Embed Size (px)
Citation preview

Embedded Computing Systems for Signal Processing ApplicationsPart 1: IntroductionOctober 21 st 2011Eric Debes

� What is this about?� Introduction to power/performance tradeoffs and system architecture� Overview of existing processor and system architectures � Consumer vs. Industrial/Embedded
� Why do we care? � Engineering added value is in complex and critical system architecture
Introduction
2
� Engineering added value is in complex and critical system architecture � Need to know different components available� Software/Hardware System Architecture and Modelling� Power/Performance/Price Tradeoffs
� What’s the plan?

1. Introduction 2. General-Purpose Processors and Parallelism3. Application Specific Processors: DSPs, FPGAs, accelerators,
SoCs4. PC Architecture vs. Embedded System Architecture5. Hard Real-time Systems and RTOS6. Power Constraints
Outline
3
6. Power Constraints7. Critical and Complex Systems, MDE, MDA
� Embedded� Size and thermal constraints� Sometime battery life (energy) constraints
� Real-time� Time constraints� Can be hard real-time
Embedded Real-time Systems
4
� Can be hard real-time � Or soft-real time
� Systems� Typically includes multiple components� Requires different expertises:
� Signal Processing, computer vision, machine learning/Cognition and other algorithmic expertise
� Software Architecture� Hardware/Computing Architecture� Thermal and mechanical engineering

� Consumer : DVD/video players, Set-top-box, Playstation, printers, disk drives, GPS, cameras, mp3 players
� Communications: Cellphone, Mobile Internet Devices, Netbooks, PDAs with WiFi, GSM/3G, WiMax, GPS, cameras, music/video
Application Examples
5
cameras, music/video� Automotive: Driving innovation
for many embedded applications, e.g. Sensors, buses, info-tainment
� Industrial Applications: Process control, Instrumentation
� Other niche markets: video surveillance, satellites, airplanes, sonars, radars, military applications

� Texec = NI * CPI * Tc � NI = Number of Instructions� CPI = Clock per Instruction� Tc = Cycle Time
� Texec = NI / (IPC * F)� IPC = Instructions Per Cycle
Performance
6
� IPC = Instructions Per Cycle� F = Frequency
� Performance improves with� Silicon manufacturing technology
� Moore’s law contributing to higher frequency and parallelism
� Microarchitecture improvements � Higher frequencies with deeper pipelines� Higher IPC through parallelism
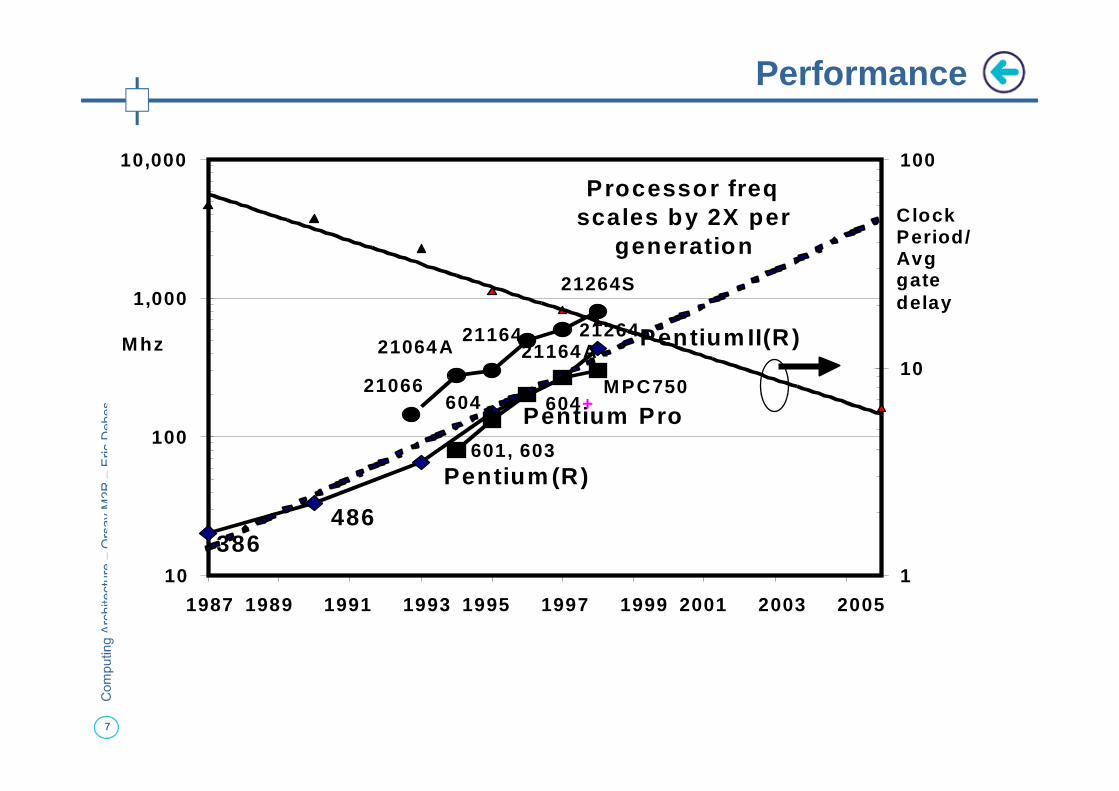
Performance
Pentium II(R)
604 604+M PC75021066
21064A21164
21164A21264
21264S1,000
10,000
M hz10
100
ClockPeriod/Avggatedelay
Processor freqscales by 2X per
generation
7
Pentium Pro
Pentium (R)
486386
601, 603
604 604+M PC75021066
10
100
1987 1989 1991 1993 1995 1997 1999 2001 2003 2005
1
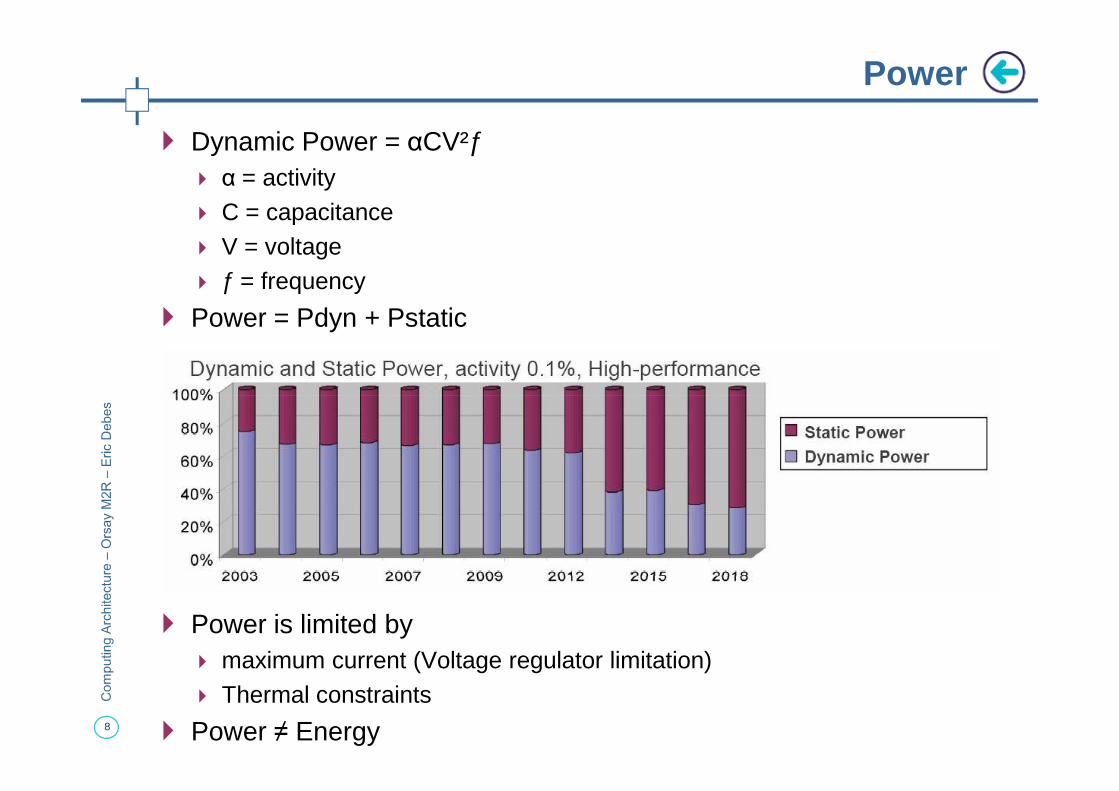
� Dynamic Power = αCV²ƒ� α = activity� C = capacitance� V = voltage� ƒ = frequency
� Power = Pdyn + Pstatic
Power
8
� Power is limited by � maximum current (Voltage regulator limitation)� Thermal constraints
� Power ≠ Energy
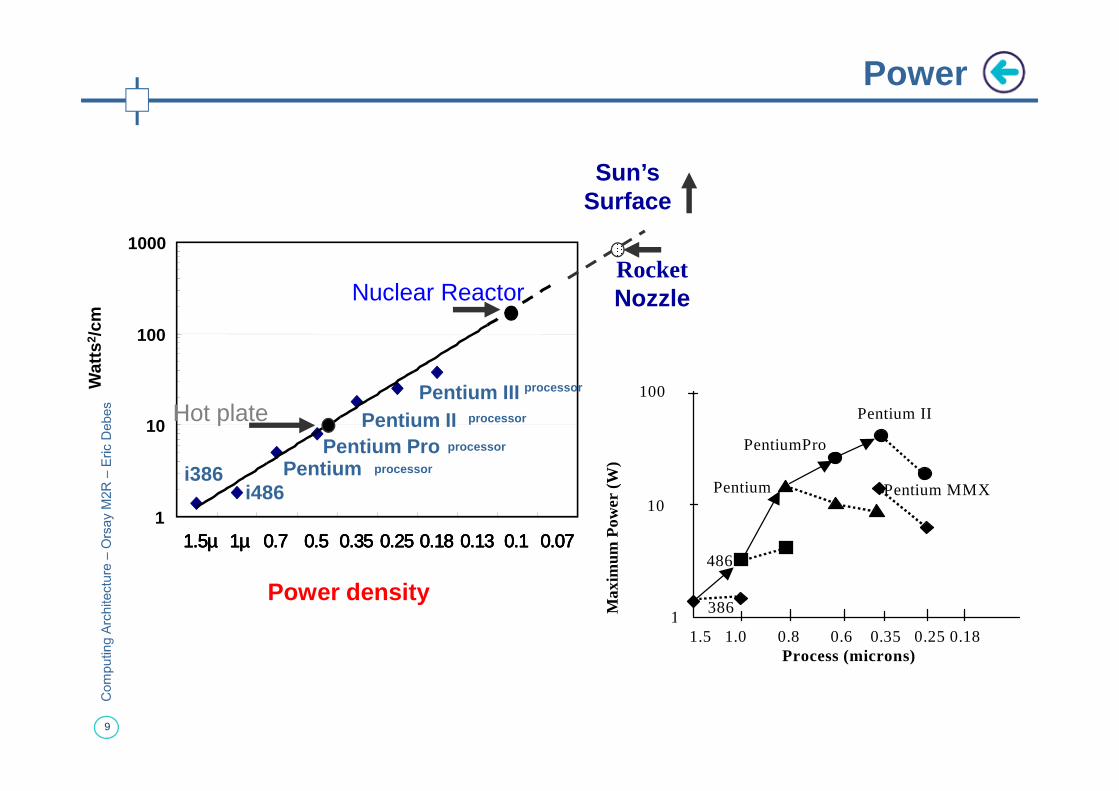
Power
100
100
1000
Wat
ts2 /
cm
Pentium III processor
Nuclear ReactorRocketNozzle
Sun’sSurface
9
100
1 386
486
Pentium Pentium MMX
PentiumPro
Pentium II
10
1.5 1.0 0.8 0.6 0.35 0.25 0.18 Process (microns)
Max
imum
Pow
er (
W)
1
10
1.5µ1.5µ1.5µ1.5µ 1µ1µ1µ1µ 0.70.70.70.7 0.50.50.50.5 0.350.350.350.35 0.250.250.250.25 0.180.180.180.18 0.130.130.130.13 0.10.10.10.1 0.070.070.070.07
i386i486
Pentium processor
Pentium Pro processor
Pentium II processor
Pentium IIIHot plate
Power density
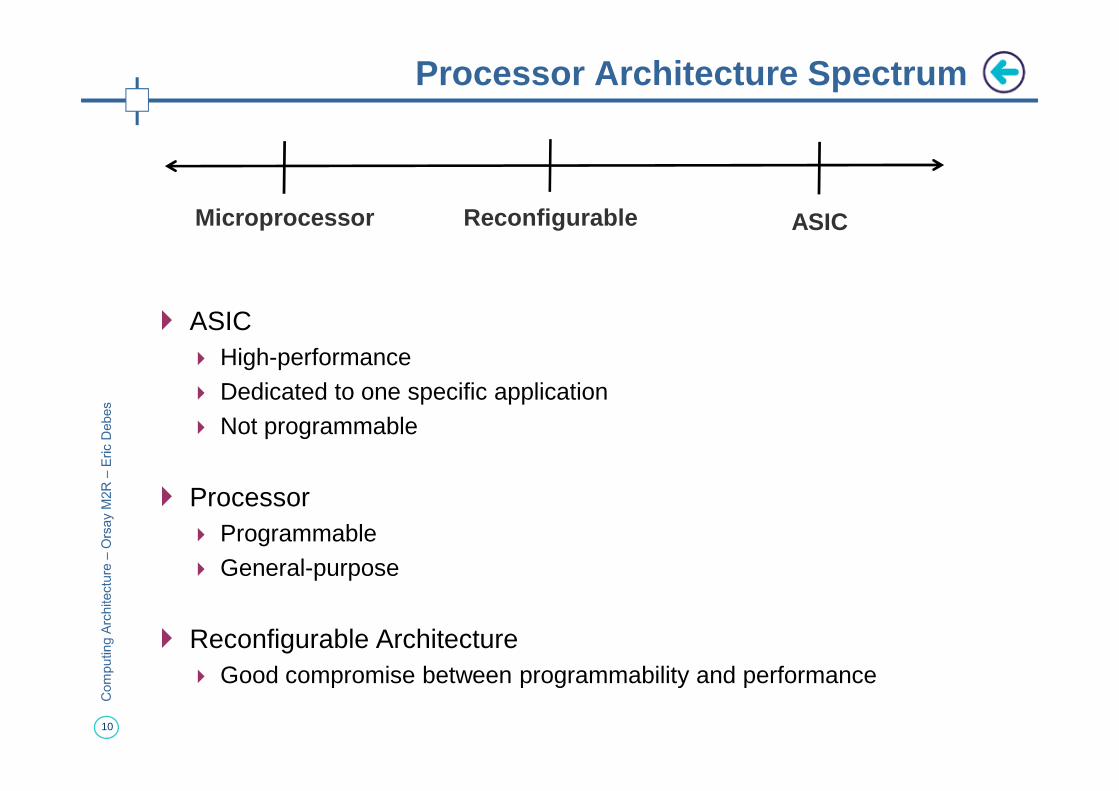
� ASIC� High-performance � Dedicated to one specific application
Processor Architecture Spectrum
Microprocessor Reconfigurable ASIC
10
� Dedicated to one specific application� Not programmable
� Processor� Programmable� General-purpose
� Reconfigurable Architecture� Good compromise between programmability and performance
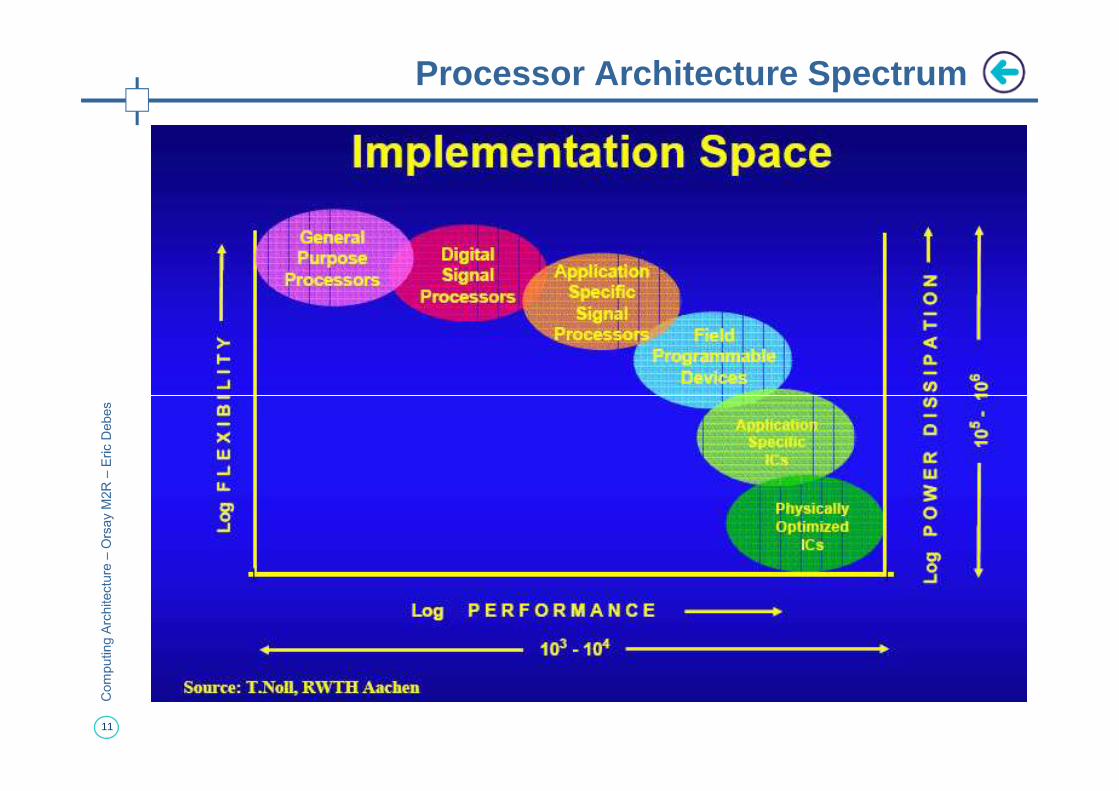
Processor Architecture Spectrum
11
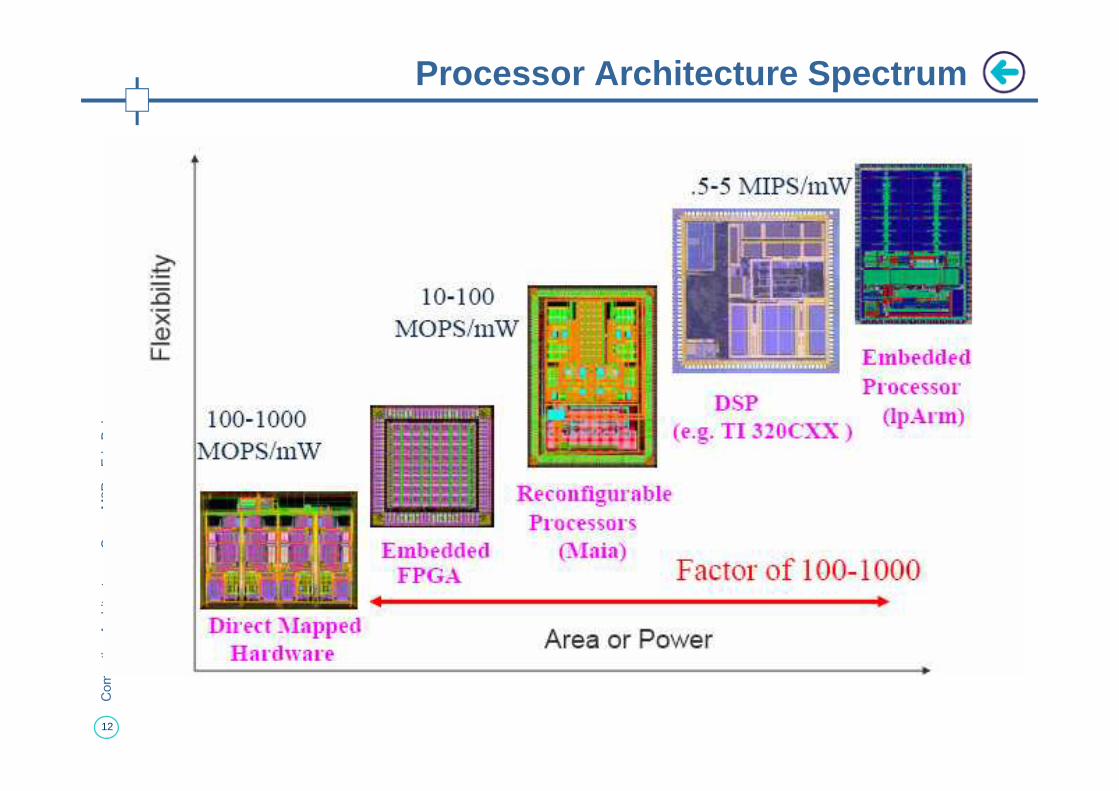
Processor Architecture Spectrum
12

What are the key components in a Computing System?
� Processor with� Arithmetic and Logic Units� Register File� Caches or local memory
Key Components of a Computing System
13
� Memory
� Buses/Interconnect
� I/O Devices

Part 2: General-purpose Processors and ParallelismOctober 21 st 2011Eric Debes
Embedded Computing Systems for Signal Processing Applications
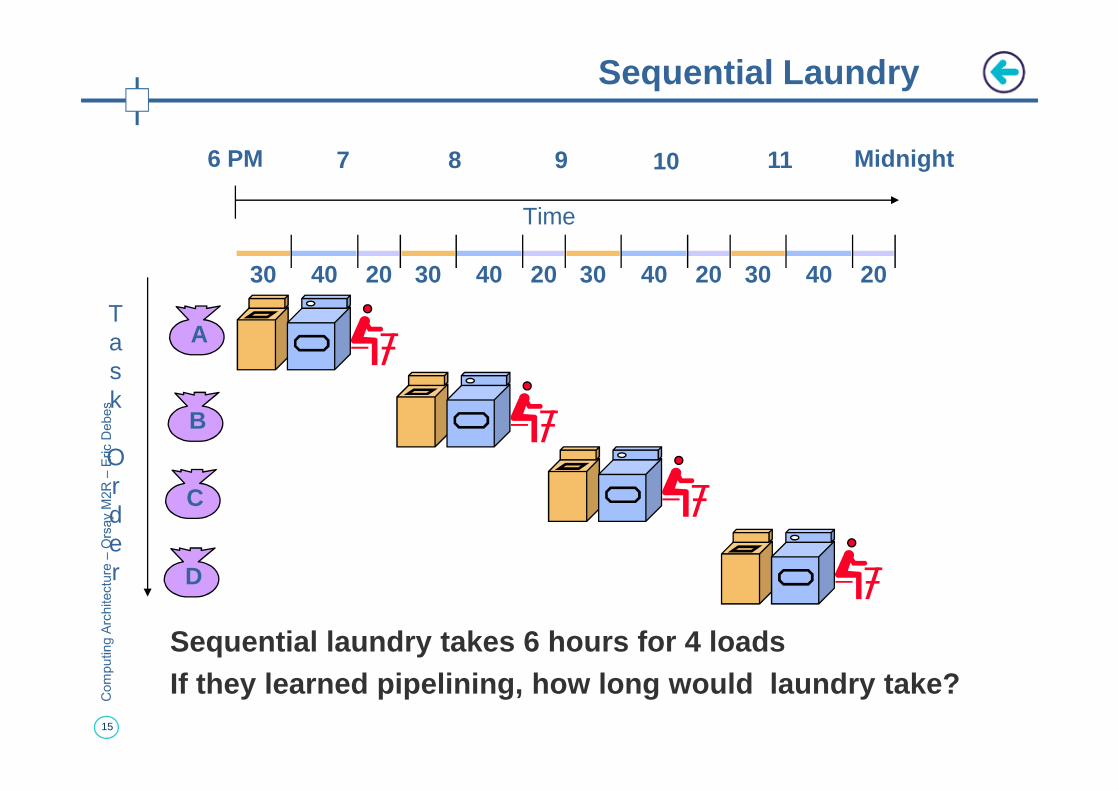
Sequential Laundry
A
30 40 20 30 40 20 30 40 20 30 40 20
6 PM 7 8 9 10 11 Midnight
Task
Time
15
Sequential laundry takes 6 hours for 4 loadsIf they learned pipelining, how long would laundry take?
B
C
D
k
Order
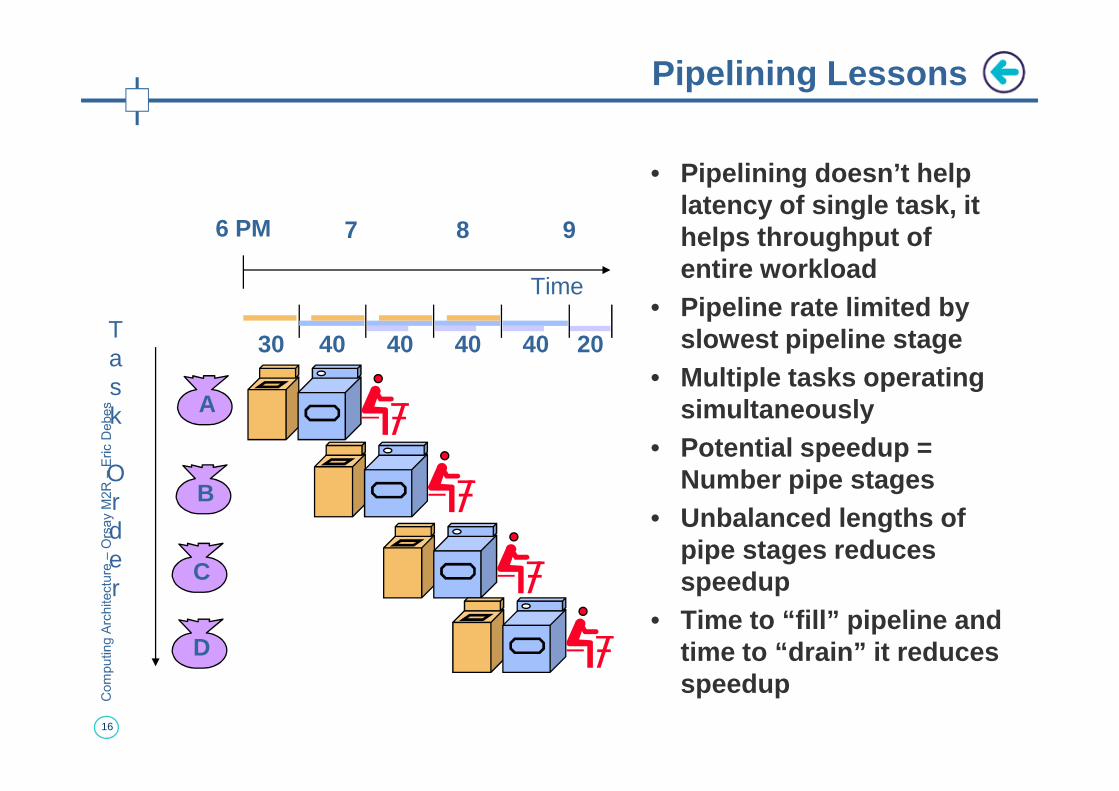
• Pipelining doesn’t help latency of single task, it helps throughput of entire workload
• Pipeline rate limited by slowest pipeline stage
• Multiple tasks operating simultaneously
Pipelining Lessons
A
6 PM 7 8 9
Tas
Time
30 40 40 40 40 20
16
simultaneously• Potential speedup =
Number pipe stages• Unbalanced lengths of
pipe stages reduces speedup
• Time to “fill” pipeline and time to “drain” it reduces speedup
A
B
C
D
sk
Order
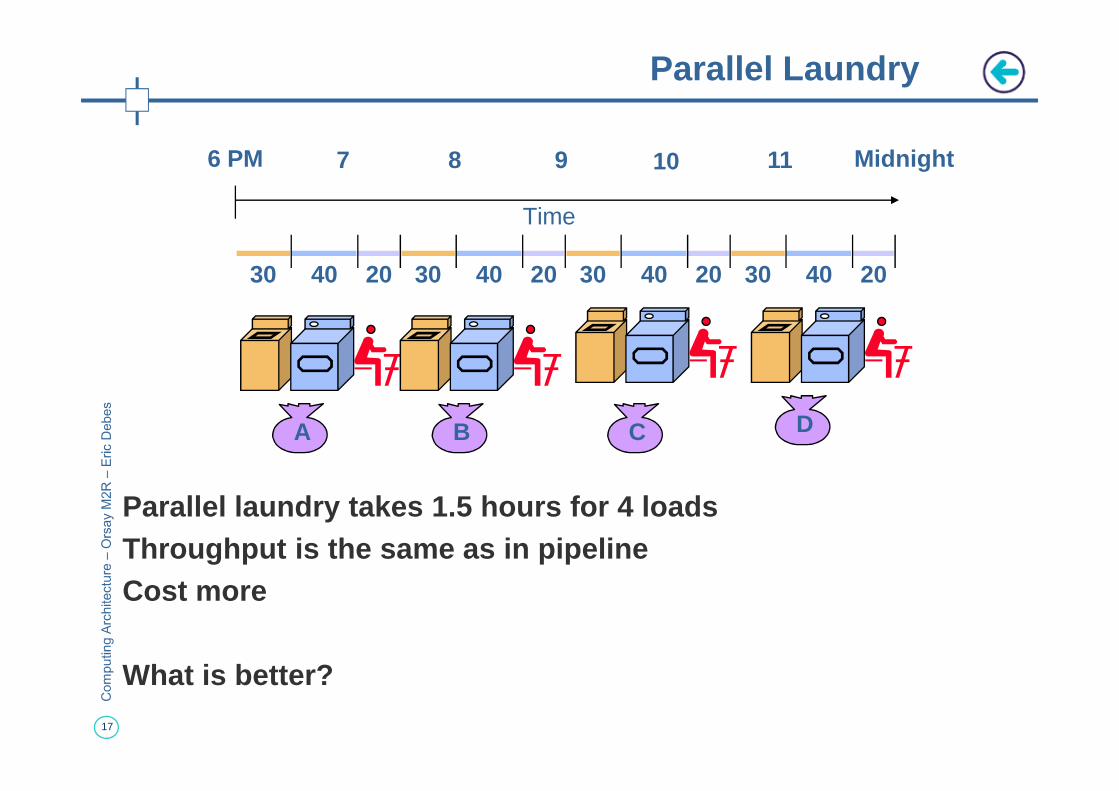
Parallel Laundry
30 40 20 30 40 20 30 40 20 30 40 20
6 PM 7 8 9 10 11 Midnight
Time
17
Parallel laundry takes 1.5 hours for 4 loadsThroughput is the same as in pipelineCost more
What is better?
A B C D
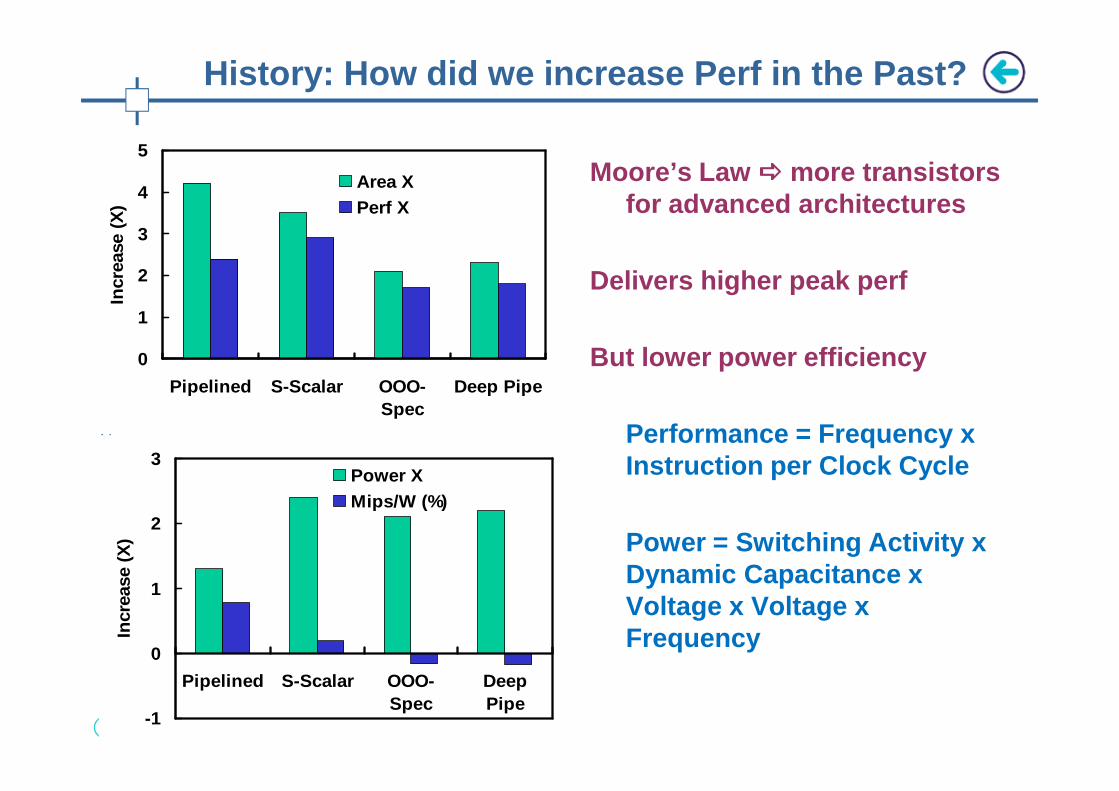
Moore’s Law ���� more transistors for advanced architectures
Delivers higher peak perf
But lower power efficiency
History: How did we increase Perf in the Past?
0
1
2
3
4
5
Pipelined S-Scalar OOO- Deep Pipe
Incr
ease
(X
)
Area XPerf X
18
Performance = Frequency x Instruction per Clock Cycle
Power = Switching Activity x Dynamic Capacitance x Voltage x Voltage x Frequency
Pipelined S-Scalar OOO-Spec
Deep Pipe
-1
0
1
2
3
Pipelined S-Scalar OOO-Spec
DeepPipe
Incr
ease
(X
)
Power XMips/W (%)

In many systems today power is the limiting factor and will drive most of the architecture decisions
Why Multi-Cores?
19
New Goal: optimize performance in a given power env elope

Dual Core
VoltageVoltage FrequencyFrequency PowerPower PerformancePerformance1%1% 1%1% 3%3% 0.66%0.66%
Rule of thumb (in the same process technology)
Cache Cache
How to maximize performance in the same power envelo pe?
Power = Dynamic Capacitance x Voltage x Voltage x F requency
20
Core
Cache
Core
Cache
Core
Voltage = 1Freq = 1Area = 1Power = 1Perf = 1
Voltage = -15%Freq = -15%Area = 2Power = 1Perf = ~1.8
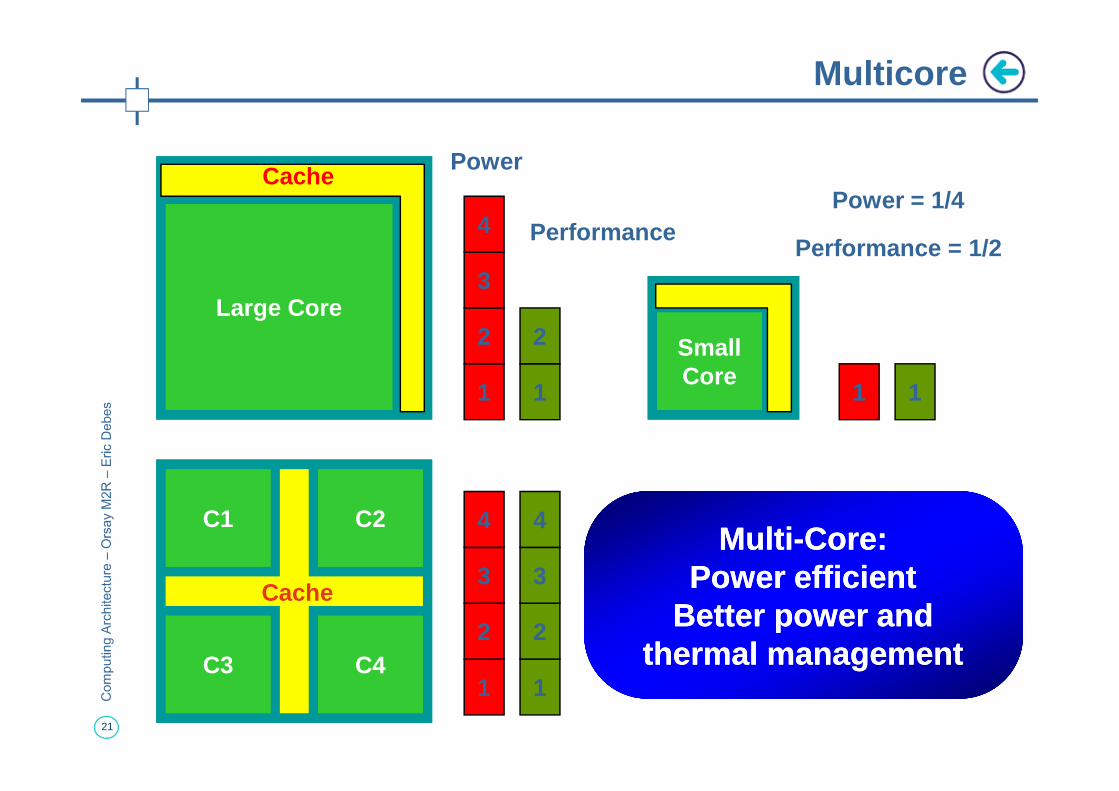
Multicore
SmallCore
1 1
Large Core
Cache
1
2
3
4
1
2
Power
PerformancePower = 1/4
Performance = 1/2
21
1 11 1
C1 C2
C3 C4
Cache
1
2
3
4
1
2
3
4MultiMulti--Core:Core:
Power efficientPower efficientBetter power and Better power and
thermal managementthermal management

Thermal is the main limitation factor in future des ign (not size)
Move away from Frequency alone to deliver performan ce
Challenges in scaling ���� need to exploit thread level parallelism to efficiently use the transistors avai lable thanks to Moore’s law.
Summary: Why Multi-Cores?
22
to Moore’s law.
Power/performance tradeoffs dictate architectural c hoices
Multi-everywhere� Multi-threading� Chip level multi-processing
Throughput oriented designs

Processors are designed to address the need of the mass market.
• Mobile applications � low power and good power management are top priorities to enable thinner systems and longer battery life
• Office, image, video � single threaded perf matters, some level of multithreaded perf � Multi-core
Application-driven Architecture Design
23
of multithreaded perf � Multi-core
• RMS (Recognition, Mining, Synthesis) Applications a nd Model based Computing � massively parallel apps, good scaling on a large number of cores � Many-core
Because of the large markets in each of the classes above, they are the focus of silicon manufacturers and are driving innovation in the semiconductor market
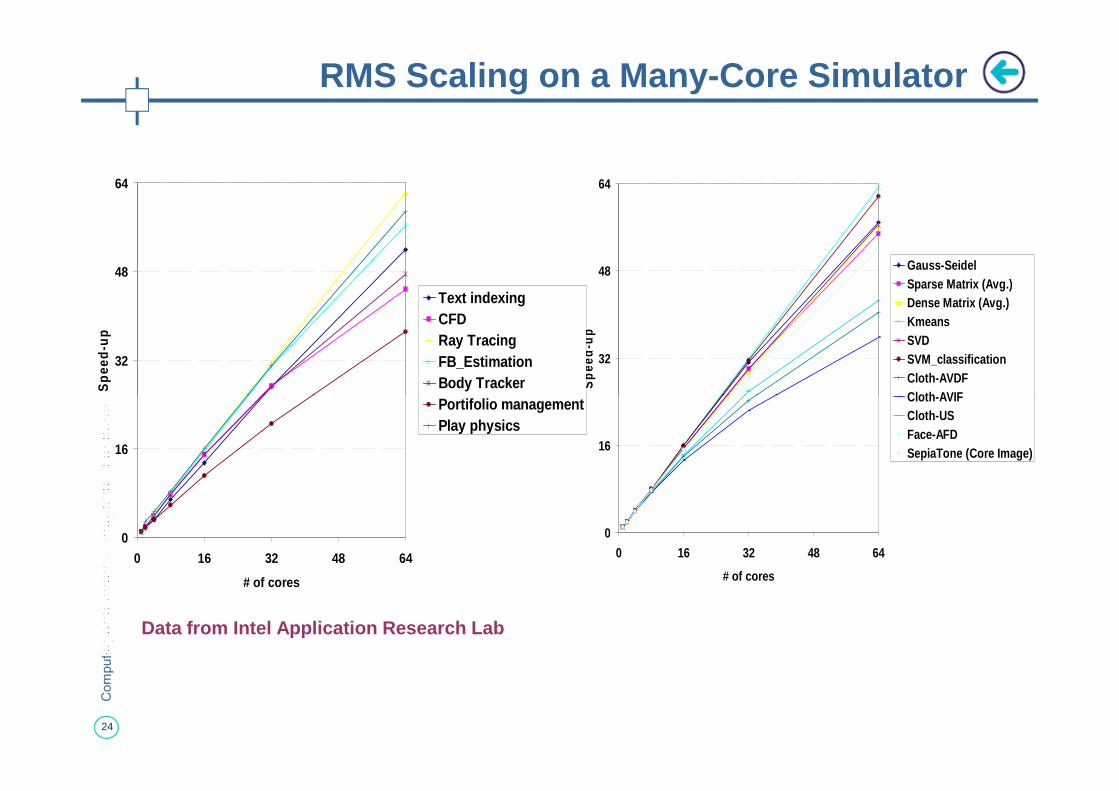
RMS Scaling on a Many-Core Simulator
32
48
64
Spe
ed-u
p
Gauss-SeidelSparse Matrix (Avg.)Dense Matrix (Avg.)KmeansSVDSVM_classificationCloth-AVDFCloth-AVIF
32
48
64
Spe
ed-u
p
Text indexingCFDRay TracingFB_EstimationBody TrackerPortifolio management
24
0
16
0 16 32 48 64
# of cores
Cloth-AVIFCloth-USFace-AFDSepiaTone (Core Image)
0
16
0 16 32 48 64
# of cores
Portifolio managementPlay physics
Data from Intel Application Research Lab
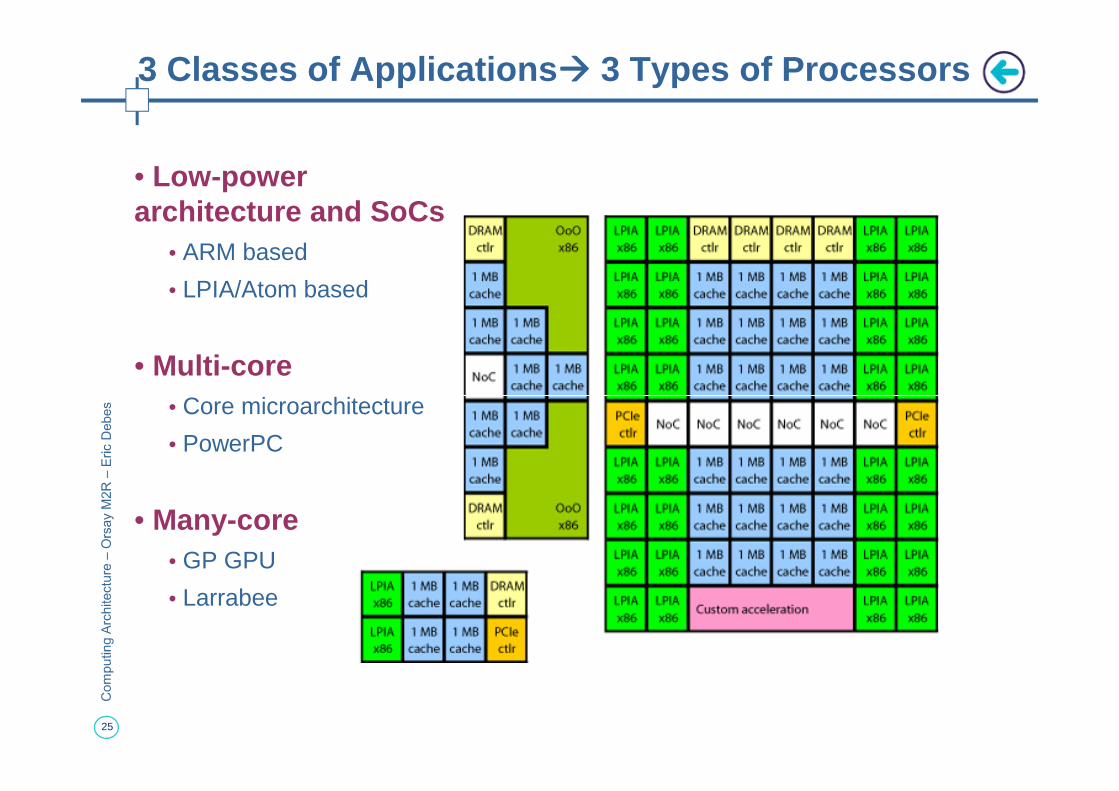
• Low-power architecture and SoCs
• ARM based
• LPIA/Atom based
• Multi-core• Core microarchitecture
3 Classes of Applications ���� 3 Types of Processors
25
• Core microarchitecture
• PowerPC
• Many-core• GP GPU
• Larrabee
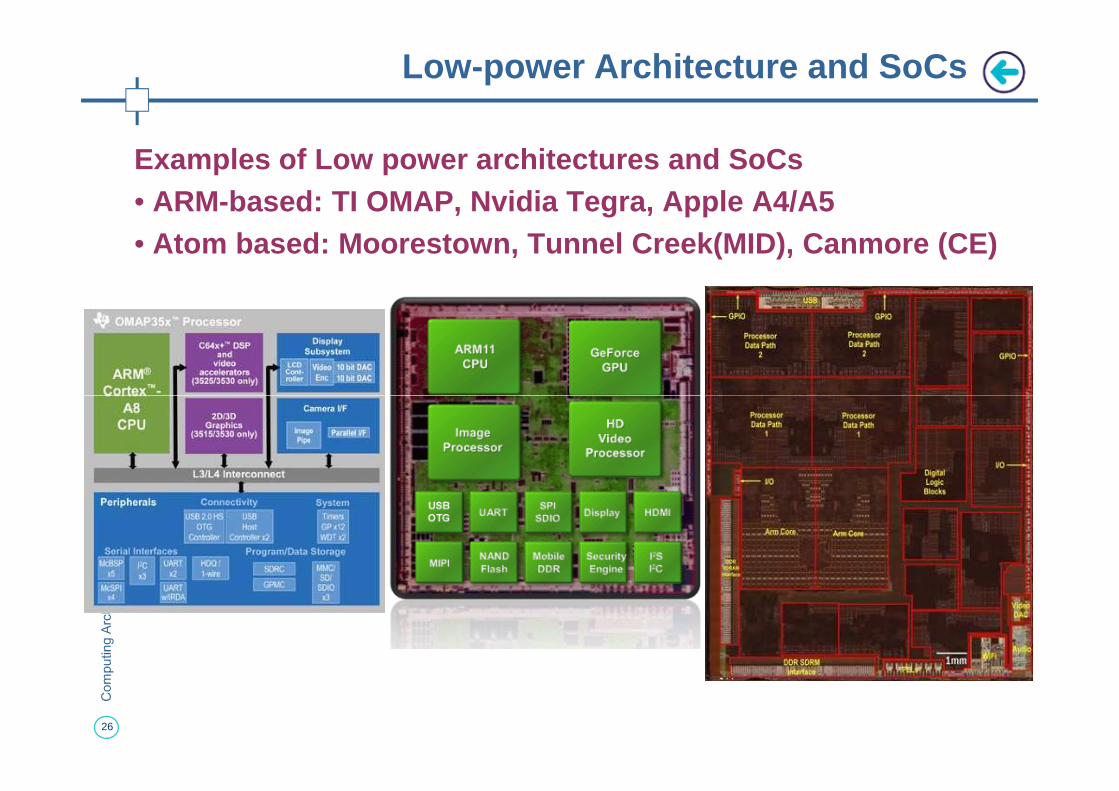
Examples of Low power architectures and SoCs• ARM-based: TI OMAP, Nvidia Tegra, Apple A4/A5• Atom based: Moorestown, Tunnel Creek(MID), Canmore (CE)
Low-power Architecture and SoCs
26
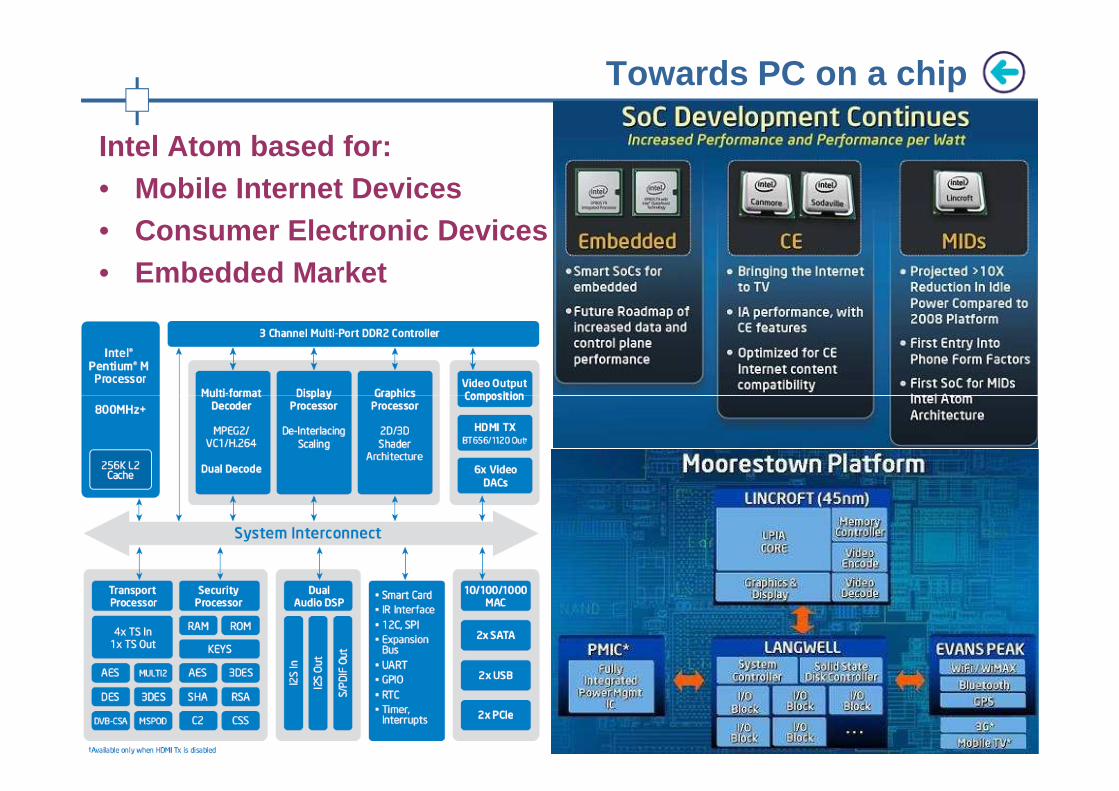
Intel Atom based for: • Mobile Internet Devices• Consumer Electronic Devices• Embedded Market
Towards PC on a chip
27
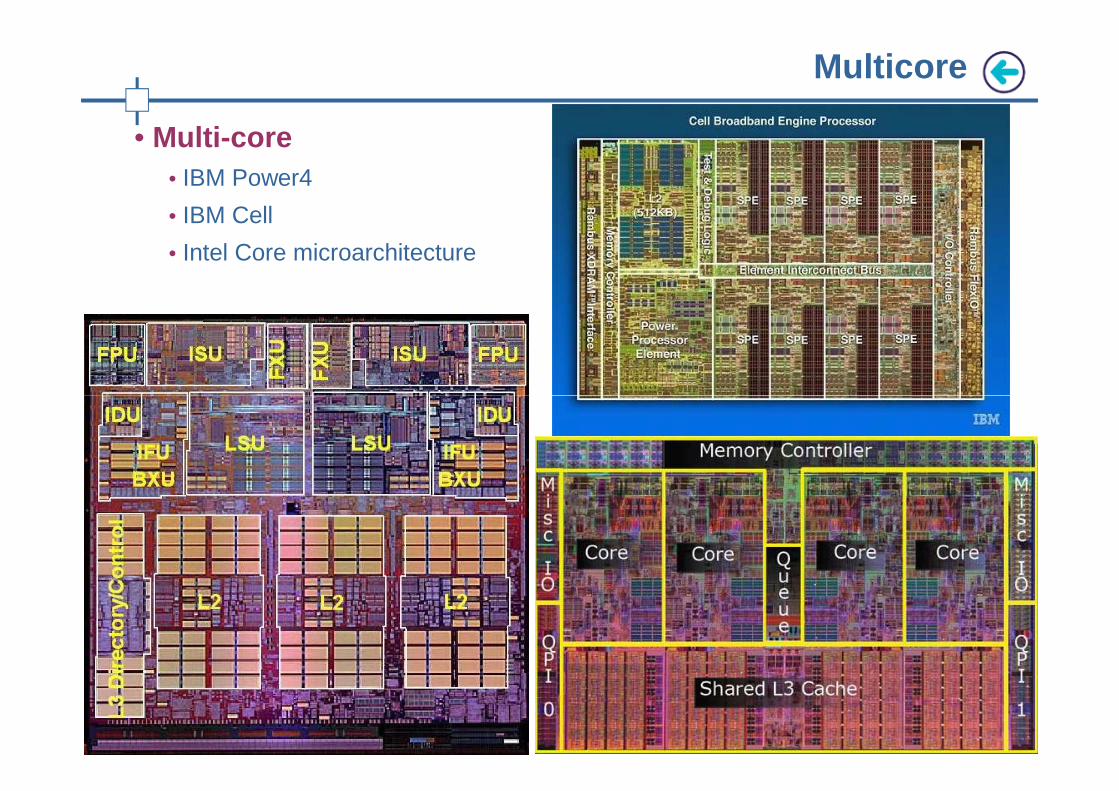
• Multi-core• IBM Power4
• IBM Cell
• Intel Core microarchitecture
Multicore
28
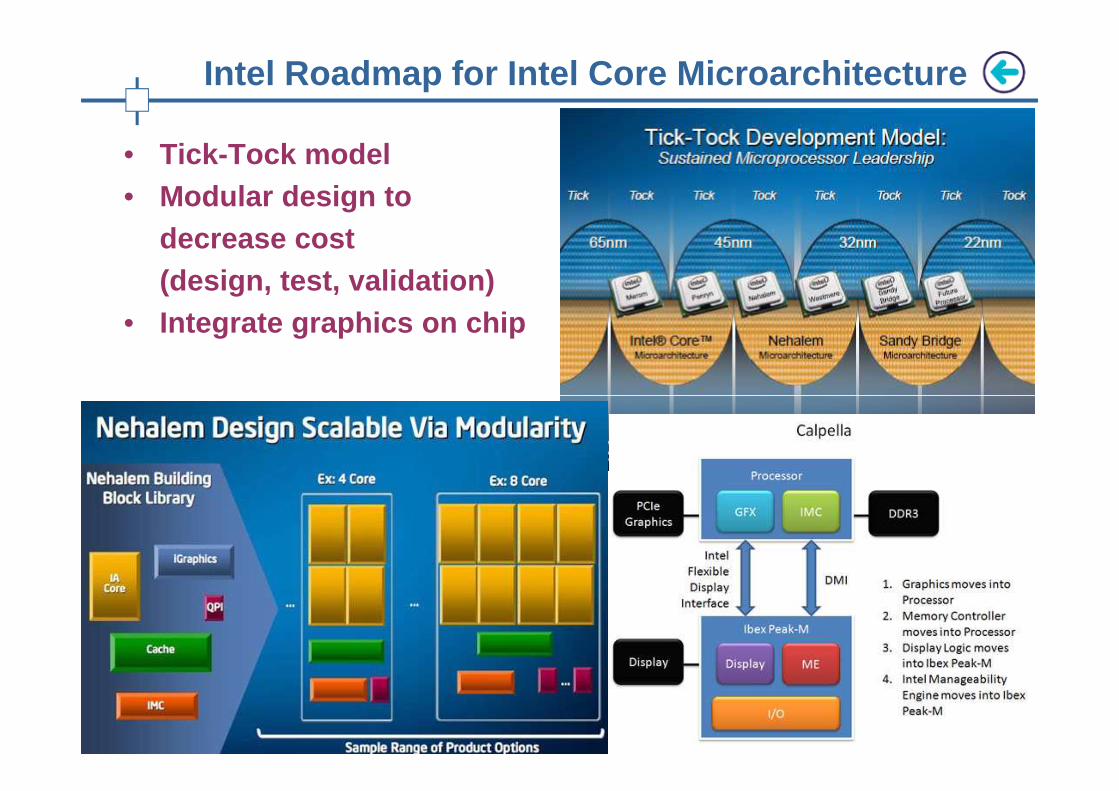
• Tick-Tock model• Modular design to
decrease cost (design, test, validation)
• Integrate graphics on chip
Intel Roadmap for Intel Core Microarchitecture
29
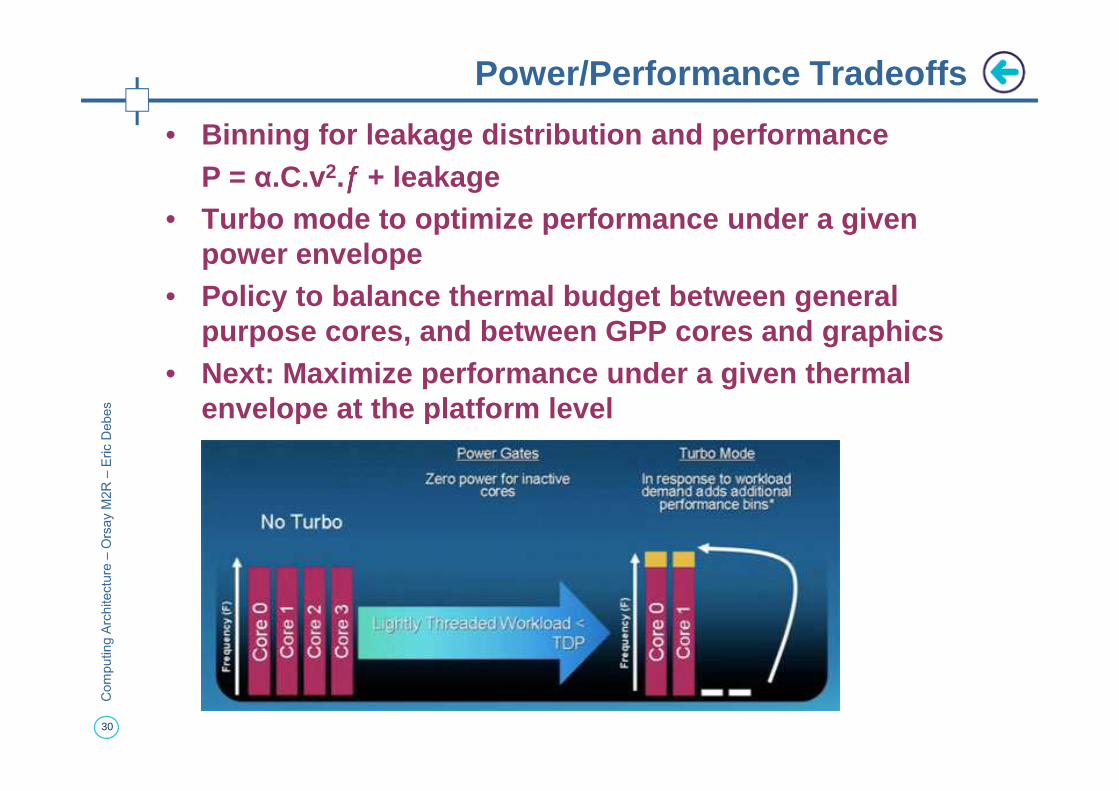
• Binning for leakage distribution and performanceP = α.C.v2.ƒƒƒƒ + leakage
• Turbo mode to optimize performance under a given power envelope
• Policy to balance thermal budget between general purpose cores, and between GPP cores and graphics
• Next: Maximize performance under a given thermal envelope at the platform level
Power/Performance Tradeoffs
30
envelope at the platform level
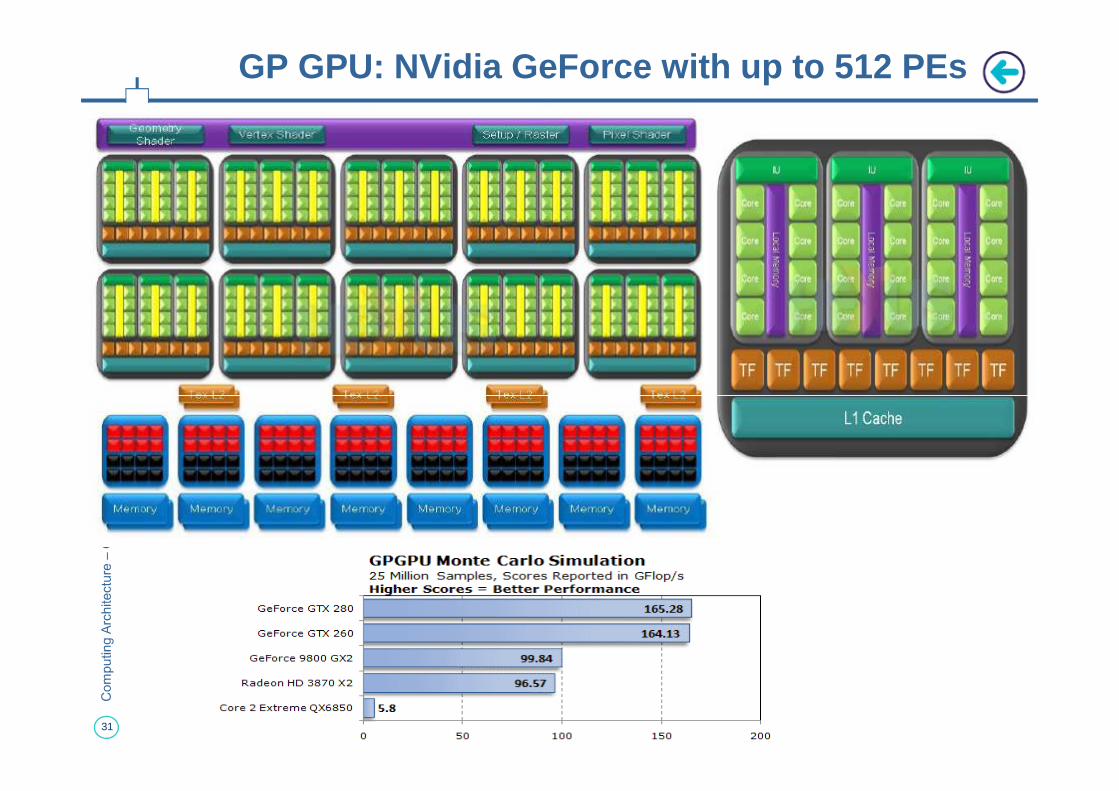
GP GPU: NVidia GeForce with up to 512 PEs
31

• No need to put a lot of cache for GPUs because the number of threads are hiding the latency. The chip is designed for DRAM latency through a huge number of threads. Local memory are still present to limit ba ndwidth to GDDR
• CPU need multi-level large caches because the data need to be close to the execution units
CPUs vs. GPUs
32
to be close to the execution units• Fast growing video game industry exerts strong
economic pressure that forces constant innovation

For a given application, processor architectures sh ould be chosen depending on the performance/power efficienc y
• MIPS/Watt or Gflops/Watt• Energy efficiency (Energy Delay Product)
This is highly dependent on the application and tar geted power envelope. Examples:
Performance/Power for different architectures
33
power envelope. Examples: • ARM and Atom are optimized for mainstream office and media apps for
a power envelope between 1W and <10W
• Core microarchitecture is optimized for high-end office and media apps for a power envelope between 15W and ~75W
• GPUs are optimized for graphics applications and some selected scientific applications between 10W and more than 400W
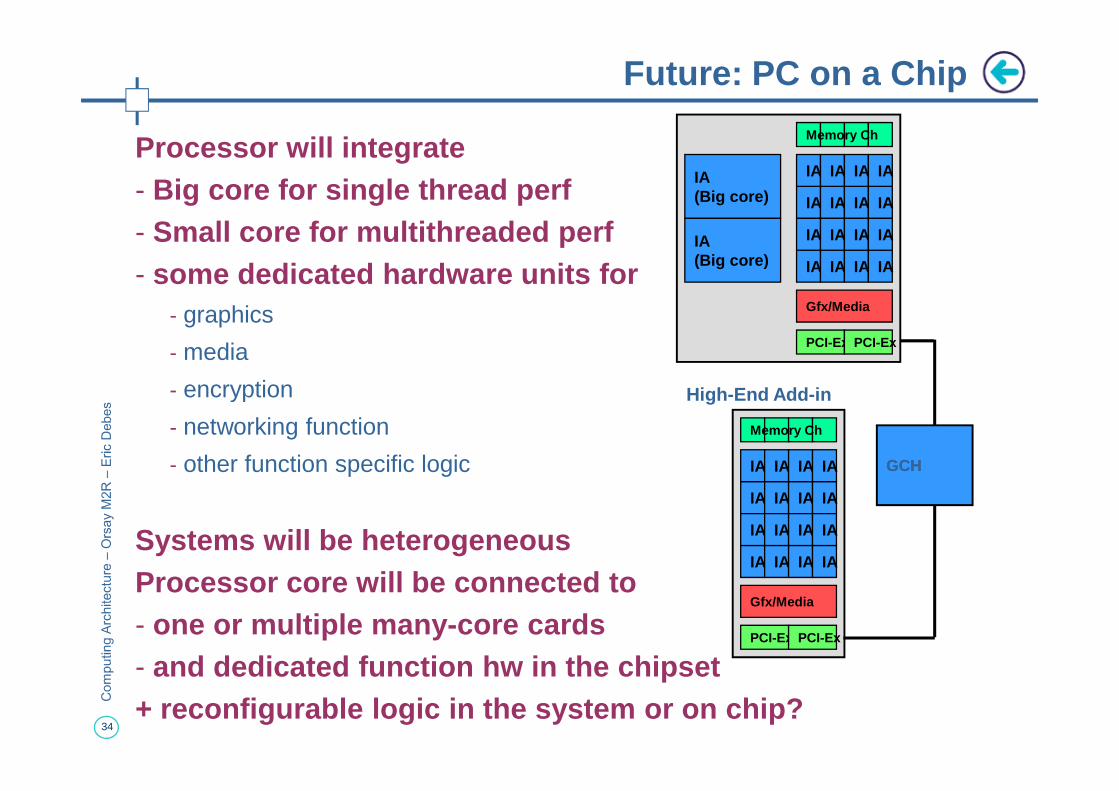
Processor will integrate- Big core for single thread perf- Small core for multithreaded perf- some dedicated hardware units for
- graphics
- media
- encryption
Future: PC on a Chip
High -End Add -in
IA IA IA IA
IA IA IA IA
IA IA IA IA
IA IA IA IA
PCI-Ex PCI-Ex
Gfx/Media
Memory Ch
IA(Big core)
IA(Big core)
34
- encryption
- networking function
- other function specific logic
Systems will be heterogeneousProcessor core will be connected to - one or multiple many-core cards- and dedicated function hw in the chipset+ reconfigurable logic in the system or on chip?
IA IA IA IA
IA IA IA IA
IA IA IA IA
IA IA IA IA
PCI-Ex PCI-Ex
Gfx/Media
Memory Ch
High -End Add -in
GCHGCH

Part 3: App Specific Proc: DSPs, FPGAs, Accelerator s, SoCsOctober 21 st 2011Eric Debes
Embedded Computing Systems for Signal Processing Applications

� What are application specific processors?� Processors or System-on-chip targeting a specific (class of)
application(s)
� Very common for � Audio: MP3, AAC coding and decoding in audio players� Image: JPEG or JPEG2000 coding and decoding, e.g. Digital cameras� Video: MPEG, H264 coding and decoding, e.g. DVD players or set-top-
boxes
Application Specific Processors
36
boxes� Encryption: RSA, AES� Communication: GSM, 3G in cellphones
� Why?� Large markets can justify the development of application specific
processors � Dedicated circuits provide higher performance with lower power
dissipation, better battery life and very often lower cost.
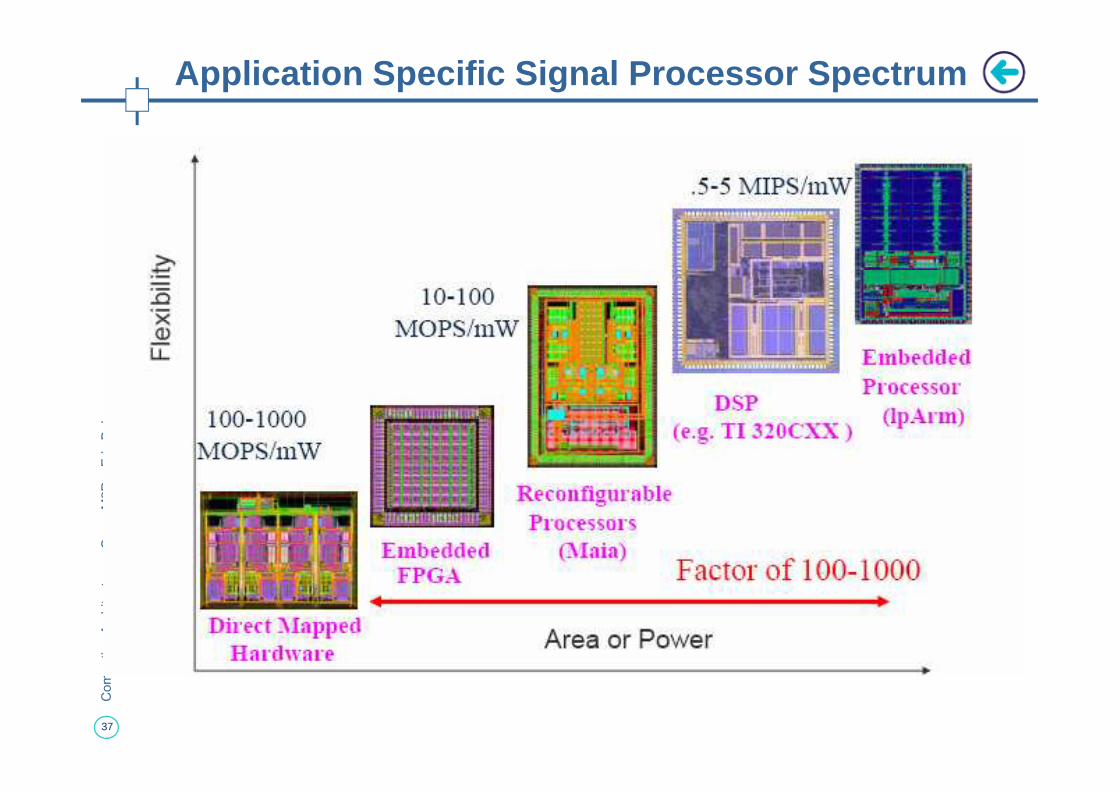
Application Specific Signal Processor Spectrum
37
� DSPs
� Dedicated ASICs
� FPGAs
� Accelerators as coprocessors
Different Types of ASPs
38
� ISA extensions
� SoCs

Summary of Architectural Features of DSPs
Data path configured for DSP
� Fixed-point arithmetic
� MAC- Multiply-accumulateMultiple memory banks and buses -
� Harvard Architecture: separate data and instruction memory
� Multiple data memoriesSpecialized addressing modes
39
Specialized addressing modes
� Bit-reversed addressing
� Circular buffersSpecialized instruction set and execution control
� Zero-overhead loops
� Support for MACSpecialized peripherals for DSP
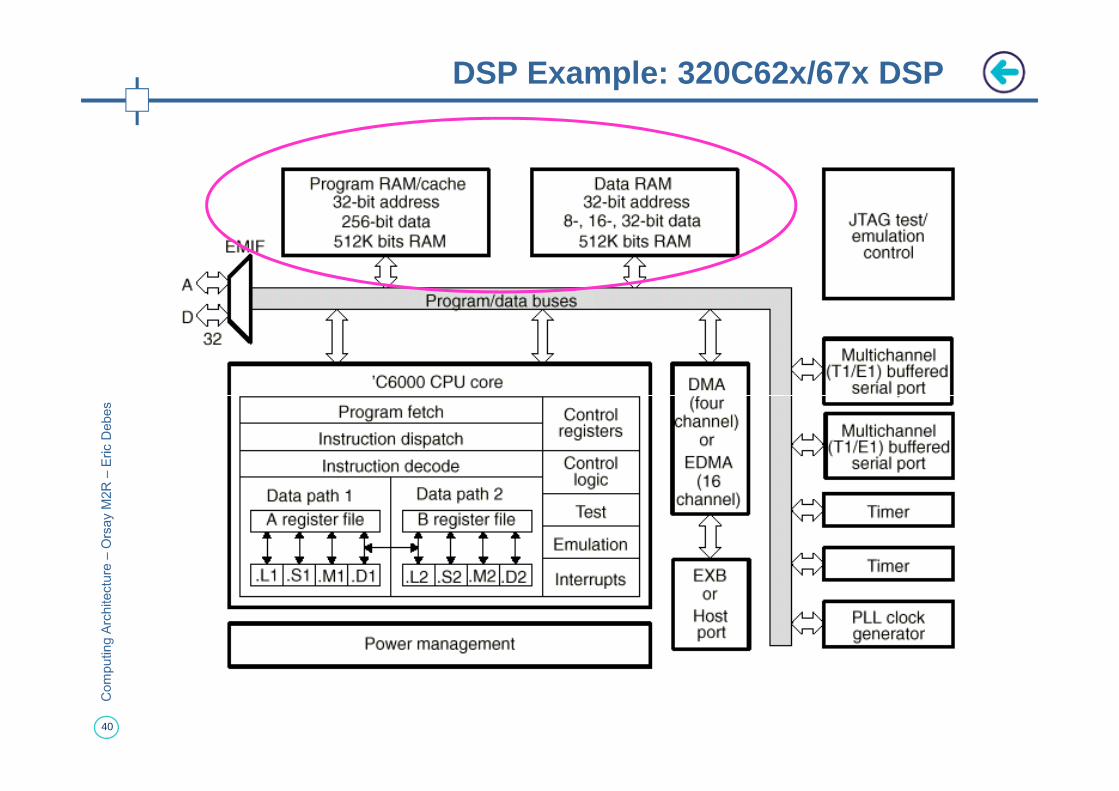
DSP Example: 320C62x/67x DSP
40

� Many dedicated ASICs exist on the market, especially for media and communication applications. Example:
� MP3 player� DVD player� Video processing engines, e.g. De-interlacing, super-resolution� Video Encoder/Decoder� GSM/3G� TCP/IP Offload engine
Dedicated ASICs
41
� Advantages:� Low power, high perf/power efficiency� Small area compared to same functionality in DSP or GPP
� Drawbacks� Cost of designing ASICs � requires large volume� Not flexible: cannot handle different applications, cannot evolve to
follow standard evolution
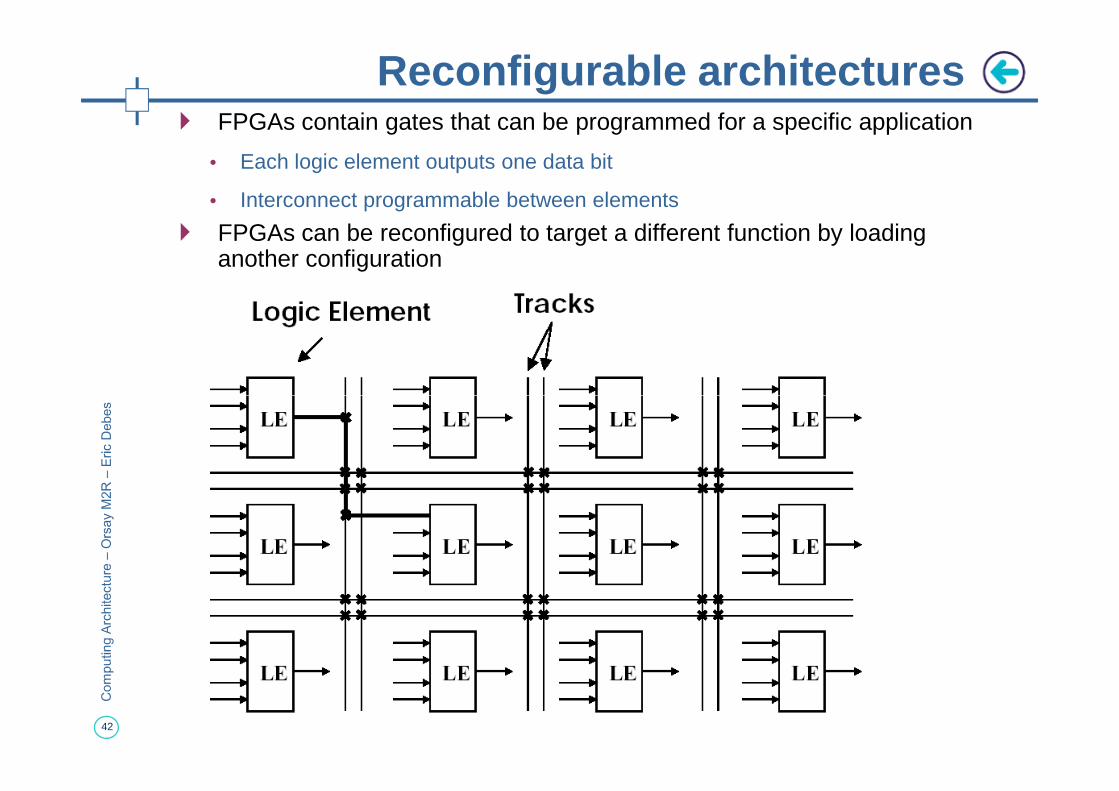
Reconfigurable architectures� FPGAs contain gates that can be programmed for a specific application
• Each logic element outputs one data bit
• Interconnect programmable between elements
� FPGAs can be reconfigured to target a different function by loading another configuration
42

�Spécifications � Input: RTL coding � structural or behavioral description
�RTL Simulation� Functional simulation � check logic and data flow (no temporal
analysis)
�Synthesis� Translate into specific hardware primitives
Flot de conception FPGAs
43
� Translate into specific hardware primitives � Optimisation to meet area and performance constraints
�Place and Route� Map hw primitives to specific places on the chip based on area
and performance for the given technology� Specify routing
� Temporal Analysis� Verification that temporal specification are met
� Test and Verification of the component on the FPGA board
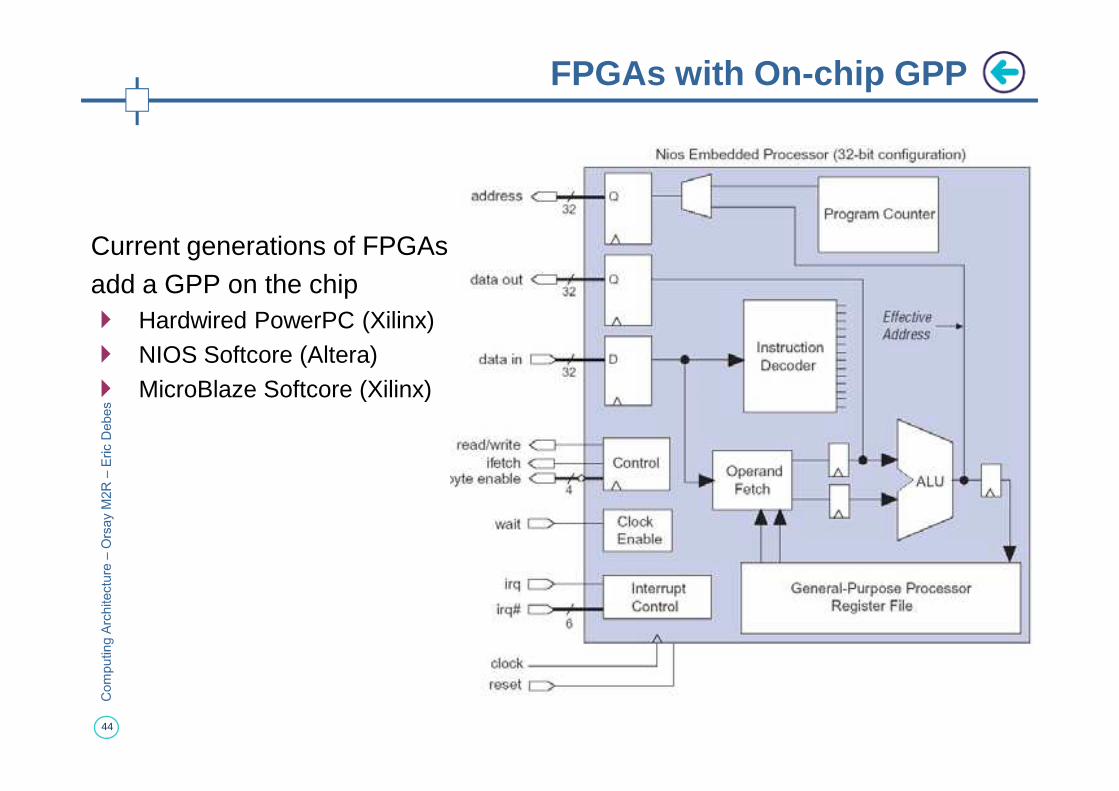
Current generations of FPGAs add a GPP on the chip� Hardwired PowerPC (Xilinx)� NIOS Softcore (Altera)� MicroBlaze Softcore (Xilinx)
FPGAs with On-chip GPP
44
� MicroBlaze Softcore (Xilinx)
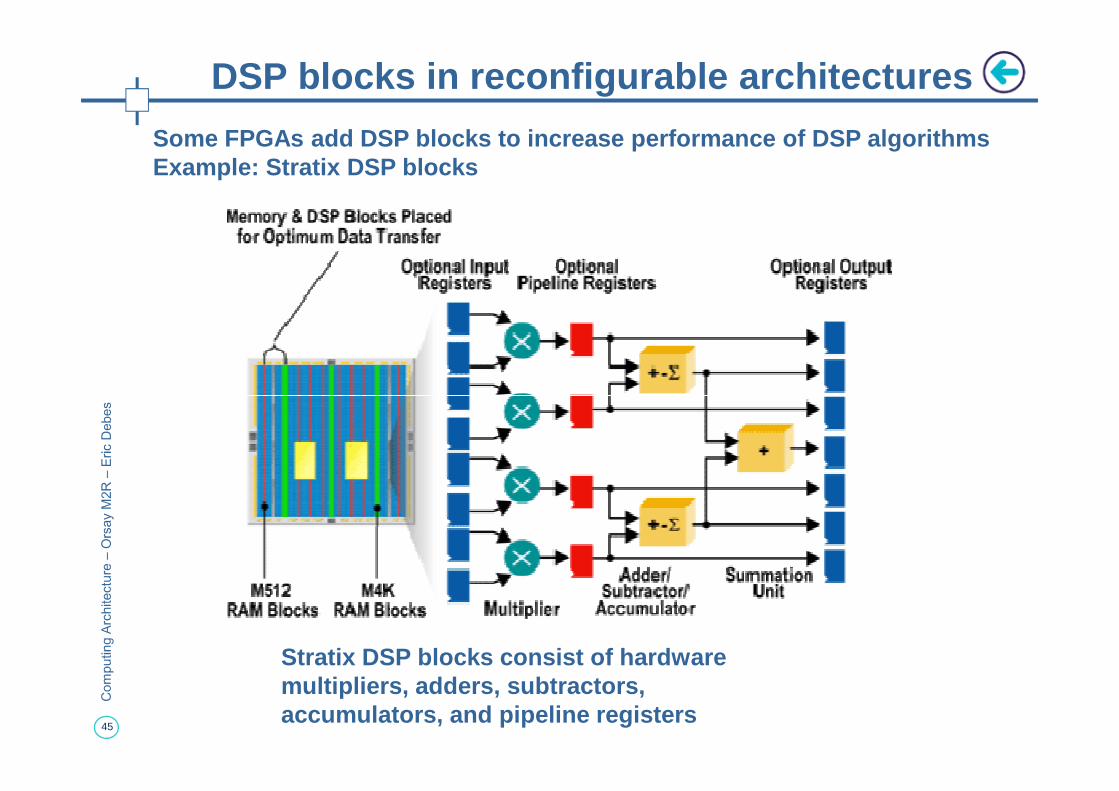
DSP blocks in reconfigurable architectures
Some FPGAs add DSP blocks to increase performance o f DSP algorithmsExample: Stratix DSP blocks
45
Stratix DSP blocks consist of hardware multipliers, adders, subtractors, accumulators, and pipeline registers
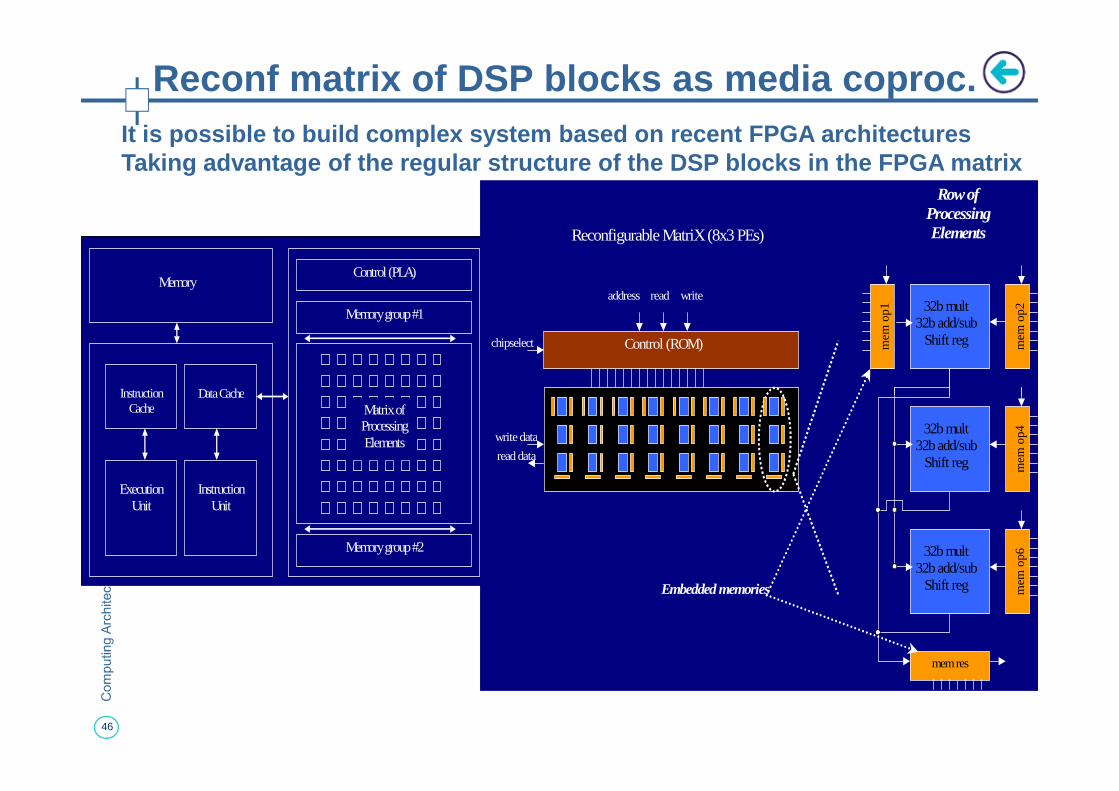
Reconf matrix of DSP blocks as media coproc.
Data Cache
Memory
Instruction
Control (PLA)
Memory group #1
32b mult 32b add/sub
Shift reg
Row of Processing Elements
mem
op1
Reconfigurable MatriX (8x3 PEs)
mem
op2
read write address
Control (ROM) chipselect
It is possible to build complex system based on rec ent FPGA architecturesTaking advantage of the regular structure of the DS P blocks in the FPGA matrix
46
Execution
Unit
Data Cache
Instruction
Unit
Instruction Cache
General purpose processor
Memory group #2
Co processor
Matrix of Processing Elements
Embedded memories
read data
write data 32b mult
32b add/sub Shift reg m
em o
p4
32b mult 32b add/sub
Shift reg
mem res
mem
op6

� Dedicated circuits to accelerate a specific part of the processor
� Typically will be connected to a general-purpose processor or a DSP
� Granularity can vary� accelerator for a DCT function� Accelerator for a whole JPEG encoder
Accelerators as Coprocessors
47
� Accelerator for a whole JPEG encoder
� Accelerators are very common in system on chip� Are typically called through an API function call from the
main CPU

� Extending the ISA of a general purpose processor with SIMD instructions and specific instructions targeting media and communication applications is very common
� It adds application specific features to a processor and turns a general purpose processor into a signal/image/video processor.
� Example:
ISA extension in General-Purpose Processors
48
� Example:� Intel MMX, SSE� PowerPC AltiVec� SUN VIS� Xscale WMMX� ARM Neon, Thumb-2, Trustzone, Jazelle, etc.
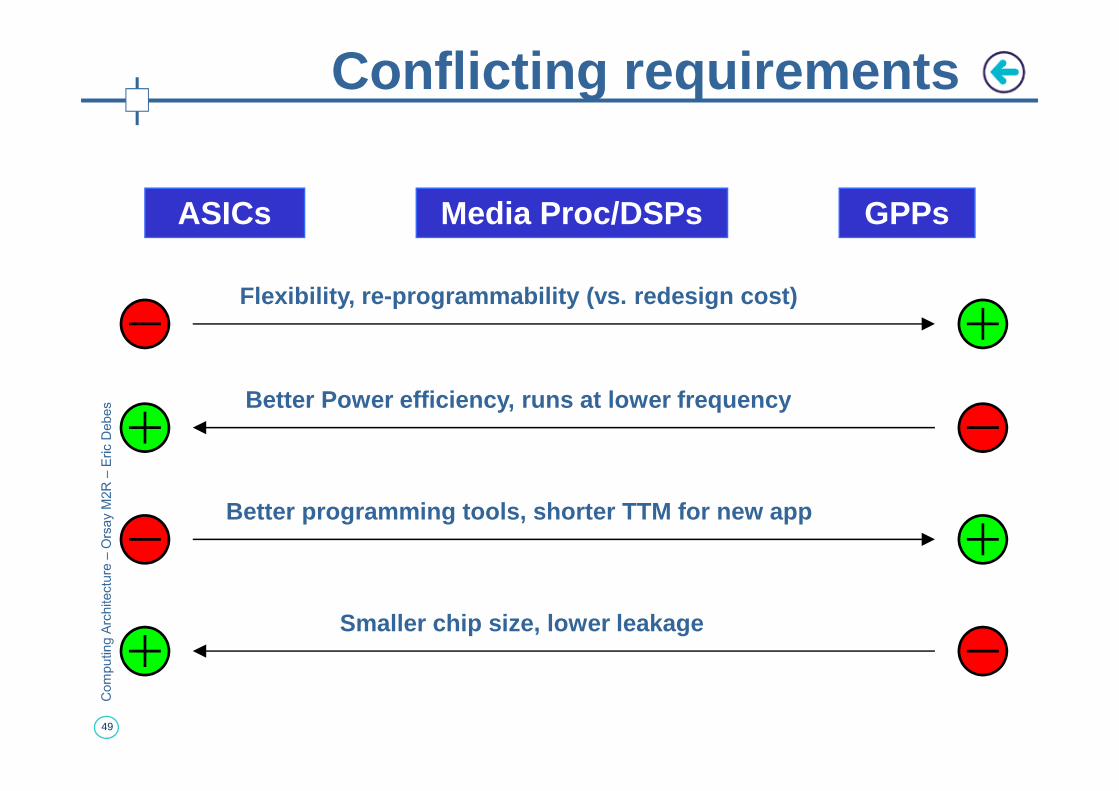
Conflicting requirements
ASICs Media Proc/DSPs GPPs
Better Power efficiency, runs at lower frequency
Flexibility, re-programmability (vs. redesign cost)
49
Better Power efficiency, runs at lower frequency
Better programming tools, shorter TTM for new app
Smaller chip size, lower leakage
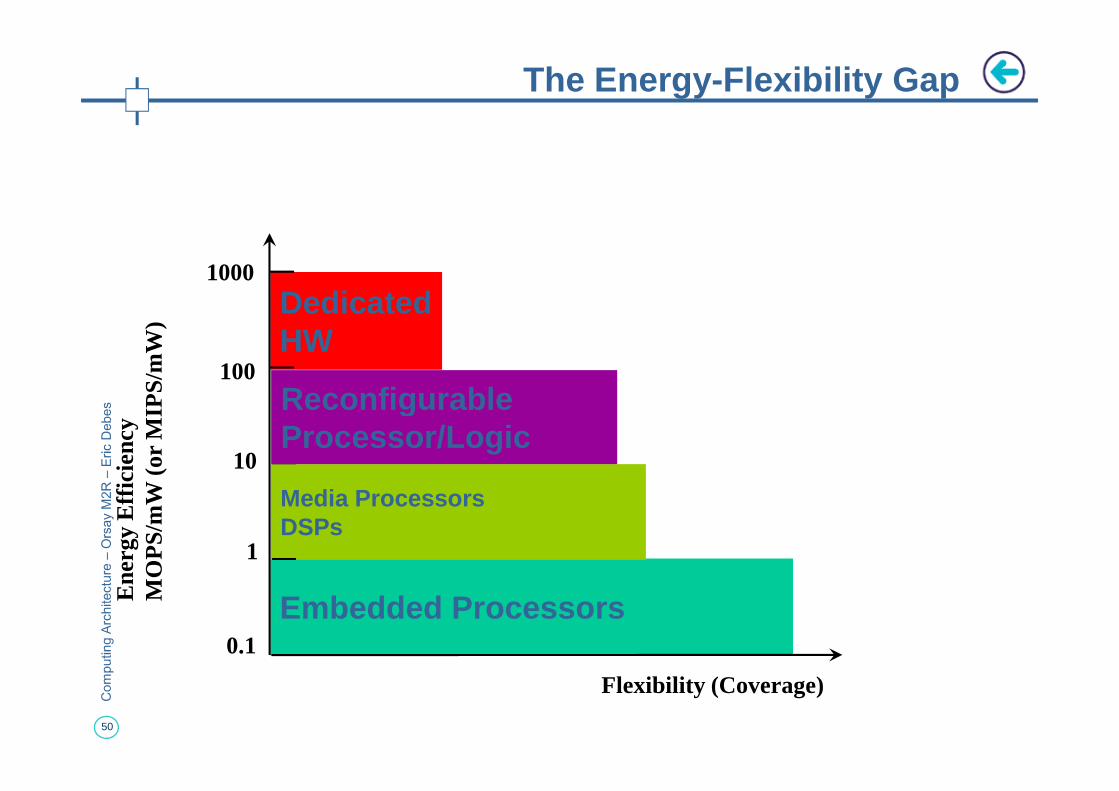
The Energy-Flexibility Gap
DedicatedHW
MO
PS/
mW
(or
MIP
S/m
W)
100
1000
Reconfigurable
50
Embedded Processors
Media ProcessorsDSPs
Flexibility (Coverage)
Ene
rgy
Eff
icie
ncy
MO
PS/
mW
(or
MIP
S/m
W)
0.1
1
10
ReconfigurableProcessor/Logic

� SoCs integrate the optimal mix of processors and dedicated hardware units for the different applications targeted by the system.
� Typically integrate a general purpose processor, e.g. ARM� Can integrate a DSP � Accelerators for specific functions� Dedicated memories
System-on-Chip
51
� Integration boosts performance, cuts cost, reduces power consumption compared to a similar mix of processors on a card
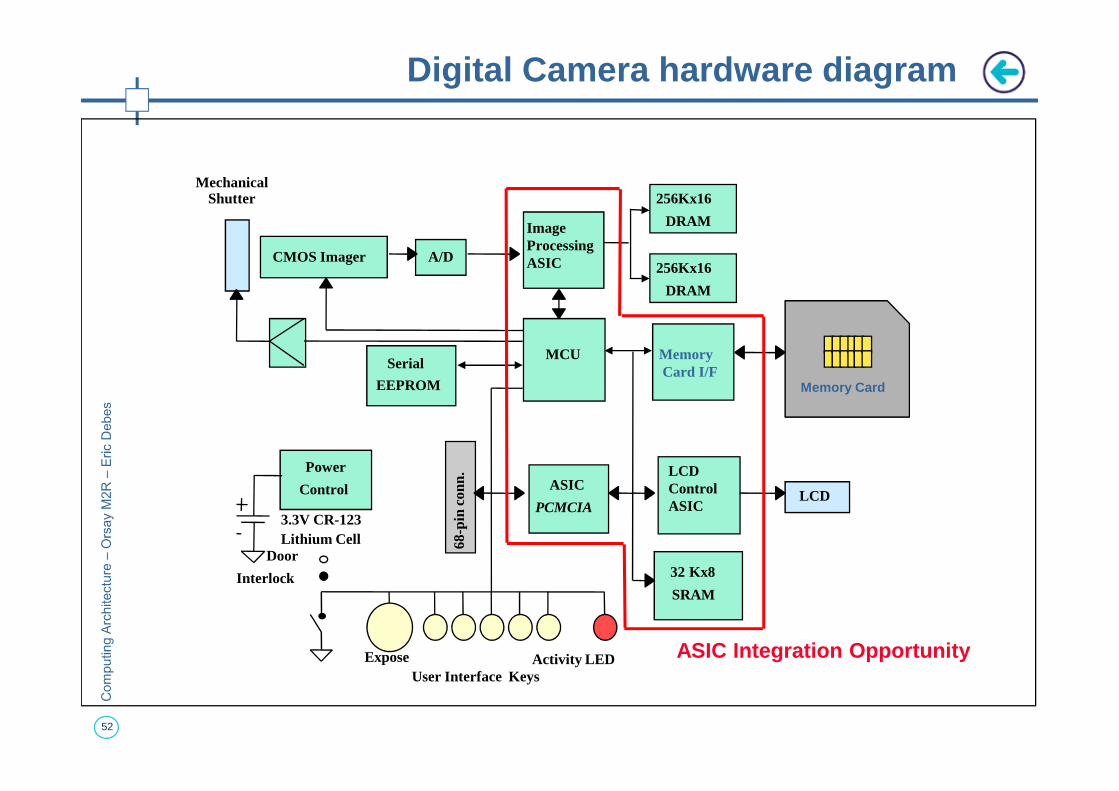
Digital Camera hardware diagram
Mechanical Shutter
A/DCMOS Imager
ImageProcessingASIC
256Kx16
DRAM
256Kx16
DRAM
MCU MemoryCard I/FSerial
EEPROM Memory Card
52
LCD ControlASIC
LCD
32 Kx8
SRAM
68-p
in c
onn. ASIC
PCMCIA
Power
Control
3.3V CR-123Lithium Cell
ExposeUser Interface Keys
Activity LED
Door
Interlock
ASIC Integration Opportunity

MPSoC: A Platform Story
What’s a platform? “A coordinated family of architectures that satisfy a set of architectural constraints imposed to support reuse of hardware and software components”
Best of all worlds: � Provides some level of flexibility
53
� Provides some level of flexibility
� While being power efficient
� And enabling some level of reusability
� Can last multiple product generations
� Requires forward-looking platform based design to integrate potential future application requirements in today’s platform
Programming model and design efficiency are key!
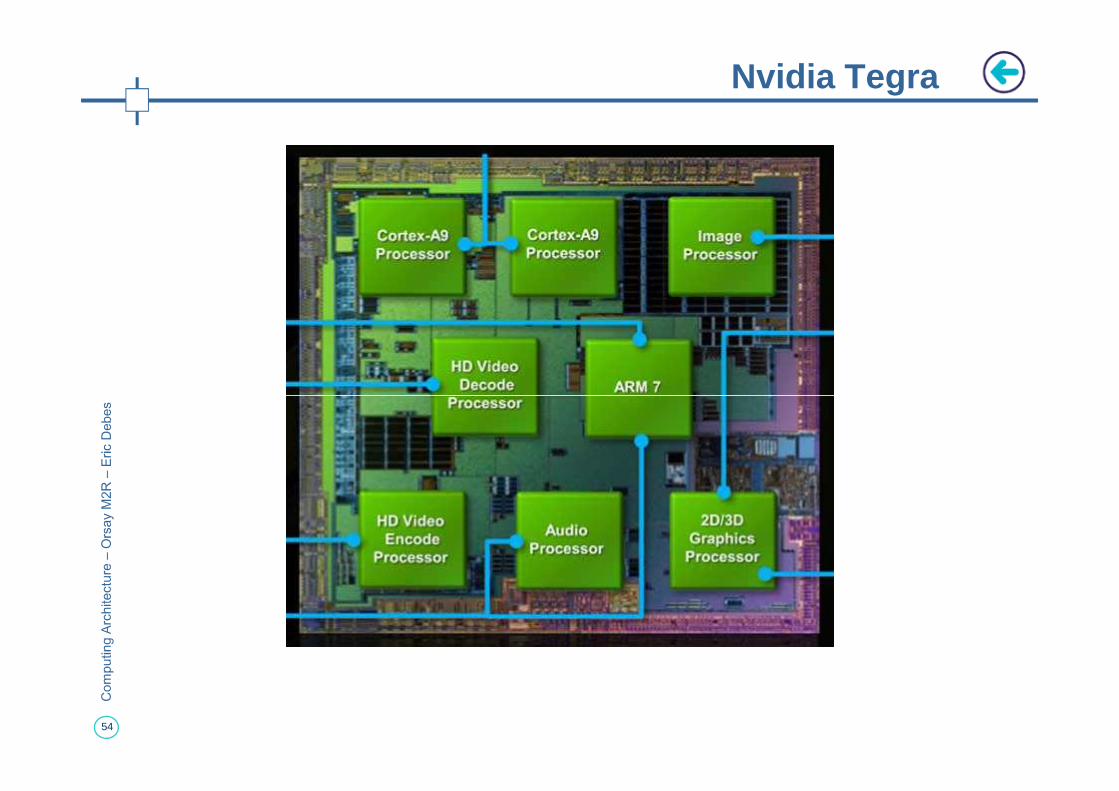
Nvidia Tegra
54
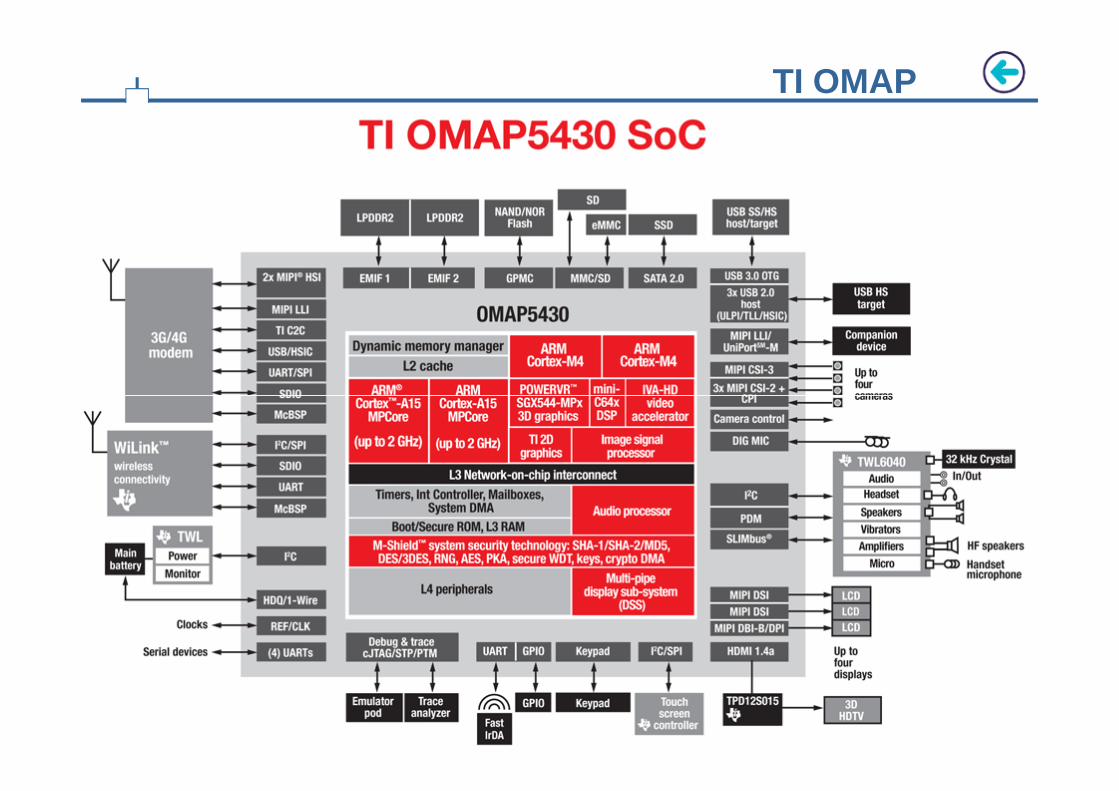
TI OMAP
55

� What features need to be supported?
� What are the constraints?
� What are the processors� General purpose processors?� DSPs?� FPGAs?
Let’s Design a SoC for a set top box!
56
� FPGAs?� Dedicated processors?� Accelerators?� SoCs?
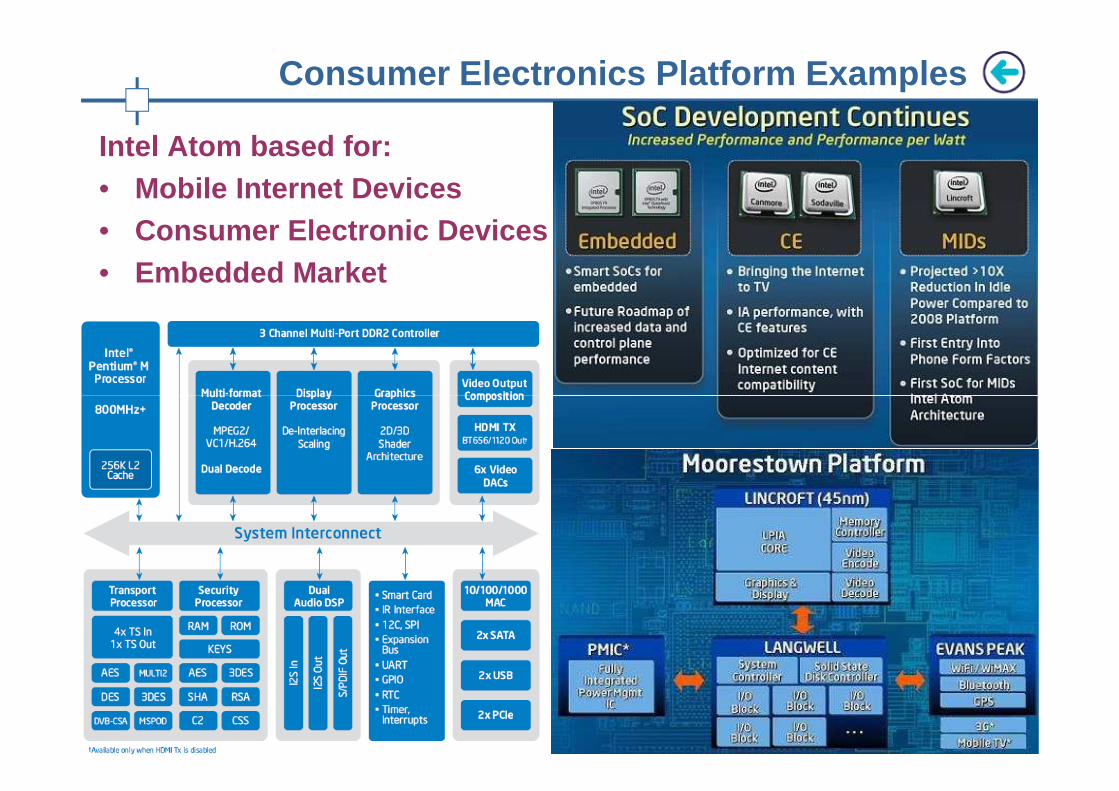
Intel Atom based for: • Mobile Internet Devices• Consumer Electronic Devices• Embedded Market
Consumer Electronics Platform Examples
57

� Embedded Signal Processing Architectures have multiple opposite constraints� Performance� Power� Size/Price
� Power/performance tradeoffs are crucial for an efficiently design
Summary
58
� Power/performance tradeoffs are crucial for an efficiently design system
� A wide spectrum of processors to handle such applications� From simple in-order pipelined general purpose processors� Out-of order processors� Symmetric multicore architectures for better power efficiency� Heterogeneous System on Chip� Many-core/GPGPUs





























