Embed Size (px)
Citation preview

Expert Systems with Applications 40 (2013) 2410–2420
Contents lists available at SciVerse ScienceDirect
Expert Systems with Applications
journal homepage: www.elsevier .com/locate /eswa
Domain driven data mining in human resource management: A reviewof current research
Stefan Strohmeier ⇑, Franca PiazzaChair of Management Information Systems, Saarland University, 66123 Saarbruecken, Germany
a r t i c l e i n f o a b s t r a c t
Keywords:Data miningHRMLiterature reviewDomain driven data miningHR data miningElectronic human resource management (e-HRM)
0957-4174/$ - see front matter � 2012 Elsevier Ltd. Ahttp://dx.doi.org/10.1016/j.eswa.2012.10.059
⇑ Corresponding author. Tel.: +49 68130264750; faE-mail address: [email protected]
An increasing number of publications concerning data mining in the subject of human resource manage-ment (HRM) indicate the presence of a prospering new research field. The current paper reviews thisresearch on HR data mining to systematically uncover recent advancements and suggest areas for futurework. Based on the approach of domain driven data mining, an initial framework with significantdomain-specific requirements is elaborated. Relevant research contributions are identified and reviewedagainst the background of this framework. The review reveals that HRM constitutes a noteworthy newdomain of data mining research that is dominated by method- and technology-oriented work. However,specific domain requirements, such as evaluating the domain success or complying with legal standards,are frequently not recognized or considered in current research. Therefore, the systematic considerationof domain-specific requirements is demonstrated here to have significant implications for future researchon data mining in HRM.
� 2012 Elsevier Ltd. All rights reserved.
1. Introduction
Data mining refers to the non-trivial process of identifying no-vel, potentially useful and valid patterns in data (Fayyad, Piatet-sky-Shapiro, & Smyth, 1996). There is a broad set of data miningapplication domains and corresponding research domains, includ-ing the management domain with well-established sub-domains,such as customer management (e.g. Ngai, Xiu, & Chau, 2009), man-ufacturing management (e.g. Choudhary, Harding, & Tiwari, 2008)or financial management (e.g. Ngai, Hu, Wong, Chen, & Sun, 2011).Recently, these sub-domains appear to be complemented by hu-man resources management (HRM). In recent years, a quicklygrowing number of research contributions aim at supporting thepractical adoption of HRM data mining. Research contributions re-fer to various HRM activities and processes, such as selectingemployees (Aiolli, de Filippo, & Sperduti, 2009) and predicting em-ployee turnover (Aviad & Roy, 2011) in the function of staffing,ascertaining competencies of employees (Zhu, Goncalves, Uren,Motta, & Pacheco, 2005) and career planning (Lockamy & Service,2011) in the function of development, planning HR costs (Juan,2009) and predicting the acceptance of severance pay (Ramesh,2001) in the function of compensation, and predicting (Thissen-Roe, 2005) and evaluating (Zhao, 2008a,b) employee performancein the function of performance management. To support these func-
ll rights reserved.
x: +49 681 30264755.(S. Strohmeier).
tions, the entire spectrum of data mining methods – decision trees(Sivaram & Ramar, 2010) cluster analysis (Karahoca, Karahoca, &Kaya, 2008), association analysis (Zhang & Deng, 2011), supportvector machines (Li, Xu, & Meng, 2009) and neural nets (Ning,2010) – is employed, while methodical advancements and innova-tions are presented (Goonawardene, Subashini, Boralessa, & Pre-maratne, 2010). In summary, browsing the literature indicates aprospering new field of data mining research that provides ampleinsights in how to generate advanced information and decisionsupport within the HR domain.
This paper is the first comprehensive review of this new fieldof research, and it purposes to uncover recent advancements andsuggest remaining tasks for future research. Given the growingdoubts concerning the ability of conventional data mining re-search to meet the requirements of practice and the correspond-ing calls for more relevant data mining research (Adejuwon &Mosavi, 2010; Cao, 2010; Cao & Zhang, 2007; Puuronen & Pec-henizkiy, 2010; Weiss, 2009), the concept of domain driven datamining (Adejuwon & Mosavi, 2010; Cao, 2010; Cao & Zhang,2007; Wang & Wang, 2009) is employed as a reference frame-work for the review.
To provide a systematic review, the method of identifying rele-vant research contributions is described, and an initial frameworkof domain driven data mining research in HR is substantiated. Sub-sequently, this framework is employed to systematically reviewthe discovered research contributions and to derive implicationsfor future research.

S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420 2411
2. Method and framework
2.1. Method
To comprehensively identify relevant research contributions, acombination of keyword searches and forward and backwardsearches was employed. To perform the keyword search, a schol-arly Internet search engine (scholar.google.com) and several schol-arly online databases (ABI/Inform, Business Source Premier,Scopus, and Science Direct) were employed. Given that HRM datamining refers to an intersection of method and domain, respectivepairs of search terms such as ‘‘data mining’’ and ‘‘HRM’’ were em-ployed. Beyond synonyms such as ‘‘KDD’’ and ‘‘talent manage-ment’’, multiple HRM sub-domains such as ‘‘recruiting’’ and‘‘compensation’’, method-categories such as ‘‘decision trees’’and ‘‘cluster analysis’’, and single mining methods such as‘‘C5.0’’and ‘‘k-means’’ were used as search terms. Ultimately, therewere over 400 pairs of search terms from the possible combina-tions. Although relevant to HRM, the area of e-learning (educa-tional data mining) was excluded because there are alreadycorresponding research reviews for this topic (Baker & Yacef,2009; Romero & Ventura, 2010). Moreover, work on data miningin employee fraud (e.g. Luell, 2010) was excluded because fraudis usually classified within compliance rather than as an HR task.The search was further restricted to English publications. This key-word-based search was complemented by a backward search,which systematically searched the references sections of the se-lected research contributions to identify additional relevant publi-cations, and by a forward search, which searched for additionalarticles that cited the previously found contributions. To compre-hensively map the existing research and to mirror research activi-ties over time, the period from 1991 to 2011 was used.
Employing this procedure initially revealed 172 publications.The abstracts of these research contributions were reviewed inde-pendently by two researchers who are familiar with both datamining and HRM. The research contributions were included onlyif both researchers agreed on their topical relevance (Cohen’sj = 0.96). Based on this procedure, 111 relevant research contribu-tions were initially rated as relevant. However, because some workwas published several times, 11 duplicate research contributionswere subtracted, leading to 100 total research contributions. Allrelevant research contributions are marked with a consecutivenumber in square brackets and all duplicate research contributionsare marked with [D] in the reference section. The selected researchcontributions were independently reviewed again by tworesearchers, while the results were stored in a database with struc-tured and unstructured fields. The results of both researchers werecompared in the final phase, and in cases of disagreement, the cor-responding research contributions were reviewed again to ensureconsistency and accuracy. The final data pool was used for this re-view with automatic and manual information retrieval.
2.2. Framework
To offer a framework with review criteria that evaluate the rel-evance of research, the approach of domain driven data mining(Cao, 2010; Cao & Zhang, 2007; Pechenizkiy, Puuronen, & Tsymbal,2008; Puuronen & Pechenizkiy, 2010; Wang & Wang, 2009) wasemployed. Domain driven data mining emerged as a response tothe lack of relevance of conventional method-oriented data miningresearch. With method-oriented research, it has been noticed that‘‘... findings are not actionable and ... lack power in solving real-worldproblems’’ (Puuronen & Pechenizkiy, 2010) and that a ‘‘... big gap be-tween academic outputs and business expectations ...’’ (Cao, 2010) hasemerged. Simply offering advanced mining methods with exam-
ples of mined patterns obviously underestimates the complexitiesof real-world data mining. Consequently, a readjustment of datamining research is suggested to shift from a method drivenapproach to a domain driven approach. The basic idea of domaindriven data mining is offering utility and relevance by carefullyconsidering relevant domain-specific requirements andconstraints. To realize this objective, a multi-dimensional researchapproach (Cao, 2010; Puuronen & Pechenizkiy, 2010) is suggestedto consider additional requirement dimensions beyond the hith-erto considered method dimension. The domain driven approachis used as framework to ensure a relevance-oriented review of cur-rent research. Given that none of the research contributions claimto follow the domain driven approach, using a domain drivenframework might appear to be unreasonable at first glance.However, even explicitly method-oriented data mining research(e.g. Aviad & Roy, 2011; Yang, Lin, Chen, & Shi, 2009; Zhang, Zhu,& Hua, 2009; Zhu et al., 2005) must consider relevance and practi-cal applicability, otherwise such research is of no use. It is bothpermissible and necessary to evaluate HRM data mining researchwith regard to its practical relevance. However, due to the presentearly stage of HRM data mining research, there is no theoretical,conceptual and/or empirical work that specifies concrete require-ments of the HR domain. Therefore, a basic model of relevantrequirement dimensions and criteria has to be derived from thegeneral work on domain driven data mining. This paper thereforewill offer insights into the requirements and provide guidingexamples for a future, relevance-oriented research.
Data mining research should focus on relevant problems to pro-vide information and decision support that is relevant and usefulfor HR practice (Coppock, 2003; Puuronen & Pechenizkiy, 2010).Assuring the functional relevance of research is, however, by nomeans a trivial task. As a consequence of the absence of domainexpertise in method- and technology-oriented research, over-triv-ialized and even imaginary problems are often addressed in datamining research (Cao, 2010; Weiss, 2009). Therefore, domain dri-ven data mining research must consider a functional dimension.As significant criteria of this dimension, the following criteria arereviewed:
� functional domain (whether and which functional HR problemare treated);� functional relevance (whether and how the relevance of the
functional HR problem is justified); and� functional success (whether and how the success of data mining
in solving the functional HR problem is evaluated).
Moreover, as in any other domain, practical data mining in theHR domain relies on suitable data mining algorithms. Given thecomprehensive research on this topic there is a broad spectrumof available methods (Puuronen & Pechenizkiy, 2010; Wang &Wang, 2009). However, it is necessary to check whether generalprefabricated algorithms fit the domain requirements or whetherthere is a need for domain-specific, i.e., customized or newly devel-oped, algorithms in HR that deal with specific domain problems.Within this method dimension, the following are used as reviewcriteria:
� methodical category (whether and which mining methods areemployed); and,� methodical adjustment (whether these data mining methods
are general or domain-specific customized/developed).
The success of practical data mining depends, crucially, on theavailability of the right number and kind of data (Bole, Jaklicb, Pa-pac, & Zabkard, 2011; Wang & Wang, 2009). It is commonlythought that in any domain the amount of available data is ever

0
10
20
30
40
50
60
70
80
90
100
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
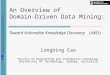
Fig. 1. Cumulative research contributions over time.
2412 S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420
increasing, and it is expected (implicitly or explicitly) that thisabundance provides the specific data required for successful datamining (Hermiz, 1999; Pechenizkiy et al., 2008). However, at pres-ent, there is little knowledge about the quality of available HR dataand whether these data are actually suitable for data mining baseddecision support (Strohmeier & Piazza, 2010). Consequently, thereis the requirement to consider an additional data dimension in datamining research with the following as a significant reviewcriterion:
� data provision (whether and how data availability and suitabil-ity is ensured).
Including and combining data and methods, suitable informationsystems (IS) are an additional compulsory pre-condition of practicaldata mining. Given the comprehensive offerings of data mining sys-tems within diverse categories (Chen, Ye, Williams, & Xu, 2007;Zhang & Segall, 2010), the systems dimension may not be consideredrelevant at first glance. However, from a domain perspective, currentdata mining systems require considerable user expertise becausethey are method-oriented and focus on analytical power. Addition-ally, because the data mining systems are not integrated into HumanResource Information Systems (HRIS), they cause media disruptions(Puuronen & Pechenizkiy, 2010; Rok, Matjaz, & Marjan, 2007).Therefore, the offering of HR domain-oriented systems may consti-tute an interesting and perhaps even mandatory measure to gainpractitioner acceptance. Consequently, within a systems dimension,the following is used as a significant review criterion:
� information systems provision (whether and which IS areprovided).
Conventional data mining research tends to pay no attention toend-user related aspects (Cao, 2010). As the domain driven ap-proach reveals, end-users are not only relevant because they arethe final addressees of research but also because they are regularlyentrusted with crucial tasks. Even if a certain concept involves datamining experts, HR end-users play a crucial role as domain experts(Bole et al., 2011; Cao & Zhang, 2007). In particular, HR end-usersplay a key role if they perform the crucial tasks by themselves(Sharma & Osei-Bryson, 2009). Therefore, domain driven data min-ing research should consider a user dimension, and employ the fol-lowing as a significant review criterion:
� user support (whether and which HR user-related tasks areintended and supported).
Finally, there is clearly an ethical and legal dimension to consider.Data mining in the HR-domain aims at supporting decisions thatoften directly affect individuals in significantly positive, as wellas negative, ways, for instance, a selection decision implies that acertain individual is accepted or refused for a desired position. Thispersonal impact on employees reveals the need to consider ethicalrequirements when supporting HR-related decisions (Pedreshi,Ruggieri, & Turini, 2008; Wahlstrom, Roddick, Sarre, Estivill-Castro,& DeVries, 2002). Moreover, there are nationally differing legal reg-ulations that have to be respected and that may pose severe limi-tations on data mining in the HR-domain (Pedreshi et al., 2008;Schermer, 2011). The review criterion for this dimension is thefollowing:
� ethical and legal awareness (whether and how ethical and legalstandards are considered).
In summary, functions, methods, data, systems, users, ethics andlaw are seen as significant dimensions of domain driven data min-
ing research. However, these dimensions and their correspondingrequirements constitute a basic model. Depending on the specificresearch settings, additional requirements within these dimen-sions and/or completely new dimensions and requirements maybe necessary.
3. Results and implications
3.1. General results and implications
The substantial number of identified publications (n = 100) ini-tially suggests that HRM constitutes a noteworthy data mining re-search domain. The analysis of publication dates reveals that HRMdata mining is a recent field of research given that nearly two-thirds of the research contributions (n = 63) were published withinthe last 4 years (see Fig. 1).
The analysis of publication outlets revealed that more than halfof the research contributions (n = 54) were from conference pro-ceedings, while research journals (n = 35), working papers (n = 6),monographs (n = 3) and book chapters (n = 2) constituted theremaining sources. The high share of research contributions fromconference proceedings further suggests the nascent state of re-search. Other than four exceptions (Kroll, 2001; Lockamy & Service,2011; Moehrle, Walter, Geritz, & Müller, 2005; Nagadevara & Srin-ivasan, 2008), all publications outlets were technology- or method-oriented. In other words, although HR data mining is an interdisci-plinary field, managerially oriented outlets have rarely publisheddata mining-related work.
3.2. Function-related results and implications
3.2.1. Functional domainsAs the first functional criterion, this paper reviews whether and
which functional HR problems are addressed in current data min-ing research. Using staffing, development, performance managementand compensation as the major four functional HR domains (Devan-na, Fombrun, & Tichy, 1984) complemented by ‘‘other functions’’,Fig. 2 reveals which general functional categories are most oftensubject to research and which data mining methods are applied.Due to clarity, the respective research contribution is listed by itsnumber assigned in the reference section.
Categorizing the domains and methods reveals a clear researchfocus on staffing (n = 67) – a sub domain of HRM that is responsiblefor planning the required quality and quantity of employees,recruiting (i.e., attracting and selecting) employees, employingemployees, assigning employees to jobs and, if necessary,

HRM Domains
Staffing Development*PerformanceManagement
Compensation Other N
Dat
a M
inin
g M
etho
ds
DecisionTrees
3, 6, 8, 9, 12,13, 14, 31, 49, 58, 61, 62, 63, 66, 73, 75, 76, 81, 89, 90, 92, 91
3, 9, 100 10, 12, 15, 37, 62, 98
93
28
Neural Nets
13, 16, 18, 19, 23, 33, 45, 46, 49, 51, 58, 66, 67, 68, 72, 74, 79, 80, 81
27, 29, 51, 59 22, 23, 37, 91 39 55
27
Support Vector Machines
1, 9, 28, 43, 56, 58, 71, 73, 83, 84, 92
9, 57, 71 15, 56, 57, 91 53
15
AssociationAlgorithms
4, 8, 25, 41, 48, 65, 77
100 52 95, 97
11
ClusterAlgorithms
3, 8, 44, 75, 84 3, 100 24, 30, 52, 98 42
11
Other
5, 7, 11, 20, 21, 35, 36, 38, 40, 47, 60, 64, 70, 78, 82, 85, 86
17, 32, 34, 38, 50, 60, 64, 70, 87, 88
11, 38, 54, 60, 70, 96
69, 70 2, 26, 60, 70, 99
29
N 67 19 20 3 11
Fig. 2. Domains and methods of HRM data mining research. (See above mentionedreferences for further information).
S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420 2413
displacing employees (Devanna et al., 1984). A first subcategory ofresearch contributions refers to planning and prediction in staffing(n = 21). Frequently, research contributions attempt to predict em-ployee turnover/retention to provide prognosis or early warninginformation (e.g. Quinn, Rycraft, & Schoech, 2002; Tzeng, Hsieh,& Lin, 2004). Corresponding employee retention measures mayalso be recommended (e.g. Chien & Chen, 2008) (n = 16). Additionalwork focuses on the prediction of employee absence due to sick-ness (Sugimori, Iida, Suka, Ichimura, & Yoshida, 2003) or the pre-diction of manpower requirements (Yang et al., 2009). By farlargest staffing subcategory, over one-third of all research contri-butions focus on the selection of employees (n = 37). Both employeeselection phases, pre-selection (e.g. Lakshmipathi, Chandrasekaran,Mohanraj, Senthilkumar, & Suresh, 2010; Tai & Hsu, 2006) and fi-nal-selection (e.g. Chen & Chien, 2011; Kroll, 2001), are seen aspossible application areas.
Research often addresses specific employee segments, such astruck drivers (Min & Emam, 2003), insurance agents (Cho & Ngai,2003) or sales representatives (Khosla & Goonesekera, 2003). Can-didate suitability is determined at a general level (e.g. Han, 2009;Jantan, Hamdan, & Othman, 2009b); however, research also at-tempts to predict candidate suitability according to specific jobrequirements (e.g. Drigas, Kouremenos, Vrettos, Vrettaros, & Kou-remenos, 2004; Li, Lai, & Kao, 2008) or the likelihood that candi-dates will stay with the company (e.g. Kroll, 2001; Lee &Drasgow, 2001). The assignment of employees to specific jobs (e.g.Lescreve, 1999), tasks (e.g. Isaias, Casaca, & Pifano, 2010), projects(e.g. Holland & Fathi, 2005), processes (e.g. Ly, Rinderle, Dadam, &Reichert, 2006) or teams (e.g. Rodrigues, Oliveira, & de Souza,2005) are additional staffing concerns (n = 14). Research in thestaffing domain also analyzes job offers (Wong, Lam, & Chen,2009) and the clustering of different employee groups (Huang,2009).
The development domain primarily comprises basic and ad-vanced training as well as career and succession planning for
employees (Devanna et al., 1984). Because the voluminous workon data mining in e-learning (educational data mining) (Baker &Yacef, 2009; Romero & Ventura, 2010) was excluded, only a smallnumber (n = 19) of additional research contributions could beidentified. These research contributions ascertain employee com-petences from specific sources, such as social networks (Dorn &Hochmeister, 2009), patent certificates (Moehrle et al., 2005) oremployee generated text documents (Rodrigues et al., 2005). As avariant, the identification of employee competences that are rele-vant for individual and/or organizational success is researched(e.g. Imai, Lin, Watada, & Tzeng, 2008a,b; Lee, 2010). Additionally,the reduction of numerous detail competences to core competenc-es has been proposed (e.g. Huang, 2009; Wu, Lee, & Tzeng, 2005).Research contributions also refer to the detection of associationsbetween different competences (Honkela, Nordfors, & Tuuli,2004) and the prediction of future employee performance to sup-port career decisions (Jantan et al., 2009b).
Managing the performance of employees refers to the setting ofperformance objectives and subsequently monitoring the achieve-ment of these objectives (Devanna et al., 1984). Some research con-tributions (n = 20) referred to this functional sub-domain, whereasmost research contributions attempted to predict employee per-formance (e.g. Chen & Wang, 2010; Han, 2009). One research con-tribution addressed methodical support to periodic performanceevaluation (Yang, 2008).
Compensation is a significant functional subcategory of HRMthat addresses the remuneration of employees facultatively com-plemented by profit and equity sharing (Devanna et al., 1984). Asa sub-domain with a large amount of numeric data and obviousapplication potential, it is surprising that only three research con-tributions could be found that offered decision support for the typeand amount of future severance payments (Juan, 2009; Ramesh,2001; Ranjan, Goyal, & Ahson, 2008).
Beyond these domains there is additional research, scatteredover diverse HR information and decision support problems, thatis subsumed as ‘‘other’’ work (n = 11). Examples include researchcontributions that addressed a semantic competence knowledgebase (ontology) (Ziebarth, Malzahn, & Hoppe, 2009), the impactof HRM on corporate performance (Karahoca et al., 2008, predict-ing HRM risks (Li et al., 2009) and acquiring general knowledgeabout employees, such as associations between socio-demographicemployee attributes (Zhang et al., 2009), job attitudes of applicants(Tung, Huang, Chen, & Shih, 2005) and characteristics of workplac-es (Zhang & Deng, 2011).
In summary, current research is characterized by a marked fo-cus on employee selection with an additional concentration on em-ployee turnover prediction, employee assignment, and employeeperformance prediction. The remaining research contributionsconstitute a patchy collection of heterogeneous HR issues. This re-view reveals that, on the one hand, there is considerable knowl-edge of potential HR application domains for data miningmanifested in an extensive collection of application examples. Onthe other hand, despite the scope of application examples, this col-lection is arbitrary and incomplete, and systematic knowledge isstill missing. Because increasing this collection of individual workwill not settle this situation, the elaboration of a structured catego-rization of HR application areas and the subsequent coverage of therespective categories is a first necessary step for future research.Ideally, this should be based on a suitable HR problem categoriza-tion. Because well-established standard applications of data min-ing, such as shopping cart- or churn-analysis in customermanagement (e.g. Ngai et al., 2009), do not exist in HRM, the iden-tification and elaboration of such standard HR application scenar-ios, which can be used in a broader range of differentcorporations, should be a further task for subsequent research tosupport HR practice.

2414 S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420
3.2.2. Functional relevanceAssuring the relevance of a functional HR problem is a key fac-
tor for research success. Interestingly, this concept does not appearto be of general concern because relevance is either not mentioned(n = 13), claimed but not substantiated (n = 38) or derived from aplausible argument (n = 43). Only very few research contributions(n = 4) use an empirical approach, such as expert interviews or casestudies, to ensure in-depth practical relevance (Färber, Weitzel, &Keim, 2003; Kane-Sellers, 2007; Lee & Drasgow; 2001; Lescreve,1999). This apparent lack of concern involves the significant issuesof data mining research where imagined problems (the problem isnot at all relevant) or over-trivialized problems (the problem isgenerally relevant, however, crucial details are overlooked) areanalyzed (e.g. Cao, 2010; Puuronen & Pechenizkiy, 2010). EvenHR problems that appear to show objective relevance, such asthe frequently addressed problem of employee selection, clearlyneed substantiation. For instance, it must be substantiated if pres-electing suitable applicants from a larger group of applicants still isof broader relevance, or if based on demographic changes, theproblem rather has switched to attracting suitable applicants. Ifproblem relevance can be substantiated, the concrete require-ments of a possible solution need thorough consideration withan in-depth description. A thorough description of the employeeselection task, for instance, may indicate that data mining has topredict not only the fit of an employee with the requirements ofa specific job but also the fit of an employee with the correspond-ing team and the entire organization (multi-level fit) – a require-ment that has not yet been met by data mining research. Thisentails the clear implication to care for relevance in future datamining research. The above cited empirical approaches, consistingof expert interviews, case studies and action research, offer valu-able suggestions for substantiating relevance, involving close inter-actions with HR experts and professionals, i.e., persons that areconfronted with the real-world problems.
3.2.3. Functional successBeyond mere relevance, the actual success of data mining in
solving a functional HR problem is critical because this success leg-itimates the application of data mining in practice. While themajority of research contributions does not evaluate functionalsuccess, some research contributions do offer a functional evalua-tion based on either argumentative (n = 4) (e.g. Chien & Chen,2007; Färber et al., 2003) or empirical (n = 8) (e.g. Chen & Chien,2011; Lakshmipathi et al., 2010) reasoning. A select few of the re-search contributions consider existing methodical alternatives(n = 4) and compare the offered data mining solution, for instance,to a solution by subject matter experts (Färber, 2005) or to a solu-tion by conventional data querying (Strohmeier & Piazza, 2010).From a domain perspective, the need for such comparative evalu-ations of functional success is evident: HRM is a well-establishedand professional corporate domain, and, consequently, for multipleinformation and decision support problems, there are long- andwell-established domain-specific methods. For instance, for theselection of employees, there is an arsenal of different decisionsupporting methods, such as psychometric tests, pre-selectioninterviews and queries of job-success (cf. the research contribu-tions in Evers, Anderson, & Smit-Voskuijl, 2005). If there are pre-established methods for the respective HR problem, any new datamining-solution competes with these methods. Consequently, datamining has to offer demonstrable advantages concerning the effec-tiveness (increased quality of information and decision support)and/or efficiency (decreased effort of providing information anddecision support) to be accepted in practice. If conventional HRmethods are both more effective and more efficient, data miningwill not be relevant for HR practice, even when considering rele-vant problems. The numerous research contributions that do not
evaluate domain success and, in particular, the research contribu-tions with basic and obvious results appear to be based on theerroneous implicit assumption that there are no methodologicalalternatives and that, therefore, even minor research contributionsto the focused HR problem are appreciated by practitioners. Be-cause this is clearly not the case, a critical implication for future re-search is to evaluate data mining results and to demonstratesuperiority compared to the results of existing, conventional HRmethods. The few research contributions with comparative-empir-ical evaluations offer valuable guidance for future research.
3.3. Method-related results and implications
3.3.1. Methodical categoriesAs expected, the analysis of applied data mining methods yields
a broad range of different methods for all known categories (seeFig. 2).There are research contributions that employ a single meth-od (n = 56), and there are also research contributions that employseveral methods (n = 32), frequently because several HR problemsare addressed (n = 22) (e.g. Jindal & Singla, 2011; Lescreve, 1999;Rodrigues et al., 2005) or because they aim at comparing diversedata mining methods to solve the same problem (n = 19) (e.g.Hong, Pai, Huang, & Yang, 2005; Sexton, McMurtrey, Michalopou-los, & Smith, 2005; Sáiz, Pérez, Herrero, & Corchado, 2011). Fre-quently employed methods were decision trees (n = 28), neuralnets (n = 27), support vector machines (n = 15), association analysis(n = 11), cluster analysis (n = 11), rough set (n = 10), discriminantanalysis (n = 4), logistic regression (n = 4) and regression (n = 3).The rest of the methods were applied in a single contributionand cover a broad range of existing methods, such as naïve Bayes,multidimensional scaling, learning preference models, etc. Surpris-ingly, time series analysis was employed only once (Han, Ren, &Dong, 2008), although it constitutes an established methodical cat-egory and shows obvious potential for multiple HR planning andforecasting problems. To detect possible relationships betweenemployed methods and functional HR domains, association analy-sis (Apriori, Srikant & Agrawal, 1995) was employed. Initially, nosystematic associations between method categories and HR (sub-) domains could be detected. However, aggregating method cate-gories with data mining functions, i.e., classification, segmentation,association, forecasting and anomaly detection, revealed that classifi-cation methods (i.e., decision trees, discriminant analysis, neuralnetworks, and support vector machines) were frequently used forturnover prediction (confidence 0.94, support 0.15), employeeselection (confidence 0.70, support 0.27), employee assignment(confidence 0.69, support 0.09) and employee performance predic-tion (confidence 0.78, support 0.11). This result can be explainedby the specific character of the addressed problems. For instance,because predicting turnover entails discriminating terminatingfrom non-terminating employees, using classification methods isan obvious choice. These insights could be used as initial indica-tions of suitable methods for future research; however, positiveindications should not block the application of other possibly suit-able methods within the respective domains.
In summary, a broad range of data mining methods appears tobe applicable across the different HR sub-domains, while there areno strict associations between methods and problems. Current re-search offers many examples of data mining method applicationsin HR; however, systematic knowledge concerning the methodproblem-fit is missing. Therefore, a structured elaboration of theapplication potentials of the diverse categories of mining methodsin HR clearly constitutes a task for future work. Ideally, this elabo-ration should be closely aligned with the categorization of HRproblems to systematically inform the practice of pairing problemswith methods.

S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420 2415
3.3.2. Methodical adjustmentsThe majority of research contributions is based on established
general mining methods (n = 84), while only a few research contri-butions customize existing methods (n = 3) or even develop newmethods (n = 5). An example of customization is a combinationof neural nets and adaptive testing to offer a method for employeeselection (Thissen-Roe, 2005), while a web-content mining algo-rithm for gathering applicant qualifications (Zhu et al., 2005) isan example of new development. Of course, adjustments to meth-ods are not an end in itself and are unnecessary if existing methodsfit the HR domain problem. However, this appears to not always bethe case. As an example, when pre-selecting employees, it may beuseful to mine sequential patterns, e.g., typical sequences of CV-positions, such as educational phases, stays abroad, previousemployments, etc., to distinguish suitable from unsuitable appli-cants based on typical sequential patterns. When mining sequen-tial patterns, diverse methods of sequential association analysisare offered (e.g. Agrawal & Srikant, 1995). However, because thesemethods were developed against the backdrop of sale transactions(shopping cart-analysis), they refer to specific points in time be-cause sale transactions take place at a certain point in time. CV-positions, however, refer to a certain period in time, i.e., they havea certain starting date, duration and end date; this is also theway they are usually stored in HRIS. Simply using existing sequen-tial algorithms for CV-mining implies that either starting dates,end dates or calculated mean dates of CV-positions must be used,thereby losing the important additional information of duration.Therefore, for mining sequential CV-positions, algorithms that con-sider time periods should be considered useful and developed. Asignificant implication is that future research should more explic-itly reflect the fit of data mining methods with a focused HR prob-lem and customize or develop domain-specific methods whereexisting methods are not perfectly fitting. This practice shouldnot only contribute to domain success, but also avoid the researchapproach of a solution in search of a problem.
3.4. Data-related results and implications
Regarding the basic data category (structured data, text data andweb data), the research contributions frequently referred to con-ventional data mining (n = 91), while text mining (n = 8) and webmining (n = 2) were less frequent categories. Furthermore, regard-ing data usage, there are research contributions that do not usedata and discuss data mining on merely a conceptual level(n = 13) (e.g. Honkela et al., 2004; Strohmeier & Piazza, 2010).Existing or specifically generated synthetic data (n = 15) are usedfor demonstration purposes (e.g. Doctor, Hagras, Roberts, & Calla-ghan, 2009; Färber et al., 2003). However, the majority of researchcontributions use real-world data (n = 72). Structured data wereretrieved from Human Resource Information Systems (HRIS) (e.g.Chen & Chien, 2011; Lakshmipathi et al., 2010), HR data ware-houses (e.g. Aiolli et al., 2009; Zhao, 2008a,b) or web job boards(e.g. Clyde, Zhang, & Yao, 1995; Kessler, Béchet, Roche, El-Bèze, &Torres-Moreno, 2008). Text data were acquired from documentsproduced by employees (Honkela et al., 2004) or job offers (Wonget al., 2009). Web content data were gathered from social networks(Dorn & Hochmeister, 2009) or company web pages (Zhu et al.,2005). From a domain perspective, the use of real data for researchis clearly preferable because using no data or using nice (Wang &Wang, 2009) synthetic data tends to disguise and even ignoreproblems of data availability and suitability as a key factor of suc-cess (Weiss, 2009). Analyzing the basic assumptions of data provi-sion reveals that a significant amount of research tends to take dataavailability and suitability for granted by assuming (implicitly orexplicitly) that necessary data are given (n = 33) or can be selectedfrom a given storage device (n = 44), while the needed and used
data are not specified in detail. This thought process follows thebasic conviction that data mining is a secondary data analysis.However, there are also research contributions based on primarydata analysis (n = 22) that explicitly determine and ascertain nec-essary data (e.g. Al-Zegaier, Al-Zu’bi, & Barakat, 2011; Goonaward-ene et al., 2010; Imai et al., 2008b; Li et al., 2008; Min & Emam,2003). For instance, given that psychological meta-studies sub-stantiate correlations between personality traits of employeesand their job performance, a standardized questionnaire for ascer-taining the big five personality factors of applicants is used to pro-vide input data for a support vector machine which predicts thesuitability of an applicant for a certain job, offering decision sup-port in employee selection (Li et al., 2008).
From a domain perspective, taking data availability and suit-ability for granted is quite risky. Certainly, there are numerous datain HRIS (e.g., the contributions in Kavanagh & Thite, 2010) and,increasingly, in HR data warehouses (e.g. Burgard & Piazza,2009). However, despite the volume of data, there is little currentknowledge of the actual scope and nature of these data. A datamining solution suggested by research may, therefore, fail in prac-tice simply because necessary data are missing. In addition, andmore problematic, it is questionable whether the available datain transactional HRIS are actually suitable for decision support pur-poses because they primarily reproduce HR decisions of the past.For instance, employee selection and hiring decisions are regularlybased on explicit hiring policies, i.e., guidelines to hire applicantsfrom certain universities, with certain specializations, certaingrades, etc. Therefore, patterns yielded by data mining based onthe data of a recruiting system will just reproduce the previous hir-ing policy. For example, applicants from certain universities, withcertain specializations and certain grades were hired, while otherswere not. Such rules are not new to HRM (as they simply map thewell-known previous hiring policy) and are also not useful (as theymerely promote the well-known previous hiring policy). To use thepotential of data mining to support selection decisions, data shouldrefer to a larger range of clearly differing applicants, i.e., from dif-fering universities, with differing specializations, grades, etc. Suchdata would have, at least, the potential for unexpected patterns,while allowing for the evaluation of existing hiring policies.However, such control group data are regularly not available inrecruiting systems simply because control groups were not hired.Generalizing this difficulty, there is the problem of self-producedpatterns, i.e., the majority of HR decisions in recruiting, develop-ment, compensation, etc., is usually based on previous HR policies.Consequently, data of corresponding HRIS and subsequently minedpatterns will simply mirror these policies and thus will providelimited potential for information and decision support. The obvi-ous implication for research is to consider necessary data moreexplicitly by evaluating where a secondary analysis approach actu-ally appears promising and where it has to be complemented oreven substituted by a primary analysis approach. With regard tothe latter, the above cited research contributions based on primaryanalysis offer valuable suggestions for future research. In particu-lar, using empirically confirmed predictors for intended targets –as demonstrated in current research for employee performance(Li et al., 2008), turnover (Saradhi & Palshikar, 2011) or absence(Sugimori et al., 2003) – is a promising approach.
3.5. Systems-related results and implications
Initially, about half of the research contributions (n = 56) do notconsider the application of IS although IS are mandatory for prac-tical data mining and constitute a crucial aspect of domain ori-ented data mining research. A second group (n = 25) namessuitable existing IS that could be used for realizing proposedsolutions, while a more frequently suggested system is Weka

2416 S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420
(e.g. Bernik, Flojancic, Crnigoj, & Bernik I., 2007; Jantan, Hamdan, &Othman, 2009a). Interestingly, a third group of research contribu-tions offers self-developed IS for realizing proposed solutions(n = 25) (e.g. Cho & Ngai, 2003; Dorn & Hochmeister, 2009; Drigaset al., 2004; Thissen-Roe, 2005). However, all of these systems arestand alone applications; i.e., they are not embedded into existingHRIS. Because the currently existing general data mining systems(e.g. Chen et al., 2007; Zhang & Segall, 2010) focus on analyticalpower rather than usability, and, therefore, require considerablemining expertise that domain experts usually do not possess (e.g.Puuronen & Pechenizkiy, 2010; Rok et al., 2007), the offering of do-main-specific IS should clearly further the acceptance and usage ofHRM data mining. Adapting mining algorithms to specific HR prob-lems, automatically importing and pre-processing necessary HRdata, presenting results in domain language, etc., clearly reducesand hides data mining complexity for end users. An even moreadvantageous, yet until now unrealized, approach is embedded datamining (e.g. Rupnik & Jaklic, 2009). For instance, to support pre-selection decisions, data mining based recommendations of suit-able candidates could be directly embedded in an e-recruiting sys-tem, where the entire application process, including pre-selection,is performed. In doing so, data mining-based decision support canbe realized directly based on the data pool of the recruiting system,and the results can be used within the additional process steps,such as directly inviting pre-selected applicants for job interviewswithout any media disruption. Therefore, directly incorporatingdata mining functionality in existing HRIS and in existing HR pro-cesses meets the requirements of ease of use and usefulness and,therefore, points the way for future domain driven research (e.g.Adejuwon & Mosavi, 2010; Romero & Ventura, 2010; Rupnik & Jak-lic, 2009).
3.6. User-related results and implications
End user-related aspects are rarely addressed in current re-search, and it appears that it is frequently expected that end-usershave the expertise, the time, and the will to duly perform datamining related tasks, such as preparing data, choosing adequatemining methods, setting up relevant method parameters, or inter-preting received results (Sharma & Osei-Bryson, 2009). However,from a domain perspective, this assumption may turn out to bea clear misjudgment. Consequently, future research should specifywhich domain members (e.g., senior HR management, HR profes-sionals, line managers with employee responsibility, etc.) are actu-ally addressed, which tasks these users have to perform, and howthis should be done concretely. As a general rule, user-relatedtasks should be reduced as far as possible, while remaining tasksshould be supported by measures such as procedure models,interpretation aids, etc. Evidently, a prominent way to reduceand support user related tasks is automating or supporting themwith domain-specific IS, as suggested above. For example, a do-main-specific system for employee selection demonstrates howdemanding tasks, such as preparing and selecting suitable data,selecting mining methods and setting method parameters, canbe automated and how results can be presented in an appealingand intelligible way (Cho & Ngai, 2003). This example clearly dem-onstrates that domain specific systems are able to substantiallyreduce the amount of time and qualification effort of end users.A second possibility for reducing and supporting end-user relatedtasks is to explicitly assign these tasks to data mining-experts whointeract with the end-users. However, the effort and cost of thismeasure are obvious, and there is ample evidence of communica-tion and cooperation problems between data mining- and do-main-experts within general data mining research (Bole et al.,2011; Cao, 2010).
3.7. Ethics- and law-related results and implications
Ethical and legal aspects are not broadly considered in currentresearch; only equality of treatment and protection of privacy is-sues are discussed.
Equality of treatment (or avoidance of discrimination) refers topreventing any unfair or unequal treatment of individuals basedon their membership to a category or a minority without regardto individual merit (Pedreshi et al., 2008). Frequently, the ethicalprinciple of equality of treatment is also codified in (nationally dif-fering) civil rights laws, which identify relevant discriminationattributes such as age, gender, ethnicity, handicap or religion,among others (e.g. Pedreshi et al., 2008; Schermer, 2011). A fewof the research contributions address equality of treatment(n = 6), mostly by excluding potentially discriminative attributesfrom mining (e.g. Chien & Chen, 2007; Lakshmipathi et al., 2010).Therefore, future research should replicate this anti-discriminationmeasure. However, besides obvious discrimination, there may alsobe hidden discrimination. If, for instance, a rule for employee selec-tion advises to not hire applicants from a certain school, this maybe non-discriminative if this school shows a decreased educationalquality and, therefore, limited applicant qualifications. However,this rule may also be clearly discriminative; for instance, if theschool is in an area with a significant minority population andthe rule is based on historic ethnic prejudices within hiring deci-sions (Pedreshi et al., 2008). Discrimination is not easy to recognizeand requires comprehensive human background knowledge com-bined with a discrimination-sensitive interpretation of results(Pedreshi et al., 2008). Moreover, the problem of stereotyping as aspecific variant of discrimination inherent to data mining (e.g.Schermer, 2011; Wang, Li, Wang, & Li, 2009b) needs special atten-tion in future research. Stereotyping refers to the unequal treat-ment of individuals due to their assignment to certain classes,segments, or rules. To give an example, when classifying employ-ees for selection purposes to the classes suitable and unsuitable,the respective error rates indicate the extent of misclassifiedemployees in each class. If corresponding classification rules thenrecommend not to invite applicants from the unsuitable class(e.g., from certain universities, with certain specializations, certaingrades etc.) the problem arises that a smaller share of applicants(the error rate) will be mistreated because they show the attributesof the class unsuitable, although they actually belong to the classsuitable. Stereotyping, therefore, involves an unfair and unequaltreatment of these individuals and also implies a limitation offunctional data mining success. The problem of stereotyping existsfor all classification and association algorithms and, depending onthe kind of application, also potentially applies for segmentationalgorithms. Unfortunately, there is no easy way to handlestereotyping.
Protection of privacy attempts to prevent information concern-ing an individual from being obtained, used or disseminated with-out the knowledge and consent of the individual (e.g. Gkoulalas-Divanis & Verykios, 2010; Wahlstrom et al., 2002). Beyond ethicalconsiderations, protection of privacy is regularly codified in(nationally differing) data protection laws. Without outliningnumerous regulations in detail, there is a general agreement thatindividuals have the right to control the storage and usage of theirpersonal data (e.g. Poullet, 2006; Wahlstrom et al., 2002). There-fore, mining personal data ascertained for other (non-mining) rea-sons without the knowledge and often without the explicit(written) permission of the affected persons is seen as not accept-able and is often illegal. There are two basic approaches to copewith privacy requirements. The permission approach aims atinforming and asking the permission of individuals; however, thisapproach takes effort and has the risk of individuals denying themining of their data. The de-personalization approach aims at

S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420 2417
measures that offer valid results on the one hand, while protectingindividual privacy on the other. This approach is chosen by a fewresearch contributions (n = 10), realized via the anonymization(e.g. Aviad & Roy, 2011) or aggregation (e.g. Huang, Wu, & Lee,2008) of data. One contribution offers privacy preserving algo-rithms for HR data mining (Zhang et al., 2009). Privacy efforts mustbe central to future research. However, this requirement is clearlylimited to the mining of personal data and is not required if exclu-sively non-personal data, such as job offer data, etc. (e.g. Al-Zegaier,Al-Zu’bi, & Barakat, 2011; Clyde et al., 1995) is mined.
Given that equality of treatment and protection of privacy areprominent, but by no means exclusive, ethical and legal require-ments, additional aspects of this dimension, such as co-determina-tion, need future consideration.
4. Conclusions
The current paper aimed at a review of research on HRM datamining against the background of a domain driven researchperspective.
The review revealed that HRM constitutes a new domain of datamining research, given the large number and broad variety of rel-evant research contributions. Besides the quite recent publicationdates and the larger share of proceedings-based research contribu-tions, the relative shortness of cross-referencing and the absence ofcumulative research clearly hint at an emerging and still nascentresearch domain. Despite the domain’s interdisciplinary character,the field is currently dominated by method- and technology-ori-ented research; managerial research rarely participates.
The review suggests that current research does not frequentlyrecognize and consider domain-specific requirements. Elaboratingand applying a domain driven framework revealed that critical as-pects, such as ensuring functional relevance and success of datamining, ensuring the provision of suitable data and informationsystems, or ensuring the compliance with ethical and legal stan-dards, have not received general consideration until now. How-ever, it must be stressed that each domain-specific requirementwas met by a smaller set of research contributions that offer valu-able guidance for future research programs. Using a domain per-spective in a comprehensive review was necessary foruncovering recent advancements and suggesting remaining tasksfor future research.
Finally, the review demonstrated that a domain perspective is afruitful approach for future research. According to the implicationselaborated within this review, future domain driven HRM datamining research needs to
� elaborate a systematic overview of functional HR applicationareas,� substantiate the relevance and characteristics of the focused HR
problem(s),� demonstrate domain success, in particular, compared to exist-
ing conventional HR methods,� evaluate existing mining methods and, if necessary, customize
existing or develop new methods,� support the specification and provision of suitable HR data,� offer domain-specific data mining IS or, preferably, embed data
mining in existing HRIS,� minimize and support remaining end-user tasks and� comply with respective ethical and legal standards.
The above implications constitute a minimal list, which mayneed to be enlarged, depending on the research context. Adoptinga domain driven perspective in the future is by no means an easyendeavor. A domain driven perspective will increase the requiredeffort and complexity of research, given that multiple and interre-
lated requirement dimensions have to be considered. A domaindriven perspective might also narrow the actual application rangeof data mining in HRM, given that certain domain restrictions, suchas the existence of superior conventional HR methods, the lack ofsuitable HR data, or simply the legal prohibition of certain miningprocedures, may persist. However, a domain driven perspective isindispensable when research aims to provide results that are rele-vant in the real world.
References
Adejuwon, A., & Mosavi, A. (2010). Domain driven data mining – Application tobusiness. International Journal of Computer Science Issues, 7(4), 41–44.
Agrawal, R., & Srikant, R. (1995). Mining sequential patterns. In 11th Internationalconference on data, engineering (pp. 3–14).
Aiolli, F., de Filippo, M., & Sperduti, A. (2009). Application of the preference learningmodel to a human resources selection task. In IEEE symposium on computationalintelligence and data mining (CIDM ’09) (pp. 203–210). [1].
Al-Zegaier, H., Al-Zu’bi, H. A., & Barakat, S. (2011). Investigating the link betweenweb data mining and strategic human resources planning. Computer andInformation Science, 4(3), 67–75. http://dx.doi.org/10.5539/cis.v4n3p67 [2].
Aviad, B., & Roy, G. (2011). Classification by clustering decision tree-like classifierbased on adjusted clusters. Expert Systems with Applications, 38, 8220–8228.http://dx.doi.org/10.1016/j.eswa.2011.01.001 [3].
Baker, R. S. J. D., & Yacef, K. (2009). The state of educational data mining in 2009: Areview and future visions. Journal of Educational Data Mining, 1, 3–17.
Bal, M., Bal, Y., & Ustundag, A. (2011). Knowledge representation and discoveryusing formal concept analysis: An HRM application. In The World congress onengineering (pp. 1068–1073). [4].
Beccera-Fernandez, I., & Rodriguez, J. (2001). Web data mining techniques forexpertise-locator knowledge management systems. In 14th international floridaartificial intelligence research society conference (pp. 280–285). [5].
Bernik, M., & Bernik, I. (2011). Knowledge management and information technologyin analyzing human resource processes. In Proceedings of the SPRING 5thinternational conference on knowledge generation, communication andmanagement (KGCM 2011). Retrieved from http://www.iiis.org/CDs2011/CD2011IMC/KGCM_2011/PapersPdf/GB772CV.pdf. [D].
Bernik, M., Flojancic, J., Crnigoj, D., & Bernik I. (2007). Using information technologyfor human resource management decisions. In 8th WSEAS internationalconference on mathematics and computers in business and economics (MCBE ’07)(pp. 130–133). [6].
Bole, U., Jaklicb, J., Papac, G., & Zabkard, J. (2011). The critical success factors of datamining in organizations. Retrieved from http://csd.ijs.si/bole/files/CSFs%20of%20DM%20in%20Org.pdf.
Burgard, M., & Piazza, F. (2009). Data warehouse and business intelligence systemsin the context of e-HRM. In T. Torres-Coronas & M. Arias-Oliva (Eds.),Encyclopedia of HRIS: Challenges in e-HRM (pp. 223–229). Hershey, PA: IGI-Global.
Cao, L. (2010). Domain-driven data mining: Challenges and prospects. IEEETransactions on Knowledge and Data Engineering, 22, 755–769. http://dx.doi.org/10.1109/TKDE.2010.32.
Cao, L., & Zhang, C. (2007). The evolution of KDD: Towards domain-driven datamining. International Journal of Pattern Recognition and Artificial Intelligence, 21,677–692. http://dx.doi.org/10.1142/S0218001407005612.
Chang, H.-Y. (2009). Employee turnover: A novel prediction solution with effectivefeature selection. WSEAS Transactions on Information Science and Applications, 3,417–426 [7].
Chang, H.-T., Wu, H.-J., & Ting, I.-H. (2009). Mining organizational networks forlayoff prediction model construction. In International conference on advances insocial network analysis and mining (ASONAM ’09) (pp. 411–416). http://dx.doi.org/10.1109/ASONAM.2009.52. [8]
Chen, L.-F., & Chien, C.-F. (2011). Manufacturing intelligence for class prediction andrule generation to support human capital decisions for high-tech industries.Flexible Services and Manufacturing Journal, 23, 263–289. http://dx.doi.org/10.1007/s10696-010-9068-x [9].
Chen, X., & Wang, F. (2010). Application of data mining on enterprise humanresource performance management. In 2010 international conference oninformation management, innovation management and industrial engineering(ICIII) (pp. 151–153). http://dx.doi.org/10.1109/ICIII.2010.200. [10].
Chen, X., Ye, Y., Williams, G., & Xu, X. (2007). A survey of open source data miningsystems. In Lecture notes in computer science. In T. Washio, Z.-H. Zhou, J. Z.Huang, X. Hu, J. Li, C. Xie, J. He, D. Zou, K.-C. Li, & M. M. Freire (Eds.). Emergingtechnologies in knowledge discovery and data mining (Vol. 4819, pp. 3–14). Berlin,Germany: Springer. http://dx.doi.org/10.1007/978-3-540-77018-3_2.
Chien, C.-F., & Chen, L.-F. (2007). Using rough set theory to recruit and retain high-potential talents for semiconductor manufacturing. IEEE Transactions onSemiconductor Manufacturing, 20, 528–541. http://dx.doi.org/10.1109/TSM.2007.907630 [11].
Chien, C.-F., & Chen, L.-F. (2008). Data mining to improve personnel selection andenhance human capital: A case study in high-technology industry. ExpertSystems with Applications, 34, 280–290. http://dx.doi.org/10.1016/j.eswa.2006.09.003. [12].

2418 S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420
Cho, V., & Ngai, E. W. T. (2003). Data mining for selection of insurance sales agents.Expert Systems with Applications, 20, 123–132. http://dx.doi.org/10.1111/1468-0394.00235. [13].
Choudhary, A. K., Harding, J. A., & Tiwari, M. K. (2008). Data mining inmanufacturing: A review based on the kind of knowledge. Journal ofIntelligent Manufacturing, 20, 501–521. http://dx.doi.org/10.1007/s10845-008-0145-x.
Clyde, S., Zhang, J., & Yao, C.-C. (1995). An object-oriented implementation of anadaptive classification of job openings. In 11th conference on artificial intelligencefor applications (pp. 9–16). http://dx.doi.org/10.1109/CAIA.1995.378795. [14].
Coppock, D. (2003). Data mining and modeling: So you have a model, now what? DMReview Magazine.
Delgado-Gómez, D., Aguado, D., Lopez-Castroman, J., Santacruz, C., & Artés-Rodriguez, A. (2011). Improving sale performance prediction using supportvector machines. Expert Systems with Applications, 38, 5129–5132. http://dx.doi.org/10.1016/j.eswa.2010.10.003 [15].
Devanna, M. A., Fombrun, C. J., & Tichy, N. (1984). A framework for strategic humanresource management. In C. J. Fombrun, N. Tichy, & M. A. Devanna (Eds.),Strategic human resource management (pp. 33–51). New York, NY: John Wiley &Sons.
Doctor, F., Hagras, H., Roberts, D., & Callaghan, V. (2009). A neuro-fuzzy based agentfor group decision support in applicant ranking within human resourcessystems. In IEEE international conference on fuzzy systems (FUZZ-IEEE 2009) (pp.744–750). http://dx.doi.org/10.1109/FUZZY.2009.5277379. [16].
Dorn, J., & Hochmeister, M. (2009). Techscreen: Mining competencies in socialsoftware. In The 13th world multi-conference on systemics, cybernetics andinformatics (pp. 115–126). [17].
Drigas, A., Kouremenos, S., Vrettos, S., Vrettaros, J., & Kouremenos, D. (2004). Anexpert system for job matching of the unemployed. Expert Systems withApplications, 26, 217–224. http://dx.doi.org/10.1016/S0957-4174(03)00136-2[18].
Evers, A., Anderson, N., & Smit-Voskuijl, O. (Eds.). (2005). Handbook of personnelselection. Malden, MA: Blackwell.
Fancello, G., Pani, C., Pisano, M., Serra, P., Zuddas, P., & Fadda, P. (2011). Prediction ofarrival times and human resources allocation for container terminal. MaritimeEconomics and Logistics, 13, 142–173. http://dx.doi.org/10.1057/mel.2011.3 [19].
Färber, F. (2005). Information systems-supported personnel selection: An automatedrecommendation approach. Norderstedt, Germany: Books on Demand [20].
Färber, F., Weitzel, T., & Keim, T. (2003). An automated recommendation approachto selection in personnel recruitment. In Proceedings of the Americas conferenceon information systems (AMCIS 2003) (pp. 2329–2339). [21].
Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996). From data mining toknowledge discovery in databases. AI Magazine, 17(3), 36–53.
Feng, D., & Gao, Y. (2009). A HRD evaluation method based on BP neural network. In2009 second international symposium on information science and engineering(ISISE) (pp. 309–312). http://dx.doi.org/10.1109/ISISE.2009.55. [22].
Gkoulalas-Divanis, A., & Verykios, V. S (2010). Privacy preserving data mining: Howfar can we go? In A. Syvajarvi & S. J. Syvajarvi (Eds.), Data mining in private andpublic sectors: Organizational and governmental applications (pp. 125–141).Hershey, PA: IGI Global. http://dx.doi.org/10.4018/978-1-60566-906-9.ch007.
Goonawardene, N., Subashini, S., Boralessa, N., & Premaratne, L. (2010). A neuralnetwork based model for project risk and talent management. In Lecture notes incomputer science. In D. Hutchison, T. Kanade, J. Kittler, J. M. Kleinberg, A. Kobsa,F. Mattern, J. C. Mitchell, M. Naor, O. Nierstrasz, C. P. Rangan, B. Steffen, M.Sudan, D. Terzopoulos, D. Tygar, & G. Weikum (Eds.). Advances in neuralnetworks (Vol. 6064, pp. 532–539). Berlin, Germany: Springer. http://dx.doi.org/10.1007/978-3-642-13318-3_66 [23].
Han, J. (2009). Application of fuzzy data mining algorithm in performanceevaluation of human resource. In International forum on computer science-technology (pp. 343–346). http://dx.doi.org/10.1109/IFCSTA.2009.90. [24].
Han, J., & Dong, Y. (2007). Application of association rules based on rough set inhuman resource management. In IEEE international engineering management:The sixth wuhan international conference on e-business-innovation managementtrack (pp. 2407–2413). [25].
Han, J., Ren, J., & Dong, Y. (2008). Research on time series model for human resourcemanagement based on web technique. In 4th international conference on wirelesscommunications, networking and mobile computing (WiCOM ’08) (pp. 11554–11557). http://dx.doi.org/10.1109/WiCom.2008.2687. [26].
Hermiz, K. B. (1999). Critical success factors for data mining projects. DM ReviewMagazine.
Holland, A., & Fathi, M. (2005). Creating graphical models as representation ofpersonalized skill profiles. In 2005 IEEE international conference on systems, manand cybernetics (pp. 560–565). http://dx.doi.org/10.1109/ICSMC.2005.1571205.[27].
Hong, W.-C., Pai, P.-F., Huang, Y.-Y., & Yang, S.-L. (2005). Application of supportvector machines in predicting employee turnover based on job performance. InLecture notes in computer science. In D. Hutchison, T. Kanade, J. Kittler, J. M.Kleinberg, F. Mattern, J. C. Mitchell, M. Naor, O. Nierstrasz, C. P. Rangan, B.Steffen, M. Sudan, D. Terzopoulos, D. Tygar, M. Y. Vardi, & G. Weikum (Eds.).Advances in natural computation (Vol. 3610, pp. 668–674). Berlin, Germany:Springer. http://dx.doi.org/10.1007/11539087_85 [28].
Honkela, T., Nordfors, R., & Tuuli, R. (2004). Document maps for competencemanagement. In Proceedings of the symposium on professional practice in AI (pp.31–39). [29].
Hou, X.-D., Dong, Y.-F., Liu, H.-P., & Gu, J.-H. (2007). Application of fuzzy data miningin staff performance assessment. International Conference on Machine Learning
and Cybernetics, 2007, 835–838. http://dx.doi.org/10.1109/ICMLC.2007.4370258[30].
Hsiung, H.-H., & Yang, K.-P. (2012). Employee behavioral options in problematicworking conditions: Response pattern analysis. The International Journal ofHuman Resource Management, 23, 1888–1907. http://dx.doi.org/10.1080/09585192.2011.610340 [31].
Huang, I. Y.-F., Wu, W.-W., & Lee, Y.-T. (2008). Simplifying essential competenciesfor Taiwan civil servants using the rough set approach. Journal of the OperationalResearch Society, 59, 259–265. http://dx.doi.org/10.1057/palgrave.jors.2602516[32].
Huang, Y. (2009). Study of college human resources data mining based on the SOMalgorithm. In Asia-Pacific Conference on information processing (APCIP 2009) (pp.324–327). http://dx.doi.org/10.1109/APCIP.2009.89. [33].
Imai, S., Lin, C.-W., Watada, J., & Tzeng, G.-H. (2008a). Knowledge acquisition inhuman resource management based on rough sets. In Portland internationalconference on management of engineering & technology (PICMET 2008) (pp. 969–974). http://dx.doi.org/10.1109/PICMET.2008.4599705. [D].
Imai, S., Lin, C.-W., Watada, J., & Tzeng, G.-H. (2008b). Rough sets approach tohuman resource development of information technology corporations.International Journal of Simulation Systems, Science and Technology, 9(2), 31–42[34].
Isaias, P., Casaca, C. & Pifano, S. (2010). Recommender systems for human resourcestask assignment. In 24th IEEE international conference on advanced informationnetworking and applications (AINA) (pp. 214–221). http://dx.doi.org/10.1109/AINA.2010.168. [35].
Jantan, H., Hamdan, A. R., & Othman, Z. A. (2009a). Knowledge discovery techniquesfor talent forecasting in human resource application. World Academy of Science,Engineering and Technology, 26, 775–783 [36].
Jantan, H., Hamdan, A. R., & Othman, Z. A. (2009b). Potential data miningclassification techniques for academic talent forecasting. In Ninth internationalconference on intelligent systems design and applications (ISDA ’09) (pp. 1173–1178). http://dx.doi.org/10.1109/ISDA.2009.64. [37].
Jantan, H., Hamdan, A. R., & Othman, Z. A. (2010a). Classification and prediction ofacademic talent using data mining techniques. In Lecture notes in computerscience. In R. Setchi, I. Jordanov, R. J. Howlett, & L. C. Jain (Eds.). Knowledge-basedand intelligent information and engineering systems (Vol. 6276, pp. 491–500).Berlin, Germany: Springer. http://dx.doi.org/10.1007/978-3-642-15387-7_53[D].
Jantan, H., Hamdan, A. R., & Othman, Z. A. (2010b). Human talent prediction in HRMusing c4.5 classification algorithm. International Journal on Computer Science andEngineering, 2, 2526–2534 [D].
Jantan, H., Hamdan, A. R., & Othman, Z. A. (2010c). Knowledge discovery techniquesfor talent forecasting in human resource application. Journal of Human andSocial Sciences, 5, 694–702.
Jindal, D., & Singla, R. (2011). Decision support system in human resourcemanagement (a study of HR intelligent techniques). International Journal ofResearch in IT, Management and Engineering, 1(4), 108–121 [38].
Juan, L. (2009). Early warning model research of state-owned enterprises’ humancapital risks based on improved neural network. International Conference onFuture BioMedical Information Engineering, 197–201. http://dx.doi.org/10.1109/FBIE.2009.5405878 [39].
Kane-Sellers, M. L. (2007). Predictive models of employee voluntary turnover in aNorth American professional sales force using data-mining analysis. Doctoraldissertation, Texas A&M University. Retrieved from http://repository.tamu.edu/bitstream/handle/1969.1/ETD-TAMU-1486/KANE-SELLERS-DISSERTATION.pdf?sequence=1. [40].
Kao, W.-H., Huang, I.-M., Shen, H.-S., & Lin, C.-C. (2009). A study of weightedassociation rule applied in human resource job requirement. In 2009 jointconferences on pervasive computing (JCPC) (pp. 839–844). http://dx.doi.org/10.1109/JCPC.2009.5420070. [41].
Karahoca, A., Karahoca, D., & Kaya, O. (2008). Data mining to cluster humanperformance by using online self regulating clustering method. In Proceedings ofthe 1st WSEAS international conference on multivariate analysis and its applicationin science and engineering (MAASE ’08) (pp. 198–203). [42].
Kavanagh, M., & Thite, M. (Eds.). (2010). Human resource information systems: Basics,applications and future directions. Los Angeles, CA: Sage.
Kessler, R., Béchet, N., Roche, M., El-Bèze, M., & Torres-Moreno, J.-M. (2008).Automatic profiling system for ranking candidates answers in human resources.In Lecture notes in computer science. In D. Hutchison, T. Kanade, J. Kittler, J. M.Kleinberg, A. Kobsa, F. Mattern, J. C. Mitchell, M. Naor, O. Nierstrasz, C. P.Rangan, B. Steffen, M. Sudan, D. Terzopoulos, D. Tygar, & G. Weikum (Eds.). Onthe move to meaningful internet systems: OTM 2008 workshops (Vol. 5333,pp. 625–634). Berlin, Germany: Springer. http://dx.doi.org/10.1007/978-3-540-88875-8_86 [D].
Kessler, R., Béchet, N., Torres-Moreno, J.-M., Roche, M., & El-Bèze, M. (2009). Job offermanagement: How improve the ranking of candidates. In J. Rauch, Z. Ras, P. Berka,& T. Elomaa (Eds.), Foundations of intelligent systems (pp. 431–441). Berlin,Germany: Springer. http://dx.doi.org/10.1007/978-3-642-04125-9_46 [D].
Kessler, R., Torres-Moreno, J. M., & El-Bèze, M. (2007). E-Gen: Automatic job offerprocessing system for human resources. In Lecture notes in computer science. InA. Gelbukh & A. F. K. Morales (Eds.). MICAI 2007: Advances in artificial intelligence(Vol. 4827, pp. 985–995). Berlin, Germany: Springer. http://dx.doi.org/10.1007/978-3-540-76631-5_94 [43].
Khosla, R., & Goonesekera, T. (2003). An online multi-agent e-sales recruitmentsystem. In IEEE/WIC international conference on web intelligence (pp. 111–117).http://dx.doi.org/10.1109/WI.2003.1241181. [44].

S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420 2419
Khosla, R., Lai, C., & Chu, M.-T. (2006). Measurement and comparison of non-verbalbehavior and cognitive behavior in human resource management – Applicationin sales recruitment. In 2006 IEEE international conference on computationalintelligence for measurement systems and applications (pp. 57–62). http://dx.doi.org/10.1109/CIMSA.2006.250749. [45].
Kirby, E., Dufner, D., & Palmer, J. (1998). An analysis of applying artificial neuralnetworks for employee selection. In Americas conference on information systems(AMCIS 1998) (pp. 76–77). [46].
Kroll, K. M. (2001). Data-mining technology lets retailers indentify which jobcandidates are likely to remain on the job. Stores Magazine, 83, 62–64 [47].
Lakshmipathi, R., Chandrasekaran, M., Mohanraj, V., Senthilkumar, J., & Suresh, Y.(2010). An intelligent agent based talent evaluation system, using a knowledgebase. International Journal of Information Technology and KnowledgeManagement, 2, 231–236 [48].
Lee, W. C., & Drasgow, F. (2001). Predicting employee retention: an examination of aretention likelihood scale (Report No. 45). Retrieved from Center for HumanResource Management website: http://www.uic.edu/classes/idsc/ids472/CHRMwp45.doc(2001). [49].
Lee, Y.-T. (2010). Exploring high-performers’ required competencies. Expert Systemswith Applications, 37, 434–439. http://dx.doi.org/10.1016/j.eswa.2009.05.064[50].
Lescreve, F. J. (1999). Data integration and classification for an officer selectionsystem. In RTO HFM workshop on officer selection (pp. 28-1–28-7). [51].
Li, F., Ge, S., & Yin, J. (2011). Research on talent introduction hazard and trainingstrategy of university based on data mining. In D. D. Wu & Y. Zhou (Eds.),modeling risk management for resources and environment in China (pp. 219–224).Berlin, Germany: Springer. http://dx.doi.org/10.1007/978-3-642-18387-4_24[52].
Li, W., Xu, S., & Meng, W. (2009). A risk prediction model of construction enterprisehuman resources based on support vector machine. In Second internationalconference on intelligent computation technology and automation (ICICTA ’09) (pp.945–948). http://dx.doi.org/10.1109/ICICTA.2009.235. [53].
Li, X.-H., Zhao, J.-H., & Li, B.-H. (2004). Investigation of fuzzy mathematical modelfor general evaluation of administrators in university. In 2004 internationalconference on machine learning and cybernetics (pp. 1977–1980). http://dx.doi.org/10.1109/ICMLC.2004.1382104. [54].
Li, Y. (2011). Research of evaluation staff satisfaction based on BP neural network. In2011 third Pacific-Asia conference on circuits, communications and system (PACCS)(pp. 1–3). http://dx.doi.org/10.1109/PACCS.2011.5990180. [55].
Li, Y.-M., Lai, C.-Y., & Kao, C.-P. (2008). Incorporate personality trait with supportvector machine to acquire quality matching of personnel recruitment. In 4thinternational conference on business and information (pp. 1–11). [56].
Liu, H., Dai, S., & Jiang, H. (2009). Application of rough set and support vectormachine in competency assessment. In Fourth international conference on bio-inspired computing, theories and applications (BIC-TA ’09) (pp. 1–4). http://dx.doi.org/10.1109/BICTA.2009.5338100. [57].
Liu, Y., Kou, Z., Perlich, C., & Lawrence, R. (2008). Intelligent system for workforceclassification. In Workshop on data mining for business applications (pp. 18–26). [58].
Lockamy, A., & Service, R. W. (2011). Modeling managerial promotion decisions usingBayesian networks: An exploratory study. Journal of Management Development,30, 381–401. http://dx.doi.org/10.1108/02621711111126846 [59].
Long, L. K., & Troutt, M. D. (2003). Data mining for human resource informationsystems. In J. Wang (Ed.), Data mining: Opportunities and challenges(pp. 366–381). Hershey, PA: Springer [60].
Luell, J. (2010). Employee fraud detection under real world conditions. Doctoraldissertation, University of Zurich, Retrieved from http://www.ifi.uzh.ch/pax/uploads/pdf/publication/1486/dissLuell.pdf.
Ly, L. T., Rinderle, S., Dadam, P., & Reichert, M. (2006). Mining staff assignment rulesfrom event-based data. In Lecture Notes in Computer Science. In D. Hutchison, T.Kanade, J. M. Kleinberg, F. Mattern, J. C. Mitchell, M. Naor, O. Nierstrasz, C. P.Rangun, B. Steffen, M. Sudan, D. Terzopoulos, D. Tygar, M. Y. Vardi, & G. Weikum(Eds.). Business process management workshops (Vol. 3812, pp. 177–190). Berlin,Germany: Springer. http://dx.doi.org/10.1007/11678564_16 [61].
Markham, I. S. (2011). Assessing the prediction of employee productivity: Acomparison of OLS vs. CART. International Journal of Productivity and QualityManagement, 8, 313–332. http://dx.doi.org/10.1504/IJPQM.2011.042511 [62].
Min, H., & Emam, A. (2003). Developing the profiles of truck drivers for theirsuccessful recruitment and retention: A data mining approach. InternationalJournal of Physical Distribution & Logistics Management, 33, 149–162. http://dx.doi.org/10.1108/09600030310469153 [63].
Moehrle, M. G., Walter, L., Geritz, A., & Müller, S. (2005). Patent-based inventorprofiles as a basis for human resource decisions in research and development.R&D Management, 35, 513–524. http://dx.doi.org/10.1111/j.1467-9310.2005.00408.x [64].
Mohanraj, V., Lakshmipathi, R., Chandrasekaran, M., Senthilkumar, J., & Suresh, Y.(2009). Intelligent agent based talent evaluation engine using a knowledgebase. In International conference on advances in recent technologies incommunication and computing (ARTCom ’09) (pp. 257–259). http://dx.doi.org/10.1109/ARTCom.2009.214. [65].
Nagadevara, V., & Srinivasan, V. (2008). Early prediction of employee attrition insoftware companies – Application of data mining techniques. Research andPractice in Human Resource Management, 16, 2020–2032 [66].
Nagadevara, V., Srinivasan, V., & Valk, R. (2008). Establishing a link betweenemployee turnover and withdrawal behaviours: Application of data miningtechniques. Research and Practice in Human Resource Management, 16, 81–99 [D].
Ngai, E. W. T., Hu, Y., Wong, Y. H., Chen, Y., & Sun, X. (2011). The application of datamining techniques in financial fraud detection: A classification framework andan academic review of literature. Decision Support Systems, 50, 559–569. http://dx.doi.org/10.1016/j.dss.2010.08.006.
Ngai, E. W. T., Xiu, L., & Chau, D. C. K. (2009). Application of data mining techniquesin customer relationship management: A literature review and classification.Expert Systems with Applications, 36, 2592–2602. http://dx.doi.org/10.1016/j.eswa.2008.02.021.
Ning, C. (2010). The application of neural network to the allocation of enterprisehuman resources. In 2010 2nd international conference on e-business andinformation system security (EBISS) (pp. 1–4). http://dx.doi.org/10.1109/EBISS.2010.5473417. [67].
Pechenizkiy, M., Puuronen, S., & Tsymbal, A. (2008). Towards more relevance-oriented data mining research. Intelligent Data Analysis, 12, 237–249.
Pedreshi, D., Ruggieri, S., & Turini, F. (2008). Discrimination-aware data mining. In14th ACM SIGKDD international conference on knowledge discovery and datamining (KDD ’08) (pp. 560–568).
Poullet, Y. (2006). EU data protection policy. The directive 95/46/EC: Ten years after.Computer Law and Security Review, 22, 206–217. http://dx.doi.org/10.1016/j.clsr.2006.03.004.
Puuronen, S., & Pechenizkiy, M. (2010). Towards the generic framework for utilityconsiderations in data mining research. In 2010 conference on data mining forbusiness applications (pp. 49–45).
Quinn, A., Rycraft, J. R., & Schoech, D. (2002). Building a model to predict caseworkerand supervisor turnover using a neural network and logistic regression. Journalof Technology in Human Services, 19(4), 65–85. http://dx.doi.org/10.1300/J017v19v04_05 [68].
Ramesh, B. (2001). GPR: A data mining tool using genetic programming.Communications of the Association for Information Systems, 5, 1–36 [69].
Ranjan, J., Goyal, D. P., & Ahson, S. I. (2008). Data mining techniques for betterdecisions in human resource management systems. International Journal ofBusiness Information Systems, 3, 464–481. http://dx.doi.org/10.1504/IJBIS.2008.018597 [70].
Rodrigues, S., Oliveira, J., & de Souza, J. M. (2005). Competence mining for teamformation and virtual community recommendation. In Ninth internationalconference on computer supported cooperative work in design (pp. 44–49).http://dx.doi.org/10.1109/CSCWD.2005.194143. [71]
Rodrigues, S., Oliveira, J., & de Souza, J. M. (2006). Recommendation for team andvirtual community formations based on competence mining. In Lecture notes incomputer science. In D. Hutchison, T. Kanade, J. Kittler, J. M. Kleinberg, F.Mattern, J. C. Mitchell, M. Naor, O. Nierstrasz, C. P. Rangan, B. Steffen, M. Sudan,D. Terzopoulos, D. Tygar, M. Y. Vardi, & G. Weikum (Eds.). Computer supportedcooperative work in design II (Vol. 3865, pp. 365–374). Berlin, Germany:Springer. http://dx.doi.org/10.1007/11686699_37 [D].
Rok, R., Matjaz, K., & Marjan, K. (2007). Integrating data mining and decisionsupport through data mining based decision support system. Journal ofComputer Information Systems, 47, 89–104.
Romero, C., & Ventura, S. (2010). Educational data mining: A review of the state ofthe art. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applicationsand Reviews, 40, 601–618. http://dx.doi.org/10.1109/TSMCC.2010.2053532.
Rupnik, R., & Jaklic, J. (2009). The deployment of data mining into operationalbusiness processes. In J. Ponce & A. Karahoca (Eds.), Data mining and knowledgediscovery in real life applications (pp. 375–388). Vienna, Austria: InTech.
Sáiz, L., Pérez, A., Herrero, A., & Corchado, E. (2011). Analyzing key factors of humanresources management. In 12th international conference on intelligent dataengineering and automated learning (IDEAL ’11) (pp. 463–473). [72].
Saradhi, V. V., & Palshikar, G. K. (2011). Employee churn prediction. Expert Systemswith Applications, 38, 1999–2006. http://dx.doi.org/10.1016/j.eswa.2010.07.134[73].
Schermer, B. W. (2011). The limits of privacy in automated profiling and datamining. Computer Law & Security Review, 27, 45–52. http://dx.doi.org/10.1016/j.clsr.2010.11.009.
Sexton, R. S., McMurtrey, S., Michalopoulos, J. O., & Smith, A. M. (2005). Employeeturnover: A neural network solution. Computers and Operations Research, 32,2635–2651. http://dx.doi.org/10.1016/j.cor.2004.06.022 [74].
Sharma, S., & Osei-Bryson, K.-M. (2009). Framework for formal implementation ofthe business understanding phase of data mining projects. Expert Systems withApplications, 36, 4114–4124. http://dx.doi.org/10.1016/j.eswa.2008.03.021.
Sivaram, N., & Ramar, K. (2010). Applicability of clustering and classificationalgorithms for recruitment data mining. International Journal of ComputerApplications, 4(5), 23–28 [75].
Srikant, R., & Agrawal, R. (1995). Mining generalized association rules. In 21stinternational conference on very large databases (VLDB ’95) (pp. 407–419).
Strohmeier, S., & Piazza, F. (2010). Informating HRM: A comparison of data queryingand data mining. International Journal of Business Information Systems, 5,186–197 [76].
Sugimori, H., Iida, Y., Suka, M., Ichimura, T., & Yoshida, K. (2003). Data mining forseeking relationships between sickness absence and Japanese worker’s profile.In Lecture notes in computer science. In R. J. Howlett, V. Palade, & L. Jain (Eds.).Knowledge-based intelligent information and engineering systems (Vol. 2774,pp. 126–410). Berlin; Germany: Springer. http://dx.doi.org/10.1007/978-3-540-45226-3_56 [77].
Tai, W.-S., & Hsu, C.-C. (2006). A realistic personnel selection tool based on fuzzydata mining method. In Proceedings of the 9th joint conference on informationsciences. [78].

2420 S. Strohmeier, F. Piazza / Expert Systems with Applications 40 (2013) 2410–2420
Teodorescu, R., Teodorescu, N., & Gavrila, C. (2009). Bayesian networks inoutplacement. Retrieved from http://www.asecib.ase.ro/simpozion/2009/full_papers/pdf/65_TEODORESCU.pdf. [79].
Thissen-Roe, A. (2005). Adaptive selection of personality items to inform a neuralnetwork predicting job performance. Doctoral dissertation, University ofWashington. Retrieved from http://www.psych.umn.edu/psylabs/catcentral/pdf%20files/th05-01.pdf. [80].
Tung, K.-Y., Huang, I.-C., Chen, S.-L., & Shih, C.-T. (2005). Mining the generation Xers’job attitudes by artificial neural network and decision tree – Empirical evidencein Taiwan. Expert Systems with Applications, 29, 783–794. http://dx.doi.org/10.1016/j.eswa.2005.06.012 [81].
Tung, Y.-H., Tseng, S.-S., Weng, J.-F., Lee, T.-P., Liao, A. Y. H., & Tsai, W.-N. (2010). Arule-based CBR approach for expert finding and problem diagnosis. ExpertSystems with Applications, 37, 2427–2438. http://dx.doi.org/10.1016/j.eswa.2009.07.037 [82].
Tzeng, H.-M., Hsieh, J.-G., & Lin, Y.-L. (2004). Predicting nurses’ intention to quitwith a support vector machine: A new approach to set up an early warningmechanism in human resource management. Computers, Informatics, Nursing,22, 232–242 [83].
Wahlstrom, K., Roddick, J. F., Sarre, R., Estivill-Castro, V., & DeVries, D. (2002). On theethics of data mining. Technical Report KDM-02-006. Retrieved from FlindersUniversity of South Australia, Knowledge Discovery and ManagementLaboratory website: http://kdm.first.flinders.edu.au/KDMTR/KDM02006.pdf.
Wang, G., & Wang, Y. (2009). 3DM: Domain-oriented data-driven data mining.Fundamenta Informaticae, 90, 395–426. http://dx.doi.org/10.3233/FI-2009-0026.
Wang, Q., Li, B., & Hu, J. (2009a). Feature selection for human resource selectionbased on affinity propagation and SVM sensitivity analysis. In World congress onnature & biologically inspired computing (NaBIC 2009) (pp. 31–36). http://dx.doi.org/10.1109/NABIC.2009.5393596. [84].
Wang, Z., Li, S., Wang, Y., & Li, S. (2009). The research of task assignment based onant colony algorithm. In International conference on mechatronics and automation(ICMA 2009) (pp. 2334–2339). http://dx.doi.org/10.1109/ICMA.2009.5246570.[85].
Weiss, G. M. (2009). Data mining in the real world: Experiences, challenges, andrecommendations. In Proceedings of the international conference on data mining(DMIN 2009) (pp. 124–130).
Wong, T.-L., Lam, W., & Chen, B. (2009). Mining employment market via text blockdetection and adaptive cross-domain information extraction. In 32ndinternational ACM SIGIR conference on research and development in informationretrieval (SIGIR ’09) (pp. 283–290). [86].
Wu, H.-J., Ting, I.-H., & Chang, H.-T. (2010). Integrating SNA and DM technology intoHR practice and research: Layoff prediction model. In I.-H. Ting, H.-J. Wu, & T.-H.Ho (Eds.), Studies in computational intelligence (pp. 53–66). Berlin, Germany:Springer. http://dx.doi.org/10.1007/978-3-642-13422-7_4 [D].
Wu, W.-W. (2009). Exploring core competencies for R&D technical professionals.Expert Systems with Applications, 36, 9574–9579. http://dx.doi.org/10.1016/j.eswa.2008.07.052 [87].
Wu, W.-W., Lee, Y.-T., & Tzeng, G.-H. (2005). Simplifying the manager competencymodel by using the rough set approach. In Lecture notes in computer science. InD. Slezak, J. Yao, J. F. Peters, W. Ziarko, & X. Hu (Eds.). Rough sets, fuzzy sets, datamining, and granular computing (Vol. 3642, pp. 484–494). Berlin, Germany:Springer. http://dx.doi.org/10.1007/11548706_51 [88].
Wu, X., & Zhang, H. (2010). A talent markets analysis method based on data mining.In 2010 IEEE international conference on intelligent computing and intelligent
systems (ICIS) (pp. 349–351). http://dx.doi.org/10.1109/ICICISYS.2010.5658634.[89].
Yang, C. C., Lin, W. T., Chen, H. M., & Shi, Y. H. (2009). Improving scheduling ofemergency physicians using data mining analysis. Expert Systems withApplications, 36, 3378–3387. http://dx.doi.org/10.1016/j.eswa.2008.02.069 [90].
Yang, S.-M. (2008). A self-adapting regression SVM model and its application onmiddle managers performance evaluation. In 2008 international conference onmachine learning and cybernetics (pp. 645–648). http://dx.doi.org/10.1109/ICMLC.2008.4620484. [91].
Ye, J., Hu, H., & Chai, C. (2009). A talent classification method based on SVM. In 2009international symposium on intelligent ubiquitous computing and education (pp.160–163). http://dx.doi.org/10.1109/IUCE.2009.63. [92].
Ye, P. (2011). The decision tree classification and its application research inpersonnel management. In 2011 international conference on electronics andoptoelectronics (ICEOE) (pp. 372–375). http://dx.doi.org/10.1109/ICEOE.2011.6013123. [93].
Youzheng, C., & Ming, G. (2008). Data mining to improve human resource inconstruction company. In International seminar on business and informationmanagement (ISBIM ’08) (pp. 275–278). http://dx.doi.org/10.1109/ISBIM.2008.187. [94].
Zhang, D., & Deng, J. (2011). The data mining of the human resources datawarehouse in university based on association rule. Journal of Computers, 6,139–146. http://dx.doi.org/10.4304/jcp.6.1.139-146 [95].
Zhang, H. (2009). Fuzzy evaluation on the performance of human resourcesmanagement of commercial banks based on improved algorithm. In 2009 2ndinternational conference on power electronics and intelligent transportation system(PEITS) (pp. 214–218). http://dx.doi.org/10.1109/PEITS.2009.5407033. [96].
Zhang, Q., & Segall, R. S. (2010). Commercial data mining software. In O. Maimon &L. Rokach (Eds.), Data Mining and Knowledge Discovery Handbook (8th ed.,pp. 1245–1268). Berlin, Germany: Springer.
Zhang, X., Zhu, Y., & Hua, N. (2009). Privacy parallel algorithm for miningassociation rules and its application in HRM. In Second internationalsymposium on computational intelligence and design (ISCID ’09) (pp. 296–299).http://dx.doi.org/10.1109/ISCID.2009.220. [97].
Zhang, X., Zhu, Y., & Hua, N. (2010). Improved paralled algorithm for miningfrequent itemset used in HRM. 2010 Seventh International Conference on FuzzySystems and Knowledge Discovery (FSKD) (pp. 2830–2833). http://dx.doi.org/10.1109/FSKD.2010.5569250. [D].
Zhao, X. (2008). An empirical study of data mining in performance evaluation ofHRM. In International symposium on intelligent information technology applicationworkshops (IITAW ’08) (pp. 82–85). http://dx.doi.org/10.1109/IITA.Workshops.2008.235. [98].
Zhao, X. (2008). A study of performance evaluation of HRM: based on data mining.In International seminar on future information technology and managementengineering (FITME ’08) (pp. 45–48). http://dx.doi.org/10.1109/FITME.2008.133.[D].
Zhu, J., Goncalves, A. L., Uren, V. S., Motta, E., & Pacheco, R. (2005). Mining web datafor competency management. In The 2005 IEEE/WIC/ACM internationalconference on web intelligence (pp. 94–100). http://dx.doi.org/10.1109/WI.2005.99. [99].
Ziebarth, S., Malzahn, N., & Hoppe, H. U. (2009). Using data mining techniques tosupport the creation of competence ontologies. In 2009 conference on artificialintelligence in education: building learning systems that care: from knowledgerepresentation to affective modeling (pp. 223–230). [100].