Embed Size (px)
Citation preview

Document clustering
and its application to web search
Claudio Carpineto
Fondazione Ugo BordoniFondazione Ugo Bordoni
Research work in collaboration with:
G. Romano, A. Bernardini, M. D’Amico, S. Mizzaro, S. Osinski, D. Weiss

Overview
Clustering methods:
K-Means
Quality-threshold clustering
Hierarchical agglomerative clustering
Concept lattices
Why so many clustering algorithms?
Web Clustering Engines:
Issues
Systems
KeySRC
Problems
New Directions
Mobile search
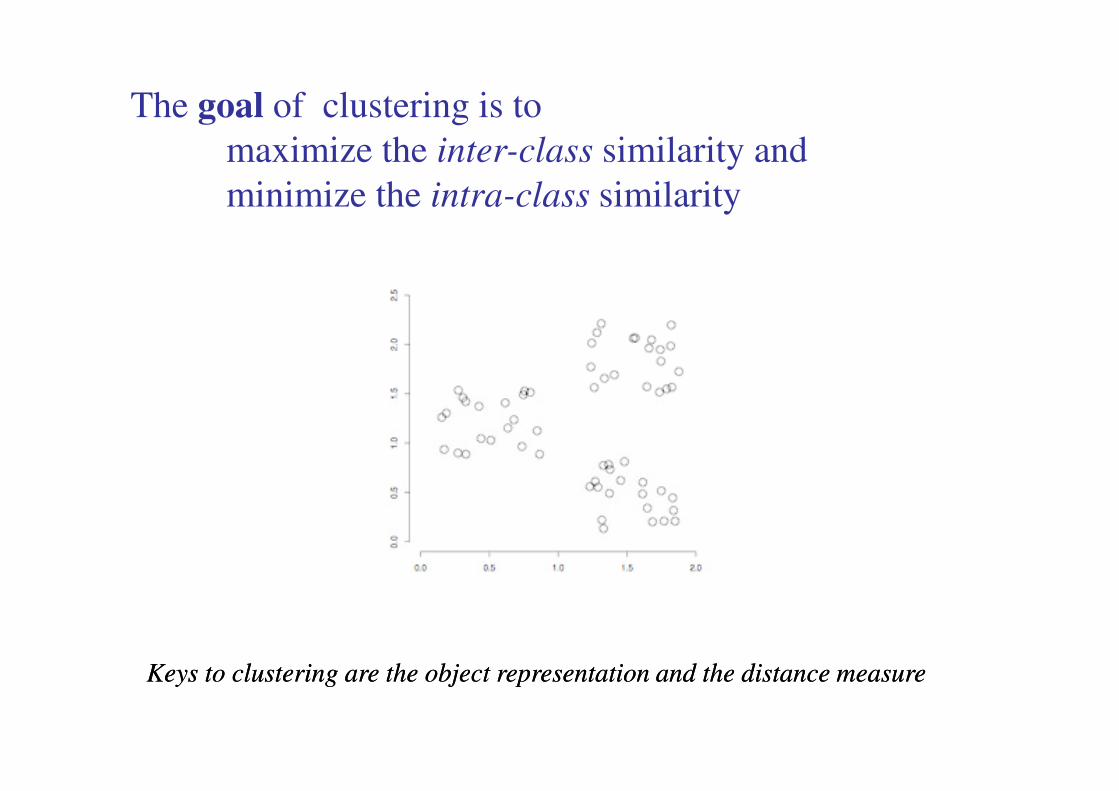
The goal of clustering is to
maximize the inter-class similarity and
minimize the intra-class similarity
Keys to clustering are the object representation and the distance measure Keys to clustering are the object representation and the distance measure
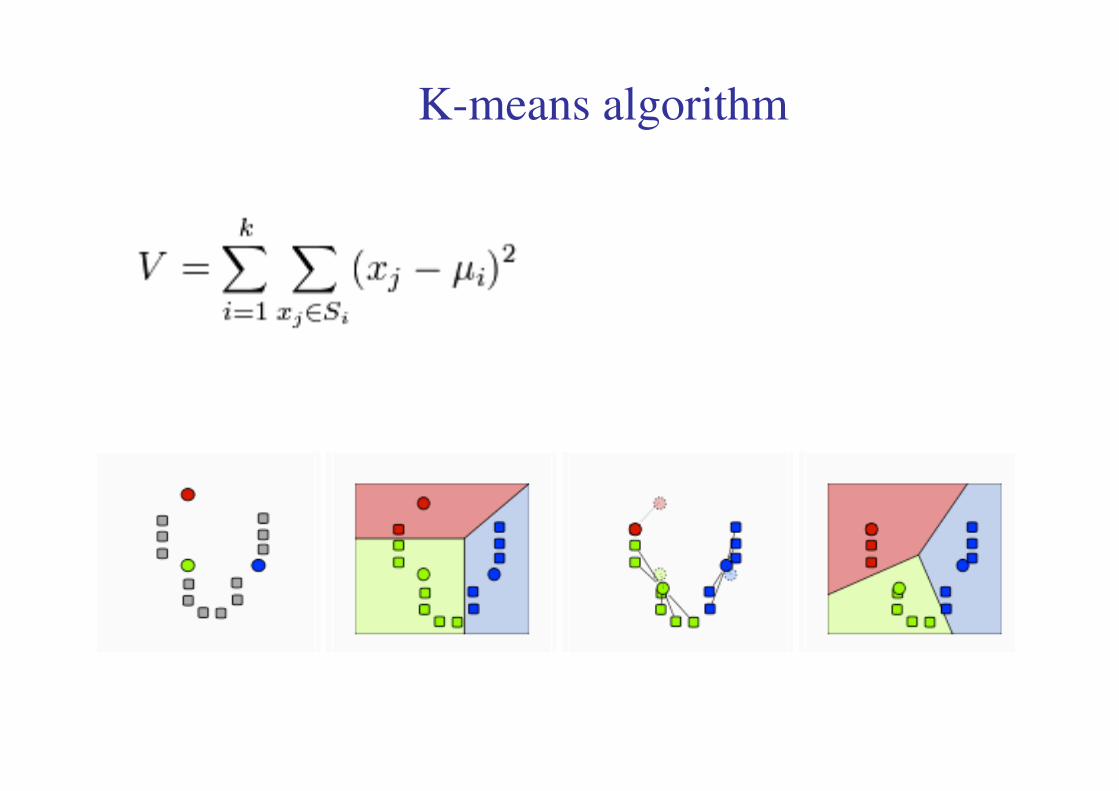
K-means algorithm

Quality threshold (QT) clusteringQuality threshold (QT) clustering
1.1. Choose a Choose a maximum diametermaximum diameter for clusters.for clusters.
2.2. Build a candidate cluster for each point Build a candidate cluster for each point by including the closest
point, the next closest, and so on, until the diameter of the cluster
surpasses the threshold.surpasses the threshold.
3. Save the candidate cluster with the most points as the first true
cluster, and remove all points in the cluster from further
consideration.
4. Recurse with the reduced set of points.

KK--means versus QT clusteringmeans versus QT clustering
kk--meansmeans QTQT
Deterministic?Deterministic? nono yesyes
Need to specifyNeed to specify yesyes nonoNeed to specifyNeed to specify yesyes nono
cluster number?cluster number?
ComputationallyComputationally nono yesyes
intensive?intensive?
Every object mustEvery object must yesyes nono
be clustered?be clustered?
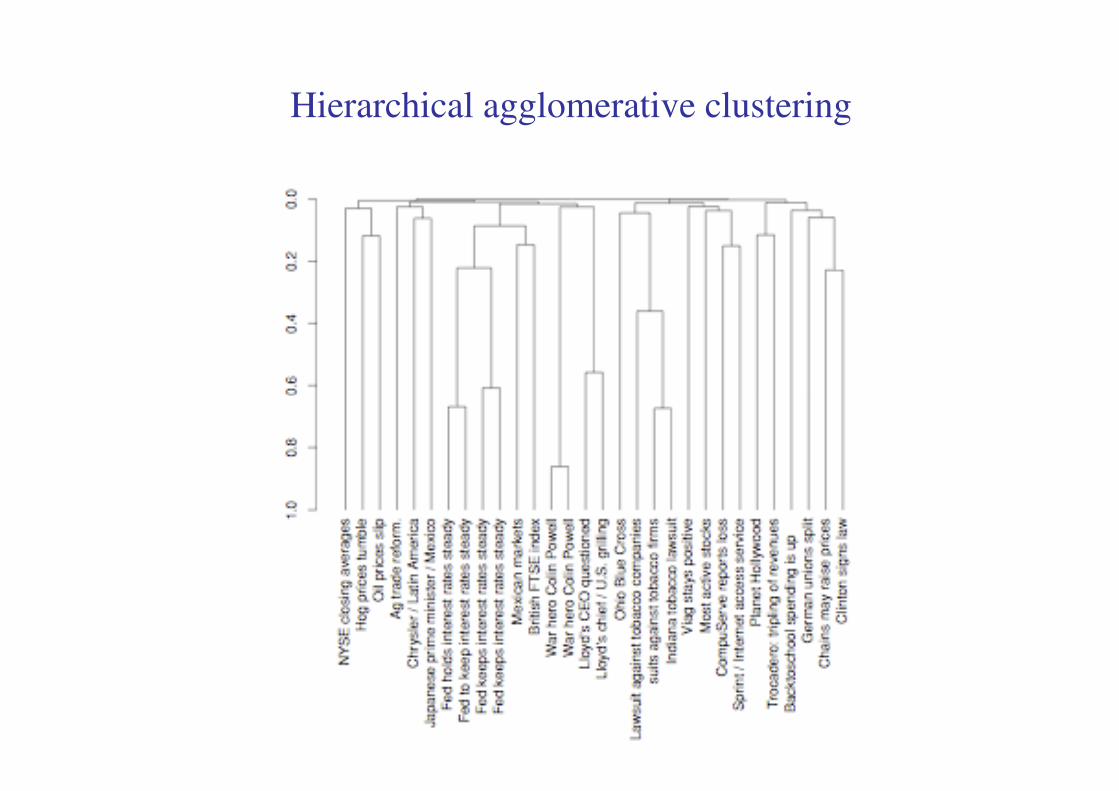
Hierarchical agglomerative clustering
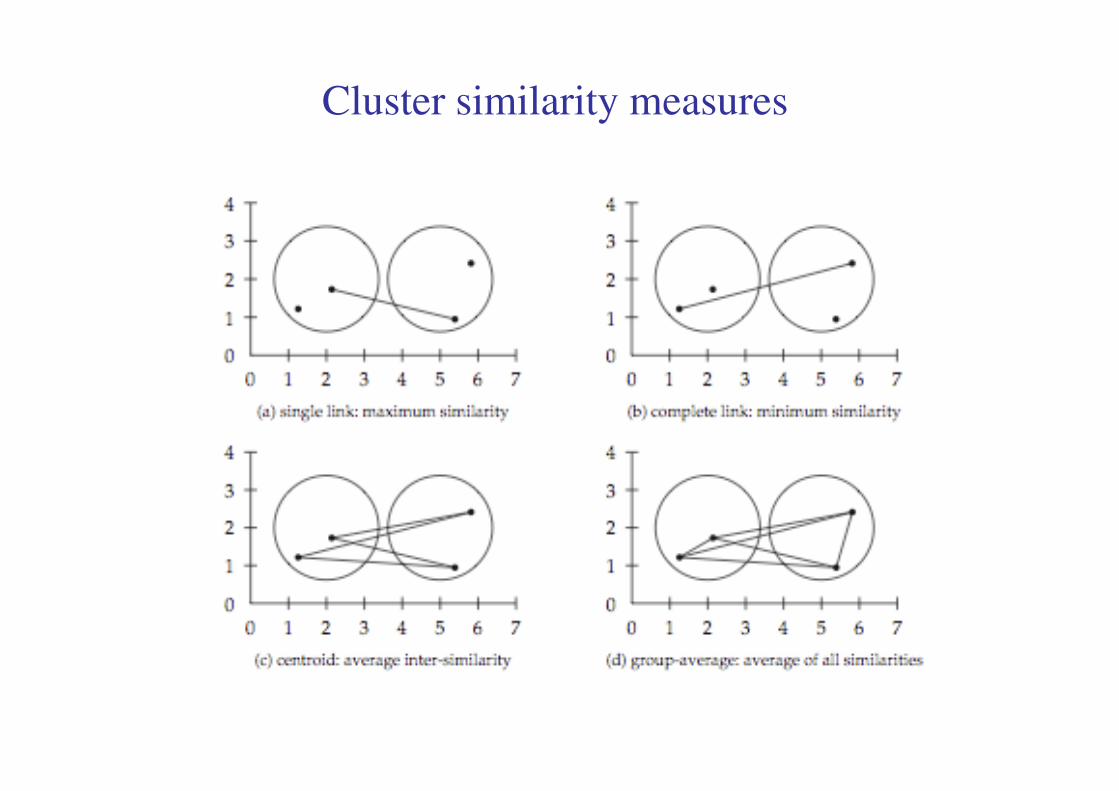
Cluster similarity measures
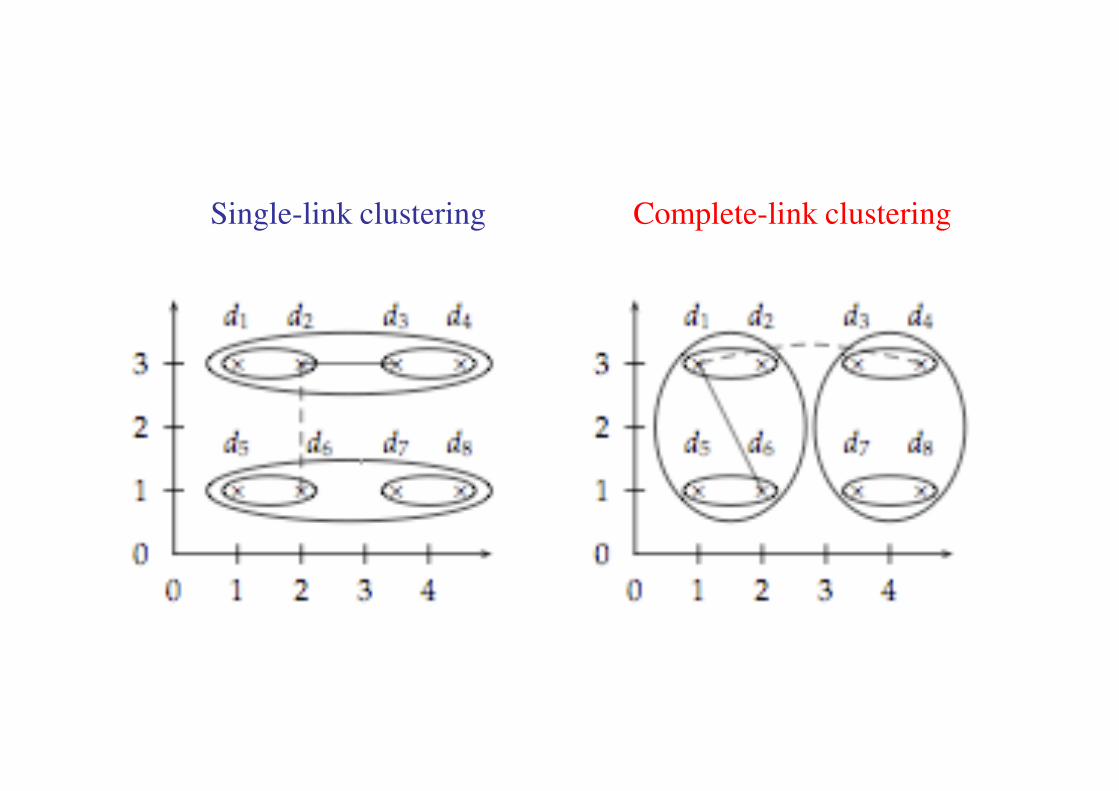
Single-link clustering Complete-link clustering
breathes
in water
(a)
can
fly
(b)
has
beak
(c)
has
hands
(d)
has
skeleton
(e)
has
wings
(f)
livesin
water
(g)
vivipar -
ous
(h)
produce
light
(i)
1 Bat x x x x
2 Eagle x x x x
3 Monkey x x x
4 Parrot fish x x x x
5 Penguin x x x x
6 Shark x x x
7 Lantern fish x x x x
e1234567
eg4567
ce245
ehefeg4567
ce245
aeg467
eh13
ef125
cef25
ceg45
cefg5
aegi7 aceg
4
deh3 befh
1 bcef2
bef12
abcdefgh∅∅∅∅

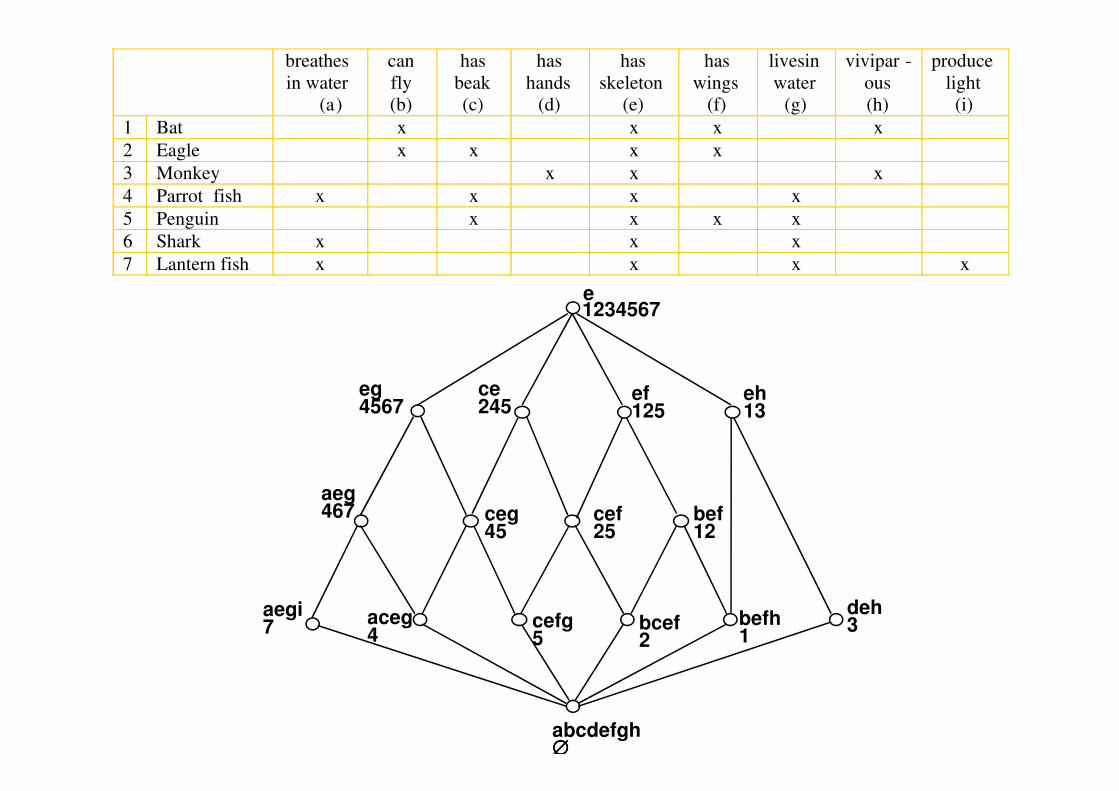
Concept lattice (definition)
Context = (G, M, I)
gIm or (g, m) ∈ I means “object g has property m”
For A ⊆ G, B ⊆ M define:
A’ = m ∈ M | gIm for all g ∈ AB’ = g ∈ G | gIm for all m ∈ B
A concept of (G, M, I) is a pair (A, B) whereA concept of (G, M, I) is a pair (A, B) where
A ⊆ G, B ⊆ M, A’= B, B’= A (A and B are called extent and intent)
A subset X ⊆ G is an extent if and only if X’’ = X; the concept is (X’’, X’)
A subset Y ⊆ M is an extent if and only if Y’’ = Y; the concept is (Y’, Y”)
(A1, B1 ) < (A2, B2) if A1 ⊆ A2 (or B1 ⊇ B2)
C(G, M, I, <) is a complete lattice and ….(The Basic Theorem of concept
lattices)


Why so many clustering algorithms?Why so many clustering algorithms?
Clusters and outliers are in the eye of the beholderClusters and outliers are in the eye of the beholder
The strategy of cluster analysis is structure seeking although its operationThe strategy of cluster analysis is structure seeking although its operation
is structureis structure--imposing (e.g., by a clustering criterion)imposing (e.g., by a clustering criterion)is structureis structure--imposing (e.g., by a clustering criterion)imposing (e.g., by a clustering criterion)
The main distinction is in the underlying model (e.g., representatives, tree The main distinction is in the underlying model (e.g., representatives, tree
search, graph search) search, graph search)
Clustering often translates into optimazion problem solved by approximate Clustering often translates into optimazion problem solved by approximate
algorithms (e.g., kalgorithms (e.g., k--means, HAC, fuzzy concept lattices)means, HAC, fuzzy concept lattices)
The clustering algorithm must be compatible with the data structure (e.g., The clustering algorithm must be compatible with the data structure (e.g.,
kk--means cannot find nonmeans cannot find non--convex clusters)convex clusters)

Web search results clustering
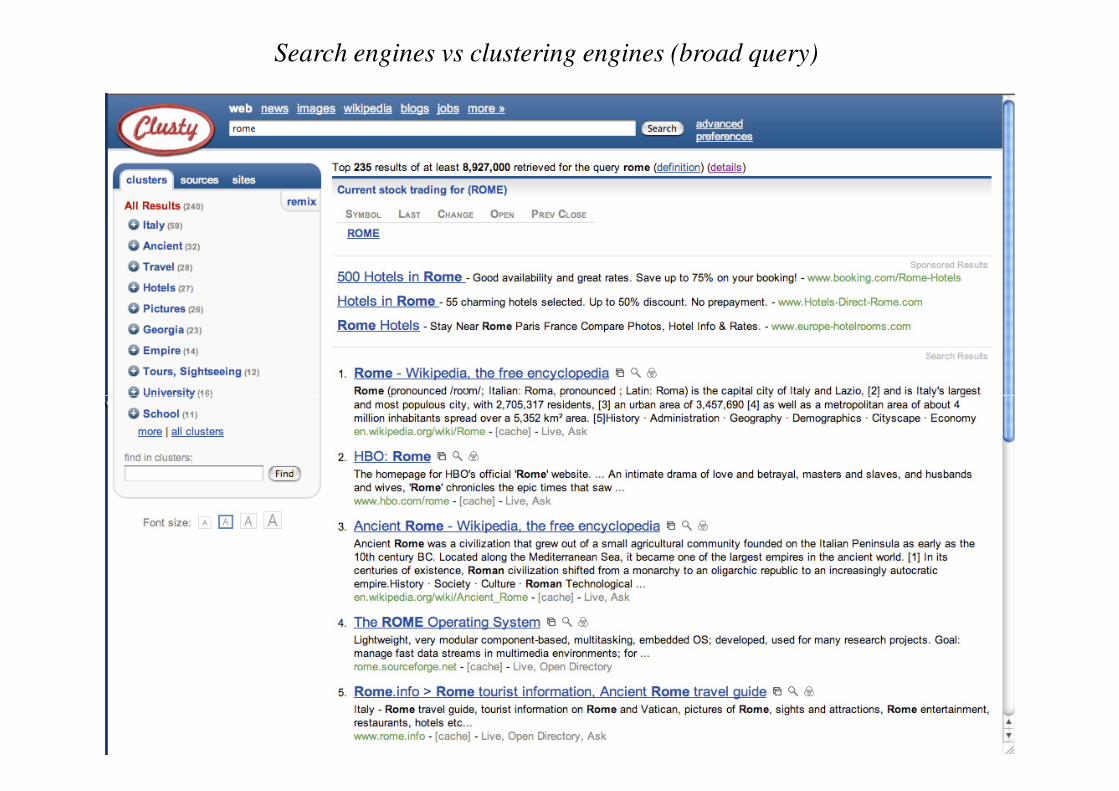
Search engines vs clustering engines (broad query)
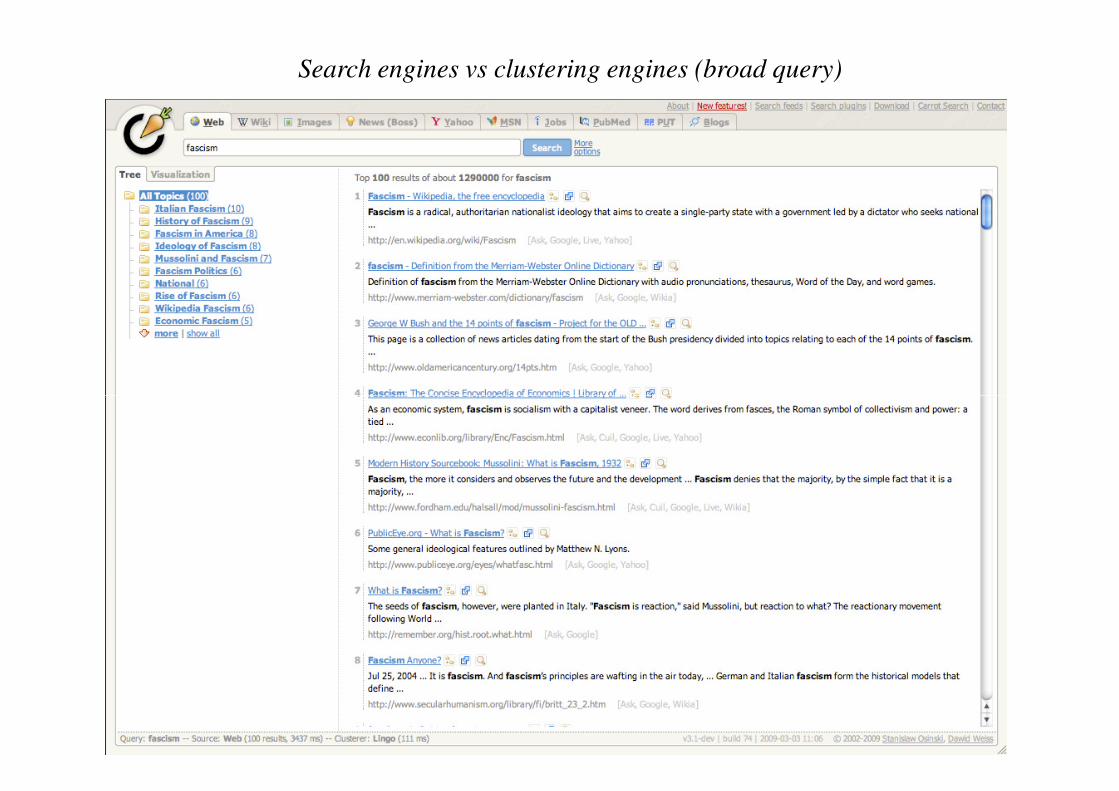
Search engines vs clustering engines (broad query)
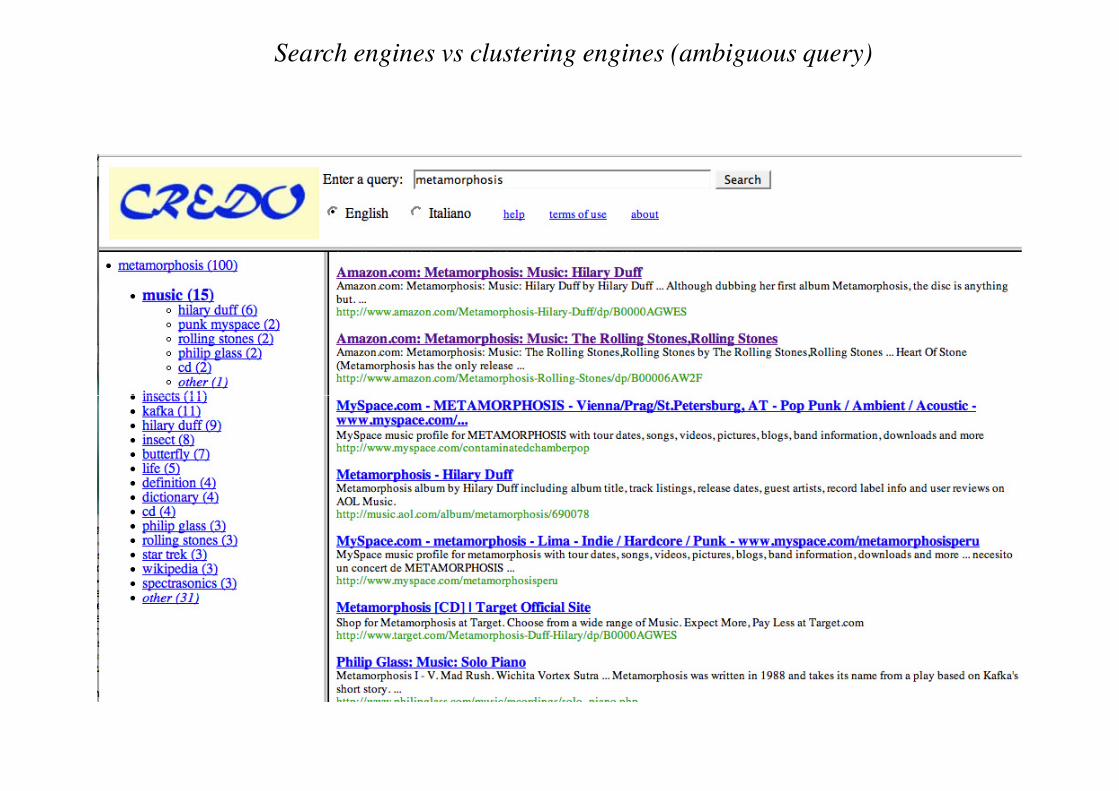
Search engines vs clustering engines (ambiguous query)

Web Clustering Engines:
• Issues
• Systems
• Problems
• New Directions

Features of clustering engines
Advantages:
• Fast subtopic retrieval
• Exploring unknown or dynamic domains• Exploring unknown or dynamic domains
• Filtering out irrelevant results
Mostly good when plain search engines fail

Search results clustering (post-retrieval)
versus
traditional document clustering (pre-retrieval)
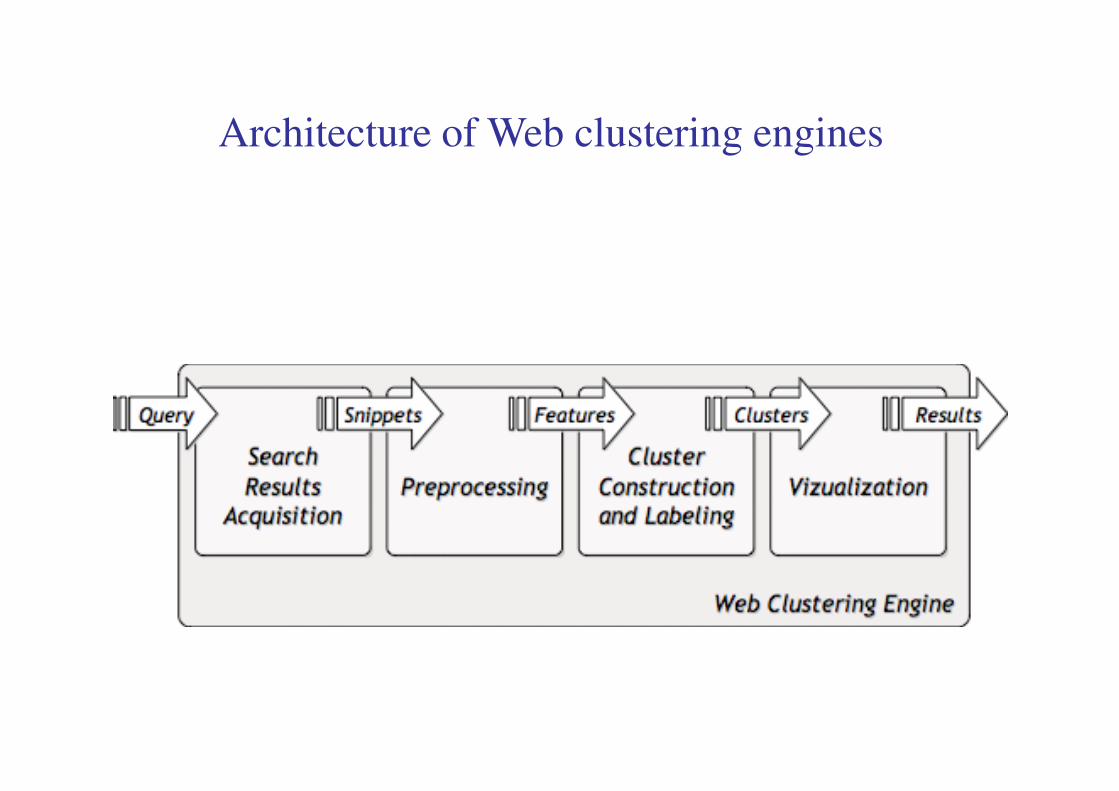
Architecture of Web clustering engines
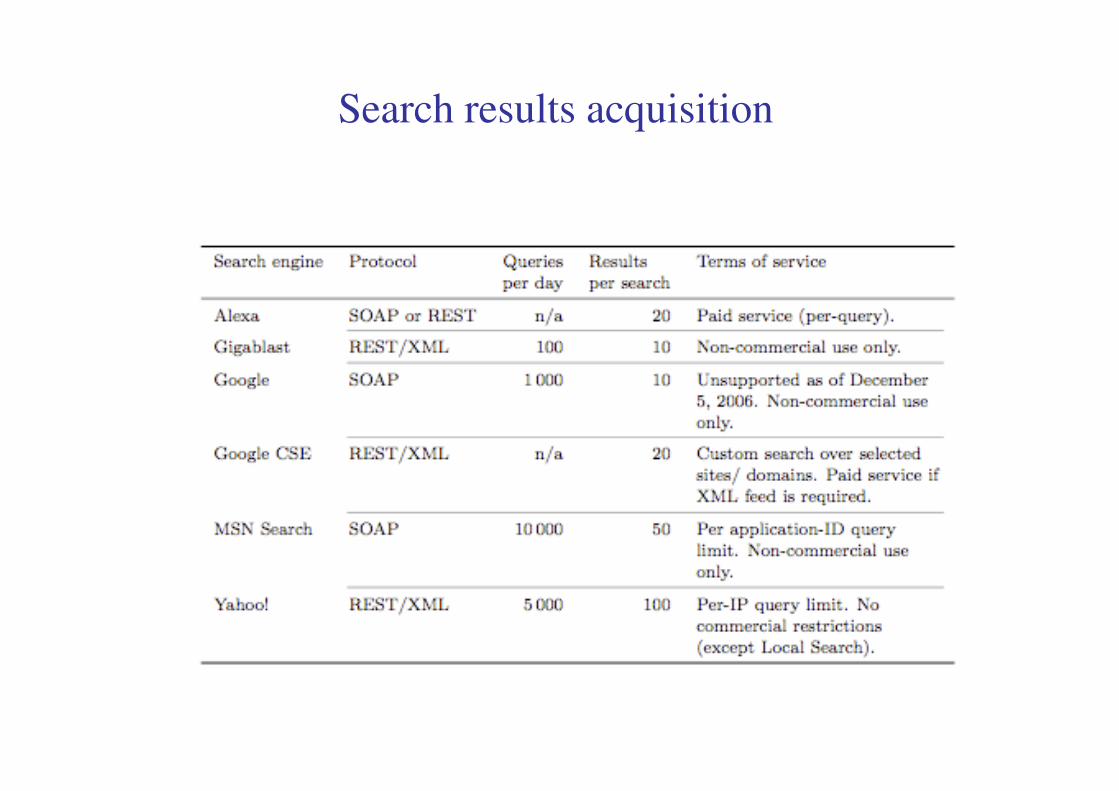
Search results acquisition

Preprocessing of search results
1. Language recognition
2. Tokenization2. Tokenization
3. Shallow language preprocessing
4. Feature selection

Cluster construction and labeling
“Description comes first”: from data-centric to
description-centric clustering algorithms

Keyphrase-based Search Results Clustering (1)
http://keysrc.fub.it

Keyphrase-based Search Results Clustering (2)
http://keysrc.fub.it
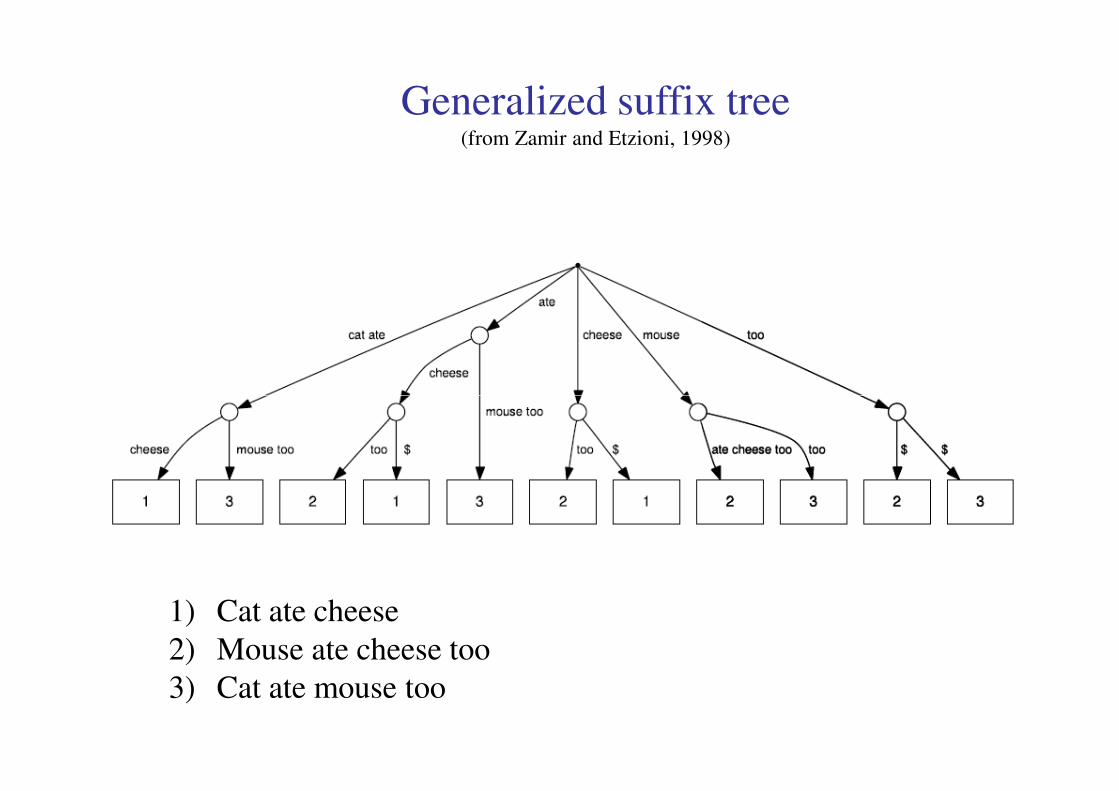
Generalized suffix tree(from Zamir and Etzioni, 1998)
1) Cat ate cheese
2) Mouse ate cheese too
3) Cat ate mouse too

KeySRC algorithmKeySRC algorithm
1.1. Search results preprocessingSearch results preprocessing
2.2. Construction of Generalized Suffix Tree (GST)Construction of Generalized Suffix Tree (GST)
3.3. Extraction of keyphrases from GSTExtraction of keyphrases from GST
(internal nodes of GST + (internal nodes of GST + << 4 words + POS tagging)4 words + POS tagging)(internal nodes of GST + (internal nodes of GST + << 4 words + POS tagging)4 words + POS tagging)
4. Keyphrase clustering4. Keyphrase clustering
5. Label assignment5. Label assignment
6. Cluster ranking6. Cluster ranking

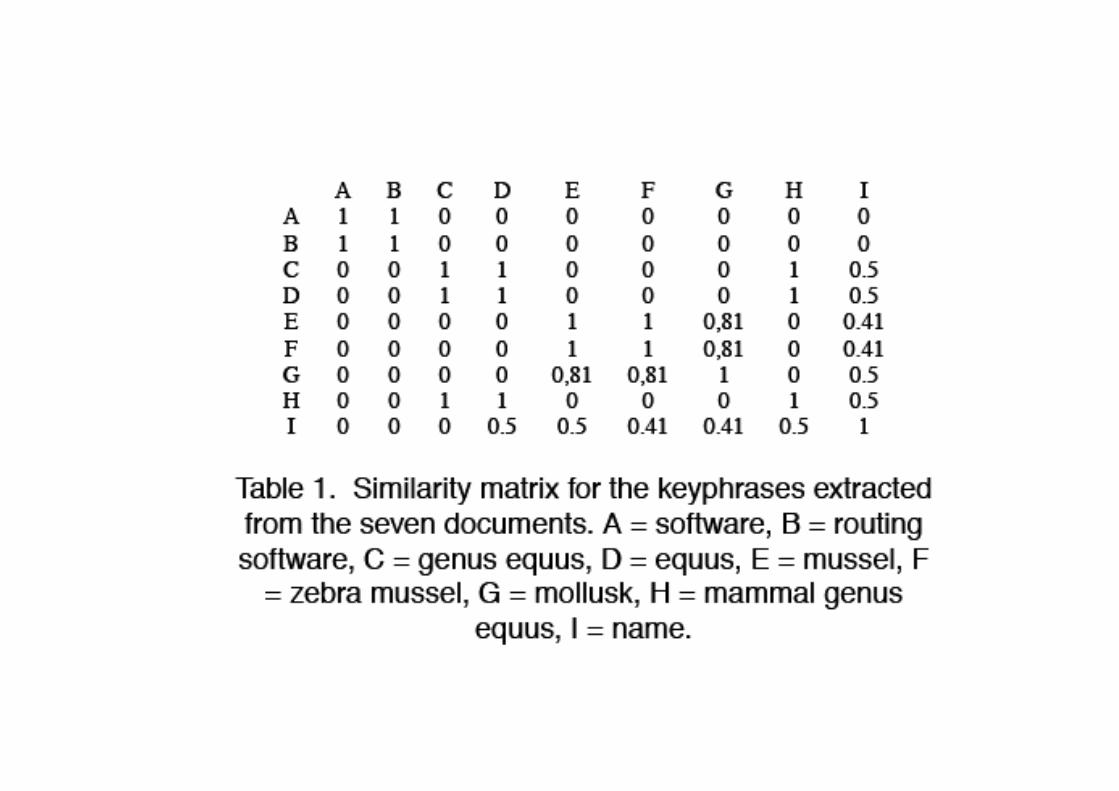
Search results for query “zebra”Search results for query “zebra”
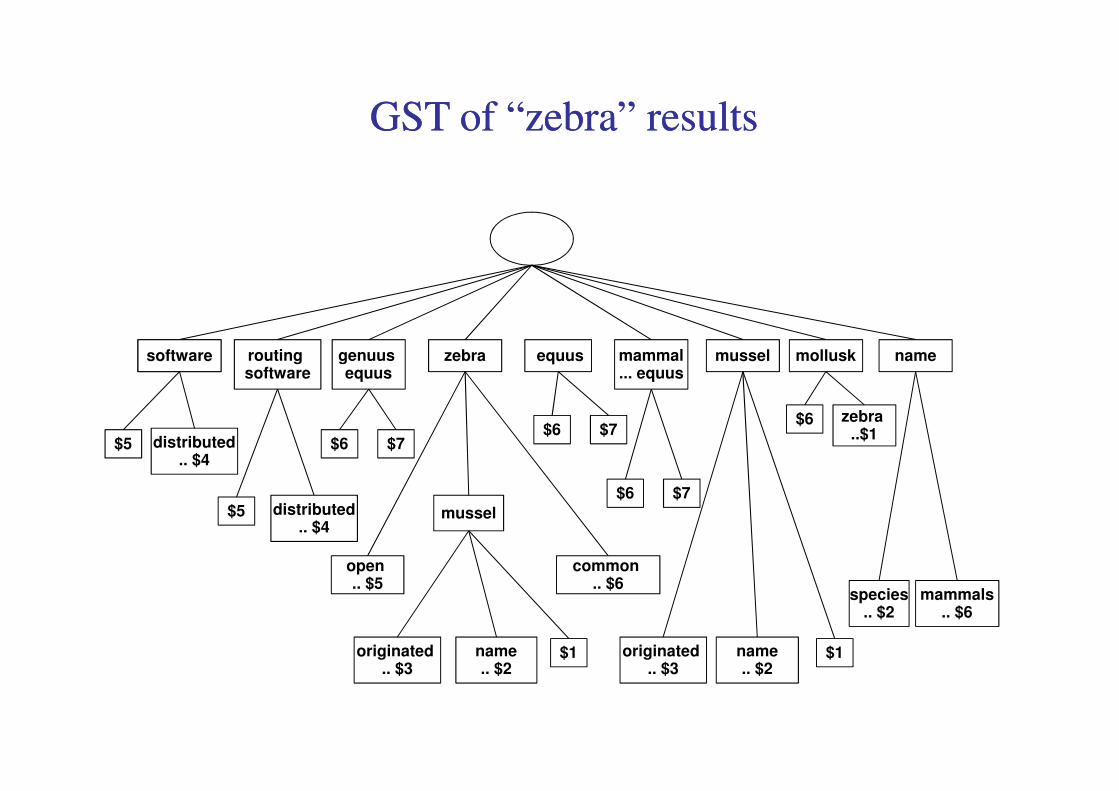
software routing software
genuus equus
zebra mammal... equus
mussel mollusk namesoftware equus
GST of “zebra” resultsGST of “zebra” results
distributed.. $4
$5
distributed.. $4
$5
$6 $7
mussel
mammals.. $6
species.. $2
$6 $7
$6 $7
$6 zebra ..$1
originated .. $3
$1name.. $2
open .. $5
common .. $6
originated .. $3
$1name.. $2
sim=1thr=0.8
sim=1thr=0.8
sim=0,873thr=0.8
sim=0,65thr=0.72
sim=0,76thr=0.8
sim=1thr=0.8
Mu
ssel
sim=1thr=0.8
so
ftw
are
rou
tin
g s
oft
ware
geu
us e
qu
us
eq
uu
s
mam
mal g
en
us e
qu
us
Mu
ssel
zeb
ra m
ussel
mo
llu
sk
nam
e
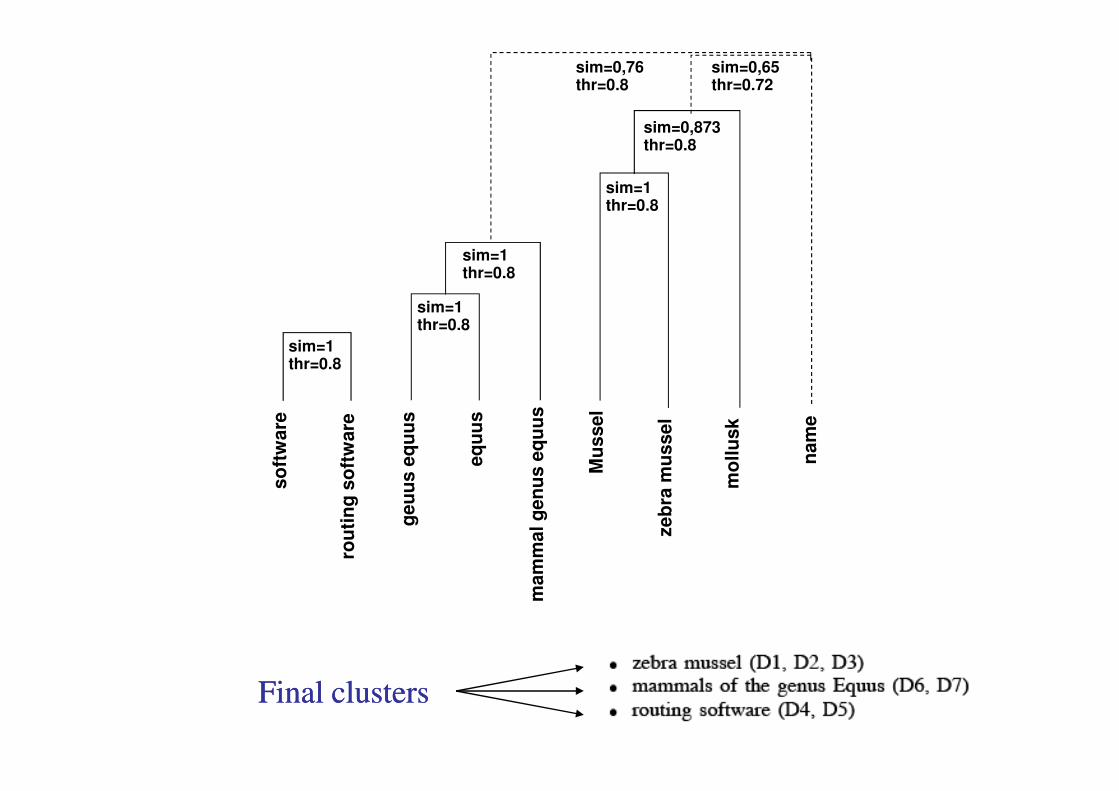
Final clustersFinal clusters

Keyword-based visualization
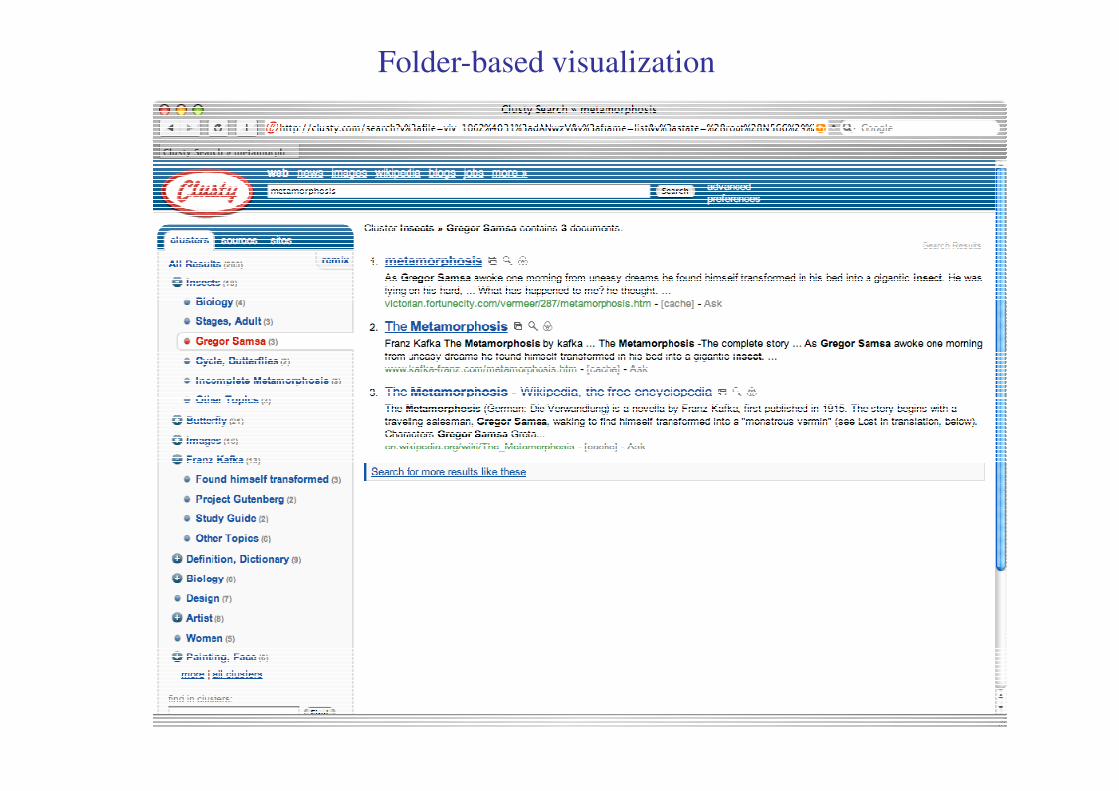
Folder-based visualization

Nesting & zooming visualization
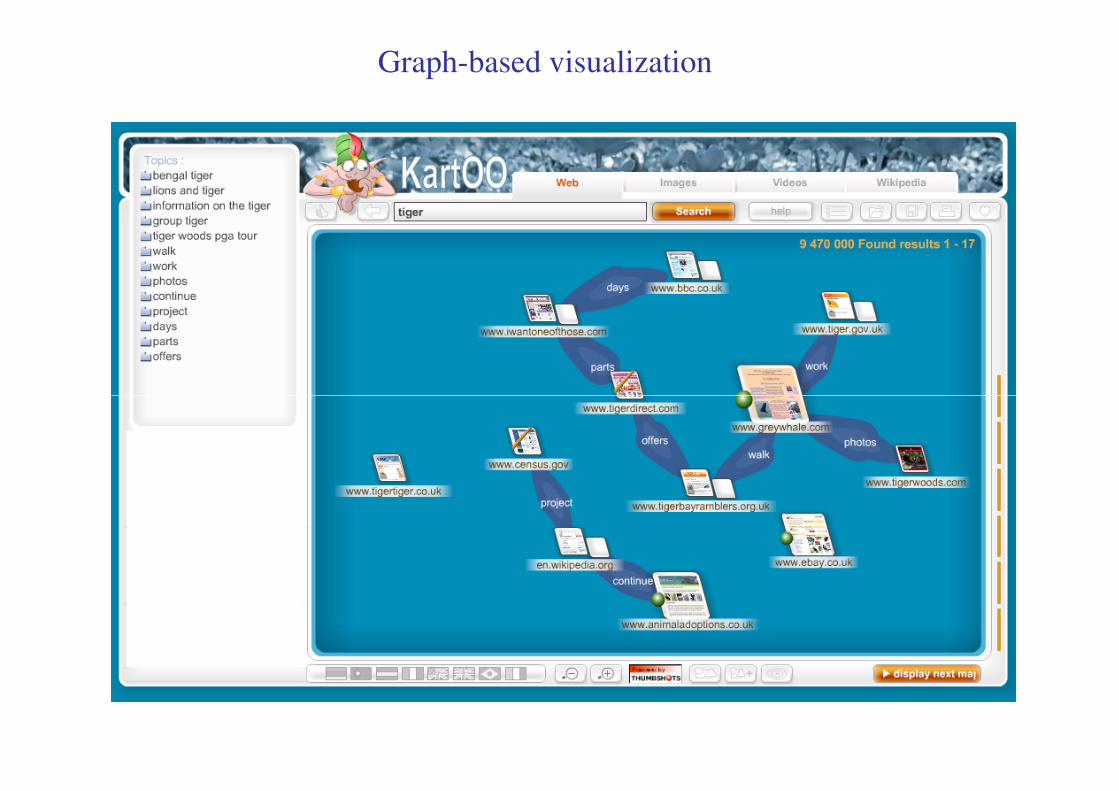
Graph-based visualization

Web Clustering Engines:
• Issues
• Systems
• Problems
• New Directions
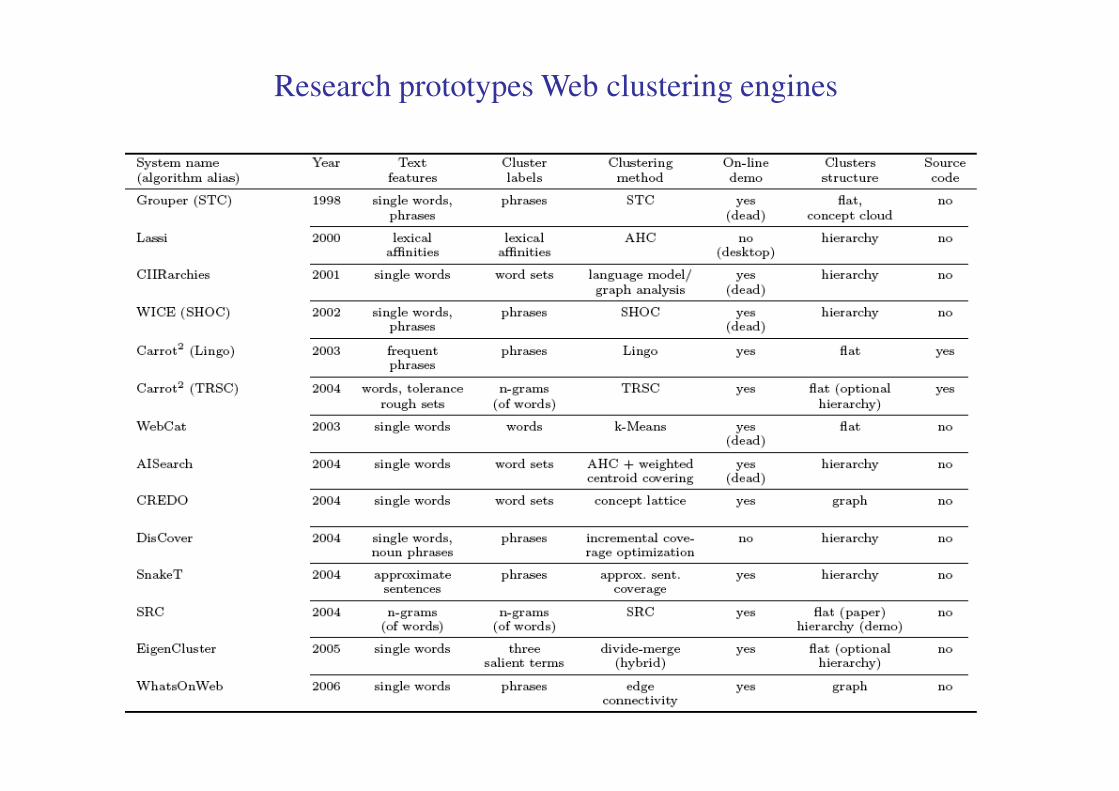
Research prototypes Web clustering engines
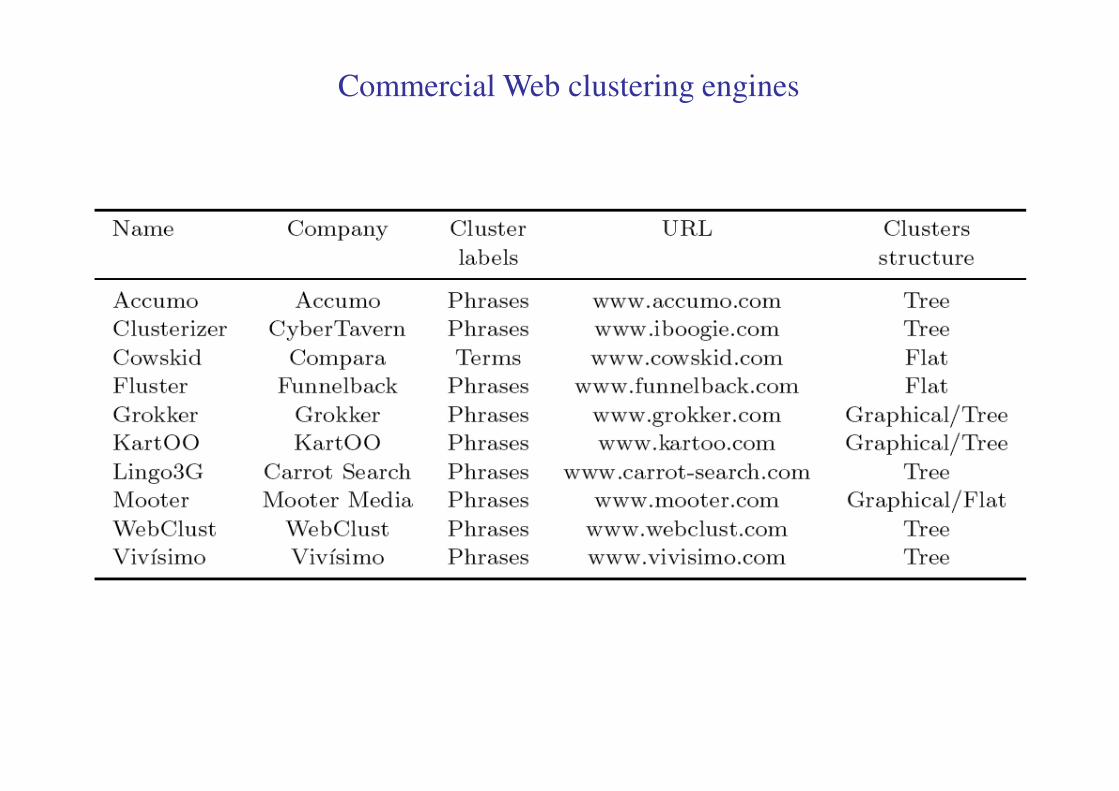
Commercial Web clustering engines

Web Clustering Engines:
• Issues
• Systems
• Problems
• New Directions
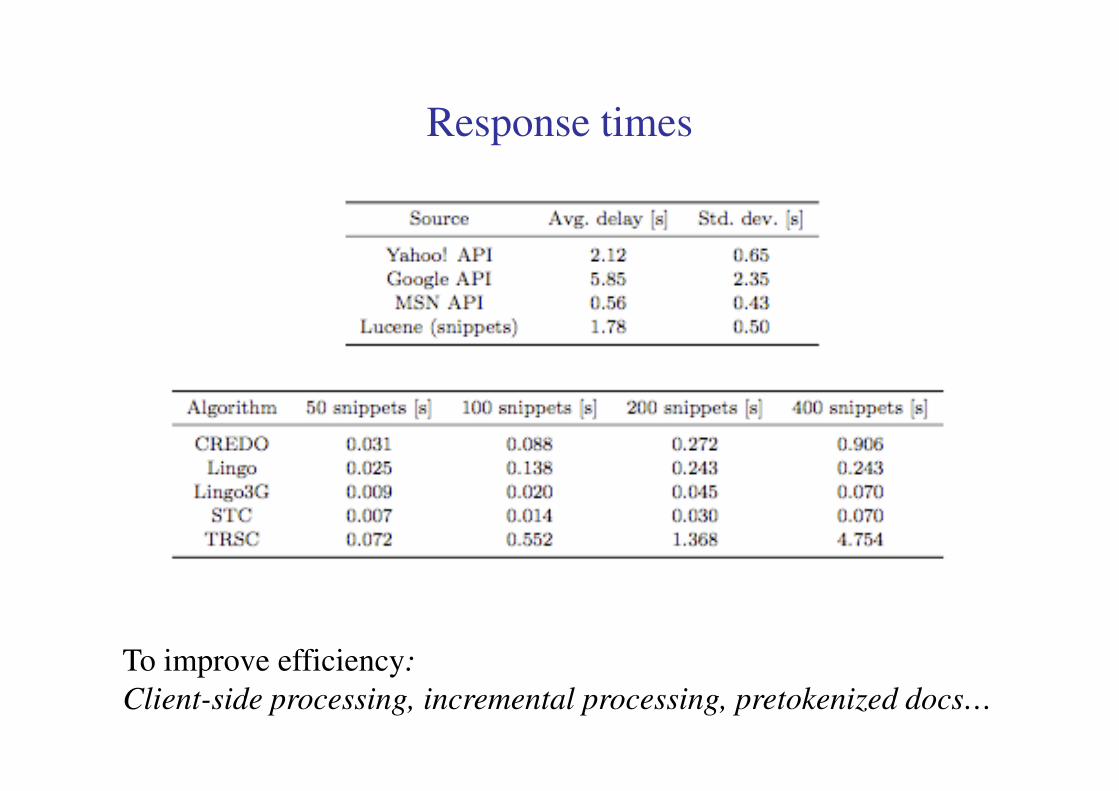
Response times
To improve efficiency:
Client-side processing, incremental processing, pretokenized docs…

Theoretical limitations of clustering engines
Quality and usability of clusters is still unsatisfactory:
- incompleteness of clusters,
- lack of intra- and inter-cluster consistency,
- label expressiveness,
- different cluster granularity
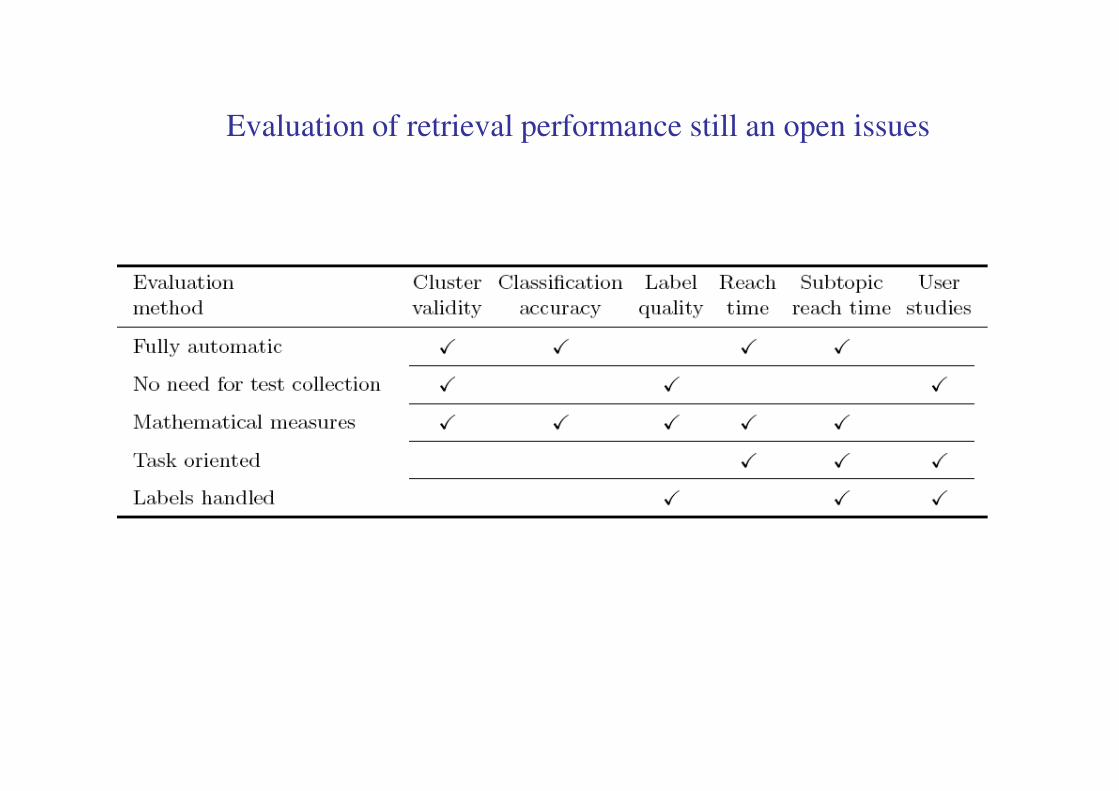
Evaluation of retrieval performance still an open issues

Subtopic reach time
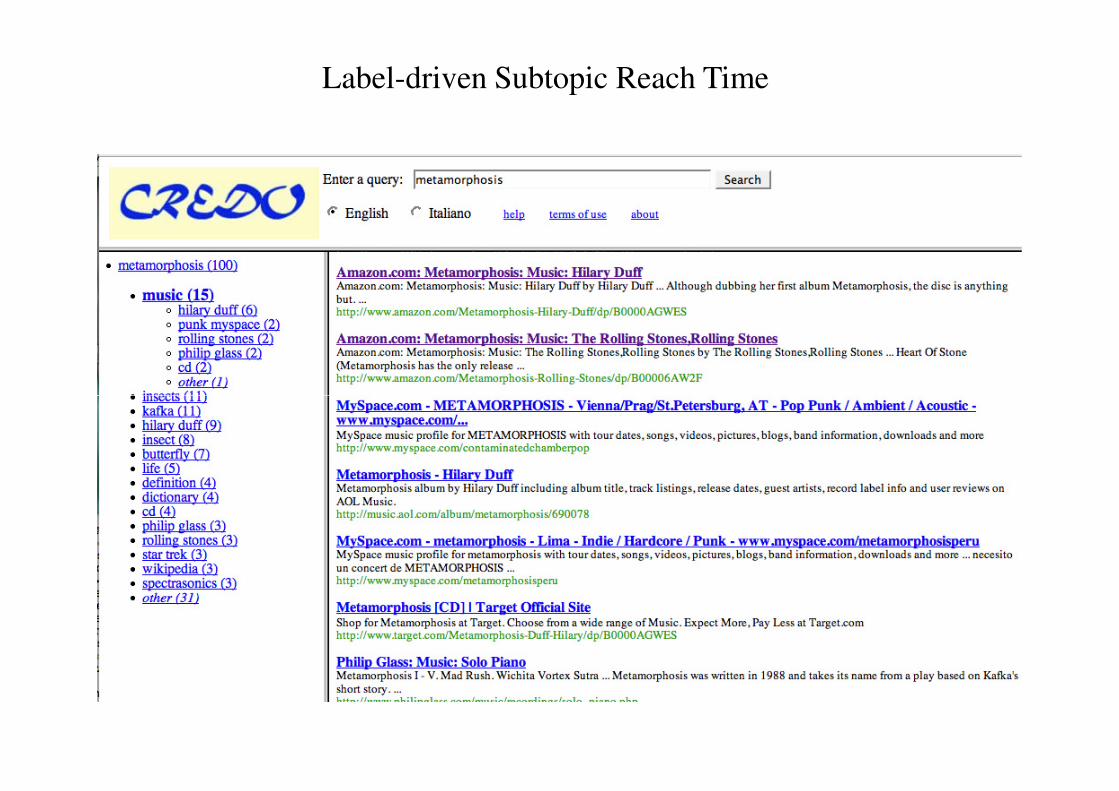
Label-driven Subtopic Reach Time
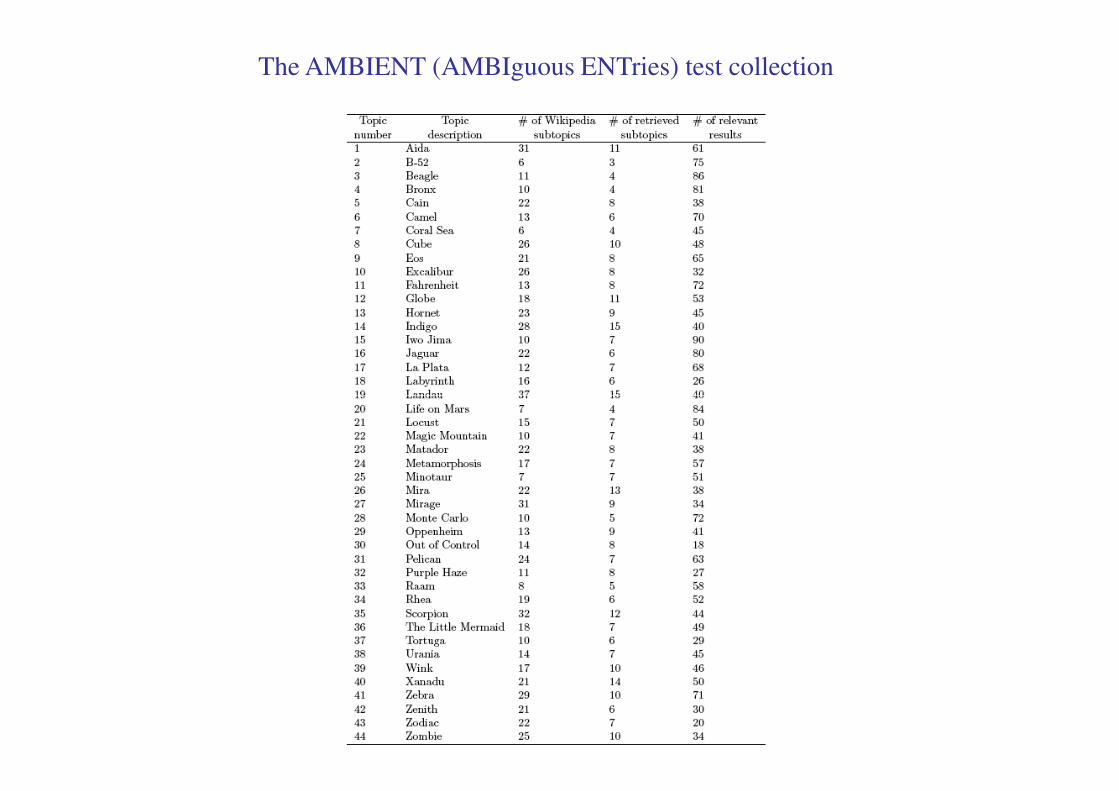
The AMBIENT (AMBIguous ENTries) test collection

Web Clustering Engines:
• Issues
• Systems
• Problems
• New Directions

Research directions
• More powerful search results indexing
• Multiple clustering methods combination
• Generation of more informative cluster labels
• Personalized clustering creation/reorganization
• Integration with ontologies

Potentials of mobile Web
clustering engines
• Reduction of scrolling
• Reduction of typing for query refinement• Reduction of typing for query refinement
• Reduction of downloaded data
• Extending mobile usage patterns to domain exploration
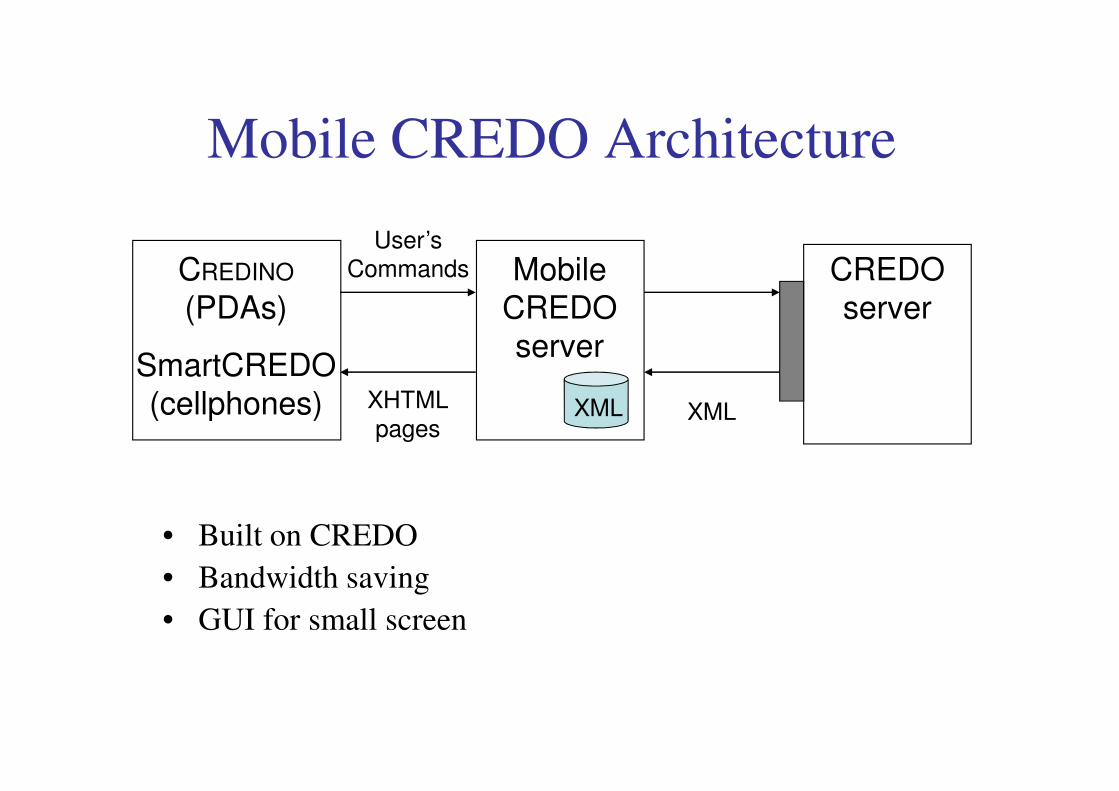
Mobile CREDO Architecture
CREDO
server
Mobile
CREDO
server
CREDINO
(PDAs)
SmartCREDO
(cellphones) XHTML
User’s
Commands
XML
• Built on CREDO
• Bandwidth saving
• GUI for small screen
(cellphones) XMLXHTML
pagesXML
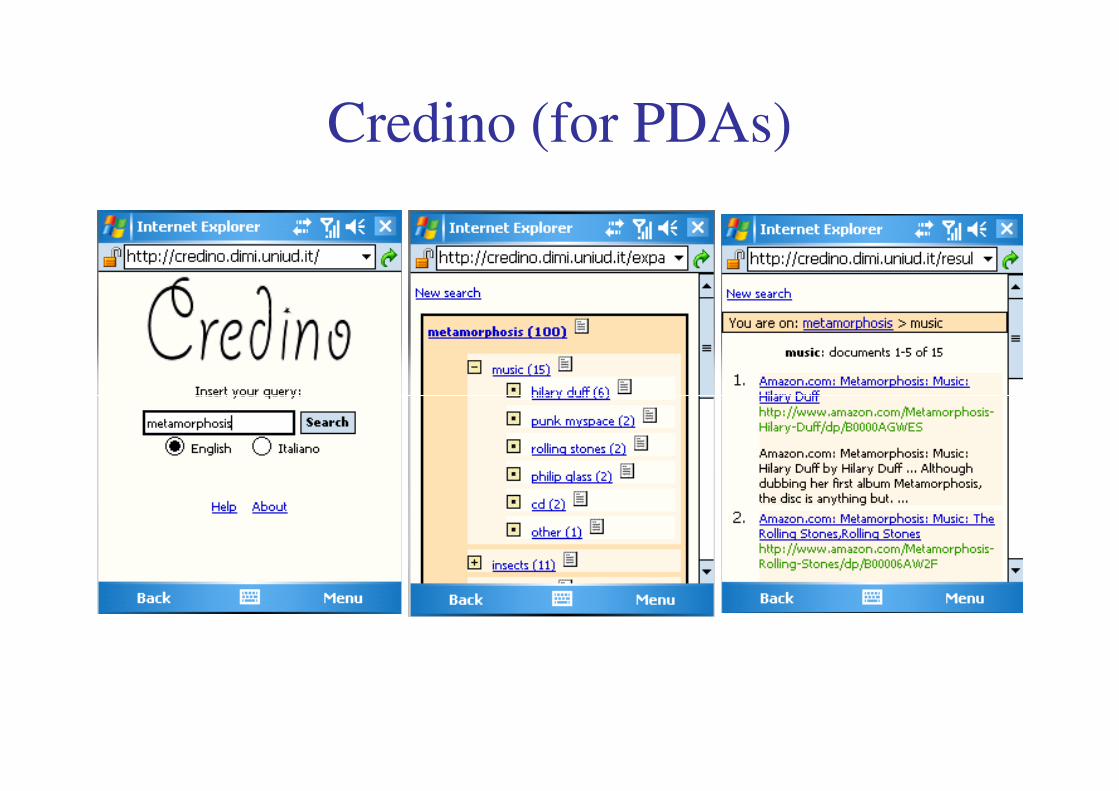
Credino (for PDAs)

SmartCREDO (for cellphones)

KeySRC on iPhone

Web search results clustering at Fondazione
Ugo Bordoni: papers and relevant URLs
• C. Carpineto, S. Osinski, G. Romano, G. Weiss (to appear). A Survey of Web Clustering Engines. To appear in ACM Computing Surveys.
• Carpineto, S. Mizzaro, G. Romano, M. Snidero (2009). Mobile Information Retrieval with Search Results Clustering: Prototypes and Evaluations. JASIST, 60(5), 877-895.
• A.Bernardini, C. Carpineto, M. D’Amico (submitted). Full-Subtopic Retrieval with Keyphrase-based Search Results Clustering. Submitted.Keyphrase-based Search Results Clustering. Submitted.
• Carpineto, C., Della Pietra, A., Mizzaro, S., and Romano, G. (2006). Mobile Clustering Engine. Proceedings of ECIR 2006.
• Carpineto, C., Romano, G.. (2004). Concept Data Analysis: Theory and Applications. John Wiley & Sons.
• CREDO http://credo.fub.it
• Credino http://credino.dimi.uniud.it
• SmartCREDO http://credino.dimi.uniud.it
• AMBIENT http://credo.fub.it/ambient
• KeySRC http://keysrc.fub.it





























