Embed Size (px)
Citation preview

DL_POLY - A Performance Overview
Analysing, Understanding and Exploiting
available HPC Technology
DL_POLY 25th
Anniversary
3rd November 2017

220 November 2017DL_POLY - A Performance Overview
Outline and Contents
1. Introduction - Processor & Interconnect Technologies
¤ The last 10 years of Intel dominance – Nehalem to Skylake
2. DL_POLY Performance - Benchmarks & Test Cases
3. Overview of two decades of DL_POLY Performance
¤ From T3E/1200E to Intel Skylake clusters
4. Understanding Performance – Useful Tools
5. Today’s Code Performance – HPC clusters in use
¤ Processors, interconnects and Power Measurements
¤ Selecting Fabrics and Optimising Performance
6. Acknowledgements and Summary

Intel Xeon : Westmere - Broadwell
320 November 2017DL_POLY - A Performance Overview
Xeon 5600
(Westmere-EP)
Xeon E5-2600
(Sandy Bridge-
EP)
Xeon E5-2600 v2
(Ivy Bridge-EP)
Xeon E5-2600 v3
“Haswell-EP”
Xeon E5-2600 v4
“Broadwell-EP”
Cores /
Threads
Up to 6 cores / 12
threads
Up to 8 cores / 16
threads
Up to 12 Cores /
24 threads
Up to 18 Cores / 36
threads
Up to 22 Cores / 44
threads
Last-level
cache12 MB Up to 20 MB Up to 30 MB Up to 45 MB Up to 55 MB
Max memory
channels,
speed /
socket
3xDDR3
channels, 1333
4xDDR3
channels, 1600
4xDDR3 channels
1866 (1DPC), 1600,
1333, 1033
4xDDR4 channels
2133 (1DPC), 1866
(2DPC), 1600, 1333
4 channels of up to
3 RDIMMs,
LRDIMMs or 3DS
LRDIMMs, 2400
MHz
New
instructionsAES-NI
AVX 1.0
8 DP Flops/Clock
AVX 1.0
8 DP Flops/Clock
AVX 2.0
16 DP Flops / Clock
AVX 2.0
16 DP Flops/Clock
QPI / UPI
Speed (GT/s)
1 QPI channels @
6.4 GT/s
2 QPI channels @
8.0 GT/s
2 QPI channels @
8.0 GT/s
2 x QPI channels @
9.6 GT/s
2 x QPI channels @
9.6 GT/s
PCIe Lanes /
Controllers /
Speed (GT/s)
36 lanes PCIe 2.0
on chipset
40 Lanes / Socket
Integrated PCIe
3.0
40 Lanes / Socket
Integrated PCIe 3.0
40 Lanes / Socket
Integrated PCIe 3.0
40 / 10 / PCIe* 3.0
(2.5, 5, 8 GT/s)
Server /
Workstation
TDP
Server /
Workstation:
130W
Up to 130W
Server; 150W
Workstation
Up to 130W
Server;
150W Workstation
Up to 145W Server;
160W Workstation55 - 145W

The Xeon Skylake Architecture
420 November 2017DL_POLY - A Performance Overview
• The architecture of Skylake is
very different from that of the prior
“Haswell” and “Broadwell” Xeon
chips
• Three basic variants that now
cover what was formerly the Xeon
E5 and Xeon E7 product lines, with
Intel converging the Xeon E5 and
E7 chips into a single socket.
• Product segmentation – Platinum, Gold, Silver, & Bronze – with 51
variants of the SP chip
• Also custom versions requested by hyperscale and OEM customers.
• All of these chips differ from each other in a number of ways, including
number of cores, clock speed, L3 cache capacity, number and speed of
UltraPath links between sockets, number of sockets supported, main
memory capacity, width of the AVX vector units etc.

FeaturesIntel Xeon Processor E5-
2600 v4
Intel Xeon Scalable
Processor
Cores per socket Up to 22 Up to 28
Threads per socket Up to 44 threads Up to 56 threads
Last-level Cache (LLC) Up to 55 MB Up to 38.5 MB (non-inclusive)
QPI / UPI Speed (GT/s) 2 x QPI channels @ 9.6 GT/s Up to 3x UPI @ 10.4 GT/s
PCIe Lanes / Controllers
/ Speed (GT/s)
40 / 10 / PCIe* 3.0 (2.5, 5, 8
GT/s)
48 / 12 / PCIe* 3.0 (2.5, 5, 8
GT/s)
Memory Population4 channels of up to 3 RDIMMs,
LRDIMMs or 3DS LRDIMMs
6 channels of up to 2 RDIMMs,
LRDIMMs or 3DS LRDIMMs
Max Memory Speed
(Mhz)Up to 2400 Mhz Up to 2666 Mhz
TDP (W) 55 - 145W 70 – 205W
Intel Xeon Scalable Processor (“Skylake”)
520 November 2017DL_POLY - A Performance Overview

Skylake Cluster Systems
620 November 2017DL_POLY - A Performance Overview
Cluster / Configuration
32 node Dell|EMC cluster running SLURM with separate partitions for each
processor SKU; Mellanox EDR:
Intel® Xeon® Gold 6150 Processor (24.75M Cache, 2.70GHz), Max Turbo frequency,
3.70 GHz. # cores 18; #threads 36; DDR4-2666; TDP 165W; # of UPI Links 3;
Intel® Xeon® Gold 6142 Processor (22M Cache, 2.60GHz), Max Turbo frequency,
3.70 GHz, # cores 16; #threads 32; DDR4-2666; TDP 150W; # of UPI Links 3.
28 node Dell|EMC cluster running SLURM: Intel OPA
Intel® Xeon® Gold 6130 Processor (22M Cache, 2.10GHz), Max Turbo frequency,
3.70 GHz, # cores 16; #threads 32; DDR4-2666; TDP 125W; # of UPI Links 3.
The 6130’s are configured with 12 × 8GB 2666 DIMMs rather than 12 × 16GB, resulting
in somewhat slower memory bandwidth (165 GB/s vs 195 GB/s STREAM Triad).
20 node Bull|ATOS cluster running SLURM;
Intel® Xeon® Gold 6150 Processor (24.75M Cache, 2.70 GHz), Max Turbo
frequency, 3.70 GHz. # cores 18; #threads 36; DDR4-2666; TDP 165W; # of UPI Links
3; SMT; Mellanox EDR.

74,309
93,486
118,605 114,367
132,035 128,083
165,974
185,863 188,641184,087
267,864
0
50,000
100,000
150,000
200,000
250,000
Bull b510"Raven"Sandy
Bridge e5-2670/2.6GHz IB-
QDR
ClusterVision e5-2650v2 2.6GHz
Dell R730Haswell e5-
2697v3 2.6GHz(T)
Dell OPA32 e5-2660v3 2.6GHz
(T) OPA
Thor Broadwelle5-2697A v42.6GHz (T)
ATOS Broadwelle5-2680v4
2.4GHz (T) OPA
Dell SkylakeGold 6130
2.1GHz (T) OPA
Dell SkylakeGold 61422.6GHz (T)
Dell SkylakeGold 61502.7GHz (T)
IBM Power8S822LC 2.92GHz
IB/EDR
AMD Epyc 76012.2 GHz
Memory B/W –STREAM performance
720 November 2017DL_POLY - A Performance Overview
TRIAD [Rate (MB/s) ]
Ivy Bridge & Haswell
E5-26xx v2,v3
OMP_NUM_THREADS (KMP_AFFINITY=physical
Broadwell
E5-26xx v4
Skylake Gold
6130, 6142, 6150

4,644
5,843
4,236
5,718
4,126
4,574
5,187
5,808
5,240
9,204
4,185
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
9,000
10,000
Bull b510"Raven"Sandy
Bridge e5-2670/2.6GHz IB-
QDR
ClusterVision e5-2650v2 2.6GHz
Dell R730Haswell e5-
2697v3 2.6GHz(T)
Dell OPA32 e5-2660v3 2.6GHz
(T) OPA
Thor Broadwelle5-2697A v42.6GHz (T)
ATOS Broadwelle5-2680v4
2.4GHz (T) OPA
Dell SkylakeGold 6130
2.1GHz (T) OPA
Dell SkylakeGold 61422.6GHz (T)
Dell SkylakeGold 61502.7GHz (T)
IBM Power8S822LC 2.92GHz
IB/EDR
AMD Epyc 76012.2 GHz
Memory B/W – STREAM / core performance
820 November 2017DL_POLY - A Performance Overview
TRIAD [Rate (MB/s) ]
OMP_NUM_THREADS (KMP_AFFINITY=physical
Ivy Bridge & Haswell
E5-26xx v2,v3
Broadwell
E5-26xx v4
Skylake Gold
6130, 6142, 6150

Memory Access and Peak Mflop Rates
920 November 2017DL_POLY - A Performance Overview

11,466.19,281
3.5
5,992
2,954
1.7
3,694
1,729
1
10
100
1,000
10,000
1.E+00 1.E+01 1.E+02 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07
IBM Power8 S822LC 2.92GHz IB/EDR
Thor Broadwell e5-2697A v4 2.6GHz (T) EDR
Intel Broadwell e5-2690v4 2.6GHz (T) EDR
Intel Broadwell e5-2690v4 2.6GHz (T) OPA
Bull Haswell E5-2680v3 2.5 GHz (T) EDR
Dell OPA32 e5-2660v3 2.6GHz (T) OPA
Bull Haswell E5-2680v3 2.5 GHz (T) Connect-IB
Cray XC30 e5-2697v2 2.7 GHz ARIES [Archer]
Dell R720 Ivy Bridge e5-2680v2 2.8 GHz (T) connect-IB
Intel Ivy Bridge e5-2697v2 2.7 GHz Mellanox FDR
ClusterVision e5-2650v2 2.6 GHz Truescale QDR
Azure A9 WE (e5-2670 2.6 GHz) IB RDMA
Merlin Xeon E5472 3.0 GHz QC + IB (mvapich2 1.4)
MPI Performance – PingPong
IMB Benchmark (Intel)
1 PE / node
Latency
Message Length (Bytes)
Mb
yte
s/s
ec
1020 November 2017DL_POLY - A Performance Overview
BE
TT
ER

96.8
426.8
137.5
207.4
5.E+01
5.E+02
5.E+03
5.E+04
5.E+05
5.E+06
1.0E+00 1.0E+01 1.0E+02 1.0E+03 1.0E+04 1.0E+05 1.0E+06 1.0E+07
QLogic NDC X5670 2.93GHz 6-C + QDR (Qlogic MPI)
Fujitsu CX250 Sandy Bridge e5-2670/2.6 GHz IB-QDR
Intel Ivy Bridge e5-2697v2 2.7 GHz Mellanox FDR
Cray XC30 e5-2697v2 2.7 GHz ARIES [Archer]
Intel Haswell e5-2697v3 2.6 GHz (T) Truescale QDR
Bull Haswell e5-2680v3 2.5 GHz (T) EDR
Dell Haswell e5-2660v3 2.6 GHz (T) OPA
Huawei Fusion CH140 e5-2683 v4 2.1GHz (T) EDR
Boston Broadwell e5-2650v4 2.2GHz (T) FDR
Boston Broadwell e5-2680v4 2.4GHz (T) OPA
Thor Broadwell e5-2697A v4 2.6GHz (T) EDR
Intel Broadwell e5-2690v4 2.6GHz (T) OPA
IBM Power8 S822LC 2.92GHz IB/EDR
MPI Collectives – Alltoallv (128 PEs)
IMB Benchmark (Intel)
128 PEs
Latency
BE
TT
ER
Message Length (Bytes)
Measured Time (usec)
Determines CASTEP
Performance
1120 November 2017DL_POLY - A Performance Overview
IBM Power 8 (EDR)
superior performance at
most message lengths

DL_POLY - A Performance Overview
Analysing, Understanding and Exploiting
available HPC Technology
Overview of
two decades of
DL_POLY
Performance

DL_POLY 4
• Test2 Benchmark
¤ NaCl Simulation;
216,000 ions, 200 time
steps, Cutoff=12Å
• Test8 Benchmark
¤ Gramicidin in water;
rigid bonds + SHAKE:
792,960 ions, 50 time
steps
The DLPOLY Benchmarks
1320 November 2017DL_POLY - A Performance Overview
DL_POLY Classic
• Bench4
¤ NaCl Melt Simulation with Ewald
sum electrostatics & a MTS
algorithm. 27,000 atoms; 500 time
steps.
• Bench5
¤ Potassium disilicate glass (with 3-
body forces). 8,640 atoms: 3,000
time steps
• Bench7
¤ Simulation of gramicidin A molecule
in 4012 water molecules using
neutral group electrostatics. 12,390
atoms: 5,000 time steps
DL_POLY_4 and Xeon Phi: Lessons
Learnt,
Alin Marin Elena , Christian Lalanne ,
Victor Gamayunov , Gilles Civario ,
Michael Lysaght , and Ilian Todorov

112
0
20
40
60
80
100
120
Cra
y T
3E
/120
0
IBM
SP
/WH
2-3
75
SG
I O
rig
in 3
80
0/R
12
k-4
00
CS
4 A
MD
1.2
GH
z/F
E
CS
6 P
III/
80
0 +
FE
/LA
M
IBM
Re
ga
tta-H
Alp
haS
erv
er
SC
ES
45/1
000
CS
13
P4/2
20
0 +
My
rin
et
CS
12
P4 X
eo
n/2
400
+ G
bit
E
SG
I A
ltix
37
00/I
tan
ium
2 1
300
SG
I A
ltix
37
00/I
tan
ium
2 1
500
CS
18
P4 X
eo
n/2
800
+ M
2k
CS
19
Op
tero
n2
46/2
.0 +
IB
CS
21
P4 E
M64
T/3
40
0 +
IB
CS
23
Path
sca
le O
pte
ron
85
2/2
.6 +
IP
HT
X
Cra
y X
T3
CS
24
Op
tero
n2
70/2
.0 D
C +
M2
k
CS
28
Op
tero
n2
75/2
.2 D
C +
IP
(E
KO
)
CS
29
Op
tero
n2
80/2
.4 D
C +
IB
CS
30
Xeo
n 5
16
0 3
.0G
Hz D
C +
IB
CS
32
Op
tero
n 2
21
8-F
2.6
GH
z D
C +
IP
HT
X
HP
SD
64
B Ita
niu
m 2
90
50
/ 1
.6G
Hz
CS
34
NW
GR
ID O
pte
ron
28
0/2
.4 D
C +
GB
itE
CS
36
Xeo
n 5
16
0 3
.0G
Hz D
C +
IP
HT
X
AM
D B
arc
elo
na 2
350
2.0
GH
z Q
C +
C-X
(S
cali
+P
SC
)
CS
45
HP
BL
46
0c X
eo
n 5
16
0/3
.0G
Hz D
C +
…
CS
50
SG
I Ic
e X
53
65
Clo
vert
ow
n 3
.0G
Hz Q
C +
…
CS
47
In
tel E
54
72 H
arp
ert
ow
n 3
.0G
Hz Q
C 1
600
…
CS
51
Bu
ll X
eo
n E
54
72
3.0
GH
z Q
C 1
600
FS
B +
…
CS
54
SG
I Ic
e X
eo
n E
544
0 2
.83
GH
z Q
C +
Vo
lta
ire…
IBM
pS
eri
es 5
75 4
.7 G
Hz D
C +
IB
Clu
ste
rVis
ion
E5
462
2.8
0G
Hz Q
C +
IB
-DD
R…
CS
59
In
tel E
54
82 3
.20
GH
z Q
C +
IB
-DD
R (
mv
ap
ich
)
Cra
y X
T4
Op
tero
n 2
.3G
Hz Q
C
CS
62
In
tel X
55
70 N
H 2
.93G
Hz Q
C +
10
GB
itE
…
CS
64
X56
70 W
SM
2.9
3G
Hz 6
-C +
C-X
QD
R…
CS
66
In
tel L
75
55
Ne
hale
mE
X 1
.87G
Hz +
IB
QD
R
Fu
jits
u "
HT
C" B
X9
22
X5
65
0 2
.66
GH
z +
IB
Bu
llx B
51
0 S
an
dy B
rid
ge
E5-2
68
0 8
-C +
IB
QD
R
CS
73
QL
og
ic N
DC
X5
67
0 2
.93
GH
z 6
-C +
QD
R…
Fu
jits
u B
X922
WS
M
X5
65
0 2
.67G
Hz I
B-Q
DR
Fu
jits
u C
X250
Sa
nd
y B
rid
ge e
5-2
69
0/2
.9G
Hz [
T]…
Inte
l Iv
y B
rid
ge
e5
-269
0v2
3.0
GH
z (
T)
Tru
e S
cale
…
Dell
R72
0 Iv
y B
rid
ge
e5-2
680
v2
2.8
GH
z (
T)…
Inte
l Iv
y B
rid
ge
e5
-269
7v2
2.7
GH
z M
ell
an
ox
FD
R
Clu
serV
isio
n Iv
y B
rid
ge
e5-2
650
v2 2
.6G
Hz…
Inte
l H
as
we
ll e
5-2
69
7v
3 2
.6G
Hz (
T)
Tru
es
ca
le Q
DR
Bu
ll H
as
we
ll e
5-2
69
5v
3 2
.3G
Hz C
on
ne
ct-
IB
Inte
l B
roa
dw
ell2
e5-2
690
v4
2.6
GH
z (
T)
OP
A
Bo
sto
n B
roa
dw
ell
e5
-268
0v4
2.4
GH
z (
T)
OP
A
IBM
Po
wer8
S8
22
LC
2.9
2G
Hz I
B/E
DR
Hu
aw
ei F
us
ion
CH
14
0 e
5-2
69
0 v
4 2
.6G
Hz (
T)
ED
R
Bu
ll|A
TO
S S
kyla
ke G
old
615
0 2
.7G
Hz (
T)
OF
A
DLPOLY 2 - Bench 4
DL_POLY Classic: Bench 4
1420 November 2017DL_POLY - A Performance Overview
Performance Relative to the Cray T3E/1200 (16 CPUs)
47
0
10
20
30
40
50
Cra
y T
3E
/120
0
IBM
SP
/WH
2-3
75
CS
3 A
MD
K7/8
50 +
My
rin
et
Cra
y L
inu
x C
lus
ter
CS
7 A
MD
K7/1
000
MP
+ S
CI
ES
40
/66
7
CS
8 I
tan
ium
/80
0 +
My
rin
et
Alp
haS
erv
er
SC
ES
45/1
000
CS
13
P4/2
20
0 +
My
rin
et
CS
12
P4 X
eo
n/2
400
+ G
bit
E
SG
I A
ltix
37
00/I
tan
ium
2 1
300
SG
I A
ltix
37
00/I
tan
ium
2 1
500
CS
18
P4 X
eo
n/2
800
+ M
2k
CS
19
Op
tero
n2
46/2
.0 +
Gb
itE
CS
21
P4 E
M64
T/3
40
0 +
IB
CS
23
Path
sca
le O
pte
ron
85
2/2
.6 +
IP
HT
X
Cra
y X
T3
CS
24
Op
tero
n2
70/2
.0 D
C +
M2
k
CS
28
Op
tero
n2
75/2
.2 D
C +
IP
(E
KO
)
CS
34
NW
GR
ID O
pte
ron
28
0/2
.4 D
C +
…
CS
31
Xeo
n 5
15
0 2
.66G
Hz D
C +
IB
HP
RX
86
40
/Ita
niu
m2 1
600
DC
CS
33
Xeo
n 5
16
0 3
.0G
Hz D
C +
IP
HT
X
CS
35
CU
BR
IC O
pte
ron
27
5/2
.2 D
C +
GB
itE
CS
42
Op
tero
n 2
21
8-F
2.6
GH
z D
C +
…
IBM
x3
55
0 H
arp
ert
ow
n 2
.83
GH
z Q
C 1
333
…
CS
45
HP
BL
46
0c X
eo
n 5
16
0/3
.0G
Hz D
C +
…
CS
46
HP
Bl4
60
c E
53
45
Clo
ve
rto
wn
…
CS
52
Clu
ste
rV E
54
30
Harp
ert
ow
n…
CS
53
SG
I Ic
e X
eo
n E
544
0 2
.83
GH
z Q
C +
…
Op
tero
n 8
38
4 S
ha
ng
ha
i 2.7
GH
z Q
C +
IB
…
SG
I Ic
e X
eo
n E
54
62 2
.83
GH
z Q
C +
C-X
…
CS
57
In
tel X
55
60 N
eh
ale
m 2
.8G
Hz Q
C +
…
CS
60
Vig
len
E5
52
0 N
EH
2.2
7G
Hz Q
C +
IB
…
CS
61
Bu
llx
X55
50
NE
H 2
.67
GH
z Q
C +
…
CS
63
In
tel X
55
70 N
EH
2.9
3G
Hz Q
C +
C-X
…
CS
66
In
tel L
75
55
NE
H-E
X 1
.87
GH
z +
IB
…
Fu
jits
u "
HT
C" B
X9
22
X5
65
0 2
.66
GH
z +
IB
Dell
PE
In
terl
ag
os
Op
tero
n 6
22
0 3
.0G
Hz…
CS
73
QL
og
ic N
DC
X5
67
0 2
.93
GH
z 6
-C +
…
CS
74
QL
og
ic N
DC
X5
67
5 3
.07
GH
z 6
-C +
…
Fu
jits
u C
X250
Sa
nd
y B
rid
ge e
5-…
Fu
jits
u C
X250
Sa
nd
y B
rid
ge e
5-…
Inte
l Iv
y B
rid
ge
e5
-269
7v2
2.7
GH
z T
rue
…
Bu
ll B
71
0 Iv
y B
rid
ge e
5-2
69
7v
2 2
.7G
Hz…
Cra
y X
C3
0 e
5-2
69
7v
2 2
.7G
Hz A
RIE
S…
Inte
l H
as
we
ll e
5-2
69
7v
3 2
.6G
Hz (
T)…
Bu
ll H
as
we
ll e
5-2
69
0v
3 2
.6G
Hz C
on
ne
ct-
IB
Bu
ll H
as
we
ll e
5-2
68
0v
3 2
.5G
Hz (
T)…
Bo
sto
n B
roa
dw
ell
e5
-265
0v4
2.2
GH
z (
T)…
Th
or
Bro
ad
well
e5
-26
97
A v
4 2
.6G
Hz (
T)…
Hu
aw
ei F
us
ion
CH
14
0 e
5-2
68
3 v
4 2
.1G
Hz…
Bu
ll|A
TO
S B
roa
dw
ell e
5-2
68
0v
4 2
.4G
Hz…
Hu
aw
ei S
ky
lak
e G
old
61
50
-2.7
GH
z [
18
c]
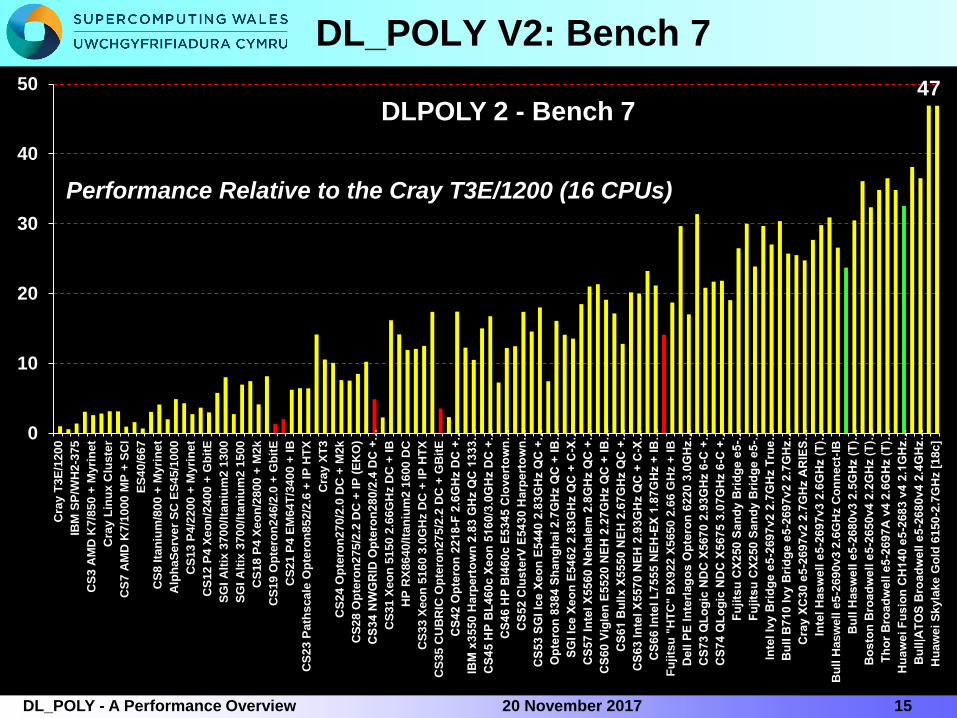
DLPOLY 2 - Bench 7
DL_POLY V2: Bench 7
1520 November 2017DL_POLY - A Performance Overview
Performance Relative to the Cray T3E/1200 (16 CPUs)
136
0.0
20.0
40.0
60.0
80.0
100.0
120.0
140.0
Fu
jits
u B
X922
WS
M
X5
65
0 2
.67G
Hz +
IB
-QD
R
PO
D W
SM
X56
75 3
.07
GH
z
Tru
es
ca
le Q
DR
Fu
jits
u C
X250
SB
e5-2
670
/2.6
GH
z I
B-Q
DR
Fu
jits
u C
X250
S
B e
5-2
690
/2.9
GH
z I
B-Q
DR
Fu
jits
u C
X250
S
B e
5-2
690
/2.9
GH
z [
T]
IB-Q
DR
PO
D S
B e
5-2
67
0 2
.6G
Hz T
rue
sca
le Q
DR
Azu
re A
9 W
E (
e5
-267
0 2
.6 G
Hz)
IB R
DM
A
Inte
l IB
e5-2
697
v2 3
.0G
Hz (
T)
Tru
e S
ca
le Q
DR
Inte
l IB
e5-2
697
v2 2
.7 G
Hz T
rue
Sca
le P
SM
De
ll R
72
0 IB
e5
-26
80
v2
2.8
GH
z (
T)
co
nn
ec
t-IB
Bu
ll B
71
0 IB
e5
-269
7v2
2.7
GH
z M
ell
an
ox
FD
R
Inte
l IB
e5-2
697
v2 2
.7 G
Hz M
ell
an
ox
FD
R
Cra
y X
C3
0 e
5-2
69
7v
2 2
.7G
Hz A
RIE
S [
Arc
her]
Clu
ste
rVis
ion
e5
-26
50
v2
2.6
GH
z T
rues
ca
le Q
DR
Inte
l H
SW
e5-2
697
v3 2
.6G
Hz T
rue
sca
le Q
DR
(T
)
Inte
l H
SW
e5-2
697
v3 2
.6G
Hz (
T)
Tru
esc
ale
QD
R
Bu
ll H
SW
e5
-26
90
v3
2.6
GH
z C
on
nec
t-IB
Bu
ll H
SW
e5
-26
95
v3
2.3
GH
z C
on
nec
t-IB
Bu
ll H
SW
e5
-26
80
v3
2.5
GH
z (
T)
ED
R
SG
I IC
E-X
HS
W e
5-2
690
v3 2
.6G
Hz (
T)
IB F
DR
Dell
R73
0 H
SW
e5
-26
97
v3
2.6
GH
z c
on
ne
ct-
IB (
T)
Dell
OP
A32 e
5-2
66
0v
3 2
.6G
Hz (
T)
OP
A
Bu
ll H
SW
e5
-26
80
v3
2.5
GH
z (
T)
Co
nn
ec
t-IB
Inte
l H
SW
e5-2
690
v4 2
.6G
Hz (
T)
OP
A
Inte
l H
SW
e5-2
690
v4 2
.6G
Hz (
T)
ED
R
Bo
sto
n H
SW
e5-2
65
0v
4 2
.2G
Hz (
T)
FD
R
Bo
sto
n H
SW
e5-2
68
0v
4 2
.4G
Hz (
T)
OP
A
Th
or
HS
W e
5-2
69
7A
v4
2.6
GH
z (
T)
ED
R
IBM
Po
wer8
S8
22
LC
2.9
2G
Hz I
B/E
DR
Hu
aw
ei F
us
ion
CH
14
0 e
5-2
68
3 v
4 2
.1G
Hz (
T)
ED
R
AT
OS
HS
W e
5-2
68
0v
4 2
.4G
Hz (
T)
ED
R
AT
OS
HS
W e
5-2
68
0v
4 2
.4G
Hz (
T)
OP
A
Dell
Sk
yla
ke
61
42 2
.6G
Hz (
T)
ED
R
Dell
Sk
yla
ke
61
50 2
.7G
Hz (
T)
ED
R
OPA, IB - EDR
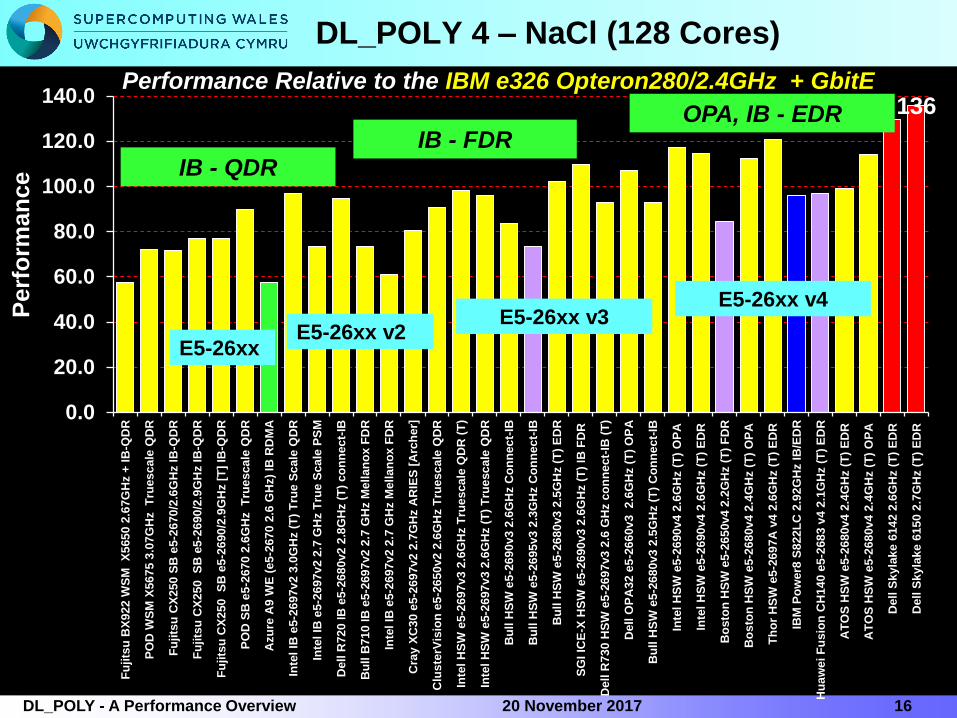
DL_POLY 4 – NaCl (128 Cores)
1620 November 2017DL_POLY - A Performance Overview
Performance Relative to the IBM e326 Opteron280/2.4GHz + GbitE
E5-26xxE5-26xx v2
E5-26xx v3E5-26xx v4
Perf
orm
an
ce IB - QDR
IB - FDR

61
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
Fu
jits
u B
X922
WS
M
X5
65
0 2
.67G
Hz +
IB
-QD
R
PO
D W
SM
X56
75 3
.07
GH
z
Tru
es
ca
le Q
DR
Azu
re A
9 W
E (
e5
-267
0 2
.6 G
Hz)
IB R
DM
A
PO
D S
B H
30
e5-2
670
2.6
GH
z T
rue
sc
ale
QD
R
Fu
jits
u C
X250
SB
e5-2
670
/2.6
GH
z I
B-Q
DR
Fu
jits
u C
X250
S
B e
5-2
690
/2.9
GH
z I
B-Q
DR
Fu
jits
u C
X250
S
B e
5-2
690
/2.9
GH
z[T
] IB
-QD
R
Inte
l IB
e5-2
697
v2 3
.0G
Hz (
T)
Tru
e S
ca
le Q
DR
Inte
l IB
e5-2
697
v2 2
.7 G
Hz T
rue
Sca
le P
SM
Dell
R72
0 IB
e5
-26
80
v2
2.8
GH
z (
T)
co
nn
ec
t-IB
Bu
ll B
71
0 IB
e5
-269
7v2
2.7
GH
z M
ell
an
ox
FD
R
Inte
l IB
e5-2
697
v2 2
.7 G
Hz M
ell
an
ox
FD
R
Cra
y X
C3
0 e
5-2
69
7v
2 2
.7G
Hz A
RIE
S [
Arc
her]
Clu
ste
rVis
ion
e5
-26
50
v2
2.6
GH
z T
rues
ca
le Q
DR
Inte
l H
SW
e5-2
697
v3 2
.6G
Hz T
rue
sca
le Q
DR
(T
)
Inte
l H
SW
e5-2
697
v3 2
.6G
Hz (
T)
Tru
esc
ale
QD
R
Bu
ll H
SW
e5
-26
90
v3
2.6
GH
z C
on
nec
t-IB
Bu
ll H
SW
e5
-26
95
v3
2.3
GH
z C
on
nec
t-IB
Bu
ll H
SW
e5
-26
80
v3
2.5
GH
z (
T)
ED
R
SG
I IC
E-X
HS
W e
5-2
690
v3 2
.6G
Hz (
T)
IB F
DR
Dell
OP
A32 e
5-2
66
0v
3 2
.6G
Hz (
T)
OP
A
Bu
ll H
SW
e5
-26
80
v3
2.5
GH
z (
T)
Co
nn
ec
t-IB
Inte
l B
DW
e5-2
690
v4
2.6
GH
z (
T)
OP
A
Inte
l B
DW
e5-2
690
v4
2.6
GH
z (
T)
ED
R
Bo
sto
n B
DW
e5
-26
50v
4 2
.2G
Hz (
T)
FD
R
Bo
sto
n B
DW
e5
-26
80v
4 2
.4G
Hz (
T)
OP
A
Th
or
BD
W e
5-2
69
7A
v4
2.6
GH
z (
T)
ED
R
IBM
Po
wer8
S8
22
LC
2.9
2G
Hz I
B/E
DR
Hu
aw
ei F
us
ion
CH
14
0 e
5-2
68
3 v
4 2
.1G
Hz (
T)
ED
R
AT
OS
BD
W e
5-2
68
0v
4 2
.4G
Hz (
T)
ED
R
AT
OS
BD
W e
5-2
68
0v
4 2
.4G
Hz (
T)
OP
A
Dell
Sk
yla
ke
61
42 2
.6G
Hz (
T)
ED
R
Dell
Sk
yla
ke
61
50 2
.7G
Hz (
T)
ED
R
DL_POLY 4 – Gramicidin (32 Cores)
1720 November 2017DL_POLY - A Performance Overview
Performance Relative to the IBM e326 Opteron280/2.4GHz + GbitE
E5-26xxE5-26xx v2
E5-26xx v3E5-26xx v4
Perf
orm
an
ce

103
0.0
20.0
40.0
60.0
80.0
100.0F
ujits
u B
X922
WS
M
X5
65
0 2
.67G
Hz +
IB
-QD
R
PO
D W
SM
X56
75 3
.07
GH
z
Tru
es
ca
le Q
DR
Azu
re A
9 W
E (
e5
-267
0 2
.6 G
Hz)
IB R
DM
A
PO
D S
B H
30
e5-2
670
2.6
GH
z T
rue
sc
ale
QD
R
Fu
jits
u C
X250
SB
e5-2
670
/2.6
GH
z I
B-Q
DR
Fu
jits
u C
X250
S
B e
5-2
690
/2.9
GH
z I
B-Q
DR
Fu
jits
u C
X250
S
B e
5-2
690
/2.9
GH
z[T
] IB
-QD
R
Inte
l IB
e5-2
697
v2 3
.0G
Hz (
T)
Tru
e S
ca
le Q
DR
Inte
l IB
e5-2
697
v2 2
.7 G
Hz T
rue
Sca
le P
SM
Dell
R72
0 IB
e5
-26
80
v2
2.8
GH
z (
T)
co
nn
ec
t-IB
Bu
ll B
71
0 IB
e5
-269
7v2
2.7
GH
z M
ell
an
ox
FD
R
Inte
l IB
e5-2
697
v2 2
.7 G
Hz M
ell
an
ox
FD
R
Cra
y X
C3
0 e
5-2
69
7v
2 2
.7G
Hz A
RIE
S [
Arc
her]
Clu
ste
rVis
ion
e5
-26
50
v2
2.6
GH
z T
rues
ca
le Q
DR
Inte
l H
SW
e5-2
697
v3 2
.6G
Hz T
rue
sca
le Q
DR
(T
)
Inte
l H
SW
e5-2
697
v3 2
.6G
Hz (
T)
Tru
esc
ale
QD
R
Bu
ll H
SW
e5
-26
90
v3
2.6
GH
z C
on
nec
t-IB
Bu
ll H
SW
e5
-26
95
v3
2.3
GH
z C
on
nec
t-IB
Bu
ll H
SW
e5
-26
80
v3
2.5
GH
z (
T)
ED
R
SG
I IC
E-X
HS
W e
5-2
690
v3 2
.6G
Hz (
T)
IB F
DR
Dell
OP
A32 e
5-2
66
0v
3 2
.6G
Hz (
T)
OP
A
Bu
ll H
SW
e5
-26
80
v3
2.5
GH
z (
T)
Co
nn
ec
t-IB
Inte
l B
DW
e5-2
690
v4
2.6
GH
z (
T)
OP
A
Inte
l B
DW
e5-2
690
v4
2.6
GH
z (
T)
ED
R
Bo
sto
n B
DW
e5
-26
50v
4 2
.2G
Hz (
T)
FD
R
Bo
sto
n B
DW
e5
-26
80v
4 2
.4G
Hz (
T)
OP
A
Th
or
BD
W e
5-2
69
7A
v4
2.6
GH
z (
T)
ED
R
IBM
Po
wer8
S8
22
LC
2.9
2G
Hz I
B/E
DR
Hu
aw
ei F
us
ion
CH
14
0 e
5-2
68
3 v
4 2
.1G
Hz (
T)
ED
R
AT
OS
BD
W e
5-2
68
0v
4 2
.4G
Hz (
T)
ED
R
AT
OS
BD
W e
5-2
68
0v
4 2
.4G
Hz (
T)
OP
A
Dell
Sk
yla
ke
61
42 2
.6G
Hz (
T)
ED
R
Dell
Sk
yla
ke
61
50 2
.7G
Hz (
T)
ED
R
DL_POLY 4 – Gramicidin (128 cores)
1820 November 2017DL_POLY - A Performance Overview
Performance Relative to the IBM e326 Opteron280/2.4GHz / GbitE
E5-26xxE5-26xx v2
E5-26xx v3E5-26xx v4
Perf
orm
an
ce

DL_POLY - A Performance Overview
Analysing, Understanding and Exploiting
available HPC Technology
Understanding
Performance –
Useful Tools

IPM Performance Monitoring
2020 November 2017DL_POLY - A Performance Overview
http://ipm-hpc.sourceforge.net/userguide.html
IPM is a profiling tool that helps analyse MPI programs.
• Very easy to use, requires no code modifications (unless you want more
information), and provides a lightweight profiling interface (with very low
overhead <2%).
• Can create html O/P that include graphical representation of the data
To run a program with IPM profiling; There are two ways of using IPM.
1. set an environment variable before you run your program:
$ export LD_PRELOAD=/application/tools/ipm-2.0.6/install-impi/lib/libipm.so
2. Recompile your program with IPM enabled:
$ mpicc -L/path/to/ipm/lib -lipm your_program.c -o your-program
When executing a program with ipm, an xml file is created that can be parsed to text
or html using ''ipm_parse -html xmlfile''.
IPM 2.0.6
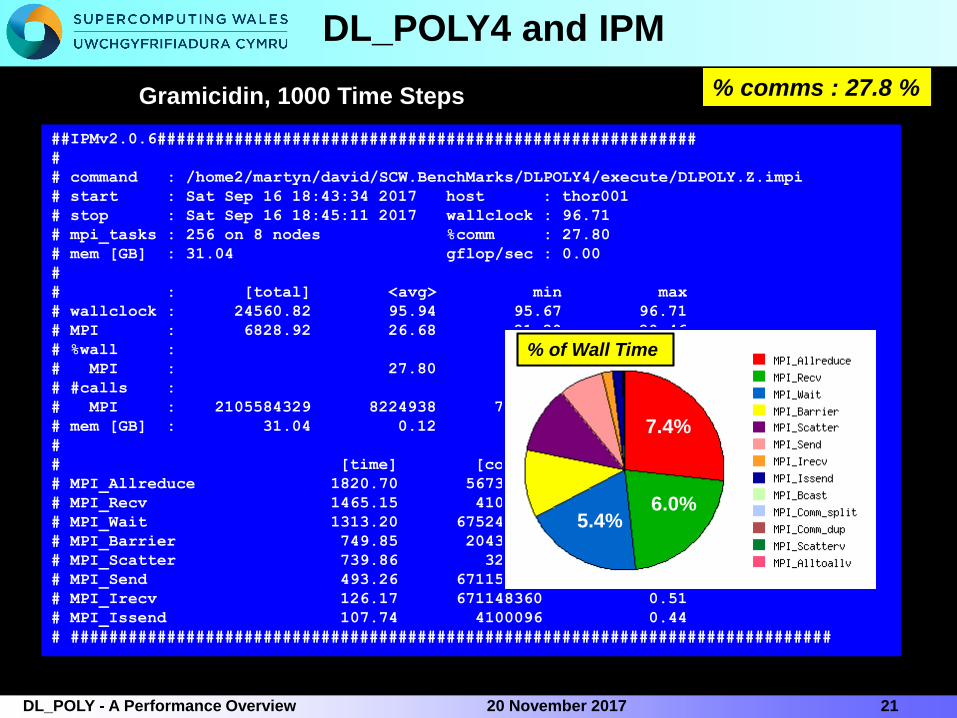
##IPMv2.0.6########################################################
#
# command : /home2/martyn/david/SCW.BenchMarks/DLPOLY4/execute/DLPOLY.Z.impi
# start : Sat Sep 16 18:43:34 2017 host : thor001
# stop : Sat Sep 16 18:45:11 2017 wallclock : 96.71
# mpi_tasks : 256 on 8 nodes %comm : 27.80
# mem [GB] : 31.04 gflop/sec : 0.00
#
# : [total] <avg> min max
# wallclock : 24560.82 95.94 95.67 96.71
# MPI : 6828.92 26.68 21.39 29.46
# %wall :
# MPI : 27.80 22.12 30.77
# #calls :
# MPI : 2105584329 8224938 7814127 8678067
# mem [GB] : 31.04 0.12 0.12 0.15
#
# [time] [count] <%wall>
# MPI_Allreduce 1820.70 56734976 7.41
# MPI_Recv 1465.15 4102391 5.97
# MPI_Wait 1313.20 675248456 5.35
# MPI_Barrier 749.85 20433665 3.05
# MPI_Scatter 739.86 327680 3.01
# MPI_Send 493.26 671150655 2.01
# MPI_Irecv 126.17 671148360 0.51
# MPI_Issend 107.74 4100096 0.44
# ###############################################################################
% comms : 27.8 %
DL_POLY4 and IPM
2120 November 2017DL_POLY - A Performance Overview
% of Wall Time
5.4%
7.4%
6.0%
Gramicidin, 1000 Time Steps

Allinea Performance Reports
Allinea Performance Reports provides a
mechanism to characterize and understand the
performance of HPC application runs through a
single-page HTML report.
2220 November 2017DL_POLY - A Performance Overview
• Based on Allinea MAP's adaptive sampling technology that keeps data
volumes collected and application overhead low.
• Modest application slowdown (ca. 5%) even with 1000’s of MPI
processes.
• Runs on existing codes: a single command added to execution scripts.
• If submitted through a batch queuing system, then the submission script
is modified to load the Allinea module and add the 'perf-report' command
in front of the required mpiexec command.
• perf-report mpiexec -n 4 $code
• A Report Summary: This characterizes how the application's wallclock
time was spent, broken down into CPU, MPI and I/O
• All examples updated on Broadwell Mellanox Cluster (E5-2697A v4)

Allinea Performance Reports
A Report Summary: This characterizes how the application's wallclock
time was spent, broken down into CPU, MPI and I/O. e.g.
CPU - Time spent computing. % of wall-clock time spent in application and in
library code, excluding time spent in MPI calls and I/O calls.
MPI - Time spent communicating. % of wall-clock time spent in MPI calls such
as MPI - Send, MPI Reduce and MPI Barrier.
I/O - Time spent reading from and writing to the filesystem. % of wall-clock time
spent in system library calls such as read, write and close.
CPU Breakdown
Breaks down the time spent further by analyzing the kinds of instructions that this
time was spent on.
Scalar numeric ops - %-time spent executing arithmetic operations - does not
include time spent using the more efficient vectorized versions of operations.
Vector numeric ops - %-time spent executing vectorized arithmetic operations
such as Intel's SSE / AVX extensions. (2x – 4x performance improvements).
Memory accesses - %-time spent in memory access operations. A high figure
shows the application is memory-bound and is not able to make full use of the
CPU's resources. 2320 November 2017DL_POLY - A Performance Overview

Performance Data (32-256 PEs)
DL_POLY4 – NaCl Simulation Perf Report
Smooth Particle Mesh Ewald Scheme
2420 November 2017DL_POLY - A Performance Overview
CPU Time Breakdown
Total Wallclock Time
Breakdown
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
80.0
90.0
32 PEs
64 PEs
128 PEs
256 PEs
CPU (%)
MPI (%)
0.0
10.0
20.0
30.0
40.0
50.0
60.0
32 PEs
64 PEs
128 PEs
256 PEs
CPU Scalar numeric ops (%)
CPU Vector numeric ops (%)
CPU Memory accesses (%)

0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
32 PEs
64 PEs
128 PEs
256 PEs
CPU Scalar numeric ops (%)
CPU Vector numeric ops (%)
CPU Memory accesses (%)
Performance Data (32-256 PEs)
DL_POLY4 – Gramicidin Perf Report
Smooth Particle Mesh Ewald Scheme
2520 November 2017DL_POLY - A Performance Overview
CPU Time Breakdown
Total Wallclock Time Breakdown
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
80.0
90.0
32 PEs
64 PEs
128 PEs
256 PEs
CPU (%)
MPI (%)

DL_POLY - A Performance Overview
Analysing, Understanding and Exploiting
available HPC Technology
Today’s Code
Performance –
HPC clusters in
use

2.0
3.5
5.9
3.1
5.9
9.6
2.9
5.8
9.9
3.4
6.6
10.9
3.5
6.8
11.1
3.4
6.1
3.8
7.2
11.5
4.2
7.7
12.4
4.5
8.6
14.9
0.0
3.0
6.0
9.0
12.0
15.0
32 64 128
Fujitsu BX922 Westmere X5650 2.67GHz IB-QDR
Fujitsu CX250 Sandy Bridge e5-2670/2.6GHz IB-QDR
ClusterVision Ivy Bridge e5-2650v2 2.6GHz True Scale QDR
Dell R720 Ivy Bridge e5-2680v2 2.8GHz (T) Connect-IB
Bull Haswell e5-2695v3 2.3GHz Connect-IB
Bull Haswell e5-2680v3 2.5GHz (T) Connect-IB
Boston Broadwell e5-2680v4 2.4GHz (T) OPA
Intel Broadwell2 e5-2690v4 2.6GHz (T) OPA
IBM Power8 S822LC 2.92GHz IB/EDR
Dell Skylake Gold 6142 2.6GHz (T) EDR
Dell Skylake Gold 6150 2.7GHz (T) EDR
Bull|ATOS Skylake Gold 6150 2.7GHz (T) OFA
DL_POLY Classic – Bench 4
Number of Processing Elements
Performance
Performance Data (32-128 PEs)
Relative to the Fujitsu HTC X5650 2.67 GHz 6-C (16 PEs)
BE
TT
ER
NaCl 27,000 atoms; 500 time steps
2720 November 2017DL_POLY - A Performance Overview

1.7
2.6
3.3
2.8
4.4
5.6
2.8
4.3
5.6
3.2
4.9
6.3
3.3
5.1
6.6
5.0
6.7
3.5
5.3
6.9
3.7
5.6
7.2
4.3
6.6
8.9
0.0
2.0
4.0
6.0
8.0
32 64 128
Fujitsu BX922 Westmere X5650 2.67GHz IB-QDR
Fujitsu CX250 Sandy Bridge e5-2670/2.6GHz IB-QDR
ClusterVision Ivy Bridge e5-2650v2 2.6GHz True Scale QDR
Dell R720 Ivy Bridge e5-2680v2 2.8GHz (T) Connect-IB
Bull Haswell e5-2695v3 2.3GHz Connect-IB
Bull Haswell e5-2680v3 2.5GHz (T) Connect-IB
Boston Broadwell e5-2680v4 2.4GHz (T) OPA
Thor Broadwell e5-2697A v4 2.6GHz (T) EDR
Intel Broadwell2 e5-2690v4 2.6GHz (T) OPA
Dell Skylake Gold 6142 2.6GHz (T) EDR
Dell Skylake Gold 6150 2.7GHz (T) EDR
Bull|ATOS Skylake Gold 6150 2.7GHz (T) OFA
DLPOLY Classic – Bench 7
Number of Processing Elements
Performance
Performance Data (32-128 PEs)
Relative to the Fujitsu HTC X5650 2.67 GHz 6-C (16 PEs)
BE
TT
ER
Gramicidin A: 12,390 atoms; 5,000
time steps
2820 November 2017DL_POLY - A Performance Overview
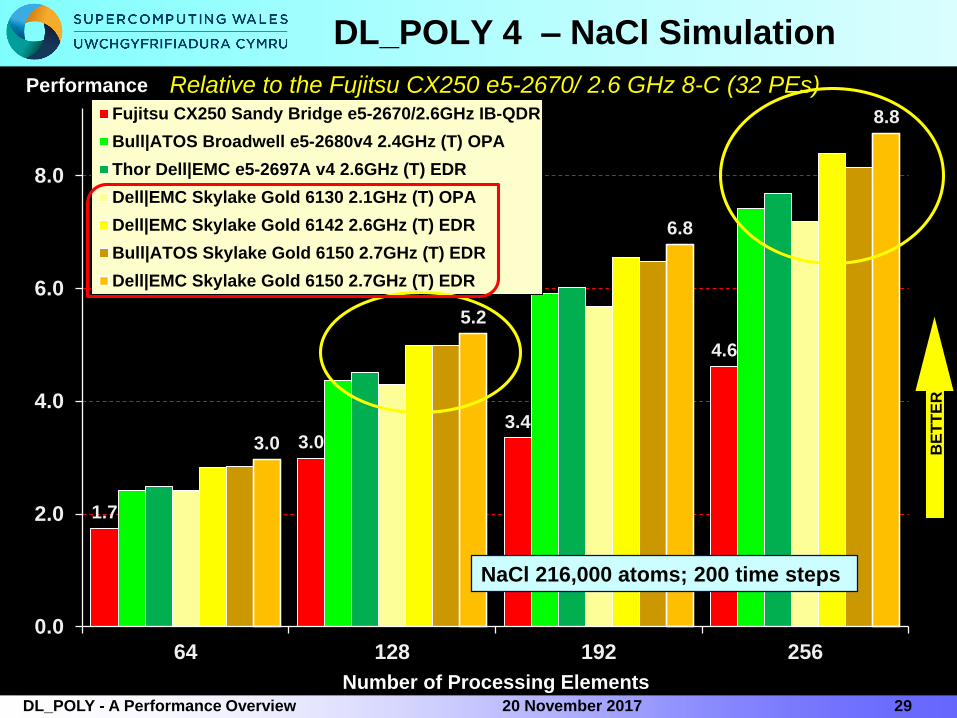
1.7
3.03.4
4.6
3.0
5.2
6.8
8.8
0.0
2.0
4.0
6.0
8.0
64 128 192 256
Fujitsu CX250 Sandy Bridge e5-2670/2.6GHz IB-QDR
Bull|ATOS Broadwell e5-2680v4 2.4GHz (T) OPA
Thor Dell|EMC e5-2697A v4 2.6GHz (T) EDR
Dell|EMC Skylake Gold 6130 2.1GHz (T) OPA
Dell|EMC Skylake Gold 6142 2.6GHz (T) EDR
Bull|ATOS Skylake Gold 6150 2.7GHz (T) EDR
Dell|EMC Skylake Gold 6150 2.7GHz (T) EDR
DL_POLY 4 – NaCl Simulation
Number of Processing Elements
Performance Relative to the Fujitsu CX250 e5-2670/ 2.6 GHz 8-C (32 PEs)
BE
TT
ER
NaCl 216,000 atoms; 200 time steps
2920 November 2017DL_POLY - A Performance Overview

1.8
3.1
4.0
4.9
3.2
5.6
7.3
9.5
0.0
2.0
4.0
6.0
8.0
10.0
64 128 192 256
Fujitsu CX250 Sandy Bridge e5-2670/2.6GHz IB-QDR
Bull|ATOS Broadwell e5-2680v4 2.4GHz (T) OPA
Thor Dell|EMC e5-2697A v4 2.6GHz (T) EDR
Dell|EMC Skylake Gold 6130 2.1GHz (T) OPA
Dell|EMC Skylake Gold 6142 2.6GHz (T) EDR
Bull|ATOS Skylake Gold 6150 2.7GHz (T) EDR
Dell|EMC Skylake Gold 6150 2.7GHz (T) EDR
DL_POLY 4 – Gramicidin Simulation
Number of Processing Elements
Performance Relative to the Fujitsu CX250 e5-2670/ 2.6 GHz 8-C (32 PEs)
BE
TT
ER
3020 November 2017DL_POLY - A Performance Overview
e5-2690v4
~ 1.22 X e5-2660v3
Gramicidin 792,960 atoms; 50 time steps

Performance Data (256 PEs)DLPOLY 4 - IPM Reports
3120 November 2017DL_POLY - A Performance Overview
10.1%
9.1%
wallclock : 73.63 secs
# mpi_tasks : 256 on 8 nodes
%comm : 27.73%
3.0%
% of Total Time
Gramicidinwallclock : 96.71 secs
# mpi_tasks : 256 on 8 nodes
%comm : 27.80%
NaCl
% of Total Time
7.4%
6.0%5.4%

DL_POLY - A Performance Overview
Analysing, Understanding and Exploiting
available HPC Technology
Selecting
Fabrics and
Optimising
Performance

• Intel MPI Library - can select a communication fabric at runtime without
having to recompile the application. By default, it automatically selects the most
appropriate fabric based on both S/W and H/W configuration i.e. in most cases
you do not have to worry about manually selecting a fabric.
• Specifying a particular fabric can boost performance. Can specify fabrics for both
intra-node and inter-node communications. Following fabrics available:
• For inter-node communication, it uses the first available fabric from the default
fabric list. This list is defined automatically for each H/W and S/W configuration
(see I_MPI_FABRICS_LIST).
• For most configurations, this list is as follows: dapl, ofa, tcp, tmi, ofi
Selecting Fabrics – MPI Optimisation
3320 November 2017DL_POLY - A Performance Overview
Fabric Network hardware and software used
shm Shared memory (for intra node communication only).
dapl Direct Access Programming Library (DAPL) fabrics, such as InfiniBand (IB)
and iWarp (through DAPL).
ofa OpenFabrics Alliance (OFA) fabrics e.g. InfiniBand (through OFED verbs).
tcp TCP/IP network fabrics, such as Ethernet and InfiniBand (through IPoIB).
tmi Tag Matching Interface (TMI) fabrics, such as Intel True Scale Fabric, Intel
Omni Path Architecture and Myrinet (through TMI).
ofi OpenFabrics Interfaces* (OFI) - capable fabrics, such as Intel True Scale
Fabric, Intel Omni Path Architecture, IB and Ethernet (through OFI API).

Mellanox HPC-X Toolkit
The Mellanox HPC-X Toolkit provides a comprehensive MPI, SHMEM and
UPC software suite for HPC environments. Delivers “enhancements to
significantly increase the scalability & performance of message
communications in the network”. Includes:
¤ Complete MPI, SHMEM, UPC package, including Mellanox MXM and
FCA acceleration engines
¤ Offload collectives communication from MPI process onto Mellanox
interconnect hardware
¤ Maximize application performance with underlying hardware
architecture. Optimized for Mellanox InfiniBand and VPI interconnects
¤ Increase application scalability and resource efficiency
¤ Multiple transport support including RC, DC and UD
¤ Intra-node shared memory communication
• Performance comparison conducted on the Mellanox HP Proliant- E5-
2697A v4 EDR based Thor cluster
3420 November 2017DL_POLY - A Performance Overview
http://www.mellanox.com/related-docs/prod_acceleration_software/PB_HPC-X.pdf

Application Performance & Interconnect
Two comparison exercises undertaken:
¤ For each application (and associated data sets) analyse the
performance as a function of interconnect – Mellanox EDR and
Intel OPA – as a function of increasing core count.
• DLPOLY4 & GROMACS – 128-1024 cores
• VASP PdO (128-384 cores) & Zeolite (128-512 cores)
• Quantum ESPRESSO (Au112, 64-512; GRIR443, 128-1024)
• OpenFOAM (64-512 cores)
¤ On the Mellanox HP Proliant- E5-2697A v4 EDR based Thor
cluster, compare for each application (and associated data sets)
the relative performance undertaken using Intel MPI and
Mellanox HPCX i.e.
T HPCX / T Intel-MPI
3520 November 2017DL_POLY - A Performance Overview
http://www.mellanox.com/related-docs/prod_acceleration_software/PB_HPC-X.pdf

4.7
8.1
13.0
18.7
4.6
7.5
12.4
16.8
4.8
8.2
12.9
14.8
5.0
8.1
12.9
0.0
3.0
6.0
9.0
12.0
15.0
18.0
128 256 512 1024
Bull|ATOS Broadwell e5-2680v4 2.4GHz (T) OPA
Thor Dell|EMC e5-2697A v4 2.6GHz (T) EDR IMPI
Thor Dell|EMC e5-2697A v4 2.6GHz (T) EDR HPCX
Thor Dell|EMC e5-2697A v4 2.6GHz (T) OPA
Dell|EMC Skylake Gold 6130 2.1GHz (T) OPA
Bull|ATOS Skylake Gold 6150 2.7GHz (T) EDR
DL_POLY 4 – NaCl Simulation
Number of Processing Elements
Performance Relative to the Fujitsu CX250 e5-2670/ 2.6 GHz 8-C (32 PEs)
BE
TT
ER
NaCl 216,000 atoms; 200 time steps
3620 November 2017DL_POLY - A Performance Overview

4.9
8.4
13.8
19.2
5.2
8.9
13.7
19.3
5.3
9.1
13.7
0.0
3.0
6.0
9.0
12.0
15.0
18.0
128 256 512 1024
Bull|ATOS Broadwell e5-2680v4 2.4GHz (T) OPA
Thor Dell|EMC e5-2697A v4 2.6GHz (T) EDR IMPI
Thor Dell|EMC e5-2697A v4 2.6GHz (T) EDR HPCX
Thor Dell|EMC e5-2697A v4 2.6GHz (T) OPA
Dell|EMC Skylake Gold 6130 2.1GHz (T) OPA
Bull|ATOS Skylake Gold 6150 2.7GHz (T) EDR
DL_POLY 4 – Gramicidin
Number of Processing Elements
Performance Relative to the Fujitsu CX250 e5-2670/ 2.6 GHz 8-C (32 PEs)
BE
TT
ER
3720 November 2017DL_POLY - A Performance Overview
Gramicidin 792,960 atoms; 50 time steps
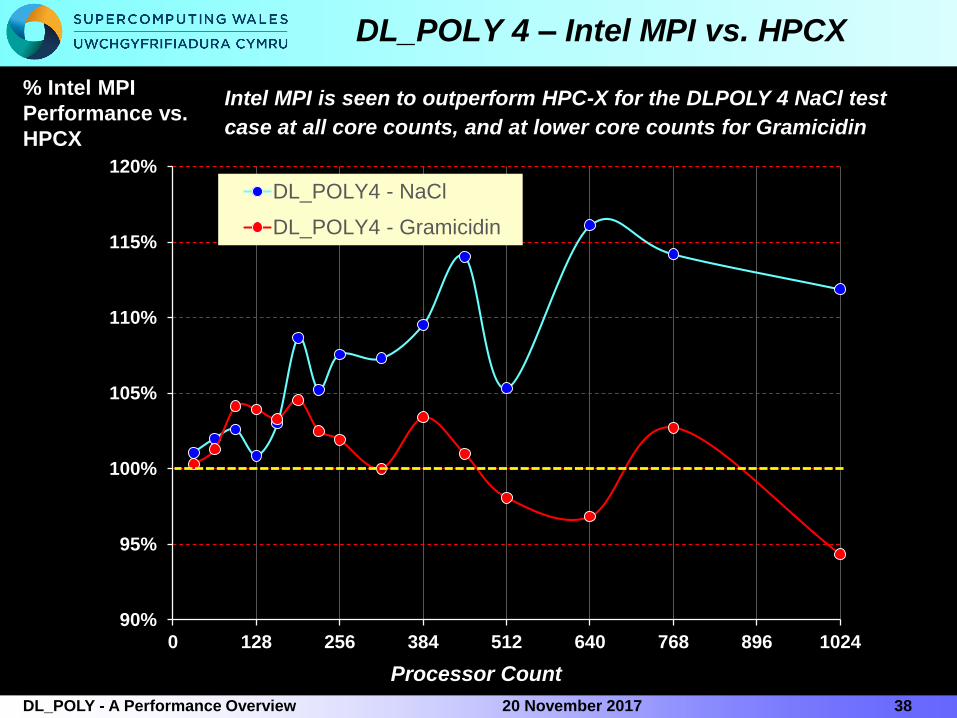
DL_POLY 4 – Intel MPI vs. HPCX
3820 November 2017DL_POLY - A Performance Overview
% Intel MPI
Performance vs.
HPCX
Processor Count
Intel MPI is seen to outperform HPC-X for the DLPOLY 4 NaCl test
case at all core counts, and at lower core counts for Gramicidin
90%
95%
100%
105%
110%
115%
120%
0 128 256 384 512 640 768 896 1024
DL_POLY4 - NaCl
DL_POLY4 - Gramicidin

65%
75%
85%
95%
105%
0 128 256 384 512 640 768
Quantum Espresso - GRIR443
Quantum Espresso - Au112
Quantum Espresso – Intel MPI vs. HPCX
3920 November 2017Supercomputing Wales Performance Tests
% Intel MPI Performance vs. HPCX
Processor Count
Significantly different to the MD codes – as with VASP,
HPCX is seen to outperform Intel MPI for the larger core
counts

0.0
0.2
0.4
0.6
0.8
1.0
DLPOLY-4Gramicidin
DLPOLY-4 NaCl
GROMACS ion-channel
GROMACSlignocellulose
OpenFoam -3d3M
QE Au112
QE GRIR443
VASP Example3
VASP Example4
BSMBenchBalance
Bull b510 "Raven" SandyBridge e5-2670/2.6 GHz IB-QDR
Fujitsu CX250 Sandy Bridgee5-2670/2.6 GHz IB-QDR
ATOS Broadwell e5-2680v42.4GHz (T) OPA
Thor Dell|EMC e5-2697A v42.6GHz (T) EDR IMPI
Thor Dell|EMC e5-2697A v42.6GHz (T) EDR HPCX
Dell Skylake Gold 61302.1GHz (T) OPA
Dell Skylake Gold 61422.6GHz (T) EDR
Dell Skylake Gold 61502.7GHz (T) EDR
Target Codes and Data Sets – 256 PEs
4020 November 2017DL_POLY - A Performance Overview
256 PE Performance [Applications]

DL_POLY - A Performance Overview
Analysing, Understanding and Exploiting
available HPC Technology
DL_POLY
Performance –
Power Usage6148 Gold ‘Skylake’ CPUs,
192GB memory fitted; all
tests run with 40 cores

Measurement Equipment and process
• Power collection is made from an administrative
node using IPMI LAN interface
• Using the tool written in C named ISCoL
• Collection of System, Processor and Memory power usage is
made using Intel NodeManager API version 3.0
• No software agents are running on CPUs: all queries are
administered by BMC => zero overhead to users applications
• The following fields are collected and stored in
CSV format for each node:
• TIME_US: time stamp in microseconds from start
• POWER_GLOB_SYS: system power read from PSUs
• POWER_GLOB_CPU: Combined processor domain power
• POWER_GLOB_MEM: Memory (DIMM) domain power
• DTS_CPU?: Thermal headroom for each CPU socket in °C
• When DTS value reaches Tcontrol (8-10°C) - the system
fans spin up to max
• When DTS reached 0°C – thermal throttling is initiated
• TEMP_CPU?CH?DIMM?: absolute temperature in °C for
each DIMM installed in the system
• Data pooled every 50 ms. (20 times per second):
• Actual time between samples varies depending on the management network utilization
• File buffering is employed to reduce disk load, so the monitoring has to be terminated properly to avoid loss of
collected data
CPU0
PCH
BMC
CPU0
CH0
CH1
CH2
CH3
CPU0CPU1
CH0
CH1
CH2
CH3
ME
NIC
PSUPSU
Memory Power
Domain
ProcessorPower
Domain
SystemPower
Domain
ISCoL
Dual socket Xeon (rack)
20 November 2017DL_POLY - A Performance Overview 48

Overview of Results
Application # nodes Test:Mean
(W)
Peak
(W)
DLPOLY1 Gramicidin 1 Node 347.97 469
16 Gramicidin 16 Nodes 310.38 448
GROMACS
1 ion_channel 1 Node 383.23 493
4 ion_channel 4 Nodes 341.45 464
8 lignocellulose 8 Nodes 403.56 486
16 lignocellulose 16 Nodes 409.19 454
VASP
1 Pd-O 1 Node 537.35 599
8 Pd-O 3 8 Nodes 450.22 505
1 Zeolite Cluster 1 Node 517 617
8 Zeolite Cluster 8 nodes 459.42 534
QE
2 AUSURF112 2 Nodes 454.84 590
7 AUSURF112 7 Nodes 409.6 560
7 GRIR443 7 Nodes 509.79 614
13 GRIR443 13 Nodes 505.27 636
OpenFOAM 4 Cavity 3d-3M 4 Nodes 430.89 543
20 November 2017DL_POLY - A Performance Overview

Mean and Peak Power Usage
0
100
200
300
400
500
600
700
DL
_P
OL
Y 1
Nod
e
DL
_P
OL
Y 1
6 N
ode
s
Gro
ma
cs io
n_
cha
nn
el 1
Node
Gro
ma
cs io
n_
cha
nn
el 4
No
de
s
Gro
ma
cs lig
no
cellu
lose 8
No
de
s
Gro
ma
cs lig
no
cellu
lose 1
6N
ode
s
VA
SP
exam
ple
3 1
No
de
VA
SP
exam
ple
3 8
No
de
s
VA
SP
exam
ple
4 1
No
de
VA
SP
exam
ple
4 8
nod
es
QE
AU
SU
RF
11
2 2
Nod
es
QE
AU
SU
RF
11
2 7
Nod
es
QE
GR
IR4
43
7 N
ode
s
QE
GR
IR4
43
13
No
de
s
OpenF
OA
M 4
Nodes
BS
Mb
en
ch
3 N
ode
s
Application Mean and Peak Power
Mean Peak
20 November 2017DL_POLY - A Performance Overview

DL_POLY_4 - Gramicidin
1 Node 8 Nodes
Nodes Mean Peak
1 347.97W 469W
16 310.38W 448W
20 November 2017DL_POLY - A Performance Overview

4620 November 2017DL_POLY - A Performance Overview
Acknowledgements
• Ludovic Sauge, Johann Peyrard and Andy Grant (Bull/ATOS) for
informative performance discussions and access to the Haswell &
Broadwell cluster “Genji” at the Bull Benchmarking Centre.
• Pak Lui, David Cho, Gilad Shainer, Colin Bridger & Steve Davey for
access to the “Thor” cluster at the HPC Advisory Council and
“Hercules” partition in Mellanox.
• Doug Mark, Farid Parpia, John Simpson, Ludovic Enault, Xinghong
He, James Kuchler & Luke Willett for access to and assistance on the
IBM Power8 S822LC cluster in Poughkeepsie.
• David Power for access to two Skylake nodes in Boston /BIOSIT.
• Jamie Wilcox (Intel) for past access to and help with a host of
processors and for access to the Swindon Broadwell clusters.
• Joshua Weage, Martin Hilgeman, Dave Coughlin, Gilles Civario and
Christopher Huggins for access to, and assistance with, the variety of
Skylake SKUs at the Dell Benchmarking Centre.

4720 November 2017DL_POLY - A Performance Overview
Summary
1. Rapid overview of Processor & Interconnect Technologies
¤ The last 10 years of Intel dominance – Nehalem to Skylake
2. DL_POLY Performance - Benchmarks & Test Cases
3. Overview of two decades of DL_POLY Performance
¤ From T3E/1200E to Intel Skylake clusters
4. Considered Tools useful in understanding Performance
5. Today’s Code Performance – HPC clusters in use
¤ Processors, interconnects and Power Measurements
¤ Selecting Fabrics and Optimising Performance
6. Acknowledgements





























