Embed Size (px)
DESCRIPTION
nice lect
Citation preview

June 24, 2009 CS-524(NED) Lec 01 2
CS-524 Distributed Computer Systems
M. Engg. (Computer Systems) Fall Semester – 2009
Instructor: Shahab Tahzeeb (Assistant Professor)Department of Computer & Information Systems Engineering
NED University of Engineering & Technology, Karachi
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx

June 24, 2009 CS-524(NED) Lec 01 3
Today’s Agenda
• Getting to know each other• Describing our roles to make this course a
real success • Overview of the Course

June 24, 2009 CS-524(NED) Lec 01 4
My Role
Continuously strive to expose you to the subject knowledge in a manner that helps save your time in getting hold of details

June 24, 2009 CS-524(NED) Lec 01 5
Your Role
• Continuously strive to be regular in every aspect– schedule some time for review of lectures before
coming to the class– Take sessional work seriously– Ask questions. There are NO stupid questions– Learning-centered approach
• You learn as well as earn good grade
– Grading-centered approach• You may get good grade but you never learn

June 24, 2009 CS-524(NED) Lec 01 6
Academic Calendar• 9 weeks Teaching
– 22nd June, 2009 to 22nd August, 2009
• 5 weeks (Ramazan/Eid Break)– 24th August, 2009 to 26th September, 2009
• 7 weeks Teaching– 26th September, 2009 to 14th November, 2009
• Final Examinations– 1st December, 2009 to 15th December, 2009
• Results’ Declaration– Last week of December, 2009

June 24, 2009 CS-524(NED) Lec 01 7
Books• Andrew S. Tanenbaum and Maarten van Steen
Distributed Systems: Principles and ParadigmsPrentice Hall
• George Coulouris, Jean Dollimore and Tim KindbergDistributed Systems: Concepts and DesignPearson Education

June 24, 2009 CS-524(NED) Lec 01 8
Topics• Introduction• Communication• Processes• Naming• Synchronization• Consistency and Replication• Fault Tolerance• Security
* We shall add topics to this list if time permits

June 24, 2009 CS-524(NED) Lec 01 9
Course Objectives• Describe fundamental concepts of and techniques in distributed
systems• Analyze distributed systems according to desired qualities (such as
performance, reliability, or availability)• Apply distributed systems techniques (such as Remote Procedure
Call, event-based communication, or transactions) to implement distributed system designs
• Compare and contrast concepts of and techniques in distributed systems with respect to their ability to fulfill desired qualities
• Design distributed systems according to desired qualities by choosing among introduced concepts and techniques

June 24, 2009 CS-524(NED) Lec 01 10
Grading • Quizzes 05%
– 3 announced quizzes • weeks 3, 6 and 12
– 2 surprise quizzes • 2 announced and 1 surprise quiz will be graded
• Homework 05%• Class Participation 05%• Term Paper 05%• Mid-Term (09th Week) 10%• Final 70%• No early or makeup exams please!

June 24, 2009 CS-524(NED) Lec 01 11
Web Group for Course Management
http://groups.yahoo.com/group/cs524-09B

June 24, 2009 CS-524(NED) Lec 01 12
Distributed Computer Systems
Fundamentals

June 24, 2009 CS-524(NED) Lec 01 13

June 24, 2009 CS-524(NED) Lec 01 14
What’s a Distributed System?

June 24, 2009 CS-524(NED) Lec 01 15
Definition # 1
• A collection of independent computers that act as an integrated system and hence appear to the end user as a single computer (i.e. a virtual uniprocessor)
• Two aspects– Hardware: autonomous machines– Software: users think they’re dealing with a
single system

June 24, 2009 CS-524(NED) Lec 01 16
Definition # 1
• User’s view of a Distributed System:– Multiple computers that work together in a more or
less seamless fashion (single system image)• To support heterogeneous computers and
networks and still present a single-system image, systems may rely on middleware: – a software layer that provides a consistent interface to
the user, regardless of the underlying platform.
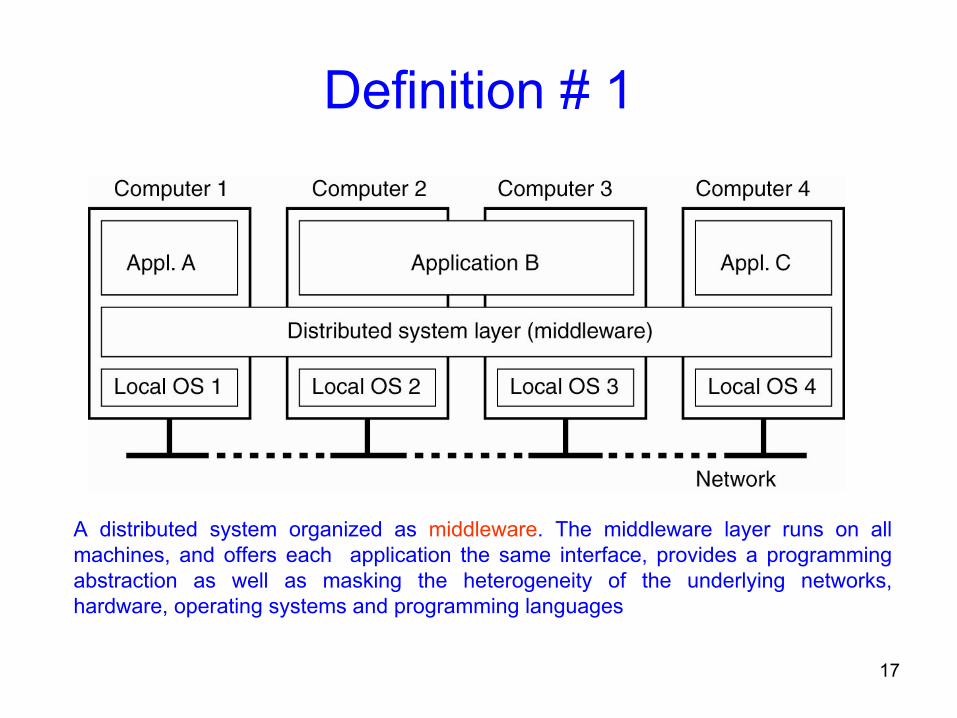
June 24, 2009 CS-524(NED) Lec 01 17
Definition # 1
A distributed system organized as middleware. The middleware layer runs on all machines, and offers each application the same interface, provides a programming abstraction as well as masking the heterogeneity of the underlying networks, hardware, operating systems and programming languages

June 24, 2009 CS-524(NED) Lec 01 18
CORBA: A Middleware Example
• CORBA is the OMG's open, vendor-independent architecture and infrastructure that computer applications use to work together over networks.
• Using the standard protocol IIOP, a CORBA-based program from any vendor, on almost any computer, operating system, programming language, and network, can interoperate with a CORBA-based program from the same or another vendor, on almost any other computer, operating system, programming language, and network.

June 24, 2009 CS-524(NED) Lec 01 19
Other Middleware Examples
• DCOM– Distributed Component Object Management
• RPC– Remote Procedure Call
• RMI– Remote Method Invocation

June 24, 2009 CS-524(NED) Lec 01 20
ONC RPC
• Open Network Computing Remote Procedure Call, is a widely deployed remote procedure call system.
• ONC was originally developed by Sun Microsystems as part of their Network File System project, and is sometimes referred to as Sun ONC or Sun RPC

June 24, 2009 CS-524(NED) Lec 01 21
Definition # 2
• Enslow:– A distributed system is the one, wherein
hardware, control and data achieve some degree of decentralization and resources’distribution is transparent to the user

June 24, 2009 CS-524(NED) Lec 01 22
Definition # 2• H1. A single CPU with one control unit.• H2. A single CPU with multiple ALUs. There is only one
control unit.• H3. Separate specialized functional units, such as one
CPU with one floating-point coprocessor.• H4. Multiprocessor with single I/O system and a global
memory.• H5. Multicomputer with multiple I/O systems and local
memories.
• C1. Single fixed control point. Note that physically the system may or may not have multiple CPUs.
• C2. Single dynamic control point. In multiple CPU cases the controller changes from time to time among CPUs.
• C3. A fixed master/slave structure. For example, in a system with one CPU and one coprocessor, the CPU is a fixed master and the coprocessor is a fixed slave.
• C4. A dynamic master/slave structure. The role of master/slave is modifiable by software.
• C5. Multiple homogeneous control points where copies of the same controller are used.
• C6. Multiple heterogeneous control points where different controllers are used.
• D1. Centralized databases with a single copy of both files and directory.
• D2. Distributed files with a single centralized directory and no local directory.
• D3. Replicated database with a copy of files and a directory at each site.
• D4. Partitioned database with a master that keeps a complete duplicate copy of all files.
• D5. Partitioned database with a master that keeps only a complete directory.
• D6. Partitioned database with no master file or directory.
Extension to Enslow’s Definition
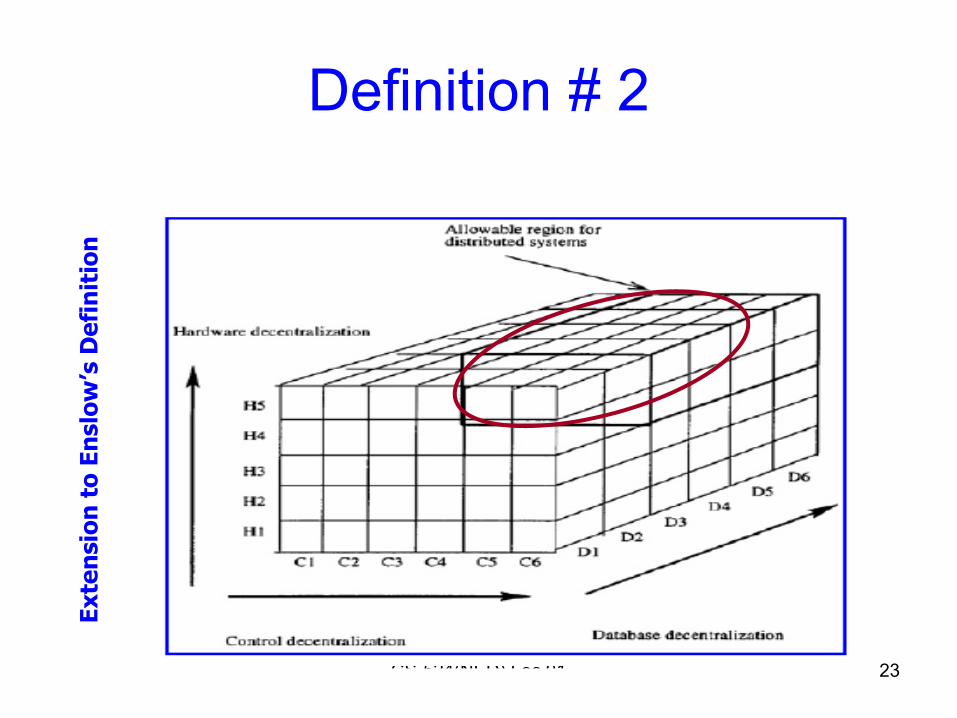
June 24, 2009 CS-524(NED) Lec 01 23
Definition # 2Ex
ten
sion
to
Ensl
ow’s
Def
init
ion

June 24, 2009 CS-524(NED) Lec 01 24
Definition # 3
• An Intimidating Definition– A distributed system is one in which failure of
a computer you even didn’t know existed can render your own computer unusable(Leslie Lamport)

June 24, 2009 CS-524(NED) Lec 01 25
Examples of Distributed Systems (1)
• Internet• Mobile and Ubiquitous Computing• P2P Systems• Sensor Networks• Distributed Mobile Robots• Air Traffic Control (ATC) System• Banking, Stock Markets, Stock Brokerages• Heath Care, Hospital Automation• Control of Power Plants, Electric Grid• Telecommunications Infrastructure

June 24, 2009 CS-524(NED) Lec 01 26
Examples of Distributed Systems (2)
• Electronic Commerce and Electronic Cash on the Web (very important emerging area)
• Corporate “Information” Base: a company’s memory of decisions, technologies and strategies
• Military Command, Control, and Intelligence Systems• Embedded Systems: automotive control systems
– Mercedes S-Klasse automobiles these days are equipped with 50+ autonomous embedded processors
– Connected through proprietary bus-like LANs

June 24, 2009 CS-524(NED) Lec 01 27
Distributed System vs. Network
• There’s no or little coordination among networked machines
• Users are aware of separate machines in a network while a distributed system operates in a seamless fashion.

June 24, 2009 CS-524(NED) Lec 01 28
Motivation (1)• Inherently Distributed Applications
– Distributed systems have come into existence in some very natural ways, e.g., in our society people are distributed and information should also be distributed.
– Applications which require sharing or dissemination of information among distant entities are “natural” distributed systems
– Distributed database system information is generated at different branch offices (sub databases), so that a local access can be done quickly.
– The system also provides a global view to support various globaloperations.
– E.g. ATM, airline reservation systems, remote monitoring, etc.

June 24, 2009 CS-524(NED) Lec 01 29
Motivation (2)
• Improved PCR– The parallelism of distributed systems reduces
processing bottlenecks and provides improved all-around performance, at much lower cost.
• Resource Sharing– Distributed systems can efficiently support information
and resource (hardware and software) sharing for users at different locations.

June 24, 2009 CS-524(NED) Lec 01 30
Motivation (3)
• Fault Tolerance– With the multiplicity of storage units and processing
elements, distributed systems have the potential ability to continue operation in the presence of failures in the system.
• Scalability – Distributed systems are capable of incremental growth and
have the added advantage of facilitating modification or extension of a system to adapt to a changing environment without disrupting its operations.
• Think of upgrading a mainframe or super computer!

June 24, 2009 CS-524(NED) Lec 01 31
Motivation (4)• Distribution as an Artifact
– Distribution may be an artifact of an engineering solution to satisfy some specific requirements such as
• Fault-tolerance• Load-balancing• Minimum level of Quality of Service (QoS)
– E.g. Replicated servers• Functional Distribution
– Computers have different functional capabilities • Client / server• Host / terminal• Data gathering / data processing

June 24, 2009 CS-524(NED) Lec 01 32
Driving Forces
• There are two main stimuli for the current interest in distributed systems:– Technological Enhancement
• microelectronics– fast and inexpensive processors
• communication– highly efficient computer networks
– User Needs• many enterprises are cooperative in nature

June 24, 2009 CS-524(NED) Lec 01 33
Classes of Distributed Systems
• Distributed Computing Systems• Distributed Information Systems• Distributed Pervasive Systems

June 24, 2009 CS-524(NED) Lec 01 34
Distributed Computing Systems
• High-Performance Computing Systems– Cluster computing– Grid computing

June 24, 2009 CS-524(NED) Lec 01 35
Cluster Computing• A collection of similar processors (PCs, workstations)
running the same (commodity) operating system, connected by a high-speed network.
• Runs parallel programs• Popular because they offer parallel computing
capabilities using inexpensive PC hardware; an organization may be able to capitalize on machines it already has.
• Microsoft, Sun, and others sell clustering software and you can also buy turnkey systems
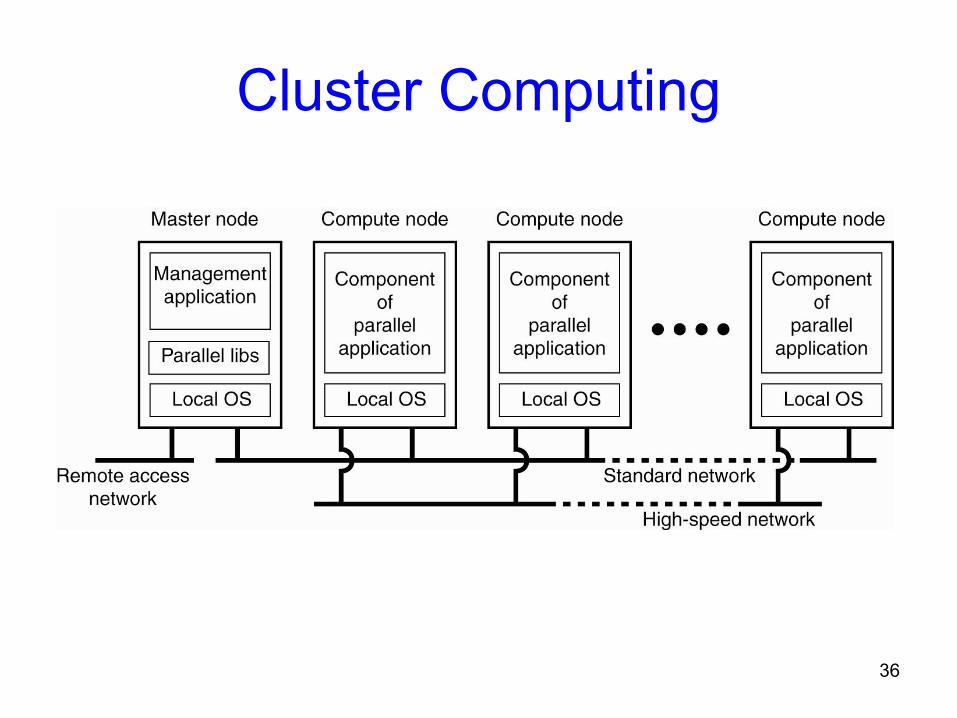
June 24, 2009 CS-524(NED) Lec 01 36
Cluster Computing

June 24, 2009 CS-524(NED) Lec 01 37
Clusters – Beowulf Model• Linux-based• Structured according to master-slave paradigm
– One processor is the master; allocates tasks to other processors, maintains batch queue of submitted jobs, handles interface to users
– Libraries to handle message-based communication or other features

June 24, 2009 CS-524(NED) Lec 01 38
Clusters – MOSIX Model
• Provides a symmetric, rather than hierarchical paradigm – High degree of distribution transparency– Processes can migrate between nodes
dynamically and preemptively

June 24, 2009 CS-524(NED) Lec 01 39
Grid Computing Systems• Modeled loosely on the electrical grid.• Unlike clusters, computers in grids are highly heterogeneous in their
hardware, software, networks, security policies, etc.• Grids support virtual organizations: a collaboration of users who pool
resources (servers, storage, databases) and share them• Grid software is concerned with managing sharing across
administrative domains– each part potentially under a different administrative domain,
hardware/software/network• Key issue –sharing resources across organizations
– much pain goes into standards and interfaces
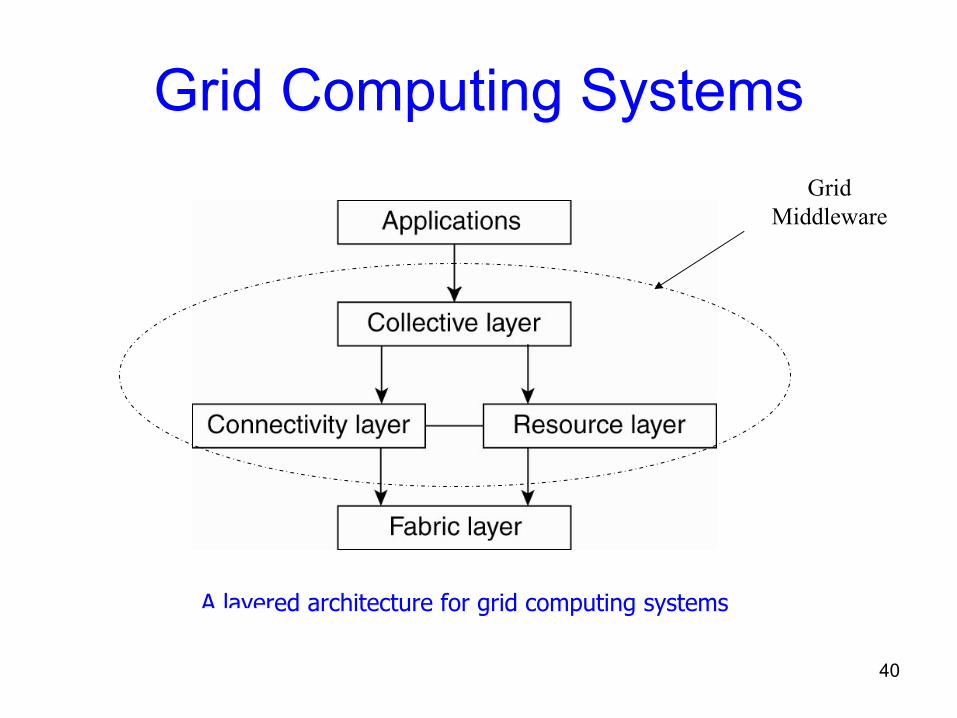
June 24, 2009 CS-524(NED) Lec 01 40
Grid Computing SystemsGrid
Middleware
A layered architecture for grid computing systems
June 24, 2009 CS-524(NED) Lec 01 41
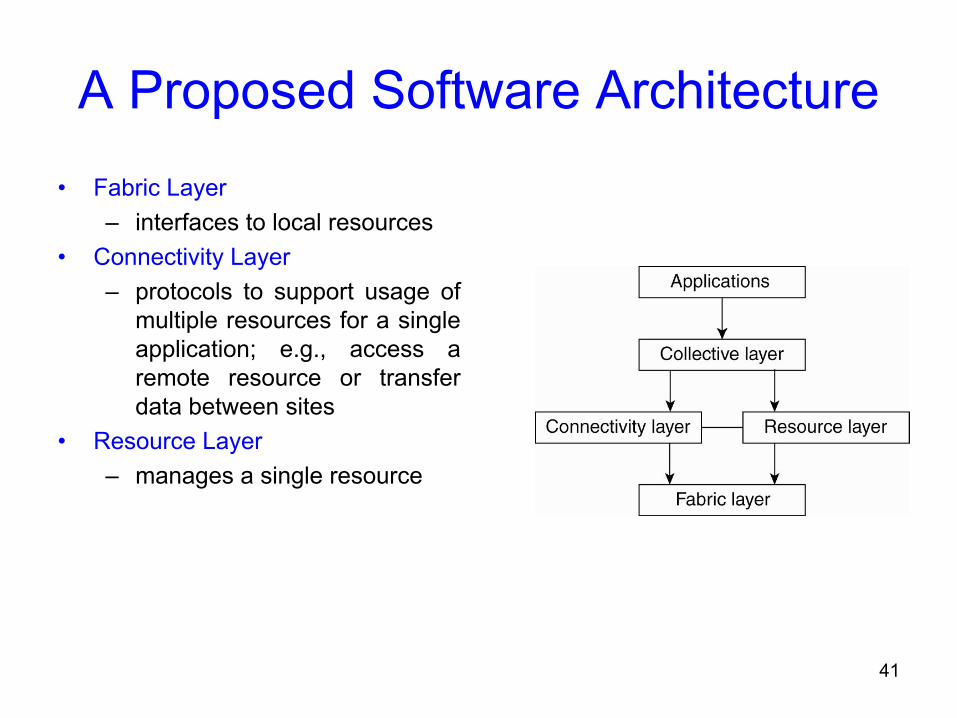
A Proposed Software Architecture• Fabric Layer
– interfaces to local resources• Connectivity Layer
– protocols to support usage of multiple resources for a single application; e.g., access a remote resource or transfer data between sites
• Resource Layer– manages a single resource
June 24, 2009 CS-524(NED) Lec 01 42
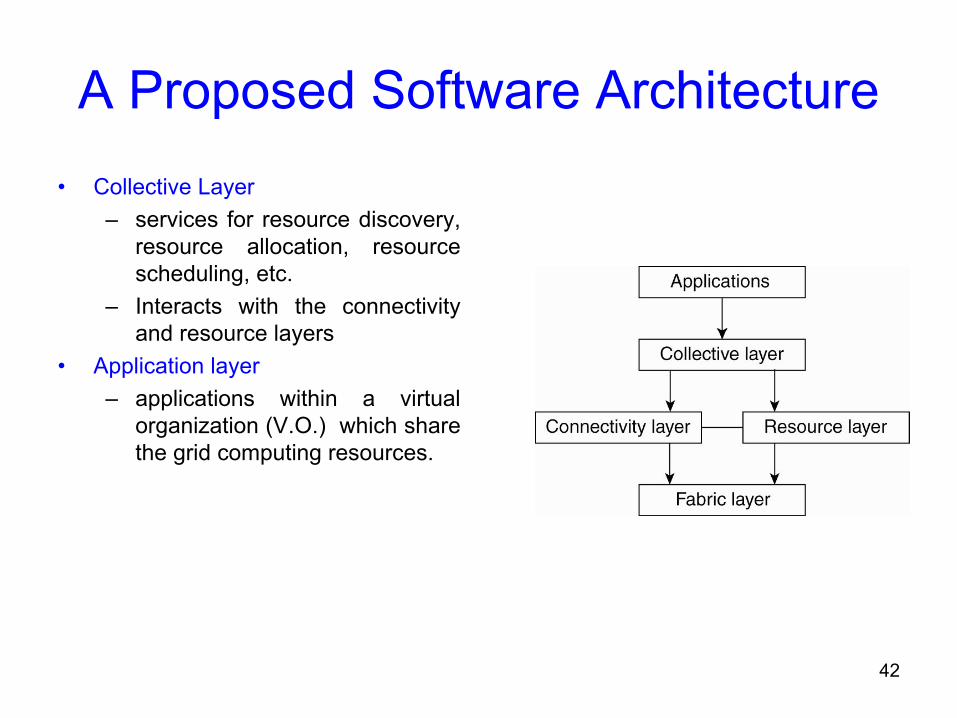
A Proposed Software Architecture• Collective Layer
– services for resource discovery, resource allocation, resource scheduling, etc.
– Interacts with the connectivity and resource layers
• Application layer– applications within a virtual
organization (V.O.) which share the grid computing resources.

June 24, 2009 CS-524(NED) Lec 01 43
OGSA – A Grid Architecture
• Open Grid Services Architecture– a service-oriented architecture– sites that offer resources to share do so by
offering specific Web services.• The architecture of the OGSA model is more
complex than the previous layered model.

June 24, 2009 CS-524(NED) Lec 01 44
Other Grid Resources
• The Globus Alliance– a community of organizations and individuals developing
fundamental technologies behind the Grid, which lets people share computing power, databases, instruments, and other on-line tools securely across corporate, institutional, and geographic boundaries without sacrificing local autonomy
• Grid Computing Info Centre– aims to promote the development and advancement of
technologies that provide seamless and scalable access to wide-area distributed resources

June 24, 2009 CS-524(NED) Lec 01 45
Distributed Information Systems
• Business-oriented• Systems to make a number of separate network
applications interoperable and build “enterprise-wide information systems”.
• Two types are discussed here:– Transaction Processing Systems– Enterprise Application Integration

June 24, 2009 CS-524(NED) Lec 01 46
Transaction Processing Systems
• Provide a highly structured client-server approach for database applications
• Transactions obey the ACID properties:– Atomic: all or nothing at all– Consistent: invariants are preserved (if
consistent before, consistent after)– Isolated concurrent transactions don’t
interfere with each other– Durable: committed operations can’t be
undone

June 24, 2009 CS-524(NED) Lec 01 47
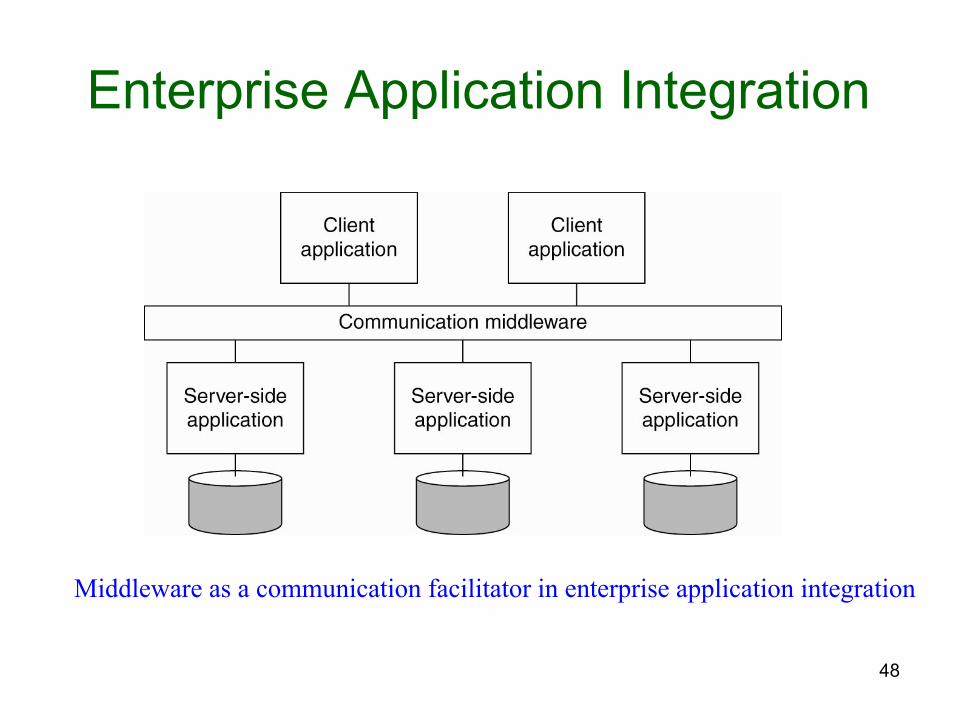
Enterprise Application Integration
• Supports a less-structured approach (as compared to transaction-based systems)
• Application components are allowed to communicate directly
• Communication mechanisms to support this include – Remote Procedure Call (RPC) – Remote Method Invocation (RMI)
June 24, 2009 CS-524(NED) Lec 01 48
Enterprise Application Integration
Middleware as a communication facilitator in enterprise application integration

June 24, 2009 CS-524(NED) Lec 01 49
Distributed Pervasive Systems
• The first two types of systems are characterized by their stability: nodes and network connections are more or less fixed
• This type of system is likely to incorporate small, battery-powered, mobile devices– Home systems– Electronic health care systems – patient monitoring– Sensor networks – data collection, surveillance
June 24, 2009 CS-524(NED) Lec 01 50
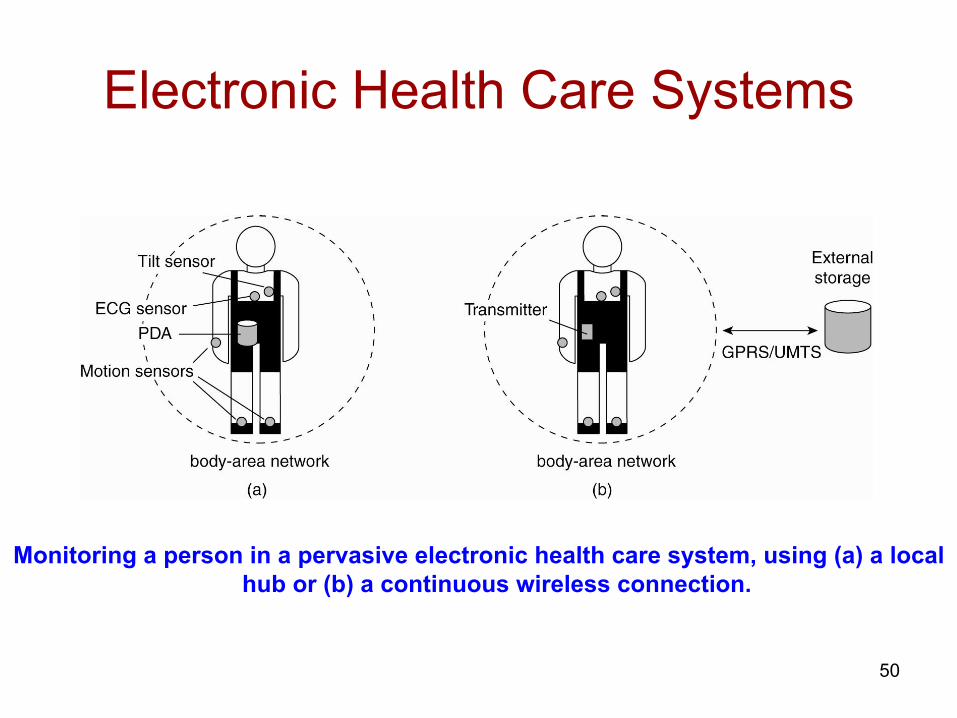
Electronic Health Care Systems
Monitoring a person in a pervasive electronic health care system, using (a) a local hub or (b) a continuous wireless connection.
June 24, 2009 CS-524(NED) Lec 01 51
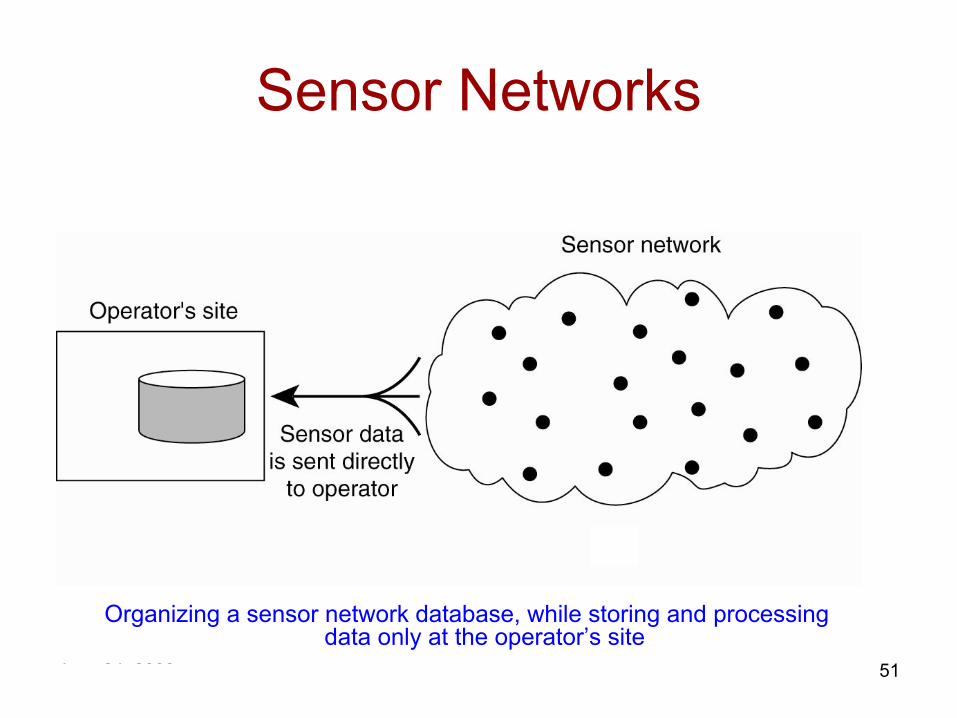
Sensor Networks
Organizing a sensor network database, while storing and processing data only at the operator’s site
June 24, 2009 CS-524(NED) Lec 01 52
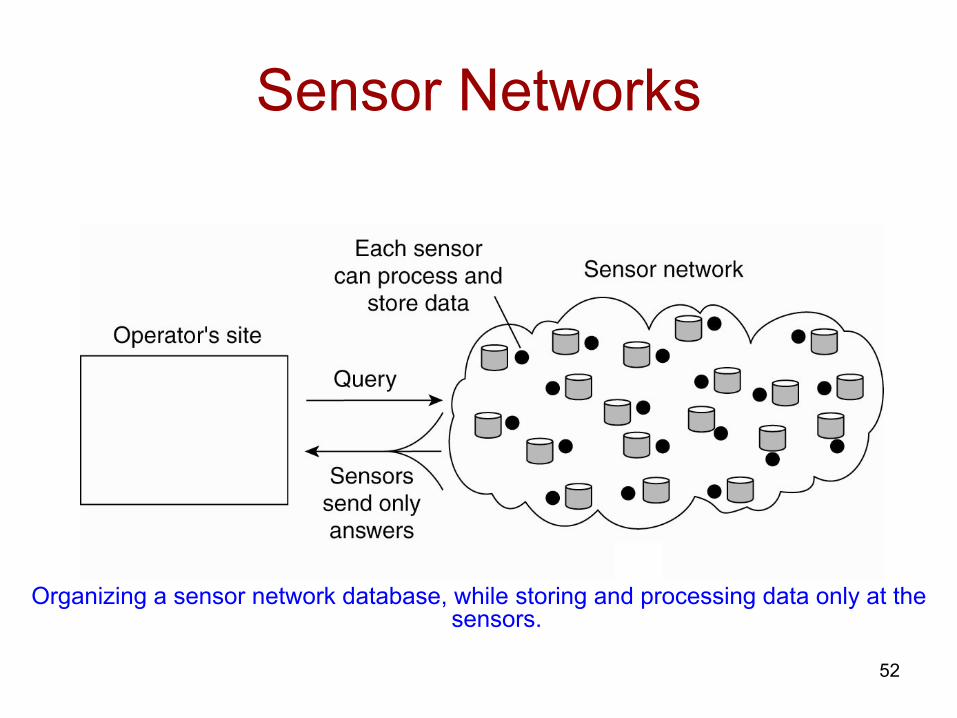
Sensor Networks
Organizing a sensor network database, while storing and processing data only at the sensors.

June 24, 2009 CS-524(NED) Lec 01 53
Distributed Systems vs. Parallel Systems
• DS often refers to a system that is to be used by multiple (distributed) users.
– e-commerce or business applications.
• generally refers to a cooperative work environment
• Security is much more of a concern– This is not an option, for example, in
the design of a distributed database for e-commerce. By its very nature, this system must be accessible to the real world -- and as a consequence must be designed with security in mind.
• PS often has the connotation of a system that is designed to have only a single user or user process
– scientific applications• typically refers to an environment
designed to provide the maximum parallelization and speed-up for a single task
• If the only goal of a super computer is to rapidly solve a complex task, it can be locked in a secure facility, physically and logically inaccessible --security problem solved.

June 24, 2009 CS-524(NED) Lec 01 54
Distributed System Challenges• Resource Accessibility• Security• Concurrency • Heterogeneity • Transparency• Openness• Scalability• Reliability• Lack of Global Clock and Global State

June 24, 2009 CS-524(NED) Lec 01 55
Resource Accessibility• Support user access to remote resources (printers, data
files, web pages, CPU cycles) and the fair sharing of the resources– making convenient to share resources

June 24, 2009 CS-524(NED) Lec 01 56
Security• Sharing, as always, introduces security issues• Confidentiality
– avoiding the disclosure of the content of a message to a party distinct from the intended receiver
• Integrity– avoiding the corruption of the transmitted contents by a third
party
• Availability– the capability of providing a service in all circumstances

June 24, 2009 CS-524(NED) Lec 01 57
Concurrency
• Resources can be shared by clients in a distributed system, therefore several clients may access a shared resource at the same time
• Not acceptable that each request be processed in turn, must be able to process requests concurrently
• For each object that represents a shared resource, its operations must be synchronized in such a way that its data remains consistent

June 24, 2009 CS-524(NED) Lec 01 58
Heterogeneity - I• Heterogeneity (variety and difference) applies to:
– Networks–differences are masked by the fact that all of the computers use the Internet protocols to communicate.
– Hardware–data types, such as integers, may be represented in different ways on different sorts of hardware (byte ordering: big-endian, little-endian)
– Operating Systems–do not provide the same application API to the Internet protocols.
– Programming languages–use different representations for characters and data structures, such as arrays and records.
– Developers–representation of primitive data items and data structures needs to be agreed upon (standards)
• Middleware– Software layer that abstracts from the above providing a uniform computational model
– All middleware deals with the differences in operating systems and hardware.

June 24, 2009 CS-524(NED) Lec 01 59
Heterogeneity - II
• Mobile Code– A code that can be sent from one computer to another and runs
at the destination (e.g. Java applets).
– Machine code suitable for running on one type of computer hardware is not suitable for running on another.
• Virtual Machines Approach– provides a way of making code executable on any hardware: the
compiler for a particular language generates code for a virtual machine instead of a particular hardware.

June 24, 2009 CS-524(NED) Lec 01 60
TransparencyTransparency
• A distributed system that appears to its users & applications to be a single computer system is said to be transparent.– Users & applications should be able to access
remote resources in the same way they access local resources.
• Aims to conceal the component-based structure of the system, and facilitate a perception of the system as a whole

June 24, 2009 CS-524(NED) Lec 01 61
Transparency Classes (1)• Access Transparency
– Hides differences in data representation, different architectures and file-name conventions of machines
– Enables interoperability
• Location Transparency– Hides location of resource i.e. the user can use the resource without
being aware of its location
– The key is naming
– E.g. URLs, email, etc.
(Access + Location) Transparency = Network Transparency(Access + Location) Transparency = Network Transparency

June 24, 2009 CS-524(NED) Lec 01 62
Transparency Classes (2)• Migration Transparency
– Hides from the user that the resource being used has moved to another location
• Relocation Transparency– Hides from the user that the resource being used is being moved
– Enables mobile computing
• Persistence Transparency– Hides whether a resource is in memory or on disk

June 24, 2009 CS-524(NED) Lec 01 63
Transparency Classes (3)• Replication Transparency
– Hides that multiple copies of the resource exist (for reliability and/or availability)
• Concurrency Transparency– Hides that the resource may be shared concurrently
• Failure Transparency– Hides failure and (possible) recovery of the resource
– Email is eventually delivered, even when servers or communication links fail.
• Scaling Transparency– Allows system and applications to expand without need to change structure or application
algorithms
• Performance Transparency– Adaptation of the system to varying load situations without the user noticing it

June 24, 2009 CS-524(NED) Lec 01 64
Degrees of Transparency• Performance
– e.g. multiple attempts to contact a remote server can slow down the system – should you report failure and let user cancel request?
• Convenience
– e.g. direct the print request to my local printer, not one on the next floor
• Too much emphasis on transparency may prevent the user from understanding system behavior
• Transparency is sometimes against application’s goals – e.g. pervasive computing and location awareness

June 24, 2009 CS-524(NED) Lec 01 65
Openness - I
• Services should follow agreed-upon rules on component syntax & semantics for interoperability and portability
• Using interfaces, any process that needs a service should be able to communicate with a process that provides the service.
• Multiple implementations of the same service may be provided, as long as the interface is maintained

June 24, 2009 CS-524(NED) Lec 01 66
Openness - II• Interoperability
– The ability of two different systems or applications to work together by relying on each other’s services as specified by a common standard
• Portability– The ability of an application designed to run on distributed system A to run on
distributed system B which implements the same interface, without modification
• Extensibility– If a distributed system is open (implements standard interfaces) it should be
possible to add and delete components without affecting the system as a whole.
• e.g., replace the file system

June 24, 2009 CS-524(NED) Lec 01 67
Scalability – I• A system is scalable if it will remain effective if there is a significant
increase in the number of resources and the number of users• The design of scalable distributed system poses the following
challenges– Controlling Cost of Physical Resources
• For a system with n users to be scalable, the quantity of physical resources required to support them should be at most O(n) –that is, proportional to n. E.g., if a single file server can support 20 users, then two such servers should be able to support 40 users.
– Controlling Performance Loss• Maximum performance loss should be no worse than O(log n) where n is size of data.
– Preventing Software Resources Running Out• IP Addresses (initially 32 bits in IPv4). 128-bit in IPv6

June 24, 2009 CS-524(NED) Lec 01 68
Scalability – II
• With respect to size
• With respect to geographical distribution
• With respect to the number of administrative organizations it spans– Most systems account only, to a certain extent, for
size scalability.
– Today, the challenge lies in geographical and administrative scalability.

June 24, 2009 CS-524(NED) Lec 01 69
Size Scalability• The more users and resources a system has, the harder
it is to support a centralized model.• Scalability is affected when the system is based on
– Centralized server• one for all users
– Centralized data• a single database for all users
– Centralized algorithms• e.g. for routing: one site collects all information,
processes it, distributes the results to all sites

June 24, 2009 CS-524(NED) Lec 01 70
Size Scalability
• A single centralized server, running on a single machine, can saturate if the workload becomes too heavy.
– Communication links around the server can limit performance, as well
• Centralized data storage is impractical for large databases
– If the Internet’s Domain Name Service consisted of a single table, it would be virtually impossible to resolve a URL in reasonable time

June 24, 2009 CS-524(NED) Lec 01 71
Size Scalability• Centralized algorithms rely on a central coordinator that
collects data from all sites in the network and then makes decisions.– Complete knowledge
• good
– Time and network traffic• bad
• Wherever possible, distributed algorithms are desirable.

June 24, 2009 CS-524(NED) Lec 01 72
Size Scalability
• Decentralized or Distributed Algorithms– No machine has complete information about the
system state
– Machines make decisions based only on local information
– Failure of a single machine doesn’t ruin the algorithm
– There is no assumption that a global clock exists.

June 24, 2009 CS-524(NED) Lec 01 73
Geographic Scalability• Early distributed systems ran on LANs; relied on
synchronous communication– requesting client blocks until it gets a response,
makes it hard to scale

June 24, 2009 CS-524(NED) Lec 01 74
Administrative Scalability
• Different domains may have different policies about resource usage, management, security, etc.
• Trust often stops at administrative boundaries

June 24, 2009 CS-524(NED) Lec 01 75
Scaling Techniques
• Scalability affects performance more than anything else.
• Three techniques to improve scalability:– Hiding Communication Latencies– Distribution– Replication

June 24, 2009 CS-524(NED) Lec 01 76
Scalability – Amazon.com• Werner Vogels’ talk Order in the Chaos: Building the Amazon.com
Platform
• 1995: Started out with a single web service on a single server
• Today Amazon has about 150 web services on its homepage alone.
• 1 million merchant partners; 60 million customers
• 1999: A misstep during this exponential growth period was movingto mainframe from distributed server. – Failed to meet scalability, reliability and performance; it was scratched
in 2000.

June 24, 2009 CS-524(NED) Lec 01 77
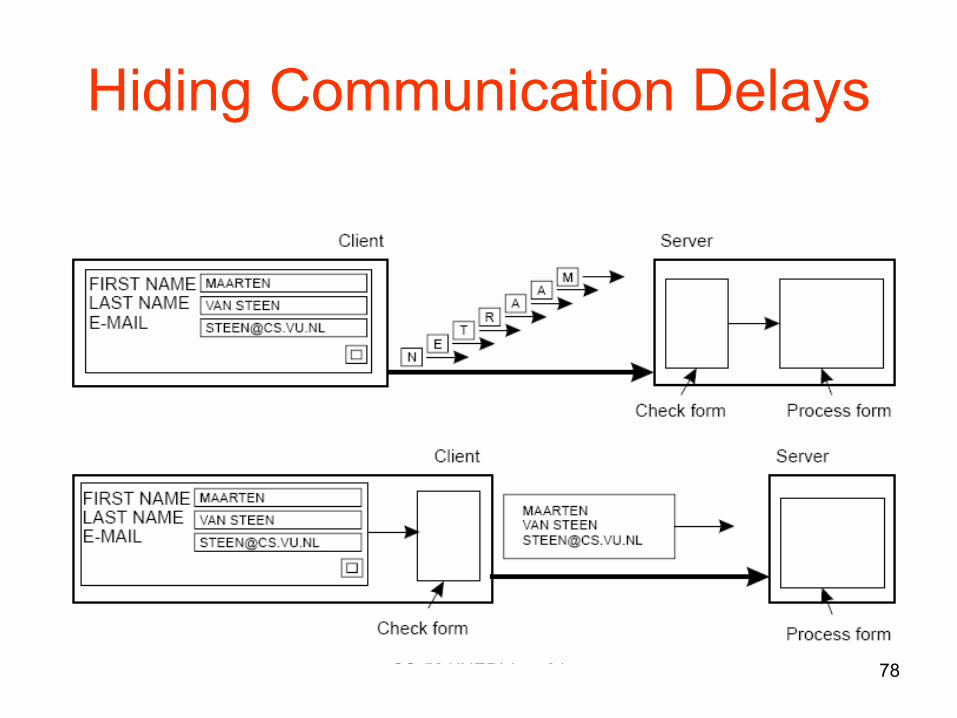
Hiding Communication Delays• Key for geographic scalability • Structure applications to use asynchronous communication (no
blocking for replies)– While waiting for one answer, do something else; create one
thread to wait for the reply and let other threads continue to process or schedule another task
• Download part of the computation to the requesting platform to speed up processing– E.g. Filling in forms to access a DB:
• send a separate message for each field• download form/code and submit finished version. JavaScript and
Java applets support this approach.
June 24, 2009 CS-524(NED) Lec 01 78
Hiding Communication Delays

June 24, 2009 CS-524(NED) Lec 01 79
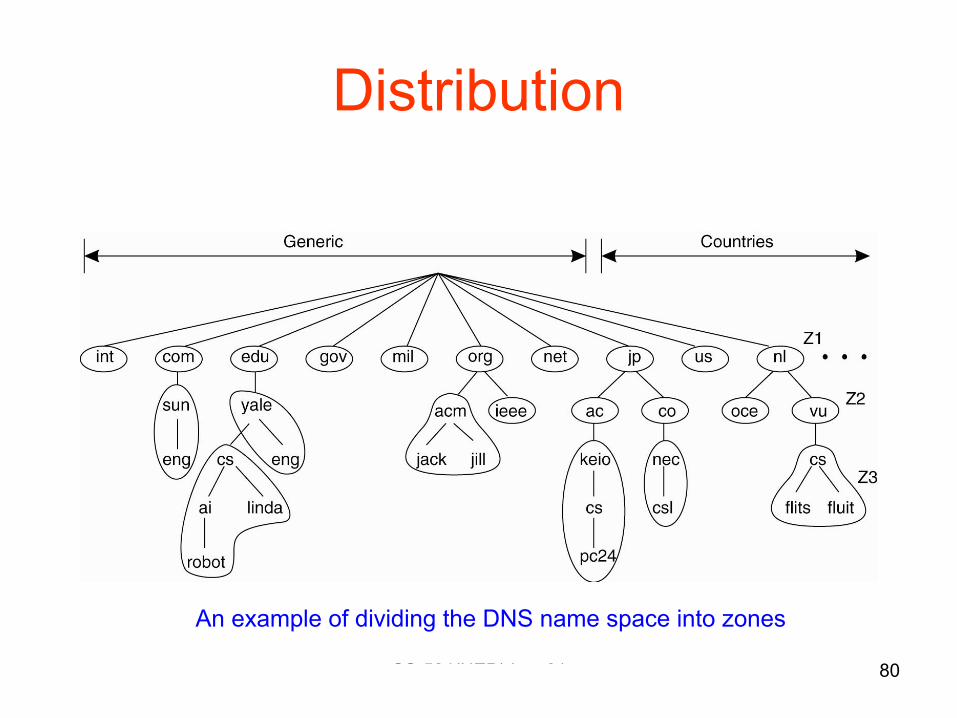
Distribution
• Instead of one centralized service, divide into parts and distribute them geographically
– Example: DNS namespace is organized as a tree of domains; each domain is divided into zones; names in each zone are handled by a different name server
June 24, 2009 CS-524(NED) Lec 01 80
Distribution
An example of dividing the DNS name space into zones

June 24, 2009 CS-524(NED) Lec 01 81
Replication
• Replication: multiple identical copies of something
• Replication– Increases availability– Improves performance through load balancing– May avoid latency by improving proximity of
resource

June 24, 2009 CS-524(NED) Lec 01 82
Replication - Caching
• Caching is a form of replication– Normally creates a (temporary) replica of
something closer to the user• User decides to cache, system decides to
replicate• Replication is more permanent• Both lead to consistency problems

June 24, 2009 CS-524(NED) Lec 01 83
Replication - Caching
• Having multiple copies (cached or replicated), leads to inconsistencies: – modifying one copy makes that copy different from the rest.
• Always keeping copies consistent and in a general way requires global synchronization on each modification.– Global synchronization precludes large-scale solutions.
• If we can tolerate inconsistencies, we may reduce the need for global synchronization.
• Tolerating inconsistencies is application dependent.

June 24, 2009 CS-524(NED) Lec 01 84
Reliability – Failure Handling• Techniques
– Failure Detection• message checksum
– Failure Masking• making a detected failure hidden or less severe• email retransmission
– Tolerating Failures• Web pages (informing users about failure)
– Failure Recovery• permanent data rolled back
– Redundancy (use of redundant components)• Duplication in routes, hardware,• DNS –every name table replicated in at least two different servers• Databases –replicated in several serversseveral servers

June 24, 2009 CS-524(NED) Lec 01 85
Reliability – Failure Handling
• Availability– Measure of the proportion of time a system is
available for use. – DS provide a high degree of availability
regarding hardware faults.

June 24, 2009 CS-524(NED) Lec 01 86
Lack of Global Clock & State
• There are limits on the precision with which processes in a distributed system can synchronize their clocks
• There is no single process in the distributed system that would have a knowledge of the current global state of the system

June 24, 2009 CS-524(NED) Lec 01 87
Fallacies of Distributed Computing
• Source: Peter Deutsch (The following false assumptions add to the challenges)– The network is reliable– Latency is zero– Bandwidth is infinite– The network is secure– Topology doesn’t change– There is one administrator– Transport cost is zero– The network is homogeneous

June 24, 2009 CS-524(NED) Lec 01 88
Summary • Distributed computing brings transparent access to as much computer
power and data as the user needs to accomplish any given task, and at the
same time, achieves high performance and reliability objectives
• Despite the failure, uncertainty, and lack of specialized hardware support,
we can build and effectively use systems that are an order of magnitude
more powerful. In fact we can do this while providing a more available, more
robust, more convenient solution.
• Middleware is a key facility for building distributed systems
• Its difficult to design a good distributed system: there are a lot of problems
in getting “good” characteristics, not the least of which is people.





























