Embed Size (px)
Citation preview

Internet & Security Focus 2013 3월호 79
FOCUS
최근 세계 각국에서는 보건・의료, 공공부문, 유통, 마케팅, 제조업 등 다양한 분야에서
빅데이터를 활용하여 서비스를 제공하기 위하여 노력하고 있다. 하지만, 빅데이터를 활용할 때
간과할 수 없는 부분은 바로 개인정보와 프라이버시 문제이다. 빅데이터 분석 과정에서 이용될 수
개인정보는 안전하게 이용되어야 한다. 왜냐하면, 빅데이터를 활용하여 다양한 분석을 하게 되면
기존에 알 수 없었던 사용자 개개인의 성향이 분석될 수도 있고, 이러한 정보는 곧 개인정보이자
개인의 프라이버시가 될 수 있기 때문이다. 이러한 정보를 활용하여 서비스 제공자는 기존에
제공할 수 없었던 개개인에 특화된 맞춤형 서비스를 제공할 수 있지만, 반대로 이러한 정보가
오・남용될 경우 서비스 이용자의 프라이버시를 침해하는 양날의 검이 될 수 있다. 이에 본 고는
빅데이터 환경에서 개인정보를 활용할 때 발생할 수 있는 개인정보 침해에 대한 필요 조치를
살펴보고, 그에 따라 필요한 개인정보보호 기술들을 제안한다.
빅데이터 환경에서 개인정보보호를 위한 기술
FOCUS 4
이재식*
Ⅰ. 서론
Ⅱ. 빅데이터 개요 및 분석 절차
1. 빅데이터 개요
2. 빅데이터 분석 절차
Ⅲ. 빅데이터 환경에서 필요한 개인정보보호 기술
1. 개인정보보호를 위해 필요한 조치
2. 개인정보보호 기술
Ⅳ. 결론
✽ 본 고는 한국인터넷진흥원이 성신여자대학교 산학협력단에 위탁한 「빅데이터 기반 개인정보보호 기술수요 분석 보고서」를
참조하여 작성되었습니다.
Internet & Security Focus 2013 3월호80
FOCUS
Ⅰ. 서론
지금은 바야흐로 빅데이터(BigData) 시대라 해도 과언이 아니다. 2011년 전세계 디지털
정보생산량은 약 1.8ZB(제타바이트)라고 한다. 1.8ZB는 2000억개 이상의 고화질(HD)영화를
4700만년 동안 시청할 수 있는 정도의 엄청난 정보량을 뜻한다. 이처럼 전세계적으로 생산되는
수많은 데이터를 활용・분석하여 가치 있는 정보를 추출하는 것을 빅데이터 기술이라 할 수 있다.
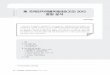
2012년 가트너의 융합기술에 대한 Hype Cycle1)을 살펴보면 빅데이터 기술은 [그림 1]과 같이
발생기(Technology Trigger)2)를 지나 버블기(Peak of Inflated Expectations)3)에 접어든 기술로
나타나고 있어, 빅데이터와 관련된 기술의 관심이 고조된 상태임을 알 수 있다.
1) Hype Cycle : 시장조사기관 가트너(Gartner)가 기술들의 발전단계를 설명하기 위해 개발한 방법론으로, 시간의 경과에 따른
기술의 성숙도(x축)와 업계에 회자되는 가시성(y축)을 이용해 기술의 진화를 설명하고 있으며, 1995년 최초로 선보인 이후
매년 분야별 Hype Cycle을 발표하고 있음
2) 발생기(Technology Trigger) : 기술의 잠재성으로 발생하는 기술 상품이며, 미디어에서 관심을 보이지만 종종 상품성이 떨어져
보이거나, 상품화 되지 못할 수 있는 영역
3) 버블기(Peak of Inflated Expectations) : 초기 다수의 성공 스토리들이 발표가 되나 많은 기업들이 참여하지는 않는 영역으로
관심 고조기
[그림 1] Hype Cycle for Emerging Technologies, 2012

Internet & Security Focus 2013 3월호 81
FOCUS
활용영역 내용
보건・의료의약품 연구개발 관련 데이터, 임상 데이터, 의료비 청구와 비용 관련 데이터, 환자 행태 및 감정 관련 데이터를 활용
공공부문 국민, 국토, 경제, 사회, 문화 등 다양한 분야에 대해 축적된 데이터를 활용
유통부문 마케팅, 상품기획, 영업, 공급망 관리, 새로운 비즈니스 모델 개발에 활용
제조업공급망 관리의 수요예측 및 공급계획을 위해 활용생산과정에서 검출되는 센서 데이터를 활용판매후 내장된 센서를 통한 검출 데이터 활용
위치기반서비스이용자 위치기반의 내비게이션, 위치기반소셜네트워크 서비스등에 활용고속도로 통행료 징수, 구조 요청자 위치 찾기등의 공공서비스에 활용
Ⅱ. 빅데이터 개요 및 분석 절차
1. 빅데이터 개요
빅데이터란? 대용량 데이터를 활용・분석하여 가치 있는 정보를 추출하고, 생성된 지식을
바탕으로 능동적으로 대응하거나 변화를 예측하기 위한 정보화 기술을 의미한다.4) 그 외에도
기술적, 규모적, 방법적인 빅데이터 정의를 살펴보면 다음과 같다.
- (기술적 정의) 다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고,
데이터의 초고속 수집, 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍처 (IDC, 2011)
- (규모적 정의) 일반적인 데이터베이스 SW가 저장, 관리, 분석할 수 있는 범위를 초과하는
규모의 데이터 (매킨지, 2011)
- (방법적 정의) 빅 데이터는 당초 수십-수천 테라바이트에 달하는 거대한 데이터 집합
자체만을 지칭하였으나, 점차 관련 도구, 플랫폼, 분석기법까지 포괄하는 용어로 변화
(삼성경제연구소, 2010)
또한, 빅데이터는 크기(Volume), 속도(Velocity), 다양성(Variety)의 3V의 특징을 가지고 있으며,
최근에는 가치(Value)라는 키워드를 추가하여 4V의 특징을 가지고 있다고 이야기한다. [그림 2]는
이러한 빅데이터의 특징을 보여준다.
4) “빅데이터를 활용한 스마트 정부 구현”, 국가정보화전략위원회, 2011년 11월.
<표 1> 빅데이터 5대 활용영역

Internet & Security Focus 2013 3월호82
FOCUS
크기(Volume)는 물리적인 크기뿐만 아니라 개념적인 범위까지 대규모인 데이터를 의미하는
것으로, 과거의 데이터 크기에 비하여 상대적으로 처리가 어려울 정도의 양을 의미한다.
속도(Velocity)는 데이터가 생성되는 속도 및 데이터를 처리하는 속도를 의미한다.
다양성(Variety)은 과거의 정형화된 데이터에 비하여 비정형화된 데이터까지 포함한 데이터 형식
및 데이터를 수집하는 공간이 내부 뿐만 아니라 외부의 데이터 까지를 의미한다. 그리고 이러한
특징을 바탕으로 도출된 결과를 가치(Value)라고 할 수 있다. 이와 같은 3V(Volume, Velocity,
Variety)의 3가지 특징을 바탕으로 하둡(Hadoop) 및 데이터웨어하우스(DW) 응용과 같은
인프라를 바탕으로, 고성능 BI(Business Intelligence)와 외부 데이터 분석 등의 분석 플랫폼을
활용하여, 텍스트 기반의 비정형 데이터를 포함한 분석이 이루어 질 때 비로소 가치(Value)있는
정보를 생성할 수 있을 것이다.
2. 빅데이터 분석 절차
빅데이터를 활용하여 분석하고, 결과를 도출하는 분석과정은 크게 5가지 단계로 나누어 볼 수
있다. 첫 번째 단계는, 분석대상이 되는 데이터를 수집하는 단계이다. 두 번째 단계는, 수집된
데이터를 저장하고 관리하는 단계이다. 세 번째 단계는 저장된 데이터의 처리 및 분석하는
단계이고, 네 번째 단계는 분석된 결과를 가시화 하고 의미를 도출하여 이용하는 단계이다. 마지막
다섯 번째 단계는 저장된 데이터를 폐기하는 단계이다. 이번 절에서는 「 빅데이터 기반
개인정보보호 기술수요 분석 보고서」5)를 참조하여, 각 단계별 세부 기술에 관하여 설명한다.
[그림 2] 빅데이터의 특징
5) 한국인터넷진흥원 (2012) “빅데이터 기반 개인정보보호 기술수요 분석”, 성신여자대학교 산학협력단, 2012.12.

Internet & Security Focus 2013 3월호 83
FOCUS
빅데이터의 분석 절차를 살펴봄으로써, 각 단계별로 발생할 수 있는 개인정보보호와 관련된 이슈
및 필요 기술을 도출할 수 있다.
1) 데이터 수집 단계
빅데이터 분석 절차의 첫 번째 단계는, 분석 대상이 되는 데이터를 수집하는 단계이다. 데이터
수집을 위한 방법은 매우 다양하고, 광범위하다. 따라서 본 고에서는 데이터 수집 시 수집하는
주체의 능동성 여부에 따라서 데이터 수집을 두 가지 형태로 분류한다. 즉, 수집되는 데이터를
능동적으로 입력 받는 형태의 수집과 수동적으로 모으는 형태의 수집이다. 능동적 데이터 수집의
대표적인 예로 로그데이터 등을 들 수 있으며, 수동적 데이터 수집의 예로 웹 크롤러를 들 수 있다.
(1) 능동적 데이터 수집
“능동적 데이터 수집”이란 데이터를 가지고 있는 주체가 데이터 수집을 원하는 주체에게
능동적으로 데이터를 전달하는 데이터 수집방법이다. 예를 들어, 생산설비에 있어서 생산과
관련된 데이터를 남기게 되는데 이러한 형태로 데이터를 제공받는 것을 능동적 데이터 수집으로
볼 수 있다. 또한 통계적 분석을 위한 설문조사를 통한 데이터 수집도 설문에 참여한 참여 주체가
능동적으로 데이터를 작성한 능동적 데이터 수집으로 볼 수 있다.
① 대량의 로그 기록 수집
대량의 로그를 기록하고 수집하는 기술로 Chukwa, Scribe, Flume 등을 들 수 있다.
Chukwa는 분산되어 있는 노드들의 로그 데이터를 수집하고, 수집된 데이터를 저장하며
분석하기 위해 만들어진 오픈소스 프로젝트 이다. Chukwa가 수집하는 로그는 모니터링 로그,
응용프로그램 로그, Hadoop 로그 등 다양한 데이터를 수집하며, 테라바이트 단위 이상의
로그데이터를 모니터링 하기위하여 개발되었다. [그림 3]은 Chukwa의 처리과정을 나타낸다.
[그림 3] Chukwa 처리 과정

Internet & Security Focus 2013 3월호84
FOCUS
Chukwa는 데이터를 제공하는 각각의 시스템으로부터 로그를 수집하여 Chukwa Agent를
통하여 Chukwa Collector로 보내지고, 최종적으로 HDFS 파일시스템에 로그를 저장한다. Chukwa
Agent는 초 단위로 동작하며, 100 개의 Agent 들로부터 전송된 로그데이터를 하나의 Chukwa
Collector에 집결되어 처리한다. 처음 모아진 데이터는 별도의 파싱이나 수정을 하지 않고 단순히
정렬하고 그룹화 한다. 그리고 두 번째로 로그파일들을 파싱하여 Key-Velue 쌍으로 이루어진
Chukwa Records를 생성하고 MapRecude를 이용하여 분석한다. 그리고 사용자는 HICC(Hadoop
Infrastructure Care Center)라는 웹-포탈 인터페이스를 통하여 초단위로 생성되는 파일이나
블록수와 같은 HDFS의 상태를 실시간으로 모니터링 할 수 있다.
Scribe는 Facebook에서 개발된 대규모의 서버로부터 실시간으로 스트리밍 로그 데이터 수집을
위한 애플리케이션이다. Scribe는 네트워크와 시스템의 장애를 위해 고안된 것으로, 확장성과
신뢰성을 목표로 두고 있다. Facebook에서는 수 천대 규모로 설치, 운영되고 있고 있으며 하루에
100억 개의 메시지를 수집하고 있다. [그림 4]는 Scribe의 구조를 보여준다.
하나의 중앙 Scribe 서버와 여러 대의 Local Scribe 서버 구조로 구성되어 있으며 Scribe 서버는
시스템의 모든 노드들 위에서 동작한다. 만약 중앙 Scribe 서버가 동작하지 못하면, Local Scribe
서버가 Local Disk에 있는 파일에 메시지를 작성하고, 중앙 Scribe 서버가 복구되었을 때 다시
메시지를 전송하여 메시지의 손실을 방지한다. 중앙 Scribe 서버는 분산 파일 시스템 같은 마지막
목적지의 파일에 메시지를 작성하거나, 다른 층의 Scribe 서버로 메시지를 전송한다. 이때,
Scribe는 메시지 저장을 위해 Store라는 개념을 사용하여 여러 가지 타입의 Store를 제공하고, 이를
이용하면 HDFS에도 메시지를 저장할 수 있다. 로그 기록은 파일에도 할 수 있고, HDFS에
실시간으로도 할 수 있다.
Flume은 커다란 규모의 분산 데이터를 수집하고 효율적으로 전송하는 시스템으로 클러스터
환경에서 신뢰성 있는 로깅뿐만 아니라 안정적인 확장성을 제공한다. Flume의 주된 사용처는
로깅 시스템이며, 다양한 시스템으로부터 수집되고 모아지는 데이터를 하둡 같은 중앙 처리 저장
[그림 4] Scribe 구조

Internet & Security Focus 2013 3월호 85
FOCUS
시스템에 저장해주는 역할을 한다. Flume의 주된 설계 목적은 신뢰성, 가용성, 관리성, 그리고
확장성으로 [그림 5]와 같이 3-tier 구조로 되어있다. 첫 번째 tier는 agent-tier로 에이전트 노드는
일반적으로 로그를 생산하는 시스템에 설치되며 데이터의 초기 시작점으로 설정되어 데이터를
collect-tier로 보낸다. 두 번째 tier인 collect-tier는 분산된 데이터 흐름 에이전트로부터 데이터를
수집하고, 이를 세 번째 tier인 저장소 영역 HDFS 노드에 전송한다.
② RSS와 같은 구독형태의 데이터 수집
RSS(Really Simple Syndication)는 다양한 웹 사이트의 콘텐츠를 요약하고 상호공유 할 수 있도록
만든 XML기반의 간단한 콘텐츠 배급 프로토콜이다. RSS는 뉴스나 공지사항과 같이 콘텐츠가 자주
갱신되는 웹 사이트의 정보를 이용자들에게 실시간으로 쉽고 빠르게 제공하기 위해 만들어진
포맷이다. RSS 제공자는 RSS 피드(feed)의 형태를 통하여, 콘텐츠를 배포하고, 이용자는 RSS 리더
프로그램을 이용하여 RSS 채널을 등록하고 원하는 RSS 피드를 읽을 수 있다. RSS의 네트워크는
[그림 6]과 같이 3개의 주요한 컴포넌트로 구성이 되어있다. 첫 번째는 컨텐츠 제공자 (Content
Provider)로서 각 제공 뉴스 정보과 자신의 정보에 관한 RSS 파일을 제공한다. 두 번째는 다양한
경로를 통해 RSS 정보를 읽거나 수집하는 콘텐츠 수집자(Content Aggregator)로서 인덱스를
수집하고 그 인덱스를 통해 화제가 되는 특정 뉴스의 헤드라인을 수집하고 제공한다. 세 번째는
[그림 5] Flume의 구조

Internet & Security Focus 2013 3월호86
FOCUS
콘텐츠를 보여주는 헤드라인 뷰어(Headline Viewer)로서 이용자는 RSS 리더 프로그램을 통하여
콘텐츠를 제공 받고 읽을 수 있다.
③ 정보생산 주체로부터의 직접적인 데이터 수집
마지막 수집 방법으로 정보생산 주체로부터 직접 데이터를 수집 받는 방법이다. 기존에 운영
중인 서비스 시스템의 데이터베이스를 활용하는 방법, 시스템 설비 상에서 발생하는 각종
로그정보를 모으는 방법, 웹사이트 홈페이지를 통하여 설문조사와 같이 사용자로부터 직접
데이터를 수집하는 방법 등이 여기에 해당한다. 정보생산 주체로부터 직접적인 데이터 수집의
장점은 수집되는 데이터가 명확히 정의되어 있어 활용이 쉽다는 것이다. 왜냐하면 기존에 운영
중인 데이터베이스에 저장된 데이터를 활용한다는 것은 이미 데이터와 관련된 정보구조를 가지고
데이터를 이미 확보하였기 때문이다. 또한, 설문조사와 같이 신규로 데이터를 수집하는 경우는
조사항목을 미리 설정하여 데이터를 수집받기 때문이다. 직접적인 데이터 수집 시 장점은,
수집정보의 동의에 있어서 명확히 사용자의 동의를 받을 수 있다는 점이다.
(2) 수동적 데이터 수집
“수동적 데이터 수집”이란 데이터를 소유하고 있는 주체가 데이터 수집을 원하는 주체에게
수동적으로 데이터를 전달하는 데이터 수집방법이다. 예를 들어, 웹 로봇이나 웹 크롤러 등과 같이
웹 페이지에 게시되어 있는 정보를 수집하는 수집기법을 수동적 데이터 수집으로 볼 수 있다.
[그림 6] RSS 네트워크 구조

Internet & Security Focus 2013 3월호 87
FOCUS
① 웹 로봇(Web Robot)
웹 로봇(Web Robot)은 웹 문서를 돌아다니면서 필요한 정보를 수집하고 이를 색인해 정리하는
기능을 수행하며 주로 검색엔진에서 사용되고 있다. 검색엔진에서 사용하는 웹 로봇은 전 세계의
웹 문서를 돌아다니면서 관련된 정보들을 자신의 데이터베이스에 색인해둔 것들을 검색한다. 웹
로봇은 지정된 URL리스트에서 시작하여 웹 문서를 수집하고, 수집된 웹 문서에 포함된 URL들을
추출하여 새롭게 발견된 URL에 대한 웹 문서 수집 과정을 반복하는 소프트웨어이다. 일반적으로
웹 로봇은 [그림 7]과 같이 수집기와 분류기, 데이터처리기로 나눌 수 있다. 수집기는 정해진 웹
페이지에서 정보를 수집하거, 중복 URL을 방지하기 위하여 데이터베이스를 가지고 있다. 또한
필요에 따라 수집된 정보의 분류를 위한 인덱스를 생성하거나 요약문을 생성하는 모듈을 포함할
수 있다. 분류기는 규칙, 확률 또는 학습 기반으로 문서를 분류하며, 좀 더 정확한 분류를 위해
관리자 또는 전문가가 개입할 수 있도록 분류 승인 모듈을 갖는다. 데이터처리기는 분류된 정보를
사용자의 요구에 따라 메일링 서비스하거나 데이터베이스 테이블에 업로드하는 기능을 수행한다.
② 웹 크롤러(Web Crawler)
웹 크롤러(Web Crawler)는 조직적, 자동화된 방법으로 월드와이드웹(World Wide Web)을
탐색하는 컴퓨터 프로그램이다. 대체로 방문한 사이트의 모든 페이지 복사본을 생성하는데
[그림 7] 일반적인 웹 로봇 구조

Internet & Security Focus 2013 3월호88
FOCUS
사용되며, 검색 엔진은 이렇게 생성된 페이지의 보다 빠른 검색을 위하여 인덱싱을 수행한다. 또한
웹 크롤러는 링크 체크나 HTML 코드 검증과 같은 웹 사이트의 자동 유지 관리 작업을 위해
사용되기도 하며, 자동 이메일 수집과 같은 웹 페이지의 특정 형태의 정보를 수집하는 데도
사용된다. 웹 크롤러는 최초의 탐색을 위하여, 시드(seed)라고 불리는 URL리스트를 이용하여
탐색을 시작하며, 페이지 내에 존재하는 모든 하이퍼링크를 인식하여 URL리스트를 갱신하고,
갱신된 URL리스트는 재귀적으로 다시 방문한다. 웹 서버를 순회하며 각 홈페이지에 있는 텍스트
정보, 수치 정보, 사실 정보, 그림 정보, 멀티미디어 정보 등 수 많은 정보를 수집하며, 자동으로 웹
페이지의 내용을 분석하고 그 안의 포함되어 있는 URL들을 추출한 후 그 URL들로 하나씩
이동하면서 정보를 수집한다.
2) 데이터 저장 및 관리 단계
빅데이터 분석 절차의 두 번째 단계는, 수집된 데이터를 저장하고 관리하는 단계이다. 기존에
사용되던 데이터 저장 방식은, 정형화된 데이터를 저장하는 형태가 주를 이루었다. 하지만,
빅데이터 환경에서는 정형화 되지 않은 비정형데이터를 저장할 수 있어야 하며, 대량의 데이터가
저장되야 하므로 기존의 데이터 저장・관리 기술 이외의 새로운 기술을 필요로 한다.
(1) 대용량 분산 파일 시스템
빅 데이터 환경에서 생산되는 데이터는 그 규모와 크기가 방대하기 때문에 기존의 파일 시스템
체계를 그대로 사용할 경우 많은 시간과 높은 처리비용을 필요로 한다. 따라서 대용량의 데이터를
분석하기 위해 두 대 이상의 컴퓨터를 이용하여 적절히 작업을 분배하고 다시 조합하며, 일부
작업에 문제가 생겼을 경우 문제가 발생 된 부분만 재처리가 가능한 분산 컴퓨팅 환경을 요구한다.
이를 지원하는 가장 대표적이며 널리 알려진 도구가 아파치(Apache)의 하둡(Hadoop)이다.
하둡은 대용량의 데이터를 처리하기 위해 대규모의 컴퓨터 클러스터에서 동작하는 분산
애플리케이션 개발을 위한 자바 오픈소스 프레임워크이다.
(2) HDFS(Hadoop Distributed File System)
HDFS는 아파치 하둡 프로젝트의 분산 파일 시스템으로, 처음에는 아파치 넛치 웹 검색 엔진
프로젝트를 위한 하부 구조로 만들어졌었다. HDFS은 여러 개의 노드에 걸쳐 큰 파일을 저장하며,
단일 호스트에서 RAID 스토리지를 이용하지 않고 안정성을 달성하고 있지만, 여러 개의 호스트에
데이터를 복사하는 단점을 가지고 있다. 기본적으로 HDFS 파일 시스템은 3개의 노드(2개는 같은

Internet & Security Focus 2013 3월호 89
FOCUS
랙, 1개는 다른 랙)에 데이터를 저장한다. 파일 시스템은 데이터 노드들의 클러스터를 통해서
구축되며, 각각의 서버들은 데이터 블럭을 네트워크를 통해서 제공한다. HDFS는 HTTP
프로토콜을 통해서 웹 브라우저나 다른 클라이언트를 통해서 모든 컨텐츠에 대해 접근할 수 있고,
데이터 노드들은 복사본을 옮기거나 데이터의 복제를 위해 데이터의 재밸런싱 작업을 한다.
(3) 인-데이터베이스(In-Database)
인-데이터베이스는 데이터베이스 내에 분석을 직접 수행할 수 있는 기능을 포함하고 있다.
따라서 분석의 시점이 데이터베이스와 분석 소프트웨어의 분리로 인한 데이터의 처리 및
프로세스 등의 여러 단계를 거치지 않고 보다 신속하게 데이터를 분석할 수 있도록 지원할 수
있다. 또한 인-데이터베이스 방식은 자동화된 마이닝 프로세스와 실시간 혹은 실시간에 근접한
기능을 지원하는 분석을 가능하게 한다. 이러한 기능을 지원하는 대표적인 인-데이터베이스는
테라데이터(Teradata), IBM 네티자(Netezza), 그린플럼(Greenplum), 애스터 데이터 시스템(Aster
Data Systems)등과 같은 주요 데이터 웨어하우징 벤더들에 의해 지원된다.
(4) 인-메모리(In-Memory)
인-메모리 기술은 데이터를 보다 빠르게 접근하고 처리하여, 신뢰성 높고 효율적인 의사결정을
도와주는 기술이다. 전통적인 비즈니스 인텔리전스 기술은 디스크와 같은 공간에 저장된
데이터를 대상으로 로딩하고 처리를 하지만, 인-메모리 기술은 디스크 대신 메모리를 이용하여
색인을 만들고 데이터를 처리하기 때문에 데이터 모형을 만들고 질의를 분석하며 다양한 관점의
분석을 처리하는 데 소요되는 시간을 줄일 수 있다. 인-메모리 기술의 장점은 물론 디스크와 같은
일반적인 데이터베이스에 접속하지 않아도 되기 때문에 데이터베이스 서버의 부담을 줄일 수
있으며, 메모리 기반으로 처리되기 때문에 처리속도가 상대적으로 빠르다는 것이다.
(5) NoSQL
분산 데이터베이스 가운데 대용량의 비정형 데이터를 데이블 구조가 아닌 다른 형태로
저장하고 처리하기 위한 기술로 NoSQL이 각광을 받고 있다. NoSQL은 Not-Only SQL,혹은 No
SQL을 의미하며, 전통적인 관계형 데이터베이스와 다르게 설계된 비 관계형 데이터베이스를
의미한다. 관계형 데이터베이스의 경우 모든 노드가 같은 시간에 같은 데이터를 보여주는
일관성과 일부 노드가 다운되어도 다른 노드에 영향을 주지 않아야 하는 유효성에 중점을 두고
있는 반면, NoSQL기술은 네트워크 전송 중 일부 데이터를 손실하더라도 시스템이 정상동작을
Internet & Security Focus 2013 3월호90
FOCUS
하는 분산가능성에 중점을 두고 일관성과 유효성은 보장하지 않는다. 이러한 특성으로 NoSQL
데이터베이스들은 기존의 관계형 데이터베이스에 비해 특수한 목적에 따라 보다 빠른 처리가
가능하여, 대용량의 데이터를 분산시켜 저장하고 실시간으로 처리할 수 있는 기능을 제공한다.
(6) 구글 파일 시스템(GFS)
구글 파일 시스템은 급속히 늘어나는 구글의 데이터 처리를 위하여 설계된 대용량 분산 파일
시스템이다. 구글 파일 시스템은 크게 마스터(Master), 청크서버(Chunk Server),
클라이언트(Client)로 구성된다. 마스터는 구글 파일 시스템 전체를 관리하며, 청크서버는
물리적인 하드디스크에 실제 입출력을 처리하고, 클라이언트는 파일을 읽고 쓰는 동작을
요청하는 어플리케이션이다. 구글 파일 시스템의 동작과정을 살펴보면, 우선 클라이언트는
마스터에게 파일의 읽기/쓰기를 요청한다. 요청을 받은 마스터는 클라이언트와 제일 가까운
청크서버의 정보를 클라이언트에게 전달해주고, 클라이언트는 전달받은 정보를 바탕으로
청크서버와 직접 통신하며 파일의 읽기/쓰기를 실행한다. 청크서버가 고장날 경우, 마스터는
고장나지 않은 청크 서버를 이용하여 파일의 읽기/쓰기를 실행할 수 있으며, 마스터 서버가
고장나는 경우, 별도의 외부 장비가 마스터서버의 고장유무를 체크하여, 다른 서버가 마스터
서버의 기능을 대체하게 된다. 이러한 방식으로 무정지 기능(Failuer Tolerance)을 구현하고 있다.
3) 데이터 처리 및 분석 단계
빅데이터를 분석하기 위한 기법들은 통계학과 전산학, 특히 기계학습/데이터 마이닝 분야에서
이미 사용되던 기법들이며, 이 분석기법들의 알고리즘을 대규모 데이터 처리에 맞도록 개선하여
빅데이터 처리에 적용시키고 있다. 최근 소셜미디어 등 비정형 데이터의 증가로 인해, 다양한 분석
기법들 가운데 텍스트/오피니언 마이닝, 소셜네트워크 분석, 군집분석 등이 주목을 받고 있다.
빅데이터의 분석 기법들은 테라바이트 또는 페타바이트 규모의 데이터에 적용되고 있으며,
이러한 엄청난 규모의 빅데이터 분석(처리)을 수행하고 데이터를 저장, 관리하기 위해서는 이에
맞는 인프라 기술을 필요로 한다.
(1) 텍스트 마이닝(Text Mining)
텍스트 마이닝(Text Mining)이란 자연어로 구성된 비정형 텍스트 데이터에서 패턴 또는 관계를
추출하여 가치와 의미 있는 정보를 찾아내는 마이닝 기법으로, 사람들이 말하는 언어를 이해할 수
있는 자연어처리(Natural Language Processing) 기술에 기반 한 기술이다.

Internet & Security Focus 2013 3월호 91
FOCUS
(2) 맵리듀스(MapReduce)
맵리듀스(Map Reduce)는 구글이 분산컴퓨팅을 지원하기 위한 목적으로 제작하여, 2004년
발표한 소프트웨어 프레임워크이다. 이 프레임워크는 페타바이트(PB) 이상의 대용량 데이터를
신뢰할 수 없는 컴퓨터로 구성된 클러스터 환경에서 병렬로 처리하기 위해 개발되었다. 맵
리듀스는 맵 단계와 리듀스 단계로 처리과정을 나누어 작업한다. 맵(map)은 흩어져 있는
데이터를 연관성 있는 데이터끼리 분류로 묶는 작업이며, 리듀스(Reduce)는 맵 작업 후, 중복
데이터를 제거하고 원하는 데이터를 추출하는 작업이다. 대표적 맵리듀스 프레임워크 중 가장
주목을 받는 것이 아파치(Apache)의 하둡(Hadoop) 기술이다.
(3) 빅 쿼리(Big Query)
구글 `빅 쿼리'는 빅 데이터를 클라우드 상에서 신속하게 분석해주는 서비스다. 이용자가 구글
클라우드 스토리지에 분석하고자 하는 데이터를 업로드하면 웹 브라우저를 통해 해당 데이터가
분석된다. 따라서 기업은 별도 인프라를 구축하지 않고도 데이터를 분석할 수 있다. 빅 쿼리는 초당
수십억 단위 행(rows) 데이터를 다룰 수 있으며, 데이터 탐색 범위를 테라바이트 규모까지 확장할
수 있다. 빅 쿼리 인프라를 사용해 기업들은 자체 서버와 솔루션을 구축하지 않고도 데이터를
저장하고, 이를 분석하는 프로그램 역시 빅 쿼리를 통해 개발해 서비스를 운영할 수 있다.
(4) PPDM(Private Preserving Data Mining)
PPDM이란 프라이버시 보존형 데이터 마이닝을 뜻하며 데이터 소유자의 프라이버시를
침해하지 않으면서도 데이터에 함축적으로 들어 있는 지식이나 패턴을 찾아내는 기술을 말한다.
데이터 마이닝(data mining)은 많은 양의 데이터에 함축적으로 들어 있는 지식이나 패턴을
찾아내는 기술이다. 데이터 마이닝은 1983년 IBM Almaden 연구소를 중심으로 Quest 데이터
마이닝 프로젝트가 시작된 이후로 활발하게 연구가 진행되고 있다. 데이터를 모으고 이를 여러
가지 방법으로 분석하는 과정에서 프라이버시와 관련된 문제는 자연스럽게 대두된다. 특히,
데이터 마이닝이 전자상거래나 마케팅과 같은 분야에 주로 활용되면서, 개인프라이버시 침해
이외에도 경쟁 회사들 사이에 이윤추구를 위해 협력하는 경우 개별 회사가 수집한 정보의 노출이
문제시 되었다. 데이터 소유자의 프라이버시를 침해하지 않으면서 유용한 정보를 추출하는 것은
정보를 공유하는 것과 프라이버시를 유지하고자 하는 것의 취사선택(trade-off)에 대한 문제로 볼
수 있으며, 이를 해결하고자 프라이버시 보존형 데이터 마이닝(PPDM)에 대한 연구가 시작되었다.

Internet & Security Focus 2013 3월호92
FOCUS
4) 데이터 분석결과 가시화 및 이용 단계
빅데이터 분석 가시화 기술은 비전문가가 데이터 분석을 수행할 수 있는 환경을 제공하는
분석도구 기술과 분석 결과를 함축적으로 표시하고 직관적인 정보를 제공하는 인포그래픽스
기술로 구성된다. 대표적인 분석도구 기술의 예로 R이 있으며, 인포그래픽스 기술로 InVis(An
Interactive Visualization Framework for Massive Data supporting Multiple Users)가 있다. 오픈소스
프로젝트 R은 통계 계산 및 시각화를 위한 언어 및 개발환경을 제공한다. R 언어와 개발환경을
이용하면 기본적인 통계 기법부터 모델링, 최신 데이터 마이닝 기법까지 구현과 개선이 가능하다.
이렇게 구현한 결과는 그래프 등으로 시각화할 수 있다. InVis는 대용량 데이터의 실시간 가시화를
위해 고안된 새로운 가시화 시스템으로, 병렬 처리의 효율을 높이고 사용자의 접근성을 높인
인터페이스를 제공한다. 또한 유연한 컴퓨팅 자원 할당이 가능하며 다중 사용자에 대해서도 가시화
서비스를 제공한다. InVis 시스템은 대용량 데이터의 효과적인 가시화를 위한 인터페이스인
IVI(InVis Integrated Visualization Interface)와 데이터 가공 및 가시화 오브젝트인 폴리곤의 생성을
담당하는 IVE(InVis Visualization Engine)로 나누어진다. 빅데이터 시각화 기술은 데이터 분석
결과를 시각적으로 표현해주는 기술로 Facebook 사용자의 활동을 정보의 흐름과 빈도로
표시해주는 Facebook Transction이나 위키피디아의 문서 변화를 보여주는 History Flow 등이 있다.
5) 데이터 폐기 단계
데이터 폐기 단계에서는 데이터 분석을 위해 이용된 데이터를 삭제하는 단계이다. 개인정보와
같은 데이터는 다른 법령에서 명시하고 있지 않는 한 이용목적을 달성 후 지체 없이 파기해야
한다. 이와 같이 데이터 폐기를 위해 물리적으로 하드디스크 등을 파기하는 솔루션 등이 있으며,
소프트웨어 적으로는 여러 번 덮어쓰기(OverWritting) 등의 기술이 사용되고 있다. 하지만, 데이터
폐기를 위한 방법들은 데이터를 저장하고 있는 물리적/논리적 공간 전체를 폐기하는 방법으로
일부의 데이터만 삭제가 어려워, HDFS와 같이 데이터를 여러 곳에 복제하여 분산 저장하는
환경에서 모든 데이터의 폐기가 제대로 이루어졌는지 검증하기란 어려울 수 있다.

Internet & Security Focus 2013 3월호 93
FOCUS
Ⅲ. 빅데이터 환경에서 필요한 개인정보보호 기술
1. 개인정보보호를 위해 필요한 조치
빅데이터 환경에서 필요한 개인정보보호 기술을 도출하기 위하여, 빅데이터 분석의 각 단계 별
발생할 수 있는 개인정보의 침해 가능성을 예방하기 위한 조치를 살펴보면 다음과 같다.
1) 데이터 수집 단계
(1) 능동적 데이터 수집
① 수집되는 데이터에 대한 동의
능동적 데이터 수집을 통해 데이터를 확보하는 경우, 데이터를 생성하는 주체에 사전에 동의를
받고 데이터를 수집하여야 한다. 상대적으로 수동적 데이터 수집에 비하여, 능동적 데이터 수집의
경우 데이터 생성주체의 동의를 받기가 수월하다. 이는 데이터를 수집 시, 데이터 생성주체가
데이터 수집여부의 인지를 쉽게 할 수 있기 때문이다. 예를 들어, 설문조사와 같은 경우, 설문에
응하는 사용자로부터 해당 설문 데이터를 수집한다는 동의를 받고 설문조사 결과를 수집할 수
있다. 또한, 대량의 로그 기록을 수집하는 시스템과 같이, 내부적으로 이용되는 데이터에 대한
수집은 데이터의 소유권이 데이터를 수집하는 주체에 있어 내부적인 정책에 따라 수집에 대한
동의가 용의하다. 그리고 이미 보유하고 있는 데이터에 대한 활용도 일종의 데이터 수집이라 할 수
있다. 하지만, 이때 이미 보유하고 있던 데이터를 활용하기 위한 동의를 사전에 미리 받아야 하며,
이용 목적으로 동의된 데이터를 이용 목적에 맞게 사용해야만 한다. RSS와 같은 구독형태로
데이터를 수집하는 경우, 데이터를 제공하는 제공자는 이미 오픈된 형태로 데이터를 제공한다.
따라서 별도의 동의 없이 해당 데이터를 수집하여 이용할 수 있다. RSS를 수집하는 데이터의 예로,
신문 방송과 같은 언론 데이터 또는 블로그 등과 같은 웹출판물 형태의 데이터가 될 수 있다.
② 수집되는 데이터의 접근 통제
능동적 데이터 수집에 있어서, 내부적인 시스템 로그와 같은 데이터는 외부로 유출되지 말아야
하며, 내부적으로만 이용할 수 있도록 해야 한다. 따라서, 생성되는 데이터에 대한 접근 통제가
이루어져야 하며, 권한이 부여된 시스템만 해당 데이터를 수집하고 저장할 수 있도록 해야 한다.
또한, 설문조사와 같은 형태로 이루어진 특정 사용자로부터 입력받은 데이터 또한 설문결과가
입력되는 단계에서, 지정된 시스템으로만 해당 데이터가 저장되어야 한다.

Internet & Security Focus 2013 3월호94
FOCUS
(2) 수동적 데이터 수집
① 수집되는 데이터에 대한 동의
수동적 데이터 수집의 경우, 일반적으로 자동화된 시스템을 통하여 데이터를 수집한다.
인터넷상에 존재하는 다양한 데이터 중 데이터의 소유자가 인지하고, 데이터를 공개하는 경우도
있지만, 그렇지 않는 경우도 존재한다. 이러한 경우, 해당 데이터 소유자로부터 수집되는 데이터에
대한 동의를 받고 데이터를 활용해야 하지만, 수집과정이 자동으로 이루어져 데이터 소유자에게
수집에 대한 동의를 별도로 받기는 어렵다. 이때, 수집 후 해당 데이터 소유주에게 데이터를
수집하여 이용한다는 고지를 취할 수 있다. 하지만, 수집되는 데이터가 개인정보 등을 포함한
민감한 정보일 경우 법적인 이슈가 존재 할 수 있으므로, 수집 주체는 수집되는 데이터에 따라
주의를 기울여서 수집해야 한다. 수동적 데이터 수집의 대표적인 영역으로, 소셜네트워크서비스
영역에서의 데이터 수집을 들 수 있다. 페이스북과 같은 소셜네트워크서비스 영역의 데이터는
서비스 이용자에 따라 공개・비공개의 설정을 할 수 있다. 따라서 공개된 데이터에 한하여
데이터를 수집해야 한다. 하지만, 공개된 영역에서의 데이터 수집이라 할지라도, 서비스 이용자의
민감정보 등이 포함되어 개인의 사생활을 침해할 수 있는 경우 법적인 사항을 고려하여 데이터를
수집해야 한다.
② 수집되는 데이터의 접근 통제
수동적 데이터 수집의 경우, 수집되는 데이터는 이미 외부에서 접근 가능하도록 오픈된 상태의
데이터를 수집한다. 하지만 일부 웹페이지의 경우 “Robot.txt" 파일을 통하여 웹봇(Web Robot)
등으로부터 데이터 수집을 거부할 수 있다. 이때, 해당 데이터는 수집되지 말아야 하지만 악의적인
수집자는 이를 무시하고 해당 데이터를 수집할 수 있다. 따라서, 수집을 명확히 거부하려는 데이터
제공자는 데이터에 대한 접근 통제를 통하여 자동화된 웹봇이 데이터를 수집하는 것을
원천적으로 차단해야 한다.
2) 데이터 저장 및 관리 단계
① 데이터의 안전한 저장 및 관리
데이터 수집단계를 통하여 수집된 데이터는 안전하게 저장되어야 한다. 이는 저장되는
데이터가 외부의 시스템 침입 등에 의하여 불법적으로 유출되었을 경우에 대비하기 위함이다. 즉,
데이터에 대한 암호화 조치 등을 취하여 데이터가 유출되었을 경우도 해당 데이터의 안전성을
확보해야 한다. 또한 데이터를 저장하고 있는 시스템에 대한 접근권한을 설정하는 등 접근에 대한

Internet & Security Focus 2013 3월호 95
FOCUS
통제가 마련되어 있어야 한다. 이는 논리적인 시스템 접근 통제뿐만 아니라 물리적인 시스템의
접근 통제를 포함하여야 한다.
② 데이터 필터링 및 등급 분류
데이터 수집 단계를 통하여 수집된 데이터는 그 종류에 따라서 필터링 되어 저장되거나 또는
데이터의 등급별로 분류하여 별도 관리하여야 한다. 또한, 빅데이터 환경에서 수집되는 데이터는
기존의 정형화된 데이터 이외에도 정형화되지 않은 비정형화된 데이터들이 존재한다. 따라서
이러한 비정형된 데이터들도 저장하고, 처리 가능한 형태로 변형되어 저장되어야 한다. 만약
수집되는 데이터 중 개인정보의 신상과 관련된 민감한 정보라던지 혹은 불필요하게 과도한
개인정보가 수집되는 경우 일정 부분의 데이터를 마스킹 처리하여 식별 불가능하도록 저장하는
등 개인정보에 대한 필터링 처리 후 데이터를 저장하여야 한다. 예를 들어, 데이터 수집 중
주민등록번호와 같은 고유식별정보가 수집되었을 경우, 해당 정보 중 나이에 해당하는 태어난
년도의 정보와 성별에 해당하는 정보만을 이용하고 나머지 정보는 저장하지 않을 수 있다. 그리고
수집되는 정보 중 개인정보에 해당하는 부분을 일정 기준에 따라 등급을 분류하여, 등급별로 처리
기준을 수립하고 안전하게 저장 및 관리하여야 한다.
3) 데이터 처리 및 분석 단계
① 익명화된 데이터 처리 및 분석
데이터 처리에 있어서, 이미 수집된 데이터를 이용하거나 또는 외부의 데이터를 이용하여
데이터를 처리 및 분석 할 수 있다. 이미 수집된 데이터의 경우 데이터 수집의 주체가 데이터의
소유주이기 때문에 데이터 수집 시 적법한 절차에 따라 데이터를 수집하였다면, 이를 빅데이터
솔루션을 이용하여 처리하고 분석하면 된다. 하지만 외부의 데이터를 이용할 경우, 해당 데이터에
대한 이용에 있어서 개인정보 등이 포함된 경우 프라이버시를 침해할 가능성이 존재한다. 예를
들어, 통계적인 목적으로 특정 지역의 건강정보를 이용한다고 하자. 이때, 건강과 관련된 통계적
수치만을 이용해야 하지만, 제공되는 데이터를 개별적인 것으로 본다면 각 데이터 별로 개인에
대한 신상정보가 함께 저장되어 있다. 따라서, 데이터를 처리 및 분석하는 주체가 악의적인 경우
해당 개인정보는 쉽게 유출될 수 있다. 이처럼 제공되는 데이터에 개인적인 정보가 포함되었을
경우 해당 정보에 대한 익명화 과정을 거처 데이터에 존재하는 개인정보를 제거한 형태의 처리 및
분석과정이 필요하다.

Internet & Security Focus 2013 3월호96
FOCUS
② 암호화된 데이터의 처리
데이터 처리 과정에서 유출될 수 있는 개인정보를 근본적으로 해결하기 위하여 저장되는
데이터를 모두 암호화 하고, 암호화된 형태로 데이터를 처리한다면 데이터 처리 과정의 투명성을
보장할 수 있을 것이다. 즉, 데이터 소유주인 이용자만이 알고 있는 암호키 값을 이용하여
수집되는 데이터를 암호화 한다면, 그 외의 주체는 해당 정보를 알 수 없을 것이다. 하지만,
암호화된 데이터는 일반적으로 복호화 되기 전까지 해당 데이터를 이용하여 어떠한 처리과정을
거칠 수 없다. 이는 암호화된 데이터는 복호화되기 전까지 의미를 알기 어렵기 때문이다.
③ 이용 목적 외의 처리 및 분석
데이터를 저장하고 있는 주체는 데이터 수집 시 법적 절차에 의하여 동의를 받았던 이용목적
이외의 데이터 처리 및 분석을 해서는 안된다. 즉, 마케팅이나 기타 다른 목적으로 수집된
데이터의 분석이 이루어지면 안된다. 또한, 프라이버시를 침해하지 않는 목적으로 분석이 이루어
졌다고 해도, 분석된 결과가 프라이버시를 침해할 수도 있다. 이는 빅데이터 환경에서는 어떠한
데이터가 개별적인 데이터 상태에서는 프라이버시를 침해하지 않을지라도, 분석된 결과와 결합될
경우 데이터가 프라이버시를 침해할 수도 있기 때문이다.
4) 데이터 분석결과 가시화 및 이용 단계
① 개인정보를 침해할 수 있는 정보의 생성
빅데이터 분석을 통하여, 분석된 결과는 개인정보를 침해할 수 있는 민감한 정보를 포함할 수
있다. 이러한 경우, 해당 정보를 이용하여 개인에 서비스를 제공하게 되면 문제가 될 수 있다. 최근
미국에서는 빅데이터 분석을 통하여, 고등학생에게 출산용품을 권장하는 광고를 한 사례가
있었다.6) 이처럼 빅데이터 분석을 통하여 기존에 알 수 없었던 새로운 사실을 알게 된 경우 해당
정보는 개인정보를 침해할 수 있다.
② 분석된 정보의 무단 이용
데이터를 분석하여 도출된 결과는, 데이터 분석을 위해 수집된 데이터로부터 도출된 결과이다.
따라서 도출된 데이터 결과를 데이터 수집 시 동의 받은 목적 외에 사용하거나 제공되어서는 안된다.
「 빅데이터 기반 개인정보보호 기술수요 분석 보고서」에 따르면, 정보의 무단 이용은 크게 3가지로
6) 매일경제, “[Trend] 허리케인 올 때 맥주 쌓아둔 월마트, 왜?”, 2013.02.15

Internet & Security Focus 2013 3월호 97
FOCUS
분류할 수 있다.7) 첫째 개인정보보호정책에 명시되지 않은 위탁사업자나 제 3서비스 제공자에게
개인정보를 제공하는 경우이다. 개인정보보호정책은 서비스를 제공받는 모든 서비스 이용자가
자신의 개인정보의 수집, 저장 및 관리, 이용 및 제공에 대한 사항을 세부적으로 확인하는
장치이므로 개인정보보호정책에는 서비스 사업자가 관리하는 모든 서비스 제공자, 위탁사업자와
제공 개인정보 항목 및 목적, 기간 등이 반드시 포함되어야 하며, 개인정보는 개인정보보호정책을
준수하여 제공되어야 한다. 둘째, 개인정보보호정책에 명시되지 않은 개인정보 항목을 제공하는
경우이다. 개인정보보호정책에 명시된 위탁사업자 또는 제 3서비스 제공자라 하더라도 모든
개인정보 항목을 제공하여서는 안되며, 반드시 제공항목에 해당하는 개인정보만을 제공하여야
한다. 셋째, 온라인 또는 오프라인으로 개인정보를 제 3자에게 양도하는 등 불법적 거래의 경우이다.
서비스 사업자는 서비스 이용자의 중요한 개인정보를 포함하고 있으므로, 저장된 개인정보의 이용
및 제공은 반드시 접근 권한을 가진 담당자에 의해서만 합법적으로 수행되어야 한다.
5) 데이터 폐기 단계
① 데이터 폐기에 대한 확인
수집된 데이터는 이용목적을 달성하면 지체 없이 파기해야 한다. 하지만 이용목적 달성 후에도
해당 데이터가 파기되었는지 이용자 입장에서는 알기 어렵다. 만약 이용목적 달성 후에도 해당
데이터가 파기되지 않고 계속 존재한다면, 이러한 정보는 잠재적인 유출 위험이 존재한다고 볼 수
있으며, 관련된 법안에도 위배된 사항이다. 따라서, 데이터의 폐기에 대한 객관적인 모니터링 및
확인이 필요하다.
② 완전한 데이터 폐기
빅데이터 환경에서 저장되는 데이터는 여러 곳에 분산되어 저장될 수 있으며, 저장되는 데이터
또한 여러 곳에 복제되어 저장될 수 있다. 따라서 데이터 폐기 시, 기존의 폐기방식을 통하여
폐기하는 경우 완벽하게 폐기되지 않을 수 있다. 또한 일반적인 삭제 명령등을 통한 데이터 폐기는
데이터를 완벽히 삭제하지 않는다. 따라서 논리적으로 안전한 방법을 통하여 데이터를 폐기해야
하며, 또는 물리적인 방법으로 복구 불가능 하도록 폐기하여야 한다. 잊혀질 권리 등과 같은
이슈가 부각되고 있는 가운데, 데이터 폐기의 중요성은 더욱 강조되고 있다.
7) 한국인터넷진흥원 (2012) “빅데이터 기반 개인정보보호 기술수요 분석”, 성신여자대학교 산학협력단, 2012.12.

Internet & Security Focus 2013 3월호98
FOCUS
2. 개인정보보호 기술
1) 데이터 수집 단계
데이터 수집 단계에서 필요한 개인정보보호 기술은 수집되는 데이터에 대한 동의와 관련된
기술과 이에 대한 법률적 위반사항을 검토할 수 있는 기술이다. 또한 웹봇 및 웹크롤러 등에 의해
자동으로 수집되는 것을 막기 위한 데이터 수집에 대한 거부 기술도 필요하다.
① 데이터 수집 시 동의 관련 기술
데이터를 수집할 경우, 수집되는 데이터에 개인정보가 포함되어 있는 경우 해당 데이터의
주체로부터 동의를 받아야 한다. 특히, 수동적 데이터 수집의 경우 동의를 받는 과정이 능동적
데이터 수집에 비해 매우 어렵다. 따라서 이를 도와줄 수 있는 기술이 필요하다. 또한 수집되는
데이터가 개인정보가 아닌 일반적인 정보 및 개인을 식별할 수 없는 통계적인 정보인 경우 해당
데이터에 대한 주체가 명확하지 않아 별도의 동의를 받지 않아도 된다. 따라서, 수집되는 정보가
개인정보인지 아닌지 판별할 수 있는 기술도 필요하다. 이러한 기술을 통하여 데이터를 수집하는
주체는, 데이터 수집 시 동의에 대한 부담을 줄일 수 있을 것으로 기대한다.
② 데이터 수집 시 법률적 위반사항 검토 기술
개인정보와 관련된 내용을 수집 시 관계법령에 따라 데이터를 수집해야 한다. 예를 들어,
개인정보보호법이 적용되는 경우, 개인정보의 수집・이용목적, 수집하려는 개인정보의 항목,
개인정보의 보유 및 이용 기간, 동의를 거부할 권리가 있다는 사실 및 동의 거부에 따른 불이익이
있는 경우에는 그 불이익의 내용 등을 명시하고 동의를 받아야 한다. 또한 개인정보와 민감정보를
분리해서 별도의 동의를 받아야 한다. 이처럼 법률에 대한 지식이 없는 사람도, 데이터 수집 시,
수집과정에 대해서 법률적인 위반사항에 대한 자동화된 검토 기술이 존재한다면 데이터 수집에
대하여 자동화 된 형태로 매우 편리하게 데이터를 모을 수 있을 것이다.
③ 데이터 수집 거부 기술
웹사이트에서 제공하는 정보는 웹 로봇 또는 웹크롤러등과 같은 자동화된 데이터 수집 시스템을
통하여 수집될 수 있다. 이러한 자동화된 수집을 방지하고자 로봇 배제 표준이 생겨났으나, 이 규약은
권고안으로 반드시 지켜야 하는 것은 아니다. 그러므로 로봇 배제 표준을 적용한다 하더라도
웹사이트에서 제공되는 데이터가 수집될 수 있어, 웹사이트에서 제공되는 데이터의 수집을 거부하기
위한 기술 개발이 필요하다. 즉, 정상적인 사용자에 대하여는 데이터를 제공하지만 로봇과 같이

Internet & Security Focus 2013 3월호 99
FOCUS
자동으로 대량의 데이터를 가져가는 형태에 대해서는 차단하는 기술이 필요하다.
2) 데이터 저장 및 관리 단계
데이터를 저장 및 관리하는 단계에서 필요한 개인정보보호 기술은 데이터 암호화 기술 및
접근통제 기술, 그리고 데이터 필터링 및 등급 분류 기술이다.
① 데이터 암호화 기술
저장되는 데이터를 보호하기 위해서는 데이터 암호화 기술이 필요하다. 이는 데이터베이스
서버의 자료 유출로부터 데이터의 기밀성을 유지할 수 있도록 도와주기 때문이다. 데이터 암호화
기술은 암・복호화를 처리하는 물리적인 위치에 따라 API 방식, Plug-In방식, 하드웨어 방식으로
나누어진다. API 방식은 데이터베이스 솔루션 외부의 어플리케이션에서 데이터의 암・복호화가
수행되어 데이터베이스 서버에 부하가 발생하지 않는 장점을 가진다. Plug-In방식은
데이터베이스 서버에 제품이 설치되어 암・복호화가 수행되는 구조로, 기존의 데이터베이스
어플리케이션의 수정이 거의 발생하지 않는 장점이 있으나, 데이터베이스 자체에 부하가
발생하는 단점이 있다. 하드웨어 방식은 별도의 서버외부에 암호화장비를 설치하여 시스템의
과부하를 감소시키는 방식이다. 하지만, 빅데이터 환경에서 HDFS와 같은 방식의 데이터 저장은
데이터의 복제 및 분산이 일어나 기존의 데이터 암호화 기술을 적용하기 어려울 수 있다. 따라서,
빅데이터 환경에 맞는 데이터 암호화 기술이 필요하다.
② 데이터 접근통제 기술
데이터가 저장된 데이터베이스에 대한 접근통제 기술이 필요하다. 데이터가 저장되어 있는
공간인 데이터베이스는 일반적인 서버 시스템과 크게 다르지 않기 때문이다. 따라서, 데이터에
대한 접근통제 기술은 일종의 시스템 접근통제 기술로 볼 수 있다. 시스템 접근통제를 위한
기술로는 침입탐지시스템, 침입차단시스템, VPN 등과 같은 네트워크 기반의 기술들이 있다. 또한,
데이터에 접근하는 사용자 인증과 권한에 대한 계정관리를 위한 기술도 필요하다.
③ 데이터 필터링 및 등급 분류 기술
저장되는 데이터에 따라 등급을 분류하고 이에 맞춰 데이터를 관리하는 기술이 필요하다.
데이터의 분류는 필터링에 의하여 자동으로 수행될 수 있다. 또한, 개인정보에 자동으로
비식별성을 추가하여, 법적인 이슈가 없도록 만들어주는 필터링 기술도 필요하다.

Internet & Security Focus 2013 3월호100
FOCUS
3) 데이터 처리 및 분석 단계
데이터 처리 및 분석 단계에서 필요한 개인정보보호 기술은 익명화된 데이터 처리 기술 및
암호화된 데이터 처리 기술이다.
① 익명화된 데이터 처리 기술
PPDM과 같은 프라이버시를 보호하며 데이터를 처리 및 분석 하는 기술이 필요하다. 대표적인
프라이버시 보호 분석기술로 K-익명성, L-다양성, 차분프라이버시 등의 익명화된 방식으로
데이터를 처리하는 기술이 있다. K-익명성(K-anonymity) 기술은 데이터베이스의 연관성을
줄이기 위해 제안된 방법으로, 데이터와 관련된 개인의 프라이버시를 보호하는 것이 주된
목적이다. K-익명성은 K값을 정하여, K 값에 따라 데이터의 익명성을 보장하는 방식이다. 예를
들어 K 값이 3인 경우 3개의 데이터는 동일한 형태로 취급되어 구분이 불가능하다. K값이
커질수록 익명성은 높아지나, K 값이 무한대라면, 결국 데이터베이스의 모든 내용의 구분이
불가능할 것이다. 반대로 K 값이 1이라면, 기존의 데이터베이스와 동일한 형태로 모든 값의
구별이 가능하다. 결국, 분석되는 데이터의 성격에 따라서 K 값을 정하여 이용해야 할 것이다.
몇몇 경우 K-익명성을 이용하여 데이터를 분석할 때, 데이터 간의 구분이 쉽지 않은 경우가
발생한다. 이때 이용할 수 있는 기술이 L-다양성(L-diversity) 기술이다. 즉, K-익명성 기술과
L-다양성 기술을 이용하여, 데이터베이스의 특정 데이터의 익명성을 구현하여 통계적인 정보만
제공할 수 있다.
② 암호화된 데이터 처리 기술
암호화된 데이터 처리 기술로, 순서보존 암호 및 연산보존 암호와 같은 기술이 필요하다.
순서보존암호는 암호화가 된 상태의 데이터도 검색 및 정렬이 용의하여, 데이터의 처리가
가능하도록 하는 기술이다. 이를 위하여 평문 집합을 일정 구간(Bucket)으로 분할하고, 평문을
Bucket 구간에 해당하는 데이터로 변환하여 별도의 테이블에 저장한다. 이를 이용하면 Bucket
자체로 평문의 내용은 알 수 없지만 데이터의 처리는 가능해진다. 연산보존 암호(Homomorphic
Encryption)는 암호화가 된 상태에서도 연산이 가능한 암호화방식으로 ‘4세대 암호기술’로도
불린다. 연산보존 암호는 2011년 MIT가 선정한 10대 미래유망기술의 하나로 정보를 최소로
노출하면서 연산이 가능한 기술이다. [그림 8]과 같이 가트너의 프라이버시 보호기술 Hype
Cycle에 따르면 연산보존암호는 노출최소화기술(Limited Disclosure Technology)의 한 종류로
아직 기술 발생기(Technology Trigger)에 머물러 있으며, 최소 10년 이상 더 연구가 되어야 할

Internet & Security Focus 2013 3월호 101
FOCUS
기술 분야로 알려져 있다. 국내에서도 연산보존암호 기술에 대한 활발한 연구가 이루어지고
있으며, 올해 세계 3대 암호학술대회인 EuriCrypt 2013에서 관련 기술에 대한 발표가 될
예정이다.8)
4) 데이터 분석결과 가시화 및 이용 단계
① 이용자 동의와 관련된 기술
빅데이터 분석을 통하여 도출된 결과는 개인정보를 침해할 수 있는 정보일 수 있다. 따라서,
도출된 결과를 이용하여 어떠한 서비스를 제공하려 할 때, 서비스를 제공받길 원하는 이용자에게
사전에 미리 서비스이용에 대한 범위를 설정하고 해당 범위 안에 속하는 경우 데이터 분석결과와
연관된 정보를 이용하여 서비스를 제공해야 한다. 이러한 제공을 위하여 빅데이터 분석을 통해
도출될 영역을 미리 예측하는 기술이 필요하다. 또한 사전에 이용자 동의를 받지 못한 경우,
사후에 동의를 받기 위한 기술이 필요하다. 이때 중요한 점은, 동의를 받는 행위 자체가 이용자의
프라이버시를 침해 할 수 있기 때문에 이러한 사항도 고려해야 할 수 있는 기술이여야 한다는 것이다.
8) 매일경제, “서울대 천정희 교수팀 ‘4세대 암호 기술’ 국내서 개발(암호 해제하지 않고도 연산·검색 가능)”. 2013.1.27
[그림 8] Hype cycle for Privacy, 2012

Internet & Security Focus 2013 3월호102
FOCUS
② 분석정보의 이용 모니터링 기술
빅데이터 분석을 통하여 도출된 결과의 이용에 대한 모니터링 기술이 필요하다. 이러한
기술은 해당 정보가 안전하게 사용되는지 확인 가능하여, 개인정보침해를 사전에 예방할 수
있기 때문이다. 하지만 모든 정보에 대하여 모니터링을 하는 것은 불가능 할 수 있다. 따라서,
특정 기준점을 설정하여, 그에 해당하는 정보는 서비스 이용자들에게 해당 정보의 이용내역에
대한 고지 등을 통하거나 또는 해당정보의 이용과정을 투명하게 공개하는 등 정보에 대한
모니터링을 제공하여 데이터 처리 과정의 투명성을 제공할 수 있다.
5) 데이터 폐기 단계
① 데이터 폐기 모니터링 기술
수집된 데이터는 이용목적을 달성하면 지체없이 파기해야 한다. 하지만 이용목적 달성 후에도
해당 데이터가 파기되었는지 이용자 입장에서는 알기 어렵다. 만약 이용목적 달성 후에도 해당
데이터가 파기되지 않고 계속 존재한다면, 이러한 정보는 잠재적인 유출 위험이 존재한다고 볼
수 있으며, 관련된 법안에도 위배된 사항이다. 따라서, 데이터의 폐기에 대한 모니터링 및 확인
기술이 필요하다.
② 분산 환경에서 완전한 데이터 폐기 기술
빅데이터 환경에서 저장되는 데이터는 여러 곳에 분산되어 저장될 수 있으며, 저장되는
데이터 또한 여러 곳에 복제되어 저장될 수 있다. 따라서 데이터 폐기 시, 기존의 폐기방식을
통하여 폐기하는 경우 완벽하게 폐기되지 않을 수 있다. 또한 일반적인 삭제 명령 등을 통한
데이터 폐기는 데이터를 완벽히 삭제하지 않는다. 그러므로 논리적으로 안전한 방법을 통하여
분산된 환경에서의 완벽한 데이터를 폐기하는 기술이 필요하다.
Ⅳ. 결론
빅데이터를 바라보는 관점은 빅데이터를 활용하는 이해관계자에 따라 다를 수 있다. 하지만,
빅데이터도 결국은 사람을 위한 기술 중 하나 일 것이다. 개인정보보호법의 입법 목적은
개인정보를 보호함으로써, 개인의 존엄과 가치를 구현한다는데 있다. 빅데이터의 활용에

Internet & Security Focus 2013 3월호 103
FOCUS
있어서도 개인정보보호법의 입법 목적과 같이 개인의 존엄과 가치를 구현하고자 한다면,
빅데이터를 활용하는 이해관계자는 반드시 개인정보를 안전하게 처리해야 할 것이다. 이에 본
고에서는 빅데이터 환경에서 필요한 개인정보보호 기술을 도출하고자, 빅데이터의 분석 절차를
총 5단계로 나누고, 각 단계별 관련 기술을 살펴보았다. 그리고 단계별로 발생할 수 있는
개인정보를 침해할 수 있는 이슈 및 이를 해결하기 위한 조치를 살펴보고, 그에 따라 필요한
개인정보보호 기술을 제안하였다. 제안된 기술을 기술의 성숙도, 필요도, 난이도에 따라 상/중/
하로 구분하면 [표 2]와 같이 정리될 수 있다.9)
데이터 처리 단계 필요기술기술성숙도(상/중/하)
기술필요도(상/중/하)
기술난이도(상/중/하)
데이터 수집 단계
데이터 수집 시 동의 관련 기술 중 상 하
데이터 수집 시 법률적 위반사항 검토 기술 하 중 상
데이터 수집 거부 기술 하 상 상
데이터 저장 및 관리 단계
데이터 암호화 기술 상 상 중
데이터 접근통제 기술 상 상 하
데이터 필터링 및 등급 분류 기술 하 중 하
데이터 처리 및 분석 단계익명화된 데이터 처리 기술 중 상 상
암호화된 데이터 처리 기술 하 상 상
데이터 분석결과 가시화 및 이용 단계
이용자 동의와 관련된 기술 하 상 상
분석정보의 이용 모니터링 기술 하 중 상
데이터 폐기 단계데이터 폐기 모니터링 기술 하 중 상
분산 환경에서 완전한 데이터 폐기 기술 하 상 중
대부분의 빅데이터 관련 기술은 기술성숙도가 “하”로 낮음을 알 수 있다. 기존의 데이터 암호화
및 접근통제와 같은 기술등은 비교적 기술이 많이 성숙되어 있으나, 그 외의 빅데이터 환경에서
필요한 데이터의 이용에 대한 동의 및 모니터링 등 많은 기술의 연구가 필요해 보인다. 특히 기술
필요도 측면에서 살펴보면, 데이터의 모니터링을 제외한 대부분의 기술들이 빅데이터 환경에서
매우 필요한 기술로 볼 수 있다. 기술의 난이도 측면에서는 데이터의 이용과 관련하여 법적인 이슈
사항(법률 위반여부 확인 및 수집된 데이터의 처리 등)과 관련된 기술은 난이도가 높다고 할 수
있다. [표 2]를 통하여 기술의 난이도가 낮고, 필요도가 높은 기술인 “데이터 수집 시 동의 관련
기술”, “데이터 접근 통제 기술”, “데이터 필터링 및 등급 분류 기술”등은 단기적인 연구를 통하여
9) 본 고에서 제시한 <표2>의 기술성숙도/기술필요도/기술난이도는 본 고를 집필하기 위해 조사한 자료를 토대로 작성된 필자의
주관적인 견해임을 알려드립니다.
<표 2> 빅데이터 기반 개인정보보호 필요기술의 기술성숙도/기술필요도/기술난이도

Internet & Security Focus 2013 3월호104
FOCUS
기술을 빠르게 개발하여 적용할 수 있어 보인다. 또한 기술의 성숙도가 낮고 필요도가 높으며
기술의 난이도도 상대적으로 높은 “데이터 수집 거부 기술”, “암호화된 데이터 처리 기술”,
“이용자 동의와 관련된 기술”, “분산 환경에서 완전한 데이터 폐기 기술” 과 같은 기술은
중장기적인 관점에서 꾸준한 연구가 필요해 보인다. 본 고에서 제안한 기술 중 “데이터 수집 시
법률적 위반사항 검토 기술”과 같이 법률적 사항과 관련된 기술은 기술을 통해 도출된 결과가
반드시 법률적 사항에 적합하다고 확신하기 힘들 수도 있다. 하지만, 본 고에서 언급한
개인정보보호를 위해 필요한 기술들에 대한 관심과 연구가 지속적으로 이루어지고, 중장기적인
관점에서의 기술 개발 및 단기적 관점에서의 기술개발과 그 결과의 적용 등 빅데이터와 관련된
개인정보보호 기술을 꾸준히 연구하고 개발한다면, 빅데이터 환경에서 제공되는 서비스가
개인정보에 보다 안전한 형태로 제공될 수 있을 것이라 기대한다.
참고문헌
김형중, 통계적 익명성을 위한 Privacy 보호 기술. NIA Privacy Issues. 2012.6.20
국가정보화전략위원회, 빅데이터를 활용한 스마트정부 구현(안)
손상영, 빅데이터·온라인 마케팅과 프라이버시 보호, 『 정보통신정책연구원』. 2013.1.31
원호섭, 서울대 천정희 교수팀 ‘4세대 암호 기술’ 국내서 개발. 『 매일경제』. 2013.1.27
한국정보화진흥원, 신가치창출 엔진, 빅 데이터의 새로운 가능성과 대응 전략. 2011.12.30
한국인터넷진흥원, 인터넷&시큐리티 이슈 2월호. 2012.2
한국인터넷진흥원, 빅데이터 기반 개인정보보호 기술수요 분석. 성신여자대학교 산학협력단. 2012.12
빅데이터 연구반, 빅데이터 시대 준비를 위한 개인정보보호 법제화 방향 연구. 개인정보보호 법제정비 연구포럼.
2012.11.21
Fay Chang·Jeffrey Dean·Sanjay Ghemawat·Wilson C. Hsieh·Deborah A. Wallach·
Mike Burrows·Tushar Chandra·Andrew Fikes·Robert E. Gruber, Bigtable:
ACM Transactions on Computer Systems, 26(2). 2008.6
Carsten Casper, Hype Cycle for Privacy, 2012. Gartner. 2012.7.25
Hung LeHong, Jackie Fenn, Hype Cycle for Emerging Technologies, 2012. Gartner. 2012.7.31
Cloudera, Flume User Guide, (2013.2.12 검색), <http://archive.cloudera.com/cdh/3/flume/UserGuide>










![공공부문 문화예술 비정규직 노동실태와 개선방향klsi.org/sites/default/files/field/[이슈페이퍼2015-04] 공공부문 문화예술... · 사이 약 5,861명](https://img.pdfslide.net/doc/110x75/6026885ab3ada273b72c77c3/eeee-e-eeoe-eefoe-eoeeklsiorgsitesdefaultfilesfield2015-04.jpg)
![문재인정부의 공공부문 비정규직 정규직화 정책 진단 …klsi.org/sites/default/files/field/[2019-03호]_문재인...2 2. 공공부문 정규직화 정책의 주요](https://img.pdfslide.net/doc/110x75/5e53619dab446576e367dc4d/ee-eeee-eeoe-eoe-e-klsiorgsitesdefaultfilesfield2019-03e.jpg)

![¥ 2 ñ - klsi.orgklsi.org/sites/default/files/field/[27호] 공공부문 정책이슈 보고서.pdf · 위탁집행형 준정부기관은 2015년 금융위원회 산하의 한국거래소가](https://img.pdfslide.net/doc/110x75/5e06879ec1f902684c63abbe/-2-klsi-27-eeee-eeoepdf-oef.jpg)