Embed Size (px)
Citation preview

Fouille de
données Web
1

Plan du cours1. Le pré-traitement des données
2. Méthodes non supervisées
3. Méthodes non supervisées
4. Méthodes semi-supervisées
5. Fouille de données Web
2

3
Fouille du Web
1. Introduction 2. Fouille de contenus Web 3.Fouille de structure
1. Indicateurs structurels 2. Evaluation de la qualité des pages Web 3.Découvertes de communautés
4.Fouille des usages du Web

Introduction

5
Objectifs
Appliquer des méthodes de fouille de données sur des données provenant du Web ou de ses services
Principe
Particularités du Web• Un répertoire immense, distribué à grande échelle, largement
hétérogène de donnée de type hyper-texte, hyper-média, fortement connectées
• Le Web est une collection immense de document plus : – Des liens entre ces documents – Et des informations associées à l’utilisation e ces documents

Exemple d’applications
- Fouiller ce que retourne un moteur de recherche
- Identifier les pages/acteurs qui font autorité
- Identification de communautés
- Classification de documents Web
- Analyse des logs d’utilisation des sites
- Améliorer les réponses des moteurs de recherche

TaxonomieWeb Content Mining
Web Structure Mining
Web Usage Mining
Analyse de sentiment, classification thématique, découverte de controverse, recherche d’information, …
Découverte de leader/pages qui font autorité, extraction de communautés, …
Découverte de chemin de navigation fréquents, caractérisation des internautes, …

8
Analyse de contenus Web

Qu’est ce que la fouille de texte ?
- A pour objectif de trouver, de façon automatique, quelque chose d’utile dans un corpus de texte
- Différent de la recherche d’information
- Différent de l’interrogation d’une BD relationnelle

Exemples d’approches de fouille de texte (1)
- Analyse d’association de mots-clé ou de termes - Classification de documents / sentiments - Regroupement de documents
- Selon l’auteur
- Selon la source
- Selon leur proximité sémantique
- Recherche d’information intelligente- Extraction d’information- Détection d’avis frauduleux

Exemples d’approches de fouille de texte (2)
- Découverte de phrases fréquentes - Segmentation automatique de texte - Résumé automatique - Détection d’évènements - …

12
Données- Un jeu de données d’apprentissage - Décrites selon un ensemble d’attributs et dotées d’une classe (le thème
du document)
RésultatUn modèle pour prédire la classe du document
Techniques- Classification bayésienne naïve - SVM - …
Classification thématique

13
Problématique- Soit D un ensemble de documents - Prédire si le document est positif ou négatif - Essentiel pour les sites marchands - Assez proche de la classification thématique - L’essentiel des approches se situe au niveau du document
Classification de sentiments
Catégories d’approches- Basées sur les sentiments exprimés dans chaque phrase - Basées sur les caractéristiques du produit

14
Un algorithme en 3 temps1. Etiquetage morpho-syntaxique et filtrage des phrases
2. Caractérisation de l’orientation sémantique de chaque phrase retenue
3. Agrégation des caractérisations
Classification de sentiments Basées sur les phrases
Approche proposée par Turney en 2002 à la conférence ACL
Résultats- Précision de 84% sur des avis automobiles
- Précision de 66% sur des critiques de films

15
Etiquetage et filtre- Etiqueter les mots en fonction de sa catégorie grammaticale
- Ne conserver que les phrases contenant des adverbes ou des adverbes
- Problème d’ambiguïté
- Solution :
Extraction de deux mots consécutifs (l’un est l’adjectif ou l’adverbe et l’autre est le contexte Filtre par rapport à un motif défini par l’auteur, e.g., un adjectif suivi d’un nom
Classification de sentiments Basées sur les phrases
Etape 1

16
Calcul de l’orientation sémantique des phrases retenues- Calcul de l’information mutuelle ponctuelle (pointwise mutual information)
- Calcul de l’orientation sémantique
- Probabilités calculées à partir des pages retournées par un moteur de
recherche
Classification de sentiments Basées sur les phrases
Etape 2

17
Classification- On considère l’orientation sémantique moyenne
- Le texte sera positif si la moyenne est supérieure à 0 et négatif
sinon
Classification de sentiments Basées sur les phrases
Etape 3
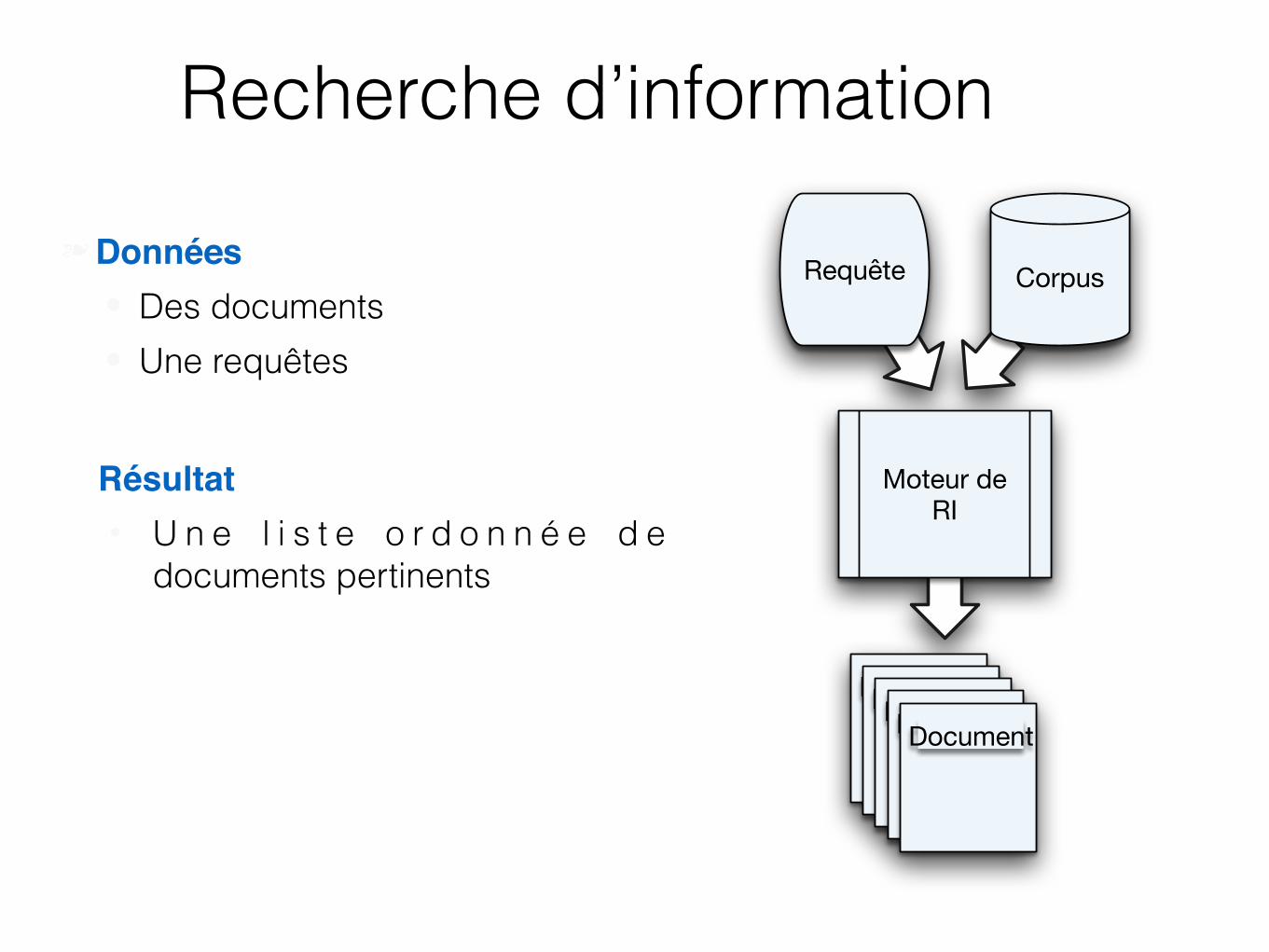
Recherche d’information
❧Données● Des documents ● Une requêtes
Résultat• U n e l i s t e o r d o n n é e d e
documents pertinents
Moteur de RI
DocumentDocumentDocumentDocumentDocument
CorpusRequête

Recherche d’Information Intelligente
❧ Sémantique des mots- Gestion de la synonymie - Identification de l’ambiguïté
❧ Prise en compte de l’ordre des mots- hot dog stand in the amusement park - hot amusement stand in the dog park
❧ Prise en compte des interactions entre le système et l’utilisateur - direct feedback - indirect feedback
❧ Autorité de la source● Le Monde est a priori une source plus fiable que le cousin de mon
cousin

20
DonnéesUn corpus de documents Une requête bien formée
RésultatsTrouver les phrases/paragraphes pertinents Ignorer les informations non-pertinentes Agréger les différentes facettes retrouvées
Extraction d’information

21
Extraction d’information Exemple
Salvadoran President-elect Alfredo Cristiania condemned the terrorist killing of Attorney General Roberto Garcia Alvarado and accused the Farabundo Marti Natinal Liberation Front (FMLN) of the crime. … Garcia Alvarado, 56, was killed when a bomb placed by urban guerillas on his vehicle exploded as it came to a halt at an intersection in downtown San Salvador. … According to the police and Garcia Alvarado’s driver, who escaped unscathed, the attorney general was traveling with two bodyguards. One of them was injured.
Type d’incident : attentat Commanditaire : guerilla urbaine Cible : Roberto Garcia Alvarado
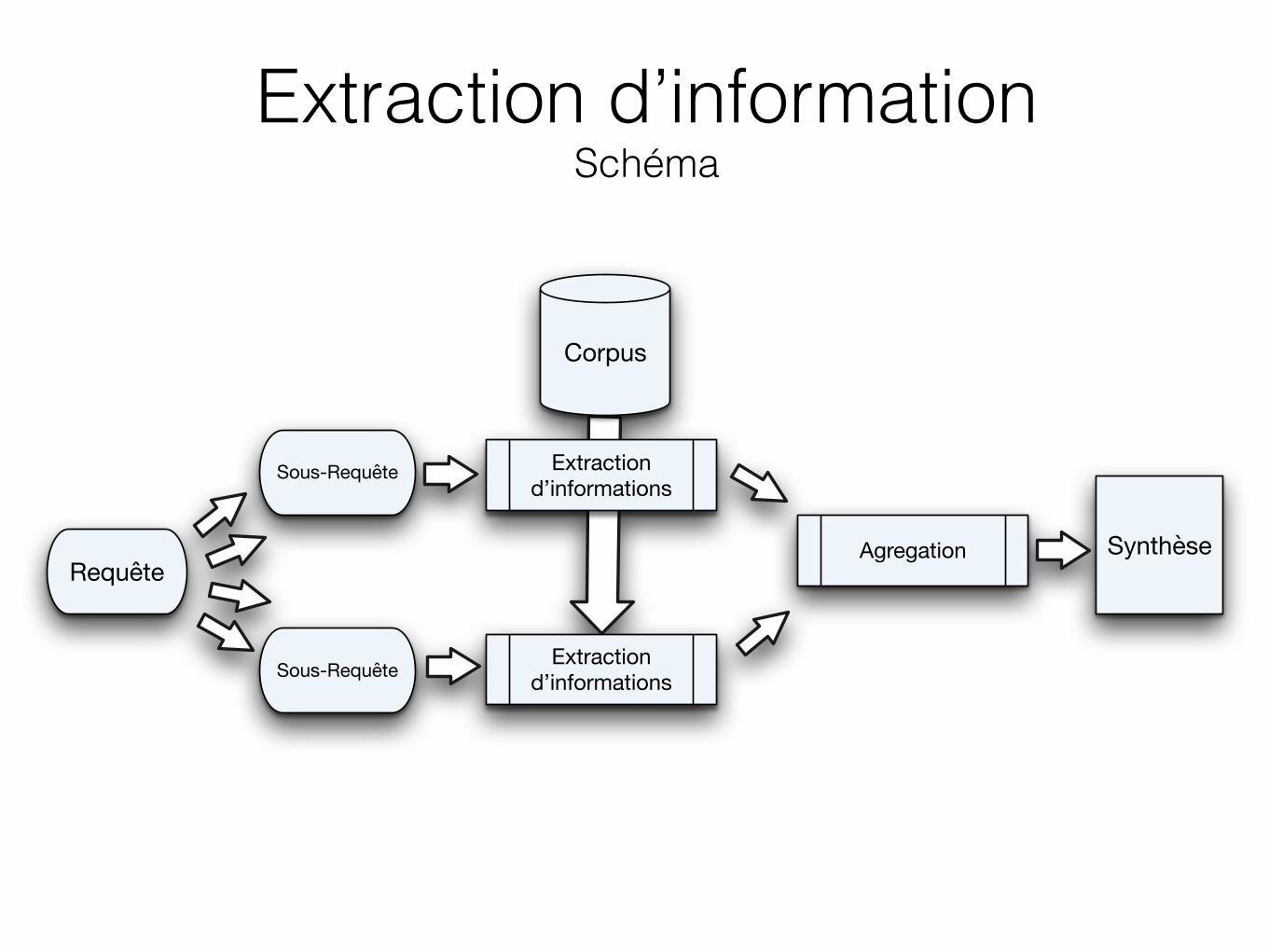
Extraction d’information Schéma
Extractiond’informations
Synthèse
Corpus
Requête
Sous-Requête
Sous-Requête Extractiond’informations
Agregation

23
Contexte- Opinions de plus en plus déterminantes dans l’acte d’achat - Recrudescence des faux avis
Détection d’opinions frauduleuses
Objectifs- Promouvoir un produit - Critiquer un produit concurrent - Ennuyer le lecteur - Tromper les solutions de détection automatique d’avis frauduleux
Actions- Rédaction d’avis dithyrambiques - Rédiger des avis injustement négatifs et diffamatoires

24
Rédacteur isolé- Bonne réputation initiale via la rédaction d’avis de qualité - Inscription avec des identifiants de connexion différents sur différents PC - Le rédacteur donne une bonne note mais critique fortement le produit - Rédaction d’un avis très critique sur un produit concurrent ou (exclusif)
un avis très favorable sur le produit à promouvoir
Détection d’opinions frauduleuses Techniques utilisées
Groupe de rédacteurs- Chaque membre du groupe évalue le même produit (diminution de la
déviation) - Chaque membre du groupe évalue le produit juste après sa sortie - Chaque membre du groupe évalue un produit à des temps différents - Division du groupe : un qui critique la concurrence, l’autre qui encense le
produit à promouvoir

25
Approches supervisées- Peut être vu comme un problème de classification - Jeu d’apprentissage est difficile à trouver - Plusieurs types de features peuvent être considérées:
- Basées sur la review - Basées sur le reviewer - Basées sur le produit
- Regression logistique efficace dans ce contexte
Détection d’opinions frauduleuses Techniques de détection
Approches non supervisées- Analyse du comportement des reviewers - Analyse basée sur les avis - Analyse basée sur les logs de serveurs

26
Détection d’opinions frauduleuses Analyse du comportement des reviewers
- Détection des avis précoces
Avis frauduleux fréquents au lancement d’un produit, effet pic
- Contrebalancer systématiquement les nouveaux avis
“Répondre” à un avis positif (resp. négatif) par un avis négatif (resp.
positif)
- Comparer les avis d’un même utilisateur
Comparaison sur produits similaires, en fonction de la marque
- Comparer l’heure de rédaction des avis
Fraudeur : de nombreux avis dans période courte

27
Détection d’opinions frauduleuses Analyse des avis
- Comparaison des avis d’un même utilisateur
Recherche de copies quasi conformes
- Détection de notes aberrantes
On suppose que les avis frauduleux sont minoritaires
- Comparer les avis sur plusieurs sites
Adaptation de la technique précédente au cas multi-sites
- Détecter des pics de notations
Regarder la distribution temporelle d’avis similaires

28
Détection d’opinions frauduleuses Analyse des logs des serveurs
- Etude des avis émis par la même IP
Si une même IP utilisée par plusieurs comptes et que ces comptent
rédigent plusieurs avis sur le même produit (ou produits de même marques), il s’agit d’un bon indice de fraude
Conclusion générale
Seule la combinaison de ces approches s’avère efficace !

29
Fouille de structures

30
(1970) Les chercheurs ont proposé une méthode pour évaluer la qualité de leurs publication scientifiques
Evaluation de produitsNon pas basée sur ses caractéristiques ou la publicité mais sur les opinions des consommateurs
Différence entre des publications scientifiques et des pages Web- La sémantique des liens diffère - Une page faisant autorité ne va pas pointer vers son concurrent - Les pages faisant autorité contiennent rarement une description de
leur contenu
Background

Indicateurs structurels sur réseaux sociaux
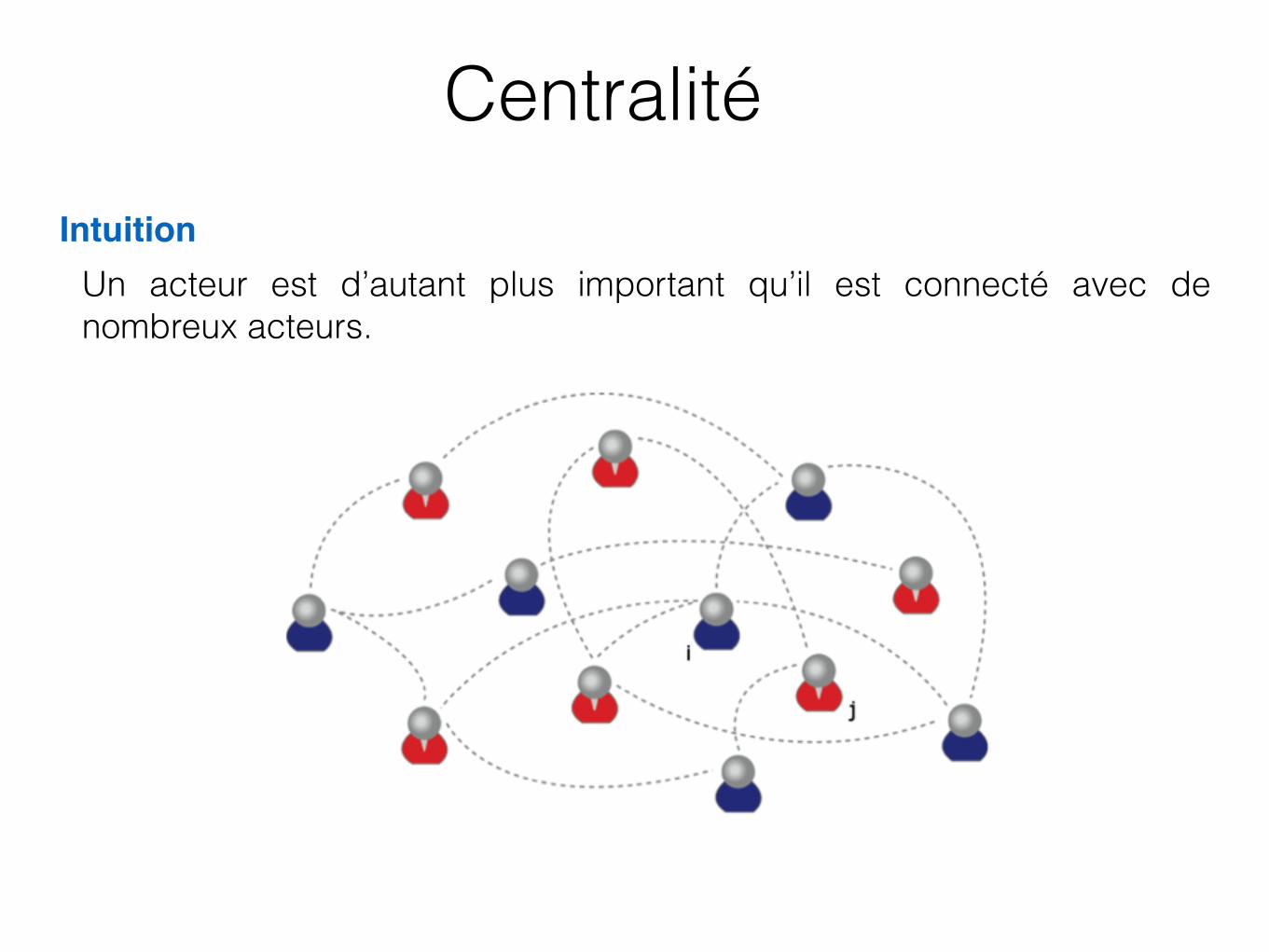
CentralitéIntuition
Un acteur est d’autant plus important qu’il est connecté avec de nombreux acteurs.
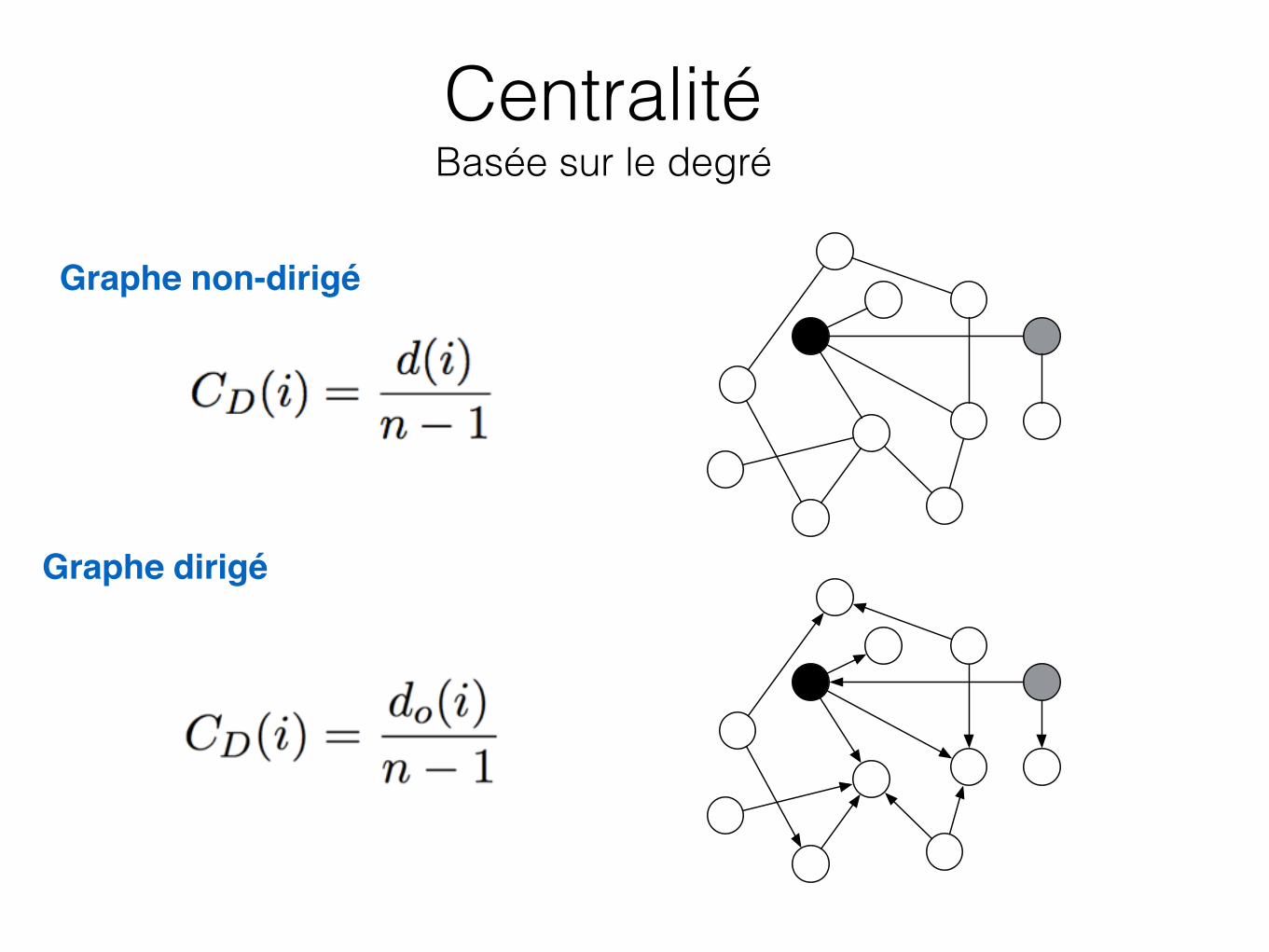
Centralité Basée sur le degré
Graphe non-dirigé
Graphe dirigé
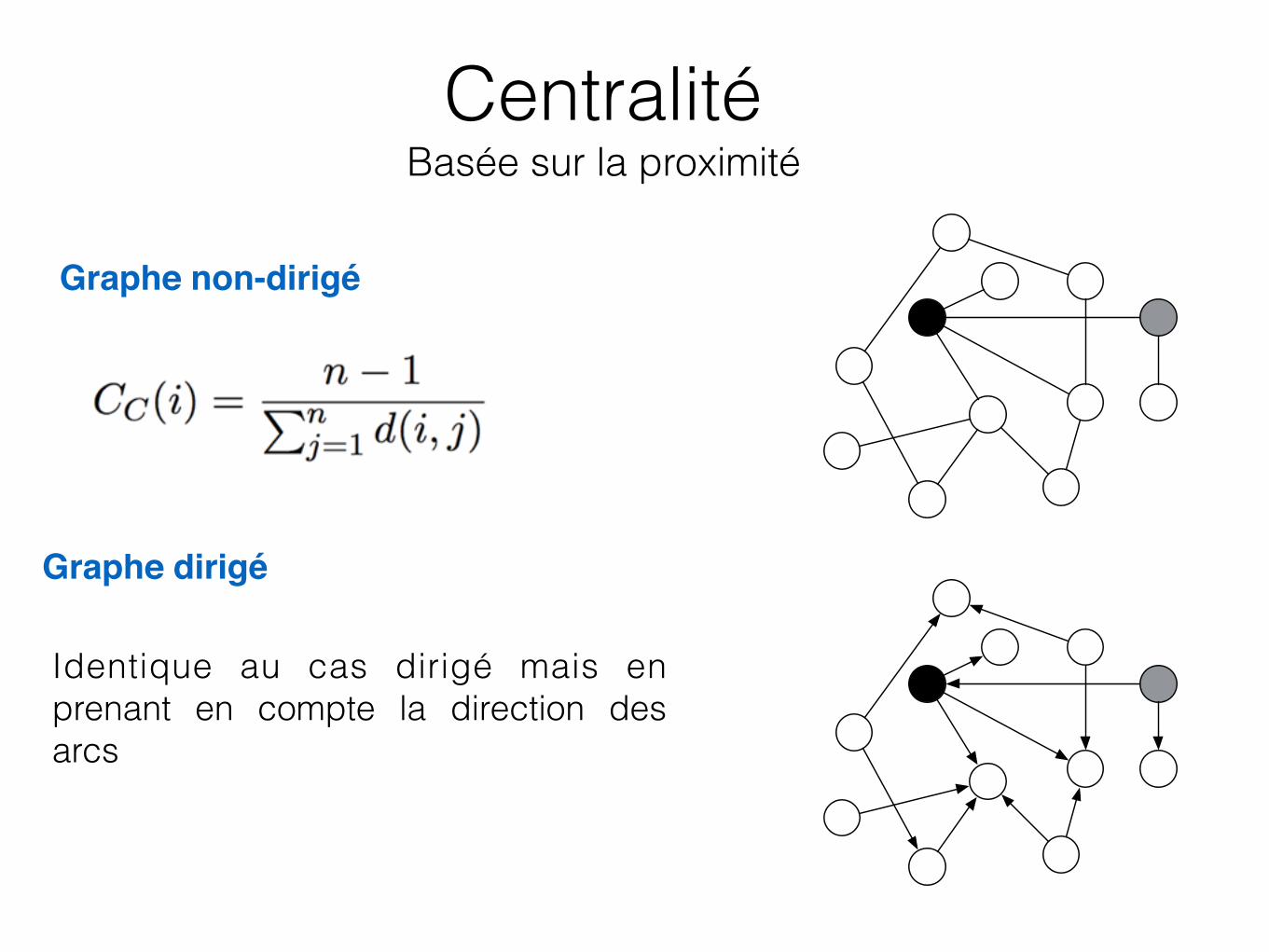
Centralité Basée sur la proximité
Graphe non-dirigé
Graphe dirigé
Identique au cas dirigé mais en prenant en compte la direction des arcs
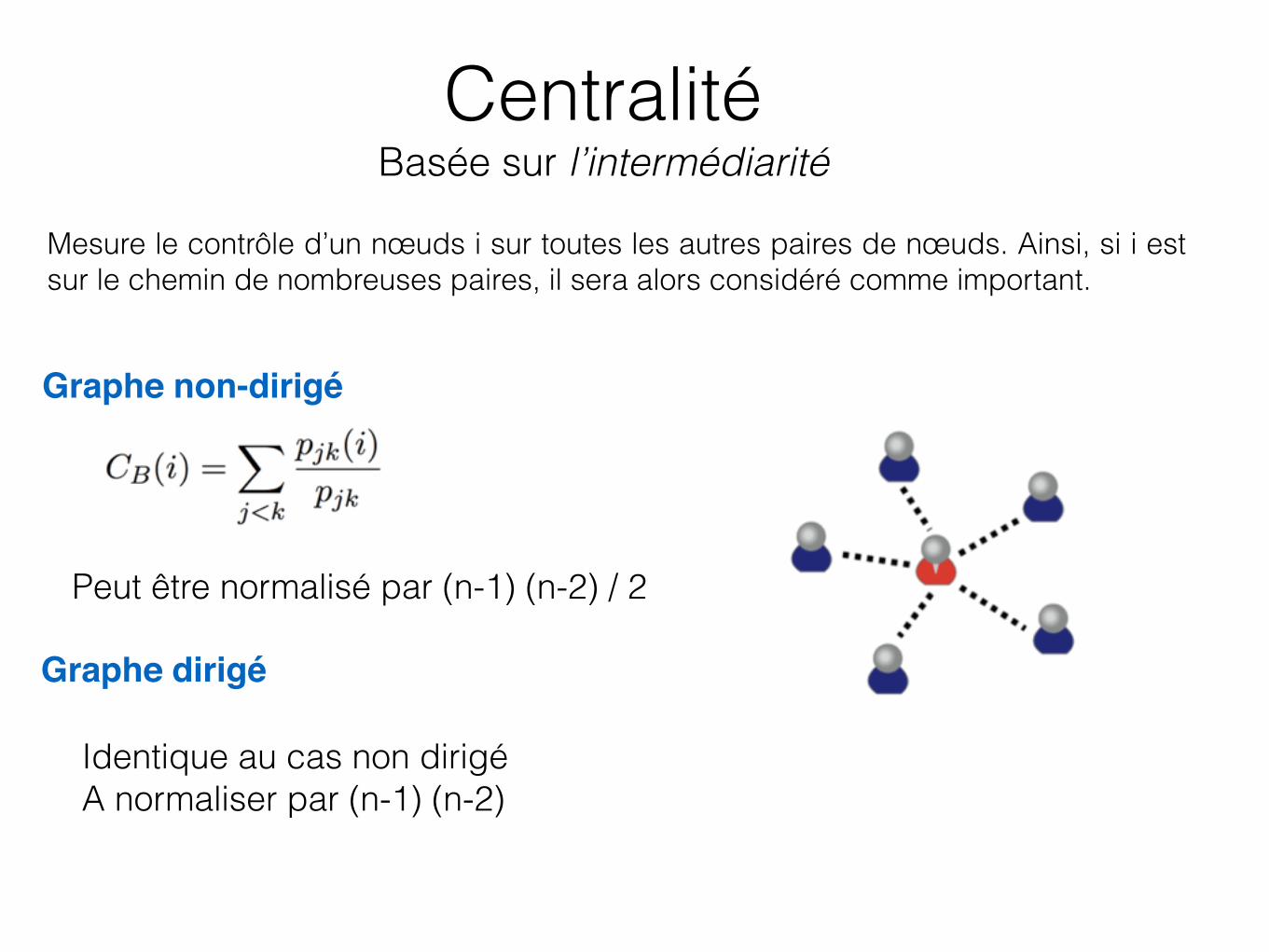
Centralité Basée sur l’intermédiarité
Graphe non-dirigé
Graphe dirigé
Peut être normalisé par (n-1) (n-2) / 2
Mesure le contrôle d’un nœuds i sur toutes les autres paires de nœuds. Ainsi, si i est sur le chemin de nombreuses paires, il sera alors considéré comme important.
Identique au cas non dirigé A normaliser par (n-1) (n-2)

PrestigeIntuition
Mesure plus fine que que la centralité : - Distinction entre liens entrants et sortants - Un acteur prestigieux est un acteur souvent référencé - Seuls les liens entrants sont considérés - Ne fait sens que sur des graphes dirigés
Différentes définitions du prestige- Basé sur le degré - Basé sur la proximité - Basé sur le rang
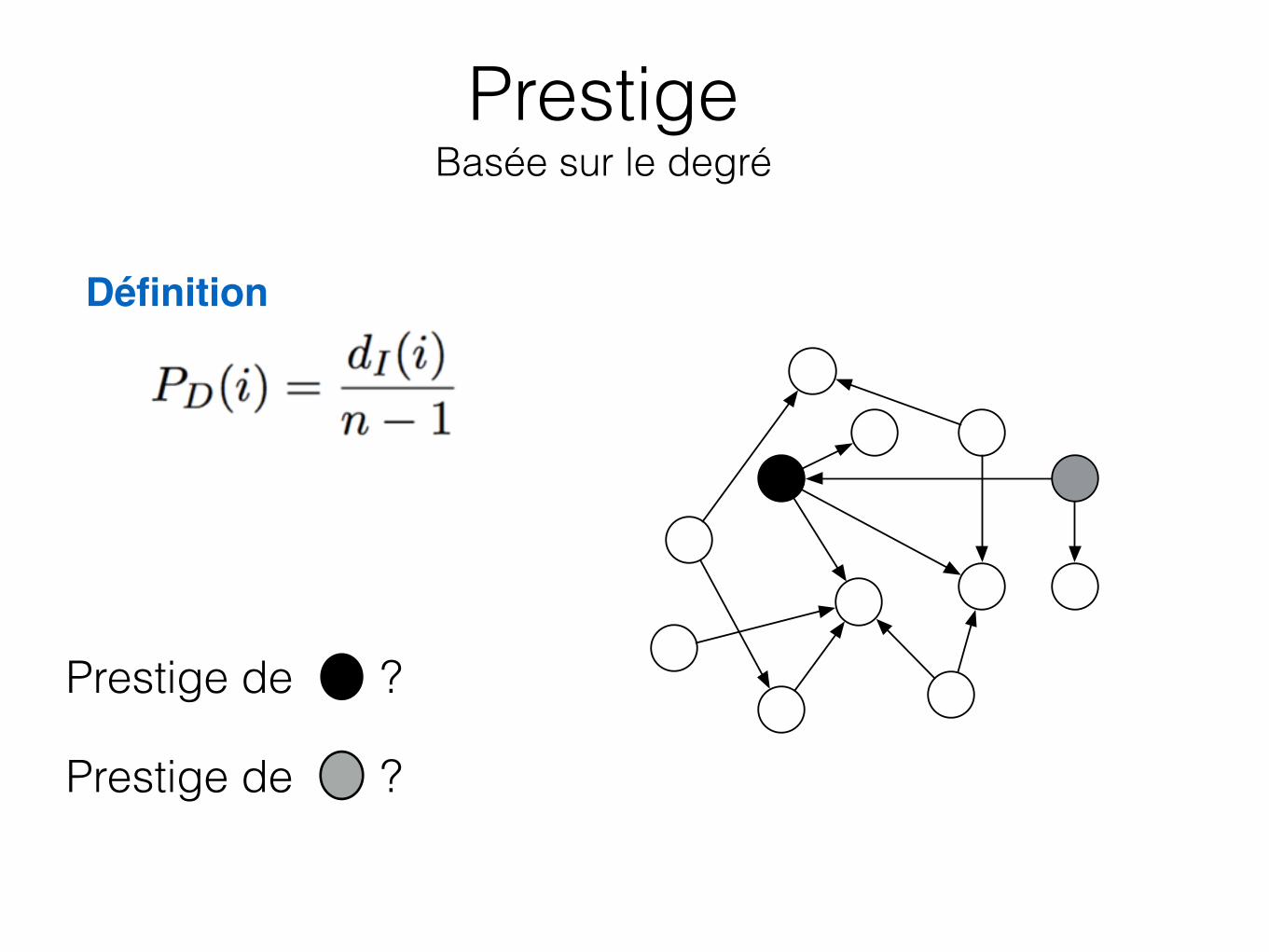
Prestige Basée sur le degré
Définition
Prestige de ?
Prestige de ?
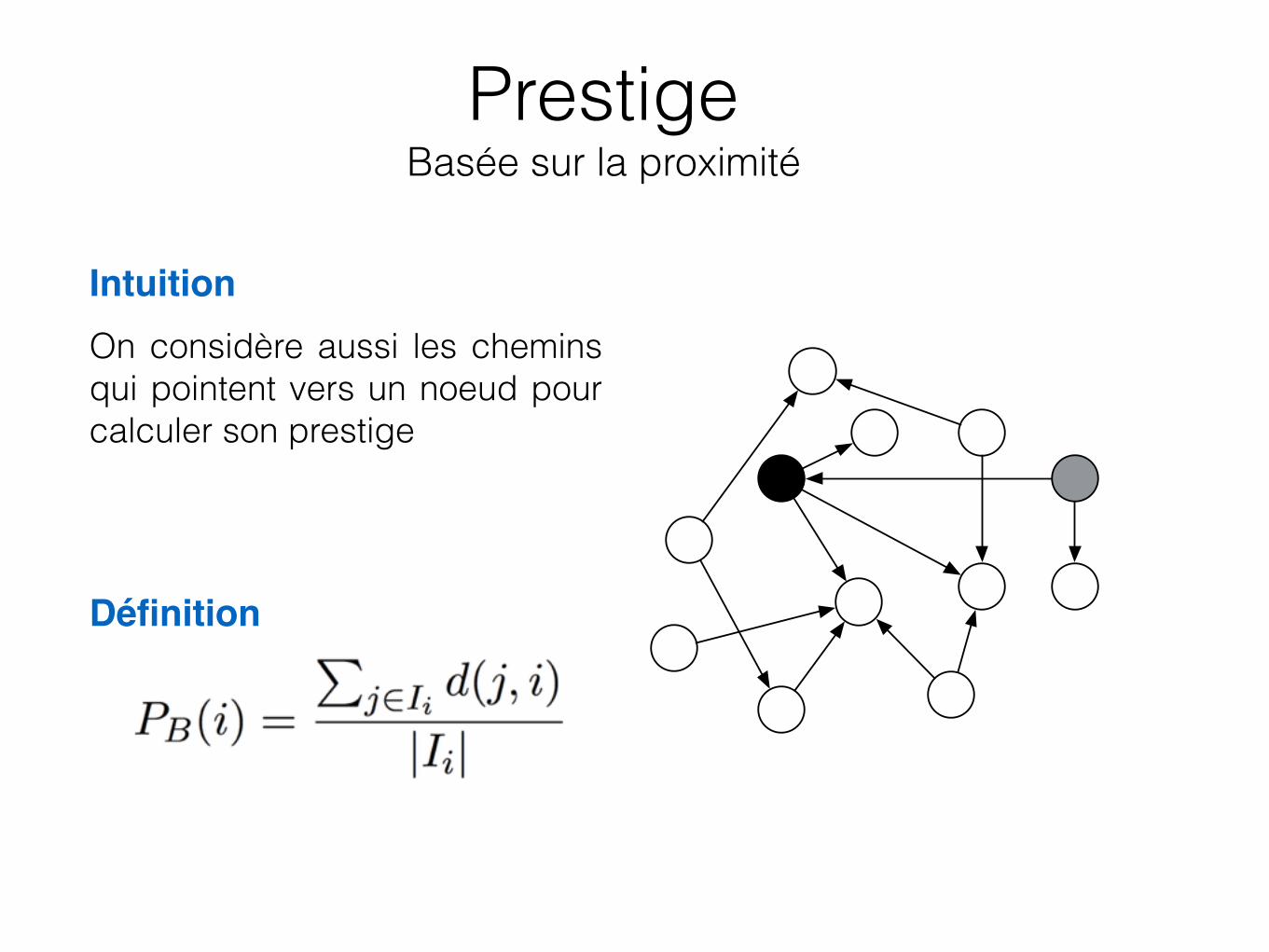
Prestige Basée sur la proximité
IntuitionOn considère aussi les chemins qui pointent vers un noeud pour calculer son prestige
Définition

Prestige Basée sur le rang
IntuitionLe prestige d’un noeud est fonction de l’importance des noeuds qui pointent vers ce noeud.
Définition
Représentation matricielle

Evaluation de la qualité des pages Web Un point de vue structurel

Sur le WebDeux approches populaires
1. Page Rank pour la découverte des pages les plus importantes (popularisé par Google)
2. Hubs et autorités: une vision plus détaillée de l’importance des pages
Définition basique de l’importanceUne page sera importante si des pages importantes pointent vers elle
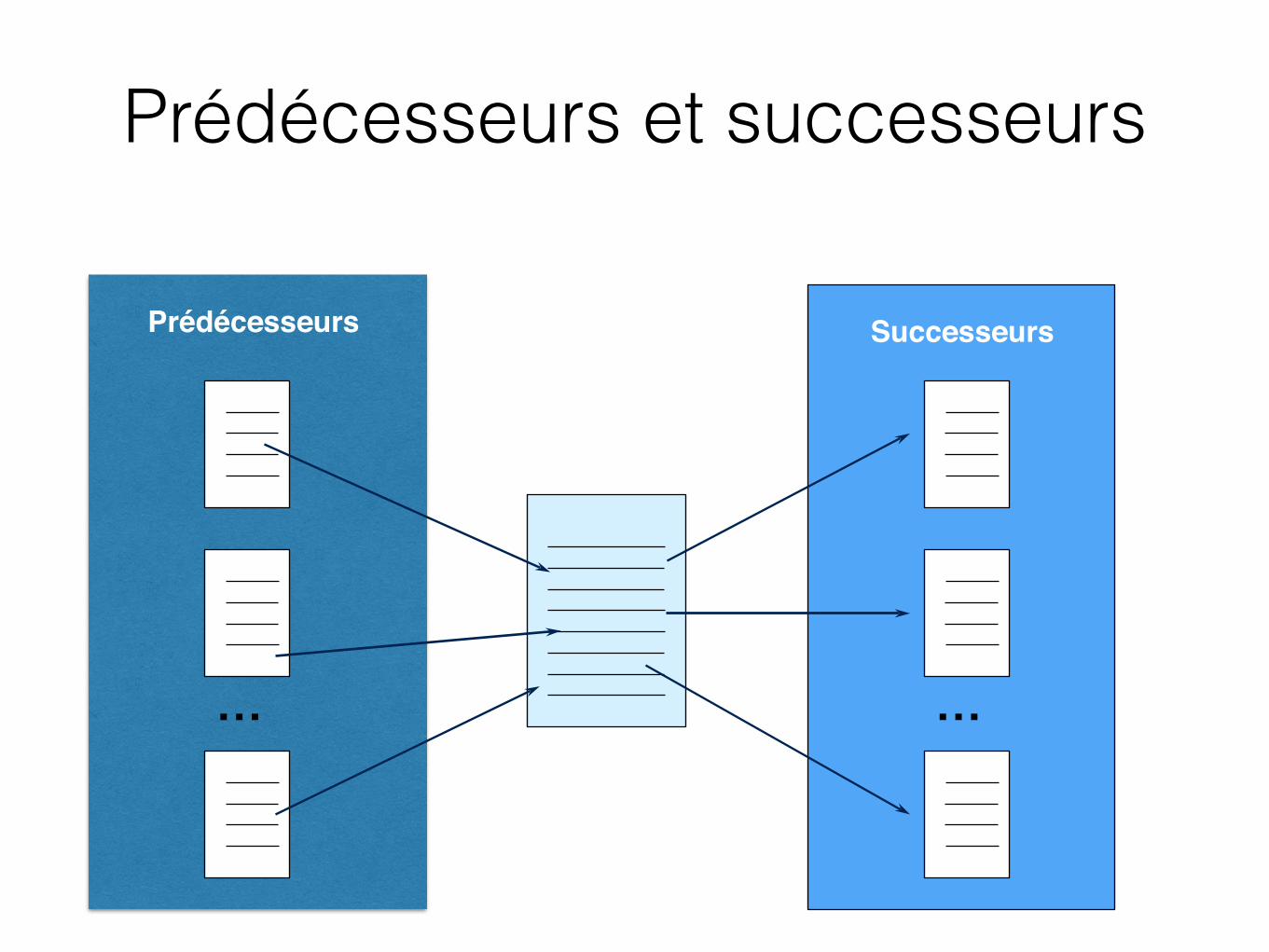
42
Prédécesseurs et successeurs
30
… …
Prédécesseurs Successeurs

43
Page Rank (1)
Modélisation
Une matrice stochastique où :
- Chaque page i correspond à la ligne i et la colonne i
- Si la page j a n successeurs (liens), la cellule ij de la matrice
est égale à 1/n si est un successeur de la page j et 0 sinon

Intuition
- Initialement, chaque page a la même importance (1). A chaque itération, chaque page partage son importance avec ses successeurs (et reçoit donc de l’importance de ses prédécesseurs)
- L’importance de chaque page atteint une limite après un certain nombre d’itérations
- L’importance d’une page peut être vue comme la probabilité qu’un internaute, partant d’une page, choisie au hasard, et naviguant au hasard, atterrisse sur la page en question après avoir suivi une longue série de liens
Page Rank (2)
A
B
C
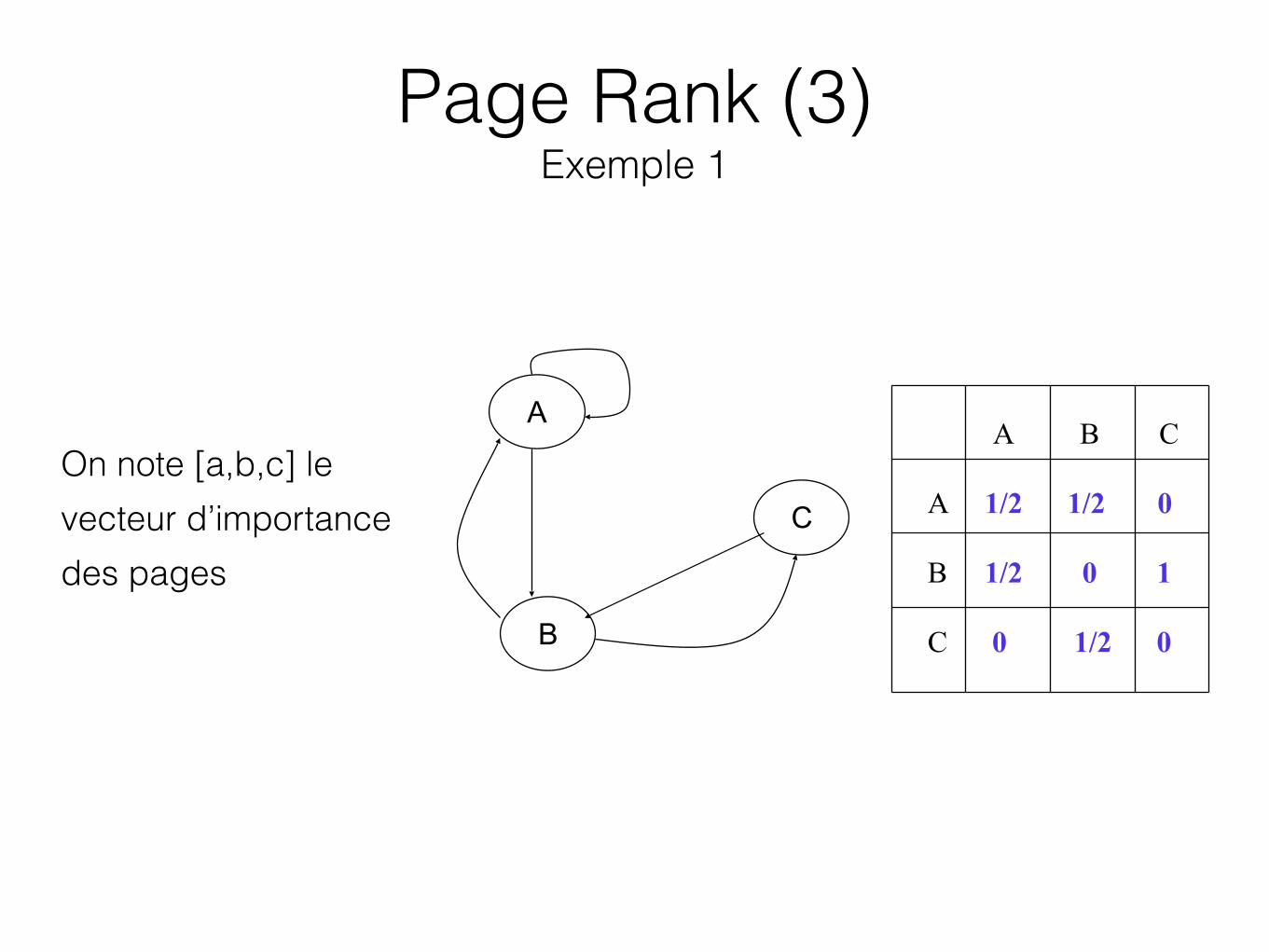
On note [a,b,c] le vecteur d’importance des pages
A B C
A 1/2 1/2 0
B 1/2 0 1
C 0 1/2 0
Page Rank (3) Exemple 1

46
Valeur asymptotique des importances:
a 1/2 1/2 0 a b = 1/2 0 1 b c 0 1/2 0 c
On peut résoudre de telles équations en démarrant avec a = b = c = 1 et en appliquant la matrice à l’importance courante. Les premières itérations donnent :
a = 1 1 5/4 9/8 5/4 … 6/5 b = 1 3/2 1 11/8 17/16 … 6/5 c = 1 1/2 3/4 1/2 11/16 ... 3/5
Page Rank (3) Exemple 1

47
Puit Une page qui n’a pas de successeur ne peut pas propager son importance
Spider trapsUn ensemble de page(s) qui n’ont pas de lien sortant
Page Rank (4) Problème avec des graphes réels
48
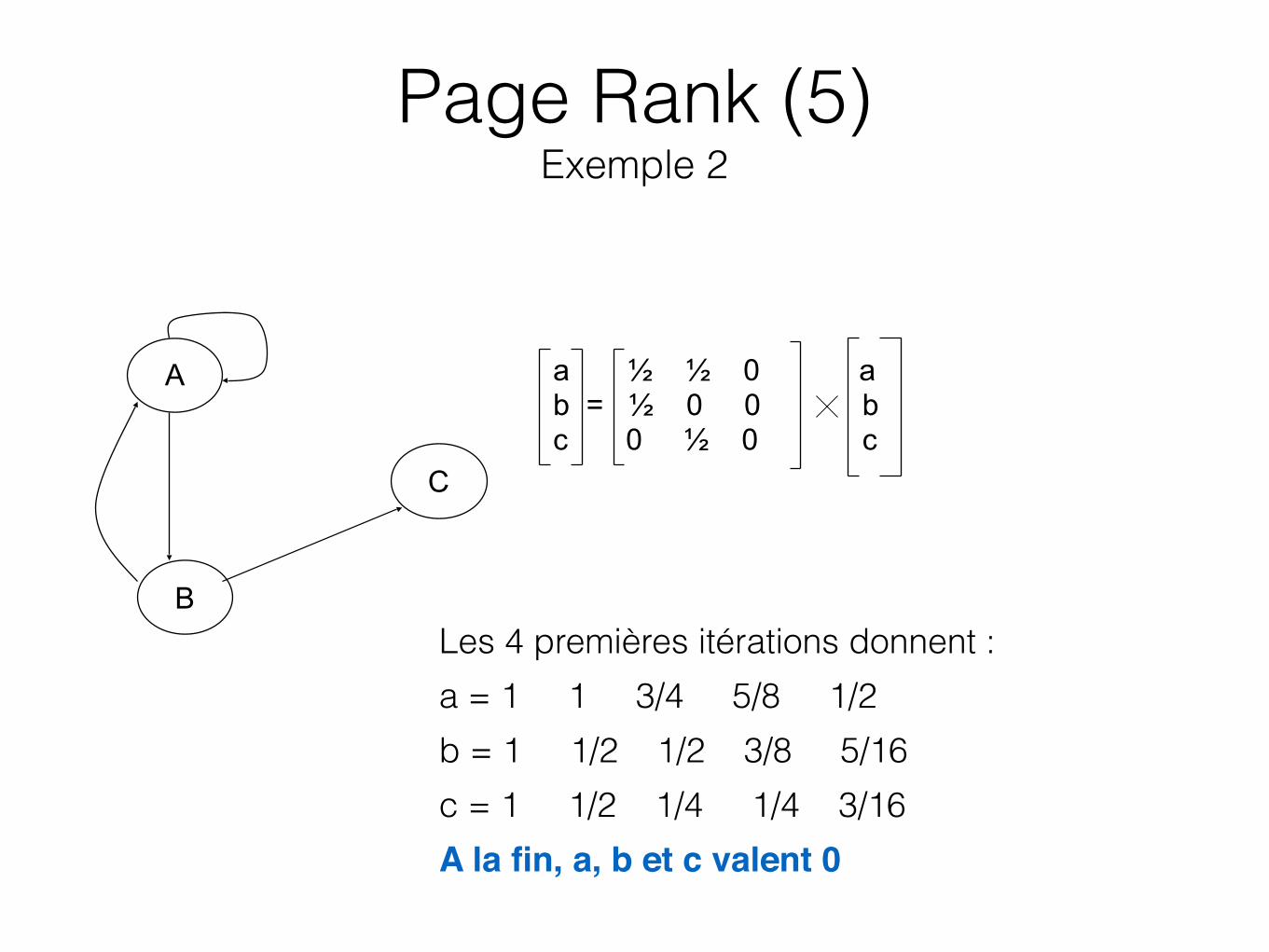
a ½ ½ 0 a b = ½ 0 0 b c 0 ½ 0 c
A
B
C
Les 4 premières itérations donnent : a = 1 1 3/4 5/8 1/2 b = 1 1/2 1/2 3/8 5/16 c = 1 1/2 1/4 1/4 3/16 A la fin, a, b et c valent 0
Page Rank (5) Exemple 2
49
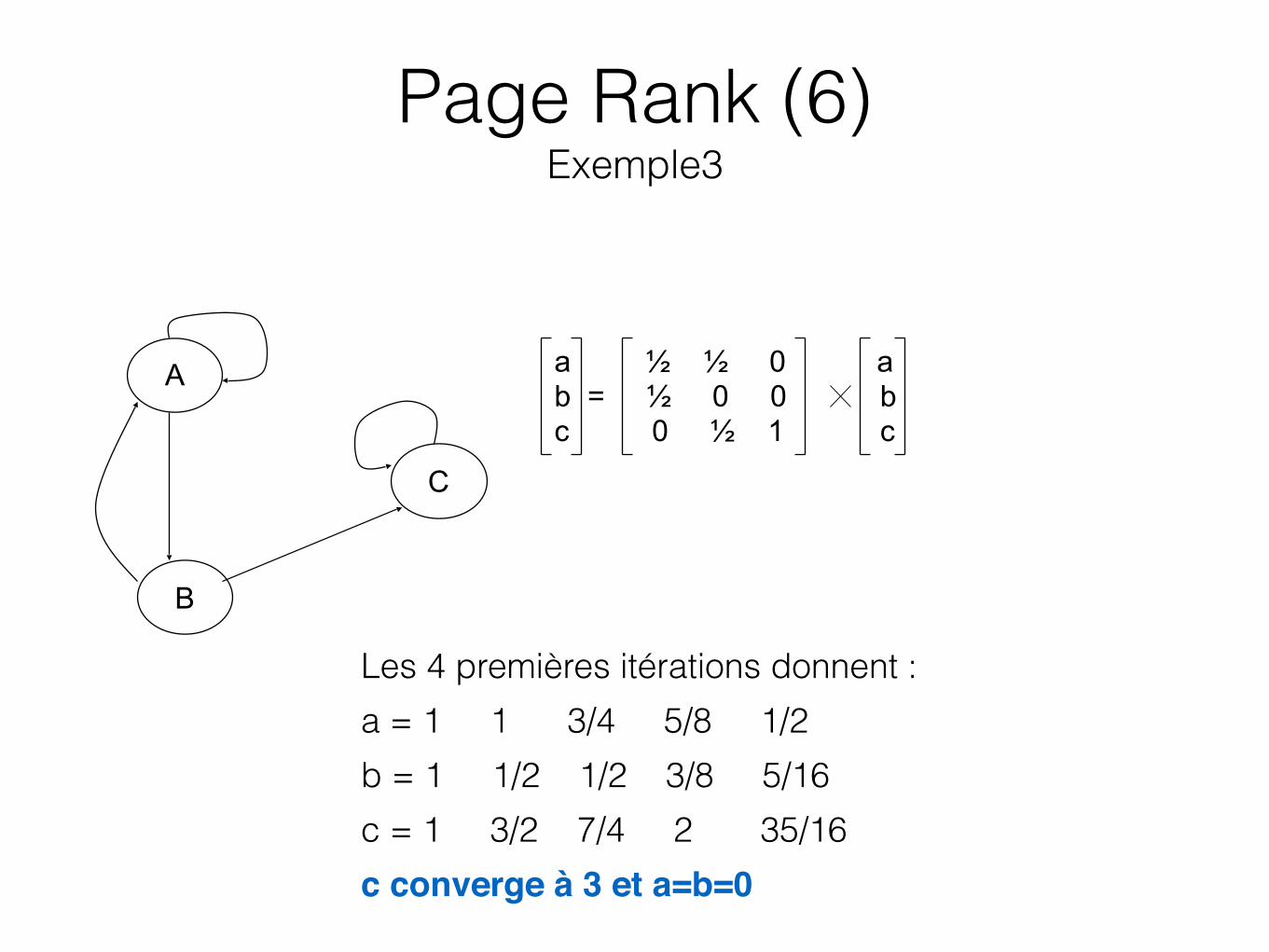
a ½ ½ 0 a b = ½ 0 0 b c 0 ½ 1 c
A
B
C
Les 4 premières itérations donnent : a = 1 1 3/4 5/8 1/2 b = 1 1/2 1/2 3/8 5/16 c = 1 3/2 7/4 2 35/16 c converge à 3 et a=b=0
Page Rank (6) Exemple3

50
Plutôt que d’appliquer la matrice directement, chaque page recoît une taxe (un certain pourcentage de son importance actuelle). C’est cette importance taxée qui est distribuée aux successeurs.
Exemple: avec 20% de taxe, l’équation de l’exemple précédent devient : a = 0.8 * (½*a + ½ *b +0*c) b = 0.8 * (½*a + 0*b + 0*c) c = 0.8 * (0*a + ½*b + 1*c)
La solution est donc : a=7/11, b=5/11, and c=21/11
Page Rank (7) La solution Google

Google Anti-Spam Solution• La tentative, par des pages Web, de faire croire qu’ils traitent d’un sujet
sans que cela soit le cas.
• Solutions
- Google utilise les textes des liens qui pointent vers une page
- Par définition, le Page Rank prévient des tentatives des spammer
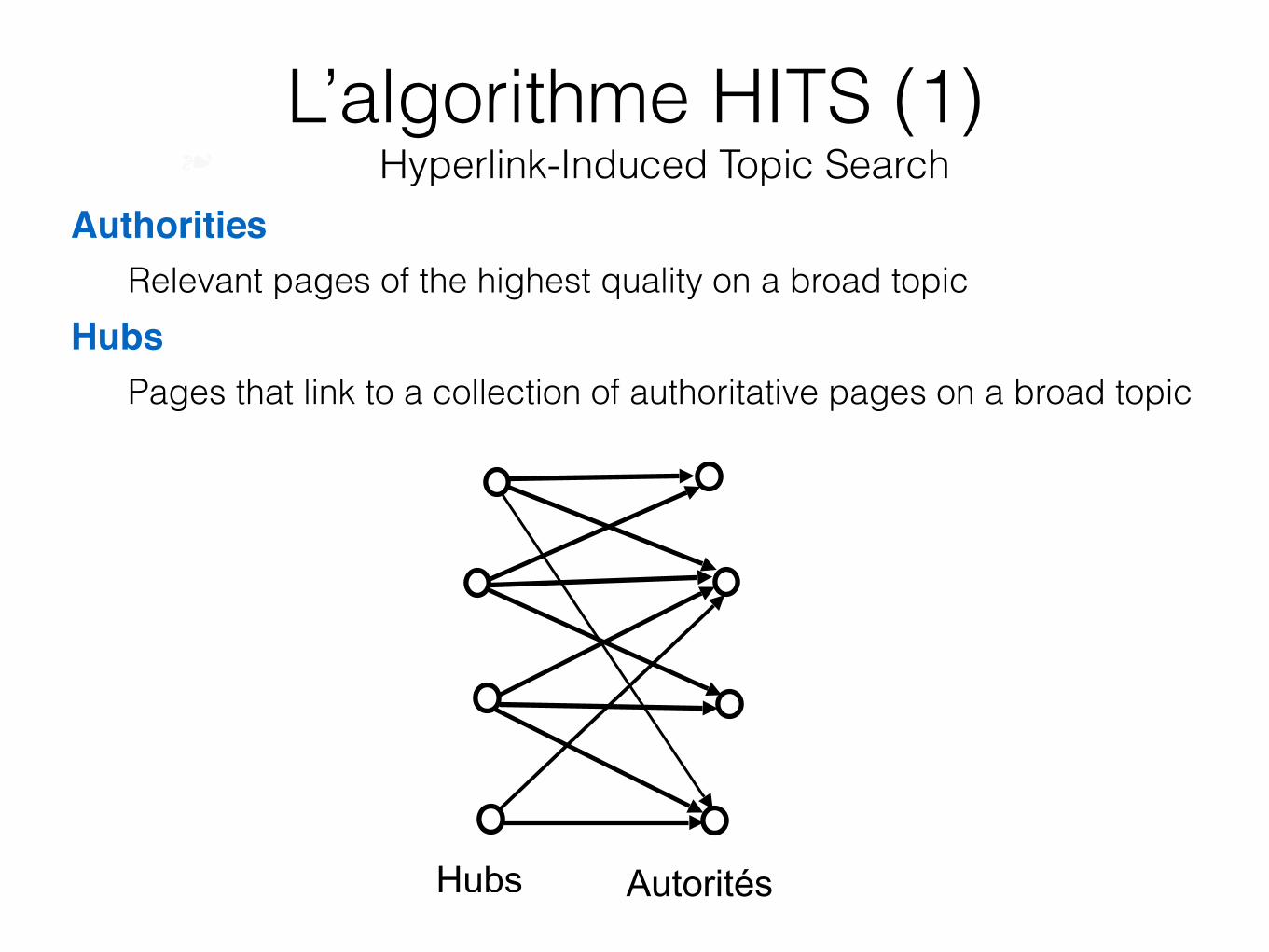
L’algorithme HITS (1) ❧ Hyperlink-Induced Topic Search
Authorities Relevant pages of the highest quality on a broad topic Hubs Pages that link to a collection of authoritative pages on a broad topic
Hubs Autorités

Un algorithme en 2 temps
1.Collecte du jeu de données- Constitution d’une collection racine (200 éléments) à partir des mots
de la requêtes via l’utilisation d’un moteur de recherche - Extension de l’ensemble racine en considérant les pages qui pointent
vers des pages de l’ensemble initial
2.Calcul des scores- Propagation itérative des poids pour obtenir les scores de hub et
d’autorité
L’algorithme HITS (2) ❧ Hyperlink-Induced Topic Search

- Définition d’une matrice A t.q. Aij=1 si la page i pointe vers la page j
- Soient a et h deux vecteurs tels que ai (resp. hi) sont les scores d’autorité (resp. de hub) courants
- h = A × a. Le score de hub d’une page est la somme des autorités des pages pointant vers elle
- a = AT × h. Le score d’autorité d’une page est la somme des scores de hub des pages pointant vers elle
- Alors, a = AT × A × a et h = A × AT × h
L’algorithme HITS (3) ❧ Hub et Autorité
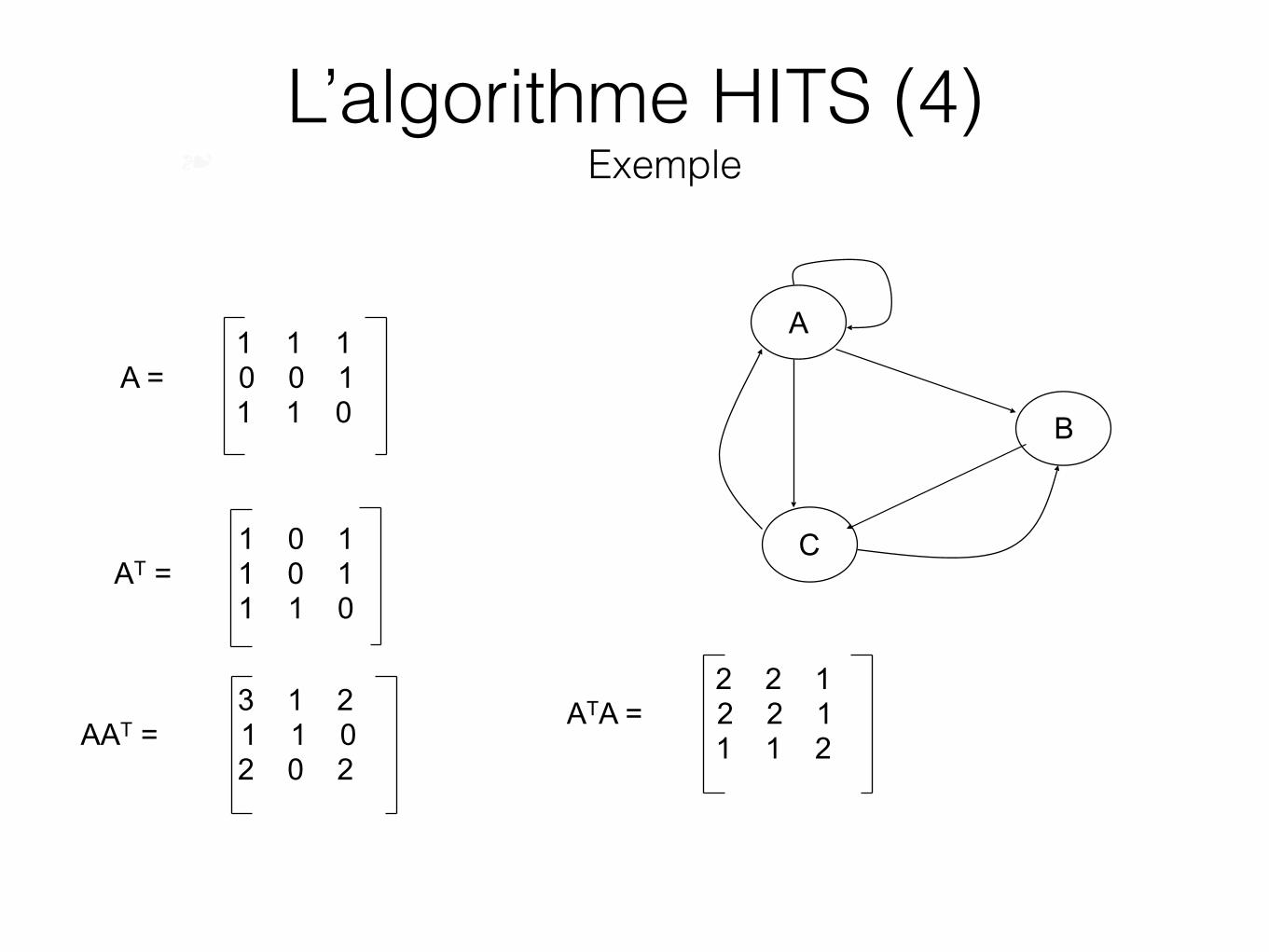
A
C
B
1 1 1 A = 0 0 1 1 1 0
1 0 1 AT = 1 0 1 1 1 0
3 1 2 AAT = 1 1 0 2 0 2
2 2 1 ATA = 2 2 1 1 1 2
L’algorithme HITS (4) ❧ Exemple

En supposant h = [ ha, hb, hc ] et a = [ aa, ab, ac ] sont initialisés à [ 1,1,1 ], les 3 premières itérations donnent pour a et h les résultats suivants :
aa = 1 5 24 114 ab = 1 5 24 114 ac = 1 4 18 84 ha = 1 6 28 132 hb = 1 2 8 36 hc = 1 4 20 96
L’algorithme HITS (5) ❧ Exemple

Découvertes de communautés Un point de vue structurel

Cyber-communautés Définition générale
• Définition • Un groupe de pages qui partagent un intérêt commun
- Un groupe de pages autour de la musique Pop - Un groupe de pages autour de la coupe du monde de rugby
• Propriétés principales– Les pages au sein d’une même communauté doivent être
similaires – Les pages d’une communauté doivent être différentes des pages
d’une autre communauté – Très proche des clusters

❧ Définition❧ Une communauté est composée de membres qui ont plus de
lien entre eux que vers l’extérieur de la communauté
Cyber-communautés Point de vue structurel
Problème NP-complet
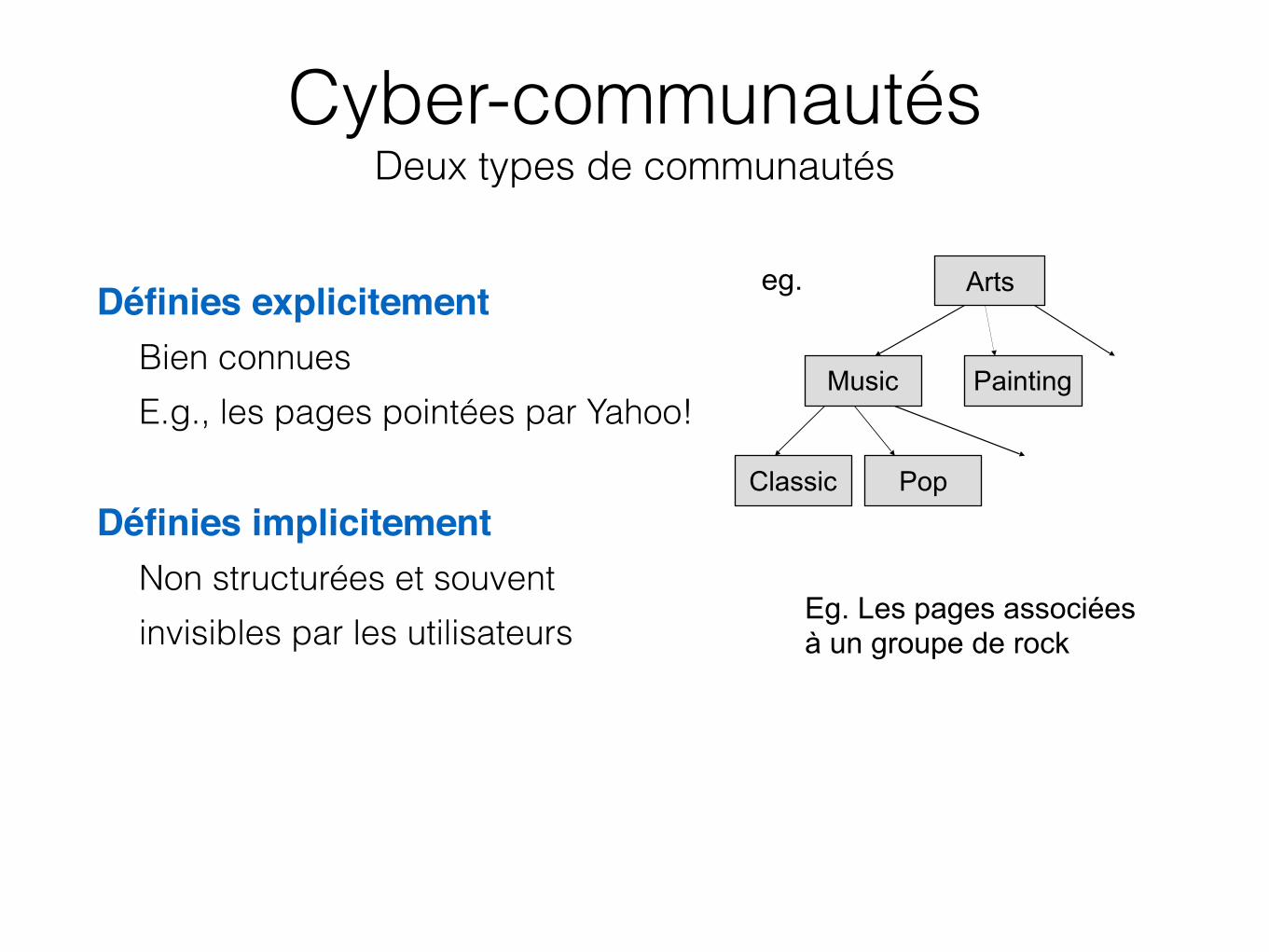
• Définies explicitement– Bien connues – E.g., les pages pointées par Yahoo!
• Définies implicitement– Non structurées et souvent – invisibles par les utilisateurs
Arts
Music
Classic Pop
Painting
eg.
Eg. Les pages associées à un groupe de rock
Cyber-communautés Deux types de communautés

• Un objectif proche du clustering
• Méthode 1– Les pages A et B sont proches si elles pointent l’une vers l’autre
– Peu satisfaisant (par exemple, Yahoo et Google)
Page A
Page B
Cyber-communautés Similarité entre pages
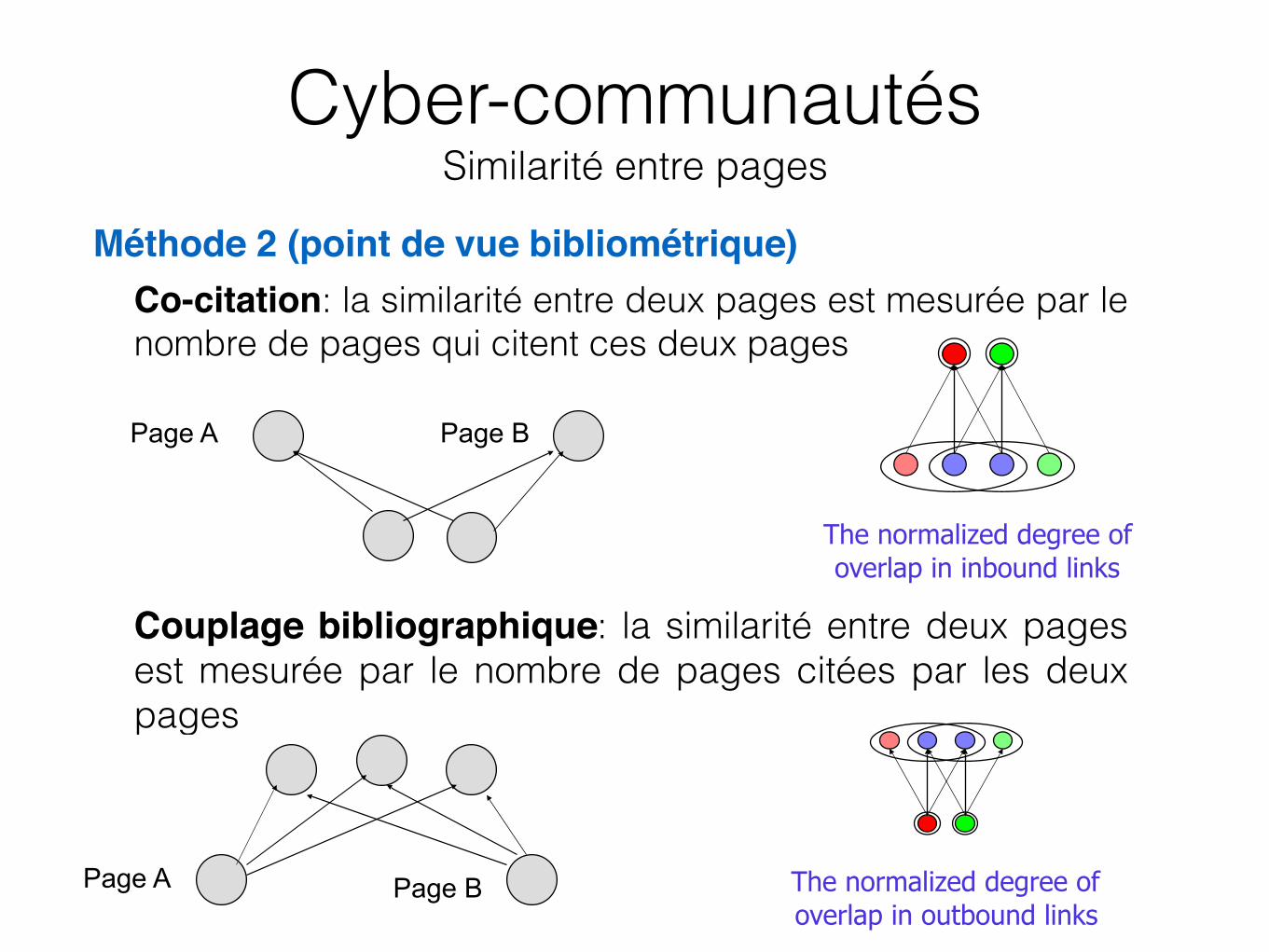
• Méthode 2 (point de vue bibliométrique)– Co-citation: la similarité entre deux pages est mesurée par le
nombre de pages qui citent ces deux pages
– Couplage bibliographique: la similarité entre deux pages est mesurée par le nombre de pages citées par les deux pages
Page A Page B
Page A Page B The normalized degree of overlap in outbound links
The normalized degree of overlap in inbound links
Cyber-communautés Similarité entre pages
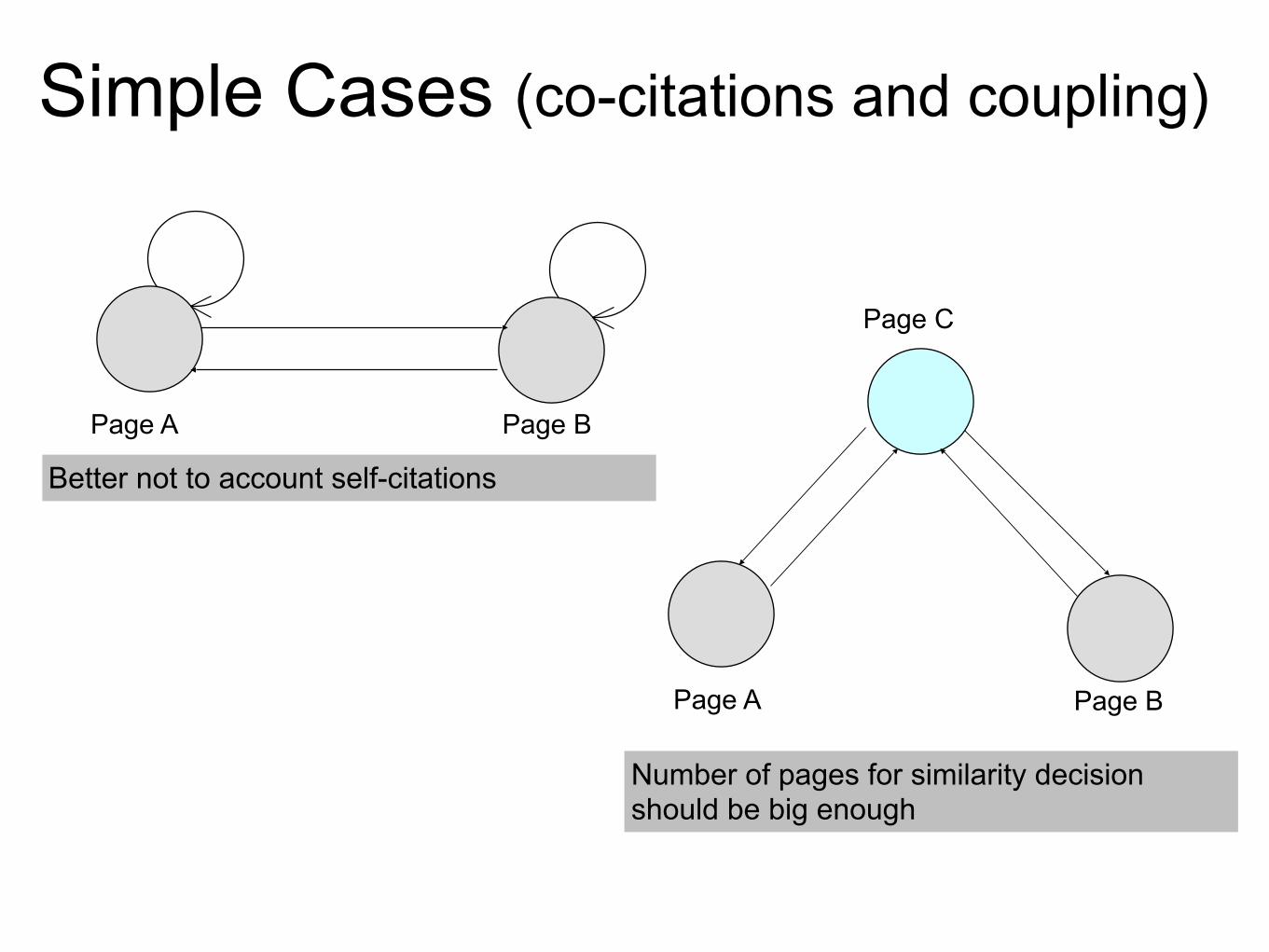
63
Simple Cases (co-citations and coupling)
Page A Page B
Better not to account self-citations
Page A Page B
Page C
Number of pages for similarity decision should be big enough

- Une approche basée sur le clustering
- Développée au centre de recherche d’IBM à Almaden
- Implémentée sur des graphes de près de 200M noeuds
- Très efficace et efficient
Cyber-communautés Communities Trawling [Kumar, et al., 1999]
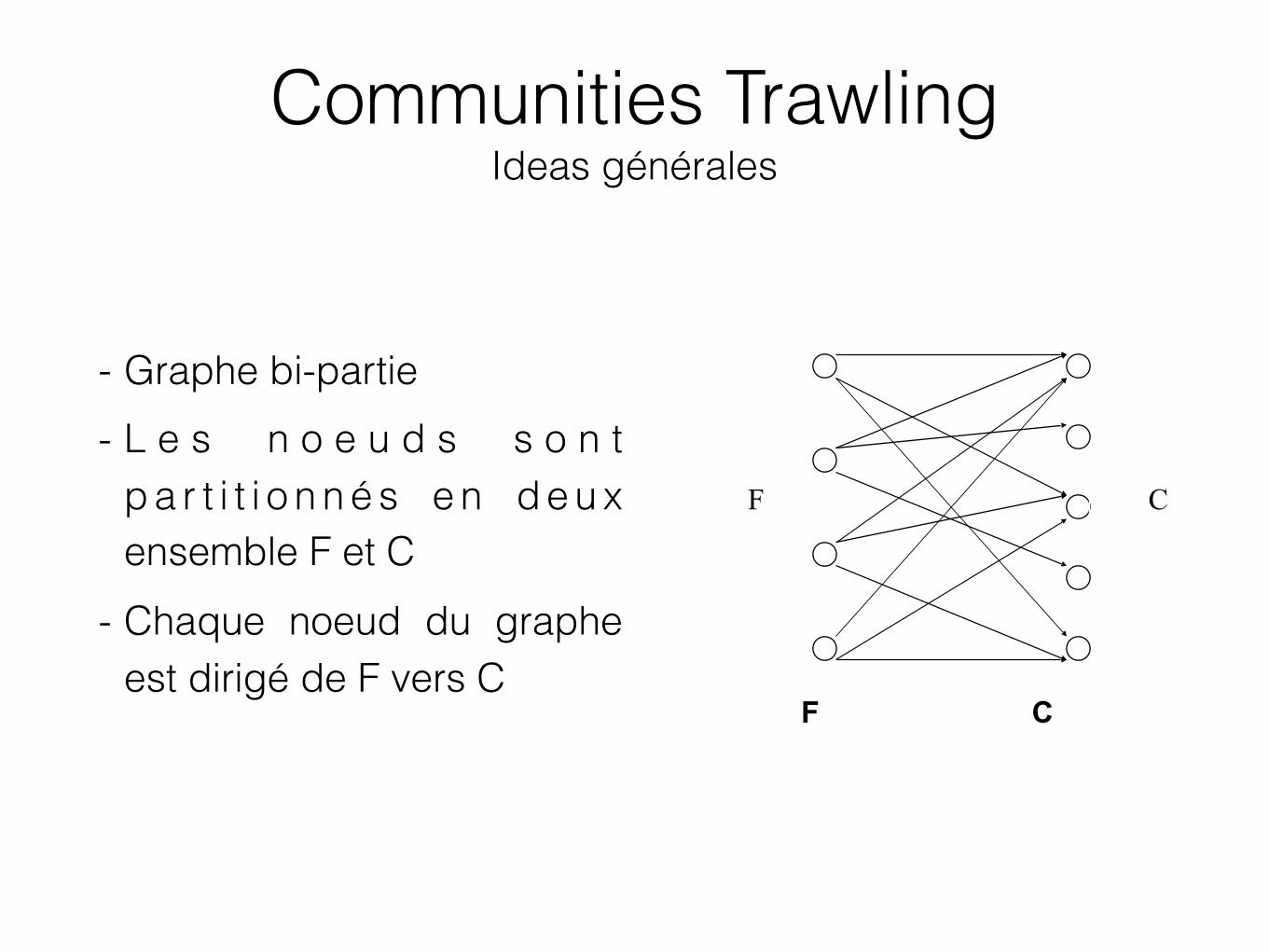
65
- Graphe bi-partie - L e s n o e u d s s o n t
p a r t i t i o n n é s e n d e u x ensemble F et C
- Chaque noeud du graphe est dirigé de F vers C
F C
F C
Communities Trawling Ideas générales
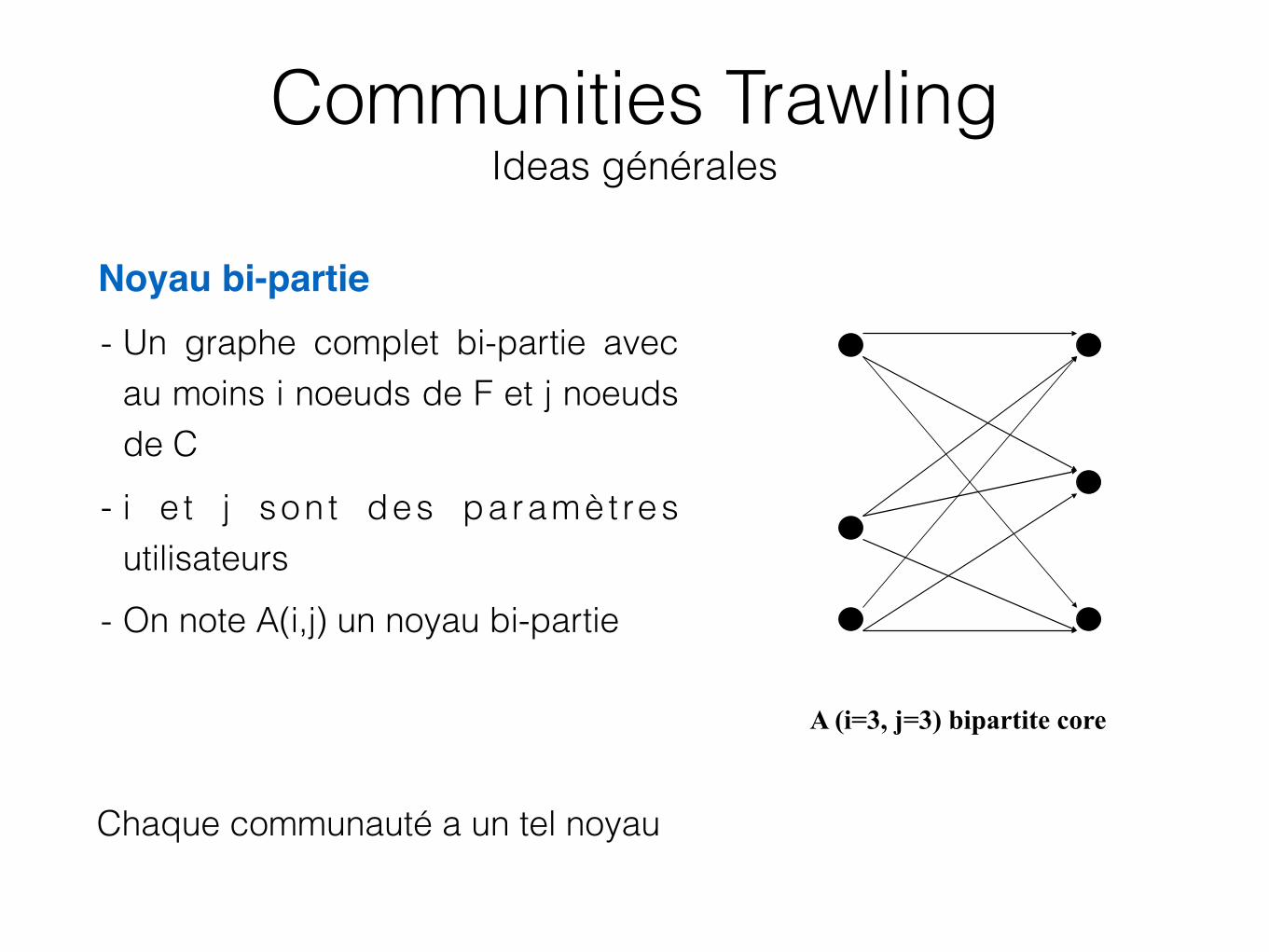
• Noyau bi-partie- Un graphe complet bi-partie avec
au moins i noeuds de F et j noeuds de C
- i e t j son t des paramèt res utilisateurs
- On note A(i,j) un noyau bi-partie
• Chaque communauté a un tel noyau
A (i=3, j=3) bipartite core
Communities Trawling Ideas générales

67
Communautés Web

68
Fouille des usages du Web

• Le Web est une collection de fichiers interconnectés hébergés sur de nombreux serveurs
• Définition➔Découvrir des motifs intéressants à partir des données générées
par les interactions client-serveur • Sources de données
➔Access logs, referrer logs, agent logs,et cookies ➔Profils utilisateurs ➔Meta-données: attributs des pages, attributs sur le contenu des
pages
Fouille d’usages

Des statistiques basiques- Les top URLs - A list of top referrers - Les navigateurs les plus utilisés - Le traffic par heure/jour/semaine/année - Le traffic par domaine
Apprentissage- Qui visite un site - Le chemin fréquent de visites - Le temps passé sur chaque page - La page de départ la plus fréquente - A partir d’où les visiteurs quittent le site
Fouille d’usages Applications
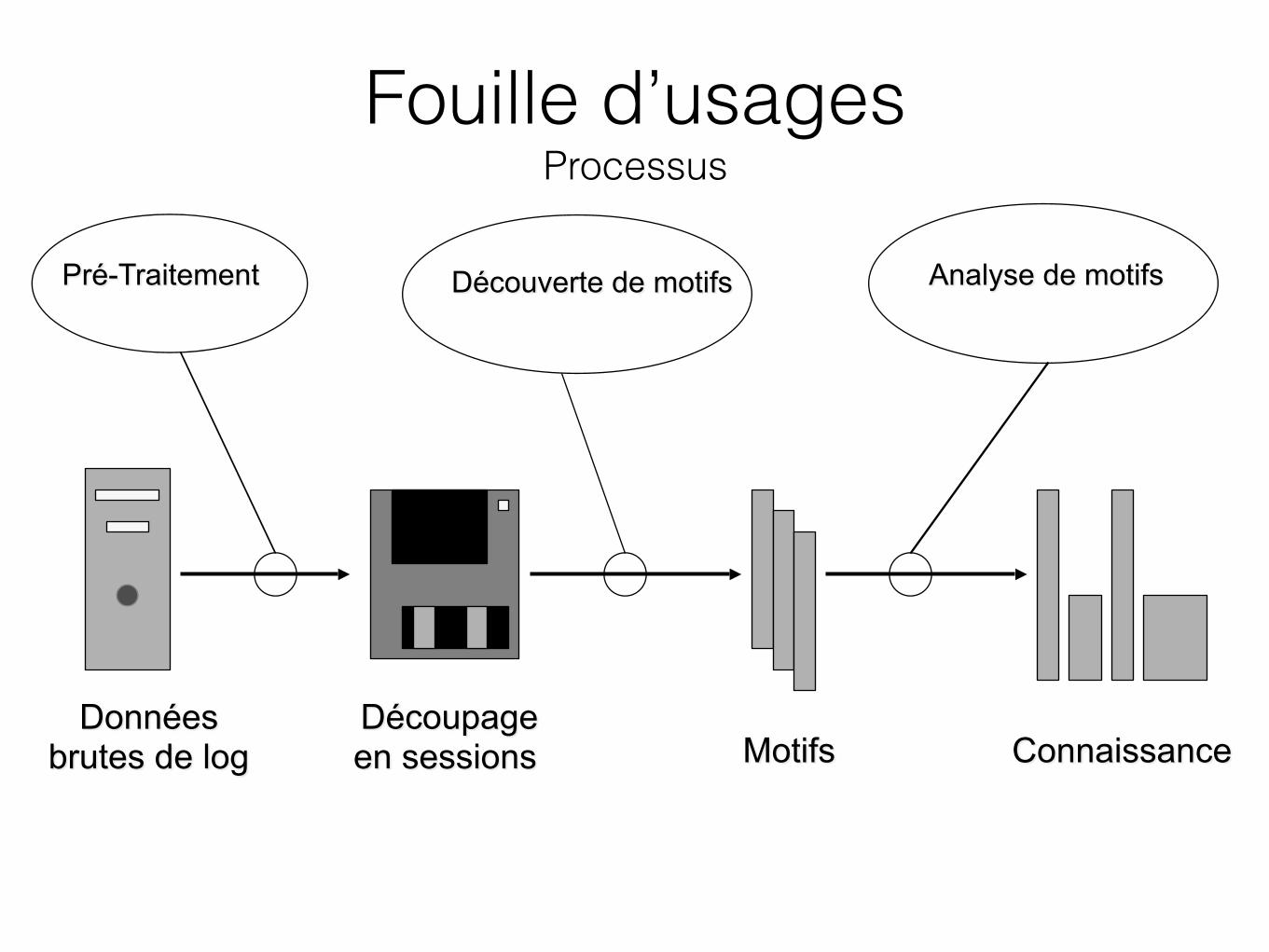
Pré-Traitement Découverte de motifs Analyse de motifs
Données brutes de log
Découpage en sessions Motifs Connaissance
Fouille d’usages Processus
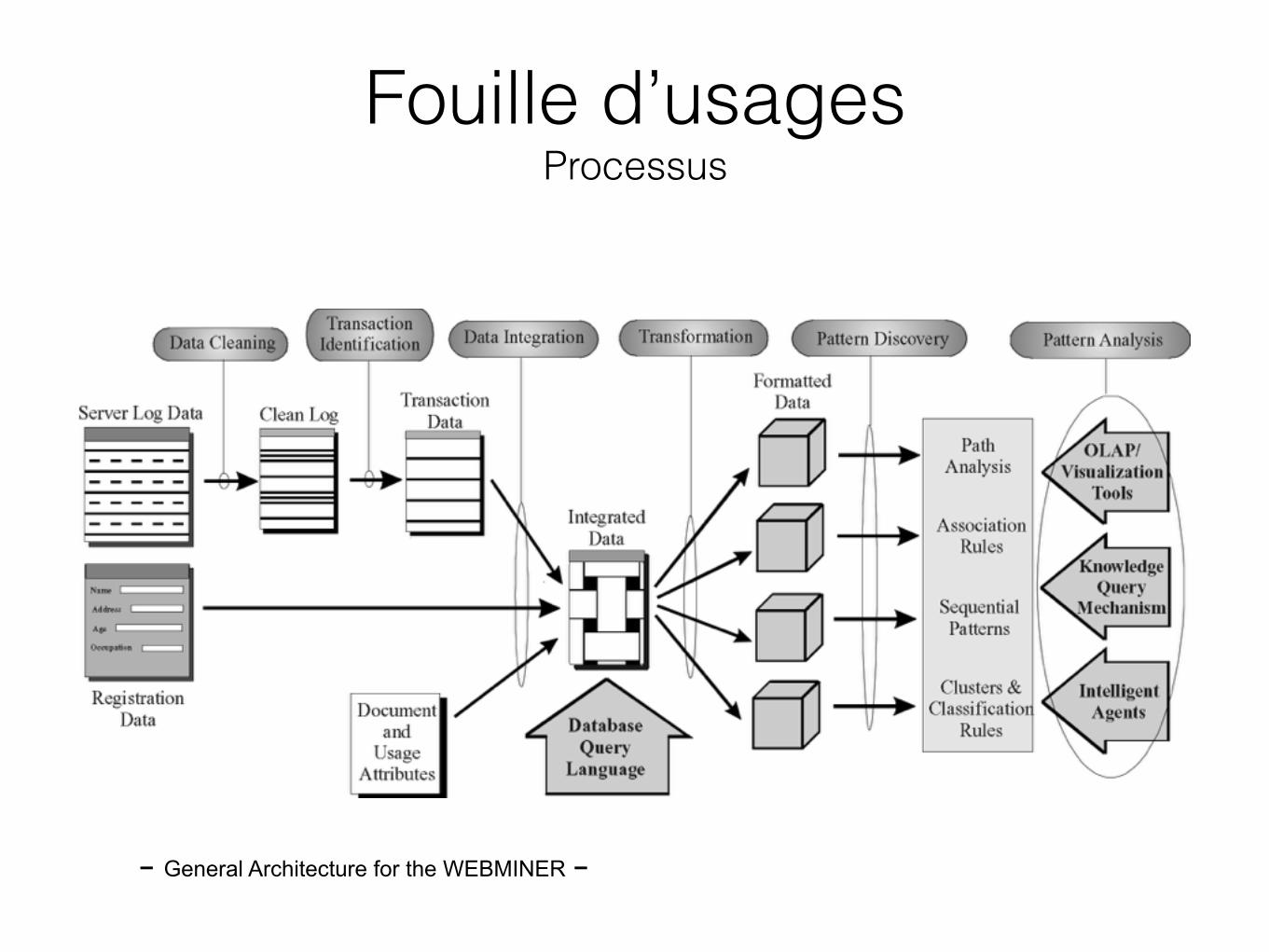
- General Architecture for the WEBMINER -
Fouille d’usages Processus

• Typical Data in a Server Access Loglooney.cs.umn.edu han - [09/Aug/1996:09:53:52 -0500] "GET mobasher/courses/cs5106/cs5106l1.html HTTP/1.0" 200 mega.cs.umn.edu njain - [09/Aug/1996:09:53:52 -0500] "GET / HTTP/1.0" 200 3291 mega.cs.umn.edu njain - [09/Aug/1996:09:53:53 -0500] "GET /images/backgnds/paper.gif HTTP/1.0" 200 3014 mega.cs.umn.edu njain - [09/Aug/1996:09:54:12 -0500] "GET /cgi-bin/Count.cgi?df=CS home.dat\&dd=C\&ft=1 HTTP mega.cs.umn.edu njain - [09/Aug/1996:09:54:18 -0500] "GET advisor HTTP/1.0" 302 mega.cs.umn.edu njain - [09/Aug/1996:09:54:19 -0500] "GET advisor/ HTTP/1.0" 200 487 looney.cs.umn.edu han - [09/Aug/1996:09:54:28 -0500] "GET mobasher/courses/cs5106/cs5106l2.html HTTP/1.0" 200 . . . . . . . . .
Format IP address userid time method url protocol status size
Fouille d’usages Logs
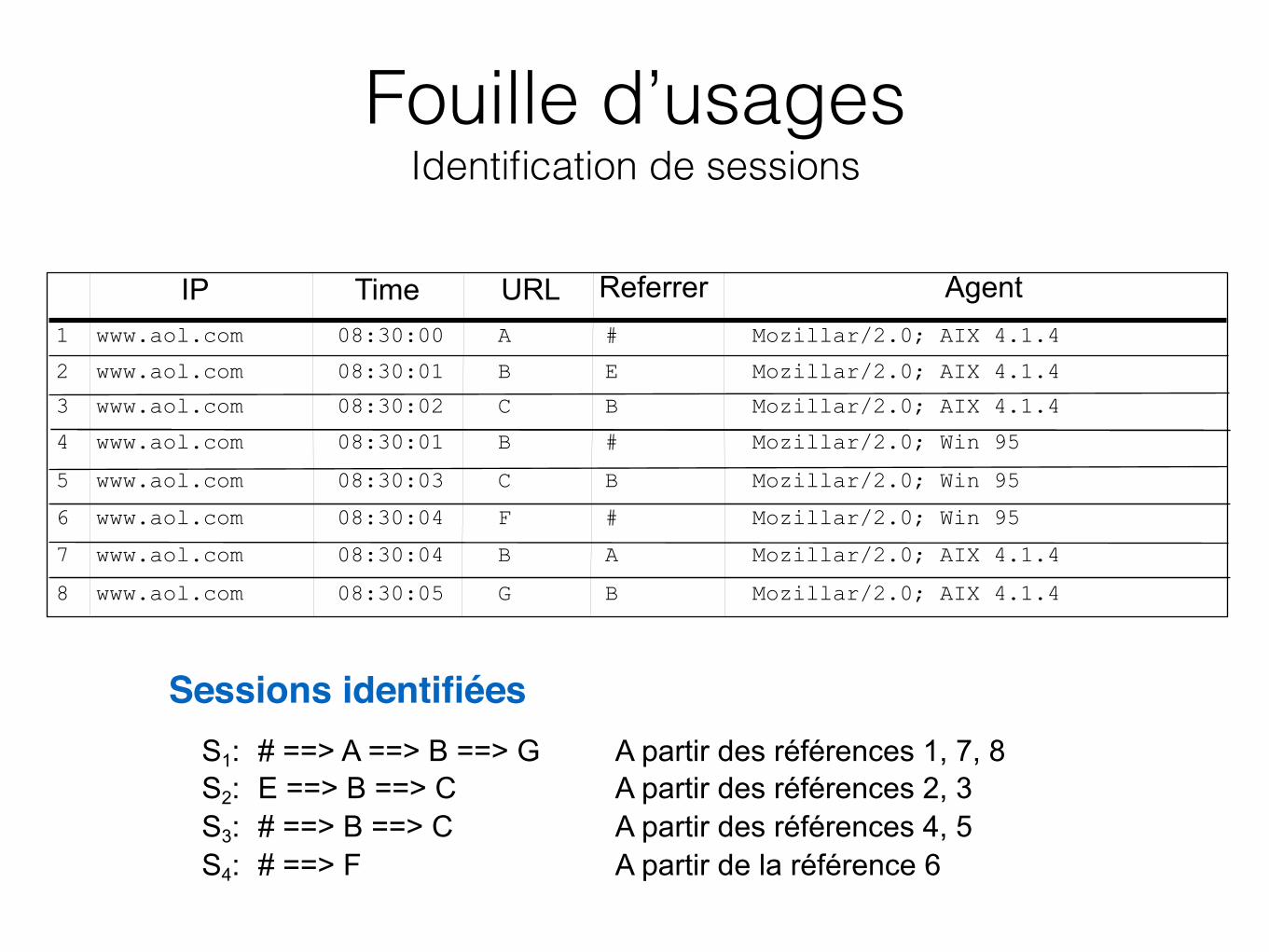
IP Time URL Referrer Agent1 www.aol.com 08:30:00 A # Mozillar/2.0; AIX 4.1.4
2 www.aol.com 08:30:01 B E Mozillar/2.0; AIX 4.1.4
3 www.aol.com 08:30:02 C B Mozillar/2.0; AIX 4.1.4
4 www.aol.com 08:30:01 B # Mozillar/2.0; Win 95
5 www.aol.com 08:30:03 C B Mozillar/2.0; Win 95
6 www.aol.com 08:30:04 F # Mozillar/2.0; Win 95
8 www.aol.com 08:30:05 G B Mozillar/2.0; AIX 4.1.4
7 www.aol.com 08:30:04 B A Mozillar/2.0; AIX 4.1.4
Sessions identifiées S1: # ==> A ==> B ==> G A partir des références 1, 7, 8 S2: E ==> B ==> C A partir des références 2, 3 S3: # ==> B ==> C A partir des références 4, 5 S4: # ==> F A partir de la référence 6
Fouille d’usages Identification de sessions

• Règles d’association- 60% des clients qui ont accédé à /products/, ont aussi accédé à /
products/software/webminer.htm. - 30% des clients qui ont accédé à /special-offer.html ont commandé
un logiciel sur la page /products/software/
Fouille d’usages Techniques
• Motifs séquentiels- 30% des clients qui ont visité /products/software/, ont au préalable
effectué une recherche “Logiciel” sur Yahoo! - 60% des clients qui ont commandé WEBMINER ont également
commandé un autre logiciel dans les 15 jours suivants

• Clustering et classification- Les clients qui accèdent souvent à /products/software/
webminer.html semblent provenir du milieu universitaire
- Les clients qui achètent des logiciels sont majoritairement des étudiants entre 20 et 25 ans qui vivent au USA
- 75% des clients qui ont téléchargés des logiciels à partir de la page products/software/demos/ l’ont fait entre 19h et 23h le week-end
Fouille d’usages Techniques

77
Références
- Data Mining - Concepts and Techniques par J. Han et M.Kamber (ed. Morgan Kauffman)
- Web Data Mining - ExploringHyperlink, Contents and Usage Data par B. Liu (ed. Springer)
- Statistiques Exploratoires Multidimensionnelles par L. Lebart et al. (ed. Dunod)
Ces ouvrages pointent vers de nombreuses références d’articles scientifiques décrivant les approches vues en cours ou des variantes de celles-ci





























