Embed Size (px)
Citation preview

Emotion Related Structures in Large Image Databases
Martin SolliITN, Linköping University
SE-60174 Norrköping, [email protected]
Reiner LenzITN, Linköping University
SE-60174 Norrköping, [email protected]
ABSTRACTWe introduce two large databases consisting of 750 000 and1.2 million thumbnail-sized images, labeled with emotion-related keywords. The smaller database consists of imagesfrom Matton Images, an image provider. The larger databaseconsists of web images that were indexed by the crawler ofthe image search engine Picsearch. The images in the Pic-search database belong to one of 98 emotion related cate-gories and contain meta-data in the form of secondary key-words, the originating website and some view statistics. Weuse two psycho-physics related feature vectors based on theemotional impact of color combinations, the standard RGB-histogram and two SIFT-related descriptors to character-ize the visual properties of the images. These features arethen used in two-class classification experiments to explorethe discrimination properties of emotion-related categories.The clustering software and the classifiers are available inthe public domain, and the same standard configurationsare used in all experiments. Our findings show that for emo-tional categories, descriptors based on global image statistics(global histograms) perform better than local image descrip-tors (bag-of-words models). This indicates that content-based indexing and retrieval using emotion-based approachesare fundamentally different from the dominant object- recog-nition based approaches for which SIFT-related features arethe standard descriptors.
Categories and Subject DescriptorsH.3.1 [Information Storage and Retrieval]: ContentAnalysis and Indexing—Indexing methods; I.4.9 [Image Pro-cessing and Computer Vision]: Applications
General TermsTheory, Experimentation
KeywordsImage databases, image indexing, emotions
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.CIVR ’10, July 5-7, Xi’an, ChinaCopyright c©2010 ACM 978-1-4503-0117-6/10/07 ...$10.00.
1. INTRODUCTIONMost available systems for image classification and Con-
tent Based Image Retrieval are focused on object and scenerecognition. Typical tasks are classifying or finding imagescontaining vehicles, mountains, animals, faces, etc. (see forinstance Liu et al. [20] for an overview). In recent years,however, the interest in classification and retrieval methodsincorporating emotions and aesthetics has increased. In asurvey by Datta et al. [8], the subject is listed as one of theupcoming topics in Content Based Image Retrieval.
The main question dealt with in this paper is whether it ispossible to use simple statistical measurements, for instanceglobal image histograms, to classify images in categories re-lated to emotions and aesthetics? We compare the imagedatabase from an Internet search service provider, whereimages and meta-data are crawled from the Internet (thisdatabase is made available for the research community),with a database from an image provider, where images areselected and categorized by professionals. This leads us toour second question: Is there a difference between classifica-tion in databases collected from the Internet, and databasesused by professionals? Can we increase the performance onthe Internet database by training a supervised learning al-gorithm on the professional database? In our experimentswe compare five different image descriptors, where four ofthem incorporates color information. Three descriptors arebased on global image histograms, and two are bag-of-wordsstrategies, where the descriptors are histograms derived forlocal image patches. Standard tools are used for clusteringin the feature space (if needed), and for building the classifi-cation model by supervised learning. Earlier attempts havebeen made in comparing global and local image descriptors(recently by Douze et al. [12], and van de Sande et al. [28]),but not in an emotion context.
A general problem with investigations involving emotionsand aesthetics is the lack of ground truth. The conceptsof emotions and aesthetics is influenced by many factors,such as perception, cognition, culture, etc. Even if researchhas shown that people in general perceive color emotions insimilar ways, some individuals may have different opinions.The most obvious example is people who have a reducedcolor sensitivity. Moreover, since our predictions are mainlybased on color content, it is, of course, possible to find im-ages with other types of content, for instance objects in thescene, that are the cause of the perceived emotions. Con-sequently, we cannot expect a correct classification resultfor every possible image, or a result that will satisfy everypossible user.

Finally, we emphasize that this paper is mainly addressingvisual properties within image databases, and not linguisticproperties. Moreover, the term high-level semantics refers toemotional and aesthetical properties, and we use keywordsin English (or American English) in all investigations.
2. RELATED WORKEven if the interest for image emotions and aesthetics
has increased, relatively few papers are addressing the prob-lem of including those topics in image indexing. Papers byBerretti et al. [1], and Corridoni et al. [6][5], were amongthe earliest in this research field. They used clustering inthe CIELUV color space, together with a modified k-meansalgorithm, for segmenting images into homogenous color re-gions. Then fuzzy sets are used to convert intra-region prop-erties (warmth, luminance, etc.), and inter-region properties(hue, saturation, etc.), to a color description language. Asimilar method is proposed by Wang and Yu [30]. Cho andLee [3] present an approach where features are extractedfrom wavelets and average colors. Hong and Choi [14] pro-pose a search scheme called FMV (Fuzzy Membership Value)Indexing, which allow users to retrieve images based on high-level keywords, such as ”soft”, ”romantic” etc. Emotion con-cepts are derived using the HSI color space.
We mention three papers that to some extent incorporatepsychophysical experiments in the image retrieval model.Yoo [32] proposes a method using descriptors called querycolor code and query gray code, which are based on hu-man evaluation of color patterns on 13 emotion scales. Thedatabase is queried with one of the emotions, and a feedbackmechanism is used for dynamically updating the search re-sult. Lee et al. [17] present an emotion-based retrieval sys-tem based on rough set theory. They use category scalingexperiments, where observers judge random color patternson three emotion scales. Intended applications are primarilywithin indexing of wall papers etc. Wang et al. [31] identifyan orthogonal three-dimensional emotion space, and designthree emotion factors. From histogram features, emotionalfactors are predicted using a Support Vector Machine. Themethod was developed and evaluated for artwork.
Datta et al. [7][9] use photos from a photo sharing webpage, peer-rated in two qualities, aesthetics and originality.Visual or aesthetical image features are extracted, and therelationship between observer ratings and extracted featuresare explored through Support Vector Machines and classifi-cation trees. The primary goal is to build a model that canpredict the quality of an image. In [10], Datta et al. discussthe future possibilities in inclusion of image aesthetics andemotions in, for instance, image classification.
Within color science, research on color emotions, espe-cially for single colors and two-color combinations, has beenan active research field for many years. Such experimentsusually incorporate observer studies, and are often carriedout in controlled environments. See [21][22][23][13][16] fora few examples. The concept of harmony has also been in-vestigated in various contexts. See for instance Cohen-Or etal. [4], where harmony is used to beautify images.
Labeling and search strategies based on emotions have notyet been used in commercial search engines, with one excep-tion, the Japanese emotional visual search engine EVE1.
1http://amanaimages.com/eve/, with Japanese documenta-tion and user interface
3. IMAGE COLLECTIONSOur experiments are based on two different databases,
containing both images and meta-data, such as keywordsor labels. The first database is collected from the imagesearch engine2 belonging to Picsearch AB (publ). The sec-ond database is supplied by the image provider Matton Im-ages3. In the past 5-10 years, numerous large image databaseshave been made publicly available by the research com-munity (examples are ImageNet [11], CoPhIR [2], and thedatabase use by Torralba et al. [27]). However, most databasesare targeting objects and scenes, and very few are address-ing high-level semantics, such as emotions and aesthetics.To help others conducting research in this upcoming topicwithin image indexing, major parts of the Picsearch databaseare made available for public download.4
Picsearch: The Picsearch database contains 1.2 millionthumbnail images, with a maximum size of 128 pixels (heightor width). Original images were crawled from public webpages around March 2009, using 98 keywords related toemotions, like ”calm”, ”elegant”, ”provocative”, ”soft”, etc.Thumbnails were shown to users visiting the Picsearch im-age search engine, and statistics of how many times each im-age has been viewed and clicked during March through June2009 were recorded. The ratio between number of clicks andnumber of views (for images that have been viewed at least50 times) is used as a rough estimate of popularity. The cre-ation of the database is of course depending on how peopleare presenting images on their web-sites, and on the perfor-mance of the Picsearch crawler when interpreting the sites.A challenging but interesting aspect with images gatheredfrom the Internet is that images where labeled (indirect) by awide range of people, not knowing that their images and textwill be used in emotional image classification. The drawbackis that we cannot guarantee the quality of the data since im-ages and keywords have not been checked afterwards. Pic-search uses a ”family filter” for excluding non-appropriateimages, otherwise we can expect all kinds of material in thedatabase.
Matton: The Matton database is a subset of a commercialimage database maintained by Matton Images in Stockholm,Sweden. Our database contains 750 000 images. Each imageis accompanied with a set of keywords, assigned by profes-sionals. Even if images originate from different sources, weexpect the labeling in the Matton database to be more con-sistent than in the Picsearch database. But we don’t knowhow the professionals choose the high-level concepts whenlabeling the images. To match the Picsearch database, allimages are scaled to a maximum size of 128 pixels.
3.1 Data Sets for Training and TestingThe Picsearch database was created from 98 keywords
which are related to emotions. To illustrate two-categoryclassification, we selected pairs of keywords that representsopposing emotional properties, like vivid-calm. The experi-ments are done with the 10 pairs of keywords given in Ta-ble 1. Opposing emotions were selected based on an intu-itive feeling. In upcoming research, however, a linguist or
2http://www.picsearch.com/3http://www.matton.com/4http://diameter.itn.liu.se/emodb/

Table 1: The Keyword Pairs Used in the Experi-ments, Representing Opposing Emotion Properties.
1: calm-intense 6: formal-vivid2: calm-vivid 7: intense-quiet3: cold-warm 8: quiet-wild4: colorful-pure 9: soft-spicy5: formal-wild 10: soft-vivid
psychologist can be involved to establish the relevance ofeach selected pair. For keyword k we extract subsets of thePicsearch database, denoted Pi, and the Matton database,denoted Ma. Image number i, belonging to the keywordsubset k, is denoted Pi(k, i) and Ma(k, i) respectively.
Picsearch subsets: All images in each category Pi(k, :)are sorted based on the popularity measurement describedearlier in this section. A category subset is created, contain-ing 2000 images: The 1000 most popular images, saved inPi(k, 1, ..., 1000), and 1000 images randomly sampled fromthe remaining ones, saved in Pi(k, 1001, ..., 2000).
Matton subsets: Since we do not have a popularity mea-surement for the Matton database, only 1000 images areextracted and indexed in Ma(k, 1, ..., 1000) using each key-word k as query. For the following two categories, the queryresulted in less than 1000 images; intense: 907 images, spicy :615 images.
We divide each image category into one training and onetest set, where every second image, i = 1 : 2 : end, is usedfor training, and remaining ones, i = 2 : 2 : end, are used fortesting. If one of the categories contains fewer images thanthe other (occurs when working with categories intense orspicy from the Matton database, or when we mix data fromthe two databases), the number of images in the opposingcategory is reduced to the same size by sampling the subset.
4. IMAGE DESCRIPTORSThe selection of image descriptors is a fundamental prob-
lem in computer vision and image processing. State-of-the-art solutions in object and scene classification often involvebag-of-features models (also known as bag-of-words mod-els), where interest points, for instance corners or local max-ima/minima, are detected in each image. The characteris-tics for a patch surrounding each interest point is saved ina descriptor, and various training methods can be used forfinding relationships between descriptor content and cate-gories belonging to specified objects or scenes.
Finding interest points corresponding to corners etc. workswell in object and scene classification, but using the same de-scriptors in classification of emotional and aesthetical prop-erties can be questioned. Instead, we assume that the overallappearance of the image, especially the color content, playsan important role. Consequently, we focus our initial ex-periments on global image descriptors, like histograms. Arelated approach that is assumed to be useful in emotionalclassification is to classify the image based on homogeneousregions, and transitions between regions, as proposed in [26].
We select three different global histogram descriptors inour experiments. For comparison, we also include two im-plementations of traditional bag-of-words models, where the
descriptors are histograms for image patches correspondingto found interest points. Other image descriptors could alsobe used, but a comprehensive comparison between differentdescriptors is beyond the scope of this initial study. Listedbelow are the five image descriptors:
RGB-histogram: We choose the commonly used 512 binsRGB-histogram, where each color channel is quantized into8 equally sized bins.
Emotion-histogram: A descriptor proposed in [25], where512 bins RGB-histograms are transformed to 64 bins emotion-histogram. A kd-tree decomposition is used for mappingbins from the RGB-histogram to a three-dimensional emo-tion space, spanned by three emotions related to human per-ception of colors. The three emotions incorporate the scales:warm-cool, active-passive, and light-heavy. The color emo-tion metric used originates from perceptual color science,and was derived from psychophysical experiments by Ou etal. [21][22][23]. The emotion metric was originally designedfor single colors, and later extended to include pairs of col-ors. In [25], the model was extended to images, and used inimage retrieval. A general description of an emotion metricis a set of equations that defines the relationship betweena common color space (for instance CIELAB), and a spacespanned by emotion factors. A set of emotion factors areusually derived in psychophysical experiments.
Bag-of-Emotions: This is a color-based emotion-relatedimage descriptor, described in [26]. It is based on the sameemotion metric as in the emotion-histogram mentioned above.For this descriptor, the assumption is that perceived coloremotions in images are mainly affected by homogenous re-gions, defined by the emotion metric, and transitions be-tween regions. RGB coordinates are converted to emotioncoordinates, and for each emotion channel, statistical mea-surements of gradient magnitudes within a stack of low-passfiltered images are used for finding interest points corre-sponding to homogeneous regions and transitions betweenregions. Emotion characteristics are derived for patchessurrounding each interest point, and contributions from allpatches are saved in a bag-of-emotions, which is a 112 binshistogram. Notice that the result is a single histogram de-scribing the entire image, and not a set of histograms (orother descriptors) as in ordinary bag-of-features models.
SIFT: Scale Invariant Feature Transform, is a standard toolin computer vision and image processing. Here we use aSIFT implementation by Andrea Vedaldi5, both for detect-ing interest points, and for computing the descriptors. Theresult is a 128 bins histogram for each interest point.
Color descriptor: The color descriptor proposed by Weijerand Schmid [29] is an extension to SIFT, where photometricinvariant color histograms are added to the original SIFTdescriptor. Experiments have shown that the color descrip-tor can outperform similar shape-based approaches in manymatching, classification, and retrieval tasks.
In the experimental part of the paper, the above descrip-tors are referred to as ”RGB”, ”ehist”, ”ebags”, ”SIFT”, and
5http://www.vlfeat.org/∼vedaldi/

”cdescr”. For SIFT and the Color descriptor, individual de-scriptors are obtained for each interest point found. Theaverage number of found interest points per image, in thePicsearch and Matton database respectively, are 104 and115. The difference originates from a difference in image size.It is possible to find images smaller than 128 pixels in thePicsearch database, whereas such images are not present inthe Matton database. The number of found interest pointsis believed to be sufficient for the intended application. Acommon approach in bag-of-words models is to cluster thedescriptor space (also known as codebook generation), andby vector quantization obtain a histogram that describesthe distribution over cluster centers (the distribution overcodewords). We use k-means clustering, with 500 clusters,and 10 iterations, each with a new set of initial centroids.Cluster centers are saved for the iteration that returns theminimum within-cluster sums of point-to-centroid distances.Clustering is carried out in each database separately, with1000 descriptors randomly collected from each of the 12 cat-egories used in the experiments. State of the art solutions inimage classification are often using codebooks of even greatersize. But since we use thumbnail images, where the numberof found interest points is relatively low, we find it appro-priate to limit the size to 500 cluster centers. Preliminaryexperiments with an increased codebook size did not resultin increased performance.
4.1 Dimensionality ReductionFor many types of image histograms, the information in
the histograms are quite similar in general; therefore his-tograms can be described in a lower dimensional subspace,with only minor loss in discriminative properties (see for in-stance Lenz and Latorre-Carmona [18]). There are two ad-vantages of reducing the number of bins in the histograms:1) Storage and computational savings. 2) Easier comparisonbetween methods when the number of dimensions are thesame. We use Principal Component Analysis (or Karhunen-Loeve expansion) to reduce the number of dimensions, leav-ing dimensions with highest variance.
5. CLASSIFICATION METHODSWith images separated into opposing emotion pairs, the
goal is to predict which emotion an unlabeled image shouldbelong to. A typical approach is to use some kind of super-vised learning algorithm. Among common methods we findSupport Vector Machines, the Naive Bayes classifier, Neu-ral Networks, and Decision tree classifiers. In this work weutilize a Support Vector Machine, SVMlight, by ThorstenJoachims [15]. For simplicity and reproducibility reasons,all experiments are carried out with default settings, which,for instance, means that we use a linear kernel function.
5.1 Probability EstimatesMost supervised learning algorithms produce classification
scores that can be used for ranking examples in the testset. However, in some situations, it might be more usefulto obtain an estimate of the probability that each examplebelongs to the category of interest. Various methods havebeen proposed in order to find these estimates. We adopt amethod proposed by Lin et al. [19], which is a modificationof a method proposed by Platt [24].
The basic idea is to estimate the probability using a sig-moid function. Given training examples xi ∈ Rn, with cor-
responding labels yi ∈ {−1, 1}, and the decision functionf(x) of the SVM. The category probability Pr(y = 1|x) canbe approximated by the sigmoid function
Pr(y = 1|x) =1
1 + exp(Af(x) + B)(1)
where A and B are estimated by solving
min(A,B)
{−l∑
i=1
(ti log(pi) + (1− ti) log(1− pi))} (2)
for
pi =1
1 + exp(Af(xi) + B), and ti =
{Np+1
Np+2if yi = 1
1Nn+2
if yi = −1
(3)where Np and Nn are the number of examples belong to thepositive and negative category respectively.
5.2 Probability ThresholdWhen working with emotions and aesthetics, it is hard to
define the ground truth, especially for images lying close tothe decision plane. We can refer to these images as ”neutral”,or images that belong to neither of the keywords. Since ourdatabases, especially the Picsearch database, contain dataof varying quality, we suspect that a large portion of theimages might belong to a ”neutral” category. By defininga probability threshold t, we only classify images with aprobability estimate pi that lies above or below the interval{0.5 − t ≤ pi ≤ 0.5 + t}. Images with probability estimateabove the threshold, pi ∈ {pi|pi > 0.5 + t}, are assigned tothe positive category, and images with probability estimatebelow the threshold, pi ∈ {pi|pi < 0.5 − t}, belong to thenegative category. This method is only applicable when theintended application allows an exclusion of images from thetwo-category classification. On the other hand, for imagesreceiving a label, the accuracy will in most cases increase.Moreover, a probability threshold can be useful if we applythe method on a completely unknown image, where we don’tknow if the image should belong to one of the keywords.
6. EXPERIMENTSIn all experiments, the classification accuracy is given by
the proportion of correctly labeled images. A figure of, forinstance, 0.8, means that a correct label was predicted for80% of the images in the test set.
6.1 Classification StatisticsThe result of two-category classifications in the Picsearch
and Matton database respectively can be seen in Table 2and Table 3. Here we use the default descriptor sizes: 512bins for the RGB-histograms, 64 bins for the emotion his-togram, 112 bins for bags-of-emotions, and 500 bins (equalsthe codebook size) for bag-of-features models using SIFTor Color descriptor. We notice that the classification accu-racy varies between keyword pairs and descriptors. Higheraccuracy is usually obtained for keyword pairs 4 (colorful-pure), 5 (formal-wild), 6 (formal-vivid), and 9 (soft-spicy),whereas pairs 1 (calm-intense), 3 (cold-warm), and 10 (soft-vivid) perform poorer. The three models based on globalhistograms perform better than bag-of-features models us-ing region-based histograms. Moreover, the classificationaccuracy is increased when the Matton database is used.
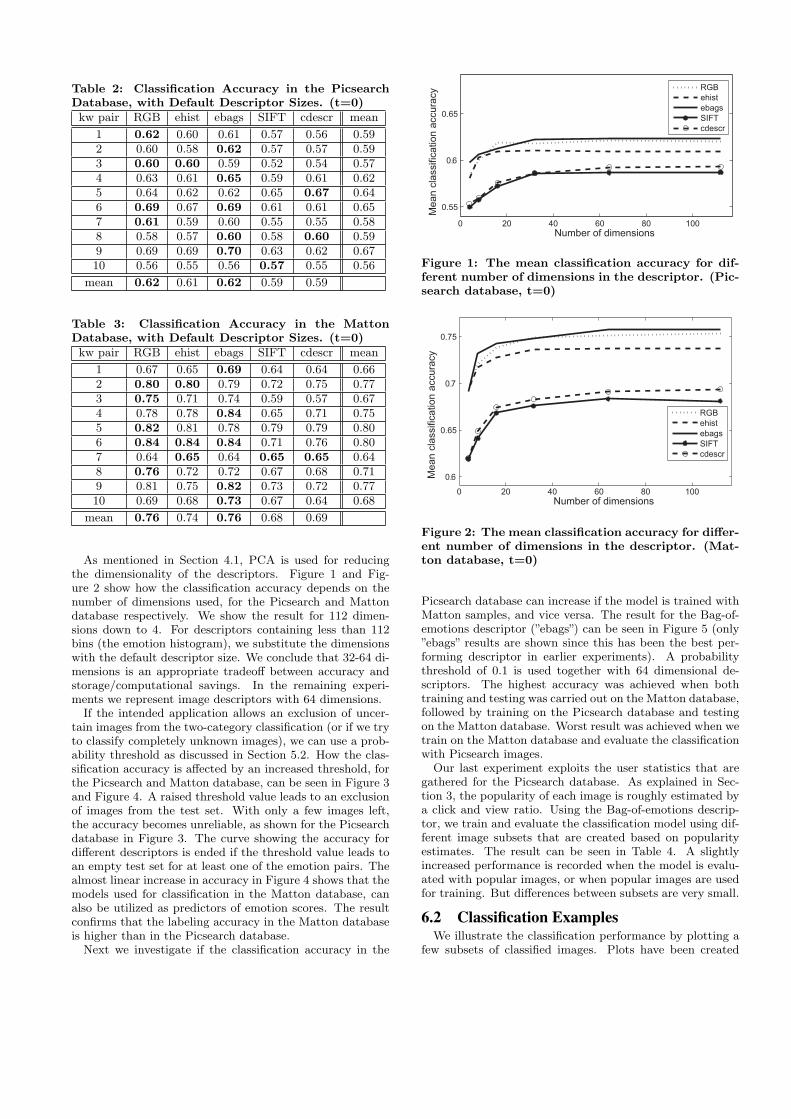
Table 2: Classification Accuracy in the PicsearchDatabase, with Default Descriptor Sizes. (t=0)kw pair RGB ehist ebags SIFT cdescr mean
1 0.62 0.60 0.61 0.57 0.56 0.592 0.60 0.58 0.62 0.57 0.57 0.593 0.60 0.60 0.59 0.52 0.54 0.574 0.63 0.61 0.65 0.59 0.61 0.625 0.64 0.62 0.62 0.65 0.67 0.646 0.69 0.67 0.69 0.61 0.61 0.657 0.61 0.59 0.60 0.55 0.55 0.588 0.58 0.57 0.60 0.58 0.60 0.599 0.69 0.69 0.70 0.63 0.62 0.6710 0.56 0.55 0.56 0.57 0.55 0.56
mean 0.62 0.61 0.62 0.59 0.59
Table 3: Classification Accuracy in the MattonDatabase, with Default Descriptor Sizes. (t=0)kw pair RGB ehist ebags SIFT cdescr mean
1 0.67 0.65 0.69 0.64 0.64 0.662 0.80 0.80 0.79 0.72 0.75 0.773 0.75 0.71 0.74 0.59 0.57 0.674 0.78 0.78 0.84 0.65 0.71 0.755 0.82 0.81 0.78 0.79 0.79 0.806 0.84 0.84 0.84 0.71 0.76 0.807 0.64 0.65 0.64 0.65 0.65 0.648 0.76 0.72 0.72 0.67 0.68 0.719 0.81 0.75 0.82 0.73 0.72 0.7710 0.69 0.68 0.73 0.67 0.64 0.68
mean 0.76 0.74 0.76 0.68 0.69
As mentioned in Section 4.1, PCA is used for reducingthe dimensionality of the descriptors. Figure 1 and Fig-ure 2 show how the classification accuracy depends on thenumber of dimensions used, for the Picsearch and Mattondatabase respectively. We show the result for 112 dimen-sions down to 4. For descriptors containing less than 112bins (the emotion histogram), we substitute the dimensionswith the default descriptor size. We conclude that 32-64 di-mensions is an appropriate tradeoff between accuracy andstorage/computational savings. In the remaining experi-ments we represent image descriptors with 64 dimensions.
If the intended application allows an exclusion of uncer-tain images from the two-category classification (or if we tryto classify completely unknown images), we can use a prob-ability threshold as discussed in Section 5.2. How the clas-sification accuracy is affected by an increased threshold, forthe Picsearch and Matton database, can be seen in Figure 3and Figure 4. A raised threshold value leads to an exclusionof images from the test set. With only a few images left,the accuracy becomes unreliable, as shown for the Picsearchdatabase in Figure 3. The curve showing the accuracy fordifferent descriptors is ended if the threshold value leads toan empty test set for at least one of the emotion pairs. Thealmost linear increase in accuracy in Figure 4 shows that themodels used for classification in the Matton database, canalso be utilized as predictors of emotion scores. The resultconfirms that the labeling accuracy in the Matton databaseis higher than in the Picsearch database.
Next we investigate if the classification accuracy in the
0 20 40 60 80 100
0.55
0.6
0.65
Number of dimensions
Me
an
cla
ssific
atio
n a
ccu
racy
RGB
ehist
ebags
SIFT
cdescr
Figure 1: The mean classification accuracy for dif-ferent number of dimensions in the descriptor. (Pic-search database, t=0)
0 20 40 60 80 100
0.6
0.65
0.7
0.75
Number of dimensions
Me
an
cla
ssific
atio
n a
ccu
racy
RGB
ehist
ebags
SIFT
cdescr
Figure 2: The mean classification accuracy for differ-ent number of dimensions in the descriptor. (Mat-ton database, t=0)
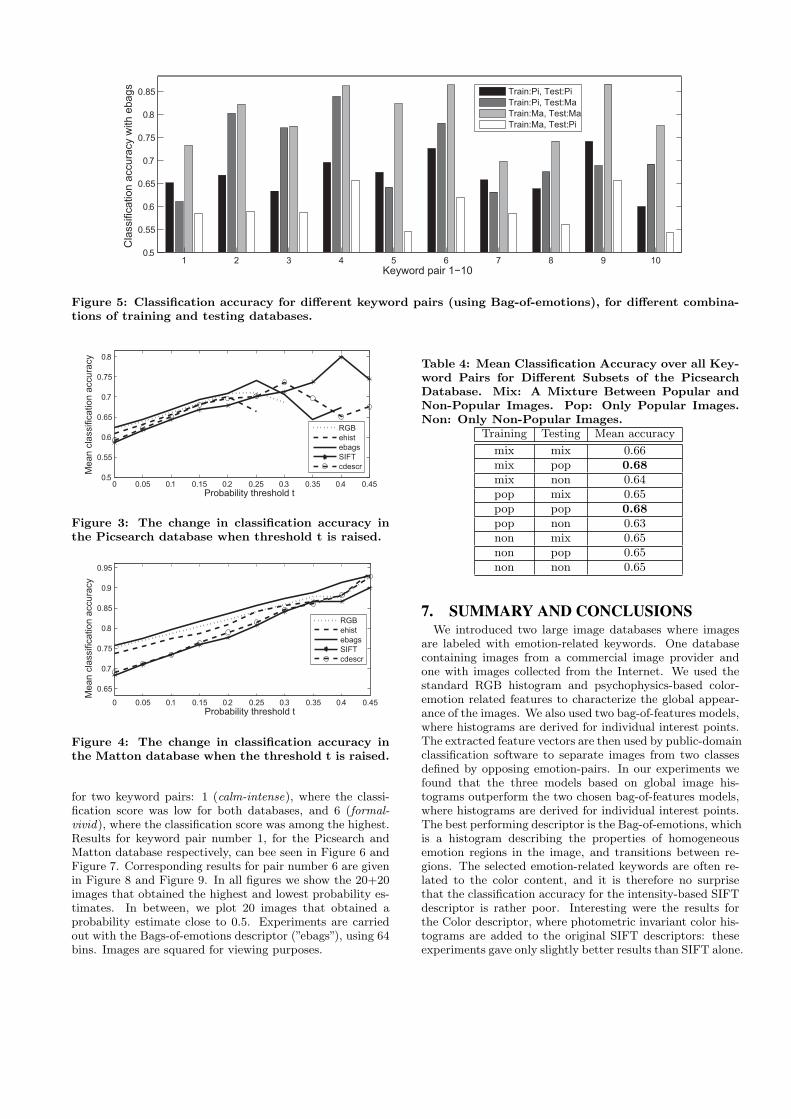
Picsearch database can increase if the model is trained withMatton samples, and vice versa. The result for the Bag-of-emotions descriptor (”ebags”) can be seen in Figure 5 (only”ebags” results are shown since this has been the best per-forming descriptor in earlier experiments). A probabilitythreshold of 0.1 is used together with 64 dimensional de-scriptors. The highest accuracy was achieved when bothtraining and testing was carried out on the Matton database,followed by training on the Picsearch database and testingon the Matton database. Worst result was achieved when wetrain on the Matton database and evaluate the classificationwith Picsearch images.
Our last experiment exploits the user statistics that aregathered for the Picsearch database. As explained in Sec-tion 3, the popularity of each image is roughly estimated bya click and view ratio. Using the Bag-of-emotions descrip-tor, we train and evaluate the classification model using dif-ferent image subsets that are created based on popularityestimates. The result can be seen in Table 4. A slightlyincreased performance is recorded when the model is evalu-ated with popular images, or when popular images are usedfor training. But differences between subsets are very small.
6.2 Classification ExamplesWe illustrate the classification performance by plotting a
few subsets of classified images. Plots have been created
1 2 3 4 5 6 7 8 9 100.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
Keyword pair 1−10
Cla
ssific
ation a
ccura
cy w
ith e
bags
Train:Pi, Test:Pi
Train:Pi, Test:Ma
Train:Ma, Test:Ma
Train:Ma, Test:Pi
Figure 5: Classification accuracy for different keyword pairs (using Bag-of-emotions), for different combina-tions of training and testing databases.
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.450.5
0.55
0.6
0.65
0.7
0.75
0.8
Probability threshold t
Me
an
cla
ssific
atio
n a
ccu
racy
RGB
ehist
ebags
SIFT
cdescr
Figure 3: The change in classification accuracy inthe Picsearch database when threshold t is raised.
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45
0.65
0.7
0.75
0.8
0.85
0.9
0.95
Probability threshold t
Mean c
lassific
ation a
ccura
cy
RGB
ehist
ebags
SIFT
cdescr
Figure 4: The change in classification accuracy inthe Matton database when the threshold t is raised.
for two keyword pairs: 1 (calm-intense), where the classi-fication score was low for both databases, and 6 (formal-vivid), where the classification score was among the highest.Results for keyword pair number 1, for the Picsearch andMatton database respectively, can bee seen in Figure 6 andFigure 7. Corresponding results for pair number 6 are givenin Figure 8 and Figure 9. In all figures we show the 20+20images that obtained the highest and lowest probability es-timates. In between, we plot 20 images that obtained aprobability estimate close to 0.5. Experiments are carriedout with the Bags-of-emotions descriptor (”ebags”), using 64bins. Images are squared for viewing purposes.
Table 4: Mean Classification Accuracy over all Key-word Pairs for Different Subsets of the PicsearchDatabase. Mix: A Mixture Between Popular andNon-Popular Images. Pop: Only Popular Images.Non: Only Non-Popular Images.
Training Testing Mean accuracy
mix mix 0.66mix pop 0.68mix non 0.64pop mix 0.65pop pop 0.68pop non 0.63non mix 0.65non pop 0.65non non 0.65
7. SUMMARY AND CONCLUSIONSWe introduced two large image databases where images
are labeled with emotion-related keywords. One databasecontaining images from a commercial image provider andone with images collected from the Internet. We used thestandard RGB histogram and psychophysics-based color-emotion related features to characterize the global appear-ance of the images. We also used two bag-of-features models,where histograms are derived for individual interest points.The extracted feature vectors are then used by public-domainclassification software to separate images from two classesdefined by opposing emotion-pairs. In our experiments wefound that the three models based on global image his-tograms outperform the two chosen bag-of-features models,where histograms are derived for individual interest points.The best performing descriptor is the Bag-of-emotions, whichis a histogram describing the properties of homogeneousemotion regions in the image, and transitions between re-gions. The selected emotion-related keywords are often re-lated to the color content, and it is therefore no surprisethat the classification accuracy for the intensity-based SIFTdescriptor is rather poor. Interesting were the results forthe Color descriptor, where photometric invariant color his-tograms are added to the original SIFT descriptors: theseexperiments gave only slightly better results than SIFT alone.

calm
intense
neutral
Figure 6: Classification examples for keyword paircalm-intense, using the Picsearch database.
calm
intense
neutral
Figure 7: Classification examples for keyword paircalm-intense, using the Matton database.
The Picsearch database contains images and meta-datacrawled from the Internet, whereas the images in the databasefrom Matton are labeled by professionals (although the key-words vary depending on the original supplier of the images).As expected, the highest classification accuracy was achievedfor the Matton database. In general, a high accuracy is ob-tained when training and testing is carried out on imagesfrom the same database source. However, we notice thatthe accuracy decreases considerably when we train on theMatton database, and test on the Picsearch database, com-pared to the opposite. A probable explanation is that thePicsearch database is much more diverse (various images, in-consistent labeling, etc.) than the Matton database. Whentraining is conducted on the Matton database we obtain aclassifier that is highly suitable for that type of image source,but presumably not robust enough to capture the diversityof the Picsearch database. Hence, if we want a robust clas-sification of images from an unknown source, the classifiertrained on the Picsearch database might be preferred.
An unexpected conclusion is that the use of popular andnon-popular images in the Picsearch database could not sig-nificantly influence the performance. One conclusion couldbe that the popularity of an image depends less on its visualfeatures, and more on the context. The relations betweenthe visual content and the emotional impact of an image arevery complicated and probably depending on a large number
formal
vivid
neutral
Figure 8: Classification examples for keyword pairformal-vivid, using the Picsearch database.
formal
vivid
neutral
Figure 9: Classification examples for keyword pairformal-vivid, using the Matton database.
of different factors. This is why we proposed a probabilitythreshold on the SVM output. This means that we shouldavoid classifying images that receives a probability estimateclose to 0.5 (in middle between to emotions). Instead, theseimages can be assigned to a ”neutral” category. We believethis is a way to increase the acceptance of emotions andaesthetics among end-users in daily life search experiments.
8. FUTURE WORKThe experiments reported in this paper are only a first at-
tempt in exploring the internal structure of these databases.The results show that the way the databases were constructedlead to profound differences in the statistical properties ofthe images contained in them. The Picsearch database isdue to the larger variations much more challenging. In theseexperiments we selected those opposing keyword categorieswhere the keywords of the different categories also have a vi-sual interpretation. Images in other categories (like funny)are probably even more visually diverse. Further studies arealso needed to investigate if the visual properties are some-how related to the visual content. Classification into oppo-site categories is one of the easiest approaches to explore thestructure of the database. Others like clustering and multi-class classifications are other obvious choices. Also differentfeature extraction methods suitable for large-scale databaseshave to be investigated.

9. ACKNOWLEDGMENTSPresented research is included in the project Visuella Varl-
dar, financed by the Knowledge Foundation, Sweden. Pic-search AB (publ) and Matton images, Stockholm (Sweden),are gratefully acknowledged for their contributions.
10. REFERENCES[1] S. Berretti, A. Del Bimbo, and P. Pala. Sensations and
psychological effects in color image database. IEEE IntConf on Image Proc, 1:560–563, Santa Barbara, 1997.
[2] P. Bolettieri, A. Esuli, F. Falchi, C. Lucchese,R. Perego, T. Piccioli, and F. Rabitti. CoPhIR: A testcollection for content-based image retrieval.arXiv:0905.4627v2, 2009.
[3] S.-B. Cho and J.-Y. Lee. A human-oriented imageretrieval system using interactive genetic algorithm.IEEE Trans Syst Man Cybern Pt A Syst Humans,32(3):452–458, 2002.
[4] D. Cohen-Or, O. Sorkine, R. Gal, T. Leyvand, andY.-Q. Xu. Color harmonization. In ACM SIGGRAPH2006, 25:624–630, Boston, MA, 2006.
[5] J. Corridoni, A. Del Bimbo, and P. Pala. Imageretrieval by color semantics. Multimedia Syst,7(3):175–183, 1999.
[6] J. Corridoni, A. Del Bimbo, and E. Vicario. Imageretrieval by color semantics with incompleteknowledge. JASIS, 49(3):267–282, 1998.
[7] R. Datta, D. Joshi, J. Li, and J. Wang. Studyingaesthetics in photographic images using acomputational approach. In 9th Eu Conf on ComputerVision, ECCV 2006, 3953:288–301, Graz, 2006.
[8] R. Datta, D. Joshi, J. Li, and J. Wang. Imageretrieval: Ideas, influences, and trends of the new age.ACM Comput Surv, 40(2), 2008.
[9] R. Datta, J. Li, and J. Wang. Learning the consensuson visual quality for next-generation imagemanagement. In 15th ACM Int Conf on Multimedia,MM’07, p.533–536, Augsburg, 2007.
[10] R. Datta, J. Li, and J. Z. Wang. Algorithmicinferencing of aesthetics and emotion in naturalimages: An exposition. 15th IEEE Int Conf on ImProc, 2008. ICIP 2008., p.105–108, 2008.
[11] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, andL. Fei-Fei. Imagenet: A large-scale hierarchical imagedatabase. In CVPR09, 2009.
[12] M. Douze, H. Jegou, H. Sandhawalia, L. Amsaleg, andC. Schmid. Evaluation of GIST descriptors forweb-scale image search. In ACM Int Conf on Im andVideo Retr, CIVR 2009, p. 140-147, 2009.
[13] X.-P. Gao, J. Xin, T. Sato, A. Hansuebsai, M. Scalzo,K. Kajiwara, S.-S. Guan, J. Valldeperas, M. Lis, andM. Billger. Analysis of cross-cultural color emotion.Color Res Appl, 32(3):223–229, 2007.
[14] S. Hong and H. Choi. Color image semanticinformation retrieval system using human sensationand emotion. In Proceedings IACIS, VII, p. 140–145,2006.
[15] T. Joachims. Making large-scale support vectormachine learning practical. Advances in kernelmethods: support vector learning, p. 169–184,Cambridge, USA 1999.
[16] S. Kobayashi. Color Image Scale. Kodansha Intern.,1991.
[17] J. Lee, Y.-M. Cheon, S.-Y. Kim, and E.-J. Park.Emotional evaluation of color patterns based on roughsets. In 3rd Intern Conf on Natural Computation,ICNC 2007, 1:140–144, Haikou, Hainan, 2007.
[18] R. Lenz, and P. Latorre-Carmona. HierarchicalS(3)-Coding of RGB Histograms. VISIGRAPP 2009,Communications in Computer and InformationScience, 68:188–200, 2010.
[19] H.-T. Lin, C.-J. Lin, and R. C. Weng. A note onplatt’s probabilistic outputs for support vectormachines. Mach. Learn., 68(3):267–276, 2007.
[20] Y. Liu, D. Zhang, G. Lu, and W.-Y. Ma. A survey ofcontent-based image retrieval with high-levelsemantics. Pattern Recogn., 40(1):262–282, 2007.
[21] L.-C. Ou, M. Luo, A. Woodcock, and A. Wright. Astudy of colour emotion and colour preference. part i:Colour emotions for single colours. Color Res Appl,29(3):232–240, 2004.
[22] L.-C. Ou, M. Luo, A. Woodcock, and A. Wright. Astudy of colour emotion and colour preference. part ii:Colour emotions for two-colour combinations. ColorRes Appl, 29(4):292–298, 2004.
[23] L.-C. Ou, M. Luo, A. Woodcock, and A. Wright. Astudy of colour emotion and colour preference. part iii:Colour preference modeling. Color Res Appl,29(5):381–389, 2004.
[24] J. C. Platt. Probabilistic outputs for support vectormachines and comparisons to regularized likelihoodmethods. In Advances in Large Margin Classifiers, p.61–74. MIT Press, 1999.
[25] M. Solli and R. Lenz. Color emotions for imageclassification and retrieval. In Proceedings CGIV 2008,p. 367–371, 2008.
[26] M. Solli and R. Lenz. Color based bags-of-emotions. InCAIP ’09: Proceedings of the 13th InternationalConference on Computer Analysis of Images andPatterns, p. 573–580, Berlin, Heidelberg, 2009.
[27] A. Torralba, R. Fergus, and W. T. Freeman. 80 milliontiny images: A large data set for nonparametric objectand scene recognition. IEEE Trans. Pattern Anal.Mach. Intell., 30(11):1958–1970, 2008.
[28] K. van de Sande, T. Gevers, and C. Snoek. Evaluatingcolor descriptors for object and scene recognition.IEEE Trans Pattern Anal Mach Intell (in print), 2009.
[29] J. van de Weijer and C. Schmid. Coloring local featureextraction. In European Conference on ComputerVision, II:334–348. Springer, 2006.
[30] W.-N. Wang and Y.-L. Yu. Image emotional semanticquery based on color semantic description. In Int Confon Mach Learn and Cybern, ICMLC 2005,p.4571–4576, Guangzhou, 2005.
[31] W.-N. Wang, Y.-L. Yu, and S.-M. Jiang. Imageretrieval by emotional semantics: A study of emotionalspace and feature extraction. In 2006 IEEE Int Confon Syst, Man and Cybern, 4:3534–3539, Taipei, 2007.
[32] H.-W. Yoo. Visual-based emotional descriptor andfeedback mechanism for image retrieval. J. Inf. Sci.Eng., 22(5):1205–1227, 2006.









![Decoupling Partitioning and Grouping: Overcoming ...hjs/pubs/samettods04.pdf · databases; spatial databases and GIS; E.1 [Data Structures]: Trees General Terms: Algorithms, Theory](https://img.pdfslide.net/doc/110x75/5f7421d4821859519824b9ef/decoupling-partitioning-and-grouping-overcoming-hjspubssamettods04pdf.jpg)










![Databases and Data Structures [Individual Assignment]](https://img.pdfslide.net/doc/110x75/577d2fdd1a28ab4e1eb2e89a/databases-and-data-structures-individual-assignment.jpg)







![SUBMISSION TO IEEE TRANSACTIONS ON IMAGE PROCESSING 1 … · B. Emotion Recognition Benchmarks Most databases that deal with emotion recognition [39]– [42] were recorded by color](https://img.pdfslide.net/doc/110x75/5e60adb5954db75cd94026d7/submission-to-ieee-transactions-on-image-processing-1-b-emotion-recognition-benchmarks.jpg)