Embed Size (px)
Citation preview

Disciplina: Processamento Estatıstico de Sinais(ENGA83) - Aula 08 / Extracao de Caracterısticas
Prof. Eduardo Simas([email protected])
Programa de Pos-Graduacao em Engenharia Eletrica/PPGEEUniversidade Federal da Bahia
ENGA83 - Semestre 2012.1
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 1 / 48

Conteudo
1 Introducao
2 Analise de Componentes Principais
3 Analise de Componentes Independentes
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 2 / 48

Introducao
Em muitos problemas de processamento de sinais multidimensionais 1 deseja-se encontrar uma transformacao que, de algummodo, torne a estrutura essencial dos dados mais acessıvel.
Entre as tecnicas lineares que buscam, atraves de premissas distintas,uma nova representacao para os sinais multi-dimensionais, pode-semencionar:
- Analise de Componentes Principais (PCA - Principal ComponentAnalysis).
- Analise de Componentes Independentes (ICA - IndependentComponent Analysis).
- Componentes Principais de Discriminacao (PCD - PrincipalComponents for Discrimination).
1Sinais multi dimensionais sao, em geral, produzidos por sistemas de medicao commultiplos sensores, mas tambem podem surgir a partir da aplicacao de transformacoes(como a transformada de Fourier ou Wavelet) a sinais uni-dimensionais.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 3 / 48

Introducao
Exemplos de sinais multidimensionais comuns:
- Sinais de audio (musica, voz) gravados com mais de um microfone;
- Sinais de imagem (fotografias, video);
- Series Temporais de Bolsas de Valores;
- Sistemas sem fio com multiplos usuarios;
- Sinais de inspecao acustica de maquinas;
- Sinais de instrumentacao de exames medicos (ECG, EEG, Ultra-som,etc);
- Sinais temporais unidimensionais “transformados” para domıniosdiferentes (Fourier, wavelet, etc).
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 4 / 48

Introducao - Extracao de Caracterısticas para Classificacao
Sabe-se que sistemas de classificacao sofisticados (como as redesneurais artificiais) podem, essencialmente, realizar quaisquermapeamentos nao-lineares.
Entretanto, pode-se observar experimentalmente que, o uso direto dosdados brutos (do modo como foram medidos) como entradas para osclassificadores geralmente produz um desempenho pior do que quandoalgum pre-processamento e aplicado.
Porque isso acontece ?
Da teoria da informacao, considerando x (vetor de caracterısticas) e c(os rotulos de classes), para qualquer transformacao determinısticaT (·), a informacao mutua (I ) entre T (x) e c e:
I (T (x); c) ≤ I (x; c),
ou seja, nenhuma transformacao e capaz de acrescentar informacao arespeito das classes c ao conjunto de caracterısticas x.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 5 / 48

Introducao - Extracao de Caracterısticas para Classificacao
Sabe-se que sistemas de classificacao sofisticados (como as redesneurais artificiais) podem, essencialmente, realizar quaisquermapeamentos nao-lineares.
Entretanto, pode-se observar experimentalmente que, o uso direto dosdados brutos (do modo como foram medidos) como entradas para osclassificadores geralmente produz um desempenho pior do que quandoalgum pre-processamento e aplicado.
Porque isso acontece ?
Da teoria da informacao, considerando x (vetor de caracterısticas) e c(os rotulos de classes), para qualquer transformacao determinısticaT (·), a informacao mutua (I ) entre T (x) e c e:
I (T (x); c) ≤ I (x; c),
ou seja, nenhuma transformacao e capaz de acrescentar informacao arespeito das classes c ao conjunto de caracterısticas x.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 5 / 48

Introducao - Extracao de Caracterısticas para Classificacao
Considerando o resultado anterior, o que justifica o melhordesempenho dos classificadores apos a etapa de pre-processamento,uma vez que ela nao e capaz de adicionar informacao a respeito doproblema?
A resposta pode ser encontrada considerando-se que os sistemas declassificacao sao projetados, em geral, a partir de um processoiterativo de treinamento.
Entao, um pre-processamento capaz de revelar caracterısticasdiscriminantes pode se tornar decisivo para a obtencao de umclassificador com melhor desempenho.
Todas as informacoes utilizadas para a discriminacao estao presentesnos dados brutos. O pre-processamento (extracao decaracterısticas), e responsavel apenas por uma transformacao quetorna as caracterısticas discriminantes mais acessıveis.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 6 / 48

Introducao - Extracao de Caracterısticas para Classificacao
Considerando o resultado anterior, o que justifica o melhordesempenho dos classificadores apos a etapa de pre-processamento,uma vez que ela nao e capaz de adicionar informacao a respeito doproblema?
A resposta pode ser encontrada considerando-se que os sistemas declassificacao sao projetados, em geral, a partir de um processoiterativo de treinamento.
Entao, um pre-processamento capaz de revelar caracterısticasdiscriminantes pode se tornar decisivo para a obtencao de umclassificador com melhor desempenho.
Todas as informacoes utilizadas para a discriminacao estao presentesnos dados brutos. O pre-processamento (extracao decaracterısticas), e responsavel apenas por uma transformacao quetorna as caracterısticas discriminantes mais acessıveis.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 6 / 48

Introducao - A maldicao da dimensionalidade
Um outro aspecto a ser analisado e a chamada “maldicao dadimensionalidade” (do ingles curse of dimensionality).
Sabe-se que a utilizacao de um numero elevado de entradas para osistema classificador acaba dificultando o processo de treinamento.
Quanto maior a dimensao dos dados de entrada, maior acomplexidade do problema.
A solucao adotada, na maioria dos casos, e pre-processar os sinaiscom uma transformacao que reduza a dimensionalidade do problema,e consequentemente a redundancia e o ruıdo (informacoes naorelevantes) para a classificacao.
Porem, e preciso escolher adequadamente a informacao a serdescartada para minimizar a chance da perda de caracterısticasrelevantes para a discriminacao das classes.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 7 / 48

Introducao
A transformacao otima deve, entre outras coisas:
- mapear os atributos disponıveis num numero reduzido decaracterısticas;
- eliminar a redundancia;
- manter toda a informacao discriminante para o problema.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 8 / 48

Introducao
A extracao de caracterısticas pode tambem ser aplicada em problemasque nao envolvem a classificacao do sinais.
Neste caso, o objetivo e encontrar informacoes ou estruturasimportantes no conjunto de sinais para a melhor caracterizacao doproblema.
Entre as principais tarefas pode-se destacar:
- Selecao da informacao relevante;
- Reducao do ruıdo;
- Remocao da interferencia em sistemas de instrumentacao commultiplos sensores;
- Etc.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 9 / 48

Analise de Componentes Principais
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 10 / 48

Analise de Componentes Principais
A analise de componentes principais (PCA - Principal ComponentAnalysis) e uma tecnica estatıstica de processamento de sinaisdiretamente ligada a transformacao de Karhunen-Loeve.
O objetivo da PCA e encontrar uma transformacao linear tal que ossinais projetados sejam nao-correlacionados (ortogonais) e grandeparcela da energia (variancia) esteja concentrada num pequenonumero de componentes.
Para isso, sao exploradas informacoes estatısticas de ate segundaordem (medias e variancias).
A ideia da PCA foi proposta inicialmente por Pearson em 1901.
Rotacao do eixo de coordenadas para um novo eixo no qual asdirecoes das coordenadas sao ortogonais e ordenadas em termos daquantidade da variacao do sinal que elas “explicam”.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 11 / 48

Analise de Componentes Principais
Considerando-se um vetor x = [x1, ..., xN ]T aleatorio com Nelementos, assume-se que ele tenha media zero:
E{x} = 0,
Se x tem media nao nula, faz-se x← x− E{x}.
A projecao zi de x na direcao de vi pode ser expressa por:
zi = vTi x =N∑
k=1
vkixk .
Na transformacao por PCA, os componentes zi (i = 1, ...,N) devemser ortogonais e ordenados (de modo decrescente) pela variancia dasprojecoes, sendo, entao, z1 a projecao de maxima variancia.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 12 / 48

Analise de Componentes Principais
Para tornar a variancia independente da norma de vi , faz-se:
vi ←vi‖vi‖
Fazendo-se com que ||vi || = 1, torna-se a variancia funcao apenas dadirecao das projecoes.
Como E{x} = 0, entao E{zi} = 0, logo a variancia da projecao zi ecalculada por E{z2
i }.
Seguindo a definicao da PCA, z1 tem maxima variancia; logo, v1
pode ser encontrado pela maximizacao de:
JPCA1 (v1) = E{z2
i } = E{(vT1 x)2} = vT1 E{xxT}v1 = vT1 Cxv1,
onde Cx e a matriz de covariancia de x.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 13 / 48

Analise de Componentes Principais
A solucao para o problema de maximizacao de JPCA1 pode ser
encontrada na algebra linear, em funcao dos autovetores e1, e2, ..., eNda matriz Cx .
A ordem dos autovetores e tal que os autovalores associadossatisfazem d1 > d2 > ... > dN . Desta forma, tem-se:
vi = ei , 1 ≤ i ≤ N
A transformacao por PCA pode ser expressa na forma matricial:
z = Vx
sendo z = [z1, z2, . . . , zN ]T e V = [v1, v2, . . . , vN ]T
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 14 / 48

PCA - Curva de Carga
A curva de carga e utilizada para possibilitar uma visualizacao daconcentracao da energia (variancia) em funcao do numero decomponentes.
0 1 2 3 4 5 6 7 80
10
20
30
40
50
60
70
80
90
100
Componentes
Ene
rgia
Acu
mul
ada
(%)
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 15 / 48

Reducao da Dimensao de um PA Multivariado por PCA
Alem da descorrelacao, a principal aplicacao da PCA e a compactacaoda informacao.
A reducao de dimensao e obtida utilizando-se para a reconstrucao dosinal N-dimensional original x um numero K de componentesprincipais, sendo K < N.
O numero de componentes e escolhido visando a preservar umaparcela Ve da energia total, de modo que x ≈ x.
A variancia explicada Ve (em %) de um conjunto de componentespode ser calculada usando-se:
Ve(K ) = 100×K∑i=1
di
/ N∑i=1
di ,
sendo di o autovalor da matriz Cx de covariancia do processocorrespondente ao componente i .
x x
y
Nx1
Kx1
Nx1
PCA PCA-1
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 16 / 48

Reducao da Dimensao de um PA Multivariado por PCA
Diagrama do processo de compactacao da informacao utilizando PCA.
O sinal de informacao x e substituıdo por sua versao compactada apartir da projecao nos k componentes principais mais energeticos y.
x x
y
Nx1
Kx1
Nx1
PCA PCA-1
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 17 / 48

Estimacao da PCA por redes neurais
Limitacoes computacionais na estimacao da PCA a partir da decomposicaoem valores singulares aparecem quando a dimensao N do vetor x aumenta.
Uma solucao e utilizar metodos iterativos como as redes neurais:
No modelo auto associativode Kramer, a rede e treinadacom entrada e saıda alvoiguais a y (sinal a sercompactado).
Os componentes principaissao estimados nas saıdas Ti
dos neuronios da camada degargalo (bottleneck).
Este modelo pode ser usadopara PCA e NLPCA(conforme sera mostrado aseguir).
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 18 / 48

PCA Nao Linear
A PCA nao-linear (NLPCA - Non-linear PCA) e uma extensao naolinear da PCA.
Enquanto o objetivo da PCA e minimizar o erro medio quadratico dereconstrucao do sinal projetando os componentes numa baseortonormal, a NLPCA pode ser definida de modo simples atraves dafuncao-objetivo a ser minimizada:
J(w1,w2, ...,wn) = E{||x−n∑
i=1
gi (wTi x)wi ||2},
onde g1(.), g2(.), ..., gn(.) e um conjunto de funcoes escalares enao-lineares, e os vetores wi formam a base de um novo espaco.
Quando o mınimo de J(w1,w2, ...,wn) for encontrado, o produtowT
i x dara os componentes principais nao-lineares. Se gi (y) = y paratodo i , entao equacao acima se reduz a funcao objetivo da PCA.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 19 / 48

Compactacao por PCA em Sistemas de Classificacao
A transformacao por PCA e otima no sentido de representacao dosinal nas primeiras componentes, mas nao ha garantia de que acompactacao facilite o processo de classificacao.
Quando as direcoes de maior variancia coincidem com as de melhordiscriminacao das classes, entao a PCA e tambem util para oreconhecimento de padroes.
Caso contrario, a reducao de dimensao pode dificultar a separacao.
Entretanto, em problemas de classificacao onde a dimensao daentrada e excessivamente grande a compactacao por PCA reduz ocusto computacional e consequentemente o tempo de processamento.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 20 / 48

Compactacao por PCA em Sistemas de Classificacao
−60 −40 −20 0 20 40 60−30
−20
−10
0
10
20
30Original Data Base
X
Y
Pattern 1
Pattern 2
−60 −40 −20 0 20 40 60−10
−5
0
5
10Patterns After PCA Projection
PCA 1
PC
A 2
Pattern 1
Pattern 2
−60 −40 −20 0 20 40 600
10
20
30
40
50Projection onto the First PCA (96% of Variance)
Projection Value
Counts
Pattern 1
Pattern 2
−10 −5 0 5 100
20
40
60
80Projection onto the Second PCA ( 4% of Variance)
Projection Value
Counts
Pattern 1
Pattern 2
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 21 / 48

Aplicacoes da PCA - Compactacao de Imagens
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 22 / 48

Aplicacoes da PCA - Compactacao de Imagens
No caso de processamento de imagens os componentes podem serinterpretados como uma “linha” ou “coluna” da imagem.
E possıvel manter uma boa qualidade da imagem mesmo com altacompactacao da informacao.
Neste exemplo (foto de Lena), reduzindo-se de 512 componentes paraapenas 64 (compactacao de 87,5%) ainda e possıvel obter umaqualidade “aceitavel”.
E importante destacar que, neste caso, a compactacao e feita comperda de informacao (diferente dos softwares de compactacao dearquivos *.zip, *.rar, *.tar-gz, nos quais nao ha perdas).
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 23 / 48

Aplicacoes da PCA - Remocao da Redundancia
Num problema de classificacao utilizando informacoes das transformadasdiscretas de Wavelet (DWT) e de cossenos (DCT), foi observada altacorrelacao entre os coeficientes estimados:
Coeficientes da DWT
Co
efie
nte
s a
DC
T
50 100 150
20
40
60
80
100
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Eficiencia do classificador com: DWT = 99,67% e DCT = 99,46%
Eficiencia alimentando o classificador com os coeficientes das duastransformadas: sem PCA = 99,35% e apos a PCA = 99,85%.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 24 / 48

Aplicacoes da PCA - Remocao da Redundancia
A existencia de forte correlacao entre as variaveis de entrada produziuuma maior confusao no sistema de classificacao.
A reducao da redundancia (correlacao) favoreceu o processo detreinamento do classificador.
Neste caso, hove tambem a compactacao da informacao,mantendo-se os componentes que representam aproximadamente 95%da energia total do sinal.
A compactacao possibilita a eliminacao de componentes quecarregam predominantemente ruıdo.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 25 / 48

Analise de Componentes Independentes
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 26 / 48

Analise de Componentes Independentes
A analise de componentes independentes (ICA - IndependentComponent Analysis) busca por uma transformacao linear onde oscomponentes na saıda sao mutuamente independentesestatisticamente.
A ICA vem sendo aplicada na solucao de diversos problemas na areade processamento de sinais como:
- cancelamento de ruıdo
- sonar passivo
- telecomunicacoes
- reconhecimento facial
- biomedica
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 27 / 48

Independencia Estatıstica
Quando duas VAs y1 e y2 sao independentes, entao o conhecimentode uma nao traz nenhuma informacao a respeito da outra.
Matematicamente, y1 e y2 sao independentes estatisticamente se esomente se:
py1,y2(y1, y2) = py1(y1)py2(y2),
onde py1,y2(y1, y2), py1(y1) e py2(y2) sao respectivamente as funcoesde densidade de probabilidade conjunta e marginais.
Pode-se obter uma expressao equivalente se, para todas as funcoesg(y1) e h(y2) absolutamente integraveis em y1 e y2, vale a igualdade:
E{g(y1)h(y2)} = E{g(y1)}E{h(y2)}
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 28 / 48

Independencia Estatıstica
A estimacao das funcoes de densidade de probabilidade e umproblema de difıcil solucao (em geral os componentes independentessao desconhecidos).
Uma vantagem da segunda expressao e que as pdfs nao saonecessarias.
A definicao de independencia pode ser facilmente estendida para maisde duas variaveis aleatorias.
O conceito de independencia envolve o conhecimento de toda aestatıstica dos dados, sendo assim muito mais abrangente que adescorrelacao (utilizada pela PCA), que somente utiliza estatıstica desegunda ordem (variancia).
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 29 / 48

Modelo Basico da ICA
Na ICA, considera-se que um sinal multi-dimensionalx(t) = [x1(t), ..., xN(t)]T observado (ou medido) e gerado a partir dacombinacao linear das fontes independentes s(t) = [s1(t), ..., sN(t)]T : x1(t)
...xN(t)
=
a11 . . . a1N...
. . ....
aN1 . . . aNN
︸ ︷︷ ︸
A
×
s1(t)...
sN(t)
,
Na forma matricial e omitindo o ındice temporal:
x = As ,
onde A e a matriz de mistura.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 30 / 48

Analise de Componentes Independentes
O objetivo final da ICA e encontrar uma aproximacao y das fontesindependentes, utilizando apenas os sinais observados x.
O vetor y e definido por:
y = Wx,
sendo W a matriz de separacao.
Se W = A−1 → y = s, entao o problema foi completamentesolucionado.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 31 / 48

Analise de Componentes Independentes
Diagrama do problema considerado pelo modelo basico da ICA2:
2O modelo basico da ICA consideram que o meio de propagacao dos sinais e linear enao introduz atrasos temporais aos sinais.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 32 / 48

Analise de Componentes Independentes
Um problema classico que pode ser solucionado usando-se a ICA econhecido como cocktail-party problem.
Considerando que numa sala existem duas pessoas falandosimultaneamente e dois microfones em diferentes posicoes, os sinaisgravados x1(t) e x2(t), omitindo atrasos temporais e outrosfenomenos fısicos, como a existencia de multiplas reflexoes, podemser considerados como uma soma ponderada das fontes s1(t) e s2(t):
x1(t) = a11s1(t) + a12s2(t)x2(t) = a21s1(t) + a22s2(t);
os coeficientes aij dependem das distancias dos microfones aspessoas, e sao os elementos da matriz de mistura A, sendo:
A =
[a11 a12
a21 a22
].
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 33 / 48

Analise de Componentes Independentes
Diagrama do cocktail-party problem mostrando a propagacao dossinais das fontes ate os sensores.
Fontes
Sensores
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 34 / 48

ICA - Exemplo de Aplicacao
As fontes s1(t) e s2(t) foram misturadas linearmente, gerando ossinais medidos x1(t) e x2(t).
0 20 40 60 80 100−1
−0.5
0
0.5
1
Tempo (s)
s1(t
)
0 20 40 60 80 100−1
−0.5
0
0.5
1
Tempo (s)
s2(t
)
(Fontes)
0 20 40 60 80 100−5
0
5
Tempo (s)
x1(t
)0 20 40 60 80 100
−2
0
2
Tempo (s)
x2(t
)
(Medidos)
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 35 / 48

ICA - Exemplo de Aplicacao
Apos a aplicacao de um algoritmo de ICA:
0 20 40 60 80 100−2
−1
0
1
2
Tempo (s)sr
ec1(
t)
0 20 40 60 80 100−2
−1
0
1
2
Tempo (s)
srec
2(t)
(Recuperados)
Os sinais recuperados sao copias dos originais, a menos de fatoresmultiplicativos (limitacao inerente ao modelo da ICA, nao ha comogarantir o fator de escala ou a ordem de extracao dos componentes).
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 36 / 48

Princıpios para Estimar o Grau de Dependencia
O princıpio basico para a extracao dos componentes independentes eobtido do teorema do limite central:
A soma de duas variaveis aleatorias independentes e sempre maisproxima de uma distribuicao normal do que as variaveis originais.
Sabando que os sinais misturados xi sao gerados a partir dosomatorio ponderado das fontes si , entao xi tem distribuicoes deprobabilidade mais semelhantes a Gaussiana se comparados a si .
Ou seja, as fontes si podem ser obtidas entao pela maximizacao danao-Gaussianidade.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 37 / 48

Estimando a Gaussianidade - Curtose
A curtose (kurt) e o cumulante de quarta ordem, e para uma variavely de media zero e variancia unitaria e definida por:
kurt(y) = E{y 4} − 3(E{y 2})2
Variando no intervalo [−2,∞), a curtose e igual a zero para umavariavel gaussiana, os valores negativos indicam sub-gaussianidade eos positivos super-gaussianidade.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 38 / 48
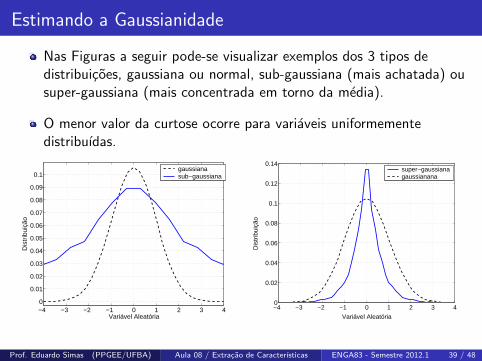
Estimando a Gaussianidade
Nas Figuras a seguir pode-se visualizar exemplos dos 3 tipos dedistribuicoes, gaussiana ou normal, sub-gaussiana (mais achatada) ousuper-gaussiana (mais concentrada em torno da media).
O menor valor da curtose ocorre para variaveis uniformementedistribuıdas.
−4 −3 −2 −1 0 1 2 3 40
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
Variável Aleatória
Dis
trib
uiçã
o
gaussianasub−gaussiana
−4 −3 −2 −1 0 1 2 3 40
0.02
0.04
0.06
0.08
0.1
0.12
0.14
Variável Aleatória
Dis
trib
uiçã
o
super−gaussianagaussianana
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 39 / 48

Estimando a Gaussianidade - Curtose
A curtose e um parametro estatıstico facilmente calculado a partir dasrealizacoes da variavel aleatoria.
Porem seu valor pode ser bastante influenciado por um pequenoconjunto de pontos na cauda da distribuicao, sendo, nesse caso,pouco robusta para a estimativa da nao-gaussianidade.
Conhecidos como intrusos (ou outliers) esses pontos podemrealmente pertencer a variavel aleatoria ou ter sido artificialmenteintroduzidos por algum fenomeno desconhecido, como:
- erro de medida;
- erro de digitacao;
- ruıdo impulsivo.
→ Para mais detalhes sobre a curtose consulte a apresentacao especıficasobre o tema.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 40 / 48

Estimando a Gaussianidade - Entropia
Uma estimacao alternativa da nao-gaussianidade pode ser obtida apartir da negentropia, que e calculada por
J(y) = H(ygauss)− H(y),
onde H(.) e a entropia e ygauss e uma variavel aleatoria gaussianacom a mesma media e variancia de y .
A entropia e um dos conceitos da teoria da informacao e pode serinterpretada como o grau de informacao contido numa variavel.
Para uma variavel aleatoria discreta, a entropia e definida como:
H(Y ) = −∑i
P(Y = ai )logP(Y = ai )
onde os ai sao os possıveis valores da variavel Y , e P(Y = ai ) e aprobabilidade de Y ser igual a ai .
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 41 / 48

Estimando a Gaussianidade - Entropia
Um resultado importante obtido a partir da teoria da informacao eque uma variavel gaussiana tem a maxima entropia entre todas asvariaveis de mesma variancia.
Considerando a equacao anterior, a negentropia e sempre naonegativa e zero quando a variavel e gaussiana, servindo como uma“medicao” da gaussianidade.
O grande problema no calculo de J(.) e a necessidade de se estimaras probabilidades para o calculo da entropia.
Para evitar esse problema utilizam-se aproximacoes da negentropiaconforme mostradas a seguir.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 42 / 48

Estimando a Gaussianidade - Entropia
Aproximacoes da negentropia usando cumulantes:
J(Y ) ≈ 1
12E{Y 3}2 +
1
48kurt(Y )2,
ou utilizando funcoes nao polinomiais:
J(Y ) ≈ [k1(E{G1(Y )})2 + k2(E{G2(Y )} − E{G2(ν)})2],
onde ν e uma variavel aleatoria gaussiana de media zero e varianciaunitaria. As funcoes nao-lineares recomendadas na literatura saoG1(y) = y exp(−y 2/2) e G2(y) = |y | ou G2(y) = exp(−y 2/2).
O uso de cumulantes traz de volta o problema da pouca robustez aoutliers.
→ Para mais detalhes sobre a entropia consulte a apresentacaoespecıfica sobre Teoria da Informacao.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 43 / 48

ICA atraves da Descorrelacao Nao-Linear
A igualdade da equacao:
E{g(x)h(y)} = E{g(x)}E{h(y)}
garante que as variaveis x e y sao independentes quando todasfuncoes g(.) e h(.),integraveis em x e y sao descorrelacionadas.
A ICA pode ser obtida testando-se a correlacao entre todas as funcoesnao-lineares g(.) e h(.) (o que nao e um procedimento pratico).
Existem alguns algoritmos propostos na literatura para o problema dadecorrelacao nao-linear, como o de Herault-Jutten e oChichocki-Unbehauen
Como nao e possıvel testar a descorrelacao entre todas as funcoesnao-lineares o algoritmo Herault-Jutten, por exemplo, aconselha o usode f (y) = y 3 e g(y) = tan−1(y), ja o Chichocki-Unbehauen sugereuma funcao polinomial e a tangente hiperbolica.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 44 / 48

Pre-Processamento dos Sinais para ICA
Os algoritmos de extracao dos componentes independentes tem seutrabalho simplificado quando os sinais sao centralizados, ou seja, temsua media removida fazendo-se:
x← x− E{x}
E importante tambem realizar:
- normalizacao (xi ← xi/σxi );
- descorrelacao (usando por exemplo a PCA)
- reducao de ruıdo.
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 45 / 48

Principais Algoritmos para ICA
...
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 46 / 48

Aplicacoes da ICA
...
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 47 / 48

Analise de Componentes Independentes
...
Prof. Eduardo Simas (PPGEE/UFBA) Aula 08 / Extracao de Caracterısticas ENGA83 - Semestre 2012.1 48 / 48





























