Embed Size (px)
Citation preview

Mentorierte Arbeit in Fachdidaktik Mathematik
Der K-Means Algorithmus
David Stotz
Inhalt Im ersten Kapitel wird die Problemstellung anhand einerAnwendung motiviert. Das zweite Kapitel gibt eine kurzeEinfuhrung in die Datenanalyse und das dri�e Kapitel behandeltden Schwerpunkt einer endlichen Punktmenge. Im vierten Kapi-tel wird der K-Means Algorithmus vorgestellt und untersucht.Die Implementierung und Anwendung des Algorithmus auf dasEinfuhrungsbeispiel sind Gegenstand des fun�en Kapitels.
Zielpublikum 3.–4. Klasse Kurzzeitgymnasium (11.–12. Schuljahr)
Voraussetzungen Grundkenntnisse in Vektorgeometrie, Algorithmen undInformatik
Form Lesetext mit Aufgaben
Bearbeitungsdauer 5 Lektionen
Betreuung Kristine Barro
Datum 28. Juli 2016

Inhaltsverzeichnis
1 Einfuhrung 3
2 Datenanalyse 42.1 Cluster und ihre Reprasentanten . . . . . . . . . . . . . . . . . . . . . . . . 5
3 Der Schwerpunkt einer endlichen Punktmenge 63.1 Geometrische Eigenscha� des Schwerpunktes . . . . . . . . . . . . . . . . 8
4 Clustering mit demK-Means Algorithmus 104.1 Spielzeugbeispiel in Geogebra . . . . . . . . . . . . . . . . . . . . . . . . . 114.2 Beispiel mit synthetischen Daten . . . . . . . . . . . . . . . . . . . . . . . . 13
5 Implementierung des Algorithmus und Anwendung auf ein Photo 195.1 Implementierung des Algorithmus . . . . . . . . . . . . . . . . . . . . . . . 215.2 Ergebnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25

Didaktische Vorbemerkungen
Gemessen an der derzeitigen wissenscha�lichen, industriellen und wirtscha�lichen Be-deutung der Datenanalyse, ist diese im heutigen Schulcurriculum unterreprasentiert. Das�ema fur die Unterrichtseinheit wurde ausgewahlt, um den Schulerinnen und Schulerneinen Zugang zur Mathematik der Datenanalyse zu ermoglichen und ihnen die Anwen-dung auf praktische Probleme erfahrbar zu machen.Als zentraler Motivationsanker dient die Anwendung des K-Means Algorithmus auf
eine Photo-Datei, um das Photo in einer geringen Anzahl von Farben moglichst gut dar-zustellen. Das Beispiel eignet sich einerseits gut zur Motivation der Schulerinnen undSchuler, da viele von ihnen einen Bezug zu Photo-Dateien mitbringen und die Ergebnis-se direkt sichtbar gemacht werden konnen. Andererseits spielt das Anwendungsbeispielin der tatsachlichen Datenanalyse eine eher marginale Rolle, da in der Bildverarbeitungandere Algorithmen demK-Means Algorithmus uberlegen sind. Die Starke desK-MeansAlgorithmus liegt vor allem in seiner Einfachheit, wodurch er �exibel in andere Algorith-men integriert werden kann. Aus dieser Uberlegung heraus wurde versucht, die Bedeu-tung der Datenanalyse und des Clusterns von Daten auch in einem allgemeineren Kontextzumindest anzudiskutieren.
Lernziele
• Probleme in der Datenkomprimierung und praktische Anwendung eines Algorith-mus kennenlernen.
• DenK-Means Algorithmus mathematisch analysieren.
• Die Bedeutung des Schwerpunktes eines endlichen Systems kennenlernen.
• Ein Grundverstandnis der Implementierung entwickeln.
benotigtes Vorwissen
• Grundlagen in der Vektorgeometrie, insbesondere Vektoralgebra und Abstandsbe-gri�
• Verstandnis daruber, was ein Algorithmus ist
• Grundwissen in der Informatik (if-Bedingung, for-Schleifen)
1

�ellen
Die Beschreibung des Algorithmus und die Idee fur die Anwendung stammt aus[Bishop, 2006]. Die Beweisidee fur die Konvergenz des K-Means Algorithmus in endlichvielen Schri�en stammt aus [jkabrg, 2015].
2

1 Einfuhrung
Daten enthalten Informationen. Im digitalen Zeitalter werden Unmengen von Datenerzeugt, gespeichert und zwischen Geraten ubertragen, alleine schon durch Mi�eilungen,Bilder und Videos auf unseren Smartphones und PCs. Experten schatzen, dass derInternet-Datenverkehr im Jahr 2016 circa 1.1 Ze�abyte betragen wird [Cisco, 2016],das sind 1.1 Billionen Gigabyte und entspricht ungefahr der Grosse eines Liedes miteiner Spieldauer von einer Milliarden Jahre. Beim Umgang mit grossen Datenmengenstossen Computer an ihre Kapazitatsgrenzen. Ein wichtiger Faktor, um Datenmengenzu verkleinern und dennoch dabei die relevanten Informationen zu erhalten, ist dieKomprimierung von Daten. Zur Veranschaulichung der Komprimierung untersuchen wirein Beispiel einer Photo-Datei.
Abbildung 1: Beispielphoto
Das Photo besteht aus einer Anzahl von Pixeln, von denen jedes eine bestimmte Farbeannehmen kann. Da fur eine naturgetreue Abbildung sehr viele Farben und Scha�ierungenzu Verfugung stehen mussen, ist die Datenmenge, die das Photo beschreibt, relativ gross.Um die Datenmenge zu verkleinern, konnten wir die Anzahl der moglichen Farben undScha�ierungen einschranken. Je nachdem auf welche Farben wir uns dabei beschranken,resultiert daraus ein mehr oder weniger grosser �alitatsverlust bei der Abbildung.Angenommen wir mochten das abgebildete Photo mit nur funf Farben moglichst gut
wiedergeben, welche Farben wurden wir wahlen? Durch Betrachten des Photos konntenwir darauf kommen, rot zu wahlen, um das Spielzeugauto im Vordergrund darzustel-
3

len, orange, um den Blumentopf abzubilden, grun fur die Straucher im Hintergrund undschwarz fur das Lenkrad des Spielzeugautos sowie das Auto im Hintergrund. Ist das ei-ne gute Wahl? Welche Farben wurden wir wahlen, wenn wir zehn Farben auswahlenkonnten?In dieser Projektarbeit werden wir einen mathematischen Algorithmus kennenlernen,
der automatisch gute Farben auswahlt. Der Algorithmus teilt zunachst die Pixel in Gruppenein, die spater jeweils die gleiche Farbe erhalten. Diese Farben werden dann vom Algorith-mus so bestimmt, dass in einem gewissen Sinn, den wir mathematisch prazisieren werden,der �alitatsverlust der Abbildung moglichst gering ist.
2 Datenanalyse
Die Verarbeitung von grossen Datenmengen hat in den letzten Jahrzehnten enorm an Be-deutung gewonnen. Empirische Wissenscha�en, wie Physik, Biologie und Chemie sindimmer starker mit der Herausforderung konfrontiert, die Vielfalt von Messungen auszu-werten und zu interpretieren.Einen grossen Schub hat die Entwicklung der Datenanalyse durch die Finanzindustrie
und grosse Internet�rmen erfahren. Die statistische Auswertung von Aktienkursen undPreisentwicklungen sind das zentrale Werkzeug fur das Tre�en von Handelsentscheidun-gen von Banken an den Aktienmarkten. Suchmaschinen wie Google basieren fundamentaldarauf, auf schnelle Art und Weise relevante Informationen aus dem Datendschungel desInternets herauszu�ltern. Schliesslich verwenden auch soziale Netzwerke wie Facebookhochentwickelte Algorithmen um Informationen uber die Nutzer zu sammeln und zumBeispiel fur personalisierte Werbeanzeigen auszuwerten.Um mathematische Analyseverfahren einsetzen zu konnen, ist es zunachst wichtig, den
Informationen geeignete Zahlenwerte zuzuordnen. Fur dieMesswerte in empirischenWis-senscha�en ist dies zumeist schon der Fall, jedoch ist zum Beispiel nicht klar, wie manden Beziehungsstatus eines Facebookpro�ls durch eine Zahl ausdrucken soll. Ein naiverAnsatz ist, fur jede solche Information eine Regel zu er�nden und diese durch eine Zahlauszudrucken. Zum Beispiel konnten wir vereinbaren, dass single durch eine 0 und in ei-ner Beziehung durch eine 1 ausgedruckt wird. Wenn wir dies in ahnlicher Weise fur allemoglichen Parameter durchfuhren, konnen wir schliesslich ein Facebookpro�l durch eineDatenpunkt darstellen, dessen Koordinaten durch die Werte all dieser Parameter gege-ben sind. Jede Koordinate entspricht dabei einer Dimension des Raums, in dem der Punkt
4

liegt; zum Beispiel liegt ein Punkt (−3, 5), bestehend aus zwei Koordinaten, im zweidi-mensionalen Raum. Da in der beschriebenen Situation viele Parameter einen Datenpunktbeschreiben, liegen die Datenpunkte in einem hoch-dimensionalen Raum.Fur die Entwicklung von Verfahren zur Datenverarbeitung stellen wir uns von nun al-
so eine grosse (aber endliche) Menge von Datenpunkten in einem hoch-dimensionalenRaum vor, sodass wir nicht genugend Rechenleistung zu Verfugung haben, um jeden Da-tenpunkt individuell zu untersuchen. Die informationelle Gehalt dieser Daten hangt vonder jeweiligen Anwendung ab und soll hier nicht im Zentrum der Diskussion stehen.
2.1 Cluster und ihre Reprasentanten
Ein grundlegendes Konzept bei der Analyse von Daten ist, die Datenpunkte zu clustern, dasheisst, in Gruppen einzuteilen, die “ahnlich” aussehen. Die Ahnlichkeit kann zum Beispielgemessen werden durch den Abstand, den die Datenpunkte im umgebenden Raum besit-zen. Wenn wir dann jeden Cluster durch einen geeigneten “reprasentantiven” Datenpunktersetzen, konnen wir so die Anzahl der zu untersuchenden Datenpunkte erheblich redu-zieren. Bei diesem Prozess verlieren wir o�enbar Informationen, denn wir kennen nichtmehr die exakte Positionen aller Datenpunkte, jedoch ho�en wir, dass wir durch gutesClustering die fur uns wichtigen Informationen erhalten konnen.Wennwir zum Beispiel ein Tier durch viele Parameter wie Geschlecht, Grosse, Alter, Le-
bensraum, Nahrung usw. beschreiben (jeweils durch Zahlen ausgedruckt), und diese Datenfur sehr viele Tiere sammeln, so konnen wir durch Gruppierung der Daten eine moglicheEinteilung in Tierarten erhalten. Wir konnen auch noch einen Schri� weitergehen und in-nerhalb jeder Tierart die Daten erneut gruppieren und so eine Tierart weiter in bestimmteGa�ungen unterteilen. Eine solche Gruppierung erleichtert bekanntlich den Umgang mitden Informationen uber Tiere, da wir uns nicht mehr nur auf spezielle Individuen beziehenmussen.Nachdem wir die Daten in Cluster eingeteilt haben, mochten wir fur jeden der Cluster
einen geeigneten Reprasentanten auswahlen, der die “typischen” Eigenscha�en der Da-ten innerhalb eines Clusters moglichst gut wiedergibt. Wir konnen solche Reprasentantenauf unterschiedliche Weise wahlen, je nachdem welche spezi�schen Eigenscha�en erfulltwerden sollen. Zum Beispiel konnten wir versuchen, denjenigen Punkt zu �nden, der dieSumme aller Abstande zu den Punkten im Cluster minimiert. Diese Wahl hat den Nach-teil, dass die Bestimmung dieses Punktes relativ aufwendig ist und er sich nicht durcheine einfache Formel berechnen lasst. Fur einen Cluster, der aus drei Punkten A,B,C be-
5

steht, ist der Punkt, der die Summe der Abstande zu A,B,C minimiert, bekannt als derFermat-Punkt des Dreiecks ABC . Die Koordinaten dieses Punktes sind nicht leicht zu be-stimmen und die Situation wird bei grosseren Clustern noch erheblich komplizierter. Wirwerden daher sta�dessen den im Folgenden besprochenen Schwerpunkt des Clusters alsReprasentanten verwenden, der eine ahnliche Eigenscha� erfullt, sich jedoch mit deutlichweniger Aufwand bestimmen lasst.
3 Der Schwerpunkt einer endlichen Punktmenge
Stell dir vor, du legst einige gleich schwere Bauklotze an verschiedenen Stellen auf einLineal. An welcher Stelle musstest du das Lineal mit dem Finger balancieren, damit es imGleichgewicht bleibt?
Abbildung 2: Ein Lineal balancieren
In einer idealisierten Situation stellenwir uns vor, dass jede Einzelmasse jeweils in einemPunkt konzentriert ist. Der gesuchte Punkt, an dem wir das Lineal balancieren konnen,heisst der Schwerpunkt des physikalischen Systems. Liegen in den Punkten P1, . . . , Pn
die Massen m1, . . . ,mn, so wird im Physikunterricht gezeigt, dass der Schwerpunkt desphysikalischen Systems durch das gewichtete Mi�el
m1~p1 + . . .+m2~pnm1 + . . .+mn
gegeben ist.1 In der Situation, die wir betrachten, sollen alle Einzelmassen gleich gross1Fur zwei Massen m1,m2 an den Positionen P1, P2 auf dem Lineal folgt diese Formel sofort aus dem He-
6

sein, das heisst m1 = . . . = mn. Wenn wir diese Masse mit m bezeichnen, so lasst sichder Ortsvektor zum Schwerpunkt folglich durch die Formel
~s =m(~p1 + . . .+ ~pn)
mn
=1
n(~p1 + . . .+ ~pn) (1)
berechnen. In diesem Fall wird die Lage des Schwerpunktes also nur durch die relativePosition der Massenpunkte bestimmt und ist unabhangig von der tatsachlichen Masse min den Punkten.Die Berechnungsformel kann fur 1-dimensionale Vektoren (also Zahlen), 2-
dimensionale Vektoren, 3-dimensionale Vektoren oder auch 217-dimensionale Vektoren(das sind Vektoren mit 217 Komponenten) angewendet werden. Wir konnen alsoSchwerpunkte berechnen von Objekten in beliebig hoch dimensionalen Raumen.Handelt es sich um eine Punktmenge, die nur aus zwei Punkten besteht, so besagt die
Formel, dass der Schwerpunkt den Ortsvektor 12(~p1 + ~p2) besitzt, also gerade mit dem
Mi�elpunkt der beiden Punkte P1 und P2 ubereinstimmt.
Aufgabe 1 Betrachte die idealisierte Form der Situation in Abbildung 2, bei der die dreiMassen jeweils an den (eindimensionalen) Punkten P1 = (1.8), P2 = (3.9) und P3 =
(11.7) konzentriert sind. Berechne die Stelle, an der wir das Lineal balancieren mussten,damit es im Gleichgewicht bleibt.
Aufgabe 2 Berechne (im 4-dimensionalen Raum) den Schwerpunkt der Punktmenge{P1, . . . , P5} mit den Ortsvektoren
~p1 =
3
0
1
−2
, ~p2 =
1
2
0
4
, ~p3 =
0
3
0
1
, ~p4 =
−2−16
2
, ~p5 =
3
1
−20
.
Aufgabe 3
(a) Bestimme den Schwerpunkt der Punktmenge {A,B,C} wobei A = (1, 2, 0), B =
(0, 4, 1) und C = (−1,−1,−1).
belgesetz. Im allgemeinen Fall folgt die Formel ebenso leicht aus dem Drehmomentensatz.
7

(b) Stelle die Geradengleichungen der Seitenhalbierenden im Dreieck ABC auf undzeige, dass sich diese im Schwerpunkt der Punktmenge {A,B,C} schneiden.
Abbildung 3: Aufgabe 4
Aufgabe 4
(a) Bestimme geometrisch den Schwerpunkt der in Abbildung 3 abgebildeten Punkt-menge.Tipp: Du kannst den Schwerpunkt als Mi�elpunkt zwischen den beiden Diagonalen-mi�elpunkten bestimmen. Begrunde dies anhand der Berechnungsformel (1).
(b) Wie wurdest du das Bild durch einen weiteren Punkt im abgebildeten Bereicherganzen, sodass der Schwerpunkt der neuen Punktmenge ausserhalb des VierecksABCD liegt?
3.1 Geometrische Eigenscha� des Schwerpunktes
Wir wollen nun eine weitere Eigenscha� des Schwerpunktes kennenlernen. O�ne hierzudie Geogebra-Datei “uebung4.ggb”, welche die Situation aus Abbildung 3 zeigt.
8

Aufgabe 5
(a) Konstruiere in der Geogebra-Datei den Schwerpunkt der Punktmenge bestehend ausA, B, C, D auf die Weise aus Aufgabe 4(a).
(b) Zeichne einen beliebigen weiteren Punkt “X” ein und gebe
d=D i s t an c e [A , X] ˆ 2+ D i s t an c e [B , X] ˆ 2+D i s t an c e [C , X] ˆ 2+ D i s t an c e [D , X] ˆ 2
in die Inputzeile (am unteren Rand des Geogebra-Fensters) ein. (In der deutschenAusgabe von Geogebra muss “Distance” durch “Abstand” ersetzt werden.)
(c) Was fallt dir auf, wenn du X in die Nahe des Schwerpunktes aus Teilaufgabe (a)verschiebst? Stelle eine allgemeine Vermutung auf, welche Eigenscha� der Schwer-punkt einer endlichen Punktmenge erfullt.
Die Eigenscha�, die wir in Aufgabe 5 kennengelernt haben, gilt tatsachlich immer furden Schwerpunkt. Wir werden nun versuchen, die Eigenscha� zu beweisen fur den Fall,dass die Punkte im eindimensionalen Raum liegen.
Aufgabe 6 Es seien p1, . . . , pn ∈ R Punkte im eindimensionalen Raum. Zeige, dass dieFunktion
d(x) = (p1 − x)2 + (p2 − x)2 + . . .+ (pn − x)2
ihr (globales) Minimum annimmt an der Stelle s = 1n(p1 + p2 + . . .+ pn).
Mithilfe der Vektorrechnung ist der Beweis auch im hoherdimensionalen Fall leicht zuadaptieren (siehe Losungen). Wir halten das Resultat hier nochmals explizit fest:
Fur eine endliche Punktmenge {P1, . . . , Pn} nimmt die Funktion
d(~x) = ‖~p1 − ~x‖2 + ‖~p2 − ~x‖2 + . . .+ ‖~pn − ~x‖2
den minimalen Wert fur ~x = ~s an, wobei ~s in (1) de�niert wurde. In Worten heisst das:Die Summe der Abstandsquadrate einer endlichen Punktmenge zu einem Punkt X istminimal, wenn X der Schwerpunkt der Punktmenge ist.
9

4 Clustering mit dem K-Means Algorithmus
Wir mochten nun einen Algorithmus kennenlernen, der eine gegebene Menge von Daten-punkten automatisch clustert. Das Ziel ist, dass jeweils diejenigen Datenpunkte, die sichin einem Gebiet sammeln, dem selben Cluster zugeordnet werden. Schliesslich sollen furjeden Cluster gute Reprasentanten gefunden werden, das heisst der Fehler, der durch dasErsetzen der Cluster durch die Reprasentanten entsteht, soll moglichst klein sein.
BeimK-Means Algorithmus handelt es sich um einen iterativenAlgorithmus, das heisst,der Algorithmus besteht aus einem Grundschri�, der dann wiederholt2 durchlaufen wird,bis ein gewunschtes Ergebnis erreicht ist. Beim Finden von geeigneten Reprasentantenspielt der Schwerpunkt, den wir zuvor besprochen haben, eine wichtige Rolle. Daher ent-springt auch der Name des Algorithmus, wobei “Means”3 sich auf die Schwerpunktsformel(1) bezieht und als eine Verallgemeinerung des Durchschni�s auf die Vektorgeometrie ver-standen wird.
Beschreibung desK-Means Algorithmus
Ausgangslage (Input): N “Datenpunkte”,K “Clusterpunkte”, wobei N � K
1. Schri�: Clustering Ordne jeden Datenpunkt dem nachstgelegenen Clusterpunkt zu.Anschaulich: Fur jeden Clusterpunkt haben wir einen Sack, und ein Datenpunkt kommtin den Sack, der zum nachstgelegenen Clusterpunkt gehort.
2. Schri�: Update der Clusterpunkte Berechne fur jeden Sack den Schwerpunkt aller Da-tenpunkte innerhalb eines Sacks. Ersetze die Clusterpunkte durch diese Schwerpunkte.
Gehe zuruck an den Anfang mit den neuen Clusterpunkten.
Das Verfahren wird beendet, entweder nach einer zu Beginn festgelegten Anzahl an Ite-rationen (Durchlaufen), oder wenn sich in einem Durchgang die Zuordnung in die Sackenicht mehr verandert im Vergleich zum vorherigen Durchgang.
Der Input, mit dem der Algorithmus aufgerufen wird, besteht aus der gegebenen Mengevon Datenpunkten und zusatzlich K Clusterpunkten. Die Wahl der Anfangsclusterpunk-te, mit denen die Iteration das erste Mal durchlaufen wird, kann unterschiedlich erfolgen,zum Beispiel konnen gute Reprasentanten geschatzt werden oder einfach zufallig aus den2lat. iterativus = wiederholend3engl. mean = Durchschni�
10

Datenpunkten ausgewahlt werden. Diese Clusterpunkte werden im Laufe jedes Durch-gangs durch modi�zierte Clusterpunkte ersetzt, die dann als Input fur die nachste Itera-tion dienen. Die am Ende der Durchlaufe erhaltenen Clusterpunkte sollen dann gute Re-prasentanten fur die erhaltenen Cluster ergeben. Wichtig ist es zu bemerken, dass wir unszu Beginn festlegen auf die Anzahl K von Clustern, in die wir die Datenpunkte einteilenmochten.
4.1 Spielzeugbeispiel in Geogebra
Um ein Verstandnis fur die Funktionsweise des Algorithmus zu entwickeln, sollst du ihnnun einmal selbst durchspielen. O�ne hierzu die Geogebra-Datei “kmeans.ggb”. Gegebensind die folgenden 10 Datenpunkte (A-J) und 2 Clusterpunkte (Y und Z) im zweidimensio-nalen Raum.
Abbildung 4: Spielzeugbeispiel
Um den ersten Schri� desK-Means Algorithmus durchzufuhren, mussen wir jeden Da-tenpunkt dem nachstgelegenen Datenpunkt zuordnen.
11

Aufgabe 7
(a) Wie kannst du fur einen Datenpunkt geometrisch bestimmen, welche der nahereClusterpunkt ist, ohne dazu alle Abstande berechnen zu mussen?
(b) Fuhre den ersten Schri� desK-Means Algorithmus aus und farbe jeden Datenpunktentsprechend der Farbe des naheren Clusterpunktes ein.
Nun haben wir jeden der Datenpunkte in einen von zwei Sacken gesteckt. Imzweiten Schri� mussen wir jeweils den Schwerpunkt aller Punkte innerhalb einesSackes bestimmen. Mochten wir in Geogebra den Schwerpunkt S der Punktmenge{P1, P2, P3, P4, P5} bestimmen, so konnen wir dies erreichen, indem wir
S=Ba ry c en t e r [{ P1 , P2 , P3 , P4 , P5 } , { 1 , 1 , 1 , 1 , 1 } ]
in die Inputzeile (am unteren Rand des Geogebra-Fensters) eingeben. (In der deutschenVersion muss “Barycenter” durch “Massenmittelpunkt” ersetzt werden.) Das Bary-zentrum einer Punktmenge ist eine allgemeinere Form des Schwerpunktes, bei dem jederPunkt in der Menge unterschiedlich gewichtet werden kann. In obigem Befehl stehen dieZahlen im zweiten Argument fur die Gewichtungsfaktoren. Den Schwerpunkt erhaltenwir, wenn wir, wie oben, die Gewichtungsfaktoren alle auf 1 setzen. Das heisst, im zwei-ten Argument des Befehls muss die Anzahl an 1en gerade der Anzahl an Punkten in deruntersuchten Menge entsprechen.
Aufgabe 8 Fuhre fur das Beispiel den zweiten Schri� des K-Means Algorithmus aus.Die neuen Clusterpunkte sollen “Y2” und “Z2” heissen.
Nun haben wir eine vollstandige Iteration des Algorithmus durchgefuhrt und konnenwieder von vorne beginnen, wobei die Clusterpunkte nun durch Y2 und Z2 ersetzt werden.
Aufgabe 9
(a) Fuhre eine weitere Iteration aus. Die neuen Clusterpunkte sollen “Y3” und “Z3” heis-sen.
(b) Was ist bei einer dri�en Iteration zu beobachten?
Bei den einzelnen Iterationen konnen wir gut erkennen, wie sich durch die Zuordnungin die beiden Sacke die Clusterpunkte verschieben und sich dadurch wiederum die Zuord-nung in die Sacke im nachsten Schri� verandert.
12

4.2 Beispiel mit synthetischen Daten
Wir haben nun die Funktionsweise desK-Means Algorithmus in einem Spielzeugbeispielkennengelernt. Da wir alle Schri�e von Hand ausgefuhrt haben, konnten wir in diesemBeispiel nur eine relativ kleine Punktmenge untersuchen. Als nachstes betrachten wir einegrossere, kunstlich erzeugte Menge von Datenpunkten, die naher an der Anwendungssi-tuation liegen soll als das Spielzeugbeispiel.Die folgenden Datenpunkte im zweidimensionalen Raum wurden mit einer Simulati-
onsso�ware erzeugt.
Abbildung 5: Datenpunkte
Aus dem Bild lassen sich vier Cluster von Datenpunkten erkennen. Um eine solcheEinteilung zu erreichen, mochten wir den K-Means Algorithmus mit K = 4 anwenden.Hierfur werden zunachst zufallig vier Punkte aus den Datenpunkten als Anfangscluster-punkte deklariert. Dann wird der K-Means Algorithmus mit diesen Datenpunkten undClusterpunkten gefu�ert und mit einem Computer ausgefuhrt.
Das Ergebnis der einzelnen Iterationen ist in Abbildung 6 zu sehen. Es lasst sich guterkennen, wie sich die Clusterpunkte gegenseitig in eine Gleichgewichtslage verschiebenund am Ende in der Tat die Datenpunkte in die vier Cluster eingeteilt sind, die einemoptisch plausibel erscheinen.
Aufgabe 10 Untersuche Abbildung 6 und begrunde in jedem Schri� stichwortartig,warum sich die Clusterpunkte wie dargestellt verschieben.
13
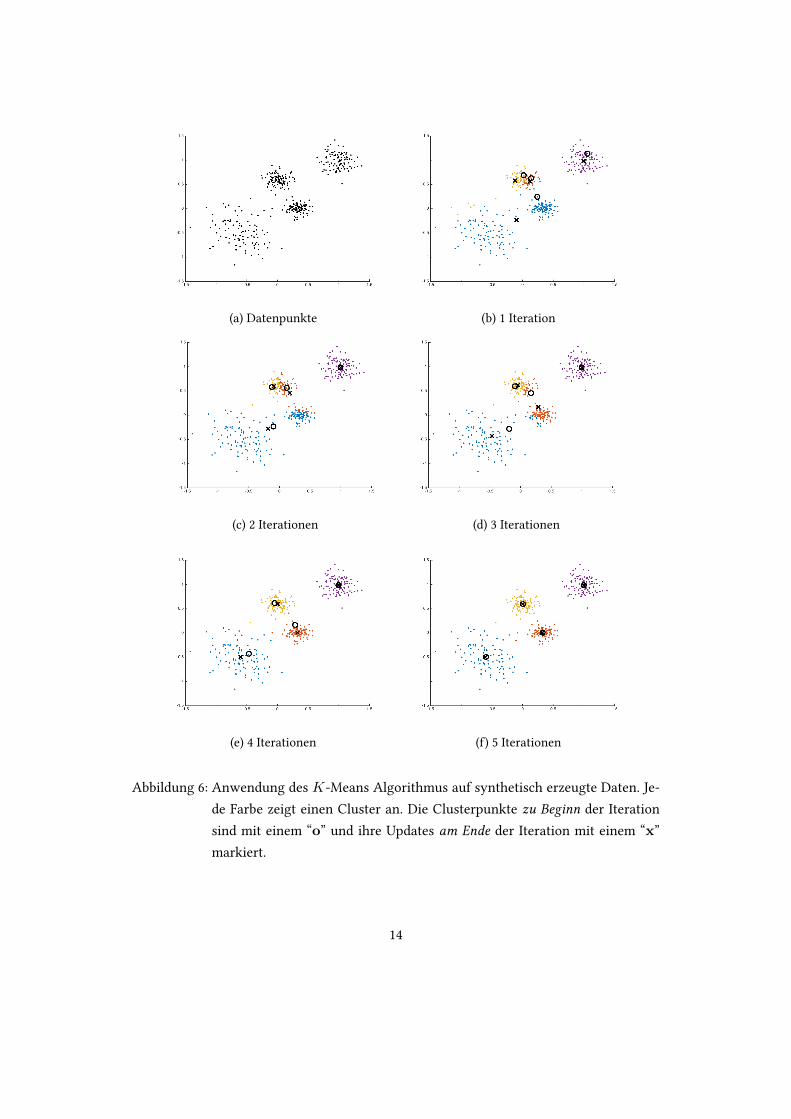
(a) Datenpunkte (b) 1 Iteration
(c) 2 Iterationen (d) 3 Iterationen
(e) 4 Iterationen (f) 5 Iterationen
Abbildung 6: Anwendung des K-Means Algorithmus auf synthetisch erzeugte Daten. Je-de Farbe zeigt einen Cluster an. Die Clusterpunkte zu Beginn der Iterationsind mit einem “o” und ihre Updates am Ende der Iteration mit einem “x”markiert.
14

Abhangigkeit von der Wahl der Anfangsclusterpunkte
Eine wichtige Frage, die es zu erortern gilt, ist die Abhangigkeit des Ergebnisses von derWahl an Anfangsclusterpunkten, mit denen wir denK-Means Algorithmus fu�ern. Wennder Algorithmus jedes mal die selbe Einteilung liefern wurde, unabhangig von der Wahlder Anfangsclusterpunkte, dann brauchtenwir uns keine Gedankenmachen, was eine “gu-te” und was eine “schlechte” Wahl von Anfangsclusterpunkten ware. In Abbildung 7 wirdder Algorithmus auf die gleichen Datenpunkte wie in Abbildung 6 angewendet, jedoch miteiner anderen Wahl von Anfangsclusterpunkten. Es zeichnet sich nach 5 Iterationen eineandere Einteilung in Cluster ab als in Abbildung 6, woraus wir schliessen konnen, dassdie Einteilung in Cluster, dir wir aus der Anwendung desK-Means Algorithmus erhalten,tatsachlich von der Wahl der Anfangsclusterpunkte abhangt.
Aufgabe 11 Untersuche Abbildung 7 und versuche zu beschreiben, wie die Lage derAnfangsclusterpunkte zu der am Ende erhaltenen Einteilung gefuhrt hat.
Aufgrund der grossen Menge an Datenpunkten ist es kompliziert, alle moglichenAblaufe, die aus der Wahl von Anfangsclusterpunkten resultieren konnen, mathematischexakt zu beschreiben. Zwei einfache Moglichkeiten, mit der Abhangigkeit umzugehen, diein der Praxis hau�g gut funktionieren, sind:
• Wahle die Anfangsclusterpunkte zufallig aus den Datenpunkten und fuhre das Ex-periment mehrmals durch, bis das Ergebnis zufriedenstellend ist.
• Schatze eine “gute” Wahl von Anfangsclusterpunkten aus den Datenpunkten.
15
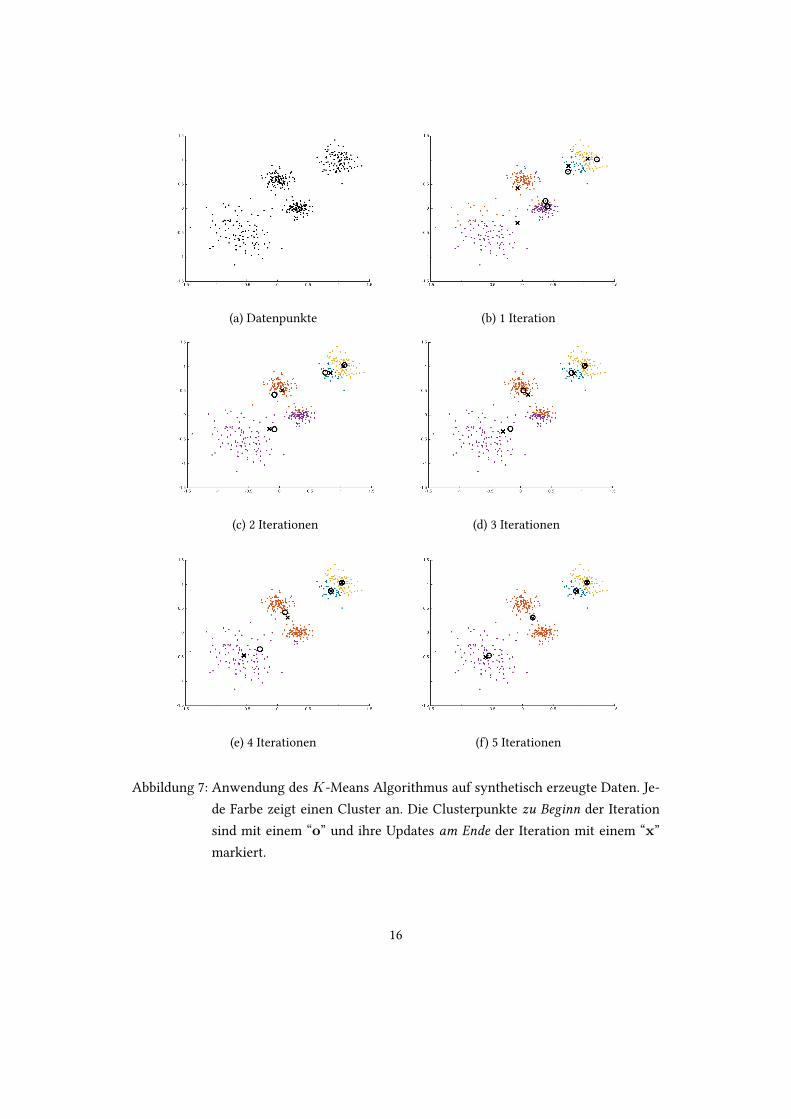
(a) Datenpunkte (b) 1 Iteration
(c) 2 Iterationen (d) 3 Iterationen
(e) 4 Iterationen (f) 5 Iterationen
Abbildung 7: Anwendung des K-Means Algorithmus auf synthetisch erzeugte Daten. Je-de Farbe zeigt einen Cluster an. Die Clusterpunkte zu Beginn der Iterationsind mit einem “o” und ihre Updates am Ende der Iteration mit einem “x”markiert.
16

Kostenfunktion
In welchem Sinne verbessert sich die Situation am Ende einer Iteration im Vergleich zumBeginn? Wir haben in den bisherigen Beispielen beobachten konnen, wie sich im Lau-fe der Iterationen eine Dynamik entwickelt, die am Ende zu einer plausiblen Gruppierungder Datenpunkte fuhrt. Um zu verstehen, warum das so ist und wie die Bezeichnung “plau-sibel” mathematisch zu verstehen ist, werden wir eine neue Funktion kennenlernen, dieein wesentliches Merkmal desK-Means Algorithmus ist.
Wir bleiben bei dem Beispiel aus Abbildung 6 und bezeichnen in jeder Iteration mit dblaudie Summe der Abstandsquadrate zu ihrem Clusterpunkt, das heisst
dblau = ‖~b1 − ~sblau‖2 + ‖~b2 − ~sblau‖2 + . . .+ ‖~bn − ~sblau‖2
wobei~b1,~b2, . . . ,~bn die Ortsvektoren zu den blauen Punkten sind und ~sblau der OrtsvektorzumClusterpunkt des blauen Clusters ist. In gleicherWeise de�nierenwir dgelb, dorange unddviole�. Schliesslich zahlen wir alle diese Grossen zusammen und bezeichnen die Summemit dgesamt:
dgesamt = dblau + dgelb + dorange + dviole�
Die Grosse dgesamt heisst Kostenfunktion zum K-Means Algorithmus. Sie hangt ab vonder Einteilung in die Cluster und von den Lagen der Clusterpunkte. Der Name “Kosten-funktion” bezeichnet allgemein bei der �eorie von Algorithmen eine Grosse, die es zuminimieren gilt. Mit Hilfe der Kostenfunktion konnen wir nun prazise erklaren, in wiefern sich die Situation am Ende einer Iteration verbessert hat, namlich, dass sich die Kos-ten verringert haben.
Aufgabe 12
(a) Argumentiere, warum dgesamt bei der Durchfuhrung des 1. Schri�s imK-Means Al-gorithmus (siehe S. 10) hochstens kleiner (aber nicht grosser) werden kann.
(b) Argumentiere, warum dgesamt bei der Durchfuhrung des 2. Schri�s imK-Means Al-gorithmus (siehe S. 10) hochstens kleiner (aber nicht grosser) werden kann.Tipp: Schaue dir noch einmal Abschni� 3.1 an.
Ist es moglich, dass unendlich viele Iterationen notig sind?
In der Beschreibung desK-Means Algorithmus wurde vereinbart (siehe S. 10):
17

“Das Verfahren wird beendet, entweder nach einer zu Beginn festgelegten Anzahl anDurchlaufen, oder wenn sich in einem Durchgang die Zuordnung in die Sacke nichtmehr verandert im Vergleich zum vorherigen Durchgang.”
Wenn wir darauf warten, dass sich die Zuordnung in die Sacke (Cluster) nicht mehrverandert, sollten wir sicherstellen, dass es in jedem Falle irgendwann einmal dazu kommt,denn andernfalls warten wir womoglich fur immer darauf. Es ware namlich denkbar,dass sich in einer bestimmten Situation bei jeder Iteration die Zuordnung in die Clusterverandert, und somit unendlich viele Iterationen notig sind.Der Schlussel zur Losung dieses Problems ist wiederum die Kostenfunktion. Wenn
wir einen Datenpunkt einem Cluster zuteilen mochten, so haben wir K Moglichkeitendies zu tun. Fur die Einteilung von zwei Datenpunkten haben wir fur jeden der beidenK Moglichkeiten, also insgesamt K2 mogliche Zuteilungen in Cluster. Indem wir dieseUberlegung weiterfuhren �nden wir, dass wir KN mogliche Einteilungen der N Daten-punkte in K Cluster haben. Dies ist zwar eine grosse Anzahl, jedoch konnen wir nunargumentieren, dass wir niemals mehr alsKN Iterationen benotigen, bevor der Algorith-mus beendet wird. Insbesondere ist es also unmoglich, dass unendlich viele Iterationenbenotigt werden. In Aufgabe 12 haben wir uns uberlegt, dass der Wert von dgesamt imLaufe einer Iteration entweder gleich bleibt (wenn sich in der Zuordnung in die Clusternichts verandert und der Algorithmus somit beendet wird) oder kleiner wird. SpatestensnachKN Iterationen kann es aber keine Zuordnung in Cluster mehr geben, bei der dgesamt
noch kleiner wird als den Wert, den wir schon erreicht haben. Somit muss dgesamt gleichbleiben und der Algorithmus �ndet ein Ende.
Aufgabe 13 Erklare nochmals in eigenen Worten, warum es nicht moglich ist, dasssich in unendlich vielen aufeinanderfolgenden Iterationen die Zuordnung in die Clusterverandert.
Globales oder lokales Minimum
Wir haben nun gelernt, dass der K-Means Algorithmus beendet wird, wenn die Kosten-funktion dgesamt in einer Iteration nichtmehr kleinerwird sondern sta�dessen gleich bleibt.Nun konnte man meinen, dass in diesem Falle der minimal mogliche Wert von dgesamt er-reicht wurde. Dem muss aber keineswegs so sein. Alles was man weiss ist, dass man mitden erreichten Clusterpunkten keine bessere Einteilung in Cluster erreichen kann, und
18

sich somit die Lage stabilisiert wie in Abbildung 6 und 7 jeweils nach 5 Iterationen zu se-hen. Moglicherweise existiert aber noch eine ganz andere Wahl von Clusterpunkten, mitdenen man noch einen kleinerenWert von dgesamt erreichen kann. Dieser Sachverhalt lasstsich gut mit dem Verhaltnis von lokalen und globalen Minima erklaren: Wenn der Algo-rithmus aufgrund einer Stabilisierung der Einteilung beendet wird, wissen wir lediglich,dass wir ein lokales Minimum der Kostenfunktion erreicht haben, jedoch nicht, ob es sichhierbei auch um ein globales Minimum handelt. Die Frage, in welchem lokalen Minimumwir landen, wird entschieden durch die Wahl der Anfangsclusterpunkte.
5 Implementierung des Algorithmus und Anwendung aufein Photo
Um den Nutzen des K-Means Algorithmus zu demonstrieren, soll er nun auf das Photoaus dem Einfuhrungsbeispiel angewendet werden.
Abbildung 8: Beispielphoto
Das Photo hat eine Au�osung von 500×667 und besteht somit aus 500×667 = 333500
Pixeln. Die Farbtiefe des Photos betragt 8 bit pro Farbkanal im RGB-Farbraum. Was be-deutet das? Jeder Pixel kann eine Farbe annehmen, die aus einem Rot-, Grun- und Blauan-teil zusammengesetzt ist; die Grundfarben rot, grun und blau sind die sogenannten Farb-kanale. Innerhalb eines Farbkanals stehen 8 bit, das heisst, 28 = 256Werte, zur Abstufungder Helligkeit zu Verfugung. Diese Werte werden durch eine ganze Zahl zwischen 0 und255 ausgedruckt, wobei 0 = dunkel und 255 = hell. Eine mogliche Farbe besteht so-mit aus drei Zahlen, zum Beispiel (34, 144, 80), die die Helligkeitsstufen des Rot-, Grun-
19

und Blauanteils (in dieser Reihenfolge) beschreiben. Ausfuhrliche Informationen uber denRGB-Farbraum kannst du in [Wikipedia, 2016] �nden.
Aufgabe 14
(a) Wieviele Farben lassen sich mit 8 bit pro Farbkanal audrucken?
(b) Versuche, in Abbildung 9 die folgenden Farben zu �nden: (0, 255, 0), (255, 0, 255),(0, 0, 153), (0, 204, 204)
Abbildung 9: Farben im RGB-Farbraum (�elle: [rgb, 2016])
Damit wir die Grosse der Datei reduzieren, mochten wir nun das Photo in Abbildung 8durch eine geringere Anzahl an Farben darstellen. Dabei soll jedoch das dargestellte Motivmoglichst gut erhalten bleiben. Wie konnen wir eine geeignete Auswahl fur die Farbentre�en? Fur dieses Vorhaben werden wir denK-Means Algorithmus einsetzen.Da die Farbe jedes Pixels durch ein Tupel aus drei Zahlen festgelegt ist, konnen wir
uns diese Information als einen Punkt im 3-dimensionalen Raum vorstellen. Das gesamtePhoto ist somit dargestellt als eine Menge von 333500 (Daten-)punkten im Raum. Den Ortjedes Pixels im Bild merken wir uns und legen diese Information dann fur fur den Momentbeiseite (zum Beispiel konnen wir alle Pixel durchnummerieren).
Aufgabe 15 Was bedeutet es, die vorliegenden Datenpunkte im Raum zu clustern? Wasreprasentieren dabei die Cluster und was die Clusterpunkte?
Damit wir eine “gute” Darstellung des Motivs im Photo erhalten, mussen wir also dievorliegenden Datenpunkte geeignet clustern. DerK-Means Algorithmus liefert nicht nur
20

diese Einteilung, sondern auch die zugehorigen Clusterpunkte. Dabei reprasentieren dieClusterpunkte jeweils diejenige Farbe, durch die die tatsachliche Farbe eines Pixels imOriginalphoto ersetzt wird.
5.1 Implementierung des Algorithmus
Der folgende Code implementiert den K-Means Algorithmus in der mathematischen Si-mulationsso�ware MATLAB. Alternativ kann der identische Code auch in der kostenlosenSo�ware Octave [Eaton, 2016] eingesetzt werden. Du kannst den untenstehenden Codein das Programm kopieren und auf eigene Photos oder andere Daten anwenden, um siezu clustern. Neben dem elementaren Syntax zur De�nition von Konstanten, Vektoren undMatrizen, werden hierbei dieMATLAB-Funktionen “norm” und “min” verwendet. Daruberhinaus kommen einige for-Schleifen zum Einsatz. Wir werden hier nicht jeden Befehl be-sprechen, sondern nur die wichtigsten Schri�e fur den Algorithmus erklaren. Falls du diegenaue Funktion bestimmter Befehle verstehen mochtest, kannst du [MathWorks, 2016]konsultieren.
K-Means Zunachst wird eine Funktion “kmeans” programmiert, welche unter Angabeder Datenpunkte, Anfangsclusterpunkte undAnzahl an durchzufuhrenden Iterationen denK-Means Algorithmus durchfuhrt und am Ende jeden Datenpunkt durch den zugehorigenClusterpunkt (aus der letzten Iteration) ersetzt.Der Name “MATLAB” ist eine Abkurzung fur matrix laboratory und das Programm ba-
siert darauf, moglichst viele mathematische Grossen als Matrizen zu behandeln. In diesemGeiste stellen wir uns beim Programmieren der Funktion fur den K-Means Algorithmusvor, dass die Datenpunkte nicht als Menge gegeben sind, sondern die Koordinaten jedesPunktes zeilenweise in einer Matrix A gespeichert sind. Ebenso seien die Anfangscluster-punkte in den Zeilen einer Matrix S gespeichert. Mit diesem Model konnen wir also dieAnzahl an Datenpunkten N in Zeile 8 direkt aus der Anzahl an Zeilen in A bestimmen.
In den Zeilen 11–42 programmieren wir die Iterationsschleife, die die darauf folgen-de K-Means-Iteration M Mal durchlau�. Der Schri� des Clustering wird in Zeile 19–27 programmiert. Um jeden Datenpunkt dem nachstgelegenen Clusterpunkt zuordnen zukonnen, berechnen wir in Zeile 23 die Distanz vom i-ten Datenpunkt zum k-ten Cluster-punkt fur alle moglichen i = 1, . . . , N und k = 1, . . . ,K und speichern den Wert in einerDistanzmatrix D. In der i-ten Zeile von D stehen dann die Distanzen vom i-ten Daten-punkt zu allen Clusterpunkten. Mit Hilfe des min-Befehls konnen wir in Zeile 25 nicht nur
21

den minimalen Wert in der i-ten Zeile von D bestimmen, sondern, was fur uns vor allemwichtig ist, den Index dieses minimalenWertes in der i-ten Zeile �nden. Dieser Index wirdin L(i) gespeichert und sagt uns also, welcher der zum i-ten Datenpunkt nachstgelegeneClusterpunkt ist.Als nachstes berechnen wir im zweiten Schri� der Iteration die neuen Clusterpunkte
(ab Zeile 29). In Zeile 33–37 addieren wir alle Datenpunkte, die demselben Clusterpunktzugeordnet wurden und speichern dies in den Zeilen der Clusterpunktmatrix S. Dabeizahlen wir in Zeile 36 mit, wie viele Datenpunkte wir jeweils addieren, da zur Berechnungdes Schwerpunktes in (1) durch diese Anzahl noch dividiert werden muss. Diese Divisionwird in Zeile 39–41 durchgefuhrt.
Nachdem wir alle M Iterationen durchgefuhrt haben, konstruieren wir die Output-Matrix X , in dessen i-ter Zeile derjenige Clusterpunkt steht, der zum i-ten Datenpunktam nachsten liegt.
1 function X = kmeans (A , S , M)2 %I n pu t : − Datenpunk t e a l s Z e i l e n i n Mat r i x A ,3 % − C l u s t e r p u n k t e a l s Z e i l e n i n Mat r i x S ,4 % − Anzahl d e r Du r c h l a e u f e M de s A l g o r i t hmus5 %Output : Ma t r i x X , i n d e r j e d e r Datenpunkt durch den6 % n a e c h s t g e l e g e n e n C l u s t e r p u n k t e r s e t z t wurde78 N= s i z e (A , 1 ) ; %Def . Anzahl d e r Da t enpunk t e9 X=zeros ( s i z e (A ) ) ; %Def . Ou tpu tma t r i x1011 for m=1 :M %D u r c h l a u f s c h l e i f e d e s A l g o r i t hmus1213 K= s i z e ( S , 1 ) ; %Def . Anzahl C l u s t e r p u n k t e14 D=zeros (N , K ) ; %Def . e i n e r ‘ ‘ D i s t an zma t r i x ’ ’15 L=zeros (N , 1 ) ; %Def . e i n e s ‘ ‘ L a b e l v e k t o r s ’ ’16 Z=zeros (N , 1 ) ; %Def . e i n e s H i l f s v e k t o r s1718 %C l u s t e r i n g19 for i = 1 :N % Best imme n a e c h s t g e l e g e n e n20 % C l u s t e r p u n k t zum i−t e n Datenpunkt21 for k =1 :K % Best imme D i s t a n z vom i−t e n Datenpunkt22 % zum k−t e n C l u s t e r p u n k t23 D( i , k )=norm (A( i , : ) − S ( k , : ) ) ;24 end
22

25 [Z ( i ) L ( i ) ] =min (D( i , : ) ) ; % S e t z e L ( i ) a l s den I nd e x d e s26 % Abs tands−min imi e r enden C l u s t e r p u n k t s27 end2829 % Bere chnung d e r neuen C l u s t e r p u n k t e30 S=zeros ( s i z e ( S ) ) ; % Lo e s c h e a l t e C l u s t e r p u n k t e31 n=zeros (K , 1 ) ; % Def . ‘ ‘ Z a e h l v e k t o r ’ ’3233 for i = 1 :N % Summiere a l l e Da t enpunk t e mit g l e i c h em Lab e l34 l =L ( i ) ; % Def . L a b e l d e s i−t e n Da t enpunk t e s35 S ( l , : ) = S ( l , : ) + A( i , : ) ;36 n ( l )= n ( l ) + 1 ; % Erhoehe Za e h l e r zum l−t e n Lab e l37 end3839 for k =1 :K % T e i l e d i e Summen durch d i e Anzahl d e r Summanden40 S ( k , : ) = 1 / n ( k ) ∗ S ( k , : ) ;41 end4243 end4445 for i = 1 :N % Def . i−t e Z e i l e d e r Ou tpu tma t r i x durch den zum46 % i−t e n Datenpunkt n a e c h s t l i e g e n d e n C l u s t e r p u n k t47 l =L ( i ) ;48 X( i , : ) = S ( l , : ) ;49 end5051 end
Anwendungsbefehl Fur die Anwendung auf die Photo-Datei schreiben wir alsnachstes einen kurzen Befehl, der die eingelesene Datei geeignet umformt und dann diekmeans-Funktion mit zufallig ausgewahlten Anfangsclusterpunkten aufru�.Die eingelesene Photo-Datei A ist eine Matrix, in der jeder Eintrag einen Pixel re-
prasentiert, das heisst in jedem Eintrag steht ein 3-dimensionaler Vektor aus dem RGB-Farbraum. Damit wir unseren kmeans-Befehl auf diese Daten anwenden konnen, mussenwir A so umformen, dass die Datenpunkte in den Zeilen einer Matrix stehen.
Wir bestimmen zunachst in Zeile 9 die Gesamtanzahl m an Pixeln im Photo. Dadie Eintrage aus der eingelesenen Photo-Datei A RGB-Farbwerte mit 8 bit Farbtiefe re-prasentieren, konnen diese nur ganze Zahlwerte zwischen 0 und 255 annehmen. Dieser
23

Typ heisst uint8. Wir mochten jedoch bei der Berechnung von Schwerpunkten auchWer-te zulassen, die nicht ganzzahlig sind. Daher andern wir in Zeile 10 den Typ in single,der alle Dezimalzahlen (auf “single-precision”) speichern kann. In Zeile 11 organisierenwir die Matrix A so um, dass wir eine Matrix mitm Zeilen und 3 Spalten erhalten. DieseSpalten enthalten gerade die Koordinaten im RGB-Farbraum.Nun mussen wir noch die Anfangsclusterpunkte auswahlen. In Zeile 12 generieren wir
hierzu K zufallige Zahlen zwischen 1 und m und wahlen in Zeile 13 die entsprechen-den Zeilen von A als die Anfangsclusterpunkte. Schliesslich wenden wir in Zeile 15 denkmeans-Befehl an und wandeln das Ergebnis wieder in den uint-Typ zuruck (dabei wirdjeweils auf einen ganzzahligen Wert gerundet). Das Ergebnis wird in Zeile 19 angezeigt.
1 function X = anwendung (A , K , M)2 %I n pu t : − Datenpunk t e A aus e i n g e l e s e n e r B i l d d a t e i3 % − Anzahl d e r zu fo rmenden C l u s t e r K ,4 % − Anzahl d e r Du r c h l a e u f e M de s A l g o r i t hmus5 %Output : − Mat r i x X , i n d e r j e d e r Datenpunkt durch den6 % n a e c h s t g e l e g e n e n C l u s t e r p u n k t e r s e t z t wurde78 n1= s i z e (A , 1 ) ; n2= s i z e (A , 2 ) ; % Def . G r o e s s e d e s B i l d e s9 m=n1 ∗ n2 ; % Def . Anzahl an P i x e l10 A= s i n g l e (A ) ; % Anpassung Dat en typ von A11 A=reshape (A , [m, 3 , 1 ] ) ; % O r g a n i s a t i o n i n Z e i l e n e i n e r Ma t r i x12 c=randperm (m, K ) ; % K z u f a e l l i g e Zah l en zw i s ch en 1 und m13 S=A( c , : ) ; % Def . S a l s K z u f a e l l i g e Z e i l e n von A1415 X=kmeans (A , S ,M) ; % Anwendung d e r kmeans−f u n k t i o n16 X= u i n t 8 (X ) ; % Anpassung Dat en typ von X17 X=reshape (X , [ n1 , n2 , 3 ] ) ; % R e o r g a n i s a t i o n i n Form de s B i l d e s1819 imshow (X ) ; % Anze i g e d e s E r g e b n i s s e s2021 end
Aufruf Mochten wir den Algorithmus 3Mal auf die Datei bild.jpg anwenden und dasBild in 4 Farben darstellen lassen, so geben wir folgendes in die Befehlszeile ein:
A=imread ( ’ b i l d . j pg ’ ) ; %E i n l e s e n d e r B i l d d a t e ianwendung (A , 3 , 4 ) ; %Auf ru f d e s Anwendung sb e f eh l s
24

5.2 Ergebnis
In Abbildung 10 sehen wir schliesslich das Ergebnis fur K = 2, 3, 5, 10, 30 jeweils nach5 Iterationen desK-Means Algorithmus. Man beachte, dass die Anfangsclusterpunkte je-weils zufallig aus den Datenpunkten gewahlt wurden und das Ergebnis von dieser Wahlabhangt (siehe S. 15). Es lasst sich erkennen, dass wir das Motiv durch sorgfaltige Auswahlan Farben schon mit 10 bzw. 30 Farben gut abbilden konnen.
(a) 2 Farben (b) 3 Farben (c) 5 Farben
(d) 10 Farben (e) 30 Farben (f) Original
Abbildung 10: Anwendung desK-Means Algorithmus auf ein Photo
25

Losungen zu den Aufgaben
Aufgabe 1 Das Lineal muss am Schwerpunkt balanciert werden, der sich zu s = 13(1.8+
3.9 + 11.7) = 5.8 berechnet.
Aufgabe 2
~s =1
5(~p1 + . . .+ ~p5) =
1
1
1
1
Aufgabe 3
(a)
~s =1
3(~a+~b+ ~c) =
0
5/3
0
(b) Die Mi�elpunkte der Seiten a, b und c ergeben sich zu Ma = (−1/2, 3/2, 0),
Mb = (0, 1/2,−1/2) und Mc = (1/2, 3, 1/2). Fur die Geradengleichungen derSeitenhalbierenden erhalten wir dann
sa : ~x =
1
2
0
+ α
−3/2−1/20
sb : ~x =
0
4
1
+ β
0
−7/2−3/2
sc : ~x =
−1−1−1
+ γ
3/2
4
3/2
26

Wir schneiden exemplarisch die beiden Geraden sa und sb. Durch Gleichsetzen er-halten wir das Gleichungssystem
1− 3
2α = 0
2− 1
2α = 4− 7
2β
0 = 1− 3
2β
Es ergibt sich direkt α = β = 23 und somit erhalten wir den Schni�punkt S =
(0, 5/3, 0) wie in Teilaufgabe (a). Durch das Schneiden der anderen Paare von Ge-raden erhalten wir das gleiche Ergebnis.
Aufgabe 4
(a) Wir konnen den Schwerpunkt bestimmen, indem wir zunachst zwei Paar von Punk-ten bilden, zum Beispiel A und B sowie C und D. Dann konstruieren wir die Mit-telpunkte der Paare ~m1 = 1
2(~a + ~b) und ~m2 = 12(~c +
~d). Der Mi�elpunkt dieserMi�elpunkte ist dann 1
2(~m1 + ~m2) =14(~a+
~b+ ~c+ ~d) und stimmt somit mit demSchwerpunkt der vier Punkte uberein.
(b) Indem wir den zusatzlichen Punkt moglichst weit im rechten unteren Bildranwahlen, konnen wir den Schwerpunkt so weit verschieben, dass er nicht mehr in-nerhalb des Vierecks ABCD liegt.
Aufgabe 5
(c) Der Wert von d wird minimal am Schwerpunkt. Hieraus ergibt sich die allgemeineVermutung, dass der Schwerpunkt die Summe der Abstandsquadrate zu den Punktenaus der Menge minimiert.
Aufgabe 6 Wir werden zeigen, dass fur beliebiges x ∈ R
d(x)− d(s) > 0
27

gilt, und somit d an der Stelle s das globale Minimum besitzt. Hierzu berechnen wir
d(x)− d(s) = (p1 − x)2 + . . .+ (pn − x)2 −((p1 − s)2 + . . .+ (pn − s)2
)= nx2 − 2(p1 + . . .+ pn)x+ (p21 + . . .+ p2n)
−(ns2 − 2(p1 + . . .+ pn)s+ (p21 + . . .+ p2n)
)= nx2 − ns2 − 2(x− s)(p1 + . . .+ pn)
(∗)= n(x2 − s2 − 2(x− s)s)
= n(x2 − 2xs+ s2)
= n(x− s)2.
In demmit (∗) markierten Schri� habenwir dabei den Faktorn ausgeklammert und sodann(p1 + . . . + pn)/n durch s ersetzt. Da �adrate nie negativ sind, gilt n(x − s)2 > 0 undwir haben die Behauptung bewiesen.Der identische Beweis gilt ebenso im mehrdimensionalen Fall. Hierfur mussen wir nur
die pi, sowie x und s durch entsprechende Vektoren ersetzen und alle Multiplikationenvon Vektoren als Skalarprodukte interpretieren.
Aufgabe 7
(a) Indem wir die Mi�elsenkrechte zwischen Y und Z konstruieren, konnen wir direktentscheiden, zu welchem der beiden Punkte ein gegebener Punkt weiter entfernt ist,je nachdem auf welcher Seite der Mi�elsenkrechten er liegt.
(b) Siehe Geogebra-Datei.
Aufgabe 8 Siehe Geogebra-Datei.
Aufgabe 9
(a) Siehe Geogebra-Datei.
(b) Die Zuordnung zu den Clusterpunkten andert sich nicht mehr und somit bleiben dieClusterpunkte identisch.
Aufgabe 10
28

• Iteration 1: Drei der vier Anfangsclusterpunkte liegen im Zentrum der Datenpunkte.Dem untersten der drei werden fast alle Datenpunkte (blau) aus der linken unterenWolke zugewiesen, dadurch verschiebt er sich auch in diese Richtung. Der vierteAnfangsclusterpunkt liegt alleine in der rechten oberen Wolke und besetzt folglichdiesen Cluster (viole�).
• Iterationen 2–4: Durch die Verschiebung des Clusterpunktes zum blauen Clusterwerden mehr und mehr Datenpunkte der mi�leren unteren Wolke dem orangenenCluster zugewiesen, dessen Clusterpunkte sich infolgedessen auch weiter in dieseRichtung verschiebt.
• Iteration 5: Die Clusterpunkte zu Beginn und am Ende der Iteration sind identisch,die Situation hat sich stabilisert und wir haben eine optisch plausible Einteilung inCluster erhalten.
Aufgabe 11 Die beiden Anfangsclusterpunkte oben rechts teilen sich die dortigen Da-tenpunkte zunachst auf. Die beiden anderen Anfangsclusterpunkte verschieben sich im-mer mehr so, dass einer die linke untere Wolke besetzt (viole�) und der andere die beidenWolken in der Mi�e (orange). Dadurch, dass die beiden mi�leren Wolken naher beieinan-der liegen als die rechte obere, verliert der orangene Cluster keine Datenpunkte an denblauen Cluster und die Situation stabilisiert sich.
Aufgabe 12
(a) Wird ein Datenpunkt zum Beispiel aus dem blauen Cluster neu dem gelben Clusterzugewiesen, dann liegt der Datenpunkt naher am Clusterpunkt zum gelben Clus-ter als am Clusterpunkt zum blauen Cluster. In diesem Fall verschwindet nach derIteration aus dblau das zugehorige Abstandsquadrat und in dgelb erscheint ein neu-es. Dieses neue Abstandsquadrat ist aber dann kleiner als das, das verschwunden ist.Somit ist insgesamt dgesamt kleiner geworden. Falls kein Clusterpunkt einem anderenCluster zugewiesen wird, so bleibt dgesamt konstant.
(b) Wenn wir innerhalb zum Beispiel des blauen Clusters den Clusterpunkt durch denSchwerpunkt des Clusters ersetzen so kann dblau nicht grosser werden, da derSchwerpunkt nach Abschni� 3.1 die Summe der Abstandsquadrate minimiert.
29
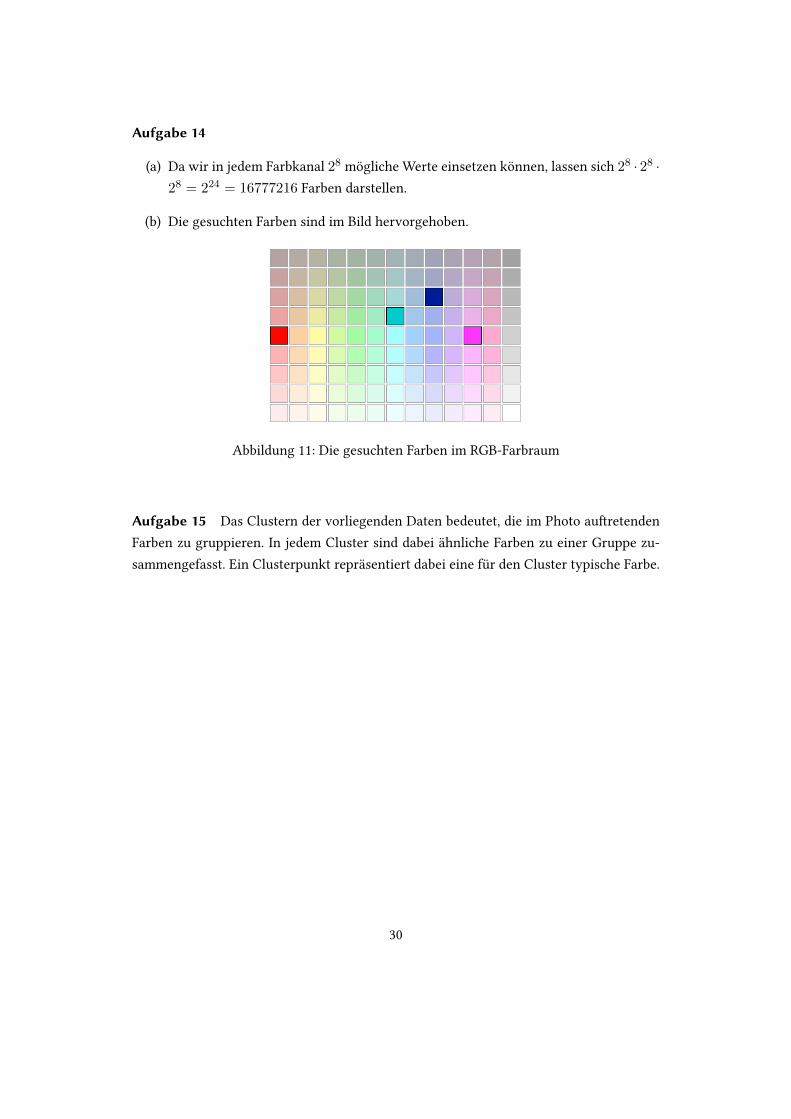
Aufgabe 14
(a) Da wir in jedem Farbkanal 28 mogliche Werte einsetzen konnen, lassen sich 28 · 28 ·28 = 224 = 16777216 Farben darstellen.
(b) Die gesuchten Farben sind im Bild hervorgehoben.
Abbildung 11: Die gesuchten Farben im RGB-Farbraum
Aufgabe 15 Das Clustern der vorliegenden Daten bedeutet, die im Photo au�retendenFarben zu gruppieren. In jedem Cluster sind dabei ahnliche Farben zu einer Gruppe zu-sammengefasst. Ein Clusterpunkt reprasentiert dabei eine fur den Cluster typische Farbe.
30

Literatur
[rgb, 2016] (2016). RGB color codes chart. http://www.rapidtables.com/web/
color/RGB Color.htm. Abgerufen am 10.06.2016.
[Bishop, 2006] Bishop, C. M. (2006). Pa�ern Recognition and Machine Learning. Informa-tion Science and Statistics. Springer.
[Cisco, 2016] Cisco (2016). �e ze�abyte era—trends and analysis.http://www.cisco.com/c/en/us/solutions/collateral/
service-provider/visual-networking-index-vni/
vni-hyperconnectivity-wp.html. Abgerufen am 09.06.2016.
[Eaton, 2016] Eaton, J. (2016). GNU Octave. https://www.gnu.org/software/
octave/. Abgerufen am 10.06.2016.
[jkabrg, 2015] jkabrg (2015). Proof of convergence of k-means.http://stats.stackexchange.com/questions/188087/
proof-of-convergence-of-k-means. Abgerufen am 10.06.2016.
[MathWorks, 2016] MathWorks (2016). MATLAB Documentation.http://ch.mathworks.com/help/matlab/. Abgerufen am 10.06.2016.
[Wikipedia, 2016] Wikipedia (2016). RGB-Farbraum. https://de.wikipedia.org/
wiki/RGB-Farbraum. Abgerufen am 10.06.2016.
























![Q[1].2. Lesetext](https://img.pdfslide.net/doc/110x75/5571fa1449795991699134f2/q12-lesetext.jpg)



