Embed Size (px)
Citation preview

Louis Monier@louis_monier
https://www.linkedin.com/in/louismonier
Deep Learning BasicsGo Deep or Go Home
Gregory Renard@redohttps://www.linkedin.com/in/gregoryrenard
Class 1 - Q1 - 2016

Supervised Learning
cathatdogcatmug
…
… =?
prediction
dog (89%)
training set …
Training(days)
Testing(ms)

Single Neuron to Neural Networks

Single Neuron
+
x
w1
xpos
x
w2
ypos
w3
ChoiceScore
Linear Combination Nonlinearity
3.4906 0.9981, red
Inputs
3.45
1.21
-0.314
1.59
2.65

More Neurons, More Layers: Deep Learning
input1
input2
input3
input layer hidden layers output layer
circleiris
eye
face
89% likely to be a face

How to find the best values for the weights?
w = Parameter
Error
a
b
Define error = |expected - computed| 2
Find parameters that minimize average error
Gradient of error wrt w is
Update:
take a step downhill

Egg carton in 1 million dimensions
Get to here
or here
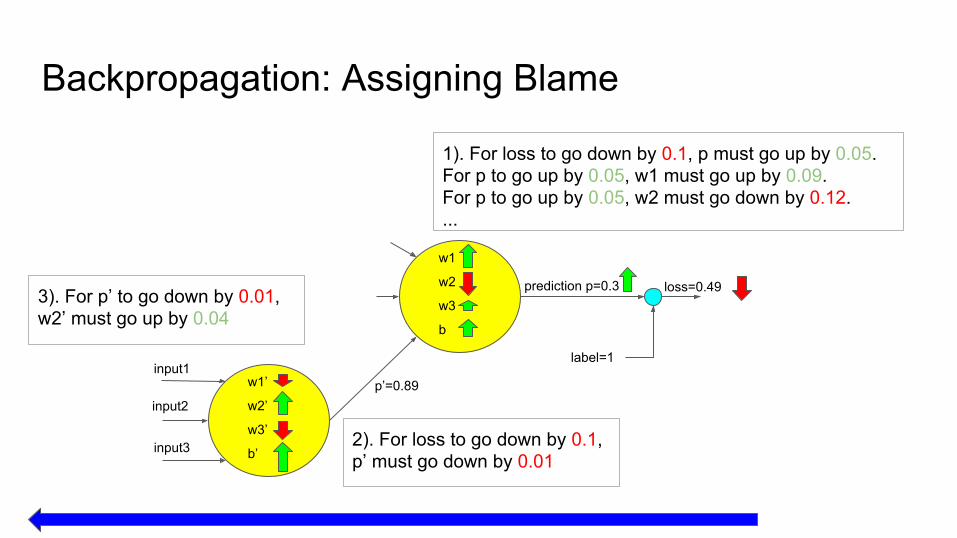
Backpropagation: Assigning Blame
input1
input2
input3
label=1
loss=0.49
w1
w2
w3
b
w1’
w2’
w3’
b’
1). For loss to go down by 0.1, p must go up by 0.05.For p to go up by 0.05, w1 must go up by 0.09.For p to go up by 0.05, w2 must go down by 0.12....
prediction p=0.3
p’=0.89
2). For loss to go down by 0.1, p’ must go down by 0.01
3). For p’ to go down by 0.01, w2’ must go up by 0.04

Stochastic Gradient Descent (SGD) and Minibatch
It’s too expensive to compute the gradient on all inputs to take a step.
We prefer a quick approximation.
Use a small random sample of inputs (minibatch) to compute the gradient.
Apply the gradient to all the weights.
Welcome to SGD, much more efficient than regular GD!

Usually things would get intense at this point...
Chain rule
Partial derivatives
HessianSum over paths
Credit: Richard Socher Stanford class cs224d
Jacobian matrix
Local gradient
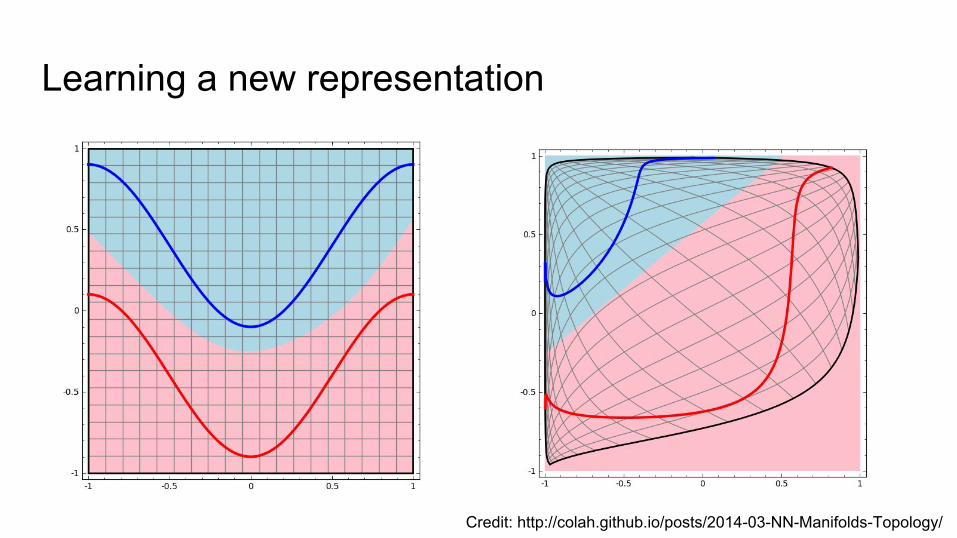
Learning a new representation
Credit: http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/

Training Data
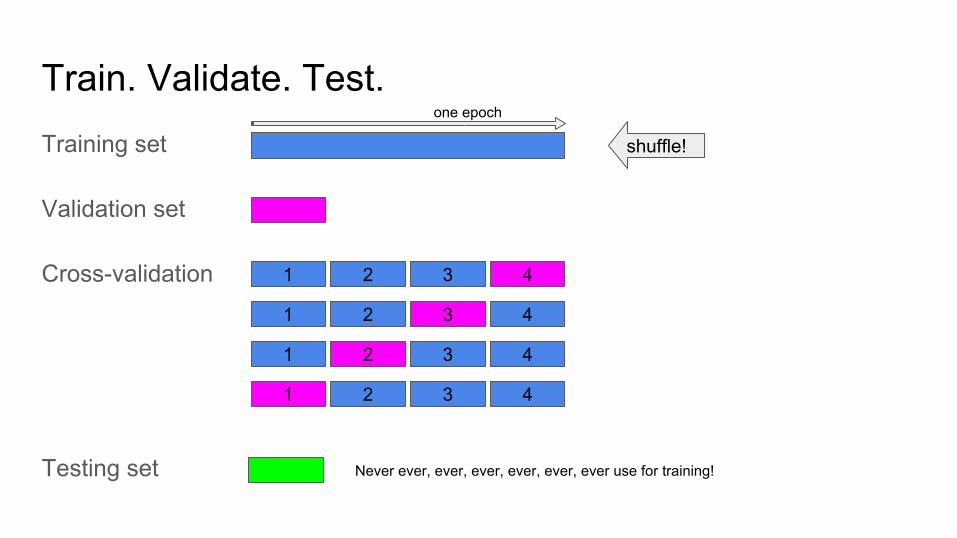
Train. Validate. Test.Training set
Validation set
Cross-validation
Testing set
2 3 41
2 3 41
2 3 41
2 3 41
shuffle!
one epoch
Never ever, ever, ever, ever, ever, ever use for training!

Tensors

Tensors are not scary
Number: 0D
Vector: 1D
Matrix: 2D
Tensor: 3D, 4D, … array of numbers
This image is a 3264 x 2448 x 3 tensor
[r=0.45 g=0.84 b=0.76]

Different types of networks / layers

Fully-Connected NetworksPer layer, every input connects to every neuron.
input1
input2
input3
input layer hidden layers output layer
circleiris
eye
face
89% likely to be a face

Recurrent Neural Networks (RNN)Appropriate when inputs are sequences.
We’ll cover in detail when we work on text.
pipe a not is this
t=0t=1t=2t=3t=4
this is not a pipe
t=0 t=1 t=2 t=3 t=4

Convolutional Neural Networks (ConvNets)Appropriate for image tasks, but not limited to image tasks.
We’ll cover in detail in the next session.

HyperparametersActivations: a zoo of nonlinear functions
Initializations: Distribution of initial weights. Not all zeros.
Optimizers: driving the gradient descent
Objectives: comparing a prediction to the truth
Regularizers: forcing the function we learn to remain “simple”
...and many more

ActivationsNonlinear functions

Sigmoid, tanh, hard tanh and softsign

ReLU (Rectified Linear Unit) and Leaky ReLU

Softplus and Exponential Linear Unit (ELU)

Softmax
x1 = 6.78
x2 = 4.25
x3 = -0.16
x4 = -3.5
dog = 0.92536
cat = 0.07371
car = 0.00089
hat = 0.00003
Raw scores Probabilities
SOFTMAX

Optimizers

Various algorithms for driving Gradient DescentTricks to speed up SGD.
Learn the learning rate.
Credit: Alex Radford

Cost/Loss/Objective Functions
=?

Cross-entropy Loss
x1 = 6.78
x2 = 4.25
x3 = -0.16
x4 = -3.5
dog = 0.92536
cat = 0.07371
car = 0.00089
hat = 0.00003
Raw scores Probabilities
SOFTMAX
dog: loss = 0.078
cat: loss = 2.607
car: loss = 7.024
hat: loss = 10.414
If label is:
=?
label (truth)

RegularizationPreventing Overfitting

Overfitting
Very simple.Might not predict well.
Just right? Overfitting. Rote memorization.Will not generalize well.

Regularization: Avoiding Overfitting
Idea: keep the functions “simple” by constraining the weights.
Loss = Error(prediction, truth) + L(keep solution simple)
L2 makes all parameters medium-size
L1 kills many parameters.
L1+L2 sometimes used.

At every step, during training, ignore the output of a fraction p of neurons.
p=0.5 is a good default.
Regularization: Dropout
input1
input2
input3

One Last Bit of Wisdom


Workshop : Keras & Addition RNNhttps://github.com/holbertonschool/deep-learning/tree/master/Class%20%230









![Cat. 2 classe F - golfodue.it. 2 classe F.pdf · VIA DELLA CONCIA 62/64 19121 ... olio di follone [04.01.99] ... polveri e rifiuti solidi da processi dl lavorazione e depurazione](https://img.pdfslide.net/doc/110x75/5c6c8e4909d3f287198c68c3/cat-2-classe-f-2-classe-fpdf-via-della-concia-6264-19121-olio-di.jpg)