Embed Size (px)
Citation preview

Empirical Analysis of Affix Removal Stemmers
Ms. Rupam Gupta
Assistant Professor,MCA Department
SVIT, Vasad
Gujarat Technological University
Dr. Anjali Ganesh Jivani
Head, Department of Computer Science &
Engineering
The M. S. University of Baroda
Abstract
This paper contains analysis of four different affix-
removal stemmers after empirically executing them on different text data. The stemmers were Porter, Lovins,
Paice and Krovetz-Stemmer. Each algorithm’s
individual step’s and its functionality shows how each
one identifies affix for removing and recoding the
words to generate stem term. The strength of individual
stemmer and computational time are also calculated
here. This paper also focuses on variation in stem
terms generation by these four stemmers from same
input data-set. All set of stem terms shown in this
paper, are created by execution of our comparative
stemming tool implemented in java using standard
input data-set.
Keywords: stemming, Index Compression Factor
(ICF), suffix, Porter, Lovins, Paice, Krovetz
Stemmer(KStemmer)
1. Introduction
English text is a collection of words including stop
words where many words used in the text, are
morphological variants of a single basic root word e.g.
dove/dive, acceptance/acceptable/accept, ability
/abilities [1]. Stemming techniques help to reduce different semantically similar variant forms of a single
root word into a single stem term. Stemming
algorithms are applicable in natural language text
analysis e.g. summarization, categorization and any
information retrieval search-engine. If the searcher is
entering query “symbol of maths”, Search Engine (SE)
displays “mathematical symbols”, “symbol in
mathematics”, “symbolic maths”. If query is
“competition in Bank exam”, SE displays “competitive
exam of bank”. So, stemming is beneficial for
decreasing size of index files used in IR. Instead of
storing individual word, single stem term for all
morphological variants of a single root word is stored
and hence compression factor of over 50 percent is
achieved. Efficiency of any stemming algorithm is
measured based on degree of closeness in-between
stem term and original root morpheme of the word
“word” which to be stemmed and computational time
taken by different stemmer. This paper is focused on
generation of large variety of stem words using various
affix removal stemmers for some DUC standard text, some set of morphed word list
(http://www.comp.lancs.ac.uk/computing/research/stem
ming/Links/resources.htm) and also on computational
time variation in-between different stemmers. In this
paper, we address the working process of each step of
four affix removal stemmers Porter, Lovins, Paice,
KStemmer using above mentioned text and word list
that depicts the variation in-between different
stemming rules. We are also computing Index
Compression Factor (ICF) of each affix removal
stemmer for individual document and also for different
set of morphed word variant of single root word. I CF
represents the difference between number of unique
words before stemming and after stemming. Greater
ICF value indicates better strength of stemmer [3].
N = Number of unique words before stemming S = Number of unique stems after stemming
ICF = Index Compression factor
ICF = (N-S)/N
2. Stemming Process
To get single term from different morphological
variants of a single root word, conflation technique is
needed. Conflation is a process through which set of
words are fused into one term. Conflation can be either
manual or automatic. Automated conflation is called as
Stemming.
Automated Conflation method is categorized into four
techniques. Categories are as follows-
Rupam Gupta et al, Int.J.Computer Technology & Applications,Vol 5 (2),393-399
IJCTA | March-April 2014 Available [email protected]
393
ISSN:2229-6093
Affix Removal, Successor Variety, Table Lookup, n-gram. Affix Removal is also sub-categorized into two
techniques, Longest Match and Simple Removal.
Affix removal methods eliminates suffixes or prefixes
from actual word to get a stem form. Affix Removal
Stemmer applies a set of transformation rule on each
word for eliminating known prefix or suffix.
J.B Lovins first introduced affix removal stemming
algorithm in 1968 [4]. Other affix removal algorithms
are introduced by Porter and Chris D. Paice in 1980 [5,
6, and 7]. Krovetz stemmer is also one prominent
stemmer that removes inflectional suffix, developed by
Bob Krovetz, at the University of Massachusetts, in
1993 [8].
3. Working methods of Stemmers
3.1 Porter Stemmer Porter stemmer contains six steps which check the
existence of different suffixes within a word and based
on the of type of suffix, each step applies their own
rule to generate stem term.
1st step gets rid of plurals endings with “–sses”, “-ies”,
“-s” and also recodes to generate stem word e.g. actresses->actress, abilities->abiliti, pennies->penni,
rats->rat. This step also removes endings “-ed” used in
past tense of any word and “-ing” of present continuous
e.g. abbreviated->abbriviat , assembling->assembl.
“assembl” term is recoded into “assemble” word using
“-bl into “-ble” recode conversion rule. “-at” ending is
recoded into “-ate” in “abbriviat” to “abbreviate”
conversion.
2nd
step recodes terminal „y‟ into „i‟ in presence of
another vowel in stem word e.g. “penny” is recoded
into “penni”. So “pennies” and “penny”, these two
words are conflated into single stem word “penni”.
”Pennies” word is converted into “penni” in step-1
using “-ies->i” suffix rule. “ability” word is recoded
into “abiliti” stem word in step-2, so “abilities” and
“ability” both are conflated into single “abiliti” stem
word. 3
rd step maps double suffices into single suffix and
recodes “-ational” ending into “–ate” ending / “-tional”
into ”-tion”/”-izer” into ”-ize” / “-ation” into ”-ate” / “-
fullness” into ”-full” etc. This step recodes
“application” word into “applicate”.
4th
step handles “-ic“, “-icate “, “-full”, “-ness” ended
words by removing and recoding endings for
generating stem words. “Applicate” stem word
generated in step-3 from “application” word, is
stemmed into “applic” final stem word using “-
icate”>”-ic” conversion rule.
5th
step removes “-ance”, “-er”, “-able”, “-ant”, “-iti” endings from word with context <c>vcvc<v>.
“Acceptance” and “acceptable” both words are
conflated into “accept” stem word by removing “-ance”
and “-able” suffix respectively. “Reporter” word is
conflated into “report” by eliminating “-er” ending.
“Reporting” word is also stemmed into “report” word
using “-ing” suffix rule in step-1. “Abiliti” generated
from “ability” and ”abilities” word in step-2/step-1, is
conflated into “abil” term by removing “-iti” ending in
step-5. So, “ability” and “abilities” are stemmed into a
single stem “abil”.
6th
step removes “-e” ending from any stem word.
“Assemble” word is conflated into “assembl” stem
word. So “assembling” and “assemble” words are
conflated into same stem word “assembl”.
So porter stemmer is not using any stem-dictionary. It
only uses list of endings to be removed and list of
conversion rule for recoding to get stem word through step1 to step 5 and removes final –e from stem words
in step 6. This algorithm is already implemented in C,
JAVA, perl and is quite simple [7, 8].
Stem terms list which are generated after execution of
our comparative tool on some set of morphological
variants of some unique words, are shown below.
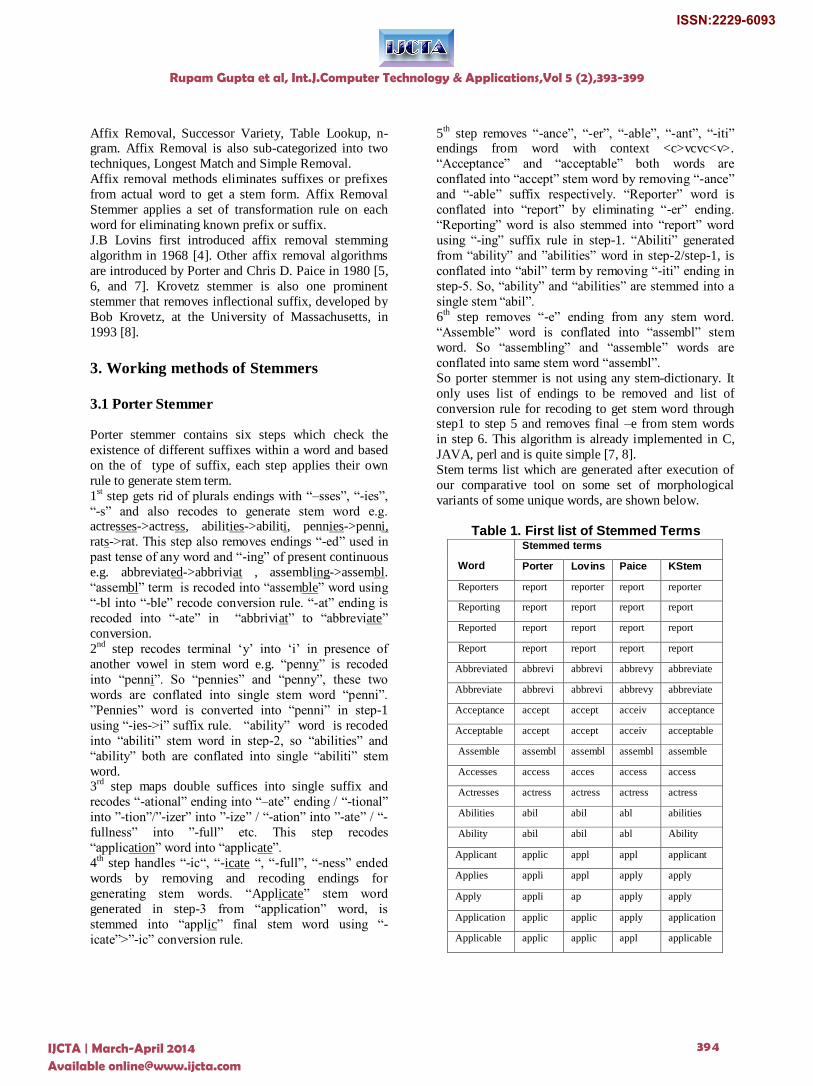
Table 1. First list of Stemmed Terms
Word
Stemmed terms
Porter Lovins Paice KStem
Reporters report reporter report reporter
Reporting report report report report
Reported report report report report
Report report report report report
Abbreviated abbrevi abbrevi abbrevy abbreviate
Abbreviate abbrevi abbrevi abbrevy abbreviate
Acceptance accept accept acceiv acceptance
Acceptable accept accept acceiv acceptable
Assemble assembl assembl assembl assemble
Accesses access acces access access
Actresses actress actress actress actress
Abilities abil abil abl abilities
Ability abil abil abl Ability
Applicant applic appl appl applicant
Applies appli appl apply apply
Apply appli ap apply apply
Application applic applic apply application
Applicable applic applic appl applicable
Rupam Gupta et al, Int.J.Computer Technology & Applications,Vol 5 (2),393-399
IJCTA | March-April 2014 Available [email protected]
394
ISSN:2229-6093
3.2 Lovins Stemmer
It is the first developed, most popular algorithm
published in 1968 [4].
This algorithm [4] uses a large list of 294 suffices, 29 context sensitive conditions based on different suffix
and 35 word ending transformation rules for generating
stem word.
This algorithm is decomposed into two steps, first step
removes suffix from original word based on a condition
taken from 29 conditions list and then 2nd
step recodes
the ending of word based on a transformation rule from
35 context sensitive rules to generate final stem word.
“Believed” and “believe” words are considered as input
for generating stem words based on Lovins algorithm.
Step-1 [4]: Algorithm matches “-ed” suffix of
“believed” word in suffix list based on “ed E” ending
and then applies condition rule “E” from condition rule
list based on “-ed” suffix. 1st step generates stem word
“believ”.
Step-2 [4]: Recoding/transformation rule “2” [iev
ief] is applied and generate final stem word “belief” from “believ”. For “believe” word, “believ” term is
generated in 1st step based on “e A” ending and then
recoded into “belief” final stem word in 2nd
step. So,
“believe”, “believed”, “belief” words are conflated into
“belief” stem word.
Lovins algorithm also handles irregular singular-plural
e.g. .index/indices, formula/formulae. Word “index” is
recoded into “indic” stem word using recoding rule
“11” [dex-dic] in step 2. Word “indices” is stemmed
into “indic” based on “es E” ending in step 1 and
nothing is done in step 2.
This algorithm [4] also treats double letter word
(running, sitting) correctly. Recoding/transformation
rule „1‟[rule 1: eliminate one of double letters
b,d,g,l,m,n,p,r,s,t] is applied to get same stem word .
e.g. “running” and “run” both words are stemmed into
“run” stem word. Lovins algorithm generates single stem term for
individual set from some set of morphological variants
of single root words, where as other affix removal
stemmer can not generate unique stem term for the
same, which are shown below.
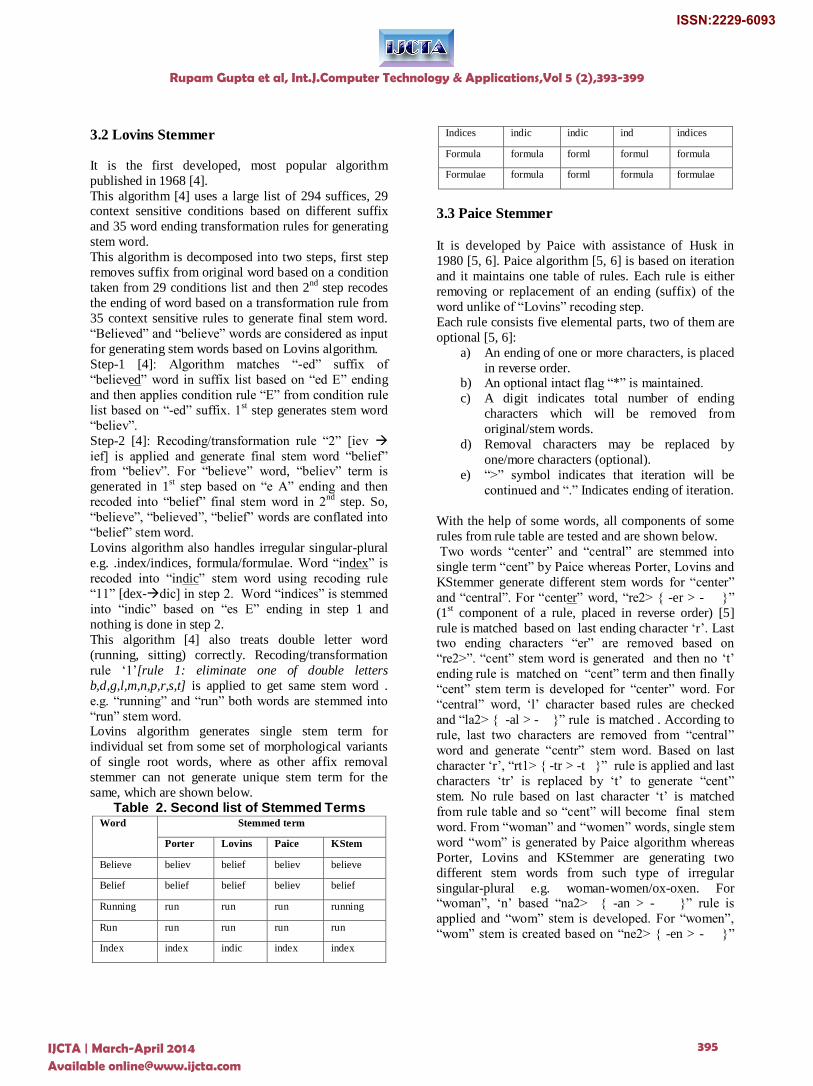
Table 2. Second list of Stemmed Terms Word Stemmed term
Porter Lovins Paice KStem
Believe believ belief believ believe
Belief belief belief believ belief
Running run run run running
Run run run run run
Index index indic index index
Indices indic indic ind indices
Formula formula forml formul formula
Formulae formula forml formula formulae
3.3 Paice Stemmer It is developed by Paice with assistance of Husk in
1980 [5, 6]. Paice algorithm [5, 6] is based on iteration
and it maintains one table of rules. Each rule is either
removing or replacement of an ending (suffix) of the
word unlike of “Lovins” recoding step.
Each rule consists five elemental parts, two of them are
optional [5, 6]:
a) An ending of one or more characters, is placed
in reverse order. b) An optional intact flag “*” is maintained.
c) A digit indicates total number of ending
characters which will be removed from
original/stem words.
d) Removal characters may be replaced by
one/more characters (optional).
e) “>” symbol indicates that iteration will be
continued and “.” Indicates ending of iteration.
With the help of some words, all components of some
rules from rule table are tested and are shown below.
Two words “center” and “central” are stemmed into
single term “cent” by Paice whereas Porter, Lovins and
KStemmer generate different stem words for “center”
and “central”. For “center” word, “re2> { -er > - }”
(1st component of a rule, placed in reverse order) [5]
rule is matched based on last ending character „r‟. Last two ending characters “er” are removed based on
“re2>”. “cent” stem word is generated and then no „t‟
ending rule is matched on “cent” term and then finally
“cent” stem term is developed for “center” word. For
“central” word, „l‟ character based rules are checked
and “la2> { -al > - }” rule is matched . According to
rule, last two characters are removed from “central”
word and generate “centr” stem word. Based on last
character „r‟, “rt1> { -tr > -t }” rule is applied and last
characters „tr‟ is replaced by „t‟ to generate “cent”
stem. No rule based on last character „t‟ is matched
from rule table and so “cent” will become final stem
word. From “woman” and “women” words, single stem
word “wom” is generated by Paice algorithm whereas
Porter, Lovins and KStemmer are generating two
different stem words from such type of irregular
singular-plural e.g. woman-women/ox-oxen. For “woman”, „n‟ based “na2> { -an > - }” rule is
applied and “wom” stem is developed. For “women”,
“wom” stem is created based on “ne2> { -en > - }”
Rupam Gupta et al, Int.J.Computer Technology & Applications,Vol 5 (2),393-399
IJCTA | March-April 2014 Available [email protected]
395
ISSN:2229-6093
rule of rule table. Paice also generates single stem term for “ox, “oxen” irregular singular-plural.
Paice generates single stem word “distinct” from
“distinguish” and “distinguishing” words. Paice applies
rule “hsiug5ct. { -guish > -ct }" for “distinguish” word
from rule table where ending “guish " is replaced by
“ct” ending and then generates “distinct” stem term.
“Distinct” stem word is final stem word because last
character „.‟ of the rule indicates termination of
applying the rule. For “distinguishing” word, "gni3>
{ -ing > - }" rule is applied and ending “ing” will be
removed to generate “distinguish” stem word.
“Distinct” final stem is generated after applying
“hsiug5ct. { -guish > -ct }" rule. With the help of
exhaustive list of rules in Paice algo., most of the root
words and its‟ morphed words are stemmed correctly.
The above mentioned morphed words which are
correctly conflated into single stem term, are listed
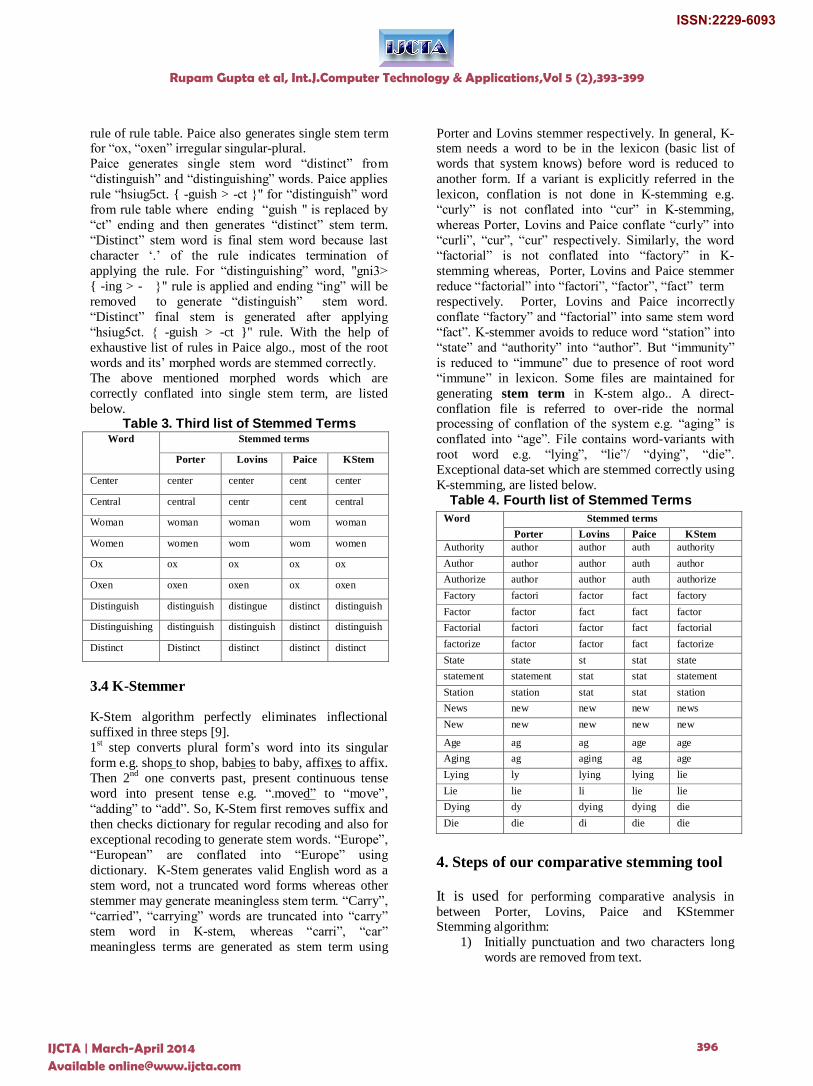
below. Table 3. Third list of Stemmed Terms
Word Stemmed terms
Porter Lovins Paice KStem
Center center center cent center
Central central centr cent central
Woman woman woman wom woman
Women women wom wom women
Ox ox ox ox ox
Oxen oxen oxen ox oxen
Distinguish distinguish distingue distinct distinguish
Distinguishing distinguish distinguish distinct distinguish
Distinct Distinct distinct distinct distinct
3.4 K-Stemmer K-Stem algorithm perfectly eliminates inflectional
suffixed in three steps [9].
1st step converts plural form‟s word into its singular
form e.g. shops to shop, babies to baby, affixes to affix.
Then 2nd
one converts past, present continuous tense
word into present tense e.g. “.moved” to “move”,
“adding” to “add”. So, K-Stem first removes suffix and
then checks dictionary for regular recoding and also for
exceptional recoding to generate stem words. “Europe”,
“European” are conflated into “Europe” using
dictionary. K-Stem generates valid English word as a
stem word, not a truncated word forms whereas other
stemmer may generate meaningless stem term. “Carry”,
“carried”, “carrying” words are truncated into “carry”
stem word in K-stem, whereas “carri”, “car”
meaningless terms are generated as stem term using
Porter and Lovins stemmer respectively. In general, K-stem needs a word to be in the lexicon (basic list of
words that system knows) before word is reduced to
another form. If a variant is explicitly referred in the
lexicon, conflation is not done in K-stemming e.g.
“curly” is not conflated into “cur” in K-stemming,
whereas Porter, Lovins and Paice conflate “curly” into
“curli”, “cur”, “cur” respectively. Similarly, the word
“factorial” is not conflated into “factory” in K-
stemming whereas, Porter, Lovins and Paice stemmer
reduce “factorial” into “factori”, “factor”, “fact” term
respectively. Porter, Lovins and Paice incorrectly
conflate “factory” and “factorial” into same stem word
“fact”. K-stemmer avoids to reduce word “station” into
“state” and “authority” into “author”. But “immunity”
is reduced to “immune” due to presence of root word
“immune” in lexicon. Some files are maintained for
generating stem term in K-stem algo.. A direct-
conflation file is referred to over-ride the normal processing of conflation of the system e.g. “aging” is
conflated into “age”. File contains word-variants with
root word e.g. “lying”, “lie”/ “dying”, “die”.
Exceptional data-set which are stemmed correctly using
K-stemming, are listed below.
Table 4. Fourth list of Stemmed Terms
4. Steps of our comparative stemming tool
It is used for performing comparative analysis in
between Porter, Lovins, Paice and KStemmer Stemming algorithm:
1) Initially punctuation and two characters long
words are removed from text.
Word Stemmed terms
Porter Lovins Paice KStem
Authority author author auth authority
Author author author auth author
Authorize author author auth authorize
Factory factori factor fact factory
Factor factor fact fact factor
Factorial factori factor fact factorial
factorize factor factor fact factorize
State state st stat state
statement statement stat stat statement
Station station stat stat station
News new new new news
New new new new new
Age ag ag age age
Aging ag aging ag age
Lying ly lying lying lie
Lie lie li lie lie
Dying dy dying dying die
Die die di die die
Rupam Gupta et al, Int.J.Computer Technology & Applications,Vol 5 (2),393-399
IJCTA | March-April 2014 Available [email protected]
396
ISSN:2229-6093

2) Numeric values and proper nouns used in text, are eliminated using Stanford Part-of-Speech
software tool.
3) Stop words which have length greater than
two, are removed.
4) Duplicate words used in text, are eliminated
and then only unique words of the text are
sorted.
5) Finally Porter, Lovins, Paice and KStemming
algorithm are executed on those above
mentioned filtered sorted unique words which
are acquired from text.
6) Execution time taken by Porter, Lovins, Paice
and KStemming algorithm on given text, are
computed using java thread.
7) For set of words, our comparative tool is
directly executed for four affix-removal
stemmers for generation of stem terms.
Filtration steps are not applicable for word set. Input:
1) DUC text documents ( http://www-
nlpir.nist.gov/projects/duc/data.html)
2) Common word List.
http://www.comp.lancs.ac.uk/computing/r
esearch/stemming/Links/resources.htm
(Grouped WordList A)
Output:
a) Input file:
DUC\ducdocs\d061j/AP880911-0016
Above mentioned DUC text‟s sample
Output is shown below.
Table 5. Fifth list of Stemmed Terms Word Stemmed terms
Porter Lovins Paice KStem
Alarm alarm alarm alarm alarm
Alert alert alers alert alert
Alerted alert alers alert alert
Approaching approach approach approach approach
Area area are are area
Around around around around around
Associated associ associ assocy associate
Briefly briefli brief brief brief
b) Input: Grouped Wordlist - A
Sample output is given below
Table 6. Sixth list of Stemmed Terms Word Stemmed terms
Porter Lovins Paice KStem
Aardvark aardvark aardvarkk aardvarkk aardvarkk
Aardvarks aardvark aardvark aardvark aardvark
Aback aback Aback aback aback
Abacus abacu Abac abac abacus
Abacuses abacus Abacus abacus abacus
Abalone abalon Abalone abalon abalone
Abalones abalone abalone abalone abalone
5. Comparative analysis of four stemmers
Seventh list of stemmed terms is shown with respect to
number of stem word generation for a set of wordlist-
http://www.comp.lancs.ac.uk/computing/research/stem
ming/Links/resources.htm (Grouped WordList A)
Table 7. Seventh list of Stemmed Terms List of
Morphed
Words
Number of Stemmed terms
Porte
r
Lovin
s
Paic
e
KS
tem
mer
Abilities
Ability
1 1 1 2
Abnormal
Abnormally
1 1 1 1
Abolish
Abolished
Abolishes
Abolishing
Abolition
2
3
2
2
Table-8 shows comparison in between stemmers with
respect to ICF value, are given below.
Rupam Gupta et al, Int.J.Computer Technology & Applications,Vol 5 (2),393-399
IJCTA | March-April 2014 Available [email protected]
397
ISSN:2229-6093
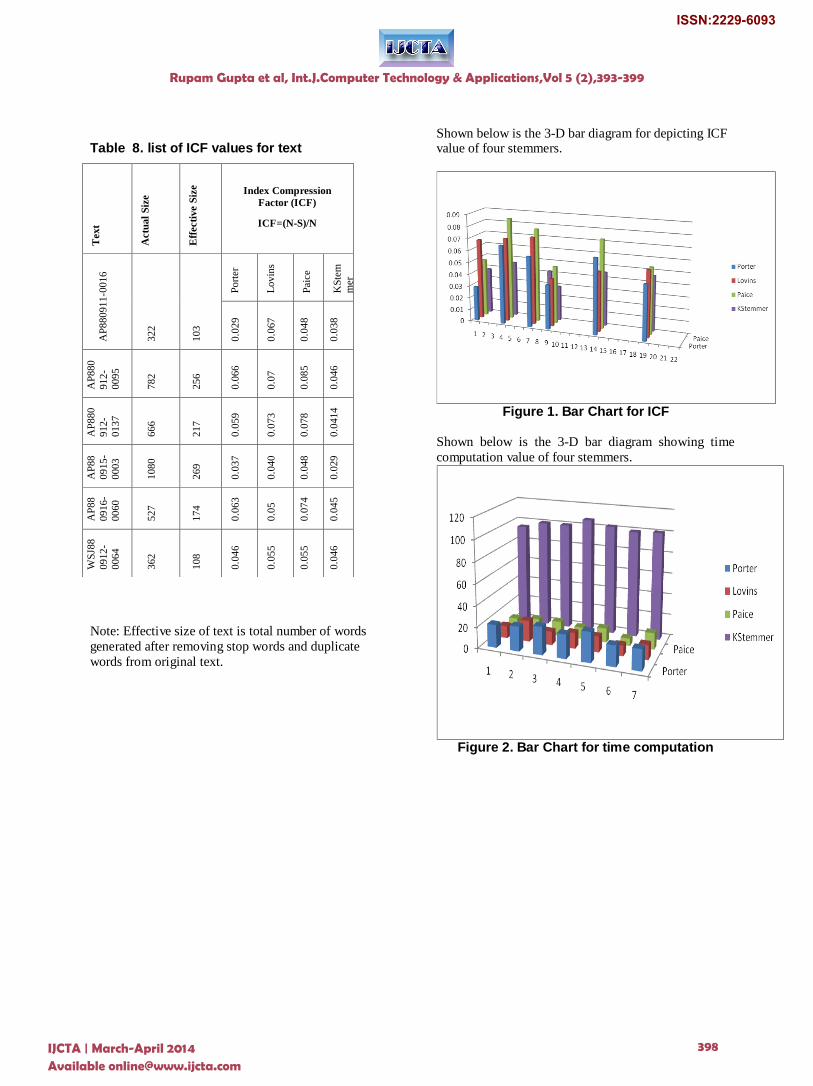
Table 8. list of ICF values for text
Note: Effective size of text is total number of words
generated after removing stop words and duplicate
words from original text.
Shown below is the 3-D bar diagram for depicting ICF value of four stemmers.
Figure 1. Bar Chart for ICF
Shown below is the 3-D bar diagram showing time
computation value of four stemmers.
Figure 2. Bar Chart for time computation
Tex
t
Actu
al
Siz
e
Eff
ecti
ve S
ize
Index Compression
Factor (ICF)
ICF=(N-S)/N
AP
88
09
11
-00
16
32
2
10
3
Po
rter
Lo
vin
s
Pai
ce
KS
tem
mer
0.0
29
0.0
67
0.0
48
0.0
38
AP
88
0
91
2-
00
95
78
2
25
6
0.0
66
0.0
7
0.0
85
0.0
46
AP
880
912
-
0137
666
217
0.0
59
0.0
73
0.0
78
0.0
414
AP
88
0915
-
0003
1080
269
0.0
37
0.0
40
0.0
48
0.0
29
AP
88
0916
-
0060
527
174
0.0
63
0.0
5
0.0
74
0.0
45
WS
J88
0912
-
0064
362
108
0.0
46
0.0
55
0.0
55
0.0
46
Rupam Gupta et al, Int.J.Computer Technology & Applications,Vol 5 (2),393-399
IJCTA | March-April 2014 Available [email protected]
398
ISSN:2229-6093
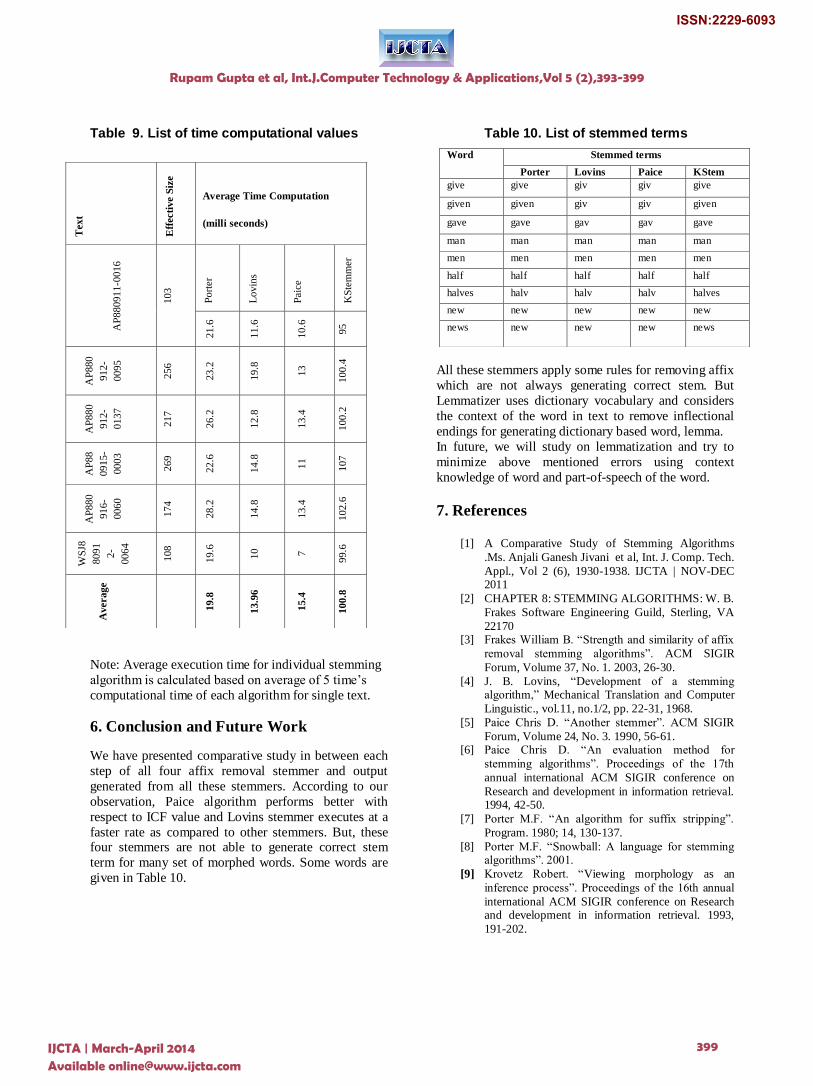
Table 9. List of time computational values
Note: Average execution time for individual stemming
algorithm is calculated based on average of 5 time‟s
computational time of each algorithm for single text.
6. Conclusion and Future Work
We have presented comparative study in between each
step of all four affix removal stemmer and output
generated from all these stemmers. According to our
observation, Paice algorithm performs better with
respect to ICF value and Lovins stemmer executes at a
faster rate as compared to other stemmers. But, these four stemmers are not able to generate correct stem
term for many set of morphed words. Some words are
given in Table 10.
Table 10. List of stemmed terms
All these stemmers apply some rules for removing affix
which are not always generating correct stem. But
Lemmatizer uses dictionary vocabulary and considers
the context of the word in text to remove inflectional
endings for generating dictionary based word, lemma.
In future, we will study on lemmatization and try to
minimize above mentioned errors using context
knowledge of word and part-of-speech of the word.
7. References
[1] A Comparative Study of Stemming Algorithms
.Ms. Anjali Ganesh Jivani et al, Int. J. Comp. Tech.
Appl., Vol 2 (6), 1930-1938. IJCTA | NOV-DEC 2011
[2] CHAPTER 8: STEMMING ALGORITHMS: W. B.
Frakes Software Engineering Guild, Sterling, VA
22170 [3] Frakes William B. “Strength and similarity of affix
removal stemming algorithms”. ACM SIGIR
Forum, Volume 37, No. 1. 2003, 26-30.
[4] J. B. Lovins, “Development of a stemming algorithm,” Mechanical Translation and Computer
Linguistic., vol.11, no.1/2, pp. 22-31, 1968.
[5] Paice Chris D. “Another stemmer”. ACM SIGIR
Forum, Volume 24, No. 3. 1990, 56-61. [6] Paice Chris D. “An evaluation method for
stemming algorithms”. Proceedings of the 17th
annual international ACM SIGIR conference on
Research and development in information retrieval. 1994, 42-50.
[7] Porter M.F. “An algorithm for suffix stripping”.
Program. 1980; 14, 130-137.
[8] Porter M.F. “Snowball: A language for stemming algorithms”. 2001.
[9] Krovetz Robert. “Viewing morphology as an
inference process”. Proceedings of the 16th annual
international ACM SIGIR conference on Research and development in information retrieval. 1993,
191-202.
Tex
t
Eff
ecti
ve S
ize
Average Time Computation
(milli seconds)
AP
88
09
11
-00
16
10
3
Po
rter
Lo
vin
s
Pai
ce
KS
tem
mer
21
.6
11
.6
10
.6
95
AP
88
0
91
2-
00
95
25
6
23
.2
19
.8
13
10
0.4
AP
880
912-
0137
217
26.2
12.8
13.4
100.2
AP
88
0915
-
0003
269
22.6
14.8
11
107
AP
880
916
-
0060
174
28.2
14.8
13.4
102.6
WS
J8
8091
2-
0064
108
19.6
10
7
99.6
Average
19.8
13.9
6
15.4
100.8
Word Stemmed terms
Porter Lovins Paice KStem
give give giv giv give
given given giv giv given
gave gave gav gav gave
man man man man man
men men men men men
half half half half half
halves halv halv halv halves
new new new new new
news new new new news
Rupam Gupta et al, Int.J.Computer Technology & Applications,Vol 5 (2),393-399
IJCTA | March-April 2014 Available [email protected]
399
ISSN:2229-6093





























