Embed Size (px)
Citation preview

エヌビディア コーポレーション ソリューション アーキテクチャ & エンジニアリング
副社長 マーク・ハミルトン
基調講演

ビジュアルコンピューティングの世界的リーダー
ENTERPRISE 自動車ゲーム HPC & クラウドエンタープライズ

GPU コンピューティングの大きな飛躍20152008
3,000,000CUDA ダウンロード
150,000CUDA ダウンロード
60,000 学術論文
4,000学術論文
800大学の CUDA コース
60大学の CUDA コース
54,000スーパーコンピューティングテラフロップス
77スーパーコンピューティング
テラフロップス
450,000Tesla GPU
6,000Tesla GPU
319CUDA アプリ
27CUDA アプリ

GEFORCE NOW
You listen to music on Spotify. You watch movies on Netflix. GeForce Now lets you play games the same way.
Instantly stream the latest titles from our powerful cloud-gaming supercomputers. Think of it as your game console in the sky.
Gaming is now easy and instant.
先進のレンダリングから仮想PCまで
製品の可視化建築サイエンス
先進のレンダリングが可能にする次世代バーチャル製品開発
GRID 2.0 が実現する拡張性、仮想 PC におけるセキュリティ
リアルタイム可視化が HPC データセンターに新たな価値を
建築
製品デザイン
リアルタイム可視化

東京工業大学学術国際情報センター 副センター長GPU コンピューティング研究会 主査共同利用推進室 室長
CUDA Fellow 青木尊之教授

スパコンにおける VDI の必要性
大規模データ 数100GB~数10TB
プリ・ポスト処理(可視化)
※ 膨大なデータ転送時間
※ 巨大なローカルストレージ
数時間~数日 (~数10MB/s)

大規模データ 数100GB~数10TB
プリ・ポスト処理
※ データ転送時間の削減
※ セキュリティの大幅向上
スパコンにおける VDI の必要性
シンクライアント デスクトップ画面のみインターネット (~10Mbps)
スパコン直結VDIシステム

TSUBAME2.5直結 VDI システム (概要)計算ノード 4224 GPU (Tesla K20X)
NVIDIA GRID K2 x 3
HP ProLiant SL250s × 3Xeon(R) CPU E5-2660 v2
2.20GHz ×2
128GB
インターネット

TSUBAMEで動作するCAEアプリケーションのインタラクティブ・ポスト処理(CST MWStudio)
TSUBAMEで行った大規模計算をTSUBAME上で可視化した計算結果のフルHD
動画再生
個別要素法の粒子計算によるバンカーショット (1670万個)
粒子法(SPH) による多数の浮遊物を含んだ津波シミュレーション (8700万個)
メッシュ(VOF) 法による気液二相流シミュレーション (1.1億メッシュ)
TSUBAME2.5直結 VDI システム (デモ)

NVIDIA GRID 2.0

ハイパーバイザ
仮想マシンvGPU
NVIDIA GRID vGPU アーキテクチャ
クライアントデバイス
データセンターサーバー
VMwareHorizon View
CitrixXenDesktop
ゲスト OSWindows
NVIDIA ドライバ
ゲスト OSLinux
NVIDIA ドライバ
仮想マシンvGPU
サーバー
vGPU マネージャー
GRIDCPU

NVIDIA GRID は誰のため?
よりよいユーザーエクスペリエンスを期待する
ビジネスユーザー
中小規模のファイルを扱うエンジニアとデザイナー
最高のグラフィックス性能を必要とする
エンジニアとデザイナー

GRID 拡張仮想ワークステーション
GRID 仮想ワークステーション
GRID 仮想 PC
NVIDIA データセンター GPU (TESLA M6/M60)
ソフトウェア・サポート + アップデートサブスクリプション 一年更新
ソフトウェアライセンス(一括払い)
ハードウェア
NVIDIA GRID 2.0

ディープラーニング

典型的なネットワーク例
ディープラーニングとは?
目的
顔認識
トレーニングデータ
1,000万~1億イメージ
ネットワークアーキテクチャ
10 層
10 億パラメータ
ラーニングアルゴリズム
30 エクサフロップスの計算量
GPU を利用して30日

木
猫
犬
機械学習ソフトウェア
“亀”
フォワード プロパゲーション
“亀” から “犬” へ計算の重み付けを更新
バックワード プロパゲーション
学習済みモデル
“猫”
反復
トレーニング
推論

なぜディープラーニングが注目を集めるのか?
ビッグデータの存在 GPU の計算パワー新しいアルゴリズム
毎日 3億5000万枚の画像がアップロード
毎時 2.5 ペタバイトの顧客データ
毎分 300 時間分のビデオがアップロード

エヌビディア ディープラーニング
アプリケーション
DIGITS ツール
開発 運用
ディープラーニング フレームワーク
ソフトウェア システム ハードウェア ソフトウェア システム ハードウェア
cuDNN DevBox TITAN X システム管理 TESLA

NVIDIA cuDNN
ハイパフォーマンス ニューラルネットワーク トレーニング
Caffe、Chainer、Theano、Torch などのディープラーニング フレームワークを GPU で高速化
pooling、ReLU、sigmoid、softmax、TANH など様々なタイプのレイヤーをサポート
最新のエヌビディア GPU アーキテクチャに最適化
Linux、Windows、OSX および Linux for Tegra (ARM) をサポート
GPU が加速するディープラーニング フレームワーク
http://developer.nvidia.com/cuDNN
0
20
40
60
80
cuDNN 1(TITAN Black)
cuDNN 2(TITAN X)
cuDNN 3(TITAN X)
性能向上
1日で学習できる画像の数(100万枚単位)

NVIDIA DIGITSインタラクティブ ディープラーニング GPU トレーニング システム
Test Image
トレーニング進捗確認DNN の構成データ処理 レイヤーの可視化
http://developer.nvidia.com/digits

DIGITS デモ
エヌビディア
CUDA エンジニア
村上真奈

音声認識 画像分析 自然言語処理
エヌビディアが加速するディープラーニング フレームワーク
エンドユーザ アプリケーション
DIGITS
ディープラーニング フレームワーク (Caffe, Chainer, Torch, Theano)
高度に最適化された cuDNN ライブラリ
CUDA プログラミング ツールキット
GPU ハードウェア

GPUコンピューティングDL ライブラリ
DL の技術開発力Chainer
Chainerおよび関連技術の開発期間の短縮
各産業へのディープラーニングの適用を促進
×

株式会社 Preferred Networks
代表取締役社長 西川 徹様

Distributed Cooperative Deep Learning次世代ビッグデータ・IoT技術基盤の確立を目指して
分散協調型強化学習
学習結果はリアルタイムに反映

From Sensing to Controlling ActionIoT デバイスはセンシングだけでなくリモートでのコントロール・アクションを実現する
Data Collection
Control
Sensing
Cooperate

Chainer
ChainerはCUDAを採用
GPUを数行のコードで動かせる
複数GPUでの実行も可能
パワフル
Pythonの任意の制御構文を使って逆伝播可能なコードが書ける
コードは直観的で、デバッグも容易
直観的
様々なネットワークアーキテクチャをサポート
feed-forward、convnet、recurrent、 recursive nets
バッチごとに異なるアーキテクチャも記述可能
フレキシブル
A Powerful, Flexible, and Intuitive Framework of Neural Networks

DAVE
ディープラーニングによるロボットナビゲーション
ディープニューラルネットワークが人間の運転手を「見て」、対応を学習
DARPA 自動走行車 (2004年)
“右に曲れ”
“左に曲れ”

エヌビディア コーポレーション 自動車担当シニアディレクター
ダニー・シャピロ
自動運転を目指して

NVIDIA オートモーティブ
世界中の道路に
さらにこれから…
800万台以上
20以上のブランド 100以上のモデル

NVIDIA

フォトリアル デザイン シミュレーション

効率を改善するためのシミュレーション

シミュレーションによるより良い、より速い車作り

実際のクラッシュ クラッシュシミュレーション
シミュレーションによる、より良い、より速い車作り

ソフトウェア ディファインド カー

ソフトウェア ディファインド カー

ソフトウェア ディファインド カー

ソフトウェア ディファインド カー

ソフトウェア ディファインド カー

ソフトウェア ディファインド カー

ソフトウェア ディファインド カー


今日の ADAS
FPGA
CV ASIC
SENSE ACTPLAN
CPU
BRAKE
WARN

次世代の ADAS
ACTSENSE ACT
ACCELERATE
PLAN
STEER
BRAKE
WARN
FPGA
CV ASICCPU

次世代の ADAS

自動運転にはディープラーニングが必須の技術に
FPGA
CV ASIC
SENSE ACT
ACCELERATE
PLAN
CPU
DNN
STEER
BRAKE
WARN

ディープラーニングによる車の分類
画像 “Audi A7”
Image source: “Unsupervised Learning of Hierarchical Representations with Convolutional Deep Belief Networks” ICML 2009 & Comm. ACM 2011.Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Ng.

DRIVE PX 自動運転用カーコンピューター
NVIDIA GPU によるディープラーニングスーパーコンピューター
学習済みのニューラルネットモデル
分類された対象物
!
より良く見える、そして学習する自動車へ
カメラ入力
正しく認識されなかった対象物をフィードバック


NVIDIA DRIVE™ PX自動運転用カーコンピューター
2.3 テラフロップス
12 カメラ入力
センサーフュージョンとディープラーニング

Video: Danny-05

ADAS Today
歩行者

乗用車

スクールバス


救急車

株式会社 ZMP
代表取締役社長 谷口 恒様

©2015 ZMP Inc. All Rights Reserved.
農業機械
自動運転技術
物流支援ロボットタクシー社
様々な応用事業を実現していく
鉱山・建設機械
自律移動技術
ロボット技術
エアロセンス社
Robot of Everything
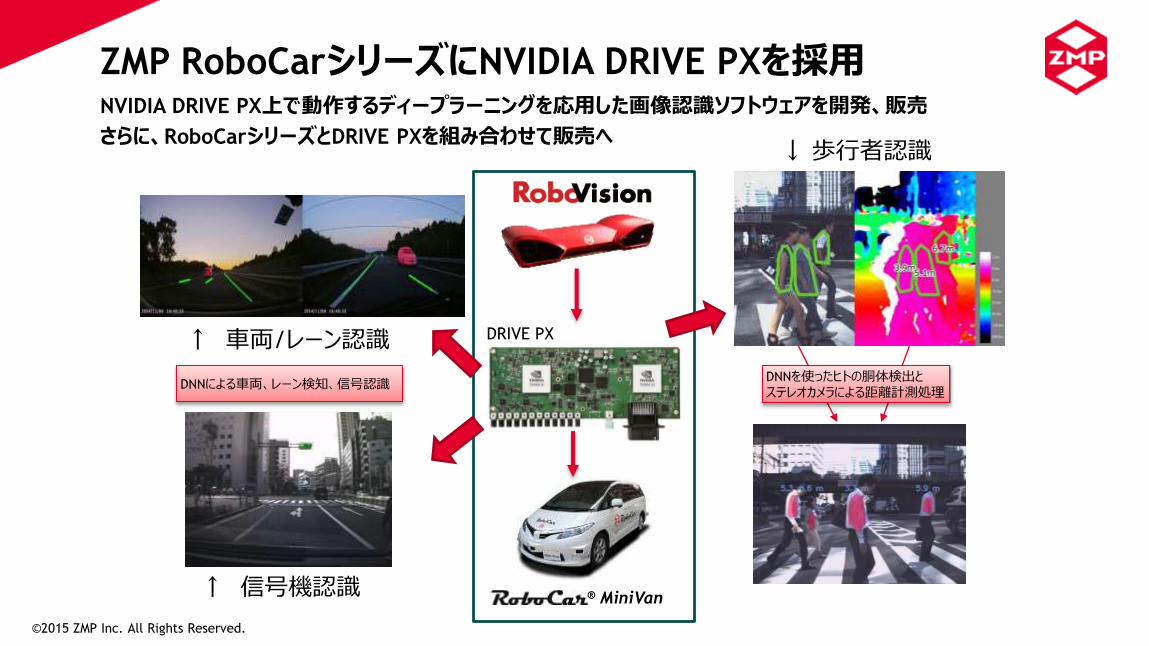
ZMP RoboCarシリーズにNVIDIA DRIVE PXを採用
©2015 ZMP Inc. All Rights Reserved.
NVIDIA DRIVE PX上で動作するディープラーニングを応用した画像認識ソフトウェアを開発、販売
さらに、RoboCarシリーズとDRIVE PXを組み合わせて販売へ
DRIVE PX
® MiniVan
↓歩行者認識
DNNを使ったヒトの胴体検出とステレオカメラによる距離計測処理
↑ 車両/レーン認識
↑ 信号機認識
DNNによる車両、レーン検知、信号認識

イノベーションのためのモデル
OEM
TIER 1
チップサプライヤー
TIER 1
OEM
SILICON VALLEY
伝統的なモデル

MERCI 月面での自動運転

未来の GPU テクノロジー

2012 20142008 2010 2016 2018
48
36
12
0
24
60
72
TeslaFermi
Kepler
Maxwell
Pascal混合精度演算倍精度演算3D メモリNVLink
Volta
GPU ロードマップ
SG
EM
M /
W

ユニファイドメモリ単一メモリ空間による容易なプログラミング
NVLink ハイスピードインターコネクトPCIE Gen 3 の5倍の性能
メモリバンド幅メモリ容量およびバンド幅の大幅な向上
Pascal: 次世代 GPU
パフォーマンス世界最高の倍精度演算

NVIDIA OpenACC ツールキットアクセラレイテッドコンピューティングへのシンプルかつ強力なパスを無償提供
http://www.nvidia.com/openacc からダウンロード
PGI コンパイラアカデミックユーザーへ OpenACC コンパイラを無償提供
NVProf プロファイラコンパイラディレクティブの挿入箇所を容易に発見
コードサンプル実際のアプリケーションのアルゴリズムから学ぶ
ドキュメントクィックスタートガイド、ベストプラクティス、フォーラム

世界の HPC のリーダーシップへ
2017年運用開始予定
100-300 ペタフロップス
10倍のアプリケーション性能
IBM POWER9 CPU と NVIDIA Volta GPU
NVLink ハイスピードインターコネクト
40,000 個の Volta GPU
CORAL プロジェクト 米国国家戦略計算イニシアティブ
2023年までに米国でエクサフロップスシステムを作る大統領令
ポストムーアの法則時代への明確なパス
現行の米国最速スパコンの30倍の性能
GPU がプレエクサおよびエクサスケールマシンを実現
研究開発予算 5 億ドル (2016-22)

日本アイ・ビー・エム株式会社ハイエンド・システム事業部 理事 朝海 孝様

74
HPCの新潮流 –Data Centric Computing-
IBM POWER9 CPU + NVIDIA Volta GPU
NVLink 超高速インターコネクト
ノード当り 40 テラフロップス以上
3,400ノード以上
2017年稼動予定
SUMMIT SIERRAピーク性能
150-300 ペタフロップスピーク性能
100 ペタフロップス以上
データを動かさずに処理する“新しい設計思想”に準拠したデータセントリックシステム時代の幕開け!

75
ビッグデータの有効利活用で
社会に貢献!
豊かな日本社会へ
データセントリック推進センターで
オープンコラボレーション!
日本発のInnovation
標準製品・低消費電力で
超高速ビッグデータ分析を!
POWER+GPGPU
データセントリック推進センターを日本に開設へ
豊かな日本社会へ POWER + GPGPU 日本発の Innovation

TESLA アクセラレイテッド データセンタープラットフォーム
TESLA データセンター サーバー / ラック
QUADRO
デザイン &
レンダリング
VCA, Iray
DESIGNWORKS
GRID
仮想PC &ワークステーション
vGPU
HPC
OpenACC
CUDA
ディープラーニング
cuDNN
DIGITS
TESLA システム管理およびコミュニケーションミドルウェア

Enjoy GTC Japan 2015!

WELCOME TO THE FUTURE

![近未来テクノロジー2019 - noma.or.jpGUIDE]Futuristic technology... · 2.ディープラーニング aiが普及するきっかけとなったテクノロジーであるディープラーニング。](https://img.pdfslide.net/doc/110x75/5e25a62917c3641c3511ed37/eoeffff2019-nomaorjp-guidefuturistic-technology-2ifffffff.jpg)



























