Embed Size (px)
Citation preview

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
1. Introduction

1. Introduction
I. Epidémiologie
II. Différents types d’enquêtes
III. Population cible et population source
IV. Fluctuations d’échantillonnage
V. Biais en épidémiologie

I. Epidémiologie
• Historique
Étude des épidémies (maladies transmissibles, comptage)
Recherche des causes (variations géographiques, temporelles, entre groupes)
Généralisation aux maladies non contagieuses
Étude de la distribution des maladies et des facteurs qui influencent cette distribution
Étude de l’étiologie des pathologies
• Recherche observationnelle analytique (ou étiologique)
• Rechercher l’existence d’une relation entre une exposition et la survenue d’une maladie
(mesure de risque) et mesurer cette relation (mesure d’association)
• Un facteur E est un facteur de risque pour une maladie M si l’exposition à E modifie la
vitesse d’apparition de la maladie M
• Notion et critères de causalité

Quelques questions en épidémiologie
• Question I : Quelle est la ″fréquence″ d’une pathologie ou d’un comportement?
• Ex : cancers du sein, pratique des mammographies (selon l’âge, le sexe ou la région
géographique)
Décrire et quantifier un phénomène de santé
• Question II : Comment évolue la fréquence d’une pathologie ou d’un comportement au cours
du temps ?
• Ex : usage du préservatif entre 1980 et 2000, épidémie de sida en France entre 1980 et 2000.
Surveiller les tendances évolutives, mettre en place des systèmes d’alerte
• Question III : Comment varie la fréquence d’une pathologie d’un endroit à un autre?
• Ex : variation géographique de la fréquence de l’infarctus du myocarde
Corrélations écologiques
EPIDEMIOLOGIE DESCRIPTIVE générer des hypothèses

Quelques questions en épidémiologie
• Question IV : Peut-on identifier des facteurs associés à une maladie ou à un comportement donné ?
• Ex : facteurs associés au cancer du poumon
Facteurs d’exposition Phénomène étudié (Recherche analytique)
• Question V : Y a- t- il une relation causale entre un facteur d’exposition et une maladie ou un
comportement donné ?
• Ex : l’infection à HPV est- elle susceptible de provoquer la survenue de cancer du col de l’utérus ?
Facteurs d’exposition Phénomène étudié (Recherche analytique)
EPIDEMIOLOGIE ANALYTIQUE
• Question VI : Quelle est l’efficacité d’une intervention sur un facteur d’exposition ou d’un
traitement pour diminuer la survenue d’une maladie ou modifier un comportement?
• Ex : Quelle est l’efficacité d’un programme de dépistage du cancer du sein dans une population
sur la mortalité par ce type de cancer ?
Recherche expérimentale, évaluation d’intervention
EPIDEMIOLOGIE EVALUATIVE
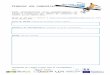
II. Différents types d’enquêtes
Enquêtes expérimentales Enquêtes observationnelles
Enquêtes descriptives
- A l’aveugle ou non
- Randomisé ou non (avec ou sans tirage au sort)
Cohorte
Intervention ou contrôle de l’exposition ?
oui non
Etude de variations
Enquêtes analytiques (étiologiques)
Cas-témoin
Transversale Etudes diagnostiques
Essais thérapeutiques
Essais d’intervention Avant/après Ici/ ailleurs Sondage
Données disponibles

Enquête descriptive
• Étude de la fréquence et de la répartition des paramètres de santé ou des
facteurs de risque dans une population.
• Études de variations
• Variations dans le temps
• Ex : Augmentation de la fréquence de certaines maladies permet de soupçonner
l’introduction progressive d’un nouvel agent toxique (Tabac, amiante,…).
• Variations géographiques
• Ex : Moins de cancer du sein au Japon qu’en Europe (facteur génétique ou
environnementaux ?) => Étude de migration (taux identiques entre femmes
américaines et descendances d’immigrants Japonais) => facteurs
environnementaux
• Les « clusters » (agrégats spatio-temporels)
• Plusieurs cas d’une maladie rare en des lieux proches et dans un intervalle de
temps court (agents cancérigènes, …)

Enquête descriptive
• Statistiques disponibles
• Statistiques vitales : naissance et causes médicales de mortalité (CepiDc)
• Statistiques de morbidité : registre des cancers, des maladies cardio-vasculaires, …
• Statistiques d’exposition à des facteurs de risque : expositions professionnelles, …
• Statistiques hospitalières, programme de médicalisation des systèmes d'information
(PMSI)
• Déclarations obligatoires : maladies transmissibles, sida, certificat de santé des
enfants, …
• Réseaux sentinelles de médecins ou de biologistes : grippe, rougeole, coqueluche …
• Enquêtes spécifiques (de grande envergure pour mieux comprendre un problème de
santé : l’importance, les déterminants, …)
• Enquêtes peu couteuses et rapides permettant d’évaluer une hypothèse ou
d’alimenter un faisceau d’arguments

Enquête expérimentale
• Le chercheur a le contrôle complet de l’exposition (la nature précise de l’exposition, le moment
de son utilisation, du choix des sujets qui vont en bénéficier et du déroulement de l’essai).
Objectif : éviter l’apparition de différences autres que l’effet de l’exposition.
• Le statut de l’exposition peut être
• Connu du patient
• A l’aveugle : le patient ne connait pas son exposition
• En double aveugle : le patient et l’examinateur ne connaissent pas l’exposition
Objectif : éviter les biais d’interprétation (fonction de la conviction des protagonistes)
• L’expérience peut être randomisée ou non randomisée
• Non randomisé : les groupes traités et témoins sont choisis par l’investigateur.
• Randomisé : les groupes comparés sont constitués par tirage au sort
Objectif : éviter que l’attribution du traitement soit influencée par l’état de santé (biais de
sélection) ou par une autre caractéristique (biais confusion).

Enquête expérimentale
• Ex : essai thérapeutique permet d’évaluer l’effet d’un traitement,
l’exposition est le placebo ou le traitement
• L’essai randomisé à l’aveugle est la meilleure méthode d’évaluation
permet de montrer la causalité !
(si ce n’est pas le cas, le niveau de preuve est plus faible)
• Limites
• La randomisation n’est pas toujours possible pour des raisons éthiques
Ex : effet du tabac, évaluation d’une prévention, …
• Les conditions de l’expérience ne sont pas toujours vérifiée dans la pratique

Enquête quasi-expérimentale
• Enquête "avant-après"
• comparaison les situations avant et après une intervention
• Les sujets peuvent être leur propre témoin
• Ex : étude sur le comportement vis à vis du tabagisme avant et après une campagne de prévention contre le tabac.
• Difficulté : variation spontanée des indicateurs qui se serait produite même en l'absence de l’intervention (mise en place au même moment d'autres mesures de santé, changements socioculturels, ...)
• Enquête "ici-ailleurs"
• Comparaison, au même moment, des groupes distincts géographiquement où l’un reçoit l’intervention et l’autre pas
• Ex: deux services hospitaliers pratiquant ou non l’intervention
• Difficulté : possibilité d’une différence initiale entre les deux populations comparées

Enquête analytique
• Enquête sur un échantillon de sujets veillant à recueillir des informations
individuelles sur la maladie et les expositions
• Sélection d’un échantillon de la population cible et mesures d’indicateurs
adaptés
• Etude des associations à un niveau individuel
• Prise en compte de facteurs de confusion
• Prise en compte de la chronologie des évènements
• Etudier la relation entre la maladie et les expositions et fournir des
arguments en faveur d’une interprétation causale (force de l’association,
relation dose-effet, chronologie …)
• Souvent les seules enquêtes possibles
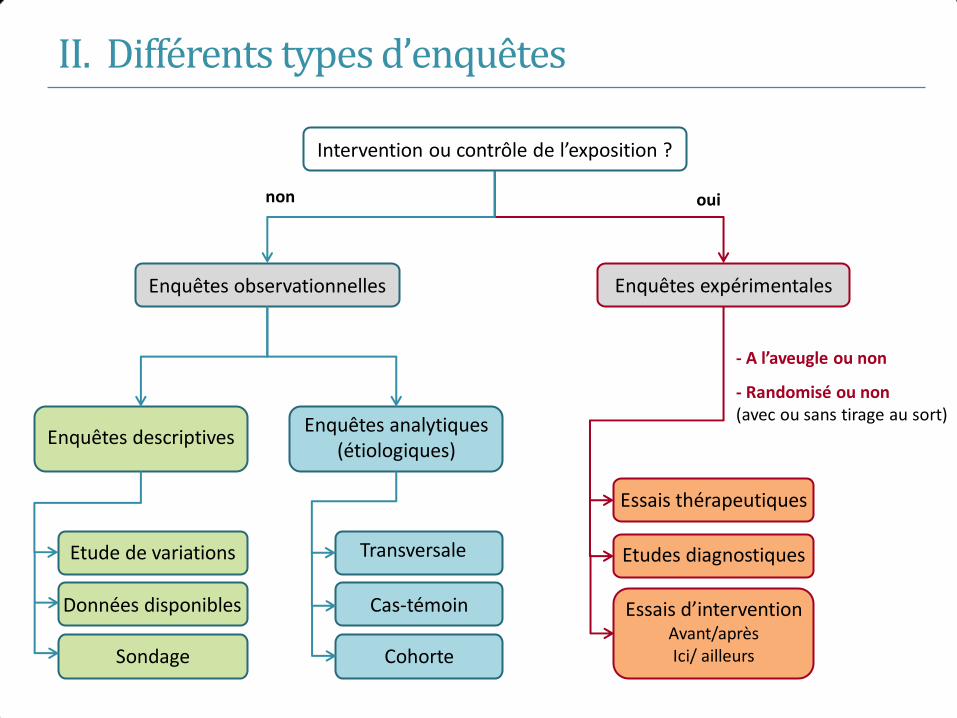
E- M- E+ M-
E+ M+
E- M+
Population
Enquête analytique : transversale
• Etude d’un échantillon représentatif de la population étudiée : pas de sélection sur
l’exposition (cohorte) ou la maladie (cas-témoins)
• Objectif : étudier l’association entre l’exposition et la maladie
• Image instantanée d’un phénomène: recueil des informations au moment de l’inclusion
Exposition
E+ E-
Maladie M+ a b
M- c d
d c
a b
Echantillon

Enquête analytique : transversale
• Avantages
• Enquête facile à mettre en œuvre, rapide et peu coûteuse
• Limites
• Pas adapté aux maladie rares et aux expositions rares
• Biais de sélection possible dans la sélection de l’échantillon
• Chronologie des évènements E-M (séquence temporelle) pas évidente
• Recueil de l’exposition souvent rétrospectif (biais de mémorisation)
• Enquête observationnelle avec le plus faible niveau de preuve
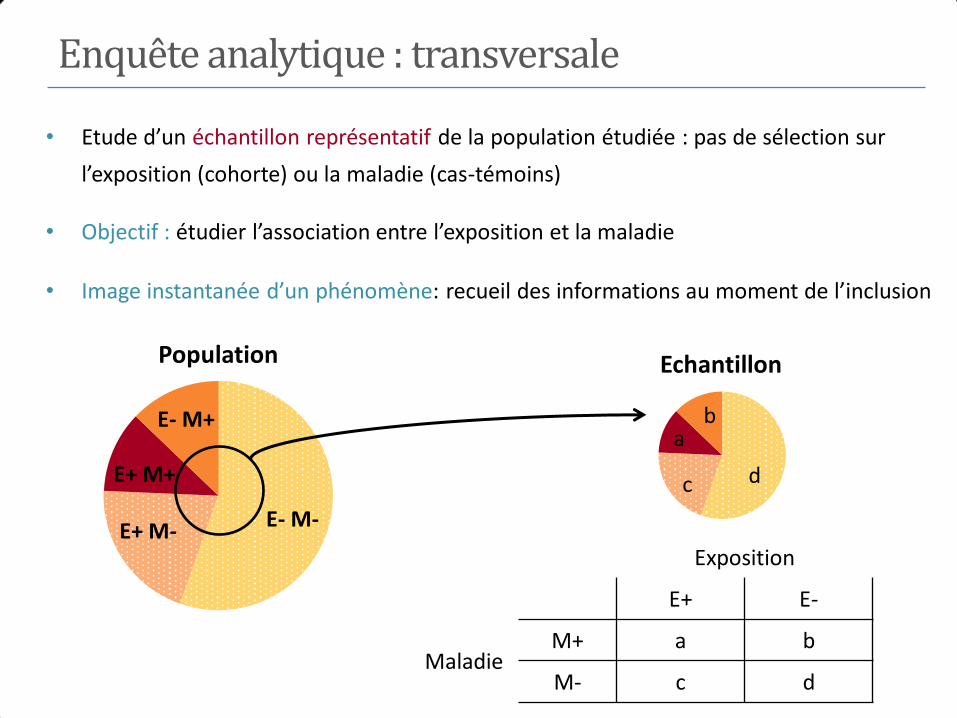
Enquête analytique : cohorte
E- M- E+ M-
E+ M+
E- M+
Population
• Cohorte : suivi dans le temps (étude longitudinale), selon un protocole pré-établi, d’un
groupe de sujets qui répondent à une définition donnée
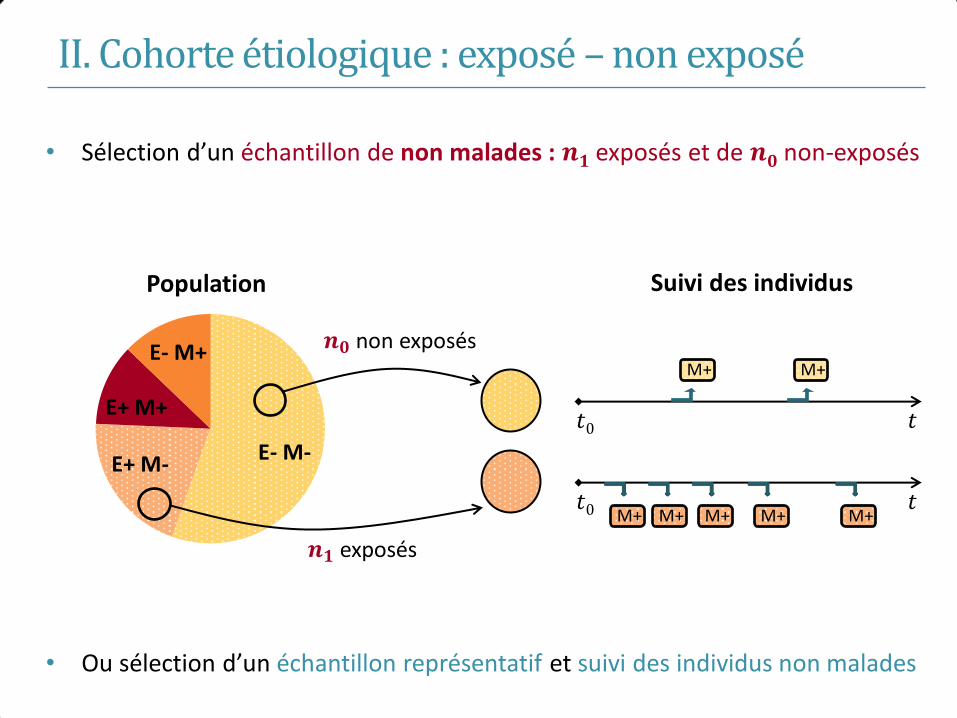
• Sélection d’un échantillon de non malades : 𝒏𝟏 exposés et de 𝒏𝟎 non-exposés
• Objectif : comparer la survenue de la maladie chez les E+ et les E-
𝒏𝟎 non exposés
𝒏𝟏 exposés
Suivi des individus
𝑡 𝑡0
M+
𝑡 𝑡0
M+
M+ M+ M+ M+ M+
E- M- E+ M-
E+ M+
E- M+
Population
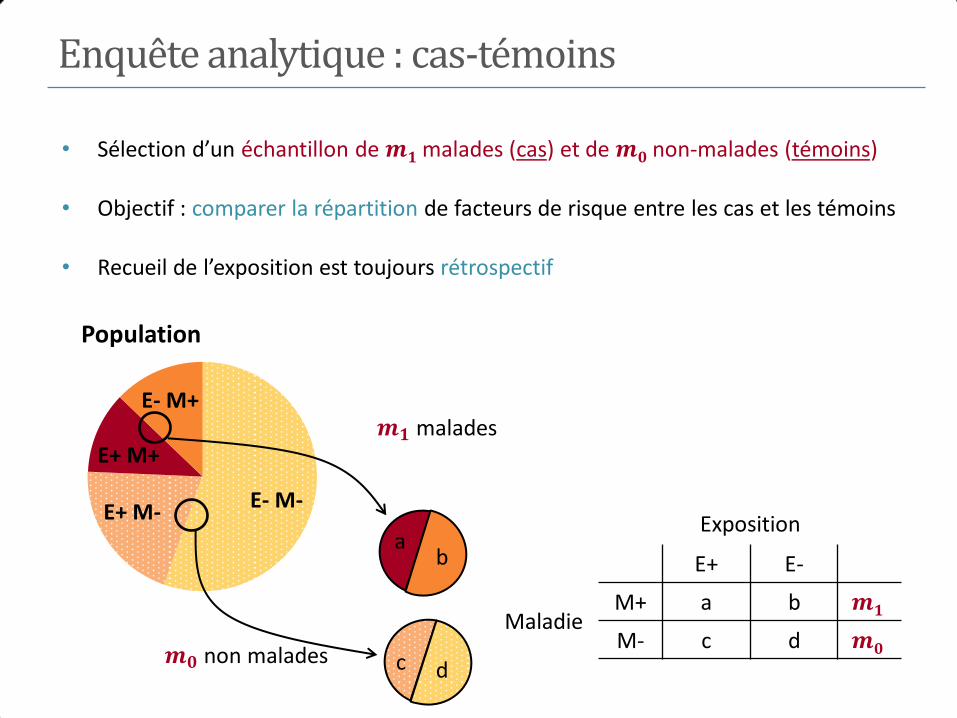
Enquête analytique : cas-témoins
• Sélection d’un échantillon de 𝒎𝟏 malades (cas) et de 𝒎𝟎 non-malades (témoins)
• Objectif : comparer la répartition de facteurs de risque entre les cas et les témoins
• Recueil de l’exposition est toujours rétrospectif
Exposition
E+ E-
Maladie M+ a b 𝒎𝟏
M- c d 𝒎𝟎
a b
d c
𝒎𝟏 malades
𝒎𝟎 non malades

III. Population cible et population source
• La population cible est l’ensemble des sujets visés par l’enquête, c'est‐à‐dire la
population pour laquelle les résultats de l’enquête pourront être généralisés
• La population source est l’ensemble des sujets à partir desquels on va constituer
l’échantillon. La population source doit être voisine de la population cible et
généralement plus facile d’accès parce que rassemblée (entreprise, hôpital, école)
• La population de l’enquête est soit la population source (exhaustivité) soit un
échantillon représentatif de la population source
Population générale
Population cible
Population source Echantillon représentatif

• Les enquêtes épidémiologiques sont souvent réalisées à partir d’un échantillon de la
population source
• L’échantillon doit être représentatif de la population source
• L’échantillonnage par tirage au sort est la seule méthode qui permet d’obtenir un échantillon
représentatif à partir d’une liste exhaustive de la population source
Difficultés: - aucune liste n’est exhaustive en population générale
- risque de biais de sélection liés aux non-réponses
• La sélection d’un échantillon représentatif est sujette a une erreur liée aux
fluctuations d’échantillonnage
erreur aléatoire (imprévisible)
IV. Fluctuations d’échantillonnage
• Erreur aléatoire entre 𝑅𝑅 et 𝑅𝑅 prise en compte dans les tests statistiques
• Les estimations doivent être données avec leur intervalle de confiance à 95%.
intervalle dans lequel la vraie valeur a de fortes chances (95%) de se situer
• Erreur diminue quand la taille de l’échantillon augmente
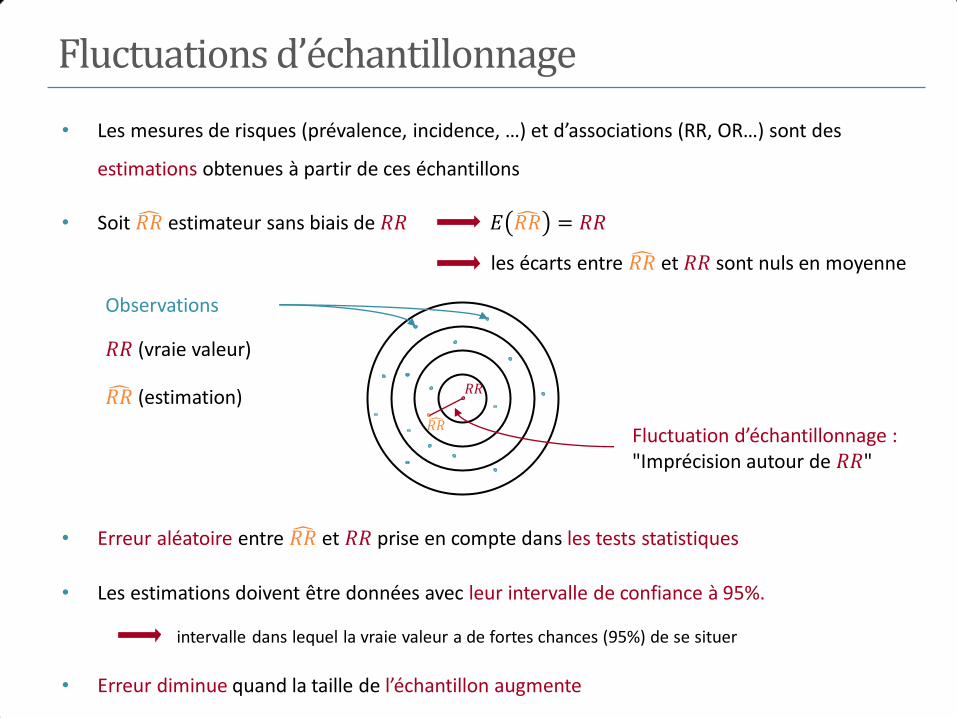
Fluctuations d’échantillonnage
Observations
𝑅𝑅 (vraie valeur)
𝑅𝑅 (estimation)
• Les mesures de risques (prévalence, incidence, …) et d’associations (RR, OR…) sont des
estimations obtenues à partir de ces échantillons
• Soit 𝑅𝑅 estimateur sans biais de 𝑅𝑅 𝐸 𝑅𝑅 = 𝑅𝑅
les écarts entre 𝑅𝑅 et 𝑅𝑅 sont nuls en moyenne
𝑅𝑅
𝑅𝑅 Fluctuation d’échantillonnage : "Imprécision autour de 𝑅𝑅"

V. Biais en épidémiologie
• Un biais est une erreur systématique qui fausse les résultats dans un sens donné.
• Erreur qui se répète sur chaque échantillon
• Le biais ne diminue pas avec la taille de l’échantillon
• Soit 𝑅𝑅 estimateur biaisé de 𝑅𝑅 𝐸 𝑅𝑅 = 𝑅𝑅 ≠ 𝑅𝑅
les écarts entre 𝑅𝑅 et 𝑅𝑅 ne sont pas nuls en moyenne
Observations
𝑅𝑅(vraie valeur)
𝑅𝑅 (estimation)
Biais : "Erreur de visée"
𝑅𝑅 = 𝐸 𝑅𝑅
𝑅𝑅
𝑅𝑅
𝑅𝑅
Fluctuation d’échantillonnage : "Imprécision autour de 𝑅𝑅 "

• Biais de sélection : erreur liée à la sélection des sujets à inclure et au suivi des sujets : problèmes de
représentativité ou de comparabilité des groupes
• Echantillon non représentatif
• Vision déformée de la population source
• Biais de classement : erreur due à une mesure erronée de l’exposition ou de la maladie
(subjectivité de l’enquêteur, mauvais outil de mesure, biais de mémorisation, …)
• Echantillon représentatif mais classement erroné
• Vision déformée de la réalité
• Biais de confusion : erreur due à la présence d’un tiers facteur lié à l’exposition et à la maladie
• Echantillon représentatif mais difficultés à observer (isoler) la relation entre E et M (même
problème dans la population cible)
• Ce n’est pas un biais au sens statistique
• Ex : le tabagisme peut être un facteur de confusion dans la relation entre la consommation
d’alcool et le risque de cancer du poumon.
Biais en épidémiologie : 3 types de biais

• Biais différentiel
• Les erreurs affectent différemment les groupes comparés.
• Peut entraîner une surestimation ou une sous‐estimation de l’association (RR, OR, …)
• Ex : diagnostic non objectif de la maladie en connaissant le statut sur l’exposition
• Biais non différentiel
• Les erreurs affectent indifféremment les groupes comparés
• Entraîne toujours une diminution de l’association (RR se rapproche de 1)
• Ex : erreur systématique sur un appareil de mesure nécessaire au diagnostic
• Description d’un biais : le type, différentiel ou non, la direction et son importance
• Contrôle des biais au moment de la planification ou de l’analyse statistique
Biais en épidémiologie

Plan
2. Enquête de cohorte
3. Enquête cas-témoins
4. Mesures de risques
5. Mesures d’association
6. Biais de sélection
7. Biais de classement
8. Biais de confusion
9. Stratégie d’analyse
10. Puissance
11. Modèles multivariés
12. Régression logistique

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
2. Enquête de cohorte

2. Enquête de cohorte
I. Définitions d’une cohorte
II. Cohorte étiologique : enquête exposé – non exposé
III. Méthodologie générale
• Recueil de données, mode de recrutement des sujets, choix du groupe de
référence, prévalence de l’exposition
IV. Mise en place d’une enquête exposé‐non exposé
• Constitution de la cohorte, recueil des informations
• Suivi, perdus de vue et biais dans une enquête de cohorte
V. Avantages et limites

I. Définitions d’une cohorte
• Définitions : (1) division de la légion romaine, (2) groupe
• Définition (Epidémiologie) : Suivi dans le temps (étude longitudinale),
selon un protocole pré-établi, d’un groupe de sujets qui répondent à
une définition donnée :
• exposé-non exposé : cohorte étiologique
• sélectionnés en population générale : cohorte descriptive
• ou souffrant d’une pathologie particulière
• L’objectif des enquêtes de cohorte est de mesurer et de comparer la
survenue d'une pathologie dans une population en fonction de
l’exposition à un ou plusieurs facteurs prédictifs.
E- M- E+ M-
E+ M+
E- M+
Population
• Sélection d’un échantillon de non malades : 𝒏𝟏 exposés et de 𝒏𝟎 non-exposés
𝒏𝟎 non exposés
II. Cohorte étiologique : exposé – non exposé
𝒏𝟏 exposés
Suivi des individus
𝑡 𝑡0
M+
𝑡 𝑡0
M+
M+ M+ M+ M+ M+
• Ou sélection d’un échantillon représentatif et suivi des individus non malades

• Objectif : épidémiologie observationnelle analytique
Rechercher l’existence d’une relation entre une exposition et la
survenue d’une maladie et mesurer l’intensité de cette relation
• Déroulement se rapproche des études expérimentale
• Recrutement des sujets non malades exposés ou non exposés au facteur
étudié
• Les sujets sont suivis dans le temps et chaque nouveau cas de la maladie est
enregistré
• Estimation et comparaison des incidences de la maladie chez les exposés et
les non exposés
Cohorte étiologique : exposé – non exposé

III. Méthodologie générale
• Type de cohorte selon la chronologie du recueil de données
Cohorte prospective, cohorte rétrospective, cohorte historico‐prospective
• Type de cohorte selon de recrutement des sujets
Cohorte fixe, cohorte dynamique, cohorte mixte
• Type de cohorte selon le choix du groupe de référence
Groupe de référence interne, groupe de référence externe
• Type de cohorte selon la prévalence de l’exposition
Prévalence forte et diffuse, prévalence faible et concentrée
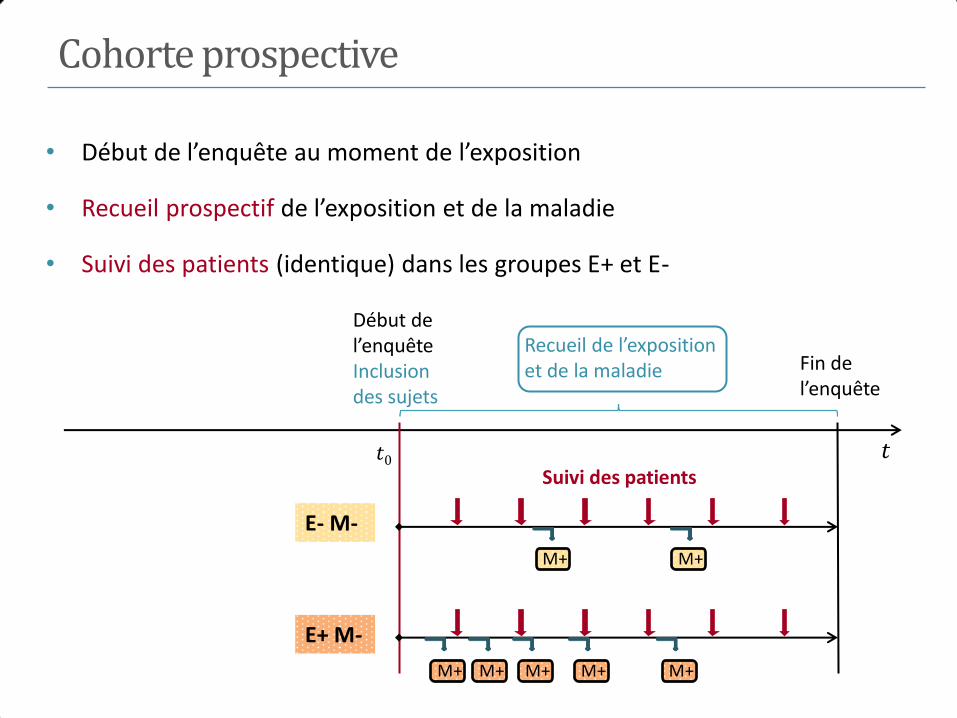
Cohorte prospective
• Début de l’enquête au moment de l’exposition
• Recueil prospectif de l’exposition et de la maladie
• Suivi des patients (identique) dans les groupes E+ et E-
Début de l’enquête Inclusion des sujets
Fin de l’enquête
M+ M+
M+ M+ M+ M+ M+
𝑡 𝑡0
E- M-
E+ M-
Suivi des patients
Recueil de l’exposition et de la maladie
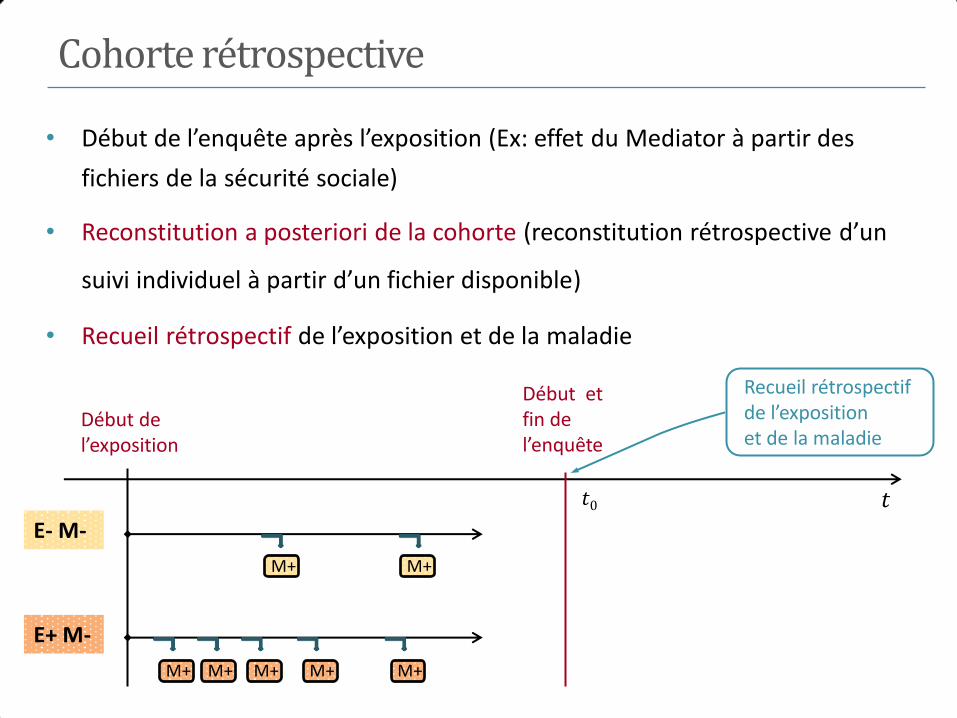
Cohorte rétrospective
• Début de l’enquête après l’exposition (Ex: effet du Mediator à partir des
fichiers de la sécurité sociale)
• Reconstitution a posteriori de la cohorte (reconstitution rétrospective d’un
suivi individuel à partir d’un fichier disponible)
• Recueil rétrospectif de l’exposition et de la maladie
Début et fin de l’enquête
M+ M+
M+ M+ M+ M+ M+
𝑡 𝑡0
E- M-
E+ M-
Début de l’exposition
Recueil rétrospectif de l’exposition et de la maladie
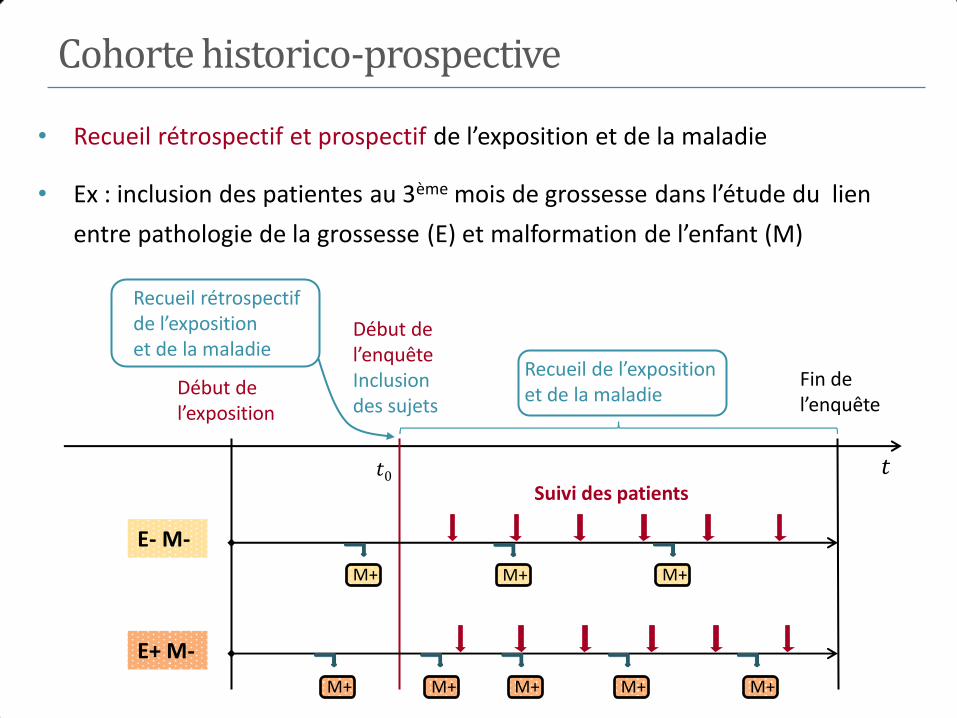
Cohorte historico-prospective
• Recueil rétrospectif et prospectif de l’exposition et de la maladie
• Ex : inclusion des patientes au 3ème mois de grossesse dans l’étude du lien
entre pathologie de la grossesse (E) et malformation de l’enfant (M)
Début de l’enquête Inclusion des sujets
Fin de l’enquête
M+ M+
M+ M+ M+ M+ M+
𝑡 𝑡0
E- M-
E+ M-
Suivi des patients
Recueil de l’exposition et de la maladie
M+
Recueil rétrospectif de l’exposition et de la maladie
Début de l’exposition

Cohorte prospective ou rétrospective ?
• Cohorte prospective
• (+) Recueil planifié des expositions et de la maladie
• (+) Evaluation des expositions avant la survenue de la maladie
• (+) Limite les perdus de vue
• (-) Enquête longue et réponse retardée sur une exposition actuelle (temps de
latence)
• Cohorte rétrospective
• (+) Enquête et réponse rapide sur un risque lié à exposition passée
• (-) Recueil hétérogène et souvent incomplet des expositions et des maladies
• (-) Nombreux perdus de vue
• (-) Information sur les facteurs de confusions potentiels rare et peu fiable
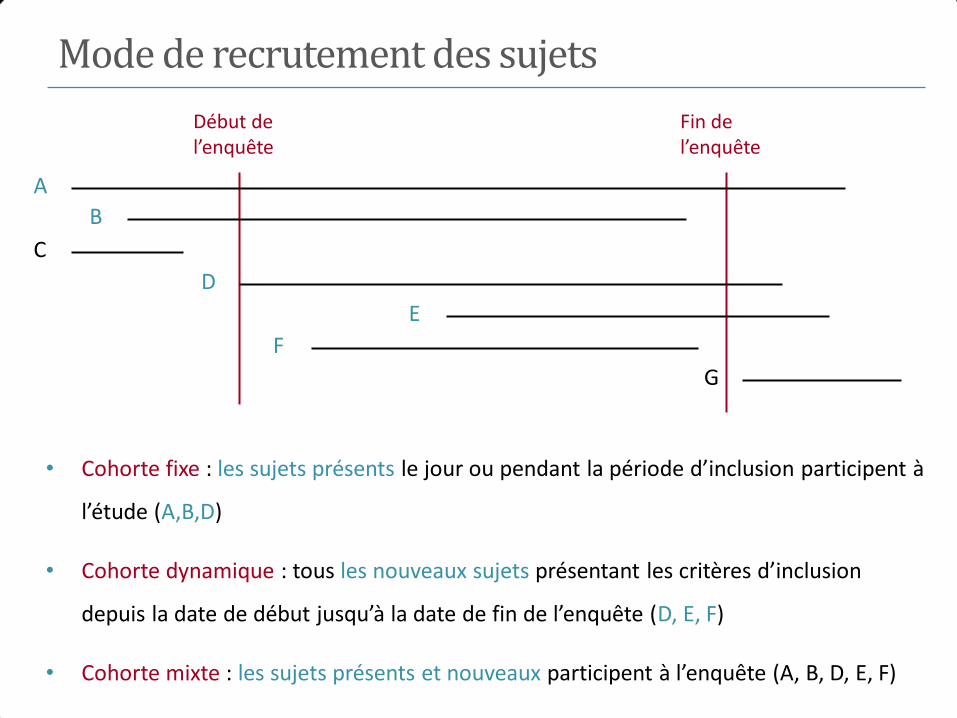
Mode de recrutement des sujets
• Cohorte fixe : les sujets présents le jour ou pendant la période d’inclusion participent à
l’étude (A,B,D)
• Cohorte dynamique : tous les nouveaux sujets présentant les critères d’inclusion
depuis la date de début jusqu’à la date de fin de l’enquête (D, E, F)
• Cohorte mixte : les sujets présents et nouveaux participent à l’enquête (A, B, D, E, F)
Début de l’enquête
Fin de l’enquête
A
B
C
D
E
F
G

Mode de recrutement des sujets
• Cohorte fixe
• Biais de sélection possible particulièrement en milieu de travail : si l’exposition est
liée à une maladie silencieuse, les sujets sélectionnés sont les plus résistants et les
moins exposés (sujets prévalents) : «Healthy worker effect»
• Recrutement rapide
• Cohorte dynamique
• Limite le biais de sélection (sujets incidents)
• Recrutement long
• Cohorte mixte
• Permet d’étudier l’effet du biais de sélection en comparant les sujets incidents et
prévalents

Choix du groupe de référence
• Définition du groupe de référence
• Sujets non malade et non exposé aux facteurs étudiés
• Suivi et recueil de l’information sur la maladie possible et similaire au groupe exposé
• Sujets comparables au groupe exposé sauf sur l’exposition
• Issu de la même population source que le groupe exposé
• Idéalement, comparable sur toutes les caractéristiques ayant un lien avec la maladie étudiée (âge, sexe, catégorie socioprofessionnelle, lieu d’habitation, …)
• Les différences peuvent constituer des facteurs de confusion potentiels

Choix du groupe de référence
• Groupe de référence interne
• Le plus utilisé dans les études prospectives
• Les groupes E+ et E- sont définis au sein de la même cohorte (avant ou après le
recrutement)
• Suivi identique des groupes E+ et E- (mesures standardisées)
• Mesure de l’exposition connu pour chaque individu (idéalement, suffisamment
élevée et hétérogène pour étudier une relation dose-effet)
• Ajustement possible sur des facteurs de confusions individuels (variables mesurées à
l’inclusion et pendant le suivi)

Choix du groupe de référence
• Groupe de référence externe
• Le groupe E- n’est pas issu de la cohorte (population nationale, registre, …)
• Nécessite une population de référence où l’incidence de la maladie est connue
• Utilisé dans les enquêtes rétrospectives (commode quand on dispose déjà de
statistiques sur une population)
• Rarement dans les études prospectives (sauf si l’exposition est homogène ou non
connu individuellement dans la cohorte)
• Inconvénients :
• Pas de mesures des facteurs de confusion : ajustement limité à quelques facteurs socio-
démographiques (âge, sexe, catégorie socioprofessionnelle, lieu d’habitation, …)
• Nombreux biais plusieurs références externes !
• population source différente (biais de sélection)
• Si prévalence de l’exposition importante dans la population générale (biais de classement)

Prévalence de l’exposition
• Prévalence de l’exposition élevée et diffuse
• Enquête sur un échantillon de population générale avec groupe de référence interne
• Ex : pollution atmosphérique, facteurs alimentaires, tabac, alcool, consommation de
médicaments courants,…
• Prévalence de l’exposition faible et concentrée
• Cohorte exposée issue d’un groupe de sujets particulièrement exposé (Ex: individus
d’un groupe professionnel)
• groupe de référence interne ou externe (souvent la population générale)
• Ex : expositions professionnelles

IV. Mise en place d’une enquête exposé‐non exposé
• Constitution de la cohorte
• Identification de la population source
• Critères d’inclusion
• Suivi et recueil de l’information
• Modalités de suivi
• Mesure de l’exposition
• Mesure des critères de jugements
• Mesure des facteurs de confusion
• Suivi, perdus de vue et biais dans une cohorte

Constitution de la cohorte : population source
• Critères pour choisir la population source
• Facilité de recueil des informations (ex : cohorte captive, médecine du travail)
• Motivation des sujets (ex : médecins, infirmières, adhérents d’une mutuelle)
• Exemples de population source
• Population générale (grandes bases de données nationales)
• Patients consultants dans un ou plusieurs centre(s) hospitalier(s)
• Adhérents à une assurance, une mutuelle (Ex: MGEN), un ordre professionnel (Ex :
médecins britanniques pour l’étude tabac et cancer du poumon, Doll et Hill
1951‐1954)
• Si l’exposition est rare, la population source devra être importante pour
permettre le recrutement de suffisamment de sujets exposés

Constitution de la cohorte : critères d’inclusion
• Sujets non atteints par la maladie étudiée à l’inclusion
• Sujets pour lesquels on dispose d’une information précise sur l’exposition
• Plusieurs niveaux d’exposition pour l’étude d’une relation dose-effet
• Durée d’exposition suffisante pour la survenue de la maladie
• Sujets pour lesquels la durée de suivi est suffisante
• Eviter les perdus de vue (accès au statut vital indispensable)
• Exclusion de certains individus (étrangers, les sujets difficiles à suivre (travailleurs
intérimaires), …)
• Minimiser la non participation à l’enquête (biais de sélection possible) en
informant et en expliquant la problématique aux individus

Constitution de la cohorte : biais
• Biais de sélection liés au mode de recrutement dans une cohorte fixe (cas prévalents)
• Particulièrement en milieu professionnel ou on sélectionne les sujets les plus
résistants et les moins exposés (Healthy worker effect)
• Biais de sélection lors de la constitution de la cohorte :
• l’échantillon de l’enquête n’est pas représentatif de la population cible*
• le groupe exposé n’est pas comparable au groupe non exposé*
• Biais liés au choix du groupe de référence externe
• Biais de sélection si le groupe exposé pas comparable à la population de référence*
• Biais de classement si la prévalence de l’exposition est élevée dans la population de
référence
* pour les caractéristiques ayant un lien avec la maladie étudiée

Suivi et recueil de l’information
• Recueil de l’information au cours du suivi
• Variables sociodémographiques (sexe, date de naissance, …),
• Exposition
• Statut vital ou statut de la maladie
• Facteurs de confusion potentiels
• Dates de recrutement, date des dernières nouvelles, perdus de vue
• Modalités de suivi
• Suivi identique dans les deux groupes (guides de procédure)
• Durée du suivi dépend du délai d’apparition de la maladie (long pour certains cancers)
• Suivi programmé : convocation, relance, enquêteur ou questionnaire postal
• Veiller à la fiabilité du recueil (formation des enquêteurs, contrôle qualité)
• Minimiser les données manquantes et les perdus de vue (explications, informations, contacts)

• Les études de cohorte permettent la mesure précise de l’exposition (absence
de biais de mémorisation des enquêtes cas-témoin
• Recueil de l’exposition doit être
• Mesuré avec un outil validé, fiable et standardisé (questionnaire, interrogatoire,
appareil de mesure, examen clinique, examens biologiques, prélèvements
environnementaux …)
• Détaillé avec différentes intensité dans les niveaux d’exposition
• Complet avec la date de début, la durée, les changements d’intensité
Recueil de l’exposition

• Critère de jugement : mortalité, morbidité, qualité de vie
• Recueil du critère de jugement doit être
• Mesuré avec un outil validé et fiable (examens biologiques, interview avec un
questionnaire validé, CépiDC INSERM)
• Standardisé et identique pour les exposés et non exposés
• Effectué à l’aveugle du groupe d’exposition (si pas d’outil objectif)
• Daté pendant le suivi pour vérifier la chronologie E-M, estimer la durée d’apparition
de la maladie et étudier l’évolution de la maladie
Recueil du critère de jugement

Mortalité
(+) standardisé, accessible, exhaustif
(+) diagnostic indépendant des expositions
(+) valeurs de référence connues en population
générale
(-) certaines causes mal classées
(-) non adapté aux pathologies non létales
(-) ne permet pas toujours d’évaluer le risque
de survenue de la maladie ou la qualité du
système de soin
Morbidité (état de santé)
(+) interprétation plus facile pour évaluer le
risque de survenue d’une maladie
(-) moins standardisé, moins accessible et valeurs
de référence pas toujours connues en
population générale
(-) Risque de biais différentiels selon l’exposition
Recueil du critère de jugement
Qualité de vie
• Dépend des thématiques
• Existence de questionnaires validés

Suivi, perdus de vue et biais
• Le suivi de patients dans le temps engendre des individus perdus de vue
• Perdus de vue : personnes dont le suivi est interrompu pour différentes raisons
(déménagement, changement de médecin, état de santé qui s’améliore, …)
état de santé non déterminé à la fin de l’étude
• Biais de sélection si le fait d’être perdu de vue est lié à l’exposition ou à la maladie
Ex : cohorte professionnelle avec une mauvaise tolérance à l’exposition
les individus fortement exposés sont plus souvent perdus de vue
(pré‐retraite, reclassement, licenciement, …)
• Limiter le nombre de perdus de vue :
• % de perdus de vue : critère de qualité d’une étude de cohorte
• Suivi exhaustif des exposés et des non‐exposés jusqu’à la fin de l’étude
• Recherches complémentaires pour connaître le devenir des perdus de vue

V. Avantages et limites des études de cohorte
• Avantages
• Adaptés quand l’exposition est rare
• Permettent d’examiner les conséquences multiples d’une même
exposition
• Permettent d’établir la séquence chronologique exposition‐maladie
• Recueil prospectif limite les biais de mesure de l’exposition et de la
maladie
• Estimation de l’incidence de la maladie dans les groupes exposé et
non‐exposé
• Niveau de preuve supérieur à celui des enquêtes cas-témoins

Avantages et limites des études de cohorte
• Limites
• Non adaptée aux maladies rares ou à un long délai d’apparition
• Prospectives : longues et couteuses
• Rétrospectives : biais possibles, nécessitent de disposer des informations
appropriés
• Validité des résultats à discuter en fonction des difficultés du suivi :
perdus de vue, changement des expositions au cours du temps,
modification des critères diagnostiques

Pour approfondir !
STROBE stands for an international, collaborative initiative of epidemiologists,
methodologists, statisticians, researchers and journal editors involved in the
conduct and dissemination of observational studies, with the common aim of
STrengthening the Reporting of OBservational studies in Epidemiology.
http://www.strobe-statement.org/
http://www.strobe-statement.org/index.php?id=available-checklists

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
3. Enquête cas-témoins

3. Enquête cas-témoins
I. Définition d’une enquête cas-témoins
II. Méthodologie générale
• Recueil de données, mode de recrutement des sujets , choix des témoins
III. Recueil des informations
• Réalisation pratique
• Mesure de l’exposition et de la maladie
IV. Avantages et limites

I. Définition d’une enquête cas-témoins
• Objectif : comparer la répartition (fréquence) d’une exposition entre deux
groupes appelés ″cas″ et ″témoins″
• Le facteur à expliquer appelé ″maladie″
• Etat de santé, évènement de santé, pathologie, …
• Constitution de deux groupes
• Cas qui présentent l’évènement de santé
• Témoins qui ne présentent pas l’évènement de santé
• Mesure de ″l’exposition″ à un facteur donné antérieure à la maladie
• Plusieurs autres facteurs explicatifs possibles
• Facteurs de risque
• Facteurs protecteurs
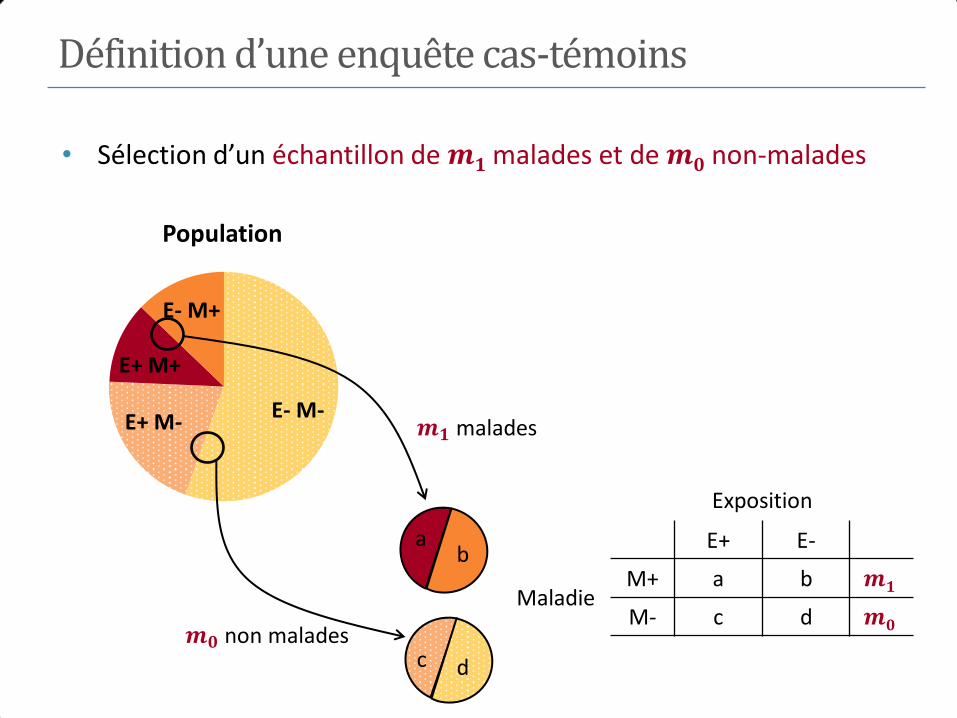
E- M- E+ M-
E+ M+
E- M+
Population
Définition d’une enquête cas-témoins
• Sélection d’un échantillon de 𝒎𝟏 malades et de 𝒎𝟎 non-malades
Exposition
E+ E-
Maladie M+ a b 𝒎𝟏
M- c d 𝒎𝟎
a b
d c
𝒎𝟏 malades
𝒎𝟎 non malades

Exemple d’enquêtes cas-témoins
• Question précise ou hypothèse à tester
• Ex : les femmes atteintes de cancer du sein ont-elles plus antécédents de prise
d'oestroprogestatifs que les autres (indemnes de cette maladie)?
• Ex : les enfants leucémiques ont-ils plus souvent que d'autres (non leucemiques)
une mère qui a reçu une irradiation pendant sa grossesse ?
• Etude exploratoire
• Phénomène de sante important non expliqué (urgence)
• Pas d’idée sur la cause possible de la maladie
• Ex : Nombre de cas de cancer du vagin anormalement élevé chez des adolescentes
dans le Massachussetts en 1971
Enquête exploratoire sur 8 cas et 32 témoins
Prise de Distilbène par la mère chez 7 cas sur 8 et jamais chez les témoins

II. Méthodologie générale
• Recueil de l’information toujours rétrospectif !
• Recherche de l’exposition effectué au moment de l’inclusion dans l’étude pour
les cas et les témoins
• Possible uniquement sur les patients vivant au moment de l’étude ou si
l’information peut être donnée par l’entourage ou par un dossier médical
• Risque de biais de classement (différentiel ou non)

Mode de recrutement
• Inclusion des cas (malades)
• Cas prévalents : nouveaux et anciens malades accessibles au moment de l’inclusion
• Ne tiens pas compte de l’ancienneté du diagnostic
• Risque de biais de sélection : survie sélective
prise en compte des ″vieux″ cas : plus résistants et moins exposés
• Biais de classement (si modification de l’exposition et des comportements entre le
diagnostic de la maladie et le début de l’étude)
• Cas incidents : uniquement les nouveaux malades
• Contrôle de la définition et du diagnostic de la maladie
• Limite le biais de survie sélective et le biais de classement
• Période de recrutement plus longue (nécessite un tau d’incidence élevé)
• Plus de sites participants (hétérogénéité possible)
• Inclusion des témoins (non malades) Issus de la même population que les cas

Choix des témoins
• Témoins représentatifs de la population dont sont issus les cas (comparable aux cas
en tous points sauf pour l’exposition et la maladie)
• Effectifs équilibré (1 cas pour 1 témoin) ou déséquilibré (1 cas pour 2 ou 4 témoins)
Origine des cas Sélection des témoins
Population générale (Registres, dépistage, déclaration obligatoire)
Population générale
Milieu hospitalier (hôpitaux, cliniques)
Milieu hospitalier (même hôpital)
Malades d’une cohorte (nested case control study)
Non malade de la même cohorte

Sélection des témoins
• Témoins en population générale
• Utilisation d’une base de sondage :
• Liste de logement, listes électorales, certificats d’immatriculation, fichier de
l’assurance maladie, appels au hasard de numéros de téléphone
• Témoins hospitaliers
• Issus du même établissement que les cas
• Hospitalisés pour une pathologie sans lien avec la maladie ou l’exposition étudiées
• Exclure les maladies liés à l’exposition étudiée
• Service où le recrutement est comparable à celui des cas (limiter les biais de sélection)
• Considérer plusieurs services pour avoir plusieurs pathologie représentées (plusieurs groupes témoins possibles)

Sélection des témoins
• Sélection des témoins peut être
• Aléatoire : chaque sujet a une chance identique d‘être tiré au sort
• Systématique : tous les 𝑘𝑖è𝑚𝑒𝑠 individus de la liste après tirage au sort du premier
• Apparié : à chaque cas est associé par tirage au sort des témoins répondant a
certains critères identiques (Ex : âge, sexe, CSP)
• Stratifié : tirage au sort des témoins dans des sous groupes ou strates (Ex: région,
ville) de la population cible (appariement par classe)
Appariement et stratification visent à équilibrer la répartition de
certains facteurs de confusion dans le groupe des cas et des témoins
• Possible de restreindre la population cible pour avoir des cas et des témoins
suffisamment exposés et homogènes (même âge, sexe, région, …)
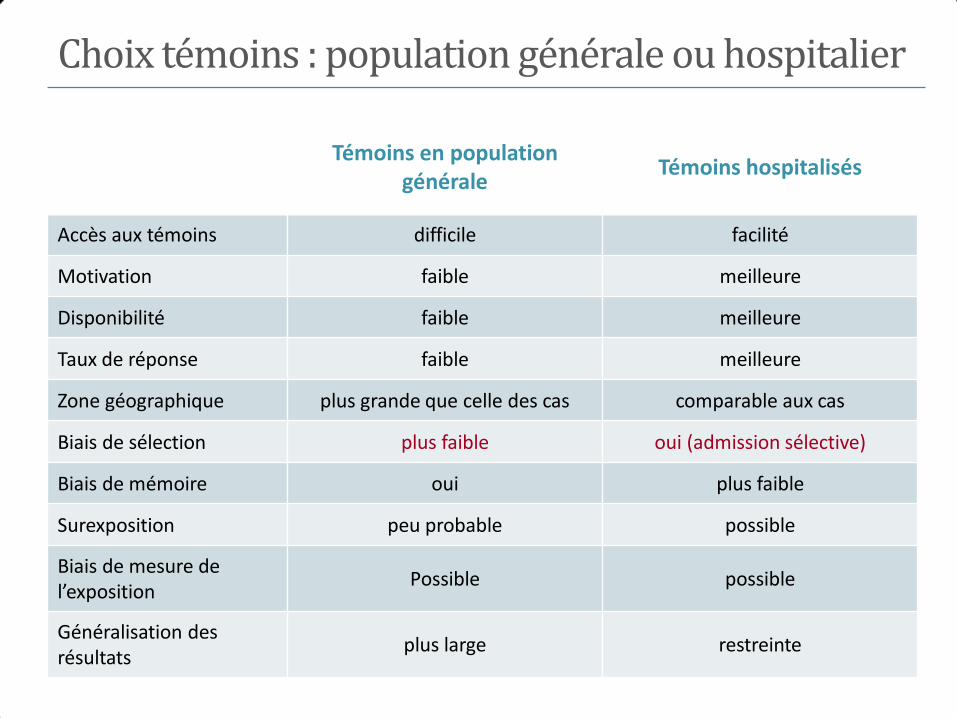
Choix témoins : population générale ou hospitalier
Témoins en population générale
Témoins hospitalisés
Accès aux témoins difficile facilité
Motivation faible meilleure
Disponibilité faible meilleure
Taux de réponse faible meilleure
Zone géographique plus grande que celle des cas comparable aux cas
Biais de sélection plus faible oui (admission sélective)
Biais de mémoire oui plus faible
Surexposition peu probable possible
Biais de mesure de l’exposition
Possible possible
Généralisation des résultats
plus large restreinte

Sélection des témoins : exemple de biais
• Enquête cas- témoins appariée : cancer de la vessie et consommation de cigarette
• Le tabac est associé aux maladies cardiovasculaires
L’appariement sur un témoin atteint d’une maladie cardiovasculaire
revient à apparier sur l’exposition
• L’association disparait par un mauvais choix du groupe témoins
Odds ratio
Paires dont le témoins à une maladie cardiovasculaire
Autres paires Nombre de cigarettes
Non fumeur 1 1
< 20 1,48 (p > 0,05) 3,26 (p <0,01)
20 – 39 1,28 (p > 0,05) 4,41 (p <0,01)
≥ 40 0,7 (p > 0,05) 6,92 (p <0,01)

Sélection des témoins : exemple de biais
• Enquête cas- témoins appariée : facteurs de risque d’une grossesse extra-utérine (GEU)
• Cas : femmes traitées pour une GEU dans plusieurs maternités (M = 903)
• Témoins : femmes ayant accouchée juste après dans la même maternité (N = 1527)
• Pb : certains témoins ont déjà eu des GEU (connaissent les facteurs de risques)
• Pb : les témoins ont tous choisi de mener leur grossesse à terme (couple "stable")
• Restriction aux femmes vivant maritalement et sans contraception
M = 903 M’ = 570 (63%)
N = 1527 N’ = 1385 (90,7%)

III. Recueil des informations
• Qualités d'un outil de recueil
• Validité : capacité a mesurer ce qu’il est censé mesurer
• Reproductibilité : les mêmes réponses doivent être obtenues quand on soumet
le questionnaire plusieurs fois a la même personne dans les mêmes
circonstances
• Concordance : les mêmes réponses doivent être obtenues quand deux
enquêteurs différents soumettent le questionnaire à la même personne
• Acceptabilité par le patient et facilité de réalisation du recueil
• Informations, explications et relance des sujets pour éviter la non
participation et les données manquantes

Mesure de l’exposition
• Toujours rétrospectif et obtenue à partir d’archives (dossiers médicaux…),
interview (direct ou téléphonique), auto-questionnaire postal
• Risque de biais de classement (notamment différentielle) liées au recueil
d’informations anciennes (biais de mémorisation)
• Pour éviter les biais de classement
• Utiliser des informations objectives (marqueurs biologiques, Ex : l’HbA1c
pour l’exposition au diabète)
• Formation des enquêteurs
• Standardisation et contrôle de l’outil de recueil
• Recueil ″à l’aveugle″ du statut cas ou témoins
• Recueil dans les mêmes conditions pour les cas et les témoins
• Attribuer des cas et des témoins à chaque enquêteur

Mesure de la maladie
• Critères et méthodes de diagnostiques bien définis et standardisés
• Réalisation identique et dans les mêmes conditions pour tous les sujets (cas
et témoins)
• Si possible ″à l’aveugle″ du statut exposé ou non exposé
• Sinon éviter que le diagnostic soit fait à l’occasion d’un examen motivé par
une exposition particulière

IV. Avantages et limites des études cas-témoins
• Avantages
• Adaptées aux maladies rares et à un long délai d’apparition
• Souvent plus courtes et moins couteuses que les cohortes
• Limites
• Pas adaptées aux exposition rares
• Choix des témoins souvent difficile (biais de sélection)
• Recueil rétrospectif de l’exposition (biais de mémorisation)
• Pas d’estimation de la prévalence (nombre de cas fixé), de l’incidence ou
du risque de la maladie (pas de suivi)
• Niveau de preuve inférieur à celui des enquêtes de cohorte

Pour approfondir !
STROBE stands for an international, collaborative initiative of epidemiologists,
methodologists, statisticians, researchers and journal editors involved in the
conduct and dissemination of observational studies, with the common aim of
STrengthening the Reporting of OBservational studies in Epidemiology.
http://www.strobe-statement.org/
http://www.strobe-statement.org/index.php?id=available-checklists

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
4. Mesures de risques

4. Mesures de risques
I. Prévalence
II. Taux d’incidence
• Personnes-temps
• Enquêtes de cohorte
• Enquêtes transversale répétées
• Données de surveillance épidémiologique
III. Risque de la maladie
• 𝑇𝐼 constant
• 𝑇𝐼 variables
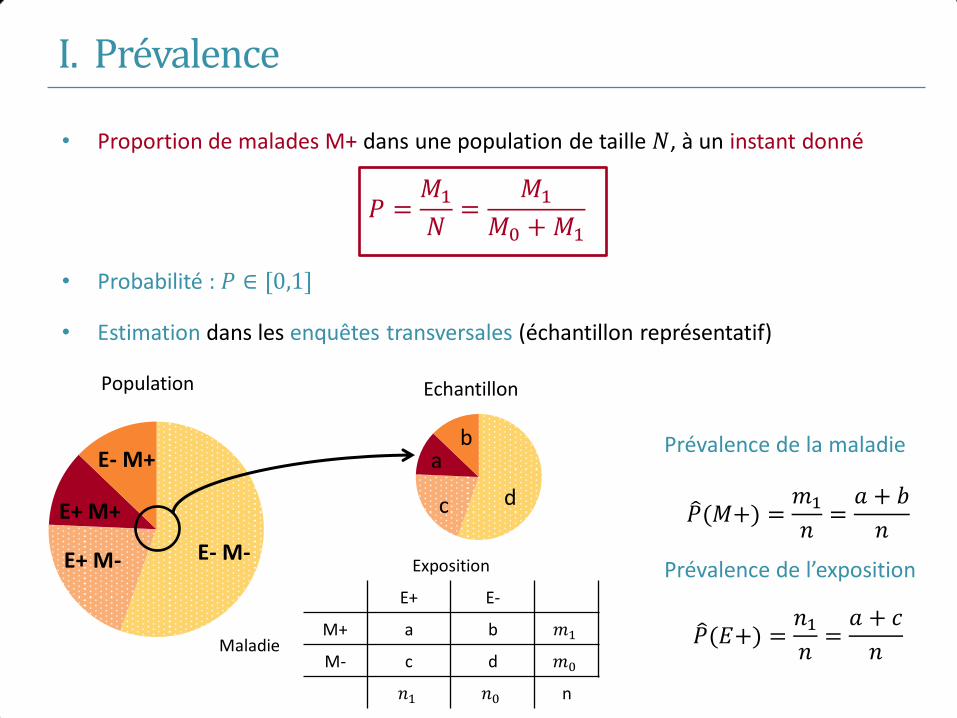
I. Prévalence
• Proportion de malades M+ dans une population de taille 𝑁, à un instant donné
𝑃 =𝑀1
𝑁=
𝑀1
𝑀0 + 𝑀1
• Probabilité : 𝑃 ∈ [0,1]
• Estimation dans les enquêtes transversales (échantillon représentatif)
E- M- E+ M-
E+ M+
E- M+
Population
Exposition
E+ E-
Maladie M+ a b 𝑚1
M- c d 𝑚0
𝑛1 𝑛0 n
d c
a b
Echantillon
Prévalence de la maladie
𝑃 (𝑀+) =𝑚1
𝑛=
𝑎 + 𝑏
𝑛
Prévalence de l’exposition
𝑃 (𝐸+) =𝑛1
𝑛=
𝑎 + 𝑐
𝑛

Prévalence
• Prévalence de la maladie 𝑃(𝑀+) =𝑀1
𝑁=
𝑀1
𝑀0+𝑀1
• Estimation de la prévalence dans un échantillon représentatif 𝑃 =𝑚1
𝑛
• Intervalle de confiance de niveau
𝐼𝐶𝛼 𝑃 = 𝑃𝑖𝑛𝑓 ; 𝑃𝑠𝑢𝑝 = 𝑃 − 𝑧𝛼
2𝑉𝑎𝑟 𝑃 ; 𝑃 + 𝑧𝛼
2𝑉𝑎𝑟 𝑃 avec 𝑉𝑎𝑟 𝑃 =
𝑃 1−𝑃
𝑛
Conditions d’applications
• approximation de la loi Normale par la loi Binomiale : 𝐵(𝑛, 𝑝)𝑛→∞
𝑁 𝑛𝑝, 𝑛𝑝(1 − 𝑝)
• en pratique, 𝑛𝑃𝑖𝑛𝑓 ≥ 5, 𝑛𝑃𝑠𝑢𝑝 ≥ 5, 𝑛𝑄𝑖𝑛𝑓 ≥ 5, 𝑛𝑄𝑠𝑢𝑝 ≥ 5 (𝑄 = 1 − 𝑃)

Prévalence : exemple
• Echantillon de 100 travailleurs d’une usine
• Estimation de la prévalence 𝑃 =𝑚1
𝑛=
20
100= 0.2
• Intervalle de confiance à 95%
𝐼𝐶0.05 𝑃 = 0.2 ± 1.960. 2 × (1 − 0.8)
100 = 0.12 ; 0.28
• Conditions d’applications :
• 100 × 0.12 = 12 ≥ 5; 100 × 0.28 = 28
• 100 × 0,88 = 88 ≥ 5; 100 × 0,72 = 72
Cancer M+ 20
M- 80
100

Prévalence
• Pas toujours un bon indicateur :
• dépend de la durée de la maladie
durée augmente prévalence augmente
• dépend de la vitesse d’apparition des nouveaux cas de la maladie
vitesse augmente prévalence augmente
• Ex : prévalence d’une maladie chronique et d’une infection aigue
• Ex : augmentation de la prévalence lié à des améliorations de santé
• Photographie à un moment donné : introduction d’un nouvel indicateur
Taux d’incidence

II. Taux d’incidence
• Taux d’incidence représente la vitesse d’apparition de nouveaux (vitesse moyenne)
𝑇𝐼 =𝐼
𝑃𝑇=
𝑁𝑏𝑟𝑒 𝑑𝑒 𝑛𝑜𝑢𝑣𝑒𝑎𝑢𝑥 𝑐𝑎𝑠 𝑑𝑒 𝑙𝑎 𝑚𝑎𝑙𝑎𝑑𝑖𝑒
𝑁𝑏𝑟𝑒 𝑑𝑒 "𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑡𝑒𝑚𝑝𝑠"
• 𝑃𝑇 est la somme des temps d’exposition de chaque sujet pendant la période de suivi
• Ex: 20 sujets suivis pendant 2 ans correspondent à 40 personnes-année
• Unité du taux d’incidence : nombre de nouveaux cas par "𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑡𝑒𝑚𝑝𝑠"
• Intervalle de confiance de niveau
𝐼𝐶𝛼 𝑇𝐼 = 𝑇𝐼𝑖𝑛𝑓 ; 𝑇𝐼𝑠𝑢𝑝 = 𝑇𝐼 − 𝑧𝛼
2𝑉𝑎𝑟 𝑇𝐼 ; 𝑇𝐼 + 𝑧𝛼
2𝑉𝑎𝑟 𝑇𝐼
avec 𝑉𝑎𝑟 𝑇𝐼 =𝐼
𝑃𝑇2

Taux d’incidence : personnes-temps
• Sujet à risque : sujet non malade susceptible de devenir malade
• "𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑡𝑒𝑚𝑝𝑠" d’un sujet à risque
• Temps d’exposition = durée pendant laquelle un sujet peut être enregistré comme cas s’il
développe la maladie étudiée
• Le nombre de "𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑡𝑒𝑚𝑝𝑠" est spécifique à chaque individu et dépend de
• la date de début du suivi : 𝑡0𝑖
• la date de fin du suivi : 𝑡𝑓𝑖
𝑃𝑇𝑖 = ∆𝑡𝑖 = 𝑡0𝑖 − 𝑡𝑓𝑖
• La date de fin de suivi peut être due à
• La survenue de la maladie M
• La censure à droite
• Exclu-vivant : fin de l’étude et du suivi
• Perdu de vue (déménagement, décès, arrêt volontaire du suivi, …)

Taux d’incidence : estimation
• Estimation du taux d’incidence
a. Les enquêtes de cohorte
population fermée et suivi individuel des sujets
a. Les enquêtes transversales répétées
population fermée mais dates d’évènement inconnues
a. Les données de surveillance épidémiologique
population ouverte et données groupées

Taux d’incidence : enquête de cohorte
a) Taux d’incidence à partir d’une enquête de cohorte
• On connait les temps d’exposition individuel
∆𝑡𝑖 = 𝑡0𝑖 − 𝑡𝑓𝑖
𝑃𝑇 = ∆𝑡𝑖
𝑛
𝑖=1
• On connait le nombre de nouveau cas 𝐼 sur la période de suivi
• Le taux d’incidence peut être estimé par
𝑇𝐼 =𝐼
∆𝑡𝑖𝑛𝑖=1
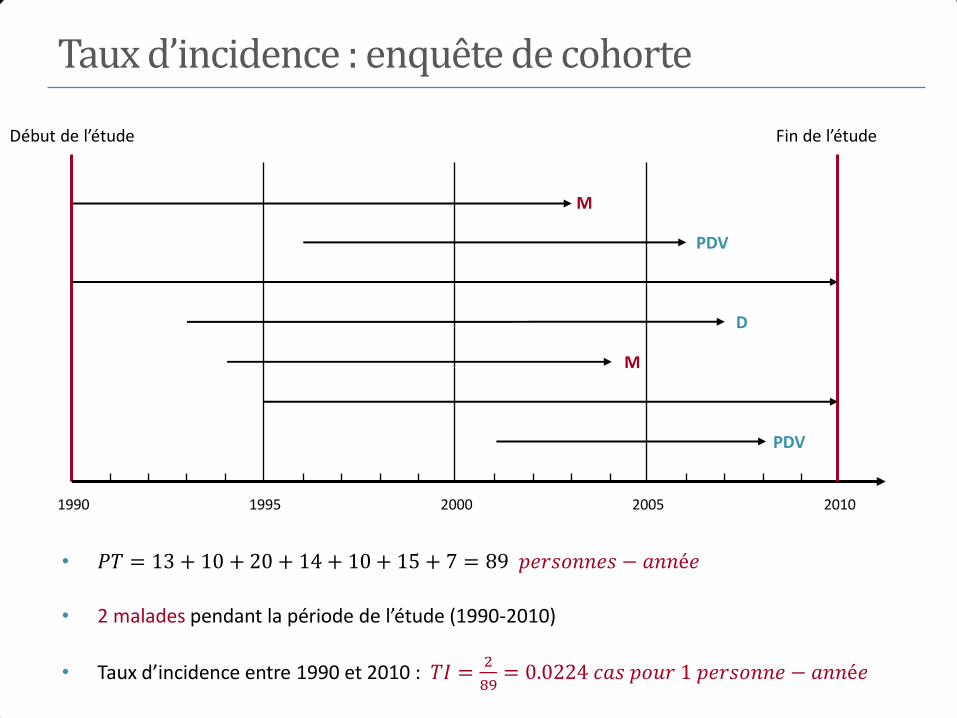
Taux d’incidence : enquête de cohorte
• 𝑃𝑇 = 13 + 10 + 20 + 14 + 10 + 15 + 7 = 89 𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑎𝑛𝑛é𝑒
• 2 malades pendant la période de l’étude (1990-2010)
• Taux d’incidence entre 1990 et 2010 : 𝑇𝐼 =2
89= 0.0224 𝑐𝑎𝑠 𝑝𝑜𝑢𝑟 1 𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒 − 𝑎𝑛𝑛é𝑒
Fin de l’étude Début de l’étude
1990 2010 1995 2000 2005
M
PDV
D
M
PDV

Taux d’incidence : enquête de cohorte
• 𝑃𝑇 = 89 𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑎𝑛𝑛é𝑒
= 89 𝑠𝑢𝑗𝑒𝑡𝑠 𝑠𝑢𝑖𝑣𝑖 𝑝𝑒𝑛𝑑𝑎𝑛𝑡 1 𝑎𝑛𝑛é𝑒
= 1068 𝑠𝑢𝑗𝑒𝑡 𝑠𝑢𝑖𝑣𝑖 𝑝𝑒𝑛𝑑𝑎𝑛𝑡 1 𝑚𝑜𝑖𝑠
= 1 𝑠𝑢𝑗𝑒𝑡 𝑠𝑢𝑖𝑣𝑖 𝑝𝑒𝑛𝑑𝑎𝑛𝑡 89 𝑎𝑛𝑛é𝑒𝑠
= 0.89 𝑠𝑢𝑗𝑒𝑡 𝑠𝑢𝑖𝑣𝑖 𝑝𝑒𝑛𝑑𝑎𝑛𝑡 1 𝑠𝑖è𝑐𝑙𝑒
• 𝑇𝐼 =2
89= 0.0224 𝑐𝑎𝑠 𝑝𝑜𝑢𝑟 1 𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒 − 𝑎𝑛𝑛é𝑒 = 0,0224 𝑐𝑎𝑠/𝑃𝐴
= 22,4 𝑐𝑎𝑠 𝑝𝑜𝑢𝑟 1000 𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑎𝑛𝑛é𝑒
• 𝑇𝐼 =2
1068= 0.0019 𝑐𝑎𝑠 𝑝𝑜𝑢𝑟 1 𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒 − 𝑚𝑜𝑖𝑠 = 0,0019 𝑐𝑎𝑠/𝑃𝑀
= 1.9 𝑐𝑎𝑠 𝑝𝑜𝑢𝑟 1000 𝑝𝑒𝑟𝑠𝑜𝑛𝑛𝑒𝑠 − 𝑚𝑜𝑖𝑠

Taux d’incidence : enquête de cohorte
• Calcul des personnes-temps par intervalle de temps
Nombre de personnes-année par tranche d’âge
• 𝐴𝑔𝑒 ∈ [15 − 20[ → 3 𝑃𝐴
• 𝐴𝑔𝑒 ∈ [20 − 30[ → 10 𝑃𝐴
• 𝐴𝑔𝑒 ∈ [30 − 40[ → 2 𝑃𝐴
• Taux d’incidence en fonction de l’âge (Maladie coronarienne et contraception orale)
1990 2010 1995 2000 2005
17 ans 20 ans 30 ans 32 ans
Age I PA TI × 103
[15 − 20[ 40 9228 4.3
[20 − 30[ 88 8376 10.5
[30 − 40[ 130 7092 18.3
258 24696 10.4
Augmentation du taux d’incidence avec l’âge

Taux d’incidence : enquêtes transversales répétées
b) Taux d’incidence à partir d’une enquête transversale recontactée après une période ∆𝑡
• On dispose de l’informations sur
• Le nombre de sujets 𝑁 inclus dans l’étude et recontactés après une période ∆𝑡
• Le nombre de perdus de vue 𝑃𝐷𝑉 sur la période ∆𝑡
• Le nombre de décès 𝐷 sur la période ∆𝑡
• Le nombre sujets 𝐼 qui ont développés la maladie sur la période ∆𝑡
• Le nombre de personnes-temps peut être estimé par
𝑃𝑇 = 𝑁 × ∆𝑡 − 𝐼 + 𝑃𝐷𝑉 + 𝐷 ×∆𝑡
2= 𝑁 −
𝐼 + 𝑃𝐷𝑉 + 𝐷
2× ∆𝑡
• en supposant que la survenue des décès, des cas et des PDV est uniforme, c’est-à-dire
qu’elle se produit en moyenne au milieu de l’intervalle
• Le taux d’incidence : 𝑇𝐼 =𝐼
𝑃𝑇

Taux d’incidence : données de surveillance
c) Taux d’incidence à partir des données de surveillance épidémiologique
• Population ouverte (Ex: une ville, une région, …), on dispose de l’informations sur
• Une estimation du nombre moyen de sujets 𝑁 de la population sur la période ∆𝑡
obtenu à partir d’un ou plusieurs recensements ou estimations intercensitaires
• Le nombre sujets 𝐼 qui ont développés la maladie sur la période ∆𝑡
obtenu à partir d’un système d’enregistrement des cas (registre, …)
• On suppose un renouvellement constant de la population (autant d’entrées que de sorties :
naissances, décès, immigrations, émigrations)
Le nombre de personnes-temps peut être estimé par 𝑃𝑇 = 𝑁 × ∆𝑡
• En supposant que la survenue de la maladie est uniforme, le taux d’incidence peut être estimé
𝑇𝐼 =𝐼
𝑃𝑇

III. Risque de la maladie
• Le risque de la maladie représente la probabilité de devenir malade au cours d’une
période de temps ∆𝑡
• Soit 𝑋 le temps écoulé avant l’apparition de la maladie
𝑅 ∆𝑡 = 𝑃 𝑋 < 𝑡 = 1 − 𝑃 𝑋 ≥ 𝑡 = 1 − exp − 𝑇𝐼 𝑑𝑡∆𝑡
0
𝑅 ∆𝑡 = 1 − exp (−𝑇𝐼 × ∆𝑡)
• Le risque sur une période ∆𝑡 peut être estimé par
𝑅 ∆𝑡 = 1 − exp −𝑇𝐼 × ∆𝑡
• Hypothèse : 𝑇𝐼 est constant sur la période ∆𝑡

Risque de la maladie
• Intervalle de confiance de niveau de R
𝐼𝐶𝛼 𝑅 = 𝑅𝑖𝑛𝑓 ; 𝑅𝑠𝑢𝑝 = 1 − exp (−𝑇𝐼𝑖𝑛𝑓 × ∆𝑡) ; 1 − exp (−𝑇𝐼𝑠𝑢𝑝 × ∆𝑡)
𝐼𝐶𝛼 𝑇𝐼 = 𝑇𝐼𝑖𝑛𝑓 ; 𝑇𝐼𝑠𝑢𝑝 = 𝑇𝐼 − 𝑧𝛼
2𝑉𝑎𝑟 𝑇𝐼 ; 𝑃 + 𝑧𝛼
2𝑉𝑎𝑟 𝑇𝐼 avec 𝑉𝑎𝑟 𝑇𝐼 =
𝐼
𝑃𝑇2
• Si 𝑇𝐼 × ∆𝑡 est petit alors 𝑅 (∆𝑡) ≈ 𝑇𝐼 × ∆𝑡
• Remarque : concordance des unités
• Si ∆𝑡 en années utiliser un 𝑇𝐼 annuel (cas/PA)
• Si ∆𝑡 en mois utiliser un 𝑇𝐼 mensuel (cas/PM)

Risque de la maladie : exemple
• 1200 sujets inclus dans une étude
• Au bout de 5 ans, on observe 65 cas de maladie, 50 perdus de vue et 10 décès
• Taux d’incidence 𝑇𝐼
𝑇𝐼 =𝐼
𝑃𝑇=
65
1200−50+10+65
2×5
= 0.0114 = 114 𝑐𝑎𝑠 𝑝𝑜𝑢𝑟 10 000 𝑃𝐴
𝐼𝐶95% 𝑇𝐼 = 𝑇𝐼𝑖𝑛𝑓 ; 𝑇𝐼𝑠𝑢𝑝 = 𝑇𝐼 − 1.96𝐼
𝑃𝑇2 ; 𝑇𝐼 + 1.96𝐼
𝑃𝑇2 = 0.086 ; 0.142
• Risque de développer la maladie dans les 5 ans
𝑅 ∆𝑡 = 1 − exp −𝑇𝐼 × ∆𝑡 = 1 − exp −0.0114 × 5 = 5.54 × 10−2 5.54%
𝐼𝐶95% 𝑅 = 1 − exp (−𝑇𝐼𝑖𝑛𝑓) ; 1 − exp (−𝑇𝐼𝑠𝑢𝑝) = 4.2 × 10−2 ; 6.9 × 10−2
• Risque de développer la maladie dans les 3 ans
𝑅 ∆𝑡 = 1 − exp −𝑇𝐼 × ∆𝑡 = 1 − exp −0.0114 × 3 = 3.4 × 10−2 3.4%

Risque de la maladie : TI variables
• Soit 𝑇𝐼𝑖 le taux d’incidence sur [𝑡𝑖−1, 𝑡𝑖[, 𝑇𝐼𝑖 supposé constant sur [𝑡𝑖−1, 𝑡𝑖[
• Le risque sur une période ∆𝑡 est
𝑅 ∆𝑡 = 1 − exp − 𝑇𝐼𝑘 × ∆𝑡𝑘𝑘
• Le risque sur une période ∆𝑡 peut être estimé par
𝑅 ∆𝑡 = 1 − exp − 𝑇𝐼 𝑘 × ∆𝑡𝑘
𝑘
𝑡0
𝑇𝐼1 𝑇𝐼2 𝑇𝐼3 𝑇𝐼4
𝑡5 = 𝑡 𝑡1 𝑡2 𝑡3 𝑡4
𝑇𝐼5
∆𝑡1 ∆𝑡2 ∆𝑡3 ∆𝑡4 ∆𝑡5
∆𝑡 = 𝑡 − 𝑡0
∆𝑡𝑖 = 𝑡𝑖 − 𝑡𝑖−1
∆𝑡 = ∆𝑡𝑘𝑘
Taux d’incidence variables sur la période ∆𝑡

Risque de la maladie : TI variables
• Intervalle de confiance de niveau de A = 𝑇𝐼𝑘 × ∆𝑡𝑘𝑘
𝐼𝐶𝛼 𝐴 = 𝐴𝑖𝑛𝑓 ; 𝐴𝑠𝑢𝑝 = 𝐴 − 𝑧𝛼2
𝑉𝑎𝑟 𝐴 ; 𝐴 + 𝑧𝛼2
𝑉𝑎𝑟 𝐴
𝐴 = 𝑇𝐼 𝑘 × ∆𝑡𝑘𝑘 et 𝑉𝑎𝑟 𝐴 = 𝑉𝑎𝑟 𝑇𝐼𝑘 × ∆𝑡𝑘
2𝑘 =
𝐼𝑘
𝑃𝑇𝑘2 × ∆𝑡𝑘
2𝑘
• Intervalle de confiance de niveau de R
𝐼𝐶𝛼 𝑅 = 𝑅𝑖𝑛𝑓 ; 𝑅𝑠𝑢𝑝 = 1 − exp (−𝐴𝑖𝑛𝑓) ; 1 − exp (−𝐴𝑠𝑢𝑝)
• Si 𝑇𝐼𝑘 × ∆𝑡𝑘 est petit alors 𝑅 (∆𝑡) ≈ 𝑇𝐼𝑘 × ∆𝑡𝑘𝑘
• Remarque : concordance des unités

Risque de la maladie : TI variables
• Risque de décéder pendant une période donnée ?
• Hypothèses : - 𝑇𝐼 constant dans chaque tranche d’âge
- Pas d’effet génération (risque de décéder entre 50 et 55 ans est une
bonne estimation pour un individu de 30 ans)
• Décès par maladie coronarienne : 343 hommes d’une entreprise de sulfure de carbone suivis
pendant 10 ans
Age Décès PA 𝑇𝐼 pour 1000 PA
[25 − 40[ 0 480 0
[40 − 45[ 1 587 1.7
[45 − 50[ 3 680 4.4
[50 − 55[ 5 541 9.2
[55 − 60[ 8 479 16.7
[60 − 65[ 8 356 22.5
[65 − 70[ 4 157 25.5
29 3280 8.8

Risque de la maladie : TI variables
• Risque de décéder entre 25 et 55 ans
𝑅 25 − 55 = 1 − exp − 𝑇𝐼𝑘 × ∆𝑡𝑘𝑘
= 1 − exp − 0 × 15 + 5 × 0.0017 + 0.0044 + 0.0092
= 1 − exp −0.0765 = 0,0736
Le risque de décéder entre 25 et 75 ans est de 7.36%
• Intervalle de confiance
• 𝐴 = 𝑇𝐼 𝑘 × ∆𝑡𝑘𝑘 = 0.0765
• 𝑉𝑎𝑟 𝐴 = 𝐼𝑘
𝑃𝑇𝑘2 × ∆𝑡𝑘
2𝑘 =
0
4802 × 152 +1
5872 × 52 +3
6802 × 52 +5
5412 × 52 = 0.0007
𝐼𝐶95% 𝐴 = 𝐴𝑖𝑛𝑓 ; 𝐴𝑠𝑢𝑝 = 0.0765 ± 1.96 0.0007 = 0.026 ; 0.127
𝐼𝐶95% 𝑅 = 1 − exp (−0.026) ; 1 − exp (−0.127)
𝐼𝐶95% 𝑅 = 0.025 ; 0.119

Taux d’incidence et prévalence
• Relation entre le taux d’incidence et la prévalence
𝑃 =𝑇𝐼 × 𝑑
1 + 𝑇𝐼 × 𝑑
• 𝑑 est la durée moyenne de la maladie
• 𝑇𝐼 le taux d’incidence
• 𝑃 la prévalence
• Hypothèse : population stable
• Si 𝑇𝐼 est petit alors 𝑃 ≈ 𝑇𝐼 × 𝑑

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
5. Mesures d’association

5. Mesures d’association
I. Mesures d’association
• Estimation du risque relatif et de l’odds ratio
• Intervalles de confiance et test d’une association
• Mesures d’association et types d’enquêtes
II. Notion de causalité
• Critères de Bradford Hill
III. Mesures d’impact potentiel
• Intervalles de confiance

• Exposition est t’elle associée à la maladie ?
Mesures d’association : Risque relatif, Odds ratio
• Est-ce une relation causale ?
Critères de causalité, faisceau d’arguments
• Si relation causale, quelle est la proportion de cas attribuable à l’exposition ?
Mesures d’impact potentiel
Exposition
E+ E-
Maladie M+ A B M1
M- C D M0
N1 N0

I. Mesures d’association
• Modèle additif Différence de risque : Δ = 𝑃1 − 𝑃0
• Modèle multiplicatif Risque relatif : 𝑅𝑅 =𝑃1
𝑃0
Odds ratio : 𝑂𝑅 =𝑃1 (1−𝑃1)
𝑃0 (1−𝑃0)
• Absence d’association : Δ = 0 𝑅𝑅 = 1 𝑂𝑅 = 1
𝑃1 = 𝑃 𝑀 + 𝐸 + =𝐴
N1
𝑃0 = 𝑃 𝑀 + 𝐸 − =𝐵
N0
Exposition
E+ E-
Maladie M+ A B M1
M- C D M0
N1 N0

Estimation des mesures d’association
• Différence de risque : Δ = 𝑃 1 − 𝑃 0 =𝑎
𝑛1−𝑏
𝑛0
• Risque relatif : 𝑅𝑅 =𝑃 1
𝑃 0=𝑎𝑛1
𝑏𝑛0
• Odds ratio : 𝑂𝑅 =𝑃 1 (1−𝑃 1)
𝑃 0 (1−𝑃 0)
=𝑎𝑑
𝑏𝑐
𝑃 1 = 𝑃 𝑀 + 𝐸 + =𝑎
n1
𝑃 0 = 𝑃 𝑀 + 𝐸 − =𝑏
n0
Exposition
E+ E-
Maladie M+ a b m1
M- c d m0
n1 n0 n

Exemple 1
Alcool (consommation quotidienne)
≥ 40 cl <40 cl
Hypotrophie fœtale
M+ 20 189 209
M- 392 7372 7764
412 7561
𝑅𝑅 =20/412
189/7561= 1.94 𝑂𝑅 =
20 × 7372
189 × 392= 1.99
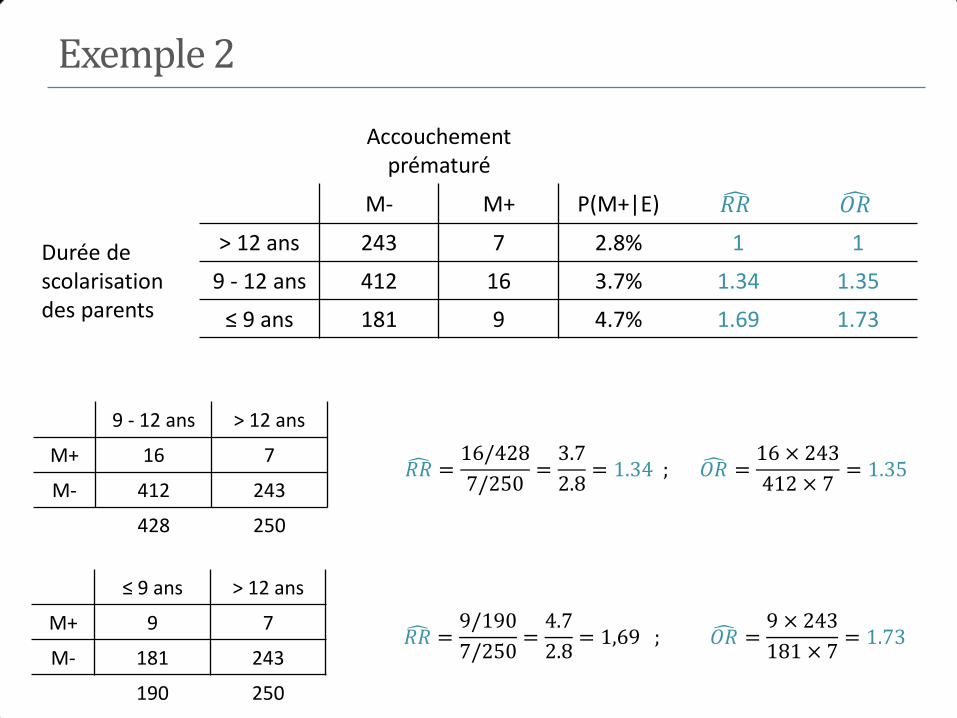
Exemple 2
Accouchement prématuré
M- M+ P(M+|E) 𝑅𝑅 𝑂𝑅
Durée de scolarisation des parents
> 12 ans 243 7 2.8% 1 1
9 - 12 ans 412 16 3.7% 1.34 1.35
≤ 9 ans 181 9 4.7% 1.69 1.73
𝑅𝑅 =16/428
7/250=3.7
2.8= 1.34 ; 𝑂𝑅 =
16 × 243
412 × 7= 1.35
9 - 12 ans > 12 ans
M+ 16 7
M- 412 243
428 250
𝑅𝑅 =9/190
7/250=4.7
2.8= 1,69 ; 𝑂𝑅 =
9 × 243
181 × 7= 1.73
≤ 9 ans > 12 ans
M+ 9 7
M- 181 243
190 250

Intervalles de confiance
• ln(𝑅𝑅 ) et ln(𝑂𝑅 ) convergent vers des lois normales quand 𝑛
𝐼𝐶𝛼( ln(𝑅𝑅) )≔ [𝐵𝑖𝑛𝑓; 𝐵𝑠𝑢𝑝] = ln(𝑅𝑅 ) ± 𝑧𝛼2𝑉𝑎𝑟 ln(𝑅𝑅 ) et 𝑉𝑎𝑟 ln(𝑅𝑅 ) =
𝑐
𝑎×𝑛1+
𝑑
𝑏×𝑛0
𝐼𝐶𝛼( ln(𝑂𝑅) )≔ [𝐿𝑖𝑛𝑓; 𝐿𝑠𝑢𝑝] = ln(𝑂𝑅 ) ± 𝑧𝛼2𝑉𝑎𝑟 ln(𝑂𝑅 ) et 𝑉𝑎𝑟 ln(𝑂𝑅 ) =
1
𝑎+1
𝑏+1
𝑐+1
𝑑
• Intervalle de confiance de niveau pour RR et OR
𝐼𝐶𝛼 𝑅𝑅 ≔ [𝑒𝐵𝑖𝑛𝑓; 𝑒𝐵𝑠𝑢𝑝]
𝐼𝐶𝛼 𝑂𝑅 ≔ [𝑒𝐿𝑖𝑛𝑓; 𝑒𝐿𝑠𝑢𝑝]
𝑅𝑅 =𝑎𝑛1
𝑏𝑛0
𝑂𝑅 =𝑎𝑑
𝑏𝑐
E+ E-
M+ a b m1
M- c d m0
n1 n0 n

Exemple 1 (suite)
Alcool (consommation quotidienne)
≥ 40 cl <40 cl
Hypotrophie fœtale
M+ 20 189 209
M- 392 7372 7764
412 7561
𝑅𝑅 =20/412
189/7561= 1.94 ; ln 𝑅𝑅 = 0.67
𝑉𝑎𝑟 ln 𝑅𝑅 =392
20 × 412+
7372
189 × 7561
= 0.053
𝐼𝐶95% ln 𝑅𝑅 ≔ 0.67 ± 1.96 0.053
0.219 ; 1.121
𝐼𝐶95% 𝑅𝑅 ≔ 𝑒0.219 ; 𝑒1.121
[ 1.25 ; 3.07 ]
𝑂𝑅 =20× 7372
189 × 392= 1.99 ; ln 𝑂𝑅 = 0.69
𝑉𝑎𝑟 ln 𝑂𝑅 =1
20+1
189+1
392+1
7372
= 0.058
𝐼𝐶95% ln 𝑂𝑅 ≔ 0.69 ± 1,96 0.058
0.218 ; 1.162
𝐼𝐶95% 𝑂𝑅 ≔ 𝑒0.218 ; 𝑒1.162
[ 1.24 ; 3.20 ]

Test d’une association : test du Chi-2
• Test d’indépendance du Chi-2 : sous 𝐻0 , 𝐶𝑖𝑗=𝑛𝑖𝑚𝑗
𝑛
Χ𝑎 = (𝑂𝑖𝑗 − 𝐶𝑖𝑗)
2
𝐶𝑖𝑗𝑖=0,1𝑗=0,1
=𝑛(𝑎𝑑 − 𝑏𝑐)2
𝑛1𝑛0𝑚1𝑚0 𝑒𝑡 Χ𝑎 ≡ 𝜒
2(1)
Χ𝑏 =𝑎 −
𝑛1𝑚1𝑛
2
𝑛1𝑛0𝑚1𝑚0𝑛2(𝑛 − 1)
=𝑛
(𝑛 − 1)Χ𝑎 𝑒𝑡 Χ𝑏 ≡ 𝜒
2(1)
• Conditions d’application ∶ 𝐶𝑖𝑗≥ 5 𝑝𝑜𝑢𝑟 𝑡𝑜𝑢𝑡 𝑖 𝑒𝑡 𝑗.
E+ E-
M+ a b m1
M- c d m0
n1 n0 n
Test de l’hypothèse H0 contre H1
𝐻0∶ 𝑃 𝑀 + 𝐸+) = 𝑃 𝑀 + 𝐸−)
⟺𝐻0∶ 𝑅𝑅 = 1 (𝑜𝑢 𝑂𝑅 = 1) 𝐻1: 𝑃 𝑀 + 𝐸+) ≠ 𝑃 𝑀 + 𝐸−)
⟺ 𝐻1∶ 𝑅𝑅 ≠ 1 (𝑜𝑢 𝑂𝑅 ≠ 1)

Test d’une association : test du Chi-2
• Au niveau , 𝐻0 ∶ 𝑅𝑅 = 1 (𝑜𝑢 𝑂𝑅 = 1)
• Rejet de 𝐻0 si Χ𝑎 ≥ 𝜒2𝛼
où 𝜒2𝛼
est le quantile de niveau d’une 𝜒2 1
• 𝑝 = 𝑃 𝜒2 1 > Χ𝑎 p degrés de signification
• Rq : Rejet de 𝐻0 si l’IC du RR ou de l’OR ne contient pas la valeur 1
• Test unilatéral 𝐻0 ∶ 𝑅𝑅 = 1 𝑐𝑜𝑛𝑡𝑟𝑒 𝐻1 ∶ 𝑅𝑅 > 1
• Rejet de 𝐻0 𝑠𝑖 Χ𝑎 ≥ 𝜒22𝛼
et si 𝑅𝑅 > 1
• 𝑝 =1
2𝑃 𝜒2 1 > Χ𝑎 p degrés de signification

Test d’une association : test du Chi-2
• Si 3 ≤ 𝐶𝑖𝑗< 5 : Test du Chi-2 corrigé de Yates
Χ𝑐 = ( 𝑂𝑖𝑗 − 𝐶𝑖𝑗 − 0,5)
2
𝐶𝑖𝑗𝑖=0,1𝑗=0,1
=𝑛 𝑎𝑑 − 𝑏𝑐 −
𝑛2
2
𝑛1𝑛0𝑚1𝑚0 𝑒𝑡 Χ𝑐 ≡ 𝜒
2(1)
• Si 𝐶𝑖𝑗< 3 : Test exact de Fisher
Consiste à calculer les p-values exactes en calculant les
probabilités d’obtenir chacun des tableaux possibles

Exemple 1 (suite)
Alcool (consommation quotidienne)
≥ 40 cl <40 cl
Hypotrophie fœtale
M+ 20 189 209
M- 392 7372 7764
412 7561 7973
• Test de l’association
Χ𝑎 =7973×(20×7372−189×392)2
412×7561×209×7764= 8.49
8.49 = Χ𝑎 > 𝜒20.05= 3.84 Rejet de 𝐻0
𝑃 𝜒2 1 > 8.49 = 𝑝 < 0.01
• Mesures d’association
𝑅𝑅 = 1.94 𝐼𝐶95% 𝑅𝑅 ∶ 1.25 ; 3.07
𝑂𝑅 = 1.99 𝐼𝐶95% 𝑂𝑅 ∶ [ 1.24 ; 3.20 ]

Mesures d’association et type d’enquête
• Risque relatif : 𝑅𝑅 =𝑃 1
𝑃 0=𝑎𝑛1
𝑏𝑛0 ≠𝑃 𝐸1
𝑃 𝐸0
• Odds ratio : 𝑂𝑅 =𝑃 1 (1−𝑃 1)
𝑃 0 (1−𝑃 0)
=𝑎𝑑
𝑏𝑐=
𝑃 𝐸1 (1−𝑃 𝐸1)
𝑃 𝐸0 (1−𝑃 𝐸0)
𝑃 1 = 𝑃 𝑀 + 𝐸 + =𝑎
n1
𝑃 0 = 𝑃 𝑀 + 𝐸 − =𝑏
n0
𝑃 𝐸1 = 𝑃 𝐸 + 𝑀 + =𝑎
𝑚1
𝑃 𝐸0 = 𝑃 𝐸 + 𝑀 − =𝑐
𝑚0
Exposition
E+ E-
Maladie M+ a b m1
M- c d m0
n1 n0 n

Enquête transversale
• Prévalence de M+ chez les E+ et les E- estimables : 𝑃 1 =𝑎
n1 et 𝑃 0 =
𝑏
n0
• Prévalence de E+ chez les M+ et les M- estimables : 𝑃 𝐸1 =𝑎
m1 et 𝑃 𝐸0 =
𝑐
m0
• Risque relatif et odds ratio sont estimables
𝑅𝑅 =𝑃 1
𝑃 0=𝑎𝑛1
𝑏𝑛0
𝑂𝑅 =𝑃 1 (1−𝑃 1)
𝑃 0 (1−𝑃 0)
=
𝑃 𝐸1 (1−𝑃 𝐸1)
𝑃 𝐸0 (1−𝑃 𝐸0)
=𝑎𝑑
𝑏𝑐
Exposition
E+ E-
Maladie M+ a b m1
M- c d m0
n1 n0 n

Enquête exposé – non exposé
• Prévalence de M+ chez les E+ et les E- estimables : 𝑃 1 =𝑎
n1 et 𝑃 0 =
𝑏
n0
• Prévalence de E+ chez les M+ et les M- non estimables
• Risque relatif et odds ratio sont estimables
𝑅𝑅 =𝑃 1
𝑃 0=𝑎𝑛1
𝑏𝑛0
𝑂𝑅 =𝑃 1 (1−𝑃 1)
𝑃 0 (1−𝑃 0)
=𝑎𝑑
𝑏𝑐
Exposition
E+ E-
Maladie M+ a b m1
M- c d m0
n1 n0 n
Fixes

Enquête cas-témoins
• Prévalence de M+ chez les E+ et les E- non estimables
• Prévalence de E+ chez les M+ et les M- estimables : 𝑃 𝐸1 =𝑎
m1 et 𝑃 𝐸0 =
𝑐
m0
• Risque relatif non estimable
• Odds ratio estimable par l’intermédiaire de 𝑃 𝐸1 et 𝑃 𝐸0
𝑂𝑅 =
𝑃 𝐸1 (1 − 𝑃 𝐸1)
𝑃 𝐸0 (1 − 𝑃 𝐸0)
=𝑎𝑑
𝑏𝑐
Exposition
E+ E-
Maladie M+ a b m1
Fixes M- c d m0
n1 n0 n

Choix des mesures d’association
• Risque relatif
• Interprétation simple
• Non estimable dans les enquêtes cas-témoins
• Odds ratio
• Estimable dans tous les types d’enquêtes
• Interprétation : O𝑅 ≈ 𝑅𝑅 quand la maladie est rare dans la population
• Relation entre risque relatif et odds ratio
𝑅𝑅 =𝑂𝑅
1 + 𝑃0(𝑂𝑅 − 1) 𝑒𝑡 𝑂𝑅 =
𝑅𝑅( 1 − 𝑃0)
1 − 𝑃0 × 𝑅𝑅
Si 𝑃0 = 𝑃 𝑀 + 𝐸 − et 𝑃1 = 𝑃 𝑀 + 𝐸 + = 𝑃0 × 𝑅𝑅 petits alors O𝑅 ≈ 𝑅𝑅

II. Notion de causalité
• Enquêtes expérimentales randomisées
• difficultés pratiques
Preuve de causalité
• Enquêtes observationnelles
• Enquête transversale, cas-témoins, cohorte
• Souvent les seules possibles
• Pas d’interprétation causale
Présomption de causalité

Critères de présomption causale de Bradford Hill
Critères internes à l’étude
1. Force de l'association
2. Relation dose- effet
3. Pas d'ambiguïté sur la chronologie
4. Spécificité de l'association
Critères internes à l’étude
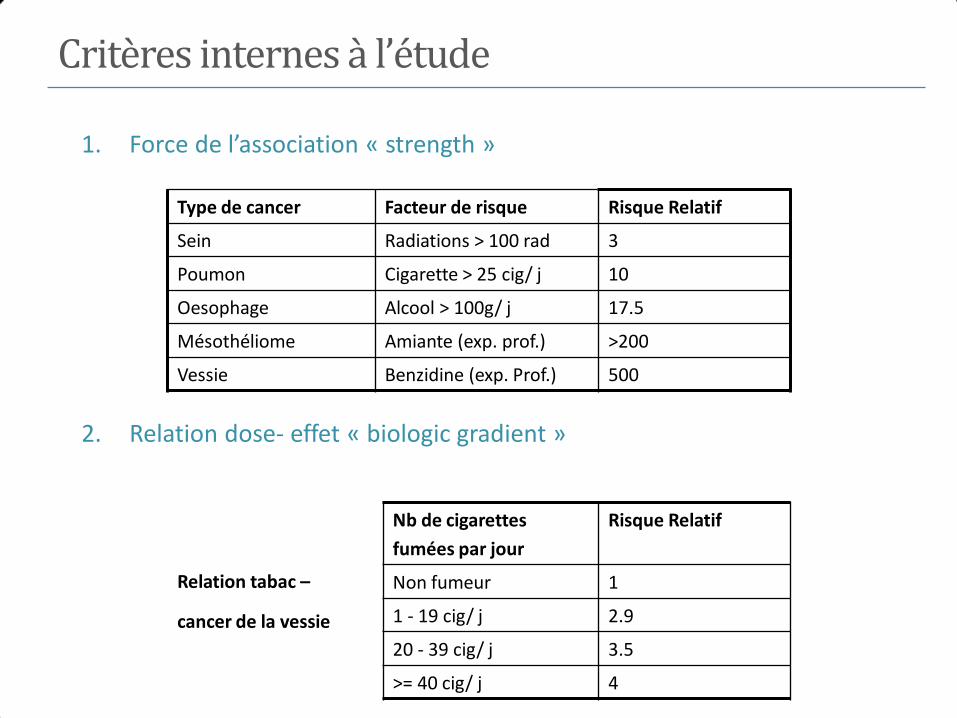
1. Force de l’association « strength »
2. Relation dose- effet « biologic gradient »
Relation tabac –
cancer de la vessie
Nb de cigarettes
fumées par jour
Risque Relatif
Non fumeur 1
1 - 19 cig/ j 2.9
20 - 39 cig/ j 3.5
>= 40 cig/ j 4
Type de cancer Facteur de risque Risque Relatif
Sein Radiations > 100 rad 3
Poumon Cigarette > 25 cig/ j 10
Oesophage Alcool > 100g/ j 17.5
Mésothéliome Amiante (exp. prof.) >200
Vessie Benzidine (exp. Prof.) 500

Critères internes à l’étude
3. Chronologie « temporality » : l’exposition (la cause) doit précéder l’effet
• Problème si enquête transversale ou cas-témoins
• Ex : Lien entre cancer du pancréas et diabète
4. Spécificité des associations : la cause doit conduire à un seul effet
• Critère critiqué
• Par exemple: Tabac associé au cancer du poumon et aux pathologies cardio-vasculaires
• Ex : Exposition au Benzène associée à un type bien particulier de leucémie
Diabète
oui non
Cancer pancréas
oui a b
non c d
Diabète Cancer pancréas
?

Critères de présomption causale de Bradford Hill
Critères externes à l’étude
5. Constance des résultats dans diverses études (reproductibilité)
6. Plausibilité biologique de l'hypothèse
7. Cohérence des résultats avec les hypothèses qui ont conduit à la mise en
œuvre de l’étude (cohérence interne des résultats d’un sous-groupe à
l’autre)

III. Mesures d’impact potentiel
• Exemple : Amiante est la cause de la maladie
• Quelle est la proportion de cas attribuables au l’amiante ?
• Nombre de malade : 𝑀 = 𝑃(𝑀+) × 𝑁
Prévalence de la maladie taille de l’échantillon
• Nombre de malades à cause de l’exposition :
𝑀∗ = 𝑀 − 𝑃 𝑀 + 𝐸−) × 𝑁
prévalence de la maladie chez les non exposés E-

Risque attribuable à l’exposition
• 𝑃𝑀 = 𝑃 𝑀 + 𝑃0 = 𝑃 𝑀 + 𝐸−) 𝑃1 = 𝑃 𝑀 + 𝐸+)
𝑃𝐸 = 𝑃(𝐸+) 𝑅𝑅 =𝑃1
𝑃0
𝑃𝑀 = 𝑃𝐸𝑃1 + 1 − 𝑃𝐸 𝑃0 = 𝑃0𝑃𝐸𝑃1𝑃0− 1 + 𝑃0
• Risque attribuable à une exposition
𝑅𝐴 =𝑀∗
𝑀=𝑃𝑀 − 𝑃0𝑃𝑀
=𝑃𝐸 𝑅𝑅 − 1
𝑃𝐸 𝑅𝑅 − 1 + 1

Exemple
• Risque relatif entre une maladie et l’amiante 𝑅𝑅 = 9.77
• Prévalence de l’amiante dans la population 𝑃𝐸 = 5%
𝑅𝐴 =𝑃𝐸 𝑅𝑅 − 1
𝑃𝐸 𝑅𝑅 − 1 + 1=
0.05 9.77 − 1
0.05 9.77 − 1 + 1= 0.30
30% des cas de la maladie sont attribuables à l’exposition à l’amiante
• Prévalence de l’amiante dans la population 𝑃𝐸 = 10%
𝑅𝐴 =𝑃𝐸 𝑅𝑅 − 1
𝑃𝐸 𝑅𝑅 − 1 + 1=
0.1 9.77 − 1
0.1 9.77 − 1 + 1= 0.47
47% des cas de la maladie sont attribuables à l’exposition à l’amiante

Risque attribuable et type d’enquête
Enquête transversale et enquête de cohorte où 𝑷𝑬 est estimable
𝑅𝐴 =𝑃𝐸 𝑅𝑅 − 1
𝑃𝐸 𝑅𝑅 − 1 + 1
Enquête cas-témoins
𝑅𝑅, 𝑃𝑀 et 𝑃𝐸 non estimables 𝑃𝐸 = 𝑃𝑀𝑃(𝐸 + |𝑀+) + 1 − 𝑃𝑀 𝑃(𝐸 + |𝑀−)
Si la maladie est rare dans la population,
𝑅𝐴 =𝑃𝐸0 𝑂𝑅 − 1
𝑃𝐸0 𝑂𝑅 − 1 + 1
Prévalence de l’exposition
chez les témoins 𝑃 (𝐸 + |𝑀−)

Intervalles de confiance
• ln(1 − 𝑅𝐴 ) converge vers une loi normale quand 𝑛
𝐼𝐶𝛼( ln(1 − 𝑅𝐴) ): = [𝐵𝑖𝑛𝑓; 𝐵𝑠𝑢𝑝] = ln(1 − 𝑅𝐴 ) ± 𝑧𝛼2𝑉𝑎𝑟 ln(1 − 𝑅𝐴 )
• Intervalle de confiance de niveau pour 𝑅𝐴
𝐼𝐶𝛼 𝑅𝐴 := 1 − 𝑒𝐵𝑠𝑢𝑝 ; 1 − 𝑒𝐵𝑖𝑛𝑓
E+ E-
M+ a b m1
M- c d m0
n1 n0 n
𝑅𝐴 =𝑃𝐸 𝑅𝑅 − 1
𝑃𝐸 𝑅𝑅 − 1 + 1

Intervalle de confiance
𝐼𝐶𝛼( ln(1 − 𝑅𝐴) ) ≔ ln(1 − 𝑅𝐴 ) ± 𝑧𝛼2𝑉𝑎𝑟 ln(1 − 𝑅𝐴 )
• Enquête transversale
𝑉𝑎𝑟 ln(1 − 𝑅𝐴 ) =1
𝑛
𝑐 + 𝑅𝐴 (𝑎 + 𝑑)
𝑏
• Enquête cas-témoins
𝑉𝑎𝑟 ln(1 − 𝑅𝐴 ) =𝑎
𝑏 × 𝑚1+
𝑐
𝑑 × 𝑚0
• Enquête de cohorte où 𝑃𝐸 estimable
𝑉𝑎𝑟 ln(1 − 𝑅𝐴 ) = 𝑃𝐸2 1 − 𝑅𝐴
4𝑅𝑅 2
𝑐
𝑎𝑛1+𝑐
𝑏𝑛0

Exemple : enquête transversale
• 𝑉𝑎𝑟 ln(1 − 𝑅𝐴 ) =1
1000
135+0.22 (15+820)
30= 0.0105
• 𝐼𝐶95%( ln(1 − 𝑅𝐴) ) : = ln 1 − 0.22 ± 1.96 0.0105 = −0.444 ;−0.042
• 𝐼𝐶95% 𝑅𝐴 := 1 − 𝑒−0.042; 1 − 𝑒−0.444 = 0.04 ; 0.36
E+ E-
M+ 15 30 15
M- 135 820 955
150 850 1000
𝑃𝐸 =150
1000= 0.15
𝑅𝑅 =15 150
30 850 = 2.83
𝑅𝐴 =0.15 2.83 − 1
0.15 2.83 − 1 + 1= 0.22

Exemple : enquête cas-témoins
• 𝑉𝑎𝑟 ln(1 − 𝑅𝐴 ) =70
130×200+
22
178×200= 0.0033
• 𝐼𝐶95%( ln(1 − 𝑅𝐴) ) : = ln 1 − 0.27 ± 1.96 0.0033 = −0.427 ;−0.202
• 𝐼𝐶95% 𝑅𝐴 := 1 − 𝑒−0.202; 1 − 𝑒−0.427 = [0.18 ; 0.35]
E+ E-
M+ 70 130 200
M- 22 178 200
92 308 400
𝑃𝐸0 =22
200= 0.11
𝑂𝑅 =70 × 178
22 × 130= 4.36
𝑅𝐴 =0.11 4.36−1
0.11 4.36−1 +1= 0.27

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
6. Biais de sélection

6. Biais de sélection
I. Définition
• Biais et paramètre étudié
II. Situations classiques de biais de sélection
• Enquêtes cas-témoins
• Enquête de cohorte
• Healthy worker effect
• Non réponses et refus de participation
III. Limiter les biais de sélection
• Au moment de la planification
• Au moment de l’analyse
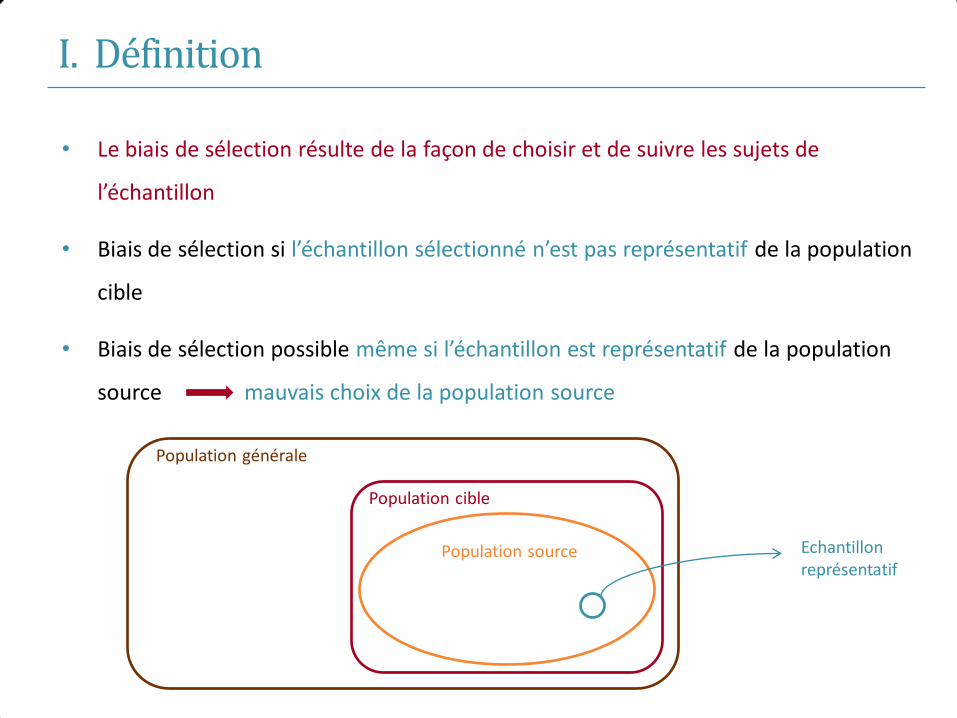
I. Définition
• Le biais de sélection résulte de la façon de choisir et de suivre les sujets de
l’échantillon
• Biais de sélection si l’échantillon sélectionné n’est pas représentatif de la population
cible
• Biais de sélection possible même si l’échantillon est représentatif de la population
source mauvais choix de la population source
Population générale
Population cible
Population source Echantillon représentatif

Biais et paramètre étudié
Ex: Etude de l’association entre le multi partenariat (E+ : >2 partenaires; E- : ≤1 partenaire)
et une MST dans une ville de 500 000 habitants
• Population source = patients consultant gynécos et généralistes de la ville
• On sélectionne plus de M+ (car les malades ont tendance à plus consulter)
• On sélectionne la même proportion de E+ et de E- (parmi les M+ et les M-)
E+ E- 𝑃 =
20000
500000= 0.04
𝑂𝑅 =𝑃1 1−𝑃1
𝑃0 1−𝑃0= 2.43
M+ 10 000 10 000
M- 140 000 340 000
Population cible (𝑁 = 500 000) Population source (𝑁 = 52 000)
• Sélection pas indépendante de la maladie Biais sur l’estimation de la prévalence
• 𝑃1 = 𝑃(𝑀 +/𝐸+) et 𝑃0 = 𝑃(𝑀 +/𝐸−) différentes dans population cible et source
𝑃𝐸1= 𝑃(𝐸 +/𝑀+) et 𝑃𝐸0
= 𝑃(𝐸 +/𝑀−) inchangées dans population cible et source
Pas de biais pour l’estimation de l’odds ratio 𝑐𝑎𝑟 𝑂𝑅 =𝑃𝐸1 1−𝑃𝐸1
𝑃𝐸0 1−𝑃𝐸0
Biais pour l’estimation du RR
E+ E-
𝑃 = 0.077 𝑂𝑅 = 2.43
M+ 2 000 (20%) 2 000 (20%)
M- 14 000 (10%) 34 000 (10%)
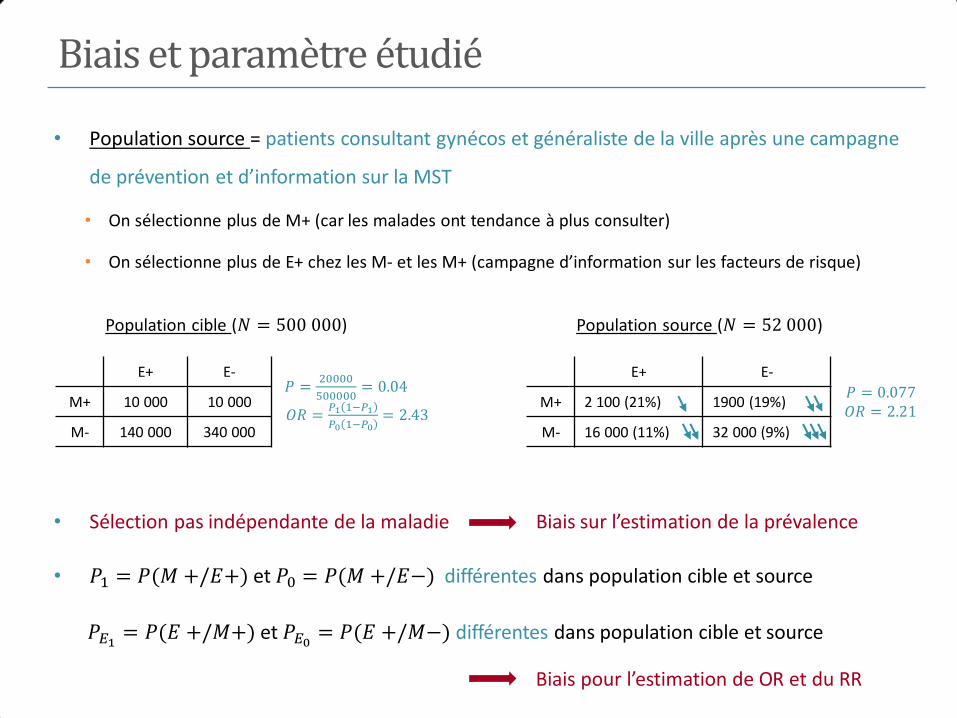
Biais et paramètre étudié
• Population source = patients consultant gynécos et généraliste de la ville après une campagne
de prévention et d’information sur la MST
• On sélectionne plus de M+ (car les malades ont tendance à plus consulter)
• On sélectionne plus de E+ chez les M- et les M+ (campagne d’information sur les facteurs de risque)
E+ E- 𝑃 =
20000
500000= 0.04
𝑂𝑅 =𝑃1 1−𝑃1
𝑃0 1−𝑃0= 2.43
M+ 10 000 10 000
M- 140 000 340 000
Population cible (𝑁 = 500 000) Population source (𝑁 = 52 000)
E+ E-
𝑃 = 0.077 𝑂𝑅 = 2.21
M+ 2 100 (21%) 1900 (19%)
M- 16 000 (11%) 32 000 (9%)
• Sélection pas indépendante de la maladie Biais sur l’estimation de la prévalence
• 𝑃1 = 𝑃(𝑀 +/𝐸+) et 𝑃0 = 𝑃(𝑀 +/𝐸−) différentes dans population cible et source
𝑃𝐸1= 𝑃(𝐸 +/𝑀+) et 𝑃𝐸0
= 𝑃(𝐸 +/𝑀−) différentes dans population cible et source
Biais pour l’estimation de OR et du RR

Biais et paramètre étudié
• Population source = patients consultant gynécos et généraliste de la ville après une campagne
de prévention et d’information sur une MST asymptomatique
• On sélectionne autant de M+ que de M- (car MST asymptomatique)
• On sélectionne plus de E+ chez les M- et les M+ (campagne d’information sur les facteurs de risque)
E+ E- 𝑃 =
20000
500000= 0.04
𝑂𝑅 =𝑃1 1−𝑃1
𝑃0 1−𝑃0= 2.43
M+ 10 000 10 000
M- 140 000 340 000
Population cible (𝑁 = 500 000) Population source (𝑁 = 50 000)
E+ E-
𝑃 = 0.04 𝑂𝑅 = 3
M+ 1200 (12%) 800 (8%)
M- 16 000 (11%) 32 000 (9%)
• Sélection indépendante de la maladie Pas de biais sur l’estimation de la prévalence
• 𝑃1 = 𝑃(𝑀 +/𝐸+) et 𝑃0 = 𝑃(𝑀 +/𝐸−) différentes dans population cible et source
𝑃𝐸1= 𝑃(𝐸 +/𝑀+) et 𝑃𝐸0
= 𝑃(𝐸 +/𝑀−) différentes dans population cible et source
Biais pour l’estimation de OR et du RR

II. Situations classiques de biais de sélection
1. Dans une enquête transversale
• Echantillon non constitué par tirage au sort (Ex : échantillon de volontaire)
2. Dans une enquêtes cas-témoins
• Constitution du groupe "témoin"
• Biais de survie sélective (recrutement de cas prévalent)
3. Dans une enquête de cohorte
• Constitution du groupe "exposé"
• Perdus de vue
4. "Healthy worker effect" dans les enquêtes transversale et de cohorte
5. Refus de participation

Biais de sélection et enquête cas-témoins
• Le recrutement de témoins en milieu hospitalier (souvent impossible de recruter les cas
dans un registre) qui ne sont pas représentatifs de la population cible (biais de Berkson)
• Etude de l’association entre le cancer bronchique et le tabac
• Cas : malades hospitalisés pour un cancer broncho-pulmonaire
• Témoins : malades hospitalisés pour d’autres pathologies pulmonaires ou cardiovasculaires
(souvent liées au tabac) les témoins fument plus que dans la population cible
E+ E-
M+ a b
M- c d
Population cible
E+ E-
M+ a’=a b’=b
M- c’>>c d’<<d
Population source
𝑂𝑅′ =𝑎𝑑′
𝑏𝑐′ <𝑎𝑑
𝑐𝑏= 𝑂𝑅 sous-estimation de l’OR

Biais de sélection et enquête cas-témoins
• Autre exemple de biais de sélection lié aux choix des témoins
• Association entre le cancer des cervicales et un faible niveau socio-économique
• Cas : recrutés dans plusieurs hôpitaux d’une région
• Témoins : recrutés par porte à porte autour des hôpitaux de 9h à 17h
• Cas et témoins sélectionnés par des mécanismes différents
voisinage des hôpitaux pour les témoins et toute la région pour les cas
• De plus, les témoins inclus dans l’étude ont plus de chance d’être sans emploi
les témoins ont plus de chance d’être enrôlé s’ils sont exposés
E+ E-
M+ a b
M- c d
Population cible
E+ E-
M+ a’=a b’=b
M- c’>>c d’<<d
Population source
𝑂𝑅′ =𝑎𝑑′
𝑏𝑐′ <𝑎𝑑
𝑐𝑏= 𝑂𝑅 sous-estimation de l’OR

Biais de sélection et enquête cas-témoins
• Biais liés à une différence de surveillance
• Association entre la thrombose et un contraceptif oral
• Cas : femme ayant une thrombose recrutés dans un hôpital
• Témoins : femme du même âge hospitalisées pour une autre pathologie (non associée)
• Les résultats obtenus donne un 𝑂𝑅 ≈ 10 !!
• Plusieurs études avaient déjà relevé ce résultat les médecins étaient plus vigilants pour
les patients exposés et les admettaient plus facilement à l’hôpital en cas de thrombose ou de
signe suspect surreprésentation des cas malades et exposés
E+ E-
M+ a b
M- c d
Population cible
E+ E-
M+ a’>>a b’=b
M- c’=c d’=d
Population source
𝑂𝑅′ =𝑎𝑑′
𝑏𝑐′ >𝑎𝑑
𝑐𝑏= 𝑂𝑅 sur-estimation de l’OR

Biais de sélection et enquête cas-témoins
• Biais de survie sélective lié à la sélection de cas prévalents dans les enquêtes cas-témoins
• Témoins : représentatifs de la population cible
• Cas : sélection des patients qui sont toujours en vie individus les moins exposés
E+ E-
M+ a b
M- c d
Population cible
E+ E-
M+ a’<<a b’<b
M- c d
Population source
D
Début de l’étude : inclusion des cas vivants
D
D
E-
E-
E-
E+
E+
E+
𝑂𝑅′ =𝑎′𝑑
𝑐𝑏′ <𝑎𝑑
𝑐𝑏= 𝑂𝑅
sous-estimation de l’OR
M+

Biais de sélection et enquête de cohorte
• Biais lié à sélection des exposés et non exposés dans les enquête rétrospectives
• Ex : enquête de cohorte rétrospective sur une exposition à un polluant 15-20 ans avant dans
une usine
• Exposés et non exposés recrutés à partir des dossiers d’embauche
• Les vieux dossiers ont tendance à être plus souvent perdus
• Les dossiers des employés malades sont plus souvent conservés
On sélectionne en majorité les individus exposés qui ont développé la maladie
et moins les individus exposés qui n’ont pas développé la maladie
E+ E-
M+ a b
M- c d
Population cible
E+ E-
M+ a’=a b’<b
M- c’<c d’<d
Population source
𝑂𝑅′ =𝑎′𝑑′
𝑐′𝑏′ >𝑎𝑑
𝑐𝑏= 𝑂𝑅
sur-estimation de l’OR

Biais de sélection et enquête de cohorte
• Biais lié aux perdus de vus dans les enquêtes de cohorte (censure dépendante de M)
• Ex : Les exposés sont plus souvent perdus de vus : les sujets exposés quittent l’entreprise pour se soustraire à
l’exposition (particulièrement lors des premiers signes de la maladie)
• Ex : Sida, asthme, effet du prozac, … Biais d’attrition lié aux sorties d’études et
interruption de traitement
E+ E-
M+ a b
M- c d
Population cible
E+ E-
M+ a’<<<a b’<b
M- c’<<c d’<d
Population source
Début de l’étude
PDV
M
PDV
E-
E-
E-
E+
E+
E+
PDV
M
Fin de l’étude
𝑂𝑅′ =𝑎′𝑑′
𝑐′𝑏′ <𝑎𝑑
𝑐𝑏= 𝑂𝑅
sous-estimation de l’OR

Biais de sélection : "Healthy worker effect"
• Biais du travailleur en bonne santé dans les enquêtes de cohorte et transversales
• Les sujets les plus exposés sont en meilleure santé
• Biais moins important pour les maladies silencieuses
Avant l’emploi Pendant l’emploi
Exposition forte
Exposition moyenne
Exposition légère
Quittent l’entreprise
Personnes en âge de travailler
Restent sans emploi
Excellente santé
Bonne santé
Mauvaise santé
Santé incertaine
Changement de poste
Changement de poste
Changement de poste
Il reste les personnes en bonne santé

Biais de sélection : "Healthy worker effect"
• Ex: mortalité de travailleurs fabriquant du PVC (E+)
• Comparaison à la population générale avec le SMR (standardisation indirecte)
• SMR<1 : mortalité plus faible que dans la population générale (E-)
• SMR>1 : mortalité plus forte que dans la population générale
Cause de décès SMR
Travailleurs actuels Ex-travailleurs
Tous cancers 0.89 1.3
Cancer du poumon 0.5 1.56
Maladie cardiaques 0.63 1.11

Biais de sélection : "Healthy worker effect"
• Ex: enquête transversale pour évaluer l’effet de l’exposition à la peinture automobile
en milieu professionnel et les pathologie pulmonaire
E- E+ Soustraits à l’exposition
Pathologie pulmonaire 5 5 9
Aucune pathologie 46 52 5
Individus ne faisant pas partie de l’échantillon
Il faut faire un suivi des sujets exposés
Enquête de cohorte
E+ E-
M+ a=14 b=5
M- c=57 d=46
Population cible
E+ E-
M+ a’=5 <<a b’=5
M- c’=52 <c d’=46
Population source
𝑂𝑅 = 2.26 𝑂𝑅 = 0.88 < 𝑂𝑅

Refus de participation
• Les non réponses et le refus de participation à une enquête engendre un biais si les
sujets qui refusent de participer sont différents des sujets qui participent.
• Ex: dans une étude sur l’alcoolisme, il y aura un biais de sélection si les sujets
alcooliques de veulent pas participer à l’enquête
• La population de l’étude devient différente de la population cible
• Si la participation est trop faible, on cherche à recruter des participants (volontaires)
• Si l’exposition ou la maladie sont liées à la participation ou non à l’enquête
Certaines catégories peuvent être surreprésentées
Biais d’auto sélection

III. Limiter les biais de sélection
• Au moment de la planification de l’enquête
• Eviter au maximum la non participation des sujets éligibles
• Assurer un bon suivi des sujets inclus dans une cohorte, recontacter les perdus de vue
• Privilégier la sélection de cas incidents dans les enquêtes de cohorte
• Rechercher des populations sources comportant des phénomènes de sélection comparables
pour l’inclusion des cas et des témoins (ou des E+ et des E-)
• Limite importante des enquêtes cas-témoins
• Essayer de choisir plusieurs groupes témoins
• Healthy worker effect : prendre des témoins d’une autre entreprise (sélection comparable)
• Au moment de l’analyse
• Chercher à déterminer la direction et l’importance du biais
• Comparer à des enquêtes indépendantes pour évaluer la reproduction des conclusions

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
7. Biais de classement

7. Biais de classement
I. Biais de classement
II. Biais de classement différentiel
• Exemples
• Situations générant des biais différentiels
III. Biais de classement non différentiel
• Exemples
• Situations générant des biais non différentiels
IV. Sensibilité, spécificité
V. Limiter les biais de classement

I. Biais de classement
• Le biais de classement ou biais d’information est une erreur systématique résultant
d’une observation incorrecte d’un phénomène et conduisant à un mauvais classement
• des sujets malades / non malades
• des sujets exposés / non-exposés
E+ E-
M+ a b
M- c d
Population de taille 𝑁 sans erreur de classement
E+ E-
M+ a’ b’
M- c’ d’
La population est identique dans les deux cas : 𝑎 + 𝑏 + 𝑐 + 𝑑 = 𝑎′ + 𝑏′ + 𝑐′ + 𝑑′
Même population
avec erreur de classement

Biais de classement
• Biais de classement non différentiel
• Les erreurs de classement affectent avec la même probabilité les groupes comparés (E+/E-
ou M+/M-) les erreurs affectent identiquement les groupes
• Erreurs de nature aléatoire et souvent dues à des imprécisions ou à une mauvaise qualité
des instruments de mesure
Perte de puissance
• Biais de classement différentiel
• Les erreurs de classement affectent différemment les groupes comparés
• Erreurs de classement de la maladie sont différentes dans le groupe E+ et E-
• Erreurs de classement de l’exposition sont différentes dans le groupe M+ et M-
Peut créer, renforcer ou diminuer une association

II. Biais de classement différentiel
• Biais de classement différentiel de l’exposition
• Uniquement dans les enquêtes cas-témoins ou transversale
dans les cohorte, le statut M+/M- est inconnu au moment de l’évaluation de l’exposition
• Situation classique: sous évaluation de l’exposition chez les M-
sur évaluation de l’exposition chez les M+
Population sans erreur de classement Même population avec erreur de classement
E+ E-
M+ 9 000 7 000
M- 123 000 346 000
𝑂𝑅 = 3.62
E+ E-
M+ 9 700 6 300
M- 98 400 370 600
𝑂𝑅 = 5.80
20% des E+ sont classés E- chez les M-
10% des E- sont classés E+ chez les M+

Biais de classement différentiel
• Biais de classement différentiel de la maladie
• Uniquement dans les enquêtes de cohorte ou transversale
dans les cas-témoins, le statut E+/E- est inconnu au moment de l’évaluation de la maladie
• Situation classique: sous diagnostic de la maladie chez les E-
sur diagnostic de maladie chez les E+
Population sans erreur de classement Même population avec erreur de classement
E+ E-
M+ 1 000 500
M- 9 000 12 000
𝑂𝑅 = 2.67
E+ E-
M+ 1 900 400
M- 8 100 12 100
𝑂𝑅 = 7.10
20% des M+ sont classés M- chez les E-
10% des M- sont classés M+ chez les E+

Biais de classement différentiel : situations
• Situations susceptibles de générer des biais de classement différentiel
• Biais de subjectivité (ou biais de suspicion) apparaît quand
• La connaissance de l’exposition peut amener à approfondir la recherche de la maladie auprès des
sujets E+ et moins auprès des sujets E-
• La connaissance du diagnostic de la maladie peut amener à approfondir la recherche de l’exposition
auprès des sujets M+ et moins auprès des sujets M-
• Biais d’enquêteur si plusieurs enquêteurs (Ex: un enquêteur pour les M+ et un pour les M-)
• Biais de mémoire (ou biais de rappel) dû au fait qu’un sujet malade
• se souvient davantage de ces expositions passées.
• surestime ou sous-estime (volontairement ou déni) son exposition (Ex: alcool et cirrhose)
• Biais de non-réponses lié au droit des participants à ne pas répondre
Ex: Patients atteints d’une cirrhose (M+) ne veulent pas répondre sur leur consommation d’alcool (E+)
• Biais de suivi lié à des différences de prise en charge entre les E+ et les E-

III. Biais de classement non différentiel
• Biais de classement non différentiel quand les erreurs de classement affectent
identiquement les groupes comparés : E+/E- ou M+/M-
• Situations susceptibles de générer des biais de classement non différentiel
• Imprécisions ou erreurs matérielles
• Mauvaise qualité des instruments de mesures (dossier, questionnaire, évaluation d’experts)
• Erreur de diagnostic de la maladie à l’aveugle (de l’exposition)
• Erreur d’évaluation de l’exposition à l’aveugle (de la maladie)
• Un biais de classement différentiel entraine une perte de puissance
L’estimation de l’𝑂𝑅 ou du 𝑅𝑅 est plus proche de la valeur 1

Biais de classement non différentiel
• Ex : biais de classement non différentiel sur l’exposition
Expositions professionnelles évalués par des experts à l’aveugle (de la maladie)
• Ex : biais de classement non différentiel sur la maladie
Evaluation de la maladie à partir des certificats de décès
• En pratique, les erreurs sont souvent commises dans les deux sens
E+ E-
M+ 70 30
M- 50 50
𝑂𝑅 = 2.33
E+ E-
M+ 56 44
M- 40 60
𝑂𝑅 = 1.91
E+ E-
M+ 70 30
M- 50 50
𝑂𝑅 = 2.33
E+ E-
M+ 56 24
M- 64 56
𝑂𝑅 = 2.04
20% des M+ sont classés M-
20% des E+ sont classés E-

IV. Sensibilité, spécificité
• La qualité d’une méthode de classement peut être mesurée par sa sensibilité et la spécificité
• Evaluation du classement de l’exposition (idem maladie) en connaissant la méthode de référence
• Sensibilité (𝑆𝑒) = proportion de sujet classés E + parmi les sujets E +
• Spécificité (𝑆𝑝) = proportion de sujet E − correctement classés E −
• Absence d’erreur de classement ⟺ 𝑆𝑒 = 𝑆𝑝 = 1
Nouvelle méthode
E + E −
Méth
od
e de
référence
E + a b a+b
E − c d c+d
𝑆𝑒 =#(E +∩E+) #E+
=𝑎
𝑎+𝑏
𝑆𝑝 =#(E −∩E−) #E−
=𝑑
𝑐+𝑑
b est le nombre de faux négatif
c est le nombre de faux positif

Sensibilité, spécificité
• Si la maladie est rare (alors 𝑅𝑅 ≈ 𝑂𝑅) on montre que
• 𝑂𝑅 l’odds ratio obtenu avec la nouvelle méthode de classement
• 𝑂𝑅 l’odds ratio obtenu avec la méthode de référence
• 𝑃𝐸 la probabilité d’être exposé
• Si le marqueur de l’exposition E + est quantitatif (Ex: volume expiratoire maximum par seconde)
et si le diagnostic de l’exposition est fondé sur le fait que E + dépasse un certain seuil 𝐿
Courbe ROC (Receiver Operating Characteristics)
𝑂𝑅 =𝑆𝑒×𝑂𝑅×𝑃𝐸+(1−𝑆𝑝)(1−𝑃𝐸) × (1−𝑆𝑒)𝑃𝐸+𝑆𝑝(1−𝑃𝐸)
𝑆𝑒×𝑃𝐸+(1−𝑆𝑝)(1−𝑃𝐸) × 1−𝑆𝑒 ×𝑂𝑅×𝑃𝐸+𝑆𝑝(1−𝑃𝐸)
Pour comparer les méthodes de classement on trace
(pour chaque méthode) la courbe 𝑆𝑒 en fonction de
1 − 𝑆𝑝 pour plusieurs valeurs de 𝐿

V. Limiter les biais de classement
• Au moment de la planification de l’enquête
• Limiter les erreurs de classement
• Vérification du matériel de mesure
• Evaluation de l’exposition et de l’état de santé par des examens objectifs et reproductibles (définition précises des critères de jugement)
• Questionnaires standardisés, validés et testés
• Eviter que les erreurs soient différentielles
• Choisir des groupes (M+/M- ou E+/E-) dont la coopérativité, la mémorisation, ou la
surveillance épidémiologique sont a priori comparables
• Evaluer l’exposition (ou l’état de santé) à l’aveugle su statut de la maladie (de l’exposition)
• Standardisation des mesures et condition d’interview identiques dans les groupes (M+/M- ou E+/E-)

Limiter les biais de classement
• Pendant l’enquête
• Insister, informer et expliquer pour éviter les non-réponses
• Vérifier le matériel de mesure
• Au moment de l’analyse de l’enquête
• Décrire les caractéristiques des non répondants et les comparer aux autres
• Discuter l’ampleur et la direction des biais de classements éventuels

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
8. Biais et facteurs de confusion

8. Biais et facteurs de confusion
I. Biais de confusion
II. Phénomène d’interaction : Test du Chi-2 d’interaction
III. Méthode d’ajustement de Mantel-Haenszel
• Mesure de risque ajusté sur F
• Test de la mesure de risque ajusté
IV. Définition d’un facteur de confusion
• Facteur de confusion potentiel
• Facteur de confusion : définition
V. Prise en compte d’un facteur de confusion
• Au moment de la planification de l’enquête
• Au moment de l’analyse statistique
• Difficultés pratiques
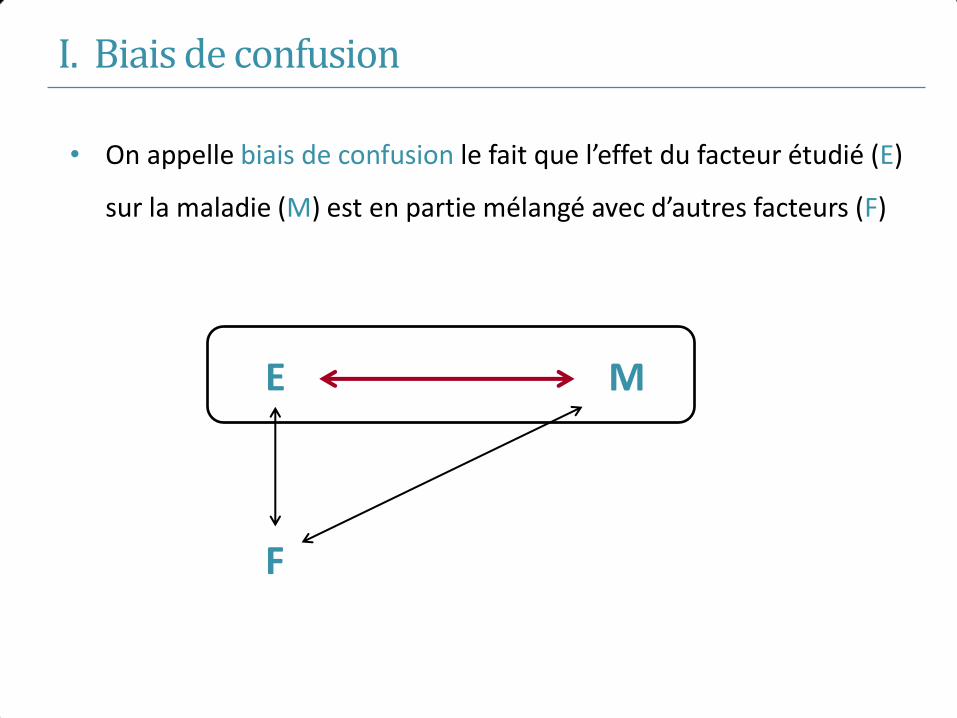
I. Biais de confusion
• On appelle biais de confusion le fait que l’effet du facteur étudié (E)
sur la maladie (M) est en partie mélangé avec d’autres facteurs (F)
M E
F
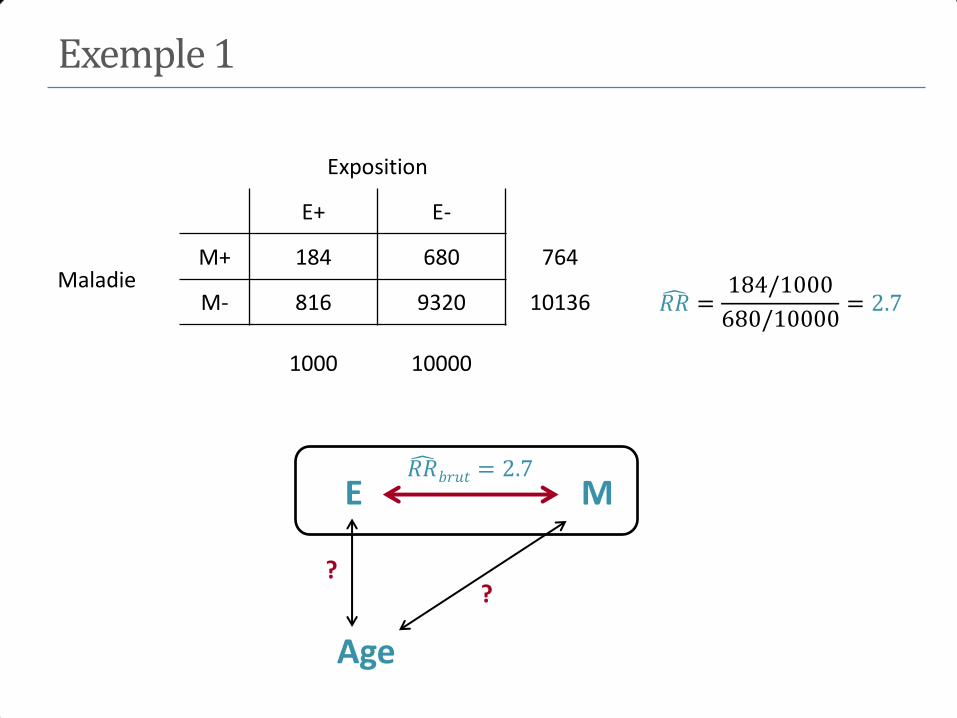
Exemple 1
Exposition
E+ E-
Maladie M+ 184 680 764
M- 816 9320 10136
1000 10000
𝑅𝑅 =184/1000
680/10000= 2.7
M E
Age
? ?
𝑅𝑅 𝑏𝑟𝑢𝑡 = 2.7

Exemple 1
Exposition
E+ E-
Age <25 ans 200 5000 PE+ = 0.038
25-40 ans 300 3000 PE+ = 0.091
>40 ans 500 2000 PE+ = 0.2
1000 10000
Maladie
M+ M-
Age <25 ans 216 4984 PM+ = 0.042
25-40 ans 248 3012 PM+ = 0.076
>40 ans 360 2140 PM+ = 0.144
1000 10000
Relation Age - Exposition
Relation Age – Maladie
L’exposition est
d’autant plus fréquente
que les sujets sont âgés
La maladie est
d’autant plus fréquente
que les sujets sont âgés
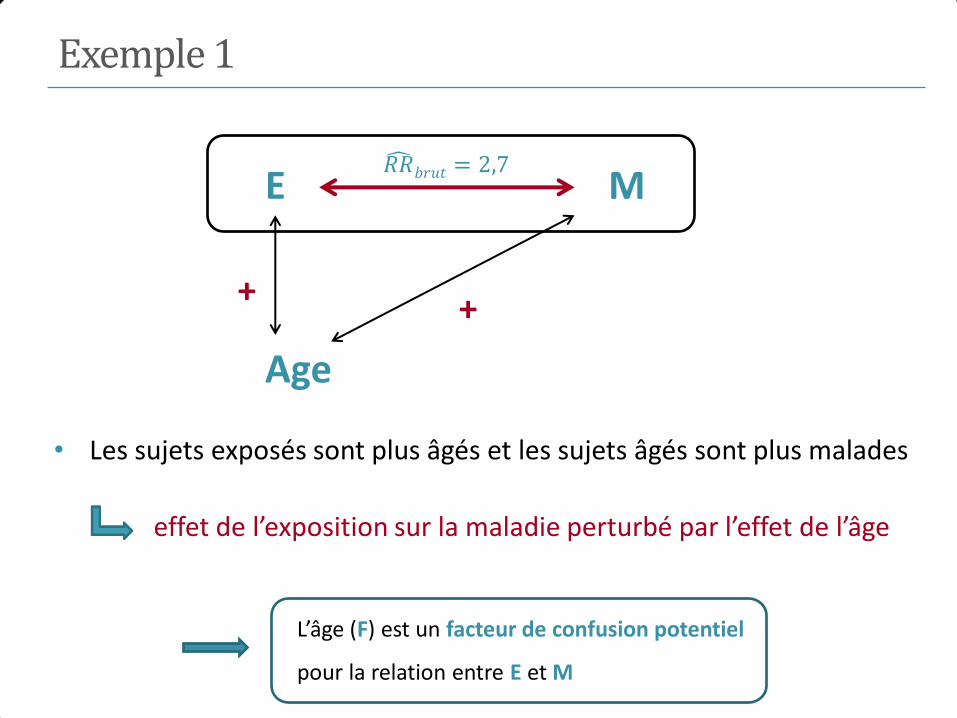
Exemple 1
M E
Age
+ +
• Les sujets exposés sont plus âgés et les sujets âgés sont plus malades
effet de l’exposition sur la maladie perturbé par l’effet de l’âge
𝑅𝑅 𝑏𝑟𝑢𝑡 = 2,7
L’âge (F) est un facteur de confusion potentiel
pour la relation entre E et M
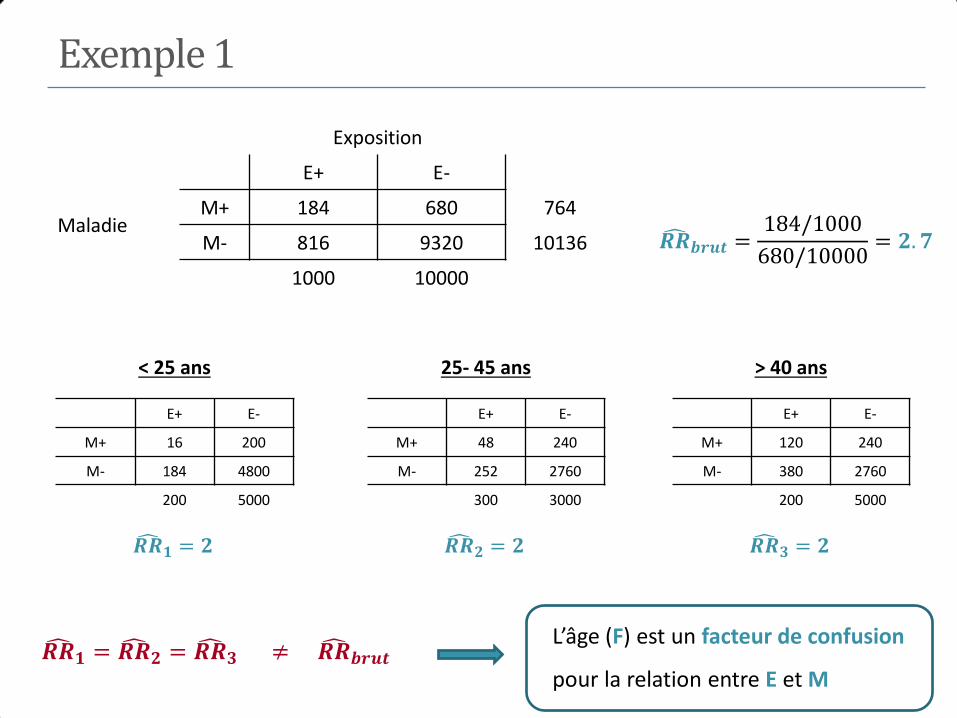
Exemple 1
Exposition
E+ E-
Maladie M+ 184 680 764
M- 816 9320 10136
1000 10000
< 25 ans
E+ E-
M+ 16 200
M- 184 4800
200 5000
𝑹𝑹 𝟏 = 𝟐
𝑹𝑹 𝒃𝒓𝒖𝒕 =184/1000
680/10000= 𝟐. 𝟕
25- 45 ans
E+ E-
M+ 48 240
M- 252 2760
300 3000
𝑹𝑹 𝟐 = 𝟐
> 40 ans
E+ E-
M+ 120 240
M- 380 2760
200 5000
𝑹𝑹 𝟑 = 𝟐
𝑹𝑹 𝟏 = 𝑹𝑹 𝟐 = 𝑹𝑹 𝟑 ≠ 𝑹𝑹 𝒃𝒓𝒖𝒕 L’âge (F) est un facteur de confusion
pour la relation entre E et M

Exemple 2
Sujets inhalant la fumée
Brun Blond
M+ 267 32
M- 134 39
𝑶𝑹 𝟏 = 𝟐.𝟒𝟑
Sujets n’inhalant pas la fumée
Brun Blond
M+ 86 22
M- 119 34
𝑶𝑹 𝟐 = 𝟏.𝟎𝟕
𝑶𝑹 𝟏 ≠ 𝑶𝑹 𝟐 Il y a interaction entre E et F pour la
relation avec M
Exposition : Tabac
Brun : E+ Blond : E-
Maladie M+ 353 54
M- 253 73
𝑶𝑹 𝒃𝒓𝒖𝒕 =353 × 72
253 × 54= 𝟏. 𝟖𝟗
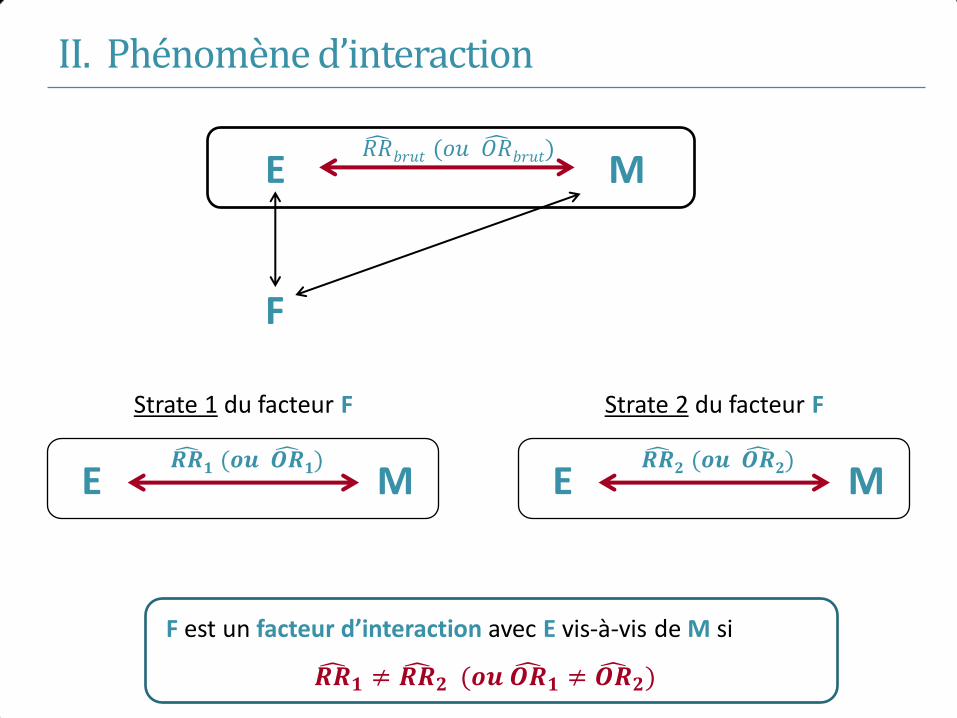
II. Phénomène d’interaction
F est un facteur d’interaction avec E vis-à-vis de M si
𝑹𝑹 𝟏 ≠ 𝑹𝑹 𝟐 (𝒐𝒖 𝑶𝑹 𝟏 ≠ 𝑶𝑹 𝟐)
M E
F
𝑅𝑅 𝑏𝑟𝑢𝑡 (𝑜𝑢 𝑂𝑅 𝑏𝑟𝑢𝑡)
Strate 1 du facteur F
M E 𝑹𝑹 𝟏 (𝒐𝒖 𝑶𝑹
𝟏)
Strate 2 du facteur F
M E 𝑹𝑹 𝟐 (𝒐𝒖 𝑶𝑹
𝟐)

Test du Chi-2 d’interaction
• Soit un facteur F à 𝑘 classes, pour tout i = 1,… , 𝑘
Strate i du facteur F
E+ E-
M+ ai bi m1i
M- ci di m0i
n1i n0i ni
𝑹𝑹 𝒊 =𝑎𝑖/𝑛1𝑖𝑏𝑖/𝑛0𝑖, 𝑽𝒂𝒓 (𝑳𝒏(𝑹𝑹 𝒊 )) =
𝑐𝑖𝑎𝑖 × 𝑛1𝑖+𝑑𝑖𝑏𝑖 × 𝑛0𝑖
𝑶𝑹 𝒊 =𝑎𝑖 × 𝑑𝑖𝑐𝑖 × 𝑏𝑖, 𝑽𝒂𝒓 (𝑳𝒏(𝑶𝑹 𝒊 )) =
1
𝑎𝑖+1
𝑏𝑖+1
𝑐𝑖+1
𝑑𝑖
Test d’égalité des 𝑅𝑅𝑖
𝐻0: 𝑅𝑅1 = ⋯ = 𝑅𝑅𝑘
𝐻1: ∃ 𝑎𝑢 𝑚𝑜𝑖𝑛𝑠 𝑢𝑛𝑒 𝑑𝑖𝑓𝑓é𝑟𝑒𝑛𝑐𝑒
Test d’égalité des 𝑂𝑅𝑖
𝐻0: 𝑂𝑅1 = ⋯ = 𝑂𝑅𝑘
𝐻1: ∃ 𝑎𝑢 𝑚𝑜𝑖𝑛𝑠 𝑢𝑛𝑒 𝑑𝑖𝑓𝑓é𝑟𝑒𝑛𝑐𝑒
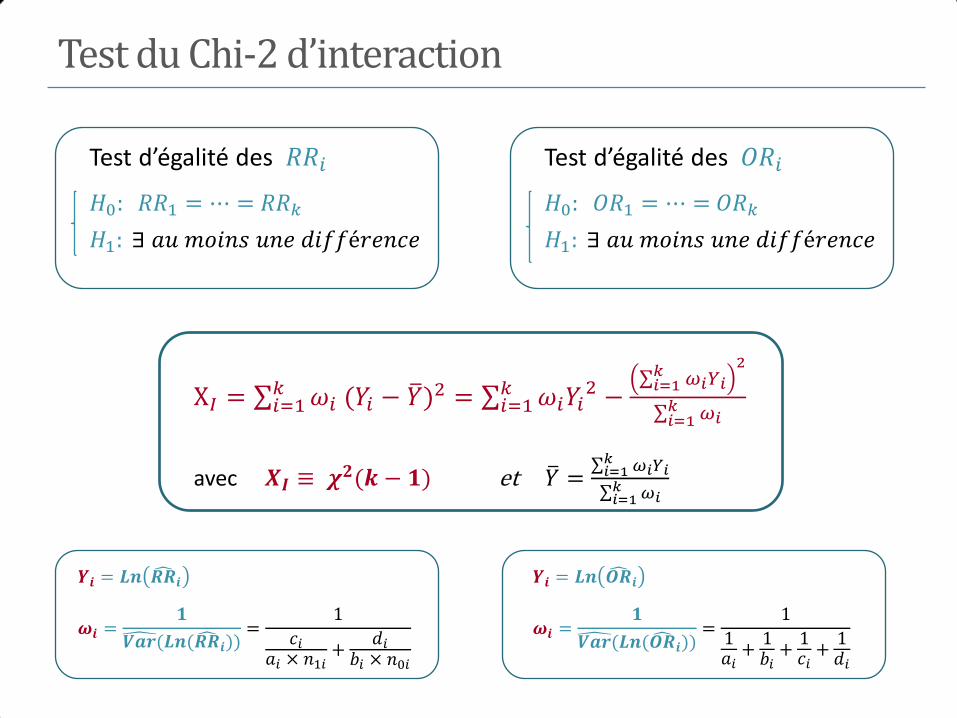
Test du Chi-2 d’interaction
Test d’égalité des 𝑅𝑅𝑖
𝐻0: 𝑅𝑅1 = ⋯ = 𝑅𝑅𝑘
𝐻1: ∃ 𝑎𝑢 𝑚𝑜𝑖𝑛𝑠 𝑢𝑛𝑒 𝑑𝑖𝑓𝑓é𝑟𝑒𝑛𝑐𝑒
Test d’égalité des 𝑂𝑅𝑖
𝐻0: 𝑂𝑅1 = ⋯ = 𝑂𝑅𝑘
𝐻1: ∃ 𝑎𝑢 𝑚𝑜𝑖𝑛𝑠 𝑢𝑛𝑒 𝑑𝑖𝑓𝑓é𝑟𝑒𝑛𝑐𝑒
𝒀𝒊 = 𝑳𝒏 𝑶𝑹 𝒊
𝝎𝒊 =𝟏
𝑽𝒂𝒓 (𝑳𝒏(𝑶𝑹 𝒊))=
1
1𝑎𝑖+1𝑏𝑖+1𝑐𝑖+1𝑑𝑖
𝒀𝒊 = 𝑳𝒏 𝑹𝑹 𝒊
𝝎𝒊 =𝟏
𝑽𝒂𝒓 (𝑳𝒏(𝑹𝑹 𝒊))=
1
𝑐𝑖𝑎𝑖 × 𝑛1𝑖+𝑑𝑖𝑏𝑖 × 𝑛0𝑖
Χ𝐼 = 𝜔𝑖 (𝑌𝑖 − 𝑌 )2𝑘
𝑖=1 = 𝜔𝑖𝑌𝑖2 − 𝜔𝑖𝑘𝑖=1 𝑌𝑖
2
𝜔𝑖𝑘𝑖=1
𝑘𝑖=1
avec 𝜲𝑰 ≡ 𝝌𝟐(𝒌 − 𝟏) et 𝑌 =
𝜔𝑖𝑘𝑖=1 𝑌𝑖
𝜔𝑖𝑘𝑖=1

Exemple 2
Sujets inhalant la fumée
Brun Blond
M+ 267 32
M- 134 39
𝑶𝑹 𝟏 = 𝟐. 𝟒𝟑 𝐿𝑛 𝑂𝑅 1 = 0.887
𝜔𝑖 =1
𝑉𝑎𝑟 (𝐿𝑛(𝑂𝑅 1))= 14.684
Sujets n’inhalant pas la fumée
Brun Blond
M+ 86 22
M- 119 34
𝑶𝑹 𝟐 = 𝟏. 𝟎𝟕 𝐿𝑛 𝑂𝑅 2 = 0.066
𝜔𝑖 =1
𝑉𝑎𝑟 (𝐿𝑛(𝑂𝑅 2))= 10.762
𝛸𝐼 = 4.19 > 𝜒2𝛼1 = 3.84
On rejette l’hypothèse 𝐻0: 𝑂𝑅 1 = 𝑂𝑅 2
Il y a interaction entre E et F pour la
relation avec M
Exposition : Tabac
Brun : E+ Blond : E-
Maladie M+ 353 54
M- 253 73
𝑶𝑹 𝒃𝒓𝒖𝒕 =353 × 72
253 × 54= 𝟏. 𝟖𝟗

Test du Chi-2 d’interaction
• Le test d’interaction est peu puissant, il rejette difficilement 𝐻0
• Interprétation du test du Chi-2 d’interaction
• On rejette 𝐻0: 𝑂𝑅1 = ⋯ = 𝑂𝑅𝑘
Le facteur F est un facteur d’interaction avec l’exposition E pour la
relation avec le risque de maladie M
Analyse séparée des associations entre E et M dans chaque strate du
facteur de confusion F
• On ne rejette pas 𝐻0: 𝑂𝑅1 = ⋯ = 𝑂𝑅𝑘
Il n’y a pas interaction
Méthode d’ajustement de Mantel-Haenszel

III. Méthode d’ajustement de Mantel-Haenszel
• Uniquement après avoir éliminé un phénomène d’interaction
• Démarche générale
1. Estimer une valeur du 𝑅𝑅 (ou O𝑅) entre E et M ajusté sur F
𝑅𝑅 ajusté de Mantel-Haenszel
2. Tester si l’association entre E et M reste significative après ajustement sur F
Test du Chi-2 de Mantel-Haenszel
3. F est-il un facteur de confusion ?
Evaluation qualitative de la différence entre 𝑅𝑅 et 𝑅𝑅 ajusté (pas de test statistique)
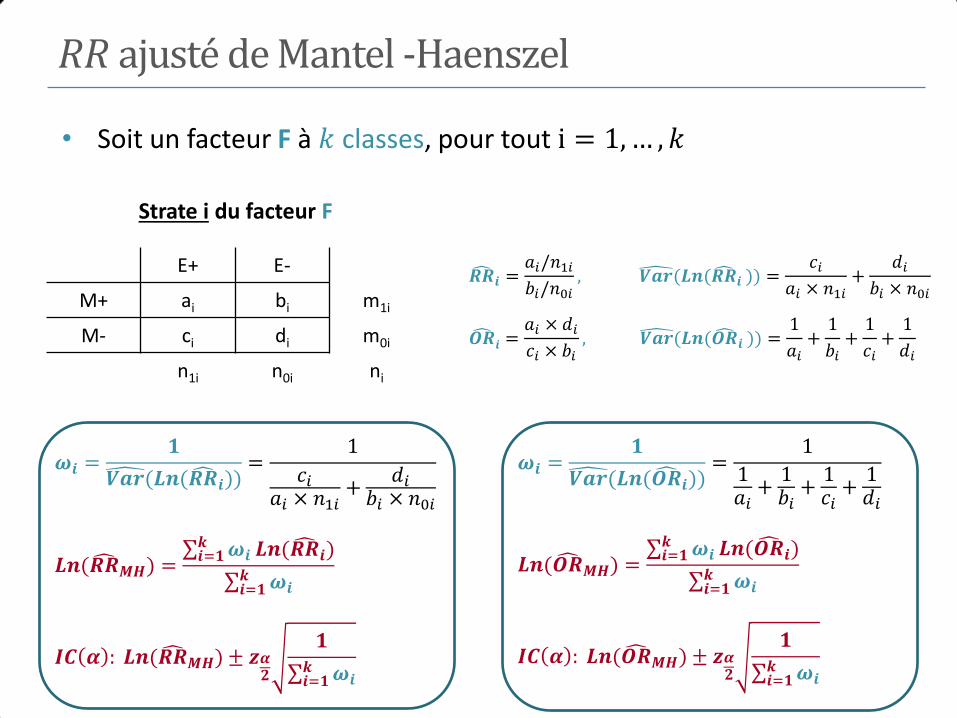
𝑅𝑅 ajusté de Mantel -Haenszel
• Soit un facteur F à 𝑘 classes, pour tout i = 1,… , 𝑘
Strate i du facteur F
E+ E-
M+ ai bi m1i
M- ci di m0i
n1i n0i ni
𝑹𝑹 𝒊 =𝑎𝑖/𝑛1𝑖𝑏𝑖/𝑛0𝑖, 𝑽𝒂𝒓 (𝑳𝒏(𝑹𝑹 𝒊 )) =
𝑐𝑖𝑎𝑖 × 𝑛1𝑖+𝑑𝑖𝑏𝑖 × 𝑛0𝑖
𝑶𝑹 𝒊 =𝑎𝑖 × 𝑑𝑖𝑐𝑖 × 𝑏𝑖, 𝑽𝒂𝒓 (𝑳𝒏(𝑶𝑹 𝒊 )) =
1
𝑎𝑖+1
𝑏𝑖+1
𝑐𝑖+1
𝑑𝑖
𝝎𝒊 =𝟏
𝑽𝒂𝒓 (𝑳𝒏(𝑹𝑹 𝒊))=
1
𝑐𝑖𝑎𝑖 × 𝑛1𝑖+𝑑𝑖𝑏𝑖 × 𝑛0𝑖
𝑳𝒏(𝑹𝑹 𝑴𝑯) = 𝝎𝒊𝒌𝒊=𝟏 𝑳𝒏(𝑹𝑹 𝒊)
𝝎𝒊𝒌𝒊=𝟏
𝑰𝑪 𝜶 : 𝑳𝒏(𝑹𝑹 𝑴𝑯) ± 𝒛𝜶𝟐
𝟏
𝝎𝒊𝒌𝒊=𝟏
𝝎𝒊 =𝟏
𝑽𝒂𝒓 (𝑳𝒏(𝑶𝑹 𝒊))=
1
1𝑎𝑖+1𝑏𝑖+1𝑐𝑖+1𝑑𝑖
𝑳𝒏(𝑶𝑹 𝑴𝑯) = 𝝎𝒊𝒌𝒊=𝟏 𝑳𝒏(𝑶𝑹 𝒊)
𝝎𝒊𝒌𝒊=𝟏
𝑰𝑪 𝜶 : 𝑳𝒏(𝑶𝑹 𝑴𝑯) ± 𝒛𝜶𝟐
𝟏
𝝎𝒊𝒌𝒊=𝟏

Test du Chi-2 de Mantel -Haenszel
• Test de l’absence d’association : 𝐻0: 𝑅𝑅𝑀𝐻 = 1 ou 𝑂𝑅𝑀𝐻 = 1
𝐻1: 𝑅𝑅𝑀𝐻 ≠ 1 ou 𝑂𝑅𝑀𝐻 ≠ 1
𝜲𝑴𝑯 = 𝒂𝒊−𝑬(𝑨𝒊)𝒌𝒊=𝟏
𝟐
𝑽(𝑨𝒊)𝒌𝒊=𝟏
avec 𝜲𝑴𝑯 ≡ 𝝌𝟐 𝟏
𝐸 𝐴𝑖 =𝑛1𝑖×𝑚1𝑖
𝑛𝑖 et 𝑉(𝐴𝑖) =
𝑛0𝑖×𝑛1𝑖×𝑚0𝑖×𝑚1𝑖
𝑛𝑖2(𝑛𝑖−1)
E+ E-
M+ ai bi m1i
M- ci di m0i
n1i n0i ni
Strate i du facteur F
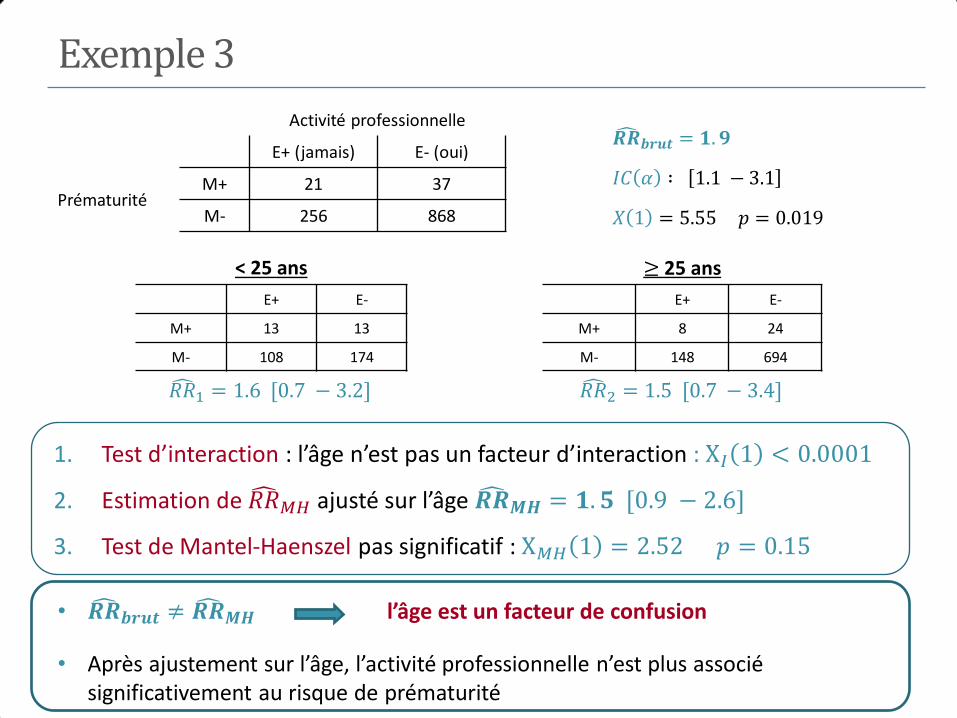
Exemple 3
Activité professionnelle
E+ (jamais) E- (oui)
Prématurité M+ 21 37
M- 256 868
< 25 ans
E+ E-
M+ 13 13
M- 108 174
𝑅𝑅 1 = 1.6 [0.7 − 3.2]
𝑹𝑹 𝒃𝒓𝒖𝒕 = 𝟏. 𝟗
𝐼𝐶 𝛼 ∶ 1.1 − 3.1
𝛸 1 = 5.55 𝑝 = 0.019
≥ 25 ans
E+ E-
M+ 8 24
M- 148 694
𝑅𝑅 2 = 1.5 [0.7 − 3.4]
1. Test d’interaction : l’âge n’est pas un facteur d’interaction : Χ𝐼 1 < 0.0001
2. Estimation de 𝑅𝑅 𝑀𝐻 ajusté sur l’âge 𝑹𝑹 𝑴𝑯 = 𝟏. 𝟓 [0.9 − 2.6]
3. Test de Mantel-Haenszel pas significatif : Χ𝑀𝐻 1 = 2.52 𝑝 = 0.15
• 𝑹𝑹 𝒃𝒓𝒖𝒕 ≠ 𝑹𝑹 𝑴𝑯 l’âge est un facteur de confusion
• Après ajustement sur l’âge, l’activité professionnelle n’est plus associé significativement au risque de prématurité
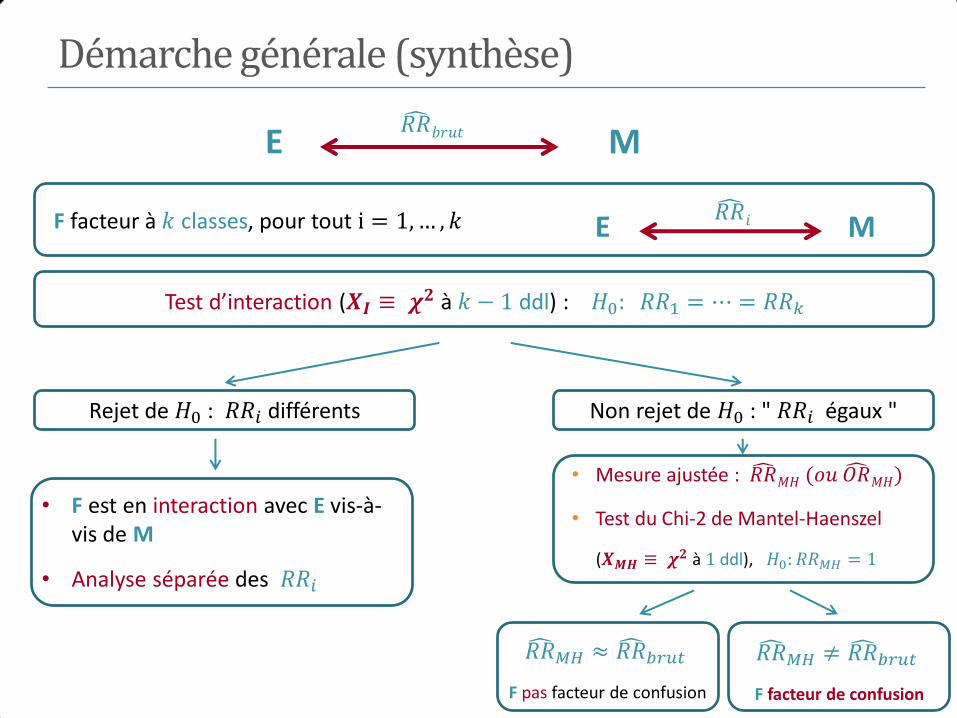
Démarche générale (synthèse)
F facteur à 𝑘 classes, pour tout i = 1,… , 𝑘
M E 𝑅𝑅 𝑏𝑟𝑢𝑡
M E 𝑅𝑅 𝑖
Test d’interaction (𝜲𝑰 ≡ 𝝌𝟐 à 𝑘 − 1 ddl) : 𝐻0: 𝑅𝑅1 = ⋯ = 𝑅𝑅𝑘
• Mesure ajustée : 𝑅𝑅 𝑀𝐻 (𝑜𝑢 𝑂𝑅 𝑀𝐻)
• Test du Chi-2 de Mantel-Haenszel
(𝜲𝑴𝑯 ≡ 𝝌𝟐 à 1 ddl), 𝐻0: 𝑅𝑅𝑀𝐻 = 1
Rejet de 𝐻0 : 𝑅𝑅𝑖 différents Non rejet de 𝐻0 : " 𝑅𝑅𝑖 égaux "
𝑅𝑅 𝑀𝐻 ≈ 𝑅𝑅 𝑏𝑟𝑢𝑡
F pas facteur de confusion
𝑅𝑅 𝑀𝐻 ≠ 𝑅𝑅 𝑏𝑟𝑢𝑡
F facteur de confusion
• F est en interaction avec E vis-à-vis de M
• Analyse séparée des 𝑅𝑅𝑖
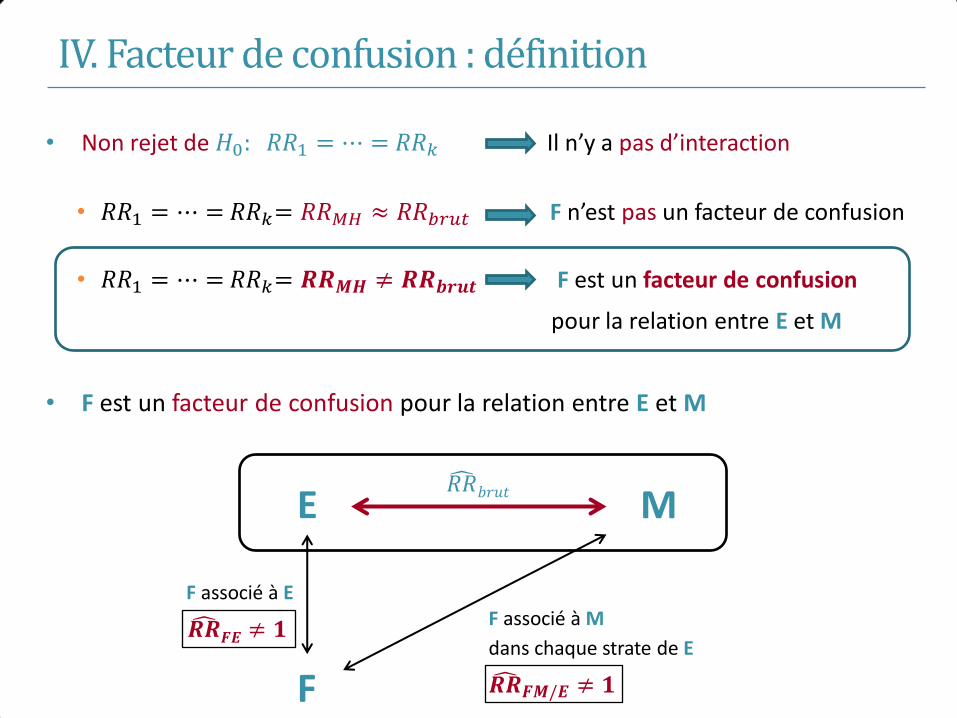
IV. Facteur de confusion : définition
• Non rejet de 𝐻0: 𝑅𝑅1 = ⋯ = 𝑅𝑅𝑘 Il n’y a pas d’interaction
• 𝑅𝑅1 = ⋯ = 𝑅𝑅𝑘= 𝑅𝑅𝑀𝐻 ≈ 𝑅𝑅𝑏𝑟𝑢𝑡 F n’est pas un facteur de confusion
• 𝑅𝑅1 = ⋯ = 𝑅𝑅𝑘= 𝑹𝑹𝑴𝑯 ≠ 𝑹𝑹𝒃𝒓𝒖𝒕 F est un facteur de confusion
pour la relation entre E et M
• F est un facteur de confusion pour la relation entre E et M
M E
F
𝑅𝑅 𝑏𝑟𝑢𝑡
F associé à E
𝑹𝑹 𝑭𝑬 ≠ 𝟏 F associé à M
dans chaque strate de E
𝑹𝑹 𝑭𝑴/𝑬 ≠ 𝟏

Facteur de confusion : définition
• Non rejet de 𝐻0: 𝑂𝑅1 = ⋯ = 𝑂𝑅𝑘 Il n’y a pas d’interaction
• 𝑂𝑅1 = ⋯ = 𝑂𝑅𝑘= 𝑂𝑅𝑀𝐻 ≈ 𝑂𝑅𝑏𝑟𝑢𝑡 F n’est pas un facteur de confusion
• 𝑂𝑅1 = ⋯ = 𝑂𝑅𝑘= 𝑶𝑹𝑴𝑯 ≠ 𝑶𝑹𝒃𝒓𝒖𝒕 F est un facteur de confusion
pour la relation entre E et M
• F est un facteur de confusion pour la relation entre E et M
M E
F
𝑂𝑅 𝑏𝑟𝑢𝑡
F associé à M
dans chaque strate de E
𝑶𝑹 𝑭𝑴/𝑬 ≠ 𝟏
F associé à E
dans chaque strate de M
𝑶𝑹 𝑭𝑬/𝑴 ≠ 𝟏
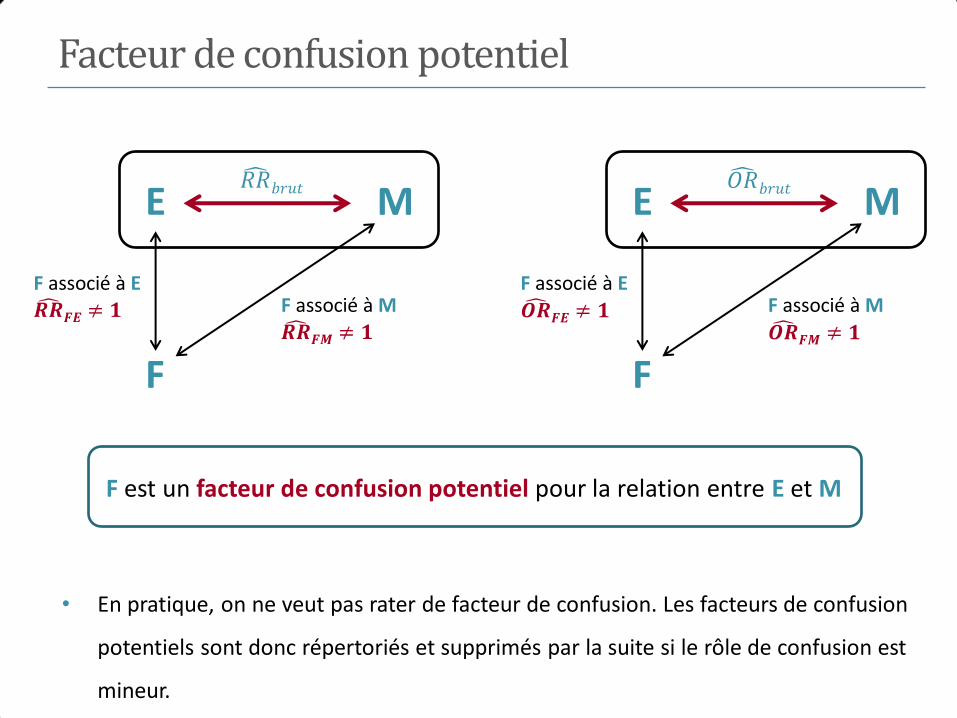
Facteur de confusion potentiel
M E
F
𝑅𝑅 𝑏𝑟𝑢𝑡
F associé à E
𝑹𝑹 𝑭𝑬 ≠ 𝟏 F associé à M
𝑹𝑹 𝑭𝑴 ≠ 𝟏
M E
F
𝑂𝑅 𝑏𝑟𝑢𝑡
F associé à E
𝑶𝑹 𝑭𝑬 ≠ 𝟏 F associé à M
𝑶𝑹 𝑭𝑴 ≠ 𝟏
F est un facteur de confusion potentiel pour la relation entre E et M
• En pratique, on ne veut pas rater de facteur de confusion. Les facteurs de confusion
potentiels sont donc répertoriés et supprimés par la suite si le rôle de confusion est
mineur.

V. Prise en compte d’un facteur de confusion
1. Au moment de la planification de l’enquête
• Relever les facteurs de risque connus du phénomène étudié M (littérature)
• Relever les facteurs de risque potentiels (plausibilité, intuitions)
• Relever les facteurs d’interaction potentiels
2. Au moment de la conception de l’enquête
• Recueillir les informations sur les facteurs de confusion et d’interaction
• Définir les modalités d’échantillonnage
a) Randomiser l’exposition
b) Restreindre la population d’étude à une catégorie du facteur de confusion
c) Stratifier ou apparier sur un ou plusieurs facteurs de confusion
3. Au moment de l’analyse statistique
4. Les difficultés pratiques

Au moment de la conception de l’enquête
a) Randomiser l’exposition
• Consiste à répartir au hasard les sujets qui recevront l’exposition
• Les facteurs de confusion potentiels ont en moyenne la même distribution
dans les groupes exposés et non exposés
• Les facteurs de confusion potentiels ne sont pas associés à l’exposition
Interprétation causale
• Possible en situation expérimentale : traitements ou intervention
• Impossible en situation d’observation : tabagisme, expositions
professionnelles, précarité sociale

Au moment de la conception de l’enquête
b) Restreindre la population d’étude
• Effectuer l’étude dans une catégorie du facteur de confusion F
Femme, enfants, sportifs, …
• Exclure certains sujet appartenant à une catégorie rare du facteur de confusion F
Dans l’étude des facteurs de risque du cancer de la vessie, exclusion des
patients atteints de bilharziose (rare en Europe et facteur de risque connu
du cancer de la vessie)
Limite la portée de l’étude à un sous groupe de F

Au moment de la conception de l’enquête
c) Stratifier ou apparier sur certains facteurs de confusion
• Appariement (Ex : âge, sexe, CSP, zone de résidence, …)
• Pour chaque cas, on sélectionne un (ou plusieurs témoins) du même âge, sexe, CSP
• Pour chaque 𝐸 +, on sélectionne un 𝐸 − du même âge, sexe, CSP
• Stratification, appariement par classe (Ex : pays, régions, hôpital de recrutement, …)
• Cas et témoins sélectionnés au sein de chaque pays, région, hôpital
• 𝐸 + et 𝐸 − sélectionnés au sein de chaque pays, région, hôpital
• Objectif : Equilibrer la répartition du facteur de confusion F dans les groupe comparés
F n’est pas lié à M (ou E) dans une enquête cas-témoins (ou cohorte)
• Difficultés : − Difficile de trouver un témoin quand appariement sur plusieurs facteurs
− Le lien entre F et M (ou E) ne peut pas être étudié

Au moment de l’analyse statistique
1. Au moment de la planification de l’enquête
2. Au moment de la conception de l’enquête
3. Au moment de l’analyse statistique
• Analyse univariée, étudier l’association entre M, E et différents facteurs F
• Analyse stratifiée (méthode de Mantel-Haenszel) analyse préliminaire
M et E doivent être binaire (2 classes)
Le facteur d’ajustement F doit être qualitatif (k classes)
A cause de la stratification, analyse de peu de facteurs de confusion F en même temps
• Analyse multivariée
Possibilité de prendre plusieurs facteurs de confusion simultanément
Possibilité d’utiliser des variables qualitatives et quantitatives
Régression linéaire, régression logistique, modèle de survie (Cox, …)
4. Les difficultés pratiques

Les difficultés pratiques
1. Au moment de la planification de l’enquête
2. Au moment de la conception de l’enquête
3. Au moment de l’analyse statistique
4. Les difficultés pratiques
a) Sur-appariement
b) Facteur de confusion déséquilibré dans les groupes de F
c) Sur-ajustement : Variable prise en compte à tort dans le modèle
d) Valeurs manquantes
e) Erreurs de classement sur le facteur de confusion F
f) Facteur intermédiaire

Les difficultés pratiques
a) Sur-appariement
• L’appariement sur des facteurs de confusion entraîne sans le savoir un
appariement sur l’exposition
Peut faire disparaître artificiellement une association
• Exemple: choisir les témoins parmi les amis ou la famille des cas (cancer du
seins et pilule)
Cas et témoins peuvent se ressembler pour les facteurs de
confusion (niveau social, mode de vie) mais aussi pour
l’exposition (contraception)

Les difficultés pratiques
b) Facteur de confusion déséquilibré dans les groupes de F
< 30 ans
E+ E-
M+ 50 2
M- 150 15
150 17
≥ 30 ans
E+ E-
M+ 0 28
M- 4 201
4 229
L’exposition est confondue avec l’âge
Ajustement sur l’âge est impossible
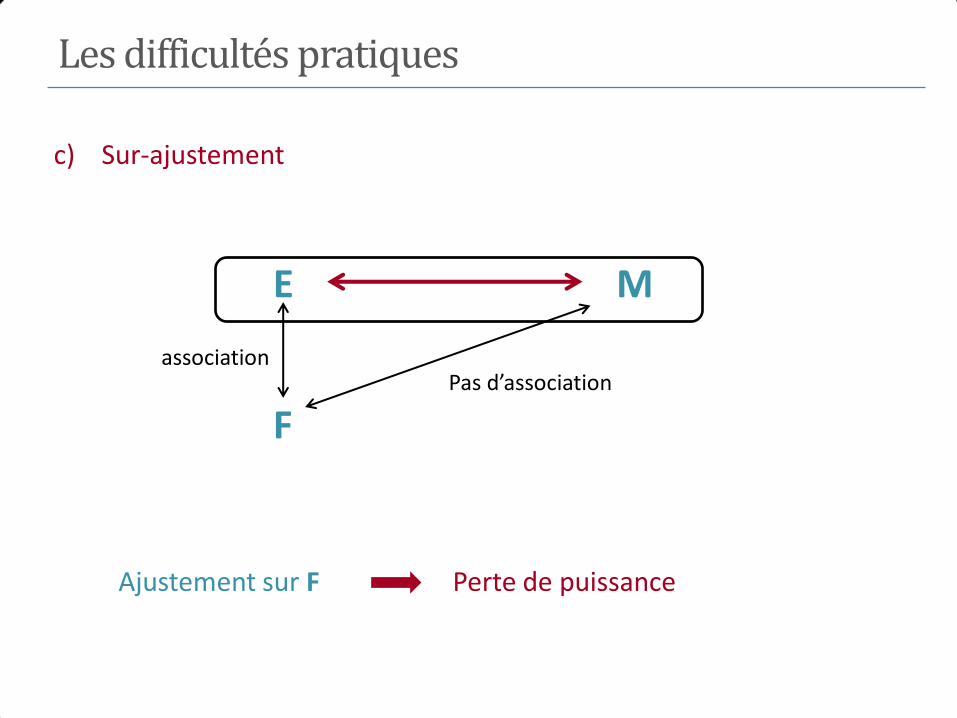
Les difficultés pratiques
c) Sur-ajustement
Ajustement sur F Perte de puissance
M E
F Pas d’association
association

Les difficultés pratiques
• Exemple sur-ajustement : ajustement sur l’âge
< 30 ans
E+ E-
M+ 9 1
M- 36 9
45 10
𝑶𝑹 𝟏 = 𝟐. 𝟐𝟓
≥ 30 ans
E+ E-
M+ 1 4
M- 4 36
4 40
𝑶𝑹 𝟐 = 𝟐. 𝟐𝟓
• Age est très lié à l’exposition (𝐸 + sont jeunes et 𝐸 − sont vieux)
• 𝑂𝑅 𝑀𝐻 = 𝑂𝑅 𝑏𝑟𝑢𝑡 = 2.25 l’âge n’est pas un facteur de confusion
• 𝑉𝑎𝑟 𝐿𝑛 𝑂𝑅 𝑏𝑟𝑢𝑡 = 0.347 < 0.886 = 𝑉𝑎𝑟 𝐿𝑛 𝑂𝑅 𝑀𝐻
Ajustement sur l’âge entraine une perte de puissance
𝑂𝑅 𝑏𝑟𝑢𝑡 = 2.25 0.7 − 7.1 𝑂𝑅 𝑀𝐻 = 2.25 0.4 − 11.4

Les difficultés pratiques
Logement salubre
E+ E-
M+ 11 21
M- 189 559
n1 = 780 200 580
𝑹𝑹 𝟏 = 𝟏. 𝟓 [𝟎. 𝟕 − 𝟑. 𝟏]
Logement insalubre
E+ E-
M+ 4 14
M- 39 218
n2 = 285 53 232
𝑹𝑹 𝟐 = 𝟏. 𝟑 [𝟎. 𝟒 − 𝟑. 𝟔]
Chi-2 d’interaction (𝛸𝐼 = 0.08), pas d’interaction
𝑅𝑅 𝑀𝐻 = 1.4 [0.8 − 2.6]
d) Données manquantes pour le facteur de confusion
Biais possible
Manque de puissance
Activité professionnelle
Prématurité
E+ (jamais) E- (oui)
M+ 21 37
M- 256 868
n = 1182 277 905
𝑹𝑹 𝒃𝒓𝒖𝒕 = 𝟏. 𝟗 [𝟏. 𝟏 − 𝟑. 𝟏]
La salubrité est un facteur de confusion?
Activité professionnelle
Prématurité
E+ (jamais) E- (oui)
M+ 15 35
M- 238 777
n = 1065 2534 812
𝑹𝑹 𝒃𝒓𝒖𝒕 = 𝟏. 𝟒 [𝟎. 𝟖 − 𝟐. 𝟓]
na

Les difficultés pratiques
e) Erreur de classement sur le facteur de confusion
Biais de classement non différentiel manque de puissance
Biais de classement non différentiel peut créer une association
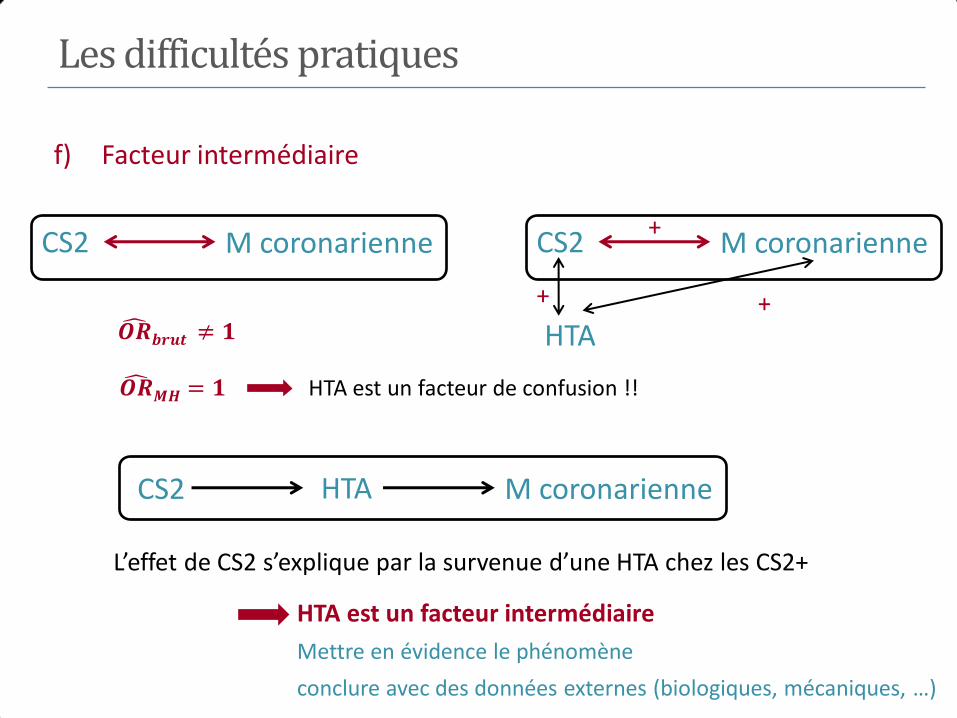
Les difficultés pratiques
f) Facteur intermédiaire
HTA
+ +
M coronarienne CS2 M coronarienne CS2
𝑶𝑹 𝒃𝒓𝒖𝒕 ≠ 𝟏
𝑶𝑹 𝑴𝑯 = 𝟏 HTA est un facteur de confusion !!
HTA est un facteur intermédiaire
Mettre en évidence le phénomène
conclure avec des données externes (biologiques, mécaniques, …)
M coronarienne CS2
+
HTA
L’effet de CS2 s’explique par la survenue d’une HTA chez les CS2+

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
9. Protocole et stratégie d’analyse

9. Protocole et stratégie d’analyse
I. Objectifs de l’enquête
II. Choix du type d’enquête
III. Modalités de réalisation
IV. Puissance et nombre de sujets nécessaires
V. Démarche de l’analyse statistique
VI. Interprétation des résultats

I. Objectifs de l’enquête
• Enquêtes descriptives
• Estimer la fréquence d’une maladie
• Décrire les tendances temporelles et spatiales
• Générer des hypothèse
• Enquêtes analytiques
• Identifier des facteurs de risque
• Identifier des facteurs causaux
• Identifier les facteurs expliquant un comportement
• Enquêtes expérimentales
• Démontrer l’efficacité d’un traitement ou d’une intervention

II. Choix du type d’enquête
• Enquêtes descriptives
• Surveillance épidémiologique à partir de données d’enregistrement continu
• générer des hypothèses
• Enquêtes analytiques
• Enquêtes observationnelles (Enquêtes de cohorte, Cas-témoins et transversale)
• Causalité non démontrable (faisceau d’arguments)
• Enquêtes quasi-expérimentales
• Enquêtes "avant-après" ou "ici-ailleurs"
• Niveau de preuve plus faible qu’une enquête expérimentale
• Enquêtes expérimentales
• Essai contrôlé, randomisé, en double aveugle
• Causalité démontrée
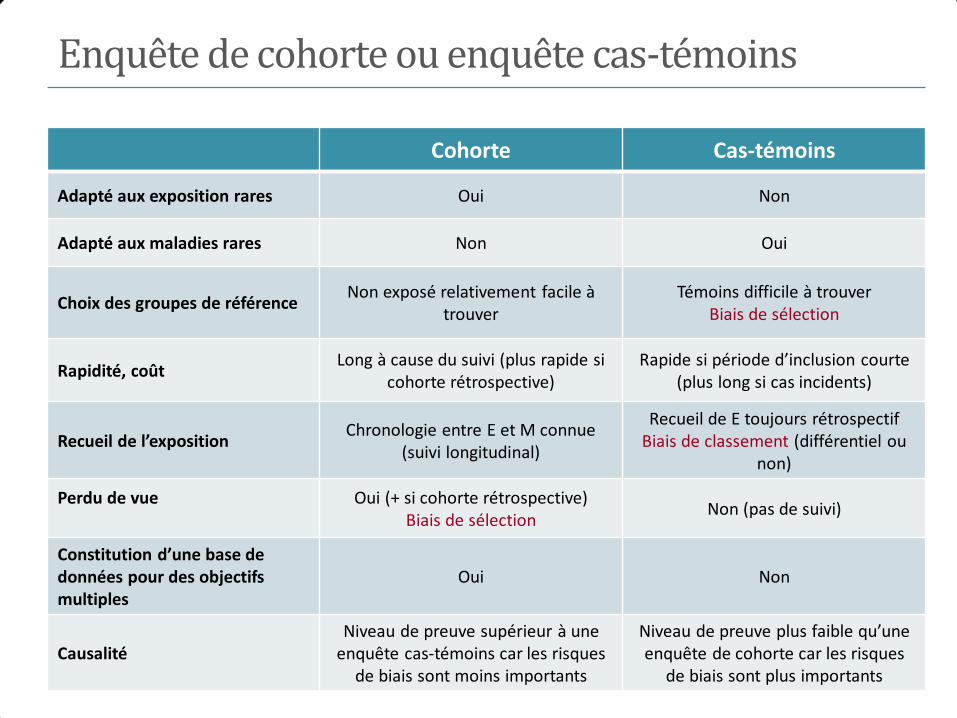
Enquête de cohorte ou enquête cas-témoins
Cohorte Cas-témoins
Adapté aux exposition rares Oui Non
Adapté aux maladies rares Non Oui
Choix des groupes de référence Non exposé relativement facile à
trouver Témoins difficile à trouver
Biais de sélection
Rapidité, coût Long à cause du suivi (plus rapide si
cohorte rétrospective) Rapide si période d’inclusion courte
(plus long si cas incidents)
Recueil de l’exposition Chronologie entre E et M connue
(suivi longitudinal)
Recueil de E toujours rétrospectif Biais de classement (différentiel ou
non)
Perdu de vue
Oui (+ si cohorte rétrospective) Biais de sélection
Non (pas de suivi)
Constitution d’une base de données pour des objectifs multiples
Oui Non
Causalité Niveau de preuve supérieur à une
enquête cas-témoins car les risques de biais sont moins importants
Niveau de preuve plus faible qu’une enquête de cohorte car les risques
de biais sont plus importants

Enquête de cohorte ou enquête cas-témoins
• Quantités estimables dans une enquête de cohorte
• Prévalence de l’exposition si construite à partir d’une enquête transversale
• Risque relatif et odds ratio
• Le suivi longitudinal permet d’estimer
• Le risque de la maladie et le taux d’incidence
• Analyse de survie (modèle de Cox, …)
• Quantités estimables dans une enquête cas-témoins
• Prévalence de l’exposition chez les cas
• Prévalence de l’exposition chez les témoins généralisation possible à la population source
• Odds ratio mais pas le risque relatif (car pas d’estimation de la prévalence de la maladie)
• Pas d’estimation du risque de la maladie et du taux d’incidence (pas de suivi)

III. Modalités de réalisation
1. Définition des populations cibles et sources
2. Mode d’échantillonnage
3. Recueil des données
4. Modalités pratiques
Chacun de ces points est détaillé dans les chapitres concernant
les enquêtes cas-témoins et les enquêtes de cohorte

IV. Puissance et nombre de sujets nécessaires
• La puissance d’une enquête pour mettre en évidence une association entre E et M
• Dépend du nombre de sujets exploitables pour l’analyse statistique
• Nombre de sujets à calculer au moment de la mise en place de l’enquête
• Choisir une population source (et un protocole) permettant de minimiser le risque de non participation, de données manquantes et de perdus de vue
• Dépend du choix des groupes comparés
• Choisir des groupes les plus contrastés possible (grande différence entre les groupes)
• Choisir des groupes homogènes (faible variation au sein d’un groupe)
• La puissance meilleure si les effectifs sont équilibrés (préférer les enquêtes de cohorte et cas-témoins)
• La puissance peut être meilleure en cas d’échantillon apparié
• Dépend du choix des instruments de mesure de l’exposition et de la maladie
• Instruments de mesure standardisés, objectifs et précis
• Instruments de mesure avec une bonne sensibilité et une bonne spécificité
limiter les biais de classement non différentiel (qui ramène l’estimation de l’OR et du RR vers 1)

V. Démarche de l’analyse statistique
• Lien entre l’exposition (E) est la maladie (M)
• E significativement associée à M ?
• Estimation des mesures d’association (Odds ratio, risque relatif, …)
• Intervalle de confiance
• Test statistique (p-value)
• E fortement associée à M ?
• Grande valeur de la mesure d’association
• E est la cause de M ?
• Pas de preuve scientifique dans les enquêtes observationnelles
• Faisceau d’argument, critère de présomption causale de Bradford Hill
• Contribution de E au taux d’incidence de la maladie
• Suppose que E est la cause de M
• Risque attribuable

Démarche de l’analyse statistique
1. Analyses descriptives : contrôle de cohérence et de la qualité des données
• Préparation d’un fichier propre, rechercher les données aberrantes
• Vérifier la comparabilité des groupes comparés
• E+/E- ou M+/M- issus de la même population
• Contrôler la qualité de l’appariement
• Evaluer une déformation possible par rapport à la sélection initiale
• Non réponse (totale ou partielle), perdus de vue
• Décrire les expositions
• Répartition, niveau, durée, type
• Evaluer la mortalité et/ou la morbidité (taux d’incidences)
• Uniquement dans les enquêtes de cohorte
• Comparer les résultats obtenus avec ceux de la littérature (recherche de relations connues)

Démarche de l’analyse statistique
2. Première analyses statistiques : analyses univariées et stratifiées
• Comparaison (interne) des groupes E+/E- ou M+/M-
• Estimation des risques relatifs (uniquement cohorte) ou des odds ratios
• Analyses stratifiées
• Recherche des interactions et estimation des RR (ou OR) ajustés par la méthode de Mantel -
Haenszel
• Comparaison externe (uniquement dans les enquêtes de cohorte)
• Standardisation des mesures de risques (taux d’incidence, prévalence, …)
• SMR : standardisation indirecte (basée sur la mesure de risque de la population de référence)
• CMF : standardisation directe (basée sur la structure d’âge de la population de référence)

Démarche de l’analyse statistique
3. Analyses approfondies de la relation dose-effet
• Type d’exposition, délais depuis le début ou l’arrêt de l’exposition, dose totale d’exposition
• Etude conjointe de la durée, du niveau et de la dose d’exposition
• Analyse en fonction de sous-catégories
• Recherche d’effet seuil, évaluation de la période d’induction
4. Analyses statistiques multivariées
• Dans les enquêtes de cohorte (analyse des données longitudinales)
• Analyse de survie (Modèle de Cox), modèle mixte, modèle multi-états, …
• Modèle de Poisson (si données groupées)
• Dans les enquêtes cas-témoins
• Régression logistique
• Autres méthodes de classification supervisée (SVM, CART, forêt aléatoire, …)

VI. Interprétation des résultats
• Résultats significatifs
• Discussion sur les biais possibles
• Biais de sélection
• Biais de classement différentiels
• Facteurs de confusion pas ou mal pris en compte
• Arguments en faveur de la causalité
• Critères internes à l’étude
• force de l’association
• Relation dose-effet
• Pas d’ambiguïté sur la chronologie
• Spécificité de l’association
• Critères externes à l’étude
• Constance des résultats dans la littérature
• Plausibilité biologique (mécanismes explicatifs)
• Cohérence des résultats avec les hypothèses de départ

Interprétation des résultats
• Résultats non significatifs
• Ajustement sur un facteur intermédiaire (suppression de l’association)
• Sur-appariement
• Discussion sur les biais
• Biais de sélection, biais de classement différentiel
• Facteur de confusion non ou mal pris en compte
• Manque de puissance
• Nombre de sujets plus faible que prévu (non réponse, perdus de vues)
• Biais de classement non différentiel
• Evaluer la puissance a posteriori
• Si la puissance est ≥ 80% on peut conclure à l’absence d’association
• Si la puissance est < 80% il y a peut être une différence mais on ne la voit pas

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
10. Puissance d’un test statistique

10. Puissance d’un test statistique
I. Précision de l’estimation et nombre de sujets
• Estimation d’un pourcentage
• Estimation d’une moyenne
II. Rappels sur la puissance
III. Puissance et nombre de sujets nécessaire
• Comparaison de moyennes
• Comparaison de pourcentages, d’un OR et d’un RR à la valeur 1
• Comparaison d’un SMR à la valeur 1
IV. Puissance dans une enquête

I. Précision de l’estimation et nombre de sujets
• Contexte
• Estimation d’une moyenne ou d’un pourcentage
• Calcul d’un intervalle de confiance avec un risque d’erreur 𝛼 fixé
• Objectif
• Nombre de sujets nécessaire pour estimer le paramètre avec une précision 𝑖 fixée
• Soit 𝜃 un estimateur et 𝐼𝐶𝛼 𝜃 = 𝜃𝑖𝑛𝑓 ; 𝜃𝑠𝑢𝑝 = 𝜃 − 𝑖 ; 𝜃 + 𝑖 son intervalle de confiance
• Déterminer le nombre de sujets nécessaire pour obtenir la précision 𝑖 souhaitée

Estimation d’un pourcentage
• Rappels
• Considérons un échantillon de taille 𝑛
• Soit 𝑃 le vrai pourcentage et 𝑃 un estimateur de 𝑃 obtenu sur l’échantillon
• Intervalle de confiance de 𝑃 de niveau 𝛼
𝐼𝐶𝛼 𝑃 = 𝑃 − 𝑖 ; 𝑃 + 𝑖 = 𝑃 − 𝑧𝛼2
𝑃 1 − 𝑃
𝑛 ; 𝑃 + 𝑧𝛼
2
𝑃 1 − 𝑃
𝑛
• Contexte
• On souhaite déterminer 𝑛 pour estimer 𝑃 avec une certaine précision 𝑖 fixée
• On se base sur une idée a priori 𝑃 (littérature) de la valeur de 𝑃 attendue dans la population
𝑛 =𝑧𝛼2
2
𝑖2× 𝑃 (1 − 𝑃 )

Estimation d’une moyenne
• Rappels
• Considérons un échantillon de taille 𝑛
• Soit 𝑀 la vraie moyenne et 𝑀 un estimateur de 𝑀 obtenu sur l’échantillon
• Intervalle de confiance de 𝑀 de niveau 𝛼
𝐼𝐶𝛼 𝑀 = 𝑀 − 𝑖 ;𝑀 + 𝑖 = 𝑀 − 𝑧𝛼2
𝜎 2
𝑛 ;𝑀 + 𝑧𝛼
2
𝜎 2
𝑛
• Contexte
• On souhaite déterminer 𝑛 pour estimer 𝑀 avec une certaine précision 𝑖 fixée
• On se base sur une idée a priori 𝜎 2 (littérature) de la valeur de 𝜎2 attendue dans la population
𝑛 =𝑧𝛼2
2
𝑖2× 𝜎 2

Exemples
• Estimation du pourcentage 𝑃 de fumeur d’une population
• Données a priori : le pourcentage de fumeur serait de 30% dans la population
• Nombre de sujets à prévoir dans l’échantillon pour estimer 𝑃 avec une précision de ±3% au
risque 𝛼 = 5%
𝑛 =1.96 2
0.032× 0.3 1 − 0.3 = 897
• Estimation du poids de naissance 𝑀 moyen dans une population
• Données a priori : le poids moyen serait de 3500𝑔 et l’écart-type de 500𝑔
• Nombre de sujets à prévoir dans l’échantillon pour estimer 𝑀 avec une précision de ±50𝑔 au
risque 𝛼 = 5%
𝑛 =1.96 2
502× 5002 = 384
(𝑖 = ±5% 𝑛 = 323)
(𝜎 2 = 250𝑔 𝑛 = 92)

II. Rappels sur la puissance
• Principe d’un test d’hypothèse (statistique)
• Consiste à rejeter ou à ne pas rejeter une hypothèse 𝐻0 à partir d’un échantillon
• Deux risques d’erreur
• On contrôle le risque d’erreur de 1ère espèce 𝛼 (en général fixé à 5%) : erreur la plus grave
• Ex: Justice condamner un innocent ou relâcher un coupable
• 𝐻0 : accusé est innocent et 𝐻1 : accusé coupable
• 𝛼 = "condamner un innocent" et 𝛽 = "relâcher un coupable"
Décision
Rejet de 𝐻0 Non rejet de 𝐻0 (≠ accepter 𝐻1)
Vérité
𝐻0 vraie Erreur de 1ère espèce
𝛼 = 𝑃(𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0|𝐻0 𝑣𝑟𝑎𝑖𝑒)
Pas d’erreur
1 − 𝛼 = 𝑃(𝑛𝑜𝑛 𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0|𝐻0 𝑣𝑟𝑎𝑖𝑒)
𝐻1 vraie Pas d’erreur
1 − 𝛽 = 𝑃(𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0|𝐻1 𝑣𝑟𝑎𝑖𝑒)
Erreur de 2ème espèce
𝛽 = 𝑃(𝑛𝑜𝑛 𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0|𝐻1 𝑣𝑟𝑎𝑖𝑒)

Rappels sur la puissance
• Erreur 𝛼 = 𝑃(𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0|𝐻0 𝑣𝑟𝑎𝑖𝑒) erreur possible quand on rejette 𝐻0
• Erreur 𝛽 = 𝑃(𝑛𝑜𝑛 𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0|𝐻1 𝑣𝑟𝑎𝑖𝑒) erreur possible quand on ne rejette pas 𝐻0
• Puissance = 1 − 𝛽 = 𝑃(𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0|𝐻1 𝑣𝑟𝑎𝑖𝑒)
• La puissance mesure la capacité d’un test à mettre en évidence une différence qui existe
réellement
• Exemples :
• Justice : on veut une puissance (1 − 𝛽) suffisante pour ne pas relâcher un coupable (erreur 𝛽)
• Comparaison de l’effet de deux traitements : éviter de passer à coté d’une différence qui
pourrait permettre des progrès thérapeutique

Rappels sur la puissance
• Calcul de la puissance pour la comparaison d’une moyenne à une moyenne théorique
• Hypothèses
• 𝑋1, … , 𝑋𝑛 un échantillon indépendant et de même loi que 𝑋 de moyenne 𝑚 et de variance 𝜎2
• 𝑋𝑖 normale ou 𝑛 ≥ 30 ⇒ la moyenne estimée 𝑋 est une variable normale : 𝑋 ∼ 𝑁 𝑚,𝜎2
𝑛
• 𝜎2 connue (pour simplifier) et identique sous 𝐻0 et 𝐻1
• Test bilatéral 𝐻0 ∶ 𝑚 = 𝑚0 (𝑚 la vraie moyenne et 𝑚0 la moyenne théorique)
𝐻1 ∶ 𝑚 ≠ 𝑚0
• Sous 𝐻0, 𝑚 = 𝑚0 la statistique de student 𝑍 =𝑋 −𝑚0
𝜎2
𝑛
∼ 𝑁 0,1
• Sous 𝐻1, on pose 𝑚 = 𝑚1 la statistique de student 𝑍 =𝑋 −𝑚0
𝜎2
𝑛
∼ 𝑁𝑚1−𝑚0
𝜎2
𝑛
, 1
• Pour calculer la puissance on doit spécifier l’hypothèse 𝐻1
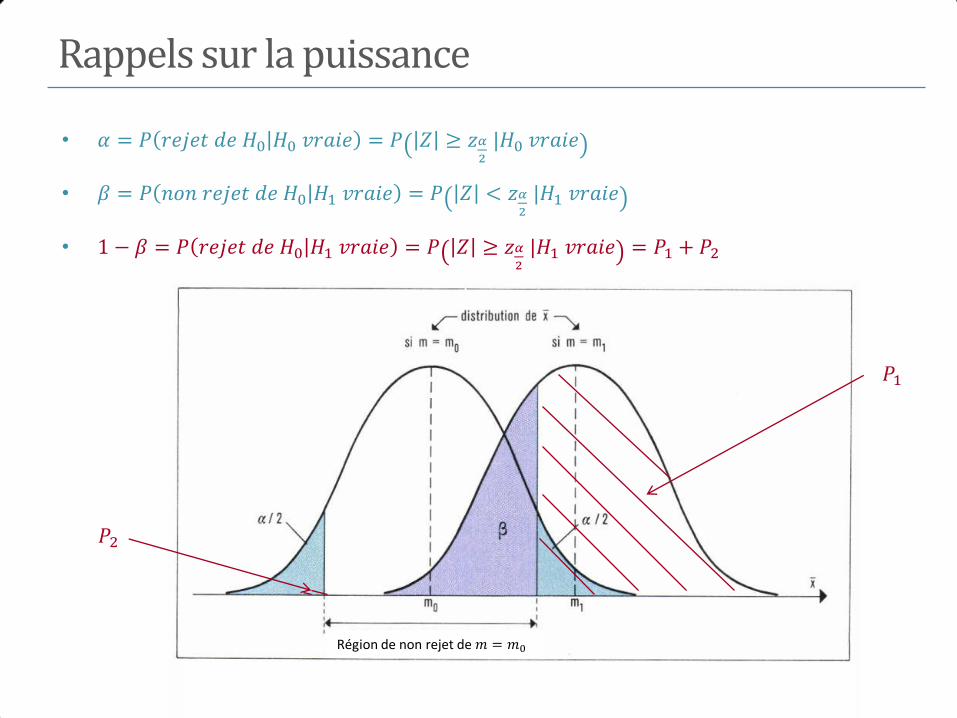
Rappels sur la puissance
• 𝛼 = 𝑃 𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0 𝐻0 𝑣𝑟𝑎𝑖𝑒 = 𝑃 𝑍 ≥ 𝑧𝛼
2 |𝐻0 𝑣𝑟𝑎𝑖𝑒
• 𝛽 = 𝑃 𝑛𝑜𝑛 𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0 𝐻1 𝑣𝑟𝑎𝑖𝑒 = 𝑃 𝑍 < 𝑧𝛼
2 |𝐻1 𝑣𝑟𝑎𝑖𝑒
• 1 − 𝛽 = 𝑃 𝑟𝑒𝑗𝑒𝑡 𝑑𝑒 𝐻0 𝐻1 𝑣𝑟𝑎𝑖𝑒 = 𝑃 𝑍 ≥ 𝑧𝛼
2 |𝐻1 𝑣𝑟𝑎𝑖𝑒 = 𝑃1 + 𝑃2
𝑃1
𝑃2
Région de non rejet de 𝑚 = 𝑚0
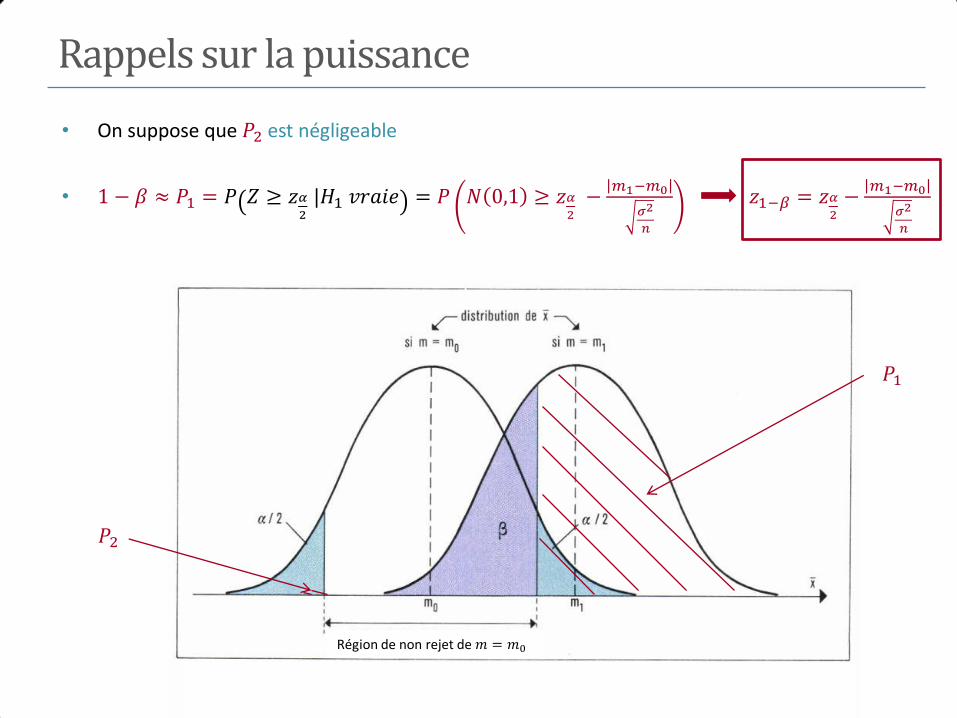
Rappels sur la puissance
• On suppose que 𝑃2 est négligeable
• 1 − 𝛽 ≈ 𝑃1 = 𝑃 𝑍 ≥ 𝑧𝛼
2 |𝐻1 𝑣𝑟𝑎𝑖𝑒 = 𝑃 𝑁 0,1 ≥ 𝑧𝛼
2 −
𝑚1−𝑚0
𝜎2
𝑛
𝑧1−𝛽 = 𝑧𝛼
2−
𝑚1−𝑚0
𝜎2
𝑛
𝑃1
𝑃2
Région de non rejet de 𝑚 = 𝑚0
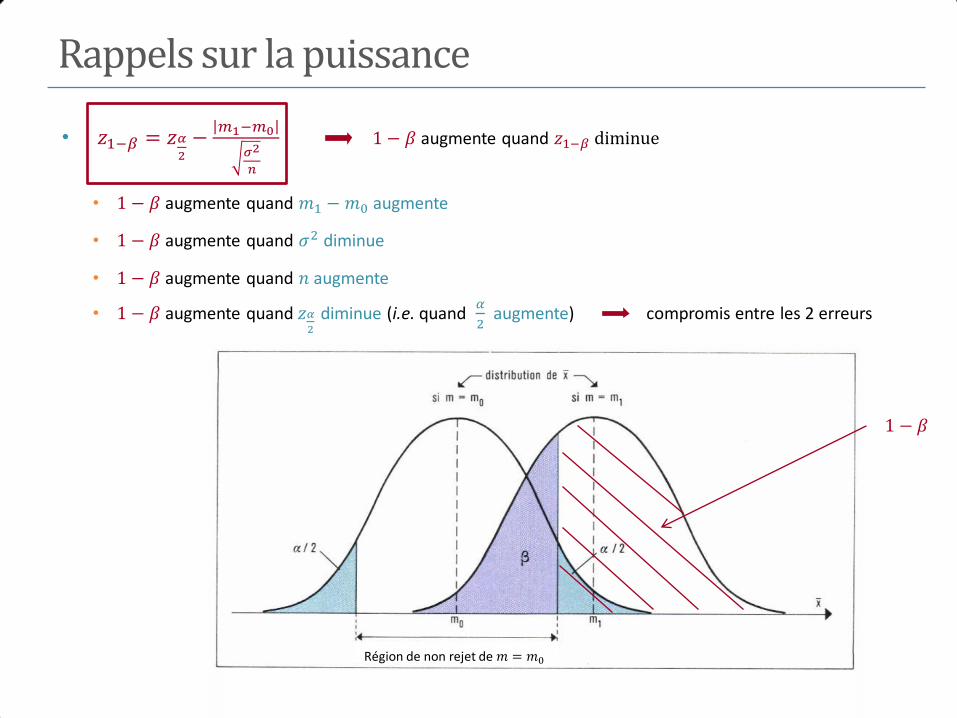
Rappels sur la puissance
• 𝑧1−𝛽 = 𝑧𝛼
2−
𝑚1−𝑚0
𝜎2
𝑛
1 − 𝛽 augmente quand 𝑧1−𝛽 diminue
• 1 − 𝛽 augmente quand 𝑚1 − 𝑚0 augmente
• 1 − 𝛽 augmente quand 𝜎2 diminue
• 1 − 𝛽 augmente quand 𝑛 augmente
• 1 − 𝛽 augmente quand 𝑧𝛼
2 diminue (i.e. quand
𝛼
2 augmente) compromis entre les 2 erreurs
1 − 𝛽
Région de non rejet de 𝑚 = 𝑚0

III. Puissance et nombre de sujets nécessaire
Comparaison d’une moyenne à une moyenne théorique
• Pour 𝛼 = 5% ∶ 𝑧𝛼
2= 1.96 et 𝑧α = 1.64
Test bilatéral : 𝐻0 ∶ 𝑚 = 𝑚0 𝐻1 ∶ 𝑚 ≠ 𝑚0
Test unilatéral : 𝐻0 ∶ 𝑚 = 𝑚0 𝐻1 ∶ 𝑚 > 𝑚0
Puissance (Table de la loi normale Table 1 du livre "rose")
𝑧1−𝛽 = 𝑧𝛼2−
𝑚1 − 𝑚0
𝜎2
𝑛
𝑧1−𝛽 = 𝑧𝛼 −𝑚1 − 𝑚0
𝜎2
𝑛
Puissance (Table 4a et 4b)
𝜙 =𝑚1 − 𝑚0
𝜎2
𝑛
= 𝑧𝛼2− 𝑧1−𝛽 𝜙 =
𝑚1 − 𝑚0
𝜎2
𝑛
= 𝑧𝛼 − 𝑧1−𝛽
Nombre de sujets nécessaire
𝑛 =𝜎2
𝑚1 − 𝑚02× 𝑧𝛼/2 − 𝑧1−𝛽
2 𝑛 =
𝜎2
𝑚1 − 𝑚02× 𝑧𝛼 − 𝑧1−𝛽
2

Exemple
• Comparaison de l’effet antalgique de 2 médicaments A et B données successivement aux mêmes
malades. On mesure le nombre d’heures sans douleur 𝑥𝐴 et 𝑥𝐵
• Echantillon apparié pour chaque patient on calcule 𝑑 = 𝑥𝐴 − 𝑥𝐵
• Données a priori : la variance de 𝑑 = 12
• Objectif : calculer le nombre de sujets nécessaire pour détecter une différence de 0.7h avec une
puissance de 80%
• 𝐻0 ∶ 𝑚𝑑 = 0 et 𝐻1 ∶ 𝑚𝑑 ≠ 0 avec 𝛼 = 5%
• 𝑛 =𝜎2
𝑚1−𝑚02 × 𝑧𝛼/2 − 𝑧1−𝛽
2=
122
0.7 2 × 1.96 − −0.8422= 193
• Il faut sélectionner 193 sujets qui recevront chacun 2 traitements

Puissance : comparaison de deux moyennes
Test bilatéral : 𝐻0 ∶ 𝑚1 = 𝑚2 𝐻1 ∶ 𝑚1 ≠ 𝑚2
Test unilatéral : 𝐻0 ∶ 𝑚1 = 𝑚2 𝐻1 ∶ 𝑚1 > 𝑚2
Puissance (Table de la loi normale Table 1 du livre "rose")
𝑧1−𝛽 = 𝑧𝛼2−
𝑚1 − 𝑚2
𝜎2 1𝑛1
+1𝑛2
𝑧1−𝛽 = 𝑧𝛼 −𝑚1 − 𝑚2
𝜎2 1𝑛1
+1𝑛2
Puissance (Table 4a et 4b)
𝜙 =𝑚1 − 𝑚2
𝜎2 1𝑛1
+1𝑛2
= 𝑧𝛼2− 𝑧1−𝛽 𝜙 =
𝑚1 − 𝑚2
𝜎2 1𝑛1
+1𝑛2
= 𝑧𝛼 − 𝑧1−𝛽
Nombre de sujets nécessaire
𝑛1 = 𝑛2 = 𝑛
𝑛 =2𝜎2
𝑚1 − 𝑚22× 𝑧𝛼/2 − 𝑧1−𝛽
2 𝑛 =
2𝜎2
𝑚1 − 𝑚22× 𝑧𝛼 − 𝑧1−𝛽
2
Nombre de sujets nécessaire
𝑛2 = 𝑘 × 𝑛1
𝑛1 =𝑘 + 1
𝑘
𝜎2
𝑚1 − 𝑚22 × 𝑧𝛼/2 − 𝑧1−𝛽
2
𝑛2 = 𝑘 × 𝑛1
𝑛1 =𝑘 + 1
𝑘
𝜎2
𝑚1 − 𝑚22 × 𝑧𝛼 − 𝑧1−𝛽
2
𝑛2 = 𝑘 × 𝑛1
• On suppose que les deux populations de vraie moyenne 𝑚1 et 𝑚2 ont la même variance 𝜎2
• Sous 𝐻1, 𝑍 =𝑋 −𝑌
𝜎2 1
𝑛1+
1
𝑛2
𝐻1
𝑁𝑚1−𝑚2
𝜎2 1
𝑛1+
1
𝑛2
, 1

Exemple
• Comparaison les poids de naissance des nouveau nés selon que la mère a consommé ou non du
tabac pendant la grossesse
• Données a priori : Ecart-type du poids de naissance est de 500g
• Objectif : calculer la puissance pour détecter une différence de 100g avec un échantillon de 300
femmes fumeuses et 300 non fumeuses
• 𝐻0 ∶ 𝑚𝐹 = 𝑚𝑁𝐹 et 𝐻1 ∶ 𝑚𝐹 ≠ 𝑚𝑁𝐹 avec 𝛼 = 5%
• 𝜙 =𝑚F−𝑚𝑁𝐹
𝜎2 1
𝑛1+
1
𝑛2
=100
5002 1
300+
1
300
= 2.449 Table 4a 1 − 𝛽 = 69%
• 𝑧1−𝛽 = 𝑧𝛼
2−
𝑚F−𝑚𝑁𝐹
𝜎2 1
𝑛1+
1
𝑛2
= 1.96 −100
5002 1
300+
1
300
= −0.489 Table 1 1 − 𝛽 = 69%

Puissance : comparaison d’un pourcentage
• Hypothèses
• 𝑋1, … , 𝑋𝑛 un échantillon indépendant et de même loi que 𝑋~𝐵(𝑝)
• 𝑛𝑝 ≥ 5 et 𝑛(1 − 𝑝) ≥ 5 ⇒ la moyenne estimée 𝑋 vérifie 𝑋 → 𝑁 𝑝,𝑝(1−𝑝)
𝑛
• Problème : la variance dépend de 𝑝 et n’est pas identique sous 𝐻0 et 𝐻1
• Solution : on utilise la transformation 𝑉 = arcsinus 𝑝
• La distribution de 𝑉 est approximativement une loi normale
• 𝑉𝑎𝑟(𝑉) est indépendante de 𝑝 → 𝑉𝑎𝑟 𝑉 =1
4𝑛
• Il faut se placer en mode "radian" pour calculer l’arcsinus
• Comparaison de 2 pourcentages : la variance de la statistique de test est identique
sous 𝐻0 et 𝐻1

Puissance : comparaison d’un pourcentage
Test bilatéral : 𝐻0 ∶ 𝑝 = 𝑝0 𝐻1 ∶ 𝑝 ≠ 𝑝0
Test unilatéral : 𝐻0 ∶ 𝑝 = 𝑝0 𝐻1 ∶ 𝑝 > 𝑝0
Puissance (Table de la loi normale Table 1 du livre "rose"
Table 5 : valeur de Arcsin
𝑧1−𝛽 = 𝑧𝛼2−
Arcsin( 𝑝1) − Arcsin( 𝑝0)
14𝑛
𝑧1−𝛽 = 𝑧𝛼 −Arcsin( 𝑝1) − Arcsin( 𝑝0)
14𝑛
Puissance (Table 4a et 4b)
𝜙 =Arcsin( 𝑝1) − Arcsin( 𝑝0)
14𝑛
= 𝑧𝛼2− 𝑧1−𝛽 𝜙 =
Arcsin( 𝑝1) − Arcsin( 𝑝0)
14𝑛
= 𝑧𝛼 − 𝑧1−𝛽
Nombre de sujets nécessaire
𝑛 =𝑧𝛼/2 − 𝑧1−𝛽
2
4 Arcsin( 𝑝1) − Arcsin( 𝑝0)2 𝑛 =
𝑧𝛼 − 𝑧1−𝛽2
4 Arcsin( 𝑝1) − Arcsin( 𝑝0)2
• Soit 𝑝0 (resp. 𝑝1) le pourcentage théorique sous 𝐻0(resp. 𝐻1)

Puissance : comparaison de deux pourcentages
• Soit 𝑝1 (resp. 𝑝2) le vrai pourcentage dans la population 1 (resp. population 2)
• Sous 𝐻1, 𝑍 =Arcsin( 𝑝1)−Arcsin( 𝑝2)
1
4𝑛1+
1
4𝑛2
𝐻1
𝑁Arcsin( 𝑝1)−Arcsin( 𝑝2)
1
4𝑛1+
1
4𝑛2
, 1
Test bilatéral : 𝐻0 ∶ 𝑝1 = 𝑝2 𝐻1 ∶ 𝑝1 ≠ 𝑝2
Test unilatéral : 𝐻0 ∶ 𝑝1 = 𝑝2 𝐻1 ∶ 𝑝1 > 𝑝2
Puissance (Table de la loi normale Table 1 du livre "rose"
Table 5 : valeur de Arcsin
𝑧1−𝛽 = 𝑧𝛼2−
Arcsin( 𝑝1) − Arcsin( 𝑝2)
14𝑛1
+1
4𝑛2
𝑧1−𝛽 = 𝑧𝛼 −Arcsin( 𝑝1) − Arcsin( 𝑝2)
14𝑛1
+1
4𝑛2
Puissance (Table 4a et 4b)
𝜙 =Arcsin( 𝑝1) − Arcsin( 𝑝2)
14𝑛1
+1
4𝑛2
= 𝑧𝛼2− 𝑧1−𝛽 𝜙 =
Arcsin( 𝑝1) − Arcsin( 𝑝2)
14𝑛1
+1
4𝑛2
= 𝑧𝛼 − 𝑧1−𝛽
Nombre de sujets nécessaire
𝑛1 = 𝑛2 = 𝑛
𝑛 =𝑧𝛼/2 − 𝑧1−𝛽
2
2 Arcsin( 𝑝1) − Arcsin( 𝑝2)2 𝑛 =
𝑧𝛼 − 𝑧1−𝛽2
2 Arcsin( 𝑝1) − Arcsin( 𝑝2)2
Nombre de sujets nécessaire
𝑛2 = 𝑘 × 𝑛1
𝑛1 =𝑘 + 1
𝑘
𝑧𝛼/2 − 𝑧1−𝛽2
4 Arcsin( 𝑝1) − Arcsin( 𝑝2)2
𝑛2= 𝑘 × 𝑛1
𝑛1 =𝑘 + 1
𝑘
𝑧𝛼 − 𝑧1−𝛽2
4 Arcsin( 𝑝1) − Arcsin( 𝑝2)2
𝑛2 = 𝑘 × 𝑛1

Exemple
• Comparaison des taux d’échec de grossesse selon la consommation ou non de café
• Données a priori : pourcentage d’échec de l’ordre de 10% sans consommation de café
• Objectif : calculer la puissance pour détecter une augmentation de 10% chez les consommatrices
avec un échantillon de 100 femmes consommatrices et 100 non consommatrices
• 𝐻0 ∶ 𝑝𝐶 = 𝑝𝑁𝐶et 𝐻1 ∶ 𝑝𝐶 ≠ 𝑝𝑁𝐶 avec 𝛼 = 5%
• 𝑝𝑁𝐶 = 0.1 Arcsin 𝑝𝑁𝐶 = 0.322 (Table 5)
• 𝑝𝐶 = 0.2 Arcsin 𝑝𝐶 = 0.464 (Table 5)
• 𝜙 =Arcsin( 𝑝𝐶)−Arcsin( 𝑝𝑁𝐶)
1
4𝑛1+
1
4𝑛2
=0.464−0.322
1
4×100+
1
4×100
= 2.008 Table 4a 1 − 𝛽 = 52%

Exemple
• Comparaison des taux d’échec de grossesse selon la consommation ou non de café
• Données a priori : pourcentage d’échec de l’ordre de 10% sans consommation de café
• Objectif : calculer le nombre de sujets nécessaire pour détecter une fréquence d’échec de 20%
avec la consommation de café et une puissance de 80% (𝑧1−𝛽 = 0.842)
• 𝐻0 ∶ 𝑝𝐶 = 𝑝𝑁𝐶 et 𝐻1 ∶ 𝑝𝐶 ≠ 𝑝𝑁𝐶 avec 𝛼 = 5%
• 𝑝𝑁𝐶 = 0.1 Arcsin 𝑝𝑁𝐶 = 0.322 (Table 5)
• 𝑝𝐶 = 0.2 Arcsin 𝑝𝐶 = 0.464 (Table 5)
• 𝑛 =𝑧𝛼/2−𝑧1−𝛽
2
2 Arcsin( 𝑝𝐶)−Arcsin( 𝑝𝑁𝐶) 2 =1.96− −0.842
2
2× 0.464−0.322 2 = 195
• Il faut sélectionner 195 femmes par groupe

Comparaison d’un OR ou d’un RR à la valeur 1
• On se ramène à la comparaison de deux pourcentages (⟺ 𝑂𝑅 = 1 ou 𝑅𝑅 = 1)
• Dans une enquête transversale ou une enquête de cohorte
• 𝑛𝐸+ nombre de patients exposés et 𝑛𝐸− nombre de non exposés
• 𝑃0 = 𝑃(𝑀 + |𝐸−)
• 𝑃1 = 𝑃 𝑀 + 𝐸 + = 𝑅𝑅 × 𝑃0
• 𝑃1 = 𝑃 𝑀 + 𝐸 + =𝑂𝑅×𝑃0
1+(𝑂𝑅−1)𝑃0
𝐻0 ∶ 𝑅𝑅 = 1
𝐻0 ∶ 𝑂𝑅 = 1 𝑧1−𝛽 = 𝑧𝛼
2−
Arcsin( 𝑃1) − Arcsin( 𝑃0)
14𝑛𝐸+
+1
4𝑛𝐸−

Comparaison d’un OR ou d’un RR à la valeur 1
• Dans une enquête cas-témoins
• 𝑛𝑀+ nombre de patients malades et 𝑛𝑀− nombre de non malades
• La fréquence de la maladie n’est pas estimable (formule de l’OR avec les fréquence d’exposition)
• 𝑃𝐸0= 𝑃(𝐸 + |𝑀−)
• 𝑃𝐸1= 𝑃 𝐸 + 𝑀 + =
𝑂𝑅×𝑃𝐸0
1+(𝑂𝑅−1)𝑃𝐸0
• Tables du livre "rose"
• Table 4a : Puissance 1 − 𝛽 en fonction des valeurs de 𝜙 pour 𝛼 = 0.05, test bilatéral
• Table 4b : Puissance 1 − 𝛽 en fonction des valeurs de 𝜙 pour 𝛼 = 0.05, test unilatéral
• Table 6a : Nombre de sujets pour une puissance de 80% en fonction de l’OR et de 𝑃0 (ou de 𝑃𝐸0 dans une
enquête cas-témoins) pour 𝛼 = 0.05
• Table 6b : Valeur de l’OR garantissant une puissance de 80% en fonction de 𝑃0 et du nombre d’exposés et de
non exposés (ou de 𝑃𝐸0 et du nombre de témoins et de cas dans une enquête cas-témoins)
pour 𝛼 = 0.05 et 𝑛1 = 𝑛2
𝐻0 ∶ 𝑂𝑅 = 1 𝑧1−𝛽 = 𝑧𝛼2−
Arcsin( 𝑃𝐸1) − Arcsin( 𝑃𝐸0
)
14𝑛𝑀+
+1
4𝑛𝑀−

Exemple
• Evaluer l’effet de l’exposition à des solvants chez des patients atteints d’un cancer et des témoins
• Données a priori : pourcentage de l’exposition autour de 20% en population générale (témoins)
• Objectif : calculer la puissance pour mettre en évidence un 𝑂𝑅 = 2 avec un échantillon de 100
cas et de 100 témoins
• 𝐻0 ∶ 𝑂𝑅 = 1 et 𝐻1 ∶ 𝑂𝑅 ≠ 1 avec 𝛼 = 5%
• 𝑝𝐸0 = 0.2 Arcsin 0.2 = 0.464
• 𝑝𝐸1 =𝑂𝑅×𝑃𝐸0
1+(𝑂𝑅−1)𝑃𝐸0
=2×0.2
1+(2−1)×0.2= 0.33 Arcsin 0.33 = 0.612
• 𝜙 =Arcsin( 𝑝𝐸1)−Arcsin( 𝑝𝐸0)
1
4𝑛𝑀++
1
4𝑛𝑀−
=0.612−0.464
1
4×100+
1
4×100
= 2.093
• Table 4a 1 − 𝛽 = 55%
Table 6a : Il faut 170 témoins et 170 cas pour mettre en évidence un 𝑂𝑅 = 2 avec une puissance de 80% Table 6b : Avec 100 témoins et 100 cas et une puissance de 80% on peut mettre en évidence un 𝑂𝑅 > 2.43

Comparaison d’un SMR à la valeur 1
• Soit M le nombre de cas observés et E le nombre de cas attendus
• Test unilatéral : 𝐻0 ∶ 𝑆𝑀𝑅 = 1
𝐻1 ∶ 𝑆𝑀𝑅 > 1
• Sous 𝐻1, 𝑍 = 2 𝑀 − 𝐸 𝐻1
𝑁 2 𝐸 × 𝑆𝑀𝑅 − 1 , 1
• 𝑧1−𝛽 = 𝑧α − 𝜙 avec 𝜙 = 2 𝐸 × 𝑆𝑀𝑅 − 1
• Tables du livre "rose"
• Table 4a : Puissance 1 − 𝛽 en fonction des valeurs de 𝜙 pour 𝛼 = 0.05, test bilatéral
• Table 4b : Puissance 1 − 𝛽 en fonction des valeurs de 𝜙 pour 𝛼 = 0.05, test unilatéral
• Table 7a : Valeur de la puissance selon E et la valeur du SMR pour 𝛼 = 0.05, test unilatéral
• Table 7b : Valeur du SMR qu’on peut mettre en évidence en fonction de la puissance et de E, 𝛼 = 0.05, test unilatéral

Exemple
• Comparaison du nombre de cas de cancers dans une cohorte de 400 hommes d’une entreprise
du Bas-Rhin au nombre attendu si le taux d’incidence est égal à celui de la population du
département
• Nombre de cas attendu 𝐸 = 20.71 (Nombre Personnes/année = 2216)
• Objectif : calculer la puissance pour mettre en évidence un SMR de 2
• 𝐻0 ∶ 𝑆𝑀𝑅 = 1et 𝐻1 ∶ 𝑆𝑀𝑅 > 1 avec 𝛼 = 5%
• 𝜙 = 2 𝐸 × 𝑆𝑀𝑅 − 1 = 2 20.71 × 2 − 1 = 3.770
• Table 4b 1 − 𝛽 = 98%
• Table 7b Pour 𝐸 = 20 et 1 − 𝛽 = 80% on peut mettre en évidence un 𝑆𝑀𝑅 = 1.67

IV. Puissance dans une enquête
• La puissance d’une enquête dépend de
• La différence des valeurs comparées (puissance augmente quand la différence augmente)
• De la variabilité de la variable étudiée (puissance augmente quand la variance diminue)
• Cas des moyennes : 𝜎2 petite
• Cas des pourcentages : 𝑝1et 𝑝2 le plus écartés possibles et éloignés de 0.5
• Du nombre de sujets inclus (puissance augmente quand la taille des échantillons augmente)
• De l’erreur de 1ère espèce 𝛼 (puissance augmente quand 𝛼 augmente)
• En général 𝛼 est fixé à 5%

Optimiser la puissance au niveau du protocole
• Choix des populations comparées
• Ecart entre les populations le plus grand possible (différence importante)
Ex : Non fumeur et gros fumeur
• Choisir des populations sensibles pour mieux observer les effets (différence importante)
Ex : personnes âgées, jeunes, femmes enceintes
• Choisir des populations homogènes (pour avoir une petite variance)
Ex : Comparer le personnels d’un atelier (plutôt que le personnel d’une usine) à des témoins
L’exposition est moins homogène dans une usine que dans un atelier
• Attention : − ne pas générer un biais de sélection
− ne répond pas toujours à l’objectif initial

Optimiser la puissance au niveau du protocole
• Choix des paramètres de santé et d’exposition
• Choisir des paramètres les plus spécifiques possibles
Ex : Effet des champs électromagnétiques leucémies plutôt que tous les cancers
Ex : Etude d’un cancer spécifique à l’amiante amiante plutôt que toutes les poussières
• Limiter les erreurs et imprécisions de mesure, définitions précises et standardisées
Limiter les biais de classement non différentiels (perte de puissance)
• Choix du mode d’échantillonnage
• Puissance meilleure dans enquête cas‐témoins ou exposés/non exposés que dans une enquête transversale
• A nombre de sujets égal, la puissance est meilleure quand les effectifs des groupes comparés sont équilibrés
• Appariement et stratification peuvent apporter un gain de puissance lors des tests de comparaison
• Choisir des tailles d‘échantillons le plus importantes possible
• Anticiper et estimer la proportion de non participation, de non réponse, de perdus de vue

Interprétation des résultats
• Résultats significatifs : rejet de 𝐻0 On peut faire l’erreur de 1ère espèce 𝛼
• Résultats non significatifs: non rejet de 𝐻0 On peut faire l’erreur de 2ème espèce β
• Calculer la puissance a posteriori (à partir des données réellement disponibles)
• Soit il n’y a pas de différence (𝐻0 vraie, il n’y a pas de différence)
• Décision possible si la puissance a priori et à posteriori est ≥ 80%
• Soit il y a un manque de puissance (𝐻1 vraie mais on ne voit pas la différence)
• Décision possible si la puissance a priori et à posteriori est < 80%
• Calcul de la différence minimale détectable
• Ex : On trouve que la différence détectable pour une puissance de 70% est ∆= 5
On peut conclure que "la vraie différence est vraisemblablement inférieure à 5" avec un risque
d’erreur de 30% (plutôt que "on n’a pas mis en évidence de différence")

Interprétation des résultats
• Remarque importante
• Quand la différence n’est pas significative, on ne conclut pas "qu’on accepte 𝐻0"
• En effet, le risque d’erreur encouru est inconnu car il dépend de " la valeur sous 𝐻1" qui est
inconnue
• " Image du microscope " :
• Si on voit une différence c’est qu’il y en a une
• Si on ne voit rien, c’est peut être que la différence est trop petite et qu’on ne l’a pas vue

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
11. Modèles multivariés

11. Modèles multivariés
I. Principaux modèles multivariés
• Régression linéaire
• Régression logistique
• Modèle de Cox (analyse de survie)
II. Concepts de l’analyse multivariée
• Maximum de vraisemblance
• Intervalle de confiance
• Tests statistiques
• Interaction entre variables
• Codage des variables
• Sélection de modèle

I. Principaux modèles multivariés
• Dans les cours précédents
• Relation univariée entre E et M ne tient pas compte d’autres facteurs (covariables)
• Méthode de Mantel-Haenszel ajustement possible sur un nombre limités de facteurs F
M et E doivent être binaire et F qualitatif
• Modèles multivariés
• Prise en compte de plusieurs covariables simultanément avec leurs interactions
• Effet d’une variable ajusté sur les autres variables
• Covariables peuvent être qualitatives ou quantitatives
• Contexte
• Soit 𝑌 une variable à expliquer
• Soit 𝑋1, 𝑋2, … , 𝑋𝑘 des variables explicatives
• On cherche à expliquer la variables 𝑌 par les variables 𝑋1, 𝑋2, … , 𝑋𝑘

Variables à expliquer et variables explicatives
• Les variables explicatives peuvent être de nature
• Qualitative à 2 classes ou binaire (Ex: Non fumeur / Fumeur)
• Qualitative ordonnée (Ex: Non fumeur / Fumeur passif / Fumeur)
• Qualitative non ordonnée (Ex: Chômeur / Etudiants / Actif / Au foyer / Retraité)
• Quantitative (Ex: Nombre de cigarettes par jour)
• La variable à expliquer peut être de nature
• Quantitative (Ex : terme de naissance) Régression linéaire
• Binaire (Ex: terme<37sem / terme ≥ 37 sem) Régression logistique
• Qualitative (Ex : terme<32 / terme 32-37 / terme ≥ 37) Régression logistique ordinale
• Temps avant un évènement (Ex: temps avant le décès) Modèle de Cox (analyse de survie)

Régression linéaire
• La variable à expliquer 𝑌 est quantitative
• La moyenne de la variable 𝑌 est exprimée comme une fonction linéaire des variables
explicatives 𝑋1, 𝑋2, … , 𝑋𝑘
𝐸 𝑌 𝑋1, 𝑋2, … , 𝑋𝑘 = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘
• Ou encore
𝑌 = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯+ 𝛽𝑘𝑋𝑘 + 𝜀 avec (en général) 𝜀 ∼ 𝑁(0, 𝜎2)
• Estimation des paramètres de régression 𝛼, 𝛽1, 𝛽2, … , 𝛽𝑘
• Méthodes des moindres carrés
𝛽 = min𝛽
𝑌 − (𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘) 2
• Maximum de vraisemblance (identique à l’estimateur des moindres carrés dans le cas gaussien)

Régression logistique
• La variable à expliquer 𝑌 est binaire (Ex: la maladie dans une enquête cas-témoins)
• La probabilité que 𝑌 = 1 est exprimée comme une fonction logistique d’une
combinaison linéaire des variables explicatives 𝑋1, 𝑋2, … , 𝑋𝑘
𝑃(𝑌 = 1|𝑋1, 𝑋2, … , 𝑋𝑘) =1
1 + 𝑒− 𝛼+𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘
• Estimation des paramètres de régression 𝛼, 𝛽1, 𝛽2, … , 𝛽𝑘
• Maximum de vraisemblance
• Fonction logistique 𝑦 =1
1+𝑒−𝑥

Modèle de Cox (analyse de survie)
• La variable à expliquer 𝑌 est une durée avant un évènement (Ex : données de cohorte)
• L’évènement d’intérêt (Ex : décès) peut être observé ou non observé
• Evènement non observé à cause de la censure (perdus de vue, exclus vivants)
• On sait si l’évènement à eu lieu ou non
• La durée d’intérêt n’est pas toujours observée Analyse de survie
• Le taux d’incidence 𝜆 𝑡 est exprimé comme un risque de base et d’une fonction log-
linéaire des variables explicatives 𝑋1, 𝑋2, … , 𝑋𝑘
𝜆 𝑡|𝑋1, 𝑋2, … , 𝑋𝑘 = 𝜆0(𝑡) × 𝑒𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘
• Estimation des paramètres de régression 𝛽1, 𝛽2, … , 𝛽𝑘 Vraisemblance partielle de Cox

II. Concepts de l’analyse multivariée
Quelques notions essentielle pour l’analyse multivariée
• Maximum de vraisemblance
• Intervalles de confiance
• Tests statistiques
• Interaction entre variables
• Codage des variables
• Sélection de modèle

Maximum de vraisemblance
• Vraisemblance: consiste à calculer la probabilité d’observer un échantillon de données
• En général,
• les observations 𝑋𝑖 d’un échantillon sont supposées 𝑖. 𝑖. 𝑑. (indépendantes et identiquement
distribuées)
• Les observations sont indépendantes et suivent la même la loi de probabilité connue de
densité paramétrique 𝑓𝜃 . la densité dépend du même paramètre 𝜃
• La vraisemblance dépend du paramètre d’intérêt 𝜃
𝐿 𝜃 = 𝑓𝜃 𝑥1, … , 𝑥𝑛|𝜃 = 𝑓𝜃 𝑥𝑖|𝜃
𝑛
𝑖=1
• Le paramètre 𝜃 peut être estimé par l’estimateur du maximum de vraisemblance
𝜃 = max𝜃∈Θ
𝐿 𝜃

Maximum de vraisemblance
• L’estimateur du maximum de vraisemblance 𝜃 a de bonnes propriétés mathématiques
• Estimateur converge presque sûrement : 𝜃 𝑛→∞
𝜃
• En général, l’estimateur asymptotiquement sans biais : 𝐸 𝜃 𝑛→∞
𝜃
• Estimateur de variance minimale parmi les estimateurs sans biais (borne de Cramer-Rao)
• La variance de l’estimateur 𝜃 peut être estimée par l’inverse de la matrice d’information de
Fisher : 𝑉𝑎𝑟 𝜃 = 𝐼 𝜃 −1
où 𝐼 𝜃 = −𝐸𝜕2ln𝐿(𝜃)
𝜕2𝜃
• Estimateur asymptotiquement normal : 𝑛 𝜃 − 𝜃𝑛→∞
𝑁(0, 𝐼(𝜃)−1)
permet de construire des tests statistiques: Wald, Likelihood Ratio Test, Score

Exemple
• Echantillon d’observations 𝑋1, … , 𝑋𝑛 de loi de Bernoulli 𝐵 𝑝
• Ex : 𝑋𝑖 = 0 si l’individu est non malade et 𝑋𝑖 = 1 si l’individu est malade
le paramètre 𝑝 correspond à la probabilité d’être malade
• Sur un échantillon de taille 𝑛, on observe k individus malades
𝐿 𝑝 = 𝐶𝑛𝑘 𝑃 𝑋𝑖 = 1
𝑘
𝑖=1
𝑃 𝑋𝑖 = 0
𝑛−𝑘
𝑖=1
= 𝐶𝑛𝑘𝑝𝑘(1 − 𝑝)𝑛−𝑘
• En remarquant que 𝑘 = 𝑋𝑖𝑛𝑖=1 et en annulant la dérivée de 𝐿 𝑝 par rapport à 𝑝
𝑝 = 𝑋𝑖
𝑛𝑖=1
𝑛
• Ex: 𝑛 = 20 et 𝑝 = 5 𝑝 = 0.25
𝐿 0.1 = 0.03; 𝐿 0.5 = 0.015; 𝐿 0.25 = 0.2

Intervalle de confiance
• Normalité asymptotique de l’estimateur du maximum de vraisemblance permet
d’obtenir les intervalles de confiance des coefficients de régression
• La matrice d’information de Fisher permet d’obtenir une estimation de la variance des
coefficients de régression : soit 𝑠 𝜃 une estimation de l’écart-type de 𝜃
• Intervalle de confiance de 𝜃 de niveau 𝛼
𝐼𝐶𝛼(θ): = [𝜃𝑖𝑛𝑓; 𝜃𝑠𝑢𝑝] = 𝜃 ± 𝑧𝛼2
𝑉𝑎𝑟 (𝜃 ) = 𝜃 ± 𝑧𝛼2
× 𝑠 𝜃
• Soit 𝜃 = (𝜃1, 𝜃2), un intervalle de confiance de 𝜃1 + 𝜃2 de niveau 𝛼
𝐼𝐶𝛼(𝜃1 + 𝜃2) ≔ (𝜃 1 + 𝜃 2) ± 𝑧𝛼
2× 𝑠 (𝜃 1+𝜃 2) avec 𝑠 (𝜃 1+𝜃 2) = 𝑉𝑎𝑟 𝜃 1 + 𝑉𝑎𝑟 𝜃 2 + 2𝐶𝑜𝑣 (𝜃 1, 𝜃 2)

Tests statistiques
• Normalité asymptotique de l’estimateur du maximum de vraisemblance permet de
définir 3 statistiques de test utiles pour comparer des modèles emboîtés
• Soit 𝜃 = (𝜃1, … , 𝜃𝑘) ∈ ℝ𝑘, on souhaite tester des hypothèses de la forme
𝐻0: 𝜃 = 𝜃0
𝐻1: 𝜃 ≠ 𝜃0
• Test de Wald (rejet de 𝐻0 si 𝜒𝑊> quantile à 95% d’une Chi-2 à 𝑘 ddl)
𝜒𝑊 = 𝜃 − 𝜃0′𝐼 𝜃 𝜃 − 𝜃0
𝐻0𝜒(𝑘)
• Test du rapport de vraisemblance (rejet de 𝐻0 si 𝜒𝐿𝑅𝑇> quantile à 95% d’une Chi-2 à 𝑘 ddl)
𝜒𝐿𝑅𝑇 = 2 ln𝐿(𝜃 ) − ln𝐿(𝜃0) 𝐻0
𝜒(𝑘)
• Test du score (rejet de 𝐻0 si 𝜒𝑆> quantile à 95% d’une Chi-2 à 𝑘 ddl)
𝜒𝑆 =𝜕ln𝐿(𝜃)
𝜕𝜃 𝜃0
′
𝐼(𝜃0)−1
𝜕ln𝐿(𝜃)
𝜕𝜃 𝜃0
𝐻0
𝜒(𝑘)

Tests statistiques
• Ex : modèle de Cox 𝜆 𝑡|𝑋1, 𝑋2, … , 𝑋𝑘 = 𝜆0(𝑡) × 𝑒𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘
• En général : tester le lien entre une variable explicative et la variable à expliquer
𝐻0: 𝛽𝑖 = 0𝐻1: 𝛽𝑖 ≠ 0
• Rejet de 𝐻0: 𝛽𝑖 = 0 association statistiquement significative
• Non rejet de 𝐻0: 𝛽𝑖 = 0 on ne rejette pas l’absence d’association
• On peut tester l’effet de chaque variable séparément avec les tests précédents
Soit 𝛽 0 = 𝛽 1, … , 𝛽 𝑖−1, 0, 𝛽 𝑖+1, … , 𝛽 𝑘
• Test de Wald : 𝜒𝑊 = 𝛽 − 𝛽 0′𝐼 𝛽 𝛽 − 𝛽 0 =
𝛽𝑖 2
𝜎 2(𝛽𝑖 )
𝐻0
𝜒(1) (ou encore 𝛽𝑖
𝑠 𝛽𝑖
𝐻0
𝑁(0,1) )
• Test du rapport de vraisemblance : 𝜒𝐿𝑅𝑇 = 2 ln𝐿(𝛽 ) − ln𝐿(𝛽 0) 𝐻0
𝜒(1)
• Test du score : 𝜒𝑆 =𝜕ln𝐿(𝛽)
𝜕𝛽 𝛽 0
′𝐼(𝛽 0)
−1 𝜕ln𝐿(𝛽)
𝜕𝛽 𝛽 0
𝐻0
𝜒(1)

Tests statistiques
• Ces tests permettent de comparer les modèles emboîtés entre eux
Le nombre de ddl des lois de Chi-2 est égal à la différence entre le nombre de paramètres de chaque modèle
• Exemple avec le test du rapport de vraisemblance
• Modèle 1 (complet) : 𝜆 𝑡|𝑋1, 𝑋2, … , 𝑋𝑘 = 𝜆0(𝑡) × 𝑒𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘 Vraisemblance 𝐿1
• Modèle 2 (𝑋2 n’a pas d’effet) : 𝜆 𝑡|𝑋1, 𝑋2, … , 𝑋𝑘 = 𝜆0′(𝑡) × 𝑒𝛽1′𝑋1+𝛽3
′𝑋3+…+𝛽𝑘′𝑋𝑘 Vraisemblance 𝐿2
• Modèle 3 (𝑋1 et 𝑋2 n’ont pas d’effet) : 𝜆 𝑡|𝑋1, 𝑋2, … , 𝑋𝑘 = 𝜆0′′(𝑡) × 𝑒𝛽3′′𝑋3+…+𝛽𝑘
′′𝑋𝑘 Vraisemblance 𝐿3
• Test de l’association de la variable 𝑋2 𝐻0: 𝛽2 = 0 (𝐻1: 𝛽𝑖 ≠ 0)
𝜒𝐿𝑅𝑇 = 2 ln𝐿1 − ln𝐿2 𝐻0
𝜒(𝑘 − (𝑘 − 1)) ≡ 𝜒(1)
• Test simultanément les associations des variables 𝑋1 et 𝑋2 𝐻0: 𝛽1 = 𝛽2 = 0 (𝐻1: ∃𝛽𝑖 ≠ 0)
𝜒𝐿𝑅𝑇 = 2 ln𝐿1 − ln𝐿3 𝐻0
𝜒(𝑘 − (𝑘 − 2)) ≡ 𝜒(2)
• Remarque : les modèles 2 et 3 sont emboîtés dans le modèle 1 (cas particuliers du modèle 1)

Interaction entre variables
• Exemple du modèle de Cox
• Modèle sans interaction : 𝜆 𝑡|𝑋1, 𝑋2 = 𝜆0(𝑡) × 𝑒𝛽1𝑋1+𝛽2𝑋2 Vraisemblance 𝐿1
• Modèle avec interaction : 𝜆 𝑡|𝑋1, 𝑋2 = 𝜆0′(𝑡) × 𝑒𝛽1′𝑋1+𝛽2
′𝑋2+𝛾𝑋1𝑋2 Vraisemblance 𝐿2
• Test de l’interaction
• 𝐻0: 𝛾 = 0𝐻1: 𝛾 ≠ 0
• Test de Wald : 𝜒𝑊 =𝛾
𝑠 𝛾
𝐻0 𝑁 0,1
• Test du rapport de vraisemblance : 𝜒𝐿𝑅𝑇 = 2 ln𝐿2 − ln𝐿1 𝐻0
𝜒(1)
• Effet de la variable 𝑋1 (Exemple avec 𝑋1 et 𝑋2 binaires)
• Modèle sans interaction : 𝑒𝛽1 (le risque est multiplié par 𝑒𝛽1 quand 𝑋1 = 1)
• Modèle avec interaction : 𝑒𝛽1 quand 𝑋2 = 0
𝑒𝛽1+𝛾 quand 𝑋2 = 1 (Rq: IC d’une somme de paramètres)
• Interprétation complexe l’effet dépend de la valeur des autres variables
limiter le nombre d’interactions et les interactions d’ordre supérieur

Codage des variables
• Codage d’une variable qualitative à deux classes
• Codage naturel 𝑋 = 0 et 𝑋 = 1
• Ex : modèle de Cox 𝜆 𝑡|𝑋 = 𝜆0(𝑡) × 𝑒𝛽𝑋
• Le risque est multiplié par 𝑒𝛽 pour les patients codés 1 par rapport aux patients codés 0
• Si on utilise un autre codage 𝑋 = 2 et 𝑋 = 5
• L’estimation du coefficient de régression sera différente 𝛽′
• Néanmoins, l’interprétation reste identique
• Le risque est multiplié par 𝑒3𝛽′= 𝑒𝛽 pour les patients codé 5 par rapport aux patients
codés 2
• Le codage n’a pas d’importance

Codage des variables
• Codage d’une variable qualitative à k classes ordonnées
• Ex : Niveau d’étude primaire, secondaire, supérieur
• Codage en une variable binaire facilité d’interprétation mais perte d’informations
• Codage "linéaire" en k classes
• 𝑋 = 0 (primaire), 𝑋 = 1 (secondaire) et 𝑋 = 2 (supérieur)
• Le codage implique une relation linéaire pour l’interprétation (dépend du codage)
• Ex : modèle de Cox 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽𝑋
• Risque multiplié par 𝑒𝛽 pour les patients codés 1 par rapport aux patients codés 0
• Risque multiplié par 𝑒2𝛽 pour les patients codés 2 par rapport aux patients codés 0
• Risque multiplié par 𝑒𝛽 pour les patients codés 2 par rapport aux patients codés 1
• Rien ne justifie cette relation linéaire il faut tester cette hypothèse

Codage des variables
• Codage d’une variable qualitative à k classes ordonnées
• Ex : Niveau d’étude primaire, secondaire, supérieur
• Codage "dichotomique" en utilisant k-1 variables binaires
• Soit 𝑋0 et 𝑋1 deux variables binaires
Niveau d’étude
Codage linéaire
Codage dichotomique (1)
𝑋 𝑋0 𝑋1
primaire 0 0 0
secondaire 1 1 0
supérieur 2 0 1
Ex : modèle de Cox 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽0𝑋0+𝛽1𝑋1
• Risque multiplié par 𝑒𝛽0 pour les patients "secondaire" par rapport aux patients "primaire"
• Risque multiplié par 𝑒𝛽1 pour les patients "supérieur" par rapport aux patients "primaire"
• Risque multiplié par 𝑒(𝛽1−𝛽0) pour les patients "supérieur" par rapport aux patients "secondaire"
Niveau d’étude
Codage linéaire
Codage dichotomique (2)
𝑋 𝑋0 𝑋1
primaire 0 0 0
secondaire 1 1 0
supérieur 2 1 1
• Risque multiplié par 𝑒(𝛽1+𝛽2) pour les patients "supérieur" par rapport aux patients "primaire"
• Risque multiplié par 𝑒𝛽2 pour les patients "supérieur" par rapport aux patients "secondaire"

Codage des variables
• Codage d’une variable qualitative à k classes ordonnées
• Ex : Niveau d’étude primaire, secondaire, supérieur
• Codage "dichotomique" en utilisant k-1 variables binaires
• Il n’y a plus d’hypothèse de linéarité
• Les effets sont spécifiques à chaque classe
• L’interprétation est indépendante du codage
• Ce codage doit toujours être étudié car il ne fait aucune hypothèse
• On compare ensuite le codage "dichotomique" avec le codage "linéaire" avec un test du
rapport de vraisemblance

Codage des variables
• Codage d’une variable qualitative à k classes ordonnées
• Comparaison du codage "linéaire" avec le codage "dichotomique"
𝐿1 (1 paramètre) 𝐿2 (𝑘 − 1 paramètres)
• Le modèle avec codage "linéaire" est emboîté dans le modèle avec codage "dichotomique"
𝜒𝐿𝑅𝑇 = 2 ln𝐿2 − ln𝐿1 𝐻0
𝜒((𝑘 − 1) − 1) ≡ 𝜒(𝑘 − 2)
• Résultat du test 𝐻0: codage "linéaire" contre 𝐻1: codage "dichotomique"
• Résultat significatif (Rejet de 𝐻0) : on conserve le codage "dichotomique"
le codage dichotomique s’ajuste mieux aux données
• Résultat non significatif (Non rejet de 𝐻0) : on conserve le codage "linéaire"
les deux codages apportent la même information: garder modèle avec le moins de paramètres

Codage des variables
• Codage d’une variable qualitative à k classes ordonnées
• Exemple : Lien entre le niveau d’étude et le risque de développer la maladie d’Alzheimer
Ex : modèle de Cox
• Codage "binaire" 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛾𝑍
• Codage "linéaire" 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽𝑋
• Codage "dichotomique" 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽0𝑋0+𝛽1𝑋1
0
0,2
0,4
0,6
0,8
1
1,2
Primaire Secondaire Supérieur
"Linéaire"
"Dichotomique"
"binaire"
Test du rapport de vraisemblance
• M1 emboîté dans M3 rejet du codage "binaire"
𝜒𝐿𝑅𝑇 = 2 × ln𝐿𝐷𝑖𝑐ℎ𝑜 − ln𝐿𝐵𝑖𝑛 = 5 > 3.84 = 𝜒95% 1
• M2 emboîté dans M3 non rejet du codage "linéaire"
𝜒𝐿𝑅𝑇 = 2 × ln𝐿𝐿𝑖𝑛 − ln𝐿𝐵𝑖𝑛 = 0.6 < 3.84 = 𝜒95% 1
• M1 n’est pas emboité dans M2
Niveau d’étude
M1: Codage binaire
M2: Codage linéaire
M3: Codage dichotomique
Z 𝑋 𝑋0 𝑋1
primaire 0 0 0 0
secondaire 1 1 1 0
supérieur 1 2 0 1

Codage des variables
• Codage d’une variable qualitative à k classes non ordonnées
• Nécessite d’avoir un coefficient différent pour chaque classe car il n’y a pas d’ordre naturel
Toujours utiliser en priorité un codage "dichotomique"
• Exemple : Relation entre le cancer de la vessie et le type de tabac consommé
Type de tabac
Codage linéaire
Codage dichotomique
𝑋 𝑋0 𝑋1 𝑋2
Non fumeur 0 0 0 0
Tabac brun 1 1 0 0
Tabac mixte 2 0 1 0
Tabac blond 3 0 0 1
Ex : modèle de Cox
• Codage "linéaire" 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽𝑋
• Codage "dichotomique" 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽0𝑋0+𝛽1𝑋1+𝛽2𝑋2
0
2
4
6
8
10
12
14
NF Brun Mixte Blond
"Linéaire"
"Dichotomique"𝑒𝛽0 = 5.3
𝑒𝛽1 = 12.9
𝑒𝛽2 = 6 𝑒2𝛽 = 4.2
𝑒3𝛽 = 8.7
𝑒𝛽 = 2.1
Test du rapport de vraisemblance
• On rejette l’hypothèse de linéarité
• Le résultat peut dépendre du codage

Codage des variables
• Codage d’une variable quantitative
• Recodage en une variable binaire facilité d’interprétation mais perte d’informations
• Recodage en une variable qualitative ordonnée
• Facilité d’interprétation mais perte d’informations
• Attention à l’hypothèse de linéarité codage "linéaire" ou "dichotomique" à évaluer
• Conserver une variable quantitative
• Pas de perte d’informations (à privilégier si possible)
• Permet d’avoir un seul coefficient facilité d’interprétation
• Attention à l’hypothèse de linéarité à évaluer en utilisant des variables qualitatives
• Attention: un modèle avec une variable quantitative ne sera jamais emboîté dans un modèle
avec une variable qualitative (pas de comparaison possible avec les tests présentés)

Codage des variables
• Codage d’une variable quantitative
• Exemple : Relation entre le cancer de la vessie et le nombre de cigarettes / jour
Evaluer l’hypothèse de linéarité
Nombre de
cigarettes
Codage linéaire
Codage dichotomique
𝑋 𝑋0 𝑋1 𝑋2 𝑋3
0 0 0 0 0 0
[0;20[ 1 1 0 0 0
[20;40[ 2 0 1 0 0
[40;60[ 3 0 0 1 0
≥ 60 4 0 0 0 1
Ex : modèle de Cox
• Codage "linéaire" 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽𝑋
• Codage "dichotomique" 𝜆 𝑡|𝑋 = 𝜆0 𝑡 × 𝑒𝛽0𝑋0+𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3
0
5
10
15
0 [0;20[ [20;40[ [40;60[ ≥ 60
"Linéaire"
"Dichotomique"𝑒𝛽0 = 2,7
𝑒𝛽1 = 7,7 𝑒𝛽2 =7
𝑒2𝛽 = 3,6
𝑒4𝛽 = 12,9
𝑒𝛽 = 1,9
𝑒𝛽3 = 13
𝑒3𝛽 = 6,8
Test du rapport de vraisemblance
ln𝐿𝐿𝑖𝑛 = −279 et ln𝐿𝐷𝑖𝑐ℎ𝑜 = −276
𝜒𝐿𝑅𝑇 𝐻0
𝜒(𝑘 − 2) ≡ 𝜒 3
𝜒𝐿𝑅𝑇 = 2 × −276 − (−279) = 6 < 7.81 = 𝜒95% 3
On ne rejette pas l’hypothèse de linéarité

Sélection de modèle
• Choix des variables à inclure dans le modèle initial
• Facteurs de risque connus de la maladie (connaissances, bibliographie)
• Variables d’appariement et/ou de stratification (car jamais parfait)
• Facteurs de risques de la maladie identifiés avec l’analyse univariée
Garder les variables tel que 𝑝 < 20% ou 25%
• Attention : groupe de variable très corrélées entre elles
• Faire des groupes de variables corrélées
• Ex: variables socio-économiques revenu, CSP, diplôme, scolarité
• Dans chaque groupe, sélectionner une ou plusieurs variables à conserver

Sélection de modèle
• Codage des variables
• Variables binaires
• Variables qualitatives non ordonnées à k classes codage "dichotomique"
• Variables qualitatives ordonnées à k classes
1. Modèle avec un codage utilisant la variable qualitative à k classes (codage "linéaire")
2. Modèle avec un codage utilisant 𝑘 − 1 variables binaires (codage "dichotomique")
3. Tester la linéarité en comparant les 2 codages (test du rapport de vraisemblance)
4. Si le codage "linéaire" est rejeté (rejet de la linéarité) utiliser un codage dichotomique
• Variable quantitative
1. Modèle avec la variable quantitative
2. Modèle avec un codage "linéaire"
3. Modèle avec un codage "dichotomique"
4. Si le codage "linéaire" est rejeté utiliser un codage dichotomique sinon utiliser la variable quantitative

Sélection de modèle
• Prise en compte des interactions
• Rechercher les interactions éventuelles par une analyse stratifiée (Mantel-Haenszel)
• En pratique, on recherche rarement les interactions d’ordre supérieur à 2 (Ex: 𝑋1𝑋2𝑋3)
• Retenir le minimum de termes d’interaction car interprétation devient difficile
• En présence d’interaction entre 𝑋1 et 𝑋2
• L’effet de 𝑋1 varie en fonction de la valeur de 𝑋2
• Donner l’estimation de l’effet dans chaque strate de 𝑋2
• Ex : modèle de Cox avec 𝑋1 et 𝑋2 binaires 𝑒𝛽1 pour 𝑋2 = 0 et 𝑒𝛽1+𝛾 pour 𝑋2 = 1

Sélection de modèle
• Sélection des variables à inclure dans le modèle final
• Tests de Wald, du LRT et du score pour comparer des modèles emboîtés
• Ex: modèle de Cox M1 : 𝜆 𝑡|𝑋1 , 𝑋2, 𝑋3 = 𝜆0(𝑡) × 𝑒𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3
M2 : 𝜆 𝑡|𝑋1 , 𝑋2 = 𝜆0′(𝑡) × 𝑒𝛽1′𝑋1+𝛽2
′𝑋2
• Si le test rejette 𝐻0: 𝛽3 = 0 (𝑝 < 0.01) on conserve le modèle M1
• Si le test ne rejette pas 𝐻0: 𝛽3 = 0 ("M1≈M2") on sélectionne le modèle M2 (moins de paramètre)
• La variable 𝑋3 n’est pas associée au risque d’évènement
• Retirer la variable 𝑋3 ne modifie pas trop la vraisemblance
• Il faut vérifier que retirer la variable 𝑋3 ne modifie pas trop l’estimation des coefficients restants
• On peut aussi choisir le modèle qui maximise le coefficient 𝑅2
minimise les critères AIC, BIC, 𝐶𝑝 de Mallows

Sélection de modèle
• Procédures de sélection automatique
• Si le modèle de départ à p variables, il y a 2𝑝 sous-modèles à explorer
Utilisation d’algorithme de sélection efficaces pour ne pas explorer tous les sous-modèles
• Procédure forward (ascendante) : on part du modèle avec aucune variable et on ajoute les variables une a
une. A chaque pas, on ajoute celle qui améliore le plus le modèle (la plus petite p-value avec le test du LRT,
Wald, Score, qui engendre la plus forte augmentation ou diminution du 𝑅2, AIC, BIC, 𝐶𝑝 de Mallows). On
s’arrête quand aucune variable n’améliore le modèle.
• Procédure backward (descendante): on part du modèle avec toutes les variables et on retire les variables
une a une. A chaque pas, on retire celle qui améliore le plus le modèle en étant supprimée.
• Procédure stepwise : mixte des deux premières procédures (on ajoute ou on supprime à chaque étape)
• En général on évite la procédure forward (l’effet d’une variable peut changer quand on ajoute
d’autres variables)

Sélection de modèle
• Problème lié à la multiplicité des tests (comparaisons multiples)
• Lorsque plusieurs tests sont réalisés successivement le risque d’erreur global de 1ère espèce 𝛼
augmente avec le nombre de test
• On montre que pour 𝑘 tests de niveau 𝛼, le risque d’erreur global est
𝛼𝑔𝑙𝑜𝑏𝑎𝑙 = 1 − 1 − 𝛼 𝑘 > 𝛼
• Il faut utiliser des méthodes pour corriger la multiplicités des tests
• Méthode de Bonferroni : utiliser un risque 𝛼
𝑘 au lieu de 𝛼
Le risque global est < 𝛼 mais la puissance du test devient faible
• Méthode de Holm-Bonferroni (plus puissante)
• Correction de S ida k
• False discovery rate

Sélection de modèle
• Règles hiérarchiques pour le retrait des variables
• En présence d’interaction conserver les variables qui interviennent dans une interaction
• En cas de codage dichotomique
• Conserver toutes les variables utilisés pour le codage dans le modèle
• Sinon l’interprétation est modifiée !
• Ex : Catégorie socio-professionnelle
Catégorie socio-professionnelles
Codage linéaire
Codage dichotomique
𝑋 𝑋0 𝑋1 𝑋2 𝑋3
Ouvrier 0 0 0 0 0
Cadre 1 1 0 0 0
Agriculteur 2 0 1 0 0
Chômeur 3 0 0 1 0
Autres 4 0 0 0 1
• 𝑒𝛽1 représente l’augmentation du risque pour un
"Agriculteur" par rapport à la catégorie "Ouvrier"
• Si on supprime la variable 𝑋2
𝑒𝛽1 devient l’augmentation du risque pour les
agriculteurs par rapport à la catégorie "Ouvrier" +
"Chômeur"

Sélection de modèle
• Equilibre à trouver entre
• Modèle saturé (toutes les variables et toutes les interactions)
• Bonne adéquation
• Risque de sur-ajustement (perte de puissance pour étudier le lien entre la maladie et l’exposition)
• Interprétation difficile (beaucoup de coefficients)
• Modèle non saturé (modèle avec peu de variables)
• Moins bonne adéquation du modèle
• Possibilité de confusion résiduelle
• Interprétation plus facile (moins de coefficient)

Epidémiologie
Philippe Saint Pierre
Université Pierre et Marie Curie – Paris 6
12. Régression logistique

12. Régression logistique
I. Exemples
II. Modèle logistique
III. Estimation du maximum de vraisemblance
IV. Fonction Logit
V. Odds ratio
VI. Intervalles de confiance
VII. Tests statistiques
VIII. Interaction entre variables
IX. Méthodes alternatives

I. Exemples
• Exemple 1 : Enquête cas-témoins étudier le lien entre une exposition et une maladie
• Echantillon de 𝑚1 malades et 𝑚0 non malades
• On observe le statut malade (𝑌 = 1) ou non (𝑌 = 0)
• On observe l’exposition, fumeur (𝑋1 = 1) ou non (𝑋1 = 0)
• On observe également d’autres covariables (𝑋2 , … , 𝑋𝑘)
• On cherche à étudier l’effet du tabac en tenant comte des covariables sur la probabilité d’être malade
• Attention : on ne pourra pas estimer la probabilité d’être malade pour un individu (individus sélectionnés sur le statut malade non malades)
• Exemple 2 : Echantillon représentatif de 173 femelles limule
• La présence (𝑌 = 1) ou l'absence (𝑌 = 0) de mâle dans l'entourage
• La largeur de leur abdomen : 𝑋1 en cm
• La teinte de leur carapace : 𝑋2 = 1 (foncée) ou 𝑋1 = 0 (clair)
• Objectif : expliquer la présence ou l'absence de partenaire en fonction des variables "largeur" et "teinte".
Fumeur
E+ E-
Cancer du poumon
M+ a b 𝒎𝟏
M- c d 𝒎𝟎

• Soit 𝑌 une variable binaire qu’on cherche à expliquer
• La probabilité que 𝑌 = 1 est exprimée comme une fonction logistique d’une combinaison linéaire
des variables explicatives 𝑋1, 𝑋2, … , 𝑋𝑘
𝑃(𝑌 = 1|𝑋1, 𝑋2, … , 𝑋𝑘) =1
1 + 𝑒− 𝛼+𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘
• L’objectif est d’estimer les coefficients 𝛼, 𝛽1, … , 𝛽𝑘 à partir d’un échantillon
𝑌𝑖 , 𝑋𝑖1, … , 𝑋𝑖𝑘 𝑖=1,…,𝑛
• Pour chaque individu, on pourra déduire la probabilité d’être malade (si indépendance des
observations : pas le cas dans les enquêtes cas-témoins)
𝑃(𝑌𝑖 = 1|𝑋𝑖1, 𝑋𝑖2, … , 𝑋𝑖𝑘) =1
1 + 𝑒− 𝛼+𝛽1𝑋𝑖1+𝛽2𝑋𝑖2+⋯+𝛽𝑘𝑋𝑖𝑘
II. Modèle logistique
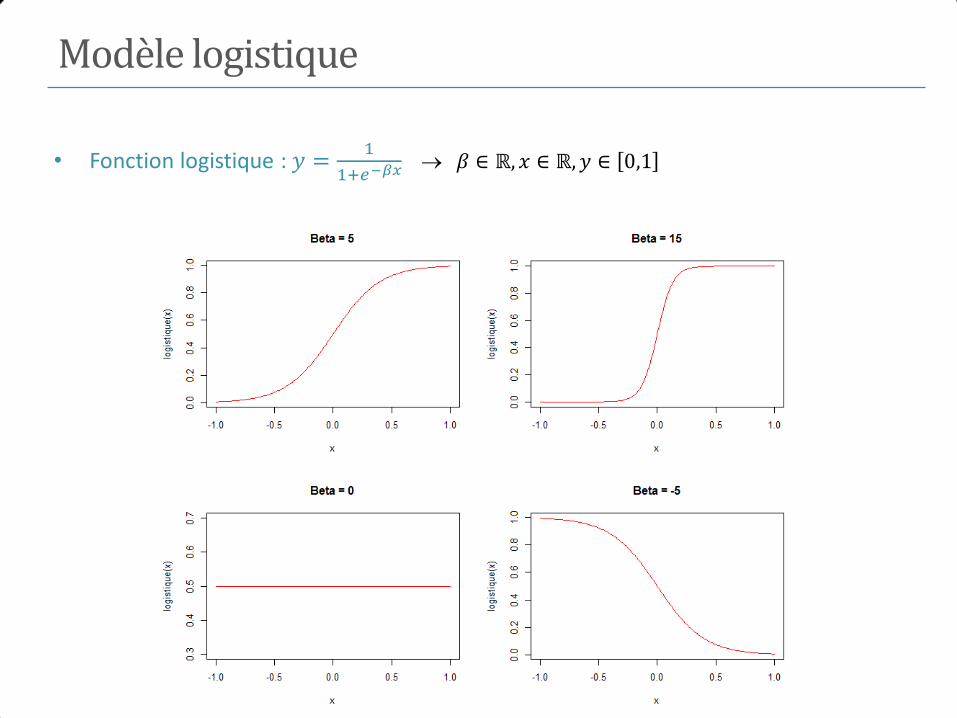
Modèle logistique
• Fonction logistique : 𝑦 =1
1+𝑒−𝛽𝑥 𝛽 ∈ ℝ, 𝑥 ∈ ℝ, 𝑦 ∈ 0,1

III. Estimation par maximum de vraisemblance
• Estimation des paramètres de régression 𝛼, 𝛽1, 𝛽2, … , 𝛽𝑘 par maximum de
vraisemblance à partir d’un échantillon 𝑌𝑖 , 𝑋𝑖1, … , 𝑋𝑖𝑘 𝑖=1,…,𝑛
𝐿 𝛼, 𝛽1, … , 𝛽𝑘 = 𝑃(𝑌𝑖 = 𝑦𝑖 |𝑋𝑖1 , 𝑋𝑖2 , … , 𝑋𝑖𝑘)𝑛𝑖=1
= 𝑃(𝑌𝑖 = 1 |𝑋𝑖1 , 𝑋𝑖2 , … , 𝑋𝑖𝑘) 𝑦𝑖 𝑃(𝑌𝑖 = 0 |𝑋𝑖1 , 𝑋𝑖2 , … , 𝑋𝑖𝑘) 1−𝑦𝑖𝑛𝑖=1
= 1
1+𝑒− 𝛼+𝛽1𝑋𝑖1+𝛽2𝑋𝑖2+⋯+𝛽𝑘𝑋𝑖𝑘
𝑦𝑖 𝑒− 𝛼+𝛽1𝑋𝑖1+𝛽2𝑋𝑖2+⋯+𝛽𝑘𝑋𝑖𝑘
1+𝑒− 𝛼+𝛽1𝑋𝑖1+𝛽2𝑋𝑖2+⋯+𝛽𝑘𝑋𝑖𝑘
1−𝑦𝑖𝑛𝑖=1
• Estimateur du maximum de vraisemblance
𝛽 = 𝛼 , 𝛽1 , … , 𝛽𝑘
= max𝛽∈ℝ𝑘+1
log 𝐿 𝛼, 𝛽1, … , 𝛽𝑘
• Estimation par des méthodes itératives : algorithme de Nawton-Raphson

IV. Fonction Logit
• Modèle logistique
𝑃(𝑌 = 1|𝑋1, 𝑋2, … , 𝑋𝑘) =1
1 + 𝑒− 𝛼+𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘
• Considérons la fonction Logit .
Logit 𝑝 = ln 𝑝
1 − 𝑝
• La fonction Logit . permet de "linéariser" 𝑃(𝑌 = 1|𝑋1, 𝑋2, … , 𝑋𝑘)
Logit 𝑃(𝑌 = 1|𝑋1 , 𝑋2, … , 𝑋𝑘) = ln1
𝑒− 𝛼+𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘= 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘

V. Odds ratio
• Relation entre Logit(p) et l’odds ratio d’une enquête cas-témoins M+ (𝑌 = 1) et M- (𝑌 = 0)
• Soit 𝑃1 = 𝑃 𝑀 + 𝐸 + et 𝑃0 = 𝑃 𝑀 + 𝐸 −
𝑂𝑅 =
𝑃1 (1 − 𝑃1)
𝑃0 (1 − 𝑃0)
• Ln 𝑂𝑅 = Ln𝑃1
1−𝑃1− Ln
𝑃0
1−𝑃0= Logit 𝑃1 − Logit 𝑃0 = Ln 𝑂𝑅
• Cas où il y a une seule variable explicative qui est l’exposition E
• Modèle logistique : 𝑃(𝑀 + |𝐸) =1
1+𝑒− 𝛼+𝛽𝐸 ou Logit 𝑃(𝑀 + |𝐸) = 𝛼 + 𝛽𝐸
• Ln 𝑂𝑅 = Logit 𝑃1 − Logit 𝑃0 = 𝛼 + 𝛽 × 1 − 𝛼 + 𝛽 × 0 = 𝛽
𝑂𝑅 = exp (𝛽) OR brut entre E et M
𝐸 = 1 si E+ 𝐸 = 0 si E-

Odds ratio
• Cas où il y a d’autres variables explicatives en plus de l’exposition E
• Modèle logistique : 𝑃(𝑀 + |𝐸, 𝑋1 , 𝑋2 , … , 𝑋𝑘) =1
1+𝑒− 𝛼+𝛽𝐸+𝛽1𝑋1+𝛽2𝑋2+⋯+𝛽𝑘𝑋𝑘
• Logit 𝑃(𝑀 + |𝐸, 𝑋1, 𝑋2 , … , 𝑋𝑘) = 𝛼 + 𝛽𝐸 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘
• Soit 𝑃1 = 𝑃 𝑀 + 𝐸+, 𝑋1 , 𝑋2 , … , 𝑋𝑘 et 𝑃0 = 𝑃 𝑀 + 𝐸−, 𝑋1, 𝑋2 , … , 𝑋𝑘
• Ln 𝑂𝑅 = Logit 𝑃1 − Logit 𝑃0
= 𝛼 + 𝛽 × 1 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘 − 𝛼 + 𝛽 × 0 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘 = 𝛽
𝑂𝑅 = exp (𝛽) OR entre E et M ajusté sur 𝑋1, 𝑋2, … , 𝑋𝑘
𝐸 = 1 si E+ 𝐸 =0 si E-

VI. Intervalles de confiance
• Modèle logistique Logit 𝑃(𝑀 + |𝐸) = 𝛼 + 𝛽𝐸
• Intervalle de confiance de 𝛽 de niveau 𝛼
𝐼𝐶𝛼(𝛽): = [𝛽𝑖𝑛𝑓; 𝛽𝑠𝑢𝑝] = 𝛽 ± 𝑧𝛼2
𝑉𝑎𝑟 (𝛽 )
• Intervalle de confiance de 𝑂𝑅 = exp(𝛽) de niveau 𝛼
𝐼𝐶𝛼(𝑂𝑅): = 𝑒𝛽𝑖𝑛𝑓; 𝑒𝛽𝑠𝑢𝑝
• Modèle logistique Logit 𝑃(𝑀 + |𝐸, 𝑋1) = 𝛼 + 𝛽𝐸 + 𝛽1𝑋1 + 𝛾𝐸𝑋1
• Intervalle de confiance de 𝛽 + 𝛾 de niveau 𝛼
𝐼𝐶𝛼(𝛽 + 𝛾) ≔ [Γ𝑖𝑛𝑓 ; Γ𝑠𝑢𝑝] = (𝛽 + 𝛾 ) ± 𝑧𝛼
2𝑉𝑎𝑟 𝛽 + 𝑉𝑎𝑟 𝛾 + 2𝐶𝑜𝑣 (𝛽 , 𝛾 )
• Intervalle de confiance de 𝑂𝑅 = exp(𝛽 + 𝛾) de niveau 𝛼 : 𝐼𝐶𝛼 ≔ 𝑒Γ𝑖𝑛𝑓; 𝑒Γ𝑠𝑢𝑝
OR entre E et M en présence d’interaction dans la strate 𝑋1 = 1

VII. Tests statistiques
• Modèle logistique Logit 𝑃(𝑀 + |𝑋1, 𝑋2, … , 𝑋𝑘) = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘
• Test de l’association entre une variable et la maladie
𝐻0: 𝛽𝑖 = 0𝐻1: 𝛽𝑖 ≠ 0
⇔ 𝐻0: 𝑂𝑅𝑖 = 1𝐻1: 𝑂𝑅𝑖 ≠ 1
• Rejet de H0: 𝛽𝑖 = 0 association statistiquement significative
• Non rejet de H0: 𝛽𝑖 = 0 on ne rejette pas l’absence d’association
• Pour chaque variables on peut tester l’association entre la variable 𝑖 et la maladie
Soit 𝛽 0 = 𝛽 1 , … , 𝛽 𝑖−1, 0, 𝛽 𝑖+1, … , 𝛽 𝑘
• Test de Wald : 𝜒𝑊 = 𝛽 − 𝛽 0′𝐼 𝛽 𝛽 − 𝛽 0 =
𝛽𝑖 2
𝑉𝑎𝑟 (𝛽𝑖 )
𝐻0
𝜒(1) (ou encore 𝛽𝑖
𝑠 𝛽𝑖
𝐻0
𝑁(0,1) )
• Test du rapport de vraisemblance : 𝜒𝐿𝑅𝑇 = 2 ln𝐿(𝛽 ) − ln𝐿(𝛽 0) 𝐻0
𝜒(1)

Tests statistiques
• Modèle logistique Logit 𝑃(𝑀 + |𝑋1, 𝑋2, … , 𝑋𝑘) = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘
• On peut comparer des modèles emboîtés entre eux, par exemple
Modèle A : Logit 𝑃(𝑀 + |𝑋1, 𝑋2, … , 𝑋𝑘) = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑘𝑋𝑘
Modèle B : Logit 𝑃(𝑀 + |𝑋1) = 𝛼 + 𝛽1𝑋1
𝐻0: 𝛽2 = ⋯ = 𝛽𝑘 = 0 𝐻1: ∃ 𝛽𝑖≠ 0, 𝑖 = 2, … , 𝑘
⇔ 𝐻0: 𝑂𝑅2 = ⋯ = 𝑂𝑅𝑘 = 1 𝐻1: ∃ 𝑂𝑅𝑖≠ 1, 𝑖 = 2, … , 𝑘
• Rejet de H0 on rejette le modèle B
• Non rejet de H0 on peut raisonnablement considérer le modèle B
• Test du rapport de vraisemblance : 𝜒𝐿𝑅𝑇 = 2 ln𝐿𝐴 − ln𝐿𝐵 𝐻0
𝜒 𝑘 + 1 − 2 ≡ 𝜒 𝑘 − 1
Nombre de paramètres du modèle A − Nombre de paramètres du modèle B

VIII. Interaction entre variables
• Modèle sans interaction : Logit 𝑃(𝑀 + |𝑋1, 𝑋2) = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2 Vraisemblance 𝐿1
• Modèle avec interaction : Logit 𝑃(𝑀 + |𝑋1, 𝑋2) = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2+𝛾𝑋1𝑋2 Vraisemblance 𝐿2
• Test de l’interaction avec le test de Wald ou du rapport de vraisemblance
𝐻0: 𝛾 = 0𝐻1: 𝛾 ≠ 0
• Test de Wald : 𝜒𝑊 =𝛾
𝑠 𝛾
𝐻0 𝑁 0,1
• Test du rapport de vraisemblance : 𝜒𝐿𝑅𝑇 = 2 ln𝐿2 − ln𝐿1 𝐻0
𝜒(1)
• OR entre variable 𝑋1 et la maladie (Exemple avec 𝑋1 et 𝑋2 binaires)
• Modèle sans interaction : 𝑂𝑅 = 𝑒𝛽1
• Modèle avec interaction : 𝑂𝑅 = 𝑒𝛽1 quand 𝑋2 = 0
𝑂𝑅 = 𝑒𝛽1+𝛾 quand 𝑋2 = 1 (Rq: IC d’une somme de paramètres)

VIII. Méthodes alternatives
• Régression logistique est un modèle très populaire
• Régression logistique fait partie des Modèles Linéaires Généralisés (modèle binomial)
• Extension possible dans le cas où la variable à expliquer est qualitative ordonnée
Régression logistique polytomique ou ordinale
• Méthodes alternatives méthode d’apprentissage supervisé
• Arbre de décision (algorithme CART)
• Forêt aléatoire
• Support Vector Machine
• Méthode des 𝑘 plus proches voisins