Embed Size (px)
Citation preview

Distributed Transactions:
Distributed deadlocksRecovery techniques

Distributed Deadlocks
We have talked about deadlocks in a single server environment
Deadlocks have to be either Prevented or Detected and resolved
Distributed deadlock Detection
Global wait-for graph
Simple idea Central server takes the role of global deadlock detector

Interleavings of transactions U, V and W
U V W
d.deposit(10) lock D
b.deposit(10) lock B
a.deposit(20) lock A at Y
at Xc.deposit(30) lock C
b.withdraw(30) wait at Y at Z
c.withdraw(20) wait at Z
a.withdraw(20) wait at X
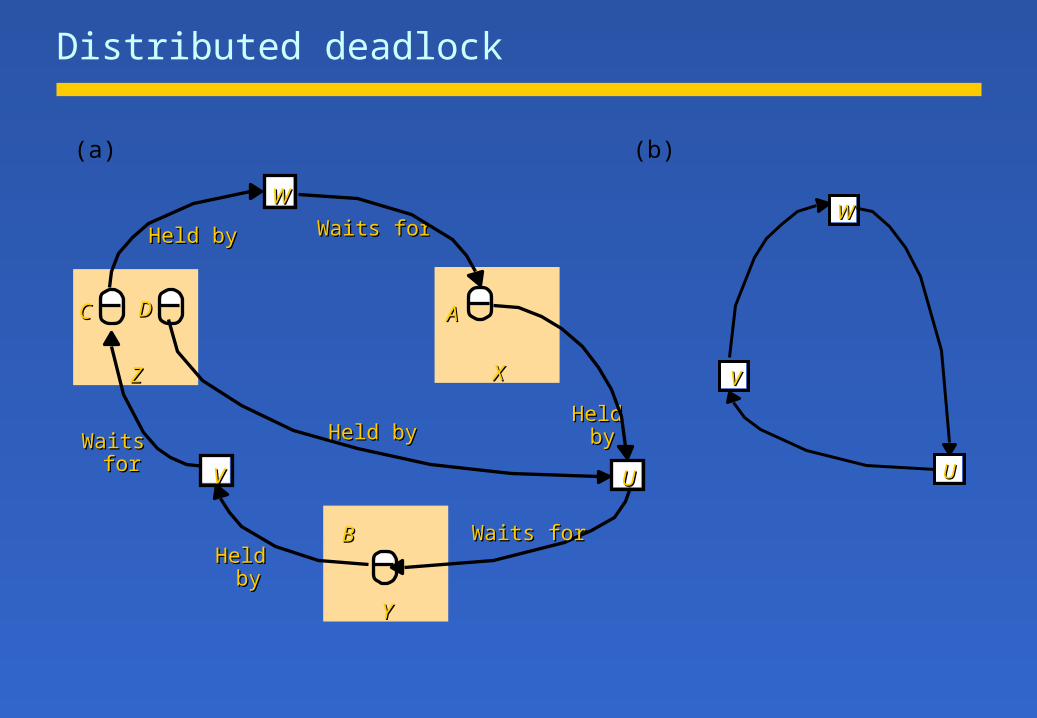
Distributed deadlock
DD
Waits forWaits for
WaitsWaitsforfor
Held byHeld by
HeldHeldbyby
BB Waits forWaits forHeldHeld
byby
XX
YY
ZZ
Held byHeld by
WW
UUVV
AACC
WW
VV
UU
(a) (b)
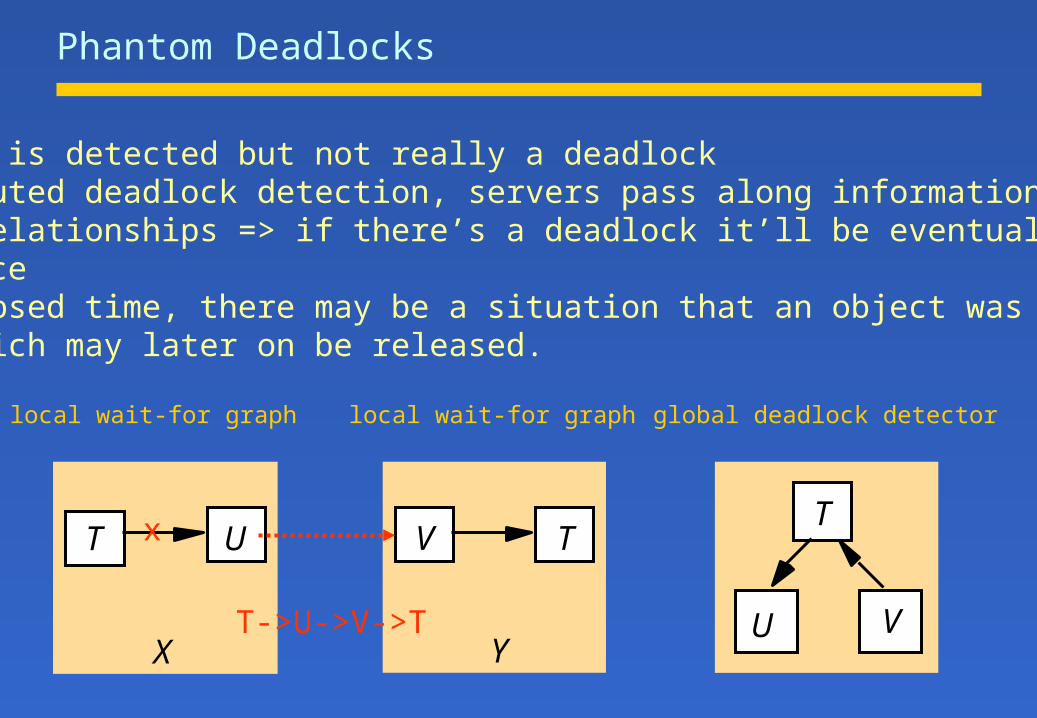
Phantom Deadlocks
A deadlock is detected but not really a deadlockIn distributed deadlock detection, servers pass along information aboutwait-for relationships => if there’s a deadlock it’ll be eventually detectedat one placeDue to elapsed time, there may be a situation that an object was detected aslocked, which may later on be released.
X
T U
Y
V TT
U V
local wait-for graph local wait-for graph global deadlock detector
x
T->U->V->T
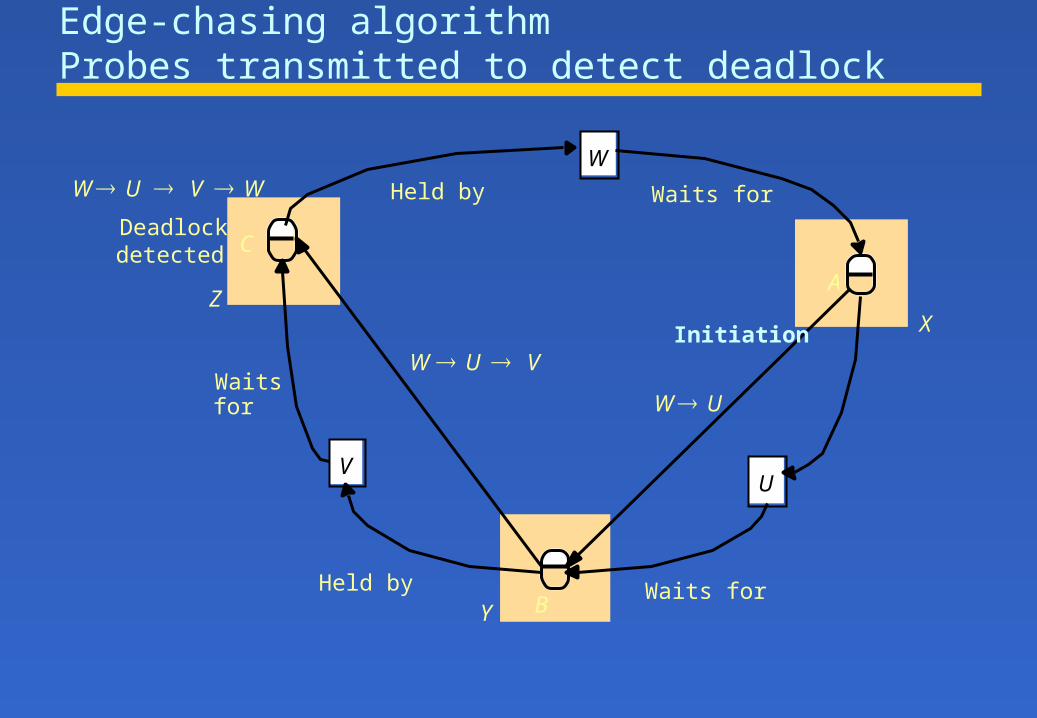
Edge-chasing algorithmProbes transmitted to detect deadlock
V
Held by
W
Waits forHeld by
Waitsfor
Waits for
Deadlockdetected
U
C
A
B
Initiation
W U V W
W U
W U V
Z
Y
X
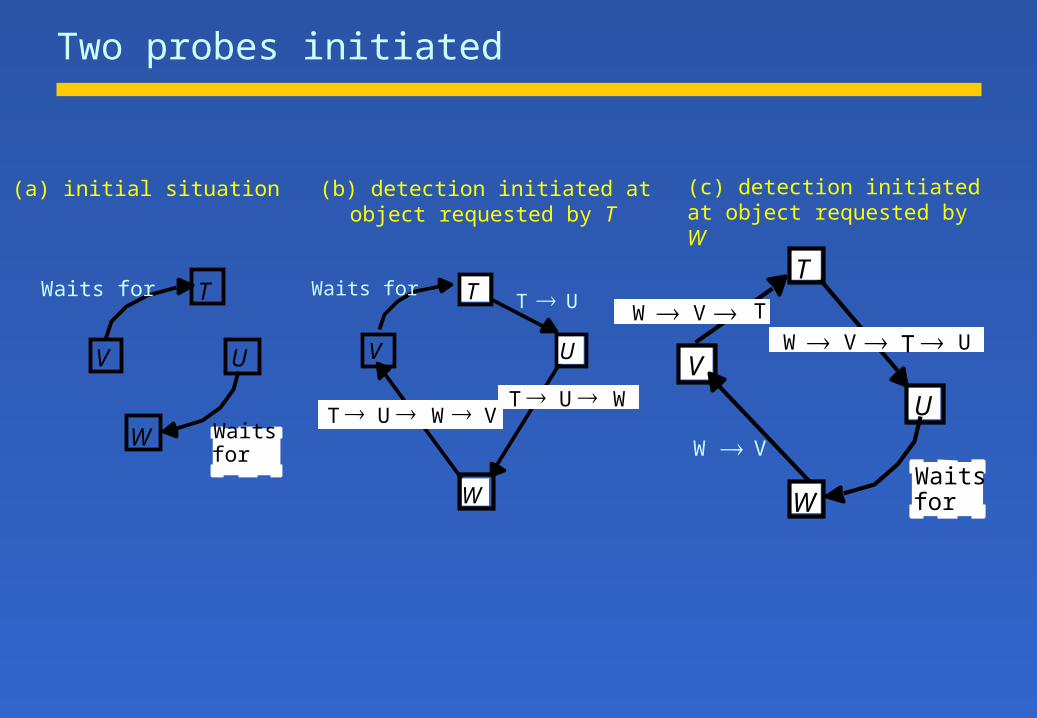
Two probes initiated
(a) initial situation (b) detection initiated at object requested by T
U
T
V
W
Waits for
Waitsfor
V
W
U
T
T U W VT U W
T UWaits for
U
V
T
W
W V T W V T U
W V
Waitsfor
(c) detection initiated at object requested by W
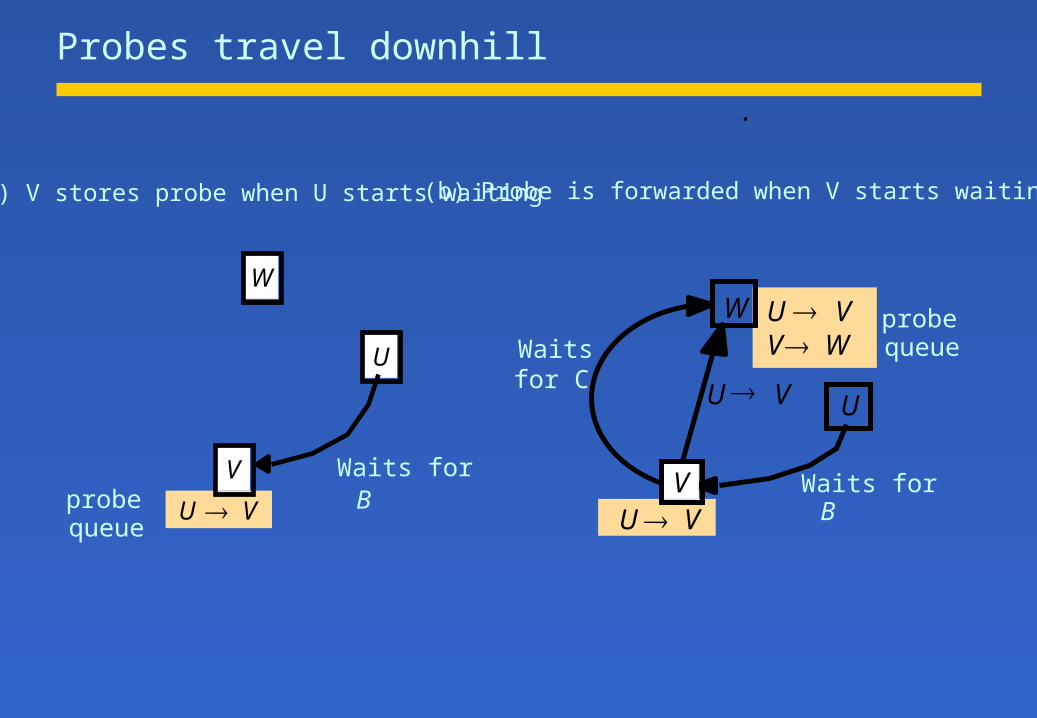
Probes travel downhill
.
(b) Probe is forwarded when V starts waiting(a) V stores probe when U starts waiting
U
W
Vprobequeue
U V
Waits forB
Waits forB
Waitsfor C
V WU V
VU V
U V U
W probequeue

Recovery
Atomicity propertyDurability and failure atomicity
• Durability: objects are saved in a permanent storage• Failure: effects of transaction are atomic even when the server
crashesAssumptions
• a running server keeps all its objects in volatile memory and records of committed transactions in a recovery file.
Recovery:• restoring the server with its latest committed versions of its
objects from the permanent storageRecovery manager:
• save objects in permanent storage for committed transactions• restore server’s objects after a crash• reorganize the recovery file to improve performance• reclaim storage space

Types of entry in a recovery file
Type of entry Description of contents of entry
Object A value of an object.
Transaction status Transaction identifier, transaction status ( prepared , committedaborted ) and other status values used for the two-phasecommit protocol.
Intentions list Transaction identifier and a sequence of intentions, each ofwhich consists of <identifier of object>, <position in recoveryfile of value of object>.
To deal with the recovery process:
Object value, status of the transaction, Intentions list (list of references and values of all objects altered by that transaction, useful in 2PC)
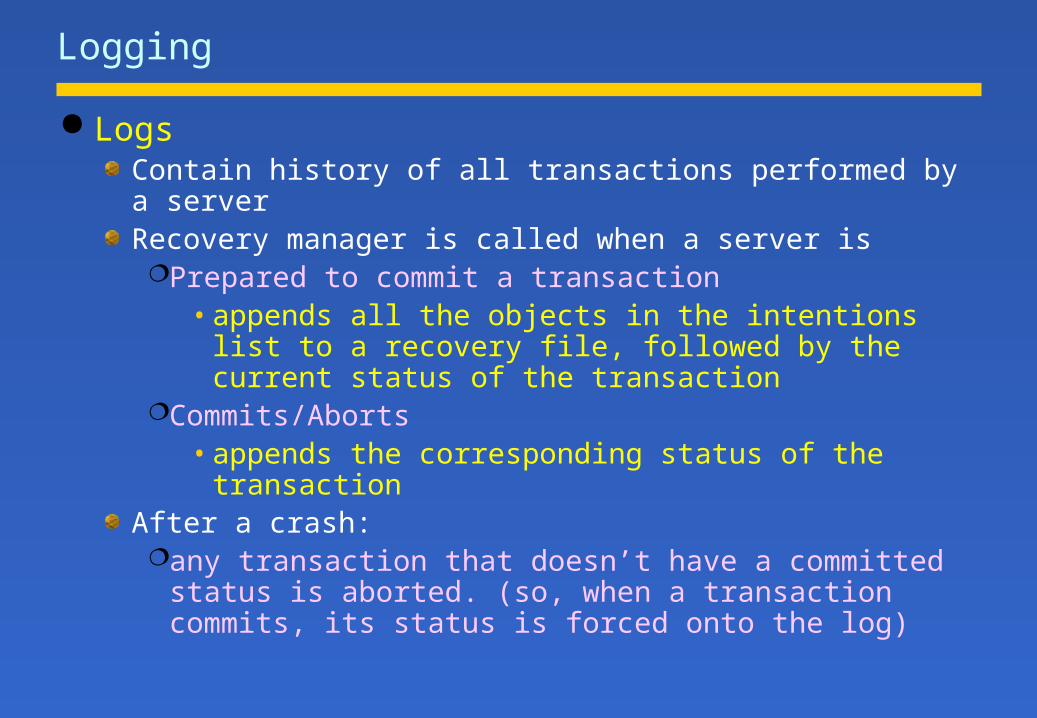
Logging
LogsContain history of all transactions performed by a serverRecovery manager is called when a server isPrepared to commit a transaction
• appends all the objects in the intentions list to a recovery file, followed by the current status of the transaction
Commits/Aborts• appends the corresponding status of the transaction
After a crash:any transaction that doesn’t have a committed status is
aborted. (so, when a transaction commits, its status is forced onto the log)
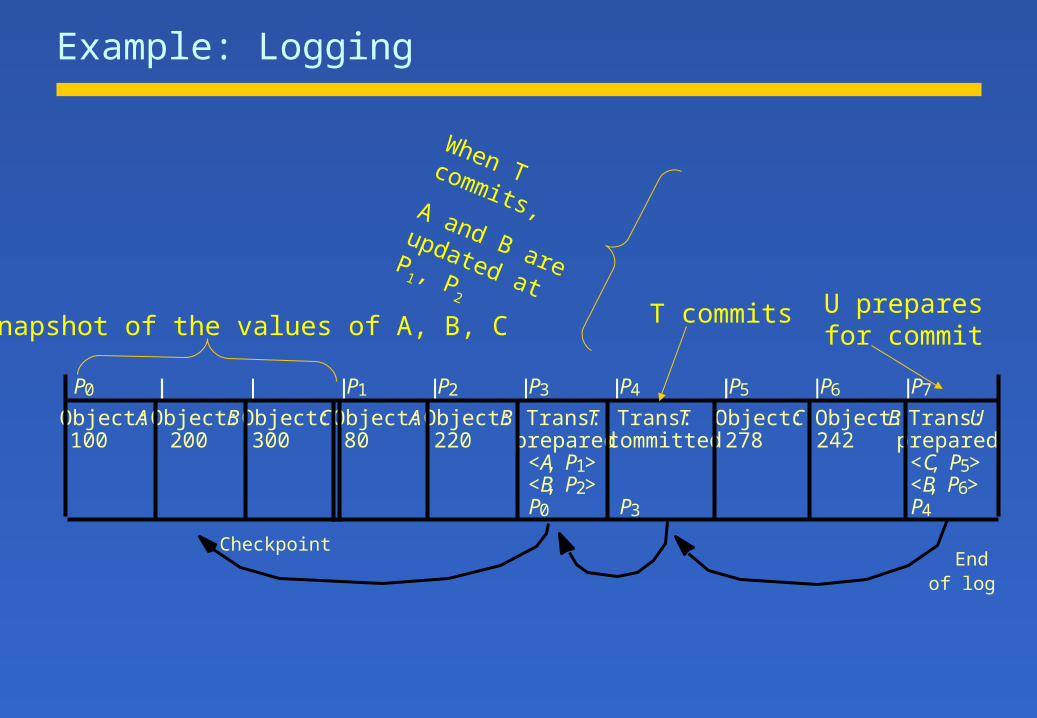
Example: Logging
P0 P1 P2 P3 P4 P5 P6 P7
Object:A Object:B Object:C Object:A Object:B Trans:T Trans:T Object:C Object:B Trans:U100 200 300 80 220 prepared committed 278 242 prepared
<A, P1> <C, P5><B, P2> <B, P6>P0 P3 P4
CheckpointEnd
of log
Snapshot of the values of A, B, C T commits U preparesfor commit
When T commits,A and B are updated at P
1 , P2

Recovery
Server restarts after crashSets default initial values for objects and starts the recovery manager.Two approaches:
Forward:The recovery manager starts from the beginning and restores all the
object values starting from the most recent checkpoint. It then reads the values of all the objects and associates them with
their intentions list, for committed transactions replaces the values of the obj.
Like replaying Backward:
Uses the backward pointersCommitted transactions are used to restore objects that are not
restored. It continues until all of the server’s objects are restored.
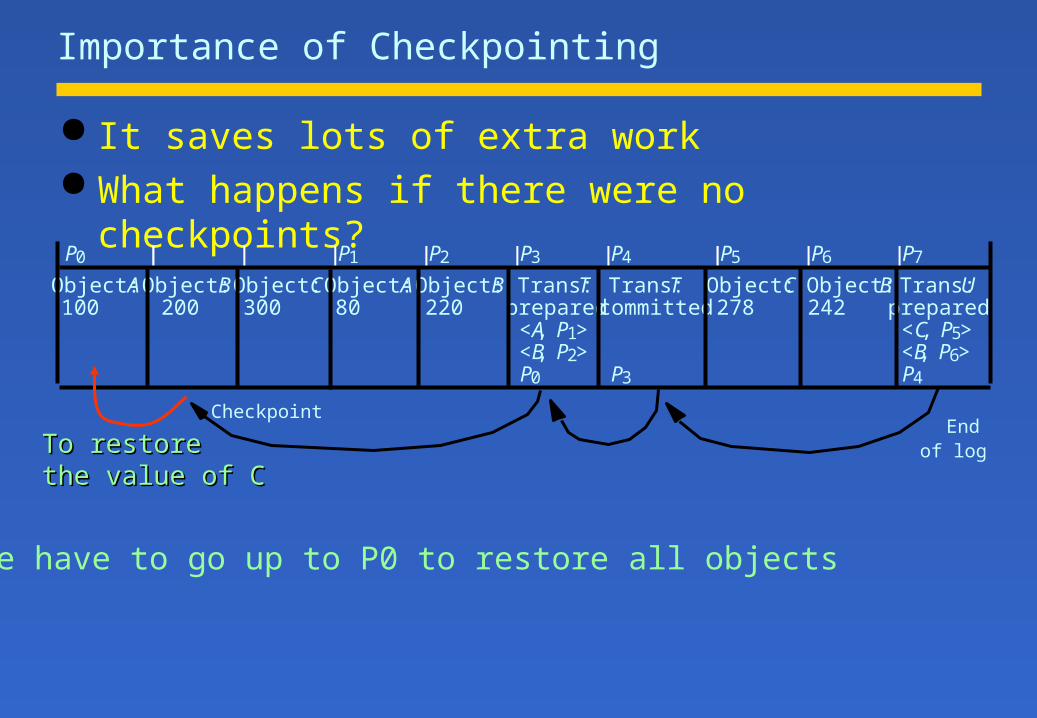
Importance of Checkpointing
It saves lots of extra work What happens if there were no checkpoints?
P0 P1 P2 P3 P4 P5 P6 P7
Object:A Object:B Object:C Object:A Object:B Trans:T Trans:T Object:C Object:B Trans:U100 200 300 80 220 prepared committed 278 242 prepared
<A, P1> <C, P5><B, P2> <B, P6>P0 P3 P4
CheckpointEnd
of log
We have to go up to P0 to restore all objects
To restoreTo restorethe value of Cthe value of C

Shadow versions
An alternate approachuses a map to locate versions of objects in a file called version storemap -- Object id to positions of current version in version storeThe versions written by each transactions are shadows of committed
transactions
How does it work:When a transaction is prepared to commit, any of the objects changed
by the transaction is added to the version store => “shadow version”When a transaction commits, a new map is made by copying the old
map and entering the positions of the shadow versions.The new map replaces the old map.
Recovery:The RM reads the map and uses it to locate the objects in the version
store.
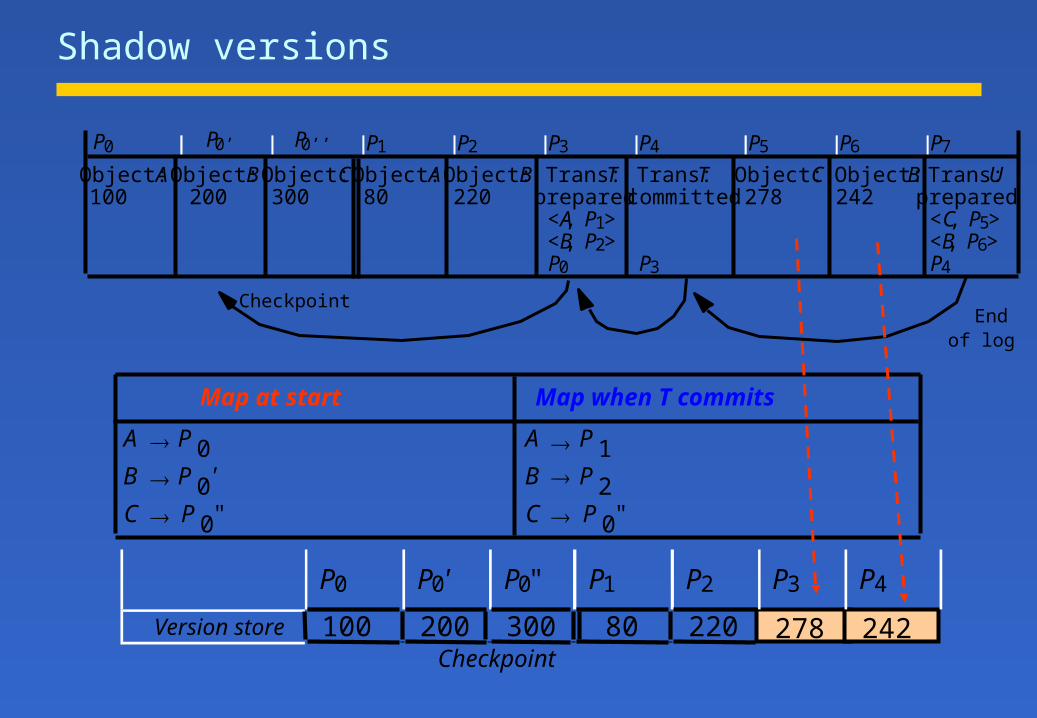
Shadow versions
Checkpoint
P0 P0' P0" P1 P2 P3 P4
Version store 100 200 300 80 220 278 242
Map at start Map when T commits
A P 0 A P 1B P 0 ' B P 2C P 0" C P 0"
P0 P1 P2 P3 P4 P5 P6 P7
Object:A Object:B Object:C Object:A Object:B Trans:T Trans:T Object:C Object:B Trans:U100 200 300 80 220 prepared committed 278 242 prepared
<A, P1> <C, P5><B, P2> <B, P6>P0 P3 P4
CheckpointEnd
of log
P0’ P0’’
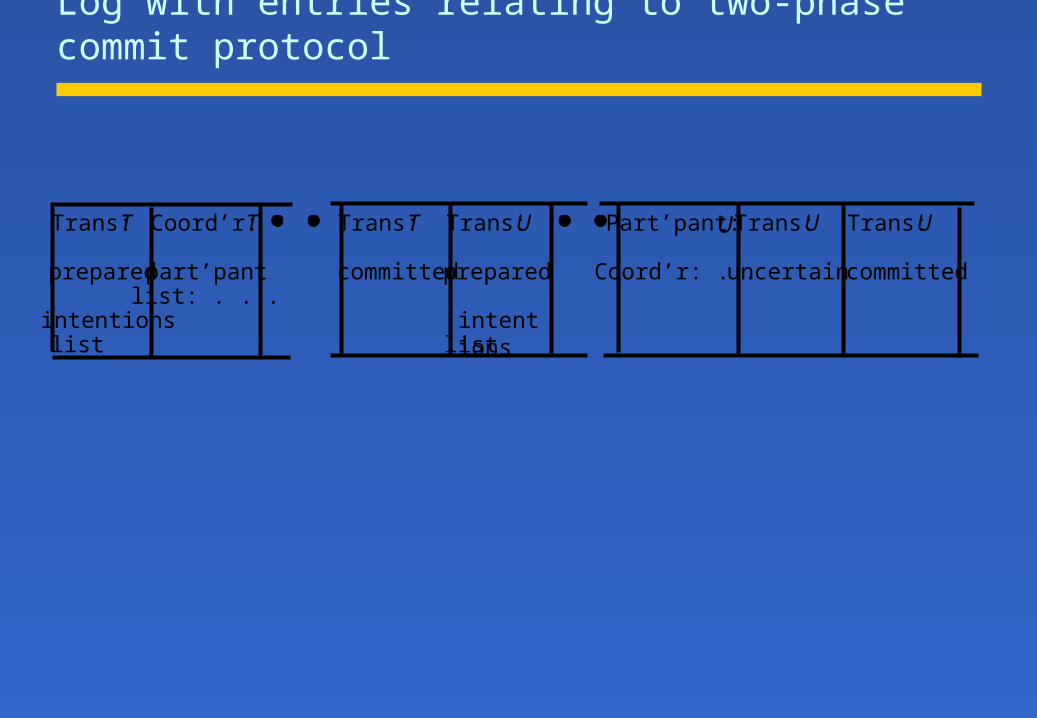
Log with entries relating to two-phase commit protocol
Trans:T Coord’r:T Trans:T Trans:U Part’pant:U Trans:U Trans:U
prepared part’pantlist: . . .
committed prepared Coord’r: . . uncertain committed
intentionslist
intentionslist
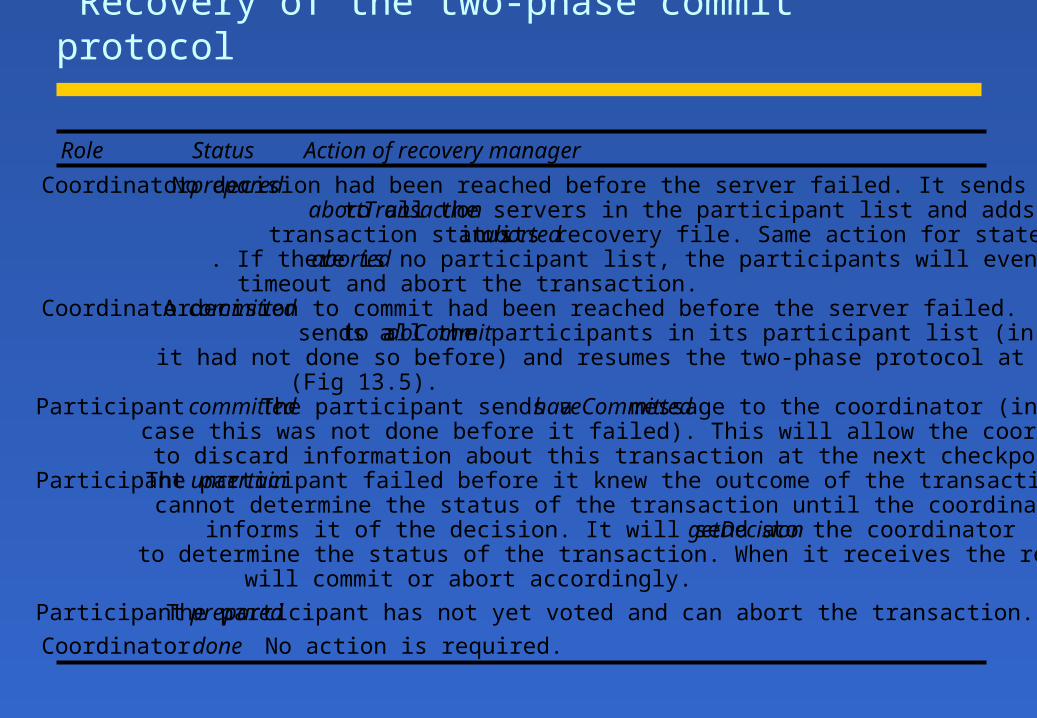
Recovery of the two-phase commit protocol
Role Status Action of recovery manager
Coordinator prepared No decision had been reached before the server failed. It sendsabortTransaction to all the servers in the participant list and adds thetransaction status aborted in its recovery file. Same action for stateaborted. If there is no participant list, the participants will eventuallytimeout and abort the transaction.
Coordinator committed A decision to commit had been reached before the server failed. Itsends a doCommit to all the participants in its participant list (in caseit had not done so before) and resumes the two-phase protocol at step 4(Fig 13.5).
Participant committed The participant sends a haveCommitted message to the coordinator (incase this was not done before it failed). This will allow the coordinatorto discard information about this transaction at the next checkpoint.
Participant uncertain The participant failed before it knew the outcome of the transaction. Itcannot determine the status of the transaction until the coordinatorinforms it of the decision. It will send a getDecision to the coordinatorto determine the status of the transaction. When it receives the reply itwill commit or abort accordingly.
Participant prepared The participant has not yet voted and can abort the transaction.
Coordinator done No action is required.





























