Embed Size (px)
Citation preview

20
Afternoon Session
Network Platforms Group 22
Bond
QoS SchedLink
Status Interrupt
L3fwd
Load Balancer
KNI
IPv4 Multicast
L2fwd Keep Alive
Packet Distrib IP Pipeline
Hello World
Exception Path
L2fwd Jobstats
L2fwd IVSHME
M
Timer
IP Reass
VMDqDCB
PTP Client
Packet OrderingCLI
DPDK
Multi Process
Ethtool
L3fwd VF
IP Frag
QoS Meter
L2fwd
Perf Thread
L2fwd Crypto
RxTx Callbacks
Quota & W’mark
Skeleton
TEP Term
Vhost
VM Power Manager
VMDq
L3fwd Power
L3fwd ACL
Netmap
Vhost Xen
QAT
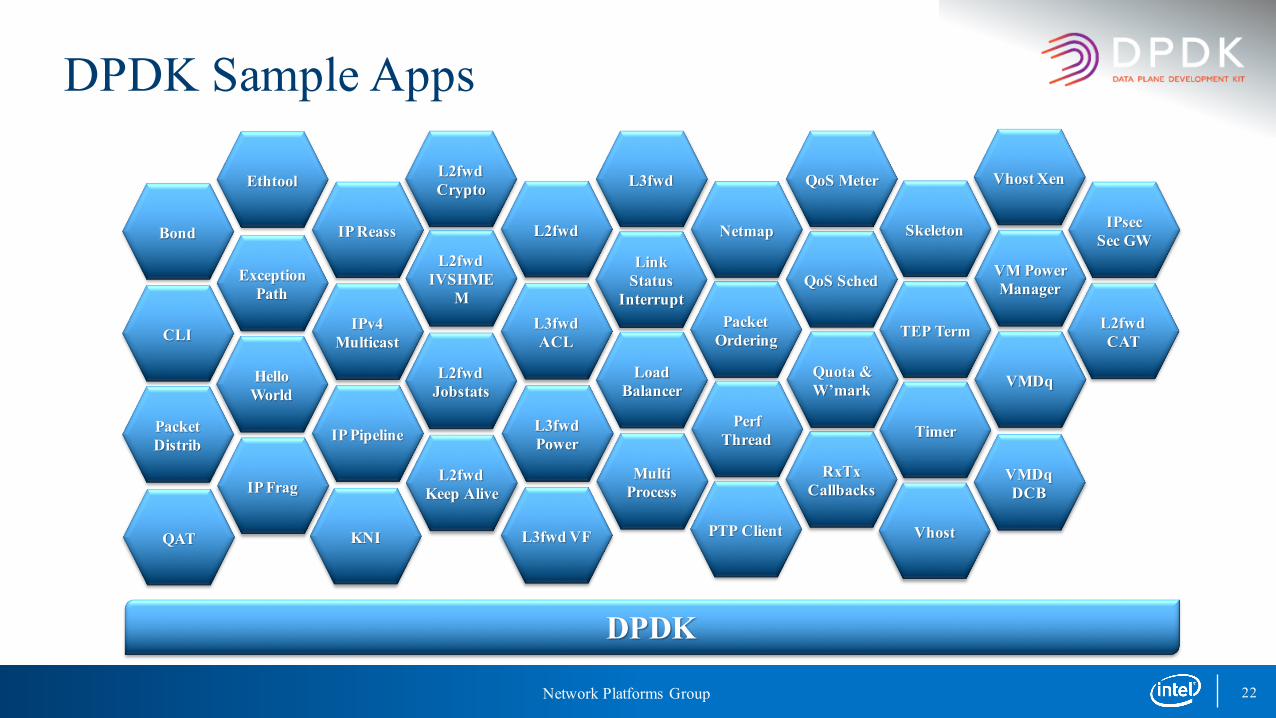
DPDK Sample Apps
L2fwd CAT
IPsecSec GW
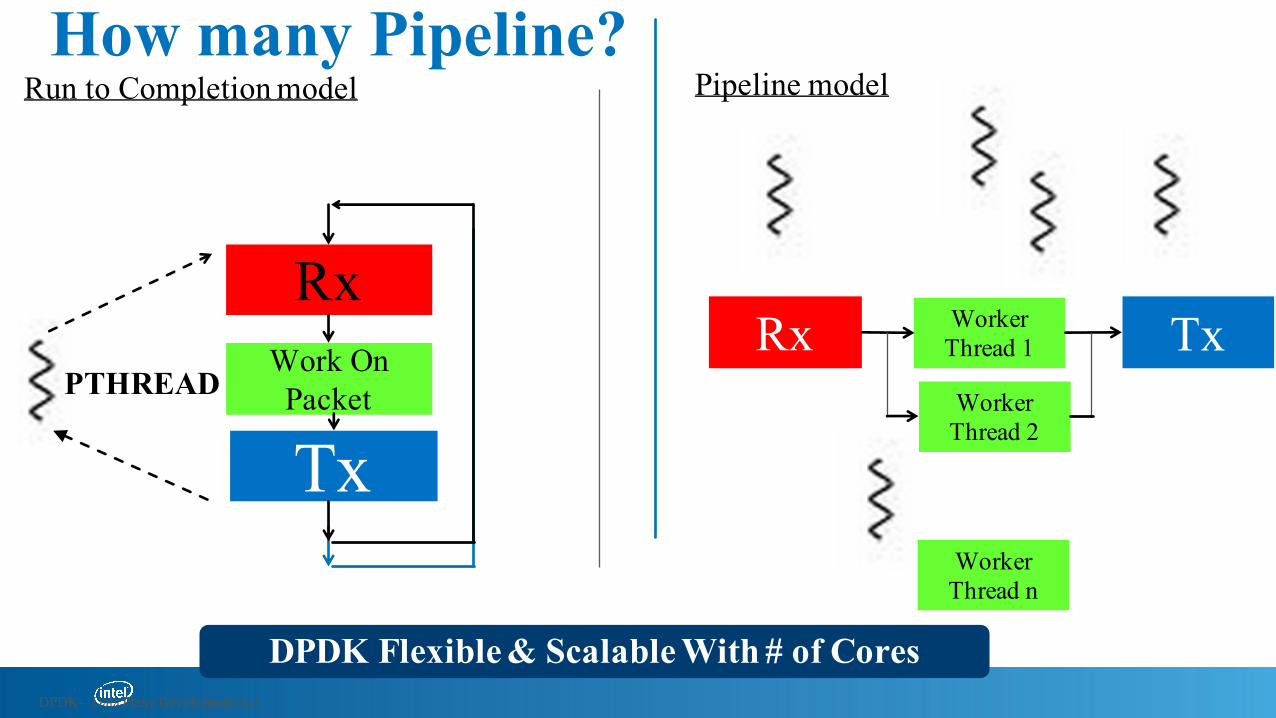
How many of you used Run to Completion? How many Pipeline?
Run to Completion model
RxWork On Packet
TxPTHREAD
TxWorkerThread 1Rx
Pipeline model
WorkerThread 2
WorkerThread n
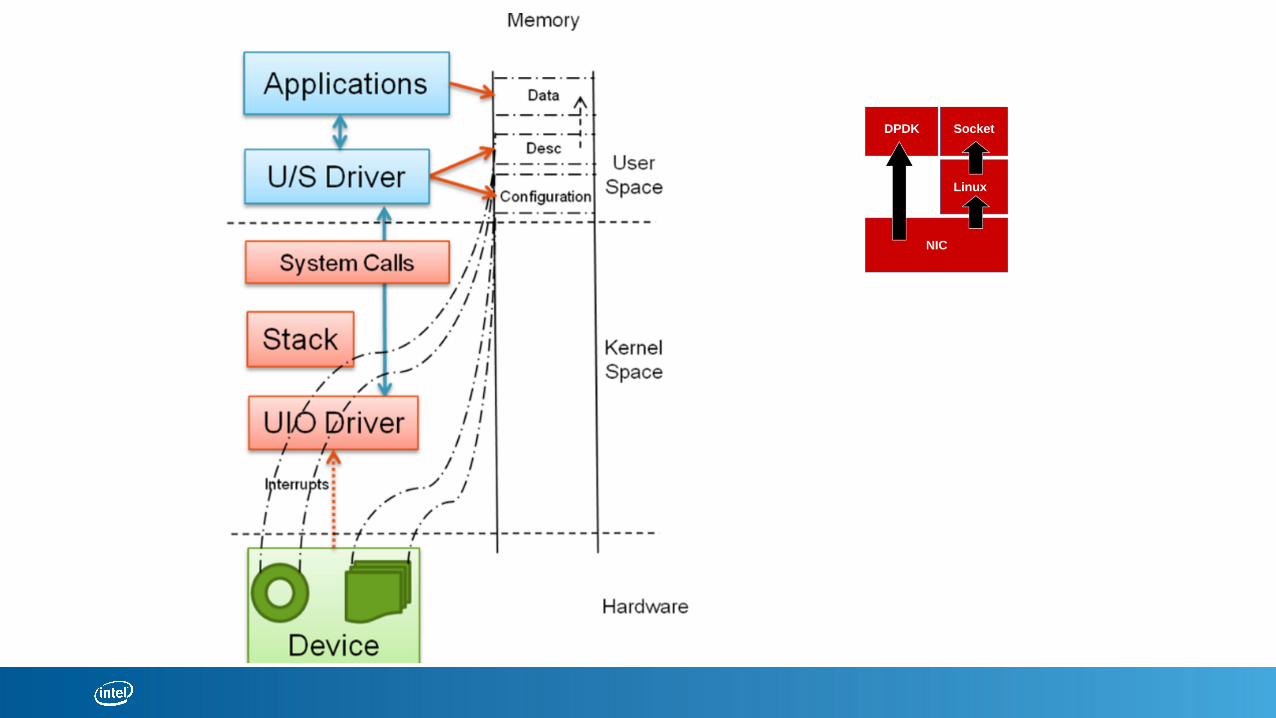
DPDK Flexible & Scalable With # of CoresDPDK – Data Plane Development Kit

ObjectiveCode Walkthrough of
1) Life Of a Packet from Rx to Pkt Processing to Tx
2) How Developer uses DPDK Objects and configures their Properties?
3) How DPDK Poll mode Driver gets initiated into all the Lcores in the system?
Where To Begin?
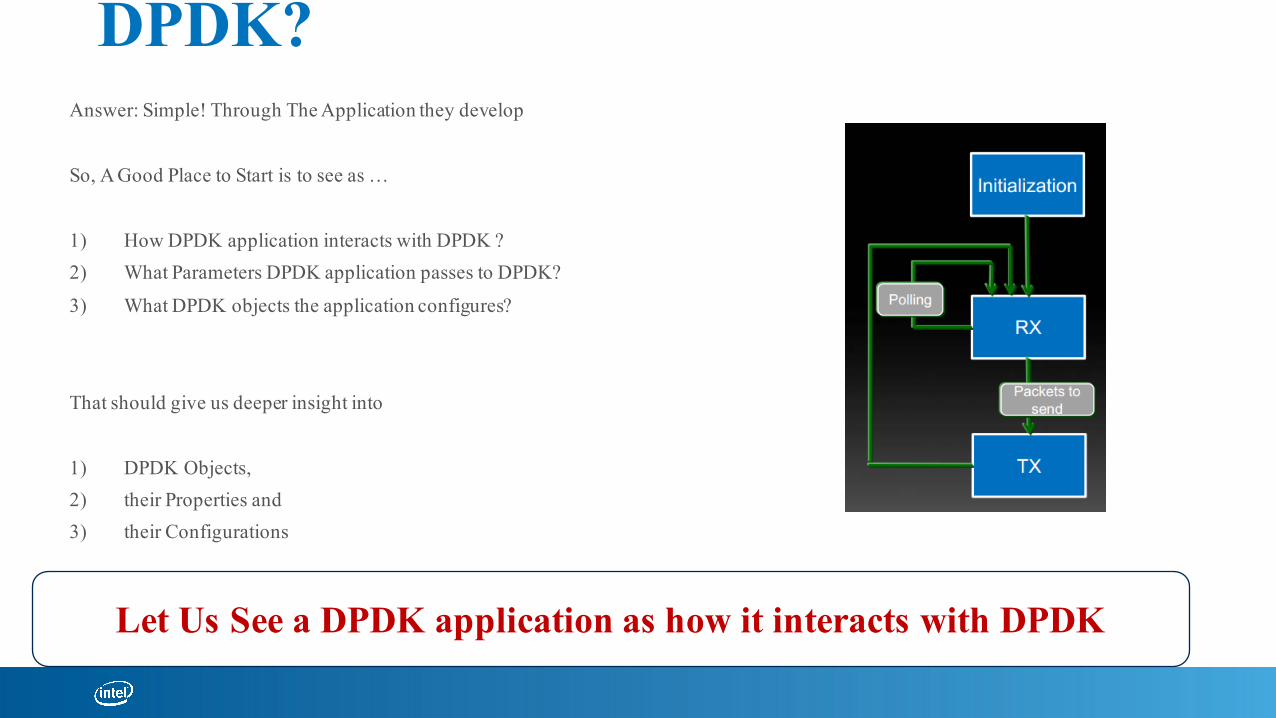
How will A Developer Interact With DPDK?
Answer: Simple! Through The Application they develop
So, A Good Place to Start is to see as …
1) How DPDK application interacts with DPDK ?2) What Parameters DPDK application passes to DPDK?
3) What DPDK objects the application configures?
That should give us deeper insight into
1) DPDK Objects, 2) their Properties and 3) their Configurations
Let Us See a DPDK application as how it interacts with DPDK

DPDK Objects & Their Properties
Objects: Lcores, Ports, Rings, Mbufs, MemPools;; Properties: Burst_Sizes, Behavior

27
Achieving Performance – Silicon FeaturesAttribute Comments
Vector instruction set CPU core supports vector instruction set for integer and floating point (SSE: 128-bit integer, AVX1:128-bit integer, AVX2: 256-bit integer)
Huge-pages Intel CPUs support 4K, 2MB and 1GB page sizes. Picking the right page size for the data structure minimizes TLB thrashing. DPDK uses hugetlbfs to manage physically mapped huge page area
Hardware prefetch Intel CPUs support prefetching data into all levels of the cache hierarchy (L1, L2, LLC).
Cache and memory alignment DPDK aligns all its data structures to 64B multiples. This avoids elements straddling cache lines and DDR memory lines fulfilling requests with single read cycles
Intel Data Direct I/O (DDIO) Is a methodology on Xeon E5 and E7 Platforms where packet I/O data is placed directly in LLC on ingress and sourced from LLC on egress
Cache QoS Allows way-allocation control of LLC between multiple applications, controlled by software
CPU Frequency scaling/Turbo Allows the core to temporarily boost CPU frequency higher for single threaded performance
NUMA Non-Uniform Memory Architecture – as much as possible, DPDK tries to allocate memory as close to the core where the code is executing.
28
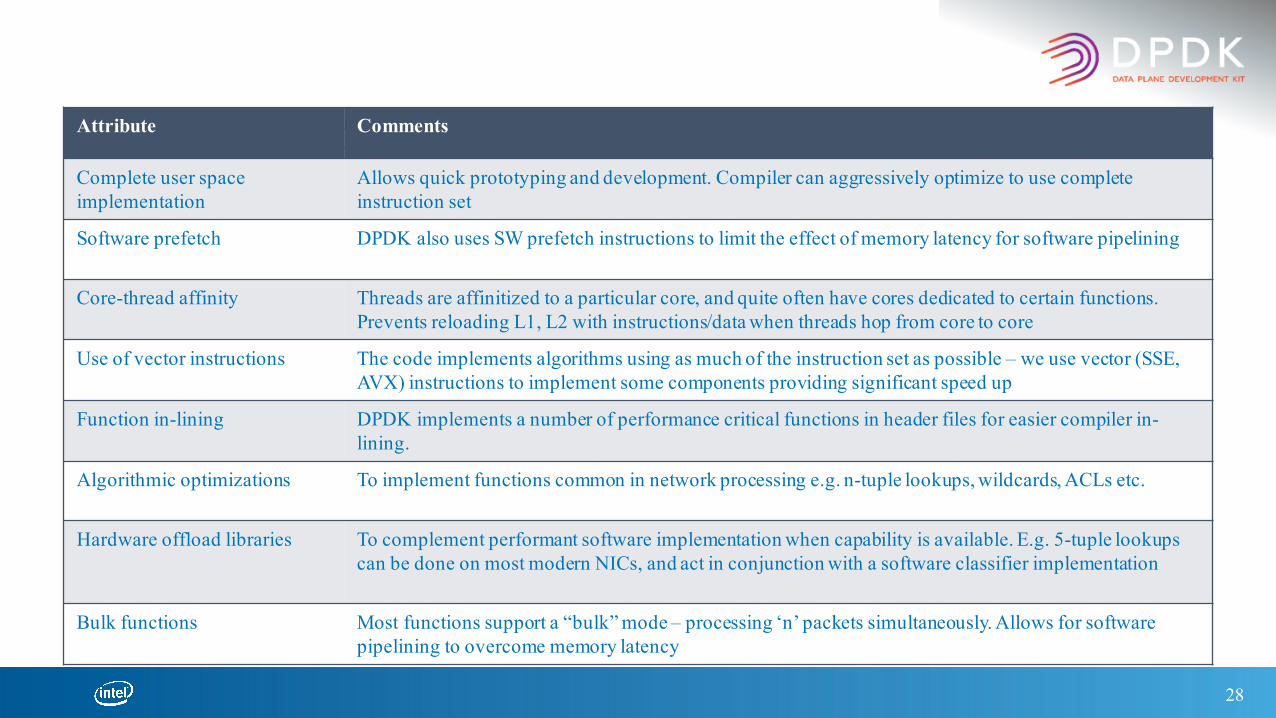
Achieving Performance – Software ConceptsAttribute Comments
Complete user space implementation
Allows quick prototyping and development. Compiler can aggressively optimize to use complete instruction set
Software prefetch DPDK also uses SW prefetch instructions to limit the effect of memory latency for software pipelining
Core-thread affinity Threads are affinitized to a particular core, and quite often have cores dedicated to certain functions. Prevents reloading L1, L2 with instructions/data when threads hop from core to core
Use of vector instructions The code implements algorithms using as much of the instruction set as possible – we use vector (SSE, AVX) instructions to implement some components providing significant speed up
Function in-lining DPDK implements a number of performance critical functions in header files for easier compiler in-lining.
Algorithmic optimizations To implement functions common in network processing e.g. n-tuple lookups, wildcards, ACLs etc.
Hardware offload libraries To complement performant software implementation when capability is available. E.g. 5-tuple lookups can be done on most modern NICs, and act in conjunction with a software classifier implementation
Bulk functions Most functions support a “bulk” mode – processing ‘n’ packets simultaneously. Allows for software pipelining to overcome memory latency

Question: What Objects You Saw In Previous Foil?
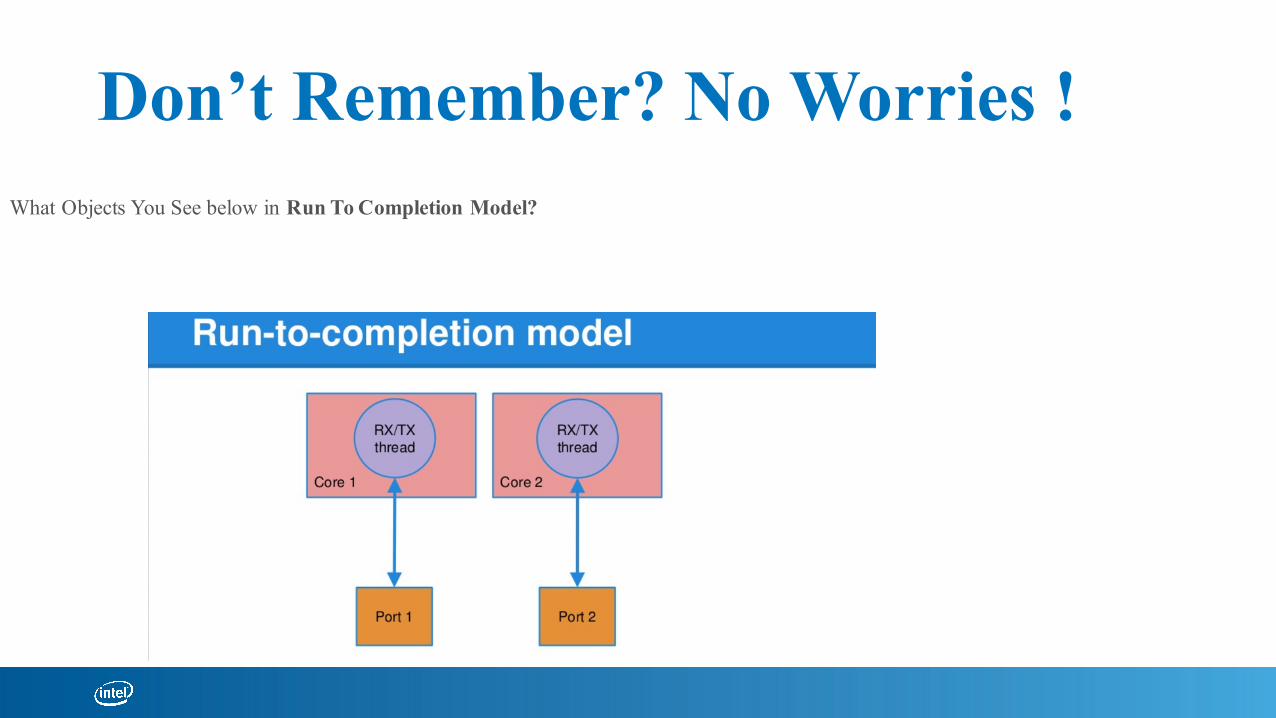
Don’t Remember? No Worries !What Objects You See below in Run To Completion Model?
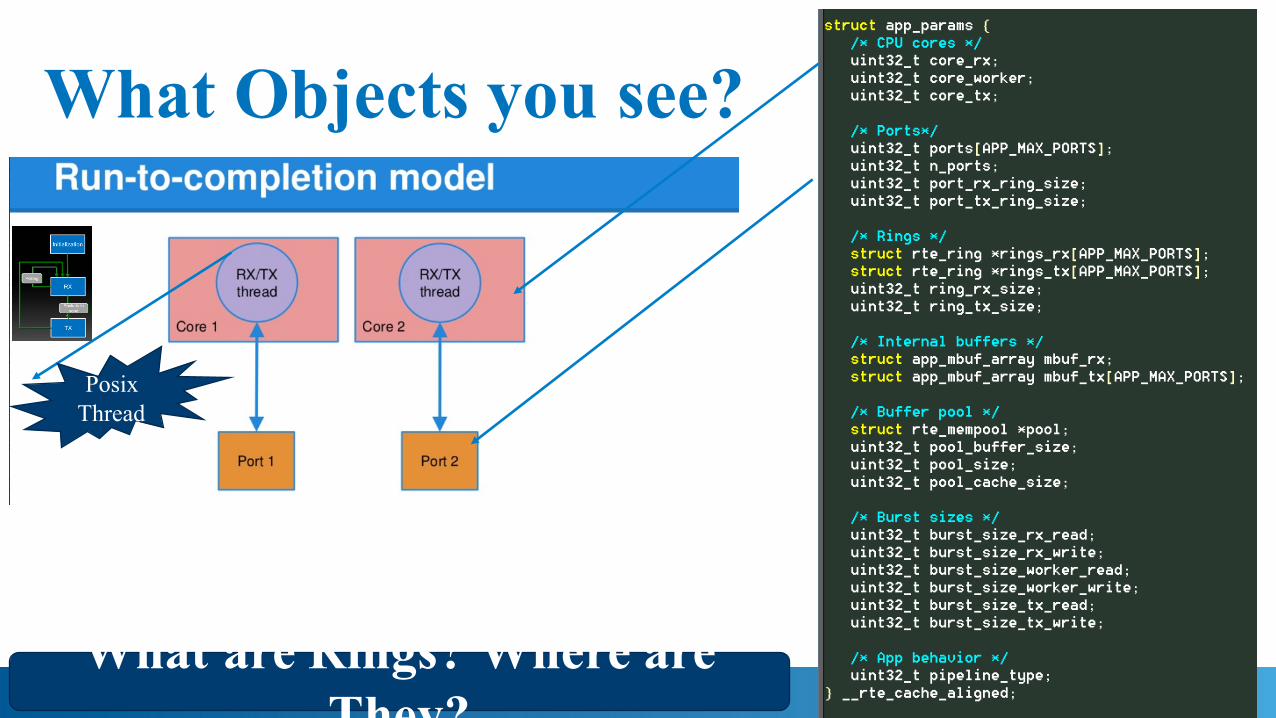
What Objects you see?
What are Rings? Where are They?
PosixThread
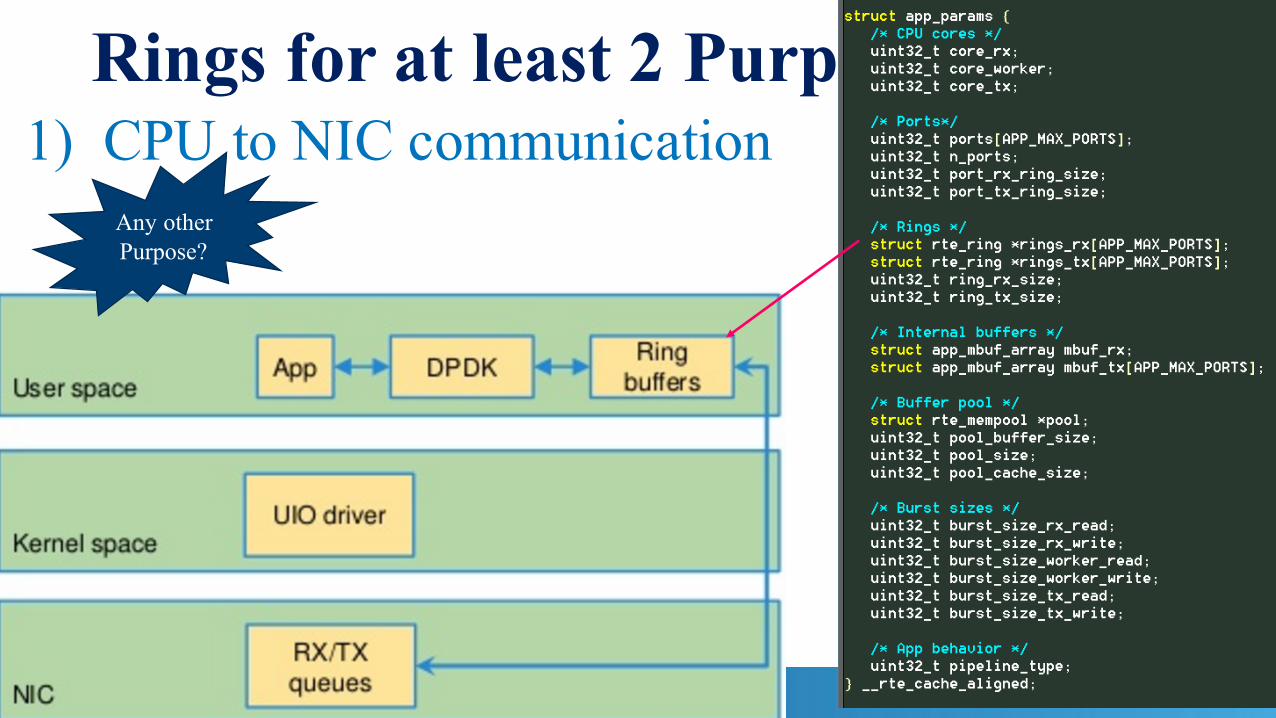
Rings for at least 2 Purposes1) CPU to NIC communication
Any other Purpose?

To Answer That, Let us Look at Pipeline Model
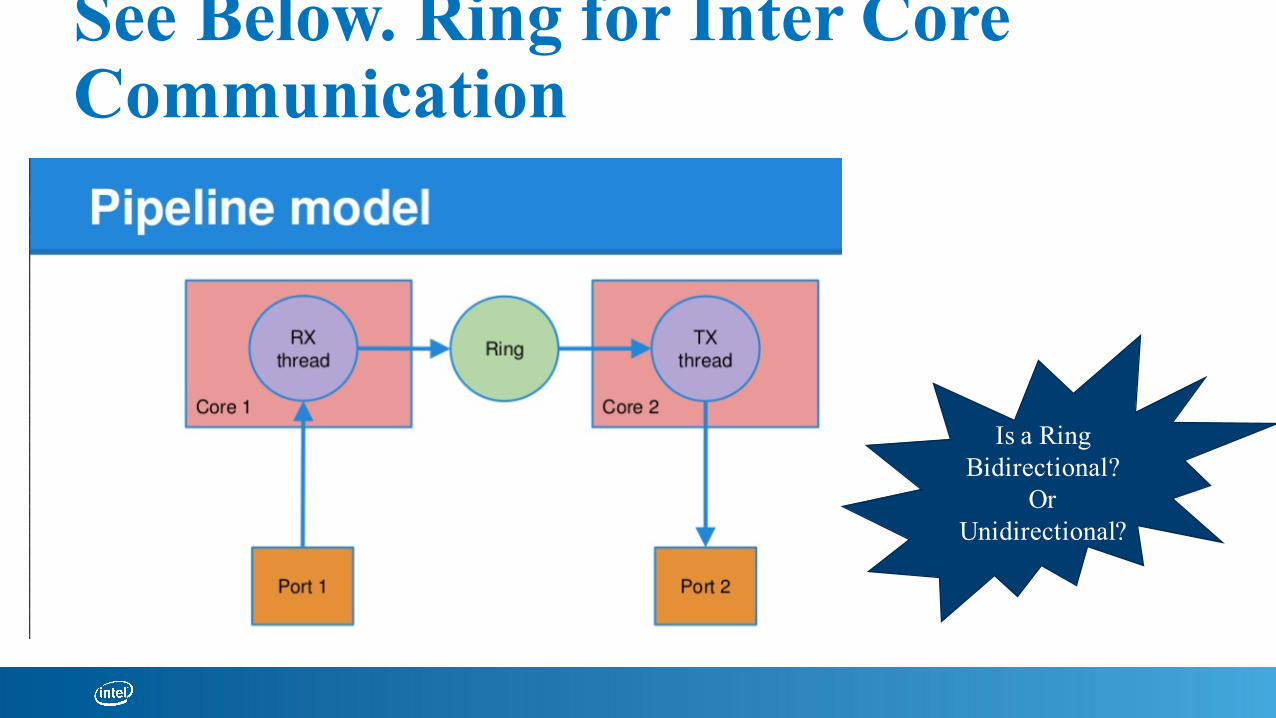
See Below. Ring for Inter Core Communication
Is a Ring Bidirectional?
Or Unidirectional?
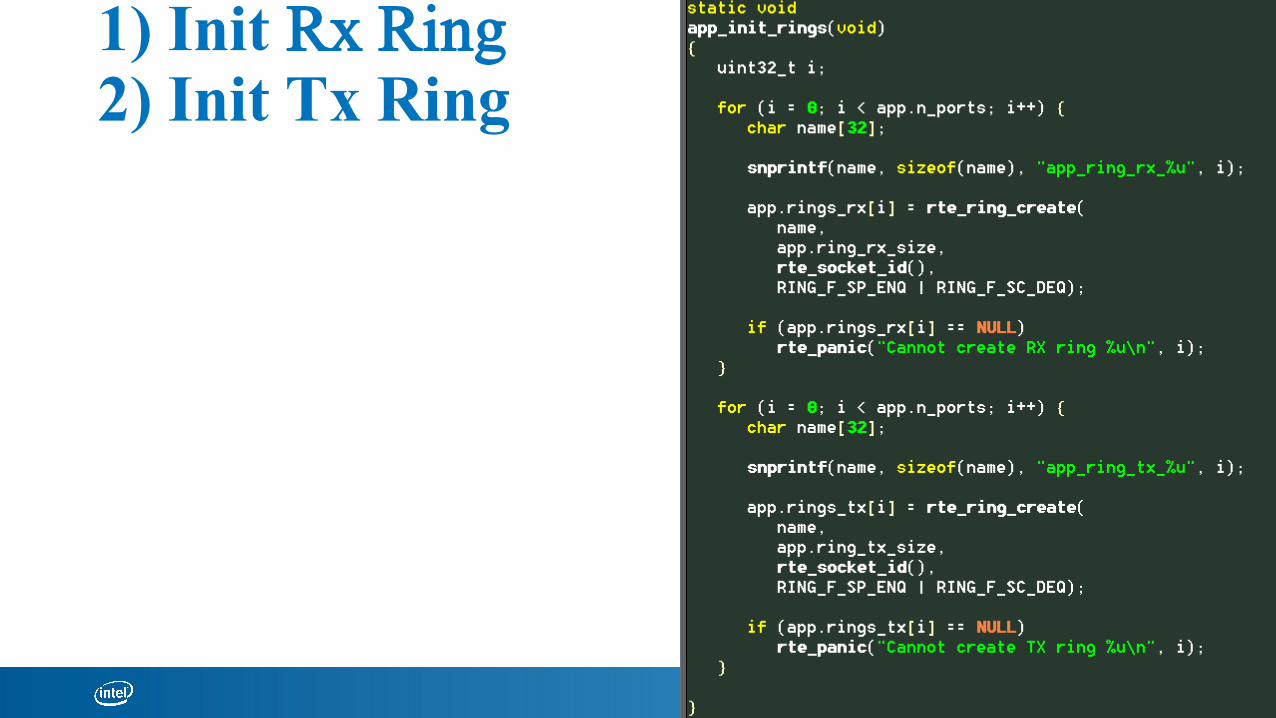
1) Init Rx Ring 2) Init Tx Ring

Summing up
1) CPU Cores
2) NIC Ports
3) Rings – Hardware RX & TX Rings to interface with NIC
4) Rings – Software RX & TX Rings for Inter Core Communication
5) MBUF – RX & TX Mbuf Memory Buffers (they also have a/c keeping rings)
6) MemPool – Memory Pool to allocate Space for Mbufs from

What if I can do packet processing without writing code to move them?
Setting a bit here & there.
Configuring a file or two?
I still want to use s/w - NFV & cores

Your Value Add With ip-pipeline:
The Next Hands-On You will be doing
38

Lego Blocks ! Imagine The Possibilities!!
39
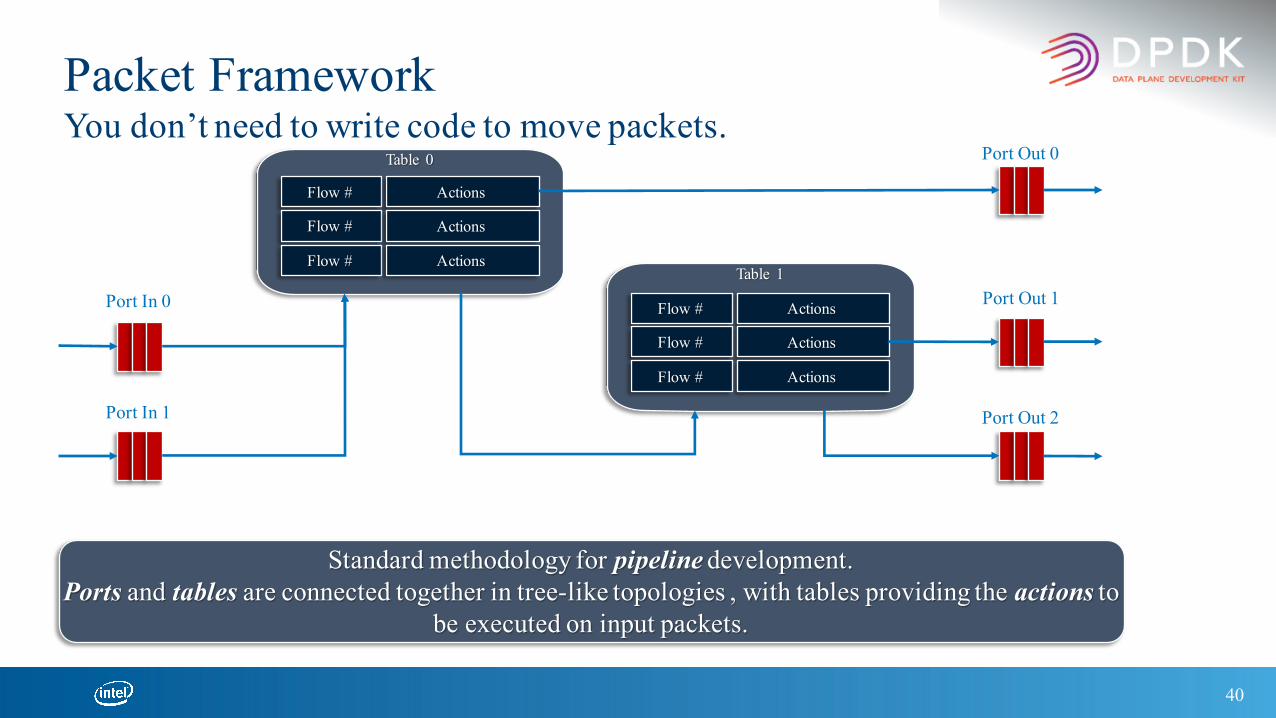
40
Packet FrameworkYou don’t need to write code to move packets.
Port In 0
Port In 1
Port Out 0
Port Out 1
Port Out 2
Table 0
Flow #
Flow #
Flow #
Actions
Actions
ActionsTable 1
Flow #
Flow #
Flow #
Actions
Actions
Actions
Standard methodology for pipeline development.Ports and tables are connected together in tree-like topologies , with tables providing the actions to
be executed on input packets.

Your Value Add With ip-pipeline: The Next Hands-On You will be doing
• If you are familiar more with hardware based packet processing – just setting up bits in control registers – moves packets
• No need to write code to move packets
• Similar look and feel as “setting bits in control register” - here you set objects in Config files and rules in scripts
• Lego block type application generator – Object model – highly scalable and flexible
• Fast prototyping of your applications
• Great tool to plan ahead - Application to Architecture mapping Experimentation - Run To Completion Vs Pipeline
• Quick Evaluation of Processor Budgeting and Performance trade-off
41
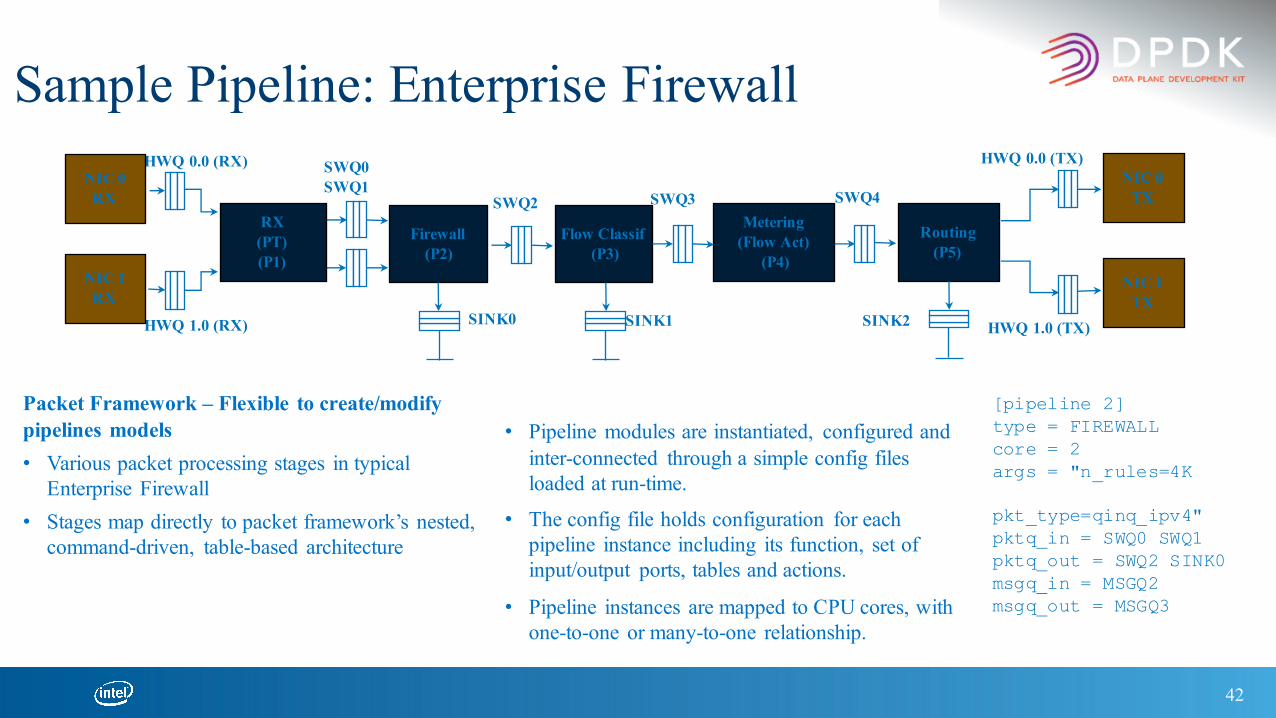
42
Sample Pipeline: Enterprise Firewall
SWQ4SWQ3SWQ2
SINK1SINK0
SWQ0SWQ1
HWQ 1.0 (TX)SINK2
HWQ 0.0 (TX)
HWQ 1.0 (RX)
HWQ 0.0 (RX)NIC 0
RX
NIC 1RX
NIC 0TX
NIC 1TX
Routing(P5)
RX(PT)(P1)
Firewall(P2)
Flow Classif(P3)
Metering(Flow Act)
(P4)
Packet Framework – Flexible to create/modify pipelines models• Various packet processing stages in typical
Enterprise Firewall• Stages map directly to packet framework’s nested,
command-driven, table-based architecture
[pipeline 2]type = FIREWALLcore = 2args = "n_rules=4K
pkt_type=qinq_ipv4"pktq_in = SWQ0 SWQ1pktq_out = SWQ2 SINK0msgq_in = MSGQ2msgq_out = MSGQ3
• Pipeline modules are instantiated, configured and inter-connected through a simple config files loaded at run-time.
• The config file holds configuration for each pipeline instance including its function, set of input/output ports, tables and actions.
• Pipeline instances are mapped to CPU cores, with one-to-one or many-to-one relationship.
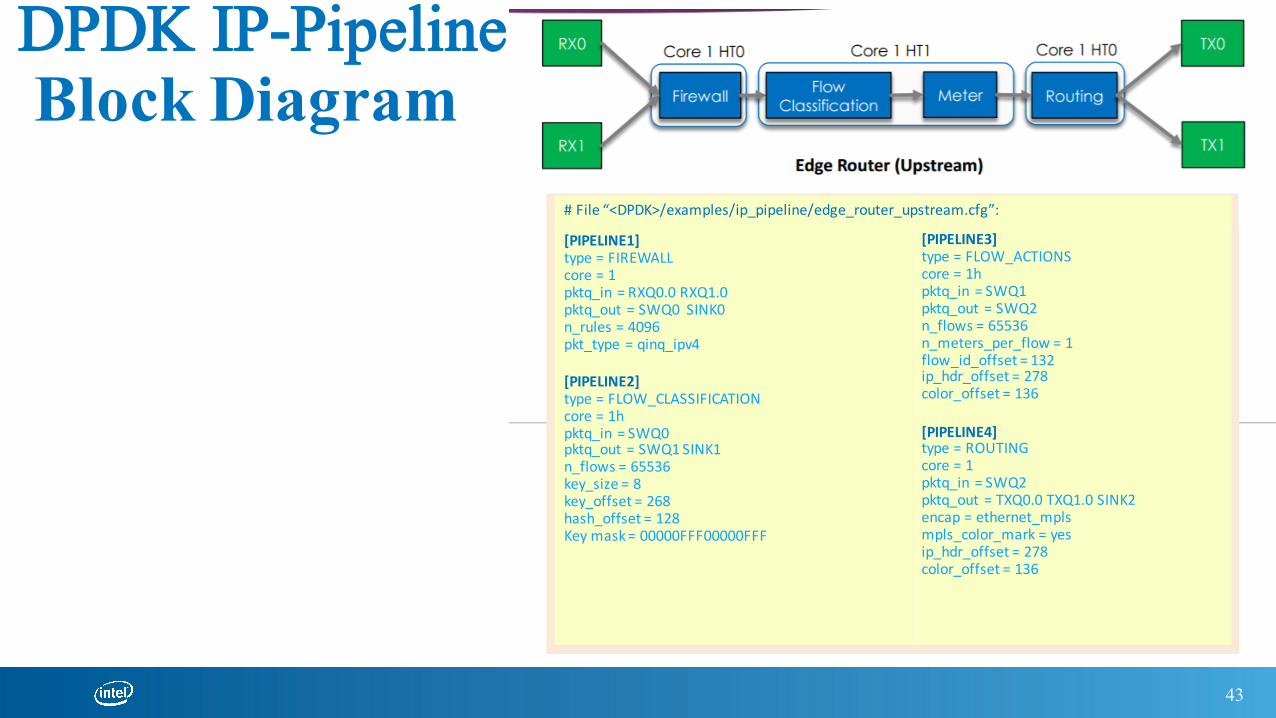
DPDK IP-PipelineBlock Diagram
43
[PIPELINE1]type=FIREWALLcore=1pktq_in =RXQ0.0RXQ1.0pktq_out =SWQ0 SINK0n_rules =4096pkt_type =qinq_ipv4
[PIPELINE2]type=FLOW_CLASSIFICATIONcore=1hpktq_in =SWQ0pktq_out =SWQ1SINK1n_flows =65536key_size =8key_offset =268hash_offset =128Keymask=00000FFF00000FFF
[PIPELINE3]type=FLOW_ACTIONScore=1hpktq_in =SWQ1pktq_out =SWQ2n_flows =65536n_meters_per_flow =1flow_id_offset =132ip_hdr_offset =278color_offset =136
[PIPELINE4]type=ROUTINGcore=1pktq_in =SWQ2pktq_out =TXQ0.0TXQ1.0SINK2encap =ethernet_mplsmpls_color_mark =yesip_hdr_offset =278color_offset =136
#File“<DPDK>/examples/ip_pipeline/edge_router_upstream.cfg”:
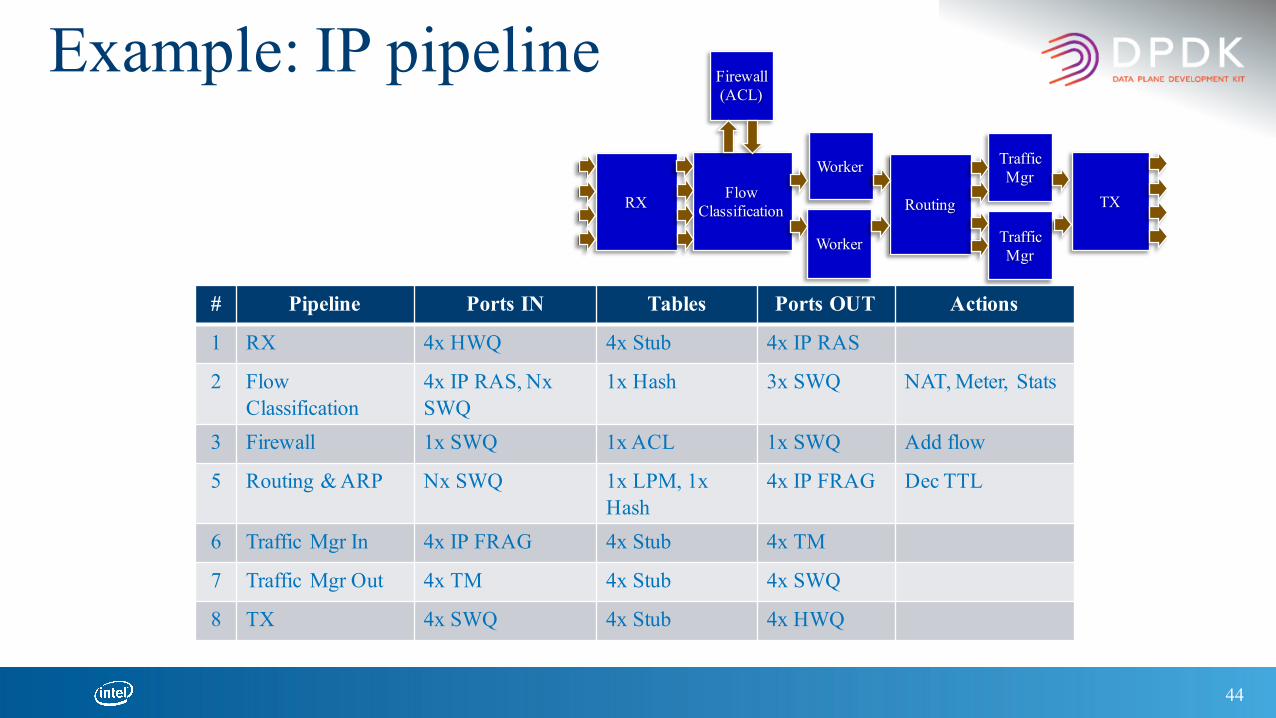
44
Flow ClassificationRX
Firewall(ACL)
Worker
Worker
Routing
Traffic Mgr
Traffic Mgr
TX
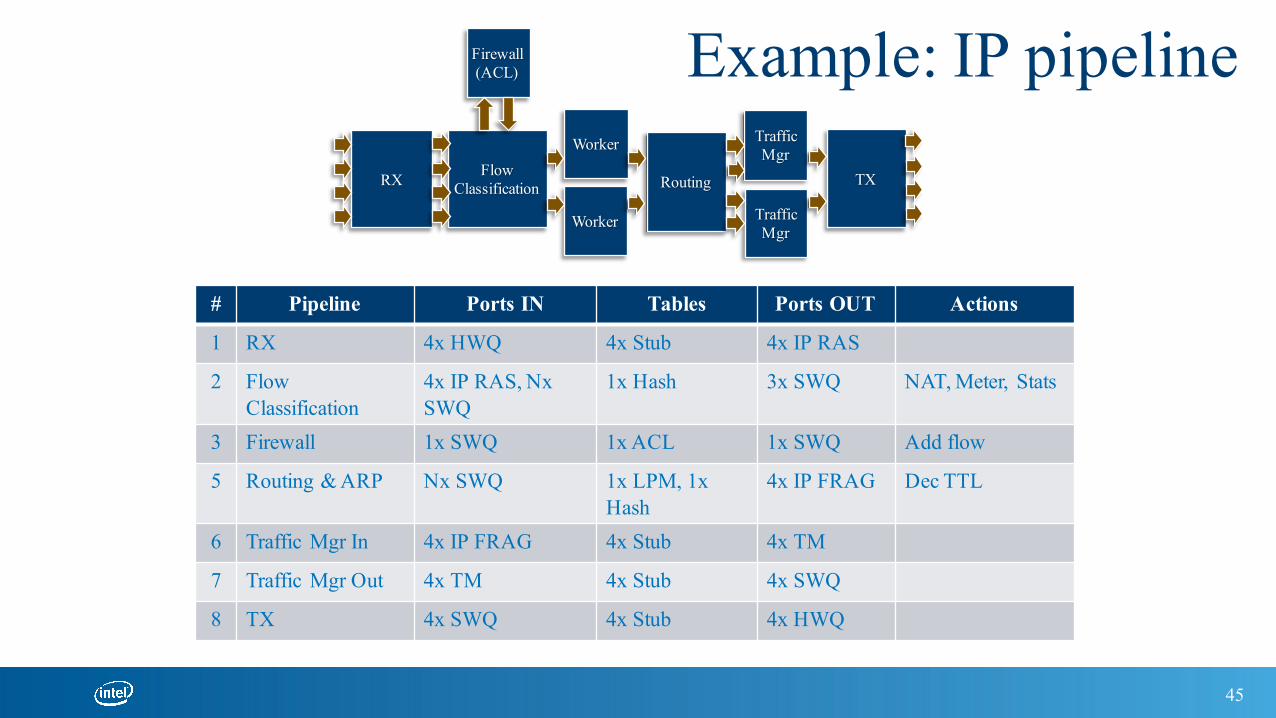
# Pipeline Ports IN Tables Ports OUT Actions
1 RX 4x HWQ 4x Stub 4x IP RAS
2 Flow Classification
4x IP RAS, NxSWQ
1x Hash 3x SWQ NAT, Meter, Stats
3 Firewall 1x SWQ 1x ACL 1x SWQ Add flow
5 Routing & ARP Nx SWQ 1x LPM, 1x Hash
4x IP FRAG Dec TTL
6 Traffic Mgr In 4x IP FRAG 4x Stub 4x TM
7 Traffic Mgr Out 4x TM 4x Stub 4x SWQ
8 TX 4x SWQ 4x Stub 4x HWQ
Example: IP pipeline
45
# Pipeline Ports IN Tables Ports OUT Actions
1 RX 4x HWQ 4x Stub 4x IP RAS
2 Flow Classification
4x IP RAS, NxSWQ
1x Hash 3x SWQ NAT, Meter, Stats
3 Firewall 1x SWQ 1x ACL 1x SWQ Add flow
5 Routing & ARP Nx SWQ 1x LPM, 1x Hash
4x IP FRAG Dec TTL
6 Traffic Mgr In 4x IP FRAG 4x Stub 4x TM
7 Traffic Mgr Out 4x TM 4x Stub 4x SWQ
8 TX 4x SWQ 4x Stub 4x HWQ
Flow ClassificationRX
Firewall(ACL)
Worker
Worker
Routing
Traffic Mgr
Traffic Mgr
TX
Example: IP pipeline
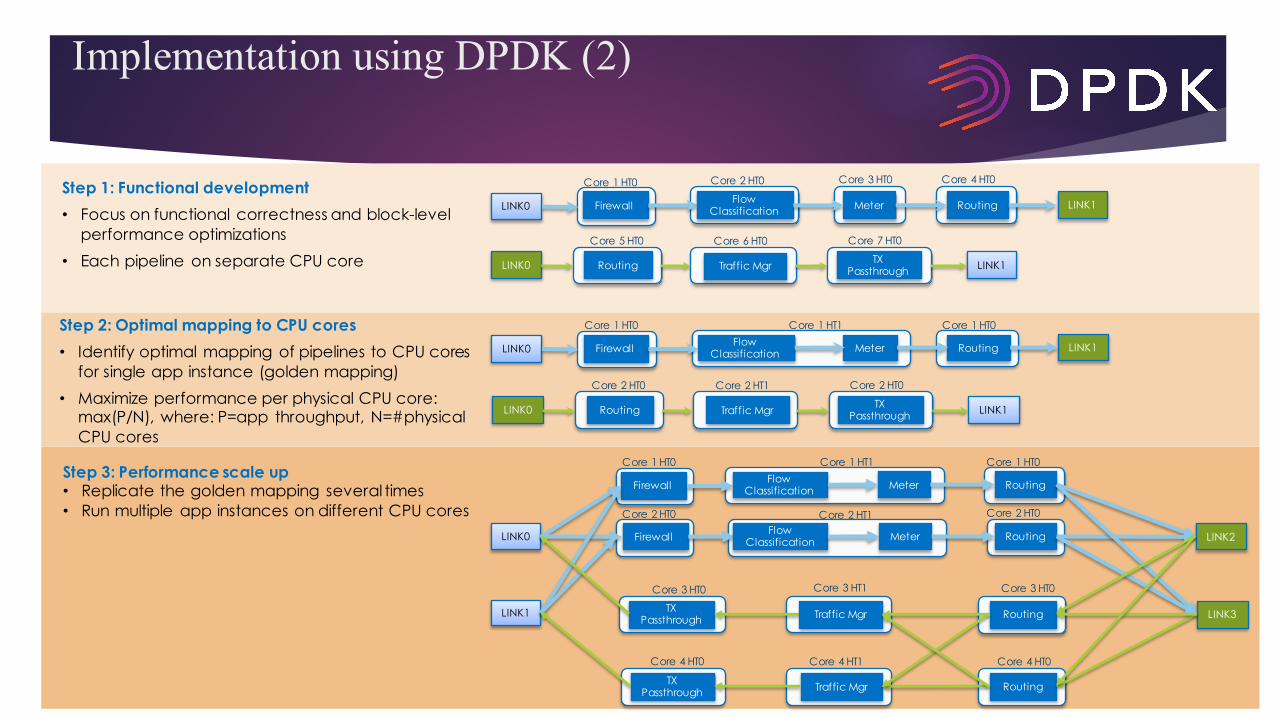
Implementation using DPDK (2)
Core 1 HT0
LINK0 LINK2
Firewall Meter RoutingFlow Classification
TX Passthrough RoutingTraffic MgrLINK1 LINK3
Firewall Meter RoutingFlow Classification
TX Passthrough RoutingTraffic Mgr
Core 2 HT0
Core 3 HT0
Core 4 HT0
Core 3 HT1
Core 4 HT1
Core 3 HT0
Core 4 HT0
Core 1 HT1 Core 1 HT0
Core 2 HT1 Core 2 HT0
Core 1 HT0
LINK0 LINK1 Firewall Meter RoutingFlow Classification
LINK1LINK0 TX PassthroughRouting Traffic Mgr
Core 2 HT0Core 2 HT1Core 2 HT0
Core 1 HT1 Core 1 HT0
Core 1 HT0
LINK0 LINK1 Firewall Meter RoutingFlow Classification
LINK1LINK0 TX PassthroughRouting Traffic Mgr
Core 7 HT0Core 6 HT0Core 5 HT0
Core 2 HT0 Core 4 HT0Core 3 HT0Step 1: Functional development• Focus on functional correctness and block-level
performance optimizations• Each pipeline on separate CPU core
Step 2: Optimal mapping to CPU cores• Identify optimal mapping of pipelines to CPU cores
for single app instance (golden mapping)• Maximize performance per physical CPU core:
max(P/N), where: P=app throughput, N=#physical CPU cores
Step 3: Performance scale up• Replicate the golden mapping several times• Run multiple app instances on different CPU cores

Dispatch Loop -
47
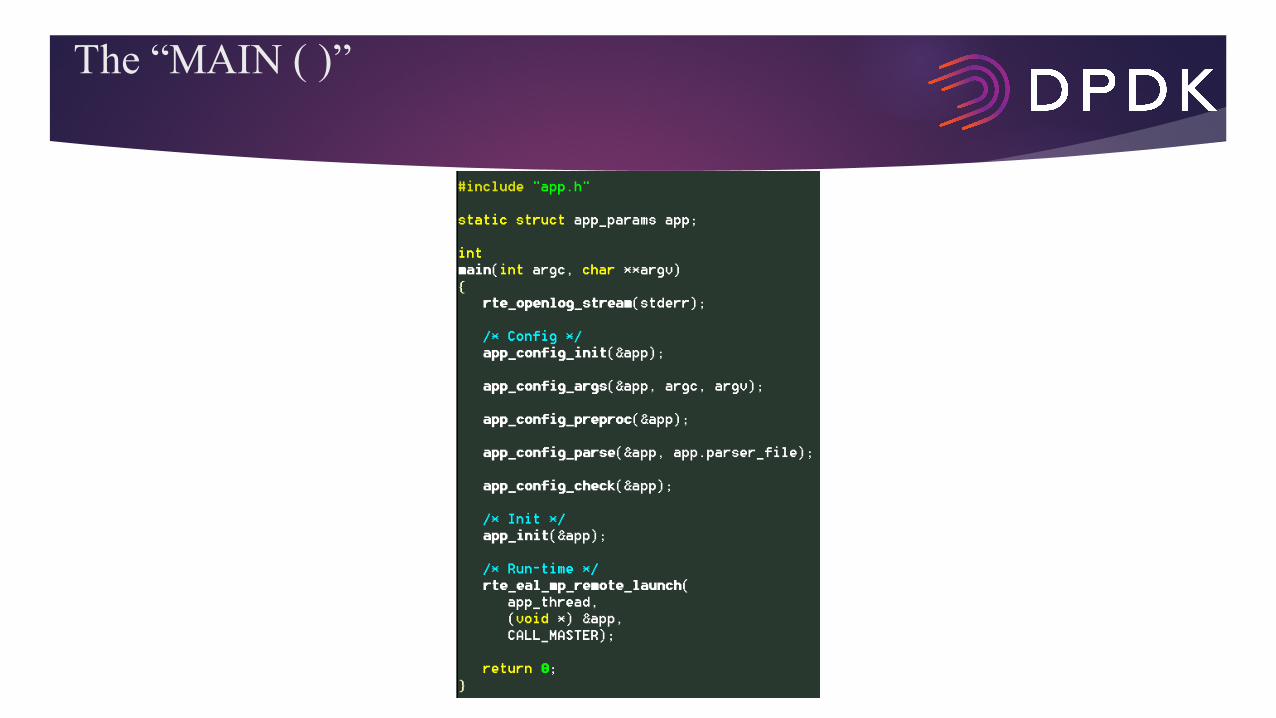
The “MAIN ( )”
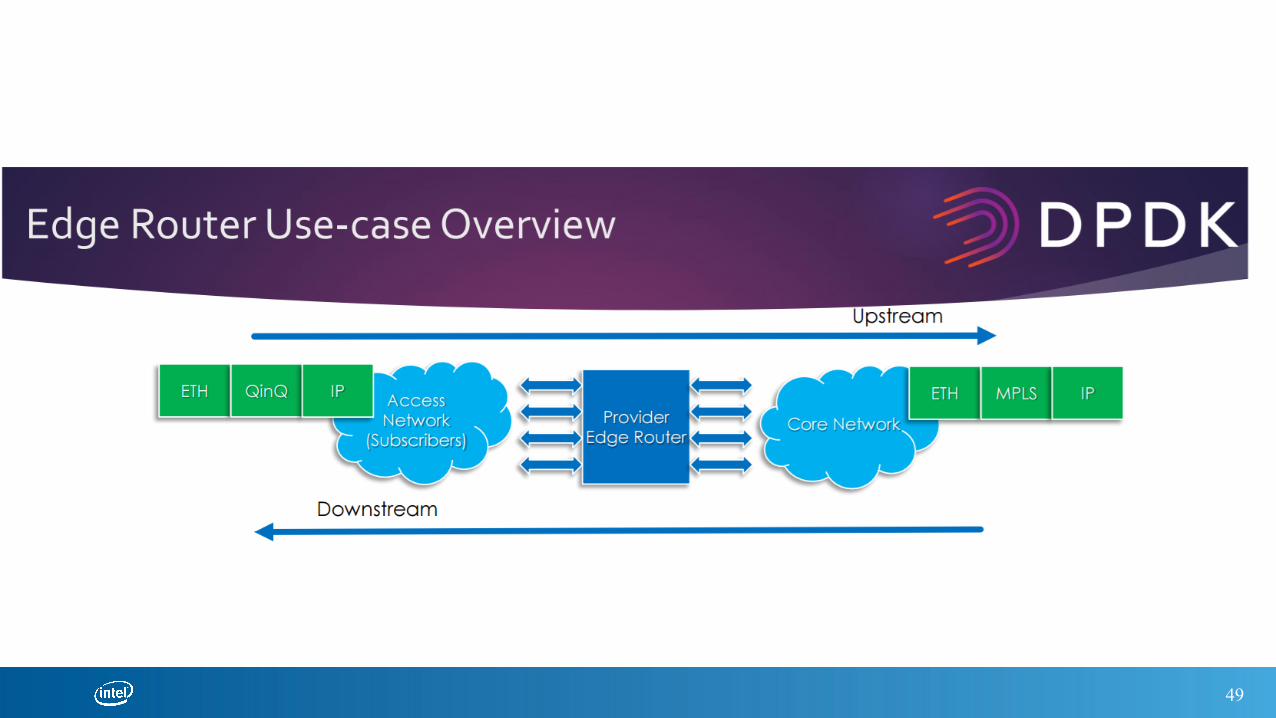
49
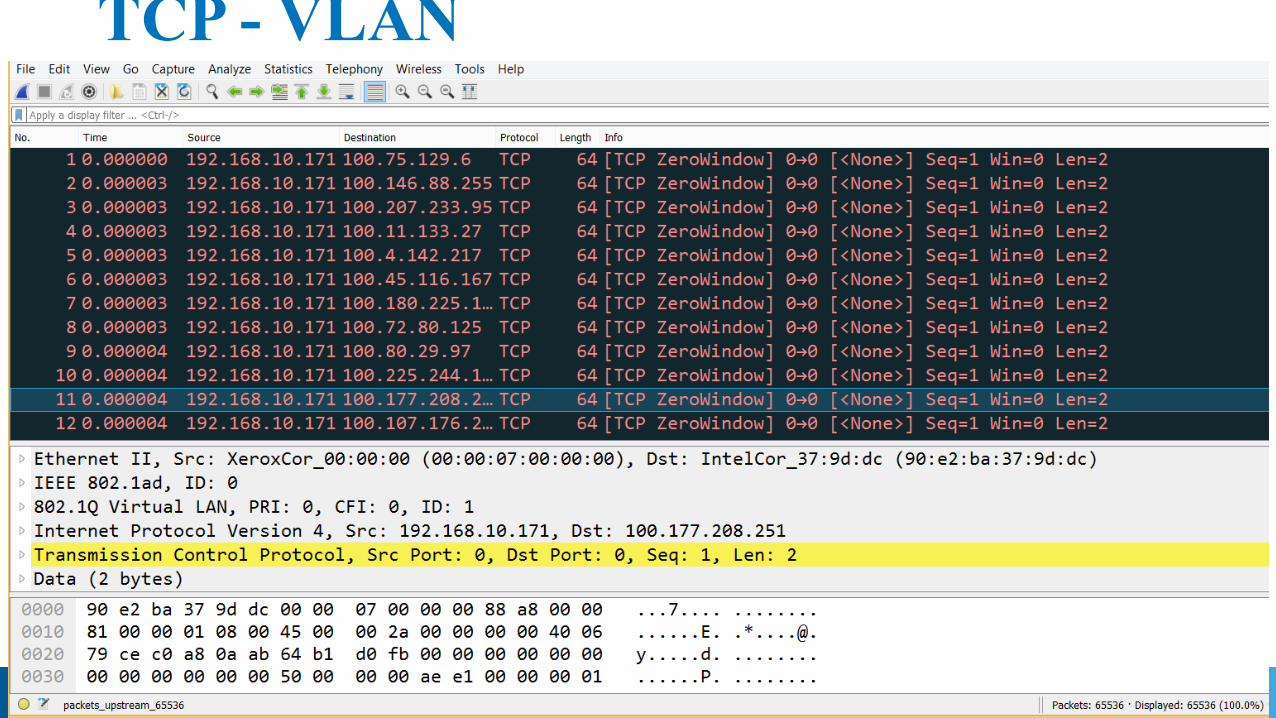
Input Stream – From Edge - header TCP - VLAN
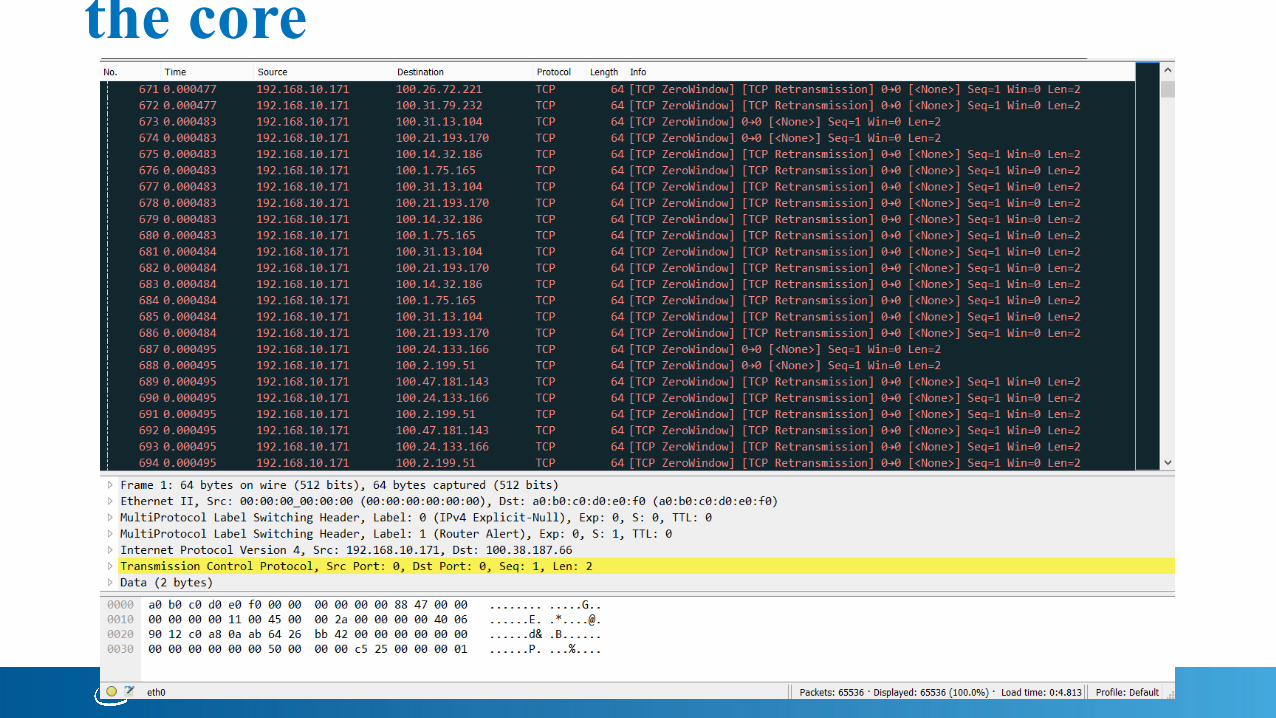
Output Stream - MPLS - Upstream to the core
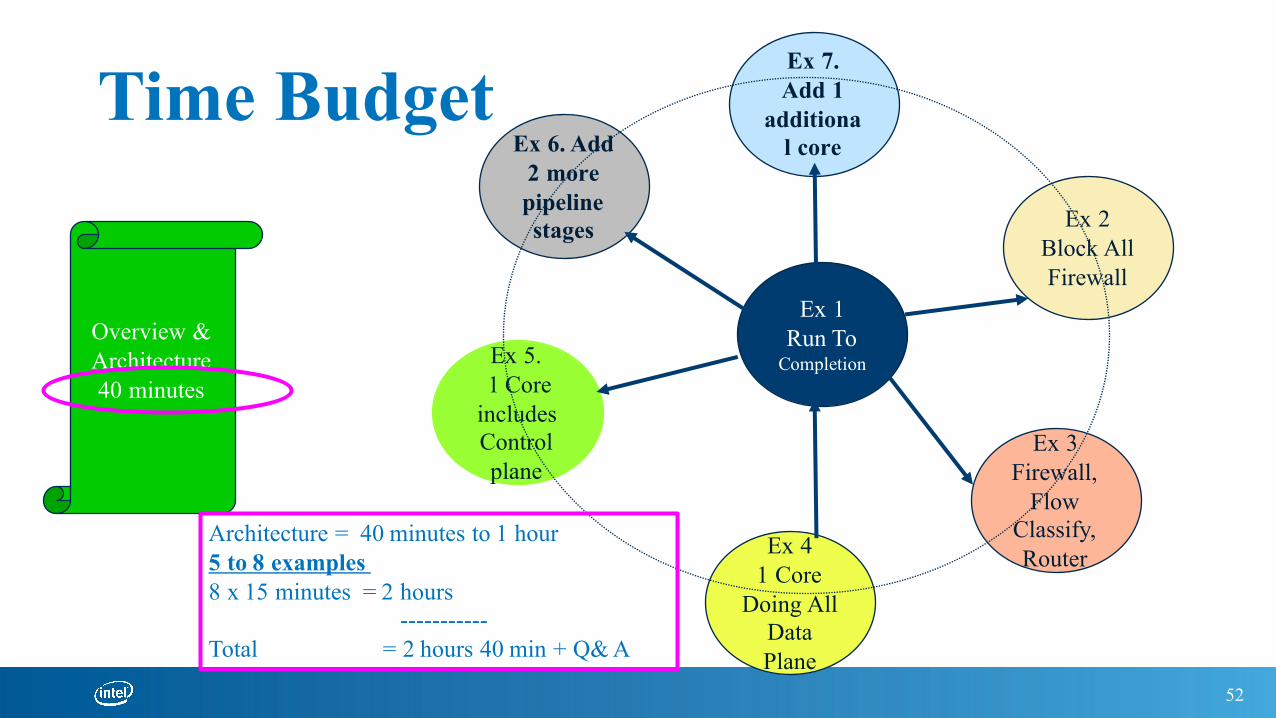
Time Budget
52
Overview & Architecture 40 minutes
Ex 7.Add 1
additional core
Ex 1 Run To
Completion
Ex 6. Add 2 more pipeline stages
Ex 5.1 Core
includes Control plane
Ex 4 1 Core
Doing All Data Plane
Ex 2Block All Firewall
Ex 3Firewall,
Flow Classify, Router
Architecture = 40 minutes to 1 hour5 to 8 examples 8 x 15 minutes = 2 hours
-----------Total = 2 hours 40 min + Q& A

What You will do in HANDS-ON in the class?Trace function call stack – So that you can chart “LIFE OF PACKET IN IP_PIPELINE”
You will ADD, You will DELETE additional pipeline stages
You will generate egress traffic and analyse
You will ping the pipeline stages
You will add rules to the tables – Firewall table, Flow Classifier Table, Router Table to name a few
You will debug a SEGABORT program to root cause and fix it
You will run performance microbenchmarks
You will take home additional homeworks
53

What will be my call to action after leaving the classCreate a new type of pipeline for some custom task
Add a new CLI command for one of the pipelines
Link CLI command: print a new field from the DPDK internal structure that is currently not printed: if link physical signal/cable is ON or OFF (struct rte_eth_link, field link_status), CPU socket where NIC is physically located, MTU size, etc
Routing pipeline: decrement TTL and update checksum (see l3fwd app on how to do this efficiently), check TTL and drop packets with TTL = 0
Routing pipeline: add stats counters per route, print them using a new CLI command
Flow classification pipeline: add stats counters per flow, print them using new CLI command
Firewall pipeline: add stats counters per rule, print them using new CLI command
54

Open one more PuTTY to your HostVM-<M>Open 2 PUTTY
55
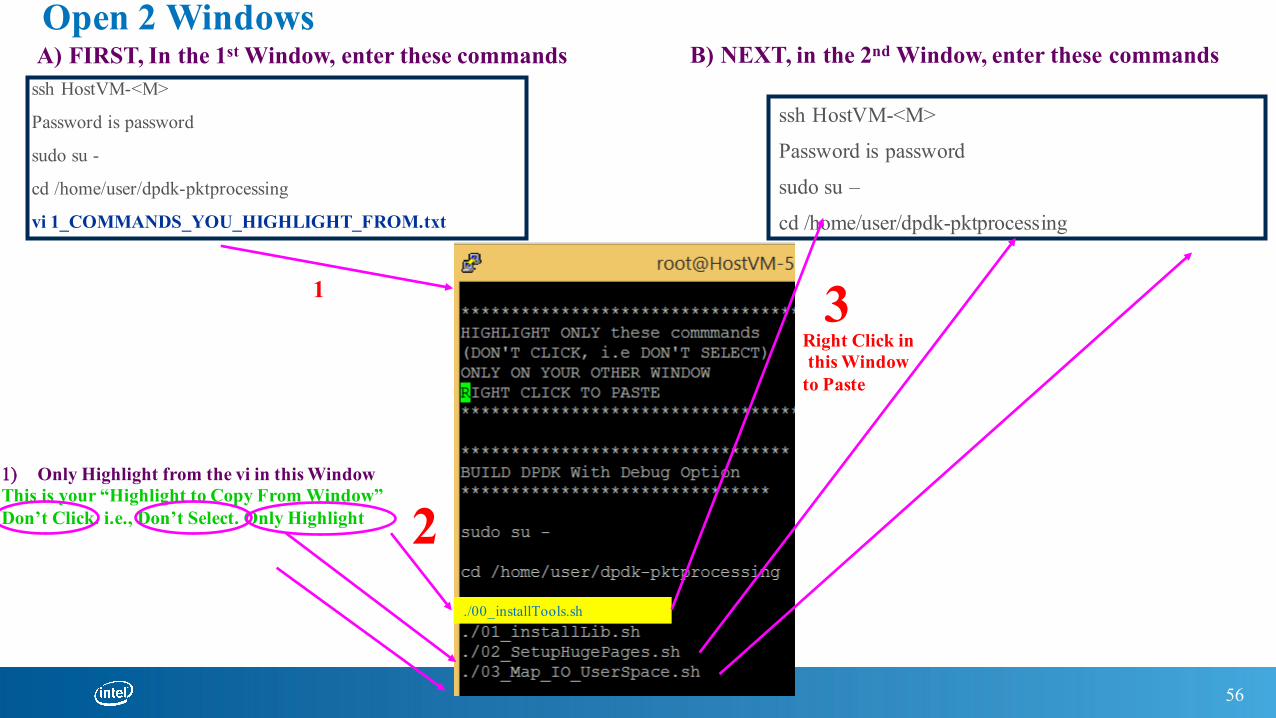
Open 2 Windows
ssh HostVM-<M>
Password is password
sudo su –
cd /home/user/dpdk-pktprocessing
56
ssh HostVM-<M>
Password is password
sudo su -
cd /home/user/dpdk-pktprocessing
vi 1_COMMANDS_YOU_HIGHLIGHT_FROM.txt
B) NEXT, in the 2nd Window, enter these commandsA) FIRST, In the 1st Window, enter these commands
1) Only Highlight from the vi in this WindowThis is your “Highlight to Copy From Window”Don’t Click. i.e., Don’t Select. Only Highlight
./00_installTools.sh
1
2
3Right Click inthis Window
to Paste

PLEASE READ OUTPut message of each script and act on it
./00_InstallTools.sh
./01_InstallLib.sh
./02_SetupHugePages.sh
./03_Map_IO_UserSpace.sh
57

Just only Execute the script files ./00…. To ./04…
58

Now That 1) Huge page is set, 2) DPDK library is built, 3] i/o is mapped
Time for building a Simple application?
Shall we start with a sample Application first?
That is your Best Known Method
59
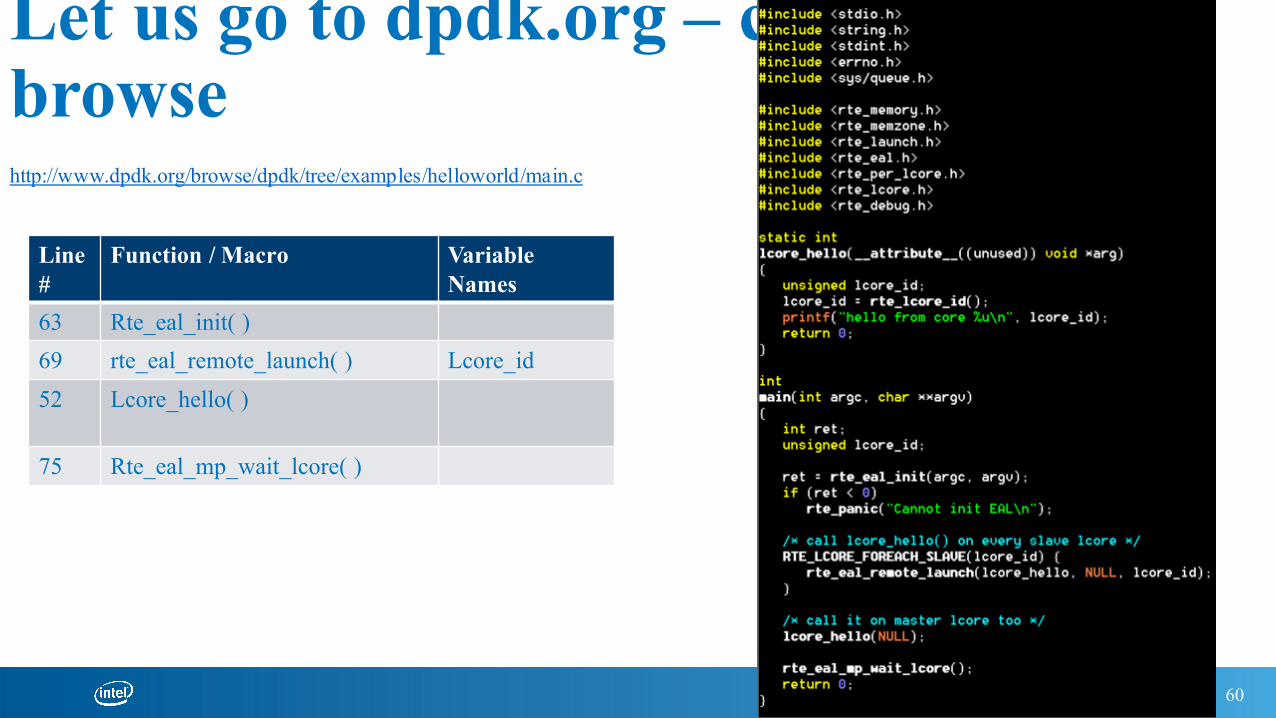
Let us go to dpdk.org – code browse
60
Line#
Function / Macro Variable Names
63 Rte_eal_init( )69 rte_eal_remote_launch( ) Lcore_id52 Lcore_hello( )
75 Rte_eal_mp_wait_lcore( )
http://www.dpdk.org/browse/dpdk/tree/examples/helloworld/main.c

http://www.dpdk.org/browse/dpdk/tree/examples/helloworld/main.c
61
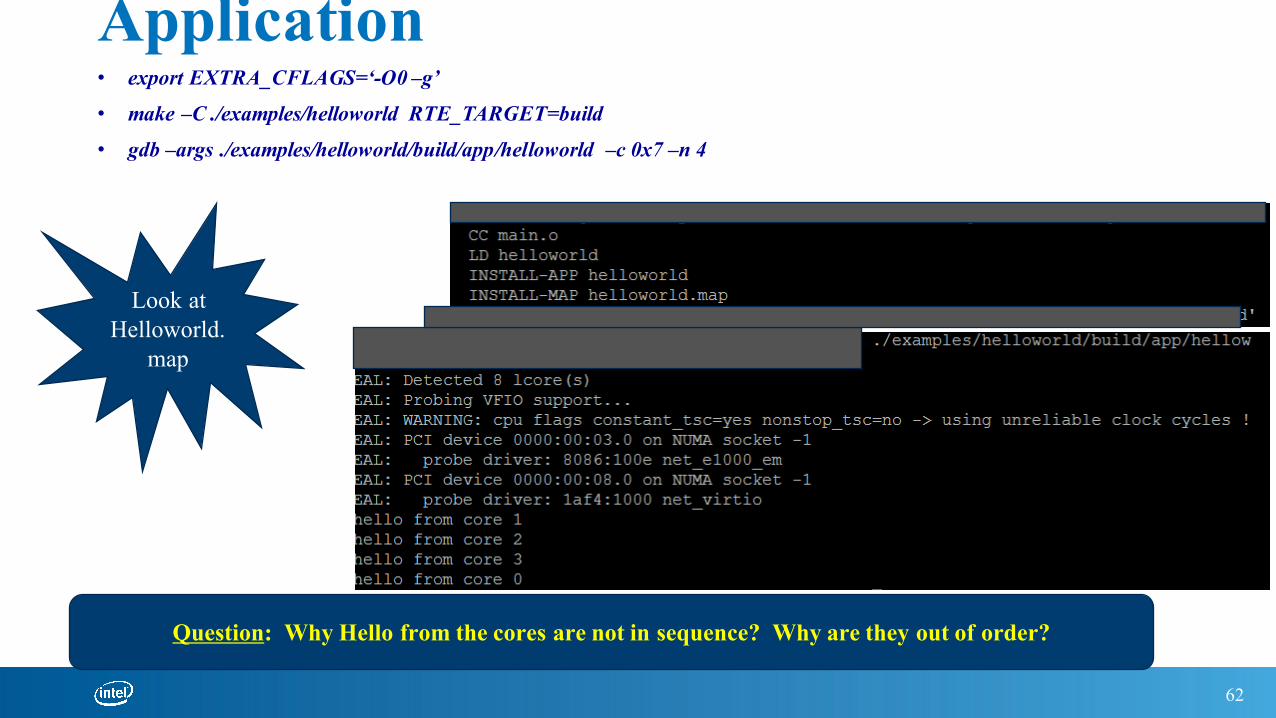
Build & RUN A Simple Hello World Application• export EXTRA_CFLAGS=‘-O0 –g’
• make –C ./examples/helloworld RTE_TARGET=build
• gdb –args ./examples/helloworld/build/app/helloworld –c 0x7 –n 4
62
Question: Why Hello from the cores are not in sequence? Why are they out of order?
Look atHelloworld.
map

Ip-pipeline main( )
63
http://www.dpdk.org/doc/api/ip_pipeline_2main_8c-example.html
http://www.dpdk.org/doc/api/ip_pipeline_2init_8c-example.html
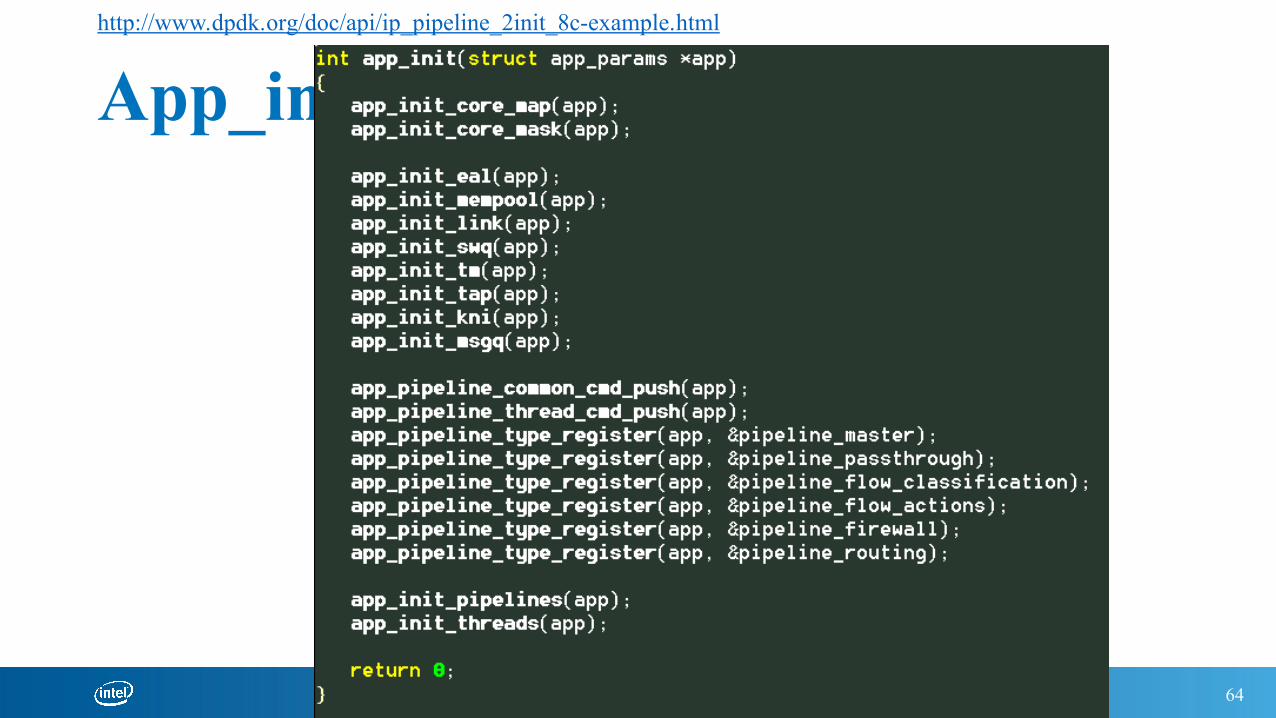
App_init ( )
64
http://www.dpdk.org/doc/api/ip_pipeline_2init_8c-example.html

How Front End Messages get CARRIED OUT IN Back End? pipeline_common_be.c
65
http://www.dpdk.org/doc/api/ip_pipeline_2pipeline_2pipeline_common_be_8c-example.html
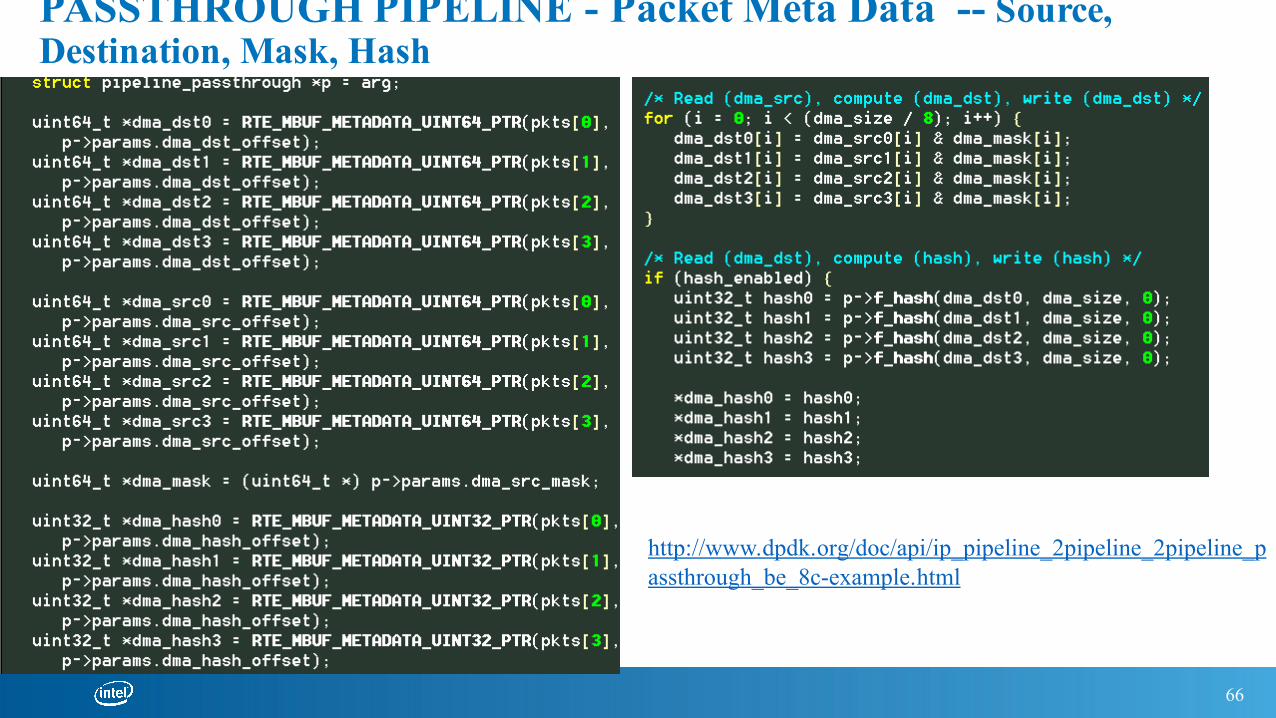
PASSTHROUGH PIPELINE - Packet Meta Data -- Source, Destination, Mask, Hash
66
http://www.dpdk.org/doc/api/ip_pipeline_2pipeline_2pipeline_passthrough_be_8c-example.html

Out IT Goes…
67

Flow Chart is Great ! Can we look at the code?
68

Which one is interesting to you?
69
http://www.dpdk.org/doc/api/examples.html
70
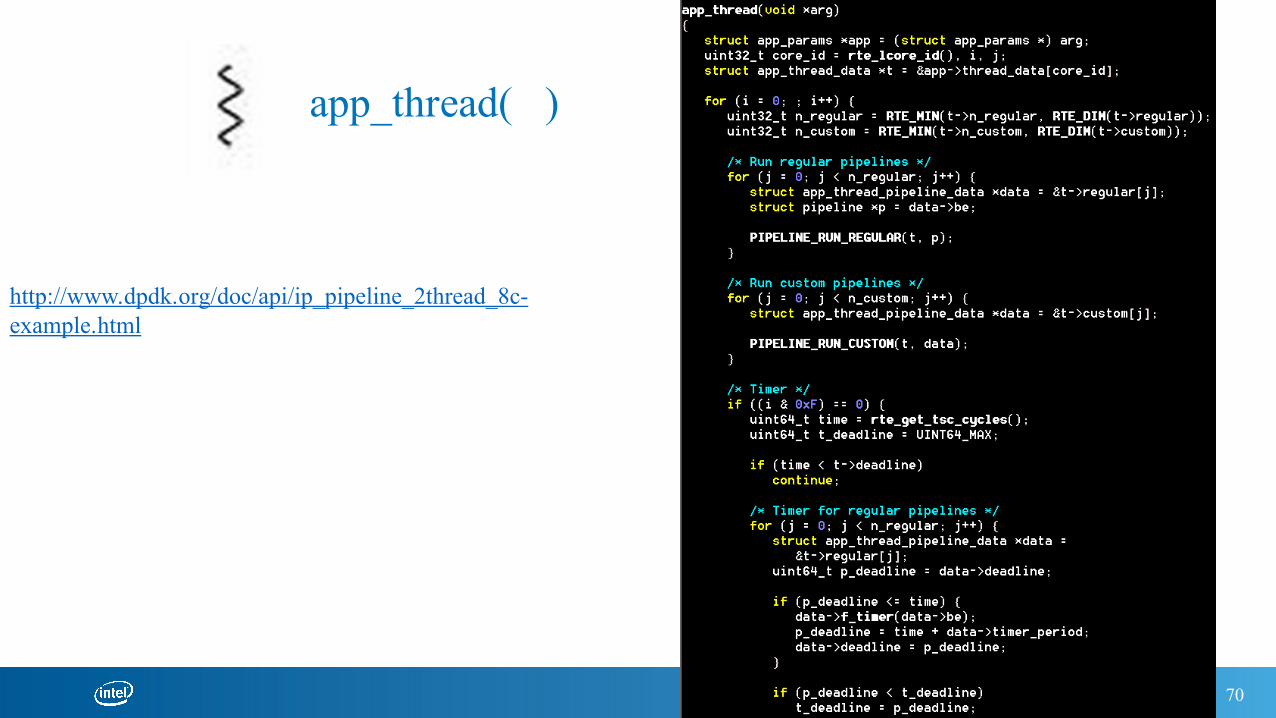
http://www.dpdk.org/doc/api/ip_pipeline_2thread_8c-example.html
app_thread( )
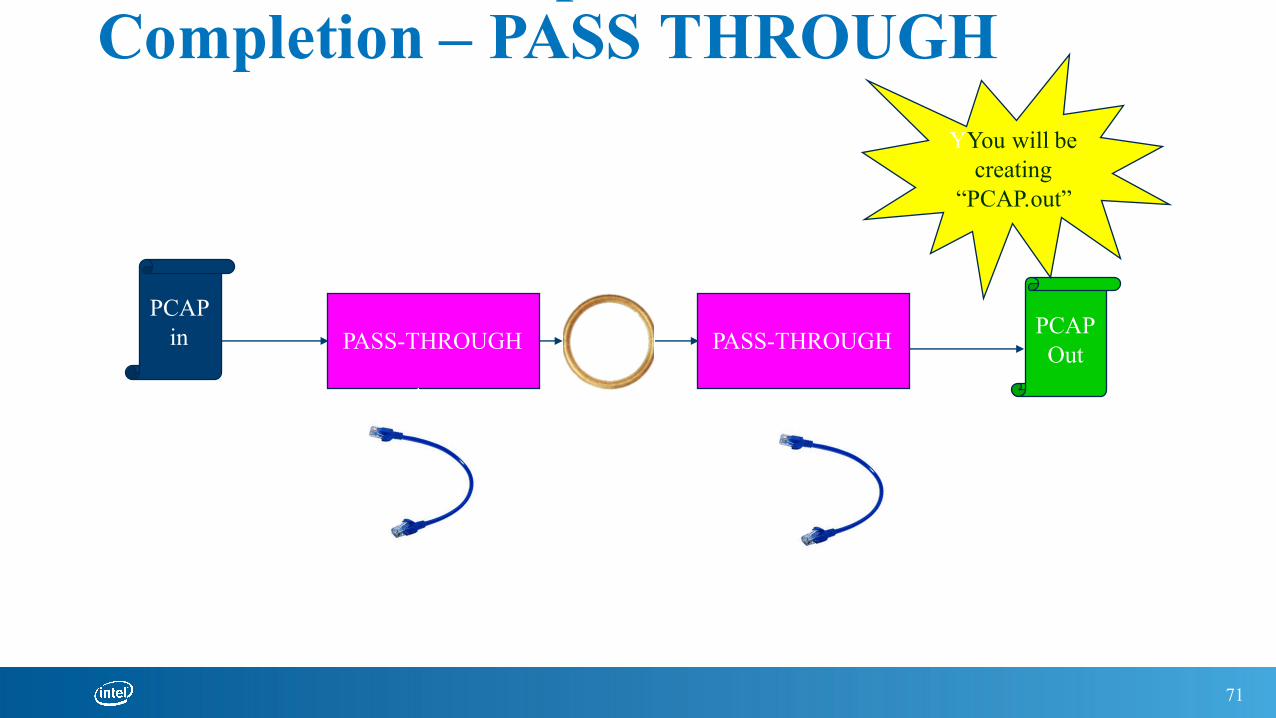
Exercise 1 – Simple Run To Completion – PASS THROUGH
71
PASS-THROUGH PASS-THROUGHPCAP
in PCAPOut
YYou will be creating
“PCAP.out”
72

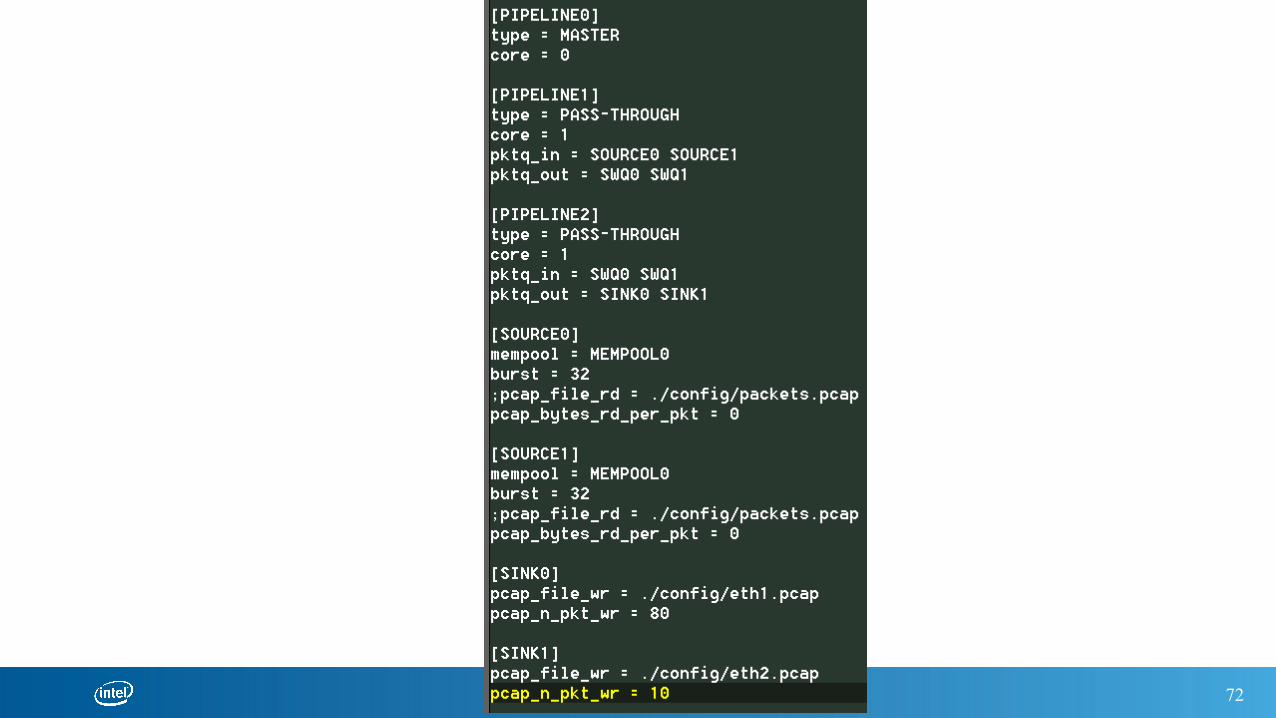
Pcap file for exercise 1
73

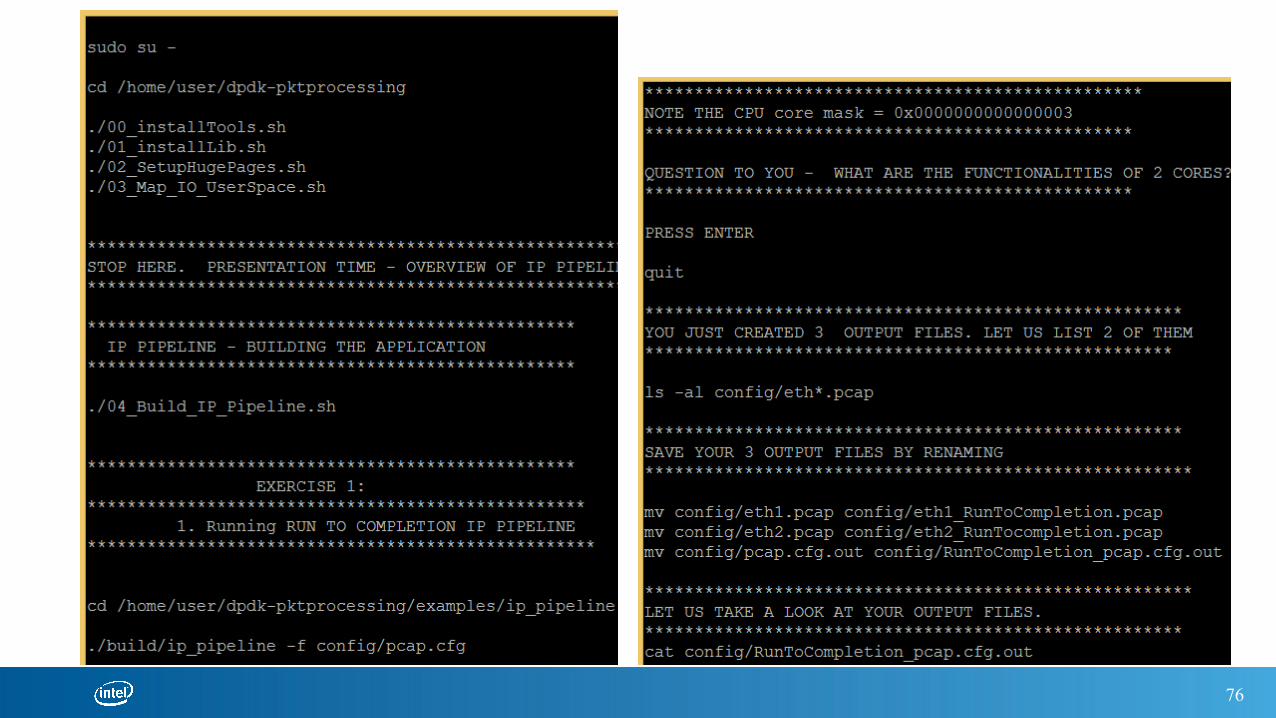
./04_Build_IP_Pipeline.sh
cd /home/user/dpdk-pktprocessing/examples/ip_pipeline
cat config/pcap.cfg
./build/ip_pipeline –f config/pcap.cfg
<STOP FOR QUESTIONS & DISCUSSIONS>
PRESS ENTER
QUIT
74

ls –al config/eth*.pcap
mv config/eth1.pcap config/eth1_RunToCompletion.pcapmv config/eth2.pcap config/eth2_RunToCompletion.pcapmv config/pcap.cfg.out config/RunToCompletion_pcap.cfg.out
cat config/RunToCompletion_pcap.cfgout
75
76

Exercise 1: Discussion Questions
77
What new info is added to cfg.out filesDiscuss Your Observations

ExErcise 2: FIREWALL BLOCKS ALL
78
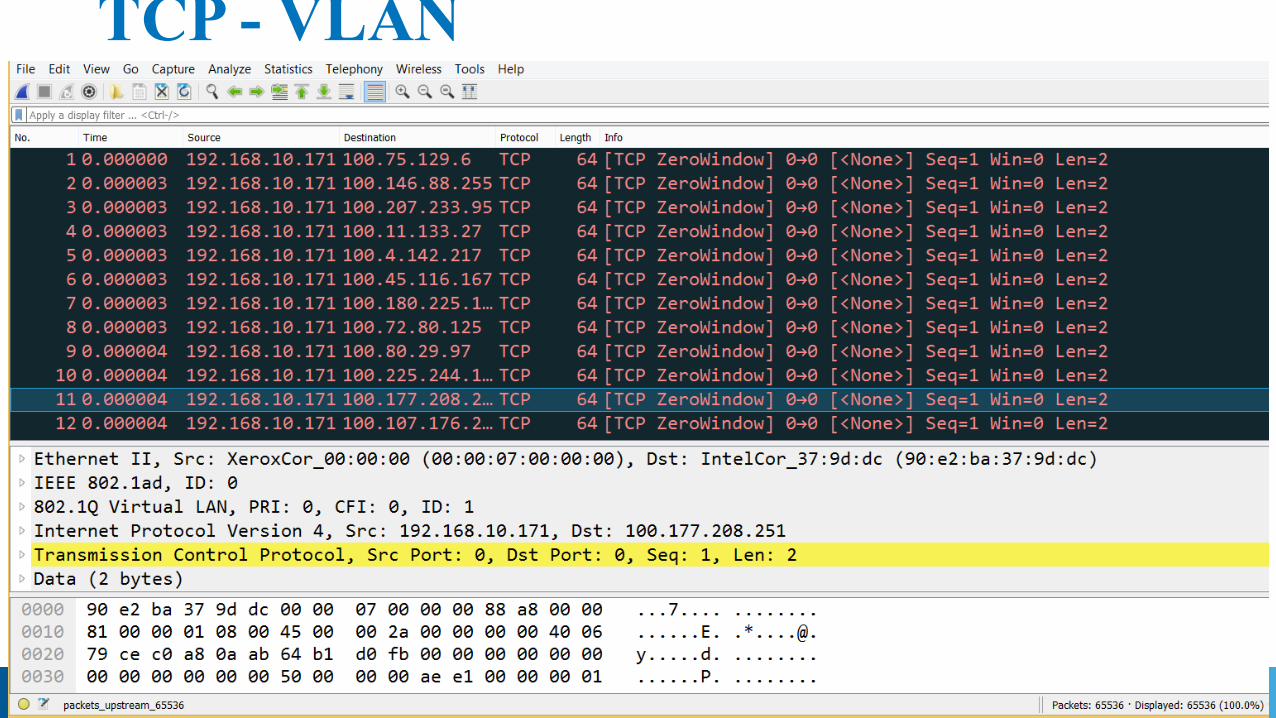
Input Stream – From Edge - header TCP - VLAN
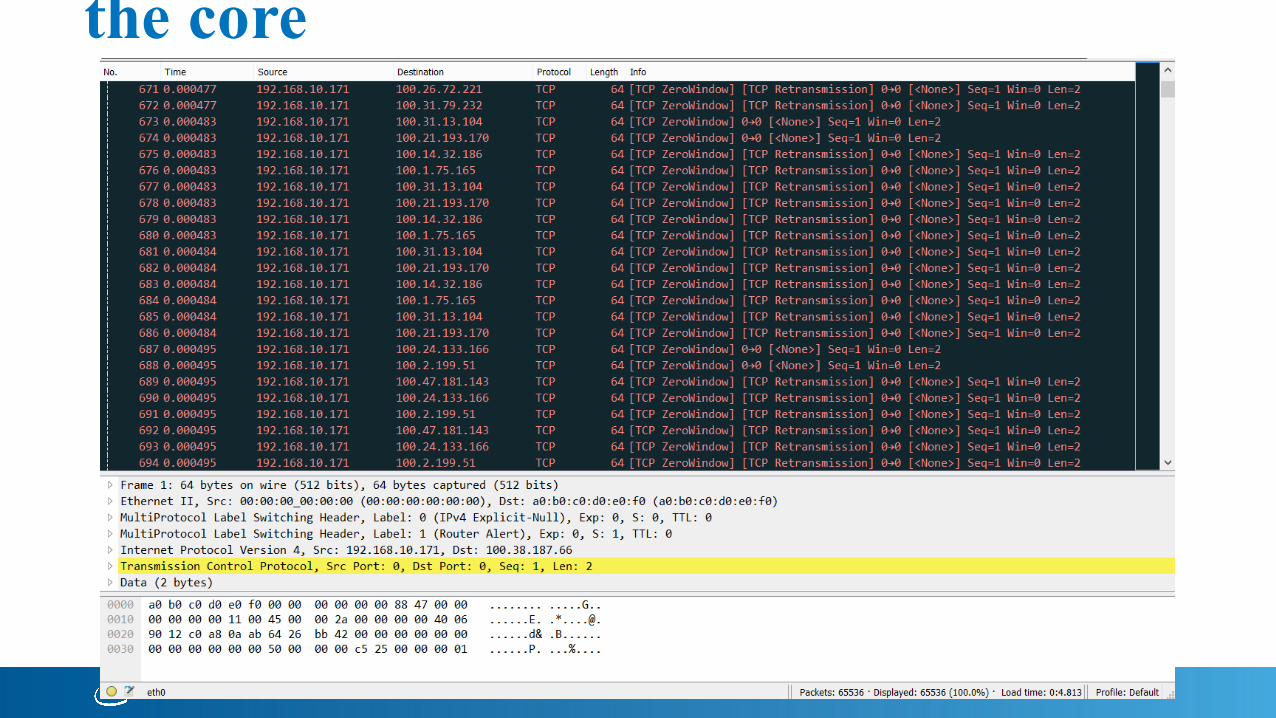
Output Stream - MPLS - Upstream to the core
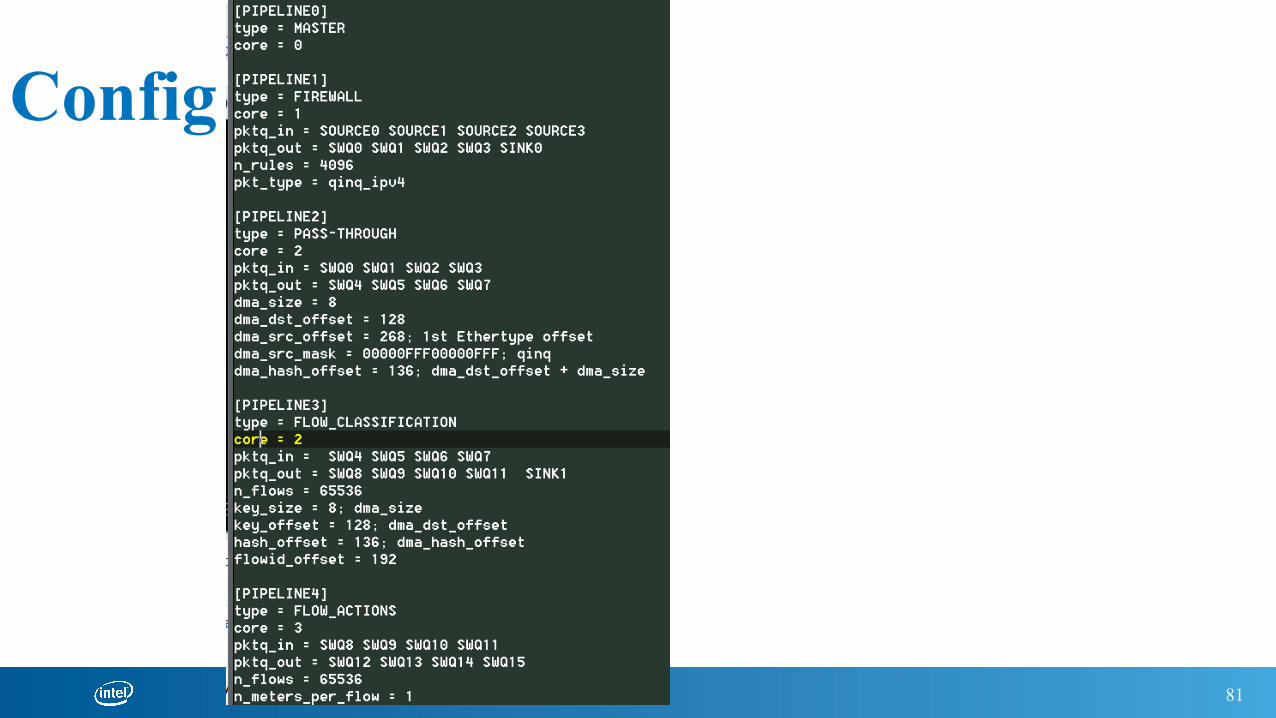
Config file
81
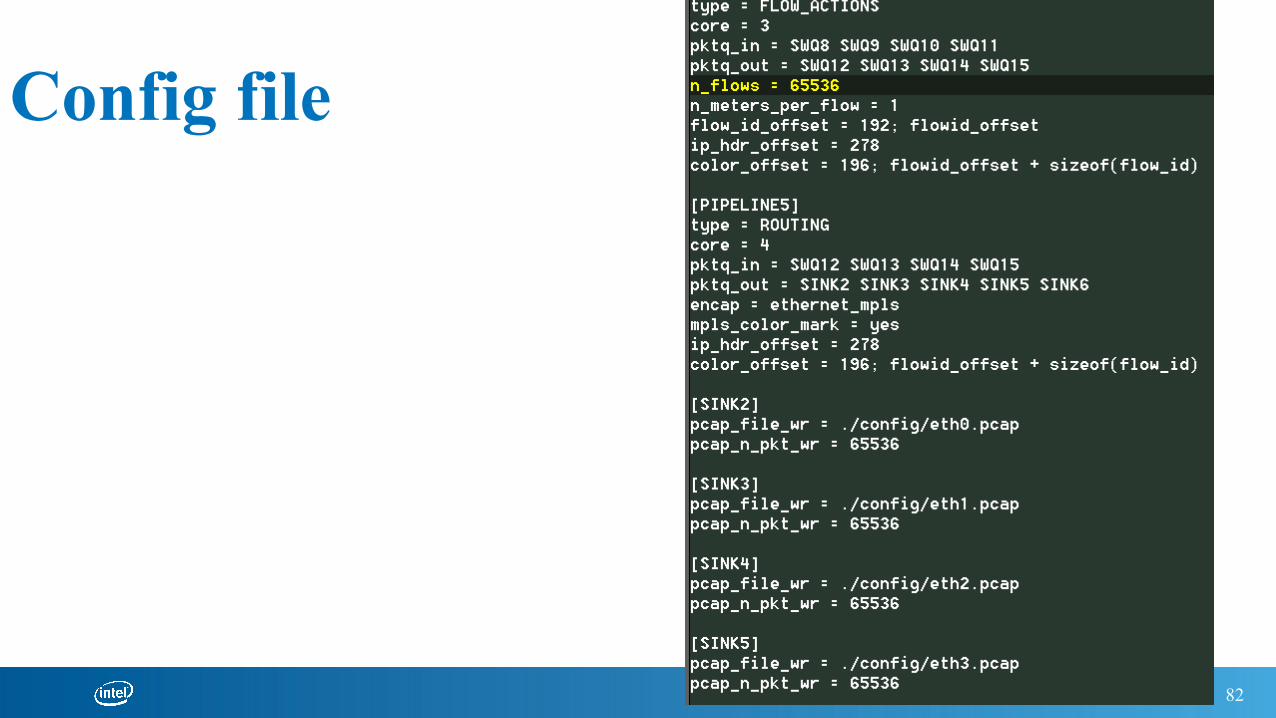
Config file
82
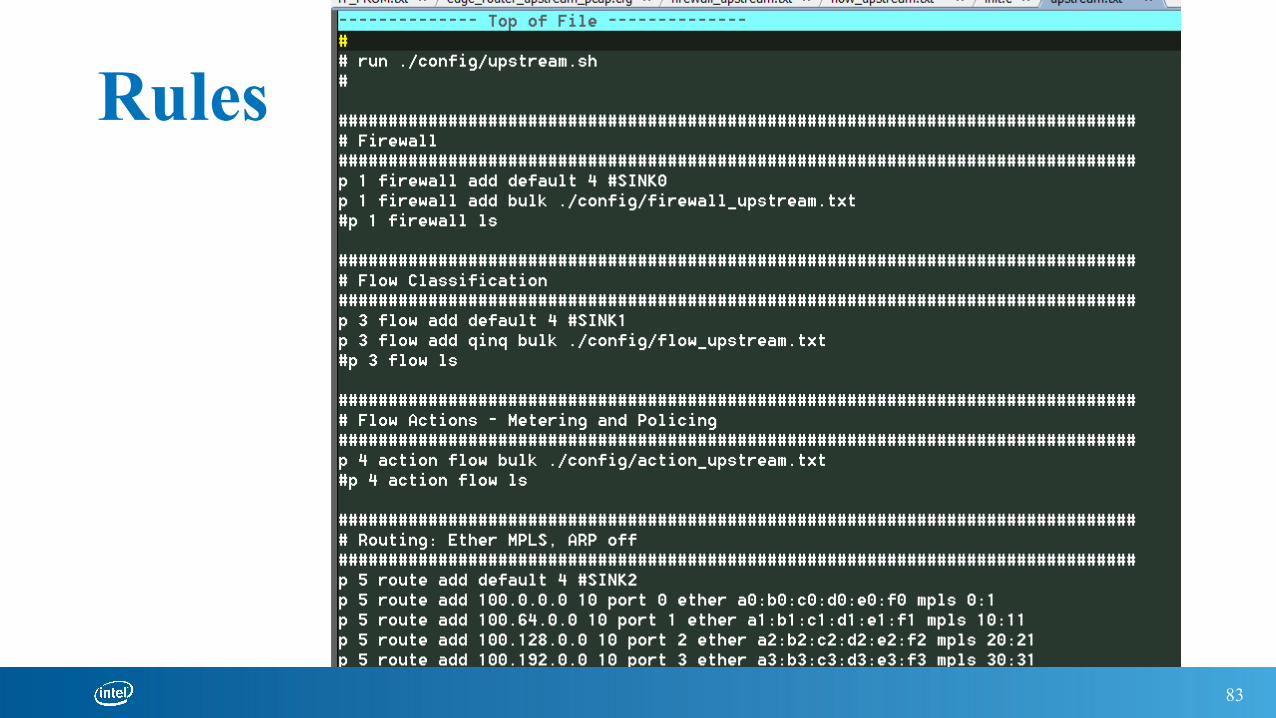
Rules
83
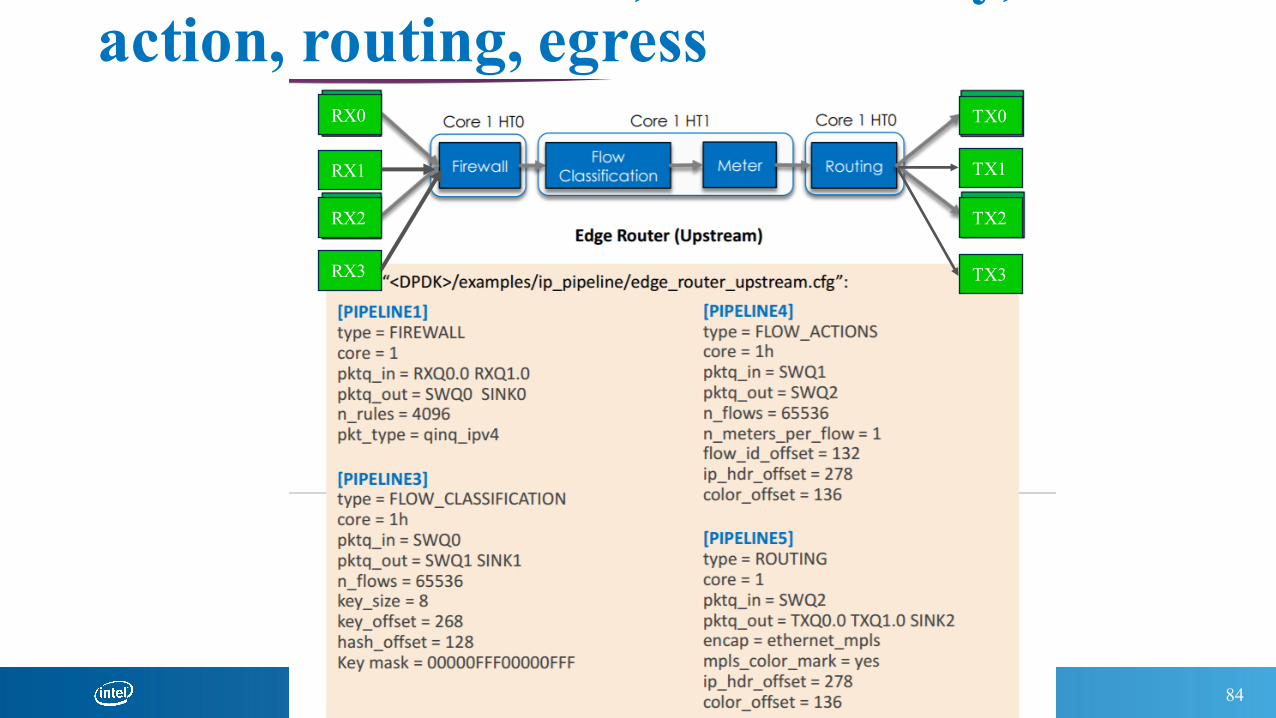
Exercise 3: firewall, flow classify, action, routing, egress
84
RX2
RX3
RX0
TX1
TX2
TX3
TX0
RX1
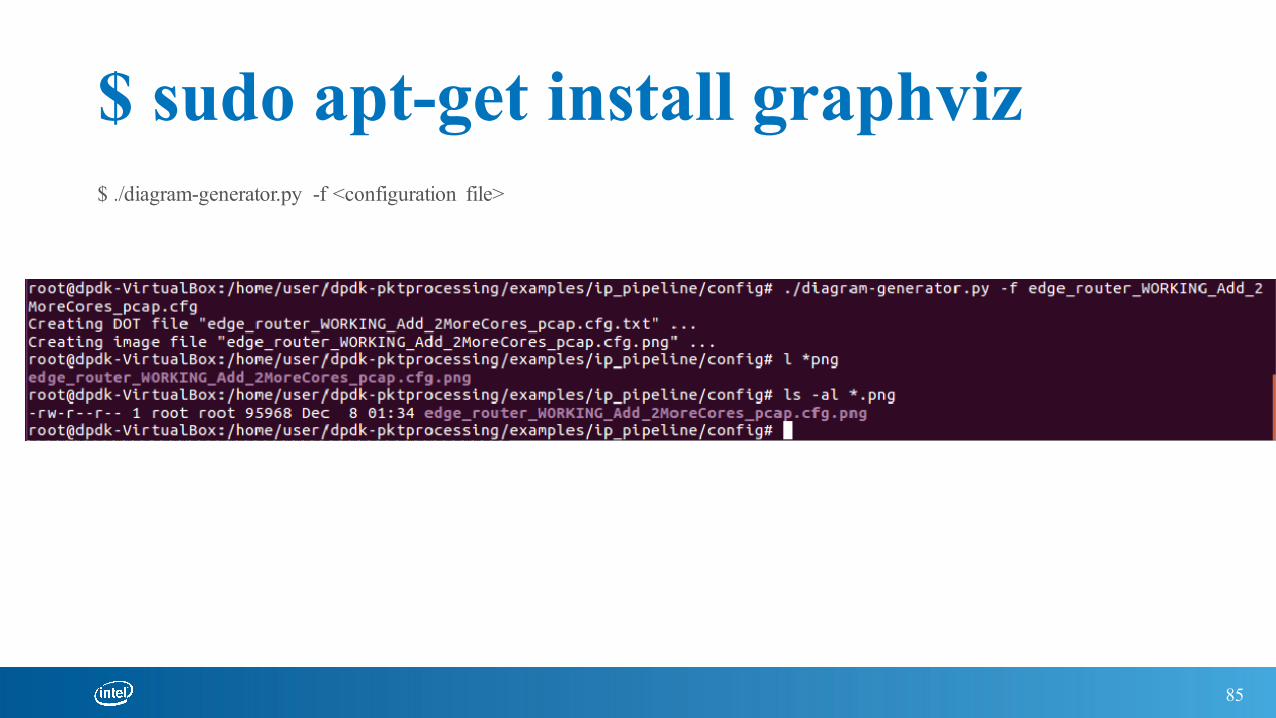
$ sudo apt-get install graphviz$ ./diagram-generator.py -f <configuration file>
85
86
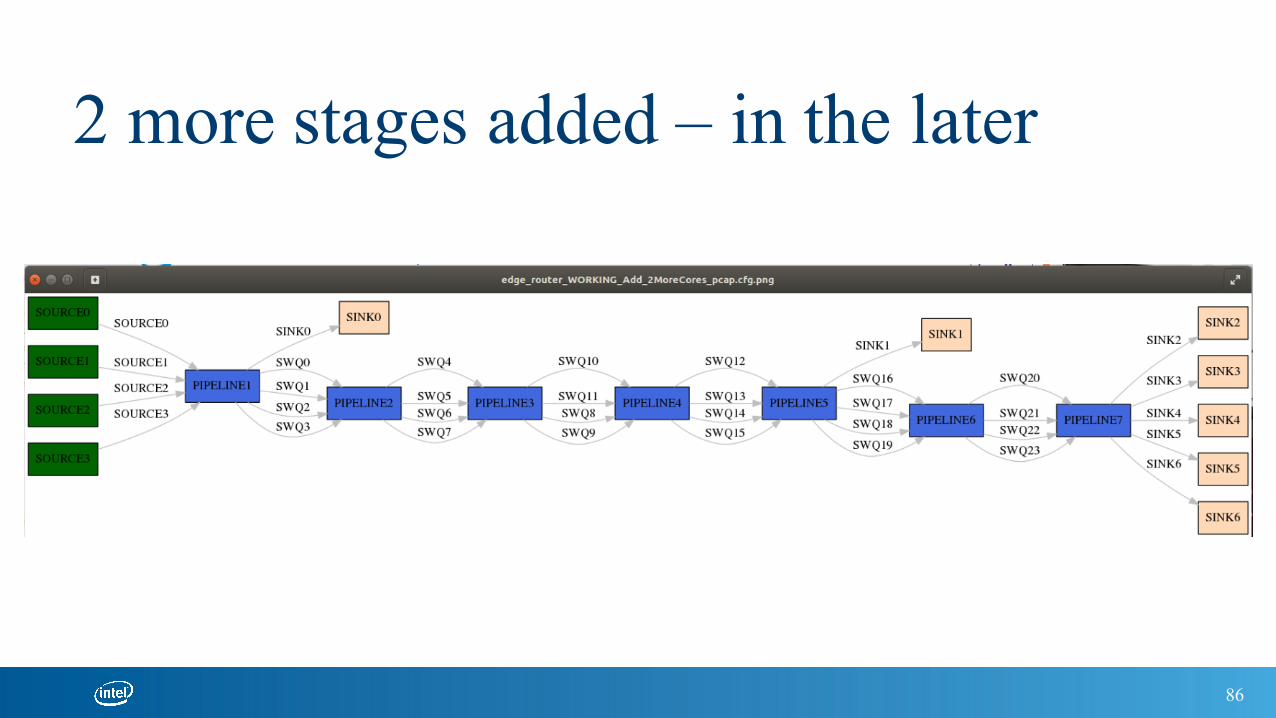
2 more stages added – in the later

Flow_upstream.txt
87

Firewall_upstream.txt
88

Exercise 2 – Firewall blocking all flows
89

Exercise 2: Discussion Points
90
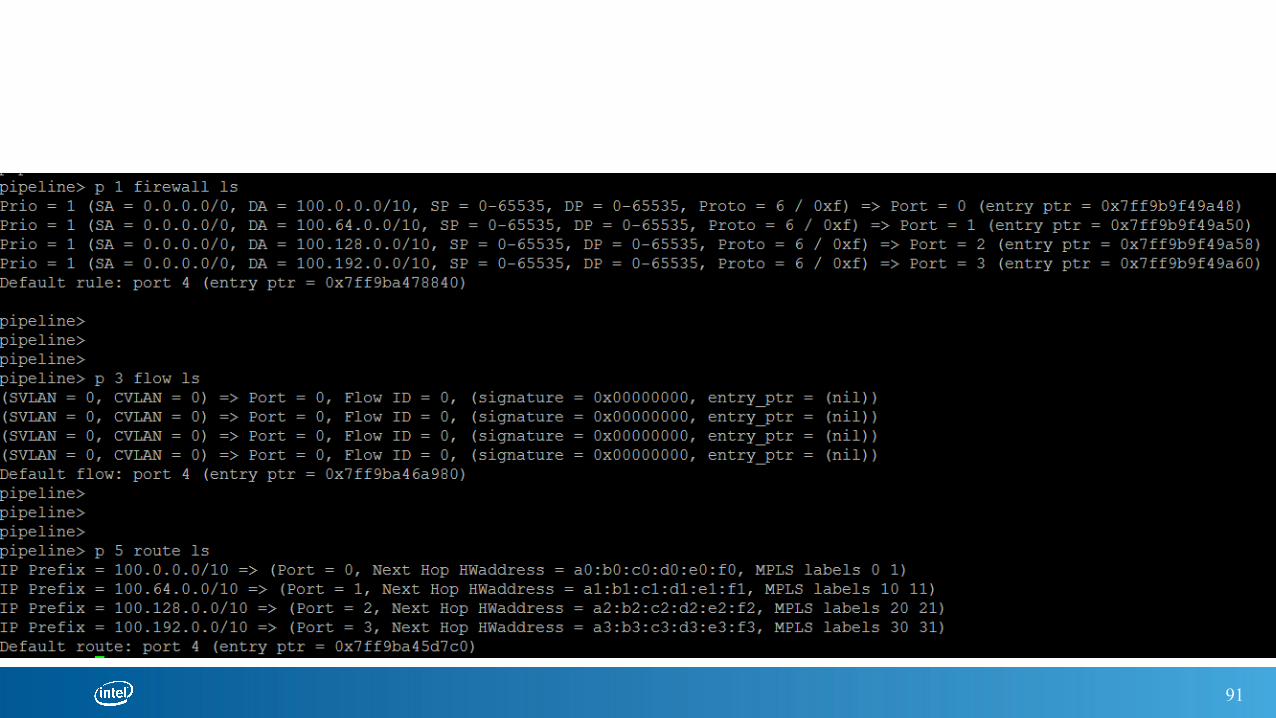
91
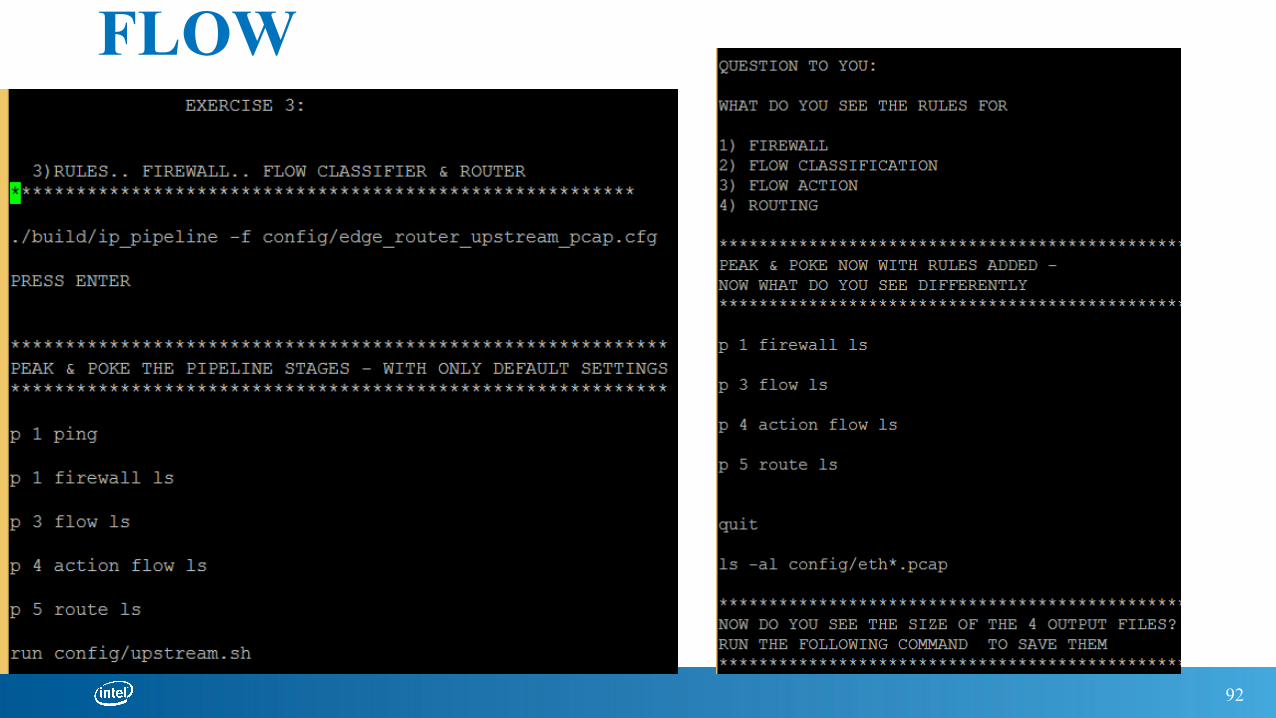
PEEK TABLES – FIREWALL, FLOW
92