Embed Size (px)
Citation preview

Etiquetage morphosyntaxique probabiliste
Traitement Automatique des LanguesMaster Informatique
Université Paris-Est Marne-la-Vallée
Matthieu Constant

Références de base du cours
Christopher D. Manning and Hinrich Schütze, 1999, Foundations of Statistical Natural Language Processing, Massachussetts Insititute of Technology
Ruslan Mitkov, 2003, The Oxford Handbook of Computational Linguistics, Oxford University Press

Plan
● introduction– étiquettes morphosyntaxiques et ambiguïté
– caratéristiques des analyseurs
– quelques rappels sur les probabilités
● analyseurs stochatisques– architecture d'un analyseur
– par modèles de Markov
– par apprentissage de règles de transformation (Brill)

INTRODUCTION

Analyse morphosyntaxique
● processus d'assigner une étiquette morphosyntaxique à chaque mot d'un texte
● exemple :
Max donne une pomme à Léa N V DET N PREP N
● terminologie équivalente :– étiquette morphosyntaxique
– partie du discours (Part-of-Speech = POS)

INTRODUCTIONEtiquettes morphosyntaxiques et ambiguïté

Etiquettes - 1
● en général, les étiquettes sont données aux mots en utilisant des critères formels :
– distribution syntaxique (ex. DET A N)
– fonction syntaxique (ex. nom tête d'un groupe nominal)
– appartenance à une classe morphologique ou syntaxique

Etiquettes - 2
● le jeu d'étiquettes utilisé est très variable suivant les analyseurs
● une étiquette peut contenir les informations suivantes :– une catégorie grammaticale (obligatoire)
ex. verbe, nom, adjectif, adverbe, déterminant, ...
– des informations flexionnellesex. genre, nombre, personne, temps, mode, ...
– des informations morphosyntaxiquesex. distinction entre nom propre et nom commun

Etiquettes - 3
● extension possible : une étiquette peut contenir des traits sémantiques
● quelques traits : humain, concret, abstrait
● exemple d'entrée : avocat– avocat => nom commun humain
– avocat => nom commun concret
● mais la limite entre étiquetage morphosyntaxique et étiquetage morphosyntaxique devient flou !

Echantillon de jeu d'étiquettes pour l'anglais - 1
AT : article (ex. a)BEZ : mot isIN : préposition (ex. for)JJ : adjectif (ex. beautiful)JJR : adjectif comparatif (ex. clearer)MD : modal (ex. should)NN : nom commun singulier (ex. car)NNP : nom propre singulier (ex. George)NNS : nom commun pluriel (ex. cars)PN : pronom personnel (ex. we)

Echantillon de jeu d'étiquettes pour l'anglais - 2
RB : adverbe (ex. nicely)RBR : adverbe comparatif (ex. sooner)TO : mot toVB : verbe à l'infinitif (ex. sing)VBD : verbe au passé (ex. changed)VBG : verbe au gérondif (ex. eating)VBN : verbe au participe passé (ex. been)

Ambiguïté - 1
● exemple de phrase ambigue :
La belle femme ferme le voile.
● ambiguités :– la : déterminant, nom ou pronom
– belle : adjectif ou nom
– ferme : adjectif, nom ou verbe
– le : déterminant ou pronom
– voile : nom ou verbe

Ambiguïté - 2
● en général, les mots sont ambigus
● certains mots n'ont qu'une seule étiquette– âge : nom masculin singulier
– ânerie : nom féminin singulier
– éducatif : adjectif masculin singulier

INTRODUCTIONCaractéristiques des analyseurs

Caractéristiques des étiqueteurs
● les mots sont des tokens
● utilisation de contextes très locaux (2-3 mots)
● bonne précision : 96-98% de mots correctement étiquetés

Approches
● règles construites manuellement
● modèle de Markov
● modèle de Markov caché
● transformations automatiquement apprises
● arbres de décisions ...

Quelques applications
● recherche d'information
● extraction d'information
● analyse syntaxique

INTRODUCTIONQuelques rappels sur les probabilités

Probabilités
● soit A un événement dans un univers donné
● la probabilité de cet événement est notée P(A) :
avec– f(A) : nombre de fois que A se produit
– n : nombre de tous les possibles dans l'univers
P A=f An
∈[0,1]

Probabilité conditionnelle - 1
● soient A et B deux événements
● on note P(A|B), la probabilité conditionnelle que A se produise sachant que B s'est déjà produit :
avec P(A,B) la probabilité que les deux événements A et B se produisent ensemble
P A∣B=P A ,BP B

Probabilité conditionnelle - 2
● soient les n événements A1, ..., A
n
● généralisation :
P A1 ,... , An=P A1. P A2∣A1. P A3∣A1 , A2...P An∣A1 ...An−1

Indépendance
● deux événements A et B sont indépendants l'un de l'autre si
P(A,B) = P(A).P(B)
● A et B sont aussi conditionnellement indépendant :
soit C un événement, alors
P(A,B|C) = P(A|C).P(B|C)

Indépendance
● Soient les n événements A1, ..., A
n indépendants
● Généralisation :
P A1 ,... , An∣C =P A1∣C.P A2∣C ...P An∣An−1

Théorème de Bayes
● théorème :
● déterminer l'événement B qui maximise P(B|A)
car P(A) est constante quelque soit B
P B∣A =P B , AP A
=P A∣B. P B
P A
argmaxB
P A∣B.P BP A
= argmaxBP A∣B. P B

Hypothèses de Markov
● on suppose que les événements A1, ..., A
n apparaissent
dans un certain ordre
● Markov fait deux approximations :– horizon limité : un événement ne dépendant que de son
précédent
– invariant temporel : la probabilité ne dépend pas du temps
P An1∣A1 , ... , An = P An1∣An

Plan
● introduction– étiquettes morphosyntaxiques et ambiguïté
– caratéristiques des analyseurs
– quelques rappels sur les probabilités
● analyseurs stochatisques– architecture d'un analyseur
– par modèles de Markov
– par apprentissage de règles de transformation (Brill)

ANALYSEURS STOCHASTIQUES

ANALYSEURS STOCHASTIQUESArchitecture des analyseurs

Architecture générale
● tokenisation
● analyse lexicale ambigüe
● levée d'ambiguité

Tokenisation
● découpage d'une séquence de caractères en tokens
● un token peut être :
– un mot simple
– un symbole de ponctuation
– un nombre
– un caractère blanc

Analyse lexicale ambigue
● assigner à chaque token l'ensemble des étiquettes possibles
● méthodes :– utilisation d'un lexique
● listes de mots● modèles à états finis
– utilisation d'un “guesser” (devineur)● application de règles morphologiques● application de règles contextuelles● application de priorités

Levée d'ambiguité probabiliste
● à base de deux types d'informations
– information sur le mot à étiqueter
– information contextuelle syntaxique
● combinaison de ces deux informations
● apprentissage des ces informations sur des corpus en général annotés (étiquetés) à la main

Informations sur les mots - 1
● étant donné un mot, on est capable de déterminer la probabilité de lui assigner une étiquette
● soient un mot w et une étiquette t, la probabilité d'avoir l'étiquette t sachant que l'on a le mot w est :
– f(w,t) est le nombre de fois que w est étiqueté par t dans le corpus d'apprentissage
– f(w) est le nombre d'occurrences du mot
P t∣w =f w ,t f w

Informations sur les mots - 2
● implémentation simpliste d'un étiqueteur :
on assigne à chaque mot l'étiquette la plus probable indépendement du contexte
● exemple :
le mot tables serait étiqueté comme nom, car il apparaît plus souvent comme un nom que comme un verbe.
● résultats plutôt bons : environ 90% de précision

informations sur les mots - 3
● étant donné une étiquette t, on peut aussi calculer la probabilité qu'elle soit celle d' un mot w
● moins intuitif ! Mais utile pour la suite ...
P w∣t =f w ,t f t

Information contextuelle syntaxique
● on est capable de déterminer la probabilité d'avoir une étiquette tk quand elle est précédée de l'étiquette tj dans le texte
● exemple : a new play
P(NN|JJ) = 0.45P(VBP|JJ) = 0.0005
dans le Brown Corpus, d'après (Manning et Schütze, 1999)
P tk∣t j =f t j , tk f t j

ANALYSEURS STOCHASTIQUESModèle de Markov

Définition du problème - 1
● Soient
– w1,n
= w1 w
2 ... w
n, une séquence de n mots
– t1,n
= t1 t
2 ... t
n, une séquence d'étiquettes associée à w
1,n
● Etant donné w1,n
, le but est de trouver t = t1,n
tel qu'elle
maximise P(t1,n
|w1,n
)
cf. théorème de Bayes
t = argmax t1,nP t1,n∣w1,n
= argmaxt1,nP w1,n∣t1,n .P t1,n

Définition du problème - 2
● en appliquant trois hypothèses :– horizon limité (Markov) :
P(tn|t1,n-1) = P(t
n|t
n-1)
– indépendance des mots : P(w
1, ..., w
n) = P(w
1)....P(w
n)
– l'identité d'un mot dépend de son étiquette : P(w
i|t
1,n) = P(w
i|t
i)
● on obtient [avec P(t1|t
0) = 1.0 par convention] :
t = argmax t1,n∏i=1
nP w i∣t i . P t i∣t i−1

Algorithme d'apprentissage
après parsing d'un corpus annoté
pour chq étiquette tk faire pour chq étiquette tj faire P(tk|tj) = f(tj,tk)/f(tj) finfin
pour chq étiquette tj faire pour chq mot wi faire P(wi|tj) = f(wi,tj)/f(tj) finfin
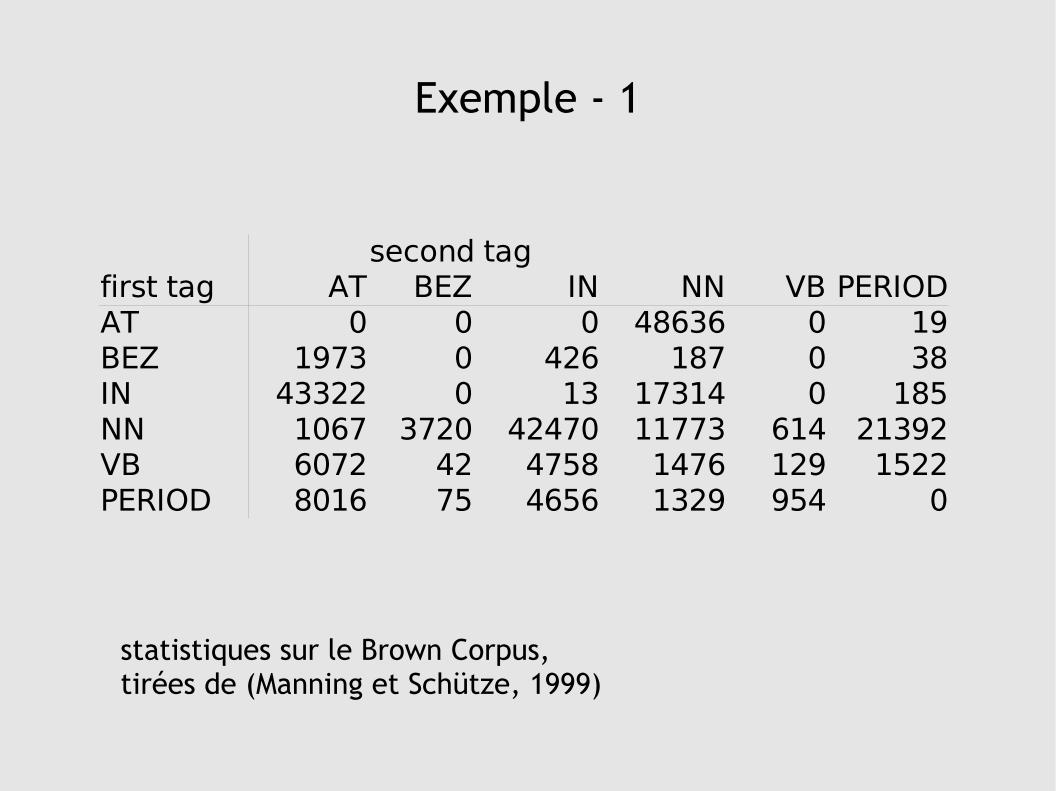
Exemple - 1
second tagfirst tag AT BEZ IN NN VB PERIODAT 0 0 0 48636 0 19BEZ 1973 0 426 187 0 38IN 43322 0 13 17314 0 185NN 1067 3720 42470 11773 614 21392VB 6072 42 4758 1476 129 1522PERIOD 8016 75 4656 1329 954 0
statistiques sur le Brown Corpus, tirées de (Manning et Schütze, 1999)
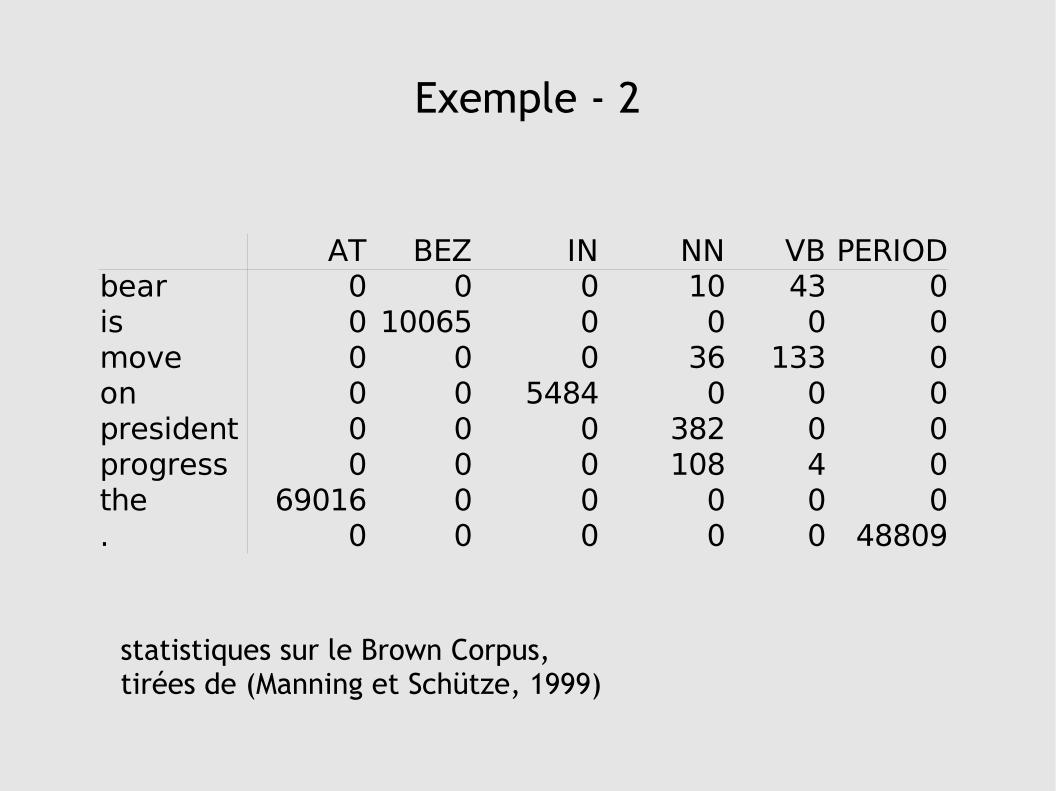
Exemple - 2
AT BEZ IN NN VB PERIODbear 0 0 0 10 43 0is 0 10065 0 0 0 0move 0 0 0 36 133 0on 0 0 5484 0 0 0president 0 0 0 382 0 0progress 0 0 0 108 4 0the 69016 0 0 0 0 0. 0 0 0 0 0 48809
statistiques sur le Brown Corpus, tirées de (Manning et Schütze, 1999)
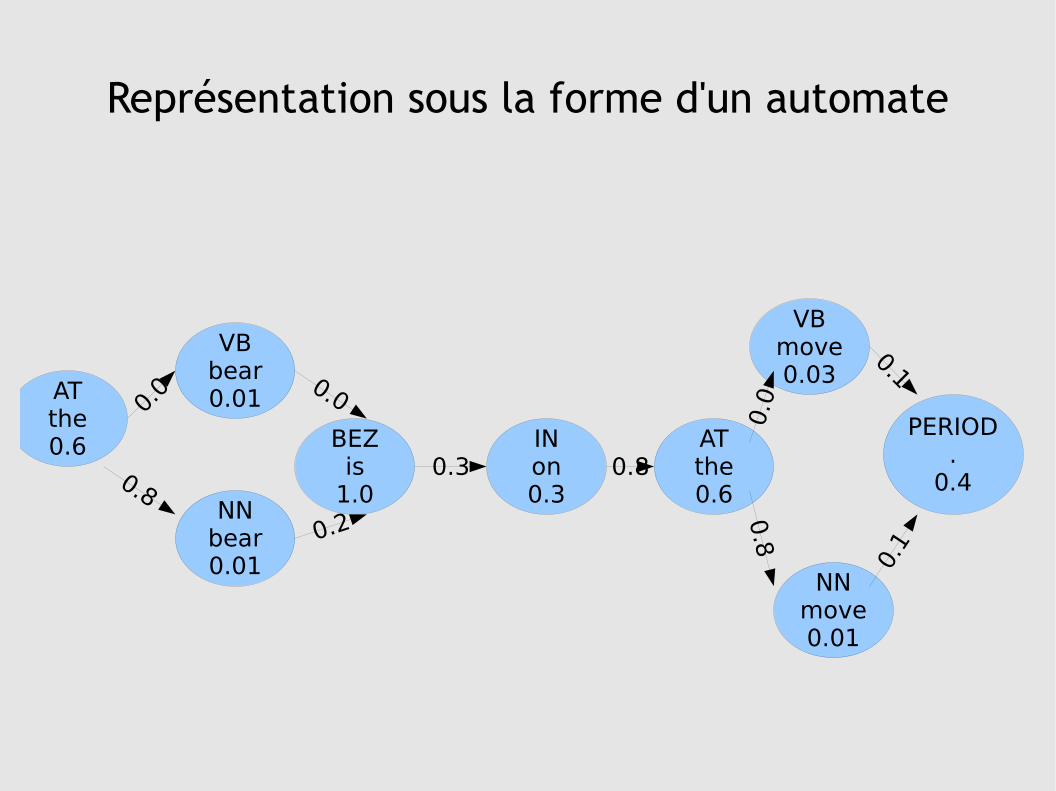
Représentation sous la forme d'un automate
ATthe0.6
VBbear0.01
NNbear0.01
BEZis
1.0
INon0.3
VBmove0.03
NNmove0.01
ATthe0.6
PERIOD.
0.4
0.0
0.8
0.0
0.2
0.3 0.8
0.0
0.8
0.1
0.1
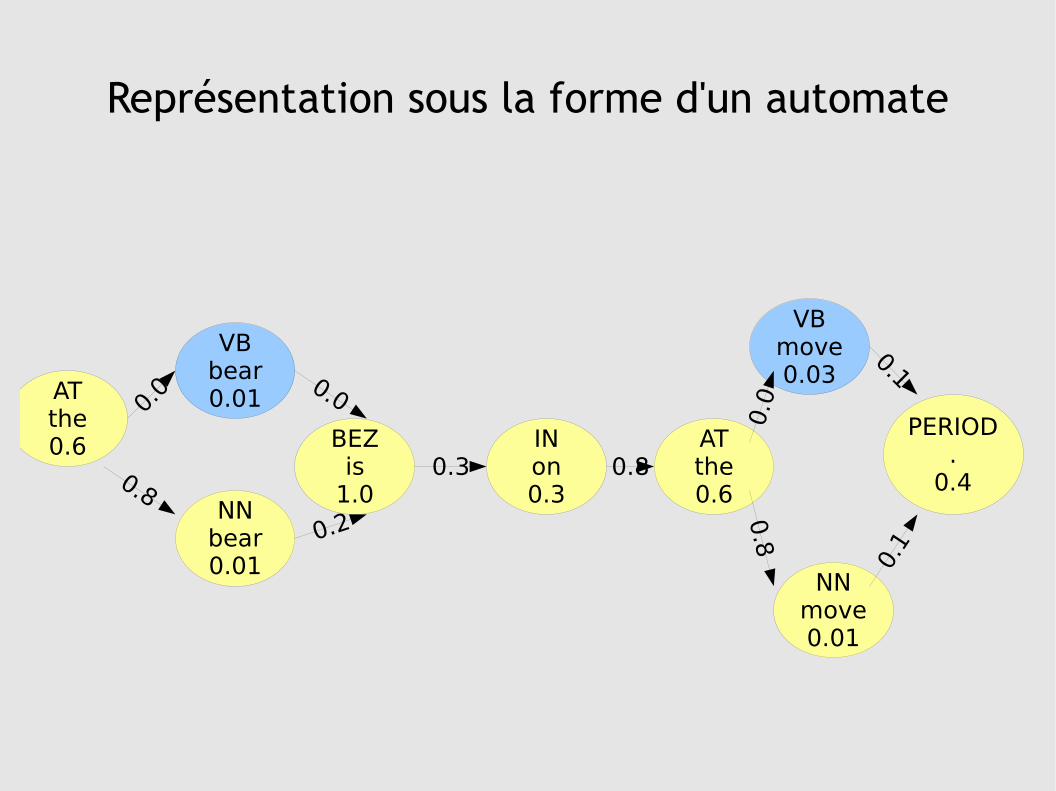
Représentation sous la forme d'un automate
ATthe0.6
VBbear0.01
NNbear0.01
BEZis
1.0
INon0.3
VBmove0.03
NNmove0.01
ATthe0.6
PERIOD.
0.4
0.0
0.8
0.0
0.2
0.3 0.8
0.0
0.8
0.1
0.1

Résolution du problème
● méthode naïve :
on évalue l'équation pour chaque possibilité d'étiquetage=> complexité exponentielle
● méthode itérative : algorithme de Viterbi
en partant de la position 1 jusqu'à n à chaque état de cette position, on calcule le meilleur chemin (et sa probabilité) en se servant des états et transitions entrants.

Algorithme de Viterbi
● trois étapes :– initialisation
– induction
– finalisation
● calcul de deux fonctions :
– di(j) indique la probabilité d'être dans l'état j (ou étiq j) au
mot i
– gi+1
(j) indique l'état (ou étiq) le plus probable au mot i
sachant que nous sommes dans l'état j du mot i + 1

Algorithme
#initialisationd1(PERIOD) = 1.0
d1(t) = 0.0 pour chq étiq t PERIOD
#induction#n: longueur de la phrasepour i=1 à n faire
pour chq étiq tj fairedi+1(tj) = max
tk(d
i(tk).P(w
i+1|tj).P(tj|tk))
gi+1(t
j) = argmax
tk(d
i(tk).P(w
i+1|tj).P(tj|tk))
finfin

Algorithme
# terminaison#X1, ...,Xn : étiquettes assignées
Xn+1 = argmax
t d
n+1(t)
pour j = n à 1 faire [pas -1] X
j = g
j+1(X
j+1)
fin

ANALYSEURS STOCHASTIQUESEtiqueteurs basés sur des transformations

Etiqueteurs basés sur des transformations
● limitation des approches par le modèle de Markov : le contexte est limité à 2 mots (voire 3)
● idée : – pourquoi ne pas étendre à des contextes plus grand
capturant des informations complexes
– transformations : transforme un étiquetage imparfait en un autre avec moins d'erreurs, si l'on se trouve dans certains contextes
– les types de contextes sont spécifiés à la main
– les transformations sont apprises automatiquement





























