connectivity options. Still others simply consist of software components that programmers can reuse in their own software. Finally, the products differ in terms of how they are packaged, licensed, and supported. So, finding a common basis for comparison is difficult and requires some serious forethought. To meet this challenge, it is important to
1. Stay focused on those issues that are important to an particular integration project 2. Establish a set of evaluation criteria that is meaningful with respect to those issues

39
3. Measure products against the criteria using pre-planned testing techniques or test cases
3.4.2 Obtaining evaluation software The second challenge is obtaining evaluation software. The project team found that most of the vendors were not willing to let others test their products. However, several offered to run our test data through their system themselves and then send us the results. There are several possible reasons that might explain the vendors� reluctance. First, they did not perceive this project as resulting in a potential sale and therefore not worth the effort. Obviously, this issue would not exist if an individual project conducted an evaluation for the purpose of making a purchase. Second, many of products are not easy to set up, configure, or train. For the evaluation to be fair and represent a product in its best light, the vendor might have to invest considerable time and effort in assisting with the evaluation. This issue might be more true for served-based and SDK products than for stand-alone products, since their setup is typically considerably more involved.
3.4.3 Obtaining or creating meaningful test data The third challenge is obtaining or creating meaningful test data. Although the CDC test data set is good, it is small and oriented towards immunization registries. It may not reflect the kinds and percentages of errors that occur in a given integrated child health information system. As a result, the evaluation could produce misleading results. For example, if an information system contains a high percentage of duplicates with first-name spelling problems but the test data only has a few and the products don�t do well with first-name matching, then the test results would be higher than they should be.
3.4.4 Interpretation of results The fourth challenge is properly interpreting the results of de-duplication activities. Each product may use different terminology and report results in a slightly different fashion. This can easily cause the tester to misunderstand what is actually taking place. For example, to analyze the number of duplicates found by category, the CDC analysis tool relied on the de-duplication assigning the same �Patient Id� to all the records in a cluster of possible matches. PostalSoft, however, did not do this directly (or so it seemed). As a result, the tester made a serious error in preparing the data for the analyzer, which altered what the analyzer thought it would match and led to inaccurate accuracy statistics. Fortunately, the error was discovered, and as it turns out, PostalSoft does produce a matching group number that could serve the same purpose as the Patient Id. Although this was a case of human error, it does illustrate a potential problem for any de-duplication tool evaluation. Because of its inherent complexity and the wide range of products, it is easy to misinterpret the results for any particular accuracy test case. Testers must ensure that they fully understand the product and the meaning of the data.

40
4. Review of De-duplication in Integrated Child-Health Information Systems in Eight Connections Projects A primary goal of this project is to review existing integrated child-health information systems and report on what they are doing in terms of de-duplication so that others can learn from their experiences. Since the Connections group consists of public-health agencies that are all attempting to integrate child-health information systems and are willing to share their experiences, its members and their corresponding projects became the subjects of this review. Descriptions of these projects, based on Project Briefs dated December 2001, are available on the Connections website [11]. The review proceeded in three steps:
1. Initial survey instrument developed with participant input 2. Analysis of initial survey responses 3. Review of individual project scope and objectives 4. Summary of projects and their de-duplication issues
The initial survey instrument, shown in a condensed form in Figure 4.1, sought information about the scope of the integrated child-health information systems and their current status with respect to de-duplication. This survey was sent out to all Connection members via e-mail and discussed on several Connection conference calls. Eight groups in seven different jurisdictions responded with sufficient details to proceed to the next steps. Tables 4.1 � 4.9 summarize the findings of the survey responses in the following areas.
1. Birth Cohorts 2. Health-care programs involved in the integration 3. Use of a master or individual indices 4. Sources considered most authoritative for demographic information 5. Degree of automation for de-duplication activities 6. Front-end vs. Back-end de-duplication 7. Data elements used in the matching process 8. Quality assurance procedures 9. Use of off-the-shelf software
It�s important to note that the initial survey captured a static view of the integration projects and their use of de-duplication technology for a single point in time. This helped the project team do some rough analysis and organization of ideas prior to conducting individual project reviews. The individual project reviews focused on obtaining a more dynamic understanding of each individual project. Through one-on-one phone calls, e-mail messages, and exchange of project documentation, the project team was able to probe de-duplication issues that were

41
unique to the individual projects and meaningful with respect to their current efforts. Some of the projects, such as Rhode Island�s KIDSnet, for example, are in the process of re-designing their systems and so the review looked at both current and future use of de-duplication technology. Other projects, like Utah, are still waiting on the resolutions of a few organizational issues before deploying their integrated health-care system, so the review focused on de-duplication in individual participating programs, the introduction of a new Birth Record Number for three of those programs, and on what the integrated system will be able provide in the future. The project team summarized the information gathered during the individual project reviews in eight project abstracts. These abstracts appear at the end of this section, in descending order based on the number of programs that they involve.

42
Figure 4.1a � Condensed version on the initial survey, page 1
Initial Survey on
Record Matching and De-duplication Technologies for Child Health Integrated Systems
This survey aims to gather basic information about de-duplication software and procedures currently being used in child health integrated systems. Please take a few minutes to answer the questions below in the context of your integrated system. Feel free to contact Stephen Clyde at 435-797-2307 or [email protected] if you have questions. Name: Organization: Integration Project:
1) How large is your Birth Cohort? ________ (Births/Year)
2) Which health-care systems are currently involved in your integration project? (check all that apply)
! Immunization ! Newborn screening ! Hearing screening ! Lead screening ! Vital Records ! Early Intervention ! Women, Infants, and Children (WIC) ! Birth Defects Registry ! Medicaid ! Family Services ! NEDDS ! Other 3) Does your integrated system keep a separate child or person index that acts as a “master” or
“authority” for the de-duplication process? ! Yes (skip to question 5) ! No 4) Which of the participating systems (those listed in question #3), if any, keep a child or person
index that acts as an “authority” in the de-duplication process? ! Immunization ! Newborn screening ! Hearing screening ! Lead screening ! Vital Records ! Early Intervention ! Women, Infants, and Children (WIC) ! Birth Defects Registry ! Medicaid ! Family Services ! NEDDS ! Other ! None 5) Among all the participating systems, which one is considered to have the most authoritative
demographic information about persons? ! Immunization ! Newborn screening
! Hearing screening ! Lead screening

43
Figure 4.1b � Condensed version on the initial survey, page 2
6) Would you consider your de-duplication process to be fully automated, manual, or semi-
automated. ! Fully automated ! Manual ! Semi-automated If semi-automated, how does the user interact with the software to do de-duplication?
7) Is your overall process a front-end or back-end or some combination approach? (check all that
apply)
! Front-end (record searching, matching, and merging occurs prior to entering new records into the database)
! Back-end (record searching, matching, and merging occurs after entering new records into the database)
! Other, please specify: ______________________________________
8) If your system uses a front-end approach, please answer following:
a. What percentage of records matched existing records in the system as they are entered or imported? _____ % (estimate the percentage the best you can).
b. What percentage of entered or imported records did not match any existing record,
but probably should have been? _____ % (estimate the percentage the best you can).
c. Is your record front-end matching software based on probabilistic record matching? Typically, a probabilistic approach will return search results that list potential matches with some kind of score or ranking that indicates how likely each one is to be an actual match.
! Yes ! No ! Don’t know
d. Is your front-end matching software based on machine-learning technology? You can
assume that it is if someone had to “train” the system on known matches prior to being used for real.
! Yes ! No ! Don’t know

44
Figure 4.1c � Condensed version on the initial survey, page 3
9) If your system uses back-end de-duplication, please answer the following: a. What percentage of the records entered or imported into your integrated system are
duplicates? ____ % (estimate percentage the best you can).
Note: If your integrated system uses a central database, then this is the percentage of duplicates that get into that database. If your system involves multiple databases, then this is the percentage of unlinked or uncorrelated duplicates across all those participating databases.
b. Eventually, the back-end de-duplication process finds what percentage of the
duplicate records in your integrated system? ____ % (estimate the percentage the best you can).
c. Is your back-end de-duplication software based on probabilistic record matching?
Typically, a probabilistic approach will return search results that list potential matches with some kind of score or ranking that indicates how likely each one is to be an actual match.
! Yes ! No ! Don’t know
d. Is your back-end de-duplication software based on machine-learning technology? You can assume that it is if someone had to “train” the system on known matches prior to being used for real.
! Yes ! No ! Don’t know
10) On which data elements or combinations of data elements does your de-duplication software base its matching (e.g., child’s last name, birth date, mother’s last name, etc.)? List them in order of most important (or most heavily weighted) to least.
11) Did you test other data elements or combinations of data elements prior to arriving at present
configuration? ! Yes ! No
12) Briefly describe your quality assurance procedures or constraints for checking incoming
information from Clinics and Hospitals, if any? For example, when adding or importing a child’s record into the system, does your system require certain data elements, like child’s last name and birth date, to be present? Or, do birth dates have to be complete or can they be approximate (i.e. just the month and year)?
13) Does your integrated system use any off-the-self software for record matching or de-
duplication?
! No ! Yes, please provide product names and vendors 14) Who are the best persons to contact for further technical details related to record de-

45
Table 4.1 - Integration Projects and Their Birth Cohorts
Project Organization Birth CohortKIDSNET RI, DOH 13,500FAMILYNET OR, DOH 46,000ALERT OR, Imm. 47,000Master Child Index (MCI) NYC, DOHMH 125,000MOHSAIC MO, DOHSS 75,000Community Early Childhood Screening & Tracking
KS, DOH 6,500
ImmPact ME, BOH 13,000CHARM UT, DOH 47,000
Table 4.2 - Health-care programs involved in the integration
Involved Systems
Project IR HS NBS LS VS EI WIC BDR MC FS NEDDS PRAM other KIDSNET Y Y Y Y Y Y Y Y Newborn
Development Risk Assessment; Home Visiting
FAMILYNET Y Y Y Y Y Y Perinatal & Child health programs
ALERT Y Y MCI Y Y Y Communicable
Disease Surveillance System in the future
MOHSAIC Y Y Y Y Community Early Childhood Screening & Tracking
Y Y ?
ImmPact Y Y Y Y CHARM Y Y Y
IR Immunization Registry HS Hearing Screening NBS Newborn Screening LS Lead Screening VS Vital Statistics EI Early Intervention WIC Women, Infants, and Children BDR Birth Defects Registry MC Medicaid FS Family Services NEDDS National Electronic Disease Surveillance Systems PRAM
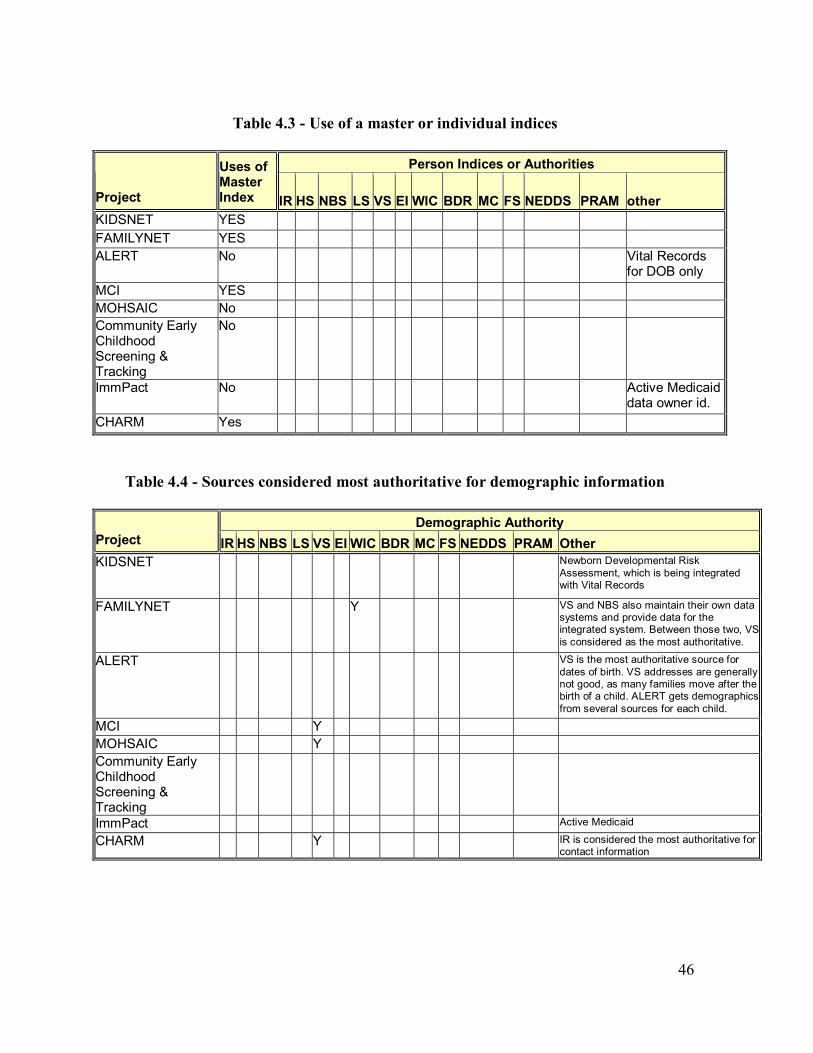
46
Table 4.3 - Use of a master or individual indices
Person Indices or Authorities
Project
Uses of Master Index IR HS NBS LS VS EI WIC BDR MC FS NEDDS PRAM other
KIDSNET YES FAMILYNET YES ALERT No Vital Records
for DOB only MCI YES MOHSAIC No Community Early Childhood Screening & Tracking
No
ImmPact No Active Medicaid data owner id.
CHARM Yes
Table 4.4 - Sources considered most authoritative for demographic information
Demographic Authority Project IR HS NBS LS VS EI WIC BDR MC FS NEDDS PRAM Other KIDSNET Newborn Developmental Risk
Assessment, which is being integrated with Vital Records
FAMILYNET Y VS and NBS also maintain their own data systems and provide data for the integrated system. Between those two, VS is considered as the most authoritative.
ALERT VS is the most authoritative source for dates of birth. VS addresses are generally not good, as many families move after the birth of a child. ALERT gets demographics from several sources for each child.
MCI Y
MOHSAIC Y
Community Early Childhood Screening & Tracking
ImmPact Active Medicaid
CHARM Y IR is considered the most authoritative for contact information

47
Table 4.5 - Degree of automation for de-duplication activities
Automation
Project FullManual Semi Notes KIDSNET Y Y Y The matching process is fully automated on the front end and manual on the back
end. Text files are imported and matched using established algorithms. Any incoming records that do not match undergo human review and are adjusted for spelling or DOB so that they match and get imported. The merge process is manual, though a software development project is underway that would allow semi-automated merging. The user would need to determine which data elements he wants to keep between the two records and then the system would automatically merge the data elements into a single child record.
FAMILYNET Y The current, back-end process for WIC and public health immunization records produces matched records that user manually examine and de-duplicate. The current front-end linking of newborn birth certificate, heel-stick, and hearing screening data requires clerical review of records that do not meet the match weight criteria for automated linking. We are developing a more sophisticated system that will combine these approaches.
ALERT Y Custom designed de-duplication software (called RESOLVE) checks records at the time of import. It identifies children who cannot be matched up with an existing unique ID and whose name and date of birth indicate a possible match with an existing child in ALERT. Children with existing records automatically get updates to their existing shot records without manual review if the unique ID is the same. Records specialists use RESOLVE to examine records and merge children with same/similar last names and/or dates of birth. Specialists validate discrepancies in DOBs with birth records. Using strict matching rules, they examine the records and manually deduplicate the children and immunizations. All permanent record merging happens in RESOLVE. ALERT also uses RESOLVE to store "matched lists" of names from Soundex, etc. These files speed the human review time for permanently merging records in RESOLVE.
MCI Y De-duplication clerks review pairs of records that the Choicemaker program cannot determine to be a definite match, but have a high score for potentially being the same.
MOHSAIC Y Working towards automation, using various tools to cluster candidate listings,, manual review/or business rules determine records to be merged or deleted. The merge process itself is semi-automated. The matching process identifies the duplicates, the process of removing duplicates itself can be incredibly complex. For example, the MOHSAIC application uses the person's or organization�s ID as a foreign key in dozens of tables and each software release may add additional tables. We have to maintain a special application just to track down which tables have the client's keys in it, and then determine how to merge the data. We have not yet developed an app for provider keys that are duplicated. Organizations are more difficult to match, and undoing an incorrect merge is much more difficult than fixing a client's record.
Community Early Childhood Screening & Tracking
Y De-duplication is embedded in the clinic support system which includes all public health clinic activities at the given health department. In other words, we are working with all the clients that have presented themselves at the given health department in their various clinic offerings.
ImmPact Y Uses a screen to display pairs of records that meet criteria indicating potential matches. The user decides to merge or disassociate each pair of records. Medicaid patient records are automatically merged with existing patients where there is an exact match on first name, last name, middle initial, date of birth and SSN.
CHARM Y A staff member resolves matches that are close, but not exactly the same.

48
Table 4.6 - Front-end and back-end de-duplication
Front-end Details Back-end Details
Project Match False Negative Prob. Learning Duplicates Match Prob. Learning
KIDSNET 50% 30%No No 1% 90% No No FAMILYNET 10% 5%Y No 10 93% No No ALERT 84% 14%No No 14 96% No No MCI ? ?Y Y ? ? Yes Yes
MOHSAIC 90% 7%No No 7 3% No No Community Early Childhood Screening & Tracking
Y No Yes No
ImmPact 65% 20%Y No 50 40% Yes No CHARM Y Yes
*Note that all the projects reported that they support some degree of front-end and back-end de-duplication.
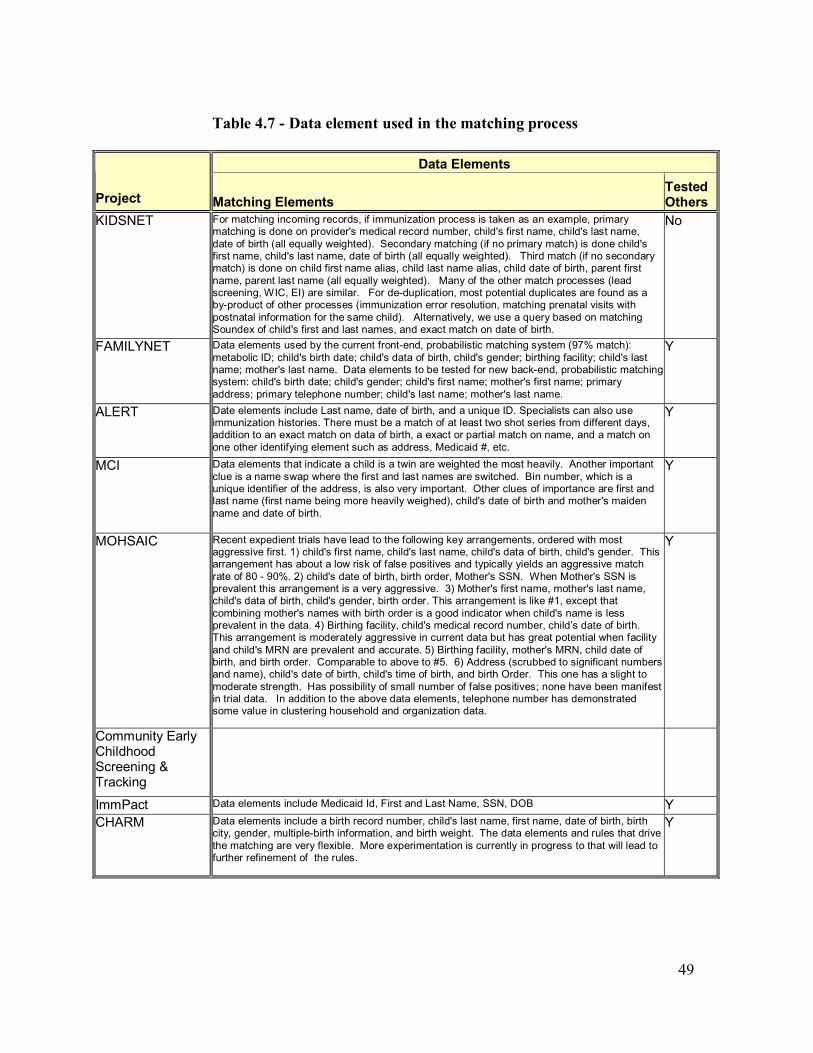
49
Table 4.7 - Data element used in the matching process
Data Elements
Project Matching Elements Tested Others
KIDSNET For matching incoming records, if immunization process is taken as an example, primary matching is done on provider's medical record number, child's first name, child's last name, date of birth (all equally weighted). Secondary matching (if no primary match) is done child's first name, child's last name, date of birth (all equally weighted). Third match (if no secondary match) is done on child first name alias, child last name alias, child date of birth, parent first name, parent last name (all equally weighted). Many of the other match processes (lead screening, WIC, EI) are similar. For de-duplication, most potential duplicates are found as a by-product of other processes (immunization error resolution, matching prenatal visits with postnatal information for the same child). Alternatively, we use a query based on matching Soundex of child's first and last names, and exact match on date of birth.
No
FAMILYNET Data elements used by the current front-end, probabilistic matching system (97% match): metabolic ID; child's birth date; child's data of birth, child's gender; birthing facility; child's last name; mother's last name. Data elements to be tested for new back-end, probabilistic matching system: child's birth date; child's gender; child's first name; mother's first name; primary address; primary telephone number; child's last name; mother's last name.
Y
ALERT Date elements include Last name, date of birth, and a unique ID. Specialists can also use immunization histories. There must be a match of at least two shot series from different days, addition to an exact match on data of birth, a exact or partial match on name, and a match on one other identifying element such as address, Medicaid #, etc.
Y
MCI Data elements that indicate a child is a twin are weighted the most heavily. Another important clue is a name swap where the first and last names are switched. Bin number, which is a unique identifier of the address, is also very important. Other clues of importance are first and last name (first name being more heavily weighed), child's date of birth and mother's maiden name and date of birth.
Y
MOHSAIC Recent expedient trials have lead to the following key arrangements, ordered with most aggressive first. 1) child's first name, child's last name, child's data of birth, child's gender. This arrangement has about a low risk of false positives and typically yields an aggressive match rate of 80 - 90%. 2) child's date of birth, birth order, Mother's SSN. When Mother's SSN is prevalent this arrangement is a very aggressive. 3) Mother's first name, mother's last name, child's data of birth, child's gender, birth order. This arrangement is like #1, except that combining mother's names with birth order is a good indicator when child's name is less prevalent in the data. 4) Birthing facility, child's medical record number, child�s date of birth. This arrangement is moderately aggressive in current data but has great potential when facility and child's MRN are prevalent and accurate. 5) Birthing facility, mother's MRN, child date of birth, and birth order. Comparable to above to #5. 6) Address (scrubbed to significant numbers and name), child's date of birth, child's time of birth, and birth Order. This one has a slight to moderate strength. Has possibility of small number of false positives; none have been manifest in trial data. In addition to the above data elements, telephone number has demonstrated some value in clustering household and organization data.
Y
Community Early Childhood Screening & Tracking
ImmPact Data elements include Medicaid Id, First and Last Name, SSN, DOB Y CHARM Data elements include a birth record number, child's last name, first name, date of birth, birth
city, gender, multiple-birth information, and birth weight. The data elements and rules that drive the matching are very flexible. More experimentation is currently in progress to that will lead to further refinement of the rules.
Y

50
Table 4.8 - Quality assurance procedures
Project Quality Assurance Procedures KIDSNET There were several ways a new child record can e added to KIDSNET. a) Manual Entry - In order to
manually enter a new child, the following information is required: Child first name, child last name, child DOB, child sex, parent first name, parent last name, parent DOB, relationship to child, street address, city, state, and ZIP code. b) Automatic Insert - In order to automatically insert a new child, the same information is required as for Manual Entry. c) Semi-automated Adds - Currently developing a semi-automated "add" process to be used chiefly to insert kids who were born out of state and therefore do not match a child from Rhode Island newborn information. The criteria have not yet been established.
FAMILYNET Required fields are first and last name and birth date. Fields listed as required, but that have default or 'don't know' response categories are: address, telephone number, race, ethnicity; language written, language spoken. Guardian's name is not required, but is usually present. The WIC module of the system allows linking of parent and child via an ID number. The module in development will allow linking of all family members and multiple family configurations. De-duplication may become easier (or harder) with this linking capacity.
ALERT There are checks for valid fields and immunization records that do not match previous imports. Partial dates of birth or immunization dates are not allowed. Methods include: range checking, frequency distribution for each essential data element, values within each data element to identify upper and lower values, identify statistical outliers, pattern checking of dates, check for inconsistency with Vital Records dates of birth, identify unknown, invalid, and unlikely combinations of values between variables, develop data quality audit summary report that includes: data item, number of invalid values, percent of records with invalid values, number of invalid values.
MCI We require that record contain first name, last name, a sequence number and a record type.
MOHSAIC First name, last name, and complete date of birth required. External data loads require a Department Client Number, which may be imputed from matching a client's name and date of birth to VS data.
Community Early Childhood Screening & Tracking
All the data is captured in the same system environment. Our problem is more related to persons using multiple names, the clerks not adequately researching the client register before creating a new client master, and confusion on Hispanic names.
ImmPact Requires patient's first and last name, date of birth, contact first name, last name, address (street, city, state, zip). Birth dates must be complete and in prescribed format and valid.
CHARM Currently, first name, last name and data of birth must be present. The date of birth must be complete. Generic names, like "baby" are rejected. Provider ID must match an existing provider. SSN's are edited. Gender is edited. Address is edited. Many demographic items are edited against valid codes.
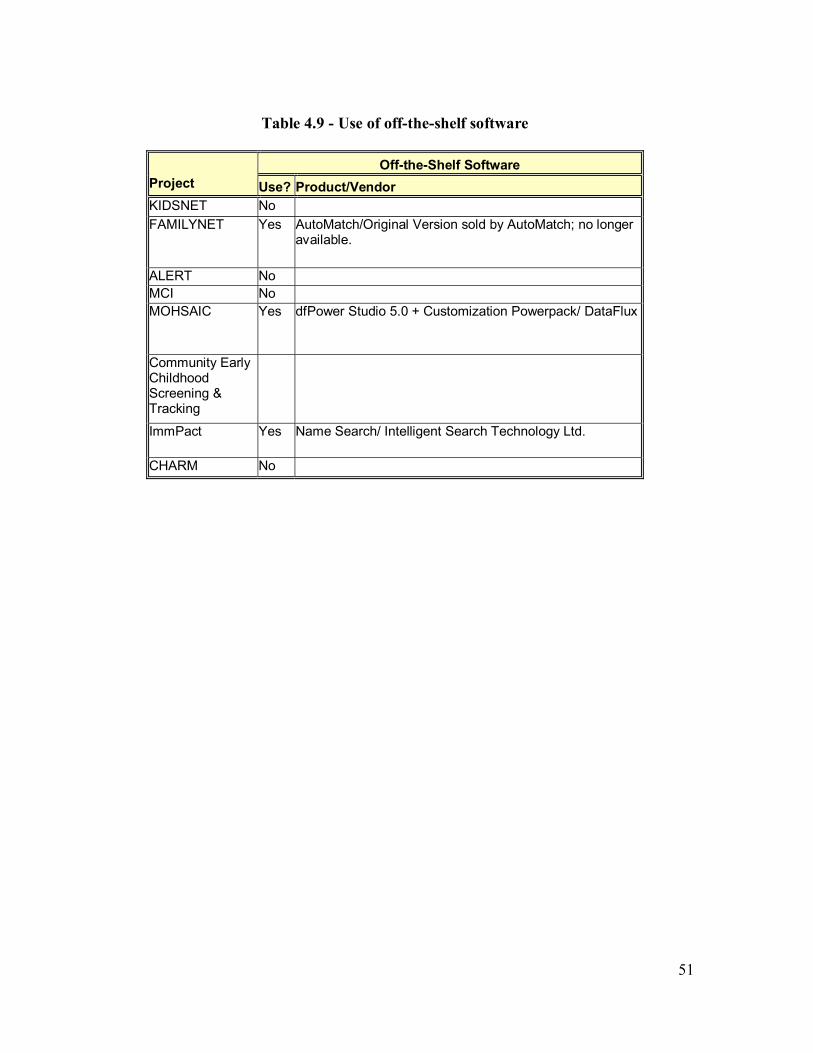
51
Table 4.9 - Use of off-the-shelf software
Off-the-Shelf Software
Project Use? Product/Vendor KIDSNET No FAMILYNET Yes AutoMatch/Original Version sold by AutoMatch; no longer
available.
ALERT No MCI No MOHSAIC Yes dfPower Studio 5.0 + Customization Powerpack/ DataFlux
Community Early Childhood Screening & Tracking
ImmPact Yes Name Search/ Intelligent Search Technology Ltd.
CHARM No

52
4.1 Rhode Island Project Name: KIDSNET [1, 11] Responsible Organization: Rhode Island Department of Health Geographic Area: State of Rhode Island Annual Birth Cohort: ~12,500
Project Overview: KIDSNET is designed to integrate data from the following databases and/or programs: Universal Newborn Screening for Developmental Risk, Immunization, Lead Screening, WIC, Newborn Screening (Heel-stick), Newborn Hearing Screening, Early Intervention, Home Visiting and Risk Response, and Vital Records. Immunization, Home Visiting and Risk Response, and Universal Newborn Screening for developmental risk are currently integrated into a single database, KIDSNET. This acts as a data warehouse by storing limited information from the Lead, WIC, Newborn Hearing Screening, Early Intervention, and Vital Records databases. Data from the Newborn Screening (Heel-stick) program is not yet integrated but will be data warehoused.
Key Organizational and Staffing Issues:
• All participating programs are in the same Division of the Health Department except Vital records.
• No competing levels of government. • State DOH has authority and control. • Integration was an initial project goal even though funding was originally for just the
immunization system. • KIDSnet staff overall is 9.8 FTE with 3 FTEs data managers for error resolution and
data management and 2 FTE for data/clerical support. Community of Practice: Member of AKC 1, 2, and 3; Genetics Planning and Data Integration grant (HRSA) � AKC Project- Best Practices Source Book; HRSA/MCHB-DUE grant; CDC EHDI grant. De-duplication: KIDSnet supports both front-end and back-end de-duplication. On the front-end, data entry is done from paper forms with bar coded IDs. It is labor intensive but seems to produce fewer errors than the back-end de-duplication. Matching process is fully automated on the front end and manual on the back end. The merging process on the back-end is also manual. The user determines which data elements he/she wants to keep between the two records and then the system merges the data elements into a single child record. KIDSnet uses a pessimistic matching algorithm that is based on conservative matching criteria and yields less chance of duplicate errors but more manual matching. Records that do not match a child in KIDSNET go on hold.

53
The Rhode Island registry uses a custom developed program written in the PL/SQL programming language to generate a report of potential duplicates. Potential duplicates are identified using a Soundex comparison of last name, date of birth and gender. Once the report is generated, human review and assessment is required to determine which records need to be merged. Records are merged manually, one at a time.
KIDSNET is currently integrating and consolidating the initial data collection process for Vital Records, Newborn Hearing Screening and Universal Newborn Screening for developmental risk through a new Vital Records data system. This will allow the three programs to utilize a single identifier that will minimize data matching and redundant data entry.
Rhode Island is also in the process of developing and implementing a probabilistic matching algorithm that will be applied to the records on hold. The registry is also creating an automated import process to add records identified as �not already in the database�. Finally, an on-line automated merge tool is being developed to resolve and merge actual duplicate data into one record. Key Issues:
• Master record concept via Vital Records. • Records in hold file may be excessively delayed before being added to the file. • Merging requires a significant amount of human review. • The de-duplication processes are being re-engineered as part of a systems upgrade.

54
4.2 Oregon Project Name: FamilyNet Data System [11] Responsible Organization: Department of Human Services, Health Services, Office of
Family Health (OFH) Geographic Area: State of Oregon Annual Birth Cohort: ~45,200 Project Overview: FamilyNet has been in development since the mid 1990�s. In 2000, the Oregon Department of Human Services (DHS) began developing the public-sector module of FamilyNet, as a public-sector health information system for local agency use to integrate and coordinate health assessment and service information about children and families. FamilyNet will help public and private providers coordinate services to children and families and monitor risks, conditions, services, and outcomes over time. It will support coordination of services and evaluation of the service delivery system while assuring individual and family confidentiality and data security. The Oregon�s Children�s Plan is a 2001 legislative mandate which expands the data system beyond the FamilyNet health services model. The rationale behind FamilyNet is to create a single, cumulative record for each client by tying together module level records. FamilyNet goals include: avoiding redundant data entry by collecting data shared among programs only once; providing timely access to data for both state and local health departments; increasing accountability for state and federal program conditions including program and fiscal assurances; and reducing fragmentation of data and health care services available to the public by providing a method to coordinate services among health and social service programs. The hub is a Client Master that contains demographics and contact information (addresses, family links, telephone numbers, guardian�s name). Key Organizational and Staffing Issues:
• All participating programs are in the same Division of the Health Department. • Broad legislative mandate for program integration, but with some limitations on
sharing information outside of public health departments. • Extensive strategic planning, requirements definition and risk analysis • Development and implementation of a communications plan
Community of Practice: Genetics Planning and Data Integration grant (HRSA) � AKC Project - Best Practices Source Book; Turning Point. De-duplication: �The purpose of this document is to define the requirements for electronic matching and merging of records imported from external systems and the identification of duplicate Participants and related data. These requirements were determined based on JAD sessions with participants including DHS program and technical staff� [6].

55
The diverse sources of data received by OFH have created a significant challenge to minimize the number of duplicate participants in their databases. FamilyNet with its integrated Client Master database is intended to help eliminate the number of duplicates. OFH has put forth the following business goals with respect to FamilyNet data.
1. Maximize Data Quality a. No more than 5 � 7% of duplicate participants in Client Master. b. Maintain copies of useful old demographic data (e.g., address, phone number) c. Additional human resources may be required even after automated best
practices are implemented.
2. Define clear criteria for identifying duplicate data at the Client Master and Module Level.
a. Client Master is first priority b. Module data is second priority.
3. Create an import utility to be used for all Client Master Data Imports. Each
FamilyNet module will be responsible for the process to import, de-duplicate and merge module data.
4. Create a batch process to review Client Master data, identify duplicates and merge duplicate records based on specific match/merge rules.
5. Create an efficient on-line process for reviewing and resolving instances of duplicate (or suspected duplicate) Client Master data.
6. Wherever possible create reusable modules to support goals 3, 4 and 5.
Key Issues:
• Clear specifications • Master record concept • Decentralization of de-duplication processes to programmatic units.

56
4.3 Oregon Immunization ALERT Project Name: ALERT [2] Responsible Organization: Department of Human Services, Health Services, Office of
Family Health (OFH) Geographic Area: State of Oregon Annual Birth Cohort: ~45,200 Project Overview: ALERT is part of a long-term strategy to improve immunization coverage for Oregon�s children. Authorized users include health care providers (both private and public), health plans, schools, hospitals, and parents. It began in the early 90s and was created by public-private partnership -Oregon Health Systems in Collaboration (OHSIC) which funded ALERT in 1996 as their first collaborative project. The approach was used because most immunizations are given in the private sector in Oregon. The primary focus is on immunization records of pre-school children, although ALERT has a growing volume of records for school age children [2]. Key Organizational and Staffing Issues:
• Public �private partnership model- leverages non-governmental resources and provides more flexible administration.
• ALERT exchanges data with FamilyNet but full participation is limited by the scope of the enabling legislation that would have to be changed to allow physicians participating in ALERT to view other Family Net data.
Community of Practice: AKC 1
De-duplication: The Oregon registry uses customized software called Resolve on a daily basis to identify demographic and immunization records with matching names, dates of birth and other key identifiers [2]. This process will be further automated using the "Auto Resolve" feature of this product. The next phase to enhance and improve the de-duplication process will be to re-direct staff efforts to resolving the more difficult, less obvious duplicate records. To accomplish this, pattern recognition software will be used to employ new criteria for matching and to increase the percentage of accurate, standardized and probabilistic matches of registry demographic data. The Oregon registry currently has over 700,000 demographic records and over 5 million immunization records. Key Issues: • The ALERT immunization registry participates in FamilyNet by receiving immunization
data from the public sector Immunization module. Other records are coming mainly from sources external to public health- physicians and health plans. Family Net and Alert are not yet linked.
• Use of a customized product solution. • Moving to pattern recognition and probabilistic matches. • Data quality issues are more high profile. • Focus on data use promotes quality.

57
4.4 New York City Project Name: CIR-Lead Quest Integration Project [11] Responsible Organization: New York City Department of Health and Mental Hygiene
(DHMH) Geographic Area: New York City Annual birth Cohort: ~125,000 Project Overview: A directive to integrate the Citywide Immunization Registry (CIR) and Lead Poisoning Prevention Program (LeadQuest) databases was issued by the NYC Commissioner of Health, who recognized the potential of the project to leverage resources of the participating programs by creating a single system for provider outreach, case management and data analysis. CIR and LQ target the same population, primarily children 0-7 years of age. An integrated database would relate data for the same children across systems and help identify children at high-risk of under-immunization and lead poisoning. The integrated system will provide immunization and lead status on-line, improve data quality across both systems by consolidating records and create a centralized de-duplication service to be used by different units within DOHMH. The linkage involves the creation of a Master Child Index (MCI) and a Data Warehouse to identify and track the health of NYC children. Birth data from vital statistics data maintained by the NYCDOH will be incorporated to populate the system. The CIR-LeadQuest (LQ) integration is the first part of a larger, phased-approach initiative to create a comprehensive citywide child health registry in the DOH.
The two databases will not be combined, but will be integrated through a Master Child Index (MCI). All children found in the two systems (and subsequent systems to be integrated) will be "registered" in the MCI to facilitate matching children across these systems. The MCI will use sophisticated business rules to match new information to children in the MCI, de-duplicate children with multiple records or duplicate information within a record, and merge children across the databases. The MCI will contain identifying and demographic information for every child contained in at least one of the participating systems. Each participating system will interact with the MCI to: (1) add data to an existing MCI record or register a new child in the MCI and load its data; (2) use MCI�s services (a record de-duplication service); (3) access MCI demographic information; (4) identify whether there is information in another participating system that is available for display to a user via the MCI connection; and (5) transport the requested information from one system to the other in real time and present it through existing applications (or make it available to existing batch processes). These capabilities will be provided through a set of standard "services" available on the network to authenticated, eligible systems.
Key Organizational and Staffing Issues:
• No previous program integration between Lead and Immunizations-merger of two cultures.

58
• Reorganization at start of project moved the data integration activities into a new office of health surveillance.
• Enforced multi-vendor contract responsibility reinforced differences in program and technology cultures and complicated development and deployment.
• Source programs are now in different organizational divisions of NYC Department of Health and Mental Hygiene following change of mayoral administration and reorganization in 2002.
• Changes in project leadership staff. • NYC is responsible for its own Vital Records, separate from the state.
Community of Practice: CIR a participant in AKC 1, 2, and 3. CIR Project Director is President of AIRA.
Deduplication: The NYC uses a commercial product, now called Choicemaker, for its de-duplication. The NY Citywide Immunization Registry (CIR) has about a 30% de-duplication rate.. Given the size of the CIR ( 2.3 million records, and over 14 million immunizations) and the large volume of monthly submissions, an automated solution to this problem is vital. CIR has adopted CMT (now called Choicemaker), which uses a new technique from statistical Artificial Intelligence. Choicemaker assigns a probability score to candidate record pairs based on a number of features which 'fire' depending on whether they are the same or different in each record pair. The weight of each feature is acquired during a 'learning' process by which Choicemaker is trained on a set of record pairs tagged by Registry staff. Each feature's weight depends on how well it persuades the human scorer that two records do or do not belong to the same child. For example zip-code-same feature received a lower weight than the telephone-same feature. The overall probability for each record pair is based on the number and weight of the features arguing for or against a merge. Record pairs with a high probability are automatically merged. Currently Choicemaker�s features include exact and Soundex matches on first and last names, date of birth, gender, street number, Medicaid and medical record numbers, zip code, mother's maiden name and mother's date of birth. Choicemaker succeeds in removing 96% of record pairs from human review with more than 99% accuracy. Choicemaker has already successfully de-duplicated the 1997 and 1998 birth cohorts. The success of Choicemaker rests heavily on its being trained by knowledgeable users.
CIR and LQ data quality is expected to improve with MCI. 1. Fewer fragmented / duplicate records in CIR and LQ due to front-end Choicemaker software 2. Values in all demographic fields will be stacked

59
• No time will be spent deciding which value is �right� � stacked values will be used to review incoming values
• Easy and successful identification of children o by DOHMH ( always use DOHMH) staff o by providers and parents o Providers will be more motivated to report accurately
3. Better able to identify MCI/CIR/LQ true population - denominator: Improved denominator data for LPPP because of inclusion of Vital records Improved denominator data for LPPP and CIR because of inclusion of children not born in NYC who have immunizations or lead tests but not both. 4. Enhancement of LPPP data because of access to race and Medicaid status (particularly for non-cases). 5. Verification of LPPP data via access to Vital Record Data. Key Issues:
• NYC has the most productized deduplication software. • Research orientation of the initial software developer and NYC staff contribute to its
sophistication and functionality. • Expense, level of effort and resources consistent with size of NYC database, (2.3
million children, 14 million immunizations) but may not be sustainable or replicable to projects of lesser scale and staff.
• Product vendor has codified much of the learning developed by NYC into a feature called Clue Maker which it intends to make available for future sales. The efficacy of reuse of the learning in a new live production environment has not been tested.
• Delays in scheduled deployment exacerbated by multi-vendor environment. • Strategy of moving deduplication engine into MCI not yet proven in operation as
MCI is still not running in production.

60
4.5 Missouri Project Name: Missouri Health Strategic Architectures and Information
Cooperative (MOHSAIC) Responsible Organization: Center for Health Information Management and Evaluation
(CHIME) Missouri Department of Health Geographic Area: State of Missouri Annual Birth Cohort: ~75,000 Project Overview: The Missouri Department of Health and Senior Services (MODHSS) is developing an integrated public health information system to support all programs and systems that relate to surveillance, and/or client services (both health care and regulated clients). Common functionality has been identified and grouped together. The application has been developed to support common functions: registration, scheduling, inventory, disease reporting, etc. All data are being integrated in an Oracle Database with each user having the ability to view data based on his/her function and security level. The data are organized around a specific client and his/her relationship to other providers and services. To date, the following components have been integrated:
Surveillance Area Communicable and Vaccine Preventable Disease and other reportable conditions
Client Health Management Area Client Registration, Scheduling and Household Management; Inventory Management; Immunizations; TB Skin Testing; Family Planning; Family Care Safety Registry)
Regulated Client Area Regulated functions for Bureau of Narcotics and Dangerous Drugs; Lead Abatement Inspector Registration
Components currently in a phase of analysis, design or development include: Surveillance Area (Reporting of STD/HIV cases; Elevated Blood Lead Levels; Electronic reporting of laboratory results); Client Health Management Area (Service Coordination for Special Health Care Needs and other children; Inquiries and Complaint Tracking; Resource and Referral Services; Blood Lead Level Screenings; Newborn Metabolic and Hearing Screenings and Case Management; Newborn Home Visitation; WIC Registration); and Regulated Client Area (Child Care Licensing). In addition, MOHSAIC staff is completing the necessary infrastructure applications for quality assurance and security activities. This approach resulted from a comprehensive assessment of MODHSS�s organizational strengths and weaknesses that revealed weaknesses in overall strategic use of communications technology. It became clear to the department director that an integrated system was needed to reach Year 2000 goals. Other key factors were the cost and difficulty of maintaining over 60 program-specific computer systems serving individual health

61
programs. The systems ran on a variety of platforms since there were no hardware or software standards. In the mid 1990�s, the National Immunization Survey ranked Missouri 49
th in the nation for
two-year-olds who were adequately immunized. Governor Mel Carnahan and legislators agreed to address this issue with a statewide immunization registry. General Revenue funds were appropriated to create the registry and provide access to all local public health agencies. The resulting infrastructure and Immunizations and TB skin testing formed the first components of the MOHSAIC integrated system. Subsequent programs have built on this initial system. Key Organizational Issues:
• Gubernatorial and legislative action to develop immunization registry. • Strategic planning and resultant architectural design allow MO to use diverse funding
streams to develop pieces of the system even if not in the most desirable order. • Gubernatorial and legislative support for improving immunization coverage. • Immunization registry was the driver and initial building block of the system. • Strong information technology support • Strong and influential leaders in national IT initiatives.
Community of Practice: MO an early INPHO state, INPHO 2 and 3; Genetics Planning and Data Integration grant (HRSA) �AKC Project- Best Practices Source Book; Turning Point (Local Public Health) De-duplication: Integrated database: Health Management is client-centered, Surveillance is case-centered. Surveillance system can look into health management system if necessary. Created a registration/demographics/scheduling/vaccine inventory core first, which includes immunization for all ages and TB for skin tests. DCN (Client ID) being used by Social Services, WIC, Medicaid. Added it to Birth Certificate and other systems retrospectively. Integrated plan enrollment information into the central database. Integration with laboratory is not quite there yet. Other pieces are in different states of development or deployment. Merged data is transformed and brought into MOHSAIC. Linked data is only viewed through MOHSAIC. Even with this tight integration, some systems have to remain separate either because they are purchased or because it makes sense for them to be separate. Took time to understand that some systems need to be linked or merged instead of integrated. Only local health departments in two sites in MO are not using central Immunization Registry. They have access to see immunizations and MO is working to absorb their records from other systems. Private Provider systems have had data absorbed. (Medicaid, large health systems have had data abstracted and absorbed). Basic De-duplication Process Steps Overview:
• Determine candidate duplicates • Verify duplication • Determine what data is to be deleted and what is to be consolidated • Reconcile the duplicate information

62
• De-duplication and Data Quality Issues • How to correct match errors • How to undo the reconciliation if an error is made. (Twins come to mind as a
frequent culprit of this situation.) • Model and table structures to support the De-duplication process • Which data is the most current
Master Index Concept: Incoming data is first compared to VS statistics data. So, VS is acting as an authoritative source for matching. Some secondary matching is done using the Department of Social Services ID. When children are added to MOHSAIC, they are assigned a unique ID, called a Party ID. The Party ID is used throughout the system as a foreign key. When a match is determined and records need to be merged, the merge process involves
• merging physical records (and obsolescing any old records). • changing all references to obsolete records to the new merged record. Because there
are many tables where the ID is used as a foreign key, this is a cumbersome task. (See MOSHAIC de-duplication process diagram in Appendix A.)
The Department�s OIS staff is responsible for the de-duplication process. Key Issues:
• Current de-duplication tool allows them to merge records, but not to locate and find them.
• Several different tools are used in different stages of processing. • Issues with records in hold file- quantity not yet known. • De-duplication responsibilities centralized in OIS.

63
4.6 Kansas Project Name: Community Early Childhood Screening & Tracking, a integral
part of the Kansas Integrated Public Health System (KIPHS) [11]
Responsible Organization: Community Early Childhood Screening and Tracking integration project is a project of the Wichita-Sedgwick County Department of Community Health. KIPHS is a managed by a partnership between Kansas Health Foundation (KHF), Kansas Health Institute (KHI), and the Kansas Association of Local Health Departments (KALHD)
Geographic Area: Wichita-Sedgwick County, Kansas Annual Birth Cohort: ~6,500 Project Overview: The Community Early Childhood Screening and Tracking project, now in the requirements determination stage, is a software application designed to ensure children receive necessary testing and follow-up. Specifically, it will link data from the immunization registry, metabolic and hearing screening programs. Public health providers and private providers will have access to the data. The software application will run on a community information system infrastructure. In addition, certain components of the integration project, particularly the immunization tracking portion, will be integrated with the broader Kansas Integrated Public Health System project. Components will be integrated by a variety of integration strategies, including common relational database architecture, mirroring strategies (primarily state and local immunization registries), and common access routines. The basic design of KIPHS is one of an integrated client encounter system. It is client centered, utilizing a centralized client registry so that all health programs and services are linked to a common client record. With the exception of WIC, KIPHS has integrated all public health client service provision activities at the local health department level. WIC will be fully integrated at the local level under contracts currently being negotiated. KIPHS is constructing the first local health department- to- state integration module that will cover all MCH program reporting data from all health departments, once the KIPHS implementation is complete in 2002. The specific integration project is in the initial requirements determination stage. The decision to integrate was part of the overall plan for state IS support developed in the mid-1990�s. The initial planning efforts for KIPHS began in the fall of 1991 with the development of a strategic plan for the Wichita-Sedgwick County Department of Community Health public health information needs. The plan identified the need for integration of services at the local level while simultaneously fulfilling the reporting and data needs to the state health department. Interaction with KDHE personnel led to the decision to develop a similar plan at the state level prior to developing a new and comprehensive information system in Wichita. KIPHS has resulted in a much greater level of interaction among different programs in the state and county health departments, since the same software supports all programs.

64
Key Organizational and Staffing Issues:
• Community-based approach with county level planning for data integration to report to the state as driver for state-level planning
• Vendor leadership role • Extensive strategic planning and rigorous requirements setting. • Common technical architecture among programs • Low sustainability due to new public health and funding priorities
Community of Practice: First INPHO fellow assigned to KIPHS project; Turning Point De-duplication: KIPHS is used by the health departments as an on-line encounter system. There is a routine in KIPHS in place to enable a user to look for a duplicate client. Duplicates are created because the intake clerk does not properly search for an existing record, and relies on the clients when they say they never have been to the health department before. Often clients don�t want the clerk to pull up their records with a balance due in most cases. Some times the clerk doesn't correctly verify the client's name, etc). The routine allows the user to combine service records, but does not allow the user to integrate the financial history. Key Issues:
• KIPHS de-duplication work is not tied to the integration project but would use the de-duplication routine already in the base application.
• Centralized client index relies on input person doing a thorough search to avoid adding a new record; but may be compromised by client presenting misinformation and/or lax user habits or press of workflow.
• Not really tested in the integrated environment due to insufficient deployment.

65
4.7 Maine Project Name: Maine Public Health Information System-MPHIS [11] Responsible Organization: Maine Department of Human Services, Bureau of Health Geographic Area: State of Maine Annual birth cohort: 13,720 (1998 preliminary) Project Overview: The Maine Public Heath Information System (MPHIS) will support real-time, web-based public health communication and data transactions with primary care, laboratory, hospital emergency departments, health engineering, and community based provider agencies (e.g., immunization administration and vaccine ordering, selected health screening and lab test results, infectious disease reporting, restaurant and other facility inspections, and seamless interface to secure two-way health alert communications). It also will provide current data for the Bureau and its programs for planning, operations and evaluation. MPHIS will feed a public health data warehouse for release to community partners, other state agencies, and the public through a web site and other means. MPHIS will incorporate the National Electronic Disease Surveillance System (NEDSS) base system, with the functionality of Maine�s ImmPact Immunization Registry. ImmPact, the Maine and New Hampshire Immunization Registry, began implementation in 1998. It is a state-wide, web-based system that calculates vaccine and preventive health care visit requirements from birth through death, provides reminder recall services for Immunization, preventive health care visits, client notification of EPSDT eligibility, and end of eligibility notices for Medicaid clients approaching 21 years old. MPHIS will be fully accessible to and used by all medical providers, health care facilities, and community health agencies (as appropriate to respective functions). NEDSS data will be stored in a data repository or warehouse that will also receive data from other public health databases (such as vital records, the Maine Cancer Registry, Maine Behavioral Risk Factor Surveillance system.) The data repository will be accessible to the Bureau of Health (and other state agencies per data sharing agreements) for public health assessment, program planning and evaluation. The data repository will also feed data to a public web-based community health information system that will be an independent, stand-alone system that provides up-to-date comprehensive information on health status, quality of care and population-based health outcomes. The MPHIS is expected to be fully designed and in pilot by the end of one year and fully operational within three years. Program development and operations have been categorical, driven by funding, yet focus populations and key internal and external partners overlap. Due to a lack of historical information system collaborative planning processes, information systems within the Department of Human Services and the Bureau of Health, and even within individual programs of the Bureau, were being developed without a larger comprehensive direction. Recent efforts to assess the Bureau�s information system needs and capacity, and the rapidly evolving information system technology have encouraged a vision of integrated public health

66
information that serves public health officials, medical practitioners, community health agencies, and the public at large. The existing ImmPact Immunization Registry serves as a successful example of a web based information system developed by a collaborative effort between the Bureau of Health and Maine Medicaid, which was easily adopted by local medical practitioners. Other federally driven efforts such as NEDSS and the Health Alert Network (HAN) identify additional goals and objectives of public health information systems, and offer a feasible base system. Key Organizational Issues:
• Integrated public health information systems concept relatively new. • Funding sources have driven development without an overall architecture • Collaborating with Medicaid improved provider participation in immunization
system. Community of Practice: AKC 3; Turning Point (Medicaid case development). De-duplication: Maine has a semi-automated de-duplication process, using a probabilistic approach to its front end and back end processing. OTS products, Name Search and Intelligent Search Technologies, are used to identify the probable matches. This process creates a screen to display pairs of records that meet a score criteria indicating a potential. The user decides to merge or disassociate each pair of records. Medicaid patient records are automatically merged with existing patients where there is an exact match on first name, last name, middle initial, date of birth and SSN. A detailed discussion of the manual deduplication is referenced in Appendix A. Incoming records are tagged with an ownership code based on business rules. Some important features of the process include the reliance on Medicaid as the authoritative source of information over a provider record for the same patient. Record date is a key field, and the newer record is presumed to be the better one. Date of birth (DOB) is a key field that is required to be complete and correctly formatted. If duplicate patient records are identified by the results of a patient search, these records can be merged using a series of steps against the back-end. Only the ImmPact System administrator or technical staff designated by the system administrator should attempt this process. The information that exists in the duplicate patient record but not in the original patient record will be added to the original patient record. Key Issues:
• Data cleaning and formatting are done prior to the de-duplication process.

67
• Because of the Medicaid partnership, Medicaid rules for changing data on addresses pre-empt other possible better sources of authoritative data.
• Immunization Registry and its associated data feeds are subject to this process. • Other business rules and processes will likely be required for full integration project.

68
4.8 Utah Project Name: Child Health Advanced Records Management (CHARM) Responsible Organization: Office of the Chief Information Systems Officer, Utah
Department of Health Geographic Area: State of Utah Annual Birth Cohort: 47,000 Project Overview: CHARM is integrating the state�s immunization registry (USIIS), newborn hearing screening (HiTrack), Vital Statistics, Newborn Screening, Baby Watch and Early Intervention, Birth Defects Network, Children with Special Health Care Needs, Women Infants & Children (WIC), Neonatal Follow-up Program, Medicaid, Child Health Evaluation and Care (Utah�s version of Early Periodic Screening and Diagnosis and Treatment, or EPSDT), Child Health Insurance Program, Lead Screening and other child information systems. However, the current version of CHARM only integrates the first three. CHARM uses a middleware solution to link the operational systems within the participating programs and thus provides services to a virtual �Child Health Profile� database of shared data elements.
In addition to CHARM, some of the participating programs currently share data directly. For example, the Medicaid and child welfare programs share a common intake process that results in a common identifier. Also, the immunization registry and WIC systems import data directly from the Vital Statistics as a means of populating their databases.
In 1997, the Utah Department of Health adopted an Information Systems Vision. It called for data to be entered only once, to be complete, uniform and accurate, to be readily available to authorized users, and to meet the users� needs of availability and usefulness. In early 1999, the department�s executive leadership made an investment in, and a long-term commitment to, systems integration by hiring a CIO with a clear department-wide integrative mission. That summer, the UDOH formulated and adopted its first department-wide business principle calling for a client-centric way of doing business. In the fall of 1999, a new integrative strategy was formulated during two joint program-IT retreats. This strategy is currently being pursued, and CHARM is one of the five strategic initiatives adopted at that time. Perceived benefits of having different programs working together include enhanced client satisfaction, improved client services, improved multi-problem response, reduced cost, improved assessment, outcome measurement, information for private providers, and improved monitoring of program coverage. Key Organizational and Staffing Issues:
• Continuous proactive leadership - 10 year tenure of Health Officer • Adoption of Information Systems Vision and hiring of CIO • Collaboration with Utah State University�s Department of Computer Science • Continuous project updating and quality improvement

69
Community of Practice: INPHO; Connections; Genetics Planning and Data Integration grant (HRSA) �AKC Project- Best Practices Source Book; Leadership in NAPHSIS De-duplication: CHARM doesn�t have a central repository of all child information. Instead, it creates the illusion of a shared repository, but actually retrieves data from individual participating programs on demand. The complete set of shared data for a child forms a virtual record that is not stored in any single place. CHARM calls these virtual records Child-Health Profiles (CHPs). For CHARM the de-duplication problem involves correctly matching child records among the participating programs and removing duplicates by either merging records or linking related records. It addresses the de-duplication problem by providing a suite of front-end and back-end features and by taking advantage of as much available information about a child as possible. One front-end feature is the ability for a user in any participating program to search the set of known CHPs for matches to a child that is being added to the participating program�s system. If matches are found (meaning the child was already known to one or more participating programs), the user can choose to have that information populate the local record and to have this resulting record logically linked to that CHP in the integrated system. The users can also choose to create new CHPs for new records in their systems or merge records as needed. Users can also interactively try to match existing records in a local system with existing CHPs. If matches are found, the user can choose to immediately merge matching records so all the information for a child is logically linked together or defer that activity to another time or for another person to handle. CHARM�s back-end features include processes for periodically scanning the CHPs for matches. If a cluster of potential matches is found, the system will either process the merge automatically (if the match is certain enough) or it will record that information for manual resolution. CHARM�s matching algorithm is a rule-based system driven by an easily configurable set of weighted rules. Each rule is made up of some number of weighted comparisons. Each comparison can reference one or more pieces of data (e.g. first name, last name, birth date, etc.) and compare them using a specific function. CHARM supports a variety of equality and fuzzy comparisons, such as edit distance. If the sum of all the weighted comparisons for a rule is greater than a specific threshold, then the action of the rule is performed (e.g. the records are determined to be absolute matches, possible matches, or definite non-matches. The comparisons can reference a wide range of fields, including the names for the child, mother and father; contact information of all kinds such as address and phone number; birth place, time, weight, multiplicity, and order; medical identifiers, and dates of health care events. The comparisons can also take advantage of a new Birth Record Number system that has recently been implemented in the Vital Statistics, Newborn Screening, and Newborn

70
Hearing Systems. This identifier comes from the newborn kits distributed to hospitals and helps to uniquely identity newborns across the state. Key Issues:
• CHARM provide features for both front-end and back-end de-duplication. • The user�s view of the front-end features depends on how a participating program is
integrated with CHARM. • The CHARM matching algorithm is a rule-based system, but is highly configurable
and can take advantage of a large variety of data fields and comparison functions. • The CHP includes good identifiers and discriminators, such as the Birth Record
Number. • Matches can be merged immediately or deferred • Matches can be merged automatically when they are absolute matches and the
merging is straightforward. • The resolution of questionable matches can be deferred and handled manually. • CHARM�s approach to de-duplication has not yet been proven in operation, it is still
waiting for final deployment.

71
5. Observations from Study There is no question that poor data quality can degrade the value of an information system and even render it useless. A critical part of obtaining and maintaining high-quality data is ensuring that a system contains as little redundant information as possible. This can be particularly challenging for integrated child-health information systems since the data comes from a variety of sources, each with potential quality problems of its own and slight variations in the semantics of common data fields. This study has looked at the de-duplication problem from both a technological and case study perspective. Section 5.1 summarizes technical observations from this work that might help current and future integration projects improve their approaches to de-duplication. Section 5.2 lists a number of important issues that go beyond the technology, but are critical to the overall success of de-duplication in any integrated child-health information system. Finally, the study uncovered a number of issues that were beyond of the scope of this project, but would benefit the public health community if they were researched further. These issues are listed in Section 5.3.
5.1 Technical Observations
5.1.1 Overall de-duplication processes and algorithms No single solution would work for all integrated information systems. There are too many variations in how the systems receive data from participating child-health programs, the structure of that data, the quality of the data from the individual sources, the timing of when the data becomes available, and even the intended uses of the integrated data. So, instead of looking for a canned solution, integration projects should consider the following technical issues and formulate an overall solution that is customized or adapted to their own situations.
1. When will matching occur? 2. What piece of information among the shared data can best be used to identify
potential matches? 3. How will the data be standardized so searching and comparing operations are more
effective? Can off-the-shelf software help with this? If so, how? 4. What kind of matching algorithm (multi-field, rule-based, machine-learning, etc.)
would be most effective given the type and quality of the available data? 5. How will be potential matches be verified (automatically or manually)? 6. How will actual matches be merged or linked? 7. Will the results of the matching and merging be propagated back to the original
sources? 8. How will mistakes in matching records be identified and undone?
5.1.2 Level of automation It is not clear whether front-end or back-end systems are more automated. Both involve decision points that require human interactions. By separating the de-duplication problem

72
into data-item cleaning, matching, and merging processes, it is possible to conclude that the processes for standardizing data item values and for identifying potential duplicates are often more automated than processes for determining actual duplicates and merging data. However, beyond this basic observation, the project team noted considerable variance in the degree of automation among the available software projects reviewed in Section 3 and among the subject systems described in Section 4.
5.1.3 Record Matching The range of products that deal with record matching was staggering. They differed in how they connect (or don�t) to information systems, how they search for potential matches, the number and type field comparisons they support, the level and type of user interaction, and how they can be customized. Determining which product is best suited for a particular system depends of the specific requirements of that system. Because of this and the huge variance in products, it was impractical to evaluate off-the-shelf products in a general way. Instead, this research provided a framework for conducting such evaluations and a sample evaluation of one product. See Section 3. The integrated child-health systems reviewed in Section 4 also differ greatly with respect record matching. For example, New York City�s system uses a machine-learning approach, whereas Utah�s approach uses a rule-based approach that supports weighted, fuzzy comparisons. Missouri�s is also rule-based, but the comparisons are more straightforward. The Oregon and Rhode Island systems take advance of Soundex technology for some of their field comparisons. Although most of projects use some kind of scoring or weighting scheme, none of them appear to be using true probabilistic field comparisons, which take into account the frequency of the possible data values in determining the strength of a match. This may be an interesting area for future research. See Section 5.3. In general, there is insignificant data to conclude whether one matching approach is better than another. In fact, it is not reasonable to do such a comparison because the differences in the overall approaches and situations make it difficult to come up with a common basis. Instead, to determine the effectiveness of record matching, an integrated system must be prepared to evaluate itself, independent of others, using test data that is representative of conditions found in its real data. See Section 5.3 for ideas on future research with respect to test data.
5.1.4 Source of information and effective data element for matching Below is a list of observations regarding the sources of information and the effectiveness of various data elements in identifying potential matches:
• Most systems consider vital statistics the authoritative source for birth date data, but not for addresses.

73
• In Maine, where Medicaid owns the authoritative demographic record, there is a problem when other non-Medicaid information needs to be merged with the Medicaid information. Medicaid does not allow other providers to update active Medicaid providers.
• Medicaid and WIC have similar rules that restrict address changes to their respective programs. Addresses cannot be changed or superimposed by another program. This restriction is typically stated in the Memorandum of Understanding (MOU), which allows certain of their data to be shared by other programs.
• There is a presumption by some projects that the data with the most current date is the most authoritative. Business rules to establish which date is used, for example, date of last contact or date into the system, date of last transaction or some other measure would contribute to more efficacy of this approach.
• To offset the problem of determining valid addresses, some projects �stack� the addresses so that more than one can be used in matching, and also to provide additional addresses for outreach as many of the target clients are transient. NYC had adopted this approach.
• Other than in Maine, no single program emerged as an authoritative source of demographic information, although Rhode Island is looking at making newborn screening an authoritative source. This is an important result because it indicates that the health systems are very different and that no single approach to de-duplication would work.
• It is also interesting that the program which sponsors the integration is usually not the Vital Statistics, which is the authoritative source for certain key data elements (although there seems to be a tighter coupling of the VS program in UT.)
• Use of VR demographic information in records that are accessible by people outside of Public Health Departments is generally restricted by state privacy laws, but it is often permitted to be used in matching programs as corroboration of information that comes in via another record source- e.g. a provider records. Projects that use this practice may �mark� the VR demographic information to make sure that it is used only for matching and not displayed.
• Many projects use the mother�s birth name (maiden name) as a key field, as this is one of the National Vaccine Advisory Board (NVAC) core data elements required for Immunization Registries. However, while this can always be obtained from the birth record, it is not consistently used in other records with Mother�s Name, particularly in medical or claims systems (unless the mother is still known by her birth name.) Some projects find the mother�s first name is the one least likely to change and is more reliable
5.1.5 Record Merging All of the projects indicate they have both a front-end and a back end process. In most cases, the front-end process is to match records entering the system while the back end processing is mainly to remove duplicates. Some systems have special screens and design tools to facilitate the record merge process.

74
5.1.6 Deployment Timetables A common theme seen in all of the integration projects is a great underestimation of the time and effort to plan and execute de-duplication processes. Almost all of the projects had exceeded their target deployment dates. Where integrated projects work only with internal health-department systems, it is more possible to control implementation timing. Where external stakeholders are involved, decisions made within their own organizations can affect the timing and also specification of the de-duplication effort. The deployment of a master index approach to de-duplication is more heavily impacted by decisions made by individual programs or stakeholders than a more incremental approach that applies de-duplication to specific files and applications. Therefore, none of the projects using master index de-duplication engines were or had been in production at the time of this study, so the efficacy of this approach is not yet known.
5.2 Non-technical Issues
5.2.1 Scope and Organization of the Integration Effort The integrated projects varied considerably in scope. At the time of this study, none of them integrated exactly the same set of programs. Most of them plan on adding additional programs in the near or long-term future. Currently, Rhode Island and Oregon�s FamilyNet have the highest programmatic involvement, 9 and 7 respectively; Missouri and Maine have 4; New York City and Utah have 3; and Kansas has 2. There is a difference in the level of integration that has been implemented as compared to that which is conceptual or planned. Missouri and Rhode Island are among the most mature integration projects, but these are vastly different state environments. Also, there seems to be more programmatic than technical control in Rhode Island, with the opposite in Missouri. Another way integration projects differ from an organizational perspective is whether the de-duplication activities are centralized or decentralized. New York City, Oregon, and Rhode Island (all original AKC sites) have adopted a Master Client Index approach. Utah also uses a Master Client Index of sorts, the client data is represented with virtual records and not is a single repository. With a centralized approach, there is a potential for the following pitfalls:
• Operations become an �orphan� from a funding or administrative perspective • Programs may feel that they are losing control over their data
5.2.2 Intended Use of the Integrated Data Establishing the intended use of the integrated data is important to how de-duplication is approached. Four broad uses are clinical support, case management, program operations, and long-term analysis. For clinical support, the integrated data must be extremely complete and accurate because health-care professionals may use it as a basis for clinical decisions. This intended use may require a level of quality that is beyond what is practical for many systems. Case management and program operations require data that are mostly complete and relatively accurate. Some errors may exist, without life-or-death consequences. A quality level sufficient for these uses should be obtainable for most integrated systems. Data

75
analysis often requires only aggregate or statistical data. A certain degree of error (e.g. duplication) can exist without dramatically affecting the results.
5.2.3 Role of the Immunization Registry Beginnings Work on immunization registries have had a significant impact on the integration systems and de-duplication within those systems. Here are some observations, in no particular order.
• All systems include immunization registries driven by AKC and CDC funding. • Only Rhode Island and Missouri initially developed the immunization registry within
an integrated system concept. . • For three of the projects, (Rhode Island, New York City and Oregon�s ALERT),
immunization records are received almost entirely from provider practices. In other areas, there is a large public health component in which immunizations given in the public sector are primary in the registry.
• Immunization registries were among the first that required public health to establish a regular data exchange with private practices and health plans and to address business rules and quality control policies with external parties.
• The term de-duplication was coined based on the issues confronting immunization projects.
• The All Kids Count conferences on Immunization Registries, initially for their grantees and later expanded to all registry developers, provided a forum for best practices and enlarged the body of knowledge about de-duplication.
• The CDC National Immunization Program Immunization Registry Support team continued to focus on de-duplication by adding it to the Registry Functional Requirements and Core Data Elements (approved by NVAC and required for registry certification).
The CDC has developed a de-duplication testing toolkit with 500 test cases for the testing of de-duplication algorithms in immunization registries.
5.2.4 Role of Vital Records Below are some observations about the role of Vital Records:
• All of the projects except KS (which is a community-based initiative) include Vital Records
• Vital Records is the authoritative file for date of birth, but not addresses, as well as providing the population base (denominator) for the project.
• All states have implemented electronic vital records and many are upgrading and re-engineering them.
• It is also interesting that the program which sponsors the integration is usually not Vital Records, which is the authoritative source for certain key data elements (although there seems to be a tighter coupling of the VR program in Utah.)
• State law controls who has access to VR data and which data elements may be used or shared and under what conditions. This is less problematic within the public health component of health departments but may be an issue for records the provider may be

76
able to see. VR as a matching file often has to be a background verifying-activity not a data source itself.
• Experience with immunization registries highlighted the problem of matching incoming records from provider offices with VR name and address because of variations of birth name and name actually used, and with address changes.
• Newborn screening/VR integrations highlight these discrepancies earlier and may lead to the development of better information. (Rhode Island and Utah are looking at this.)
• The process of birth/infant death matching which states perform often provide the gold standard for record matching, but a study performed by the Arkansas DOH indicates that even small changes in the algorithm can affect the accuracy. The AR study indicated some differences in state definitions and practices that impact comparability.
• The NAPHSIS project to re-engineer the VR process for all states may contribute to the greater usability of these files as reference data for de-duplication.
5.2.5. Role of Communities of Practice Participation in Communities of Practice has helped shape many of the ideas and solutions for de-duplication in the integrated system. Below are some observations:
• Many of the projects have roots in defined or implicit communities of practice including: CDC�s INPHO, All Kids Count, Turning Point, and Genetics Planning and Data Integration grant (HRSA) � AKC Project- Best Practices.
• In addition to the information sharing that benefited many programs, there have been tool and technique transfers.
• Grant funding allows special projects to be done within a larger undertaking, which might otherwise not be possible.
• Sustainability is at risk with priority and funding changes. Belonging to a community of practice provides high visibility and external support to programs that may get buried in a changing department. Connections site visits served to bolster such projects.
• Communities of practice provide a forum for publicizing and disseminating best practices and research results.
• De-duplication processes will be ongoing as more health information is electronic and at the point of care or use. A continuing forum for the sharing of experience and techniques will be necessary to meet the needs of the varied programs and environments where child health information is integrated.
5.2.6 Program Mandates and Organizational Structure Obviously there are many external factors, like program mandates and organizational structure that can impact an integration project and specifically de-duplication efforts. Here are some specific observations made in this area during this study.
• Oregon has a legislative mandate for integration; in Utah, Rhode Island, New York City and Missouri, an executive mandate by the health officer/ commissioner establish the programmatic goals for integration. These include improving program

77
coordination and performance within constituent public agencies and providing better information for program planning and evaluating program effectiveness.
• However, there is a new customer-based focus to provide a coherent view of the health department to the outside community, particularly to aid families and providers in the care of children in a medical home.
• This requirement shines the spotlight on and places the greatest burden on the de-duplication activities because compromised data quality failure is public.
• Differences in the organizational structure and the placement of responsibility for programmatic and technical tasks vary among the projects. In some, de-duplication is centralized in the IT organization; in others it is decentralized to the programmatic components.
• Often, the IT organization is able to use more sophisticated tools and perform multiple iterations of automated processes.
• However, even where data quality assurance and de-duplication resides with the technical organization, programmatic participation is required to establish the business rules and the quality thresholds and to ultimately resolve certain records manually.
• Staff and resources for de-duplication may vary depending on whether legislative budget support is more favorable for programs with constituents or for IT as a general support activity for the Department.
• This may also affect decisions on whether to buy a product, use existing staff to develop software, use freeware, or use manual methods, depending on whether body count, contracts or just money are the budgetary targets.
• Changes in Administration or departmental leadership, policy and funding have already affected systems integration in NYC and KS. De-duplication is an �un-sexy,� but necessary activity for integration that may be threatened by these changes.
5.2.7 Academic Research Leveraging academic resources has benefited several projects.
• Utah and New York City de-duplication processes owe much to academic research. Choicemaker arose from research at New York University and was later developed into a software product; Utah has an ongoing partnership with Utah State University.
• Other projects have benefited from funded research from HRSA, CDC and AKC to contribute to the product�s effectiveness by working in an iterative way and modifying the product on the basis of the experience.
• Testing can provide only basic information about a product; using it and working collaboratively with the developer is the best approach but one not always practical for an organization.
5.2.8 Strategic Planning Strategic planning (both organization wide or specific to IT) preceded integration activities in most of the projects. These were driven primarily by programmatic coordination and service delivery goals, even if developed to support integration not foreseen initially. The best developed of these include a systems architecture which encompasses systems planned to be linked or integrated into a future system as well as initial core systems.

78
In some cases, technology goals of improving performance and streamlining processes resulted in the adoption of a system�s standards addressing the platforms supported, systems development, systems acquisitions and operational procedures. However, even with planning, changing the culture of constituent programs and incorporating legacy systems still challenge projects in data quality activities. Finally, strategic planning is important because programmatic requirements and systems characteristics identify records where information is linked rather than integrated, which may pose different types of de-duplication strategies.
5.3 Future Study There is still much that could be done in terms of de-duplication research that would be beneficial to child-health information systems. Below is a list of potential research projects, in no particular order.
5.3.1 Testing and Assessment A critical success factor for any information system project is the ability to test the system and measure its effectiveness. For de-duplication, this requires
• Meaningful data-quality metrics • Ways of describing or classifying different kinds of duplicates • Meaningful test data • Tools for measuring the data-quality of various data sets
The CDC De-duplication Toolkit is a first step in this direction. It provides a small, but useful set of test data, a duplication classification scheme, and a tool for measuring the number of duplication remaining in the test data set after de-duplication has been performed. The problem is that this toolkit was built for immunization registries and therefore doesn�t fully represent the type of information found in integrated child-health information systems. Also, the data set is relatively small and the frequency of the errors it contains is based on national statistics, and therefore, may not be very representative of the data for any given information system. A future research project could look at creating a new de-duplication toolkit that would provide
• A more robust set of data-quality metrics • A tool for generating data sets (instead of a providing a fix data set) that were
representative of locale-specific data characteristics • A more robust set of measurement tools
This research project could also review testing strategies and methods, as well as provide inside into how to manage testing activities, in general.

79
5.3.2 Useful Data Elements and Types of Comparisons More beneficial research could be done on the question of which data elements are the most value in the matching process and what types of comparisons are the most practical and effective. A future research project could experiment with different data elements and look at some of the more sophistication matching techniques, such as true probabilistic field comparisons.
5.3.3 Impact of Privacy Issues Another important area that needs considerable attention is how privacy concerns affect record matching and merging. For example, if an integrated system contains two records that may result the same child and one of them include some kind of indicator that means the child has �opted-out� of the system, then what consequence does it have for the matching and merging processes? Can that record be matched against others? If it is and a merge is performed, is the new, combined record flagged as �opted-out�. On the surface, these may seem like questions that an integration project simply has to answer for itself. However, there are profound consequences to their answers that represent interpretation of confidentiality policies and could establish an undesired precedent. Research into this issue could be of significant value to the public health community.
5.3.4 Birth-Death Matching Matching birth and death records is a sticky problem, usually solved with a manual process. This type of matching is often considered the Gold Standard in de-duplicated records. A study in Arkansas indicated that even small changes in the algorithm could affect the accuracy on this matching process. More research is needed to determine how it can be improved. 5.3.5 Organizational Support and Technical Assistance De-duplication comprises a set of informatics processes, which are widely used. Public Health is moving toward more data and file integration both in child health and through the Public Health Information Network (PHIN). This creates an even greater requirement for effective de-duplication. Ongoing de-duplication research activities even if performed within an individual organization will not benefit the public health community unless there is a forum for discussion of approaches and findings and for the dissemination of results and best practices. More likely, an individual organization will not be able to fund and support individual research, much less discussion. In addition, it would not have the benefit of knowing what other organizations might be researching. A future role for the Public Health Informatics Institute would be to provide organizational support and technical assistance for collaborative research on de-duplication as an extension of this Connections study within and across communities of public health practice.

80
References [1] Berry, M. Studies on Deduplication. (2003, March 6). Meeting Briefs. Rhode Island Department of
Health and HLN Consulting, Rhode Island. [2] Canavan, B. (2002, June, 25-27). Presentation on ALERT Immunization Registry. Connections Site Visit. [3] Coding Address Support System Technical Guide. (2003, January). Last retrieved September 6, 2003,
from Address Management, National Customer, Support Center, Memphis, TN. Web site: http://ribbs.usps.gov/files/cass/casstech.pdf
[4] Cummings, D. (1988). American English Spelling: An Informal Description. Baltimore: Johns Hopkins
University Press. [5] Deduplication Test Cases. Last retrieved September 24, 2003, from Centers for Disease Control and
Prevention. Web site: http://www.cdc.gov/nip/registry/dedup/dedup.htm [6] DHS/OFH FamilyNet Data Integration Strategic Plan. Version 1.0. (2003, April 9). Merge/Match/
Deduplication Requirements, DHS Office of Family Health, Prepared By CSG Professional Services, Inc., 5201 SW Westgate Drive, Suite 208, Portland, Oregon 97221.(503) 292-0859.
[7] Galhardas, H., Florescu, D., and Shasha, D. (2000). An Extensible Framework for Data Cleaning -
Retrieved October 18, 2003 From http://citeseer.nj.nec.com/galhardas00extensible.html [8] Green, S. and Lutz, R. (2002, August). Measuring phonological similarity: The case of personal names.
Retrieved June 6, 2003 from Language Analysis Systems, Inc. 2001. Web site: http://ww.las-inc.com/nameinfor/wp_lsa.htm.
[9] Laver, J. (1994). Principles of Phonetics. Cambridge: Cambridge University Press. [10] Lutz, R. and Greene, S. The use of phonological information in automatic name searching. Retrieved
June 6, 2003, from Language Analysis Systems, Inc., 2001. Web site: http://www.las-inc.com/extra/whitepapers/LAS_Phonology_White_Paper.pdf
[11] Patman, F. and Shaefer, L. (2002, August). Is soundex good enough for you? On the Hidden Risks of
Soundex-Based Name Searching. Last retrieved June 6, 2003, from Onomastix/Language Analysis Systems, Inc. 2001. Web site: http://www.las-inc.com/nameinfo/wp_soundex.htm
[12] Project Briefs. Last retrieved October 9, 2003, from
http://www.allkidscount.org/loose%20pages/briefs.html [13] Smith, Craig. Historical Record Name Authority and Standardization (Masters Thesis, Utah State
University, 2003) [14] User Manual for Deduplication Evaluation Toolkit. (2002, June) Retrieved September 24, 2003, from
Center for Disease Control and Prevention. Web site: http://www.cdc.gov/nip/registry/dedup/dedupkit.zip
[15] USPS - CASS� (Coding Accuracy Support System). Last retrieved September 6, 2003, from United State
Postal Service. Web site:http://www.usps.com/ncsc/addressservices/certprograms/cass.htm [16] USPS Vendors and Licenses. Retrieved September 6, 2003, from United States Postal Service. Web
site:http://www.usps.com/ncsc/ziplookup/vendorslicensees.htm

81
APPENDIX A � Additional Reference Material
Survey Questionnaire • Questionnaire-2003626.doc
Information from Rhode Island • Studies on Deduplication performed by Mike Berry of HLN Consulting, LLC
pursuant to GSA contract with RIDOH. • Matching Project Bibliography, RI_MatchingBibliography_1.pdf • A variation of the Matching Project Bibliography, RI_MatchingBibliography_2.pdf • A market survey of product vendors, RI_MarketSurvey.pdf
Information from Oregon • DHS/OFH FamilyNet Data Integration Strategic Plan Merge/Match De-duplication
Requirements, DHS Office of Family Health, Prepared By CSG Professional Services, Inc., 5201 SW Westgate Drive, Suite 208, Portland, Oregon 97221, (503) 292-0859, http://www.csgpro.com April 9, 2003, Version 1.0, OR_MergeMatchRequirementsV1.doc
Information from Maine • Description of manual de-duplication process, Manual_Dedup_Code.doc
Information from Missouri • Diagram of de-duplication process, MO_DiagramOfProcess.ppt • Data Quality and Assurance presentation, MO_DataQualityAndAssurance.ppt
Information from Arkansas Project • Interview with Doug Murray, Director of Vital Statistics,
AR_NotesFromInterviewWithDougMurray-20030626.doc • Issues in Linking Public Health Information Systems: An Art or Science,
AR_IssuesInLinkingSystems.pdf