Embed Size (px)
Citation preview

MatthewE.Peters†,MarkNeumann†,Mohit Iyyer†,MattGardner†ChristopherClark�,KentonLee�,LukeZettlemoyer†�
†AllenInstituteforArtificialIntelligence
�PaulG.AllenSchoolofComputerScience&Engineering,Universityof Washington
Deep ContextualizedWord Representation
Presenter: Liyuan Liu (Lucas)
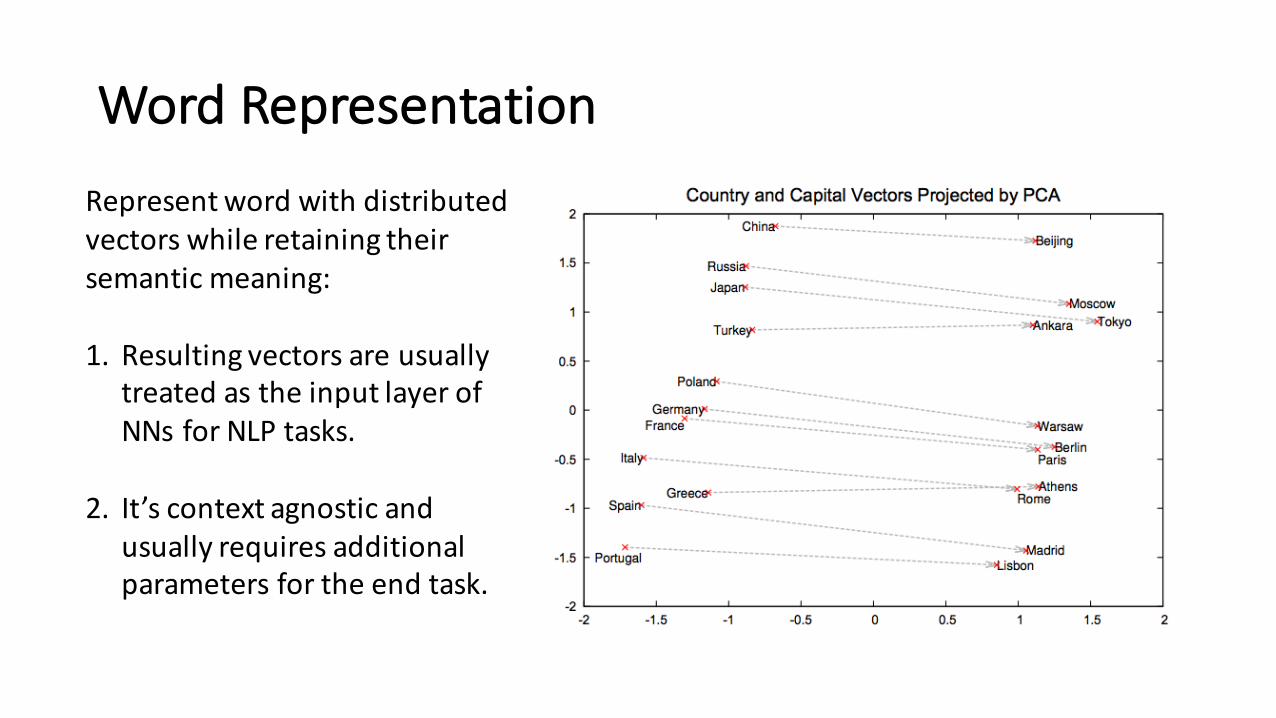
Word Representation
Representword with distributedvectors while retaining theirsemantic meaning:
1. Resulting vectors are usuallytreated as the input layer ofNNs for NLP tasks.
2. It’s context agnostic andusually requires additionalparameters for the end task.
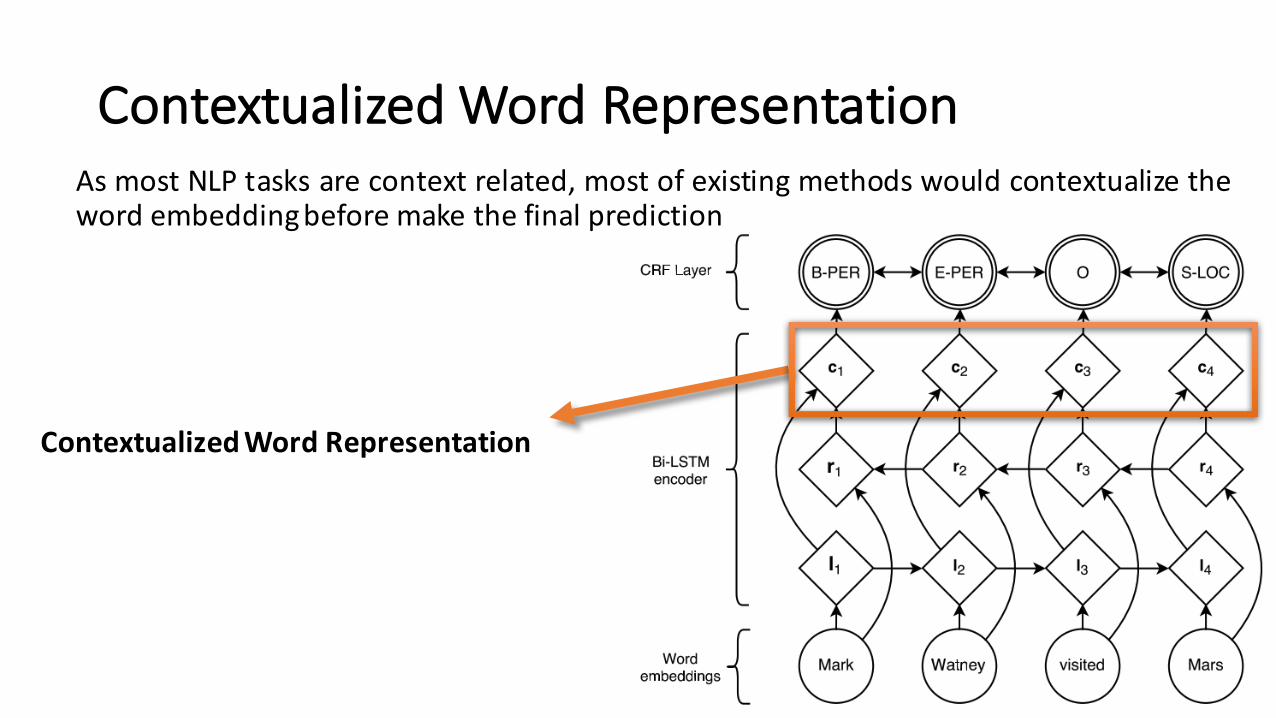
Contextualized Word RepresentationAs most NLP tasks are context related, most of existing methods would contextualize theword embeddingbefore make the final prediction
ContextualizedWord Representation

Contextualized Word Representation
• However, complicated neural models requires extensive training data:
• Models pre-trained on the ImageNet are widely used for Computer Vision tasks
• What’s the proper way to conduct pre-training for NLP?

Basic Intuition
• Leveraging Language Modeling to get pre-trained contextualizedrepresentationmodels.
• Highlight:• 1. rely on large corpora, instead of human annotations• 2. works very well ---- improve the performance of existing SOAmethods a lot

What is languagemodeling?
• Describing the generation of text:• predicting the next word based on previous contexts
Input words: Obama was born
Target words: was born in
1000
0100
0010
0.3-0.40.5
0.70.30.2
0.20.1-0.4
0.50.41.52.2
1.0-3.32.21.5
0.11.21.12.4
word embedding

What is languagemodeling?
• Describing the generation of text:• predicting the next word based on previous contexts
• Pros:• does not require any human annotations• resultingmodels can generate sentences of an unexpectedlyhighquality:
Input words: Obama was born
Target words: was born in
1000
0100
0010
0.3-0.40.5
0.70.30.2
0.20.1-0.4
0.50.41.52.2
1.0-3.32.21.5
0.11.21.12.4
word embedding
Nearly unlimited training corpora

What is languagemodeling?
• Describing the generation of text:• predicting the next word based on previous contexts
• Pros:• does not require any human annotations• resultingmodels can generate sentences of an unexpectedlyhighquality:
Input words: Obama was born
Target words: was born in
1000
0100
0010
0.3-0.40.5
0.70.30.2
0.20.1-0.4
0.50.41.52.2
1.0-3.32.21.5
0.11.21.12.4
word embedding
'''Seealso''':[[Listofethicalconsentprocessing]]
==Seealso==*[[Iender domeoftheED]]*[[Anti-autism]]
===[[Religion|Religion]]===*[[FrenchWritings]]*[[Maria]]*[[Revelation]]*[[MountAgamul]]
generated character-by-character
Nearly unlimited training corpora
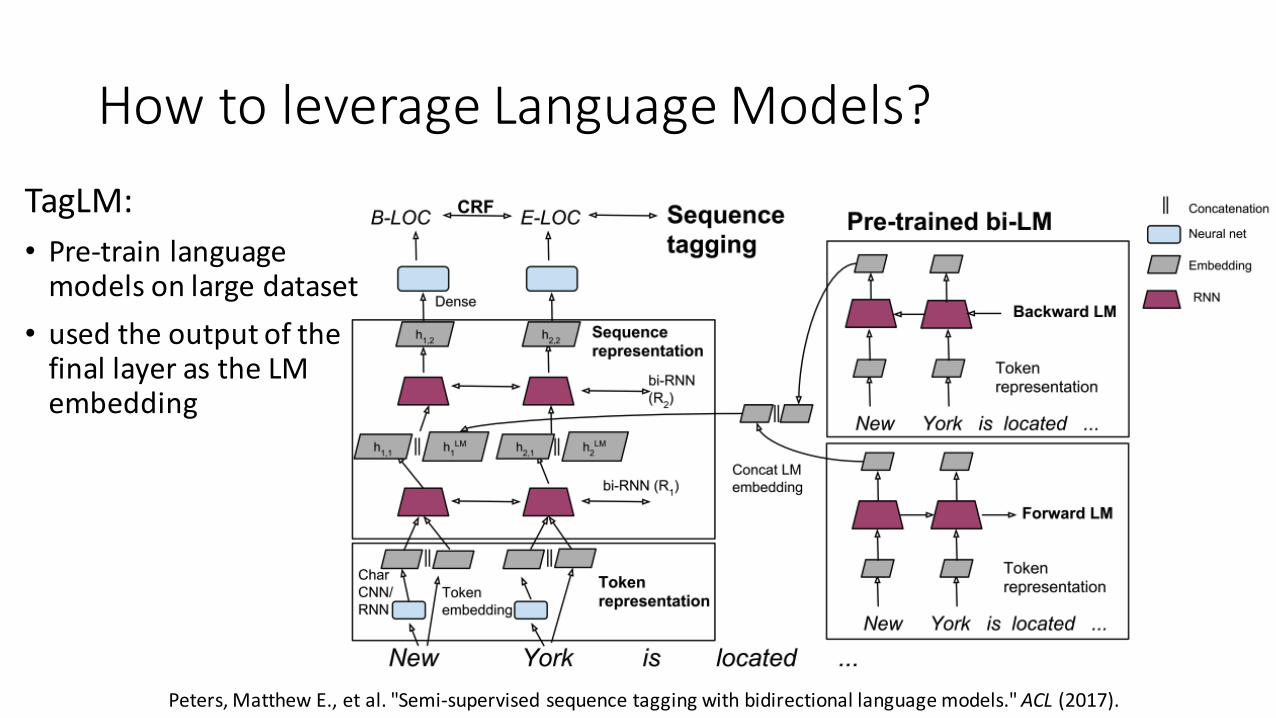
How to leverage LanguageModels?TagLM:• Pre-train languagemodels on large dataset• used the output of thefinal layer as the LMembedding
Peters,MatthewE.,etal."Semi-supervisedsequencetaggingwithbidirectionallanguagemodels."ACL (2017).

ELMo: Embeddings fromLanguageModels
• For k-th token, L-layer bi-directional Language Models computes 2L+1representations
• For a specific down-stream task, ELMowould learn a weight tocombine these representations

Use ELMo for supervised NLP tasks
• Add ELMo at the input of RNN. For some tasks (SNLI, SQuAD), includingELMo at the output brings further improvements
• Keypoint:
• freeze the weight of the biLM
• Regularization is necessary:
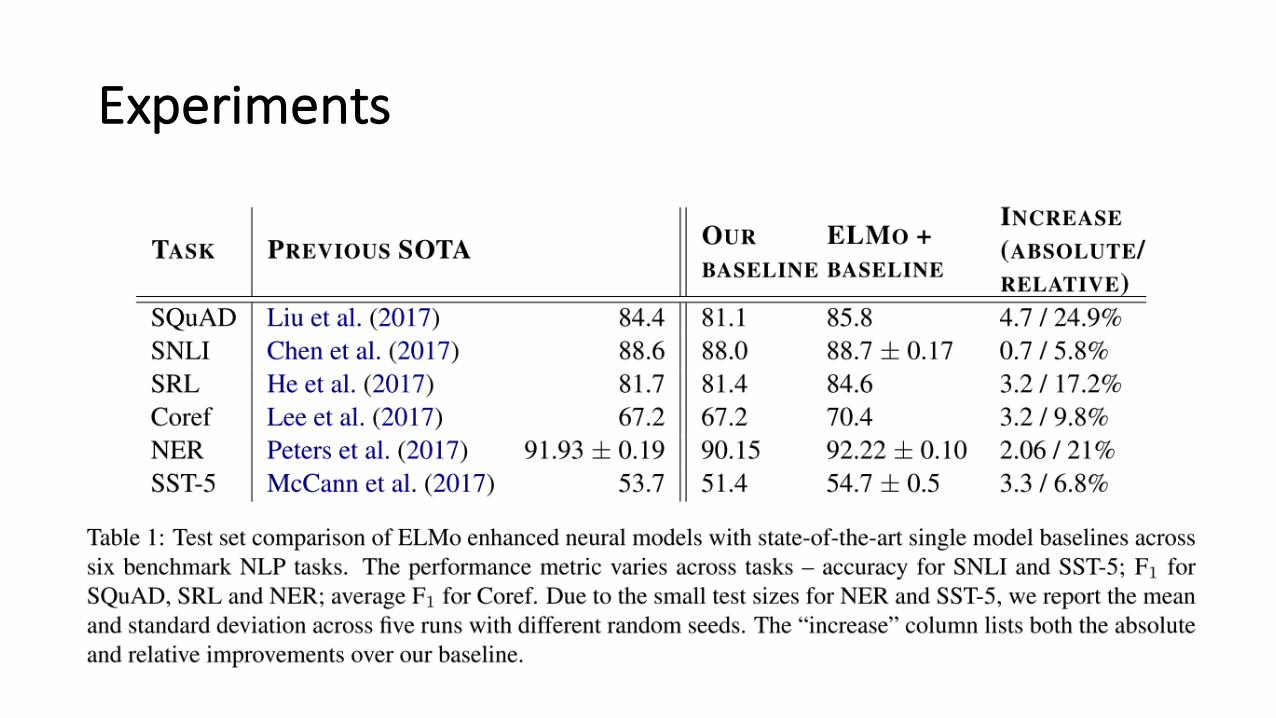
Experiments
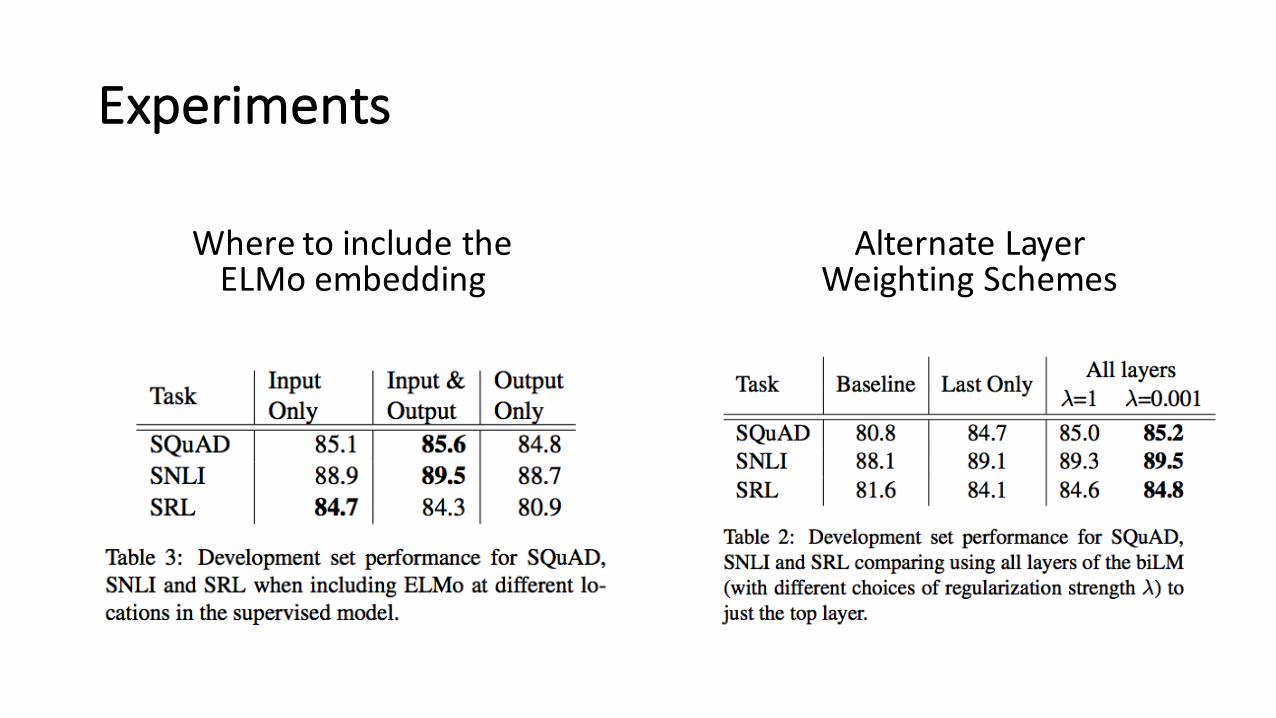
Experiments
Where to include theELMo embedding
Alternate LayerWeighting Schemes

Experiments

Experiments• Word sense disambiguation:
• Calculate the average of representationof each sense in the training data
• Conduct 1-nearest neighbor search atthe test set

Experiments• POS-Tagging:
• Directly learn a multi-class classifier forthe POS-tagging

Misc
• Podcast by the author (MatthewE.Peters):
• https://soundcloud.com/nlp-highlights/56-deep-contextualized-word-representations-with-matthew-peters
• A follow-up work on further improving the efficiency:
• EfficientContextualizedRepresentation:LanguageModelPruningforSequenceLabeling (https://arxiv.org/abs/1804.07827)

Take aways…• Language Modeling is effective in constructing contextualizedrepresentation (could be helpful for a variety of tasks);
• Outputs of all Layers are useful;













![Automated WordNet Construction Using Word Embeddings · (WOLF) [4] Universal Wordnet [5] Extended Open Multilingual Wordnet [6] Synset Representation Synset Representation + Sense](https://img.pdfslide.net/doc/110x75/5f0fb0bf7e708231d44567ef/automated-wordnet-construction-using-word-embeddings-wolf-4-universal-wordnet.jpg)


![String Representation in C C Strings 1cs2505/summer2019/Notes/T12_CStrings.… · String Representation in C char Word[7] = "foobar"; C treats char arrays as a special case in a number](https://img.pdfslide.net/doc/110x75/5ec5e7eb2d616a7d5b655379/string-representation-in-c-c-strings-1-cs2505summer2019notest12cstrings-string.jpg)











