Embed Size (px)
Citation preview

DOCUMENT UPDATE DOCUMENT UPDATE SUMMARIZATION USING SUMMARIZATION USING
INCREMENTAL HIERARCHICAL INCREMENTAL HIERARCHICAL CLUSTERING CLUSTERING CIKM’10 (DINGDING WANG, TAO LI)CIKM’10 (DINGDING WANG, TAO LI)
Advisor: Koh, Jia-Ling Presenter: Nonhlanhla Shongwe
1

Preview Preview • Introduction• Incremental Hierarchical Clustering
Based Document Update Summarization• Incremental Hierarchical Sentence
Clustering (IHSC)oThe COBWEB algorithmoCOBWEB for text• Algorithm
• Evaluation measures • Experiments and results
2

Introduction Introduction • Document summarization has
been receiving much attention due to• Increasing number of documents on
the internet• Helping readers to extract their
interested information efficiently • Most document summarization
techniques perform in a batch mode
3

Introduction Introduction cont’scont’s
• Two most widely used summarization methods
• Firstly: Clustering based• Term sentence matrices formed from
the document• Sentences are grouped into different
clusters• Score is attached to each sentence
using average cosine similarity• Sentences with the highest score in
each cluster form the summary
4

Introduction Introduction cont’scont’s
• Secondly: Graph-ranking based• Constructs a sentence graph, each node
is a sentence in a document collection• An edge is formed between sentence
pairs if• The similarity between a pair of sentence is
above the threshold• They belong to the same document
• Sentences are selected to form the summary by voting from their neighbors
5

Introduction Introduction cont’scont’s
• With the rapid growth of document, • There is a necessity to update the
existing summaries when new documents arrives.
• Traditional methods are not suitable for this task• Most of the methods work in batch way:• Meaning that all the documents need to be
process again once new documents come, which causes inefficiency
6

Introduction Introduction cont’scont’s
• In this paper • To integrate document
summarization techniques into an incremental hierarchical clustering framework • To be able to re-organize sentence
clusters immediately after new documents arrive so that their corresponding summaries can be updated efficiently.
7

INCREMENTAL HIERARCHICAL INCREMENTAL HIERARCHICAL CLUSTERING BASED DOCUMENT CLUSTERING BASED DOCUMENT UPDATE SUMMARIZATIONUPDATE SUMMARIZATION
1. Framework 2. Preprocessing3. Incremental Hierarchical Sentence Clustering (IHSC)
I. The COBWEB algorithm
II. COBWEB for text4. Representative Sentence Selection for Each Node of the
Hierarchy5. The Algorithm
8
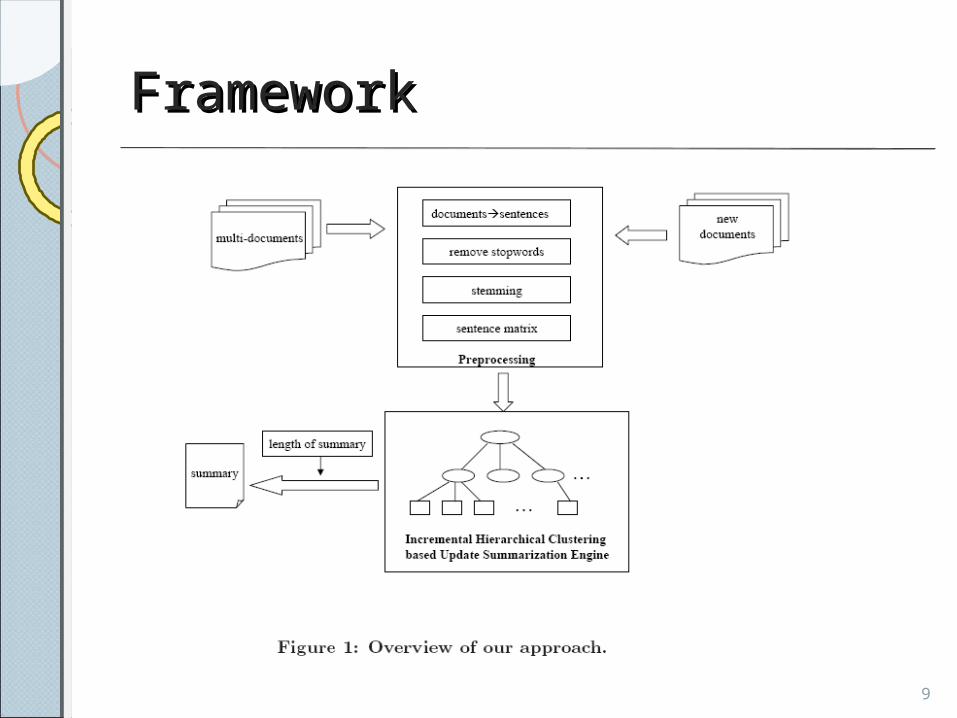
Framework Framework
9

Preprocessing Preprocessing
• Data preprocessing • Given a collection of documents
1. Decompose the documents into sentences
2. Stop words are removed 3. Word stemming is performed4. Sentence matrix is constructed and each
element is the term frequency
10

Incremental Hierarchical Incremental Hierarchical Sentence Clustering (IHSC)Sentence Clustering (IHSC)• For update summarization system• Used an Incremental Hierarchical
Clustering (IHC)• Benefits of IHC method• The method can efficiently process the
dynamic documents, new documents are added• A hierarchy is built to facilitate users• The number of clusters is not pre-
defined
11

The COBWEB algorithmThe COBWEB algorithm
• Used COBWEB, most popular incremental hierarchical clustering algorithms• Based on the heuristic measures called
Category Utility (CU)
• Clusters • Probability of a document belong to a cluster• Total number of clusters K
12

The COBWEB algorithm The COBWEB algorithm cont’scont’s
• Ai = The ith attribute of the items being clustered
• Vij = jth value of the ith attributeFor example:A1 Є {male, female} , A2 Є {Red, Green, Blue}V12= female V22= Green
Probability matching guessing strategyExpected number of times we can correctly guess the value of multinomial variable Ai to be Vij for an item in a cluster kA good cluster, in which the attributes of the items take similar values will have high values
COBWEB maximizes sum score over all possible assignment of a document to a cluster
13

The COBWEB algorithm The COBWEB algorithm cont’scont’s
• The COBWEB algorithm can perform• Insert: add the sentence into an existing
cluster • Create: create a new cluster • Merge: combine two clusters into a single
cluster• Split: divide an existing cluster into several
clusters
14
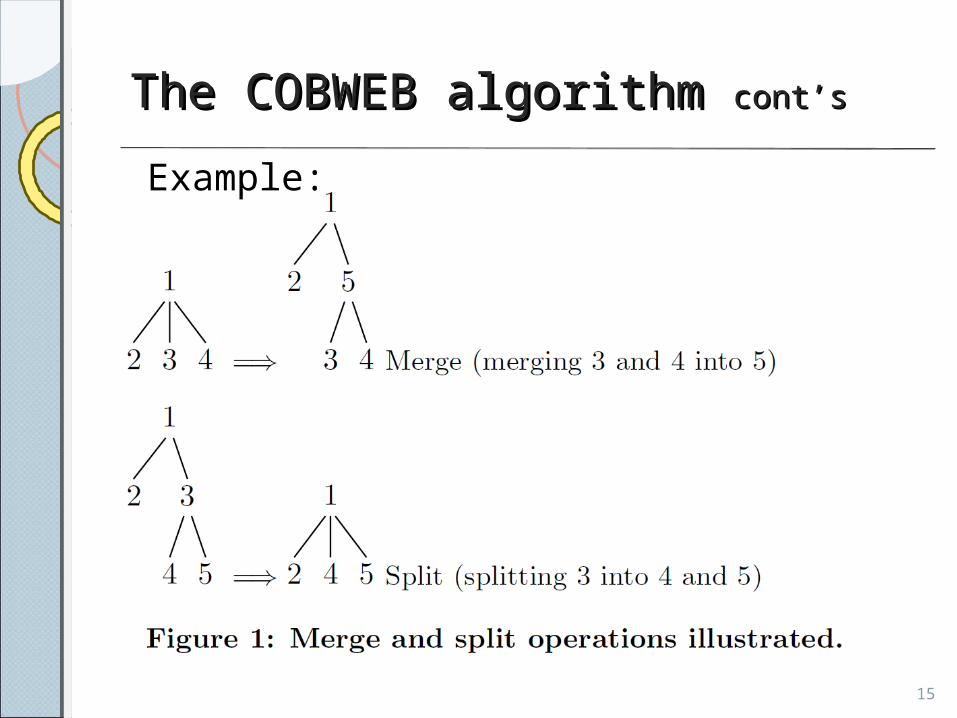
The COBWEB algorithm The COBWEB algorithm cont’s cont’s
Example:
15

COBWEB for textCOBWEB for text
• The COBWEB algorithm • Using normal attributes distribution is
not suitable for text data• Documents • Are represented in the “bag of words”
where terms are attributes• Best method• Calculating CU using Katz’s
distribution
16

COBWEB for text COBWEB for text cont’scont’s
• Katz’s model• Assuming word i occurs k times in
document then
= 1 – (df/N)df = document frequency N = total number of
documents
p = (cf - df) / cfcf = collection frequency
= Pr(the word repeats | the word occurs )
Therefore:(1 - p) = the probability of the word occurring only once
17

COBWEB for text COBWEB for text cont’scont’s
18
Substitute with p
K=0, using p δk =1Adding both formulasp(0) = 1- αpα = (1-p(0))/p

COBWEB for text COBWEB for text cont’scont’s
Where attribute value f=Vij
to the contribution of the attribute i towards the category utility of the cluster k
19

Representation sentence Representation sentence selection for Each Node of the selection for Each Node of the Hierarchy Hierarchy • Update summarization system• Select the most representative
sentences to summarize each node and subtrees• Once a new sentence arrives, the
sentence hierarchy is changed by either of the four operations
20

Representation sentence Representation sentence selection for Each Node of the selection for Each Node of the Hierarchy Hierarchy cont’scont’s
• Case 1 : Insert a sentence into cluster k• Recalculate the representative sentence Rk of
cluster K
• Where • K : number of sentences in the cluster• Sim() : similarity function between sentence pairs• Cosine similarity
• α = parameter • α = 0.6
21

Representation sentence Representation sentence selection for Each Node of the selection for Each Node of the Hierarchy Hierarchy cont’scont’s• Case 2: Create a new clusterk
• Newly sentence represents a new cluster• Rk = snew
• Case 3: Merge two clusters (clustera and clusterb ) into a new cluster (clusterc)• Sentence obtaining the higher similarity with
the query is selected as the representative sentence at the new merged node
22

Representation sentence Representation sentence selection for Each Node of the selection for Each Node of the Hierarchy Hierarchy cont’scont’s• Case 4: split cluster into a set of
clusters• (clustera into cluster1, cluster2,…clustern)• Remove node a • Substitute it using the roots of its sub-
trees• Corresponding representative sentences
are the representative sentences for the original sub-tree roots
23

The AlgorithmThe Algorithm• Input: a query/topic the user is interested in
a sequence of documents/sentences
1. Read one sentence and check if it is relevant to the given topic i.e., checkrelevance(sentence,topic)
24

The Algorithm The Algorithm cont’scont’s
2. If relevant :initialize the hierarchy tree, sentence as the root
Otherwise: remove it and read in the next sentence and repeat Step1
: until root node is formed
3. repeat
25

The Algorithm The Algorithm cont’scont’s
4. Read in the next sentence, start from the root node• If the node is a leaf, go to Step 5 otherwise
choose one of the following with the highest CU score
1. Insert a node and conduct case 1 summarization
2. Create a node and conduct case 2 summarization
3. Merge a node and conduct case 3 summarization
4. Split a node and conduct case 4 summarization5. If a leaf node is reached, create a new leaf node
and merge the old leaf and the new leaf into a node and case 2 and case 3 are conducted
26

The Algorithm The Algorithm cont’scont’s
6. Until the stopping condition is satisfied
7. Cut the hierarchy tree at one layer to obtain a summary with the corresponding length.
• Output: A sentence hierarchy
The updated summary
27

EXPERIMENTS EXPERIMENTS Data DescriptionBaselinesEvaluations MeasuresExperimental Results
28

Data DescriptionData Description• Hurricane Wilman
Releases(Hurricane)• 1700 documents divided into 3 phases
• TAC 2008 Update Summarization Track (TAC08)• Benchmark dataset from update
summarization • 48 topics and 20 newswire articles in
each topic
29

BaselinesBaselines
Baseline Description
Random Selects sentences randomly for each document collection
Centroid Extracts sentences according to centroid value, positional value and first sentence overlap
LexPageRank
Constructs a sentence connectivity graph based on cosine similarity then selects important sentences based on the concepts of eigenvector centrality
LSA Performs latent semantic analysis on terms by sentences matrix to select sentences having the greatest combined weights across all important topics
30
• Implemented the following used multi-document summarization methods as the baseline systems

Evaluations MeasuresEvaluations Measures• Rouge toolkit• To compare with the human
summaries
Method Description
ROUGE-1 Uses unigrams
ROUGE-2 Uses bigrams
ROUGE-L Uses the longest common subsequence (LCS)
ROUGE-SU Skip-bigram plus unigram 31
• Count match(gram n) maximum number of n-grams co-occurring in a candidate summary• Count(gram n) number of n-grams in the reference summaries
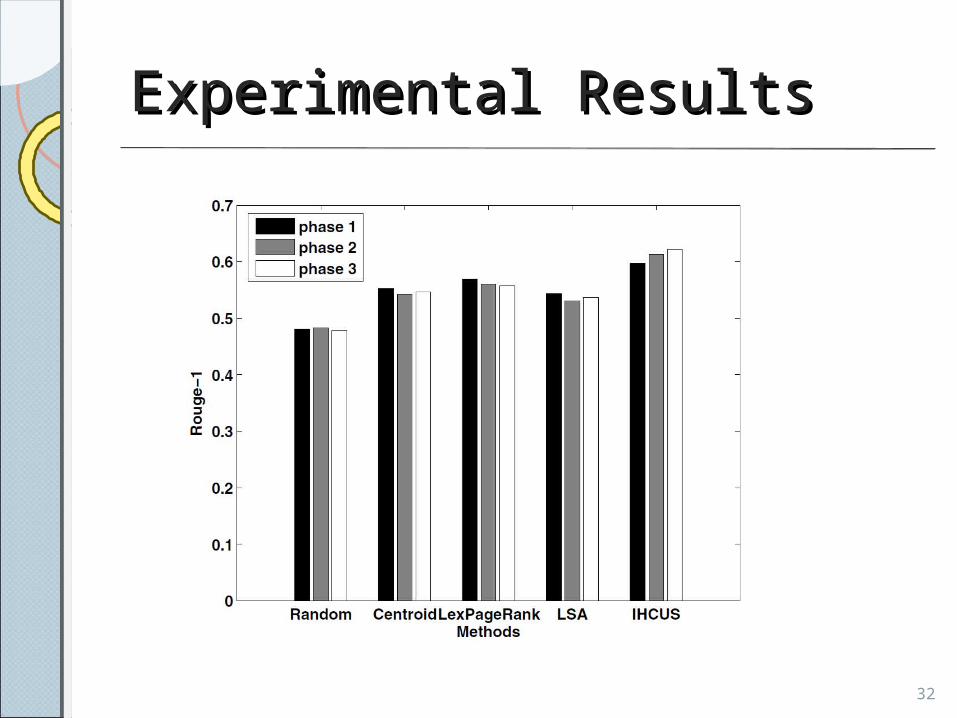
Experimental Results Experimental Results
32
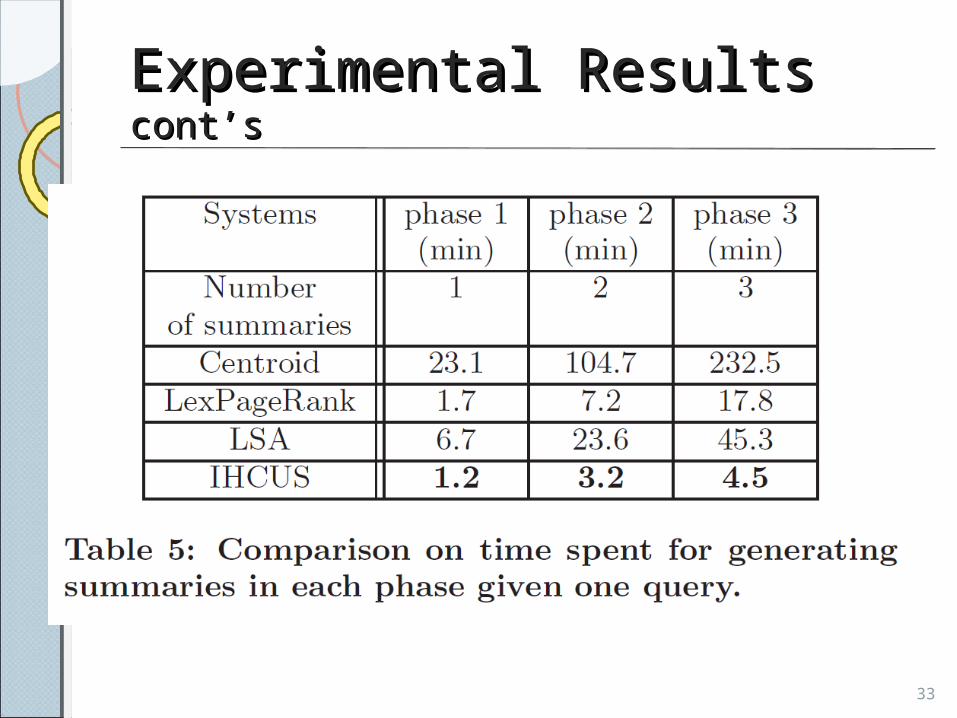
Experimental Results Experimental Results cont’scont’s
33

Experimental Results Experimental Results cont’scont’s
34

Conclusion Conclusion • Traditional methods perform in batch
way and are not suitable of incrementing summaries
• Incremental Hierarchical Clustering Based Document Update Summarization
• Incremental Hierarchical Sentence Clustering (IHSC)• Algorithm called COBWEB for text• Can perform Insert, Create, Merge, Split
• IHSC outperforms the traditional methods and its more efficient.
35

THANK YOU!THANK YOU!
36


![KM 454e-20190510122747 · substituted herein by Marrie Nonhlanhla Shabangu, a duly appointed representative in the estate of the First Plaintiff. REOUEST FOR AN AWARD OF COSTS [5]](https://img.pdfslide.net/doc/110x75/5e1ce6b4ad62b5328e5b44aa/km-454e-substituted-herein-by-marrie-nonhlanhla-shabangu-a-duly-appointed-representative.jpg)


























