Embed Size (px)
Citation preview

T A R T U Ü L I K O O L
MATEMAATIKATEADUSKOND
Arvutiteaduse instituut
Tarkvarasüsteemide õppetool
Heli Uibo
Eesti keele sõnavormide arvutianalüüs ja -süntees
kahetasemelist morfoloogiamudelit rakendades
Magistritöö
Juhendaja: dots. T. Roosmaa
TARTU 1999

2
Sissejuhatus ___________________________________________________________ 3
1. Taust _______________________________________________________________ 4
1.1. Morfoloogiatarkvara loomise strateegiad ____________________________________ 4
1.2. Kahetasemelise morfoloogiamudeli kohast ja eelistest _________________________ 5
1.3. Senised tulemused eesti keele morfoloogilise analüüsi-sünteesi automatiseerimise vallas______________________________________________________________________ 7
2. Ülevaade kahetasemelisest morfoloogiamudelist ____________________________ 8
2.1. Kahetasemelised reeglid __________________________________________________ 8
2.2. Sõnastikud_____________________________________________________________ 16
3. Eesti keele morfoloogia kirjeldamine kahetasemelise morfoloogiamudeli vahenditega___________________________________________________________ 18
3.1. Ülevaade eesti keele morfoloogiast_________________________________________ 18
3.2. Kahetasemelised reeglid eesti keele jaoks ___________________________________ 26 3.2.1. Astmevahelduse reeglid _______________________________________________________28 3.2.2. Fonotaktika reeglid___________________________________________________________36 3.2.3. Morfeemipiiridel toimivad reeglid ______________________________________________41 3.2.4. Ortograafiareeglid ___________________________________________________________43 3.2.5. Mittetähelistele süvasümbolitele vaikimisi-väärtuste omistamise reeglid__________________44 3.2.6. Probleemid reeglite kirjutamisel_________________________________________________44
3.3. Eesti keele sõnastike süsteem _____________________________________________ 46 3.3.1. Käändsõnade sõnastikud ______________________________________________________49 3.3.2. Pöördsõnade sõnastikud _______________________________________________________54 3.3.3. Muutumatute sõnade sõnastikud_________________________________________________56 3.3.4. Produktiivne sõnatuletus ______________________________________________________58 3.3.5. Liitsõnade moodustamine______________________________________________________59 3.3.6. Probleemid sõnastikega _______________________________________________________62
3.5. Sõnavormide analüüs ja süntees koostatud sõnastike ja reeglite ning programmide lexc ja twolc abil ___________________________________________________________ 63
3.6. Süsteemi edasiarendamise võimalustest ____________________________________ 64
Kokkuvõte____________________________________________________________ 65
Abstract______________________________________________________________ 67
Lisa 1. Näiteid tööst programmiga twolc - kahetasemeliste reeglite kompileerimine ja testimine._____________________________________________________________ 71
Lisa 2. Näiteid tööst programmiga lexc - leksikonide kompileerimine ning leksikonide ja reeglite ühendamine, sõnavormide testimine. _____________________________ 73
Lisa 3. Eesti keele kahetasemelised reeglid. _________________________________ 79
Lisa 4. Eesti keele kahetasemelise morfoloogia (mittetäielik) sõnastike süsteem. ___ 86

3
Sissejuhatus
Täielik loomuliku keele töötlus sisaldab morfoloogia-, süntaksi- ja semantika-
komponenti, paremal juhul ka teadmisi tervikteksti osade vahelistest seostest.
Loomuliku keele morfoloogilise analüüsi sisendiks on sõnavorm, väljundiks
algvorm e. lemma ja grammatilised tähendused. Morfoloogilise sünteesi sisendiks on
algvorm ja grammatilised tähendused ning väljundiks sõnavorm.
Järgnevalt on antud loetelu morfoloogilise analüüsi ja sünteesi kasutusvõimalustest,
mida võiks veelgi jätkata (Sproat 1992:1-14):
� täielikku loomuliku keele töötlust eeldavad rakendused: keeleanalüsaatorid ja –
generaatorid, masintõlge (viimaseks on vajalikud nii lähtekeele analüüs kui
resultaatkeele süntees);
� sõnastike koostamise vahendid (õigekeelsus- või vormisõnastikud,
erialaterminoloogiasõnastikud jne.);
� kõnesünteesi- ja kõnetuvastusvahendid;
� õigekirjakontrollijad;
� infootsisüsteemid (Lemmatiseerimine väga vajalik, kuna algvormis esitatud päring on
efektiivsem, konkreetse morfoloogilise sõnavormi otsing omab tavaliselt vähe mõtet.
Ilma morfoloogiatöötluseta infootsisüsteemides tuleb päringud anda ette kujul "tüvi*",
s.o. jätta muutuv tüvelõpp ja formatiivid ära, aga näiteks eesti keeles muutuvad
astmevahelduslikel sõnadel ka tüve sisehäälikud);
� lingvistilise uurimistöö vahendid (näiteks keelekorpuse märgendamiseks ja uurimiseks,
tekstide sõnavara analüüsiks (eeldab lemmatiseerimist) jne.);
� keeleõppeprogrammid - sealhulgas nii keele kui suhtlemisvahendi omandamiseks kui ka
filoloogiatudengitele morfoloogiakursuse tarvis.
� jne.
Keeletehnoloogia on valdkond, kus “rahvuslikul”, konkreetse keele iseärasusi
arvestaval tarkvaral on suhteliselt suur osa. Kuid nüüdisajal püütakse ka
keeletöötlustarkvara üldistada, nii et programm on eraldatud konkreetse keele kirjeldusest.
Koostades sobivas formalismis keele grammatika peaks ideaalsel juhul saama programmi

4
rakendada mistahes keelele. Käesolev uurimus on näide sellise lähenemisviisi ühest
realiseerimisest.
1. Taust
1.1. Morfoloogiatarkvara loomise strateegiad
Keeletehnoloogia arengukäiku jälgides võib märgata suunda sõnastik-lahendustelt
reeglistik-lahendustele. Põhjus on selles, et sõnastik vajab pidevalt täiendamist, samuti
nõuab suur sõnastik rohkem mälu ning selles otsimine aega. Järgmised neli strateegiat (Viks
1994b; Kuusik, Viks 1998) ongi kirja pandud arenguloolises järjestuses - iga järgmine
meetod kasutab kuigivõrd eelmisi ning lisandub ka midagi põhimõtteliselt uut.
� Otsingustrateegia põhineb täielikult sõnastikul, kus on loetletud kõikide sõnade
kõikvõimalikud muutevormid. Kuna eesti keeles on igal noomenil keskmiselt 30 ja igal
verbil keskmiselt 45 erinevat muutevormi (Kuusik, Viks 1998), kasvab sõnastik väga
suureks.
� Liigendus-liitmisstrateegia korral koosneb sõnavorm väiksematest üksustest
(tüvi+formatiiv või morfeem1+...+morfeemn). Üksusi hoitakse sõnastikus ning
morfotaktika reeglitega kirjeldatakse nende omavahelise kombineerimise võimalusi:
millised morfeemid ja kuidas moodustavad formatiive ning millised formatiivid
seostuvad milliste tüvedega. Varieeruvate üksuste puhul lisanduvad allotaktika reeglid
variantide omavahelise sobivuse määramiseks: milline tüvevariant seostub millise
formatiivivariandiga. Morfotaktika reeglitele vastab sõnade jaotus morfoloogilistesse
sõnaklassidesse, allotaktika reeglitele - sõnade jaotus muuttüüpidesse.
� Teisendusstrateegia puhul teisendatakse varieeruvad üksused ühele kindlale kujule,
mida hoitakse sõnastikus. Selleks võib olla kas abstraktne süvakuju, mis on mingis
mõttes kõikide tüve- või formatiivivariantide üldistus, või keeles reaalselt eksisteeriv
vorm (näiteks algvorm). Eelmise strateegia reeglitele lisanduvad nüüd teisendusreeglid,
mis transformeerivad erinevad tüvevariandid sõnastikus hoitavale kujule ja vastupidi -
moodustavad sõnastikukujust lähtudes kõik tüvevariandid.

5
� Tuvastusstrateegia eeldab, et sõna algvormi fonoloogiline struktuur (häälikkoostis ja
silpide arv) sisaldab piisavalt infot otsustamaks, millised eelmiste tasandite reeglid
(morfotaktika, allotaktika ja teisendusreeglid) saavad antud sõnale rakenduda.
Lisanduvad tuvastusreeglid, mis määravad lemma fonoloogilise struktuuri alusel
kindlaks sõnaliigi ja muuttüübi.
1.2. Kahetasemelise morfoloogiamudeli kohast ja eel istest
Helsingi Ülikooli arvutuslingvistika professor Kimmo Koskenniemi esitas 1983.
aastal oma doktoriväitekirjas (Koskenniemi 1983) loomuliku keele morfoloogia kirjelduse
kahetasemelise mudeli.
Klassikaline generatiivne fonoloogia põhineb ülekirjutusreeglitel.
Ülekirjutusreeglid on kujul uXv ���� uYv. See tähendab, et mitteterminaalse sümboli X
asemele kirjutatakse Y, kui X-i vasakpoolseks kontekstiks on u ja parempoolseks
kontekstiks v. Ülekirjutusreeglitest koosnev grammatika peab (morfoloogia tasandil)
reeglite järjestrakendamisel tuletama keele kõik lubatavad sõnavormid ja ainult need.
Ka kahetasemeline morfoloogiamudel kasutab teisendusreegleid, kuid generatiivse
fonoloogia ülekirjutusreeglid peavad olema järjestatud, samal ajal kui kahetasemelises
mudelis ei ole reeglite rakendamise järjekord oluline, sest iga reegel töötab ülejäänutest
sõltumatult.
Generatiivse fonoloogia üheks puuduseks oli ka see, et tuletusprotsessi ajal
kättesaadavad fonoloogilised tunnused ei suutnud kirjeldada kogu selle taga olevat
morfoloogiat (Karlsson 1974). Kahetasemelistele reeglitele on kättesaadavad nii
fonoloogilised kui morfoloogilised tunnused, mis on tegelikult mõlemad aluseks sõnade
klassifitseerimisel muuttüüpidesse.
Mudeli realisatsioon on suhteliselt väikese arvutuskeerukusega, kuna see põhineb
enamjaolt väikestel lõplikel automaatidel.
Mudeli kahetasemelisus väljendub selles, et paralleelselt on vaatluse all sõnavormi
kaks esitust: pindesitus (ehk lihtsalt kirjapilt) ja süvaesitus (ehk sõnastikuesitus).

6
Näide 1. Paneme kirja sõnavormi ‘künkail’ süva- ja pindesituse:
süvaesitus: k ü n K a S + i + l #
pindesitus: k ü n k a 0 0 i 0 l 0
Kokkuleppeliselt märgitakse süvaesituses suurtähtedega morfofoneeme, millel on
pindesituses rohkem kui üks variant. Nii on siin K-ga tähistatud süvaesituse neljas foneem,
mis tugeva astme vormides vastab k-le, nõrga astme vormides aga g-le. Tüvelõpu-S, mis
tugeva astme vormides kaob, on samuti süvaesituses suurtäheline. Morfofoneeme, millel
on ainult üks variant, märgitakse ka süvaesituses väiketähega. Süvaesitusse saab märkida ka
morfoloogilisi tunnuseid ja morfeemide ning liitsõnaosade piire. Näites 1 viitab märk “+”
käändelõpu või tunnuse järgnemisele ning märk “#” tähistab sõnavormi lõppu. Pindesituses
on seda tüüpi sümbolite kohal 0, et säilitada teineteisele vastavate süva- ja pindsümbolite
kohakuti asetsemine.
Kahetasemelisus ning idee realiseerida fonoloogiareeglid lõplike automaatidena
esinesid juba 1981. aastal R. Kaplani ja M. Kay poolt loodud arvutimorfoloogia süsteemis
(Koskenniemi 1983). Kuid reeglid olid järjestatud, nagu generatiivsele fonoloogiale kohane,
ning reeglitekogu kompileerimiseks ühendati üksikreeglitele vastavad automaadid.
Probleeme tekitas see, et ühendatud automaat kasvas mõningatel juhtudel väga suureks, eriti
siis, kui mõni reegel pidi arvestama suvalisel kaugusel olevat konteksti.
Kahetasemelises mudelis saab reeglitega käsitlematute, kuid siiski korduvate
nähtuste (näiteks fonoloogiliselt põhjendamatud tüvelõpumuutused) kirjeldamiseks
kasutada minisõnastikke.
Märkimata ei saa jätta ka kahetasemelise morfoloogia kahesuunalisust - s.o. mudel
kujutab endast keele morfoloogilise süsteemi kirjeldust ning pole otseselt orienteeritud
morfoloogilisele analüüsile ega sünteesile. Seejuures nii analüüsi kui sünteesi
realiseerimiseks on olemas efektiivne algoritm.
Jaotises 1.1 käsitletud strateegiatest kasutab kahetasemeline mudel kolmandat,
teisendusstrateegiat (sisaldab endas ühtlasi otsingu- ja tuletus-liigendusstrateegiat):
otsing - tüvedesõnastikest otsitakse sõnavormi algusotsaga kokkulangevat stringi;
tuletus-liigendus - sõnavormi kombineerimiseks liigutakse sõnastike võrgus mööda
morfotaktika reeglitele vastavaid viitu;

7
teisendus - kahetasemelised reeglid teisendavad pindesituse süvaesituseks ja vastupidi.
Kahjuks ei ole kahetasemelises mudelis kohta tuvastusreeglitele, seega mudeli
baasil realiseeritud süsteemi sõnastik vajab aeg-ajalt uuendamist. Kuid tuvastusreeglid
võivad kuuluda eraldiseisvasse sõnastiku uuendamisprogrammi, mis tuvastab tundmatute
sõnade tüübid ning koostab korrektsed tüvedesõnastiku kirjed. Teisendusstrateegia kasuks
võrreldes tuletus-liigendusstrateegiaga räägib eesti keele puhul asjaolu, et eesti keeles on
mitut liiki tüvemuutused väga levinud ning suurem osa sõnadest kahe- (luge|da-loe|n,
kallas-kalda) või kolmetüvelised (käski|da-käsi|n-käs|takse, sõber-sõbra-sõpra). Pelgalt
tuletus-liigendusstrateegiat kasutades peaksid sõnastikus leiduma kõik erinevad
tüvevariandid, seega tüvedesõnastiku kirjeid oleks umbes kaks korda rohkem kui vastavaid
algvorme.
Praegu on kahetasemeline mudel maailmas üldtuntud ning kasutamist leidnud
paljude keelte (inglise, saksa, rootsi, soome, suahiili jt.) morfoloogiliste analüsaatorite ja
süntesaatorite alusena. Mudeli realiseerimiseks vajalikku tarkvara töötavad välja Soome
Helsingi Ülikooli Üldkeeleteaduse osakond ja Soome keeletehnoloogiafirma Lingsoft ning
Xeroxi Euroopa Uurimiskeskus Grenoble’is (Xerox Research Centre of Europe = XRCE).
Programmide demonstratsioonid on üleval nende kodulehekülgedel http://www.lingsoft.fi/
ning http://www.xrce.xerox.com/research/mltt/. Firmas Lingsoft on katsetusi tehtud ka eesti
keelega, kuid ilma reegliteta: kogu kirjeldus põhineb sõnastikel.
1.3. Senised tulemused eesti keele morfoloogilise a nalüüsi-sünteesi automatiseerimise vallas
Eesti keele morfoloogia automatiseerimisega on tegeldud ja tegeldakse nii Eesti
Keele Instituudis (EKI) kui Tartu Ülikoolis (TÜ). EKI-s on sellealane juhtivteadur praegu
Ülle Viks, kes on loonud uue, kujundite tuvastamise teoorial põhineva morfoloogilise
klassifikatsiooni. Seda käsitleb doktoriväitekiri “Klassifikatoorne morfoloogia” (Viks
1994a), mis ühtlasi võtab kokku eelneva töö morfoloogilise klassifikatsiooni loomisel -
verbide (Viks 1980) ja noomenite (Viks 1982) morfoloogilise klassifikatsiooni ning
"Väikese vormisõnastiku" (Viks 1992).

8
Uue lähenemise eesti keele automaatsesse morfoloogiasse tõid ka Evelin Kuusiku
tüübituvastusreeglid (Kuusik 1996; Kuusik, Viks 1998). See tähendab avatud
morfoloogiamudeli idee realiseerimist: kõik produktiivsed ja regulaarsed
morfoloogianähtused kirjeldatakse ja realiseeritakse aktiivse morfoloogia reeglite abil,
sõnastikus esitatakse vaid erandid. Tundmatud sõnad püütakse analüüsida
tüübituvastusreeglite abil ja enamasti see ka õnnestub, kuna uued keelde tulevad sõnad
muutuvad reeglipäraselt.
Praegu EKI-s olemasolevad morfoloogiat käsitlevad arvutiprogrammid on üleval
veebileheküljel http://www.eki.ee/tarkvara/. On võimalik tutvuda morfoloogilise analüüsi,
sünteesi, tüübituvastus- ja silbitusprogrammidega.
Heiki-Jaan Kaalepi morfoloogilise analüüsi programm estmorf (Kaalep 1999) ning
MS Office '97 õigekirjakontrollija põhinevad samuti suures osas "Väikesel
vormisõnastikul". Nende programmidega saab tutvuda TÜ arvutuslingvistika töörühma
koduleheküljel http://www.cl.ut.ee/ ning MS Word '97-ga eestikeelset teksti toimetades.
Nagu eelnevast selgub, on eesti keele morfoloogilist analüüsi ja sünteesi käsitlev
tarkvara põhiliselt juba olemas. Sellegipoolest pole veel praktilist kogemust, kas ja kuidas
võimaldab eesti keele morfoloogiat kirjeldada kahetasemeline morfoloogiamudel, mis
paljude keelte puhul on osutunud edukaks. Seda lünka püüab käesolev töö täita.
2. Ülevaade kahetasemelisest morfoloogiamudelist
Kahetasemeline morfoloogiakirjeldus koosneb reeglitest ja sõnastikest.
2.1. Kahetasemelised reeglid
Kahetasemelisi reeglid peavad ära kirjeldama kõik erinevused süva- ja pindesituse
vahel. Tervet reeglite kogu võib vaadelda kui filtrit, läbi mille näeb sõnavormi süvaesitust
pindesitusena ja vastupidi. Reeglite rakendamise järjekord pole määratud: kõik
keelekirjeldusreeglid peavad olema rahuldatud üheaegselt. Reeglid realiseeritakse

9
sümbolipaaride jadasid töötlevate lõplike teisendajatena (finite-state transducer).
Kui kirjutada süva- ja pindesitus üksteise alla, moodustavad kohakuti asetsevad
sümbolid paari. Näitest 1 (lk. 6) saame järgmise sümbolipaaride jada:
(k:k) (ü:ü) (n:n) (K:k) (a:a) (S:0) (+:0) (i:i) (+:0) (l:l) (#:0)
Lõplikud automaadid ja lõplikud teisendajad on loomuliku keele töötluses osutunud
väga efektiivseteks: nende abil on realiseeritud nii sõnastikke, morfoloogilise analüüsi,
morfoloogilise ühestamise kui süntaktilise analüüsi reegleid (FSLP 1997).
Definitsioon 1. Lõplik automaat (finite-state automaton) on korteež A = (�, Q, q1, F, d),
kus
1) � on sisendtähestik;
2) Q = {q1, … , q n} on lõplik olekute hulk;
3) d: Q x �* -> 2Q on olekuteisendusfunktsioon, s. o. eeskiri, mis määrab, kuidas automaat
iga konkreetse oleku ja sümbolipaari korral käitub (sellise eeskirja saab kirja panna näiteks
olekuteisendustabelina);
4) q1 on automaadi algolek;
5) F � Q on lõppolekute hulk. Need on olekud, milles automaat oma töö lõpetab.
Lõppolekuid võib olla mitu, kuid iga olek ei tarvitse olla lõppolek.
Definitsioon 2 (FSLP 1997:14). Lõplik teisendaja on korteež T = (�1, �2, Q, q1, F, E), kus
� �1 on lõplik sisendtähestik;
� �2 on lõplik väljundtähestik;
� Q on lõplik olekute hulk;
� q1 � Q on algolek;
� F � Q on lõppolekute hulk;
� E � Q x �1* x �2
*x Q on kaarte hulk (vaadeldes teisendajat graafina)
Kaarte hulga asemel võib vaadelda ka olekuteisendusfunktsiooni d : Q x �1* � 2Q ja
väljundfunktsiooni � : Q x �1* x Q � 2�2
* .
Olekuteisendusfunktsioon on oleku q � Q ja sisendtähestiku sümboli a � �1* korral
defineeritud järgmiselt:
d(q, a) = {q' � Q | � (q, a, b, q') � E}
����������
����������

10
Väljundfunktsioon on defineeritud järgmiselt:
�(q, a, q’) = {b � �2 | � (q, a, b, q') � E}
Kahetasemelise morfoloogia reeglite puhul
�1 = S (süva- e. sõnastikuesituse tähestik);
�2 = Sp (pindesituse tähestik e. konkreetse kirjakeele tähestik + tühisümbol).
�1 x �2 = S x Sp = {(a:b) | a � S, b � Sp} - kõikvõimalike paaride hulk, kus esimene sümbol
on süvaesituse sümbolite hulgast ning teine sümbol pindsümbolite hulgast, kusjuures
S = Sp � Ss � Sm
Eesti keele puhul näiteks võiksid vastavad tähestikud olla järgmised:
Sp= { a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,š,z,ž,t,u,v,õ,ä,ö,ü,0 } - pindsümbolid;
Ss = { A,B,D,E,G,I,K,P,S,T,U } - morfofoneemid, millel on pindesituses mitu varianti;
Sm = { $ , +, #, &} - morfofonoloogilised tunnused ja sõnaosade piirid.
Definitsioon 3 (FSLP 1997:15). Olgu T = (�1, �2, Q, q1, F, E) lõplik teisendaja. Teisendaja
T tee on selline kaarte järjend (pi, ai, bi, qi)i=1,n, et qi = pi+1 iga i=1, ..., n-1 korral. (S.t. iga
järgmine kaar algab sealt, kus eelmine lõpeb.)
Definitsioon 4 (FSLP 1997:15). Teisendaja edukas tee on selline tee, mis algab algolekus
ja lõpeb lõppolekus (p1 = q1 ja qn � F).
Kahetasemeline reegel kui filter laseb sümbolipaaride stringi läbi, kui reeglile vastav
lõplik teisendaja, saades sisendiks selle sümbolipaaride stringi, läbib mingi eduka tee.
Lõplikku teisendajat võib tõlgendada lõpliku automaadina, mille sisendiks on
sümbolipaaride (mitte üksiksümbolite string) ehk mille iga kaar on märgendatud
sümbolipaariga, mitte ühe sümboliga. Seega kahetasemeliste reegel-automaatide sisendiks
on sümbolipaaride stringid, kus paari esimene komponent on süvaesitusest ning teine
komponent pindesitusest.
Lõplik automaat A defineerib keele L(A) = {w � �* | d(q1,w) F �}.
Definitsioon 5 (FSLP 1997:15). Keelt L nimetatakse regulaarseks, kui leidub lõplik
automaat L(A), mis keele L defineerib.

11
Kleene'i teoreem (FSLP 1997:5): Regulaarsete keelte pere tähestikus �* langeb kokku
vähima keelte perega tähestikus �*, mis sisaldab tühja hulka, üheelemendilisi hulki ning
mis on suletud Kleene'i sulundioperatsiooni, konkatenatsiooni ja ühendi suhtes.
Kleene'i teoreem ütleb teisisõnu, et regulaarsed avaldised on samaväärsed lõplike
automaatidega.
Seega on lõplikku automaati (või lõplikku teisendajat) võimalik kirja panna:
a) olekugraafina (definitsioon olekuid ühendavate kaarte kaudu);
b) olekuteisendustabelina (definitsioon olekuteisendusfunktsiooni kaudu);
c) regulaarse avaldisena (Kleene'i teoreem).
Näide 2. (Uibo 1998) Esitame reegli "Pikk vokaal lüheneb enne i-ga algavat
formatiivi" (nt. maa-maid, tee-teid) kõigil kolmel viisil. Suvalise täishääliku märkimiseks
defineerime potentsiaalsete lühenevate vokaalide hulga LyhVok = {a, e, o, u, õ, ä, ö, ü}.
Automaadi koostamiseks annab K. Koskenniemi (Koskenniemi 1983:103-105)
järgmised näpunäited:
1) Kõigepealt kirjeldada olekud, mis tunnevad ära reegli vasakpoolse konteksti. Selles
näites otsitakse vokaali.
2) Anda vaadeldava probleemi kirjeldus, antud juhul oleks see niisugune: "Kui järgmise
sümboli süvaesituses järgneb teine samasugune vokaal, siis vaadata pindesitust ja veel kahte
järgmist sümbolipaari":
a) pindesituses 0 ja järgmised kaks paari +:0 ja i:i � aktsepteerida (lõppolek)
b) pindesituses vokaal ja järgmised kaks paari +:0 ja i:i � lükata sõna tagasi (olek
nr. 0)
3) Anda tagasipöördumise kirjeldus (kui sama olukord võib sõnas ka hiljem esineda).

12
a) Olekugraaf:
Joonis 1. Näide lõpliku automaadi esitusest olekugraafina.
Graafis on ülevaatlikkuse huvides märkimata jäetud kõik silmused e. kaared, mis
algavad ja lõpevad samas olekus. Kui sisendist loetav sümbolipaar ühtib mingi antud
olekust lähtuva kaare märgendiga, siis läheb automaat uude olekusse, milles see kaar lõpeb.
Kõikvõimalike muude sisendpaaride korral jääb automaat endisesse olekusse.
b) Olekuteisendustabel:
+ i LyhVok LyhVok = 0 i LyhVok 0 = -------------------------------------------------------------------- 1. 1 1 2 1 1 2: 2 2 3 4 1 3: 3 0 3 3 3 4: 5 4 0 0 4 5: 5 1 5 5 5 --------------------------------------------------------------------
Lõppoleku numbri järel on punkt, teiste järel koolon. Võrdusmärgid tähistavad
kõikvõimalikke ülejäänud sümbolipaare - need on antud reegli seisukohast indiferentsed.
LyhVok:LyhVok
i:i
LyhVok:
+:0
i:i
LyhVok:0
1
2 3
0 5
4
LyhVok:LyhVok

13
c) Regulaarne avaldis (kolmest esitusest kõige hõlpsamini kirjapandav ja loetav):
V1:0 � V1 _ %+: i ; where V1 in LyhVok;
Tõlgendus: Hulgas LyhVok sisalduvale täishäälikule vastab pindesituses 0 (ehk ta kaob)
parajasti siis, kui tema vasakpoolseks kontekstiks on seesama täishäälik ning vahetu
parempoolse konteksti süvaesituses + ja seejärel i nii süva- kui pindesituses.
Järgnevalt vaatleme põhjalikumalt kahetasemelistes reeglites kasutatavate
regulaarsete avaldiste süntaksi ja semantikat (Karttunen 1997).
Regulaarsed avaldised tähistavad hulki . Lihtsaim regulaarne avaldis koosneb ühest
sümbolist (näiteks a on regulaarne avaldis ja tähistab hulka {a}).
Stringide hulka nimetatakse keeleks. Sümbolipaaridest koosnevat hulka nimetatakse
relatsiooniks. Regulaarne avaldis võib siis kirjeldada regulaarset keelt või regulaarset
relatsiooni.
Lihtsaim relatsiooni märkiv regulaarne avaldis on sümbolipaar (näiteks a:b on
regulaarne avaldis ja tähistab järjestatud paaride hulka {<a:b>}).
Regulaarset relatsiooni saab alati vaadelda kui kujutust ühest regulaarsest keelest
teise. Kahetasemelise mudeli puhul on esimeseks keeleks sõnastikuesituse sõnede hulk,
teiseks keeleks eesti keele sõnade hulk, mida sõnastik võimaldab genereerida. Et neid keeli
eristada, nimetame esimest keelt relatsiooni ülemiseks keeleks ja teist alumiseks keeleks
(analoogia näitega 1, kus pindesitus oli süvaesituse alla kirjutatud).
Keerulisemaid regulaarseid avaldisi saab ehitada järgmiste operaatorite abil:
� " " (tühik) - konkatenatsioon A B = {ab| a � A, b � B}
� "|" - ühend (alternatiivid) A | B = {"a" | a � A � B}
� "-" - vahe A - B = {a | a � A & a B}
� Alamavaldiste grupeerimiseks võib kasutada kandilisi sulge: a b [a | b] � a b a | b, kuid
esimene on paremini loetav.

14
� Tühisõnest1 koosnev keel [] = {0}
� Regulaarse avaldise valikulised osad pannakse ümarsulgudesse: (a ) � [ a | [] ]
� Universaalne keel U koosneb kõikvõimalikest, suvalise pikkusega sõnedest,
kaasaarvatud tühisõne.
Erilise tähendusega sümbolid:
� 0 - tühisõne
� ? - suvaline sümbol
� .#. - sõna algus või lõpp
� % - escape-sümbol (kaotab järgneva sümboli spetsiaalse tähenduse). Näiteks %0="0".
Unaarsed operatsioonid:
� ~ - täiend ~A = {a| a � U - A}
� * - Kleene'i tärn e. iteratsioon A* = {0, a, a a, a a a, ... | a � A}
� + - Kleene'i pluss e. positiivne iteratsioon A+ = A* - {0}
� $ - sisalduvus $A � [?* A ?*]
Regulaarseid avaldisi kasutatakse kahetasemelistes reeglites sümbolipaari vasak- ja
parempoolse konteksti kirjeldamiseks.
Kahetasemelise reegli üldkuju (Koskenniemi 1983) on
CP op LC _ RC, kus op � {�, �, �}
Sõltuvalt sümbolipaari CP2 ja konteksti (LC - vasakpoolne kontekst, RC -
parempoolne kontekst) seosest on kolme tüüpi reegleid. Olgu konkreetne sümbolipaar q,
tema vasakpoolne kontekst L ja parempoolne kontekst R. Seega reegli kui automaadi
sisendiks on konfiguratsiooni CF = L q R.
1) Kui op = “�”, siis on tegemist konteksti piirava reegliga. Seda tüüpi reegel määrab
ümbruse, milles vastavus võib esineda.
Formaalselt: [(CF = L q R) & (q � CP)] � [(L � LC) & (R � RC)]
1 "0" ei tähista siin mitte arvu 0, vaid tühisõnet. 2 Paneme tähele, et CP, LC ja RC on hulgad, mitte kon kreetsed sümbolid või sümbolijärjendid: reeglites võib kasutada mitme süm boli tähistamiseks hulki, nagu näites 1 LyhVok.

15
2) Kui op = “�”, siis nimetatakse seda pindsümboli sunnireegliks. Niisugune reegel
ütleb, et vastavus, mille leksikaalne komponent on määratletud reegli vasaku poolega,
realiseerub reegli parempoolses kontekstis reegli vasakul poolel esitatud pindsümbolina.
Formaalselt: [(CF = L q R) & (CP = x:Y) & (q = x:z)] � [(L � LC) & (R � RC) �(z � Y)]
3) Kui op = “�”, siis saame liitreegli , mis tähendab, et reegli vasakul poolel seisev
vastavus on aktsepteeritav selles ja ainult selles kontekstis, mille esitab reegli parem pool.
Formaalselt: [CF = L q R] � [(q � CP) � (L � LC) & (R � RC)]
Nii reegli vasakul kui paremal poolel võib esineda loetelu. Vasakul pool võib olla
mitu vastavust:
CP1, CP2, ..., CPn op LC _ RC
Seda interpreteeritakse kui n reeglit, kus vastavused on erinevad, kuid kontekst sama.
Üks ja sama vastavus võib esineda erinevates kontekstides. Seegi on kirjapandav ühe
reegliga:
CP op LC1 _ RC1
LC2 _ RC2
...
LCn _ RCn
Vaatleme iga elementaarreeglit kui tingimust CTXi (L, q, R), mis kontrollib, kas q
esineb konfiguratsioonis CF = L q R nii, nagu i-ndas reeglis ette nähtud.
Kuidas käsitleb terve reeglite kogu konkreetset konfiguratsiooni CF = L q R?
1) Kui sama q jaoks on rohkem kui üks �-reegel (q � CPj, ..., q � CPm), siis peavad nad
kõik olema rahuldatud: CTXj (L, q, R) & ... & CTXm (L, q, R).
2) Kui sama q jaoks on mitu �-reeglit (q � CPk, ..., q � CPn), siis peab vähemalt üks neist
olema rahuldatud: CTXk (L, q, R) � ... � CTXn (L, q, R).
3) Kui sama konfiguratsiooni jaoks on rohkem kui üks �-reegel, siis peavad nad kõik
olema rahuldatud.

16
2.2. Sõnastikud
Sõnastike võrk defineerib keele morfotaktika- ja allotaktikareeglid. Sisu järgi võib
eristada järgmisi sõnastikke:
1) juurtesõnastikud;
2) tüvelõpumuutuste sõnastikud;
3) tunnuste ja lõppude sõnastikud;
4) hargnemissõnastikud (esialgse mudeli jätkuklasside (continuation classes) asemel)
Seejuures on kõikide sõnastike struktuur ühesugune. Esialgu, Koskenniemi
doktoritöös (Koskenniemi 1983:28) oli väja pakutud veidi erinev sõnastiku struktuur.
Muudatus tuli sellest, et sõnastikud on nüüd realiseeritud kui sõnastik-teisendajad (lexical
transducer).
Morfoloogilise analüüsi suunas on sõnastik-teisendaja võimeline sõnastikust välja
tooma sõnavormi need omadused, mis sõna häälikkoostises ei ilmne, järgmist algoritmi
järgides (Sproat 1992:6). Sõnastik-teisendaja alustab algolekust q1. Niipea kui teisendaja
leiab, et sisendsõne algusosa ühtib mõne kaare märgendi alumise poolega, liigub ta vastavat
kaart mööda järgmisse olekusse, seejärel lõikab sisendstringi algusest ära juba leitud jupi ja
väljastab selle jupi kohta käiva grammatilise informatsiooni. Teisendaja töö lõpeb edukalt,
kui ta on jõudnud kaari mööda liikudes sõne lõppu. Morfoloogilise sünteesi puhul on
sisendiks algvorm ja grammatiline info ning sobiva sisendi korral väljastab ta jupp-jupilt
vastava sõnavormi.
Tekstifailis on sõnastiku kohustuslik struktuur järgmine:
<sõnastik> ::= “LEXICON” <nimi>
<kirjete loetelu>
<kirjete loetelu> ::= kirje [<kirjete loetelu>]
kirje ::= <morfoloogiline info> “:” <süvaesitus> <jätkuviit> “;”

17
Jätkuviit näitab, millisesse sõnastikku edasi minna. Jätkuviitade abil ühendatud
sõnastike võrk võimaldab arvestada morfeemide sõnasiseseid järgnevusi.
Näide 3. Kindla kõneviisi oleviku pöördelõppude sõnastik eesti keeles.
LEXICON Pr
+Sg1:+n #;
+Sg2:+d #;
+Sg3:+b #;
+Pl1:+me #;
+Pl2:+te #;
+Pl3:+vad #;
Märk "#" jätkuviida kohal tähendab, et midagi rohkemat sõnavormile liituda ei saa.
Reaalses sõnastike süsteemis on muidugi olemas sõnastikud, mis viitavad sõnastikule Pr -
nendeks on erinevate pöördkondade kindla kõneviisi oleviku tüvest moodustatavate
vormide sõnastikud (näiteks V12 - vt. lisa 4 lk. 132). Vastava morfoloogilise märgendi
+Ind+Pr saavad sõnad just sealt külge. Algvorm ja sõnaliik (+V = verb) aga saadakse
kätte verbitüvede sõnastikust, kus tüve sõnastikuesituse järel on viit esimese pöördkonna
jätkusõnastikule V1.
Sõnalist seletust sõnastikevahelistest seostest illustreerib näide 4.
Näide 4. Kindla kõneviisi oleviku moodustamine verbist " elama" sõnastikevahelisi
viitu järgides.
LEXICON Verb LEXICON V1 LEXICON V12 LEXICON Pr
............ V10; +Ind+Pr:0 Pr; +Sg1:+n #;
elama+V:ela V1; V11; +Imp+Pr+Sg2:0 #; .................
............. V12; +Ind+Pr+Ps+Neg:0 #; +Pl3:+vad #;
V13; +Knd+Pr:0 Knd-Pr;

18
3. Eesti keele morfoloogia kirjeldamine kahetasemel ise morfoloogiamudeli vahenditega
3.1. Ülevaade eesti keele morfoloogiast
Eesti keel on tugevalt morfoloogiline keel (Viks, Kuusik 1998) - grammatilisi
tähendusi väljendatakse tunnuste ja lõppude abil, mis liituvad tüvele (mitte ees- ega
tagasõnade abil).
Eesti keelele on suures osas omane aglutinatiivsus - sõnavormid moodustuvad
morfoloogiliste formatiivide liitumisel sõnatüvele. Sõnavorm liigendub tüveks, mis
väljendab leksikaalset tähendust ja formatiiviks , mis väljendab grammatilist tähendust.
Detailsema liigenduse kohaselt koosneb tüvi juurest ja tuletusliidetest ning formatiiv
üksikmorfeemidest.
Näide 5. Sõnavormi "juhuslikkudest" liigendamine.
juhuslikku+dest juhus +likku +de +st
tüvi + formatiiv juur+tuletusliide+mitmuse tunnus+käändelõpp
Eesti keeles võib eristada järgmisi morfoloogilisi sõnaklasse:
� käändsõnad e. noomenid,
� pöördsõnad e. verbid,
� muutumatud sõnad e. indeklinaablid.
Sõnaliigid arvestavad ka süntaktilisi ja semantilisi tunnuseid ning neid on
rohkem:
� Noomenite liigitus:
1) nimisõnad e. substantiivid,
2) omadussõnad e. adjektiivid,
3) asesõnad e. pronoomenid,
4) arvsõnad e. numeraalid.

19
� Verbide klass langeb sõnaliigiga kokku:
5) tegusõnad
� Muutumatute sõnade liigitus:
6) määrsõnad e. adverbid,
7) kaassõnad e. pre- ja postpositsioonid,
8) sidesõnad e. konjunktsioonid,
9) hüüdsõnad e. interjektsioonid.
Eesti keel on rikas erinevate muutevormide poolest. Näitena olgu toodud tabelid
nimisõna "käsi" (tabel 1) ja tegusõna "muutma" (tabel 2) kõikvõimalikest
muutevormidest. Morfoloogiliste tunnuste tähistustes on siin ja edaspidi põhiliselt
järgitud Ü. Viksi "Väikese vormisõnastiku" (Viks 1992) eeskuju. Erinevus on vaid
selles, et lihtsuse huvides jätsin verbivormide morfoloogilises infos igal pool
markeerimata jaatava kõne, markeerides vaid eitava.
Noomenitel on (erinevate teooriate kohaselt) 14-15 käänet ainsuses ja mitmuses,
sageli mitmuses ka paralleelvormid i-mitmuse või tüvemitmuse näol.
Ü. Viksi eeskujul on vaadeldud ka lühikest sisseütlevat iseseisva käände -
suunduva e. aditiivina, mis pole küll kõikide sõnade puhul moodustatav. Näiteks pole
reeglit selle kohta, missugustest sõnadest tohib aditiivi moodustada II ja III käändkonnas,
mõnedest sõnadest on see kasutusel, mõnedest mitte. Peale selle esineb aditiivi üksikutel
sõnadel I (maha, öhe, pähe), IV (mõisa, tasku, põrgu) ja VII (taeva) käändkonnast.
Verbidel on neli kõneviisi (kindel, tingiv, käskiv, kaudne), neli aega (olevik,
lihtminevik, täisminevik ja enneminevik), kaks tegumoodi (isikuline ja umbisikuline),
kaks kõneliiki (jaatav ja eitav), kolm isikut (1., 2., 3.) ning kaks arvu (ainsus ja mitmus).
Paralleelvormid esinevad ele-tüüpi sõnadel. Lisaks esineb nii käänd- kui pöördsõnade
hulgas sõnu, mis võivad muutuda kahe erineva muuttüübi eeskujul. Need on juhtumid,
mille puhul kirjakeele reeglite paikapanijad on "valele" kõnekeelele vastu tulnud. Näiteks
on praegu sõna sulgema lubatud pöörata nii sulgeda-sulen kui ka sulgeda-sulgen.

20
Tabel 1. Noomeni võimalikud muutevormid sõna “käsi” näitel.
Arv Kääne Käände lühend
Ainsus e. singular (Sg) Mitmus e. pluural (Pl)
Nimetav e. nominatiiv N käsi käed
Omastav e. genitiiv G käe käte
Osastav e. partitiiv P kätt käsi
Sisseütlev e. illatiiv Ill käesse kätesse e. käsisse
Seestütlev e. inessiiv In käes kätes e. käsis
Seestütlev e. elatiiv El käest kätest e. käsist
Alaleütlev e. allatiiv All käele kätele e. käsile
Alalütlev e. adessiiv Ad käel kätel e. käsil
Alaltütlev e. ablatiiv Abl käelt kätelt e. käsilt
Saav e. terminatiiv Ter käeks käteks e. käsiks
Rajav e. translatiiv Trl käeni käteni
Olev e. essiiv Es käena kätena
Ilmaütlev e. abessiiv Ab käeta käteta
Kaasaütlev e. komitatiiv Kom käega kätega
Aditiiv Adt kätte -

21
Tabel 2. Verbi võimalikud muutevormid sõna “muutma” näitel
Vorm Lühend Näide
1. Infiniitsed e. käändelised vormid
Supiin e. ma-infinitiiv (illatiiv) Sup muutma
---- " ---- inessiiv Sup In muutmas
---- " ---- elatiiv Sup El muutmast
---- " ---- translatiiv Sup Tr muutmaks
---- " ---- abessiiv Sup Ab muutmata
---- " ---- umbisikuline Sup Ips muudetama
Infinitiiv e. da-infinitiiv Inf muuta
Gerundium e. des-vorm Ger muutes
Partitsiibid e. kesksõnad (Pts):
isikuline (Ps) Pts Pr Ps muutev oleviku (Pr)
kesksõna umbisikuline (Ips) Pts Pr Ips muudetav
isikuline Pts Pt Ps muutnud mineviku (Pt)
kesksõna umbisikuline Pts Pt Ips muudetud
2. Finiitsed e. pöördelised vormid
2.1. Kindel kõneviis e. indikatiiv (Ind)
Isikuline tegumood e. personaal (Ps)
1. isik Ind Pr Ps Sg1 muudan
2. isik Ind Pr Ps Sg2 muudad
Sg
3. isik Ind Pr Ps Sg3 muudab
1. isik Ind Pr Ps Pl1 muudame
2. isik Ind Pr Ps Pl2 muudate
Jaatav
kõne
Pl
3. isik Ind Pr Ps Pl3 muudavad
Olevik e.
preesens
(Pr)
Eitav kõne (Neg) Ind Pr Ps Neg ei muuda

22
1. isik Ind Ipt Ps Sg1 muutsin
2. isik Ind Ipt Ps Sg2 muutsid
Sg
3. isik Ind Ipt Ps Sg3 muutis
1. isik Ind Ipt Ps Pl1 muutsime
2. isik Ind Ipt Ps Pl2 muutsite
Jaatav
kõne
Pl
3. isik Ind Ipt Ps Pl3 muutsid
Liht-
minevik e.
imperfekt
(Ipt)
Eitav kõne Ind Ipt Ps Neg ei muutnud
Jaatav kõne Ind Pf Ps on muutnud Täis-
minevik e.
perfekt (Pf) Eitav kõne Ind Pf Ps Neg ei ole muutnud
Jaatav kõne Ind Ppf Ps oli muutnud Enne-
minevik e.
pluskvam-
perfekt
(Ppf)
Eitav kõne Ind Ppf Ps Neg ei olnud muutnud
Umbisikuline tegumood e. impersonaal (Ips)
Jaatav kõne Ind Pr Ips muudetakse Olevik
Eitav kõne Ind Pr Ips Neg ei muudeta
Jaatav kõne Ind Ipt Ips muudeti Liht-
minevik Eitav kõne Ind Ipt Ips Neg ei muudetud
Jaatav kõne Ind Pf Ips on muudetud Täis-
minevik Eitav kõne Ind Pf Ips Neg ei ole muudetud
Jaatav kõne Ind Ppf Ips oli muudetud Enne-
minevik Eitav kõne Ind Ppf Ips Neg ei olnud muudetud
2.2 Kaudne kõneviis e. kvotatiiv (Kvt)
Isikuline tegumood
Jaatav kõne Kvt Pr Ps muutvat Olevik (Pr)
Eitav kõne Kvt Pr Ps Neg ei muutvat

23
Jaatav kõne Kvt Pt Ps olevat muutnud Minevik
(Pt) Eitav kõne Kvt Pt Ps Neg ei olevat muutnud
Umbisikuline tegumood
Jaatav kõne Kvt Pr Ips muudetavat Olevik
Eitav kõne Kvt Pr Ips Neg ei muudetavat
Jaatav kõne Kvt Pt Ips olevat muudetud Minevik
Eitav kõne Kvt Pt Ips Neg ei olevat muudetud
2.3. Tingiv kõneviis e. konditsionaal
Isikuline tegumood
1. isik Knd Pr Ps Sg1 muudaksin
2. isik Knd Pr Ps Sg2 muudaksid
Sg
3. isik Knd Pr Ps Sg3 muudaks
1. isik Knd Pr Ps Pl1 muudaksime
2. isik Knd Pr Ps Pl2 muudaksite
Jaatav
Pl
3. isik Knd Pr Ps Pl3 muudaksid
Olevik
Eitav Knd Pr Ps Neg ei muudaks
1. isik Knd Pt Ps Sg1 oleksin muutnud
e. muutnuksin
Minevik Jaatav Sg
2. isik Knd Pt Ps Sg2 oleksid muutnud
e. muutnuksid
3. isik Knd Pt Ps Sg3 oleks muutnud
e. muutnuks
1. isik Knd Pt Ps Pl1 oleksime muutnud
e. muutnuksime
2. isik Knd Pt Ps Pl2 oleksite muutnud
e. muutnuksite
Pl
3. isik Knd Pt Ps Pl3 oleksid muutnud
e. muutnuksid

24
Eitav Knd Pt Ps Neg ei oleks muutnud
e. ei muutnuks
Umbisikuline tegumood
Jaatav Knd Pr Ips muudetaks Olevik
Eitav Knd Pr Ips Neg ei muudetaks
Jaatav Knd Pt Ips oleks muudetud Minevik
Eitav Knd Pt Ips Neg ei oleks muudetud
2.4. Käskiv kõneviis e. imperatiiv
Isikuline tegumood
1. Imp Pr Ps Sg1 muutku
2. Imp Pr Ps Sg2 muuda
Sg
3. Imp Pr Ps Sg3 muutku
1. Imp Pr Ps Pl1 muutkem
2. Imp Pr Ps Pl2 muutke
Jaatav
Pl
3. Imp Pr Ps Pl3 muutku
1. Imp Pr Ps Neg Sg1 ärgu muutku
2. Imp Pr Ps Neg Sg2 ära muuda
Sg
3. Imp Pr Ps Neg Sg3 ärgu muutku
1. Imp Pr Ps Neg Pl1 ärgem muutkem
2. Imp Pr Ps Neg Pl2 ärge muutke
Olevik
Eitav
Pl
3. Imp Pr Ps Neg Pl3 ärgu muutku
Jaatav Imp Pt Ps olgu muutnud Minevik
Eitav Imp Pt Ps Neg ärgu olgu muutnud
Umbisikuline tegumood
Jaatav kõne Imp Pr Ips muudetagu Olevik
Eitav kõne Imp Pr Ips Neg ärgu muudetagu
Jaatav kõne Imp Pt Ips olgu muudetud Minevik
Eitav kõne Imp Pt Ips Neg ärgu olgu muudetud

25
Eesti keeles liigitatakse sõnad muuttüüpidesse enamasti järgmiste tunnuste alusel:
1) astmevaheldus (tüve sisehäälikute ja/või välte muutumine): nõrgenev, tugevnev,
puudub;
Käändsõna astmevaheldust loetakse nõrgenevaks, kui ainsuse nimetav ja
osastav on tugevas astmes ning ainsuse omastav nõrgas astmes (laud-laua-lauda),
tugevnevaks, kui ainsuse nimetav on nõrgas ja ainsuse omastav tugevas astmes (hinne-
hinde-hinnet).
Pöördsõna astmevaheldust loetakse nõrgenevaks, kui da-infinitiiv on tugevas ja
kindla kõneviisi olevik nõrgas astmes (õppida-õpin), tugevnevaks vastupidisel juhul
(hüpata-hüppan).
Astmevahelduseta sõnadel võib muutuda ainult tüvelõpp (raamat-raamatu,
kõnelda-kõnelen) või jääb tüvi täiesti muutumatuks (karu-karu, kirjutada-kirjutan).
Astmevahelduse võib täpsemalt liigitada
a) laadivahelduseks (häälikukadu (nägu-näo), assimilatsioon (lendama-
lennata) või asendumine (sadama-sajab) nõrgas astmes);
b) klusiilide (k, p, t) vältevahelduseks (pilt-pildi);
c) prosoodiliseks vältevahelduseks (vein (III v.) - veini (II v.)).
2) tüvelõpumuutused (Viks 1979):
a) lisandumine või kadu: tüvevokaal (klass-klassi), tüvelõpu-S (vilgas-vilka), silp
-da või -me (tore-toreda, mõõde-mõõtme);
b) hääliku(ühendi) asendumine: ne-se (inimene-inimese), ne-sa (õnnis-õndsa), s-
ne (küüs-küüne), s-kse (juus-juukse), i-e (lumi-lume), le-el (vaidlema-
vaielda) jt.;
c) nii kadu kui lisandumine: number-numbri , armas-armsa
3) silpide arv: 1, 2 , 3 ja enam;
Silpide arvu loetakse käändsõnadel ainsuse omastavast, seega sõna tool (Sg G tooli) on 2-
silbiline, tänav (Sg G tänava) 3-silbiline. Pöördsõna silpide arv saadakse, kui algvormi
lõpust eraldatakse ma-formatiiv. Niisiis on verb kuula|ma 2-silbiline.
4) välde: I, II, III;

26
5) morfoloogiliste formatiivide valik (näiteks: mitmuse tunnus -de või -te, umbisikulise
tegumoe tunnus -t või -d);
6) erinevate tüvekujude paiknemine paradigmas (tugeva- ja nõrgaastmelise tüve ning
lemma- ja muutetüvede paiknemine paradigmas - vt. näidet 10 jaotisest 3.3).
3.2. Kahetasemelised reeglid eesti keele jaoks
Kuna iga reegel vaatleb korraga vaid ühte süva- ja pindsümboli vastavust, on
loomulik kirjeldada reeglitega need häälikumuutused, mis puudutavad ühte häälikut.
Kahetasemelised reeglid ei suuda korraga teisendada ühte tervet segmenti teiseks ning
teisenduse läbiviimine mitme reegli abil nõuab reeglite omavahelist koordinatsiooni.
Seepärast kirjeldatakse “ebaloomulikud”, fonoloogiliselt ja morfoloogiliselt põhjendamatud
häälikumuutused minisõnastikega. Reeglitega saab kirjeldada nii fonoloogiast kui
morfoloogiast tingitud häälikumuutusi, kuna kontekstides võivad esineda nii pind- kui
süvaesituse sümbolid. Fonotaktilise häälikumuutuse korral piisab enamasti pindkontekstist,
morfo(fono)loogiline muutus aga nõuab ka süvaesituse kaasamist konteksti.
Eesti keele puhul osutub kasulikuks see, et reeglite kontekstides saab kasutada
sõnaosade piire märkivaid tunnuseid. Näiteks astmevahelduse reeglid vaatlevad ainult
sõnatüve sisehäälikuid ning tüve lõppu paigutatava nõrga astme tunnust (näiteks
astmevaheldus), suur osa reeglitest käivitub just tüve ja tunnuse/lõpu piiril või liitsõnapiiril
(näiteks reegel: "umbisikulise tegumoe tunnus d�t pärast s-i või h-ga lõppevat tüve").
Töös kirjeldatav eesti keele kahetasemeliste reeglite kogu on täielikult esitatud
lisas 3. Järgnevalt kommenteeritakse reeglitefaili struktuuri ja üksikreeglite sisu
põhjalikumalt.
Reeglitefaili alguses kirjeldatakse kasutatav tähestik, kus on üles loetud esiteks
kõik pindesituse sümbolid ning seejärel võimalikud paarid, millesse süvaesituse sümbolid
võivad kuuluda. Tüüpiliselt on üks paaridest nn. vaikimisi-paar (default), ülejäänute
esinemist piiravad reeglid.

27
Eesti keele kahetasemeliste reeglite kogu sõnastik on järgmine:
a b c d e f g h i j k l m n o p q r s sh z zh t u v õ ä ö ü x y G:g G:0 B:b B:0 T:d T:0 S:s S:0
S:r %+:0 %$:0 %&:0 A:a A:0 E:e E:0 U:u U:0 %.:a %=:0 2:0
Reeglite kirjutamise käigus tekkisid järgmised tähestiku alamhulgad:
Kons = b d g h j k l m n p r s sh z zh t v ; (konsonandid)
Vok = a e i o u õ ä ö ü ; (vokaalid)
Alfa = Kons Vok; (kogu eesti keele tähestik)
AV = G B D K P T S ; (astmevaheldust markeerivad suurtähed)
AVT = g b d k p t s ; (eelmiste tugevat astet märkivad häälikud)
VaheVok = A E U ; (vokaalid, mis võivad kahe konsonandi vahelt kaduda)
TyveVok = a e i u ; (võimalikud tüvevokaalid)
LyhVok = a e o u õ ä ö ü ; (kõik vokaalid peale i ehk need, mis võivad lüheneda enne i-ga
algavat formatiivi)
LV = B G D S T K; (laadivahelduslikud häälikud süvaesituses)
LVTA = b g d s t p; (laadivahelduslike häälikute tugevad astmed)
Klus = k p t ; (tugevad klusiilid)
NorkKlus = g b d ; (nõrgad klusiilid)
AVKlus = K P T ; (astmevaheldusele alluvad tugevad klusiilid)
Liq = l r ;
TavaKons = h j l m n r s t v ; (mitte-klusiilid)
Kui mingi alamavaldis esineb reeglites sageli, võib talle anda nime, eriti kui see
alamavaldis omab sisulist tähendust.
Definitsioonid:
Piir = [.#. | %+: | %&:]; (morfeemipiir - tüve ja formatiivi vahel on +, liitsõnaosade vahel
& , sõnalõpus .#.)
Algus = [.#. | Kons+ | %&:] ; (sõna, liitsõna komponendi või silbi algus)

28
3.2.1. Astmevahelduse reeglid
Ajalooliselt sõltus eesti keele sõnade astmevahelduslikkus ja astmevahelduse tüüp sõna
häälikulisest kujust. Aja jooksul on eesti keel aga läbi teinud palju muutusi, kõige
olulisemateks neist võib pidada tüvevokaali kadu ainsuse nimetavas ja omastava käände lõpu -
n kadumist. Samuti on vokaal a(ä) kadunud käändelõppudest. Soome keeles on need praegugi
säilinud (vrd. keel-keele-keelt ja kieli-kielen-kieltä).
Tänapäeva eesti keeles ei määra sõna häälikuline kuju enam tema astmevahelduslikkust
(Hint 1980). Astmevaheldus on tänapäeva eesti keeles leksikaalselt tingitud, ta on sõnade
eriomadus, mis ei tulene paratamatult sõna häälikulisest struktuurist. Seega tuleb
astmevahelduslikud sõnad märgendada, seejuures ära märkides ka selle, missugused vormid on
tugevas ja missugused nõrgas astmes.
Näide 6. Tüvevahelduste sõltumatus sõna häälikkoosseisust.
ainsuse nimetav pude ude kude lagi nagi
ainsuse omastav pudeda udeme koe lae nagi
ainsuse osastav pudedat udet kudet lage nagi
Näitest 6 selgub, et häälikkoostiselt väga sarnastel sõnadel võib esineda erinevusi
igal pool: nii astme- (d:0, g:0 vs. AV-ta) kui tüvelõpuvahelduste (0:me, 0:da,
muutumatu), liituvate formatiivide (osastava lõpp -0 või -t) ning allotaktika (kas osastava
lõpp liitub lisasilbiga või lisasilbita tüvele) seisukohalt.
Kahetasemeline morfoloogiamudel annab võimaluse astmevaheldust siiski
reeglitega käsitleda. Kuna reegel vaatleb korraga sümbolipaari, mis koosneb vastavatest
süva- ja pindesituse sümbolitest, saab reeglis viidata ka muudele sümbolitele peale
otseselt sõnavormis esinevate häälikute. Astmevahelduslike sõnade puhul märgitakse
muutuv foneem süvaesituses mingi pindtähestikus mitte sisalduva sümboliga, võimaluse
korral tugevale astmele vastava suurtähega. Sellel suurtähel on pindesituses kaks varianti,

29
mis vastavad parajasti nõrgale ja tugevale astmele. Tegemaks valikut nõrga ja tugeva
astme vahel, markeeritakse nõrgaastmeline tüvi markeriga “$”. Astmevahelduse reegel,
kohates sobivat suurtähte, otsib sõnatüve lõpust nõrga astme markerit. Kui marker leidub,
aktsepteeritakse reeglis esinev sümbolipaar, vastasel korral läheb käiku reeglitekogu
tähestikus vaikimisi kehtestatud vastavus.
Näide 7. Nõrgaastmelise tüve markeri "$" mõju.
Vastavused k o o K i $ + d ja k o o K i + d e + s t on aktsepteeritavad, k o o g i 0 0 d k o o k i 0 d e 0 s t kuid vastavused k o o K i $ + d ja k o o K i + d e + s t mitte. k o o k i 0 0 d k o o g i 0 d e 0 s t
"$"-ga markeeritud tüves sobib nõrgale astmele vastav paar K:g, markeerimata
tüves läheb läbi vaikimisi kehtiv vastavus K:k.
Esmapilgul näib, et astmevahelduse reeglid võivad siis olla kõik ühesugused.
Reegli vasakul poolel on vastavus <suurtäht>:<nõrgale astmele vastav häälik>, vasak
kontekst pole oluline ning kusagil paremas kontekstis peab leiduma marker "$". Kuid
eesti keele astmevaheldussüsteemis pole vastavus tugeva ja nõrga astme allomorfide
vahel üksühene: ühele ja samale tugeva astme allomorfile võib nõrgas astmes vastata
erinevaid häälikuid.
Näide 8. Astmevaheldustüüpide mitmekesisus eesti keeles
tuba-toa (b:0), tõmbama-tõmmata (b:m), varvas-varba, kaebama-kaevata (b:v)
jalg-jala, kurg-kure, nuga-noa (g:0), selg-selja, järg-järje (g:j)
rida-rea, luud-luua (d:0), sada-saja (d:j), känd-kännu (d:n), kallas-kalda (d:l), kord-korra
(d:r)
käsi-käe (s:0), vars-varre (s:r)
kott-koti, laht-lahe, ütlema-öelda (t:0), pilt-pildi (t:d)
kukkuma-kukun, käskima-käsin, õhk-õhu (k:0), telk-telgi, pank-panga, virk-virga (k:g)
lipp-lipu (p:0), karp-karbi, tulp-tulbi (p:b)

30
Analüüsides näites 8 esinevaid vastavusi tugeva ja nõrga astme häälikute vahel
saame paaride hulga {(b:m), (b:v), (g:0), (g:j), (d:0), (d:j), (d:n), (d:l), (d:r), (b:0), (s:0),
(s:r), (t:0), (t:d), (k:0), (k:g), (p:0), (p:b)} Selles hulgas esineb mitmeid paare, kus tugevat
astet märkiv häälik on üks ja seesama, kuid nõrga astme häälikud erinevad. Üks võimalus
oleks iga paari esimene sümbol süvaesituses erinevalt tähistada ja niimoodi vabaneda
mitmesusest. Kuid see ähmastab sõnatüve sõnastikuesitust. Mõistlikum lahendus oleks
kontekstide eristamine, kuid kas see on kõikide astmevaheldustüüpide puhul võimalik?
Järgnevalt vaatleme eraldi kõiki tugeva astme häälikuid ning analüüsime kõikvõimalikke
vastavusi ning kontekste.
1) b:0, b:m, b:v
b assimileerub eelseisva konsonandiga m, kaob lühikese lahtise silbi järel ning
muutub v-ks pika silbi järel (kaks vokaali või vokaal + liikvida). Neid kolme
astmevahelduse tüüpi käsitlevad järgmised kahetasemelised reeglid:
� "AV 4-5: assimilatsioonid s:r ja b:m" !näited: vars-varre; tõmbama-tõmmata
SB:RM � RM _ (TyveVok) (S:) %$: ; where SB in (S B)
RM in (r m)
matched;
"where ... matched" osa on kasulik reeglites, kus olemuslikult sama nähtus
hõlmab terve hulga häälikute teisenemist mingiteks teisteks häälikuteks. Tänu sellele pole
iga vastavuse jaoks vaja kirjutada eraldi reeglit, piisab vaid vastavate sümbolihulkade
kirjeldamisest.
� "AV 9: b kadu"
B:0 � Algus Vok: _ (Vok:) %$:;
� "AV 19: b:v"
B:v � Vok [Vok|Liq] _ (Vok) %$:; !kaebama-kaevata, kõlbama-kõlvata, värbama-
värvata
2) g:0, g:j

31
Siin on kontekstide eristamine keerulisem. Kui g-le eelneb vahetult vokaal, siis ta
nõrgas astmes kaob:
G:0 � Vok _ %$:;
Kui aga g-le eelneb l või r , siis ühetähelisest vasak- ja parempoolsest kontekstist
ei piisa:
LC = l, RC = a LC = r, RC = e
jalg-jala (g:0) kurg-kure (g:0)
selg-selja (g:j) särg-särje (g:j)
Uurime, kas l-le või r -le eelneva vokaali kaasamine konteksti võimaldab neid
astmevahelduse tüüpe eristada. Kirjutame tabeli 3 vasakpoolsesse tulpa g:0-tüüpi sõnad
ning parempoolsesse tulpa g:j-tüüpi sõnad ning toome välja kahetähelise vasakpoolse
ning ühetähelise parempoolse konteksti. Grupeerime ühesuguse esisilbi vokaaliga sõnad.
Tabelist 3 selgub, et esisilbi vokaali a, i, u ja õ puhul ei pea paremat konteksti ehk
tüvevokaali arvestama: astmevahelduse tüübiks on siin g:0. Kastiga ümbritsetud ja seega
problemaatilised on sõnad, millel esisilbi vokaaliks on e, ä või ü. Siin aga otsustab
tüvevokaal, kumma astmevaheldustüübiga on tegemist. Seejuures saab kõik kolm juhtu
ühte reeglisse kokku võtta: “Kui esisilbi vokaal on e, ä või ü ja tüvevokaal on i või u, siis
tugeva astme g nõrgas astmes kaob, kui tüvevokaal on a või e, siis vastab g nõrgas astmes
j-le”.
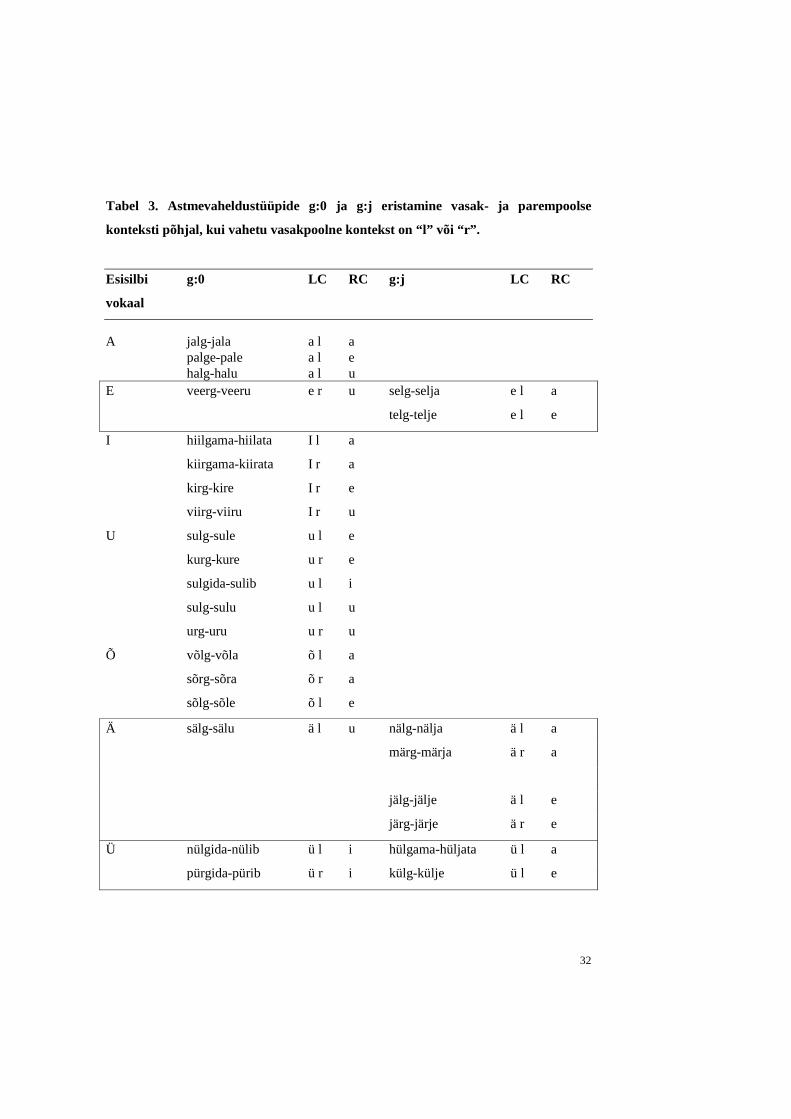
32
Tabel 3. Astmevaheldustüüpide g:0 ja g:j eristamine vasak- ja parempoolse
konteksti põhjal, kui vahetu vasakpoolne kontekst on “l” või “r”.
Esisilbi g:0 LC RC g:j LC RC
vokaal
A jalg-jala a l a
palge-pale a l e halg-halu a l u
E veerg-veeru e r u selg-selja e l a
telg-telje e l e
I hiilgama-hiilata I l a
kiirgama-kiirata I r a
kirg-kire I r e
viirg-viiru I r u
U sulg-sule u l e
kurg-kure u r e
sulgida-sulib u l i
sulg-sulu u l u
urg-uru u r u
Õ võlg-võla õ l a
sõrg-sõra õ r a
sõlg-sõle õ l e
Ä sälg-sälu ä l u nälg-nälja ä l a
märg-märja ä r a
jälg-jälje ä l e
järg-järje ä r e
Ü nülgida-nülib ü l i hülgama-hüljata ü l a
pürgida-pürib ü r i külg-külje ü l e

33
G laadivaheldust käsitlevad kahetasemelised reeglid on siis järgmised:
� "AV 11: g kadu" ! jalg-jala, kirg-kire
G:0 � Vok _ (Vok|h) %$: ;
[ a | i | õ | u ] [ l | r ] _ (Vok) %$: ;
[ e | ä | ü ] [ l | r ] _ [ i | u ] %$: ;
� "AV 17: g:j" !märg-märja, hüljes-hülge
G:j � [ e | ä | ü ] [ l | r ] _ [ a | e ] (S: ) %$: ;
3) d:0, d:j, d:l, d:n, d:r
Iseäranis palju on neid laadivahelduse tüüpe, milles tugevat astet esindab d.
Erinevaid nõrga astme variante on siin viis: 0, j, l, n ja r. Kolmel viimasel juhul on
tegemist assimilatsiooniga ning need astmevahelduse tüübid on väga selgelt vasaku
kontekstiga määratud: d assimileerub selle konsonandiga hulgast {l, n, r}, mis talle
vahetult eelneb. D assimilatsioonireeglid on niisiis üpris lihtsad:
� "AV 6: assimilatsioon d-l"
D:l � Algus Vok l _ (TyveVok) (S:) %$:;
� "AV 7: assimilatsioon d-n"
D:n �n _ (Vok) (S:) %$:;
� "AV 8: assimilatsioon d-r"
D:r � Algus Vok r _ (TyveVok) (S:) %$:;
Sarnaselt g:0 ja g:j-ga on problemaatiline d:0 ja d:j kontekstide eristamine. Kui d-
le eelneb pikk silp, siis d nõrgas astmes kaob (laud-laua, siirdama-siirata), kuid lühikese
silbi järel võib d kas kaduda või muutuda j-ks (vedada-vean, madu-mao, rida-rea, õde-õe,
küdeda-köeb (d:0), aga rada-raja, sadu-saju, koda-koja, sõda-sõja (d:j)). Analoogilisel
kontekstide võrdlemisel, nagu tegime tabelis 3, ilmneb, et
� esisilbi vokaalide3 e, i, u, ü puhul on vastavus alati d:0;
3 Esisilbi vokaali võtame algvormist, mitte arvestad es vokaali madaldumist

34
� esisilbi vokaali o puhul on vastavus alati d:j;
� esisilbi õ ja tüvevokaali e puhul esineb kadu (õde-õe), aga tüvevokaalide a ja u puhul
muutub d nõrgas astmes j-ks (sõda-sõja-sõjust);
� esisilbi a ja tüvevokaali a puhul alati vastavus d:j, kuid tüvevokaal u sunnib lisaks
vaatama sõnaalguse konsonanti - võiks öelda, et siin on tegemist väga ebareeglipärase
juhtumiga, kuna fonoloogiliselt kujult väga sarnased sõnad muutuvad erinevalt, vrd.
sadu-saju, rada-(radadelt e.) rajult ning madu-mao, ladu-lao, kadu-kao. Siin tuleb
sisuliselt kõik üksikjuhtumid panna reeglisse, mis pole just hea stiil. Kuid uusi sõnu
d:j-tüüpi tõenäoliselt ei tule, kuna laadivaheldus on tänapäeva eesti keeles muutunud
ebaproduktiivseks, s.t. laadivaheldus taandub vananevast mitteaktiivsest sõnavarast
ning uued keelde tulevad sõnad ei ühine laadivahelduslike tüüpidega (Hint 1997).
Saame reeglid:
� "AV 18: d:j"
D:j � [ a | o | õ ] _ a %$:; !sadada-sajab, sõda-sõja
[ [[ r | s ] a] | o | õ ] _ u %$: ; !sadu-saju, kodu-koju
� "AV 10: d kadu"
D:0 � Algus Vok Vok: _ (TyveVok:) (l) %$:; !laud-laua, vaidlema-vaielda
Vok Vok Liq _ TyveVok %$:; !siirdama-siirata
[ e | i: | u: | ü: ] _ TyveVok: %$: ; !vedada-vean, rida-rea
õ _ e %$: ; !õde-õe, põdeda-põen
[Kons- [r|s] ] a _ u %$: ; !ladu-lao, kaduda-kaon
Reeglis 10 on esimeses ja kolmandas kontekstis viidatud leksikaalse esituse
vokaalidele, kuna neile mõjub vokaali madaldumise reegel (vt. jaotis 3.2.2), mille
tulemusena pindsümbol ei lange leksikaalsega enam kokku.
4) s:0, s:r
S allub nii laadi- (assimilatsioon ja kadu) kui vältevaheldusele (ss-s, nt. kauss-
kausi). Assimilatsioonireegel s:r on kokku võetud b:m assimilatsiooniga (vt. 1)). S-i
nõrgas astmes (näiteks rida-rea- esisilbis i, kududa-koon - esisilbis u).

35
astmevahelduslik kadu esineb vokaalide vahel või s-i järel. Peale selle esineb ka S-i
lõpukadu (küngas-künka, rahvas-rahva, sipelgas-sipelga), mis pole alati seotud
astmevaheldusega. Arvestades, et kõige paremad on parajasti-siis-kui-reegleid ning need
kaks nähtust kontekstide poolest teineteist segada ei saa, siis võime nad kokku võtta ühte
reeglisse. Seejuures paneme tähele, et kui S-i lõpukadu esineb astmevahelduslikes
sõnades, siis on ilma S-ita vorm tugevaastmeline.
� "AV 12-13: s sise- ja lõpukadu"
S:0 � Vok [Kons+] (AV:AVT) TyveVok: _ Piir;
Vok AV:AVT TavaKons Vok _ Piir;
Algus (Vok) Vok (s) _ (Vok) %$:; !
where AV in (G B D K P T )
AVT in (g b d k p t )
matched;
5) k:0, k:g, p:0, p:b, t:0, t:d
Üheselt on siin ennustatav pikale vokaalile, diftongile või sonorandile (l, m, n, r)
järgneva tugeva klusiili p, t, k vaheldumine vastava nõrga klusiiliga b, d, g. Viimase
kontekstina on kõigi kolme klusiili puhul kirjeldatud sõber-tüüp, mida iseloomustab
lisaks astmevaheldusele vahevokaali kadu.
� "AV 14 k-g"
K:g � Vok [Liq | n | Vok] _ (Vok) (S:|l) %$:; !kook-koogi, pilk-pilgu, küngas-
künka
Vok _ VaheVok: Liq (Vok) %$:; !kogre-kokre
� "AV 15 p-b"
P:b � Vok [Liq | m | Vok] _ Vok (S:) %$:0 ; !karp-karbi, kimp-kimbu, loopida-
loobin
Vok _ [Liq|j] Vok (S:) %$:; !lupjama-lubjata, kobras-kopra
Vok _ VaheVok: Liq (Vok) %$:; !sõpra-sõbra

36
� "AV 16 t-d"
T:d �Vok [Vok|Liq | n] _ Vok %$:; !paat-paadi, kaart-kaardi, elevant-elevandi
Vok Vok _ e l %$:; !vaatlema-vaadelda
Vok _ VaheVok: Liq (Vok) %$:; !putru-pudru
Lühikese silbi järel, t ja k puhul h järel ning k puhul s järel leiab aset klusiili kadu: � "AV 1-2 - k ja p kadu" !kukk-kuke, lipp-lipu, õhk-õhu, kask-kase
AVKlus:0 � Vok (r) [Klus|h|s] _ Vok (S:|l) %$:;
where AVKlus in (K P)
Klus in (k p)
matched;
� "AV 3 - t kadu"
T:0 �Vok [t|h] _ Vok (S:) %$:; !tt-t (rott-roti) ja ht-h (ehtima-ehib)
Algus Vok: _ e (l) %$:; !ütlema-öelda, jätma-jäetakse
Eesti keeles esineb ka prosoodiline astmevaheldus, mis kirjapildis ei avaldu,
kuna teise ja kolmanda välte erinevus ilmneb kirjapildis ainult klusiilidel. Kuivõrd see
astmevahelduse tüüp kirjapilti ei mõjuta, jääb astmevahelduslikkus nende tüvedes
markeerimata.
3.2.2. Fonotaktika reeglid
Fonotaktika reeglid ütlevad, millised häälikujärjendid sobivad eesti keele
sõnadeks ja millised mitte (tähendusega pole siin midagi tegemist). Nad keelavad ära
teatud häälikujärjendid, mõne hääliku esinemise järgsilbis jne. Fonotaktika reegleid on
üldiselt rohkem, kui käesolevas reeglistikus formaliseeritud. Siin pööratakse tähelepanu
ainult nendele häälikujärjenditele, mis võivad morfoloogiliste formatiivide liitumisel või
tüvevahelduse (eeskätt astmevahelduse) mõjul tekkida.

37
Allikast (Hint 1978) võib välja tuua järgmised kasulikud seaduspärasused:
� Häälik h saab olla pearõhulise silbi lühikese vokaali järel ja sõna alguses ning ainult
seal. H esinemise piirangutest on tekkinud vokaali lühenemine vormides maha, töhe, öhe,
sohu, pähe.
"pikk vokaal lüheneb enne h-d"
%.:0 � _ h Vok;
Samal ajal toimib ka teine fonotaktika reegel:
� Järgsilpides pole o, ö, ä lubatud ning toimub teisenemine o����u, ö����e, ä����e.
"vokaalide o, ö, ä teisenemine järgsilbis vastavalt u, e, e-ks"
V1:V2 �Vok %.: h _ Piir; where V1 in (o ö ä)
V2 in (u e e)
matched;
� Võimalikud on kõik pikad vokaalid, piiranguid on diftongidele:
i võib diftongi 2. komponendiks olla suvalise 1. komponendi korral,
u ei saa olla ö, ü järel,
e saab olla a, o, õ, ä järel,
a võib olla ainult e järel.
Sellest tulenevad häälikumuutused astmevahelduslikes sõnades:
tugi-tue* �toe ue����oe
tuba-tua*�toa ua����oa
rida-ria*�rea ia����ea
süsi-süe*�söe üe����öe
Põhjus: häälikukaol tekkivad diftongid ei sobi eesti keele häälikusüsteemi.
"Vokaali madaldumine"
KorgeVok:MadalVok � Algus _ LV: [a|e|i:|u:](l) %$: ;
Algus Vok LV: _ %$: ;
where KorgeVok in (u ü i)
MadalVok in (o ö e)
matched ;

38
Veel ümbrusest tingitud teisenemisi:
� lumi-lumd*�lund
leem-leemt*�leent m����n enne t-d või d-d
"m �n t|d ees"
m:n � _ %+: [d | t] ;
� lodi-lotji* �lotje
ori-orji* �orje
osi-osji* �osje
Siin keelab fonotaktika häälikujärjendi ji , mis morfoloogilise reeglipära järgi peaks tekkima.
� laps-lapst*�last
"pst � st ja p kaashäälikuühendis"
p:0 � _ s %+: t ; !pst � st
Kons Vok _ :p (%$:)(%+:) [Kons-p+]; !kaashäälikuühend
� uks-ukst*�ust - kirjakeel on vastu tulnud häälduspärasusele.
"skt � st, kst �st ja k kaashäälikuühendis"
k:0 � s _ (%$:)(%+:) t ;
_ s (%$:)(%+:) t ;
Kons Vok _ :k (%$:)(%+:) [Kons-p+]; !kaashäälikuühend
K:0 � s _ (%$:)(%+:) t ; !skt-> st, kui k on astmevahelduslik (süvaesituses suur K)
* Vokaal a, e või u kaob l, m, n, r eest, kui lisandub tüvevokaal:
sõber-sõbra kannel-kandle
vaagen-vaagna koorem-koorma
"Vahevokaali kadu"
VaheVok:0 � _ [Liq | m | n | v | s] (%+:) TyveVok ;
Vahevokaal tuleb sõnastikuesituses märkida suurtäheliselt, kuna kaduva vahevokaali
markeerimata jätmisel oleks kaoreegel hakanud toimima ka sellistele laensõnadele nagu
kanal-kanali (kanli*), pinal-pinali (pinli*) jt.
� "oo+i, öö+i �õi" !sööma-sõi, jooma-jõi
V1:õ � _ %.: %+: i [.#. | d | n | m e | t e]; where V1 in (o ö);

39
Eesti keele jaoks on olemas mitmuse tüvevokaali valikureeglid, lähtudes
tüvevokaalist ja esisilbi struktuurist (Viitso 1990), kuid nendest on erandeid. Alati kehtivad
järgmised kolm reeglit:
ainsuse osastav mitmuse osastav
e i
u e
i e
Keerulisemad on a-tüvelised sõnad, kus mitmuse tüvevokaal võib olla i, u või e.
1) a -> i, kui a) pikas esisilbis {u o}, v.a. kui a-le eelneb j;
b) esisilbis {ü ö ä e}, v. a. kui a-le eelneb j;
c) erandid pikk, silm, king (ajalooliselt ä-tüvelised)
2) a -> u, kui a) esisilbis {a, õ, äi, ei}, v.a. 1c) erandid;
b) eelneb {äCj eCj}, C - konsonant
3) a -> e, kui a) lühikeses esisilbis {u o};
b) eelneb {uCj oCj üCj}
Lahendus:
1. Erandite jaoks kirjutada nende muutumist käsitlev jätkusõnastik.
2. Teised pesa-tüüpi sõnad saab kirjeldada kahe jätkusõnastikuga PESA ja PESA-Adt
(eraldi tuleb vaadelda neid sõnu, millest saab aditiivi moodustada ja neid, millest ei saa).
Mitmuse tüvevokaali tähistatakse sõnastikuesituses suurtähelise foneemiga "V", millele
seatakse a-tüveliste sõnade puhul eeskirja 1)-3) kohaselt ning e- u- ja i-tüvelistel eespool
kirjeldatud reegli kohaselt pindesituses vastavusse i, u või e.
Näide 9. Pesa-tüüpi sõnu käsitlevad reeglid ja sõnastikud.
LEXICON Nimisõna ............................. kala+S:kala PESA; maja+S:maj=a PESA-Adt; pori+S:por=i PESA-Adt; vana+S:vana PESA; ............................

40
LEXICON PESA-Adt PESA; +Sg+Adt:2 #; LEXICON PESA +Sg+N:0 #; +Sg+G:0 #; +Sg:0 S1; +Sg+P:0 #; +Pl+N:+d #; +Pl+G:+de #; +Pl:+de S1; +Pl+P:+sid #; +Pl+P:+V #; +Pl:+V S5;
Aditiivi moodustamiseks on vaja reeglit, mis markeri "2" olemasolu korral tüve
lõpus kahekordistab "="-märgi ees olevat konsonanti. Vaikimisi vastab võrdusmärgile
pindesituses tühisümbol.
� "Konsonandi kahekordistumine"
%=:K1 � K1 _ (TyveVok:) 2:; !mitte-klusiilid
NorkKlus: _ (TyveVok:) 2:; !klusiilid
where K1 in TavaKons;
Konsonandi kahekordistamine esineb lisaks pesa-tüüpi sõnade aditiivile ka tulema-tüüpi
verbidel da-infinitiivis ja sellest moodustatavates vormides:
s ü l = e 2 m a j = a 2 n i n = a 2 t u l = + a 2 p a n = 2 + a s u r = 2+ e s
s ü l l e 0 m a j j a 0 n i n n a 0 t u l l 0 a 0 p a n n 0 0 a s u r r 0 0 e s
Kirjeldatud reegel üksi ei võimalda kolmandasse vältesse viia nõrku klusiile
(b�pp, d�tt ja g�kk), sest kahetasemelised reeglid ei saa teisendada tervet segmenti
korraga. Kui tahame seda teisendust siiski reeglitega teha, siis peab olema kaks reeglit:
üks, mis seab vastavuse <%=:tugev klusiil> ja teine, mis seab vastavuse <nõrk
klusiil:tugev klusiil>:

41
� "Nõrga klusiili pikendamine"
NorkKlus:Klus � _ %=: (TyveVok:) 2:;
where NorkKlus in (g b d)
Klus in (k p t)
matched;
Järgmised kolm on mitmuse vokaali valikureeglid:
� "mitmuse vokaal i"
V:i � e: %+: _ ; ! e-tüvelised
Algus [e| o| u| ä| ö| ü] [Kons-j] (%=:) a: %+: _ ; !"eks ämm söö kodus sütt"
� "mitmuse vokaal e"
V:e � [i: | u:] %+: _ ; ! i- ja u-tüvelised
Algus [u | o] Kons (%=:) a: %+: _ ; !a-tüvelised, lühikeses esisilbis u või o
Algus [u | o | ü] Kons j: a: %+: _ ; !a-tüvelised, esisilbis uCj, oCj, üCj (kuri)
� "mitmuse vokaal u"
V:u � [a | õ | ä i | e i] Kons (%=:) a: %+: _ ; !"kass kõrtsis ei käi"
[ä | e] Kons j: a: %+: _ ; !a-tüvelised, esisilbis äCj, eCj (väli)
3.2.3. Morfeemipiiridel toimivad reeglid
Ü. Viksi "VVS"-i grammatikast (Viks 1992) võib leida kaks üldisemat laadi
morfofonoloogilise distributsiooni reeglit:
� Pikk vokaal lüheneb enne i-ga algavat formatiivi (nt. kuu-kuid).
"Pika vokaali lühenemine enne i-d ning täishäälikuühendi normaliseerimine" ! Võõrsõnades
ainult 'e': !idee-ideid, aga miljöö-miljöösid,depoo-depoosid,kanuu-kanuusid
%.:0 � [Vok [Kons+] e] | [Algus LyhVok] _ %+: i ;
a _ [D:|G:] i %$:; !praadida-praeb, saagida-saeb V1 V1 V2 � V1 V2
Reegli teine osa kuulub pigem fonotaktika valdkonda, kuid reeglite testimine on hõlpsam,
kui kõik võimalikud kontekstid, milles vastavus võib esineda, kokku võtta ühte �-reeglisse.

42
� i�e enne i-ga algavat formatiivi (nt. naaskli-naaskleid, kauni-kauneim).
"i � e enne i-ga algavat formatiivi"
i:e � Kons _ (S:) %+: i ;
Järgmine reegel, mis kahetasemeliste reeglite omapära tõttu on jagatud kaheks, on näitena
toodud Ü. Viksi dissertatsioonis (Viks 1994a):
� " Pikk madal vokaal kõrgeneb a ja e ees - 1" ! oo+a->uua, öö+a->üüa
V1:V2 � _ %.: %+: [a | e s];
where V1 in (o ö)
V2 in (u ü)
matched;
� " Pikk madal vokaal kõrgeneb a ja e ees 2" ! oo+a->uua, öö+a->üüa
%.:V2 � V1: _ %+: [a | e s];
where V1 in (o ö)
V2 in (u ü)
matched;
Samast on leitud ka järgmine, konsonantidevahelise siirdevokaali reegel:
� "v �ev konsonanttüvelistel verbidel"
%+:e � [Kons | AV: ] _ v .#.;
� "Tüvevokaal kaob tüvemitmuse vokaali eest" !sõna+u=sõnu
TyveVok:0 � _ %+: V:;
Teised, praktilise testimise käigus kasulikuks osutunud morfeemipiiridel kehtivad
reeglid:
� "Morfeemipiiril kaks s-i saavad üheks" !inimes+sse=inimesse
s:0 �_ [:0*] %+: :s :i;
� "Morfeemipiiril kaks d-d saavad üheks ning dt saab t-ks"
d:0 � D: %+: _d; !and+da=anda
D: %+: _t; !and+tud=antud

43
� "Käskiva kõneviisi formatiivi -gu või -ge alguse g läheb k-ks helitu konsonandi järel
või NA-tüves a järel"
g:k � [h | D:d | T:t] [:0*] %+: _ [e|u]; !tehke, andke, võtke
a %$: %+: _ [e|u]; !hakake
� "Formatiivi alguse d läheb t-ks helitu konsonandi järel"
d:t � s %+: _ [a | e s]; !seis+da=seista
� "Tüvevokaal kaob us-liite ees" !raske+us=raskus, puhta+us=puhtus
V1:0 � _ (S:) %+: u s ; where V1 in (a e u);
� "e�i enne tegijanime tunnust 'ja'" !olija, tegija, nägija
e:i � [l | :g] _ %+: j a;
3.2.4. Ortograafiareeglid
Kaashäälikuühendis (Erelt 1997:9) kirjutatakse kõik häälikud ühekordselt, näiteks
kukk ru*�kukru, kristallne*�kristalne.
� "Konsonantühendi reegel "
K1:0 � Vok _ :K1 (%$:)(%+:) [Kons-K1]; where K1 in TavaKons ;
Sama täishäälikuühendi kohta:
� "Vokaalühendi reegel"
V1:0 �Vok _ D: V1 %$:; where V1 in (a u);
Kolm või enam ühesugust häälikut kõrvuti eraldatakse loetavuse huvides
sidekriipsuga (Erelt 1997:79).
� "Liitsõnapiirile sidekriips kolme ühesuguse hääliku korral" !plekk-katus, jää-äär
%&:%- � :A1 :A1 _ :A1; where A1 in (a e f h i k l m n o p r s sh t u õ ä ö ü);

44
Silbi (siis ka sõna) lõpus kirjutatakse i (Erelt 1997:7).
� "j � i sõna lõpus" (kirj*�kiri, purj*�puri)
j:i � _ [.#.|%&:] ;
3.2.5. Mittetähelistele süvasümbolitele vaikimisi-väärtuste omistamise reeglid
Mittetähelistele sõnastikuesituses leiduvatele sümbolitele tuleb vaikimisi-väärtus omistada
reeglitega siis, kui sõltuvalt kontekstist võib vaikimisi-väärtus olla erinev.
Punkt märgib vaikimisi eelneva vokaali pikendamist:
m a . t ö . + l
m a a t ö ö 0 l
� "Pikk vokaal vaikimisi"
%.:V1 � V1 (h) _ ~[%+:0 i | [D:|G:] i %$:] ; where V1 in LyhVok;
3.2.6. Probleemid reeglite kirjutamisel
Reeglite koostamisel tuli kokku puutuda mitmete probleemidega, mis osaliselt
johtuvad kasutatava formalismi iseärasustest, osaliselt eesti keele morfoloogilise süsteemi
keerukusest.
� Tähistusprobleemid:
Süvaesitusse uute sümbolite lisamisel oleks mõistlik silmas pidada, et sümbol oleks
tähenduselt nähtusega kuidagi samastatav.
� Astmevahelduse korral näiteks oleks hea, kui süvaesituse sümbol ühtiks
tugeva astme allomorfiga. Üksikasjaliku kontekstide analüüsi teel õnnestus
seda põhimõtet ka järgida.
� Vokaali kadu ilmneb mitmel juhul, kusjuures kaduvate vokaalide hulgad on
teatava ühisosaga, kuid täielikult ei kattu:

45
1) Vahevokaali kao reeglisse on haaratud a, e, u. Kaduv vokaal tuli siin
kindlasti markeerida (vastavate suurtähtedega A, E, U), kuna sarnane
häälikuline kuju seda nähtust alati ei põhjusta.
2) Pikad vokaalid aa, ee, oo, uu, ää, öö, üü lühenevad enne i-ga algavat
formatiivi. Pika vokaali traditsiooniline tähistus, näiteks häälduse
märkimisel, on koolon. Kahetasemelistes reeglites on koolon aga süva- ja
pindsümboli eraldajaks reegli vasakul poolel. Selline tähistus oleks küll
lubatav, kui kirjutada kooloni ette protsendimärk, aga reegli loetavuse
seisukohalt on see ikkagi halb. Mingi teine täht tekitaks ka segadust.
Seetõttu sai valitud pika vokaali teise komponendi süvasümboliks punkt.
Vaikimisi pikendab punkt eelseisvat vokaali, mitmuse formatiiv i tekitab
aga pindesitusse nullsümboli.
3) Tüvevokaal (a, e, i, u) kaob tüvemitmuse vokaali eest. Kuna siin on parem
kontekst väga selgelt piiritletud (+: V:), siis võib need vokaalid jätta
sõnastikus väiketähelisteks.
Kui markereid tuleb palju, siis pole tähistuse mõtestatuse idee teostatav, veelgi
halvem: klaviatuurisümbolid võivad otsa lõppeda. Kahetasemelised reeglid võtavad aga
süvaesitusest ühe sümboli korraga, seega pikemaid tähiseid ei saa kasutada. Teine
probleem on see, et regulaarsete avaldiste süntaksis on suurem osa mittetähelistest
sümbolitest juba kasutusel. Nende tähenduse saab hetkeks protsendimärgiga küll
tühistada, aga sellega halveneb reeglite loetavus.
� Eesti keeles on palju astmevahelduse tüüpe, kusjuures vastavus tugeva ja nõrga astme
allomorfide vahel pole üksühene. Mõnel juhul on kontekstid, milles esineb üks ja
teine vastavus, raskesti eristatavad (vrd. jälg-jälje ja jalg-jala, ladu-lao ja sadu-saju).
� Häälikumuutuste käsitlemine reeglitega on mõnikord raske. Näiteks lööma-lõi,
jooma-jõi, aga töö-töid (mitte tõid*), soo-soid (mitte sõid*). Samal ajal pole meil
reeglis võimalik kasutada infot sõnaliigi kohta. Et seda nähtust reegliga käsitleda,
peab leksikonis tegema vahet: tö.+i+d � töid, aga to.+id � tõid. See tähendab, et
verbi formatiiv jääb algosadeks lahutamata.

46
� Puudub võimalus ühe reegliga käsitleda tervet segmenti. Näiteks jooma-juua
(oo�uu), saba-sappa (b�pp) tuli ära teha kahe reegliga). Niisugusel juhul peab aga
vältima olukorda, kus reeglid kasutavad vastastikku teineteise vasaku poole
pindsümbolit kontekstis - muidu tekib nõiaring ja reeglite kogu rakendamine
ebaõnnestub. Kindlaim viis seda vältida on süvaesituse kontekstide kasutamine, kui
vähegi võimalik. Samal ajal aga peaks see olema just kahetasemeliste reeglite suur
eelis, et reeglite kontekstides saab osutada mõlema taseme sümbolitele.
� Kui mitmed reeglid kasutavad sulundioperatsiooni *, siis võtab automaatide korrutise
leidmine aega ning korrutis läheb väga suureks. Näiteks astmevahelduse käsitlemisel
üldiste reeglitega nagu
D:0 � _ (Alfa) * $:;
kulus ühendautomaadi koostamiseks 10 minutit. Sisuliselt sama, kuid täpsustatud,
sulundioperatsiooni vältivate kontekstidega reeglitekogu ühendamiseks sõnastikuga
kulus vaevalt 1 sekund. Konteksti täpsustamine osutub tüübiloendite võrdlemisel tihti
võimalikuks, kuigi esialgu on mugavam kirjutada üldisema kontekstiga reegleid.
Koskenniemi (Koskenniemi 1997) märgib sama probleemi lõplikel automaatidel
põhineva süntaksi puhul.
3.3. Eesti keele sõnastike süsteem
Sõnastike süsteemi ülesandeks kahetasemelises mudelis on defineerida kõik
morfotaktiliselt võimalikud morfeemijadad. Töö autori koostatud eesti keele sõnastike
süsteem on täielikult esitatud lisas 4. Hetkel ulatub juursõnastike kirjete arv vaid 350-ni,
kuid juba nii väikestki hulka erinevaid leksikaalseid tähendusi kasutades on sõnastike
süsteem võimeline genereerima üle 20 000 lihtsõnavormi ning lõpmatu arvu liitsõnu (kuna
liitsõnakomponentide arv pole piiratud).
Kirjete grupeerimine erinevatesse sõnastikesse on tavaliselt määratud nende
võimaliku kombinatoorikaga, s.o. millele antud sõnaosa enamasti eelneb ja millele järgneb.
Iga jätkamisviit osutab ühele või mitmele sõnastikule, millest otsida sobivat sõnajuppi

47
jätkamiseks. Selline viitstruktuur väldib kordusi: näiteks pole meil tarvis kahte eraldi
sõnastikku nimi- ja omadussõnade käändelõppude jaoks.
Eesti keel on rikas tüvevahelduste poolest. Kahetasemeline morfoloogiamudel
pakub kaks võimalust tüvevahelduste käsitlemiseks (Koskenniemi 1983):
1) Reeglid. Juhul, kui pindkontekst ega morfoloogilised tunnused pole piisavad,
tuleb defineerida mingi märgend, mis lisatakse seda tüüpi sõnade
sõnastikuesitusse ning mille olemasolu kontrollil reegel põhineb. Käesolevas
töös on nii kirjeldatud näiteks kogu astmevaheldus (kasutatakse nõrga astme
markerit $) ja konsonandi pikenemine pesa-tüüpi noomenite aditiivis ja tulema-
tüüpi verbide da-infinitiivi tüves (sümbol = ja tüve lõpus marker 2).
2) Vahelduvate mustrite (alternation patterns) sõnastikud. Eesti keeles on
sobilik kirjeldada vahelduvate mustritega ne-s-sõnad, tüvelõpu lisasilbid -da ja
-me, soome keeles produktiivne, aga eesti keeles paari erandsõnaga piirduv
muster s-kse (vennas-vennakse-vennast, omas-omakse-omast). Üldiselt
loetakse isegi paari-kolme tüve poolt viidatavat vahelduvate mustrite
sõnastikku odavamaks kui mitme tüvevariandi kirjutamist sõnastikku.
Seega võimaldavad sõnastikud käsitleda nii astme- ja tüvelõpuvaheldusmalle.
Mingi sõnatüübi astmevaheldusmall (Viks 1994a) iseloomustab tugeva (T) ja nõrga (N)
astme positsioone paradigmas. Lõpuvaheldusmall iseloomustab lemmatüve (A) ja
muutetüvede (B, C) positsioone paradigmas.
Näide 10. Astme- ja tüvelõpuvaheldusmallid
põhivormid astmevaheldusmall tüvelõpuvaheldusmall
kõndi|ma - kõndi|da - kõnni|n - kõnni|tud TTNN AAAA
vehkle|ma - vehel|da - vehkle|n - vehel|dud TNTN ABAB
jooks|ma - joos|ta - jookse|n - joos|tud TNTN AABA
liige - liikme - liige|t - liikme|d - liikme|id NTNTT ABABB
sinine - sinise - sinis|t - sinise|d - sinise|id AV-ta ABCBB

48
Keeleajalooliselt on eesti keele tüvevaheldusmallid olnud suurel määral
morfofonoloogiliselt tingitud (Viks 1994a). Astmevaheldust mõjutas sõnavormi
silbistruktuur: kahesilbilistes tüvedes põhjustas kinnine teine silp nõrga astme tekke, lahtise
silbi korral kujunes tugev aste. Lõpuvaheldus oli seotud kindlate vormidega: kahetüvelistel
sõnadel oli teatud vormides kasutusel vokaaltüvi, teatud vormides konsonanttüvi. Tänaseks
on keeles toimunud palju häälikumuutusi, mille tagajärjel tüvevaheldusi põhjustanud
tegurid võivad olla kadunud, kuid vaheldusmallid ise on säilinud. Seetõttu on
tüvevaheldusmallid saanud suurel määral sõna individuaalseks iseärasuseks ning neid ei saa
enam üldiste, häälikulisel ümbrusel põhinevate reeglitega kirjeldada, vaid vastav info tuleb
paigutada sõnastikku.
Lemmatüvede levik paradigmas on verbil ja noomenil erinev (Viks 1990): verbide
lemmatüvede levik langeb alati kokku vastavalt kas tugeva või nõrga astme levikuga.
Noomenitel tuleb lemmatüvi tavaliselt esile ainult ainsuse nimetavas, kõigis teistes
vormides figureerib muutetüvi, sõltumata sellest, kas ta on seal tugevas või nõrgas astmes
või astmevahelduseta. Kuid umbes 300 noomeni puhul on levik teistsugune: nendes
astmevahelduslikes muuttüüpides, kus ainsuse nimetav on nõrgas astmes, kandub
lemmatüvi üle ka teistesse nõrgaastmelistesse vormidesse. Kuid sõber- ja padi-tüübis
seevastu on ainult ainsuse nimetav nõrgas astmes ning lemmatüvi teistesse
nõrgaastmelistesse vormidesse ei kandu.
Näide 11. Lemma- ja muutetüvede paiknemine erinevate sõnade puhul
hammas - hamba - hammast - hammaste - hambaid
liige - liikme - liiget - liikmete - liikmeid
aga: sõber - sõbra - sõpra - sõprade - sõpru
Formatiivide variandid on algselt samuti olnud morfofonoloogiliselt tingitud,
sõltudes formatiivi asendist sõnavormi silbistruktuuris, silbi rõhulisusest ja eelnevatest
häälikutest. Keeleajaloolised arengud on sellegi sõltuvuse paljudel juhtudel kaotanud ja
jätnud formatiivivariantide valiku sõna individuaalseks iseärasuseks. Vahel saab
formatiivivariandi siiski reegliga määrata, nagu näites 12.

49
Näide 12. Formatiivivariandi valik reegliga.
naerma-tüüpi verbide puhul kehtib reegel (vt. jaotis 3.2.3): "Formatiivi alguse d�t pärast
helitu häälikuga lõppevat tüve". Näiteks seis+da=seista
3.3.1. Käändsõnade sõnastikud
Morfotaktika üldreegel (Viks 1994a) noomenivormide moodustamiseks on järgmine:
tüvi+arv+kääne Noomenite puhul on olemas teatavad üldised reeglid selle kohta, millistest tüvedest
missugused käänded moodustatakse (tabel 4).
Tabel 4. Noomeni paradigmas tavaliselt üksteisest moodustatavad käänded (Viitso
1990):
-sse, -s, -st, -le, -l, -lt, -ks, -ni,
-na, -ta, -ga, -d
ainsuse käänded sisseütlevast
kaasaütlevani ning mitmuse nimetav
-te või –de mitmuse omastav
ainsuse omastav +
(-te või -de) + -sse, -s, -st, -le,
-l, -lt, -ks, -ni, -na, -ta, -ga
mitmuse käänded sisseütlevast
kaasaütlevani
Selles rühmas on vormimoodustus aglutinatiivne: ainsuse omastavast saadakse
kõik ülejäänud vormid (mitmuse tunnuse ja) käändelõpu lisamisel. Nimetatud
reeglipärast lähtudes on kirjeldatud sõnastikud S1 (käändelõpud sisseütlevast
kaasaütlevani) ning S2 (de-mitmuse käänded). Ainsuse käänded sisseütlevast
kaasaütlevani saadakse kõikide muuttüüpide puhul kirjest
+Sg:<ainsuse omastava tüvi> S1;
ning de-mitmuse käänded (tüüpidel, mille mitmuse tunnus on –de, mitte –te ja mitmuse
osastava lõpp -sid) kirjest
+Pl:<ainsuse omastava tüvi> S2;
kusjuures sõnastikud S1 ja S2 on järgmised:

50
LEXICON S1 ! käändelõpud sisseütlevast kuni kaasaütlevani
+Ill:+sse #; +In:+s #; +El:+st #; +All:+le #; +Ad:+l #; +Abl:+lt #; +Ter:+ks #; +Trl:+ni #; +Es:+na #; +Ab:+ta #; +Kom:+ga #;
LEXICON S2 ! de-mitmuse käänded
+N:+d #; +G:+de #; :+de S1; +P:+sid #; Ühe põhivormina toimib ka mitmuse osastava lühike vorm (N: sõna-sõnu-sõnus,
sõnust jne.), kuid nõrgeneva astmevaheldusega tüüpide puhul selline
vormimoodustusmuster ei toimi. Seal tuleb mitmuse osastava tugev aste asendada
muudes tüvemitmuse vormides nõrga astmega (N: jalg-jalgu-jalus, jalust jne.).
Tüvemitmuse lõppude sõnastikud on S4 ja S5, kusjuures S4 = S5 � {osastava,
rajava, oleva käände lõpud} ja S5 = {käändelõpud sisseütlevast saavani}, kuna üldiselt pole
viimases neljas käändes tüvemitmus kasutatav (Kaalep 1999:27). H.-J. Kaalepi praktika
eestikeelsete tekstide analüüsimisel näitab veel, et lugemik-tüübis on tüvemitmus kasutatav
kõigis käänetes, i-mitmusega sõnadel on vokaalmitmus võimatu kahe viimase käände puhul
ning seitsme erandsõna puhul on vokaalmitmus võimatu kolmes viimases käändes.
Lugemik-tüüpi sõnade puhul saab niisiis tüvemitmuse käänete moodustamiseks viidata
tavalisele käändelõppude sõnastikule S1, mis sisaldab käändelõppe sisseütlevast
kaasaütlevani. Tüvemitmusega sõnade lühikese mitmuse käänded saab kätte sõnastikust S5,
i-mitmusega sõnade jaoks on tüvemitmuse lõppude sõnastik S4 ja eranditel on
jätkusõnastikus lisakirje rajava käände kohta ning ülejäänud tüvemitmuse käänete
moodustamiseks viidatakse samuti sõnastikule S4.

51
Näide 13. liige-tüüpi sõnade jätkusõnastikud
LEXICON ME/T' ! tugevnev astmevaheldus, tüvelõpuvaheldus 0-me, nt. liige
+Sg+N:e$ #; +Sg+P:e$+t #; +Sg:me S1; +Pl+N:me+d #; +Pl+G:me+te #; +Pl:me+te S1; +Pl:me+i S4; LEXICON S4 ! i-mitmuse lõpud ('kuu', 'tütar', 'mõte', 'aasta' , ‘liige’ jt.)
+P:+d #; +Trl:+ni #; +Es:+na #; S5;
LEXICON S5 !Tüvemitmuse lõpud (ilma 4 viimase käändeta ja osastavata)
+Ill:+sse #; +In:+s #; +El:+st #; +All:+le #; +Ad:+l #; +Abl:+lt #; +Ter:+ks #;
3.3.1.1. Nimisõnad
Nimisõnajuurte sõnastikus on hetkel sadakond kirjet ning nende morfoloogiat
kirjeldavad järgmised minisõnastikud:
1) Astme- ja tüvelõpuvahelduseta sõnatüübid: KUU, MAA (erandvorm "maha"), AASTA,
TIBU, PESA-Adt (pesa), PESA (kana), 0-T-SID (kõne, tubli);
2) Astmevahelduseta, kuid tüvelõpuvaheldusega: A (tänav), U (suhkur), I-E (nimi), I-E-D
(lumi), 0-DA (hõbe), 0-ME (süda), S-KSE (juus);
2.1) ne-s-tüübid: NE-SEID (hobune), NE-SI (inimene), E-SI (küsimus), NE-SI-1 (naine);

52
3) Astmevahelduslikud tüübid:
3.1) Nõrgenev astmevaheldus: I/N (tund), U/N (jutt), E/N (külg), A-I/N (vend), A-U/N
(laud), LV/N (madu), LV/N-Adt (tuba), I-E-T/N (käsi), JALG, VARS, IK (lugemik),
A/NNT (sõber), 0-A-I (ilm), 0-A-U (kõrv), 0-E-I (talv), 0-U-E (arv), E-TE (laps), E-DE
(juur);
3.2) Tugevnev AV: T (hammas), A/T (aken), E/T (tütar), ME/T (liige);
Erandlikud tüübid: ES-HE (mees), EA-ÄI (pea), ED-IA (aed), EG-JA (aeg).
Jätkusõnastike nimeks on mõnedel juhtudel võetud tüüpsõna nimi (KUU, AASTA,
JALG jt.), tüvelõpuvaheldusega sõnade jätkusõnastiku nimes kajastub vahelduse tüüp (A,
U, 0-DA, S-KSE) ning astmevahelduslikel tüüpidel on sõnastiku nimesse märgitud, kas
tegemist on tugevneva või nõrgeneva astmevaheldusega (LV/N – nõrgenev laadivaheldus, T
– tüvelõpuvahelduseta tugevnev astmevaheldus).
Astmevaheldus kombineerub teiste tüvemuutustega (Hint 1997:49):
1) vokaal- ja konsonanttüve vaheldumine (näiteks I/N – muutetüves tüvevokaal i, nõrgenev
astmevaheldus, E/T – muutetüves tüvevokaal e, tugevnev astmevaheldus);
2) tüvevokaali teisenemine (näiteks I-E-T/N – lemmatüve vokaal i, muutetüvel e, osastava
lõpp t, nõrgenev astmevaheldus);
3) me-sufiksi esinemine-puudumine (ME/T, vt. ka näidet 13).
Tüvelõpumuutused ei tarvitse noomenite puhul "käia ühte jalga" astmevaheldusega
(pole üldist reeglit, et nõrgaastmeline tüvi on vokaaltüveline ja tugevaastmeline tüvi
konsonanttüveline vms.), seetõttu võib astmevahelduslike noomenitüüpide jätkuleksikonide
arv ulatuda kuni järgmise korrutiseni:
astmevaheldusliikide arv (nõrgenev, tugevnev) x tüvelõpumuutuste arv
Prosoodilise astmevaheldusega sõnad saab suunata samu muutelõppe kasutava
kirjapildis ilmneva astmevaheldusega tüübi jätkuleksikoni. Prosoodilise
astmevaheldusega sõna sõnastikuesituses lihtsalt ei leidu ühtegi suurtähte, mis reageeriks
trigerile "$".
Sõnastikus tuleb käsitleda ka astmevahelduseta tüüpide tüvelõpuvaheldused,
seejuures iga erineva tüvelõpuvahelduse jaoks oma jätkusõnastik, sest tüvevokaal ega
lisasilp omastavas käändes pole reeglitega ennustatav.

53
Pesa-tüübis ning nõrgeneva laadivaheldusega tüübis on eristatud sõnaderühmad,
milles on aditiivi moodustatav ja milles ei ole - vastavalt PESA ja PESA-Adt ning LV/N ja
LV/N-Adt. Pesa-tüübis on selline jaotus küll üsna tinglik _ vormide kehha, suvve jne.
kasutamine on maitseküsimus.
3.3.1.2. Omadussõnad
Omadussõna paradigma erineb nimisõna omast võrdlusastmete olemasolu poolest.
Igast omadussõnast saab moodustada kesk- ja ülivõrde, kusjuures need käänduvad nagu
tavalised tänav-tüüpi noomenid (muutetüve vokaal a, vähemalt 3 silpi). Keskvõrre (ja
ühtlasi ka kõige-ülivõrre) moodustatakse ainsuse omastava tüvest, i-ülivõrre ehk lühike
ülivõrre tüvemitmuse tüvest (kui see esineb). Kui tüvi lõpeb i-ga, toimib siin reegel "i�e
enne i-ga algavat formatiivi" (kallis-kallim-kalleim). Kui tekib häälikujärjend "ji" (tühi-
tühjem-tühjim*), siis lühikest ülivõrret moodustada ei saa, kuna järjendit "ji" eesti keele
fonotaktika ei luba. Samuti ei ole lühikest ülivõrret i-tüvelistel omadussõnadel (karm-
karmim-kõige karmim).
Näide 14. Omadussõnatüübi “õnnelik” jätkuleksikon IK/O.
LEXICON IK/O !õnnelik
+A:0 IK'; +A+Cmp:u$+m A'; +A+Spr:$+em A'; kus:+us E-SI; kult+Adv:u$+lt #;
Algvõrde kõik käänded moodustatakse nagu lugemik-tüübis (viidates sõnastikule IK’).
Kesk- ja ülivõrre moodustatakse nõrga astme tüvest ja need käänduvad nagu tänav
(minisõnastik A’). Igast seda tüüpi sõnast saab –us-liite abil tuletada nimisõna (käändub
nagu küsimus) ning –lt-liite abil määrsõna.

54
3.3.1.3. Arv- ja asesõnad
Asesõnade hulgas on väga palju erandlikult käänduvaid sõnu. Seepärast on nende
jaoks loodud leksikonid MA, TA, ME, NAD, SEE, NEED, ISE, KES (vt. lisa 4) jt. Need
asesõnad, mis pole erandlikud, käänduvad nimisõnatüüpide eeskujul. Arvsõnad üks, kaks
ja kümme viitavad erandtüüpide sõnastikele YKS ja KYMME, teised arvsõnad kasutavad
nimisõnade jätkusõnastikke.
3.3.2. Pöördsõnade sõnastikud
Verbi morfotaktiline struktuur on üsna keeruline ja hõlmab järgmisi grammatilisi
kategooriaid (Viks 1980): kõneviis, aeg, tegumood, arv, isik, kõneliik. Seejuures eitav
kõneliik ning täis- ja enneminevik moodustatakse abisõnadega (vastavalt ei, ära jne. ning
abiverb olema).
Kõikide grammatiliste kategooriate tunnused ei pea olema fonoloogilisel tasandil
esindatud. Mõned neist on koguni teineteist välistavad, näiteks arv ja isik saavad esineda
ainult isikulises tegumoes. Iga grammatilise kategooria kõige tavalisemad variandid -
isikuline tegumood, kindel kõneviis, olevik ja jaatav kõneliik - on tunnuseta.
Näide 15. Sõnavormi "naernuksime" liigendus morfeemideks. 0 naer +nu +0 +ksi +me � � � � � � kõneliik tüvi aeg tegumood kõneviis arv ja isik (jaatav) (minevik) (isikuline) (tingiv) (mitmuse 1. isik)
Ü. Viksi klassifikatsiooni kohaselt võib verbid üldisemalt liigitada kolme
pöördkonda (Viks 1980). Verbil võib olla maksimaalselt neli erinevat tüve:
1) ma-tegevusnime tüvi;
2) da-tegevusnime tüvi;
3) isikulise tegumoe kindla kõneviisi oleviku tüvi;

55
4) umbisikulise tegumoe tüvi.
Ü. Viks annab kõigi kolme pöördkonna jaoks analoogiareeglid, mille alusel saab
kindlaks teha, milline tüvi esineb millistes muutevormides.
Näiteks I pöördkond (tüübid elama (üle 5000 sõna), õppima (üle 2000 sõna), naerma (44
sõna), hakkama (üle 700 sõna)).
1) -ma, -mas, -mast, -maks, -mata, -vat, -v, -sin, -sid, -s, -sime, -site
2) -da, -des, -ge, -gu, -gem, -nud, -nuksin, -nuksid, -nuks, -nuksime, -nuksite, -nuvat
3) -n, -d, -b, -me, -te, -vad, -0 (imp pr sg 2, ind pr ps neg), -ksin, -ksid, -ks, -ksime, -ksite
4) -tud, -ti, -taks, -tuks, -tavat, -tuvat, -tagu, -tama, -ta, -tav
Ü. Viksi verbide koondklassifikatsiooni (Viks 1980) kohaselt kasutavad I ja III
pöördkond tüvevariantide saamiseks kõiki nelja nimetatud põhivormi, II pöördkond
põhivorme 1), 2) ja 4). Ü. Viksi klassifikatsioonile toetudes on koostatud verbide
jätkuleksikonid V1, V10-V13 (I pöördkond), V20-V23 (II pöördkond), V30-V32 (III
pöördkond).
Kõige produktiivsem verbitüüp “elama” (täiesti muutumatu tüvega) on kirjeldatud
jätkusõnastikus V1, mis omakorda viitab sõnastikele V10-V13. ele-lõpuliste tegusõnade
muutumist kirjeldavad sõnastikud V10-V14 (Sõnastikule V14 viidates saab moodustada
umbisikulise tegumoe tüvest lähtuvad vormid, kui umbisikulise tegumoe tunnus on -t).
I pöördkonda kuuluvad ka tugevneva ja nõrgeneva astmevaheldusega tüübid.
Need kasutavad samuti jätkusõnastikke V10-V14. Erinevalt noomenitest on verbidel
lemmatüvi (ma-tegevusnime tüvi) alati tugevas astmes.
Tugevnevat astmevaheldust käsitlevad jätkusõnastikud TUG
(tüvelõpuvahelduseta, nt. hakkama), TUG-PROS (tüvelõpuvahelduseta prosoodiline
astmevaheldus, nt. pöörama), LE-EL/T (tüvelõpuvaheldus le-el, nt. vaidlema).
Nõrgeneva astmevaheldusega tüübid kasutavad jätkusõnastikke N
(tüvelõpuvahelduseta, nt. õppima), N-PROS (tüvelõpuvahelduseta prosoodiline
astmevaheldus, nt. istuma), 0-A (tüvelõpuvaheldus 0-a, nt. laulma), 0-E
(tüvelõpuvaheldus 0-e, nt. kuulma), TAHTMA, TEGEMA, 0-A/N (tüvelõpuvaheldus 0-
a, tt-t, pp-p, t-d või prosoodiline, da-infinitiiv –a, nt. saatma), JÄTMA, PIDA-SIN, PID-
IN, I-0/N (umbisikulises tegumoes konsonanttüvi, nt. käskima).

56
Verbidel on kolme tüüpi lihtmineviku lõppe, mis on vastavalt kirja pandud
sõnastikes Ipt1 (-sin, -sid, -is, -sime, -site, -sid), Ipt2 (-in, -id, -i, -ime, -ite, -id) ja Ipt3 (-
sin, -sid, -s, -sime, -site, -sid). Käskiva kõneviisi muutelõpud (-gu, -gem, -ge) on
sõnastikus Imp, tingiva kõneviisi oleviku lõpud sõnastikus Knd-Pr ning tingiva ja kaudse
kõneviisi mineviku lõpud sõnastikus Knd,Kvt-Pt.
3.3.3. Muutumatute sõnade sõnastikud
Kuivõrd side- ja hüüdsõnade kirjeldus on triviaalne - kõik juursõnastiku kirjed on kujul
sõna+liik:sõna #;
- on nad esialgu sõnastike süsteemi lisamata jäetud.
Ka kaas- ja määrsõnad on reeglina käändumatud, kuid mõned kohamäärsõnad
käänduvad sise- või väliskohakäänetes.
Näide 16. Väljavõte kaassõnade juurtesõnastikust ning väliskohakäänete sõnastik
LE-LT.
LEXICON Kaassõna
....................... järel LE-LT; !LE-LT genereerib kaassõnad järele, järel, järelt järgi+K:järgi #; kaudu+K:kaudu #; korral+K:korral #; kõrval LE-LT; mööda+K:mööda #; peal LE-LT; pool LE-LT; .....................
LEXICON LE-LT !väliskohakäänetes käänduvate kaas- ja määrsõnade jaoks
e+K:e #; +K:0 #; t+K:t #;

57
Mõned määrsõnad võivad olla ka liitsõna eeskomponendiks. Määrsõnade liitumist
käsitleb sõnastik PREFIX. Määrsõnad, mis liitsõnu ei moodusta, saavad minisõnastikust
ÜKSIK külge sõnaliigi märgendi.
Näide 17. Väljavõte määrsõnade sõnastikust ning jätkusõnastikud ÜKSIK ja
PREFIX.
LEXICON Määrsõna
............................... sees PREFIX; seest PREFIX; siis ÜKSIK; sisse PREFIX; taga PREFIX; tagant PREFIX; teel PREFIX; vahel LE-LT/Adv; vaid ÜKSIK; vastu PREFIX; veel ÜKSIK; ........................
LEXICON PREFIX
+Adv: #; +:& Verbituletis;
LEXICON ÜKSIK
+Adv: #;

58
3.3.4. Produktiivne sõnatuletus
Tuletusliigenduse puhul kirjeldavad morfotaktika reeglid ka tüve
tuletusstruktuuri, s.o. millised derivatsioonisufiksid ja millises järjestuses võivad juurele
liituda.
Igast verbist saab moodustada järgmised tuletised (Viks 1992):
Tabel 5. Verbituletised.
tuletussufiks näide (lugema) tuletise sõnaliik
-ja
-mine
-v
-tav
-nud
-tud
-nu
-tu
lugeja
lugemine
lugev
loetav
lugenud
loetud
lugenu
loetu
nimisõna
nimisõna
omadussõna
omadussõna
omadussõna
omadussõna
nimisõna
nimisõna
Omadussõnast saab tuletusliite –us abil moodustada nimisõna ning liidete -sti ja -
lt abil moodustada määrsõnu. Kahe viimase kasutamine on tegelikult sõnati erinev: mõne
omadussõna puhul on võimalikud nii –sti- kui –lt-tuletis, mõne sõna puhul ainult üks või
teine.
Määrsõnade tuletatavuse poolest erinevad grupid ei pruugi üldiselt ühtida
morfoloogiliste muuttüüpidega (vrd. näitest 18 halb, nõrk, pikk – sama muuttüüp, kuid
erinevad tuletised, samuti kauge ja kõrge, kuri ja tühi). Ka Ü. Viksi seisukoht on, et
enamasti peab konkreetse sõna juures ära märkima, kas talle mingi tuletusliide sobib või
ei (Viks 1994a).

59
Näide 18. Omadussõnadest tuletatavad määrsõnad.
omadussõna -sti -lt muuttüüpi määravad tunnuused
-----------------------------------------------------------------------------------------------------------
halb halvasti - nõrgenev AV, lõpuvaheldus 0-a
kauge - kaugelt tüvemuutusteta
kuri kurjasti kurjalt nõrgenev AV, lõpuvaheldus
i-ja
kõrge kõrgesti kõrgelt tüvemuutusteta
noor - noorelt nõrgenev AV, lõpuvaheldus 0-e
nõrk nõrgasti nõrgalt nõrgenev AV, lõpuvaheldus 0-a
pikk - pikalt nõrgenev AV, lõpuvaheldus 0-a
suur suuresti suurelt nõrgenev AV, lõpuvaheldus 0-e
tühi - tühjalt nõrgenev AV, lõpuvaheldus i-ja
Probleem on ka astmevahelduslike verbide tuletistega. Nimelt on verbi algvorm
alati tugevaastmeline, kuid verbituletise morfoloogiline info peab sisaldama tuletise,
mitte alusverbi tüve. Sõnastik-teisendaja korjab verbitüve juurest alguses üles
tugevaastmelise tüve ja sõnaliigi V (verb), kuid tuletusliite leidmisel võib osutuda, et
tegemist on hoopis nimi- või omadussõnaga, mille juur on nõrgaastmeline. Nii nõrgeneva
kui tugevneva astmevaheldusega sõnadel liitub osa tuletussufiksitest nõrgaastmelisele
tüvele. Seetõttu peab astmevahelduslike verbide tüved kaks korda - nii tugeva- kui
nõrgaastmelisena sõnastikku panema.
3.3.5. Liitsõnade moodustamine
Vastavalt eesti keele õigekirjareeglitele ei ole liitsõna osade vahel enamasti
mingeid markereid (mõningatel juhtudel siiski on sidekriips, näiteks siis, kui kõrvuti
satub kolm või neli ühesugust häälikut). Liitsõnade analüüsimine on eesti keele puhul üks
keerulisemaid probleeme, kuna üheltpoolt on liitsõnamoodustus suhteliselt vaba,

60
semantiliselt mõistlike liitsõnade genereerimine ja äratundmine on arvutile aga väga
raske.
Loodud sõnastike süsteemis on lahendus esialgu väga üldine: omavahel saab
kombineerida kõiki nimisõnu, osa määrsõnu saab olla liitsõna eelkomponendiks ning
omadussõnad ja verbide partitsiipidest tuletatud nimi- ja omadussõnad võivad olla
liitsõna järelkomponendiks.
Nimisõnade liitumine on korraldatud minisõnastikega N-LIIT (liitumine ainsuse
nimetavas, nt. tütarlaps), G-LIIT (liitumine ainsuse omastavas, nt. võtmekimp) ja PLG-
LIIT (liitumine mitmuse omastavas, nt. õiteaeg). Kuna ainult liitsõna viimane komponent
käändub ning käändsõnalised eelkomponendid on kas ainsuse nimetavas või omastavas
käändes (erandid välja arvatud), siis tuli nimisõnade jätkusõnastike arvu kahekordistada.
Esimene sõnastik, millele juurtesõnastikust viidatakse, on hargnemissõnastik, millest
saab edasi minna kas liitsõnamoodustusse või käänamisse. Näide 19 illustreerib
liitsõnade moodustamise protsessi.
Näide 19. Liitsõna “tütarlapsed” moodustamine sõnastike süsteemis.
Nimisõna E/T N-LIIT Nimisõna E-TE E-TE’
………………. +S: E/T'; +S+Sg+N:0 #; ………… +S: E-TE'; +Sg:e S1;
tütar:tütAr E/T; N-LIIT; +:& Nimisõna; laps E-TE; N-LIIT; +Sg+P:+t #;
………………. :e G-LIIT; +:& Omadussõna; ………… :e G-LIIT; +Pl+N:e+d #;
+Pl+G:te #;
+Pl:te S1;
+Pl+P:i #;
+Pl:i S5;
Mõnda tüüpi sõnade puhul võib tüvi liitumisel ka lüheneda, näiteks
laulmine+tund=laulmistund (mitte laulmisetund*), inimene+vihkaja=inimvihkaja
(võimalik ka inimesevihkaja), nii et reeglid ei saa tegelikult olla üldised, tervet
muuttüüpi haaravad. Kuid igasugune muuttüüpidega mittekattuvate loendite
sissetoomine sõnastike süsteemi on äärmiselt kulukas, kuna sõnastike struktuuri on idee
poolest üles ehitatud morfotaktilisele struktuurile.

61
Määrsõnade kuulumist liitsõnade koosseisu reguleerib minileksikon PREFIX.
Kui määrsõna saab olla liitsõna eelkomponendiks, siis on tema järel tüvesõnastikus viit
leksikonile PREFIX. Sellest leksikonist saab edasi minna verbituletiste leksikoni, kuna
enamasti tavalise nimi- ega omadussõna ette määrsõna ei liitu.
Liitsõna järelkomponendiks võib olla verbist tuletatud käändsõna, kuid mitte
"puhas" verb - seetõttu ei olnud muud väljapääsu kui verbituletiste jaoks omaette sõnastik
teha. Selle tagajärjel on iga verbi tüvi nüüd kirjas kaks (astmevahelduseta või kirjapildis
mitte kajastuva astmevaheldusega) või kolm korda (astmevahelduslikud verbid) – üks
kord verbijuurte sõnastikus, teine (ja kolmas) kord verbituletiste sõnastikus.
Näide 20. Liitsõnade morfoloogiline analüüs ja süntees.
Praegune sõnastike võrk võimaldab genereerida ja ära tunda nii normaalseid kui naljakaid
liitsõnu. Viimased on, tõsi küll, vormiliselt korrektsed.
lexc> random-surf (Neid sõnu ei genereeritud järjest, see on valik mitmest seansist)
ehtejutud
hõbejõud
veahobust
arvuvabasti
grupiööõiguseks
õnnetusabigrupinägu
kõrvanõrku
unihambasoojuseaastateta
lexc> lookup õppimistuba
õppimine+tuba+S+Sg+N
õppimine+tuba+S+Sg+P
lexc> lookup riigikeelesõnaraamatuid
riik+keel+sõna+raamat+S+Pl+P
lexc> lookup südamesõpra
süda+sõber+S+Sg+Adt
süda+sõber+S+Sg+P

62
lexc> lookup silmarõõmuks
silm+rõõm+S+Sg+Tr
silm+rõõm+uks+S+Sg+N
lexc> lookdown sõber+mees+S+Pl+P
sõbramehi
lexc> lookup muldvanadest
muld+vana+S+Pl+El
muld+vana+A+Pl+El
3.3.6. Probleemid sõnastikega
Kahetasemelise morfoloogiamudeli sõnastike süsteem tundub esmapilgul
suurepärane: viitade abil saab sõnajuured, tuletusliited, morfoloogilised tunnused ja lõpud
sobivalt ühendada ning sõnavormid ongi olemas. Praktilises töös tekib aga rida
probleeme:
� Kuna eesti keeles on palju muuttüüpe, tekib väga palju minisõnastikke ning sõnastike
süsteemis on raske orienteeruda.
� Võiks arvata, et tänu viitade süsteemile võidame palju sõnastiku mahus, kuid iga
verbitüvi tuleb siiski 2-3 korda sisse – üks kord sõnastikku “Tegusõna” ning 1-2
korda sõnastikku “Verbituletis”, sõltuvalt sellest, kas sõna on astmevahelduslik.
Verbid käituvad morfotaktiliselt siiski hoopis teisiti kui verbituletised – ainult
viimased saavad olla liitsõna komponendiks.
� Eesti keeles on palju erandsõnu ja mõningate erandvormidega sõnu, iga vähegi erinev
rühm tekitab uue jätkusõnastiku.
� Mudeliga põhimõtteliselt sobimatu on loendite sissetoomine sõnastikku, kuid
derivatsiooni ja liitsõnamoodustuse puhul on see möödapääsmatu. Sõnatuletus on küll
osaliselt produktiivne, kuid tihti sõltub liite sobivus konkreetsest sõnast. Iga loend

63
tähendab tegelikult sama viitstruktuuri kordamist teise nime all ning suurendab
muidugi ka sõnastiku mahtu.
� Ei õnnestu järgida põhimõtet, et sõnastikes kirjeldatakse morfotaktika põhimõtted ja
tüvevariantide vaheldusmallid ning reeglitega tüvevariantide omavahelised
fonoloogilised seosed. Tüvelõpuvaheldusi ei saa üldiselt reeglitega käsitleda, sest
need on kujunenud sõna individuaalseks omaduseks.
� Filoloogile meelepärane morfotaktika reegleid väljendav sõnastik peaks olema selline,
kus sõnavormi moodustamisel morfeemidest vastab igale morfeemile täpselt üks
sõnastik, aga eesti keele puhul tuleb sageli morfeeme tükeldada, mis muudab
sõnastikud raskesti loetavaks.
3.5. Sõnavormide analüüs ja süntees koostatud sõnas tike ja reeglite ning programmide lexc ja twolc abil
Koostatud sõnastike süsteem ja reeglid võimaldavad juurtesõnastikesse sisestatud
tüvede piires genereerida ja ära tunda eestikeelseid sõnavorme. XRCE-st
uurimisotstarbeliseks kasutamiseks saadud programm lexc (lexicon compiler) (Karttunen
1993) teeb õige struktuuriga sõnastikefailist lõpliku teisendaja ning programm twolc
(two-level compiler) (Karttunen, Beesley 1992) kompileerib kõik reeglitefailis sisalduvad
regulaarsete avaldistena esitatud reeglid lõplikeks teisendajateks. Programmis twolc on
tervet reeglite kogu võimalik testida käsuga lex-test. Sisendiks tuleb anda mingi
sõnavormi sõnastikuesitus ning programm genereerib reeglite põhjal pindsümbolite
stringi, mis langeb kokku korrektse sõnavormiga, kui reeglid töötavad õigesti. Niimoodi
saab reegleid muidugi pisteliselt kontrollida. Otstarbekas on reeglite kogu testida pärast
iga uue reegli lisamist, et kontrollida, kas see töötab ootuspäraselt. Testimisel on võimalik
kasutada ka süvastringide testfaili. Lõpuks saab programmiga lexc sõnastik-teisendaja ja
reegel-teisendajad ühendada ning tulemust testida.
Programmis lexc on järgmised testimisvõimalused:
1) sõnavormide juhuslik genereerimine pind-, süva- või paralleelselt mõlemas esituses
(vastavalt käsud random-surf; random-lex ning random);

64
2) üksiksõnavormi morfoloogiline analüüs (lookup sõnavorm);
3) üksiksõnavormi morfoloogiline süntees (lookdown algvorm+morfoloogiline info);
Noomeni puhul on morfoloogiliseks infoks sõnaliik+arv+kääne, verbi pöördeliste
vormide puhul sõnaliik+kõneviis+aeg(+tegumood)(+isik), käändeliste vormide puhul
sõnaliik+infinitiivi liik(+kääne). Sulgudes olevad osad ei esine kõikide muutevormide
puhul.
4) kõikvõimalike sõnavormide genereerimine (check-all) - saab salvestada faili. Kui aga
sõnastike võrk on tsirkulaarne (nagu see liitsõnamoodustuse sissetoomisest saadik on),
siis on kõikvõimalikke sõnavorme lõpmatu arv ja seda varianti kasutada ei saa.
Kommenteeritud näiteseansid tööst programmidega twolc ja lexc, sealhulgas
konkreetsete sõnavormide testimisest, on lisades 1 ja 2.
Nagu ülaltoodud kirjeldusest nähtub, võimaldavad programmid twolc ja lexc
kahetasemelist grammatikat testida sõnavormikaupa. Kuna aga kahetasemelises mudelis
on keelekirjeldus programmidest sõltumatu, siis korrektselt kokku pandud eesti keele
sõnastike ja reeglite olemasolul peaks XEROXis väljatöötatud morfoloogial põhinevat
tarkavara (speller, infootsija, keelemõistataja jm.) saama automaatselt rakendada
eestikeelsetele tekstidele.
3.6. Süsteemi edasiarendamise võimalustest
Sõnastiku edasiarendamiseks saab kasutada E. Kuusiku tüübituvastusreeglitel
(Kuusik 1996) põhinevat programmi tdtest (http://www.eki.ee/tarkvara), et määrata
sõnastikku veel mitte kuuluvate sõnade muuttüübid. Kuivõrd Ü. Viksi morfoloogiline
klassifikatsioon (Viks 1994a) ei lange päriselt kokku käesolevas töös loodud tüübistikuga
(viimane on detailsem, näiteks erineva tüvevokaaliga ja muidu sarnaselt muutuvad sõnad
on erinevates tüüpides), siis tuleb kahe tüübistiku vahel korraldada vastavus ning
mitmese vastavuse puhul kasutada morfoloogilist sünteesi, et saada kätte teised
tüvevariandid ning nende põhjal mingite reeglite abil (näiteks tüvevokaali põhjal)
otsustada, millise jätkusõnastiku viit kirjutada selle sõna kirje järele juursõnastikus.

65
Baassõnastikuna on algusest peale kasutatud Eesti Kirjakeele Korpuse
sagedussõnastikku (http://www.cl.ut.ee/). Päris selle sagedussõnastiku järjestuses pole
sõnatüvesid siiski lisatud, sest esiteks on see sõnastik tekkinud morfoloogiliselt
ühestamata tekstist ning teiseks oli sõnastike süsteemi loomisel tähtsaim võimalikult
palju erinevaid tüvemuutusi sisse võtta, et reeglite kogu saaks täielik ja et reegleid saaks
kohe testida. Sagedussõnastiku aluseks võtmise kasuks räägib asjaolu, et sagedasemad
sõnad on enamasti keerulisema morfoloogiaga. Ka päris erandsõnad on just need kõige
igapäevasemad (näiteks ise:enda, üks:ühe, olema:on, minema:läks, hea:parem).
Seepärast võib eeldada, et uusi muuttüüpe enam oluliselt juurde ei tule. Sõnastiku
uuendamine seisneb siis põhiliselt sõnaliikide juursõnastike täiendamises uute kirjetega.
Kokkuvõte
Hinnates kahetasemelise morfoloogiamudeli sobivust eesti keelele võib esile tuua
mudeli järgmisi häid külgi.
1. Kahetasemelisus on üldiselt kasulik, kuna sõnastikuesitus võib sisaldada
informatsiooni, mida sõna häälikkoostisest välja ei loe:
1.1. Eriliselt saab tähistada need foneemid, millel on tüvevahelduse tõttu pindesituses
rohkem kui üks variant. Nimelt ei sõltu tüvevahelduse tüüp tänapäeva eesti keeles
sageli tüve foneemilisest kujust.
1.2. Sõnastikuesitusse saab kirjutada morfofonoloogilisi tunnuseid ja morfeemipiire. Neid
on reeglites tihtipeale vaja.
2. Reeglid ei ole järjestatud. Järjestatud reeglitekogu koostamine on keeruline, kuna võib
olla raske ette näha kõigi eelmiste reeglite mõju kontekstile.
3. Reeglites on võimalik viidata suvalisel kaugusel asuvale kontekstile. Näiteks võib olla
reegel, kus tuleb kontrollida tüve lõpus asuvat sümbolit, teadmata tüve silpide arvu.

66
4. Kui süva- ja pindsümboli vastavus esineb mitmes kontekstis, millel pole sisu ega
vormi poolest midagi ühist, siis võib vastavad kontekstid loetleda ühe ja sama reegli
paremal poolel. See säästab uute süvasümbolite kasutuselevõtust, mis üldjuhul toob
kaasa seosetuid tähiseid. Näiteks on vastavus S:0 võimalik nii laadivaheldusliku sõna
nõrgas astmes kui S-lõpuliste sõnade lõpus. Esimesel juhul asub S vokaalide vahel,
aga teisel juhul tüve lõpus.
5. Sõnastikud võimaldavad mugavalt käsitleda
� fonoloogiliselt põhjendamatuid tüvelõpumuutusi;
� morfotaktika reegleid;
� produktiivset sõnatuletust ja liitsõnamoodustust (osaliselt).
Puudustena võib märkida raskusi mitmesümboliliste segmentide teisendamisel
reeglitega ning morfotaktika reeglitest sõltumatute loendite sobimatust sõnastike süsteemi.
Kahetasemelisse mudelisse peaks lisama ka täiustuse selles osas, et sõnajuure
morfoloogilist informatsiooni saaks kustutada, kui derivatsioon tekitab uue sõnaliigi. Praegu
on probleem lahendatud tüvede dubleerimisega tuletiste sõnastikus.
Lõpetuseks võiks öelda, et eesti keele kirjeldamine kahetasemelise morfoloogia
formalismis on teatava täpsuseni ja teatavate rakenduste jaoks (morfoloogiline analüüs,
lemmatiseerimine) võimalik. Kahjuks ei saa praegu küll hinnata mudeli aja- ja
mälukeerukust võrreldes teiste eesti keele morfoloogiliste analüsaatorite-süntesaatoritega,
kuna sõnastiku maht pole veel konkurentsivõimeline, kuid teoreetiliselt peaks lõplikel
teisendajatel põhinev rakendus töötama efektiivselt ja see annaks kahetasemelisele
morfoloogiale teatud rakenduste puhul eelise.

67
Abstract
The Computerised Analysis and Generation of Estonian Word-forms
Using the Two-level Morphology Model
Heli Uibo The thesis deals with the application of the two-level morphology model
developed by Kimmo Koskenniemi to the Estonian language.
The brief outlines of the model and its theoretical foundations are given.
The morphological system of Estonian is described and illustrated with examples.
The two-level rule set (Appendix 3) compiled and tested by the author of the thesis is
thoroughly commented. The two-level rules of stem flexion, phonotactics, orthography
and morphophonological distribution are given.
The network of lexicons (Appendix 4) represents the rules of morphotactics and
allotactics. It is also used to handle unnatural stem end changes. Pointers between
lexicons implement the productive derivation and compounding of Estonian words as
well.
The problems occurred while constructing the rule and lexicon system are
discussed. The examples of Estonian morphological analysis and synthesis are given
(Appendices 1 and 2) using the compiled net of lexicons and two-level rules as input for
the programs lexc (Karttunen 1993) and twolc (Karttunen, Beesley 1992) developed in
Xerox Research Centre of Europe.
The advantages and disadvantages of the two-level morphology model
considering Estonian language are discussed.
Summarising, the two-level model can be used for describing Estonian
morphology to some extent and for some applications, e.g. morphological analysis and
lemmatisation. The efficiency of the implementation as finite-state transducers is
undoubtedly an advantage.

68
However, the productive derivation procedure could be better supported. To
improve the two-level model in this sense the deleting of the word stem's morphological
information should be possible if a derivation suffix changes the word class.

69
Kirjandus
1. (Erelt 1997) Erelt, T. Eesti ortograafia. Tallinn 1997.
2. (FSLP 1997) Finite-state Language Processing / edited by E. Roche and Y. Schabes.
Language, Speech, and Communication Series. The MIT Press, Cambridge,
Massachusetts, London, England 1997.
3. (Hint 1997) Hint, M. Eesti keele astmevahelduse ja prosoodiasüsteemi tüpoloogilised
probleemid (Typological Problems of Estonian Grade Alternation and Prosodical
System). Dissertation at the University of Helsinki, Dept of Baltic-Finnic Languages.
Tallinn/Helsingi 1997.
4. (Hint 1978) Hint, M. Häälikutest sõnadeni: emakeele häälikusüsteem
üldkeeleteaduslikul taustal. Tallinn "Valgus" 1978.
5. (Kaalep 1999) Kaalep, H.-J. Eesti keele ressursside loomine ja kasutamine
keeletehnoloogilises arendustöös. Dissertationes philologiae estonicae Universitatis
Tartuensis - 7. Tartu 1999.
6. (Karlsson 1974) Karlsson, F. Phonology, Morphology and Morphophonemics.
Gothenburg Papers in Theoretical Linguistics. Göteborg 1974.
7. (Karttunen 1997) Karttunen, L. Syntax and Semantics of Regular Expressions. The
Document Company Xerox 1997.
8. (Karttunen 1993) Karttunen, L. Finite-State Lexicon Compiler. Technical Report.
ISTL-NLTT-1993-04-02. April 1993. Xerox Palo Alto Research Centre. Palo Alto,
California. 1993.
9. (Karttunen, Beesley 1992) Karttunen, L. and K. R. Beesley Two-Level Rule Compiler.
Technical Report. ISTL-92-2. October 1992. Xerox Palo Alto Research Centre. Palo
Alto, California. 1992.
10. (Koskenniemi 1997) Koskenniemi, K. Representations and Finite-State Components
in Natural Language. In: Finite-state Language Processing / edited by E. Roche and
Y. Schabes. Language, Speech, and Communication Series. The MIT Press,
Cambridge, Massachusetts, London, England 1997.

70
11. (Koskenniemi 1983) Koskenniemi, K. Two-level Morphology: A General
Computational Model for Word-Form Recognition and Production. University of
Helsinki, Dept of General Linguistics. Publications No. 11. Helsinki 1983.
12. (Kuusik 1996) Kuusik, E. Eesti tüvemuutuste süsteemi modelleerimine. Magistritöö.
TTÜ 1996.
13. (Kuusik, Viks 1998) Kuusik, E., Viks, Ü. Reeglipõhine morfoloogiline süntees.
Arvutimaailm 1/1998, lk. 43-45, 63 ja 2/1998, lk. 19-21.
14. (Sproat 1992) Sproat, R. Morphology and Computation. ACL-MIT Press Series in
Natural Language Processing. The MIT Press. Cambridge, Massachusetts, London,
England 1992.
15. (Uibo 1998) Uibo, H. Kahetasemeline morfoloogiamudel ja eesti keel. Keel ja
Kirjandus 1/1998, lk. 13-21
16. (Viitso 1990) Viitso, T.-R. Eesti keele kujunemine flekteerivaks keeleks. Keel ja
Kirjandus 8/1990, lk. 456-461 ja 9/1990, lk. 542-548.
17. (Viks 1994b) Viks, Ü. Eesti keele morfoloogiline analüsaator. Automaatanalüüsi
võimalused ja võimatused. Keel ja Kirjandus 3/1994, lk. 150-163.
18. (Viks 1988) Viks, Ü. Fonoloogiliste ja morfoloogiliste mallide seosed.
Arvutuslingvistika sektori aastaraamat 1988, lk. 160-166. Tallinn 1990.
19. (Viks 1994a) Viks, Ü. Klassifikatoorne morfoloogia. Doktoriväitekiri. Tartu 1994.
20. (Viks 1982) Viks, Ü. Klassifikatoorne morfoloogia. Noomen. Eesti NSV TA Keele ja
Kirjanduse Instituut. Tallinn "Valgus" 1982.
21. (Viks 1980) Viks, Ü. Klassifikatoorne morfoloogia. Verb. Eesti NSV TA Keele ja
Kirjanduse Instituut. Tallinn "Valgus" 1980.
22. (Viks 1979) Viks, Ü. Kuidas formaliseerida tüvemuutusi. Keel ja Kirjandus 11/1979,
lk. 671-677.
23. (Viks 1992) Viks, Ü. Väike vormisõnastik. 1. Sissejuhatus & grammatika. 2. Sõnastik
ja lisad. Eesti Teaduste Akadeemia Keele ja Kirjanduse Instituut. Tallinn 1992.

71
Lisa 1. Näiteid tööst programmiga twolc - kahetasemeliste reeglite kompileerimine ja testimine.
[heli@augustus ~/bin]$ twolc
********************************************* ************* * Two-Level Compiler 2.7.4 (6.0.5) * * created by * * Lauri Karttunen, Todd Yampol, * * Kenneth R. Beesley, and Ronald M. Kaplan. * * Copyright © 1991-97 by the Xerox Corporation. * * All Rights Reserved. * ********************************************* ************* Input/Output ------------------------------------------------------------------ Rules: read-grammar. Transducers: install-binary, save-binary, save-tabular. Lexicon: install-lexicon, uninstall-lexicon. Operations -------------------------------------------------------------------- Compilation: compile, redo. Intersection: intersect. Testing: lex-test, lex-test-file, pair-test, pair-test-file. Switches: closed-sigma, quit-on-fail, resolve, time, trace. Display ----------------------------------------------------------------------- Result: labels, list-rules, show, show-rules. Misc: banner, storage, switches. Help: completion, help, history, ?. Type 'quit' to exit.
Reeglitefail loetakse mällu käsuga "read-grammar <fail>":
twolc> read-grammar rules.txt
Järgnevalt kompileeritakse reeglid kui regulaarsed avaldised lõplikeks automaatideks:
twolc> compile
Käsuga "lex-test" saab kompileeritud reeglitekogu põhjal genereerida etteantud süvaesitusest pindesituse:
twolc> lex-test
Lexical string ('q' = quit): varSe$+ga varrega v a r S:r - assimilatsioon nõrgas astmes e $:0 - vaikimisi ja alati +:0 -----"-------- g a

72
Lexical string ('q' = quit): tõmBa$+nud tõmmanud
t õ m B:m - assimilatsioon a $:0 +:0 n u d Lexical string ('q' = quit): ma.+st maast m a .:a - pikk vokaal vaikimisi +:0 s t Lexical string ('q' = quit): ma.h. maha m a .:0 - pikk vokaal lüheneb enne h-d h .:a - pikk vokaal vaikimisi Lexical string ('q' = quit): so.h. sohu s o .:0 - pikk vokaal lüheneb enne h-d h .:u - o->u järgsilbis Lexical string ('q' = quit): tütAre+i+d tütreid t ü t A:0 - vahevokaali kadu r e +:0 i +:0 d

73
Lexical string ('q' = quit): luGe$+n loen l u:o - vokaali madaldumine G:0 - g kadu nõrgas astmes e $:0 +:0 n Lexical string ('q' = quit): luGu$+st loost l u:o - vokaali madaldumine G:0 - g kadu nõrgas astmes u:o - vokaali madaldumine $:0 +:0 s t Lexical string ('q' = quit): küDe$+b köeb k ü:ö - vokaali madaldumine D:0 - d kadu nõrgas astmes e $:0 +:0 b
Lisa 2. Näiteid tööst programmiga lexc - leksikonid e kompileerimine ning leksikonide ja reeglite ühendam ine, sõnavormide testimine.
[heli@augustus ~/bin]$ lexc
****************************************** ************* * Finite-State Lexicon Compiler 2.7.6 (5.7.2) * * created by * * Lauri Karttunen and Todd Yampol * * Copyright © 1993-97 by the Xerox Corporation. * * All Rights Reserved. * ****************************************** ************* Input/Output ------------------------------------------------------------------ Source: compile-source, merge-source, read-source, result-to-source, save-source. Rules: read-rules. Result: merge-result, read-result, save-result, source-to-result. Properties: add-props, reset-props, save-props.

74
Operations -------------------------------------------------------------------- Composition: compose-result, extract-surface-forms, invert-source, invert-result. Checking: check-all, lookdown, lookup, random, random-lex, random-surf. Switches: ambiguities, duplicates, failures, obey-flags, quit-on-fail, singles, time. Scripts: begin-script, end-script, run-script. Display ----------------------------------------------------------------------- Misc: banner, labels, props, status, storage. Help: completion, help, history, ?. Type 'quit' to exit. lexc> run-script s 1. Sõnastikud kompileeritakse lõplikuks teisendajaks käsuga "compile-source <fail>". Töö käigus
näidatakse ekraanil nende sõnastike nimesid ja kirjete arve, mida parasjagu kompileeritakse. >>> SCRIPT: compile-source lex1.txt Opening 'lex1.txt'... Sõnastik...8, Arvsõna...10, ÜKS...11, KÜMME...8, Asesõna...20, NEED...5, SEE...4, TEMA...4, NEMAD...4, NAD...5, MINA...4, MEIE...2, MEIE-1...3, ME...2, MA...5, TA...5, LOPUD...7, KES...4, ISE...4, Kaassõna...37, LE-LT...3, K...1, Määrsõna...47, PREFIX...2, ÜKSIK...1, LE-LT/Adv...3, Omadussõna...49, 0-T-SID/O...5, 0-DA/O...6, SOE...10, HEA...11, S14-TE-IS/O...5, S14-TE-E/O...6, S14-TE/O...6, NE-SA/O...13, NE-SI/O...5, E-SE-SI/O...5, NE-SEID/O...4, NE-SE-SET/O...10, IK/O...5, E-DE/O...5, U/N/O...4, A-U/N/O...4, JA-JE/N/O...4, A-I/N/O...4, A-U/O...6, A-U-AM/O...5, 0-A-U/O...4, U/O...5, AS/T/O...5, S-DUS/T/O...5, R-A/O...5, S-A/O...5, L-A/O...5, A/O...5, A-DUS/O...5, Nimisõna...153, 0-T-SID...2, 0-T-SID'...4, IK...2, IK'...10, Nimisõna...153, 0-T-SID...2, 0-T-SID'...4, IK...2, IK'...10, A/NNT...2, A/NNT'...9, S-KSE...3, S-KSE'...6, 0-DA...2, 0-DA'...7, E-ME...2, E-ME'...7, 0-ME...4, 0-ME'...6, A/T...2, A/T'...7, KODU...2, KODU'...4, A-S012...2, A-S012'...3, U-S012...2, U-S012'...1, I-S012...2, I-S012'...1, VARS...3, VARS'...8, 0-A-I...3, 0-A-I'...6, 0-A-U...3, 0-A-U'...6, 0-E-I...2, 0-E-I'...7, 0-U-E...3, 0-U-E'...6, ES-HE...3, ES-HE'...6, I-E-D...3, I-E-D'...5, I-E...3, I-E'...5, EA-ÄI...2, EA-ÄI'...5, MAA...2, MAA'...1, TCC...2, TCC'...1, ED-IA...3, ED-IA'...8, EG-JA...2, EG-JA'...9, S14-TE...2, S14-TE'...7, ME/T...2, ME/T'...7, I-E-T/N...3, I-E-T/N'...8, A-TT/N...2, A-TT/N'...4, A-PP/N...2, A-PP/N'...4, U-KK/N...2, U-KK/N'...3, I-KK/N...2, I-KK/N'...3, LV/N...2, LV/N'...2, NLV-Sg...3, NLV-Pl...4, A-E/N...3, A-E/N'...1, A-I/N...3, A-I/N'...2, A-U/N...3, A-U/N'...3, JALG...3, JALG'...3, E/N...3, E/N'...1, U/N...3, U/N'...1, I/N...3, I/N'...1, NVV...8, T...2, T'...7, E/T...3, E/T'...5, E-SI...2, E-SI'...1, E-SEID...2, E-SEID'...3, NE-SEID...2, NE-SEID'...2, NE...1, SE...3, NE-SI-1...2, NE-SI-1'...2, INIM...5, NE-SI...3, NE-SI'...2, S...3, 0-SE-SI...2, 0-SE-SI'...1, SE-SI-1...4, SE-SI...2, E-DE...2, E-DE'...1, E-TE...3, E-TE'...6, E...3, E'...5, A...2, A'...7, U...2, U'...7, A-U...2, A-U'...2, A-I...2, A-I'...3, S012...3, S1234...4, S0...3, S1...11, S2...4, S3...3, S4...2, S5...7, N-LIIT...4, G-LIIT...4, PLG-LIIT...4, Verbituletis...166, KESKSÕNA-1...8, KESKSÕNA-2...8, KESKSÕNA-3...8, KESKSÕNA-4...8, KESKSÕNA/T-N/TUD...6, KESKSÕNA/T-N...6, KESKSÕNA/T-T...2, KESKSÕNA/N-N...4, KESKSÕNA/N-T...4, NUD...2, KESKSÕNA/TEGEMA...3, KESKSÕNA/PROS...3, KESKSÕNA/ANDMA...4, TULET...3, Tegusõna...102, OLEMA...15, MINEMA...13,

75
ELE-LLA...4, E-0...4, V20...11, V21...12, V22...4, TOOMA...3, VIIMA...3, VÕIMA...2, SAAMA...2, V30...18, V31...16, TUG-PROS...5, TUG...5, TAHTMA...5, DT-E/N...5, DT-A/N...5, 0-A...5, 0-E...5, PID-IN...5, TEGEMA...19, LE-EL/T...5, 0-A/N...5, JÄTMA...5, PIDA-SIN...5, I-0/N...5, N...5, N-PROS...5, ELE...7, V1...6, V10...7, V11...6, V12...4, V13...11, V14...11, V15...6, Pr...6, Ipt1...6, Ipt2...6, Ipt3...6, Imp...5, Knd-Pr...6, Knd,Kvt-Pt...2 Building lexicon...Minimizing...Done! SOURCE: 1648 states, 3940 arcs, Circular.
2. Järgnevalt loetakse sisse reegel-automaadid:
>>> SCRIPT: read-rules rules.fst
Opening 'rules.fst'...
40 nets read.
3. Reegel-automaadid ja sõnastik-teisendaja ühendatakse:
>>> SCRIPT: compose-result No epenthesis.
No surrounding word boundaries added.
..........................................................................................................................................
...........................Done.
8484 states, 17363 arcs, Circular.
Minimizing...Done.
1922 states, 4941 arcs, Circular.
>>> End of script 's'.
4. Kõige lihtsam testimise vorm: süsteemil lastakse genereerida pseudojuhuslikke sõnavorme:
lexc> random-surf
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
õpiku
käed
pessa
öeldavaid
kohaehe
endaks
vanalt
pimeduse
ülejätnuiks
eemaltõppijad
nähtuta

76
ukseta
autosid
läksin
läinud
5. Järgmine käsk võimaldab näha sõnastikest juhuslikult tuletatud morfoloogilisi informatsioone (saab
kontrollida, kas vastavad morfotaktika reeglitele):
lexc> random-lex
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
öelnud+A+Sg+N
pidama+V+Ind+Ipt+Pl2
ära+Adv
vaikne+A+Sg+N
rahvas+S+Sg+All
andma+V+Pts+Pt+Ips
olemine+Sg+Ill
nimi+S+Sg+Ad
lind+õhk+S+Pl+N
pakkuma+V+Pts+Pr+Ips
lööja+S+Pl+G
kell+S+Pl+All
ehe+S+Sg+P
oodatu+S+Sg+Ill
hea+A+Cmp+Pl+In
6. Käsk "lookup <sõnavorm>" annab sõnavormi morfoloogilise analüüsi:
lexc> lookup maailmameredel
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
maa+ilm+meri+S+Pl+Ad
lexc> lookup riigikeeleõpikuis
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
riik+keel+õpik+S+Pl+In

77
lexc> lookup ajalehepoisina
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
aeg+leht+poiss+S+Sg+Ess
lexc> lookup parimateks
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
hea+A+Spr+Pl+Trl
lexc> lookup kuuldavasti
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
kuuldavasti+Adv
lexc> lookup pead
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
pea+S+Sg+P
pea+S+Pl+N
pidama+V+Ind+Pr+Sg2
lexc> lookup kuule
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
kuulma+V+Imp+Pr+Sg2
kuulma+V+Ind+Pr+Ps+neg
kuu+S+Sg+All
7. Käsk "lookdown" genereerib algvormi ja morfoloogilise info põhjal sõnavormi:
lexc> lookdown sõna+S+Pl+P
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
sõnasid
sõnu
lexc> lookdown kallis+A+Spr+Pl+El

78
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
kalleimaist
kalleimatest
lexc> lookdown hakkama+V+Knd+Pt+Ips
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
hakatuks
lexc> lookdown vaidlema+V+Inf
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
vaielda
lexc> lookdown minema+V+Ind+Ipt+Pl1
Use (s)ource or (r)esult? [r]:
NOTE: Using RESULT.
läksime

79
Lisa 3. Eesti keele kahetasemelised reeglid. (fail rules.txt) Alphabet a b c d e f g h i j k l m n o p q r s sh z zh t u v õ ä ö ü x y G:g G:0 B:b B:0 B:m D:d D:0 D:l D:n D:r K:k K:g K:0 P:p P:b P:0 T:t T:d T:0 S:s S:0 S:r %+:0 %$:0 %&:0 A:a A:0 E:e E:0 U:u U:0 %.:a %.:e %.:o %.:u %.:ö %.:ä %.:0 %=:0 2:0; Sets Kons = b d g h j k l m n p r s sh z zh t v ; Vok = a e i o u õ ä ö ü ; Alfa = Kons Vok; AV = G B D K P T S ; AVT = g b d k p t s ; VaheVok = A E U ; TyveVok = a e i u ; LyhVok = a e o u õ ä ö ü ; LV = B G D S T ; LVTA = b g d s t ; Klus = k p t ; AVKlus = K P T ; NorkKlus = g b d G B D; Liq = l r ; TavaKons = h j l m n r s t v ; Definitions Algus = [.#. | Kons+ | %&:] ; Piir = [.#. | %+: | %&:] ; Rules ! ------------------Astmevahelduse reeglid------------------------------ "AV 1-2 - k ja p kadu" !kukk-kuke, lipp-lipu, õhk-õhu, kask-kase AVKlus:0 <=> Vok (r) [Klus|h|s] _ Vok (S:|l) %$:; s _ (%$:)(%+:) t ; !fonotaktika reegel skt->st where AVKlus in (K P) Klus in (k p) matched ;

80
"AV 3 - t kadu" T:0 <=>Vok [t|h] _ Vok (S:) %$:; !tt-t (rott-roti) ja ht-h (ehtima-ehib) Algus Vok: _ e (l) %$:; !ütlema-öelda, jätma-jäetakse "AV 4-5- assimilatsioonid s-r ja b-m" !vars-varre, tõmbama-tõmmata SB:RM <=> RM _ (TyveVok) (S:) %$: ; where SB in (S B) RM in (r m) matched; "AV 6 - assimilatsioon d-l" D:l <=> Algus Vok l _ (TyveVok) (S:) %$:; "AV 7 - assimilatsioon d-n" D:n <=> n _ (Vok) (S:) %$:; "AV 8 - assimilatsioon d-r" D:r <=> Algus Vok r _ (TyveVok) (S:) %$:; "AV 9 - b kadu" B:0 <=> Algus Vok: _ (Vok:) %$:; "AV 10 - d kadu" D:0 <=> Algus Vok Vok: _ (TyveVok:) (l) %$:; !laud-laua, vaidlema-vaielda Vok Vok Liq _ TyveVok %$:; !siirdama-siirata [ e | i: | u: | ü: ] _ TyveVok: %$: ; !vedada-vean, rida-rea õ _ e %$: ; !õde-õe, põdeda-põen [Kons- [r|s] ] a _ u %$: ; !ladu-lao, kaduda-kaon

81
"AV 11 - g kadu" ! jalg-jala, kirg-kire G:0 <=> Vok _ (Vok|h) %$: ; [ a | i | õ | u ] [ l | r ] _ (Vok) %$: ; [ e | ä | ü ] [ l | r ] _ [ i | u ] %$: ; "AV 12-13 - s sise- ja lõpukadu" S:0 <=> Vok [Kons+] (AV:AVT) TyveVok: _ Piir; Vok AV:AVT TavaKons Vok _ Piir; Algus (Vok) Vok (s) _ (Vok) %$:; where AV in (G B D K P T ) AVT in (g b d k p t ) matched; "AV 14 k-g" K:g <=> Vok [Liq | n | Vok] _ (Vok) (S:|l) %$:; !kook-koogi, pilk-pilgu, küngas-künka Vok _ VaheVok: Liq (Vok) %$:; !kogre-kokre "AV 15 p-b" P:b <=> Vok [Liq | m | Vok] _ Vok (S:) %$:0 ; !karp-karbi, kimp-kimbu, loopida-loobin Vok _ [Liq|j] Vok (S:) %$:; !lupjama-lubjata, kobras-kopra Vok _ VaheVok: Liq (Vok) %$:; !sõpra-sõbra "AV 16 t-d" T:d <=> Vok [Vok|Liq | n] _ Vok %$:; !paat-paadi, kaart-kaardi, elevant-elevandi Vok Vok _ e l %$:; !vaatlema-vaadelda Vok _ VaheVok: Liq (Vok) %$:; !põtra-põdra "AV 17: g-j" !märg-märja, hüljes-hülge G:j <=> [ e | ä | ü ] [ l | r ] _ [ a | e ] (S: ) %$: ; "AV 18: d-j" D:j <=> [ a | o | õ ] _ a %$:; !sadada-sajab, sõda-sõja [ [[ r | s ] a] | o | õ ] _ u %$: ; !sadu-saju, kodu-koju

82
"AV 19: b-v" B:v <=> Vok [Vok|Liq] _ (Vok) %$:; !kaebama-kaevata, kõlbama-kõlvata, värbama-värvata, varb-varva !-----------------Fonotaktika- ja ortograafiareeglid----------------- "Konsonantühendi reegel " ! Konsonantühendis kirjutatakse kõik häälikud ühekordselt, nt. kukkru->kukru, kristallne->kristalne. K1:0 <=> Vok _ :K1 (%$:)(%+:) [Kons-K1]; where K1 in TavaKons ; "Liitsõnapiirile sidekriips kolme ühesuguse hääliku korral" !nt. plekk-katus, jää-äär %&:%- <=> :A1 :A1 _ :A1; where A1 in (a e f h i k l m n o p r s sh t u õ ä ö ü); "Tüvevokaal kaob us-liite ees" !raske+us=raskus, puhta+us=puhtus V1:0 <=> _ (S:) %+: u s ; where V1 in (a e u); "i -> e enne i-ga algavat formatiivi" !kauni+im=kauneim i:e <=> Kons _ (S:) %+: i ; "e->i enne tegijanime tunnust 'ja'" !olija, tegija, nägija e:i <=> [l | :g] _ %+: j a; "Vahevokaali kadu" ! Kui l,m,n,r,v-lõpulisele sõnale lisandub tüvevokaal, siis vahevokaal kaob, nt. tütar-tütre, suhkur-suhkru. VaheVok:0 <=> _ [Liq | m | n | v | s] (%+:) TyveVok ; "Vokaali annihileerumine nõrgas astmes" V1:0 <=> Vok _ D: V1 %$:; where V1 in (a u);

83
"Vokaali madaldumine" ! fonotaktika reegel 1: Nõrgeneva AV tõttu tekivad mõnedes !’rida'-tüüpi sõnades häälikuühendid ua, üi jm, mis on´fonotaktiliselt lubamatud ning teisenevad vastavalt oa-ks, öe-ks jm. Seejuures 2 erinevat konteksti, kuna madalduda võib nii sise- (siga->sea) kui lõppvokaal (kadu->kao) KorgeVok:MadalVok <=> Algus _ LV: [a|e|i:|u:](l) %$: ; Algus Vok LV: _ %$: ; where KorgeVok in (u ü i) MadalVok in (o ö e) matched ; "vokaalide teisenemine järgsilbis o->u, ö->e, ä->e" %.:V2 <=> V1 %.: h _ Piir; where V1 in (a o u ö ä) V2 in (a u u e e) matched; "Konsonandi kahekordistumine" !nt. elu-ellu, nime-nimme, tulema-tulla %=:K1 <=> K1 _ (TyveVok:) 2:; !mitte-klusiilid NorkKlus: _ (TyveVok:) 2:; !klusiilid where K1 in TavaKons; "Nõrga klusiili pikendamine III-välteliseks" NorkKlus:Klus <=> _ %=: (TyveVok:) 2:; where NorkKlus in (g G b B d D) Klus in (k k p p t t) matched; "pst -> st ja p kaashäälikuühendis" !fonotaktika reegel 2: pst -> st (lapst->last) p:0 <=> _ s %+: t ; Kons Vok _ :p (%$:)(%+:) [Kons-p+]; !kaashäälikuühend "m -> n t|d ees" !fonotaktika reegel 3: (lumd->lund) m:n <=> _ %+: [d | t] ;

84
"skt -> st, kst -> st ja k kaashäälikuühendis" !fonotaktika reeglid 4 ja 5: (lasktud->lastud), (ukst->ust) k:0 <=> s _ (%$:)(%+:) t ; _ s (%$:)(%+:) t ; Kons Vok _ :k (%$:)(%+:) [Kons-p+]; !kaashäälikuühend "j -> i sõna lõpus" !fonotaktika reegel 6 (kirj->kiri, purj->puri) j:i <=> _ [.#.|%&:] ; ! Järgmised kolm on mitmuse vokaali valikureeglid: "mitmuse vokaal i" V:i <=> e: %+: _ ; ! e-tüvelised Algus [e| o| u| ä| ö| ü] [Kons-j] (%=:) a: %+: _ ; !"eks ämm söö kodus sütt" "mitmuse vokaal e" V:e <=> [i: | u:] %+: _ ; ! i- ja u-tüvelised Algus [u | o] Kons (%=:) a: %+: _ ; !a-tüvelised, lühikeses esisilbis u või o Algus [u | o | ü] Kons j: a: %+: _ ; !a-tüvelised, esisilbis uCj, oCj, üCj (kuri) "mitmuse vokaal u" V:u <=> [a | õ | ä i | e i] Kons (%=:) a: %+: _ ; !"kass kõrtsis ei käi" [ä | e] Kons j: a: %+: _ ; !a-tüvelised, esisilbis äCj, eCj (väli) !-----------------morfeemipiiridel kehtivad reeglid----------- "Pika vokaali lühenemine enne i-d ja h-d" ! Pikk vokaal lüheneb enne i-ga algavat !formatiivi, nt.maa+id->maid, maaha->maha. Võõrsõnades ainult 'e': idee-ideid, aga miljöö-!miljöösid,depoo-depoosid,kanuu-kanuusid %.:0 <=> [Vok [Kons+] e] | [Algus LyhVok] _ [%+: i| h] ; a _ [D:|G:] i %$:; !praadida-praeb, saagida-saeb "Pikk vokaal vaikimisi" %.:V1 => V1 _ ~[%+:0 i | [D:|G:] i %$:] ; where V1 in LyhVok;

85
"morfeemipiiril kaks s-i saavad üheks" s:0 <=> _ [:0*] %+: :s :i; "morfeemipiiril kaks d-d saavad üheks ning dt saab t-ks" d:0 <=> D: %+: _; T: %+: _; "käskiva kõneviisi formatiivi alguse g läheb k-ks helitu konsonandi järel või NA-tüves a järel" g:k <=> [h | D:d | T:t] [:0*] %+: _ [e|u]; a %$: %+: _ [e|u]; "formatiivi alguse d läheb t-ks helitu konsonandi järel" d:t <=> s %+: _ [a | e s]; "v ->ev konsonanttüvelistel verbidel" %+:e <=> [Kons | AV: ] _ v .#.; "Tüvevokaal kaob us-liite ees" !raske+us=raskus, puhta+us=puhtus V1:0 <=> _ (S:) %+: u s ; where V1 in (a e u); "i->e enne i-ga algavat formatiivi" !kauni+im=kauneim i:e <=> Kons _ (S:) %+: i ; "e->i enne tegijanime tunnust 'ja'" !olija, tegija, nägija e:i <=> [l | :g] _ %+: j a;

86
Lisa 4. Eesti keele kahetasemelise morfoloogia (mit tetäielik) sõnastike süsteem. Multichar_Symbols !nendest koosneb morfoloogiline info +S +A +Num +Pron +V +K +Adv +Sg +Pl +N +G +P +Ill +Adt +In +El +All +Ad +Abl +Ter +Trl +Es +Ab +Kom +Cmp +Spr +Ind +Imp +Knd +Kvt +Pr +Pt +Ipt +Sg1 +Sg2 +Sg3 +Pl1 +Pl2 +Pl3 +neg +Ips +Ps +Inf +Sup +Pts +Ger LEXICON Sõnastik Nimisõna; Omadussõna; Arvsõna; Asesõna; Tegusõna; Verbituletis; Määrsõna; Kaassõna; LEXICON Arvsõna üks+Num:ü ÜKS; kaks+Num:ka ÜKS; kolm+Num:kolm 0-E-I'; neli+Num:nelj A-U'; viis+Num:vii VARS'; kuus+Num:kuu VARS'; seitse+Num:seits ME/T'; kaheksa+Num:kaheksa AASTA'; üheksa+Num:üheksa AASTA'; kümme+Num:küm KÜMME; LEXICON ÜKS +Sg+N:ks #; +Sg+G:he #; +Sg:he S1; +Sg+P:ht #; +Sg+P:hte #; +Sg+Adt:hte #; +Pl+N:he+d #; +Pl+G:hte+de #; +Pl:hte+de S1; +Pl+P:hte+sid #; +Pl+P:ksi #;

87
LEXICON KÜMME +Sg+N:me #; +Sg+G:ne #; +Sg:ne S1; +Sg+P:me+t #; +Pl+N:ne+d #; +Pl+G:ne+te #; +Pl:ne+te S1; +Pl+P:ne+id #; LEXICON Asesõna ise+Pron:0 ISE; kes+Pron:ke KES; kumb+Pron:kumB A-I/N; ma+Pron:m MA; me+Pron:m ME; meie+Pron:mei MEIE; mina+Pron:min MINA; mis+Pron:mi KES; nad+Pron:0 NAD; need+Pron:ne NEED; nemad+Pron:0 NEMAD; nood+Pron:no NEED; sa+Pron:s MA; see+Pron:se SEE; sina+Pron:sin MINA; ta+Pron:t TA; te+Pron:t ME; teie+Pron:tei MEIE; tema+Pron:te TEMA; too+Pron:to SEE; LEXICON NEED +Pl+N:.d #; +Pl+G:nde #; +Pl:nde S1; +Pl+P:i+d #; +Pl:i LOPUD; LEXICON SEE +Sg+N:. #; +Sg+G:lle #; +Sg:lle S1; +Sg+P:da #;

88
LEXICON TEMA +Sg+N:ma #; +Sg+G:ma #; +Sg:ma S1; +Sg+P:da #; LEXICON NEMAD +Pl+N:nemad #; +Pl+G:nende #; +Pl:nende S1; +Pl:nei LOPUD; LEXICON NAD +Pl+N:nad #; +Pl+G:nende #; +Pl:nei LOPUD; +Pl:nende S1; +Pl+P:neid #; LEXICON MINA +Sg+N:a #; +Sg+G:u #; +Sg:u S1; +Sg+P:+d #; LEXICON MEIE +Pl+N:e #; MEIE-1; LEXICON MEIE-1 +Pl+G:e #; +Pl:0 LOPUD; +Pl+P:d #; LEXICON ME +Pl+N:e #; 0:ei MEIE-1; LEXICON MA +Sg+N:a #; +Sg+G:u #; +Sg:u LOPUD; +Sg:inu S1; +Sg+P:ind #;

89
LEXICON TA +Sg+N:a #; +Sg+G:a #; +Sg:a LOPUD; +Sg:ema S1; +Sg+P:eda #; LEXICON LOPUD +Ill:sse #; +In:+s #; +El:+st #; +All:+le #; +Ad:+l #; +Abl:+lt #; +Ter:+ks #; LEXICON KES +Sg+N:s #; +Sg+G:lle #; +Sg:lle S1; +Sg+P:da #; LEXICON ISE +Sg+N:ise #; +Sg+G:enda #; +Sg:enda S1; +Sg+P:ennas+t #; LEXICON Kaassõna abil K; all K; alla K; alt K; ees K; eest K; ette K; ilma K; jaoks K; juurde K; juures K; juurest K; järel LE-LT; järgi K; kaudu K; korral K;

90
kõrval LE-LT; mööda K; peal LE-LT; pool LE-LT; puhul K; põhjal K; sees K; seest K; sisse K; suhtes K; taha K; taga K; tagant K; teel K; tõttu K; vahel LE-LT; vastu K; üle K; üles K; ümber K; ümbert K; LEXICON LE-LT !väliskohakäänetes käänduvate kaas- ja määrsõnade jaoks e+K:e #; +K:0 #; t+K:t #; LEXICON K +K: #; LEXICON Määrsõna all PREFIX; alla PREFIX; alt PREFIX; ainult ÜKSIK; eemal LE-LT/Adv; ees PREFIX; eest PREFIX; ette PREFIX; halvasti ÜKSIK; ilma PREFIX; juba ÜKSIK; juurde PREFIX; juures PREFIX; juurest PREFIX;

91
järel LE-LT/Adv; järsult ÜKSIK; ka ÜKSIK; kogu ÜKSIK; kord ÜKSIK; kui ÜKSIK; kõrval LE-LT/Adv; küll ÜKSIK; mitte PREFIX; mööda PREFIX; nagu ÜKSIK; nii ÜKSIK; nõrgalt ÜKSIK; nüüd ÜKSIK; palju PREFIX; peal LE-LT/Adv; pikalt ÜKSIK; sees PREFIX; seest PREFIX; siis ÜKSIK; sisse PREFIX; taga PREFIX; tagant PREFIX; teel PREFIX; vahel LE-LT/Adv; vaid ÜKSIK; vastu PREFIX; veel ÜKSIK; ära PREFIX; üle PREFIX; üles PREFIX; ümber PREFIX; ümbert ÜKSIK; LEXICON PREFIX +Adv: #; +:& Verbituletis; LEXICON ÜKSIK +Adv: #; LEXICON LE-LT/Adv e PREFIX; PREFIX; t PREFIX;

92
LEXICON Omadussõna avalik:avalikK IK/O; halb:halB A-U/N/O; h:0 HEA; hirm:hirmUs S-A/O; ilu A-DUS/O; järgmi NE-SI/O; järsk:järsK U/N/O; kaug:kauge AASTA-E/O; kalli:kalliS S-DUS/T/O; kauni:kauniS S-DUS/T/O; keskmi NE-SI/O; kind:kindEl L-A/O; kirju AASTA/O; kur:kurj JA-JE/N/O; kõrg:kõrge AASTA-E/O; lai 0-A-U/O; liht NE-SA/O; noor E-DE/O; nõrk:nõrK A-U/N/O; oluli NE-SI/O; pidev A/O; pikk:pikK A-I/N/O; pime 0-DA/O; puh:puhTaS AS/T/O; rask:raske AASTA-E/O; rõõm:rõõmUs S-A/O; so SOE; sood NE-SA/O; suur E-DE/O; terv AASTA-IS/O; tihe 0-DA/O; tubli 0-T-SID/O; tugev A/O; tähtis:tähtIs A/O; täp NE-SE-SET/O; tüh:tühj JA-JE/N/O; vaba:vab A-U-AM/O; vaik NE-SE-SET/O; valg:valge AASTA-E/O; van A-U/O; veid:veidEr R-A/O; viimane:viima NE-SEID/O; visa 0-T-SID/O; võimalik:võimalikK IK/O;

93
väik E-SE-SI/O; õig:õige AASTA-E/O; õnnetu AASTA/O; ühi NE-SEID/O; üksik U/O; LEXICON 0-T-SID/O !tubli +A:0 0-T-SID'; +A+Cmp:+m A'; dus:d+us E-SI; sti+Adv:+sti #; lt+Adv:+lt #; LEXICON 0-DA/O !pime +A:0 0-DA'; +A+Cmp:da+m A'; +A+Spr:da+im A'; dus:d+us E-SI; dasti+Adv:da+sti #; dalt+Adv:da+lt #; LEXICON SOE e+A+Sg+N:e #; e+A+Sg+G:.ja #; e+A+Sg:.ja S1; e+A+Sg+P:.ja #; e+A+Sg+Adt:.ja #; e+A+Pl:.ja S2; e+A+Pl+P:.je #; e+A+Cmp:.jem A'; ojus:.j+us E-SI; ojalt+Adv:.ja+lt #; LEXICON HEA ea+A+Sg+N:hea #; ea+A+Sg+G:hea #; ea+A+Sg:hea S1; ea+A+Sg+P:hea+d #; ea+A+Pl:hea S2; ea+A+Pl:hea+de S1; ea+A+Pl:häi S4; ea+A+Cmp:parem A'; ea+A+Spr:parim A'; eadus:head+us E-SI; ästi+Adv:hä+sti #;

94
LEXICON AASTA-IS/O !terve - tervis e+A:e AASTA'; e+A+Cmp:e+m A'; e+A+Spr:e+im A'; is:+is E-SI; elt+Adv:e+lt #; LEXICON AASTA-E/O !raske e+A:0 AASTA'; e+A+Cmp:+m A'; e+A+Spr:+im A'; us:+us E-SI; elt+Adv:+lt #; esti+Adv:+sti #; LEXICON AASTA/O !õnnetu +A:0 AASTA'; +A+Cmp:+m A'; +A+Spr:+im A'; s:+us E-SI; lt+Adv:+lt #; sti+Adv:+sti #; LEXICON NE-SA/O !lihtne ne+A+Sg+N:ne #; ne+A+Sg+G:sa #; ne+A+Sg:sa S1; ne+A+Sg+P:sa+t #; ne+A+Pl+N:sa+d #; ne+A+Pl+G:sa+te #; ne+A+Pl:sa+te S1; ne+A+Pl:sa+i S4; ne+A+Cmp:sa+m A'; ne+A+Spr:sa+im A'; sus:s+us E-SI; salt+Adv:sa+lt #; sasti+Adv:sa+sti #; LEXICON NE-SI/O !oluline, järgmine ne+A:0 NE-SI'; ne+A+Cmp:se+m A'; ne+A+Spr:s+im A'; sus:s+us E-SI; selt+Adv:se+lt #;

95
LEXICON E-SE-SI/O !väike e+A:e 0-SE-SI'; e+A+Cmp:se+m A'; e+A+Spr:se+im A'; sus:s+us E-SI; selt+Adv:se+lt #; LEXICON NE-SEID/O !soolane ne+A:0 NE-SEID'; ne+A+Cmp:se+m A'; ne+A+Spr:se+im A'; sus:s+us E-SI; LEXICON NE-SE-SET/O !vaikne ne+A+Sg+N:ne #; ne+A+Sg+G:se #; ne+A+Sg:se S1; ne+A+Sg+P:se+t #; ne+A+Pl+N:se+d #; ne+A+Pl+G:se+te #; ne+A+Pl:se+te S1; ne+A+Pl:se+i S4; sus:s+us E-SI; selt+Adv:se+lt #; LEXICON IK/O !õnnelik +A:0 IK'; +A+Cmp:u$+m A'; +A+Spr:$+em A'; kus:+us E-SI; kult+Adv:u$+lt #; LEXICON E-DE/O !suur +A:0 E-DE'; +A+Cmp:e+m A'; +A+Spr:+im A'; us:+us E-SI; esti+Adv:e+sti #; LEXICON U/N/O !järsk +A:0 U/N'; +A+Cmp:e$+m A'; +A+Spr:i$+m A'; us:+us E-SI;

96
LEXICON A-U/N/O !halb, nõrk +A:0 JALG'; +A+Cmp:e$+m A'; +A+Spr:$+im A'; us:+us E-SI; LEXICON JA-JE/N/O !kuri, tühi i+A:0 A-E/N'; i+A+Cmp:e$+m A'; jus:+us E-SI; jalt+Adv:a$+lt #; LEXICON A-I/N/O !pikk +A:0 A-I/N'; +A+Cmp:e$+m A'; +A+Spr:i$+m A'; us:+us E-SI; LEXICON A-U/O !vana (vanem) a+A:0 A-U'; a+A+Cmp:e+m A'; a+A+Spr:+im A'; us:+us E-SI; asti+Adv:a+sti #; alt+Adv:a+lt #; LEXICON A-U-AM/O !vaba (vabam) +A:0 A-U'; +A+Cmp:a+m A'; dus:a+dus E-SI; sti+Adv:a+sti #; lt+Adv:a+lt #; LEXICON 0-A-U/O !lai +A: 0-A-U'; +A+Cmp:e+m A'; us:+us E-SI; alt+Adv:a+lt #; LEXICON U/O !üksik +A: U'; +A+Cmp:u+m A; +A+Spr:u+im A'; us:=+us E-SI; ult+Adv:u+lt #;

97
LEXICON AS/T/O !puhas as+A: T'; as+A+Cmp:+m A'; as+A+Spr:+im A'; tus:+us E-SI; talt+Adv:+lt #; LEXICON S-DUS/T/O !kallis, kaunis s+A: T'; s+A+Cmp:+m A'; s+A+Spr:+im A'; dus:+dus E-SI; lt+Adv:+lt #; LEXICON R-A/O !veider er+A: A'; er+A+Cmp:a+m A'; er+A+Spr:a+im A'; rus:+us E-SI; rasti+Adv:a+sti #; LEXICON S-A/O !hirmus, rõõmus us+A: A'; us+A+Cmp:a+m A'; us+A+Spr:a+im A'; sus:+us E-SI; sasti+Adv:a+sti #; LEXICON L-A/O !kindel el+A: A'; el+A+Cmp:a+m A'; el+A+Spr:a+im A'; lus:+us E-SI; lasti+Adv:a+sti #; LEXICON A/O !tugev +A: A'; +A+Cmp:a+m A'; +A+Spr:a+im A'; us:+us E-SI; asti+Adv:a+sti #; LEXICON A-DUS/O !ilus s+A:s A'; s+A+Cmp:sa+m A';

98
s+A+Spr:sa+im A'; dus:d+us E-SI; sasti+Adv:sa+sti #; LEXICON Nimisõna aasta AASTA; abi PESA; aed:a ED-IA; aeg:a EG-JA; aine T; aken:akEn A/T; arv 0-U-E; auto 0-T-SID; ehe:ehTe T; elu:el=u PESA-Adt; ema TIBU; grupp:grupP I/N; hammas:hamBaS T; hinne:hinDe T; hobune:hobu NE-SEID; hulk:hulK A-I/N; hõbe 0-DA; hääl E-DE; hüljes:hülGeS T; !Q:g TA Q:j NA hüpe:hüpPe T; ilm 0-A-I; inimene:inim INIM; isa TIBU; jada:jad A-U; jalg:jalG JALG; juht:juhT I/N; jutt:jutT U/N; juur E-DE; juus:juu S-KSE; jõgi:jõG I-KK/N; jõud:jõuD U/N; kallas:kalDaS T; kalle:kalDe T; kana:kan A-U; karp:karP I/N; kate:katTe T; kee KUU; keel E-DE; kell 0-A-I; kese:kesK E-ME;

99
kevad E; kiik:kiiK E/N; kild:kilD U/N; kinnas:kinDaS T; kiri:kirj 0-A-U; kirre:kirDe T; kobras:koPraS T; kodu:koDu KODU; !Y:d TA Y:j NA koht:kohT A-I/N; komme:komBe T; kool I/N; kord:korD A-I/N; kork:korK I/N; kott:kotT I/N; kuhi:kuhj A-E/N; kukkur:kukkUr U; kuu:ku. KUU; kõne 0-T-SID; kõrv 0-A-U; käsi:käS I-E-T/N; külg:külG E/N; küngas:künKaS T; küsimus:küsimus E-SI; küte:kütTe T; lagi:laG=i NLV-Adt; laps E-TE; laud:lauD A-U/N; leht:lehT E/N; leib:leiB JALG; liige:liiK ME/T; liit:liiT U/N; lind:linD U/N; linn 0-A-U; loom 0-A-I; lugemik:lugemikK IK; lugu:luG=u NLV-Adt; lukk:lukK U/N; lumi:lum I-E-D; lõpp:lõpP U/N; maa:ma MAA; madu:maDu LV/N; maja:maj=a PESA-Adt; mees:me ES-HE; meri:mer I-E-D; muld:mulD A-I/N;

100
mure 0-T-SID; mõju:mõj=u PESA-Adt; mõte:mõtTe T; naine:nai NE-SI-1; nimi:nim I-E; nina:nin=a PESA-Adt; nägu:näG=u NLV-Adt; näide:näiTe T; osa:os=a PESA-Adt; pea:p EA-ÄI; pesa:pes=a PESA-Adt; pilge:pilKe T; pilt:pilT I/N; poeg:po EG-JA; poiss:poisS I/N; probleem I/N; puu:pu. KUU; põhi:põhj 0-A-U; põhjus E-SEID; põld:põlD U/N; päev 0-A-I; päike 0-SE-SI; raamat U; rahvas:rahvaS T; raud:rauD A-U/N; riik:riiK I/N; rike:rikKe T; rõõm U/N; saar 0-E-I; selg:selG A-I/N; silm 0-A-I; suhe:suhTe T; suhkur:suhkUr U; suu:su MAA; suvi:suv I-E; sõber:sõPEr A/NNT; sõda:sõD=a NLV-Adt; sõna PESA; süda 0-ME; sügis E-SEID; talv 0-E-I; tee:te. KUU; tegu:teGu LV/N; tibu TIBU; tipp:tipP U/N;

101
tuba:tuB=a NLV-Adt; tuli:tul I-E-D; tunne:tunDe T; tund:tunD I/N; täht:tähT E/N; tänav A; töö:tö MAA; tüdruk U; tütar:tütAr E/T; uks E-TE; uni:un I-E-D; vana PESA; varras:varDaS T; vars:var VARS; vend:venD A-I/N; vesi:veS I-E-T/N; viga:viGa LV/N; võimalus E-SI; õde:õDe LV/N; õhk:õhK U/N; õhtu AASTA; õpik U; öö:ö MAA; LEXICON PESA-Adt PESA; +S+Sg+Adt:2 #; LEXICON PESA +S: PESA’; G-LIIT; LEXICON PESA’ +Sg+N:0 #; +Sg:0 S1; +Sg+P:0 #; +Pl+N:+d #; +Pl+G:+de #; +Pl:+de S1; +Pl+P:+sid #; +Pl+P:+V #; +Pl:+V S5;

102
LEXICON 0-T-SID +S: 0-T-SID'; G-LIIT; LEXICON 0-T-SID' !tubli, kõne +Sg+N:0 #; +Sg:0 S1; +Sg+P:+t #; +Pl:0 S2; LEXICON IK +S: IK'; 0:u$ G-LIIT; LEXICON IK' !lugemik (erinevus U/N tüübist: vok. mitmuses võimalikud kõik käänded) +Sg+N:$ #; +Sg:u$ S1; +Sg+P:u #; +Sg+Adt:u #; +Pl+N:u$+d #; +Pl+G:u+de #; +Pl:u+de S1; +Pl+P:u+sid #; +Pl+P:e #; +Pl:e$ S1; LEXICON A/NNT +S: A/NNT'; 0:a$ G-LIIT; LEXICON A/NNT' !nt. sõber +Sg+N:$ #; +Sg:a$ S1; +Sg+P:a #; +Sg+Adt:a #; +Pl+N:a$+d #; +Pl+G:a+de #; +Pl:a+de S1; +Pl+P:a+sid #; +Pl+P:u #; LEXICON S-KSE +S: S-KSE'; 0:s N-LIIT; 0:kse G-LIIT;

103
LEXICON S-KSE' !nt. juus +Sg:kse S1; +Sg+P:s+t #; +Pl+N:kse+d #; +Pl+G:kse+te #; +Pl:kse+te S1; +Pl:kse+i S4; LEXICON 0-DA +S: 0-DA'; N-LIIT; LEXICON 0-DA' !nt. hõbe +Sg+G:da #; +Sg:da S1; +Sg+P:da+t #; +Pl+N:da+d #; +Pl+G:da+te #; +Pl:da+te S1; +Pl:da+i S4; LEXICON E-ME +S: E-ME'; 0:me G-LIIT; LEXICON E-ME' !nt. kese +Sg+N:$ #; +Sg:me S1; +Sg+P:e$+t #; +Pl+N:me+d #; +Pl+G:me+te #; +Pl:me+te S1; +Pl:me+i S4; LEXICON 0-ME +S: 0-ME'; N-LIIT; 0:me G-LIIT; 0:me+te PLG-LIIT; LEXICON 0-ME' !nt. süda +Sg:me S1; +Sg+P:n+t #; +Pl+N:me+d #;

104
+Pl+G:me+te #; +Pl:me+te S1; +Pl:me+i S4; LEXICON A/T +S: A/T'; 0:a G-LIIT; LEXICON A/T' !nt. aken +Sg+N:0 #; +Sg:a S1; +Sg+P:+t #; +Pl+N:a+d #; +Pl+G:+de #; +Pl:+de S1; +Pl:a+i S4; LEXICON KODU +S: KODU'; G-LIIT; LEXICON KODU' +Sg:0 S0; ! N=G=P +Sg+Adt:$ #; +Sg:0 S1; +Pl:0 S2; LEXICON VARS +S: VARS'; 0:S N-LIIT; 0:Se$ G-LIIT; LEXICON VARS' +Sg:Se$ S1; +Sg+P:+t #; +Sg+Adt:de #; +Pl+N:Se$+d #; +Pl+G:+te #; +Pl:+te S1; +Pl+P:Si #; +Pl:Si S5; LEXICON 0-A-I +S: 0-A-I'; N-LIIT;

105
0:a G-LIIT; LEXICON 0-A-I' !nt. päev, silm +Sg:a S1; +Sg+P:a #; +Sg+Adt:a #; +Pl:a S2; +Pl+P:i #; +Pl:i S5; LEXICON 0-A-U +S: 0-A-U'; N-LIIT; 0:a G-LIIT; LEXICON 0-A-U' !nt. linn +Sg:a S1; +Sg+P:a #; +Sg+Adt:a #; +Pl:a S2; +Pl+P:u #; +Pl:u S5; LEXICON 0-E-I +S: 0-E-I'; 0:e G-LIIT; LEXICON 0-E-I' !nt. talv +Sg+N:0 #; +Sg:e S1; +Sg+P:e #; +Sg+Adt:e #; +Pl:e S2; +Pl+P:i #; +Pl:i S5; LEXICON 0-U-E +S: 0-U-E'; N-LIIT; 0:u G-LIIT; LEXICON 0-U-E' !nt. arv +Sg:u S1; +Sg+P:u #; +Sg+Adt:u #;

106
+Pl:u S2; +Pl+P:e #; +Pl:e S5; LEXICON ES-HE +S: ES-HE'; 0:es N-LIIT; 0:he G-LIIT; LEXICON ES-HE' !nt. mees +Sg:he S1; +Sg+P:es+t #; +Pl+N:he+d #; +Pl+G:es+te #; +Pl:es+te S1; +Pl+P:hi #; LEXICON I-E-D +S: I-E-D'; 0:i N-LIIT; 0:e G-LIIT; LEXICON I-E-D' !nt. tuli +Sg:e S1; +Sg+P:+d #; +Sg+Adt:=e #; +Pl:e S2; +Pl:e+de S1; LEXICON I-E +S: I-E'; 0:i N-LIIT; 0:e G-LIIT; LEXICON I-E' !nt. nimi +Sg:e S1; +Sg+P:e #; +Sg+Adt:=e #; +Pl:e S2; +Pl:e+de S1; LEXICON EA-ÄI +S: EA-ÄI'; 0:ea S3;

107
LEXICON EA-ÄI' !pea +Sg:ea S1; +Sg+Adt:ähe #; +Pl:ea S2; +Pl:ea+de S1; +Pl:äi S4; LEXICON MAA +S: MAA'; 0:. KUU; LEXICON MAA' !maa; suu +S+Sg+Adt:h. #; LEXICON ED-IA +S: ED-IA'; :ed N-LIIT; :ia G-LIIT; LEXICON ED-IA' !nt. aed +Sg:ia S1; +Sg+P:eda #; +Sg+Adt:eda #; +Pl+N:ia+d #; +Pl+G:eda+de #; +Pl:eda+de S1; +Pl+P:eda+sid #; +Pl+P:edu #; LEXICON EG-JA +S: EG-JA'; 0:ja G-LIIT; LEXICON EG-JA' !nt. aeg +Sg+N:eg #; +Sg:ja S1; +Sg+P:ega #; +Sg+Adt:ega #; +Pl+N:ja+d #; +Pl+G:ega+de #; +Pl:ega+de S1; +Pl+P:ega+sid #; +Pl+P:egu #;

108
LEXICON AASTA +S: AASTA'; G-LIIT; LEXICON AASTA' !AV-ta, alati vokaaltüvi, te- ja i-mitmus (aasta) +Sg+N:0 #; +Sg+P:+t #; +Sg:0 S1; +Pl+N:+d #; +Pl+G:+te #; +Pl:+te S1; +Pl:i S4; LEXICON ME/T +S: ME/T'; 0:me G-LIIT; LEXICON ME/T' !nt. liige +Sg+N:e$ #; +Sg+P:e$+t #; +Sg:me S1; +Pl+N:me+d #; +Pl+G:me+te #; +Pl:me+te S1; +Pl:me+i S4; LEXICON I-E-T/N +S: I-E-T/N'; :i N-LIIT; :e$ G-LIIT; LEXICON I-E-T/N' ! nt. vesi +Sg+P:$+tt #; +Sg:e$ S1; +Sg+Adt:$tte #; +Pl+N:e$+d #; +Pl+G:$+te #; +Pl:$+te S1; ! te-mitmus +Pl+P:i #; +Pl:i S5; ! vokaalmitmus LEXICON NLV-Adt +S: NLV-Adt'; NLV-Sg;

109
LEXICON NLV-Adt' ! nt. sõda +Pl:0 NLV-Pl; +Sg+P:0 #; +Sg+Adt:2 #; +Pl+P:0 #; LEXICON LV/N +S: LV/N'; NLV-Sg; LEXICON LV/N' !nt. madu +Pl: NLV-Pl; +Sg+P: #; LEXICON NLV-Sg ! nõrgenev LV, ainsus - tuba, lagi, madu jne. +S+Sg+N:0 #; :$ G-LIIT; +S+Sg:$ S1; LEXICON NLV-Pl !nõrgenev LV, a. os. ja mitmus - tuba, lagi, madu +N:$+d #; +G:+de #; +P:+sid #; 0:+de S1; LEXICON A-E/N +S: A-E/N'; N-LIIT; :a NVV; LEXICON A-E/N' ! a-tüvelised nõrgeneva AV-ga,mitmuse vok. e - nt. tühi, lodi,kuhi +Pl+P:e #; LEXICON A-I/N +S: A-I/N'; N-LIIT; :a NVV; LEXICON A-I/N' ! a-tüvelised nõrgeneva AV-ga,mitmuse vok. i - nt. vend +Sg+N:0 #; +Pl+P:i #;

110
LEXICON A-U/N +S: A-U/N'; N-LIIT; :a NVV; LEXICON A-U/N' ! a-tüvelised nõrgeneva AV-ga, mitmuse vok. u - raud +Pl+P:u #; +Pl+Adt:u #; +Pl:u S5; LEXICON JALG ! nagu eelmine, aga vok. mitmus nõrgaastmeline +S: JALG'; N-LIIT; :a NVV; LEXICON JALG' +Pl+P:u #; +Pl+Adt:u #; +Pl:u$ S5; LEXICON E/N +S: E/N'; N-LIIT; :e NVV; LEXICON E/N' ! e-tüvelised nõrgeneva AV-ga, nt. kiik +Pl+P:i #; LEXICON U/N +S: U/N'; N-LIIT; :u NVV; LEXICON U/N' !tüvevok. u, nõrgenev AV - tipp +Pl+P:e #; LEXICON I/N +S: I/N'; N-LIIT; :i NVV; LEXICON I/N' !tüvevok. i, nõrgenev AV - karp +Pl+P:e #;

111
LEXICON NVV ! nõrgenev vältevaheldus - tipp, karp, kiik jne. :$ G-LIIT; +S+Sg:$ S1; +S+Sg+P:0 #; +S+Sg+Adt:0 #; +S+Pl+N:$+d #; +S+Pl+G:+de #; +S+Pl:+de S1; +S+Pl+P:+sid #; LEXICON T +S: T'; G-LIIT; LEXICON T' ! tugevnev AV - mõte +Sg+N:$ #; +Sg+P:$+t #; +Sg:0 S1; ! TA (omastava) tüvele liituvad +Pl+N:+d #; +Pl+G:$+te #; +Pl:$+te S1; ! te-mitmus +Pl:+i S4; ! i-mitmus LEXICON E/T +S: E/T'; N-LIIT; :e G-LIIT; LEXICON E/T' ! 'tütar' - e-tüvelised kirjapildis mitte kajastuva tugevneva AV-ga +Sg:e S1; +Sg+P:+t #; +Pl:e+i S4; ! i-mitmus +Pl+G:de #; +Pl:de S1; ! de-mitmus LEXICON E-SI +S: E-SI'; E-TE; LEXICON E-SI' ! õigus, võimalus +Sg+Ill:se #; LEXICON E-SEID +S: E-SEID'; N-LIIT;

112
LEXICON E-SEID' ! sügis :e SE; !vokaaltüvele liituvad (nagu ne-se sõnadel) S; !konsonanttüvele liituvad (sg p ja te-mitmus) +Pl:e+i S4; !i-mitmus LEXICON NE-SEID +S: NE-SEID'; 0:se SE; LEXICON NE-SEID' !hobune :ne NE; :s S; LEXICON NE +Sg+N:0 #; LEXICON SE G-LIIT; +S+Sg:0 S1; +S+Pl+N:+d #; LEXICON NE-SI-1 +S: NE-SI-1'; SE-SI-1; LEXICON NE-SI-1' !naine-naisesse :ne NE; :s S; LEXICON INIM !inimene +:& Nimisõna; +:& Omadussõna; +:& Verbituletis; :e SE-SI; +S:e NE-SI'; LEXICON NE-SI +S: NE-SI'; SE-SI; +:s& Nimisõna; LEXICON NE-SI' !oluline-olulisse e. olulisesse :ne NE; :s S;

113
LEXICON S +Sg+P:+t #; +Pl+G:+te #; +Pl:+te S1; LEXICON 0-SE-SI +S: 0-SE-SI'; SE-SI-1; LEXICON 0-SE-SI' !päike +Sg+N:0 #; LEXICON SE-SI-1 :se G-LIIT; +S+Sg:se S1; +S+Pl+N:se+d #; +S+Pl+P:s+i #; LEXICON SE-SI +Sg+Ill:+sse #; SE-SI-1; LEXICON E-DE +S: E-DE'; E-TE; LEXICON E-DE' ! e-tüvelised kirjapildis mitte kajastuva nõrgeneva AV-ga ja de- +Sg+Adt:de #; ! aditiiviga (keel, juur) LEXICON E-TE +S: E-TE'; N-LIIT; :e G-LIIT; LEXICON E-TE' ! e-tüvelised kirjapildis mitte kajastuva nõrgeneva AV-ga (laps) +Sg:e S1; +Sg+P:+t #; +Pl+G:te #; +Pl:te S1; ! te-mitmus +Pl+P:i #; +Pl:i S5; ! i-mitmus LEXICON E +S: E'; N-LIIT; :e G-LIIT;

114
LEXICON E' ! e-tüvelised AV-ta (kevad) +Sg:e S1; +Sg+P:e+t #; +Pl+G:e+te #; +Pl:e+te S1; ! te-mitmus +Pl:e+i S4; ! i-mitmus LEXICON A +S: A'; :a G-LIIT; LEXICON A' ! a-tüvelised AV-ta (tänav) +Sg+N:0 #; +Sg:a S1; +Sg+P:a+t #; +Pl+N:a+d #; +Pl+G:a+te #; +Pl:a+te S1; +Pl:a+i S4; LEXICON U +S: U'; 0:u G-LIIT; LEXICON U' ! u-tüvelised AV-ta (õpik) +Sg+N:0 #; +Sg:u S1; +Sg+P:u+t #; +Pl+N:u+d #; +Pl+G:u+te #; +Pl:u+te S1; +Pl:u+i S4; LEXICON TIBU ! 'tibu' - ainult de-mitmus S0; +S+Sg:0 S1; +S+Pl:0 S2; LEXICON KUU ! 'kuu' - de- ja i-mitmus S3; +S+Sg:0 S1; +S+Pl:0 S2; +S+Pl:+i S4;

115
LEXICON S0 ! nimetav=omastav=osastav +S+Sg+N:0 #; G-LIIT; +S+Sg+P:+0 #; LEXICON S1 ! käändelõpud sisseütlevast kuni kaasaütlevani +Ill:+sse #; +In:+s #; +El:+st #; +All:+le #; +Ad:+l #; +Abl:+lt #; +Ter:+ks #; +Trl:+ni #; +Es:+na #; +Ab:+ta #; +Kom:+ga #; LEXICON S2 ! de-mitmuse käänded +N:+d #; +G:+de #; :+de S1; +P:+sid #; LEXICON S3 ! 'kuu' ainsuse 3 esimest käänet +S+Sg+N: #; G-LIIT; +S+Sg+P:+d #; LEXICON S4 ! i-mitmuse lõpud ('kuu', 'tütar', 'mõte', 'aasta' , 'liige' jt.) +P:+d #; +Trl:+ni #; +Es:+na #; S5; LEXICON S5 !Tüvemitmuse lõpud (ilma 4 viimase käändeta ja osastavata) +Ill:+sse #; +In:+s #; +El:+st #; +All:+le #; +Ad:+l #; +Abl:+lt #; +Tr:+ks #;

116
LEXICON N-LIIT +S+Sg+N:0 #; +:& Nimisõna; +:& Omadussõna; +:& Verbituletis; LEXICON G-LIIT +S+Sg+G: #; +:& Nimisõna; +:& Omadussõna; +:& Verbituletis; LEXICON PLG-LIIT +S+Pl+G:0 #; +:& Nimisõna; +:& Omadussõna; +:& Verbituletis; LEXICON Verbituletis aida KESKSÕNA/T-N/TUD; aita KESKSÕNA/T-T; ala KESKSÕNA/T-N/TUD; alga KESKSÕNA/T-T; an KESKSÕNA/N-N; and KESKSÕNA/ANDMA; ela KESKSÕNA-1; haka KESKSÕNA/T-N/TUD; hakka KESKSÕNA/T-T; hinda KESKSÕNA/T-T; hinna KESKSÕNA/T-N/TUD; hülga KESKSÕNA/T-T; hülja KESKSÕNA/T-N/TUD; istu KESKSÕNA/PROS; jäe KESKSÕNA/N-N; jät:jätT KESKSÕNA/ANDMA; jää KESKSÕNA-3; kadu KESKSÕNA/N-T; kao KESKSÕNA/N-N; kaeba KESKSÕNA/T-T; kaeva KESKSÕNA/T-N/TUD; kara KESKSÕNA/T-N/TUD; karga KESKSÕNA/T-T; kasuta KESKSÕNA-1; kiira KESKSÕNA/T-N/TUD; kiirga KESKSÕNA/T-T;

117
kirjuta KESKSÕNA-1; korda KESKSÕNA/T-T; korra KESKSÕNA/T-N/TUD; koo KESKSÕNA/N-N; kudu KESKSÕNA/N-T; kukku KESKSÕNA/N-T; kuku KESKSÕNA/N-N; kuul KESKSÕNA-4; kõlba KESKSÕNA/T-T; kõlva KESKSÕNA/T-N/TUD; kõnel KESKSÕNA-2; kõndi KESKSÕNA/N-T; kõnni KESKSÕNA/N-N; käi KESKSÕNA-3; käsi KESKSÕNA/N-N; käski KESKSÕNA/N-T; laisel KESKSÕNA/T-N; laiskle KESKSÕNA/T-T; laul KESKSÕNA-4; lei KESKSÕNA/N-N; leid KESKSÕNA/ANDMA; lenda KESKSÕNA/T-T; lenna KESKSÕNA/T-N/TUD; liigel KESKSÕNA/T-N; liikle KESKSÕNA/T-T; liigu KESKSÕNA/N-N; liiku KESKSÕNA/N-T; loo KESKSÕNA-3; loode KESKSÕNA/N-N; loot KESKSÕNA/N-T; loe KESKSÕNA/N-N; luge KESKSÕNA/N-T; läinu+S:läinu AASTA'; läinud+A+Sg+N:läinud #; löö KESKSÕNA-3; mine KESKSÕNA/T-T; mõist KESKSÕNA/N-T; mõiste KESKSÕNA/N-N; mõel KESKSÕNA/T-N; mõtel KESKSÕNA/T-N; mõtle KESKSÕNA/T-T; märgi KESKSÕNA/N-N; märki KESKSÕNA/N-T; nõu KESKSÕNA/N-N; nõud KESKSÕNA/ANDMA;

118
nä KESKSÕNA/TEGEMA; näi KESKSÕNA-3; näida KESKSÕNA/T-N/TUD; näita KESKSÕNA/T-T; ol KESKSÕNA-2; oma KESKSÕNA-1; ooda KESKSÕNA/T-N/TUD; oota KESKSÕNA/T-T; pakku KESKSÕNA/N-T; paku KESKSÕNA/N-N; pan KESKSÕNA-2; pett KESKSÕNA/N-T; pete KESKSÕNA/N-N; pee KESKSÕNA/N-N; pida KESKSÕNA/N-T; pildu KESKSÕNA/N-T; pillu KESKSÕNA/N-N; põla KESKSÕNA/T-N/TUD; põlga KESKSÕNA/T-T; pööra KESKSÕNA/PROS; püri KESKSÕNA/N-N; pürgi KESKSÕNA/N-T; püü KESKSÕNA/N-N; püüd KESKSÕNA/ANDMA; räägi KESKSÕNA/N-N; rääki KESKSÕNA/N-T; saa KESKSÕNA-3; sae KESKSÕNA/N-N; saagi KESKSÕNA/N-T; saade KESKSÕNA/N-N; saat KESKSÕNA/N-T; sada KESKSÕNA/N-T; saja KESKSÕNA/N-N; sea KESKSÕNA/N-N; sead KESKSÕNA/ANDMA; seis KESKSÕNA-4; seo KESKSÕNA/N-N; sidu KESKSÕNA/N-T; siira KESKSÕNA/T-N/TUD; siirda KESKSÕNA/T-T; sõide KESKSÕNA/N-N; sõit KESKSÕNA/N-T; söö KESKSÕNA-3; sündi KESKSÕNA/N-T; sünni KESKSÕNA/N-N;

119
tahe KESKSÕNA/N-N; taht KESKSÕNA/N-T; tea KESKSÕNA/N-N; tead KESKSÕNA/ANDMA; te KESKSÕNA/TEGEMA; tegel KESKSÕNA-2; teki KESKSÕNA/N-N; tekki KESKSÕNA/N-T; tohi KESKSÕNA/N-N; tohti KESKSÕNA/N-T; too KESKSÕNA-3; tul KESKSÕNA-2; tun KESKSÕNA/N-N; tund KESKSÕNA/ANDMA; tõmba KESKSÕNA/T-T; tõmma KESKSÕNA/T-N/TUD; tõste KESKSÕNA/N-N; tõst KESKSÕNA/N-T; tõus KESKSÕNA-4; täide KESKSÕNA/N-N; täit KESKSÕNA/N-T; usu KESKSÕNA/N-N; usku KESKSÕNA/N-T; vaada KESKSÕNA/T-N/TUD; vaata KESKSÕNA/T-T; vaadel KESKSÕNA/T-N; vaatle KESKSÕNA/T-T; vaidle KESKSÕNA/T-T; vaiel KESKSÕNA/T-N; vaja KESKSÕNA-1; vasta KESKSÕNA/PROS; veda KESKSÕNA/N-T; vee KESKSÕNA/N-N; vehi KESKSÕNA/N-N; vehki KESKSÕNA/N-T; viha KESKSÕNA/T-N/TUD; vihka KESKSÕNA/T-T; vii KESKSÕNA-3; visa KESKSÕNA/T-N/TUD; viska KESKSÕNA/T-T; või KESKSÕNA-3; võrdle KESKSÕNA/T-T; võrrel KESKSÕNA/T-N; võe KESKSÕNA/N-N; võt:võtT KESKSÕNA/ANDMA;

120
õpi KESKSÕNA/N-N; õppi KESKSÕNA/N-T; öel KESKSÕNA/T-N; ütel KESKSÕNA/T-N; ütle KESKSÕNA/T-T; LEXICON KESKSÕNA-1 ! elama v:+v A/O; tav:+tav A/O; tav+S:+tav A'; tud+A+Sg+N:+tud #; tu+S:+tu AASTA'; nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; TULET; LEXICON KESKSÕNA-2 !tulema ev:+ev A/O; dav:+dav A/O; dav+S:+dav A'; dud+A+Sg+N:+dud #; du+S:+du AASTA'; nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; e TULET; LEXICON KESKSÕNA-3 !tooma v:+v A/O; dav:+dav A/O; dav+S:+dav A'; dud+A+Sg+N:+dud #; du+S:+du AASTA'; nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; TULET; LEXICON KESKSÕNA-4 !konsonanttüvelised (tõusma, laulma) ev:+Ev A/O; dav:+dav A/O; dav+S:+dav A'; dud+A+Sg+N:+dud #; du+S:+du AASTA'; nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; TULET;

121
LEXICON KESKSÕNA/T-N/TUD tav:+tav A/O; tav+S:+tav A'; tud+A+Sg+N:+tud #; tu+S:+tu AASTA'; nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; LEXICON KESKSÕNA/T-N dav:+dav A/O; dav+S:+dav A'; dud+A+Sg+N:+dud #; du+S:+du AASTA'; nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; LEXICON KESKSÕNA/T-T v:+v A/O; TULET; LEXICON KESKSÕNA/N-N tav:+tav A/O; tav+S:+tav A'; tud+A+Sg+N:+tud #; tu+S:+tu AASTA'; LEXICON KESKSÕNA/N-T v:+v A/O; nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; TULET; LEXICON NUD nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; LEXICON KESKSÕNA/TEGEMA ge KESKSÕNA/T-T; i NUD; h KESKSÕNA/N-N; LEXICON KESKSÕNA/PROS !prosoodiline vältevaheldus (istuma, pöörama) KESKSÕNA/N-N; KESKSÕNA/N-T; TULET;

122
LEXICON KESKSÕNA/ANDMA nud+A+Sg+N:+nud #; nu+S:+nu AASTA'; ev:+ev A/O; TULET; LEXICON TULET ja+S:+ja AASTA'; !tegijanimi mine:+mi NE-SI; !teonimi mata+A:+mata #; !omadussõna (nt. tegemata töö) LEXICON Tegusõna aitama+V:aiTa TUG; algama+V:alGa TUG; andma+V:anD DT-A/N; elama+V:ela V1; hakkama+V:hakKa TUG; hindama+V:hinDa TUG; hülgama+V:hülQa TUG; istuma+V:istu N-PROS; jõudma+V:jõuD DT-A/N; jätma+V:jä JÄTMA; jääma+V:jä. SAAMA; kaduma+V:kaDu N; kaebama+V:kaeBa TUG; kandma+V:kanD DT-A/N; kargama+V:karGa TUG; kasutama+V:kasuta V1; kiirgama+V:kiirGa TUG; kirjutama+V:kirjuta V1; kordama+V:korDa TUG; kuduma+V:kuDu N; kukkuma+V:kukKu N; kuulma+V:kuul 0-E; kõlbama+V:kõlBa TUG; kõnelema+V:kõnel ELE; kõndima+V:kõnDi N; käima+V:käi VIIMA; käskima+V:käsK I-0/N; laisklema+V:laisK LE-EL/T; laulma+V:laul 0-A; leidma+V:leiD DT-A/N; lendama+V:lenDa TUG; liiklema+V:liiK LE-EL/T;

123
liikuma+V:liiKu N; looma+V:lo. TOOMA; lootma+V:looT 0-A/N; lugema+V:luGe N; lööma+V:lö. TOOMA; minema+V:0 MINEMA; mõistma+V:mõist 0-A/N; mõtiskelema+V:mõtiskel ELE-LLA; mõtlema+V:mõt LE-EL/T; mõtlema+V:mõT LE-EL/T; märkima+V:märKi N; nõuma+V:nõuD DT-A/N; nägema+V:näG TEGEMA; näima+V:näi VÕIMA; näitama+V:näiTa TUG; olema+V:o OLEMA; omama+V:oma V1; ootama+V:ooTa TUG; pakkuma+V:pakKu N; panema+V:pan E-0; petma+V:petT 0-A/N; pidama+V:piD PIDA-SIN; pidama+V:piD PID-IN; pilduma+V:pilDu N; põlgama+V:põlGa TUG; pöörama+V:pööra TUG-PROS; pürgima+V:pürGi N; püüma+V:püüD DT-A/N; rääkima+V:rääKi N; saama+V:sa. SAAMA; saagima+V:sa.Gi N; saatma+V:saaT 0-A/N; sadama+V:saYa N; seadma+V:seaD DT-A/N; seisma+V:seis 0-A; siduma+V:siDu N; siirdama+V:siirDa TUG; sõitma+V:sõiT 0-A/N; sööma+V:sö. TOOMA; sündima+V:sünDi N; tahtma+V:tahT TAHTMA; teadma+V:teaD DT-A/N; tegelema+V:tegel ELE; tegema+V:teG TEGEMA; tekkima+V:tekKi N;

124
tohtima+V:tohTi N; tooma+V:to. TOOMA; tulema+V:tul E-0; tundma+V:tunD DT-E/N; tõmbama+V:tõmBa TUG; tõstma+V:tõst 0-A/N; tõusma+V:tõus 0-A; täitma+V:täiT 0-A/N; uskuma+V:usKu N; vaatama+V:vaaTa TUG; vaatlema+V:vaaT LE-EL/T; vaidlema+V:vaiD LE-EL/T; vajama+V:vaja V1; vastama+V:vasta TUG-PROS; vedama+V:veD PIDA-SIN; vehkima+V:vehKi N; vihkama+V:vihKa TUG; viima+V:vii VIIMA; viskama+V:visKa TUG; võima+V:või VÕIMA; võrdlema+V:võrD LE-EL/T; võtma+V:võ JÄTMA; õppima+V:õpPi N; ütlema+V:üt LE-EL/T; !ütlema-ütelda ütlema+V:üT LE-EL/T; !ütlema-öelda LEXICON OLEMA :le V10; +Ind+Pr+Sg1:le+n #; +Ind+Pr+Sg2:le+d #; +Ind+Pr+Sg3:n #; +Ind+Pr+Pl1:le+me #; +Ind+Pr+Pl2:le+te #; +Ind+Pr+Pl3:n #; +Imp+Pr+Sg2:le #; +Ind+Pr+Ps+neg:le #; +Knd+Pr:le Knd-Pr; +Ind+Ipt:l Ipt2; :l V21; :l V22; +Pts+Pr+Ps:l+ev #; +Pts+Pr+Ips:l+dav #; LEXICON MINEMA :mine V10;

125
+Ind+Pr:lähe Pr; +Imp+Pr+Sg2:mine #; +Ind+Pr+Ps+neg:lähe #; +Knd+Pr:lähe Knd-Pr; +Ind+Ipt:läk Ipt3; :min V21; +Ind+Pr+Ips:min=a+kse #; +Imp+Pr:min Imp; +Pts+Pt+Ps:läi+nud #; :läi Knd,Kvt-Pt; +Pts+Pr+Ps:min+ev #; +Pts+Pr+Ips:min+dav #; LEXICON ELE-LLA !mõtiskelema :e V20; +Ind+Ipt:e Ipt2; V21; V22; LEXICON E-0 !tulema :e V20; +Ind+Ipt: Ipt2; V21; V22; LEXICON V20 !algvormi tüvest +Sup:+ma #; +Sup+In:+mas #; +Sup+El:+mast #; +Sup+Trl:+maks #; +Sup+Ab:+mata #; +Kvt+Pr+Ps:+vat #; +Ind+Pr:0 Pr; +Imp+Pr+Sg2:0 #; +Ind+Pr+Ps+neg:0 #; +Knd+Pr:0 Knd-Pr; +Pts+Pr+Ps:+v #; LEXICON V21 !da-inf tüvest +Inf:=+a #; +Ger:=+es #; +Pts+Pt+Ips:+dud #; +Ind+Ipt+Ips:+di #; +Knd+Pr+Ips:+da+ks #;

126
+Knd+Pt+Ips:+du+ks #; +Kvt+Pr+Ips:+da+vat #; +Kvt+Pt+Ips:+du+vat #; +Imp+Pr+Ips:+da+gu #; +Sup+Ips:+da+ma #; +Ind+Pr+Ips+neg:+da #; +Pts+Pr+Ips:+dav #; LEXICON V22 !umbisikulise tegumoe tüvest +Ind+Pr+Ips:=a+kse #; +Imp+Pr:0 Imp; +Pts+Pt+Ps:+nud #; Knd,Kvt-Pt; LEXICON TOOMA V20; V31; +Ind+Ipt: Ipt2; LEXICON VIIMA V20; V31; +Ind+Ipt: Ipt1; LEXICON VÕIMA V30; +Ind+Ipt:0 Ipt3; LEXICON SAAMA V30; +Ind+Ipt: Ipt2; LEXICON V30 !algvormi tüvest (saama, võima) +Sup:+ma #; +Sup+In:+mas #; +Sup+El:+mast #; +Sup+Trl:+maks #; +Sup+Ab:+mata #; +Kvt+Pr+Ps:+vat #; +Inf:+da #; +Ind+Pr+Ips+neg:+da #; +Ger:+des #; +Ind+Pr:0 Pr; +Knd+Pr:0 Knd-Pr; V13;

127
Knd,Kvt-Pt; +Imp+Pr:0 Imp; +Imp+Pr+Sg2:0 #; +Ind+Pr+Ps+neg:0 #; +Pts+Pt+Ps:+nud #; +Pts+Pr+Ps:+v #; LEXICON V31 !da-inf tüvest (tooma, viima) +Inf:+a #; +Ger:+es #; +Pts+Pt+Ips:+dud #; +Ind+Ipt+Ips:+di #; +Knd+Pr+Ips:+da+ks #; +Knd+Pt+Ips:+du+ks #; +Kvt+Pr+Ips:+da+vat #; +Kvt+Pt+Ips:+du+vat #; +Imp+Pr+Ips:+da+gu #; +Sup+Ips:+da+ma #; +Ind+Pr+Ips+neg:+da #; +Ind+Pr+Ips:+a+kse #; +Imp+Pr:0 Imp; +Pts+Pt+Ps:+nud #; Knd,Kvt-Pt; +Pts+Pr+Ips:+dav #; LEXICON TUG-PROS !prosoodiline AV, nt. pöörata-pööran V10; !ma-sup TA V15; !da-inf NA, ta-tunnus +Ind+Ipt: Ipt3; V12; !kindla kv olevik TA V14; !umbis NA LEXICON TUG !hakkama (hakata-hakkan) V10; !ma-sup TA :$ V15; !da-inf NA, ta-tunnus +Ind+Ipt: Ipt3; V12; !kindla kv olevik TA :$ V14; !umbis NA LEXICON TAHTMA !tahtma (tahta-tahan-tahetakse) V10; +Ind+Ipt: Ipt1; V11; !TA :a$ V12; !NA :e$ V14; !umbis

128
LEXICON DT-E/N !tundma (tunda-tunnen-tuntakse) V10; +Ind+Ipt:0 Ipt1; V11; !TA :e$ V12; !NA V14; !umbis LEXICON DT-A/N !andma (anda-annan-antakse) V10; +Ind+Ipt: Ipt1; V11; !TA :a$ V12; !NA V14; !umbis LEXICON 0-A !laulma, seisma V10; +Ind+Ipt: Ipt1; V11; :a V12; V13; LEXICON 0-E !kuulma V10; +Ind+Ipt: Ipt1; V11; :e V12; V13; LEXICON PID-IN :a V10; +Ind+Ipt: Ipt2; :a V11; :a$ V12; :e$ V14; LEXICON TEGEMA :e V10; +Ind+Ipt:0 Ipt2; +Inf:h$+a #; +Ind+Pr+Ips+neg:h$+ta #; +Ger:$+hes #; +Imp+Pr:h$ Imp; +Pts+Pr+Ps:+ev #;

129
+Pts+Pr+Ips:h$+tav #; +Pts+Pt+Ps:$i+nud #; :i$ Knd,Kvt-Pt; +Pts+Pt+Ips:h$+tud #; +Ind+Pr+Ips:h$a+kse #; +Ind+Ipt+Ips:h$+ti #; +Knd+Pr+Ips:h$+ta+ks #; +Knd+Pt+Ips:h$+tu+ks #; +Kvt+Pr+Ips:h$+ta+vat #; +Kvt+Pt+Ips:h$+tu+vat #; +Imp+Pr+Ips:h$+ta+gu #; +Sup+Ips:h$+ta+ma #; LEXICON LE-EL/T !LE-EL tüvelõpus, tugevnev AV (vaidlema, liiklema) :le V10; +Ind+Ipt:le Ipt3; :el$ V11; :le V12; :el$ V13; LEXICON 0-A/N !nõrgenev AV (tt-t, pp-p, t-d või prosoodiline), tüvevaheldus a-0, ! ! da-inf -a (saatma) V10; +Ind+Ipt: Ipt1; V11; :a$ V12; :e$ V14; LEXICON JÄTMA !nagu 0-A/N, aga umbis. tm erandlik (jäetakse, jäetud) :tT V10; +Ind+Ipt:tT Ipt1; :tT V11; :tTa$ V12; :Te$ V14; LEXICON PIDA-SIN !nõrgenev AV (nagu N), aga erandlik tüvi umbis. tm-s (peetud) :a V10; +Ind+Ipt:a Ipt3; :a V11; :a$ V12; :e$ V14;

130
LEXICON I-0/N !nõrgenev AV, umbis. tegumoes konsonanttüvi (käskima) :i V10; +Ind+Ipt:i Ipt3; :i V11; :i$ V12; :$ V14; LEXICON N !nõrgenev AV, tüvelõpumuutuseta (õppima) V10; +Ind+Ipt:0 Ipt3; V11; :$ V12; :$ V14; LEXICON N-PROS !prosoodiline (kirjapildis tuvastamatu) nõrgenev AV, tüvelõpumuutuseta (istuda-istun) V10; +Ind+Ipt: Ipt3; V11; :$ V12; :$ V14; LEXICON ELE !kõnelema :e V10; +Ind+Ipt:e Ipt3; V11; !paralleelvormid: kõnelda :e V11; !kõneleda :e V12; V13; !paralleelvormid: kõneldud :e V14; !kõneletud LEXICON V1 !kõige produktiivsem verbitüüp (elama) V10; +Ind+Ipt: Ipt2; V11; V12; V14; +Pts+Pr+Ips:+v #; LEXICON V10 !algvormi tüvest +Sup:+ma #; +Sup+In:+mas #; +Sup+El:+mast #; +Sup+Trl:+maks #; +Sup+Ab:+mata #;

131
+Kvt+Pr+Ps:+vat #; +Pts+Pr+Ps:+v #; LEXICON V11 !da-inf tüvest +Inf:+da #; +Ind+Pr+Ips+neg:+da #; +Ger:+des #; +Imp+Pr:0 Imp; +Pts+Pt+Ps:+nud #; Knd,Kvt-Pt; LEXICON V12 !kindla kõneviisi oleviku tüvest +Ind+Pr:0 Pr; +Imp+Pr+Sg2:0 #; +Ind+Pr+Ps+neg:0 #; +Knd+Pr:0 Knd-Pr; LEXICON V13 !umbisikulise tegumoe tüvest, d-tunnus +Pts+Pt+Ips:+dud #; +Ind+Pr+Ips:+da+kse #; +Ind+Ipt+Ips:+di #; +Knd+Pr+Ips:+da+ks #; +Knd+Pt+Ips:+du+ks #; +Kvt+Pr+Ips:+da+vat #; +Kvt+Pt+Ips:+du+vat #; +Imp+Pr+Ips:+da+gu #; +Sup+Ips:+da+ma #; +Ind+Pr+Ips+neg:+da #; +Pts+Pr+Ips:+dav #; LEXICON V14 !umbisikulise tegumoe tüvest, t-tunnus (hakkama)) +Pts+Pt+Ips:+tud #; +Ind+Pr+Ips:+ta+kse #; +Ind+Ipt+Ips:+ti #; +Knd+Pr+Ips:+ta+ks #; +Knd+Pt+Ips:+tu+ks #; +Kvt+Pr+Ips:+ta+vat #; +Kvt+Pt+Ips:+tu+vat #; +Imp+Pr+Ips:+ta+gu #; +Sup+Ips:+ta+ma #; +Ind+Pr+Ips+neg:+ta #; +Pts+Pr+Ips:+tav #;

132
LEXICON V15 !da-inf tüvest, ta-tunnus +Inf:+ta #; +Ger:+tes #; +Imp+Pr:0 Imp; +Pts+Pt+Ps:+nud #; Knd,Kvt-Pt; +Pts+Pr+Ips:+Ev #; LEXICON Pr !kindla kv oleviku pöördelõpud +Sg1:+n #; +Sg2:+d #; +Sg3:+b #; +Pl1:+me #; +Pl2:+te #; +Pl3:+vad #; LEXICON Ipt1 !lihtmineviku pöördelõpud: laulma, kuulma, saatma +Sg1:+sin #; +Sg2:+sid #; +Sg3:+is #; +Pl1:+sime #; +Pl2:+site #; +Pl3:+sid #; LEXICON Ipt2 !lihtmineviku pöördelõpud: tulema, saama, sööma +Sg1:+in #; +Sg2:+id #; +Sg3:+i #; +Pl1:+ime #; +Pl2:+ite #; +Pl3:+id #; LEXICON Ipt3 !lihtmineviku pöördelõpud: võima, hakkama, kõnelema +Sg1:+sin #; +Sg2:+sid #; +Sg3:+s #; +Pl1:+sime #; +Pl2:+site #; +Pl3:+sid #; LEXICON Imp !käskiva kv olevik, v.a. Sg2 +Sg1:+gu #; +Sg3:+gu #; +Pl1:+gem #; +Pl2:+ge #; +Pl3:+gu #;

133
LEXICON Knd-Pr !tingiva kv olevik +Sg1:+ksi+n #; +Sg2:+ksi+d #; +Sg3:+ks #; +Pl1:+ksi+me #; +Pl2:+ksi+te #; +Pl3:+ksi+d #; LEXICON Knd,Kvt-Pt !tingiva ja kaudse kv minevik +Knd+Pt:+nu Knd-Pr; +Kvt+Pt:+nuvat #;





























