Embed Size (px)
Citation preview

1/30/11
1
WebDocumentModeling
PeterBrusilovsky
WithslidesfromJae‐wookAhnandJumpolPolvichai
IntroducEon
• Modelingmeans“theconstruc+onofanabstractrepresenta+onofthedocument”– UsefulforallapplicaEonsaimedatprocessinginformaEonautomaEcally.
• Whybuildmodelsofdocuments?– Toguidetheuserstotherightdocumentsweneedtoknowwhattheyareabout,whatistheirstructure
– SomeadaptaEontechniquescanoperatewithdocumentsas“blackboxes”,butothersarebasedontheabilitytounderstandandmodeldocuments

1/30/11
2
Documentmodeling
DocumentsDocumentsDocuments
DocumentModels‐ Bagofwords‐ Tag‐based‐Link‐based
‐Concept‐based‐ AI‐based
ProcessingApplica+on
‐ Matching(IR)‐ Filtering‐ AdapEve
presentaEon,etc.
3
DocumentmodelExample
thedeathtollrisesinthemiddleeastastheworstviolenceinfouryearsspreadsbeyondjerusalem.thestakesarehigh,theraceisEght.preppingforwhatcouldbeadecisivemomentinthepresidenEalbaYle.howaEnytowniniowabecameaboomingmelEngpotandtheimagethatwillnotsoonfade.themanwhocapturedittellsthestorybehindit.
4

1/30/11
3
Outline
• ClassicIRbasedrepresenta+on– Preprocessing– Boolean,ProbabilisEc,VectorSpacemodels
• Web‐IRdocumentrepresenta+on– Tagbaseddocumentmodels– Linkbaseddocumentmodels–HITS,GoogleRank
• Concept‐baseddocumentmodeling– LSI
• AI‐baseddocumentrepresenta+on– ANN,SemanEcNetwork,BayesianNetwork
5
MarkupLanguages AMarkupLanguageisatext‐basedlanguagethatcombinescontentwith
itsmetadata.MLsupportstructuremodeling• Presenta+onalMarkup
– ExpressdocumentstructureviathevisualappearanceofthewholetextofaparEcularfragment.
– Exp.Wordprocessor
• ProceduralMarkup– FocusesonthepresentaEonoftext,butisusuallyvisibletotheuser
ediEngthetextfile,andisexpectedtobeinterpretedbysocwarefollowingthesameproceduralorderinwhichitappears.
– Exp.Tex,PostScript• Descrip+veMarkup
– ApplieslabelstofragmentsoftextwithoutnecessarilymandaEnganyparEculardisplayorotherprocessingsemanEcs.
– Exp.SGML,XML

1/30/11
4
ClassicIRmodelProcess
DocumentsDocumentsDocuments
SetofTerms“BagofWords”
Preprocessing
TermweighEng
Query(ordocuments)
Matching(byIRmodels)
7
PreprocessingMoEvaEon
• Extractdocumentcontentitselftobeprocessed(used)
• RemovecontrolinformaEon– Tags,script,stylesheet,etc
• Removenon‐informaEvefragments– Stopwords,word‐stems
8

1/30/11
5
PreprocessingHTMLtagremoval
• Removes<.*>partsfromtheHTMLdocument(source)
9
PreprocessingHTMLtagremoval
DETROIT—Withitsaccesstoagovernmentlifelineinthebalance,GeneralMotorswaslockedinintensenegoEaEonsonMondaywiththeUnitedAutomobileWorkersoverwaystocutitsbillsforreEreehealthcare.
10

1/30/11
6
PreprocessingTokenizing/casenormalizaEon
• Extractterm/featuretokensfromthetext
detroitwithitsaccesstoagovernmentlifelineinthebalancegeneralmotorswaslockedinintensenegoEaEonsonmondaywiththeunitedautomobileworkersoverwaystocutitsbillsforreEreehealthcare
11
PreprocessingStopwordremoval
• Verycommonwords
• Donotcontributetoseparateadocumentfromanothermeaningfully
• Usuallyastandardsetofwordsarematched/removed
detroitwithitsaccesstoagovernmentlifelineinthebalancegeneralmotorswaslockedinintensenegoEaEonsonmondaywiththeunitedautomobileworkersoverwaystocutitsbillsforreEreehealthcare
12

1/30/11
7
PreprocessingStemming
• Extractsword“stems”only• AvoidwordvariaEonthatarenotinformaEve– apples,apple – Retrieval,retrieve,retrieving– Should they be dis.nguished? Maybe not.
• Porter• Krovetz
13
PreprocessingStemming(Porter)
• MarEnPorter,1979
• CyclicalrecogniEonandremovalofknownsuffixesandprefixes
14

1/30/11
8
PreprocessingStemming(Krovetz)
• BobKorvetz,1993• MakesuseofinflecEonallinguisEcmorphology
• RemovesinflecEonalsuffixesinthreesteps– singleform(e.g.‘‐ies’,‘‐es’,‘‐s’)– pasttopresenttense(e.g.‘‐ed’)– removalof‘‐ing’
• CheckinginadicEonary• Morehuman‐readable
15
PreprocessingStemming
• Porterstemmingexmple[detroitaccessgovernlifelinbalancgenermotorlockintensnegoEmondaiunitautomobilworkerwaicutbillreErehealthcare]
• Krovetzstemmingexample[detroitaccessgovernmentlifelinebalancegeneralmotorlockintensenegoEaEonmondayunitedautomobileworkerwayscutbillreEreehealthcare]
16

1/30/11
9
Termweigh+ng
• Howshouldwerepresenttheterms/featuresacertheprocessessofar?
17
detroitaccessgovernmentlifeline
balancegeneralmotorlockintensenegoEaEon
mondayunitedautomobileworkerwayscutbillreEreehealthcare
?
Termweigh+ngDocument‐termmatrix
• Columns–everytermappearedinthecorpus(notasingledocument)
• Rows–everydocumentinthecollecEon
• Example– IfacollecEonhasNdocumentsandMterms…
18
T1 T2 T3 … TM
Doc1 0 1 1 … 0
Doc2 1 0 0 … 1
… … … … … …
DocN 0 0 0 … 1

1/30/11
10
Termweigh+ngDocument‐termmatrix
• Document‐termmatrix– Binary(ifappears1,otherwise0)
• Everytermistreatedequivalently
aGract benefit book … zoo
Doc1 0 1 1 … 0
Doc2 1 0 0 … 1
Doc3 0 0 0 … 1
19
Termweigh+ngTermfrequency
• So,weneed“weigh&ng”– Givedifferent“importance” todifferentterms
• TF– Termfrequency– HowmanyEmesatermappearedinadocument?– Higherfrequencyhigherrelatedness
20

1/30/11
11
Termweigh+ngTermfrequency
21
Termweigh+ngIDF
• IDF– InverseDocumentFrequency
– Generalityofatermtoogeneral,notbeneficial– Example• “Informa+on”(inACMDigitalLibrary)
– 99.99%ofarEcleswillhaveit– TFwillbeveryhighineachdocument
• “Personaliza+on”– Say,5%ofdocumentswillhaveit
– TFagainwillbeveryhigh
22

1/30/11
12
Termweigh+ngIDF
• IDF
– DF=documentfrequency=numberofdocumentsthathavetheterm
– IfACMDLhas1Mdocuments• IDF(“informaEon”)=Log(1M/999900)=0.0001
• IDF(“persoanlizaEon”)=Log(1M/50000)=30.63
€
log( NDF
)
23
Termweigh+ngIDF
• informa+on,personaliza+on,recommenda+on• Canwesay…
– Doc1,2,3…areaboutinformaEon?
– Doc1,6,8…areaboutpersonalizaEon?– Doc5isaboutrecommendaEon?
Doc1 Doc2 Doc3 Doc4
Doc5 Doc6 Doc7 Doc8
24

1/30/11
13
Termweigh+ngTF*IDF
• TF*IDF– TFmulEpliedbyIDF
– ConsidersTFandIDFatthesameEme– HighfrequencytermsfocusedinsmallerporEonofdocumentsgetshigherscores
25
Document benef aGract sav springer book
d1 0.176 0.176 0.417 0.176 0.176
d2 0.000 0.350 0.000 0.528 0.000
d3 0.528 0.000 0.000 0.000 0.176
Termweigh+ngBM25
• OKAPIBM25– OkapiBestMatch25
– ProbabilisEcmodel–calculatestermrelevancewithinadocument
– Computesatermweightaccordingtotheprobabilityofitsappearanceinarelevantdocumentandtotheprobabilityofitappearinginanon‐relevantdocumentinacollecEonD
26

1/30/11
14
Termweigh+ngEntropyweighEng
• EntropyweighEng
– Entropyoftermti• ‐1:equaldistribuEonofalldocuments• 0:appearingonly1document
27
IRmodels
• Boolean• ProbabilisEc• VectorSpace
28

1/30/11
15
IRModelsBooleanmodel
• BasedonsettheoryandBooleanalgebra
• d1,d3
29
IRModelsBooleanmodel
• Simpleandeasytoimplement• Shortcomings– Onlyretrievesexactmatches• NoparEalmatch
– Noranking– DependsonuserqueryformulaEon
30

1/30/11
16
IRModelsProbabilisEcmodel
• Binaryweightvector• Query‐documentsimilarityfuncEon
• Probabilitythatacertaindocumentisrelevanttoacertainquery
• Ranking–accordingtotheprobabilitytoberelevant
31
IRModelsProbabilisEcmodel
• SimilaritycalculaEon
• SimplifyingassumpEons– NorelevanceinformaEonatstartup
32
BayesTheoremandremovingsomeconstants

1/30/11
17
IRModelsProbabilisEcmodel
• Shortcomings– Divisionofthesetofdocumentsintorelevant/non‐relevantdocuments
– TermindependenceassumpEon
– Indexterms–binaryweights
33
IRModelsVectorspacemodel
• Document=mdimensionalspace(m=indexterms)
• Eachtermrepresentsadimension
• ComponentofadocumentvectoralongagivendirecEontermimportance
• Queryanddocumentsarerepresentedasvectors
34

1/30/11
18
IRModelsVectorspacemodel
• Documentsimilarity– Cosineangle
• Benefits– TermweighEng– ParEalmatching
• Shortcomings– Termindependency
35
t1
t2
d1
d2
Cosineangle
IRModelsVectorspacemodel
• Example– Query=“springerbook”– q=(0,0,0,1,1)– Sim(d1,q)=(0.176+0.176)/(√1+√(0.1762+0.1762+0.4172+0.1762+0.1762)=0.228
– Sim(d2,q)=(0.528)/(√1+√(0.3502+0.5282))=0.323
– Sim(d3,q)=(0.176)/(√1+√(0.5282+0.1762))=0.113
Document benef aGract sav springer book
d1 0.176 0.176 0.417 0.176 0.176
d2 0.000 0.350 0.000 0.528 0.000
d3 0.528 0.000 0.000 0.000 0.176
36

1/30/11
19
IRModelsVectorspacemodel
• Document–documentsimilarity• Sim(d1,d2)=0.447
• Sim(d2,d3)=0.0
• Sim(d1,d3)=0.408
Document benef aGract sav springer book
d1 0.176 0.176 0.417 0.176 0.176
d2 0.000 0.350 0.000 0.528 0.000
d3 0.528 0.000 0.000 0.000 0.176
37
Curseofdimensionality
• TDT4– |D|=96,260– |ITD|=118,205
• Iflinearlycalculatessim(q,D)– 96,260(pereachdocument)*118,205(innerproduct)comparisons
• However,documentmatricesareverysparse– Mostly0’s– Space,calculaEoninefficienttostorethose0’s
38

1/30/11
20
Curseofdimensionality
• Invertedindex– Indexfromtermtodocument
39
Web‐IRdocumentrepresenta+on
• EnhancestheclassicVSM• PossibiliEesofferedbyHTMLlanguages
• Tag‐based• Link‐based– HITS– PageRank
40

1/30/11
21
Web‐IRTag‐basedapproaches
• Givedifferentweightstodifferenttags– Sometextfragmentswithinatagmaybemoreimportantthanothers
– <body>,<Etle>,<h1>,<h2>,<h3>,<a>…
41
Web‐IRTag‐basedapproaches
• WEBORsystem• Sixclassesoftags
• CIV=classimportancevector• TFV=classfrequencyvector
42

1/30/11
22
Web‐IRTag‐basedapproaches
• TermweighEngexample– CIV={0.6,1.0,0.8,0.5,0.7,0.8,0.5}– TFV(“personalizaEon”)={0,3,3,0,0,8,10}– W(“personalizaEon”)=(0.0+3.0+2.4+0.0+0.0+6.4+5.0)*IDF
43
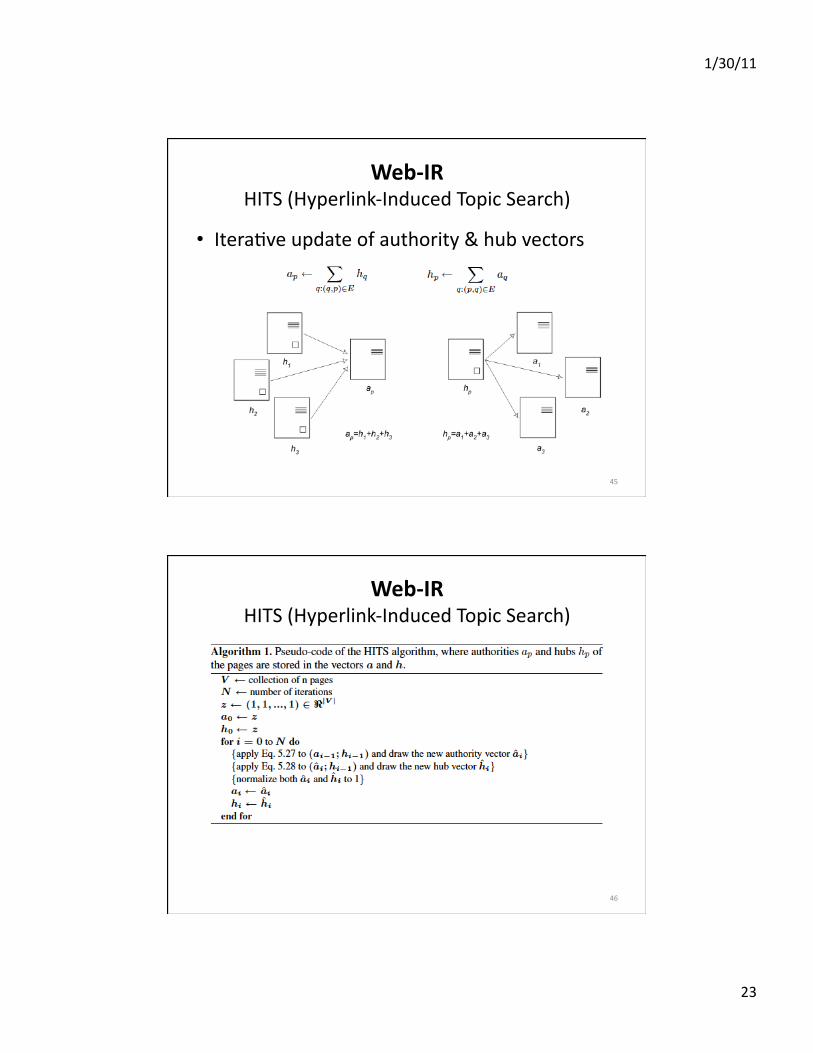
Web‐IRHITS(Hyperlink‐InducedTopicSearch)
• Link‐basedapproach• PromotesearchperformancebyconsideringWebdocumentlinks
• WorksonaniniEalsetofretrieveddocuments• HubandauthoriEes– Agoodauthoritypageisonethatispointedtobymanygoodhubpages
– Agoodhubpageisonethatispointedtobymanygoodauthoritypages
– Circular defini&on iteraEvecomputaEon
44
1/30/11
23
Web‐IRHITS(Hyperlink‐InducedTopicSearch)
• IteraEveupdateofauthority&hubvectors
45
Web‐IRHITS(Hyperlink‐InducedTopicSearch)
46

1/30/11
24
Web‐IRHITS(Hyperlink‐InducedTopicSearch)
• N=1– A=[0.3710.5570.743]– H=[0.6670.6670.333]
• N=10– A=[0.3440.5730.744]– H=[0.7220.6190.309]
• N=1000– A=[0.3280.5910.737]– H=[0.7370.5910.328]
47
Doc0
Doc2Doc1
Web‐IRPageRank
• Google• UnlikeHITS
– NotlimitedtoaspecificiniEalretrievedsetofdocuments
– Singlevalue
• IniEalstate=nolink• Evenlydividescoresto4
documents• PR(A)=PR(B)=PR(C)=
PRD(D)=1/4=0.25
48
A
B
C
D

1/30/11
25
Web‐IRPageRank
• PR(A)=PR(B)+PR(C)+PR(D)=0.25+0.25+0.25=0.75
49
A
B
C
D
Web‐IRPageRank
• PR(B)toA=0.25/2=0.125• PR(B)toC=0.25/2=0.125• PR(A)
=PR(B)+PR(C)+PR(D)=0.125+0.25+0.25=0.625
50
A
B
C
D
1/30/11
26
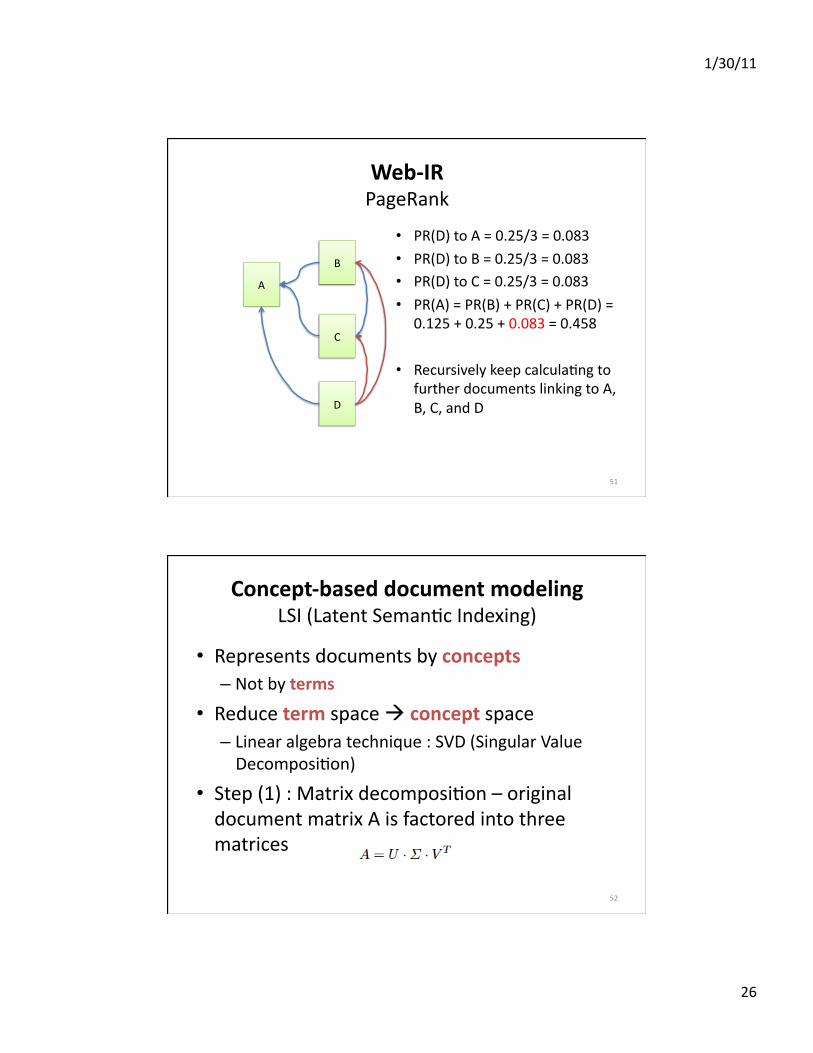
Web‐IRPageRank
• PR(D)toA=0.25/3=0.083• PR(D)toB=0.25/3=0.083• PR(D)toC=0.25/3=0.083• PR(A)=PR(B)+PR(C)+PR(D)=
0.125+0.25+0.083=0.458
• RecursivelykeepcalculaEngtofurtherdocumentslinkingtoA,B,C,andD
51
A
B
C
D
Concept‐baseddocumentmodelingLSI(LatentSemanEcIndexing)
• Representsdocumentsbyconcepts– Notbyterms
• Reducetermspaceconceptspace– Linearalgebratechnique:SVD(SingularValueDecomposiEon)
• Step(1):MatrixdecomposiEon–originaldocumentmatrixAisfactoredintothreematrices
52

1/30/11
27
Concept‐baseddocumentmodelingLSI
• Step(2):ArankkisselectedfromtheoriginalequaEon(k=reduced#ofconceptspace)
• Step(3):Theoriginalterm‐documentmatrixAisconvertedtoAk
53
Concept‐baseddocumentmodelingLSI
• Document‐termmatrixA
54

1/30/11
28
Concept‐baseddocumentmodelingLSI
• DecomposiEon
55
Concept‐baseddocumentmodelingLSI
• LowrankapproximaEon(k=2)
56

1/30/11
29
Concept‐baseddocumentmodelingLSI
• FinalAk– Columns:documents
– Rows:concepts(k=2)
57
‐1
‐0.8
‐0.6
‐0.4
‐0.2
0
0.2
0.4
0.6
‐0.9 ‐0.8 ‐0.7 ‐0.6 ‐0.5 ‐0.4 ‐0.3 ‐0.2 ‐0.1 0
VT=SVDDocumentMatrix
d2
d3
d1
AI‐basedapproachesArEficialNeuralNetworks
• Query,term,documentsseparatedinto3layers
• Term‐documentweight=norm.TF‐IDF
• QuerytermacEvaEonsumofthesignalsexceedsathresholddocumentretrieval
58
1/30/11
30
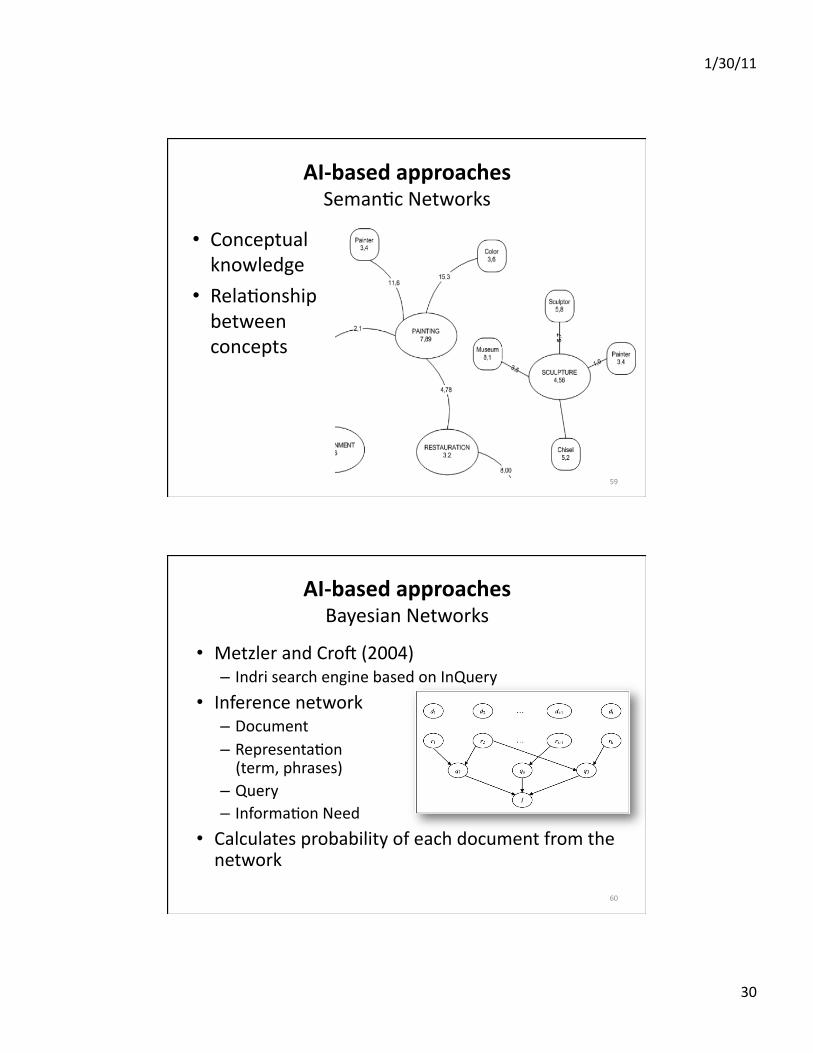
AI‐basedapproachesSemanEcNetworks
• Conceptualknowledge
• RelaEonshipbetweenconcepts
59
AI‐basedapproachesBayesianNetworks
60
• MetzlerandCroc(2004)– IndrisearchenginebasedonInQuery
• Inferencenetwork– Document– RepresentaEon(term,phrases)
– Query– InformaEonNeed
• Calculatesprobabilityofeachdocumentfromthenetwork





























