Embed Size (px)
Citation preview

Distributed Search over the Hidden Web:
Hierarchical Database Sampling and Selection

Hilit Achiezra - sdbi seminar
2
AgendaThe Hidden – Web Database selection algorithms An algorithm to extracts a document sampleDatabase classificationAn algorithm for content summary constructionEstimating document frequencies, ActualDF() frequenciesDatabase selection algorithms using categorization and content summaryExperiments

Hilit Achiezra - sdbi seminar
3
The Hidden Web
Also know as the Deep Web
Most of the Web's information is buried far down on dynamically generated sites
Standard search engines never find it.

Hilit Achiezra - sdbi seminar
4
The Hidden Web
Search engines create their indexes by spidering or crawling Web pages.
To be discovered, the page must be static and linked to other pages.
Search engines can not retrieve content in the Hidden Web

Hilit Achiezra - sdbi seminar
5
The Hidden WebThose pages do not exist until they are created dynamically as the result of a specific search.
Hidden Web sources store their content in searchable databases
Those databases only produce results dynamically in response to a direct request.
A direct query is a "one at a time" laborious way to search.

Hilit Achiezra - sdbi seminar
6
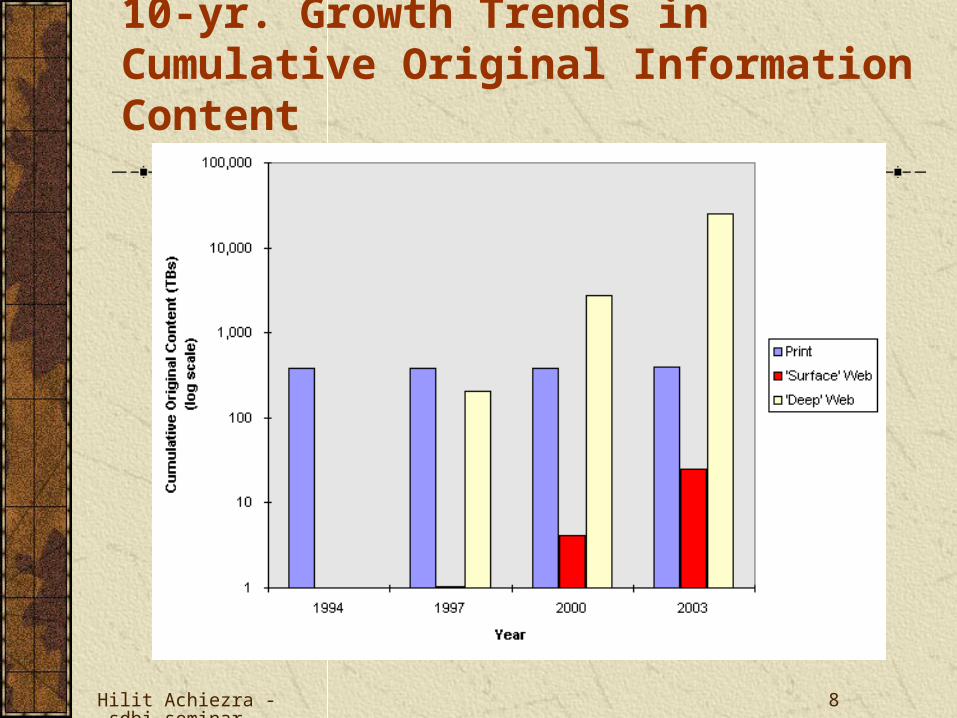
The Size of the Hidden WebAccording to a study based on data collected
between March 13 and 30, 2000 :
Public information on the hidden Web is currently 400 to 550 times larger than the commonly defined World Wide Web.
Total quality content of the hidden Web is 1,000 to 2,000 times greater than that of the Web
The hidden Web is the largest growing category of new information on the Internet.

Hilit Achiezra - sdbi seminar
7
Putting those Findings in Perspective
Highest indexed search engines (Google , Northern Light etc.) index up to 16% of the Web.
Since they are missing the hidden Web when they use such search engines
Internet searchers are searching only 0.03% of the pages available to them today.
Hilit Achiezra - sdbi seminar
8
10-yr. Growth Trends in Cumulative Original Information Content

Hilit Achiezra - sdbi seminar
9
The main Issues
An algorithm to derive content summaries from “uncooperative” databases by using “focused query probes”
A novel database selection algorithm that exploits both the extracted content summaries and a hierarchical classification of the databases.

Hilit Achiezra - sdbi seminar
10
Some Techniques we will discussed
A document sampling technique for text databases that results in higher quality database content summaries
A technique to estimate the absolute document frequencies of the words in the content summaries

Hilit Achiezra - sdbi seminar
11
Some techniques we will discussed(2)
A database selection algorithm that proceeds hierarchically over a topical classification scheme.
Experimental evaluation of the new algorithms using both “controlled” databases and 50 real web accessible databases.

Hilit Achiezra - sdbi seminar
12
An Example
Searching in the medical database CANCERLIT – www.cancer.gov the query [lung and cancer] returns 68,430 matches
Searching Google with the query [“lung” and “cancer” site:www.cancer.gov] returns 23 matches
None of the pages which return corresponds to the database documents.

Hilit Achiezra - sdbi seminar
13
An Example (2)
The results shows that the valuable CANCERLIT content is not indexed by this search engine

Hilit Achiezra - sdbi seminar
14
MetasearchersOne-stop access to the information in text databases.Performs three main tasks:
After receiving a query, it finds the best databases to evaluate the query (database selection) It translates the query in a suitable form for each database (query translation) It retrieves and merges the results from the different databases (result merging) and returns them to the user.

Hilit Achiezra - sdbi seminar
15
Database selection algorithms
Based on statistics that characterize each database’s content
They refer to the statistics as content summaries
Usually include the document frequencies of the words that appear in the database

Hilit Achiezra - sdbi seminar
16
Database selection algorithms(2)
Provide sufficient information to the database selection component of a metasearcher to decide
which databases are the most promising to evaluate a given query.

Hilit Achiezra - sdbi seminar
17
Database selection algorithms(3)
Tries to find the best databases to evaluate a given query
Uses the document frequency of the word : the number of different documents that contain each word
Uses the NumDocs – the number of documents stored in the database

Hilit Achiezra - sdbi seminar
18
An example - bGlOSS – Boolean Glossary-of- Servers Server
A Flat Selection Algorithm
Documents are represented as words with position information.
Queries are expressions composed of words, and connectives such as \and," \or," \not," and proximity operations such as \within k words of.“
The answer to a query is the set of all the documents that satisfy the Boolean expression.
Hilit Achiezra - sdbi seminar
19
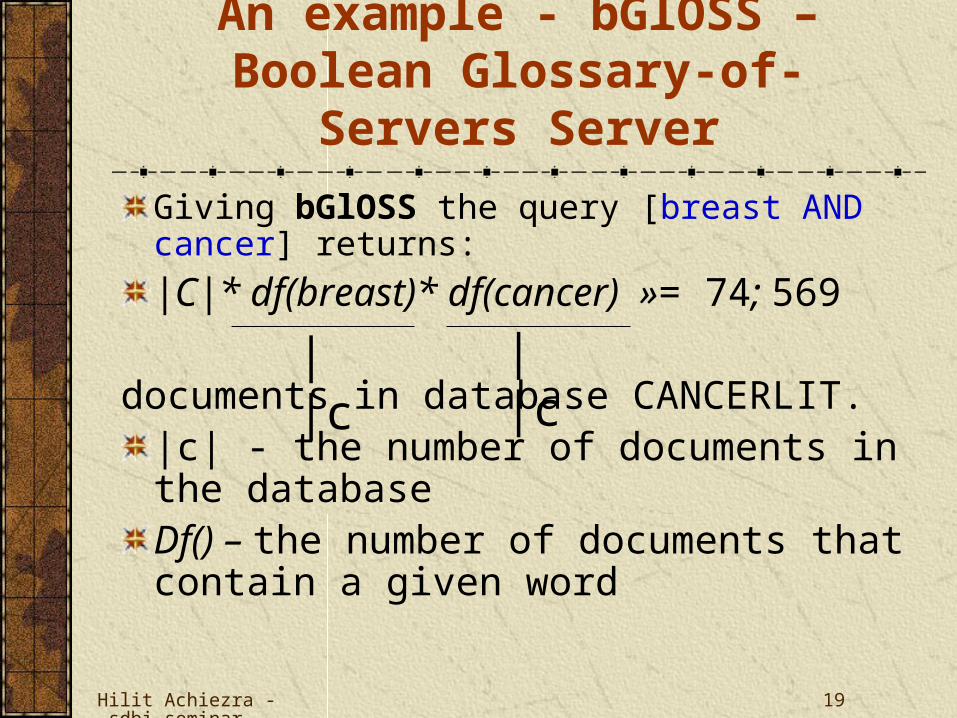
An example - bGlOSS – Boolean Glossary-of- Servers Server
Giving bGlOSS the query [breast AND cancer] returns:
|C|* df(breast)* df(cancer) »= 74; 569
documents in database CANCERLIT.|c| - the number of documents in the databaseDf() – the number of documents that contain a given word
|c| |c|

Hilit Achiezra - sdbi seminar
20
Supply the Content Summary
The metasearcher rely on the database to supply the content summary
If the databases do not report any detailed metadata about their contents - then
Metasearcher will rely on manually generated descriptions of the database contents.
This doesn’t match thousands of text databases

Hilit Achiezra - sdbi seminar
21
START – Stanford Protocol for Internet
Retrieval and Search
An emerging protocol for Internet retrieval and search that facilitated the task of querying multiple document sources.
.

Hilit Achiezra - sdbi seminar
22
START – Stanford Protocol for Internet Retrieval and Search(2)
The goal – to facilitate the main three task a metasearcher preforms:
Choosing the best source to evaluate a query
Evaluating the query at these sources
Merging the query results from these sources.
Mainly deals with what information needs to exchanged between sources and metasearchers

Hilit Achiezra - sdbi seminar
23
An Algorithm to extracts a document sample from a given database
SampleDF(w) - Computes the frequency of each observed word w in the sample,

Hilit Achiezra - sdbi seminar
24
An Algorithm to extracts a document sample from a given database(2)
1. Starts with an empty content summary where SampleDF(w) = 0 for each word w, and a general comprehensive word dictionary.
2. Pick a word and sent it as a query to database D
3. Retrieve the top-k documents returned
4. If the number of retrieved documents exceeds a prespecified threshold
then stop. else continue the sampling process – return to step 2

Hilit Achiezra - sdbi seminar
25
2 Versions of the algorithm
RS-Ord – RandomSampling- OtherResource
Picks a random word from the dictionary for step 2.
RS-Lrd –RandomSampling- LearnedResource Selects the next query from among the words that have been already discovered during sampling.

Hilit Achiezra - sdbi seminar
26
More about the algorithm
The actual frequency ActualDF(w) for each word w
is not revealed by this processes
The calculated document frequencies contain
information about the relative ordering of the words in the database.

Hilit Achiezra - sdbi seminar
27
More about the algorithm (2)
Two databases with the same focus but differing significantly in size might be assigned similar content summaries.
A word that is randomly picked from the dictionary, is likely not to occur in any document of arbitrary database

Hilit Achiezra - sdbi seminar
28
Database Classification
A way to characterize the contents of a text database is:
To classify it in hierarchy of topics according to the type of the documents that it contains.

Hilit Achiezra - sdbi seminar
29
Database Classification
A method to automate the classification of web accessible databases based on the principle of “focused probing”
A rule based document classifier – a set of logical rules defining classification decisions

Hilit Achiezra - sdbi seminar
30
Hierarchy Classification
Categories can be further divided into subcategories,
Resulting in multiple levels of classifiers, one of each internal node of a classification hierarchy
It is possible to create a hierarchical classifier that will recursively divide the space into successively smaller topics.

Hilit Achiezra - sdbi seminar
31
Classify a database
An algorithm that uses a hierarchical scheme,
automatically maps rule based document classifiers into queries,
which are then used to probe and classify text databases.

Hilit Achiezra - sdbi seminar
32
Classify a database(2)
The algorithm provides a way to zoom in on the topics that are most representative of a given database’s contents
we can then exploit it for accurate and efficient content summary construction

Hilit Achiezra - sdbi seminar
33
Focused Probing for content Summary Construction - Algorithm
The algorithm consists of two main steps:1. Query the database using focused probing in
order to:a. Retrieve a document sample.
b. Generate a preliminary content summary
c. Categorize the database.
2. Estimate the absolute frequencies of the words retrieved from the database.

Hilit Achiezra - sdbi seminar
34
Generating a content summary for a database using focused query probing

Hilit Achiezra - sdbi seminar
35
Generating a content summary for a database using focused query probing(2)

Hilit Achiezra - sdbi seminar
36
Generating a content summary for a database using focused query probing(3)

Hilit Achiezra - sdbi seminar
37
Building Content Summaries from Extracted Documents
ActualDF(w): The actual number of documents in the database that contain word w. The algorithm knows this number only if [w] is a single word query probe that was issued to the database
SampleDF(w): The number of documents in the extracted sample that contain word w.

Hilit Achiezra - sdbi seminar
38
Building Content Summaries from Extracted Documents(2)
Retrieves the top-k documents returned by each query .
Computes SampleDF(w).
If a word w appears in document samples retrieved during later phases of the algorithm
then all SampleDF(w) values are added together
Keeps track of the number of matches produced by each single word query[w] – ActualDF(w) frequency.

Hilit Achiezra - sdbi seminar
39
Estimating Absolute Document Frequencies
Exploit the SampleDF(.) frequenciesderived from the document sample to rank all observed words
• from most frequent to least frequent.
Exploit the ActualDF(.) frequencies derived from one word query probes to potentially boost the document frequencies
• of “nearby” words w for which we only know SampleDF(w) but not ActualDF(w)

Hilit Achiezra - sdbi seminar
40
Focused Probing Technique for Content Summary Construction - Summary
The technique
Estimates the absolute document frequency of the words in a database.
Automatically classifies the database in a hierarchical classification scheme along the way.

Hilit Achiezra - sdbi seminar
41
Estimating Unknown ActualDF (¢) Frequencies
After probing we get The rank of all observed words in the sample documents retrieved.
The actual frequencies of some of those words in the database

Hilit Achiezra - sdbi seminar
42
Estimating Unknown ActualDF (¢) Frequencies(2)
A relationship between the rank r and the frequencies f of a word
f= P(r+p) -B
P, B and p are parameters of the specific documents collection

Hilit Achiezra - sdbi seminar
43
Estimating Unknown ActualDF (¢) Frequencies(3)
Sort words in descending order of their SampleDF(¢) frequencies
to determine the rank ri of each word wi.
Focus on words with known ActualDF (¢) frequencies.
Use the SampleDF-based rank and ActualDF frequencies to find the P, B, and p parameter values that best fit the data.

Hilit Achiezra - sdbi seminar
44
Estimating Unknown ActualDF (¢) Frequencies(4)
Estimate ActualDF (wi) for all words wi with unknown ActualDF (wi) as P(ri+p) -B, where ri is the rank of word wi as computed in Step 1.

Hilit Achiezra - sdbi seminar
45
A Database Selection Algorithm that Exploits the Database Categorization and Content
Summaries Selection
1. “Propagate” the database content summaries
to the categories of the hierarchical classification scheme
2. Use the content summaries of categories and databases
to perform database selection hierarchically by zooming in on the most relevant portions of the topic hierarchy

Hilit Achiezra - sdbi seminar
46
Creating Content Summaries for Topic Categories
Assumption – Databases classified under similar topics tend to have similar vocabularies.
Problem – Database selection algorithms might produce inaccurate conclusions for queries with one or more words missing from relevant content summaries.

Hilit Achiezra - sdbi seminar
47
Creating Content Summaries for Topic Categories (2)
Solution – Associate content summaries with the categories of the topic hierarchy used by the probing algorithm.
Treat each category as a large “database” and perform database selection hierarchically

Hilit Achiezra - sdbi seminar
48
Selecting Database Hierarchically
The algorithm chooses the best databases for a query.
By exploiting the database categorization, this hierarchical algorithm manages to
Compensate for the necessarily incomplete database content summaries produced by query probing

Hilit Achiezra - sdbi seminar
49
Selecting the K most specific databases for a query hierarchically
HierSelect(Query Q, Category C, int K)
1: Use a database selection algorithm to assign a score for Q to each subcategory of C
2: if there is a subcategory C with a non-zero score
3: Pick the subcategory Cj with the highest score

Hilit Achiezra - sdbi seminar
50
Selecting the K most specific databases for a query hierarchically(2)
4: if NumDBs(Cj) >= K //Cj has enough databases
5: return HierSelect(Q,Cj ,K)
6: else // Cj does not have enough databases
7: return DBs(Cj)
FlatSelect(Q,C-Cj,K-NumDBs(Cj))
8: else // no subcategory C has non-zero score
9: return FlatSelect(Q,C,K)
Hilit Achiezra - sdbi seminar
51
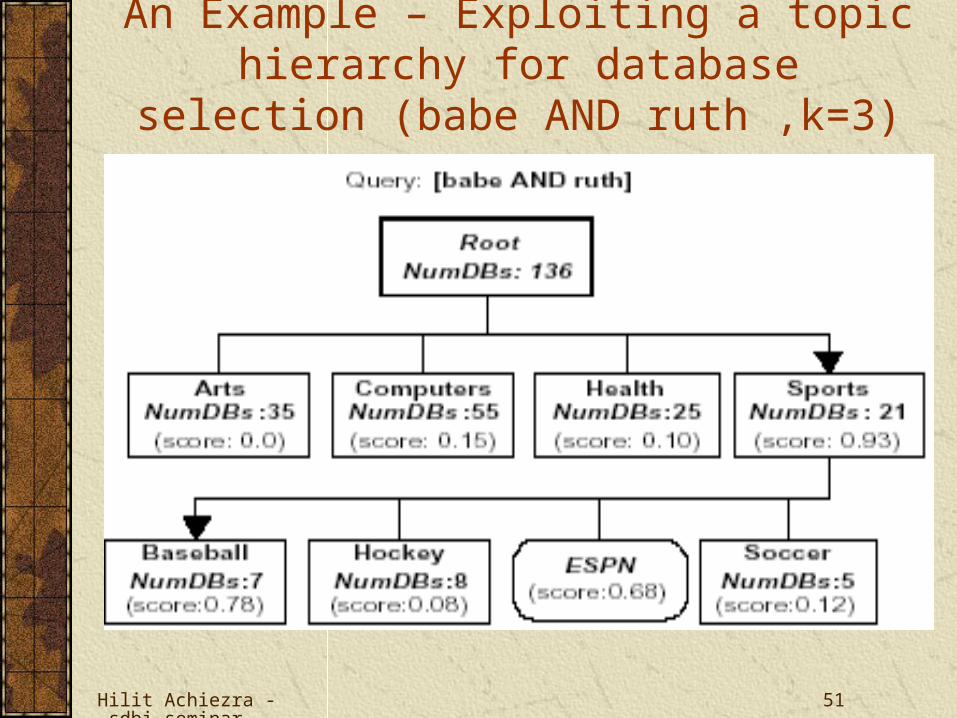
An Example – Exploiting a topic hierarchy for database selection (babe AND ruth ,k=3)

Hilit Achiezra - sdbi seminar
52
The Data for the Experiments -
Controlled Database Set
They gathered 500,000 newsgroup articles from 54 newsgroup.
They used 81,000 articles to train documents classifiers over the 72 – node topic hierarchy.
The remaining 419,000 articles used to build the set of Controlled Databases – contained 500 databases.
350 were with documents from a single category,
The remaining 150 with a variety of category mixes.

Hilit Achiezra - sdbi seminar
53
The Data for the Experiments –
Web Database Set
They used a set of 50 real web accessible databases.
The databases were picked randomly from 2 directories of hidden-web databases

Hilit Achiezra - sdbi seminar
54
Content Summary Construction
As the initial dictionary for the methods RS-Ord, RS-Lrd
They used the set of all words that appear in the databases of the Controlled set.
For Focused ProbingThey evaluate configurations with different underlying document classifiers for query probe creation
Different values for the thresholds Ts and Tc that define the granularity of sampling performed by the algorithm.

Hilit Achiezra - sdbi seminar
55
Content Summary Construction(2)
To keep the number of experiments manageable
They fix the coverage threshold Tc =10, varying only the specificity threshold Ts.

Hilit Achiezra - sdbi seminar
56
Testing Database Selection Effectiveness – Underlying Database Selection Algorithm
The hierarchical algorithm
Relies on a “flat” database selection algorithm.
They consider two such algorithms: CORI, bGlOSS
The algorithms work with the category content summaries

Hilit Achiezra - sdbi seminar
57
Testing Database Selection Effectiveness – Underlying Database Selection Algorithm(2)
There purpose to ensure That their techniques behave similarly for different flat database selection algorithms.

Hilit Achiezra - sdbi seminar
58
Testing Database Selection effectiveness - Content Summary Construction
Evaluated how their hierarchical database selection algorithm behaves over content summaries generated by different techniques.

Hilit Achiezra - sdbi seminar
59
Testing Database Selection Effectiveness
- QPilot
Qpilot – a strategy that exploits HTML links to characterize text databases.
QPilot builds a content summary for a web-accessible database D as follows:

Hilit Achiezra - sdbi seminar
60
Testing Database Selection Effectiveness
– Qpilot(2)
Query a general search engine to retrieve pages that link to the web page for D.
Retrieve the top-m pages that point to D.
Extract the words in the same line as a link to D.
Include only words with high document frequency in the content summary for D.

Hilit Achiezra - sdbi seminar
61
Testing Database Selection Effectiveness - Hierarchical vs. Flat Database
Selection
They compare The effectiveness of the hierarchical algorithm against that of the underlying “flat” database selection strategies.

Hilit Achiezra - sdbi seminar
62
Experimental Results – Content Summary Quality
They used Controlled Database Set for the experiments.
They measure the content summaries coverage of the actual database vocabulary.
The coverage of the Focused Probing summaries
increases for lower thresholds of Ts, since the number of documents retrieved for lower thresholds is larger.

Hilit Achiezra - sdbi seminar
63
Experimental Results – Content Summary Quality
They increase the sample size RS-Ord and RS-Lrd
To retrieve the same number of documents as the Focused Probing methods
The achieved coverage of RS-Ord and RS-Lrd was still lower than that of the
respective Focused Probing method.The difference between RS-Ord and RS-Lrd is small.

Hilit Achiezra - sdbi seminar
64
Experimental Results – Content Summary Quality(2)
Spearman Rank Correlation Coefficient (SRCC for short) –
Used to measure how well a content summary orders words by frequencies
With respect to the actual word frequency order in the database.
The Focused Probing method have higher SRCC values than the RS-Ord and RS-Lrd.

Hilit Achiezra - sdbi seminar
65
Experimental Results – Content Summary Quality – Efficiency
They report the sum of The number of queries sent to a database
And the number of documents retrieved.
Focused Probing techniques on average retrieve one document per query sent,

Hilit Achiezra - sdbi seminar
66
Experimental Results – Content Summary Quality – Efficiency(2)
RS-Lrd retrieves about one document per two queries.
RS-Ord unnecessarily issues many queries that produce no document matches.

Hilit Achiezra - sdbi seminar
67
Experimental Results – Content Summary Quality
Focused Probing techniques Produce significantly better-quality summaries than RS-Ord and RS-Lrd do,• in terms of vocabulary coverage • and word ranking preservation.

Hilit Achiezra - sdbi seminar
68
Experimental Results – Content Summary Quality(2)
The cost of Focused Probing in terms Of number of interactions with the databases is
• comparable to or less than that for RS-Lrd,
• and significantly less than that for RS-Ord.

Hilit Achiezra - sdbi seminar
69
Experimental Results – Database Selection Effectiveness
To evaluate how the content summaries affects the database selection task
they use the Web set of real web-accessible databases.
Each database selection algorithm picked 3 databases for the query.

Hilit Achiezra - sdbi seminar
70
Experimental Results – Database Selection Effectiveness(2)
For each selected database they retrieved the top 5 documents for the query.
They asked human evaluators to judge
the relevance of each retrieved document for the query
following the guidelines given for each query

Hilit Achiezra - sdbi seminar
71
Experimental Results – Database Selection Effectiveness(3)
They compare two hierarchical algorithm relies on a “flat” database selection algorithm.
They consider two such algorithms: CORI, bGlOSS
QPilot, RS-Ord and RS-Lrd do not classify databases while building content summaries.

Hilit Achiezra - sdbi seminar
72
Experimental Results – Database Selection Effectiveness(4)
They choose RS-Ord over RS-Lrd Because it superior performance in the evaluation.
To analyze the effect of content summary construction algorithms on database selection,
They tested how the quality of content summaries generated by RS-Ord, Focused Probing, and Qpilot
affects the database selection process.

Hilit Achiezra - sdbi seminar
73
Experimental Results – Database Selection Effectiveness(5)
All the flat selection techniques suffer From the incomplete coverage of the underlying probing-generated summaries.
QPilot summaries do not work well for database selection
Because they generally contain only a few words and are hence highly incomplete.

Hilit Achiezra - sdbi seminar
74
Hierarchical vs. flat database selection
The hierarchical algorithm using CORI as flat database selection has
50% better precision than CORI for flat selection with the same content summaries.
For bGlOSS, the improvement in precision is even more dramatic at 92%.
The reason is that the topic hierarchy helps compensate for incomplete content summaries.

Hilit Achiezra - sdbi seminar
75
Hierarchical vs. flat database selection(2)
They measured the fraction of times that their hierarchical database selection algorithm picked a database for a query
That produced matches for the query
And was given a zero score by the flat database selection algorithm of choice.
This was the case for 34% of the databases picked by the hierarchical algorithm with bGlOSS

Hilit Achiezra - sdbi seminar
76
Hierarchical vs. flat database selection(3)
For 23% of the databases picked by the hierarchical algorithm with CORI.
These numbers support their hypothesis that hierarchical database selection compensates for content-summary incompleteness.

Hilit Achiezra - sdbi seminar
77
ConclusionsConstruction of content summaries of web accessible text databases.
The algorithm creates content summaries of higher quality then current approaches and, Categorizes databases in classification scheme.
A hierarchical database selection algorithm that exploits the database content summaries
That produce accurate results even for imperfect content summaries.
According to the experimental results the techniques improve the state of the art in content summary construction and database selection.

Hilit Achiezra - sdbi seminar
78
References
P. G. Ipeirotis and L. Gravano. Distributed Search over the Hidden Web: Hierarchical Database Sampling and Selection.
http://www.brightplanet.com/deepcontent/tutorials/DeepWeb/
L. Gravano, C.-C. K. Chang, H. Garcia-Molina, and A. Paepcke. STARTS: Stanford proposal for Internet metasearching. In SIGMOD’97, 1997.





























