Embed Size (px)
Citation preview

Embedded Systems in SiliconTD5102
Data Management (2)Loop transformations & Data reuse
Henk Corporaalhttp://www.ics.ele.tue.nl/~heco/courses/EmbSystems
Technical University Eindhoven
DTI / NUS Singapore
2005/2006

Thanks to the IMEC DTSE experts:
Erik Brockmeyer
IMEC, Leuven, Belgium
and also
Martin Palkovic, Sven Verdoolaege, Tanja van Achteren, Sven Wuytack, Arnout Vandecappelle, Miguel Miranda,
Cedric Ghez, Tycho van Meeuwen, Eddy Degreef, Michel Eyckmans, Francky Catthoor, e.a.

H.C. TD5102 3
DM methodology
Dataflow Transformations
Analysis/Preprocessing
Loop/control-flow transformations
Data Reuse
Storage Cycle Budget Distribution
Memory Allocation and Assignment
Memory Layout organisation
C-out
C-in
Address optimization

H.C. TD5102 4
for (i=0; i < 8; i++) A[i] = …;for (i=0; i < 8; i++) B[7-i] = f(A[i]);
Location
Time
Production
Consumption
for (i=0; i < 8; i++) A[i] = …; B[7-i] = f(A[i]);
Location
Time
Production
Consumption
Locality of Reference

H.C. TD5102 5
Regularity
for (i=0; i < 8; i++) A[i] = …;for (i=0; i < 8; i++) B[i] = f(A[7-i]);
Location
Time
for (i=0; i < 8; i++) A[i] = …;for (i=0; i < 8; i++) B[7-i] = f(A[i]);
Location
Time
ProductionConsumption
H.C. TD5102 6
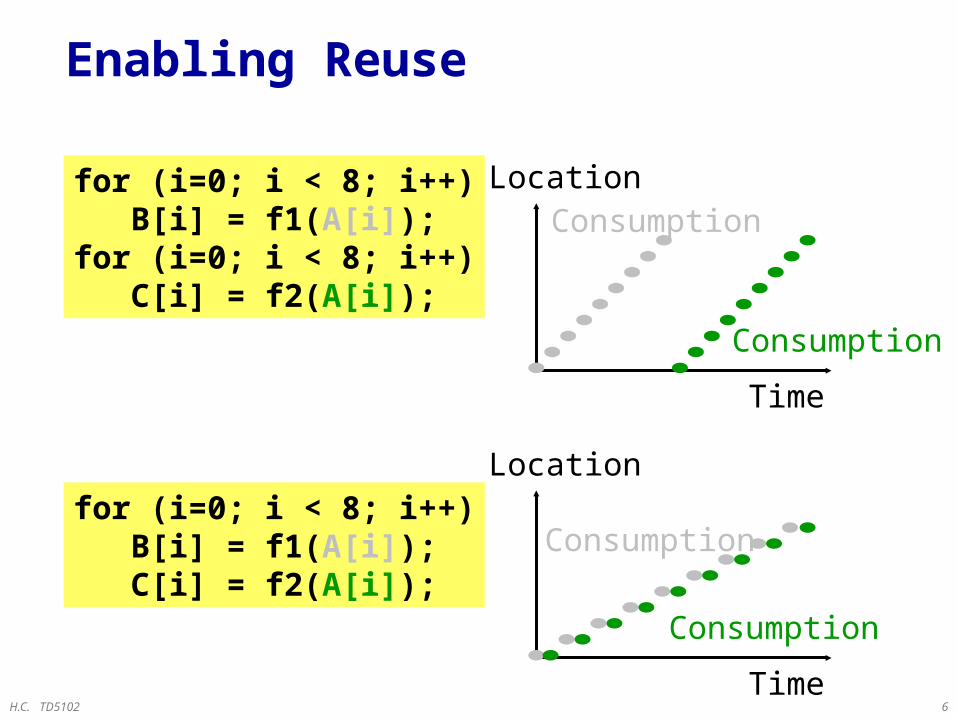
for (i=0; i < 8; i++) B[i] = f1(A[i]);for (i=0; i < 8; i++) C[i] = f2(A[i]);
Location
Time
Consumption
Consumption
Location
Time
Consumption
Consumption
Enabling Reuse
for (i=0; i < 8; i++) B[i] = f1(A[i]); C[i] = f2(A[i]);

H.C. TD5102 7
How to do these loop transformations automatically?
Requires cost function
Requires technique
Let's introduce some terminology
- iteration spaces
- polytopes
- ordering vector / execution order

H.C. TD5102 8
0 1 j2 3 4 50
i
1
2
3
4
5
Iteration space and polytopes
// assume A[][] exists
for (i=1; i<6; i++) {
for (j=2; j<6; j++) {
B[i][j] = g( A[i-1][j-2]);
} }
--- iteration space
--- consumption space
--- production space
--- dependency vector
H.C. TD5102 9
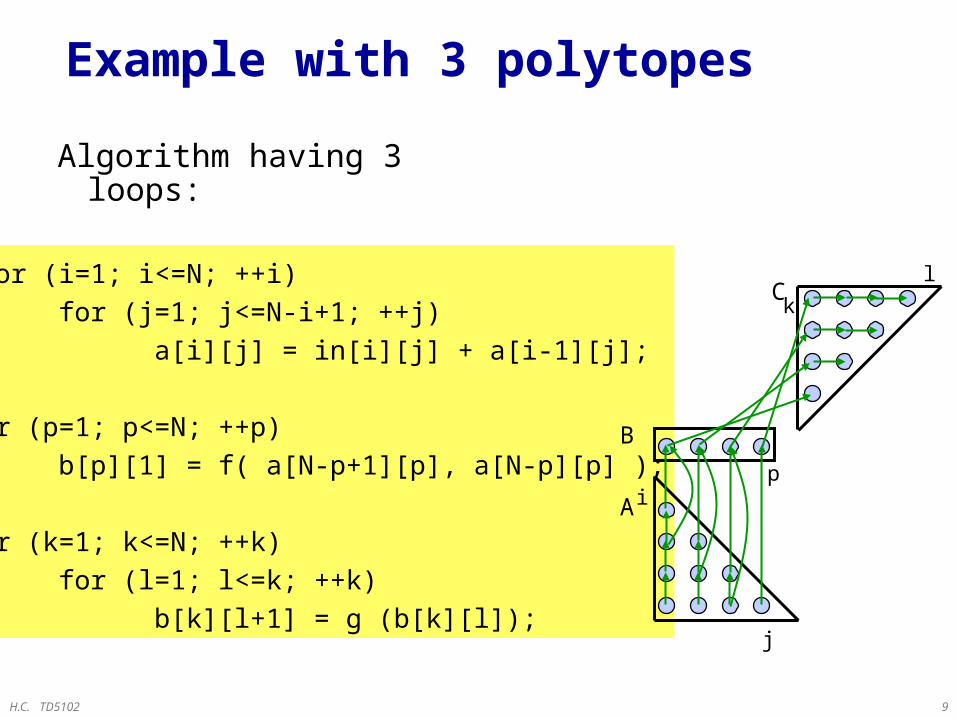
Example with 3 polytopes
A: for (i=1; i<=N; ++i)
for (j=1; j<=N-i+1; ++j)
a[i][j] = in[i][j] + a[i-1][j];
B: for (p=1; p<=N; ++p)
b[p][1] = f( a[N-p+1][p], a[N-p][p] );
C: for (k=1; k<=N; ++k)
for (l=1; l<=k; ++k)
b[k][l+1] = g (b[k][l]);
A
B
C
Algorithm having 3 loops:
j
i
k
p
l

H.C. TD5102 10
Common iteration space
for (i=1; i<=(2*N+1); ++i)
for (j=1; j<=2*N; ++j)
if (i>=1 && i<=N && j>=1 && j<=N-i+1)
a[i][j] = in[i][j] + a[i-1][j];
if (i==N+1 && j>=1 && j<=N)
b[j][1] = f( a[N-j+1][j], a[N-j][j] ); if (i>=N+2 && i<=2*N+1 && j>=N+1 && j<=N+k)
b[i-N-1][j-N+1] = g (b[i-N-1][j-N]);
j
i
1
2*N+1
1 2*N
Initial solution having a common iteration space:
Bad locality Bad regularity Requires 2N memory locations Many dummy iterations
Ordering vector

H.C. TD5102 11
Cost function needed for automation
RegularityEqual direction for dependency vectorsAvoid that dependency vectors cross each otherGood for storage size
Temporal localityEqual length of all dependency vectorsGood for storage sizeGood for data reuse

H.C. TD5102 12
Regularity
Regular
Irregular

H.C. TD5102 13
Bad regularity limits the ordering freedom
j
i
1
2*N+1
1 2*N
Ordering freedom = 90 degrees

H.C. TD5102 14
Locality estimates
P
C
C
C
C
P
C
C
C
C
P = productionC = consumption
P
C
C
C
C
C
Dependency vector length is measure for localityQ: Which length is the best estimate?
Sum{di} Max {di} Spanning tree
di

H.C. TD5102 15
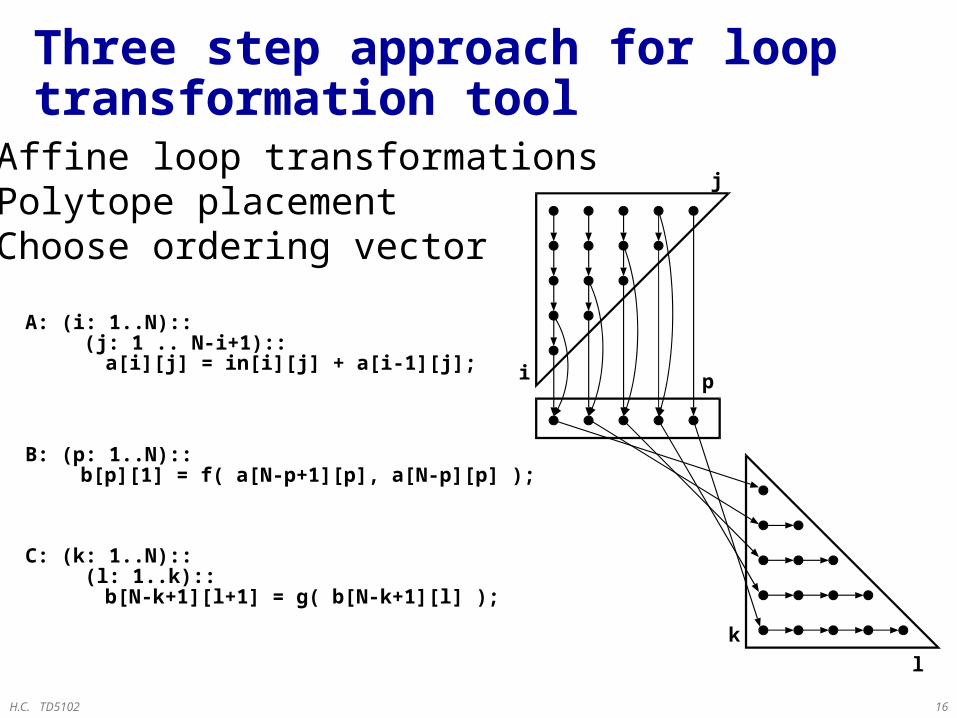
1. Affine loop transformations
1. Only geometric information is available during placement
2. Rotation, skewing, interchange, reverse
2. Polytope placement
1. Only geometric information is available during placement
2. Translation
3. Choose ordering vector
Three step approach for loop transformation tool
y
x
j
iu
j
iT
y
x
u
Combined transformation:
H.C. TD5102 16
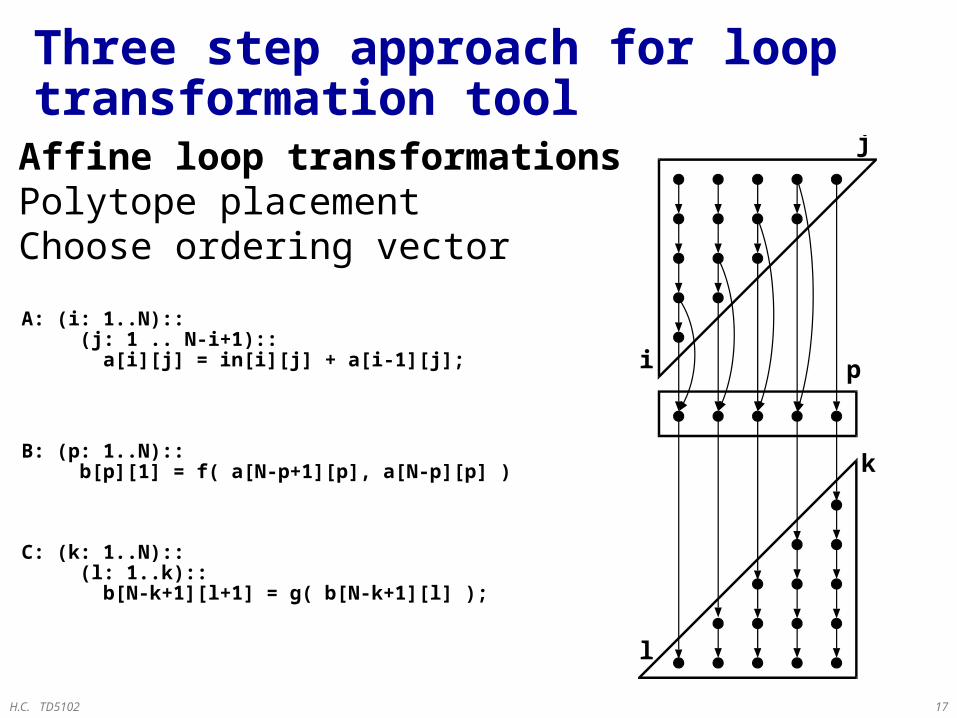
A: (i: 1..N):: (j: 1 .. N-i+1):: a[i][j] = in[i][j] + a[i-1][j];
C: (k: 1..N):: (l: 1..k):: b[N-k+1][l+1] = g( b[N-k+1][l] );
B: (p: 1..N):: b[p][1] = f( a[N-p+1][p], a[N-p][p] );
i
j
p
k
l
• Affine loop transformations• Polytope placement• Choose ordering vector
Three step approach for loop transformation tool
H.C. TD5102 17
Three step approach for loop transformation tool
i
j
A: (i: 1..N):: (j: 1 .. N-i+1):: a[i][j] = in[i][j] + a[i-1][j];
C: (k: 1..N):: (l: 1..k):: b[N-k+1][l+1] = g( b[N-k+1][l] );
pB: (p: 1..N):: b[p][1] = f( a[N-p+1][p], a[N-p][p] );
k
l
i
j
p
k
l
• Affine loop transformations• Polytope placement• Choose ordering vector

H.C. TD5102 18
Three step approach for loop transformation tool
i
p
k
l
j
i
j
A: (i: 1..N):: (j: 1 .. N-i+1):: a[i][j] = in[i][j] + a[i-1][j];
C: (k: 1..N):: (l: 1..k):: b[N-k+1][l+1] = g( b[N-k+1][l] );
pB: (p: 1..N):: b[p][1] = f( a[N-p+1][p], a[N-p][p] );
k
l
• Affine loop transformations• Polytope placement = merging loops• Choose ordering vector

H.C. TD5102 19
Choose optimal ordering vector
Ordering Vector 1 Ordering Vector 2

H.C. TD5102 20
From the Polyhedral model back to C
for (j=1; j<=N; ++j){ for (i=1; i<=N-j+1; ++i) a[i][j] = in[i][j] + a[i-1][j]; b[j][1] = f( a[N-j+1][j], a[N-j][j] ); for (l=1; l<=j; ++l) b[j][l+1] = g( b[j][l] );}
i
l
j
• Affine loop transformations• Polytope placement• Choose ordering vector
Optimized solution having a common iteration space:
Optimal locality Optimal regularity Requires 2 memory locations
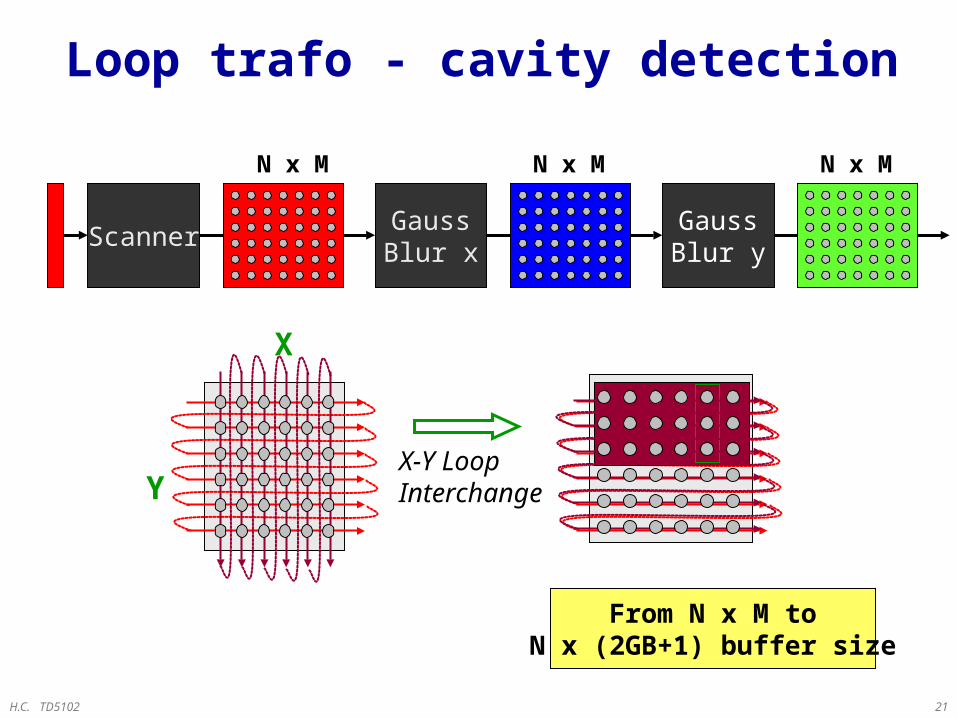
H.C. TD5102 21
Scanner
Loop trafo - cavity detection
GaussBlur y
GaussBlur x
N x M
X-Y LoopInterchange
N x M
From N x M toN x (2GB+1) buffer size
X
Y
N x M
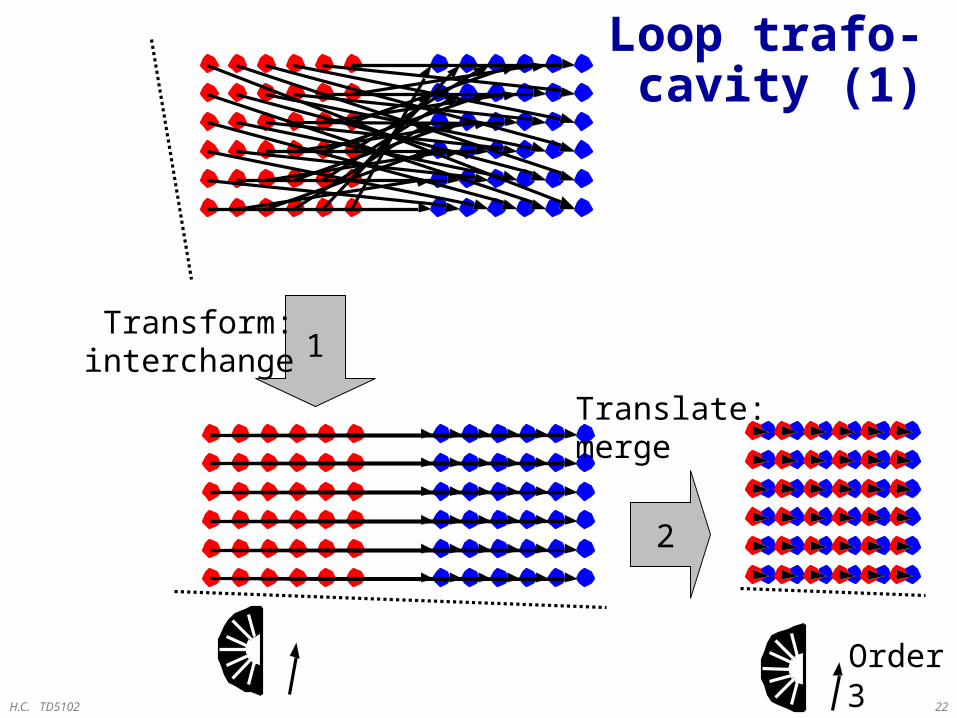
H.C. TD5102 22
Loop trafo-cavity (1)
1Transform:
interchange
2
Translate:merge
3Order
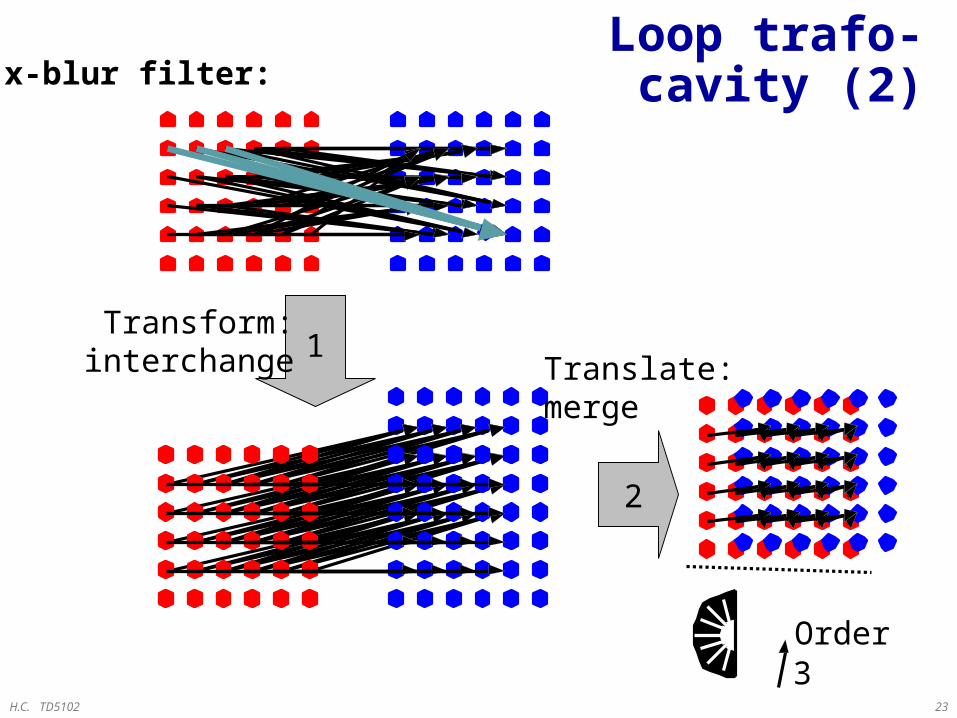
H.C. TD5102 23
Loop trafo-cavity (2)
1Transform:
interchange
2
Translate:merge
3Order
x-blur filter:
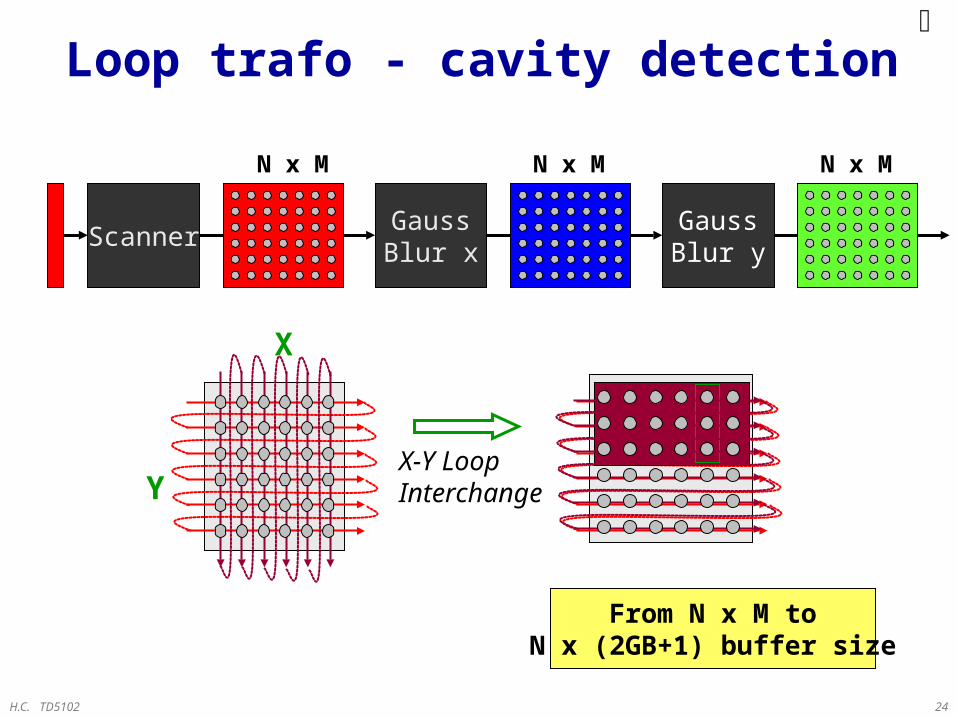
H.C. TD5102 24
Scanner
Loop trafo - cavity detection
GaussBlur y
GaussBlur x
N x M
X-Y LoopInterchange
N x M
From N x M toN x (2GB+1) buffer size
X
Y
N x M

H.C. TD5102 25
Loop trafo-cavity (3)
2Translate 1:
2 Translate 2:
3
Comparingdifferenttranslations

H.C. TD5102 26
Loop trafo-cavity (4)
33Order
+ =
Combining (merging) multiple polytopes

H.C. TD5102 27
Result on gauss filter for (y=0; y<M+GB; ++y) { for (x=0; x<N+GB; ++x) { if (x>=GB && x<=N-1-GB && y>=GB && y<=M-1-GB) { gauss_x_compute = 0; for (k=-GB; k<=GB; ++k) gauss_x_compute += image_in[x+k][y]*Gauss[abs(k)]; gauss_x_image[x][y] = gauss_x_compute/tot;
} else if (x<N && y<M) gauss_x_image[x][y] = 0;
if (x>=GB && x<=N-1-GB && (y-GB)>=GB && (y-GB)<=M-1-GB) { gauss_xy_compute = 0; for (k=-GB; k<=GB; ++k) gauss_xy_compute += gauss_x_image[x][y-GB+k]* Gauss[abs(k)]; gauss_xy_image[x][y-GB] = gauss_xy_compute/tot; } else if (x<N && (y-GB)>=0 && (y-GB)<M) gauss_xy_image[x][y-GB] = 0;

H.C. TD5102 28
Intermezzo Before we continue with data reuse, have a look at other
loop transformations

H.C. TD5102 29
DM methodology
Dataflow Transformations
Analysis/Preprocessing
Loop/control-flow transformations
Data Reuse
Storage Cycle Budget Distribution
Memory Allocation and Assignment
Memory Layout organisation
C-out
C-in
Address optimization

H.C. TD5102 30
Layer 1 Layer 2 Layer 3Datapaths
Memory hierarchy and Data reuse1. Determines reuse candidates
2. Combine reuse candidates into reuse chains
3. If multiple access statements/array combine into reuse trees
4. Determine number of layers (if architecture is not fixed)
5. Select candidates and assign to memory layers
6. Add extra transfers between the different memory layers(for scratchpad RAM; not for caches)

H.C. TD5102 31
TI C55@200MHz example platform
Register file+
Core
4Kx16dual
32xTotal 256Kb1 elem in 1 cycle
16Kx16ROM
OffchipMAX: 8MBx16SRAM/EPROM/ SDRAM/SBSRAM
TMS320vc5510@200MHzVdd= 1.5 VP = unknown
8xTotal 64Kb2 elem in 1 cycle
4Kx16dual
4Kx16dual
4Kx16sing
4Kx16sing
4Kx16sing
ROM (Data/program/DMA)first 3 cycles, next 2 cyclesIt seems this can be in parallel with the 256Kb memory Bandwidth 100M words/S
Bandwidth 400M words/s
Size 32kB
Size 320kB
ROM partition
Variable size RAM partition
Bandwidth 50M words/sSize 16 MB Fixed size RAM partition
Bandwidth 4.8Gwords/sSize 2x16 registersProcessor partition
BW: 50M Word/ssingle port
L2
L0
L1
BW: 400M Word/sdual port

H.C. TD5102 32
M
P = 1
Exploiting Memory Hierarchy for reduced Power: principle
Processor Data Paths
RegisterFile
Processor Data Paths
RegisterFile
A
P = 1
#A = 100%
P total (before) = 100%

H.C. TD5102 33
P total (before) = 100%
M
P = 1
A
P = 1
A’
P = 0.3
100% 5%
Exploiting Memory Hierarchy for reduced Power: principle
P total (after) = 100%x0.01+10%x0.1+1%x1 = 3%
M
P = 1
A
P = 1
A’
P = 0.1
A’’
P = 0.01
100% 1%10%Processor Data Paths
RegisterFile
Processor Data Paths
RegisterFile

H.C. TD5102 34
M
Data reuse decision and memory hierarchy: principle
Processor Data Paths
RegisterFile
Processor Data Paths
RegisterFile
BA
A’A’’
customized connections
Customized connections in the memory subsystem to bypass the memory hierarchy and avoid the overhead.

H.C. TD5102 35
Step 1: identify arrays with data reuse potential
for (i=0; i<4; i++) for (j=0; j<3; j++) for (k=0; k<6; k++) … = A[i*4+k];
timecopy3 copy4copy1 copy2
Time frame 1 Time frame 2 Time frame 3 Time frame 4
arrayindex
intra-copyreuse
inter-copyreuse

H.C. TD5102 36
Importance of high level cost estimate
for (i=0; i<4; i++) for (j=0; j<3; j++) for (k=0; k<6; k++) … = A[i*4+k];
timecopy3 copy4copy1 copy2
Time frame 1 Time frame 2 Time frame 3 Time frame 4
arrayindex
6
Mk
Array copies arestored in-place!

H.C. TD5102 37
Step 1: determine gains Intra-copy reuse factor
for (i=0; i<4; i++) for (j=0; j<3; j++) for (k=0; k<6; k++) … = A[i*4+k];
timecopy3 copy4copy1 copy2
Time frame 1 Time frame 2 Time frame 3 Time frame 4
arrayindex
6
Mk
intra-copyreuse
factor= 3
j iterator =not presentso intra-copy reuse
3

H.C. TD5102 38
Step 1: determine gains Inter-copy reuse factor
timecopy3 copy4copy1 copy2
Time frame 1 Time frame 2 Time frame 3 Time frame 4
arrayindex
inter-copyreuse factor
= 1/(1-1/3)=3/2
6
Mk
for (i=0; i<n; i++) for (j=0; j<3; j++) for (k=0; k<6; k++) … = A[i*4+k];
for (i=0; i<4; i++) for (j=0; j<3; j++) for (k=0; k<6; k++) … = A[i*4+k];
i iterator has smaller weightthan k range so
inter-copy reuse

H.C. TD5102 39
5Mm
tf 1 tf 2 tf 3 tf 4 tf 5 tf 6 tf 7 tf 8 tf 9
Possibility for multi-level hierarchy
arrayindex
time
for (i=0; i<10; i++) for (j=0; j<2; j++) for (k=0; k<3; k++) for (l=0; l<3; l++) for (m=0; m<5; m++) … = A[i*15+k*5+m];
Mk
15
time frame 1 time frame 2
5Mm
tf 1.1 tf 1.2 tf 1.3 tf 1.4 tf 1.5 tf 1.6 tf 2.1 tf 2.2 tf 2.3

H.C. TD5102 40
Step 2: determine data reuse chains for each memory access
R1(A)
A
A’
R1(A)
A
A’
R1(A)
A
A’
A’’
Many reuse possibilities
Cost estimate needed
Prune for promising ones
R1(A)
A

H.C. TD5102 41
Cost function needs both size and number of accesses to intermediate array
for (i=0; i<10; i++) for (j=0; j<2; j++) for (k=0; k<3; k++) for (l=0; l<3; l++) for (m=0; m<5; m++) … = A[i*15+k*5+m];
Gk
155
Gm
estimate #misses from different levels for one iteration of i
R1(A)
2*3*3*5=90
A’
3*5=15
A’
2*3*5=30
estimate size
0 5 10 15 20#elements
0
20
40
60
80
100#
mis
ses

H.C. TD5102 42
R1(A)
A
A’
R1(A)
A
A’
R1(A)
A
A’
A’’
R1(A)
A
30
90 90 9090
15 15
30
90 30 15 15
120105 45
120
150 150 150 150
515 15
5
135 45 22 22
616 7
6
135 51 38 35150 155 165 170
140 150 160 170 180
Area Estimate
0
50
100
150
En
erg
y E
stim
ate
Very simplistic power and area estimation for different data-reuse versions
xyz
accessessizeenergy

H.C. TD5102 43
R1(A)
A
A’
A’’
for (i=0; i<10; i++) for (j=0; j<2; j++) for (k=0; k<3; k++) for (l=0; l<3; l++) for (m=0; m<5; m++) … = A[i*15+k*5+m];
Step 3: determine data reuse trees for multiple accesses
R2(A)
A
A’ for (x=0; x<8; x++) for (y=0; y<5; y++) … = A[i*5+y];

H.C. TD5102 44
R1(A)
A
A’
A’’
R2(A)
A
A’
Reuse tree
A
R1(A)
A’
A’’
R2(A)
A’
Step 3: determine data reuse trees for multiple accesses

H.C. TD5102 45
Assign all data reuse trees (multiple arrays) to memory hierarchy
A
R1(A)
A’
A’’
R2(A)
A’
R1(B)
B
B’
B’’
B’’’
Layer 1
Layer 2
Layer 3
A
R1(A)
A’
A’’
R2(A)
A’
R1(B)
B
B’
B’’’

H.C. TD5102 46
Step 4: Determine number of layers
B
B'
FG
A
A'
FG
Data reusetrees A
Data reusetrees B
FG
Hierarchylayers
Layer1
Layer2
Layer3
Foreground mem.Datapath

H.C. TD5102 47
Step 5: Select and assign reuse candidates
A
A'
FG
FG
Data reusetrees
Hierarchylayers
hierarchy assignments
FG
A
A'
1
FG
A
A'
2
FG
A
A'
3
FG
A
A
4
FG
A
5
FG
all
H.C. TD5102 48
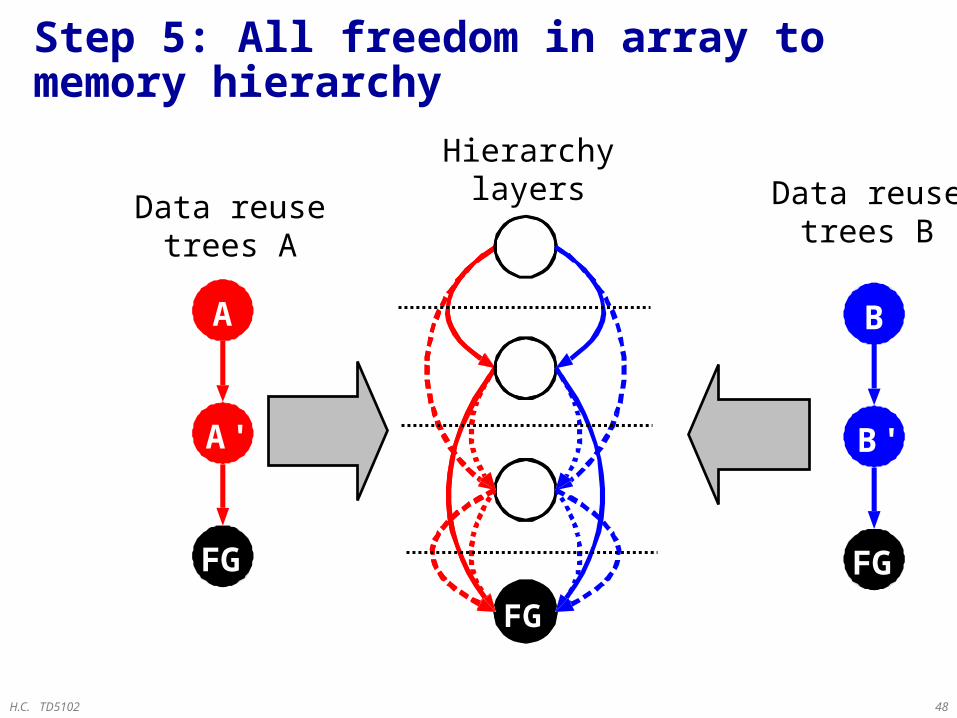
Step 5: All freedom in array to memory hierarchy
A
A'
FG
Data reusetrees A
Hierarchylayers
B
B'
FG
Data reusetrees B
FGFG

H.C. TD5102 49
Step 5: Prune reuse graph (platform independent)
Hierarchy layersFull freedom
FG FG
Hierarchy layersPruned
Quite some solutions never make sense

H.C. TD5102 50
Step 5: Prune reuse graph further (platform dependent)
FG
Hierarchy layersPruned
FG
Final solution4 layer platform
A
B
B'
A'
FG
Final solution4 layer platform

H.C. TD5102 51
int in[H][W+8], out[H][W];const int c[] = {1,0,1,2,2,1,0,1};for (r=0; r < H; r++) for (c=0; c < W; c++) for (dc=0; dc < 8; dc++) out[r][c] += in[r][c+dc]*c[dc];
int in[H][W+8], out[H][W], buf[8];const int c[] = {1,0,1,2,2,1,0,1};for (r=0; r < H; r++) for (i=0; i<7; i++) buf[i]=in[r][i]; for (c=0; c < W; c++) buf[(c+7)%8] = in[r][c+7]; for (dc=0; dc < 8; dc++) out[r][c] += buf[(c+dc)%8]*c[dc];
Introducing 1D reuse buffer
Reuse Factor =7
intermediatelevel decl.
additional copy
initial copy
reread from buffer

H.C. TD5102 52
Data Reuse on 1D horizontal convolutionHow to make explicit copies?
initbuffer
reusedata
newdata
Image NxM, traversed row order

H.C. TD5102 53
Introducing line buffers for vertical filtering
whole image
size[N][M]
set of lines [2GB+1]
Why keep the whole image in that case?
[N]

H.C. TD5102 54
Simplified “reuse script”
1. Identify arrays with sufficient reuse potential
2. Determine reuse chains and prune these
(for every array read)
3. Determine reuse trees and prune these
(for every array)
4. Determine reuse graph including bypasses and
prune (for entire application)
5. Determine memory hierarchy layout assignment incorporating given background memory restrictions (layers) and real-time constraints
6. Introduce copies in code: init, update, use code For scratchpad memories only For caches we need a different approach

H.C. TD5102 55
Data re-use trees: cavity detector
N*M
N*1
3*1
image_in
N*3
1*3
gauss_x
N*3
3*3
gauss_xy/comp_edge
N*3
1*1
N*M*3
N*M
N*M N*M*3
N*M*3
N*M*3 N*M
N*M
image_out
0
N*M*8 N*M*8
CPU CPUCPU CPU CPU
Array reads: Array write:

H.C. TD5102 56
Memory hierarchy assignment: cavity detector
N*M
3*1
image_in
N*3
gauss_x gauss_xy comp_edgeimage_out
3*3 1*1 3*3 1*1
L2
N*M
N*M*3 N*M*3 N*M
N*M
0
N*M*3 N*M
N*M*3 N*M*8 N*M*8 N*M*8 N*M*8
N*3 N*3
L3
L1
1MB
SDRAM
16KB
Cache
128 B
RegFile

H.C. TD5102 57
Data reuse & memory hierarchy
0
100
200
300
400
500
600
accesses size cycles
Original
DF trafo
Loop trafo
Data reuse





























