Embed Size (px)
Citation preview

EnterpriseandDesktopSearch
Lecture2:SearchingtheEnterpriseWeb
PavelDmitrievYahoo!Labs
Sunnyvale,CAUSA
PavelSerdyukovUniversityof
TwenteNetherlands
SergeyChernovL3SResearchCenter
HannoverGermany

Outline
• SearchingtheEnterpriseWeb– Whatworksandwhatdoesn’t(Fagin03,Hawking04)
• UserFeedbackinEnterpriseWebSearch– ExplicitvsImplicitfeedback(Joachims02,Radlinski05)
– UserAnnotaWons(Dmitriev06,Poblete08,Chirita07)– SocialAnnotaWons(Millen06,Bao07,Xu07,Xu08)– UserAcWvity(Bilenko08,Xue03)– Short‐termUserContext(Shen05,Buscher07)

SearchingtheEnterpriseWeb

• HowisEnterpriseWebdifferentfromthePublicWeb?– Structuraldifferences
• Whatarethemostimportantfeaturesforsearch?– UseRankAggregaWontoexperimentwithdifferentrankingmethodsandfeatures
Searching the Workplace Web
Ronald Fagin Ravi Kumar Kevin S. McCurley
Jasmine Novak D. Sivakumar
John A. Tomlin David P. Williamson
IBM Almaden Research Center650 Harry Road
San Jose, CA 95120
ABSTRACT
The social impact from the World Wide Web cannot be un-derestimated, but technologies used to build the Web arealso revolutionizing the sharing of business and governmentinformation within intranets. In many ways the lessonslearned from the Internet carry over directly to intranets,but others do not apply. In particular, the social forces thatguide the development of intranets are quite different, andthe determination of a “good answer” for intranet search isquite different than on the Internet. In this paper we studythe problem of intranet search. Our approach focuses on theuse of rank aggregation, and allows us to examine the effectsof different heuristics on ranking of search results.
Categories and Subject Descriptors
H.3.3 [Information Storage and Retrieval]: InformationSearch and Retrieval
General Terms
Algorithms, Measurement, Experimentation
1. INTRODUCTIONThe corporate intranet is an organism that is at once
very similar to and very unlike the Internet at large. Awell-designed intranet, powered by a high-quality enterpriseinformation portal (EIP), is perhaps the most significantstep that corporations can make—and have made in recentyears—to improve productivity and communication betweenindividuals in an organization. Given the business of EIPsand their impact, it is natural that the search problem forintranets and EIPs is growing into an important business.
Despite its importance, however, there is little scientificwork reported on intranet search, or intranets at all for thatmatter. For example, in the history of the WWW confer-ence, there appear to have been only two papers that referto an “intranet” at all in their title [28, 22], and as bestwe can determine, all previous WWW papers on intranetsare case studies in their construction for various companiesand universities [18, 22, 12, 4, 21, 29, 6]. It is not surprisingthat few papers are published on intranet search: companieswhose livelihood depends on their intranet search productsare unlikely to publish their research, academic research-ers generally do not have access to corporate intranets, andCopyright is held by the author/owner(s).WWW2003, May 20–24, 2003, Budapest, Hungary.ACM 1-58113-680-3/03/0005.
most researchers with access to an intranet have access onlyto that of their own institution.
One might wonder why the problem of searching an in-tranet is in any way different from the problem of search-ing the web or a small corpus of web documents (e.g., sitesearch). In Internet search, many of the most significanttechniques that lead to quality results are successful becausethey exploit the reflection of social forces in the way peoplepresent information on the web. The most famous of theseare probably the HITS [24, 10, 11] and the PageRank [7] al-gorithms. These methods are motivated by the observationthat a hyperlink from a document to another is an impli-cit conveyance of authority to the target page. The HITSalgorithm takes advantage of a social process in which au-thors create “hubs” of links to authoritative documents ona particular topic of interest to them.
Searching an intranet differs from searching the Internetbecause different social forces are at play, and thus searchstrategies that work for the Internet may not work on anintranet. While the Internet reflects the collective voice ofmany authors who feel free to place their writings in publicview, an intranet generally reflects the view of the entitythat it serves. Moreover, because intranets serve a differentpurpose than the Internet at large, the kinds of queries madeare different, often targeting a single “right answer”. Theproblem of finding this “right answer” on an intranet is verydifferent from the problem of finding the best answers to aquery on the Internet.
In this paper we study the problem of intranet search.As suggested by the argument above, part of such a studynecessarily involves observations of ways in which intranetsdiffer from the Internet. Thus we begin with a high-levelunderstanding of the structure of intranets. Specifically, wepostulate a collection of hypotheses that shed some light onhow—and why—intranets are different from the Internet.These “axioms” lead to a variety of ranking functions orheuristics that are relevant in the context of intranet search.
We then describe an experimental system we built tostudy intranet ranking, using IBM’s intranet as a case study.Our system uses a novel architecture that allows us to eas-ily combine our various ranking heuristics through the useof a “rank aggregation” algorithm [16]. Rank aggregationalgorithms take as input multiple ranked lists from the var-ious heuristics and produces an ordering of the pages aimedat minimizing the number of “upsets” with respect to theorderings produced by the individual ranking heuristics.
Rank aggregation allows us to easily add and remove heuris-
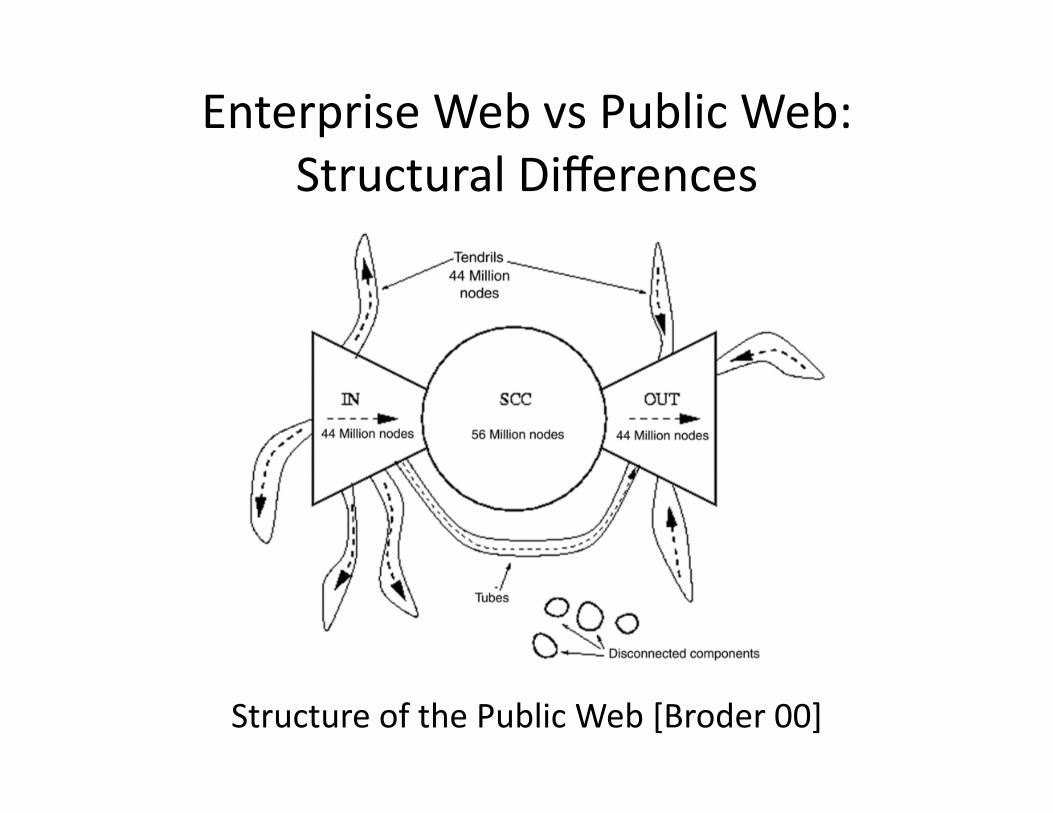
EnterpriseWebvsPublicWeb:StructuralDifferences
StructureofthePublicWeb[Broder00]
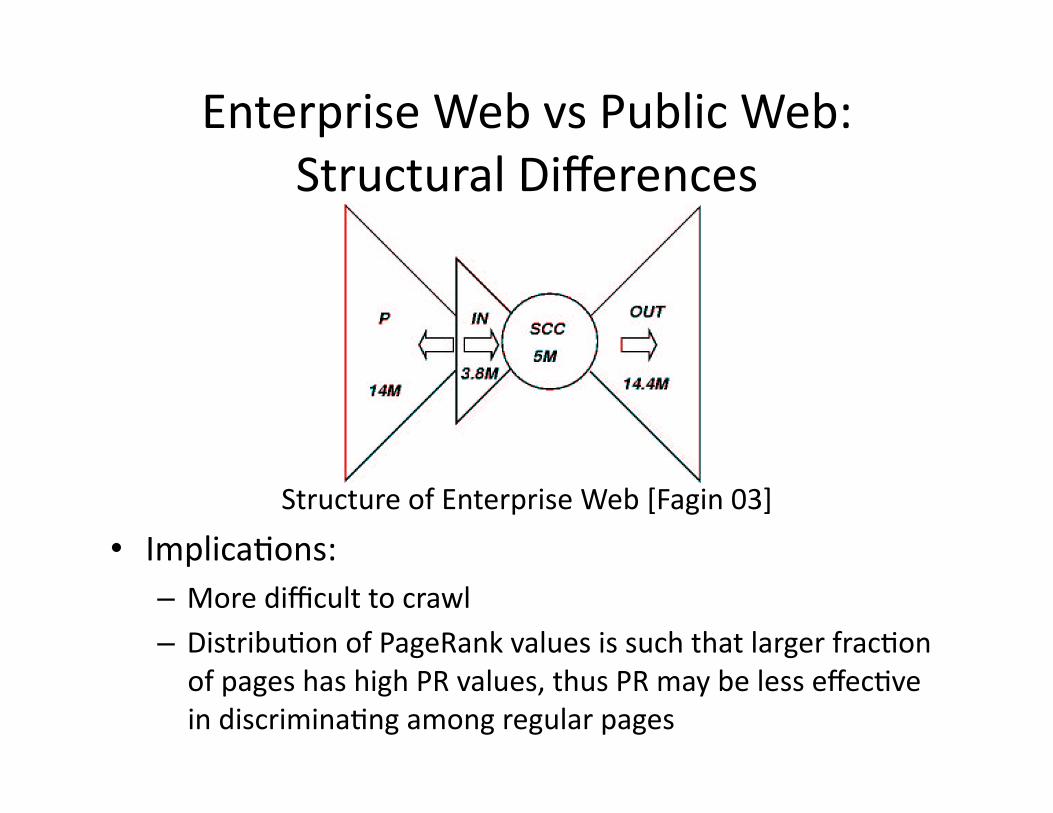
EnterpriseWebvsPublicWeb:StructuralDifferences
StructureofEnterpriseWeb[Fagin03]
• ImplicaWons:– Moredifficulttocrawl– DistribuWonofPageRankvaluesissuchthatlargerfracWonofpageshashighPRvalues,thusPRmaybelesseffecWveindiscriminaWngamongregularpages
intranets from the Internet; these arise from the internal ar-chitecture of the intranet, the kind of servers used, documenttypes specific to an organization (e.g., calendars, bulletinboards that allow discussion threads), etc. For example,the IBM intranet contains many Lotus Domino servers thatpresent many different views of an underlying document for-mat by exposing links to open and close individual sections.For any document that contains sections, there are URLsto open and close any subset of sections in an arbitraryorder, which results in exponentially many different URLsthat correspond to different views of a single document. Thisis an example of a more general and serious phenomenon:large portions of intranet documents are not designed tobe returned as answers to search queries, but rather to beaccessed through portals, database queries, and other spe-cialized interfaces. This results in our fourth axiom.
Axiom 4. Large portions of intranets are not search-engine-friendly.
There is, however, a positive side to the arguments under-lying this axiom: adding a small amount of intelligence tothe search engine could lead to dramatic improvements inanswering fairly large classes of queries. For example, con-sider queries that are directory look-ups for people, projects,etc., queries that are specific to sites/locations/organizationaldivisions, and queries that can be easily targeted to specificinternal databases. One could add heuristics to the searchengine that specifically address queries of these types, anddivert them to the appropriate directory/database lookup.
2.1 Intranets vs. the Internet: structural dif-ferences
Until now, we have developed a sequence of hypothesesabout how intranets differ from the Internet at large, fromthe viewpoint of building search engines. We now turn tomore concrete evidence of the structural dissimilarities be-tween intranets and the Internet. One of the problems inresearching intranet search is that it is difficult to obtain un-biased data of sufficient quantity to draw conclusions from.We are blessed (beleaguered?) with working for a very largeinternational corporation that has a very heterogeneous in-tranet, and this was used for our investigations. With afew notable exceptions, we expect that our experience fromstudying the IBM intranet would apply to any large multi-national corporation, and indeed may also apply to muchsmaller companies and government agencies in which au-thority is derived from a single management chain.
The IBM intranet is extremely diverse, with content onat least 7000 different hosts. Because of dynamic content,the IBM intranet contains an essentially unbounded numberof URLs. By crawling we discovered links to approximately50 million unique URLs. Of these the vast majority aredynamic URLs that provide database access to various un-derlying databases. IBM’s intranet has nearly every kindof commercially available web server represented on the in-tranet as well as some specialty servers, but one feature thatdistinguishes IBM from the Internet is that a larger fractionof the web servers are Lotus Domino. These servers influencequite a bit of the structure of IBM’s intranet, because theURLs generated by Lotus Domino servers are very distinc-tive and contribute to some of the problems in distinguishingduplicate URLs. Whenever possible we have made an effortto identify and isolate their influence. As it turns out, thiseffort led us to an architecture that is easily tailored to the
specifics of any particular intranet.From among the approximately 50 million URLs that were
identified, we crawled about 20 million. Many of the linksthat were not crawled were forbidden by robots, or weresimply database queries of no consequence to our experi-ments. Among the 20 million crawled pages, we used aduplicate elimination process to identify approximately 4.6million non-duplicate pages, and we retained approximately3.4 million additional pages for which we had anchortext.
The indegree and outdegree distributions for the intranetare remarkably similar to those reported for the Internet [8,14]. The connectivity properties, however, are significantlydifferent. In Figure 1, SCC refers to the largest stronglyconnected component of the underlying graph, IN refers tothe set of pages not in the SCC from which it is possible toreach pages in the SCC via hyperlinks, OUT refers to the setof pages not in the SCC that are reachable from the SCC viahyperlinks, and P refers to the set of pages reachable fromIN but that are not part of IN or SCC. There is an assort-ment of other kinds of pages that form the remainder of theintranet. On the Internet, SCC is a rather large componentthat comprises roughly 30% of the crawlable web, while INand OUT have roughly 25% of the nodes each [8]. On theIBM intranet, however, we note that SCC is quite small,consisting of roughly 10% of the nodes. The OUT segmentis quite large, but this is expected since many of these nodesare database queries served by Lotus Domino with no linksoutside of a site. The more interesting story concerns thecomponent P, which consists of pages that can be reachedfrom the seed set of pages employed in the crawl (a stan-dard set of important hosts and pages), but which do notlead to the SCC. Some examples are hosts dedicated to spe-cific projects, standalone servers serving special databases,and pages that are intended to be “plain information” ratherthan be navigable documents.
Figure 1: Macro-level connectivity of IBM intranet
One consequence of this structure of the intranet is thedistribution of PageRank [7] across the pages in the intranet.The PageRank measure of the quality of documents in ahyperlinked environment corresponds to a probability dis-tribution on the documents, where more important pagesare intended to have higher probability mass. We comparedthe distribution of PageRank values on the IBM intranetwith the values from a large crawl of the Internet. On theintranet, a significantly larger fraction of pages have highvalues of PageRank (probability mass in the distribution al-luded to), and a significantly smaller fraction of pages have

RankAggregaWon
• Input:severalrankedlistsofobjects
• Output:asinglerankedlistoftheunionofalltheobjectswhichminimizesthenumberof“inversions”wrtiniWallists
• NP‐hardtocomputefor4ormorelists• VarietyofheurisWcapproximaWonsexistforcompuWngeitherthewholeorderingortopk[Dwork01,Fagin03‐1]
RankAggregaWoncanalsobeusefulinEnterpriseSearchforcombiningrankingsfromdifferentdatasource

Whatarethemostimportantfeatures?
• Create3indices:Content,Title,Anchortext(aggregatedtextfromthe<a>tagspoinWngtothepage)
• Gettheresults,rankthembyl‐idf,andfeedtotherankingheurisWcs
• CombinetheresultsusingRankAggregaWon
• EvaluateallpossiblesubsetsofindicesandheurisWcsonveryfrequent(Q1)andmediumfrequency(Q2)querieswithmanuallydeterminedcorrectanswers
it would often be more general and have links to pages thatare lower in the hierarchy.
Discriminator. This is a “pure hack” to discriminate infavor of certain classes of URLs over others. The favoredURLs in our case consisted of those that end in a slash / orindex.html, and those that contain a tilde ∼. Those thatwere discriminated against are certain classes of dynamicURLs containing a question mark, as well as some DominoURLs. This heuristic is neutral on all other URLs, and iseasily tailored to knowledge of a specific intranet.
The exact choice of heuristics is not etched in stone, andour system is designed to incorporate any partial orderingon results. Others that we considered include favoritism forsome hosts (e.g., those maintained by the CIO), differentcontent types, age of documents, click distance, HostRank(Pagerank on the host graph), etc.
In our experiments these factors were combined in thefollowing way. First, all three indices are consulted to getthree ranked lists of documents that are scored purely onthe basis of tf·idf (remembering that the title and anchortextindex consists of virtual documents). The union of these listsis then taken, and this list is reordered according to each ofthe seven scoring factors to produce seven new lists. Theselists are all combined in rank aggregation. In practice if kresults are desired in the final list, then we chose up to 2kdocuments to go into the individual lists from the indices,and discard all but the top k after rank aggregation.
Discriminator
URL depth
URL length
Words in URL
Discovery date
Indegree
PageRank
Anchortext Index
Title Index
Content Index
!
"
"""""""
""""""""""
Rank
Aggregation
"Result
Figure 2: Rank aggregation: The union of resultsfrom three indices is ordered by many heuristics andfed with the original index results to rank aggrega-tion to produce a final ordering.
Our primary goal in building this system was to exper-iment with the effect of various factors on intranet searchresults, but it is interesting to note that the performancecost of our system is reasonable. The use of multiple indicesentails some overhead, but this is balanced by the small sizesof the indices. The rank aggregation algorithm described inSection 4.1 has a running time that is quadratic in the lengthof the lists, and for small lists is not a serious factor.
5. EXPERIMENTAL RESULTSIn this section we describe our experiments with our in-
tranet search system. The experiments consist of the follow-ing steps: choosing queries on which to test the methods,identifying criteria based on which to evaluate the quality ofvarious combinations of ranking heuristics, identifying mea-sures of the usefulness of individual heuristics, and finally,analyzing the outcome of the experiments.
5.1 Ranking methods and queriesBy using the 10 ranking heuristics (three directly based
on the indices and the seven auxiliary heuristics), one couldcreate 1024 combinations of subsets of heuristics that couldbe aggregated. However, the constraint that at least one ofthe three indices needs to be consulted eliminates one-eighthof these combinations, leaving us with 896 combinations.
Our data set consists of the following two sets of queries,which we call Q1 and Q2, respectively.
The first set Q1 consists of the top 200 queries issued toIBM’s intranet search engine during the period March 14,2002 to July 8, 2002. Several of these turned out to be broadtopic queries, such as “hr,” “vacation,” “travel,” “autonomiccomputing,” etc.—queries that might be expected to be inthe bookmarks of several users. These queries also tend to beshort, usually single-word queries, and are usually directedtowards “hubs” or commonly visited sites on the intranet.These 200 queries represent roughly 39% of all the queries;this suggests that on intranets there is much to be gained byoptimizing the search engine, perhaps via feedback learning,to accurately answer the top few queries.
The second set Q2 consists of 150 queries of median fre-quency, that is these are the queries near the 50th percentileof the query frequency histogram (from the query logs inthe period mentioned above). These are typically not the“bookmark” type queries; rather, they tend to arise whenlooking for something very specific. In general, these tendto be longer than the popular queries; a nontrivial fractionof them are fairly common queries disambiguated by termsthat add to the specificity of the query (e.g., “american ex-press travel canada”). Other types of queries in this cate-gory are misspelled common queries (e.g., “ebusiness”), orqueries made by users looking for specific parts in a catalogor an specific invoice code (e.g., “cp 10.12”, which refers toa corporate procedure). Thus Q2 represents the “typical”user queries; hence the satisfaction experienced by a user ofthe search engine will crucially depend on how the searchengine handles queries in this category.
We regard both sets of queries as being important, but fordifferent reasons. The distribution of queries to the IBM in-tranet resembles that found in Internet search engines in thesense that they both have a heavy-tail distribution for queryfrequency. A very few queries are very common, but mostof the workload is on queries that individually occur veryrarely. To provide an accurate measure of user satisfaction,we included both classes of queries in our study.
To be able to evaluate the performance of the rankingheuristics and aggregations of them, it is important that wehave a clear notion of what “ground truth” is. Therefore,once the queries were identified, the next step was to collectthe correct answers for these queries. A subtle issue here isthat we cannot use the search engine that we are testing tofind out the correct answers, as that would be biasing theresults in our favor. Therefore, we resorted to the use ofthe existing search engine on the IBM intranet, plus a bit ofgood old browsing; in a handful of cases where we could notfind any good page for a query, we did employ our search en-gine to locate some seed answers, which we then refined byfurther browsing. If the query was ambiguous (e.g., “ameri-can express”, which refers to both the corporate credit cardand the travel agency) or if there were multiple correct an-swers to a query (e.g., “sound driver”), we permitted all ofthem to be included as correct answers.
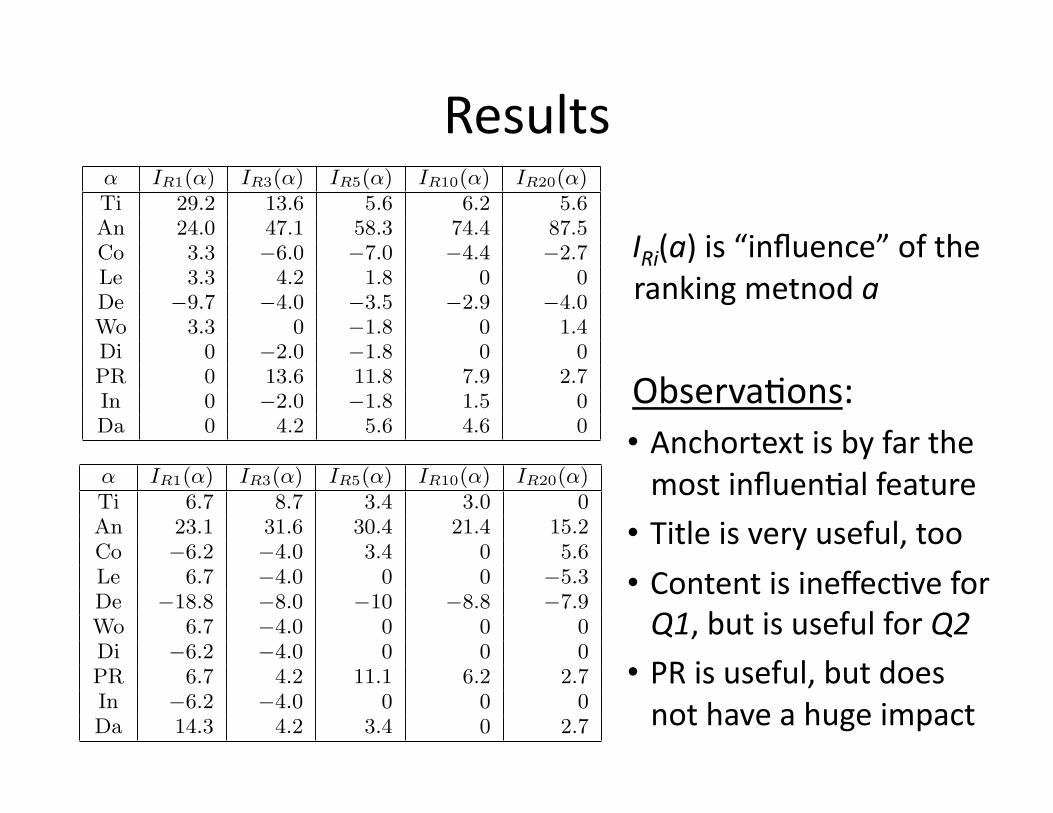
Results
IRi(a)is“influence”oftherankingmetnoda
ObservaWons:• AnchortextisbyfarthemostinfluenWalfeature
• Titleisveryuseful,too• ContentisineffecWveforQ1,butisusefulforQ2
• PRisuseful,butdoesnothaveahugeimpact
(3) Some URL canonicalizations were missed, leading theevaluation to believe that the correct result was missed whileit was reported under an alias URL.
Tables 1 and 2 present the results for the influences ofvarious heuristics. For a ranking method α and a measure ofgoodness µ, recall that Iµ(α) denotes the influence (positiveor negative) of α with respect to the goodness measure µ.Our µ’s are the recall value at various top k positions—1, 3,5, 10, and 20; we will abbreviate “recall at 1” as “R1,” etc.
Legend. The following abbreviations are used for the 10ranking heuristics:
Ti = index of titles, keywords, etc., An = anchortext, Co= content, Le = URL length, De = URL depth, Wo = querywords in URL, Di = discriminator, PR = PageRank, In =indegree, Da = discovery date.
α IR1(α) IR3(α) IR5(α) IR10(α) IR20(α)Ti 29.2 13.6 5.6 6.2 5.6An 24.0 47.1 58.3 74.4 87.5Co 3.3 −6.0 −7.0 −4.4 −2.7Le 3.3 4.2 1.8 0 0De −9.7 −4.0 −3.5 −2.9 −4.0Wo 3.3 0 −1.8 0 1.4Di 0 −2.0 −1.8 0 0PR 0 13.6 11.8 7.9 2.7In 0 −2.0 −1.8 1.5 0Da 0 4.2 5.6 4.6 0
Table 1: Influences of various ranking heuristics onthe recall at various positions on the query set Q1
α IR1(α) IR3(α) IR5(α) IR10(α) IR20(α)Ti 6.7 8.7 3.4 3.0 0An 23.1 31.6 30.4 21.4 15.2Co −6.2 −4.0 3.4 0 5.6Le 6.7 −4.0 0 0 −5.3De −18.8 −8.0 −10 −8.8 −7.9Wo 6.7 −4.0 0 0 0Di −6.2 −4.0 0 0 0PR 6.7 4.2 11.1 6.2 2.7In −6.2 −4.0 0 0 0Da 14.3 4.2 3.4 0 2.7
Table 2: Influences of various ranking heuristics onthe recall at various positions on the query set Q2
Some salient observations. (1) Perhaps the most note-worthy aspect of Tables 1 and 2 is the amazing efficacy ofanchortext. In Table 1, the influence of anchortext can beseen to be progressively better as we relax the recall param-eter. For example, for recall at position 20, anchortext hasan influence of over 87%, which means that using anchortextleads to essentially doubling the recall performance!
(2) Table 1 also shows that the title index (which, thereader may recall, consists of words extracted from titles,meta-tagged information, keywords, etc.) is an excellent con-tributor to achieving very good recall, especially at the top 1and top 3. Specifically, notice that adding information fromthe title index improves the accuracy at top 1 by nearly
30%, the single largest improvement for the top 1. Interest-ingly enough, at top 20, the role of this index is somewhatdiminished, and, compared to anchortext, is quite weak.
One way to interpret the information in the first two rowsof Table 1 is that anchortext fetches the important pagesinto the top 20, and the title index pulls up the most ac-curate pages to the near top. This is also evidence thatdifferent heuristics have different roles, and a good aggrega-tion mechanism serves as a glue to bind them seamlessly.
(3) Considering the role of the anchortext in Table 2,which corresponds to the query set Q2 (the “typical,” asopposed to the “popular” queries), we notice that the mono-tonic increase in contribution (with respect to the position)of anchortext is no longer true. This is not very surprising,since queries in this set are less likely to be extremely impor-tant topics with their own web pages (which is the primarycause of a query word being in some anchortext). Neverthe-less, anchortext still leads to a 15% improvement in recallat position 20, and is the biggest contributor.
The effect of the title index is also less pronounced inTable 2, with no enhancement to the recall at position 20.
Observations (1)–(3) lead to several inferences.Inference 1. Information in anchortext, document titles,
keyword descriptors and other meta-information in docu-ments, is extremely valuable for intranet search.
Inference 2. Our idea of building separate indices basedon this information, as opposed to treating this as auxiliaryinformation and using it to tweak the content index, is par-ticularly effective. These indices are quite compact (roughly5% and 10% of the size of the content index), fairly easy tobuild, and inexpensive to access.
Inference 3. Information from these compact indices isquery-dependent; thus, these ranking methods are dynamic.The rank aggregation framework allows for easy integrationof such information with static rankings such as PageRank.
Continuing with our observations on Tables 1 and 2:(4) The main index of information on the intranet, namely
the content index, is quite ineffective for the popular queriesin Q1. However, it becomes increasingly more effective whenwe consider the query set Q2, especially when we considerrecall at position 20. This fact is in line with our expec-tations, since a large number of queries in Q2 are pointedqueries on specialized topics, ones that are more likely to bediscussed inside documents rather than in their headers.
Inference 4. Different heuristics have different perfor-mances for different types of queries, especially when wecompare their performances on “popular” versus “typical”queries. An aggregation mechanism is a convenient way tounify these heuristics, especially in the absence of “classi-fiers” that tell which type a given query is. Such a classifier,if available, is a bonus, since we could choose the right heu-ristics for aggregation depending on the query type.
(5) The ranking heuristics based on URL length (Le), pre-sence of query words in the URL (Wo), discovery date (Da),and PageRank (PR) form an excellent support cast in therank aggregation framework. The first three of these areseen to be especially useful in Q2, the harder set of queries.An interesting example is discovery date (Da), which hasquite a significant effect on the top 1 recall for Q2.
(6) While PageRank is uniformly good, contrary to itshigh-impact role on the Internet, it does not add much valuein bringing good pages into the top 20 positions; its value
(3) Some URL canonicalizations were missed, leading theevaluation to believe that the correct result was missed whileit was reported under an alias URL.
Tables 1 and 2 present the results for the influences ofvarious heuristics. For a ranking method α and a measure ofgoodness µ, recall that Iµ(α) denotes the influence (positiveor negative) of α with respect to the goodness measure µ.Our µ’s are the recall value at various top k positions—1, 3,5, 10, and 20; we will abbreviate “recall at 1” as “R1,” etc.
Legend. The following abbreviations are used for the 10ranking heuristics:
Ti = index of titles, keywords, etc., An = anchortext, Co= content, Le = URL length, De = URL depth, Wo = querywords in URL, Di = discriminator, PR = PageRank, In =indegree, Da = discovery date.
α IR1(α) IR3(α) IR5(α) IR10(α) IR20(α)Ti 29.2 13.6 5.6 6.2 5.6An 24.0 47.1 58.3 74.4 87.5Co 3.3 −6.0 −7.0 −4.4 −2.7Le 3.3 4.2 1.8 0 0De −9.7 −4.0 −3.5 −2.9 −4.0Wo 3.3 0 −1.8 0 1.4Di 0 −2.0 −1.8 0 0PR 0 13.6 11.8 7.9 2.7In 0 −2.0 −1.8 1.5 0Da 0 4.2 5.6 4.6 0
Table 1: Influences of various ranking heuristics onthe recall at various positions on the query set Q1
α IR1(α) IR3(α) IR5(α) IR10(α) IR20(α)Ti 6.7 8.7 3.4 3.0 0An 23.1 31.6 30.4 21.4 15.2Co −6.2 −4.0 3.4 0 5.6Le 6.7 −4.0 0 0 −5.3De −18.8 −8.0 −10 −8.8 −7.9Wo 6.7 −4.0 0 0 0Di −6.2 −4.0 0 0 0PR 6.7 4.2 11.1 6.2 2.7In −6.2 −4.0 0 0 0Da 14.3 4.2 3.4 0 2.7
Table 2: Influences of various ranking heuristics onthe recall at various positions on the query set Q2
Some salient observations. (1) Perhaps the most note-worthy aspect of Tables 1 and 2 is the amazing efficacy ofanchortext. In Table 1, the influence of anchortext can beseen to be progressively better as we relax the recall param-eter. For example, for recall at position 20, anchortext hasan influence of over 87%, which means that using anchortextleads to essentially doubling the recall performance!
(2) Table 1 also shows that the title index (which, thereader may recall, consists of words extracted from titles,meta-tagged information, keywords, etc.) is an excellent con-tributor to achieving very good recall, especially at the top 1and top 3. Specifically, notice that adding information fromthe title index improves the accuracy at top 1 by nearly
30%, the single largest improvement for the top 1. Interest-ingly enough, at top 20, the role of this index is somewhatdiminished, and, compared to anchortext, is quite weak.
One way to interpret the information in the first two rowsof Table 1 is that anchortext fetches the important pagesinto the top 20, and the title index pulls up the most ac-curate pages to the near top. This is also evidence thatdifferent heuristics have different roles, and a good aggrega-tion mechanism serves as a glue to bind them seamlessly.
(3) Considering the role of the anchortext in Table 2,which corresponds to the query set Q2 (the “typical,” asopposed to the “popular” queries), we notice that the mono-tonic increase in contribution (with respect to the position)of anchortext is no longer true. This is not very surprising,since queries in this set are less likely to be extremely impor-tant topics with their own web pages (which is the primarycause of a query word being in some anchortext). Neverthe-less, anchortext still leads to a 15% improvement in recallat position 20, and is the biggest contributor.
The effect of the title index is also less pronounced inTable 2, with no enhancement to the recall at position 20.
Observations (1)–(3) lead to several inferences.Inference 1. Information in anchortext, document titles,
keyword descriptors and other meta-information in docu-ments, is extremely valuable for intranet search.
Inference 2. Our idea of building separate indices basedon this information, as opposed to treating this as auxiliaryinformation and using it to tweak the content index, is par-ticularly effective. These indices are quite compact (roughly5% and 10% of the size of the content index), fairly easy tobuild, and inexpensive to access.
Inference 3. Information from these compact indices isquery-dependent; thus, these ranking methods are dynamic.The rank aggregation framework allows for easy integrationof such information with static rankings such as PageRank.
Continuing with our observations on Tables 1 and 2:(4) The main index of information on the intranet, namely
the content index, is quite ineffective for the popular queriesin Q1. However, it becomes increasingly more effective whenwe consider the query set Q2, especially when we considerrecall at position 20. This fact is in line with our expec-tations, since a large number of queries in Q2 are pointedqueries on specialized topics, ones that are more likely to bediscussed inside documents rather than in their headers.
Inference 4. Different heuristics have different perfor-mances for different types of queries, especially when wecompare their performances on “popular” versus “typical”queries. An aggregation mechanism is a convenient way tounify these heuristics, especially in the absence of “classi-fiers” that tell which type a given query is. Such a classifier,if available, is a bonus, since we could choose the right heu-ristics for aggregation depending on the query type.
(5) The ranking heuristics based on URL length (Le), pre-sence of query words in the URL (Wo), discovery date (Da),and PageRank (PR) form an excellent support cast in therank aggregation framework. The first three of these areseen to be especially useful in Q2, the harder set of queries.An interesting example is discovery date (Da), which hasquite a significant effect on the top 1 recall for Q2.
(6) While PageRank is uniformly good, contrary to itshigh-impact role on the Internet, it does not add much valuein bringing good pages into the top 20 positions; its value

Thisstudyconfirmsmostofthefindingsif[Fagin03]on6differentEnterpriseWebs(resultsfor4datasetsareshown)
• AnchortextandWtlearesWllthebest
• Contentisalsouseful
Challenges in Enterprise Search
David Hawking
CSIRO ICT Centre,GPO Box 664,
Canberra, Australia [email protected]
Abstract
Concerted research effort since the nineteen fifties haslead to effective methods for retrieval of relevant doc-uments from homogeneous collections of text, such asnewspaper archives, scientific abstracts and CD-ROMencyclopaedias. However, the triumph of the Webin the nineteen nineties forced a significant paradigmshift in the Information Retrieval field because of theneed to address the issues of enormous scale, fluidcollection definition, great heterogeneity, unfetteredinterlinking, democratic publishing, the presence ofadversaries and most of all the diversity of purposesfor which Web search may be used. Now, the IRfield is confronted with a challenge of similarly daunt-ing dimensions – how to bring highly effective searchto the complex information spaces within enterprises.Overcoming the challenge would bring massive eco-nomic benefit, but victory is far from assured. Thepresent work characterises enterprise search, hints atits economic magnitude, states some of the unsolvedresearch questions in the domain of enterprise searchneed, proposes an enterprise search test collectionand presents results for a small but interesting sub-problem.
Keywords: Information Retrieval; enterprise search;search quality evaluation.
1 Introduction
The IDC report entitled “The High Cost of Not Find-ing Information” (Feldman and Sherman, 2003) quan-tifies the significant economic penalties caused bypoor quality search within enterprises, both in theform of lost opportunities and through lost productiv-ity. CSIRO’s observations of a large number of Aus-tralasian organisations suggest that these were notisolated or exceptional cases – in fact, very poor en-terprise search is the norm and, while employees andcustomers may complain or laugh about it, the organ-isation as a whole typically fails either to recognize theseriousness of the situation or the possibility of doingbetter.
I interpret the term enterprise search to include:
• any organisation with text content in electronicform;
Copyright c©2004, Australian Computer Society, Inc. This pa-per appeared at Fifteenth Australasian Database Conference(ADC2004), Dunedin, NZ. Conferences in Research and Prac-tice in Information Technology, Vol. 27. Klaus-Dieter Scheweand Hugh Williams, Ed. Reproduction for academic, not-forprofit purposes permitted provided this text is included.
• search of the organisation’s external website;
• search of the organisation’s internal websites (it’sintranet);
• search of other electronic text held by the organ-isation in the form of email, database records,documents on fileshares and the like.
In general, search of non-textual and continuous me-dia is included but here I consider only retrieval me-diated by text (e.g. retrieving a video by matchingtextual annotations associated with it against a textquery rather than by measuring its visual or auditorysimilarity to a video query).
An obvious reason for poor enterprise search isthat a high performing text retrieval algorithm de-veloped in the laboratory cannot be applied withoutextensive engineering to the enterprise search problembecause of the complexity of typical enterprise infor-mation spaces. Out of the hundreds of search engineson the market, so few are able to work with the rangeof databases, content management systems, email for-mats, document formats, operational and security re-quirements typical of medium scale enterprises thatquality of search results is often forgotten when pur-chasing decisions are made. (See Stenmark (1999) foran illustration.)
Not only does enterprise information complexityrestrict the range of applicable commercial searchproducts and increase the cost of deploying them butit makes it difficult to measure the quality of searchresults obtained and also, we hypothesise, makes ithard to approach the effectiveness level achieved bystate-of-the-art whole-of-Web search engines.
For researchers in the Information Retrieval (IR)field and for commercial companies, the problem ofenterprise search is a formidable challenge but onefor which a solution would deliver enormous benefit.
No solution can be presented here, but it is hopedthat a characterisation of the problem, a list of openresearch questions, a discussion of approaches anda preliminary proposal for an evaluation frameworkmay attract researchers to work in the area andthereby accelerate progress toward a solution.
Section 2 characterises the problem of enterprisesearch in the light of past work and in terms of sometypical enterprise search scenarios. Section 3 enu-merates and characterises a number of open researchproblems, including the development of a test collec-tion for enterprise search. Section 4 addresses thespecific problem of searching enterprise data held inweb format and reports new results across a range ofoutward-facing enterprise web sites. It also includes
P@
1 (%
)
Aust. Post - 94 queries; 2088 documents
10.0
20.0
30.0
40.0
50.0
60.0
70.0
UR
L w
ords
UR
L w
ords
title
title
desc
riptio
nde
scrip
tion
subj
ect
subj
ect
cont
ent
cont
ent
anch
ors
anch
ors P
@1
(%)
Comm. Bank - 145 queries; 2967 documents
10.0
20.0
30.0
40.0
50.0
60.0
70.0
UR
L w
ords
UR
L w
ords
title
title
desc
riptio
nde
scrip
tion
subj
ect
subj
ect
cont
ent
cont
ent
anch
ors
anch
ors
P@
1 (%
)
CSIRO - 130 queries; 95,907 documentss
10.0
20.0
30.0
40.0
50.0
60.0
70.0
UR
L w
ords
UR
L w
ords
title
title
desc
riptio
nde
scrip
tion
subj
ect
subj
ect
cont
ent
cont
ent
anch
ors
anch
ors S
@1
(%)
Curtin Uni. - 332 queries; 79,296 documents
10.0
20.0
30.0
40.0
50.0
60.0
70.0
UR
L w
ords
UR
L w
ords
title
title
desc
riptio
nde
scrip
tion
subj
ect
subj
ect
cont
ent
cont
ent
anch
ors
anch
ors
S@
1 (%
)
DEST - 62 queries; 8416 documents
10.0
20.0
30.0
40.0
50.0
60.0
70.0
UR
L w
ords
UR
L w
ords
title
title
desc
riptio
nde
scrip
tion
subj
ect
subj
ect
cont
ent
cont
ent
anch
ors
anch
ors P
@1
(%)
unimelb - 415 queries
10.0
20.0
30.0
40.0
50.0
60.0
70.0
UR
L w
ords
UR
L w
ords
title
title
desc
riptio
nde
scrip
tion
subj
ect
subj
ect
cont
ent
cont
ent
anch
ors
anch
ors
Figure 3: The relative value of different types of query-dependent evidence for navigational search on theexternal web sites of six different enterprises. Within a graph, the height of a bar reflects the effectivenessachieved on a navigational search task, when the Okapi BM25 scoring function is applied to pseudo documentscontaining only parts of the available text: content, title, URL words, subject and description metadata andpropagated referring anchortext. In each case the sitemap from which the navigational queries were derivedwas excluded from the index. Exact duplicates of correct answers were accepted as equally correct.

Summary
• EnterpriseWebandPublicWebexhibitsignificantstructuraldifferences
• ThesedifferencesresultinsomefeaturesveryeffecWveforwebsearchnotbeingsoeffecWveforEnterpriseWebSearch– Anchortextisveryuseful(butthereismuchlessofit)
– Titleisgood– ContentisquesWonable– PageRankisnotasuseful

UsingUserFeedbackinEnterpriseWebSearch

UsingUserFeedback• OneofthemostpromisingdirecWonsinEnterpriseSearch– Cantrustthefeedback(nospam)– CanprovideincenWves– Candesignasystemtofacilitatefeedback– Canactuallyimplementit
• Wewilllookatseveraldifferentsourcesoffeedback– Clicks(verybriefly)– ExplicitAnnotaWons– Queries– SocialAnnotaWons– BrowsingTraces

SourcesofFeedbackinWebSearch
• ExplicitFeedback– Overheadforuser– Onlyfewusersgivefeedback=>notrepresentaWve
• ImplicitFeedback– Queries,clicks,Wme,mousing,scrolling,etc.
– NoOverhead– Moredifficulttointerpret
[Joachims02,Radlinski05]
8/22/09 8:25 PMRuSSIR 2009 - Google Search
Page 1 of 2http://www.google.com/search?client=safari&rls=en&q=RuSSIR+2009&ie=UTF-8&oe=UTF-8
Web Images Videos Maps News Shopping Gmail more ! [email protected] | Web History | My Account | Sign out
RuSSIR 2009 SearchAdvanced SearchPreferences
Results 1 - 10 of about 143,000,000 for RuSSIR 2009. (0.44 seconds)
Did you mean: RuSSIA 2009
3 rd Russian Summer School in Information Retrieval - RuSSIR'2009 ... - 3 visits - Jul 23
The 3rd Russian Summer School in Information Retrieval will be held September 11 -16,2009 in Petrozavodsk, Russia. The school is co-organized by the Russian ...romip.ru/russir2009/eng/index.html - Cached - Similar -
good result
Make a public comment Cancel
RuSSIR'2009: III "#$$%&$'() *+,-)) .'#*( /# %-0#12(3%#--#24 /#%$'4 - 2 visits -
Feb 25 - [ Translate this page ]5+*% "#$$%&$'#& *+,-+& .'#*6 /# %-0#12(3%#--#24 /#%$'4 (RuSSIR) — /#7-('#2%,8$*4.(,+*+& $# $/+',1#2 $#91+2+--6: /1#;*+2 % 2+,#<#9 %-0#12(3%#--#=# /#%$'(, ...romip.ru/russir2009/ - Cached - Similar -
Show more results from romip.ru
RuSSIR 2009: call for participation | PASCAL 2RuSSIR 2009 is co-located with the yearly ROMIP meeting (http://romip.ru/) and RussianConference on Digital Libraries 2009 ...www.pascal-network.org/?q=node/106 - Cached - Similar -
3rd Russian Summer School in Information Retrieval (RuSSIR 2009 ...RuSSIR 2009 is co-located with the yearly ROMIP meeting (http://romip.ru/) and RussianConference on Digital Libraries 2009 ...www.pascal-network.org/?q=node/78 - Cached - Similar -
[PDF] 3rd Russian Summer School in Information Retrieval (RuSSIR 2009)File Format: PDF/Adobe Acrobat - View11>16, 2009 in Petrozavodsk, Russia. The school is co>organized by the. Russian ...RuSSIR 2009 is co>located with the yearly ROMIP meeting (http:// ...sci.tech-archive.net/pdf/Archive/sci.image.../2008.../msg00046.pdf - Similar -
3rd Russian Summer School in Information Retrieval (RuSSIR 2009)FIRST CALL FOR COURSE PROPOSALS ... The 3rd Russian Summer School inInformation Retrieval will be held ... RuSSIR 2009 is co-located with the yearly ROMIP ...sci.tech-archive.net/Archive/sci.image...11/msg00046.html - Cached - Similar -
ru_ir: RUSSIR 2009 - [ Translate this page ]
?1+,8) "#$$%&$'() *+,-)) .'#*( /# %-0#12(3%#--#24 /#%$'4 (RuSSIR 2009) /1#&<+,$ 11 /# 16 $+-,);1) 9 @+,1#7(9#<$'+, -+/#$1+<$,9+--# /+1+< ...community.livejournal.com/ru_ir/74129.html - Similar -
3rd Russian Summer School in Information Retrieval (RuSSIR ...3rd Russian Summer School in Information Retrieval (RuSSIR 2009) Friday September 11 -Wednesday September 16, 2009. Petrozavodsk, Russia ...linguistlist.org/callconf/browse-conf-action.cfm?ConfID... - Cached - Similar -
SELF-EVALUATION FORMS - CORDIS: FP7: Find a CallIdentifier: FP7-NMP-2009-EU-Russia. Publication Date: 19 November 2008. Budget: A 4650 000. Deadline: 31 March 2009 at 17:00:00 (Brussels local time) ...cordis.europa.eu/fp7/dc/index.cfm?fuseaction=usersite... - Cached - Similar -
Economic Survey of Russia 2009Home: Economics Department > Economic Survey of Russia 2009 ... Additional information|. The next Economic Survey of Russia will be prepared for 2011. ...www.oecd.org/.../0,3343,en_2649_33733_43271966_1_1_1_1,00.html -Cached - Similar -
Web Show options...
Please remember comments are public.
Comments will be visible to others and identified by your Google Account nickname.
Yes, continue. Cancel

UsingClickDatatoImproveSearch
• VeryacWveareaofresearchinbothacademiaandindustry,mostlyinthecontextofPublicWebsearch,butcanbeappliedtoEnterpriseWebsearchaswell
• Theideaistreatclicksasrelevancevotes(“clicked”=“relevant”),oraspreferencevotes(“clickedpage”>“non‐clickedpage”),andthenusethisinformaWontomodifythesearchengine’srankingfuncWon
SeeRuSSIR’07,“MachineLearningforWeb‐RelatedProblems”,lecture3.

ExplicitandImplicitAnnotaWons

• AnchortextisthemostimportantrankingfeatureforEnterpriseWebSearch
• ButthequanWtyoftheanchortextisverylimitedintheEnterprise
• CanweuseuserannotaWonsasasubsWtuteforanchortext?
Using Annotations in Enterprise Search
Pavel A. DmitrievDepartment of Computer Science
Cornell UniversityIthaca, NY 14850
Nadav EironGoogle Inc.
1600 Amphitheatre Pkwy.Mountain View, CA 94043∗
Marcus FontouraYahoo! Inc.
701 First AvenueSunnyvale, CA, 94089
Eugene ShekitaIBM Almaden Research Center
650 Harry RoadSan Jose, CA 95120
ABSTRACT
A major difference between corporate intranets and the Internet is
that in intranets the barrier for users to create web pages is much
higher. This limits the amount and quality of anchor text, one of
the major factors used by Internet search engines, making intranet
search more difficult. The social phenomenon at play also means
that spam is relatively rare. Both on the Internet and in intranets,
users are often willing to cooperate with the search engine in im-
proving the search experience. These characteristics naturally lead
to considering using user feedback to improve search quality in in-
tranets. In this paper we show how a particular form of feedback,
namely user annotations, can be used to improve the quality of in-
tranet search. An annotation is a short description of the contents
of a web page, which can be considered a substitute for anchor
text. We propose two ways to obtain user annotations, using ex-
plicit and implicit feedback, and show how they can be integrated
into a search engine. Preliminary experiments on the IBM intranet
demonstrate that using annotations improves the search quality.
Categories and Subject Descriptors
H.3.3 [Information Systems]: Information Search and Retrieval
General Terms
Algorithms, Experimentation, Human Factors
Keywords
Anchortext, Community Ranking, Enterprise Search
1. INTRODUCTIONWith more and more companies having a significant part of their
information shared through a corporate Web space, providing high
quality search for corporate intranets becomes increasingly impor-
tant. It is particularly appealing for large corporations, which often
have intranets consisting of millions of Web pages, physically lo-
cated in multiple cities, or even countries. Recent research shows
∗This work was done while these authors were at IBM AlmadenResearch Center.
Copyright is held by the International World Wide Web Conference Com-mittee (IW3C2). Distribution of these papers is limited to classroom use,and personal use by others.WWW 2006, May 23–26, 2006, Edinburgh, Scotland.ACM 1-59593-323-9/06/0005.
that employees spend a large percentage of their time searching for
information [16]. An improvement in quality of intranet search re-
duces the time employees spend on looking for information they
need to perform their work, directly resulting in increased em-
ployee productivity.
As it was pointed out in [15], social forces driving the develop-
ment of intranets are rather different from the ones on the Internet.
One particular difference, that has implications on search, is that
company employees cannot freely create their own Web pages in
the intranet. Therefore, algorithms based on link structure analysis,
such as PageRank [24], do not apply to intranets the same way they
apply to the Internet. Another implication is that the amount of an-
chor text, one of the major factors used by Internet search engines
[14, 1], is very limited in intranets.
While the characteristics of intranets mentioned above make in-
tranet search more difficult compared to search on the Internet,
there are other characteristics that make it easier. One such char-
acteristic is the absence of spam in intranets. Indeed, there is no
reason for employees to try to spam their corporate search engine.
Moreover, in many cases intranet users are actually willing to co-
operate with the search engine to improve search quality for them-
selves and their colleagues. These characteristics naturally lead to
considering using user feedback to improve search quality in in-
tranets.
In this paper we explore the use of a particular form of feedback,
user annotations, to improve the quality of intranet search. An an-
notation is a short description of the contents of a web page. In
some sense, annotations are a substitute for anchor text.
One way to obtain annotations is to let users explicitly enter an-
notations for the pages they browse. In our system, users can do so
through a browser toolbar. When trying to obtain explicit user feed-
back, it is important to provide users with clear immediate benefits
for taking their time to give the feedback. In our case, the anno-
tation the user has entered shows up in the browser toolbar every
time the user visits the page, providing a quick reminder of what a
page is about. The annotation will also appear on the search engine
results page, if the annotated page is returned as a search result.
While the methods described above provide the user with use-
ful benefits for entering annotations, we have found many users
reluctant to provide explicit annotations. We therefore propose an-
other method for obtaining annotations, which automatically ex-
tracts them from the search engine query log. The basic idea is to
use the queries users submit to the search engine as annotations for
pages users click on. However, the naı̈ve approach of assigning a

ExplicitAnnotaWons• CreateaToolbartoallowusersannotatepagestheyvisit
• ProvideincenWvestoannotate:– PersonalannotaWonappearsinthetoolbareveryWmeuservisitsthepage
– AggregatedannotaWonsfromallusersappearinsearchengineresults
Figure 1: The Trevi Toolbar contains two fields: a search field to search IBM intranet using Trevi, and an annotation field to submit
an annotation for the page currently open in the browser.
query as an annotation to every page the user clicks on may assign
annotations to irrelevant pages. We experiment with several tech-
niques for deciding which pages to attach an annotation to, making
use of the users’ click patterns and the ways they reformulate their
queries.
The main contributions of this paper include:
• A description of the architecture for collecting annotations
and for adding annotations to search indexes.
• Algorithms for generating implicit annotations from query
logs.
• Preliminary experimental results on a real dataset from the
IBM intranet, consisting of 5.5 million web pages, demon-
strating that annotations help to improve search quality.
The rest of the paper is organized as follows. Section 2 briefly re-
views basic Web IR concepts and terminology. Section 3 describes
in detail our methods for collecting annotations. Section 4 explains
how annotations are integrated into the search process. Section 5
presents experimental results. Section 6 discusses related work,
and section 7 concludes the paper.
2. BACKGROUNDIn a Web IR system retrieval of web pages is often based on the
pages’ content plus the anchor text associated with them. Anchor
text is the text given to links to a particular page in other pages that
link to it. Anchor text can be viewed as a short summary of the
content of the page authored by a person who created the link. In
aggregate, anchor text from all incoming links provides an objec-
tive description of the page. Thus, it is not surprising that anchor
text has been shown to be extremely helpful in Web IR [1, 14, 15].
Most Web IR systems use inverted indexes as their main data
structure for full-text indexing [29]. In this paper, we assume an in-
verted index structure. The occurrence of a term t within a pagep is called a posting. The set of postings associated to a termt is stored in a posting list. A posting has the form <pageID,payload>, where pageID is the ID of the page p and where the pay-load is used to store arbitrary information about each occurrence of
t within p. For example, payload can be used to indicate whetherthe term came from the title of the page, from the regular text, or
from the anchor text associated with the page. Here, we use part
of the payload to indicate whether the term t came from content,
anchor text, or annotation of the page and to store the offset within
the document.
For a given query, a set of candidate answers (pages that match
the query words) is selected, and every page is assigned a relevance
score. The score for a page usually contains a query-dependent
textual component, which is based on the page’s similarity to the
query, and a query-independent static component, which is based
on the static rank of the page. In most Web IR systems, the textual
component of the score follows an additive scoring model like tf ×
idf for each term, with terms of different types, e.g. title, text, an-
chor text, weighted differently. Here we adopt a similar model, with
annotation terms weighted the same as terms from anchor text. The
static component can be based on the connectivity of web pages, as
in PageRank [24], or on other factors such as source, length, cre-
ation date, etc. In our system the static rank is based on the site
count, i.e., the number of different sites containing pages that link
to the page under consideration.
3. COLLECTING ANNOTATIONSThis section describes how we collect explicit and implicit an-
notations from users. Though we describe these procedures in the
context of the Trevi search engine for the IBM intranet [17], they
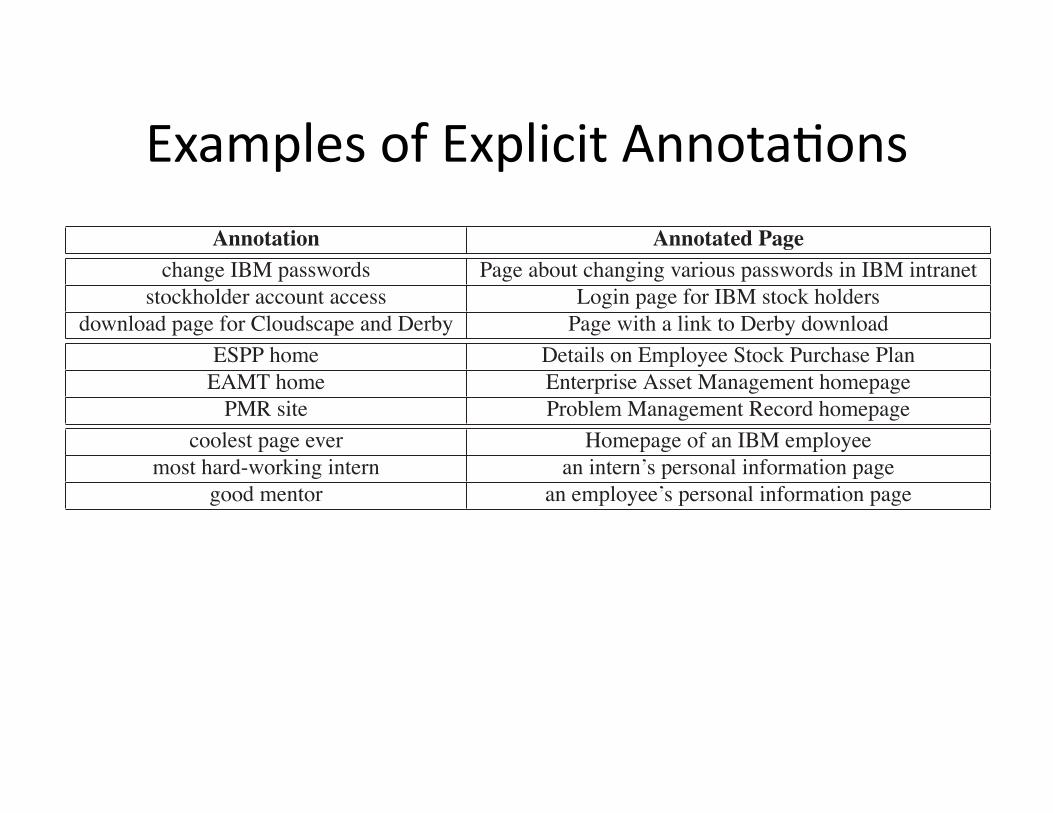
ExamplesofExplicitAnnotaWons
Annotation Annotated Page
change IBM passwords Page about changing various passwords in IBM intranet
stockholder account access Login page for IBM stock holders
download page for Cloudscape and Derby Page with a link to Derby download
ESPP home Details on Employee Stock Purchase Plan
EAMT home Enterprise Asset Management homepage
PMR site Problem Management Record homepage
coolest page ever Homepage of an IBM employee
most hard-working intern an intern’s personal information page
good mentor an employee’s personal information page
Table 1: Examples of Annotations
of annotated pages is 12433 for the first and the third strategies,
8563 for the second strategy, and 4126 for the fourth strategy.
Given the small number of explicit annotations we were able to
collect, relative to the size of the dataset (5.5 million pages), the
results presented below can only be viewed as very preliminary.
Nevertheless, we observed several interesting characteristics of an-
notations, which highlight their usefulness in enterprise search.
5.1 Types of AnnotationsTable 1 shows examples of explicit annotations. The most typi-
cal type of annotations were concise descriptions of what a page is
about, such as the first set of annotations in Table 1. While these
annotations do not usually introduce new words into the descrip-
tion of a page, in many cases they are still able to increase the rank
of the page for relevant queries. Consider, for example, the annota-
tion ”download page for Cloudscape and Derby”, attached to a page
with the link to Derby download. Cloudscape is a popular IBM Java
RDBMS, which was recently renamed Derby and released under an
open source license. Cloudscape has been integrated in many IBM
products, which resulted in frequent co-occurence of the ”down-
load” and ”Cloudscape” on the same page. The renaming also led
to replacement of Cloudscape with Derby on some of the pages. As
a result, neither of the queries ”download Cloudscape” or ”down-
load Derby” return the correct page with a high rank. However,
with the above annotation added to the index, the page is ranked
much higher for both queries, because the keywords occur close to
each other in the annotation, and Trevi’s ranking function takes this
into account.
Another common type of annotations were abbreviations (the
second set in Table 1). At IBM, like at any other big company,
everything is given a formal sounding, long name. Thus, employees
often come up with abbreviations for such names. These abbrevia-
tions, widely used in spoken language, are not always mentioned in
the content of the web pages describing the corresponding entities.
We observed that entering an abbreviation as an annotation for a
page describing a program or a service was a very common type
of annotations. Such annotations are extremely useful for search,
since they augment the page with a keyword that people frequently
use to refer to the page, but which is not mentioned in its content.
The third type of annotations reflect an opinion of a person re-
garding the content of the web page. The last set of annotations
in Table 1 gives examples of such annotations. While a few an-
notations of this type that we have in our dataset do not convey
any serious meaning, such annotations have a potential to collect
opinions of people regarding services or other people, which em-
ployees do not have an opportunity to express otherwise. One can
imagine, for example, that a query like ”best physical training class
at Almaden” will indeed return as the first hit a page describing the
most popular physical training program offered to IBM Almaden
employees, because many people have annotated this page with the
keyword ”best”.
5.2 Impact on Search QualityTo evaluate the impact of annotations on search quality we gener-
ated 158 test queries by taking explicit annotations to be the queries,
and the annotated pages to be the correct answers. We used perfor-
mance of the search engine without annotations as a baseline for
our experiments. Table 2 shows the performance of explicit and
implicit annotations in terms of the percentage of queries for which
the correct answer was returned in the top 10 results.
Baseline EA IA 1 IA 2 IA 3 IA 4
8.9% 13.9% 8.9% 8.9% 9.5% 9.5%
Table 2: Summary of the results measured by the percentage
of queries for which the correct answer was returned in the top
10. EA = Explicit Annotations, IA = Implicit Annotations.
Adding explicit annotations to the index results in statistically
significant at 95% level improvement over the baseline. This is
expected, given the nice properties of annotations mentioned above.
However, even with explicit annotations the results are rather low.
One reason for that is that many of the annotations were attached to
dynamically generated pages, which are not indexed by the search
engine. As mentioned above, only 14 pages out of 67 annotated
pages were actually in the index.
Implicit annotations, on the other hand, did not show any signifi-
cant improvement over the baseline. There was also little difference
among the different implicit annotation strategies. A closer inves-
tigation showed that there was little overlap between the pages that
received implicit annotations, and the ones that were annotated ex-
plicitly. We suspect that, since the users knew that the primary goal
of annotations is to improve search quality, they mostly tried to
enter explicit annotations for pages they could not find using Trevi.
We conclude that a different experimentation approach is needed to
evaluate the true value of implicit annotations, and the differences
among the four annotation strategies.
6. RELATEDWORKThere are three categories of work related to this paper: enter-
prise search, page annotations on the Web, and improving search
quality using user feedback. We discuss each of these categories in
subsequent sections.
6.1 Enterprise SearchWhile there are many companies that offer enterprise search so-
lutions [2, 3, 5, 7], there is surprisingly little work in this area in
the research community.

ImplicitAnnotaWons
• MineannotaWonsfromquerylogs– TreatqueriesasannotaWonsforrelevantpages– WhilesuchannotaWonsareoflowerquality,alargenumberofthemcanbecollectedeasily
• Howtodetermine“relevant”pages?[Joachims02,Radlinski05]
can be implemented with minor modifications on top of any intranet
search engine. One assumption our implementation does rely on is
the identification of users. On the IBM intranet users are identified
by a cookie that contains a unique user identifier. We believe this
assumption is valid as similar mechanisms are widely used in other
intranets as well.
3.1 Explicit AnnotationsThe classical approach to collecting explicit user feedback asks
the user to indicate relevance of items on the search engine results
page, e.g. [28]. A drawback of this approach is that, in many cases,
the user needs to actually see the page to be able to provide good
feedback, but after they got to the page they are unlikely to go back
to the search results page just for the purpose of leaving feedback.
In our system users enter annotations through a toolbar attached
to the Web browser (Figure 1). Each annotation is entered for the
page currently open in the browser. This allows users to submit
annotations for any page, not only for the pages they discovered
through search. This is a particularly promising advantage of our
implementation, as annotating only pages already returned by the
search engine creates a “rich get richer” phenomenon, which pre-
vents new high quality pages from becoming highly ranked in the
search engine[11]. Finally, since annotations appear in the toolbar
every time the user visits the page he or she has annotated, it is easy
for the user to modify or delete their annotations.
Currently, annotations in our system are private, in the sense that
only the user who entered the annotation can see it displayed in the
toolbar or search results. While there are no technical problems
preventing us from allowing users to see and modify each other’s
annotations, we regarded such behavior undesirable and did not
implement it.
3.2 Implicit AnnotationsTo obtain implicit annotations, we use Trevi’s query log, which
records the queries users submit, and the results they click on.
Every log record also contains an associated userID, a cookie auto-
matically assigned to every user logged into the IBM intranet (Fig-
ure 2). The basic idea is to treat the query as an annotation for
pages relevant to the query. While these annotations are of lower
quality than the manually entered ones, a large number of them can
be collected without requiring direct user input. We propose sev-
eral strategies to determine which pages are relevant to the query,
i.e., which pages to attach an annotation to, based on clickthrough
data associated with the query.
LogRecord ::= <Query> | <Click> Query ::= <Time>\t<QueryString>\t<UserID> Click ::= <Time>\t<QueryString>\t<URL>\t<UserID>
Figure 2: Format of the Trevi log file.
The first strategy is based on the assumption that if the user
clicked on a page in the search results, they thought that this page
is relevant to the query in some way. For every Click record, the
strategy produces a (URL, Annotation) pair, where Annotationis the QueryString. This strategy is simple to implement, and
gives a large number of annotations.
The problem with the first strategy is that, since the user only
sees short snippets of page contents on the search results page, it is
possible that the page they clicked on ends up not being relevant to
the query. In this case, the strategy will attach the annotation to an
irrelevant page.
Typically, after clicking on an irrelevant link on a search engine
results page, the user goes back to the results page and clicks on
another page. Our second strategy accounts for this type of behav-
ior, and is based on the notion of a session. A session is a time-
ordered sequence of clicks on search results that the user makes
for a given query. We can extract session data from the query log
based on UserIDs. Our second strategy only produces a (URL,
Annotation) pair for a click record which is the last record in a
session. Annotation is still the QueryString.
The two other strategies we propose try to take into account the
fact that users often reformulate their original query. The strategies
are based on the notion of a query chain [25]. A query chain is a
time-ordered sequence of queries, executed over a short period of
time. The assumption behind using query chains is that all subse-
quent queries in the chain are actually refinements of the original
query.
The third and the fourth strategies for extracting implicit anno-
tations are similar to the previous two, except that they use query
chains instead of individual queries. We extract query chains from
the log file based on the time stamps of the log records. The third
strategy, similarly to the first one, produces a (URL, Annotation)
pair for every click record, but Annotation now is the concate-
nation of all QueryStrings from the corresponding query chain.
Finally, the fourth strategy produces a (URL, Annotation) pair
for a click record which is the last record in the last session in
a query chain, and Annotation is, again, the concatenation of
QueryStrings from the corresponding query chain.
Recent work has demonstrated that the naı̈ve strategy of regard-
ing every clicked page as relevant to the query (our first strategy)
produces biased results, due to the fact that the users are more
likely to click on the higher ranked pages irrespective of their rele-
vance [21]. Our hope is that the session-based strategies will help to
eliminate this bias. However, these strategies produce significantly
smaller amounts of data comparing to the original strategy. Using
query chains helps to increase the amount of data, by increasing the
size of the annotation data added to a page.
3.3 The Value of AnnotationsAnnotations, both explicit and implicit, have the potential to in-
fluence retrieval and ranking in many ways. One particular instance
in which annotations are helpful is in enriching the language used
to describe a concept. Like anchor text, annotations let users use
their own words to describe a concept that the annotated page talks
about. Users’ vocabulary may be radically different in some cases
than the one used by authors. This dichotomy in vocabulary is par-
ticularly prevalent in intranets, where corporate policy dictate that
certain terms be avoided in official documents or web pages. We
expect that the similarity between anchor text vocabulary and query
vocabulary [14] will also be present in annotations. This is obvi-
ously the case for our method of collecting implicit annotations, as
those annotations are just old queries.
As an example, the United States Federal Government went through
a restructuring lately that changed the name of the agency that
is responsible for immigration from “Immigration and Naturaliza-
tion Service”, or INS, to “Unites States Citizenship and Immigra-
tion Services”, or USCIS1. While all formal web pages describing
government immigration-related activities no longer mention the
words “INS”, users might still search by the old, and better known,
name of the agency. We can therefore expect that annotations will
also use these terms. This is true even of implicit annotations, as
many search engines do not force all terms to be present in a search
1While this example does not directly applies to most intranets,similar examples are common in many large intranets.

Strategy1
• Assumeeveryclickedpageisrelevant– Simpletoimplement
– ProducesalargenumberofannotaWons– ButmayasachanannotaWontoanirrelevantpage

Strategy2
• Session=Wmeorderedsequenceofclicksausermakesforagivenquery
• Assumeonlythelastclickinthesessionisrelevant– ProduceslessannotaWons– AvoidsassigningannotaWonstoirrelevantpages

Strategies3&4
• QueryChain=WmeorderedsequenceofqueriesexecutedoverashortperiodofWme
• Strategy3:Assumeeveryclickinthequerychainisrelevant
• Strategy4:Assumeonlythelastclickinthelastsessionofthequerychainisrelevant
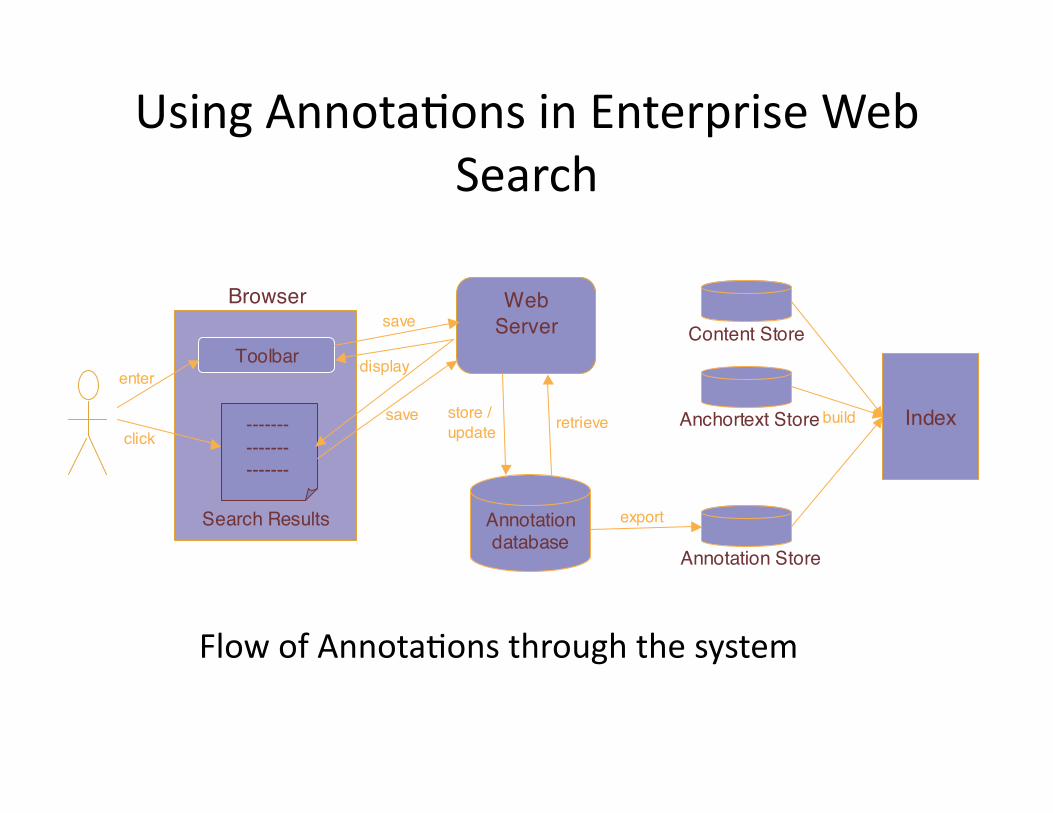
UsingAnnotaWonsinEnterpriseWebSearch
FlowofAnnotaWonsthroughthesystem
Toolbar
Search Results
Browser Web
Server
Annotationdatabase
-------
--------------
Content Store
Anchortext Store
Annotation Store
Index
enter
save
display
store /
updateretrieve
export
build
click
save
Figure 3: Flow of annotations through the system.
result. Thus, someone searching for “INS H1-B visa policies” may
actually find a USCIS page talking about the subject. An implicit
annotation of such a page will still be able to add the term “INS”
to that page, improving its ranking for users using the older terms
in future queries, or in queries where the term “INS” is required to
appear.
4. USING ANNOTATIONS IN INTRANET
SEARCHIn order for annotations to be integrated into the search process,
they must be included in the search engine index. One way to
achieve this is to augment the content of pages with annotations
collected for these pages [22]. However, this does not take into
account the fact that annotations have different semantics. Being
concise descriptions of content, annotations should be treated as
meta-data, rather than content. From this point of view, they are
similar to anchor text [14]. Thus, we decided to use annotations in
a similar way to how anchor text is used in our system.
The flow of annotations through the system is illustrated in Fig-
ure 3. After submitted by the user, explicit annotations are stored in
a database. This database is used to display annotations back to the
user in the toolbar and search results. Periodically (currently once
a day), annotations are exported into an annotation store – a special
format document repository used by our indexing system [17]. The
annotation store is combined with the content store and anchor text
store to produce a new index. This is done by sequentially scanning
these three stores in batch mode and using a disk-based sort merge
algorithm for building the index [17]. Once the new index is ready,
it is substituted for the old one.
The index build algorithm takes the pages from the stores as in-
put and produces the inverted index, which is basically a collection
of posting lists, one list for each token that appears in the corpus.
To reduce storage and I/O costs, posting lists are compressed us-
ing a simple variable-byte scheme based on computing the deltas
between positions.
As the stores are scanned, tokens from each page are streamed
into a sort, which is used to create the posting lists. The primary
sort key is on token, the secondary sort key is on the pageID, and
the tertiary sort key is on offset within a document. By sorting on
this compound key, token occurrences are effectively grouped into
ordered posting lists.
Since we use an optimized fixed-width radix sort [12, 26], we
hash the variable length tokens to produce a 64-bit token hash.
Therefore our sort key has the form (tokenID, pageID, section/offset),
where tokenID is a 64-bit hash value, pageID is 32 bits, and sec-
tion/offset within a document is 32 bits. The encoding of the sort
key is illustrated in Figure 4. In the posting list data structure the
section/offset is stored in the payload for each posting entry.
As shown in Figure 4, we use two bits to denote the section of
a document. This is so a given document can be streamed into
the sort in different sections. To index anchor text and annotation
tokens, the anchor and annotation stores are scanned and streamed
into the sort after the content store is scanned. The section bits
are used to indicate whether a token is for content, anchor text, or
annotation. Consequently, after sorting, the anchor text tokens for a
page P follow the content tokens for P , and the annotations tokensfollow the anchor text.
tokenID (64 bits) pageID (32 bits) offset (30 bits)
section (2 bits)
00 = content
01 = anchor text10 = annotation
payload
tokenID (64 bits) pageID (32 bits) offset (30 bits)
section (2 bits)
00 = content
01 = anchor text10 = annotation
payload
Figure 4: Sort key used to sort content, anchor text, and anno-
tation tokens
Within each pageP , tokens are streamed into the sort in the orderin which they appear in P , that is, in offset order. Taking advantageof the fact that radix sort is stable, this allows us to use a 96-bit sort
key that excludes offset, rather than sorting on the full 128-bit key.
Currently, for retrieval and ranking purposes annotations are treated
as if they were anchor text. However, one can imagine a ranking
function that would treat annotations and anchor text differently.
Experimenting in this direction is one of the areas for our future
work.
The process for including implicit annotations is similar, except
that the annotation store is built from search engine log files instead
of the database.
5. EXPERIMENTAL RESULTSIn this section we present experimental results for search with
explicit and implicit annotations. We implemented our approaches
on the Trevi search engine for the IBM intranet, currently searching
more than 5.5 million pages.
The explicit annotations dataset consists of 67 pages, annotated
with a total of 158 annotations by users at IBM Almaden Research
Center over a period of two weeks during summer 2005. Out of
the 67 annotated pages, 14 were contained in the Trevi index. The
implicit annotations dataset consists of annotations extracted from
Trevi log files for a period of approximately 3 months. The number

ExperimentalResults
• Dataset:5.5MindexofIBMintranet• Queries:158testquerieswithmanuallyidenWfiedcorrectanswers
• EvaluaWonwasconductedauer2weekssincestarWngcollecWngtheannotaWons
Annotation Annotated Page
change IBM passwords Page about changing various passwords in IBM intranet
stockholder account access Login page for IBM stock holders
download page for Cloudscape and Derby Page with a link to Derby download
ESPP home Details on Employee Stock Purchase Plan
EAMT home Enterprise Asset Management homepage
PMR site Problem Management Record homepage
coolest page ever Homepage of an IBM employee
most hard-working intern an intern’s personal information page
good mentor an employee’s personal information page
Table 1: Examples of Annotations
of annotated pages is 12433 for the first and the third strategies,
8563 for the second strategy, and 4126 for the fourth strategy.
Given the small number of explicit annotations we were able to
collect, relative to the size of the dataset (5.5 million pages), the
results presented below can only be viewed as very preliminary.
Nevertheless, we observed several interesting characteristics of an-
notations, which highlight their usefulness in enterprise search.
5.1 Types of AnnotationsTable 1 shows examples of explicit annotations. The most typi-
cal type of annotations were concise descriptions of what a page is
about, such as the first set of annotations in Table 1. While these
annotations do not usually introduce new words into the descrip-
tion of a page, in many cases they are still able to increase the rank
of the page for relevant queries. Consider, for example, the annota-
tion ”download page for Cloudscape and Derby”, attached to a page
with the link to Derby download. Cloudscape is a popular IBM Java
RDBMS, which was recently renamed Derby and released under an
open source license. Cloudscape has been integrated in many IBM
products, which resulted in frequent co-occurence of the ”down-
load” and ”Cloudscape” on the same page. The renaming also led
to replacement of Cloudscape with Derby on some of the pages. As
a result, neither of the queries ”download Cloudscape” or ”down-
load Derby” return the correct page with a high rank. However,
with the above annotation added to the index, the page is ranked
much higher for both queries, because the keywords occur close to
each other in the annotation, and Trevi’s ranking function takes this
into account.
Another common type of annotations were abbreviations (the
second set in Table 1). At IBM, like at any other big company,
everything is given a formal sounding, long name. Thus, employees
often come up with abbreviations for such names. These abbrevia-
tions, widely used in spoken language, are not always mentioned in
the content of the web pages describing the corresponding entities.
We observed that entering an abbreviation as an annotation for a
page describing a program or a service was a very common type
of annotations. Such annotations are extremely useful for search,
since they augment the page with a keyword that people frequently
use to refer to the page, but which is not mentioned in its content.
The third type of annotations reflect an opinion of a person re-
garding the content of the web page. The last set of annotations
in Table 1 gives examples of such annotations. While a few an-
notations of this type that we have in our dataset do not convey
any serious meaning, such annotations have a potential to collect
opinions of people regarding services or other people, which em-
ployees do not have an opportunity to express otherwise. One can
imagine, for example, that a query like ”best physical training class
at Almaden” will indeed return as the first hit a page describing the
most popular physical training program offered to IBM Almaden
employees, because many people have annotated this page with the
keyword ”best”.
5.2 Impact on Search QualityTo evaluate the impact of annotations on search quality we gener-
ated 158 test queries by taking explicit annotations to be the queries,
and the annotated pages to be the correct answers. We used perfor-
mance of the search engine without annotations as a baseline for
our experiments. Table 2 shows the performance of explicit and
implicit annotations in terms of the percentage of queries for which
the correct answer was returned in the top 10 results.
Baseline EA IA 1 IA 2 IA 3 IA 4
8.9% 13.9% 8.9% 8.9% 9.5% 9.5%
Table 2: Summary of the results measured by the percentage
of queries for which the correct answer was returned in the top
10. EA = Explicit Annotations, IA = Implicit Annotations.
Adding explicit annotations to the index results in statistically
significant at 95% level improvement over the baseline. This is
expected, given the nice properties of annotations mentioned above.
However, even with explicit annotations the results are rather low.
One reason for that is that many of the annotations were attached to
dynamically generated pages, which are not indexed by the search
engine. As mentioned above, only 14 pages out of 67 annotated
pages were actually in the index.
Implicit annotations, on the other hand, did not show any signifi-
cant improvement over the baseline. There was also little difference
among the different implicit annotation strategies. A closer inves-
tigation showed that there was little overlap between the pages that
received implicit annotations, and the ones that were annotated ex-
plicitly. We suspect that, since the users knew that the primary goal
of annotations is to improve search quality, they mostly tried to
enter explicit annotations for pages they could not find using Trevi.
We conclude that a different experimentation approach is needed to
evaluate the true value of implicit annotations, and the differences
among the four annotation strategies.
6. RELATEDWORKThere are three categories of work related to this paper: enter-
prise search, page annotations on the Web, and improving search
quality using user feedback. We discuss each of these categories in
subsequent sections.
6.1 Enterprise SearchWhile there are many companies that offer enterprise search so-
lutions [2, 3, 5, 7], there is surprisingly little work in this area in
the research community.

• WanttogeneratepersonalizedwebpageannotaWonsbasedondocumentsontheuser’sDesktop
• SupposewehaveanindexofDesktopdocumentsontheuser’scomputer(files,email,browsercache,etc.)
P-TAG: Large Scale Automatic Generation ofPersonalized Annotation TAGs for the Web
Paul - Alexandru Chirita1∗, Stefania Costache1, Siegfried Handschuh2, Wolfgang Nejdl1
1L3S Research Center / University of Hannover, Appelstr. 9a, 30167 Hannover, Germany{chirita,costache,nejdl}@l3s.de
2National University of Ireland / DERI, IDA Business Park, Lower Dangan, Galway, [email protected]
ABSTRACTThe success of the Semantic Web depends on the availability ofWeb pages annotated with metadata. Free form metadata or tags, asused in social bookmarking and folksonomies, have become moreand more popular and successful. Such tags are relevant keywordsassociated with or assigned to a piece of information (e.g., a Webpage), describing the item and enabling keyword-based classifica-tion. In this paper we propose P-TAG, a method which automat-ically generates personalized tags for Web pages. Upon browsinga Web page, P-TAG produces keywords relevant both to its textualcontent, but also to the data residing on the surfer’s Desktop, thusexpressing a personalized viewpoint. Empirical evaluations withseveral algorithms pursuing this approach showed very promisingresults. We are therefore very confident that such a user orientedautomatic tagging approach can provide large scale personalizedmetadata annotations as an important step towards realizing the Se-mantic Web.
Categories and Subject DescriptorsH.3.1 [Information Storage and Retrieval]: Content Analysisand Indexing; H.3.5 [Information Storage and Retrieval]: On-line Information Services
General TermsAlgorithms, Experimentation, Design
KeywordsWeb Annotations, Tagging, Personalization, User Desktop
1. INTRODUCTIONThe World Wide Web has had a tremendous impact on society
and business in recent years by making information instantly andubiquitously available. The Semantic Web is seen as an extensionof the WWW, a vision of a future Web of machine-understandabledocuments and data. One its main instruments are the annotations,which enrich content with metadata in order to ease its automaticprocessing. The traditional paradigm of Semantic Web annotation∗Part of this work was performed while the author was visitingYahoo! Research, Barcelona, Spain.
Copyright is held by the International World Wide Web Conference Com-mittee (IW3C2). Distribution of these papers is limited to classroom use,and personal use by others.WWW 2007, May 8–12, 2007, Banff, Alberta, Canada.ACM 978-1-59593-654-7/07/0005.
(i.e., annotating Web sites with the help of external tools) has beenestablished for a number of years by now, for example in the formof applications such as OntoMat [20] or tools based on Annotea[23], and the process continues to develop and improve. However,this paradigm is based on manual or semi-automatic annotation,which is a laborious, time consuming task, requiring a lot of expertknow-how, and thus only applicable to small-scale or Intranet col-lections. For the overall Web though, the growth of a Semantic Weboverlay is restricted because of the lack of annotated Web pages. Inthe same time, the tagging paradigm, which has its roots in socialbookmarking and folksonomies, is becoming more and more pop-ular. A tag is a relevant keyword associated with or assigned to apiece of information (e.g., a Web page), describing the item andenabling keyword-based classification of the information it is ap-plied to. The successful application of the tagging paradigm can beseen as evidence that a lowercase semantic Web1 could be easier tograsp for the millions of Web users and hence easier to introduce,exploit and benefit from. One can then build upon this lowercasesemantic web as a basis for the introduction of more semantics,thus advancing further towards the Web 2.0 ideas.
We argue that a successful and easy achievable approach is toautomatically generate annotation tags for Web pages in a scalablefashion. We use tags in their general sense, i.e., as a mechanism toindicate what a particular document is about [4], rather than for ex-ample to organize one’s tasks (e.g., “todo”). Yet automatically gen-erated tags have the drawback of presenting only a generic view,which does not necessary reflect personal interests. For example, aperson might categorize the home page of Anthony Jameson2 withthe tags “human computer interaction” and “mobile computing”,because this reflects her research interests, while another would an-notate it with the project names “Halo 2” and “MeMo”, becauseshe is more interested in research applications.
The crucial question is then how to automatically tag Web pagesin a personalized way. In many environments, defining a user’sviewpoint would rely on the definition of an interest profile. How-ever, these profiles are laborious to create and need constant main-tenance in order to reflect the changing interest of the user. Fortu-nately, we do have a rich source of user profiling information avail-able: everything stored on her computer. This personal Desktopusually contains a very rich document corpus of personal informa-tion which can and should be exploited for user personalization!There is no need to maintain a dedicated interest profile, since the
1Lowercase semantic web refers to an evolutionary approach forthe Semantic Web by adding simple meaning gradually into thedocuments and thus lowering the barriers for re-using information.2http://www.dfki.de/˜jameson
WWW 2007 / Track: Semantic Web Session: Semantic Web and Web 2.0
845

ExtracWngtagsfromDesktopdocuments
• Givenawebpagetoannotate,thealgorithmproceedsasfollows:– Step1:Extractimportantkeywordsfromthepage– Step2:RetrieverelevantdocumentsusingtheDesktopsearch
– Step3:ExtractimportantkeywordsfromtheretrieveddocumentsasannotaWons
• Usersjudged70%‐80%ofannotaWonscreatedusingthisalgorithmasrelevant

• WhenhavelotsofannotaWonsforagivenpage,whichonesshouldweuse?
• ThispaperproposestoperformfrequentitemsetminingtoextractrecurringgroupsoftermsfromannotaWons– ShowthatthistypeofprocessingisusefulforwebpageclassificaWon
– MayalsobeusefulforimprovingsearchqualitybyeliminaWngnoisyterms
Query-Sets: Using Implicit Feedback and Query Patternsto Organize Web Documents
Barbara PobleteWeb Research Group
University Pompeu FabraBarcelona, Spain
Ricardo Baeza-YatesYahoo! Research &
Barcelona Media Innovation CenterBarcelona, Spain
ABSTRACT
In this paper we present a new document representationmodel based on implicit user feedback obtained from searchengine queries. The main objective of this model is to achievebetter results in non-supervised tasks, such as clustering andlabeling, through the incorporation of usage data obtainedfrom search engine queries. This type of model allows usto discover the motivations of users when visiting a certaindocument. The terms used in queries can provide a betterchoice of features, from the user’s point of view, for summa-rizing the Web pages that were clicked from these queries. Inthis work we extend and formalize as query model an exist-ing but not very well known idea of query view for documentrepresentation. Furthermore, we create a novel model basedon frequent query patterns called the query-set model. Ourevaluation shows that both query-based models outperformthe vector-space model when used for clustering and labelingdocuments in a website. In our experiments, the query-setmodel reduces by more than 90% the number of featuresneeded to represent a set of documents and improves byover 90% the quality of the results. We believe that thiscan be explained because our model chooses better featuresand provides more accurate labels according to the user’sexpectations.
Categories and Subject Descriptors
H.3.3 [Information Search and Retrieval]: Clustering; H.2.8 [Information Systems]: Data Mining; H.4.m [Information Systems Applications]: Miscella-neous
General Terms
Algorithms, Experimentation, Human Factors
Keywords
Feature Selection, Labeling, Search Engine Queries, UsageMining, Web Page Organization
1. INTRODUCTIONAs the Web’s contents grow, it becomes increasingly dif-
ficult to manage and classify its information. Optimal or-ganization is especially important for websites, for example,
Copyright is held by the International World Wide Web Conference Com-mittee (IW3C2). Distribution of these papers is limited to classroom use,and personal use by others.WWW 2008, April 21–25, 2008, Beijing, China.ACM 978-1-60558-085-2/08/04.
where classification of documents into cohesive and relevanttopics is essential to make a site easier to navigate and moreintuitive to its visitors. The high level of competition in theWeb makes it necessary for websites to improve their orga-nization in a way that is both automatic and effective, sousers can reach effortlessly what they are looking for. Webpage organization has other important applications. Searchengine results can be enhanced by grouping documents intosignificant topics. These topics can allow users to disam-biguate or specify their searches quickly. Moreover, searchengines can personalize their results for users by rankinghigher the results that match the topics that are relevant tousers’ profiles. Other applications that can benefit from au-tomatic topic discovery and classification are human editeddirectories, such as DMOZ1 or Yahoo!2. These directoriesare increasingly hard to maintain as the contents of the Webgrow. Also, automatic organization of Web documents isvery interesting from the point of view of discovering newinteresting topics. This would allow to keep up with user’strends and changing interests.
The task of automatically clustering, labeling and clas-sifying documents in a website is not an easy one. Usuallythese problems are approached in a similar way for Web doc-uments and for plain text documents, even if it is known thatWeb documents contain richer and, sometimes, implicit in-formation associated to them. Traditionally, documents arerepresented based on their text, or in some cases, also usingsome kind of structural information of Web documents.
There are two main types of structural information thatcan be found in Web documents: HTML formatting, whichsometimes allows to identify important parts of a document,such as title and headings, and link information betweenpages [15]. The formatting information provided by HTMLis not always reliable, because tags are more often used forstyling purposes than for content structuring. Informationgiven by links, although useful for general Web documents,is not of much value when working with documents from aparticular website, because in this case, we cannot assumethat this data has any objectiveness, i.e.: any informationextracted from the site’s structure about that same site, isa reflection of the webmaster’s criteria, which provides nowarranty of being thorough or accurate, and might be com-pletely arbitrary. A clear example of this, is that manywebsites that have large amounts of contents, use some kindof content management system and/or templates, that givepractically the same structure to all pages and links within
1http://www.dmoz.org2http://www.yahoo.com
41
WWW 2008 / Refereed Track: Data Mining - Log Analysis April 21-25, 2008 · Beijing, China

Summary
• UserAnnotaWonscanhelpimprovesearchqualityintheEnterprise
• AnnotaWonscanbecollectedbyexplicitlyaskinguserstoprovidethem,orbyminingquerylogsandusers’Desktopcontents
• Post‐processingtheresulWngannotaWonsmayhelptoimprovethesearchquality

SocialAnnotaWons

Tagging• Easywayfortheuserstoannotatewebobjects• Peopledoit(noonereallyknowswhy)

Tagging
• VerypopularontheWeb,becomingmoreandmorepopularintheEnterprise– Usersaddtagstoobjects(pages,pictures,messages,etc.)
– TaggingSystemkeepstrackof<user,obj,tag>triplesandmines/organizesthisinformaWonforpresenWngittotheuser(moreinLecture3)
• Inthislecturewewillseehowtagscanbeusedtoimprovesearchinenterpriseweb

UsingTaggingtoImproveSearch
• Approach1:Mergetagswithcontentoranchortext
• Approach2:Keeptagsseparateandrankqueryresultsby
α×content_match+(1–α)×tag_match
• Otherapproaches:explorethesocial/collaboraWveproperWesoftags– Givemoreweighttosomeusersandtagsvsothers– ComputesimilariWesbetweentagsanddocumentsandincorporateitintoranking

• ObservaWon:similar(semanWcallyrelated)annotaWonsareusuallyassignedtosimilar(semanWcallyrelated)webpages– ThesimilarityamongannotaWonscanbeidenWfiedbysimilarwebpagestheyareassignedto
– ThesimilarityamongwebpagescanbeidenWfiedbysimilarannotaWonstheyareannotatedwith
• ProposediteraWvealgorithmtocomputethesesimilariWesandusethemtoimproveranking
!"#$%$&$'()*+,)-+./01)23$'()-40$.5)6''4#.#$4'3)!"#$%"&'()'*+,-(./'*0&'$(1&+,-()#$(2#/3-(4&/5*$%(.&#+-(6"*$%(!&3-('$7(8*$%(8&+(
(+!"'$%"'/(9/'*:*$%(;$/<#5=/>0(!"'$%"'/-(3??3@?-(A"/$'(
B=""C'*-(D&E0-(%5E&#-(00&FG'H#EI=J>&I#7&IK$(
((((3L)M(A"/$'(N#=#'5K"(O'C()#/J/$%-(+???P@-(A"/$'(
BQ#/C#$-(=&R"*$%FGK$I/CSIK*S(
!
!"#$%!&$!"#$%!&'&()!(*&+,)(%!-#(!.%(!,/!%,0$'+!'11,-'-$,1%!-,!$2&),3(!4(5!
%(')0#6! 7,4'8'9%:! 2'19! %()3$0(%:! (6;6! 8(+6$0$,6.%:! #'3(! 5((1!
8(3(+,&(8!/,)!4(5!.%()%!-,!,);'1$<(!'18!%#')(!-#($)!/'3,)$-(!4(5!
&';(%! ,1! +$1(! 59! .%$1;! %,0$'+! '11,-'-$,1%6!=(! ,5%()3(! -#'-! -#(!
%,0$'+! '11,-'-$,1%! 0'1! 5(1(/$-!4(5! %(')0#! $1! -4,! '%&(0-%>! ?@! -#(!
'11,-'-$,1%! ')(! .%.'++9! ;,,8! %.22')$(%! ,/! 0,))(%&,18$1;! 4(5!
&';(%A!B@!-#(!0,.1-!,/!'11,-'-$,1%!$18$0'-(%!-#(!&,&.+')$-9!,/!4(5!
&';(%6! "4,! 1,3(+! '+;,)$-#2%! ')(! &),&,%(8! -,! $10,)&,)'-(! -#(!
'5,3(! $1/,)2'-$,1! $1-,! &';(! )'1C$1;>! ?@! D,0$'+D$2E'1C! FDDE@!
0'+0.+'-(%! -#(! %$2$+')$-9! 5(-4((1! %,0$'+! '11,-'-$,1%! '18! 4(5!
G.()$(%A!B@!D,0$'+H';(E'1C!FDHE@!0'&-.)(%!-#(!&,&.+')$-9!,/!4(5!
&';(%6! H)(+$2$1')9! (*&()$2(1-'+! )(%.+-%! %#,4! -#'-! DDE! 0'1! /$18!
-#(! +'-(1-! %(2'1-$0! '%%,0$'-$,1! 5(-4((1!G.()$(%! '18! '11,-'-$,1%:!
4#$+(!DHE!%.00(%%/.++9!2('%.)(%!-#(!G.'+$-9!F&,&.+')$-9@!,/!'!4(5!
&';(! /),2! -#(! 4(5! .%()%I! &()%&(0-$3(6! =(! /.)-#()! (3'+.'-(! -#(!
&),&,%(8! 2(-#,8%! (2&$)$0'++9! 4$-#! JK! 2'1.'++9! 0,1%-).0-(8!
G.()$(%! '18! LKKK! '.-,M;(1()'-(8! G.()$(%! ,1! '! 8'-'%(-! 0)'4+(8!
/),2! 8(+6$0$,6.%6! N*&()$2(1-%! %#,4! -#'-! 5,-#! DDE! '18! DHE!
5(1(/$-!4(5!%(')0#!%$;1$/$0'1-+96!!
&'()*+,-)./'01/#234)5(/6).5,-7(+,.!O6L6L!P809+,:'(-+0/#;.():.Q>!R1/,)2'-$,1!D(')0#!'18!E(-)$(3'+6!
<)0),'=/$),:.>!S+;,)$-#2%:!N*&()$2(1-'-$,1:!O.2'1!T'0-,)%6!
?);@+,1.>/D,0$'+!'11,-'-$,1:!%,0$'+!&';(!)'1C:!%,0$'+!%$2$+')$-9:!4(5!%(')0#:!(3'+.'-$,1!
AB) 8C$%D6E&$8DC/U3()!-#(!&'%-!8(0'8(:!2'19!%-.8$(%!#'3(!5((1!8,1(!,1!$2&),3$1;!
-#(! G.'+$-9! ,/! 4(5! %(')0#6! V,%-! ,/! -#(2! 0,1-)$5.-(! /),2! -4,!
'%&(0-%>! ?@! ,)8()$1;! -#(! 4(5! &';(%! '00,)8$1;! -,! -#(! G.()9M
8,0.2(1-! %$2$+')$-96! D-'-(M,/M-#(M')-! -(0#1$G.(%! $10+.8(! '10#,)!
-(*-! ;(1()'-$,1! PB?:! BW:! LXQ:! 2(-'8'-'! (*-)'0-$,1! PLYQ:! +$1C!
'1'+9%$%! PLXQ:! '18! %(')0#! +,;! 2$1$1;! P?KQA! B@! ,)8()$1;! -#(! 4(5!
&';(%! '00,)8$1;! -,! -#($)! G.'+$-$(%6! R-! $%! '+%,! C1,41! '%! G.()9M
$18(&(18(1-!)'1C$1;:!,)!%-'-$0!)'1C$1;6!T,)!'!+,1;!-$2(:!-#(!%-'-$0!
)'1C$1;! $%! 8()$3(8! 5'%(8! ,1! +$1C! '1'+9%$%:! (6;6:! H';(E'1C! P?YQ:!
OR"D! P?JQ6! E(0(1-+9:! -#(! /('-.)(%! ,/! 0,1-(1-! +'9,.-:! .%()! 0+$0CM
-#),.;#%! (-06! ')(! '+%,! (*&+,)(8:! (6;6:! /E'1CP?ZQ6! [$3(1! '! G.()9:!
-#(! )(-)$(3(8! )(%.+-%! ')(! )'1C(8! 5'%(8! ,1! 5,-#! &';(! G.'+$-9! '18!
G.()9M&';(!%$2$+')$-96!
E(0(1-+9:!4$-#!-#(!)$%(!,/!=(5!B6K!-(0#1,+,;$(%:!4(5!.%()%!4$-#!
8$//()(1-! 5'0C;),.18%! ')(! 0)('-$1;! '11,-'-$,1%! /,)!4(5! &';(%! '-!
'1! $10)(8$5+(! %&((86! T,)! (*'2&+(:! -#(! /'2,.%! %,0$'+! 5,,C2')C!
4(5! %$-(:! 8(+6$0$,6.%! PXQ! F#(10(/,)-#! )(/())(8! -,! '%! \](+$0$,.%^@:!
#'%! 2,)(! -#'1! ?! 2$++$,1! )(;$%-()(8! .%()%! %,,1! '/-()! $-%! -#$)8!
5$)-#8'9:! '18! -#(! 1.25()! ,/! ](+$0$,.%! .%()%! #'3(! $10)('%(8! 59!
2,)(!-#'1!BKK_!$1!-#(!&'%-!1$1(!2,1-#%!P?LQ6!D,0$'+!'11,-'-$,1%!
')(!(2();(1-!.%(/.+!$1/,)2'-$,1!-#'-!0'1!5(!.%(8!$1!3')$,.%!4'9%6!
D,2(!4,)C!#'%!5((1!8,1(!,1!(*&+,)$1;!-#(!%,0$'+!'11,-'-$,1%!/,)!
/,+C%,1,29!PBQ:!3$%.'+$<'-$,1!P?WQ:!%(2'1-$0!4(5!PL`Q:!(1-()&)$%(!
%(')0#! PBLQ! (-06! O,4(3():! -,! -#(! 5(%-! ,/! ,.)! C1,4+(8;(:! +$--+(!
4,)C!#'%!5((1!8,1(!,1!$1-(;)'-$1;!-#$%!3'+.'5+(!$1/,)2'-$,1!$1-,!
4(5!%(')0#6!O,4!-,!.-$+$<(!-#(!'11,-'-$,1%!(//(0-$3(+9!-,!$2&),3(!
4(5!%(')0#!5(0,2(%!'1!$2&,)-'1-!&),5+(26!!
R1! -#$%! &'&():! 4(! %-.89! -#(! &),5+(2! ,/! .-$+$<$1;! %,0$'+!
'11,-'-$,1%! /,)! 5(--()! 4(5! %(')0#:! 4#$0#! $%! '+%,! )(/())(8! -,! '%!
\%,0$'+!%(')0#^!/,)!%$2&+$0$-96!V,)(!%&(0$/$0'++9:!4(!,&-$2$<(!4(5!
%(')0#! 59! .%$1;! %,0$'+! '11,-'-$,1%! /),2! -#(! /,++,4$1;! -4,!
'%&(0-%>!!!
!( #-:-=',-(;/ ,'0F-0*:! 4#$0#! 2('1%! -#(! (%-$2'-(8!
%$2$+')$-9! 5(-4((1! '! G.()9! '18! '! 4(5! &';(6! "#(!
'11,-'-$,1%:! &),3$8(8! 59! 4(5! .%()%! /),2! 8$//()(1-!
&()%&(0-$3(%:! ')(! .%.'++9! ;,,8! %.22')$(%! ,/! -#(!
0,))(%&,18$1;! 4(5! &';(%6! T,)! (*'2&+(:! -#(! -,&! J!
'11,-'-$,1%! ,/! S2'<,1I%! #,2(&';( ? !$1! ](+$0$,.%! ')(!
"#$%%&'()!*$$+")!,-,.$')!-/"&0!'18!"1$23)!4#$0#!8(&$0-!
-#(! &';(! ,)! (3(1! -#(! 4#,+(! 4(5%$-(! (*'0-+96! "#(%(!
'11,-'-$,1%! &),3$8(! '! 1(4! 2(-'8'-'! /,)! -#(! %$2$+')$-9!
0'+0.+'-$,1! 5(-4((1! '! G.()9! '18! '!4(5! &';(6!O,4(3():!
/,)! '! %&(0$/$0! 4(5! &';(:! -#(! '11,-'-$,1! 8'-'! 2'9! 5(!
%&')%(! '18! $10,2&+(-(6!"#()(/,)(:! '!2'-0#$1;!;'&! (*$%-%!
5(-4((1! -#(! '11,-'-$,1%! '18! G.()$(%! F(6;6:! 5(-4((1!
\%#,&^!'18!\%#,&&$1;^@6!O,4!-,!5)$8;(!-#(!;'&!)(2'$1%!'!
0).0$'+! &),5+(2! $1! /.)-#()! $2&),3$1;! -#(! %$2$+')$-9!
)'1C$1;6! =(! &),&,%(! '! 1(4! %$2$+')$-9! (%-$2'-$,1!
'+;,)$-#2:!D,0$'+D$2E'1C!FDDE@!-,!'88)(%%!-#$%!&),5+(26!
!( #('(-5/ ,'0F-0*:! -#(!'2,.1-!,/!'11,-'-$,1%!'%%$;1(8! -,!'!
&';(! $18$0'-(%! $-%! &,&.+')$-9! '18! $2&+$(%! $-%! G.'+$-9! $1!
%,2(!%(1%(:!9(-!-)'8$-$,1'+!%-'-$0!)'1C$1;!'+;,)$-#2%!%.0#!
'%!H';(E'1C!#'3(!1,!4'9!-,!2('%.)(!-#$%!C$18!,/!G.'+$-96!
T,)! (*'2&+(:! -#,.%'18%! ,/! ](+$0$,.%! .%()%! 0,++(0-! -#(!
&,&.+')!&'--()1!$1-),8.0-$,1!&';(B!'%!-#($)!/'3,)$-(!4$-#!'!
3')$(-9!,/! '11,-'-$,1%:!5.-! -#$%! %$-(! $%! ;$3(1! '!H';(E'1C!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!
a! H')-! ,/! D#(1;#.'! b',! '18!c$',9.'1!=.d%!4,)C! ,/! -#$%! &'&()!
4'%!0,18.0-(8!$1!RbV!e#$1'!E(%(')0#!f'56!
?!#--&>gg4446'2'<,160,2!
B!!#--&>ggLY%$;1'+%60,2g&'&()%g$1-),-,&'--()1%g!
!
e,&9)$;#-! $%!#(+8!59! -#(! R1-()1'-$,1'+!=,)+8!=$8(!=(5!e,1/()(10(!
e,22$--((! FR=LeB@6! ]$%-)$5.-$,1! ,/! -#(%(! &'&()%! $%! +$2$-(8! -,!
0+'%%),,2!.%(:!'18!&()%,1'+!.%(!59!,-#()%6!
444!5667:!V'9!Wh?B:!BKKY:!b'1//:!S+5()-':!e'1'8'6!
SeV!ZYWM?MJZJZLM`JXMYgKYgKKKJ6!
WWW 2007 / Track: Search Session: Search Quality and Precision
501

SimilarityofannotaWonsaiandaj
Similarityofpagespiandpj
Sumoverallpairsofpagesannotatedwithaioraj
SumoverallpairsofannotaWonsassignedtoaioraj
!"# $%&'# ()$'$*# $%&'# +),'$#&)-# (%".)/"# %"0-# .1'# )""%.)./%"#
2!"!#$!3# '4,4*# 5'6# +),'# %4# 71'"# ,/8'"# .1'# 9:';-# (%".)/"/",#
2&'#!(3*# .1'# +),'# .1).# %"0-# 1)$# 2!"!#$!3# &)-# 6'# </0.';'=# %:.#
/&+;%+';0-# 6-# $/&+0'# .';&>&).(1/",# &'.1%=4# ?8'"# /<# .1'# +),'#
(%".)/"$#6%.1#)""%.)./%"$#2!"!#$!3#)"=#2&'#!(3*#/.#/$#"%.#+;%+';#.%#
()0(:0).'#.1'#$/&/0);/.-#6'.5''"#.1'#9:';-#)"=#.1'#=%(:&'".#:$/",#
.1'# @'-5%;=# 2&'#!(3# %"0-4#A"# 'B+0%;)./%"# %<# $/&/0);/.-# 6'.5''"#
2!"!#$!3#)"=#2&'#!(3#&)-#<:;.1';#/&+;%8'#.1'#+),'#;)"@/",4#
7%#'B+0%;'#.1'#)""%.)./%"$#5/.1#$/&/0);#&')"/",$*#5'#6:/0=#)#
6/+);./.'>,;)+1#6'.5''"#$%(/)0#)""%.)./%"$#)"=#5'6#+),'$#5/.1#/.$#
'=,'$# /"=/()./",# .1'# :$';# (%:".4# A$$:&'# .1).# .1';'# );'# )*#
)""%.)./%"$*#)+#5'6#+),'$#)"=#),#5'6#:$';$4#-*+# /$# .1'#)*C)+#
)$$%(/)./%"# &).;/B# 6'.5''"# )""%.)./%"$# )"=# +),'$4# -*+D%(./0E#
='"%.'$#.1'#":&6';#%<#:$';$#51%#)$$/,"#)""%.)./%"#%(#.%#+),'#/04#
F'../",12*16'#.1'#)*C)*#&).;/B#51%$'#'0'&'".#2*D%'*#%3E#/"=/().'$#
.1'# $/&/0);/.-# $(%;'# 6'.5''"# )""%.)./%"$#%'# )"=#%3# )"=#2+16'# .1'1
)+C)+# &).;/B# ')(1# %<# 51%$'# '0'&'".# $.%;'$# .1'# $/&/0);/.-##
6'.5''"# .5%# 5'6# +),'$*# 5'# +;%+%$'# G%(/)0G/&H)"@DGGHE*# )"#
/.';)./8'# )0,%;/.1&# .%# 9:)"./.)./8'0-# '8)0:).'# .1'# $/&/0);/.-#
6'.5''"#)"-#.5%#)""%.)./%"$4#
!"#$%&'()*+,*-$.&/"-&)0/12*3--04*
-'56*+# !"#$%&&&&&&'($&2*I#D%'*#%3E#J#K#<%;#')(1#%'1J#%3#%.1';5/$'#I#
2+I#D/'*#/3E#J#K#<%;#')(1#/'1J#/3#%.1';5/$'#I&
-'56*7* )*&8&
+*,&(-./&)""%.)./%"#+)/;#D%'.1%3E&0*&
#
! !" "
#"
ELDL
K
ELDL
K
K
EEDE*DDEE*DE**D&)BD
EE*DE**D&/"D
LEDLLEDLE*D
' 3%+
4
%+
#
3#'4
5
+
#3*+4'*+
#3*+4'*+
3'
*3'
5
*
%+%+2/%-/%-
/%-/%-
%+%+
6%%2
1111*& DME
* +*,&(-./&+),'#+)/;#D1/'.1/3E#0*& #
! !" "
#
#"
LEDL
K
LEDL
K
K
K
EEDE*DDEE*DE**D&)BD
EE*DE**D&/"D
LEDLLEDLE*D
' 3/*
4
/*
#
3#'45*
3#*+'4*+
3#*+'4*+
3'
+3'
5+
/*/*2/%-/%-
/%-/%-
/*/*
6//2
*& DNE
* 91"$#2#2*D%'*#%3E#(%"8';,'$4&#
-'56*:# 34$54$%&2*D%'*#%3E#
O';'*# 6*# )"=# 6+# ='"%.'# .1'# =)&+/",# <)(.%;$# %<# $/&/0);/.-#
+;%+),)./%"#<%;#)""%.)./%"$#)"=#5'6#+),'$*#;'$+'(./8'0-4#+D%'E# /$#
.1'#$'.#%<#5'6#+),'$#)""%.).'=#5/.1#)""%.)./%"#%'##)"=#*D/3E##/$#.1'#
$'.# %<# )""%.)./%"$#,/8'"# .%# +),'#/371+48%'9# ='"%.'$# .1'#4.1# +),'#
)""%.).'=#6-#%'#)"=#*48/'9#='"%.'$#.1'#4.1#)""%.)./%"#)$$/,"'=#.%#
+),'#/'4#!"#%:;#'B+';/&'".$*#6%.1#6*#)"=#6+1);'#$'.#.%#I4P4#
Q%.'#.1).#.1'#$/&/0);/.-#+;%+),)./%"#;).'#/$#)=R:$.'=#)((%;=/",#
.%# .1'# ":&6';# %<# :$';$# 6'.5''"# .1'# )""%.)./%"# )"=# 5'6# +),'4#
7)@'#?9:)./%"#DME# <%;#)"#'B)&+0'*# .1'#&)B/&)0#+;%+),)./%"#;).'#
()"#6'#)(1/'8'=#%"0-#/<#-*+D%'.1/4E#/$#'9:)0#.%#-*+1D%3.1/#E4#S/,:;'#
MD6E# $1%5$# .1'# </;$.# /.';)./%"T$# GGH# ;'$:0.# %<# .1'# $)&+0'# =).)#
51';'#6*#)"=#6+1);'#$'.#.%#K4#
71'#(%"8';,'"('#%<# .1'#)0,%;/.1&#()"#6'#+;%8'=# /"#)#$/&/0);#
5)-# )$#G/&H)"@# UVW4# S%;# ')(1# /.';)./%"*# .1'# ./&'# (%&+0'B/.-# %<#
.1'# GGH# )0,%;/.1&# /$# :D)*M)+
ME4# X/.1/"# .1'# =).)# $'.# %<# %:;#
'B+';/&'".*#6%.1#.1'#)""%.)./%"#)"=#5'6#+),'#$/&/0);/.-#&).;/('$#
);'#9:/.'# $+);$'# )"=# .1'# )0,%;/.1&#(%"8';,'$# 9:/(@0-4#Y:.# /<# .1'#
$()0'#%<#$%(/)0#)""%.)./%"$#@''+$#,;%5/",#'B+%"'"./)00-*#.1'#$+''=#
%<#(%"8';,'"('#<%;#%:;#)0,%;/.1&$#&)-#$0%5#=%5"4#7%#$%08'#.1/$#
+;%60'&*# 5'# ()"# :$'# $%&'# %+./&/Z)./%"# $.;).',-# $:(1# )$#
/"(%;+%;)./",# .1'# &/"/&)0# (%:".# ;'$.;/(./%"# UVW# .%# &)@'# .1'#
)0,%;/.1&#(%"8';,'#&%;'#9:/(@0-4#
F'../",#;J[;K*;M*\*;#]#6'#)#9:';-#51/(1#(%"$/$.$#%<1##9:';-#
.';&$#)"=#*D/EJ[%K*%M*\*#%4]#6'#.1'#)""%.)./%"#$'.#%<#5'6#+),'#/*#
?9:)./%"#D^E#$1%5$#.1'#$/&/0);/.-#()0(:0)./%"#&'.1%=#6)$'=#%"#.1'#
G%(/)0G/&H)"@4##
!!" "
"#
'
4
3
3'*22< %;2/;='4K K
E*DE*D# *# D^E
:;:! </#5*=>/"&'?*@A'&)/'&$1*BA&1#*-$.&/"*
!11$'/'&$1A*?B/$./",# $.)./(# ;)"@/",# &'.1%=$# :$:)00-# &')$:;'# +),'$T# 9:)0/.-#
<;%&#.1'#>?"1/%@?1AB?%$CB=D*#%;#.1'#=?%BAE1?#@'#?1!=?B=D1+%/".#%<#
8/'54#H'()00#.1).#/"#S/,:;'#K*#.1'#'$./&)./%"#%<#_),'H)"@#UKPW#/$#
$:6R'(.#.%#>?"1AB?%$CB=*#)"=#.1'#<H)"@#UKVW#/$#()0(:0).'=#6)$'=#%"#
6%.1#>?"1/%@?1AB?%$CB=# )"=# =?%BAE1 ?#@'#?1!=?B=T# )(./8/./'$4#71'#
$%(/)0#)""%.)./%"$#);'#.1'#"'5#/"<%;&)./%"#.1).#()"#6'#:./0/Z'=#.%#
()+.:;'# .1'# 5'6# +),'$T# 9:)0/.-# <;%&# >?"1 /%@?1 %##C$%$CB=D1
+';$+'(./8'4#
F7F7G! 2CA'%&+%@?<%#51*&@CB'$E41CDA5%E/'&$1* 7,* H'@E1 ;!%&'$01 >?"1 /%@?=1 %B?1 !=!%&&01 /C/!&%B&01
%##C$%$?I1%#I1/C/!&%B*>?"1/%@?=.1!/J$CJI%$?1>?"1!=?B=1%#I1EC$1
=CA'%&1 %##C$%$'C#=1 E%K?1 $E?1 LC&&C>'#@1 B?&%$'C#=M1 /C/!&%B1 >?"1
/%@?=1 %B?1 "CC54%B5?I1 "014%#01 !/J$CJI%$?1 !=?B=1 %#I1 %##C$%$?I1
"01 EC$1 %##C$%$'C#=N1 !/J$CJI%$?1 !=?B=1 &'5?1 $C1 "CC54%B51 /C/!&%B1
/%@?=1 %#I1 !=?1 EC$1 %##C$%$'C#=N1 EC$1 %##C$%$'C#=1 %B?1 !=?I1 $C1
%##C$%$?1/C/!&%B1>?"1/%@?=1%#I1!=?I1"01!/J$CJI%$?1!=?B=7##
Y)$'=#%"#.1'#%6$';8)./%"#)6%8'*#5'#+;%+%$'#)#"%8'0#)0,%;/.1&*#
")&'0-#G%(/)0_),'H)"@#DG_HE#.%#9:)"./.)./8'0-#'8)0:).'#.1'#+),'#
9:)0/.-#D+%+:0);/.-E#/"=/().'=#6-#$%(/)0#)""%.)./%"$4#71'#/".:/./%"#
6'1/"=# .1'# )0,%;/.1&# /$# .1'#&:.:)0# '"1)"('&'".# ;'0)./%"# )&%",#
+%+:0);* 5'6# +),'$*# :+>.%>=).'# 5'6# :$';$# )"=# 1%.# $%(/)0#
)""%.)./%"$4# S%00%5/",*# .1'# +%+:0);/.-# %<# 5'6# +),'$*# .1'# :+>.%>
=).'"'$$# %<# 5'6# :$';$# )"=# .1'# 1%."'$$# %<# )""%.)./%"$# );'# )00#
;'<';;'=#.%1)$1/C/!&%B'$01<%;#$/&+0/(/.-4##
A$$:&'# .1).# .1';'# );'#)*# )""%.)./%"$*#)+#5'6#+),'$#)"=#),#
5'6# :$';$4# F'.#-+,# 6'# .1'# )+C),1 )$$%(/)./%"# &).;/B# 6'.5''"#
+),'$# )"=# :$';$*1 -*+1 6'# .1'#)*C)+1 )$$%(/)./%"#&).;/B# 6'.5''"#
)""%.)./%"$# )"=# +),'$# )"=# -,*..1'1 ),C)*1 )$$%(/)./%"# &).;/B#
6'.5''"# :$';$# )"=# )""%.)./%"$4# ?0'&'".#-+,# D/'*!3E# /$# )$$/,"'=#
5/.1#.1'#(%:".#%<#)""%.)./%"$#:$'=#6-#:$';#!3#.%#)""%.).'#+),'#/'4#
?0'&'".$#%<#-*+1)"=1-,*#);'# /"/./)0/Z'=#$/&/0);0-4#F'.#+I#6'# .1'#
8'(.%;# (%".)/"/",# ;)"=%&0-# /"/./)0/Z'=# G%(/)0_),'H)"@# $(%;'$4##
`'.)/0$#%<#.1'#G%(/)0_),'H)"@#)0,%;/.1&#);'#+;'$'".'=#)$#<%00%5$4##
!"#$%&'()*7,*-$.&/"</#50/12*3-<04*
-'56*+*!"54$%&
A$$%(/)./%"# &).;/('$1 -+,*1 -*+.1 )"=1 -,** )"=# .1'#
;)"=%&#/"/./)0#G%(/)0_),'H)"@#$(%;'#+I##
WWW 2007 / Track: Search Session: Search Quality and Precision
504

UsingAnnotaWonSimilarityforRanking
• Givenaqueryq={q1,…,qn},apagep,andasetofannotaWonsA(p)={a1,…,am},“socialsimilarity”ofqandpcanbecomputedasfollows:
• CombinedifferentrankingfeaturesusingRankSVM(Joachims02)
*See (Xu 07) for how to use annotation similarity in a Language Modeling framework
!"# $%&'# ()$'$*# $%&'# +),'$#&)-# (%".)/"# %"0-# .1'# )""%.)./%"#
2!"!#$!3# '4,4*# 5'6# +),'# %4# 71'"# ,/8'"# .1'# 9:';-# (%".)/"/",#
2&'#!(3*# .1'# +),'# .1).# %"0-# 1)$# 2!"!#$!3# &)-# 6'# </0.';'=# %:.#
/&+;%+';0-# 6-# $/&+0'# .';&>&).(1/",# &'.1%=4# ?8'"# /<# .1'# +),'#
(%".)/"$#6%.1#)""%.)./%"$#2!"!#$!3#)"=#2&'#!(3*#/.#/$#"%.#+;%+';#.%#
()0(:0).'#.1'#$/&/0);/.-#6'.5''"#.1'#9:';-#)"=#.1'#=%(:&'".#:$/",#
.1'# @'-5%;=# 2&'#!(3# %"0-4#A"# 'B+0%;)./%"# %<# $/&/0);/.-# 6'.5''"#
2!"!#$!3#)"=#2&'#!(3#&)-#<:;.1';#/&+;%8'#.1'#+),'#;)"@/",4#
7%#'B+0%;'#.1'#)""%.)./%"$#5/.1#$/&/0);#&')"/",$*#5'#6:/0=#)#
6/+);./.'>,;)+1#6'.5''"#$%(/)0#)""%.)./%"$#)"=#5'6#+),'$#5/.1#/.$#
'=,'$# /"=/()./",# .1'# :$';# (%:".4# A$$:&'# .1).# .1';'# );'# )*#
)""%.)./%"$*#)+#5'6#+),'$#)"=#),#5'6#:$';$4#-*+# /$# .1'#)*C)+#
)$$%(/)./%"# &).;/B# 6'.5''"# )""%.)./%"$# )"=# +),'$4# -*+D%(./0E#
='"%.'$#.1'#":&6';#%<#:$';$#51%#)$$/,"#)""%.)./%"#%(#.%#+),'#/04#
F'../",12*16'#.1'#)*C)*#&).;/B#51%$'#'0'&'".#2*D%'*#%3E#/"=/().'$#
.1'# $/&/0);/.-# $(%;'# 6'.5''"# )""%.)./%"$#%'# )"=#%3# )"=#2+16'# .1'1
)+C)+# &).;/B# ')(1# %<# 51%$'# '0'&'".# $.%;'$# .1'# $/&/0);/.-##
6'.5''"# .5%# 5'6# +),'$*# 5'# +;%+%$'# G%(/)0G/&H)"@DGGHE*# )"#
/.';)./8'# )0,%;/.1&# .%# 9:)"./.)./8'0-# '8)0:).'# .1'# $/&/0);/.-#
6'.5''"#)"-#.5%#)""%.)./%"$4#
!"#$%&'()*+,*-$.&/"-&)0/12*3--04*
-'56*+# !"#$%&&&&&&'($&2*I#D%'*#%3E#J#K#<%;#')(1#%'1J#%3#%.1';5/$'#I#
2+I#D/'*#/3E#J#K#<%;#')(1#/'1J#/3#%.1';5/$'#I&
-'56*7* )*&8&
+*,&(-./&)""%.)./%"#+)/;#D%'.1%3E&0*&
#
! !" "
#"
ELDL
K
ELDL
K
K
EEDE*DDEE*DE**D&)BD
EE*DE**D&/"D
LEDLLEDLE*D
' 3%+
4
%+
#
3#'4
5
+
#3*+4'*+
#3*+4'*+
3'
*3'
5
*
%+%+2/%-/%-
/%-/%-
%+%+
6%%2
1111*& DME
* +*,&(-./&+),'#+)/;#D1/'.1/3E#0*& #
! !" "
#
#"
LEDL
K
LEDL
K
K
K
EEDE*DDEE*DE**D&)BD
EE*DE**D&/"D
LEDLLEDLE*D
' 3/*
4
/*
#
3#'45*
3#*+'4*+
3#*+'4*+
3'
+3'
5+
/*/*2/%-/%-
/%-/%-
/*/*
6//2
*& DNE
* 91"$#2#2*D%'*#%3E#(%"8';,'$4&#
-'56*:# 34$54$%&2*D%'*#%3E#
O';'*# 6*# )"=# 6+# ='"%.'# .1'# =)&+/",# <)(.%;$# %<# $/&/0);/.-#
+;%+),)./%"#<%;#)""%.)./%"$#)"=#5'6#+),'$*#;'$+'(./8'0-4#+D%'E# /$#
.1'#$'.#%<#5'6#+),'$#)""%.).'=#5/.1#)""%.)./%"#%'##)"=#*D/3E##/$#.1'#
$'.# %<# )""%.)./%"$#,/8'"# .%# +),'#/371+48%'9# ='"%.'$# .1'#4.1# +),'#
)""%.).'=#6-#%'#)"=#*48/'9#='"%.'$#.1'#4.1#)""%.)./%"#)$$/,"'=#.%#
+),'#/'4#!"#%:;#'B+';/&'".$*#6%.1#6*#)"=#6+1);'#$'.#.%#I4P4#
Q%.'#.1).#.1'#$/&/0);/.-#+;%+),)./%"#;).'#/$#)=R:$.'=#)((%;=/",#
.%# .1'# ":&6';# %<# :$';$# 6'.5''"# .1'# )""%.)./%"# )"=# 5'6# +),'4#
7)@'#?9:)./%"#DME# <%;#)"#'B)&+0'*# .1'#&)B/&)0#+;%+),)./%"#;).'#
()"#6'#)(1/'8'=#%"0-#/<#-*+D%'.1/4E#/$#'9:)0#.%#-*+1D%3.1/#E4#S/,:;'#
MD6E# $1%5$# .1'# </;$.# /.';)./%"T$# GGH# ;'$:0.# %<# .1'# $)&+0'# =).)#
51';'#6*#)"=#6+1);'#$'.#.%#K4#
71'#(%"8';,'"('#%<# .1'#)0,%;/.1&#()"#6'#+;%8'=# /"#)#$/&/0);#
5)-# )$#G/&H)"@# UVW4# S%;# ')(1# /.';)./%"*# .1'# ./&'# (%&+0'B/.-# %<#
.1'# GGH# )0,%;/.1&# /$# :D)*M)+
ME4# X/.1/"# .1'# =).)# $'.# %<# %:;#
'B+';/&'".*#6%.1#.1'#)""%.)./%"#)"=#5'6#+),'#$/&/0);/.-#&).;/('$#
);'#9:/.'# $+);$'# )"=# .1'# )0,%;/.1&#(%"8';,'$# 9:/(@0-4#Y:.# /<# .1'#
$()0'#%<#$%(/)0#)""%.)./%"$#@''+$#,;%5/",#'B+%"'"./)00-*#.1'#$+''=#
%<#(%"8';,'"('#<%;#%:;#)0,%;/.1&$#&)-#$0%5#=%5"4#7%#$%08'#.1/$#
+;%60'&*# 5'# ()"# :$'# $%&'# %+./&/Z)./%"# $.;).',-# $:(1# )$#
/"(%;+%;)./",# .1'# &/"/&)0# (%:".# ;'$.;/(./%"# UVW# .%# &)@'# .1'#
)0,%;/.1&#(%"8';,'#&%;'#9:/(@0-4#
F'../",#;J[;K*;M*\*;#]#6'#)#9:';-#51/(1#(%"$/$.$#%<1##9:';-#
.';&$#)"=#*D/EJ[%K*%M*\*#%4]#6'#.1'#)""%.)./%"#$'.#%<#5'6#+),'#/*#
?9:)./%"#D^E#$1%5$#.1'#$/&/0);/.-#()0(:0)./%"#&'.1%=#6)$'=#%"#.1'#
G%(/)0G/&H)"@4##
!!" "
"#
'
4
3
3'*22< %;2/;='4K K
E*DE*D# *# D^E
:;:! </#5*=>/"&'?*@A'&)/'&$1*BA&1#*-$.&/"*
!11$'/'&$1A*?B/$./",# $.)./(# ;)"@/",# &'.1%=$# :$:)00-# &')$:;'# +),'$T# 9:)0/.-#
<;%&#.1'#>?"1/%@?1AB?%$CB=D*#%;#.1'#=?%BAE1?#@'#?1!=?B=D1+%/".#%<#
8/'54#H'()00#.1).#/"#S/,:;'#K*#.1'#'$./&)./%"#%<#_),'H)"@#UKPW#/$#
$:6R'(.#.%#>?"1AB?%$CB=*#)"=#.1'#<H)"@#UKVW#/$#()0(:0).'=#6)$'=#%"#
6%.1#>?"1/%@?1AB?%$CB=# )"=# =?%BAE1 ?#@'#?1!=?B=T# )(./8/./'$4#71'#
$%(/)0#)""%.)./%"$#);'#.1'#"'5#/"<%;&)./%"#.1).#()"#6'#:./0/Z'=#.%#
()+.:;'# .1'# 5'6# +),'$T# 9:)0/.-# <;%&# >?"1 /%@?1 %##C$%$CB=D1
+';$+'(./8'4#
F7F7G! 2CA'%&+%@?<%#51*&@CB'$E41CDA5%E/'&$1* 7,* H'@E1 ;!%&'$01 >?"1 /%@?=1 %B?1 !=!%&&01 /C/!&%B&01
%##C$%$?I1%#I1/C/!&%B*>?"1/%@?=.1!/J$CJI%$?1>?"1!=?B=1%#I1EC$1
=CA'%&1 %##C$%$'C#=1 E%K?1 $E?1 LC&&C>'#@1 B?&%$'C#=M1 /C/!&%B1 >?"1
/%@?=1 %B?1 "CC54%B5?I1 "014%#01 !/J$CJI%$?1 !=?B=1 %#I1 %##C$%$?I1
"01 EC$1 %##C$%$'C#=N1 !/J$CJI%$?1 !=?B=1 &'5?1 $C1 "CC54%B51 /C/!&%B1
/%@?=1 %#I1 !=?1 EC$1 %##C$%$'C#=N1 EC$1 %##C$%$'C#=1 %B?1 !=?I1 $C1
%##C$%$?1/C/!&%B1>?"1/%@?=1%#I1!=?I1"01!/J$CJI%$?1!=?B=7##
Y)$'=#%"#.1'#%6$';8)./%"#)6%8'*#5'#+;%+%$'#)#"%8'0#)0,%;/.1&*#
")&'0-#G%(/)0_),'H)"@#DG_HE#.%#9:)"./.)./8'0-#'8)0:).'#.1'#+),'#
9:)0/.-#D+%+:0);/.-E#/"=/().'=#6-#$%(/)0#)""%.)./%"$4#71'#/".:/./%"#
6'1/"=# .1'# )0,%;/.1&# /$# .1'#&:.:)0# '"1)"('&'".# ;'0)./%"# )&%",#
+%+:0);* 5'6# +),'$*# :+>.%>=).'# 5'6# :$';$# )"=# 1%.# $%(/)0#
)""%.)./%"$4# S%00%5/",*# .1'# +%+:0);/.-# %<# 5'6# +),'$*# .1'# :+>.%>
=).'"'$$# %<# 5'6# :$';$# )"=# .1'# 1%."'$$# %<# )""%.)./%"$# );'# )00#
;'<';;'=#.%1)$1/C/!&%B'$01<%;#$/&+0/(/.-4##
A$$:&'# .1).# .1';'# );'#)*# )""%.)./%"$*#)+#5'6#+),'$#)"=#),#
5'6# :$';$4# F'.#-+,# 6'# .1'# )+C),1 )$$%(/)./%"# &).;/B# 6'.5''"#
+),'$# )"=# :$';$*1 -*+1 6'# .1'#)*C)+1 )$$%(/)./%"#&).;/B# 6'.5''"#
)""%.)./%"$# )"=# +),'$# )"=# -,*..1'1 ),C)*1 )$$%(/)./%"# &).;/B#
6'.5''"# :$';$# )"=# )""%.)./%"$4# ?0'&'".#-+,# D/'*!3E# /$# )$$/,"'=#
5/.1#.1'#(%:".#%<#)""%.)./%"$#:$'=#6-#:$';#!3#.%#)""%.).'#+),'#/'4#
?0'&'".$#%<#-*+1)"=1-,*#);'# /"/./)0/Z'=#$/&/0);0-4#F'.#+I#6'# .1'#
8'(.%;# (%".)/"/",# ;)"=%&0-# /"/./)0/Z'=# G%(/)0_),'H)"@# $(%;'$4##
`'.)/0$#%<#.1'#G%(/)0_),'H)"@#)0,%;/.1&#);'#+;'$'".'=#)$#<%00%5$4##
!"#$%&'()*7,*-$.&/"</#50/12*3-<04*
-'56*+*!"54$%&
A$$%(/)./%"# &).;/('$1 -+,*1 -*+.1 )"=1 -,** )"=# .1'#
;)"=%&#/"/./)0#G%(/)0_),'H)"@#$(%;'#+I##
WWW 2007 / Track: Search Session: Search Quality and Precision
504
!"#$%&%
%
!"#$
!"#$%
!$#$%&&
!'#$%&&
!(#$%&&
!)#$%&&
!*#$%&&
+
*
++
++
+
!"#!
!#$!
!$"!
!$"!
!#$!
!"#!
#%"
$%#
"%$
$%"
#%$
"%#
&
&
&
!"
!"
!"
!"
!"
!"
#
&
%&'()&"!$,-./01203#&
%$!
!"#$%'(% *+',+'#$
"'4&560&,-./01207&8-,9:;<:20=:.>&3,-10#$
850?&*&7-03&560&9.959:;9@:59-.#&A.&850?&)B&"!B&#!B&:.7&$!&70.-50&
560&?-?C;:195D&/0,5-13&-E&?:203B&C3013B& :.7&:..-5:59-.3& 9.& 560& !56&
9501:59-.#&"!F()#!
FB&:.7&$!F&:10&9.501G079:50&/:;C03#&H3&9;;C351:507&9.&
I92C10& (B& 560& 9.5C959-.& J069.7& KLC:59-.& %$!& 93& 56:5& 560& C3013F&
?-?C;:195D&,:.&J0&7019/07&E1-G&560&?:203&560D&:..-5:507&%$#*!M&560&
:..-5:59-.3F& ?-?C;:195D& ,:.& J0& 7019/07& E1-G& 560& ?-?C;:195D& -E&
C3013& %$#)!M& 39G9;:1;DB& 560& ?-?C;:195D& 93& 51:.3E01107& E1-G&
:..-5:59-.3& 5-&N0J& ?:203& %$#(!B&N0J& ?:203& 5-& :..-5:59-.3& %$#'!B&
:..-5:59-.3&5-&C3013&%$#$!B&:.7&560.&C3013&5-&N0J&?:203&:2:9.&%$#"!#&&
I9.:;;DB&N0&205&"'& :3& 560&-C5?C5&-E&8-,9:;<:20=:.>& %8<=!&N60.&
560&:;2-1956G&,-./01203#&8:G?;0&8<=&/:;C03&:10&29/0.&9.&560&19265&
?:15&-E&I92C10&(#&&
&
)*+,-#&'.&%/00,1"-2"*34%35%6,20*"7%"-241*"*34%8#"9##4%":#%
,1#-1;%2443"2"*341;%24<%$2+#1%*4%":#%!=>%20+3-*":?&
A.& 0:,6& 9501:59-.B& 560& 59G0& ,-G?;0O95D& -E& 560& :;2-1956G& 93&
*%+#+"&P)+$&+"&P)+#&+$&!#&89.,0&560&:7Q:,0.,D&G:519,03&:10&/01D&
3?:130& 9.& -C1& 7:5:& 305B& 560& :,5C:;& 59G0& ,-G?;0O95D& 93& E:1& ;-N01#&
R-N0/01B&9.&S0J&0./91-.G0.5B&560&39@0&-E&7:5:&:10&9.,10:39.2&:5&:&
E:35& 3?007B& :.7& 3-G0& :,,0;01:59-.& 5-& 560& :;2-1956G& %;9>0& TUV& E-1&
<:20=:.>!&36-C;7&J0&70/0;-?07#&
,-,-.! /0123453163)07)8"9)$:504!;<=)R010B& N0& 29/0& :& J190E& ?1--E& -E& 560& ,-./0120.,0& -E& 560& 8<=&
:;2-1956G#&A5&,:.&J0&7019/07&E1-G&560&:;2-1956G&56:54&
W
*
* !%!% "%%"%%" !&
!
&
! !!"!!"#
#B& %"!
N6010&
$"#$"# %%%% !!" #& %U!
H&35:.7:17&103C;5&-E&;9.0:1&:;20J1:&%0#2#&TXV!&35:503&56:5&9E&%>&93&
:& 3DGG0519,) G:519OB& :.7& 2& 93& :& /0,5-1& .-5& -156-2-.:;& 5-& 560&
?19.,9?:;&0920./0,5-1&-E&560&G:519O)!*%%>!B&560.&560&C.95&/0,5-1&9.&
560&7910,59-.&-E&%%>!?2),-./01203&5-&!*%%>!&:3&?&9.,10:303&N956-C5&
J-C.7#&R010&%%&)93&:&3DGG0519,&G:519O&:.7)"W&93&.-5&-156-2-.:;&
5-&!*%%%&!B& 3-& 560& 30LC0.,0&"!& ,-./01203& 5-& :& ;9G95&"
YB& N69,6&
392.:;3&560&501G9.:59-.&-E&560&8<=&:;2-1956G#&
'.@! A742?*B%>24C*4+%9*":%!3B*20%
/453-?2"*34%
,-@-A! BC1D=!6)9D1?!15)%3;<0E)ZC0&5-&560&;:120&.CGJ01&-E&E0:5C103B&G-701.&N0J&30:1,6&0.29.03&
C3C:;;D& 1:.>& 103C;53& JD& ;0:1.9.2& :& 1:.>& EC.,59-.#&[:.D&G056-73&
6:/0&J00.&70/0;-?07&E-1&:C5-G:59,&%-1&30G9\:C5-G:59,!&5C.9.2&-E&
3?0,9E9,& 1:.>9.2& EC.,59-.3#& <10/9-C3& N-1>& 0359G:503& 560& N092653&
561-C26& 10210339-.& T)"V#& =0,0.5& N-1>& -.& 5693& 1:.>9.2& ?1-J;0G&
:550G?53& 5-& 7910,5;D& -?59G9@0& 560& -17019.2& -E& 560& -JQ0,53& T(B& ))B&
()V#&&
H3&793,C3307&9.&T$VB&56010&:10&20.01:;;D&5N-&N:D3&5-&C59;9@0&560&
0O?;-107& 3-,9:;& E0:5C103& E-1& 7D.:G9,& 1:.>9.2& -E& N0J& ?:2034& %:!&
510:59.2& 560& 3-,9:;& :,59-.3& :3& 9.70?0.70.5& 0/970.,0& E-1& 1:.>9.2&
103C;53B& :.7& %J!& 9.5021:59.2& 560& 3-,9:;& E0:5C103& 9.5-& 560& 1:.>9.2&
:;2-1956G#&A.&-C1&N-1>B&N0&9.,-1?-1:50&J-56&39G9;:195D&:.7&35:59,&
E0:5C103& 0O?;-9507& E1-G& 3-,9:;& :..-5:59-.3& 9.5-& 560& 1:.>9.2&
EC.,59-.&JD&C39.2&=:.>8][&T()V#&
,-@-.! F3D;G43>)S0&79/9707&-C1&E0:5C10&305&9.5-&5N-&GC5C:;;D&0O,;C39/0&,:502-19034&
LC01D\?:20&39G9;:195D&E0:5C103&:.7&?:20F3&35:59,&E0:5C103#&^:J;0&*&
703,19J03&0:,6&-E&56030&E0:5C10&,:502-1903&9.&705:9;#&
D280#%E.&I0:5C103&9.&3-,9:;&30:1,6&
H4&&LC01D\7-,CG0.5&E0:5C103&
B068!=!:D4!;C)& 89G9;:195D&J05N00.&LC01D&:.7&?:20&,-.50.5&
&34=%D;6<!15)
%^[!)
89G9;:195D& J05N00.& LC01D& :.7& :..-5:59-.3&
C39.2&560&501G&G:5,69.2&G056-7#&
806!D:8!=9D1?)
%88=!)
89G9;:195D& J05N00.& LC01D& :.7& :..-5:59-.3&
J:307&-.&8-,9:;89G=:.>#&
_4&&7-,CG0.5&35:59,&E0:5C103&
H005:3"D539D1?)
%<=!)
^60&N0J&?:20F3&<:20=:.>&-J5:9.07&E1-G&560&
`--2;0F3&5--;J:1&H<A#&
806!D:"D539D1?)
%8<=!)
^60& ?-?C;:195D& 3,-10& ,:;,C;:507& J:307& -.&
8-,9:;<:20=:.>&:;2-1956G#&
@.! FG=F>/HFIDJK%>F!LKD!%
@.E! A#0*B*3,1%A2"2%^6010& :10& G:.D& 3-,9:;& J-->G:1>& 5--;3& -.& S0J& T(WV#& I-1& 560&
0O?019G0.5B&N0&C30&560&7:5:&,1:N;07&E1-G&Z0;9,9-C3&7C19.2&[:DB&
)WW"B& N69,6& ,-.39353& -E& *BU("B)"X& N0J& ?:203& :.7& )"aB$""&
79EE010.5&:..-5:59-.3#&
H;56-C26& 560&:..-5:59-.3& E1-G&Z0;9,9-C3&:10&0:3D& E-1&6CG:.&
C3013& 5-& 10:7&:.7&C.70135:.7B& 560D&:10&.-5&70392.07& E-1&G:,69.0&
C30#&I-1&0O:G?;0B&C3013&G:D&C30&,-G?-C.7&:..-5:59-.3&9.&/:19-C3&
:&
,&
J&&
&
&
&
8-,9:;&:..-5:59-.3&
%:!& %J!&
!3B*20=2+#>24C1(%
8<=%:!b&W#W*$$&
8<=%J!b&W#WW')&
8<=%,!&bW#W)*X&
S0J&?:203&
S0J&?:20&:..-5:5-13&
&
%$#*!&
%$#"!%$#$!&
%$#)!&
&
&
%$#(!&
%$#'!&
WWW 2007 / Track: Search Session: Search Quality and Precision
505

ExperimentalResults
• DatafromDelicious:1,736,268pages,269,566differentannotaWons
Example:Top4relatedannotaWonsfordifferentcategories
!"#$%&%'()&*%& !"#"$%&'(&"))*+(&"#& !"#",%&'(&"))*+(+&,-&%./01&
1)-%-&*22"1*10"2%& 021"& %1*23*#3&4"#3%&401)& 1)-&)-/.&"!&,"#35-1&
6789&:-!"#-&'%02;&1)-$&02&1)-&-<.-#0$-21%+&
!"#! $%&'(&)*+,-+.-/,,+)&)*+,-0*1*'&2*)*34-=2& "'#& -<.-#0$-21%>& 1)-& ?"(0*/?0$@*2A& */;"#01)$& ("2B-#;-3&
401)02&CD&01-#*10"2%+&E*:/-&D&%)"4%&1)-&%-/-(1-3&*22"1*10"2%&!#"$&
!"'#& (*1-;"#0-%>& 1";-1)-#& 401)& 1)-0#& 1".& F& %-$*210(*//G& #-/*1-3&
*22"1*10"2%+&,01)& 1)-& -<./"#-3& %0$0/*#01G& B*/'-%>&4-& *#-& *:/-& 1"&
!023&$"#-&%-$*210(*//G&#-/*1-3&4-:&.*;-%&*%&%)"42&/*1-#+&
5&6'3-#"-H<./"#-3&%0$0/*#&*22"1*10"2%&:*%-3&"2&?"(0*/?0$@*2A&
5378,+'+9:-23'&)3;<&
3':/02& $-1*3*1*>&%-$*210(>&%1*23*#3>&"4/&
3-:0*2& 30%1#0:'10"2>&30%1#">&':'21'>&/02'<&
$7+,+1:-23'&)3;<&
*3%-2%-& %-2%->&*3B-#10%->&-21#-.#-2-'#>&$"2-G&
IJJ& 2'$:-#>&30#-(1"#G>&.)"2->&:'%02-%%&
$,)32)&*,13,)-23'&)3;<&
*/:'$& ;*//-#G>&.)"1";#*.)G>&.*2"#*$*>&.)"1"& &
()*1& $-%%-2;-#>&K*::-#>&0$>&$*("%<&&
$,)*):--23'&)3;<&
-02%1-02& %(0-2(->&%A-.10(>&-B"/'10"2>&L'*21'$&
()#0%10*2&& 3-B"1->&!*01)>&#-/0;0"2>&;"3&&
!"=! $%&'(&)*+,-+.-0>?-?34(')4-,-& ":1*02-3& -*()& 4-:& .*;-M%& ?N@& %("#-& '%02;& 1)-& */;"#01)$&
3-%(#0:-3& 02& %-(10"2& 7+7+& =2& "'#& -<.-#0$-21%>& 1)-& */;"#01)$&
("2B-#;-3& 401)02& O& 01-#*10"2%+& H*()& .*;-M%& N*;-@*2A& 4*%& */%"&
-<1#*(1-3& !#"$& 1)-& P"";/-M%& 1""/:*#& QN=& 3'#02;& R'/G>& DJJS+&
T-#-*!1-#>& 4-& '%-& N*;-@*2A& 1"& 3-.0(1& 1)-& -<1#*(1-3& P"";/-M%&
N*;-@*2A&:G&3-!*'/1+&
-$.$/! 0123#4$31"(52"+6378*49&*:;9*'+3<+"=>4*4?3U0;'#-&F&%)"4%&1)-&*B-#*;-&("'21%&"!&*22"1*10"2%&*23&*22"1*1"#%&
"B-#& 4-:& .*;-%& 401)& 30!!-#-21& N*;-@*2A& B*/'-%>& *23& !"#& 1)-&
@+*A;53<++'9"9*'+&/02->&1)-&B*/'-&$-*2%&1)-&("'21&"!&*22"1*10"2%&
1)*1& *#-& 30!!-#-21& 401)& -*()& "1)-#+& U#"$& 1)-& !0;'#->& 4-& (*2&
("2(/'3-& 1)*1& 02&$"%1&(*%-%>& 1)-&.*;-&401)&*&)0;)-#&N*;-@*2A& 0%&
/0A-/G&1"&:-&*22"1*1-3&:G&$"#-&'%-#%&401)&$"#-&*22"1*10"2%+&&
&
@*9(23&!"&-/%32&93-7+(,)-;*4)2*6()*+,-+%32->&93?&,A-
E"& !'#1)-#& 02B-%10;*1-& 1)-& 30%1#0:'10"2>& ("'21%& "!& *22"1*10"2%&
*23& *22"1*1"#%& !"#& *//& ("//-(1-3& .*;-%& 401)& 30!!-#-21& N*;-@*2A&
B*/'-%& *#-& ;0B-2& 02& U0;'#-& 8V*W+& =1& 0%& -*%G& 1"& %--& 1)*1& 1)-& .*;-%&
401)& -*()& N*;-@*2A& B*/'-& 30B-#%0!G& *& /"1& "2& 1)-& 2'$:-#& "!&
*22"1*10"2%&*23&'%-#%+&,-:&.*;-%&401)&*&#-/*10B-/G&/"4&N*;-@*2A&
$*G&"42&$"#-&*22"1*10"2%&*23&'%-#%&1)*2&1)"%-&4)"&)*B-&)0;)-#&
N*;-@*2A+&U"#&-<*$./->&%"$-&.*;-%&401)&N*;-@*2A&J&)*B-&$"#-&
'%-#%&*23&*22"1*10"2%&1)*2&1)"%-&4)"&)*B-&N*;-@*2A&CJ+&
&,-&*../0-3&1)-&?N@&*/;"#01)$&1"& 1)-&("//-(1-3&3*1*+&U"#&-*%G&
'23-#%1*2302;>&?N@&0%&2"#$*/0X-3&021"&*&%(*/-&"!&JYCJ&%"&1)*1&?N@&
*23&N*;-@*2A&)*B-&1)-&%*$-&2'$:-#&"!&.*;-%&02&-*()&;#*3-&!#"$&
J&1"&CJ+&U0;'#-&8V:W&%)"4%&1)-&3-1*0/-3&("'21%&"!&*22"1*10"2%&*23&
'%-#%&"!&.*;-%&401)&30!!-#-21&?"(0*/N*;-@*2A&B*/'-%+&=1&0%&-*%G&1"&
%--& 1)*1& ?"(0*/N*;-@*2A& %'((-%%!'//G& ()*#*(1-#0X-%& 1)-& 4-:&
.*;-%M&.".'/*#01G&3-;#--%&*$"2;&4-:&*22"1*1"#%+&
&&&&&&& -
B&C-/,,+)&)*+,4-&,;-(4324-+%32->&93?&,A& B6C-/,,+)&)*+,4-&,;-(4324-+%32-0+7*&'>&93?&,A&
@*9(23&D"-E*4)2*6()*+,-&,&':4*4-+.-4+7*&'-&,,+)&)*+,4--
WWW 2007 / Track: Search Session: Search Quality and Precision
506

ExperimentalResults
• Twoquerysets:– MQ50:50queriesmanuallygeneratedbystudents
– AQ3000:3000queriesauto‐generatedfromODP
• MeasureNDCGandMAP:
!
!"#$%&!'(!)*+,-)./)0)12%)3.4&5"6&7))3.4&5"6&)89:7)
.6;))3.4&5"6&)8<<=)12%)>.%?"6#)0)
9.@5&)A(!"#$%&'()#*!#+!,-.!/01200*!)($(3&'(14!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!AB,! :=>;>?! :=??CD!
3.4&5"6&)A<<=) B(A'CD) B(EEAD)
!"!"#! $%&'()*+,'&-)&.+/0)&.+12,+E(F5'0!G!)6#2)!160!H#$%&'()#*!/01200*!IJ"K!#+!.&F0L&*M!&*7!
N#H(&3.&F0L&*M!#*! 160!-8!)01=!<#16!N.L!&*7!.&F0L&*M!/0*0+(1!
20/!)0&'H6=!B60!/0110'! '0)531! ()!&H6(0O07!/4!N.L=!-F&(*P!)($(3&'!
H#*H35)(#*! H&*! /0! 7'&2*! +'#$! B&/30! 9P! 26(H6! )6#2)! 160!
H#$%&'()#*!#+!,-.!#*!160!12#!Q50'4!)01)=!
!
!"#$%&!D(!)*+,-)./)!"12%)3:FG7))3:FGHI=7).6;))
3:FGH<I=)12%)>.%?"6#)!)
)
9.@5&)G(!"#$%&'()#*!#+!,-.!/01200*!)1&1(H!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!A.L! :=>?>?! :=??RR!
3.4&5"6&!8<I=! B(AFDJ) B(EFFG)
!"!"3! $%&'()*+,'&-)&.+/0)&.+4567+11,+'&8+12,+<4! (*H#'%#'&1(*F! /#16! N#H(&3N($L&*M! &*7! N#H(&3.&F0L&*MP! 20!
H&*!&H6(0O0!160!/0)1!)0&'H6!'0)531!&)!)6#2*!(*!B&/30!R=!BS10)1)!#*!
,-.!)6#2!)1&1()1(H&334!)(F*(+(H&*1!($%'#O0$0*1)!T%SO&350U:=:9V=!!
)9.@5&)'(!J4*&$(H!'&*M(*F!2(16!/#16!NNL!&*7!N.L!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
3.4&5"6&8<<=7<I=) B(ADFA)K8EA(JBLM) B(EN'A)K8FG(BFLM)
!"!"9! :'0;+16<8%+B#!5*70')1&*7!6#2!160)0!($%'#O0$0*1)!&'0!&H6(0O07P!20!%'0)0*1!
&!H&)0!)1574!60'0=!E#'!)($%3(H(14P!160!)($(3&'(14!/01200*!160!Q50'4!
&*7!7#H5$0*1!H#*10*1!()!*#1!H#*)(70'07=!
K(O0*! 160! Q50'4! W')=>'=;XP! ;?D! 20/! %&F0)! &'0! &))#H(&107!
16'#5F6!160!)#H(&3!&**#1&1(#*)!&*7!160!1#%S>!20/!%&F0)!&HH#'7(*F!
1#!N.L!)H#'0)!&'0!)6#2*! (*!B&/30!G=!B6'#5F6! 160! '0O(02)!#+! 160!
1'&O03! )(10)! 3(M0! 0YH0330*1S'#$&*1(HSO&H&1(#*)!9P! 20! H&*! H#*H3570!
16&1!160!)#H(&3!&**#1&1(#*)!&'0!5)0+53!&*7!N.L!&'0!'0&334!0++0H1(O0=!
E#'!0Y&$%30P!160!)(10!766?@AABBB"-'%'-"*5(A!2(16!1#%!N.L!)H#'0!()!
&3)#! '&*M07! +(')1! /4! 0YH0330*1S'#$&*1(HSO&H&1(#*)! &*7! H&3307!
WK##F30!#+!B'&O03!N(10)X=!
9.@5&)D(!Z0/!%&F0)!&))#H(&107!/4!&**#1&1(#*!W&('+&'0X!
O=P4) <I=)
611%[\\222=M&4&M=H#$\!!!!!! @!
611%[\\222=1'&O03#H(14=H#$\!! D!
611%[\\222=1'(%&7O()#'=H#$\!! D!
611%[\\222=0Y%07(&=H#$\!!!! D!
B60*! /4! 5)(*F! NNL! '&*MP! 20! +(*7! 160! 1#%S>! )($(3&'! 1&F)! 1#!
W')=>'=;X!&'0!W6)*-;6XP!W>C).76XP!W756;CXP!&*7!W')=C)&;X=!B6'#5F6!160!
&*&34)()P!20!+(*7!$#)1!#+!160!1#%!'&*M07!20/!)(10)!(*!B&/30!G!&'0!
&**#1&107! /4! 160)0! )($(3&'! &**#1&1(#*)! &)! 2033=! <0)(70)P! 160)0!
)($(3&'!&**#1&1(#*)!&3)#! (*1'#75H0!)#$0!*02!20/!%&F0)=!B&/30!D!
)6#2)! 160! 1#%SN.L!]L^)! 16&1! &'0! *#1! &**#1&107! /4! W')=>'=;X! (*!
#5'!H#'%5)=!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!
9611%[\\222=0YH0330*1S'#$&*1(HSO&H&1(#*)=H#$\/0)1S&('+&'0S
)0&'H6S0*F(*0=61$3!!
WWW 2007 / Track: Search Session: Search Quality and Precision
508
!
!"#$%&!'(!)*+,-)./)0)12%)3.4&5"6&7))3.4&5"6&)89:7)
.6;))3.4&5"6&)8<<=)12%)>.%?"6#)0)
9.@5&)A(!"#$%&'()#*!#+!,-.!/01200*!)($(3&'(14!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!AB,! :=>;>?! :=??CD!
3.4&5"6&)A<<=) B(A'CD) B(EEAD)
!"!"#! $%&'()*+,'&-)&.+/0)&.+12,+E(F5'0!G!)6#2)!160!H#$%&'()#*!/01200*!IJ"K!#+!.&F0L&*M!&*7!
N#H(&3.&F0L&*M!#*! 160!-8!)01=!<#16!N.L!&*7!.&F0L&*M!/0*0+(1!
20/!)0&'H6=!B60!/0110'! '0)531! ()!&H6(0O07!/4!N.L=!-F&(*P!)($(3&'!
H#*H35)(#*! H&*! /0! 7'&2*! +'#$! B&/30! 9P! 26(H6! )6#2)! 160!
H#$%&'()#*!#+!,-.!#*!160!12#!Q50'4!)01)=!
!
!"#$%&!D(!)*+,-)./)!"12%)3:FG7))3:FGHI=7).6;))
3:FGH<I=)12%)>.%?"6#)!)
)
9.@5&)G(!"#$%&'()#*!#+!,-.!/01200*!)1&1(H!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!A.L! :=>?>?! :=??RR!
3.4&5"6&!8<I=! B(AFDJ) B(EFFG)
!"!"3! $%&'()*+,'&-)&.+/0)&.+4567+11,+'&8+12,+<4! (*H#'%#'&1(*F! /#16! N#H(&3N($L&*M! &*7! N#H(&3.&F0L&*MP! 20!
H&*!&H6(0O0!160!/0)1!)0&'H6!'0)531!&)!)6#2*!(*!B&/30!R=!BS10)1)!#*!
,-.!)6#2!)1&1()1(H&334!)(F*(+(H&*1!($%'#O0$0*1)!T%SO&350U:=:9V=!!
)9.@5&)'(!J4*&$(H!'&*M(*F!2(16!/#16!NNL!&*7!N.L!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
3.4&5"6&8<<=7<I=) B(ADFA)K8EA(JBLM) B(EN'A)K8FG(BFLM)
!"!"9! :'0;+16<8%+B#!5*70')1&*7!6#2!160)0!($%'#O0$0*1)!&'0!&H6(0O07P!20!%'0)0*1!
&!H&)0!)1574!60'0=!E#'!)($%3(H(14P!160!)($(3&'(14!/01200*!160!Q50'4!
&*7!7#H5$0*1!H#*10*1!()!*#1!H#*)(70'07=!
K(O0*! 160! Q50'4! W')=>'=;XP! ;?D! 20/! %&F0)! &'0! &))#H(&107!
16'#5F6!160!)#H(&3!&**#1&1(#*)!&*7!160!1#%S>!20/!%&F0)!&HH#'7(*F!
1#!N.L!)H#'0)!&'0!)6#2*! (*!B&/30!G=!B6'#5F6! 160! '0O(02)!#+! 160!
1'&O03! )(10)! 3(M0! 0YH0330*1S'#$&*1(HSO&H&1(#*)!9P! 20! H&*! H#*H3570!
16&1!160!)#H(&3!&**#1&1(#*)!&'0!5)0+53!&*7!N.L!&'0!'0&334!0++0H1(O0=!
E#'!0Y&$%30P!160!)(10!766?@AABBB"-'%'-"*5(A!2(16!1#%!N.L!)H#'0!()!
&3)#! '&*M07! +(')1! /4! 0YH0330*1S'#$&*1(HSO&H&1(#*)! &*7! H&3307!
WK##F30!#+!B'&O03!N(10)X=!
9.@5&)D(!Z0/!%&F0)!&))#H(&107!/4!&**#1&1(#*!W&('+&'0X!
O=P4) <I=)
611%[\\222=M&4&M=H#$\!!!!!! @!
611%[\\222=1'&O03#H(14=H#$\!! D!
611%[\\222=1'(%&7O()#'=H#$\!! D!
611%[\\222=0Y%07(&=H#$\!!!! D!
B60*! /4! 5)(*F! NNL! '&*MP! 20! +(*7! 160! 1#%S>! )($(3&'! 1&F)! 1#!
W')=>'=;X!&'0!W6)*-;6XP!W>C).76XP!W756;CXP!&*7!W')=C)&;X=!B6'#5F6!160!
&*&34)()P!20!+(*7!$#)1!#+!160!1#%!'&*M07!20/!)(10)!(*!B&/30!G!&'0!
&**#1&107! /4! 160)0! )($(3&'! &**#1&1(#*)! &)! 2033=! <0)(70)P! 160)0!
)($(3&'!&**#1&1(#*)!&3)#! (*1'#75H0!)#$0!*02!20/!%&F0)=!B&/30!D!
)6#2)! 160! 1#%SN.L!]L^)! 16&1! &'0! *#1! &**#1&107! /4! W')=>'=;X! (*!
#5'!H#'%5)=!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!
9611%[\\222=0YH0330*1S'#$&*1(HSO&H&1(#*)=H#$\/0)1S&('+&'0S
)0&'H6S0*F(*0=61$3!!
WWW 2007 / Track: Search Session: Search Quality and Precision
508
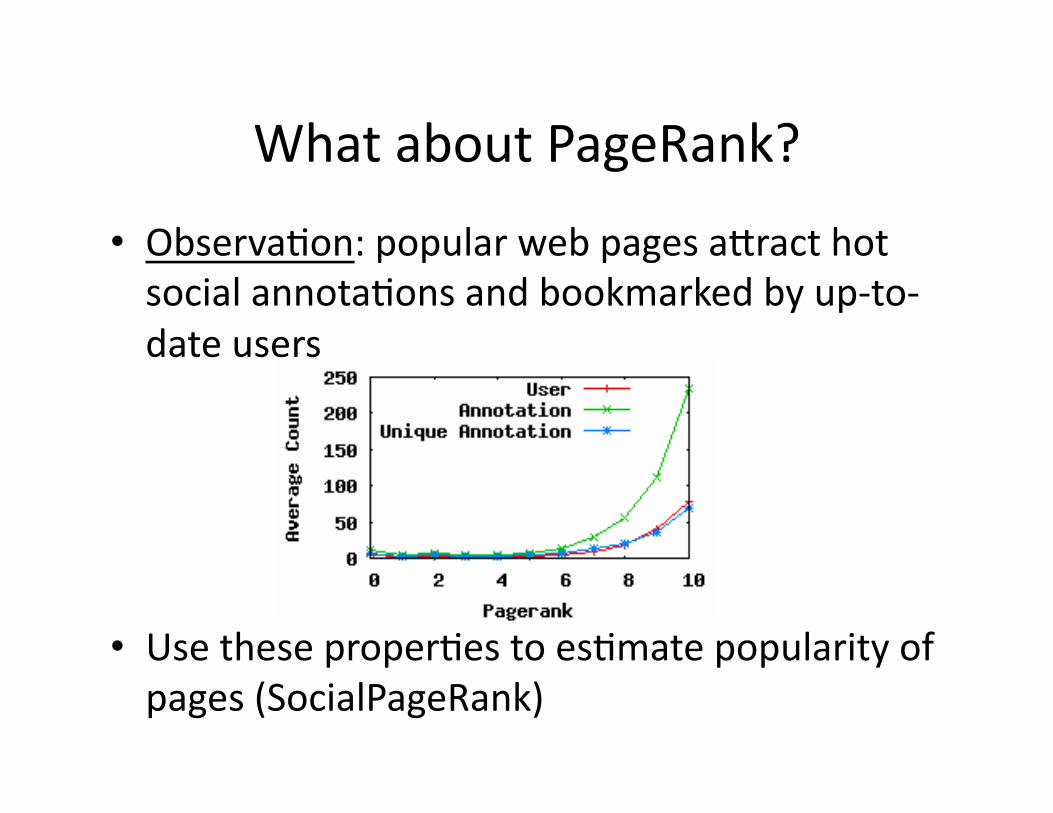
WhataboutPageRank?
• ObservaWon:popularwebpagesasracthotsocialannotaWonsandbookmarkedbyup‐to‐dateusers
• UsetheseproperWestoesWmatepopularityofpages(SocialPageRank)
!"#$%&%'()&*%& !"#"$%&'(&"))*+(&"#& !"#",%&'(&"))*+(+&,-&%./01&
1)-%-&*22"1*10"2%& 021"& %1*23*#3&4"#3%&401)& 1)-&)-/.&"!&,"#35-1&
6789&:-!"#-&'%02;&1)-$&02&1)-&-<.-#0$-21%+&
!"#! $%&'(&)*+,-+.-/,,+)&)*+,-0*1*'&2*)*34-=2& "'#& -<.-#0$-21%>& 1)-& ?"(0*/?0$@*2A& */;"#01)$& ("2B-#;-3&
401)02&CD&01-#*10"2%+&E*:/-&D&%)"4%&1)-&%-/-(1-3&*22"1*10"2%&!#"$&
!"'#& (*1-;"#0-%>& 1";-1)-#& 401)& 1)-0#& 1".& F& %-$*210(*//G& #-/*1-3&
*22"1*10"2%+&,01)& 1)-& -<./"#-3& %0$0/*#01G& B*/'-%>&4-& *#-& *:/-& 1"&
!023&$"#-&%-$*210(*//G&#-/*1-3&4-:&.*;-%&*%&%)"42&/*1-#+&
5&6'3-#"-H<./"#-3&%0$0/*#&*22"1*10"2%&:*%-3&"2&?"(0*/?0$@*2A&
5378,+'+9:-23'&)3;<&
3':/02& $-1*3*1*>&%-$*210(>&%1*23*#3>&"4/&
3-:0*2& 30%1#0:'10"2>&30%1#">&':'21'>&/02'<&
$7+,+1:-23'&)3;<&
*3%-2%-& %-2%->&*3B-#10%->&-21#-.#-2-'#>&$"2-G&
IJJ& 2'$:-#>&30#-(1"#G>&.)"2->&:'%02-%%&
$,)32)&*,13,)-23'&)3;<&
*/:'$& ;*//-#G>&.)"1";#*.)G>&.*2"#*$*>&.)"1"& &
()*1& $-%%-2;-#>&K*::-#>&0$>&$*("%<&&
$,)*):--23'&)3;<&
-02%1-02& %(0-2(->&%A-.10(>&-B"/'10"2>&L'*21'$&
()#0%10*2&& 3-B"1->&!*01)>&#-/0;0"2>&;"3&&
!"=! $%&'(&)*+,-+.-0>?-?34(')4-,-& ":1*02-3& -*()& 4-:& .*;-M%& ?N@& %("#-& '%02;& 1)-& */;"#01)$&
3-%(#0:-3& 02& %-(10"2& 7+7+& =2& "'#& -<.-#0$-21%>& 1)-& */;"#01)$&
("2B-#;-3& 401)02& O& 01-#*10"2%+& H*()& .*;-M%& N*;-@*2A& 4*%& */%"&
-<1#*(1-3& !#"$& 1)-& P"";/-M%& 1""/:*#& QN=& 3'#02;& R'/G>& DJJS+&
T-#-*!1-#>& 4-& '%-& N*;-@*2A& 1"& 3-.0(1& 1)-& -<1#*(1-3& P"";/-M%&
N*;-@*2A&:G&3-!*'/1+&
-$.$/! 0123#4$31"(52"+6378*49&*:;9*'+3<+"=>4*4?3U0;'#-&F&%)"4%&1)-&*B-#*;-&("'21%&"!&*22"1*10"2%&*23&*22"1*1"#%&
"B-#& 4-:& .*;-%& 401)& 30!!-#-21& N*;-@*2A& B*/'-%>& *23& !"#& 1)-&
@+*A;53<++'9"9*'+&/02->&1)-&B*/'-&$-*2%&1)-&("'21&"!&*22"1*10"2%&
1)*1& *#-& 30!!-#-21& 401)& -*()& "1)-#+& U#"$& 1)-& !0;'#->& 4-& (*2&
("2(/'3-& 1)*1& 02&$"%1&(*%-%>& 1)-&.*;-&401)&*&)0;)-#&N*;-@*2A& 0%&
/0A-/G&1"&:-&*22"1*1-3&:G&$"#-&'%-#%&401)&$"#-&*22"1*10"2%+&&
&
@*9(23&!"&-/%32&93-7+(,)-;*4)2*6()*+,-+%32->&93?&,A-
E"& !'#1)-#& 02B-%10;*1-& 1)-& 30%1#0:'10"2>& ("'21%& "!& *22"1*10"2%&
*23& *22"1*1"#%& !"#& *//& ("//-(1-3& .*;-%& 401)& 30!!-#-21& N*;-@*2A&
B*/'-%& *#-& ;0B-2& 02& U0;'#-& 8V*W+& =1& 0%& -*%G& 1"& %--& 1)*1& 1)-& .*;-%&
401)& -*()& N*;-@*2A& B*/'-& 30B-#%0!G& *& /"1& "2& 1)-& 2'$:-#& "!&
*22"1*10"2%&*23&'%-#%+&,-:&.*;-%&401)&*&#-/*10B-/G&/"4&N*;-@*2A&
$*G&"42&$"#-&*22"1*10"2%&*23&'%-#%&1)*2&1)"%-&4)"&)*B-&)0;)-#&
N*;-@*2A+&U"#&-<*$./->&%"$-&.*;-%&401)&N*;-@*2A&J&)*B-&$"#-&
'%-#%&*23&*22"1*10"2%&1)*2&1)"%-&4)"&)*B-&N*;-@*2A&CJ+&
&,-&*../0-3&1)-&?N@&*/;"#01)$&1"& 1)-&("//-(1-3&3*1*+&U"#&-*%G&
'23-#%1*2302;>&?N@&0%&2"#$*/0X-3&021"&*&%(*/-&"!&JYCJ&%"&1)*1&?N@&
*23&N*;-@*2A&)*B-&1)-&%*$-&2'$:-#&"!&.*;-%&02&-*()&;#*3-&!#"$&
J&1"&CJ+&U0;'#-&8V:W&%)"4%&1)-&3-1*0/-3&("'21%&"!&*22"1*10"2%&*23&
'%-#%&"!&.*;-%&401)&30!!-#-21&?"(0*/N*;-@*2A&B*/'-%+&=1&0%&-*%G&1"&
%--& 1)*1& ?"(0*/N*;-@*2A& %'((-%%!'//G& ()*#*(1-#0X-%& 1)-& 4-:&
.*;-%M&.".'/*#01G&3-;#--%&*$"2;&4-:&*22"1*1"#%+&
&&&&&&& -
B&C-/,,+)&)*+,4-&,;-(4324-+%32->&93?&,A& B6C-/,,+)&)*+,4-&,;-(4324-+%32-0+7*&'>&93?&,A&
@*9(23&D"-E*4)2*6()*+,-&,&':4*4-+.-4+7*&'-&,,+)&)*+,4--
WWW 2007 / Track: Search Session: Search Quality and Precision
506

Page‐UserassociaWonmatrix
!"# $%&'# ()$'$*# $%&'# +),'$#&)-# (%".)/"# %"0-# .1'# )""%.)./%"#
2!"!#$!3# '4,4*# 5'6# +),'# %4# 71'"# ,/8'"# .1'# 9:';-# (%".)/"/",#
2&'#!(3*# .1'# +),'# .1).# %"0-# 1)$# 2!"!#$!3# &)-# 6'# </0.';'=# %:.#
/&+;%+';0-# 6-# $/&+0'# .';&>&).(1/",# &'.1%=4# ?8'"# /<# .1'# +),'#
(%".)/"$#6%.1#)""%.)./%"$#2!"!#$!3#)"=#2&'#!(3*#/.#/$#"%.#+;%+';#.%#
()0(:0).'#.1'#$/&/0);/.-#6'.5''"#.1'#9:';-#)"=#.1'#=%(:&'".#:$/",#
.1'# @'-5%;=# 2&'#!(3# %"0-4#A"# 'B+0%;)./%"# %<# $/&/0);/.-# 6'.5''"#
2!"!#$!3#)"=#2&'#!(3#&)-#<:;.1';#/&+;%8'#.1'#+),'#;)"@/",4#
7%#'B+0%;'#.1'#)""%.)./%"$#5/.1#$/&/0);#&')"/",$*#5'#6:/0=#)#
6/+);./.'>,;)+1#6'.5''"#$%(/)0#)""%.)./%"$#)"=#5'6#+),'$#5/.1#/.$#
'=,'$# /"=/()./",# .1'# :$';# (%:".4# A$$:&'# .1).# .1';'# );'# )*#
)""%.)./%"$*#)+#5'6#+),'$#)"=#),#5'6#:$';$4#-*+# /$# .1'#)*C)+#
)$$%(/)./%"# &).;/B# 6'.5''"# )""%.)./%"$# )"=# +),'$4# -*+D%(./0E#
='"%.'$#.1'#":&6';#%<#:$';$#51%#)$$/,"#)""%.)./%"#%(#.%#+),'#/04#
F'../",12*16'#.1'#)*C)*#&).;/B#51%$'#'0'&'".#2*D%'*#%3E#/"=/().'$#
.1'# $/&/0);/.-# $(%;'# 6'.5''"# )""%.)./%"$#%'# )"=#%3# )"=#2+16'# .1'1
)+C)+# &).;/B# ')(1# %<# 51%$'# '0'&'".# $.%;'$# .1'# $/&/0);/.-##
6'.5''"# .5%# 5'6# +),'$*# 5'# +;%+%$'# G%(/)0G/&H)"@DGGHE*# )"#
/.';)./8'# )0,%;/.1&# .%# 9:)"./.)./8'0-# '8)0:).'# .1'# $/&/0);/.-#
6'.5''"#)"-#.5%#)""%.)./%"$4#
!"#$%&'()*+,*-$.&/"-&)0/12*3--04*
-'56*+# !"#$%&&&&&&'($&2*I#D%'*#%3E#J#K#<%;#')(1#%'1J#%3#%.1';5/$'#I#
2+I#D/'*#/3E#J#K#<%;#')(1#/'1J#/3#%.1';5/$'#I&
-'56*7* )*&8&
+*,&(-./&)""%.)./%"#+)/;#D%'.1%3E&0*&
#
! !" "
#"
ELDL
K
ELDL
K
K
EEDE*DDEE*DE**D&)BD
EE*DE**D&/"D
LEDLLEDLE*D
' 3%+
4
%+
#
3#'4
5
+
#3*+4'*+
#3*+4'*+
3'
*3'
5
*
%+%+2/%-/%-
/%-/%-
%+%+
6%%2
1111*& DME
* +*,&(-./&+),'#+)/;#D1/'.1/3E#0*& #
! !" "
#
#"
LEDL
K
LEDL
K
K
K
EEDE*DDEE*DE**D&)BD
EE*DE**D&/"D
LEDLLEDLE*D
' 3/*
4
/*
#
3#'45*
3#*+'4*+
3#*+'4*+
3'
+3'
5+
/*/*2/%-/%-
/%-/%-
/*/*
6//2
*& DNE
* 91"$#2#2*D%'*#%3E#(%"8';,'$4&#
-'56*:# 34$54$%&2*D%'*#%3E#
O';'*# 6*# )"=# 6+# ='"%.'# .1'# =)&+/",# <)(.%;$# %<# $/&/0);/.-#
+;%+),)./%"#<%;#)""%.)./%"$#)"=#5'6#+),'$*#;'$+'(./8'0-4#+D%'E# /$#
.1'#$'.#%<#5'6#+),'$#)""%.).'=#5/.1#)""%.)./%"#%'##)"=#*D/3E##/$#.1'#
$'.# %<# )""%.)./%"$#,/8'"# .%# +),'#/371+48%'9# ='"%.'$# .1'#4.1# +),'#
)""%.).'=#6-#%'#)"=#*48/'9#='"%.'$#.1'#4.1#)""%.)./%"#)$$/,"'=#.%#
+),'#/'4#!"#%:;#'B+';/&'".$*#6%.1#6*#)"=#6+1);'#$'.#.%#I4P4#
Q%.'#.1).#.1'#$/&/0);/.-#+;%+),)./%"#;).'#/$#)=R:$.'=#)((%;=/",#
.%# .1'# ":&6';# %<# :$';$# 6'.5''"# .1'# )""%.)./%"# )"=# 5'6# +),'4#
7)@'#?9:)./%"#DME# <%;#)"#'B)&+0'*# .1'#&)B/&)0#+;%+),)./%"#;).'#
()"#6'#)(1/'8'=#%"0-#/<#-*+D%'.1/4E#/$#'9:)0#.%#-*+1D%3.1/#E4#S/,:;'#
MD6E# $1%5$# .1'# </;$.# /.';)./%"T$# GGH# ;'$:0.# %<# .1'# $)&+0'# =).)#
51';'#6*#)"=#6+1);'#$'.#.%#K4#
71'#(%"8';,'"('#%<# .1'#)0,%;/.1&#()"#6'#+;%8'=# /"#)#$/&/0);#
5)-# )$#G/&H)"@# UVW4# S%;# ')(1# /.';)./%"*# .1'# ./&'# (%&+0'B/.-# %<#
.1'# GGH# )0,%;/.1&# /$# :D)*M)+
ME4# X/.1/"# .1'# =).)# $'.# %<# %:;#
'B+';/&'".*#6%.1#.1'#)""%.)./%"#)"=#5'6#+),'#$/&/0);/.-#&).;/('$#
);'#9:/.'# $+);$'# )"=# .1'# )0,%;/.1&#(%"8';,'$# 9:/(@0-4#Y:.# /<# .1'#
$()0'#%<#$%(/)0#)""%.)./%"$#@''+$#,;%5/",#'B+%"'"./)00-*#.1'#$+''=#
%<#(%"8';,'"('#<%;#%:;#)0,%;/.1&$#&)-#$0%5#=%5"4#7%#$%08'#.1/$#
+;%60'&*# 5'# ()"# :$'# $%&'# %+./&/Z)./%"# $.;).',-# $:(1# )$#
/"(%;+%;)./",# .1'# &/"/&)0# (%:".# ;'$.;/(./%"# UVW# .%# &)@'# .1'#
)0,%;/.1&#(%"8';,'#&%;'#9:/(@0-4#
F'../",#;J[;K*;M*\*;#]#6'#)#9:';-#51/(1#(%"$/$.$#%<1##9:';-#
.';&$#)"=#*D/EJ[%K*%M*\*#%4]#6'#.1'#)""%.)./%"#$'.#%<#5'6#+),'#/*#
?9:)./%"#D^E#$1%5$#.1'#$/&/0);/.-#()0(:0)./%"#&'.1%=#6)$'=#%"#.1'#
G%(/)0G/&H)"@4##
!!" "
"#
'
4
3
3'*22< %;2/;='4K K
E*DE*D# *# D^E
:;:! </#5*=>/"&'?*@A'&)/'&$1*BA&1#*-$.&/"*
!11$'/'&$1A*?B/$./",# $.)./(# ;)"@/",# &'.1%=$# :$:)00-# &')$:;'# +),'$T# 9:)0/.-#
<;%&#.1'#>?"1/%@?1AB?%$CB=D*#%;#.1'#=?%BAE1?#@'#?1!=?B=D1+%/".#%<#
8/'54#H'()00#.1).#/"#S/,:;'#K*#.1'#'$./&)./%"#%<#_),'H)"@#UKPW#/$#
$:6R'(.#.%#>?"1AB?%$CB=*#)"=#.1'#<H)"@#UKVW#/$#()0(:0).'=#6)$'=#%"#
6%.1#>?"1/%@?1AB?%$CB=# )"=# =?%BAE1 ?#@'#?1!=?B=T# )(./8/./'$4#71'#
$%(/)0#)""%.)./%"$#);'#.1'#"'5#/"<%;&)./%"#.1).#()"#6'#:./0/Z'=#.%#
()+.:;'# .1'# 5'6# +),'$T# 9:)0/.-# <;%&# >?"1 /%@?1 %##C$%$CB=D1
+';$+'(./8'4#
F7F7G! 2CA'%&+%@?<%#51*&@CB'$E41CDA5%E/'&$1* 7,* H'@E1 ;!%&'$01 >?"1 /%@?=1 %B?1 !=!%&&01 /C/!&%B&01
%##C$%$?I1%#I1/C/!&%B*>?"1/%@?=.1!/J$CJI%$?1>?"1!=?B=1%#I1EC$1
=CA'%&1 %##C$%$'C#=1 E%K?1 $E?1 LC&&C>'#@1 B?&%$'C#=M1 /C/!&%B1 >?"1
/%@?=1 %B?1 "CC54%B5?I1 "014%#01 !/J$CJI%$?1 !=?B=1 %#I1 %##C$%$?I1
"01 EC$1 %##C$%$'C#=N1 !/J$CJI%$?1 !=?B=1 &'5?1 $C1 "CC54%B51 /C/!&%B1
/%@?=1 %#I1 !=?1 EC$1 %##C$%$'C#=N1 EC$1 %##C$%$'C#=1 %B?1 !=?I1 $C1
%##C$%$?1/C/!&%B1>?"1/%@?=1%#I1!=?I1"01!/J$CJI%$?1!=?B=7##
Y)$'=#%"#.1'#%6$';8)./%"#)6%8'*#5'#+;%+%$'#)#"%8'0#)0,%;/.1&*#
")&'0-#G%(/)0_),'H)"@#DG_HE#.%#9:)"./.)./8'0-#'8)0:).'#.1'#+),'#
9:)0/.-#D+%+:0);/.-E#/"=/().'=#6-#$%(/)0#)""%.)./%"$4#71'#/".:/./%"#
6'1/"=# .1'# )0,%;/.1&# /$# .1'#&:.:)0# '"1)"('&'".# ;'0)./%"# )&%",#
+%+:0);* 5'6# +),'$*# :+>.%>=).'# 5'6# :$';$# )"=# 1%.# $%(/)0#
)""%.)./%"$4# S%00%5/",*# .1'# +%+:0);/.-# %<# 5'6# +),'$*# .1'# :+>.%>
=).'"'$$# %<# 5'6# :$';$# )"=# .1'# 1%."'$$# %<# )""%.)./%"$# );'# )00#
;'<';;'=#.%1)$1/C/!&%B'$01<%;#$/&+0/(/.-4##
A$$:&'# .1).# .1';'# );'#)*# )""%.)./%"$*#)+#5'6#+),'$#)"=#),#
5'6# :$';$4# F'.#-+,# 6'# .1'# )+C),1 )$$%(/)./%"# &).;/B# 6'.5''"#
+),'$# )"=# :$';$*1 -*+1 6'# .1'#)*C)+1 )$$%(/)./%"#&).;/B# 6'.5''"#
)""%.)./%"$# )"=# +),'$# )"=# -,*..1'1 ),C)*1 )$$%(/)./%"# &).;/B#
6'.5''"# :$';$# )"=# )""%.)./%"$4# ?0'&'".#-+,# D/'*!3E# /$# )$$/,"'=#
5/.1#.1'#(%:".#%<#)""%.)./%"$#:$'=#6-#:$';#!3#.%#)""%.).'#+),'#/'4#
?0'&'".$#%<#-*+1)"=1-,*#);'# /"/./)0/Z'=#$/&/0);0-4#F'.#+I#6'# .1'#
8'(.%;# (%".)/"/",# ;)"=%&0-# /"/./)0/Z'=# G%(/)0_),'H)"@# $(%;'$4##
`'.)/0$#%<#.1'#G%(/)0_),'H)"@#)0,%;/.1&#);'#+;'$'".'=#)$#<%00%5$4##
!"#$%&'()*7,*-$.&/"</#50/12*3-<04*
-'56*+*!"54$%&
A$$%(/)./%"# &).;/('$1 -+,*1 -*+.1 )"=1 -,** )"=# .1'#
;)"=%&#/"/./)0#G%(/)0_),'H)"@#$(%;'#+I##
WWW 2007 / Track: Search Session: Search Quality and Precision
504
!"#$%&%
%
!"#$
!"#$%
!$#$%&&
!'#$%&&
!(#$%&&
!)#$%&&
!*#$%&&
+
*
++
++
+
!"#!
!#$!
!$"!
!$"!
!#$!
!"#!
#%"
$%#
"%$
$%"
#%$
"%#
&
&
&
!"
!"
!"
!"
!"
!"
#
&
%&'()&"!$,-./01203#&
%$!
!"#$%'(% *+',+'#$
"'4&560&,-./01207&8-,9:;<:20=:.>&3,-10#$
850?&*&7-03&560&9.959:;9@:59-.#&A.&850?&)B&"!B&#!B&:.7&$!&70.-50&
560&?-?C;:195D&/0,5-13&-E&?:203B&C3013B& :.7&:..-5:59-.3& 9.& 560& !56&
9501:59-.#&"!F()#!
FB&:.7&$!F&:10&9.501G079:50&/:;C03#&H3&9;;C351:507&9.&
I92C10& (B& 560& 9.5C959-.& J069.7& KLC:59-.& %$!& 93& 56:5& 560& C3013F&
?-?C;:195D&,:.&J0&7019/07&E1-G&560&?:203&560D&:..-5:507&%$#*!M&560&
:..-5:59-.3F& ?-?C;:195D& ,:.& J0& 7019/07& E1-G& 560& ?-?C;:195D& -E&
C3013& %$#)!M& 39G9;:1;DB& 560& ?-?C;:195D& 93& 51:.3E01107& E1-G&
:..-5:59-.3& 5-&N0J& ?:203& %$#(!B&N0J& ?:203& 5-& :..-5:59-.3& %$#'!B&
:..-5:59-.3&5-&C3013&%$#$!B&:.7&560.&C3013&5-&N0J&?:203&:2:9.&%$#"!#&&
I9.:;;DB&N0&205&"'& :3& 560&-C5?C5&-E&8-,9:;<:20=:.>& %8<=!&N60.&
560&:;2-1956G&,-./01203#&8:G?;0&8<=&/:;C03&:10&29/0.&9.&560&19265&
?:15&-E&I92C10&(#&&
&
)*+,-#&'.&%/00,1"-2"*34%35%6,20*"7%"-241*"*34%8#"9##4%":#%
,1#-1;%2443"2"*341;%24<%$2+#1%*4%":#%!=>%20+3-*":?&
A.& 0:,6& 9501:59-.B& 560& 59G0& ,-G?;0O95D& -E& 560& :;2-1956G& 93&
*%+#+"&P)+$&+"&P)+#&+$&!#&89.,0&560&:7Q:,0.,D&G:519,03&:10&/01D&
3?:130& 9.& -C1& 7:5:& 305B& 560& :,5C:;& 59G0& ,-G?;0O95D& 93& E:1& ;-N01#&
R-N0/01B&9.&S0J&0./91-.G0.5B&560&39@0&-E&7:5:&:10&9.,10:39.2&:5&:&
E:35& 3?007B& :.7& 3-G0& :,,0;01:59-.& 5-& 560& :;2-1956G& %;9>0& TUV& E-1&
<:20=:.>!&36-C;7&J0&70/0;-?07#&
,-,-.! /0123453163)07)8"9)$:504!;<=)R010B& N0& 29/0& :& J190E& ?1--E& -E& 560& ,-./0120.,0& -E& 560& 8<=&
:;2-1956G#&A5&,:.&J0&7019/07&E1-G&560&:;2-1956G&56:54&
W
*
* !%!% "%%"%%" !&
!
&
! !!"!!"#
#B& %"!
N6010&
$"#$"# %%%% !!" #& %U!
H&35:.7:17&103C;5&-E&;9.0:1&:;20J1:&%0#2#&TXV!&35:503&56:5&9E&%>&93&
:& 3DGG0519,) G:519OB& :.7& 2& 93& :& /0,5-1& .-5& -156-2-.:;& 5-& 560&
?19.,9?:;&0920./0,5-1&-E&560&G:519O)!*%%>!B&560.&560&C.95&/0,5-1&9.&
560&7910,59-.&-E&%%>!?2),-./01203&5-&!*%%>!&:3&?&9.,10:303&N956-C5&
J-C.7#&R010&%%&)93&:&3DGG0519,&G:519O&:.7)"W&93&.-5&-156-2-.:;&
5-&!*%%%&!B& 3-& 560& 30LC0.,0&"!& ,-./01203& 5-& :& ;9G95&"
YB& N69,6&
392.:;3&560&501G9.:59-.&-E&560&8<=&:;2-1956G#&
'.@! A742?*B%>24C*4+%9*":%!3B*20%
/453-?2"*34%
,-@-A! BC1D=!6)9D1?!15)%3;<0E)ZC0&5-&560&;:120&.CGJ01&-E&E0:5C103B&G-701.&N0J&30:1,6&0.29.03&
C3C:;;D& 1:.>& 103C;53& JD& ;0:1.9.2& :& 1:.>& EC.,59-.#&[:.D&G056-73&
6:/0&J00.&70/0;-?07&E-1&:C5-G:59,&%-1&30G9\:C5-G:59,!&5C.9.2&-E&
3?0,9E9,& 1:.>9.2& EC.,59-.3#& <10/9-C3& N-1>& 0359G:503& 560& N092653&
561-C26& 10210339-.& T)"V#& =0,0.5& N-1>& -.& 5693& 1:.>9.2& ?1-J;0G&
:550G?53& 5-& 7910,5;D& -?59G9@0& 560& -17019.2& -E& 560& -JQ0,53& T(B& ))B&
()V#&&
H3&793,C3307&9.&T$VB&56010&:10&20.01:;;D&5N-&N:D3&5-&C59;9@0&560&
0O?;-107& 3-,9:;& E0:5C103& E-1& 7D.:G9,& 1:.>9.2& -E& N0J& ?:2034& %:!&
510:59.2& 560& 3-,9:;& :,59-.3& :3& 9.70?0.70.5& 0/970.,0& E-1& 1:.>9.2&
103C;53B& :.7& %J!& 9.5021:59.2& 560& 3-,9:;& E0:5C103& 9.5-& 560& 1:.>9.2&
:;2-1956G#&A.&-C1&N-1>B&N0&9.,-1?-1:50&J-56&39G9;:195D&:.7&35:59,&
E0:5C103& 0O?;-9507& E1-G& 3-,9:;& :..-5:59-.3& 9.5-& 560& 1:.>9.2&
EC.,59-.&JD&C39.2&=:.>8][&T()V#&
,-@-.! F3D;G43>)S0&79/9707&-C1&E0:5C10&305&9.5-&5N-&GC5C:;;D&0O,;C39/0&,:502-19034&
LC01D\?:20&39G9;:195D&E0:5C103&:.7&?:20F3&35:59,&E0:5C103#&^:J;0&*&
703,19J03&0:,6&-E&56030&E0:5C10&,:502-1903&9.&705:9;#&
D280#%E.&I0:5C103&9.&3-,9:;&30:1,6&
H4&&LC01D\7-,CG0.5&E0:5C103&
B068!=!:D4!;C)& 89G9;:195D&J05N00.&LC01D&:.7&?:20&,-.50.5&
&34=%D;6<!15)
%^[!)
89G9;:195D& J05N00.& LC01D& :.7& :..-5:59-.3&
C39.2&560&501G&G:5,69.2&G056-7#&
806!D:8!=9D1?)
%88=!)
89G9;:195D& J05N00.& LC01D& :.7& :..-5:59-.3&
J:307&-.&8-,9:;89G=:.>#&
_4&&7-,CG0.5&35:59,&E0:5C103&
H005:3"D539D1?)
%<=!)
^60&N0J&?:20F3&<:20=:.>&-J5:9.07&E1-G&560&
`--2;0F3&5--;J:1&H<A#&
806!D:"D539D1?)
%8<=!)
^60& ?-?C;:195D& 3,-10& ,:;,C;:507& J:307& -.&
8-,9:;<:20=:.>&:;2-1956G#&
@.! FG=F>/HFIDJK%>F!LKD!%
@.E! A#0*B*3,1%A2"2%^6010& :10& G:.D& 3-,9:;& J-->G:1>& 5--;3& -.& S0J& T(WV#& I-1& 560&
0O?019G0.5B&N0&C30&560&7:5:&,1:N;07&E1-G&Z0;9,9-C3&7C19.2&[:DB&
)WW"B& N69,6& ,-.39353& -E& *BU("B)"X& N0J& ?:203& :.7& )"aB$""&
79EE010.5&:..-5:59-.3#&
H;56-C26& 560&:..-5:59-.3& E1-G&Z0;9,9-C3&:10&0:3D& E-1&6CG:.&
C3013& 5-& 10:7&:.7&C.70135:.7B& 560D&:10&.-5&70392.07& E-1&G:,69.0&
C30#&I-1&0O:G?;0B&C3013&G:D&C30&,-G?-C.7&:..-5:59-.3&9.&/:19-C3&
:&
,&
J&&
&
&
&
8-,9:;&:..-5:59-.3&
%:!& %J!&
!3B*20=2+#>24C1(%
8<=%:!b&W#W*$$&
8<=%J!b&W#WW')&
8<=%,!&bW#W)*X&
S0J&?:203&
S0J&?:20&:..-5:5-13&
&
%$#*!&
%$#"!%$#$!&
%$#)!&
&
&
%$#(!&
%$#'!&
WWW 2007 / Track: Search Session: Search Quality and Precision
505
User‐Ann.associaWonmatrixAnn.‐PageassociaWonmatrix
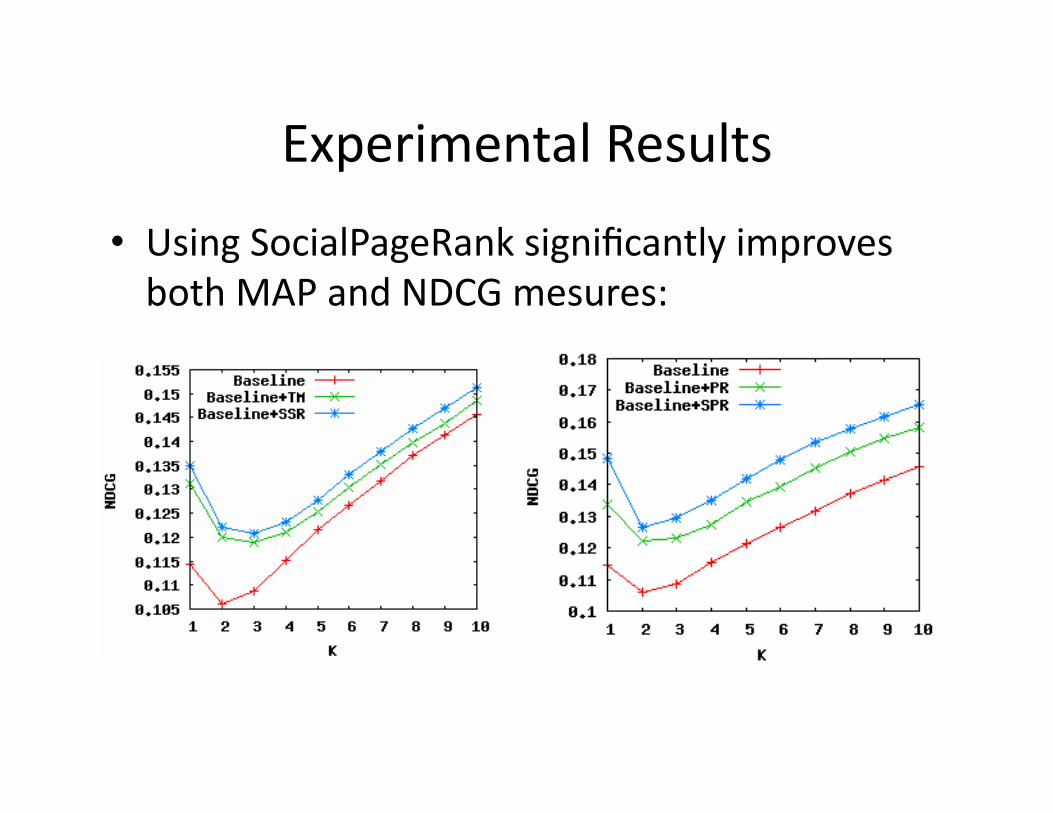
ExperimentalResults
!
!"#$%&!'(!)*+,-)./)0)12%)3.4&5"6&7))3.4&5"6&)89:7)
.6;))3.4&5"6&)8<<=)12%)>.%?"6#)0)
9.@5&)A(!"#$%&'()#*!#+!,-.!/01200*!)($(3&'(14!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!AB,! :=>;>?! :=??CD!
3.4&5"6&)A<<=) B(A'CD) B(EEAD)
!"!"#! $%&'()*+,'&-)&.+/0)&.+12,+E(F5'0!G!)6#2)!160!H#$%&'()#*!/01200*!IJ"K!#+!.&F0L&*M!&*7!
N#H(&3.&F0L&*M!#*! 160!-8!)01=!<#16!N.L!&*7!.&F0L&*M!/0*0+(1!
20/!)0&'H6=!B60!/0110'! '0)531! ()!&H6(0O07!/4!N.L=!-F&(*P!)($(3&'!
H#*H35)(#*! H&*! /0! 7'&2*! +'#$! B&/30! 9P! 26(H6! )6#2)! 160!
H#$%&'()#*!#+!,-.!#*!160!12#!Q50'4!)01)=!
!
!"#$%&!D(!)*+,-)./)!"12%)3:FG7))3:FGHI=7).6;))
3:FGH<I=)12%)>.%?"6#)!)
)
9.@5&)G(!"#$%&'()#*!#+!,-.!/01200*!)1&1(H!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!A.L! :=>?>?! :=??RR!
3.4&5"6&!8<I=! B(AFDJ) B(EFFG)
!"!"3! $%&'()*+,'&-)&.+/0)&.+4567+11,+'&8+12,+<4! (*H#'%#'&1(*F! /#16! N#H(&3N($L&*M! &*7! N#H(&3.&F0L&*MP! 20!
H&*!&H6(0O0!160!/0)1!)0&'H6!'0)531!&)!)6#2*!(*!B&/30!R=!BS10)1)!#*!
,-.!)6#2!)1&1()1(H&334!)(F*(+(H&*1!($%'#O0$0*1)!T%SO&350U:=:9V=!!
)9.@5&)'(!J4*&$(H!'&*M(*F!2(16!/#16!NNL!&*7!N.L!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
3.4&5"6&8<<=7<I=) B(ADFA)K8EA(JBLM) B(EN'A)K8FG(BFLM)
!"!"9! :'0;+16<8%+B#!5*70')1&*7!6#2!160)0!($%'#O0$0*1)!&'0!&H6(0O07P!20!%'0)0*1!
&!H&)0!)1574!60'0=!E#'!)($%3(H(14P!160!)($(3&'(14!/01200*!160!Q50'4!
&*7!7#H5$0*1!H#*10*1!()!*#1!H#*)(70'07=!
K(O0*! 160! Q50'4! W')=>'=;XP! ;?D! 20/! %&F0)! &'0! &))#H(&107!
16'#5F6!160!)#H(&3!&**#1&1(#*)!&*7!160!1#%S>!20/!%&F0)!&HH#'7(*F!
1#!N.L!)H#'0)!&'0!)6#2*! (*!B&/30!G=!B6'#5F6! 160! '0O(02)!#+! 160!
1'&O03! )(10)! 3(M0! 0YH0330*1S'#$&*1(HSO&H&1(#*)!9P! 20! H&*! H#*H3570!
16&1!160!)#H(&3!&**#1&1(#*)!&'0!5)0+53!&*7!N.L!&'0!'0&334!0++0H1(O0=!
E#'!0Y&$%30P!160!)(10!766?@AABBB"-'%'-"*5(A!2(16!1#%!N.L!)H#'0!()!
&3)#! '&*M07! +(')1! /4! 0YH0330*1S'#$&*1(HSO&H&1(#*)! &*7! H&3307!
WK##F30!#+!B'&O03!N(10)X=!
9.@5&)D(!Z0/!%&F0)!&))#H(&107!/4!&**#1&1(#*!W&('+&'0X!
O=P4) <I=)
611%[\\222=M&4&M=H#$\!!!!!! @!
611%[\\222=1'&O03#H(14=H#$\!! D!
611%[\\222=1'(%&7O()#'=H#$\!! D!
611%[\\222=0Y%07(&=H#$\!!!! D!
B60*! /4! 5)(*F! NNL! '&*MP! 20! +(*7! 160! 1#%S>! )($(3&'! 1&F)! 1#!
W')=>'=;X!&'0!W6)*-;6XP!W>C).76XP!W756;CXP!&*7!W')=C)&;X=!B6'#5F6!160!
&*&34)()P!20!+(*7!$#)1!#+!160!1#%!'&*M07!20/!)(10)!(*!B&/30!G!&'0!
&**#1&107! /4! 160)0! )($(3&'! &**#1&1(#*)! &)! 2033=! <0)(70)P! 160)0!
)($(3&'!&**#1&1(#*)!&3)#! (*1'#75H0!)#$0!*02!20/!%&F0)=!B&/30!D!
)6#2)! 160! 1#%SN.L!]L^)! 16&1! &'0! *#1! &**#1&107! /4! W')=>'=;X! (*!
#5'!H#'%5)=!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!
9611%[\\222=0YH0330*1S'#$&*1(HSO&H&1(#*)=H#$\/0)1S&('+&'0S
)0&'H6S0*F(*0=61$3!!
WWW 2007 / Track: Search Session: Search Quality and Precision
508
• UsingSocialPageRanksignificantlyimprovesbothMAPandNDCGmesures:
!
!"#$%&!'(!)*+,-)./)0)12%)3.4&5"6&7))3.4&5"6&)89:7)
.6;))3.4&5"6&)8<<=)12%)>.%?"6#)0)
9.@5&)A(!"#$%&'()#*!#+!,-.!/01200*!)($(3&'(14!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!AB,! :=>;>?! :=??CD!
3.4&5"6&)A<<=) B(A'CD) B(EEAD)
!"!"#! $%&'()*+,'&-)&.+/0)&.+12,+E(F5'0!G!)6#2)!160!H#$%&'()#*!/01200*!IJ"K!#+!.&F0L&*M!&*7!
N#H(&3.&F0L&*M!#*! 160!-8!)01=!<#16!N.L!&*7!.&F0L&*M!/0*0+(1!
20/!)0&'H6=!B60!/0110'! '0)531! ()!&H6(0O07!/4!N.L=!-F&(*P!)($(3&'!
H#*H35)(#*! H&*! /0! 7'&2*! +'#$! B&/30! 9P! 26(H6! )6#2)! 160!
H#$%&'()#*!#+!,-.!#*!160!12#!Q50'4!)01)=!
!
!"#$%&!D(!)*+,-)./)!"12%)3:FG7))3:FGHI=7).6;))
3:FGH<I=)12%)>.%?"6#)!)
)
9.@5&)G(!"#$%&'()#*!#+!,-.!/01200*!)1&1(H!+0&15'0)!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
<&)03(*0!A.L! :=>?>?! :=??RR!
3.4&5"6&!8<I=! B(AFDJ) B(EFFG)
!"!"3! $%&'()*+,'&-)&.+/0)&.+4567+11,+'&8+12,+<4! (*H#'%#'&1(*F! /#16! N#H(&3N($L&*M! &*7! N#H(&3.&F0L&*MP! 20!
H&*!&H6(0O0!160!/0)1!)0&'H6!'0)531!&)!)6#2*!(*!B&/30!R=!BS10)1)!#*!
,-.!)6#2!)1&1()1(H&334!)(F*(+(H&*1!($%'#O0$0*1)!T%SO&350U:=:9V=!!
)9.@5&)'(!J4*&$(H!'&*M(*F!2(16!/#16!NNL!&*7!N.L!
,016#7! ,89:! -8;:::!
<&)03(*0! :=>??9! :=?:@?!
3.4&5"6&8<<=7<I=) B(ADFA)K8EA(JBLM) B(EN'A)K8FG(BFLM)
!"!"9! :'0;+16<8%+B#!5*70')1&*7!6#2!160)0!($%'#O0$0*1)!&'0!&H6(0O07P!20!%'0)0*1!
&!H&)0!)1574!60'0=!E#'!)($%3(H(14P!160!)($(3&'(14!/01200*!160!Q50'4!
&*7!7#H5$0*1!H#*10*1!()!*#1!H#*)(70'07=!
K(O0*! 160! Q50'4! W')=>'=;XP! ;?D! 20/! %&F0)! &'0! &))#H(&107!
16'#5F6!160!)#H(&3!&**#1&1(#*)!&*7!160!1#%S>!20/!%&F0)!&HH#'7(*F!
1#!N.L!)H#'0)!&'0!)6#2*! (*!B&/30!G=!B6'#5F6! 160! '0O(02)!#+! 160!
1'&O03! )(10)! 3(M0! 0YH0330*1S'#$&*1(HSO&H&1(#*)!9P! 20! H&*! H#*H3570!
16&1!160!)#H(&3!&**#1&1(#*)!&'0!5)0+53!&*7!N.L!&'0!'0&334!0++0H1(O0=!
E#'!0Y&$%30P!160!)(10!766?@AABBB"-'%'-"*5(A!2(16!1#%!N.L!)H#'0!()!
&3)#! '&*M07! +(')1! /4! 0YH0330*1S'#$&*1(HSO&H&1(#*)! &*7! H&3307!
WK##F30!#+!B'&O03!N(10)X=!
9.@5&)D(!Z0/!%&F0)!&))#H(&107!/4!&**#1&1(#*!W&('+&'0X!
O=P4) <I=)
611%[\\222=M&4&M=H#$\!!!!!! @!
611%[\\222=1'&O03#H(14=H#$\!! D!
611%[\\222=1'(%&7O()#'=H#$\!! D!
611%[\\222=0Y%07(&=H#$\!!!! D!
B60*! /4! 5)(*F! NNL! '&*MP! 20! +(*7! 160! 1#%S>! )($(3&'! 1&F)! 1#!
W')=>'=;X!&'0!W6)*-;6XP!W>C).76XP!W756;CXP!&*7!W')=C)&;X=!B6'#5F6!160!
&*&34)()P!20!+(*7!$#)1!#+!160!1#%!'&*M07!20/!)(10)!(*!B&/30!G!&'0!
&**#1&107! /4! 160)0! )($(3&'! &**#1&1(#*)! &)! 2033=! <0)(70)P! 160)0!
)($(3&'!&**#1&1(#*)!&3)#! (*1'#75H0!)#$0!*02!20/!%&F0)=!B&/30!D!
)6#2)! 160! 1#%SN.L!]L^)! 16&1! &'0! *#1! &**#1&107! /4! W')=>'=;X! (*!
#5'!H#'%5)=!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!
9611%[\\222=0YH0330*1S'#$&*1(HSO&H&1(#*)=H#$\/0)1S&('+&'0S
)0&'H6S0*F(*0=61$3!!
WWW 2007 / Track: Search Session: Search Quality and Precision
508

• ObservaWon:socialannotaWonscharacterizewelltopicsofpagesandinterestsofusers
• Rankqueryresultsforqueryq,pagep,useruasfollows:
• Computertopic(u,p)ascosinesimilaritybetweenannotaWonsofuandannotaWonsofp
omy, and then discuss in detail the approach we propose forpersonalized search.
3.1 Analysis of FolksonomyWhat folksonomy can bring us in personalized search?
The best way to answer this question is to analyze it.Social Annotations as Category Names. In the folk-
sonomy systems, the users are free to choose any social an-notations to classify and organize their bookmarks. Thoughthere may be some noise, each social annotation representsa topic that is related to its semantic meaning [17]. Basedon this, the social annotations owned by the web pages andthe users reflect their topics and interests respectively.
Social Annotations as Keywords. As discussed in [2,4, 27] the annotations are very close to human generatedkeywords. Thus, the social annotations usually can well de-scribe or even complement the content of the web pages.
Collaborative Link Structure. One of the most impor-tant benefits that online folksonomy systems bring is the col-laborative link structure created by the users unconsciously.The underlying link structure of the tagging systems hasbeen explored in many prior efforts [4, 18, 27]. The wholeunderlying structures of folksonomy systems are rather com-plex. Different researchers may reduce the complexity ofmodeling the structure by various simplified model, e.g. in[27], the structure is modeled through a latent semantic layerwhile in [4] the relations between the annotations and theweb pages are modeled using a bipartite graph. In our work,since the relations between the users and the web pages arevery important, we model the structure using a user-webpage bipartite graph as shown in Figure 1.
!"!# !$!%
!&
!'
!(
)" )% )# )*
+" +#+% +,
Figure 1: User-web page bipartite structure
where ui, i = 1, 2, · · · , n denote n users, pj , j = 1, 2, · · · , mdenote m web pages, Wk, k = 1, 2, · · · , l are the weights ofthe links, i.e. the bookmarking actions of the users. One ofthe simplest implementation of the weights is the number ofannotations a user assigned to a web page.
3.2 A Personalized Search FrameworkIn the classical non-personalized search engines, the rel-
evance between a query and a document is assumed to beonly decided by the similarity of term matching. However,as pointed in [21], relevance is actually relative for each user.Thus, only query term matching is not enough to generatesatisfactory search results for various users.
In the widely used Vector Space Model(VSM), all thequeries and the documents are mapped to be vectors in auniversal term space. The similarity between a query anda document is calculated through the cosine similarity be-tween the query term vector and the document term vector.Though simple, the model shows amazing effectiveness andefficiency.
Inspired by the VSM model, we propose to model theassociations between the users and the web pages using atopic space. Each dimension of the topic space representsa topic. The topics of the web pages and the interests of
the users are represented as vectors in this space. Furtherwe define a topic similarity measurement using the cosinefunction. Let !pti = (w1,i, w2,i, · · · , wα,i) be the topic vectorof the web page pi where α is the dimension of the topicspace and wk,i is the weight of the kth dimension. Similarly,let !utj = (w1,j , w2,j , · · · , wα,j) be the interest vector of theuser uj . The topic similarity between pi and uj is calculatedas Equation 1.
simtopic(pi, uj) =!pti • !utj
| !pti|× | !utj |(1)
Based on the topic space, we make a fundamental person-alized search assumption, i.e. Assumption 1.
Assumption 1. The rank of a web page p in the result listwhen a user u issues a query q is decided by two aspects, aterm matching between q and p and a topic matching betweenu and p.
When a user u issues a query q, we assume two searchprocesses, a term matching process and a topic matchingprocess. The term matching process calculates the similaritybetween q and each web page to generate a user unrelatedranked document list. The topic matching process calculatesthe topic similarity between u and each web page to generatea user related ranked document list. Then a merge operationis conducted to generate a final ranked document list basedon the two sub ranked document lists. We adopt rankingaggregation to implement the merge operation.
Ranking Aggregation is to compute a “consensus” ran-king of several sub rankings [11]. There are a lot of rank ag-gregation algorithms that can be applied in our work. Herewe choose one of the simplest, Weighted Borda-Fuse (WBF).Equation 2 shows our idea.
r(u, q, p) = γ · rterm(q, p) + (1 − γ) · rtopic(u, p) (2)
where rterm(q, p) is the rank of the web page p in theranked document list generated by query term matching,rtopic(u, p) is the rank of p in the ranked document list gen-erated by topic matching and γ is the weight that satisfies0 ≤ γ ≤ 1.
Obviously, how to select a proper topic space and howto accurately estimate the user interest vectors and the webpage topic vectors are two key points in this framework. Thenext two subsections discuss these problems.
3.3 Topic Space SelectionIn web page classification, the web pages are classified
to several predefined categories. Intuitively, the categoriesof web page classification are very similar to the topics ofthe topic space. In today’s World Wide Web, there aretwo classification systems, the traditional taxonomy suchas ODP and the new folksonomy. The two classificationsystems can be both applied in our framework. Since ourwork focuses on exploring the folksonomy for personalizedsearch, we set the ODP topic space as a baseline.
3.3.1 Folksonomy: Social Annotations as Topics
Based on the categorization feature, we set the social an-notations to be the dimensions of the topic space. Thus,the topic vector of a web page can be simply estimated byits social annotations directly. In the same way, the interest
157
Exploring Folksonomy for Personalized Search
Shengliang Xu∗
Shanghai Jiao Tong UniversityShanghai, 200240, China
Shenghua Bao∗
Shanghai Jiao Tong UniversityShanghai, 200240, China
Ben FeiIBM China Research LabBeijing, 100094, China
Zhong SuIBM China Research LabBeijing, 100094, China
Yong YuShanghai Jiao Tong UniversityShanghai, 200240, China
ABSTRACT
As a social service in Web 2.0, folksonomy provides the usersthe ability to save and organize their bookmarks online with“social annotations” or “tags”. Social annotations are highquality descriptors of the web pages’ topics as well as goodindicators of web users’ interests. We propose a personal-ized search framework to utilize folksonomy for personalizedsearch. Specifically, three properties of folksonomy, namelythe categorization, keyword, and structure property, are ex-plored. In the framework, the rank of a web page is decidednot only by the term matching between the query and theweb page’s content but also by the topic matching betweenthe user’s interests and the web page’s topics. In the evalu-ation, we propose an automatic evaluation framework basedon folksonomy data, which is able to help lighten the com-mon high cost in personalized search evaluations. A seriesof experiments are conducted using two heterogeneous datasets, one crawled from Del.icio.us and the other from Do-gear. Extensive experimental results show that our person-alized search approach can significantly improve the searchquality.
Categories and Subject Descriptors
H.3.3 [Information Search and Retrieval]: Informationsearch and Retrieval—Search Process
General Terms
Algorithms, Measurement, Experimentation, Performance
Keywords
Folksonomy, Personalized Search, Topic Space, Web 2.0, Au-tomatic Evaluation Framework∗Part of this work was done while Shengliang Xu andShenghua Bao were interns at IBM China Research Lab.
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.SIGIR’08, July 20–24, 2008, Singapore.Copyright 2008 ACM 978-1-60558-164-4/08/07 ...$5.00.
1. INTRODUCTIONIn today’s search market, the most popular search paradi-
gm is keyword search. Despite simplicity and efficiency, key-word queries can not accurately describe what the users re-ally want. People engaged in different areas may have differ-ent understandings of the same literal keywords. Authors of[26], concluded that people differ significantly in the searchresults they considered to be relevant for the same query.
One solution to this problem is Personalized Search. Byconsidering user-specific information [21], search engines canto some extent distinguish the exact meaning the users wantto express by the short queries. Along with the evolution ofthe World Wide Web, many kinds of personal data have beenstudied for personalized search, including user manually se-lected interests [16, 8], web browser bookmarks [23], users’personal document corpus [7], search engine click-throughhistory [10, 22, 24], etc. In all, search personalization is oneof the most promising directions for the traditional searchparadigm to go further.
In recent years, there raises a growing concern in the newWeb 2.0 environment. One feature of Web 2.0 that distin-guishes it from the classical World Wide Web is the socialdata generation mode. The service providers only provideplatforms for the users to collaborate and share their dataonline. Such services include folksonomy, blog, wiki and soon. Since the data are generated and owned by the users,they form a new set of personal data. In this paper, we focuson exploring folksonomy for personalized search.
The term “folksonomy” is a combination of “Folk” and“Taxonomy”to describe the social classification phenomenon[3]. Online folksonomy services, such as Del.icio.us , Flickrand Dogear [19] , enable users to save and organize theirbookmarks, including any accessible resources, online withfreely chosen short text descriptors, i.e. “social annotations”or “tags”, in flat structure. The users are able to collabo-rate during bookmarking and tagging explicitly or implicitly.The low barrier and facility of this service have successfullyattracted a large number of users to participate.
The folksonomy creates a social association between theusers and the web pages through social annotations. Morespecifically, a user who has a given annotation may be in-terested in the web pages that have the same annotation.Inspired by this, we propose to model the associations be-tween the users and the web pages using a topic space. Theinterests of each user and the topics of each web page can
155
ExperimentalResults
records, denoted as DEL.gt500. The 3 test beds from theDogear data set are built in the same way as Del.icio.us,denoted as DOG.5-10, DOG.80-100 and DOG.gt500 respec-tively. The purpose of building the 6 test beds is not onlyto evaluate the model in the two different environments, i.e.web and enterprise, but also to evaluate it in the situationsof different amount of data.
Before the experiments we perform two data preprocess-ing processes. 1)Several of the annotations are too personalor meaningless, such as “toread”, “Imported IE Fa-vorites”,“system:imported”, etc. We remove some of them manually.2) Some users may concatenate several words to form anannotation , e.g. javaprogramming, java/programming, etc.We split this kind of annotations with the help of a dictio-nary. Table 2 presents the statistics of the two data sets andthe 6 test beds after data preprocessing where “num.users”denotes the number of users, “max.tags” denotes the maxi-mum number of distinct tags owned by each user, the restcolumns have the similar meanings as “max.tags”. As for
Table 2: Statistics of the user owned tags and webpages of the experiment data
Data Set Num.
Users
Max.
Tags
Min.
Tags
Avg.
Tags
Max.
Pages
Min.
Pages
Avg.
Pages
Delicious 9813 2055 1 56.04 1790 1 40.35Dogear 5192 2288 1 47.43 4578 1 46.78DEL.gt500 31 1133 74 464.42 1790 506 727.55DEL.80-100 100 456 2 107.51 100 80 88.43DEL.5-10 100 64 1 18.53 10 5 7.44DOG.gt500 92 2147 42 543.87 4578 500 999.04DOG.80-100 85 295 9 126.96 100 80 89.32DOG.5-10 100 41 2 16.11 10 5 6.99
each test bed, we randomly split them into 2 parts, a 80%training part and a 20% test part. The training parts areused to estimate the models while the test parts are used forevaluating. All the preprocessed data sets are used in theexperiments. No other filtering is conducted.
5.1.2 Personalized Search Framework Implementa-tion
Our personalized search framework needs two separatedranked lists of web pages. In practice, instead of generatingtwo full ranked lists of all the web pages, an alternative ap-proach that costs less is to rerank only the top ranked resultsfetched by the text matching model. In the experiments, weconduct such reranking based on two state-of-the-art textretrieval model, BM25 and Language Model for IR (LMIR).Firstly, a ranked list by a text retrieval model is generated.Then top 100 web pages in the ranked list are reranked byour personalized search model.
5.1.3 Parameter Setting
Before the experiments, there are three sets of parametersthat must be set. The first two parameters are the α and βin the Topic Adjusting Algorithm in Section 3.4. We simplyset them both 0.5 to keep the same influence for the initialsocial annotations’ literal contents and the link structure.The second set of parameters are the set of γs in the rankingaggregation when using various search models under varioustest beds, i.e. Equation 2. We conduct a simple trainingprocess to estimate the γs as shown in Procedure 1. Theconcrete values of γ under each search model and test bed
Procedure 1. Ranking aggregation parameter
training process
foreach test bed TB ∈ 6 test beds do1
split the training part of TB into 4 parts TNi, 1 ≤ i ≤ 42
foreach TN ∈ TNi do3
training the interest vectors and the topic vectors4
using other 3 training partsrun the evaluation 11 times using TN with γ set to5
0.0, 0.1, · · · , 1.0 respectivelyrecord the γ that leads to the optimal performance6
set the average of the 4 γs as the final parameter7
is listed in Table 3. In addition, we set the three parametersk1, k3 and b in BM25 1.2, 7 and 0.75 respectively, which arethe default parameter scheme in the lemur toolkit1. For theLMIR we accept jelinek-mercer smoothing [28] with α set to0.3.
5.1.4 Baseline Models
In the experiments we select 4 baseline models, one is thenon-personalized text matching model using no extra infor-mation except for contents, the second is the model usingthe top 16 ODP categories as topic space which is denoted as“ODP1”, the third is the model using 1171 ODP categoriesas topics which is denoted as “ODP2”, and the last is themodel proposed in [20], which is actually a simplified caseof our personalized search framework when the topic spaceis set to be folksonomy and the topic matching function isset to simply counting the number of matched annotations.We refer to it as the “AC” model.
5.1.5 Evaluation Metric
The main evaluation metric we used in our work is meanaverage precision (MAP), which is a widely used evaluationmetric in the IR community. More specifically, in our work,we calculate MAP for each user and then calculate the meanof all the MAP values. We refer it as Mean MAP or MMAP.
MMAP =
∑Nui=1
MAPi
Nu
where MAPi represents the MAP value of the ith user andNu is the number of users.
In addition, we perform t-tests on average precisions overall the queries issued by all the users in each experimentaldata set to show whether the experimental improvementsare statistical significant or not.
5.2 Performance
Table 3 lists all the 120 experimental results. The columns“text”, “ODP1”, “ODP2”, “AC”, “f.tfidf” and “f.bm25” de-note the non-personalized text model, the 16 top most ODPtopic space personalized model, the 1171 ODP topic spacepersonalized model, the AC model, the folksonomy topicspace personalized model using tfidf weighting scheme andthe folksonomy topic space personalized model using BM25weighting scheme. The sub columns “B. A.” and “A. A.” de-note“Before Adjusting by link structure”and“After Adjust-ing by link structure”, respectively. The“*”s in the“MMAP”row stand for four significance levels of the t-test, satisfying0.05 ≥ * > 0.01 ≥ ** > 0.001 ≥ ***.
As we can see from the table, the 5 personalized searchmodels all outperform the simple text retrieval models sig-1http://www.lemurproject.org/
160
• Observed75%‐250%improvementinMAPforalldatasets
• Improvementislargerforthedatasetswhereuserswhoownlessbookmarks,becausetypicallytheirannotaWonsaresemanWcallyricher

Summary
• SocialAnnotaWons(tags)canhelpimprovesearchqualityintheEnterprise
• WhiletheycanbedirectlyusedasfeaturesfortherankingfuncWon,exploiWngtheircollaboraWveproperWeshelpstofurtherimprovesearchquality
• AnnotaWonscanalsobeusedtoinferusers’interestsandprovidepersonalizedsearchresults

Users’BrowsingTraces

• Observeusers’browsingbehaviorauerenteringaqueryandclickingonasearchresult
• Rankwebsitesforanewquerybasedonhowheavilytheywerebrowsedbyusersauerenteringsameorsimilarqueries
• Useitasafeatureinsearchrankingalgorithm
Mining the Search Trails of Surfing Crowds:Identifying Relevant Websites From User Activity
Mikhail BilenkoMicrosoft ResearchOne Microsoft Way
Redmond, WA 98052, [email protected]
Ryen W. WhiteMicrosoft ResearchOne Microsoft Way
Redmond, WA 98052, [email protected]
ABSTRACT
The paper proposes identifying relevant information sources from
the history of combined searching and browsing behavior of many
Web users. While it has been previously shown that user inter-
actions with search engines can be employed to improve docu-
ment ranking, browsing behavior that occurs beyond search re-
sult pages has been largely overlooked in prior work. The pa-
per demonstrates that users’ post-search browsing activity strongly
reflects implicit endorsement of visited pages, which allows esti-
mating topical relevance of Web resources by mining large-scale
datasets of search trails. We present heuristic and probabilistic
algorithms that rely on such datasets for suggesting authoritative
websites for search queries. Experimental evaluation shows that
exploiting complete post-search browsing trails outperforms alter-
natives in isolation (e.g., clickthrough logs), and yields accuracy
improvements when employed as a feature in learning to rank for
Web search.
Categories and Subject Descriptors
H.2.8 [DatabaseManagement]: DataMining; H.3.3 [Information
Storage and Retrieval]: Information Search and Retrieval
Keywords
Learning from user behavior, Mining search and browsing logs,
Implicit feedback, Web search
1. INTRODUCTIONTraditional information retrieval (IR) techniques identify docu-
ments relevant to a given query by computing similarity between
the query and the documents’ contents [36]. Challenges posed by
IR on Web scale motivated a number of approaches that exploit
data sources beyond document contents, such as the structure of
the hyperlink graph [10, 23, 26], or users’ interactions with search
engines [17, 2, 4, 42], as well as machine learning methods that
combine multiple features for estimating resource relevance [5, 7,
33, 19].
A common theme unifying many of these recent IR algorithms is
the use of evidence stemming from unorganized behavior of many
individuals for estimating document authority. Hyperlink structure
created by millions of individual Web page authors is one example
of phenomena arising from local activity of many users, which is
exploited by such algorithms as HITS [23] and PageRank [26], as
Copyright is held by the International World Wide Web Conference Com-mittee (IW3C2). Distribution of these papers is limited to classroom use,and personal use by others.WWW 2008, April 21–25, 2008, Beijing, China.ACM 978-1-60558-085-2/08/04.
well as many others. Another group of IR algorithms that lever-
age user behavior on a large scale includes methods that utilize
search engine clickthrough logs, where users’ clicks on search re-
sults provide implicit affirmation of the corresponding pages’ au-
thority and/or relevance to the original query [17, 48, 2, 4]. Addi-
tionally, search engine query logs can be used to incorporate query
context derived from users’ search histories, leading to better query
language models that improve search accuracy [42].
While query and clickthrough logs from search engines have
been shown to be a valuable source of implicit supervision for train-
ing retrieval methods, the vast majority of users’ browsing behav-
ior takes place beyond search engine interactions. It has been re-
ported in previous studies that users’ information seeking behavior
often involves orienteering: navigating to desired resources via a
sequence of steps, instead of attempting to reach the target doc-
ument directly via a search query [43]. Therefore, post-search
browsing behavior provides valuable evidence for identifying doc-
uments relevant to users’ information goals expressed in preceding
search queries.
This paper proposes exploiting a combination of searching and
browsing activity of many users to identify relevant resources for
future queries. To the best of our knowledge, previous approaches
have not considered mining the history of user activity beyond search
results, and our experimental results show that comprehensive logs
of post-search behavior are an informative source of implicit feed-
back for inferring resource relevance. We also depart from prior
work in that we propose term-based models that generalize to pre-
viously unseen queries, which comprise a significant proportion of
real-world search engine submissions.
To demonstrate the utility of exploiting collective search and
browsing behavior for estimating document authority, we describe
several methods that rely on such data to identify relevant web-
sites for new queries. Our initial approach is motivated by heuris-
tic methods used in traditional vector-space information retrieval.
Next, we improve on it by employing a probabilistic generative
model for documents, queries and query terms, and obtain our best
results using a variant of the model that incorporates a simple random-
walk modification. Intuitively, all of these algorithms leverage user
behavior logs to suggest websites for a new query that were heavily
browsed by users after entering similar (or same) queries.
We evaluate the proposed algorithms using an independent dataset
of Internet search engine queries for which human judges identi-
fied relevant Web pages, as well as an automatically constructed
dataset consisting of previously unseen queries. Results demon-
strate that relevant websites are identified most accurately when
complete post-search browsing trails with associated dwell times
are used, compared with using just users’ search result clicks, or
ignoring dwell times. We also show that a query-term model is

SearchTrails
• Startwithasearchenginequery• ConWnueunWlaterminaWngevent
– Anothersearch– Visittoanunrelatedsite(socialnetworks,webmail)– Timeout,browserhomepage,browserclosing
q (p1, p2, p1, p3, p4, p3, p5)

UsingSearchTrailsforRanking
• Approach1:AdaptBM25scoringfuncWon
• Approach2:ProbabilisWcmodel
4.1 Heuristic Retrieval Model
First, we consider an ad-hoc model motivated by the empiri-
cal success of the term frequency × inverse document frequency
(TF.IDF) heuristic and its variants for traditional content-based re-
trieval. Based on the search trail corpus D, we construct a vector-space representation for documents, where each document di is
represented via the agglomeration of queries following which the
page was visited in the search trails. Every document is thus de-
scribed as a sparse vector, every non-zero element of which en-
codes the relative weight of the corresponding term.
Weights in this model must capture the frequency with which
users have visited the document following queries containing each
term, scaled proportionally to the term’s relative specificity across
the query corpus. Then, given the search trail corpusD, the compo-nent corresponding to term tj in the vector representing document
di can be computed as a product of query-based term frequency
QTFi,j and the term’s inverse query frequency IQFj :
wdi,tj = QTFi,j · IQFj =
=(λ + 1)n(di, tj)
λ((1 − β) + β n(di)n̄(di)
) + n(di, tj)· log
Nd − n(tj) + 0.5n(tj) + 0.5
where:
• λ and β are smoothing parameters; while in this work we useλ = 0.5 and β = 0.75, we found that results are relativelyrobust to the choice of specific values;
• n(di, tj) =∑
q!di,tj∈q f(q ! di) is the term frequency
aggregated over all trails that begin with queries containing
term tj and include document di, where the aggregation is
performed via the feature function f(q ! di) computed forthe document from each trail;
• n(di) is the total number of terms in all queries followed bysearch trails that include document di;
• n̄(di) is the average value of n(di) over all documents inD;
• n(tj) is the number of documents for which queries leadingto them include the term tj ;
• Nd is total number of documents.
This formula is effectively an adaptation of the BM25 scoring
function, which is a variant of the traditional TF.IDF heuristic that
has provided good performance on a number of retrieval bench-
marks [34]. To instantiate the term frequencies computed from all
trails leading from queries containing the term to the document,
n(di, qj), different instantiations of the feature function f(q!di)are possible that weigh the contribution of each particular trail. In
this work, we consider three variants of this feature function:
• Raw visitation count: f(q!di) = 1;
• Dwell time: f(q!di) = τ(q!di), where τ(q!di) is thetotal dwell time for document di in this particular trail;
• Log of dwell time: f(q!di) = log τ(q!di).
Given the large size of typical search trail datasets D, computa-tion of the document vectors can be performed efficiently in sev-
eral passes over the data for term and document index construc-
tion, term-document frequency computation, and final estimation
of document-term scores.
Given a new query q̂ = {t̂1, . . . , t̂k}, candidate documents areretrieved from the inverted index and their relevance is computed
via the dot product between the document and query vectors:
RelH(di, q̂) =∑
t̂j∈q̂
wdi,t̂j· wt̂j
(1)
where wt̂jis the relative weight of each term in the query, com-
puted using inverse query frequency over the set of all queries in
the dataset: wt̂j= log
Nq−n(t̂j)+0.5
n(t̂j)+0.5, withNq and n(t̂j) being the
total number of queries and the number of queries containing term
t̂j , respectively.
4.2 Probabilistic Retrieval Model
Statistical approaches to content-based information retrieval have
been considered alongside heuristic methods for several decades,
and have attracted increasing attention recently. Besides theoret-
ical elegance, probabilistic retrieval models provide competitive
performance and can be used to explain the empirical success of
the heuristics (e.g., a number of papers have proposed generative
interpretations of the IDF heuristic). Hence, we employ a statisti-
cal framework to formulate an alternative approach for retrieving
documents most relevant to a given query, provided a large dataset
of users’ past searching and browsing behavior.
We consider a generative model for queries, terms, and docu-
ments, where every query q instantiates a multinomial distributionover its terms. Every term in the vocabulary is in turn associated
with a multinomial distribution over the documents, which can be
viewed as the likelihood of a user browsing to the document after
submitting a query that contains the term (or the likelihood of the
user viewing the document per unit time, depending on the partic-
ular instantiation of the distribution). In effect, this probability en-
codes the topical relevance of the document for the particular term.
Then, the probability of selecting document di given a new query
q̂ can be used to estimate the document’s relevance:
RelP (di, q̂) = p(di|q̂) =∑
t̂j∈q
p(t̂j |q̂)p(di|t̂j) (2)
Selecting particular parameterizations for the query-term distri-
bution p(t̂j |q̂) and the distribution over documents for a given termp(di|t̂j) allows instantiating different retrieval functions. In thiswork, we estimate the instantaneous multinomial query-term like-
lihood p(t̂j |q̂) via a negative exponentiated term prior estimated
from the query corpus, which has an effect similar to IDF weight-
ing: less frequent terms have higher influence on selection of doc-
uments:
p(t̂j |q̂) =exp(−p(t̂j))
∑
t̂l∈q̂ exp(−p(t̂l))=
exp(−n(t̂j)+µ
∑
t̂s∈D n(t̂s)+µ)
∑
t̂l∈q̂ exp(− n(t̂l)+µ∑
t̂s∈D n(t̂s)+µ)
(3)
where n(t̂j) is the number of queries containing term t̂j , as in pre-
viuos subsection, and µ is a smoothing constant (we set µ = 10in all experiments; alternative smoothing approaches are possible,
e.g., those used in language modeling [49]).
Document probabilities for every query term can be estimated as
maximum-likelihood estimates over the training data for all paths
inD that originate with queries containing t̂j . Using Laplace smooth-
ing for more robust estimation, term-document probabilities be-
come:
p(di|t̂j) =n(di, t̂j)
∑
dl∈D n(dl, t̂j)(4)
InsteadoftermfrequencyinadocumentusesumoflogsofdwellWmesondifromqueriescontainingtj
Insteadinversedocfrequencyuse#docsforwhichqueriesleadingtothemincludetj
4.1 Heuristic Retrieval Model
First, we consider an ad-hoc model motivated by the empiri-
cal success of the term frequency × inverse document frequency
(TF.IDF) heuristic and its variants for traditional content-based re-
trieval. Based on the search trail corpus D, we construct a vector-space representation for documents, where each document di is
represented via the agglomeration of queries following which the
page was visited in the search trails. Every document is thus de-
scribed as a sparse vector, every non-zero element of which en-
codes the relative weight of the corresponding term.
Weights in this model must capture the frequency with which
users have visited the document following queries containing each
term, scaled proportionally to the term’s relative specificity across
the query corpus. Then, given the search trail corpusD, the compo-nent corresponding to term tj in the vector representing document
di can be computed as a product of query-based term frequency
QTFi,j and the term’s inverse query frequency IQFj :
wdi,tj = QTFi,j · IQFj =
=(λ + 1)n(di, tj)
λ((1 − β) + β n(di)n̄(di)
) + n(di, tj)· log
Nd − n(tj) + 0.5n(tj) + 0.5
where:
• λ and β are smoothing parameters; while in this work we useλ = 0.5 and β = 0.75, we found that results are relativelyrobust to the choice of specific values;
• n(di, tj) =∑
q!di,tj∈q f(q ! di) is the term frequency
aggregated over all trails that begin with queries containing
term tj and include document di, where the aggregation is
performed via the feature function f(q ! di) computed forthe document from each trail;
• n(di) is the total number of terms in all queries followed bysearch trails that include document di;
• n̄(di) is the average value of n(di) over all documents inD;
• n(tj) is the number of documents for which queries leadingto them include the term tj ;
• Nd is total number of documents.
This formula is effectively an adaptation of the BM25 scoring
function, which is a variant of the traditional TF.IDF heuristic that
has provided good performance on a number of retrieval bench-
marks [34]. To instantiate the term frequencies computed from all
trails leading from queries containing the term to the document,
n(di, qj), different instantiations of the feature function f(q!di)are possible that weigh the contribution of each particular trail. In
this work, we consider three variants of this feature function:
• Raw visitation count: f(q!di) = 1;
• Dwell time: f(q!di) = τ(q!di), where τ(q!di) is thetotal dwell time for document di in this particular trail;
• Log of dwell time: f(q!di) = log τ(q!di).
Given the large size of typical search trail datasets D, computa-tion of the document vectors can be performed efficiently in sev-
eral passes over the data for term and document index construc-
tion, term-document frequency computation, and final estimation
of document-term scores.
Given a new query q̂ = {t̂1, . . . , t̂k}, candidate documents areretrieved from the inverted index and their relevance is computed
via the dot product between the document and query vectors:
RelH(di, q̂) =∑
t̂j∈q̂
wdi,t̂j· wt̂j
(1)
where wt̂jis the relative weight of each term in the query, com-
puted using inverse query frequency over the set of all queries in
the dataset: wt̂j= log
Nq−n(t̂j)+0.5
n(t̂j)+0.5, withNq and n(t̂j) being the
total number of queries and the number of queries containing term
t̂j , respectively.
4.2 Probabilistic Retrieval Model
Statistical approaches to content-based information retrieval have
been considered alongside heuristic methods for several decades,
and have attracted increasing attention recently. Besides theoret-
ical elegance, probabilistic retrieval models provide competitive
performance and can be used to explain the empirical success of
the heuristics (e.g., a number of papers have proposed generative
interpretations of the IDF heuristic). Hence, we employ a statisti-
cal framework to formulate an alternative approach for retrieving
documents most relevant to a given query, provided a large dataset
of users’ past searching and browsing behavior.
We consider a generative model for queries, terms, and docu-
ments, where every query q instantiates a multinomial distributionover its terms. Every term in the vocabulary is in turn associated
with a multinomial distribution over the documents, which can be
viewed as the likelihood of a user browsing to the document after
submitting a query that contains the term (or the likelihood of the
user viewing the document per unit time, depending on the partic-
ular instantiation of the distribution). In effect, this probability en-
codes the topical relevance of the document for the particular term.
Then, the probability of selecting document di given a new query
q̂ can be used to estimate the document’s relevance:
RelP (di, q̂) = p(di|q̂) =∑
t̂j∈q
p(t̂j |q̂)p(di|t̂j) (2)
Selecting particular parameterizations for the query-term distri-
bution p(t̂j |q̂) and the distribution over documents for a given termp(di|t̂j) allows instantiating different retrieval functions. In thiswork, we estimate the instantaneous multinomial query-term like-
lihood p(t̂j |q̂) via a negative exponentiated term prior estimated
from the query corpus, which has an effect similar to IDF weight-
ing: less frequent terms have higher influence on selection of doc-
uments:
p(t̂j |q̂) =exp(−p(t̂j))
∑
t̂l∈q̂ exp(−p(t̂l))=
exp(−n(t̂j)+µ
∑
t̂s∈D n(t̂s)+µ)
∑
t̂l∈q̂ exp(− n(t̂l)+µ∑
t̂s∈D n(t̂s)+µ)
(3)
where n(t̂j) is the number of queries containing term t̂j , as in pre-
viuos subsection, and µ is a smoothing constant (we set µ = 10in all experiments; alternative smoothing approaches are possible,
e.g., those used in language modeling [49]).
Document probabilities for every query term can be estimated as
maximum-likelihood estimates over the training data for all paths
inD that originate with queries containing t̂j . Using Laplace smooth-
ing for more robust estimation, term-document probabilities be-
come:
p(di|t̂j) =n(di, t̂j)
∑
dl∈D n(dl, t̂j)(4)
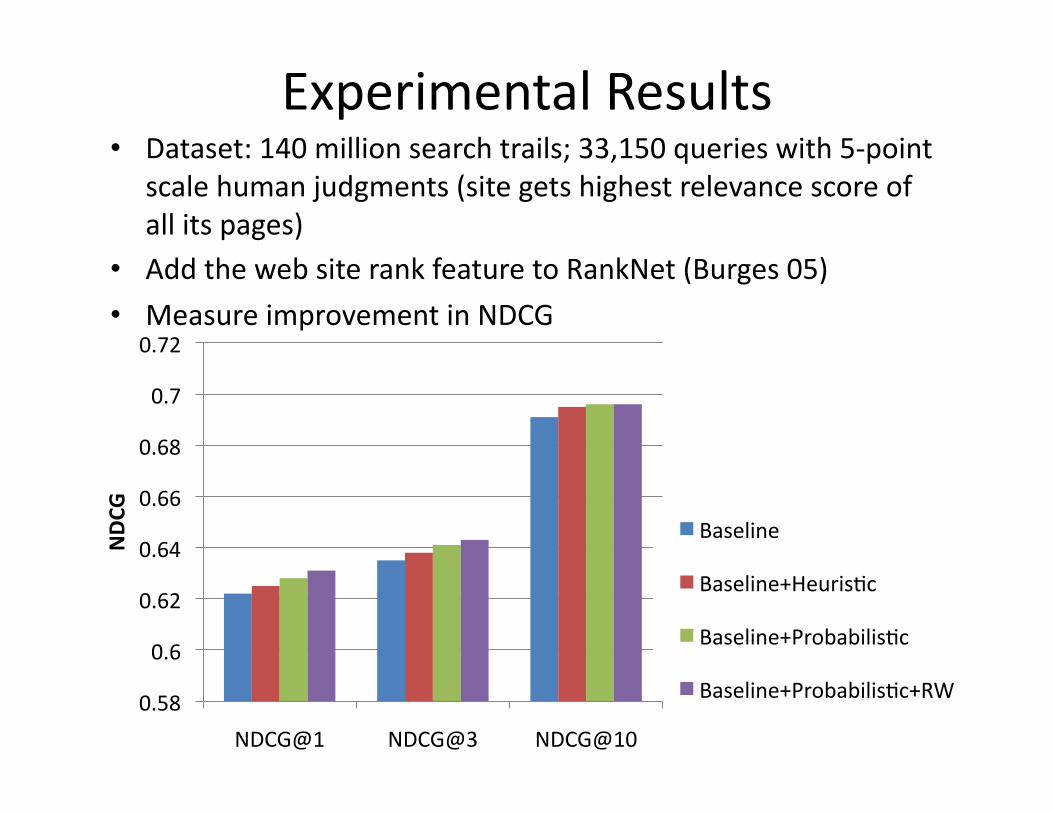
ExperimentalResults• Dataset:140millionsearchtrails;33,150querieswith5‐point
scalehumanjudgments(sitegetshighestrelevancescoreofallitspages)
• AddthewebsiterankfeaturetoRankNet(Burges05)• MeasureimprovementinNDCG
0.58
0.6
0.62
0.64
0.66
0.68
0.7
0.72
NDCG@1 NDCG@3 NDCG@10
NDCG
Baseline
Baseline+HeurisWc
Baseline+ProbabilisWc
Baseline+ProbabilisWc+RW

• Useallusers’browsingtracestoinfer“implicitlinks”betweenpairsofwebpages
• IntuiWvely,thereisanimplicitlinkbetweentwopagesiftheyarevisitedtogetheronmanybrowsingpaths
• ConstructagraphwithpagesasnodesandimplicitlinksasedgesanduseittocalculatePageRank
!
Implicit Link Analysis for Small Web Search Gui-Rong Xue
1 Hua-Jun Zeng
2 Zheng Chen
2 Wei-Ying Ma
2 Hong-Jiang Zhang
2 Chao-
Jun Lu1
1Computer Science and Engineering
Shanghai Jiao-Tong University
Shanghai 200030, P.R.China
[email protected], [email protected]
2Microsoft Research Asia
5F, Sigma Center, 49 Zhichun Road
Beijing 100080, P.R.China
{i-hjzeng, zhengc, wyma, hjzhang}@microsoft.com
!
!"#$%!&$'"#$$%&'!(%)!*%+$,-!%&./&%*!.%&%$+001!/234*%!0/&5!+&+01*/*6)+*%7!
$%6$+&5/&.!4&!8%)63+.%!$%'$/%9+0:!;48%9%$<!'-%!*+2%!'%,-&/=#%*<!
8-%&! +330/%7! 7/$%,'01! '4! *2+00! 8%)! *%+$,-! *#,-! +*! /&'$+&%'! +&7!
*/'%! *%+$,-<! ,+&&4'! +,-/%9%! '-%! *+2%! 3%$>4$2+&,%! )%,+#*%! '-%/$!
0/&5!*'$#,'#$%*!+$%!7/>>%$%&'!>$42!'-%!.04)+0!(%):!?&!'-/*!3+3%$<!8%!
3$434*%! +&! +33$4+,-! '4! ,4&*'$#,'/&.! /230/,/'! 0/&5*! )1! 2/&/&.!
#*%$*@! +,,%**! 3+''%$&*<! +&7! '-%&! +3301! +! 247/>/%7! A+.%B+&5!
+0.4$/'-2! '4! $%6$+&5! 8%)63+.%*! >4$! *2+00! 8%)! *%+$,-:! C#$!
%D3%$/2%&'+0! $%*#0'*! /&7/,+'%! '-+'! '-%! 3$434*%7! 2%'-47!
4#'3%$>4$2*! ,4&'%&'6)+*%7! 2%'-47! )1! EFG<! %D30/,/'! 0/&56)+*%7!
A+.%B+&5!)1!HIG!+&7!J/$%,';/'!)1!EKG<!$%*3%,'/9%01:!
&()*+,-.*/'(01'#234*5)'6*/5-.7),-/';:L:L!M809,-:().,0'#),-(+*'(01'%*)-.*;(<NO!?&>4$2+'/4&!P%+$,-!
+&7!B%'$/%9+0!6!!"#$%&'($)%"!!*'$"+$,"-#.'/)0".!Q!;:H:R!M6()(3(/*'
=(0(+*:*0)>O!J+'+)+*%!S330/,+'/4&*!6!1#+#'/,2,23'
?*0*-(<'$*-:/'S0.4$/'-2*<!TD3%$/2%&'+'/4&!
@*AB,-1/'?&>4$2+'/4&!$%'$/%9+0<!8%)!*%+$,-<!0/&5!+&+01*/*<!04.!2/&/&.!
CD' 80)-,125).,0'U04)+0!*%+$,-!%&./&%*!*#,-!+*!U44.0%!MEKN!+&7!S0'+V/*'+!MHN!+$%!
8/7%01! #*%7! )1! 3%430%! '4! >/&7! /&>4$2+'/4&! 7/$%,'01! 4&! '-%!(%):!
W%9%$'-%0%**<! '4! .%'! 24$%! *3%,/>/,! +&7! #36'467+'%! /&>4$2+'/4&<!
3%430%! 4>'%&! .4! 7/$%,'01! '4! *42%! *3%,/>/,! 8%)*/'%*! +&7! ,4&7#,'!
*/'%!*%+$,-:!?&'$+&%'!*%+$,-!/*!+&4'-%$!/&,$%+*/&.01!/234$'+&'!+$%+!
>4$!+&!4$.+&/X+'/4&! '4!2+&+.%!+&7!*%+$,-! /'*!48&!74,#2%&'*:! ?&!
)4'-!,+*%*<!*%+$,-!4,,#$*!/&!+!,04*%7!*#)6*3+,%!4>!'-%!(%)<!8-/,-!
/*!,+00%7!!/#..'4"5'!"#$%&!/&!'-/*!3+3%$:!!
TD/*'/&.! *2+00! 8%)! *%+$,-! %&./&%*! .%&%$+001! #*%! '-%! *+2%!
'%,-&404./%*! +*! '-4*%! #*%7! /&! .04)+0! *%+$,-! %&./&%*:! ;48%9%$<!
'-%/$! 3%$>4$2+&,%*! +$%! 3$4)0%2+'/,:! S*! $%34$'%7! /&! +! Y4$$%*'%$'
*#$9%1!MEZN<!,#$$%&'!*/'%6*3%,/>/,!*%+$,-!%&./&%*!>+/0!'4!7%0/9%$!+00!
'-%!$%0%9+&'!,4&'%&'<!/&*'%+7!$%'#$&/&.!'44!2#,-!/$$%0%9+&'!,4&'%&'!
'4! 2%%'! '-%! #*%$@*! /&>4$2+'/4&! &%%7*:! ?&! '-%! *#$9%1<! '-%! *%+$,-!
>+,/0/'/%*!4>!ZI!8%)*/'%*!8%$%!'%*'%7<!)#'!&4&%!4>!'-%2!$%,%/9%7!+!
*+'/*>+,'4$1!$%*#0':!Y#$'-%$24$%<!/&!'-%![BT"6R!P2+00!(%)![+*5<!
0/''0%!)%&%>/'!/*!4)'+/&%7!>$42!'-%!#*%!4>!0/&56)+*%7!2%'-47*!MEFN<!
8-/,-! +0*4! /&7/,+'%*! '-%! 048! 3%$>4$2+&,%! 4>! %D/'/&.! *%+$,-!
'%,-&404./%*!/&!*2+00!8%)!*%+$,-:!!
[-%!$%+*4&!4>!'-/*!048!3%$>4$2+&,%!0/%*!/&!*%9%$+0!+*3%,'*:!Y/$*'<!/'!
-+*! )%%&! 5&48&! '-+'! $+&5/&.! )1! ,4&'%&'6)+*%7! */2/0+$/'1! >+,%*!
7/>>/,#0'/%*! *#,-! +*! *-4$'&%**! +&7! +2)/.#/'1! 4>! =#%$/%*:! P%,4&7<!
0/&5!+&+01*/*! '%,-&404./%*!8-/,-!-+9%!)%%&!*#,,%**>#0!+330/%7! '4!
%&-+&,%!.04)+0!8%)!*%+$,-!,4#07!&4'!)%!7/$%,'01!+330/%7!)%,+#*%!
'-%!0/&5!*'$#,'#$%!4>!+!*2+00!8%)!/*!7/>>%$%&'!>$42!'-%!.04)+0!(%):!
(%!8/00!%D30+/&!'-/*!7/>>%$%&,%!/&!7%'+/0!/&!P%,'/4&!L:![-/$7<!%9%&!
'-4#.-! /'! /*! #&7%$*'447! '-+'! #*%$*@! +,,%**! 04.*! ,4&'+/&! 9+0#+)0%!
/&>4$2+'/4&! +)4#'!8%)63+.%*@! /234$'+&,%<! *4! >+$! >%8! *#,,%**>#0!
%>>4$'*!/&!'-/*!7/$%,'/4&!8%$%!2+7%!%D,%3'!J/$%,';/'!MELN:!
?&! '-/*! 3+3%$<! +! 2%'-47! /*! 3$434*%7! '4! .%&%$+'%! /230/,/'! 0/&5!
*'$#,'#$%!)+*%7!4&!#*%$!+,,%**!3+''%$&!2/&/&.!>$42!(%)!04.*:!(%!
7%24&*'$+'%! -48! /230/,/'! 0/&5*! ,4#07! )%! /&>%$$%7! +&7! %D'$+,'%7:!
[-%! 0/&5! +&+01*/*! +0.4$/'-2*! '-%&! #*%! '-%*%! /230/,/'! 0/&5*! '4!
,423#'%! $+&5! *,4$%*! 4>! 8%)63+.%*! >4$! /23$49/&.! '-%! *%+$,-!
3%$>4$2+&,%:! [-%! %D3%$/2%&'+0! $%*#0'*! $%9%+0! '-+'! .%&%$+'%7!
/230/,/'! 0/&5*! ,4&'+/&! 24$%! $%,422%&7+'/4&! $%0+'/4&*-/3*! '-+&!
%D30/,/'! 0/&5*:! [-%! *%+$,-! %D3%$/2%&'*! ,4&7#,'%7! 4&! \%$5%0%1!
8%)*/'%! /00#*'$+'%! '-+'!4#$!2%'-47!4#'3%$>4$2*! '-%! ,4&'%&'6)+*%7!
2%'-47! )1! EFG<! %D30/,/'! 0/&56)+*%7! A+.%B+&5! )1! HIG! +&7!
J/$%,';/'!)1!EKG<!$%*3%,'/9%01:!
[-%! $%*'! 4>! '-/*! 3+3%$! /*! 4$.+&/X%7! +*! >40048*:! ?&! P%,'/4&! H<!8%!
/&'$47#,%! *42%! $%0+'%7! 84$5*! 4&! *2+00! 8%)! *%+$,-! +&7! 0/&5!
+&+01*/*:! ?&! P%,'/4&! L<! 8%! 3$%*%&'! '-%! )+*/,! 0/&5! *'$#,'#$%! 4>! +!
*2+00! 8%)<! +&7! 7%*,$/)%! '-%! 2/&/&.! '%,-&404.1! '4! ,4&*'$#,'!
/230/,/'! 0/&5!*'$#,'#$%!+&7!'-%!$+&5/&.!3$4,%**:!C#$!%D3%$/2%&'+0!
$%*#0'*!+$%!3$%*%&'%7!/&!P%,'/4&!K:!Y/&+001<!,4&,0#*/4&*!+&7!>#'#$%!
84$5*!+$%!7/*,#**%7!/&!P%,'/4&!Z:!
ED' %*<()*1'F,-G']+&1! $%*%+$,-%*! +&7! 3$47#,'*! -+9%! )%%&! 7%94'%7! '4! *2+00! 8%)!
*%+$,-:!]4*'!4>!'-%2!#*%!'-%!^>#00!'%D'!*%+$,-_!'%,-&404./%*!8-/,-!
$%'$/%9%! +! 0+$.%! +24#&'! 4>! 74,#2%&'*! ,4&'+/&/&.! '-%! *+2%!
5%184$7*!'4!'-%!=#%$1!+&7!$+&5!'-%2!)1!5%184$76*/2/0+$/'1:!Y4$!
%D+230%<!S0'+V/*'+!3$49/7%!+!,4&'%&'6)+*%7!*/'%!*%+$,-!%&./&%!MENQ!
\%$5%0%1@*! "-+6"-+! *%+$,-! %&./&%! 4$.+&/X%*! '-%! *%+$,-! $%*#0'*!
/&'4!*42%!,+'%.4$/%*!'4!$%>0%,'!'-%!#&7%$01/&.!/&'$+&%'!*'$#,'#$%!M`NQ!
+&7! '-%! &+9/.+'/4&! *1*'%2! )1! ]:! a%9%&,%! %'! +0:! MHLN! $%'#$&*! +!
*%=#%&,%! 4>! 0/&5%7! 3+.%*! '4! -%03! '-%! %&76#*%$! '4! )$48*%! '-%!
*%+$,-! $%*#0'*:! [-%*%! *1*'%2*! 74! &4'! #*%! 0/&5! +&+01*/*! /&! $%6
$+&5/&.! '-%! *%+$,-! $%*#0'*<! '-#*! '-%$%! /*! *'/00! -%+7! $442! >4$!
/23$49/&.!'-%!*%+$,-!3$%,/*/4&:!!
!
A%$2/**/4&!'4!2+5%!7/./'+0!4$!-+$7!,43/%*!4>!+00!4$!3+$'!4>!'-/*!84$5!>4$!
3%$*4&+0!4$!,0+**$442!#*%!/*!.$+&'%7!8/'-4#'!>%%!3$49/7%7!'-+'!,43/%*!+$%!
&4'! 2+7%! 4$! 7/*'$/)#'%7! >4$! 3$4>/'! 4$! ,422%$,/+0! +79+&'+.%! +&7! '-+'!
,43/%*! )%+$! '-/*! &4'/,%! +&7! '-%! >#00! ,/'+'/4&! 4&! '-%! >/$*'! 3+.%:! [4! ,431!
4'-%$8/*%<! 4$! $%3#)0/*-<! '4! 34*'! 4&! *%$9%$*! 4$! '4! $%7/*'$/)#'%! '4! 0/*'*<!
$%=#/$%*!3$/4$!*3%,/>/,!3%$2/**/4&!+&7b4$!+!>%%:!
67879:;<<!c#01!HRdS#.#*'!E<!HIIL<![4$4&'4<!"+&+7+:!
"431$/.-'!HIIL!S"]!E6ZREEL6FKF6LbILbIIIefgZ:II:!
56

ImplicitLinkGeneraWon
• UseglidingwindowtomoveovereachbrowsingpathgeneraWngallorderedpairsofpagesandcounWngoccurrenceofeachpair
• Selectpairswhichhavefrequency>tasimplicitlinks
!
"#!$%&$&'#! (&!)&*'(%+)(!,!*#-!!"#$!%!&' $!()'.%,$/' 0*'(#,1!&2! (/#!
&%0.0*,3! *+#$!%!&' $!()'.%,$/! 0*! ,! '4,33!-#56!7/0'! *#-! .%,$/! 0'! ,!
-#0./(#1!10%#)(#1!.%,$/!,!!8! 9-:!.!;:!-/#%#!-! 0'! ',4#!,'!,5&<#!
5+(!.!!#*)&4$,''#'!(/#!04$30)0(!30*='!5#(-##*!$,.#'6!>+%(/#%4&%#:!
#,)/! 04$30)0(! 30*=! $!/0".!! 0'! ,''&)0,(#1! -0(/! ,! *#-! $,%,4#(#%!
?910@1!;!1#*&(0*.!(/#!)&*10(0&*,3!$%&5,5030(A!&2! (/#!$,.#!10! (&!5#!
<0'0(#1!.0<#*!)+%%#*(!$,.#!1!6!
B+%!.&,3!0'!(&!#C(%,)(!04$30)0(!30*='!.!!5A!,*,3AD0*.!(/#!&5'#%<#1!
+'#%'E! 5%&-'0*.! 5#/,<0&%'6! 7/#! 01#,! 0'! (/,(! -#! ),*! ,''+4#! .!!
)&*(%&3'! /&-! (/#! +'#%! (%,<#%'#'! 0*! (/#! '4,33! -#56! F,'#1! &*! (/#!
04$30)0(! 30*=!.%,$/!,!! ,*1!#C$30)0(! 30*=!.%,$/!,:!-#!),*!,''+4#!
(/#%#! #C0'('! ,! .#*#%,(0<#!4&1#3! 2&%! +'#%! 3&.6!7/#! #*(0%#! +'#%! 3&.!
)&*'0'('!&2!,!*+45#%!&2!5%&-'0*.!'#''0&*'!2'8!G3H:!3I:!3J:!K;6!L,)/!
'#''0&*!0'!.#*#%,(#1!5A!(/#!2&33&-0*.!'(#$'M!
9H;! N,*1&43A!'#3#)(!,!$,.#!1!'2%&4!-!,'!(/#!'(,%(0*.!$&0*(O!
9I;! P#*#%,(#! ,*! 04$30)0(! $,(/! 91!:!10:!1):!K;! ,))&%10*.! (&! (/#!
04$30)0(! 30*='!.!! ,*1! (/#! ,''&)0,(#1! $%&5,5030(0#':!-/#%#!-#!
,''+4#! #,)/! '#3#)(0&*! &2! 04$30)0(! 30*=! 0'! 0*1#$#*1#*(! &*!
$%#<0&+'!'#3#)(0&*'O!
9J;! >&%!#,)/!$,0%!&2!,1Q,)#*(!$,.#'!1!!,*1!10!0*!(/#!04$30)0(!$,(/:!
%,*1&43A!'#3#)(!,! '#(!&2! 0*R5#(-##*!$,.#'!1+H:!1+I:!K:'1+"',))&%10*.!(&!(/#!#C$30)0(!30*=''.!(&!2&%4!,*!#C$30)0(!$,(/!91!:!
1+H:!1+I:!K:'1+":!10;6!!
S*!&(/#%!-&%1':! (/0'!4&1#3!)&*(%&3! (/#!.#*#%,(0&*!&2! (/#!+'#%! 3&.!
5,'#1! &*! 04$30)0(! 30*='! ,*1! #C$30)0(! 30*='6! 7/#! 20*,3! +'#%! 3&.!
)&*(,0*'!,5+*1,*(! 0*2&%4,(0&*!&2!,33! 04$30)0(! 30*='6!7/+'!-#!),*!
#C(%,)(! 04$30)0(! 30*='!5A!,*,3AD0*.! (/#!&5'#%<#1!#C$30)0(!$,(/'! 0*!
(/#!+'#%!3&.6!!
"#! +'#! ,! '04$3#! (-&R0(#4! '#T+#*(0,3! $,((#%*! 40*0*.!4#(/&1! (&!
10')&<#%! $&''053#! 04$30)0(! 30*='6! 7/0'! 4#(/&1! +'#'! ,! .3010*.!
-0*1&-! (&! 4&<#! &<#%! #,)/! #C$30)0(! $,(/:! .#*#%,(0*.! ,33! (/#!
&%1#%#1! $,0%'! ,*1! )&+*(0*.! (/#! &))+%%#*)#! &2! #,)/! 10'(0*)(! $,0%6!
7/#!.3010*.!-0*1&-!'0D#!%#$%#'#*('!(/#!4,C04+4!0*(#%<,3!,!+'#%!
)30)='!5#(-##*!(/#!'&+%)#!$,.#!,*1!(/#!(,%.#(!$,.#6!>&%!#C,4$3#:!
2&%! ,*!#C$30)0(! $,(/! 91!H:!1!I:!1!J:!K:'1!);:! &+%!4#(/&1!.#*#%,(#'!
$,0%'!9!H:!!I;:!9!H:!J;:!K:!9!H:!!);:!9!I:!J;:!K:!9!I:! !);:!K!S2!&*#!&2!
(/#!$,0%':!#6.6!9!:!0;:!)&%%#'$&*1'!(&!,*!04$30)0(!30*=!9$!/0".!;:!$,(/'!
&2!(/#!$,((#%*!91!:!K:!10;!'/&+31!&))+%!2%#T+#*(3A!0*!(/#!3&.:!-0(/!
1022#%#*(!0*R5#(-##*!$,.#'6!!
U33!$&''053#!&%1#%#1!$,0%'!,*1!(/#0%!2%#T+#*)A!,%#!),3)+3,(#1!2%&4!
,33! (/#! 5%&-'0*.! '#''0&*'! 2:! ,*1! 0*2%#T+#*(! &))+%%#*)#'! ,%#!
203(#%#1!5A!,!40*04+4!'+$$&%(!(/%#'/&316!?%#)0'#3A:!(/#!'+$$&%(!&2!
,*! 0(#4! !:! 1#*&(#1! ,'! 34##9!;:! %#2#%'! (&! (/#! $#%)#*(,.#! &2! (/#!
'#''0&*'!(/,(!)&*(,0*!(/#!0(#4!!6!7/#!'+$$&%(!&2!,!(-&R0(#4!$,0%!9!:!
0;:! 1#*&(#1! 34##9!:! 0;:! 0'! 1#20*#1! 0*! ,! '0403,%! -,A6! U! (-&R0(#4!
&%1#%#1!$,0%!0'!2%#T+#*(!02!0('!'+$$&%(!34##9!:!0;#'"!(534##:!-/#%#!
"!(634##!0'!,!+'#%!'$#)020#1!*+45#%6!
U2(#%!(-&R0(#4!'#T+#*(0,3!$,((#%*'!,%#!.#*#%,(#1:!(/#A!,%#!+'#1!(&!
+$1,(#!(/#!04$30)0(!30*=!.%,$/!,!!8!9-:!.!;!1#')%05#1!$%#<0&+'3A6!
U33!(/#!-#0./('!&2!#1.#'!0*!.!!,%#!0*0(0,30D#1!(&!D#%&6!>&%!#,)/!
(-&R0(#4!'#T+#*(0,3!$,((#%*!9!:!0;:!-#!,11!0('!'+$$&%(!34##9!:!0;!(&!
(/#!-#0./(!&2!(/#!#1.#!$!:!06!U33!(/#!-#0./('!,%#!*&%4,30D#1!(&!
%#$%#'#*(!(/#!%#,3!$%&5,5030(A6!7/#!%#'+3(0*.!.%,$/!0'!+'#1!0*!,!
'+5'#T+#*(!30*=!,*,3A'0'!,3.&%0(/46!
S(! 0'!)3#,%! (/,(!*+4#%&+'! %#1+*1,*(!$,0%'!&(/#%! (/,*! %#,3! 04$30)0(!
30*='! 4,A! ,3'&! 5#! 0*)3+1#1! 5#),+'#! (/#! +'#%E'! 5%&-'0*.! /,'! (&!
2&33&-! (/#! #C$30)0(! 30*='6! V&-#<#%:! 5,'#1! &*! &+%! '(,(0'(0),3!
,*,3A'0':!(/0'!#22#)(!0'!'4,336!W$#)020),33A:!02!(/#!)&**#)(0<0(A!0*!,!
'4,33! -#5! 0'! /0./! ,*1! (/#! +'#%'! /,<#! *&! '0.*020),*(! 50,'! 0*!
'#3#)(0*.! $,(/':! 04$30)0(! 30*='! )&+31! 5#! '#$,%,(#1! 2%&4! #C$30)0(!
30*='!5A!'#((0*.!,*!,$$%&$%0,(#!40*04+4!'+$$&%(6!>&%!(/#!1#(,03!&2!
(/#!,*,3A'0':!$3#,'#!%#2#%!(&!(/#!U$$#*10C!U6!
!"#$ %&&'()*+$,-+./-*0$12$34&')5)1$6)*07$U2(#%! &5(,0*0*.! (/#! 04$30)0(! 30*=! '(%+)(+%#:! -#! ,$$3A! ,! 30*=!
,*,3A'0'! ,3.&%0(/4! '0403,%! (&!?,.#N,*=! XIYZ! (&! %#R%,*=! (/#!-#5R
$,.#'! 2&%!,!'4,33!-#5!'#,%)/6!"#!)&*'(%+)(!,!4,(%0C! (&!1#')%05#!
(/#!.%,$/6! S*!$,%(0)+3,%:! ,''+4#! (/#!.%,$/!)&*(,0*'!(!$,.#'6!7/#!
($(! ,1Q,)#*)A!4,(%0C! 0'! 1#*&(#1! 5A!%! ,*1! (/#! #*(%0#'!7X!:! 0Z! 0'!
1#20*#1!(&!5#!(/#!-#0./(!&2!(/#!04$30)0(!30*='!$!/06!!
7/#!,1Q,)#*)A!4,(%0C! 0'!+'#1! (&!)&4$+(#! (/#! %,*=!')&%#!&2!#,)/!
$,.#6! S*! ,*! [01#,3\! 2&%4:! (/#! %,*=! ')&%#! 89!! &2! $,.#! 1!! 0'!
#<,3+,(#1! 5A! ,! 2+*)(0&*! &*! (/#! %,*=! ')&%#'! &2! ,33! (/#! $,.#'! (/,(!
$&0*(!(&!$,.#!1!'M!!
! %"
&'.$0
0!
0!
!078989M
Z:X ! 9J;!
7/0'!%#)+%'0<#!1#20*0(0&*!.0<#'!#,)/!$,.#!,!2%,)(0&*!&2!(/#!%,*=!&2!
#,)/! $,.#! $&0*(0*.! (&! 0(]0*<#%'#3A!-#0./(#1! 5A! (/#! '(%#*.(/! &2!
(/#! 30*='!&2! (/,(!$,.#6!7/#!,5&<#!#T+,(0&*!),*!5#!-%0((#*! 0*! (/#!
2&%4!&2!4,(%0C!,'M!
! 8989 !' ! 9^;!
V&-#<#%:!0*!$%,)(0)#:!4,*A!$,.#'!/,<#!*&!0*R30*='!9&%!(/#!-#0./(!
&2!(/#4!0'!_;:!,*1!(/#!#0.#*<#)(&%!&2!(/#!,5&<#!#T+,(0&*!0'!4&'(3A!
D#%&6!7/#%#2&%#:!(/#!5,'0)!4&1#3!0'!4&1020#1!(&!&5(,0*!,*![,)(+,3!
4&1#3\!+'0*.!:;(<="'1;$)6!`$&*!5%&-'0*.!,!-#5R$,.#:!-0(/!(/#!
$%&5,5030(A!HR(:!,!+'#%! %,*1&43A!)/&&'#'!&*#!&2! (/#! 30*='!&*! (/#!
)+%%#*(! $,.#! ,*1! Q+4$'! (&! (/#! $,.#! 0(! 30*='! (&O! ,*1! -0(/! (/#!
$%&5,5030(A!(:! (/#!+'#%! [%#'#(\!5A! Q+4$0*.! (&! ,!-#5R$,.#! $0)=#1!
+*02&%43A! ,*1! ,(! %,*1&4! 2%&4! (/#! )&33#)(0&*6! 7/#%#2&%#! (/#!
%,*=0*.!2&%4+3,!0'!4&1020#1!(&!(/#!2&33&-0*.!2&%4M!
! %"
&)*'.$0
0!
!0
!0789(
89:M
Z:X;H9 (( ! 9a;!
B%:!0*!(/#!4,(%0C!2&%4M!
! 89*(
89 !;H9 ((
)*'! ! 9b;!
-/#%#! *!
!0'!(/#!<#)(&%!&2!,33!HE':!,*1!(!9_c(cH;!0'!,!$,%,4#(#%6!S*!
&+%! #C$#%04#*(:! -#! '#(! (! (&! _6Ha6! S*'(#,1! &2! )&4$+(0*.! ,*!
#0.#*<#)(&%:! (/#! '04$3#'(! 0(#%,(0<#! 4#(/&1]d,)&50! 0(#%,(0&*! 0'!
+'#1!(&!%#'&3<#!(/#!#T+,(0&*6!
7/#! %#R%,*=0*.! 4#)/,*0'4! 0'! 5,'#1! &*! (-&! (A$#'! &2! 30*#,%!
)&450*,(0&*M! (/#! ')&%#! 5,'#1! %#R%,*=0*.! ,*1! (/#! &%1#%! 5,'#1! %#R
%,*=0*.6!7/#!')&%#!5,'#1!%#R%,*=0*.!+'#'!,!30*#,%!)&450*,(0&*!&2!
)&*(#*(R5,'#1!'0403,%0(A!')&%#!,*1!(/#!?,.#N,*=!<,3+#!&2!,33!-#5R
$,.#'M!
' 2%=:*91;!8!+2!"'e!9HR!+;!89!!!!9+"!X_:!HZ;! 9Y;!
-/#%#!2!"'0'!(/#!)&*(#*(R5,'#1!'0403,%0(A!5#(-##*!-#5R$,.#'!,*1!
T+#%A!-&%1':!,*1!89!0'!(/#!?,.#N,*=!<,3+#6!!
7/#!&%1#%!5,'#1!%#R%,*=0*.!0'!5,'#1!&*!(/#!%,*=!&%1#%'!&2!(/#!-#5R
$,.#'6! V#%#! -#! +'#! ,! 30*#,%! )&450*,(0&*! &2! $,.#'E! $&'0(0&*'! 0*!
(-&!30'('!0*!-/0)/!&*#!30'(!0'!'&%(#1!5A!'0403,%0(A!')&%#'!(/#!&(/#%!
30'(!0'!'&%(#1!5A!?,.#N,*=!<,3+#'6!7/,(!0':!
58
!
"#!$%&$&'#! (&!)&*'(%+)(!,!*#-!!"#$!%!&' $!()'.%,$/' 0*'(#,1!&2! (/#!
&%0.0*,3! *+#$!%!&' $!()'.%,$/! 0*! ,! '4,33!-#56!7/0'! *#-! .%,$/! 0'! ,!
-#0./(#1!10%#)(#1!.%,$/!,!!8! 9-:!.!;:!-/#%#!-! 0'! ',4#!,'!,5&<#!
5+(!.!!#*)&4$,''#'!(/#!04$30)0(!30*='!5#(-##*!$,.#'6!>+%(/#%4&%#:!
#,)/! 04$30)0(! 30*=! $!/0".!! 0'! ,''&)0,(#1! -0(/! ,! *#-! $,%,4#(#%!
?910@1!;!1#*&(0*.!(/#!)&*10(0&*,3!$%&5,5030(A!&2! (/#!$,.#!10! (&!5#!
<0'0(#1!.0<#*!)+%%#*(!$,.#!1!6!
B+%!.&,3!0'!(&!#C(%,)(!04$30)0(!30*='!.!!5A!,*,3AD0*.!(/#!&5'#%<#1!
+'#%'E! 5%&-'0*.! 5#/,<0&%'6! 7/#! 01#,! 0'! (/,(! -#! ),*! ,''+4#! .!!
)&*(%&3'! /&-! (/#! +'#%! (%,<#%'#'! 0*! (/#! '4,33! -#56! F,'#1! &*! (/#!
04$30)0(! 30*=!.%,$/!,!! ,*1!#C$30)0(! 30*=!.%,$/!,:!-#!),*!,''+4#!
(/#%#! #C0'('! ,! .#*#%,(0<#!4&1#3! 2&%! +'#%! 3&.6!7/#! #*(0%#! +'#%! 3&.!
)&*'0'('!&2!,!*+45#%!&2!5%&-'0*.!'#''0&*'!2'8!G3H:!3I:!3J:!K;6!L,)/!
'#''0&*!0'!.#*#%,(#1!5A!(/#!2&33&-0*.!'(#$'M!
9H;! N,*1&43A!'#3#)(!,!$,.#!1!'2%&4!-!,'!(/#!'(,%(0*.!$&0*(O!
9I;! P#*#%,(#! ,*! 04$30)0(! $,(/! 91!:!10:!1):!K;! ,))&%10*.! (&! (/#!
04$30)0(! 30*='!.!! ,*1! (/#! ,''&)0,(#1! $%&5,5030(0#':!-/#%#!-#!
,''+4#! #,)/! '#3#)(0&*! &2! 04$30)0(! 30*=! 0'! 0*1#$#*1#*(! &*!
$%#<0&+'!'#3#)(0&*'O!
9J;! >&%!#,)/!$,0%!&2!,1Q,)#*(!$,.#'!1!!,*1!10!0*!(/#!04$30)0(!$,(/:!
%,*1&43A!'#3#)(!,! '#(!&2! 0*R5#(-##*!$,.#'!1+H:!1+I:!K:'1+"',))&%10*.!(&!(/#!#C$30)0(!30*=''.!(&!2&%4!,*!#C$30)0(!$,(/!91!:!
1+H:!1+I:!K:'1+":!10;6!!
S*!&(/#%!-&%1':! (/0'!4&1#3!)&*(%&3! (/#!.#*#%,(0&*!&2! (/#!+'#%! 3&.!
5,'#1! &*! 04$30)0(! 30*='! ,*1! #C$30)0(! 30*='6! 7/#! 20*,3! +'#%! 3&.!
)&*(,0*'!,5+*1,*(! 0*2&%4,(0&*!&2!,33! 04$30)0(! 30*='6!7/+'!-#!),*!
#C(%,)(! 04$30)0(! 30*='!5A!,*,3AD0*.! (/#!&5'#%<#1!#C$30)0(!$,(/'! 0*!
(/#!+'#%!3&.6!!
"#! +'#! ,! '04$3#! (-&R0(#4! '#T+#*(0,3! $,((#%*! 40*0*.!4#(/&1! (&!
10')&<#%! $&''053#! 04$30)0(! 30*='6! 7/0'! 4#(/&1! +'#'! ,! .3010*.!
-0*1&-! (&! 4&<#! &<#%! #,)/! #C$30)0(! $,(/:! .#*#%,(0*.! ,33! (/#!
&%1#%#1! $,0%'! ,*1! )&+*(0*.! (/#! &))+%%#*)#! &2! #,)/! 10'(0*)(! $,0%6!
7/#!.3010*.!-0*1&-!'0D#!%#$%#'#*('!(/#!4,C04+4!0*(#%<,3!,!+'#%!
)30)='!5#(-##*!(/#!'&+%)#!$,.#!,*1!(/#!(,%.#(!$,.#6!>&%!#C,4$3#:!
2&%! ,*!#C$30)0(! $,(/! 91!H:!1!I:!1!J:!K:'1!);:! &+%!4#(/&1!.#*#%,(#'!
$,0%'!9!H:!!I;:!9!H:!J;:!K:!9!H:!!);:!9!I:!J;:!K:!9!I:! !);:!K!S2!&*#!&2!
(/#!$,0%':!#6.6!9!:!0;:!)&%%#'$&*1'!(&!,*!04$30)0(!30*=!9$!/0".!;:!$,(/'!
&2!(/#!$,((#%*!91!:!K:!10;!'/&+31!&))+%!2%#T+#*(3A!0*!(/#!3&.:!-0(/!
1022#%#*(!0*R5#(-##*!$,.#'6!!
U33!$&''053#!&%1#%#1!$,0%'!,*1!(/#0%!2%#T+#*)A!,%#!),3)+3,(#1!2%&4!
,33! (/#! 5%&-'0*.! '#''0&*'! 2:! ,*1! 0*2%#T+#*(! &))+%%#*)#'! ,%#!
203(#%#1!5A!,!40*04+4!'+$$&%(!(/%#'/&316!?%#)0'#3A:!(/#!'+$$&%(!&2!
,*! 0(#4! !:! 1#*&(#1! ,'! 34##9!;:! %#2#%'! (&! (/#! $#%)#*(,.#! &2! (/#!
'#''0&*'!(/,(!)&*(,0*!(/#!0(#4!!6!7/#!'+$$&%(!&2!,!(-&R0(#4!$,0%!9!:!
0;:! 1#*&(#1! 34##9!:! 0;:! 0'! 1#20*#1! 0*! ,! '0403,%! -,A6! U! (-&R0(#4!
&%1#%#1!$,0%!0'!2%#T+#*(!02!0('!'+$$&%(!34##9!:!0;#'"!(534##:!-/#%#!
"!(634##!0'!,!+'#%!'$#)020#1!*+45#%6!
U2(#%!(-&R0(#4!'#T+#*(0,3!$,((#%*'!,%#!.#*#%,(#1:!(/#A!,%#!+'#1!(&!
+$1,(#!(/#!04$30)0(!30*=!.%,$/!,!!8!9-:!.!;!1#')%05#1!$%#<0&+'3A6!
U33!(/#!-#0./('!&2!#1.#'!0*!.!!,%#!0*0(0,30D#1!(&!D#%&6!>&%!#,)/!
(-&R0(#4!'#T+#*(0,3!$,((#%*!9!:!0;:!-#!,11!0('!'+$$&%(!34##9!:!0;!(&!
(/#!-#0./(!&2!(/#!#1.#!$!:!06!U33!(/#!-#0./('!,%#!*&%4,30D#1!(&!
%#$%#'#*(!(/#!%#,3!$%&5,5030(A6!7/#!%#'+3(0*.!.%,$/!0'!+'#1!0*!,!
'+5'#T+#*(!30*=!,*,3A'0'!,3.&%0(/46!
S(! 0'!)3#,%! (/,(!*+4#%&+'! %#1+*1,*(!$,0%'!&(/#%! (/,*! %#,3! 04$30)0(!
30*='! 4,A! ,3'&! 5#! 0*)3+1#1! 5#),+'#! (/#! +'#%E'! 5%&-'0*.! /,'! (&!
2&33&-! (/#! #C$30)0(! 30*='6! V&-#<#%:! 5,'#1! &*! &+%! '(,(0'(0),3!
,*,3A'0':!(/0'!#22#)(!0'!'4,336!W$#)020),33A:!02!(/#!)&**#)(0<0(A!0*!,!
'4,33! -#5! 0'! /0./! ,*1! (/#! +'#%'! /,<#! *&! '0.*020),*(! 50,'! 0*!
'#3#)(0*.! $,(/':! 04$30)0(! 30*='! )&+31! 5#! '#$,%,(#1! 2%&4! #C$30)0(!
30*='!5A!'#((0*.!,*!,$$%&$%0,(#!40*04+4!'+$$&%(6!>&%!(/#!1#(,03!&2!
(/#!,*,3A'0':!$3#,'#!%#2#%!(&!(/#!U$$#*10C!U6!
!"#$ %&&'()*+$,-+./-*0$12$34&')5)1$6)*07$U2(#%! &5(,0*0*.! (/#! 04$30)0(! 30*=! '(%+)(+%#:! -#! ,$$3A! ,! 30*=!
,*,3A'0'! ,3.&%0(/4! '0403,%! (&!?,.#N,*=! XIYZ! (&! %#R%,*=! (/#!-#5R
$,.#'! 2&%!,!'4,33!-#5!'#,%)/6!"#!)&*'(%+)(!,!4,(%0C! (&!1#')%05#!
(/#!.%,$/6! S*!$,%(0)+3,%:! ,''+4#! (/#!.%,$/!)&*(,0*'!(!$,.#'6!7/#!
($(! ,1Q,)#*)A!4,(%0C! 0'! 1#*&(#1! 5A!%! ,*1! (/#! #*(%0#'!7X!:! 0Z! 0'!
1#20*#1!(&!5#!(/#!-#0./(!&2!(/#!04$30)0(!30*='!$!/06!!
7/#!,1Q,)#*)A!4,(%0C! 0'!+'#1! (&!)&4$+(#! (/#! %,*=!')&%#!&2!#,)/!
$,.#6! S*! ,*! [01#,3\! 2&%4:! (/#! %,*=! ')&%#! 89!! &2! $,.#! 1!! 0'!
#<,3+,(#1! 5A! ,! 2+*)(0&*! &*! (/#! %,*=! ')&%#'! &2! ,33! (/#! $,.#'! (/,(!
$&0*(!(&!$,.#!1!'M!!
! %"
&'.$0
0!
0!
!078989M
Z:X ! 9J;!
7/0'!%#)+%'0<#!1#20*0(0&*!.0<#'!#,)/!$,.#!,!2%,)(0&*!&2!(/#!%,*=!&2!
#,)/! $,.#! $&0*(0*.! (&! 0(]0*<#%'#3A!-#0./(#1! 5A! (/#! '(%#*.(/! &2!
(/#! 30*='!&2! (/,(!$,.#6!7/#!,5&<#!#T+,(0&*!),*!5#!-%0((#*! 0*! (/#!
2&%4!&2!4,(%0C!,'M!
! 8989 !' ! 9^;!
V&-#<#%:!0*!$%,)(0)#:!4,*A!$,.#'!/,<#!*&!0*R30*='!9&%!(/#!-#0./(!
&2!(/#4!0'!_;:!,*1!(/#!#0.#*<#)(&%!&2!(/#!,5&<#!#T+,(0&*!0'!4&'(3A!
D#%&6!7/#%#2&%#:!(/#!5,'0)!4&1#3!0'!4&1020#1!(&!&5(,0*!,*![,)(+,3!
4&1#3\!+'0*.!:;(<="'1;$)6!`$&*!5%&-'0*.!,!-#5R$,.#:!-0(/!(/#!
$%&5,5030(A!HR(:!,!+'#%! %,*1&43A!)/&&'#'!&*#!&2! (/#! 30*='!&*! (/#!
)+%%#*(! $,.#! ,*1! Q+4$'! (&! (/#! $,.#! 0(! 30*='! (&O! ,*1! -0(/! (/#!
$%&5,5030(A!(:! (/#!+'#%! [%#'#(\!5A! Q+4$0*.! (&! ,!-#5R$,.#! $0)=#1!
+*02&%43A! ,*1! ,(! %,*1&4! 2%&4! (/#! )&33#)(0&*6! 7/#%#2&%#! (/#!
%,*=0*.!2&%4+3,!0'!4&1020#1!(&!(/#!2&33&-0*.!2&%4M!
! %"
&)*'.$0
0!
!0
!0789(
89:M
Z:X;H9 (( ! 9a;!
B%:!0*!(/#!4,(%0C!2&%4M!
! 89*(
89 !;H9 ((
)*'! ! 9b;!
-/#%#! *!
!0'!(/#!<#)(&%!&2!,33!HE':!,*1!(!9_c(cH;!0'!,!$,%,4#(#%6!S*!
&+%! #C$#%04#*(:! -#! '#(! (! (&! _6Ha6! S*'(#,1! &2! )&4$+(0*.! ,*!
#0.#*<#)(&%:! (/#! '04$3#'(! 0(#%,(0<#! 4#(/&1]d,)&50! 0(#%,(0&*! 0'!
+'#1!(&!%#'&3<#!(/#!#T+,(0&*6!
7/#! %#R%,*=0*.! 4#)/,*0'4! 0'! 5,'#1! &*! (-&! (A$#'! &2! 30*#,%!
)&450*,(0&*M! (/#! ')&%#! 5,'#1! %#R%,*=0*.! ,*1! (/#! &%1#%! 5,'#1! %#R
%,*=0*.6!7/#!')&%#!5,'#1!%#R%,*=0*.!+'#'!,!30*#,%!)&450*,(0&*!&2!
)&*(#*(R5,'#1!'0403,%0(A!')&%#!,*1!(/#!?,.#N,*=!<,3+#!&2!,33!-#5R
$,.#'M!
' 2%=:*91;!8!+2!"'e!9HR!+;!89!!!!9+"!X_:!HZ;! 9Y;!
-/#%#!2!"'0'!(/#!)&*(#*(R5,'#1!'0403,%0(A!5#(-##*!-#5R$,.#'!,*1!
T+#%A!-&%1':!,*1!89!0'!(/#!?,.#N,*=!<,3+#6!!
7/#!&%1#%!5,'#1!%#R%,*=0*.!0'!5,'#1!&*!(/#!%,*=!&%1#%'!&2!(/#!-#5R
$,.#'6! V#%#! -#! +'#! ,! 30*#,%! )&450*,(0&*! &2! $,.#'E! $&'0(0&*'! 0*!
(-&!30'('!0*!-/0)/!&*#!30'(!0'!'&%(#1!5A!'0403,%0(A!')&%#'!(/#!&(/#%!
30'(!0'!'&%(#1!5A!?,.#N,*=!<,3+#'6!7/,(!0':!
58

UsingImplicitLinksinRanking
• CalculatePageRankbasedonthewebgraphwithimplicitlinks
• CombinePageRankandcontent‐basedsimilarityusingaweightedlinearcombinaWon
• Approach1:userawscores
• Approach2:useranksinsteadofscores
!
"#!$%&$&'#! (&!)&*'(%+)(!,!*#-!!"#$!%!&' $!()'.%,$/' 0*'(#,1!&2! (/#!
&%0.0*,3! *+#$!%!&' $!()'.%,$/! 0*! ,! '4,33!-#56!7/0'! *#-! .%,$/! 0'! ,!
-#0./(#1!10%#)(#1!.%,$/!,!!8! 9-:!.!;:!-/#%#!-! 0'! ',4#!,'!,5&<#!
5+(!.!!#*)&4$,''#'!(/#!04$30)0(!30*='!5#(-##*!$,.#'6!>+%(/#%4&%#:!
#,)/! 04$30)0(! 30*=! $!/0".!! 0'! ,''&)0,(#1! -0(/! ,! *#-! $,%,4#(#%!
?910@1!;!1#*&(0*.!(/#!)&*10(0&*,3!$%&5,5030(A!&2! (/#!$,.#!10! (&!5#!
<0'0(#1!.0<#*!)+%%#*(!$,.#!1!6!
B+%!.&,3!0'!(&!#C(%,)(!04$30)0(!30*='!.!!5A!,*,3AD0*.!(/#!&5'#%<#1!
+'#%'E! 5%&-'0*.! 5#/,<0&%'6! 7/#! 01#,! 0'! (/,(! -#! ),*! ,''+4#! .!!
)&*(%&3'! /&-! (/#! +'#%! (%,<#%'#'! 0*! (/#! '4,33! -#56! F,'#1! &*! (/#!
04$30)0(! 30*=!.%,$/!,!! ,*1!#C$30)0(! 30*=!.%,$/!,:!-#!),*!,''+4#!
(/#%#! #C0'('! ,! .#*#%,(0<#!4&1#3! 2&%! +'#%! 3&.6!7/#! #*(0%#! +'#%! 3&.!
)&*'0'('!&2!,!*+45#%!&2!5%&-'0*.!'#''0&*'!2'8!G3H:!3I:!3J:!K;6!L,)/!
'#''0&*!0'!.#*#%,(#1!5A!(/#!2&33&-0*.!'(#$'M!
9H;! N,*1&43A!'#3#)(!,!$,.#!1!'2%&4!-!,'!(/#!'(,%(0*.!$&0*(O!
9I;! P#*#%,(#! ,*! 04$30)0(! $,(/! 91!:!10:!1):!K;! ,))&%10*.! (&! (/#!
04$30)0(! 30*='!.!! ,*1! (/#! ,''&)0,(#1! $%&5,5030(0#':!-/#%#!-#!
,''+4#! #,)/! '#3#)(0&*! &2! 04$30)0(! 30*=! 0'! 0*1#$#*1#*(! &*!
$%#<0&+'!'#3#)(0&*'O!
9J;! >&%!#,)/!$,0%!&2!,1Q,)#*(!$,.#'!1!!,*1!10!0*!(/#!04$30)0(!$,(/:!
%,*1&43A!'#3#)(!,! '#(!&2! 0*R5#(-##*!$,.#'!1+H:!1+I:!K:'1+"',))&%10*.!(&!(/#!#C$30)0(!30*=''.!(&!2&%4!,*!#C$30)0(!$,(/!91!:!
1+H:!1+I:!K:'1+":!10;6!!
S*!&(/#%!-&%1':! (/0'!4&1#3!)&*(%&3! (/#!.#*#%,(0&*!&2! (/#!+'#%! 3&.!
5,'#1! &*! 04$30)0(! 30*='! ,*1! #C$30)0(! 30*='6! 7/#! 20*,3! +'#%! 3&.!
)&*(,0*'!,5+*1,*(! 0*2&%4,(0&*!&2!,33! 04$30)0(! 30*='6!7/+'!-#!),*!
#C(%,)(! 04$30)0(! 30*='!5A!,*,3AD0*.! (/#!&5'#%<#1!#C$30)0(!$,(/'! 0*!
(/#!+'#%!3&.6!!
"#! +'#! ,! '04$3#! (-&R0(#4! '#T+#*(0,3! $,((#%*! 40*0*.!4#(/&1! (&!
10')&<#%! $&''053#! 04$30)0(! 30*='6! 7/0'! 4#(/&1! +'#'! ,! .3010*.!
-0*1&-! (&! 4&<#! &<#%! #,)/! #C$30)0(! $,(/:! .#*#%,(0*.! ,33! (/#!
&%1#%#1! $,0%'! ,*1! )&+*(0*.! (/#! &))+%%#*)#! &2! #,)/! 10'(0*)(! $,0%6!
7/#!.3010*.!-0*1&-!'0D#!%#$%#'#*('!(/#!4,C04+4!0*(#%<,3!,!+'#%!
)30)='!5#(-##*!(/#!'&+%)#!$,.#!,*1!(/#!(,%.#(!$,.#6!>&%!#C,4$3#:!
2&%! ,*!#C$30)0(! $,(/! 91!H:!1!I:!1!J:!K:'1!);:! &+%!4#(/&1!.#*#%,(#'!
$,0%'!9!H:!!I;:!9!H:!J;:!K:!9!H:!!);:!9!I:!J;:!K:!9!I:! !);:!K!S2!&*#!&2!
(/#!$,0%':!#6.6!9!:!0;:!)&%%#'$&*1'!(&!,*!04$30)0(!30*=!9$!/0".!;:!$,(/'!
&2!(/#!$,((#%*!91!:!K:!10;!'/&+31!&))+%!2%#T+#*(3A!0*!(/#!3&.:!-0(/!
1022#%#*(!0*R5#(-##*!$,.#'6!!
U33!$&''053#!&%1#%#1!$,0%'!,*1!(/#0%!2%#T+#*)A!,%#!),3)+3,(#1!2%&4!
,33! (/#! 5%&-'0*.! '#''0&*'! 2:! ,*1! 0*2%#T+#*(! &))+%%#*)#'! ,%#!
203(#%#1!5A!,!40*04+4!'+$$&%(!(/%#'/&316!?%#)0'#3A:!(/#!'+$$&%(!&2!
,*! 0(#4! !:! 1#*&(#1! ,'! 34##9!;:! %#2#%'! (&! (/#! $#%)#*(,.#! &2! (/#!
'#''0&*'!(/,(!)&*(,0*!(/#!0(#4!!6!7/#!'+$$&%(!&2!,!(-&R0(#4!$,0%!9!:!
0;:! 1#*&(#1! 34##9!:! 0;:! 0'! 1#20*#1! 0*! ,! '0403,%! -,A6! U! (-&R0(#4!
&%1#%#1!$,0%!0'!2%#T+#*(!02!0('!'+$$&%(!34##9!:!0;#'"!(534##:!-/#%#!
"!(634##!0'!,!+'#%!'$#)020#1!*+45#%6!
U2(#%!(-&R0(#4!'#T+#*(0,3!$,((#%*'!,%#!.#*#%,(#1:!(/#A!,%#!+'#1!(&!
+$1,(#!(/#!04$30)0(!30*=!.%,$/!,!!8!9-:!.!;!1#')%05#1!$%#<0&+'3A6!
U33!(/#!-#0./('!&2!#1.#'!0*!.!!,%#!0*0(0,30D#1!(&!D#%&6!>&%!#,)/!
(-&R0(#4!'#T+#*(0,3!$,((#%*!9!:!0;:!-#!,11!0('!'+$$&%(!34##9!:!0;!(&!
(/#!-#0./(!&2!(/#!#1.#!$!:!06!U33!(/#!-#0./('!,%#!*&%4,30D#1!(&!
%#$%#'#*(!(/#!%#,3!$%&5,5030(A6!7/#!%#'+3(0*.!.%,$/!0'!+'#1!0*!,!
'+5'#T+#*(!30*=!,*,3A'0'!,3.&%0(/46!
S(! 0'!)3#,%! (/,(!*+4#%&+'! %#1+*1,*(!$,0%'!&(/#%! (/,*! %#,3! 04$30)0(!
30*='! 4,A! ,3'&! 5#! 0*)3+1#1! 5#),+'#! (/#! +'#%E'! 5%&-'0*.! /,'! (&!
2&33&-! (/#! #C$30)0(! 30*='6! V&-#<#%:! 5,'#1! &*! &+%! '(,(0'(0),3!
,*,3A'0':!(/0'!#22#)(!0'!'4,336!W$#)020),33A:!02!(/#!)&**#)(0<0(A!0*!,!
'4,33! -#5! 0'! /0./! ,*1! (/#! +'#%'! /,<#! *&! '0.*020),*(! 50,'! 0*!
'#3#)(0*.! $,(/':! 04$30)0(! 30*='! )&+31! 5#! '#$,%,(#1! 2%&4! #C$30)0(!
30*='!5A!'#((0*.!,*!,$$%&$%0,(#!40*04+4!'+$$&%(6!>&%!(/#!1#(,03!&2!
(/#!,*,3A'0':!$3#,'#!%#2#%!(&!(/#!U$$#*10C!U6!
!"#$ %&&'()*+$,-+./-*0$12$34&')5)1$6)*07$U2(#%! &5(,0*0*.! (/#! 04$30)0(! 30*=! '(%+)(+%#:! -#! ,$$3A! ,! 30*=!
,*,3A'0'! ,3.&%0(/4! '0403,%! (&!?,.#N,*=! XIYZ! (&! %#R%,*=! (/#!-#5R
$,.#'! 2&%!,!'4,33!-#5!'#,%)/6!"#!)&*'(%+)(!,!4,(%0C! (&!1#')%05#!
(/#!.%,$/6! S*!$,%(0)+3,%:! ,''+4#! (/#!.%,$/!)&*(,0*'!(!$,.#'6!7/#!
($(! ,1Q,)#*)A!4,(%0C! 0'! 1#*&(#1! 5A!%! ,*1! (/#! #*(%0#'!7X!:! 0Z! 0'!
1#20*#1!(&!5#!(/#!-#0./(!&2!(/#!04$30)0(!30*='!$!/06!!
7/#!,1Q,)#*)A!4,(%0C! 0'!+'#1! (&!)&4$+(#! (/#! %,*=!')&%#!&2!#,)/!
$,.#6! S*! ,*! [01#,3\! 2&%4:! (/#! %,*=! ')&%#! 89!! &2! $,.#! 1!! 0'!
#<,3+,(#1! 5A! ,! 2+*)(0&*! &*! (/#! %,*=! ')&%#'! &2! ,33! (/#! $,.#'! (/,(!
$&0*(!(&!$,.#!1!'M!!
! %"
&'.$0
0!
0!
!078989M
Z:X ! 9J;!
7/0'!%#)+%'0<#!1#20*0(0&*!.0<#'!#,)/!$,.#!,!2%,)(0&*!&2!(/#!%,*=!&2!
#,)/! $,.#! $&0*(0*.! (&! 0(]0*<#%'#3A!-#0./(#1! 5A! (/#! '(%#*.(/! &2!
(/#! 30*='!&2! (/,(!$,.#6!7/#!,5&<#!#T+,(0&*!),*!5#!-%0((#*! 0*! (/#!
2&%4!&2!4,(%0C!,'M!
! 8989 !' ! 9^;!
V&-#<#%:!0*!$%,)(0)#:!4,*A!$,.#'!/,<#!*&!0*R30*='!9&%!(/#!-#0./(!
&2!(/#4!0'!_;:!,*1!(/#!#0.#*<#)(&%!&2!(/#!,5&<#!#T+,(0&*!0'!4&'(3A!
D#%&6!7/#%#2&%#:!(/#!5,'0)!4&1#3!0'!4&1020#1!(&!&5(,0*!,*![,)(+,3!
4&1#3\!+'0*.!:;(<="'1;$)6!`$&*!5%&-'0*.!,!-#5R$,.#:!-0(/!(/#!
$%&5,5030(A!HR(:!,!+'#%! %,*1&43A!)/&&'#'!&*#!&2! (/#! 30*='!&*! (/#!
)+%%#*(! $,.#! ,*1! Q+4$'! (&! (/#! $,.#! 0(! 30*='! (&O! ,*1! -0(/! (/#!
$%&5,5030(A!(:! (/#!+'#%! [%#'#(\!5A! Q+4$0*.! (&! ,!-#5R$,.#! $0)=#1!
+*02&%43A! ,*1! ,(! %,*1&4! 2%&4! (/#! )&33#)(0&*6! 7/#%#2&%#! (/#!
%,*=0*.!2&%4+3,!0'!4&1020#1!(&!(/#!2&33&-0*.!2&%4M!
! %"
&)*'.$0
0!
!0
!0789(
89:M
Z:X;H9 (( ! 9a;!
B%:!0*!(/#!4,(%0C!2&%4M!
! 89*(
89 !;H9 ((
)*'! ! 9b;!
-/#%#! *!
!0'!(/#!<#)(&%!&2!,33!HE':!,*1!(!9_c(cH;!0'!,!$,%,4#(#%6!S*!
&+%! #C$#%04#*(:! -#! '#(! (! (&! _6Ha6! S*'(#,1! &2! )&4$+(0*.! ,*!
#0.#*<#)(&%:! (/#! '04$3#'(! 0(#%,(0<#! 4#(/&1]d,)&50! 0(#%,(0&*! 0'!
+'#1!(&!%#'&3<#!(/#!#T+,(0&*6!
7/#! %#R%,*=0*.! 4#)/,*0'4! 0'! 5,'#1! &*! (-&! (A$#'! &2! 30*#,%!
)&450*,(0&*M! (/#! ')&%#! 5,'#1! %#R%,*=0*.! ,*1! (/#! &%1#%! 5,'#1! %#R
%,*=0*.6!7/#!')&%#!5,'#1!%#R%,*=0*.!+'#'!,!30*#,%!)&450*,(0&*!&2!
)&*(#*(R5,'#1!'0403,%0(A!')&%#!,*1!(/#!?,.#N,*=!<,3+#!&2!,33!-#5R
$,.#'M!
' 2%=:*91;!8!+2!"'e!9HR!+;!89!!!!9+"!X_:!HZ;! 9Y;!
-/#%#!2!"'0'!(/#!)&*(#*(R5,'#1!'0403,%0(A!5#(-##*!-#5R$,.#'!,*1!
T+#%A!-&%1':!,*1!89!0'!(/#!?,.#N,*=!<,3+#6!!
7/#!&%1#%!5,'#1!%#R%,*=0*.!0'!5,'#1!&*!(/#!%,*=!&%1#%'!&2!(/#!-#5R
$,.#'6! V#%#! -#! +'#! ,! 30*#,%! )&450*,(0&*! &2! $,.#'E! $&'0(0&*'! 0*!
(-&!30'('!0*!-/0)/!&*#!30'(!0'!'&%(#1!5A!'0403,%0(A!')&%#'!(/#!&(/#%!
30'(!0'!'&%(#1!5A!?,.#N,*=!<,3+#'6!7/,(!0':!
58
!
! "#$%&"'#!$!!(")*!%!"&'!!#(+,!!!!"!"!()*!&+#! ",#!
-./0/!(")*!123!(+,!10/!456787526!59!41:/!'!72!67;7<1078=!6>50/!<768!
123!?1:/@12A!<768*!0/64/>87B/<=C!
DE0!/F4/07;/281<!0/6E<8!7237>18/3!8.18! 8./!503/0'G16/3!0/'012A72:!
4/0950;6!G/88/0!8.12!8./!6>50/'G16/3!0/'012A72:C!
!"# $%&'()*'+,-#H2! 8.76! 6/>8752*! -/! 376>E66! 8./! /F4/07;/281<! 3181! 6/8*! 5E0!
/B1<E18752! ;/807>6*! 123! 8./! 0/6E<8! 59! 5E0! 68E3=! G16/3! 52! 8.56/!
;/807>6C!
!".# /*&0)1),#2)+3#4'+'(5,)6+#I./!:51<!59!5E0!-50A!76!85!7;405B/!6;1<<!-/G!6/10>.!G=!121<=J72:!
8./!E6/0!1>>/66! <5:! 72! 8./!-/G!678/C!I5!>523E>8! 8./! /F4/07;/286*!
8./! -/G678/! 18! .884KLL---C>6CG/0A/</=C/3EL<5:6L! -78.! M';528.!
><7>A'8.0E! <5:6! -16! E6/3C! N/950/! ;7272:! 950! 8./! E6/0! 1>>/66!
4188/026! 52! 8.76! <5:*! -/! 40/405>/66! 8./! <5:! G=! 4/0950;72:! 3181!
></1272:*! 6/66752! 73/28797>18752! 123! >526/>E87B/! 0/4/8787526!
/<7;7218752C! O181! ></1272:! 76! 352/! G=! 67;4<=! 97<8/072:! 5E8! 8./!
1>>/66! /2807/6! 950! /;G/33/3! 5GP/>86! 6E>.! 16! 7;1:/6! 123! 6>07486C!
Q98/0-103*! E6/06! 10/! 376872:E76./3! G=! 8./70! H?! 1330/66*! 7C/C! -/!
166E;/! 8.18! >526/>E87B/! 1>>/66/6! 905;! 8./! 61;/! H?! 3E072:! 1!
>/08172!87;/!728/0B1<!10/!905;!1!61;/!E6/0C!!
H2! 503/0! 85! .123</! 8./! >16/! 59!;E<87'E6/06! -78.! 8./! 61;/! H?*! H?!
1330/66/6! -.56/! 41:/! .786! >5E28! /F>//36! 65;/! 8.0/6.5<3! 10/!
0/;5B/3C! I./! >526/>E87B/! /2807/6! 10/! 8./2! :05E4/3! 7285! 1!
G05-672:!6/66752C!O799/0/28!:05E472:!>078/071!.1B/!G//2!;53/</3!
123! >5;410/3! 72! (&)+C! H2! 8.76! 414/0*! -/! >.556/! 8./! R5B/087;/S!
>078/0752! 67;7<10! 85! (&)+*! 7C/C*! 1! 2/-! 6/66752! 681086! -./2! 8./!
3E018752!59!8./!-.5</!:05E4!59!801B/061<6!/F>//36!1!87;/!8.0/6.5<3C!
T526/>E87B/!0/4/8787526!-78.72!1!6/66752!10/!8./2!/<7;7218/3*!/C:C*!
6/66752! "-.! -.! /.! 0.! 0.! 0#! 76! >5;41>8/3! 85! "-.! /.! 0#C! Q98/0!
40/405>/6672:*! 8./! <5:! >5281726! 1G5E8! U))*)))! 801261>87526*!
&V)*)))!41:/6!123!W)*)))!E6/06C!!
I./!507:721<!-/G'41:/6!123!<72A!680E>8E0/!76!35-2<513/3!905;!8./!
-/G678/C!QG5E8!&V)*)))!41:/6!10/!35-2<513/3!123!723/F/3!G=!8./!
DA147!6=68/;!(U)+C!X50!/1>.!41:/*!12!YIZ[!4106/0!76!144<7/3!85!
0/;5B72:! 81:6! 123! /F801>872:! <72A6! 72! 41:/6C! X721<<=*! -/! :58!
\&W*VM,!.=4/0<72A6!72!8581<C!
]/!97F/3!6/B/01<!4101;/8/06!950!8./!0/68!/F4/07;/286C!7C/C!-7235-!
67J/! 16! M*! ;727;E;! 6E44508! 8.0/6.5<3! 16! V*! E672:! 6E44508'
-/7:.8/3!13P1>/28!;1807F*!123!503/0'G16/3!0/'012A72:!950!6/10>.C!
I./6/! 4101;/8/06! 10/! 3/8/0;72/3! G16/3! 52! 12! /F8/267B/!
/F4/07;/28!-.7>.!-7<<!G/!376>E66/3!72!^/>8752!MCUC!DE0!1<:5078.;!
76!>5;410/3!-78.!6/B/01<!6818/'59'8./'108!1<:5078.;6!72><E372:!9E<<!
8/F8! 6/10>.*! /F4<7>78! <72A'G16/3! ?1:/@12A*! O70/>8Y78*! 123!
;53797/3'YHI^!1<:5078.;!(\_+C!
Q98/0! 8-5'78/;! 6/`E/2871<! 4188/02!;7272:*! UUW*,&\! 7;4<7>78! <72A6!
10/!:/2/018/3C!X7:E0/!\!6.5-6!8./0/!10/!\\*&\\!<72A6!8.18!10/!G58.!
72!8./!/F4<7>78!<72A6!123!8./!:/2/018/3!7;4<7>78!<72A6C!I.18!76*!&&a!
59!8./!<72A6!10/!5B/0<144/3*!-.7>.!76!6;1<<C!!!
!7)89('#:;#<='(05>#)*&0)1),#0)+3-#5+?#'%&0)1),#0)+3-"#
^5;/!/B73/2>/6! 6.5E<3!G/!:7B/2! 85!405B/! 8.18! 8./! 7;4<7>78! <72A6!
618769=!8./!0/>5;;/2318752!166E;48752C!]/!3/B/<54!1!40/37>8752!
;53/<!G=!E672:!7;4<7>78!<72A6*!-.7>.!76!67;7<10!85!(U\+C!I.76!;53/<!
40/37>86!-./8./0!1!41:/!-7<<!G/!B7678/3!G=!1!E6/0!72!8./!2/F8!68/4C!
I./! 40/37>8752! 1>>E01>=! 370/>8<=! 0/9</>86! 8./! >500/>82/66! 59! 8./!
41:/!0/>5;;/2318752C!]/!81A/!ML_!59!8./!<5:!3181!16!8./!8017272:!
3181!85!>0/18/!7;4<7>78!<72A6!123!&L_!59!8./!3181!16!8/6872:!3181C!I./!
95<<5-72:!40/>76752!76!E6/3!16!5E0!/B1<E18752!;/807>6C!!
! ?0/37>8752!40/>76752$
#" #$
$
$ ++
+ ! "b#!
-./0/! +%! 123! +'! 10/! 8./! 2E;G/06! 59! >500/>8! 123! 72>500/>8!
40/37>87526*!0/64/>87B/<=C!
Q6! 6818/3! 40/B75E6<=! 72! ^/>8752! UC\*! 8./! 7;4<7>78! <72A6! 10/!
:/2/018/3!G=! 8./!0/6807>8752!59! 8./!;727;E;!6E44508C!I./!.7:./0!
8./! 6E44508!59! 8./! 7;4<7>78! <72A*! 8./!.7:./0! 8./!405G1G7<78=!59! 8./!
<72A/3!41:/6!1>>/66/3!18!8./!61;/!6/66752C!Q6!6.5-2!72!X7:E0/!U*!
8./!40/37>8752!40/>76752!;5258525E6<=!72>0/16/6!16! 8./!;727;E;!
6E44508!72>0/16/6C!H8!7237>18/6!8.18!5E0!7;4<7>78!<72A!76!1>>E018/!123!
0/9</>86!E6/0c6!G/.1B7506!123!728/0/686C!!
)
)C\
)CM
)CW
)C,
) \ M W , &) &\ &M &W;72d6E44
?0/>76752!59!40/37>8752
!7)89('#@;#A('1)-)6+#6>#&58'#&('?)1,)6+#BC#)*&0)1),#0)+3-"#
I./!`E1<78=!59!7;4<7>78!<72A6!76!/B1<E18/3!905;!.E;12!4/064/>87B/C!
]/!01235;<=!6/</>8!8.0//!6EG6/86!-.7>.!>528172!UV_!7;4<7>78!<72A6!
72!8581<C!^/B/2!B5<E28//0!:013E18/3!68E3/286!-.5!10/!91;7<710!-78.!
8./! 6EGP/>86! 59! 8./! 41:/6! 10/! >.56/2! 16! 5E0! /B1<E18752! 6EGP/>86C!
I./=! 10/! 16A/3! 85! /B1<E18/! -./8./0! 8./! 7;4<7>78! <72A6! 10/!
0/>5;;/2318752! <72A6! 1>>50372:! 85! 8./! >528/28! 59! 8./! 41:/6C!Q6!
6.5-2!72!8./!E44/0!4108!59!I1G</!&*!1G5E8!WVa!59!7;4<7>78!<72A6!72!
1B/01:/!10/!0/>5;;/2318752!<72A6C!Q258./0!8.0//!6EG6/86!6/</>8/3!
905;!/F4<7>78! <72A6! 76! 6.5-2! 72! 8./! <5-/0!4108!59!I1G</!&*!-./0/!
8./!1B/01:/!0/>5;;/2318752!<72A!01875!76!PE68!1G5E8!UbaC!!
D5B0'#.;#E'16**'+?5,)6+#0)+3-#)+#)*&0)1),#5+?#'%&0)1),#0)+3-"#
^EG6/8! H;4<7>78!<72A! @/>5;;C!<72A! @1875!
&! &\,! ,V! )CW,!
\! &&M! ,\! )CV\!
U! &UU! ,M! )CWU!
QB/01:/! F"GH#
^EG6/8! eF4<7>78!<72A! @/>5;;C!<72A! @1875!
&! &)V! MV! )CMM!
\! ,M! \W! )CU&!
U! bb! M\! )CM\!
QB/01:/! F"@I#
!
^/B/01<!/F1;4</6!59!8./6/!7;4<7>78!<72A6!10/!6.5-2!72!I1G</!\C!X50!
/F1;4</*!8./!95E08.!7;4<7>78!<72A!RfE12<52:c6!>5E06/K!T^&,,S!%!
R]7</26A=c6!>5E06/K!T^&,,S!0/40/6/286!8./!61;/!>5E06/!81E:.8!G=!
3799/0/28!72680E>8506C!]./2!8./!E6/0!B7678/3!8./!41:/!RfE12<52:c6!
59

ExperimentalResults
• Dataset:4‐monthslogsfromwww.cs.berkeley.edu(300,000traces;170,000pages;60,000users)
• 216,748explicitlinks;336,812implicitlinks(11%arecommontobothsets)
• 10queries;volunteersidenWfyrelevantpagesand10mostauthoritaWvepagesforeachqueryoutoftop30results
• Measure“Precision@30”and“Authority@10”
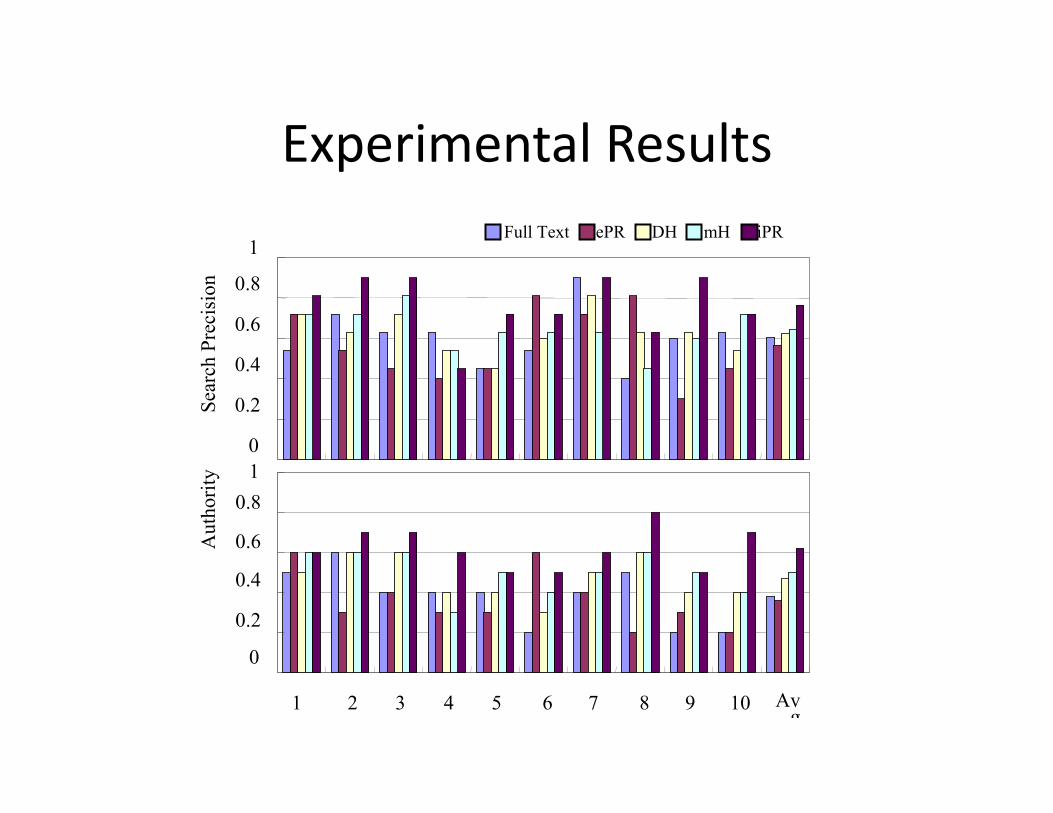
ExperimentalResults
!
"#$%&'(! )*+,,-.! /01'! 2345'6&789&! "#$%&'(! )*+,,-! "#$5:! ;'!
%'"#<<'6:':=!>0;5'!?!05&#!&@#A&!B@0B!/0%B&!#C!B@'!4</54"4B!5467&!
0%'! #D'%50//':!A4B@! B@'! 'E/54"4B! 5467&.!A@4"@! 0%'! "%'0B':! ;8! B@'!
0$B@#%!06:!&0B4&C8!B@'!%'"#<<'6:0B4#6!0&&$</B4#6=!!
!"#$%&'(&)*"+,$%-&./&01%&2+,$2320&$245-6&
7& 8.9:3%&;"<%& !":<%0&;"<%& )*,$"4"02.4& )*,6&
=245>&
+=!
F##7(!G%B4C4"405!
H6B'5541'6"'(!G!
I#:'%6!G//%#0"@!
>@'!;##79&!&54:'! G!;##7!06:!4B&!
&54:'&!
J!
?=!K#%:069&!L#<'/01'! G6:%'A!M1N&!
L#<'/01'!
>'0"@'%!06:!
&B$:'6B!
J!
O=!P0%4#$&!/4"B$%'&! Q06:&"0/'!
/@#B#1%0/@&!
R4"B$%'! M!
S=!T$065#619&!"#$%&'(!
)*+,,!
345'6&789&!"#$%&'(!
)*+,,!
*0<'!"#$%&'! M!
U=!G6B@#68!K#&'/@9&!
L#<'/01'!
F%406!L0%D'89&!
L#<'R01'!
R'#/5'!46!
P4&4#6!1%#$/!
M!
V=!GH!#6!B@'!3';! I0"@46'!5'0%6461!
&#CBA0%'!
I0"@46'!
5'0%6461!
M!
W=!*'X$469&!"#$%&'(!
)*?,S!
*'X$469&!"#$%&'(!
)*?,U!
)#$%&'!#C!
&0<'!/'%!
M!
!
?6'& 8%":31&@%-9$0&F'"0$&'!#$%!&8&B'<!#658!%'Y%067&!B@'!%'&$5B&!#C!B@'!C$55!B'EB!&'0%"@!
'6146'&.!B@'!15#;05!&'0%"@!/%'"4&4#6!4&!6#B!"@061':=!L#A'D'%.!B@'!
/%'"4&4#6!#C! B#/!<0B"@'&!4&! 4</%#D':=!Z4D'6!0!X$'%8!!.! 5'B!"!;'!
B@'!&'B!#C!B@'!%'5'D06B!/01'&!B#!B@'!X$'%8!06:!["[!;'!B@'!6$<;'%!#C!
/01'&=!G&&$<'!B@'!&8&B'<!1'6'%0B'&!0!%'&$5B!&'B.!A'!#658!B07'!B@'!
B#/!O\!C%#<!B@'!%'&$5B!&'B!0&!#=!>@'!/%'"4&4#6!#C!&'0%"@!4&!:'C46':!
0&(!
$ %&'()*)+,$]!
[[
[[
#
#"! ! ^+\_!
H6! #%:'%! B#! 'D05$0B'! #$%! <'B@#:! 'CC'"B4D'58.! A'! /%#/#&'! 0! 6'A!
'D05$0B4#6!<'B@#:#5#18(! B@'!:'1%''!#C!0$B@#%4B8=!Z4D'6!0!X$'%8.!
A'! 0&7! B@'! &'D'6! D#5$6B''%&! B#! 4:'6B4C8! B@'! B#/! +\! 0$B@#%4B0B4D'!
/01'&!0""#%:461!B#!0!@$<06!/'%&/'"B4D'!%067461!#C!055!B@'!%'&$5B&=!
>@'!&'B!#C!+\!0$B@#%4B0B4D'!A';Y/01'&!4&!:'6#B':!;8!-!06:!B@'!&'B!
#C!B#/!+\!%'&$5B&!%'B$%6':!;8!&'0%"@!'6146'&!4&!:'6#B':!;8!.=!
$ #/01+&)02$]!
[[
[[
-
.- ! ! ^++_!
>@'! /%'"4&4#6! <'0&$%'&! B@'! :'1%''! B#! A@4"@! B@'! 051#%4B@<!
/%#:$"'&! 06! 0""$%0B'! %'&$5B`! A@45'! B@'! 0$B@#%4B8! <'0&$%'&! B@'!
0;454B8!#C!B@'!051#%4B@<!B#!/%#:$"'!B@'!/01'&!B@0B!0%'!<#&B!547'58!
B#! ;'! D4&4B':! ;8! B@'! $&'%! #%! B@'! 0$B@#%4B8! <'0&$%'<'6B! 4&! <#%'!
%'5'D06B!B#!$&'%9&!&0B4&C0"B#%8!:'1%''!#6!B@'!/'%C#%<06"'!#C!&<055!
A';!&'0%"@!'6146'=!
>@'! D#5$6B''%&! A'%'! 0&7':! B#! 'D05$0B'! ;#B@! /%'"4&4#6! 06:!
0$B@#%4B8!#C!&'0%"@!%'&$5B&! C#%! B@'!&'5'"B':!+\!X$'%4'&! ^A@4"@!0%'!
3+&45,6$7)*)+,6$#&0)8)()59$:,0'99);',('6$<52'*)5,$.'0=+&>6$=)&'9'**$
.'0=+&>6$ ?'(/&)026$ "'),8+&('@',06$ AB:6$ C505$ -),),;6$ 06:!
B?DEE_=! >@'! C4605! %'5'D06"'! a$:1<'6B! C#%! '0"@! :#"$<'6B! 4&!
:'"4:':!;8!<0a#%4B8!D#B'&=!b41$%'!S!&@#A&!B@'!"#</0%4!#C!#$%!
0//%#0"@! A4B@! C$55! B'EB! &'0%"@.! R01'c067.! d4%'"BL4B! 06:!
<#:4C4':YLH>*! 051#%4B@<&=! L'%'! )%".! '%".! @A! 06:! CA!
"#%%'&/#6:! B#! 4</54"4B! 5467Y;0&':! R01'c067.! 'E/54"4B! 5467Y;0&':!
R01'c067.!<#:4C4':YLH>*.!06:!d4%'"BL4B.!%'&/'"B4D'58=!>@'!%41@BY
<#&B!50;'5!2GD1-!&B06:&!C#%!B@'!0D'%01'!D05$'!C#%!B@'!+\!X$'%4'&=!
G&! "06! ;'! &''6! C%#<! b41$%'! S.! #$%! 051#%4B@<! #$B/'%C#%<&! B@'!
#B@'%! S! 051#%4B@<&=! >@'! 0D'%01'! 4</%#D'<'6B! #C! /%'"4&4#6! #D'%!
B@'!C$55!B'EB!4&!+Ve.!R01'c067!?\e.!d4%'"BL4B!+Se!06:!<#:4C4':Y
LH>*!+?e=!3@45'!B@'!0D'%01'!4</%#D'<'6B!#C!0$B@#%4B8!#D'%!B@'!
C$55! B'EB! 4&! ?Se.! R01'c067! ?Ve.! d4%'"BL4B! +Ue! 06:! <#:4C4':Y
LH>*!+Se=!
!A2<9:%& ?(& ;:%32-2.4& "4B& "901.:20C& ./& 01%& B2//%:%40& :"4524<&
+%01.B-6&
b%#<! b41$%'! S.! A'! C#$6:! B@0B! B@'! /'%C#%<06"'! #C! 'E/54"4B! 5467Y
;0&':! R01'c067! 4&! 'D'6! A#%&'! B@06! B@0B! #C! B@'! C$55! B'EB! &'0%"@!
B'"@64X$'.! :'<#6&B%0B461! B@'! $6%'540;454B8! #C! 'E/54"4B! 5467!
&B%$"B$%'!#C!B@4&!A';&4B'=!
H6! b41$%'! S.! d4%'"BL4B! @0&! 0! <':4$<! /'%C#%<06"'! 46! 055! B@'!
051#%4B@<&=!d4%'"BL4B!#$B/'%C#%<&!C$55!B'EB!&'0%"@!;'"0$&'!4B!B07'&!
$&01'! 46C#%<0B4#6! 46B#! 0""#$6B=! L#A'D'%.! d4%'"BL4B! "#$5:! 6#B!
%'D'05! B@'! %'05! 0$B@#%4B0B4D'6'&&! #C! A';Y/01'&=! >@'! 'E/'%4<'6B!
05&#!&@#A&!B@0B!d4%'"BL4B!#658!4</%#D'&!0!/0%B!#C!/#/$50%!X$'%4'&9!
/%'"4&4#6=! *#! B@'! 0D'%01'! /%'"4&4#6! 4&! 6#B! 0&! 1##:! 0&! #$%!
051#%4B@<=!!
!"#$%&D(&@"45-&./&E9%:C&FG2-2.4H&24&B2//%:%40&+%01.B6&
3';Y/01'!d'&"%4/B4#6&! )%"$ '%"$ @A$ CA$
f)!F'%7'5'8!)#</$B'%!P4&4#6!Z%#$/! +! S+! ?! ,!
d0D4:!b#%&8B@N&!F##7(!)#</$B'%!P4&4#6! ?! gS! +! S!
d0D4:!b#%&8B@N&!F##7(!)#</$B'%!
P4&4#6^O%:!d%0CB_!O! g! O! +\!
G!A#%7&@#/!#6!P4&4#6!06:!Z%0/@4"&! S! SS! ?\! +!
f)!F'%7'5'8!)#</$B'%!P4&4#6!Z%#$/! U! ?! +O! W!
)*!?,\!L#<'!R01'! V! +S! +\! ++!
>@#<0&!Q'$61N&!R$;54"0B4#6&! W! UU! S! O+!
K4B'6:%0!I05479&!F%4'C!F4#1%0/@8! ,! +W! W! V!
G6!#D'%D4'A!#C!Z%#$/461!06:!
R'%"'/B$05!h%1064i0B4#6!g! U! ?+! U!
d0D4:!b#%&8B@N&!L#<'/01'! +\! ,W! ?g! OU!
G!/0/'%!#C!R@45! +O! +! V! g!
j4<9!k$3@06!%'&$<'! +,! O! U! ?!
G!&54:'!#C!Q06:089&!B057!0;#$B!M#B'/05&!! OW! S! OO! +S!
K#@6!G=!L0::#69&!/$;54"0B4#6! Og! ?O! S+! +O!
G!&54:'!#C!Q06:089&!B057!0;#$B!M#B'/05&!! S+! V! S?! +,!
)@%4&!F%'15'%N&!R$;54"0B4#6&! SS! ?W! ,! S?!
)#$%&'(!G//'0%06"'!I#:'5&!C#%!
)#</$B'%!Z%0/@4"&!06:!P4&4#6!U+! VO! SW! O!
c'C'%'6"'!#C!h;a'"B!c'"#164B4#6! V?! Ug! g! +W!
!
\!
\=?!
\=S!
\=V!
\=,!
+!
+! ?! O! S! U! V! W! ,! g! +\! GD1
*'0%"@!R%'"4&4#6!
\!
\=?!
\=S!
\=V!
\=,!
+!
G$B@#%4B8!
b$55!>'EB!!!!!!'Rc!!!!!!dL!!!!!!<L!!!!!!4Rc!
60

Summary
• UserbrowsingtracescanbecollectedeasilyintheEnterprise
• Twotypesoftraces:– TracesstarWngfromsearchenginequeries– Arbitrarytraces
• TracesareveryusefulforcalculaWngauthoritaWvenessofwebpagesandwebsites,andcanbesuccessfullyusedtoimprovesearchranking

Short‐termUserContextandEye‐trackingbasedFeedback

• TwotypesofusercontextinformaWon:– Short‐termcontext– Long‐termcontext
• Long‐termcontext:– User’stopicsofinterest,departmentandposiWon,accumulatedqueryhistory,desktopcontext,etc.
• Short‐termcontext:– Queriesandclicksinthesamesession,thetextuserhasreadinthepast5min,etc.
Context-Sensitive Information Retrieval UsingImplicit Feedback
Xuehua ShenDepartment of Computer
ScienceUniversity of Illinois atUrbana-Champaign
Bin TanDepartment of Computer
ScienceUniversity of Illinois atUrbana-Champaign
ChengXiang ZhaiDepartment of Computer
ScienceUniversity of Illinois atUrbana-Champaign
ABSTRACT
A major limitation of most existing retrieval models and systemsis that the retrieval decision is made based solely on the query anddocument collection; information about the actual user and searchcontext is largely ignored. In this paper, we study how to ex-ploit implicit feedback information, including previous queries andclickthrough information, to improve retrieval accuracy in an in-teractive information retrieval setting. We propose several context-sensitive retrieval algorithms based on statistical language modelsto combine the preceding queries and clicked document summarieswith the current query for better ranking of documents. We usethe TREC AP data to create a test collection with search contextinformation, and quantitatively evaluate our models using this testset. Experiment results show that using implicit feedback, espe-cially the clicked document summaries, can improve retrieval per-formance substantially.
Categories and Subject Descriptors
H.3.3 [Information Search and Retrieval]: Retrieval models
General Terms
Algorithms
Keywords
Query history, query expansion, interactive retrieval, context
1. INTRODUCTIONIn most existing information retrieval models, the retrieval prob-
lem is treated as involving one single query and a set of documents.From a single query, however, the retrieval system can only havevery limited clue about the user’s information need. An optimal re-trieval system thus should try to exploit as much additional contextinformation as possible to improve retrieval accuracy, whenever itis available. Indeed, context-sensitive retrieval has been identifiedas a major challenge in information retrieval research[2].
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.SIGIR’05, August 15–19, 2005, Salvador,Brazil.Copyright 2005 ACM 1-59593-034-5/05/0008 ...$5.00.
There are many kinds of context that we can exploit. Relevancefeedback [14] can be considered as a way for a user to providemore context of search and is known to be effective for improv-ing retrieval accuracy. However, relevance feedback requires thata user explicitly provides feedback information, such as specifyingthe category of the information need or marking a subset of re-trieved documents as relevant documents. Since it forces the userto engage additional activities while the benefits are not always ob-vious to the user, a user is often reluctant to provide such feedbackinformation. Thus the effectiveness of relevance feedback may belimited in real applications.For this reason, implicit feedback has attractedmuch attention re-
cently [11, 13, 18, 17, 12]. In general, the retrieval results using theuser’s initial query may not be satisfactory; often, the user wouldneed to revise the query to improve the retrieval/ranking accuracy[8]. For a complex or difficult information need, the user may needto modify his/her query and view ranked documents with many iter-ations before the information need is completely satisfied. In suchan interactive retrieval scenario, the information naturally availableto the retrieval system is more than just the current user query andthe document collection – in general, all the interaction history canbe available to the retrieval system, including past queries, informa-tion about which documents the user has chosen to view, and evenhow a user has read a document (e.g., which part of a document theuser spends a lot of time in reading). We define implicit feedbackbroadly as exploiting all such naturally available interaction historyto improve retrieval results.A major advantage of implicit feedback is that we can improve
the retrieval accuracy without requiring any user effort. For ex-ample, if the current query is “java”, without knowing any extrainformation, it would be impossible to know whether it is intendedto mean the Java programming language or the Java island in In-donesia. As a result, the retrieved documents will likely have bothkinds of documents – some may be about the programming lan-guage and some may be about the island. However, any particularuser is unlikely searching for both types of documents. Such anambiguity can be resolved by exploiting history information. Forexample, if we know that the previous query from the user is “cgiprogramming”, it would strongly suggest that it is the programminglanguage that the user is searching for.Implicit feedback was studied in several previous works. In [11],
Joachims explored how to capture and exploit the clickthrough in-formation and demonstrated that such implicit feedback informa-tion can indeed improve the search accuracy for a group of peo-ple. In [18], a simulation study of the effectiveness of differentimplicit feedback algorithms was conducted, and several retrievalmodels designed for exploiting clickthrough information were pro-
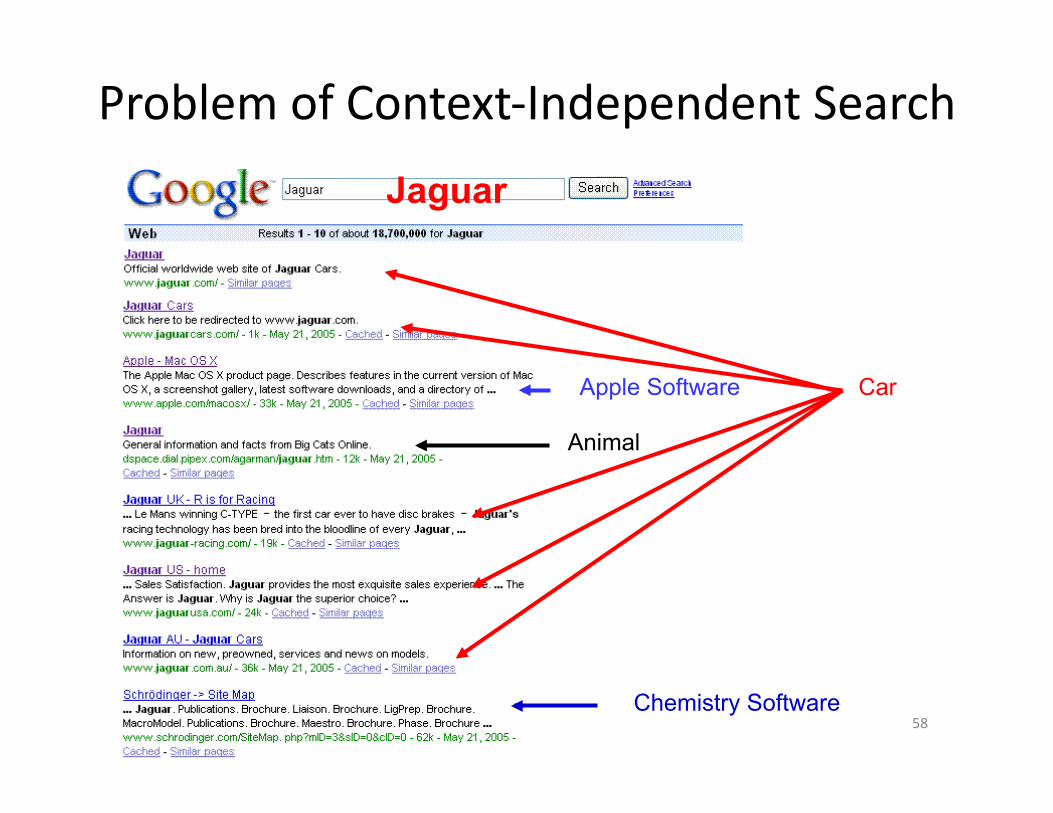
ProblemofContext‐IndependentSearch
58
Jaguar
Car Apple Software
Animal
Chemistry Software

Pu�ngSearchinContext
59
Other Context Info: Dwelling time Mouse movement
Clickthrough
Query History
Apple software
Hobby …

Short‐termContexts
• Willlookat2typesofshort‐termcontexts:– SessionQueryHistory:precedingqueriesissuedbythesameuserinthecurrentsession
– SessionClickedSummary:concatenaWonofthedisplayedtextabouttheclickedurlsinthecurrentsession
• WilluselanguagemodelingframeworktoincorporatetheabovedataintotherankingfuncWon

UsingShort‐termContextsforRanking
• BasicRetrievalModel:– ForeachdocumentDbuildaunigramlanguagemodelθD,specifyingp(ω|θD)
– GivenaqueryQ,buildaquerylanguagemodelθQ,specifyingp(ω|θQ)
– RankthedocumentsaccordingtotheKLdivergenceofthetwomodels:
• Assuminguseralreadyissuedk-1queriesQ1,..,Qk-1,wanttoesWmatethe“contextquerymodel” θk specifying p(ω|θk) forthecurrentquery Qk to use instead of θQ
�
D(θQ ||θD ) = P(ω |θQω∑ )log
P(ω |θQ )P(ω |θD )

UsingShort‐termContextsforRanking
• FixedCoefficientInterpolaWon:
current queryQk, as well as the query historyHQ and clickthrough
historyHC . We now describe several different language models for
exploiting HQ and HC to estimate p(w|θk). We will use c(w, X)to denote the count of word w in text X, which could be either aquery or a clicked document’s summary or any other text. We will
use |X| to denote the length of textX or the total number of words
inX.
3.2 Fixed Coefficient Interpolation (FixInt)Our first idea is to summarize the query history HQ with a un-
igram language model p(w|HQ) and the clickthrough history HC
with another unigram language model p(w|HC). Then we linearlyinterpolate these two history models to obtain the history model
p(w|H). Finally, we interpolate the history model p(w|H) withthe current query model p(w|Qk). These models are defined asfollows.
p(w|Qi) =c(w, Qi)|Qi|
p(w|HQ) =1
k − 1
i=k−1
i=1
p(w|Qi)
p(w|Ci) =c(w, Ci)|Ci|
p(w|HC) =1
k − 1
i=k−1
i=1
p(w|Ci)
p(w|H) = βp(w|HC) + (1 − β)p(w|HQ)
p(w|θk) = αp(w|Qk) + (1 − α)p(w|H)
where β ∈ [0, 1] is a parameter to control the weight on each his-tory model, and where α ∈ [0, 1] is a parameter to control theweight on the current query and the history information.
If we combine these equations, we see that
p(w|θk) = αp(w|Qk) + (1 − α)[βp(w|HC) + (1 − β)p(w|HQ)]
That is, the estimated context query model is just a fixed coefficient
interpolation of three models p(w|Qk), p(w|HQ), and p(w|HC).
3.3 Bayesian Interpolation (BayesInt)One possible problem with the FixInt approach is that the coeffi-
cients, especially α, are fixed across all the queries. But intuitively,if our current query Qk is very long, we should trust the current
query more, whereas if Qk has just one word, it may be beneficial
to put more weight on the history. To capture this intuition, we treat
p(w|HQ) and p(w|HC) as Dirichlet priors andQk as the observed
data to estimate a context query model using Bayesian estimator.
The estimated model is given by
p(w|θk) =c(w, Qk) + µp(w|HQ) + νp(w|HC)
|Qk| + µ + ν
=|Qk|
|Qk| + µ + νp(w|Qk)+
µ + ν
|Qk| + µ + ν[
µ
µ + νp(w|HQ)+
ν
µ + νp(w|HC)]
where µ is the prior sample size for p(w|HQ) and ν is the priorsample size for p(w|HC). We see that the only difference betweenBayesInt and FixInt is the interpolation coefficients are now adap-
tive to the query length. Indeed, when viewing BayesInt as FixInt,
we see that α = |Qk||Qk|+µ+ν , β = ν
ν+µ , thus with fixed µ and ν,we will have a query-dependent α. Later we will show that such anadaptive α empirically performs better than a fixed α.
3.4 Online Bayesian Updating (OnlineUp)Both FixInt and BayesInt summarize the history information by
averaging the unigram language models estimated based on pre-
vious queries or clicked summaries. This means that all previous
queries are treated equally and so are all clicked summaries. How-
ever, as the user interacts with the system and acquires more knowl-
edge about the information in the collection, presumably, the refor-
mulated queries will become better and better. Thus assigning de-
caying weights to the previous queries so as to trust a recent query
more than an earlier query appears to be reasonable. Interestingly,
if we incrementally update our belief about the user’s information
need after seeing each query, we could naturally obtain decaying
weights on the previous queries. Since such an incremental online
updating strategy can be used to exploit any evidence in an interac-
tive retrieval system, we present it in a more general way.
In a typical retrieval system, the retrieval system responds to
every new query entered by the user by presenting a ranked list
of documents. In order to rank documents, the system must have
some model for the user’s information need. In the KL divergence
retrieval model, this means that the system must compute a query
model whenever a user enters a (new) query. A principled way of
updating the query model is to use Bayesian estimation, which we
discuss below.
3.4.1 Bayesian updating
We first discuss how we apply Bayesian estimation to update a
query model in general. Let p(w|φ) be our current query modeland T be a new piece of text evidence observed (e.g., T can be a
query or a clicked summary). To update the query model based on
T , we use φ to define a Dirichlet prior parameterized as
Dir(µT p(w1|φ), ..., µT p(wN |φ))
where µT is the equivalent sample size of the prior. We use Dirich-
let prior because it is a conjugate prior for multinomial distribu-
tions. With such a conjugate prior, the predictive distribution of φ(or equivalently, the mean of the posterior distribution of φ is givenby
p(w|φ) =c(w, T ) + µT p(w|φ)
|T | + µT(1)
where c(w, T ) is the count of w in T and |T | is the length of T .Parameter µT indicates our confidence in the prior expressed in
terms of an equivalent text sample comparable with T . For exam-ple, µT = 1 indicates that the influence of the prior is equivalent toadding one extra word to T .
3.4.2 Sequential query model updating
We now discuss how we can update our query model over time
during an interactive retrieval process using Bayesian estimation.
In general, we assume that the retrieval system maintains a current
query model φi at any moment. As soon as we obtain some implicit
feedback evidence in the form of a piece of text Ti, we will update
the query model.
Initially, before we see any user query, we may already have
some information about the user. For example, we may have some
information about what documents the user has viewed in the past.
We use such information to define a prior on the query model,
which is denoted by φ′0. After we observe the first query Q1, we
can update the query model based on the new observed data Q1.
The updated query model φ1 can then be used for ranking docu-
ments in response to Q1. As the user views some documents, the
displayed summary text for such documents C1 (i.e., clicked sum-
maries) can serve as some new data for us to further update the
current queryQk, as well as the query historyHQ and clickthrough
historyHC . We now describe several different language models for
exploiting HQ and HC to estimate p(w|θk). We will use c(w, X)to denote the count of word w in text X, which could be either aquery or a clicked document’s summary or any other text. We will
use |X| to denote the length of textX or the total number of words
inX.
3.2 Fixed Coefficient Interpolation (FixInt)Our first idea is to summarize the query history HQ with a un-
igram language model p(w|HQ) and the clickthrough history HC
with another unigram language model p(w|HC). Then we linearlyinterpolate these two history models to obtain the history model
p(w|H). Finally, we interpolate the history model p(w|H) withthe current query model p(w|Qk). These models are defined asfollows.
p(w|Qi) =c(w, Qi)|Qi|
p(w|HQ) =1
k − 1
i=k−1
i=1
p(w|Qi)
p(w|Ci) =c(w, Ci)|Ci|
p(w|HC) =1
k − 1
i=k−1
i=1
p(w|Ci)
p(w|H) = βp(w|HC) + (1 − β)p(w|HQ)
p(w|θk) = αp(w|Qk) + (1 − α)p(w|H)
where β ∈ [0, 1] is a parameter to control the weight on each his-tory model, and where α ∈ [0, 1] is a parameter to control theweight on the current query and the history information.
If we combine these equations, we see that
p(w|θk) = αp(w|Qk) + (1 − α)[βp(w|HC) + (1 − β)p(w|HQ)]
That is, the estimated context query model is just a fixed coefficient
interpolation of three models p(w|Qk), p(w|HQ), and p(w|HC).
3.3 Bayesian Interpolation (BayesInt)One possible problem with the FixInt approach is that the coeffi-
cients, especially α, are fixed across all the queries. But intuitively,if our current query Qk is very long, we should trust the current
query more, whereas if Qk has just one word, it may be beneficial
to put more weight on the history. To capture this intuition, we treat
p(w|HQ) and p(w|HC) as Dirichlet priors andQk as the observed
data to estimate a context query model using Bayesian estimator.
The estimated model is given by
p(w|θk) =c(w, Qk) + µp(w|HQ) + νp(w|HC)
|Qk| + µ + ν
=|Qk|
|Qk| + µ + νp(w|Qk)+
µ + ν
|Qk| + µ + ν[
µ
µ + νp(w|HQ)+
ν
µ + νp(w|HC)]
where µ is the prior sample size for p(w|HQ) and ν is the priorsample size for p(w|HC). We see that the only difference betweenBayesInt and FixInt is the interpolation coefficients are now adap-
tive to the query length. Indeed, when viewing BayesInt as FixInt,
we see that α = |Qk||Qk|+µ+ν , β = ν
ν+µ , thus with fixed µ and ν,we will have a query-dependent α. Later we will show that such anadaptive α empirically performs better than a fixed α.
3.4 Online Bayesian Updating (OnlineUp)Both FixInt and BayesInt summarize the history information by
averaging the unigram language models estimated based on pre-
vious queries or clicked summaries. This means that all previous
queries are treated equally and so are all clicked summaries. How-
ever, as the user interacts with the system and acquires more knowl-
edge about the information in the collection, presumably, the refor-
mulated queries will become better and better. Thus assigning de-
caying weights to the previous queries so as to trust a recent query
more than an earlier query appears to be reasonable. Interestingly,
if we incrementally update our belief about the user’s information
need after seeing each query, we could naturally obtain decaying
weights on the previous queries. Since such an incremental online
updating strategy can be used to exploit any evidence in an interac-
tive retrieval system, we present it in a more general way.
In a typical retrieval system, the retrieval system responds to
every new query entered by the user by presenting a ranked list
of documents. In order to rank documents, the system must have
some model for the user’s information need. In the KL divergence
retrieval model, this means that the system must compute a query
model whenever a user enters a (new) query. A principled way of
updating the query model is to use Bayesian estimation, which we
discuss below.
3.4.1 Bayesian updating
We first discuss how we apply Bayesian estimation to update a
query model in general. Let p(w|φ) be our current query modeland T be a new piece of text evidence observed (e.g., T can be a
query or a clicked summary). To update the query model based on
T , we use φ to define a Dirichlet prior parameterized as
Dir(µT p(w1|φ), ..., µT p(wN |φ))
where µT is the equivalent sample size of the prior. We use Dirich-
let prior because it is a conjugate prior for multinomial distribu-
tions. With such a conjugate prior, the predictive distribution of φ(or equivalently, the mean of the posterior distribution of φ is givenby
p(w|φ) =c(w, T ) + µT p(w|φ)
|T | + µT(1)
where c(w, T ) is the count of w in T and |T | is the length of T .Parameter µT indicates our confidence in the prior expressed in
terms of an equivalent text sample comparable with T . For exam-ple, µT = 1 indicates that the influence of the prior is equivalent toadding one extra word to T .
3.4.2 Sequential query model updating
We now discuss how we can update our query model over time
during an interactive retrieval process using Bayesian estimation.
In general, we assume that the retrieval system maintains a current
query model φi at any moment. As soon as we obtain some implicit
feedback evidence in the form of a piece of text Ti, we will update
the query model.
Initially, before we see any user query, we may already have
some information about the user. For example, we may have some
information about what documents the user has viewed in the past.
We use such information to define a prior on the query model,
which is denoted by φ′0. After we observe the first query Q1, we
can update the query model based on the new observed data Q1.
The updated query model φ1 can then be used for ranking docu-
ments in response to Q1. As the user views some documents, the
displayed summary text for such documents C1 (i.e., clicked sum-
maries) can serve as some new data for us to further update the
Queryhistorymodel
Clicksummarymodel

UsingShort‐termContextsforRanking
• ProblemwithFixedCoefficientInterpolaWonisthatthecoefficientsarethesameforallqueries.Wanttotrustthecurrentquerymoreifitislongerandlessifitisshorter
• BayesianInterpolaWon:
current queryQk, as well as the query historyHQ and clickthrough
historyHC . We now describe several different language models for
exploiting HQ and HC to estimate p(w|θk). We will use c(w, X)to denote the count of word w in text X, which could be either aquery or a clicked document’s summary or any other text. We will
use |X| to denote the length of textX or the total number of words
inX.
3.2 Fixed Coefficient Interpolation (FixInt)Our first idea is to summarize the query history HQ with a un-
igram language model p(w|HQ) and the clickthrough history HC
with another unigram language model p(w|HC). Then we linearlyinterpolate these two history models to obtain the history model
p(w|H). Finally, we interpolate the history model p(w|H) withthe current query model p(w|Qk). These models are defined asfollows.
p(w|Qi) =c(w, Qi)|Qi|
p(w|HQ) =1
k − 1
i=k−1
i=1
p(w|Qi)
p(w|Ci) =c(w, Ci)|Ci|
p(w|HC) =1
k − 1
i=k−1
i=1
p(w|Ci)
p(w|H) = βp(w|HC) + (1 − β)p(w|HQ)
p(w|θk) = αp(w|Qk) + (1 − α)p(w|H)
where β ∈ [0, 1] is a parameter to control the weight on each his-tory model, and where α ∈ [0, 1] is a parameter to control theweight on the current query and the history information.
If we combine these equations, we see that
p(w|θk) = αp(w|Qk) + (1 − α)[βp(w|HC) + (1 − β)p(w|HQ)]
That is, the estimated context query model is just a fixed coefficient
interpolation of three models p(w|Qk), p(w|HQ), and p(w|HC).
3.3 Bayesian Interpolation (BayesInt)One possible problem with the FixInt approach is that the coeffi-
cients, especially α, are fixed across all the queries. But intuitively,if our current query Qk is very long, we should trust the current
query more, whereas if Qk has just one word, it may be beneficial
to put more weight on the history. To capture this intuition, we treat
p(w|HQ) and p(w|HC) as Dirichlet priors andQk as the observed
data to estimate a context query model using Bayesian estimator.
The estimated model is given by
p(w|θk) =c(w, Qk) + µp(w|HQ) + νp(w|HC)
|Qk| + µ + ν
=|Qk|
|Qk| + µ + νp(w|Qk)+
µ + ν
|Qk| + µ + ν[
µ
µ + νp(w|HQ)+
ν
µ + νp(w|HC)]
where µ is the prior sample size for p(w|HQ) and ν is the priorsample size for p(w|HC). We see that the only difference betweenBayesInt and FixInt is the interpolation coefficients are now adap-
tive to the query length. Indeed, when viewing BayesInt as FixInt,
we see that α = |Qk||Qk|+µ+ν , β = ν
ν+µ , thus with fixed µ and ν,we will have a query-dependent α. Later we will show that such anadaptive α empirically performs better than a fixed α.
3.4 Online Bayesian Updating (OnlineUp)Both FixInt and BayesInt summarize the history information by
averaging the unigram language models estimated based on pre-
vious queries or clicked summaries. This means that all previous
queries are treated equally and so are all clicked summaries. How-
ever, as the user interacts with the system and acquires more knowl-
edge about the information in the collection, presumably, the refor-
mulated queries will become better and better. Thus assigning de-
caying weights to the previous queries so as to trust a recent query
more than an earlier query appears to be reasonable. Interestingly,
if we incrementally update our belief about the user’s information
need after seeing each query, we could naturally obtain decaying
weights on the previous queries. Since such an incremental online
updating strategy can be used to exploit any evidence in an interac-
tive retrieval system, we present it in a more general way.
In a typical retrieval system, the retrieval system responds to
every new query entered by the user by presenting a ranked list
of documents. In order to rank documents, the system must have
some model for the user’s information need. In the KL divergence
retrieval model, this means that the system must compute a query
model whenever a user enters a (new) query. A principled way of
updating the query model is to use Bayesian estimation, which we
discuss below.
3.4.1 Bayesian updating
We first discuss how we apply Bayesian estimation to update a
query model in general. Let p(w|φ) be our current query modeland T be a new piece of text evidence observed (e.g., T can be a
query or a clicked summary). To update the query model based on
T , we use φ to define a Dirichlet prior parameterized as
Dir(µT p(w1|φ), ..., µT p(wN |φ))
where µT is the equivalent sample size of the prior. We use Dirich-
let prior because it is a conjugate prior for multinomial distribu-
tions. With such a conjugate prior, the predictive distribution of φ(or equivalently, the mean of the posterior distribution of φ is givenby
p(w|φ) =c(w, T ) + µT p(w|φ)
|T | + µT(1)
where c(w, T ) is the count of w in T and |T | is the length of T .Parameter µT indicates our confidence in the prior expressed in
terms of an equivalent text sample comparable with T . For exam-ple, µT = 1 indicates that the influence of the prior is equivalent toadding one extra word to T .
3.4.2 Sequential query model updating
We now discuss how we can update our query model over time
during an interactive retrieval process using Bayesian estimation.
In general, we assume that the retrieval system maintains a current
query model φi at any moment. As soon as we obtain some implicit
feedback evidence in the form of a piece of text Ti, we will update
the query model.
Initially, before we see any user query, we may already have
some information about the user. For example, we may have some
information about what documents the user has viewed in the past.
We use such information to define a prior on the query model,
which is denoted by φ′0. After we observe the first query Q1, we
can update the query model based on the new observed data Q1.
The updated query model φ1 can then be used for ranking docu-
ments in response to Q1. As the user views some documents, the
displayed summary text for such documents C1 (i.e., clicked sum-
maries) can serve as some new data for us to further update the
Coefficientsdependonthequerylength

ExperimentalResults
• Dataset:TRECAssociatedPresssetofnewsarWcles(~250,000arWcles)
• Select30mostdifficulttopics,havevolunteersissue4queriesforeachtopicandrecordqueryreformulaWonandclickthroughinformaWon
• MeasureMAPandPrecision@20
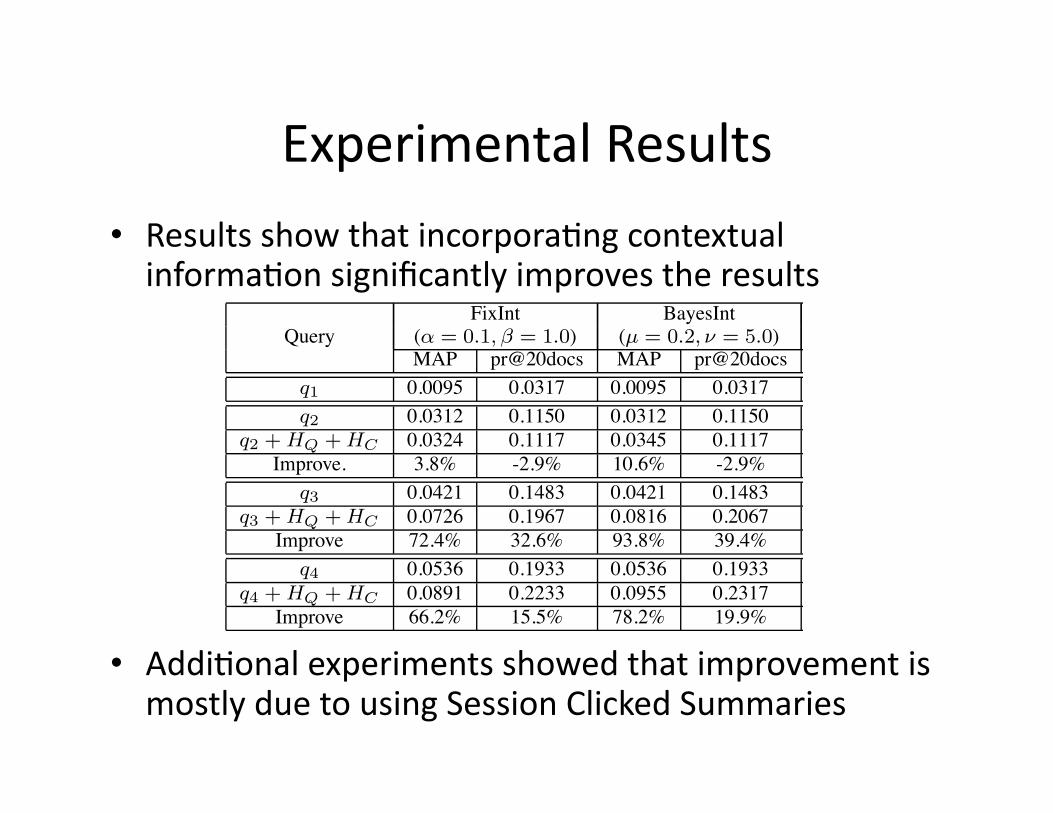
ExperimentalResults
• ResultsshowthatincorporaWngcontextualinformaWonsignificantlyimprovestheresults
• AddiWonalexperimentsshowedthatimprovementismostlyduetousingSessionClickedSummaries
FixInt BayesInt OnlineUp BatchUpQuery (α = 0.1, β = 1.0) (µ = 0.2, ν = 5.0) (µ = 5.0, ν = 15.0) (µ = 2.0, ν = 15.0)
MAP pr@20docs MAP pr@20docs MAP pr@20docs MAP pr@20docs
q1 0.0095 0.0317 0.0095 0.0317 0.0095 0.0317 0.0095 0.0317
q2 0.0312 0.1150 0.0312 0.1150 0.0312 0.1150 0.0312 0.1150
q2 + HQ + HC 0.0324 0.1117 0.0345 0.1117 0.0215 0.0733 0.0342 0.1100
Improve. 3.8% -2.9% 10.6% -2.9% -31.1% -36.3% 9.6% -4.3%
q3 0.0421 0.1483 0.0421 0.1483 0.0421 0.1483 0.0421 0.1483
q3 + HQ + HC 0.0726 0.1967 0.0816 0.2067 0.0706 0.1783 0.0810 0.2067
Improve 72.4% 32.6% 93.8% 39.4% 67.7% 20.2% 92.4% 39.4%
q4 0.0536 0.1933 0.0536 0.1933 0.0536 0.1933 0.0536 0.1933
q4 + HQ + HC 0.0891 0.2233 0.0955 0.2317 0.0792 0.2067 0.0950 0.2250
Improve 66.2% 15.5% 78.2% 19.9% 47.8% 6.9% 77.2% 16.4%
Table 1: Effect of using query history and clickthrough data for document ranking.
is 34.4 words. Among 91 clicked documents, 29 documents arejudged relevant according to TREC judgment file. This data set is
publicly available 1.
5. EXPERIMENTS
5.1 Experiment designOur major hypothesis is that using search context (i.e., query his-
tory and clickthrough information) can help improve search accu-
racy. In particular, the search context can provide extra information
to help us estimate a better query model than using just the current
query. So most of our experiments involve comparing the retrieval
performance using the current query only (thus ignoring any con-
text) with that using the current query as well as the search context.
Since we collected four versions of queries for each topic, we
make such comparisons for each version of queries. We use two
performance measures: (1) Mean Average Precision (MAP): This
is the standard non-interpolated average precision and serves as a
good measure of the overall ranking accuracy. (2) Precision at 20
documents (pr@20docs): This measure does not average well, but
it is more meaningful than MAP and reflects the utility for users
who only read the top 20 documents. In all cases, the reported
figure is the average over all of the 30 topics.
We evaluate the four models for exploiting search context (i.e.,
FixInt, BayesInt, OnlineUp, and BatchUp). Each model has pre-
cisely two parameters (α and β for FixInt; µ and ν for others).Note that µ and ν may need to be interpreted differently for dif-ferent methods. We vary these parameters and identify the optimal
performance for each method. We also vary the parameters to study
the sensitivity of our algorithms to the setting of the parameters.
5.2 Result analysis
5.2.1 Overall effect of search context
We compare the optimal performances of four models with those
using the current query only in Table 1. A row labeled with qi is
the baseline performance and a row labeled with qi + HQ + HC
is the performance of using search context. We can make several
observations from this table:
1. Comparing the baseline performances indicates that on average
reformulated queries are better than the previous queries with the
performance of q4 being the best. Users generally formulate better
and better queries.
2. Using search context generally has positive effect, especially
when the context is rich. This can be seen from the fact that the
1http://sifaka.cs.uiuc.edu/ir/ucair/QCHistory.zip
improvement for q4 and q3 is generally more substantial compared
with q2. Actually, in many cases with q2, using the context may
hurt the performance, probably because the history at that point is
sparse. When the search context is rich, the performance improve-
ment can be quite substantial. For example, BatchUp achieves
92.4% improvement in the mean average precision over q3 and
77.2% improvement over q4. (The generally low precisions also
make the relative improvement deceptively high, though.)
3. Among the four models using search context, the performances
of FixInt and OnlineUp are clearly worse than those of BayesInt
and BatchUp. Since BayesInt performs better than FixInt and the
main difference between BayesInt and FixInt is that the former uses
an adaptive coefficient for interpolation, the results suggest that us-
ing adaptive coefficient is quite beneficial and a Bayesian style in-
terpolation makes sense. The main difference between OnlineUp
and BatchUp is that OnlineUp uses decaying coefficients to com-
bine the multiple clicked summaries, while BatchUp simply con-
catenates all clicked summaries. Therefore the fact that BatchUp
is consistently better than OnlineUp indicates that the weights for
combining the clicked summaries indeed should not be decaying.
While OnlineUp is theoretically appealing, its performance is infe-
rior to BayesInt and BatchUp, likely because of the decaying coef-
ficient. Overall, BatchUp appears to be the best method when we
vary the parameter settings.
We have two different kinds of search context – query history
and clickthrough data. We now look into the contribution of each
kind of context.
5.2.2 Using query history only
In each of four models, we can “turn off” the clickthrough his-
tory data by setting parameters appropriately. This allows us to
evaluate the effect of using query history alone. We use the same
parameter setting for query history as in Table 1. The results are
shown in Table 2. Here we see that in general, the benefit of using
query history is very limited with mixed results. This is different
from what is reported in a previous study [15], where using query
history is consistently helpful. Another observation is that the con-
text runs perform poorly at q2, but generally perform (slightly) bet-
ter than the baselines for q3 and q4. This is again likely because
at the beginning the initial query, which is the title in the original
TREC topic description, may not be a good query; indeed, on av-
erage, performances of these “first-generation” queries are clearly
poorer than those of all other user-formulated queries in the later
generations. Yet another observation is that when using query his-
tory only, the BayesInt model appears to be better than other mod-
els. Since the clickthrough data is ignored, OnlineUp and BatchUp

• Feedbackonsub‐documentlevelshouldallowforbeserretrievalimprovements
• Useaneye‐trackertoautomaWcallydetectwhichporWonsofthedisplayeddocumentwerereadorskimmed
• Determinewhichpartsofthedocumentarerelevant
Attention-Based Information Retrieval
Georg Buscher German Research Center for Artificial Intelligence (DFKI)
Kaiserslautern, Germany
ABSTRACT In the proposed PhD thesis, it will be examined how attention data
from the user can be exploited in order to enhance and personalize
information retrieval.
Up to now, nearly all implicit feedback sources that are used for
information retrieval are based on mouse and keyboard input like
clickthrough, scrolling and annotation behavior. In this work, an
unobtrusive eye tracker will be used as an attention evidence source
being able to precisely detect read or skimmed document passages.
This information will be stored in attention-annotated documents
(e.g., containing read, skimmed, highlighted, commented passages).
Based on such annotated documents, the user’s current thematic
context will be estimated.
First, this attention-based context will be utilized for attention-based
changes concerning the index of vector-space based IR methods. It
is intended to regard the contexts as virtual documents, which will
be included in the index. In this way, local desktop or enterprise-
wide search engines could be enhanced by allowing new types of
queries, e.g., “Find a set of documents on my computer concerning
the current topic that I have formerly used in a similar context”.
Second, the thematic context will be utilized for pre- and
postprocessing steps concerning the retrieval process, e.g., for query
expansion and result reranking. Therefore, attention-enhanced
keyword extraction techniques will be developed that take the
degree of attention from the user into account.
Categories and Subject Descriptors H.3.1 [Content Analysis and Indexing]: Indexing methods, H.3.3
[Information Search and Retrieval]: Relevance feedback
General Terms
Algorithms, Human Factors
Keywords
Eye tracking, implicit feedback, attention-based index
1. INTRODUCTION In the last years it could be observed that the human-centered
perspective came more and more into the focus of IR research. In
this regard, a recent trend is of strong importance: the environment
of the user gets more and more personalized; the narrower and
broader context of a user is considered in order to better understand
the user’s needs (e.g., see [2], [3], [21]). This context is increasingly
taken into account in information retrieval systems.
However, context is a relatively vague term. For instance, context
can be generated implicitly or explicitly, it can be meant in a
thematic way (based on content) or rather in an environmental way
(e.g., based on application structures, people worked with, etc.), or it
can be seen as a short-term or as a long-term context, etc.
One of the current challenges is to elicit the context of a user. This
can be done explicitly, for example by asking the user, whether a
document is currently relevant or not (i.e., explicit relevance
feedback). To use such explicitly generated context is suggestive
and yields better results in IR than without considering any user
context. However, asking the user about explicit feedback requires a
higher effort on the user’s side and should therefore be avoided.
Thus, implicit feedback recently gained in importance, i.e.,
observing the user’s actions and environment and trying to infer
what might be relevant for him.
Up to now, the main sources for implicitly generating thematic
context are the user’s click-through, scrolling and typing behavior
(see [12]); thus, data, which is provided by all normally available
input devices that are used to interact with a computer.
A very interesting new evidence source for implicit feedback are the
user’s eye movements, because mostly they reflect the user’s visual
attention directly. The eye trackers of today are unobtrusive and are
able to identify the user’s gaze with high precision (e.g., see [24]).
Therefore, applying an eye tracker as a new evidence source for the
user’s attention introduces a potentially very valuable new
dimension of contextual information in information retrieval. It is
clear that eye trackers will not be wide spread in the near future due
to their expensiveness. However, if becoming less expensive, they
might well be interesting for knowledge workers in middle- or
large-sized enterprises.
Motivated by these thoughts, in this proposed dissertation, the
impact of attention evidence data especially obtained by an eye
tracker on information retrieval methods will be examined.
Therefore, the focus lies on local desktop and enterprise-wide
search. It primarily shall be concentrated on attention-based changes
concerning the index of vector-space based IR methods, but also on
attention-enhanced pre- and postprocessing steps like query
expansion and reranking mechanisms. As an eye tracker is not the
only source for attention evidence, a model shall be developed,
which integrates different attention evidence sources so that a
standardized overall level of attention can be derived for any piece
of text in a document.
2. BACKGROUND AND RELATED WORK Relevance feedback has been considered in information retrieval
research for some decades, now. While it has first been focused on
explicit relevance feedback, the focus now lies more on implicit
feedback due to the lower effort it requires from the user. The
/
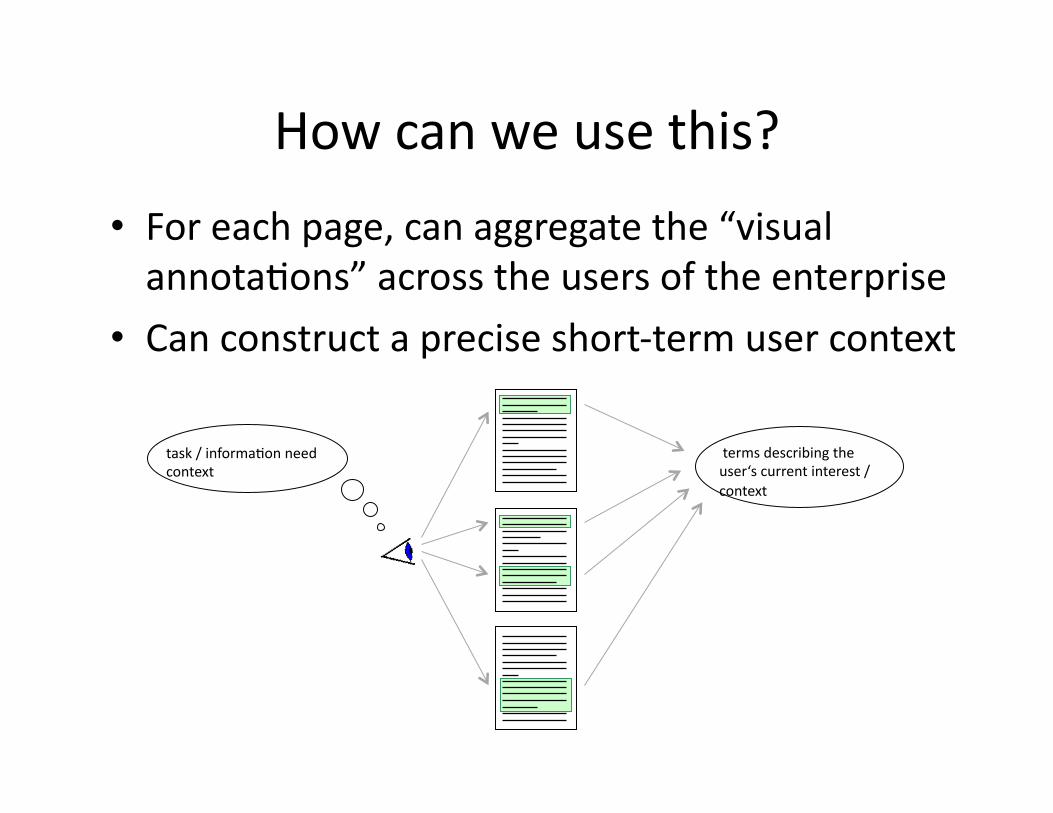
Howcanweusethis?
• Foreachpage,canaggregatethe“visualannotaWons”acrosstheusersoftheenterprise
• Canconstructapreciseshort‐termusercontext
task/informaWonneedcontext
termsdescribingtheuser‘scurrentinterest/context

Summary
• Usingshort‐termusercontexttoimprovesearchqualityisanewandverypromisingdirecWonofresearch
• IniWalresultsshowthatitcanbeveryeffecWve• Usingeyetrackingcanhelptoimprovethequalityandincreasetheamountofthecontextdata
• ManyunexploredapplicaWons:on‐the‐flyreranking,abstractpersonalizaWon,etc.

InteresWngProblemsandPromisingResearchDirecWons
• ApplyingthetechniqueswetalkedabouttoimproveEnterpriseWebsearch,extendingthemtobesersuitEnterpriseenvironment
• ModelsfortheEnterpriseWebwhichtakeintoaccountitscomplexstructureandallowforexpressingdifferentusagedata
• PersonalizaWonintheEnterpriseWebsearch(usagedata+employeepersonalinfo)
• Usingcontext(recenthistory+desktopinfo)toimproveEnterpriseWebsearch

References• [Fagin03]Fagin.R.,Kumar,R.,McCurley,K.S.,Novak,J.,Sivakumar,D.,Tomlin,J.A.,
Williamson,D.P.“SearchingtheWorkplaceWeb”.WWWConference,May2003,Budapest,Hungary.
• [Hawking04]Hawking,D.“ChallengesinEnterpriseSearch”.ADCConference,Dunedin,NZ.
• [Dmitriev06]Dmitriev,P.,Eiron,N.,Fontoura,M.,Shekita,E.“UsingAnnotaWoninEnterpriseSearch”.WWWConference,May2006,Edinburgh,Scotland.
• [Poblete08]Poblete,B.,Baeza‐Yates,R.“Query‐Sets:UsingImplicitFeedbackandQueryPasernstoOrganizeWebDocuments”.WWWConference,April2008,Beijing,China.
• [Joachims02]Joachims,T.OpWmizingSearchEnginesUsingClickthroughData.KDDConference,2002.
• [Radlinski05]Radlinski,F.,Joachims,T.“QueryChains:learningtorankfromimplicitfeedback”.KDDConference,2005,NewYork,USA.
• [Broder00]Broder,A.,Kumar,R.,Maghoul,F.,Raghavan,P.,Rajagopalan,S.,Stata,R.,Tomkins,A.,Wiener,J.“GraphStructureintheWeb”.WWWConference,2000.
• [Dwork01]Dwork,C.,Kumar,R.,Naor,M.,Sivkumar,D.“RankAggregaWonMethodsfortheWeb”.WWWConference,2001.
• [Shen05]Shen,X.,Tan,B.,Zhai,C.“Context‐SensiWveInformaWonRetrievalUsingImplicitFeedback”.SIGIRConference,2005.

References• [Fagin03‐1]Fagin,R.,Lotem,A.,Naor,M.“OpWmalAggregaWonAlgorithmsfor
Middleware”.JournalofComputerandSystemsSciences,66:614‐656,2003.• [Chirita07]Chirita,P.‐A.,Costache,S.,Handschuh,S.,Nejdl,W.“P‐TAG:LargeScale
GeneraWonofPersonalizedAnnotaWonTAGsfortheWeb”.WWWConference,2007.
• [Bao07]Bao,S.,Wu,X.,Fei,B.,Xue,G.,Su,Z.,Yu,Y.“OpWmizingWebSearchUsingSocialAnnotaWons”.WWW‐Conference,2007.
• [Xu07]Xu,S.,Bao,S.,Cao,Y.,Yu,Y.“UsingSocialAnnotaWonstoImproveLanguageModelforInformaWonRetrieval”.CIKMConference,2007.
• [Millen06]Millen,D.R.,Feinberg,J.,Kerr,B.“Dogear:SocialBookmarkingintheEnterprise”.CHIConference,2006.
• [Bilenko08]Bilenko,M.,White,R.W.“MiningtheSearchTrailsofSurfingCrowds:IdenWfyingRelevantWebSitesfromUserAcWvity”.WWWConference,2008.
• [Xue03]Xue,G.‐R.,Zeng,H.‐J.,Chen,Z.,Ma,W.‐Y.,Zhang,H.‐J.,Lu,C.‐J.“ImplicitLinkAnalysisforSmallWebSearch”.SIGIRConference,2003.
• [Burges05]Burges,C.J.C.,Shaked,T.,Renshaw,E.,Lazier,A.,Deeds,M.,Hamilton,N.,Hullender,G.N.“LearningtoRankUsingGradientDescent”.ICMLConference,2005.
• [Buscher07]Buscher,G.“AsenWon‐BasedInformaWonRetrieval”.DoctoralConcorWum,SIGIRConference,2007.





























