Embed Size (px)
Citation preview

EECS 470Superscalar Architectures and the
Pentium 4Lecture 12

Optimizing CPU Performance
• Golden Rule: tCPU = Ninst*CPI*tCLK
• Given this, what are our options– Reduce the number of instructions executed– Reduce the cycles to execute an instruction– Reduce the clock period
• Our next focus: Further reducing CPI– Approach: Superscalar execution– Capable of initiating multiple instructions per cycle– Possible to implement for in-order or out-of-order
pipelines
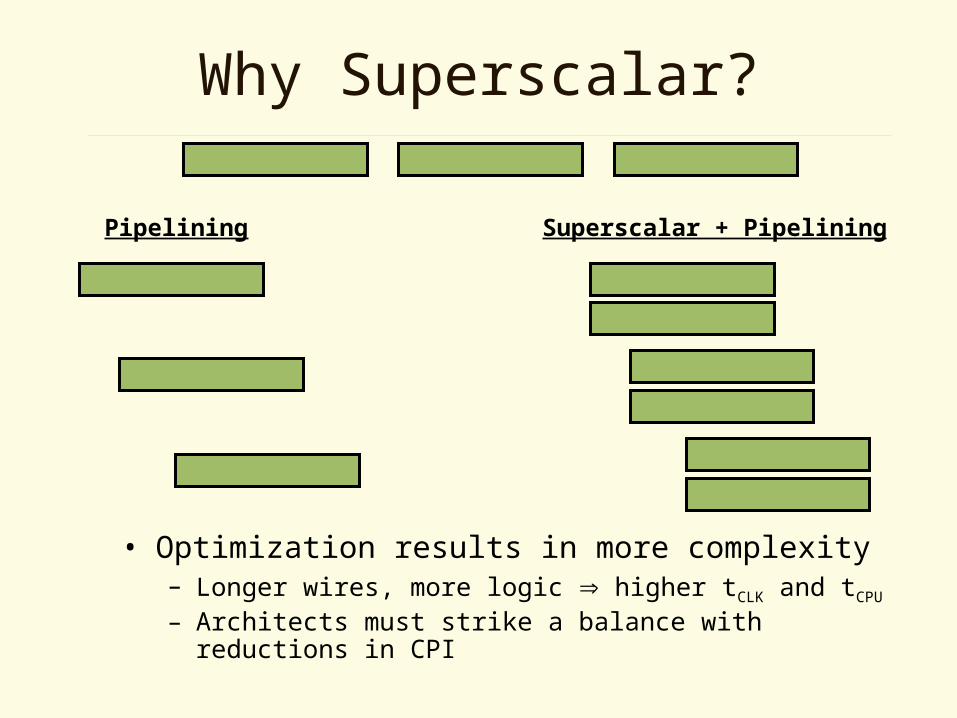
Why Superscalar?
Pipelining Superscalar + Pipelining
• Optimization results in more complexity– Longer wires, more logic higher tCLK and tCPU
– Architects must strike a balance with reductions in CPI

Implications of Superscalar Execution
• Instruction fetch?– Taken branches, multiple branches, partial cache lines
• Instruction decode?– Simple for fixed length ISA, much harder for variable length
• Renaming?– Multi-port RT, inter-inst dependencies must be recognized
• Dynamic Scheduling?– Requires multiple results buses, smarter selection logic
• Execution?– Multiple functional units, multiple result buses
• Commit?– Multiple ROB/ARF ports, dependencies must be
recognized

P4 Overview
• Latest iA32 processor from Intel– Equipped with the full set of iA32
SIMD operations– First flagship architecture since
the P6 microarchitecture– Pentium 4 ISA = Pentium III ISA
+ SSE2– SSE2 (Streaming SIMD
Extensions 2) provides 128-bit SIMD integer and floating point operations + prefetch
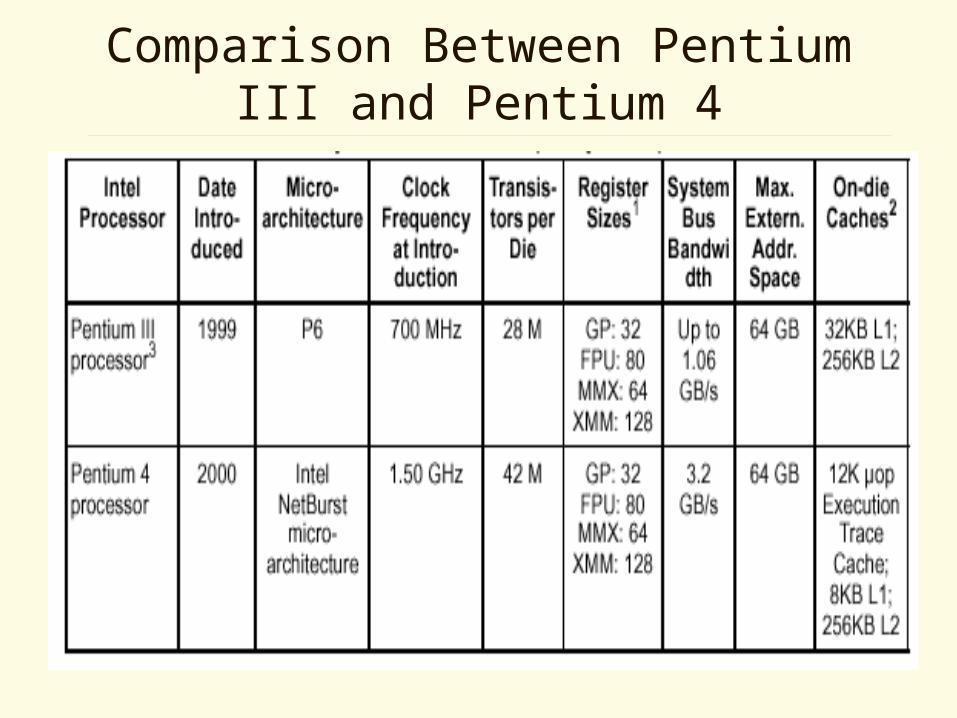
Comparison Between Pentium III and Pentium 4
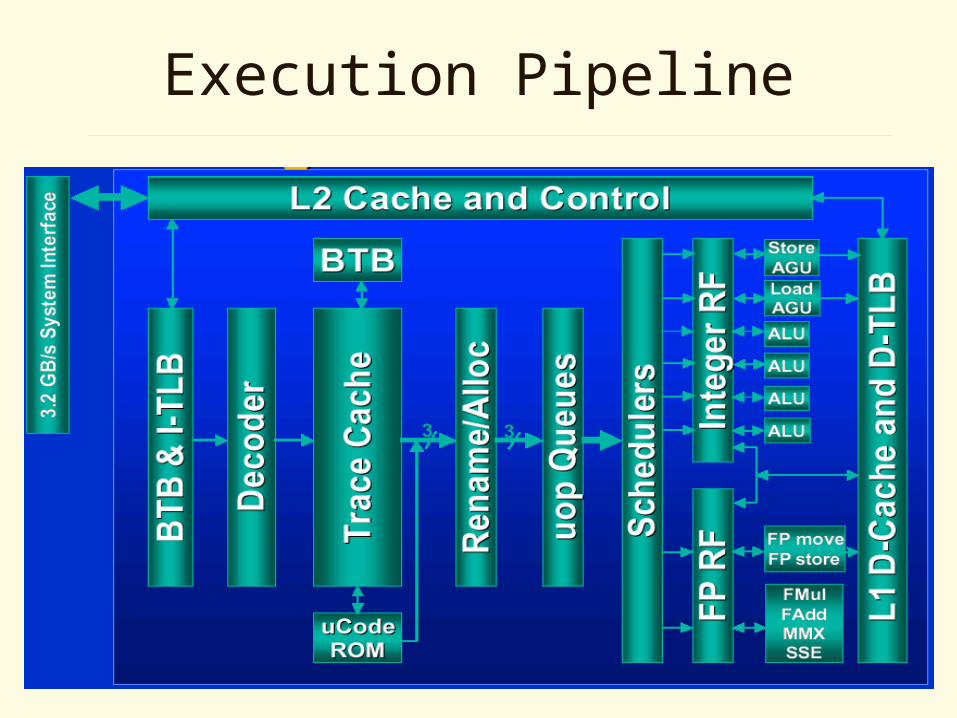
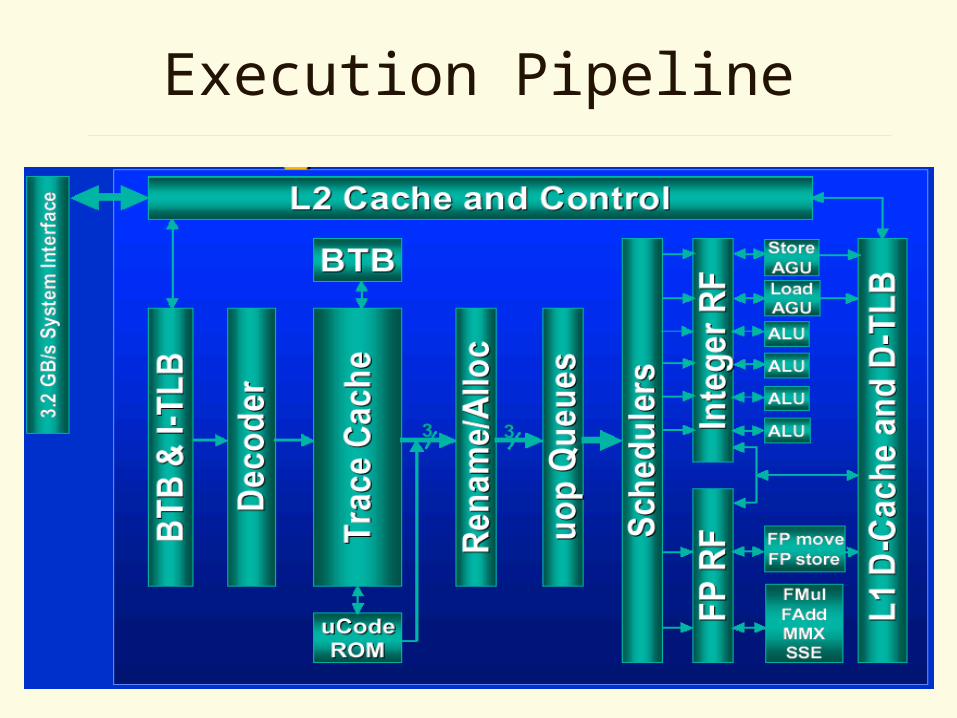
Execution Pipeline

Front End
• Predicts branches
• Fetches/decodes code into trace cache
• Generates ops for complex instructions
• Prefetches instructions that are likely to be executed

Branch Prediction
• Dynamically predict the direction and target of branches based on PC using BTB
• If no dynamic prediction available, statically predict– Taken for backwards looping branches– Not taken for forward branches– Implemented at decode
• Traces built across (predicted) taken branches to avoid taken branch penalties
• Also includes a 16-entry return address stack predictor

Decoder
• Single decoder available– Operates at a maximum of 1 instruction per cycle
• Receives instructions from L2 cache 64 bits at a time
• Some complex instructions must enlist the micro-ROM– Used for very complex iA32 instructions (> 4 ops)– After the microcode ROM finishes, the front-end
resumes fetching ops from the Trace Cache
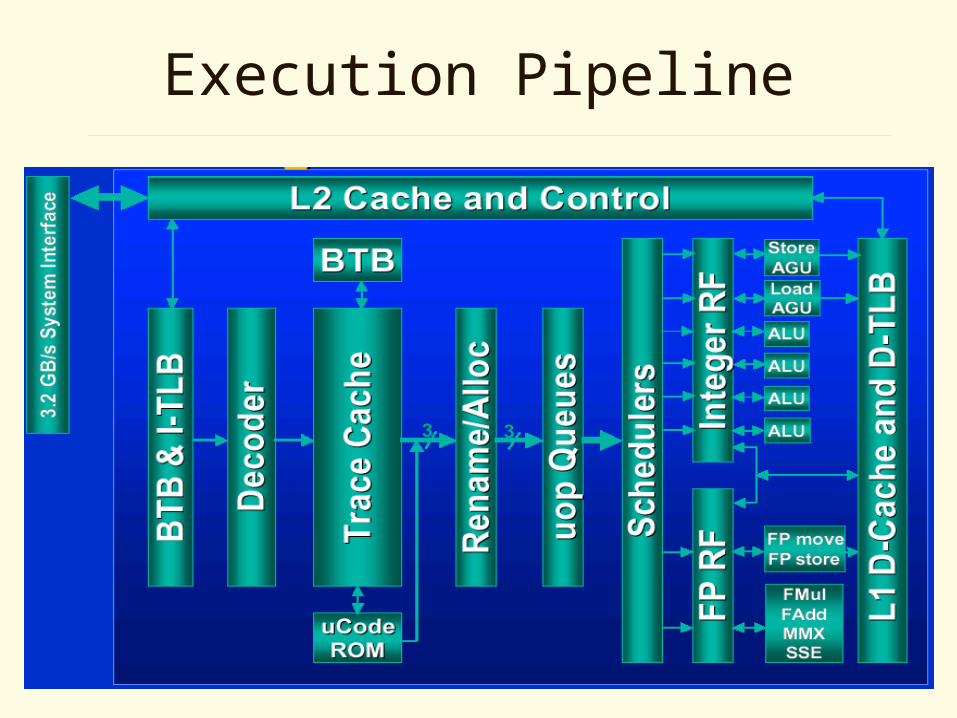
Execution Pipeline

Trace Cache
• Primary instruction cache in P4 architecture– Stores 12k decoded ops
• On a miss, instructions are fetched from L2
• Trace predictor connects traces
• Trace cache removes– Decode latency after mispredictions
– Decode power for all pre-decoded instructions

Branch Hints
• P4 software can provide hints to branch prediction and trace cache– Specify the likely direction of a branch– Implemented with conditional branch prefixes– Used for decode-stage predictions and trace
building
Execution Pipeline

Execution Pipeline

Execution
• 126 ops can in flight at once– Up to 48 loads / 24 stores
• Can dispatch up to 6 ops per cycle
• 2x trace cache and retirement op bandwidth– Provides additional B/W for scheduling
mispeculation

Execution Units
Register Renaming

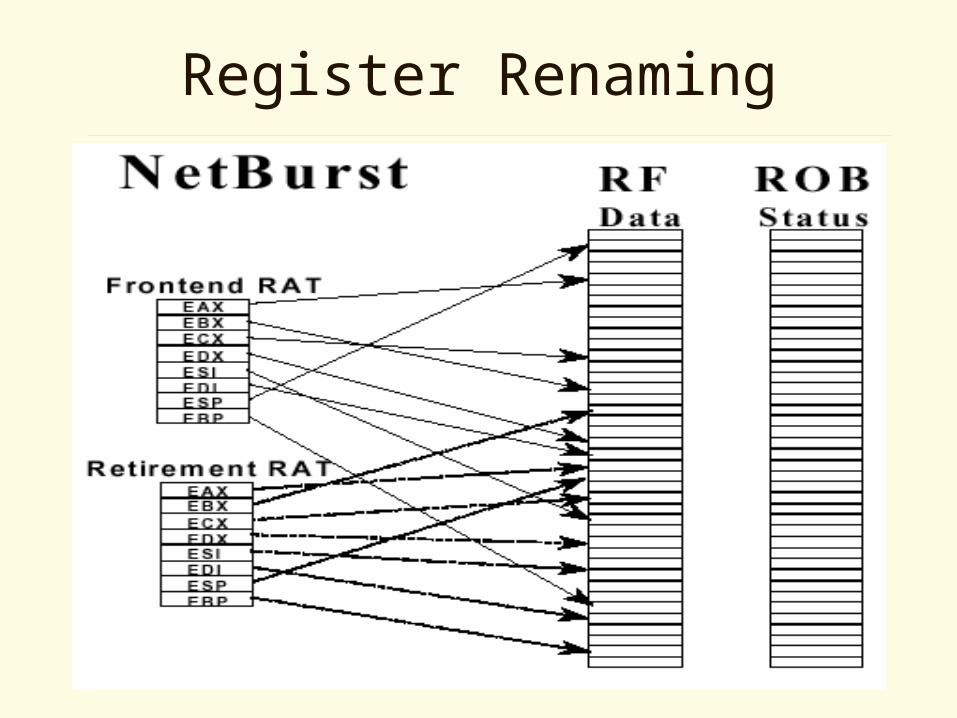
Register Renaming
• 8-entry architectural register file
• 128-entry physical register file
• 2 RAT (Front-end RAT and Retirement RAT)
• Retirement RAT eliminates register writes into ARF

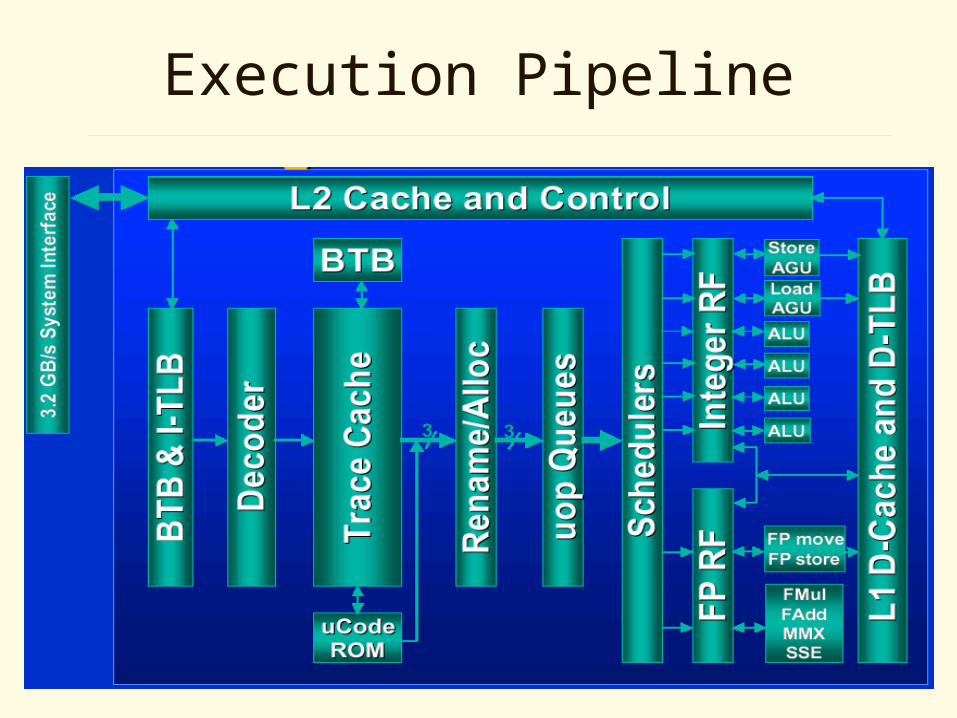
Store and Load Scheduling
• Out of order store and load operations
Stores are always in program order
• 48 loads and 24 stores could be in flight
• Store/load buffers are allocated at the allocation stage– Total 24 store buffers and 48 load buffers
Execution Pipeline

Retirement
• Can retire 3 ops per cycle
• Implements precise exceptions
• Reorder buffer used to organize completed ops
• Also keeps track of branches and sends updated branch information to the BTB
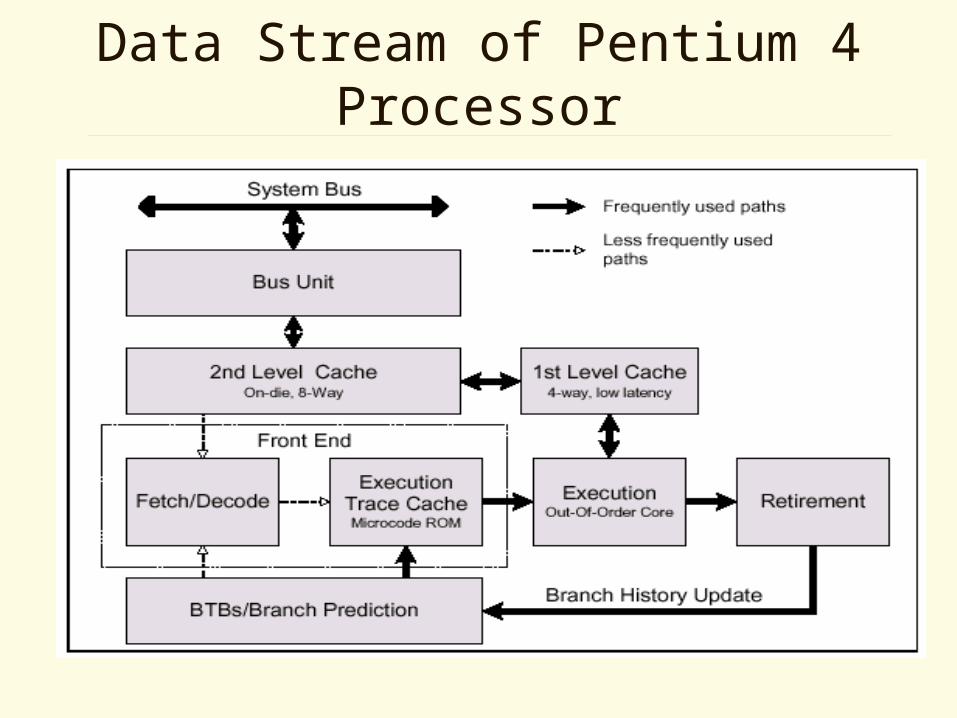
Data Stream of Pentium 4 Processor

On-chip Caches
• L1 instruction cache (Trace Cache)• L1 data cache• L2 unified cache
– All caches use a pseudo-LRU replacement algorithm
• Parameters:

L1 Data Cache
• Non-blocking– Support up to 4 outstanding load misses
• Load latency– 2-clock for integer – 6-clock for floating-point
• 1 Load and 1 Store per clock• Load speculation
– Assume the access will hit the cache– “Replay” the dependent instructions when miss
detected

L2 Cache
• Non-blocking• Load latency
– Net load access latency of 7 cycles
• Bandwidth– 1 load and 1 store in one cycle– New cache operations may begin every 2
cycles– 256-bit wide bus between L1 and L2– 48Gbytes per second @ 1.5GHz

L2 Cache Data Prefetcher
• Hardware prefetcher monitors the reference patterns
• Bring cache lines automatically
• Attempts to fetch 256 bytes ahead of current access
• Prefetch for up to 8 simultaneous independent streams

System Bus
Deliver data with 3.2Gbytes/S
• 64-bit wide bus
• Four data phase per clock cycle (quad pumped)
• 100MHz clocked system bus
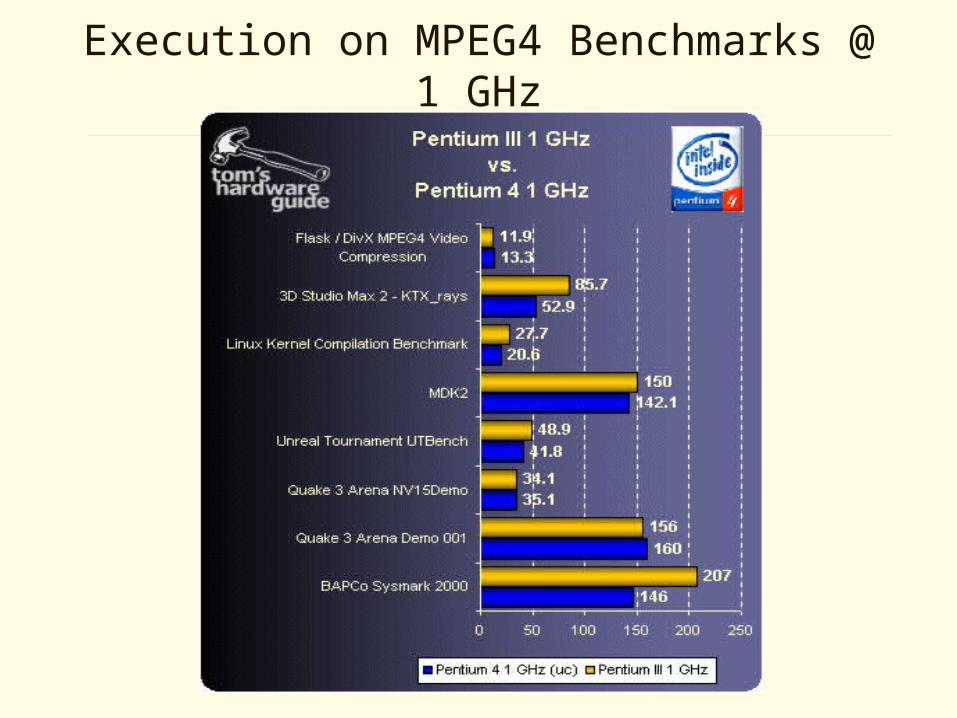
Execution on MPEG4 Benchmarks @ 1 GHz
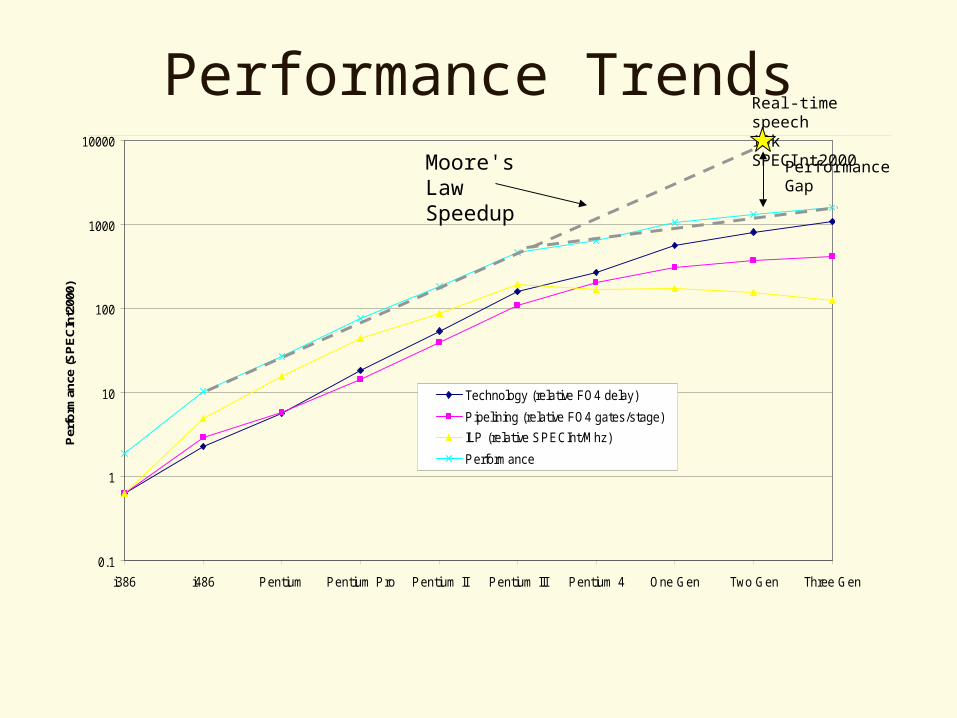
Performance Trends
0.1
1
10
100
1000
10000
i386 i486 Pentium Pentium Pro Pentium II Pentium III Pentium 4 One Gen Two Gen Three Gen
Per
form
ance
(S
PE
CIn
t200
0)
Technology (relative FO4 delay)
Pipelining (relative FO4 gates/stage)
ILP (relative SPECInt/Mhz)
Performance
Moore's Law Speedup
PerformanceGap
Real-time speech10k SPECInt2000
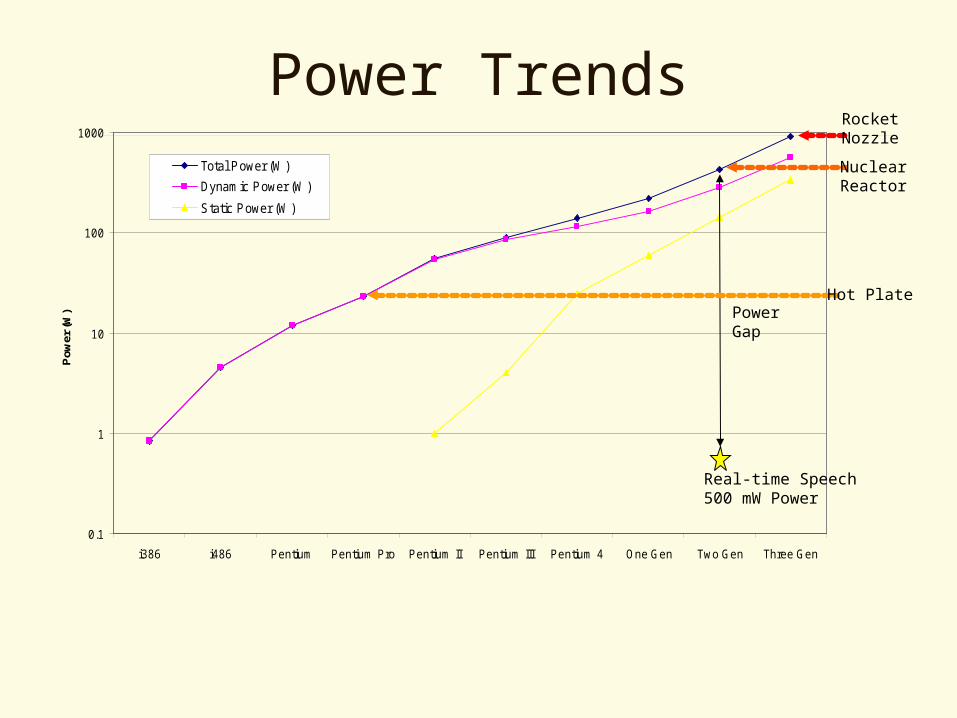
Power Trends
0.1
1
10
100
1000
i386 i486 Pentium Pentium Pro Pentium II Pentium III Pentium 4 One Gen Two Gen Three Gen
Pow
er (W
)
Total Power (W)
Dynamic Power (W)
Static Power (W)
Real-time Speech500 mW Power
Power GapHot Plate
NuclearReactor
RocketNozzle

![Designingenergyefficient’ microprocessor:Howtofight ... Memory ... [MHz] 8086 80286 386DX 486DX 486DX4 Pentium Pentium Pro Pentium II Pentium MMX Pentium III ... Delay buffers are](https://img.pdfslide.net/doc/110x75/5ac1a5637f8b9ac6688d9ef1/designingenergyecient-microprocessorhowtoght-memory-mhz-8086.jpg)



























