Embed Size (px)
Citation preview

EENG449b/SavvidesLec 17.1
4/1/04
April 1, 2004
Prof. Andreas Savvides
Spring 2004
http://www.eng.yale.edu/courses/eeng449bG
EENG 449bG/CPSC 439bG Computer Systems
Lecture 17
Memory Hierachy Design Part I

EENG449b/SavvidesLec 17.2
4/1/04
Announcements
• HWK 2 is out:– Text problems 3.6, 4.2, 4.13, 5.3, 5.4, 5.23– Due date April 20th
• Midterm 2 on April 22• 2 sets of final project presentations
– Set 1 – Friday April 23– Set 2 – Tuesday April 27
• Final project reports due May 4, midnight
EENG449b/SavvidesLec 17.3
4/1/04
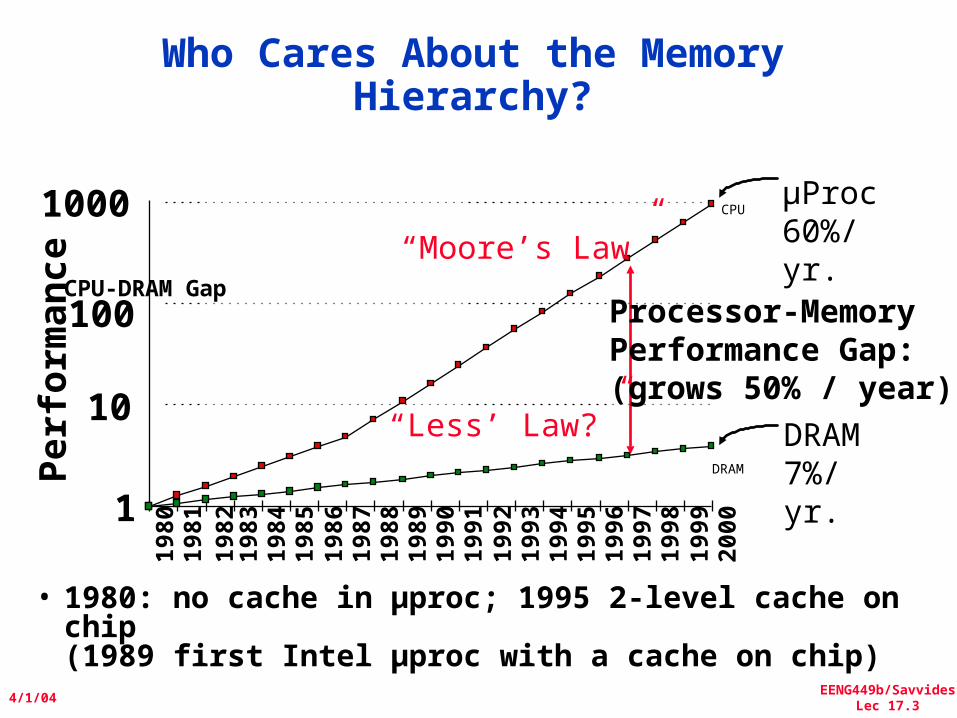
CPU-DRAM Gap
• 1980: no cache in µproc; 1995 2-level cache on chip(1989 first Intel µproc with a cache on chip)
Who Cares About the Memory Hierarchy?
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
“Moore’s Law”
“Less’ Law?”

EENG449b/SavvidesLec 17.4
4/1/04
Review of Caches
• Cache is the name given to the first level of the memory hierarchy encountered one the address leaves the CPU
– Cache hit / cache miss when data is found / not found
– Block – a fixed size collection of data containing the requested word
– Spatial / temporal localities– Latency – time to retrieve the first word in the
block– Bandwidth – time to retrieve the rest of the block– Address space is broken into fixed-size blocks
called pages– Page fault – when CPU references something that
is not on cache or main memory

EENG449b/SavvidesLec 17.5
4/1/04
Generations of Microprocessors
• Time of a full cache miss in instructions executed:
1st Alpha: 340 ns/5.0 ns = 68 clks x 2 or 136
2nd Alpha: 266 ns/3.3 ns = 80 clks x 4 or 320
3rd Alpha: 180 ns/1.7 ns =108 clks x 6 or 648
• 1/2X latency x 3X clock rate x 3X Instr/clock 5X

EENG449b/SavvidesLec 17.6
4/1/04
Processor-Memory Performance Gap “Tax”
Processor % Area %Transistors
(cost) (power)• Alpha 21164 37% 77%• StrongArm SA110 61% 94%• Pentium Pro 64% 88%
– 2 dies per package: Proc/I$/D$ + L2$
• Caches have no “inherent value”, only try to close performance gap
EENG449b/SavvidesLec 17.7
4/1/04
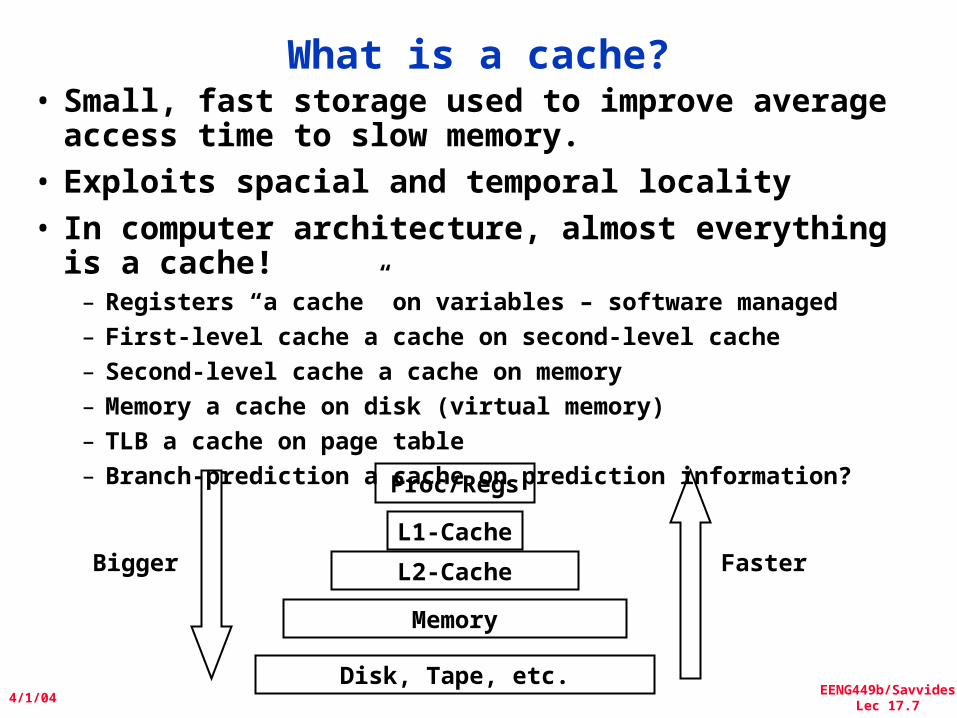
What is a cache?• Small, fast storage used to improve average
access time to slow memory.• Exploits spacial and temporal locality• In computer architecture, almost everything is a
cache!– Registers “a cache” on variables – software managed– First-level cache a cache on second-level cache– Second-level cache a cache on memory– Memory a cache on disk (virtual memory)– TLB a cache on page table– Branch-prediction a cache on prediction information?Proc/Regs
L1-Cache
L2-Cache
Memory
Disk, Tape, etc.
Bigger Faster

EENG449b/SavvidesLec 17.8
4/1/04
• Miss-oriented Approach to Memory Access:
– CPIExecution includes ALU and Memory instructions
CycleTimeyMissPenaltMissRateInst
MemAccessExecution
CPIICCPUtime
CycleTimeyMissPenaltInst
MemMissesExecution
CPIICCPUtime
Review: Cache performance
• Separating out Memory component entirely
– AMAT = Average Memory Access Time
– CPIALUOps does not include memory instructionsCycleTimeAMAT
Inst
MemAccessCPI
Inst
AluOpsICCPUtime
AluOps
yMissPenaltMissRateHitTimeAMAT DataDataData
InstInstInst
yMissPenaltMissRateHitTime
yMissPenaltMissRateHitTime

EENG449b/SavvidesLec 17.9
4/1/04
Impact on Performance•Suppose a processor executes at
– Clock Rate = 200 MHz (5 ns per cycle), Ideal (no misses) CPI = 1.1
– 50% arith/logic, 30% ld/st, 20% control
•Suppose that 10% of memory operations get 50 cycle miss penalty
•Suppose that 1% of instructions get same miss penalty
•CPI = ideal CPI + average stalls per instruction=1.1(cycles/ins) +[ 0.30 (DataMops/ins)
x 0.10 (miss/DataMop) x 50 (cycle/miss)] +
[ 1 (InstMop/ins) x 0.01 (miss/InstMop) x 50
(cycle/miss)] = (1.1 + 1.5 + .5) cycle/ins = 3.1
•58% of the time the proc is stalled waiting for memory!

EENG449b/SavvidesLec 17.10
4/1/04
Traditional Four Questions for Memory Hierarchy Designers
• Q1: Where can a block be placed in the upper level? (Blockplacement)
– Fully Associative, Set Associative, Direct Mapped
• Q2: How is a block found if it is in the upper level?(Blockidentification)
– Tag/Block
• Q3: Which block should be replaced on a miss? (Blockreplacement)
– Random, LRU
• Q4: What happens on a write? (Writestrategy)
– Write Back or Write Through (with Write Buffer)

EENG449b/SavvidesLec 17.11
4/1/04
Q1: Where can a Block Be Placed in a Cache?

EENG449b/SavvidesLec 17.12
4/1/04
Set Associatively
• Direct mapped = one-way set associative
• Fully associative = set associative with 1 set
• Most popular cache configurations in today’s processors
– Direct mapped, 2-way set associative, 4-way set associative
EENG449b/SavvidesLec 17.13
4/1/04
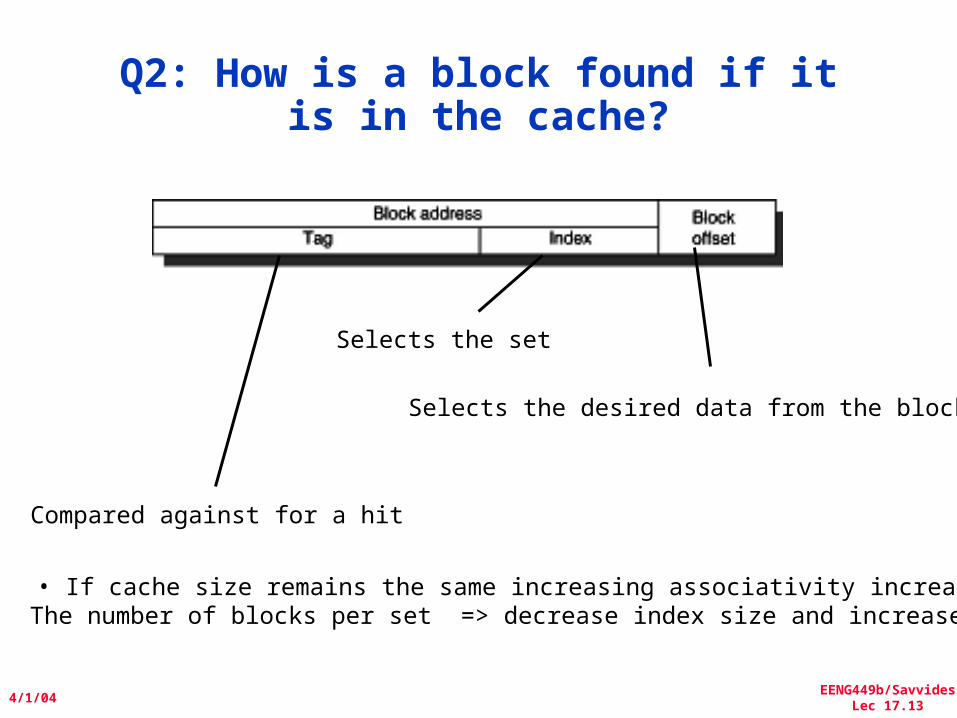
Q2: How is a block found if it is in the cache?
Selects the desired data from the block
Selects the set
Compared against for a hit
• If cache size remains the same increasing associativity increases The number of blocks per set => decrease index size and increase tag

EENG449b/SavvidesLec 17.14
4/1/04
Q3: Which Block Should be Replaced on a Cache Miss?
• Directly mapped cache– No choice – a single block is checked for a hit. If
there is a miss, data is fetched into that block
• Fully associative and set associative – Random– Least Recently Used(LRU) – locality principles– First in, First Out(FIFO) - Approximates LRU

EENG449b/SavvidesLec 17.15
4/1/04
Q4: What Happens on a Write?
• Cache accesses dominated by reads• E.g on MIPS 10% stores and 37% loads = 21%
of cache traffic is writes• Writes are much slower than reads
– Block is read from cache at the same time a block is read and compared
» If the write is a hit the block is passed to the CPU – Writing cannot begin unless the address is a hit
• Write through – information is written to both the cache and the lower-level memory
• Write back – information only written to cache. Written to memory only on block replacement
EENG449b/SavvidesLec 17.16
4/1/04
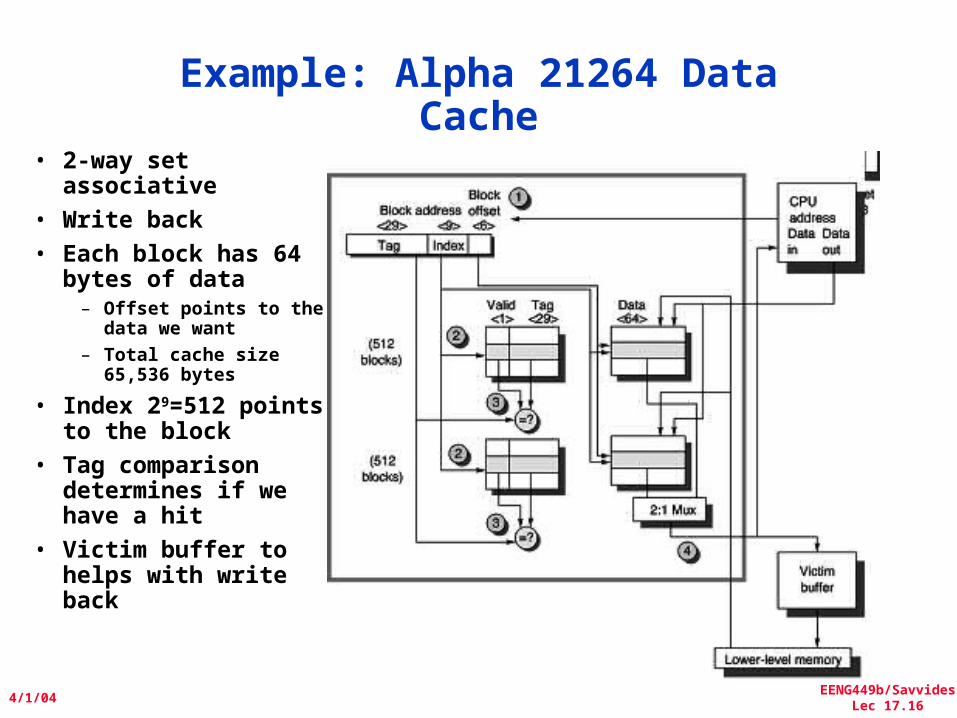
Example: Alpha 21264 Data Cache
• 2-way set associative
• Write back• Each block has 64
bytes of data– Offset points to the
data we want– Total cache size
65,536 bytes
• Index 29=512 points to the block
• Tag comparison determines if we have a hit
• Victim buffer to helps with write back

EENG449b/SavvidesLec 17.17
4/1/04
Address Breakdown
• Physical address is 44 bits wide, 36-bit block address and 6-bit offset
• Calculating cache index size
• Blocks are 64 bytes so offset needs 6 bits
• Tag size = 38 – 9 = 29 bits
92512264
356,652
ityAssociativSet sizeBlock size CacheIndex
EENG449b/SavvidesLec 17.18
4/1/04
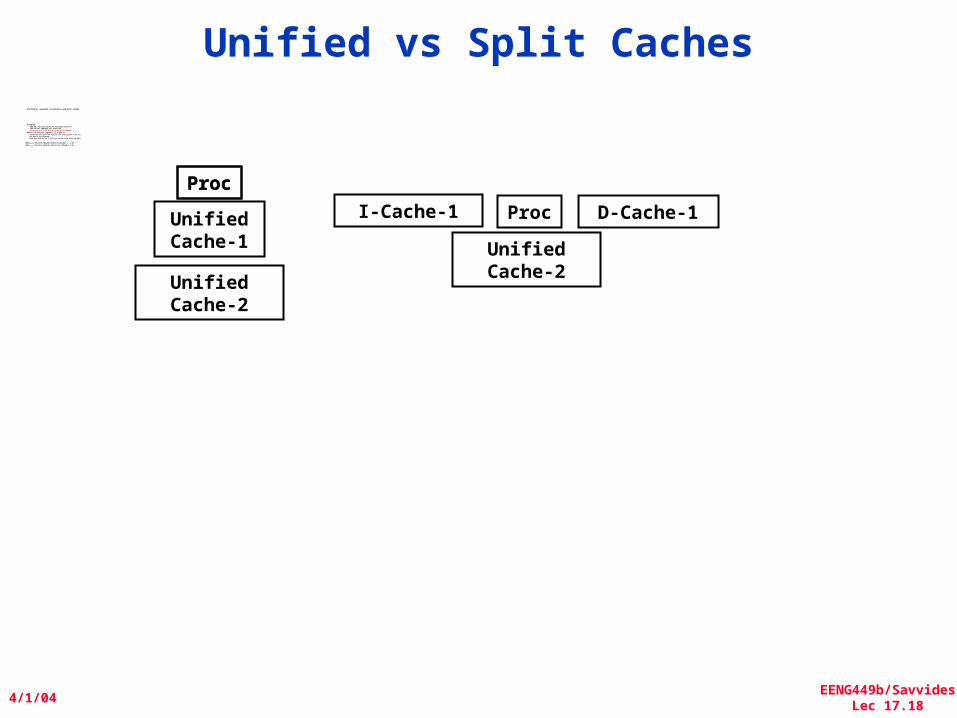
Unified vs Split Caches• Unified vs Separate Instruction and Data caches
• Example:– 16KB I&D: Inst miss rate=0.64%, Data miss rate=6.47%– 32KB unified: Aggregate miss rate=1.99%– Using miss rate in the evaluation may be misleading!
• Which is better (ignore L2 cache)?– Assume 25% data ops 75% accesses from instructions (1.0/1.33)– hit time=1, miss time=50– Note that data hit has 1 stall for unified cache (only one port)
AMATHarvard=75%x(1+0.64%x50)+25%x(1+6.47%x50) = 2.05AMATUnified=75%x(1+1.99%x50)+25%x(1+1+1.99%x50)= 2.24
ProcI-Cache-1
Proc
UnifiedCache-1
UnifiedCache-2
D-Cache-1
Proc
UnifiedCache-2

EENG449b/SavvidesLec 17.19
4/1/04
Impact of Caches on Performance
• Consider a in-order execution computer
– Cache miss penalty 100 clock cycles, CPI=1– Average miss rate 2% and an average of 1.5
memory references per instruction– Average # of cache misses 30 per 1000
instructions
Performance with cache misses
time cycleClock nInstructiocycles stall Memory
CPIIC time CPU execution
time cycleClock 4.00IC
time cycleClock 100))(30/1000(1.0ICtime CPU cache with

EENG449b/SavvidesLec 17.20
4/1/04
Impact of Caches on Performance
• Calculate the performance using miss rate
time cycleClock penalty Miss
nInstructioaccesses Memory
rate MissCPIIC time CPU execution
time cycleClock 4.00IC
time cycleClock 100))2%(1.5(1.0ICtime CPU cache with
• 4x increase in CPU time from “perfect cache”• No cache – 1.0 + 100 x 1.5 = 151 – a factor of 40 compared to a system with cache• Minimizing memory access does not always imply reduction in CPU time

EENG449b/SavvidesLec 17.21
4/1/04
How to Improve Cache Performance?
Fourmaincategoriesofoptimizations1. Reducingmisspenalty
- multilevel caches, critical word first, read miss before write miss, merging write buffers and victim caches
2. Reducing miss rate- larger block size, larger cache size, higher associativity, way prediction and
pseudoassociativity and computer optimizations
2. Reduce the miss penalty or miss rate via parallelism- non-blocking caches, hardware prefetching and compiler prefetching
3. Reduce the time to hit in the cache- small and simple caches, avoiding address translation, pipelined cache access
yMissPenaltMissRateHitTimeAMAT

EENG449b/SavvidesLec 17.22
4/1/04
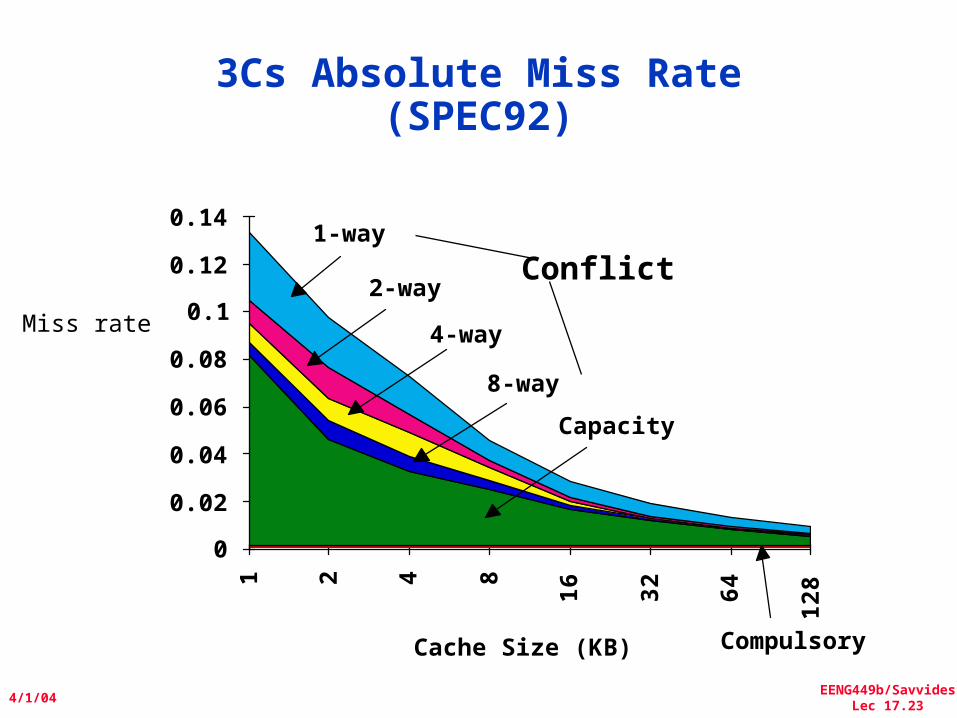
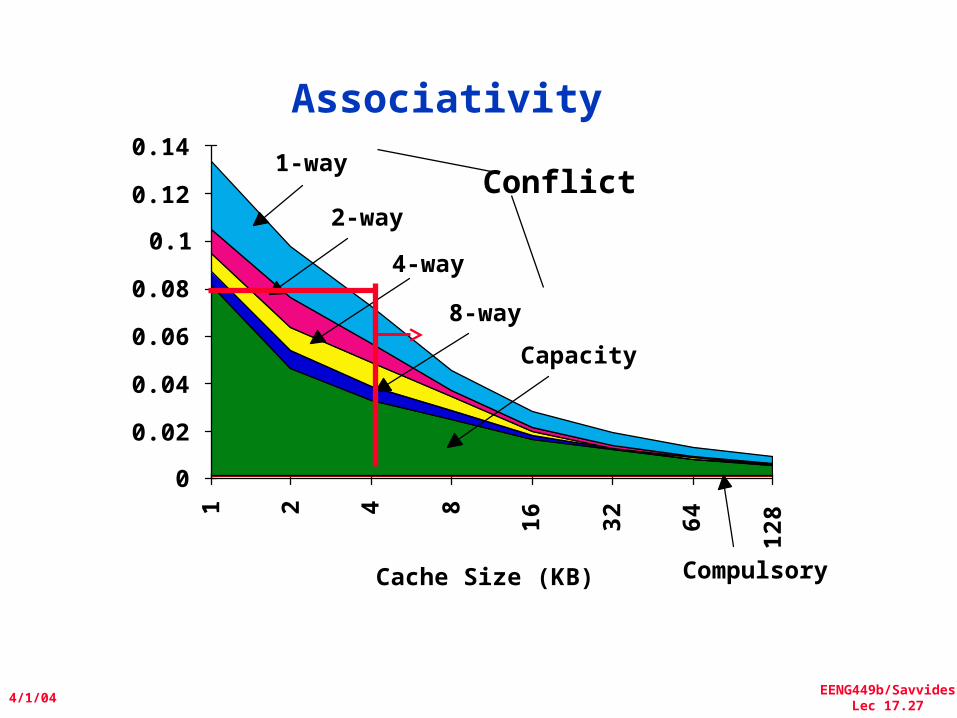
Where to misses come from?• Classifying Misses: 3 Cs
– Compulsory—The first access to a block is not in the cache, so the block must be brought into the cache. Also called coldstartmisses or firstreferencemisses.(MissesinevenanInfiniteCache)
– Capacity—If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved.(MissesinFullyAssociativeSizeXCache)
– Conflict—If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collisionmisses or interferencemisses.(MissesinN-wayAssociative,SizeXCache)
• 4th “C”:– Coherence - Misses caused by cache coherence.
EENG449b/SavvidesLec 17.23
4/1/04
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0
0.02
0.04
0.06
0.08
0.1
0.12
0.141 2 4 8
16
32
64
12
8
1-way
2-way
4-way
8-way
Capacity
Compulsory
3Cs Absolute Miss Rate (SPEC92)
Conflict
Miss rate
EENG449b/SavvidesLec 17.24
4/1/04
Cache Size
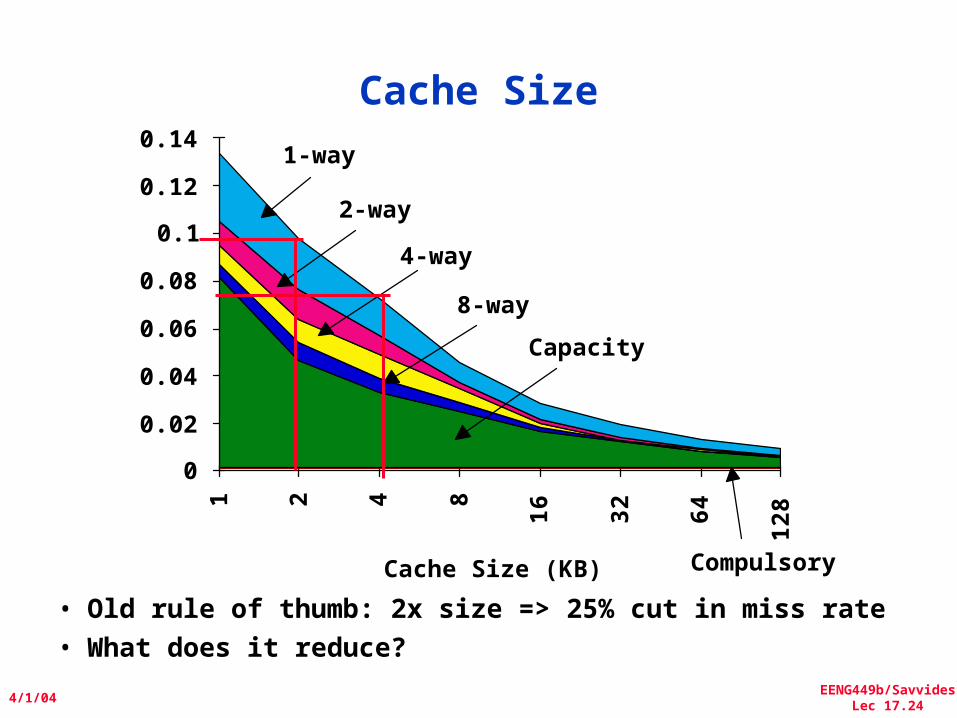
• Old rule of thumb: 2x size => 25% cut in miss rate• What does it reduce?
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8
16
32
64
12
8
1-way
2-way
4-way
8-way
Capacity
Compulsory

EENG449b/SavvidesLec 17.25
4/1/04
Cache Organization?
• Assume total cache size not changed:• What happens if:
1) Change Block Size:
2) Change Associativity:
3) Change Compiler:
Which of 3Cs is obviously affected?
EENG449b/SavvidesLec 17.26
4/1/04
Block Size (bytes)
Miss Rate
0%
5%
10%
15%
20%
25%
16
32
64
12
8
25
6
1K
4K
16K
64K
256K
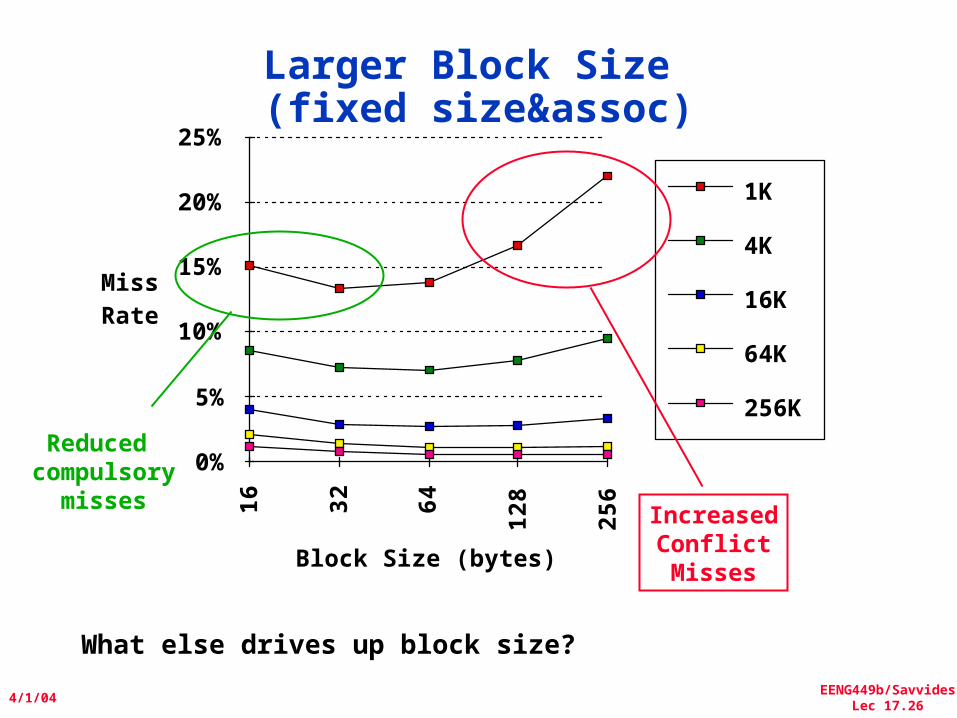
Larger Block Size (fixed size&assoc)
Reduced compulsory
missesIncreasedConflictMisses
What else drives up block size?
EENG449b/SavvidesLec 17.27
4/1/04
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8
16
32
64
12
8
1-way
2-way
4-way
8-way
Capacity
Compulsory
Associativity
Conflict
EENG449b/SavvidesLec 17.28
4/1/04
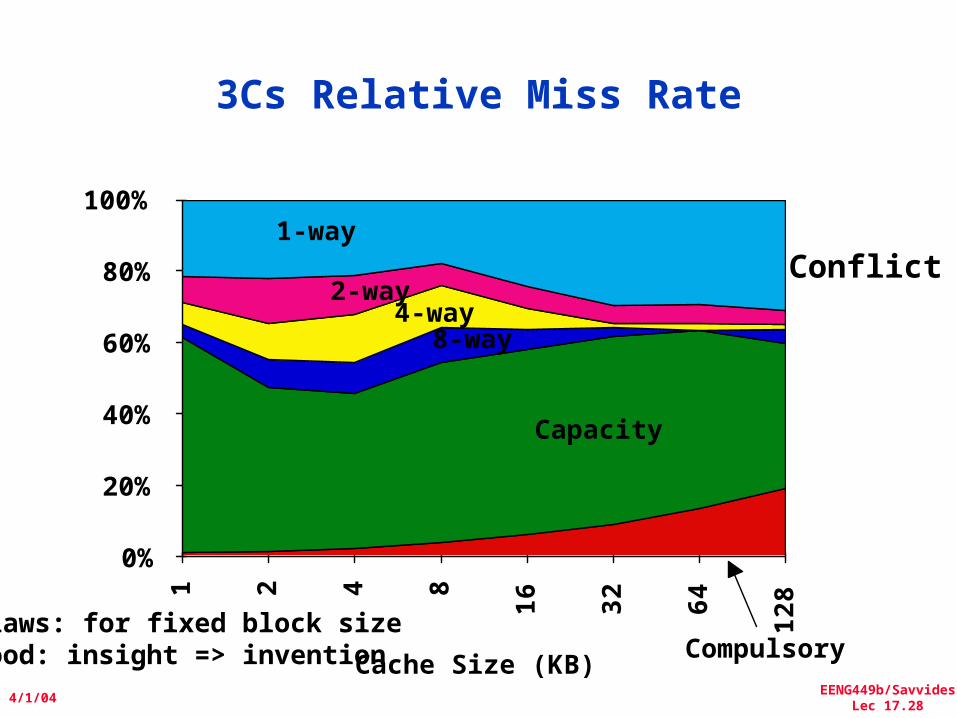
3Cs Relative Miss Rate
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0%
20%
40%
60%
80%
100%1 2 4 8
16
32
64
12
8
1-way
2-way4-way
8-way
Capacity
Compulsory
Conflict
Flaws: for fixed block sizeGood: insight => invention

EENG449b/SavvidesLec 17.29
4/1/04
Associativity vs Cycle Time
•Beware: Execution time is only final measure!
•Why is cycle time tied to hit time?
•Will Clock Cycle time increase?– Hill [1988] suggested hit time for 2-way vs. 1-way
external cache +10%, internal + 2%
– suggested big and dumb caches
Effective cycle time of assocpzrbski ISCA

EENG449b/SavvidesLec 17.30
4/1/04
Next Time
• Cache Tradeoffs for Performance• Reducing Miss Penalties• Reducing Hit Times





























