Embed Size (px)
Citation preview

EidgenössischeTechnische Hochschule
Zürich
Ecole polytechnique fédérale de ZurichPolitecnico federale di Zurigo
Swiss Federal Institute of Technology Zurich
25th Annual International Symposium on Computer Architecture
7th Workshop on Scalable Shared Memory Multiprocessor
Memory System Performance of High End SMPs, PCs and
Clusters of PCs
Ch. Kurmann, T. Stricker
Laboratory for Computer SystemsETHZ - Swiss Institute of Technology
CH-8092 Zurich
Color Slides: http://www.cs.inf.ethz.ch/CoPs/isca98ws/

2
Memory Systems
Low End designs in PCs: extremely low cost standard I/O interface
High End designs in “Killer” Workstations: well engineered memory systems support for additional datastreams better I/O busses
Are Low End SMPs the universal compute nodes for parallel and distributed systems?

3
Contribution
The answer is probably the memory system performance.
How significant are the differences in memory system performance?
Limitations of Low End memory systems for local computation (e.g. in scientific applications) for inter-node communication (e.g. in databases)

4
Extended Copy Transfer Characterization
ECT is a method to characterize the performance of memory systems (ISCA95 and HPCA97): Categories
Access pattern, stride (spatial locality) Working set (temporal locality)
Value Transfer bandwidth (large amount of data)
Same chart resulting from one microbenchmark Local and Remote transfers compute and communicate accesses

5
Measurement Problems
Some parameter combinations are hard tomeasure, even with carefully tuned C code: Reduced performance for large strides and small
working-sets in L1 caches is a measurement artifact and not architecture related.
Compilers occasionally generate suboptimal instruction schedules for loads / stores.
6
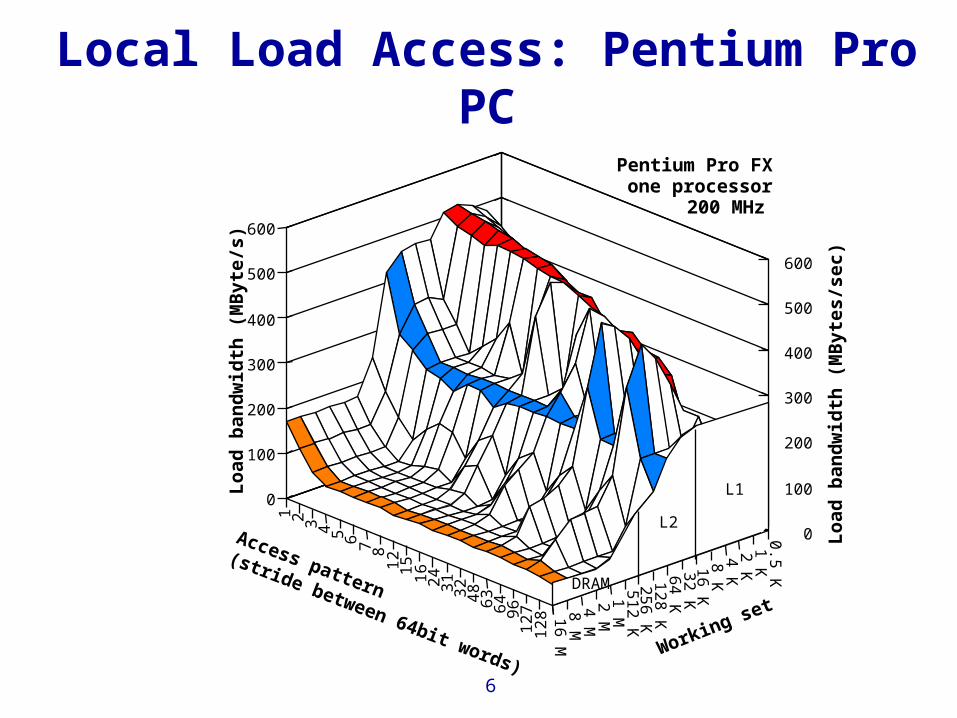
Local Load Access: Pentium Pro PC
Working set
Access pattern
(stride between 64bit words)
12
81
279664634832312416151287654321
16
M8
M4
M2
M1
M5
12
K2
56
K1
28
K6
4 K
32
K1
6 K
8 K
4 K
2 K
1 K
0.5
K
600
500
400
300
200
100
0
600
500
400
300
200
100
0
Lo
ad b
and
wid
th (
MB
ytes
/sec
)
Lo
ad b
and
wid
th (
MB
yte/
s)
Pentium Pro FXone processor
200 MHz
DRAM
L1
L2
7
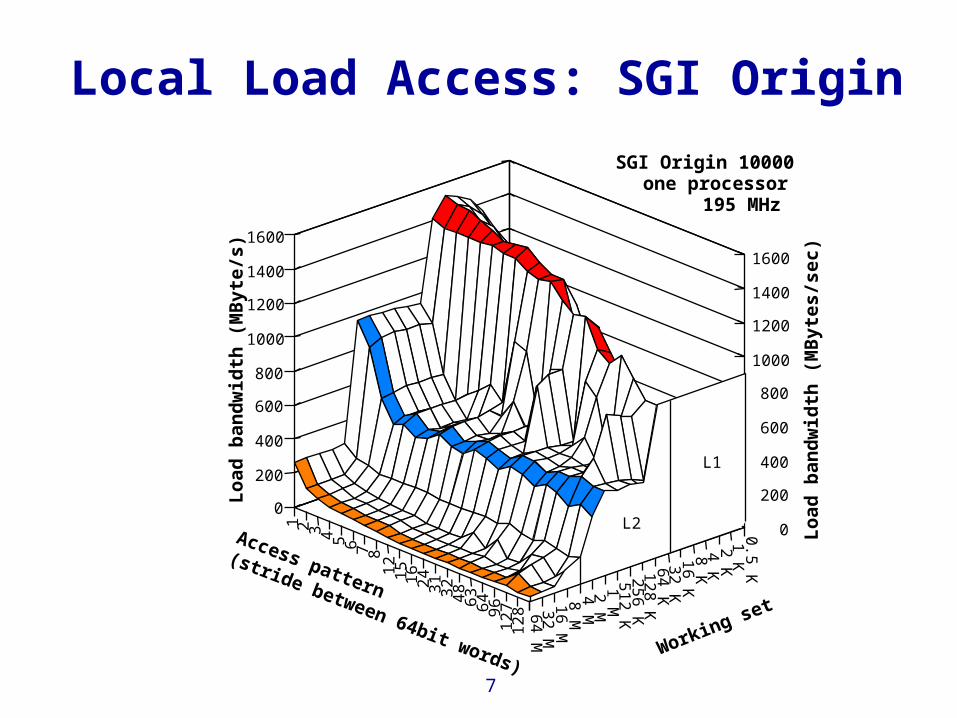
Local Load Access: SGI Origin
12
81
279664634832312416151287654321
64
M3
2 M
16
M8
M4
M2
M1
M5
12
K2
56
K1
28
K6
4 K
32
K1
6 K
8 K
4 K
2 K
1 K
0.5
K
1600
1400
1200
1000
800
600
400
200
0
1600
1400
1200
1000
800
600
400
200
0
Lo
ad b
and
wid
th (
MB
ytes
/sec
)
Lo
ad b
and
wid
th (
MB
yte/
s)
SGI Origin 10000one processor
195 MHz
L1
L2
Working set
Access pattern
(stride between 64bit words)
8
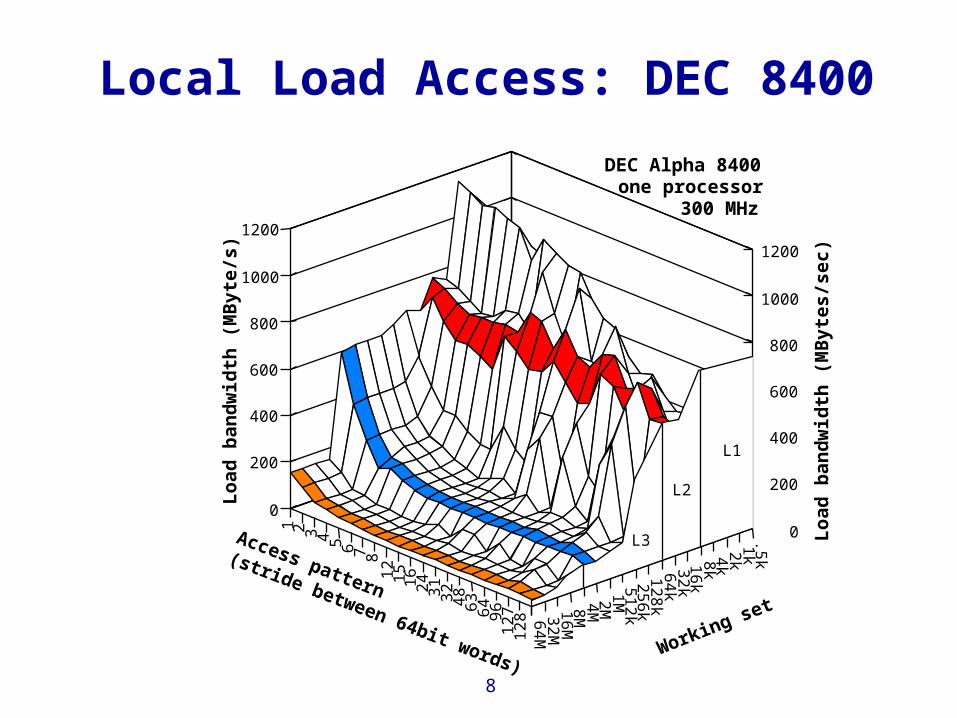
Local Load Access: DEC 8400
12
81
279664634832312416151287654321
64
M3
2M
16
M8
M4
M2
M1
M5
12
k2
56
k1
28
k6
4k
32
k1
6k
8k
4k
2k
1k
.5k
1200
1000
800
600
400
200
0
1200
1000
800
600
400
200
0
Lo
ad b
and
wid
th (
MB
ytes
/sec
)
Lo
ad b
and
wid
th (
MB
yte/
s)
DEC Alpha 8400one processor
300 MHz
L2
L3
L1
Working set
Access pattern
(stride between 64bit words)
9
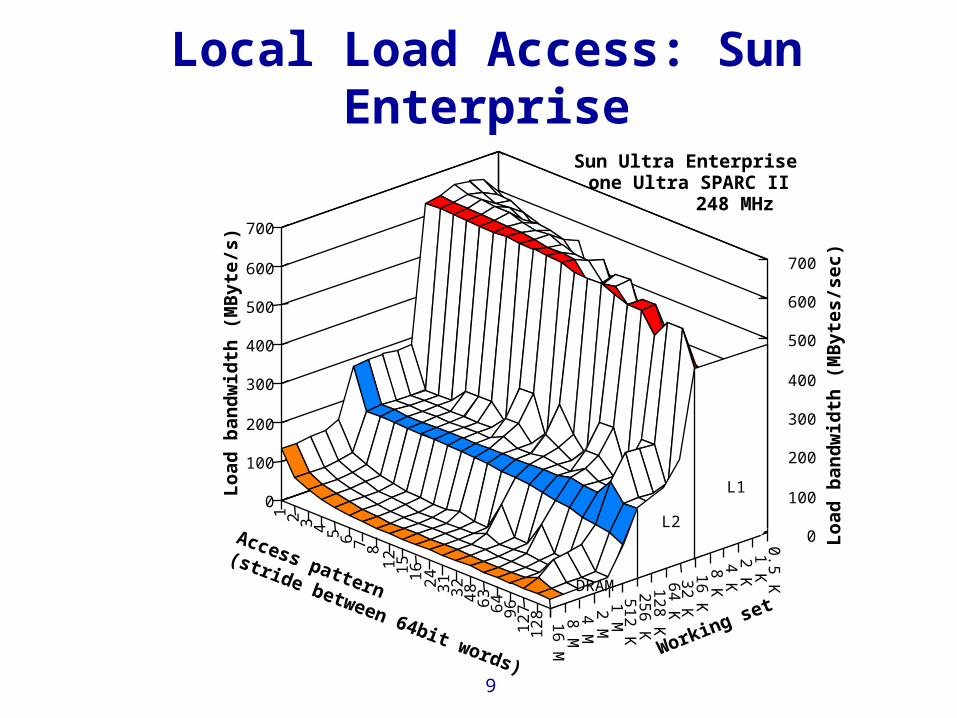
Local Load Access: Sun Enterprise
Working set
Access pattern
(stride between 64bit words)
12
81
279664634832312416151287654321
16
M8
M4
M2
M1
M5
12
K2
56
K1
28
K6
4 K
32
K1
6 K
8 K
4 K
2 K
1 K
0.5
K
700
600
500
400
300
200
100
0
700
600
500
400
300
200
100
0
Lo
ad b
and
wid
th (
MB
ytes
/sec
)
Lo
ad b
and
wid
th (
MB
yte/
s)
Sun Ultra Enterpriseone Ultra SPARC II
248 MHz
DRAM
L1
L2
10
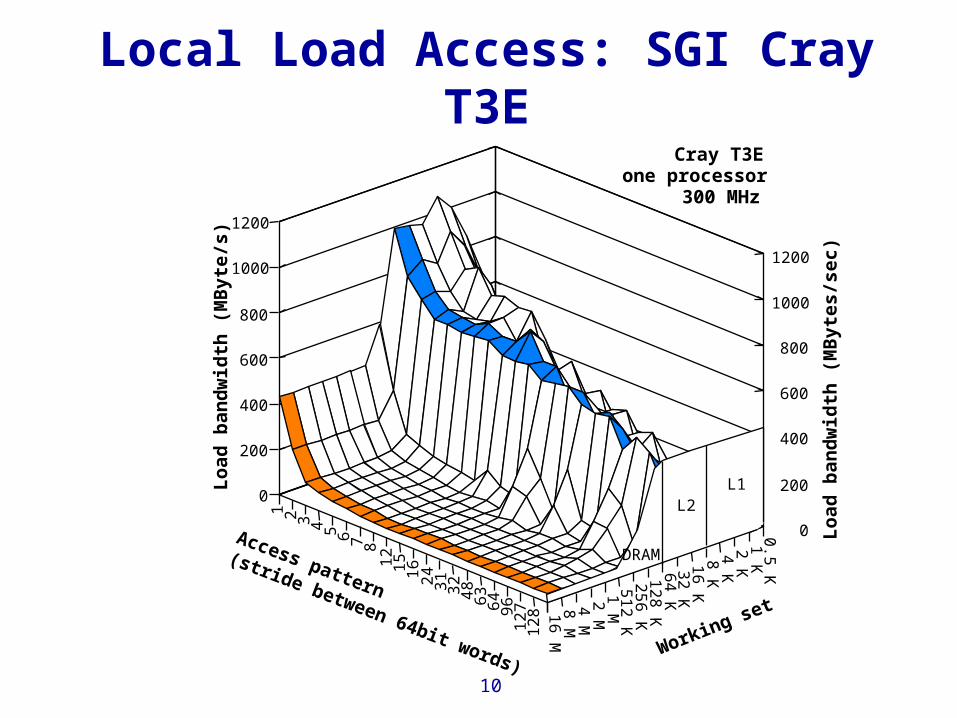
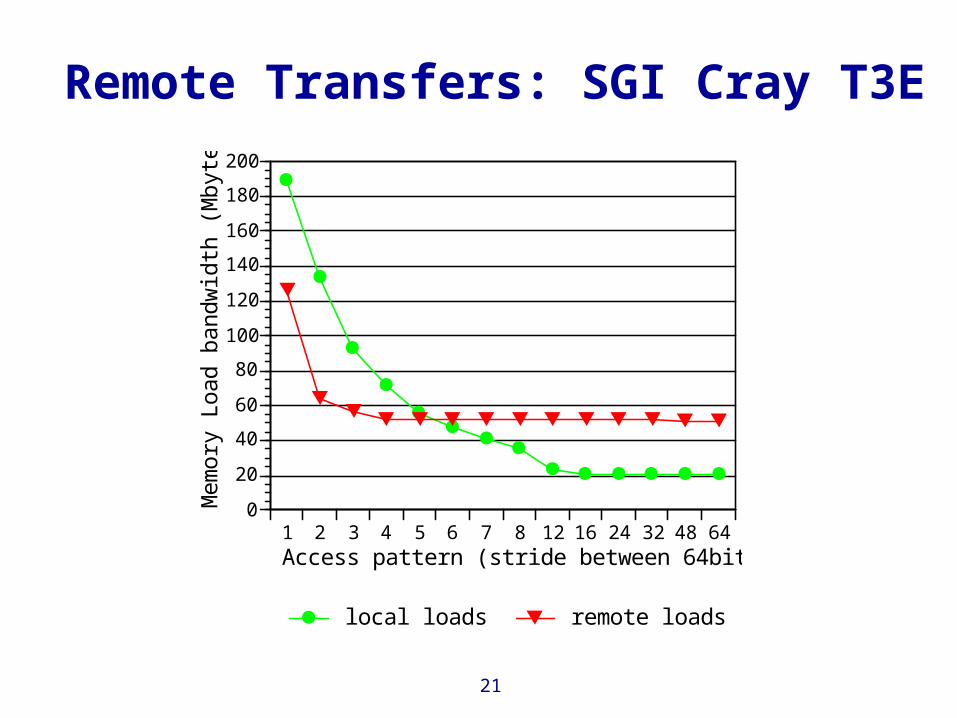
Local Load Access: SGI Cray T3E
12
81
279664634832312416151287654321
16
M8
M4
M2
M1
M5
12
K2
56
K1
28
K6
4 K
32
K1
6 K
8 K
4 K
2 K
1 K
0.5
K
1200
1000
800
600
400
200
0
1200
1000
800
600
400
200
0
Lo
ad b
and
wid
th (
MB
ytes
/sec
)
Lo
ad b
and
wid
th (
MB
yte/
s)
Cray T3Eone processor
300 MHz
DRAM
L1L2
Working set
Access pattern
(stride between 64bit words)

11
Comparison - Local Access
1 2 3 4 5 6 7 81
21
51
62
43
1 32
48
63
64
96
12
71
28
19
2
0
50
100
150
200
250
300
Me
mo
ry L
oa
d b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
Pentium Pro
SGI Origin
DEC 8400
Sun Enterp.
Cray T3E
450

12
Performance in an SMP setting
Copy bandwidth decreases for simultaneous access with 1, 2, 4 and 8 processors
Topics of interest: small working sets in caches: performance remains
same large working sets in memory: interesting
differences behavior for even/uneven strides
“Gather copy stream” (strided load / contiguous store)
13
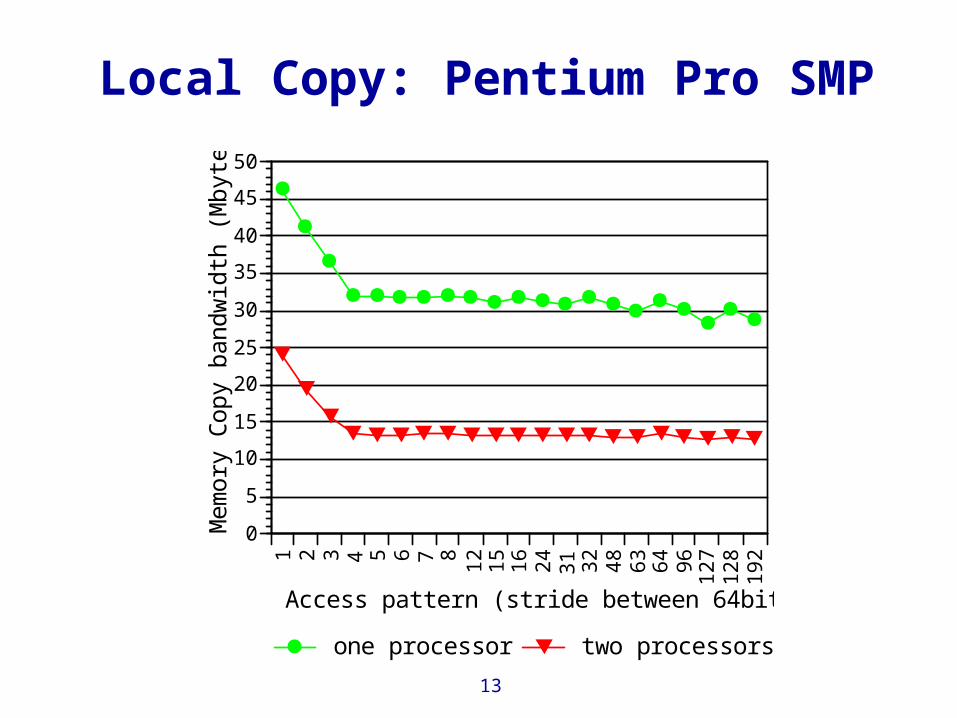
Local Copy: Pentium Pro SMP
1 2 3 4 5 6 7 81
21
51
62
43
1 32
48
63
64
96
12
71
28
19
2
0
5
10
15
20
25
30
35
40
45
50
Me
mo
ry C
op
y b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
one processor two processors
14
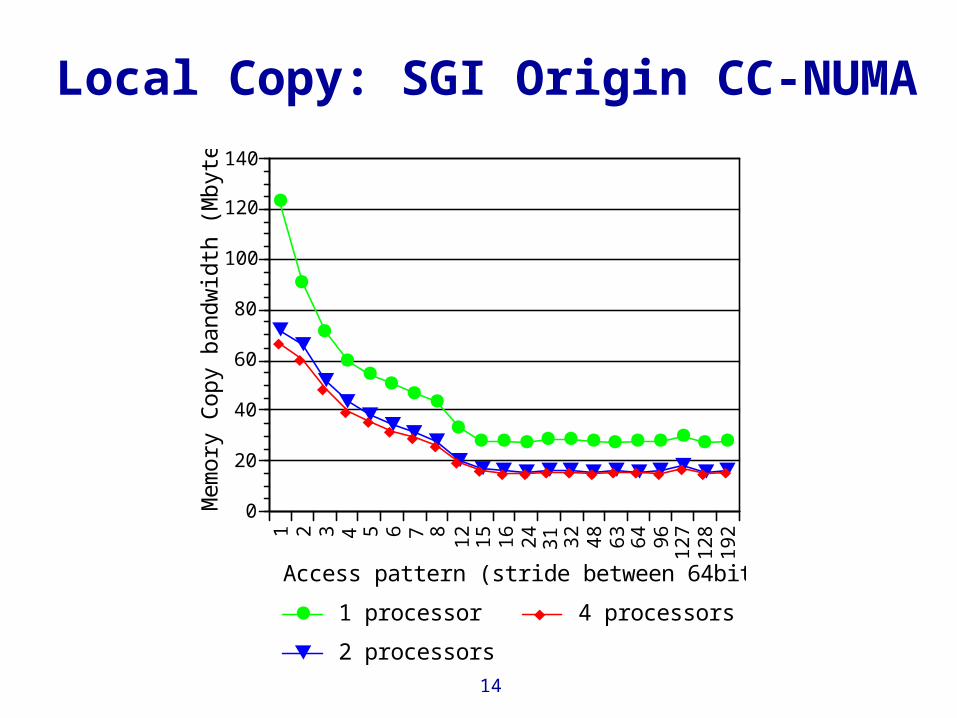
Local Copy: SGI Origin CC-NUMA
1 2 3 4 5 6 7 81
21
51
62
43
1 32
48
63
64
96
12
71
28
19
2
0
20
40
60
80
100
120
140
Me
mo
ry C
op
y b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
1 processor
2 processors
4 processors
15
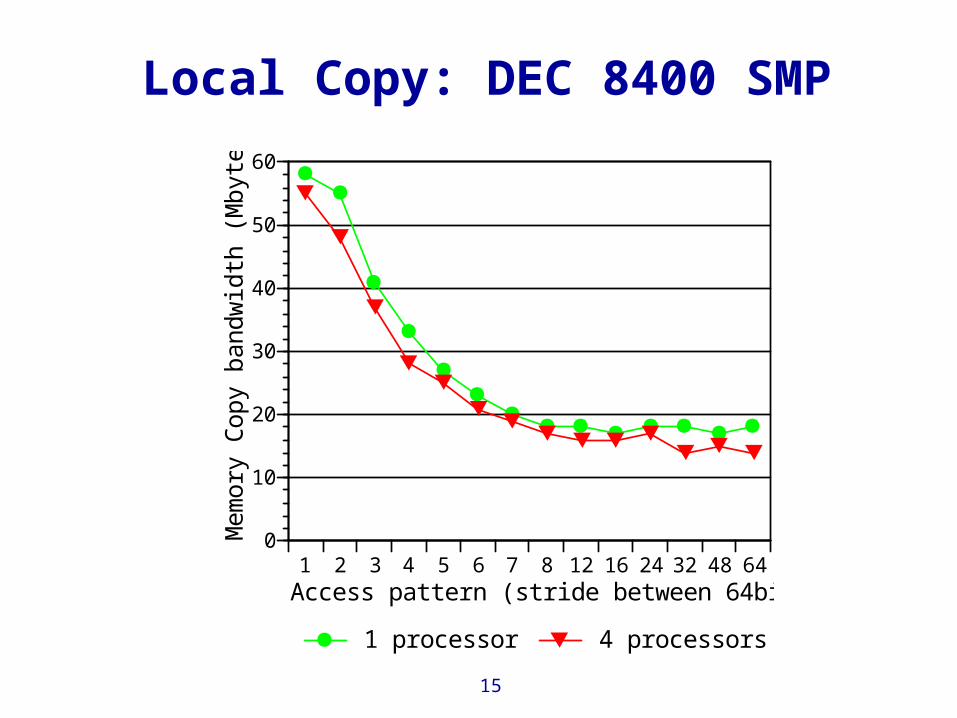
Local Copy: DEC 8400 SMP
1 2 3 4 5 6 7 8 12 16 24 32 48 640
10
20
30
40
50
60
Me
mo
ry C
op
y b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
1 processor 4 processors
16
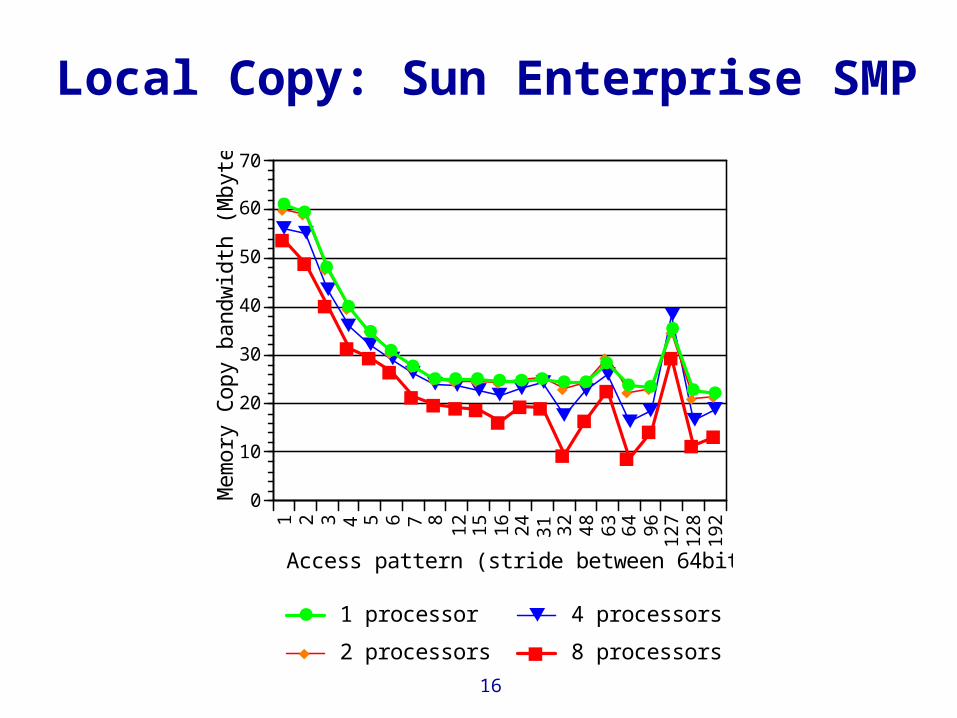
Local Copy: Sun Enterprise SMP
1 2 3 4 5 6 7 81
21
51
62
43
1 32
48
63
64
96
12
71
28
19
2
0
10
20
30
40
50
60
70
Me
mo
ry C
op
y b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
8 processors
4 processors
2 processors
1 processor
17
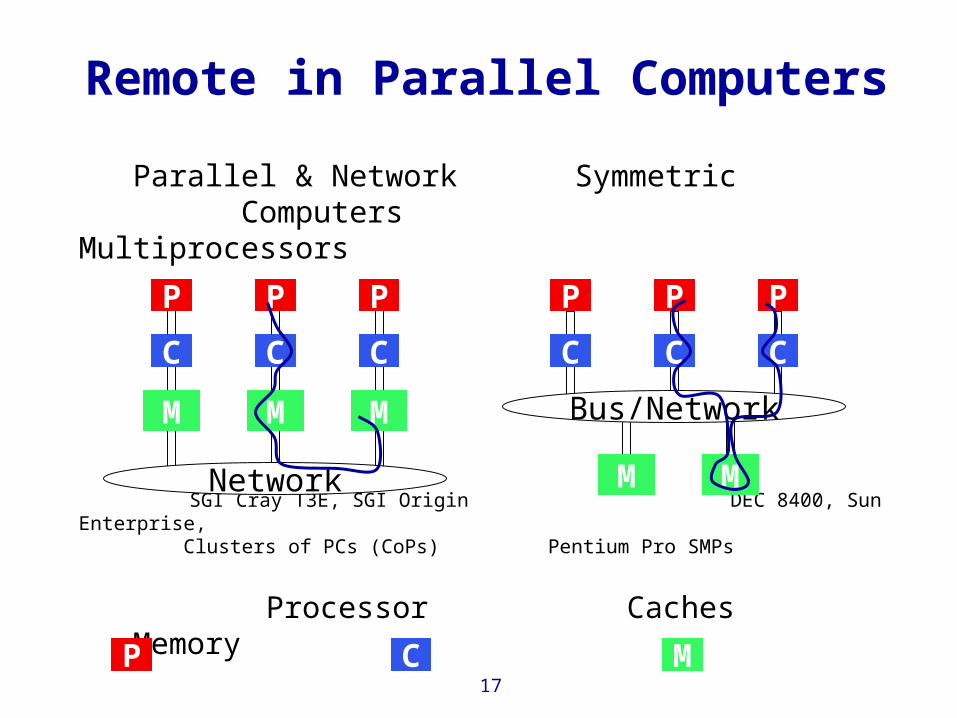
Remote in Parallel Computers
Parallel & Network Symmetric Computers Multiprocessors
SGI Cray T3E, SGI Origin DEC 8400, Sun Enterprise, Clusters of PCs (CoPs) Pentium Pro SMPs
Processor Caches Memory
P
C
M
P
C
M
P
C
M
Network
P
C
P
C
P
C
M M
Bus/Network
P C M
18
1 2 3 4 5 6 7 8 12 16 24 32 48 640
10
20
30
40
50
60
70
80
Rem
ote
Cop
y ba
ndw
idth
(M
byte
/s)
Access pattern (stride between 64bit words)
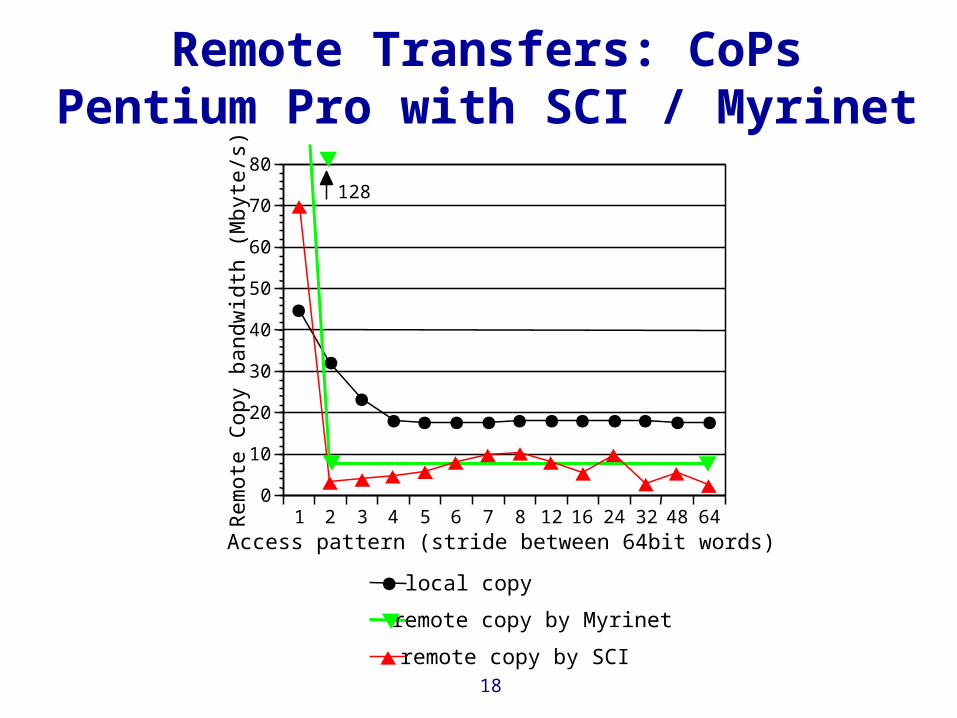
local copy
remote copy by Myrinet
remote copy by SCI
128
Remote Transfers: CoPsPentium Pro with SCI / Myrinet
19
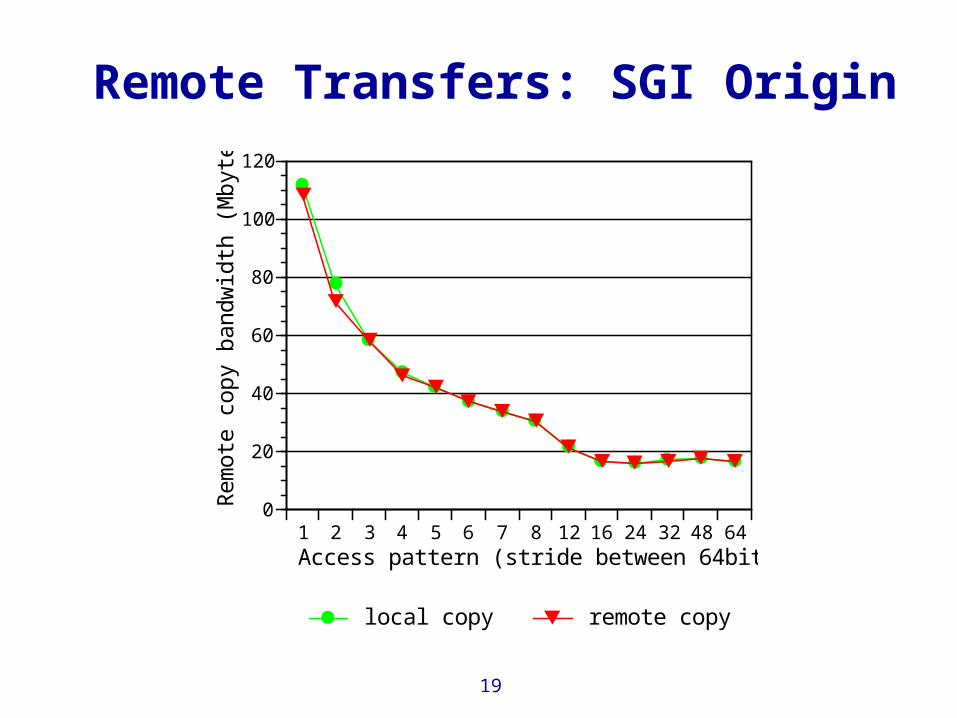
Remote Transfers: SGI Origin
1 2 3 4 5 6 7 8 12 16 24 32 48 640
20
40
60
80
100
120
Re
mo
te c
op
y b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
local copy remote copy

20
Remote Transfers: DEC 8400
1 2 3 4 5 6 7 8 12 16 24 32 48 640
20
40
60
80
100
120
140
160
Me
mo
ry L
oa
d b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
local loads remote loads
21
Remote Transfers: SGI Cray T3E
1 2 3 4 5 6 7 8 12 16 24 32 48 640
20
40
60
80
100
120
140
160
180
200
Me
mo
ry L
oa
d b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
local loads remote loads
22
1 2 3 4 5 6 7 8 12 16 24 32 48 640
20
40
60
80
100
120
140
160
180
200
Me
mo
ry L
oa
d b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
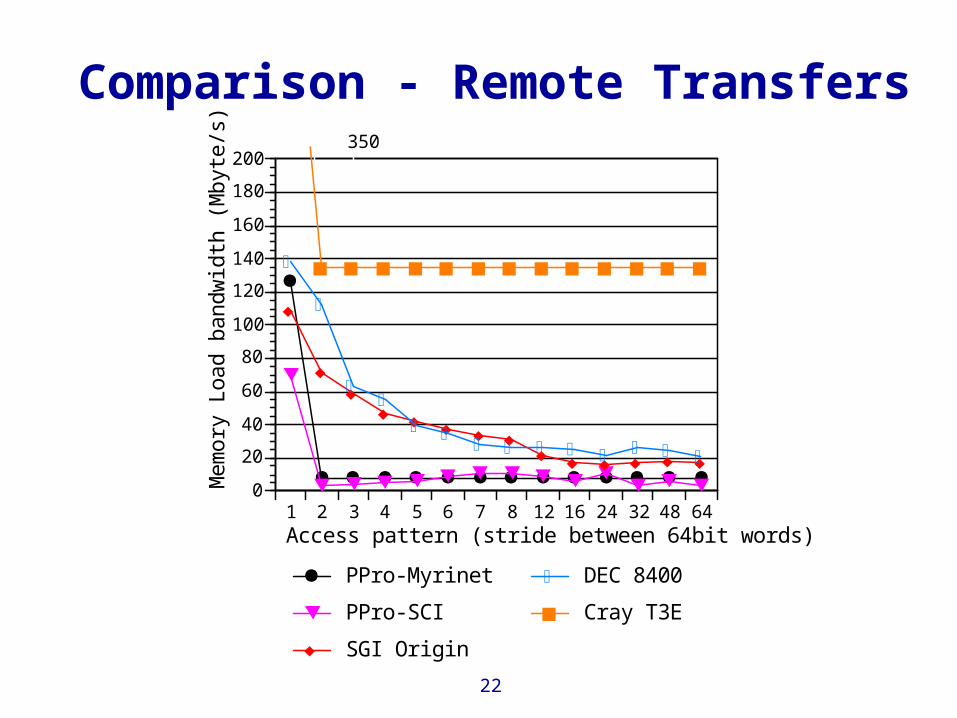
PPro-Myrinet
PPro-SCI
SGI Origin
DEC 8400
Cray T3E
350
Comparison - Remote Transfers
23
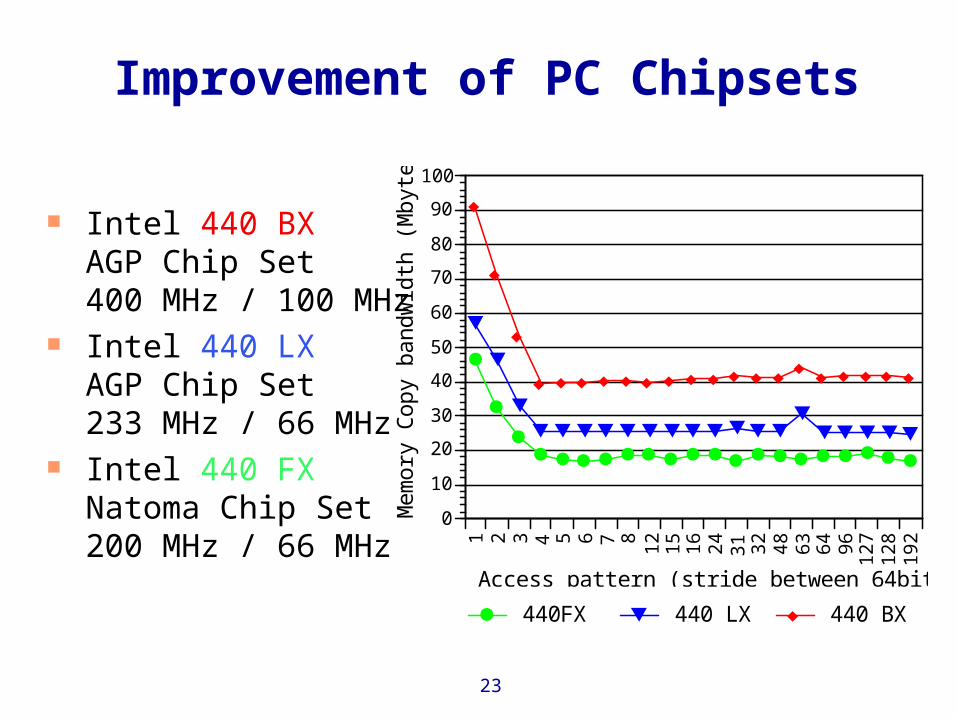
Improvement of PC Chipsets
Intel 440 BX AGP Chip Set400 MHz / 100 MHz
Intel 440 LX AGP Chip Set233 MHz / 66 MHz
Intel 440 FX Natoma Chip Set200 MHz / 66 MHz
1 2 3 4 5 6 7 81
21
51
62
43
1 32
48
63
64
96
12
71
28
19
2
0
10
20
30
40
50
60
70
80
90
100
Me
mo
ry C
op
y b
an
dw
idth
(M
byt
e/s
)
Access pattern (stride between 64bit words)
440FX 440 LX 440 BX

24
Conclusion
ECT-Characterizations for different memory systems: T3E (MMP-Node), Origin (NUMA), DEC8400 (SMP) CoPs Intel P6 SMPs and Clusters
High End SMP vs. Low End SMP: Less than half performance on two processor PCs.
Fast communication puts high demands on the memory system: Unlike in traditional SMPs and CC-NUMAs fine grained
remote access do not perform at all in PC-SMPs and CoPs Adding more commodity microprocessors processors
without reinforcing the memory system is therefore questionable.





























