Embed Size (px)
Citation preview

Fundamental Issues inParallel and Distributed Computing
Assaf Schuster, Computer Science, Technion

Multiple instructions in parallel
Serial vs. parallel program
One instruction at a time
Task=תהליך

Levels of parallelism
• Transistors
• Hardware modules
• Architecture, pipeline
• Superscalar
• Multicore
• Symmetric multi-processors
• Hardware connected multi-processors
• Tightly-coupled machine clusters
• Distributed systems
• Geo-distributed systems
• Internet-scale systems
• Interstellar systems

Flynn's HARDWARE Taxonomy

SIMD
Lock-step execution
Example: vector operations

MIMD
Example: multicores

Why parallel programming?
Most software will have to be written as a parallel software
Why ?
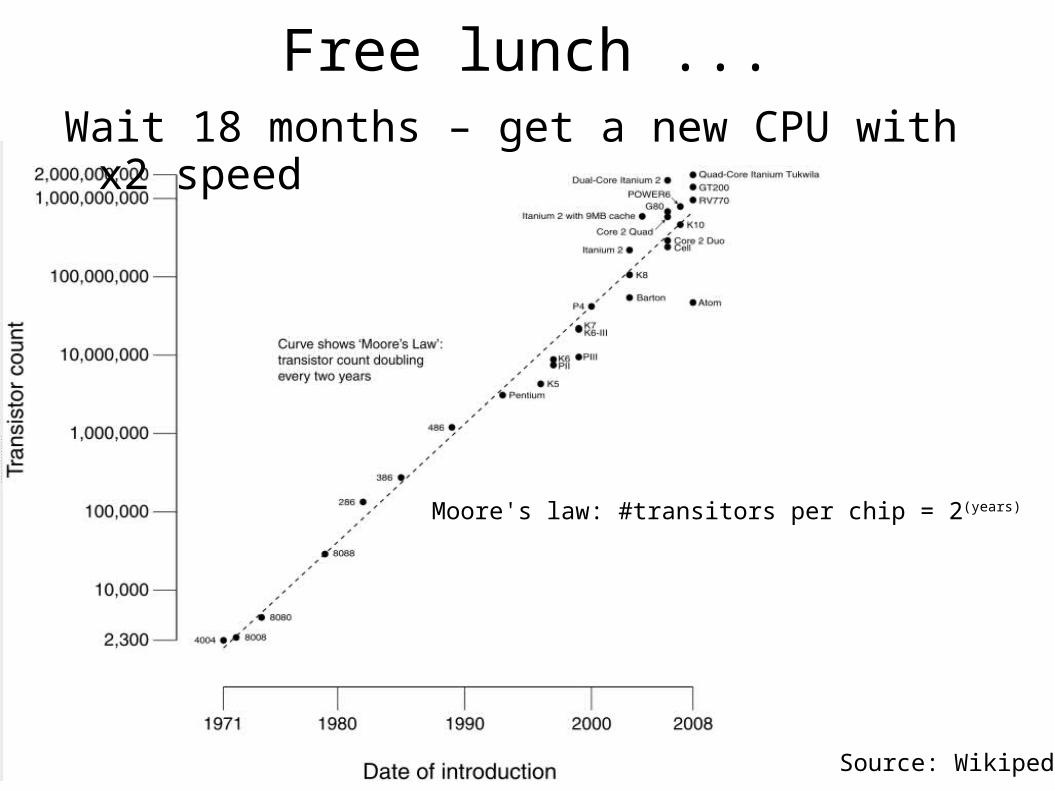
Wait 18 months – get a new CPU with x2 speed
Free lunch ...
Source: Wikipedia
Moore's law: #transitors per chip = 2(years)

… is over
More transistors = more execution units BUT performance per unit does not improve
Bad news: serial programs will not run faster Good news: parallelization has high performance
potential May get faster on newer architectures

Parallel programming is hard Need to optimize for performance
Understand management of resources Identify bottlenecks
No one technology fits all needs Zoo of programming models, languages, run-times
Hardware architecture is a moving target Parallel thinking is NOT intuitive Parallel debugging is not fun
But there is no detour

Parallelizing Game of Life(Cellular automaton of pixels)
Given a 2D grid vt(i,j)=F(vt-1(of all its neighbors))
i-1,j
i,j-1
i+1,j
i,j+1
i,j

Problem partitioning Domain decomposition
(SPMD) Input domain Output domain Both
Functional decomposition (MPMD) Independent tasks Pipelining

We choose: domain decomposition
The field is split between processors
CPU 0 CPU 1
i-1,j
i,j-1
i+1,j
i,j+1
i,j

Issue 1. Memory
Can we access v(i+1,j) from CPU 0 as in serial program?
CPU 0 CPU 1
i-1,j
i,j-1
i+1,j
i,j+1
i,j

It depends...
NO: Distributed memory space architecture: disjoint memory space
YES: Shared memory space architecture: same memory space
CPU 0 CPU 1
Memory
Memory
Network
CPU 0 CPU 1
Memory

Tradeoff: Programability vs. Scalability
Someone has to pay
Harder to program, easier to build hardware
Easier to program, harder to build hardware
CPU 0 CPU 1
Memory
Memory
Network
CPU 0 CPU 1
Memory

“Scalability” – the holy grail
Improving efficiency on larger problems when more processors are available.
• Single machine, multicore - vertical scalability
• Multiple machines – horizontal scalability, scale out

Memory architecture –latency in accessing data
CPU0: Time to access v(i+1,j) = Time to access v(i-1,j)?
CPU 0 CPU 1
i-1,j
i,j-1
i+1,j
i,j+1
i,j

Hardware shared memory, flavors 1
Uniform memory access: UMA Same cost of accessing any data by all processors
SMP = Symmetric Multi-Processor

Hardware shared memory, flavors 2 NON-Uniform memory access: NUMA
Tradeoff: Scalability vs. Latency

Software Distributed Shared Memory (SDSM)
CPU 0 CPU 1
Memory
Memory
Network
Process 1 Process 2
DSM daemons
Software - DSM: emulation of NUMA in software over distributed memory space

Memory-optimized programming
Most modern systems are NUMA or distributed Architecture is easier to scale up by scaling out
Access time difference: local vs. remote data:
x100-10000
Locality: most important optimization parameter for program speed serial or parallel

Issue 2: Control Can we assign one pixel per CPU? Can we assign one pixel per process/logical task?
i-1,j
i,j-1
i+1,j
i,j+1
i,j

Task management overhead
Each task has a state that should be managed More tasks – more state to manage
Who manages tasks?
How many tasks should be run by a cpu? … depends on the complexity of F
v(i,j)= F(all v's neighbors)

Question
Every process reads the data from its neighbors Will it produce correct results?
i-1,j
i,j-1
i+1,j
i,j+1
i,j

Issue 3: Synchronization
The order of reads and writes made in different tasks is non-deterministic
Synchronization is required to enforce the order Locks, semaphores, barriers, conditionals

Check point
Fundamental hardware-related issues: Memory accesses
Optimizing locality of accesses Control
Overhead Synchronization
Goals and tradeoffs:
Ease of Programing, Correctness, Scalability

Parallel programming issues
CPU 0 CPU 1
CPU 2 CPU 4
We decide to split this 3x3 grid like this:
• OK?
i-1,j
i,j-1
i+1,j
i,j+1
i,j

Issue 1: Load balancing
Always waiting for the slowest task Solutions?
CPU 0 CPU 1
CPU 2 CPU 4
i-1,j
i,j-1
i+1,j
i,j+1
i,j

Issue 2: Granularity G=Computation/Communication Fine-grain parallelism (small G)
Good load balancing Potentially high overhead
Coarse-grain parallelism (large G) Potentially bad load balancing Low overhead
What granularity works for you?Must balance overhead and CPU utilization

Issue 3: Memory Models
a=0,b=0
Print(b) Print(a)
a=1 b=1
Printed:0,0?
Printed:1,0?
Printed:1,1?
Which writes by a task are seen by which reads of the other tasks?

Memory Consistency Models
Pi: R V; W V,7; R V; R VPj: R V; W V,13; R V; R V
Example program:
A consistency/memory model is an “agreement” between theexecution environment (H/W, OS, middleware) and the processes. Runtime guarantees to the application certain properties on theway values written to shared variables become visible to reads.This determines the memory model, what’s valid, what’s not.
Example execution: Pi: R V,0; W V,7; R V,7; R V,13Pj: R V,0; W V,13; R V,13; R V,7
Order of writes to V as seen to Pi: (1) W V,7; (2) W V,13Order of writes to V as seen to Pj: (1) W V,13; (2) W V,7

Memory Model: CoherenceCoherence is the memory model in which (the system guarantees to the program that) writes performed by the processes for every specific variable are viewed by all processes in the same order.
Example program: All valid executions under Coherence:
Pi:W V,7R VR V
Pj:W V,13R VR V
The Register Property: the view of a process consists of the values it “sees” in its reads, and the writes it performs. If a R V in P which is later than W V,x in P sees value different than x, then a later R V cannot see x.
Pi:W V,7R V,7R V,7
Pj:W V,13R V,13R V,7
Pi:W V,7R V,7R V,7
Pj:W V,13R V,7R V,7
Pi:W V,7R V,7R V,13
Pj:W V,13R V,13R V,13
Pi:W V,7R V,13R V,13
Pj:W V,13R V,13R V,13
Pi:W V,7R V,7R V,7
Pj:W V,13R V,13R V,13



Tradeoff: Memory Model/Programability vs. Scalability

Parallelism and scalability do not come for free Overhead Memory-aware access Synchronization Load balancing Granularity Memory Models
Does it worth the trouble? Depends on how hard are above vs. potential gain
How would you know? Some tasks cannot be parallelized
Summary

“Speedup” – yet another holy grail
time of best available serial program
-------------------------------------------------
time of parallel program

3939
An upper bound on the speedup
Amdahl's law Sequential component limits the speedup Split program serial time Tserial=1 into
Ideally parallelizable: A Cannot be parallelized: 1-A Ideal parallel time Tparallel= A/#CPUs+(1-A)
Ideal speedup(#CPUs)=Tserial/Tparallel
<=1/(A/#CPUs+(1-A))
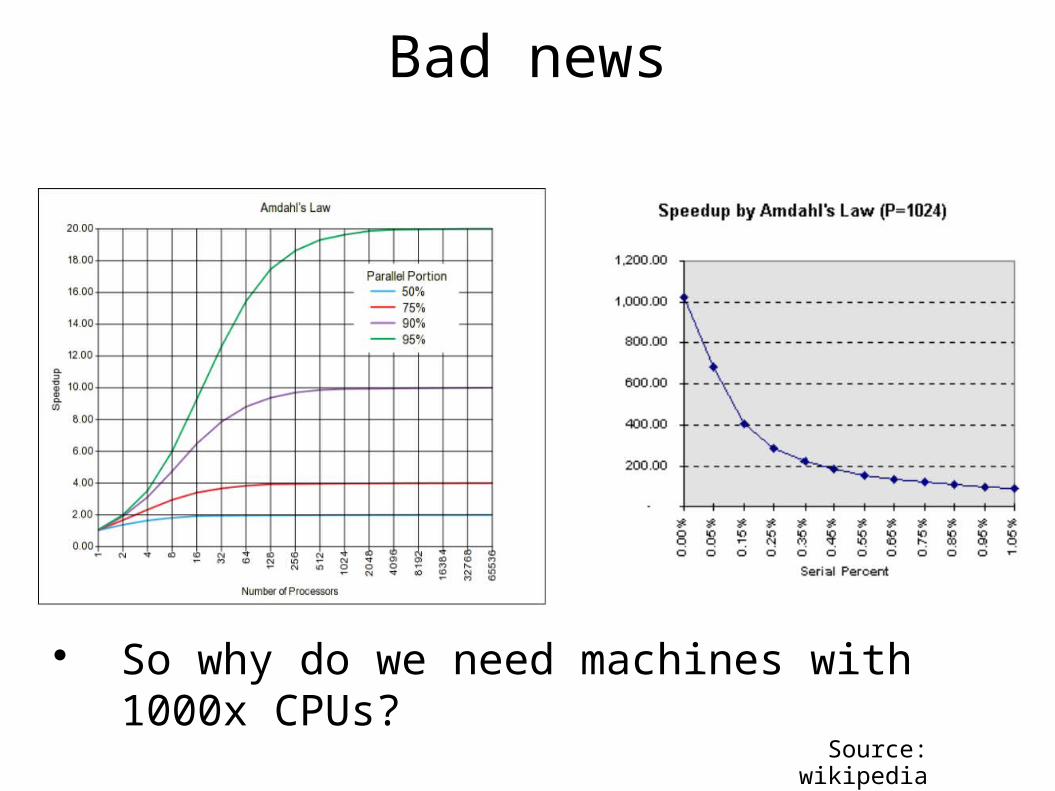
Bad news
Source: wikipedia
So why do we need machines with 1000x CPUs?

The larger the problem the smaller the serial partand the closer the simulation to the best serial program

Super-linear speedups
• Do they exist?


True Super-Linear Speedups
• Suppose data does not fit a single cpu cache
• But after domain decomposition it does

Debugging Parallel Programs





General Purpose Computing on Graphic Processing Unit (GPU)


NVIDIA’sStreaming
Multi-Processor
NVIDIA’sStreaming
Multi-Processor
CUDA=Compute Unified Device
Architecture

NVIDIA’s Kepler = 2 Tera-instructions/sec (real)

54





























