Embed Size (px)
Citation preview

Quelques aspects des chaînes de Markov
Djalil Chafaï
Décembre 2006, Biskra, Algérie.Compilé le 18 janvier 2007

2
Fig. 1 – Andrei Andreyevich Markov
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 2.

Table des matières
0.1 Suites ou chaînes ? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50.2 La propriété de Markov forte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100.3 Les chaînes dans tous leurs états . . . . . . . . . . . . . . . . . . . . . . . . . . . 110.4 Simulation d’une chaîne de Markov . . . . . . . . . . . . . . . . . . . . . . . . . 140.5 Atteinte, absorption, harmonicité, martingales . . . . . . . . . . . . . . . . . . . 160.6 Invariance et récurrence positive . . . . . . . . . . . . . . . . . . . . . . . . . . . 180.7 Loi forte des grands nombres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200.8 Périodicité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230.9 Convergence en loi et couplage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240.10 Réversibilité et noyau de Metropolis-Hastings . . . . . . . . . . . . . . . . . . . 270.11 Estimation du noyau et de la mesure invariante . . . . . . . . . . . . . . . . . . 310.12 Cas des espaces d’états finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
0.12.1 Récurrence, invariance, apériodicité, ergodicité . . . . . . . . . . . . . . . 320.12.2 Convergence géométrique vers l’équilibre et couplage . . . . . . . . . . . 350.12.3 Temps de recouvrement . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
0.13 Coalescences et algorithme de Letac-Propp-Wilson . . . . . . . . . . . . . . . . . 370.13.1 Coalescences de suites récurrentes aléatoires . . . . . . . . . . . . . . . . 370.13.2 Algorithme de Letac-Propp-Wilson . . . . . . . . . . . . . . . . . . . . . 39
0.14 Quelques exemples classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390.14.1 Processus de vie ou de mort sur N . . . . . . . . . . . . . . . . . . . . . . 390.14.2 Marche aléatoire simple sur Zd . . . . . . . . . . . . . . . . . . . . . . . . 410.14.3 Urne d’Ehrenfest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 440.14.4 Modèle de Wright-Fisher . . . . . . . . . . . . . . . . . . . . . . . . . . . 460.14.5 Google et Pagerank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
Bibliographie 55
3

4 TABLE DES MATIÈRES
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 4.

Quelques aspects des chaînes deMarkov
Ce chapitre est consacré aux chaînes de Markov homogènes à espace d’état au plus dénom-brable. Leurs trajectoires peuvent se concevoir comme celles de suites récurrentes aléatoires(Xn) de la forme Xn+1 = g(Xn, Un) où les (Un) sont indépendantes et équidistribuées. Toutcomme les martingales, les chaînes de Markov sont des suites de variables aléatoires caracté-risées par une forme particulière de dépendance, qui leur confère des propriétés remarquables,et un rôle important en modélisation. Les chaînes de Markov ont été introduites par AndreiAndreyevich Markov vers 1906, à l’âge de cinquante ans, dans son article [23].
Dans toute la suite, un ensemble au plus dénombrable E est toujours muni de la topologie (ettribu) de toutes ses parties, qui rend continue (et mesurable) toute fonction f : E → R. Une me-sure de Borel µ sur E vérifie µ(A) =
∑x∈A µ(x) pour tout A ⊂ E, où µ(x) := µ({x}) ∈ R+. Une
fonction f : E → R est µ-intégrable lorsque la somme au plus dénombrable∑
x∈E |f(x)|µ(x)converge, et dans ce cas,
∫Ef(x) dµ(x) =
∑x∈E f(x)µ(x). On dit qu’une mesure µ sur E charge
l’état x ∈ E lorsque µ(x) > 0. Les mesures sont toujours supposées non identiquement nulles :elles chargent donc au moins un état.
La seconde partie du chapitre est consacrée au cas particulier des chaînes de Markov àespace d’état fini. Leur étude bénéficie de la théorie des matrices.
0.1 Suites ou chaînes ?Soit (Xn) une suite de variables aléatoires à valeurs dans un ensemble au plus dénombrable
E. La loi de la suite (Xn) est une loi sur EN muni de la tribu engendrée par les cylindres. Envertu d’un célèbre théorème de Carathéodory, la loi de la suite (Xn) est caractérisée par sesmarges de dimension finie, c’est-à-dire par la loi des vecteurs aléatoires (X0, . . . , Xn) pour toutn ∈ N. Or E est au plus dénombrable, et donc la loi de (X0, . . . , Xn) est caractérisée à son tourpar la donnée de P(Xn = xn, . . . , X0 = x0) pour tout x0, . . . , xn dans E. À ce stade, on peutécrire par conditionnements successifs
P(Xn = xn, . . . , X0 = x0) =n−1∏k=0
P(Xk+1 = xk+1 |Xk = xk . . . , X0 = x0)P(X0 = x0).
5

6 TABLE DES MATIÈRES
Si un événement de la forme {Xk = xk . . . , X0 = x0} est négligeable, il en va de même del’événement {Xn = xn, . . . , X0 = x0}. Aussi, dans toute la suite, ces cas particuliers sontsystématiquement omis par souci de concision, malgré le manque de rigueur que cela entraîne.Définition 0.1.1 (Chaîne de Markov). On dit qu’une suite (Xn) de variables aléatoires à valeursdans un ensemble au plus dénombrable E est une chaîne de Markov d’espace d’état E lorsquepour tout k ∈ N, tout x0, . . . , xk+1 dans E,
P(Xk+1 = xk+1 |Xk = xk, . . . , X0 = x0) = P(Xk+1 = xk+1 |Xk = xk).
Cela s’écrit également
L(Xk+1 | (Xk, . . . , X0)) = L(Xk+1 |Xk) pour tout k ∈ N.
On dit que la chaîne est homogène lorsque pour tout k ∈ N et tout x et y dans E,
P(Xk+1 = y |Xk = x) = P(X1 = y |X0 = x).
Cela s’écrit également
L(Xk+1 |Xk = x) = L(X1 |X0 = x) pour tout k ∈ N et tout x ∈ E.
L’indice n de la suite (Xn) est interprété comme un temps. La variable Xk représente laposition spatiale à l’instant k, la tribu σ(X0, . . . , Xk−1) représente son passé tandis que la tribuσ(Xk+1, Xk+1, . . .) représente son futur. Les chaînes de Markov sont des suites aléatoires sansmémoire, en quelque sorte.Exemple 0.1.2 (Suites récurrentes aléatoires). Soit X0 une variable aléatoire à valeurs dansun ensemble au plus dénombrable E. Soit (Un)n>1 une suite de variables aléatoires à valeursdans un espace mesurable F , indépendantes et de même loi, et indépendantes de X0. Soitg : E × F → E une application mesurable. La suite (Xn) définie par la relation de récurrenceXn+1 := g(Xn, Un+1) est une chaîne de Markov homogène sur E. Le théorème 0.4.1 fournit unesorte de réciproque.
Dans toute la suite, les chaînes de Markov considérées sont toutes homogèneset à espace d’état au plus dénombrable.
Noyaux de transition
Soit (Xn) une chaîne de Markov d’espace d’état E. On appelle noyau de transition de lachaîne l’application P : E × E → [0, 1] définie pour tout x et y dans E par
P(x, y) := P(X1 = y |X0 = x).
On a également P(Xn+1 = y |Xn = x) = P(x, y) pour tout n ∈ N et tout x et y dans E. Ennotant ν := L(X0), la définition 0.1.1 entraîne que pour tout n ∈ N et tout x0, . . . , xn dans E,
P(Xn = xn, . . . , X0 = x0) = ν(x0)n−1∏k=0
P(xk, xk+1).
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 6.

0.1. SUITES OU CHAÎNES ? 7
n n + 1
p p p
1 − p 1 − p
Fig. 2 – Zoom sur le graphe des transitions du processus de Bernoulli de l’exemple 0.1.5.
Ainsi, la loi de la suite (Xn) est entièrement caractérisée par la loi initiale ν := L(X0) et lenoyau de transition P. Dans toute la suite, la notation CM(E,ν,P) signifie « chaîne de Markovd’espace d’état E, de loi initiale ν, et de noyau de transition P ». Chaque couple ν,P définitde manière unique une loi de probabilité sur EN. Si (Yn) est une suite de variables aléatoiressur E de même loi que (Xn), alors (Yn) est également une CM(E,ν,P).Exemple 0.1.3 (Suites récurrentes aléatoires). Le noyau de transition de la chaîne de Markov(Xn) de l’exemple 0.1.2 est donné par P(x, y) = P(g(x, U) = y), pour tout x et y dans E, oùU est une variable aléatoire sur F , de même loi que les (Un)n>1.Exemple 0.1.4 (Marche aléatoire simple sur le cercle). Soit d > 0 un entier, et (Yn)n>1 unesuite de variables aléatoires i.i.d. à valeurs dans E := Z/dZ, de loi commune 1
2(δ−1 + δ+1). Soit
X0 une variable aléatoire de loi ν sur E. La suite (Xn) définie par la relation de récurrenceXn+1 := Xn + Yn+1 = X0 + Y1 + · · ·+ Yn+1 est une CM(E,ν,P) de noyau
P(x, y) :=
{12
si |x− y| = 1 dans Z/dZ0 sinon
.
Exemple 0.1.5 (Le processus de Bernoulli du jeu de pile ou face). Soit (Yn)n>1 une suite devariables aléatoires indépendantes et équidistribuées de loi de Bernoulli pδ1 + (1 − p)δ0 oùp ∈ [0, 1]. Soit B0 une variable aléatoire à valeurs dans N. La suite (Bn)n>0 définie pour toutn > 1 par Bn := B0 + Y1 + · · · + Yn est une chaîne de Markov d’espace d’état E = N, de loiinitiale L(B0), et de noyau de transition P donné pour tout x, y dans N par
P(x, y) =
p si y = x + 1
1− p si y = x
0 sinon.
Cette chaîne est appelée processus de Bernoulli. Elle correspond au graphe des transitions dela figure 2. La variable aléatoire Bn représente le nombre de gains après n lancers à un jeu depile ou face avec probabilité de gagner p et fortune initiale B0. Lorsque p = 1 (resp. p = 0), lachaîne a une évolution déterministe puisque dans ce cas Bn+1 = Bn + 1 (resp. Bn+1 = Bn).
La notion de noyau peut être isolée du concept de chaîne.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 7.

8 TABLE DES MATIÈRES
0 1
p0
p1
1 − p0 1 − p1
Fig. 3 – Graphe des transitions de la chaîne à deux états de l’exemple 0.1.7.
Définition 0.1.6 (Noyau de transition). Soit E un espace d’état. Une application P : E×E → Rest un noyau de transition sur E si et seulement si pour tout x et y dans E
0 6 P(x, y) 6 1 et∑z∈E
P(x, z) = 1.
Un noyau de transition P associe à tout x ∈ E la loi∑
y∈E P(x, y)δy sur E. La constructioneffective d’une chaîne de Markov de mesure initiale et de noyau de transition prescrits estdonnée par le théorème 0.4.1.Exemple 0.1.7 (Chaîne à deux états). Soient p0 et p1 dans [0, 1]. Le noyau de transition P dela chaîne de Markov à deux états sur E := {0, 1} est donné par P(0, 1) = 1 − P(0, 0) = p0 etP(1, 0) = 1−P(1, 1) = p1. Vue comme une matrice 2× 2,
P =
(P(0, 0) P(0, 1)P(1, 0) P(1, 1)
)=
(1− p0 p0
p1 1− p1
).
Cette chaîne correspond au graphe des transitions de la figure 3. Pour p0 = p1 = 1, on retrouvela marche aléatoire simple sur Z/2Z de l’exemple 0.1.4.
Quitte à numéroter les éléments de E, un noyau de transition P peut être vu comme unematrice carrée, infinie si E est infini, dont chaque ligne est une loi sur E.
E = {x0, x1, x2, . . .} et P =
P(x0, x0) P(x0, x1) P(x0, x2) · · ·P(x1, x0) P(x1, x1) P(x1, x2) · · ·
... ... ... . . .
.
Structure de l’ensemble des noyaux
Si P et Q sont deux noyaux de transition sur E, et si α et β sont deux réels positifs telsque α + β = 1, alors αP(x, y) + βQ(x, y) définit un noyau de transition sur E noté αP + βQ.D’autre part,
∑z∈E P(x, z)Q(z, y) définit également un noyau de transition sur E noté PQ.
Ainsi, l’ensemble des noyaux de transition sur E est convexe, et forme un semi-groupe pour leproduit, d’élément neutre I défini par I(x, y) = 1 si x = y et I(x, y) = 0 sinon.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 8.

0.1. SUITES OU CHAÎNES ? 9
Noyaux itérés
Soit (Xn) une CM(E,ν,P). L’application Pn : E × E → [0, 1] donnée par
Pn(x, y) := P(Xn = y |X0 = x)
est un noyau de transition sur E, vérifiant L(Xn |X0 = x) =∑
y∈E Pn(x, y)δy. D’autre part,P1 = P, et P0 = I. Nous pouvons écrire pour tout entier n > 1 et tout x0 et xn dans E,
Pn(x0, xn) = P(Xn = xn |X0 = x0) =∑
x1,...,xn−1∈E
P(X1 = x1, . . . , Xn = xn |X0 = x0).
La suite x0, . . . , xn constitue un « chemin » dans E. Par récurrence sur n, on établit que
Pn(x0, xn) =∑
x1,...,xn−1∈E
P(x0, x1) · · ·P(xn−1, xn) =∑x∈E
Pn−1(x0, x)P(x, xn).
Ces formules sont exactement celles du produit matriciel. Ainsi, Pn = PPn−1 = Pn−1P.Exemple 0.1.8 (Processus de Bernoulli). Si (Bn) est la CM(N,ν,P) de l’exemple 0.1.5, alorsL(Bn |B0 = x) est la loi binomiale de paramètre p sur {x, x + 1, . . . , x + n}. Par conséquent,
Pn(x, y) =
{Cy−x
n py−x(1− p)n−(y−x) si 0 6 y − x 6 n
0 sinon.
On a également L(Bn) = ν ∗ L(Bn |B0 = 0) = ν ∗ B(n, p) = ν ∗ B(1, p)∗n, où B(n, p) désigne laloi binomiale de paramètre p sur {0, 1, . . . , n}.
Écritures matricielles
On assimile toute loi ν sur E à un vecteur ligne, et toute fonction f : E → R à un vecteurcolonne. Ainsi, la moyenne de f pour la mesure ν s’écrit
νf =∑x∈E
f(x)ν(x).
On assimile également tout noyau de transition à une matrice. Ainsi, si (Xn) est une CM(E,ν,P),alors L(Xn) = νPn et E(f(Xn)) = νPnf . En effet,
E(f(Xn)) =∑y∈E
P(Xn = y)f(y) =∑
x,y∈E
ν(x)Pn(x, y)f(y) = νPnf.
Calcul récursif des lois instantanées
Si (Xn) est une CM(E,ν,P), alors νn := L(Xn) = νPn pour tout n. La suite (νn) se calculepar la formule de récurrence linéaire ν0 := ν et νn+1 = νnP pour tout n.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 9.

10 TABLE DES MATIÈRES
Notation conditionnelle
Si (Xn) est une chaîne de Markov sur E, alors pour tout x ∈ E, tout événement A et toutevariable aléatoire Z, on note
Px(A) := P(A |X0 = x) et Ex(Z) := E(Z |X0 = x).
0.2 La propriété de Markov forteSoit (Xn) une CM(E,ν,P). L’usage direct de la définition 0.1.1 conduit pour tout m et n à
L((Xm+n, . . . , Xm) | (Xm, . . . , X0)) = L((Xm+n, . . . , Xm) |Xm)
etL((Xm+n, . . . , Xm) |Xm = x) = L((Xn, . . . , X0) |X0 = x).
Cela entraîne la propriété de Markov faible : pour tout m ∈ N, et conditionnellement à l’événe-ment {Xm = x}, la suite (Xn+m)n est une CM(E,δx,P) indépendante de σ(X0, . . . , Xm). Cettepropriété s’étend à certains changements de temps aléatoires.Théorème 0.2.1 (Propriété de Markov forte). Soit (Xn) une CM(E,ν,P) et τ un temps d’arrêt àvaleurs dans N∪{∞} pour la filtration (σ(X0, . . . , Xn)). Pour tout x ∈ E, et conditionnellementà {τ < ∞ et Xτ = x}, la suite (Xτ+n) est une CM(E,δx,P), indépendante de σ(X0, . . . , Xτ ).Lorsque τ est constant et égal à m, on retrouve la propriété de Markov faible.
Démonstration. Dire que τ est un temps d’arrêt signifie que {τ = m} ∈ σ(X0, . . . , Xm) pourtout m. Par suite, A∩{τ = m}∩{Xτ = x} ∈ σ(X0, . . . , Xm) pour tout A ∈ σ(X0, . . . , Xm), toutx ∈ E, et tout m. Il en découle, en vertu de la propriété de Markov faible, que la probabilité
P({Xτ+n = xn, . . . , Xτ = x0} ∩ A ∩ {τ = m} ∩ {Xτ = x})
et égale à P(Xn = xn, . . . , X0 = x0)P(A ∩ {τ = m} ∩ {Xτ = x}). En sommant sur m, il vient
P({Xτ+n = xn, . . . , Xτ = x0, } ∩ A ∩ {Xτ = x}) = P(Xn = xn, . . . , X0 = x0)P(A ∩ {Xτ = x}).
La propriété désirée s’obtient alors en divisant par P(τ < ∞ et Xτ = x).
Temps de premier passage et temps d’atteinte
Soit (Xn) une CM(E,ν,P). Pour tout F ⊂ E, le temps de premier passage en F et le tempsd’atteinte de F sont définis par
TF := inf {n > 0; Xn ∈ F} et τF := inf {n > 0; Xn ∈ F}.
Ces variables aléatoires prennent leurs valeurs dans {1, 2, . . .} ∪ {∞} et {0, 1, 2, . . .} ∪ {∞}respectivement. Ce sont des temps d’arrêt pour la filtration naturelle (σ(X0, . . . , Xn)). Ellessont égales sur {X0 6∈ F}. Sur {X0 ∈ F}, la variable TF est également le temps de retour en F .
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 10.

0.3. LES CHAÎNES DANS TOUS LEURS ÉTATS 11
Nombre de visites et potentiel
Le nombre de visites en F est comptabilisé par les variables aléatoires suivantes, qui prennentleurs valeurs dans N ∪ {∞}.
MF :=∞∑
n=1
I{Xn∈F} et NF :=∞∑
n=0
I{Xn∈F}.
On a {TF = ∞} = {MF = 0} et {τF = ∞} = {NF = 0}. Lorsque F = {x}, on note Tx, τx,Mx, et Nx les quantités T{x}, τ{x}, M{x} et N{x} respectivement. Les nombres moyens de visitesen y partant de x sont donnés par les quantités déterministes suivantes dans N ∪ {∞} :
G(x, y) := Ex(My) =∞∑
n=1
Pn(x, y) et H(x, y) := Ex(Ny) =∞∑
n=0
Pn(x, y).
L’application H : E × E → N ∪ {∞} est appelée potentiel du noyau de transition P, et vérifieH = I + G, de sorte que H(x, x) = 1 + G(x, x) et H(x, y) = G(x, y) pour x 6= y. La propriétéde Markov forte pour les temps d’arrêt Tx et Ty conduit à
Px(Nx = ∞) = Px(Nx = ∞)Px(Tx < ∞) et G(x, y) = H(y, y)Px(Ty < ∞).
Pour tout λ > 0, la série Gλ(x, y) :=∑∞
n=1 e−λnPn(x, y) converge car 0 6 Pn(x, y) 6 1. Lapropriété de Markov forte fournit la formule (1+Gλ(y, y))Ex(e−λTy) = Gλ(x, y). La transforméede Laplace de Ty est donc donnée par
Ex(e−λTy) =Gλ(x, y)
1 + Gλ(y, y).
À présent, limλ→0 Gλ(x, y) = G(x, y) par le théorème de convergence dominée, tandis quelimλ→0 Ex(e−λTy) = Px(Ty < ∞) par le théorème de convergence monotone. Il en découle que
Px(Tx < ∞) = 1 si et seulement si G(x, x) = ∞.
De plus, si G(y, y) < ∞, alors G(x, y) < ∞ pour tout x et
Px(Ty < ∞) =G(x, y)
1 + G(y, y).
0.3 Les chaînes dans tous leurs étatsSoit (Xn) une CM(E,ν,P). Définissons la quantité ρ(x, y) := Px(Ty < ∞). Un état x est
qualifié de récurrent lorsque les propriétés équivalentes suivantes sont réalisées : ρ(x, x) = 1,G(x, x) = ∞, H(x, x) = ∞. Il est qualifié de transitoire sinon. Le tableau 1 regroupe des
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 11.

12 TABLE DES MATIÈRES
État x récurrent État x transitoireρ(x, x) = 1, H(x, x) = ∞ ρ(x, x) < 1, H(x, x) < ∞
ρ(x, y) > 0 ⇒ Px(Ny = ∞) = 1 Px(Nx = ∞) = 0ρ(y, x) = Py(Nx = ∞) L(Nx |X0 = x) = G(ρ(x, x))
ρ(y, x) > 0 ⇒ H(y, x) = ∞ H(y, x) = ρ(y, x)/(1− ρ(x, x)) < ∞
Tab. 1 – Propriétés des états récurrents et transitoires, valables pour tout y ∈ E.
propriétés utiles. Pour un état récurrent x, la propriété de Markov forte appliquée récursivementpermet de définir une infinité de temps de retours successifs en x, qui délimitent des excursionsde même loi enracinées en x (cela correspond à un système de renouvellement sur N∗).
On note ER l’ensemble des états récurrents et ET = E \ER celui des états transitoires. Ondit que F ⊂ E est clos lorsque Px(TF c < ∞) = 0 pour tout x ∈ F . La chaîne ne s’échappejamais d’un ensemble clos. Un état x est dit absorbant (ou point cimetière) lorsque les conditionséquivalentes suivantes sont réalisées : {x} est clos, P(x, x) = 1.Exemple 0.3.1 (Processus de Bernoulli). Considérons le processus de Bernoulli de l’exemple0.1.5. Si p > 0, alors tous les états sont transitoires car Px(Tx = ∞) = 1. Si p = 0, tous lesétats sont absorbants (la chaîne est constante).Exemple 0.3.2 (Marches aléatoires sur Z). Une marche aléatoire sur Z est une suite (Xn) quis’écrit Xn+1 = Xn+Yn = X0+Y1+· · ·+Yn où (Yn) est une suite i.i.d. de loi η sur Z. La suite (Xn)est une chaîne de Markov sur Z de noyau de transition P donné par P(x, y) = η(y−x). Notonsque Pn(x, y) = P(x+Y1+· · ·+Yn = y). En particulier, Pn(x, x) = P(Y1+· · ·+Yn = 0) = P(0, 0).Ainsi, H(x, x) = H(0, 0) =
∑∞n=0 Pn(0, 0). Les états sont donc soit tous récurrents soit tous
transitoires. Lorsque X0 prend ses valeurs dans N et η = (1 − p)δ0 + pδ1 avec p ∈ [0, 1], onretrouve le processus de Bernoulli de l’exemple 0.1.5. Considérons le cas où η = 1
2(δ−1 + δ+1).
On dit alors que la marche aléatoire est simple. Comme (Y1 + 1 + · · · + Yn + 1)/2 suit la loibinomiale B(n, 1/2), on a P2k+1(0, 0) = 0 et P2k(0, 0) = 2−2k(2k)!/(k!)2. La formule de Stirling1
conduit à H(0, 0) = ∞, et ainsi tous les états sont récurrents.Pour tout x et y dans E, on note x → y lorsqu’il existe n ∈ N tel que Pn(x, y) > 0. Cela
signifie que x et y sont reliés par un chemin qui suit les flèches dans le graphe des transitionsde P. On note x ↔ y lorsqu’à la fois x → y et y → x. Avec cette définition, on a toujoursx ↔ x, même lorsque P(x, x) = 0. Si x 6= y, on dit que x mène à y lorsque x → y et que x ety communiquent lorsque x ↔ y. Si x 6= y, alors x → y si et seulement si H(x, y) > 0. Si x → yet y 6→ x alors x est transitoire.Théorème 0.3.3 (Décomposition de l’espace d’état). Pour tout noyau de transition P sur E, larelation binaire ↔ est une relation d’équivalence qui partitionne l’espace d’état E en une uniondisjointe de classes appelées classes irréductibles. La propriété de récurrence est constante sur
1Formule de Stirling : n! ∼ nne−n√
2πn.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 12.

0.3. LES CHAÎNES DANS TOUS LEURS ÉTATS 13
x y
(x, y)
(y, x)
(x, x) (y, y)
Fig. 4 – Transitions possibles entre x et y pour le noyau P. On omet en général les flèches quicorrespondent à des probabilités de transition nulles.
ces classes. Les classes constituées d’états récurrents sont closes et sont appelées classes derécurrence. Les classes constituées d’état transitoires sont appelées classes transitoires.
En quelque sorte, les ensembles clos, comme par exemple les classes de récurrence, sontabsorbants. Presque sûrement, une chaîne partant d’un état récurrent repasse une infinité defois par son état initial, ne s’échappe jamais de sa classe de récurrence, et visite une infinitéde fois tous les états qui constituent cette classe de récurrence. Le cas des états absorbantsest singulier puisque leur classe de récurrence est réduite à eux-même. Presque sûrement, unechaîne partant d’un état transitoire ne peut repasser qu’un nombre fini de fois par son étatinitial, et peut être capturée par une classe de récurrence ou visiter d’autres états transitoires(un nombre fini de fois pour chacun).
L’ensemble des état transitoires peut être infini, et la chaîne peut ne jamais être capturéepar une classe de récurrence. C’est toujours le cas lorsqu’il n’y a pas d’états récurrents, commepar exemple pour le processus de Bernoulli avec p > 0. Contrairement aux classes de récurrence,les classes transitoires peuvent ne pas être closes. Des passages (à sens unique) peuvent existerentre elles, ainsi que vers les classes de récurrence. Sur le graphe des transitions, les flèches quipénètrent dans une classe close proviennent toujours d’états transitoires.
On dit que P est irréductible lorsque E est constitué d’une unique classe, c’est-à-dire lorsquetous les états communiquent : pour tout x et y, il existe n tel que Pn(x, y) > 0. On dit que Pest récurrent lorsque ET est vide, et transitoire lorsque ER est vide. Ces termes sont égalementutilisés, au féminin, pour toute chaîne de Markov de noyau P.
noyau irréductible{
(1) une seule classe de récurrence (noyau récurrent)(2) une seule classe transitoire (noyau transitoire)
noyau réductible
(3) plusieurs classes de récurrence et aucun état transitoire(4) au moins une classe de récurrence et des états transitoires(5) plusieurs classes transitoires
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 13.

14 TABLE DES MATIÈRES
L’étude des classes de récurrence des cas (3-4) se ramène au cas (1). L’étude des classestransitoires closes des cas (4-5) se ramène au cas (2).Exemple 0.3.4. Considérons le noyau de transition P sur E = {a, b, c, d} donné par
P :=1
4
4 0 0 00 2 1 10 0 1 30 0 2 2
.
L’état a est absorbant et donc récurrent. L’état b est transitoire car b → c mais aucun état demène à b. Les états c, d sont récurrents car le temps d’atteinte de c partant de d et de c partantde d sont tous deux finis presque sûrement (lois géométriques). Ainsi, les classes irréductiblesde P sont {a}, {c, d}, {b}, et seules les deux premières sont closes (et récurrentes).Remarque 0.3.5 (Le cas i.i.d.). Soit (Xn) une suite de variables aléatoires i.i.d. de loi µ sur E.Quitte à remplacer E par {x ∈ E; µ(x) > 0}, on peut supposer que µ(x) > 0 pour tout x ∈ E.La suite (Xn) est une chaîne de Markov de loi initiale µ et de noyau de transition P donné parP(x, y) := µ(y) pour tout x et y. Ce noyau est irréductible car P(x, y) > 0 pour tout x et y.De plus, Px(Tx = n) = (1− µ(x))n−1µ(x) pour tout n > 0, et donc Tx suit une loi géométriquesur N∗. En particulier, Px(Tx < ∞) = 1 et Ex(Tx) = 1/µ(x). Ainsi, P est récurrent irréductible.Notons que Pn(x, y) = µ(y), de sorte que H(x, x) =
∑∞n=0 Pn(x, x) =
∑∞n=0 µ(x) = ∞.
Dans le cas i.i.d. de la remarque 0.3.5, la loi initiale se confond avec le noyau. Il importantde comprendre qu’en général, le comportement d’une chaîne de Markov dépend à la fois de laloi initiale et de la classification des états associée au noyau. Cependant, nous allons voir quepour certains noyaux, le comportement asymptotique des chaînes associées ne dépend que dunoyau et plus de la loi initiale.
0.4 Simulation d’une chaîne de MarkovApproche récursive
La propriété de Markov faible indique que pour simuler une trajectoire (xn) d’une chaînede Markov (Xn), il suffit de procéder récursivement, en simulant la loi initiale ν := L(X0), cequi donne x0, puis la loi P(x0, ·), ce qui donne x1, etc.Théorème 0.4.1 (Suite récurrentes aléatoires). Pour tout noyau de transition P sur E, et touteloi ν sur E, il existe des fonctions f : [0, 1] → E et g : E× [0, 1] → E telles que pour toute suite(Un) de variables aléatoires i.i.d. de loi uniforme sur [0, 1], la suite (Xn) définie par X0 = f(U0)et Xn+1 := g(Xn, Un+1) est une CM(E,ν,P).
Démonstration. Après avoir identifié E à N, on pose f(u) := min{m ∈ N; ν(0)+· · ·+ν(m) > u}et g(n, u) := min{m ∈ N;P(n, 0)+ · · ·+P(n,m) > u} pour tout n ∈ N et u ∈ [0, 1]. Ce sont les
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 14.

0.4. SIMULATION D’UNE CHAÎNE DE MARKOV 15
fonctions de répartition inverses des lois ν et P(n, ·), conformément à la méthode de simulationpar inversion.
Pour simuler récursivement une trajectoire (xn) d’une CM(E,ν,P), on simule une réalisationx0 = f(u0) de la loi initiale ν, puis le reste de la trajectoire par la formule de récurrencexn+1 = g(xn, un+1). Cela fait envisager les chaînes de Markov comme des suites récurrentesaléatoires. Le théorème 0.4.1 réduit également la construction effective des CM(E,ν,P) à celledes suites i.i.d. de loi uniforme sur [0, 1].
Approche par sauts et générateur
Soit (Xn) une CM(E,ν,P). La suite (Sn) des temps de saut de (Xn) est définie par :
S0 := 0 et Sn+1 := inf{k > Sn; Xk 6= XSn}.
On adopte la convention inf ∅ = ∞, de sorte que ces variables aléatoires sont bien définies etprennent leurs valeurs dans N∪{∞}. La suite (Xn) est constante et égale à XSn sur l’intervallede temps aléatoire {m ∈ N; Sn 6 m < Sn+1}. En vertu de la propriété de Markov forte, laprobabilité P(Sn+1 − Sn = m; XSn+1 = y |XSn = x) vaut P(x, x)m−1P(x, y) si m > 0 et y 6= x,et vaut 0 sinon. Il en découle que pour tout état x et tout temps n,
– soit P(x, x) = 1, alors P(Sn+1 = ∞|XSn = x) = 1 et on dit que x est absorbant;– soit P(x, x) < 1, alors P(Sn+1 < ∞|XSn = x) = 1, les variables aléatoires Sn+1 − Sn et
XSn+1 sont indépendantes conditionnellement à {XSn = x}, et de plus
∀m > 0, P(Sn+1 − Sn = m |XSn = x) = (P(x, x))m−1(1−P(x, x))
et∀y 6= x, P(XSn+1 = y |XSn = x) =
P(x, y)
1−P(x, x).
On appelle générateur de la chaîne l’application L : E×E → R définie par L := P−I. Il vérifieL(x, x) = P(x, x)−1 et L(x, y) = P(x, y) si x 6= y. La décomposition en sauts fournit un nouvelalgorithme de simulation des trajectoires, basé sur la simulation des deux lois G(−L(x, x)) et∑
y 6=x(−L(x, y)/L(x, x))δy, qui correspondent aux temps des sauts et aux positions des sauts.Ici, G(p) := p
∑∞n=1(1 − p)n−1δn désigne la loi géométrique sur N∗ de moyenne 1/p. Comparé
à la méthode de simulation récursive directe, ce nouvel algorithme par sauts est d’autant pluspréférable que les coefficients diagonaux de P sont proches de 1.
Approche matricielle
Dans certains cas, comme par exemple pour le jeu de pile ou face, le noyau itéré Pn possèdeune formulation explicite simple. Pour simuler Xn sur l’événement {X0 = x0} sans passer parla trajectoire x0, . . . , xn, il suffit d’utiliser la loi Pn(x0, ·) sur E. Lorsque E est de cardinal d, le
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 15.

16 TABLE DES MATIÈRES
coût peut être réduit en calculant par récurrence la loi discrète L(Xn) = νPn par multiplicationdu vecteur ligne νPk par la matrice P, pour k = 0, . . . , n. Cela nécessite de l’ordre de nd2
opérations élémentaires.
0.5 Atteinte, absorption, harmonicité, martingalesSoit (Xn) une chaîne de Markov sur E. Lorsque que F ⊂ E est clos, le temps d’atteinte τF
de F devient un temps d’absorption puisque la chaîne ne peut pas s’échapper de F . C’est lecas lorsque F est une classe de récurrence. Le vecteur des probabilités d’atteinte (uF (x))x∈E etle vecteur des temps moyens d’atteinte (vF (x))x∈E sont définis par
aF (x) := Px(τF < ∞) et mF (x) := Ex(τF ). (1)
Les valeurs prises sont respectivement dans [0, 1] et R+ ∪ {∞}. Notons que mF (x) = Ex(TF )si x 6∈ F . On a toujours uF = 0 et vF = ∞ sur tout ensemble clos G disjoint de F . C’est parexemple le cas avec avec G = ER \ F lorsque F est une classe de récurrence.Théorème 0.5.1 (Atteinte et absorption). Soit (Xn) une CM(E,ν,P), et F ⊂ E.
1. Le vecteur (aF (x))x∈E est solution positive ou nulle minimale2 du système linéaire
aF (x) =
{1 si x ∈ F∑
y∈E P(x, y)aF (y) si x 6∈ F.
Si F est clos, le système s’écrit PaF = aF où aF est pris comme vecteur colonne.2. Le vecteur (mF (x))x∈E est solution positive ou nulle minimale du système linéaire
mF (x) =
{0 si x ∈ F
1 +∑
y∈E P(x, y)mF (y) si x 6∈ F.
Démonstration. L’écriture pour F clos est immédiate. Les deux assertions principales s’éta-blissent de la même manière. Il est clair que aF = 1 sur F . Pour tout x 6∈ F , on écritaF (x) =
∑y∈E Px(τF < ∞|X1 = y)P(x, y). Or τF > 1 sur {X0 = x} car x 6∈ F , et donc
par la propriété de Markov faible Px(τF < ∞|X1 = y) = Py(τF < ∞) = aF (y) pour tout y.Ainsi, aF est bien solution. Si a est une autre solution positive, alors a = aF = 1 sur F . Six 6∈ F , alors par par substitutions successives dans a(x) =
∑y∈F P(x, y) +
∑y 6∈F P(x, y)a(y),
a(x) = Px(X1 ∈ F ) + · · ·+ Px(X1 6∈ F, . . . , Xn−1 6∈ F, Xn ∈ F ) + εn
pour tout n, où εn :=∑
x1,...,xn 6∈F P(x, x1)P(x1, x2) · · ·P(xn−1, xn)a(xn). Il en découle quea(x) > Px(τF 6 n) puisque εn > 0. La limite quand n →∞ donne enfin a(x) > aF (x).
2Signifie que si a est également une solution positive ou nulle, alors aF (x) 6 a(x) pour tout x ∈ E.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 16.

0.5. ATTEINTE, ABSORPTION, HARMONICITÉ, MARTINGALES 17
Seule la somme sur F c intervient dans l’équation vérifiée par vF car vF (x) = 0 si x ∈ F .Exemple 0.5.2 (Marche aléatoire sur N et ruine du joueur). Soit 0 < p < 1. Considérons unjoueur qui, à chaque étape, peut gagner un Euro avec probabilité p ou perdre un Euro avecprobabilité 1− p. Le joueur commence le jeu avec une fortune initiale X0, et cesse de jouer dèsque sa fortune est nulle. La suite (Xn) est une chaîne de Markov sur N de noyau de transitionP vérifiant P(0, 0) = 1, P(x, x + 1) = p et P(x, x − 1) = 1 − p pour tout x > 0. Une tellechaîne constitue également une marche aléatoire sur N, tuée en 0. L’ensemble F := {0} est closcar l’état 0 est absorbant. En vertu du théorème 0.5.1, le vecteur des probabilités d’absorptionu := uF est solution minimale des équations u(0) = 1 et u(x) = pu(x + 1) + (1 − p)u(x − 1)pour tout x > 0. Supposons que le jeu est équitable, c’est-à-dire que p = 1/2. Les solution dela récurrence linéaire sont de la forme u(x) = α + βx. Les conditions u(0) = 0 et 0 6 u 6 1entraînent α = 1 et β = 0. Ainsi, u(x) = 1 pour tout x, ce qui signifie que quelque soit sa fortuneinitiale x, le joueur finira ruiné presque sûrement ! Ce modèle tolère des fortunes arbitrairementgrandes au cours du jeu, ce qui n’est pas réaliste.Théorème 0.5.3 (Martingales). Soit (Xn) une CM(E,ν,P) et L := P − I son générateur. Sif : E → R est intégrable pour toutes les lois νPn, alors la suite (Yn) définie par
Y0 := 0 et Yn := f(Xn)− f(X0)−n−1∑k=0
(Lf)(Xk) pour tout n > 0
est une martingale pour la filtration (σ(X0, . . . , Xn)) de (Xn).
Démonstration. Le résultat découle de l’identité suivante valable pour tout n > 0 :
Yn =n∑
k=1
[f(Xk)− (Pf)(Xk−1)] =n∑
k=1
[f(Xk)− E(f(Xk)|Xk−1)].
Une fonction f : E → R est harmonique pour P lorsque Lf = 0, ou de manière équivalentelorsque Pf = f . Dans ce cas, la martingale se réduit à (f(Xn)). En vertu du théorème 0.5.1, levecteur aF des probabilités d’atteinte d’un ensemble clos F est harmonique et bornée.Corollaire 0.5.4. Soit (Xn) une CM(E,ν,P) avec E ⊂ R. Si x =
∑y∈E yP(x, y) pour tout
x ∈ E, et si∑
y∈E |y|ν(y) < ∞ alors (Xn) est une martingale.Exemple 0.5.5 (Marches aléatoires sur Z). Soit (Xn) comme dans l’exemple 0.3.2. Si ν = δ0 et siη admet le réel t comme moyenne, alors la suite (Xn− tn) est une martingale. Cela correspondà la fonction f(n) = tn. En particulier, la suite (Xn) est une martingale lorsque η est centrée.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 17.

18 TABLE DES MATIÈRES
0.6 Invariance et récurrence positiveMesures et lois invariantes
On dit qu’une mesure µ sur E est invariante pour le noyau de transition P lorsque pourtout y, la série
∑x∈E µ(x)P(x, y) converge et vaut µ(y). Cela s’écrit µP = µ, ou encore µL = 0.
En particulier, µ est aussi invariante pour Pn pour tout n. Pour une loi µ, son invariance pourP revient à dire que si (Xn) est une chaîne de Markov de noyau P et de loi initiale µ, alorsL(Xn) = µ pour tout n. Les lois de probabilités invariantes représentent donc des équilibres enloi pour la chaîne. Une mesure invariante n’est pas toujours une loi.Exemple 0.6.1 (Cas i.i.d.). En vertu de la remarque 0.3.5, si (Xn) est une suite i.i.d. de loi µsur E, alors (Xn) est une chaîne de Markov sur E et µ est invariante.Exemple 0.6.2 (Chaîne à deux états). Une mesure µ est invariante pour la chaîne à deux étatsde l’exemple 0.1.7 si et seulement si p0µ(0) = p1µ(1). En particulier, lorsque p0 + p1 > 0, lamesure µ définie par µ(0) = p1/(p0 + p1) et µ(1) = p0/(p0 + p1) est l’unique loi invariante. Sip0 = p1 = 0, toutes les mesures sont invariantes (la chaîne est constante).Exemple 0.6.3 (Multiplicité des mesures invariantes). Considérons la marche aléatoire sur Z del’exemple 0.3.2 avec η = (1 − p)δ−1 + pδ+1 et 0 < p < 1. Une mesure µ est invariante si etseulement si µ(x) = α + β(p/(1− p))x pour tout x ∈ Z, où α et β sont des constantes réelles.Il n’y a donc pas unicité de la mesure invariante à multiplication près par une constante.Exemple 0.6.4 (Absence de mesure invariante). Pour le processus de Bernoulli de l’exemple0.1.5, une mesure µ sur N est invariante si et seulement si µ(0) = (1 − p)µ(0) et µ(x) =(1 − p)µ(x) + pµ(x − 1) pour tout x > 0. Par conséquent, si 0 < p < 1, alors il n’y a pas demesure invariante. Si p = 0, toutes les mesures sont invariantes, tandis que si p = 1, alors toutemesure invariante µ est constante (c’est-à-dire que x ∈ E 7→ µ(x) est constante).
Structure de l’ensemble des mesures invariantes
La linéarité de l’équation µP = µ entraîne que l’ensemble des mesures invariantes est un côneconvexe : si µ1 et µ2 sont invariantes et si α1 et α2 sont deux réels positifs avec α1+α2 > 0, alorsla mesure α1µ1 + α2µ2 est également invariante. L’ensemble des lois de probabilité invariantes,lorsqu’il est non-vide, est également convexe (prendre α1 + α2 = 1). Si µ est une mesureinvariante, alors tout multiple de µ est également invariante. En particulier, si µ est invarianteet vérifie µ(E) < ∞ (toujours vrai si E est fini), alors µ(E)−1µ est une loi invariante.
Récurrence positive et récurrence nulle
Un état x est absorbant si et seulement si la masse de Dirac δx est invariante. Plus géné-ralement, pour tout état récurrent x, on introduit le nombre moyen de passages en y avant le
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 18.

0.6. INVARIANCE ET RÉCURRENCE POSITIVE 19
retour en x, noté µx(y) et donné par
µx(y) := Ex
(Tx−1∑n=0
I{Xn=y}
).
Notons que µx(y) = δx(y) si x est absorbant. De plus, µx(y) > 0 si et seulement si x → y.Théorème 0.6.5. Si P un noyau de transition récurrent irréductible sur E, alors,
1. µx(y) =∑
z∈E µx(z)P(z, x) pour tout x, y ∈ E ;2. 0 < µx(y) < ∞ pour tout x, y ∈ E.
Cela définit pour tout x ∈ E une mesure µx sur E, invariante pour P, qui vérifie µx(x) = 1.
Démonstration. On écrit µx(y) = Ex(∑∞
n=1 I{Xn=y;Tx>n}) =∑∞
n=1 Px(Xn = y; Tx > n). Enpartitionnant selon la valeur de Xn−1 puis en utilisant la propriété de Markov faible, onobtient µx(y) =
∑z∈E µx(z)P(z, y). Pour la seconde propriété, on écrit µx(x)Pm2
x,y 6 µx(y)et µx(y)Pm2(y, x) 6 µx(x). Il suffit alors de choisir m1 et m2 tels que Pm1(x, y) > 0 etPm2(y, x) > 0 par irréductibilité de P, et d’utiliser le fait que µx(x) = 1.
La formule Tx =∑
y∈F
∑Tx−1n=0 I{Xn=y} donne µx(E) = Ex(Tx). On dit qu’un état récurrent x
est récurrent positif lorsque µx(E) < ∞, et récurrent nul lorsque µx(E) = ∞. La propriété deMarkov forte entraîne que la nature de la récurrence ainsi définie est constante sur les classesde récurrence. Un état absorbant est toujours récurrent positif.
classe de récurrence{
(1) la classe est récurrente positive(2) la classe est récurrence nulle
Théorème 0.6.6 (Mesures invariantes des noyaux irréductibles). Soit (Xn) une CM(E,ν,P) ir-réductible. Alors toute mesure invariante µ charge tous les états, et vérifie µ(y) > µ(x)µx(y)pour tout x et y. De plus, il y a trois cas distincts.
1. P est transitoire. Dans ce cas, µ(E) = ∞ pour toute mesure invariante µ. En particulier,E est nécessairement infini et il n’y a pas de loi invariante ;
2. P est récurrent. Dans ce cas, pour tout x, la mesure µx est invariante. De plus, les mesuresinvariantes sont toutes proportionnelles. Si µ en fait partie, alors µ(y) = µ(x)µx(y) pourtout x et y. En particulier, µx(y)µy(x) = 1 pour tout x et y.(a) P est récurrent positif. Dans ce cas, il existe une unique loi de probabilité invariante
µ donnée par µ(x)Ex(Tx) = 1 pour tout x ;(b) P est récurrent nul. Dans ce cas, µ(E) = ∞ pour toute mesure invariante µ. En
particulier, E est nécessairement infini, et il n’y a pas de loi invariante.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 19.

20 TABLE DES MATIÈRES
Démonstration. Soit µ une mesure invariante. Il existe au moins un état z tel que µ(z) > 0.Pour tout y, il existe un entier n tel que Pn(z, y) > 0 car P est irréductible. Il en découle queµ(y) =
∑x µ(x)Pn(x, y) > µ(z)Pn(z, y) > 0. Ainsi, µ charge tous les états.
Soit µ invariante avec µ(x) = 1. La formule µ(y) = µ(x)P(x, x) +∑
z 6=x µ(z)P(z, y) utiliséerécursivement conduit pour y 6= x à µ(y) > Px(X1 = y; Tx > 1) + · · · + Px(Xn = y; Tx > n).Lorsque n →∞, cela donne µ(y) > µx(y).
Cas où P est récurrent. Si µ est invariante avec µ(x) = 1, alors nous savons que µ > µx,et donc µ − µx est une mesure sur E. Or µx est invariante en vertu du théorème 0.6.5, et parconséquent, (µ− µx)P = (µ− µx). De plus, µ(x)− µx(x) = 0, ce qui entraîne que µ = µx.
Cas où P est transitoire. Dans ce cas, on a H(x, y) < ∞ pour tout x et y, et donclimn Pn(x, y) = 0. Supposons que µ(E) < ∞. Le théorème de convergence dominée entraîneque µ(y) = limn
∑y µ(x)Pn(x, y) = 0 pour tout y, ce qui est impossible. Ainsi, µ(E) = ∞.
Remarque 0.6.7 (Classes closes des noyaux réductibles). Il découle du théorème 0.6.6 que pourtout noyau de transition, les classes de récurrence positives sont les seules classes irréductiblescloses qui peuvent être finies (elles ne le sont pas toujours). Ce sont les seules classes irréductiblescloses qui portent une loi invariante.
Le théorème 0.6.6 montre que les mesures invariantes liées aux classes de récurrence s’ex-priment au moyen des quantités trajectorielles moyennes µx(y) et 1/Ex(Tx). Réciproquement,la résolution du système linéaire µP = µ fournit les quantités µx(y) et 1/Ex(Tx). La section sui-vante renforce ce lien entre trajectoires et mesures invariantes. Pour certains noyaux, le calculde Ex(Tx) est plus simple que la résolution de l’équation µP = µ.
0.7 Loi forte des grands nombresChaque trajectoire d’une chaîne de Markov partant d’un état récurrent x se décompose en
une suite infinie d’excursions autour de x. La propriété de Markov forte suggère que ces excur-sions sont indépendantes et équidistribuées. Cette observation conduit au théorème suivant.Théorème 0.7.1 (Nombre de passages et temps de retour). Soit (Xn) une chaîne de Markov surE, et Nn
x := card{0 6 k 6 n− 1; Xk = x} le nombre de passages en x avant le temps n. Si lachaîne est irréductible, alors pour tout x ∈ E, et quelque soit la loi initiale,
1
nNn
x
p.s−→n→+∞
1
Ex(Tx).
Si la chaîne est récurrente irréductible, alors pour tout x, y ∈ E, et quelque soit la loi initiale,
Nnx
Nny
p.s−→n→+∞
1
Ex(∑Tx−1
n=0 I{Xn=y}
) .
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 20.

0.7. LOI FORTE DES GRANDS NOMBRES 21
Démonstration. Fixons x dans E. Si la chaîne est transitoire, alors presque sûrement, le nombrede passages en x est fini, et donc (Nn
x /n) converge vers 0. Si la chaîne est récurrente irréductible,alors le temps d’atteinte de x est fini presque sûrement, et on peut donc supposer que la chaînepart de x pour établir les propriétés. De plus, presque sûrement, la suite strictement croissante(T n
x ) des temps de retour successifs en x est bien définie et converge vers ∞. On convient queT 0
x := 0 et que T 1x = Tx. Les définitions de (Nx
x ) et (T nx ) donnent TNn−1
xx 6 n − 1 et n 6 TNn
x ,et par conséquent,
TNn−1x
x
Nnx
6n
Nnx
6T
Nnx
x
Nnx
.
La propriété de Markov forte entraîne que la suite (T n+1x − T n
x ) est constituée de variablesaléatoires indépendantes et de même loi que Tx. En vertu de la loi forte des grands nombres, lasuite (T n
x /n) converge presque sûrement vers Ex(Tx). D’autre part, la récurrence et l’irréducti-bilité entraînent que (Nn
x ) converge presque sûrement vers ∞. Ces deux convergences utiliséesconjointement dans l’encadrement précédent entraînent que (n/Nn
x ) converge presque sûrementvers Ex(Tx). La seconde propriété s’établit de manière similaire en considérant le nombre depassages en y avant le temps n, partant de x.
La loi forte des grands nombres, qui concerne les suites i.i.d., reste valable pour les chaînesde Markov récurrentes irréductibles positives, en dépit de la structure de dépendance liée aumécanisme de transition. La loi invariante de la chaîne remplace la loi commune du cas i.i.d.Théorème 0.7.2 (Loi forte des grands nombres). Soit (Xn) une chaîne de Markov sur E ré-currente irréductible, de loi initiale quelconque. Alors pour toute mesure invariante µ et pourtoutes fonctions f, g : E → R µ-intégrables avec g > 0, on a
f(X1) + · · ·+ f(Xn)
g(X1) + · · ·+ g(Xn)
p.s−→n→+∞
∑z∈E f(z)µ(z)∑z∈E g(z)µ(z)
.
Si la chaîne est récurrente nulle, alors pour toute fonction f : E → R µ-intégrable,f(X1) + · · ·+ f(Xn)
n
p.s−→n→+∞
0.
Si la chaîne est récurrente positive, et si µ désigne son unique loi invariante donnée par µ(x) :=1/Ex(Tx) pour tout x ∈ E, alors pour toute fonction f : E → R µ-intégrable,
f(X1) + · · ·+ f(Xn)
n
p.s−→n→+∞
∑z∈E
f(z)µ(z).
Démonstration. La dernière propriété découle de la première avec g ≡ 1. D’autre part, pourf = I{x} et g = I{y}, la première propriété découle des théorèmes 0.6.6 et 0.7.1. Le résultat restevrai pour des fonctions à support fini par combinaison linéaire. La généralisation aux fonctionsintégrables est laissé au lecteur à titre d’exercice. Il est possible de procéder directement enreprenant la preuve du théorème 0.7.1. La seconde propriété s’établit de la même manière quela première.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 21.

22 TABLE DES MATIÈRES
En vertu de la remarque 0.3.5, une suite (Xn) de variables aléatoires i.i.d. de loi µ chargeanttous les états est une chaîne de Markov récurrente irréductible positive, de loi invariante µ. Deplus, µ(x) = 1/Ex(Tx) pour tout x. Dans ce cas, le théorème 0.7.2 coïncide avec la loi forte desgrands nombres pour la suite i.i.d. (f(Xn)).
Le théorème 0.7.2 exprime que le fait que qu’une moyenne en temps (f(X1)+· · ·+f(Xn))/nconverge vers une moyenne en espace
∑z∈E f(z)µ(z). Le long de presque toute trajectoire, la
fraction de temps passée sur un état (fréquence de passage), converge vers la masse qu’affectela loi invariante à cet état, qui est exactement l’inverse du temps de retour moyen à cet état.L’expression (f(X1) + · · · + f(Xn))/n est la moyenne de f pour la mesure empirique Pn, quiest la loi aléatoire définie par Pn := 1
n(δX1 + · · ·+ δXn). Une autre façon d’exprimer le résultat
de convergence consiste à dire que presque-sûrement, la suite (Pn) converge en tant que suitede lois sur E vers la loi invariante µ lorsque n →∞.
Le théorème 0.7.2 est une conséquence d’un travail de Chacon et Ornstein publié dans [6],prouvant une conjecture de Hopf en théorie ergodique. Les liens avec la théorie des martingalessont présentés dans [25] par exemple.Théorème 0.7.3 (Théorème limite central). Soit (Xn) une CM(E,ν,P) récurrente irréductiblepositive, µ sa loi invariante, L := P − I son générateur. Si g : E → R est de carré intégrablepour toutes les lois νPn et si [P(g2)− (Pg)2] est intégrable pour µ, alors
1√n
n∑k=1
[g(Xk)− (Pg)(Xk−1)]L−→
n→+∞N(0, µ[P(g2)− (Pg)2
]).
En particulier, si f := Lg est bornée, alors µf = 0 et
f(X1) + · · ·+ f(Xn)√n
L−→n→+∞
N(0, µ[P(g2)− (Pg)2
]).
Démonstration. La seconde propriété découle immédiatement de la première. En vertu duthéorème 0.5.3, la suite (Yn) définie par Y0 := 0 et Yn :=
∑nn=1 g(Xk) − (Pg)(Xk−1) pour
n > 0 est une martingale de carré intégrable. Son processus croissant est donné par 〈Y 〉n =∑nk=1 [P(g2)− (Pg)2](Xk−1). Le théorème 0.7.1 assure que ( 1
n〈Y 〉n) converge presque sûrement
vers µ[P(g2)− (Pg)2]. Le résultat désiré s’obtient en montrant que la condition de Lindebergdu théorème limite central pour les martingales a bien lieu.
Le théorème 0.7.3 généralise le théorème de la limite centrale des suites i.i.d. En effet, lorsque(Xn) est une suite i.i.d. de loi µ, alors P(x, ·) = µ pour tout x, et (Pg)(x) =
∑x∈E µ(x)g(x)
ne dépend pas de x. Il s’agit de la moyenne mµ(g) de g pour µ. D’autre part, la fonctionP(g2)− (Pg)2 =
∑x∈E µ(x)g2(x)−m(g)2 est également constante. Il s’agit de la variance σ2
µ(g)de g pour µ, et µ[P(g2)− (Pg)2] = σ2
µ(g). Notons de plus que Lg = mµ(g)− g.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 22.

0.8. PÉRIODICITÉ 23
0.8 PériodicitéSoit (Xn) une CM(E,ν,P) récurrente irréductible positive et µ son unique loi invariante
donnée par µ(x) := 1/Ex(Tx). La quantité Nnx /n du théorème 0.7.1 est une variable aléatoire
bornée par 1, dont l’espérance est
1
n
(E(I{X0=x}) + · · ·+ E(I{Xn−1=x})
)=
1
n
((νP0)(x) + · · ·+ (νPn−1)(x)
).
En vertu du théorème 0.7.1 et du théorème de convergence dominée, cette espérance convergevers µ(x) lorsque n → ∞. Ainsi, la suite de lois de probabilité (νPn) converge vers µ au sensde Césaro.
Considérons une chaîne de Markov (Xn) sur Z/dZ de noyau de transition P défini parP(x, y) := 1 si y = x + 1 dans Z/dZ et P(x, y) = 0 sinon. Il s’agit du processus de Bernoullimodulo d avec p = 1. Le noyau P est récurrent irréductible positif, et la loi uniforme sur Z/dZest invariante. Cependant, L(Xdk+i |X0) = δX0+i pour tout k ∈ N et tout 0 6 i < d. Celas’écrit également Pnk+i = Pi. Ainsi, bien que (νPn) converge au sens de Césaro vers µ, desphénomènes périodiques peuvent empêcher sa convergence au sens usuel.Théorème 0.8.1 (Période). Pour tout noyau de transition irréductible P sur E, il existe unentier d > 0 appelé période et une partition E := C0 ∪ · · · ∪ Cd−1 tels que, avec la conventionCnd+i = Ci,
1. si Pn(x, y) > 0 alors (x, y) ∈ Ci × Ci+n pour un certain i;2. pour tout x, y ∈ Ci, et tout i, il existe un entier r tel que Pnd(x, y) > 0 pour tout n > r;3. pour tout z, l’entier d est le PGCD de l’ensemble Sz := {n > 0;Pn(z, z) > 0}.
En particulier, le noyau Pd possède d classes irréductibles, qui sont C0, . . . , Cd−1.
Démonstration. Nous reprenons la preuve de [26, Théorème 1.8.4]. Fixons z, et considéronsn2 > n1 dans Sz tels que la différence d := n2 − n1 soit la plus petite possible. On définit alorsl’ensemble Ci pour 0 6 i 6 d− 1 par
Ci := {x ∈ E;Pnd+i(z, x) > 0 pour un entier n > 0}.
L’irréductibilité de P entraîne que C0 ∪ · · · ∪ Cd−1 = E. Supposons que x ∈ Ci ∩ Cj. On adonc Pnd+i(z, x) > 0 et Pnd+j(z, x) > 0. L’irréductibilité de P assure que Pm(x, z) > 0 pourun entier m. Il en découle que Pnd+i+m(z, z) > 0 et Pnd+j+m(z, z) > 0. Ceci n’est possible quesi i = j, par minimalité de d. Ainsi, les ensembles C0, . . . , Cd−1 forment une partition de E.
Démontrons la premières propriété. Soit x ∈ Ci et supposons que Pn(x, y) > 0. AlorsPmd+i(z, x) > 0 pour un entier m, et donc Pmd+n+i(z, y) > 0, ce qui entraîne que y ∈ Cn+i.Notons qu’en prenant x = y = z, on voit que d divise tout élément de Sz, et donc divise n1.
Si nd > n21, alors nd = qn1 + r avec 1 6 r < n1 6 q. Comme d divise n1, il divise
également r. En écrivant r = mq, on obtient nd = (q − m)n1 + mn2. Ainsi, nous avonsPnd(z, z) > (Pn1(z, z))q−m(Pn2(z, z))m > 0, et donc nd ∈ Sz.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 23.

24 TABLE DES MATIÈRES
Démontrons la seconde propriété. Soient x, y ∈ Ci. L’irréductibilité de P entraîne quePm1(x, z) > 0 et Pm2(y, z) > 0 pour des entiers m1 et m2. Il en découle que si nd > n2
1
alors Pm1+nd+m2(x, y) > Pm1(x, z)Pnd(z, z)Pm2(z, y) > 0. Or m1 + m2 est alors un multiple ded par la première propriété, ce qui fournit le résultat.
Pour la troisième et dernière propriété, nous savons que d divise les éléments de Sz. Si kdivise les éléments de Sz, alors il divise n1 et n2 et donc d. Par conséquent, d = PGCD(Sz).
Ainsi, une chaîne irréductible de noyau P traverse les ensembles C0, . . . , Cd−1 successivementet de façon cyclique. Si le support de L(X0) est inclus dans Ci, alors le support de L(X1) estinclus dans Ci+1, etc. Ce phénomène rend la convergence en loi de la chaîne impossible si d > 1.La période de la chaîne sur Z/dZ considérée précédemment vaut d.
On dit qu’un noyau de transition irréductible est apériodique lorsque sa période est égale à1. Le théorème 0.9.3 exprime, pour les chaînes à noyau apérodique, un phénomène d’oubli dela loi initiale au profit de la loi invariante, qui représente un équilibre, et qui ne dépend que dunoyau de transition.
0.9 Convergence en loi et couplageOn dit qu’une suite de mesures (µn) sur un espace d’état E converge (étroitement) vers la
mesure µ lorsque pour toute fonction f : E → R continue et bornée, la suite (µnf)n convergevers µf . Comme E est au plus dénombrable, cela implique que (µn(x))n converge vers µ(x) pourtout x (prendre f = I{x}), mais la réciproque n’est vraie que lorsque E est fini (dispersion de lamasse à l’infini : prendre f constante et µn = (δ0+· · ·+δn)/n). Si une suite de lois de probabilité(µn) converge vers une mesure µ, alors µ est également une loi (prendre f constante). Si (Xn)est une suite de variables aléatoires sur E et µ une loi sur E, alors (Xn) converge en loi vers µsi et seulement si (L(Xn)) converge vers µ.
Il est commode de quantifier l’écart entre deux lois de probabilité µ et ν sur E par leurdistance en variation totale, définie par
‖µ− ν‖VT := supF⊂E
|µ(F )− ν(F )|.
Comme E est au plus dénombrable, on dispose de l’expression alternative suivante :
‖µ− ν‖VT =1
2sup
f :E→[−1,+1]
|µf − νf |.
La borne supérieure est atteinte pour la fonction f(x) := signe(µ(x)− ν(x)), qui donne
‖µ− ν‖VT =1
2
∑x∈E
|µ(x)− ν(x)|.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 24.

0.9. CONVERGENCE EN LOI ET COUPLAGE 25
Si (Xn) est une suite de variables aléatoires sur E vérifiant limn→∞ ‖L(Xn)− µ‖VT = 0 pourune loi µ, alors (Xn) converge en loi vers µ. Autrement dit, la convergence en variation totaleentraîne la convergence en loi. La distance en variation totale est reliée aux couples de variablespar la formule suivante :
‖µ− ν‖VT = infX∼µ,Y∼ν
P(X 6= Y ).
L’infimum porte sur les couples de variables aléatoires (X, Y ) de lois marginales µ et ν. Obser-vons que lorsque X et Y sont indépendantes, alors L((X, Y )) = µ⊗ ν.
Si P est un noyau de transition sur E, un couplage de P est une suite (Zn) := ((Xn, Yn))sur E×E telle que ses deux composantes (Xn) et (Yn) sont toutes deux des chaînes de Markovde noyau P. Les suites marginales (Xn) et (Yn) ne sont pas forcément indépendantes, n’ontpas forcément la même loi initiale, et la suite couplée (Zn) n’est pas forcément une chaîne deMarkov sur E×E. On appelle temps de couplage de (Xn) et (Yn) la variable aléatoire à valeursdans N ∪ {∞} définie par
TC := inf{n > 0; Xn = Yn}.Pour tout n, {TC > n} ⊂ {Xn 6= Yn}, avec égalité si le couplage (Zn) est coalescent (cela signifieque Xn = Yn pour tout n > TC). Le temps de couplage TC s’interprète également comme letemps d’atteinte TC = inf{n > 0; Zn ∈ C} de la diagonale C := {(x, x); x ∈ E} de E × E. Lethéorème suivant montre que le temps de couplage permet de contrôler la variation totale.Théorème 0.9.1 (Couplage). Soit P un noyau de transition sur E et (Zn) := ((Xn, Yn)) unesuite de variables aléatoires à valeurs dans E × E. Soit TC le temps de couplage des suitesmarginales (Xn) et (Yn). Supposons que
1. les suites marginales (Xn) et (Yn) sont des chaînes de Markov sur E de noyau P;2. pour tout 0 6 k 6 n, et sur l’événement {TC = k},
L(Xn |Z0, . . . , Zk) = L(Xn |Xk) et L(Yn |Z0, . . . , Zk) = L(Yn |Yk).
Alors, pour tout entier n,‖L(Xn)− L(Yn)‖VT = ‖L(X0)P
n − L(Y0)Pn‖VT 6 P(TC > n).
Démonstration. Soit f : E → R une fonction bornée. Nous avons
νPnf = E(f(Xn)) = E(f(Xn)I{TC>n}) +n∑
k=0
E(f(Xn)I{TC=k}).
Or E(f(Xn)I{TC=k}) = E(I{TC=k}E(f(Xn) |Z0, . . . , Zk)), et par hypothèse sur (Xn) et (Yn),E(f(Xn) |Z0, . . . , Zk) = (Pn−kf)(Xk).
Ainsi, E(f(Xn)I{TC=k}) = E(f(Yn)I{TC=k}) car Xk = Yk sur {TC = k}. Par conséquent,
|L(X0)Pnf − L(Y0)P
nf | 6 E(|f(Xn)− f(Yn)|) 6 2
(supx∈E
|f(x)|)
P(TC > n).
Notons que P(TC > n) dépend des lois initiales L(X0) et L(Y0) via la loi de (Zn).
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 25.

26 TABLE DES MATIÈRES
Proposition 0.9.2 (Contraction markovienne). Pour tout noyau de transition P sur E et touteslois ν1 et ν2, sur E, la contraction suivante à lieu :
‖ν1P− ν2P‖VT 6 ‖ν1 − ν2‖VT.
Démonstration. Si f : E → [−1, +1], alors Pf : E → [−1, +1], et donc en posant g := Pf :
|ν1Pf − ν2Pf | = |ν1Pf − ν2Pf | = |ν1g − ν2g| 6 ‖ν1 − ν2‖VT.
En particulier, si µ est une loi invariante pour un noyau de transition P, alors pour touteloi ν et tout entier n, la contraction suivante a lieu :
‖νPn − µ‖VT 6 ‖ν − µ‖VT.
Ainsi, la loi d’une chaîne de Markov ne peut pas s’éloigner d’une loi invariante en variationtotale. Le théorème ci-dessous renforce cette propriété.Théorème 0.9.3 (Convergence en loi vers l’équilibre). Soit P un noyau de transition, récurrentirréductible positif et apériodique sur E. Soit µ son unique loi invariante donnée par µ(z) =1/Ez(Tz) pour tout z ∈ E. Alors pour toute loi de probabilité ν sur E,
limn→∞
‖νPn − µ‖VT = 0.
En d’autres termes, toute chaîne de Markov (Xn) de noyau P converge en loi vers µ, quelquesoit L(X0). Autrement dit, limn→∞ Pn(x, y) = µ(y) pour tout x et y dans E.
Démonstration. Soient (Xn) et (Yn) deux chaînes indépendantes de même noyau P sur E, etde lois initiales ν1 et ν2. Alors (Zn) := ((Xn, Yn)) est une CM(E × E,ν1 ⊗ ν2,P⊗P) avec
(ν1 ⊗ ν2)(x, y) = ν1(x)ν2(y) et (P⊗P)((x, y), (x′, y′)) = P(x, y)P(x′, y′).
De plus, les hypothèses du théorème 0.9.1 sont satisfaites. Soit TC le temps de couplage de (Xn)et (Yn). Le noyau P est irréductible et apériodique, par conséquent, en vertu du théorème 0.8.1,pour tout (x, y) et (x′, y′) dans E ×E, il existe des entiers r1 et r2 tels que Pn(x, x′) > 0 pourtout n > r1 et Pn(y, y′) > 0 pour tout n > r2. Il en découle que (P⊗P)n((x, x′), (y, y′)) > 0 pourtout n > max(r1, r2). Par conséquent, P⊗P est irréductible. Or µ⊗µ est une loi de probabilitéinvariante pour P⊗P, et par suite, P⊗P est récurrent positif en vertu du théorème 0.6.6. Enparticulier, P(TC < ∞) = 1, et donc limn→∞ P(TC > n) = P(TC = ∞) = 0. Le théorème 0.9.1entraîne alors que pour toutes lois ν1 et ν2 sur E,
limn→∞
‖ν1Pn − ν2P
n‖VT = 0.
Le résultat voulu s’obtient pour ν1 = ν et ν2 = µ. Il est possible de lever l’hypothèse de positivitésur P, en la remplaçant par l’existence d’un état x ∈ E tel que
∑∞n=0(P(x, x))2 = ∞. Dans ce
cas, (x, x) est récurrent pour P ⊗ P, et donc P ⊗ P est récurrent irréductible. Cependant, Pn’admet pas de loi invariante s’il n’est pas positif, et seule la propriété avec ν1 et ν2 subsiste.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 26.

0.10. RÉVERSIBILITÉ ET NOYAU DE METROPOLIS-HASTINGS 27
Nous avons vu que le théorème 0.7.1 entraîne que (νPn) converge vers µ au sens de Césaro,dès que P est récurrent irréductible positif. Le théorème 0.9.3 précise que (νPn) converge vers µau sens usuel lorsque P est de plus apériodique. Ainsi, bien que les théorèmes 0.7.1 et 0.9.3 soientde natures différentes, une conséquence du premier est renforcée par le second. Il important deretenir que le résultat du théorème 0.9.3 énonce une convergence en loi. Cela ne dit rien pourune trajectoire donnée, contrairement au résultat du théorème 0.7.1.Remarque 0.9.4 (Fonctions de chaînes). Si (Xn) et (Yn) sont deux chaînes de Markov indé-pendantes sur E et F , de lois initiales ν1 et ν2 et de noyaux de transition P1 et P2, alorsle couple ((Xn, Yn)) est une chaîne de Markov sur l’espace produit E × F , de loi initiale(ν1⊗ν2)(x1, x2) := ν1(x1)ν2(x2) et de noyau (P1⊗P2)((x1, x2), (x
′1, x
′2)) := P1(x1, x
′1)P2(x2, x
′2).
Cela n’a pas lieu en général sans l’hypothèse d’indépendance. De plus, si ((Xn, Yn)) est unechaîne de Markov sur E × F , ses composantes (Xn) et (Yn) ne sont pas forcément des chaînesde Markov sur E et F . Plus généralement, si (Zn) est une chaîne de Markov sur E et sif : E → F est une fonction, alors (f(Zn)) n’est pas toujours une chaîne de Markov sur F .Remarque 0.9.5 (Apériodicité par perturbation). Soit P un noyau de transition, et soit 0 < p < 1.Le graphe des transitions du noyau Pp := (1 − p)P + pI s’obtient à partir de celui de P enajoutant une boucle de poids p pour chaque état qui n’en possède pas et en corrigeant les autrespoids. Cela autorise la chaîne de noyau Pp à rester sur place à chaque transition avec probabilitép. La loi Pp(x, ·) est le mélange des lois P(x, ·) et δx au moyen de la loi de Bernoulli de paramètrep. Comme Pp(x, x) > 0 pour tout x, il en découle que Pp est irréductible et apériodique dèsque P est irréductible. Les noyaux Pp et P possèdent les mêmes mesures invariantes. Enfin,limp→0 Pp(x, y) = P0(x, y) = P(x, y), pour tout x, y.
La technique du couplage pour les chaînes de Markov a été introduite par Doeblin en 1938dans [12]. Le livre [22] contient une reproduction de la preuve originelle.
0.10 Réversibilité et noyau de Metropolis-HastingsMesures symétriques et lois réversibles
On dit que la mesure µ sur E est symétrique pour le noyau de transition P lorsqueµ(x)P(x, y) = µ(y)P(y, x) pour tout x et y dans E. De manière équivalente, cela revient àdire que pour tout n et toute suite x0, . . . , xn dans E :
µ(x0)P(x0, x1) · · ·P(xn−1, xn) = µ(xn)P(xn, xn−1) · · ·P(x1, x0).
Il en découle qu’une loi µ est symétrique pour P si et seulement si elle est réversible pour P :pour toute chaîne (Xn) de noyau P et de loi initiale µ et tout entier r,
L((X0, X1, . . . , Xr)) = L((Xr, Xr−1, . . . , X0)).
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 27.

28 TABLE DES MATIÈRES
Si une mesure µ est symétrique et vérifie µ(E) < ∞, alors la loi de probabilité µ(E)−1µ estréversible. D’autre part, si une mesure µ est symétrique, alors elle est invariante car∑
x∈E
µ(x)P(x, y) = µ(y)∑x∈E
P(y, x) = µ(y).
Le noyau Pp de la remarque 0.9.5 possède les mêmes mesures symétriques que P.La mesure de comptage κE sur E est définie par κE(x) = 1 pour tout x dans E. Elle vérifie
κE(F ) = card(F ) ∈ N ∪ {∞} pour tout F ⊂ E, ce qui explique son nom. Pour une mesureµ sur E, si x ∈ E 7→ µ(x) est constante alors µ est un multiple de κE. Enfin, κ(E) < ∞ siet seulement si E est fini. Dans ce cas, la loi κ(E)−1κE est appelée loi uniforme sur E. La loiuniforme n’existe pas si E est infini.Exemple 0.10.1 (Mesure de comptage et loi uniforme). La loi uniforme sur Z/dZ est réversiblepour la marche aléatoire simple sur Z/dZ de l’exemple 0.1.4. La mesure de comptage sur Zest symétrique pour la marche aléatoire simple sur Z de l’exemple 0.3.2. De manière générale,l’application P> : E ×E → [0, 1] définie par P>(x, y) := P(y, x) n’est pas forcément un noyaude transition sur E. Cependant, la mesure de comptage est invariante pour P si et seulement siP> est également un noyau de transition. Elle est symétrique pour P si et seulement si P> = P.Cela permet de construire des noyaux dont les mesures invariantes ne sont pas symétriques.
Soit µ une mesure invariante pour un noyau de transition P. Soit x un état repéré sur legraphe des transitions de P. Multiplions le poids de chaque flèche arrivant en x par le poids µ(y)où y est l’état de départ de la flèche. La somme totale de ces produits doit être égale à µ(x).Cependant, il est plus facile de rechercher une mesure symétrique qu’une mesure invariante.
Soit P un noyau de transition sur E vérifiant P(x, y) > 0 pour tout x et y. Toute mesureµ symétrique pour P vérifie alors µ(x) > 0 pour tout x et µ(x)/µ(y) = P(y, x)/P(x, y) pourtout x et y. Ainsi, lorsque P admet une mesure symétrique, elle est unique à une constantemultiplicative près. Il en découle également que P admet une mesure symétrique si et seulementsi la propriété de cocycle est vérifiée : pour x, y, z dans E,
P(x, y)P(y, z)P(z, x) = P(x, z)P(z, y)P(y, x).
Cela signifie que le poids d’un cycle triangulaire ne dépend pas du sens de son parcours. Récipro-quement, partant d’une mesure µ, la construction de Metropolis-Hastings présentée ci-dessousfournit un noyau qui admet µ comme mesure symétrique.
Noyau de Metropolis-Hastings
Soit µ une mesure sur E qui charge tous les états, et Q un noyau de transition auxiliairesur E vérifiant Q(x, y) = 0 si et seulement si Q(y, x) = 0. Pour tout x 6= y, on pose
α(x, y) := min
(1,
µ(y)Q(y, x)
µ(x)Q(x, y)
)si Q(x, y) > 0 et α(x, y) = 0 sinon.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 28.

0.10. RÉVERSIBILITÉ ET NOYAU DE METROPOLIS-HASTINGS 29
Le noyau de Metropolis-Hastings P associé à µ et Q est définit pour tout x, y dans E par
P(x, y) :=
{Q(x, y)α(x, y) si x 6= y∑
z 6=x P(x, z) si x = y.
Il s’agit bien d’un noyau de transition sur E car 0 6 P(x, y) 6 Q(x, y) pour tout x 6= y. Ils’avère que la mesure µ est symétrique (et donc invariante) pour le noyau P. En particulier,lorsque µ(E) < ∞, la loi µ(E)−1µ est réversible pour P. Tout l’intérêt du noyau P réside dansle fait que sa construction dépend des rapports µ(x)/µ(y) mais pas de µ(E).
En général, le choix du noyau Q dépend de la nature de l’espace E. Lorsque E est munid’une distance d vérifiant nx := card{y ∈ E; d(x, y) = 1} < ∞ pour tout x, il est commode deprendre par exemple Q(x, y) = 1/nx si d(x, y) = 1 et Q(x, y) = 0 sinon.Remarque 0.10.2 (Noyau de Barker). Il s’obtient de la même manière que le noyau de Metropolis-Hasting, avec la fonction d’acceptation α définie ci-dessous. Il jouit des mêmes propriétés.
α(x, y) =µ(y)Q(y, x)
µ(y)Q(y, x) + µ(x)Q(x, y)si Q(x, y) > 0 et α(x, y) = 0 sinon.
Simulation des trajectoires
La simulation des trajectoires d’une chaîne de Markov de noyau P par la méthode récursiverevient à simuler la loi P(x, ·). Cela peut être fait très simplement via Q et α. En effet, soit Yune variable aléatoire qui suit la loi Q(x, ·) sur E, et U une variable aléatoire de loi uniformesur [0, 1], indépendante de Y . Soit Z la variable aléatoire définie par Z = Y si U < α(x, Y ) etZ = x sinon. Alors pour tout y 6= x,
P(Z = y) = P(U < α(x, Y ), Y = y) = α(x, y)Q(x, y) = P(x, y).
Par conséquent, Z suit la loi P(x, ·). Il est remarquable que l’évaluation de P(x, x) soit inutiledans la simulation. La fonction α est parfois appelée fonction d’acceptation-rejet tandis que lenoyau Q est parfois appelé noyau d’exploration.
Si gQ : E × [0, 1] → E est une fonction récursive associée à Q par le théorème 0.4.1, alorsla fonction gP : E × [0, 1]2 → E définie ci-dessous est une fonction récursive associée à P. Elledoit être utilisée sous la forme xn+1 = gP (xn, Wn+1) où (Wn) est une suite i.i.d. de variablesaléatoires uniformes sur [0, 1]2. Les deux composantes de Wn sont donc indépendantes et de loiuniforme sur [0, 1].
gP (x, (u, v)) :=
{gQ(x, v) si u < α(x, gQ(x, v))
x sinon.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 29.

30 TABLE DES MATIÈRES
Algorithme de Metropolis-Hastings
Cet algorithme, introduit par Metropolis dans [24] puis généralisé par Hastings dans [17],fait aujourd’hui partie des méthodes MCMC (Monte Carlo Markov Chains), qui consistent àutiliser des chaînes de Markov pour simuler des lois de probabilité.
Soit µ une mesure sur E qui charge tous les états, et qui vérifie µ(E) < ∞. Soit Q unnoyau récurrent irréductible apériodique et positif sur E. Le noyau de Metropolis-Hastings Passocié à la mesure µ et au noyau Q est irréductible apériodique et admet µ comme mesuresymétrique. Comme µ(E) < ∞, le noyau P est récurrent irréductible positif apériodique. Laloi µ(E)−1µ est symétrique et donc invariante et réversible pour P.
En vertu du théorème 0.9.3, si (Xn) est une CM(E,ν,P), alors (Xn) converge en loi versµ(E)−1µ. L’algorithme de Metropolis-Hastings pour la simulation de µ(E)−1µ consiste à simulerune longue trajectoire x0, x1, . . . , xn de la chaîne (Xn), puis à considérer son dernier pas xn
comme une réalisation approchée de la loi de probabilité invariante µ(E)−1µ. Cet algorithmene nécessite pas le calcul de µ(E), mais fait appel aux rapports µ(x)/µ(y) et à la simulationdes lignes de Q. Typiquement, µ est une mesure de Boltzmann-Gibbs, ce qui signifie qu’elles’écrit µ(x) = exp(−H(x)) où la fonction H : E → R est connue.
Échantillonneur de Gibbs
Soit F un ensemble au plus dénombrable et µ une loi sur E := F k chargeant tous les états.Pour tout 1 6 i 6 k et tout v ∈ E, on note v−i := (v1, . . . , vi−1, vi+1, . . . , vk). On note égalementµi,v−i
la loi conditionnelle de Vi sachant {V−i = v−i} lorsque V suit la loi µ. Il s’agit d’une loisur F . Introduisons enfin le noyau de transition Q sur E défini pour tout x et y par
Q(x, y) =k∑
i=1
q(i)µi,x−i(yi)I{xi=yi},
où q est une loi sur {1, . . . , k} chargeant tous les états (par exemple la loi uniforme surF ). L’algorithme de Metropolis-Hastings associé à la loi de probabilité µ et au noyau Q ci-dessus est appelé échantillonneur de Gibbs. Il permet de simuler approximativement µ. Celanécessite la simulation de la loi Q(x, ·). Pour cela, on procède de la manière suivante. Soiti une réalisation de la loi q sur {1, . . . , k}. Soit yi une réalisation de la loi µi,x(−i) sur F .Alors (x1, . . . , xi−1, yi, xi+1, . . . , xk) est une réalisation de la loi Q(x, ·). L’échantillonneur deGibbs nécessite donc la simulation des lois conditionnelles µi,x(−i). D’autre part, si α désignela fonction d’acceptation de l’algorithme de Metropolis-Hastings, alors α(x, y) = 1 dès quecard{1 6 i 6 k; xi 6= yi} 6 1.
L’exemple le plus célèbre est fourni par le modèle de magnétisme du physicien Ising. Dansce modèle, µ est une mesure sur {−1, +1}Λ où Λ est une partie de Zd. L’ensemble Λ représenteun morceau de cristal, et chaque élément i de Λ représente un site, qui porte un spin (uneorientation magnétique) valant soit −1 soit +1. Un élément x de {−1, +1}Λ représente une
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 30.

0.11. ESTIMATION DU NOYAU ET DE LA MESURE INVARIANTE 31
configuration magnétique du morceau de cristal. La mesure µ est évaluable ponctuellement parune formule du type µ(x) = e−βH(x) où β > 0 est une constante connue et
H(x) :=∑
‖i−j‖1=1
εxixj + m∑
i
xi,
où ε et m sont également des constantes réelles connues. Dans ce modèle, 1/β représenteune température, ε une constante d’interaction entre sites voisins dans le cristal, m la valeurd’un champ magnétique externe, et H(x) l’énergie de la configuration x. La mesure µ favoriseles configurations de basse énergie. En identifiant {−1, +1}Λ à E := {−1, +1}card(Λ), l’échan-tillonneur de Gibbs présenté précédemment permet de simuler approximativement la loi deprobabilité µ(E)−1µ sans avoir à calculer la quantité µ(E), appelée fonction de partition enphysique. Un problème statistique intéressant consiste à estimer les réels β, m et ε à partirde l’observation de réalisations i.i.d. de µ(E)−1µ, ou d’une trajectoire d’une chaîne de mesureinvariante µ.
0.11 Estimation du noyau et de la mesure invarianteEstimation du noyau de transition
Soit (Xn) une CM(E,ν,P) récurrente irréductible positive, et soit µ son unique loi invariante.La suite ((Xn, Xn+1)) est une chaîne de Markov sur E×E de noyau Q((x, x′), (y, y′)) = P(y, y′)si x′ = y et Q((x, x′), (y, y′)) = 0 sinon. Ce noyau est récurrent irréductible positif. Sa loiinvariante est donnée par (x, x′) 7→ µ(x)P(x, x′). En vertu du théorème 0.7.1, on obtient toutx et y dans E
card{1 6 k 6 n; (Xk−1, Xk) = (x, y)}card{1 6 k 6 n; Xk = x}
p.s−→n→+∞
µ(x)P(x, y)
µ(x)= P(x, y).
Cela fournit un estimateur de P(x, y). Il se trouve qu’il s’agit de l’estimateur de maximum devraisemblance qui maximise la log-vraisemblance
P 7→ log
(ν(X0)
n∏k=1
P(Xk−1, Xk)
)= log(ν(X0)) +
n∑k=1
log(P(Xk−1, Xk))
sur l’ensemble convexe des noyaux de transition sur E. Lorsque le noyau à estimer est défini demanière paramétrique, le maximum de vraisemblance reste un estimateur tout à fait intéressant.
Estimation de la mesure invariante
Soit (Xn) une CM(E,ν,P), irréductible récurrente positive, et µ son unique loi invariantedonnée par µ(x) = 1/Ex(Tx). Il est bien sûr possible d’estimer µ via Tx, à partir d’une seule
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 31.

32 TABLE DES MATIÈRES
trajectoire de la chaîne, ou de plusieurs trajectoires de la chaîne. Alternativement, le théorème0.7.1 fournit un estimateur direct Nn
x /n de µ(x) à partir d’une trajectoire de la chaîne. Plusgénéralement, ce théorème montre que l’histogramme des valeurs prises par la chaîne le longd’une trajectoire fournit un estimateur de la mesure µ.
Lorsque P est récurrent irréductible mais pas positif, la mesure invariante µ n’est définiequ’à une constante multiplicative près. Un estimateur de µ(y)/µ(x) = µx(y) s’obtient de lamême manière grâce au théorème (0.7.1).
Lorsque P est apériodique, toutes les lignes de Pn convergent vers µ, en vertu du théorème0.9.3. La suite récurrente définie par ν0 = ν et νn+1 = νnP converge vers µ. Il est égalementpossible d’estimer µ en utilisant un échantillon de la loi L(Xn) lorsque cela est plus commode.
0.12 Cas des espaces d’états finis
Lorsque E est fini, de cardinal m, nous assimilons les noyaux de transition sur E à desmatrices m × m, les mesures sur E aux vecteurs lignes de Rm, et les fonctions de E dansR à des vecteurs colonnes de Rm. Le terme noyau de transition est souvent remplacé par leterme matrice markovienne ou matrice stochastique. Le noyau spécial I n’est rien d’autre quela matrice identité. Comme E est fini, toute mesure µ vérifie µ(E) < ∞ et µ(E)−1µ est une loisur E. Toutes les fonctions sont bornées et intégrables pour toutes les mesures.
0.12.1 Récurrence, invariance, apériodicité, ergodicité
Soit P un noyau de transition sur E fini et de cardinal m. Une mesure µ est invariante siet seulement si le vecteur colonne µ> est un vecteur propre de P> associé à la valeur propre 1.De même, une fonction f est harmonique si et seulement si le vecteur colonne f est un vecteurpropre de P associé à la valeur propre 1.
Existence de loi invariante par un argument spectral
Le vecteur (1, . . . , 1)> est toujours harmonique pour P. Autrement dit, le réel 1 est toujoursvaleur propre de P, associée au vecteur propre (1, . . . , 1)>. Il en découle que 1 est égalementvaleur propre de P>, mais les espaces propres ne sont pas ceux de P en général. Cependant, soitx un vecteur propre (complexe) de P> associé à la valeur propre 1, alors il en est de même duvecteur (|x1|, . . . , |xm|)> où m := card(E), et le vecteur ligne (
∑mi=1 |x|i)−1xi constitue donc une
loi invariante pour P. En effet, si yi := |xi| et z := P>y− y, alors zi >∣∣(P>x)i
∣∣− |xi| = 0 pourtout i en vertu de l’inégalité triangulaire car P est à coefficients réels positifs. Or z1+· · ·+zm = 0car P est un noyau de transition, d’où z = 0.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 32.

0.12. CAS DES ESPACES D’ÉTATS FINIS 33
Unicité de la loi invariante par un théorème de Liouville
Soit f une fonction harmonique pour un noyau irréductible P. Comme E est fini, il existeun x ∈ E tel que f(x) = M où M := maxz∈E f(z). Supposons qu’il existe y tel que f(y) <M . Comme P est irréductible, Pn(x, y) > 0 pour un entier n. La fonction f est égalementharmonique pour Pn, et donc f(x) =
∑z∈E Pn(x, z)f(z) = Pn(x, y)f(y)+
∑z 6=y Pn(x, z)f(z) <
M , ce qui contredit la définition de x. Ainsi, les fonctions harmoniques d’un noyau irréductiblesur E fini sont les fonctions constantes. Par conséquent, l’espace propre de P associé à la valeurpropre 1 est de dimension 1, et il en est donc de même pour P>. Ainsi, un noyau irréductibleadmet une unique loi invariante (nous savons déjà qu’elle existe).
Existence de loi invariante par un argument de convexité-compacité
En utilisant l’écriture matricielle, l’ensemble ΛE des lois de probabilité sur E est le sous-ensemble de Rm formé par les vecteurs ligne (p1, . . . , pm) avec p1 > 0, . . . , pm > 0 et p1 + · · ·+pm = 1. Soit µ0 ∈ ΛE. Comme ΛE est convexe, µn := 1
n+1(µ0 + µ0P + · · · + µ0P
n) ∈ ΛE pourtout n. D’autre part, comme ΛE est compact dans Rm, le théorème de Bolzano-Weierstrassassure l’existence d’une sous-suite convergente (µnk
)k de limite µ ∈ ΛE. On a alors µP = µ car
µnkP =
1
1 + nk
(µ0P + · · ·+ µ0P1+nk) = µnk
+1
1 + nk
(µ0 − µ0P1+nk).
Toute valeur d’adhérence de (µn) est une loi invariante pour P. La réciproque est vraie car si µ0
est invariante pour P, la suite (µn) est constante et égale à µ0. Lorsque E est infini, l’argumentde convexité subsiste, mais celui de compacité ne tient plus.
Caractérisations de l’apériodicité
Lorsque E est fini, la période d d’un noyau est toujours inférieure ou égale au cardinal deE. Pour un noyau P irréductible sur E fini, il y a équivalence entre
1. P est apériodique ;2. 1 est la seule valeur propre (complexe) de P de module supérieur ou égal à 1 ;3. il existe un entier r tel que Pr(x, y) > 0 pour tout x et y et tout n > r.
Une preuve de cette équivalence se trouve par exemple dans [3, théorème 6.6]. Elle fait appel àdes arguments simples concernant l’algèbre des entiers et l’algèbre linéaire.
Récurrence et invariance
Le théorème suivant complète l’étude du cas fini.Théorème 0.12.1 (Récurrence et invariance). Si (Xn) est une CM(E,ν,P) sur E fini, alors
1. ER est non vide et il n’y a pas d’état récurrents nuls. Toutes les classes de récurrence sontpositives. Si P est irréductible, alors il est récurrent irréductible positif;
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 33.

34 TABLE DES MATIÈRES
2. P(TER< ∞) = 1. La chaîne est presque sûrement capturée par une classe de récurrence.
Quand tous les états récurrents sont absorbants, la chaîne finit p.s. par être constante;3. si (Pn(x, ·)) converge, sa limite est une loi de probabilité invariante;4. les mesures invariantes ne chargent pas ET , et si R1, . . . , Rr sont les classes de récurrence
de P, alors chaque Ri porte une unique loi invariante µi. Les mesures invariantes pour Psont les combinaisons convexes de la forme α1µ1 + · · ·+ αrµr où α1, . . . , αr sont des réelspositifs ou nuls. Les lois de probabilité invariantes correspondent aux cas où α1+· · ·+αr =1;
5. l’espace propre de (PRi×Ri)> associé à la valeur propre 1 est de dimension 1, et contient
un unique vecteur à composantes positives dont la somme vaut 1, qui est précisément µi;6. P est irréductible si et seulement si P admet une unique loi invariante;7. une classe irréductible est close si et seulement si elle est récurrente. Les classes irréduc-
tibles dont aucune flèche ne sort sont récurrentes, tandis que les autres sont transitoires.Un état x est transitoire si et seulement s’il existe un état y tel que x → y et y 6→ x. La dé-composition de l’espace d’état ne dépend que de la connectivité du graphe des transitions,c’est-à-dire des flèches mais pas de leur poids.
Démonstration. Si y ∈ ET , alors∑∞
n=0 Pn(x, y) = H(x, y) < ∞ donc limn→∞ Pn(x, y) = 0.L’usage de la somme finie
∑y∈E Pn(x, y) = 1 donne alors limn→∞ Px(Xn ∈ ER) = 1. En
particulier, ER ne peut pas être vide. De plus Px(TER= ∞) = Px(NER
= 0) 6 Px(Xn 6∈ ER)pour tout n > 1. Il en découle que Px(TER
= ∞) = 0 pour tout x ∈ E. Enfin, comme lesclasses de récurrence sont finies, elles sont récurrentes positives en vertu du théorème 0.6.6.La troisième assertion est immédiate en écrivant Pn+1(x, ·) = Pn(x, ·)P. Pour montrer que lesmesures invariantes ne chargent pas ET , on constate que
∑∞n=0 Pn(x, y) = H(x, y) < ∞ pour
tout y ∈ ET et tout x. En particulier, (Pn(x, y)) converge vers 0 quand n → ∞, et si µ estinvariante, alors µ(y) =
∑x∈E µ(x)Pn(x, y), qui converge vers 0 quand n →∞. Le reste découle
des remarques précédentes.
Loi forte des grands nombres
Quand E est fini, la loi forte des grands nombres du théorème 0.7.2 peut être obtenue par uneméthode de martingales. En effet, on peut supposer que card(E) > 1 et que f est de moyennenulle pour µ sans difficulté. Le cas où f est identiquement nulle est sans intérêt. Comme E estfini, toutes les fonctions sont bornées et intégrables pour toutes les mesures. Pour toute fonc-tion g : E → R, la suite (Yn) définie par Y0 := 0 et Yn := −g(Xn) + g(X0) +
∑nk=1(Lg)(Xk−1)
est une martingale de carré intégrable (théorème 0.5.3). Son processus croissant vérifie 〈Y 〉n =∑nk=1 [P(g2)− (Pg)2](Xk−1) = O(n). En vertu d’un théorème sur les martingales, la suite
(n−1Yn) converge p.s. vers 0. D’autre part, limn→∞ n−1(−g(Xn)+ g(X0)) = 0 p.s. car g est bor-née. Comme P est irréductible sur E fini, les fonction harmoniques sont les fonctions constantes(propriété de Liouville), et par conséquent l’équation de Poisson Lg = f a une solution g si et
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 34.

0.12. CAS DES ESPACES D’ÉTATS FINIS 35
seulement si f est de moyenne nulle. Cette solution n’est pas constante car f est non identi-quement nulle.
0.12.2 Convergence géométrique vers l’équilibre et couplageLe théorème 0.12.2 ci-dessous fournit une borne supérieure géométrique pour la vitesse de
la convergence vers l’équilibre. Il renforce le théorème 0.9.3. Ce résultat permet par exempleun contrôle de l’erreur dans l’algorithme de Metropolis-Hastings.Théorème 0.12.2 (Convergence géométrique vers l’équilibre). Soit P un noyau de transition surE fini, irréductible et apériodique, et soit µ son unique loi invariante. Alors limn→∞ ‖Pn(x, ·)− µ‖VT =0 pour tout x dans E. De plus, il existe un réel 0 < ρ < 1 et un entier r > 0 qui dépendent deP tels que maxx∈E ‖Pn(x, ·)− µ‖VT 6 ρbn/rc.
Démonstration. L’hypothèse sur P assure l’existence d’un entier r tel que Pr ait tous sescoefficients non nuls. Par ailleurs, la loi invariante µ charge tous les états. Par conséquent, ilexiste un réel 0 < ε < 1 tel que Pr(x, y) > εµ(y) pour tout x et y. Posons ρ := 1− ε. Soit Mle noyau de transition sur E dont toutes les lignes sont identiques à µ. Grâce à la définitionde ε, la matrice Q := ρ−1(Pr − (1 − ρ)M) est un noyau de transition sur E. Notons quePr = (1− ρ)M + ρQ. Pour tout entier k, on a
Prk = (1− ρk)M + ρkQk.
Pour le voir, on observe que RM = M pour tout noyau de transition R (car les lignes de Msont identiques), et que MR = M pour tout noyau de transition R qui admet µ comme mesureinvariante. Il en découle que pour tout entier i,
Prk+i −M = ρk(QkPi −M).
Par conséquent, il vient Prk+i(x, y) − µ(y) = (Prk+i − M)(x, y) = ρk(QkPi − M)(x, y) pourtout x et y dans E. Comme QkPi et M sont des noyaux de transition,∑
y∈E
∣∣Prk+i(x, y)− µ(y)∣∣ 6 ρk
∑y∈E
(QkPi(x, y) + M(x, y)) = 2ρk.
Cela entraîne ‖Prk+i(x, ·)− µ‖VT 6 ρk. Le résultat final s’obtient en écrivant n = kr + i aveck = bn/rc où bn/rc désigne la partie entière du réel n/r. La méthode est valide pour toutρ > 1−minx,y∈E(Pr(x, y)/µ(y)). Elle est tirée de [21, Chapitre 3].
Remarque 0.12.3 (Spectre). L’étude des noyaux de transition sur un espace d’état fini bénéficiede la théorie spectrale des matrices à coefficients réels positifs, élaborée au tout début duvingtième siècle par Perron et Frobenius, et esquissée par exemple dans [16, section 6.8], [18,Chapitre 8], ou encore [2]. D’autre part, il est possible de relier la constante ρ du théorème0.12.2 à la seconde plus grande valeur propre du noyau PP∗, où P∗ désigne le noyau définipar P∗(x, y) := µ(x)P(x, y)/µ(y). Certains aspects sont développés par exemple dans [29], enliaison avec des inégalités fonctionnelles de type Poincaré et Sobolev logarithmique.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 35.

36 TABLE DES MATIÈRES
Remarque 0.12.4 (Convergence abrupte). Dans bon nombre de modèles, la décroissance envariation totale est bien plus abrupte qu’une simple suite géométrique. Ce phénomène estillustré sur l’exemple de l’urne d’Ehrenfest de la section 0.14.3 page 44.
Il est possible d’établir le théorème 0.12.2 en reprenant la preuve du théorème 0.9.3 baséesur un couplage indépendant. En effet, comme P est irréductible et apériodique sur E fini,il existe un entier r tel que ε := minx,y∈E Pr(x, y) > 0. Soit (Xn) et (Yn) deux chaînes deMarkov indépendantes de noyau Pr et de lois initiales δx et µ, où µ est l’unique loi invariantede P. La suite (Zn) est une chaîne de Markov sur E × E de loi initiale δx ⊗ µ et de noyauQ((x, y), (x′, y′)) := Pr(x, x′)Pr(y, y′). En particulier, minz,z′∈E×E Q(z, z′) > ε2. Si TC désignele temps de couplage de (Xn) et (Yn), alors pour tout entier k, en notant z∗ := (x, x),
P(TC > k) 6 P(Z1 6= z∗, . . . , Zk 6= z∗)
=∑
y,z1 6=z∗,...,zk 6=z∗
µ(y)Q((x, y), z1) · · ·Q(zk−1, zk)
6 (1− ε2)k.
Comme L(Yk) = µPkr = µ et L(Xk) = δxPkr = Pkr(x, ·), le théorème 0.9.1 conduit à
‖Pkr(x, ·)− µ‖VT 6 (1− ε2)k.
À présent, tout entier n s’écrit n = kr + i avec k = bn/rc et 0 6 i < r. On a enfin
‖Pn(x, ·)− µ‖VT = ‖Pkr(x, ·)Pi − µ‖VT 6 ‖Pkr(x, ·)− µ‖VT 6 (1− ε2)bn/rc.
0.12.3 Temps de recouvrementSoit (Xn) une chaîne de Markov irréductible d’espace d’état fini E. Le temps de recouvrement
de E par la chaîne est la variable aléatoire T := min{n > 0; E = {X0, . . . , Xn}}. Cette variablealéatoire est finie presque sûrement car la chaîne est récurrente irréductible.
Considérons par exemple la marche aléatoire simple sur le tore discret E := Z2/dZ2. Letemps de recouvrement dépend de d, mais ne dépend pas de la loi initiale car le noyau esthomogène en espace. Dembo, Perez, Rosen, et Zeitouni ont établi en 2004 dans [8] que
T(d log(d))2
P−→d→+∞
4
π,
prouvant ainsi une conjecture formulée par Aldous vers 1989. La preuve repose sur un résultatsimilaire pour le mouvement brownien sur le tore continu. L’étude des temps de recouvrementest délicate. Certaines techniques sont présentées dans le cours [7] par exemple. L’écriture d’unprogramme illustrant le résultat précédent constitue un excellent exercice.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 36.

0.13. COALESCENCES ET ALGORITHME DE LETAC-PROPP-WILSON 37
0.13 Coalescences et algorithme de Letac-Propp-WilsonSoient (Xn) et (Yn) deux chaînes de Markov indépendantes de même noyau de transition P,
et TC leur temps de couplage. La suite (Zn) := ((Xn, Yn)) est une chaîne de Markov sur E×E,et ses deux composantes (Xn) et (Yn) sont des chaînes de Markov indépendantes de noyau P.Cependant, bien que XTC
= YTC, les suites (Xn) et (Yn) n’ont aucune raison de rester accolées
après le temps TC . Posons Z ′n := (Xn, Yn) si n < TC et Z ′
n := (Xn, Xn) si n > TC . En vertu dela propriété de Markov forte, les composantes (Xn) et (Y ′
n) de (Z ′n) sont des chaînes de Markov
sur E de noyau P. Par construction, elles restent accolées après l’instant de première rencontre(coalescence). Elles ne sont pas indépendantes. De plus, la suite (Z ′
n) est une chaîne de Markovsur E × E, de noyau Q donné par
Q((x, y), (x′, y′)) =
P(x, x′)P(y, y′) si x 6= y
0 si x = y et x′ 6= y′
P(x, x′) si x = y et x′ = y′.
La suite (Z ′n) constitue le couplage coalescent de P, construit à partir du couplage indépendant
(Zn). Les composantes des suites (Zn) et (Z ′n) possèdent le même temps de couplage TC .
Lorsque P possède une loi invariante µ, rien ne garantit que la variable aléatoire XTC(qui
est égale à YTC) suive la loi µ. Il parait donc vain d’utiliser un couplage coalescent pour accéder
à µ en un temps fini. Cette intuition est fausse.
0.13.1 Coalescences de suites récurrentes aléatoiresNous reprenons ici l’approche récursive utilisée pour construire et simuler les chaînes de
Markov. Soit P un noyau de transition sur E et g : E × [0, 1] → E la fonction associée fourniepar le théorème 0.4.1. On note G : E → E la fonction aléatoire définie par G(x) := g(x, U), oùU suit la loi uniforme sur [0, 1]. Soient (Gn) une suite i.i.d. de fonctions aléatoires de E dansE, de même loi que G, construites à la manière de G en utilisant une suite (Un) de variablesaléatoires i.i.d. de loi uniforme sur [0, 1]. Pour tout n, on construit les applications aléatoiresAn : E → E et Bn : E → E en posant
An := Gn ◦ · · · ◦G1 et Bn := G1 ◦ · · · ◦Gn.
On convient que A0 et B0 sont égales à l’application identité de E. Pour tout x ∈ E et toutn, les variables aléatoires An(x) et Bn(x) suivent la loi Pn(x, ·). Les suites (An(x)) et (Bn(x))ont les mêmes lois marginales de dimension 1, mais n’ont pas la même loi en général. La suite(An(x)) est une chaîne de Markov sur E de noyau P et de loi initiale δx. En revanche, la suite(Bn(x)) n’a aucune raison d’être une chaîne de Markov, car le temps est inversé en quelquesorte. Nous définissons à présent les temps de contraction TA et TB à valeurs dans N∪{∞} par
TA := inf{n > 0; card(An(E)) = 1} et TB := inf{n > 0; card(Bn(E)) = 1}.
On dit que G est contractante lorsque p := P(card(G(E)) = 1) > 0.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 37.

38 TABLE DES MATIÈRES
Théorème 0.13.1. Si G est contractante, alors P(TB < ∞) = 1 et il existe une variable aléatoirexB à valeurs dans E telle que Bn(x) = xB pour tout x ∈ E et tout n > TB. De plus, si µB
désigne la loi de xB, alors limn→∞ Pn(x, y) = µB(y) pour tout x et y. En particulier, µB estl’unique loi invariante de P.
Démonstration. Par construction, les événements Cn := {card(Gn(E)) = 1} sont indépendantset de même probabilité p := P(card(G(E)) = 1) > 0. Le lemme de Borel-Cantelli entraîne quepresque sûrement, card(Gn(E)) = 1 pour une infinité de valeurs de n. Cela assure en particulierque P(TB < ∞) = 1. Le temps aléatoire TB définit presque sûrement un singleton aléatoire{xB} tel que BTB
(x) = xB pour tout x ∈ E. Il en découle que Bn(x) = xB pour tout x ∈ Eet tout n > TB. En effet, Bn(x) = BTB
((GTB+1 ◦ · · · ◦ Gn)(x)) = xB. Cela correspond à unecoalescence des trajectoires des suites (Bn(x)) quelque soit leur état initial x. Si µB désigne laloi de xB, alors le théorème de convergence dominée entraîne que pour tout x ∈ E et toutefonction bornée f : E → R,
limn→∞
E(f(Bn(x)) = limn→∞
E(f(Bn(x))I{TB>n}) = E(f(xB)) = µBf.
Comme E(f(Bn(x))) = Pn(x, ·)f , on obtient limn→∞ Pn(x, y) = µB(y) pour tout x et y.
Lorsque G est contractante, on a également P(TA < ∞) = 1 et TA définit presque sûrementun singleton aléatoire {xA}, vérifiant ATA
(x) = xA pour tout x ∈ E. Cependant, la définitionde (An) n’assure pas que An(x) = xA pour n > TA et tout x ∈ E, et le raisonnement utilisépour µB ne peut pas être utilisé pour la loi µA de xA. Observons que pour tout x et y dans E,la suite ((Xn, Yn)) := ((An(x), An(y))) est un couplage coalescent de P, de loi initiale δx ⊗ δy.Si TC désigne le temps de couplage associé, alors TC 6 TA. La suite ((Bn(x), Bn(y))) quant àelle est parfois qualifiée de couplage par le passé, ou encore CFTP (Coupling From The Past).
En pratique, il n’est pas commode de déterminer le temps de coalescence TB car il faitintervenir tous les états initiaux possibles. Le résultat suivant fournit une alternative.Théorème 0.13.2. Supposons que E soit ordonné et que g(x, ·) : [0, 1] → E est constante parmorceaux et croissante pour tout x ∈ E. Supposons également que E possède un plus petitélément x∗ vérifiant ε := infx∈E P(x, x∗) > 0. Soit σ le temps aléatoire à valeur dans N∗ et deloi géométrique de moyenne 1/ε défini par
σ := inf{n > 1; Un < ε}.
Alors Bn(x) = Bσ−1(x∗) pour tout x ∈ E et tout n > σ. Si µ désigne la loi de Bσ−1(x∗), alorslimn→∞ Pn(x, y) = µ(y) pour tout x et y dans E. En particulier, µ est l’unique loi invariantede P.
Démonstration. L’application aléatoire G est contractante car P(G(E) = {x∗}) > ε > 0 pardéfinition de ε. La mesure de Lebesgue du premier morceau de la fonction g(x, ·) vaut P(x, x∗).Par conséquent, g(x, u) = x∗ pour u < ε et tout x ∈ E. Notons que P(σ < ∞) = 1. La définition
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 38.

0.14. QUELQUES EXEMPLES CLASSIQUES 39
de σ assure alors que Gσ(x) = g(x, Uσ) = x∗ pour tout x ∈ E. Ainsi, Gσ(E) = {x∗} et parconséquent Bσ(E) = {Bσ−1(x∗)} est un singleton. Ainsi, Bn(x) = Bσ−1(x∗) pour tout x ∈ E ettout n > σ. Il suffit alors de procéder comme dans la preuve du théorème 0.13.1.
0.13.2 Algorithme de Letac-Propp-WilsonComme E est au plus dénombrable, il est toujours identifiable à N, ce qui le muni d’un ordre
total et d’un plus petit élément x∗. Il suffit alors de choisir pour g(x, ·) : [0, 1] → E l’inverse dela fonction de répartition de P(x, ·), qui est bien constante par morceaux et croissante. LorsqueP est irréductible et apériodique sur E fini, alors ε := minx,y Pr(x, y) > 0 pour un entier r.Définissons le temps aléatoire σ avec cette valeur de ε. Le théorème 0.13.2, appliqué au noyauPr en lieu et place du noyau P, assure que la loi µ de Bσ−1(x∗) constitue l’unique loi invariantede Pr. Comme la loi invariante de P est également invariante pour Pr, il en découle que µ estl’unique loi invariante de P. Cet méthode permet de simuler de façon exacte la loi invariante µ.La complexité de l’algorithme est géométrique, puisque σ suit une loi géométrique de moyenne1/ε.
Réciproquement, partant d’une loi µ sur E fini, il est toujours possible de construire unnoyau P irréductible et apériodique pour lequel µ est invariante. Un noyau de Metropolis-Hastings peut convenir par exemple. Si la fonction g associée est bien choisie, la loi µ peut alorsêtre simulée en simulant la variable aléatoire Bσ−1(x) construite à partir d’une puissance Pr
adéquate et d’un état initial x quelconque. Cet algorithme de simulation est attribué en généralà Propp et Wilson, suite à leur article [27] publié en 1996. Cependant, le principe de cetteméthode remonte en réalité à un travail beaucoup plus ancien de Letac publié en 1986 dans[20], comme le soulignent très justement Diaconis et Freedman dans [10, 11]. Contrairement àl’algorithme de Metropolis-Hastings, l’algorithme de Letac-Propp-Wilson permet de simuler µde façon exacte. Il nécessite cependant de bien choisir la fonction g.
0.14 Quelques exemples classiques
0.14.1 Processus de vie ou de mort sur NCes processus correspondent aux chaînes de Markov sur N dont le noyau vérifie P(x, y) = 0
si |x− y| > 1. Ils permettent de modéliser des phénomènes discrets qui ne peuvent varier qued’une unité à chaque étape. Soit p, q, r : N → [0, 1] trois fonctions telles p + q + r = 1 sur N etq(0) = 0. Le processus de vie ou de mort associé est la chaîne de Markov sur N de noyau detransition P donné par P(x, ·) = q(x)δx−1 + r(x)δx + p(x)δx+1. En d’autres termes,
P(x, y) =
q(x) si y = x− 1
r(x) si y = x
p(x) si y = x + 1
.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 39.

40 TABLE DES MATIÈRES
x
r(x)
q(x) p(x)
−1 +1
Fig. 5 – Mouvements possibles pour un processus de vie ou de mort.
Cas irréductible général
Supposons que p > 0 sur N, et q > 0 sur N∗, ce qui garantit que P est irréductible.Considérons le système d’équations associé à la probabilité d’atteinte de 0 fourni par le théorème0.5.1. Recherchons la solution positive ou nulle minimale a{0}(x) := Px(τ0 < ∞). Si a estsolution, alors (a(x + 1)− a(x))p(x) = (a(x)− a(x− 1))q(x) pour tout x > 0, et a(0) = 1. Enposant γ(0) := 1 et pour x > 0
γ(x) :=q(1) · · · q(x)
p(1) · · · p(x),
il vient a(x + 1) = 1 + (γ(0) + · · · + γ(x))(a(1) − 1). Maintenant, si∑∞
x=0 γ(x) = ∞, alors lacondition 0 6 a(x + 1) 6 1 entraîne que a(1) = 1, et donc que a{0}(x) = 1 pour tout x. Si enrevanche
∑∞x=0 γ(x) < ∞, alors la solution positive ou nulle minimale est donnée par
a{0}(x) =
∑∞y=x γ(y)∑∞y=0 γ(y)
.
En vertu de la propriété de Markov forte, P0(T0 < ∞) = P(0, 0) + P(0, 1)P1(T0 < ∞). OrP(0, 0) + P(0, 1) = 1 avec P(0, 1) = p(1) > 0, et P1(T0 < ∞) = P1(τ0 < ∞) = a{0}(1). Parconséquent, P est récurrent si et seulement si a{0}(1) = 1, c’est-à-dire si et seulement si
∞∑x=0
γ(x) = ∞.
Il en découle en particulier que le noyau P est récurrent si lim supx→∞(q(x)/p(x)) > 1, ettransitoire si lim infx→∞(q(x)/p(x)) < 1. Un calcul direct montre qu’une mesure µ sur N estinvariante pour P si et seulement si pour tout x > 0,
µ(x + 1)p(0) · · · p(x) = µ(0)q(1) · · · q(x + 1).
Le théorème 0.6.6 entraîne alors que P est récurrent positif si et seulement si∞∑
x=0
1
γ(x)p(x)< ∞.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 40.

0.14. QUELQUES EXEMPLES CLASSIQUES 41
Marche aléatoire simple sur N réfléchie en 0
Correspond au cas où r est identiquement nulle et p(x) = q(x) = 1/2 pour tout x > 0. Dansce cas, la chaîne est récurrente nulle et les mesures invariantes sont les mesures proportionnellesà la mesure de comptage sur N. La période vaut 2.
Processus de mort
Correspond au cas où la fonction p est identiquement nulle et où q est strictement positive(sur N∗). L’état 0 est absorbant, et tous les autres états sont transitoires. Les classes irréduc-tibles sont des singletons. Les trajectoires sont décroissantes, et la chaîne est presque-sûrementabsorbée par 0.
Processus de vie
Correspond au cas où la fonction q est identiquement nulle et où p est strictement positive.Les trajectoires sont presque-sûrement croissantes. Tous états sont transitoires, et les classesirréductibles sont des singletons. Lorsque p est constante, on retrouve le processus de Bernoullide l’exemple 0.1.5.
Files d’attente à temps discret
Dans cette interprétation, Xn représente le nombre de clients dans la file d’attente à l’instantn. Sur l’événement {Xn = x}, p(x) (resp. q(x)) est la probabilité que la file perde (resp. gagne)un client.
0.14.2 Marche aléatoire simple sur Zd
Le concept de marche aléatoire est apparu dans les travaux du physicien Rayleigh en acous-tique vers 1880 et dans ceux du statisticien Pearson vers 1905 en biométrie. Le nom « Marchealéatoire » est attribué au mathématicien George Pólya vers 1920. On lui doit la classificationdes états en toute dimension dans [28].
Une suite de variables aléatoires (Xn) à valeurs dans Zd est une marche aléatoire simplelorsque la suite de ses accroissements (Yn) := (Xn+1 − Xn) est i.i.d. de loi uniforme sur{±e1, . . . ,±ed} où {e1, . . . , ed} désigne la base canonique de Rd. On a donc
Xn+1 = Xn + Yn = X0 + Y1 + · · ·+ Yn.
La suite (Xn) est une martingale pour sa filtration naturelle. La suite (Xn) est également unechaîne de Markov sur Zd, de noyau de transition P donné pour tout x et y dans Zd par
P(x, y) =
{12d
si ‖x− y‖1 := |x1 − y1|+ · · ·+ |xd − yd| = 1
0 sinon.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 41.

42 TABLE DES MATIÈRES
b
b
b
bb +e1−e1
+e2
−e2
1
4
1
4
1
4
1
4
Fig. 6 – Mouvements possibles pour une marche aléatoire simple dans Z2.
La condition ‖x− y‖1 = 1 signifie que x et y sont voisins sur le réseau Zd. Tous les étatscommuniquent, et la chaîne est irréductible. Les seules mesures invariantes sont les multiplesde la mesure de comptage sur Zd. Elles sont de plus symétriques. Il n’y a pas de loi invariante.Il en découle que les états sont soit tous transitoires, soit tous récurrents nuls. La périodevaut 2. Lorsque d = 1, les entiers relatifs Xn − X0 et n sont de même parité, et la suite(1
2(Xn −X0 + n)) est un processus de Bernoulli de paramètre 1
2. Plus généralement, pour tout
d > 1, la loi L(Xn −X0) = L(Xn|X0 = 0) = Pn(0, ·) est la loi image par l’application
(k1, . . . , k2d) ∈ N2d 7→ (k1 − k2, . . . , k2d−1 − k2d) ∈ Zd
de la loi multinomiale symétrique sur N2d suivante :(1
2d(δe1 + · · ·+ δe2d
)
)∗n= (2d)−n
∑k1+···+k2d=n
n!
k1! · · · k2d!δ(k1,...,k2d).
Il faut penser à n jets indépendants d’un dé à 2d faces étiquetées {+e1,−e1, . . . , +ed,−ed}.Cette formulation multinomiale fournit immédiatement pour tout d et tout n,
Pn(0, 0) =∑
2r1+···+2rd=n
n!
r1!2 · · · rd!2.
En particulier, P2n+1(0, 0) = 0 pour tout n et d, ce qui n’est pas surprenant car la période vaut2. Nous avons déjà obtenu dans l’exemple 0.3.2 la récurrence de P lorsque d = 1, en démontrantque H(0, 0) :=
∑∞n=0 Pn(0, 0) = ∞ grâce à la formule de Stirling. Lorsque d = 2, nous avons
P2n(0, 0) = 4−2n∑
r1+r2=n
(2n)!
r1!2r2!2=
(2n)!
42nn!2
∑r1+r2=n
(n!
r1!r2!
)2
=(2n)!
42nn!2(2n)!
n!2,
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 42.

0.14. QUELQUES EXEMPLES CLASSIQUES 43
de sorte que H(0, 0) :=∑∞
n=0 Pn(0, 0) = ∞ en vertu de la formule de Stirling. Ainsi, P estrécurrent pour d = 2. Il est possible de procéder de la sorte pour établir que P est transitoirepour d = 3. Cependant, cette approche combinatoire est difficile à mettre en œuvre pourles dimensions d supérieures. Une méthode basée sur la transformée de Fourier permet plusgénéralement d’établir que H(0, 0) = ∞ pour tout d > 3. Ainsi, tous les états sont récurrentsnuls lorsque d 6 2 tandis qu’ils sont tous transitoires quand d > 3. On trouve dans [30], [14],et [19] les estimées précises de Hn :=
∑nk=0 Pk suivantes dérivées d’un TLC local :
Hn(x, x) = Hn(0, 0) =
√
2nπ
+ O(1) si d = 11π
log(n) + O(1) si d = 2
constante + O(n(2−d)/2) si d > 3
.
La suite (Yn) des accroissements de (Xn) sur Zd peut s’écrire Yn = VnDn pour tout n > 0 où(Dn) est une suite i.i.d. de loi uniforme sur {e1, . . . , ed} et (Vn) une suite i.i.d. de loi uniformesur {−1, +1}, indépendante de (Dn). Supposons à présent que d > 1. Écrivons Xn sous la formeXn = (Xn,1, . . . , Xn,d) = Xn,1e1 + · · · + Xn,ded. Les composantes (Xn,1), . . . , (Xn,d) ne sont pasindépendantes, et ne sont pas des marches aléatoires simples unidimensionnelles. Ce sont enrevanche des chaînes de Markov de même loi, de noyau commun Q sur Z donné par
Q(x, y) =
12d
si |x− y| = 1d−1
dsi x = y
0 sinon.
Il est irréductible, apériodique, et récurrent nul, et s’écrit Q = 1dP1 + (1 − 1
d)I où P1 est
le noyau de la marche aléatoire simple sur Z. Réciproquement, soient (Zn,1), . . . , (Zn,d) desmarches aléatoires simples sur Z, indépendantes. La suite (Zn) à composantes indépendantesdéfinie par Zn := (Zn,1, . . . , Zn,d) = Zn,1e1 + · · ·+ Zn,ded est une chaîne de Markov sur Zd dontle noyau de transition R est donné par
R(x, y) =
{12d si |x1 − y1| = · · · = |xd − yd| = 1
0 sinon.
Le noyau P impose une évolution parallèle aux axes, tandis que R impose une évolution « diago-nale ». De plus, z ↔ z′ pour R si et seulement si les d composantes de z−z′ sont toutes de mêmeparité. Lorsque d = 2, le noyau R possède deux classes irréductibles (celles de 0 et e1), tandisque P n’en possède qu’un seule. Cependant, les projections orthogonales (Xn,1 + Xn,2)/
√2 et
(Xn,1 −Xn,2)/√
2 de la marche aléatoire simple bidimensionnelle sur les deux diagonales prin-cipales de Z2 sont indépendantes et constituent des marches aléatoires simples sur Z/
√2. Il est
possible d’utiliser cette propriété pour montrer que (0, 0) est récurrent pour P lorsque d = 2.� �function masunidim (x , r , n )
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 43.
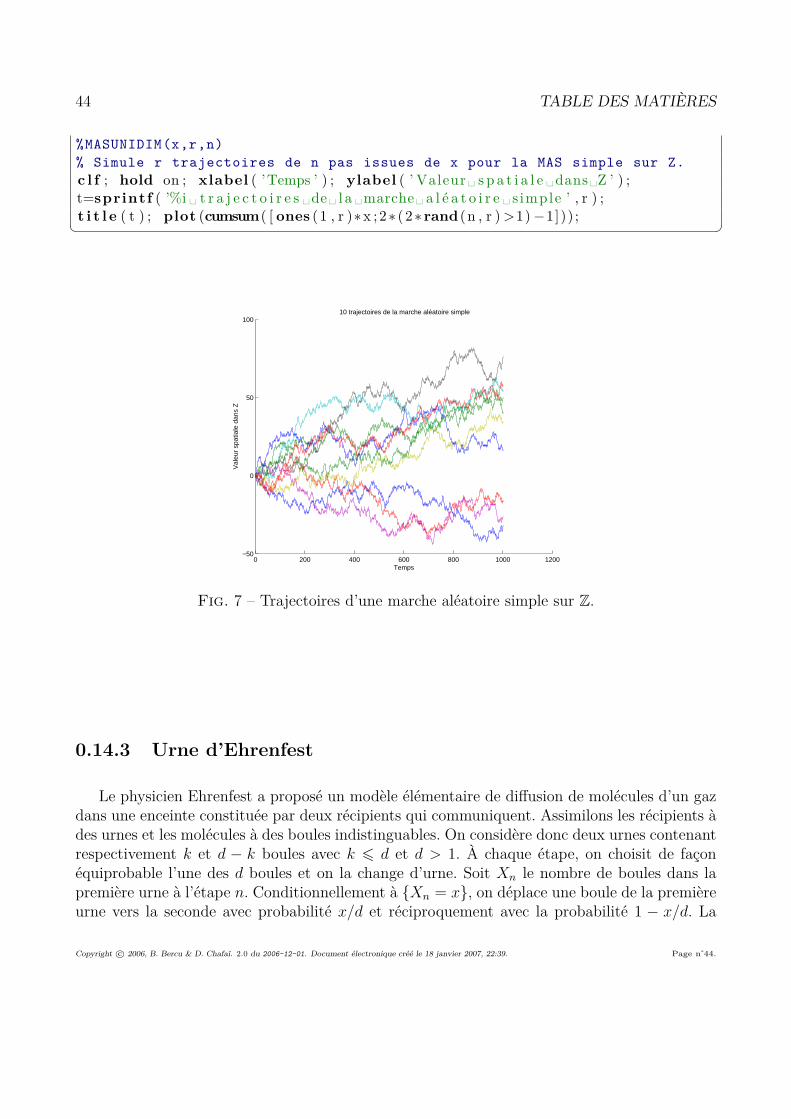
44 TABLE DES MATIÈRES
%MASUNIDIM(x,r,n)% Simule r trajectoires de n pas issues de x pour la MAS simple sur Z.c l f ; hold on ; xlabel ( ’Temps ’ ) ; ylabel ( ’ Valeur s p a t i a l e dans Z ’ ) ;t=sprintf ( ’%i t r a j e c t o i r e s de l a marche a l é a t o i r e s imple ’ , r ) ;t i t l e ( t ) ; plot (cumsum( [ ones (1 , r )∗x ;2∗ (2∗ rand (n , r ) >1)−1])) ;� �
0 200 400 600 800 1000 1200−50
0
50
100
Temps
Val
eur
spat
iale
dan
s Z
10 trajectoires de la marche aléatoire simple
Fig. 7 – Trajectoires d’une marche aléatoire simple sur Z.
0.14.3 Urne d’Ehrenfest
Le physicien Ehrenfest a proposé un modèle élémentaire de diffusion de molécules d’un gazdans une enceinte constituée par deux récipients qui communiquent. Assimilons les récipients àdes urnes et les molécules à des boules indistinguables. On considère donc deux urnes contenantrespectivement k et d − k boules avec k 6 d et d > 1. À chaque étape, on choisit de façonéquiprobable l’une des d boules et on la change d’urne. Soit Xn le nombre de boules dans lapremière urne à l’étape n. Conditionnellement à {Xn = x}, on déplace une boule de la premièreurne vers la seconde avec probabilité x/d et réciproquement avec la probabilité 1 − x/d. La
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 44.

0.14. QUELQUES EXEMPLES CLASSIQUES 45
0 1 2 3 4 5 6
Fig. 8 – Graphe des transitions de la chaîne d’Ehrenfest pour d = 6.
suite (Xn) est une chaîne de Markov sur {0, . . . , d} de matrice de transition
P =
0 1 0 01d
0 d−1d
0 2d
0 d−2d
. . . . . . . . .d−2
d0 2
d0
d−1d
0 1d
0 0 1 0
.
En d’autres termes, L(Xn+1 |Xn) = d−Xn
dδXn+1 + Xn
dδXn−1. Tous les états communiquent et la
chaîne est donc récurrente irréductible positive puisque l’espace d’état est fini. La loi binomialeµ := B(d, 1/2) := 2−d
∑dk=0 Ck
d δk est symétrique donc invariante et réversible. En particulier,Ex(Tx) = 1/µ(x) = 2d/Cx
d pour tout x. Lorsque d est pair, cette espérance est minimale pourx = d/2 et maximale pour x = 0 et x = d. La formule de Stirling donne Ed/2(Td/2) ∼d
√πd/2.
De même, Ed(Td) = E0(T0) ∼d 2d, et cette quantité est considérable lorsque d est de l’ordre dunombre d’Avogradro3. L’expression de L(Xn+1 |Xn) fournit E(Xn+1 |Xn) = (1− 2
d)Xn + 1. Par
récurrence sur n, on obtient également que
E(Xn |X0) =d
2+
(1− 2
d
)n(X0 −
d
2
).
Par conséquent, (Ex(Xn)) converge vers d/2 pour tout x. En moyenne, la chaîne oublie l’étatinitial. Cependant, la période vaut 2, et la chaîne ne converge pas en loi. En vertu de laremarque 0.9.5, le modèle peut être rendu apériodique en introduisant un mélange : une fois laboule choisie, on tire à pile ou face pour décider de l’urne qui va l’accueillir. Ainsi, la boule nechange d’urne qu’avec probabilité p ∈ [0, 1]. La nouvelle matrice de transition est pP+(1−p)I.
3Le nombre d’Avogadro a vaut environ 6.02× 1023. Par définition, une mole contient a molécules. Une moled’un gaz parfait occupe un volume d’environ 22.4 litres aux conditions normales de température et de pression.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 45.

46 TABLE DES MATIÈRES
Par exemple, pour p = d/(d + 1), on obtient
d
d + 1P +
1
d + 1I =
1
d + 1
1 d 0 01 1 d− 10 2 1 d− 2
. . . . . . . . .d− 2 1 2 0
d− 1 1 10 0 d 1
.
Cette nouvelle chaîne est apériodique dès que 0 < p < 1 et sa mesure invariante est toujours laloi binomiale B(d, 1/2) (qui est également symétrique et donc réversible).� �function [VT, lo inv ,P] = eh r e n f e s t c u t o f f (d , x , n )%[VT,loinv ,P]=EHRENFESTCUTOFF(d,x,n)% Renvoie l’évolution de l’écart en variation totale à la loi invariante% d’une chaîne d’Ehrenfest apériodique sur {0,...,d}, d’état initial x.% Le temps maximum est n.
l o i nv = b incoe f ( [ 0 : d ] , d∗ones (1 , d+1))/2^d ;l o i n i = zeros (1 , d+1); l o i n i ( x ) = 1 ;VT=zeros (1 , n ) ; VT(1) = sum(abs ( l o i n i−l o i nv ) ) / 2 ;
P = diag (ones (1 , d+1))/(d+1);for i =1:d , P( i , i +1) = (d+1− i ) / ( d+1); P( i +1, i ) = i /(d+1); end
l o i = l o i n i ;for i =1:n , l o i = l o i ∗ P; VT( i ) = sum(abs ( l o i−l o i nv ) ) / 2 ; end� �
La figure 9 page 47 illustre la convergence en variation totale vers l’équilibre pour d = 150,p = d/(d + 1) et X0 = 1. Le graphe possède trois phases distinctes : un plateau, puis une chuteabrupte, suivie enfin d’une décroissance exponentielle vers 0. Le théorème 0.12.2 ne décrit pas cephénomène de convergence abrupte (cutoff en anglais). Une telle convergence abrupte se produitpour un grand nombre de modèles, et serait due à une multiplicité élevée de certaines valeurspropres. Cependant, l’étude mathématique de ce phénomène n’est pas très avancée, et aucunethéorie générale n’a été dégagée à l’heure actuelle, malgré les efforts de plusieurs mathématicienstalentueux. La convergence abrupte de la chaîne d’Ehrenfest a été mathématiquement établiepar Aldous et Diaconis. D’autres exemples sont proposés dans [9] et [33].
0.14.4 Modèle de Wright-FisherCe modèle a été étudié par Fisher dans [15], puis par Wright dans [32]. Considérons une
population de taille fixe d > 0 dans laquelle chaque individu est soit de type A soit de type B.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 46.

0.14. QUELQUES EXEMPLES CLASSIQUES 47
0 50 100 150 200 250 300 350 400 450 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Convergence abrupte d’une chaîne d’Ehrenfest apériodique avec d=150 particules.P(x,x−1) = (x−1)/d, P(x,x) = 1/d, P(x,x+1) = (d−x)/d. La chaîne part de 1.
Le logarithme de min(P(x,y)/mu(y)) vaut −43.296258.Les valeurs propres de P de plus grand module sont 1.000000 et 0.986667.
Temps
Var
iatio
n to
tale
Fig. 9 – Convergence en variation totale pour une chaîne d’Ehrenfest apériodique.
En génétique, ces types sont par exemple les deux allèles possibles d’un gène particulier dansune population à reproduction haploïde.
Soit Xn le nombre d’individus de la nième génération qui possèdent l’allèle A. Idéalement, lepassage de la génération n à la génération n + 1 s’effectue en tirant au sort avec remise les dindividus de la génération n + 1 parmi ceux de la génération n (qui donc meurent tous). Poursimplifier ce procédé, on ne retient de la génération n que la fréquence Xn/d de l’allèle A. Pourobtenir la génération n+1, on effectue alors d tirages indépendants de loi de Bernoulli B(Xn/d).Ainsi, le nombre de A obtenus à la génération n + 1 suit la loi binomiale B(d,Xn/d). Cettesimplification consiste en quelque sorte, pour définir les d individus de la génération n + 1, àeffectuer un échantillonnage de taille d dans une population de taille infinie dont la fréquencede l’allèle A est Xn/d. La suite (Xn) est à valeurs dans {0, 1, . . . , d} et vérifie
L(Xn+1 |Xn) = B(
d,Xn
d
),
La suite (Xn) est une chaîne de Markov sur E := {0, 1, . . . , d} de noyau P donné par
P(x, y) := Cyd
(x
d
)y(1− x
d
)d−y
.
Les états 0 et d sont absorbants donc récurrents, tandis que les états 1, . . . , d−1 communiquentet sont tous transitoires. Les lois δ0 = B(d, 0) et δd = B(d, 1) sont donc les seules mesuresinvariantes. L’absorption par 0 (respectivement d) correspond à l’extinction de l’allèle A (res-pectivement B). La suite (Xn/d) est une chaîne de Markov sur {0/d, 1/d, . . . , d/d} ⊂ [0, 1].Cette chaîne décrit l’évolution du paramètre pn = Xn/d d’une loi binomiale de taille d. Plus
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 47.
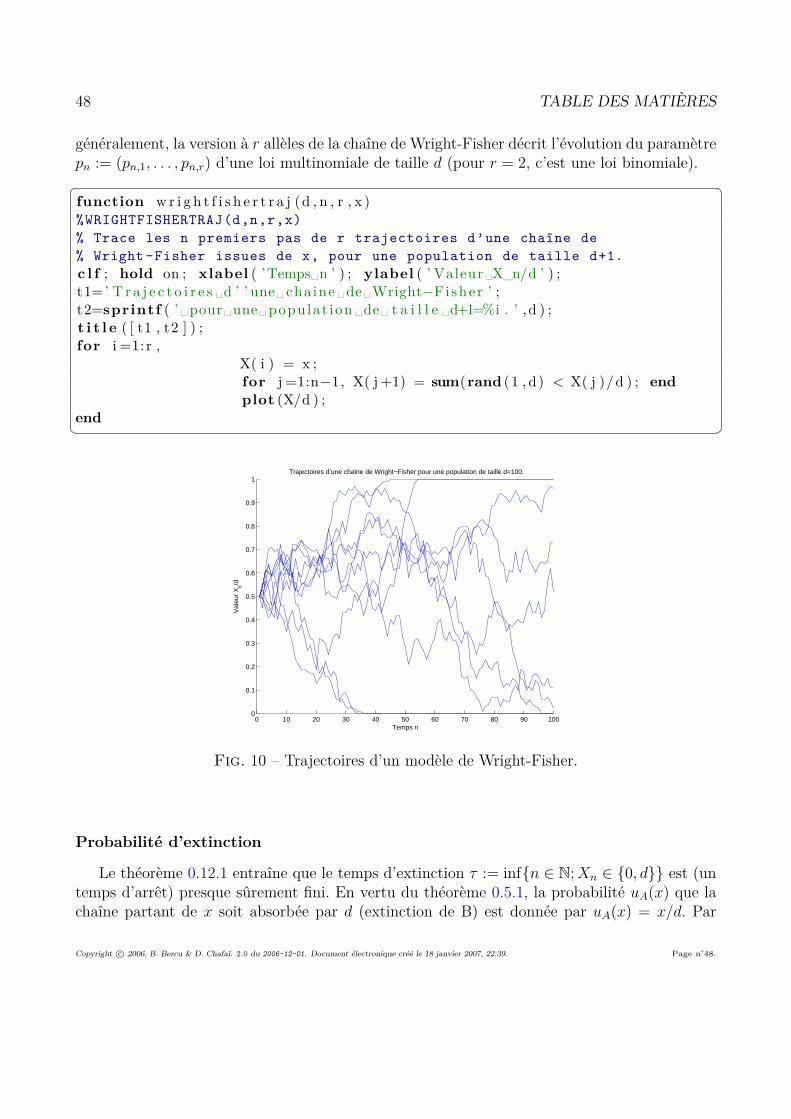
48 TABLE DES MATIÈRES
généralement, la version à r allèles de la chaîne de Wright-Fisher décrit l’évolution du paramètrepn := (pn,1, . . . , pn,r) d’une loi multinomiale de taille d (pour r = 2, c’est une loi binomiale).� �function wr i g h t f i s h e r t r a j (d , n , r , x )%WRIGHTFISHERTRAJ(d,n,r,x)% Trace les n premiers pas de r trajectoires d’une chaîne de% Wright -Fisher issues de x, pour une population de taille d+1.c l f ; hold on ; xlabel ( ’Temps n ’ ) ; ylabel ( ’ Valeur X_n/d ’ ) ;t1=’ T r a j e c t o i r e s d ’ ’ une chaine de Wright−Fisher ’ ;t2=sprintf ( ’ pour une populat ion de t a i l l e d+1=%i . ’ ,d ) ;t i t l e ( [ t1 , t2 ] ) ;for i =1: r ,
X( i ) = x ;for j =1:n−1, X( j +1) = sum(rand (1 , d) < X( j )/d ) ; endplot (X/d ) ;
end� �
0 10 20 30 40 50 60 70 80 90 1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Temps n
Val
eur
Xn/d
Trajectoires d’une chaine de Wright−Fisher pour une population de taille d=100.
Fig. 10 – Trajectoires d’un modèle de Wright-Fisher.
Probabilité d’extinction
Le théorème 0.12.1 entraîne que le temps d’extinction τ := inf{n ∈ N; Xn ∈ {0, d}} est (untemps d’arrêt) presque sûrement fini. En vertu du théorème 0.5.1, la probabilité uA(x) que lachaîne partant de x soit absorbée par d (extinction de B) est donnée par uA(x) = x/d. Par
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 48.

0.14. QUELQUES EXEMPLES CLASSIQUES 49
0 1 · · ·d − 1 d
Fig. 11 – Graphe des transitions pour la chaîne de Wright-Fisher sans mutation.
symétrie, la probabilité que la chaîne partant de x soit absorbée par 0 (extinction de A) est(d− x)/d.
Martingale
Pour tout n ∈ N, on a E(Xn+1 |Xn) = dXn/d = Xn. La suite (Xn) est donc une martingalebornée. Elle converge alors presque sûrement (et dans tout Lp avec p > 1) vers une variablealéatoire intégrable X∞. On a L(X∞ |X0 = x) = uA(x)δd+(1−uA(x))δ0, et donc x = Ex(X0) =Ex(X∞) = uA(x)d. On retrouve bien uA(x) = x/d.
Temps moyen d’extinction
En vertu du théorème 0.5.1, le temps d’extinction moyen v(x) := Ex(τ) vérifie v(x) =1 +
∑y∈E P(x, y)v(y) pour tout x 6∈ {0, d}. Il est difficile d’en déduire une expression explicite
pour v en fonction de x et d. Cependant, lorsque x/d → p ∈ ]0, 1[ quand d →∞, il est possiblede montrer que le vecteur v/d converge vers la fonction v∗ : [0, 1] → R+ qui vérifie
p(1− p)v′′∗(p) = −2 pour 0<p<1 et v∗(0) = v∗(1) = 0.
La résolution de cette équation différentielle donne v∗(p) := −2(p log(p) + (1 − p) log(1 − p)).Ainsi, v(x) ∼d dv∗(x/d). Pour une grande population, v(x) ≈ −2 log(2)d ≈ 1.39d lorsquex ≈ d/2, tandis que v(x) ≈ 2 log(d) lorsque x ≈ 1/d. Ainsi, lorsque d est de l’ordre de kmilliards, le temps moyen d’extinction est de l’ordre de d lorsque l’état initial est équilibré,tandis qu’il est de l’ordre de k lorsque l’état initial est très déséquilibré.
Mutations
Afin de rendre la chaîne de Wright-Fisher plus réaliste, on introduit la possibilité de mu-tations. Le passage de la génération n à la génération n + 1 se fait d’abord en provoquant defaçon indépendante pour chacun des d individus de la génération n une mutation de A à B avecprobabilité pAB et une mutation de B à A avec probabilité pBA. Ensuite, on procède commepour le cas sans mutation pour obtenir les d individus de la génération n+1. La nouvelle chaîne(X ′
n) est donnée par
L(X ′n+1 |X ′
n) = B(
d, qABX ′
n
d+ pBA
(1− X ′
n
d
))= B
(d, pBA + (qAB − pBA)
X ′n
d
),
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 49.

50 TABLE DES MATIÈRES
où qAB := 1− pAB et qBA := 1− pBA. L’état 0 (resp. 1) n’est plus absorbant dès que pBA > 0(resp. pAB > 0). Lorsque qAB = pBA, la suite (X ′
n) est i.i.d. de loi B(d, p). La chaîne estrécurrente irréductible positive apériodique si 0 < pABpBA < 1. Dans ce cas, la suite (X ′
n)converge en loi vers la loi invariante. Cependant, elle n’est pas une sous-martingale ni une sur-martingale puisque E(X ′
n+1 |X ′n) = dpBA + (qAB − pBA)X ′
n. On peut alternativement effectuerles mutations après coup, ce qui conduit à la chaîne de Markov (X ′′
n) définie par
L(X ′′n+1 |X ′′
n) = qAB B(
d,X ′′
n
d
)+ pBA B
(d, 1− X ′′
n
d
).
� �function wr i g h t f i s h e r t i n v (d , p , x , n)%[P,N,loi] = WRIGHTFISHERINV(d,p,x,n)% Estime la loi invariante d’une chaîne de Wright -Fisher% pour une population de taille d+1 et proba de mutation p.% P = noyau de transition de la chaîne% N = estimation par fréquences de passages (LGN)% le long d’une seule trajectoire partant de x% et de longeur inférieure à n.% loi = loi au temps n partant de x (calcul récursif).c l f ; hold on ;xlabel ( ’ Etats x ’ ) ; ylabel ( ’ Est imation de l a p r o b ab i l i t e en x ’ ) ;t1=’ Est imation de l a l o i i nva r i an t e de Wright−Fisher . ’ ;t2=sprintf ( ’ \ nPopulation de t a i l l e d+1=%i , ’ ,d+1);t3=sprintf ( ’ p r o b ab i l i t e de mutation p=%f , ’ ,p ) ;t4=sprintf ( ’ e t a t i n i t i a l x=%i . ’ , x ) ;t i t l e ( [ t1 , t2 , t3 , t4 ] ) ;% Utilisation de la LGN sur une trajectoire de longueur nN = zeros (n , d+1); N(: ,1+x) = 1 ; m = f ix (n /10 ) ;for i = 1 : n−1,
N( i +1 , : ) = N( i , : ) ;x = sum(rand (1 , d) < p+(1−2∗p)∗x/d ) ;N( i +1,1+x) = N( i +1,1+x) + 1 ;
endplot ( [ 0 : d ] ,N(n , : ) / n , ’ r+’ ) ; plot ( [ 0 : d ] ,N(m, : ) /m, ’ go ’ ) ;% Calcul récursif de la loi à l’instant nP = zeros (d+1,d+1); l o i n i = zeros (1 , d+1); l o i n i ( x ) = 1 ;for x = 0 : d , P(x+1 , : ) = dbinom ( [ 0 : d ] , d , p+(1−2∗p)∗x/d ) ; endl o i = l o i n i ; for i = 1 : n−1, l o i = l o i ∗ P; end% Tracésplot ( [ 0 : d ] , l o i , ’ b ’ ) ;l 1 = sprintf ( ’LGN sur une s eu l e t r a j . de longueur %i ’ ,n ) ;l 2 = sprintf ( ’LGN sur une s eu l e t r a j . de longueur %i ’ ,m) ;l 3 = sprintf ( ’ Calcu l r e c u r s i f de l a l o i au temps %i ’ ,n ) ;
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 50.

0.14. QUELQUES EXEMPLES CLASSIQUES 51
legend ( l1 , l2 , l3 , 3 ) ;� �Remarque 0.14.1. Cette étude du modèle de Wright-Fisher illustre une démarche générale.Lorsque tous les états récurrents sont absorbants, l’étude porte en général sur le temps d’ab-sorption. En revanche, lorsque tous les états sont récurrents, l’étude porte tout naturellementsur les lois invariantes.
Construction poissonnienne et processus de Galton-Watson
Soit d > 0 un entier et soient (Zn,m)n,m des variables aléatoires i.i.d. de loi µ sur N. Lasuite (Yn) définie par Y0 := d et Yn+1 := Zn,1 + · · ·+ Zn,Yn pour tout n > 0 est un processus deGalton-Watson de taille initiale d et de loi de reproduction µ. Dans ce modèle, Yn représentele nombre d’individus de la génération n, tandis que Zn,1 + · · · + Zn,Yn représente le nombred’enfants de la génération n. Les individus ne vivent qu’une seule génération. La suite (Yn) estune chaîne de Markov sur N de noyau W donné par W(x, ·) = µ∗x, où µ∗x désigne la loi deZn,1 + · · ·+ Zn,x.
La chaîne de Wright-Fisher peut être obtenue en considérant la propagation d’un caractèrehéréditaire dans un processus de Galton-Watson de loi de reproduction poissonnienne, condi-tionné à rester de taille constante. Plus précisément, soit d′ un entier vérifiant 0 6 d′ 6 d.Soit ν := L(P1, . . . , Pd |P1 + · · · + Pd = d), où P1, . . . , Pd sont i.i.d. de loi µ. Soient à présent(Z ′
n,m)n,m des variables aléatoires indépendantes, telles que Z ′n,1, . . . , Z
′n,d sont i.i.d. de loi ν
pour tout n. Définissons la suite (Y ′n) par Y ′
0 := d′ et Y ′n+1 := Z ′
1 + · · · + Z ′Y ′
npour tout n > 0.
Lorsque µ est une loi de Poisson, alors L(Y ′n+1 |Y ′
n) = B(d, Y ′n/d), et la suite (Y ′
n) est donc unechaîne de Wright-Fisher. Ce résultat découle du lemme 0.14.2 ci-dessous. Cette interprétationpoissonnienne est le point de départ d’une étude généalogique du modèle de Wright-Fisher viala notion de processus ancestral, étudiée par exemple dans [31], voir également [13]. Elle joueun rôle important en phylogénie.Lemme 0.14.2 (Poisson et multinomiale). Soit P1, . . . , Pd des variables aléatoires indépendantesde loi de Poisson de moyennes respectives λ1 > 0, . . . , λd > 0. Alors, pour tout n > 1, la loiconditionnelle L((P1, . . . , Pd) |P1 + · · ·+ Pd = n) est la loi multinomiale sur Nd donnée par
(p1δe1 + · · ·+ pdδed)∗n =
∑n1+···+nd=n
n!
n1! · · ·nd!pn1
1 · · · pndd δ(n1,...,nd),
où pi := λi/(λ1 + · · ·+ λd) et où {e1, . . . , ed} est la base canonique de Rd.
Démonstration. P(P1 = n1, . . . , Pd = nd) = e−λ1−···−λdλ
n11 ···λnd
d
n1!···nd!pour tout d-uplet d’entiers
(n1, . . . , nd). D’autre part P(P1 + · · ·+Pd = n) = e−λ1−···−λd(λ1 + · · ·+λd)n/n! car P1 + · · ·+Pd
suit la loi de Poisson de moyenne λ1 + · · · + λd (la somme de variables aléatoires de Poissonindépendantes est encore une variable aléatoire de Poisson).
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 51.
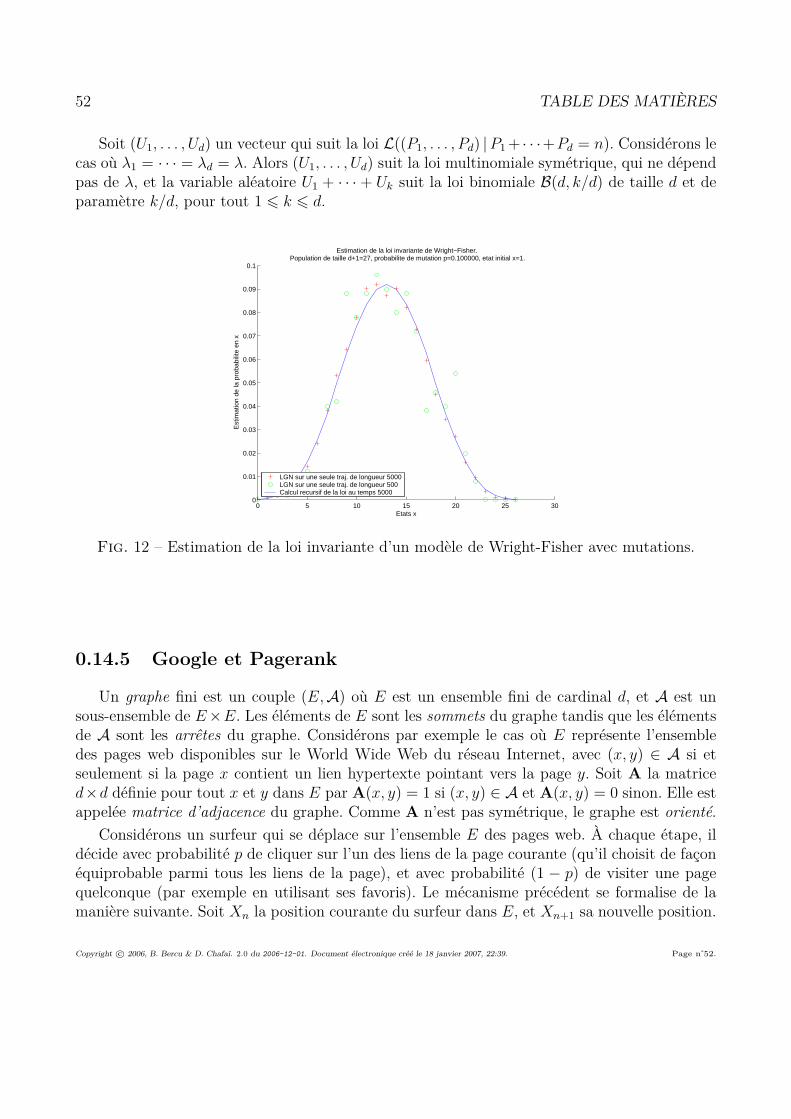
52 TABLE DES MATIÈRES
Soit (U1, . . . , Ud) un vecteur qui suit la loi L((P1, . . . , Pd) |P1 + · · ·+Pd = n). Considérons lecas où λ1 = · · · = λd = λ. Alors (U1, . . . , Ud) suit la loi multinomiale symétrique, qui ne dépendpas de λ, et la variable aléatoire U1 + · · · + Uk suit la loi binomiale B(d, k/d) de taille d et deparamètre k/d, pour tout 1 6 k 6 d.
0 5 10 15 20 25 300
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
Etats x
Est
imat
ion
de la
pro
babi
lite
en x
Estimation de la loi invariante de Wright−Fisher.Population de taille d+1=27, probabilite de mutation p=0.100000, etat initial x=1.
LGN sur une seule traj. de longueur 5000LGN sur une seule traj. de longueur 500Calcul recursif de la loi au temps 5000
Fig. 12 – Estimation de la loi invariante d’un modèle de Wright-Fisher avec mutations.
0.14.5 Google et Pagerank
Un graphe fini est un couple (E,A) où E est un ensemble fini de cardinal d, et A est unsous-ensemble de E×E. Les éléments de E sont les sommets du graphe tandis que les élémentsde A sont les arrêtes du graphe. Considérons par exemple le cas où E représente l’ensembledes pages web disponibles sur le World Wide Web du réseau Internet, avec (x, y) ∈ A si etseulement si la page x contient un lien hypertexte pointant vers la page y. Soit A la matriced×d définie pour tout x et y dans E par A(x, y) = 1 si (x, y) ∈ A et A(x, y) = 0 sinon. Elle estappelée matrice d’adjacence du graphe. Comme A n’est pas symétrique, le graphe est orienté.
Considérons un surfeur qui se déplace sur l’ensemble E des pages web. À chaque étape, ildécide avec probabilité p de cliquer sur l’un des liens de la page courante (qu’il choisit de façonéquiprobable parmi tous les liens de la page), et avec probabilité (1 − p) de visiter une pagequelconque (par exemple en utilisant ses favoris). Le mécanisme précédent se formalise de lamanière suivante. Soit Xn la position courante du surfeur dans E, et Xn+1 sa nouvelle position.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 52.

0.14. QUELQUES EXEMPLES CLASSIQUES 53
Conditionnellement à l’événement {Xn = x}, on a
Xn+1 =
{L si B = 1
M si B = 0
où B, L et M sont des variables aléatoires indépendantes qui suivent respectivement la loi deBernoulli pδ1 + (1 − p)δ0 sur {0, 1}, la loi uniforme sur l’ensemble {y ∈ E;A(x, y) = 1}, et laloi uniforme sur E. Ainsi, (Xn) est une chaîne de Markov sur E, dont le noyau de transition P
s’écrit P = pA + (1− p)C, où les noyaux de transition A et C sont définis par
A(x, y) :=A(x, y)∑
y∈E A(x, y)et C(x, y) :=
1
n
pour tout x et y dans E. Lorsque 0 < p < 1, le noyau de transition P est irréductible etapériodique car tous ses coefficients sont strictement positifs. Comme l’espace d’état E est fini,le noyau P possède une unique loi invariante µ. Pour tout x ∈ E, la quantité µ(x) représente laprobabilité que le surfeur se trouve sur la page x à l’équilibre. Il modélise la « popularité » de lapage x, en quelque sorte. Le nombre total de pages web d = card(E) est supérieur à plusieursmilliards depuis les années 2000. Il augmente régulièrement.
Du point de vue de l’utilisateur, le moteur de recherche Google renvoie, à partir de mots clésconstituant une requête, une liste totalement ordonnée de pages web constituant la réponse à larequête. Soit F ⊂ E l’ensemble des pages web correspondant à une requête particulière. Googlemet à profit un modèle markovien pour opérer le tri de F . Google trie les éléments de F par ordredécroissant sur µ. Ainsi, pour Google, une page web x ∈ F est d’autant plus « importante »qu’elle possède un poids µ(x) important. Le tri nécessite seulement la connaissance des rapportsµ(x)/µ(y). La valeur de p utilisée par Google est voisine de 0, 85. Cet algorithme est connu sousle nom de PageRank. Le PageRank d’une page web x ∈ E n’est rien d’autre que µ(x). Bienentendu, le PageRank réellement utilisé par Google n’est pas exactement celui décrit ici. Lemoteur de recherche Google et son algorithme PageRank ont été mis au point par Page et Brinà la fin des année 1990. Ils en présentent les principes dans [5]. Une étude markovienne dePageRank se trouve dans [1].
Du point de vue de Google, le problème est d’évaluer efficacement A, p, et µ. Du point de vuedes auteurs de pages web, le problème est de trouver des stratégies permettant d’améliorer lesPageRank de leurs pages, en créant des liens, c’est-à-dire en modifiant la matrice A localement.Cela permet à ces pages d’être mieux référencées par Google. Cela revient en quelque sorte àconcevoir la loi invariante µ comme une fonction de la matrice d’adjacence A du graphe.
La détermination de l’ensemble F associé à une requête particulière est possible grâce àd’immenses bases de données. Ces bases de données détenues par Google sont mises à jourrégulièrement par une horde de robots surfeurs – les googlebots – qui parcourent de façonautomatisée le graphe des pages web et extraient des mots clés. Ce parcours régulier du WorldWide Web permet également de mettre à jour la matrice A qui représente la géométrie dugraphe des pages web, ainsi que l’estimation de µ.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 53.

54 TABLE DES MATIÈRES
La chaîne de Markov (Xn) est un cas très particulier de chaîne de Markov sur un graphe.La marche aléatoire simple sur Zd abordée précédemment est une chaîne de Markov sur legraphe infini et non orienté Zd, pour lequel la matrice d’adjacence est définie par A(x, y) = 1si ‖x− y‖1 = 1 et A(x, y) = 0 sinon. La géométrie du graphe Zd est régulière, contrairement àcelle du graphe du World Wide Web.
Le modèle du surfeur que nous avons introduit ne tient pas compte du fait que le graphe luimême est aléatoire, et fluctue au cours du temps. On peut par exemple considérer que la matriced’adjacence est aléatoire. La taille de l’espace d’état peut également varier au cours du temps.L’étude mathématique des graphes aléatoires constitue un champ important de recherche àl’heure actuelle. De nombreux modèles issus de la physique, de l’informatique, et de la biologiefont intervenir des structures de graphes aléatoires. En physique, le phénomène de la percolationpeut être modélisé par des graphes aléatoires. En informatique, les réseaux pair-à-pair (Peer-to-Peer ou P2P) constituent des graphes aléatoires. Le lecteur pourra consulter le livre accessible[4] consacré aux graphes aléatoires.
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 54.

Bibliographie
[1] Konstantin Avrachenkov and Nelly Litvak, Decomposition of the Google PageRank and OptimalLinking Strategies, Rapport de recherches INRIA 501 - projet Maestro, Janvier 2004. 53
[2] R. B. Bapat and T. E. S. Raghavan, Nonnegative matrices and applications, Encyclopedia ofMathematics and its Applications, vol. 64, Cambridge University Press, Cambridge, 1997. MRMR1449393 (98h:15038) 35
[3] Philippe Barbe and Michel Ledoux, Probabilités, De la licence à l’agrégation, Belin, 1998. 33[4] Béla Bollobás, Random graphs, second ed., Cambridge Studies in Advanced Mathematics, vol. 73,
Cambridge University Press, Cambridge, 2001. MR MR1864966 (2002j:05132) 54[5] S. Brin and L. Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine,
WWW7/Computer Networks 30 (1998), no. 1-7, 107–117, disponible gratuitement : http://dbpubs.stanford.edu:8090/pub/1998-8. 53
[6] R. V. Chacon and D. S. Ornstein, A general ergodic theorem, Illinois J. Math. 4 (1960), 153–160.MR MR0110954 (22 #1822) 22
[7] Amir Dembo, Favorite points, cover times and fractals, Lectures on probability theory and sta-tistics, Lecture Notes in Math., vol. 1869, Springer, Berlin, 2005, pp. 1–101. MR MR222838336
[8] Amir Dembo, Yuval Peres, Jay Rosen, and Ofer Zeitouni, Cover times for Brownian motion andrandom walks in two dimensions, Ann. of Math. (2) 160 (2004), no. 2, 433–464. MR MR2123929(2005k:60261) 36
[9] Persi Diaconis, The cutoff phenomenon in finite Markov chains, Proc. Nat. Acad. Sci. U.S.A. 93(1996), no. 4, 1659–1664. MR MR1374011 (97b:60112) 46
[10] Persi Diaconis and David Freedman, Graphical illustration of some examples related to the ar-ticle: “Iterated random functions” [SIAM Rev. 41 (1999), no. 1, 45–76 (electronic); MR1669737(2000c:60102)] by P. Diaconis and D. Freedman, SIAM Rev. 41 (1999), no. 1, 77–82 (electronic).MR MR1669733 (2000c:60103) 39
[11] , Iterated random functions, SIAM Rev. 41 (1999), no. 1, 45–76 (electronic). MRMR1669737 (2000c:60102) 39
[12] W. Doeblin, Exposé de la théorie des chaînes simples constantes de Markov à un nombre finid’états, Rev. Math. Union Interbalkanique 2 (1938), 77–105. 27
[13] Rick Durrett, Probability models for DNA sequence evolution, Probability and its Applications(New York), Springer-Verlag, New York, 2002. MR MR1903526 (2003b:60003) 51
55

56 BIBLIOGRAPHIE
[14] William Feller, An introduction to probability theory and its applications. Vol. II., John Wiley &Sons Inc., New York, 1971. 43
[15] R. A. Fisher, On the dominance ratio, Proc. Roy. Soc. Edin. (1922), no. 42, 321–431. 46[16] Dominique Foata and Aimé Fuchs, Processus stochastiques - processus de poisson, chaînes de
markov et martingales, Dunod, 2002. 35[17] W. K. Hastings, Monte Carlo sampling methods using Markov chains and their applications,
Biometrika (1970), no. 57, 97–109. 30[18] R.A Horn and C.R. Johnson, Matrix Analysis, Cambridge University Press, 1990. 35[19] Gregory F. Lawler, Intersections of random walks, Probability and its Applications, Birkhäuser
Boston Inc., Boston, MA, 1991. MR MR1117680 (92f:60122) 43[20] Gérard Letac, A contraction principle for certain Markov chains and its applications, Random
matrices and their applications (Brunswick, Maine, 1984), Contemp. Math., vol. 50, Amer. Math.Soc., Providence, RI, 1986, pp. 263–273. MR MR841098 (88a:60121) 39
[21] David Levin, Yuval Peres, and Elisabeth Wilmer, Markov Chains and Mixing Times, disponiblegratuitement : http://www.oberlin.edu/markov/book/, Juin 2006. 35
[22] Torgny Lindvall, Lectures on the coupling method, Dover Publications Inc., Mineola, NY, 2002,Corrected reprint of the 1992 original. MR MR1924231 27
[23] A.A. Markov, Extension de la loi des grands nombres à des quantités dépendantes, Izvestiia Fiz.-Matem. Obsch. Kazan Univ. (seconde série) 15 (1906), 135–156, (en russe). 5
[24] N. Metropolis, A. Rosenbluth, M. Rosenbluth, A. Teller, and E. Teller, Equations of State Cal-culations by Fast Computing Machines, Journal of Chemical Physics (1953), no. 21, 1087–1092.30
[25] Jacques Neveu, Relations entre la théorie des martingales et la théorie ergodique, Ann. Inst.Fourier (Grenoble) 15 (1965), no. fasc. 1, 31–42, disponible gratuitement : http://www.numdam.org/. MR MR0219699 (36 #2778) 22
[26] J. R. Norris, Markov chains, Cambridge University Press, Cambridge, 1998, Reprint of 1997original. 23
[27] James David Propp and David Bruce Wilson, Exact sampling with coupled Markov chains andapplications to statistical mechanics, Proceedings of the Seventh International Conference on Ran-dom Structures and Algorithms (Atlanta, GA, 1995), vol. 9, 1996, pp. 223–252. MR MR1611693(99k:60176) 39
[28] Georg Pólya, Über eine Aufgabe der Wahrscheinlichkeitsrechung betreffend die Irrfahrt imStraßennetz, Mathematische Annalen (1921), no. 84, 149–160. 41
[29] Laurent Saloff-Coste, Lectures on finite Markov chains, Lectures on probability theory and statis-tics (Saint-Flour, 1996), Lecture Notes in Math., vol. 1665, Springer, Berlin, 1997, pp. 301–413.MR MR1490046 (99b:60119) 35
[30] F. Spitzer, Principes des cheminements aléatoires, Dunod, Paris, 1970. 43[31] Simon Tavaré, Ancestral inference in population genetics, Lectures on probability theory and
statistics, Lecture Notes in Math., vol. 1837, Springer, Berlin, 2004, pp. 1–188. MR MR207163051
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 56.

BIBLIOGRAPHIE 57
[32] Sewal Wright, Evolution in Mendelian populations, Genetics (1931), no. 16, 97–159. 46[33] Bernard Ycart, Cutoff for Markov chains: some examples and applications, Complex systems
(Santiago, 1998), Nonlinear Phenom. Complex Systems, vol. 6, Kluwer Acad. Publ., Dordrecht,2001, pp. 261–300. MR MR1886358 (2004a:60126) 46
Copyright c© 2006, B. Bercu & D. Chafaï. 2.0 du 2006-12-01. Document électronique créé le 18 janvier 2007, 22:39. Page n 57.





























