Embed Size (px)
DESCRIPTION
ECE 526 – Network Processing Systems Design. Network Processor Introduction Chapter 11,12: D. E. Comer. Goal. Understanding the inefficiency of 1 st , 2 nd and 3 rd generation network processing systems Scalability plus flexibility - PowerPoint PPT Presentation
Citation preview

ECE 526 – Network ECE 526 – Network Processing Systems Processing Systems
DesignDesignNetwork Processor Introduction
Chapter 11,12: D. E. Comer

Ning Weng ECE 526 2
GoalGoal• Understanding the inefficiency of 1st, 2nd and 3rd
generation network processing systems─ Scalability plus flexibility
• Recognizing the necessity of new solution: 4th generation (network processor technology)
• Learning─ courage to appreciate the challenges─ skill to characterize the “real” problem─ art to propose an engineering solution
• Be aware of current network processor is a conceptual and general term
Ning Weng ECE 526 3
Recall 1Recall 1STST
• 1st generation network processing system
• Feasibility study─ Design a software router
• data rate 10Gbps• Assuming small packets (64B)• Assuming each packet need 10,000 instruction to process
─ Can Intel 80986@2007 do the job?• CPU:24Ghz• MIPs:125,000 (Million Instruction Per Second)• 1 billion transistors ….
─ Conclusion: not feasible• What is the real problem here?
Ning Weng ECE 526 4
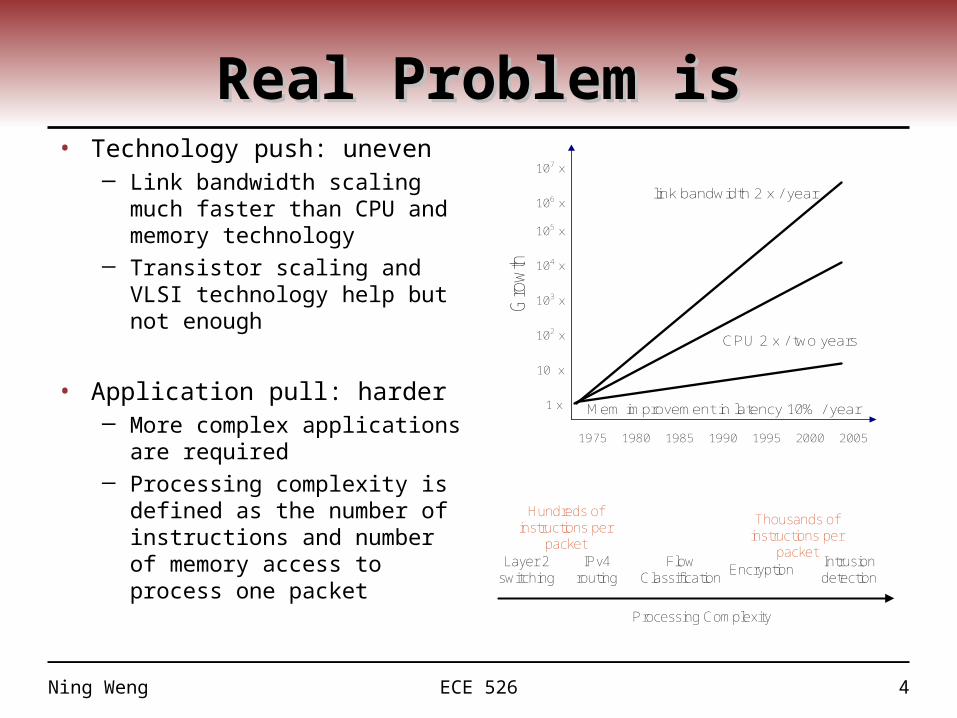
Real Problem isReal Problem is• Technology push: uneven
─ Link bandwidth scaling much faster than CPU and memory technology
─ Transistor scaling and VLSI technology help but not enough
• Application pull: harder─ More complex applications
are required ─ Processing complexity is
defined as the number of instructions and number of memory access to process one packet
105 x
104 x
103 x
102 x
10 x
1 x
106 x
107 x
link bandwidth 2 x / year
CPU 2 x / two years
1975 1980 1985 1990 1995 2000 2005
Gro
wth
Mem improvement in latency 10% / year
Processing Complexity
Hundreds of instructions per
packet
Thousands of instructions per
packetLayer 2
switchingIPv4
routingFlow
ClassificationEncryption
Intrusiondetection
5
What is the ideal platform?What is the ideal platform?
•Structured ASIC
•FPGA
•Network Processor
•Reconfigurable Co-
processors

Ning Weng ECE 526 6
22ndnd and 3 and 3rdrd Generations Generations• 2nd generation: offloading and decentralized
• 3rd generation: further offloading and using specialized devices (ASIC + embedded processors)
• Problems: losing the flexibility and very cost, why?

Ning Weng ECE 526 7
Why not ASIC?Why not ASIC?• High cost to develop
─ Network processing moderate quantity market
• Long time to market─ Network processing quickly changing services
• Difficult to simulate─ Complex protocol
• Expensive and time-consuming to change• Little reuse across products• Limited reuse across versions• No consensus on framework or supporting chips• Requires expertise
Ning Weng ECE 526 8
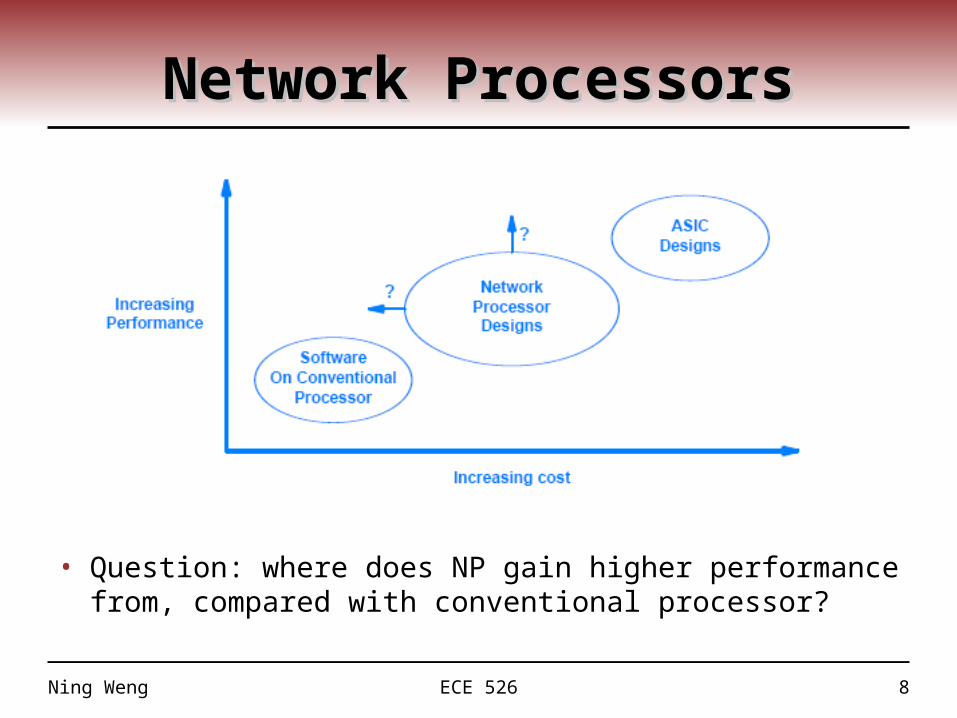
Network ProcessorsNetwork Processors
• Question: where does NP gain higher performance from, compared with conventional processor?

Ning Weng ECE 526 9
Instruction Set: minimalityInstruction Set: minimality• Not general as RISC and CISC processor
─ E.g. no floating point instructions─ Optimized for packet processing functions only
• Not specific to a protocol or part a protocol• Seek a minimal set of instruction set of
instructions sufficient to handle arbitrary protocol, ─ plus specific instructions for protocol processing
• Example : atomic operation
─ Hard problem and will cover later

Ning Weng ECE 526 10
Architecture: Architecture: multiprocessormultiprocessor
• Parallelism─ The nature of workload network processing: high parallel
• Flow-level• Queue-level• Packet-level• Protocol-level
• Pipelining─ Pipeline will help system performance at cost of longer delay─ Is this acceptable?
• System-on-chip─ Processing: RISC core─ Memory: register, cache, instruction store, scratch pad, SRAM
and SDRAM─ I/O: network /switch fabric interfaces
• Question: how hard to build and use this NPs?

Ning Weng ECE 526 11
Typical ProcessingTypical Processing

12
Case Study: IPv4 Packet Case Study: IPv4 Packet ForwardingForwarding
•a •a •b •a •e
•b•b •c •d•d
•000
•001
•002
•003 •FFE
•FFF
•0 •1 •F •0 •1 •F
•0 •1 •F
•Root
•Memory access 1
•Memory access 2
•Memory access 5
•Memory access 6
•a•b•c•d•e
•Prefix (hex : binary)•: 0*•002 : *•002F : *•FFE : 000*•FFF : *
•From (0) •To (0)
•From (1) •To (1)
•Lookup•IPRoute
•2-port router
(2 Gbps)
•IP Lookup: •longest prefix match•(trie lookup algorithm)
•Xilinx Virtex-II Pro FPGA (2VP30)

13
Multiprocessor for Header Multiprocessor for Header ProcessingProcessing
•Pack
et
Rece
pti
on
•Pack
et
Tra
nsm
issi
on
•Lookup-1 •Transmit•Verify
•Lookup-1 •Transmit•Verify
•Lookup-1 •Transmit•Verify
•FSL
•BRAM •BRAM•RS232•Timer
•LEDs
•Lookup-2
•Lookup-2
•Lookup-2
•Lookup-1 •Transmit•Verify •Lookup-2
•BRAM •BRAM
•OPB
•FIFO queues
Ning Weng ECE 526 14
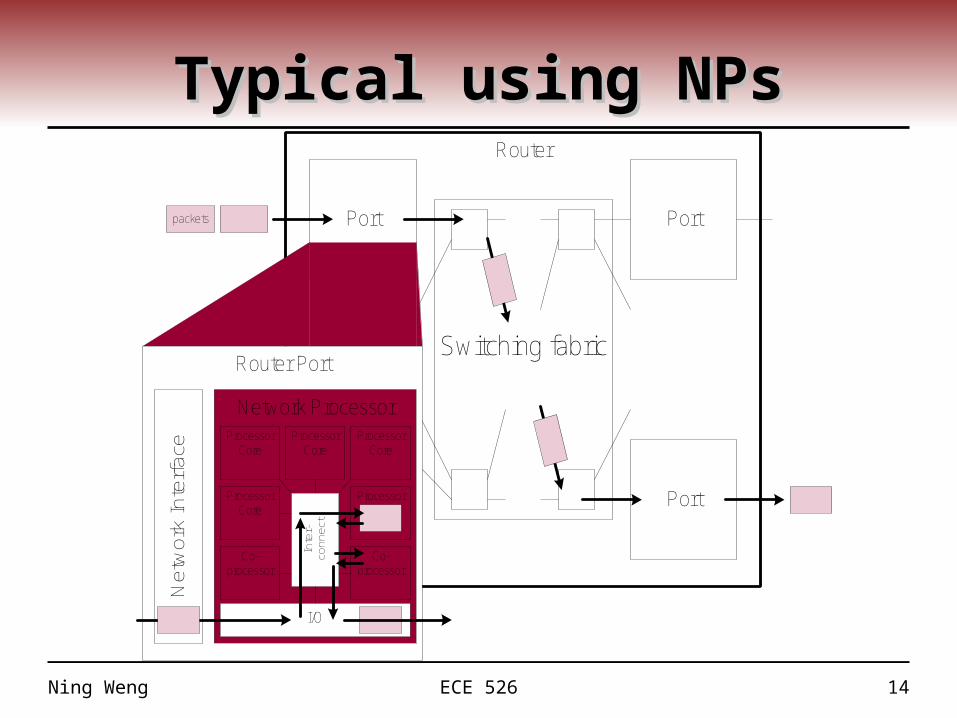
Typical using NPsTypical using NPsRouter
Switching fabric
PortPort
Port
Port
Router Port
Network Processor
Ne
two
rk I
nte
rfa
ce
I/O
packets
Processor Core
Processor Core
Processor Core
Co-processor
Co-processor
Processor Core
Processor Core
Inte
r-co
nn
ect

Ning Weng ECE 526 15
System Implementation System Implementation SpaceSpace

Ning Weng ECE 526 16
Memory ArchitectureMemory Architecture• Memory access bottleneck• Memory is area consuming
─ Limited memory-on-chip─ Limited bandwidth to off-chip
memory: pin and package cost
─ Off-chip memory access is slow: 100 cycles
• Possible solutions─ Profiling application memory
access pattern─ Propose heterogeneous
memory architecture─ Memory aware mapping─ Transactional memory
(project topic)
Ning Weng ECE 526 17
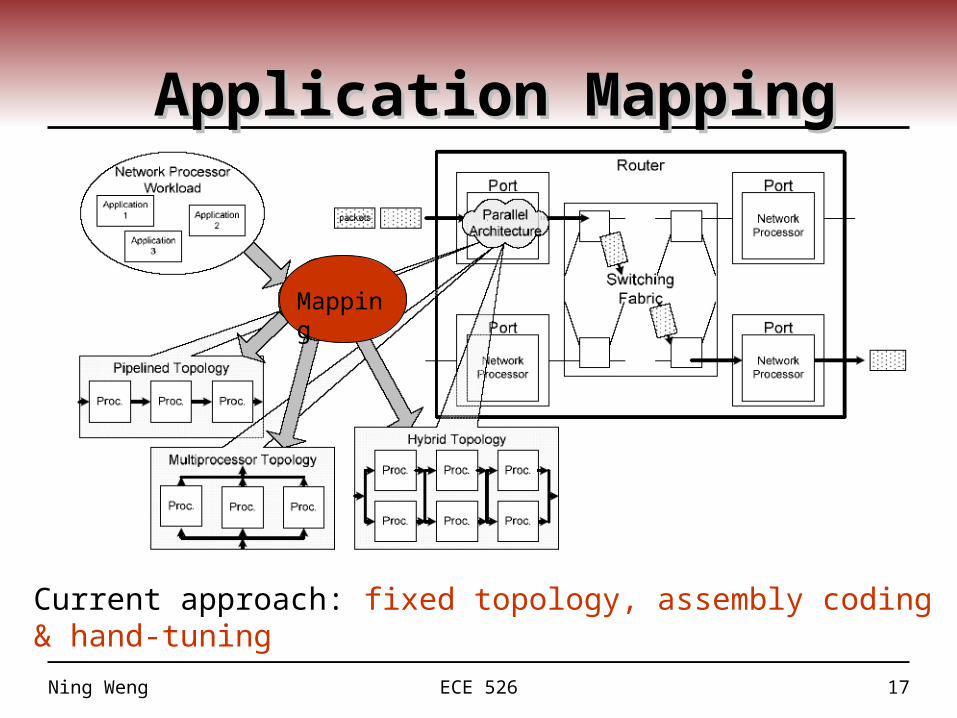
Application MappingApplication Mapping
Current approach: fixed topology, assembly coding & hand-tuning
Mapping

18
Basic Steps for MappingBasic Steps for Mapping
•Application description
•High-level optimizations
•Task graph •(platform specific)
•Architecture configuration
•HW / SW partitioning•Task allocation
•Data layout•Communication
assignment
•Compilation / Synthesis
•Profile•PE•FPGA
•PE•FPGA
•PE •FPGA
•PE •FPGA
•MEM
•MEM •MEM
•MEM
•MEM
•From (0) •To (0)
•From (1) •To (1)
•Lookup•IPRoute

Ning Weng ECE 526 19
SummarySummary• Network Processor
─ Special purpose, programmable hardware device─ Optimized for network processing─ Building blocks of network processing systems─ Fundamental ideas
• Flexibility through programmability• Scalability with parallelism and pipelining
• Here, NP is a concept─ We will learn example of network processor soon

Ning Weng ECE 526 20
For Next Class & For Next Class & AnnouncementAnnouncement
• Read Comer: chapter 13 and 14• Lab 1 total grade reduce to 82• HW 1 due Wed.• Project topic will be announced after Wed.

















![Ece v Digital Signal Processing [10ec52] Notes](https://img.pdfslide.net/doc/110x75/552bbbc74a7959dc7c8b4588/ece-v-digital-signal-processing-10ec52-notes.jpg)
![Ece Vii Image Processing [06ec756] Solution](https://img.pdfslide.net/doc/110x75/552bbb4a5503464c158b45a9/ece-vii-image-processing-06ec756-solution.jpg)



![ECE-V-DIGITAL SIGNAL PROCESSING [10EC52]-NOTES.pdf](https://img.pdfslide.net/doc/110x75/56d6cbe71a28ab30169caa7d/ece-v-digital-signal-processing-10ec52-notespdf.jpg)






