Embed Size (px)
Citation preview

Fouille de données: Classifica1on
Translated from Tan, Steinbach, Kumar Lecture Notes for Chapter 4 Introduc1on to Data Mining

Défini1on de la classifica1on
• Étant donné une collec1on de données (training set) – Chaque enregistrement con1ent des aHributs, et un de ces aHributs est la classe
• Trouver un modèle pour l’aHribut de classe en fonc1on des valeurs des autres aHributs
• Objec1f: prédire la classe de nouveaux enregistrements – Un test set est u1lisé pour déterminer la précision du modèle

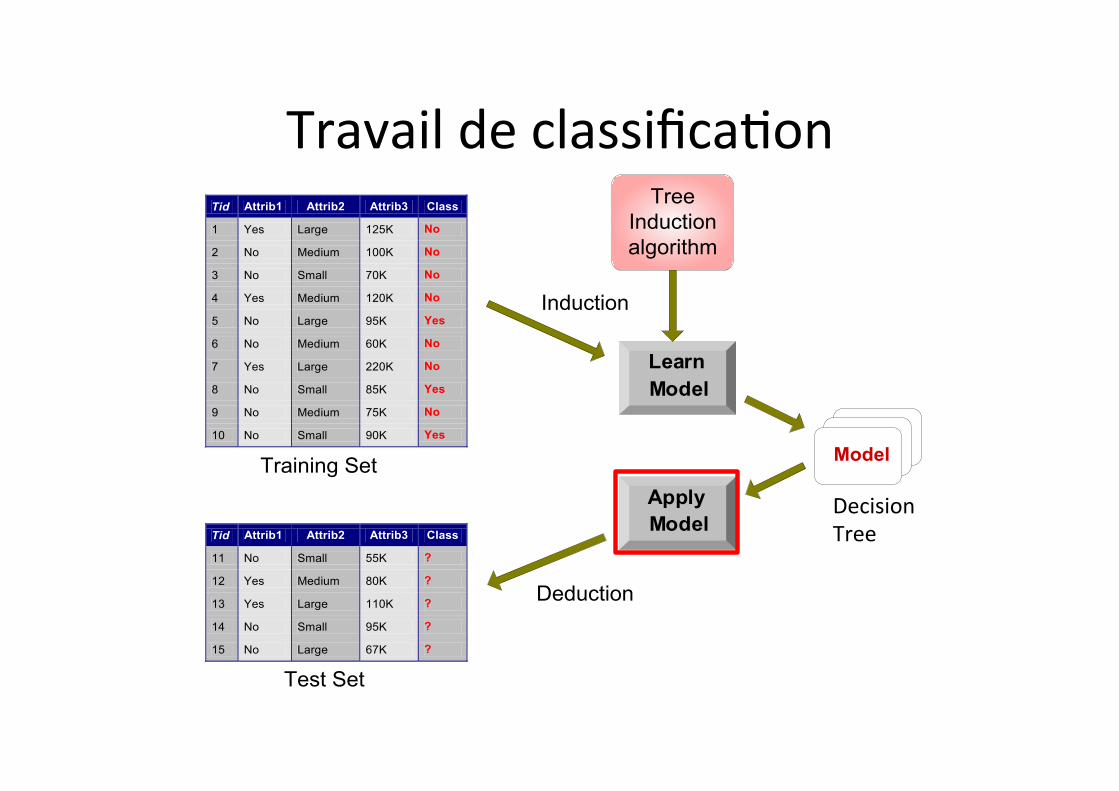
Illustra1on de la classifica1on
Apply Model
Induction
Deduction
Learn Model
Model
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Test Set
Learningalgorithm
Training Set

Exemples de tâches de classifica1ons
• Prédire si des cellules sont cancéreuses ou non
• Classifier des opéra1ons de carte de crédit (fraude ou légi1me)
• Classifier des structures de protéines • Catégoriser des news en finance, météo, diver1ssement, sport …

Techniques de classifica1on
• De nombreuses méthodes – Dans ce cours: arbres de classifica1on – Réseaux de neurones – Approches Bayésiennes – Machines à vecteurs de support – …

Exemple d’arbre de décision
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Splitting Attributes
Model: Decision Tree

Autre exemple d’arbre de décision
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10
MarSt
Refund
TaxInc
YES NO
NO
NO
Yes No
Married Single,
Divorced
< 80K > 80K
On peut créer plusieurs arbres pour les mêmes données
Travail de classifica1on
Apply Model
Induction
Deduction
Learn Model
Model
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Test Set
TreeInductionalgorithm
Training Set
Decision Tree

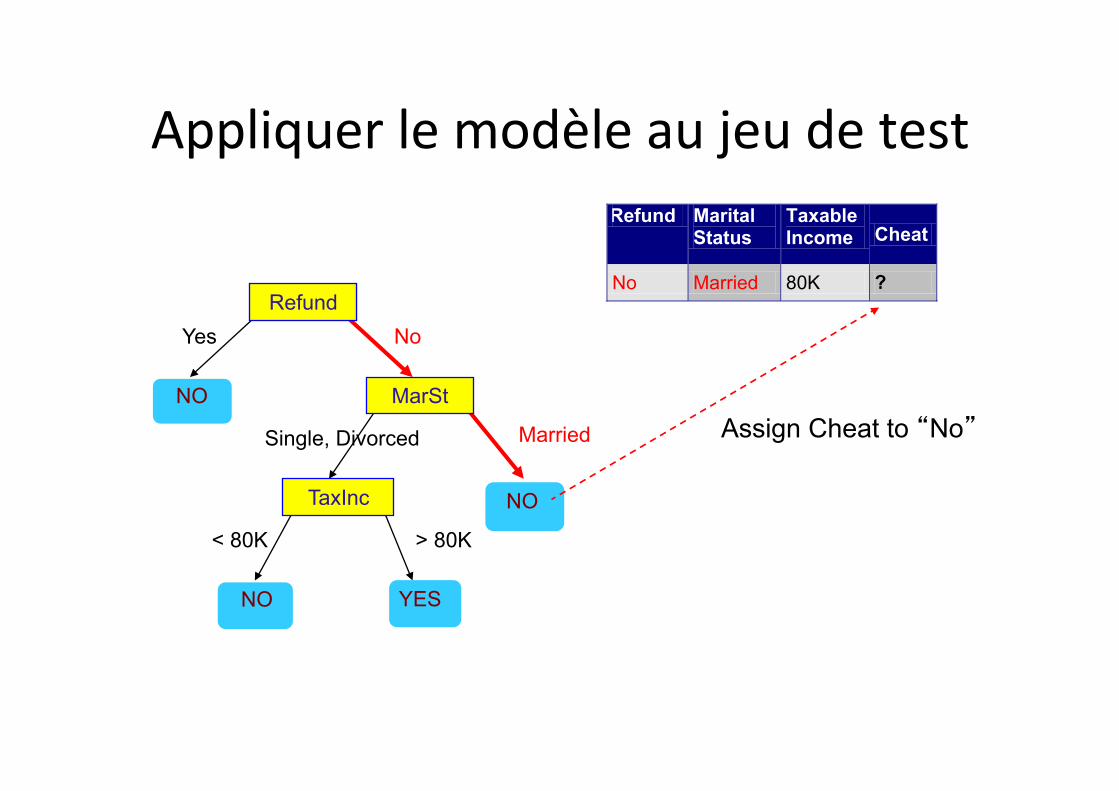
Appliquer le modèle au jeu de test
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
On part de la racine de l’arbre

Appliquer le modèle au jeu de test
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10

Appliquer le modèle au jeu de test
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10

Appliquer le modèle au jeu de test
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10

Appliquer le modèle au jeu de test
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Appliquer le modèle au jeu de test
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Assign Cheat to “No”

Arbre de décision
Apply Model
Induction
Deduction
Learn Model
Model
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Test Set
TreeInductionalgorithm
Training Set
Decision Tree

Étape d’induc1on (construc1on) de l’arbre
• De nombreux algorithmes – Algorithme de Hunt – CART – ID3, C4.5 – SLIQ, SPRINT

Structure générale de l’algorithme de Hunt
• Soit Dt l’ensemble des enregistrements qui aHeignent le nœud t
• Procédure générale: – Si Dt ne con1ent que des enregistrements de la même classe, alors t est une feuille avec le label yt
– SI Dt est un ensemble vide, alors t est une feuille avec le label par défaut, yd
– Si Dt con1ent des enregistrements de plusieurs classes différentes, u1liser un aHribut pour diviser les enregistrements en plusieurs sous-‐ensembles. Appliquer ceHe procédure récursivement.
Tid Refund Marital Status
Taxable Income Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
Dt
?

Algorithme de Hunt
Don’t Cheat
Refund
Don’t Cheat
Don’t Cheat
Yes No
Refund
Don’t Cheat
Yes No
Marital Status
Don’t Cheat
Cheat
Single, Divorced Married
Taxable Income
Don’t Cheat
< 80K >= 80K
Refund
Don’t Cheat
Yes No
Marital Status
Don’t Cheat Cheat
Single, Divorced Married
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10

Induc1on d’arbre
• Stratégie « gloutonne » – Diviser les enregistrements suivant i, aHribut qui op1mise un critère donné
• Problème – Déterminer comment diviser les enregistrements
• Comment spécifier le test sur l’aHribut ? • Comment déterminer quelle est la meilleure division ?
– Quand doit on s’arrêter de diviser ?

Induc1on d’arbre
• Stratégie « gloutonne » – Diviser les enregistrements suivant i, aHribut qui op1mise un critère donné
• Problème – Déterminer comment diviser les enregistrements
• Comment spécifier le test sur l’aHribut ? • Comment déterminer quelle est la meilleure division ?
– Quand doit on s’arrêter de diviser ?

Comment spécifier la condi1on de test sur l’aHribut ?
• Dépend du type d’aHribut – Nominal – Ordinal – Con1nu
• Dépend du nombre de divisions – 2 (2-‐way split) – Plusieurs (mul1-‐way split)
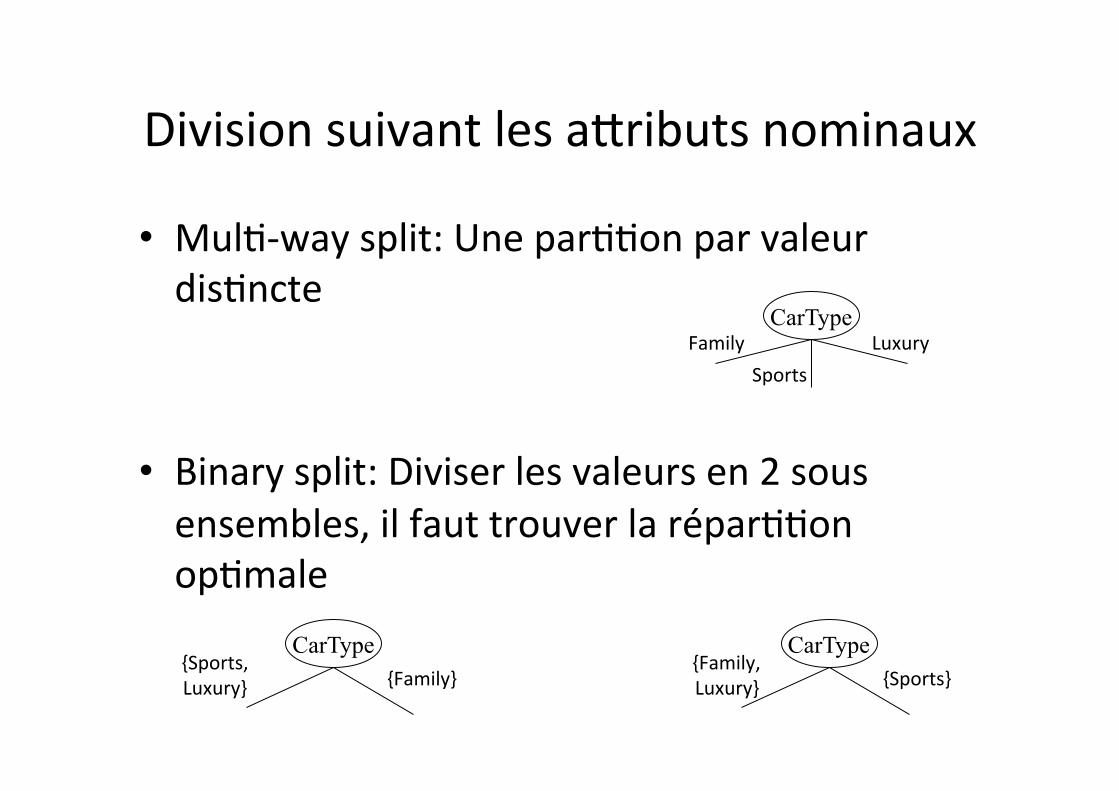
Division suivant les aHributs nominaux
• Mul1-‐way split: Une par11on par valeur dis1ncte
• Binary split: Diviser les valeurs en 2 sous ensembles, il faut trouver la répar11on op1male
CarType Family
Sports Luxury
CarType {Family, Luxury} {Sports}
CarType {Sports, Luxury} {Family}

Division suivant les aHributs nominaux
• Mul1-‐way split: Une par11on par valeur dis1ncte
• Binary split: Diviser les valeurs en 2 sous ensembles, il faut trouver la répar11on op1male
• AHen1on aux valeurs ordinales: il faut respecter l’ordre
CarType Family
Sports Luxury
CarType {Family, Luxury} {Sports}
CarType {Sports, Luxury} {Family}
Size {Small, Large} {Medium}

Division suivant des aHributs con1nus
• Différentes façon de procéder – Discré1sa1on en un espace ordinal de catégories
• Sta1que: on discré1se avant la construc1on de l’arbre • Dynamique: on choisit l’intervalle au moment de la division (buckets, fréquence égale (cen1les), clustering
– Décision binaire (A < v) ou (A ≥ v) • Considérer toutes les possibilités de division et trouver la meilleure
• Plus coûteux en calcul

Division sur des aHributs con1nus
TaxableIncome> 80K?
Yes No
TaxableIncome?
(i) Binary split (ii) Multi-way split
< 10K
[10K,25K) [25K,50K) [50K,80K)
> 80K

Induc1on d’arbre
• Stratégie « gloutonne » – Diviser les enregistrements suivant i, aHribut qui op1mise un critère donné
• Problème – Déterminer comment diviser les enregistrements
• Comment spécifier le test sur l’aHribut ? • Comment déterminer quelle est la meilleure division ?
– Quand doit on s’arrêter de diviser ?

Comment déterminer la meilleure division
OwnCar?
C0: 6C1: 4
C0: 4C1: 6
C0: 1C1: 3
C0: 8C1: 0
C0: 1C1: 7
CarType?
C0: 1C1: 0
C0: 1C1: 0
C0: 0C1: 1
StudentID?
...
Yes No Family
Sports
Luxury c1c10
c20
C0: 0C1: 1
...
c11
Avant division: 10 enregistrements de classe 0 et 10 de classe 1
Quelle condi1on de division est la meilleure ?

Comment déterminer la meilleure division
• Approche gloutonne – Les nœuds avec une distribu1on homogène sont privilégiés
• Il faut une mesure de « pureté » C0: 5C1: 5
C0: 9C1: 1
Non-‐homogène,
Haut niveau d’impureté
Homogène,
Faible niveau d’impureté

Mesure d’impureté
• Index de Gini • Entropie • Erreurs de classifica1on

Comment trouver le meilleur split ?
B?
Yes No
Node N3 Node N4
A?
Yes No
Node N1 Node N2
Avant division:
C0 N10 C1 N11
C0 N20 C1 N21
C0 N30 C1 N31
C0 N40 C1 N41
C0 N00 C1 N01
M0
M1 M2 M3 M4
M12 M34

Mesure d’impureté: GINI
• Index de Gini donné au nœud t par la formule Avec p(j|t) fréquence rela1ve de la classe j au nœud t – Maximum (1-‐1/nc) lorsque les enregistrements sont répar1s équitablement entre toutes les classes
– Minimum 0 lorsque tous les enregistrements font par1e de la même classe, cad que c’est une bonne division
∑−=j
tjptGINI 2)]|([1)(
C1 0C2 6Gini=0.000
C1 2C2 4Gini=0.444
C1 3C2 3Gini=0.500
C1 1C2 5Gini=0.278

Exemples de calcul de GINI
C1 0 C2 6
C1 2 C2 4
C1 1 C2 5
P(C1) = 0/6 = 0 P(C2) = 6/6 = 1
Gini = 1 – P(C1)2 – P(C2)2 = 1 – 0 – 1 = 0
∑−=j
tjptGINI 2)]|([1)(
P(C1) = 1/6 P(C2) = 5/6
Gini = 1 – (1/6)2 – (5/6)2 = 0.278
P(C1) = 2/6 P(C2) = 4/6
Gini = 1 – (2/6)2 – (4/6)2 = 0.444

Division basée sur GINI
• U1lisé dans CART, SLIQ et SPRINT • Lorsqu’un nœud p est divisé en k par11ons, la qualité de la division est donnée par avec ni = nombre d’enregistrements dans la division i n = nombre d’enregistrements au nœud p
∑=
=k
i
isplit iGINI
nnGINI
1
)(

AHributs binaires: calcul d’index GINI
• Divise en 2 par11ons • Effet de la pondéra1on des par11ons
– On cherche des par11ons grandes et pures B?
Yes No
Node N1 Node N2
Parent C1 6
C2 6 Gini = 0.500
N1 N2 C1 5 1 C2 2 4 Gini=0.333
Gini(N1) = 1 – (5/7)2 – (2/7)2 = 0.408
Gini(N2) = 1 – (1/5)2 – (4/5)2 = 0.32
Gini(Children) = 7/12 * 0.408 + 5/12 * 0.32 = 0.371

AHributs de catégories: calcul de l’index GINI
• Pour chaque valeur d’aHribut, calculer le nombre d’occurrences de chaque classe
• U1liser la matrice de comptage pour prendre la décision
CarType{Sports,Luxury} {Family}
C1 3 1C2 2 4Gini 0.400
CarType
{Sports} {Family,Luxury}C1 2 2C2 1 5Gini 0.419
CarTypeFamily Sports Luxury
C1 1 2 1C2 4 1 1Gini 0.393
Multi-way split Two-way split (find best partition of values)

AHributs con1nus: calcul de l’index GINI
• U1liser une décision binaire suivant une valeurs
• Différentes possibilités pour diviser les valeurs – Nombre de possibilités de division = nombre
de valeurs dis1nctes • Chaque division a une matrice de comptage
associée – Comptage des différentes classes dans les
par11ons, A < v et A ≥ v • Méthode simple pour choisir le meilleur v
– Pour chaque v, parcourir la base de donnée pour créer la matrice de comptage et calculer l’index de Gini
– Peu efficace ! Calculs redondants.
Tid Refund Marital Status
Taxable Income Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
TaxableIncome> 80K?
Yes No

AHributs con1nus: calcul de l’index de GINI
• Pour un calcul efficace – Trier les aHributs suivant les valeurs – Scanner ces valeurs en meHant à jour la matrice de comptage et calculer l’index de Gini
– Choisir la par11on qui a l’index le plus faible Cheat No No No Yes Yes Yes No No No No
Taxable Income
60 70 75 85 90 95 100 120 125 220
55 65 72 80 87 92 97 110 122 172 230<= > <= > <= > <= > <= > <= > <= > <= > <= > <= > <= >
Yes 0 3 0 3 0 3 0 3 1 2 2 1 3 0 3 0 3 0 3 0 3 0
No 0 7 1 6 2 5 3 4 3 4 3 4 3 4 4 3 5 2 6 1 7 0
Gini 0.420 0.400 0.375 0.343 0.417 0.400 0.300 0.343 0.375 0.400 0.420
Split Positions Sorted Values

Critère de division alterna1f basé sur l’informa1on
• L’entropie pour un nœud t est donnée par Avec p(j|t) fréquence rela1ve de la classe j au nœud t
– Mesure d’homogénéité pour un nœud • Maximum (log nc) lorsque les enregistrements sont répar1s équitablement entre les classes (cad peu d’informa1on)
• Minimum 0 lorsque tous les enregistrements sont dans la même classe (cad beaucoup d’informa1on)
– Les méthodes basées sur le calcul d’entropie sont similaires à celles basées sur l’index de Gini
∑−=j
tjptjptEntropy )|(log)|()(

Exemples de calcul d’entropie
C1 0 C2 6
C1 2 C2 4
C1 1 C2 5
P(C1) = 0/6 = 0 P(C2) = 6/6 = 1
Entropy = – 0 log 0 – 1 log 1 = – 0 – 0 = 0
P(C1) = 1/6 P(C2) = 5/6
Entropy = – (1/6) log2 (1/6) – (5/6) log2 (1/6) = 0.65
P(C1) = 2/6 P(C2) = 4/6
Entropy = – (2/6) log2 (2/6) – (4/6) log2 (4/6) = 0.92
∑−=j
tjptjptEntropy )|(log)|()(2

Division basée sur l’informa1on • Gain d’informa1on nœud parent p divisé en k par11ons, ni est le nombre d’enregistrements dans la par11on i – Mesure la réduc1on d’entropie obtenue par la division, on choisit la division qui réduit le plus l’entropie (maximise GAIN)
– U1lisée dans ID3 et C4.5 – Désavantage: tend à préférer les divisions qui résultent en de nombreuses par11ons, avec chaque par11on pe1te mais pure
⎟⎠⎞
⎜⎝⎛−= ∑
=
k
i
i
splitiEntropy
nnpEntropyGAIN
1)()(

Division basée sur l’informa1on • Ra1o de gain nœud parent p divisé en k par11ons, ni est le nombre d’enregistrements dans la par11on i – Ajuste le gain d’informa1on par l’entropie du par11onnement (SplitINFO). Une haute entropie de par11onnement (cad beaucoup de pe1tes par11ons) est pénalisée
– U1lisé dans C4.5 – Conçu pour dépasser les désavantages de la mesure de gain d’informa1on seule
SplitINFOGAIN
GainRATIO Split
split= ∑
=−=
k
i
ii
nn
nnSplitINFO
1log

Critère de décision basé sur les erreurs de classifica1on
• Erreur de classifica1on maximale pour un nœud t
• Mesures d’erreurs de classifica1on faites par un nœud – Maximum (1-‐1/nc) lorsque les enregistrements sont distribués uniformément parmi les classes (cad peu d’informa1on)
– Minimum 0 lorsque les enregistrements font par1e d’une même classe (cad beaucoup d’informa1on)
)|(max1)( tiPtErrori
−=

Exemples de calcul d’erreur de classifica1on
C1 0 C2 6
C1 2 C2 4
C1 1 C2 5
P(C1) = 0/6 = 0 P(C2) = 6/6 = 1
Error = 1 – max (0, 1) = 1 – 1 = 0
P(C1) = 1/6 P(C2) = 5/6
Error = 1 – max (1/6, 5/6) = 1 – 5/6 = 1/6
P(C1) = 2/6 P(C2) = 4/6
Error = 1 – max (2/6, 4/6) = 1 – 4/6 = 1/3
)|(max1)( tiPtErrori
−=

Comparaison des méthodes de division
• Pour un problème à 2 classes

Erreurs de classifica1on vs GINI A?
Yes No
Node N1 Node N2
Parent C1 7
C2 3 Gini = 0.42
N1 N2 C1 3 4 C2 0 3 Gini=0.361
Gini(N1) = 1 – (3/3)2 – (0/3)2 = 0
Gini(N2) = 1 – (4/7)2 – (3/7)2 = 0.489
Gini(Children) = 3/10 * 0 + 7/10 * 0.489 = 0.342
Gini improves !!

Induc1on d’arbre
• Stratégie « gloutonne » – Diviser les enregistrements suivant i, aHribut qui op1mise un critère donné
• Problème – Déterminer comment diviser les enregistrements
• Comment spécifier le test sur l’aHribut ? • Comment déterminer quelle est la meilleure division ?
– Quand doit on s’arrêter de diviser ?

Critère d’arrêt dans la construc1on de l’arbre
• Arrêter d’étendre un nœud quand tous les enregistrements font par1e de la même classe
• Arrêter d’étendre un nœud quand tous les enregistrements ont des valeurs d’aHributs similaires
• Autre condi1on (présenté par la suite)

Classifica1on basée sur les arbres de décision
• Avantages – Peut coûteux à construire – Très rapide pour la phase de classifica1on – Facile à interpréter pour les arbres de pe1te taille – Précision comparable à d’autres méthodes de classifica1on pour des données « simples »

Exemple: C4.5
• Construc1on de l’arbre « depth-‐first » • U1lise le gain d’informa1on (entropie) • Trie les aHributs con1nue et par11onne suivant un seuil
• Nécessite que les données soient en1èrement en mémoire (RAM) – Pas adapté aux grands jeux de données

Problèmes pra1ques en classifica1on
• Underfi~ng and overfi~ng (sous et sur-‐appren1ssage)
• Valeurs manquantes • Coûts de classifica1on

Underfi~ng et overfi~ng
Underfi~ng: lorsque le modèle est trop simple, les erreurs sur le training et le tes1ng sets sont très élevées
Overfi~ng

Overfi~ng dû au bruit
La fron1ère entre les classes est déformée par une aberra1on

Overfi~ng dû à un manque de données
Le manque de données dans le bas du diagramme rend la prédic1on rend difficile la prédic1on des données de ceHe région La taille limitée du training set dans ceHe région fait que l’arbre de décision prédit ceHe région à par1r d’autres données qui n’en font pas par1e

Notes sur l’overfi~ng
• L’overfi~ng cause la créa1on d’arbres de décision plus complexes que nécessaire
• Les erreurs sur les données d’entrainement ne fournissent plus une bonne indica1on sur la performance de l’arbre sur les données de test
• Il faut trouver de nouvelles façons d’es1mer les erreurs

Es1ma1on des erreurs de généralisa1on
• Erreurs de re-‐subs1tu1on: erreurs sur le training set (Σe(t)) • Erreurs de généralisa1on: erreurs sur le tes1ng set (Σe’(t)) • Méthodes pour es1mer les erreurs de généralisa1on
– Approche op1miste: e(t)=e’(t) – Approche pessimiste
• Pour chaque feuille de l’arbre e’(t)=e(t)+0.5 • Nombre d’erreurs total: e’(t)=e(t)+N×0.5 (N: nombre de feuilles) • Pour un arbre avec 30 feuilles et 10 erreurs sur le training set (sur 1000 enregistrements)
– Erreur sur le training set = 10/1000 = 1% – Erreur de généralisa1on = (10 + 30×0.5)/1000 = 2.5%
– Simplifica1on de l’arbre pour réduire l’erreur • U1lise des données de valida1on pour es1mer l’erreur de généralisa1on

Rasoir d’Ockham (Occam’s razor)
• Si 2 modèles produisent les mêmes erreurs de généralisa1on, alors on doit préférer le modèle le plus simple
• Les modèles complexes ont plus de chances d’avoir appris des données aberrantes
• Par conséquent, on doit inclure la complexité du modèle dans son évalua1on

Longueur de descrip1on minimale (MDL)
• Cost(Model,Data) = Cost(Data|Model) + Cost(Model) – Cost est le nombre de bits nécessaires à l’encodage – On cherche le modèle le moins coûteux
• Cost(Data|Model) encode les erreurs de classifica1on • Cost(Model) u1lise l’encodage des nœuds (nombre de fils) et un encodage de la condi1on de par11onnement
A B
A?
B?
C?
10
0
1
Yes No
B1 B2
C1 C2
X yX1 1X2 0X3 0X4 1… …Xn 1
X yX1 ?X2 ?X3 ?X4 ?… …Xn ?

Comment luHer contre l’overfi~ng
• Pré-‐élagage (règle d’arrêt an1cipé) – Arrêter l’algorithme avant d’avoir complètement étendu l’arbre
– Condi1ons d’arrêt courantes pour un nœud • Arrêter si tous les enregistrements font par1e de la même classe • Arrêter si toutes les valeurs d’aHributs sont égales
– Condi1ons plus restric1ves • Arrêter si le nombre d’enregistrements est inférieur à un seuil spécifié
• Arrêter si la distribu1on des classes est indépendantes des aHributs (ex en u1lisant un test χ 2)
• Arrêter d’étendre si le nœud courrant n’améliore pas la mesure d’impureté (Gini, entropie …)

Comment luHer contre l’overfi~ng
• Après élagage – Construire l’arbre de décision en en1er – Éliminer les nœuds de l’arbre de bas en haut – Si l’erreur de généralisa1on est améliorée par l’élagage, remplacer le sous arbre par une feuille
– La classe d’une feuille est déterminée par la classe majoritaire dans le sous arbre
– On peut u1liser MDL pour l’élagage

Exemple d’élagage Erreurs sur le training set (avant le par11onnement): 10/30 Erreur pessimiste: (10+0.5)/30 = 10.5/30 Erreur de training après par11onnement: 9/30 Erreur pessimiste (après par11onnement): (9+4*0.5)/30=11/30 à Élagage
A?
A1
A2 A3
A4
Class = Yes 20
Class = No 10
Error = 10/30
Class = Yes 8 Class = No 4
Class = Yes 3 Class = No 4
Class = Yes 4 Class = No 1
Class = Yes 5 Class = No 1

Exemple d’élagage
• Erreur op1miste ? – Pas d’élagage dans les 2 case
• Erreur pessimiste ? – Pas d’élagage dans le cas 1, élagage dans le cas 2
• Élagage par réduc1on d’erreur ? – Dépend des données de valida1on
C0: 11 C1: 3
C0: 2 C1: 4
C0: 14 C1: 3
C0: 2 C1: 2
Case 1:
Case 2:

Traitement des valeurs d’aHributs manquantes
• Les valeurs manquantes affectent la construc1on de l’arbre de classifica1on de 3 façons différentes: – Affecte le calcul de la mesure d’impureté – Affecte la distribu1on des enregistrements dont les données manquent sur les nœuds fils
– Affecte la façon dont une donnée de test est classifiée

Calcul de mesure d’impureté Tid Refund Marital
Status Taxable Income Class
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 ? Single 90K Yes 10
Class = Yes
Class = No
Refund=Yes 0 3 Refund=No 2 4
Refund=? 1 0
Par11onnement sur Refund:
Entropy(Refund=Yes) = 0
Entropy(Refund=No) = -‐(2/6)log(2/6) – (4/6)log(4/6) = 0.9183
Entropy(Children) = 0.3 (0) + 0.6 (0.9183) = 0.551
Gain = 0.9 × (0.8813 – 0.551) = 0.3303
Valeur manquante
Avant par11onnement: Entropy(Parent) = -‐0.3 log(0.3)-‐(0.7)log(0.7) = 0.8813

Distribu1on des instances Tid Refund Marital
Status Taxable Income Class
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No 10
Refund Yes No
Class=Yes 0
Class=No 3
Cheat=Yes 2
Cheat=No 4
Refund Yes
Tid Refund Marital Status
Taxable Income Class
10 ? Single 90K Yes 10
No
Class=Yes 2 + 6/9
Class=No 4
Probabilité de Refund=Yes is 3/9
Probabilité de Refund=No is 6/9
Assigner l’enregistrement au fils gauche avec le poids 3/9 et au fils droit avec le poids 6/9
Class=Yes 0 + 3/9
Class=No 3

Classifier les enregistrements
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Married Single Divorced Total
Class=No 3 1 0 4
Class=Yes 6/9 1 1 2.67
Total 3.67 2 1 6.67
Tid Refund Marital Status
Taxable Income Class
11 No ? 85K ? 10
Nouvel enregistrement:
Probabilité que Marital Status = Married est 3.67/6.67
Probabilité que Marital Status ={Single,Divorced} est 3/6.67

Autres problèmes
• Fragmenta1on des données • Stratégie de recherche • Expressivité • Réplica1on d’arbre

Fragmenta1on des données
• Le nombre d’enregistrements devient plus pe1t à mesure que l’on descend dans l’arbre
• Le nombre d’enregistrements aux feuilles peut devenir trop pe1t pour avoir une significa1on sta1s1que

Stratégie de recherche
• Trouver l’arbre de décision op1mal est NP-‐hard
• L’algorithme présenté dans ce cours u1lise une approche gloutonne, top-‐down, récursive, pour par11onner les données et obtenir une solu1on raisonnable
• Autres stratégies ? – BoHom-‐up – Bi-‐direc1onnelle

Expressivité • Les arbres de décision permeHent l’appren1ssage de fonc1ons à valeurs discrètes – Mais ils ne se généralisent pas bien à certains types de fonc1ons booléennes
• Exemple: la parité – Class = 1 si il y a un nombre paire d’aHributs booléens de valeur true
– Class = 0 si il y a un nombre impaire d’aHributs booléens de valeur true
– Pas suffisamment expressif pour modéliser des variables con1nues
• En par1culier lorsque la condi1on de test n’implique qu’un aHribut à la fois

Fron1ère de décision
• La ligne entre 2 régions de classes différentes est appelée fron1ère de décision
• La fron1ère est parallèle aux axes parce que la condi1on de test ne porte que sur un aHribut à la fois
y < 0.33?
: 0 : 3
: 4 : 0
y < 0.47?
: 4 : 0
: 0 : 4
x < 0.43?
Yes
Yes
No
No Yes No
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
y

Arbres de décision obliques
• La condi1on de test peut impliquer plusieurs aHributs • Représenta1on plus expressive • Trouver la condi1on op1male est plus coûteux en calcul
x + y < 1
Class = + Class =

Réplica1on d’arbre
• Même arbre dans plusieurs sous branches
P
Q R
S 0 1
0 1
Q
S 0
0 1

Modèle d’évalua1on
• Métrique d’évalua1on de performance – Comment évaluer les performances d’un modèle ?
• Méthode d’évalua1on de performances – Comment obtenir des es1mateurs fiables ?
• Méthode de comparaison de modèles – Comment comparer les performances de plusieurs modèles ?

Modèle d’évalua1on
• Métrique d’évalua1on de performance – Comment évaluer les performances d’un modèle ?
• Méthode d’évalua1on de performances – Comment obtenir des es1mateurs fiables ?
• Méthode de comparaison de modèles – Comment comparer les performances de plusieurs modèles ?
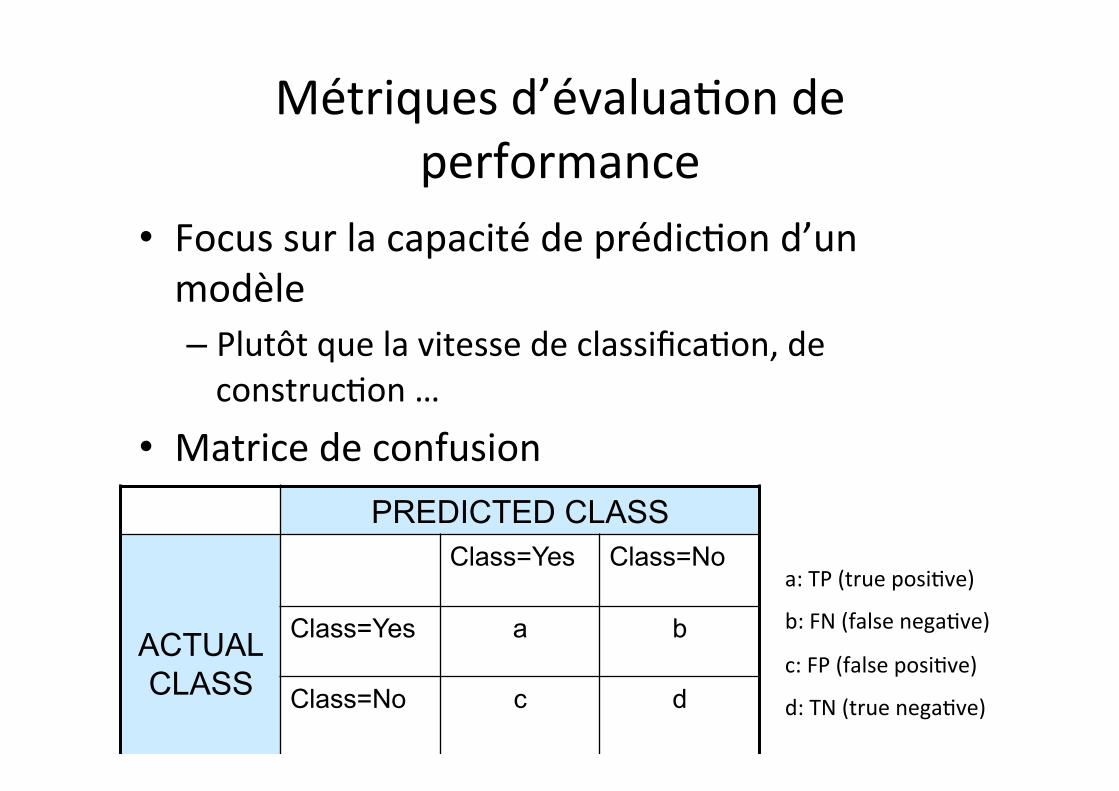
Métriques d’évalua1on de performance
• Focus sur la capacité de prédic1on d’un modèle – Plutôt que la vitesse de classifica1on, de construc1on …
• Matrice de confusion PREDICTED CLASS
ACTUAL CLASS
Class=Yes Class=No
Class=Yes a b
Class=No c d
a: TP (true posi1ve)
b: FN (false nega1ve)
c: FP (false posi1ve)
d: TN (true nega1ve)

Métriques d’évalua1on de performance
• Métrique la plus u1lisée
PREDICTED CLASS
ACTUAL CLASS
Class=Yes Class=No
Class=Yes a (TP)
b (FN)
Class=No c (FP)
d (TN)
Précision = a+ da+ b+ c+ d
=TP +TN
TP +TN +FP +FN

Limita1ons de la précision
• Considérons un problème à 2 classes – Nombre d’enregistrements de classe 0 : 9990 – Nombre d’enregistrements de class 1 : 10
• Si le modèle prédit que tout est de classe 0, la précision est de 9990/10000 = 99.9% – Résultat trompeur puisque le modèle ne détecte aucun enregistrement de classe 1

Matrice de coût
• C(i|j): coût de mal classifier un enregistrement de classe j en classe i
PREDICTED CLASS
ACTUAL CLASS
C(i|j) Class=Yes Class=No
Class=Yes C(Yes|Yes) C(No|Yes)
Class=No C(Yes|No) C(No|No)

Calcul du coût de classifica1on Cost Matrix
PREDICTED CLASS
ACTUAL CLASS
C(i|j) + - + -1 100 - 1 0
Model M1 PREDICTED CLASS
ACTUAL CLASS
+ - + 150 40 - 60 250
Model M2 PREDICTED CLASS
ACTUAL CLASS
+ - + 250 45 - 5 200
Accuracy = 80% Cost = 3910
Accuracy = 90% Cost = 4255

Coût contre précision Count PREDICTED CLASS
ACTUAL CLASS
Class=Yes Class=No
Class=Yes a b
Class=No c d
Cost PREDICTED CLASS
ACTUAL CLASS
Class=Yes Class=No
Class=Yes p q
Class=No q p
N = a + b + c + d
Précision = (a + d)/N
Coût = p (a + d) + q (b + c)
= p (a + d) + q (N – a – d)
= q N – (q – p)(a + d)
= N [q – (q-‐p) × Accuracy]
La précision est propo1onnelle au coût si 1. C(Yes|No)=C(No|Yes) = q 2. C(Yes|Yes)=C(No|No) = p

Mesures sensibles au coût
cbaa
prrp
baa
caa
++=
+=
+=
+=
222(F) measure-F
(r) Recall
(p)Precision
Precision impacté par C(Yes|Yes) & C(Yes|No) Recall impacté par C(Yes|Yes) & C(No|Yes) F-‐measure impactée par tout sauf C(No|No)
dwcwbwawdwaw
4321
41Accuracy Weighted+++
+=

Modèle d’évalua1on
• Métrique d’évalua1on de performance – Comment évaluer les performances d’un modèle ?
• Méthode d’évalua1on de performances – Comment obtenir des es1mateurs fiables ?
• Méthode de comparaison de modèles – Comment comparer les performances de plusieurs modèles ?

Méthodes d’évalua1on de performance
• Comment obtenir une es1ma1on fiable de la performance ?
• La performance d’un modèle peut dépendre de facteurs indépendants de l’algorithmes d’appren1ssage – Distribu1on des classes – Coût d’erreur de classifica1on – Taille des collec1ons d’entrainement et de test

Courbe d’appren1ssage • La courbe
d’appren1ssage change suivant la taille de l’ensemble d’appren1ssage
• Nécessite un échan1llonnage pour créer la courbe
• Effet de pe1ts échan1llons – Biais dans l’es1ma1on
– Variance de l’es1ma1on

Méthodes d’es1ma1on • Holdout
– 2/3 en training, 1/3 en tes1ng • Échan1llonnage aléatoire
– Holdout répété • Cross-‐valida1on
– Par11onner les données en k sous ensembles disjoints – K-‐fold: entrainement sur k-‐1, test sur le sous ensemble restant – Leave-‐one-‐out: k=n
• Sampling stra1fié • Bootstrap
– Sampling avec remplacement

Modèle d’évalua1on
• Métrique d’évalua1on de performance – Comment évaluer les performances d’un modèle ?
• Méthode d’évalua1on de performances – Comment obtenir des es1mateurs fiables ?
• Méthode de comparaison de modèles – Comment comparer les performances de plusieurs modèles ?

ROC (Receiver Opera1ng Characteris1c)
• Développé dans les années 1950 pour l’analyse de signaux – Caractérise le trade-‐off entre vrai posi1fs (TP) et faux posi1fs (FP)
• La courbe de ROC affiche les TP en axe des y en fonc1on des FP sur l’axe des x
• La performance de chaque classifieur représente un point sur la courbe de ROC – Changer le seul de l’algorithme, la distribu1on de l’échan1llonnage, ou la matrice de coût change la posi1on du point

Courbe ROC
Au seuil t:
TP=0.5, FN=0.5, FP=0.12, FN=0.88
-‐Données sur 1 dimension, 2 classes (posi1f et néga1f)
-‐ Tous les points points tels que x > t sont classifiés en posi1f

Courbe ROC (TP,FP): • (0,0): tout est dans la
classe néga1ve • (1,1): tout est dans la
classe posi1ve • (1,0): idéal • Ligne diagonale:
– Classifieur aléatoire – Sous la diagonale:
• Prédit l’opposé de la bonne classe

U1lisa1on de la ROC pour comparer des modèles
Aucun modèle n’est toujours meilleur M1 est meilleur pour
un pe1t FPR M2 est meilleur pour
un grand FPR
Aire sous la courbe ROC Idéal:
§ Aire = 1 Aléatoire:
§ Aire = 0.5

Comment construire la courbe ROC ? Instance P(+|A) True Class
1 0.95 + 2 0.93 + 3 0.87 - 4 0.85 - 5 0.85 - 6 0.85 + 7 0.76 - 8 0.53 + 9 0.43 -
10 0.25 +
• U1liser un classifieur qui produit une probabilité P(+|A) pour chaque instance de test
• Trier les enregistrements en fonctoin de ceHe probabilité P(+|A) dans l’ordre décroissant
• Faire un seul pour chaque valeur de P(+|A)
• Compter le nombre de TP, FP, TN et FN à chaque seuil
• TP rate, TPR = TP/(TP+FN) • FP rate, FPR = FP/(FP + TN)

Comment construire la courbe ROC ? Class + - + - - - + - + +
P 0.25 0.43 0.53 0.76 0.85 0.85 0.85 0.87 0.93 0.95 1.00
TP 5 4 4 3 3 3 3 2 2 1 0
FP 5 5 4 4 3 2 1 1 0 0 0
TN 0 0 1 1 2 3 4 4 5 5 5
FN 0 1 1 2 2 2 2 3 3 4 5
TPR 1 0.8 0.8 0.6 0.6 0.6 0.6 0.4 0.4 0.2 0
FPR 1 1 0.8 0.8 0.6 0.4 0.2 0.2 0 0 0
Threshold >=
ROC Curve:

Test de significa1on sta1s1que
• Étant donné 2 modèles – Modèle M1: précision = 85%, testé sur 30 enregistrements – Modèle M2: précision = 75%, testé sur 5000 enregistrements
• Peut on dire que M1 est meilleur que M2 ? – Quelle confiance a t’on sur la précision de M1 et M2 ? – Est ce que la différence de performance peut s’expliquer par les fluctua1ons aléatoires de l’ensemble de test ?
à Calcul d’un intervalle de confiance (non présenté dans ce cours)





























