Embed Size (px)
Citation preview

EECE476: Computer Architecture
Lecture 18: PipeliningControl Hazards
Chapter 6.6
The University ofBritish Columbia EECE 476 © 2005 Guy Lemieux

2
Administratia• Project
– Phase 1 now online– Phases 2, 3 coming soon…
• Partner signup deadline: OCTOBER 21– MUST work in pairs
• EMAIL ME IMMEDIATELY IF YOU’RE STILL ALONE– MUST email to project TA: 2 names, stud #s, emails– Late penalty: 5% of final grade
• Phase 1: single-cycle CPU– Suggest you finish by November 1
• Phase 2: convert to 5-stage pipelined CPU with FDU & HDU– Do phase 1 first !!!!– While doing phase 1, keep in mind that you’ll be adding pipelining later

3
Review: Hazards• 3 Types of Hazards
– Structural Hazard– Data Hazard– Control Hazard
• Structural – functional unit is busy– Eg, multicycle multiplier which is not fully pipelined
• Data Hazards– Cause: Dependency between instructions– 3 Types of Data Hazards (RAW, WAR, WAW)
• Control Hazards– Today!

4
Review: Dependencies
• Dependency definition– Two instructions
• Executed closely together in time• Share linkage by using a common register
– Desired outcome is clear• Defined by ORIGINAL PROGRAM ORDER
• Data hazard problem– Hardware sometimes overlaps or reorders instructions– Potential violation of dependency
• Solution– Original dependency must be preserved!– Hardware must obey ORIGINAL PROGRAM ORDER semantics

5
Review: Data Hazards• Three kinds of data hazards: RAW, WAR, WAW
– In each case below, instruction pairs form a dependency– Consider what may happen if the two instructions are re-ordered
– Read after Write (aka true dependence)ADD $s0, $s1,$s2 <- writes $s0ADD $s3,$s0,$s0 <- reads $s0
– Write after Read (aka false dependence)• Doesn’t occur in our simple MIPS pipelineADD $s0,$s1,$s2 <- reads $s1ADD $s1,$s2,$s2 <- writes $s1
– Write after Write (aka output dependence)• Doesn’t occur in our simple MIPS pipelineADD $s0,$s1,$s2 <- writes $s0ADD $s0,$s3,$s4 <- writes $s0
• WAR, WAW occur in more complex CPUs with multiple pipelines

6
Review: RAW Hazards
• Main data hazard in our pipeline– Read-After-Write (RAW)
• Problem– Write to register in first instruction– Read register in subsequent instruction– Read gets stale value from RegFile due to pipelining
• Possible solutions– Forwarding, stalls, compiler (NOPs or reordering code)
• Forwarding doesn’t always work– Load-use delay– Result after “M” stage is too late, must stall

7
Control Hazards
• Control hazards arize due to changes in control flow• This is a software thing• Not the same as the “control unit” in hardware
• Control flow
– Normal software execution is PC+4 (straight-line)
– Only branches, jumps change the execution path• We say the “flow of control” has changed
– Often, path taken depends on outcome of operation (eg, beq)• Data-dependent• Hard to predict in advance

8
Pipelined Branching Logic, “beq”

9
Control Hazards
• Consider “beq” instructionIf (Rs – Rt) == 0 then
PC (PC+4) + SgnExt(Imm16)
ElsePC (PC+4)
• (Rs – Rt) computed by ALU, available after “X”– ALU generates “Zero” output– “Zero” decides next PC
• Controls PCSrc mux: PC+4 or PC+4+SgnExt(Imm16)
– “Zero” computed in X stage

10
Branching Example
• Control hazard example due to branch• Consider the machine code
40 BEQ $1, $3, 744 AND $12,$2,$548 OR $13, $6,$252 ADD $14, $2,$2…72 LW $4,50($7)
• Let’s see the pipeline details
BEQ target is ahead by7*4=28 bytes,
44+28=72

11
Branching Details, Cycle 1BEQ $1,$3, 7
4044

12
Branching Details, Cycle 2BEQ $1,$3, 7
[$1]
[$3]
7
44
AND $12,$2,$5
4448

13
Branching Details, Cycle 3AND $12,$2,$5
[$2]
[$5]
?
BEQ $1,$3, 7
[$1]
[$3]
7*4
48
OR $13,$6,$2
48 44+2852

14
Branching Details, Cycle 4aOR $13,$6,$2
[$2]
[$5]
?
AND $12,$2,$5
[$2]
[$5]
?
52
ADD $14,$2,$2
52 48+?
BEQ $1,$3, 7
7256

15
Branching Details, Cycle 4bOR $13,$6,$2
[$2]
[$5]
?
AND $12,$2,$5
[$2]
[$5]
?
52
ADD $14,$2,$2
52 48+?
BEQ $1,$3, 7
72
72
56

16
Branching Details, Cycle 5ADD $14,$2,$2
[$2]
[$2]
?
OR $13,$6,$2
[$6]
[$2]
?
56
LW $4,50($7)
72 ?
AND $12,$2,$5
?
76
76
BEQ$1,$3,7(nothingleft todo here)

17
BEQ Executes in “M” Stage
• PCSrc generated in “M” stage– Like “lw”, “beq” outcome not available until “M”
• Consequence?– 3 instructions follow “BEQ” into the pipeline– Instructions from PC+4, PC+8, PC+12
• What if we take the branch?– 3 instructions in pipeline must NOT be executed!– Control hazard arises!– How to prevent their execution?

18
Control Hazard Solution 1: Stall
• Stall after every branch/jump– Stop fetching new instructions– Let branch/jump advance in pipeline
• Wait for branch/jump outcome to be decided– After branch/jump decided…– ….fetch from final target PC– Resume normal pipelining
• Performance impact– Always wastes 3 cycles
• Problem– We can’t recognize the branch instruction until it reaches D stage– Already fetched PC+4 in I stage– Must now flush instruction in I stage

19
Control Hazard Solution 2: Nullify
• Branch result is in “M” stage– Next 3 instructions (AND,OR,ADD) after branch are fetched– Only partially executed– They alter state of machine (eg, RegFile or DataMem contents)
• State altered only if they reach M stage or W stage– If branch taken
• We can squash, cancel or nullify them before they reach M or W
• How to nullify?– Change control signals to “NOP” instruction (usually all zeros)– Extra control logic!
• Note– 4th instruction fetched (LW) is correct and is always executed

20
Nullify Performance Impact?
• If branch is taken– We must nullify 3 instructions– Wasted CPU effort (3 CPU cycles!)
• If branch is not taken– We did useful work
• What is frequency of taken vs not taken ?– About 80-90% backward branches are taken (loops)– About 50% of forward branches are taken (if/else statements)
• Taken is most frequent, so we often nullify !!!– Only a small performance gain

21
Control Hazard Solution 3:Branch Delay Slots
• Basic idea– Be optimistic and always execute – No stalls, no nullify
• Propose New ISA Rule– Always execute 3 instructions after branch– Here, we say branch has “3 Branch Delay Slots”
• Compiler places useful instructions after a branch– Utilizes “wasted” CPU cycles– Turns “disadvantage” into a “feature” ??
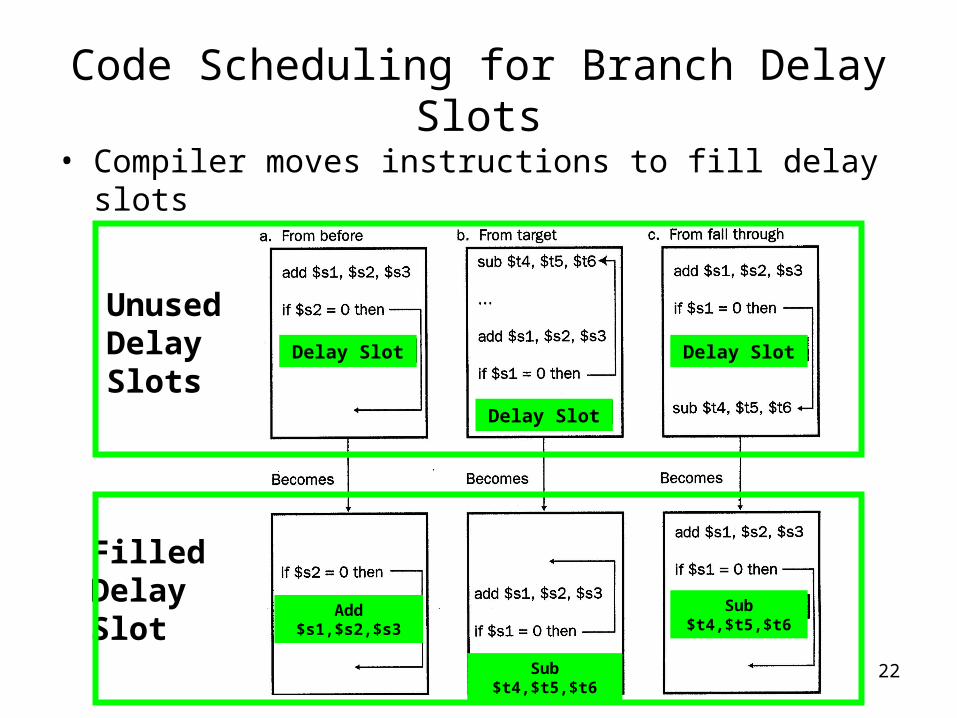
22
Code Scheduling for Branch Delay Slots
• Compiler moves instructions to fill delay slots
UnusedDelaySlots
FilledDelaySlot
Delay Slot
Delay Slot
Delay Slot
Sub $t4,$t5,$t6
Sub $t4,$t5,$t6
Add $s1,$s2,$s3

23
Code Scheduling for Branch Delay Slots
• Compiler checks dependencies to verify it is safe to Compiler checks dependencies to verify it is safe to move instructionsmove instructions
UnusedDelaySlots
FilledDelaySlot
Delay Slot
Delay Slot
Delay Slot
Sub $t4,$t5,$t6
Sub $t4,$t5,$t6
Add $s1,$s2,$s3

24
Compiler Checks
• When we move an instruction– Check move is valid – involves checking
dependencies– Reordering code is tricky subject
• Eg, Consider moving instruction forward in code/time from location A to B– Destination register must be ok to move
• Check no instructions between A and B use the destination register
– Source register(s) must be ok to move• Check no instructions between A and B change the source
registers

25
Branch Delay SlotPerformance Impact?
Cool idea, but…• Benefit
– Compiler can put 3 useful instructions after each branch
• Compiler difficulty– Only ~50% of 1st delay slots filled with “useful” instruction– Remaining delay slots are even harder!
• Another problem…– A pipeline detail is now exposed to software
• ISA Rule is now tied to current pipeline organization
– Difficult to change pipeline organization in future• Deeper pipeline will need more branch delay slots• If we add more branch delay slots, old software will be incompatible

26
Final Word on Branch Delay Slots
• Delay slots once touted as a “feature”– But are now heavily discouraged
• MIPS ISA rules (older design)– Delay slots defined in ISA
• 1 branch delay slot• 1 jump delay slot
– Compiler must insert “NOP” or independent instruction
• NIOS-II ISA rules (more recent design)– 0 branch delay slots– 0 jump delay slots– Hardware choice: either stall or nullify to handle control hazards

27
Directly Reducing Penaltyof Control Hazards
• Control hazards demand solutions:– Stalling– Nullify– Branch delay slots– All of these negatively impact performance (in various ways)
• Alternative– Can we directly reduce the negative impact of control hazards?
• Yes!– Execute branch/jump instruction earlier in pipeline– Outcome known sooner– Fetch fewer instructions enter pipeline after branch (before outcome
known)– For BEQ, we must detect “equals” earlier





























