Embed Size (px)
Citation preview

Yeast 14, 1453–1469 (1998)
Expanding Yeast Knowledge Online
KARA DOLINSKI1, CATHERINE A. BALL1, STEPHEN A. CHERVITZ1, SELINA S. DWIGHT1,MIDORI A. HARRIS1, SHANNON ROBERTS1, TAIYUN ROE1, J. MICHAEL CHERRY* ANDDAVID BOTSTEIN1
1Department of Genetics, Stanford University, Stanford, CA 94305-5120, U.S.A.
The completion of the Saccharomyces cerevisiae genome sequencing project11 and the continued development ofimproved technology for large-scale genome analysis have led to tremendous growth in the amount of new yeastgenetics and molecular biology data. Efficient organization, presentation, and dissemination of this information areessential if researchers are to exploit this knowledge. In addition, the development of tools that provide efficientanalysis of this information and link it with pertinent information from other systems is becoming increasinglyimportant at a time when the complete genome sequences of other organisms are becoming available. The aim of thisreview is to familiarize biologists with the type of data resources currently available on the World Wide Web(WWW). ? 1998 John Wiley & Sons, Ltd.
— World Wide Web; Saccharomyces Genome Database; Munich Information Center for ProteinSequences; Yeast Protein Database
CONTENTS
Introduction. . . . . . . . . . . . . . . . . . . . . . . . . . . . 1453SGD: Saccharomyces Genome Database . . . 1453MIPS: Munich Information Center for
Protein Sequences . . . . . . . . . . . . . . . . . . . . . 1457YPD: Yeast Protein Database . . . . . . . . . . . . 1458Systematic gene expression sites . . . . . . . . . . . 1460Other useful yeast sites. . . . . . . . . . . . . . . . . . . 1462Yeast-related and laboratory sites . . . . . . . . . 1462Useful Schizosaccharomyces pombe and
Candida albicans web sites . . . . . . . . . . . . . . 1464Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1468References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1468
INTRODUCTION
There are now three major Saccharomyces data-bases that maintain web servers: SaccharomycesGenome Database (SGD), Munich InformationCenter for Protein Sequences (MIPS) and YeastProtein Database (YPD).6,14,15 We focus thisreview on these three databases because theyrepresent the most comprehensive and relevant
CCC 0749–503X/98/161453–17 $17.50? 1998 John Wiley & Sons, Ltd.
information for yeast researchers. In addition toSGD, MIPS and YPD, several other usefulbudding yeast web sites are included. Since thenumber of these sites is growing rapidly, we onlyreview those that contain a significant amount ofdata and resources and apologize for the omissionof any new sites. In addition to these S. cerevisiaedatabases, there are several useful Schizosaccharo-myces pombe and Candida albicans sites, which webriefly summarize in tables. None of these descrip-tions is meant to be exhaustive. Instead, we high-light the general features and mention particularlyuseful or unique tools at each site, keeping in mindthat these databases are constantly evolving. AllURLs mentioned in this review can be obtainedfrom:
http://genome–www.stanford.edu/Saccharomyces/yeast_review_URLs.html
*Correspondence to: J. Michael Cherry, Department ofGenetics, Stanford University, Stanford, CA 94305-5120,U.S.A. Tel: 1-650-723-7541; fax: 1-650-723-7016; e-mail:
SGD: SACCHAROMYCES GENOMEDATABASE
URL: http://genome–www.stanford.edu/Saccharomyces
SGD was established to provide a fast, easy, andreliable method for members of the yeast commu-
nity to obtain information about the S. cerevisiaeReceived 14 August 1998

1454 . .
genome, the genes it contains and their inter-actions. SGD provides current, annotated yeastsequence through the WWW and via FTP. Inaddition to providing an on-line genome database,SGD also provides access to other information ofinterest to the budding yeast community. SGD isresponsible for maintaining the official S. cerevi-siae Gene Registry. The Gene Registry helps tomaintain yeast gene names in a standardized for-mat, and SGD mediates resolution of gene namingconflicts. On-line submission forms to register genenames are found at the SGD site. In addition,yeast researchers are encouraged to add theirnames and contact information to the list of col-leagues at SGD, where this list can be browsed andsearched. Community information such as yeastmeetings are announced on the SGD page, and a‘Virtual Yeast Library’ that contains hyperlinks toother useful yeast web pages is also provided.
The genome information in SGD is currentlyorganized around a ‘Locus’ page for each ORF,containing a brief summary of the gene, its productand any mutant phenotypes. In addition, the‘Locus’ page contains several links to the DNAsequence, protein information, a literature guide(Gene-Info), and other relevant sites. Many of theSGD features described below can be reachedthrough hyperlinks from the ‘Locus’ page.
SGD: sequence analysisAmong the WWW-based yeast resources, SGD
encompasses a wide array of sequence tools, in-cluding several sequence search, retrieval andanalysis options. The central location on the SGDsite for accessing sequence information is theGene/Sequence Resources page. Here users cansearch by gene name, ORF name, chromosomalregion, or raw DNA or protein sequence and selectretrieve options for viewing information about thegene or sequence they entered (Figure 1). There aremultiple options under the topic headings ofBiology/Literature, Maps/Tables, Sequence Analy-sis and Sequence Retrieval. Each link allows usersto perform the next logical step in their analysis.For instance, when the researcher chooses to re-trieve a protein sequence, the sequence is subse-quently displayed along with links to BLAST2 andFASTA18,19 searches, making sequence retrievaland subsequent analysis very straightforward forthe user.
In addition to BLAST and FASTA, SGD hasdeveloped other tools for exploring sequence
? 1998 John Wiley & Sons, Ltd.
patterns and similarities and displaying the resultsin a user-friendly manner. The Pattern Matchingprogram can search for short DNA or peptidesequences, allowing for ambiguous and/ordegenerate patterns. Researchers may also viewthe results of S. cerevisiae chromosome-by-chromosome comparisons using the Genome-wideDNA Similarity View and protein-by-protein com-parisons using the Genome-wide Protein SimilarityView.
SGD: unique featuresThe Global Gene Hunter search program, a
unique feature of SGD, is a powerful tool thatquickly performs a broad survey of the informa-tion available anywhere on the WWW for a par-ticular gene. After the user enters a gene name, theGlobal Gene Hunter simultaneously searchesSGD, GenBank, PubMed, Sacch3D, Swiss-Prot,MIPS, YPD and PIR for information aboutthe gene.3,10,22,24,26,30 Results are presented aslinks, providing very fast access to many differentinformation sources.
SGD also includes a section dedicated to variouslists and tables, including lists of gene names,tRNAs, commonly used auxotrophic markers, andfiles available for downloading via anonymousFTP. An interesting example is the MammalianHomology to Yeast table, which allows users toview the results of a BLAST search comparingeach yeast protein to all unique human, mouse,rat, cow and sheep protein sequences from a recentversion of GenBank. The results are summarizedin tables that contain hyperlinked entries. Asimilar table is also provided at MIPS.
A tool of practical use to the bench scientist isthe Web Primer feature, which designs primers forusers for PCR or DNA sequencing of a particulargene or raw sequence. Another useful bench re-source is the Yeast Genome Restriction Analysisprogram. This program generates and displays arestriction map from a raw DNA sequence, genename, ORF name, clone name, GenBank sequencename or accession number.
One of the newest features at SGD is the SAGEtag viewer (Figure 2). SAGE, or Serial Analysis ofGene Expression, is a technique that utilizes shortsequences that are associated with RNA tran-scripts to analyse gene expression at the genome-wide level. With the SAGE tag viewer, the usercan search data from a yeast SAGE study32 byentering a gene or ORF name, or by selecting a
Yeast 14, 1453–1469 (1998)

1455
section of a chromosome using the SGD GenomicView.
Figure 1. The Gene/Sequence Resources information retrieval Page at SGD. After searching by gene name (here, ACT1) at theGene/Sequence Resources search form (http://genome–www2.stanford.edu/cgi–bin/SGD/seqTools), the results are displayed asshown. Each of the categories is linked to the relevant ACT1 site. For instance, if the user clicks on BLAST Search under SequenceAnalysis, the BLAST form is displayed, already containing the ACT1 sequence.
Sacch3DSacch3D is a component of SGD that collects
and presents three-dimensional structural informa-tion for S. cerevisiae proteins obtained from the
? 1998 John Wiley & Sons, Ltd.
Protein Data Bank (PDB).1,23 A user can obtainavailable structural information for any given geneor ORF name and display available 3D structuresfor a yeast protein as well as structures for proteinswith significant sequence similarity to the yeastprotein. A variety of information is presented foreach PDB structure, including the protein descrip-
Yeast 14, 1453–1469 (1998)

1456 . .
Figure 2. The SAGE tag viewer at SGD. After searching for ACT1 at the Query SAGE data page (http://genome–www.stanford.edu/cgi–bin/SGD/SAGE/querySAGE), this SAGE map is displayed. By clicking on the SAGE sequence tag onthe graphic display of the chromosome, the user can retrieve detailed information about that particular SAGE sequence tag,including its sequence and expression results. Links at the bottom of the page (Genomic View, Gene/Sequence Resources)provide access to other information about the chromosomal region.
tion, source organism, BLAST scores and links tointeractive 3D viewers (Java/RasMol, Cn3D) andother structural databases. Also available from thestructural information page are links to pre-
? 1998 John Wiley & Sons, Ltd.
existing BLAST reports against the PDB and otherdatasets (GenBank, ESTs, mammalian), motifsearches to assign functional class, secondarystructure predictions and, if a PDB homologue
Yeast 14, 1453–1469 (1998)

1457
exists, the 3D structure for the yeast protein basedon its sequence.
MIPS: MUNICH INFORMATION CENTERFOR PROTEIN SEQUENCES
URL: http://speedy.mips.biochem.mpg.de/mips/yeast/index.htmlx
MIPS coordinated the collaborative efforts ofEuropean groups during the Saccharomycesgenome sequencing project and now manages aWWW server that provides the community withaccess to several genome databases. In addition tosupplying molecular biologists with a comprehen-sive yeast database, MIPS also provides updateson the progress of several other genome projects,including genome data from other microorganismsand Arabidopsis.
The information and features at MIPS areorganized into several different categories,namely Search, Chromosome Display, Tables andGraphics, and Protein Catalogues. In addition,each of these categories, along with a list of itscontents, is accessible from their home page.
MIPS: sequence analysisThe MIPS yeast database contains the sequence
data from the entire Saccharomyces genome. Themitochondrial and nuclear genomes have beenanalysed to extract potential ORFs, RNA genes,and genetic elements such as centromeres andtelomeres. From the MIPS yeast genome page,information may be retrieved in ways similar tothose used by other yeast web sites. The ORFsmay be searched by name or accession number,and information about the biochemistry orphysiological function of each gene is available.
Like SGD, MIPS also provides tools that allowthe user to analyse the yeast genome as a whole.Entire chromosomes or chromosomal segmentscan be viewed graphically or in tabular form toscrutinize ORFs or genetic elements in detail. Thegenome can also be examined for redundancy; onechromosome can be compared against another, oragainst all other 15 chromosomes.
MIPS: sequence searchesUsers may utilize the BLAST program at MIPS
to search for homologues of their favourite gene. Aprecomputed set of FASTA results is also avail-able at MIPS; it displays related proteins and their
? 1998 John Wiley & Sons, Ltd.
alignments. A table describing the yeast homo-logues of human disease-associated genes providesdescriptions of the disease, the BLAST searchresults and a hyperlink to the gene’s entry.
MIPS: unique featuresMIPS has several useful and unique features.
For instance, excerpts from several recent reviewsare provided at the MIPS site under a sectionentitled ‘Selected Yeast Reviews’. An exhaustiveset of S. cerevisiae zinc finger proteins is alsoavailable. Other information found at the reviewsection of the web page includes a description ofperoxins and peroxisome biogenesis genes, tRNAgenes and retrotransposable elements, and theclassification of the major facilitator superfamily.The genes listed in these tables are hyperlinkedto their central locus sites, making retrieval ofsupplementary information about a particulargene simple and intuitive.
One of the most valuable contributions of MIPSis the yeast catalogue section. These cataloguescontain lists of ORFs grouped together by severalbiological topics. For instance, the Functionalcatalogue groups genes by function, using bothgeneral (e.g. signal transduction) and specificcategories (e.g. pheromone response). Othercatalogues group genes by Prosite Motif,3,4
Enzyme Activity, Protein Class, Protein Complex,Phenotype, Physiological and Genetic Pathways,and Subcellular Localization. The Physiologicaland Genetic Pathways are displayed graphically toillustrate the relationships between different geneproducts as they work together to perform acellular process. In addition, all of the cataloguesare hyperlinked to the annotations for each gene inthe database; when a gene is retrieved in a search,all relevant catalogues will appear as links on theORF’s page.
MIPS also provides a useful reference sectionentitled, ‘Selected Tables and Graphics’, whichincludes lists of intron-containing ORFs, essentialand non-essential genes, genetic and physicalprotein interactions, small ORFs, and predictedtransmembrane domains. Two links from thissection are displayed graphically: the YeastCentromeres page and the proteasome/proteaseprotein table (designated ‘YTA’ protein table atMIPS). On the Yeast Centromere page, the centro-meres are aligned, and multiple colours are effec-tively used to illustrate highly conserved regions(Figure 3). The user may click on a centromere
Yeast 14, 1453–1469 (1998)

1458 . .
name to retrieve more information about thatparticular centromere. The YTA protein link goesto a list of related topics that each lead to aschematic diagram (Figure 4). The protein namesin the schematic are linked to information abouttheir respective genes; the graphics effectively con-vey information about the localization, functionalrelationships and homologues of these proteins.
PedantPedant,9,20 another service offered by MIPS, is
an automated genome analysis resource focusedon assigning functions to protein sequences. Theresults from many different sequence analysis tech-niques are integrated and made accessible via anintuitive user interface. Users can browse the set ofyeast ORFs based on the MIPS or bacterial func-tional categories, PIR keywords, PIR superfamily
? 1998 John Wiley & Sons, Ltd.
names or Prosite pattern categories. For any givenORF, Pedant provides a PileUp21 multiple se-quence alignment against proteins from the majorsequence databases, a list of sequence motifs fromthe BLOCKS13 and Prosite databases, a list ofPDB structural homologues, a raw BLAST report,and a general report page that contains functionalinformation, the amino acid sequence and second-ary structure prediction. Pedant also containsinformation from the analysis of many othergenomes and is regularly updated.
Figure 3. Alignment of the yeast centromeres at MIPS. This multiple sequence alignment of all the yeast centromeres wascreated with PILEUP. Each centromere name is linked to the MIPS page containing detailed information about it. In addition,there is a link at the bottom of the page to literature characterizing the centromeres.
YPD: YEAST PROTEIN DATABASE
URL: http://www.proteome.com/YPDhome.html
YPD began as a protein database rather than agenome database; thus, its information is centred
Yeast 14, 1453–1469 (1998)

1459
around amino acid rather than nucleic acid se-quences. In this regard, it is different conceptuallyfrom MIPS and SGD. For instance, there is noaccess to DNA sequences through YPD. Instead,emphasis is placed on providing detailed informa-tion about the Saccharomyces proteins themselves.Although much of YPD’s protein reports areincluded in MIPS and SGD, YPD excels at pre-senting its information in a very readable, compactform. Moreover, most of the data for a givenprotein is usually available with minimal scrollingand within one click from the yeast ‘protein re-port’. YPD is a product of Proteome, Inc; notethat, while YPD is free for academic use, non-academic users must pay a fee to access this site.
YPD: searching the protein databaseYPD provides a single search page (in a long or
short version) for accessing the data. With the long
? 1998 John Wiley & Sons, Ltd.
form, users have the ability to do simple yetpowerful Boolean (true/false) searches for proteinsthat match criteria in 14 different categories,including items such as subcellular localization,viability or inviability of the knockout mutant,molecular weight and number of potential trans-membrane domains (Figure 5). For instance, theuser could search the YPD for all essential proteinslocalized to the nucleus that contain transmem-brane domains. YPD, with its long search form,sets an example of new developments in searchcapabilities that will greatly benefit researchers.
Figure 4. Cellular localization of YTA proteins at MIPS. Each yeast protein name is linked to the MIPS page describing thecharacteristics of the protein and the gene encoding it.
YPD: protein reportsYPD’s protein reports are presented in tabular
form, with most of the information organized sothat it is either on this report or just one click away(Figure 6). A brief yet informative description ofthe protein is provided at the top of the table. In
Yeast 14, 1453–1469 (1998)

1460 . .
this table, YPD also lists synonyms for the geneencoding the protein, links to various databases(e.g. SGD, GenBank, PIR, Swiss-Prot), physicalcharacteristics of the protein [e.g. molecularweight, PI, CAI (codon adaptation index28)] andinformation about protein modifications and/ormotifs. Another nice feature of the protein reportis that the user can click on ‘Related Genes’ toobtain pre-computed protein sequence compari-sons of that ORF against other yeast, Drosophilaand human proteins.
One of the most impressive aspects of YPD isthe excellent literature summary that accompanieseach protein report. These annotations are dividedinto different categories, such as ‘Phenotypes’ and‘Related to’. Each annotation is associated withone or more numbers that are linked to the refer-ence(s) that support the annotation. The referencesare conveniently located at the bottom of thereport, and the references are linked to PubMed.In addition to these annotations, the proteinreports also contain links to information about‘Interactions’, ‘Regulations’ and ‘Modifications’.For instance, by clicking on ‘Interactions’, usersfind a list of proteins (that are linked to theirprotein reports) with which their protein of interestgenetically or physically associates.
YPD: unique featuresThere are other notable features at the YPD site.
A spreadsheet version of their database is available
? 1998 John Wiley & Sons, Ltd.
upon request (for a fee to commercial users). Forthose who may still prefer the convenience of usinga book rather than a computer terminal, YPD alsosells a printed version of their database, called theYeast Proteome Handbook. The web site includesan extensive user manual that is yet anotherfeature that makes YPD friendly and easy to use.Finally, the YPD site includes images of theoreti-cal two-dimensional gels for several classes ofproteins.
SYSTEMATIC GENE EXPRESSION SITES
Here we briefly summarize the web sites thatpresent data from systematic gene expressionprojects.
Figure 5. Long search form at YPD (http://www.proteome.com/search1.html). The user can search for sets of proteins thatbelong to several categories; the subcellular localization parameters are shown here.
Yale Genome Analysis CenterURL: http://ycmi.med.yale.edu/YGAC/
home.html
The investigators at the Yale Genome AnalysisCenter are using a transposon-based system toconstruct DNA libraries that generate randomfusions of genes to lacZ or GFP as well as full-length, HA-tagged proteins in yeast. The trans-formants can then be screened to identify genesthat are expressed in particular conditions (forinstance, during sporulation), and to determine thelocalization of proteins and the phenotypes of
disruption mutants. This project is being pursuedYeast 14, 1453–1469 (1998)

1461
Figure 6. Protein report at YPD. After searching for the gene name CTT1 with the YPD short search form (http://www.proteome.com/search0.html), the Protein Report is displayed; shown here is the first page. By scrolling down, the user canview an extensive summary of the literature, which contain links to the PubMed abstracts.24
? 1998 John Wiley & Sons, Ltd. Yeast 14, 1453–1469 (1998)

1462 . .
with several innovations that will greatly improvethe rate at which interesting transformants can bestudied and made publicly available.5
While the tools for searching and examiningdata are still being developed and it is a littledifficult to find the links containing backgroundinformation, this web site provides a convenientform for requesting reagents, links to useful anddetailed protocols, and maps and descriptions ofthe libraries and other DNA reagents.
Exploring the metabolic and genetic control ofgene expression on a genomic scale
URL: http://cmgm.stanford.edu/pbrown/explore/index.html
This Web site is associated with a Science paperof the same title8 and is maintained by PatrickBrown’s laboratory at Stanford University. Thissite describes the use of microarrays to investigatethe temporal expression of yeast genes during theshift from fermentation to respiration. The Brownlaboratory does a great job in describing this newtechnology with both graphics and text. There iseven a protocol with instructions on how to buildyour own microarrayer.
Saccharomyces Cell Cycle Expression DatabaseURL: http://genomics.stanford.edu/yeast/
cellcycle.html
This site, maintained by Ron Davis’s laboratoryat Stanford University, describes a project to char-acterize cell cycle-dependent gene expression in theyeast genome using DNA chip technology. Theexperiments identify 422 ORFs whose mRNAlevels show periodic variation during the cell cycle.The methods are described at the site, and the rawdata can be downloaded. Some figures summariz-ing the data are also available. Genes are organ-ized into functional categories, and mammalianhomologues are identified. Most of this informa-tion is available to the general public although onelink, the Access Expression Database, requires apassword.
OTHER USEFUL YEAST SITES
GeneQuizURL: http://www.sander.ebi.ac.uk/genequiz/
genomes/sc
GeneQuiz27 is a system for large-scale biologicalsequence analysis that uses a variety of sequence
? 1998 John Wiley & Sons, Ltd.
search and expert system analysis methods toassign function to protein sequences. In January1997, GeneQuiz analysed all ORFs in the yeastgenome and assigned function based on sequencesimilarity against the major DNA and proteindatabases. All ORFs were classified into fivegroups: ‘3D’ shows clear similarity to a protein ofknown 3D structure; ‘clear function’ has strongsimilarity to a protein with functional annotation;‘tentative function’ means there is weak similarityto a protein with functional annotation; ‘homo-logue’ denotes strong similarity to a protein with-out functional annotation; and ‘no homologue’.
Genome NavigatorURL: http://www.mpimg–berlin–
dahlem.mpg.de/2andy/GN/S.cerevisiae/
The Genome Navigator12 provides an inter-active Java-based map viewer (‘DerBrowser’) forbrowsing features along yeast chromosomes. Userscan view ORFs along a chromosome based onfunctional category and obtain information fromseveral external databases for a selected ORF(SGD, YPD, MIPS, Pedant, GeneQuiz, Geneduplications). A separate interactive Java applet isalso available at the Genome Navigator site forviewing duplications in the yeast genome. Thisapplet is integrated with the yeast gene duplicationwebsite,33 discussed below.
Yeast Gene DuplicationsURL: http://acer.gen.tcd.ie/2khwolfe/yeast/nova/
The yeast gene duplication website permitsaccess to data for duplicated chromosomal regionsin the Saccharomyces genome.33 The duplicatedregions are contained in 55 blocks that togetheroccupy half of the genome. The different blocks,including the genes contained within them, can bebrowsed. For each gene, users can obtain BLASTPdatabase search and Smith–Waterman18,29 pair-wise comparison results of a protein sequenceagainst all yeast proteins. Pairwise alignments forall hits are available. Dot matrix plots comparingthe duplicated chromosomal segments are pro-vided. The duplication map was in the processof being updated as this manuscript was beingprepared in August 1998.
YEAST-RELATED AND LABORATORYSITES
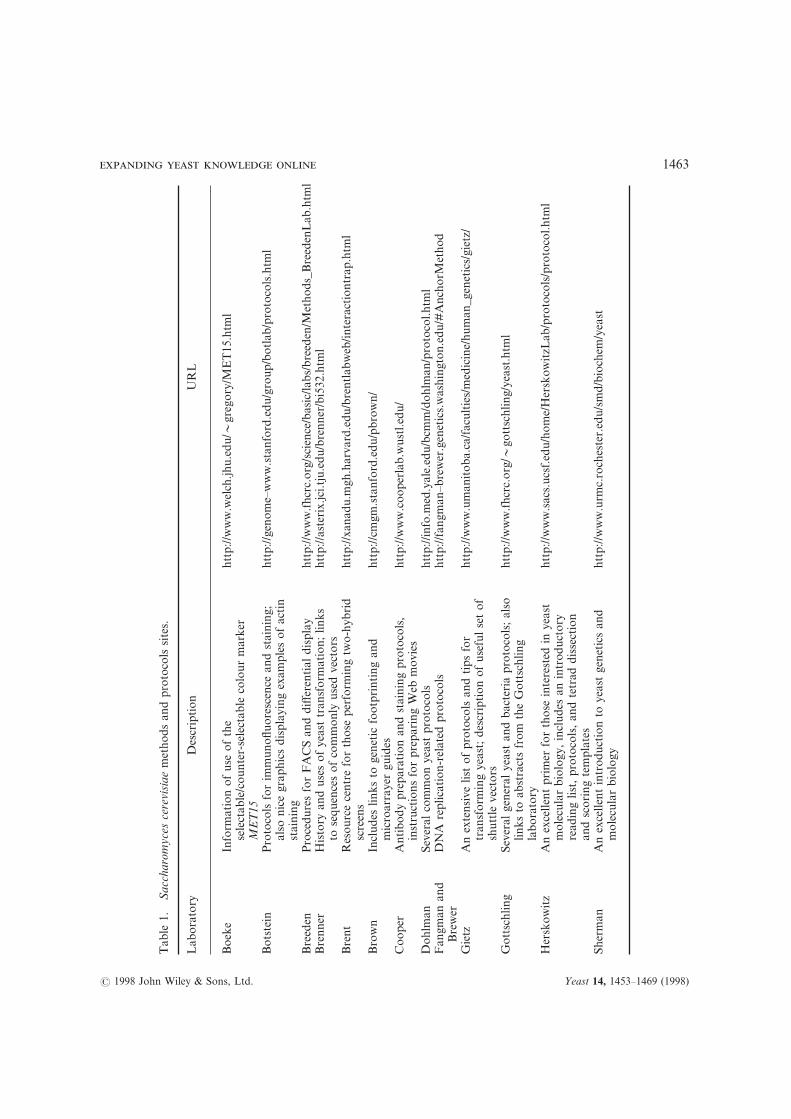
Several yeast laboratories maintain helpful sites
that provide on-line protocols (Table 1) and otherYeast 14, 1453–1469 (1998)
mic
roar
raye
rgu
ides
1463
1.Sac
char
omyc
esce
revi
siae
met
hods
and
prot
ocol
ssi
tes.
ator
yD
escr
ipti
onU
RL
Info
rmat
ion
ofus
eof
the
sele
ctab
le/c
ount
er-s
elec
tabl
eco
lour
mar
ker
ME
T15
http
://w
ww
.wel
ch.jh
u.ed
u/2
greg
ory/
ME
T15
.htm
l
inP
roto
cols
for
imm
unofl
uore
scen
cean
dst
aini
ng;
also
nice
grap
hics
disp
layi
ngex
ampl
esof
acti
nst
aini
ng
http
://ge
nom
e–w
ww
.sta
nfor
d.ed
u/gr
oup/
botl
ab/p
roto
cols
.htm
l
enP
roce
dure
sfo
rF
AC
San
ddi
ffer
enti
aldi
spla
yht
tp://
ww
w.f
hcrc
.org
/sci
ence
/bas
ic/la
bs/b
reed
en/M
etho
ds_B
reed
enL
ab.h
tml
erH
isto
ryan
dus
esof
yeas
ttr
ansf
orm
atio
n;lin
ksto
sequ
ence
sof
com
mon
lyus
edve
ctor
sht
tp://
aste
rix.
jci.t
ju.e
du/b
renn
er/b
i532
.htm
l
Res
ourc
ece
ntre
for
thos
epe
rfor
min
gtw
o-hy
brid
scre
ens
http
://xa
nadu
.mgh
.har
vard
.edu
/bre
ntla
bweb
/inte
ract
iont
rap.
htm
l
Incl
udes
links
toge
neti
cfo
otpr
inti
ngan
dht
tp://
cmgm
.sta
nfor
d.ed
u/pb
row
n/
Tab
le
Lab
or
Boe
ke
Bot
ste
Bre
edB
renn
Bre
nt
Bro
wn
? 1998 John Wiley & Sons, Ltd.
erA
ntib
ody
prep
arat
ion
and
stai
ning
prot
ocol
s,in
stru
ctio
nsfo
rpr
epar
ing
Web
mov
ies
http
://w
ww
.coo
perl
ab.w
ustl
.edu
/
anSe
vera
lco
mm
onye
ast
prot
ocol
sht
tp://
info
.med
.yal
e.ed
u/bc
mm
/doh
lman
/pro
toco
l.htm
lan
and
wer
DN
Are
plic
atio
n-re
late
dpr
otoc
ols
http
://fa
ngm
an–b
rew
er.g
enet
ics.
was
hing
ton.
edu/
#A
ncho
rMet
hod
An
exte
nsiv
elis
tof
prot
ocol
san
dti
psfo
rtr
ansf
orm
ing
yeas
t;de
scri
ptio
nof
usef
ulse
tof
shut
tle
vect
ors
http
://w
ww
.um
anit
oba.
ca/f
acul
ties
/med
icin
e/hu
man
_gen
etic
s/gi
etz/
chlin
gSe
vera
lge
nera
lye
ast
and
bact
eria
prot
ocol
s;al
solin
ksto
abst
ract
sfr
omth
eG
otts
chlin
gla
bora
tory
http
://w
ww
.fhc
rc.o
rg/2
gott
schl
ing/
yeas
t.ht
ml
owit
zA
nex
celle
ntpr
imer
for
thos
ein
tere
sted
inye
ast
mol
ecul
arbi
olog
y,in
clud
esan
intr
oduc
tory
read
ing
list,
prot
ocol
s,an
dte
trad
diss
ecti
onan
dsc
orin
gte
mpl
ates
http
://w
ww
.sac
s.uc
sf.e
du/h
ome/
Her
skow
itzL
ab/p
roto
cols
/pro
toco
l.htm
l
anA
nex
celle
ntin
trod
ucti
onto
yeas
tge
neti
csan
dm
olec
ular
biol
ogy
http
://w
ww
.urm
c.ro
ches
ter.
edu/
smd/
bioc
hem
/yea
st
Coo
p
Doh
lmF
angm
Bre
Gie
tz
Got
ts
Her
sk
Sher
m
Yeast 14, 1453–1469 (1998)

1464 . .
useful information; lists of laboratory sites can beobtained from either of the following URLS:
http://genome–www.stanford.edu/Saccharomyces/yeastlabs.html
http://genome–www.stanford.edu/Saccharomyces/VL–yeast.html
In addition, there are a number of excellent sitesthat do not specialize in S. cerevisiae per se butinstead emphasize comparative genomics studies,which may prove useful to yeast researchers. Welist a few such sites here.
Entrez Genome PageURL: http://www3.ncbi.nlm.nih.gov/Entrez/
Genome/org.html
The Entrez Genomes Division is supported bythe National Center of Biotechnology Information(NCBI) and provides access to the genomic se-quence of S. cerevisiae as well as other organisms.In addition, it has physical and genetic mappingdata for organisms whose genomic sequence isstill incomplete. The S. cerevisiae genomic se-quence supplied by the Entrez Genome Division iscompiled from assorted GenBank files into a singleDNA sequence for each chromosome.
The S. cerevisiae page can be reached from theEntrez Genome Page. The NCBI offers both textand graphic means of surveying the sequence of all16 S. cerevisiae chromosomes. Each chromosomecan be seen as a GenBank text file of an ‘Overview’display, which illustrates the entire chromosomegraphically along with labelled ORFs. Differentcolours in the graphical overview illustrate wheredifferent GenBank files were required to assemblethe virtual chromosome sequence. By clicking onan ORF name on the chromosome, the user canzoom in on that particular region of the chromo-some to view a more detailed map of that chromo-somal region. Additionally, the Genome Query, atthe top of the page, allows the user to search thechromosome for an ORF name. The resultingdisplay highlights the ORF along with neighbour-ing ORFs. All of the ORF names displayed arelinked to GenBank text files describing the ORF inmore detail. By selecting a button beside thegraphic displays, the user can utilize the ‘ORFFinder’ program to search for annotated as well asun-annotated ORFs. Using a minimum size as lowas 50 nucleotides, ‘ORF Finder’ displays all poss-ible ORFs in six reading frames for a 10 kb region.Any ORF identified by ORF Finder can then be
? 1998 John Wiley & Sons, Ltd.
seen in various sequence formats or used in aBLAST search. The positions of start, stop andalternative start codons can be seen in the ‘SixFrame’ view. On every page, the Genome Querypages contain links to the home pages of NCBI,Entrez, Entrez FTP sites, SGD and YPD.
Clusters of Orthologous GroupsURL: http://www.ncbi.nlm.nih.gov/COG/
The ‘Clusters of Orthologous Groups’ (COGs)project is part of NCBI’s comparative genomeefforts.31 Protein sequences from seven sequencedorganisms, including S. cerevisiae, were comparedto find proteins that contained sequence similarityand therefore represent possible orthologs, i.e.putative homologous proteins between differentspecies.
What Is There?URL: http://wit.mcs.anl.gov/WIT2
The What Is There? (WIT) project is attemptingto model the metabolism of about 30 organisms,including S. cerevisiae, with sequenced or partiallysequenced genomes. Their metabolic reconstruc-tions consist of diagrams of metabolic pathways,function and pathway classification schemes, andassignments of ORFs to functional roles.
Kyoto Encyclopedia of Genes and GenomesURL: http://www.genome.ad.jp/kegg/kegg2.html
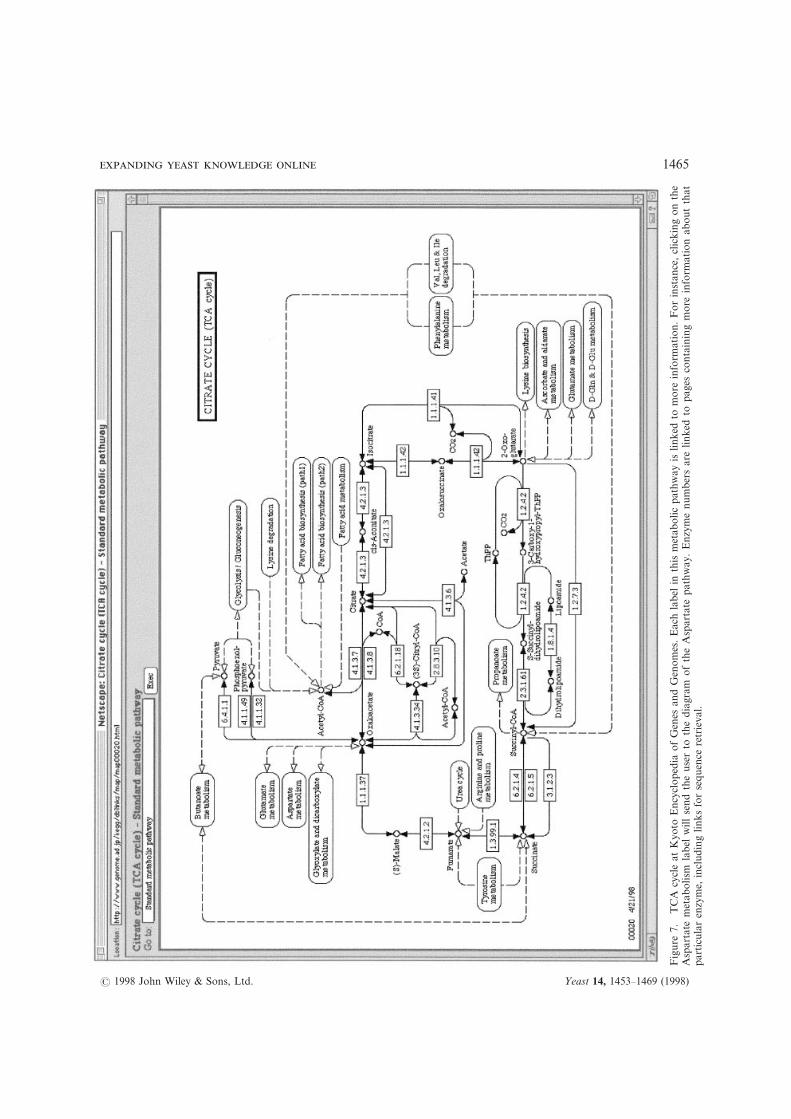
The Kyoto Encyclopedia of Genes and Ge-nomes (KEGG) project in Japan has severalfeatures that may prove useful to yeast researchers.At their ‘Identify gene clusters in two genomes’page, the user can choose two genomes from a listof sequenced genomes (including S. cerevisiae) andperform a search for homologous gene clusters.The KEGG site also contains many well-drawnmetabolic and regulatory diagrams that are organ-ized within hierarchical classification schemes. Theuser can choose to see what portions of thosediagrams have been identified in a particularorganism (Figure 7).
USEFUL SCHIZOSACCHAROMYCESPOMBE AND CANDIDA ALBICANS WEBSITES
Summarized here are the contents of a handfulof S. pombe Web sites. Other S. pombe and
Yeast 14, 1453–1469 (1998)
.
1465
and
Gen
omes
.E
ach
labe
lin
this
met
abol
icpa
thw
ayis
linke
dto
mor
ein
form
atio
n.F
orin
stan
ce,
clic
king
onth
eag
ram
ofth
eA
spar
tate
path
way
.E
nzym
enu
mbe
rsar
elin
ked
topa
ges
cont
aini
ngm
ore
info
rmat
ion
abou
tth
at
es diticu
lar
enzy
me,
incl
udin
glin
ksfo
rse
quen
cere
trie
val
? 1998 John Wiley & Sons, Ltd.
ure
7.T
CA
cycl
eat
Kyo
toE
ncyc
lope
dia
ofG
enpa
rtat
em
etab
olis
mla
bel
will
send
the
user
toth
e
FigA
spa
r
Yeast 14, 1453–1469 (1998)

etin
gF
issi
onY
east
Mee
ting
,23
–30
Sept
embe
r
1466 . .
2.A
sele
ctio
nof
S.
pom
bew
ebsi
tes.
Des
crip
tion
UR
L
Spri
ngH
arbo
rS
.po
mbe
uenc
ing
proj
ect
Hom
epa
gefo
rC
SHS
.po
mbe
geno
mic
sequ
enci
ngpr
ojec
tht
tp://
nucl
eus.
cshl
.org
/pom
bew
eb
nal
colle
ctio
nof
yeas
tcu
ltur
esSo
urce
ofst
rain
sof
S.
pom
bean
dot
her
yeas
tht
tp://
ww
w.if
rn.b
bsrc
.ac.
uk/n
cyc/
Def
ault
.htm
le
reso
urce
sat
AT
CC
Stra
ins,
plas
mid
s,ot
her
reag
ents
from
AT
CC
http
://w
ww
.atc
c.or
g/hi
light
s/sp
_inf
o.ht
ml
tern
atio
nal
Fis
sion
Yea
stIn
form
atio
nab
out
the
1st
Inte
rnat
iona
lht
tp://
ww
w.e
d.ac
.uk/
2eb
mv2
6/po
mbe
mee
ting
.htm
l
Tab
le
Site
Col
d seq
Nat
ioP
omb
1st
In Me
? 1998 John Wiley & Sons, Ltd.
1999
iona
lca
tego
ries
ofS
.po
mbe
Cat
egor
izat
ion
ofS
.po
mbe
met
abol
icpr
oces
ses;
part
ofth
eP
UM
Apr
ojec
tat
Arg
onne
Nat
iona
lL
abor
ator
y
http
://w
ww
–c.m
cs.a
nl.g
ov/h
ome/
com
pbio
/PU
MA
/P
rodu
ctio
n/N
odeO
bjec
ts/S
chiz
osac
char
omyc
es_p
ombe
.htm
l
bem
itoc
hond
rial
geno
me
Fun
gal
mit
ocho
ndri
alge
nom
epr
ojec
t(F
MG
P),
fund
edby
MR
CC
anad
aht
tp://
meg
asun
.bch
.um
ontr
eal.c
a/P
eopl
e/la
ng/s
peci
es/s
po/s
pom
be.h
tml
beex
pres
sion
syst
ems
Incl
udes
links
toge
nera
lpo
mbe
info
rmat
ion
and
lists
ofco
mm
erci
ally
avai
labl
eex
pres
sion
syst
ems;
unde
rco
nstr
ucti
on
http
://w
ww
.jeto
n.or
.jp/u
sers
/hto
hda
Fun
ct
S.
pom
S.
pom
Yeast 14, 1453–1469 (1998)

daA
dher
ence
Myc
olog
yR
esea
rch
Ref
eren
cefo
rpr
ojec
tsab
out
Can
dida
adhe
renc
eht
tp://
ww
w.u
nr.e
du/m
ycol
ogy/
1467
3.A
sele
ctio
nof
Can
dida
albi
cans
web
site
s.
Des
crip
tion
UR
L
andi
daw
ebsi
te,
Uni
vers
ity
ofne
sota
Ver
yni
cesi
tew
ith
map
s,ge
neti
cin
form
atio
n,se
quen
ce,
stra
ins,
met
hods
and
othe
rre
sour
ces
http
://al
ces.
med
.um
n.ed
u/C
andi
da.h
tml
Tab
le
Site
The
CM
inC
andi
? 1998 John Wiley & Sons, Ltd.
it daal
bica
nsse
quen
cing
proj
ect
Info
rmat
ion
onth
eC
andi
dase
quen
cing
proj
ect
and
acce
ssto
the
sequ
ence
data
base
http
://ca
ndid
a.st
anfo
rd.e
du/
Pro
tC
andi
dase
quen
ces
Can
dida
sequ
ence
data
base
atSw
iss-
Pro
tht
tp://
ww
w.e
xpas
y.ch
/cgi
–bin
/list
s?ca
lbic
an.t
xtda
albi
cans
pilo
tse
quen
cing
ject
Info
rmat
ion
abou
tth
epi
lot
sequ
enci
ngpr
ojec
tat
the
Sang
erC
entr
eht
tp://
ww
w.s
ange
r.ac
.uk/
Pro
ject
s/C
_alb
ican
s
Un
Can
di
Swis
s-C
andi
pro
Yeast 14, 1453–1469 (1998)

1468 . .
Candida albicans sites are summarized inTables 2 and 3. There is also a Candida newsmailing list; to subscribe, send e-mail to:[email protected]
The Sanger Centre, Cambridge, UKSchizosaccharomyces pombe genome sequencingproject
URL: http://www.sanger.ac.uk/Projects/S_pombe/
Begun in 1995, the S. pombe genome sequencingproject is predicted to be completed within twoyears. The Sanger Centre page reports the currentstatus of the project, organized by chromosome,and provides some raw sequences via FTP. Thecosmids used in systematic sequencing are listedfor each chromosome, and sources are identified.PomBase, a compilation of protein and DNAsequences, genetic and physical maps, references,and gene designations, is also available by FTP.Other useful features include a BLAST server anda link to Pedant, which provides an automatedanalysis of protein translations. The introductorypage and BLAST forms are well-designed and easyto use; cosmid clones and sequencing progress arethoroughly documented.
WWW information on Schizosaccharomycespombe
URL: http://www.bio.uva.nl/pombe/
Frans Hochstenbach at the University ofAmsterdam maintains this useful pombe page.This site contains information about genomicsequencing efforts, including the Sanger Centre’sproject described above, as well as other sequenc-ing projects. Hochstenbach’s site also containssummaries of S. pombe phylogeny and early re-search and links to many other relevant web sites.Of particular interest is the online Fission YeastHandbook, which covers numerous research proto-cols. The home page contains a large amount oftext, but is reasonably well organized. Some of thehighlighted items, such as an animation of celldivision, require a password.
The Forsburg Lab Pombe PagesURL: http://pingu.salk.edu/users/forsburg/
Susan Forsburg maintains her laboratory pageat the Salk Institute for Biological Studies. Thissite includes an introduction to S. pombe biology,with emphasis on DNA replication and the cell
? 1998 John Wiley & Sons, Ltd.
cycle. An impressive array of technical informationis available, including sources of strains and plas-mids, technical references, vectors and selectablemarkers, and more. There is also a list of S. pombelaboratory home pages. Forsburg’s pages are re-markably well designed and organized, combiningclear text with well-chosen graphics. The sitecontains a wealth of information and is easy andfun to use.
CONCLUSION
The completion of the S. cerevisiae genomic se-quence has provided a staggering wealth of infor-mation available on-line. Sequence informationand new biological techniques have changed thestrategies of bench scientists. The on-line resourcesdescribed in this review both reflect these changesand foreshadow the revolution to come. System-atic functional analysis projects are on the cusp offacilitating another quantum leap in the data avail-able to describe the yeast cell. The yeast commu-nity can confidently expect that the computerresources at their disposal now will be available toorganize, analyse and disseminate the functionalanalysis data.
REFERENCES
1. Abola, E. E., Sussmann, J. L., Prilusky, J. andManning, N. O. (1997). Protein Data Bankarchives of three-dimensional macromolecularstructures. Meth. Enz. 277, 556–571.
2. Altschul, S. F., Gish, W., Miller, W., Myers, E. W.and Lipman, D. J. (1990). Basic local alignmentsearch tool. J. Mol. Biol. 215, 403–410.
3. Bairoch, A. and Apweiler, R. (1997). The SWISS-PROT protein sequence data bank and its supple-ment TrEMBL. Nucl. Acids Res. 25, 31–36.
4. Bairoch, A., Bucher, P. and Hofmann, K. (1997).The PROSITE database, its status in 1997. Nucl.Acids Res. 25, 217–221.
5. Burns, N., Grimwade, B., Ross-Macdonald, P. B.,Choi, E.-Y., Finberg, K., Roeder, G. S. andSnyder, M. (1996). Large-scale characterization ofgene expression, protein localization, and genedisruption in Saccharomyces cerevisiae. Genes Dev.8, 1087–1105.
6. Cherry, J. M., Adler, C., Ball, C., Chervitz, S. A.,Dwight, S. S., Hester, E. T., Jia, Y., Juvik, G., Roe,T., Schroeder, M., Weng, S. and Botstein, D.(1998). SGD: Saccharomyces Genome Database.Nucl. Acids Res. 26, 73–79.
7. Cn3D: http://www.ncbi.nlm.nih.gov/Structure/
cn3d.htmlYeast 14, 1453–1469 (1998)

1469
8. DeRisi, J. L., Iyer, V. R. and Brown, P. O. (1997).Exploring the metabolic and genetic control on agenomic scale. Science 278, 680–686.
9. Frishman, D. and Mewes, H. W. (1997). PEDANTic genomic analysis. Trends Genet. 13, 415–416.
10. GenBank: http://www.ncbi.nlm.nih.gov/Web/Genbank/
11. Goffeau, A., Barrell, B. G., Bussey, H., Davis,R. W., Dujon, B., Feldmann, H., Galibert, F.,Hoheisel, J. D., Jacq, C., Johnston, M. et al.(1996). Life with 6000 genes. Science 274, 546.
12. Grigoriev, A. (1997). Genomes with a view. TrendsGenet. 13, 499.
13. Henikoff, J. G. and Henikoff, S. (1996). Blocksdatabase and its applications. Meth. Enz. 266,88–105.
14. Hodges, P. E., Payne, W. E. and Garrels, J. I.(1998). The Yeast Protein Database (YPD): acurated proteome database for Saccharomycescerevisiae. Nucl. Acids Res. 26, 68–72.
15. Mewes, H. W., Hani, J., Pfeiffer, F. and Frishman,D. (1998). MIPS: a database for protein sequencesand complete genomes. Nucl. Acids Res. 26, 33–37.
16. Murzin, A. G., Brenner, S. E., Hubbard, T. andChothia, C. (1995). SCOP: a structural classifica-tion of proteins database for the investigationof sequences and structures. J. Mol. Biol. 247,536–540.
17. NCBI: http://www.ncbi.nlm.nih.gov/18. Pearson, W. R. (1991). Searching protein sequence
libraries: comparison of the sensitivity andselectivity of the Smith–Waterman and FASTAalgorithms. Genomics 11, 635–650.
19. Pearson, W. R. and Lipman, D. J. (1988). Im-proved tools for biological sequence comparison.Proc. Natl Acad. Sci. USA 85, 2444–2448.
? 1998 John Wiley & Sons, Ltd.
20. Pedant: http://pedant.mips.biochem.mpg.de/21. PileUp: part of the Wisconsin Package, Genetics
Computer Group (GCG): http://www.gcg.com22. PIR: http://www–nbrf.georgetown.edu/pir/23. Protein Database (PDB): http://www.pdb.bnl.gov/24. PubMed: http://www.ncbi.nlm.nih.gov/PubMed/25. RasMol: http://www.umass.edu/microbio/rasmol26. Sacch3D: http://genome–www.stanford.edu/Sacch
3D/27. Scharf, M., Schneider, R., Casari, G., Bork, P.,
Valencia, A., Ouzounis, C. and Sander, C. (1994).GeneQuiz: a workbench for sequence analysis.In Altman, R., Brutlag, D., Karp, P., Lathrop, R.and Searls, D. (Eds), Proceedings of the SecondInternational Conference on Intelligent Systems forMolecular Biology. AAAI Press, Menlo Park, CA,pp. 348–353.
28. Sharp, P. and Li, W. H. (1987). The CodonAdaptation Index—a measure of directionalsynonymous codon usage bias, and its potentialapplications. Nucl. Acids Res. 15, 1281–1295.
29. Smith, T. F. and Waterman, M. S. (1981). Identi-fication of common molecular subsequences. J.Molec. Biol. 147, 195–197.
30. Swiss-Prot: http://www.expasy.ch/sprot/31. Tatusov, R. L., Koonin, E. V. and Lipman, D. J.
(1997). A genomic perspective on protein families.Science 278, 631–637.
32. Velculescu, V. E., Zhang, L., Zhou, W., Vogelstein,J., Basrai, M. A., Bassett, D. E. Jr, Hieter, P.,Vogelstein, B. and Kinzler, K. W. (1997). Charac-terization of the yeast transcriptome. Cell 88, 243–251.
33. Wolfe, K. H. and Shields, D. C. (1997). Molecularevidence for an ancient duplication of the entireyeast genome. Nature 387, 708–713.
Yeast 14, 1453–1469 (1998)





























