Embed Size (px)
Citation preview

G22.3250-001
Robert GrimmNew York University
(with some slides by Steve Gribble)
Distributed Data Structuresfor Internet Services

Altogether Now:The Three Questions
What is the problem? What is new or different or notable? What are the contributions and limitations?

Clusters, Clusters, Clusters
Let’s broaden the goals for cluster-based services Incremental scalability High availability Operational manageability And also data consistency
But what to do if the data has to be persistent? TACC works best for read-only data Porcupine works best for a limited group of services
Email, news, bulletin boards, calendaring

Enter Distributed Data Structures (DDS)
In-memory, single site application interface Persistent, distributed, replicated implementation Clean consistency model
Atomic operations (but no transactions) Independent of accessing nodes (functional homogeneity)

DDS’s as an Intermediate Design Point
Relational databases Strong guarantees (ACID) But also high overhead, complexity
Logical structure very much independent of physical layout
Distributed data structures Atomic operations, one-copy equivalence Familiar, frequently used interface: hash table, tree, log
Distributed file systems Weak guarantees (e.g., close/open consistency) Low-level interface with little data independence
Applications impose structure on directories, files, bytes

Design Principles
Separate concerns Service code implements application Storage management is reusable, recoverable
Appeal to properties of clusters Generally secure and well-administered
Fast network, uninterruptible power
Design for high throughput and high concurrency Use event-driven implementation
Make it easy to compose components
Make it easy to absorb bursts (in event queues)

Assumptions
No network partitions within cluster Highly redundant network
DDS components are fail-stop Components implemented to terminate themselves
Failures are independent Messaging is synchronous
Bounded time for delivery
Workload has no extreme hotspots (for hash table) Population density over key space is even Working set of hot keys is larger than # of cluster nodes

Distributed Hash Tables(in a Cluster…)
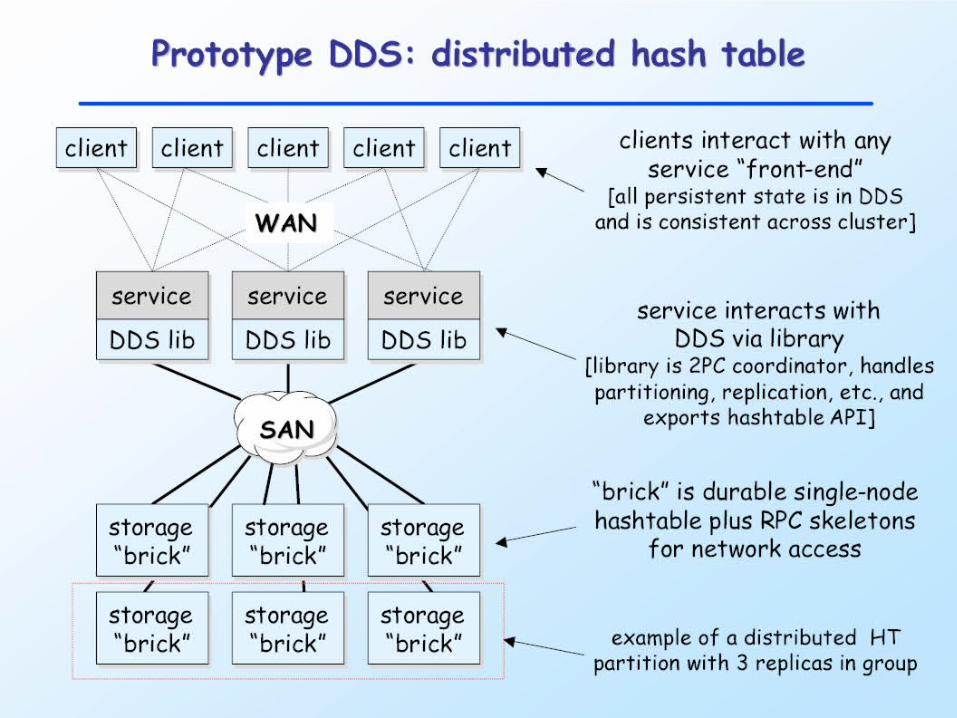
DHT Architecture

Cluster-Wide Metadata Structures

Metadata Maps
Why is two-phasecommit acceptablefor DDS’s?

Recovery

Experimental Evaluation
Cluster of 28 2-way SMPs and 38 4-way SMPs To a total of 208 500 MHZ Pentium CPUs 2-way SMPs: 500 MB RAM, 100 Mbs switched Ethernet 4-way SMPs: 1 GB RAM, 1 Gbs switched Ethernet
Implementation written in Jāvā Sun’s JDK 1.1.7v3, OpenJIT, Linux user-level threads Load generators run within cluster
80 nodes necessary to saturate 128 storage bricks

Scalability: Reads and Writes
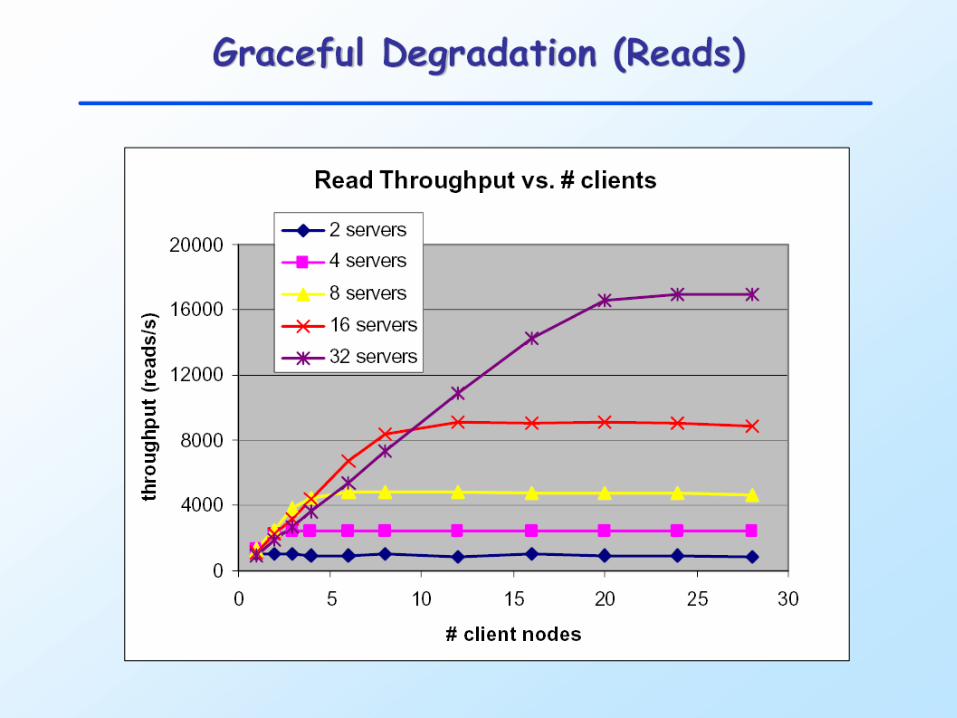
Graceful Degradation (Reads)

Unexpected Imbalance (Writes)
What’s going on?

Capacity
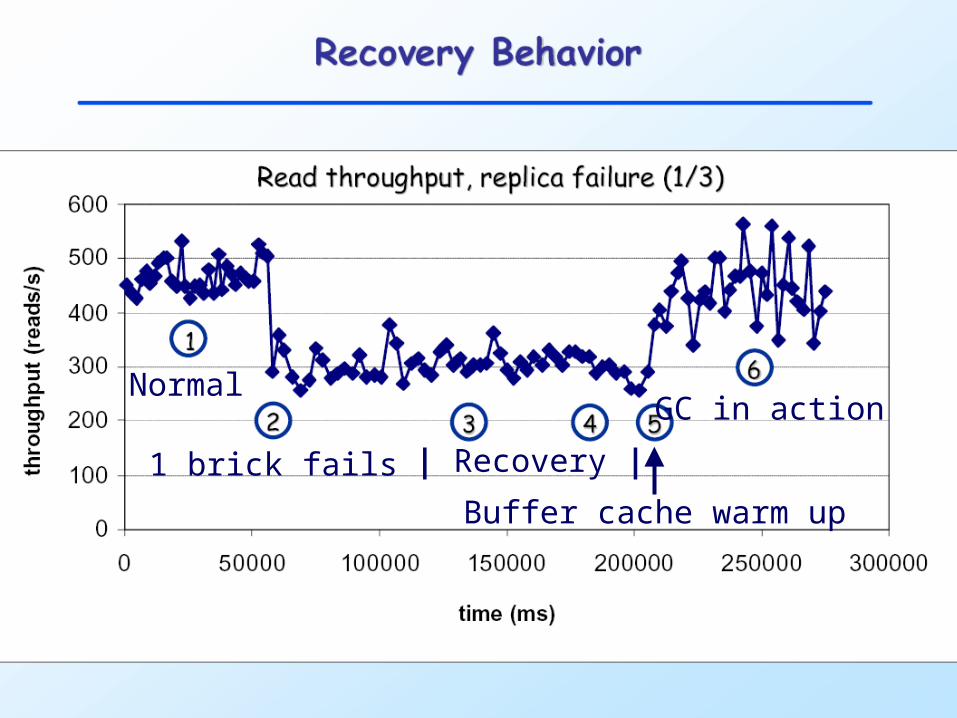
Recovery Behavior
1 brick fails | Recovery |
GC in action
Buffer cache warm up
Normal

So, All Is Good?

Assumptions Considered Harmful!
Central insight, based on experience with DDS “Any system that attempts to gain robustness solely
through precognition is prone to fragility”
In other words Complex systems are so complex that they are
impossible to understand completely, especially when operating outside their expected range

Assumptions in Action
Bounded synchrony Timeout four orders of magnitude higher than common case
round trip time But garbage collection may take a very long time The result is a catastrophic drop in throughput
Independent failures Race condition in two-phase commit caused latent memory
leak (10 KB/minute under normal operation) All bricks failed predictably within 10-20 minutes of each other
After all, they were started at about the same time
The result is a catastrophic loss of data

Assumptions in Action (cont.)
Fail-stop components Session layer uses synchronous connect() method Another graduate student adds firewalled machine to
cluster, resulting in nodes locking up for 15 minutes at a time
The result is a catastrophic corruption of data

What Can We Do?
Systematically overprovision the system But doesn’t that mean predicting the future, again?
Use admission control But this can still result in livelock, only later…
Build introspection into the system Need to easily quantify behavior in order to adapt
Close the control loop Make the system adapt automatically (but see previous)
Plan for failures Use transactions, checkpoint frequently, reboot proactively

What Do You Think?





























