Embed Size (px)
Citation preview

Distributed Systems
Early Examples

Projects
• NOW – a Network Of WorkstationsUniversity of California, BerkelyTerminated about 1997 after demonstrating the feasibility of their approach
• Condor – University of Wisconsin-MadisonStarted about 1988Is now an ongoing, world-wide system of shared computing clusters.

NOW: a Network of Workstationshttp://now.cs.berkeley.edu/
• Scale: A NOW system consists of a building-wide collection of machines providing memory, disks, and processors.
• Basic Ideas– Use idle CPU cycles for parallel processing on
clusters of workstations– Use memories as disk cache to break the I/O
bottleneck (slow disk access times)– Share the resources over fast LANs

NOW “Opportunities”: Memory
• Network RAM: fast networks, high bandwidth make it reasonable to page across the network.– Instead of paging out to slow disks, send over fast
networks to RAM in an idle machine• Cooperative file caching: improve performance by
using neetwork RAM as a very large file cache– Shared files can be fetched from another client’s
memory rather than server’s disk– Active clients can extend their disk cache size by using
memory of idle clients.

NOW Opportunities: “RAWD”(Redundant Arrays of Workstation Disks)
• RAID systems provide fast performance by connecting arrays of small disks. By reading/ writing data in parallel, throughput is increased.
• Instead of a hardware RAID, build software version by writing data across the work stations in the network– Especially useful for parallel programs running on
separate machines in the network

NOW Opportunities: “Parallel Computing”
• Harnessing the power of multiple idle workstations in a NOW can support high- performance parallel applications.
• NOW principles: – avoid going to disk by using RAM on other network nodes
(assumes network faster than disk)– Further speedup may be achieved by parallelizing the computation
and striping the data to multiple disks.– allow user processes to access the network directly rather than
going through the operating system

Berkeley NOW Features
• GLUnix (Global Layer UNIX) is a layer on top of UNIX OS’s running on the workstations
• Applications running on GLUnix have a protected virtual operating system layer which catches UNIX system calls and translates them into GLUnix calls.
• Serverless Network File System – xFS– Avoids central server bottleneck– Cooperative file system (basically, peer-to-peer)

Summary
• Successful, in their opinion. • Ran for several years in the late 90s on the
Berkeley CS system • Key enabling technologies– Scalable, high performance network– Fast access to the network for user processes– Global operating system layer to support system
resources as a true shared pool.

CONDORhttp://research.cs.wisc.edu/condor/
• Goal: “…to develop, implement, deploy, and evaluate mechanisms and policies that support High Throughput Computing (HTC) on large collections of distributively owned computing resources”– HTC computing – “… problems that require weeks or
months of computation to solve. …this type of research need a computing environment that delivers large amounts of computational power over a long period of time.”
– Compare to High Performance computing (HPC) which “…delivers a tremendous amount of power over a short period of time.”

Overview
• Condor can be used to manage computing clusters. It is designed to take advantage of idle machines
• Condor lets users submit many jobs at the same time. Result: tremendous amounts of computation with very little user intervention.
• No need to rewrite code - just link to Condor libraries

Features
• Checkpoints: save complete state of the process– Critical for programs that run for long periods of
time to recover from crashes or to vacate machines whose user has returned, or for process migration due to other reasons.
• Remote system calls: data resides on the home machine and system calls are directed there. Provides protection for host machines.

Features
• Jobs can run anywhere in the cluster (which can be a physical cluster, a virtual cluster, or even a single machine)
• Different machines have different capabilities; when submitting a job Condor uses can specify the kind of machine they wish to run on.
• When sets of jobs are submitted it’s possible to define dependencies; i.e., “don’t run Job 3 until jobs 1 and 2 have completed.”

Slides
• From a talk by Myron Livny, “The Principles and Power of Distributed Computing”,International Winter School on Grid Computing 2010.http://research.cs.wisc.edu/condor/talks.html
• Livny is a professor at the U of Wisconsin-Madison where he heads the Condor Project, and other grid/distributed computing projects or centers.

Condor Daemons
• Title unknown, by Hans Holbein the Younger, from Historiarum Veteris Testamenti icones, 1543
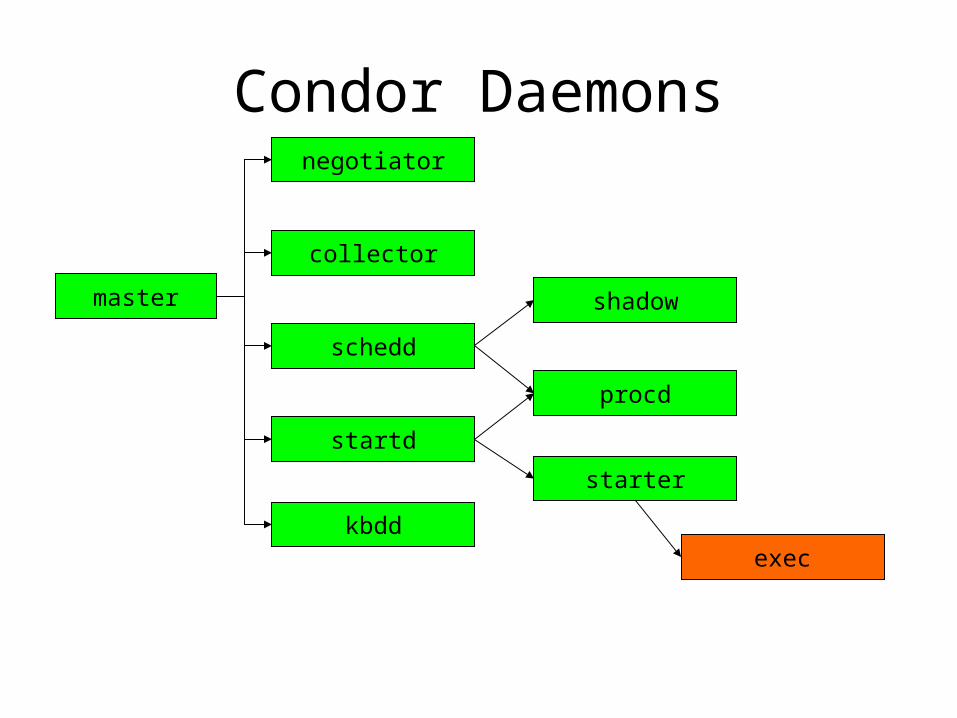
Condor Daemons
master
negotiator
collector
schedd
startd
starter
shadow
procd
kbddexec

Condor today
• http://research.cs.wisc.edu/condor/map/





























