Embed Size (px)
Citation preview

UNIVERZA V MARIBORU
FAKULTETA ZA NARAVOSLOVJE IN MATEMATIKO
Oddelek za matematiko in rač unalniš tvo
DIPLOMSKO DELO
Ksenija Ofentavšek
Maribor, 2013


UNIVERZA V MARIBORU
FAKULTETA ZA NARAVOSLOVJE IN MATEMATIKO
Oddelek za matematiko in računalništvo
Diplomsko delo
PODATKOVNO SKLADIŠČE ZA IZOBRAŽEVALNO USTANOVO
(Data warehouse for educational institution)
Mentorica: izr. prof. dr. Krista Rizman Žalik Diplomantka: Ksenija Ofentavšek
Maribor, 2013

ZAHVALA
Rada bi se zahvalila svoji mentorici izr. prof. dr. Kristi Rizman Žalik za strokovno svetovanje,
potrpežljivost in spodbudo pri nastajanju diplomskega dela.
Posebna zahvala tudi moji družini, ki je verjela vame, in partnerju Jerneju Bregarju, ki mi je ves čas
stal ob strani, me spodbujal in mi pomagal.

UNIVERZA V MARIBOU
FAKULTETA ZA NARAVOSLOVJE IN MATEMATIKO
IZJAVA
Podpisana Ksenija Ofentavšek, rojena 1. decembra 1982, študentka Fakultete za naravoslovje in
matematiko Univerze v Mariboru, študijskega programa Računalništvo in matematika, izjavljam, da je
diplomsko delo z naslovom
PODATKOVNO SKLADIŠČE ZA IZOBRAŽEVALNO USTANOVO
pri mentorici izr. prof. dr. Kristi Rizman Žalik avtorsko delo. V diplomskem delu so uporabljeni viri in
literatura korektno navedeni; teksti niso uporabljeni brez navedbe avtorjev.
Maribor, 30. 01. 2013
Ksenija Ofentavšek

OFENTAVŠEK KSENIJA: Podatkovno skladišče za izobraževalno ustanovo.
Diplomsko delo, Univerza v Mariboru, Fakulteta za naravoslovje in matematiko, Oddelek za
matematiko in računalništvo, 2013.
Povzetek Diplomsko delo opisuje zgradbo in uporabo podatkovnih skladišč. Podrobneje so opisane
distribuirane, centralizirane in federativne arhitekture podatkovnih skladišč. Prikazana je uporaba
podatkovnih skladišč v podjetjih ter izobraževalnih ustanovah skupaj z orodji za razvoj in poizvedbo
in bazami, ki jih uporabljajo. Jedro podatkovnih skladišč je OLAP kocka, ki jo modeliramo s
snežinkasto in zvezdno podatkovno shemo. Vrtilne tabele omogočajo enostaven prikaz podatkov,
zbranih v OLAP kocki. Prikazana je izdelava vrtilnih tabel v programu Excel. V diplomskem delu je
predstavljen izdelan model podatkovnega skladišča za izobraževalno ustanovo in bazo v Accessu in
poročila, izdelana s pomočjo vrtilnih tabel v Excelu.
Ključne besede: podatkovno skladišče, proces ETL, kocka OLAP, zvezdna shema, snežinkasta shema,
arhitektura podatkovnih skladišč

OFENTAVŠEK KSENIJA: Data warehouse for educational institution.
Graduation Thesis, University of Maribor, Faculty of Natural Sciences and Mathematics,
Department of Mathematics and Computer Science, 2013.
Abstract This thesis describes composition of data warehouse and its usage. Distributed, centralised and federal
architectures of data warehouse are described in details. It shows usage of data warehouse by some
companies and educational institutions together with their used tolls for development and querying.
Core of data warehouse is OLAP cube that can be realized with snowflake or star scheme. Pivot tables
provide simple dissemination of data stored in OLAP cubes. There is shown how pivot tables in Excel
are made.Thesis shows a model of data warehouse done for educational institution and data in Access.
There are also some analysis and reports made with pivot tables in Excel.
Key words: data warehouse, process ETL, cube OLAP, star scheme, snowflake data scheme,
arcitecture of data warehous

6
Kazalo: 1. UVOD ................................................................................................................................................. 8 2. PODATKOVNA SKLADIŠČA .......................................................................................................... 8
2.1 PROCES ETL ............................................................................................................................... 9 2.1.1 PRIDOBIVANJE PODATKOV .......................................................................................... 10 2.1.2 PREOBLIKOVANJE .......................................................................................................... 10 2.1.3 NALAGANJE...................................................................................................................... 11
3. ZGODOVINA ................................................................................................................................... 11 4. ARHITEKTUA PODATKOVNIH SKLADIŠČ ............................................................................... 12
4.1 NORMALIZIRAN PRISTOP V PRIMERJAVI Z DIMENZIONALNIM PRISTOPOM ......... 13 4.2 SKLADNOST INFORMACIJ .................................................................................................... 14 4.3 OD ZGORAJ NAVZDOL V PRIMERJAVI Z OD SPODAJ NAVZGOR METODOLOGIJO
OBLIKOVANJA .............................................................................................................................. 15 4.3.1 Od spodaj navzgor ali pristop, imenovan distribuirana arhitektura (angl. Bottom-up design)
...................................................................................................................................................... 15 4.3.1.1 Podatkovni model v distribuirani arhitekturi podatkovnega skladišča ......................... 16 4.3.1.2 Ostale posebnosti .......................................................................................................... 16
4.3.2 Od zgoraj navzdol ali pristop, imenovan centralizirana arhitektura (angl. Top-down design)
...................................................................................................................................................... 16 4.3.2.1 Načrtovanje in gradnja centraliziranega podatkovnega skladišča ................................ 17 4.3.2.2 Podatkovni model v centralizirani arhitekturi podatkovnega skladišča ....................... 17 4.3.2.3 Področno skladišče in operativna podatkovna hramba v centralizirani arhitekturi
podatkovnega skladišča ............................................................................................................ 18 4.3.2.4 Osnovne značilnosti, ki ločujejo področno in podatkovno skladišče ........................... 18
4.3.3 Hibridna rešitev ali pristop, imenovan federativna arhitektura ali kombiniran pristop ....... 19 4.3.3.1 Gradnja hibridnega ali federativnega podatkovnega skladišča .................................... 19
5. PODATKOVNO SKLADIŠČE V PRIMERJAVI Z OPERATIVNIM SISTEMOM ...................... 20 5.1 RAZVOJ PODATKOVNIH SKLADIŠČ V ORGANIZACIJSKI UPORABI ........................... 21
6. OLAP ............................................................................................................................................... 22 6.1 OLAP KOCKA .......................................................................................................................... 23 6.2 PODATKOVNI MODEL – KOCKE IN PODATKOVNEGA SKLADIŠČA ........................... 23
6.2.1 ZVEZDNA SHEMA ........................................................................................................... 24 6.2.2 SNEŽINKASTA SHEMA ................................................................................................... 25 6.2.3 PRIMERJAVA ZVEZDNE IN SNEŽINKASTE SHEME ................................................. 26
6.3 DIMENZIJE OLAP KOCKE ...................................................................................................... 26 6.4 MERILA (ANGL. MEASURES) V OLAP KOCKI .................................................................. 28 6.5 OLAP IN PODATKOVNA SKLADIŠČA ................................................................................. 28 6.6 UČINKOVITA UPORABA OLAPA ......................................................................................... 28
7. UNIVERZE V SVETU Z RAZLIČNIMI PODATKOVNIMI SKLADIŠČI .................................... 29 8. ORODJA ZA POVPRAŠEVANJE, ANALIZE IN POROČILA IZ PODATKOVNIH SKLADIŠČ
IN EXCEL VRTILNE TABELE........................................................................................................... 36 8.1 EXCEL VRTILNE (VRTLJIVE) TABELE ............................................................................... 36
8.1.1 DELO Z VRTILNIMI TABELAMI .................................................................................... 36 9. PRIMER PODATKOVNEGA SKLADIŠČA ZA IZOBRAŽEVALNO USTANOVO V ACCESSU
............................................................................................................................................................... 46 9.1 SHEMA PODATKOVNEGA SKLADIŠČA ............................................................................. 47 9.2 POIZVEDBE IZ PODATKOVNEGA SKLADIŠČA ZA IZOBRAŽEVALNO USTANOVO 48
10. ZAKLJUČEK .................................................................................................................................. 57

7
Kazalo slik:
Slika 1: Tipična arhitektura podatkovnih skladišč. .................................................................. 13
Slika 2: Federativna arhitektura podatkovnih skladišč. ........................................................... 20 Slika 3: Primer olap kocke. ...................................................................................................... 23 Slika 4: Primer zvezdne sheme. ............................................................................................... 25 Slika 5: Primer snežinkaste sheme. .......................................................................................... 26 Slika 6: Primer hierarhične predstavitve dimenzij, ki vsebujejo več kot en nivo. ................... 27
Slika 7: Pregled podatkovnega skladišča univerze Arizona State University. ........................ 34 Slika 8: Zgradba podatkovne baze in skladišča. ...................................................................... 35 Slika 9: Ustvarjanje vrtilne tabele z uporabo zunanjega vira podatkov. .................................. 37 Slika 10: Izbiranje povezave (iskanje Accessove datoteke). .................................................... 38 Slika 11: Izbira poizvedb in tabel. ............................................................................................ 39
Slika 12: Ogrodje vrtilne tabele. .............................................................................................. 40
Slika 13: Vsota vpisnine vseh študentov po abecednem vrstnem redu v vrtilni tabeli. ........... 41 Slika 14: Prikaz filtriranja podatkov. ....................................................................................... 42
Slika 15: Slika prikaza možnosti povpraševanja v vrtilnih tabelah.......................................... 43 Slika 16: Slika prikaza možnosti dopolnjevanja praznega prostora v vrtilnih tabel. .............. 44 Slika 17: Vrtilni grafikon. ........................................................................................................ 45 Slika 18: Prikaz tabele s pomočjo ikone Selektor poročil. ....................................................... 45
Slika 19: Model relacij za primer 'študenta'. ............................................................................ 48 Slika 20: Struktura poizvedbe 1. .............................................................................................. 49
Slika 21: Prikaz filtriranja podatkov. ....................................................................................... 51 Slika 22: Struktura poizvedbe 2. .............................................................................................. 55
Kazalo tabel:
Tabela 1: Poizvedba 1. ............................................................................................................. 49 Tabela 2: Vrtilna tabela dimenzije predmeta. .......................................................................... 50
Tabela 3: Vrtilna tabela za povprečno oceno na smereh Matematika in ter Računalništvo in 52 Tabela 4: Vrtilna tabela števila študentov, vpisnine in povprečne ocene na fakultetah. .......... 53
Tabela 5: Vrtilna tabela števila študentov po letnicah diplomiranja in smereh študija. ........... 54 Tabela 6: Poizvedba 2 za število študentov po krajih. ............................................................. 55 Tabela 7: Tabela števila študentov po krajih. ........................................................................... 56

8
1. UVOD
Dandanes je uspešnost podjetja odvisna od sprejemanja hitrih in zanesljivih odločitev. Uspešna
podjetja se od ostalih razlikujejo po tem, da znajo pravočasno predvideti spremembe v okolju in se
nanje hitro odzvati. Hitre in pravilne odločitve temeljijo na informacijah, ki so podjetjem v danem
trenutku na voljo. V informacijskih sistemih se hrani veliko število podatkov, informacij. Zgodi se, da
ni pravih informacij ob pravem času. Zato si lahko pomagamo s podatkovnimi skladišči. Projekt
podatkovnega skladiščenja temelji na izgradnji enotne baze vseh poslovnih podatkov podjetja ter tako
ponuja uporabnikom izdelavo enostavnih analiz. Podatkovna skladišča so potrebna za učinkovite
analize tudi v izobraževalnih ustanovah.
2. PODATKOVNA SKLADIŠČA
Podatkovna skladišča (angl. Data Warehouse) so skladišča shranjenih podatkov. Oblikovana so za
lajšanje poročanja in izdelavo analiz daljšega časovnega obdobja.
Pomembne komponente za podatkovni skladiščni sistem so: sredstva za nalaganje in analiziranje
podatkov, sredstva za pridobivanje in nalaganje podatkov ter sredstva za upravljanje podatkovnega
slovarja.
Podatkovna skladišča vsebujejo veliko različnih podatkov, ki predstavljajo jasno sliko o pogojih
poslovanja na enem mestu v določenem času. Razvoj podatkovnega skladiščenja obsega razvoj
sistemov za pridobivanje podatkov iz operacijskih sistemov ter namestitev podatkovnega skladišča, ki
omogoča upravljavcem prilagodljiv dostop do podatkov. Pojem skladiščenja podatkov se na splošno
nanaša na kombinacijo več različnih baz podatkov v celotnem podjetju.
Tako razširjena definicija podatkovnega skladiščenja vključuje orodja za poslovno obveščanje, orodja
za pridobivanje, preoblikovanje in nalaganje podatkov v skladišča ter orodja za upravljanje in
nalaganje meta podatkov. [6]
Meta podatki so podatki o podatkih in so ključnega pomena za razumevanje podatkov, shranjenih v
podatkovnih skladiščih. [22]
Podatkovna skladišča potrebujejo organizacijo za zanesljivo, urejeno ter enotno integrirano poročanje
in analizo njihovih podatkov na različnih stopnjah združevanja. [3]
Na podlagi prečiščenih in združenih podatkov lahko izdelamo podatkovno skladišče, ki nam omogoča
jasen pregled vseh podatkov v določeni organizaciji.
Podatkovno skladišče je temelj za poslovno inteligenco. [11]
V vsakem podjetju oziroma organizaciji se sprejemajo odločitve, ki vplivajo na delovanje ali
poslovanje celotnega podjetja. Na podlagi vseh informacij, ki jih imamo na voljo, pa se odločamo o

9
delovanju podjetja. Informacije in informacijski procesi so torej nujni in obvezni pogoj za uspešno
vodenje in upravljanje podjetja. Podatkovna skladišča so tista, ki nam omogočajo, da z združevanjem
in organiziranjem določenih podatkov, s katerimi razpolaga podjetje, pridemo do dobrih poslovnih
informacij, ki so bistvene za uspešno delovanje podjetja.
V praksi so podatki shranjeni v zbirkah heterogenih sistemov. Poglejmo primer izobraževalne
ustanove. Ta ima lahko en sistem, ki obravnava študente, en sistem, ki obravnava zaposlene, enega, ki
obravnava opravljane izpitov, spet naslednjega, ki obravnava financiranje in vpisnino študentov.
V organizaciji so lahko vsi ti sistemi zelo slabo povezani ali pa sploh niso. Tako lahko pride do
zapletov oziroma do dolgotrajnega iskanja podatkov, čeprav so podatki na voljo nekje v različnih
podatkovnih sistemih. [1, 6, 25]
2.1 PROCES ETL ETL ali pridobivanje, preoblikovanje in nalaganje (ang. Extract Transform Load) je proces potreben za
nalaganje podatkovnega skladišča. Proces ETL je eden izmed najpomembnejših procesov, ki je skupaj
s podatkovnim skladiščem pomemben sestavni del vsakega sistema za poslovno obveščanje. Vendar
pa je ta proces tudi najbolj zapostavljen, sploh s strani naročnika, ker ne pozna njegove zmožnosti in
zaradi tega prihaja do napak pri izvajanju.
ETL vsebuje funkcije, ki nam izvorne podatke iz izvornih sistemov preoblikuje v uporabne
informacije, ki bodo shranjene v podatkovnem skladišču. Te informacije so pomembne pri
pridobivanju pomembnih strateških informacij za podjetje. Vendar pa, če izvorni podatki niso pravilno
preoblikovani, izvlečeni, prečiščeni in naloženi na pravilen način, bodo podatki v podatkovnem
skladišču netočni ali napačni.
Proces ETL vključuje:
1) pridobivanje (ekstrakcija) podatkov iz zunanjih virov (angl. extract),
2) preoblikovanje (transformacija) podatkov v skladu s poslovnimi potrebami (angl.
transform) in
3) nalaganje podatkov v podatkovno skladišče (angl. load).
Proces ETL potrebuje za izgradnjo podatkovnega skladišča kar 70 do 80 odstotkov časa. Ko so
podatkovna skladišča v produkcijski rabi, se proces ETL izvede kar avtomatično; periodično se sproži
na podatkovni bazi in poskrbi, da se podatki iz operativnih sistemov naložijo v podatkovna skladišča.
Ker se podatki lahko ves čas spreminjajo, je priporočljivo, da se sistem nadgradi s sistemom za
upravljanje polnjenja, ki administratorju podatkovnih skladišč pregledno pokaže, kateri podatki so se
naložili in spremenili ter kateri ne.

10
Proces ETL je zelo zahteven in kompleksen. Največji problem predstavlja obseg podatkov in njihovo
zajemanje, saj so v večini primerov razpršeni po različnih transakcijskih sistemih. [4, 9, 25]
Nekaj razlogov za težavnost procesa ETL:
- raznolikost in neskladnost izvornih sistemov,
- izvorni sistemi se lahko nahajajo na različnih platformah in v različnih
operacijskih sistemih,
- večina izvornih sistemov vsebuje stare aplikacije, ki tečejo na zastarelih
podatkovnih tehnologijah,
- izvorni sistemi ne hranijo predhodnih podatkov, ko se podatki spremenijo,
- natančnost podatkov je vprašljiva v sistemih, ki so nastajali dlje časa,
- zaradi novih poslovnih zahtev se spreminja struktura izvornih sistemov, pri čemer
pa moramo ustrezno prilagoditi tudi že delujoči proces ETL. [25]
2.1.1 PRIDOBIVANJE PODATKOV
Ekstrakcija podatkov oz. pridobivanje, zajemanje podatkov pomeni, da podatke najprej izvlečemo iz
izvornih sistemov, nato pa jih ustrezno preoblikujemo. Preverimo tudi kakovost podatkov. Podatke, ki
jih ne potrebujemo, zavržemo. Prečiščene podatke naložimo v podatkovna skladišča.
Pridobivanje podatkov je prva faza procesa ETL. Podatke pri večini podatkovnih skladišč zajemamo
oziroma pridobivamo iz različnih sistemskih virov. Sistemski viri so po navadi ločeni, vsak pa ima
lahko različno strukturo in obliko podatkov. Najpogosteje se uporabljajo relacijske podatkovne baze in
nepovezane datoteke. Proces ekstrakcije se izvaja vsakodnevno, pri tem pa moramo paziti, da ne
preobremenimo izvornega sistema v času, ko se izvajajo tekoča opravila. [18, 25]
2.1.2 PREOBLIKOVANJE
Ko podatke zajamemo iz izvornega sistema, še niso primerni in pripravljeni za nalaganje v
podatkovno skladišče. Zajete podatke moramo preoblikovati na način, da ustrezajo tako poslovnim
zahtevam kot tudi zahtevam skladišča. Določene podatke, ki jih zajamemo, je potrebno izboljšati,
dopolniti, saj je kvaliteta teh podatkov v starejših sistemih vprašljiva.
Preden podatke uporabimo, morajo v podatkovnem skladišču iti skozi številne pretvorbe oziroma
skozi številna preoblikovanja. Največ časa in dela nam vzame proces izboljšanja kvalitete podatkov.
Posledice preoblikovanja podatkov se vidijo pri analizah in pri sprejemanju dobrih ali slabih poslovnih
odločitev. [18, 25]

11
Glavne naloge transformacije (preoblikovanja) so:
- selekcija,
- razcepitev/združenje,
- pretvorba,
- seštevanje,
- oplemenitenje (izboljšanje). [25]
2.1.3 NALAGANJE
Proces nalaganja je zadnja faza v procesu ETL. V koraku nalaganja oziroma polnjenja naložimo
preoblikovane in očiščene podatke v podatkovno skladišče. Obseg procesa je odvisen od velikosti
podjetja (organizacije) in od njegovih zahtev. Nalaganje zahteva veliko časa, saj v času nalaganja
podatkovno skladišče ne sme biti dostopno za ostale uporabnike. Za nalaganje je potrebno najti
ustrezen časovni termin. Ker je to dolgotrajen postopek, je potrebno dobro premisliti o razdelitvi
procesa. Lahko ga izvajamo vzporedno, kar pomeni, da v podatkovno skladišče naložimo več manjših
paketov podatkov. Del podatkovnega skladišča, v katerem so podatki že naloženi, lahko uporabljamo,
medtem ko se v ostalem delu izvaja proces nalaganja. [4,18, 25]
3. ZGODOVINA
Koncept skladiščenja sega v pozna 80-ta leta, ko sta IBM-ova raziskovalca Barry Devlin in Paul
Murphy razvila poslovno podatkovno skladišče. Razvit koncept je bil namenjen zagotavljanju
arhitekturnega modela za tok podatkov iz operacijskega sistema za določitev podpore različnih okolij.
Koncept poskuša razjasniti probleme, povezane s tem tokom, v glavnem stroške le-tega. Ker
arhitekture skladiščenja podatkov ni bilo, je bila zahtevana ogromna odpravnina za podporo večjih
določitev podpore različnih okolij. V večjih podjetjih je bilo to običajno za neodvisno delovanje teh
odločitev. Vsako okolje je postreglo z različnimi uporabniki, vendar pogosto zahtevalo mnogo enakih
shranjenih podatkov. Proces zbiranja, čiščenja in integriranja podatkov različnih virov (navadno
dolgoročno obstoječih operativnih sistemov - vgrajenih sistemov) je bil tipično delno obnovljen za
vsako okolje. Po vrhu vsega pa so se pojavile nove zahteve in operativni sistemi so bili ponovno
preučeni kot nova odločitev. Potrebne zahteve zbiranja, čiščenja in integriranja novih podatkov so bile
pogosto prilagojene za hiter dostop uporabnikov.

12
Nekaj ključnih dogodkov v prvih letih skladiščenja podatkov:
- 1960 General Mills in Dartmount College v projekt skupnih raziskav razvijeta pogoja
(dimenzije) in (dejstva).
- 1970 Cnielsen zagotovi dimenzijske podatke za prodajo na drobno.
- 1983 Teradata uvaja sistem upravljanja baze podatkov, posebej za podporo odločanju.
- 1988 Barry Develin in Paul Murphy objavita članek Arhitekture za poslovne in informacijske
sisteme v IBM Sistem časopisu, kjer uvedejo izraz 'poslovanje skladiščenja podatkov'.
- 1990 Red Brick Systems uvaja Red Brick Warehouse, upravljanje podatkovnih baz posebej za
skladiščenje podatkov.
- 1991 Rešitve Prism uvajajo Prism Warehous Manager, programsko opremo za razvoj
podatkovnega skladišča.
- 1991 Bill Inmon objavi knjigo Izgradnja podatkovnih skladišč.
- 1995 je utemeljen 'The Data Warehouse Institute'; to je neprofitna organizacija, ki spodbuja
skladiščenje podatkov.
- 1996 Ralph Kimball objavi knjigo The Data Warehouse Toolkit.
- 1997 Oracle 8 s podporo zvezdne poizvedbe
Izumitelja podatkovnih skladišč in svetovno priznana strokovnjaka sta William H. Inmon in Ralph
Kimball. Slednji je avtor tem o skladiščenju podatkov in poslovne inteligence. Na splošno velja za
enega prvih arhitektov skladiščenja podatkov in pravi, da morajo biti podatkovna skladišča zasnovana
razumljivo in hitro.[6]
4. ARHITEKTUA PODATKOVNIH SKLADIŠČ
Ni prave ali napačne arhitekture, pač pa je več arhitektur, ki obstajajo v podporo številnim okoljem in
situacijam. Vrednost arhitekture ocenimo na podlagi zgradbe, vzdrževanja in uporabe podatkovnih
skladišč.
Arhitektura podatkovnih skladišč sestoji iz sledečih medsebojnih plasti:
- operativna baza podatkov; viri podatkov za podatkovno skladišče. Sem spadajo operativni
sistemi in zunanji viri (slika 1).
- plast dostopa do podatkov; vmesnik med informativno in informacijsko plastjo dostopa.
Sem spadajo orodja za pridobivanje, preoblikovanje in nalaganje podatkov v skladišče.

13
- plast meta podatkov; imenik podatkov (slika 1).
Je navadno bolj podroben kot operativni sistemi podatkov. Tu so slovarji za celotno skladišče in
včasih slovarji za podatke, ki so dostopni z orodjem poročanja in analize.
- Plast informacijskega dostopa; podatki dostopni za poročanje in analiziranje ter orodje za
poročanje in analiziranje podatkov.
Sem spada orodje poslovne inteligence in tudi razlike o metodologiji oblikovanja. [4, 6]
Slika 1: Tipična arhitektura podatkovnih skladišč.
Vir: : http://dataminingtools.net/wiki/introdw.php
Zgornja slika prikazuje da podatki v podatkovnem skladišču prihajajo iz baze operacijskih
sistemov pa tudi od drugih zunanjih virov. Ti podatki ki gredo skozi proces ETL, kjer podatke
pridobijo, jih preoblikujejo in nalagajo. Podatki se shranijo v podatkovno skladišče. To
uporabimo za analize, poročila in podatkovno rudarjenje.
4.1 NORMALIZIRAN PRISTOP V PRIMERJAVI Z DIMENZIONALNIM PRISTOPOM
Obstajata dva vodilna pristopa k shranjevanju podatkov v podatkovno skladišče: dimenzionalni pristop
in normalizirani pristop.
V dimenzionalnem pristopu so podatki o poslovnem dogodku razdeljeni na 'dejstva', ki so v glavnem
številski podatki o poslovnem dogodku, ali na 'dimenzije', ki so referenčne informacije, ki dejstva
uvrščajo v kontekst.

14
Podatki, ki jih za opravljanje izpita na fakulteti potrebujemo, so dejstva: število študentov prijavljenih
na izpit, imena študentov, indeks število, datum prijave na izpit, ime predmeta, ime profesorja.
Prednost tega pristopa je v tem, da je podatkovno skladišče uporabniku lažje razumljivo in tako lažje
za uporabo. Tudi iskanje podatkov iz skladišča po navadi poteka hitreje.
Glavne pomanjkljivosti pristopa pa so:
- Predvsem ohranitev integracije dejstev in dimenzij zaradi različnih operativnih sistemov za
nalaganje podatkov v skladišča, ki so zelo kompleksni.
- Težavno spreminjanje strukture podatkovnega skladišča, če organizacija, ki sprejme ta pristop,
spremeni način poslovanja.
Podatki so v skladišču shranjeni po pravilih glede na stopnjo normalizacije baze podatkov. Tabele so
sestavljene po področjih, ki odsevajo splošne kategorije podatkov (podatki o strankah, izdelkih,
financah ... ). Glavna prednost tega pristopa ja enostavnost dodajanja podatkov v bazo. Pomanjkljivost
pa je, da je zaradi števila vključenih tabel za uporabnike težje združevanje podatkov iz različnih virov
in težje dostopanje do informacij brez natančnega razumevanja virov podatkov in strukture podatkov v
skladišču.
Ta dva pristopa se medsebojno ne izključujeta, obstajajo pa tudi drugi pristopi. Dimenzionalni pristopi
vključujejo normalizacijo podatkov do določene mere. [2, 6]
4.2 SKLADNOST INFORMACIJ
Skladna dimenzija je dimenzija, katere značilnost je, da ima enoličen pomen, ne glede na to, s katero
tabelo dejstev jo povežemo in zagotavlja, da je podatek predstavljen le enkrat. [5]
Vprašanje je, kako uskladiti podatke. Na primer prvi operativni sistem za shranjevanje podatkov lahko
uporabi 'M' in 'Ž' za označevanje spola zaposlenega, medtem ko drugi operativni sistem lahko uporabi
oznaki 'moški' oziroma 'ženski'. Čeprav je to preprost primer, je ogromno dela pri usklajevanju
podatkov. Uporabljajo se orodja za pridobivanje, preoblikovanje in nalaganje informacij.
Cilj upravljanja s podatki je torej uskladiti podatke, ki jih uporabimo kot mere ali dimenzije. [6]

15
4.3 OD ZGORAJ NAVZDOL V PRIMERJAVI Z OD SPODAJ NAVZGOR METODOLOGIJO OBLIKOVANJA
4.3.1 Od spodaj navzgor ali pristop, imenovan distribuirana arhitektura (angl. Bottom-up design)
Ralph Kimball je zagovornik pristopa od spodaj navzgor. Njegova teorija pravi da, je podatkovno
skladišče skupek vseh podatkov znotraj podjetja. Informacije pa so vedno shranjene v
dimenzionalnem modelu. [21]
Področna skladišča ali manjše podatkovne shrambe ali (angl. Data marts), ki jih ustvarimo, zagotovijo
podatke za analize in poročanja za specifične poslovne procese. Podatki vsebujejo dimenzije in
dejstva. Isti podatki vsebujejo tudi osnovne podatke in po potrebi prevzete podatke. Sčasoma se
podatki združijo z namenom ustvariti celovito podatkovno skladišče.
Tako hitro, kakor se lahko ustvarijo podatki, se lahko spremeni poslovna vrednost. Ohranjanje
nadzora nad zgradbo podatkovnega skladišča je temeljnega pomena za ohranitev celovitosti popolnega
podatkovnega skladišča. Najpomembnejša naloga upravljanja pa je zagotavljanje, da so dimenzije med
podatki dosledne. S Kimballovimi besedami to pomeni, da se dimenzije skladajo.[6]
Področno skladišče je podmnožica podatkovnega skladišča določene organizacije. V distribuirani
arhitekturi je podatkovno skladišče vsota vseh področnih skladišč. Področno skladišče igra ponavadi
vlogo oddelčnega, krajevnega ali funkcionalnega podatkovnega skladišča in podpira eno ali več
specifičnih področij.
Področna skladišča postavljajo natančno določene oblikovalske zahteve. Vsako mora biti
predstavljeno z dimenzijskim delom, ki mora biti znotraj enotnega podatkovnega skladišča skladen.
Glavna naloga vseh, ki načrtujejo podatkovnega skladišča pri oblikovanju distribuirane arhitekture
podatkovnega skladišča je vzpostavitev, objava in vzdrževanje skladnih dimenzij in zagotavljanje
njihove dosledne uporabe. Brez upoštevanja pravil skladnih dimenzij podatkovno skladišče ne more
delovati kot povezana celota.[5]
Torej, distribuirana arhitektura temelji na množici povezanih, vendar samostojnih področnih shramb,
ki tvorijo podatkovno skladišče. Pomembno je, da obstaja skupno podatkovno vodilo, ki omogoča
izgradnjo podatkovnega skladišča. [6]

16
4.3.1.1 Podatkovni model v distribuirani arhitekturi podatkovnega skladišča
Struktura podatkovnih skladišč je denormalizirana, v nekaterih primerih pa delno normalizirana.
Osnovni podatkovni model je dimenzijski, za osnovno modelirno tehniko pa uporabljamo dimenzijsko
modeliranje.
Dimenzije, še posebej skladne, imajo navadno osnovne podatke. To so podatki, ki imajo najnižjo
raven podrobnosti in so shranjeni v podatkovnem skladišču. To pomeni, da morajo biti tudi osnovne
tabele dejstev na najnižjem nivoju, ki obstaja med pripadajočimi dimenzijami. To pa nam omogoča, da
podatki lažje prehajajo iz operativnih podatkovnih baz v tabele dejstev. [6]
4.3.1.2 Ostale posebnosti
Arhitektura omogoča precej hitro gradnjo prvega področnega skladišča, ki ima velik poslovni vpliv in
ga je in ga lahko enostavno izvedemo. Iz poslovnih zahtev so razvidne analize, ki jih organizacije
potrebujejo. Tak pristop je pomemben, ker nam omogoča, da v kratkem času pridobimo delujoče
podatkovno skladišče in tako tudi podporo vseh uporabnikov. To pa nam omogoča gradnjo novega
področnega skladišča.[5]
4.3.2 Od zgoraj navzdol ali pristop, imenovan centralizirana arhitektura (angl. Top-down design)
Eden prvih avtorjev na področju skladiščenja podatkov je Bill Inmon, ki je definiral podatkovno
skladišče kot centralno skladišče celotnega podjetja. Je eden izmed vodilnih zagovornikov pristopa od
zgoraj navzdol pri oblikovanju podatkovnega skladišča, v katerem je le-to oblikovano z uporabo
normaliziranega modela podatkov.
Po mnenju Inmona je podatkovno skladišče del sistema splošne poslovne inteligence. Je center
sistema, ki ponuja logično orodje za zagotavljanje poslovne inteligence in upravljanje poslovne
zmogljivosti. [6]
Podjetje ima le eno podatkovno skladišče, in podatki iz podatkovnega skladišča so vir. [21]
Izjavlja, da je podatkovno skladišče:
SUBJEKTIVNO ORIENTIRANO
- Podatki so orientirani tako, da se vsi elementi podatkov povezujejo z naslednjim dogodkom ali
predmetom. Vsi ti elementi so med seboj povezani.

17
NEOHLAPNO
- Podatki v skladišču niso nikoli prepisani ali izbrisani. Ko so enkrat v skladišču, so statični,
samo za branje in jih hranijo za nadaljnje poročanje.
INTEGRIRANIO
- Podatkovno skladišče vsebuje podatke iz večine ali celotnega operativnega sistema in ti
podatki so usklajeni.
Metodologija od zgoraj navzdol ustvari usklajene dimenzionalne poglede podatkov, saj so le-ti
naloženi iz centralnega skladišča. Ta pristop je izkazal tudi zanesljivost pri spremembah v poslovanju.
Ustvarjanje novih dimenzionalnih podatkov v primerjavi s podatki, ki so shranjeni v podatkovnem
skladišču, je relativno lahka naloga. Glavna pomanjkljivost pri tem pristopu je, da predstavlja zelo
velik projekt z zelo širokim obsegom. Trajanje projekta od samega začetka in vse do točke, ko končni
uporabniki izkusijo začetne prednosti, je lahko dolgo. Poleg tega je lahko ta metodologija
neprilagodljiva in se ne odziva na potrebe oddelka med fazami izvedbe.
Torej, centralizirano podatkovno skladišče je sestavljeno iz osrednjega podatkovnega skladišča in iz
množice področnih skladišč. Značilnost te arhitekture je, da se področna skladišča polnijo izključno iz
osrednjega. [6]
4.3.2.1 Načrtovanje in gradnja centraliziranega podatkovnega skladišča
Razlike med operativnim svetom in sistemom podatkovnega skladiščenja so močno vidne iz opisa
razvojnih ciklov. Operativno okolje je podprto s klasičnim razvojnim ciklom, ki ga vodijo zahteve. Te
zahteve je potrebno dobro razumeti, da lahko preidemo v faze načrtovanja in razvoja. Razvojni cikel
podatkovnega skladišča je podatkovno voden, pričnemo ga s podatki. Po tem ko so podatki združeni,
pogledamo, če je potrebno njihovo dodatno usklajevanje. Ko so rezultati programov analizirani, šele
na koncu razumemo zahteve. Vidimo, da je vrstni red posameznih faz razvojnega cikla in okolja
podatkovnega skladišča tako popolnoma obrnjen. [2, 5]
4.3.2.2 Podatkovni model v centralizirani arhitekturi podatkovnega skladišča
Struktura podatkovnega skladišča je normalizirana, v nekaterih primerih pa je delno denormalizirana.
To pomeni delno odstopanje od zahtev po doseganju tretje normalne oblike. Kako to uredimo, je
opisano v naslednjih korakih:

18
- Kjer je znano, da se bodo odvečni podatki redno uporabljali skupaj z drugimi podatki in to
tudi dovoljujemo.
- Kjer so enkrat izračunani podatki večkrat uporabljeni.
- Če sklepamo, da bodo neke skupine podatkov pogosto uporabljene skupaj, izdelamo zanje nov
skupen prostor. Tako lahko npr. mesečne podatke za mesece od januarja do decembra fizično
nakopičimo samo na eno lokacijo in s tem poenostavimo dostop.
- Če sklepamo, da se verjetnost dostopa do posameznih elementov pri uporabi bistveno
razlikuje in zato izvedemo ločitev podatkov. [2, 5]
4.3.2.3 Področno skladišče in operativna podatkovna hramba v centralizirani arhitekturi podatkovnega skladišča
Operativna podatkovna shramba je v tej strukturi eden izmed podatkovnih virov podatkovnega
skladišča. Je hibridna struktura, ki izpolnjuje hibridne in analitična zahteve. Nudi kratek transakcijski
odzivni čas, hkrati pa je tudi prostor združenih podatkov. V primerjavi s podatkovnimi skladišči
izpolnjuje zahteve po predmetni usmerjenosti, združenosti, ne vsebuje pa zgodovinskih podatkov,
ampak le trenutne, aktualne in podrobne podatke določene organizacije.
Ker izhaja iz arhitekture centraliziranega podatkovnega skladišča je osrednje podatkovno skladišče
edini vir podatkov za področno skladišče.[5]
4.3.2.4 Osnovne značilnosti, ki ločujejo področno in podatkovno skladišče
Te so:
- Podatkovno skladišče vsebuje zelo veliko količino podrobnih podatkov daljšega obdobja v
enostavnih strukturah, področno skladišče pa le združene podatke za določeno časovno
obdobje v preteklosti v veliko bolj zapletenih strukturah.
- Strukture podatkovnega skladišča so namenjene neznani uporabi, strukture področnega
skladišča so načrtovane za točno določene, znane namene.
- Področna skladišča so manjša.
- Podatkovno skladišče ne vsebuje samo istovrstnih podatkov, ampak tudi skupne podatke
poslovanja celotne organizacije. [5]

19
4.3.3 Hibridna rešitev ali pristop, imenovan federativna arhitektura ali kombiniran pristop
Zagovorniki obeh pristopov od zgoraj navzdol (ali centralizirana arhitektura) in spodaj navzgor (ali
distribuirana arhitektura) so spoznali, da imata oba ugodnosti in tveganja. Hibridna metodologija se je
razvila, da bi izkoristila hiter časovni preobrat pristopa od spodaj navzgor in široko (podjetno)
usklajenost podatkov pristopa zgoraj navzdol. Za izbiro pravilne, učinkovite in ustrezne arhitekture
podatkovnega skladišča, ki zagotavlja primerne odzivne čase in ustrezno izbiro virov, je obvezno
poznavanje lastnosti posameznih arhitektur, njihovih prednosti in pomanjkljivosti. Pravilna odločitev
zmanjša tveganje, znižuje stroške izgradnje in vzdrževanja ter omogoča optimalno delovanje. [6]
4.3.3.1 Gradnja hibridnega ali federativnega podatkovnega skladišča
1. Obdelovanje obstoječih sistemov podatkovnih in področnih skladišč lahko prikažemo v
diagramu, ki prikazuje sisteme in vse podatkovne tokove med njimi.
2. Obdelovanje obstoječih sistemov na nivoju toka podatkov vključuje podatkovni tok,
pripadajoče korake povezovanja in združevanja ter hrambo meta podatkov. Vsak podatkovni
element mora biti ocenjen, preverjena kakovost, razpoložljivost in enostavnost dostopa.
3. Določitev podatkov, ki prinašajo dodatno vrednost in imajo dovolj velik pomen v celotnem
sistemu.
4. Zbiranje podatkov iz prejšnjega koraka in analiziranje njihovega vpliva in možnosti za
izvršitev. V tem koraku se tudi izbere ustrezne kandidate, ki najbolj prispevajo k strateškemu
načrtu organizacije in so tudi najbolj tvegani. Podatke, ki jih uporablja le majhna količina
uporabnikov, izpustimo.
5. Izvedba orodja za zajem, preoblikovanje in nalaganje podatkov, ki podpira skupno, celotno
shrambo meta podatkovnih sistemov in področnih skladišč.
6. Sledi gradnja manjše federativne arhitekture in nato analiza in poročilo narejenega. To
potrebujemo za nadaljnje združevanje. Te združitve morajo biti majhne in se morajo
osredotočiti na najbolj pomembne točke poslovanja. [2, 5]
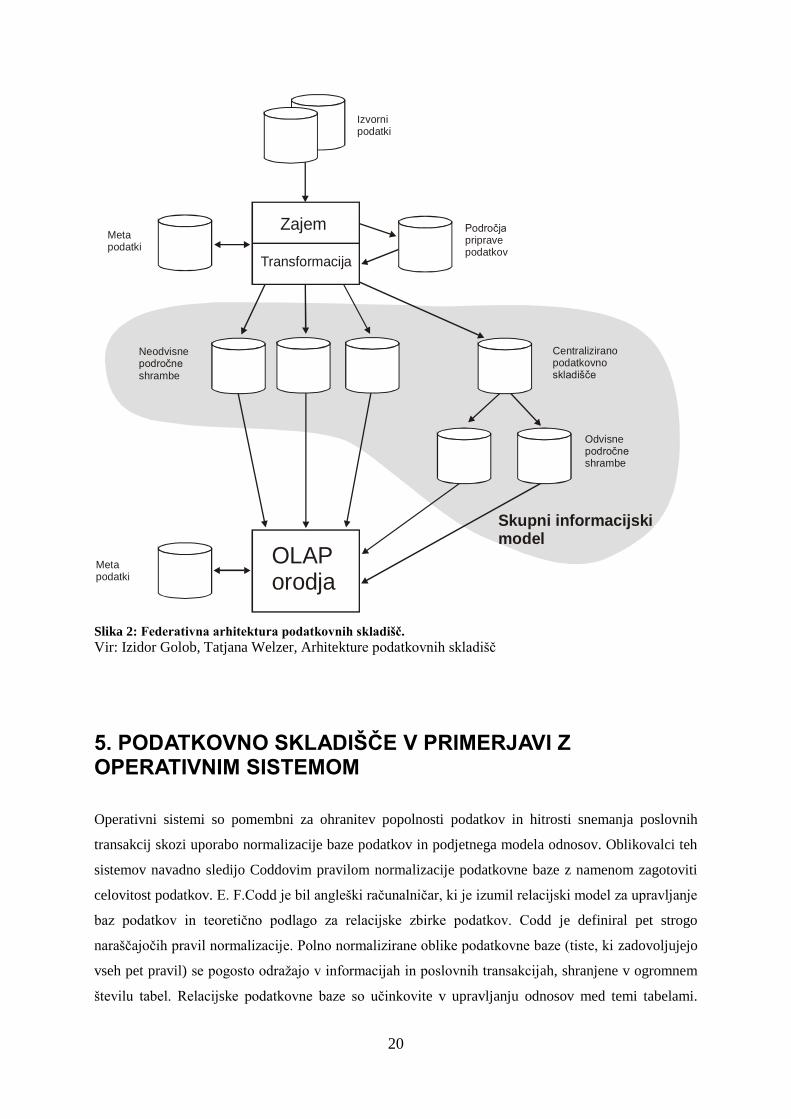
20
Metapodatki
Izvornipodatki
Zajem
Transformacija
Področjapripravepodatkov
Neodvisnepodročneshrambe
Centraliziranopodatkovnoskladišče
Odvisnepodročneshrambe
Skupni informacijskimodel
Metapodatki
OLAPorodja
Slika 2: Federativna arhitektura podatkovnih skladišč.
Vir: Izidor Golob, Tatjana Welzer, Arhitekture podatkovnih skladišč
5. PODATKOVNO SKLADIŠČE V PRIMERJAVI Z OPERATIVNIM SISTEMOM
Operativni sistemi so pomembni za ohranitev popolnosti podatkov in hitrosti snemanja poslovnih
transakcij skozi uporabo normalizacije baze podatkov in podjetnega modela odnosov. Oblikovalci teh
sistemov navadno sledijo Coddovim pravilom normalizacije podatkovne baze z namenom zagotoviti
celovitost podatkov. E. F.Codd je bil angleški računalničar, ki je izumil relacijski model za upravljanje
baz podatkov in teoretično podlago za relacijske zbirke podatkov. Codd je definiral pet strogo
naraščajočih pravil normalizacije. Polno normalizirane oblike podatkovne baze (tiste, ki zadovoljujejo
vseh pet pravil) se pogosto odražajo v informacijah in poslovnih transakcijah, shranjene v ogromnem
številu tabel. Relacijske podatkovne baze so učinkovite v upravljanju odnosov med temi tabelami.

21
Baze imajo zelo hiter vnosni, nadgradnji čas, kjer je le majhna količina podatkov teh tabel
uporabljenih vsakokrat, ko se obdela transakcija. Na koncu so starejši podatki, ki so z namenom
izboljšati učinkovitost, po navadi periodično odstranjeni iz operativnega sistema.
Podatkovna skladišča so optimizirana za hitrost analize podatkov. Pogosto so podatki v skladišču
denormalizirani preko dimenzioniranega dela. Da bi pospešili iskanje podatkov, so v skladiščih le-ti
večkrat shranjeni v njihovih najbolj enovitih in povzetih oblikah, ki jih imenujemo agregati. Isti
podatki, podatki iz skladišč, so zbrani iz operativnega sistema in v skladišču shranjeni tudi potem, ko
so bili iz sistema odstranjeni. [6, 24]
5.1 RAZVOJ PODATKOVNIH SKLADIŠČ V ORGANIZACIJSKI UPORABI
Organizacije v glavnem začnejo z relativno preprosto uporabo skladiščenja podatkov. Čez čas pa
razvijejo tudi bolj prefinjene oblike skladiščenja podatkov.
Splošne stopnje uporabe podatkovnih skladišč se delijo na:
- Operativna podatkovna baza
V tej začetni fazi so podatkovna skladišča razvila kopiranje podatkov iz operacijskega sistema na drug
strežnik, kjer prenos podatkov obremeni opravila operativnega sistema.
- Odklučno (angl. Off line) podatkovno skladišče
Skladišče je v tej fazi nadgrajeno s podatki operativnega sistema, na ravni redne baze in podatki iz
skladišča so shranjeni v podatkovne strukture, zasnovane za lažje poročanje.
- Časovno realna podatkovna skladišča
V tej fazi so skladišča nadgrajena vsakokrat, ko operativni sistem opravi transakcijo (naročilo,
dostavo, rezervacijo pošiljke).
- Integrirano podatkovno skladišče
V tej fazi podatkovno skladišče zbere podatke iz različnih področij poslovanja, tako lahko uporabnik v
drugih sistemih poišče informacije, ki jih potrebuje.
PREDNOSTI
Prednosti, ki jih ponuja podatkovno skladišče:
- Je navaden podatkovni model za podatke, ne glede na vir podatkov. Tako je poročanje in
analiza informacij lažja, kot če bi obstajalo več podatkovnih modelov za pridobivanje
informacij ( na primer: prodajni računi, naročilnice ... ).
- Podatki se nalagajo v skladišče, problemi pa so identificirani in razrešeni. To pa zelo
poenostavi poročanje in analizo.

22
- Informacije v skladišču so pod nadzorom uporabnikov skladišča tudi, če je sistem virov
podatkov čez čas odstranjen. Informacije so lahko varno shranjene za daljšo časovno obdobje.
- Ker so podatki ločeni od operativnega sistema, podatkovna skladišča ponujajo iskanje
podatkov brez upočasnjevanja operativnega sistema.
- Podatkovna skladišča lahko delujejo v povezavi z izboljšanjem vrednosti operativnih
poslovnih aplikacij, zlasti s sistemom upravljanja odnosa s strankami.
- Podatkovna skladišča lajšajo odločitve aplikacij podpornega sistema, kot je trend poročila (na
primer postavke z večino prodaje na določenem območju v zadnjih dveh letih), razen pri
poročilih, ki prikazujejo dejansko uspešnost v primerjavi s cilji. [3,6]
POMANJKLJIVOSTI
Nekatere pomanjkljivosti podatkovnega skladišča:
- Podatkovna skladišča niso optimalno okolje za nestrukturirane podatke.
- Podatki v skladišču imajo v času svojega obstoja visoke stroške.
- Podatki v skladišču lahko relativno hitro zastarajo. Tukaj se pojavi strošek dostave
neoptimalnih podatkov.
- Pogosto je majhna razlika med podatkovnim skladiščem in operativnim sistemom.
PRIMERI APLIKACIJ
Nekaj primerov aplikacij, v katerih se lahko uporabijo podatkovna skladišča:
- analiza kreditne kartice,
- analiza prevare zavarovanja,
- analiza zapisa (seznama) klicev,
- upravljanje logistike. [6]
6. OLAP
OLAP kocka je vizualni model za oblikovanje podatkov v podatkovnih skladiščih. OLAP
(angl.OnLine Analytical Processing) pomeni sprotna analitična obdelava. Je programska oprema ali pa
tudi postopek, ki je vgrajen v programsko opremo, ki nam omogoča, da v zelo kratkem času
analiziramo veliko količino podatkov. Podatke prikazuje večrazsežno. Taki strukturi pravimo OLAP
kocka. [8]

23
6.1 OLAP KOCKA OLAP kocka je osnovna podatkovna struktura v večdimenzionalnem sistemu OLAP. Predstavlja
oziroma prikazuje nam množico podatkov, ki so shranjeni in prikazani na večdimenzionalen način.
Kako je zgrajena kocka, natančno opisujejo množice dimenzij in merila. S pomočjo dimenzij
analiziramo podatke, merila pa predstavljajo vrednost ali velikost podatka, ki ga analiziramo.
Množica podatkov kocke je sestavljena iz podmnožice podatkov podatkovnega skladišča. Podmnožice
podatkovnega skladišča so pomembne, ker taka baza s podmnožicami ni preobremenjena s tekočimi
podatki in je bolj primerna za procesiranje kock kot živa baza. Baza podatkovnega skladišča se po
potrebi polni v nekem določenem časovnem intervalu. Na primer: lahko jo polnimo dnevno, tedensko,
mesečno ali letno. Tako se tudi procesiranje kock izvaja v nekem določenem časovnem intervalu. Še
preden pa ima uporabnik dostop do kocke, si kocka pri procesiranju pripravi tabelo oziroma strukturo,
ki vsebuje vnaprej preračunane podatke. [8]
Slika 3: Primer olap kocke.
Slika prikazuje primer enostavne kocke s tremi dimenzijami in eno meritvijo. Vsaka kocka vsebuje
shemo. [8]
6.2 PODATKOVNI MODEL – KOCKE IN PODATKOVNEGA SKLADIŠČA
Shema kocke je množica povezanih tabel v podatkovnem skladišču, iz katerih kocka črpa vir
podatkov. Shema kocke vsebuje več tabel, tabelo dejstev in tabele dimenzij. Tabela dejstev se nahaja v

24
središču sheme in ima svoj vir v meritvah kocke. Tabele dimenzij pa imajo vir v dimenzijah kocke.
Meritve in dimenzije torej tvorijo množico tabel, ki se imenuje shema kocke. Vsaka shema kocke je
sestavljena iz tabele dejstev in ene ali več tabel dimenzij.
Poznamo dva tipa podatkovnih modelov za podatkovna skladišča. Prvi je zvezdna shema in drugi je
snežinkasta shema. [8]
6.2.1 ZVEZDNA SHEMA
Zvezdna shema je dobila ime po obliki podatkovnega modela, kjer so tabele v modelu razporejene v
obliki zvezde. Ta model vsebuje glavno (osrednjo) tabelo, imenovano tabela dejstev, ki je obkrožena z
večjim številom dimenzijskih tabel.
Primer na spodnji sliki (slika 4) prikazuje, da tabela dejstev zajema podatke o študentu in ključe vseh
dimenzij, preko katerih je tabela dejstev povezana z ostalimi dimenzijskimi tabelami. V tem primeru
zvezdne sheme so to študent, delavec, naslov, izpiti in fakulteta.
Tabela dejstev vsebuje poleg ključev, preko katerih je povezana z ostalimi dimenzijskimi tabelami,
tudi dva atributa, ki vsebujeta vrednost. [8]

25
Slika 4: Primer zvezdne sheme.
6.2.2 SNEŽINKASTA SHEMA
Iz zvezdne sheme izpeljemo model snežinkaste sheme. Dimenzijske tabele v snežinkasti shemi
vsebujejo normalizirane podatke, to pa dosežemo z dodatno tabelo in s tem preprečimo podvajanje
atributov. S tem prihranimo prostor za shranjevanje podatkov, saj se zmanjša število zapisov v tabelah,
izgubimo pa učinkovitost. Snežinkasta shema ni tako priljubljena kot zvezdna. Njena največja težava
je kompleksnost poizvedb, kar je posledica bolj zapletenega podatkovnega modela. Kompleksnejše
poizvedbe podaljšujejo čas izvedbe in zmanjšujejo učinkovitost. [8]

26
Slika 5: Primer snežinkaste sheme.
6.2.3 PRIMERJAVA ZVEZDNE IN SNEŽINKASTE SHEME
Največja razlika med zvezdno in snežinkasto shemo se pokaže pri določanju dimenzijskih tabel. V
dimenzijskih tabelah, kjer se vrednosti v poljih posameznih atributov ponavljajo, takšne ponavljajoče
atribute prenesemo v pomožno tabelo. Ta pomožna tabela je z dimenzijsko tabelo povezana s ključem.
Normalizacija v nadaljevanju lahko sledi tudi v pomožni tabeli, tako da k tej tabeli povežemo še eno
pomožno tabelo. [8]
6.3 DIMENZIJE OLAP KOCKE
Vsaka kocka vsebuje dimenzije. V bazi podatkov je vsaka dimenzija predstavljena kot dimenzijska
tabela. Vsaka vsebuje atribute, ki opisujejo to posamezno dimenzijo. Vsaka dimenzija vsebuje enega
ali več nivojev, po katerih je dovoljeno spuščanje in dviganje, torej premikanje po eni dimenziji. S tem
je omogočeno, da si podatke pogledamo na različnih hierarhičnih nivojih. Dimenzije kategorizirajo
podatke kock na hierarhičen način, sestavljene so iz več nivojev. Nivo je naziv množice članov v
hierarhični dimenziji, kjer so vsi člani množice enako oddaljeni od korena do hierarhije. Pa si
poglejmo primer.

27
Razširimo časovno dimenzijo. V tem primeru bo vsebovala tri nivoje. Pri datumu diplomiranja nam
zadostujejo trije nivoji. To so:
1. Leto
2. Mesec
3. Dan
V našem primeru bodo nivoji oziroma množice članov vsebovali naslednje člane:
1. V nivoju Leto bomo imeli člane 2010, 2011, 2012.
2. V nivoju Mesec bomo imeli člane Januar, Februar, Marec ..., December.
3. V nivoju Dan bomo imeli merila od prvega do zadnjega dneva v mesecu. To merilo je odvisno od
vnosa zadnjega datuma diplomiranja, če delamo analizo nad operativno bazo. Če pa delamo analizo
nad podatkovnim skladiščem, bo zadnji tisti datum, ko je bilo zadnje polnjenje iz operativno baze
podatkov v podatkovno skladišče.
Posamezni členi so znotraj dimenzije urejeni hierarhično. Tako je nadrejeni člen vedno seštevek vseh
njemu podrejenih členov. Iz stolpcev tabele dimenzije so izpeljani nivoji, ki razvrščajo člane po
hierarhiji. V vsaki posamezni dimenziji so podatki prikazani od najvišjega do najnižjega, torej od
najbolj splošnega do najbolj podrobnega.[8]
Slika 6: Primer hierarhične predstavitve dimenzij, ki vsebujejo več kot en nivo.
Privatna dimenzija je dimenzija, ki se uporablja samo v eni kocki. Kocka te dimenzije ne deli z drugo
kocko.

28
Deljene dimenzije si kocke lahko delijo med seboj. Pogosto si kocke delijo med seboj časovne
dimenzije. [8]
6.4 MERILA (ANGL. MEASURES) V OLAP KOCKI
Množica vrednosti v kocki, ki temelji na stolpcu v tabeli dejstev kocke in so pogosto numerična, so
merila kocke. Vrednosti za vsaka merila vsebuje celica kocke, ki je najosnovnejši element kocke. Za
merila je podana funkcija agregacije, s pomočjo katere se določa, na kakšen način so vrednosti iz
nižjih nivojev združene na višjem nivoju. Kocka lahko vsebuje več meril.
Agregacije vnaprej izračunamo in shranimo povzetke podatkov, ki izboljšajo odzivne čase poizvedb.
Agregacije podatkov uporabljamo pri zahtevnejših analizah, ko želimo sproti prikazati čim več
informativnih in izpeljanih podatkov. [8]
6.5 OLAP IN PODATKOVNA SKLADIŠČA
Vloga tehnologije OLAP je, da iz velike količine podatkov izlušči pravila ali dejstva, ki jih na prvi
pogled ne opazimo. Primerna je za obdelavo velike količine ustrezno pripravljenih podatkov iz sistema
OLTP (transakcijski procesni sistem). Ta sistem je osnovni poslovni sistem, ki deluje na operacijskem
nivoju podjetja. Pomemben je za izvajanje dnevnih opravil v podjetju, ki so potrebna za normalno
delovanje ali poslovanje.
Sama uporaba OLAP tehnologije v transakcijskem sistemu OLTP nam ne bi prinesla pravilnih
rezultatov, zato se tehnologija OLAP vedno uporablja s podatki v podatkovnem skladišču. [23]
6.6 UČINKOVITA UPORABA OLAPA
Po procesu ETL v določenih časovnih obdobjih napolnimo podatkovno skladišče. Če so podatki v
podatkovnem skladišču že urejeni, nas čaka le še analiziranje. Tehnologija OLAP je pri tem
najprimernejša, saj v osnovi ponuja pogled na združene podatke z več dimenzij.
Poglejmo si za primer delovanja ene velike univerze. Če hočemo analizirati delovanje te izobraževalne
ustanove, potrebujemo naslednje dimenzije (celina, država, mesto), naziv fakultete (kratko ime, dolgo
ime), čas študiranja (leto, mesec, dan), študent (naslov, poštna številka, priimek, ime) in smer študija
(smer, letnik, semester).

29
Na študente lahko gledamo z več dimenzij, kot so dimenzija fakultete, časa, kraja in podobno. Temu
strokovno pravimo, da gledamo na podatke v podatkovnem skladišču večdimenzionalno, torej z več
vidikov hkrati. Vendar pa nam ni potrebno za vsako vprašanje upoštevati vse dimenzije, ampak v
analize vključujemo samo tiste dimenzije, ki nas trenutno zanimajo in so zanimive za analiziranje.
Preko dimenzij gledamo neko opravljeno povpraševanje (število študentov, vpisnina, smer študija in
podobno), za vsako povpraševanje pa določimo, kaj od tega bo merljivo. Vedno moramo vnaprej
določiti, glede na katero merljivo količino bomo pregledovali podatke prek več dimenzij. [8]
Slika 3 prikazuje število diplomiranih študentov od leta 2009 do leta 2012 na fakultetah FNM, FERI,
FF in PF ter iz katere regije prihajajo diplomiranci. Za vsako fakulteto lahko vidimo, koliko študentov
je diplomiralo v določenem letu.
Tabeli, v kateri shranjujemo podatke, pravimo tabela dejstev (fact table). Merimo število študentov, to
so dejstva. Časovno dimenzijo lahko razdelimo na leto, mesec, dneve, dimenzijo kraja na celino,
državo, mesto, občino, regijo, študente pa po fakultetah, kjer so diplomirali, FNM, FERI, FF, PF. Zdaj
vemo, kaj so dimenzije in kaj tabele dejstev. Oboje skupaj pa imenujemo kocka, kar se dobro vidi na
sliki 3.
Glede na podatke, ki jih imamo v podatkovnem skladišču, lahko izvajamo različne analize. Več kot je
dimenzij, bolj so analize zanimivejše in kompleksnejše. Tehnologija OLAP na tem področju upraviči
svojo uporabnost in obstoj. [8, 10]
7. UNIVERZE V SVETU Z RAZLIČNIMI PODATKOVNIMI SKLADIŠČI
V nadaljevanju bom predstavila nekaj svetovno znanih univerz. Prikazala bom, katero podatkovno
bazo, orodja za nalaganje podatkov orodja za podatkovno modeliranje, meta data orodja in katere
operacijske sisteme uporabljajo.
1) California Community Colleges
Predmetna področja: AC (Awards, Course, Curriculum, Faculty Loads), EN (Enrollment), FA:
(Financial Aid), FI (Fee Waiver Analysis), HR (Human Resources, Labor Distribution), ST:
(Assessment, Student Demographics).
Baza, ki jo uporabljajo: Microsoft SQL Server 7.0/Teradata
ETL orodja za nalaganje podatkov: N/A
Meta data orodja: N/A

30
Tip sheme: ASCII Extract files
Server OS: Win 2000 SQL / Unix (Teradata)
2) Georgetown University
Predmetna področja: AC (Awards – In progress, Course), FI (Budgeting – Actual vs Budgets, General
Ledger – PeopleSoft; HR Labor Distribution, Payroll Genesys), ST (Students Records – SCT/IA)
Baza, ki jo uporabljajo: Oracle
ETL orodja za nalaganje podatkov: Informatica
Orodja za podatkovno modeliranje: Erwin
Meta data orodja: Home grown Oracle tables
Server OS: Unix
3) Harvard University
Predmetno področje: AD (Development/Advancment), FI (Accounts Payable – OracleApps,
Budgeting – OracleApps, General Ledger – OracleApps, Purchasing – OracleApps), HR (Human
Resources – People Soft, Payroll – People Soft), ST (Student Information), OT (Catering Services,
Grant Mnagement)
Baza, ki jo uporabljajo: Oracle 8.1.6, 9.2.0.2
ETL orodja za nalaganje podatkov: Informatica, BCV of OraApps 10.7 NCA OLTP,
Orodja za podatkovno modeliranje: Oracle Designer
Meta data orodja: Oracle Designer
Server OS: Solaris
4) Indiana University
Predmetno področje: AC (Course, Library, Student Credit Hours), EN (Admissions, Enrolment,
Recruiting, Student Profiles), FA (Financial Aid) FI (Finance), HR (Human Resources, Payroll), ST
(Student)
Baza, ki jo uporabljajo: Oracle 9.2.03
ETL orodja za nalaganje podatkov: Informatica
Orodja za podatkovno modeliranje: različna kombinacija orodij
Meta data orodja: različna kombinacija orodij
Server OS: Unix delujoč na IBM SP Frame
5) Ithaca College
Predmetno področje: AD (Alumni/Development, Development/Advancment), FI (Acounts Payable,
Budgeting, General Ledger, Purchasing), HR (Human Resources)
Baza, ki jo uporabljajo: Oracle 8i

31
ETL orodja za nalaganje podatkov: Oracle Warehouse Builder
Orodja za podatkovno modeliranje: Oracle Designer
Server OS: Win NT/2000
6) Kentucky Community & Tehnical College System
Predmetno področje: /
Baza, ki jo uporabljajo: Oracle 10g in Oracle 11g
ETL orodja za nalaganje podatkov: Microsoft SQL Server 2000 (RDM), Ascential DataStage - Oracle
10g
Orodja za podatkovno modeliranje: Sybase – PowerDesigner, Ascential MetaStage, Pencil & Paper
Meta data orodja: Sybase – PowerDesigner, Ascential MetaStage
Tip sheme: Denormalizirane tabele, Dimezionalna in Zvezdna shema
Server OS: Solaris in Windows Server 2003
7) Nevada System of Higher Education
Predmetno področje: FI (Finance), HR (Human Resources), ST (Student Information), OT (Campus
Directory)
Baza, ki jo uporabljajo: Oracle 10g
ETL orodja za nalaganje podatkov: cobol, pl/sql
Orodja za podatkovno modeliranje: Designer, Pencil & Paper
Server OS: Unix
8) North Dakota University System
Predmetno področje: FI (Finance, General Ledger, Purchasing), HR (Humanic Resouces, Payroll), ST:
(Student)
Baza, ki jo uporabljajo: Oracle 8i
ETL orodja za nalaganje podatkov: Oracle Data Mart Suite
Orodja za podatkovno modeliranje: Designer component of Oracle Data Mart Suite
Meta data orodja: Designer component of Oracle Data Mart Suite
Tip sheme: zvezdnata shema, Oracle tables in tabela dejstev
9) Pennsylvania State System of Higher Education
Podatkovno področje: AD (Alumni/Development) EN (Admissions, Enrollment), FA (Financial Aid),
FI (Finance) HR (Human Resources), ST: (Student)
Baza, ki jo uporabljajo: MS SQL 2000
ETL orodja za nalaganje podatkov: MS DTS
Orodja za podatkovno modeliranje: SQL Server
Server OS: Windows 2000

32
10) Priceton University
Predmetno področje: EN (Admissions Un/Graduate, Recruiting), FA (Financial Aid), FI: (Accounts
Payable, Finance, General Ledger, Revenue), HR (Human Resources), ST (Graduation, Majors,
Student, Test Scores), OT (Campus Directory, Telephone Billing)
Baza, ki jo uporabljajo: Oracle
ETL orodja za nalaganje podatkov: Cognos Decision Stream/Data Manager
Orodja za podatkovno modeliranje: ERWIN, Visio
Tip sheme: zvezdnata shema, denormalized tables
Server OS: Sun Unix (Solaris)
11) South Orange County Community College District
Baza, ki jo uporabljajo: SQL Server DBMS
ETL orodja za nalaganje podatkov: SQL Server Integration Services
12) Trinity College
Predmetno področje: AD (Development/Advancement – People Soft), FI (Finance)
Baza, ki jo uporabljajo: Microsoft SQL
ETL orodja za nalaganje podatkov: Cognos Decision & SQL Code
Orodja za podatkovno modeliranje: Microsoft Visio
Meta data orodja: Microsoft Visio
Tip sheme: zvezdna shema
Server OS: Microsoft 2000
13) Tufts University
Predmetno področje: AC (Course, Student Credits Hours), AD (Alumni, Development/
Advancement), EN (Admissions – Undergraduate, Enrollment), ST (Degerss, Graduatins, Majors,
Students Demographics/ Records/ Registration), OT (Management, Telephone Billing)
Baza, ki jo uporabljajo: Oracle 10g
ETL orodja za nalaganje podatkov: pl/sql, sql loader, Business Objects Data Integrator
Orodja za podatkovno modeliranje: ER/Studio
Meta data orodja: MS Access, Exel
Tip sheme: zvezdna shema
Server OS: AIX
14) University of Michigan

33
Predmetno področje: AC (Instructional Activity), AD (Alumni/Development), EN: (Admission), FA
(Financial Aid), FI (Budgeting), HR (Human Resources), ST (Other – Students Financial)
Baza, ki jo uporabljajo: Oracle in SQL Server
ETL orodja za nalaganje podatkov: SQL Loader, PL/I SSIS
Orodja za podatkovno modeliranje: ER/Studio Data Architect, Visio
Meta data orodja: Informatica Metadata Maneger, Microsoft Word, Excel
Tip sheme: zvezdna shema, kocka (SSAS), denormalized relational
Server OS: AIX za Oracle, Windows za SQL Server, in Business Objects
15) Yale University
Predmetno področje: AC, AD, EN, FA, FI, HR, ST
Baza, ki jo uporabljajo: Oracle 10g R2 10.2.0.4
ETL orodja za nalaganje podatkov: Oracle PL/SQL Informatica PowerCenter 8.6
Orodja za podatkovno modeliranje: Oracle SQL Data Modeler
Tip sheme: zvezdna in snežinkasta shema
Server OS: DW delujoč na IBM AIX
16) Arizona State University
Predmetno področje: AC (Course – Homegrown System (IDMS), Research – COEUS (MIT)), FA
(Financial Aid – SIGMA (UDB)), FI: (Finance – Advantage (DB2)), HR (Human Resources – Integral
(DB2)), ST (Student – Homegrown System (IDMS), Student Fees – Homegrown System (IDMS)), OT
(Facolities/ Property – Homegrown System (Sybase))
Baza, ki jo uporabljajo: Sybase
ETL orodja za nalaganje podatkov: Cobol ali Sybase, Embracadero D/T Studio
Orodja za podatkovno modeliranje: PowerDesigner (Data Architect)
Meta data orodja: njihove narejene tabele, preko katerih dostopajo do BrioQuery
Orodja za povpraševanje podatkov: BrioQuery, MS-Access, ASP, JAVA, ColdFusion, Crystal Reports
Tip sheme: Denormalized E/R in Pseudo Star Schemas Extract Files, ali zvezdna shema
Serve OS: Unix. [19]
Kot je razvidno iz predstavljenih univerz po svetu, uporabljajo različno tehnologijo.
Podatkovna baza, ki jo uporabljajo v večini univerz, je Oracle. Sledijo pa MS SQL in Sybase.
Najpogostejša ETL orodja za nalaganje podatkov so: Informatica, različne verzije Oracla, op/sql, sql,
SQL Server Integration Services, Cobol, Cognos Decision, SQLCode ...

34
Meta data orodja, ki jih uporbljajo so: Oracle tabele, Oracle Designer, Sybase – PowerDesigner,
Ascential MetaStage, MS Access, Excel, Microsoft Word, Informatica Metadata Manager ... Tukaj
vidimo, da uporabljajo podobno orodja, kot jih uporabljamo v izobraževanju tudi v Sloveniji.
Operacijske sisteme, ki jih uporabljajo so: Windos 2000 SQL, Unix, Solaris, Win NT/2000, Windows
Server 2003, Microsoft 2000 ... Ponovno lahko vidimo, da uporabljajo operacijske sisteme, kot jih
uporabljamo tudi v Sloveniji.
Tipe shem, ki jih uporabljajo: ASCII Extract files, zvezdno shemo, kocko, denormalizirano shemo,
Oracle tabele in tabele dejstev, snežinkasta shema. Opazimo, da uporabljamo enake tipe shem tudi v
Sloveniji.
Slika 7: Pregled podatkovnega skladišča univerze Arizona State University.
Vir: http://www.asu.edu/data_admin/data_warehouse-overview.html
Slika 7 prikazuje podatkovno skladišče, ki ima svojo bazo. Ima tudi druge vire podatkov, kot so
transakcijski podatki, študenti in kadri na drugih bazah in računalnikih.

35
Vsi podatki te univerze so združeni, povezani v neko celoto, nato preoblikovani, na koncu pa naloženi
v podatkovno skladišče. To ima lahko različne kliente.
Slika 8: Zgradba podatkovne baze in skladišča.
Vir: http://www.asu.edu/data_admin/data_warehouse-Data%20Diagrams.html
Slika 8 prikazuje tri stolpce. V levem so primarne baze študentov. Tukaj so opisani študenti, njihovi
šolski predmeti, finančno stanje, kadrovski oddelek, sponzorji, popis, imenik storitev. Te so javno
dostopne primarne baze.
Srednji stolpec prikazuje uporabnike baze podatkov in opisuje uporabnikove tabele.
Desni stolpec prikazuje baze, ki imajo omejen vstop. Ti opisujejo študentsko pomoč, njihove vpisnine
in takse.

36
8. ORODJA ZA POVPRAŠEVANJE, ANALIZE IN POROČILA IZ PODATKOVNIH SKLADIŠČ IN EXCEL VRTILNE TABELE
Podatke iz podatkovnih skladišč lahko prenesemo v nekatere druge programe in jih med seboj
povezujemo, analiziramo ter primerjamo. V našem šolstvu je velik poudarek na Excelu. V svetu pa
med drugimi uporabljajo tudi Oracle Discoverer. V Excelu si bomo ogledali vrtilne/vrtljive tabele.
8.1 EXCEL VRTILNE (VRTLJIVE) TABELE Vrtilna tabela (angl. pivot table) je Excelovo orodje, ki povzame podatke danega izbora in jih
predstavi na način, ki nam, uporabnikom, nekaj pomeni. Omogoča nam hitro in preprosto izdelavo
različnih povzetkov, analiz in pregled podatkov iz različnih seznamov, tudi podatkovnih skladišč.
Večji kot je seznam, bolj pride do izraza vrtilna tabela. V kombinaciji z vrtilnimi tabelami poznamo
tudi vrtilne grafikone. Delo med njima je zelo povezno. S pomočjo vrtilnih grafikonov imamo boljšo
preglednost nad informacijami, ki jih dobimo z vrtilno tabelo.
8.1.1 DELO Z VRTILNIMI TABELAMI
V Excelu želimo narediti vrtilne tabele. V našem primeru smo vse tabele in poizvedbe naredili
v Accessu. Zato smo morali podatke naložiti v Excel, da smo lahko naredili vrtilne tabele. Ko
podatke prenašamo iz Accessa v Excel, da lahko naredimo vrtilne tabele, ne prenesemo vseh
podatkov, ampak samo polja, ki jih potrebujemo za izdelavo vrtilnih tabel. Ne prenašamo
vseh podatkov in tabel, kajti to so v večini primerov ogromne količine podatkov in s tem bi
otežili in upočasnili naše delo.
Kako to naredimo, prikazujejo spodnje tri slike.

37
Slika 9: Ustvarjanje vrtilne tabele z uporabo zunanjega vira podatkov.
Slika 9 prikazuje ustvarjanje vrtilne tabele, kjer uporabimo zunanji vir podatkov. V Excelu kliknemo
zavihek Vstavljanje, Vrtilna tabela, še enkrat Vrtilna tabela, tam obkljukamo Uporabi zunanji vir
podatkov in Izberi povezavo.

38
Slika 10: Izbiranje povezave (iskanje Accessove datoteke).
Slika 10 prikazuje naslednji korak pri ustvarjanju vrtilnih tabel. Najprej se nam prikaže levo okno
Obstoječe povezave, kjer moramo klikniti na Poišči več … , nato se nam odpre desno okno Izberi vir
podatkov. Tukaj sedaj poiščemo v mapi našo Accessovo datoteko in kliknemo Odpri. Prikaže se nam
spodnje okno.

39
Slika 11: Izbira poizvedb in tabel.
Slika 11 prikazuje tabele in poizvedbe, ki smo jih naredili vAccessu, in jih sedaj lahko prenesemo v
Excel. Označimo želeno poizvedboa ali tabelo in kliknemo V redu. Prikaže se nam ogrodje vrtilne
tabele (Slika 12). Sedaj lahko ustvarjamo vrtilne tabele v Excelu.
V nadaljevanju določimo obseg podatkov, ki jih želimo uporabiti, in kam se naj vrtilna tabela postavi.
Na novem delovnem listu se pojavi ogrodje vrtilne tabele (slika 12), na katerega bomo dodajali polja
za analiziranje podatkov. Ko je ogrodje vrtilne tabele pripravljeno, lahko z vlečenjem in spuščanjem
polj iz okna Seznam polj vrtilne tabele začnemo z analizo podatkov in spreminjanjem njene oblike.
Na desni strani v tabeli se nam prikaže Seznam polj vrtilne tabele (angl. pivot tabele field list). Sem se
shranijo seznami polj, ki smo jih ustvarili (Priimek, Ime, Naslov, Vpisnina ... ).
Pod Seznamom polj vrtilne tabele imamo štiri bela prazna polja: Oznake vrstice (angl. row fields), kjer
iz seznam polj vrtilne tabele povlečemo in spustimo želeno polje. Filter poročila, Oznake stolpcev,
Oznake vrstic in Vrednosti.
Filter poročila pomaga pri upravljanju prikazovanja velike količine podatkov, kjer izmed mnogih
podatkov izberemo (obkljukamo) samo želene podatke. V Oznako vrstic povlečemo polja, ki jih
želimo imeti prikazana v vrsticah v Oznako stolpcev pa polja, ki jih želimo imeti prikazana po
stolpcih. V Vrednosti vstavljamo številčna polja, vrednosti s številkami. V Vrednostih si nastavimo
sami, kaj želimo početi s podatki, jih seštevati, računati povprečje, minimum, maksimum …

40
V našem primeru smo v Oznake vrstice povlekli Priimek, v Oznake stolpca letnice, v Vrednosti pa
vpisnino. Tako nam je Excel sam izračunal skupno vsoto vpisnine (slika 13). V vrtilnih tabelah lahko
uporabimo Filter poročila za filtriranje podatkov. Ko v filter v povlečemo element iz Seznama polj
vrtilne table, se nam prikažejo v vrtilni tabeli ti elementi. Če na primer v polju Priimek izberemo samo
priimek Ofentavšek, se pokažejo le podatki s tem priimkom (slika 14).
Slika 12: Ogrodje vrtilne tabele.
Slika 12 prikazuje ogrodje vrtilne tabele za primer Študent iz naslednjega poglavja.

41
Slika 13: Vsota vpisnine vseh študentov po abecednem vrstnem redu v vrtilni tabeli.
Slika 13 je primer izdelane vrtilne tabele in prikazuje seznam vseh študentov vpisanih po abecednem
vrstnem redu v vrtilni tabeli in vsoto vpisnin, ki so jo študentje plačali v določenem letu in skupno
vsoto vpisnine.

42
Slika 14: Prikaz filtriranja podatkov.
Ko je vrtilna tabela ustvarjena, jo lahko spreminjamo. Najpogosteje spreminjamo obliko vrtilne tabele.
Gre za premik polj na nov položaj ali dodajanje in brisanje polj.
Ko določimo položaj polj v vrtilni tabeli, lahko izpeljemo različne vrste urejanj in analiz podatkov
glede na ustrezno polje.
Lahko izračunamo skupno vsoto, povprečje, minimum, maksimum, zmnožek itd.

43
Slika 15: Slika prikaza možnosti povpraševanja v vrtilnih tabelah.
Slika 15 prikazuje, kako izberemo različne vrednosti v tabelah. To naredimo na naslednji način. V
tabeli kliknemo z desno tipko na miški na izbrano vrednost (številko), odpre se nam okno, kjer
izberemo Povzemi vrednosti po … in kliknemo na želeno vrednost
44
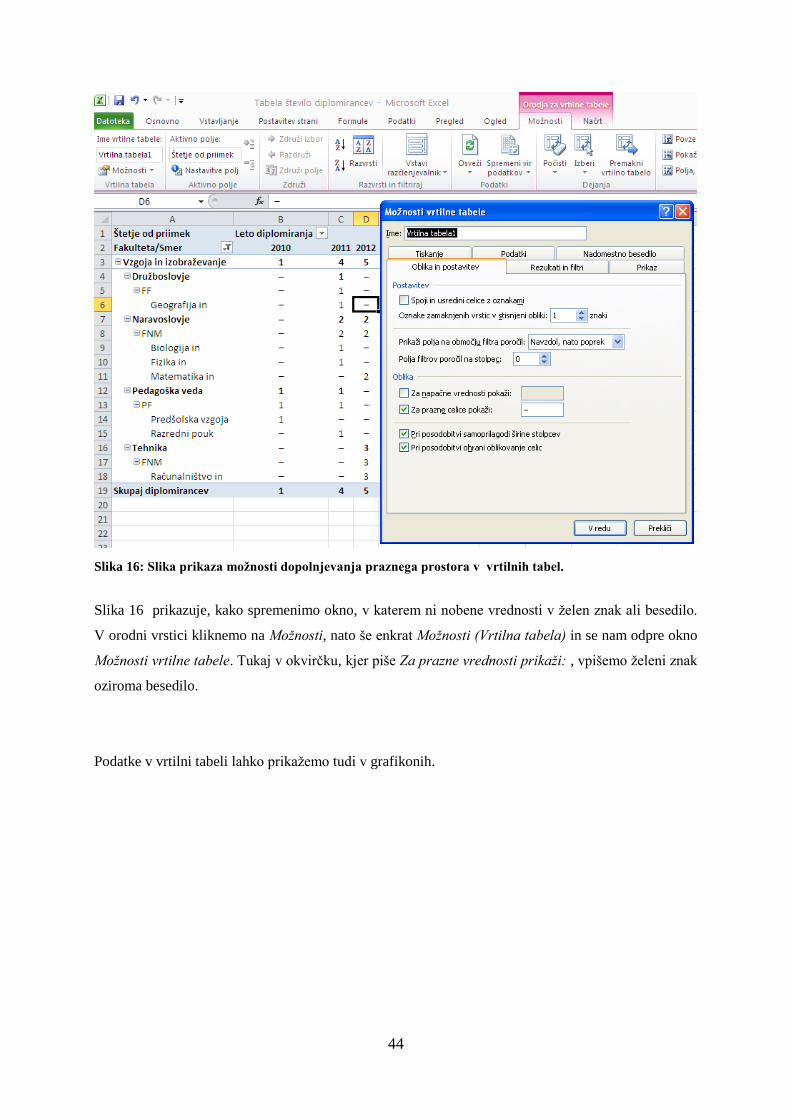
Slika 16: Slika prikaza možnosti dopolnjevanja praznega prostora v vrtilnih tabel.
Slika 16 prikazuje, kako spremenimo okno, v katerem ni nobene vrednosti v želen znak ali besedilo.
V orodni vrstici kliknemo na Možnosti, nato še enkrat Možnosti (Vrtilna tabela) in se nam odpre okno
Možnosti vrtilne tabele. Tukaj v okvirčku, kjer piše Za prazne vrednosti prikaži: , vpišemo želeni znak
oziroma besedilo.
Podatke v vrtilni tabeli lahko prikažemo tudi v grafikonih.

45
Slika 17: Vrtilni grafikon.
Slika 17 prikazuje število diplomiranih študentov v letih 2010, 2011 in 2012 na treh fakultetah. V
priročnem meniju smo izbrali Vstavljanje, kjer smo izbrali obliko grafikona, ki ga želimo imeti.
Vrtilne tabele nam omogočajo, da s pomočjo Selektorja poročil (angl. format report) naredimo tabele,
ki nam jih ponuja že sam program. S klikom na to ikono se nam prikažejo že oblikovane tabele.
Slika 18: Prikaz tabele s pomočjo ikone Selektor poročil.

46
Slika 18 nam prikazuje naše podatke (ime, priimek, naslov, starost in vpisnino). Iz Seznama polj
vrtilne tabele smo povlekli polja v Oznake vrstice, Oznake stolpcev in v Vrednosti. Naredila se nam je
tabela, mi pa smo jo oblikovali s pomočjo orodne vrstice, ki nam sama ponuja veliko možnosti. Lahko
izbiramo razne oblike tabel, barve tabel, sloge celic …
9. PRIMER PODATKOVNEGA SKLADIŠČA ZA IZOBRAŽEVALNO USTANOVO V ACCESSU
V tej diplomski nalogi bom predstavila primer relacijske baze 'študenta' v programu Microsoft Access,
ki je del družine Microsoft Office okolja. Ustvarila sem bazo podatkov, ki sem jo poimenovala
Študent. Podatki v njej so shranjeni v tabelah, ki predstavljajo osnovo zbirke podatkov, te tabele pa so
med seboj povezane. Tabele predstavljajo vrstice s podatkovnimi zapisi. Vsak zapis je sestavljen iz
ene ali več celic. Vsebina, ki je vpisana v celice, je določena z imeni polj. Vsako polje dobi tudi
določen podatkovni tip. Nujno moramo določiti tudi primarni ključ v posamezni tabeli, ki nam
omogoča, da je vsak zapis v tabeli enoznačno določen.
Spodnji primer relacijske baze Študenta predstavlja študenta, ki je vpisan na fakulteto in opravlja
izpite. Iz te relacije izvemo naslednje:
- vpisno številko študenta,
- njegov priimek in ime,
- naslov (ulica, hišna številka, kraj, občina, regija, država),
- priimek in ime profesorja, pri katerem opravlja izpit,
- naziv profesorja in njegovo predmetno področje,
- ime fakultete,
- smer študija,
- letnik študija,
- oceno predmeta,
- prostor, kjer opravlja izpit,
- datum izpita,
- ime predmeta,
- leto vpisa in diplomiranja na fakulteto,
- cena izpita,
- vpisnino.

47
Naslovi tabel v relacijski bazi Študent so:
- Delavec
- Dimenzija naslova
- Dimenzija ocene
- Naslov
- Dimenzija predmet
- Organizacijska dimenzija
- Prostorska dimenzija
- Tabela dejstev (izpiti)
- Študent
Vse tabele v tem primeru vsebujejo eno ali več polj in vsako polje ima svoj podatkovni tip.
9.1 SHEMA PODATKOVNEGA SKLADIŠČA Spodnji primer Študent vsebuje devet tabel s polji.
1) Tabela Študent vsebuje naslednja polja: vpisna številka, TK šifra organizacijske enote, priimek,
ime, TK naslov študent, leto diplomiranja, vpisnina, leto vpisa, mesec diplomiranja.
2) Tabela Delavec vsebuje naslednja polja: šifra delavca, ime profesorja, priimek profesorja, naziv,
predmeti, predmetno področje.
3) Tabela Dimenzija ocene vsebuje naslednja polja: ID ocena, pozitivno – negativno, ocena.
4) Tabela Prostorska dimenzija vsebuje naslednja polja: šifra, zgradba, nadstropje, številka učilnice.
5) Tabela Dimenzija predmet vsebuje naslednje polje: predmet, podveda, predmetno področje, smer,
veda, podpodročje.
6) Tabela Naslov vsebuje naslednja polja: TK naslov, ulica, hišna številka, kraj, občina_ID.
7) Tabela Organizacijska dimenzija vsebuje naslednja polja: šifra, fakulteta, smer, letnik, semester.
8) Tabela Dimenzija naslova vsebuje naslednja polja: TK_ občina, poštna številka, občina_ime, regija,
država.
9) Tabela Tabela dejstev (izpiti) vsebuje naslednja polja: ID_dogodek, TK študenta, TK ocenjevalec,
TK šifra ocene, TK datum, TK šifra prostora, Ime_predmeta, dogodek, Plačilo prvega izpita, Plačilo
drugega izpita.
Tabele so med seboj povezane z relacijami. V tem primeru so med seboj povezane ena proti mnogo.

48
Slika 19: Model relacij za primer 'študenta'.
Slika prikazuje model relacij za primer 'Študent'. Tabele so napolnjene s testnimi podatki.
9.2 POIZVEDBE IZ PODATKOVNEGA SKLADIŠČA ZA IZOBRAŽEVALNO USTANOVO
Za prikaz podatkov v Excelovih tabelah je potrebno v Accessu pripraviti poizvedbe.
Poizvedba je zahteva za določene podatke. S poizvedbo je mogoče odgovoriti na preprosta ali
specifična vprašanja, izvesti izračune, združevati podatke iz različnih tabel. S poizvedbami
podatke filtriramo oziroma jih povzamemo. [26]
Sedaj bom vse podatke oziroma več tabel v poizvedbah, ki sem jih vnesla v bazo Študent v programu
Access, uporabila v vrtilnih tabelah. Vrtilne tabele sem naredila v Excelu, podatke sem uvozila iz
Accessa, kot sem opisala na slikah 9, 10 in 11.
Baza je napolnjena s testnimi podatki.

49
Tabela 1: Poizvedba 1.
Zgornja poizvedba predstavlja polja, ki jih potrebujemo za spodnje štiri vrtilne tabele.
Slika 20: Struktura poizvedbe 1.

50
Slika prikazuje strukturo poizvedbe 1. Polja, ki jih prikazuje poizvedba 1, so zapisana v tabelah:
Organizacijska dimenzija, Študent, Tabela dejstev (izpiti) in Dimenzija predmet. Med seboj so
povezana kot prikazuje zgornja slika.
Tabela 2: Vrtilna tabela dimenzije predmeta.
Štetje od priimek Letnik
Smer/Fakulteta prvi drugi tretji četrti Skupaj študentov
Nepedagoška 1 – 2 1 4
Naravoslovje 1 – 2 1 4
FNM 1 – 2 1 4
algebra – – – 1 1
analiza 1 – – – 1
biofizika – – 1 – 1
botanika – – 1 – 1
Vzgoja in izobraževanje 4 4 2 – 10
Družboslovje 1 – – – 1
FF 1 – – – 1
fizična geografija 1 – – – 1
Naravoslovje – 3 1 – 4
FNM – 3 1 – 4
algebra – 1 – – 1
analiza – – 1 – 1
astronomija – 1 – – 1
genetika – 1 – – 1
Pedagoška veda 2 – – – 2
PF 2 – – – 2
vzgoja 2 – – – 2
Tehnika 1 1 1 – 3
FNM 1 1 1 – 3
informacijski sistemi 1 1 – – 2
programiranje – – 1 – 1
Skupaj študentov 5 4 4 1 14
Tabela 2 prikazuje, koliko študentov je na določeni fakulteti, na katerem predmetnem področju so,
kateri predmet opravljajo in podvrsta predmeta.
Kot prikazuje zgornja tabela, vidimo, da določena okna nimajo nobenih vrednosti. Da ti prostori v
tabeli ne ostanejo prazni, jih lahko nadomestimo s poljubnimi znaki.
V naslednji vrtilni tabeli bomo pokazali povprečno oceno študentov leta 2012 na smereh Matematika
in ter Računalništvo in. Da lahko to prikažemo moramo narediti filter. Filter nam omogoča, da
prikažemo samo tiste podatke, ki jih želimo. V našem primeru bomo izmed vseh predmetov izbrali
samo dva predmeta in samo leto 2012.

51
Kot prikazuje spodnja slika moramo v Seznamu polj vrtilne tabele izbrati želeno polje, v našem
primeru smer, z miško klikniti na filter ob polju in odpre se okno. Tukaj obkljukamo želene predmete
in v vrtilni tabeli se nam bodo nato prikazali le ti.
Slika 21: Prikaz filtriranja podatkov.

52
Tabela 3: Vrtilna tabela za povprečno oceno na smereh Matematika in ter Računalništvo in.
Fakulteta/Smer 2012
FNM 8,2
Matematika in 8,0 drugi 6,0 tretji 8,0 četrti 10,0
Računalništvo in 8,3 prvi 9,0 drugi 8,0 tretji 8,0
Povprečna ocena 8,2
Tabela 3 prikazuje povprečno oceno na fakulteti FNM na smeri študija Matematika in in
Računalništvo in leta 2012. Vidimo, da je na študijski smeri Matematika in povprečna ocena študentov
8, na študijski smeri Računalništvo in pa 8,3, torej skupna ocena na fakulteti FNM je 8,2.
V naslednji vrtilni bomo pokazali, da lahko le na eni vrtilni tabeli prikažemo več različnih vrednosti.
Nas je zanimalo, koliko študentov je na določeni fakulteti, smeri in letniku, koliko so plačili vpisnino
in kolikšna je njihova povprečna ocena.

53
Tabela 4: Vrtilna tabela števila študentov, vpisnine in povprečne ocene na fakultetah.
Področje/Fakulteta Število študentov Vsota vpisnine Povprečna ocena
Nepedagoška 4 6250 9,0
Naravoslovje 4 6250 9,0
FNM 4 6250 9,0
Ekologija 1 1500 9,0
Fizika 1 1300 8,0
Matematika 2 3450 9,5
Vzgoja in izobraževanje 10 17450 8,6
Družboslovje 1 2000 8,0
FF 1 2000 8,0
Geografija in 1 2000 8,0
Naravoslovje 4 7150 8,5
FNM 4 7150 8,5
Biologija in 1 1450 10,0
Fizika in 1 1700 10,0
Matematika in 2 4000 7,0
Pedagoška veda 2 3200 9,5
PF 2 3200 9,5
Predšolska vzgoja 1 1800 10,0
Razredni pouk 1 1400 9,0
Tehnika 3 5100 8,3
FNM 3 5100 8,3
Računalništvo in 3 5100 8,3
Skupaj 14 23700 8,7
Tabela 4 prikazuje število študentov na določenem letniku na določeni smeri študija in fakulteti.
Prikazuje tudi vsoto vpisnine, ki so jo študentje plačali in povprečno oceno študentov po smereh
študija, po fakultetah in po vedah.
Kot vidimo, smo v zgornji tabeli šteli študente, izračunali skupno vsoto vpisnine in izračunali
povprečno oceno.
Poleg štetja, računanja vsote in povprečja lahko še iščemo minimum, maksimum, zmnožek in še več.
54
Tabela 5: Vrtilna tabela števila študentov po letnicah diplomiranja in smereh študija.
Štetje od priimek Leto diplomiranja
Fakulteta/Smer 2010 2011 2012 Skupaj diplomirancev
Nepedagoška 2 – 2 4
Naravoslovje 2 – 2 4
FNM 2 – 2 4
Ekologija – – 1 1
Fizika 1 – – 1
Matematika 1 – 1 2
Vzgoja in izobraževanje 1 4 5 10
Družboslovje – 1 – 1
FF – 1 – 1
Geografija in – 1 – 1
Naravoslovje – 2 2 4
FNM – 2 2 4
Biologija in – 1 – 1
Fizika in – 1 – 1
Matematika in – – 2 2
Pedagoška veda 1 1 – 2
PF 1 1 – 2
Predšolska vzgoja 1 – – 1
Razredni pouk – 1 – 1
Tehnika – – 3 3
FNM – – 3 3
Računalništvo in – – 3 3
Skupaj diplomirancev 3 4 7 14
Tabela 5 je vrtilna tabela, ki prikazuje število študentov, ki so diplomirali na določenih smereh študija
v letih 2010, 2011 in 2012. (Primer: na nepedagoški smeri na naravoslovju sta leta 2010 diplomirala
dva študenta, ki sta obiskovala fakulteto FNM, in sicer eden na smeri Fizika in eden na smeri
Matematika. Na smeri Ekologija pa leta 2010 ni diplomiral nihče.)

55
Tabela 6: Poizvedba 2 za število študentov po krajih.
Poizvedba 2 prikazuje polja, ki jih potrebujemo za spodnjo vrtilno tabelo.
Slika 22: Struktura poizvedbe 2.
Slika prikazuje strukturo poizvedbe 2. Polja priimek, leto diplomiranja, občina_ime, država in regija
se nahajajo v treh tabelah. Te so Dimenzija naslov, Naslov in Študent, ki so povezane med seboj, kot
prikazuje slika 22.
S pomočjo zgornje poizvedbe bomo naredili vrtilno tabelo, kjer nas zanima, od kod prihajajo
študentje.
56
Tabela 7: Tabela števila študentov po krajih.
Štetje od priimek Leto dipl.
Kraj 2010 2011 2012 Skupaj diplomirancev
Slo 3 5 8 16
Osrednjeslo – 3 4 7
Domžale – 3 1 4
Ljubljana – – 3 3
Primorska 1 – 1 2
Nova Gorica 1 – 1 2
Štajerska 2 2 3 7
Celje – 2 – 2
Maribor 1 – 1 2
Vojnik 1 – 2 3
Skupaj diplomirancev 3 5 8 16
Tabela 7 prikazuje, od kod so študentje (iz katere države, regije in iz katere občine v regiji prihajajo),
ki so diplomirali v letu 2010, 2011 in 2012. (Primer: en študent iz Slovenije iz štajerske regije,
natančneje iz Maribora, je diplomiral leta 2010, leta 2011 iz Maribora ni nihče diplomiral, leta 2012 pa
zopet en študent. Torej skupaj dva diplomiranca iz Maribora.)
Kot vidimo, nam poizvedbe iz tabele Študent prikažejo veliko količino uporabnih ali pa tudi
neuporabnih podatkov. S pomočjo vrtilnih tabel lahko te podatke obračamo oziroma vrtimo, tako da
pridemo do želenih informacij.

57
10. ZAKLJUČEK
Podatki so danes vir informacij in uspešnega poslovanja. Podjetja, šole in vse ostale izobraževalne
ustanove shranjujejo veliko količino podatkov. Ni dovolj, da imamo različne podatke oziroma
informacije samo zapisane in zabeležene. Biti morajo tudi primerno in čim bolj enostavno urejene.
Zaradi velike količine podatkov lahko pride do hitre zamenjave podatkov. Da so podatki in
informacije za daljše obdobje čim bolj urejeni, omogočajo podatkovna skladišča.
V diplomski nalogi so predstavljena podatkovna skladišča. Natančneje sem opisala arhitekturo
podatkovnih skladišč. Centralizirana arhitektura je sestavljena iz osrednjega podatkovnega skladišča in
področnih skladišč. Ta pa se polnijo le iz osrednjega podatkovnega skladišča. Značilnost distribuirane
arhitekture je, da temelji na množici povezanih, vendar samostojnih področnih shramb, ki tvorijo
podatkovno skladišče. Najnovejša je federativna arhitektura, ki temelji na skupnem poslovnem
modelu.
Pri izbiri ustrezne arhitekture podatkovnih skladišč je potrebno podrobno poznati prednosti in slabosti
vseh treh tipov arhitektur, da smo lahko uspešni.
Pomembno vlogo pri podatkovnih skladiščih ima OLAP (angl. OnLine Analiytical processing). Ta
omogoča hitrejšo analizo in pregled velike količine podatkov. Pomembna je tudi OLAP kocka kot
konceptualni model podatkovnih skladišč in analiz. Vsaka OLAP kocka je sestavljena iz mer in
dimenzij. Podatkovni model kocke je lahko zvezdna in snežinkasta shema. Slednja je izpeljana iz prve.
Univerze po svetu tudi uporabljajo podatkovna skladišča, različne podatkovne baze in orodja za
nalaganje podatkov. Najpogostejši bazi, ki ju univerze v svetu uporabljajo, sta Oracle in Microsoft
SQL.
Baza, ki sem jo naredila v programu Access, je izdelan model podatkovnega skladišča za
izobraževalno ustanovo. Da se študent vpiše na fakulteto, prijavlja na izpite, jih opravi in nato
diplomira, je potrebno veliko število podatkov. S temi podatki sem naredila analize in poročila s
pomočjo vrtljivih tabel v Excelu.

58
Literatura:
[1] C. S.R. Prabhu. Data warehousing: concepts, techniques, products and applications,
Pratice Hall, 2002.
[2] M. Humphries, M. W. Hawkins, M. C. Dy. Data warehousing: architecture and implementation,
Pratice Hall, 1999.
[3] M. J. Corey, M. Abbey. Oracle Data Warehousing, McGraw-Hill, 1997.
[4] R. Kimball, J. Caserta. The Data Warehouse ETL Toolkit, Indianapolis: Wiley, 2004.
Spletni viri:
[5] Golob I., Welzer T. (pridobljeno 20. 6. 2011). Arhitekture podatkovnih skladišč. Maribor:
Univerza v Mariboru, Fakulteta za elektrotehniko, računalništvo in informatiko.
[6] http://en.wikipedia.org/wiki/Data_warehouse (pridobljeno 5. 6. 2010)
[7] http://www.bilab.si/?show=content&id=10&men=14&oce=13&oce=13 (pridobljeno 10. 9. 2011)
[8] http://wiki.fmf.uni-lj.si/wiki/OLAP (pridobljeno 4. 7. 2011)
[9] http://www.bilab.si/index.php?show=content&id=12&men=16 (pridobljeno 12. 5. 2011)
[10] http://www.bilab.si/uploads/clanki/arhivirana_datoteka_5.pdf (pridobljeno 12. 5. 2011)
[11] http://www.bilab.si/?show=content&id=5&men=10&oce=6 (pridobljeno 13. 5. 2011)
[12] http://www.lancom.si/resitve/informacijske/poslovne/podatkovna-skladisca/page.html
(pridobljeno 11. 9. 2011)
[13] http://www.rtvslo.si/blog/globo/podatkovno-skladisce/41880 (pridobljeno 15. 9. 2011)
[14] http://www.add.si/poslovne_resitve/add_bi/tehnologija/ (pridobljeno 6. 6. 2011)
[15] http://dataminingtools.net/wiki/introdw.php (pridobljeno 15. 5. 2011)
[16] http://wiki.fmf.uni-lj.si/wiki/Slika:StarShema1.jpg (pridobljeno 5. 7. 2011)
[17] http://wiki.fmf.uni-lj.si/wiki/Slika:SnowFlakeShema.JPG (pridobljeno 5. 7. 2011)
[18] http://www.cek.ef.uni-lj.si/u_diplome/tomic4088.pdf (pridobljeno 20. 7. 2011)
[19] http://www.asu.edu/data_admin/data_warehouse-overview.html (pridobljeno 9. 7. 2010)
[20] http://www.asu.edu/data_admin/data_warehouse-Data%20Diagrams.html (pridobljeno 9. 7. 2010)
[21] http://www.1keydata.com/datawarehousing/inmon-kimball.html (pridobljeno 10.1.2013)
[22] http://www.islovar.org/forumi/sporocila.asp?id=287&idk=5&debatestran=29 (pridobljeno 27. 11.
2011)
[23] http://en.wikipedia.org/wiki/Online_analytical_processing (pridobljeno 15. 7. 2011)
[24] http://en.wikipedia.org/wiki/Edgar_F._Codd (pridobljeno 15. 9. 2012)
[25] http://en.wikipedia.org/wiki/Extract,_transform,_load (pridobljeno 6. 6. 2010)
[26] http://office.microsoft.com/sl-si/access-help/uvod-v-poizvedbe-HA010341786.aspx (pridobljeno
4. 12. 2012)





























